trabalho de conclusão de curso - instituto de...
TRANSCRIPT

UNIVERSIDADE FEDERAL DO RIO GRANDE DO SULINSTITUTO DE INFORMÁTICA
CURSO DE ENGENHARIA DA COMPUTAÇÃO
Trabalho de Conclusão de Curso
Flavio Alles RodriguesClaudio Geyer
Pedro de Botelho Marcos
1

Caracterização do Consumo Energético do
Hadoop MapReduce
Flavio Alles RodriguesClaudio Geyer
Pedro de Botelho Marcos
2

Sumário1. Motivação
2. Objetivos
3. MapReduce/Hadoop
4. Estado da Arte
5. Metodologia
6. Testes & Resultados
7. Conclusões & Trabalhos Futuros
3

Sumário1. Motivação
2. Objetivos
3. MapReduce/Hadoop
4. Estado da Arte
5. Metodologia
6. Testes & Resultados
7. Conclusões & Trabalhos Futuros
4

Motivação
• Crescimento dos conjuntos de dados (GORTON et al., 2008) (KOUZES et al., 2009) (WHITE, 2012)
• Computação Intensiva em Dados
• Modelos de programação paralela e distribuída para o desenvolvimento aplicações intensivas em dados
• MapReduce (DEAN; GHEMAWAT, 2008)
• Dryad (ISARD et al., 2007)
• Spark (ZAHARIA et al., 2010)
5

Motivação• Programas desenvolvidos com estes frameworks são
altamente escaláveis, podendo utilizar milhares de máquinas em uma computação (DEAN; GHEMAWAT, 2008)
• Computação intensiva em dados demanda muitos recursos computacionais
• Alto consumo energético
• Problemas
• Financeiro
• Ambiental
6

Motivação
(BARROSO, 2005)
7

Motivação
• Queima de combustíveis fosséis é um dos fatores chave para mudanças climáticas (IPCC, 2013)
• Nos EUA, 68% da eletricidade é gerada a partir de combustíveis fosséis (EIA, 2013)
• Data centers localizados nos EUA foram responsáveis pelo consumo de ~1.5% da eletricidade gerada no país - com uma tendência de crescimento neste consumo de 12% ao ano (KURP, 2008)
8

Motivação
• Sistemas computacionais (hardware e software) devem ser projetados para serem eficientes energeticamente
9

Sumário1. Motivação
2. Objetivos
3. MapReduce/Hadoop
4. Estado da Arte
5. Metodologia
6. Testes & Resultados
7. Conclusões & Trabalhos Futuros
10

Objetivos
• Caracterizar o consumo energético de um sistema de processamento de grandes quantidades de dados
• Hadoop - implementação de código aberto do modelo de programação MapReduce - é o sistema escolhido para a caracterização
• A caracterização será acompanhada de considerações sobre o desempenho do framework
11

Sumário1. Motivação
2. Objetivos
3. MapReduce/Hadoop
4. Estado da Arte
5. Metodologia
6. Testes & Resultados
7. Conclusões & Trabalhos Futuros
12

MapReduce/Hadoop• Google (DEAN; GHEMAWAT, 2008)
• Duas funções: map & reduce
• Runtime
• Distribuição de dados
• Escalonamento de tarefas
• Comunicação entre nós
• Tolerância a falhas
• Sistema de arquivos distribuído (GHEMAWAT; GOBIOFF; LEUNG, 2003)
• Hadoop
• Implementação do modelo de programação MapReduce mais popular (WHITE, 2012), inspirado em (DEAN; GHEMAWAT, 2008)
13

MapReduce/Hadoop
(DEAN; GHEMAWAT, 2008)
14

Sumário1. Motivação
2. Objetivos
3. MapReduce/Hadoop
4. Estado da Arte
5. Metodologia
6. Testes & Resultados
7. Conclusões & Trabalhos Futuros
15

Estado da Arte
• Avaliação de Consumo Energético
• (CHEN; GANAPATHI; KATZ, 2010)
• Compressão de dados
• (LANG; PATEL, 2010)
• (WIRTZ; GE, 2011)
• O MapReduce é apenas uma carga de trabalho para avaliar diferentes mecanismos de gerenciamento energético de clusters.
16

Estado da Arte
• Avaliação de Consumo Energético (cont.)
• (LEVERICH; KOZYRAKIS, 2010)
• (KAUSHIK; BHANDARKAR, 2010)
• (MAHESHWARI; NANDURI; VARMA, 2012)
• Alterações sobre distribuição de dados para possibilitar que diferentes mecanismos de gerenciamento de energia de clusters que ligam/desligam nós com base na utilização
17

Sumário1. Motivação
2. Objetivos
3. MapReduce/Hadoop
4. Estado da Arte
5. Metodologia
6. Testes & Resultados
7. Conclusões & Trabalhos Futuros
18

