rodrigo de souza lima espinha suporte topológico em
TRANSCRIPT

Rodrigo de Souza Lima Espinha
Suporte topológico em paralelo para malhas de elementos
finitos em análises dinâmicas de fratura e fragmentação
Tese de Doutorado
Tese apresentada ao Programa de Pós-graduação em Informática do Departamento de Informática da PUC-Rio como requisito parcial para obtenção do título de Doutor em Informática.
Orientador: Prof. Waldemar Celes Filho
Rio de Janeiro
Abril de 2011
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

Rodrigo de Souza Lima Espinha
Suporte topológico em paralelo para malhas de elementos
finitos em análises dinâmicas de fratura e fragmentação
Tese apresentada como requisito parcial para obtenção do título de Doutor pelo Programa de Pós-graduação em Informática da PUC-Rio. Aprovada pela Comissão Examinadora abaixo assinada.
Prof. Waldemar Celes Filho Orientador
Departamento de Informática - PUC-Rio
Prof. Marcelo Gattass Departamento de Informática - PUC-Rio
Profa. Noemi Rodriguez Departamento de Informática - PUC-Rio
Prof. Glaucio H. Paulino University of Illinois at Urbana-Champaign, USA
Prof. Ricardo Farias Universidade Federal do Rio de Janeiro (UFRJ)
Prof. Luiz Fernando Martha Departamento de Engenharia Civil - PUC-Rio
Prof. José Eugênio Leal Coordenador(a) Setorial do Centro Técnico Científico - PUC-Rio
Rio de Janeiro, 05 de abril de 2011
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

Todos os direitos reservados. É proibida a reprodução total ou parcial do trabalho sem autorização do autor, do orientador e da universidade.
Rodrigo de Souza Lima Espinha
Possui graduação em Engenharia de Computação e mestrado em Informática pela Pontifícia Universidade Católica do Rio de Janeiro (PUC-Rio), onde continuou seus estudos no programa de Doutorado em Informática. Durante a permanência nesta instituição, atuou em projetos voltados à indústria do petróleo, no laboratório de Computação Gráfica – Tecgraf/PUC-Rio.
Ficha Catalográfica
Espinha, Rodrigo de Souza Lima
Suporte topológico em paralelo para malhas de elementos finitos em análises dinâmicas de fratura e fragmentação / Rodrigo de Souza Lima Espinha; orientador: Waldemar Celes Filho. – 2011.
122 f.: il. (color.) ; 30 cm
Tese (doutorado) – Pontifícia Universidade Católica do Rio de Janeiro, Departamento de Informática, 2011.
Inclui bibliografia
1. Informática – Teses. 2. Modelo de zona coesiva extrínseco. 3. Elemento coesivo. 4. Estrutura de dados topológica. 5. Malha adaptativa. 6. Simulação paralela de fratura. 7. Fragmentação. I. Celes Filho, Waldemar. II. Pontifícia Universidade Católica do Rio de Janeiro. Departamento de Informática. III. Título.
CDD: 004
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

À minha família.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

Agradecimentos
A Deus, pois sem Ele nada teria sido possível.
A meus pais e esposa, Herisangela, pelo incentivo em todos os momentos.
Ao meu orientador, Prof. Waldemar Celes, pelo grande apoio, motivação e o
conhecimento que me foi transmitido ao longo do curso.
Ao Prof. Glaucio Paulino, pela oportunidade única de ter convivido e aprendido
muito com pessoas brilhantes durante o tempo que passei com seu grupo de
pesquisa na Universidade de Illinois, e por todo o suporte recebido ao longo
daquele período.
A Kyoungsoo Park, pelo apoio fundamental com as simulações numéricas de
fraturas, pela paciência e amizade de uma grande pessoa como ele.
Ao laboratórioTecgraf/PUC-Rio, pela oportunidade de aprender todos os dias e
de encontrar novos desafios a serem resolvidos.
A todos os colegas e amigos da PUC-Rio.
O presente trabalho foi realizado com apoio do CNPq, Conselho Nacional de
Desenvolvimento Científico e Tecnológico - Brasil
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

Resumo
Espinha, Rodrigo de Souza Lima; Celes Filho, Waldemar. Suporte topológico em paralelo para malhas de elementos finitos em análises dinâmicas de fratura e fragmentação. Rio de Janeiro, 2011. 122p. Tese de Doutorado - Departamento de Informática, Pontifícia Universidade Católica do Rio de Janeiro.
Fenômenos de propagação de fraturas e fragmentação em sólidos podem
ser descritos por Modelos de Zona Coesiva e simulados com o Método dos
Elementos Finitos. Entre as abordagens computacionais de recente interesse
para a representação de fraturas em malhas de elementos finitos, encontram-se
as baseadas em elementos coesivos. Nelas, o comportamento de fraturas é
representado por elementos coesivos inseridos nas interfaces entre elementos
volumétricos da malha original. Os modelos de elementos coesivos podem ser
classificados como intrínsecos ou extrínsecos. Modelos intrínsecos requerem
elementos coesivos pré-inseridos em todas as interfaces volumétricas passíveis
de fraturas. Por outro lado, modelos extrínsecos requerem que elementos
coesivos sejam inseridos de forma adaptativa, apenas onde e quando
necessários. Porém, a representação de malhas tradicional (elementos e nós)
não é suficiente para tratar malhas adaptativas eficientemente, o que faz
necessário um suporte topológico apropriado. Em geral, modelos coesivos de
fratura também requerem um alto nível de refinamento de malha, para que
resultados precisos sejam obtidos. Isso implica em um consumo de memória e
processamento que pode ser proibitivo a estações de trabalho tradicionais.
Assim, ambientes paralelos tornam-se importantes na solução de problemas de
fraturas. Entretanto, devido às dificuldades de paralelização de modelos
extrínsecos, as abordagens existentes utilizam modelos intrínsecos ou
implementam simulações extrínsecas baseadas em elementos coesivos pré-
inseridos ou representados como atributos de elementos volumétricos. Com o
objetivo de viabilizar a simulação de fraturas e fragmentação extrínsecas em
grandes modelos de forma simples e eficiente, esta tese propõe o sistema
ParTopS, um suporte topológico em paralelo para malhas de elementos finitos
em análises dinâmicas de fratura e fragmentação. Em especial, é apresentada
uma representação compacta e eficiente de malhas de fraturas distribuídas.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

Elementos coesivos são representados explicitamente e tratados como
elementos regulares da malha. Com base na representação de malha
distribuída, propõe-se um algoritmo paralelo escalável para a inserção adaptativa
de elementos coesivos em malhas bidimensionais e tridimensionais. Operações
topológicas simétricas são exploradas para reduzir a comunicação entre
partições de malha. O sistema ParTopS foi empregado na paralelização de
simulações sequenciais extrínsecas existentes. A escalabilidade e a corretude
do suporte topológico em paralelo são demonstradas através de experimentos
computacionais realizados em um ambiente massivamente paralelo. Os
resultados alcançados mostram que o sistema ParTopS pode ser aplicado de
forma eficaz para viabilizar simulações de grandes modelos.
Palavras-chave
Modelo de zona coesiva extrínseco; elemento coesivo; estrutura de dados
topológica; malha adaptativa; simulação paralela de fratura; fragmentação
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

Abstract
Espinha, Rodrigo de Souza Lima; Celes Filho, Waldemar. Parallel topological support for finite element meshes in dynamic fracture and fragmentation analyses. Rio de Janeiro, 2011. 122p. DSc Thesis - Departamento de Informática, Pontifícia Universidade Católica do Rio de Janeiro.
Fracture propagation and fragmentation phenomena in solids can be
described by Cohesive Zone Models and simulated with the Finite Element
Method. Among the computational approaches of recent interest for fracture
representation in finite element meshes are those based on cohesive elements.
In those approaches, fracture behavior is represented by cohesive elements
inserted at the interfaces between volumetric (bulk) elements of the original
mesh. Cohesive element models can be classified into intrinsic or extrinsic.
Intrinsic models require pre-inserted cohesive elements at every volumetric
interface in which fracture is allowed to happen. On the other hand, extrinsic
models require that cohesive elements be adaptively inserted, wherever and
whenever necessary. However, the traditional mesh representation (elements
and nodes) is not sufficient for handling adaptive meshes, which makes an
appropriate topological support necessary. In general, cohesive models of
fracture also require a high level of mesh refinement near crack tips, such that
accurate results can be achieved. This implies in memory and processor
consumption that may be prohibitive for traditional workstations. Thus, parallel
environments become important for the solution of fracture problems. However,
due to the difficulties for the parallelization of extrinsic models, the existing
approaches use intrinsic models or implement extrinsic simulations based on pre-
inserted cohesive elements or cohesive elements represented as attributes of
volumetric elements. In order to allow fracture and fragmentation simulations of
large models in a simple and efficient way, this thesis proposes the ParTopS
system, a parallel topological support for finite element meshes in dynamic
fracture and fragmentation analyses. Specifically, a compact and efficient
representation of distributed fracture meshes is presented. Cohesive elements
are explicitly represented and treated as regular elements in the mesh. Based on
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

the distributed mesh representation, we propose a scalable parallel algorithm for
adaptive insertion of cohesive elements in both bidimensional and tridimensional
meshes. Symmetrical topological operations are exploited in order to reduce
communication among mesh partitions. The ParTopS system has been employed
in order to parallelize existing serial extrinsic simulations. The scalability and
correctness of the parallel topological support is demonstrated through
computational experiments executed on a massively parallel environment. The
achieved results show that ParTopS can be effectively applied in order to enable
simulations of large models.
Keywords
Extrinsic cohesive zone model; cohesive element; topological data
structure; adaptive mesh; parallel fracture simulation; fragmentation
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

Sumário
1 Introdução 12
1.1. Objetivo 15
1.2. Contribuições 16
1.3. Organização deste documento 17
2 Trabalhos relacionados 18
2.1. Atualização de dados compartilhados por múltiplas partições 18
2.2. Particionamento da malha de elementos finitos 20
2.3. Malhas adaptativas 21
2.4. Estruturas de dados topológicas para malhas distribuídas dinâmicas 22
2.4.1. MDB/PMDB 23
2.4.2. AOMD/PAOMD 23
2.4.3. FMDB 24
2.4.4. LibMesh 25
2.4.5. SIERRA 25
2.4.6. ParFUM 26
2.5. Simulações paralelas de fraturas coesivas extrínsecas 28
2.6. TopS 30
2.6.1. Entidades topológicas 31
2.6.2. Elementos coesivos 34
2.6.3. Inserção adaptativa sequencial de elementos coesivos 36
2.6.4. Conjuntos de atributos densos e esparsos 38
3 ParTopS: suporte topológico compacto em paralelo para representação de
fraturas 40
3.1. Representação de malha distribuída 40
3.1.1. Camada de comunicação 41
3.1.2. Construção da camada de comunicação 48
3.1.3. Vizinhança de uma partição 49
3.1.4. Representação distribuída de atributos 52
3.2. Inserção dinâmica de elementos coesivos em paralelo 54
3.2.1. Operações topológicas simétricas 54
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3.2.2. Descrição do algoritmo paralelo 55
3.2.2.1. Inserção sequencial de elementos coesivos (Fase 1) 57
3.2.2.2. Atualização das entidades proxies criadas (Fase 2) 59
3.2.2.3. Atualização das entidades ghosts afetadas (Fase 3) 61
3.2.3. Interface para a inserção de elementos coesivos 67
3.2.4. Análise de escalabilidade 68
4 Simulações de fraturas extrínsecas em ambientes paralelos 70
4.1. Requisitos de sincronização de entidades 70
4.2. Estrutura da simulação sequencial 72
4.3. Padrões de computação 74
4.4. Computações simétricas 75
4.4.1. Computações elementos-a-nó simétricas com iteradores estáveis 76
4.5. Interface de programação paralela 78
4.5.1. Funções exportadas à aplicação numérica 79
4.5.2. Implementação da interface de programação 80
4.6. Estrutura da simulação paralela 83
4.6.1. Abordagem baseada em computações apenas em entidades locais 84
4.6.2. Abordagem baseada em computações replicadas 87
4.6.3. Abordagem baseada em computações simétricas 89
4.6.4. Abordagem mista 90
5 Experimentos computacionais 92
5.1. Representação topológica de fraturas e fragmentação em paralelo 92
5.1.1. Corretude e eficiência 93
5.1.2. Escalabilidade 99
5.2. Simulações numéricas em paralelo 101
5.2.1. Comparação entre abordagens paralelas 102
5.2.2. Desempenho em relação à simulação sequencial 103
5.2.3. Desempenho relativo 106
5.2.4. Escalabilidade 109
5.2.5. Simulação de fraturas com microrramificações 111
6 Conclusão 115
6.1. Trabalhos futuros 116
7 Referências bibliográficas 118
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

1 Introdução
Simulações numéricas computacionais são importantes para a análise de
problemas complicados de engenharia. Grande parte desses problemas está
relacionada à solução de sistemas de equações diferenciais parciais em
domínios geométricos contínuos. Um método numérico muito utilizado para isso
é o Método dos Elementos Finitos (MEF) (Zienkiewicz et al., 2005). Nesse
método, o domínio geométrico é discretizado por um conjunto finito de
subdomínios, ou elementos, interconectados através de pontos chamados nós; o
conjunto de elementos e nós forma uma malha. A malha, mais as propriedades
de domínio a ela associadas para a solução do problema numérico, é chamada
modelo de elementos finitos. Uma aproximação numérica para uma solução do
sistema de equações diferenciais é, então, calculada com base no domínio
discreto representado pelo modelo de elementos finitos.
Uma das principais aplicações do MEF é na solução de problemas na área
de mecânica estrutural (Zienkiewicz et al., 2005; Cook et al., 2001). Neste caso,
uma simulação numérica (ou análise de elementos finitos) é realizada a fim de
se obter resultados para grandezas físicas como deslocamentos, deformações e
tensões, em resposta a cargas aplicadas a uma estrutura.
Fenômenos de propagação de fraturas e fragmentação podem ser
modelados através de Modelos de Zona Coesiva (Xu & Needleman, 1994;
Camacho & Ortiz, 1996; Zhang & Paulino, 2005; Park et al., 2009), e simulados
com base no MEF. Entre as principais abordagens computacionais para a
representação de fraturas a partir de modelos de zona coesiva, encontram-se as
que empregam elementos especiais, chamados coesivos. Nessas abordagens,
elementos coesivos são usados para representar o comportamento de fraturas,
enquanto que os elementos volumétricos tradicionais representam deformações
do meio contínuo. Os elementos coesivos são inseridos nas interfaces entre
pares de elementos volumétricos adjacentes na malha de elementos finitos.
Os modelos baseados em elementos coesivos podem ser classificados
como: intrínsecos ou extrínsecos. Na abordagem intrínseca (Xu & Needleman,
1994), elementos coesivos possuem uma resposta inicial elástica, como ilustrado
pela curva de tração-separação da Figura 1a. A partir da origem, a tração T
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
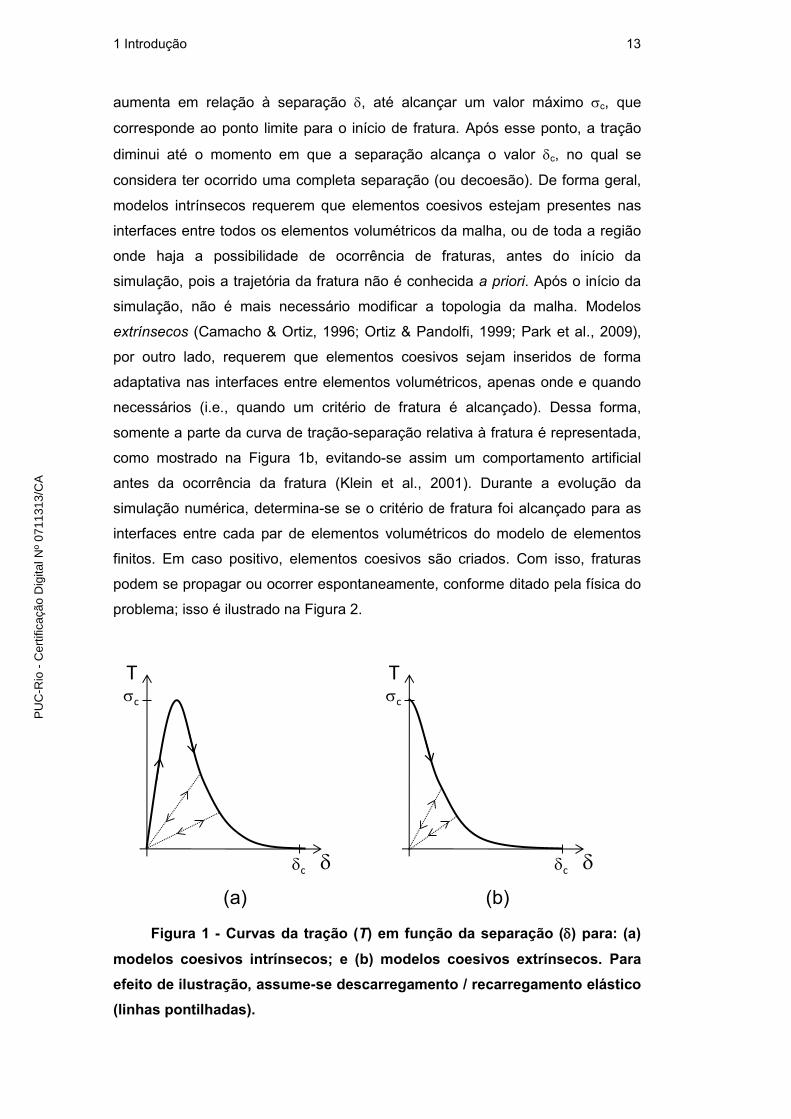
1 Introdução 13
aumenta em relação à separação , até alcançar um valor máximo c, que
corresponde ao ponto limite para o início de fratura. Após esse ponto, a tração
diminui até o momento em que a separação alcança o valor c, no qual se
considera ter ocorrido uma completa separação (ou decoesão). De forma geral,
modelos intrínsecos requerem que elementos coesivos estejam presentes nas
interfaces entre todos os elementos volumétricos da malha, ou de toda a região
onde haja a possibilidade de ocorrência de fraturas, antes do início da
simulação, pois a trajetória da fratura não é conhecida a priori. Após o início da
simulação, não é mais necessário modificar a topologia da malha. Modelos
extrínsecos (Camacho & Ortiz, 1996; Ortiz & Pandolfi, 1999; Park et al., 2009),
por outro lado, requerem que elementos coesivos sejam inseridos de forma
adaptativa nas interfaces entre elementos volumétricos, apenas onde e quando
necessários (i.e., quando um critério de fratura é alcançado). Dessa forma,
somente a parte da curva de tração-separação relativa à fratura é representada,
como mostrado na Figura 1b, evitando-se assim um comportamento artificial
antes da ocorrência da fratura (Klein et al., 2001). Durante a evolução da
simulação numérica, determina-se se o critério de fratura foi alcançado para as
interfaces entre cada par de elementos volumétricos do modelo de elementos
finitos. Em caso positivo, elementos coesivos são criados. Com isso, fraturas
podem se propagar ou ocorrer espontaneamente, conforme ditado pela física do
problema; isso é ilustrado na Figura 2.
Figura 1 - Curvas da tração (T) em função da separação () para: (a)
modelos coesivos intrínsecos; e (b) modelos coesivos extrínsecos. Para
efeito de ilustração, assume-se descarregamento / recarregamento elástico
(linhas pontilhadas).
c
T
c
c
T
c
(a) (b)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
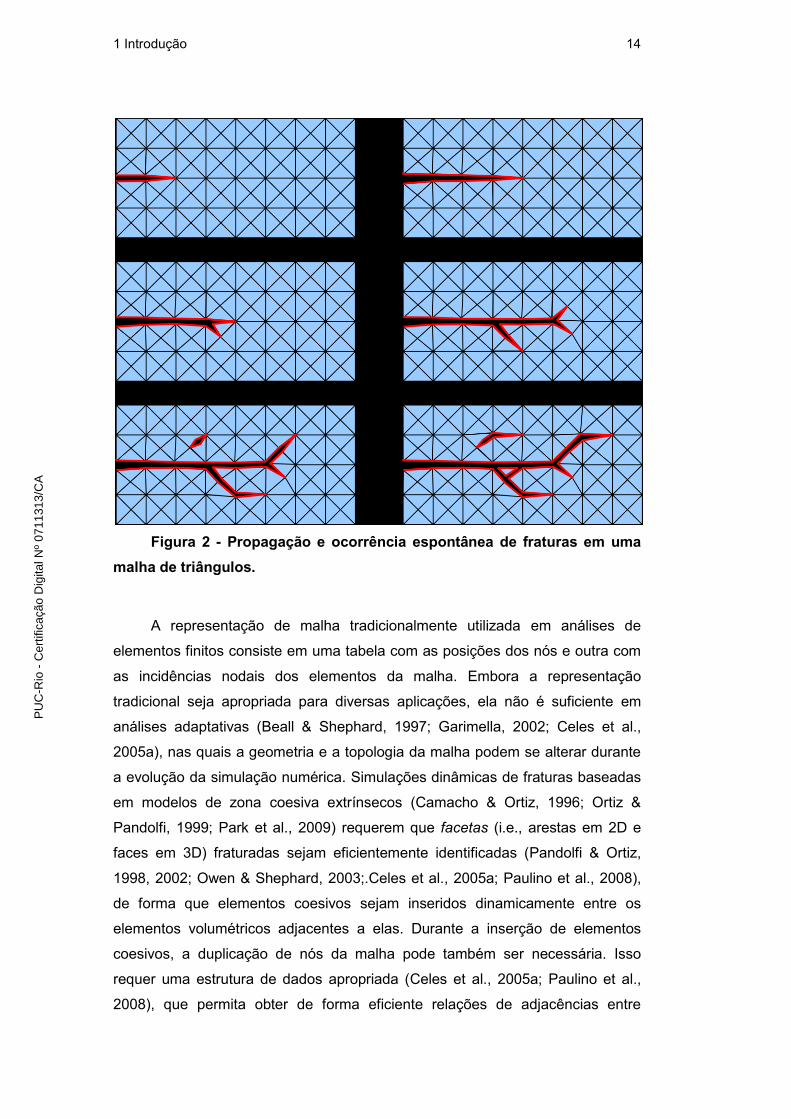
1 Introdução 14
Figura 2 - Propagação e ocorrência espontânea de fraturas em uma
malha de triângulos.
A representação de malha tradicionalmente utilizada em análises de
elementos finitos consiste em uma tabela com as posições dos nós e outra com
as incidências nodais dos elementos da malha. Embora a representação
tradicional seja apropriada para diversas aplicações, ela não é suficiente em
análises adaptativas (Beall & Shephard, 1997; Garimella, 2002; Celes et al.,
2005a), nas quais a geometria e a topologia da malha podem se alterar durante
a evolução da simulação numérica. Simulações dinâmicas de fraturas baseadas
em modelos de zona coesiva extrínsecos (Camacho & Ortiz, 1996; Ortiz &
Pandolfi, 1999; Park et al., 2009) requerem que facetas (i.e., arestas em 2D e
faces em 3D) fraturadas sejam eficientemente identificadas (Pandolfi & Ortiz,
1998, 2002; Owen & Shephard, 2003;.Celes et al., 2005a; Paulino et al., 2008),
de forma que elementos coesivos sejam inseridos dinamicamente entre os
elementos volumétricos adjacentes a elas. Durante a inserção de elementos
coesivos, a duplicação de nós da malha pode também ser necessária. Isso
requer uma estrutura de dados apropriada (Celes et al., 2005a; Paulino et al.,
2008), que permita obter de forma eficiente relações de adjacências entre
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

