protÓtipo de sistema Óptico de captura do …rodacki/tcc/248976_1_1.pdf · padronizada acima de...
TRANSCRIPT

UNIVERSIDADE REGIONAL DE BLUMENAU
CENTRO DE CIÊNCIAS EXATAS E NATURAIS
CURSO DE CIÊNCIAS DA COMPUTAÇÃO
(Bacharelado)
PROTÓTIPO DE SISTEMA ÓPTICO DE CAPTURA DO MOVIMENTO HUMANO, SEM A UTILIZAÇÃO DE
MARCAÇÕES ESPECIAIS
TRABALHO DE CONCLUSÃO DE CURSO SUBMETIDO À UNIVERSIDADE REGIONAL DE BLUMENAU PARA A OBTENÇÃO DOS CRÉDITOS NA
DISCIPLINA COM NOME EQUIVALENTE NO CURSO DE CIÊNCIAS DA COMPUTAÇÃO — BACHARELADO
LEANDRO AUGUSTO FRATA FERNANDES
BLUMENAU, JUNHO/2002
2002/1-45

ii
PROTÓTIPO DE SISTEMA ÓPTICO DE CAPTURA DO MOVIMENTO HUMANO, SEM A UTILIZAÇÃO DE
MARCAÇÕES ESPECIAIS
LEANDRO AUGUSTO FRATA FERNANDES
ESTE TRABALHO DE CONCLUSÃO DE CURSO FOI JULGADO ADEQUADO PARA OBTENÇÃO DOS CRÉDITOS NA DISCIPLINA DE TRABALHO DE
CONCLUSÃO DE CURSO OBRIGATÓRIA PARA OBTENÇÃO DO TÍTULO DE:
BACHAREL EM CIÊNCIAS DA COMPUTAÇÃO
Prof. Paulo César Rodacki Gomes — Orientador na FURB
Prof. José Roque Voltolini da Silva — Coordenador do TCC
BANCA EXAMINADORA
Prof. Paulo César Rodacki Gomes Prof. Dalton Solano dos Reis Prof. Marcel Hugo

iii
AGRADECIMENTOS
Agradeço a todos aqueles que direta ou indiretamente, proporcionaram, contribuíram e
ajudaram o desenvolvimento deste trabalho, em especial a meus pais João Fernandes e Sônia
Regina Frata Fernandes, pois a eles devo tudo; à minha namorada Raquel Franco, por ter sido
meu esteio e amparo; a meu orientador Paulo César Rodacki Gomes, por me guiar com
profissionalismo e competência; aos professores do Departamento de Sistemas e Computação
e do Departamento de Matemática, em especial aos professores Arthur Alexandre Hackbarth
Neto e Carlos Efrain Stein, por ajudarem na busca de soluções; e ao pessoal da FURB TV por
disponibilizar o equipamento utilizado na captura dos dados.
Muito obrigado.

iv
SUMÁRIO LISTA DE FIGURAS ........................................................................................................... VIII
LISTA DE EQUAÇÕES ..........................................................................................................XI
LISTA DE QUADROS ...........................................................................................................XII
LISTA DE SIGLAS E ABREVIATURAS ...........................................................................XIV
RESUMO ............................................................................................................................... XV
ABSTRACT ..........................................................................................................................XVI
1 INTRODUÇÃO .....................................................................................................................1
1.1 OBJETIVOS........................................................................................................................2
1.2 RELEVÂNCIA ...................................................................................................................3
1.3 ORGANIZAÇÃO DO TRABALHO ..................................................................................3
2 CONCEITOS DE CAPTURA DO MOVIMENTO ..............................................................4
2.1 BREVE HISTÓRICO..........................................................................................................4
2.2 CLASSIFICAÇÕES DOS SISTEMAS DE MOCAP .........................................................5
2.2.1 TECNOLOGIA.................................................................................................................5
2.2.1.1 Sistema Mecânico ...........................................................................................................5
2.2.1.2 Sistema Óptico................................................................................................................7
2.2.1.3 Sistema Eletromagnético ................................................................................................8
2.2.1.4 Sistema Acústico ............................................................................................................9
2.2.2 FONTE EMISSORA X SENSORES/MARCADORES...................................................9
2.2.2.1 Inside-In ..........................................................................................................................9
2.2.2.2 Inside-Out .....................................................................................................................10
2.2.2.3 Outside-In .....................................................................................................................10
2.2.3 AQUISIÇÃO DOS DADOS...........................................................................................10

v
2.2.3.1 Aquisição Direta ...........................................................................................................10
2.2.3.2 Aquisição Indireta.........................................................................................................10
2.3 ONDE MOCAP NA PRÁTICA É APLICADA E QUAIS OS PRODUTOS DO
SISTEMA ÓPTICO DISPONÍVEIS NO MERCADO .....................................................11
3 SISTEMA ÓPTICO DE MOCAP EM TEMPO REAL ......................................................14
3.1 ORIGEM E CAPTURA DOS DADOS DE ENTRADA..................................................14
3.2 REMOÇÃO DO FUNDO DA CENA E DETECÇÃO DE OBJETOS EM MOVIMENTO
.........................................................................................................................................15
3.3 ANÁLISE DAS SILHUETAS E LOCALIZAÇÃO DA PROVÁVEL FIGURA
HUMANA .........................................................................................................................17
3.4 SEGMENTAÇÃO DA SILHUETA PARA IDENTIFICAÇÃO DO
POSICIONAMENTO 2D DAS PARTES DO CORPO....................................................18
3.5 IDENTIFICAÇÃO DO POSICIONAMENTO 3D DAS PARTES DO CORPO.............21
3.6 RECONSTITUIÇÃO DOS MOVIMENTOS DO ATOR.................................................23
4 JAVATM MEDIA FRAMEWORK (JMF) ...........................................................................24
4.1 CLASSES E INTERFACES RELEVANTES ..................................................................25
4.1.1 CONTROLE DO TEMPO ..............................................................................................25
4.1.2 ADMINISTRAÇÃO DE RECURSOS ...........................................................................26
4.1.3 GERENCIAMENTO DE EVENTOS.............................................................................26
4.1.4 GERENCIAMENTO E FORMATO DOS DADOS ......................................................28
4.1.5 CONTROLES .................................................................................................................29
4.1.6 APRESENTAÇÃO E PROCESSAMENTO DA MÍDIA...............................................30
4.2 FLUXO DOS DADOS......................................................................................................32
5 CONCEITOS MATEMÁTICOS ENVOLVIDOS..............................................................35
5.1 CONCEITOS ESTATÍSTICOS ........................................................................................35
5.1.1 CENTRO DE UMA DISTRIBUIÇÃO, A MÉDIA........................................................35

vi
5.1.2 DISPERSÃO DE UMA DISTRIBUIÇÃO, O DESVIO PADRÃO ...............................35
5.1.3 DISTRIBUIÇÕES DE PROBABILIDADE E ESTIMATIVA POR INTERVALO......36
5.1.3.1 Distribuição Normal .....................................................................................................37
5.1.3.2 Distribuição de Student.................................................................................................39
5.2 CONCEITOS GEOMÉTRICOS .......................................................................................40
5.2.1 PROJEÇÃO DE UM VETOR ........................................................................................40
6 DESENVOLVIMENTO DO PROTÓTIPO ........................................................................42
6.1 REQUISITOS IDENTIFICADOS ....................................................................................42
6.2 ESPECIFICAÇÃO ............................................................................................................43
6.2.1 MÓDULO 2D .................................................................................................................44
6.2.2 MÓDULO 3D .................................................................................................................50
6.3 IMPLEMENTAÇÃO ........................................................................................................52
6.3.1 ORIGEM E CAPTURA DOS DADOS DE ENTRADA................................................52
6.3.2 REMOÇÃO DO FUNDO DA CENA E DETECÇÃO DE OBJETOS EM
MOVIMENTO................................................................................................................57
6.3.2.1 Mínimo e máximo valor RGB ......................................................................................58
6.3.2.2 Média da distância IP + erro Normal............................................................................61
6.3.2.3 Média da distância IP + erro Student............................................................................65
6.3.2.4 Média da distância IP + erro Empírico .........................................................................68
6.3.3 ANÁLISE DAS SILHUETAS E LOCALIZAÇÃO DA PROVÁVEL FIGURA
HUMANA.......................................................................................................................68
6.3.4 SEGMENTAÇÃO DA SILHUETA PARA IDENTIFICAÇÃO DO
POSICIONAMENTO 2D DAS PARTES DO CORPO .................................................71
6.3.5 CONSTRUÇÃO DA MARIONETE VIRTUAL............................................................73
6.4 FUNCIONAMENTO DO PROTÓTIPO ..........................................................................74
6.5 ANÁLISE DOS RESULTADOS......................................................................................80

vii
6.6 SITUAÇÃO DE DIFÍCIL TRATAMENTO.....................................................................82
7 CONCLUSÕES ...................................................................................................................83
7.1 EXTENSÕES ....................................................................................................................84
REFERÊNCIAS BIBLIOGRÁFICAS .....................................................................................86
ANEXO A: TABELA DE PROBABILIDADE ACUMULADA NA CAUDA DIREITA DA
CURVA NORMAL PADRONIZADA ...............................................................................90
ANEXO B: TABELA DE PONTOS CRÍTICOS DA DISTRIBUIÇÃO DE STUDENT.......91
ANEXO C: DIAGRAMA DE SEQÜÊNCIA DOS PRINCIPAIS MÉTODOS DO
MOCAPPLAYER ...................................................................................................................92
ANEXO D: DIAGRAMA DE ESTADOS DO PROCESSOR .................................................93
ANEXO E: DIAGRAMA DE SEQÜÊNCIA DO MÉTODOS PROCESS() DO
MOCAPCODEC .....................................................................................................................94
ANEXO F: DIAGRAMA DE SEQÜÊNCIA DO MÉTODO TRATARBUFFER() DO
MOCAPCODECMODULO2D ..................................................................................................95
ANEXO G: COMPARAÇÃO VISUAL DE RESULTADOS OBTIDOS COM FUNDO DE
CENA DE COR PREDOMINANTE AZUL.......................................................................96
ANEXO H: COMPARAÇÃO VISUAL DE RESULTADOS OBTIDOS COM FUNDO DE
CENA DE COR PREDOMINANTE PRETA.....................................................................97
ANEXO I: COMPARAÇÃO QUANTITATIVA DA CORRETA CLASSIFICAÇÃO DE
PIXELS PELOS MÉTODOS IMPLEMENTADOS............................................................98
ANEXO J: COMPARAÇÃO QUANTITATIVA DO APROVEITAMENTO DE QUADROS
DO VÍDEO PARA OS MÉTODOS IMPLEMENTADOS.................................................99

viii
LISTA DE FIGURAS FIGURA 2.1 – ANIMATTION , SISTEMA MECÂNICO DE CAPTURA ...............................6
FIGURA 2.2 – MARIONETE MECÂNICA DO FILME STARSHIP TROOPERS ..................6
FIGURA 2.3 – SISTEMA ÓPTICO DE CAPTURA.................................................................7
FIGURA 2.4 – MOTION STAR, SISTEMA ELETROMAGNÉTICO DE CAPTURA ............8
FIGURA 2.5 – GARBI, ROBÔ SUBMARINO.......................................................................12
FIGURA 2.6 – EXOESQUELETO VIRTUAL DE GARBI....................................................13
FIGURA 3.1 – MODELO DE COR PROPOSTO NO ESPAÇO TRIDIMENSIONAL RGB16
FIGURA 3.2 – EXEMPLO DE RESULTADO DA SUBTRAÇÃO DO FUNDO..................17
FIGURA 3.3 – EXEMPLO DE RESULTADO DA SEGMENTAÇÃO REALIZADA PELO
SISTEMA GHOST ...........................................................................................................20
FIGURA 3.4 – EXEMPLO DE RESULTADO DA SEGMENTAÇÃO A PARTIR DA
IDENTIFICAÇÃO DAS CORES DA ROUPA ...............................................................20
FIGURA 3.5 – DIAGRAMA DO PROCESSO DE LOCALIZAÇÃO 2D DAS PARTES DO
CORPO DO ATOR ..........................................................................................................22
FIGURA 3.6 – DIAGRAMA DA TOPOLOGIA PARA A CAPTURA DO
POSICIONAMENTO 3D DAS PARTES DO CORPO...................................................22
FIGURA 3.7 – MARIONETES VIRTUAIS............................................................................23
FIGURA 4.1 – DIAGRAMA DE CLASSES QUE MOSTRA AS CLASSES FILHAS DE
CONTROLLEREVENT ......................................................................................................27
FIGURA 4.2 – DIAGRAMA DE CLASSES QUE MOSTRA AS CLASSES FILHAS DE
DATASINKEVENT ...........................................................................................................28
FIGURA 4.3 – DIAGRAMA DE CLASSES QUE MOSTRA AS CLASSES FILHAS DE
FORMAT............................................................................................................................29
FIGURA 4.4 – DIAGRAMA DE CLASSES QUE MOSTRA AS SUPER-INTERFACES DE
TRACKCONTROL .............................................................................................................30

ix
FIGURA 4.5 – DIAGRAMA DE CLASSES QUE MOSTRA O CONTROLLER E SUAS
INTERFACES FILHAS...................................................................................................31
FIGURA 4.6 – ANALOGIA ENTRE ELEMENTOS DO MUNDO REAL E CLASSES E
INTERFACES DA JMF...................................................................................................32
FIGURA 4.7 – MODELO DE FLUXO, UTILIZANDO UM PLAYER ..................................32
FIGURA 4.8 – MODELO DE FLUXO, UTILIZANDO UM PROCESSOR ...........................33
FIGURA 4.9 – ESTÁGIOS DO FLUXO DENTRO DO PROCESSOR ..................................33
FIGURA 5.1 – EXEMPLO DE HISTORIOGRAMA DE FREQÜÊNCIA RELATIVA........36
FIGURA 5.2 – DISTRIBUIÇÃO NORMAL PADRONIZADA.............................................37
FIGURA 5.3 – PROBABILIDADE COMPREENDIDA PELA CURVA NORMAL
PADRONIZADA ACIMA DE UM PONTO Z0 ..............................................................38
FIGURA 5.4 – PROJEÇÃO DO VETOR ur
SOBRE O VETOR vr .......................................40
FIGURA 6.1 – DIAGRAMA DAS INTERFACES QUE MANTÉM A FORMATAÇÃO DAS
IMAGENS DO VÍDEO....................................................................................................45
FIGURA 6.2 – DIAGRAMA DA CLASSE MOCAPPLAYER .................................................45
FIGURA 6.3 – DIAGRAMA DA CLASSE MOCAPCODEC....................................................47
FIGURA 6.4 – DIAGRAMA DA CLASSE FILHA DE MOCAPCODEC QUE EXIBE A
ANÁLISE DA VARIAÇÃO DOS VALORES RGB DE UM PIXEL DURANTE A
EXIBIÇÃO DO VÍDEO...................................................................................................48
FIGURA 6.5 – DIAGRAMA DAS CLASSES FILHAS DE MOCAPCODEC QUE
REALIZAM A CAPTURA DO MOVIMENTO NO MÓDULO 2D ..............................49
FIGURA 6.6 – DIAGRAMA DE CLASSES DA CLASSE MOCAPPARTE ...........................50
FIGURA 6.7 – DIAGRAMA DE CLASSES QUE REALIZAM A ANIMAÇÃO DA
MARIONETE VIRTUAL NO MÓDULO 3D.................................................................51
FIGURA 6.8 – FORMATAÇÃO DOS DADOS NO BUFFER...............................................58
FIGURA 6.9 – MODELO DE COR COM APLICAÇÃO DO MÍNIMO E MÁXIMO
VALOR RGB ...................................................................................................................61

x
FIGURA 6.10 – MODELO DE COR COM APLICAÇÃO DA MÉDIA DA DISTÂNCIA IP
+ ERRO DE AMOSTRAGEM ........................................................................................64
FIGURA 6.11 – DIFERENÇA ENTRE CONTORNO EXTERNO E CONTORNO
INTERNO.........................................................................................................................69
FIGURA 6.12 – IDENTIFICAÇÃO DOS PIXELS VIZINHOS DO PIXEL ATUAL ............69
FIGURA 6.13 – MARIONETE VIRTUAL 3D .......................................................................73
FIGURA 6.14 – VISÃO SISTEMÁTICA DOS OBJETOS QUE COMPÕE A MARIONETE
VIRTUAL 3D...................................................................................................................74
FIGURA 6.15 – JANELA PRINCIPAL DO MÓDULO 2D ...................................................75
FIGURA 6.16 – BARRA DE ATIVAÇÃO DO MÓDULO 2D ..............................................75
FIGURA 6.17 – JANELA DE EXIBIÇÃO DO VÍDEO TRATADO .....................................76
FIGURA 6.18 – JANELA DE EXIBIÇÃO DO DESEMPENHO DO CODEC ATIVO ........77
FIGURA 6.19 – JANELA DE HISTÓRICO DA VARIAÇÃO DOS VALORES RGB DE UM
PIXEL DURANTE A EXECUÇÃO DO VÍDEO ............................................................77
FIGURA 6.20 – JANELA DE CONFIGURAÇÃO DO PROCESSO DE REMOÇÃO DO
FUNDO DA CENA..........................................................................................................78
FIGURA 6.21 – JANELA DE CONFIGURAÇÃO DO PROCESSO DE ANÁLISE DAS
SILHUETAS ENCONTRADAS, PARA A DETECÇÃO DA FIGURA HUMANA .....79
FIGURA 6.22 – JANELA DE EXIBIÇÃO DO RESULTADO DA ANÁLISE DAS
SILHUETAS ENCONTRADAS E DA SEGMENTAÇÃO DA SILHUETA
ENCONTRADA...............................................................................................................79
FIGURA 6.23 – JANELA DE CONFIGURAÇÃO DA CONEXÃO ENTRE O MÓDULO 2D
E O MÓDULO 3D ...........................................................................................................80

xi
LISTA DE EQUAÇÕES
EQUAÇÃO 5.1 – MÉDIA ARITMÉTICA..............................................................................35
EQUAÇÃO 5.2 – DESVIO PADRÃO ....................................................................................36
EQUAÇÃO 5.3 – ESTIMATIVA DA MÉDIA POPULACIONAL A PARTIR DA MÉDIA
AMOSTRAL ....................................................................................................................37
EQUAÇÃO 5.4 – TRANSFORMAÇÃO PARA DISTRIBUIÇÃO NORMAL
GENERALIZADA ...........................................................................................................38
EQUAÇÃO 5.5 – GRAUS DE LIBERDADE .........................................................................39
EQUAÇÃO 5.6 – ESTIMATIVA DA MÉDIA POPULACIONAL A PARTIR DA
DISTRIBUIÇÃO DE STUDENT ....................................................................................39
EQUAÇÃO 5.7 – PROJEÇÃO DO VETOR ur SOBRE O VETOR vr ...................................40
EQUAÇÃO 5.8 – PROJEÇÃO DE OA SOBRE OB PARA A OBTENÇÃO DO PONTO P
..........................................................................................................................................41
EQUAÇÃO 6.1 – CÁLCULO DO COMPRIMENTO DO VETOR QUE CONTÉM OS
DADOS DO BUFFER .....................................................................................................58

xii
LISTA DE QUADROS QUADRO 6.1 – PSEUDO-CÓDIGO IMPLEMENTADO NA JANELA DE INTERFACE
COM O USUÁRIO E UTILIZADO PARA CONFIGURAR E INICIALIZAR O
MOCAPPLAYER................................................................................................................53
QUADRO 6.2 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPPLAYER,
CHAMADO PELA JANELA DE INTERFACE COM O USUÁRIO E QUE É
RESPONSÁVEL POR CONFIGURAR OS COMPONENTES DO JMF ......................54
QUADRO 6.3 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPPLAYER,
CHAMADO DE FORMA ASSÍNCRONA PELO PROCESSOR QUANDO ESTE
MUDA DE ESTADO.......................................................................................................55
QUADRO 6.4 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPPLAYER,
CHAMADO PELA JANELA DE INTERFACE COM O USUÁRIO E QUE É
RESPONSÁVEL POR INICIAR A EXECUÇÃO DA MÍDIA.......................................56
QUADRO 6.5 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPPLAYER,
CHAMADO PELA JANELA DE INTERFACE COM O USUÁRIO E QUE É
RESPONSÁVEL POR FINALIZAR A EXECUÇÃO DA MÍDIA.................................56
QUADRO 6.6 – CÓDIGO IMPLEMENTADO NA CLASSE
MOCAPREMOCAOFUNDOMINIMOMAXIMOVALORRGB .................................................59
QUADRO 6.7 – CÓDIGO IMPLEMENTADO NA CLASSE
MOCAPREMOCAOFUNDOMEDIADISTANCIAIPNORMAL.............................................61
QUADRO 6.8 – CÓDIGO IMPLEMENTADO NA CLASSE
MOCAPREMOCAOFUNDOMEDIADISTANCIAIPSTUDENT ..........................................65
QUADRO 6.9 – LÓGICA DO MÉTODO IMPLEMENTADO NO
MOCAPANALISESILHUETAORDENADA8CONEXO E QUE É RESPONSÁVEL PELA
IDENTIFICAÇÃO DA SILHUETA HUMANA.............................................................70

xiii
QUADRO 6.10 – CÓDIGO DO MÉTODO IMPLEMENTADO NO
MOCAPANALISESILHUETAORDENADA8CONEXO E QUE É RESPONSÁVEL PELA
IDENTIFICAÇÃO DA SILHUETA HUMANA.............................................................70
QUADRO 6.11 – LÓGICA DO CÁLCULO DA POSIÇÃO DO CENTRÓIDE DE UM
POLÍGONO EM UMA IMAGEM RASTER....................................................................72
QUADRO 6.12 – CÓDIGO DO MÉTODO IMPLEMENTADO NO
MOCAPSEGMENTACAOSILHUETACENTROIDE E QUE É RESPONSÁVEL PELA
LOCALIZAÇÃO DO CENTRÓIDE DA SILHUETA HUMANA.................................72

xiv
LISTA DE SIGLAS E ABREVIATURAS
2D Duas Dimensões
3D Três Dimensões
API Application Program Interface
AVI Audio Video Interleaved
JMF JavaTM Media Framework
MoCap Motion Capture, Captura do Movimento
RGB Red-Green-Blue
RTP Real-Time Transport Protocol
UML Unified Modeling Language

xv
RESUMO
O termo Captura de Movimento refere-se a técnicas de reconhecimento do movimento
de objetos. Usualmente, sistemas de captura de movimento que utilizam dispositivos
mecânicos, eletromagnéticos ou acústicos apresentam uma série de problemas que
influenciam no processo de captura. Assim, o presente trabalho estuda uma alternativa óptica
de captura do movimento humano sem utilização de marcações especiais sobre o corpo do
ator. Para implementação desta alternativa, são abordados problemas relativos aos processos
de captura dos dados de câmeras de vídeo, remoção do fundo da cena e detecção de objetos
em movimento, análise da silhueta dos objetos para a localização da figura humana,
segmentação da silhueta humana para identificação do posicionamento 2D das partes do
corpo, identificação do posicionamento 3D das partes do corpo e reconstituição dos
movimentos em uma marionete virtual 3D. No presente trabalho, as técnicas desenvolvidas
para remoção do fundo da cena e análise das silhuetas para identificação da figura humana
constituem contribuições originais não encontradas previamente na bibliografia sobre o
assunto. Como validação do método proposto, é apresentado um protótipo de software
desenvolvido na linguagem Java que implementa da etapa de captura dos dados de entrada até
a localização da figura humana e parte do processo de segmentação dessa figura humana.

xvi
ABSTRACT
Motion Capture methods consist in techniques for recognition of movements of
ordinary objects. Typically, motion capture systems based on mechanical, electromagnetic or
acoustic devices have several problems which influences in the capture process. Therefore,
the present work deals with optic based methods for the capture of human motion data
without the use of special markings on the actor’s body. The implementation of such task
comprehends the digitalization of video data, background scene removal, detection of moving
objects in the video scene, analysis of the silhouette for objects in the scene, in order to detect
the human being figure, segmentation of the silhouette for identification of the body parts’ 2D
positioning, identification of the 3D positioning of the body parts and reconstitution of the
movements in a 3D virtual marionette. This work presents innovative techniques for
background scene removal and analysis of the silhouette for objects in the scene. The
techniques presented here are original contributions to the literature. As validation for the
considered method, a software prototype was developed using the Java language implements
from the digitalization of video data to detection of the human being figure and part of the
segmentation process of the human being figure.

1
1 INTRODUÇÃO A visão do futuro, mostrada na World’s Fair de 1939, deslumbra equipamentos com
fantástica interface homem-máquina. Idéias expostas nessa feira mostram eletrodomésticos
equipados com câmeras, respondendo a controles gestuais intuitivos (Freeman, 1999).
Alcançar tal grau de naturalidade na interação entre homens e máquina é o objetivo de muitas
das pesquisas atuais.
Numa publicação recente (Freeman, 1999) é exposta a análise computacional da
imagem como uma área ativa de pesquisa. Comprovando essa idéia, Takahashi (1999) realça
que a análise da movimentação humana tornou-se muito importante e aplicável na área de
comunicação visual e realidade virtual. Especialmente, a avaliação da postura humana em
tempo real é muito importante para muitas aplicações como jogos eletrônicos, diversão e
avançados sistemas de interface homem-máquina. Bottino (2000?) cita ainda outras áreas de
aplicação, como robótica, ergonomia, simulação de acidentes com manequim, biomecânica e
análise médica e de desempenho esportivo.
Conforme Sturman (1997), as técnicas de reconhecimento do movimento dos objetos
em um ambiente real, para análise posterior ou imediata, recebem o nome de captura de
movimento. A informação captada está ligada ao posicionamento de corpos no espaço a um
determinado tempo e que a captura de movimento para animação de personagens virtuais
envolve o mapeamento dos movimentos de um objeto real e reprodução desse movimento em
um personagem virtual.
Segundo Furniss (1999), os sistemas de captura de movimento podem ser divididos em
três grupos: sistema mecânico, sistema óptico e sistema eletromagnético. Completando essa
classificação, Trager (1997) cita ainda um quarto sistema para captura de movimento, o
sistema acústico.
No intuito de atender aplicações da captura de movimento onde o sistema adotado não
possa interferir na naturalidade da movimentação das pessoas envolvidas no processo de
captura, como no caso de análise médica e de desempenho esportivo, é escolhido como tema
deste trabalho o grupo de sistemas ópticos de captura de movimento.

