machine learning, uma peça-chave na transformação dos ... · 4 ilustrar o desenvolvimento da...
TRANSCRIPT

P & D www.managementsolutions.com
Machine Learning,uma peça-chave na transformação dos modelos de negócio
MachineLearningPT_VDEF_Maquetación 1 13/07/2018 10:42 Página 1

Design e diagramaçãoDepartamento de Marketing e ComunicaçãoManagement Solutions - Espanha
FotografIasArquivo fotográfico da Management SolutionsiStock
© Management Solutions 2018Todos os direitos reservados. Proibida a reprodução, distribuição, comunicação ao público, no todo ou em parte, gratuita ou paga, por qualquer meio ou processo, sem o prévio consentimento por escrito da Management Solutions.O material contido nesta publicação é apenas para fins informativos. A Management Solutions não é responsável por qualquer uso que terceiros possam fazer destainformação. Este material não pode ser utilizado, exceto se autorizado pela Management Solutions.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 2

3
Índice
Introdução
Sumário executivo
A revolução digital e a transformação dos modelos de negócio
Exercício quantitativo
Bibliografia
8
4
12
Conceito e tendências em aprendizagem automática 18
30
38
Glossário 40
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 3

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
4
Introdução
I believe that at the end of the century the use of words and generaleducated opinion will have altered so much that one will be able tospeak of machines thinking without expecting to be contradicted
Alan Turing1
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 4

5
A revolução digital está provocando mudanças profundas noshábitos de consumo dos clientes, devido, entre outros fatores, aum maior acesso aos dados e a um crescente desenvolvimentode novas tecnologias. Isso tudo nos convida a repensarprofundamente os atuais modelos de negócio.
Uma alavanca fundamental para a transformação dos modelosde negócio é a ciência de dados (ou Data Science), que estábaseada no uso combinado de técnicas de aprendizagemautomática, inteligência artificial, matemática, estatística, basesde dados e otimização2, conceito que já foi amplamenteabordado em uma publicação anterior da ManagementSolutions3.
Existem diversos fatores, com origem principalmente natecnologia, que impulsionam o uso destas técnicas de DataScience em um conjunto amplo de setores. Estes fatores podemser agrupados em quatro eixos: (1) o aumento sem precedentesdo volume e da tipologia de dados disponíveis; (2) aconectividade e o acesso aos dados; (3) a melhoria dosalgoritmos utilizados; e (4) o aumento da capacidadecomputacional dos sistemas.
Em relação ao volume de dados, existem diversos estudos quereúnem diferentes métricas que permitem evidenciar amagnitude desse crescimento. Para citar alguns dos maisrelevantes:
4 De acordo con relatórios recentes, 90% dos dados criadosem toda a história da humanidade foram criados no últimoano e estima-se um crescimento de 40% anuais para apróxima década4. Atualmente, devido ao avanço dascomunicações conhecidas como Machine to Machine (M2M),e ao desenvolvimento da chamada Internet das Coisas (IoT),o volume de dados disponíveis é ainda maior.
4 Estudos publicados por grandes empresas detelecomunicações5 mostram que o número de dispositivosconectados à internet será três vezes maior que a populaçãomundial em 2021 e que o número de conexões IoT chegaráa 13,7 bilhões nesse mesmo ano, sendo que em 2016 essenúmero foi de 5,8 bilhões.
4 Como consequência disso, em 2020 o total de dadosexistentes chegará aos 44 trilhões de gigabytes6.
4 Entre eles, um grande conjunto de dados é geradodiretamente no ambiente digital, como buscas no Google(40.000 buscas por segundo), mensagens no Facebook (31milhões de mensagens por minuto) ou aumento de dadosem vídeos e fotos (300 horas de vídeos carregados noYouTube a cada hora).
4 Estima-se que, em 2020, 100% dos dispositivos móveis irãoincluir tecnologia biométrica7. Da mesma forma, para esteano, estima-se que pelo menos um terço dos dados passarápela nuvem8.
Em segundo lugar, as melhorias na conectividade implicam umsalto qualitativo que permite o desenvolvimento de novosserviços e modelos de negócio ligados à geração de dados emtempo real, bem como a sua análise, para adaptar o serviço e opreço em função do uso: a geração e a coleta de dados érealizada de forma automática através da sensorização e dadigitalização dos terminais no ponto de venda, o que cria umfluxo contínuo de informações. Uma grande parte destaconectividade é realizada entre máquinas: uma vez que umaação é realizada, os dados gerados por diferentes elementosdigitais envolvidos são conectados com servidores, com oobjetivo de armazenar e analisar as informações. Este tipo deconexões M2M, cresceu até chegar a 1,1 bilhões de conexõesem 20179.
Em terceiro lugar, a melhoria dos algoritmos permitiu tantootimizar o tratamento de grandes volumes de dados (através detécnicas de escalada, resampling, etc.) quanto obter métodosmais eficientes e robustos e tratar missings, variáveis nãonuméricas e atípicos. Apesar de a maior parte dos algoritmoster sido desenvolvida antes do ano 2000, agora é que asempresas estão investindo mais na implementação destesalgoritmos, obtendo melhores resultados que os alcançadospor humanos. Por exemplo:
1Turing, A.M. (1950). Matemático considerado o pai da ciência da computação.Decifrou a máquina Enigma durante a 2ª Guerra Mundial. Foi o precursor dainformática moderna e da inteligência artificial.2Dahr, V. (2013). Professor da Stern School of Business e Diretor no Center forDigital Economy Research, Nova Iorque.3Management Solutions (2015).4Ministério de Indústria, Energia e Turismo. Governo da Espanha (2018).5Cisco (2017). 6Forbes (2015).7Acuity Market Intelligence (2016).8Forbes (2015).9Statista (2017).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 5

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
6
Aprendizagem automática: mais de meioséculo de história
As técnicas de aprendizagem automática (ou MachineLearning) estão experimentando um auge sem precedentesem diferentes âmbitos, tanto no mundo acadêmico como noempresarial, e são uma importante alavanca de transformação.Ainda que estas técnicas já fossem conhecidas nos doisâmbitos, diversos fatores estão fazendo com o que seu usoseja mais intensivo, quando antes era minoritário, e se estendaa outros campos, quando antes praticamente não eramutilizadas, tanto pelos altos custos de implementação quantopelos escassos benefícios inicialmente esperados por suaaplicação.
As técnicas de aprendizagem automática podem ser definidascomo um conjunto de métodos capazes de detectarautomaticamente padrões nos dados15. Com esta definição, o
4 Atualmente, os algoritmos de DeepMind AlphaZero eAlphaGo têm um nível de jogo superior a qualquer humanonos jogos de xadrez e go.
4 Um algoritmo baseado em inteligência artificial é capaz dedetectar um câncer de mama 30 vezes mais rapidamente doque um médico e com um um grau de confiabilidade de99%10.
4 Nos Estados Unidos, os roboadvisors11 possuem 25,83milhões de usuários, o que representa um grau depenetração de 1,8% em 2018. Espera-se que este índicechegue a 8,3% em 202212.
Por último, o aumento da capacidade de computação, que nasúltimas décadas cresceu enormemente apoiada na melhoriados processadores, agora conta com outros fatores comoprincipais impulsionadores: entre outros, a grande evolução daslinguagens de programação (tanto generalistas comodedicadas a processamento de dados, visualização, algoritmosetc.), o cloud computing e, especialmente, a criação de novasarquiteturas de computação dirigidas especificamente a tarefasde aprendizagem automática, análise de dados e aplicações deengenharia (conhecidas como GPUs13).
Em resumo, nas últimas duas décadas, a disponibilidade dedados digitais aumentou quase mil vezes, ao mesmo tempo emque se registrou uma eficiência dez vezes maior nos algoritmos,e a velocidade de computação aumentou cem vezes o seudesempenho14. Isso tudo levou a um interesse renovado nestastécnicas como uma fórmula para obtenção de informações comvalor agregado no novo ambiente de negócios.
10Forbes (2016).11Algoritmos automáticos que proporcionam assessoria e gestão online com umamínima intervenção humana.12Statista (2018).13Graphics processing unit.14Brynjolfsson, E. y McAfee, A. (2017). Brynjolfsson, professor no MIT Sloan Schoolof Management. Diretor do MIT Initiative on the Digital Economy, Diretor do MITCenter of Digital Business. É conhecido por sua contribuição ao mundo deProdutividade de IT. McAfee, codiretor do MIT Initiative on the Digital Economy eDiretor associado do Center for Digital Business.15Murphy, K. (2012). Pós-doutorado no MIT, professor em Ciências da computaçãona Universidade de British Columbia (Canadá), esse livro recebeu o prêmioDeGroot em 2013. Atualmente é pesquisador no Google (Califórnia) sobreInteligência Artificial, Machine Learning, computer vision, e entendimento delinguagem natural.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 6

7
Neste contexto, o presente estudo pretende dar uma visãosobre a revolução digital e seu impacto na transformação dosnegócios, com um foco especial nas técnicas de aprendizagemautomática. Para isso, o documento está estruturado em trêsseções, que atendem a três objetivos:
4 Ilustrar o desenvolvimento da revolução digital e seuimpacto em diferentes frentes.
4 Introduzir a disciplina de aprendizagem automática,descrever diferentes abordagens e expor as tendênciasatuais nesta área.
4 Expor um caso de estudo para ilustrar a aplicação detécnicas de Machine Learning no caso específico do setorfinanceiro.
conceito de aprendizagem automática existe pelo menos desdeos anos 50, período em que foram descobertos e redefinidosdiversos métodos estatísticos, e foram aplicados àaprendizagem automática através de algoritmos simples,circunscritos quase que exclusivamente ao âmbito acadêmico.
Este conceito de aprendizagem automática inclui, desde então,o uso de padrões detectados para realizar previsões ou paratomar outros tipos de decisões em ambientes de incerteza16.
Comparada às técnicas estatísticas clássicas, a introdução detécnicas de Machine Learning permite melhorar o processo deestimativa de modelos, não só em relação ao aumento de poderde previsão através de novas metodologias e técnicas deseleção de variáveis, mas também na melhoria da eficiência dosprocessos através da automatização.
16Ibid.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 7

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
8
Sumário executivo
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 8

9
Conceito e tendências na aprendizagemautomática
6. Um dos elementos estruturadores desta transformaçãodigital é a aprendizagem automática, ou Machine Learning: aaplicação de técnicas e algoritmos capazes de aprender apartir de diferentes e novas fontes de informação,construindo algoritmos que melhorem de forma autônomacom a experiência. Isso permite a utilização de métodoscapazes de detectar automaticamente padrões nos dados eusá-los para prever dados futuros em um ambiente deincerteza.
7. Os componentes principais da aprendizagem automáticapodem ser classificados em quatro grupos:
- As fontes de informação, que podem trazer dados tantoestruturados como não estruturados, que são a basedos demais componentes.
- As técnicas e os algoritmos para o tratamento deinformações não estruturadas (texto, voz, vídeo etc.) epara a obtenção de padrões a partir dos dados.
- A capacidade de autoaprendizagem, que permite que oalgoritmo se adapte às mudanças nos dados.
- O uso de sistemas e software como veículo para avisualização da informação e a programação.
8. O desenvolvimento destes componentes representa umaevolução em relação ao enfoque tradicional da modelagem.Isso implica, entre outros elementos, o uso de um maiornúmero de tipologias de fontes de informação, acapacidade de detecção de padrões ocultos nos dados apartir de métodos indutivos, a manutenção do poder deprevisão durante mais tempo, bem como a necessidade deuma maior capacidade de armazenamento eprocessamento dos dados. Deste modo, a seleção da técnicade aprendizagem automática mais apropriada entre asmúltiplas existentes dependerá, em grande parte, doselementos citados.
9. Por um lado, algumas técnicas podem ser utilizadas para atransformação de informações não estruturadas (textos,sons, imagens etc.) em dados que possam ser analisados eprocessados por um computador. Entre estas técnicas éimportante destacar o uso de estatísticas ou a classificaçãode palavras em categorias para a compreensão do textoescrito, o uso de redes neurais para o reconhecimento devoz ou de imagens, a aplicação de cadeias de Markov para a
A revolução digital e a transformação dosmodelos de negócio
1. A mudança de paradigma introduzida pela digitalização nosconvida a repensar os atuais modelos de negócio.
2. O celular e a internet como porta de acesso a serviços on-line, as redes sociais como fonte de dados, a inteligênciaartificial e as arquiteturas big data, as infraestruturas para acomputação distribuída e o uso de aplicativos na nuvem, odesenvolvimento das tecnologias de computação porblocos (blockchain), a aplicação de criptografia e biometria,a denominada internet das coisas, os robôs e assistentesvirtuais, a impressão 3D e a realidade virtual e etc., sãoferramentas úteis ao alcance das empresas que por um ladomudam o próprio ambiente e que, por outro, impulsionamuma reelaboração dos modelos de negócio neste novoambiente.
3. Na era digital, os dados se convertem em uma clara fonte devalor. Seu volume aumenta exponencialmente peladigitalização dos processos e as crescentes interações comclientes, funcionários e fornecedores através de canaisdigitais.
4. Também adquirem um maior protagonismo: a experiênciado cliente, a personalização da oferta, ou o conceito deacesso ao serviço em contraposição à propriedade; e se dá,ao mesmo tempo, a entrada de novos competidores cujaproposta de valor está baseada fundamentalmente emelementos tecnológicos.
5. A realidade é que a introdução da dimensão digital mudatudo na empresa, impactando em sua definição daestratégia, na governança, na organização e na cultura detrabalho, em seus processos comerciais e operacionais, noacesso, no armazenamento, no processamento e namodelagem de dados, na gestão e no controle de riscos(onde aparecem novos riscos, como os de segurançacibernética ou os relativos à proteção de dados pessoais, ouna ética da inteligência artificial); bem como na própriaregulação, que se torna mais global.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 9

