sistema de pesquisa integrada em bases de dados de acesso...
TRANSCRIPT

Sistema de Pesquisa Integrada em Bases de Dados de
Acesso Livre
Milene Monteiro nº22042
Trabalho realizado sob a orientação de
Professor Paulo Matos
Doutora Clarisse Pais
Informática de Gestão
2011/2012


iii
Sistema de Pesquisa Integrada em Bases de Dados de
Acesso Livre
Relatório da UC de Projecto de Informática
Licenciatura em Informática de Gestão
Escola Superior de Tecnologia e de Gestão
Milene Monteiro
2011/2012

iv
A Escola Superior de Tecnologia e Gestão não se responsabiliza pelas opiniões
expressas neste relatório.

v
Certifico que li este relatório e que na minha opinião, é adequado no seu
conteúdo e forma como demonstrador do trabalho desenvolvido no
âmbito da UC de Projecto de Informática.
___________________________________________
Paulo Matos - Orientador
Certifico que li este relatório e que na minha opinião, é adequado no seu
conteúdo e forma como demonstrador do trabalho desenvolvido no
âmbito da UC de Projecto de Informática.
___________________________________________
Clarisse Pais - Coorientadora
Certifico que li este relatório e que na minha opinião, é adequado no seu
conteúdo e forma como demonstrador do trabalho desenvolvido no
âmbito da UC de Projecto de Informática.
___________________________________________
- Arguente
Aceite para avaliação da UC de Projecto de Informática

vi

vii
Dedicatória
Dedico este projecto aos meus pais, a quem honro pelo esforço e dedicação que sempre
tiveram comigo, para que eu fosse o que hoje sou.

viii

ix
Agradecimentos
Em primeiro lugar quero agradecer ao meu Orientador Professor Paulo Matos e a
minha Coorientadora Doutora Clarisse Pais pela disponibilidade, orientação, paciência
e simpatia.
Os meus agradecimentos finais vão para a minha família e amigos pelo apoio
constante e incentivos ao longo da realização deste trabalho.

x

xi
Resumo
Este documento trata-se de um relatório final do projecto de Informática e tem por objectivo
optimizar o processo de pesquisa no Micro-Site dos Serviços e Documentação e Bibliotecas
do IPB, permitindo que esta pesquisa seja feita através de um único ponto de acesso de modo
a economizar tempo de pesquisa e recuperação de texto integral.
Para a realização deste projecto foram realizadas pesquisas sobre os protocolos utilizados nas
Bibliotecas Digitais.
A utilização da pesquisa do Google CSE foi o método adoptado neste trabalho.
Toda a implementação foi baseada num conjunto de tecnologias, nomeadamente, : HTML,
PHP e XML.
Palavras-chave: Biblioteca Digital, Base de dados de acesso livre

xii

xiii
Abstract
This document is a final report for Information Technology Project and aims to optimize the
search process of the IPB library site, allowing to research through a single access point,
save search time, and retrieving the full text.
For this project were conducted several researches on the protocols used in digital libraries.
The use of CSE Google was the method adopted in this work.
The entire implementation was done using several technologies, like: HTML, PHP and
XML.
Keywords: Digital Library, Databases

xiv
Conteúdo
1 Introdução ................................................................................................ 1
1.1 Enquadramento do Problema .............................................................................. 1
1.2 Objectivo ......................................................................................................... 2
1.3 Organização do relatório .................................................................................... 2
2 Open Acess e os Protocolos Pesquisados ..................................................... 3
2.1 Open Acess ...................................................................................................... 3
2.1.1 Importância do Open Access ........................................................................ 3
2.2 Protocolos pesquizados ...................................................................................... 4
2.2.1 OAI-PMH .................................................................................................. 4
2.2.2 Z39.50 ....................................................................................................... 7
3 Google CSE ............................................................................................. 11
3.1 Conceitos ....................................................................................................... 11
3.2 Aplicação ....................................................................................................... 11
3.2.1 Criar mecanismo de pesquisa personalizado ................................................. 12
4 Construção das páginas web .................................................................... 16
4.1 Implementação................................................................................................ 16 4.1.1 Pesquisa ................................................................................................... 17 4.1.2 Armazenagem do código do Google CSE .................................................... 18
4.1.3 Resultado da Pesquisa ................................................................................ 21
5 Conclusão ................................................................................................ 23
5.1 Considerações Finais ....................................................................................... 23
5.2 Trabalhos Futuros ........................................................................................... 23
Referências bibliográficas ................................................................................. 1