Metodologia
1. Metodologia de Testes (JAIN, 1991)
2. Metodologia de Mensuração de Consumo Energético
19

Metodologia (Testes)• Objetivo: Caracterização do consumo energético e do desempenho
de um framework para desenvolvimento de aplicações intensivas em dados
• Sistema: Hadoop
• HDFS não faz parte da avaliação
• Métricas
• Consumo de Energia [J]
• Tempo de Execução [s]
• Técnica de Avaliação
• Experimentação
20

Metodologia (Testes)
• Aproximadamente 190 parâmetros de configuração
• (HERODOTOU; BABU, 2011)
• (ZAHARIA et al., 2010)
21

Metodologia (Testes)
(HERODOTOU; BABU, 2011)
22

Metodologia (Testes)
(HERODOTOU; BABU, 2011)
23

Metodologia (Testes)• mapred.jobtracker.taskScheduler
• FIFO (Padrão)
• HFS (ZAHARIA et al., 2010)
• Escalonamento justo (compartilhamento de recursos)
• Maximizar escalonamento local (Delay Scheduling)
• «HFS can increase throughput by up to 2x while preserving fairness»
24

Metodologia (Testes)
• Aplicações
• CPU Bound & IO Bound
• (HUANG et al., 2010)
• CPU Bound: WordCount
• IO Bound: Sort
25
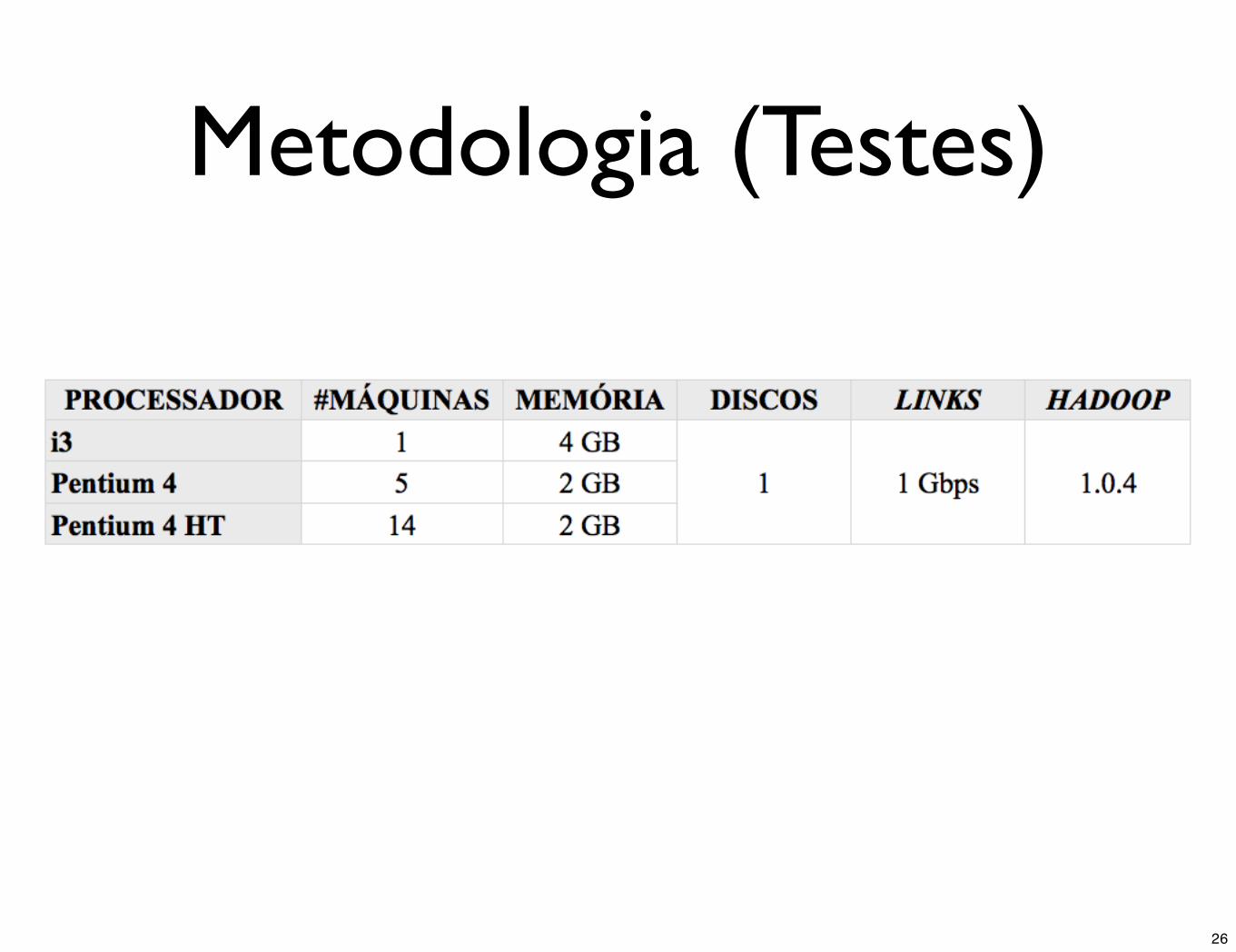
Metodologia (Testes)
26