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
10
construção de textos em linguagem natural, ou a aplicaçãode algoritmos não supervisionados de classificação para aorganização de imagens.
10. Por outro lado, as técnicas de modelagem utilizadas cominformações estruturadas podem ser classificadas comoaprendizagem supervisionada ou não supervisionada, emfunção das informações utilizadas para a aprendizagem. Naaprendizagem supervisionada há uma variável-objetivoobservada nos dados, enquanto que na aprendizagem nãosupervisionada, o objetivo é encontrar padrões ou relaçõesentre eles.
11. No processo de modelagem, costuma-se realizar umaprimeira fase de organização e preparação do conjunto dedados inicial, com o objetivo de facilitar e otimizar seu usoposterior. Para isso, são realizadas tarefas de análisedescritiva e preparação dos dados (incluindo técnicasespecíficas de regularização, como por exemplo a aplicaçãode redes elásticas).
12. Entre as técnicas utilizadas na aprendizagem supervisionadapodem ser destacadas as redes neurais (incluindo suaextensão ao deep learning), as máquinas de vetor suporte, osclassificadores bayesianos ou as árvores de regressão eclassificação.
13. Estas técnicas podem ser combinadas com algoritmos quepermitem melhorar a capacidade preditiva, chamadosmétodos ensemble, que consistem na combinação demodelos para geração de um modelo mais preditivo oumais estável.
14. Dentro da aprendizagem não supervisionada vale destacaras técnicas de clustering ou as técnicas de Data Analysis,como a de redução da dimensionalidade.
15. A aplicação destas técnicas faz com que os métodos devalidação de resultados devam ser mais sofisticados, como obootstrapping ou o cross-validation, que permitem analisar omodelo em mais de uma amostra de validação. Além disso,a natureza dinâmica destas técnicas dificulta arastreabilidade dos modelos.
16. Há um grande número de casos de implementação detécnicas de aprendizagem automática em diferentessetores. Como exemplos, destacam-se as aplicações nossetores de educação (como tutores inteligentes), nasfinanças (para o trading automático, roboadvisors, detecçãoda fraude, mensuração do risco, ou na elaboração demodelos prospect com fins comerciais), na saúde (odiagnóstico por imagem, a gestão de consultas detratamento e sugestões, compilação de informaçõesmédicas ou a cirurgia robótica), ou, de modo transversal, namelhoria da eficiência das organizações (através, porexemplo, da melhoria da função de TI).
17. Entre as principais tendências na implementação detécnicas de Machine Learning, pode-se destacar o uso defontes de informação que compilam dados em tempo real, a
maior importância dada para obter um poder preditivoelevado em relação à interpretabilidade dos modelos,incorporar a capacidade de que o algoritmo seja modificadode forma autônoma em função das mudanças que vãoocorrendo na população-objetivo, ou o investimento emarquiteturas e infraestruturas tecnológicas que garantem aescalabilidade na capacidade de armazenamento de dadose uma maior velocidade de processamento, combinadascom soluções baseadas em Cloud e no uso deinfraestruturas de edge computing, onde são oferecidasfunções já previamente instaladas preparadas para seu usodireto (Functions as a Service).
18. Tudo isso pressupõe uma série de desafios e dificuldades. Ouso de novas fontes de informação acarreta a necessidadede realizar um investimento econômico para identificarnovas fontes de dados relevantes, incorporar técnicas dedata quality, garantir a proteção das informações ouestabelecer controles e sistemas de segurança cibernética.
19. A aplicação de novas técnicas e algoritmos acarretatambém a necessidade de reforçar a função de gestão dorisco de modelo, realizar uma escolha prévia do algoritmomais adequado entre uma ampla variedade depossibilidades ou verificar se os resultados automáticos nãoimplicam na aparição de tratamentos discriminatórios.Incorporar a característica da autoaprendizagem nosmodelos pode dificultar a sua validação e exige considerarnovos elementos, como o controle dos graus de liberdadena automatização, uma maior frequência na avaliação dopoder discriminante ou outras técnicas de contraste.Finalmente, tudo isso acarreta a necessidade de realizarinvestimentos em recursos e infraestruturas de TI.
20. Além disso, a introdução da aprendizagem automática nasorganizações pressupõe a necessidade de contar comrecursos humanos com um alto grau de preparação eespecialização, capazes de compreender e trabalhar comlinguagens de programação, algoritmos, matemática,estatística e arquiteturas tecnológicas complexas.
Exercício quantitativo: uso de técnicas deMachine Learning na construção de ummodelo de scoring
21. Os objetivos do exercício proposto foram: (i) analisar eilustrar o impacto do uso de técnicas de Machine Learningno desenvolvimento de modelos e (ii) avaliar a variação doprocesso de estimativa e os resultados obtidos mediante ouso de Técnicas de Machine Learning.
22. Para isso, um modelo de scoring foi treinado, utilizandodiferentes algoritmos de Machine Learning, e os resultadosforam comparados com os obtidos com técnicastradicionais.
23. O estudo foi realizado utilizando um conjunto de mais de500 mil empréstimos, que compreendem mais de 10 anos
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 10

11
se melhorar a área sob a curva ROC de 81,5% no modelotradicional até 88,2%, o que representa um aumentopercentual de 8,2%. O segundo melhor método é aaplicação da rede elástica, com a qual os valores de taxa deacerto e a área sob a curva ROC chegam a 79% e 86,4%respectivamente. Isto representa um aumento percentualde 6% em ambos os indicadores.
28. Este aumento do poder preditivo implica que, com ummesmo volume de negócio, a taxa de inadimplência sereduziria em 48%, no caso do random forest (utilizando umponto de corte ideal com o modelo clássico, chegaria a umataxa de inadimplência de 2,1%, que se reduz a 1,1% com orandom forest se o volume de operações aprovadas formantido), e 30% no caso da rede elástica (em que a taxa deinadimplência se reduz a 1,4%). Da mesma forma, bemcomo a taxa de inadimplência, o volume de negócioaumentaria 16% no caso do random forest e 13% no caso darede elástica.
29. No entanto, estas melhorias foram alcançadas através de umaumento da complexidade em relação ao modelotradicional, tendo utilizado um total de 80 variáveis entre as50 árvores que compõem o bosque, no caso do randomforest, e um total de 45 variáveis após a aplicação da redeelástica, em comparação com 11 variáveis no modelotradicional.
30. Portanto, como foi observado no estudo realizado, astécnicas de Machine Learning permitem melhorar o poderdiscriminante dos modelos, o que implica em melhorias nonegócio, mas à custa de uma maior complexidade tanto deum ponto de vista estatístico quanto pelo volume deinformação utilizada, o que gera uma maior dificuldade nahora de analisar a interpretação dos resultados e anecessidade de reforço dos procedimentos de validação(entre outros, utilizando modelos replicáveis que façamchallenge em relação aos modelos de Machine Learning eexplicando as diferenças nas saídas de ambos os modelos).
de história, com uma taxa de inadimplência de 6%. Aamostra inclui informações relativas à operação e ao cliente,bem como outras informações que podem ser úteis namodelagem, como comissões, número de transaçõesrealizadas etc.
24. Em uma primeira fase de knowledge discovery foi realizadoum tratamento de missings (mediante técnicas de alocaçãoatravés, entre outros, do uso de algoritmos de clustering oude modelos de regressão), uma análise e tratamento deatípicos e um processo de simplificação e agrupamento devariáveis (utilizando novamente algoritmos de clustering).Isto permitiu reduzir o número de variáveis, com o objetivode melhorar a eficiência dos processos posteriores epreparar as informações existentes para adequar osrequisitos específicos dos diferentes modelos e possíveislimitações dos algoritmos.
25. Em uma segunda fase foram avaliados diferentes modelos:uso tradicional (logístico) que serve como comparação ecinco técnicas de Machine Learning: um modelo comtécnicas de regularização (rede elástica), dois métodosensemble (um random forest e um adaboost) e duasmáquinas de vetor suporte (utilizando, respectivamente,uma função linear e uma radial). Posteriormente, realizou-seo cálculo de duas medidas da capacidade discriminantesobre uma amostra de validação: a taxa de acerto domodelo (baseada em uma estimativa do ponto de corte) e aárea sob a curva ROC.
26. Após a comparação com estas estatísticas observa-se quetrês das técnicas analisadas permitem melhorar o poderpreditivo do modelo, tanto na taxa de acerto17 como nopoder discriminante: o random forest, a aplicação da redeelástica e o adaboost.
27. Particularmente, o random forest é o que apresenta omelhor resultado comparado às demais metodologias: emtermos de taxa de acerto melhora de 74,7% do modelotradicional para 80,3%, o que representa um aumentopercentual de 7,5% sobre o obtido através de técnicastradicionais; em termos de poder discriminante, consegue-
17Porcentagem de operações corretamente classificadas pelo modelo, definidoum ponto de corte.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 11

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
12
A revolução digital e a transformação dos modelos de negócio
Technology doesn’t provide value to a business. Instead, technology’s value comes from doing business
differently because technology makes it possibleGeorge Westerman18
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 12

13
Além disso, também afeta os intermediários de serviços aocorrigir, pelo menos parcialmente, algumas imperfeições demercado como as informações assimétricas, os custos detransação ou as assimetrias no fechamento de oferta edemanda, através do uso de plataformas B2B ou P2P21 com umamínima intervenção de terceiros.
Além disso, a gestão de dados passou a ser um ativofundamental para a empresa, sendo ao mesmo tempo matéria-prima e gerador de negócio. A digitalização dos processos e ainteração com clientes, funcionários e fornecedores através decanais digitais traz uma grande quantidade de informação quepode ser aproveitada para novas oportunidades. A modoilustrativo, segundo a Comissão Europeia, o valor da economiados dados na União poderia chegar em 2020 a até 4% do PIB(mais do dobro em relação à situação atual).
Por último, também representa uma mudança de paradigma nomercado de trabalho, já que requer a execução de tarefas maisqualificadas, o que implica na necessidade de realização de ummaior investimento tanto no sistema educativo como nosplanos de treinamento contínuo das empresas.
No entanto, como será comentado mais adiante, atransformação digital não se refere às novas aplicações e usosda tecnologia, mas sim a como estas tecnologias modificam oambiente em que as empresas operam e como elas devem seadaptar a este novo ambiente (Figura 1), utilizandoprecisamente estas tecnologias nos processos e sistemas, mastambém mudando sua organização e estratégia.
Há alguns anos vêm aparecendo inúmeras iniciativas para atransformação, tanto dos processos quanto dos sistemasutilizados pelas empresas, o que impacta definitivamente namaneira de trabalhar. Estas iniciativas surgem tanto no âmbitoda empresa privada quanto no setor público e se fundamentamna combinação de infraestruturas físicas com elementos novos,provenientes do desenvolvimento da tecnologia digital e dabiotecnologia.
Este conjunto de mudanças não é simplesmente umacontinuação e uma sofisticação dos sistemas de produçãoatuais, mas implica em um novo paradigma, a chamada quartarevolução industrial. Este paradigma se baseia em mudançasradicais na produção, ligados à velocidade de implementaçãosem precedentes históricos, e no alcance dessa transformação,que afeta um conjunto elevado de elementos da cadeia devalor19.
Dentro desta revolução industrial, o conceito de transformaçãodigital aglutina as iniciativas relacionadas diretamente com astecnologias digitais. Segundo alguns autores20, a transformaçãodigital pode ser definida como:
“The use of new digital technologies (social media, mobile,analytics or embedded devices) to enable major businessimprovements (such as enhancing customer experience,streamlining operations or creating new business models)”
Estas tecnologias digitais impactam diretamente os processos,em questões relativas à velocidade, à segurança ou àtransparência, o que permite o desenvolvimento de novosserviços que antes não existiam, por falta de mercado ou derentabilidade, já que as tecnologias digitais, em geral,apresentam poucas barreiras de entrada e com custosmarginais que tendem a zero.
Figura 1. Elementos da transformação digital
18Westerman, G. (2017). Pesquisador no MIT Initiative on the Digital Economy e Co-autor do best seller “Leading Digital: Turning Technology Into BusinessTransformation”19Schwab, K. (2016). Economista e empresário alemão, conhecido principalmentepor ser o fundador do Fórum Mundial de Economia.20Fitzgerald et al. (2013). Editor e colaborador em temas relacionados àtransformação digital no MIT Sloan Management Review. 21B2B: Business to Business. P2P: Peer to Peer.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 13