1 Introdução 15
entidades topológicas e realizar a inserção de elementos coesivos de maneira
consistente.
Modelos coesivos de fratura, em geral, requerem um alto nível de
refinamento de malha em regiões ao redor de pontas de fraturas, de forma que o
comportamento não linear nessas regiões possa ser corretamente capturado
(Zhang, 2007). Além disso, a direção de propagação de fraturas tende a ser
altamente dependente do nível de refinamento (Zhang et al., 2007; Papoulia et
al., 2006). Devido às limitações dos recursos computacionais atuais, modelos de
dimensões reduzidas são utilizados (Zhang et al., 2007). Porém, estes não
permitem reproduzir os experimentos originais completamente, devido a escalas
de comprimento dependentes de material (Zhang et al., 2007). Dessa forma,
para se obterem resultados precisos e pouco sensíveis à malha utilizada, é
necessária uma grande quantidade de memória e poder de processamento. Uma
vez que o custo das simulações pode se tornar proibitivo para estações de
trabalho tradicionais, ambientes paralelos se tornam uma ferramenta importante
para a solução eficaz de problemas de propagação de fraturas.
A paralelização de simulações numéricas permite contornar as limitações
de capacidade de memória e/ou processamento impostas pelas abordagens
sequenciais tradicionais. Porém, também apresenta alguns desafios a serem
tratados, para que possa ser vantajosa em relação às abordagem sequenciais.
Entre eles, encontram-se: o desenvolvimento de métodos numéricos paralelos, a
representação eficiente de malhas distribuídas, e a paralelização de técnicas de
refinamento de malha adaptativo, com o correspondente balanceamento
dinâmico da carga dos processadores. Simulações de fraturas baseadas em
elementos coesivos, em especial os modelos extrínsecos, apresentam desafios
adicionais, como a representação e inserção adaptativa de elementos coesivos
em paralelo, que incluem a manutenção da topologia da malha e propagação de
mudanças topológicas para elementos vizinhos de forma consistente e eficiente.
1.1. Objetivo
Esta pesquisa teve como objetivo o desenvolvimento de um suporte
topológico que ofereça ferramentas para a representação de malhas distribuídas
em ambiente paralelo, com os operadores topológicos necessários à realização
de simulações dinâmicas de fraturas e fragmentação baseadas em modelos de
zona coesiva extrínsecos.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

1 Introdução 16
1.2. Contribuições
As seguintes contribuições são apresentadas por este trabalho:
1. Representação compacta e eficiente de malhas distribuídas para
simulações de fratura e fragmentação extrínsecas. É apresentado o
sistema ParTopS (Espinha et al., 2009), que fornece uma
representação compacta para malhas distribuídas de elementos
finitos utilizadas em simulações de fraturas e fragmentação
extrínsecas. Diferentemente de abordagens anteriories, elementos
coesivos são representados explicitamente e tratados como
entidades regulares da malha de elementos finitos.
2. Um algoritmo paralelo eficiente e escalável para a inserção
dinâmica de elementos coesivos em paralelo (Espinha et al., 2009).
No algoritmo proposto, elementos coesivos são tratados de
maneira uniforme, tanto em malhas bidimensionais (2D) como
tridimensionais (3D), e podem ser inseridos entre diferentes tipos
de elementos (ex. T3 (triângulo linear), T6 (triângulo quadrático),
Tet4 (tetraedro linear), Tet10 (tetraedro quadrático), Brick8
(hexahedro linear) e Brick20 (hexahedro quadrático), entre outros).
A inserção é feita de forma adaptativa, onde e quando determinado
pela simulação, conforme requerido pelo modelo coesivo
extrínseco. O sincronismo topológico entre partições de malha é
baseado em operações simétricas e comunicação em lote (batch).
Isso permite reduzir a comunicação entre partições para a
propagação de alterações topológicas, e eliminar a necessidade de
acesso exclusivo (locks) a entidades topológicas (lock-free
approach) ou aquisições temporárias das mesmas por uma
partição.
3. Simulações computacionais paralelas escaláveis de problemas de
propagação de fratura tridimensionais baseados em modelos
extrínsecos. Simulações sequenciais são paralelizadas com base
na representação de malha distribuída proposta neste trabalho,
mostrando que modelos coesivos extrínsecos podem ser simulados
de forma escalável. Computações simétricas são empregadas para
a redução da sincronização de dados entre partições de malha.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

