comparação de métodos de estimação para proporções em ... · banco de dados cadastros de...
TRANSCRIPT

Comparação de Métodos de Estimação para
Proporções em Pequenas Áreas: o caso da TIC
Educação
Isabela Bertolini Coelho
Lúcia Pereira Barroso
V Escola de Amostragem e Metodologia da Pesquisa
Cuiabá, 19 de Outubro de 2017
V ESAMP 1 / 50

Sumário
Sumário
1 Introdução
2 Banco de dados
3 Conceitos
4 Comparação utilizando dados reais
5 Simulação
6 Conclusões
7 Referências bibliográ�cas
V ESAMP 2 / 50

Introdução
Introdução
V ESAMP 3 / 50

Introdução Considerações preliminares
TIC = Tecnologias de Informação e Comunicação
� TIC são recursos tecnológicos facilitadores do acesso às informações e
ao conhecimento, como: computador, Internet e telefone celular.
� As TIC provocam mudanças na forma da sociedade atual se comunicar,
agir e perceber a realidade.
V ESAMP 4 / 50

Introdução Considerações preliminares
� Albino, 2015:
�[...] o desenvolvimento sócio-econômico de uma nação está diretamente
relacionado à educação que acompanha e impulsiona as mudanças, e, ao
mesmo tempo, se apropria das tecnologias disponíveis�.
� É necessário um processo educacional criativo e �exível, incorporando as
TIC, para formar uma sociedade crítica.
� Inserir as TIC sem alterar as práticas de ensino não trazem resultados
satisfatórios.
V ESAMP 5 / 50

Introdução Motivação
� Pesquisas para medir o uso das TIC nas escolas são necessárias para
compreender a realidade da adoção das novas tecnologias.
ë Pesquisa TIC Educação conduzida anualmente pelo CETIC.br
� Produção de dados estatísticos auxiliam os gestores públicos na
construção e implementação de políticas públicas na área educacional.
� A baixa qualidade da educação pública brasileira é um empecilho para a
solução de problemas econômicos e sociais existentes.
V ESAMP 6 / 50

Introdução Objetivos
Obter estimativas con�áveis para a proporção de escolas em que os
professores usam a Internet em atividades de ensino-aprendizagem
com os alunos para cada UF
Comparar estimativas de pequenas áreas
V ESAMP 7 / 50

Banco de dados
Banco de dados
V ESAMP 8 / 50

Banco de dados Cadastros de referência
Censo Escolar (INEP):
Principal levantamento estatístico a respeito das escolas de educação
básica no Brasil;
Informações sobre estabelecimentos de ensino, turmas oferecidas,
alunos e pro�ssionais escolares;
Universo: todas as escolas públicas e particulares.
Pesquisa TIC Educação (CETIC.br / CGI.br):
Desde 2010 levanta dados sobre posse, uso, adoção e apropriação das
TIC em escolas brasileiras;
Informações coletadas com alunos, professores, coordenadores
pedagógicos e diretores.
V ESAMP 9 / 50

Banco de dados Banco de dados �nal
Cadastros utilizados: TIC Educação 2013 e Censo Escolar 2013;
População alvo:
Situação de atividade: em atividade;
Rede: municipal, estadual e particulares;
Área: urbana;
Modalidade de ensino: regular;Etapas de ensino:
5o ano do Ensino Fundamental;
9o ano do Ensino Fundamental;
2o ano do Ensino Médio / Integrado / Normal / Magistério.
Tipo de atendimento: turmas que não estejam alocadas em hospitais,
prisões etc.
Tamanho �nal do cadastro:
Censo Escolar: 73.564 escolas;
TIC Educação: 927 escolas.
V ESAMP 10 / 50