2
Normalmente, os sistemas ópticos fazem uso de marcações especiais sobre o corpo do
ator em cena para facilitar o processo de captura. No entanto, para ampliar a quantidade de
dados coletados, foi escolhido o sistema óptico que não utilize marcações artificiais sobre o
corpo do ator. Ao invés disso, utiliza-se de técnicas especiais para estimação da postura
humana, como: remoção do fundo das cenas e detecção de objetos em movimento; análise das
silhuetas e localização da provável figura humana; segmentação corporal e identificação do
posicionamento bidimensional (2D) das partes do corpo. Após a execução dessas tarefas é
possível fazer a identificação do posicionamento tridimensional (3D) das partes do corpo e a
reconstituição dos movimentos do ator, através da animação de uma marionete virtual.
Para a realização desse trabalho também foi necessário o estudo de uma Application
Program Interface (API) específica da linguagem Java, a API JavaTM Media Framework
(Sun, 1999 e 2000a), utilizada na obtenção dos dados captados pela câmera de vídeo ou
extraídos de arquivos de vídeo.
1.1 OBJETIVOS Desenvolver um sistema que a partir de um conjunto de dados, vindos de uma ou mais
câmeras de vídeo, identifique e analise o movimento de uma figura humana, com a intenção
de reproduzir esse movimento em uma marionete virtual.
Os objetivos específicos do trabalho são:
a) Capturar os dados vindos dos dispositivos de entrada, as câmeras de vídeo;
b) Analisar os dados de entrada, removendo o fundo das cenas e detectando os objetos
em movimento;
c) Analisar a silhueta dos objetos em movimento para a identificação de uma figura
humana;
d) Realizar a identificação do posicionamento 2D das partes do corpo da figura
humana, segmentando a silhueta;
e) Fazer a reconstituição 3D do movimento humano, através da animação de uma
marionete virtual no dispositivo de saída, o monitor do computador.

3
1.2 RELEVÂNCIA Na implementação do trabalho serão utilizadas técnicas de visão computacional 3D em
tempo real, para a detecção e análise do movimento humano, provendo assim o controle da
animação de uma marionete virtual.
O trabalho envolve técnicas de Computação Gráfica, no que diz respeito à análise das
imagens provenientes dos dispositivos de entrada e na composição da animação exibida no
dispositivo de saída.
1.3 ORGANIZAÇÃO DO TRABALHO O trabalho está organizado conforme descrito abaixo.
O capítulo 2 apresenta os conceitos de captura do movimento, mostrando o histórico
da tecnologia, os tipos de sistemas existente e a aplicação dos mesmos, assim como os
sistemas ópticos de captura disponíveis no mercado.
O capítulo 3 aborda de forma específica o sistema óptico de captura do movimento em
tempo real, sem a utilização de marcações especiais, enumerando as etapas do processo e a
dependência existente entre cada uma dessas etapas.
O capítulo 4 concentra-se na apresentação das principais características da API JavaTM
Media Framework, cujos recursos foram utilizados na implementação do protótipo.
O capítulo 5 contém os principais conceitos matemáticos envolvidos na
implementação do protótipo, sobretudo conceitos relacionados a técnicas de análise
estatísticas e geometria analítica.
O capítulo 6 apresenta a especificação, implementação e o funcionamento do protótipo
de um sistema óptico de captura do movimento humano, sem a utilização de marcações
especiais, demonstrando a aplicação de algumas técnicas pesquisadas no capítulo 3, 4 e 5.
No capítulo 7 são apresentadas as conclusões provenientes da execução desse trabalho,
bem como as possíveis extensões que dele podem ser desenvolvidas.

4
2 CONCEITOS DE CAPTURA DO MOVIMENTO O termo Captura do Movimento não é o único utilizado para referenciar tal tecnologia.
Talvez o termo mais aplicado seja Motion Capture, ou simplesmente sua abreviação MoCap.
Porém, outras nomenclaturas são comuns, tais como Captura de Atuação, do inglês
Performance Capture, e Animação por Atuação, do inglês Performance Animation.
No presente trabalho serão utilizados os termos MoCap e Captura do Movimento na
referencia à tecnologia.
Nesse capítulo, a seção 2.1 apresenta um breve histórico da captura de movimento. Na
seção 2.2 serão enumeradas as formas de classificação dos sistemas de MoCap. A seção 2.3
mostra a aplicação e sistemas ópticos de captura disponíveis no mercado.
2.1 BREVE HISTÓRICO MoCap surgiu no início da década de 70 e foi criada para uso militar, no
acompanhamento de pilotos em manobras de combate (Furniss, 1999). Porém, de acordo com
Sturman (1997), apenas no fim da década de 70 começou a ser aplicada na animação de
personagens, tornando-se difundida nas duas últimas décadas.
O conceito de animação é antigo, tendo sido pela primeira vez utilizado pelo cartunista
Winsor McKey, em 1911. Winsor conseguiu obter o movimento de um personagem
desenhando-o em múltiplos pedaços de papel, que eram visualizados segundo uma certa taxa
de amostragem (Silva, 1997).
Com a necessidade de se atribuir movimentos mais realistas aos personagens
animados, foi desenvolvida a técnica conhecida como rotoscoping, que consiste em desenhar
o movimento dos personagens animados sobre imagens de atores reais realizando o
movimento desejado, gerando assim animações bidimensionais. De acordo com Trager
(1997), a técnica de rotoscoping foi usada pela primeira vez pelos estúdios Disney.
Nos anos 80, relata Trager (1997), MoCap ainda era uma extensão da técnica de
rotoscoping. Nesse período a utilização de mais que uma câmera no processo de captura e
marcações especiais no corpo dos atores dava aos animadores a estimativa do posicionamento

5
3D do personagem, porém os métodos de extração da informação continuavam manuais. Essa
técnica foi chamada de photogammetry.
Ao fim dos anos 80 a MoCap passou a ser como é conhecida hoje. Sistemas
computadorizados auxiliavam na captura da posição e forma dos objetos no espaço.
O uso de estruturas aramadas para o controle de personagens 3D tornou-se popular nos
anos 90. A animação de estruturas aramadas permitiu aos artistas posicionar e controlar a
rotação dos pontos de uma personagem de maneira fácil e prática.
Conforme Silva (1997), MoCap foi aplicada pela primeira vez em produtos comerciais
no ano de 1993.
2.2 CLASSIFICAÇÕES DOS SISTEMAS DE MOCAP São várias as formas de classificação dos sistemas de MoCap atuais. A literatura
pesquisada aponta três maneiras distintas de classificação:
a) Quanto à tecnologia;
b) Quanto à fonte emissora x sensores/marcadores;
c) Quanto à aquisição dos dados.
Dentro de cada uma dessas formas de classificação, podem ser destacadas subdivisões
que agrupam sistemas de acordo com elementos em comum. As características de cada uma
dessas subdivisões são descritas a seguir.
2.2.1 TECNOLOGIA Esta classificação é muito importante, pois define explicitamente o processo utilizado
para a aquisição dos movimentos. Nela os sistemas de MoCap são divididos em: mecânico,
óptico, eletromagnético e acústico.
2.2.1.1 SISTEMA MECÂNICO
No sistema mecânico o ator veste um exoesqueleto preso em suas costas que
acompanha seus movimentos através de sensores, alojados em cada uma das articulações e

6
responsáveis por captar a amplitude de seus movimentos (Furniss, 1999). Outros exemplos de
MoCap pelo sistema mecânico são as de luvas de captura de dados e marionetes articuladas.
Exemplos de sistemas mecânicos são mostrados na fig. 2.1 e na fig. 2.2.
FIGURA 2.1 – ANIMATTION , SISTEMA MECÂNICO DE CAPTURA
Fonte: Silva (1998, p. 34)
A principal vantagem apontada por Furniss (1999) e Silva (1997), na utilização do
sistema mecânico, é o fato de não sofrerem interferência de campos luminosos ou magnéticos.
Como desvantagem os autores comentam que o equipamento precisa ser calibrado antes de
seu uso; que a posição absoluta do ator não é conhecida, mas sim calculada a partir da rotação
das articulações; e que não são capturadas informações como a distância do ator em relação
ao chão no momento do pulo.
FIGURA 2.2 – MARIONETE MECÂNICA DO FILME STARSHIP TROOPERS
Fonte: Silva (1998, p. 34)

7
2.2.1.2 SISTEMA ÓPTICO
De acordo com Silva (1997), nesse tipo de sistema o ator veste marcações refletivas ou
de luz própria que são seguidas por um conjunto de câmeras. Cada câmera gera uma
coordenada 2D para cada refletor. O conjunto de dados 2D capturados pelas câmeras
independentes é então analisado por um software, que fornecerá as coordenadas 3D dos
refletores. Furniss (1997) relata que os primeiros sistemas ópticos foram desenvolvidos para
aplicações na área esportiva.
Um exemplo desse sistema de captura é mostrado na fig. 2.3.
FIGURA 2.3 – SISTEMA ÓPTICO DE CAPTURA
Fonte: Silva (1998, p. 37)
Como pontos positivos do sistema óptico, Furniss (1999) aponta a liberdade do ator na
execução dos movimentos, pois não existem cabos presos a seu corpo; a possibilidade de
captura dos movimentos de mais de um ator por vez; e a alta taxa de amostragem de dados
que, de acordo com Silva (1997), permite a captura de movimentos rápidos como os
executados em artes marciais e esportes olímpicos.
O sistema óptico apresenta também uma série de pontos negativos. Dentre eles está a
interferência de fontes luminosas; o bloqueio de marcações por partes do corpo do ator ou
outras estruturas; a necessidade de se calcular a rotação de certas partes do corpo; e a
informação precisa ser pós-processada para ser obtida, não permitindo ao ator uma visão
completa em tempo real de sua atuação. Tanto Silva (1997) quanto Furniss (1999) apontam o
último ponto negativo citado como sendo o mais prejudicial.

8
2.2.1.3 SISTEMA ELETROMAGNÉTICO
No sistema eletromagnético o ator veste um conjunto de receptores magnéticos que
monitoram e identificam a posição 3D de cada receptor em relação a um transmissor
magnético de posicionamento estático. Cada receptor necessita de um cabo para se conectar
ao computador responsável pelos cálculos (Furniss, 1999).
Um exemplo desse sistema de captura é mostrado na fig. 2.4.
FIGURA 2.4 – MOTION STAR, SISTEMA ELETROMAGNÉTICO DE CAPTURA
Fonte: Silva (1998, p. 36)
Dentre as vantagens na utilização desse sistema, Furniss (1999) aponta a captura da
posição dos receptores; a determinação da orientação do corpo no espaço; a possibilidade de
captura em tempo real, permitindo ao ator o acompanhamento de sua atuação também em
tempo real; e o baixo custo do equipamento. De acordo com Silva (1997), a captura em tempo
real é possível nesse sistema pois o custo computacional é baixo.
Dentre as desvantagens na utilização desse sistema, são apontadas as distorções
magnéticas que ocorrem a grandes distâncias do receptor; interferências causadas por campos
magnéticos provenientes de objetos metálicos; e a limitação nos movimentos do ator, uma vez
que esse precisa atuar com cabos conectados a um computador.
Sistemas eletromagnéticos sem fio são citados por Silva (1997), porém, esses sistemas
ainda são novos no mercado e de custo elevado.

9
2.2.1.4 SISTEMA ACÚSTICO
O sistema acústico consiste em uma série de emissores sonoros anexados ao corpo do
ator e a três receptores de localização fixa.
De acordo com Silva (1997), os transmissores são acionados de forma seqüencial e o
som produzido é captado pelos receptores, que então calculam o posicionamento 3D. Para o
cálculo da posição de cada transmissor é necessário conhecer o tempo decorrido entre a
emissão do ruído pelo transmissor e seu recebimento pelo receptor, e a velocidade do som no
ambiente. Para calcular a posição 3D de cada transmissor, é feita a triangulação das distâncias
deles em relação aos três receptores.
As vantagens apontadas na utilização do sistema acústico são a não ocorrência de
oclusão, típica de sistemas óticos, e a não interferência gerada por objetos metálicos,
percebidos em sistemas eletromagnéticos.
Em contra partida, existe a dificuldade de se obter uma descrição correta dos dados
num instante desejado, devido ao caráter seqüencial do disparo dos transmissores no corpo do
ator; ocorre também o incômodo causado pelos cabos; a reflexão do som emitido pelos
transmissores; e interferência de ruídos externos.
2.2.2 FONTE EMISSORA X SENSORES/MARCADORES Essa classificação divide os sistemas de MoCap em três categorias: inside-in, inside-
out e outside-in (Mulder 1994 apud Silva 1997).
Silva (1997) descreve a semântica desta classificação de forma simples quando diz: “a
primeira palavra refere-se à localização do sensor ou marcador no sistema (inside, se o sensor
está no corpo do ator; e outside, caso esteja fora). Já a segunda palavra indica a posição da
fonte emissora (por exemplo, a câmera dos sistemas óticos), em relação ao corpo do ator”.
2.2.2.1 INSIDE-IN
Neste tipo de sistema, os sensores e fonte transmissora estão localizados no corpo do
ator. Os sistemas mecânicos são inseridos nessa categoria.

10
2.2.2.2 INSIDE-OUT
Inside-out são sistemas onde os sensores estão conectados ao corpo do ator, e que
respondem a sinais emitidos por uma fonte emissora externa. Os sistemas magnéticos e
acústicos são inseridos nessa categoria.
2.2.2.3 OUTSIDE-IN
Em sistemas deste tipo, a fonte emissora está localizada no corpo do ator, enquanto
que os sensores externos capturam seus sinais. São inseridos nessa categoria os sistemas
ópticos, onde as fontes emissoras são os marcadores cobertos com material refletivo ou de luz
própria.
2.2.3 AQUISIÇÃO DOS DADOS Nessa classificação é fornecida uma indicação de como são obtidos os dados
capturados. Dessa forma, os sistemas de MoCap são divididos em: aquisição direta e indireta
(Silva, 1997).
2.2.3.1 AQUISIÇÃO DIRETA
São aqueles cujos dados obtidos não necessitam de nenhum processamento posterior à
captura. Os sistemas de aquisição direta limitam os movimentos do ator e possuem uma baixa
taxa de amostragem. Sendo assim, Silva (1997) inclui nessa categoria os sistemas mecânicos,
eletromagnéticos e acústicos.
2.2.3.2 AQUISIÇÃO INDIRETA
São aqueles que permitem uma maior liberdade ao ator e possuem uma alta taxa de
amostragem. Porém, devido a sua alta tecnologia, são extremamente caros. Nesse tipo de
sistema, os dados obtidos durante o processo são agrupados e analisados, de modo a gerar o
produto final.
Silva (1997) classifica apenas os sistemas ópticos como de aquisição indireta.

11
2.3 ONDE MOCAP NA PRÁTICA É APLICADA E QUAIS OS PRODUTOS DO SISTEMA ÓPTICO DISPONÍVEIS NO MERCADO MoCap é mais aplicável em situações onde é necessário ter uma movimentação
realística ou quando muitos movimentos distintos são atribuídos a um mesmo personagem.
Mas para o caso de animar um personagem de desenho, onde os movimentos são exagerados
e há a necessidade de realismo, a técnica de animação por quadros-chave (keyframing) é mais
utilizada. Existem ainda casos onde ambas as técnicas precisam ser combinadas para obter o
resultado desejado (Pyros, 2001). Animação por quadros-chave consiste em demarcar a forma
e posição de objetos em quadros específicos de uma seqüência animada para depois, através
de sistemas computadorizados, gerar quadros intermediários, criando assim a animação desses
objetos.
Atualmente, várias empresas presentes no mercado disponibilizam soluções em
sistemas de MoCap, dentre elas a Motion Analysis Corporation, que trabalha principalmente
com sistemas ópticos. Sua solução, chamada Motion Analysis RealTime HiRES 3D System, é
composta por uma cadeira de marcadores ópticos que ficam anexados ao corpo do ator e uma
ou mais câmeras de vídeo responsáveis por mapear esse marcadores durante a performance
(Motion, 2001a). O RealTime HiRES 3D é utilizado no auxílio à reabilitação de pacientes
com problemas físicos (Motion, 2001b); na medicina esportiva, com o acompanhamento do
desempenho de atletas (Motion, 2001c) e no desenvolvimento de jogos eletrônicos da EA
Sports, como a série Tiger Woods PGA Tour, que conta com a participação do aclamado
jogador de golfe Tiger Woods (Motion, 2001d).
Conforme Silva (1997), o uso de MoCap na indústria cinematográfica é crescente, pois
torna o trabalho de animação mais fácil. A rapidez de produção e o realismo da animação
gerada fazem desse tipo de processo uma ferramenta extremamente interessante para as
produtoras de efeitos especiais.
Emissoras de televisão também utilizam dessa tecnologia, e já foram criados
programas apresentados por “atores virtuais”. Um exemplo é Moxy, que apresentou um
programa de desenhos animados no Cartoon Netwoork. Moxy utiliza uma mistura de
animação convencional com MoCap, onde os dados capturados de um ator real são mapeados

12
em um personagem animado dos desenhos (Silva, 1997). Moxy não utilizava um sistema
óptico e sim um eletromagnético.
Em meio às fontes pesquisadas não foram encontradas empresas que aplicam
comercialmente a captura do movimento pelo sistema óptico sem a utilização de marcações
especiais. No entanto, muitas aplicações interessantes surgiram em meio acadêmico. Entre
elas figuram os sistemas de animação de personagens, que serão detalhados no capítulo 3, e o
sistema de controle de robôs submarinos proposto em Amat (2001).
O sistema proposto em Amat (2001) consiste na tele-operação de robôs submarinos.
Tele-operação é o uso de meios de comunicações como a linguagem natural ou gestos comuns
na interface homem-máquina. O objetivo da tele-operação é possibilitar a qualquer tipo de
usuário a operação de equipamentos em diferentes ambientes de trabalho, com pouco ou
nenhum treinamento. Isso é possível porque a interação homem-máquina passa a ser muito
mais confortável e prática.
O controle de robôs a partir de um joystick é muito comum em áreas como a
engenharia civil, limpeza de esgotos, etc. Mas quando o grau de liberdade dos movimentos do
robô é alto ou a operação de controle exige grande habilidade por parte do controlador, é
conveniente usar dispositivos mais sofisticados.
Garbi, mostrado na fig. 2.5, é um robô submarino com braços articulados, criado para
executar tarefas simples como vasculhar e coletar amostras no fundo de mares, rios e lagos.
FIGURA 2.5 – GARBI, ROBÔ SUBMARINO
Fonte: Amat (2001, p. 8)

13
De acordo com Amat (2001) a navegação do robô Garbi é controlada por joystick e o
controle de seus braços mecânicos é feito pela captura do movimento do controlador,
atendendo os seguintes passos:
a) Processamento de imagens do operador em tons de cinza para detecção de
movimento;
b) Detecção e extração do posicionamento de pontos significativos dos braços do
operador;
c) Cálculo do posicionamento 3D dos braços do operador, através de um modelo
geométrico simples pré-construído, gerando um exoesqueleto virtual, como
mostrado na fig. 2.6;
d) Controle dos braços mecânicos do robô a partir das coordenadas obtidas no modelo
3D.
FIGURA 2.6 – EXOESQUELETO VIRTUAL DE GARBI
Fonte: Amat (2001, p. 9)
Nesse capítulo, procurou-se abordar os conceitos de captura do movimento,
apresentando seu histórico, classificação e dando uma visão geral da utilidade e da aplicação
de sistemas ópticos. O próximo capítulo apresenta uma visão geral sobre os principais
conceitos e técnicas envolvidas na implementação de um protótipo de sistema para captura de
movimento sem marcações especiais, usando como ponto de partida princípios encontrados
na bibliografia pesquisada.

14
3 SISTEMA ÓPTICO DE MOCAP EM TEMPO REAL Nas seções anteriores foram abordados conceitos básicos e gerais da captura do
movimento. No presente capítulo são apresentados os conceitos mais específicos do sistema
óptico de captura em tempo real, sem a utilização de marcações especiais.
De modo geral, os sistemas que realizam essa forma de captura possuem os seguintes
estágios de processamento:
a) Captura dos dados de entrada a partir de câmeras de vídeo;
b) Remoção do fundo da cena e detecção dos objetos em movimento;
c) Análise da silhueta dos objetos em movimento e localização da possível figura
humana;
d) Segmentação da silhueta para identificação do posicionamento 2D das partes do
corpo do ator;
e) Identificação do posicionamento 3D das partes do corpo;
f) Reconstituição dos movimentos do ator.
As seções seguintes descrevem cada um dos estágios citados.
3.1 ORIGEM E CAPTURA DOS DADOS DE ENTRADA Os dados de entrada podem ser obtidos com o uso de câmeras de vídeo, que podem
captar imagens em tons de cinza ou coloridas a uma freqüência de n quadros por segundo.
Conforme Davis (1999), câmeras de vídeo, assim como scanners, medem a
intensidade da luz refletida pelos objetos no ambiente sobre uma matriz de espaçamentos
regulares. Cada uma das células dessa matriz é chamada de pixel e, geralmente, câmeras
filmadoras usadas para a televisão capturam os quadros do vídeo em matrizes de 512x480
pixels a uma freqüência de trinta quadros por segundo.
Para filmes em tons de cinza, cada pixel de coordenada (x,y) armazena um valor, que é
proporcional à iluminação do ambiente naquele ponto. Para filmes coloridos, cada pixel de
coordenada (x,y) armazena três valores, que indicam a intensidade de vermelho, verde e azul
(RGB, Red-Green-Blue) que compõe a cor do ambiente naquele ponto.

15
De acordo com Macintyre (2000?) o fato das câmeras de vídeo usarem matrizes para a
representação das imagens capturadas às caracteriza como dispositivo de captura raster 2D
com sistema de referência absoluto.
3.2 REMOÇÃO DO FUNDO DA CENA E DETECÇÃO DE OBJETOS EM MOVIMENTO Uma forma de discriminar um objeto em movimento do fundo da cena é o método
chamado Background Subtraction (subtração do fundo). Esse método é descrito por Davis
(2000?), Elgammal (2000) e Horprasert (2000a? e 2000b?). A subtração do fundo consiste em
subtrair a imagem atual de uma imagem usada como referência, contendo apenas o fundo da
cena e construída a partir de uma seqüência de imagens durante um período de treinamento. A
subtração deixa visível apenas objetos não estáticos e novos objetos. Elgammal (2000) utiliza
a subtração do fundo em imagens em tons de cinza, enquanto Davis (2000?) e Horprasert
(2000a? e 2000b?) utilizam em imagens coloridas, por esse motivo os dois autores serão
usados como referência no restante desta seção.
De acordo com os autores citados anteriormente, uma das habilidades fundamentais da
visão humana é a fidelidade à cor. Os seres humanos tendem a associar uma cor constante a
um objeto mesmo que esse esteja sob a influência de variações de luminosidade. A fidelidade
à cor é importante na remoção do fundo da cena pois permite ao programa a correta
classificação dos objetos, independente da projeção de sombras sobre eles. Com isso sombras
de objetos em movimento são ignoradas e não classificadas também como objetos em
movimento.
Na tentativa de reproduzir essa característica humana, foi desenvolvido um modelo de
cor capaz de separar a distorção da cor da distorção da luminosidade, a partir de uma imagem
de referência e da imagem atual. Esse modelo é mostrado na fig. 3.1, onde: i é o índice de um
pixel nas imagens; O é o ponto de origem, onde as coordenadas para R, G e B são igual a
zero; ],,[ )()()( iBiGiRi EEEE = representa o conjunto de valores RGB esperados para o pixel na
imagem de referência; ],,[ )()()( iBiGiRi IIII = representa o conjunto de valores RGB do pixel
na imagem atual, da qual se deseja subtrair o fundo; e a linha iOE , que passa pelos ponto O e

16
iE , é a “linha cromática esperada”, composta por pontos que representam o fundo da cena
com ou sem a aplicação de luz e sombra.
Usando a relação entre iI e iOE são encontrados os valores da distorção da
luminosidades ( iα ) e da distorção da cor ( iCD ), sendo iCD a distância ortogonal entre a cor
observada em iI e a linha cromática esperada; iα é um escalar, se seu valor for igual a 1,
indica a luminosidade idêntica ao fundo original, um valor maior que 1 indica o fundo mais
iluminado e um valor menor que 1 indica o fundo menos iluminado.
FIGURA 3.1 – MODELO DE COR PROPOSTO NO ESPAÇO TRIDIMENSIONAL RGB
R
G
B
0
Ei
Ii
. CDi
αiEi
Fonte: Adaptado de Horprasert (2000a)
Para realizar a subtração do fundo, o modelo de cor proposto pelos autores passa pelas
seguintes etapas:
a) Modelagem do fundo (background modeling): onde a imagem de referência E é
construída a partir de uma série de imagens contendo apenas o fundo da cena;
b) Seleção do limiar (threshold selection): onde são escolhidos os valores mínimo e
máximo aceitos para a distorção de luminosidade α e de cor CD ;
c) Operação de subtração (subtraction operation) ou classificação do pixel (pixel
classification): onde os pixels das novas imagens I informadas são classificados

17
como em movimento, pertencente ao fundo original, pertencentes ao fundo com
sombra ou ao fundo mais iluminado.
A classificação dos pixels gera uma imagem binária que indica se o pixel faz parte do
fundo (seja ele original, sombreado ou iluminado) ou em movimento. A fig. 3.2 ilustra todas
as etapas do processo da subtração do fundo da cena, onde: no canto superior esquerdo é
mostrada a imagem de referência construída; no canto superior direito é mostrada a imagem
da qual será subtraído o fundo; no canto inferior esquerdo é mostrado o resultado da
classificação dos pixels; e no canto inferior direito é mostrada a imagem binária gerada. Nesta
figura a cor preta representa o fundo da cena, a cor azul e a cor branca representam os objetos
em movimento e a cor vermelha representa o fundo sombreado.
FIGURA 3.2 – EXEMPLO DE RESULTADO DA SUBTRAÇÃO DO FUNDO
Fonte: Horprasert (2000a?, p. 4)
3.3 ANÁLISE DAS SILHUETAS E LOCALIZAÇÃO DA PROVÁVEL FIGURA HUMANA A imagem binária gerada pela operação de remoção do fundo da cena mostra quais
pixels foram classificados como fundo da cena e quais pixels foram classificados como em
movimento. No entanto, os pixels classificados como em movimento nem sempre fazem parte
da figura humana, eles podem ser o resultado das falhas do algoritmo de remoção do fundo
empregado. Os conjuntos de pixels obtidos a partir dessa falha são chamados de ruído.

