otimizaÇÃo irrestrita de modelos nebulosos ... - … · j , e ui! são respectivamente o centro...
TRANSCRIPT

40.SBAI- Simpósio Brasileiro de Automação Inteligente, São Paulo, Sp, 08-10 de Setembro de 1999
OTIMIZAÇÃO IRRESTRITA DEMODELOS NEBULOSOS E NEURAIS COM. ESTRUTURA EMCASCATA .
Ricardo J.G. B. [email protected]
Wagner C. [email protected]
DCAlFEEClUnicamp, CP 6101, CEP 13083-970,Campinas, SP
Resumo - Neste trabalho propõe-se uma nova estrutura pa-ra modelagem de sistemas estáticos ou dinâmicos não-lineares.Desenvolve-se essa estrutura a partir de modelos nebulosos ouredes neurais artificiais dispostos em cascata, o que reduz signi-ficativamenteo crescimento da dimensão desses tipos de mode-los com o aumento da complexidade do sistema a ser identifi-cado. Formula-se o problema de estimação dos parâmetros dosmodelos em cascata e obtém-se as equações necessárias para autilização de técnicas de otimização irrestrita na solução desseproblema. Neste contexto, aplica-se e compara-se o desempe- .nho dos algoritmos de gradiente de maior descida e gradienteconjugado de Fletcher-Reeves na identificação de um sistemadinâmico real através dos modelos propostos.
Palavras-Chave: Modelos nebulosos, Redes Neurais, EstruturaCascata, Otimização, Identificação.
1 INTRODUÇÃOA capacidade de processamento e memória dos sistemas com-putacionais atuais tem permitido o desenvolvimento de mode-los matemáticos mais complexos (e eficientes) baseados na teo-ria de sistemas não-lineares. Duas classses fundamentais sãoaquelas constituídas de modelos baseados em lógica nebulo-sa, conhecidos como Modelos Nebulosos (Fuzzy Models), emodelos de Redes Neurais Artificiais (Neural Networks). Osmodelos nebulosos e as redes neurais podem ser aplicados deforma eficiente a uma classe de problemas genérica I . Essacaracterística advém da capacidade de aproximação universaldesses modelos, ou seja, a capacidade de aproximar com pre-cisão arbitrária qualquer mapeamento não-linear contínuo defi-nido sobre uma região compacta (fechada e limitada) do domínio(Kosko 1992)(Haykin 1999)(Kosko 1997). Contudo, devido aessa estrutura genérica, os modelos normalmente requerem umnúmero elevado de parâmetros a serem estimados. Em geral,conforme aumenta a complexidade do mapeamento a ser apro-ximado, principalmente no que diz respeito à dimensão do seuespaço de entrada (número de variáveis envolvidas), ocorre umaumento exponencial na quantidade de parâmetros e dados ne-cessários para se obter uma precisão de aproximação arbitrária.Esse problema é conhecido como "Maldição da Dimensionali-dade" (Curse ofDimensionality) (Kosko 1992)(Haykin 1999).
Neste trabalho propõe-se uma nova estrutura de modelos nebu-
1Isso não ocorrecomos modelos considerados puramente paramétricas , quese ceslringema problemas específicos.
449
losos e redes neurais com uma arquitetura em cascata que ga-rante um crescimento linear (ao invés de exponencial) na quan-tidade de parâmetros em função do número de entradas. Pa-ra o desenvolvimento dos modelos nebulosos e neurais nes-sa nova estrutura, utiliza-se um modelo particular conheci-do como Modelo Relacional Nebuloso Simplificado (Oliveiraand Lemos 1997). Sob certas condições, pode-se demonstrar(Campello and Amaral 1999) que esse modelo é absolutamen-te equivalente a uma rede neural RBF (Radial Basis FunctionNeural Network) (Haykin 1999).
Após formulado, soluciona-se o problema de estimação dosparâmetros dos modelos em cascata através dos algoritmos deotimização irrestrita do Gradiente de Maior Descida e Gradien-te Conjugado de Fletcher-Reeves (Bazaraa and Shetty 1979). Autilização desses algoritmos proporciona garantia de convergên-cia e permite não haver necessidade de cálculo/armazenagemde matrizes Hessianas ou suas inversas, que demandam gran-de esforço computacional, principalmente na presença de umnúmero elevado de variáveis. Esses algoritmos utilizam ape-nas o gradiente da função de custo a ser minimizada, que éobtido neste trabalho a partir da técnica de retro-propagação(Backpropagation) (Haykin 1999).
