estatistica aplicada exercicios.pdf
TRANSCRIPT

1. Inferência Estatística
Inferência Estatística é o uso da informção (ou experiência ou história) para a
redução
da incerteza sobre o objeto em estudo. A informação pode ou não ser proveniente
de um experimento previamente planejado, pode ser um conjunto de dados ou não.
1.1. Definições Básicas
Definição. As quantidades da população, em geral desconhecidas, sobre as quais
tem-se interesse, são denominadas parâmetros e, usualmente, representadas por
letras gregas tais como α, β, γ, θ, μ, λ, π, ρ, σ, φ, dentre outras.
Definição. À combinação dos elementos da amostra, construída com a finalidade
de representar, ou estimar, um parâmetro de interesse na população, denomina-se
estimador ou estatística. Denota-se os estimadores por símbolos com o acento
circunflexo, tais como α�, β�, γ , θ�, μ , λ�, π�, ρ , σ�, φ�, dentre outras.
Definição. Os valores assumidos pelos estimadores denomina-se estimativas
pontuais ou simplesmente estimativas.
1.2. Propriedades dos estimadores
Definição. Um estimadores θ� é não viciado ou não viesado para um parâmetro θ
se ��θ�� = θ. Ou seja, um estimador é não viciado se o seu valor esperado é
exatamente o valor do parâmetro.
Definição. Um estimador θ� é consistente se as duas condições são satisfeitas: �)����→���θ�� = θ; ��)����→�����θ�� = 0. Ou seja, se, à medida que o tamanho da amostra aumenta, seu valor esperado
converge para o parâmetro e sua variância converge para zero.
Definição. Dado dois estimadores θ� e θ�!, não viciados em relação à θ, diz-se que θ� é mais eficiente que θ�! se ����θ� � < ����θ�!�.

Exercício: Baseado nas definições das propriedades dos estimadores demonstre
os resultados que seguem no quadro abaixo:
Parâmetro Estimador Propriedades
μ #$ = ∑ #&�&' ( Não viciado e
consistente
) )̂ = (+,-�(,�.í,012(���123��41�,�,�4���43-�í23�4�(
Não viciado e
consistente
σ! 5! = 1( − 189#& − #$)!�&'
Não viciado e
consistente
σ! σ!: = 1(89#& − #$)!�&'
Viciado e
consistente
1.3. Distribuição Amostral
1.3.1. Distribuição Amostral da Média
Seja uma população identificada pela variável aleatória X, cujos parâmetros média
populacional < = �9#) e variância populacional =! = ���9#) são supostamente
conhecidos. Retira-se todas as amostras possíveis de tamanho ( dessa população
e para cada uma delas, calcular a média X>.
Supõe-se a seguinte população ?2, 3, 4, 5E com média < = 3,5 e variância =! = 1,25.
Vamos relacionar todas as amostras possíveis de tamanho 2, com reposição, desta
população.
(2,2) (2,3) (2,4) (2,5)
(3,2) (3,3) (3,4) (3,5)
(4,2) (4,3) (4,4) (4,5)
(5,2) (5,3) (5,3) (5,5)

Agora, calcula-se a média de cada amostra. Tem-se:
2,0 2,5 3,0 3,5
2,5 3,0 3,5 4,0
3,0 3,5 4,0 4,5
3,5 4,0 4,5 5,0
Por fim, vamos calcular a média das médias, ou seja,
�9#$) = 2,0 + 2,5 + ⋯+ 5,016 = 3,5
Agora, calcula-se a variância:
���9#$) = 1(89#& − #$)!�&' = 1( 9# − #$)! + 9# − #$)! +⋯+ 9#� − #$)!
���9#$) = 1( [92,0 − 3,5)! + 92,5 − 3,5)! +⋯+ 95,0 − 3,5)!] ���9#$) = 0,625
Sendo assim, ���9#$) = KLM9N)� , em que ( é o tamanho das amostras retiradas da
população. No nosso exemplo,
���9#$) = ���9#)( = 1,252 = 0,625
Exemplo: Seja o caso de uma população Normal, isto é, a variável de interesse é
#~P1���Q9μ, σ!). Portanto, tem-se que 9# , #!,⋯ , #�) representa uma amostra
aleatória cujos elementos são independentes, e identicamente distribuídos, com
densidade Normal de média μ e variância =!, ou seja:
#&~P1���Q9<, =!), � = 1,⋯ , (;

#&é�(,-)-(,-(3-,-#S, )���31,1� ≠ U. Sabe-se que para quaisquer constantes � , �!, ⋯ , ��, a combinação linear ∑ �&�&'
também tem distribuição de probabilidade dada pelo modelo Normal. A distribuição
da média amostral segue diretamente deste resultado ao utilizar-se �& = �, para
� = 1,⋯ , (. Assim, #$~P1���QVμN$ , σN$!W, e, com o auxílio das propriedades da
esperança e variância tem-se que:
μN$ = �[#$] = � X1(8#&�&' Y = 1(� X8#&�
&' Y = 1(8�[#&]�&' = 1(8μ�
&' = 1( (μ = μ; σN$! = ���[#$] = ��� X1(8#&�
&' Y = 1(! ��� X8#&�&' Y = 1(!8���[#&]�
&' = 1(!8σ!�&' = 1(! (σ!
= 1(σ!. Conclui-se que para uma coleção de variáveis aleatórias independentes com uma
mesma distribuição de probabilidade, dada por um modelo Normal com média < e
variância =!, a média amostral #$ também terá distribuição Normal, com média < e
variância Z[� . Ou seja:
#$~P1���Q \<, =!( ] ⟹ _ = #$ − <=√( ~P1���Q90, 1).
Observação: Se a população é finita e de tamanho P conhecido, e se a amostra de
tamanho ( dela retirada é sem reposição, então:
σN$! = =√(aP − (P − 1. Onde bcd�cd é o fator de correção para população finita.
Exemplo: Seja # , #!,⋯ , #!e uma amostra aleatória de uma variável aleatória # tal
que #~P1���Q980, 26). Calcule:

a. g9#$ > 83) = gi_ > jkdjlb[m[n
o = g9_ > 2,94) = 0,001641;
b. g9#$ < 82) = gi_ < j!djlb[m[n
o = g9_ < 1,96) = 0,975002;
c. g9μN$ − 2σN$ < #$ < μN$ + 2σN$) = g \80 − 2b!r!e < #$ < 80 + 2b!r!e]
⟹ g977,96 < #$ < 82,04) = gst77,96 − 80
b2625< _ < 82,04 − 80
b2625 uv
⟹ g9−2 < _ < +2) = 0,954500.
Exercício: Seja # , #!,⋯ , #!l uma amostra aleatória de uma variável aleatória # tal
que #~P1���Q9100, 85). Calcule:
a. g995 < #$ < 105); b. g998 < #$ < 102); c. g wμN$ − Zy !z σN$ < #$ < μN$ + Zy !z σN${ = 0,95.
Teorema Central do Limite – TCL
Seja # , #!, ⋯ , #� uma amostra aleatória simples de tamanho ( de uma população
com média < e variância =! (note que o modelo da variável aleatória não é
especificado), então a média amostral #$ também terá distribuição Normal, com
média < e variância |[� , ou seja:
#$~P1���Q \<, =!( ] ⟹ _ = #$ − <=√( ~P1���Q90, 1).
Exercício: Supõe-se que o consumo mensal de água por residência em um certo
bairro mineiro tem distribuição normal com média 10 e desvio padrão 2 (em �k).

Para uma amostra de 25 dessas residências, qual é a probabilidade de a média
amostral não se afastar da verdadeira média por mais de 1�k?
Exercício: Um fabricante afirma que produz em média 75 componentes por dia com
desvio padrão de 10 componentes por dia. Para uma amostra de 1mês (25 dias
úteis), qual a probabilidade de a média amostral ficar entre 70 e 80 componentes
dia? Se o fabricante estabelecer uma meta média mensal de 80 componentes por
dia, qual a probabilidade de ser alcançada?
1.3.2. Distribuição Amostral da Proporção
Uma aplicação importante do TCL relaciona-se com a distribuição da proporção
amostral, que é definida como a fração dos indivíduos com uma dada característica
em uma amostra de tamanho (, isto é:
)̂ = (+,-�(,�.í,012(���123��41�,�,�4���43-�í23�4�( . Seja a proporção de indivíduos com a dada característica na população é ) e que os
indivíduos são selecionados aleatóriamente, tem-se assim que } , }!, ⋯ , }� formam
uma sequência de variáveis aleatórias independentes com distribuição de Bernoulli,
ou seja, }&~~-�(10QQ�9)). Desta forma:
�}& = 12-1-Q-�-(31,�)1)0Q�çã13-��4���43-�í23�4�}& = 02-1-Q-�-(31,�)1)0Q�çã1(ã13-��4���43-�í23�4�
Logo, g9}& = 1) = ), g9}& = 0) = 1 − ), �[}&] = ), ���[}&] = )91 − )). Pode-se reescrever a proporção amostral como:
)̂ = } + }! +⋯+ }�( = ∑ }&�&' ( = }$. Logo, a proporção amostral é a média de variáveis aleatórias convenientemente
definidas. Calculando a esperança e variância de )̂ tem-se que:
μ� = �[)̂] = � X1(8}&�&' Y = 1(� X8}&�
&' Y = 1(8�[}&]�&' = 1(8)�
&' = 1( () = );