1 Introdução 17
1.3. Organização deste documento
Este documento é organizado da forma descrita a seguir. O Capítulo 2
apresenta os trabalhos presentes na literatura relacionados a esta pequisa. São
revistos os sistemas existentes para a representação de malhas distribuídas
gerais, e discutidas abordagens recentes para o tratamento de simulações de
fraturas extrínsecas. A estrutura de dados topológica sequencial TopS (Celes et
al., 2005a, b; Paulino et al., 2008) também é brevemente revisitada. No Capítulo
3, propõe-se o sistema ParTopS, que oferece um suporte topológico para a
representação de fraturas em paralelo. São apresentados uma representação
distribuída de malhas de fraturas dinâmicas e um algoritmo para a inserção
adaptativa de elementos coesivos em paralelo, baseado na representação de
malha distribuída proposta. O Capítulo 4 descreve a interface fornecida por
ParTopS para o desenvolvimento de simulações numéricas propagação de
fraturas e fragmentação em paralelo e discute abordagens para a paralelização
de uma aplicação existente. Resultados de experimentos computacionais que
demonstram e validam o suporte topológico ParTopS são discutidos no Capítulo
5. O Capítulo 6 conclui este documento e apresenta direções para possíveis
trabalhos futuros.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados
Neste capítulo, são revistas as principais questões relativas à
representação distribuída de malhas de elementos finitos, e os trabalhos
relacionados propostos na literatura que visam tratá-las.
Uma abordagem comum utilizada na paralelização de aplicações que
executam uma mesma operação sobre um determinado volume de dados é o
modelo de paralelismo de dados (Foster, 1995; Mattson et al., 2004). Esse
modelo se aplica a modelos de elementos finitos, nos quais operações são
realizadas sobre os elementos e nós de uma malha. A malha é decomposta em
um conjunto de partições, e a cada partição é atribuído um subconjunto dos
elementos e nós da malha original. Uma partição representa, assim, uma
unidade local de processamento, que pode ser associada a um determinado
processador para ser executada concorrentemente com outras partições; em
geral, um processador é responsável por uma ou mais partições. Dessa forma, a
malha global passa a ser representada de forma distribuída, pelo conjunto de
partições associadas a um grupo de processadores.
A representação distribuída de malhas de elementos finitos (Remacle et
al., 2002; Seol & Shephard, 2006; Lawlor et al., 2006) oferece uma ferramenta
para a execução de análises paralelas visando a solução de problemas maiores
e/ou a redução do tempo total de simulação. Por outro lado, também introduz
questões que devem ser consideradas a fim de que a análise possa ser
realizada de forma eficiente. Algumas dessas questões são apresentadas nas
seções a seguir. Na Seção 2.4, diversos sistemas presentes na literatura para a
representação de malhas distribuídas dinâmicas são brevemente discutidos.
2.1. Atualização de dados compartilhados por múltiplas partições
Uma questão importante relativa à representação de malhas distribuídas
refere-se à manutenção da consistência de dados entre as partições de malha;
em especial, consideram-se os dados correspondentes a entidades localizadas
próximas às fronteiras das partições.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 19
Computações de resultados de simulação para uma entidade topológica do
modelo de elementos finitos muitas vezes dependem de dados associados às
entidades adjacentes a ela. Porém, uma entidade localizada na fronteira de uma
partição pode ser adjacente a entidades localizadas em outras partições. No
exemplo da Figura 3, o nó destacado é compartilhado por elementos de duas
partições de malha diferentes. Se a computação do valor do nó depender dos
valores dos elementos adjacentes, estes devem ser obtidos a partir das
partições correspondentes. Isso requer uma forma de comunicação entre as
partições envolvidas. Para que o valor do nó possa ser utilizado pelas partições
que o compartilham, ele deve ser atualizado de maneira consistente entre elas.
Figura 3 – Um nó compartilhado por elementos pertencentes a duas
partições de malha diferentes encontra-se destacado. O valor do nó deve
ser atualizado consistentemente entre as partições.
Em arquiteturas de memória compartilhada (Foster, 1995), todos os
processadores compartilham um mesmo espaço de memória virtual. Isso permite
que a partições de malha correspondentes se comuniquem de maneira
assíncrona, através de operações de escrita e leitura de dados em memória. Por
sua vez, a atualização de regiões de memória compartilhadas pode ser feita de
forma consistente por meio de mecanismos de acesso exclusivo, como travas de
acesso (locks) e semáforos (Andrews, 2000). No contexto de estruturas de
dados topológicas, Waltz (2002) apresenta algoritmos paralelos para o acesso a
entidades topológicas, que podem ser utilizados em simulações baseadas no
MEF.
Em ambientes paralelos baseados na arquitetura de memória distribuída
(Foster, 1995), nós de processamento independentes (contendo um ou mais
processadores) são interconectados por uma infraestrutura de rede (em geral, de
alto desempenho). Neste caso, o espaço de memória de um nó não é
compartilhado com os outros, e a transmissão de dados entre nós é tipicamente
realizada através do envio de mensagens através da rede. O acesso indireto a
dados remotos geralmente representa um aumento do custo da comunicação
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 20
entre partições. Por outro lado, os ambientes de memória distribuída têm se
mostrado escaláveis, permitindo que o número de processadores alcance
dezenas ou mesmo centenas de milhares, o que dificilmente é obtido apenas
com arquiteturas de memória compartilhada.
Uma solução comumente empregada em ambientes de memória
distribuída para se garantir acesso consistente e eficiente a dados remotos pelas
partições de uma malha consiste na introdução de uma camada fantasma ao
redor de cada partição de malha. Convencionalmente, essa camada é composta
por cópias locais não editáveis de entidades topológicas remotas que são
adjacentes às entidades de uma partição. Dessa forma, os valores das entidades
adjacentes podem ser acessados pela partição durante uma computação de
maneira local e transparente. As entidades fantasmas, em geral, são atualizadas
todas ao mesmo tempo, ao final de um passo de simulação, ou em qualquer
outro momento em que isso seja necessário. Assim, a frequência de requisições
de dados a outras partições é significativamente reduzida. Com a atualização de
dados de uma entidade topológica realizada por apenas uma partição,
considerada a proprietária da entidade, garante-se a consistência dos dados.
Uma variação da solução anterior é adotada pelo framework ParFUM
(Lawlor et al., 2006). O conceito de Multiphase Shared Arrays (MSA) (DeSouza
& Kalé, 2004) é utilizado para manter dados de nós (como na Figura 3)
compartilhados por partições de malha distintas atualizados de maneira
assíncrona. Para isso, um vetor distribuído é responsável por intermediar a
comunicação entre partições. Em uma primeira etapa, o acesso ao vetor é feito
através de um modo de acumulação, e os dados de cada partição são atribuídos
às posições dos nós correspondentes no vetor, que os soma (acumula)
automaticamente. Na segunda etapa, o modo de acesso é alterado para leitura,
e cada partição obtém os dados dos nós de forma consistente. Os valores dos
outros elementos e nós da camada fantasma são atualizados conjuntamente, por
meio de uma chamada de função paralela coletiva específica, ao final de cada
passo de simulação.
2.2. Particionamento da malha de elementos finitos
O particionamento da malha de elementos finitos exerce papel
fundamental na eficiência da simulação paralela, uma vez que o custo total de
um passo de simulação pode ser determinado pelo da partição de maior custo.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 21
Em geral, o custo (ou tempo) de computação de uma partição é proporcional ao
número de elementos e/ou nós que ela contém. Assim, é desejável que essas
entidades encontrem-se balanceadas entre as partições, de forma que tempos
ociosos sejam minimizados, e o tempo total de simulação reduzido.
Um ponto importante a ser considerado durante o particionamento de
malhas é o custo de comunicação entre as partições. Devido à necessidade de
comunicação para a atualização dos elementos e nós próximos às fronteiras de
partições, é desejável agrupá-los de modo a se minimizar o tamanho das
fronteiras compartilhadas com outras partições. Embora, em geral, uma partição
se comunique apenas com um pequeno número de partições vizinhas a ela, o
custo da comunicação ainda pode ser significativo, especialmente em partições
de tamanho reduzido.
Dois sistemas populares para particionamento de malhas são METIS
(Karypis & Kumar, 1995, 1998a) e sua versão paralela ParMETIS (Karypis &
Kumar, 1998b). Esses sistemas utilizam partição de grafos para decompor
grandes malhas de elementos finitos de forma eficiente, e buscam, ao mesmo
tempo, balancear o número de elementos de cada partição e minimizar as
fronteiras compartilhadas por diferentes partições. Nesta pesquisa, o sistema
METIS é empregado para particionar as malhas usadas em alguns dos
experimentos computacionais realizados.
2.3. Malhas adaptativas
Em análises adaptativas de elementos finitos, a malha é modificada
dinamicamente ao longo do processo de simulação numérica. Dessa forma, o
suporte topológico de malha deve fornecer operadores de edição apropriados.
No contexto de simulações dinâmicas de fraturas baseadas no modelo coesivo
extrínseco (Camacho & Ortiz, 1996; Ortiz & Pandolfi, 1999; Park et al., 2009),
requer-se suporte para a representação e inserção adaptativa de elementos
coesivos. Os operadores topológicos de edição de malha devem ser capazes de
manter a topologia da malha consistente após cada operação, o que apresenta
desafios adicionais à implementação em ambientes paralelos.
Para que o comportamento não-linear de regiões ao redor de pontas de
fraturas (Zhang, 2007) seja corretamente capturado, um grande grau de precisão
numérica é, em geral, requerido. Uma forma de se aumentar a precisão
numérica do MEF consiste no refinamento de elementos da malha (h-refinement)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 22
(Zienkiewicz et al., 2005). Contudo, uma vez que um alto nível de refinamento
não é necessário em regiões distantes de fraturas, é interessante que o nível de
refinamento se adapte ao grau de precisão exigido em cada região de malha.
Simulações de fraturas sequenciais que empregam refinamento e simplificação
adaptativa, e outras otimizações geométricas e topológicas de malha, com base
na estrutura de dados topológica TopS, foram recentemente apresentadas por
Paulino, Park, Celes & Espinha (2010) e Park, Paulino, Celes & Espinha (2011).
Em análises onde a malha distribuída permanece estática ao longo da
simulação, o balanceamento da carga dos processadores pode feito apenas uma
vez, durante o particionamento inicial da malha – sistemas como METIS (Karypis
& Kumar, 1995, 1998a) podem ser empregados para isso. Em análises
adaptativas, por outro lado, conforme se modifica a malha, o número de
elementos e nós em um processador pode divergir significativamente de outros,
refletindo-se nas cargas de computação correspondentes. Dessa forma, o
balanceamento de carga dinâmico (Hendrickson & Devine, 2000; Ozturan, 1995;
Devine et al., 2005) torna-se importante para a manutenção do desempenho da
simulação. A biblioteca Zoltan (Devine et al., 2002) oferece utilitários para o
gerenciamento de malhas dinâmicas distribuídas, como: partitionamento,
balanceamento de carga e procedimentos para comunicação entre partições. O
framework Charm++ (Kalé & Krishnan, 1993, 1996), para o desenvolvimento de
programas paralelos, oferece suporte ao balanceamento de carga automático e
à definição de novos balanceadores de carga pela aplicação cliente.
Esta pesquisa foca na representação e criação de fraturas dinâmicas. Para
isso, assume-se que os elementos da malha encontram-se apropriadamente
refinados e a malha distribuída corretamente balanceada. Uma vez que o
número de elementos coesivos e o custo correspondente são tipicamente muito
menores que o de elementos volumétricos, considera-se que o balanço de
cargas não é significativamente alterado com a inserção de novos elementos.
2.4. Estruturas de dados topológicas para malhas distribuídas dinâmicas
Diversos sistemas paralelos com suporte à representação distribuída de
malhas dinâmicas de elementos finitos não-estruturadas são encontrados na
literatura (Remacle et al., 2002; Lawlor et al., 2006; Seol & Shephard, 2006;
Ozturan et al., 1994; Kirk et al., 2006; Stewart & Edwards, 2004). Embora esses
sistemas sejam capazes de representar malhas gerais de elementos finitos, um
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 23
suporte apropriado para fraturas extrínsecas tridimensionais não é apresentado.
Os principais sistemas existentes são brevemente discutidos a seguir.
2.4.1. MDB/PMDB
O sistema Parallel Mesh Database (PMDB) (Ozturan et al., 1994; Ozturan,
1995) oferece operações para a manipulação de malhas distribuídas gerais.
Esse sistema é implementado com base na estrutura de dados sequencial Mesh
Database (MDB) (Beall & Shephard, 1997). São representadas entidades
topológicas como: região, face, aresta e vértice. Cada região é associada a um
único processador, enquanto que faces, arestas e vértices são duplicados em
cada processador que contém regiões adjacentes a essas entidades. Cada
entidade duplicada mantém uma lista de suas cópias em outras partições. Em
PMDB, o conceito de pertinência única de entidades é implementado. Dessa
forma, apenas uma partição pode ser considerada a proprietária de uma
entidade topológica. A partição proprietária é determinada pelo valor mínimo da
tupla (pi, ei) entre a lista de usos da entidade, onde pi é o identificador (id) da
partição e ei é o identificador (id) da cópia da entidade na partição. Entre os
operadores de malha oferecidos encontram-se a inserção e remoção de
entidades e a obtenção de informações de adjacência. Também são oferecidas
funcionalidades para particionamento de malhas e balanceamento de carga.
2.4.2. AOMD/PAOMD
O sistema Parallel Algorithm Oriented Mesh Database (PAOMD) (Remacle
et al., 2002) estende a versão sequencial anterior chamada Algorithm Oriented
Mesh Database (AOMD) (Remacle et al., 2000; Remacle & Shephard, 2003) com
suporte para malhas distribuídas. É fornecido um arcabouço (framework) para o
gerenciamento de malhas distribuídas genéricas, no qual a representação de
malhas pode ser adaptada a diferentes aplicações. Várias entidades topológicas
(vértices, arestas, faces e regiões), além de relações de adjacência entre elas,
podem ser representadas; a aplicação cliente determina quais as necessárias.
Entidades topológicas, com exceção de vértices, são definidas e
representadas por conjuntos de entidades de dimensão inferior e sua ordenação
local correspondente. PAOMD requer que um identificador global único (global
id) seja associado a cada vértice, e que uma entidade possa ser identificada pela
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 24
sua lista de vértices. Identificadores globais, entretanto, podem ser
inconvenientes à representação de malhas adaptativas, pois devem ser
corretamente mantidos entre as partições de malha. Em relação à representação
de elementos coesivos, a definição de entidades a partir de seus vértices
apresenta ambiguidades, já que esses elementos consistem de duas facetas
(faces, em 3D, ou arestas, em 2D) que são diferentes, mas podem possuir os
mesmos vértices (conforme Seção 2.6.2). Nesse caso, a representação por
vértices não é suficiente para se distinguir entre entidades diferentes.
Assim como em PMDB, cada partição é associada a um processador, e a
malha local é representada por uma malha sequencial AOMD. Entidades
classificadas nas fronteiras de uma partição devem existir na estrutura de dados
paralela e ser compartilhadas com as partições vizinhas. A conexão de uma
entidade com suas cópias em outras partições é feita por mensagem enviada a
todas as partições sempre que a malha é modificada. A mensagem contém o
endereço local da entidade e a lista dos identificadores (ids) dos seus vértices.
Procedimentos para malhas adaptativas, balanceamento de carga dinâmico e
migração de entidades entre partições são fornecidos pelo sistema.
2.4.3. FMDB
A infra-estrutura de malha paralela Flexible distributed Mesh DataBase
(FMDB) (Seol & Shephard, 2006) permite a representação de modelos genéricos
não-manifold. Assim com o sistema PAOMD, a aplicação cliente pode configurar
os tipos de entidades topológicas necessários. Cada partição é representada por
uma malha sequencial, porém as entidades nas fronteiras da malha são tratadas
de forma diferente. Elas são duplicadas em todas as partições onde são
requeridas à computação de relações de adjacências. Todavia, apenas uma
partição pode ser considerada a proprietária de uma entidade topológica. Essa
partição é a que contém o menor número de objetos entre as partições nas quais
a entidade é duplicada, a fim de evitar que a carga entre os processadores se
torne desbalanceada quando a malha é modificada. Um algoritmo para migração
eficiente de entidades topológicas entre partições é oferecido por FMDB.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 25
2.4.4. LibMesh
O sistema LibMesh (Kirk et al., 2006) trata de aspectos independentes da
física de análises de elementos finitos. São oferecidos um suporte à
representação de malha distribuída, funções para adaptação da malha e
interfaces para outros sistemas comumente utilizados em aplicações baseadas
no MEF. A representação de malha é baseada na estrutura de dados tradicional
de elementos e nós, e um identificador (id) global único é atribuído a cada
elemento e nó da malha. Elementos também possuem um identificador do
processador ao qual estão atribuídos, referências para os nós incidentes
(conectividade nodal) e aos outros elementos adjacentes às suas faces
(elementos vizinhos). Entretanto, uma cópia completa da malha é armazenada
em cada processador, apesar da decomposição lógica em partições, o que limita
o uso desse sistema em simulações de larga escala. De acordo com Kirk et al.
(2006), uma implementação completamente distribuída está sendo considerada.
2.4.5. SIERRA
O sistema SIERRA (Stewart & Edwards, 2004) oferece diversas
ferramentas para o desenvolvimento de aplicações para análises mecânicas.
Fazem parte de SIERRA uma estrutura de dados topológica distribuída para a
representação de malhas, suporte a adaptação de malha e balanceamento de
carga, e uma interface a bibliotecas de solução de sistemas lineares (linear
solvers), entre outras funcionalidades. A estrutura topológica representa
entidades como: nó, aresta, face e elemento. Elementos, faces e arestas são
definidos por um conjunto de nós que são também vértices. Cada uma dessas
entidades pode se conectar a entidades de tipos diferentes, e as conexões entre
entidades podem ser configuradas pela aplicação cliente. Por exemplo, relações
de adjacência podem ser criadas para se obterem as faces de todos os
elementos fantasmas definidos nas fronteiras de partições. Assim como outras
estruturas de dados, entidades nas fronteiras entre partições podem ser
compartilhadas entre as partições, porém apenas uma partição é a proprietária
da entidade. Entidades são univocamente identificadas pela tupla (tipo, id), onde
tipo é o tipo da entidade (i.e., nó, elemento, etc.) e id é um valor inteiro único
entre todas as entidades de um mesmo tipo. Infelizmente, SIERRA não se
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 26
encontra publicamente disponível, e poucas informações sobre esse sistema
podem ser encontradas na literatura.
2.4.6. ParFUM
O sistema ParFUM (Lawlor et al., 2006) oferece suporte à representação
distribuída de malhas não-estruturadas. Esse sistema é implementado com base
no framework paralelo Charm++ (Kalé & Krishnan, 1993, 1996) e AMPI (Huang
et al., 2003), uma implementação da especificação de interface de envio de
mensagens MPI (MPI Forum, 2010) sobre Charm++.
A estrutura de dados topológica é capaz de representar as entidades
elemento e nó, além de informações adicionais de adjacência, como as
conectividades nó-a-nó, nó-a-elemento e elemento-a-elemento. Uma partição de
malha é chamada chunk, e é geralmente associada a um único processador (ou
processo MPI). Por outro lado, um processador pode ter diversos chunks
associados a ele. A comunicação entre chunks ocorre de maneira implícita,
através de duas classes de entidades especiais (Figura 4): nós compartilhados
(shared nodes) e nós e elementos fantasmas (ghost nodes/elements). Cada
elemento é associado a um único chunk, enquanto que nós podem ser
compartilhados por elementos de chunks diferentes. Os nós classificados como
compartilhados são duplicados em cada chunk em que são usados. Durante a
simulação numérica, entidades nas fronteiras de uma partição podem precisar
de informações de entidades vizinhas representadas em outras partições. Para
isso, são criadas camadas fantasmas (ghost layers) de elementos ao redor de
cada chunk. As entidades da camada fantasma (nós e elementos fantasmas)
são disponibilizadas apenas para leitura (read-only), segundo a maneira
convencional, não podendo ser editadas.
Figura 4 – Partições com camada fantasma. Os nós compartilhados
são desenhados preenchidos. Os elementos e nós da camada fantasma
também encontram-se destacados.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 27
Em cada chunk, um índice local (relativo ao chunk) é atribuído às
entidades presentes. Se dois chunks compartilham nós, então eles mantém uma
lista mútua de índices locais de nós compartilhados, consistentemente
ordenados. Com isso, o mapeamento do índice local de um nó de um chunk para
o outro é feito de maneira direta. No caso de entidades fantasmas, o chunk que
possui a entidade real mantém uma lista de mapeamento (sendghost list),
destinada ao envio de dados às partições que possuem cópias da entidade. Um
chunk contendo uma entidade fantasma mantém uma lista de mapeamento
reversa (receivenode list). Para sincronizar os dados de entidades da camada
fantasma com as entidades reais correspondentes, são fornecidas funções
paralelas coletivas.
São suportadas operações incrementais de modificação topológica de
malhas bidimensionais. A modificação de malhas em paralelo é baseada em
operadores atômicos (Choudhury, 2006), com a atomicidade garantida por
requisições de acesso exclusivo (travas de acesso, ou locks) aos nós envolvidos.
Para que um elemento na fronteria de um chunk seja modificado, o acesso
exclusivo aos respectivos nós são requisitadas. Uma vez que a partição detém o
acesso exclusivo a todos os nós, o elemento é alterado localmente, e os chunks
se comunicam para sincronizar as informações topológicas com os chunks
vizinhos. Finalmente, as travas obtidas são liberadas e podem ser requisitadas
por outros chunks interessados. Isso permite que algoritmos de adaptação de
malha utilizem operadores sequenciais, sem a necessidade de sincronização
explícita. Por outro lado, o custo para se obter acesso exclusivo aos nós, e o
número de mensagens trocadas entre partições, pode ser significante.
Choudhury (2006) reduz esses custos com a alocação de múltiplos chunks de