Metodologia (Testes)
1. 2KR (HERODOTOU; BABU, 2011)
2. Escalonadores com Uma Aplicação
3. Escalonadores com Múltiplas Aplicações
27

Metodologia (Consumo)
• Baseado em estatísticas de uso (MOUW, 2001)
• Monitor distribuído (DUSSO, 2012)
28

Metodologia (Consumo)
• Energy-proportional (BARROSO; HÖLZLE, 2007)
• CPU (FAN; WEBER; BARROSO, 2007)
• Comportamento Estático
• Memória (HÄRDER et al., 2011)
• Disco (FAN; WEBER; BARROSO, 2007)
• Interface de Rede (SOHAN et al., 2010)
29

Metodologia (Consumo)
• TDP (Thermal Design Power) usualmente possui valores conservadores (FAN; WEBER; BARROSO, 2007)
• Modelo produz resultados com erro inferior à 10% (FAN; WEBER; BARROSO, 2007) (RIVOIRE; RAN- GANATHAN; KOZYRAKIS, 2008)
30

Metodologia (Consumo)• KCPU & KMISC (ECONOMOU et al., 2006)
• Processo de calibragem
• Correlação entre medidas em nível de hardware (PMEAS) e estatísticas de uso (M)
• Programa linear produz um resultado (s) a partir de uma função objetivo que busca minimizar o erro entre as medidas em nível de hardware (PMEAS) e a potência calculada pelo modelo (PPRED)
31

Metodologia (Consumo)
32

Metodologia (Consumo)
33

Sumário1. Motivação
2. Objetivos
3. MapReduce/Hadoop
4. Estado da Arte
5. Metodologia
6. Testes & Resultados
7. Conclusões & Trabalhos Futuros
34

Testes & Resultados
1. 2KR
2. Escalonadores com Uma Aplicação
3. Escalonadores com Múltiplas Aplicações
35

2KR
• Metodologia 2KR (Jain, 1991)
• (HERODOTOU; BABU, 2011)
• FIFO & HFS
• CPU Bound & IO Bound
• Entrada: 1 GB
• Replicações: 10
36
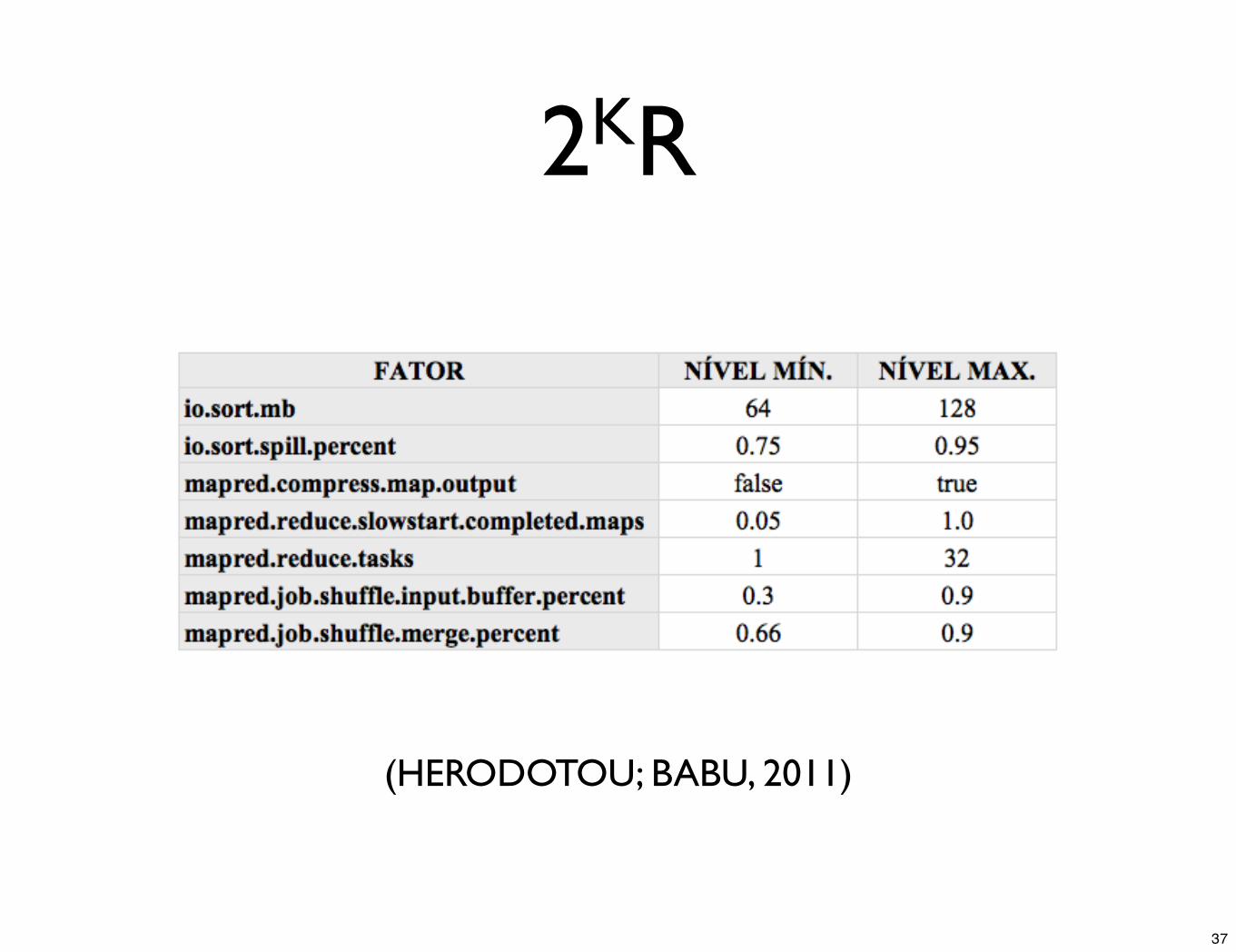
2KR
(HERODOTOU; BABU, 2011)
37

