escalas de mediÇÃo - sunprynus.comsunprynus.com/fadeup/114/fadeup114resumodeestatistica.pdf ·...
TRANSCRIPT

1
Resumos de Estatística
1ºAno, 2ºSemestre, 2010/2011 Mário Miguel Fernandes
Aula 1
ESCALAS DE MEDIÇÃO
Instrumento – Mede, com um certo grau de validade, um dado atributo ou característica de um
sujeito. Nele está implícita a fiabilidade, isto é, o erro reduzido da observação (registo).
O processo de medição dá-se por intermédio de valores numéricos, definidos em IR. Neste
sistema de números reais devem-se considerar três aspectos cruciais:
Ordem – Os números são ordenados. Números maiores representam maiores quantidades do
atributo medido.
Distância – As diferenças entre pares de números são ordenadas. Isto é, os números descrevem
a magnitude das diferenças entre unidades de observação.
Origem – As séries de números possuem uma origem única, o valor ZERO. Ao zero associa-se a
ausência total de atributo.
Podemos ter 4 tipos de escalas:
Nominal (Variável qualitativa)
o “Simples” acto de rotular ou representar sujeitos, expressando a ocorrência
da observação.
o Afirmação tipo: Os sujeitos diferem, uns dos outros, relativamente à
característica observada. Isto refere-se, essencialmente, a quantidades de
“classificação sistemática”. Por exemplo: n=100 Portistas (Np = 50)
Sportinguistas (Ns = 25) Benfiquistas (Nb = 25)
o Não se trata, exclusivamente, de atribuir números a sujeitos (objectos
individuais), mas também, e sobretudo, a classes de objectos.
o Os sujeitos devem ser classificados num conjunto de categorias
MUTUAMENTE EXCLUSIVAS e EXAUSTIVAS.
o A diferença na classificação é de natureza e não de grandeza.

2
Ordinal (Variável qualitativa)
o “Arranjo” da expressão do atributo medido numa ORDEM NUMÉRICA
(ORDENAÇÃO) – Atribuição de números a objectos ou pessoas de forma a
reflectir uma ORDEM ou POSIÇÃO no atributo em causa, de baixo a elevado.
As diferenças veiculam aumentos na quantidade das observações da variável.
Por exemplo: A é mais simpático do que B / Escalas do tipo Hickert
Intervalar (Variável quantitativa)
o Se, para além de representar as frequências de ocorrência, ordenar e
categorizar sujeitos e atributos, ainda for capaz de apresentar distâncias
numéricas entre os valores de Xi, a escala é designada de INTERVALAR.
o Os números expressam uma unidade fixa de medida, isto é, precisa, para
além dos intervalos evidenciarem consistência ao longo da escala. Por
exemplo: A diferença existente entre 40ºC e 30ºC é a mesma que a entre
60ºC e 50ºC, mas 60ºC não é o dobro de 30ºC!!! Isto porque não temos um
valor significativo para 0, logo não podemos fazer comparações deste
género.
De razão (Ratio) [Variável quantitativa]
o Escala raramente encontrada em informação proveniente de estudos
psicológicos ou sociológicos, mas muito corrente na pesquisa das ciências
mais “pesadas” do Desporto.
o É expressa pelo conteúdo da escala de intervalo e pela presença de uma
origem ou ZERO definido que nos permite comparar directamente o valor da
escala, ao contrário da Intervalar.
o Sendo assim, permite-nos dizer: Um sujeito com 190cm de estatura possui o
dobro da altura de um outro com 95cm.
RE-ESCALAR….
A expressão RE-ESCALAR uma variável refere-se à sua transformação numa outra escala
(geralmente menos precisa). Por exemplo, podemos tornar uma escala de razão, contínua, numa escala
nominal, discreta ou dicotómica.
RE-EXPRESSAR….
O termo RE-EXPRESSAR uma variável refere-se ao processo de transformação da sua métrica
para facilitar os procedimentos de análise e, em alguns casos, a sua interpretação. Por exemplo:
Simetrizar uma colecção de dados.
A partir da “estatística” podemos inferir, isto é, descobrir o valor dos parâmetros.

3
Na amostra, os dados colhidos das variáveis podem ser:
Contínuos (Altura, peso,…)
Discretos (Sexo, Força partidária,…)
ORGANIZAÇÃO DOS DADOS
Uma forma fácil de ler dada informação será, em primeiro lugar, ORDENÁ-LA (Elaboração de um rol,
lista, série ou distribuição). Este processo constitui uma DISTRIBUIÇÃO SIMPLES.
Séries de frequências
Grau de quantidade de dados, variáveis discretas cuja repetição de valores é uma constante.
Implica a “feitura” de uma lista em que todos os valores de igual grandeza estejam
representados pelo seu valor numérico e respectiva FREQUÊNCIA ou EFECTIVO.
A partir do exemplo anterior, o que há a fazer é agrupar cada valor à respectiva frequência
ABSOLUTA ou SIMPLES.
Frequência ou efectivo de cada valor da variável – Número de vezes que um valor se repete.
∑ƒ=n
Noções importantes:
Frequência absoluta (ƒ) (Vamos ter ∑ƒ=n)
Frequência relativa (ƒr) = ƒ/n e ∑ƒr (ƒrac) = 1.00
Representação gráfica:
Gráfico de barras > Linha poligonal
Histograma > Polígono de frequências
Gráfico de caule-e-folhas
Estatística Descritiva – Conjunto de métodos estatísticos que visam sumariar e descrever os
atributos mais proeminentes aos dados.
Estatística Inferencial – Conjunto de métodos estatísticos que visam caracterizar (ou inferir
sobre) uma população a partir de uma parte dela (a amostra).

4
Estatística - A Estatística é uma ciência que estuda a variabilidade apresentada pelos dados.
Permite-nos, a partir dos dados retirar conclusões, e exprimir o grau de confiança ou o erro
que devemos assumir nessas conclusões.

5
Aula 2
SÉRIES AGRUPADAS EM CLASSES
Quando se trabalha com um número elevada de registos de uma variável (por exemplo: x ≥30)
e quando a variável é contínua, é usual recorrer a séries agrupadas em classes.
O que são?
Nada mais do que dividir as séries simples num determinado número de sub-grupos
(CLASSES) e constar a ocorrência (NÚMERO) em cada uma, isto é, frequência de classe.
Nós devemos sempre considerar entre 5 e 10 classes, ou pelo menos assim o é
recomendado, sendo 7 o número de séries de Sturges, mas depende sempre de n e
forma de distribuição dos valores.
Por questões meramente operacionais (uniformização) iremos considerar a seguinte
processologia de agrupamento:
Localizar o valor mais elevado (limite superior da série) e o mais baixo (limite
inferior da série)
Determinar a amplitude total [At = Ls - Li]
Determinar o número de classes (K)
Dividir a At por K > Pretende obter a “largura” conveniente do intervalo de
cada classe
Considerar classes abertas à direita
Definições:
Centro de Classe (Ci) é o valor obtido pela fórmula seguinte: Ci = (Ls + Li)/2
De seguida deve-se proceder à construção da tabela, leitura dos dados e construção
do histograma.
O histograma é um gráfico de barras que possui barras adjacentes e a sua variável é contínua.
Gráfico de caule-e-folhas:
Representação mais clara dos dados (misto de tabela e gráfico)
Todos os valores da série são representados de uma forma subjectiva que faz lembrar um
histograma.
Utilizado para representar amostras de dois ou mais dígitos.
Consiste no seguinte: Do lado esquerdo de uma linha vertical escreve-se o(s) dígito(s) da classe
de maior grandeza, seguida das restantes.
1ºpasso: Traçar uma linha vertical e colocar do lado esquerdo os dígitos dominantes – Caule
2ºpasso: Depois de ordenar a série, colocar os valores das unidades em cada “caule” – Folhas