menor tamanho em cada processador, de forma a aumentar a concorrência e
reduzir tempos ociosos (idle time) de processadores.
Resultados de simulação de fraturas com base em ParFUM são
encontrados na literatura (Mangala et al., 2008). Entretanto, o suporte a
representação de fraturas se restringe a malhas triangulares bidimensionais, ou
utiliza elementos coesivos pré-inseridos em toda a malha, e que são ativados
sob demanda. Um suporte topológico em paralelo, completo e geral, para a
representação e inserção dinâmica de elementos coesivos realmente
extrínsecos, tanto em malhas bidimensionais (2D) como tridimensionais (3D),
ainda é necessário.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 28
2.5. Simulações paralelas de fraturas coesivas extrínsecas
Nesta seção, são revistos trabalhos propostos na literatura que abordam
simulações em paralelo de fraturas baseadas em modelos de zona coesiva
extrínsecos. A revisão é feita sob o ponto de vista da representação de dados
topológicos, conforme o foco desta pesquisa.
Quando uma abordagem intrínseca (Xu & Needleman, 1994) é utilizada,
elementos coesivos são criados ao longo de todas as interfaces entre elementos
volumétricos da malha, antes do início da simulação. Dessa forma, os elementos
estão presentes durante todo o processo de simulação, contribuindo para os
resultados calculados. Como não são necessárias modificações topológicas da
malha após o início da simulação, essa abordagem é inerentemente escalável.
As questões tratadas pela representação de malha distribuída consistem apenas
no particionamento da malha original e a comunicação entre as partições.
Modelos extrínsecos, no entanto, introduzem desafios adicionais.
Elementos coesivos devem ser inseridos sob demanda quando um critério de
fratura é alcançado. Isso faz com que a representação de malha torne-se mais
complexa, uma vez que a topologia da malha se modifica durante a simulação.
As mudanças ocorridas localmente em cada partição devem ser propagadas
para as partições vizinhas, de forma consistente e eficiente. Alguns algoritmos
para a inserção dinâmica de elementos coesivos existem na literatura (Pandolfi &
Ortiz, 1998, 2002; Mota et al., 2008; Paulino et al., 2008). Porém, devido às
dificuldades de paralelização de modelos extrínsecos, em especial para malhas
tridimensionais, poucas soluções em paralelo foram propostas.
Duas abordagens recentes contornam as dificuldades relacionadas à
representação de fraturas utilizando elementos coesivos pré-inseridos. Dooley et
al. (2009) empregam uma estratégia baseada na ativação de elementos,
implementada para malhas bidimensionais. Com isso, elementos coesivos
existem em todas as interfaces entre elementos volumétricos da malha inicial,
mas permanecem inativos até que o critério de fratura seja alcançado nas
interfaces correspondentes. Nesse momento, a lei coesiva entra em efeito, e o
elemento torna-se parte do processo de simulação. Do ponto de vista da
topologia da malha, essa abordagem equivale ao modelo intrínseco, no sentido
em que elementos coesivos são pré-inseridos em todas as interfaces onde
fraturas possam ocorrer. A diferença é que elementos coesivos são ativados na
simulação apenas quando necessários.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 29
Como a topologia da malha não se altera durante a simulação,
comunicações entre partições não são necessárias para propagar modificações
topológicas às partições vizinhas. Isso faz com que essa abordagem se torne
escalável, assim como os modelos intrínsecos. Por outro lado, também introduz
dificuldades que devem ser contornadas. Durante a construção da malha
distribuída, todo nó localizado em fronteiras compartilhadas por duas ou mais
partições é replicado tantas vezes quanto o número de elementos volumétricos
adjacentes, de forma que os elementos coesivos possam ser criados. Assim,
mesmo quando nenhum elemento coesivo está ativo na simulação, os elementos
e as cópias dos nós correspondentes existem na topologia da malha de cada
partição. Isso introduz um custo adicional para a representação de malha, em
especial em aplicações com um número pequeno de interfaces fraturadas,
devido à presença de nós e elementos desnecessários à simulação.
Além disso, a representação topológica real da malha não corresponde à
efetivamente utilizada na simulação. Dessa forma, a aplicação cliente, ou uma
camada intermediária adicional, deve ser responsável por prover o acesso
consistente aos nós replicados. Enquanto um elemento coesivo não está ativo,
cada par de nós compartilhados entre as duas arestas do elemento coesivo
bidimensional (ou faces de um elemento tridimensional) deve corresponder a um
único nó regular no contexto da simulação, embora os nós sejam representados
como entidades topológicas diferentes. Para contornar as inconsistências
resultantes de duplicações nodais desnecessárias, e assegurar a continuidade
de malha na simulação, um nó aleatório é escolhido entre as múltiplas cópias,
como nó raiz representativo ("root node"). A diferença entre a representação
topológica da malha e a usada pela simulação também afeta o acesso a
relações topológicas entre entidades da malha. O acesso a essas relações
passa a não ter um tratamento uniforme, uma vez que dois elementos
volumétricos que deveriam ser adjacentes na simulação encontram-se
separados por um elemento coesivo na representação da malha.
A implementação da abordagem de Dooley et al. (2009) baseia-se no
sistema ParFUM (Lawlor et al., 2006). O código da simulação paralela é dividido
em duas rotinas principais: init() e driver() (Dooley et al., 2009). Em init(), a malha
completa é carregada em um único processador. Após o término de init(), o
sistema particiona a malha e cria a infraestrutura de comunicação entre
partições. A simulação numérica é realizada pela rotina driver(), executada em
paralelo por cada partição de malha. Com base em ParFUM, a comunicação
entre partições é feita através de uma camada fantasma, com cópias não
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 30
editáveis de elementos e nós de partições vizinhas. A camada é criada ao redor
das fronteiras das partições. Resultados de simulações dinâmicas de fraturas
são apresentados para malhas de triângulos, com até 1,2 milhões de elementos
e 512 processadores. Um trabalho complementar de Mangala et al. (2008)
aborda o refinamento e simplificação adaptativo de malhas bidimensionais.
A abordagem proposta por Radovitzky et al. (2011) para a paralelização de
simulações de fraturas extrínsecas é baseada na adaptação dos modelos
numéricos utilizados. Dessa forma, uma formulação descontínua de Galerkin
(Discontinuous Galerkin - DG) (Noels & Radovitzky, 2006, 2008) do problema
contínuo é combinada com um modelo coesivo de fratura. Assim como a
abordagem de Dooley et al. (2009), elementos coesivos são pré-inseridos em
todas as interfaces entre elementos volumétricos, durante a construção da malha
inicial. Termos adicionais introduzidos à formulação do problema, devidos à
formulação descontínua de Galerkin, garantem a consistência da simulação na
ausência de fraturas. Quando o critério de fratura é alcançado para uma
determinada interface entre elementos volumétricos, a lei coesiva entra em
efeito, substituindo os termos da formulação descontínua de Galerkin. Com isso,
elementos coesivos permanecem na malha de forma consistente com a
simulação numérica, mesmo na ausência de fraturas, ao contrário da abordagem
anterior. A sincronização de atributos de simulação é feita utilizando-se uma
operação paralela de redução (Quinn, 2004) para somar os resultados dos nós
das fronteiras compartilhadas entre partições. Essa abordagem é escalável, de
forma similar à anterior. Resultados para simulações de propagação de ondas
(wave propagation) e fragmentação dinâmica são apresentados para malhas de
tetraedros quadráticos (Bathe, 1996) com 103 milhões de elementos e 4096
processadores.
2.6. TopS
A estrutura de dados topológica TopS, para representação sequencial de
malhas de elementos finitos, foi proposta por Celes, Paulino & Espinha (2005a,
b). Ela fornece uma representação compacta (em relação ao custo de memória)
para malhas com fronteira externa com topologia manifold (Mäntylä, 1988), uma
vez que apenas as entidades topológicas elemento e nó são armazenadas em
memória. Ao mesmo tempo, é considerada completa (Weiler, 1986, 1988), no
sentido em que permite que todas as relações de adjacências entre entidades
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 31
topológicas da malha sejam obtidas em ordem proporcional ao número de
entidades retornadas. Entre as funcionalidades oferecidas por TopS, de especial
interessse a esta pesquisa, encontra-se uma interface uniforme para a
representação e tratamento de elementos coesivos. É fornecido suporte
sequencial para a inserção adaptativa de elementos coesivos (requerida por
simulações de fraturas e fragmentação extrínsecas), a partir da classificação
topológica proposta por Paulino et al. (2008).
A representação de malha distribuída proposta neste trabalho utiliza como
base a estrutura de dados topológica sequencial TopS (Celes, Paulino &
Espinha, 2005a, b). Dessa forma, os principais conceitos de TopS relacionados a
este trabalho são revistos a seguir.
2.6.1. Entidades topológicas
Embora diversos tipos de entidades topológicas sejam definidos por TopS,
apenas as entidades elemento e nó são explicitamente representadas. Isso
significa que essas entidades possuem uma representação concreta, residindo
efetivamente no espaço de memória utilizado pela estrutura de dados. A
entidade elemento representa qualquer tipo de elemento finito que possa ser
definido por um conjunto ordenado (template) de nós, o que inclui os principais
tipos empregados em análises de elementos finitos (ex. triângulos, tetraedros e
hexahedros, de ordem linear, quadrática ou superior) (Bathe, 1996). Alguns dos
tipos de elementos, lineares e quadráticos, suportados por TopS são ilustrados
na Figura 5. A entidade nó representa nós de elementos finitos, podendo estar
associados aos cantos (Figura 5a) ou outras posições da fronteira ou interior de
um elemento, no caso de elementos não-lineares (ex. elementos quadráticos –
Figura 5b). Nós localizados sobre uma aresta e que não correspondem aos
cantos da aresta são chamados nós de meio de aresta (ou mid-side nodes).
Além de elementos e nós, a estrutura de dados também armazena
algumas informações de adjacência entre essas entidades, de forma a permitir o
acesso eficiente a elas. Assim, além da referência tradicional – conectividade
nodal – de um elemento ao seu conjunto de nós (relação elemento-a-nó), um
elemento possui uma referência para cada elemento adjacente a ele (relação
elemento-a-elemento). Da mesma forma, todo nó possui uma referência para um
de seus elementos adjacentes (relação nó-a-elemento), considerando-se uma
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 32
malha regular de domínio manifold. Todas as outras relações de adjacência
fornecidas por TopS são derivadas a partir das relações anteriores.
Figura 5 - Exemplos de elementos volumétricos (a) lineares e (b)
quadráticos suportados pela estrutura topológica TopS.
As entidades topológicas vértice, aresta, face e faceta são representadas
implicitamente pela estrutura de dados. Dessa forma, são criadas sob demanda,
de forma transparente, sempre que requisitadas pela aplicação cliente. Um
vértice representa a entidade de dimensão 0 associada a um nó de canto de um
elemento finito; aresta é definida como a entidade de dimensão 1 limitada por
dois vértices; e face é a entidade de dimensão 2 limitada por um conjunto de
arestas. A entidade faceta é definida por TopS para representar a interface entre
dois elementos volumétricos adjacentes, ou entre um elemento e a fronteira da
malha. Em uma malha bidimensional, uma faceta equivale à entidade de
dimensão 1 (aresta), enquanto que, em malhas tridimensionais, equivale à
entidade de dimensão 2 (face). Com isso, a entidade faceta provê uma
abstração conveniente para o tratamento uniforme de operações que atuam nas
interfaces entre elementos, como a inserção de elementos coesivos.
Além de vértice, aresta, face e faceta, TopS define um conjunto de
entidades implícitas adicionais, que representam os usos daquelas entidades
pelos elementos adjacentes: vértice-uso (vertex-use), aresta-uso (edge-use),
face-uso (face-use) e faceta-uso (facet-use). Os usos de uma faceta
compartilhada por dois elementos são ilustrados na Figura 6. Uma faceta-uso
independente é definida para cada elemento que compartilha (ou usa) a faceta.
Vértices e arestas podem ser compartilhados por um número arbitrário de
elementos, e assim são definidos vários usos de uma mesma entidade.
Cada elemento isoladamente é limitado por um conjunto de faces, arestas
e vértices, mapeados para os correspondentes usos de entidades do elemento.
Uma vez que a topologia local do elemento, em geral, depende unicamente do
seu tipo (ex. Tet4 (tetraedro linear), Brick20 (hexaedro quadrático), etc.), pode-se
T6
(b)
Tet10 Hex20T3 Tet4 Hex6
(a)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 33
definir uma ordenação topológica local fixa (ou element template) para as
referências às entidades locais do elemento. A ordenação fornece acesso direto
a todas as relações de adjacência entre entidades no interior dos elementos,
sendo reutilizada por todos os elementos de um mesmo tipo.
Figura 6 - A faceta f é usada pelos dois elementos adjacentes a ela,
em 2D (a) ou em 3D (b). Para cada elemento que usa a faceta, define-se
uma faceta-uso (fu) correspondente. A faceta é univocamente representada
por um de seus usos, no qual diz-se que ela está ancorada. O uso que
representa a faceta é destacado pela marca `x`.
Em TopS, entidades são acessadas por meio de referências opacas
(opaque handles) retornadas pela estrutura de dados à aplicação cliente no lugar
da própria entidade. A utilização de referências opacas fornece à aplicação
cliente uma interface transparente para o tratamento uniforme tanto de entidades
explícitas quanto implícitas. Uma referência opaca consiste em: um identificador
de elemento (Ei) ou de nó (Ni), ou o par (Ei, idlocal), no caso de entidades
implícitas. Um uso de entidade implícita (vértice-uso, aresta-uso, face-uso ou
faceta-uso) é unicamente representado por (Ei, idlocal), que é composto por uma
referência ao elemento (Ei) ao qual ele está associado, mais o índice da entidade
(idlocal) em relação à ordenação topológica fixa do elemento.
As entidades implícitas vértice, aresta, face e faceta são representadas por
um de seus usos pelos elementos adjacentes. Com isso, duas arestas que
possuem os mesmos nós podem ser identificadas pela estrutura de dados como
arestas diferentes. Esse tipo de configuração, que é comum em elementos
coesivos (Seção 2.6.3), não poderia ser representado se as arestas fossem
definidas através de outras entidades de ordem inferior (ex.: nós).
fu fu
f
f
fufu
(a)
(b)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 34
De forma a identificar o uso de entidade que representa uma entidade
topológica do tipo vértice, aresta, face ou faceta, define-se um marcador binário,
chamado âncora, que é colocado no elemento adjacente correspondente ao uso
que representa a entidade. Isso é mostrado na Figura 6. Embora dois elementos
compartilhem uma mesma faceta, apenas um deles possui o marcador de
âncora da entidade (ilustrado pela marca 'x' na figura). Assim, diz-se que a
faceta encontra-se ancorada naquele elemento, e a faceta-uso correspondente é
considerada a representante da faceta. Em TopS, a representação de entidades
implícitas é sempre associada aos elementos adjacentes a elas.
A Figura 7 ilustra a visitação de todos os usos de um vértice pelos
elementos adjacentes, em uma malha bidimensional. Um procedimento
equivalente é realizado para arestas e malhas tridimensionais (Celes, Paulino &
Espinha, 2005a). A partir de um vértice (v), obtém-se o vértice-uso que o
representa (vu0), a partir do elemento adjacente contendo o marcador de âncora
correspondente. Usando-se a ordenação local fixa do elemento, acessa-se uma
de suas facetas-uso (fu0) adjacentes ao vértice-uso (vu0). Em seguida, com
base na relação de adjacência elemento-a-elemento armazenada pela estrutura
de dados, obtém-se a faceta-uso (fu1) correspondente no elemento adjacente, e,
novamente usando-se a ordenação local fixa do elemento, obtém-se o vértice-
uso (vu1) associado ao vértice (v). O procedimento continua em cada elemento
até que todos os usos do vértice tenham sido visitados.
Figura 7 - Visitação dos usos de um vértice pelos elementos
adjacentes em uma malha bidimensional.
2.6.2. Elementos coesivos
Do ponto de vista da representação topológica, elementos coesivos
(Pandolfi & Ortiz, 1998, 2002; Paulino et al., 2008) são tipos de elementos
especiais que consistem de apenas duas facetas. Esses elementos são criados
vu1 vu0
v
fu0fu1
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 35
nas interfaces entre dois elementos volumétricos adjacentes para representar a
ocorrência de fraturas na malha de elementos finitos. A Figura 8 mostra dois
elementos coesivos (CohE3 e CohT6) compatíveis com facetas de dois
elementos volumétricos (T6 e Tet10).
Figura 8 - Exemplos de elementos volumétricos 2D (a) e 3D (b) e
elementos coesivos correspondentes (CohE3 e CohT6).
Elementos coesivos podem ter nós compartilhados entre as suas duas
facetas, f1 e f2 . Dessa forma, a seguinte incidência nodal é válida para um
elemento do tipo Coh2E3: f1:(nA, nB, nC), f2:(nA, nD, nC), onde os primeiros três
nós correspondem à primeira faceta do elemento (f1) e os restantes à segunda
(f2). Apesar do compartilhamento de nós entre as facetas, diferentes vértices-
usos, arestas-usos e faces-usos são definidos para cada faceta do elemento
coesivo. Alguns exemplos de possíveis incidências nodais de elementos
coesivos são mostrados na Figura 9.
Figura 9 - Exemplos de possíveis incidências nodais de elementos
coesivos: (a) 2D (Coh2E3); e (b) 3D (Coh3T6). Elementos coesivos podem
possuir nós compartilhados pelas duas facetas diferentes.
Tet10 CohT6T6 CohE3
(a) (b)
nA
nB
nC
nE
nD
f1 f2
nA
nB
nDnC
nA nF
nD
nE
nC
nB
nA
nB
nC
nD
nE
nF
f1
f2nA
nHnE
nD
nB
nC
nB
nC
nD
nE
nF
nInG
nA
nF
nC
nL nJ nA
nB
nD
nGnEnH
nG
nF
nA
nI
(a)
(b)
Coh2E3
Coh3T6
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 36
Da mesma forma que outros tipos de elementos (volumétricos), TopS
representa elementos coesivos explicitamente e os trata como elementos
regulares da malha de elementos finitos. Assim, elementos coesivos também
possuem uma ordenação topológica (template) local fixa e podem ter atributos
associados. Isso difere de outras abordagens, em que elementos coesivos são
tratados como atributos de elementos volumétricos (Pandolfi & Ortiz, 1998,
2002).
2.6.3. Inserção adaptativa sequencial de elementos coesivos
A estrutura de dados topológica sequencial TopS permite que elementos
coesivos sejam inseridos adaptativamente, conforme necessário. A inserção
adaptativa baseia-se na classificação sistemática de facetas proposta por
Paulino et al. (2008). Essa classificação fornece uma maneira consistente de se
identificarem as operações topológicas necessárias à atualização da estrutura de
dados, após a introdução de um novo elemento coesivo. Uma vantagem é que
ela pode ser empregada uniformemente para qualquer tipo de elemento, tanto
em malhas bidimensionais (2D) quanto tridimensionais (3D).
Os passos para a inserção de um elemento coesivo ao longo da faceta
entre os elementos E1 e E2 são ilustrados na Figura 10 e brevemente descritos
a seguir:
1. Cria-se um elemento coesivo entre E1 e E2. As adjacências dos
elementos E1 e E2 são atualizadas, de forma que E1 e E2 não são
mais adjacentes um ao outro, mas ao elemento coesivo (Figura 10a
e Figura 10d). Inicialmente, as duas facetas do elemento coesivo
possuem o mesmo conjunto de nós.
2. Para cada aresta-uso (eu) da faceta de E1 compartilhada com o
elemento coesivo (Figura 10b e Figura 10e), visitam-se todos os
outros usos da aresta correspondente, considerando as
adjacências atualizadas no passo anterior. Se o elemento E2 não
foi alcançado, duplica-se a aresta. Os nós de meio de aresta, se
existentes, também devem ser duplicados.
3. O procedimento de vértices é similar ao de arestas. Para cada
vértice-uso (vu) da faceta de E1 compartilhada com o elemento
coesivo (Figura 10c e Figura 10f), visitam-se todos os outros usos
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 37
do vértice correspondente, considerando-se as adjacências
atualizadas. Se E2 não foi alcançado, duplica-se o vértice e o nó de
canto correspondente.
As conectividades de todos os elementos envolvidos precisam ser
atualizadas para cada nó duplicado. Isso é feito pela substituição do nó original
pelo novo nos elementos visitados durante os passos 2 e 3. Elementos não
visitados não são alterados. Casos correspondentes à inserção de elementos
coesivos em uma malha bidimensional são ilustrados na Figura 11.
Figura 10 - Operações para a atualização da topologia da malha
quando um novo elemento coesivo é inserido, em 2D (a - c) e em 3D (d - f).
(a), (d) - O elemento coesivo é criado na faceta entre E1 e E2. (b), (e) - Para
cada aresta da faceta inicial, a partir de E1, os usos correspondentes são
visitados. Se o uso de E2 não é alcançado, a aresta e nós de meio da aresta
são duplicados. (c), (f) - Para cada vértice da faceta inicial, a partir de E1, os
usos correspondentes são visitados. Se o uso de E2 não é alcançado, o
vértice e o nó correspondente são duplicados.
E1 E2
E2E1
(a) (b) (c)
(d) (e) (f)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 38
Figura 11 - Casos correspondentes à inserção de elementos coesivos
em uma malha bidimensional (Paulino et al., 2008).
2.6.4. Conjuntos de atributos densos e esparsos
Para realizar uma simulação numérica, a aplicação cliente pode precisar
associar atributos próprios da simulação a entidades topológicas da malha de
elementos finitos. A fim de facilitar a gerência de atributos por aplicações que
utilizam malhas dinâmicas é fornecido suporte para conjuntos de atributos,
alocados automaticamente por TopS. Dois tipos são definidos: atributos densos
(dense attributes) e esparsos (sparse attributes). Conjuntos densos são
otimizados para dados associados a todas (ou quase todas) as entidades de um
dado tipo (ex. dados da simulação numérica em cada nó ou elemento), enquanto
que conjuntos esparsos são tipicamente empregados na representação de
dados associados a apenas parte das entidades (ex. condições de contorno, ou
forças aplicadas).
Os conjuntos de atributos densos se aplicam apenas a entidades explícitas
(nós e elementos), sendo um conjunto diferente criado para cada tipo de
elemento ou nó. A implementação consiste em um vetor dinâmico de dados, com
número de posições igual ao de entidades do tipo ao qual o vetor está
associado. Os índices do vetor de atributos correspondem aos mesmos índices
no vetor da estrutura de dados contendo os nós ou elementos relacionados
(TopS utiliza vetores distintos para representar cada tipo de elemento ou nó). O
tamanho alocado para cada valor de atributo (posição do vetor) é fixo e definido
pela aplicação durante a criação do conjunto. O vetor dinâmico é
redimensionado automaticamente, com base no número de entidades
representadas. Vários conjuntos de atributos podem ser criados para o mesmo
E1 E2
E1
E2E1
E2
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