Esse trabalho é organizado como segue. Na próxima seção osmodelos relacionais simplificados são brevemente revistos co-mo elementos comuns a ambas as classes de modelos nebulo-sos e neurais. Na Seção 3 esses modelos são apresentados emestrutura cascata. Na Seção 4 formula-se o problema de otimi-zação para estimação dos modelos e desenvolve-se as equaçõesde gradiente a partir da técnica de retro-propagação. Na Seção 5aplica-se e compara-se o desempenho dos algoritmosde gradien-te de maior descida e gradiente conjugado de Fletcher-Reevesnasolução doproblema de otimização para identificação de um sis-tema dinâmico real utilizando o modelo em cascata proposto.Finalmente, na Seção 6 apresentam-se as conclusões.
2 MODELOS RELACIONAIS SIMPLIFICA-DOS
Considere, sem perda de generalidade, o seguinte sistema commúltiplas entradas e uma saída (MISO):

j i
: i
! i..
: .....
" , s: c' 3 i
,.' /
;' ,/: .,/ >.
/- ( . - '.-.-.-',n
200
oco
(I)
onde y é a saída do modelo, O = [ 01 Om V é o vetorde parâmetros e íI' = [ íI'1 íI'm V é o vetor nebuloso deentrada. O vetor íI' é dado pelo produto de Kronecker ( (8)) dasentradas nebulosas individuais, isto é,
40. SBAI- Simpósio Brasileiro deAutomação Inteligente, SãoPaulo, SP, 08-10de Setembro de 1999
onde:Fé umoperador não-linear querealiza o mapeamento das 2000
entradasz, (i = 1,' . " n) na saída y. Esse sistema pode ser re- ,...presentado (modelado) por um modelo relacional nebuloso com 1600
estrutura simplificada (Oliveira and Lemos 1997) através da se- "ocguinte equação: 1200
(2)
As entradas X; (i = 1, "', n) são vetores de possibilida-de obtidos pela fuzzificação das entradas não nebulosas Xi
através do .conceito de discretização nebulosa (Willaeys andMalvache 1981)(Pedrycz 1984), isto é,
Figura 1: Número de parâmetros em função do número de en-tradas em modelos com estrutura convencional (para valores dec comumente utilizados).
número elevado de variáveis. Nesse contexto, justifica-se o de-senvolvimento de estruturas que permitam reduzir o problemade dimensionalidade em modelos nebulosos e neurais, como aestrutura em cascata discutida na seção seguinte .
(3)3 ESTRUTURA CASCATA
onde fi; (-) (j = 1, "', c) é o j-ésimo conjunto nebuloso dereferência na i-ésima interface de fuzzificação e c é o númerode conjuntos nebulosos de referência utilizados em cada interfa-ce. É possível demostrar (Campel!o and Amaral 1999) que se asfunções JiJ) (conjuntos nebulosos) forem Gaussianas, então omodelo relacional nebuloso dado pelas equações acima é mate-maticamente equivalente a uma rede neural do tipo RBF, poden-do ser visto como representante comum de ambas as classes demodelos (nebulosos e neurais).
A estrutura de um modelo nebuloso ou neural convencional éilustrada na Fig. 2.
Xl
X2
MN/RN
Como a equação (I) é linear no vetor de parâmetros O, essevetor pode ser estimado para um dado conjunto de valores deentradas e saída utilizando-se algoritmos do tipo Mínimos Qua-drados (Least Squares) (LjungI987). Essa é uma característi-ca interessante uma vez que esses algoritmos são computacio-nalmente simples e em condições adequadas possuem proprie-dades de convergência para valores ótimos globais (Goodwinand Payne 1977). No entanto, sabe-se que conforme aumentao número de parâmetros do modelo a serem estimados tambémaumenta a incerteza sobre esses parâmetros (principalmente napresença de ruído) e consequentemente cresce a imprecisão domodelo (Kashyap and Rao 1976).
Figura 2: Estrutura Convencional de Modelo Nebuloso (MN) ouRede Neural (RN).