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
14
Tecnologias da transformação digital
A transformação no âmbito empresarial, que abrange diversosâmbitos e propostas, fundamenta-se em uma série dedesenvolvimentos tecnológicos que, mesmo obedecendo adiferentes origens e naturezas, possuem elementos em comum:sua forte alavancagem no investimento, a geração e o uso degrandes volumes de dados e o objetivo de melhorar aexperiência do cliente e a eficiência operacional. Entre asprincipais tecnologias que impulsionam a transformação,encontram-se as seguintes (Figura 2):
4 Acesso móvel e internet: devido à generalização dastelecomunicações e ao acesso a um ampla diversidade deserviços on-line, interfaces de programação de aplicativos(APIs) estão sendo desenvolvidas pelas empresas, o que lhespermite ter novos canais de interlocução com os clientes econtar com um amplo conjunto de dados. Isto leva àaparição de novas formas relevantes de informação, como ageolocalização. Além disso, o acesso móvel permitiu auniversalização do acesso à informação e à comunicação,independentemente da localização física. Por exemplo, ascomunicações de banda larga móvel aumentaram cincovezes nas economias desenvolvidas nos últimos 10 anos22.
4 Social Media: as redes sociais são uma fonte de dados queproporciona uma melhor compreensão do comportamentodos clientes e uma maior produtividade através da melhoriada comunicação interna. As tendências relacionadas com aSocial Media são um marketingmuito mais segmentado edirecionado, além de novas formas de comunicação emtempo real.
4 Inteligência artificial, Big Data e Analytics: ferramentasde detecção de padrões e modelos de previsão decomportamento baseadas no uso de enormes bases dedados (que contêm informações tanto estruturadas comonão estruturadas23-logs de conexão à internet, mensagensem redes sociais etc.-) e na aplicação de técnicas demodelagem e algoritmos avançados. Tudo isso permiteobter um melhor conhecimento do cliente, o que melhora a
segmentação, a personalização do produto e do preço epermite um marketingmais eficiente.
4 Computação distribuída24: os recursos tecnológicos(armazenamento, processamento, fontes de dados esupercomputadores) podem ser encontrados distribuídosgeograficamente, mas sua interconexão pode seraproveitada pelos usuários em qualquer parte do mundo.
4 Cloud computing: o uso de aplicativos na nuvem tambémpermite o acesso à informação em qualquer lugar, facilitaoperações comerciais e permite maior rapidez, segurança ecustos mais baixos. Isto leva a um novo modelo de negócioem que esses recursos são oferecidos como utilities ecobrados como um serviço.
4 Distributed Ledger Technology (Blockchain): estrutura dedados que implementa um sistema de registro distribuído(ledger), ou seja, um registro criptográfico de todas asoperações realizadas e previamente validadas por uma redede nós independentes através de um algoritmo deconsenso. Isso permite o registro de qualquer ativodigitalizável, como criptomoedas, instrumentos financeirosou "smart contracts" (contratos programáveis queimplementam regras de negócio e cujo código ficaregistrado e pode ser executado de forma distribuída pelosdiferentes nós da rede). Tudo isso traz rapidez nasoperações, segurança e privacidade, através de regrascriptográficas que permitem o registro inviolável dasoperações, transparência (já que todas as operações sãoarmazenadas no registro e podem ser auditadas porqualquer membro da rede), eliminação de um ponto únicode decisão e diminuição de custos (elimina-se aintermediação para validar e registrar as operações).
4 Criptografia, cibersegurança e biometria: novasferramentas criptográficas e iniciativas que buscam amelhoria dos processos de segurança e criptografia dainformação, bem como a criação de sistemas de segurançamais robustos baseados em sensores e biometria.
4 Internet of Things: em contraposição aos sistemas decomunicação clássicos, o conceito de internet das coisas serefere à interconexão através de redes abertas dedispositivos com capacidade computacional que enviam erecebem dados sem intervenção humana, o que permite acompilação massiva e direta de dados, bem como aoperação remota em tempo real dos dispositivosconectados à internet. Esta tecnologia, por um lado,melhora a experiência do cliente, mas ao mesmo tempopermite o uso destes dados em alguns processoscomerciais, como é o caso do pricing ou a busca daeficiência.
Figura 2. Tecnologias da transformação digital.
22International Telecommunication Union (2017).23Pode ser entendida como informação estruturada aquela que está processada epreparada para ser utilizada diretamente através de linguagens estatísticas e deprogramação. A informação não estruturada é aquela que não cumpre estascaracterísticas, como as informações em linguagem natural (texto, áudio),imagens, vídeo etc.24International Telecommunication Union (2009).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 14

15
4 Robotics and automated machinery: As ferramentas RPA25
e os assistentes virtuais baseados na interpretação dalinguagem natural permitem automatizar tarefas repetitivasde baixo valor agregado, tradicionalmente realizadas deforma manual, de modo que esta capacidade disponívelpossa se orientar a tarefas de maior valor agregado. Asindústrias dirigidas ao usuário final estão adaptandorapidamente esta nova tecnologia com o objetivo demelhorar a qualidade dos produtos e reduzir os custos demanufatura.
4 Impressão 3D: dirigida à fabricação deslocalizada edescentralizada de objetos a partir da recepção remota edigitalizada do design industrial, com aplicação em diversossetores e uso direto por parte dos consumidores (nossetores aeronáutico, automotor, eletrônico, médico etc.).
4 A realidade aumentada e a realidade virtual: apresentammúltiplas aplicações, como na indústria dos vídeo-games,ou de conteúdos multimidiáticos, treinamento defuncionários de indústrias muito especializadas, o suporteem consertos e manutenção na indústria energética, o apoioem vendas de moradias, buscadores de moradia, escritóriosbancários, caixas eletrônicos etc.
O novo ambiente da transformação digital
O novo ambiente digital está modificando significativamente ascondições nas quais os mercados alcançam seu equilíbrio, tantoatravés da modificação nas empresas ofertantes como dasexpectativas e do comportamento dos consumidores, bemcomo das diferentes condições nas quais as operações sãorealizadas (compra e venda de produtos, serviços etc.).
Como será comentado nesta seção, a transformação digital estáocorrendo em um ambiente onde existem diferentesimpulsionadores. Por um lado, as novas capacidadestecnológicas são a sua origem, mas o elemento fundamentalque possibilita a transformação são as mudanças nos clientes ounos mercados provocados pela tecnologia, o que possibilita,fomenta e requer sua implementação nas empresas para poderse adaptar a este novo paradigma.
Estas mudanças são ampliadas como consequência dadesaparição das barreiras de entrada existentes nos setores (Figura 3).
Isso porque este aumento da oferta de bens e serviços estámotivado por diversos fatores. Um dos principais é a entrada denovos competidores cuja proposta de valor está baseadafundamentalmente em um elemento tecnológico, o que tem
uma influência determinante no modelo de negócio e noselementos associados (elevada capacidade de crescimento,baixo custo e custo marginal decrescente, fortementealavancado na tecnologia móvel, na análise de dados, nastecnologias cloud e na cibersegurança).
Além da entrada de novos competidores, estes em alguns casossubstituem o produto ou o serviço oferecido por um totalmentedigital ou híbrido, o que resulta em menores custos e preços, eem uma fácil e rápida substituição do serviço tradicional. Este éo caso de novos modelos de serviço baseados no uso dealgoritmos que interpretam dados de redes sociais e outrasfontes pouco convencionais para fornecer informaçõesrelevantes para seus clientes em tempo real, substituindo dessaforma as fontes tradicionais de informação.
Por último, os fornecedores podem influir também naadaptação de processos específicos ao gerar plataformas decomunicação e enfoques de negócio digitais que facilitam amigração dos processos de abastecimento de produtos ouserviços a seus clientes.
Tudo isso implica que os agentes clássicos nos mercados, emresposta, também estejam adaptando seus modelos denegócio, apesar da presença de diversos inibidores datransformação digital, como a resistência à mudança, a culturaou a falta de formação das pessoas.
Os fatores tecnológicos anteriormente comentados tambématuam indiretamente como um motor de mudança na forma deentender a prestação de serviços por parte dos clientes.
As mudanças na forma de consumir são sintetizadas pelo WorldEconomic Forum (WEF) em três elementos26:
1. Maior protagonismo da experiência do cliente: aexperiência de compra ganha mais valor, de forma quequalquer pessoa, empresa ou instituição opta por um produtoou serviço não apenas com base na sua qualidade e no seupreço, mas também pela experiência que este proporciona (porexemplo em prazos de entrega ou qualidade do serviço pós-venda).
Figura 3. Porcentagem de entrevistados que consideram muito provável queum setor seja afetado por tendências digitais.
Fonte: Harvard Business Review (2017).
25Robotic Process Automation.26Digital Consumption (2016).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 15

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
16
2. Hiperpersonalização da oferta: os clientes possuem maioresexpectativas sobre a adaptação do produto ao seu gostopessoal. A tecnologia digital permite cumprir com estasexpectativas sem aumentar drasticamente os custos.
3. Acesso, mais que propriedade: o conceito de acessosubstituindo o de propriedade está sendo generalizado. Osclientes preferem o acesso sob demanda, otimizando dessamaneira o consumo.
O sucesso de iniciativas como a da Amazon exemplificam essasquestões, em que a experiência do cliente no processo decompra é enriquecida com uma seleção personalizada deprodutos relacionados, e a oferta de valor ao cliente inclui oproduto e certa personalização nos prazos e mecanismos deentrega, ou o das plataformas de conteúdos Netflix ou Spotify,em que o cliente acessa os conteúdos sem possuir apropriedade, por um custo menor.
Paralelamente, as próprias normas internacionais estão seadaptando ao novo ambiente, tornando-se mais globais eincisivas, especialmente nos aspectos relativos à proteção dedados pessoais.
Por último, o próprio mercado de trabalho se vê impactado, comuma crescente demanda de perfis tecnológicos e quantitativos(STEP), e também a gestão dos recursos humanos, gerando umamaior flexibilidade e a fragmentação do trabalho, bem comomudanças na mensuração do desempenho, nas estratégias decontratação ou nas necessidades de formação.
Efeitos nas organizações e nos âmbitos deatuação
Muitas organizações estão incorporando novas tecnologias emseus processos (com maior ou menor grau de integração), masnem sempre com o mesmo objetivo. Algumas empresaspretendem se beneficiar das novas tecnologias com o objetivode ser mais eficientes, reduzir custos, outras como um meio dechegar a novos mercados, mas apenas algumas as aproveitampara gerar novos modelos de negócio.
Segundo uma pesquisa da Comissão Europeia27, as empresastendem a utilizar estas tecnologias, tais como serviços móveis,tecnologia cloud, social media, etc. (Figura 4), para melhorarfunções de negócio específicas, mais do que como umaferramenta inovadora para transformar os modelos de negócio.
A transformação digital nas empresas, entendida como umamudança disruptiva, tem implicações não apenas nos processose sistemas, adaptando-os às novas ferramentas e aos enfoquesde trabalho, mas em sua governança, em sua organização e naprópria definição estratégica.
É importante, portanto, posicionar-se em cada um dos principaisâmbitos de atuação afetados pela transformação digital (Figura 5).
Estratégia e mobilização. Uma aproximação estratégica aoobjetivo digital implica um questionamento dos atuais modelosde negócio e suporte. Não há uma receita universal que sirvapara qualquer empresa, mas a transformação digital não é umaopção, e sim uma necessidade cujos tempos e alcancedependerão do contexto de cada empresa.
Existem diversas fórmulas para realizar esta transformação,tanto em relação à posição de uma entidade diante das novastecnologias (early adopter, seguidor, desafiador etc.) como emrelação à participação de terceiros (joint ventures, colaboraçãocom start-ups, universidades, centros de pesquisa, fundos decapital de risco, outras empresas ou, até mesmo, através deplataformas baseadas em ambientes abertos).
Um primeiro passo muito importante é documentar bem asituação de partida de cada empresa e de seu setor para, emseguida, tentar deduzir as oportunidades e as ameaças que adigitalização apresenta.
Outra questão fundamental é a liderança da transformação, quedeve ser feita pelo primeiro executivo da empresa. Também nãose deve esquecer o impacto dessa transformação nas pessoas ena própria cultura de trabalho da empresa.
Considerando que os custos e riscos são elevados, bem como osprazos incertos, é importante sintetizar e priorizar os objetivosda transformação, assim como contar com indicadoresespecíficos (como o impacto econômico, a melhoria daexperiência do cliente ou a vinculação dos funcionários) queajudem a mensurar o grau de cumprimento de tais objetivos.
Organização, cultura e governança. A forma de trabalhar eorganizar o trabalho também está mudando. As estruturasorganizacionais ficam mais horizontais, com equipesmultidisciplinares, organizadas em projetos, adotando princípiose desenvolvendo organizações Agile. Além disso, as tecnologiasmodificam a interação, a comunicação e a tomada de decisões.
Também surgem novas funções, como as relacionadas com avisão estratégica da tecnologia, governança dos dados e dosmodelos, a proteção de dados pessoais ou a segurançainformática (cibersegurança).
Figura 4. Porcentagem da adoção das principais tecnologias.
Fonte: EC (2017)27EC (2017).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 16

17
potencial dos dados disponíveis. Isso significa contar compolíticas de gestão de consentimento e finalidade, bem comode tratamento transfronteiriço, identificar e manter repositóriosde dados de caráter pessoal, vincular ações comerciais aos usospermitidos etc., o que implica uma oportunidade para repensara estrutura e a governança dos dados de uma empresa.
Cibersegurança. Nos últimos anos, o risco cibernéticoaumentou devido a diversos fatores, como a existência de ummaior e mais complexo ambiente tecnológico nas empresas, aintegração de empresas de diferentes setores ou a própriaprofissionalização dos ataques. Os danos por ataquescibernéticos já chegaram aos 3 trilhões de dólares por ano eestima-se que em 2021 chegarão a 6 trilhões anuais29. Issoganha grande importância em um contexto de transformaçãodigital, em que um possível incidente pode ter impacto nacontinuidade de negócio da empresa.
A cibersegurança dentro da estratégia de digitalização passapela realização de iniciativas que evitem riscos durante e apósos processos de transformação. Entre as principais iniciativas,pode-se destacar a implementação de instâncias decibersegurança, a revisão da estrutura organizacional associadaà cibersegurança, à identificação e à revisão dos sistemas eserviços críticos, à mensuração do risco ou à geração derespostas eficazes em caso de incidentes.
Novas tecnologias. O investimento em novas tecnologias é umelemento decisivo em todo o processo de transformação digital.Para isso, é necessário possuir conhecimentos suficientes emtecnologia da informação e das comunicações.
Isso porque a evolução das plataformas tecnológicas aambientes de nuvem, a definição de arquiteturas de softwareque incorporam soluções abertas, a utilização de tecnologiasdisruptivas (big data, AI, block-chain, IoT, biometria, robotics,etc.) se converteram em questões centrais da estratégiaempresarial.
Processos comerciais. As empresas estão revisando seusmodelos de produção e distribuição, repensando o uso de seuscanais digitais e tradicionais. Neste contexto, destaca-se aalavanca de mobilidade. O canal móvel se transforma em umelemento centralizador da relação com o cliente.
Por outro lado, procura-se uma maior personalização daproposta de valor (interpretando as informações disponíveisatravés de sua modelagem), procurando assim melhorar aexperiência do cliente.
Processos operacionais. O objetivo fundamental datransformação dos processos operacionais (end-to-end) é amelhoria da eficiência e da qualidade do serviço aos clientes,bem como o fortalecimento do controle das operações.
Para alcançar esses objetivos, proliferam iniciativas como acriação de back offices sem papel, a digitalização dos contactcenters, a sensorização dos processos de produção, arobotização dos centros de processamento etc.
Dados e modelagem. A maior capacidade de armazenamento ede tratamento de dados, facilita uma exploração mais eficaz dasinformações disponíveis, mas também surgem novos desafios,como o uso de informações não estruturadas, a gestão degrandes volumes de dados ou a análise de informações emtempo real.
Também são incorporadas técnicas de modelagem e deaprendizagem automática (como redes neurais, redesprofundas, máquinas de vetor suporte, classificadoresbayesianos, árvores de classificação e regressão etc.), quecontribuem para a melhoria dos processos de decisão.
Proteção de dados. No contexto atual, os dados se converteramem um ativo estratégico. Por isso, as suas confidencialidade esegurança são elementos fundamentais para o negócio,especialmente no que diz respeito aos dados de caráter pessoal.
Como consequência, é necessário realizar uma gestão proativada permissão dos usuários, que permita, ao mesmo tempo,cumprir com a regulamentação e explorar adequadamente o
Figura 5. Âmbitos de atuação da transformação digital28.
28Círculo de Empresários (2018).29Cybersecurity Ventures (2017).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 17