Banco de dados Variáveis do banco de dados �nal
Variáveis do banco de dados �nal:PK_COD_ENTIDADE : código INEP de identi�cação da escola;
REGIAO: código de identi�cação da macrorregião à qual a escola
pertence;
FK_COD_ESTADO: código de identi�cação da UF à qual a escola
pertence;
SIGLA: sigla da UF à qual a escola pertence;
ID_DEPENDENCIA_ADM: dependência administrativa;
ID_LABORATORIO_INFORMATICA: existência de laboratório de
informática nas dependências da escola;
NUM_SALAS_UTILIZADAS: número de salas utilizadas como salas de
aula (dentro e fora do prédio);
NUM_EQUIP_MULTIMIDIA: quantidade de projetores multimídia
datashow ;
NUM_COMPUTADORES: quantidade de computadores na escola;
NUM_COMP_ALUNOS: quantidade de computadores para uso dos
alunos;V ESAMP 11 / 50

Banco de dados Variáveis do banco de dados �nal
ID_INTERNET : existência do acesso à Internet;
ID_BANDA_LARGA: existência do acesso à Internet banda larga;
ID_PROF_INF : existência de professor de informática no quadro de
docentes da escola;
QT_DOCENTES: quantidade de docentes existentes na escola;
MED_IDADE : média da idade dos docentes da escola;
P44_TOTAL: utilização da Internet pelos professores em atividades de
ensino-aprendizagem com os alunos na escola (variável resposta);
TIC : variável que identi�ca se a escola pertenceu à pesquisa TIC
Educação 2013;
ESTRATO_FINAL: estrato de seleção da escola;
N_AMO: tamanho da amostra dentro de cada estrato de seleção;
PROB_FINAL: probabilidade de seleção da escola;
PESO_FINAL: peso amostral da escola.
V ESAMP 12 / 50

Conceitos
Conceitos
V ESAMP 13 / 50

Conceitos SAE
Estimação em pequenas áreas (SAE)
� Rao, 2003:
�[...] o termo pequena área não se refere necessariamente a uma área
geográ�ca, mas sim a um domínio de interesse em que o tamanho da
amostra é pequeno�.
� Metodologia para a produção de estimativas con�áveis para níveis
desagregados, para características de interesse, como total populacional,
proporções, médias etc.
V ESAMP 14 / 50

Conceitos SAE
Estimação em pequenas áreas
� Design-based : inferências baseadas diretamente na distribuição de
probabilidade trazida no desenho amostral.
� Model-based : inferências são realizadas de acordo com o modelo
construído com os dados da amostra que �emprestam� informações para
áreas semelhantes.
ë Area-level
ë Unit-level
V ESAMP 15 / 50

Conceitos SAE
Ideia geral sobre utilização de model-based
Ñ P � t1, � � � ,Nu uma população �nita subdividida em D pequenos domínios, Pd ,
Pd � P, d � 1, � � � ,D de tamanho Nd , tal que N �°D
d�1Nd ;
Ñ XN�p matriz em cada linha x1dj contém as informações das variáveis auxiliares;
Ñ y o vetor de dimensão N � 1 da variável de interesse;
Ñ s é uma amostra de tamanho n N extraída de P e r � P � s as unidades
complementares;
X �
�Xs
Xr
�, y �
�ys
yr
�
Ñ Utilizamos Xs e ys para a construção do modelo e, com as informações de Xr ,
predizemos yr .
V ESAMP 16 / 50

Conceitos SAE
Relembrando o primeiro objetivo...
Obter estimativas con�áveis para a proporção de escolas em que os
professores usam a Internet em atividades de ensino-aprendizagem
com os alunos para cada UF
ó
Yd � N�1d
Nd
j�1
ydj � N�1d
�¸jPsd
ydj �¸jPrd
ydj
�, d � 1, � � � ,D
V ESAMP 17 / 50

Conceitos SAE
Relembrando o segundo objetivo...
Comparar estimativas de pequenas áreas
Abordagens:
1 Estimador direto;
2 Modelo geral;
3 Modelo por região;
4 Modelo por cluster ;
5 Modelo com efeitos aleatórios;
6 Modelo com efeitos aleatórios e efeito do plano amostral.
V ESAMP 18 / 50