Uma alternativa para reduzir os problemas de dimensionalida-de (discutidos na seção anterior) que são apresentados por essesmodelos é a estrutura em cascata ilustrada na Fig. 3.
Nesse contexto, pode-se verificar a partir das equações (2) e (3)que o número de elementos do vetor íI' em (2) é dado por m = c"(sendo a capacidade de aproximação do modelo proporcional aoparâmetro c). Esse também é o número de elementos do vetorO, e portanto a quantidade de parâmetros do modelo a seremestimados. Essa relação exponencial entre as quantidades de en-tradas n e de parâmetros m é ilustrada na Fig. 1, e caracteriza oproblema de dimensionalidade dos modelos nebulosos e neurais.
É importante observar que as consequências do problema dedimensionalidade ilustrado na Fig. 1 podem ser mais críti-cas em modelos que não possuem a propriedade de linearidadenos parâmetros, como por exemplo as redes MLP (Multi-LayerPerceptron) (Haykin 1999). Esses modelos demandam algorit-mos de otimização mais sofisticados que podem se tornar in-viáveis, devido ao esforço computacional, na presença de um
MN /RN
Figura 3: Estrutura Cascata de Modelo Nebuloso (MN) ou RedeNeural (RN).
Nessa estrutura alternativa, que já foi utilizada com suces-so na redução de regras em controladores nebulosos (Raju etai. 1991)(Jamshidi 1997), utilizam-se n - 1 blocos de processa-mento dispostos de forma hierárquica, ao invés de um único blo-co como na estrutura convencional, sendo que cada bloco possui
450
Especificação das Funções 10 e 9(.) comNormalização de Variáveis
3.2
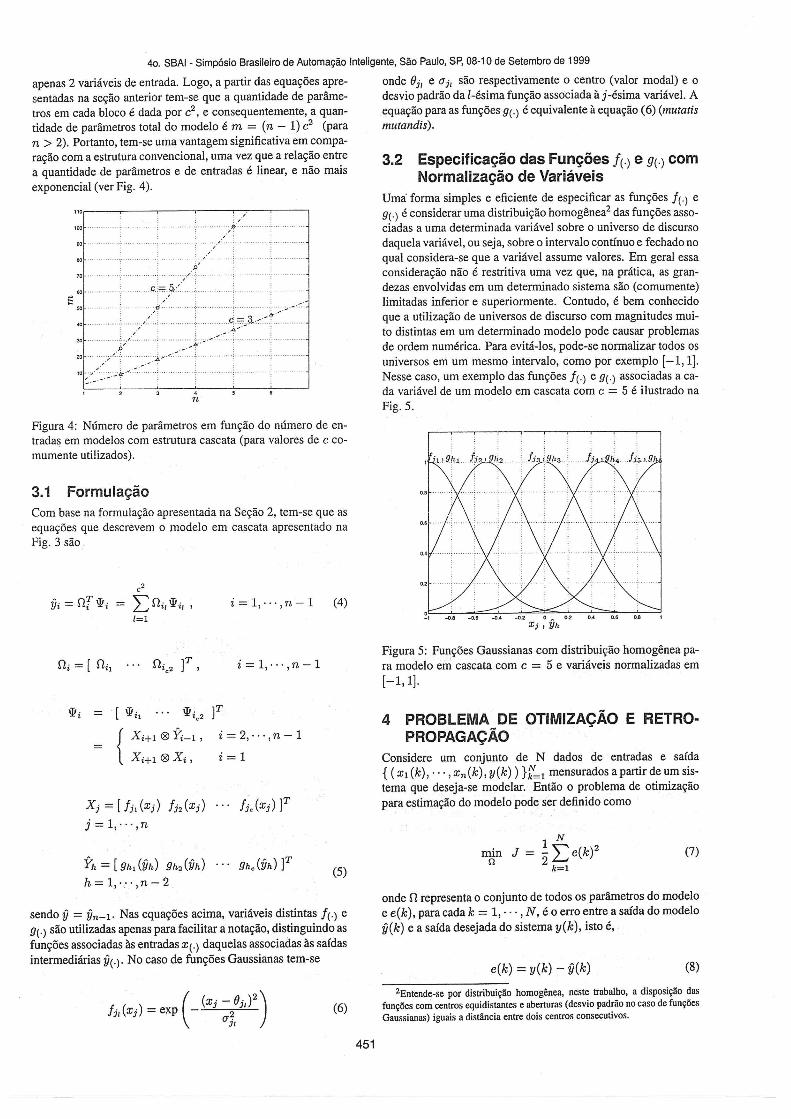
Uma' forma simples e eficiente de especificar as funções A) e9(.) é considerar uma distribuição homogênea? das funções asso-ciadas a uma determinada variável sobre o universo de discursodaquela variável , ou seja, sobre o intervalo contínuo e fechado noqual considera-se que a variável assume valores . Em geral essaconsideração não é restritiva uma vez que , na prática, as gran-dezas envolvidas em um determinado sistema são (comumente)limitadas inferior e superiormente. Contudo, é bem conhecidoque a utilização de universos de discurso com magnitudes mui-to distintas em um determinado modelo pode causar problemasde ordem numérica. Para evitá-los, pode-se normalizar todos osuniversos em um mesmo intervalo, como por exemplo [-1 ,1].Nesse caso, um exemplo das funçõesA) e 9 (.) associadas a ca-da variável de um modelo em cascata com c = 5 é ilustrado naFig.5.