xv

xvi

xvii
Lista de Figuras
Figura 1– OAI-PM ............................................................................................. 4
Figura 2– Z39.50 Modelo de recuperação de informação ........................................ 8 Figura 3– Criar conta no Google ........................................................................ 12
Figura 4– Mecanismo de pesquisa ...................................................................... 13
Figura 5– Configuração do mecanismo de pesquisa.............................................. 13
Figura 6– Configuração do mecanismo de pesquisa.............................................. 14
Figura 7– Personalização do mecanismo de pesquisa............................................ 14 Figura 8– Código do Google CSE ...................................................................... 15
Figura 9– Página para pesquisa .......................................................................... 17 Figura 10- Localização da página para pesquisa ................................................... 18
Figura 11– Página para submeter o código do Google .......................................... 20 Figura 12– Resultado da pesquisa....................................................................... 22

xviii

xix
Lista de Abreviaturas
CSE - Custom Search Engine.
HTML - HiperText Markup Language
XML - Extensible Markup Language.
CSS - Cascating Style Sheet.

xx

1
Capítulo 1
1 Introdução
O surgimento da Internet representou o início de profundas alterações a nível político, económico e social.
Estas alterações deram-se de forma quase impercetível, infiltrando-se na vida quotidiana de cada indivíduo,
tornando-se, nalguns casos, um bem indispensável (Céu, 2012).
As Bibliotecas Digitais existem para beneficiar a comunidade de utilizadores, e conseguem-no através dos
suportes e da tecnologia que utilizam, de modo a possibilitar a criação, a pesquisa e a utilização da informação.
A informação circula de forma rápida permitindo a investigadores, docentes, pesquisadores, alunos e
utilizadores aceder a informação, utiliza-la e colaborarem em termos de aprendizagem e de educação (Céu,
2012).
1.1 Enquadramento do Problema
O Micro- Site dos Serviços e Documentação e Bibliotecas do IPB, faculta um conjunto de
sites de acesso livre, mas porém a pesquisa nos sites requer entrar em cada um deles. Como o
número de sites é considerável e a tendência é para aumentar, a pesquisa torna-se uma tarefa
penosa e pouco apelativa. As expetativas atuais dos utilizadores destes recursos exigem
soluções mais práticas e eficazes.
Otimizar o processo de pesquisa permitindo que este seja feito através de um único ponto de
acesso é uma mais-valia para os utilizadores da comunidade académica, permitindo
economizar tempo de pesquisa e recuperação de texto integral, que é fundamental a atividade
pedagógica e de investigação.

2
1.2 Objectivo
Este projeto tem como objetivo desenvolver novas funcionalidades de pesquisa para o atual
Micro Site dos Serviços e Documentação e Bibliotecas do IPB, que através de um único ponto
de acesso permita efetuar pesquisas sobre várias Base de Dados de acesso livre e em texto
completo.
Consiste na construção de páginas de pesquisas segundo o template atual do Micro Site dos
Serviços e Documentação e Bibliotecas do IPB.
1.3 Organização do relatório
O relatório aqui apresentado está dividido em cinco partes distintas. Começa na primeira parte
com uma introdução ao trabalho realizado, onde são descritos o problema, os objetivos deste
projecto e a estrutura do relatório. Na segunda parte do documento é descrito o conceito do
Open Access e os protocolos de pesquisa, nomeadamente o OAI, o Z39.50 e o Open Access.
Na terceira parte do trabalho realizado é feito uma descrição do Google CSE que foi a forma
de pesquisa adotada neste trabalho.
A quarta parte refere-se a uma descrição de como foram construídas as páginas web neste
trabalho. Por fim, na quinta parte está a conclusão do projecto.

3
Capítulo 2
2 Open Acess e os Protocolos Pesquisados
2.1 Open Acess
O Open Access é uma perspectiva de acesso aberto que visa a utilização de bibliotecas
eletrônicas sem a necessidade de aquisição de material (Sobrinho, 2011).
É uma forma simples de tornar os resultados de investigação acessíveis para toda a
comunidade científica. (Sobrinho, 2011)
2.1.1 Importância do Open Access
Os investigadores publicam os seus resultados (em revistas ou outros tipos de publicações
científicas) para estabelecerem a sua autoria e para permitir que outros investigadores
desenvolvam novas pesquisas a partir deles. No caso dos artigos de revistas científicas,
apenas as instituições mais ricas têm tido capacidade para comprar uma percentagem razoável
das revistas cientificas publicadas. Muitos artigos científicos não estão acessíveis a uma parte
significativa dos investigadores a quem poderiam interessar (O que é o Acesso Livre).
As limitações ao acesso daqui decorrentes traduziram-se numa perda de eficiência do sistema
de comunicação da ciência, e em limitações ao impacto e reconhecimento dos resultados
alcançados pelos investigadores e as instituições onde trabalham.