18
Levando-se em conta a existência de ruído, é preciso desenvolver um mecanismo que
distinga o conjunto de pixels que sejam vizinhos entre si e que fazem parte da figura humana e
descarte os conjuntos de pixels que sejam vizinhos entre si e que não fazem parte da figura
humana. Para tanto, pode ser usado um método clássico da computação gráfica denominado
Contour Following (Kansas, 1999), o qual identifica os pixels que fazem parte do contorno do
objeto. Após obter o contorno de cada conjunto de pixels vizinhos, o contorno que melhor
atende aos pré-requisitos é identificado como “figura humana”. Os demais contornos passam
a ser considerados parte do fundo da cena.
Não foi encontrado, na bibliografia pesquisada, material sobre o tratamento do ruído
gerado pela remoção do fundo das cenas. A explicação detalhada do algoritmo da solução
implementada, assim como os pré-requisitos para identificar um conjunto de pixel vizinhos
como sendo a figura humana, é exposta na seção 6.3.3, e representa uma contribuição original
deste trabalho.
3.4 SEGMENTAÇÃO DA SILHUETA PARA IDENTIFICAÇÃO DO POSICIONAMENTO 2D DAS PARTES DO CORPO Ghost é um sistema em tempo real para estimação da postura do corpo humano e
detecção das partes do corpo em imagens monocromáticas. Conforme Haritaoglu (1998), esse
sistema identifica partes primárias (cabeça, mão, pés e torso) e partes secundárias (cotovelos,
joelhos, ombros, axilas, quadril e parte superior das costas) a partir da silhueta humana em
posturas genéricas, não apenas quando a pessoa está em pé como acontece na segmentação da
silhueta proposta por Horprasert (2000c?).
Haritaoglu (1998) relata que o sistema Ghost admite as seguintes posturas base por
parte do ator:
a) Em pé;
b) Sentado;
c) Engatinhando;
d) Deitado.
Para cada postura, são aceitas as seguintes visões de câmera:
a) Frontal;

19
b) Traseira;
c) Lateral direita;
d) Lateral esquerda.
Combinando as posturas base e as visões de câmera, são identificados dezesseis
estados básicos em que a silhueta pode estar inserida. O Ghost é treinado uma única vez, a
partir de vídeos com movimentação controlada e armazena informações a respeito de cada
uma dos dezesseis estados. Os dados adquiridos no treinamento são usados no
reconhecimento do posicionamento das partes primárias e secundárias do ator, executando os
seguintes passos:
a) São feitas comparações entre os principais estados armazenados e a silhueta atual, o
estado que tiver maior similaridade determina a postura estimada;
b) Um algoritmo recursivo, que identifica os pontos convexos da silhueta, é aplicado
para encontrar a possível localização das partes do corpo naquela postura
específica;
c) É localizada a cabeça do ator, a partir da utilização do maior eixo da silhueta, dos
pontos convexos encontrados e da topologia da postura estimada;
d) Após a determinação da posição da cabeça, é aplicada uma análise topológica para
eliminar os pontos convexos que não identificam partes do corpo e para mapear os
pontos convexos restantes.
Para seu correto funcionamento, o sistema parte de dois princípios:
a) Nem sempre as partes primárias fazem parte do contorno da silhueta, no entanto
partes secundárias geralmente fazem parte do contorno da silhueta, sendo assim,
elas podem ser usadas para encontrar partes primárias;
b) O corpo humano seja qual for sua posição possui uma estrutura topológica que
limita o posicionamento relativo das partes do corpo, pois é formado por estruturas
rígidas e articulações.
A fig.3.3 ilustra um exemplo do resultado obtido pelo sistema Ghost. As áreas
demarcadas com a cor amarela representam a localização dos pés do ator; as áreas marcadas
pela cor rosa representam a localização das mãos do ator; a área marcada pela cor verde
representa a cabeça do ator e a área marcada pela cor vermelha representa o torso do ator.

20
FIGURA 3.3 – EXEMPLO DE RESULTADO DA SEGMENTAÇÃO REALIZADA PELO SISTEMA GHOST
Fonte: Haritaoglu (1998, p. 8)
Uma alternativa para detecção das partes do corpo sem a utilização de silhuetas é
descrita por Elgammal (2001?). Ela consiste em uma forma de identificar as partes do corpo
do ator a partir cor das roupas que ele usa e funciona apenas para pessoas que estão em pé.
Conforme mostra a fig. 3.4, este sistema classifica as partes do corpo em superior ou
inferior, de acordo com a diferença entre a cor da camisa, camiseta ou blusa (para a parte
superior) e calça, bermuda ou saia (para a parte inferior). A posição da cabeça é estimada em
uma segunda etapa, com base em sua relação com a parte superior do corpo.
FIGURA 3.4 – EXEMPLO DE RESULTADO DA SEGMENTAÇÃO A PARTIR DA IDENTIFICAÇÃO DAS CORES DA ROUPA
Fonte: Elgammal (2001?, p. 16)
O sistema proposto por Elgammal (2001?) não é tão eficiente quanto o sistema
proposto por Haritaoglu (1998), quando o objetivo é a identificação tanto de partes primárias

21
quanto de partes secundárias do corpo, seja qual for o posicionamento do ator. No entanto,
quando o objetivo for rastrear uma pessoa em meio a uma multidão, o sistema proposto por
Elgammal (2001?) mostra-se mais prático.
3.5 IDENTIFICAÇÃO DO POSICIONAMENTO 3D DAS PARTES DO CORPO Até o momento foi exposta uma maneira de extrair a localização 2D das partes do
corpo de uma pessoa, denominada “ator”, a partir de um conjunto de imagens raster 2D
contendo apenas o cenário estático e o ator. Para recapitular cada uma das etapas do processo,
é exibida a fig. 3.5, onde: (a) é a imagem de referência construída a partir de amostras
contendo apenas o fundo da cena; (b) é um dos quadros do vídeo que está sendo analisado; (c)
é o resultado da classificação dos pixels da imagem em (b) após sua comparação com a
imagem em (a); (d) e (e) são os resultados da análise e segmentação da silhueta do objeto em
movimento; e (f) mostra a classificação de cada um dos segmentos encontrados. Ainda na fig.
3.5 é observada uma referência ao 3D Module, que tem como objetivo identificar o
posicionamento 3D das partes do corpo, tema desta seção.
Conforme Davis (2000?) e Horprasert (2000c?), a utilização de uma única câmera não
é suficiente para a obtenção do posicionamento 3D das partes do corpo do ator. No entanto,
ao utilizar mais de uma câmera é possível capturar as coordenadas 2D e estimar o
posicionamento 3D dessas partes. Outra vantagem na utilização de mais de uma câmera é a
redução da ocorrência da “oclusão”, fenômeno onde uma parte do corpo não é filmada pois
outra parte do corpo ou outro elemento em cena fica em seu caminho na obtenção das
imagens.
Por serem utilizadas várias câmeras, a situação ideal é montagem de um sistema
distribuído de processamento, conforme a fig. 3.6, onde cada câmera é ligada a um
computador que adquire o posicionamento 2D das partes do corpo identificadas. Os resultados
obtidos pelos módulos 2D são então enviados a uma central de processamento, que executará
a triangulação quadrática das posições 2D de cada parte do corpo, resultando no
posicionamento 3D dessas partes.

22
FIGURA 3.5 – DIAGRAMA DO PROCESSO DE LOCALIZAÇÃO 2D DAS PARTES DO CORPO DO ATOR
Fonte: Davis (2000?, p. 23)
Além da triangulação quadrática, Davis (2000?) e Horprasert (2000c?) também
utilizam um valor que indica o grau de confiabilidade do posicionamento da câmera para a
detecção de cada parte do corpo.
FIGURA 3.6 – DIAGRAMA DA TOPOLOGIA PARA A CAPTURA DO POSICIONAMENTO 3D DAS PARTES DO CORPO
x, y
y, z
x, z
Câmera Frontal
CâmeraLateral
Câmera Superior
x, y, z
Universo 3D
Ator

23
3.6 RECONSTITUIÇÃO DOS MOVIMENTOS DO ATOR A reconstituição dos movimentos do ator pode ser feita com a utilização de uma
marionete virtual, como as que são mostradas na fig. 3.7 e utilizadas em Horprasert (2000a e
2000c) e Iwasawa (1999).
FIGURA 3.7 – MARIONETES VIRTUAIS
Fonte: Horprasert (2000c)
Devido à grande quantidade de cálculos executados nas etapas de análise das imagens
e a necessidade de se manter a execução do vídeo em tempo real, é inevitável a perda de
alguns dos quadros do vídeo. Pressupõe-se então que o resultado obtido da triangulação
quadrática não mantém a amostragem de trinta quadros por segundo, não mantendo assim a
sensação de suavidade na animação da marionete.
Para solucionar o problema da perda de quadros, pode ser utilizada a técnica de
animação por quadros-chave, citada na seção 2.3, onde os quadros analisados seriam os
quadros-chave para a geração de quadros intermediários. Informações adicionais a respeito
dessa técnica podem ser encontradas em Santos (2000). É importante lembrar que, quando o
objetivo é gerar a animação da marionete sincronizada com a performance do ator, a
interpolação de quadros torna-se inviável, pois esse processo atrasaria a reconstituição dos
movimentos do ator na marionete.
No presente capítulo foram apresentados conceitos teóricos de sistemas ópticos de
captura em tempo real, sem a utilização de marcações especiais. O próximo capítulo é
reservado ao estudo das funcionalidades do JavaTM Media Framework, utilizado na
implementação do protótipo.

24
4 JAVATM MEDIA FRAMEWORK (JMF) Em meio à grande diversidade de equipamentos e sistemas operacionais existentes, um
dos maiores problemas das linguagens de programação é sem dúvida a portabilidade. Para a
linguagem Java isso não é uma barreira, pois foi projetada como uma linguagem de propósito
geral, orientada a objetos, de simples compreensão, portátil e com características modernas de
programação. Seu projeto original foi voltado ao uso em eletrodomésticos, porém se
popularizou ao lado da internet, onde em cada ponta da rede podem ser encontrados
computadores e sistemas operacionais de diferentes arquiteturas.
De acordo com Sun (2000b) o pacote JavaTM 2 SDK Standard Edition incorpora os
componentes básicos para o desenvolvimento de aplicações e applets Java. Para a utilização
de recursos mais específicos, são disponibilizadas API’s que buscam facilitar o
desenvolvimento de softwares.
Para a utilização de recursos multimídia e integração desses recursos com a internet é
disponibilizado um conjunto de APIs chamado de “The Java Media Family”. De acordo com
Sun (2002), esse conjunto é formado pelas seguintes APIs:
a) JavaTM 2D: provê um modelo abstrato para trabalhar com imagens do tipo raster e
do tipo vetorial 2D, que incluem linhas, sistemas de cores, transformações e
composições;
b) JavaTM Media Framework: especifica uma arquitetura unificada, protocolo de
mensagens e interface de programação para reprodução, captura, conferência de
mídia baseada em tempo. É composta por três APIs distintas: Java Media Player,
Java Media Capture e Java Media Conference;
c) JavaTM Collaboration: permite a interação e comunicação entre redes de topologia
variada;
d) JavaTM Telephony: integra o sistema telefonia com o computador e provê
funcionalidades básicas para controle de chamadas em primeira e terceira instância;
e) JavaTM Speech: provê rápido reconhecimento e síntese da fala humana;
f) JavaTM Animation: dá suporte à animação e transformações 2D de objetos,
enquanto é utilizada a JMF para sincronização, composição e controle em tempo
real;

25
g) JavaTM 3D: provê um modelo abstrato e interativo que auxilia na manipulação de
objetos 3D.
Como mencionado anteriormente, a JMF proporciona um alto nível de abstração no
que diz respeito à captura, conferência e reprodução de mídia baseada em tempo e esse foi o
principal motivo da escolha da linguagem Java para a confecção do protótipo, pois fazendo
uso dessa abstração é possível dedicar-se ao foco do problema ao invés de desviar a atenção a
detalhes como formato de arquivos, processo de captura da câmera e exibição da mídia.
Nas seções seguintes serão apresentados os principais pacotes, classes e interfaces da
JMF e a visualização de seu fluxo de dados. Informações complementares sobre a arquitetura
dessa API poderão ser encontradas em Sun (1999) e Sun (2000a).
4.1 CLASSES E INTERFACES RELEVANTES De uma forma simples, Eckel (2000) descreve as classes como sendo tipos de dados
abstratos, dos quais podem ser instanciados objetos que encapsulam um conjunto de
propriedades e se comunicam através de um conjunto de mensagens (métodos) pré-definidas.
As interfaces, por sua vez, estabelecem quais os pedidos que podem ser feitos a um objeto em
particular e os pacotes representam bibliotecas que agrupam classes, interfaces e outros
pacotes.
4.1.1 CONTROLE DO TEMPO A precisão na administração do tempo na JMF é feita em nanosegundos.
A interface Clock mantém as operações de contagem e sincronização do tempo,
necessários para a apresentação da mídia. Clock faz uso de um TimeBase, que sinaliza a
passagem do tempo, como o cristal em um relógio. A classe Time representa um instante no
tempo, em nanosegundos, e a interface Duration provê uma forma de representar a duração
da mídia.
A classe DataSource e interfaces como Player e Processor, que serão
abordadas nas seções 4.1.4 e 4.1.6, implementam as interfaces de controle do tempo citados
no parágrafo anterior.

26
4.1.2 ADMINISTRAÇÃO DE RECURSOS JMF deixa à disposição do usuário algumas “classes administradoras”. Essas classes
servem de intermediárias na integração dos recursos do sistema.
A seguir, a lista de administradores de recursos do JMF:
a) Manager: seus métodos create devem ser utilizados para instanciar um ou mais
objetos do tipo Player, Processor, DataSource ou DataSink. Esses
quatro tipos de objetos serão abordados nas seções 4.1.4 e 4.1.6;
b) PackageManager: mantém as listas de prefixos dos pacotes das classes
(caminho das classes) que gerenciam os protocolos e recursos disponíveis no
computador;
c) CaptureDeviceManager: é usado no gerenciamento dos dispositivos de
captura (câmeras, microfones, scanners, etc.). Seu principal método é o
getDeviceList(Format format), que retorna a lista de dispositivos que
satisfazem os pré-requisitos descritos em format;
d) PlugInManager: mantém a lista de plug-ins registrados, que pode ser
manipulada através dos métodos addPlugIn, removePlugIn e
setPlugInList. Esses plug-ins implementam as interfaces Multiplexer,
Demultiplexer, Codec, Effect ou Renderer, que são responsáveis pelo
processamento dos dados da mídia. Nesse trabalho o único tipo de plug-in relevante
é o que implementa a interface Codec, que será abordada com maior profundidade
na seção 4.1.6.
Com exceção do PackageManager, as demais classes administradoras foram
utilizadas na implementação do protótipo.
4.1.3 GERENCIAMENTO DE EVENTOS Para manter o sistema informado do estado atual da mídia, JMF utiliza um mecanismo
para envio e recebimento de eventos.
Quando um objeto precisa disparar um evento que informe seu estado atual, ele
instancia um MediaEvent. São quatro as classes filhas de MediaEvent:

27
a) ControllerEvent: classe base para os eventos disparados por um
Controller, exibidas na fig. 4.1;
b) DataSinkEvent: classe base para os eventos disparados por um DataSink,
exibidas na fig. 4.2;
c) GainControlEvent: esse tipo de evento é disparado por um GainControl,
para sinalizar uma mudança de estado. GainControl é uma interface específica
para trilhas de áudio, por isso não será aprofundada nesse trabalho;
d) RTPEvent: classe base para todas as notificações de um SessionManager.
Elementos de Real-Time Transport Protocol (RTP) não foram utilizados nesse
trabalho, por esse motivo não serão aprofundados.
FIGURA 4.1 – DIAGRAMA DE CLASSES QUE MOSTRA AS CLASSES FILHAS DE CONTROLLEREVENT
ControllerEvent
AudioDevic eUnavai la bleEvent
Cac hingCon trolEventControllerC los edEvent
Co ntrollerErrorEvent DataLostErrorEvent
ConnectionErrorEvent InternalErrorEvent
ResourceUnavai lable Event
DurationUpdateEvent
RateChangeEvent SizeChangeEvent
StopTimeChangeEvent
M ediaTimeSetEvent
TransitionEvent
ConfigureCom pleteEvent
PrefetchCompleteEvent
RealizeCom p leteEventStartEvent
StopEvent
DataStarvedEvent EndOfMediaEvent
Rest art ingEvent
StopAtTimeEvent
Sto pByRequestEventDeallocateEvent
MediaEvent
Fonte: Adaptado de Sun (1999)
O envio do evento fica a cargo de objetos cuja classe implementa um Controller,
Control ou DataSink.
O recebimento e tratamento de eventos do tipo ControllerEvent é feito por
classes que implementam a interface ControllerListener e que possuam o método

28
controllerUpdate(ControllerEvent event), que será chamado a cada
ControllerEvent gerado. E o recebimento e tratamento de eventos do tipo
DataSinkEvent é feito por classes que implementam a interface
datasink.DataSinkListener e que possuam o método
dataSinkUpdate(DataSinkEvent event), que será chamado a cada
DataSinkEvent gerado.
FIGURA 4.2 – DIAGRAMA DE CLASSES QUE MOSTRA AS CLASSES FILHAS DE DATASINKEVENT
MediaEvent
DataSinkEvent
DataSinkErrorEvent EndOfStreamEvent
4.1.4 GERENCIAMENTO E FORMATO DOS DADOS
Para gerenciar os dados, é usado um DataSource. Essa classe abstrai tanto a
localização quanto o protocolo utilizado para o acesso à mídia. Uma vez usado, o
DataSource não pode ser reutilizado.
A localização do dado é informada ao DataSource através da instância de um
MediaLocator, passados para ele em seu construtor DataSource(MediaLocator
source). Por sua vez, o caminho para a mídia é informado ao MediaLocator também
através de seus construtores, MediaLocator(String locatorString) e
MediaLocator(URL url). Uma vez dentro do DataSource, os dados são gerenciados
por um ou mais SourceStreams.

29
Depois de identificada a localização, o próximo passo é identificar o formato da mídia.
Para isso, é utilizada a classe Format. Essa classe origina duas outras classes filhas:
a) AudioFormat, que especifica atributos de trilhas de áudio;
b) VideoFormat, que especifica atributos de trilhas de vídeo.
A fig. 4.3 mostra a disposição das classes que identificam o formato da mídia,
observado que a classe VideoFormat dá origem a diversas outras classes, porém apenas a
RGBFormat é relevante, pois descreve dados RGB e será utilizada na implementação do
protótipo.
FIGURA 4.3 – DIAGRAMA DE CLASSES QUE MOSTRA AS CLASSES FILHAS DE FORMAT
Format
AudioFormatVideoFormat
IndexedColorForm at
RGBFormat
YUVFormat
JPEGFormat
H261Form at
H263Format
Fonte: Adaptado de Sun (1999)
4.1.5 CONTROLES
JMF define a interface Control como base para o controle do tráfego de dados, tanto
nos sentidos origem/player e player/destino, quanto nas interações feitas durante a execução
da mídia. Para esse trabalho o único Control de interesse é o TrackControl, que
permite ao Processor a consulta, controle e manipulação da mídia em trilhas individuais
de áudio e vídeo. A interface TrackControl é derivada da interface FormatControl,
que por sua vez é derivada da interface base Control, como mostra a fig. 4.4.

30
FIGURA 4.4 – DIAGRAMA DE CLASSES QUE MOSTRA AS SUPER-INTERFACES DE TRACKCONTROL
TrackControl
s etCodecChain()s etRenderer()
<<Interface>>
FormatControl
getForm at()getSupportedForm ats ()is Enabled()s etEnabled()s etForm at()
<<Interface>>
Control
getCon trolCom pone nt()
<<Interface>>
Os principais métodos de TrackControl são setCodecChain(Codec[]
codecs), que define a lista de plug-ins do tipo Codec que serão atribuídos à trilha
específica, e getFormat(), herdado de FormatControl, que identifica o formato do
dado controlado por esse TrackControl.
4.1.6 APRESENTAÇÃO E PROCESSAMENTO DA MÍDIA A apresentação da mídia é feita por classes que implementam as interfaces filhas de
Controller, Player e Processor, mostradas na fig. 4.5.
O Player utiliza um DataSource como origem dos dados e repassa as
informações para dispositivos de saída, como monitor e caixas de som.
O Processor, como filho da interface Player, também utiliza um DataSource
como origem dos dados e repassa as informações para dispositivos de saída. Porém, o
Processor está habilitado a executar certo processamento sobre os dados de entrada,
através da utilização de plug-ins junto a seu TrackControl. Também é permitida ao
Processor a criação de um DataSource como resultado de seu processamento. O
DataSource gerado na saída do Processor poderá ser utilizado como entrada de dados

31
de outro Player ou Processor, ou ainda como entrada de um DataSink, responsável
por salvar esse DataSource em um arquivo.
FIGURA 4.5 – DIAGRAMA DE CLASSES QUE MOSTRA O CONTROLLER E SUAS INTERFACES FILHAS
Clock<<Interface>>
TimeBase<<Interface>> possui um
Durat ion< <Interface >>
Controll er<<Interface>>
MediaHandler<<Interface>>
Player<<Interface>>
P rocessor<<Interface>>
DataSourcepossui um (input)
possui um (output)
Fonte: Adaptado de Sun (1999)
Codec é a interface que representa o plug-in responsável por executar algum
processamento sobre os Buffers individuais da mídia que está sendo reproduzida no
Processor. Esse processamento é feito a partir da implementação de seu método
process(Buffer in, Buffer out), onde in é o Buffer original e out é o
Buffer processado.
Buffer é a classe que carrega os dados da mídia de um estágio de processamento
para outro dentro de um Player ou Processor. Objetos do tipo Buffer mantém
informações como: o dado em si, tempo de duração, tamanho e formato de seus dados. Essas
informações são armazenadas nas propriedades data, duration, length e format,
respectivamente.

32
4.2 FLUXO DOS DADOS A melhor forma de se compreender o fluxo dos dados entre os elementos da JMF é
através da analogia entre elementos do mundo real com suas principais classes e interfaces.
Essa analogia é mostrada na fig. 4.6, onde em um primeiro estágio a câmera de vídeo (video
camera) captura os dados do ambiente e escreve esses dados para uma fita de vídeo (video
tape), que será lida pelo vídeo cassete (VCR), responsável em exibir as informações em
dispositivos de saída, como aparelhos de televisão e caixas de som.
FIGURA 4.6 – ANALOGIA ENTRE ELEMENTOS DO MUNDO REAL E CLASSES E INTERFACES DA JMF
Fonte: Sun (1999)
Adaptando o modelo real apresentado acima para um diagrama mais simples que visa a
interação do Player com os demais elementos, é construído o modelo mostrado na fig. 4.7.
Nesse modelo o elemento que captura os dados torna-se oculto, pois o DataSource abstrai
a localização física da mídia, sendo essa uma informação irrelevante ao Player.
FIGURA 4.7 – MODELO DE FLUXO, UTILIZANDO UM PLAYER
Fonte: Sun (1999)

33
Semelhante ao Player, o Processor também obtém os dados de um
DataSource e os reproduz nos dispositivos de saída, conforme mostra a fig. 4.8. No
entanto, de acordo com o exposto na seção 4.1.6, é permitido ao Processor a criação de
um DataSource que contenha os dados que seriam reproduzidos, assim como o
processamento da mídia que por ele transita. Devido a essas característica, o Processor
apresenta um fluxo interno de dados mais completo, que é mostrado na fig. 4.9.
FIGURA 4.8 – MODELO DE FLUXO, UTILIZANDO UM PROCESSOR
Fonte: Sun (1999)
FIGURA 4.9 – ESTÁGIOS DO FLUXO DENTRO DO PROCESSOR
Fonte: Adaptado de Sun (1999)
Abaixo são enumerados os estágios do fluxo interno de dados de um Processor:
a) Demultiplexação: é feita por um plug-in do tipo Demultiplexer e consiste na
análise dos dados de entrada e divisão desses dados em diferentes trilhas de áudio e
vídeo;
b) Pré-processamento: nesse estágio são aplicados efeitos sobre uma trilha de entrada
específica, visando facilitar o trabalho Codec. O pré-processamento é feito por um

34
plug-in do tipo Effect, que, diferente do Codec, não está habilitado a modificar
o formato da mídia;
c) Transcodificação: é feita por um plug-in do tipo Codec e consiste no processo de
conversão das trilhas da mídia de um formato para outro;
d) Pós-Processamento: nesse estágio são aplicados efeitos sobre a trilha
transcodificada. Assim como o pré-processamento, o pós-processamento é feito por
plug-ins do tipo Effect;
e) Multiplexação: é o processo inverso da demultiplexação. Nele várias trilhas são
convertidas em um único segmento de dados. Esse processo é feito por plug-ins do
tipo Multiplexer;
f) Renderização: é feita por plug-ins do tipo Renderer e consiste no processo de
redistribuição da mídia para exibição ao usuário.
Nesse capítulo foram apresentados os componentes do JMF relevantes na
implementação do protótipo. O próximo capítulo busca apresentar uma introdução aos
conceitos matemáticos utilizados no desenvolvimento do protótipo.