,n
. ..
.'
......:/
/ ; ,j(
.... ·i .. · .
.. ·· .. ·· .. ·
: .-....: ..,. :..... ... .,..... .
,....... ..... .. .;
30 ' \,:. •
A'20
f:: '" ..
70 '
40. SBAI - SimpósioBrasileirode Automação Inteligente, SãoPaulo, SP, 08-10de Setembrode 1999
apenas 2 variáveis de entrada. Logo, a partir das equações apre- onde Bj , e ui! são respectivamente o centro (valor modal) e osentadas na seção anterior tem-se que a quantidade de parâme- desvio padrão da l-ésima função associada à j-ésima variável. Atros em cada bloco é dada por c2 , e consequentemente, a quan- equação para as funções 9( .) é equivalente à equação (6) tmutatistidade de parâmetros total do modelo é m = (n - 1)c2 (para mutandis).n > 2). Portanto, tem-se uma vantagem significativa em compa-ração com a estrutura convencional, uma vez que a relação entrea quantidade de parâmetros e de entradas é linear, e não maisexponencial (ver Fig. 4).
100
/: ."
Figura 4: Número de parâmetros em função do número de en-tradas em modelos com estrutura cascata (para valores de c co-mumente utilizados).
3.1 FormulaçãoCom base na formulaç ão apresentada na Seção 2, tem-se que asequações que descrevem o modelo em cascata apresentado naFig. 3 são
c2
Yi =Df \lf; = L Di l \lf;,1=1
i = 1," ' ,n - 1 (4)o •»s , Yh o.•
Di = [ Di, i = 1, " ' ,n - 1Figura 5: Funções Gaussianas com distribuição homogênea pa-ra modelo em cascata com c = 5 e variáveis normalizadas em[-1 ,1].
\lf i . [ \lf i, '1' i02 V
{X i+1 0 }I;- l , i = 2,' . . ,n - 1
X i+1 0 X, , i = 1
Xj =[ fi, (Xj ) 1i2(Xj) . . . h(Xj)]Tj = 1,' " ,n
4 PROBLEMA DE OTIMIZAÇÃO E RETRO-PROPAGAÇÃO
Considere um conjunto de N dados de entradas e saída{(x1(k) , ··· , xn(k), y(k) ) }t'=1mensurados a partir de um sis-tema que deseja-se modelar. Então o problema de otimizaçãopara estimação do modelo pode ser definido como
Yh = [9h,(Yh) 9h2 (Yh) .. . 9ho (Yh) Vh= 1, ' : ' ,n -2
(5)(7)
onde D representa o conjunto de todos os parâmetros do modeloe e(k), para cada k = 1, . .. ,N, é o erro entre a saída do modeloy(k) e a saída desejada do sistema y(k), isto é,
sendo Y= Yn-1 ' Nas equações acima, variáveis distintas lo e9(.) são utilizadas apenas para facilitar a notação, distinguindo asfunções associadas às entradas x (.) daquelas associadas às saídasintermediárias YO' No caso de funções Gaussianas tem-se
e(k) =y(k) - y(k) (8)
((X·- B· )2)fiz (Xj) =exp - J U;, J I (6)
2Entende-se por distribuição homogênea, neste trabalho, a disposição dasfunções com centros equidistan tes e aberturas (desvio padrão no caso de funçõesGaussianas) iguais a distância entre dois centros consecutivos.