6
Quando se representa um conjunto de dados sob a forma de um histograma ou numa
representação de caule-e-folhas, pretende-se que se realce o ASPECTO DO HISTOGRAMA,
pois REFLECTE A FORMA DE DISTRIBUIÇÃO DOS DADOS.
o A distribuição pode ser simétrica relativamente a uma classe média;
o Pode ser enviesada, isto é, assimétrica, apresentando valores substancialmente mais
pequenos num dos lados relativamente ao outro;
o Pode ter “caudas pesadas” ou ter vários “picos”.
DESCRIÇÃO NUMÉRICA DOS DADOS
O que aqui se pretende é obter uma descrição sumária o mais completa e simples possível de
uma série simples ou agrupada em classes.
Os “sumários numéricos” (indicadores) deverão possuir algumas características:
Objectividade
Dependência de todas as observações
Ter um significado concreto
Prestar-se a cálculo algébrico.
Medidas de Tendência Central
Média (X), Mediana (Me), Moda (Mo)
Medidas de Dispersão
Variância (S2), Desvio Padrão (S), Coeficiente de variação (CV), Intervalo de variação ou
amplitude (δ)
Medidas de Assimetria
Coeficiente de assimetria (g1)
Medidas de Achatamento
Coeficiente de achatamento (g2)
Medidas de Ordem
Quartis (Qi), Decis (Di), Centis (Ci) ou Percentis (Pi)
MEDIDAS DE TENDÊNCIA CENTRAL – LOCALIZAÇÃO

7
Para se possuir uma visão ainda mais sintética dos dados exige-se uma redução, sob vários
ângulos, que nos informe das características dos dados.
As Medidas de Tendência Central ou Localização DESCREVEM as características centrais dos
dados. São as seguintes:
Média Aritmética Simples;
Mediana;
Moda.
Média Aritmética Simples
A média aritmética é a medida de tendência central por excelência. No seu cálculo considera-se
não só o número de observações, como também a sua magnitude. Esta baseia-se pois na divisão entre o
somatório de todas as observações e a totalidade de sujeitos.
X = ∑ Xi / n
Se os dados se encontrarem agrupados: X = ∑ ƒ Xi / n ou X = ∑ ƒ Xi / ∑ ƒ
Se os dados se encontrarem agrupados em classes, tiramos também conclusões com o Ci
Numa fórmula rápida e expedita de calcular X é considerar os valores de Ci : X = ∑ Ci / K, parte-se do
princípio que Ci representa a distribuição dos valores de cada classe (isto nem sempre é verdade), para
além do facto de não substituir os diferentes valores de ƒ de cada classe.
Neste caso: X = ∑ ƒr Ci . O mesmo resultado é obtido se: X = ∑ ƒ Ci /n
Importa referir que nestes últimos dois casos se está a “PESAR” os centros de classe (Ci) pela respectiva
frequência. Deste modo o que aqui temos são médias pesadas ou ponderadas.
O que está expresso no caso específico da média aritmética simples é a forte SENSIBILIDADE da média à
presença de valores muito grandes ou muito pequenos numa dada série (a média é uma medida
POUCO ou nada ROBUSTA a valores extremos).
Moda
É o valor mais frequente numa dada série. Pode ocorrer que haja mais que uma moda (bi ou
plurimodal). Pode referir-se a valores ou a classes.
Podemos calcular a moda a partir do histograma, a partir da semelhança de triângulos, por
exemplo.

8
Mediana
É uma medida de localização do centro da distribuição dos dados. Divide a série a meio (preciso
ordenar a série). Enquanto medida de ordem, não considera a magnitude de cada observação.
Para calcular a Me utiliza-se a seguinte regra depois de ordenar a série:
Se n é ímpar, a Me é o elemento “médio”
Se n é par, a mediana é a semi-soma dos dois elementos “médios”
A mediana é uma medida ROBUSTA dado não ser sensível a valores extremos da série.
Medida útil quando os dados são fortemente enviesados à direita ou à esquerda.
Qual das medidas seleccionar: Média, Mediana ou Moda?
Cada uma destas medidas expressa aspectos diferentes da noção da tendência central da
distribuição de valores.
Se se tratar do melhor palpite relativamente a um dado valor, a escolha recairá sobre a
MODA (valor mais frequente) - Trata-se da EXACTIDÃO na escolha.
Se se tratar de cometer o MENOR ERRO ABSOLUTO em função de todos os valores da série, a
MEDIANA é a solução.
Se se tratar da consideração da MAGNITUDE DO ERRO e do SEU SINAL, então a MÉDIA é a
solução.
O cálculo da mediana, séries agrupadas em classes, faz-se pelo princípio da INTERPOLAÇÃO
LINEAR, através de um Polígono de Frequências acumulado.

9
Aula 3
Medidas de Dispersão
As medidas de tendência central, por si só, são insuficientes! Há que realçar a importância da
VARIABILIDADE. O mundo vivo é caracterizado por esta.
As medidas de tendência central fornecem informação acerca de determinados aspectos da
distribuição, isto é, a sua localização. Porém, são insuficientes para a sua descrição completa.
Apesar dos valores da média e da
mediana poderem ser os mesmos em cada
série, a distribuição individual dos valores
em cada uma é DIFERENTE, isto é, cada uma
possui diferente variabilidade.
1. Intervalo de variação ou Amplitude (A)
Medida de variabilidade que transparece a diferença entre os valores mais elevado e
baixo da série. É algo “grosseira” visto que apenas considera os seus valores extremos.
2. Variância (S2)
Medida de variabilidade que considera todos os valores da série bem como a sua
magnitude. As ideias centrais para o seu cálculo pressupõem o desvio da média (Xi – X ou Xi - µ),
a soma de quadrados *∑(Xi – X)2 ou ∑(Xi - µ)
2] e os graus de liberdade.
Podemos calcular a sua variância amostral a partir das expressões: S2
=
ou S
2
=
Média dos quadrados dos desvios em relação à média
E porque é que se divide a SQ por (n-1) e não por n, dado que se tem n desvios e não n-1?
Na realidade, só aparentemente se possuem n desvios independentes. Se se
calcularem (n-1) desvios, o restante fica automaticamente calculado, uma vez que a sua soma é
igual a zero. Costuma-se referir este facto ao se dizer que se perdeu 1 grau de liberdade.
S2
=
SQ = ∑x2
–

10
Se os dados estiverem agrupados em classes podemos aproximar a variância amostral
pela fórmula: S2 =
–
Dado que o cálculo da variância envolve a soma de quadrados, a unidade em que se
exprime não é a mesma dos dados. Para obter uma medida de variabilidade na mesma unidade
de medida da variável, toma-se a raiz quadrada da variância.
3. Desvio-padrão (S)
É a raiz quadrada média positiva da variância. Este é muito sensível à presença de
valores extremos, denominados outliers, sendo desta forma uma medida de dispersão POUCO
RESISTENTE. Ou seja, um valor grande para o desvio-padrão pode ser devido a uma grande
variabilidade nos dados ou então à existência de 1 ou mais outliers.
Podemos desvendar o intervalo onde determinados valores se encontram, num modo
geral, ao adicionarmos e subtrairmos o valor do desvio padrão à média.
4. Dispersão relativa
Estas medidas servem para comparar conjuntos de dados diferentes e variações em
diferentes segmentos de uma mesma escala. Para elas, utilizamos uma coeficiente de
dispersão ou variação (CV).
CV =
x 100 (%)
5. O desvio-padrão e a distribuição normal
Neste caso, o desvio-padrão pode ser entendido enquanto medida de distância.
Ex: Quem tem 72kg de peso, está 1 desvio-padrão acima de média.
6. Comparar médias de duas distribuições: a relevância da variabilidade
Apreciar a importância do desvio-padrão na comparação de 2 médias.
7. Magnitude do efeito (ME)
Serve para expressar a diferença entre duas médias em unidades do desvio-padrão.
ME =
=
Valores “padronizados” para interpretar a ME:
ME = 0,20 Efeito pequeno ou reduzido
ME = 0,50 Efeito moderado
ME = 0,80 Efeito substancial (grande)
Processo:
I. Calcular a diferença entre médias

11
II. Calcular a SQ para cada grupo
III. Calcular o desvio-padrão comum
IV. Calcular a ME
V. Interpretação
Ex: A média de lançamento da bola do 1ºgrupo situa-se 0,5 desvio-padrão abaixo da média do
2ºgrupo. Este efeito diferenciador das médias dos dois grupos é moderado.
Medidas de Ordem
As medidas de ordem são utilizadas quando se pretende classificar sujeitos, isto é, determinar a
sua posição relativa no conjunto a que pertence.
Úteis:
Provas de classificação
Selecção de candidatos
Construção de perfis
Descrever o desempenho
Divisões:
Tercis – Escala de valores que dividem a série em 3 partes iguais
Quartis – Escala de “notas” ou valores que dividem a série em 4 partes iguais
Quintis – Escala de “notas” que dividem a série em 5 partes iguais
Decis – Escala de 10 pontos que divide a série em consideração
(Per)centis – Dividem a série em 100 partes
Ai - Amplitude da classe (série)
Cálculo simples das divisões
Ta =
Qa =
Qi =
Da =
Ca =