Conceito e tendências na aprendizagem automática
All models are wrong, but some models are usefulGeorge Box30
MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
18
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 18

19
Como já exposto, a quantidade de dados disponíveis e avariedade de fontes apresentam um crescimento exponencial,que ultrapassa a capacidade de análise do ser humano. O usode novas fontes de informação, bem como a aplicação detécnicas e algoritmos capazes de aprender a partir deinformações novas31, permite obter uma série de benefícios,entre os quais vale destacar:
4 O aumento das tipologias de dados (tanto estruturadosquanto desestruturados) e fontes de informação quepodem se incorporar aos processos de modelagem.
4 O uso eficiente de grandes quantidades de dados nosprocessos de tomada de decisões.
4 A detecção de padrões sofisticados ou não evidentes, nãobaseados em hipóteses realizadas a priori.
4 A maior automatização dos processos de modelagem eautoaprendizagem, que facilita o incremento do poderpreditivo dos modelos. Uma vez desenhados eimplementados, seus requerimentos de calibração emanutenção são inferiores aos tradicionais, reduzindo assimos tempos de modelagem e custos.
Conceito e componentes da aprendizagemautomática
A definição clássica de aprendizagem automática se baseia nosprimeiros estudos para o desenvolvimento de técnicas deaprendizagem :
"Campo de estudo que dá aos computadores a capacidade deaprender sem serem explicitamente programados".32
Assim, o campo de estudos da aprendizagem automática sededica a construir algoritmos que melhorem de formaautônoma com a experiência33. Do ponto de vista da ciência dacomputação, a experiência se materializa nas informaçõesproduzidas através de processos de armazenamento de dados.Portanto, os modelos e os algoritmos que constituem o corpodesta disciplina se fundamentam na extração de informações apartir de diferentes fontes de dados. Tudo isso leva à definiçãoformal de aprendizagem automática34:
“A computer program is said to learn from experience E withrespect to some task T and some performance measure P, if its
performance on T, as measured by P, improves withexperience E”.
De um modo menos formal, pode-se definir35 o campo deaprendizagem automática como um conjunto de métodoscapazes de detectar automaticamente padrões nos dados eusá-los para fazer previsões sobre dados futuros, ou para tomarcertas decisões em um ambiente de incerteza. Portanto, astécnicas de aprendizagem automática partem de um conjunto de
30Box, G. y Draper, N. (1987). Box, estatístico britânico que trabalhou nas áreas decontrole e qualidade, análise de séries temporais, desenho de experimentos, e nainferência bayesiana, é considerado como uma das mentes mais brilhantes daestatística do século XX. Draper, professor emérito no departamento de estatísticada universidade de Wisconsin, Madison.31Shalev-Shwartz, S. e Ben-David, S. (2014). Shalev-Shwartz, professor naFaculdade de Ciências da Computação e Engenharia da Universidade deJerusalém, Israel. Ben-David, professor na Escola de Ciências da Computação naUniversidade de Waterloo, Canadá.32Parafraseado de Samuel, A. (1959). A citação textual é: “Programming computersto learn from experience should eventually eliminate the need for much of this detailedprogramming effort”. Samuel, Master em Engenharia Elétrica pelo MIT, unificou oslaboratórios Bell, trabalhou no primeiro computador comercial de IBM e foiprofessor na Universidade de Stanford. 33Mitchell, T. (1997). Doutorado na Stanford, professor da cátedra E. Fredkin nodepartamento de Machine Learning da escola de Ciência da Computação naUniversidade de Carnegie Mellon.34Mitchell, T. (1997).35Murphy, K. (2012). Pós-doutorado no MIT, professor em Ciências da computaçãona Universidade de British Columbia (Canadá), esse livro recebeu o prêmioDeGroot em 2013. Atualmente é pesquisador no Google (Califórnia) sobreInteligência Artificial, Machine Learning, computer vision, e entendimento delinguagem natural.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 19

dados observados36, sobre os quais serão obtidas regras declassificação ou padrões de comportamento, que serão aplicadossobres dados diferentes àqueles utilizados para a análise37.
A partir dessa definição, podem ser englobados os diferentescomponentes da aprendizagem automática:
4 As fontes de informação, que refletem a experiência E daqual se aprende.- Dados estruturados: bases de dados relacionais,sistemas de arquivos, etc.
- Dados não estruturados: transacionais, Marlins, CRM,voz, imagens, etc.
4 As técnicas e os algoritmos, que se relacionam com astarefas T a serem realizadas.- Técnicas para o tratamento da informação nãoestruturada: tf-idf, parsing, mapas auto-organizativos, etc.
- Modelos supervisionados e não supervisionados:modelos de classificação, modelos estocásticos,simulação, otimização, obstina, etc.
4 A capacidade de autoaprendizagem, que melhora asmétricas de desempenho P.- Retreinamento automático a partir de nova informação.- Combinação de modelos e reponderação/ calibração.
4 O uso de sistemas e software para a visualização dainformação e a programação38: - Visualização: QlikView, Tableau, SAS Visual Analytics,Pentaho, TIBCO Spotfire, Power BI.
- Programação: R, Python, Scala, Ruby, SAS, Java, SQL,Matlab, C, Google, AWS, Azure.
O desenvolvimento destes componentes implica umaevolução em relação ao enfoque tradicional da modelagem.Essa evolução apresenta uma série de diferenças em relação aoenfoque tradicional39 (Figura 6).
Técnicas de aprendizagem automática
MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
20
Machine Learning em função da informação e oparadigma de aprendizagem
Existem diversas técnicas de aprendizagem automática,dependendo da tipologia de informação utilizada (informaçãoestruturada ou desestruturada) e do paradigma deaprendizagem utilizado (Figura 7). A seleção da técnicadependerá, entre outras coisas, do objetivo do modelo que sequer construir, bem como da tipologia de informaçãodisponível.
Existem algumas técnicas específicas que podem ser utilizadaspara a transformação de informações não estruturadas (textos,sons, imagens etc.) em dados que possam ser analisados eprocessados por um computador. Como exemplo, pode-sedestacar o processamento da linguagem natural ou aidentificação de imagens (Figura 8). Alguns exemplos são o usode estatísticas para a avaliação da relevância das palavras emtextos escritos, a classificação de palavras em categorias para acompreensão do texto escrito, o uso de redes neurais para oreconhecimento de voz ou de imagens, a aplicação de cadeiasde Markov para a construção de textos em linguagem naturalou a aplicação de algoritmos não supervisionados declassificação para a organização de imagens.
Por outro lado, as técnicas de modelação modelagem utilizadascom informações estruturadas podem ser classificadas em
Figura 6. Diferenças da aprendizagem automática em relação ao enfoque tradicional.
36Este conjunto de dados costuma ser denominado "amostra de treinamento".37No entanto, no próprio processo de construção e validação do modelo sãoutilizados dados que, mesmo que sejam observados, não são incluídos naamostra de treinamento e simulam os que seriam os dados de aplicação. Estesdados costumam conformar as denominadas "amostra de teste" e "amostra devalidação".38O uso massivo de dados implica também a implementação de ferramentas debig data e a aplicação de técnicas de eficiência computacional, ainda que esteselementos não tenham sido incluídos no conceito de Machine Learning nestapublicação.39Domingos, P. (2012). Professor na Universidade de Washington. Pesquisador deMachine Learning e conhecido por seu trabalho em Redes Lógicas de Markov.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 20

21
função das informações utilizadas para a aprendizagem40,41:
Aprendizagem supervisionada: as informações para construir oalgoritmo contêm informações sobre a característica estudada,que não está presente nos dados futuros. Portanto, asinformações que se quer prever, ou a partir das quais se querclassificar uma população, estão disponíveis nos dadosutilizados para construir o modelo. Mais formalmente, oobjetivo da aprendizagem supervisionada é treinar a aplicaçãode um conjunto de variáveis (denominadas explicativas,características ou fatores) “x” em uma variável output “y”, apartir de um conjunto de dados (denominado amostra detreinamento) de pares ∆={(x_i,y_i ),i∈1,…,N}, onde “N” é otamanho da amostra.
Quando a variável output “y” é contínua, fala-se em umproblema de regressão, mas quando é nominal ou discreta, fala-se em um problema de classificação42.
Aprendizagem não supervisionada: como conceito oposto ao
Figura 8. Métodos para Natural Language Processing e Computer Vision.
Figura 7. Tipologias e técnicas de aprendizagem automática.
40Shalev-Shwartz, S. e Ben-David, S. (2014).41Murphy, K. (2012).42Por exemplo, no caso dos modelos de classificação em função da qualidade decrédito, a variável-objetivo é dicotômica (default/não default), ou discreta (nível derating), em cujo caso se fala em um problema de classificação.43Pretendem-se encontrar diferentes grupos nos dados sem ter uma amostra ondeestes grupos tenham sido previamente observado. 44Cios, K.J. e outros (2007). Doutor em Ciência da computação pela Universidadede Ciência e Tecnologia da Cracóvia, trabalhou na agência internacional deenergia atômica. É professor e chefe do departamento de ciências da computaçãoda Universidade da Virginia Commonwealth. Seus trabalhos de pesquisa sãofocados em machine learning, data mining e informática biomédica.
caso anterior, não está disponível, na amostra de construção, ainformação de uma variável que se quer prever. Portanto, nestecaso não está disponível a variável output, de forma que oconjunto de dados é da forma ∆={x_i,i∈1,…,N}, onde “N” é otamanho da amostra43. O objetivo deste tipo de problemas éencontrar padrões ou relações nos dados. Por isso, também éconhecido como knowledge discovery (processo de identificarpadrões nos dados que sejam válidos, novos, potencialmenteúteis e compreensíveis44).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:40 Página 21

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
22
Técnicas de Machine Learning
No processo de modelação modelagem costuma-se realizaruma primeira fase de knowledge discovery. Dentro desteprocesso são realizadas, entre outras, as seguintes tarefas(Figura 9):
4 Entendimento dos dados: preparação inicial e análisedescritiva dos dados, análise da qualidade da informaçãoetc.
4 Preparação dos dados: limpeza ou tratamento dos dados(incluindo o tratamento de missings, outliers, registrosequivocados ou inconsistentes), análise multivariada,combinação ou criação de novas variáveis a partir dasexistentes, redução do número de variáveis (através daeliminação de variáveis redundantes, projeção sobresubespaços de dimensão inferior), etc.
4 Seleção da técnica apropriada e aplicação de processos deregularização, onde se transforma a dados e se preparapara a modelagem. Por exemplo, entre estes métodospodem ser considerados os seguintes:
- Homogeneização da amplitude das variáveis, porexemplo subtraindo a média e dividindo pelo desviopadrão (normalizar), dividindo pela amplitude da variável(escalar), etc.
- Identificação das variáveis mais relevantes para o modeloque se quer construir. No lugar dos métodos prévios deseleção de variáveis, como o stepwise45, podem seraplicadas técnicas como o uso de redes elásticas (elasticnets): a função que se utiliza para a estimativa dosparâmetros do modelo (denominada função-objetivo oufunção de custo, cujo valor se pretende minimizar) semodifica acrescentando um termo adicional paradetectar quais variáveis não trazem informações quandose compara o modelo em amostras de construção e deteste, o que permite, portanto, a seleção automática de
variáveis: se L é a função de custo que se utiliza paraobter os estimadores do modelo, βt=(β1,…,βn ) osestimadores, e λ1 ϵℝ, λ2 ϵℝ+,, então, a função pode sertransformada com a seguinte expressão46:
No caso particular em que λ2=0, obtém-se o métododenominado LASSO, e quando λ1=0 obtém-se ométodo denominado ridge regression47.
Dentro das técnicas de Machine Learning de aprendizagemsupervisionada, vale mencionar os chamados métodosindividuais (Figura 9), assim denominados porque podem serutilizados de forma isolada. Entre eles se destacam as redesneurais, as máquinas de vetor suporte, os classificadoresbayesianos, ou as árvores de classificação e regressão:
4 As redes neurais são modelos matemáticos multivariadosnão lineares que utilizam procedimentos iterativos, com oobjetivo de minimizar determinada função de erro e, dessaforma, classificar as observações. As redes neurais sãocompostas de neurônios conectados entre si através de nóse camadas. Tais conexões simulam os dendritos e axôniosnos sistemas nervosos biológicos, através dos quais ainformação é transmitida. São utilizados tanto emproblemas supervisados como não supervisados, com avantagem de que podem separar regiões de forma nãolinear. Sua maior desvantagem é seu caráter de "caixapreta", ou seja, a dificuldade na interpretação dosresultados e a limitação na hora de incorporar o sentido denegócio sobre a complexa estrutura de pesos.
45É um método repetitivo de construção de modelos baseado na seleçãoautomática de variáveis.46Em que ℝ representa o conjunto de números reais, ℝ+ o conjunto de númerosreais positivos .47Para uma discussão detalhada de cada método, vantagens e inconvenientes,ver Murphy, K. (2012).
Figura 9. Tarefas no processo de modelagem.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 22