2 Trabalhos relacionados 39
tipo de entidade, sendo que cada conjunto associado a um tipo de entidade
possui um identificador único, usado pela aplicação para acessá-lo.
Ao contrário de atributos densos, conjuntos de atributos esparsos podem
ser criados para quaisquer das entidades representadas por TopS, explícitas ou
implícitas. Assim como os atributos densos, os esparsos também são definidos
para cada tipo de elemento ou nó ou de entidade implícita. A implementação
consiste em uma tabela associativa dinâmica (ou uma tabela de dispersão –
hash table) indexada pelos identificadores das entidades correspondentes. A
criação de conjuntos esparsos é feita da mesma maneira que os densos.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas
Neste capítulo, propõe-se um suporte topológico para a representação de
fraturas baseada em modelos de zona coesiva em um ambiente paralelo.
Inicialmente, é desenvolvida uma representação topológica distribuída de malhas
de elementos finitos para simulações de fraturas e fragmentação dinâmicas. Em
seguida, com base na representação de malha distribuída, é proposto um
algoritmo paralelo para a inserção dinâmica de elementos coesivos. O suporte
topológico em paralelo é chamado ParTopS, e implementado como uma
extensão da estrutura topológica sequencial TopS (Celes, Paulino & Espinha;
2005a, b). Seguindo a filosofia de TopS, a malha distribuída é mantida de
maneira compacta, mas com o conjunto de funcionalidades necessárias à
representação eficiente de fraturas.
3.1. Representação de malha distribuída
A malha distribuída consiste na união das partições disjuntas do conjunto
de entidades topológicas que compõem a malha original de elementos finitos
(Figura 12). Cada partição de malha corresponde a uma unidade de computação
sequencial, executada por um processador distinto.
Durante o particionamento inicial da malha, cada elemento ou nó é
atribuído a uma única partição (Figura 12). Porém, nós das fronteiras de
partições podem ser compartilhados por elementos de partições diferentes. Para
se manter a consistência topológica dos elementos de cada partição, são criadas
cópias dos nós correspondentes em cada partição que não possui os nós
originais. Em ParTopS, essas cópias são fornecidas pela camada de
comunicação, apresentada na Seção 3.1.1, que é adicionada às fronteiras de
cada partição. Entidades implícitas (vértice, aresta, face e faceta) são atribuídas
às mesmas partições que os elementos aos quais se encontram ancoradas
(Seção 2.6.1).
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 41
Na representação de malha distribuída proposta, a malha local de cada
partição é representada pela estrutura de dados topológica TopS, estendida com
uma infraestrutura adicional para a comunicação entre partições. As extensões
de TopS que formam a representação distribuída de ParTopS são descritas nas
subseções seguintes.
Figura 12 - (a) Malha de elementos finitos original; (b) partições da
malha de elementos finitos.
3.1.1. Camada de comunicação
Durante a análise de elementos finitos, computações realizadas em
elementos e nós precisam acessar dados armazenados em entidades
adjacentes (ex.: a computação de tensões nodais requer contribuições dos
elementos adjacentes aos nós). Todavia, elementos e nós localizados nas
fronteiras de uma partição podem ser adjacentes a entidades representadas em
outras partições. Assim, torna-se necessário que a partição se comunique com
as vizinhas de modo a obter os dados necessários (Figura 13a).
Em relação à representação de elementos coesivos, podem ocorrer
inconsistências topológicas quando esses elementos são representados em
fronteiras compartilhadas por partições de malha diferentes. Por definição,
elementos coesivos só existem em interfaces entre dois elementos volumétricos
adjacentes, porém os elementos volumétricos podem ser representados por
partições diferentes. Segundo a classificação de Paulino et al. (2008), a
(a) (b)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 42
topologia de um elemento coesivo também é determinada a partir de
informações topológicas do conjunto de elementos adjacentes aos vértices,
arestas e facetas do elemento. Na inserção de elementos coesivos, a decisão se
um nó do elemento deve ser duplicado, e como será duplicado, por exemplo,
depende do conjunto de elementos adjacentes. Entretanto, nas fronteiras
compartilhadas de uma partição, o conjunto local de elementos adjacentes não é
completo.
A Figura 13b ilustra a interface de um elemento volumétrico localizado na
fronteira de uma partição, onde se pretende inserir um novo elemento coesivo. A
inserção do elemento requer operações topológicas baseadas nas entidades
adjacentes, como buscas locais ao redor de vértices, arestas e facetas. Para que
o elemento coesivo possa ser criado, é necessário que a topologia da região de
malha ao redor da interface esteja completa. Isso também é necessário para que
a representação do elemento na malha distribuída esteja consistente com sua
definição.
Figura 13 - (a) Computação ao redor de um nó requer dados de
elementos adjacentes representados em outras partições. (b) A topologia
da malha ao redor de um elemento coesivo deve ser completa para a
determinação de duplicações nodais necessárias. Isso requer o acesso a
elementos volumétricos adjacentes que podem estar representados em
partições diferentes.
Conforme discutido na Seção 2.1, uma maneira comum de se fornecer a
uma partição o acesso consistente a dados de entidades topológicas de
(a) (b)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 43
partições vizinhas consiste na criação de cópias das entidades remotas
(representadas pelas partições vizinhas) na partição local corrente. A fim de se
reduzir a quantidade de comunicação necessária para o acesso à vizinhança
completa de uma entidade, uma camada de comunicação é criada ao redor das
fronteiras da partição (Figura 14). A camada de comunicação é composta por
cópias de todos os elementos remotos adjacentes aos nós das fronteiras da
partição corrente, mais os nós desses elementos. Ela é criada logo após o
particionamento inicial da malha original e mantida durante o tempo de vida de
cada partição.
Em ParTopS, uma entidade topológica da malha original é chamada
entidade real, e a partição de malha à qual ela está atribuída é definida como a
partição proprietária da entidade. Embora, devido à camada de comunicação,
diversas partições possam ter uma cópia de uma mesma entidade real, apenas
uma é a proprietária da entidade. Nessa partição, a entidade real é representada
por uma entidade local correspondente. Em outras, ela é representada pelas
camadas de comunicação correspondentes das partições.
Figura 14 - Camada de comunicação; cópias de entidades remotas
são adicionadas ao redor dos nós das fronteiras de cada partição.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 44
Com a introdução de cópias de entidades remotas, a topologia ao redor
das fronteiras originais das partições torna-se completa. Porém, a topologia das
novas fronteiras, definidas agora pela camada de comunicação, permanece
incompleta. Para expressar essa distinção de forma consistente, diferentemente
de abordagens anteriores, propõe-se que as entidades topológicas da camada
de comunicação sejam classificadas em dois tipos: proxy e ghost. A definição
desses tipos é baseada no conceito de vizinhança direta de entidades,
apresentado a seguir.
Define-se a vizinhança direta de uma entidade topológica como o conjunto
de entidades, de dimensão diferente da entidade em questão, que são
diretamente adjacentes a ela na malha de elementos finitos original,
considerando-se uma representação de malha completa (contendo todas as
entidades topológicas representáveis). Sem perda de generalidade, isso é
ilustrado na Figura 15, para um nó (Figura 15a) e um elemento (Figura 15b) de
uma malha bidimensional. A vizinhança direta do nó corresponde ao conjunto de
elementos e outras entidades (arestas, faces e facetas) que incidem diretamente
sobre ele. Por outro lado, a vizinhança direta do elemento é composta pelos nós
e outras entidades (vértices, arestas e facetas) adjacentes ao elemento. A
vizinhança direta de uma aresta é mostrada na Figura 15c; ela consiste no
conjunto de nós, elementos e outras entidades (vértices e faces) adjacentes à
aresta.
Figura 15 - (a) Vizinhança direta de um nó; (b) vizinhança direta de um
elemento; (c) vizinhança direta de uma aresta.
A partir da vizinhança direta de entidades, podemos, então, classificar as
entidades da camada de comunicação. Uma entidade da camada de
comunicação é do tipo proxy quando a sua vizinhança direta é completamente
representada, em relação à malha original, na partição corrente. Caso contrário,
a entidade é do tipo ghost. Na Figura 16a, são destacados nós dos tipos proxy e
(b) (c)(a)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 45
ghost da camada de comunicação de uma partição. Elementos são sempre do
tipo proxy (Figura 16b), uma vez que todos os seus nós e entidades implícitas
adjacentes são representados na partição.
Entidades implícitas são definidas com base em elementos adjacentes.
Dessa forma, para se classificar uma entidade implícita, primeiramente
determina-se o tipo do elemento adjacente ao qual ela está ancorada na partição
corrente. Se o elemento é local, então a entidade também será uma entidade
local na partição. Caso contrário (o elemento é proxy), ela será parte da camada
de comunicação. Nesse caso, a vizinhança direta da entidade é utilizada para
classificá-la como proxy ou ghost, de maneira similar a nós e elementos. Na
Figura 16c, são destacadas as arestas proxies e ghosts da camada de
comunicação de uma partição. As âncoras de entidades (Seção 2.6.1) das
fronteiras compartilhadas originais da partição são mostradas (marca 'x')
próximas às arestas locais ou proxies correspondentes.
Figura 16 - (a) Nós do tipo proxy e ghost são enfatizados; (b) todos os
elementos da camada de comunicação são do tipo proxy; (c) arestas dos
tipos proxy e ghost são destacadas. As âncoras de arestas das fronteiras
compartilhadas originais (marca 'x') indicam a classificação das arestas
correspondentes.
Todo elemento e nó da camada de comunicação possui uma referência
para a entidade real correspondente, representada por uma entidade local na
partição proprietária da entidade (Figura 17). A referência é definida pelo par
ordenado: (owner_partition, owner_handle), onde owner_partition é o
identificador da partição proprietária, e owner_handle é o identificador local da
Ghost
Proxy Proxy
Ghost
Proxy
(a) (b) (c)PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 46
entidade naquela partição. Note que o par (owner_partition, owner_handle) pode
ser usado para identificar univocamente qualquer entidade real na malha
distribuída, sem a necessidade da atribuição explícita de identificadores globais.
Figura 17 - Referências de elemento proxy e nós dos tipos proxy e
ghost para as entidades reais correspondentes.
Ao contrário da abordagem convencional, as entidades da camada de
comunicação são consideradas editáveis. Assim, podem ter topologia e atributos
de simulação modificados pela aplicação cliente, da mesma forma que entidades
locais. Uma vez que a vizinhança direta de entidades locais e proxies é
completa, operações topológicas e computações que dependem de entidades
adjacentes a uma entidade local ou proxy podem ser independentemente
realizadas por cada partição. Isso torna a edição de proxies conveniente para a
redução da comunicação entre partições, através do uso de operações
simétricas, discutidas na Seção 3.2.1, para a inserção de elementos coesivos, e
no Capítulo 4, no contexto da paralelização de simulações de fraturas.
Em ParTopS, a definição de entidades do tipo ghost é empregada para
definir as fronteiras da camada de comunicação. A distinção entre proxies e
ghosts é fundamental para a inserção paralela de elementos coesivos proposta
na Seção 3.2, que a utiliza para resolver ambiguidades de elementos coesivos
localizados próximos às fronteiras das partições. Em relação à representação de
malha distribuída, entidades do tipo ghost possuem duas funções importantes:
garantir a consistência topológica local de cada partição, e prover atributos de
simulação necessários a computações que dependem de entidades adjacentes.
Com isso, a topologia de entidades ghosts deve ser consistente com relação à
malha sequencial de uma partição. Porém, isso não é requerido em relação à
malha global original.
Para garantir a consistência topológica local de uma partição, as relações
de adjacência de entidades ghosts são mapeadas para as entidades adjacentes
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 47
presentes na partição. O mesmo ocorre para as âncoras (Seção 2.6.1) das
entidades implícitas correspondentes, relativas a entidades remotas não
representadas pela partição. Isso é ilustrado na Figura 18, para o caso de nós.
Em uma malha sequencial de TopS, todo nó mantém uma referência para um
dos elementos adjacentes (relação nó-a-elemento). Porém, na malha distribuída
da Figura 18, o nó ghost destacado possuiria uma referência para um elemento
remoto que não é representado pela partição do nó. Nesse caso, a referência do
nó é, então, atribuída a um dos elementos proxies adjacentes a ele. Essa
referência, todavia, difere da correspondente na malha original, representada
pelo nó local da outra partição. A referência de um nó proxy para o elemento
correspondente, por outro lado, é a mesma em ambas as partições. Essa
correspondência garante que entidades proxies são topologicamente
consistentes em relação à malha global.
Figura 18 - Consistência topológica local de um nó proxy e outro
ghost. Embora a malha local de cada partição seja consistente, a referência
do nó ghost ao elemento adjacente é diferente em cada partição. Por outro
lado, a referência do nó proxy é idêntica.
Propriedades adicionais da camada de comunicação são descritas a
seguir:
Todos os elementos adjacentes a um nó ghost são do tipo proxy.
De forma equivalente, nós do tipo ghost não são adjacentes a
elementos locais. Considerando-se que a camada de comunicação
é criada ao redor de todos os nós das fronteiras originais de uma
partição, então a vizinhança direta desses nós é completa. Assim,
se um nó ghost fosse adjacente a um elemento local, a vizinhança
dele seria completa, o que contraria a definição desse tipo de nó.
Uma entidade implícita da camada de comunicação é do tipo ghost
se e somente se todos os nós adjacentes a ela também são ghosts.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 48
Se uma faceta ghost fosse adjacente a um nó proxy ou local, então
todos os elementos adjacentes a ela seriam representados. Como
consequência, as outras entidades implícitas também seriam
representadas localmente, e a vizinhança direta da entidade seria
completa, contrariando a definição de ghost. O mesmo ocorre para
faces e arestas. No caso de um vértice, ele é determinado pelo tipo
do nó correspondente.
3.1.2. Construção da camada de comunicação
Quando uma partição de malha é criada, um subconjunto disjunto dos
elementos e nós correspondentes da malha original é inicialmente atribuído a ela
(Figura 19a). Esses elementos e nós são representados como entidades locais
da partição. Porém, elementos são definidos por um conjunto ordenado de nós,
alguns dos quais podem ter sido atribuídos a partições diferentes. Assim, proxies
são adicionados à partição para representar os nós remotos correspondentes
(Figura 19b). Em seguida, elementos proxies, juntamente com os respectivos
nós, são criados ao redor de todos os nós localizados nas fronteiras da partição
e que possuem elementos adjacentes remotos (Figura 19c). Finalmente, os nós
de elementos proxies que não possuem a vizinhança direta completa
representada pela partição são classificados como ghosts (Figura 19d).
Considerando-se que elementos são representados de forma consistente
entre as partições da malha, entidades implícitas também serão se um critério
uniforme for usado para determinar os elementos aos quais estão ancoradas. O
critério adotado aqui consiste no elemento adjacente com a menor referência à
entidade real correspondente. Assim, o par ordenado (owner_partition,
owner_handle) Seção 3.1.1 – é comparado em ordem lexicográfica,
primeiramente owner_partition, e em seguida owner_handle. Com isso, as
âncoras de entidades locais e proxies implícitas são determinadas de maneira
simétrica sem a necessidade de comunicação entre partições.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 49
Figura 19 - Criação da camada de comunicação. (a) malha original; (b)
malha particionada; (c) partição de malha com elementos e nós proxies
iniciais; (d) partição de malha final; nós proxies que não possuem
vizinhança direta completa são convertidos em ghosts.
3.1.3. Vizinhança de uma partição
Embora a malha distribuída possa ser composta por um grande número de
partições da malha original, em geral, cada partição precisa se comunicar
apenas com um pequeno número de outras localizadas ao redor dela. Dessa
forma, para que a comunicação entre partições possa ser feita de maneira
eficiente, é necessário que cada partição conheça o seu respectivo conjunto de
partições vizinhas. Isso determina o número de mensagens que a partição
espera enviar ou receber de outras durante uma rodada de comunicação.
Em ParTopS, duas partições são consideradas vizinhas se e somente se
uma delas possui uma entidade proxy correspondente a uma entidade local da
outra. Essa definição é conveniente para a representação de malhas de fraturas
(a) (b)
(c) (d)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 50
dinâmicas, pois a inserção de novos elementos coesivos não altera a vizinhança
de uma partição (Seção 3.2), uma vez que cada elemento coesivo criado (ou nó
duplicado devido à inserção do elemento) é atribuído à partição proprietária de
um dos elementos adjacentes à nova entidade. Essa partição é a própria
partição local ou outra que faz parte do conjunto de vizinhas a ela. Com isso, a
vizinhança de uma partição não se modifica, e pode ser determinada apenas
uma única vez, durante a criação da malha distribuída.
Se entidades do tipo ghost fossem consideradas na determinação de
vizinhança de partições, as listas de vizinhança precisariam ser atualizadas
dinamicamente com a inserção de novos elementos coesivos; isso é ilustrado na
Figura 20. Quando um nó ghost é duplicado devido à inserção de elementos
coesivos, o novo nó criado deve ser atribuído a uma partição proprietária.
Porém, essa partição pode não fazer parte da vizinhança da partição que contém
o nó ghost, e assim as listas de vizinhança de ambas as partições devem ser
atualizadas para incluir uma a outra. Na Figura 20, a duplicação do nó destacado
faz com que as partições P1 e P3 se tornem vizinhas. A fim de que as vinhanças
das partições não precisassem ser atualizadas, todas as partições contendo
elementos adjacentes ao nó duplicado deveriam ser previamente consideradas
vizinhas entre si. Por esse motivo, optou-se pela definição de vizinhança
baseada em entidades proxies, para o propósito de simulações de propagação
de fraturas e fragmentação.
Considerando-se que entidades ghosts não influenciam a vizinhança de
uma partição, a partição proprietária de uma entidade ghost pode não fazer parte
do conjunto de vizinhas da partição corrente. Assim, a referência da entidade
ghost para a entidade real correspondente não pode ser usada para atualizar a
entidade ghost. Porém, observa-se que uma entidade ghost pode ser atualizada
a partir de um dos elementos adjacentes a ela, pois toda entidade ghost é
adjacente a um elemento proxy, cuja partição proprietária, por definição, faz
parte da vizinhança da partição corrente. Da mesma forma, na partição
proprietária do elemento proxy, a entidade ghost será representada por uma
entidade local ou proxy, adjacente ao elemento local correspondente. Por
hipótese, a topologia de um elemento é consistente em todas as partições em
que está presente. Então, a entidade ghost possui a mesma identificação em
relação à ordenação topológica local do elemento em ambas as partições. Logo,
requisições de dados para a atualização da entidade ghost são enviadas à
partição proprietária de um dos elementos proxies adjacentes a ele, utilizando-se
a tupla: (owner_partition, owner_element_handle, local_id), onde owner_partition
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
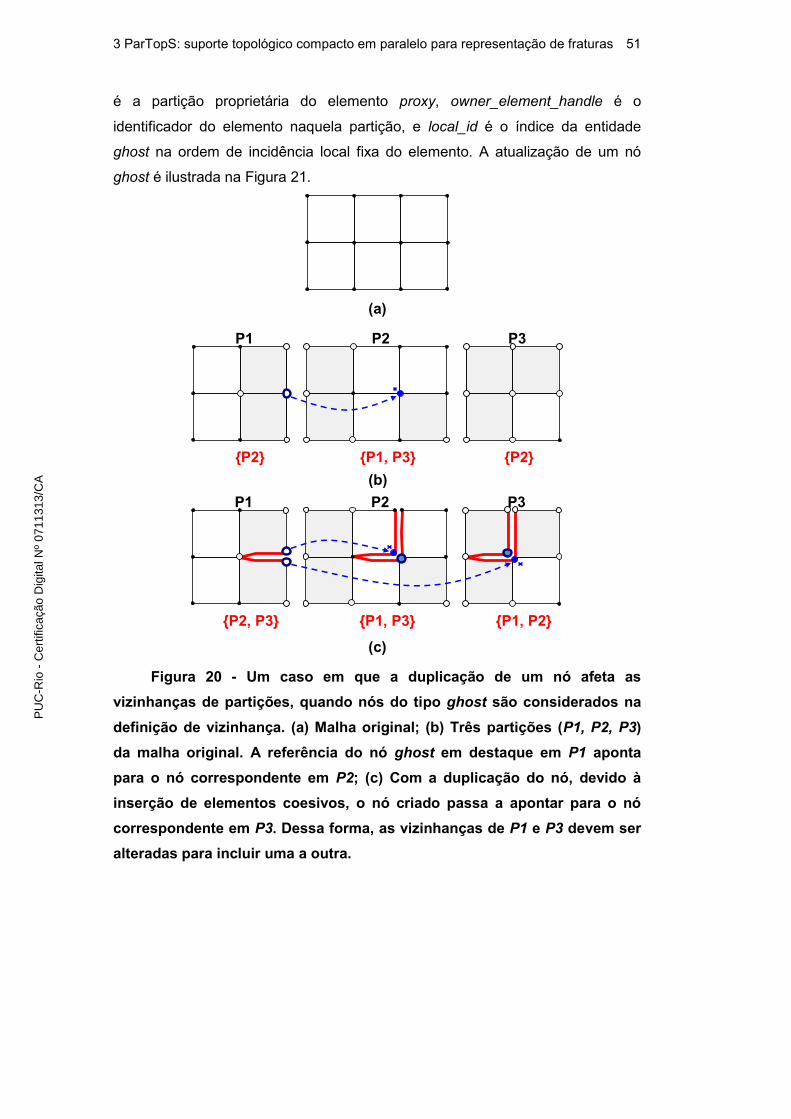
3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 51
é a partição proprietária do elemento proxy, owner_element_handle é o
identificador do elemento naquela partição, e local_id é o índice da entidade
ghost na ordem de incidência local fixa do elemento. A atualização de um nó
ghost é ilustrada na Figura 21.
Figura 20 - Um caso em que a duplicação de um nó afeta as
vizinhanças de partições, quando nós do tipo ghost são considerados na
definição de vizinhança. (a) Malha original; (b) Três partições (P1, P2, P3)
da malha original. A referência do nó ghost em destaque em P1 aponta
para o nó correspondente em P2; (c) Com a duplicação do nó, devido à
inserção de elementos coesivos, o nó criado passa a apontar para o nó
correspondente em P3. Dessa forma, as vizinhanças de P1 e P3 devem ser
alteradas para incluir uma a outra.
P1 P2 P3
{P2} {P1, P3} {P2}
P1 P2 P3
{P2, P3} {P1, P3} {P1, P2}
(a)
(b)
(c)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 52
Figura 21 - Requisição para atualização de um nó ghost (1) é enviada,
a partir de elemento proxy adjacente a ele, à partição proprietária do
elemento. Naquela partição, o nó correspondente é do tipo local ou proxy.
Os atributos do nó (ghost_attrib) são então acessados e retornados à
partição requisitante (2), e o nó ghost é atualizado com os novos valores.
3.1.4. Representação distribuída de atributos
Atributos da simulação numérica associados a nós e elementos da malha
de elementos finitos são representados por conjuntos de atributos densos,
fornecidos por TopS (Seção 2.6). Algumas extensões são adicionadas por
ParTopS para permitir a representação distribuída e a sincronização de atributos
entre partições de malha vizinhas.
Um conjunto distribuído de atributos é criado através de uma função
paralela coletiva, executada concorrentemente por todas as partições de malha.
A criação do conjunto, entretanto, não requer comunicação entre partições. Em
cada partição, a função paralela delega a criação do conjunto para uma função
sequencial correspondente, que constroi conjuntos locais relacionados ao tipo de
entidade desejado. A interface da função paralela é baseada apenas nos tipos
de nós e elementos locais (ex. T3, T6, Tet4, Tet10, Hex8, Hex20, etc.) referentes
à malha sequencial original. Porém, em cada partição, são criados ao mesmo
tempo até três conjuntos de atributos, um para cada representação de entidade
da malha distribuída: local, proxy e ghost. Assim, um conjunto distribuído de
atributos de um nó será representado em cada partição por três conjuntos de
atributos (local proxy e ghost). Da mesma forma, um elemento Tet4, por
Partição
Local
{(owner_element_handle, local_id)1, …}
{ghost_attrib1, …}
1
2
Partição
Remota
1
2
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 53
exemplo, será representado em cada partição por dois conjuntos locais à
partição: Tet4 - local e Tet4 - proxy. Uma vez que todos os conjuntos distribuídos
de atributos são criados pela mesma função paralela, um contador local é usado
por cada partição como identificador global dos conjuntos criados. Os conjuntos
locais de cada partição podem ser acessados independentemente a partir do
identificador único do conjunto distribuído.
A sincronização de um conjunto distribuído de atributos é realizada através
de uma função paralela que depende do tipo de entidade à qual o conjunto está
associado e do identificador global do conjunto. Para que os dados possam ser
transmitidos através da rede de comunicação, uma função de chamada de
retorno (callback function) é registrada pela aplicação junto ao conjunto de
atributos. A função é responsável por empacotar os dados em grupos de bytes
para transmissão, e desempacotá-los ao serem recebidos por uma partição.
Atributos de entidades proxies e ghosts são atualizados separadamente.
Para cada entidade (elemento ou nó) proxy, a partição corrente determina a
partição vizinha proprietária da entidade (owner_partition) e o identificador da
entidade naquela partição (owner_handle). Em seguida, envia para cada partição
vizinha correspondente uma mensagem contendo os identificadores das
entidades remotas (owner_handle). A partição vizinha, então, acessa
diretamente cada entidade, a partir do identificador recebido, e obtém os
atributos do conjunto local a ela. Uma mensagem contendo os dados dos
atributos é retornada à partição corrente, que atualiza as entidades proxies.
Nós do tipo ghost são sincronizados a partir de um dos elementos
volumétricos proxies adjacentes. Para cada nó ghost, a partição corrente escolhe
um elemento proxy adjacente e determina o índice do nó (local_id) na ordem de
incidência local fixa do elemento (Seção 2.6), a partição proprietária do elemento
(owner_partition), e o identificador do elemento naquela partição (owner_handle).
Em seguida, envia para cada partição vizinha correspondente uma mensagem
contendo pares de identificadores de elementos e índices de nós nos elementos
(owner_handle, local_id). A partição vizinha acessa o respectivo elemento local e
então o nó relativo ao índice recebido, e retorna uma mensagem com os
atributos requisitados à partição corrente, que atualiza os nós ghosts. Uma vez
que o nó da partição vizinha pode ser do tipo local ou proxy, é necessário que os
atributos de nós proxies encontrem-se atualizados.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 54
3.2. Inserção dinâmica de elementos coesivos em paralelo
Nesta seção, é proposto um algoritmo baseado em topologia para a
inserção dinâmica de elementos coesivos em paralelo. Diferentemente de outras
abordagens, elementos coesivos são explicitamente representados e podem ter
atributos associados da mesma forma que outros elementos regulares da malha
de elementos finitos; os elementos coesivos são criados sob demanda, e
inseridos apenas onde e quando necessários à simulação, conforme requerido
por modelos coesivos extrínsecos. O algoritmo paralelo pode ser aplicado de
maneira uniforme tanto em malhas 2D quanto 3D, de diferentes tipos de
elementos finitos.
No algoritmo proposto, a representação de malha distribuída de ParTopS,
descrita na Seção 3.1, é combinada com a classificação topológica sistemática
de facetas introduzida por Paulino et al. (2008). São exploradas operações
topológicas que produzem resultados simétricos em todas as partições de malha
para uma mesma entidade topológica. Isso permite eliminar a necessidade de
acesso exclusivo (locks) a entidades por uma única partição, e assim reduzir a
comunicação entre partições para a atualização da topologia da malha.
3.2.1. Operações topológicas simétricas