4
Assim, aumentar a visibilidade e o impacto da investigação desenvolvida, através de uma
maior acessibilidade com o Acesso Livre, é um interesse óbvio das universidades, das suas
unidades orgânicas (centros de investigação), bem como dos investigadores individualmente.
A sociedade como um todo beneficia de um amplo e acelerado ciclo de pesquisa em que a
pesquisa pode avançar de forma mais eficaz, pois os pesquisadores têm acesso imediato a
todas as conclusões que eles precisam (O que é o Acesso Livre).
2.2 Protocolos pesquizados
Para a realização deste projeto foram realizadas pesquisas sobre alguns protocolos utilizados
nas bibliotecas digitais.
Protocolos definem-se como sendo conjuntos de regras que definem o formato e a forma
como a informação é trocada.
2.2.1 OAI-PMH
O OAI-PMH (Open Archives Initiative – Protocol for Metadata Harvesting) é um protocolo
desenvolvido pela Open Archives Initiativeque, que define um mecanismo para coleta de
registros de metadados em repositórios (Segundo, 2010). O objetivo deste protocolo é
facilitar a partilha de metadados, ou seja, a recuperação e agregação desses dados para
poderem ser utilizados em novos serviços.
Figura 1– OAI-PM
Para uma coleta eficiente devem ser seguidos algumas etapas tais como (Pinto, 2006):
Base de
Dados
Coleta
Repositório
s
Repositório
s

5
1. Selecionar os repositórios dos quais se deseja coletar os metadados e descobrir os
respectivos URLs das bases de coleta (ou seja, os URLs a partir dos quais é possível
aplicar os verbos de requisição).
2. Escolher uma ferramenta apropriada para a coleta de metadados.
3. Iniciar a coleta, fornecendo uma lista com as URLs bases dos repositórios.
4. Normalizar os metadados coletados de forma a se tornarem úteis para implementação
do serviço pretendido.
De seguida descrevem-se algumas das dificuldades inerentes à execução de cada uma destas
fases.
Seleção
Decidir quais os repositórios cujos metadados participarão do seu serviço é uma tarefa manual
e exaustiva. A partir da resposta do verbo Identify, é possível descobrir algumas informações
sobre a natureza dos dados contidos no repositório. Porém, frequentemente esses dados são
insuficientes para se saber se é de interesse a coleta desses metadados. Para tal decisão, é
necessário navegar nos recursos do repositório e também verificar a qualidade da
implementação dos metadados. Desenvolver ferramentas computacionais que automatizem
essa etapa é uma proposta bastante complexa, principalmente porque o tema e a qualidade do
repositório são critérios subjetivos e sujeitos a debate (Pinto, 2006).
Ferramentas para Harvesting
Um serviço bastante útil para testar se o repositório de interesse está respondendo
adequadamente aos verbos OAI é o Repository Explorer. Basta fornecer a ele a URL base do
repositório e preencher alguns campos relativos aos verbos de requisição. Depois de testados,
é necessário fazer a coleta dos metadados. Para tal, é importante escolher uma ferramenta
adequada. No portal de ferramentas da OAI, podemos encontrar alguns harvesters de licença
livre. Suas funcionalidades e desempenho variam, por isso devem ser bem testados de acordo
com os requisitos desejados. Uma decisão mal feita aqui pode atrapalhar bastante a
implementação do serviço pretendido (Pinto, 2006).
Coleta de Metadados