2KR
38
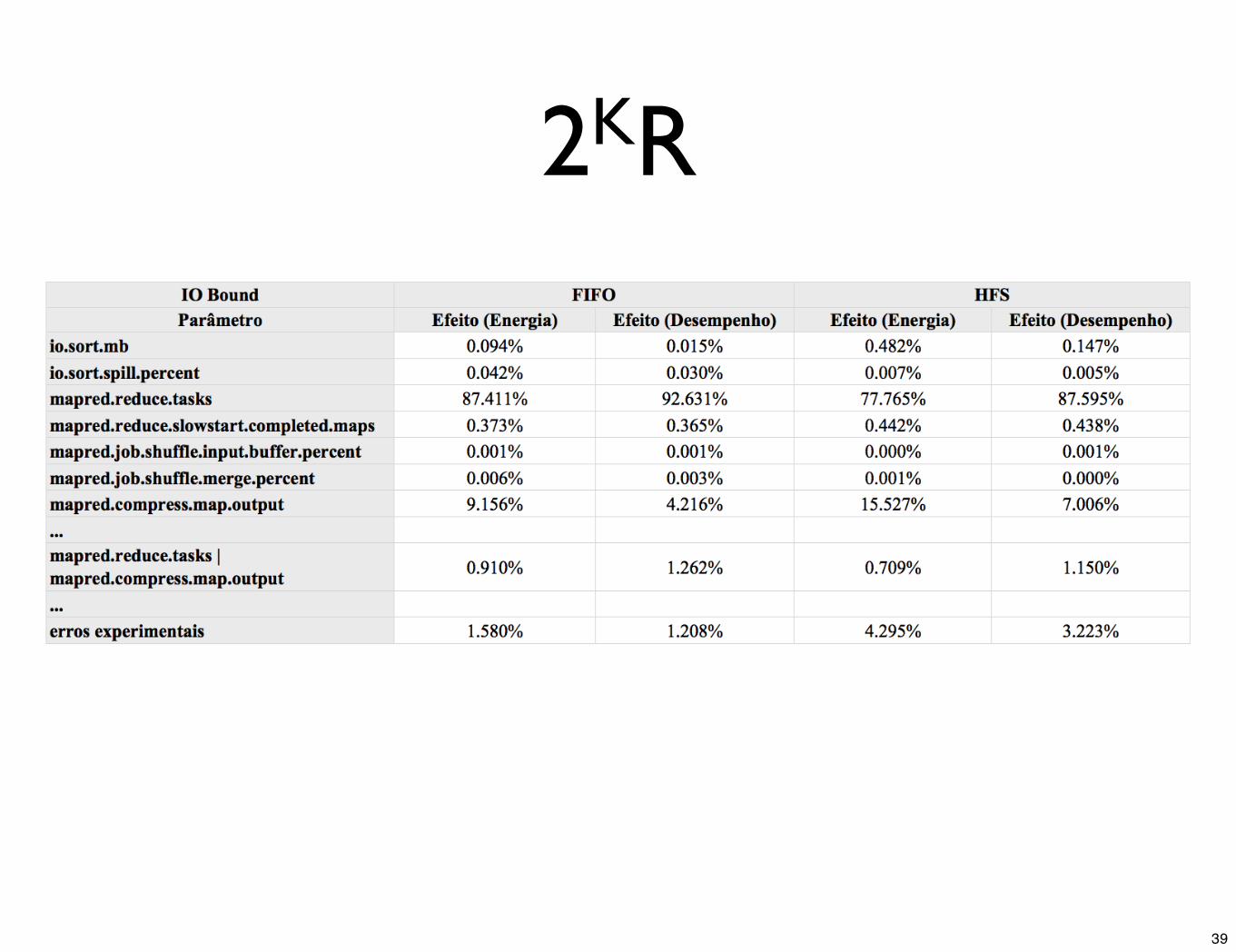
2KR
39

2KR
• Existe uma similaridade muito evidente entre os efeitos de cada fator para o consumo de energia e os efeitos de cada fator para o desempenho do sistema MapReduce
• Em linhas gerais, os parâmetros mais influentes para cada escalonador em ambas aplicações testadas - e, também, o grau de influência destes parâmetros - são semelhantes
40

Escalonadores com Uma Aplicação
• FIFO & HFS
• CPU Bound & IO Bound
• Entradas: 256 MB, 4 GB & 10 GB
• Pequena, Média & Grande
• Replicações: 10
41

Escalonadores com Uma Aplicação
• Não é possível estabelecer que um escalonador é superior ao outro para o escalonamento de uma aplicação que executa sem concorrência com outras requisições ao sistema MapReduce.
• Apesar de alcançar um de seus objetivos (maior localidade no escalonamento de tarefas map), HFS não obtém melhor desempenho ou menor consumo energético no contexto avaliado.
42