Uma dificuldade fundamental para a inserção adaptativa de elementos
coesivos em paralelo está relacionada à duplicação de nós localizados nas
fronteiras de uma partição (ou da camada de comunicação), que ocorre durante
a criação de novos elementos coesivos. Para determinar se um nó deve ser
duplicado, e assim manter a topologia da malha consistente, uma partição pode
depender de modificações ocorridas em outra, mas que não são conhecidas por
ela. Isso resulta em dependências cíclicas entre partições, as quais devem ser
resolvidas de forma apropriada.
Para garantir a consistência topológica entre as partições, propõe-se uma
abordagem baseada em operações topológicas simétricas. Uma operação
topológica simétrica é definida, aqui, como uma operação topológica que é
executada sobre um conjunto de entidades compartilhadas por partições de
malha diferentes e que produz resultados idênticos em todas as partições,
indepentemente da ordem na qual as entidades são tratadas ou da partição em
que a operação ocorre.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 55
Com base na representação de malha distribuída de ParTopS, operações
topológicas simétricas são realizadas sobre entidades locais e proxies, de forma
replicada em todas as partições que possuem uma cópia (local ou proxy) de uma
determinada entidade. Considerando-se que os mesmos resultados são obtidos
para a entidade em qualquer partição, não é necessária comunicação entre
partições para garantir a consistência das operações. Assim, a comunicação
para a atualização de entidades proxies é substituída pela replicação de
operações topológicas nas partições. Apenas entidades ghosts são atualizadas,
quando necessário, em relação às entidades locais ou proxies remotas
correspondentes, através da comunicação entre partições vizinhas.
Com essa abordagem, operações topológicas que modificam uma
entidade e, para isso, requerem a completude da vizinhança direta da entidade
são executadas concorrentemente em partições diferentes, de forma consistente
e sem requerer o acesso exclusivo à entidade por uma única partição. Da
mesma forma, evita-se a migração temporária de entidades entre partições para
se garantir a completude da vizinhança direta da entidade.
Uma vantagem de operações simétricas é o tratamento "lock-free"
fornecido para a atualização das entidades topológicas. Como o acesso
exclusivo a uma entidade não é necessário, elimina-se o uso de travas de
acesso exclusivo (ou locks), comumente empregadas para proteger o acesso às
entidades compartilhadas. Como consequência, em geral reduz-se o tempo de
espera em cada partição para acessar a entidade e limita-se a quantidade de
mensagens trocadas entre partições. Embora o emprego de travas de acesso
possa se mostrar conveniente na implementação de outros operadores paralelos
para malhas adaptativas, nesta pesquisa elas não se mostraram necessárias ao
tratamento da inserção de elementos coesivos.
3.2.2. Descrição do algoritmo paralelo
A aplicação cliente é responsável pela identificação do conjunto de facetas
fraturadas onde elementos coesivos serão inseridos. Esse conjunto é então
passado como entrada do algoritmo de inserção paralela de elementos coesivos.
Devido às características simétricas da abordagem proposta, o conjunto de
facetas fraturadas em cada partição inclui tanto facetas locais como proxies, de
maneira consistente entre todas as partições que compartilham uma mesma
faceta. Isso significa que, se uma faceta é fraturada em uma partição, então ela
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 56
é fraturada em todas as partições que possuem uma cópia local ou proxy dela;
caso contrário, ela não é fraturada em nenhuma partição. As facetas fraturadas
utilizadas para ilustrar o algoritmo proposto são mostradas na Figura 22.
Figura 22 - Exemplo de malha distribuída, utilizada para demonstrar o
algoritmo para a inserção adaptativa de elementos coesivos em paralelo.
As facetas fraturadas (determinadas pela aplicação numérica) são
destacadas.
Uma vez que as facetas fraturadas são identificadas, a inserção adaptativa
de elementos coesivos em paralelo é executada. O algoritmo proposto consiste
de três fases:
Fase 1. Elementos coesivos são inseridos em facetas locais e proxies de
cada partição, utilizando-se um algoritmo sequencial que produz resultados
topológicos simétricos para cada faceta, em qualquer partição.
Fase 2. As referências de entidades proxies criadas, elementos e nós, são
atualizadas com relação às entidades reais correspondentes.
Fase 3. As entidades ghosts afetadas pela inserção dos novos elementos
coesivos são atualizadas em relação às entidades reais correspondentes.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 57
As três fases do algoritmo são detalhadas nas seguintes subseções.
3.2.2.1. Inserção sequencial de elementos coesivos (Fase 1)
Na primeira fase do algoritmo (Fase 1), elementos coesivos são inseridos
nas facetas fraturadas locais e proxies de cada partição, com base na
classificação topológica de facetas de Paulino et al. (2008), discutida na Seção
2.6.3. Segundo essa classificação, quando um novo elemento coesivo é
adicionado à malha, pode ser necessário duplicar nós existentes. Neste ponto,
faz-se a seguinte observação: suponhamos que os mesmos resultados
topológicos possam ser obtidos para um conjunto de entidades em todas as
partições de malha, independentemente da ordem em que elementos coesivos
são inseridos localmente em cada partição, conforme a definição de operação
simétrica (Seção 3.2.1). Então, a topologia de entidades locais e proxies será
consistente para toda a malha de elementos finitos após a execução da Fase 1,
sem a necessidade de comunicação entre partições para sincronizá-la. Com
base na definição de malha distribuída de ParTopS (Seção 3.1), entretanto, nós
do tipo ghost não são duplicados neste momento, devido à incompletude da
vizinhança direta das entidades. Eles serão atualizados separadamente durante
a Fase 3 do algoritmo.
Para garantir um comportamento topológico simétrico entre as partições da
malha distribuída, adicionam-se duas restrições à definição original da
classificação de facetas de Paulino et al. (2008). A primeira requer que, em
qualquer partição onde um nó duplicado esteja presente, as cópias nodais
correspondentes possuam referência a um mesmo elemento adjacente (em
TopS, e assim ParTopS, todo nó possui uma referência a um dos elementos
adjacentes a ele - relação nó-a-elemento (Seção 2.6)). Isso pode ser obtido com
o emprego de um critério uniforme para a seleção do elemento referenciado. Por
simplicidade, pode-se escolher, dentre os elementos adjacentes ao nó no
momento da inserção de um elemento coesivo, o que possui o menor
identificador global de elemento: (owner_partition, owner_handle) – Seção 3.1.
Identificadores globais são comparados em ordem lexicográfica, primeiramente
pela partição proprietária (owner_partition) da entidade, e em seguida pelo
identificador local da entidade naquela partição (owner_handle).
A segunda restrição requer que todas as cópias de um novo nó ou
elemento coesivo sejam atribuídas, consistentemente, à mesma partição
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 58
proprietária. No caso de um nó, essa restrição é obtida atribuindo-se o nó à
partição proprietária do elemento ao qual ele faz referência. Uma vez que todas
as cópias do nó possuem referência para o mesmo elemento real (conforme a
primeira restrição), então a partição proprietária do nó é naturalmente
consistente para todas as suas cópias. Elementos coesivos são atribuídos à
mesma partição de um dos dois elementos volumétricos adjacentes a eles.
Neste caso, o elemento volumétrico representativo é escolhido com base no
mesmo critério uniforme utilizado na primeira restrição (menor valor do par
(owner_partition, owner_handle)). As âncoras que definem entidades implícitas
(Seção 2.6.1) também são atualizadas com base no mesmo procedimento.
A Fase 1 do algoritmo é ilustrada na Figura 23, para duas partições
vizinhas. Três elementos coesivos são inseridos ao redor de um nó presente em
ambas as partições (Figura 23a). Embora a ordem de inserção dos elementos
seja diferente em cada partição, os mesmos resultados topológicos são obtidos
para todas as entidades locais e proxies envolvidas na operação (Figura 23b).
Note que os mesmos elementos são referenciados pelos novos nós criados,
independentemente da partição de malha (indicados pela marca "x" na Figura
23), como resultado das restrições adicionais à classificação de facetas.
Considerando-se a definição de vizinhança de partições de ParTopS
(Seção 3.1.3), as operações topológicas realizadas não alteram o conjunto de
vizinhança de cada partição, pois as entidades criadas são atribuídas a partições
já pertencentes ao conjunto. Com isso, não é necessário que uma partição se
comunique com outras a fim de atualizá-lo.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 59
Figura 23 - Fase 1 da inserção de elementos coesivos. Três elementos
são inseridos (a - c) em facetas de duas partições vizinhas. Embora a
ordem de inserção seja diferente, os mesmos resultados topológicos são
obtidos para as entidades locais e proxies de ambas as partições (c). As
marcas 'x' identificam o elemento referenciado por cada nó modificado.
Nós ghosts não são duplicados; eles serão atualizados na Fase 3.
3.2.2.2. Atualização das entidades proxies criadas (Fase 2)
Ao final da Fase 1, a topologia de entidades locais e proxies encontra-se
consistente entre todas as partições de malha. Entretanto, as referências das
novas entidades proxies criadas (elementos coesivos e nós duplicados) para as
entidades reais correspondentes ainda precisam ser determinadas (Figura 24).
Referências para entidades reais fazem parte da definição de malha distribuída
de ParTopS (conforme Seção 3.1.1), e devem estar consistentes para que
futuras operações topológicas e a sincronização de atributos de simulação
possam ser realizadas. A partição proprietária de uma nova entidade proxy foi
determinada durante a Fase 1, uma vez que ela corresponde à partição de um
dos elementos adjacentes à entidade. Porém, o identificador local da entidade
com respeito à partição proprietária não é conhecido pela partição corrente. Essa
informação deve ser requisitada à partição proprietária.
(a) (b) (c)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 60
Figura 24 - Malha completa após a Fase 1. A partição escolhida como
proprietária de um novo elemento coesivo ou nó duplicado é a mesma de
um dos elementos volumétricos adjacentes ao coesivo (indicado pelas
marcas 'x'). Os elementos coesivos estão destacados na figura. Os proxies
correspondentes são representados por linhas tracejadas. Embora a
topologia de entidades locais e proxies esteja consistente neste ponto, as
referências para as entidades reais ainda devem ser computadas.
Dessa forma, a Fase 2 do algoritmo paralelo para a inserção de elementos
coesivos é responsável pela atualização das referências às entidades reais
correspondentes dos novos elementos coesivos e nós duplicados do tipo proxy.
Isso pode ser feito da seguinte forma: uma lista de requisições de referências é
enviada pela partição corrente a cada partição vizinha a ela. As partições
vizinhas então acessam as entidades reais correspondentes e retornam os
respectivos identificadores locais. Finalmente, a partição corrente atualiza as
referências das novas entidades proxies com os valores recebidos.
É importante notar que as próprias entidades proxies não podem ser
usadas na requisição das referências que lhes faltam. Entretanto, observa-se
também que qualquer elemento (coesivo ou volumétrico) pode ser univocamente
identificado por um dos elementos adjacentes a ele. Isso é expresso pela tripla
(owner_partitionadj, owner_element_handleadj, local_id), onde owner_partitionadj é
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 61
o identificador da partição proprietária do elemento adjacente,
owner_element_handleadj é o identificador do elemento adjacente naquela
partição, e local_id é o índice da faceta-uso incidente ao novo elemento coesivo
proxy, na ordem de incidência fixa do elemento adjacente (Seção 3.1.1). De
maneira equivalente, um nó proxy também pode ser identificado por um dos
elementos adjacentes. Com isso, elementos adjacentes são utilizados para obter
as referências faltantes das entidades proxies criadas.
Como consequência da Fase 1 do algoritmo, a partição proprietária de um
elemento coesivo corresponde à partição proprietária de um dos elementos
volumétricos adjacentes a ele. O elemento adjacente representativo é, então,
usado para a requisição da referência do elemento coesivo proxy à entidade real
correspondente. Da mesma forma, utiliza-se o elemento adjacente referenciado
por um novo nó proxy na requisição da referência do nó à entidade real
correspondente, considerando-se que, durante a Fase 1, o nó real foi atribuído à
mesma partição do elemento.
As mensagens trocadas entre partições vizinhas para atualizar as
referências das entidades proxies criadas são ilustradas na Figura 25. A
comunicação é iniciada pela partição corrente (local). A partição envia uma
mensagem consistindo de pares (owner_element_handleadj, local_id) a cada
partição vizinha (remota) que é proprietária (owner_partitionadj) dos elementos
adjacentes representativos das entidades proxies a serem atualizadas. A
mensagem de retorno contém os identificadores locais das entidades reais nas
partições proprietárias correspondentes.
Figura 25 - Diagrama de mensagens trocadas entre duas partições
para a atualização das referências de entidades proxies.
3.2.2.3. Atualização das entidades ghosts afetadas (Fase 3)
A última fase (Fase 3) do algoritmo paralelo é responsável pela atualização
de nós do tipo ghost afetados por duplicações de nós ocorridas em outras
partições, resultantes da inserção dos novos elementos coesivos (Figura 26).
Partição
Local
{(owner_element_handleadj, local_id)1, …}
{owner_entity_handle1, …}
1
2Partição
Remota
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 62
Devido à incompletude da vizinhança direta de nós do tipo ghost, as duplicações
nodais não podem ser determinadas localmente por uma partição. Por exemplo,
um elemento coesivo pode ter sido inserido em uma faceta remota que não é
conhecida pela partição corrente, mas que implica na duplicação do nó real que
corresponde a uma entidade ghost da partição. Na Figura 26, os nós ghosts
afetados pela duplicação de nós em outras partições são mostrados. Para
manter a topologia da malha da partição corrente consistente com a malha
global distribuída, pode ser necessário ao procedimento de atualização de
ghosts substituir a referência do nó ghost para uma nova entidade real
correspondente, ou mesmo duplicá-lo em novos nós ghosts distintos.
Figura 26 - Malha completa antes do início da Fase 3. Os nós ghosts
de cada partição afetados pela duplicação de nós ocorridas em outras
partições são destacados na figura. Esses nós precisam ser atualizados.
Como a partição corrente não pode determinar exatamente os nós ghost
afetados, que devem ser atualizados, uma forma simples de se garantir a
consistência topológica de nós ghosts consiste na atualização de todos em
relação às entidades reais correspondentes. Porém, é comum que, a cada passo
da simulação de fraturas, um pequeno número de elementos coesivos seja
adicionado à malha distribuída, em relação ao número total de elementos de
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 63
cada partição. Assim, é desejável uma abordagem proporcional ao número de
entidades afetadas.
Para isso, uma partição contendo nós locais ou proxies, cuja duplicação na
Fase 1 tenha afetado nós ghosts remotos, deve notificar as outras sobre as
alterações ocorridas. Contudo, a representação de malha distribuída de ParTopS
não prevê que entidades locais mantenham referências para as suas cópias
proxies e ghosts, apenas no sentido inverso. Isso evita o custo de
armazenamento e manutenção de listas explícitas de referências dinâmicas. Por
outro lado, requer que a comunicação relacionada a uma entidade real seja
iniciada pelas partições que possuem proxies ou ghosts dela.
No contexto da inserção de elementos coesivos, e a fim de se evitar a
necessidade de listas dinâmicas, optou-se por uma abordagem para a
atualização de nós ghosts baseada em elementos. Nela, em vez de cada nó
local de uma partição armazenar referências para entidades ghosts remotas, são
os elementos locais que possuem referências às partições contendo elementos
proxies correspondentes. Com isso, os elementos locais são responsáveis por
informar a outras partições sobre alterações em nós adjacentes que
potencialmente sejam representados por elas como ghosts. A vantagem dessa
abordagem é que referências existentes para elementos proxies não precisam
ser atualizadas quando novos elementos coesivos são inseridos na malha
distribuída, pois nenhum elemento proxy é substituído ou removido da malha
durante esse processo. Assim, não é necessário manter listas de referências
dinâmicas. Também, a vizinhança de cada partição não precisa ser
recomputada, considerando-se a definição da Seção 3.1.3, pois a atualização de
atributos de entidades ghosts pode ser feita a partir dos elementos proxies
adjacentes (Seção 3.1.3).
Para mostrar que a atualização baseada em elementos pode ser
empregada de forma a garantir a consistência de nós ghosts, observa-se o
seguinte. Um nó ghost faz parte da camada de comunicação de uma partição.
Logo, ele deve ser adjacente a pelo menos um elemento do tipo proxy, e todo
elemento proxy corresponde a um elemento local na sua partição proprietária. O
elemento local é adjacente a nós locais ou proxies, sendo que um deles
corresponde ao nó ghost considerado. Pela simetria imposta na Fase 1 do
algorimo, qualquer duplicação de um nó local ou proxy é consistente entre todas
as partições da malha. Então, se o nó real correspondente ao ghost tiver sido
duplicado em alguma partição, ele também será na partição proprietária do
elemento proxy adjacente ao nó ghost. Com isso, o nó ghost será afetado pela
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 64
duplicação nodal se e somente se o elemento local na partição proprietária do
elemento proxy adjacente ao nó ghost tiver o nó local ou proxy correspondente
afetado.
O procedimento para a atualização da topologia de entidades ghosts é
descrito a seguir. Inicialmente, para cada nó duplicado na partição corrente,
determinam-se os elementos locais que são adjacentes a ele e que possuem
elementos proxies em outras partições (Figura 27). Entre os elementos locais
adjacentes ao nó, vários deles podem possuir proxies em uma mesma partição
remota. Porém, apenas um por partição é selecionado. Em seguida, uma
mensagem é enviada às partições dos elementos proxies correspondentes, a fim
de notificá-las sobre as duplicações nodais. A mensagem consiste de tuplas
(owner_element_handle, local_id), onde owner_element_handle é o identificador
de um elemento local, e local_id é o índice de um nó na ordem de incidência fixa
do elemento (Figura 28). Quando a notificação é recebida por uma partição,
cada identificador de elemento é mapeado para o elemento proxy
correspondente, e o nó relativo ao índice local_id é acessado. Se o nó for do tipo
ghost, então ele é marcado como desatualizado (outdated) (Figura 27).
Para cada elemento proxy adjacente a um nó ghost desatualizado (Figura
29), uma requisição de dados nodais é criada. A requisição consiste da tupla
(owner_element_handle, local_id), onde owner_element_handle é o identificador
local do elemento em sua partição proprietária, e local_id é o índice do nó na
ordem de incidência fixa do elemento (Seção 3.1.1). Então, o conjunto de
requisições é enviado às partições proprietárias dos elementos proxies (Figura
28). Note que mais de uma requisição para um mesmo nó ghost pode ser
emitida, quando há vários elementos proxies adjacentes a ele. Entretanto, isso
garante que a duplicação de nós seja resolvida de maneira consistente para
cada elemento.
Finalmente, a partição proprietária de cada elemento proxy retorna os
dados nodais requisitados (Figura 28), e os nós ghosts são atualizados. Os
dados de um nó consistem de valores (owner_node_handle, (x, y, z)), onde
owner_node_handle é o identificador do nó na sua partição proprietária, e (x, y,
z) é a posição do nó. Embora um nó ghost possa corresponder a um nó do tipo
proxy na partição proprietária do elemento proxy adjacente a ele, o nó proxy já
foi atualizado durante a Fase 2, e, assim, os seus dados encontram-se
consistentes. Após a atualização de nós ghosts, as âncoras (Seção 2.6.1) que
definem entidades implícitas do tipo ghost são ajustadas de forma a se manter a
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 65
consistência topológica local da partição corrente. A malha final é mostrada na
Figura 30.
Figura 27 - Elementos locais que são incidentes a nós duplicados e
têm elemento proxy correspondente em outra partição são destacados.
Esses elementos notificam partições vizinhas sobre duplicações nodais
que possam afetar nós ghosts. Porém, apenas um elemento por nó
duplicado e partição vizinha é necessário (os de origem das setas
tracejadas). Nós ghosts de elementos proxies notificados são marcados
como desatualizados. Os nós ghosts destacados com bordas contínuas
devem ser atualizados.
Figura 28 - Diagrama de mensagens trocadas entre a partição
corrente (local) e uma vizinha a ela (remota), para atualizar entidades
ghosts afetadas pela duplicação de nós ocorrida na partição vizinha.
{(owner_element_handle, local_id)1, …}
{(owner_element_handle, local_id)1, …}
{(owner_node_handle, x, y, z)1, …}
1
2
3
Partição
Local
Partição
Remota
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
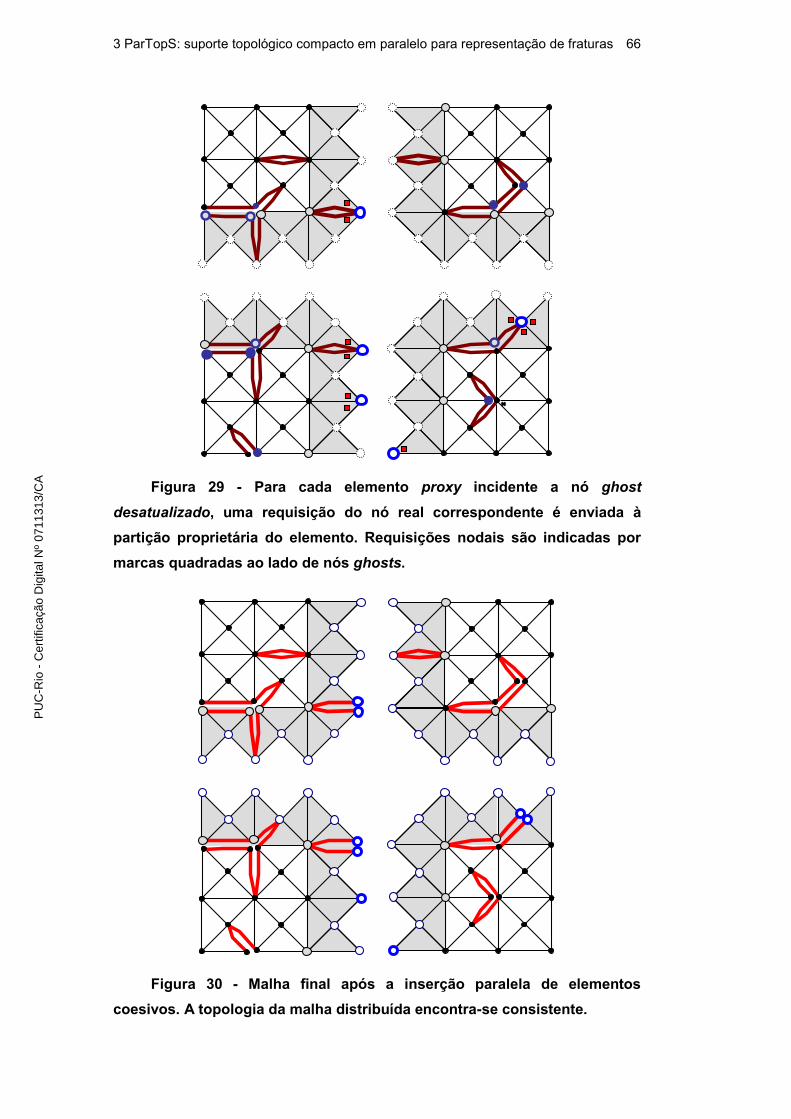
3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 66
Figura 29 - Para cada elemento proxy incidente a nó ghost
desatualizado, uma requisição do nó real correspondente é enviada à
partição proprietária do elemento. Requisições nodais são indicadas por
marcas quadradas ao lado de nós ghosts.
Figura 30 - Malha final após a inserção paralela de elementos
coesivos. A topologia da malha distribuída encontra-se consistente.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 67
A implementação da abordagem de atualização de nós ghosts baseada em
elementos adjacentes segue a filosofia de representação compacta de ParTopS.
Com isso, em vez de armazenar o conjunto de todas as partições que possuem
proxies para um determinado elemento local, um valor inteiro é empregado para
indicar a existência de proxies do elemento. Assim, quando há uma única
partição que contém um proxy para o elemento, o que corresponde ao caso mais
comum, o valor inteiro é igual ao identificador da partição. Se houver duas ou
mais partições, um valor negativo é usado como contador para indicar o número
de partições. Nesse caso, notificações de duplicações nodais relacionadas ao
elemento são enviadas a todas as partições vizinhas. Finalmente, se nenhuma
partição possui um proxy para o elemento, o valor inteiro é igual a zero.
3.2.3. Interface para a inserção de elementos coesivos
O suporte à inserção paralela de elementos coesivos é fornecido à
aplicação cliente através de uma função paralela coletiva, executada
concorrentemente por cada partição. A função recebe como parâmetros: o tipo
dos elementos coesivos a serem inseridos e o conjunto de facetas fraturadas na
partição corrente, incluindo tanto as locais quanto proxies. Do ponto de vista da
aplicação cliente, a função sequencial original, de assinatura similar, é
substituída pela versão paralela.
A função paralela não retorna os elementos coesivos que foram inseridos;
em vez disso, a aplicação é notificada sobre cada elemento coesivo criado ou nó
duplicado, por funções de chamada de retorno (callback functions) - ou funções
de chamada de volta - registradas na representação de malha distribuída. A
interface de chamadas de retorno de duplicações nodais é a mesma de TopS,
mas as funções também são chamadas para entidades proxies e ghosts.
Quando notificada, a aplicação deve criar os atributos relativos aos novos nós e
elementos. A notificação de duplicações de nós locais e proxies ocorre durante a
Fase 1 do algoritmo paralelo, enquanto que atributos de nós ghosts afetados são
atualizados na Fase 3. Ao final do algoritmo, a aplicação é notificada sobre os
elementos coesivos criados.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 68
3.2.4. Análise de escalabilidade
A escalabilidade de um sistema paralelo (Foster, 1995; Quinn, 2004) está
relacionada à capacidade de se utilizar de maneira eficiente uma quantidade
maior de recursos para resolver problemas maiores ou mais complexos.
Diversas abordagens existem para a medição de escalabilidade em diferentes
circunstâncias (Foster, 1995; Quinn, 2004; Kumar & Gupta, 1994). Nesta seção,
a métrica de isoeficiência (Grama et al., 1993) é empregada para avaliar a
escalabilidade do algoritmo proposto. Essa métrica relaciona o tamanho do
problema paralelo com o número de processadores necessários para se manter
a eficiência de um sistema. Sem perda de generalidade, um modelo
bidimensional é usado como exemplo. Resultados similares podem ser obtidos
para modelos tridimensionais.
Considere o tempo de execução T(n, p) de um sistema paralelo com
tamanho de problema n para p processadores. O tempo sequencial é T1 =
T(n, 1), e T0 = T0(n, p) é o tempo adicional introduzido devido à implementação
paralela. Então, a eficiência parelela do sistema (Grama et al., 1993) é definida
como E = 1 / (1 + T0/T1); ou de forma equivalente: T1 = (E / (1 - E)).T0 = K.T0.
Para se manter a eficiência, o tempo de computação sequencial T1 deve
aumentar a uma taxa maior ou igual ao tempo adicional paralelo T0, ou seja,
T1 ≥ K.T0. Paulino et al. (2008) demonstram a escalabilidade linear da inserção
sequencial de elementos coesivos, em função do número de elementos
inseridos. Dessa forma, o tempo da execução sequencial pode ser expresso por:
T1 = n.tc, onde n é o número de elementos coesivos inseridos, e tc é o custo
médio da operação de inserção de um elemento coesivo. Assim, a eficiência
paralela é mantida quando n ≥ C.T0, onde C = K / tc.
No algoritmo paralelo de inserção de elementos coesivos, o custo adicional
paralelo (T0) se deve à replicação de operações topológicas na camada de
comunicação e à comunicação entre partições vizinhas, como ilustrado na Figura
31. Observa-se que a replicação de operações topológicas é proporcional ao
tamanho da camada de comunicação, em média equivalente a . Por sua
vez, o número de mensagens entre partições vizinhas durante a execução do
algoritmo é constante, e o tamanho de cada mensagem proporcional ao tamanho
da camada de comunicação. Com isso, o custo paralelo de um processador
pode ser expresso por: , onde c1, c2, e c3
são multiplicadores constantes, ts é o tempo médio de inicialização da
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

