universidade federal do sul e sudeste do parÁ … · de dados, gerando aprendizado e dados...
TRANSCRIPT

UNIVERSIDADE FEDERAL DO SUL E SUDESTE DO PARÁ
INSTITUTO DE GEOCIÊNCIAS E ENGENHARIAS
Faculdade de Computação e Engenharia Elétrica
Bacharelado em Sistemas de Informação
GILVAN PEREIRA MARTINS JUNIOR
FUNDAMENTOS PARA DEFINIÇÃO DE TÉCNICAS DE MINERAÇÃO
DE DADOS BASEADA EM DOMÍNIO
MARABÁ - PA
2017

GILVAN PEREIRA MARTINS JUNIOR
FUNDAMENTOS PARA DEFINIÇÃO DE TÉCNICAS DE MINERAÇÃO
DE DADOS BASEADA EM DOMÍNIO
Trabalho de Conclusão de Curso, apresentado à
Universidade Federal do Sul e Sudeste do Pará,
como parte dos requisitos necessários para
obtenção do Título de Bacharel em Sistemas de
Informação.
Orientador:
Prof. Me. Haroldo Gomes Barroso Filho
MARABÁ - PA
2017

Dados Internacionais de Catalogação-na-Publicação (CIP)
Biblioteca Josineide da Silva Tavares da UNIFESSPA. Marabá, PA
Martins Junior, Gilvan Pereira
Fundamentos para definição de técnicas de mineração de dados
baseada em domínio / Gilvan Pereira Martins Junior ; orientador,
Haroldo Gomes Barroso Filho. — 2017.
Trabalho de Conclusão de Curso (Graduação) - Universidade Federal
do Sul e Sudeste do Pará, Campus Universitário de Marabá, Instituto de
Geociências e Engenharias, Faculdade de Computação e Engenharia
Elétrica, Curso de Bacharelado em Sistemas de Informação, Marabá, 2017.
1. Mineração de dados (Computação). 2. Linguagem de programação
de domínio específico (Computadores). 3. Ferramentas. I. Barroso Filho,
Haroldo Gomes, orient. II. Universidade Federal do Sul e Sudeste do Pará.
III. Título.
CDD: 22. ed.: 006.312
Elaborado por Alessandra Helena da Mata Nunes
Bibliotecária-Documentalista CRB2/586


Dedico aos meus queridos pais Gilvan Pereira Martins e Maria Helena da Silva Martins.

Agradecimentos
Agradeço primeiramente a Deus, por ser essencial em minha vida, criador do meu
destino, socorro presente na hora da angústia, pela saúde e força para superar as dificuldades.
À minha família, por sempre acreditar em mim.
Aos meus pais, agradeço sinceramente a Deus por existirem e dar à luz a minha vida, e
sempre me motivarem com o exemplo de vida de vocês. Que em nenhum momento, mesmo
nas dificuldades, hesitaram em me dar um ensino de qualidade, e por mostrar que o caminho
do estudo sempre me traria oportunidades na vida.
À minha mãe Maria Helena, seu cuidado, dedicação, amor e carinho foi que me deram
а esperança para seguir esta caminhada.
Ao meu pai Gilvan Pereira, que apesar de todas as dificuldades me fortaleceu е que para
mim foi muito importante.
A meu irmão Enzo Silva, obrigado por compreender todos os momentos em que tive
que deixar de jogar ou assistir séries/animes com você, para me dedicar aos trabalhos, provas e
por fim esta monografia.
À Amanda Soares, obrigado pelo amor, carinho, а paciência е por sua capacidade de me
trazer paz na correria de cada semestre.
A todos os meus amigos, em especial ao grupo “LoopInfinitoDaZueira”, pelas alegrias,
tristezas е dores compartilhas. Amigos que ganhei na faculdade, sem vocês nada disso seria
possível, pois a cada momento sempre me motivaram a seguir em frente, sempre estavam ao
meu lado desde o primeiro trabalho em grupo e até a reta final (a produção desta monografia)
estávamos juntos. Agradeço as suas sinceras amizades, e sempre levarei as experiências vividas
no decorrer da minha vida.
Aos professores da FACEEL pelos ensinamentos passados durante a minha graduação.
A todos aqueles que de alguma forma estiveram е estão próximos de mim, fazendo esta
vida valer cada vez mais а pena.
Meu muitíssimo obrigado!

“O futuro pertence àqueles que acreditam na beleza de seus sonhos”
Eleanor Roosevelt

Resumo
O presente trabalho demonstra os conceitos, tarefas, algumas áreas de aplicação, técnicas,
ferramentas que são utilizados pela Mineração de Dados. As etapas do processo de mineração
de dados são detalhadas e algumas tarefas e técnicas utilizadas durante o processo são expostas.
Nesta monografia são apresentados alguns critérios para a escolha de técnicas e ferramentas de
mineração de dados. Além de demonstrar alguns exemplos/questionamentos de como o usuário
poderá escolher da melhor maneira a técnica ou ferramenta de mineração de dados.
Palavras-chave: Mineração de dados; Técnicas; Ferramentas; Critérios de escolha.

Abstract
This study shows concepts, tasks, some areas of application, techniques and tools that are used
by data mining. Furthermore, the steps in the data mining process are detailed and some tasks
and techniques used, during the process, are exposed. Therefore, in this monograph some
elements are available for choosing techniques and tools in data mining. In addition to
demonstrating some examples/questions about how the user can choose the best technique or
tool of data mining.
Keywords: Data mining; Techniques; Tools; Selection criteria.

Lista de figuras
Figura 1 - Representação do Processo de KDD ......................................................................... 3
Figura 2 - Fases do CRISP-DM Process Model ......................................................................... 7
Figura 3 - Exemplo de Regra de Associação ............................................................................ 14
Figura 4 - Exemplo de Árvore de Decisão ............................................................................... 15
Figura 5 - Arquitetura do RBC ................................................................................................. 17
Figura 6 - Exemplo de Algoritmo Genético ............................................................................. 18
Figura 7 - Modelo de RNA ....................................................................................................... 20
Figura 8 - Arquitetura de mineração de imagens dirigida à informação .................................. 24
Figura 9 - Arquitetura DDM hierárquica baseada no agrupamento de fonte de dados ............ 25
Figura 10 - Arquitetura básica do DDM ................................................................................... 27
Figura 11 – Estrutura para avaliação das ferramentas de mineração de dados ........................ 33

Lista de tabelas
Tabela 1 - Tarefas realizadas por Técnicas de Mineração de Dados........................................ 13
Tabela 2 - Técnicas de Mineração de Dados ............................................................................ 21
Tabela 3 - Características de dados .......................................................................................... 29
Tabela 4 – Características gerais da ferramenta ....................................................................... 31
Tabela 5 – Conectividade de banco de dados da ferramenta .................................................... 32
Tabela 6 – Características de mineração de dados da ferramenta ............................................ 32
Tabela 7 - Critérios de desempenho computacional ................................................................. 35
Tabela 8 - Critérios de funcionalidade ..................................................................................... 35
Tabela 9 - Critérios de suporte de atividades principais de uma organização ou sistema ........ 36
Tabela 10 - Critérios de usabilidade ......................................................................................... 37

Lista de abreviaturas e siglas
AG Algoritmos Genéticos
CRISP-DM CRoss Industry Standard Process for Data Mining
DCPU Data Mining Central Processing Unit
DDM Distributed Data Mining
DGPU Data Mining Group Processing Unit
ER Entidade Relacionamento
KDD Knowledge Discovery in Databases
LDML Local Data Mining Layer
OWL Web Ontology Language
RBC Raciocínio Baseado em Casos
RNA Redes Neurais Artificiais
SDML Single Data Mining Layer
SWSN Sporadic Wireless Sensor Network

Sumário
1 INTRODUÇÃO ............................................................................................................. 1
1.1 Objetivo principal ......................................................................................................... 2
1.1.1 Objetivo específico ......................................................................................................... 2
1.2 Estrutura do trabalho ................................................................................................... 2
2 MINERAÇÃO DE DADOS ......................................................................................... 3
2.1 Fases da mineração de dados ....................................................................................... 6
2.1.1 Entendimento do Negócio (Business Understanding) .................................................... 7
2.1.2 Seleção dos Dados (Data Understanding) ..................................................................... 7
2.1.3 Limpeza dos Dados (Data Preparation) ........................................................................ 8
2.1.4 Modelagem dos Dados (Modeling) ................................................................................ 8
2.1.5 Avaliação do processo (Evaluation) ............................................................................... 8
2.1.6 Execução (Deployment) .................................................................................................. 9
2.2 Tarefas da mineração de dados ................................................................................... 9
2.2.1 Associação ...................................................................................................................... 9
2.2.2 Classificação ................................................................................................................. 10
2.2.3 Estimativa ..................................................................................................................... 11
2.2.4 Segmentação ................................................................................................................. 11
2.2.5 Sumarização .................................................................................................................. 12
2.2.6 Tabela de tarefas de mineração de dados ..................................................................... 12
2.3 Técnicas da mineração de dados ............................................................................... 13
2.3.1 Descoberta de regras de associação .............................................................................. 14
2.3.2 Árvores de decisão ........................................................................................................ 14
2.3.3 Raciocínio baseado em casos (RBC) ............................................................................ 16
2.3.4 Algoritmos genéticos (AG) ........................................................................................... 17
2.3.5 Redes neurais artificiais (RNA) .................................................................................... 19
2.3.6 Tabela de técnicas de mineração de dados ................................................................... 21
2.4 Áreas de aplicação da mineração de dados .............................................................. 22
3 TRABALHOS CORRELATOS ................................................................................ 23
3.1 Mineração de Dados em Imagens: da Arquitetura à Ontologia ............................. 23
3.2 A hierarchical distributed data mining architecture .................................................. 24
3.3 A reliable and intelligent protocol for distributed data mining architecture in sporadic
wireless sensor network ............................................................................................... 26
4 ESCOLHENDO A TÉCNICA DE MINERAÇÃO DE DADOS APROPRIADA 28
4.1 Critérios na escolha de técnicas de mineração de dados ......................................... 29
5 ESCOLHENDO A FERRAMENTA DE MINERAÇÃO DE DADOS
APROPRIADA ........................................................................................................... 31
5.1 Critérios na escolha de ferramentas de mineração de dados ................................. 34

6 CONSIDERAÇÕES FINAIS ..................................................................................... 39
REFERÊNCIAS....................................................................................................................40