12
Box-Plot (Diagrama de extremos e quartis | Diagrama de caixa-de-bigodes)
Representação gráfica que permite realçar as seguintes características dos dados: CENTRO,
VARIABILIDADE, SIMETRIA, OUTLIERS.
Aplicação directa dos QUARTIS (Percentis): P25/Q1 , P50/Q2/Me , P75/Q3
A1 – Valor adjacente inferior – menor valor da amostra – que é maior que: P25 – 1,5(P75 – P25)
A2 – Valor adjacente superior – maior valor da amostra – que é menor que: P75 + 1,5(P75 – P25)
Amplitude inter-quartil (Aiq) – Medida de variabilidade definida pela diferença entre o 1º e o
3ºquartil Aiq = Q3 – Q1
A Aiq é resistente à presença de valores extremos.
Eu devo juntar à média o valor da média dos valores dos afastamentos à média (desvio-padrão).
Para evitar que esta média fosse igual ou próxima de zero, elevaram-se esses valores ao quadrado para,
deste modo, só termos valores positivos (variância). Ao aproveitarmos este valor, temos de o
apresentar na mesma unidade dos resultados. Aí, aplicamos a raiz quadrada a esse valor para
chegarmos ao novo valor do desvio-padrão (Quanto maior for este valor, maior será a variação
relativamente ao conjunto de valores sobre o qual a maioria dos resultados recai, e vice-versa.)

13
Estatística Descritiva
Medidas de Tendência Central
Média Moda Mediana
Medidas de Dispersão
Variância Desvio-padrãoCoeficiente de
variaçãoAmplitude
Forma da Distribuição
Medidas de Ordem
Percentis

14
Aula 4
A DISTRIBUIÇÃO NORMAL
Não há uma distribuição normal. Há uma família delas!
Temos sempre dois parâmteros:
Medida de Tendência Central (Localização) – Média
Medida de Variação – Variância
A distribuição normal (curva de Gauss) é utilizada para DESCREVER e AVALIAR o
sentido, isto é, a magnitude de um resultado ou grupo de resultados, relativamente ao desvio-
padrão e para calcular probabilidades.
Como se distingue uma curva normal de uma outra que não o é?
I. Forma
II. Cálculo dos índices de Assimetria (G1) e Achatamento (G2)
G1 = 0 Simétrica
G1 =
G1 Assimétrica Positiva
G1 Assimétrica Negativa
G2 = 0 Simétrica/Mesocúrtica
G2 =
G2 Leptocúrtica – Pico enorme
G2 0 Platicúrtica – Caudas muitos pesadas
Características da Curva Normal:
Forma de sino
Unimodal
Simétrica
15
Assíntota – A curva nunca “toca” a abcissa. A distribuição normal é contínua para
todos os valores da variável (x) de -
É puramente teórica – Não existe no mundo real.
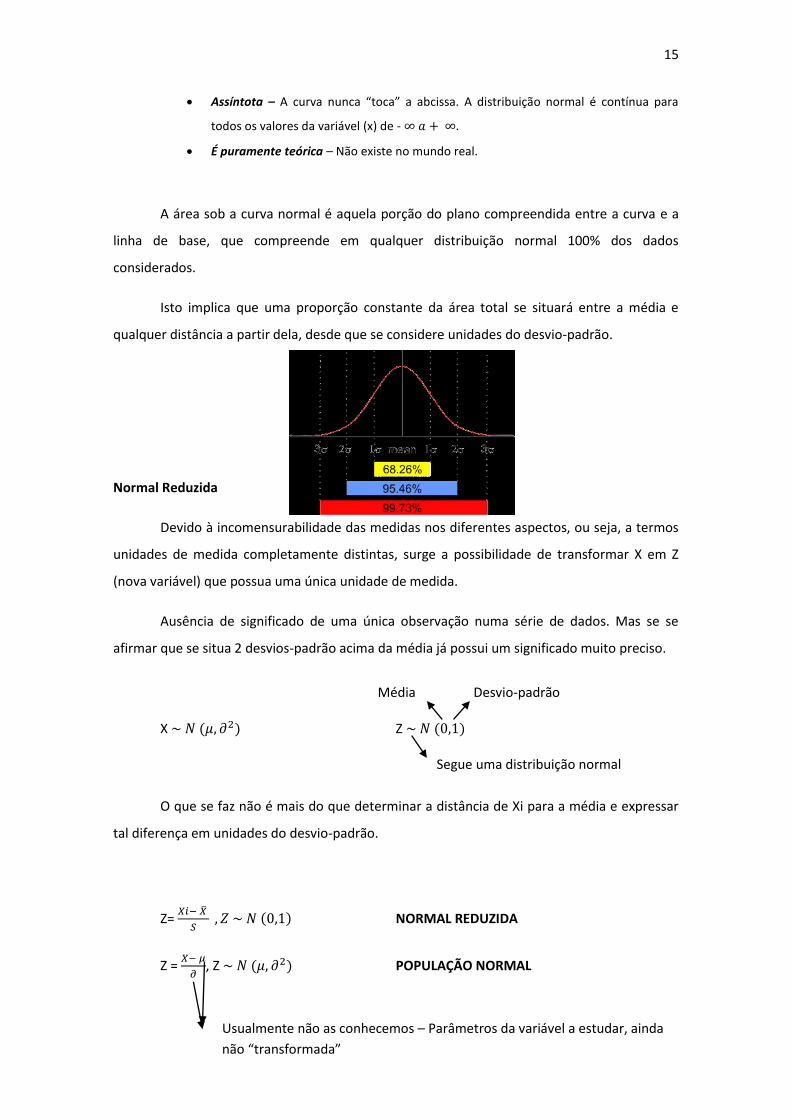
A área sob a curva normal é aquela porção do plano compreendida entre a curva e a
linha de base, que compreende em qualquer distribuição normal 100% dos dados
considerados.
Isto implica que uma proporção constante da área total se situará entre a média e
qualquer distância a partir dela, desde que se considere unidades do desvio-padrão.
Normal Reduzida
Devido à incomensurabilidade das medidas nos diferentes aspectos, ou seja, a termos
unidades de medida completamente distintas, surge a possibilidade de transformar X em Z
(nova variável) que possua uma única unidade de medida.
Ausência de significado de uma única observação numa série de dados. Mas se se
afirmar que se situa 2 desvios-padrão acima da média já possui um significado muito preciso.
X Z
O que se faz não é mais do que determinar a distância de Xi para a média e expressar
tal diferença em unidades do desvio-padrão.
Z=
NORMAL REDUZIDA
Z =
, Z POPULAÇÃO NORMAL
Média Desvio-padrão
Segue uma distribuição normal
Usualmente não as conhecemos – Parâmetros da variável a estudar, ainda
não “transformada”

16
Em avaliações, devemos:
I. Recurso aos perfis ou padrões normativos;
II. Recurso ao somatório.
Curva normal
O seu interior compreende, aproximadamente, 100% das observações realizadas
Tem a forma de sino
Média, Moda e Mediana situam-se no mesmo lugar, situando-se exactamente no centro da
curva, isto é, divide a mesma em duas partes iguais
Vai de - a +
Desvio-padrão como quantificador, unidade de medida

17
Z – Medida padrão ou transformada

18
Aula 5
Correlação Linear simples
Ideias essenciais
1. Descrever o grau de relação ou associação entre duas variáveis
2. Procurar expressar a ideia da relação entre variáveis cuja essência é, de certo modo, a
imprecisão.
No entanto, em média, alguns tendem a ser mais alguma coisa e outros tendem a
qualquer coisa.
É da variação e CO-VARIAÇÃO (isto é, Variação conjunta) em TERMOS MÉDIOS que se
ocupam a CORRELAÇÃO e a REGRESSÃO.
Correlação – Relação estatística que se estabelece entre variáveis.
A análise gráfica é ESSENCIAL para se proceder a uma “investigação” inicial da relação
entre variáveis. A representação de pares de pontos (Xi, Yi) num sistema de eixos cartesianos,
toma o nome de DIAGRAMA DE DISPERSÃO.
Neste, podem existir relações positiva (razão directa) [0,1] ou negativa (razão inversa) [-
1,0].
Coeficiente de correlação linear – Medida DESCRITIVA de associação entre duas variáveis.
Esta também pode ser designada como correlação MOMENTO-PRODUTO.
Conceito físico: Distância de um objecto (Xi) ao eixo de rotação ( ) - Dados centrados ou “padronizados”
A noção de covariância ou variação conjunta (a ideia central da correlação)
COV =
Soma de produtos cruzados