σ� ! = ���[)̂] = ��� X1(8}&�&' Y = 1(! ��� X8}&�
&' Y = 1(!8���[}&]�&' = 1(!8)91 − ))�
&' = 1(! ()91 − )) = )91 − ))( ;
Portanto, μ� = ), σ� ! = �9 d�)� , σ� = b�9 d�)� . Desta forma, pelo TCL:
)̂~P1���Q \), )91 − ))( ] ⟹ _ = )̂ − )b)91 − ))(
~P1���Q90, 1). Observação: Quando ) é desconhecida e a amostra com reposição é grande,
determina-se )̂ = �� e σ� ≈ b� 9 d� )� . Para alguns autores e estatísticos, uma amostra
é suficientemente grande quando () ≥ 5 e (91 − )) ≥ 5.
Exemplo: Em uma população, a proporção de pessoas favoráveis a uma
determinada lei é de 40%. Retira-se uma amostra de 300 pessoas dessa população.
Determine g w) − Zy !z σ� < )̂ < ) + Zy !z σ� { = 0,95.
Dado que ( = 300 e ) = 0,40, então σ� = b�9 d�)� = bl,�l9 dl,�l)kll = 0,0283. Tem-se
que Z!,e% = 1,96, então:
g90,4 − 1,96 × 0,0283 < )̂ < 0,4 + 1,96 × 0,0283) = 0,95
⟹ g90,4 − 0,0555 < )̂ < 0,4 + 0,0555) = 0,95
⟹ g90,3445 < )̂ < 0,4555) = 0,95
⟹ g934,45% < )̂ < 45,55%) = 0,95
Exemplo: Deseja-se obter a proporção de estudantes de Economia e Administração
portadores de habilidades intrínsecas de gestão e liderança. Retira-se uma amostra
de 400 estudantes, obtendo-se 8 portadores de tais habilidades. Determine um
intervalo de confiabilidade de 99% para a proporção populacional.
g w)̂ − Zy !z σ� < ) < )̂ + Zy !z σ� { = 0,99

Dado que ( = 400 e )̂ = �� = j�ll = 0,02, então σ� ≈ b� 9 d� )� = bl,l!9 dl,l!)�ll = 0,007.
Tem-se que Zl,e% = 2,57, então:
g90,02 − 2,57 × 0,007 < ) < 0,02 + 2,57 × 0,007� = 0,99
⟹ g90,02 − 0,018 < ) < 0,02 + 0,018� = 0,99
⟹ g90,002 < )̂ < 0,038� = 0,99
⟹ g90,2% < )̂ < 3,8%� = 0,99.
Exercício: Uma fábrica de peças específica em suas embalagens que a proporção
de defeitos é de 4%. Um cliente dessa fábrica inspeciona uma amostra de 200
peças e constata que 12 são defeituosas. Baseado nesses dados, em quantas
amostras o cliente encontraria uma proporção de defeitos maior que o especificado
pelo fabricante?
1.3.3. Distribuição t-Student
O trabalho desenvolvido por W. S. Gosset (que o divulgou sob o pseudônimo de 530,-(3), no começo dos anos 1900 resultou na distribuição 3 − 530,-(3, ou mais
simplesmente a distribuição 3.
Definição. Seja # , #!,⋯ , #� uma amostra aleatória de uma distribuição
#~P1���Q9<, =!�. A quandidade N$d��√� , σN$� = �√�, tem distribuição 3 − 530,-(3, com
( − 1 graus de liberdade. Ou seja:
#$ − <2√( ~3�d Pode-se verificar que:
#$ − <2√( = √(9#$ − <�2 = √(9#$ − <�=2= = √(9#$ − <�=b2!=!
= √(9#$ − <�=b9( − 1�2!=! 19( − 1�
= P90; 1�a ��d !9( − 1�
⟹ #$ 7 <2√( ~3�d .
A função de densidade de probabilidade de uma variável aleatória � que tem
distribuição 3 7 530,-(3 com ) graus de liberdade (denota-se por �~3�) é:
��93� � � w) F 12 {� w)2{
19)�� !⁄ 191 F 3! )⁄ �9�� � !⁄ , 7∞ � 3 " ∞.
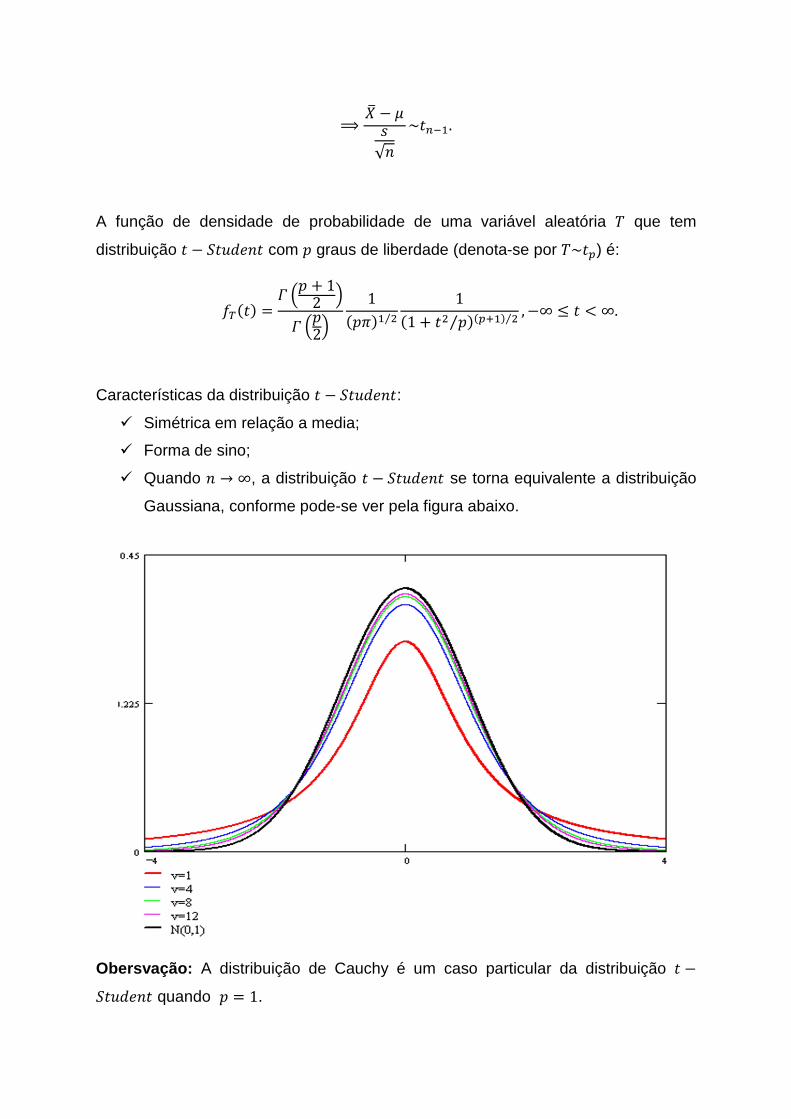
Características da distribuição 3 7 530,-(3: � Simétrica em relação a media;
� Forma de sino;
� Quando ( → ∞, a distribuição 3 7 530,-(3 se torna equivalente a distribuição
Gaussiana, conforme pode-se ver pela figura abaixo.
Obersvação: A distribuição de Cauchy é um caso particular da distribuição 3 7530,-(3 quando ) � 1.