1
1 INTRODUÇÃO
Atualmente, um grande volume de dados está sendo armazenado, e esses dados são
essenciais para obter as diversas informações que necessitamos.
Com este volume de dados crescendo rapidamente e diariamente, é importante
responder uma questão: O que fazer com os dados armazenados? As técnicas tradicionais de
exploração de dados não são mais adequadas para tratar a grande maioria dos bancos de dados
(CAMILO e SILVA, 2009).
Com este propósito em mente, foi sugerido a criação, na década de 80, da Mineração de
Dados. “A mineração de dados é uma das tecnologias mais promissoras da atualidade”, segundo
Camilo e Silva (2009). Uma das razões de se ter sucesso é o fato de dezenas, e muitas vezes
centenas de milhões de reais serem gastos pelas companhias na coleta dos dados e, no entanto,
nenhuma informação útil é identificada (CAMILO e SILVA, 2009). Em seu livro, Han et al.
(2011) refere-se a esta ocasião como "rico em dados, pobre em informação".
Utilizando a mineração de dados, torna-se possível avaliar dados comportamentais, seja
de forma automática ou semiautomática, adquirindo conhecimento que estava “oculto” na base
de dados, gerando aprendizado e dados complementares que podem influenciar no
desenvolvimento de estratégias na organização, além de permitir uma maior agilidade no
processo de tomada de decisão por parte dos gestores. Esta tecnologia está sendo usada para
descrever características do passado, assim como predizer tendências para o futuro. Sua
utilização permite avanços tecnológicos e descobertas científicas (AMORIM, 2006; SFERRA
e CORRÊA, 2003).
Chiara (2003) enfatiza que para conseguir utilizar a Mineração de Dados, é necessário
que se tenha uma coleção de dados disponível. Entretanto, o problema é conseguir dados
relevantes para se extrair deles conhecimento potencialmente útil.
A utilização de técnicas e ferramentas que auxiliem na busca, seleção e extração de
informações relevantes em grandes bases de dados, tem recebido cada vez mais importância
nas organizações, uma vez que estas ferramentas têm como principal objetivo minimizar o
trabalho manual e a disponibilização de informações corretas aos gestores (PASTA, 2011).

2
1.1 Objetivo principal
O objetivo principal desta monografia é estudar, compreender e utilizar a descoberta de
conhecimento e a mineração de dados, assim como as suas tarefas, técnicas e ferramentas, para
a obtenção de conhecimento. Além de definir alguns parâmetros para a escolha de técnicas e
ferramentas de mineração de dados.
1.1.1 Objetivo específico
Alguns objetivos específicos serão abordados no decorrer do trabalho:
Demonstrar alguns critérios para a escolha correta de alguma técnica de mineração
de dados.
Demonstrar alguns critérios para a escolha correta de alguma ferramenta de
mineração de dados.
1.2 Estrutura do trabalho
Além deste capítulo introdutório, o trabalho está organizado da seguinte maneira:
Capítulo 2: apresenta a Mineração de dados, seus conceitos, fases, tarefas e técnicas.
Capítulo 3: apresenta os trabalhos correlatos, que norteiam a pesquisa.
Capítulo 4: apresenta os critérios para escolha da técnica de mineração de dados mais
apropriada para seu problema.
Capítulo 5: apresenta os critérios para escolha da ferramenta de mineração de dados
mais apropriada para seu problema.
Capítulo 6: apresenta as considerações finais.
Por fim, são listadas as referências utilizadas.

3
2 MINERAÇÃO DE DADOS
A nível mundial há um grande aumento do número de usuários da Internet e, em
consequência, também há uma disponibilidade de grandes quantidades de informações novas
na web (SANTOS, 2014).
Para poder fazer a extração dessas informações, torna-se necessário utilizar um processo
conhecido como Knowledge Discovery in Databases (KDD ou Descoberta de Conhecimento
em Base de Dados). A definição de KDD é dada por Fayyad et al. (1996), é a seguinte: “é um
processo, não trivial, de extração de informações implícitas, previamente desconhecidas e
potencialmente úteis, a partir dos dados armazenados em um banco de dados”.
Figura 1 - Representação do Processo de KDD
Fonte: Fayyad et al., 1996.
De acordo com Castanheira (2008), iniciando um processo de KDD, a primeira etapa é
um agrupamento de forma organizada dos dados (seleção). A segunda etapa de limpeza dos
dados, acontece através de um pré-processamento dos dados, visando ajustá-los aos algoritmos
que serão utilizados. Para promover o uso das técnicas de mineração de dados, os dados podem
passar por uma transformação que os armazena adequadamente em arquivos para serem lidos
pelos algoritmos. É a partir deste momento que se chega à fase de mineração de dados, assim
começando a escolha das ferramentas (técnicas, algoritmos) a ser utilizado. Diante da técnica
ou algoritmo a ser utilizado, será criado um arquivo com as descobertas, onde o mesmo vai
poder ser interpretado, originando as conclusões que fornecem o conhecimento da base de
dados.
Os autores Castanheira (2008) e Dos Santos Silva (2004), descrevem as etapas do KDD,
da seguinte forma:

4
Definição do tipo de conhecimento a descobrir: o que pressupõe uma compreensão
do domínio da aplicação bem como do tipo de decisão que tal conhecimento pode
contribuir para melhorar.
Seleção: selecionar um conjunto de dados, ou focar num subconjunto, onde a
descoberta deve ser realizada. Levando em consideração que a etapa de seleção é
crítica, pois os dados podem não estar disponíveis em formato apropriado para serem
utilizados no processo de KDD.
Pré-processamento: operações básicas tais como remoção de ruídos quando
necessário, coleta da informação necessária para modelar ou estimar ruído, escolha
de estratégias para manipular campos de dados ausentes, formatação de dados de
forma a adequá-los à ferramenta de mineração.
Transformação: localização de características úteis para representar os dados
dependendo do objetivo da tarefa, visando a redução do número de variáveis e/ou
instâncias a serem consideradas para o conjunto de dados, bem como o
enriquecimento semântico das informações.
Mineração de dados (Data Mining): selecionar os métodos a serem utilizados para
localizar padrões nos dados, seguida da efetiva busca por padrões de interesse numa
forma particular de representação ou conjunto de representações; busca pelo melhor
ajuste dos parâmetros do algoritmo para a tarefa em questão.
Avaliação: avaliar de forma criteriosa os resultados proporcionando uma
interpretação para o modelo, de onde se extrai o conhecimento.
Implantação do conhecimento descoberto: incorporar este conhecimento à
performance do sistema, ou documentá-lo e reportá-lo às partes interessadas.
Segundo Damasceno (2005), no processo de KDD é encontrado em uma das fases, a
aplicação de técnicas para a identificação e extração de informações relevantes ocultas nos
dados. Estas técnicas são conhecidas como Mineração de Dados por identificarem padrões e
informações consideráveis para o negócio, sendo assim, a procura de informações que se
tornam relevantes.
Segundo Amorim (2006), muitas são as técnicas utilizadas, porém a mineração de dados
ainda é mais uma arte do que uma ciência. O sentimento do especialista não pode ser
dispensado, mesmo que as mais sofisticadas técnicas sejam utilizadas.

5
As principais finalidades da mineração de dados são descobrir relacionamentos
entre dados e fornecer informações para que possam prever as tendências futuras baseadas no
passado.
A mineração de dados pode ser aplicada de duas formas: como um processo de
verificação e como um processo de descoberta (GROTH, 1998 apud DIAS, 2008). No processo
de verificação, o usuário indica uma hipótese sobre a relação entre os dados e tenta validar
utilizando-se de técnicas como análises estatística e multidimensional sobre um banco de dados
contendo informações passadas. No processo de descoberta não é realizada nenhuma
proposição precipitada. Esse processo usa técnicas, tais como descoberta de regras de
associação, árvores de decisão, algoritmos genéticos e redes neurais.
De acordo com Carvalho (2005), existem alguns motivos para o grande uso da
Mineração de Dados nos dias atuais, que são as seguintes:
● O volume de dados disponível atualmente é enorme: Mineração de Dados é uma
técnica que se aplica a grandes massas de dados, pois necessita disto para calibrar
seus algoritmos e extrair dos dados conclusões confiáveis. Estes dados são passíveis
de análise por mineração;
● Os dados estão sendo organizados: Com a tecnologia do dataware house, os dados
de várias fontes estão sendo organizados e padronizados de forma a possibilitar sua
organização dirigida para o auxílio à decisão. As técnicas de mineração de dados
necessitam de bancos de dados limpos, padronizados e organizados;
● Os recursos computacionais estão cada vez mais potentes: A mineração de dados
necessita de muitos recursos computacionais para operar seus algoritmos sobre
grandes quantidades de dados. O aumento da potência computacional, devido ao
avanço tecnológico e à queda dos preços dos computadores, facilita o uso da
mineração de dados atualmente. O avanço da área de banco de dados, construindo
bancos de dados distribuídos, também auxiliou em muito à mineração de dados;
● A competição empresarial exige técnicas mais modernas de decisão: As empresas
da área de finanças, telecomunicações e seguro experimentam a cada dia mais
competição. Como estas empresas sempre detiveram em seus bancos de dados uma
enorme quantidade de informação, é natural que a mineração de dados tenha se
iniciado dentro de seus limites. Atualmente, outras empresas buscam adquirir dados
para analisar melhor seus caminhos futuros através dos sistemas de apoio à decisão.
Para empresas de serviços, a aquisição de dados é importante, pois precisam saber

6
que serviço oferecer a quem. Para outras empresas, até a venda das informações pode
ser um produto; e
● Programas comerciais de mineração de dados já podem ser adquiridos: As
técnicas de mineração de dados são conhecidas da Inteligência Artificial. Alguns
pacotes já podem ser encontrados no comércio, contendo algumas destas técnicas.
2.1 Fases da mineração de dados
A CRISP-DM (CRoss Industry Standard Process for Data Mining), é um projeto com
a intenção de padronizar as etapas da mineração de dados. Amorim (2006) cita que, este projeto
desenvolveu um modelo de processo de mineração de dados industrial e livre de ferramenta.
Começando pelos embrionários processos de descoberta de conhecimento usados nos primeiros
projetos de mineração de dados e respondendo diretamente aos requerimentos do usuário, esse
projeto definiu e validou um processo de mineração de dados que é aplicável em diversos
setores da indústria. Essa metodologia torna projetos de mineração de dados de larga escala
mais rápidos, mais baratos, mais confiáveis e mais gerenciáveis. Até mesmo projetos de
mineração de dados de pequena escala se beneficiam com o uso do CRISP-DM. O modelo
CRISP, atualmente, é uma referência para que seja desenvolvido um plano de integração para
a descoberta de conhecimento.
Amorim (2006) observa que na Figura 2, o ciclo de vida de um projeto de mineração de
dados, que o mesmo consiste de 6 (seis) fases. A sequência de fases não é obrigatória, ocorrendo
a transição para diferentes fases, dependendo do resultado de cada fase, e que etapa particular
de cada fase precisa ser executada em seguida. As setas indicam as mais importantes e mais
frequentes dependências entre as fases.