19
A covariância indica-nos se há uma associação entre as variáveis.
r =
Coeficiente de correlação de Pearson
Desvio-padrão Apresenta limites – 0 e 1 – ao contrário da variância.
Porém, uma forma “mais prática” reside no uso da fórmula seguinte:
r =
A interpretação do coeficiente de correlação é efectuada em duas etapas:
1. Conhecer o significado estatístico do rxy
a. Interpretação imediata e subjectiva antes do seu significado estatístico
i. 0.00 - Relação Indiferente
ii. 0.20 - 0.40 Relação fraca
iii. Relação ligeira a substancial
iv. Relação alta (forte)
b. No entanto, há que considerar:
i. Natureza das variáveis
ii. Variabilidade do grupo
iii. Finalidade do uso do rxy
2. Identificar a percentagem de variância comum de duas variáveis
Passos para a correlação:
1. Análise gráfica;
2. Cálculo de r;
3. Cálculo de r2 (coeficiente de determinação)
Pressupostos para o cálculo de rxy
1) Linearidade
a. Só se aplica a dados que evidenciem linearidade de comportamentos
2) Dados Intervalares

20
a. Devem estar, no mínimo, ao nível intervalar. Dados ordinais e nominais reclamam
outros coeficientes
3) Amostras aleatórias
a. Devem ter sido extraídos, de forma aleatória, de uma dada população, pois só assim
terá sentido o texto formal
4) Normalidade bi-variada
a. Espera-se que, na população, X e Y tenham distribuições normais.
Cuidados na interpretação de rxy
I. Uma correlação de r = 0.90 não representa uma correlação duas vezes mais forte que r = 0.45.
Deve-se interpretar os valores de r2.
II. O coeficiente de correlação não suporta qualquer argumento causal.
III. Podemos interpretar o valor de r a partir do coeficiente de determinação (r2).
Coeficiente de determinação (r2) – Proporção de variância comum partilhada pelas duas variáveis.
Quando temos variância comum, por exemplo, onde o coeficiente de determinação é
igual a 0.25, podemos dizer que 25% das ocorrências da variável Y podem ser explicadas
através da ocorrência da variável X.
Quando o valor de r encontrado é muito elevado, a associação entre as duas variáveis
(r2) é também muito elevada.
Quando há uma correlação ligeira e negativa entre os valores dos dois testes, a
proporção de variância comum é fraca.
Coeficiente de não-determinação (1-r2) – Quanto da variância das duas variáveis não é comum
Ex: r2
= 0.25 (25%) r = 0.50
1 – r2 = 1 – 0,25 = 0.75 ou 75%, isto é, 75% da variância não é partilhada pelas variáveis.
Busca de associações entre variáveis

21
Atentar nos efeitos de um “outlier” e da restrição na amplitude dos dados de duas variáveis.
Regressão Linear e Predição
Temos situações em que se é tentado a predizer o valor de uma variável a partir do
conhecimento da outra. Prever acontecimentos em relação a indivíduos é uma tarefa difícil, e
em alguns casos, impossível.
No entanto, conhecida a relação entre duas variáveis, pode ser possível predizer uma a partir
da outra dentro dos limites dos dados em que se baseia a correlação.
No contexto da regressão,
X – Variável independente (Variável preditora – Vai fazer prever uma outra)
Y – Variável dependente (Variável critério, valor predito ou estimado)
A melhor recta é aquela que minimize a diferença entre os pontos.
Declive da recta:
A regressão linear é a expressão da relação linear actual entre duas variáveis. A partir da
equação da recta (Y = a + mx), vem:
O declive da recta é conhecido pelo coeficiente de regressão amostral ( . O seu valor:
I. É independente da origem das variáveis e do número de pares de observações;
II. É expresso em unidades da variável dependente;
a = Ordenada na origem (valor de Y quando x=0)
b = Declive da recta, isto é, a razão da variação de Y pela variação de X

22
III. O seu valor numérico é baseado num único factor. A presença e influência de factores adicionais são
completamente ignoradas no problema da regressão linear simples – Dificuldade de precisão baseada
num único factor.
A recta que melhor se ajusta, para um determinado par de dados, é definida como a única
recta em torno da qual a soma dos quadrados dos dois triângulos dos valores observados à
recta é mínima. Estes erros de predição têm de ser minimizados:
Daí que: y = a + bx + ei Resíduos da Regressão
Os valores preditos ou estimados da recta de regressão são, num certo sentido,
estimativos da média dos valores de Y correspondentes a um dado valor de X.
Média condicional E (Y|Xi)
“Local” da média condicional (na recta) da variável dependente para um valor fixo da variável
independente.
Previsão
1) Relação entre variáveis
a. Positiva
b. Negativa
c. Não existente
2) Calcular o valor da relação (r) – Encontra-se entre -1 e 1
3) Coeficiente de Determinação (r2)

23
Aula 6
Regressão Linear simples e predição
Partindo de
A recta que melhor se ajusta é a recta de regressão. Nesta recta, os valores preditos de Y (
“cairão” nos valores de Xi (dentro dos seus limites).
A recta de regressão passa pela intersecção pelos pontos
A recta pode ser pobremente ajustada caso a relação entre as variáveis seja fraca ou se a
relação não for linear.
Assim, a partir desta soma de quadrados (igual ao mínimo) e da equação da recta de
regressão: , chegamos às fórmulas de
Caso sejam conhecidos os valores de rxy, sx e sy:
b = [
Se não forem conhecidos, então temos que:
a = ( –
O valor de b informa-nos sobre aquilo que é preciso esperar na variável dependente Y
quando o valor de X (variável independente) aumenta um valor.
a – Valor na ordenada quando X=0. Normalmente funciona como factor de correcção
b – Declive ou coeficiente de regressão linear
O coeficiente de correlação pode-nos dizer se a nossa previsão está bem ajustada ou se é
desastrosa.
Coeficiente de correlação elevado – A diferença entre os valores obtidos e da previsão
pela recta de regressão é mínima.

24
Coeficiente de correlação fraco – A diferença entre os valores obtidos e da previsão
pela recta de regressão é grande.
Quando Yi é predito a partir de Xi, a variância (Yi - representa-se por S2y.x
S2y.x =
--------- Sy.x = Sy
Erro padrão de estimativa
Sy.x – Se for 0, a previsão é perfeita. Quanto menor for a distância dos desvios, menor será este valor.
Expressa em valores da variável dependente.
S2
y.x S2
yx
O erro padrão de estimativa mede a extensão destes desvios da recta aos valores observados.
Ou seja, o que se encontra representado é o “quão perto” os pontos se aglomeram em torno
da recta.
Sempre que obtemos um resultado, , temos uma estimativa pontual. Esta trata-se de uma
correlação perfeita, se e só se Sy.x = 0
Quanto maior for a correlação, mais precisa será a previsão.
E(y) =
Passos para o cálculo da precisão
Cálculo do erro-padrão de estimativa
Cálculo da estimativa
Cálculo do intervalo de confiança
Regressão e Soma de Quadrados
Notação de co-variância
Para reflectir cerca de 68% dos resultados, 95% dos resultados
ou 98% dos resultados – Valores da normal reduzida, definidos
na tabela.