23
Como uma extensão das redes neurais, destacam-se asredes profundas, que consistem no uso das redes neuraiscom múltiplas camadas. Estes modelos, englobados no quese denomina aprendizagem profunda ou deep learning48,podem ter milhões de parâmetros, em função dacomplexidade do problema que se queira abordar. Noentanto, devido à dificuldade de estimativa, existemmúltiplas aproximações no uso desta tipologia demétodos49 (por exemplo, o uso de algoritmos de otimizaçãopara ajustar os parâmetros nas redes profundas em funçãodos erros de seus outputs; o uso de algoritmos greedy para otreinamento de redes específicas, como as redes dirigidas; ouso de auto-encoders para a redução da dimensionalidadeetc.). Graças ao desenvolvimento tecnológico, essesmétodos puderam ser incorporados, por exemplo, emprocessos de reconhecimento e criação automática detextos ou em computer vision.
4 As máquinas de vetor suporte (support vector machine ouSVM) são modelos de classificação que tentam resolver asdificuldades que podem significar amostras de dadoscomplexas, em que as relações não têm por que ser lineares.Ou seja, pretende-se classificar as observações em váriosgrupos ou categorias, mas estas não são separáveis pormeio de um hiperplano no espaço dimensional definidopelos dados. Para isso, o conjunto de dados é colocado emum espaço de dimensão superior através de uma função50
que permita separar os dados no novo espaço através deum hiperplano nesse espaço. Então, busca-se umhiperplano equidistante aos pontos mais próximos de cadacategoria (ou seja, o objetivo é encontrar o hiperplano quesepara as categorias, e mais distante das suas observaçõesde forma simultânea).
Diferenças entre inteligência artificial,Machine Learning e deep learning
Inteligência Artificial (IA), Machine Learning e DeepLearning são conceitos que estão relacionados, mashabitualmente há dificuldades para diferenciá-los. Como objetivo de ilustrar suas diferenças, propõe-se asseguintes definições:
- A inteligência artificial é o conceito mais amplo, cujoobjetivo é que as máquinas sejam capazes de realizartarefas da mesma forma que um ser humano faria. Namaioria dos casos, isso se desenvolve a partir daexecução de regras previamente programadas. NaConferência de Inteligência Artificial de Dartmouth(1956) foi definida como “todos os aspectos daaprendizagem ou qualquer outra característica dainteligência que pode, em princípio, ser precisamentedescrita de forma tal que uma máquina possa realizá-la”. Desde princípios do século XX já tivemos algunsexemplos disso em pioneiros como Alan Turing, quedecifrou a máquina Enigma, na primeira aparição doque hoje chamaríamos de redes neurais.
- Por outro lado, a aprendizagem automática (ML)pode ser considerada como uma vertente da IA e édefinida51 como “o conjunto de métodos capazes dedetectar padrões automaticamente em um conjunto dedados e usá-los para fazer previsões sobre dadosfuturos, ou para tomar outro tipo de decisões em umambiente de incerteza”.
- Por último, a Deep Learning ou aprendizagemprofunda é um ramo do Machine Learning que,definido em seu aspecto mais básico pode serexplicada como um sistema de probabilidades quepermite que modelos computacionais, que estãocompostos por múltiplas camadas de processamento,aprendam sobre dados com múltiplos níveis deabstração52.
51Murphy, K. (2012).52Bengio, Y. e outros (2015). Bengio, cientista da computação no Canadá.Conhecido principalmente por seu trabalho nas redes neuronais e emDeep Learning.
48Os algoritmos utilizados em deep learning podem ser do tipo aprendizagemsupervisionada ou não supervisionada.49Murphy, K. (2012).50Esta função é denominada kernel.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 23

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
24
4 Os classificadores bayesianos são modelos baseados noteorema de probabilidade condicionada de Bayes, queutilizam as informações conhecidas das variáveisexplicativas, ou seja, os denominados priors, para classificaras observações. Dito de outra forma, um classificadorbayesiano assume que a presença ou a ausência de certascategorias permite atribuir certa probabilidade à ausênciaou à presença de outra característica, ou definir umavariável-objetivo em função da relação existente em umaamostra entre estas características e a variável-objetivodefinida. É uma técnica simples, mas consistente, paraclassificar observações em um conjunto de categorias. Oclassificador bayesiano toma formas específicas de acordocom a distribuição assumida,que seguem as variáveisexplicativas (normal, multinomial etc.).
4 Por fim, as árvores de classificação (quando a variável-objetivo é categórica) e de regressão (quando a variável-objetivo é contínua) são técnicas de análise que permiteprever a atribuição de amostras a grupos pré-definidos emfunção de uma série de variáveis previsíveis. As árvores dedecisão são modelos simples e facilmente interpretáveis, oque faz com que sejam muito valorizadas pelos analistas. Noentanto, seu poder preditivo pode ser mais limitado do queo de outros modelos, porque realizam uma divisãoortogonal53 do espaço, o que convierte a amostra em silos elimita a capacidade preditiva dado que este tipo dealgoritmo tende ao supertreinamento.
Todos estes métodos individuais podem ser combinados comtécnicas e algoritmos que permitem melhorar a capacidadepreditiva, através de métodos ensemble (Figura 10). Estesmétodos consistem na combinação de modelos individuais paragerar um modelo mais preditivo ou mais estável, que aproveitao conhecimento do coletivo. Por exemplo, os modelos podemser combinados através do uso dos resultados de modelosindependentes (como no caso da técnica de bagging) oubuscando corrigir em cada iteração o erro cometido (como nocaso do boosting).
Finalmente, entre os modelos não supervisionados, valedestacar as técnicas de clustering ou as técnicas de DataAnalysis, como a de redução da dimensionalidade:
- O clustering é um modelo não supervisionado utilizado paraidentificar grupos (clusters) ou padrões de observaçãosimilares em um conjunto de dados. Uma das técnicas maisutilizadas é o método de k-means, que consiste em definirum ponto central de referência de cada cluster(denominado centroide) e atribuir a cada indivíduo o clusterdo centroide mais próximo em função das distânciasexistentes entre os atributos de entrada. O algoritmo parteda fixação de k centroides aleatoriamente e, mediante umprocesso iterativo, atribui cada ponto ao cluster com ocentroide mais próximo, atualizando o valor dos centroides.Este processo termina quando se alcança um determinadocritério de convergência.
- Os métodos de redução da dimensionalidade pretendemreduzir o número de dimensões do espaço de análise,determinado pelo conjunto de variáveis explicativas. Umadas técnicas á a análise de componentes principais(principal component analysis ou PCA), que converte umconjunto de variáveis correlacionadas em outro (commenor quantidade de variáveis) sem correlação, chamadascomponentes principais. A principal desvantagem deaplicar PCA sobre o conjunto de dados é que estes perdema sua interpretabilidade.
De qualquer forma, a aplicação destas técnicas significa queos métodos de validação de resultados devem ser maissofisticados. Como em muitos casos a aprendizagem écontínua e utiliza mais de uma subamostra na construção,
Figura 10. Exemplos de métodos ensemble.
53Ou seja, uma partição de um espaço n-dimensional em regiões através dehiperplanos perpendiculares a cada um dos eixos que definem as variáveisexplicativas.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 24

25
deve-se implementar técnicas que sejam adequadas paraestes novos processos, como o bootstrapping54 ou o k-fold-cross-validation55, que permitem avaliar o modelo em mais deuma amostra de validação. Também é importante prestaratenção a outros aspectos da validação, como a existência depossíveis vieses na frequência de atualização dos dados,relações espúrias ou sem uma relação causal. Por último, anatureza dinâmica destas técnicas dificulta a rastreabilidade.Isto ganha especial relevância em ambientes regulados oucom supervisão, que exigem um framework de validação e derastreabilidade específico.
Usos e tendências na aprendizagemautomática
O uso da aprendizagem automática nas indústrias
A incorporação da aprendizagem automática nodesenvolvimento dos negócios nas diferentes indústrias édesigual (Figura 11), tanto em função do setor quanto dediversos fatores relacionados ao tamanho, estilo de diretoria e,em geral, em função do ambiente em que a empresa opera.
As técnicas de aprendizagem automática estão sendoimplementadas com diferentes graus de velocidade eprofundidade em diferentes setores. Por exemplo, destacam-se
Figura 11. Presença do desenvolvimento de Machine Learning nos diferentes setores em 2016.
Fonte: Statista
54Geração de muitas amostras de validação a partir da seleção aleatória comsubstituição.55Divide-se a amostra k em grupos. Na primeira repetição, k-1 são utilizados para aconstrução e o restante para a validação. Este processo é repetido, escolhendocomo grupo de validação cada um dos k grupos construídos.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 25

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
26
bases de dados das instituições financeiras, como porexemplo os modelos de prospect de não-clientes. Nestecaso, os modelos de prospect pretendem classificarpotenciais clientes em função de sua probabilidade deinadimplência, o que é aplicável em processoscomerciais como o lançamento de campanhas ou aemissão de novos produtos. Estes modelos tambémcostumam ser interessantes nos segmentos de clientesnos quais não existem muitas informações, como nocaso de autônomos e microempresas, ou em segmentosde particulares ou autônomos que não utilizam osistema bancário. Para isso, é possível utilizarinformações sobre contas anuais (incluindo informações
algumas aplicações nas indústrias da educação, finanças,saúde ou, transversalmente, na melhoria da eficiência dasorganizações56,57:
4 No âmbito educativo58 a inteligência artificial poderáfornecer sistemas que funcionem como "companheirosde aprendizagem" durante toda a vida do aluno eacessíveis através de múltiplos canais.
4 Em finanças, os algoritmos de Machine Learning estãodirigidos a funções como o trading automático, a criaçãode roboadvisors para a gestão automática de carteiras, adetecção da fraude ou a medição do risco. Um dosâmbitos de maior crescimento é o conhecido comoRegTech59, em que se usam técnicas de Machine Learningpara cumprir com a regulamentação e a supervisão. Aprevisão é de que o mercado de RegTech chegue a 6,5bilhões de dólares em 202060. Além disso, estas técnicaspodem ser utilizadas para a análise de carteiras ondenão existe tanta informação estruturada armazenada nas
56Kaggle (2017). 57Forbes (2017).58Pearson (2016).59Regtech surge da combinação dos termos "regulatory technology" e consiste emum grupo de companhias que utilizam a tecnologia para ajudar as empresas acumprir com as normas de maneira eficiente e com baixos custos.60Frost & Sullivan (2017).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 26

sobre atividades, como rotação de inventários ou defornecedores, índices de alavancagem, de liquidez,solvência ou rentabilidade), que são complementadascom informações de produtos e serviços, ou mesmo cominformações externas não estruturadas.
4 No caso do setor da saúde, os esforços estão focados emmelhorar o diagnóstico por imagem, a gestão deconsultas de tratamento e sugestões, bem como acompilação de informações médicas para estudos oupara cirurgia robótica. Estima-se que o mercado dainteligência artificial no campo da saúde pode chegar aos6,6 bilhões de dólares em 2021 e economizarpotencialmente 150 bilhões de dólares em 2026 no setorda saúde nos EUA61.
4 Em setores como a indústria ou a logística, são propostassoluções para a melhoria da manutenção das máquinas(através do uso de modelos e sensorização para amanutenção preditiva) ou maior eficiência na
27
distribuição (por exemplo, mediante a otimização dacorrelação entre necessidades de transporte commúltiplas empresas)62.
4 Em relação à melhoria da eficiência das organizações, afunção de tecnologia e operações pode ser mais proativaem empresas nas quais os sistemas tecnológicos geramdados massivos (logs, relatórios de status, arquivos deerros etc.). A partir destas informações, os algoritmos deMachine Learning podem detectar a causa de algunsproblemas ou as falhas dos sistemas podem seratenuadas significativamente utilizando análisespreditivas. Além disso, podem ser incorporadasexperiências tecnológicas personalizadas: adisponibilidade de um assistente virtual por funcionárioajudará as empresas a maximizar a produtividade nolocal de trabalho. Este assistente será capaz de conectar
61Techemergence (2017).62Círculo de Empresários (2018).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 27

informações de uso de aplicativos do usuário com outrasbases de dados armazenadas e detectará padrões queantecipem as seguintes ações e acessos a bases de dadosde documentos por parte do funcionário.
Como exemplo ilustrativo de como está sendo realizada aincorporação destas técnicas em uma indústria clássica pode-se destacar o caso de Rolls-Royce, que chegou a um acordocom a Google para utilizar os motores de Machine Learning doGoogle em Cloud, com o objetivo de melhorar a eficiência e asegurança na navegação no curto prazo e com o objetivo dealcançar o controle remoto sem tripulação. Este caso reúnetodos os elementos típicos da aprendizagem automática:coleta de informação não estruturada baseada em sensores,tratamento da informação mediante novas técnicas, objetivode automatização completa etc.
Tendências sobre os componentes daaprendizagem automática
O uso de diferentes técnicas e a proliferação de diversosenfoques e ferramentas modificam o processo demodelagem em todos os seus vetores: os dados utilizados,novas técnicas, metodologias de estimativa e as arquiteturase os sistemas de suporte (Figura 12). No entanto, este novoenfoque significa um conjunto de desafios do ponto de vistatécnico, metodológico e de negócio63:
1. Em função das fontes de informação: Procura-se obteruma visão de 360º dos clientes através do cruzamento decanais internos e externos, utilizando dados compiladosem tempo real. Isso leva a uma série de objetivos a seremenfrentados, como o investimento econômico paraacessar fontes de informação restritas, a identificação denovas fontes de dados relevantes e sua contínuaatualização, bem como a incorporação de técnicas deData Quality capazes de tratar grandes volumes de dadosde diferentes tipologias em tempo real. Da mesma forma,
um dos grandes desafios é a aplicação dos regulamentosem matéria de proteção de dados, como a GDPR naEuropa, que implica uma análise profunda das fontes deinformação que podem ser utilizadas nos modelos deaprendizagem automática, seu tratamento e seuarmazenamento, bem como o estabelecimento decontroles e sistemas de cibersegurança.
2. Em função das técnicas e os algoritmos: Por mais queaumente a dificuldade na interpretação dos algoritmos ena justificativa dos resultados obtidos, em certos âmbitosainda prevalece o poder da previsão sobre suainterpretação. Tudo isso faz com que seja mais relevanteimplementar uma correta gestão do risco de modelodurante o ciclo de vida completo (desenvolvimento,avaliação, implementação, uso, manutenção edescontinuação). A natureza e as possíveis fontes de riscodo modelo, como carências nos dados, a incerteza naestimativa ou os erros nos modelos e o uso inadequadodo modelo64 estão igualmente presentes no uso detécnicas de aprendizagem automática. Entre os desafiosna resolução de problemas mediante o uso de técnicas deMachine Learning também se encontram a própria escolhado algoritmo mais adequado entre uma ampla gama depossibilidades (já que este pode depender tanto doobjetivo do modelo que se quer construir quanto dasinformações disponíveis), a aparição de possíveisproblemas de overfitting65 e de data dredging66, ou a
MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
28
63Jordan, M. I., Mitchell, T. M. (2015) e Kaggle (2017). Jordan, doutor em Ciênciacognitiva pela Universidade da Califórnia, além de professor do MIT e atualmenteprofessor no departamento de Engenharia Elétrica e Ciências da computação e dodepartamento de Estatística na universidade da Califórnia.64Management Solutions (2014).65Overfitting: o modelo está demasiadamente ajustado à amostra de treinamento,de forma que não obtém resultados satisfatórios sobre amostras diferentes desta(por exemplo, a amostra de validação).66O data dredging é produzido quando se encontram relações que não estãorespaldadas por hipóteses ou causas que realmente expliquem tais relações.
Figura 12. Tendências e desafios sobre os componentes da aprendizagem automática.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 28