Exemplo: Calcule as probabilidades por meio da tabela da distribuição 3 7 530,-(3. a. g93 l > 2,2281) = 0,025;
b. g93 l < −2,2281) = 0,025;
c. g93 ll > 1,9759) = 0,025;
d. g93 ll < −1,9759) = 0,025;
e. g93 ll > 1,9600) = 0,025;
f. g93 ll < −1,9600) = 0,025;
g. g93� > 1,4149) = 0,100;
h. g93� < −1,4149) = 0,100;
i. g93� > 1,8949) = 0,050;
j. g93� < −1,8949) = 0,050;
k. g93� > 2,3646) = 0,025;
l. g93� < −2,3646) = 0,025;
m. g93� > 2,9980) = 0,010;
n. g93� < −2,9980) = 0,010;
o. g93� > 3,4995) = 0,005;
p. g93� < −3,4995) = 0,005.
Exemplo: Seja # , #!,⋯ , #!e uma amostra aleatória de uma variável aleatória # tal
que #~P1���Q980, σ!). Dada a variância amostral 5! = 26 e por meio da
distribuição 3 − 530,-(3 pode-se calcular:
a. g9#$ > 83) = gi3!� > jkdjlb[m[n
o = g93!� > 2,94) = 0,0035779��4-Q); b. g9#$ < 82) = gi3!� < j!djl
b[m[no = g93!� < 1,96) = 0,9691479��4-Q);
c. g9μN$ − 2σN$� < #$ < μN$ + 2σN$�) = g \80 − 2b!r!e < #$ < 80 + 2b!r!e]

⟹ g977,96 < #$ < 82,04) = gst77,96 − 80
b2625< 3!� < 82,04 − 80
b2625 uv
⟹ g9−2 < 3!� < +2) = 0,9430609��4-Q).
Exercício: Por meio da tabela da distribuição 3 − 530,-(3: a. Calcule g93! > 0,6864); b. Calcule g93kr < −2,4345); c. Calcule g93e > 2,6757); d. Obtenha � tal que g93e > �) = 0,250;
e. Obtenha � tal que g93 � > �) = 0,100;
f. Obtenha 4 tal que g93�l > 4) = 0,050;
g. Obtenha , tal que g93�� < −,) = 0,010;
h. Obtenha - tal que g93 !l < −-) = 0,005;
Exercício: Seja # , #!,⋯ , #!l uma amostra aleatória de uma variável aleatória # tal
que #~P1���Q9100, σ!). Dada a variância amostral 5! = 85, calcule:
a. g995 < #$ < 105); b. g998 < #$ < 102); c. g wμN$ − 3y !z σN$� < #$ < μN$ + 3y !z σN$�{ = 0,95.
1.4. Intervalo de Confiança (uma população)
Em todas as áreas do conhecimento existe a necessidade de se obter conclusões a
respeito dos parâmetros de uma população. A estimação destes parâmetros pode
ser realizada por meio de estimação pontual ou estimação por intervalo.
Estimação Pontual
É pontual quando a estimativa do parâmetro é representada apenas por um valor. A
principal desvantagem é que a estimativa pontual é pouco informativa. Esta
estimação não fornece nenhuma idéia do erro que se comete ao assumir o valor da
estimativa como igual ao verdadeiro valor do parâmetro desconhecido.
Estimação Intervalar
É intervalar quando estabelece-se um intervalo que contém, com uma determinada
probabilidade pré-estabelecida, o verdadeiro valor do parâmetro desconhecido.
Uma maneira de se expressar a precisão da estimação é estabelecer limites da
forma I�, �J dy, que, probabilidade 1 7 �, incluam o verdadeiro valor do parâmetro
de interesse. Sendo assim, a estimação por intervalo consiste na fixação de dois
valores, �, e �, tais que 91 7 �� seja a probabilidade de que o intervalo, por eles
determinado, contenha o real valor de �.
O intervalo I�, �J pode ser constituído a partir das distribuições amostrais. Ou seja,
utilizando as distribuições de amostragem, pode-se obter expressões do tipo: g9� " < " �� � 1 7 � g9� " ) " �� � 1 7 � g9� " =! " �� � 1 7 �
Assim, pode-se interpretar sob as expressões acima que existe 10091 7 ��% de
confiança que o verdadeiro valor de <, ) e =! esteja contido no intervalo I�, �J. Em
outras palavras, I�, �J é uma estimativa para <, ) e =! em que a probabilidade 91 7 �� ou 10091 7 ��% expressa o grau de confiança que se tem na estimação.
Se I�, �J é uma estimativa com 10091 7 ��% de confiança para �, então,
� O intervalo Ia, bJ é chamado intervalo de confiança para θ.
� a e b são chamados “limite inferior” e “limite superior” do intervalo de
confiança para θ.
� A probabilidade 91 7 α� � 10091 7 α�% é chamada coeficiente de confiança.
� A probabilidade α é chamada nível de significância.