7
Figura 2 - Fases do CRISP-DM Process Model
Fonte: Baseado em The CRISP-DM Consortium, 2000.
A CRISP-DM (The CRISP-DM Consortium, 2000), define suas fases da seguinte forma:
2.1.1 Entendimento do Negócio (Business Understanding)
Essa fase inicial tem o foco no entendimento do negócio que visa obter conhecimento
sobre os objetivos do negócio e seus requisitos, e então converter esse conhecimento em uma
definição de um problema de mineração de dados, e um plano preliminar designado para
alcançar esses objetivos.
2.1.2 Seleção dos Dados (Data Understanding)
Consiste no entendimento dos dados, que visa à familiarização com o banco de dados
pelo grupo de projeto, utilizando-se de conjuntos de dados "modelo". Uma vez definido o
domínio sobre o qual se pretende executar o processo de descoberta, o próximo passo é
selecionar e coletar o conjunto de dados ou variáveis necessárias.
Essa fase se inicia com uma coleta inicial de dados, e com procedimentos e atividades
visando a familiarização com os dados, para identificar possíveis problemas de qualidade, ou
detectar subconjuntos interessantes para formar hipóteses.

8
2.1.3 Limpeza dos Dados (Data Preparation)
A fase de preparação de dados consiste na preparação dos dados que visa a limpeza,
transformação, integração e formatação dos dados da etapa anterior. É a atividade pela qual os
ruídos, dados estranhos ou inconsistentes são tratados. Esta fase abrange todas as atividades
para construir o conjunto de dados final (dados que serão alimentados nas ferramentas de
mineração), a partir do conjunto de dados inicial.
2.1.4 Modelagem dos Dados (Modeling)
Fase que consiste na modelagem dos dados, a qual visa a aplicação de técnicas de
modelagem sobre o conjunto de dados preparado na etapa anterior.
Nessa fase, várias técnicas de modelagem são selecionadas e aplicadas, e seus
parâmetros são calibrados para se obter valores otimizados. Geralmente, existem várias técnicas
para o mesmo tipo de problema de mineração. Algumas técnicas possuem requerimentos
específicos na forma dos dados. Consequentemente, voltar para a etapa de preparação de dados
é frequentemente necessário.
A maioria das técnicas de mineração de dados são baseadas em conceitos de
aprendizagem de máquina, reconhecimento de padrões, estatística, classificação e
clusterização.
2.1.5 Avaliação do processo (Evaluation)
A avaliação do processo visa garantir que o modelo gerado atenda às expectativas da
organização. Os resultados do processo de descoberta do conhecimento podem ser mostrados
de diversas formas. Porém, estas formas devem possibilitar uma análise criteriosa para
identificar a necessidade de retornar a qualquer um dos estágios anteriores do processo de
mineração.
Nesta etapa se construiu um modelo que parece de alta qualidade, de uma perspectiva
da análise de dados. Antes de prosseguir, é importante avaliar mais detalhadamente o modelo,
e rever as etapas executadas para construir o modelo, para se certificar de que ele conseguirá
alcançar os objetivos de negócio.

9
Deve se determinar se houve algum importante objetivo do negócio que não foi
suficientemente alcançado. No fim desta fase, uma decisão sobre o uso dos resultados da
mineração deve ser tomada.
2.1.6 Execução (Deployment)
Esta fase consiste na definição das fases de implantação do projeto de Mineração de
Dados.
A criação do modelo não é o fim do projeto. Mesmo se a finalidade do modelo for
apenas aumentar o conhecimento dos dados, o conhecimento ganho necessita ser organizado e
apresentado em uma maneira que o cliente possa usar. Dependendo das exigências, a fase de
execução pode ser tão simples quanto a geração de um relatório, ou tão complexo quanto
executar processos de mineração de dados repetidamente.
Em muitos casos será o cliente, não o analista dos dados, que realizará as etapas da
execução. Entretanto, mesmo se o analista não se encarrega da execução é importante que ele
faça o cliente compreender que medidas deverão ser tomadas a fim de empregar efetivamente
os modelos criados.
2.2 Tarefas da mineração de dados
De acordo com Carvalho (2005); De Amo (2004) e Dias (2008) existem 5 (cinco) tipos
de tarefas comumente utilizadas para a mineração de dados, que são: classificação, estimativa,
associação, segmentação e sumarização.
2.2.1 Associação
Tem como objetivo discernir padrões de ocorrência simultânea de determinados eventos
nos dados em análise.
Definir que fatos ocorrem ao mesmo tempo com probabilidade razoável ou que itens de
uma massa de dados estão presentes juntos com uma certa chance.
Na mineração de dados são comuns as tarefas de associação em:

10
Determinar que tipos de produtos costumam ser comprados juntos em um
supermercado.
Determinar os casos onde um novo medicamento pode apresentar efeitos colaterais;
As regras de associação são comumente utilizadas por esta tarefa.
2.2.2 Classificação
Segundo Amorim (2006), a classificação é uma das mais utilizadas tarefas de mineração
de dados, meramente porque é uma das mais realizadas tarefas humanas no auxílio à
compreensão do ambiente em que se vive.
As pessoas estão sempre classificando o que nota em sua volta, criando classes de
relações humanas distintas e dando a cada classe uma forma diferente de tratamento.
A tarefa de classificar geralmente exige a comparação de um objeto ou dado com outros
dados ou objetos que supostamente pertencem às classes anteriormente definidas. Para
comparar dados ou objetos utiliza-se uma métrica ou forma de medida de diferenças entre eles.
Em um processo de mineração de dados, a classificação está especificamente
voltada à atribuição de uma das classes pré-definidas pelo analista a novos fatos ou
objetos submetidos à classificação. Essa tarefa pode ser utilizada tanto para
entender dados existentes quanto para prever como novos dados irão se comportar
(EURIDITIONHOME, 2004 apud AMORIM, 2006).
Na mineração de dados são comuns as tarefas de classificação em:
Empréstimo bancário de baixo, médio ou alto risco;
Transações financeiras como legais, ilegais ou suspeitas em sistemas de fiscalização
do mercado financeiro;
Esclarecer pedidos de seguros fraudulentos;
De ações da bolsa de valores com lucros potenciais baixos, médios e altos.
Identificar a melhor forma de tratamento para um cliente;
Os algoritmos ou técnicas que normalmente a utilizam são as árvores de decisões e redes
neurais.

11
2.2.3 Estimativa
Ao contrário da classificação, a tarefa de estimativa está associada a respostas contínuas.
Estimar algum índice é definir seu valor mais aceitável diante de dados do passado ou de dados
de outros índices semelhantes sobre os quais se tem conhecimento.
Simplesmente é para determinar da melhor forma possível um valor, tendo como base
outros valores de situações semelhantes.
Na mineração de dados são comuns as tarefas de estimativa em:
Estimar a probabilidade de que um paciente morrerá baseando-se nos resultados de
um conjunto de diagnósticos médicos;
Estimar a pressão ideal de um paciente baseando-se na idade, sexo e massa corporal;
Estimar a quantia a ser gasta por uma família de quatro pessoas durante a volta às
aulas;
Prever a demanda de um consumidor para um novo produto.
Os algoritmos ou técnicas que normalmente a utilizam são as redes neurais.
2.2.4 Segmentação
A segmentação é normalmente uma tarefa preliminar, utilizada quando não se tem muita
informação sobre os dados. Visa formar grupos de objetos ou elementos mais homogêneos
entre si.
Pode ser estabelecido previamente um número de grupos a ser formado, ou então se
pode admitir ao algoritmo de agrupamento uma livre associação de unidades, de forma que a
quantidade de grupos resultante seja conhecida somente ao final do processo. Os grupos ou
classes são construídos com base na semelhança entre os elementos, cabendo ao analisador das
classes resultantes avaliar se estas significam algo útil.
Então, segmentar um mercado seria uma típica análise de agrupamentos onde
consumidores são reunidos em classes representantes dos segmentos deste mercado.
Na mineração de dados são comuns as tarefas de segmentação em:
Agrupar os clientes por região do país;
Classificação de documentos da Web;

12
Clientes com comportamento de compra similar.
Os algoritmos genéticos e redes neurais costumam ser aplicados a esta tarefa.
2.2.5 Sumarização
Segundo Fayyad et al. (1996), a tarefa de sumarização envolve métodos para encontrar
uma descrição compacta para um subconjunto de dados. A utilização da sumarização para
facilitar o entendimento dos dados, é uma estratégia muito usual que facilita e identifica
inúmeras características nos dados do usuário.
Na mineração de dados são comuns as tarefas de sumarização em:
Derivar regras de síntese.
Tabular o significado e desvios padrão para todos os itens de dados;
Os algoritmos genéticos costumam ser aplicados a esta tarefa.
2.2.6 Tabela de tarefas de mineração de dados
Na tabela 1, está representado de forma resumida as tarefas de mineração de dados
apresentadas anteriormente.

13
Tabela 1 - Tarefas realizadas por Técnicas de Mineração de Dados
TAREFA DESCRIÇÃO EXEMPLOS
Associação Usado para reconhecer padrões de
ocorrência simultânea de determinados
eventos nos dados em análise.
Determinar que tipos de produtos costumam ser
comprados juntos em um supermercado;
Determinar os casos onde um novo medicamento
pode apresentar efeitos colaterais.
Classificação
A tarefa de classificar geralmente exige
a comparação de um objeto ou dado
com outros dados ou objetos que
supostamente pertencem às classes
anteriormente definidas.
Empréstimo bancário de baixo, médio ou alto
risco;
Transações financeiras como legais, ilegais ou
suspeitas em sistemas de fiscalização do mercado
financeiro;
Esclarecer pedidos de seguros fraudulentos.
Estimativa
Determina da melhor forma possível um
valor, tendo como base outros valores
de situações semelhantes.
Estimar a probabilidade de que um paciente
morrerá baseando-se nos resultados de um
conjunto de diagnósticos médicos;
Prever a demanda de um consumidor para um
novo produto.
Segmentação Visa formar grupos de objetos ou
elementos mais homogêneos entre si.
Agrupar os clientes por região do país;
Classificação de documentos da Web;
Clientes com comportamento de compra similar.
Sumarização
Envolve métodos para encontrar uma
descrição compacta para um
subconjunto de dados.
Derivar regras de síntese;
Tabular o significado e desvios padrão para todos
os itens de dados.
Fonte: Adaptado de Dias, 2008.
2.3 Técnicas da mineração de dados
Harrison (1998 apud Dias, 2008) afirma que não há uma técnica que resolva todos os
problemas de mineração de dados.
Cada técnica e algoritmo existente serve para propósitos diferentes, sendo assim, cada
um oferece suas vantagens e desvantagens ao usuário. O costume com a utilização das técnicas
é necessário para facilitar a escolha de uma delas de acordo com os problemas apresentados.
A seguir serão apresentadas algumas técnicas e algoritmos de mineração de dados que
são comumente utilizadas.