25
A interpretação de rxy é feita a partir da interpretação da VARIÂNCIA.
O r não é uma proporção (r = 0.60 não é igual a 2 x .30)
A diferença entre dois valores de r distintos não é igual para a mesma diferença entre outros
dois valores
Na estimação de Yi a partir de Xi, o valor de Yi pode ser entendido como composto por duas partes:
Valor previsto ( . Isto é, a distância do eixo de à recta.
VARIAÇÃO EXPLICADA:
Diferença entre o valor observado de Yi e o valor previsto (
VARIAÇÃO NÃO EXPLICADA:
Estas partes são independentes e aditivas:
+
Variação Total = Variação Explicada + Variação Residual
Pode determinar-se a proporção da variância total que é variância explicada.
= r2
= r Coeficiente de correlação
Correlação «=» Regressão
Com recurso à fórmula anterior, podemos aferir que, por exemplo, 75% da variância total de Y
é previsível – explicada – a partir de X. Sendo assim, os restantes 25% da variância total de Y
não é explicada – residual – a partir da variável X.
Variância total Soma de quadrados total
Variância explicada
Variância residual ou não explicada

26
Pressupostos do Modelo de Regressão
i. Homogeneidade de Variâncias
a. Todas as distribuições de Y possuem a mesma variação.
ii. Linearidade
a. Para cada distribuição, a média situa-se na recta de regressão populacional ou
verdadeira recta de regressão.
i. E (Yi) = µi = α + βXi
ii. Os valores de α e β são parâmetros populacionais estimados a partir da
informação amostral ( .
iii. Independência
iv. Normalidade das Distribuições
v. Intervalar ou de Razão (escala de medida das variáveis)
a. As variáveis utilizadas neste modelo têm que estar medidas numa escala intervalar ou
de razão.

27
Aula 7
Distribuições amostrais
Quando, ao calcularmos a média de uma dada AMOSTRA e repetirmos esse processo algumas vezes,
denotamos que o seu valor vai ser diferente na maioria dos casos. Isto deve-se a erros amostrais, isto é,
à própria variabilidade do desempenho dos sujeitos estudados, dado ser impossível que todos tivessem o
mesmo valor de variável estudada.
Erro amostral (ei) – Diferença entre o valor de um parâmetro (Θ) e o valor da sua estimativa (Ô).
Todo este processo é semelhante ao de distribuição normal, porém enquanto neste tratamos de médias
amostrais, que funcionam com sujeitos colectivos, na DN pensamos em termos individuais.
População – Colecção total de objectos ou pessoas a ser estudada. Os seus membros são designados
por unidades ou elementos. O seu número total é dado por N e cada elemento por Xi.
Dada a impossibilidade de estudar toda a população, pesquisa um sub-conjunto suficientemente
representativo em termos de qualidade e quantidade designado de AMOSTRA, partindo-se desta para
GENERALIZAR a população.
Estatística – Sumaria um aspecto das observações amostrais.
Parâmetro – Caracteriza um aspecto da população.
Estatísticas Parâmetros
(Média amostral) µ (Média populacional)
S2 (Variância amostral) δ2 (Variância populacional)
S (Desvio-padrão amostral) δ (Desvio-padrão populacional)
rxy (Coeficiente de correlação de Pearson amostral) pxy (CC de Pearson populacional)
Estimam

28
Modelo de amostragem aleatória
Importante para inferir acerca de µ com base em
Exige uma amostra aleatória (tipo lotaria)
Seleccionar uma amostra aleatória simples
Há, essencialmente, duas grandes categorias de amostragens:
o Probabilísticas (Aleatórias)
Simples
Sistemática
Estratificada
o Não-probabilísticas (Não-aleatórias)
Por conveniência
Por contraste
Por quotas
A média populacional é a média das médias amostrais.
A Estatística Inferencial:
Estima parâmetros
Ensaia hipóteses
É um processo de tomada de decisão baseado em probabilidades e pode ser de dois tipos:
- Estimação de parâmetros – usando a informação de uma estatística amostral podem tirar-se
conclusões sobre um valor de um parâmetro populacional;
- Testes de hipóteses – usando a informação da amostra é possível decidir se uma hipótese
(pressuposto) sobre um parâmetro populacional, por exemplo, a média ou proporção, deve ou não ser
rejeitada.
Distribuição amostral das médias
A distribuição amostral das médias é uma distribuição probabilística. Ela é cada vez mais
semelhante à distribuição normal populacional à medida que o número de amostras aumenta.
Rege-se por algumas características:
1. A média da distribuição amostral das médias ( ) é igual à média da população (µ).
2. O desvio-padrão da distribuição amostral das médias é conhecido por erro-padrão da média
. Depende do valor de σ (directamente) e de n (inversamente).

29
- Será tanto maior quanto mais elevada for a magnitude de σ, isto é, maior variabilidade na
população [atenção aos outliers]
- Será tanto menor quanto maior for n – Mais precisa o valor da média amostral se torna,
relativamente ao valor da média populacional.
- Tende a aproximar-se de 0 à medida que n aumenta.
3. Forma da distribuição amostral das médias
a. De acordo com o teorema de limite central (TLC) , a distribuição amostral das médias
tende para uma distribuição normal à medida que n aumenta – Qualquer que seja o
formato da distribuição parietal da variável, a distribuição amostral das médias tende
a tornar-se uma distribuição normal à medida que o número de sujeitos aumenta.
De modo a sabermos calcular a probabilidade em obter uma média amostral em relação a dado valor,
devemos:
1) Calcular
2) Calcular o valor de Z
3) Consultar a tabela de referência
O erro-padrão da média é inversamente relacionado com a dimensão amostral. Isto é fundamental na
precisão de enquanto estimador de µ. Atenção que apenas o quadrúpulo de n duplica a precisão de
para estimar µ, já que o denominador trata-se de .

30
Aula 8
Testes de hipóteses estatísticas.
Teste para µ com σ2 conhecido.
É um processo de tomada de decisão baseado em probabilidades e pode ser de dois tipos:
- Estimação de parâmetros – usando a informação de uma estatística amostral podem tirar-se
conclusões sobre um valor de um parâmetro populacional;
- Testes de hipóteses – usando a informação da amostra é possível decidir se uma hipótese
(pressuposto) sobre um parâmetro populacional, por exemplo, a média ou proporção, deve ou não ser
rejeitada.
Este valor vai ser testado, segundo um valor teste. O passo seguinte será o transformar este para um
valor probabilístico, tendo um valor de prova (p), este que nos diz se a probabilidade de H0 é ou não
verdadeira.
Se a probabilidade for superior a 0.05 (5%), então H0 – a nossa hipótese nula – é verdadeira. Se for
inferior a esse valor, então esta é rejeitada, que é o que se pretende.
Hipótese estatística – Afirmação acerca de um parâmetro.
Hipótese nula, H0, é uma afirmação que indica não haver diferença entre a média da população, u, e o
valor hipotético assumido; isto é, nula significa que não há diferença. É assumida como sendo
verdadeira e é testada formalmente. É esta que gera a distribuição amostral a ser empregue. É objecto
de ensaio e cuja decisão final pode ser “REJEITADA” ou “NÃO REJEITADA”.
Hipótese alternativa, H1 ou HA, é uma afirmação que discorda da hipótese nula. Nunca é testada
formalmente. Pode tomar duas formas:

31
Não direccional (bilateral) – Por exemplo: H1: µ ≠ 250
Direccional (unilateral) – Por exemplo: H1: µ > 250 ou H1: µ < 250
Se a hipótese nula é rejeitada em resultado da evidência, a hipótese alternativa é a conclusão.
Se não tivermos evidência(s) suficiente para rejeitar a hipótese nula, ela mantém-se mas não a
aceitamos, dizemos apenas que não a podemos rejeitar.
É importante realçar que H0 e H1 são afirmações acerca de parâmetros e não de estatísticas
amostrais.
Etapas:
i. Ensaiar uma hipótese (Hipótese alternativa)
ii. Formalizar as hipóteses – Especificar as hipóteses nula e alternativa e o nível de
significância
iii. Seleccionar a amostra e calcular as estatísticas necessárias
a. Converter o valor da hipótese alternativa num score Z
iv. Testar a hipótese nula – Determinar a probabilidade de Z na condição da hipótese nula
v. Representação gráfica para apoio
vi. Comparações dos valores obtidos relativamente à média populacional
a. As diferenças são meros erros amostrais
b. A possibilidade de ocorrer um erro amostral já não é tão plausível
vii. Decidir
Quando o teste Z só envolve uma amostra, é designado de teste da média (com σ2 conhecido).