Conceitos Estimador direto
1 Estimador direto
Estimativas da característica de interesse com base apenas nas
observações amostradas;
Para j � 1, � � � , nd , d � 1, � � � ,D, temos:
Estimador não viesado de Horvitz - Thompson para Y d :xYd
DIR
� Nd�1¸jPsd
wdjydj
wdj é o inverso da probabilidade de inclusão da escola j da área d na
amostra sd ;
Apesar da facilidade do cálculo, só existe estimativa para áreas
onde há amostra;
V ESAMP 19 / 50

Conceitos Estimador direto
O estimador da variância é não viesado, portanto, o estimador do
EQM é igual ao estimador da variância;
Para j � 1, � � � , nd , d � 1, � � � ,D, temos:
Estimador do EQM de xYd
DIR
:
zEQMpxYd
DIR
q � xVπpxYd
DIR
q �1N2d
¸jPsd
wdjpwdj � 1qy2dj
V ESAMP 20 / 50

Conceitos Modelo de regressão logística
Abordagens baseadas em modelos:
SAE para respostas binárias utiliza teoria de modelos lineares mistos
generalizados, considerando as variáveis auxiliares com informação no
nível de unidades;
As abordagens que utilizamos a teoria de modelos lineares mistosgeneralizados são:
5 Modelo com efeito aleatórios;
6 Modelo com efeito aleatórios e efeito do plano amostral.
V ESAMP 21 / 50

Conceitos Modelo de regressão logística
Seja ud � Np0, ϕq para a pequena área d � 1, � � � ,D;
Assumimos ydj | udiid� Binp1, pdjq;
β é o vetor de coe�cientes dos efeitos �xos do modelo;
Para j � 1, � � � ,Nd , d � 1, � � � ,D, temos:
O modelo válido para toda população P :
log
�pdj
1� pdj
� x1djβ � ud
A probabilidade de sucesso pode ser escrita como:
pdj �exp!x1djβ � ud
)1� exp
!x1djβ � ud
)V ESAMP 22 / 50

Conceitos Modelo de regressão logística
Nossa quantidade de interesse é o vetor Y � pY1, � � � , YDq1,
Yd � N�1d
�¸jPsd
ydj �¸jPrd
ydj
�, d � 1, � � � ,D;
O único elemento de Yd desconhecido é°
jPrdydj ;
A estimativa da probabilidade de sucesso para j P rd , d � 1, � � � ,D é
dada por:
pdj �exp!x1dj β � ud
)1� exp
!x1dj β � ud
)
V ESAMP 23 / 50

Conceitos Modelo de regressão logística
Para j � 1, � � � ,Nd , d � 1, � � � ,D, podemos reescrever a proporção
da forma:
xYd � N�1d
�¸jPsd
ydj �¸jPrd
pdj
�
� A expressão �nal para xYd que desejamos obter é dada por:
xYd �1Nd
��¸jPsd
ydj �¸jPrd
exp!x1dj β � ud
)1� exp
!x1dj β � ud
)�
V ESAMP 24 / 50

Conceitos Modelo de regressão logística
Modelos de efeitos aleatórios são principalmente usados para descrever
relações entre a variável resposta e as variáveis independentes para
dados agrupados de acordo com algum fator de classi�cação;
Se não é razoável supor que o fator de classi�cação tenha uma
distribuição de probabilidade, utiliza-se apenas os efeitos �xos;
Não consideramos a presença de efeitos aleatórios nas seguintesabordagens:
2 Modelo geral;
3 Modelo por região;
4 Modelo por cluster.
V ESAMP 25 / 50

Conceitos Modelo de regressão logística
Assumimos ydjiid� Binp1, pdjq;
β é o vetor de coe�cientes dos efeitos �xos do modelo;
Para j � 1, � � � ,Nd , d � 1, � � � ,D, temos:
A probabilidade de sucesso passa a ser escrita como:
pdj �exp!x1djβ
)1� exp
!x1djβ
)
� A expressão �nal para xYd que desejamos obter é dada por:
xYd �1Nd
��¸jPsd
ydj �¸jPrd
exp!x1dj β
)1� exp
!x1dj β
)�
V ESAMP 26 / 50