14
2.3.1 Descoberta de regras de associação
As regras de associação trazem como princípio básico descobrir elementos que
implicam na presença de outros elementos em uma mesma transação, ou seja, descobrir
relacionamentos ou padrões frequentes entre conjuntos de dados.
Normalmente, este tipo de técnica representa padrões existentes em transações
armazenadas. Podemos dar como exemplo, a partir de uma base de dados, na qual se tem alguns
itens adquiridos por clientes, poderia gerar a seguinte regra: {camisa, calça} → {sapato}, a qual
indica que o cliente que compra camisa e calça, com um certo grau de certeza, compra também
sapato. O grau de certeza de uma regra é definido por dois índices: o fator de suporte e o fator
de confiança.
De acordo com Dias (2008), uma regra de associação tem como forma geral a expressão
X1 ^ ... ^ Xn → Y [C,S], onde X1, ..., Xn são itens que antecipam a ocorrência de Y com um
grau de confiança C e com um suporte mínimo de S e “^” denota um operador de conjunção
(AND).
Figura 3 - Exemplo de Regra de Associação
Fonte: Extraído de www.google.com.br (https://goo.gl/sBsa0E)
Como exemplos de algoritmos que implementam regras de associação tem-se: Apriori,
AprioriTid, AprioriHybrid, AIS, SETM e DHP.
2.3.2 Árvores de decisão
Segundo Castanheira (2008) as árvores de decisão são representações simples do
conhecimento e um meio eficiente de construir classificadores que predizem classe baseadas
nos valores de atributos de um conjunto de dados. Uma árvore de decisão tem a função de

15
particionar recursivamente um conjunto de treinamento, até que cada subconjunto obtido
contenha casos de uma única classe. Para atingir esta meta, o algoritmo escolhido para a árvore
de decisão examina e compara a distribuição de classe durante a construção da árvore.
As árvores de decisão são baseadas no modelo de top-down, em que o nó raiz se
direciona para as folhas. Os algoritmos de árvores de decisão utilizam da técnica de dividir para
conquistar, neste caso, o problema maior se divide em vários subproblemas, assim até achar a
solução para cada um dos problemas mais simples (CASTANHEIRA, 2008).
Os classificadores baseados em árvore de decisão procuram encontrar formas de dividir
sucessivamente o universo em vários subconjuntos, até que cada um deles contemple apenas
uma classe ou até que uma das classes demonstre uma clara maioria, não justificando
posteriores divisões (CASTANHEIRA, 2008).
A figura 4 demonstra um exemplo de árvore de decisão. Sendo os conceitos utilizados
para a criação de uma árvore de decisão de acordo com Castanheira (2008) são:
Nó: são todos os itens que aparecem na árvore;
Folhas: são nós que não tem filhos, os últimos itens da árvore;
Filhos: são os itens logo abaixo da raiz;
Raiz: é o topo da árvore.
Figura 4 - Exemplo de Árvore de Decisão
Fonte: Castanheira, 2008.

16
De acordo com Castanheira (2008), analisando a figura 4 é possível perceber a derivação
de regras do tipo “se-então” para melhorar a compreensão e interpretação de tais resultados. As
regras são escritas considerando o trajeto do nó raiz até uma folha da árvore.
Segundo Harrison (1998 apud Dias, 2008) essas regras podem ser demonstradas como
declarações lógicas, em uma linguagem como SQL, de tal modo que possam ser aplicadas
diretamente a novas tuplas. Uma das vantagens principais, é o fato de que o modelo é bem
explicável, uma vez que tem a forma de regras explícitas.
O principal problema referente a essa técnica, é que elas precisam de uma
quantia de dados considerável para mostrar estruturas complexas. Por outro lado, elas podem
ser construídas de forma consideravelmente mais rápida do que alguns métodos alternativos de
classificação, produzindo resultados com precisão similar (SOUSA, 1998 apud AMORIM,
2006).
Alguns exemplos de algoritmos de árvore de decisão são: CART, CHAID, C5.0, Quest
ID-3, SLIQ e SPRINT.
2.3.3 Raciocínio baseado em casos (RBC)
Segundo Dias (2008), o Raciocínio Baseado em Casos (RBC) tem base no método do
vizinho mais próximo. “O RBC procura os vizinhos mais próximos nos exemplos conhecidos
e combina seus valores para atribuir valores de classificação ou de previsão” (HARRISON,
1998, p. 195). Complementa dizendo que o RBC tenta solucionar um dado problema fazendo
uso direto de experiências e soluções passadas. A distância dos vizinhos dá uma medida da
exatidão dos resultados.
No enfoque do RBC, os problemas são conhecidos como casos, que são armazenados
em uma base de conhecimento ou base de casos.
Na aplicação do RBC, segundo Berry e Linoff (1997 apud Dias, 2008), existem quatro
passos importantes:
Escolher o conjunto de dados de treinamento;
Determinar a função de distância;
Escolher o número de vizinhos mais próximos; e
Determinar a função de combinação.

17
Figura 5 - Arquitetura do RBC
Fonte: Extraído de www.google.com.br (https://goo.gl/56OmXd)
Para cada novo problema:
Recuperam o caso mais similar na base de casos;
Reutilizam este caso para resolver o problema;
Revisam a solução indicada;
Retém a experiência representando o caso atual para referências futuras.
Os seguintes algoritmos implementam a técnica de raciocínio baseado em casos:
BIRCH, CLARANS e CLIQUE.
2.3.4 Algoritmos genéticos (AG)
Segundo Galvão e Marin (2009), os Algoritmos Genéticos (AG) estabelecem estratégias
de otimização algorítmica influenciadas nos princípios notados da evolução natural e da
genética, para solução de problemas. Os AG usam os operadores de seleção, cruzamento e
mutação para desenvolver consecutivas gerações de soluções - chamado de reprodução. Com a
evolução do algoritmo, somente as soluções com maior poder de previsão sobrevivem, até
convergirem numa solução ideal.

18
Figura 6 - Exemplo de Algoritmo Genético
Fonte: Extraído de www.google.com.br (https://goo.gl/F2rtdn)
Os AG compreendem em criar uma população de possíveis respostas para o problema a
ser tratado e depois ser submetido ao processo de evolução, constituindo as seguintes etapas
segundo (PÉREZ, 2000 apud ALCANTARA, 2012):
Avaliação: avalia-se a capacidade das soluções. É feita uma análise para que se
estabeleça o quão são aptas a responder ao problema proposto;
Seleção: é feita a seleção dos indivíduos para a reprodução. A probabilidade de uma
solução ser escolhida é proporcional à sua aptidão;
Cruzamento: as características das soluções escolhidas são recombinadas gerando
novos indivíduos;
Mutação: as características dos indivíduos resultantes do processo de reprodução são
alteradas, acrescentando variedade à população;
Atualização: os indivíduos criados nesta geração são inseridos na população.
Finalização: verifica se as condições do encerramento da evolução foram atingidas.
Em caso negativo volta para etapa de avaliação, se positivo, encerra a execução.

19
É comum utilizar os termos genoma e cromossoma como sinônimo de indivíduo na área
de AG. Pois essa definição sugere que um indivíduo se resume ao conjunto de genes que possui
e apresenta um problema: que toda a representação por parte do algoritmo é baseada única e
exclusivamente em seu genótipo (conjunto de genes), mas toda avaliação é baseada em seu
fenótipo (conjunto de características observáveis no objeto resultante do processo de
decodificação dos genes) (LUCAS, 2002 apud ALCANTARA, 2012).
De acordo com o mesmo autor, as características mais importantes são:
Genótipo: consiste na informação presente na estrutura de dados que engloba os
genes de um indivíduo;
Fenótipo: é o resultado do processo de decodificação do genoma de um indivíduo;
Grau de Adaptação: demonstra o quão bem a resposta representada por indivíduo
soluciona o problema proposto;
De acordo com Galvão e Marin (2009), uma das vantagens de um algoritmo genético é
a simplificação que eles permitem na formulação e solução de problemas de otimização. AG
simples, normalmente trabalham com descrições de entrada formadas por cadeias de bits de
tamanho fixo. Outros tipos de AG podem trabalhar com cadeias de bits de tamanho variável,
como por exemplo AG usados para Programação Genética. AG possuem um paralelismo
implícito decorrente da avaliação independente de cada uma dessas cadeias de bits, ou seja,
pode-se avaliar a viabilidade de um conjunto de parâmetros para a solução do problema de
otimização em questão.
Exemplos de algoritmos genéticos: Algoritmo Genético Simples, Genitor e CHC,
Algoritmo de Hillis, GA-Nuggets, GA-PVMINER.
2.3.5 Redes neurais artificiais (RNA)
O surgimento das Redes Neurais Artificiais deu-se pela tentativa de construir uma
máquina que ao imitar a estrutura de um cérebro ela apresentaria inteligência.
Segundo Galvão e Marin (2009), a Rede Neural Artificial (RNA) é uma técnica
computacional que constrói modelo matemático inspirado em um cérebro humano para
reconhecimento de imagens e sons, com capacidade de aprendizado, generalização, associação
e abstração, constituído por sistemas paralelos distribuídos em compostos de unidades simples
de processamento.