6
Apesar da interface OAI-PMH oferecer um conjunto de verbos que facilitam a coleta
automática dos metadados, podem surgir alguns problemas tais como:
1. Mudança de URL base do repositório - para coletar através do protocolo OAI, é
preciso fornecer ao programa harvester uma URL a partir da qual ele aplicará os
verbos de requisição. Porém é comum haver alterações dos URLs dos repositórios e
nem sempre é fácil descobrir a nova localização (Pinto, 2006).
2. Servidor fora de serviço – nem todas as instituições têm os recursos ou cuidados
necessários para a manutenção dos servidores, o que por vezes implica uma baixa
disponibilidade dos serviços (Pinto, 2006).
3. Falhas na implementação da interface OAI - alguns repositórios não respondem
corretamente aos seis verbos do protocolo (Pinto, 2006).
4. Interrupções na coleta por sobrecarga do servidor - por receberem muitas requisições
de harvesters, alguns servidores deixam de funcionar e interrompem a transferência
dos metadados antes de ser finalizada (Pinto, 2006).
Essas dificuldades tornam-se mais incômodas à medida que cresce o número de repositórios
dos quais fazemos a pesquisa, tornado a etapa de harvesting um tanto trabalhosa e exaustiva.
Funcionamento
O protocolo utiliza uma ferramenta de transações HTTP muito simples, baseadas em request-
response. A resposta deve ser no formato XML. Um harvester pode selecionar os metadados
que deseja colectar de forma a escolher somente os novos ou os que foram modificados desde
a última interação de coleta com o repositório. Pode também restringir os metadados que
desejam colectar ao indicar qual é conjunto de dados de interesse (alguns servidores separam
os metadados por assunto ou por ano de publicação).
Existem seis verbos de requisição do protocolo. São eles:
Identify: traz as principais informações do repositório como nome, identificador, e-
mail do administrador, informações sobre a propriedade intelectual dos dados contidos
no repositório, etc.
ListMetadataFormats: lista os formatos de metadados implementados pelo sistema do
repositório.
ListSets: traz a árvore de assuntos que classificam os documentos no repositório ou
outro conjunto de classificação.

7
ListIdentifiers: lista todos identificadores de registros do repositório.
ListRecords: lista todos registros do repositório.
GetRecord: dado um identificador, lista o registro correspondente.
Para entender a funcionalidade deste protocolo é importante conhecer o que ele não faz,
nomeadamente (Pinto, 2006):
A autenticação e a gestão de acesso não estão implementadas no protocolo.
Os repositórios podem por conta própria implementar o controlo de acesso no código
do programa.
Independente do controlo de acesso sobre os metadados, o servidor inclui um
apontador (como URL) para o objeto descrito pelos metadados.
O controlo de acesso pode ou não existir no nível do recurso.
O protocolo também não inclui um ponto importante: como os harvesters identificarão
os repositórios que eles desejam coletar, nem providenciam informação que ajude a
determinar quando a coleta deve ocorrer ou com que frequência.
A utilização deste protocolo para o acesso a base de dados foi uma proposta colocada neste
trabalho de projecto. Porém, essa solução não foi viável, pois o OAI-PMH não constitui uma
solução de pesquisa de dados, mas sim um sistema de agregação de meta-dados.
2.2.2 Z39.50
Z39.50 é um protocolo de comunicação entre computadores desenhado para permitir pesquisa
e recuperação de informação, documentos com textos completos, dados bibliográficos,
imagens, conteúdos multimédia em redes de computadores distribuídos. É baseado em uma
arquitetura cliente/servidor e opera sobre a rede Internet, este protocolo permite um número
crescente de aplicações (Rosa, 2007).
Como o ambiente onde este protocolo é aplicado, é muito dinâmico, torna-se necessário que a
norma seja constantemente analisada e atualizada para proporcionar as mudanças de que os
criadores, provedores e usuários de informação necessitam (Rosa, 2007).

8
Procura de resultados
Procura
Query Procura Query
Peo Procura
Recuperação de registos
F
Figura 2– Z39.50 Modelo de recuperação de informação
O objetivo deste protocolo é permitir a integração de diferentes sistemas de computação com
diferentes sistemas operativos, equipamentos, formas de pesquisa, sistemas de gestão de bases
de dados.
Habilitar uma interface única para conexão com múltiplos sistemas de informação, permitindo
ao utilizador final um acesso quase transparente para outro sistema.
O protocolo Z39.50 apresenta as seguintes vantagens:
Permite pesquisa e transferência de registos entre sistemas, independentemente das
especificações de hardware e software de cada sistema (Rosa, 2007).
Providencia um mecanismo de acesso simples a bases de dados através de uma única
interface (Rosa, 2007).
Reduz o tempo de aprendizagem que se gastaria para aprender sistemas específicos
(Rosa, 2007).
Funcionamento
O funcionamento deste protocolo requer a existência de um servidor Z39.50 e de aplicações
clientes que se conectam ao servidor para realizar distintas operações. Portanto, em termos de
arquitetura do sistema, o que se tem é por um lado uma interface junto ao utilizador tendo
uma aplicação que se conecta ao front end do servidor (Rosa, 2007).
Do lado do servidor, ao se receber uma solicitação do cliente, o que se faz é um acesso a base
de dados para que a resposta possa ser dada.
As principais funcionalidades deste protocolo são:
Interface do Utilizador
Conversão
Z39.50
Cliente Base de Dados
Conjunto de resultado
Conversão
Z39.50
Cliente