35
5 CONCEITOS MATEMÁTICOS ENVOLVIDOS O presente capítulo tem por objetivo fazer uma introdução aos conceitos matemáticos
utilizados no desenvolvimento do protótipo. Dentre esses conceitos são identificados dois
grupos: o grupo de conceitos estatísticos, abordados na seção 5.1, e o grupo de conceitos
geométricos, abordados na seção 5.2.
5.1 CONCEITOS ESTATÍSTICOS O objetivo da estatística é fazer inferências sobre uma população, a partir de uma
amostra da mesma (Wonnacott, 1980).
Os conceitos estatísticos expressados nesta seção são utilizados na etapa de remoção
do fundo da cena e detecção de objetos em movimento, fundamentada na seção 3.2 e
implementada na seção 6.3.2. Como referência bibliográfica para essa seção, é utilizado
Wonnacott (1980).
5.1.1 CENTRO DE UMA DISTRIBUIÇÃO, A MÉDIA A média é uma maneira de se medir o centro de uma distribuição. Sendo também
conhecida como média aritmética, a média é a mais comum das medidas de tendência central.
A média é obtida a partir da divisão do total do somatório das observações originais
pelo número de elementos observados. A equação 5.1 é utilizada no cálculo da média, onde:
X é a média propriamente dita; n é o número de elementos dos quais se quer extrair a
média; e iX é o elemento observado de índice i .
EQUAÇÃO 5.1 – MÉDIA ARITMÉTICA
∑−
=
=1
0
1 n
iiX
nX
5.1.2 DISPERSÃO DE UMA DISTRIBUIÇÃO, O DESVIO PADRÃO
Além do centro de uma distribuição, outra medida estatística importante é a dispersão
de uma distribuição. O desvio padrão é uma das formas de se medir a dispersão de uma

36
distribuição e é a forma indicada para quando o objetivo é utilizar uma amostra para fazer
inferências sobre a população.
A equação 5.2 é utilizada no cálculo do desvio padrão, onde: s é o desvio padrão
propriamente dito; n é o número de elementos que estão sendo trabalhados; iX é o elemento
observado de índice i ; e X é a média aritmética dos elementos observados.
EQUAÇÃO 5.2 – DESVIO PADRÃO
( )∑−
=
−−
=1
0
2
11 n
ii XX
ns
5.1.3 DISTRIBUIÇÕES DE PROBABILIDADE E ESTIMATIVA POR INTERVALO
As distribuições de probabilidade podem ser apresentadas em um historiograma de
freqüência relativa, como mostra a fig. 5.1, onde no eixo horizontal são apresentados os
valores observados e no eixo vertical é apresentada a freqüência de ocorrência de cada um
desses valores em relação ao número de elementos.
FIGURA 5.1 – EXEMPLO DE HISTORIOGRAMA DE FREQÜÊNCIA RELATIVA
0
0,1
0,2
0,3
0,4
... 5 6 7
Valores Observados
Freq
üênc
ia R
elat
iva
As distribuições de probabilidade são formas de representação da probabilidade de
ocorrência de um evento em uma população. A probabilidade calculada pode ser exata,
quando calculada sobre todos os dados da população, ou aproximada, quando calculada sobre
uma amostra desta população.

37
Quando se usa uma amostra da população, como é o caso deste trabalho, existe a
necessidade de se criar um intervalo de confiança e de se aceitar um erro amostral, isso
porque a média dos valores obtidos na amostra não é igual à média dos valores da população,
porém ela pode ser estimada pelo intervalo expressado na equação 5.3, onde µ é a média
populacional e X a média amostral.
EQUAÇÃO 5.3 – ESTIMATIVA DA MÉDIA POPULACIONAL A PARTIR DA MÉDIA AMOSTRAL
amostragem de erro um±= Xµ
Duas formas de se calcular a distribuições de probabilidade são: a distribuição Normal
e a distribuição de Student.
5.1.3.1 DISTRIBUIÇÃO NORMAL
A distribuição Normal utiliza uma curva específica, em forma de sino, para representar
a distribuição de probabilidade de uma variável aleatória. A essa curva é atribuído o nome de
curva normal ou curva gaussiana.
O gráfico da curva normal de uma variável aleatória Z , quando Normal Padronizada,
é igual ao gráfico exibido na fig. 5.2. Para uma variável ser considerada Normal Padronizada,
a média dos valores observados ( Z ) deve ser igual a zero e o desvio padrão ( Zs ) igual a um.
FIGURA 5.2 – DISTRIBUIÇÃO NORMAL PADRONIZADA
00,10,20,30,40,5
-3 -2 -1 0 1 2 3z
p(z)
É importante expor que maioria das variáveis X não possui a média igual a zero e o
desvio padrão igual a um, impossibilitando a aplicação direta da distribuição Normal

38
Padronizada. Sendo assim é necessário transformar a distribuição da variável em distribuição
Normal Padronizada, através da distribuição Normal Generalizada. Na distribuição Normal
Generalizada o valor de Z é obtido a partir da equação 5.4, onde: Z é a variável para
distribuição Normal Generalizada; X contem o valor que está sendo transformado; X é a
média aritmética dos elementos da amostra; e s é o desvio padrão dos elementos da amostra.
EQUAÇÃO 5.4 – TRANSFORMAÇÃO PARA DISTRIBUIÇÃO NORMAL GENERALIZADA
sXXZ −=
A área compreendida pela curva normal acima de qualquer valor especificado para 0z ,
região marcada pela cor azul na fig. 5.3, é a probabilidade Pr de ocorrência do evento 0zZ >
ou 0zZ ≥ . A medida dessa área pode ser calculada ou simplesmente obtida a partir de
consulta feita à tabela do Anexo A. Para 0z negativo a probabilidade é a igual à probabilidade
de 0z positivo, isso porque a curva normal é simétrica.
Utilizando como exemplo o gráfico da fig. 5.3, a probabilidade ( )1≥ZPr é igual a
0,1587 ou 15,87% de chance de ocorrência.
FIGURA 5.3 – PROBABILIDADE COMPREENDIDA PELA CURVA NORMAL PADRONIZADA ACIMA DE UM PONTO Z0
Agora, aplicando-se o conceito de intervalo de confiança da equação 5.3 e admitindo-
se um erro de 31,74% (15,87% em cada cauda), a média populacional de Z seria estimada

39
pelo intervalo 1010 +<<− Zµ , ou seja, todo 0z de probabilidade ( ) 6826,00 << zZPr é
considerado dentro da média populacional.
5.1.3.2 DISTRIBUIÇÃO DE STUDENT
A distribuição de Student acusa maior dispersão que a distribuição Normal, ou seja,
introduz uma incerteza adicional. Ela é mais bem aplicada em casos onde a amostra é pequena
(com até trinta elementos) e é mais fácil de ser calculada.
As duas principais diferenças entra a distribuição de Student e a distribuição Normal é
que em Student a variável Z é substituída pela variável t e não é necessário padronizar X .
As duas diferenças citadas anteriormente fazem com que a forma de se calcular o erro com
Student seja diferente da forma de se calcular o erro com a Normal.
A distribuição de Student utiliza a tabela do Anexo B para a obtenção do valor do
ponto crítico Studentt . Os parâmetros necessários para a utilização da tabela são: os graus de
liberdade ..lg , obtidos a partir da equação 5.5 onde n é o número de elementos da amostra, e
a probabilidade Pr aceita para a ocorrência de erro amostral.
EQUAÇÃO 5.5 – GRAUS DE LIBERDADE
1.. −= nlg
Em posse do valor de Studentt , o cálculo do intervalo de confiança da média é dado pela
aplicação da equação 5.3, resultando na equação 5.6, onde: X é a média amostral; s é o
desvio padrão amostral; µ é a média populacional estimada; e n é o número de elementos
utilizados na amostra.
EQUAÇÃO 5.6 – ESTIMATIVA DA MÉDIA POPULACIONAL A PARTIR DA DISTRIBUIÇÃO DE STUDENT
nstX
nstX StudentStudent ×+<<×− µ

40
5.2 CONCEITOS GEOMÉTRICOS Os conceitos geométricos expressados nesta seção são utilizados na etapa de remoção
do fundo da cena e detecção de objetos em movimento, fundamentada na seção 3.2 e
implementada na seção 6.3.2. Como referência bibliográfica para essa seção, é utilizado
Steinbruch (1987).
5.2.1 PROJEÇÃO DE UM VETOR Sejam os vetores ur e vr , com 0≠ur e 0≠vr , dois vetores de mesma origem, é
possível calcular o vetor wr a partir da equação 5.7, onde wr é a projeção de ur sobre vr , como
mostra a fig. 5.4.
EQUAÇÃO 5.7 – PROJEÇÃO DO VETOR ur
SOBRE O VETOR vr
vvvvuuprojw v
rrr
rrrr
r ×
××== .
FIGURA 5.4 – PROJEÇÃO DO VETOR ur
SOBRE O VETOR vr
.
ur
vrwrO
A
P
B
Para este trabalho o interessante na projeção de um vetor é a localização do ponto P ,
sendo OAu =r e OBv =r , onde ( )0,0,0=O , ( )AAA zyxA ,,= e ( )BBB zyxB ,,= . A
localização do ponto P pode ser estimada a partir da aplicação da equação 5.7, dando origem
à equação 5.8.

41
EQUAÇÃO 5.8 – PROJEÇÃO DE OA SOBRE OB PARA A OBTENÇÃO DO PONTO P
( ) ( )( ) ( )
( ) ( ) ( )
( )BBB
BBB
BABABA
BBBBBB
BBBAAA
zyxauxP
zyxzzyyxx
zyxzyxzyxzyx
BBBA
vvvuaux
,,
,,,,,,,,
222
×=
++×+×+×
=××
=××=
××= rr
rr
Com os assuntos abordados no presente capítulo e em capítulos anteriores pôde-se
iniciar o desenvolvimento de um protótipo de sistema óptico de MoCap. A especificação e
implementação deste protótipo compõem o tema no próximo capítulo.

42
6 DESENVOLVIMENTO DO PROTÓTIPO Com os assuntos abordados nos capítulos 3, 4 e 5, pôde-se iniciar o desenvolvimento
de um protótipo de sistema de MoCap.
A seção 6.1 apresenta uma visão geral sobre o que o protótipo deverá fazer e os pré-
requisitos identificados para seu bom funcionamento. Na seção 6.2, é apresentada a
especificação do protótipo. A seção 6.3 mostra detalhes da implementação e as seções 6.4 e
6.5 abordam o funcionamento e análise dos resultados obtidos, respectivamente. A seção 6.6 é
reservada ao estudo das situações de difícil tratamento.
6.1 REQUISITOS IDENTIFICADOS Para a construção do protótipo foram considerados sete requisitos básicos:
a) Executar tratamento sobre uma trilha de vídeo obtida de um arquivo ou dispositivo
de captura;
b) Analisar a trilha de vídeo dada como entrada e gerar a animação de uma marionete
virtual 3D a partir da captura dos movimentos da pessoa em cena;
c) Implementar as seguintes etapas para a captura do movimento: remoção do fundo
da cena; análise das silhuetas e identificação da figura humana; segmentação da
silhueta e identificação do posicionamento 2D das partes do corpo do ator;
identificação do posicionamento 3D das partes do corpo da pessoa em cena; e
animação de uma marionete virtual, reproduzindo os movimentos da pessoa em
cena;
d) Permitir a implementação de mais que um método para cada uma das etapas
identificadas no item anterior;
e) Permitir a combinação entre os diferentes métodos implementados;
f) Exibir os resultados individuais de cada uma das etapas do processo de captura do
movimento;
g) Exibir o desempenho das combinações de métodos, mostrando a quantidade de
quadros analisados e a quantidade de quadros perdidos durante o tratamento do
vídeo.

43
Para o bom funcionamento do protótipo é importante que os seguintes pré-requisitos
sejam cumpridos:
a) As câmeras devem ter posicionamento estático e não podem sofrer alterações no
foco. Para captura do movimento em duas dimensões é usada no mínimo uma
câmera e para captura do movimento em três dimensões são usadas duas ou mais
câmeras;
b) O cenário pode ser qualquer ambiente estático e não refletivo, sob qualquer tipo de
iluminação, desde que essa iluminação esteja presente e não sofra variações de
intensidade nem de posicionamento da fonte;
c) O único objeto em movimento deve ser uma figura humana, denominada ator;
d) Os dados de entrada devem ser obtidos diretamente das câmeras de vídeo ou de
arquivos Audio Video Interleaved (AVI), que utilizem o compressor Indeo® video
5.04. A imagem deve ter o tamanho de 320x240 pixels, e os pixels 24bits de
profundidade, utilizar o sistema de cores RGB e trabalhar a uma freqüência de 30
quadros/s. Para garantir o funcionamento do sistema, a trilha de vídeo deve conter
apenas o fundo da cena durante o tempo de aprendizagem, que varia de computador
para computador. Após esse tempo de aprendizagem o ator está habilitado a entrar
em cena.
6.2 ESPECIFICAÇÃO Na especificação do protótipo foi utilizada Unified Modeling Language (UML) e para
auxiliar a diagramação foi utilizada a ferramenta Rational Rose 2000 Enterprise Edition,
sendo que os diagramas escolhidos para a especificação do protótipo foram os diagramas de
classes, seqüência e estado.
O sistema especificado recebeu o nome de MOCAPBrowser e foi dividido em dois
módulos: o módulo 2D e o módulo 3D. A tarefa do módulo 2D é obter o posicionamento 2D
das partes do corpo do ator, sob o ponto de vista de uma câmera, e enviar as informações ao
módulo 3D. A tarefa do módulo 3D é receber as informações obtidas pelos módulos 2D e
gerar a animação de uma marionete virtual 3D que reconstitua a movimentação do ator.
As classes e interfaces que compõe o protótipo encontram-se agrupadas nos seguintes
pacotes:

44
a) mocapbrowser: pacote base;
b) mocapbrowser.codec: pacote que contém os codecs utilizados no
processamento das imagens no módulo 2D;
c) mocapbrowser.codec.util: pacote que contém as classes utilizadas pelos
codecs do módulo 2D no processamento das imagens, sendo que cada uma dessas
classes implementa um processo específico para uma das etapas da análise dos
dados;
d) mocapbrowser.rmi: pacote que contém as classes que desempenham o papel
de servidor no módulo 3D;
e) mocapbrowser.rmi.util: pacote que contém as classes chamadas pelo
módulo 3D para a realização da triangulação e animação da marionete virtual 3D;
f) mocapbrowser.ui: pacote que contém as classes de interface com o usuário do
sistema, tanto do módulo 2D quanto do módulo 3D;
g) mocapbrowser.ui.util: pacote que contém as classes usadas por codecs na
exibição dos resultados ao usuário do sistema.
Partindo do pacote base mocapbrowser, a primeira classe que deve ser estudada é a
classe Browser, pois é a classe detentora do método main(). Browser é utilizada tanto
na inicialização do módulo 2D quanto na inicialização do módulo 3D.
6.2.1 MÓDULO 2D As primeiras interfaces que devem ser estudadas no módulo 2D são
MOCAPImageParams e MOCAPBufferParams, exibidas na fig. 6.1. Essas interfaces
armazenam os parâmetros de formatação de imagens e buffers, respectivamente, utilizados
por muitas das classes que compõe o protótipo.
Ainda no pacote mocapbrowser, é encontrada a classe MOCAPPlayer, exibida na
fig. 6.2, responsável por abrir, reproduzir, salvar e fechar a mídia. Tal classe é um
componente visual que estende o JPanel e implementa um ControllerListener, um
DataSinkListener e um MOCAPBufferParams. O MOCAPPlayer mantém um
Processor para a reprodução da mídia, um DataSink para o salvamento da mídia, e uma
lista de MOCAPCodec, para o processamento da mídia.

45
FIGURA 6.1 – DIAGRAMA DAS INTERFACES QUE MANTÉM A FORMATAÇÃO DAS IMAGENS DO VÍDEO
MOCAPBufferParams
$ BUFFER_FRAMERATE : float(fro m m oca pbrowse r)
<<Interface>>
MOCAPImageParams
$ IMAGE_WIDTH : int$ IMAGE_HEIGHT : int$ IMAGE_BITSPERPIXEL : int$ IMAG E_MAXDATALENGTH : int$ PIXEL_COLOR_RED : int$ PIXEL_COLOR_GREEN : int$ PIXEL _CO LOR_BLUE : int
(fro m m oca pbrowse r)
<<Interface>>
FIGURA 6.2 – DIAGRAMA DA CLASSE MOCAPPLAYER
MOCAPBufferParams(f rom m oc apb row ser )
<<Interface>>ControllerListener
(from m edia )
<<Inter face>>DataSinkListener
(from da tasink)
<<Interface>>JPanel
(f rom swing)
Proces sor(f rom m edia)
Dat aSink(f rom m edia)
MOCAPCodec(from codec )
M OCAPPlayer
updateError : boolean = fals edataOutput : boolean = fa ls e
MOCAPPlayer()configurar()executarMedia()fecharMedia()obterProces s or()controllerUpdate()dataSinkUpdate()dis pos e()
(from mo cap bro wse r) -processor
-dataSink
-codecs[]

46
Os principais métodos de MOCAPPlayer são: configurar(MediaLocator
origem, MOCAPCodec[] processamento, MediaLocator saida);
executarMedia(); e fecharMedia(). Que, respectivamente, configura o player, inicia
a execução e finaliza a execução da mídia. O diagrama de seqüência que ilustra as chamadas
aos métodos dos objetos envolvidos em cada uma dessas operações é exibido no Anexo C e,
para complementar, o diagrama que ilustra as trocas de estado do Processor durante as
etapas de configuração, inicialização e finalização são exibidos no Anexo D.
Conforme visto na seção 4.1.6, o processamento dos buffers da mídia fica a cargo das
classes que implementam a interface Codec. Por esse motivo foi especificada a classe
abstrata MOCAPCodec, exibida na fig. 6.3, que implementa as interfaces Codec e
MOCAPBufferParams. Além de ser a classe base para o processamento dos buffers,
MOCAPCodec também é responsável por gerar uma estatística contendo a quantidade de
buffers aproveitados e descartados. Seus principais métodos são: process(Buffer in,
Buffer out), que executa uma série de comandos que transportam os dados do buffer de
entrada para o buffer de saída; e tratarBuffer(Object data), que é chamado pelo
método process() e que deve ser implementado pelas classes filhas de MOCAPCodec. O
diagrama de seqüência que ilustra as chamadas executadas pelo método process(), do
MOCAPCodec, é exibo no Anexo E.
A classe MOCAPDesempenho, também exibida na fig. 6.3, tem origem no pacote
mocapbrowser.ui.util e é responsável por mostrar ao usuário o desempenho do codec
em tempo real.
As classes filhas de MOCAPCodec podem ser divididas em dois grupos. O primeiro
grupo, exibido na fig. 6.4, é composto por uma única classe, a
MOCAPCodecVariacaoRGB, que monitora os valores R, G e B de um único pixel da
imagem durante a execução do vídeo e repassa esses valores para um
MOCAPHistoricoRGB, responsável por gerar gráficos a partir dos valores monitorados. O
segundo grupo, exibido na fig. 6.5, é composto pelas classes
MOCAPCodecRemocaoFundo, MOCAPCodecAnaliseSilhuetas,
MOCAPCodecSegmentacaoSilhueta e MOCAPCodecModulo2D. Os codecs do

47
segundo grupo são os principais codecs do sistema, pois são responsáveis por disparar a
execução dos processos que resultarão na captura dos movimentos do ator em 2D.
FIGURA 6.3 – DIAGRAMA DA CLASSE MOCAPCODEC
Codec(from m edia )
<<Interface>>MO CAPBufferParams
(from m ocapbrowser)
<<Interface>>
Format( from m ed ia )
MOCAPDesempenho
intervaloExibicao : long = 0
MOCAPDes em penho()atribuirValores ()lim par()
(from uti l )
MOCAPCodec
buffers Aproveitados : long = 0
MOCAPC od ec()clos e()getCo ntrol()getCo ntrols ()getSupportedInputForm ats ()getSupportedOutputForm ats ()obterBuffers Aproveitados ()open()proces s ()res et()s etInputForm at()s etOutputForm at()tratarBuffer()
(from codec)
-input
-output -s upportedIns []
-s upportedOuts []
-des em penho
JPanel(f rom swing)
Dentre as classes filhas de MOCAPCodec, a mais importante é a
MOCAPCodecModulo2D, pois ela gerencia desde o processo de remoção de fundo da cena
até o processo de comunicação com o módulo 3D. As demais servem apenas para mostrar os
resultados obtidos em processos intermediários executados no módulo 2D. O diagrama de
seqüência do método tratarBuffer() implementado no MOCAPCodecModulo2D é
exibido no Anexo F.
Os processos intermediários citados no parágrafo anterior são:
a) Remoção do fundo da cena e detecção de objetos em movimento;
b) Análise das silhuetas e localização da provável figura humana;
c) Segmentação da silhueta para identificação do posicionamento 2D das partes do
corpo do ator;
d) Envio dos dados obtidos ao módulo 3D.
Tais processos são implementados nas classes filhas das seguintes classes abstratas:
a) MOCAPRemocaoFundo;

48
b) MOCAPAaliseSilhuetas;
c) MOCAPSegmentacaoSilhueta;
d) MOCAPConexaoCliente.
FIGURA 6.4 – DIAGRAMA DA CLASSE FILHA DE MOCAPCODEC QUE EXIBE A ANÁLISE DA VARIAÇÃO DOS VALORES RGB DE UM PIXEL DURANTE A
EXIBIÇÃO DO VÍDEO
MOCAPCodec(from codec)
MOCAPHistoricoRGB
MOCAPHis toricoRGB()des enharGrafico()inform ar()
(fro m ut i l )
M OCAPC odecVar iacaoRGB
iPixelHis torico : int
MOCAPCodecVariacaoRGB()getNam e()open()tratarBuffer()
(from codec)
his toricoRGB
MOCAPHistorico
valorMinim o : double = Double.MAX_VALUEvalorMaxim o : double = Double.MIN_VALUEultim o[] : int = nullvalores [][] : double = null
MOCAPHis torico()adicionarValor()lim par()obterN()obterValor()
(fro m ut i l )
JPanel(f rom swing)
A justificativa para se modelar os processos intermediários dessa forma é que cada um
desses processos pode ter mais que uma solução a ser implementada. Com essa abordagem
torna-se simples a implementação e combinação de diferentes soluções para posterior análise
dos resultados.