Conceitos EQM
Erro Quadrático Médio (EQM)
Utilizado como medida de qualidade do ajuste do modelo;
EQM incorpora medidas de variabilidade do estimador (precisão) e de
viés (acurácia);
Segundo González-Manteiga et al. (2007), para estimadores de
pequenas áreas a forma analítica não é adequada para ser calculada
explicitamente;
Diversos autores aprimoraram o cálculo do EQM para SAE, no
entanto, para modelos logísticos ainda há uma escassez nos estudos;
V ESAMP 27 / 50

Conceitos EQM
Adotamos o método bootstrap proposto em González-Manteiga et al.
(2007): �Estimation of the mean squared error of predictors of
small area linear parameters under a logistic mixed model �;
Mais vantajoso para populações binomiais com tamanho de amostra
pequeno;
Apesar do custo computacional, o método permite estimar qualquer
característica da população.
V ESAMP 28 / 50

Conceitos EQM
Algoritmo de obtenção do EQM:
1. Ajuste o modelo com os dados da amostra de modo a obter as
estimativas β e ϕ;
2. Para b � 1, 2, � � � ,B faça:
a. Gere T1 � Np0, Iq;
b. Construa u� � pu�1, � � � , u�
Dq1 � ϕT1;
c. Construa a população P�pbq de tamanho N, tal que y�dj � Binp1, p�
djq,
j � 1, � � � ,Nd e d � 1, � � � ,D:
p�dj �
exp!x1dj β�u�
d
)1� exp
!x1dj β�u�
d
)
V ESAMP 29 / 50

Conceitos EQM
d. Determine Y �d
pbq, d � 1, � � � ,D;
e. Extraia uma amostra s� com as mesmas características da amostra original
(Amostragem Sequencial de Poisson);
f. A partir da amostra s�, calcule o preditor xY �d
pbq
, d � 1, � � � ,D;
3. A estimativa do EQMpxYdq é dada por:
zEQMpxYdq � B�1B
b�1
�xY �d
pbq
� Y �d
pbq2, d � 1, � � � ,D.
V ESAMP 30 / 50

Comparação utilizando dados reais
Comparação utilizandodados reais
V ESAMP 31 / 50

Comparação utilizando dados reais Abordagens baseadas em modelos
1. Obtenção do modelo a partir das escolas presentes na TIC Educação:
Seleção de variáveis: método stepwise;
Teste de Wald de múltiplos parâmetros;
ANOVA para obter o modelo mais parcimonioso;
Validação do modelo: validação cruzada por leave-one-out;
Classi�cação das observações em sucesso ou fracasso: Curva ROC;
Proporção de acertos do modelo: matriz de confusão;
2. Predição do valor médio para as escolas não amostradas presentes no
cadastro �nal;
3. Cálculo da estimativa bootstrap do EQM.
V ESAMP 32 / 50

Comparação utilizando dados reais Proporções
V ESAMP 33 / 50

Comparação utilizando dados reais EQM via bootstrap
V ESAMP 34 / 50

Comparação utilizando dados reais EQM via bootstrap
V ESAMP 35 / 50

Simulação
Simulação
V ESAMP 36 / 50

Simulação Objetivo
Aplicar as abordagens deste estudo em dados gerados com parâmetros
conhecidos com o intuito de analisar qual abordagem é melhor para
dados binários;
Cálculo do EQM teórico;
Geramos a população como um todo a partir de modelos de regressãologística:
1 Modelo geral;2 Modelo de intercepto aleatório;3 Modelo de intercepto e inclinação aleatórios.
V ESAMP 37 / 50

Simulação Parâmetros
População de tamanho N � 2500 para D � 5 pequenas áreas, cada
área d de tamanho Nd � 500;
Amostra aleatória estrati�cada simples de tamanho nd � 30 sem
reposição, n �°5
d�1 nd � 150;
Os parâmetros escolhidos foram:
β1 � pβ0, β1, β2q � p0, 5; 1, 5; 0, 5q;
k � 3;
ϕ � 0, 4.
Foram realizadas G � 104 repetições.
V ESAMP 38 / 50