20
Estruturalmente, uma rede neural consiste em um número de unidades de processamento
simples interconectadas (chamadas neurônios), que têm o objetivo de calcular determinadas
funções matemáticas (funções de ativação). Os neurônios são dispostos em uma ou mais
camadas e interligados por um grande número de conexões. Essas conexões estão associadas a
pesos que armazenam o conhecimento demonstrado no modelo e avaliam as entradas recebidas
por cada neurônio da rede (SOUSA, 1998 apud AMORIM, 2006).
A função básica de cada neurônio é: avaliar os valores de entrada, calcular o total para
valores de entrada combinados, comparar o total com um valor limite e determinar o valor de
saída.
Enquanto a operação de cada neurônio é bastante simples, procedimentos complexos
podem ser criados pela conexão de um conjunto de neurônios, tipicamente, as entradas dos
neurônios são ligadas a uma ou mais camadas intermediárias, que é então conectada com a
camada de saída.
As unidades de processamento são uma ou mais camadas interligadas por um grande
número de conexões; na maioria dos modelos, estas conexões estão associadas a pesos, os quais,
após o processo de aprendizagem, armazenam o conhecimento adquirido pela rede.
Figura 7 - Modelo de RNA
Fonte: Da Costa Côrtes et al., 2002.
“Uma das principais vantagens da RNA é sua variedade de aplicação, mas os seus dados
de entrada são difíceis de serem formados e os modelos produzidos por elas são difíceis de
entender” (HARRISON, 1998).

21
A RNA têm sido utilizadas com sucesso para formar relações envolvendo séries
temporais complexas em várias áreas do conhecimento. A maior vantagem das RNA sobre os
métodos convencionais é que elas não solicitam informação detalhada sobre os processos
físicos do sistema a ser modelado, sendo este descrito explicitamente na forma matemática
(modelo de entrada-saída) e ainda por ser robusta e ter uma alta taxa de acurácia preditiva. Por
meio de repetidas apresentações dos dados à rede, a RNA aprende padrões, procuram
relacionamentos e constrói modelos automaticamente (GALVÃO E MARIN, 2009).
Exemplos de redes neurais: Perceptron, Rede MLP, Redes de Kohonen, Rede
Hopfield, Rede BAM, Redes ART, Rede IAC, Rede LVQ, Rede Counterpropagation, Rede
RBF, Rede PNN, Rede Time Delay, Neocognitron, Rede BSB.
2.3.6 Tabela de técnicas de mineração de dados
Na tabela 2, está representado de forma resumida as técnicas de mineração de dados
apresentadas anteriormente.
Tabela 2 - Técnicas de Mineração de Dados
TÉCNICA DESCRIÇÃO ALGORITMOS
Descoberta de Regras de
Associação
Descobrir elementos que implicam na
presença de outros elementos em uma mesma
transação, ou seja, descobrir relacionamentos
ou padrões frequentes entre conjuntos de
dados.
Apriori,AprioriTid,AprioriHybrid,
AIS, SETM e DHP
Árvores de Decisão
Representações simples do conhecimento e
um meio eficiente de construir classificadores
que predizem classe baseadas nos valores de
atributos de um conjunto de dados.
CART, CHAID, C5.0, Quest ID-3,
SLIQ e SPRINT
Raciocínio Baseado em
Casos (RBC)
Procura os vizinhos mais próximos nos
exemplos conhecidos e combina seus valores
para atribuir valores de classificação ou de
previsão.
BIRCH, CLARANS e CLIQUE
Algoritmos Genéticos
(AG)
Formulam estratégias de otimização
algorítmica inspiradas nos princípios
observados na evolução natural e na genética,
para solução de problemas.
Algoritmo Genético Simples,
Genitor e CHC, Algoritmo de
Hillis, GA-Nuggets, GA-
PVMINER
Redes Neurais
Artificiais (RNA)
É uma técnica computacional que constrói
modelo matemático inspirado em cérebro
humano para reconhecimento de imagens e
sons, com capacidade de aprendizado,
generalização, associação e abstração,
constituído por sistemas paralelos
distribuídos em compostos de unidades
simples de processamento.
Perceptron, Rede MLP, Redes de
Kohonen, Rede Hopfield, Rede
BAM, Redes ART, Rede
IAC, Rede LVQ, Rede
Counterpropagation, Rede RBF,
Rede PNN, Rede Time Delay,
Neocognitron, Rede BSB
Fonte: Dias, 2008.

22
2.4 Áreas de aplicação da mineração de dados
Neste tópico, serão apresentadas algumas áreas de interesse que podem utilizar da
mineração de dados para sua melhoria.
Apólice de seguro: determinar quais procedimentos médicos são reivindicados juntos,
identificar padrões de comportamento de clientes perigosos, prever quais clientes comprarão
novas apólices.
Banco: detectar padrões de uso de cartão de crédito fraudulento, encontrar correlações
escondidas entre diferentes indicadores financeiros, determinar gastos com cartão de crédito
por grupos de clientes.
Biomedicina: desenvolvimento de diversos aparelhos de diagnósticos de acordo com
os padrões encontrados em populações observadas por um determinando tempo, detectar e
identificar a prevenção de doenças.
Ciência: ajudar cientistas em suas pesquisas, por exemplo, encontrar padrões em
estruturas moleculares, dados genéticos, mudanças globais de clima.
Detecção de fraudes: desenvolvimento de modelos que predizem quem será um bom
cliente ou aquele que poderá se tornar inadimplente em seus pagamentos.
Eleitoral: identificação de um perfil para possíveis votantes.
Instituições governamentais: descoberta de padrões para melhorar as coletas de
taxas ou descobrir fraudes.
Marketing: descobrir preferências do consumidor e padrões de compra, com o objetivo
de realizar marketing direto de produtos e ofertas promocionais, de acordo com o perfil do
consumidor.
Medicina: caracterizar comportamento de paciente para prever visitas, identificar
terapias médicas de sucesso para diferentes doenças, buscar por padrões de novas doenças.
Tomada de Decisão: filtrar as informações relevantes, fornecer indicadores de
probabilidade.
Transporte: determinar as escalas de distribuição entre distribuidores, analisar padrões
de carga.

23
3 TRABALHOS CORRELATOS
3.1 Mineração de Dados em Imagens: da Arquitetura à Ontologia
No trabalho de Silva e Câmara (2003), os autores discorrem sobre a Arquitetura Dirigida
à Informação (Information-Driven Framework), e tomam como base a Mineração de Dados em
Imagens. É demonstrado que bancos de dados de imagens apresentam diferenças de bancos de
dados “convencionais” (relacionais, orientados a objetos).
A semântica dos elementos da imagem e as várias possibilidades de interpretar os
padrões dela, são alguns aspectos que instigam e tornam desafiador a tarefa e técnicas para
extrair o conhecimento.
De acordo com Zhang et al. (2001 apud Silva e Câmara, 2003), ele propõe uma
arquitetura dirigida a informação que ressalta o papel da informação em alguns níveis de
entendimento. Esta arquitetura é dividida em quatro níveis, que vão ser descritos a seguir:
A base da arquitetura se encontra o Nível de Pixel, no qual consiste de informações da
imagem bruta, como: valores de pixel e características primitivas (cor, forma e textura).
Acima da base se encontra o Nível de Objeto, onde se tem as informações de objetos
baseadas nos dados primitivos do nível de pixel, no qual é identificado características essenciais
ao domínio. Utilizando os algoritmos de agrupamento e segmentação, juntamente com o
conhecimento do domínio, pode ser usado para ajudar a dividir as imagens em objetos.
O Nível de Conceito Semântico coloca os objetos e regiões no contexto das imagens,
tentando capturar conceitos abstratos no cenário formado. Raciocínio em alto nível e técnicas
de descoberta de conhecimento, são utilizados para gerar conceitos semânticos e descobrir
padrões relevantes (SILVA e CÂMARA, 2003).
No topo da arquitetura se encontra o Nível de Padrões e Conhecimento, que realiza a
integração dos dados alfanuméricos referentes ao domínio com relacionamentos semânticos
descobertos nos dados da imagem.
A realização da busca de informação em imagens busca conhecimento, esforço e
habilidade em variados domínios, ferramentas e metodologias.

24
Figura 8 - Arquitetura de mineração de imagens dirigida à informação
Fonte: Zhang et al., 2001 (apud Silva e Câmara, 2003)
3.2 A hierarchical distributed data mining architecture
No trabalho de Liu et al. (2011), os autores discorrem sobre a Arquitetura de Mineração
de Dados Distribuídos Hierárquica (Hierarchical Distributed Data Mining ou DDM
Hierárquica), e tomam como base a Mineração de Dados Distribuídos.
Os ambientes de dados distribuídos são caracterizados por heterogeneidade,
privacidade, multi-plataforma e outras restrições, é difícil utilizar mineração de dados mais
centralizada, por este fato, para acabar com as restrições que tinha, foi criada a DDM. Um
problema potencial é que os dados contidos em cada banco de dados individual podem ter
características totalmente diferentes. Em outras palavras, pode haver diferença essencial entre
as fontes de dados, que irá prejudicar a base da tabela de dados virtuais e o resultado final. Desta
forma, para melhorar a qualidade dos resultados, é proposto uma arquitetura DDM hierárquica,
agrupando as fontes de dados de acordo com sua similaridade (LIU et al., 2011).