29
Figura 13. Principais requisitos da GDPR.
Fontes de informação e restriçõesregulatórias
A rápida evolução tecnológica e a globalizaçãocriaram novos desafios no âmbito da proteção dosdados pessoais. Neste sentido, aumentousignificativamente a magnitude da coleta e dointercâmbio de dados pessoais e, atualmente, atecnologia permite o tratamento dos dados pessoaisem uma escala sem precedentes.
Estes avanços e o uso de fontes de informação queincorporam dados de caráter pessoal requerem umframework sólido e coerente para a proteção de dados,devido à importância de gerar uma confiança quepermita o desenvolvimento da economia digital.Assim, surge a necessidade de que as pessoas físicastenham o controle de seus próprios dados pessoais ede reforçar a segurança jurídica e prática para aspessoas físicas, os operadores econômicos e asautoridades públicas68. Como consequência, osreguladores desenvolveram normas para garantir aproteção desses dados. Como exemplo paradigmático,pode-se analisar o caso da União Europeia, onde aGeneral Data Protection Regulation (GDPR), que entrouem vigor em maio de 2018, estabeleceu uma série derequisitos gerais de tratamento e proteção dasinformações, homogeneizando o seu tratamento emtodos os países membros (Figura 13).
68Parlamento Europeu (2016).
67Functions as a Service, um modelo sem servidores.
necessidade de estabelecer mecanismos para que aaplicação dos resultados automáticos não implique naaparição de tratamentos discriminatórios (este risco étratado através do que se conhece como éticaalgorítmica).
3. Em função da autoaprendizagem: Incorporar acaracterística de autoaprendizagem nos modelos implicana capacidade de que o algoritmo se modifique de formaautônoma em função das mudanças que vão ocorrendona população-objetivo. Isso pode originar modificaçõesnos parâmetros ou nas variáveis relevantes para construiro algoritmo, bem como a necessidade de tomar decisõesde modelagem em tempo real. No entanto, estes ajustesaos modelos em tempo real dificultam a sua validação,que deve evoluir a partir do enfoque tradicional eincorporar novos elementos, como o controle de graus deliberdade na automatização, uma maior frequência naavaliação do poder discriminante ou outras técnicas decomparação (por exemplo, através de modelosalternativos mais simples que, mesmo que percamcapacidade de ajuste, permitam fazer challenge aosresultados). No caso específico de modelos quenecessitam a aprovação de um supervisor como, porexemplo, os modelos regulatórios no setor financeiro, umdesafio acrescentado a esta validação é a dificuldade deobter a aprovação por parte do supervisor.
4. Em função dos sistemas e do software utilizado: Investe-se em arquiteturas e infraestruturas tecnológicas quegarantam a escalabilidade na capacidade dearmazenamento de dados e uma maior velocidade deprocessamento. Também estão sendo desenvolvidassoluções baseadas em Cloud, como plataformasalternativas às implementações in-house utilizadastradicionalmente pelas empresas e incorporadasinfraestruturas de edge computing, onde são oferecidasfunções já previamente instaladas (FaaS67) preparadaspara uso direto, o que simplifica a experiência dodesenvolvedor, já que reduz o esforço de programação egestão do código. Tudo isso implica na necessidade derealizar investimentos em recursos e estruturas de TI.
Além disso, tudo isso pressupõe a necessidade de contar comrecursos humanos com um alto grau de preparação eespecialização, capazes de compreender e trabalhar comlinguagens de programação, algoritmos, matemática,estatística e arquiteturas tecnológicas complexas.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 29

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
30
Exercício quantitativo
Your job in a world of intelligent machines is to keep making surethey do what you want, both at the input (setting the goals) and at
the output (checking that you got what you asked for)Pedro Domingos69
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 30

31
diversos enfoques para avaliar o modelo). A seguir, a amostrautilizada será descrita e as diferentes fases do estudo detalhadas,bem como os resultados e as principais conclusões obtidas.
Datos utilizados
O estudo foi realizado utilizando um conjunto de mais de 500 milempréstimos, que compreendem mais de 10 anos de história,com uma taxa de inadimplência de 6%. A amostra inclui variáveisrelativas à operação (montante, prazo da operação, taxa de juros,finalidade do financiamento, etc.) ao cliente (informaçõeseconômicas como receita anual, mensal, patrimônio, variáveis deendividamento, pontuação de scorings externos etc.,informações sobre inadimplências, como quebras de registrospúblicos, contas com atrasos etc., ou variáveis de antiguidadecomo cliente e antiguidade em outros produtos), bem comorelativas a outros tipos de informações que possam ser úteis namodelagem, como comissões, número de transações realizadas,etc. Neste exercício, todas estas variáveis foram mantidas naamostra inicial, com o propósito de realizar knowledge discovery.
Desenvolvimento do estudo
O estudo foi desenvolvido em duas fases, detalhadas a seguir:
1. Fase 1: Knowledge Discovery. Inicialmente foi desenvolvidauma fase de knowledge discovery, em que foram realizadosdiferentes tratamentos de missings, outliers e agrupamento devariáveis.
2. Fase 2: Aplicação de técnicas de Machine Learning. Nasegunda fase, foi iniciado o desenvolvimento de diferentesmodelos, utilizando técnicas de modelagem sobre as amostrasde construção geradas.
As técnicas de Machine Learning introduzem diversas novidadesnas técnicas estatísticas e econométricas clássicas, alavancadasno uso de maior quantidade de informação e maiorcomplexidade dos algoritmos.
Introduz um conjunto de novos elementos no âmbito damodelagem que, se por um lado permite realizar análises maissólidas, por outro requer a resolução de questões como oaumento das variáveis disponíveis (o que aumenta acomplexidade no tratamento das dados, bem como na seleçãode informações relevantes), a correta identificação de relaçõesespúrias ou o não cumprimento das hipóteses dos modelostradicionais (por exemplo: falta de cointegrabilidade em sériestemporais ou presença de multicolinearidade e autocorrelação).
Como resultado disso, pode-se modificar o enfoque demodelagem, introduzindo diferentes ferramentas paraaproveitar os algoritmos de Machine Learning, mas evitandocometer erros ligados a estas novas ferramentas.
Nesta seção, foi desenvolvido um modelo de scoringcomportamental para classificar empréstimos bancários. Paraisso foram utilizadas algumas destas novas técnicas com afinalidade de poder comparar os resultados, bem como avaliaros objetivos que implicam o seu uso no processo demodelagem, as oportunidades que surgem e os riscosexistentes.
Objetivo
O objetivo do exercício é analisar e ilustrar o impacto do uso detécnicas de Machine Learning no desenvolvimento de modelos.Especificamente, pretende-se avaliar a variação do processo deestimativa e os resultados obtidos, partindo de diferentesabordagens de modelagem, mediante o uso de técnicas deMachine Learning.
Para isso, um modelo de scoring foi treinado, utilizandodiferentes abordagens de Machine Learning, e os resultadosforam comparados com as técnicas tradicionais. Partiu-se deuma amostra de empréstimos e foram desenvolvidas duas fasesde modelagem (tratamentos de dados em tarefas depreparação, limpeza e seleção de variáveis e aplicação de
69Domingos, P (2015). Professor na Universidade de Washington. Pesquisador deMachine Learning e conhecido por seu trabalho em Redes Lógicas de Markov.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 31

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
32
Fase 1: Knowledge Discovery
A primeira fase do desenvolvimento do exercício consiste emaplicar algumas técnicas de knowledge discovery. Alguns dostratamentos aplicados, descritos a seguir, podem ser maisadequados do que outros, dependendo do tipo de algoritmofinal utilizado para a modelagem. Desta forma, a primeira fasepermite obter um conjunto de amostras de construção quepodem ser utilizadas como dados para treinar diferentesalgoritmos.
Nesta primeira fase, observou-se que 40% das variáveisapresentam mais de 10% de observações missing. Para utilizaras informações disponíveis, foram realizados diferentestratamentos sobre estas variáveis70:
a. Foi estabelecido o valor médio (ou a moda, no caso devariáveis qualitativas ) às observações missing.
b. Um clustering analysis foi realizado, e atribui-se a média acada valor missing (ou a moda, no caso de variáveisqualitativas) do cluster. A determinação do número ideal declusters que gera a melhor classificação foi realizada atravésde métodos quantitativos71.
c. Foi realizada uma regressão sobre outras variáveis paraestimar um valor para as observações missing de umavariável em função do restante das informações.
d. Para o caso específico do Random Forest, foi estabelecidoum valor máximo (ex. 9999) com o objetivo de identificar omissing como um valor adicional para que a árvore crie, deforma automática, um galho específico para estainformação.
Por outro lado, foi realizado um tratamento de outliers, quesimplesmente consistiu em aplicar um floor no percentual 1, eum cap no percentual 99 nas variáveis com presença de valoresatípicos.
Por fim, foi realizado um processo de simplificação de variáveis.Para isso, um algoritmo de clustering foi novamente aplicado,para substituir as variáveis que permitem identificar uma boa
classificação em grupos pelo cluster atribuído (Figura 14).Também foram eliminadas as variáveis que, após uma primeiraanálise exploratória, não contêm informações relevantes(devido à má qualidade das informações, variáveis informadas aum valor constante, etc).
Após todos estes tratamentos, foram obtidas diferentesamostras de construção, que serão utilizadas para a estimativados algoritmos72.
Conjuntamente, estas técnicas permitem reduzir o número devariáveis com o objetivo de melhorar a eficiência dos processosposteriores, preparar as informações existentes para que seadequem aos requisitos específicos dos diferentes modelos epossíveis limitações dos algoritmos, bem como antecipar evalidar hipóteses para avaliar os resultados das diferentestécnicas de modelagem utilizadas.
Fase 2: Aplicação de técnicas de Machine Learning
Na segunda fase, partindo das diferentes amostras já tratadas,foram aplicadas diferentes técnicas e iniciou-se o cálculo dasdiferentes métricas da capacidade discriminante do modelosobre uma amostra de validação. As técnicas que foramdesenvolvidas são as seguintes:
a. Em primeiro lugar, para poder realizar uma comparaçãocom um método tradicional de modelagem, foi construídoum modelo logístico.
b. Foi aplicada uma rede elástica como técnica deregularização, para observar o impacto desta técnica sobrea modelagem tradicional.
Figura 14. Exemplos de clustering para K=2, K=4 e K=8 em função de duas variáveis. As variáveis X e Y serão substituídas pela variável definida pelo cluster.
70Tratamentos adicionais ao clássico, que consiste em trocar um missing por umzero e criar uma variável dummy para reconhecer onde foram atribuídos osmissing.71Existem diversos métodos quantitativos para realizar esta seleção, como o elboymethod ou o algoritmo partition around medoids (PAM). Em termos gerais,pretende-se analisar o número de clusters a partir do qual o lucro marginal deinformações na classificação se faz residual ao ampliar o número de clusters. Nestecaso, foi aplicado o algoritmo PAM. 72Ainda que possam ter diferentes amostras de construção para um únicoalgoritmo e, portanto, diferentes resultados, neste estudo mostram-se somente osresultados ideais.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 32

33
c. Foi desenvolvido um random forest como um dosmétodos ensemble.
d. Também foi estimado um adaboost, para dispor de umsegundo método ensemble.
e. Foi estimado um modelo através de uma SVM utilizandouma função linear.
f. Por último, foi estimado um segundo modelo de SVM comuma função radial.
Após aplicar estas técnicas, foram obtidos os seguintesmodelos:
a. Modelo logístico (modelo tradicional base para acomparação). Foi realizada uma pré-seleção de variáveismediante técnicas bivariadas e multivariadas, levando emconsideração o significado individual de cada variável, opoder discriminante do modelo global e diferentesmétodos e critérios de informação. Como resultado,obteve-se um modelo que conta com 11 variáveis, em queas que apresentam maior importância são do tipocomportamental (por exemplo, número de contas quenunca entraram em default, se existem dívidas pendentesou o número de contas que esteve mais de 120 dias emsituação irregular). A importância de cada variável foimensurada como a contribuição marginal dessa variável àbondade de ajuste do modelo. Portanto, pode-se analisarqual é o padrão de incorporação de cada variável emfunção de sua importância (Figura 15).
b. Modelo com técnicas de regularização. Após aplicar arede elástica, foi desenvolvido um modelo com um totalde 45 variáveis, entre as quais se destacam as variáveiscomportamentais (por exemplo, contas em situaçãoirregular, dívidas pendentes nos últimos 12 meses,informações positivas em registros públicos etc.). Foramincluídas variáveis relativas à operação e ao cliente, sendoque a importância das primeiras é muito mais significativa(Figura 16).
c. Random Forest. Foi obtido um algoritmo com 50 árvores,sendo que a máxima profundidade do galhos é três e onúmero de variáveis incluídas aleatoriamente comocandidatas em cada nó é igual a sete. No total, estãosendo utilizadas 80 variáveis para conformar o conjuntode árvores. As variáveis de maior relevância no algoritmosão as de tipo comportamental (por exemplo, existênciade dívidas pendentes, outras contas com inadimplência,números de contas ativas etc.) e algumas outras variáveisque caracterizam o cliente ou a operação (por exemplo, onível de endividamento). Observa-se que em termos deimportância, as primeiras variáveis obtêm um pesoelevado, enquanto que o resto das variáveis mantêm umaimportância relativa reduzida (Figura 17).
Figura 15. Importância das variáveis no algoritmo tradicional.
Figura 16. : Importância das variáveis após aplicar redes elásticas.
Figura 17. Importância das variáveis no algoritmo de Random Forest.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 33