Simulação Algoritmo de simulação
Algoritmo de simulação:
a. Repita g � 1, � � � ,G vezes:1. Obtenha a população simulada, P:
i. De�na o índice da pequena área d , d � 1, � � � ,D;
ii. Gere x1dj � p1, x1,dj , x2,djq com as variáveis explicativas, tal que,
j � 1, � � � ,Nd , d � 1, � � � ,D:
x1,dj � Unif
�0,
d
D
; x2,dj � Unif
�0,
�d
D
2�
iii. Faça a análise de agrupamentos através do método de k-médiasformando k grupos. As variáveis utilizadas são x1d e x2d
maxpx2d q;
V ESAMP 39 / 50

Simulação Algoritmo de simulação
iv. Gere T1 � Np0, Iq;
v. Construa u� � pu�1, � � � , u�
Dq1 � ϕT1;
vi. Gere os efeitos aleatórios das inclinações para cada pequena área
α1d � Unifp0, 1q e α2d � Unifp0, 1q, d � 1, � � � ,D;
vii. A partir dos valores �xados de β, determine:
pdj �exp tβ0 � pβ1�α1dqx1,dj � pβ2�α2dqx2,dj� udu
1� exp tβ0 � pβ1�α1dqx1,dj � pβ2�α2dqx2,dj� udu
j � 1, � � � ,Nd , d � 1, � � � ,D;
viii. Obtenha ydj � Binp1, pdjq j � 1, � � � ,Nd , d � 1, � � � ,D;
ix. Calcule a média por área Ydpgq
;
V ESAMP 40 / 50

Simulação Algoritmo de simulação
2. Selecione a amostra s por amostragem aleatória estrati�cada simples de
tamanho n sem reposição;
3. Obtenha as estimativas da média para cada área d � 1, � � � ,D pelasdiferentes abordagens:
i. Estimador direto:zY DIR
d
pgq
;
ii. Modelo geral:zY GER
d
pgq
;
iii. Modelo por cluster :zY CLU
d
pgq
;
iv. Modelo por área:zY AR
d
pgq
;
v. Modelo com efeitos aleatórios:zYMIS
d
pgq
;
V ESAMP 41 / 50

Simulação Algoritmo de simulação
b. Calcule para d � 1, � � � ,D:
Yd �1
G
G
g�1
Ydpgq
;
zY DIRd �
1
G
G
g�1
zY DIRd
pgq
; EQMDIRd �
1
G
G
g�1
�zY DIRd
pgq
� Ydpgq
�2
;
{Y GERd �
1
G
G
g�1
{Y GERd
pgq
; EQMGERd �
1
G
G
g�1
�{Y GERd
pgq
� Ydpgq
�2
;
{Y CLUd �
1
G
G
g�1
{Y CLUd
pgq
; EQMCLUd �
1
G
G
g�1
�{Y CLUd
pgq
� Ydpgq
�2
;
zY ARd �
1
G
G
g�1
zY ARd
pgq
; EQMARd �
1
G
G
g�1
�zY ARd
pgq
� Ydpgq
�2
;
{YMISd �
1
G
G
g�1
{YMISd
pgq
; EQMMISd �
1
G
G
g�1
�{YMISd
pgq
� Ydpgq
�2
.
V ESAMP 42 / 50
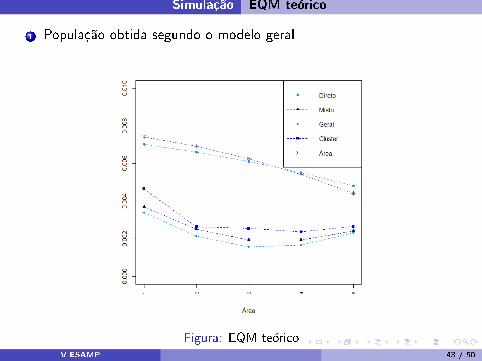
Simulação EQM teórico
1 População obtida segundo o modelo geral
Figura: EQM teóricoV ESAMP 43 / 50