451

d deri d aY2' (k) b id . d (5)on e as enva as 8y;(k) são o ti as a partir e como
Cálculo do Gradiente4.1Seja um modelo em cascata com 4 variáveis de entrada e, por-tanto, 3 blocos (camadas) de processamento, como ilustrado naFig.6.
40. SBAI • Simpósio Brasileirode Automação Inteligente, São Paulo, Sp, 08-10de Setembrode 1999
O problema (7) pode ser solucionado utilizando-se técnicas deotimização irrestrita (Bazaraa and Shetty 1979). Na quase totali-dade dessas técnicas se faz necessário o cálculo do gradiente dafunção custo J, que será abordado a seguir.
ih
MN/RN2
Figura 6: Modelo em Cascata com 4 entra.das.
ôYz;(k) _ ôgz;(Yz(k))BY2(k) - ôyz(k)
e podem ser calculadas numericamente, independente do tipode função g( .). Dessas equações pode-se calcular as derivadasparciais da função J em relação aos parâmetros da camada in-termediária, dadas por
As derivadas parciais de J em relação aos parâmetros do mo-delo são obtidas retro-propagando o erro de estimação ao longodos blocos de processamento através da regra da cadeia. Para acamada de saída tem-se
ôJ _ âJ ôe(k) ôYa(k)ôfh, - ôe(k) ôYa(k) ôn a, '
i = 1, . . . , c2 (9)
(11)
i =1"",2
A partir de (7), (8) e (4) a equação (9) pode ser reescrita como As derivadas parciais de J em relação aos parâmetros da camadade entrada são dadas por
As derivadas parciais de J em relação aos parâmetros da camadaintermediária são dadas por
i = 1," ', c2
ôJ Nôn ' = - L: e(k)lJ! a, (k) ,a, k=l
i = 1, "', c2 (10) ôJôn l ,
ôJ ôe(k) ôY3(k) ôYz(k) Byz(k)ôe(k) ôY3(k) BYz(k) ôyz(k) BYI(k)'
ÔYl (k) ÔYI (k).ÔYl (k) ôn l , '
ôJ _ ôJ ôe(k) ôYa(k) ôYz(k) ôyz(k)Bnz, - âe(k) ôYa(k) ôY2(k) ôyz(k) Bflz,i =1,"', CZ
A obtenção dos termos parciais da equação acima é feita de for-ma análoga ao caso anterior (camada intermediária). Tem-seentão
o cálculo dos termos :;3W) e é análogo ao ca-so anterior (camada de saída). Os termos são obtidoscomo segue. Escrevendo explicitamente a equação da saída domodelo tem-se
c2
Ya(k) == .E S1a,lJ!a, (k) =1=1
n a1X41(k)Y21 (k) + ... + S1acX41(k)Yzc(k)+
!la(C+l)X42(k)Y21 (k) + .. .+ S1a(2c)X42(k)Yzc (k)+
na(cL c+l)Xdk)Yzl (k) +.,. +!l3(c2 )X4c(k)Y2c(k)
Portanto, pode-se verificar que
(12)
i =1,"', c2
Analisando as equações (10), (11) e (12) pode-se induzir aequação geral para a derivada parcial da função custo J em re-lação a qualquer parâmetro de um modelo em cascata com nentradas:
452

40: SBAI - SimpósioBrasileiro deAutomação Inteligente, São Paulo, SP, 08-10de Setembrode 1999
..10..3010
•5
•
•2
1 .......\,
o
onde Àh(k) é uma função que pode ser escrita recursivamente(em h) como .
h = 1, " ',n-1
i = 1," " c2
Àh(k) =Àh+l (k)+(») Ôghj(i)h(k»f=r n(h+I)(lc+j)X(h+2)(I+l) k ôfjh(k)
h = 1,"',n- 2
Figura 7: Evolução do erro quadrático médio (EQM) para oti-mização de modelo em cascata com c = 3: Algoritmos de gra-diente de maior descida (linha cheia) e gradiente conjugado deFletcher-Reeves (linha tracejada),
4.2 Inicialização dos ParâmetrosCom a informação do gradiente disponível, pode-se aplicar osmétodos de otimização irrestrita para treinamento do modelo emcascata. Para definir o ponto de partida dos algoritmos de oti-mização inicializam-se os parâmetros nO do modelo aleatoria-mente, com distribuição uniforme suficientemente próxima a ze-ro, de tal maneira que as saídas dos blocos de processamento domodelo estejam (ao menos aproximadamente) restritas ao inter-valo de normalização [-1, 1].