32
A área da probabilidade de ocorrência da hipótese nula corresponde a um espaço
probabilístico de ocorrência da hipótese nula.
O valor de prova é uma probabilidade de ocorrência de H0 se esta for verdadeira. P é uma
medida de “raridade” dos resultados amostrais se H0 for verdadeira.
Valor de prova (p-value) - a probabilidade (p) de obter, por acaso, o resultado observado no teste
estatístico realizado, ou outro ainda mais extremo, admitindo que a hipótese nula é verdadeira.
Será que o nível de significância sugere que a hipótese nula é falsa?
Se a hipótese nula é verdadeira, α especifica a raridade de ocorrência de uma dada
média amostral. O α permite estabelecer regiões críticas, sendo que no gráfico temos
presente:
o Valor crítico
o Região de rejeição de H0
o Região de não rejeição de H0
Usualmente, o nosso nível de significância situa-se nos 5% (0.05), podendo também
corresponder a 1% (0.01) ou a 0,1% (0.001).
Rejeição de H0 Não rejeição de H0
Em termos de p p ≤ α p > α
Em termos de z Se z ≤ - zα ou z ≥ + zα Se z > - zα ou z < + zα
O nível de significância é um risco para rejeitar a hipótese nula quando esta é verdadeira.

33
Dá a probabilidade de rejeitar a hipótese nula quando é, de facto, verdadeira, é conhecido como
erro tipo I.
Se H0 for falsa e não for rejeitada, então temos um erro tipo II.
A rejeição de H0 conduz ao estabelecimento de resultados estatisticamente significativo. Se
não há rejeição, então estes são estatisticamente não significativos. Objectivamente, no
primeiro caso é irrelevante, enquanto no segundo é relevante – Não confundir
estatisticamente significativo com importante, substancial ou relevante.
O estabelecimento de H1 unidireccional, ou não, exige uma noção muito clara da substância do
problema em estudo. As implicações estatísticas são evidentes:
Problema: Colocação substantiva
Formalismo estatístico: Ensaio de hipóteses
Conclusão: Da estatística à substantiva.

34
Aula 9
Ensaio de hipóteses
Teste da média com variância populacional desconhecida
A média amostral é um bom estimador da média populacional, garantindo o
pressuposto da aleatoriedade da amostra e uma dada dimensão amostral – Quanto maior for
o número de amostras, menor será o erro-padrão da média.
Também nos é possível determinar se uma dada média pertence ou não a uma
distribuição amostral de médias.
Se a probabilidade da média amostral “estar perto” da média populacional for
reduzida, então podemos concluir que:
i. A amostra donde foi calculada a média amostral tem uma probabilidade muito
reduzida de pertencer à população parental.
ii. A amostra foi retirada da população-alvo, mas o seu processo foi viezado de tal modo
que já não é representativa da população.
O problema com o qual nos podemos deparar é com o facto de a variância populacional
ser desconhecida. Sendo assim, há que estimar o erro-padrão da média a partir do desvio-
padrão amostral.
Dado que a estatística Z é somente utilizada com a variância populacional conhecida,
quando esta não o é, recorre-se ao teste t.
t =
Incorpora a magnitude de efeito
Está expresso em unidades do desvio-padrão da média
Ele vai transformar o valor de t num valor de prova (p), que representa a probabilidade da
hipótese nula ser verdadeira [apenas consigamos verificar isto no SPSS].
A partir desta equação, somos capazes de chegar ao tamostral. O tcrítico pode ser “descoberto”
através de uma tabela própria com valores relativos a este teste.
Como interpretar o valor do tamostral?
Devemos ter em atenção a distribuição t de student, que pressupõe os conceitos de
graus de liberdade e distribuição amostral de t.

35
Graus de liberdade
Número que indica a quantidade de “peças de informação independente” que uma
dada amostra de observações providencia em termos de inferência estatística.
No estudo do desvio-padrão amostral, há necessidade de sabermos os valores da soma
de quadrados e dos graus de liberdade.
Distribuição amostral de t (Distribuição t de student)
Variância populacional (σ2) é desconhecida. Há, pois, que recorrer à distribuição t.
Pretende solucionar o problema de estimação de parâmetros e ensaiar hipóteses com
o valor acima referido desconhecido.
Tem a forma de sino, é simétrica, unimodal e a sua média é zero (só na normal
reduzida). Possui graus de liberdade (ѵ), parâmetro fundamental. A variância desta
distribuição com џ graus de liberdade é dada por ѵ/(џ-2).
À medida que o número de graus de liberdade aumenta, a distribuição t aproxima-se
de uma distribuição normal.
o Quando n ≥ 30, a ptѵ = pz
Tabela de distribuição t
o Vertical – Graus de liberdade
o Horizontal – Áreas sobre a curva
o Corpo da tabela – Valores críticos de t para um dado número de graus de liberdade e
nível de significância (testes unilaterais e bilaterais)

36
Se o tamostral for maior ao tcrítico , então devemos rejeitar a hipótese nula. Se for menor,
então não a podemos rejeitar.
Construção de um intervalo de confiança para µ com σ2 desconhecido
A fórmula para a construção de um intervalo de confiança é:
o
o dos valores de tcrítico apresentados, podemos concluir qual a área coberta
por esse intervalo de confiança
Inferências sobre médias
Processo inferencial sobre a média da população µ (desconhecida) a partir de uma
amostra (quando a variável na população segue uma distribuição normal):
Baseia-se na distribuição amostral “padronizada” N (0,1), quando o desvio-padrão da
população, σ, é conhecido.
Baseia-se na distribuição t de student, quando o desvio-padrão da população, σ, não é
conhecido, mas apenas é conhecida a sua estimativa, s, calculada a partir de amostra.

37
Se a distribuição das médias amostrais seguir a distribuição normal e se σ for conhecido, o
cálculo de intervalos de confiança e os ensaios de hipóteses para µ são calculados a partir de:
z =
Características da distribuição t de Student
É semelhante à distribuição normal: simétrica em relação à média e em forma de
sino;
É mais achatada que a normal (variabilidade da distribuição t é maior que a da
normal;
À medida que o número de graus de liberdade aumenta, vai-se aproximando da
normal.

38
Aula 10
Ensaio de hipóteses para a diferença entre 2 médias
(medidas independentes)
Nos ensaios de hipóteses com frequência tentam-se DIFERENÇAS entre DUAS médias
pertencentes a DOIS GRUPOS.
Ex: Os programas de treino de força dinâmica são mais eficazes que os da força isométrica.
Medidas Independentes – Os registos obtidos num dos grupos não estão
correlacionados ou não dependem dos obtidos no outro grupo.
H0 : µ1 = µ2 ou H0 : µ1 - µ2 = 0
H1 : µ1 ≠ µ2 ou H1 : µ1 > µ2 ou H1 : µ1 - µ2 > 0
H0 sugere:
As duas amostras foram retiradas da mesma população;
Qualquer diferença observada entre as médias amostrais é considerada
CASUAL, mero resultado de um erro aleatório no processo amostral.
Atenção
I. À luz da hipótese nula, uma diferença entre as médias amostrais (
não representa
uma verdadeira diferença entre as médias populacionais (µ1 e µ2).
II. A haver diferenças entre as médias, a hipótese nula procura explicá-la através da presença
inevitável de um erro amostral.
III. Em contrapartida, a hipótese alternativa salienta a circunstância das amostras terem sido
retiradas de populações com médias diferentes, isto é, o erro amostral não é suficiente
para explicar a magnitude das diferenças encontradas.

39
Média da distribuição amostral da diferença de médias
População 1:
População 2:
Diferença de médias amostrais:
A média da distribuição amostral da diferença de médias quando H0 é verdadeira é
= 0
O desvio-padrão desta distribuição é designado por erro padrão da diferença de
médias, σ em que:
=
Se as variâncias das duas populações forem iguais, =
, sendo que
temos de conhecer as variâncias
Este valor será tanto menor quanto mais elevados forem n efectivos de cada amostra.
Estimar
o Explicar o pressuposto da homogeneidade de variâncias
o =
o Já que nem sempre os grupos possuem o mesmo número de sujeitos, ou há vantagem
em obter uma estimativa conjunta da variância (estimativa da variância comum), vem
Diferença de
médias
amostrais:
+: d > 0
- : d < 0
TLCentral:
Distribuiç
ão
normal;
=
0

40
o
, ou então,
o A estimativa de , representada por , é:
o =
o =
Em que:
e
Se =
Teste formal para duas amostras independentes
Para duas amostras independentes, temos:
t =
Como é 0:
t =
A diferença entre e
representa a Magnitude de Efeito Absoluta.
Construção de um intervalo de confiança para
Interpretação do significado de diferença
1) Conceito de variância explicada (ω2)
2) Magnitude de Efeito (ME)