1.4.1. Intervalo de confiança para a média populaci onal
1.4.1.1. Intervalo de confiança para a média popula cional com variância
populacional ¡¢ conhecida
Pelo TCL tem-se que #$~P1���Q w<, Z[� { ⟹ _ � N$d�£√� ~P1���Q90, 1�, então:
gV7¤y !⁄ � _ � F¤y !⁄ W � 1 7 �
g \7¤y !⁄ � #$ 7 <= √(⁄ � F¤y !⁄ ] � 1 7 �
g ¥7¤y !⁄ =√( 7 #$ � 7< � F¤y !⁄ =√( 7 #$¦� 1 7 �
g ¥#$ 7 ¤y !⁄ =√( � < � #$F¤y !⁄ =√(¦ � 1 7 �
Sendo assim, o intervalo com 91 7 α� � 10091 7 α�% de confiança para < com =!
conhecida é:
§ 9̈ dy�9<� � ©#$ 7 ¤y !z =√( ; #$ F ¤y !z =√(ª.
Observação:
1. Denota-se � � #$ 7 < � ¤y !z Z√� por erro padrão ou erro de estimação;
2. Os níveis de confiança de confiança mais usados são: 1 7 α � 0,90 ⟹ ¤y !z � ¤e,l% � «1,64; 1 7 α � 0,95 ⟹ ¤!,e% � «1,96; 1 7 α � 0,99 ⟹ ¤l,e% � «2,58.
Exemplo: A especificação de uma peça é uma variável aleatória # com =! � 9. O
setor de controle de qualidade extraiu uma amostra de tamanho 25 e obteve ∑ #& � 152!e&' . Deseja-se determinar o intervalo de confiança de 90% e o erro de
estimação para a média populacional da especificação da peça.

#$ � 1258#& = 6,08!e&'
σN$ = =√( = 3√25 = 0,60
¤e,l% � «1,64
g ¥#$ − ¤y !⁄ =√( ≤ < ≤ #$+¤y !⁄ =√(¦ = 1 − �
g96,08 − 1,64 × 0,60 ≤ < ≤ 6,08 + 1,64 × 0,60) = 0,90 g95,096 ≤ < ≤ 7,064) = 0,90 §¨�l%9<� � I5,096; 7,064] ���1)�,�ã1 = ¤y !⁄ =√( = 1,64 × 0,60 = 0,984.
Exercício: Obtenha os intervalos de confiança de 95% e 99% e o erro de estimação
para a média populacional da especificação da peça do exemplo anterior.
Exemplo: De uma população de 1000 elementos com distribuição
aproximadamente Normal com =! = 400, tira-se uma amostra de 25 elementos,
obtendo-se #$ = 150. Obtenha o intervalo de confiança para um nível de significância
de � = 5%.
σN$ = =√(aP − (P − 1 = √400√25 a1000 − 251000 − 1 = 3,95
¤!,e% = ±1,96
g ¥#$ − ¤y !⁄ =√( ≤ < ≤ #$+¤y !⁄ =√(¦ = 1 − �
g9150 − 1,96 × 3,95 ≤ < ≤ 150 + 1,96 × 3,95� = 0,95 g9142,25 ≤ < ≤ 157,75� = 0,95 §¨�e%9<� = I142,25; 157,75J ���1)�,�ã1 = ¤y !⁄ =√(aP − (P − 1 = 1,96 × 3,95 = 7,742.

Exercício: Obtenha os intervalos de confiança de 90% e 99% para a média
populacional e o erro de estimação dos dados do exemplo anterior.
1.4.1.2. Intervalo de Confiança para a média popula cional com variância
populacional ¡¢ desconhecida
Pelo TCL tem-se que #$~P w<; Z[� { ⟹ _ � N$d�£√� ~P90; 1�. No entanto, quando não se
conhece a variância populacional, situação mais comum na prática, se as amostras
forem pequenas tem-se que utilizar a distribuição 3 7 530,-(3. Sabe-se ainda que
N$d��√� ~3�d , desta forma, um intervalo com 91 7 α� � 10091 7 α�% de confiança para
< é:
§ 9̈ dy�9<� � ©#$ 7 3�d ;y !z 5√( ; #$ F 3�d ;y !z 5√(ª. Onde 5 é o desvio padrão amostral e 3�d ;y !z é o valor tabelado da distribuição
3 7 530,-(3.
Observação:
1. Denota-se - � #$ 7 < � 3�d ;y !z Z√� por erro padrão ou erro de estimação;
2. Quando ( → ∞, a distribuição 3 7 530,-(3 se torna equivalente a distribuição
Gaussiana. Por esta razão, alguns autores sugerem o uso da distribuição
Gaussiana quando ( > 30.
Exemplo: A amostra ?9, 8, 12, 7, 9, 6, 11, 6, 10, 9E foi extraída de uma população
aproximadamente normal. Deseja-se construir um intervalo de confiança para < com
um nível de 95% de confiança.