ximação do modelo), tem-se o desempenho dos algoritmos deotimização ilustrados na Fig. 8. Novamente verifica-se que o al-goritmo de gradiente conjugado obtém convergência em menositerações (57 contra 81 do gradiente de maior descida) e tambémcom esforço computacional inferior (174 .761.345 Flops contra243.919.755 do gradiente de maior descida). Embora nesse casoexista um intervalo do processo de otimização no qual o algorit-mo de maior descida supera o de gradiente conjugado, pode-senotar nas Figuras 7 e 8 que o desempenho desse algoritmo dimi-nui de forma mais critica nas regiões sub-ótimas.
6 CONCLUSÕES E PERSPECTIVAS
Figura 8: Evolução do erro quadrático médio (EQM) para oti-mização de modelo em cascata com c = 5: Algoritmos de gra-diente de maior descida (linha cheia) e gradiente conjugado deFletcher-Reeves (linha tracejada).
Para análise da qualidade do modelo final (identificado com ogradiente conjugado e c = 5) geram-se simulações em previsãol-passo-à-frente e também em série sintética (simulação recursi-va). O resultado das simulações é ilustrado na Fig. 9, mostrandoque um modelo eficiente foi obtido.
Neste trabalho propôs-se uma nova estrutura para modelagemde sistemas não-lineares utilizando modelos nebulosos ou re-des neurais. Essa estrutura possui uma sequência de blocos deprocessamento dispostos em cascata que reduz sensivelmente oaumento da dimensão dos modelos quando aumenta-se a com-plexidade do sistema a ser identificado. Formulou-se o proble-
....to....'"I.
.
,•
2
s Ii,i
1 'T\'. r-,...... .....;-' .'-'. -
.... .. ,•e
1.
. • .0
2.0
Inicialmente, considera-se um modelo em cascata com c = 3.As entradas são aquelas já exaustivamente utilizadas na lite-ratura (e.g . (pedrycz 1984, Xu and Lu 1987 , Sugeno andYasukawa 1993, Lee et ai. 1994»), isto é, X l = u(k - 3),X2 =u(k-4) e X3 =y(k-1). O modelo é estimado utilizando-se os algoritmos de gradiente de maior descida e gradiente conju-gado deFletcher-Reeves. O critério de parada para os algoritmosé o erro quadrático médio (EQM) entre as saídas do sistema y(k)e do modelo fj(k) (dado por EQM = ser inferior a 0.3. Aevolução do EQM ao longo das iterações dos algoritmos é ilus-trada na Fig. 7. Nessa figura pode-se observar que o algoritmode gradiente conjugado converge em um número menor de ite-rações (20) do que o algoritmo de gradiente de maior descida (85iterações). Esse desempenho relativo também se verifica em ter-mos de esforço computacional. A dizer, as operações em pontoflutuante (Flops), com programa Matlab em estação Sun Ultra 1,foram de 27.043.785 para o gradiente conjugado e 108.461.655para o gradiente de maior descida.
Considera-se o processo de Box e Jenkins (Box and Jenkins1970) para ilustrar a identificação de um sistema dinâmico realutilizando modelos em cascata. Este processo consiste de umafornalha onde a entrada u é a taxa de alimentação de gás metano(pés cúbicos por minuto) e a saída y é a concentração de dióxidode carbono (%C02 ) em uma mistura de gases. Dispõe-se de umconjunto de 296 pares de dados de entrada-saída, amostrados doprocesso em períodos de 9 segundos.
5 EXEMPLO
Considera-se em seguida um modelo com c = 5. Repetindoos procedimentos descritos no caso anterior, porém com crité-rio de parada EQM < 0.15 (dada a maior capacidade de apro-
453

Kosko, B. (1992). Neural Networks and Fuzzy Systems: ADyna-mical Systems Approach to Machine Intelligence. PrenticeHall.