41
Problemas de interpretação centrada exclusivamente no valor de p
A. Resultado significativo (p < 0.05) e não ter qualquer significado prático
a. Muitos graus de liberdade; Tc irrelevante; H0 vai ser rejeitada;
b. Caso flagrante da dependência dos resultados á dimensão amostral e
variação reduzida em cada grupo.
B. Qual deve ser o tamanho da diferença para lhe ser atribuído relevância prática
(substantiva)?
Soluções
A. Variância explicada
a. No caso do teste t, a fórmula é a seguinte:
i. ω2 =
b. Exemplo de interpretação: Somente 4,5% da diferença de pontuação no teste
é devida à diferença entre sexos. 95,5% da variação verificada está por ser
explicada.
c. Pergunta: Qual deve ser o tamanho mínimo da variância explicada para ser
considerada importante?
d. Resposta: Depende:
i. Conhecimento que o investigador possui do problema;
ii. O que se pretende fazer como valor da variância explicada;
iii. Possibilidade de estabelecer, a priori, um valor mínimo de variância
explicada;
iv. Conjunto de enunciados por detrás do estudo;
v. NOTA: A resposta nunca é do domínio da Estatística!
B. Magnitude do Efeito
a. É um estimador da magnitude do efeito populacional, sendo estimado em função do
problema.
b. Serve para expressar a diferença entre duas médias em unidades do desvio-padrão.
c. A magnitude do efeito pode ser interpretada como um valor z (score z associado à
diferença nas médias)
d. Ex: O género tem um efeito reduzido a médio nas diferenças de flexibilidade medida
pelo teste de sit-and-reach.
ME =

42
Valores “padronizados” para interpretar a ME:
C. ME = 0,20 Efeito pequeno ou reduzido
D. ME = 0,50 Efeito moderado
E. ME = 0,80 Efeito substancial (grande)
Pressupostos essenciais do t teste independente
1. Normalidade
a. Assume-se que a população donde provieram as amostras possui uma
distribuição normal para a variável em causa.
2. Aleatoriedade
a. Parte-se do princípio que as amostras foram seleccionadas de forma aleatória.
3. Escala da Variável
a. A variável tem que ser medida numa escala de intervalos ou de razão.
4. Homogeneidade das variâncias
a. Assume-se que as amostras possuem variâncias aproximadamente iguais (se a
amostragem foi aleatória, as diferenças nas variâncias amostrais devem-se a
erros amostrais). Em regra, a variância de um grupo não deve ser superior à
outra na razão de 2:1 (Sabe-se que o t teste é robusto a violações menores
deste pressuposto).

43
Resposta a teste t de diferença de médias
1) Definir as hipóteses estatísticas (hipótese alternativa e hipótese nula)
2) Escolher o teste estatístico apropriado à hipótese nula
3) Estabelecer o nível de significância
4) Leitura do quadro de resultados
Ex: Foi realizado um teste t de medidas independentes para averiguar as possíveis diferenças de médias
de abdominais das equipas do SLB e FCP. O resultado encontrado no teste foi de -1,2, que foi
necessariamente convertido no valor de prova (p) de 0,24. A probabilidade da hipótese nula ser
verdadeira é de 24%.
Assim sendo, como o valor de prova (0,24) foi superior ao nível de significância previamente
estabelecido (0,05), não há evidência estatística para rejeitar a hipótese nula.
(Assim sendo, como o valor de prova (0,01) foi inferior ao nível de significância (0,05), então a
probabilidade de ocorrência da hipótese nula é bastante reduzida, tendo nós evidência estatísticas para
a rejeitarmos.)
[Se nos tirarem o valor de prova da tabela de resultados, e se os intervalos de confiança não passarem
pelo valor de 0, então podemos rejeitar a hipótese nula.]
[Se nos tirarem o valor de prova e os intervalos de confiança da tabela de resultados, então teremos de
recorrer ao valor do tcrítico e o do tamostral, compará-los e tirarmos as devidas conclusões.]
Passos para o cálculo do t test de medidas independentes
1) Formulação de hipóteses
2) Cálculo do t amostral (ta)
a. Cálculo do erro-padrão da diferença de médias
3) Cálculo do t crítico (tc)
4) Identificar zonas de rejeição da hipótese nula
5) Cálculo do intervalo de confiança para a diferença de médias
6) Cálculo da magnitude da diferença
a. Conceito da variância explicada
b. Conceito da magnitude do efeito

44
Aula 11
Teste de hipóteses para a média de diferenças (medidas
dependentes)
Muitas vezes, estão envolvidas na questão duas amostras, as quais são relacionadas
uma com a outra – dependência amostral (r12 ≠ 0). Podemos, assim, ter dois tipos de situações
de dependência:
Delineamento de MEDIDAS REPETIDAS
o A sua investigação envolve um ANTES e um DEPOIS.
o Ex: Verificar o efeito de um programa de força explosiva na performance do salto em
altura de 15 atletas.
o
Delineamento de EMPARELHAMENTO
o Pretende remover o efeito de diferenças iniciais nos sujeitos para não contaminar o
resultado final.
o Temos dois grupos de sujeitos.
o Ex: Pretendia conhecer-se o efeito de um programa de actividade física na redução da
frequência cardíaca de repouso. Um grupo de sujeitos foi submetido ao programa e
outro grupo serviu de controlo. Passadas 10 semanas foram avaliadas as
consequências do programa.
Problema: Sujeitos diferiam na idade, sexo e hábitos tabágicos.
Solução: Emparelhar sujeitos do mesmo sexo, que não difiram mais de 4 anos
de idade e 7 cigarros por dia.
o Delineamento, só considerando os valores finais.
Matriz de informação

45
Quando as amostras são dependentes, o erro-padrão da diferença deve ser modificado para
considerar a circunstância de haver CORRELAÇÃO entre pares de observações, a modos que:
O aumento ou redução do erro padrão da média das diferenças DEPENDE da magnitude do
r12.
Se este aumenta, então o erro padrão da média das diferenças é pequeno.
Se este diminui, então o erro padrão da média das diferenças é grande.
Quando estudamos as hipóteses estatísticas com medidas dependentes, então a nossa
hipótese nula representar-se-á por: .
Se a médias das diferenças é altamente significativa, então este valor é diferente de zero,
dependendo do pressuposto para o qual estamos a estudar as amostras.
Temos de ter em atenção quanto ao facto de a hipótese alternativa vir a ser maior ou menor
que zero, com o cálculo a ser feito do fim para o início, ou do início para o fim.
A estrutura do teste de amostras dependentes é semelhante à do teste t independente:
Um método mais simples de cálculo – o método das diferenças -, diz-nos que o erro padrão da
média das diferenças:
.

46
Daí que:
~
Nos vários exercícios que iremos ter sobre este tema, é muito vulgar a
heterogeneidade de resultados nas respostas aos programas, ou seja, cada ser humano reage
de maneira diferente aos estudos que lhe são feitos.
Passos na resolução:
1. Tabela com cálculo das diferenças (∑D; ∑D2; )
2. Estabelecimento de hipóteses e valor do tcrítico
a. H0: µD = 0
b. H1: µD < 0
3. Conclusões (Podemos expressar os valores através do módulo)
a. Ex: Dado que ta = |1,98| > tc = |1,895| rejeita-se H0 a um α = 0.05. Os valores
evidenciados pelos sujeitos no final do programa são significativamente inferiores (em
média) ao do início do programa. Por outras palavras, o programa for eficaz.
b. Contudo, se α = 0.01, o tc é igual a 2,998. Nesta condição, o programa JÁ NÃO TINHA
SIDO eficaz!
c. Daqui a necessidade da maior ponderação no estabelecimento do valor de α.
d. Ex: Depois de emparelhar os sujeitos em função da idade, sexo e hábitos tabágicos, o
programa de exercício físico não promoveu uma redução média significativa na
frequência cardíaca de repouso.
A construção de um intervalo de confiança para µD segue a fórmula seguinte:
=
Ex: Com uma confiança de 95%, a verdadeira média das diferenças na alteração da % de gordura
corporal situa-se entre ≈- 4% e +0,4%. Dito de outra maneira: A verdadeira média da redução da gordura

47
corporal situa-se, em 95% dos casos, entre +0,4% e ≈- 4%. (Um incremento de 0,4% e uma redução de
4%).
Dado que o intervalo contém o ZERO, não se verificaram diferenças significativas entre os grupos e,
deste modo, não se espera qualquer alteração substancial na FCrepouso.
Uma forma interessante, e complementar, de interpretar é a partir da PERCENTAGEM de ALTERAÇÃO.
) x 100
Ex: Quando a diferença nas médias é relativizada ao valor médio inicial, a percentagem de alteração
verificou-se em -9,8%.
Muitas vezes, quando recorremos erradamente a um método de fórmulas independentes para
estudar o comportamento das variáveis dependentes, teremos de recorrer a outro
procedimento (ex: como ao procedimento das medidas repetidas), para que tenhamos
resultados concretos e mais próximos daquilo que desejamos.
Passos para o cálculo do t test de medidas repetidas
1) Formulação de hipóteses
2) Cálculo do t amostral
3) Cálculo do t crítico
4) Cálculo do intervalo de confiança para a diferença de médias
5) Cálculo da percentagem de alteração
Relativamente ao procedimento das medidas repetidas:
, onde r surge como factor de correcção, para eliminar a
dependência dos valores finais dos valores iniciais, estando os valores finais muito
correlacionados com os iniciais.