Escalonadores com Múltiplas Aplicações
• FIFO & HFS
• 20 Aplicações
• Workload CPU Bound
• Workload IO Bound
• Entradas: 256 MB (14), 4 GB (5) & 10 GB (1)
• Workload Heterogênea (50-50)
• Entradas: 256 MB (14), 4 GB (4) & 10 GB (2)
• Replicações: 10
43
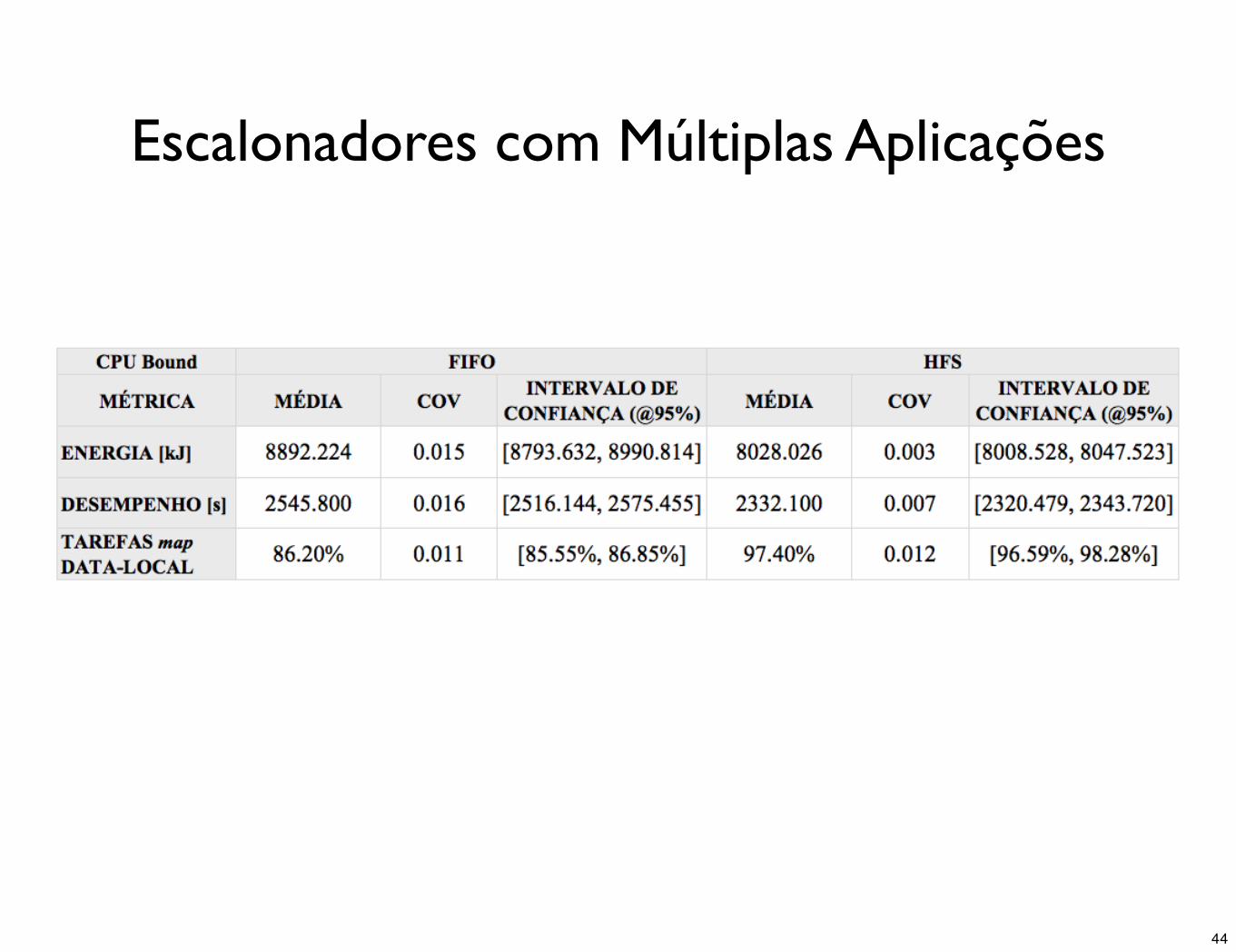
Escalonadores com Múltiplas Aplicações
44
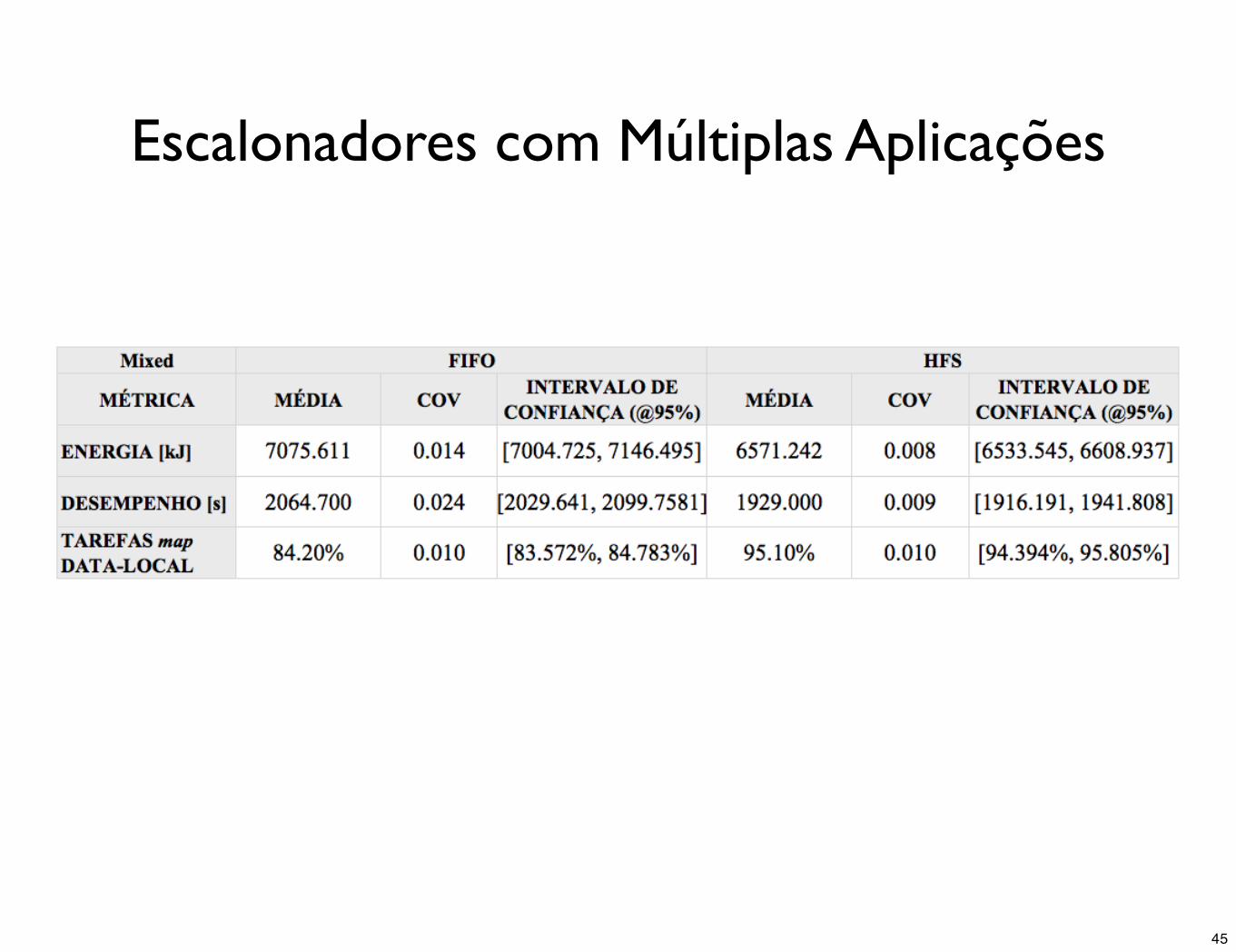
Escalonadores com Múltiplas Aplicações
45