#$ � ∑ �&�&' ( � 8,7
5! = ∑ 9�& − #$)!�&' ( − 1 ≅ 4 ⟹ 5 ≅ 2
��02,-Q��-�,�,- = ( − 1 = 10 − 1 = 9 3�d ;y !⁄ = 3�;!,e% � «2,262
§ 9̈ dy)9<) = ©#$ − 3�d ;y !z 5√( ; #$ + 3�d ;y !z 5√(ª §¨�e%9<� � ©8,7 − 2,262 2√10 ; 8,7 + 2,262 2√10ª §¨�e%9<� � I7,27; 10,13]
���1)�,�ã1 = 3�d ;y !⁄ 5√( = 2,262 × 2√10 = 1,43.
Exercício: Obtenha os intervalos de confiança de 90% e 99% para a média
populacional e o erro de estimação dos dados do exemplo anterior.
Exercício: Por meio de uma amostra aleatória simples referente ao numero de
ocorrências criminais num certo bairro na cidade de São Paulo, coletada durante 30
dias, obteve-se os seguintes valores:
7 11 8 9 10 14 6 8 8 7 8 10 14 12 14 12 9 11 13 13 8 6 8 13 10 14 5 14 10 10
Construa um intervalo de confiança de 90%, 95% e 99%.
1.4.2. Intervalo de confiança para a proporção popu lacional ®
Pelo TCL tem-se que )̂~P1���Q w), �9 d��� { ⟹ _ = � d�b¯9°±¯��
~P1���Q90, 1�. Logo, o
intervalo com 91 − �� = 10091 − ��% de confiança para ) é:
§ 9̈ dy�9)� = ²)̂ − ¤y !z a)̂91 − )̂�( ; )̂ + ¤y !z a)̂91 − )̂�( ³.
Observação:
1. Denota-se - = )̂ − ) = ¤y !z b� 9 d� �� por erro padrão ou erro de estimação;

2. Tem-se que )̂ � �� e para ( suficientemente grande σ� ≈ b� 9 d� �� . Para alguns
autores e estatísticos, uma amostra é suficientemente grande quando () ≥ 5
e (91 − )) ≥ 5;
3. Se a população é finita e de tamanho P conhecido, e se �c ≤ 0,05,
σ� ≈ b� 9 d� )� bcd�cd , onde bcd�cd é o fator de correção para população finita;
4. Pode-se utilizar )91 − )) = � se desejar ser conservador na estimativa da
variância populacional.
Exemplo: Pretende-se estimar a proporção p de peças que atendem às
especificações/exigências para exportação. Em uma amostra selecionada de
tamanho 200, escolhida ao acaso, observou-se que 160 deles apresentam as
exigências atendidas. O que pode-se dizer da proporção p na população em geral?
(use � = 5%)
�23���3�.�g1(30�Q:)̂ = �( = 160200 = 80%
¤!,e% = ±1,96
§ 9̈ dy)9)) = ²)̂ − ¤y !z a)̂91 − )̂)( ; )̂ + ¤y !z a)̂91 − )̂)( ³ §¨�e%9)) = ²0,8 − 1,96 × a0,891 − 0,8)200 ; 0,8 + 1,96 × a0,891 − 0,8)200 ³
§ 9̈�e%)9)) = [0,745; 0,855]. ���1)�,�ã1 = ¤y !z a)̂91 − )̂)( = 1,96 × a0,891 − 0,8)200 = 0,055.
Exercício: Obtenha os intervalos de confiança de 90% e 99% para a proporção
populacional e o erro de estimação dos dados do exemplo anterior.
Exercício: O setor de controle de qualidade esta intervindo em um processo
produtivo por acreditar que a proporção de peças fora das especificações esta muito
elevado. Uma amostra de 100 peças foi avaliada e observou-se 20 peças fora das