48
Aula 12
Teste de hipóteses para grupos independentes (k≥3). ANOVA I
Quando lidamos com k grupos ≥ 3, porque não efectuar, de forma sistemática, testes t distintos entre os
diferentes grupos?
Motivos:
O número possível de testes seria dado por K (K-1)/2. A partir de K=3, o número de
testes aumentaria substancialmente;
Ao reduzir a comparação a dois grupos de cada vez, haveria uma redução na potência
estatística de cada teste por não considerar a totalidade dos sujeitos;
Verifica-se um aumento do erro do tipo I à medida que aumenta o número de testes
“fraccionados”
1-(1-α)n
n – Número de pares de testes
Solução: Análise da Variância (ANOVA [Analysis of Variance])
- Classe ampla de técnicas
- O número de grupos independentes pode variar (k>2), mas só consideraremos uma
variável dependente.
Hipóteses:
H0 = µ1 = µ2 = … = µk
H1 = µi ≠µj
Lógica ANOVA a 1 factor
I. Grupos de sujeitos são distribuídos aleatoriamente pelos 3 grupos que serão
submetidos a 3 tratamentos distintos ou condições diferente.
II. A hipótese nula estabelece a ausência de diferença entre as 3 médias (a haver
diferença, tudo se deve a problemas de erro amostral)

49
III. Variação intra-grupo
a. Verifica-se VARIAÇÃO “interna”, sendo que esta é inerente a cada grupo. A
variância surge em torno de - os sujeitos não são todos iguais na variável
resposta.
b. Não reflecte diferenças causadas por diferentes tratamentos ou condições
c. (variância “livre” do efeito do tratamento
IV. Variação entre-grupos
a. As médias amostrais variam entre elas.
b. Se a hipótese nula é verdadeira, a variação entre médias dos diferentes
grupos é praticamente zero, isto é, irrelevante.
c. + efeito do tratamento
d. Quanto maior for a variação entre-grupos, maior será a probabilidade de
encontrarmos uma maior variação intra-grupo em cada grupo.
V. Teste F
a. Teste de validade da hipótese nula.
b. Espera-se, para rejeitar a hipótese nula, que o ratio F seja sempre maior que
1.
c. Calcula-se pela fracção:
d. Quando a hipótese nula é verdadeira, as variações intra-grupo e entre-grupos
são estimativas de variação irrelevante e inerente a cada grupo (σ2) e a
estatística F segue uma distribuição F em graus de liberdade associados ao
numerador e denominador.
Fórmulas Fundamentais
SQi =
SQe =
SQt =
S2
=
=
VARIAÇÃO INTRA-GRUPO
VARIAÇÃO ENTRE-GRUPOS
gli = ntotal - kgrupos

50
gle = kgrupos – 1
glt = ntotal - 1
Passos na resolução:
1. Definir hipóteses
2. Realizar testes F e outros cálculos necessários à resolução do exercício
3. Leitura e uso da tabela sumária da ANOVA I
4. Conclusões
Fórmulas de cálculo para a ANOVA I:
Teste de Tukey (HSD – Honest Significant Difference)
O facto do teste F evidenciar rejeição da hipótese nula não é, por si só, indicador da
localização das diferenças significativas no seio dos grupos. Para isso, depois de rejeitarmos a
hipótese nula, teríamos de recorrer a testes de múltipla comparação.
Sendo assim, o número de comparações possíveis dá-se pela expressão: K(K-1)/2

51
Já o valor crítico do HSD de Tukey é: HSD = q
Passos de cálculo:
1) Consultar o valor de q
2) Calcular o valor crítico de HSD
3) Construção de uma matriz de múltiplas comparações
4) Comparar cada diferença de médias com o valor crítico de HSD
a. Ex: Das múltiplas comparações possíveis, só se verificaram diferenças significativas
entre µ1 e µ2; µ1 e µ3. Há, pois, que rejeitar µ1 = µ2 e µ1 = µ3; Há que reter a H0: µ2 = µ3.
5) Quando o número de sujeitos em cada grupo é divergente, usa-se uma média harmónica, ñ, em
vez de n:
a. ñ =
Pressupostos da ANOVA I:
I. As k amostras devem ser independentes;
II. Em cada uma das k populações deve observar-se normalidade na distribuição da variável;
III. Ainda que possuam médias diferentes, assume-se que as populações possuem a mesma
variância – Pressuposto da homogeneidade de variâncias.
A magnitude do efeito, a mais simples é η2:
η2 =
Uma outra estatística é a variância explicada:
ω2 = –

52
Procedimento para as respostas aos testes de hipóteses:
1) Definir as hipóteses estatísticas;
2) Qual o teste estatístico que melhor se ajusta àquele problema;
3) Estabelecer o nível de significância;
a. Valor crítico que nos vai ajudar, no fim, a rejeitar ou não a hipótese nula;
b. Probabilidade de rejeitar erradamente a hipótese nula, porque está é
verdadeira.
4) Fazer os cálculos ou leitura do output.
Acima e abaixo da mediana temos 50%, em cada, dos resultados obtidos.
Para uma média ser igual a tal valor, e se temos quatro “buracos” livres para escolhermos um
número aleatoriamente, o último número só tem um lugar para entrar – graus de liberdade.
ANOVA
Baseia os seus cálculos na análise da variância.
Estatística
Estatística Descritiva
Medidas de Tendência Central
Média
Moda
Mediana Medidas de
Dispersão
Variância
Desvio-
padrão
Amplitude
Valor mínimo
Valor máximo
Medidas de Orde
m
Percentil
Estatística Inferencial
Estimativa de
Parâmetros
Pontual
Intervalar
(Intervalo de
confiança)
Testes de
Hipóteses
Comparar médias
1 Amostr
a
2 Amostra
s Independentes
1 Amostra em 2 Momentos de Avaliação
+2 Amostras Independentes (ANOVA)

53
Poderá existir variação:
Entre-grupos
Intra-grupo
Se o valor de F for igual a 1, os grupos são iguais.
Se o valor de F foi igual a 10 (>1), a variância entre-grupos é 10x a variância intra-
grupos, ou seja, há mais variação entre eles do que dentro deles.
Se o valor de F for menor que 1, então há variação dentro dos grupos que entre eles.
Sig. Ou p – Probabilidade da hipótese nula ser verdadeira.
Valor de prova – Probabilidade de eu obter, por acaso, o valor que encontrei no teste ou outro
ainda mais extremo do que este, assumindo que a hipótese nula é verdadeira.
Hipótese alternativa na ANOVA
Ver sig. Ou p nas tabelas.
Basta mostrar que duas médias são diferentes, não é necessário serem todas
diferentes.
Passos para o cálculo da ANOVA grupos independentes
1) Formulação das hipóteses
2) Cálculo da ANOVA
a. Somatório dos quadrados intragrupo
b. Somatório dos quadrados intergrupo
c. Somatório dos quadrados total
3) Cálculo da variância intragrupo e intergrupo
4) Cálculo de F

54
Se Fa for maior que Fc, então rejeita-se a hipótese nula.
Para sabermos em que grupos existe a tal diferença, recorremos ao Teste de Múltipla
Comparação a posteriori (TUKEY).
Passos para o cálculo de múltiplas comparações
1) Encontrar o valor de q (tabela E)
2) Calcular o valor crítico de HSD
3) Construir a matriz de múltiplas comparações
4) Comparar cada diferença de médias com o valor crítico de HSD