49
FIGURA 6.5 – DIAGRAMA DAS CLASSES FILHAS DE MOCAPCODEC QUE REALIZAM A CAPTURA DO MOVIMENTO NO MÓDULO 2D
MOCAPCodec(from codec)
MOCAPCodecRemocaoFundo
MOCAPCodecRem ocaoFundo()getNam e()tratarBuffer()
(from codec)MOCAPCodecAnaliseSilhueta
MOCAPCodecAnalis eSilhueta()getNam e()tratarBuffer()
(from codec)MOCAPCodecSegmentacaoSilhueta
MOCAPCodecSegm entacaoSilhueta()getNam e()tratarBuffer()
(from codec)
MOCAPRemocaoFundo
MOCAPRem ocaoFundo()executar()
(from u ti l )
MOCAPAnaliseSilhueta
MOCAPAnalis eSilhueta()executar()
(from u ti l )
MOCAPSegmentacaoSilhueta
MO CAPSe gm en tacaoSilhueta()executar()
(from ut il )
MOCAPConexaoCliente
MOCAPConexaoCliente()executar()
(from ut i l )
JPanel(f rom swing)
MO CAPCodecModulo2D
MOC APC odecModulo2D()getNam e()tratarBuffer()
(from codec)
As classes abstratas listadas anteriormente e suas classes filhas encontram-se no pacote
mocapbrowser.codec.util, e o principal método nessas classes é o executar(),
que recebe como parâmetro o resultado do processo anterior e retorna um objeto que contém o
resultado de seu processamento:
a) Para MOCAPRemocaoFundo é passado como parâmetro o conteúdo do buffer do
quadro que está sendo analisado e o resultado é uma matriz numérica com
dimensões idênticas às do vídeo e que contém a classificação dos pixels como
“fundo da cena” (valor igual a zero) ou “em movimento” (valor igual a um);
b) Para MOCAPAnaliseSilhueta é passado como parâmetro a matriz resultante
de MOCAPRemocaoFundo. O resultado é um objeto da classe
java.awt.Polygon, que representa a silhueta da figura humana identificada;
c) Para MOCAPSegmentacaoSilhueta é passado como parâmetro o polígono
resultante de MOCAPAnaliseSilhueta e o resultado é uma lista de objetos do
tipo MOCAPParte (fig. 6.6), que representa a localização 2D das partes
identificadas na figura humana;

50
d) Para MOCAPConexaoCliente é passada como parâmetro a lista de partes
identificadas por MOCAPSegmentacaoSilhueta, e como resultado temos o
envio dessas partes para o módulo 3D.
FIGURA 6.6 – DIAGRAMA DE CLASSES DA CLASSE MOCAPPARTE
Para finalizar a especificação do módulo 2D falta apenas a apresentação das classes
que compõe o pacote mocapbrowser.ui. Porém, por não fazerem parte do núcleo de
processamento do módulo, essas classes não serão abordada nessa seção. As janelas
resultantes da utilização dessas classes podem ser observadas na seção 6.4.
6.2.2 MÓDULO 3D Como descrito anteriormente, esse módulo é responsável por receber as informações
obtidas pelos módulos 2D e gerar a animação de uma marionete virtual 3D que reconstitui a
movimentação do ator. Para tanto, é necessário dividir as classes em processos intermediários
de:
a) Recebimento dos dados obtidos pelos módulos 2D;

51
b) Triangulação quadrática dos posicionamentos 2D das partes do corpo para obtenção
do posicionamento 3D;
c) Animação da marionete virtual 3D com e sem interpolação de quadros.
Seguindo o padrão utilizado no módulo 2D, são especificadas as classes que
implementam cada uma dessas operações, essas classes são listadas abaixo e exibidas na fig.
6.7:
a) MOCAPConexaoServidorRMI;
b) MOCAPTriangulacao;
c) MOCAPAnimacao3D.
FIGURA 6.7 – DIAGRAMA DE CLASSES QUE REALIZAM A ANIMAÇÃO DA MARIONETE VIRTUAL NO MÓDULO 3D
MOCAPInterfaceServidorRMI
informarPartes()
(from rm i )
<<Interface>>
UnicastRemoteObject(fro m server )
Remote(from rm i )
<<Interface>>
MOCAPTriangulacao
MOCAPTriangulacao()executar()
( from ut il )
MO CAPServidorRM I
MOCAPServidorRMI()inform arPartes ()
(from rm i )
MOCAPAnimacao3D
MOCAPAnim acao3 D()executar ()
( from ut il )
As classes que executam o processamento no módulo 3D são agrupadas no pacote
mocapbrowser.rmi e mocapbrowser.rmi.util. No primeiro pacote está a interface
MOCAPInterfaceServidorRMI e classe MOCAPConexaoServidorRMI, que
desempenham papel declaração dos métodos acessados pelos módulos 2D clientes e

52
implementação desses métodos, respectivamente. No segundo pacote encontram-se as classes
abstratas MOCAPTriangulacao e MOCAPAnimacao3D, bem como suas classes filhas,
que implementam o método executar().
6.3 IMPLEMENTAÇÃO Na implementação do protótipo foi utilizada a linguagem de programação Java, em seu
pacote JavaTM 2 SDK Standard Edition, versão 1.3.0_02, e a API JavaTM Media Framework,
versão 2.1.1, já abordada no capítulo 4.
Para auxiliar na utilização de Java foi selecionado o ambiente de programação Borland
JBuilder Enterprise, versão 5.0.294.0. É importante ressaltar que, mesmo tendo a disposição
uma grande variedade de componentes de implementação da Borland Software Corporation,
ao se trabalhar com JBuilder, apenas componentes JavaTM 2 SDK Standard Edition e JavaTM
Media Framework foram utilizados na confecção das classes e interfaces que fazem parte do
protótipo.
Para realizar conversão entre formatos de vídeo e redimensionamento das imagens
para o tamanho requerido, foi utilizado o Adobe Premiere 5.5.
Quanto ao hardware para a captura de dados, inicialmente foi utilizada uma WebCam
Longitech QuickCam® Web, de interface USB. Devido à necessidade de maior resolução nas
imagens uma câmera JVC Professional KY-27U 3-CCD COLOR passou a ser utilizada.
Por motivos explicados na seção 6.6, apenas as rotinas de captura dos dados de
entrada, remoção do fundo da cena e análise das silhuetas foram implementadas na íntegra. A
implementação das rotinas de segmentação da silhueta, o envio de dados do módulo 2D para
o módulo 3D e a recepção dos dados por parte do módulo 3D não foram concluídas. E,
finalmente, as partes que dizem respeito à triangulação quadrática e animação da marionete
virtual 3D não foram implementadas.
6.3.1 ORIGEM E CAPTURA DOS DADOS DE ENTRADA A obtenção e serialização dos dados de entrada são feitos exclusivamente pelo JMF.
Cabe ao programador apenas configurar alguns de seus componentes e iniciar o processo de

53
captura. No protótipo essa configuração é feita dentro da classe MOCAPPlayer e os
parâmetros são obtidos nas janelas de interface com o usuário.
O quadro 6.1 mostra o pseudo-código implementado na classe
JFrameParametro2D, que é executado no momento em que o usuário dispara o processo
de captura. Esse código tem por finalizada informar ao MOCAPPlayer a localização da
origem do vídeo, as rotinas e codecs que serão utilizados no tratamento da imagem, e qual o
destino da mídia tratada. Caso ao destino seja atribuído o valor null, como é feito no código
exemplo, então o vídeo será exibido ao usuário, caso contrário ele será salvo em um arquivo
de extensão AVI.
QUADRO 6.1 – PSEUDO-CÓDIGO IMPLEMENTADO NA JANELA DE INTERFACE COM O USUÁRIO E UTILIZADO PARA CONFIGURAR E INICIALIZAR O
MOCAPPLAYER
... // selecionar a origem dos dados MediaLocator origem = null; if (origem seja um arquivo AVI) origem = new MediaLocator("file://" + caminho_do_arquivo); else if (origem seja um dispositivo de captura de vídeo) origem = dispositivo.getLocator(); if (origem != null) { ArrayList arrayList = new ArrayList(); MOCAPDesempenho desempenho = null; MOCAPHistoricoRGB historicoRGB = null; MOCAPRemocaoFundo remocaoFundo = null; MOCAPAnaliseSilhueta analiseSilhueta = null; MOCAPSegmentacaoSilhueta segmentacaoSilhueta = null; MOCAPConexaoCliente conexaoCliente = null; // criar os objetos que executarão o tratamento dos dados de entrada if (deve mostrar desempenho do codec) desempenho = componente_que_mostra_o_desempenho; if (deve monitorar a variação dos valores RGB de um pixel) historicoRGB = componente_que_mostra_o_historico_do_RGB; if (deve executar a remoção do fundo) remocaoFundo = new classe_que_realiza_a_remoção_do_fundo; if (deve executar a análise da silhueta) analiseSilhueta = new classe_que_realiza_a_análise_da_silhueta; if (deve executar a segmentação da silhueta) segmentacaoSilhueta = new classe_que_realiza_a_segmentação_da_silhueta; if (deve executar a conexão com o módulo 3D) conexaoCliente = new classe_que_realiza_a_conexão_cliente; // criar os codecs que gerenciarão o tratamento dos dados de entrada if (deve monitorar a variação dos valores RGB de um pixel) arrayList.add(new MOCAPCodecVariacaoRGB(desempenho, historicoRGB, pixel_escolhido); JPanel panelDesenho = componente_onde_será_desenhada_a_silhueta; if (deve executar a conexão com o módulo 3D)

54
arrayList.add(new MOCAPCodecModulo2D(desempenho, panelDesenho, remocaoFundo, analiseSilhueta, segmentacaoSilhueta, conexaoCliente)); else if (deve executar a segmentação da silhueta) arrayList.add(new MOCAPCodecSegmentacaoSilhueta( desempenho, panelDesenho, remocaoFundo, analiseSilhueta, segmentacaoSilhueta)); else if (deve executar a análise da silhueta) arrayList.add(new MOCAPCodecAnaliseSilhueta( desempenho, panelDesenho, remocaoFundo, analiseSilhueta)); else if (deve executar a remoção do fundo) arrayList.add(new MOCAPCodecRemocaoFundo(desempenho, remocaoFundo)); MOCAPCodec codecs[] = new MOCAPCodec[arrayList.size()]; System.arraycopy(arrayList.toArray(), 0, codecs, 0, arrayList.size()); // definir qual o destino da mídia tratada MediaLocator destino = null; // configurar MOCAPPlayer e iniciar execução do vídeo player.configurar(origem, codecs, destino); player.executarMedia(); } ...
Como mencionado anteriormente, as janelas de interface com o usuário informam ao
MOCAPPlayer os parâmetros para configurar os componentes do JMF, e de posse desses
parâmetros o MOCAPPlayer é quem configura o JMF. As implementações das rotinas de
configuração dos componentes do JMF são exibidas nos quadro 6.2 e quadro 6.3, sendo que o
quadro 6.2 mostra o método chamado pelo JFrameParametro2D e o quadro 6.3 mostra o
método assíncrono chamado pelo Processor quando este muda de estado.
QUADRO 6.2 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPPLAYER, CHAMADO PELA JANELA DE INTERFACE COM O USUÁRIO E QUE É
RESPONSÁVEL POR CONFIGURAR OS COMPONENTES DO JMF
public void configurar(MediaLocator entrada, MOCAPCodec[] processamento, MediaLocator saida) throws IOException, MediaException, InterruptedException { if ((processor == null) && (entrada != null)) try { updateError = false; dataOutput = saida != null; codecs = processamento; // criar o DataSource (entrada) DataSource dataSource = Manager.createDataSource(entrada); // criar o Processor processor = Manager.createProcessor(dataSource); processor.addControllerListener(this); // configurar o Processor processor.configure(); while ((processor.getState() < Processor.Configured) && (! updateError))

55
synchronized (sleeper) { sleeper.wait(); } // realizar o Processor processor.realize(); while ((processor.getState() < Processor.Realized) && (! updateError)) synchronized (sleeper) { sleeper.wait(); } // caso o destino da mídia tratada seja o DataOutput, e não o VisualComponent, criar DataSink if (dataOutput) { dataSink = Manager.createDataSink(processor.getDataOutput(), saida); dataSink.addDataSinkListener(this); } } catch (Exception erro) { fecharMedia(); throw erro; } }
QUADRO 6.3 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPPLAYER, CHAMADO DE FORMA ASSÍNCRONA PELO PROCESSOR QUANDO ESTE MUDA DE
ESTADO
public synchronized void controllerUpdate(ControllerEvent event) { // evento executado quando a configuração foi completada if (event instanceof ConfigureCompleteEvent) { // verificar o destino da mídia tratada, DataOutput ou VisualComponent if (dataOutput) processor.setContentDescriptor(new FileTypeDescriptor(FileTypeDescriptor.MSVIDEO)); else processor.setContentDescriptor(null); // obter os controles de trilha específicas de vídeo, caso algum codec tenha sido designado TrackControl tracks[] = processor.getTrackControls(); TrackControl videoTrack = null; if ((codecs != null) && (codecs.length > 0) && (tracks != null)) { for (int i = 0; i < tracks.length; i++) if (tracks[i].getFormat() instanceof VideoFormat) { videoTrack = tracks[i]; break; } // coloca os MOCAPCodec's para trabalhar, caso exista alguma trilha de vídeo if (videoTrack != null) try { videoTrack.setCodecChain(codecs); } catch (UnsupportedPlugInException erro) { System.err.println("O Processor não suporta PlugIns"); } else System.err.println("A mídia presente no Processor não possui uma trilha de vídeo"); } synchronized (sleeper) { sleeper.notify(); } } // evento que requisita a execução do vídeo if (event instanceof RealizeCompleteEvent) { boolean exibir = true; Container pai = this; while ((pai != null) && (exibir)) {

56
exibir = pai.isVisible(); pai = pai.getParent(); } if (exibir) { visualComponent = processor.getVisualComponent(); if (visualComponent != null) { add("Center", visualComponent); validate(); } } synchronized (sleeper) { sleeper.notify(); } }
Os códigos utilizados para iniciar e finalizar a execução da mídia são exibidos no
quadro 6.4 e quadro 6.5, respectivamente, e são mais simples que os códigos exibidos até o
momento nesta seção.
QUADRO 6.4 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPPLAYER, CHAMADO PELA JANELA DE INTERFACE COM O USUÁRIO E QUE É
RESPONSÁVEL POR INICIAR A EXECUÇÃO DA MÍDIA
public void executarMedia() throws IOException { if ((processor != null) && (processor.getState() != Processor.Started)) try { if (dataSink != null) { dataSink.open(); dataSink.start(); } processor.start(); } catch (IOException erro) { fecharMedia(); throw erro; } }
QUADRO 6.5 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPPLAYER, CHAMADO PELA JANELA DE INTERFACE COM O USUÁRIO E QUE É
RESPONSÁVEL POR FINALIZAR A EXECUÇÃO DA MÍDIA
public void fecharMedia() { // remover o componente visual usado como saída if (visualComponent != null) { remove(visualComponent); visualComponent = null; validate(); } // parar o DataSink if (dataSink != null) { dataSink.close(); dataSink = null; dataOutput = false; }

57
// parar o Processor if (processor != null) { processor.stop(); processor.deallocate(); processor.close(); processor = null; } // limpar lista de CODECs codecs = null; // chamar o coletor de lixo System.gc(); }
6.3.2 REMOÇÃO DO FUNDO DA CENA E DETECÇÃO DE OBJETOS EM MOVIMENTO
As classes filhas de MOCAPRemocaoFundo são as classes responsáveis pela remoção
do fundo da cena e detecção de objetos em movimento. Ao todo foram implementadas três
dessas classes:
a) MOCAPRemocaoFundoMinimoMaximoValorRGB;
b) MOCAPRemocaoFuncoMediaDistanciaIPNormal;
c) MOCAPRemocaoFundoMediaDistanciaIPStudent.
A partir dessas três classes são apresentados quatro métodos de remoção do fundo:
a) Mínimo e máximo valor RGB;
b) Média da distância IP + erro Normal;
c) Média da distância IP + erro Student;
d) Média da distância IP + erro Empírico.
Onde a classe a implementa o método a, a classe b implementa o método b e a classe c
implementa os métodos c e d.
Conforme descrito na seção 3.2, as formas de remoção do fundo utilizadas passam por
três etapas: modelagem/treinamento do fundo; seleção do limiar; operação de
subtração/classificação. Todas essas etapas encontram-se implementadas no método
executar() e são chamadas de acordo com o estado atual do objeto. Como resultado o
método executar() pode retornar uma matriz que indique a classificação dos pixels como
em movimento (valor igual a zero) ou em fundo da cena (valor igual a um), caso a classe

58
esteja na etapa de classificação dos pixels, ou null, caso a classe esteja nas etapas de
modelagem/treinamento ou seleção do limiar.
O método executar()aceita como parâmetro um vetor de bytes que contém os
dados do buffer do quadro atual do vídeo. O comprimento desse vetor é dado pela equação 6.1
e a formatação do vetor é regida pela regra ilustrada na fig. 6.8, onde: i é o índice dos
elementos do buffer; j é o índice dos pixels da imagem; n é o comprimento do vetor; m é o
número de pixels da imagem; e R, G e B representam a quantidade de vermelho, verde e azul
que compõe a cor do pixel j. O pixel de índice zero encontra-se no canto superior esquerdo da
imagem e os demais pixels são enumerados da esquerda para a direita e do topo para baixo.
EQUAÇÃO 6.1 – CÁLCULO DO COMPRIMENTO DO VETOR QUE CONTÉM OS DADOS DO BUFFER
3__arg_ ××= videoalturavideouralvetorocompriment
Outra observação importante quanto ao conteúdo do buffer é a conversão de seus
elementos do tipo byte para um tipo int. No Java, o tipo byte armazena valores que vão
de –128 até 127, no entanto os valores em R, G e B estão entre 0 e 255. Para fazer a
conversão pode ser utilizado o “E Binário”: x=b&255. Onde x é uma variável do tipo int e
b é uma variável do tipo byte.
FIGURA 6.8 – FORMATAÇÃO DOS DADOS NO BUFFER
R G B B G R B G R ...
2 1 0 3 4 5 n-3 n-2 n-1 ... i =
0 1 m-1 j = ...
6.3.2.1 MÍNIMO E MÁXIMO VALOR RGB
No quadro 6.6 é exposto o código implementado na classe
MOCAPRemocaoFundoMinimoMaximoValorRGB. Essa implementação não utiliza o
modelo de cor da seção 3.2 por completo e parte do princípio de que armazenando os valores

59
mínimos e máximos observados nas coordenadas R, G e B de cada pixel das imagens do
período de modelagem é possível gerar três intervalos de confiança (um para R, um para G e
um para B) que serão utilizados na classificação dos pixels das imagens obtidas após o
período de modelagem.
QUADRO 6.6 – CÓDIGO IMPLEMENTADO NA CLASSE MOCAPREMOCAOFUNDOMINIMOMAXIMOVALORRGB
private int t = -1; // índice do buffer atual private int m = IMAGE_WIDTH*IMAGE_HEIGHT; // número de pixels por buffer private int mVezes3 = m*3; // "m" multiplicado por três private int n; // número de buffers usados no treino (amostra) private double soma2ERGB[]; // soma dos quadrados dos valores RGB para cada pixel em "E" private byte I[][]; // amostra, valores RGB dos "n" primeiros buffers tratados private double E[]; // média aritmética dos valores RGB da amostra private double erroMin[], erroMax[]; // valor subtraído e adicionado das coordenadas do ponto "P" // construtor da classe public MOCAPRemocaoFundoMinimoMaximoValorRGB(int buffersTreino) { n = buffersTreino; soma2ERGB = new double[m]; I = new byte[n][mVezes3]; E = new double[mVezes3]; Arrays.fill(E, 0.0); erroMin = new double[mVezes3]; erroMax = new double[mVezes3]; } // método que executa a remoção do fundo da cena e detecção dos objetos em movimento public byte[][] executar(byte[] I) { t++; // caso tenha acabado o período de treinamento, realizar a remoção do fundo if (t >= n) { byte pixelMovimento[][] = new byte[IMAGE_WIDTH][IMAGE_HEIGHT]; int IpB, IpG, IpR; double PpB, PpG, PpR, x; // para cada pixel da imagem atual for (int p = 0, pB, pG, pR; p < m; p++) { pB = p*3; pG = pB+1; pR = pB+2; IpB = I[pB]&255; IpG = I[pG]&255; IpR = I[pR]&255; // calcular "P", a projeção de "I" sobre o vetor determinado por "E" e o ponto Zero if (((IpB != 0.0) || (IpG != 0.0) || (IpR != 0.0)) && ((E[pB] != 0.0) || (E[pG] != 0.0) || (E[pR] != 0.0)) ) { x = (IpB*E[pB] + IpG*E[pG] + IpR*E[pR]) / soma2ERGB[p]; PpB = x * E[pB]; PpG = x * E[pG]; PpR = x * E[pR]; } else { PpB = 0.0; PpG = 0.0; PpR = 0.0; } // classificar o pixel if ((PpB-erroMin[pB] <= IpB) && (IpB <= PpB+erroMax[pB]) && (PpG-erroMin[pG] <= IpG) && (IpG <= PpG+erroMax[pG]) && (PpR-erroMin[pR] <= IpR) && (IpR <= PpR+erroMax[pR]) ) pixelMovimento[p%IMAGE_WIDTH][p/IMAGE_WIDTH] = 0; else

60
pixelMovimento[p%IMAGE_WIDTH][p/IMAGE_WIDTH] = 1; } return pixelMovimento; } // caso esteja no período de treinamento, armazenar o buffer System.arraycopy(I, 0, this.I[t], 0, mVezes3); // caso esteja no fim do período de treinamento, identificar o limiar if (t == (n-1)) { // para cada valor R, G e B dos pixels da imagem int Ii, IiMin, IiMax; for (int i = 0; i < mVezes3; i++) { IiMin = 255; IiMax = 0; // cálcular a média aritmética amostral e coleta dos valores mínimos e máximos for (int t = 0; t < n; t++) { Ii = this.I[t][i]&255; E[i] += Ii; if (Ii < IiMin) IiMin = Ii; if (Ii > IiMax) IiMax = Ii; } E[i] = E[i]/n; // cálcular do erro estimado erroMin[i] = E[i]-IiMin; erroMax[i] = IiMax-E[i]; } // para cada pixel de "E", calcular a soma dos quadrados dos valores R, G e B for (int p = 0, pB, pG, pR; p < m; p++) { pB = p*3; pG = pB+1; pR = pB+2; soma2ERGB[p] = E[pB]*E[pB] + E[pG]*E[pG] + E[pR]*E[pR]; } } return null; }
A fig. 6.9 mostra como são trabalhados os intervalos de confiança gerados nesse
método. Para eliminar o erro da classificação de fundo sombreado e fundo mais iluminado
como sendo objetos em movimento, os intervalos são criados a partir de valores relativos ao
ponto ],,[ )()()( iBiGiRi PPPP = que é um ponto na linha cromática esperada e obtido a partir da
projeção de ],,[ )()()( iBiGiRi IIII = sobre ],,[ )()()( iBiGiRi EEEE = (equação 5.8). Tais intervalos
são representados pelo paralelepípedo de cor cinza, lembrando que: i é o índice do pixel
atual; I é a imagem cujos pixels estão sendo classificados; e E é a imagem formada a partir
da média aritmética (equação 5.1) dos buffers armazenados no período de modelagem do
fundo da cena, também conhecido como período de treinamento. Na etapa de classificação, se
a cor ao pixel i estiver dentro dos limites estabelecidos o pixel é classificado como fundo da
cena, caso esteja fora dos limites estabelecidos o pixel é classificado como em movimento.