25
Figura 9 - Arquitetura DDM hierárquica baseada no agrupamento de fonte de dados
Fonte: Liu et al., 2011
Como foi mostrado na figura 9, as fontes de dados devem inicialmente passar pela
engenharia reversa para produzir os modelos de Entidade Relacionamento (ER). Para melhorar
a qualidade dos modelos, eles também devem aprender com dados de instância.
Sequencialmente, o modelo ER é traduzido para a ontologia da fonte de dados e é expresso pela
Web Ontology Language (OWL). A similaridade entre os sememas (unidades atômicas ou
indivisíveis) é medida e atua como base para medir a similaridade de conceitos diferentes e suas
relações. Em seguida, a similaridade entre ontologias de fonte de dados pode ser medida de
forma abrangente considerando os parâmetros de correspondência, tais como granularidade,
peso, limiares, etc (LIU et al., 2011).
De acordo com as semelhanças, as fontes de dados são divididas em diferentes grupos
que podem ser classificados como: Camada Única de Mineração de Dados (Single Data Mining
Layer ou SDML), Camada de Mineração de Dados Local (Local Data Mining Layer ou LDML)
e Camada de Mineração de Dados Global (Global Data Mining Layer ou GDML). As principais
funções e seus componentes de diferentes camadas são colocadas da seguinte forma:

26
A Unidade de Processamento Central de Mineração de Dados (Data Mining Central
Processing Unit ou DCPU) é responsável por medir a similaridade entre ontologias
de fonte de dados, agrupando fontes de dados, planejando tarefas DDM, despachando
recursos e integrando resultados locais.
A Unidade de Processamento do Grupo de Mineração de Dados (Data Mining Group
Processing Unit ou DGPU) é responsável pela coleta, filtragem e integração dos
resultados locais de mineração de dados.
A fonte de dados é responsável pela construção, armazenamento e upload de sua
própria ontologia para DCPU, realizando mineração de dados com recursos locais e
fazendo o upload de resultados para DGPU ou DCPU.
Para o balanceamento de carga, SDML ou LDML registra as informações do recurso
(por exemplo, recursos de computação, recursos de armazenamento, recursos de dados) no
DCPU; as fontes de dados no LDML registram seus recursos no DGPU. De acordo com a
camada em que existe desequilíbrio de carga, a DCPU ou DGPU produz a multi-árvore para
transferir as mensagens de carga e fornece os recursos de armazenamento para a migração de
carga (LIU et al, 2011).
3.3 A reliable and intelligent protocol for distributed data mining architecture in sporadic
wireless sensor network
No trabalho de Wang e Jung (2015), os autores discorrem sobre a Arquitetura de
Mineração de Dados Distribuídos (Distributed Data Mining ou DDM), com base em Uma Rede
de Sensores Sem Fio Esporádica (Sporadic Wireless Sensor Network ou SWSN).
O DDM, exerce um papel fundamental em aplicações modernas, como redes de
sensores, detecção de fraude de cartões de crédito, detecção de intrusão, detecção de
congestionamento e computação em grade. O DDM é uma “classe especial” de mineração de
dados, que tem a capacidade de superar a limitação das abordagens convencionais de mineração
de dados.
A arquitetura básica do DDM é ilustrada na Figura 10. Os sites locais produzem
independentemente conhecimento local aplicando o algoritmo DDM em suas próprias bases de
dados. Após esse processo, todo o conhecimento local descoberto é transferido para o site
central (site global), que é responsável pela mistura de todos os resultados dos sites locais para

27
produzir o conhecimento global. Existem quatro principais vantagens da DDM: custo de
comunicação, custo de armazenamento, custo computacional e privacidade (WANG e JUNG,
2015).
DDM é inteiramente dependente de uma rede confiável. Para produzir um conhecimento
global exato, é necessário que os pacotes cheguem com sucesso aos pontos de destino (site local
e site global). Ele foi revisto na maioria dos estudos que a pesquisa assumiu a rede está
disponível o tempo todo, mas praticamente não é verdade. A rede pode ser imprevisível na
maioria das vezes e problemas como falha de link ou ruptura de nó podem aparecer na rede a
qualquer momento. Este tipo de rede é chamado de Rede Esporádica Conectada ou Rede Parcial
Conectada. SWSN é uma rede sem fio onde na maioria das vezes um caminho completo não
está disponível de uma fonte para um destino, ou tal caminho é altamente confiável
(LINDGREN, 2012; LIU et al., 2015).
Figura 10 - Arquitetura básica do DDM
Fonte: Wang e Jung, 2015.

28
4 ESCOLHENDO A TÉCNICA DE MINERAÇÃO DE DADOS
APROPRIADA
Para realizar a escolha de uma técnica de mineração de dados apropriada não é uma
tarefa simples. A escolha das técnicas de mineração de dados está sujeita a qual tarefa específica
a ser executada e dos dados disponíveis para análise.
Harrison (1998 apud Dias, 2008) recomenda que a escolha das técnicas de mineração
de dados deve ser dividida em dois passos: primeiro, demonstrar o problema de negócio a ser
resolvido em séries de tarefas de mineração de dados; segundo, entender a natureza dos dados
disponíveis em termos de conteúdo e tipos de campos de dados e estrutura das relações entre
os registros.
Primeiramente deve-se fazer a escolha da técnica de mineração de dados e transformá-
la em uma ou mais das tarefas de mineração de dados.
O segundo passo seria definir as características dos dados em análise, este passo tem
como meta selecionar a técnica de mineração de dados que diminui o número e as dificuldades
de transformação de dados para, a partir destes obter bons resultados.
“Diferentes esquemas de classificação podem ser usados para categorizar
métodos de mineração de dados sobre os tipos de bancos de dados a serem estudados, os
tipos de conhecimento a serem descobertos e os tipos de técnicas a serem utilizadas” (CHEN et
al, 1996), como pode ser visto a seguir:
Com que tipos de bancos de dados trabalhar: Um sistema de descoberta de
conhecimento pode ser classificado de acordo com os tipos de bancos de dados sobre
os quais técnicas de mineração de dados são aplicadas, tais como: bancos de dados
relacionais, bancos de dados de transação, orientados a objetos, heterogêneos, banco
de informação de Internet e bases textuais.
Qual o tipo de conhecimento a ser explorado: Vários tipos de conhecimento podem
ser encontrados por extração de dados, incluindo regras de associação, regras
características, regras de classificação, grupamento, evolução e análise de desvio.
Qual tipo de técnica a ser utilizada: A extração de dados pode ser classificada de
acordo com as técnicas de mineração de dados subordinadas. Por exemplo, extração
dirigida a dados, extração dirigida a questionamento e extração de dados interativa.
Pode ser classificada, também, de acordo com a abordagem de mineração de dados

29
subordinada, tal como: extração de dados baseada em generalização, baseada em
padrões.
A tabela 3 exibe uma lista das características de dados baseada em Berry e Linoff
(1997), que auxiliará na escolha de uma técnica de mineração de dados.
Tabela 3 - Características de dados
CARACTERÍSTICAS DESCRIÇÃO
TÉCNICAS DE
MINERAÇÃO DE
DADOS
Dados ordenados
cronologicamente
Apresentam dificuldades para todas as técnicas e,
geralmente, requerem aumento dos dados de teste
com marcas ou avisos, variáveis de diferença etc.
Descoberta de regras de
associação
Rede neural intervalar
Muitos campos por
registro
Este pode ser um fator de decisão da técnica
correta para uma aplicação específica, uma vez
que os métodos de mineração de dados variam na
capacidade de processar grandes números de
campos de entrada.
Árvores de decisão
Registro de comprimento
variável
Apresentam dificuldades na maioria das técnicas
de mineração de dados, mas existem situações em
que a transformação para registros de
comprimento fixo não é desejada.
Descoberta de regras de
associação
Texto sem formatação A maioria das técnicas de mineração de dados é
incapaz de manipular texto sem formatação.
Raciocínio baseado em
casos (RBC)
Variáveis dependentes
múltiplas
Caso em que é desejado prever várias variáveis
diferentes baseadas nos mesmos dados de
entrada.
Redes neurais
Variáveis de categorias
São campos que apresentam valores de um
conjunto de possibilidades limitado e
predeterminado.
Árvores de decisão
Descoberta de regras de
associação
Variáveis numéricas São aquelas que podem ser somadas e ordenadas.
Árvores de Decisão
Raciocínio baseado em
casos (RBC)
Fonte: Adaptado de Berry e Linoff, 1997.
4.1 Critérios na escolha de técnicas de mineração de dados
Alguns critérios devem ser analisados para escolher uma técnica de mineração de dados,
são os seguintes:
Características dos dados: a escolha correta da técnica de mineração de dados às
características dos dados objetiva, diminuir as dificuldades comumente encontradas na
transformação de dados.

30
Disponibilidade de ferramenta de mineração de dados: poderá ser selecionada uma
técnica ou outra dependendo da ferramenta disponível.
Forma de aplicação da mineração de dados: a mineração de dados pode ser aplicada
como um processo de verificação, onde o usuário tenta provar uma hipótese acerca da relação
entre os dados, ou como um processo de descoberta, onde não é feita nenhuma suposição
antecipada. Existem técnicas mais propícias para o processo de verificação e outras para o
processo de descoberta (regras de associação, árvores de decisão, algoritmos genéticos e redes
neurais) (ROMÃO, 2002).
Tipo de problema de descoberta de conhecimento a ser solucionado: este critério é
adquirido com a escolha da tarefa de mineração de dados, que deve estar ajustado com os
objetivos determinados para a descoberta de conhecimento em questão.

31
5 ESCOLHENDO A FERRAMENTA DE MINERAÇÃO DE DADOS
APROPRIADA
Segundo Goebel e Gruenwald (1999), existe em algumas características que podem ser
consideradas para escolher uma ferramenta de mineração de dados, que são as seguintes:
A capacidade de processamento com referência ao tamanho do banco de dados;
A capacidade de processamento com referência ao número máximo de
atributos/tabelas/tuplas;
A capacidade de incluir modelos de dados orientados a objetos ou modelos não
padronizados (tal como multimídia, espacial ou temporal);
A habilidade de acesso a uma variedade de fontes de dados, de forma on-line e off-
line;
Tipo de linguagem de consulta;
Variedade de tipos de atributos que a ferramenta pode manipular.
Goebel e Gruenwald (1999) indicam, também, um sistema de classificação de
características que é capaz de ser usado para estudar ferramentas de descoberta de
conhecimento e de mineração de dados. Neste esquema, as características das ferramentas são
classificadas em três grupos chamados características gerais, conectividade de banco de dados
e características de mineração de dados.
As tabelas 4, 5 e 6 demonstram como tais características são classificadas.
Tabela 4 – Características gerais da ferramenta
CARACTERÍSTICAS CLASSIFICAÇÃO
Produto Nome e vendedor do produto de software
Status da Produção P = Comercial, A = Alfa, B = Beta, R = Protótipo de Pesquisa
Status Legal PD = Domínio Público, F = Freeware, S = Shareware
Licença Acadêmica Se existe licença acadêmica livre disponível ou redução de custo
Demo D = Versão Demo disponível para download na internet, R = Demo
disponível através de requisição, U = Não-conhecido
Arquitetura S = Standalone, C/S = Cliente/Servidor, P = Processamento Paralelo
Sistemas Operacionais Lista de sistemas operacionais para os quais a versão atual do software pode
ser obtida.
Fonte: Adaptado de Dias, 2008.