especificações. Sendo � � 1%, determine um intervalo de confiança para a
proporção de peças defeituosas deste processo produtivo. µ: § 9̈��%)9)) = [9,72%; 30,28%]
Exercício: Para se estimar a porcentagem de alunos de um curso favoráveis a
modificação do currículo escolar, tomou-se uma amostra de 100 alunos, dos quais, 80 foram favoráveis. Construa um intervalo de confiança a 96% para a proporção de
todos os alunos favoráveis a modificação. µ:§ 9̈�r%)9)) = [71,8%; 88,2%]
1.4.3. Intervalo de confiança para a variância popu lacional ¡¢
Uma variável aleatória obtida por �! = 9�d )¶[Z[ é definida como ·0� − ·0�,��,1 com
9( − 1) graus de liberdade. Desta forma, o intervalo com 91 − �) = 10091 − �)% de
confiança para =! é:
§ 9̈ dy)9=!) = ² 9( − 1)5!�V�d ;y !z W¸! ; 9( − 1)5!�V�d ;y !z W¹! ³. Onde 5 = b �d ∑ 9#& − #$)!�&' é o desvio padrão amostral e �V�d ;y !z W¸! e �V�d ;y !z W¹!
são os valores tabelados da distribuição ·0� − ·0�,��,1.
Exemplo: Observou-se a volatilidade (variância) da g-3�4 durante 42 dias úteis e
obteve-se uma variância amostral de 5! = 0,45945%�1�(1). Deseja-se construir
um intervalo de confiança de 95% para a volatilidade da g-3�4. �V�d ;y !z W¸! = �� ;!,e%! = 60,561
�V�d ;y !z W¹! = �� ;��,e%! = 25,215
§ 9̈ dy)9=!) = ² 9( − 1)5!�V�d ;y !z W¸! ; 9( − 1)5!�V�d ;y !z W¹! ³ §¨�e%9=!) = ©41 × 0,4560,561 ; 41 × 0,4525,215 ª §¨�e%9=!) = [30,42%; 73,17%]

Exercício: Obtenha os intervalos de confiança de 98% e 99% para a variância
populacional dos dados do exemplo anterior.
Exemplo: Observou-se a volatilidade (variância) da ��Q-5 durante 42 dias úteis e
obteve-se uma variância amostral de 5! = 0,55955%�1�(1). Deseja-se construir
um intervalo de confiança de 98% e 99% para a volatilidade da ��Q-5.
Observação: Quando a média populacional < é conhecida, o intervalo com 91 − �) = 10091 − �)% de confiança para =! é:
§ 9̈ dy)9=!) = ² (5!�V�;y !z W¸! ; (5!�V�;y !z W¹! ³. Onde 5 = b �∑ 9#& − <)!�&' é o desvio padrão amostral e �V�;y !z W¸! e �V�;y !z W¹! são os
valores tabelados da distribuição ·0� − ·0�,��,1.
1.5. Cálculo de tamanho de amostra
1.5.1. Cálculo de tamanho de amostra para a estimaç ão da média
populacional
Pelo TCL tem-se que #$~P1���Q w<, Z[� { ⟹ _ = N$d�£√� ~P1���Q90, 1), então:
_ = #$ − <=√( ⟹ #$ − < = ¤y !⁄ =√( ⟹ √( = ¤y !⁄ =#$ − < ⟹ ( = ¥¤y !⁄ =#$ − <¦! ⟹ ( = V¤y !⁄ =W!�! . Onde � = #$ − < é o erro de estimação aceitável.
Para o caso em que a população é finita, inclue-se o fator de correção bcd�cd , então:
( = PV¤y !⁄ =W!9P − 1)�! + V¤y !⁄ =W!.

1.5.2. Cálculo de tamanho de amostra para a estimaç ão da proporção
populacional
Pelo TCL tem-se que )̂~P1���Q w), �9 d�)� { ⟹ _ = � d�b¯9°±¯)�
~P1���Q90, 1), então:
_ = )̂ − )b)̂91 − )̂)(
⟹ )̂ − ) = ¤y !⁄ a)̂91 − )̂)( ⟹ √( = ¤y !⁄ º)̂91 − )̂))̂ − )
⟹ ( = »¤y !⁄ º)̂91 − )̂))̂ − ) ¼! ⟹ ( = V¤y !⁄ W!)̂91 − )̂)�! . Onde � = )̂ − ) é o erro de estimação aceitável.
Para o caso em que a população é finita, inclue-se o fator de correção bcd�cd , então:
( = PV¤y !⁄ W!)̂91 − )̂)9P − 1)�! + V¤y !⁄ W!)̂91 − )̂).
Exemplo: O Instituto DataVoto desenvolverá no próximo mês pesquisa de intenção
de voto, para um candidado particular, estabelecendo um intervalo de confiança de
99%. Deseja que a proporção amostral esteja entre ±3% da proporção
populacional. Em uma campanha eleitoral recente, estimou-se que 220 eleitores,
entre 500 entrevistados, preferem este candidato em particular. Deseja-se estimar o
tamanho de amostra adequado considerando população finita de tamanhos 1000, 10000, 20000 e população infinita.
)̂ = �( = 220500 = 44%
¤y !⁄ = 2,576
� = 3%
g���P��(�31 ⟹ ( = PV¤y !⁄ W!)̂91 − )̂)9P − 1)�! + V¤y !⁄ W!)̂91 − )̂) g���P = 1000 ⟹ ( = 100092,576)!0,4491 − 0,44)91000 − 1)0,03! + 92,576)!0,4491 − 0,44) ≈ 645)-221�2;