9
Inicialização: O cliente procura estabelecer uma ligação com o servidor e negociar um
conjunto de parâmetros para a sua interação. Esta ligação é designada muitas vezes de
associação Z. Neste processo, o servidor desempenha um papel de particular
importância na medida em que cabe a ele assumir o controlo, isto é, decidir com quem
estabelece negociações e que serviço irá fornecer. Durante a inicialização o cliente
envia ao servidor o nome e a palavra-chave de acesso, solicita-lhe um conjunto de
informações como a versão do protocolo em uso, o tamanho das mensagens,
informações de implementação outras informações opcionais (Rosa, 2007).
Pesquisa: A pesquisa constitui uma das funcionalidades principais do Z39.50,
permitindo a construção de interrogações complexas com grande flexibilidade. Existe
um conjunto de atributos que poderão ser utilizados para a realização dessas
pesquisas. Os clientes Z39.50 poderão assim fazer pesquisas com distintos níveis de
complexidade (Rosa, 2007).
Recuperação: A recuperação da informação abrange dois serviços que são, a
apresentação e segmentação. A apresentação consiste basicamente na solicitação ao
servidor de um determinado número de registos enquanto a segmentação consiste na
partição de muitos registos em números mais pequenos para melhor transmissão. A
segmentação é particularmente útil no caso em que se tem uma largura de banda baixa
e se faz pesquisas de centenas ou milhares de registos (Rosa, 2007).
Remoção: O processo de remoção consiste num simples pedido feito pelo cliente que é
efetuado pelo servidor seguido de um feedback enviado ao cliente. O cliente faz um
pedido de remoção da informação ao servidor e este devolve-lhe uma resposta (Rosa,
2007).
Ordenação: A ordenação é um serviço efetuado ao nível do servidor. Contudo muitas
implementações de clientes incluem essa funcionalidade do lado dos próprios clientes,
isto é a ordenação é feita mesmo do lado dos clientes, o que torna o funcionamento
mais rápido e mais eficiente. A ordenação faz referência aos resultados a ordenar,
resultados ordenados e directivas de ordenação (Rosa, 2007).
Procura: A procura é uma funcionalidade importante que entretanto não é suportada
por muitos servidores. Permite que se façam procuras numa lista ordenada de itens
disponíveis nos servidores. Em contraste com a pesquisa e recuperação em que um
conjunto de resultados é enviado do servidor ao cliente na sequência de uma operação

10
de pesquisa, na procura é enviada ao cliente uma lista de cabeçalhos a partir de um
determinado ponto (Rosa, 2007).
Controlo de recursos: é inicializado pelo servidor e poderá incluir um relatório sobre a
utilização dos recursos.
Desencadeamento do controlo de recursos: serviço inicializado pelo cliente e visa
essencialmente inquirir o servidor sobre o status de uma determinada conta.
Término: Essa funcionalidade permite tanto ao cliente como ao servidor, terminarem
abruptamente todas as operações ativas e iniciarem o término da interação entre os
dois. As razões para a realização dessa operação podem-se prender com violações de
segurança, limitação dos custos, etc.
Este protocolo não foi utilizado na realização deste trabalho pelo facto de não se terem
encontrado repositórios de acesso livre que disponibilizassem serviços de pesquisa com base
neste protocolo.

11
Capítulo 3
3 Google CSE
3.1 Conceitos
O CSE (Custom Search Engine) é um motor de pesquisa personalizável que permite incluir
um ou vários Web sites. Integra a caixa de pesquisa e os resultados e permite personalizar as
cores e a imagem corporativa para corresponderem as páginas web existentes.
Vantagens da pesquisa personalizada
Fornece resultados de pesquisa rápidos e relevantes;
Faz a gestão com a utilização do AdSense para pesquisas;
Pesquisa automaticamente em links, favoritos ou blogrolls com a pesquisa
personalizada imediata;
3.2 Aplicação
A aplicação da pesquisa personalizada do Google foi o método adotado neste trabalho, pois
foi criada uma página web através da qual é possível fazer pesquisas personalizadas
semelhante às do Google.
O primeiro passo foi criar um mecanismo de pesquisa personalizado no Google utilizando os
links dos sites existentes na base de dados de acesso livres do site da Biblioteca do IPB. Ao
criar esse mecanismo de pesquisa é fornecido um código que gere a respetiva pesquisa
personalizada do Google para ser utilizado em qualquer página web.