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
34
d. Adaboost: foi selecionado um algoritmo com 20 iterações,cujo parâmetro de redução foi fixado automaticamenteem um. Como resultado, foram obtidas 68 variáveissignificativas entre as quais se destacam novamente as detipo comportamental (por exemplo, a média do saldorevolving no conjunto de contas, o número de contas decartões de crédito sem inadimplências, o principaldevolvido pelo cliente etc.), bem como outras variáveisrelativas ao cliente. Neste caso, observa-se uma quedareduzida, porém paulatina, na importância das variáveis(Figura 18).
e. SVM com função linear. Foram obtidos diferentesmodelos em função das variáveis utilizadas e foiselecionado o melhor modelo, utilizando técnicas devalidação cruzada. No modelo escolhido foram obtidas 68variáveis relevantes, das quais as que apresentam maiorimportância são as comportamentais (por exemplo, asdívidas pendentes nos últimos 12 meses ou aporcentagem de contas que nunca estiveram em situaçãoirregular, Figura 19).
f. SVM com função radial. Bem como no caso linear, foi feitauma seleção entre diferentes modelos. Este modelotambém possui 68 variáveis, onde as que apresentammaior importância também são as comportamentais.Ainda que ambos os modelos de SVM sejam muitosimilares, a importância das variáveis em cada um delesdifere significativamente (Figura 20).
Figura 19. Importância das variáveis no algoritmo SVM com função linear.
Figura 20. Importância das variáveis no algoritmo SVM com função radial
Figura 18. Importância das variáveis no algoritmo Adaboost.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:41 Página 34
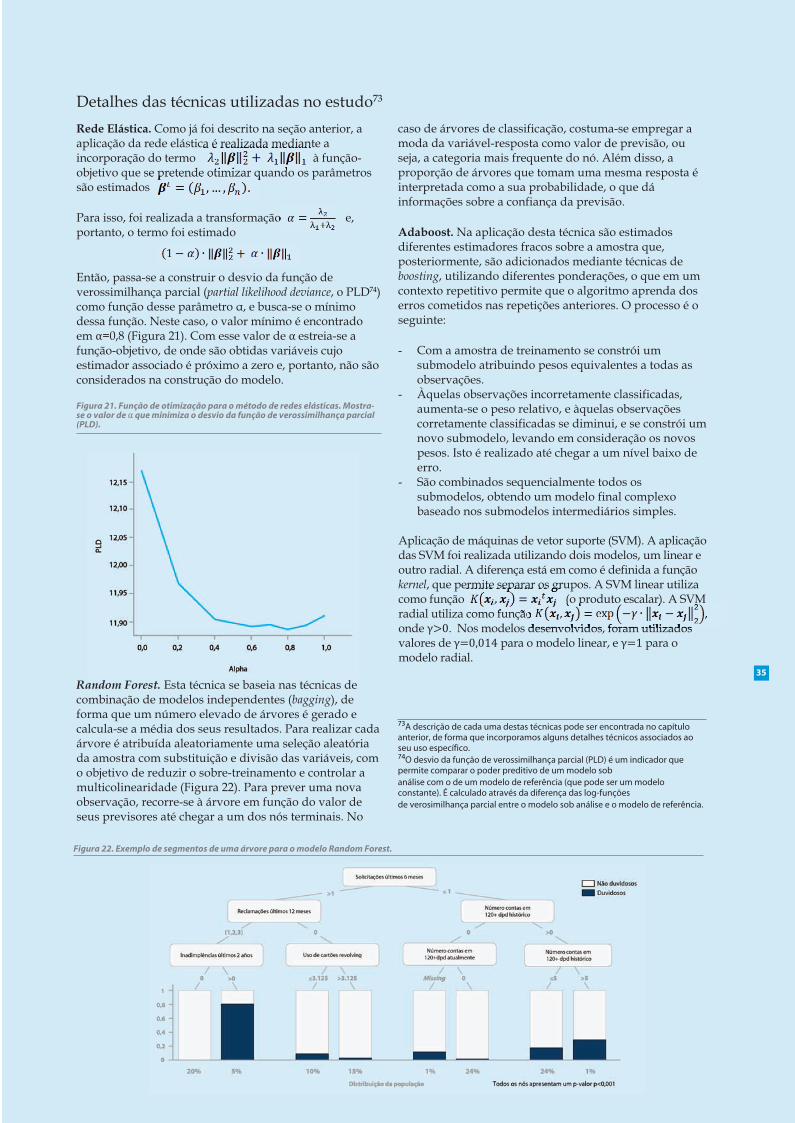
Rede Elástica. Como já foi descrito na seção anterior, aaplicação da rede elástica é realizada mediante aincorporação do termo à função-objetivo que se pretende otimizar quando os parâmetrossão estimados
Para isso, foi realizada a transformação e,portanto, o termo foi estimado
Então, passa-se a construir o desvio da função deverossimilhança parcial (partial likelihood deviance, o PLD74)como função desse parâmetro α, e busca-se o mínimodessa função. Neste caso, o valor mínimo é encontradoem α=0,8 (Figura 21). Com esse valor de α estreia-se afunção-objetivo, de onde são obtidas variáveis cujoestimador associado é próximo a zero e, portanto, não sãoconsiderados na construção do modelo.
Figura 21. Função de otimização para o método de redes elásticas. Mostra-se o valor de α que minimiza o desvio da função de verossimilhança parcial(PLD).
Random Forest. Esta técnica se baseia nas técnicas decombinação de modelos independentes (bagging), deforma que um número elevado de árvores é gerado ecalcula-se a média dos seus resultados. Para realizar cadaárvore é atribuída aleatoriamente uma seleção aleatóriada amostra com substituição e divisão das variáveis, como objetivo de reduzir o sobre-treinamento e controlar amulticolinearidade (Figura 22). Para prever uma novaobservação, recorre-se à árvore em função do valor deseus previsores até chegar a um dos nós terminais. No
35
caso de árvores de classificação, costuma-se empregar amoda da variável-resposta como valor de previsão, ouseja, a categoria mais frequente do nó. Além disso, aproporção de árvores que tomam uma mesma resposta éinterpretada como a sua probabilidade, o que dáinformações sobre a confiança da previsão.
Adaboost. Na aplicação desta técnica são estimadosdiferentes estimadores fracos sobre a amostra que,posteriormente, são adicionados mediante técnicas deboosting, utilizando diferentes ponderações, o que em umcontexto repetitivo permite que o algoritmo aprenda doserros cometidos nas repetições anteriores. O processo é oseguinte:
- Com a amostra de treinamento se constrói umsubmodelo atribuindo pesos equivalentes a todas asobservações.
- Àquelas observações incorretamente classificadas,aumenta-se o peso relativo, e àquelas observaçõescorretamente classificadas se diminui, e se constrói umnovo submodelo, levando em consideração os novospesos. Isto é realizado até chegar a um nível baixo deerro.
- São combinados sequencialmente todos ossubmodelos, obtendo um modelo final complexobaseado nos submodelos intermediários simples.
Aplicação de máquinas de vetor suporte (SVM). A aplicaçãodas SVM foi realizada utilizando dois modelos, um linear eoutro radial. A diferença está em como é definida a funçãokernel, que permite separar os grupos. A SVM linear utilizacomo função (o produto escalar). A SVMradial utiliza como função onde γ>0. Nos modelos desenvolvidos, foram utilizadosvalores de γ=0,014 para o modelo linear, e γ=1 para omodelo radial.
73A descrição de cada uma destas técnicas pode ser encontrada no capítuloanterior, de forma que incorporamos alguns detalhes técnicos associados aoseu uso específico.74O desvio da função de verossimilhança parcial (PLD) é um indicador quepermite comparar o poder preditivo de um modelo sobanálise com o de um modelo de referência (que pode ser um modeloconstante). É calculado através da diferença das log-funçõesde verosimilhança parcial entre o modelo sob análise e o modelo de referência.
Detalhes das técnicas utilizadas no estudo73
Figura 22. Exemplo de segmentos de uma árvore para o modelo Random Forest.
MachineLearningPT_VDEF_Maquetación 1 13/07/2018 10:43 Página 35

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
36
Resultados e conclusões
Para comparar os resultados obtidos neste estudo após aaplicação das diferentes técnicas, foi utilizada como medida depoder discriminante uma matriz de confusão, bem como a áreasob a curva ROC (AUC):
4 A matriz de confusão permite medir as taxas de acerto domodelo. Para isso, foi estabelecido o ponto de corte no valorque minimiza o erro de previsão.
4 Em relação ao indicador AUC, quanto maior for o valor doindicador, maior é o poder de discriminação. A experiênciaprática75 mostra que este indicador costuma tomar valoresentre 75% e 90%. Estes indicadores estão estimados sobreuma amostra de validação76.
Também foram comparados os impactos da mudança do poderpreditivo no negócio. Para isso, foi escolhido o modelotradicional como base de comparação (com o ponto de corteestabelecido a partir da otimização dos erros tipo I e tipo II).Sobre esse modelo, estimou-se a taxa de inadimplênciaresultante com cada um dos modelos analisados, mantendo omesmo nível de taxa de aceitação que o modelo tradicional (ouseja, a igualdade do volume de negócio), bem como a taxa deaceitação de cada um dos modelos, se a taxa de inadimplênciase mantém é a mesma que no modelo tradicional.
Os resultados obtidos são os seguintes77 (Figuras 23, 24 e 25):
4 Após a comparação com estas estatísticas (Figura 24),observa-se um melhor desempenho nos modelos ensembleem relação às outras metodologias. Particularmente, orandom forest é o método que apresenta os melhoresresultados: em termos de taxa de acerto aumenta de 74,7%do modelo tradicional para 80,3%, o que supõe umaumento percentual de 7,5% sobre o obtido através detécnicas tradicionais; em termos de poder discriminante,consegue-se melhorar a área sob a curva ROC de 81,5% nomodelo tradicional até 88,2%, o que representa umaumento percentual de 8,2%. No entanto, esta melhoria foiobtida aumentando a complexidade da estimativa, já queforam utilizadas muitas variáveis entre as 50 árvoresestimadas.
4 O segundo melhor método é a aplicação da rede elástica,com a qual os valores de taxa de acerto e a área sob a curvaROC chegam a 79% e 86,4%, respectivamente. Istorepresenta um aumento percentual de 6% em ambos osindicadores. Como se observa, em amostras com muitasvariáveis, a aplicação de técnicas de regularização implicamem um aumento significativo em relação a métodostradicionais de seleção de variáveis (stepwise).
4 Da mesma forma, neste caso em particular, observou-se quea dificuldade acrescentada pelo uso de SVM (tanto linealcomo radial) não significa um aumento no poder preditivodo modelo. Isto se deve a que o modelo logístico tradicionaljá apresenta um poder discriminante elevado (82%), o quecostuma ocorrer quando as variáveis permitem separarlinearmente as duas classes e, portanto, a aplicação de SVMnão incorpora informações sobre a separabilidade dascategorias (de fato, neste caso perde-se poder preditivo etaxa de acerto).
Figura 23. Resultados para as diferentes abordagens.
Figura 24. Taxa de acerto na matriz de confusão (soma da diagonal) para asdiferentes abordagens.
75BCBS (2005).76De acordo com as práticas em modelagem, a população total foi separada emamostras diferentes de construção e validação, de forma que cada modelotreinado com a amostra de construção foi utilizado para pontuar novamente aamostra de validação, e os resultados sobre a validação foram estimados sobreessa amostra.77Estes resultados foram obtidos sobre amostras de validação específicas, porémem um ambiente de Machine Learning é adequado avaliar em diferentessubamostras a adequação dos resultados (através de técnicas de bootstrapping oucross-validation).
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 36