3 ParTopS: suporte topológico compacto em paralelo para representação de fraturas 69
comunicação para o envio de uma mensagem, e tw é o tempo médio para se
enviar uma unidade de dados. O custo paralelo total (para todos os
procesadores) é então: . Nesse modelo,
assume-se que a carga dos processadores é balanceada entre eles, e, assim, os
tempos ociosos (idle times) de cada processador não são significativos.
Para um grande número de processadores, a eficiência paralela é mantida
quando o crescimento assintótico do tamanho do problema n é maior ou igual ao
de T0. Considerando-se que o crescimento de T0 é proporcional a , obtém-se
a seguinte relação: , que leva a: . Logo, quando n cresce
proporcionalmente a p, mantêm-se a eficiência do algoritmo paralelo, e, assim, a
escalabilidade linear em relação ao número de processadores é esperada.
Figura 31 - Representação de malha bidimensional de dimensões
N x N, decomposta em P partições. O padrão de comunicação
correspondente a uma partição é destacado.
P
N
N
N
P
N
P
N
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelos
Este capítulo descreve a utilização do suporte topológico ParTopS no
desenvolvimento análises numéricas em paralelo. Como exemplo, discute-se a
paralelização de uma aplicação sequencial existente para simulações de fraturas
dinâmicas. A aplicação, originalmente implementada com base na representação
de malha sequencial de TopS (Celes, Paulino & Espinha, 2005a, b; Paulino et
al., 2008), é paralelizada pela introdução do conjunto de extensões paralelas
fornecidas por ParTopS (Espinha et al., 2009). Um número pequeno de
modificações é necessário ao código original para que a análise numérica seja
executada em um ambiente paralelo de memória distribuída.
4.1. Requisitos de sincronização de entidades
Uma característica de análises dinâmicas de elementos finitos é a
interdependência de dados. A computação de um passo de tempo da simulação
numérica depende de resultados do passo anterior. Da mesma forma,
computações intermediárias de um passo também dependem de resultados
anteriores. Isso restringe a capacidade de paralelização de uma simulação, uma
vez que a computação de dados dependentes não pode ser realizada
concorrentemente. Pontos de sincronização ocorrem quando os dados
requeridos a uma computação ainda não se encontram disponíveis à partição
corrente, que deve aguardar até que eles sejam recebidos. Com isso, as
oportunidades de paralelização da simulação residem na decomposição dos
dados do domínio geométrico, que podem ser processados de forma
concorrente entre os pontos de sincronização. Como exemplo, a computação de
tensões nodais, utilizada na determinação de facetas fraturadas, requer que os
deslocamentos nodais tenham sido previamente computados. Considerando que
os deslocamentos encontram-se consistentes em cada partição, as tensões
nodais podem então ser calculadas concorrentemente por cada partição.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 71
Uma partição de malha corresponde a uma unidade sequencial de
computação. No interior dela, a computação numérica é realizada de maneira
independente a partir dos dados locais à partição. Porém, atributos de simulação
associados a entidades nas fronteiras compartilhadas com outras partições
devem se manter consistentes entre as partições envolvidas. Esses atributos são
utilizados na computação dos resultados das próprias entidades e de outras
adjacentes a elas. Com isso, a comunicação entre partições vizinhas pode se
tornar necessária para sincronizar os dados correspondentes.
A camada de comunicação adicionada por ParTopS provê as entidades
adjacentes necessárias a computações locais em entidades das fronteiras
originais de cada partição de malha. Para se manter a consistência dos dados
das entidades da camada de comunicação com as partições vizinhas, duas
classes de abordagens são avaliadas. A primeira corresponde à estratégia
convencional, na qual entidades da camada de comunicação são utilizadas
apenas para a leitura de dados, e os resultados de uma computação são
armazenados somente nas entidades locais de cada partição (note que a
computação pode usar dados fornecidos por entidades proxies adjacentes). Com
isso, os resultados de uma entidade são determinados exclusivamente por uma
única partição (a proprietária da entidade), correspondendo a um mecanismo
implícito de travas de acesso exclusivo (locks) (Andrews, 2000) à entidade.
Considerando-se que os dados das entidades adjacentes às locais encontram-se
disponíveis na partição corrente, por meio da camada de comunicação, a
computação pode proceder de forma sequencial, sem problemas de
concorrência para a atualização de entidades. Por outro lado, as entidades da
camada de comunicação devem ser sincronizadas com as entidades reais
correspondentes sempre que dados modificados precisarem ser utilizados.
A segunda classe de abordagens explora as propriedades da camada de
comunicação definida por ParTopS. Dessa forma, as entidades da camada de
comunicação são consideradas editáveis, e resultados de computações são
calculados e armazenados nelas, de forma replicada com as entidades reais
correspondentes, sempre que conveniente à aplicação. Uma vez que dados
associados a uma mesma entidade podem ser computados simultaneamente por
partições de malha diferentes, é preciso garantir que eles se encontrem
consistentes entre elas. Para isso, propõe-se o uso de computações simétricas
entre as partições, de maneira similar às operações topológicas empregadas
pelo algoritmo paralelo de inserção de elementos coesivos do Capítulo 3. Com
isso, o número de pontos de sincronização de dados entre partições é reduzido e
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 72
a estrutura da simulação paralela simplificada. A simetria de computações é
discutida na Seção 4.4.
Note que não é preciso atualizar todos os atributos de uma entidade
topológica em cada ponto de sincronização, mas somente aqueles que devem
se encontrar consistentes para a computação seguinte. A sincronização pode ser
postergada até que os dados sejam realmente necessários à simulação, ou
realizada de maneira assíncrona, enquanto computações independentes são
executadas. No entanto, a aplicação deve bloquear a execução caso os dados
requeridos não estejam disponíveis no momento esperado.
4.2. Estrutura da simulação sequencial
A estrutura do fluxo de controle básico de uma simulação numérica de
fraturas dinâmicas, para pequenas deformações, é resumida na Figura 32; a
aplicação numérica sequencial correspondente foi desenvolvida por Park (2009).
A integração temporal é baseada no método de diferenças centrais (método
explícito) (Belytschko et al., 2000), e o modelo constitutivo Park-Paulino-Roesler
(PPR) (Park et al., 2009; Park, 2009) é utilizado com um modelo de zona coesiva
extrínseco (Camacho & Ortiz, 1996; Ortiz & Pandolfi, 1999; Park et al., 2009). A
estrutura da simulação sequencial apresentada na Figura 32 é utilizada como
base da aplicação paralela discutida nas próximas seções.
Inicialize o modelo de elementos finitos
Para cada passo de tempo
1 - Compute o valor das condições de contorno
2 - Verifique a inserção de novos elementos coesivos
2.1 - Compute as tensões nodais
2.2 - Determine as facetas fraturadas
2.3 - Insira elementos coesivos
2.4 - Compute atributos de novos elementos coesivos
2.5 - Atualize os valores das massas nodais
3 - Compute o vetor de forças nodais internas
4 - Compute o vetor de forças coesivas
5 - Atualize as acelerações e velocidades nodais
6 - Atualize as forças externas e energias nos nós
7 - Aplique as condições de contorno aos nós
8 - Atualize os deslocamentos nodais
Figura 32 - Estrutura do fluxo de controle de uma simulação
sequencial de propagação dinâmica de fraturas.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 73
A simulação da propagação de fraturas ocorre ao longo de um número de
passos de tempo discretos (Figura 32). Em cada passo, a aplicação numérica
deve determinar as facetas que serão fraturadas e inserir os elementos coesivos
correspondentes (linha 2). A determinação de facetas fraturadas é feita com
base nos valores de tensão (stress) dos nós adjacentes; assim, as tensões
nodais devem ser primeiramente calculadas (linha 2.1). Os valores de tensão
(stress) são computados nos pontos de Gauss de cada elemento volumétrico, a
partir de atributos dos nós adjacentes, e então extrapolados novamente para os
nós do elemento. As tensões nodais finais são obtidas pela média das
contribuições dos elementos adjacentes a cada nó. Com as tensões dos nós
adjacentes calculadas, as facetas internas da malha (interfaces entre elementos
volumétricos) são avaliadas em relação a um critério de fratura (linha 2.2), e toda
faceta para a qual o critério de fratura é alcançado é marcada como fraturada no
passo corrente. Em seguida, elementos coesivos são criados sob demanda e
inseridos nas facetas fraturadas (linha 2.3). Os atributos dos nós duplicados são
copiados do nó anterior correspondente, através de funções de chamadas de
retorno (callbacks), registradas pela aplicação e chamadas por TopS, para cada
duplicação de nó. Atributos de novos elementos coesivos (linha 2.4) são
calculados a partir das tensões associadas aos nós adjacentes. As massas de
nós duplicados também são atualizadas; a massa de um nó corresponde ao
somatório das contribuições de massa dos elementos volumétricos adjacentes.
Após as operações relativas à verificação da inserção de elementos
coesivos (linha 2), computações adicionais são realizadas a fim de se atualizar o
estado da simulação necessário ao próximo passo de tempo ou exportado como
saída da simulação. O vetor de forças nodais internas (linha 3) é calculado a
partir do somatório das contribuições de forças dos elementos volumétricos
adjacentes a cada nó da malha de elementos finitos. A contribuição de um
elemento é baseada na rigidez (stiffness) do elemento e deslocamentos dos nós
adjacentes. Forças coesivas (linha 4), por outro lado, são calculadas apenas
para nós adjacentes a elementos coesivos. Primeiramente, separações coesivas
são computadas nos pontos de Gauss de cada elemento coesivo, a partir dos
deslocamentos dos nós adjacentes. Então, as separações e outros atributos do
elemento (ex. material e história de carregamento) são usados na computação
de trações e forças correspondentes, e a contribuição do elemento é somada a
cada nó adjacente. Finalmente (linhas 6 a 8), os valores restantes (acelerações,
velocidades, energia, condições de contorno e deslocamentos nodais) são
calculados em cada nó, com base nos atributos relativos aos próprios nós.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 74
4.3. Padrões de computação
Quatro padrões de computação básicos, relacionados à origem e o destino
de dados associados a entidades topológicas, podem ser identificados em uma
análise de elementos finitos regular. São eles: nó-a-nó, elemento-a-elemento,
nós-a-elemento e elementos-a-nó. Computações dos tipos nó-a-nó (Figura 33a)
e elemento-a-elemento (Figura 33b) ocorrem de maneira local aos nós ou
elementos correspondentes. Assim, dependem apenas dos dados das próprias
entidades que modificam. No padrão nós-a-elemento, os resultados de um
elemento são calculados a partir das contribuições de dados associados aos nós
adjacentes a ele (Figura 33c). Uma vez que os dados nodais estejam
consistentes, a computação ocorre de maneira local ao elemento destino. Por
outro lado, no padrão elementos-a-nó, os dados correspondentes a um elemento
contribuem para os resultados armazenados nos nós adjacentes a ele (Figura
33d). Quando uma estrutura topológica apropriada é empregada, os resultados
nodais podem ser calculados percorrendo-se o conjunto de nós da malha de
elementos finitos. Para cada nó, os elementos adjacentes são visitados e as
contribuições dos elementos são calculadas e combinadas no nó. Com base na
representação de malha convencional de elementos finitos (tabelas de nós e
conectividades nodais de elementos), entretanto, esse padrão é tradicionalmente
implementado percorrendo-se o conjunto de elementos da malha. Então, os
dados correspondentes a cada elemento são calculados e adicionados aos nós
adjacentes, com base na conectividade nodal do elemento.
Computações mais complexas podem depender de entradas mistas e
gerar resultados segundo padrões diferentes. Porém, essas computações
podem ser decompostas em outras computações menores baseadas nos
padrões básicos, e cada parte analisada individualmente. A classificação em
padrões de computação fornece uma maneira sistemática e abstrata para se
identificarem os requisitos de sincronização de atributos para a manutenção da
consistência de dados compartilhados entre partições de malha. Com isso, a
necessidade de sincronização é determinada apenas a partir da estrutura da
computação, de forma independente do entendimento da simulação numérica.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 75
Figura 33 - Padrões de computação. (a) nó-a-nó: o resultado de um nó
depende apenas dele próprio; (b) elemento-a-elemento: o resultado de um
elemento depende apenas dele próprio; (c) nós-a-elemento: o resultado de
um elemento depende dos nós adjacentes; (d) elementos-a-nó: o resultado
de um nó depende das contribuições relativas aos elementos adjacentes.
4.4. Computações simétricas
Uma computação é definida como simétrica quando produz os mesmos
resultados para uma entidade topológica compartilhada por partições diferentes,
independentemente da partição onde é executada. Considerando-se que os
resultados da computação são idênticos em qualquer partição, a comunicação
entre partições para sincronizar os dados alterados da entidade topológica pode
ser eliminada. Com isso, emprega-se conceito equivalente às operações
topológicas discutidas na Seção 3.2.1, com a substituição da comunicação entre
partições por computações replicadas, realizadas tanto para entidades locais
quanto proxies e ghosts de cada partição.
Entretanto, operações binárias de ponto flutuante, como adição e
multiplicação, não são associativas (Heath, 2002) e, assim, resultados diferentes
podem ser obtidos em função da ordem em que as operações são realizadas.
Dessa forma, computações executadas concorrentemente por partições
diferentes para uma mesma entidade topológica podem produzir resultados
divergentes, se a ordem das operações de ponto flutuante não for idêntica em
todas as partições. As divergências numéricas, mesmo que pequenas, podem
fazer com que decisões diferentes sejam tomadas por cada partição, por
exemplo, se uma faceta deve ser fraturada. Essas divergências também podem
se propagar ao longo dos passos de simulação, afetando a convergência da
simulação.
nónó elementoelemento elementos nónós elemento
(a) (b) (c) (d)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 76
Se pudermos garantir uma ordenação consistente das operações de ponto
flutuante, então resultados idênticos (ou simétricos) serão obtidos para uma
entidade em todas as partições, assumindo-se que a mesma representação de
ponto flutuante é utilizada por elas. Para isso, primeiramente observam-se as
características de simetria dos padrões de computação discutidos na seção
anterior. Computações dos tipos nó-a-nó e elemento-a-elemento são
naturalmente independentes de ordem e, assim, simétricas, uma vez que
requerem apenas o acesso local à própria entidade. No padrão nós-a-elemento,
os resultados de um elemento dependem da ordem em que as contribuições dos
nós adjacentes são combinadas. Contudo, a ordenação nodal é imposta pela
topologia local fixa do elemento, que é consistente entre todas as partições que
possuem uma cópia da entidade. Dessa forma, computações do tipo nós-a-
elemento também são simétricas. Por outro lado, em uma computação do tipo
elementos-a-nó, os resultados de um nó dependem da ordem em que as
contribuições dos elementos adjacentes são combinadas. As abordagens para
computações elementos-a-nó simétricas são discutidas a seguir.
4.4.1. Computações elementos-a-nó simétricas com iteradores estáveis
Resultados simétricos de computações do tipo elementos-a-nó podem ser
obtidos de duas formas. Na primeira, as contribuições fornecidas por elementos
adjacentes são explicitamente ordenadas em cada nó antes de serem
combinadas, de maneira consistente entre as partições de malha (por exemplo,
ordem crescente de valor). Isso requer que a contribuição de um elemento seja
temporariamente armazenada ou a computação replicada para cada nó
adjacente a ele. Na segunda, uma ordem consistente é imposta à visitação dos
elementos adjacentes a cada nó. Dessa forma, as contribuições dos elementos
são naturalmente combinadas de maneira simétrica em qualquer partição.
Conforme discutido na Seção 4.3, uma computação sequencial do tipo
elementos-a-nó é tradicionalmente realizada percorrendo-se os elementos da
malha de elementos finitos e adicionando-se a contribuição de cada elemento
aos nós adjacentes. Como consequência, evita-se a replicação de computações
nos elementos para os nós adjacentes e a necessidade de armazenamento de
dados temporários. De forma que a computação ocorra de maneira simétrica, os
elementos devem ser visitados segundo uma ordem global consistente em
relação à malha distribuída. Para isso, propõe-se uma abordagem baseada na
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 77
ordenação global implícita de elementos. A fim de que o percorrimento ordenado
seja feito de maneira transparente à aplicação cliente, iteradores estáveis de
elementos são adicionados à representação de malha distribuída de ParTopS.
A implementação de um iterador estável é baseada em vetores ordenados
de identificadores de elementos (owner_partition, owner_element_handle). Cada
partição de malha mantém um vetor independente, que é atualizado
(reordenado) sempre que elementos são adicionados ou removidos dela. O vetor
contém apenas elementos do tipo proxy, uma vez que os elementos locais
possuem a mesma partição proprietária (a partição corrente), e, assim, já se
encontram implicitamente ordenados com respeito a ela. A iteração ordenada é
feita da seguinte forma: visitam-se os elementos do vetor ordenado, enquanto o
identificador da partição proprietária correspondente (owner_partition) for menor
que o da partição corrente. Então, os elementos locais são visitados, segundo a
ordenação local implícita da partição, e o percorrimento do vetor é retomado a
partir da posição seguinte à última visitada.
A ordenação implícita de elementos é obtida a partir da comparação
lexicográfica dos pares ordenados (owner_partition, owner_element_handle),
que identificam univocamente os elementos da malha distribuída (Seção 3.1.1),
primeiramente pela partição proprietária (owner_partition), em seguida pelo
identificador local do elemento naquela partição (owner_element_handle). Dessa
forma, não é preciso atribuir identificadores globais explícitos a elementos, e os
custos de manutenção correspondentes são evitados. Além disso, não se requer
comunicação entre partições para a atualização da ordenação global quando a
malha é modificada. Essa abordagem difere de outras (Dooley et al., 2009), onde
operações de 128 bits de precisão são usadas para garantir a consistência de
operações de precisão dupla (64 bits) em nós compartilhados por partições
diferentes.
Diferentes vetores ordenados e iteradores podem ser criados para cada
grupo distinto de elementos. Nas simulações de fraturas realizadas foram
utilizados iteradores distintos para elementos volumétricos e coesivos. Nesse
caso, o vetor de elementos volumétricos não precisa ser atualizado quando
elementos coesivos são inseridos na malha. Considerando-se o número de
elementos coesivos normalmente muito menor que o de volumétricos, assim
como o de entidades proxies em relação às locais, o esforço de atualização do
vetor ordenado durante a simulação de fraturas não é significativo.
Com base na representação de malha distribuída de ParTopS,