12
3.2.1 Criar mecanismo de pesquisa personalizado
Para criar um mecanismo de pesquisa no Google CSE é necessário criar uma conta no
Google, depois de criar a conta é necessário iniciar sessão para que seja possível criar o
mecanismo de pesquisa personalizado.
Figura 3– Criar conta no Google
Depois de entrar na página inicial, procurar a opção “Novo mecanismo de pesquisa”.

13
Figura 4– Mecanismo de pesquisa
Nesta pagina tem que se fazer uma descrição do mecanismo de pesquisa que se pretende
realizar indicando o nome, a descrição e o idioma.
Figura 5– Configuração do mecanismo de pesquisa
A seguir indicar os links dos sites onde a pesquisa deverá incidir e por último escolher uma
edição que pode ser do tipo padrão ou Site Search. A edição padrão é gratuita, com os
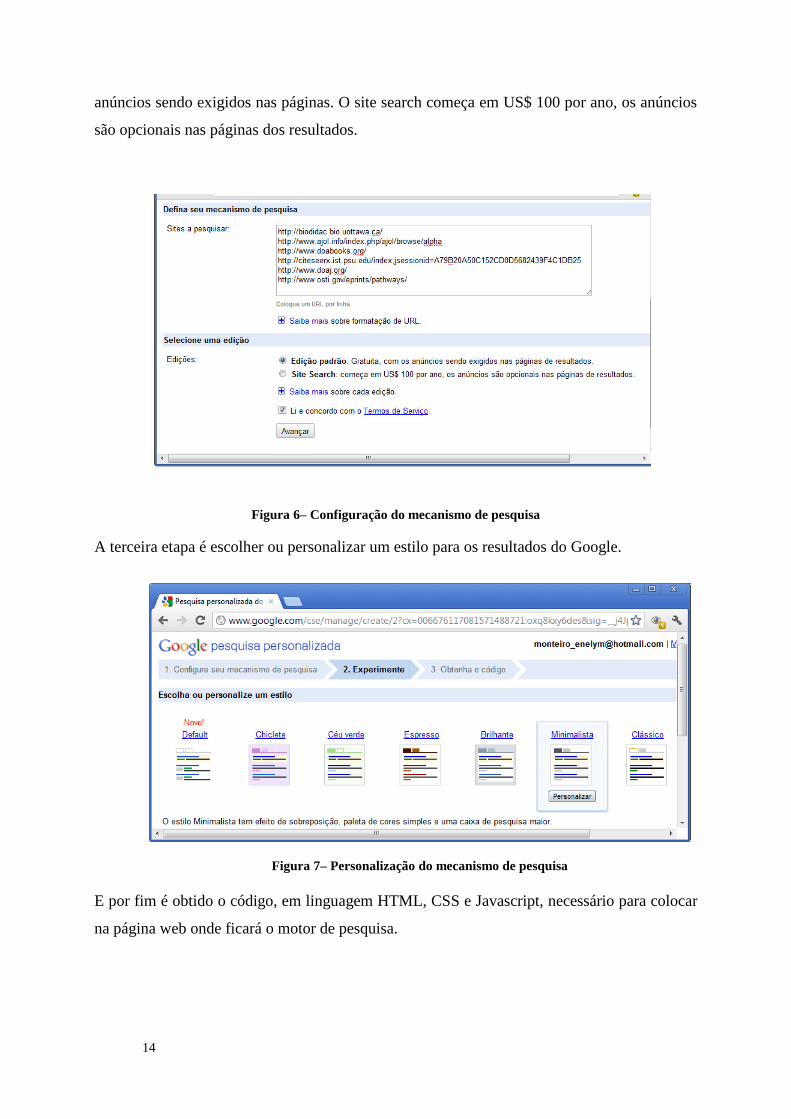
14
anúncios sendo exigidos nas páginas. O site search começa em US$ 100 por ano, os anúncios
são opcionais nas páginas dos resultados.
Figura 6– Configuração do mecanismo de pesquisa
A terceira etapa é escolher ou personalizar um estilo para os resultados do Google.
Figura 7– Personalização do mecanismo de pesquisa
E por fim é obtido o código, em linguagem HTML, CSS e Javascript, necessário para colocar
na página web onde ficará o motor de pesquisa.