32
Tabela 5 – Conectividade de banco de dados da ferramenta
CARACTERÍSTICAS CLASSIFICAÇÃO
Fontes de dados
T = Arquivos texto Ascii, D = Arquivos Dbase, P = Arquivos Paradox, F =
Arquivos Foxpro, Ix = Informix, O = Oracle, Sy = Sybase, Ig = Ingres, A =
MS Access, OC = Conexão aberta de banco de dados (ODBC), SS =
Servidor MS SQL, Ex = MS Excel, L = Lótus 1-2-3
Conexão ao banco de dados Onl = Online, Offl = Offline
Tamanho S = Pequeno (até 10.000 registros), M = Mediano (10.000 a 1.000.000
registros), L = Grande (mais de 1.000.000)
Modelo R = Relacional, O = Orientado a Objetos, 1 = Uma Tabela
Atributos Co = Contínuo, Ca = Categórico (valores numéricos discretos), S =
Simbólico
Consulta
S = Linguagem de consulta estruturada (SQL ou derivada), Sp = Uma
linguagem de consulta específica, G = Interface gráfica de usuário, N = Não
aplicável, U = Não-conhecido
Fonte: Adaptado de Dias, 2008.
Tabela 6 – Características de mineração de dados da ferramenta
CARACTERÍSTICAS CLASSIFICAÇÃO
Tarefas descobertas
Pré = Processamento de Dados (Amostragem, Filtragem), P = Predição,
Regr = Regressão, Clã = Classificação, Clu = Agrupamento, A =
Associação, Vis = Visualização do Modelo, EDA = Análise de Dados
Exploratória
Metodologia de descoberta
NN = Redes Neurais, GA = Algoritmos Genéticos, FS = Conjuntos Fuzzy,
RS = Conjuntos Irregulares (Rough), St = Métodos Estatísticos, DT =
Árvores de Decisão, RI = Indução de Regras, BN = Redes Bayseanas, RBC
= Raciocínio Baseado em Casos
Interação Humana A = Autônoma, G = Processo de descoberta guiado ao homem, H =
Altamente interativo
Fonte: Adaptado de Dias, 2008.
De acordo com Collier et al. (1999), que demonstram uma estrutura para avaliar as
ferramentas de mineração de dados e apresentam um processo para aplicar esta estrutura. As
fases da estrutura se encontram na figura 11.

33
Figura 11 – Estrutura para avaliação das ferramentas de mineração de dados
Fonte: Collier et al., 1999.
Pré-Seleção da Ferramenta: nessa etapa procura reduzir o conjunto de ferramentas e
eliminar as ferramentas que não serão selecionadas devido a restrições rígidas da organização
ou do vendedor.
Identificação de Critérios de Seleção: nessa etapa procura identificar quais critérios
adicionais que são específicos a uma organização particular; e, considerar custo de software,
restrições de plataforma, habilidades do usuário final, projetos de mineração de dados
específicos.
Atribuição de Pesos aos Critérios: nessa etapa procura apontar pesos para cada critério
dentro de cada categoria, de tal forma que o total de pesos da categoria seja 1.00 ou 100%.
Registro dos Pontos da Ferramenta: nessa etapa procura escolher uma ferramenta de
referência e atribuir 3 pontos para cada critério; registrar pontos a cada critério de seleção para
as outras ferramentas, usando uma escala de taxas discretas e baseando-se na ferramenta de
referência; atribuir peso para cada categoria de critérios, por padrão pode ser 0.20, mas os pesos
podem ser ajustados para enfatizar ou não particularidades de categorias de critérios.

34
Avaliação dos Pontos: nessa etapa procura rever os pesos assinalados para os critérios
de seleção e ajustá-los se necessário.
Seleção da Ferramenta: nessa etapa procura escolher a ferramenta com maior peso
médio.
5.1 Critérios na escolha de ferramentas de mineração de dados
Quatro categorias de critérios para avaliar ferramentas de mineração de dados podem
ser sugeridas: desempenho, funcionalidade, suporte de atividades principais de uma
organização ou sistema e usabilidade (COLLIER et al., 1999), que será explanado a seguir:
Desempenho: é a habilidade de manipular uma variedade de fontes de dados de
maneira eficiente.
Funcionalidade: é a inserção de uma variedade de capacidades, metodologias e
técnicas para mineração de dados. Ajuda avaliar o quanto a ferramenta pode se
adaptar a diferentes áreas de problema de mineração de dados.
Suporte de atividades principais de uma organização ou sistema: esta categoria
permite ao usuário realizar a limpeza, manipulação, transformação, visualização de
dados e outras tarefas para suporte à mineração de dados.
Usabilidade: é a acomodação de diferentes níveis e tipos de usuários sem perda de
funcionalidade ou utilidade. Uma boa ferramenta deve fornecer parâmetros
significativos para ajudar a depurar problemas e melhorar a saída.
As tabelas 7, 8, 9 e 10 representam, respectivamente, de forma mais ampla as
características de decisão dos critérios apresentados por Collier et al. (2009) logo acima.
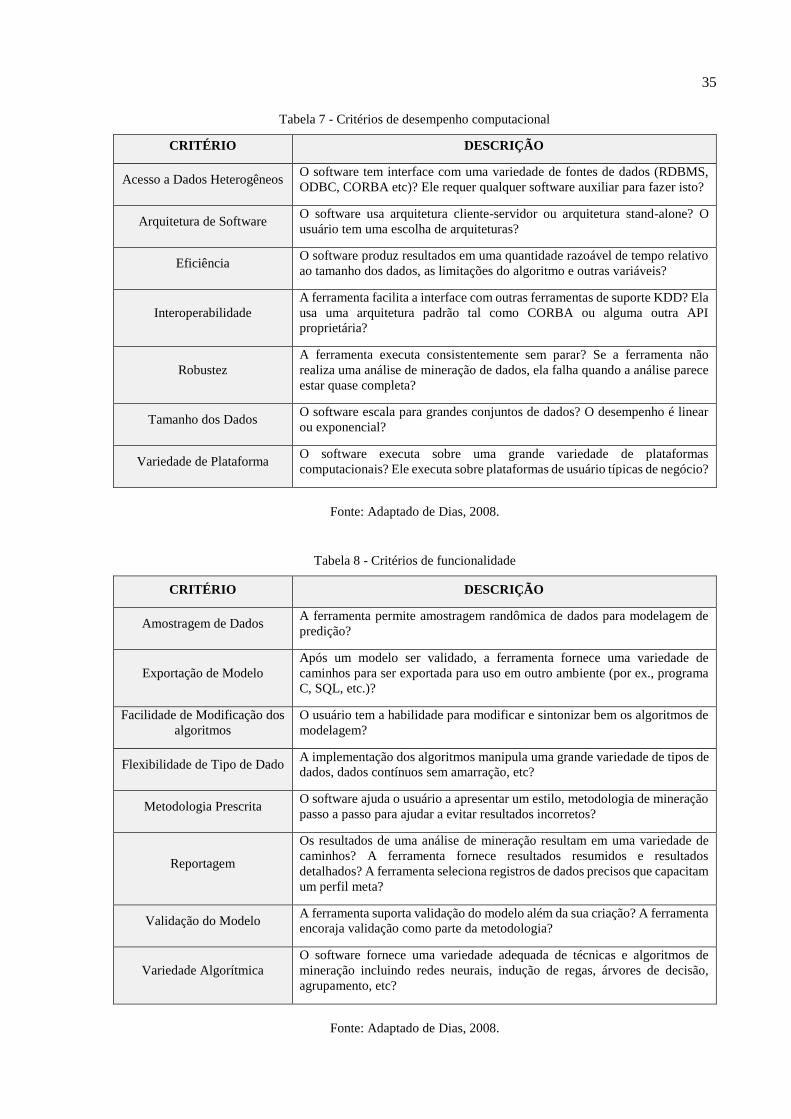
35
Tabela 7 - Critérios de desempenho computacional
CRITÉRIO DESCRIÇÃO
Acesso a Dados Heterogêneos O software tem interface com uma variedade de fontes de dados (RDBMS,
ODBC, CORBA etc)? Ele requer qualquer software auxiliar para fazer isto?
Arquitetura de Software O software usa arquitetura cliente-servidor ou arquitetura stand-alone? O
usuário tem uma escolha de arquiteturas?
Eficiência O software produz resultados em uma quantidade razoável de tempo relativo
ao tamanho dos dados, as limitações do algoritmo e outras variáveis?
Interoperabilidade
A ferramenta facilita a interface com outras ferramentas de suporte KDD? Ela
usa uma arquitetura padrão tal como CORBA ou alguma outra API
proprietária?
Robustez
A ferramenta executa consistentemente sem parar? Se a ferramenta não
realiza uma análise de mineração de dados, ela falha quando a análise parece
estar quase completa?
Tamanho dos Dados O software escala para grandes conjuntos de dados? O desempenho é linear
ou exponencial?
Variedade de Plataforma O software executa sobre uma grande variedade de plataformas
computacionais? Ele executa sobre plataformas de usuário típicas de negócio?
Fonte: Adaptado de Dias, 2008.
Tabela 8 - Critérios de funcionalidade
CRITÉRIO DESCRIÇÃO
Amostragem de Dados A ferramenta permite amostragem randômica de dados para modelagem de
predição?
Exportação de Modelo
Após um modelo ser validado, a ferramenta fornece uma variedade de
caminhos para ser exportada para uso em outro ambiente (por ex., programa
C, SQL, etc.)?
Facilidade de Modificação dos
algoritmos
O usuário tem a habilidade para modificar e sintonizar bem os algoritmos de
modelagem?
Flexibilidade de Tipo de Dado A implementação dos algoritmos manipula uma grande variedade de tipos de
dados, dados contínuos sem amarração, etc?
Metodologia Prescrita O software ajuda o usuário a apresentar um estilo, metodologia de mineração
passo a passo para ajudar a evitar resultados incorretos?
Reportagem
Os resultados de uma análise de mineração resultam em uma variedade de
caminhos? A ferramenta fornece resultados resumidos e resultados
detalhados? A ferramenta seleciona registros de dados precisos que capacitam
um perfil meta?
Validação do Modelo A ferramenta suporta validação do modelo além da sua criação? A ferramenta
encoraja validação como parte da metodologia?
Variedade Algorítmica
O software fornece uma variedade adequada de técnicas e algoritmos de
mineração incluindo redes neurais, indução de regas, árvores de decisão,
agrupamento, etc?
Fonte: Adaptado de Dias, 2008.