37
A matriz de confusão a partir do ponto decorte que minimiza os erros
Uma das técnicas para medir o poder discriminante domodelo é a matriz de confusão. Esta matriz compara aprevisão do modelo com o resultado real. No caso domodelo de scoring, permite comparar os defaultsprevistos pelo modelo com os que ocorreram realmente(Figura 26). Para isso, são calculadas as taxas de acerto(defaults corretamente previstos pelo modelo eoperações classificadas como não defaults que, ao final,não entraram em inadimplência) e os erros do modelo(os conhecidos como erro tipo I e erro tipo II79).
Figura 26. Matriz de confusão.
Considerando que os modelos outorgam umapontuação (que é uma ordenação das operações emfunção da qualidade de crédito), para poderdeterminar se o modelo prevê um default é necessárioestabelecer um ponto de corte. Uma das metodologiasaceitas na indústria é estabelecer o ponto de corte queminimiza simultaneamente os dois erros (Figura 27).
Figura 27. Ponto de corte que minimiza simultaneamente o erro tipo I e oerro tipo II.
4 Por fim, do ponto de vista do possível impacto no negóciodo aumento do poder preditivo dos modelos, conclui-seque, com um mesmo volume de negócio, a taxa deinadimplência se reduziria em 48%, no caso do randomforest (utilizando um ponto de corte ideal com o modeloclássico, chegaria a uma taxa de inadimplência de 2,1%, quese reduz a 1,1% com o random forest se o volume deoperações aprovadas for mantido) e 30% no caso da redeelástica (em que a taxa de inadimplência se reduz a 1,4%).Da mesma forma, bem como a taxa de inadimplência (2,1%),o volume de negócio aumentaria 16% no caso do randomforest e 13% no caso da rede elástica.
Para poder se beneficiar das vantagens associadas a estastécnicas é fundamental, portanto, possuir um framework e umafunção de gestão do risco de modelo de acordo aos máximospadrões de qualidade (já tratados na publicação anterior78 daManagement Solutions “Model Risk Management: Aspectosquantitativos e qualitativos da gestão do risco de modelo") queinclua, entre outros aspectos, a execução, por parte da funçãode Validação interna de um challenge efetivo, das hipótesesutilizadas e os resultados alcançados por estes modelos através,entre outras técnicas, da sua réplica e, nas entidades maisavançadas, do desenvolvimento de modelos "challenger" comtécnicas tradicionais.
Figura 25. Curvas ROC obtidas para cada uma das técnicas.
78Management Solutions (2014)
79Porcentagem de defaults erroneamente classificados pelo modelo eporcentagem de falsos defaults erroneamente previstos pelo modelo,respectivamente.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 37

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
38
Acuity Market Intelligence (2016). “The Global Biometrics andMobility Report: The Convergence of Commerce and Privacy”.Market Analysis and Forecasts 2016 to 2022.
BCBS (2005). “Studies on the Validation of Internal RatingSystems”. Bank for International Settelments.
Bengio, Y. e outros (2015). Bengio, Y. LeCun, Y. Hinton, G.: "DeepLearning"(2015) Nature.
Box, G. e Draper, N. (1987). “Empirical Model-Building andResponse Surfaces”. Wiley.
Breiman, L. (2001). “Statistical Modeling: The two cultures”, Vol16 (3), Statistical Science, 2001. p. 199-231.
Brynjolfsson, E. e McAfee, A. (2017). “The business of artificialintelligence”. Harvard Business Review.
Cios, K.J. e outros (2007). Cios, K.J., Pedrycz, W., Swiniarski, R.W.,Kurgan, L.: “Data Mining: A Knowledge Discovery Approach”.Springer 2007.
Círculo de Empresários (2018). “Alcance e implicaciones de latransformación digital: principales ámbitos de actuación”.
Cisco (2017). “The Zettabyte Era: Trends and Analysis”. Whitepaper. Junho de 2017.
Cybersecurity Ventures (2017). Cyber economy research.
Bibliografia
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 38

Ministério de Indústria, Energia e Turismo. Governo da Espanha(2018). “Nuevas tendencias y desafios en el mundo de losdatos”. Março de 2018.
Mitchell, T. (1997). Machine Learning. McGraw Hill.
Murphy, K. (2012). “Machine Learning: A probabilisticperspective”. The MIT Press.
Parlamento Europeu (2016). Regulamento (UE) 2016/679 doParlamento Europeu e do Conselho de 27 de abril de 2016.
Pearson (2016). Lukin, R. et alter: “Intelligence Unleashed: Anargument for AI in Education”. Pearson.
Samuel, A. (1959). “Some studies in Machine Learning using thegame of checkers”. IBM Journal. July 1959.
Schwab, K. (2016). “The Fourth Industrial Revolution”. WorldEconomic Forum.
Shalev-Shwartz, S. e Ben-David, S. (2014). “UnderstandingMachine Learning: From Theory to Algorithms”. CambridgeUniversity Press.
Statista (2017). “Number of Machine-to-Machine (M2M)connections worldwide from 2014 to 2021”. 2018.
Statista (2018). “Digital Market Outlook”. 2018.
Techemergence (2017). “How America’s 5 Top Hospitals areUsing Machine Learning Today”.
The Economist (2017). Axel Springer’s digital transformation.
Turing, A.M. (1950). “Computer Machinery and Intelligence”.Mind 49: p. 433-460.
Westerman, G. (2017). “Your Company Doesn’t Need a DigitalStrategy”. MITSloan Management Review.
Dahr, V. (2013). “Data Science and prediction”. Association forComputer Machinery.
Digital Consumption (2016). World Economic Forum WhitePaper Digital Transformation of Industries.
Domingos, P. (2012). “A few useful things to know aboutMachine Learning”, Vol 55 (10), Communications of the ACM,2012. p. 78-87.
Domingos, P (2015). “The Master Algorithm: How the Quest forthe Ultimate Learning Machine Will Remake Our World”. 2015.
EC (2017). Digital Transformation Scoreboard 2017. EuropeanCommission.
Fitzgerald et al. (2013). "Embracing Digital Technology: A NewStrategic Imperative”, Sloan Management Review
Forbes (2015). “Big Data: 20 Mind-Boggling Facts Everyone MustRead”.
Forbes (2016). “Artificial Intelligence Is Helping Doctors FindBreast Cancer Risk 30 Times Faster”.
Forbes (2017). Janakiram MSV: “3 Key Machine Learning TrendsTo Watch Out For In 2018”. Forbes, dezembro de 2017.
Friedman, J. H. (1997). “Data mining and statistics: what's theconnection?” Apresentado no 29th Symposium on theInterface: Computing Science and Statistics, Maio 14–17, 1997,Houston, TX, p. 3–9.
Frost & Sullivan (2017). “Global Forecast of RegTech in FinancialServices to 2020”.
International Telecommunication Union (2009). “DistributedComputing: Utilities, Grids & Clouds”. ITU-T Technology WatchReport 9.
International Telecommunication Union (2017). ITU WorldTelecommunication/ICT indicators database 2015.
Jordan, M. I., Mitchell, T. M. (2015). “Machine Learning: Trends,perspectives, and prospects”, Vol 349 (6245), Science, 2015. p.255-260.
LEGOs (2018). Still “The Apple of Toys”? Harvard Business School
Management Solutions (2014). “Model Risk Management:Aspectos cuantitativos y cualitativos de la gestión del riesgo demodelo”.
Management Solutions (2015). “Data Science y latransformación del sector financiero”.
McKinney (2018). “Python for Data Analysis”. O’Reilly Media.
39
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 39

Análise de componentes principais (PCA):método de reduçãode dimensionalidade através do qual se busca um subespaçodimensional inferior para projetar os dados para minimizar oserros de projeção, convertendo um conjunto de variáveiscorrelacionadas em outro (com menor quantidade de variáveis)sem correlação, chamadas componentes principais.
Auto-encoder: algoritmo de aprendizagem não supervisadobaseado em redes neurais que aplicam propagação retroativa,estabelecendo os valores do target para que sejam iguais aosdo input.
Big Data: qualquer quantidade volumosa de dadosestruturados, semiestruturados ou não estruturados que têm opotencial de ser extraída para obtenção de informação. Por
extensão, se refere também ao conjunto de infraestruturas earquiteturas tecnológicas que armazenam estes dados.
Blockchain: estrutura de dados que implementa um registrocriptográfico de todas as operações realizadas e previamentevalidadas por uma rede de nós independentes através de umalgoritmo de consenso.
Bootstrapping: Processo de geração de muitas amostras apartir da seleção aleatória com substituição.
Business to Business (B2B): transações comerciais entreempresas, isto é, as estabelecidas entre um fabricante e odistribuidor de um produto, ou entre o distribuidor e umvarejista.
MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
40
Glossário
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 40

Knowledge discovery: processo de identificar padrões nosdados que sejam válidos, novos, potencialmente úteis, eentendíveis.
Machine to Machine (M2M): conectividade entre máquinasonde, uma vez que uma ação é realizada, os dados geradospelos distintos elementos digitais envolvidos se conectam comservidores com o objetivo de armazenar e analisar a informação.
Overfitting (supertreinamento): característica de um modeloque se dá quando este se ajustou demasiadamente à amostrade treinamento, de forma que não consegue resultadossatisfatórios sobre amostras diferentes a esta (por exemplosobre a amostra de validação).
Partial likelihood deviance (PLD): diferença das log-funções deverossimilhança parcial entre o modelo sob análise e ummodelo de comparação (geralmente um modelo que nãodepende de nenhuma variável).
Partição ortogonal: partição de uma amostra de dados em umespaço n-dimensional perpendicular a cada um dos eixos quedefinem as variáveis explicativas.
Peer to Peer (P2P): rede de computadores que permitem ointercâmbio direto de informação em qualquer formato, entreos computadores interconectados.
RegTech: combinação dos termos “regulatory technology”, quefaz alusão a uma empresa que utiliza a tecnologia para ajudar asempresas a cumprir com a regulação de maneira eficiente e comum custo reduzido.
Regularização: técnica matemática que proporcionaestabilidade numérica a um problema mal condicionado atravésda adição de um funcional penalizador em sua formulação(como, por exemplo, o caso das redes elásticas).
Resampling: conjunto de métodos que permite reconstruir umaamostra de dados. Utilizado principalmente para criarsubconjuntos de treinamento e validação sobre a amostraoriginal.
Roboadvisor: sistema automático de gestão financeira baseadoem algoritmos, utilizado para o desenho, composição emonitoramento de carteiras de investimento de formaautomatizada.
Robotics Process Automation (RPA): desenvolvimento desoftware que replica as ações de um ser humano, interagindocom a interface de usuário de um sistema de informática.
Smart contract: contrato programável que implementa regrasde negócio, cujo código fica registrado e pode ser executado deforma distribuída pelos diferentes nós da rede.
Stepwise: método iterativo de construção de modelos baseadona seleção automática de variáveis.
Cadeia de Markov: processo estocástico discreto em que aprobabilidade de que um evento ocorra depende unicamentedo evento anterior.
Cibersegurança: conjunto de ferramentas, políticas, métodos,ações, seguros e tecnologias que podem ser utilizadas paraproteger os diferentes ativos tecnológicos e os dados de umaorganização armazenados em algum tipo de suporte físico oulógico no ciberentorno, assim como as comunicações entreestes ativos.
Computer Vision: subcampo da inteligência artificial, cujopropósito é programar um computador para que entenda umacena ou as características de uma imagem.
Curva ROC (Receiver Operating Characteristic): curvaempregada para analisar o poder preditivo de um modelo desaída binária. Representa a relação entre o erro de tipo 1(classificar incorretamente eventos adversos) e o erro tipo 2(classificar incorretamente eventos favoráveis).
Data dredging: uso de técnicas de data mining com o objetivode encontrar padrões estatisticamente significativos que nãoestão respaldados por hipóteses a priori sobre a causalidade darelação.
Função de custo: função que, a partir de um valor dosestimadores de um modelo, fornece uma medida do erro quese comete ao utilizar o modelo. O processo de treinamento deum modelo costuma consistir em obter os estimadores queminimizam a função de custo.
Function as a Service (FaaS): categoria de serviços deprogramação na nuvem proporcionado por uma plataformaque permite aos usuários desenvolver, usar e administrarfuncionalidades de uma aplicação sem a complexidade deconstruir e manter a infraestrutura tipicamente associada a estaaplicação.
Graphics Process Unit (GPU): coprocessador dedicado aoprocessamento de gráficos ou operações de ponto flutuantepara diminuir a carga de trabalho do processador central (CPU).
Greedy: algoritmo em que cada elemento a considerar éavaliado uma única vez, sendo descartado ou selecionado, detal forma que se é selecionado forma parte da solução, e se édescartado, não forma parte da solução e nem voltará a serconsiderado para a mesma.
Internet das coisas (IoT): interconexão dos objetos de usocotidiano através da Internet.
k-fold cross validation: processo de validação de amostrascruzadas que consiste em dividir a amostra em k grupos, e deforma iterativa utilizar cada um dos grupos para a validação e oresto para a construção, alterando o grupo de validação emcada iteração.
41
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 41

MANAGEM
ENT SO
LUTIONS
Machine Learning, uma peça-cha
ve na tran
sformação
dos mod
elos de negó
cio
42
A Management Solutions é uma empresa internacional deserviços de consultoria com foco em assessoria de negócios,riscos, organização e processos, tanto sobre seus componentesfuncionais como na implementação de tecnologias relacionadas.
Com uma equipe multidisciplinar (funcionais, matemáticos,técnicos, etc.) de 2.000 profissionais, a Management Solutionsdesenvolve suas atividades em 24 escritórios (11 na Europa, 12nas Américas e um na Ásia).
Para atender às necessidades de seus clientes, a ManagementSolutions estruturou suas práticas por setores (InstituiçõesFinanceiras, Energia e Telecomunicações) e por linha de negócio(FCRC, RBC, NT), reunindo uma ampla gama de competências deEstratégia, Gestão Comercial e Marketing, Gerenciamento eControle de Riscos, Informação Gerencial e Financeira,Transformação: Organização e Processos, e Novas Tecnologias.
A área de P&D presta serviço aos profissionais da ManagementSolutions e a seus clientes em aspectos quantitativos necessáriospara realizar os projetos com rigor e excelência, através daaplicação das melhores práticas e da prospecção contínua dasúltimas tendências em data science, machine learning,modelagem e big data.
Javier CalvoSócio [email protected]
Manuel A. GuzmánGerente de P&D [email protected]
Daniel RamosMetodologista de P&D [email protected]
Nosso objetivo é superar as expectativasdos nossos clientes sendo parceiros de
confiança
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 42

MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 43

Madrid Barcelona Bilbao London Frankfurt Paris Warszawa Zürich Milano Roma Lisboa Beijing New York Boston AtlantaBirmingham San Juan de Puerto Rico Ciudad de México Medellín Bogotá São Paulo Lima Santiago de Chile Buenos Aires
Management Solutions, serviços profissionais de consultoria
A Management Solutions é uma firma internacional de serviços de consultoria focada naassessoria de negócio, riscos, finanças, organização e processos
Para mais informações acesse: www.managementsolutions.com
Nos siga em:
© Management Solutions. 2018Todos os direitos reservados.
MachineLearningPT_VDEF_Maquetación 1 25/07/2018 8:42 Página 44