Escalonadores com Múltiplas Aplicações
• Workload CPU bound e a workload heterogêna, HFS é a opção de escalonamento de tarefas que apresenta melhores resultados de consumo de energia e desempenho para a situação de escalonamento de múltiplas aplicações apresentadas
• O escalonamento justo e com preferência para tarefas locais produz resultados melhores do ponto de vista de eficiência energética nas workloads citadas
• Workload IO bound não apresentou diferenças estatísticas no consumo de energia
46

Sumário1. Motivação
2. Objetivos
3. MapReduce/Hadoop
4. Estado da Arte
5. Metodologia
6. Testes & Resultados
7. Conclusões & Trabalhos Futuros
47

Conclusões & Trabalhos Futuros
• Caracterizar o consumo energético de um framework para computação intensiva em dados
• 6440 Execuções MapReduce
• 6755 GB (~6.6 TB)
48

Conclusões & Trabalhos Futuros
• Usuários podem utilizar o Hadoop com maior eficiência energética
• Desenvolvedores podem tornar o sistema ciente de seu consumo de energia
49

Conclusões & Trabalhos Futuros
• Trabalhos Futuros
• Desenvolvimento de novo escalonador de tarefas MapReduce
• Adicionar funcionalidades relacionadas ao consumo de energia ao simulador MRSG (KOLBERG et al., 2013)
• Caracterização do consumo energético do HDFS
50

Agradecimento
• Este trabalho foi realizado com apoio do projeto G R E E N - G R I D : C o m p u t a ç ã o d e A l t o Desempenho (FAPERGS)
51

Referências• BARROSO, L. A. The price of performance. Queue, [S.l.], v.3, n.7, p.48–53, 2005.
• BARROSO, L. A.; HÖLZLE, U. The case for energy-proportional computing. Computer, [S.l.], v.40, n.12, p.33–37, 2007.
• CHEN, Y.; GANAPATHI, A.; KATZ, R. H. To compress or not to compress-compute vs. IO tradeoffs for mapreduce energy efficiency. In: ACM SIGCOMM WORKSHOP ON GREEN NETWORKING . Proceedings. . . [S.l.: s.n.], 2010. p.23–28.
• DEAN, J.; GHEMAWAT, S. MapReduce: simplified data processing on large clusters. Communications of the ACM, [S.l.], v.51, n.1, p.107–113, 2008.
• DUSSO, P. M. A monitoring system for WattDB: an energy-proportional database cluster. Trabalho de Graduaç ́ão, [S.l.], 2012.
• ECONOMOU, D. et al. Full-system power analysis and modeling for server environments. In: IN PROCEEDINGS OF WORKSHOP ON MODELING, BENCHMARKING, AND SIMULATION. Anais. . . [S.l.: s.n.], 2006. p.70–77.
52

Referências• EIA. http://www.eia.gov/tools/faqs/faq.cfm?id=427&t=3. 2013.
• FAN, X.; WEBER, W.-D.; BARROSO, L. A. Power provisioning for a warehouse-sized computer. ACM SIGARCH Computer Architecture News, [S.l.], v.35, n.2, p.13–23, 2007.
• GHEMAWAT, S.; GOBIOFF, H.; LEUNG, S.-T. The Google file system. In: ACM SIGOPS OPERATING SYSTEMS REVIEW. Anais. . . [S.l.: s.n.], 2003. v.37, n.5, p.29– 43.
• GORTON, I. et al. Data-intensive computing in the 21st century. Computer, [S.l.], v.41, n.4, p.30–32, 2008.
• GHEMAWAT, S.; GOBIOFF, H.; LEUNG, S.-T. The Google file system. In: ACM SIGOPS OPERATING SYSTEMS REVIEW. Anais. . . [S.l.: s.n.], 2003. v.37, n.5, p.29– 43.
• HÄRDER, T. et al. Energy efficiency is not enough, energy proportionality is needed! In: Database Systems for Adanced Applications. [S.l.]: Springer, 2011. p.226–239.
53