Simulação EQM teórico
2 População obtida segundo o modelo de intercepto aleatório
Figura: EQM teórico
V ESAMP 44 / 50
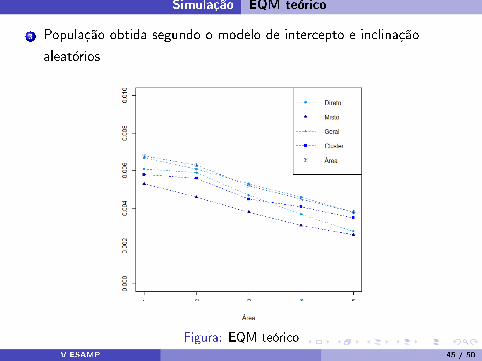
Simulação EQM teórico
3 População obtida segundo o modelo de intercepto e inclinação
aleatórios
Figura: EQM teóricoV ESAMP 45 / 50

Conclusões
Conclusões
V ESAMP 46 / 50

Conclusões
Considerações Finais
Para o caso da TIC Educação: modelo de efeitos aleatórios é superior
às demais abordagens;
Notável ganho de precisão ao comparar as estimativas obtidas entre o
estimador direto e o modelo de intercepto aleatório;
Modelos pouco estudados na literatura de SAE:
Modelo por cluster ;
Modelo de efeitos aleatório e do plano amostral.
V ESAMP 47 / 50

Conclusões
Contribuições
Fornecer estimativas con�áveis para a formulação de políticas públicas
na área educacional;
Fomentar a metodologia de SAE no Brasil;
Motivar o CETIC.br a divulgar resultados das pesquisas TIC para
pequenas áreas.
ë Apresentação C02: �Estimação de indicadores por unidades da
federação para a TIC Domicílios�
V ESAMP 48 / 50

Conclusões
Estudos Futuros
Atualização do resultado para os anos seguintes da pesquisa: 2014,
2015 e 2016;
Exploração de modelos de efeitos aleatórios e do plano amostral para
SAE;
Construção dos modelos a partir de diferentes métodos, p. ex:
abordagem Bayesiana, modelos não-paramétricos, utilização de
estruturas de correlação temporal e/ou espacial;
Modelos hierárquicos: turmas, alunos e professores.
V ESAMP 49 / 50

Referências Bibliográ�cas
Referências:
Albino, R.D. Uma visão integrada sobre o nível de uso das Tecnologias da
Informação e Comunicação em escolas brasileiras, 2015.
Barroso, L.P. e Artes, R. Análise multivariada, 2003.
Casella, G. e Berger, R.L. Statistical inference, volume 2, 2002.
Comitê Gestor da Internet no Brasil. Pesquisa sobre o uso das tecnologias de
informação e comunicação nas escolas brasileiras: TIC Educação 2013, 2014.
Cochran, W.G. Sampling techniques, 1977.
González-Manteiga, W., Lombardía, M.J., Molina, I., Morales, D. e
Santamaría, L. Estimation of the mean squared error of predictors of small
area linear parameters under a logistic mixed model, 2007.
Heeringa, S.G., West, B.T. e Berglund, P.A. Applied survey data analysis,
2010.
INEP. Censo Escolar 2013, 2014.
V ESAMP 49 / 50

Liu, B. Hierarchical Bayes estimation and empirical best prediction of
small-area proportions, 2009.
Lumley, T. Complex surveys: a guide to analysis using R, 2011.
Molina, I. e Marhuenda, Y. Basic direct and indirect estimators in sae
package, 2015.
Moura, F.A.S. Estimação em pequenos domínios, 2008.
Ohlsson, E. Sequential Poisson sampling, 1998.
Pessoa, D.G.C. e Silva, P.L.N. Análise de dados amostrais complexos, 1998.
Pfe�ermann, D. New important developments in small area estimation, 2013.
Rao, J.N.K. Small area estimation, 2003.
V ESAMP 50 / 50