g���P � 10000 ⟹ ( = 1000092,576)!0,4491 − 0,44)910000 − 1)0,03! + 92,576)!0,4491 − 0,44) ≈ 1537)-221�2; g���P = 20000 ⟹ ( = 2000092,576)!0,4491 − 0,44)920000 − 1)0,03! + 92,576)!0,4491 − 0,44) ≈ 1665)-221�2;
g���P�(��(�31 ⟹ ( = V¤y !⁄ W!)̂91 − )̂)�!
g���P�(��(�31 ⟹ ( = 92,576)!0,4491 − 0,44)0,03! ≈ 1817)-221�2.
Exercício: Estime o tamanho de amostra adequado para um erro de estimação de ±2% considerando população finita de tamanhos 5000 e 50000 e população infinita.
1.6. Intervalo de Confiança (duas populações)
1.6.1. Intervalo de confiança para diferença de méd ias 9 ½ − ¢) com
variâncias ¡½¢ e ¡¢¢ conhecidas.
Seja # ~P9< ; = !) e #!~P9<!; =!!) variáveis aleatórias associadas às populações 1 e 2. A partir de amostras ( e (! retiradas das populações, para = ! e =!! conhecidos, o
intervalo com 91 − �) = 10091 − �)% de confiança para 9< − <!) é:
§ 9̈ dy)9< − <!) = ²9#$ − #$!) − ¤y !⁄ a= !( + =!!(! ; 9#$ − #$!) + ¤y !⁄ a= !( + =!!(!³. Onde #$ é a média da amostra ( e #$! é a média da amostra (!.
Observação: O objetivo deste intervalo de confiança é concluir se há diferença
entre as duas médias. Assim, se o intervalo de confiança contiver o valor “zero”, não
tem-se evidencias significativas para afirmar que uma média difere da outra.
Exemplo: Seja duas variáveis aleatórias Gaussianas # e #! cujas variâncias
populacionais são = ! = 3,64 e =!! = 4,03. Deseja-se construir um intervalo de 95%
de confiança para a diferença de médias populacionais, considerando as amostras
obtidas apresentadas na tabela abaixo:
AMOSTRA 1 ( = 32 #$ = 16,20

AMOSTRA 2 (! � 40 #$! = 14,85
§ 9̈ dy)9< − <!) = ²9#$ − #$!) − ¤y !⁄ a= !( + =!!(! ; 9#$ − #$!) + ¤y !⁄ a= !( + =!!(!³. §¨�e%9< 7 <!� � ²916,20 − 14,85) − 1,96a3,6432 + 4,0340 ; 916,20 − 14,85) + 1,96a3,6432 + 4,0340 ³
§¨�e%9< 7 <!� � I0,44; 2,26]
Observação importante: O intervalo de confiança não contém o zero, ou seja,
pode-se concluir, ao nível de 95%, que há evidências estatísticas para afirmar que
existe diferença entre as médias populacionais entre as populações.
Exercício: Seja o número de peças produzidas, de duas unidades de negócios,
duas variáveis aleatórias Gaussianas # e #! cujas variâncias populacionais são = ! = 10,5 e =!! = 15,0. Deseja-se construir um intervalo de 98% de confiança para a
diferença de peças produzidas (médias populacionais), considerando as amostras
obtidas apresentadas na tabela abaixo. Pode-se afirmar que as unidades de
negócio apresentam a mesma produtividade?
UNIDADE DE NEGÓCIO 1 ( = 25 #$ = 121,5 UNIDADE DE NEGÓCIO 2 (! = 35 #$! = 100,5
1.6.2. Intervalo de confiança para diferença de méd ias 9 ½ − ¢� com
variâncias ¡½¢ e ¡¢¢ desconhecidas, porém iguais 9¡½¢ = ¡¢¢� Neste caso, o intervalo com 91 − �� = 10091 − ��% de confiança para 9< − <!� é:
§ 9̈ dy�9< − <!� = ²9#$ − #$!� − 3w�°��[d!;� 2z {a5�! ¥ 1( + 1(!¦ ; 9#$ − #$!� + 3w�°��[d!;� 2z {a5�! ¥ 1( + 1(!¦³. Onde 5�! é a variância amostral ponderada, ou seja, 2�! = 9�°d ��°[�9�[d ��[[�°��[d! .
1.6.3. Intervalo de confiança para diferença de méd ias 9 ½ − ¢� com
variâncias ¡½¢ e ¡¢¢ desconhecidas, porém diferentes 9¡½¢ ≠ ¡¢¢� Neste caso, o intervalo com 91 − �� = 10091 − ��% de confiança para 9< − <!� é:
§ 9̈ dy�9< − <!� = ²9#$ − #$!� − 3w¾;� 2z {a\2 !( + 2!!(!] ; 9#$ − #$!� − 3w¾;� 2z { ×a\2 !( + 2!!(!]³

Onde os graus de liberdade são dados pela fórmula de Satterthwaite 91946): ¿ = ©2 !( + 2!!(!ª!
ÀÁÁÂ ¥2 !( ¦
!( − 1ÃÄ
ÄÅ +ÀÁÁÂ ¥2!!(!¦
!(! − 1ÃÄ
ÄÅ.
Exercício: Seja as vendas (em µ$100000) durante e após a crise de 2008 duas
variáveis aleatórias Gaussianas # e #! com variâncias populacionais
desconhecidas. Construia dois intervalos de 95% de confiança para a diferença das
vendas (médias populacionais), um intervalo para o caso em que = ! = =!! e um
intervalo para o caso em que = ! ≠ =!!, considerando as amostras obtidas
apresentadas na tabela abaixo:
VENDAS DURANTE A CRISE ( = 30 #$ = 20,20 5 ! = 3,50 VENDAS DEPOIS DA CRISE (! = 42 #$! = 28,50 5!! = 4,50