61
FIGURA 6.9 – MODELO DE COR COM APLICAÇÃO DO MÍNIMO E MÁXIMO VALOR RGB
R
G
B
0
Ei
Ii
. Pi
Os parâmetros que a classe necessita para executar a remoção do fundo são:
buffersTreino, informado em seu construtor e que indica qual a quantidade de buffers
usados no período de treinamento; e o vetor I, informado como parâmetro do método
executar(), chamado a cada novo quadro do vídeo.
6.3.2.2 MÉDIA DA DISTÂNCIA IP + ERRO NORMAL
A implementação da classe MOCAPRemocaoFundoMediaDistanciaIPNormal,
exposta no quadro 6.7, faz uso do modelo de cor mencionado na seção 3.2. Sobre esse modelo
são aplicados os conceitos estatísticos expostos nas seções 5.1.1, 5.1.2 e 5.1.3.1.
QUADRO 6.7 – CÓDIGO IMPLEMENTADO NA CLASSE MOCAPREMOCAOFUNDOMEDIADISTANCIAIPNORMAL
private int t = -1; // índice do buffer atual private int m = IMAGE_WIDTH*IMAGE_HEIGHT; // número de pixels por buffer private int mVezes3 = m*3; // "m" multiplicado por três private int n; // número de buffers usados no treino (amostra) private int nMenos1; // "n" subtraído um private double raizN; // raiz quadrada de "n" private double zNormal; // ponto crítico da distribuição Normal Padronizada private double soma2ERGB[]; // soma dos quadrados dos valores RGB para cada pixel em "E" private byte I[][]; // amostra, valores RGB dos "n" primeiros buffers tratados

62
private double d[]; // distancia entre "I" da amostra e "P" nos "nt" buffers da amostra private double md[]; // média aritmética amostral das distancias entre "I" e "P" private double sd[]; // desvio padrão amostral das distancias entre "I" da amostra e "P" private double E[]; // média aritmética dos valores RGB da amostra // construtor da classe public MOCAPRemocaoFundoMediaDistanciaIPNormal(int buffersTreino, double zNormal) { n = buffersTreino; nMenos1 = n-1; raizN = Math.sqrt(n); this.zNormal = zNormal; soma2ERGB = new double[m]; I = new byte[n][mVezes3]; d = new double[n]; md = new double[m]; Arrays.fill(md, 0.0); sd = new double[m]; Arrays.fill(sd, 0.0); E = new double[mVezes3]; Arrays.fill(E, 0.0); } // método que executa a remoção do fundo da cena e detecção dos objetos em movimento public byte[][] executar(byte[] I) { t++; // caso tenha acabado o período de treinamento, realizar a remoção do fundo if (t >= n) { byte pixelMovimento[][] = new byte[IMAGE_WIDTH][IMAGE_HEIGHT]; int IpB, IpG, IpR; double PpB, PpG, PpR, x, xB, xG, xR, IP; // para cada pixel da imagem atual for (int p = 0, pB, pG, pR; p < m; p++) { pB = p*3; pG = pB+1; pR = pB+2; IpB = I[pB]&255; IpG = I[pG]&255; IpR = I[pR]&255; // calculo de "P", a projeção de "I" sobre o vetor determinado por "E" e o ponto Zero if (((IpB != 0.0) || (IpG != 0.0) || (IpR != 0.0)) && ((E[pB] != 0.0) || (E[pG] != 0.0) || (E[pR] != 0.0)) ) { x = (IpB*E[pB] + IpG*E[pG] + IpR*E[pR]) / soma2ERGB[p]; PpB = x * E[pB]; PpG = x * E[pG]; PpR = x * E[pR]; } else { PpB = 0.0; PpG = 0.0; PpR = 0.0; } // cálculo da distancia entre "I" e "P" xB = IpB-PpB; xG = IpG-PpG; xR = IpR-PpR; IP = Math.sqrt(xB*xB * xG*xG * xR*xR); // classificar o pixel double z = (IP-md[p])/sd[p]; pixelMovimento[p%IMAGE_WIDTH][p/IMAGE_WIDTH] = (zNormal < z)?(byte)1:(byte)0; } return pixelMovimento; } // caso esteja no período de treinamento, armazenar o buffer System.arraycopy(I, 0, this.I[t], 0, mVezes3); // caso esteja no fim do período de treinamento, identificar o limiar if (t == (n-1)) { int IpB, IpG, IpR; double PpB, PpG, PpR, x, xB, xG, xR; // para cada pixel das imagens que compõe a amostra for (int p = 0, pB, pG, pR; p < m; p++) {

63
pB = p*3; pG = pB+1; pR = pB+2; // cálculo da média aritmética dos valores RGB da amostra for (int t = 0; t < n; t++) { E[pB] += this.I[t][pB]&255; E[pG] += this.I[t][pG]&255; E[pR] += this.I[t][pR]&255; } E[pB] = E[pB]/n; E[pG] = E[pG]/n; E[pR] = E[pR]/n; soma2ERGB[p] = E[pB]*E[pB] + E[pG]*E[pG] + E[pR]*E[pR]; // cálculo da projeção "P" ("I" sobre "E") e das distancias de "E" e "I" em relação à "P" for (int t = 0; t < n; t++) { IpB = this.I[t][pB]&255; IpG = this.I[t][pG]&255; IpR = this.I[t][pR]&255; // cálculo dos valores RGB de "P" if (((IpB != 0.0) || (IpG != 0.0) || (IpR != 0.0)) && ((E[pB] != 0.0) || (E[pG] != 0.0) || (E[pR] != 0.0)) ) { x = (IpB*E[pB] + IpG*E[pG] + IpR*E[pR]) / soma2ERGB[p]; PpB = x * E[pB]; PpG = x * E[pG]; PpR = x * E[pR]; } else { PpB = 0.0; PpG = 0.0; PpR = 0.0; } // cálculo das distâncias entre "I" e "P" xB = IpB-PpB; xG = IpG-PpG; xR = IpR-PpR; d[t] = Math.sqrt(xB*xB * xG*xG * xR*xR); md[p] += d[t]; } // cálculo da média aritmética amostral das distancias entre "I" e "P" md[p] = md[p]/n; // cálculo do desvio padrão amostral das distâncias entre "E" e "P" e das distancias entre "I" e "P" for (int t = 0; t < n; t++) { x = d[t]-md[p]; sd[p] += x*x; } sd[p] = Math.sqrt(sd[p]/nMenos1); } } return null; }
Assim como na classe da seção anterior, é utilizado intervalo de confiança mensurado
com base nas imagens obtidas no período de modelagem, sendo esse intervalo utilizado na
classificação dos pixels das imagens obtidas após o período de modelagem. No entanto, ao
invés de se criar três intervalos para cada pixel, é criado apenas um, a partir do valor das
distâncias id ( iCD na fig. 3.1) entre ],,[ )()()( iBiGiRi IIII = e ],,[ )()()( iBiGiRi PPPP = , onde: i é
o índice do pixel atual; I é a imagem cujos pixels estão sendo classificados; P são pontos na
linha cromática esperada obtido a partir da projeção de I sobre E (equação 5.8); e E é a
imagem de referência formada a partir da média aritmética (equação 5.1) dos buffers
armazenados no período de modelagem do fundo da cena. Na prática, para cada pixel da
imagem, o intervalo de confiança único gera em torno da linha cromática esperada um
cilindro, conforme mostra a fig. 6.10, sendo que na etapa de classificação se a distância id for
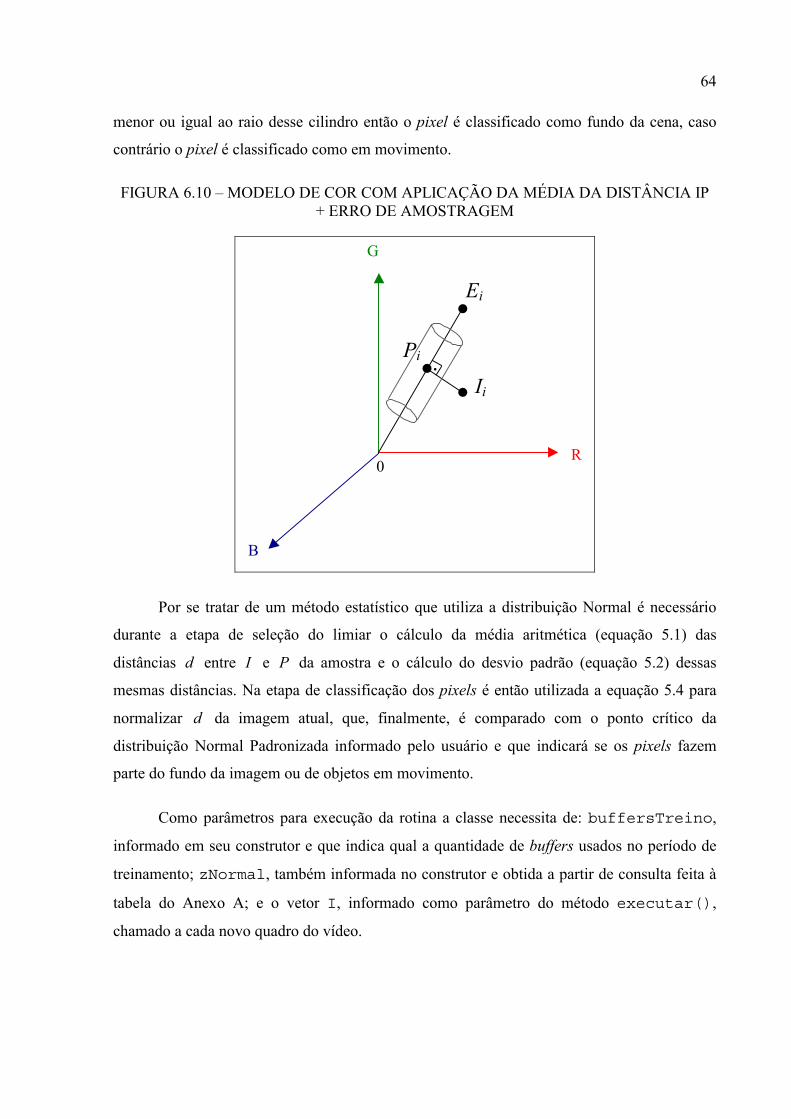
64
menor ou igual ao raio desse cilindro então o pixel é classificado como fundo da cena, caso
contrário o pixel é classificado como em movimento.
FIGURA 6.10 – MODELO DE COR COM APLICAÇÃO DA MÉDIA DA DISTÂNCIA IP + ERRO DE AMOSTRAGEM
R
G
B
0
Ei
Ii
. Pi
Por se tratar de um método estatístico que utiliza a distribuição Normal é necessário
durante a etapa de seleção do limiar o cálculo da média aritmética (equação 5.1) das
distâncias d entre I e P da amostra e o cálculo do desvio padrão (equação 5.2) dessas
mesmas distâncias. Na etapa de classificação dos pixels é então utilizada a equação 5.4 para
normalizar d da imagem atual, que, finalmente, é comparado com o ponto crítico da
distribuição Normal Padronizada informado pelo usuário e que indicará se os pixels fazem
parte do fundo da imagem ou de objetos em movimento.
Como parâmetros para execução da rotina a classe necessita de: buffersTreino,
informado em seu construtor e que indica qual a quantidade de buffers usados no período de
treinamento; zNormal, também informada no construtor e obtida a partir de consulta feita à
tabela do Anexo A; e o vetor I, informado como parâmetro do método executar(),
chamado a cada novo quadro do vídeo.

65
6.3.2.3 MÉDIA DA DISTÂNCIA IP + ERRO STUDENT
O modelo de cor mencionado na seção 3.2 também é utilizado pela classe
MOCAPRemocaoFundoMediaDistanciaIPStudent e os conceitos estatísticos
aplicados sobre esse modelo são expostos nas seções 5.1.1, 5.1.2 e 5.1.3.2.
Seguindo a linha das técnicas de remoção do fundo da cena com base em métodos
estatísticos, a implementação exposta no quadro 6.8 armazena n imagens no período de
modelagem e ao término desse período, no período de seleção do limiar, cria um intervalo de
confiança a partir do valor das distâncias id ( iCD na fig. 3.1) entre ],,[ )()()( iBiGiRi IIII = e
],,[ )()()( iBiGiRi PPPP = , onde: i é o índice do pixel atual; I é a imagem cujos pixels estão
sendo classificados; P são pontos na linha cromática esperada obtido a partir da projeção de
I sobre E (equação 5.8); e E é a imagem de referência formada a partir da média aritmética
(equação 5.1) dos buffers armazenados no período de modelagem do fundo da cena.
A representação gráfica do intervalo de confiança exposta na fig. 6.10 também é
aplicada no presente método. A diferença entre a classe desta seção e a classe da seção
anterior é que agora é utilizada a distribuição de Student, sendo então necessário durante a
etapa de seleção do limiar o calculo da média aritmética (equação 5.1) das distâncias d entre
I e P da amostra, o cálculo do desvio padrão (equação 5.2) dessas mesmas distâncias e o
cálculo do limite máximo aceito para a distância entre I e P (equação 5.6). Vale a pena
ressaltar que o limite mínimo pode ser ignorado, uma vez que todo d aceito como parte do
fundo será maior ou igual a zero e menor que a média das distâncias d mais o erro de
amostragem. Para a etapa de classificação dos pixels resta apenas verificar se o valor
encontrado para as distâncias entre os pixels da imagem atual e as linhas cromáticas esperadas
de cada pixel está dentro ou fora dos limites calculados.
QUADRO 6.8 – CÓDIGO IMPLEMENTADO NA CLASSE MOCAPREMOCAOFUNDOMEDIADISTANCIAIPSTUDENT
private int t = -1; // índice do buffer atual private int m = IMAGE_WIDTH*IMAGE_HEIGHT; // número de pixels por buffer private int mVezes3 = m*3; // "m" multiplicado por três private int n; // número de buffers usados no treino (amostra) private int nMenos1; // "n" subtraído um private double raizN; // raiz quadrada de "n" private double tStudent; // ponto crítico da distribuição de Student private double soma2ERGB[]; // soma dos quadrados dos valores RGB para cada pixel em "E"

66
private byte I[][]; // amostra, valores RGB dos "n" primeiros buffers tratados private double d[]; // distancia entre "I" da amostra e "P" nos "n" buffers da amostra private double md[]; // média aritmética amostral das distancias entre "I" e "P" private double sd[]; // desvio padrão amostral das distancias entre "I" da amostra e "P" private double E[]; // média aritmética dos valores RGB da amostra private double maxd[]; // valor máximo aceito para a distância entre "I" e "P" // construtor da classe public MOCAPRemocaoFundoMediaDistanciaIPStudent(int buffersTreino, double tStudent) { n = buffersTreino; this.tStudent = tStudent; nMenos1 = n-1; raizN = Math.sqrt(n); soma2ERGB = new double[m]; I = new byte[n][mVezes3]; d = new double[n]; md = new double[m]; Arrays.fill(md, 0.0); sd = new double[m]; Arrays.fill(sd, 0.0); E = new double[mVezes3]; Arrays.fill(E, 0.0); maxd = md; } // método que executa a remoção do fundo da cena e detecção dos objetos em movimento public byte[][] executar(byte[] I) { t++; // caso tenha acabado o período de treinamento, realizar a remoção do fundo if (t >= n) { byte pixelMovimento[][] = new byte[IMAGE_WIDTH][IMAGE_HEIGHT]; int IpB, IpG, IpR; double PpB, PpG, PpR, x, xB, xG, xR, IP; // para cada pixel da imagem atual for (int p = 0, pB, pG, pR; p < m; p++) { pB = p*3; pG = pB+1; pR = pB+2; IpB = I[pB]&255; IpG = I[pG]&255; IpR = I[pR]&255; // calculo de "P", a projeção de "I" sobre o vetor determinado por "E" e o ponto Zero if (((IpB != 0.0) || (IpG != 0.0) || (IpR != 0.0)) && ((E[pB] != 0.0) || (E[pG] != 0.0) || (E[pR] != 0.0)) ) { x = (IpB*E[pB] + IpG*E[pG] + IpR*E[pR]) / soma2ERGB[p]; PpB = x * E[pB]; PpG = x * E[pG]; PpR = x * E[pR]; } else { PpB = 0.0; PpG = 0.0; PpR = 0.0; } // cálculo da distancia entre "I" e "P" xB = IpB-PpB; xG = IpG-PpG; xR = IpR-PpR; IP = Math.sqrt(xB*xB * xG*xG * xR*xR); // classificar o pixel pixelMovimento[p%IMAGE_WIDTH][p/IMAGE_WIDTH] = (maxd[p] < IP)?(byte)1:(byte)0; } return pixelMovimento; } // caso esteja no período de treinamento, armazenar o buffer System.arraycopy(I, 0, this.I[t], 0, mVezes3); // caso esteja no fim do período de treinamento, identificar o limiar if (t == (n-1)) {

67
int IpB, IpG, IpR; double PpB, PpG, PpR, x, xB, xG, xR; // para cada pixel das imagens que compõe a amostra for (int p = 0, pB, pG, pR; p < m; p++) { pB = p*3; pG = pB+1; pR = pB+2; // cálculo da média aritmética dos valores RGB da amostra for (int t = 0; t < n; t++) { E[pB] += this.I[t][pB]&255; E[pG] += this.I[t][pG]&255; E[pR] += this.I[t][pR]&255; } E[pB] = E[pB]/n; E[pG] = E[pG]/n; E[pR] = E[pR]/n; soma2ERGB[p] = E[pB]*E[pB] + E[pG]*E[pG] + E[pR]*E[pR]; // cálculo da projeção "P" ("I" sobre "E") e das distancias de "E" e "I" em relação à "P" for (int t = 0; t < n; t++) { IpB = this.I[t][pB]&255; IpG = this.I[t][pG]&255; IpR = this.I[t][pR]&255; // cálculo dos valores RGB de "P" if (((IpB != 0.0) || (IpG != 0.0) || (IpR != 0.0)) && ((E[pB] != 0.0) || (E[pG] != 0.0) || (E[pR] != 0.0)) ) { x = (IpB*E[pB] + IpG*E[pG] + IpR*E[pR]) / soma2ERGB[p]; PpB = x * E[pB]; PpG = x * E[pG]; PpR = x * E[pR]; } else { PpB = 0.0; PpG = 0.0; PpR = 0.0; } // cálculo das distâncias entre "I" e "P" xB = IpB-PpB; xG = IpG-PpG; xR = IpR-PpR; d[t] = Math.sqrt(xB*xB * xG*xG * xR*xR); md[p] += d[t]; } // cálculo da média aritmética amostral das distancias entre "I" e "P" md[p] = md[p]/n; // cálculo do desvio padrão amostral das distâncias entre "E" e "P" e das distancias entre "I" e "P" for (int t = 0; t < n; t++) { x = d[t]-md[p]; sd[p] += x*x; } sd[p] = Math.sqrt(sd[p]/nMenos1); // cálculo do limite aceito para "IP" maxd[p] = md[p]+(tStudent*(sd[p]/raizN)); } } return null; }
Para executar a remoção do fundo e detecção dos objetos em movimento, a classe
necessita de três parâmetros: buffersTreino, informado em seu construtor e que indica
qual a quantidade de buffers usados no período de treinamento; tStudent, também
informada no construtor e obtida a partir de consulta feita à tabela do Anexo B; e o vetor I,
informado como parâmetro do método executar(), chamado a cada novo quadro do
vídeo.

68
6.3.2.4 MÉDIA DA DISTÂNCIA IP + ERRO EMPÍRICO
A partir de observações feitas em cima dos resultados obtidos com o método descrito
na seção anterior foi elaborado o método de remoção do fundo descrito nesta seção.
A classe utilizada no método do erro empírico é a classe
MOCAPRemocaoFundoMediaDistanciaIPStudent, assim como no método da seção
anterior. No entanto, ao chamar o construtor da classe o parâmetro tStudent não recebe o
ponto crítico obtido a partir da consulta à tabela de pontos críticos da distribuição t de
Student, recebe sim um valor arbitrário que ajusta a remoção do fundo da cena para aquele
vídeo específico. Para os vídeos utilizados na pesquisa o valor ideal encontrado para o
“parâmetro empírico” ficou entre 150 e 180.
Essa regulagem proporciona ao usuário do protótipo um certo desconforto, pois são
necessários alguns testes de tentativa e erro até que o valor ideal do parâmetro empírico seja
encontrado. No entanto esse método foi o que retornou o melhor resultado na remoção do
fundo da cena e detecção dos objetos em movimento.
6.3.3 ANÁLISE DAS SILHUETAS E LOCALIZAÇÃO DA PROVÁVEL FIGURA HUMANA
A análise das silhuetas e localização da provável figura humana é implementada nas
classes que estendem a classe abstrata MOCAPAnaliseSilhueta. Para o protótipo foi
criada apenas uma classe que atende tal pré-requisito, a classe
MOCAPAnaliseSilhuetaOrdenada8Conexo.
Os parâmetros que MOCAPAnaliseSilhuetaOrdenada8Conexo necessita para
executar a análise das silhuetas são: larguraMinima e alturaMinima, informados em
seu construtor e que indicam qual a largura e altura mínima para que uma silhueta seja
considerada uma pessoa, e a matriz pixelMovimento, informada como parâmetro do
método executar(), chamado a cada novo quadro do vídeo a ser tratado e que contém a
classificação de cada pixel da imagem em fundo da cena (valor igual a zero) ou em
movimento (valor igual a um). Como resultado o método executar() pode retornar um
objeto da classe java.awt.Polygon, contendo os pontos do contorno interno da pessoa
identificada, ou null, caso nenhuma pessoa tenha sido identificada.

69
Para se compreender o algoritmo do método executar(), é preciso antes estudar os
seguintes conceitos:
a) Conforme ilustra a fig. 6.11, contorno interno (internal contour) é aquele em que
todos os pontos que fazem parte do contorno são internos ao objeto e contorno
externo (external contour) é aquela em que todos os pontos que fazem parte do
contorno estão conectados ao objeto, porém não fazem parte de seu interior (Costa,
2000);
b) Conforme ilustra a fig. 6.12, é dado ao pixel atual o nome de semente (identificado
pela letra S) e seus pixels vizinhos são enumerados com um valor seqüencial que
vai de zero a sete;
c) A busca pelo contorno é executada no sentido anti-horário, que é o mesmo sentido
usado na enumeração dos pixels vizinhos à semente.
FIGURA 6.11 – DIFERENÇA ENTRE CONTORNO EXTERNO E CONTORNO INTERNO
Fonte: Costa (2000, p.339)
FIGURA 6.12 – IDENTIFICAÇÃO DOS PIXELS VIZINHOS DO PIXEL ATUAL

70
A lógica do método executar() é exposta no quadro 6.9 e seu código fonte é
exposto no quadro 6.10.
QUADRO 6.9 – LÓGICA DO MÉTODO IMPLEMENTADO NO MOCAPANALISESILHUETAORDENADA8CONEXO E QUE É RESPONSÁVEL PELA
IDENTIFICAÇÃO DA SILHUETA HUMANA
Atribui-se ao polígono mais provável o valor nulo Para cada linha da matriz pixelMovimento, faça
Para cada coluna da matriz pixelMovimento, faça Se (pixel semente está em movimento) e (pixel semente faz parte do contorno interno), então
// nesse bloco o pixel semestre é considerado o pixel atual Cria-se um novo polígono Marca-se o pixel semente como pixel inicial Identifica-se o último pixel visitado (vizinho 0) Identifica-se o próximo pixel (vizinho que faça parte do contorno interno do objeto) Adiciona-se o pixel atual na lista de pontos do contorno do polígono Enquanto próximo pixel fizer parte do contorno interno e for diferente do pixel inicial, faça
// nesse bloco o próximo pixel é considerado o pixel atual Marca-se o próximo pixel como fazendo parte da borda interna Identifica-se o último pixel visitado Identifica-se o próximo pixel Adiciona-se o pixel atual na lista de pontos do contorno do polígono
// nesse momento, o contorno da silhueta já foi identificado Obtém-se a largura, altura e área do retângulo no qual a silhueta encontra-se inscrita Se (largura atende à largura mínima) e (altura atende à altura mínima), então
Se (área é maior que a área do mais provável), então Armazena-se o polígono atual como sendo o polígono da silhueta mais provável
// resta agora retornar o resultado da função O método retorna o polígono mais provável identificado
QUADRO 6.10 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPANALISESILHUETAORDENADA8CONEXO E QUE É RESPONSÁVEL PELA
IDENTIFICAÇÃO DA SILHUETA HUMANA
private final static int DX[] = new int[] {-1, -1, 0, 1, 1, 1, 0, -1}; private final static int DY[] = new int[] { 0, 1, 1, 1, 0, -1, -1, -1}; public Polygon executar(byte[][] pixelMovimento) { final int yMax = IMAGE_HEIGHT - ((alturaMinima > 1)?alturaMinima-1:1); final int xMax = IMAGE_WIDTH - ((larguraMinima > 1)?larguraMinima-1:1); Polygon maisProvavel = null; int areaMaisProvavel = 0; // busca pelo pixel inicial for (int sy = 1; sy <= yMax; sy++) for (int sx = 1; sx <= xMax; sx++) if ((pixelMovimento[sx][sy] == 1) && ((sy == 0) || (pixelMovimento[sx-1][sy] == 0))) { // prepara para iniciar o contorno dessa silhueta Polygon silhueta = new Polygon(); int x = sx, y = sy; pixelMovimento[x][y] = -1; int ultimo = 0, proximo = obterProximo(pixelMovimento, x, y, ultimo); silhueta.addPoint(x, y);

71
// contorna a silhueta em sentido anti-horário while (pixelMovimento[x+DX[proximo]][y+DY[proximo]] > 0) { x = x + DX[proximo]; y = y + DY[proximo]; pixelMovimento[x][y] = 2; ultimo = (proximo+4)%8; proximo = obterProximo(pixelMovimento, x, y, ultimo); silhueta.addPoint(x, y); } // verificar se é a silhueta mais provável Rectangle r = silhueta.getBounds(); if ((r.width >= larguraMinima) && (r.height >= alturaMinima)) { int area = r.width * r.height; if (area > areaMaisProvavel) { maisProvavel = silhueta; areaMaisProvavel = area; } } } // retornar a silhueta mais provável return maisProvavel; } int obterProximo(byte[][] pixelMovimento, int x, int y, int ultimo) { int proximo = (ultimo+2)%8; int nx = x + DX[proximo]; int ny = y + DY[proximo]; while ((proximo != ultimo) && ( (nx < 0) || (nx >= IMAGE_WIDTH) || (ny < 0) || (ny >= IMAGE_HEIGHT) || (pixelMovimento[nx][ny] == 0) )) { proximo = (proximo+1)%8; nx = x + DX[proximo]; ny = y + DY[proximo]; } return proximo; }
O código fonte para a identificação do contorno do objeto foi adaptado de Kansas
(1999) e o critério utilizado na classificação da silhueta em “mais provável” representa uma
contribuição original deste trabalho.
6.3.4 SEGMENTAÇÃO DA SILHUETA PARA IDENTIFICAÇÃO DO POSICIONAMENTO 2D DAS PARTES DO CORPO
A segmentação da silhueta humana e a identificação do posicionamento 2D das partes
do corpo do ator são tarefas atribuídas às classes filhas de
MOCAPSegmentacaoSilhueta.