Referências• HERODOTOU, H.; BABU, S. Profiling, what-if analysis, and cost-based optimization
of MapReduce programs. Proc. of the VLDB Endowment, [S.l.], v.4, n.11, p.1111–1122, 2011.
• HUANG, S. et al. The HiBench benchmark suite: characterization of the mapreduce-based data analysis. In: DATA ENGINEERING WORKSHOPS (ICDEW), 2010 IEEE 26TH INTERNATIONAL CONFERENCE ON. Anais. . . [S.l.: s.n.], 2010. p.41–51.
• IPCC. http://www.ipcc.ch/report/ar5/. 2013.
• ISARD, M. et al. Dryad: Distributed Data-parallel Programs from Sequential Building Blocks. Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems. [S.l.: s.n.], p. 59–72, 2007.
• JAIN, R. The art of computer systems performance analysis. [S.l.]: John Wiley & Sons Chichester, 1991. v.182.
• KAUSHIK, R. T.; BHANDARKAR, M. GreenHDFS: Towards an Energy-Conserving Storage-Efficient, Hybrid Hadoop Compute Cluster. Proceedings of the USENIX Annual Technical Conference, [S.l.], p.1-9, 2010.
54

Referências
• KOLBERG, W. et al. MRSG: a MapReduce simulator over SimGrid. Parallel Computing, [S.l.], v.39, n.4-5, p.233–244, 2013.
• KOUZES, R. T. et al. The changing paradigm of data-intensive computing. Computer, [S.l.], v.42, n.1, p.26–34, 2009.
• KURP, P. Green computing. Communications of the ACM, [S.l.], v.51, n.10, p.1–13, 2008.
• LANG, W.; PATEL, J. M. Energy management for mapreduce clusters. Proceedings of the VLDB Endowment, [S.l.], v.3, n.1-2, p.129–139, 2010.
• LEVERICH, J.; KOZYRAKIS, C. On the energy (in) efficiency of hadoop clusters. ACM SIGOPS Operating Systems Review, [S.l.], v.44, n.1, p.61–65, 2010.
• MAHESHWARI, N.; NANDURI, R.; VARMA, V. Dynamic energy efficient data place- ment and cluster reconfiguration algorithm for MapReduce framework. Future Generation Computer Systems, [S.l.], v.28, n.1, p.119–127, 2012.
55

Referências• MOUW, E. Linux kernel procfs guide. Faculty of Information Technology and
Systems, [S.l.], 2001.
• RIVOIRE, S.; RANGANATHAN, P.; KOZYRAKIS, C. A Comparison of High-Level Full-System Power Models. HotPower, [S.l.], v.8, p.3–3, 2008.
• SOHAN, R. et al. Characterizing 10 Gbps network interface energy consumption. In: LOCAL COMPUTER NETWORKS (LCN), 2010 IEEE 35TH CONFERENCE ON. Anais. . . [S.l.: s.n.], 2010. p.268–271.
• WHITE, T. Hadoop: the definitive guide. [S.l.]: O’Reilly, 2012.
• WIRTZ, T.; GE, R. Improving MapReduce energy efficiency for computation intensive workloads. In: GREEN COMPUTING CONFERENCE AND WORKSHOPS (IGCC), 2011 INTERNATIONAL. Anais. . . [S.l.: s.n.], 2011. p.1–8.
• ZAHARIA, M. et al. Delay scheduling: a simple technique for achieving locality and fairness in cluster scheduling. In: EUROPEAN CONFERENCE ON COMPUTER SYS- TEMS, 5. Proceedings. . . [S.l.: s.n.], 2010. p.265–278.
• ZAHARIA, M. et al. Spark: cluster computing with working sets. Proceedings of the 2nd USENIX conference on Hot topics in cloud computing, [S.l.: s.n.] , p.10–10, 2010.
56

Caracterização do Consumo Energético do
Hadoop MapReduce
Flavio Alles RodriguesClaudio Geyer
Pedro de Botelho Marcos
57

Motivação• Computação Intensiva em Dados
• O sistema de indexação de páginas web do Google processa aproximadamente 20 TB em documentos a cada iteração (DEAN; GHEMAWAT, 2008)
• Facebook armazena aproximadamente 700 TB em bancos de dados relacionais (THUSOO et al., 2009)
• Experimentos em física de partículas em um dos quatro equipamentos que compõem o acelerador de partículas Large Hadron Collider no CERN geram 2 PB/s (KOUZES et al., 2009)
58

Estado da Arte• Avaliação de Desempenho
• (JIANG et al., 2010)
• Estudo do desempenho do MapReduce no contexto da área de bancos de dados. Todos os fatores considerados no artigo tem relação com o sistema de arquivos distribuído.
• (HUANG et al., 2010)
• (AGGARWAL; PHADKE; BHANDARKAR, 2010)
• Não explicam os resultados em termos de características próprias do sistema de execução MapReduce.
59

Escalonadores com Uma Aplicação
60

Escalonadores com Uma Aplicação
61

Escalonadores com Uma Aplicação
62

Escalonadores com Uma Aplicação
63

Escalonadores com Uma Aplicação
64

Escalonadores com Uma Aplicação
65

Escalonadores com Múltiplas Aplicações
66