15
Figura 8– Código do Google CSE

16
Capítulo 4
4 Construção das páginas web
4.1 Implementação
As tecnologias utlizadas para construir as páginas web neste trabalho foram as linguagens
HTML, PHP e XML necessárias para a concretização deste trabalho.
XML é uma linguagem de marcação que tem como objetivo facilitar o intercâmbio de documentos
estruturados na Internet. Proporciona conjuntos de regras que permitem especificar
documentos compostos por um conjunto de entidades, ou objetos, que podem conter um ou mais
elementos lógicos (Guimarães, 2005).
HTML é uma linguagem de marcação utilizada no desenvolvimento de páginas e aplicações
para a internet (Guimarães, 2005).
PHP é uma linguagem de programação do lado do servidor, gratuita, independente de
plataforma, rápida, com uma grande livraria de funções e muita documentação. Possibilita a
interacção com o utlizador através de formulários, base de dados, etc (O que é PHP, 2004).

17
4.1.1 Pesquisa
Para este trabalho foi construída uma página para pesquisa. Esta página foi gerada com base
num conjunto de scripts PHP, e esta contém o código facultado pelo Google CSE.
Figura 9– Página para pesquisa
Esta página permite ao utilizador realizar pesquisas sobre as várias bases de dados de acesso
livre e em texto completo que se encontram no Micro-Site dos Serviços e Documentação e
Bibliotecas do IPB.
Para que o utilizador possa realizar a pesquisa este deverá entrar no site do IPB, procurar a
ligação Bibliotecas, e neste encontrará uma nova ligação para recursos eletrónicos onde
encontrará a nova pagina para pesquisa.

18
Figura 10- Localização da página para pesquisa
4.1.2 Armazenagem do código do Google CSE
Devido a necessidade de adicionar e remover os sites que se encontram na base de dados de
acesso livre, foi necessário criar outras paginas web que auxiliam estas actividades.
Foi desenvolvida uma página web que permite ao utilizador fazer a sua autenticação de modo
a ter acesso a uma nova pagina que permite adicionar o código facultado pelo Google CSE.
<form action="login.php" method="post" >
<p> Nome:
<input type="text" name="nome" value ="" size="25"/>
<p> Password:
<input type="password" name="password" value ="" size="22"/>
<br></br>
<input type="submit" name="submeter" value ="entrar"
</form>
Só é possível realizar com sucesso a autenticação, se o nome e a palavra-chave corresponder a
informação guardada no documento XML.
<login>
<nome>user</nome>
<password>senha</password>
</login>
Além do documento XML foi desenvolvido um documento PHP para ler o conteúdo que se
encontra no documento XML .
<?php
$nome=$_Post["nome"];
$password=$_Post["password"];
Recursos
Electronicos
EEletrónicos
IPB
Bibliotecas
Pesquisa

19
$dom = new DOMDocument();
$dom->load("login.xml");
$dompath=new domxpath($dom);
$values =$dompath->query("//Autenticacao/login/password");
$st=0;
if($values->length>0){
$pw= $values->item(0)->nodeValue;
$values =$dompath->query("//Autenticacao/login/nome");
if($values->length>0){
$pnome= $values->item(0)->nodeValue;
// Verifica se usuário e senha conferem
if ($_POST["nome"] == $pnome && $_POST["password"] == $pw)
{
$st=1;
// session_start();
// $_SESSION["Login"] = "YES";
// echo "<h1>Bem vindo</h1>";
//echo "<p><a href='inserCod.php'>Link para o arquivo
restrito</a><p/>";
header("Location:inserCod.html");
exit();
}
}
}
if($st==0) {
session_start();
$_SESSION["Login"] = "NO";
echo "<html>
<head>
<meta http-equiv=\"Content-Type\" content=\"text/html; charset=UTF-
8\">
<title></title>
</head>
<body>";
echo "<h1>Erro no nome ou password</h1>";
echo "<p><a href='inserCod.php'>Login</a><p/>";
</body>
</html>
}
?>
Para inserir o codigo facultado pelo Google foi gerada uma pagina baseada num conjunto de
scripts PHP que vai incluir também uma Form que permite a inserção do codigo.
<div>
<form action="LerTEXTAREA.php"
method="post">
<textarea name="item" cols="40" rows="10" wrap="soft"></textarea>
<br></br>
<input type="submit" name="submeter" value ="submeter"
onClick="alert('Os dados vão ser submetidos');"/>