36
Tabela 9 - Critérios de suporte de atividades principais de uma organização ou sistema
CRITÉRIO DESCRIÇÃO
Atributos de Derivação
A ferramenta permite a criação de atributos derivados baseando-se em
atributos de herança? Existe uma grande variedade de métodos disponíveis
para derivar atributos (por ex., funções estatísticas, funções matemáticas,
funções booleanas, etc.)?
Definição de Dados
Randômicos
A ferramenta permite definir dados randômicos antes da construção do
modelo? A definição de dados randômicos é eficiente e efetiva?
Discretização
A ferramenta permite tornar dados contínuos em dados discretos para
melhorar a eficiência da modelagem? A ferramenta requer que dados
contínuos sejam discretizados ou esta decisão fica a critério do usuário?
Filtragem de Dados A ferramenta permite a seleção de subconjuntos dos dados baseando-se em
critérios de seleção definidos pelo usuário?
Limpeza de Dados A ferramenta permite ao usuário modificar valores incorretos no conjunto de
dados para desempenhar outras operações de limpeza de dados?
Manipulação de Espaços
A ferramenta permite manipular bem espaços? Ela permite que espaços sejam
substituídos com uma variedade de valores derivados? Ela permite que
espaços sejam substituídos com um valor definido pelo usuário? Se isto é
possível, pode ser globalmente bem como valor por valor?
Manipulação de Metadados
A ferramenta apresenta ao usuário descrições, tipos e códigos categóricos de
dados, fórmula para derivar atributos, etc.? Se isto é possível, a ferramenta
permite que o usuário manipule esse metadados?
Realimentação de Resultados A ferramenta permite que os resultados de uma análise de mineração sejam
retornados para uma outra análise na construção de mais modelos?
Substituição de Valores A ferramenta permite substituição global de um valor de dado por outro (por
ex., substituir ‘M’ ou ‘F’ por 1 ou 0)?
Fonte: Adaptado de Dias, 2008.

37
Tabela 10 - Critérios de usabilidade
CRITÉRIO DESCRIÇÃO
Aprendizagem A ferramenta é fácil de aprender? Ela é fácil de usar corretamente?
História de Ação
A ferramenta mantém uma história de ações realizadas no processo de
mineração? O usuário pode modificar partes de sua história e re-executar o
roteiro?
Interface do Usuário A interface do usuário é fácil de usar para navegar e não complicada? A
interface apresenta resultados de forma significativa?
Relatório de Erros
Os erros relacionados são significativos? As mensagens de erro ajudam o
usuário na depuração dos problemas? A ferramenta acomoda bem os erros ou
falsifica construção do modelo?
Tipos de Usuários
A ferramenta é projetada para usuários iniciantes, intermediários e avançados
ou uma combinação de tipos de usuários? Ela é adequada para o tipo de
usuário alvo? Ela é fácil de ser usada por analistas? Ela é fácil de ser usada
por usuários finais?
Variedade de Domínio
A ferramenta pode ser usada em uma variedade de indústrias diferentes para
ajudar a solucionar uma variedade de tipos diferentes de problemas de
negócio? A ferramenta foca bem sobre um domínio de problema? Ela foca
bem sobre uma variedade de domínios?
Visualização de Dados
A ferramenta apresenta bem os dados? A ferramenta apresenta bem os
resultados de modelagem? Existe uma variedade de métodos gráficos usados
para comunicar informação?
Fonte: Adaptado de Dias, 2008.
De acordo com Goebel e Gruenwald (1999) e Collier et al. (1999), que foram citados
anteriormente no texto, todos os critérios sugeridos são bastante relevantes, no entanto, deve-
se considerar a real necessidade da organização e feita uma análise cuidadosa de custo e
benefício na aquisição e utilização de uma ferramenta desse tipo (DIAS, 2008).
Os principais critérios para a escolha de uma ferramenta são:
Capacidade de acomodação de diferentes níveis e tipos de usuários sem perda de
funcionalidade ou utilidade;
Capacidade de adaptar-se a diferentes domínios de problema de mineração de dados;
Capacidade de desempenhar limpeza, manipulação, transformação, visualização de
dados e outras tarefas para suporte à mineração de dados;
Capacidade de incluir modelos de dados orientados a objetos ou modelos não
padronizados;
Capacidade de processamento com relação ao tamanho do banco de dados e ao
número máximo de tabelas, tuplas, atributos;
Custo x benefício;

38
Habilidade de acesso a uma variedade de fontes de dados, de forma on-line e off-
line;
Suporte técnico da empresa fornecedora;
Tipo de linguagem de consulta;
Variedade de tipos de atributos que a ferramenta pode manipular.

39
6 CONSIDERAÇÕES FINAIS
A Mineração de dados tornou-se uma área imprescindível pois através de processos e
análises aplicados a grandes bases de dados resultam em descobrimento de informações e
relações que geraram conhecimento, podendo ser aplicado na tomada de decisões nas áreas da
ciência, marketing, medicina, serviços financeiros, etc.
Diante do contexto inserido, o presente trabalho destrinchou com base na literatura a
área de mineração de dados e descoberta de conhecimento com o objetivo de mostrar as
principais tarefas e técnicas para obtenção de resultados quando utilizados a esta área.
Foram abordados como analisar de acordo com a necessidade do usuário os critérios
para a escolha de técnicas e ferramentas da mineração de dados.
Foi dado exemplos em forma de tabelas de como realizar as escolhas de acordo com o
que o usuário poderia possuir, assim, tornando mais fácil o modo de escolha da técnica ou
ferramenta, pois poderia descobrir os prós e contras de tal ao utilizar os
exemplos/questionamentos existentes nas tabelas.

40
REFERÊNCIAS
ALCANTARA, Mariana da Silva. Mineração de Dados em Redes Sociais.
Monografia (Curso de Bacharelado em Sistemas de Informação). Faculdade Sete de
Setembro – FASETE, 2012.
AMORIM, Thiago. Conceitos, técnicas, ferramentas e aplicações de Mineração de Dados
para gerar conhecimento a partir de bases de dados. Monografia (Bacharel em Ciência da
Computação). Universidade Federal de Pernambuco, 2006.
BERRY, Michael J.; LINOFF, Gordon. Data mining techniques. New York: John Wiley &
Sons, Inc., 1997
CAMILO, Cássio Oliveira; SILVA, João Carlos da. Mineração de dados: Conceitos, tarefas,
métodos e ferramentas. Universidade Federal de Goiás (UFC), p. 1-29, 2009.
CARVALHO, Luís Alfredo Vidal de. Data Mining – A Mineração de Dados no Marketing,
Medicina, Economia, Engenharia e Administração. 2005.
CASTANHEIRA, Luciana Gomes. Aplicação de técnicas de mineração de dados em
problemas de classificação de padrões. Belo Horizonte: UFMG, 2008.
CHEN, M.S. et al. Data mining: an overview from database perspective. IEEE Transactions
on Knowledge and Data Engineering,, v. 8, n.6, p. 866-883, 1996.
CHIARA, Ramon. Aplicação de Técnicas de Data Mining em Logs de Servidores Web.
Dissertação (Mestrado). Instituto de Ciências Matemáticas e de Computação - ICMCUSP. 2003.
COLLIER, Ken et al. A methodology for evaluating and selecting data mining software. In:
Systems Sciences, 1999. HICSS-32. Proceedings of the 32nd Annual Hawaii International
Conference on. IEEE, 1999. p. 11 pp.
DA COSTA CÔRTES, Sérgio; PORCARO, Rosa Maria; LIFSCHITZ, Sérgio. Mineração de
dados - funcionalidades, técnicas e abordagens. PUC, 2002.
DAMASCENO, Marcelo. Introdução a Mineração de Dados Utilizando o Weka. Instituto
Federal de Educação, Ciência e Tecnologia do Rio Grande do Norte, 2005.
DE AMO, Sandra. Técnicas de mineração de dados. Jornada de Atualização em Informática,
2004.
DIAS, Maria Madalena. Parâmetros na escolha de técnicas e ferramentas de mineração de
dados. Acta Scientiarum. Technology, v. 24, p. 1715-1725, 2008.
DOS SANTOS SILVA, Marcelino Pereira. Mineração de Dados - Conceitos, Aplicações e
Experimentos com Weka. 2004.
FAYYAD, U. M.; PIATESKY-SHAPIRO, G.; SMYTH, P. From Data Mining to Knowledge
Discovery: An Overview. In: Advances in Knowledge Discovery and Data Mining, AAAI
Press, 1996.
GALVAO, Noemi Dreyer; MARIN, Heimar de Fátima. Técnica de mineração de dados: uma
revisão da literatura. Acta paul. enferm. [online]. 2009, vol.22, n.5, pp.686-690. ISSN 1982-
0194.
GOEBEL, Michael; GRUENWALD, Le. A survey of data mining and knowledge discovery
software tools. ACM SIGKDD explorations newsletter, v. 1, n. 1, p. 20-33, 1999.

41
HAN, Jiawei; PEI, Jian; KAMBER, Micheline. Data mining: concepts and techniques.
Elsevier, 2011.
HARRISON, Thomas H. Intranet data warehouse. São Paulo: Berkeley Brasil, 1998.
LINDGREN, Anders et al. Probabilistic routing protocol for intermittently connected
networks. 2012.
LIU, Bin et al. A hierarchical distributed data mining architecture. In: Machine Learning
and Cybernetics (ICMLC), 2011 International Conference on. IEEE, 2011. p. 40-44.
PASTA, Arquelau. Aplicação da técnica de data mining na base de dados do ambiente de
gestão educacional: um estudo de caso de uma instituição de ensino superior de blumenau-
sc. 2011. Tese de Doutorado. Dissertação de mestrado.
PRASS, Fernando Sarturi et al. Estudo comparativo entre algoritmos de análise de
agrupamentos em data mining. 2004.
ROMÃO, Wesley. Descoberta de conhecimento relevante em banco de dados sobre ciência
e tecnologia. 2002. Tese de Doutorado. Universidade Federal de Santa Catarina.
SANTOS, Fernando Leandro dos. Mineração de opinião em textos opinativos utilizando
algoritmos de classificação. 2014.
SFERRA, Heloisa Helena; CORRÊA, Ângela M. C. Jorge. Conceitos e Aplicações de Data
Mining. 2003.
SILVA, M. P. S.; CÂMARA, Gilberto. Mineração de Dados em Imagens: da Arquitetura à
Ontologia. In: III Workshop dos Cursos de Computação Aplicada do Instituto Nacional de
Pesquisas Espaciais, 2003, São José dos Campos. Anais do III WORCAP. São José dos
Campos: INPE, 2003.
The CRISP-DM Consortium. CRoss Industry Standard Process for Data Mining. 2000.
Disponível em: http://www.crisp-dm.org. Acesso em: 05 nov 2016.
WAGAN, Asif Ali; JUNG, Low Tang. A reliable and intelligent protocol for distributed
data mining architecture in sporadic wireless sensor network. In: Mathematical Sciences
and Computing Research (iSMSC), International Symposium on. IEEE, 2015. p. 202-207.