72
Na seção 3.4 foram apontados uma série de detalhes que devem ser levados em
consideração no momento da segmentação da silhueta. Devido à complexidade de se tratar
todos esses detalhes, a implementação da tarefa de segmentação e identificação não foi
concluída. No entanto uma classe filha de MOCAPSegmentacaoSilhueta foi criada, a
MOCAPSegmentacaoSilhuetaCentroide. Essa classe implementa a localização do
centróide da silhueta humana, usado como ponto de partida para identificação das diagonais
principais e, posteriormente, a estimação da posição da cabeça do ator que, segundo as
referências citadas na seção 3.4, é a primeira parte do corpo a ser classificada.
De acordo com Costa (2000), o centróide de um polígono é o ponto que representa o
centro de massa do mesmo. Assumindo que a figura da qual deseja-se extrair o centróide
esteja inserida em uma imagem raster, o centróide pode ser calculado através da lógica
exibida no quadro 6.11.
QUADRO 6.11 – LÓGICA DO CÁLCULO DA POSIÇÃO DO CENTRÓIDE DE UM POLÍGONO EM UMA IMAGEM RASTER
centroide_x = 0 centroide_y = 0 area = 0 Para cada linha y da imagem, faça
Para cada coluna x da imagem, faça Se (pixel atual faz parte da região interna da figura) então
centroide_x = centroide_x + x centroide_y = centroide_y + y area = area + 1
centroide_x = centroide_x / area centroide_y = centroide_y / area
Um método mais eficiente de se calcular o centróide é apresentado em Bashein (1994).
Esse método utiliza apenas os vértices do polígono que define a silhueta e, por esse motivo,
esse método foi implementado nesse trabalho, sendo o código fonte adaptado e exposto no
quadro 6.12.
QUADRO 6.12 – CÓDIGO DO MÉTODO IMPLEMENTADO NO MOCAPSEGMENTACAOSILHUETACENTROIDE E QUE É RESPONSÁVEL PELA
LOCALIZAÇÃO DO CENTRÓIDE DA SILHUETA HUMANA
public MOCAPParte[] executar(Polygon silhueta) { // o primeiro e o último ponto precisam ser diferentes int n = silhueta.npoints; if ((n > 1) && (silhueta.xpoints[0] == silhueta.xpoints[n-1]) && (silhueta.ypoints[0] == silhueta.ypoints[n-1])

73
) n--; // verificar se a silhueta é composta por no mínimo dois pontos if (n > 1) { double ai, a = 0.0, x = 0.0, y = 0.0; for (int i = n-1, j = 0; j < n; i = j, j++) { ai = (silhueta.xpoints[i]*silhueta.ypoints[j]) - (silhueta.xpoints[j]*silhueta.ypoints[i]); a += ai; x += (silhueta.xpoints[j]+silhueta.xpoints[i]) * ai; y += (silhueta.ypoints[j]+silhueta.ypoints[i]) * ai; } if (a != 0.0) { x = x/(3*a); y = y/(3*a); // para calcular o valor real da área bastaria fazer "area = a/2" return new MOCAPParte[] { new MOCAPParte(x, y, MOCAPParte.PARTE_CENTROIDE) }; } } return null; }
6.3.5 CONSTRUÇÃO DA MARIONETE VIRTUAL A marionete virtual é utilizada na última etapa do processo de captura de movimento.
Apesar dessa etapa não ter sido implementada, houve a preocupação de se criar um modelo
3D da marionete, exposto na fig. 6.13.
FIGURA 6.13 – MARIONETE VIRTUAL 3D
Para auxiliar na modelagem 3D foi adotada a ferramenta 3D Studio Max 4 e como
base para a marionete foi utilizado o sistema “Biped”, que é disponibilizado pela ferramenta e
que combina objetos, controles e a hierarquia que resulta em uma figura humana.

74
A partir de Biped foi criado o sistema Boneco, composto por vinte e dois objetos:
Boneco, Pélvis, Dorso_0, Dorso_1, Dorso_2, Dorso_3, Pescoço, Cabeça, Clavícula_Esquerda,
Braço_Esquerdo, Antebraço_Esquerdo, Mão_Esquerda, Clavícula_Direita, Braço_Direito,
Antebraço_Direito, Mão_Direita, Coxa_Esquerda, Perna_Esquerda, Pé_Esquerdo,
Coxa_Direita, Perna_Direita e Pé_Direito. A fig. 6.14 ilustra a visão sistemática dos objetos
que compõe a marionete virtual, onde os retângulos representam os objetos e as setas indicam
quais objetos serão afetados ao ser aplicadas transformações geométricas como a rotação e
translação.
FIGURA 6.14 – VISÃO SISTEMÁTICA DOS OBJETOS QUE COMPÕE A MARIONETE VIRTUAL 3D
6.4 FUNCIONAMENTO DO PROTÓTIPO Ao ser iniciado, o software apresenta ao usuário sua janela principal (fig. 6.15).

75
No topo da janela principal é encontrada a barra de ativação do módulo 2D, mostrada
na fig. 6.16, e, no restante da tela, podem ou não estar sendo exibidas janelas de configurações
dos processos. Tais janelas serão abordadas no decorrer dessa seção.
FIGURA 6.15 – JANELA PRINCIPAL DO MÓDULO 2D
FIGURA 6.16 – BARRA DE ATIVAÇÃO DO MÓDULO 2D
91
2
3 4
5 6 7
8
A barra de ativação do módulo 2D é dividida em cinco colunas de componentes, sendo
que cada coluna possui três linhas. As duas primeiras linhas da primeira coluna (fig. 6.16,
item 1) contêm a seleção da origem do vídeo (arquivo ou dispositivo de captura). Quando

76
marcado “Arquivo de Vídeo” serão listados na combo box os arquivos AVI que estão na pasta
“..\Protótipo\video” e quando marcado “Dispositivo de Captura” serão listados os dispositivos
de captura de vídeo instalados no computador.
Na terceira linha da primeira coluna (fig. 6.16, item 2) é encontrada a caixa de
verificação “Exibir vídeo tratado”, que quando selecionada abre a janela exibida na fig. 6.17,
responsável pela exibição do vídeo que está sendo reproduzido.
FIGURA 6.17 – JANELA DE EXIBIÇÃO DO VÍDEO TRATADO
A segunda, terceira e quarta coluna da barra de ativação contêm os componentes
usados para configurar quais processos serão aplicados no vídeo. A caixa de verificação
“Exibir Desempenho” (fig. 6.16, item 3) fica habilitada toda vez que um processo de
tratamento da imagem foi selecionado e ao ser selecionada abre a janela exibida na fig. 6.18.
A janela de exibição do desempenho do codec ativo é composta por três linhas: na primeira é
mostrado o índice do último buffer/quadro tratado, na segunda é mostrado o número de
buffers/quadro tratados pelo codec e na terceira o número de buffers/quadros que o codec não
conseguiu tratar.

77
FIGURA 6.18 – JANELA DE EXIBIÇÃO DO DESEMPENHO DO CODEC ATIVO
Voltando para a barra de ativação, é encontrada na terceira coluna (fig. 6.16, item 4) a
caixa de verificação “Exibir Histórico do RGB”. A seleção dessa opção torna visível a janela
exibida na fig. 6.19. Os três gráficos colocados nessa janela mostram, respectivamente, a
variação do valor em R, G e B em um determinado pixel durante a exibição do vídeo. As
caixas de edição, colocadas na parte inferior da janela, servem para configurar qual pixel será
analisado no decorrer do vídeo. É importante ressaltar que cada gráfico é composto por
noventa e nove colunas e por duzentos e cinqüenta e seis linhas de pixels, isso porque cada
coluna representa um quadro tratado do filme (são armazenados os valores RGB dos últimos
cem quadros) e cada linha representa uma unidade aceita em R, G e B (que vai de zero até
duzentos e cinqüenta em cinco), sendo que o menor valor está na parte inferior e o maior na
parte superior do gráfico. Outra informação que deve ser levada em consideração no momento
de informar o pixel que será analisado é que o sistema de coordenadas usadas para mapear os
pixels no vídeo possui sua origem no canto superior esquerdo da imagem.
FIGURA 6.19 – JANELA DE HISTÓRICO DA VARIAÇÃO DOS VALORES RGB DE UM PIXEL DURANTE A EXECUÇÃO DO VÍDEO

78
No momento em que é selecionada a caixa de verificação “Remoção do Fundo” (fig.
6.16, item 5) na barra de ativação do módulo 2D, é exibida a combo box para seleção do
processo de remoção do fundo desejado (logo abaixo da caixa de verificação) e a janela de
configuração desse processo, exibida na fig. 6.20. A janela de configuração do processo de
remoção do fundo da cena apresenta na primeira linha a seleção do número de
quadros/buffers utilizados no período de treinamento da imagem referência. De acordo com o
processo selecionado é habilitada a segunda ou a terceira linha. Em processos onde é usado
um método estatístico para a classificação do pixel em fundo da cena ou objeto em
movimento deve ser informado o grau de confiança dado ao processo, e no método
denominado “empírico” deve ser informado o valor do parâmetro empírico, abordado na
seção 6.3. Como resultado da remoção do fundo o vídeo tratado é exibido nas cores preto e
branco, sendo que a cor preta indica o pixel classificado como fundo da cena e a cor branca o
pixel classificado como objeto em movimento.
FIGURA 6.20 – JANELA DE CONFIGURAÇÃO DO PROCESSO DE REMOÇÃO DO FUNDO DA CENA
O processo de análise das silhuetas depende do processo de remoção de fundo e é
ativado a partir da seleção da caixa de verificação “Análise da Silhueta”, na barra de ativação
do módulo 2D (fig. 6.16, item 6). Quando essa opção é selecionada torna-se visível a combo
box que mostra os processos de análise disponíveis e torna-se visível também a janela de
configuração exibida na fig. 6.21. A partir dessa janela de configuração são informadas a
largura e altura mínima para que a silhueta não seja considerada falha do método de remoção
do fundo.
O resultado obtido na análise das silhuetas é exibido na janela do vídeo tratado, por
uma linha vermelha que mostra os pontos que fazem parte do contorno do ator (fig. 6.17), e
na janela exibida na fig. 6.22, onde os pontos vermelhos novamente são os pontos que fazem

79
parte do contorno do ator e a região amarela é a área interna do polígono determinado pelo
contorno.
FIGURA 6.21 – JANELA DE CONFIGURAÇÃO DO PROCESSO DE ANÁLISE DAS SILHUETAS ENCONTRADAS, PARA A DETECÇÃO DA FIGURA HUMANA
FIGURA 6.22 – JANELA DE EXIBIÇÃO DO RESULTADO DA ANÁLISE DAS SILHUETAS ENCONTRADAS E DA SEGMENTAÇÃO DA SILHUETA ENCONTRADA
Para ativar o processo de segmentação da silhueta deve ser selecionada a caixa de
verificação “Segmentação da Silhueta”, na barra de ativação do módulo 2D (fig. 6.16, item 7).
Esse processo depende do processo de análise da silhueta e, quando ativado, torna visível a
combo box com a listagem de tipos de processo disponíveis. A segmentação da silhueta não
possui nenhuma janela especial de configuração e seu resultado também é exibido na janela
“Silhueta Detectada” (fig. 6.22), sendo que, futuramente, ao término da implementação dessa
etapa é previsto que: as prováveis localizações da cabeça, centróide, pélvis e pescoço do ator
serão marcadas pela cor azul; as regiões marcadas pela cor alaranjada serão as estruturas
bilaterais do lado direito; as regiões marcadas pela cor verde serão as estruturas bilaterais do

80
lado esquerdo; e as estruturas marcadas pela cor rosa serão as estruturas que compões o dorso
do ator.
A última etapa dos processos executados pelo módulo 2D é a conexão e envio dos
dados obtidos pelo processo de segmentação da silhueta para o módulo 3D. Essa etapa é
ativada ao selecionar a caixa de verificação “Módulo 2D, Processo Completo!”, na barra de
ativação do módulo 2D (fig. 6.16, item 8), tornando visível a janela de configurações da fig.
6.23. Os parâmetros para a conexão são todos compilados junto com a classe, com exceção do
endereço do servidor por ser conhecido apenas no momento da execução do sistema e o
identificador do módulo 2D que, por hora, não tem utilidade mas poderá no futuro indicar o
ponto de vista que está sendo captado pela câmera.
FIGURA 6.23 – JANELA DE CONFIGURAÇÃO DA CONEXÃO ENTRE O MÓDULO 2D E O MÓDULO 3D
Para concluir essa seção, falta apenas explanar sobre a funcionalidade dos botões
“Abrir”, “Fechar” e “Sobre”, que estão localizados na última coluna de componentes da barra
de ativação (fig. 6.16, item 9).
O botão “Abrir” é responsável por iniciar o processo de captura do movimento. Ao ser
chamado ele verificará qual a origem do vídeo e qual o conjunto de codecs que atendem os
processos selecionados. Caso nenhum processo tenha sido selecionado será iniciada a
reprodução do vídeo sem nenhum tratamento especial, e caso tenha sido selecionado algum
processo o vídeo será tratado pelo conjunto de codecs identificados.
O botão “Fechar” encerra a reprodução/tratamento do vídeo e o botão “Sobre” abre a
janela de informações a respeito da autoria do sistema.
6.5 ANÁLISE DOS RESULTADOS Os seguintes itens podem ser destacados como resultados alcançados:

81
a) A obtenção de dados vindos de dispositivos de captura e arquivos de vídeo foi
executada com sucesso;
b) Visualmente, de acordo com as amostras exibidas na fig. 1 dos Anexos G e H, a
etapa de remoção do fundo das cenas e detecção dos objetos em movimento
demonstrou melhores resultados no método Empírico e no método de mínimo e
máximo valor RGB. Já os métodos estatísticos que utilizam a distribuição Normal
padronizada e a distribuição de Student apresentaram um resultado com grande
quantidade de falhas na classificação dos pixels. Os resultados dessa análise visuais
são comprovados numericamente no Anexo I, onde em ambas as amostras o
método Empírico teve um melhor aproveitamento (96,32% e 97,50% de acerto),
seguido pelo mínimo e máximo valor RGB (92,17% e 92,73% de acerto),
distribuição Normal (86,21% e 88,36% de acerto) e distribuição de Student
(64,80% e 67,76% de acerto);
c) No Anexo J é exibida uma análise quantitativa de quadros aproveitados por cada
um dos métodos de remoção do fundo da cena implementados (tabela 1) e na
análise da silhueta dos objetos em movimento para identificação da figura humana
(tabela 2). Esse anexo mostra que os métodos de remoção de fundo que aproveitam
melhor os quadros do vídeo são o método Empírico e o método que utiliza a
distribuição de Student, isso porque ambos utilizam a mesma classe. Em seguidos,
quase que empatados, estão os métodos de mínimo e máximo valor RGB e
distribuição Normal. Quando analisado o aproveitamento de quadros na análise das
silhuetas para localização da figura humana, é observado melhor rendimento no
método empírico, seguido pela distribuição Normal, mínimo e máximo valor RGB
e distribuição de Student;
d) O bom desempenho da análise da silhueta dos objetos em movimento para
identificação da figura humana mostrou-se diretamente proporcional ao
desempenho na classificação dos pixels da etapa de remoção do fundo da cena,
como mostra a fig. 2 dos Anexos G e H, sendo confiável quando obedecidos os pré-
requisitos traçados na seção 6.1;
e) O desempenho das etapas que envolvem a segmentação da silhueta 2D,
triangulação quadrática e reconstituição do movimento do ator em uma marionete

82
virtual 3D não pôde ser mensurado, pois a implementação dessas etapas não foi
concluída;
f) A etapa de remoção do fundo das cenas mostrou-se pesada em computadores de
baixa capacidade de processamento e que dispõe de pouca memória. Para obter
desempenho considerável recomenda-se o uso de um Pentium III 700Mhz e 256Mb
de memória (o qual foi utilizado no desenvolvimento) e para obter melhor
desempenho, com um baixo índice de quadros não tratados, recomenda-se o uso de
um Pentium III 900Mhz e 128Mb de memória (o qual foi utilizado nos testes);
g) Os algoritmos utilizados nas etapas que seguem a remoção do fundo mostraram-se
pouco exigentes nos quesitos de processamento e memória, não sendo decisivos na
escolha do equipamento empregado.
6.6 SITUAÇÃO DE DIFÍCIL TRATAMENTO No período de implementação do protótipo foi encontrada uma situação de difícil
tratamento, a ocorrência da “oclusão”. Conforme descrito na seção 3.5, a oclusão ocorre
quando uma parte do corpo do ator fica sobreposta por outra parte do corpo do ator ou por
algum outro objeto em cena. Para tratar a oclusão, a solução encontrada é a utilização de mais
de uma câmera no processo de captura das imagens, pois assim a parte oculta em um ângulo
estaria sendo mostrada por outro ângulo. Quanto maior for o número de câmeras utilizadas
menores serão a chances de perda de informações por causa da oclusão.
Com a solução apontada para o tratamento da oclusão, surge um obstáculo para o autor
do presente trabalho, a não disponibilidade de um maior número de câmeras. As exigências
quanto à qualidade da imagem fazem com que o dispositivo de captura seja de alta resolução.
Por não ser proprietário de tais dispositivos, durante a realização deste trabalho, o
acesso a um deles foi restrito e a utilização de dois ou mais se tornou inviável.

83
7 CONCLUSÕES No decorrer desse trabalho, pôde-se observar alguns aspectos importantes no
desenvolvimento de um sistema óptico de captura de movimento humano, sem a utilização de
marcações especiais. Dentre esses aspectos é encontrada relevância na qualidade de definição
das imagens obtidas pelas câmeras e na qualidade no processamento dessas imagens, para que
seja possível a obtenção de resultados coerentes.
De forma geral, concordando com os conceitos expostos em Trager (1997), observou-
se que um sistema ideal de MoCap atende aos seguintes preceitos: deve ser de fácil
configuração e de fácil calibragem; não pode restringir os movimentos do ator; capturar tanto
movimentos sutis quanto movimentos amplos do corpo que está sendo monitorado; deve ser
preciso quando informa a posição e orientação das articulações e estruturas rígidas, para
melhor representar os movimentos; e deve oferecer uma rápida resposta aos movimentos do
ator, para que possa ser gerada a captação em tempo real.
Analisando os conceitos expostos em Trager (1997) e o objetivo do trabalho de se
construir um sistema que a partir de um conjunto de dados, vindos de uma ou mais câmeras
de vídeo, identifique e analise o movimento de uma figura humana, com a intenção de
reproduzir esse movimento em uma marionete virtual, pôde-se concluir que o presente
trabalho tenha atingido em grande parte seu objetivo.
Fazendo uma análise crítica dos objetivos do trabalho, observa-se que a operação de
capturar os dados vindos dos dispositivos de entrada é efetuada com sucesso e que a API do
JMF correspondeu a todas as expectativas, apresentando uma boa documentação e
componentes de fácil utilização. Quanto à análise dos dados de entrada, remoção do fundo das
cenas e detecção dos objetos em movimento, observa-se que o trabalho atingiu sua meta,
fazendo bom uso dos conceitos estatísticos e geométricos estudados. No que diz respeito à
análise da silhueta dos objetos em movimento para a identificação de uma figura humana
também é observado sucesso, visto que nesse passo é apontada uma solução original deste
trabalho. Já na fase de identificação do posicionamento 2D das partes do corpo da figura
humana, são observados problemas a serem trabalhados, problemas esses que refletem na não
implementação de etapas posteriores como a identificação do posicionamento 3D da partes do
corpo da figura humana e animação da marionete virtual.

84
Considerando-se os conceitos expostos em Trager (1997), observa-se que, de modo
geral, o sistema implementado apresenta um bom grau de qualidade nos processos. O sistema
atende aos quesitos que dizem respeito à fácil configuração, fácil calibragem, não restrição
dos movimentos do ator, captura de movimentos sutis e captura de movimentos amplos. No
que diz respeito à rápida resposta aos movimentos do ator, o sistema dependerá de uma
plataforma ágil de processamento para também atender esse quesito, sendo que os
computadores utilizados na fase de teste mostraram-se adequados. Já no quesito de precisão
na posição e orientação das articulações e estruturas rijas, o sistema depende da continuidade
na implementação das etapas não finalizadas.
Uma observação importante a respeito do sistema de MoCap estudado nesse trabalho é
que seu propósito não se limita à tarefa de duplicar os movimentos do ator para gerar uma
animação digitalizada. Com auxílio de um sistema como esse é possível aplicar os
movimentos capturados em situações extremas, onde ocorre risco de vida, ou quando o
produto final é uma interface amigável e natural entre o homem e a máquina.
É importante ressaltar que, apesar de ser amplamente utilizada para a captura de
movimentos humanos, MoCap pode ser utilizada para capturar o movimento de praticamente
qualquer objeto existente no nosso mundo.
7.1 EXTENSÕES As possíveis extensões que podem ser feitas a partir deste trabalho estão enumeradas a
seguir:
a) Dar continuidade ao desenvolvimento do protótipo finalizando a implementação
dos processos de segmentação da silhueta, triangulação quadrática e animação da
marionete virtual 3D;
b) Desenvolver algoritmos mais eficientes para os processos de remoção do fundo e
análise das silhuetas;
c) Desenvolver um sistema utilizando a mesma linha de raciocínio que o
implementado nesse trabalho, porém que permita a interação de um ou mais atores
ao mesmo tempo;

85
d) Desenvolver um sistema utilizando a mesma linha de raciocínio que o
implementado nesse trabalho, porém que permita a utilização de câmeras de
posicionamento não estático;
e) Dar continuidade ao desenvolvimento do protótipo fazendo com que ele gere, como
saída, arquivos que possam ser manipulados por editores gráficos como o 3D
Studio Max;
f) Desenvolver um estudo sobre os resultados obtidos pelo protótipo, fazendo uma
análise minuciosa das vantagens, desvantagens e precisão dos métodos
implementados para cada uma das etapas do processo de captura.

86
REFERÊNCIAS BIBLIOGRÁFICAS AMAT, Josep; FRIGOLA, Manel; CASALS, Alícia. Virtual exoskeleton for
telemanipulation, Barcelona, jan. 2001. Disponível em:
<http://www.ri.cmu.edu/events/iser00/ISERlist.html>. Acesso em: 22 nov. 2001.
BASHEIN, Gerard; DETMER, Paul R. Centroid of a polygon. In: HECKBERT, Paul S.
Graphics gems IV. Pittsburg: AP Professional, 1994. p. 3-6.
BOTTINO, Andrea. Motion capture system, Torino, [2000?]. Disponível em:
<http://www.polito.it/~bottino/MotionCapture/>. Acesso em: 11 out. 2001.
COSTA, Luciano da Fontoura; CESAR JR., Roberto Marcondes. Shape analysis and
classification, theory and pratice. Boca Raton: CRC Press LLC, 2000.
DAVIS, Larry. Machine vision systems, Germantown, 1999. Disponível em:
<http://www.umiacs.umd.edu/~lsd/426/426.html>. Acesso em: 16 out. 2001.
DAVIS, Larry et al. Multi-perspective analysis of human action, Germantown, [2000?].
Disponível em: <http://www.cs.umd.edu/users/thanarat/Research.html>. Acesso em: 23 out.
2001.
ECKEL, Bruce. Thinking in Java. 2. ed. New Jersey: Prentice-Hall, 2000.
ELGAMMAL, Ahmed; DURAISWAMI, Ramani; DAVIS, Larry S. Efficient kernel density
estimation using the fast gauss transform with applications to segmentation and
tracking, Germantown, [2001?]. Disponível em:
<http://www.umiacs.umd.edu/~ramani/Page2.htm>. Acesso em: 17 out. 2001.
ELGAMMAL, Ahmed; HARWOOD, David; DAVIS, Larry. Non-parametric model for
background subtraction, Germantown, 2000. Disponível em:
<http://www.cs.umd.edu/users/elgammal/MyResearch.htm>. Acesso em: 23 out. 2001.
FREEMAN, William T. et al. Computer vision for computer interaction. Computer
graphics, Los Angeles, v. 33, n. 4, nov. 1999. Disponível em:

87
<http://www.siggraph.org/publications/newsletter/v33n4/contributions/freeman.html>.
Acesso em: 9 out. 2001.
FURNISS, Maureen. Motion capture. In: MEDIA IN TRANSACTION CONFERENCE, 1.,
1999, Cambridge. Anais eletrônicos... Cambridge: Massachusetts Institute of Technology,
1999. Disponível em: <http://media-in-transition.mit.edu/articles/furniss.html>. Acesso em: 7
nov. 2001.
HARITAOGLU, Ismail; HARWOOD, David; DAVIS, Larry S. Ghost: a human body part
labeling system using silhouettes, Germantown, [1998?]. Disponível em:
<http://www.umiacs.umd.edu/~hismail/PublicationsList.html>. Acesso em: 16 out. 2001.
HORPRASERT, Thanarat; HARWOOD, David; DAVIS, Larry S. A robust background
subtraction and shadow detection, Germantown, [2000a?]. Disponível em:
<http://www.cs.umd.edu/users/thanarat/Research/bgs.html>. Acesso em: 23 out. 2001.
HORPRASERT, Thanarat; HARWOOD, David; DAVIS, Larry S. A statical approach for
real-time robust background subtraction and shadow detection, Germantown, [2000b?].
Disponível em: <http://www.cs.umd.edu/users/thanarat/Research/bgs.html>. Acesso em: 23
out. 2001.
HORPRASERT, Thanarat et al. Real-time 3D motion capture, Germantown, [2000?c].
Disponível em: <http://www.cs.umd.edu/users/thanarat/Research.html>. Acesso em: 23 out.
2001.
IWASAWA, Shoichiro et al. Real-time, 3D estimation of human body postures from
trinocular images. In: INTERNATIONAL WORKSHOP ON mPEOPLE, 1., 1999, Tokio.
Anais... Tokio: 1999. p. 3-10. Disponível em:
<http://www.mic.atr.co.jp/~tatsu/research/publication/pubtatsu.html>. Acesso em: 16 out.
2001.
KANSAS UNIVERSITY. The KUIM image processing system, Lawrence, mai. 1999.
Disponível em: <http://www.cim.mcgill.ca/~sbouix/kuim/>. Acesso em: 01 mai. 2002.
MACINTYRE, Blair. Introduction to graphics, Atlanta, [2000?]. Disponível em:
<http://www.cc.gatech.edu/classes/AY2001/cs4470_fall/>. Acesso em: 30 out. 2001.