Kosko, B. (1997) . Fuizy Engineering. Prentice Hall.
Lee, Y. c ., C. Hwang and Y. P. Shih (1994). A combined ap-proach to fuzzy model identification. IEEE Trans. Systems,Man and Cybernetics 24, 736-743.
Ljung, L. (1987). System Identification: Theory for the user.Prentice Hall.
40. SBAI - Simpósio Brasileiro de Automação Inteligente, São Paulo, SP, 08-10 de Setembro de 1999
Kashyap, R. L. and A. R. Rao (1976) . Dynamic Stochastic Mo-deis from EmpiricalData. Academic Press.
50
o 100 200amostr as
100 1500 200 250 300amostras
Figura 9: Saída do sistema y (linha cheia) e do modelo i) (li-nha pontilhada): EQM = 0.1487 em previsão l-passo-à-frente(acima) e EQM = 0.8903 em série sintética (abaixo).
ma de estimação dos parâmetros dos modelos em cascata como auxílio da técnica de retro-propagação e solucionou-se es-se problema através dos algoritmos de otimização irrestrita dogradiente de maior descida e gradiente conjugado de Fletcher-Reeves . Ilustrou-se o desempenho desses algoritmos através deum exemplo de identificação de um sistema dinâmico real. Nes-se exemplo, verificou-se a conve rgência de ambos os algoritmos(o que já era esperado a partir de resultados teóricos) e verificou-se que o desempenho do algoritmo de gradiente conjugado su-pera o gradiente de maior descida, tanto no que diz respeito aonúmero de iterações quanto ao esforço computacional.
Em trabalhos futuros pretende-se estender os resultados para ocaso de modelos com múltiplas entradas e múltiplas saídas (MI-MO) , bem como estender o problema de otimização e sua for-mulação permitindo que os par âmetros das funções lo e 9 ( .)(centro e abertura) também sejam ajustados.
Oliveira, 1. V. and 1. M. Lemos (1997) . Simplifying fuzzy re-lational structures for adaptive control. In: Proc. 7th IFSAWorld CongressoPrague/Czech Republic. pp. 330-335.
Pedrycz, W. (1984) . An identification algorithm in fuzzy relatio-nal systems. Furry Sets and Systems 13, 153-167.
Raju, G. U., J. Zhou and R. A. Kisner (1991). Hierarchical fuzzycontrol.Int. J. ofControl pp. 1201-1216.
Sugeno, M. and T. Yasukawa (1993) . A fuzzy-logic-based ap-proach to qualitative modeling.IEEE Trans. Fuzzy Systems1,7-31.
WilJaeys, D. and N. Malvache (1981). The use of fuzzy sets forthe treatment of fuzzy information by computer. Fuzzy Setsand Systems 5,323-327.
Xu, C. W. and Y. Z. Lu (1987) . Fuzzy model identification andself-leaming for dynamic systems . IEEE Trans. Systems,Man and Cybernetics SMC-17, 683-689.
AGRADECIMENTOS
Os autores agradecem ao Prof. Dr. Paulo Augusto Valente Fer-reira pelo apoio técnico e também à CAPES e à FAPESP (pro-cesso 99/03902-6) pelo apoio financeiro.
REFERÊNCIAS BIBLIOGRÁFICAS
Bazaraa, M. S. and C. M. Shetty (1979) . Nonlinear Program-ming Theory and Algorithms. John Wiley & Sons.
Box, G. E. P. and G. M. lenkins (1970) . Time Series Analysis,Forecasting and ControloHolden Day.
Campello, R. 1. G. B. and W. C. Amaral (1999) . Equivalênciaentre modelos nebulosos e redes neurais. In: 4° SBAI . SãoPaulolBrasil.
Goodwin, G. C. and R. L. Payne (1977) .Dynamic System Iden-tification: Experiment Design and Data Analysis. Vol. 136of Mathematics in Science and Engineering, AcademicPress.
Haykin, S. (1999). Neural Networks: A Comprehen sive Founda-tion. 2nd ed.. Prentice Hall.
lamshidi, M. (1997). Fuzzy control of complex systems: Struc-tures and implementation. In: Proc. 7th IFSA World Con-gress. Prague/Czech Republic. pp. 324-329.
454