20
</form>
</div>
Figura 11– Página para submeter o código do Google
O codigo inserido no textarea é guardado no mesmo documento XML que se encontra as
informações relativas a autenticação do utilizador.
<codgoogle> <div id="cse" style="width:
100%;">Loading</div>
<script src="http://www.google.com/jsapi"
type="text/javascript"></script>
<script type="text/javascript">
google.load('search', '1', {language : 'pt-BR', style :
google.loader.themes.ESPRESSO});
google.setOnLoadCallback(function() {
var customSearchOptions = {}; var customSearchControl = new
google.search.CustomSearchControl(
'006676117081571488721:akykzejwqi4', customSearchOptions);
customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESU
LTSET);
customSearchControl.draw('cse'); }, true);
</script></codgoogle>
Para que fosse possível este código gerar um novo motor de pesquisa na página de pesquisa,
foi necessário criar um novo documento baseado em scripts PHP que tem como função ler o
conteúdo do textarea.
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title></title>
</head>
<body>
<?php

21
$item=$_Post["item"];
$item=htmlentities($item);
echo($_REQUEST["item"]);
?>
</body>
</html>
4.1.3 Resultado da Pesquisa
Para realizar a pesquisa o utilizador deverá entrar na página para pesquisa, onde se encontra
implementado o novo motor de pesquisa personalizada, e depois clicar em “Pesquisar “. Ao
fazer click na opção “Pesquisar” surgirá uma nova página com os resultados de pesquisa.

22
Figura 12– Resultado da pesquisa

23
Capítulo 5
5 Conclusão
5.1 Considerações Finais
Ao longo deste projeto foi-me permitido adquiri novos conhecimentos nomeadamente ao
nível dos protocolos utilizados nas Bibliotecas Digitais, e a prática no manuseamento da
linguagem XML o que corresponde a uma mais-valia na minha futura carreira profissional.
Com a concretização do projeto, foi alcançado o objetivo de otimizar o processo de pesquisa
no Micro-Site dos Serviços de Documentação e Biblioteca do IPB.
Em suma, a realização deste projeto veio proporcionar alguns benefícios no Micro-Site dos
Serviços de Documentação e Biblioteca do IPB, pois com a implementação do novo motor
de pesquisa personalizada é possível efetuar pesquisas sobre as várias bases de dados em
acesso livre e recuperar os conteúdos indexados ao motor de pesquisa de modo a reduzir o
tempo de pesquisa.
5.2 Trabalhos Futuros
Com o trabalho desenvolvido até este ponto, seria interessante e prático estender este projecto
de modo a transformar o processo de armazenagem do código do Google CSE num processo
mais automatizado.
Assim poder-se-ia implementar um sistema que de forma automática permitisse ao
responsável pelo Micro-Site dos Serviços de Documentação e Bibliotecas do IPB, remover e
adicionar sites na base de dados de acesso livre para a pesquisa.

24

1
Referências bibliográficas
Alvarez, M. A. (13 de Outubro de 2004). Introdução as Linguagens Web.
Guimarães, C. (6 de Junho de 2005). Introdução a Linguagens de Marcação: HTML, XHTML,SGML,
XML.
Maria do Céu. (s.d.). Biblioteca Digital em contexto Universitário: O caso da universidade Fernando
Pessoa. Obtido em Maio de 2012, de Academia.edu:
http://ufp.academia.edu/NunoMagalh%C3%A3esRibeiro/Papers/497641/A_Biblioteca_Digital_em_Co
ntexto_Universitario_o_caso_da_Universidade_Fernando_Pessoa
O que é o Acesso Livre. (s.d.). Obtido em 31 de Março de 2012, de Repositório Cientifico de Acesso
Aberto de Portugal: http://projecto-
devel.rcaap.pt/index.php?option=com_content&view=article&id=23&Itemid=35&lang=pt
O que é PHP. (13 de Outubro de 2004). Obtido em 02 de Junho de 2012, de criarweb.com:
http://www.criarweb.com/artigos/202.php
Pinto, E. C. (Jullho de 2006). Repensando os Commons na Cominidade Científica. São Paulo, Brasil.
Rosa, I. B. (Abril de 2007). Protocolo Z39.50. Cabo Verde.
Segundo, J. E. (2010). Representação Iterativa: um modelo para Repositórios Digitais. Marília, São
Paulo, Brasil.
Sobrinho, A. C. (2011). Proteção da Informação digital: segurança ou privação. DataGramazo_Revista
de Ciência da Informação .

2