88
MOTION ANALYSIS CORPORATION. Camera tracker, California, 2001a. Disponível
em: <http://www.motionanalysis.com/contact_us/brochures.html>. Acesso em: 10 nov. 2001.
MOTION ANALYSIS CORPORATION. Physical medicine & rehabilitation, California,
2001b. Disponível em:
<http://www.motionanalysis.com/applications/movement/pmr/pmr.html>. Acesso em: 10
nov. 2001.
MOTION ANALYSIS CORPORATION. Sports medicine & performance, California,
2001c. Disponível em:
<http://www.motionanalysis.com/applications/movement/sports/sports.html>. Acesso em: 10
nov. 2001.
MOTION ANALYSIS CORPORATION. Tiger Woods dons mocap suit, California, 2001d.
Disponível em: <http://www.motionanalysis.com/about_mac/tigerwoods.html>. Acesso em:
10 nov. 2001.
PYROS PICTURES INC. Motion capture FAQ, California, mar. 2001. Disponível em:
<http://www.pyros.com/html/mocap_faq.html>. Acesso em: 10 nov. 2001.
SANTOS, Adriana dos. Protótipo de software para geração de animação por quadros-
chave utilizando a técnica de interpolação. 2000. 61 f. Trabalho de Conclusão de Curso
(Bacharelado em Ciências da Computação) - Centro de Ciências Exatas e Naturais,
Universidade Regional de Blumenau, Blumenau.
SILVA, Fernando Wagner Serpa Vieira da. Animação baseada em movimento capturado.
1998. 94 f. Tese (Mestrado em Computação Gráfica) - Laboratório de Computação Gráfica
COPPE/Sistemas, UFRG, Rio de Janeiro. Disponível em:
<http://orion.lcg.ufrj.br/~nando/publ.html>. Acesso em: 11 dez. 2001. cap. 6, p. 33-41.
SILVA, Fernando Wagner Serpa Vieira da. Motion capture: introdução à tecologia, Rio de
Janeiro, abr. 1997. Disponível em: <http://orion.lcg.ufrj.br/~nando/publ.html>. Acesso em: 11
dez. 2001.
STEINBRUCH, Alfredo; WINTERLE, Paulo. Geometria analítica. 2. ed. São Paulo:
Makron Books do Brasil Ltda, 1987. p. 55-59.

89
STURMAN, David J. A brief history of motion capture for computer character
animation, Paris, maio 1997. Disponível em:
<http://www.css.tayloru.edu/instrmat/graphics/hypgraph/animation/motion_capture/history1.h
tm>. Acesso em: 23 out. 2001.
SUN MICROSYSTEMS INC. JavaTM media framework API guide. Mountain View: Sun,
1999.
SUN MICROSYSTEMS INC. JavaTM media framework specification. Mountain View:
Sun, 2000a.
SUN MICROSYSTEMS INC. JavaTM 2, standard edition documentation. Mountain View:
Sun, 2000b.
SUN MICROSYSTEMS INC. Java 3DTM API collateral, Mountain View, 2002. Disponível
em: <http://java.sun.com/products/java-media/3D/collateral/j3d_api/j3d_api_2.html>. Acesso
em: 21 abr. 2002.
TAKAHASHI, Kazuhiko; SAKAGUCHI, Tatsumi; OHYA, Jun. Real-time estimation of
human body postures using Kalman filter. In: INTERNATIONAL WORKSHOP ON ROBOT
AND HUMAN INTERACTION, 8., 1999, Roma. Anais... Roma: 1999. p. 189-194.
Disponível em: <http://www.mic.atr.co.jp/~tatsu/research/publication/pubtatsu.html>. Acesso
em: 16 out. 2001.
TRAGER, Wes. A pratical approach to motion capture: acclaim’s optical motion capture
system, Paris, maio 1997. Disponível em:
<http://www.css.tayloru.edu/instrmat/graphics/hypgraph/animation/motion_capture/motion_o
ptical.htm>. Acesso em: 23 out. 2001.
WONNACOTT, Thomas H.; WONNACOTT, Ronald J. Introdução à estatística. Tradução
Alfredo Alves de Farias. Rio de Janeiro: Livros Técnicos e Científicos Editora, 1980.
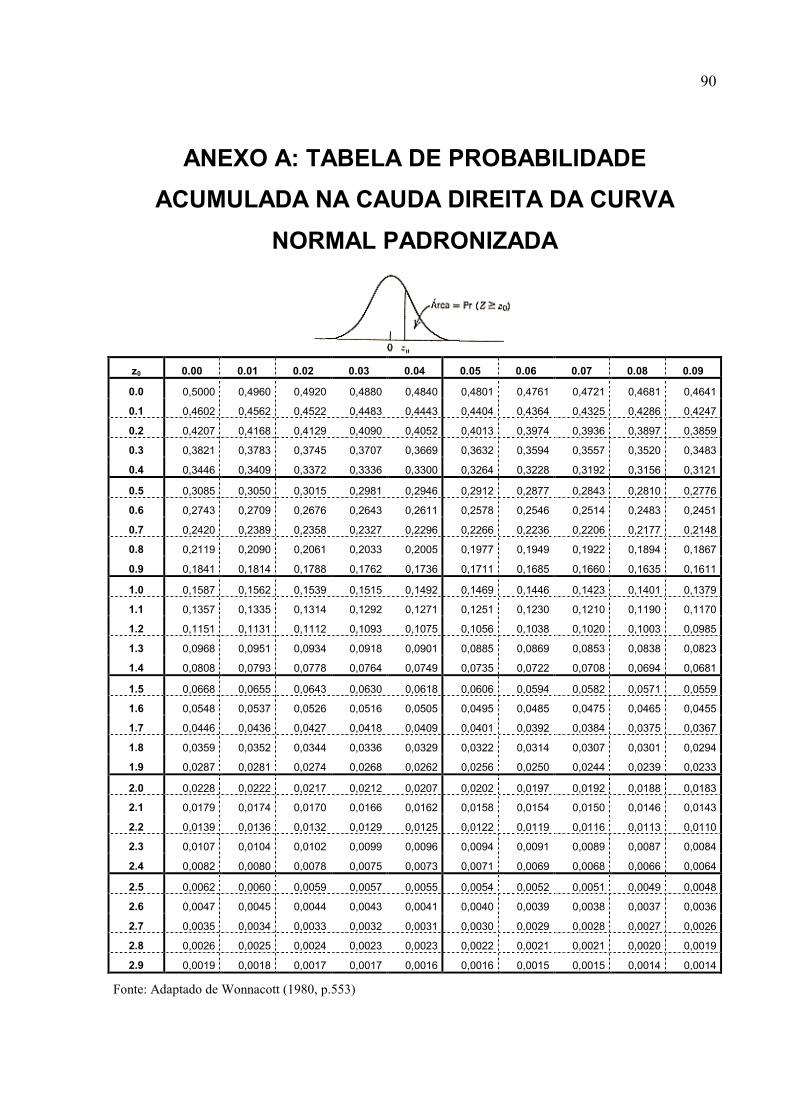
90
ANEXO A: TABELA DE PROBABILIDADE ACUMULADA NA CAUDA DIREITA DA CURVA
NORMAL PADRONIZADA
z0 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09
0.0 0,5000 0,4960 0,4920 0,4880 0,4840 0,4801 0,4761 0,4721 0,4681 0,4641
0.1 0,4602 0,4562 0,4522 0,4483 0,4443 0,4404 0,4364 0,4325 0,4286 0,4247
0.2 0,4207 0,4168 0,4129 0,4090 0,4052 0,4013 0,3974 0,3936 0,3897 0,3859
0.3 0,3821 0,3783 0,3745 0,3707 0,3669 0,3632 0,3594 0,3557 0,3520 0,3483
0.4 0,3446 0,3409 0,3372 0,3336 0,3300 0,3264 0,3228 0,3192 0,3156 0,3121
0.5 0,3085 0,3050 0,3015 0,2981 0,2946 0,2912 0,2877 0,2843 0,2810 0,2776
0.6 0,2743 0,2709 0,2676 0,2643 0,2611 0,2578 0,2546 0,2514 0,2483 0,2451
0.7 0,2420 0,2389 0,2358 0,2327 0,2296 0,2266 0,2236 0,2206 0,2177 0,2148
0.8 0,2119 0,2090 0,2061 0,2033 0,2005 0,1977 0,1949 0,1922 0,1894 0,1867
0.9 0,1841 0,1814 0,1788 0,1762 0,1736 0,1711 0,1685 0,1660 0,1635 0,1611
1.0 0,1587 0,1562 0,1539 0,1515 0,1492 0,1469 0,1446 0,1423 0,1401 0,1379
1.1 0,1357 0,1335 0,1314 0,1292 0,1271 0,1251 0,1230 0,1210 0,1190 0,1170
1.2 0,1151 0,1131 0,1112 0,1093 0,1075 0,1056 0,1038 0,1020 0,1003 0,0985
1.3 0,0968 0,0951 0,0934 0,0918 0,0901 0,0885 0,0869 0,0853 0,0838 0,0823
1.4 0,0808 0,0793 0,0778 0,0764 0,0749 0,0735 0,0722 0,0708 0,0694 0,0681
1.5 0,0668 0,0655 0,0643 0,0630 0,0618 0,0606 0,0594 0,0582 0,0571 0,0559
1.6 0,0548 0,0537 0,0526 0,0516 0,0505 0,0495 0,0485 0,0475 0,0465 0,0455
1.7 0,0446 0,0436 0,0427 0,0418 0,0409 0,0401 0,0392 0,0384 0,0375 0,0367
1.8 0,0359 0,0352 0,0344 0,0336 0,0329 0,0322 0,0314 0,0307 0,0301 0,0294
1.9 0,0287 0,0281 0,0274 0,0268 0,0262 0,0256 0,0250 0,0244 0,0239 0,0233
2.0 0,0228 0,0222 0,0217 0,0212 0,0207 0,0202 0,0197 0,0192 0,0188 0,0183
2.1 0,0179 0,0174 0,0170 0,0166 0,0162 0,0158 0,0154 0,0150 0,0146 0,0143
2.2 0,0139 0,0136 0,0132 0,0129 0,0125 0,0122 0,0119 0,0116 0,0113 0,0110
2.3 0,0107 0,0104 0,0102 0,0099 0,0096 0,0094 0,0091 0,0089 0,0087 0,0084
2.4 0,0082 0,0080 0,0078 0,0075 0,0073 0,0071 0,0069 0,0068 0,0066 0,0064
2.5 0,0062 0,0060 0,0059 0,0057 0,0055 0,0054 0,0052 0,0051 0,0049 0,0048
2.6 0,0047 0,0045 0,0044 0,0043 0,0041 0,0040 0,0039 0,0038 0,0037 0,0036
2.7 0,0035 0,0034 0,0033 0,0032 0,0031 0,0030 0,0029 0,0028 0,0027 0,0026
2.8 0,0026 0,0025 0,0024 0,0023 0,0023 0,0022 0,0021 0,0021 0,0020 0,0019
2.9 0,0019 0,0018 0,0017 0,0017 0,0016 0,0016 0,0015 0,0015 0,0014 0,0014
Fonte: Adaptado de Wonnacott (1980, p.553)

91
ANEXO B: TABELA DE PONTOS CRÍTICOS DA DISTRIBUIÇÃO DE STUDENT
g.l. / Pr 0.2500 0.1000 0.0500 0.0250 0.0100 0.0050 0.0025 0.0010 0.0005
1 1,000 3,078 6,314 12,706 31,821 63,637 127,320 318,310 636,6202 0,816 1,886 2,920 4,303 6,965 9,925 14,089 22,326 31,5983 0,765 1,638 2,353 3,182 4,541 5,841 7,453 10,213 12,9244 0,741 1,533 2,132 2,776 3,747 4,604 5,598 7,173 8,610
5 0,727 1,476 2,015 2,571 3,365 4,032 4,773 5,893 6,8696 0,718 1,144 1,943 2,447 3,143 3,707 4,317 5,208 5,9597 0,711 1,415 1,895 2,365 2,998 3,499 4,020 4,785 5,4088 0,706 1,397 1,860 2,306 2,896 3,355 3,833 4,501 5,0419 0,703 1,383 1,833 2,262 2,821 3,250 3,690 4,297 4,781
10 0,700 1,372 1,812 2,228 2,764 3,169 3,581 4,144 4,53711 0,697 1,363 1,796 2,201 2,718 3,106 3,497 4,025 4,43712 0,695 1,356 1,782 2,179 2,681 3,055 3,428 3,930 4,31813 0,694 1,350 1,771 2,160 2,650 3,012 3,372 3,852 4,22114 0,692 1,345 1,761 2,145 2,624 2,977 3,326 3,787 4,140
15 0,691 1,341 1,753 2,131 2,602 2,947 3,286 3,733 4,07316 0,690 1,337 1,746 2,120 2,583 2,921 3,252 3,686 4,01517 0,689 1,333 1,740 2,110 2,567 2,898 3,222 3,646 3,96518 0,688 1,330 1,734 2,101 2,552 2,878 3,197 3,610 3,92219 0,688 1,328 1,729 2,093 2,539 2,861 3,174 3,579 3,883
20 0,687 1,325 1,725 2,086 2,528 2,845 3,153 3,552 3,85021 0,686 1,323 1,721 2,080 2,518 2,831 3,135 3,257 3,18922 0,686 1,321 1,717 2,074 2,508 2,819 3,119 3,505 3,79223 0,685 1,319 1,714 2,069 2,500 2,807 3,104 3,485 3,76724 0,685 1,318 1,711 2,064 2,492 2,797 3,091 3,467 3,745
25 0,684 1,316 1,708 2,060 2,485 2,787 3,078 3,450 3,72526 0,684 1,315 1,706 2,056 2,479 2,779 3,067 3,435 3,70727 0,684 1,314 1,703 2,052 2,473 2,771 3,057 3,421 3,69028 0,683 1,313 1,701 2,048 2,567 2,673 3,047 3,408 3,67429 0,683 1,311 1,699 2,054 2,462 2,756 3,038 3,396 3,659
30 0,683 1,310 1,670 2,042 2,457 2,750 3,030 3,385 3,64640 0,681 1,303 1,684 2,021 2,423 2,704 2,971 3,307 3,55160 0,679 1,296 1,671 2,000 2,390 2,266 2,915 3,232 3,460120 0,677 1,289 1,658 1,980 2,358 2,617 2,860 3,160 3,373
Fonte: Adaptado de Wonnacott (1980, p.554)

92
ANEXO C: DIAGRAMA DE SEQÜÊNCIA DOS PRINCIPAIS MÉTODOS DO MOCAPPLAYER
93
ANEXO D: DIAGRAMA DE ESTADOS DO PROCESSOR
94
ANEXO E: DIAGRAMA DE SEQÜÊNCIA DO MÉTODOS PROCESS() DO MOCAPCODEC

95
ANEXO F: DIAGRAMA DE SEQÜÊNCIA DO MÉTODO TRATARBUFFER() DO MOCAPCODECMODULO2D

96
ANEXO G: COMPARAÇÃO VISUAL DE RESULTADOS OBTIDOS COM FUNDO DE CENA DE
COR PREDOMINANTE AZUL
FIGURA 1: Remoção do fundo da cena e detecção de objetos em movimento A) Mínimo e máximo valor RGB; B) Média da distância IP + erro Normal (erro aceito: 0,14%); C) Média da distância IP + erro Student (erro aceito: 0,10%); D) Média da distância IP + erro Empírico (parâmetro: 180,0). Preto: Fundo Branco: Objeto
FIGURA 2: Análise das silhuetas e localização da provável figura humana A) Mínimo e máximo valor RGB; B) Média da distância IP + erro Normal (erro aceito: 0,14%); C) Média da distância IP + erro Student (erro aceito: 0,10%); D) Média da distância IP + erro Empírico (parâmetro: 180,0).
Obs.: Vídeo de 3.072 quadros. Amostra de 121 quadros. Coletado o quadro de número 1284.

97
ANEXO H: COMPARAÇÃO VISUAL DE RESULTADOS OBTIDOS COM FUNDO DE CENA DE
COR PREDOMINANTE PRETA
FIGURA 1: Remoção do fundo da cena e detecção de objetos em movimento A) Mínimo e máximo valor RGB; B) Média da distância IP + erro Normal (erro aceito: 0,14%); C) Média da distância IP + erro Student (erro aceito: 0,10%); D) Média da distância IP + erro Empírico (parâmetro: 180,0). Preto: Fundo Branco: Objeto
FIGURA 2: Análise das silhuetas e localização da provável figura humana A) Mínimo e máximo valor RGB; B) Média da distância IP + erro Normal (erro aceito: 0,14%); C) Média da distância IP + erro Student (erro aceito: 0,10%); D) Média da distância IP + erro Empírico (parâmetro: 180,0).
Obs.: Vídeo de 1.487 quadros. Amostra de 121 quadros. Coletado o quadro de número 880.
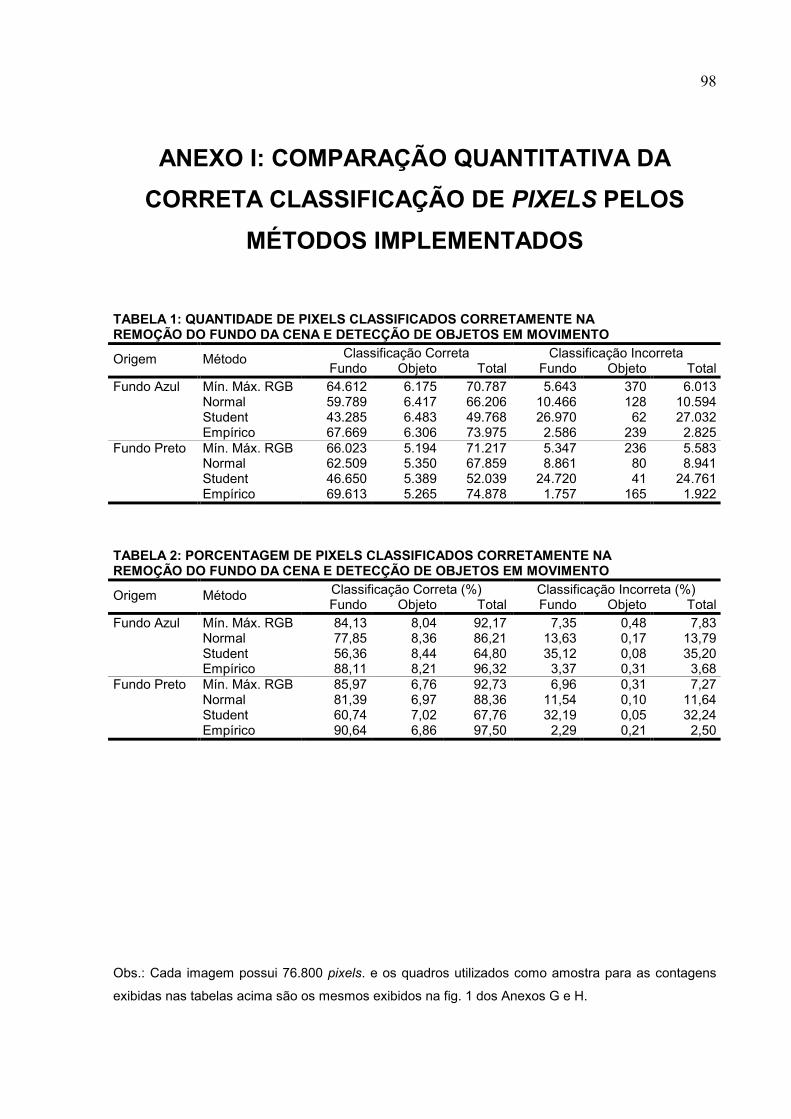
98
ANEXO I: COMPARAÇÃO QUANTITATIVA DA CORRETA CLASSIFICAÇÃO DE PIXELS PELOS
MÉTODOS IMPLEMENTADOS
TABELA 1: QUANTIDADE DE PIXELS CLASSIFICADOS CORRETAMENTE NA REMOÇÃO DO FUNDO DA CENA E DETECÇÃO DE OBJETOS EM MOVIMENTO
Classificação Correta Classificação Incorreta Origem Método Fundo Objeto Total Fundo Objeto Total
Fundo Azul Mín. Máx. RGB 64.612 6.175 70.787 5.643 370 6.013 Normal 59.789 6.417 66.206 10.466 128 10.594 Student 43.285 6.483 49.768 26.970 62 27.032 Empírico 67.669 6.306 73.975 2.586 239 2.825Fundo Preto Mín. Máx. RGB 66.023 5.194 71.217 5.347 236 5.583 Normal 62.509 5.350 67.859 8.861 80 8.941 Student 46.650 5.389 52.039 24.720 41 24.761 Empírico 69.613 5.265 74.878 1.757 165 1.922
TABELA 2: PORCENTAGEM DE PIXELS CLASSIFICADOS CORRETAMENTE NA REMOÇÃO DO FUNDO DA CENA E DETECÇÃO DE OBJETOS EM MOVIMENTO
Classificação Correta (%) Classificação Incorreta (%) Origem Método Fundo Objeto Total Fundo Objeto Total
Fundo Azul Mín. Máx. RGB 84,13 8,04 92,17 7,35 0,48 7,83 Normal 77,85 8,36 86,21 13,63 0,17 13,79 Student 56,36 8,44 64,80 35,12 0,08 35,20 Empírico 88,11 8,21 96,32 3,37 0,31 3,68Fundo Preto Mín. Máx. RGB 85,97 6,76 92,73 6,96 0,31 7,27 Normal 81,39 6,97 88,36 11,54 0,10 11,64 Student 60,74 7,02 67,76 32,19 0,05 32,24 Empírico 90,64 6,86 97,50 2,29 0,21 2,50
Obs.: Cada imagem possui 76.800 pixels. e os quadros utilizados como amostra para as contagens
exibidas nas tabelas acima são os mesmos exibidos na fig. 1 dos Anexos G e H.
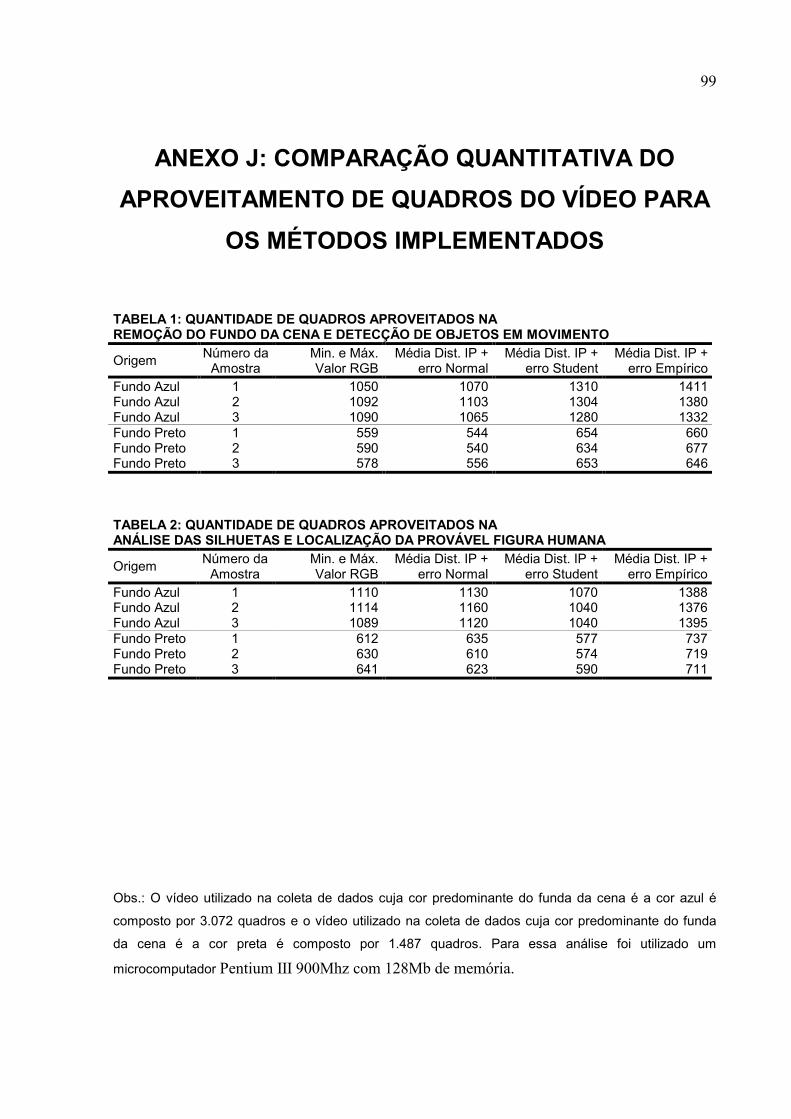
99
ANEXO J: COMPARAÇÃO QUANTITATIVA DO APROVEITAMENTO DE QUADROS DO VÍDEO PARA
OS MÉTODOS IMPLEMENTADOS
TABELA 1: QUANTIDADE DE QUADROS APROVEITADOS NA REMOÇÃO DO FUNDO DA CENA E DETECÇÃO DE OBJETOS EM MOVIMENTO
Origem Número da Amostra
Min. e Máx. Valor RGB
Média Dist. IP + erro Normal
Média Dist. IP + erro Student
Média Dist. IP + erro Empírico
Fundo Azul 1 1050 1070 1310 1411Fundo Azul 2 1092 1103 1304 1380Fundo Azul 3 1090 1065 1280 1332Fundo Preto 1 559 544 654 660Fundo Preto 2 590 540 634 677Fundo Preto 3 578 556 653 646
TABELA 2: QUANTIDADE DE QUADROS APROVEITADOS NA ANÁLISE DAS SILHUETAS E LOCALIZAÇÃO DA PROVÁVEL FIGURA HUMANA
Origem Número da Amostra
Min. e Máx. Valor RGB
Média Dist. IP + erro Normal
Média Dist. IP + erro Student
Média Dist. IP + erro Empírico
Fundo Azul 1 1110 1130 1070 1388Fundo Azul 2 1114 1160 1040 1376Fundo Azul 3 1089 1120 1040 1395Fundo Preto 1 612 635 577 737Fundo Preto 2 630 610 574 719Fundo Preto 3 641 623 590 711
Obs.: O vídeo utilizado na coleta de dados cuja cor predominante do funda da cena é a cor azul é
composto por 3.072 quadros e o vídeo utilizado na coleta de dados cuja cor predominante do funda
da cena é a cor preta é composto por 1.487 quadros. Para essa análise foi utilizado um
microcomputador Pentium III 900Mhz com 128Mb de memória.