computações simétricas ocorrem tanto para entidades locais como proxies.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 78
Entidadades do tipo ghost, que dependem de informações de outras partições,
são atualizadas a partir de resultados computados nas entidades locais ou
proxies remotas correspondentes.
4.5. Interface de programação paralela
A interface de programação (API - Application Programming Interface)
disponibilizada pelo sistema ParTopS a aplicações numéricas baseia-se no
paradigma de programação paralela SPMD (Single Program Multiple Data)
(Foster, 1995). Dessa forma, um único programa é executado concorrentemente
para todas as partições da malha distribuída, e em cada partição processa-se
uma parte diferente do conjunto de dados do modelo de elementos finitos
original. A comunicação entre partições é baseada no envio de mensagens
(Foster, 1995), podendo ser integrada com aplicações desenvolvidas com base
no padrão MPI (Message Passing Interface) (MPI Forum, 2010).
O sistema ParTopS é implementado internamente na linguagem C++
(Stroustrup, 1997), utilizando-se o sistema Charm++ (Kalé & Krishnan, 1993,
1996), uma infra-estrutura orientada a objetos para o desenvolvimento de
aplicações paralelas genéricas baseada no envio e recebimento assíncrono de
mensagens entre processadores. Esse paradigma oferece oportunidades para a
melhoria do desempenho de aplicações paralelas, pois facilita a sobreposição
entre etapas de computação e comunicação em operações executadas em
paralelo. Por outro lado, também tende a aumentar significativamente a
complexidade de programação. Assim, considerando-se a complexidade
intrínseca de simulações numéricas, optou-se por prover à aplicação cliente uma
interface funcional de programação, mais simples e fácil de usar. O objetivo é
facilitar a paralelização de aplicações numéricas existentes, e permitir ao
desenvolvedor da aplicação se concentrar no problema numérico.
A interface de programação para aplicações numéricas consiste de
funções locais, na linguagem C (Kerninghan & Ritchie, 1988), para o acesso e
manipulação de dados em cada partição de malha, mais um conjunto reduzido
de funções paralelas coletivas (executadas concorrentemente por todas as
partições) para as operações envolvendo partições diferentes. Com isso,
pretende-se manter o sistema tão simples quanto possível, embora ainda
eficiente e escalável a um grande número de processadores. A malha sequencial
local de cada partição é representada pela estrutura de dados topológica TopS,
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 79
estendida com a infra-estrutura de comunicação entre partições de ParTopS
(camada de comunicação, inserção de elementos coesivos em paralelo,
iteradores estáveis de elementos). As funções locais proveem o acesso à
representação de malha. As funções paralelas coletivas encapsulam a
comunicação entre partições diferentes.
4.5.1. Funções exportadas à aplicação numérica
Uma breve descrição das principais funções da interface de programação
paralela fornecida à aplicação numérica é apresentada abaixo:
void topParInit();
TopParModel topParModel_Create();
int topParModel_ReadMesh(TopParModel model,
char* format, char* meshfile, char* partfile);
TopModel* topParModel_GetLocalMesh(
TopParModel model);
TopAttribId topParModel_CreateNodeDenseAttrib(
TopParModel model, size_t sizeof_attrib);
void* topModel_GetNodeDenseAttribAt(
TopModel* mesh, TopAttribId attribid, TopNode node);
void topParModel_SyncProxyNodeDenseAttrib(
TopParModel model, TopAttribId attribid);
void topParModel_SyncGhostNodeDenseAttrib(
TopParModel model, TopAttribId attribid);
void topParModel_SyncFacets(
TopParModel model, TopFacet* facets);
void topParModel_InsertCohesiveAtFacets(
TopParModel model, ElemType type, TopFacet* facets);
A função coletiva topParInit(), chamada concorrentemente por todas
as partições, inicializa o suporte à representação de malha distribuída; ela deve
ser chamada uma vez ao início do programa, após a inicialização do padrão
MPI: MPI_Init() (MPI Forum, 2010). A função coletiva
topParModel_Create() cria um novo modelo de elementos finitos distribuído
(inicialmente contém apenas uma malha vazia) e retorna o identificador do
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 80
modelo criado (TopParModel). A função coletiva utilitária
topParModel_ReadMesh() lê uma malha distribuída no formato format, para
um modelo distribuído de elementos finitos (model), dado um arquivo contendo
a malha (meshfile) e outro com a descrição das partições (partfile). A
função local topParModel_GetLocalMesh() retorna um ponteiro para a
malha local da partição corrente, representada pela estrutura de dados
topológica sequencial TopS estendida com o suporte paralelo. A função coletiva
topParModel_CreateNodeDenseAttrib() adiciona ao modelo (model) um
atributo associado a todos os nós da malha distribuída, de tamanho
sizeof_attrib por nó. O identificador do atributo criado (TopAttribId) é
retornado pela função. Esse identificador é idêntico em todas as partições de
malha e pode ser usado para acessar o atributo correspondente a um nó de uma
partição qualquer, através de chamada à função local
topModel_GetNodeDenseAttribAt(), que retorna o ponteiro (void*) para a
posição de memória correspondente aos dados de um nó (node) da malha local
(mesh). As funções topParModel_SyncProxyNodeDenseAttrib() e
topParModel_SyncProxyNodeDenseAttrib() sincronizam nós proxies e
ghosts, respectivamente, em relação a um atributo (attribid) associado aos
nós reais remotos correspondentes. A função coletiva
topParModel_SyncFacets() sincroniza as listas locais de facetas fraturadas
(facets) de todas as partições de malha com as partições vizinhas. Finalmente,
a função coletiva topParModel_InsertCohesiveAtFacets() insere
adaptativamente elementos coesivos de um determinado tipo (type) em um
conjunto de facetas fraturadas (facets), que inclui consistentemente facetas
locais e proxies da partição corrente. A aplicação é notificada sobre os
elementos coesivos criados e os nós duplicados durante a inserção dos
elementos através de funções de chamada de retorno (callback functions)
registradas na malha local de cada partição pela aplicação numérica.
4.5.2. Implementação da interface de programação
A interface funcional de programação é construída com base na biblioteca
TCharm (Threaded Charm++) (University of Illinois, 2011), disponibilizada pelo
sistema Charm++, que permite o mapeamento do paradigma de objetos e
mensagens assíncronas em uma visão baseada em linhas de execução
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 81
(threads), convencionalmente empregada em aplicações paralelas. Dessa forma,
o código numérico sequencial é executado por cada partição de malha em uma
linha de execução própria. Com base em TCharm, chamadas a funções
paralelas definidas pelo padrão MPI são mapeadas, de forma transparente à
aplicação numérica, à infra-estrutura de comunicação assíncrona de Charm++,
através da biblioteca AMPI (Huang et al., 2003). As linhas de execução criadas
com TCharm podem ser migradas entre processadores e utilizar facilidades de
balanceamento de carga oferecidos por Charm++.
No paradigma de programação de Charm++, dois objetos paralelos
(Chares), P1 e P2, localizados em processadores diferentes, comunicam-se
através de chamadas remotas de métodos assíncronas. No exemplo ilustrado na
Figura 34, o método a(), executando em P1, envia uma chamada assíncrona ao
método compute(), de P2, e continua a execução de a(). A chamada a compute()
inclui uma mensagem (msg) contendo os parâmetros do método mais uma
referência a um método de retorno (cb()) em P1. Ao terminar a execução de b(),
o objeto P2 torna-se disponível ao processamento de novas mensagens (a
execução de métodos em cada processador não é interrompida pelo
recebimento de mensagens – execução não preemptiva). Então, a chamada a
compute(), recebida e armazenada em uma fila de espera, é processada e o
método executado. Ao final da execução de compute(), o método de retorno cb()
é chamado, de maneira assíncrona, para informar P1 sobre o término de
compute() e permitir que as computações subsequentes em P1 sejam
executadas. O encadeamento de computações dentro de um objeto também é
feito através de chamadas assíncronas, enviadas a si próprio. Na Figura 34, o
método a(), ao terminar sua execução em P1, chama o método c() do mesmo
objeto; a chamada é armazenada na fila de espera e processada após as qu
estiverem pendentes. A implementação interna dos operadores topológicos de
ParTopS é realizada com base nesse paradigma.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 82
Figura 34 - Comunicação por chamadas remotas de métodos
assíncronas entre dois objetos em processadores diferentes (P1 e P2).
Para encapsular as chamadas de métodos assíncronas em um paradigma
funcional, criou-se um objeto de contexto associado a uma linha de execução de
TCharm. Esse é um objeto regular (Chare) de Charm++, contendo referências à
linha de execução da aplicação e ao objeto (Chare) correspondente à partição
de malha. Cada função da interface de programação exportada para a aplicação
cliente chama um método correspondente do objeto de contexto. O método do
contexto, por sua vez, chama o método da partição de malha, passando como
parâmetro a referência a outro método do contexto que deve ser chamado como
retorno do método da partição. Então, requisita a suspensão da linha de
execução (thread) da aplicação. Quando o método de retorno (callback) é
chamado, indicando a finalização da operação paralela, este requisita a
continuação da linha de execução (thread) da aplicação. Dessa forma, a função
exportada é vista pela aplicação de maneira síncrona, da mesma forma que
funções sequenciais regulares. Um exemplo relativo à sincronização de facetas
fraturadas é mostrado abaixo, em pseudocódigo (estilo linguagem C++
(Stroustrup, 1997)):
P1 P2
a()
c()
cb()
b()
compute()
d()
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 83
// Objeto de contexto
Context {
TCharm* thread;
TopPartition* partition;
void SyncFacets(TopFacet* facets) {
Callback callback(Context::RecvSyncFacetsReply);
partition->SyncFacets(facets, callback);
thread->suspend();
}
void RecvSyncFacetsReply () {
thread->resume();
}
}
// Função exportada à aplicação numérica
void topParModel_SyncFacets (TopFacet* facets) {
context->SyncFacets(facets);
}
4.6. Estrutura da simulação paralela
A estrutura da simulação paralela é determinada a partir dos requisitos de
sincronização e padrões de computação discutidos nas seções anteriores. De
forma geral, o código paralelo corresponde ao sequencial original, executado
concorrentemente por cada partição de malha e com funções paralelas coletivas
adicionais para sincronização de atributos de simulação entre partições. A
aplicação numérica paralela é apresentada a seguir, considerando-se as
abordagens para sincronização de atributos entre partições introduzidas na
Seção 4.1. A abordagem empregada define os requisitos de sincronização da
aplicação.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 84
4.6.1. Abordagem baseada em computações apenas em entidades locais
Na estrutura da simulação paralela ilustrada na Figura 35, os resultados de
computações numéricas são armazenados apenas em entidades locais de cada
partição. Isso corresponde à primeira classe de abordagens paralelas da Seção
4.1, sendo equivalente à estratégia convencional de uso de travas de acesso
exclusivo (locks) – no caso, o lock é implícito às entidades locais. Entidades da
camada de comunicação (proxies e ghosts) são consideradas não editáveis e,
assim, servem unicamente ao propósito de fornecer os dados necessários a
computações locais próximas às fronteiras originais da partição. A consistência
de dados de entidades proxies e ghosts é garantida através de sincronizações
com as partições vizinhas, realizadas sempre que necessário. As etapas de
sincronização de atributos numéricos são destacadas em negrito na Figura 35.
Inicialize o modelo de elementos finitos
Para cada passo de tempo
1 - Compute o valor das condições de contorno
2 - Verifique a inserção de novos elementos coesivos
2.1 - Compute as tensões nodais
A1. Sincronize atributos de nós proxies
2.2 - Determine as facetas fraturadas
A2. Sincronize o conjunto de facetas fraturadas
2.3 - Insira elementos coesivos
2.4 - Atualize os valores das massas nodais
3 - Compute o vetor de forças nodais internas
4 - Compute o vetor de forças coesivas
A3. Sincronize atributos de elementos coesivos proxies
5 - Atualize as acelerações e velocidades nodais
6 - Atualize as forças externas e energias nos nós
7 - Aplique as condições de contorno aos nós
8 - Atualize os deslocamentos nodais
A4. Sincronize atributos de nós proxies
A5. Sincronize atributos de nós ghosts
Figura 35 - Estrutura do fluxo de controle da simulação de fraturas
Modo I, segundo a abordagem baseada em computações locais.
Ao início de um passo de tempo da simulação, assume-se que todas as
partições do modelo de elementos finitos encontram-se consistentes entre si.
Durante a execução do passo, entretanto, os atributos de nós e elementos são
modificados por computações intermediárias, realizadas independentemente em
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 85
cada partição. Esses atributos devem estar consistentes para que possam ser
utilizados em computações subsequentes. Os requisitos de sincronização para a
manutenção da consistência de dados entre partições são analisados a seguir,
com base nos padrões de computação observados na estrutura da simulação
numérica. A discussão é baseada no detalhamento da simulação numérica
sequencial apresentado na Seção 4.2.
A computação de tensões nodais (linha 2.1) consiste em duas etapas
sequenciais. Primeiramente, para cada elemento volumétrico, os atributos dos
nós adjacentes são trazidos temporariamente ao elemento, para a integração
das tensões; em seguida, a contribuição do elemento é extrapolada para ser
armazenada nos nós locais adjacentes (note que não é necessário armazenar os
resultados temporários de elementos). Um nó local pode ser adjacente a
elementos locais ou proxies; assim as contribuições desses elementos devem
ser determinadas. A contribuição de um elemento, por sua vez, depende dos nós
adjacentes a ele. Como um elemento proxy pode ser adjacente a nós locais,
proxies ou ghosts, os atributos dessas entidades devem estar consistentes antes
do início da computação de tensões. Isso é garantido pela sincronização de nós
proxies e ghosts realizada ao final do passo anterior (linhas A4 e A5), após a
computação dos deslocamentos nodais.
A determinação de fraturas (linha 2.2) é realizada de forma consistente
para todas as facetas locais da partição corrente. A inserção de elementos
coesivos (Seção 3.2), entretanto, é realizada por meio de uma função paralela
coletiva com entrada e saída definidas. Essa função requer que tanto facetas
fraturadas locais quanto proxies sejam fornecidas. Dessa forma, o conjunto local
de facetas fraturadas da partição é sincronizado com as partições vizinhas (linha
A2). Uma vez que uma faceta local pode ser adjacente tanto a nós locais quanto
proxies, e os atributos dos nós remotos correspondentes foram alterados pela
computação de tensões, os nós proxies devem ser sincronizados antes da
determinação de fraturas (linha A1). Após a inserção de elementos coesivos
(linha 2.3), a topologia global da malha distribuída e os atributos
correspondentes às entidades modificadas encontram-se consistentes.
As massas nodais (linha 2.4) são atualizadas com base nas contribuições
de elementos volumétricos adjacentes. Como a massa de um elemento não se
altera durante a simulação, e computações subsequentes não requerem massas
de nós proxies ou ghosts, a sincronização de atributos nodais não é necessária
antes ou após a computação.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 86
O vetor de forças internas (linha 3) é calculado em duas etapas, de
maneira similar às tensões nodais. Para cada elemento volumétrico, atributos de
nós adjacentes são trazidos temporariamente ao elemento e combinados com
outros atributos estáticos do elemento. Então, a contribuição do elemento é
adicionada aos nós locais adjacentes a ele. Como o único atributo nodal utilizado
nessa computação corresponde ao deslocamento, que não foi alterado até o
momento no passo corrente, a sincronização de entidades proxies e ghosts não
é necessária para a determinação das forças internas.
A computação de forças coesivas (linha 4) pode ser decomposta em três
partes. Na primeira, para cada elemento coesivo, atributos temporários
(separações coesivas) são calculados no elemento a partir de atributos
(deslocamentos) de nós adjacentes. Na segunda, atributos do elemento (ex.
materiais e história de carregamento) são atualizados, combinando-os com os
atributos temporários anteriores, e os resultados armazenados novamente no
elemento, se ele for do tipo local. Finalmente, a contribuição de forças do
elemento é adicionada a cada nó local adjacente. A computação modifica tanto
elementos coesivos locais quanto nós locais adjacentes a eles. Uma vez que nós
locais podem ser adjacentes a elementos locais e proxies, e esses elementos a
nós locais, proxies e ghosts, a computação depende dos atributos dessas
entidades. Porém, considerando que os atributos nodais utilizados não foram
alterados no passo corrente, é preciso sincronizar apenas atributos de elementos
coesivos (linha A3), para que estejam consistentes ao passo seguinte.
As computações restantes (acelerações e velocidades, forças externas e
energias, condições de contorno e deslocamentos nodais) (linhas 5 a 8)
dependem apenas de atributos dos próprios nós que modificam. Dessa forma, as
computações são realizadas para cada nó local da partição corrente e não
dependem de sincronizações de entidades. Conforme discutido anteriormente,
ao final do passo de simulação, os atributos de entidades proxies e ghosts são
sincronizados (linhas A4 e A5), para que o estado da simulação esteja
consistente para o passo seguinte.
Com a edição de atributos de um elemento ou nó realizada apenas pela
partição proprietária da entidade, divergências numéricas entre partições da
malha distribuída são naturalmente evitadas. Por outro lado, atributos de
entidades proxies e ghosts devem ser sincronizados de maneira apropriada.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 87
4.6.2. Abordagem baseada em computações replicadas
Nesta abordagem, a replicação de computações numéricas em elementos
e nós da camada de comunicação é explorada a fim de se reduzir a
sincronização de atributos necessária à manutenção da consistência de dados
entre partições de malha. Assim, as entidades da camada de comunicação são
consideradas editáveis, e resultados de computações armazenados nelas
sempre que conveniente.
A seguir, a estrutura da simulação paralela da Seção 4.6.1 é revisitada
(Figura 36), e os padrões de computação que nela ocorrem são analisados. Os
resultados de computações replicadas são tratados como idênticos em todas as
partições, sem modificações adicionais à simulação original para garantir uma
ordem consistente de execução de operações de ponto flutuante. Em
computações do tipo elementos-a-nó, isso pode levar a pequenas diferenças de
resultados entre partições. Para limitar a possível propagação de diferenças ao
longo de passos de tempo da simulação, realizam-se sincronizações
esporádicas dos atributos numéricos das entidades topológicas afetadas.
Inicialize o modelo de elementos finitos
Para cada passo de tempo
1 - Compute o valor das condições de contorno
2 - Verifique a inserção de novos elementos coesivos
2.1 - Compute as tensões nodais
Se o passo de tempo é múltiplo de n
A1. Sincronize atributos de nós proxies
2.2 - Determine as facetas fraturadas
A2. Sincronize o conjunto de facetas fraturadas
2.3 - Insira elementos coesivos
2.4 - Atualize os valores das massas nodais
3 - Compute o vetor de forças nodais internas
4 - Compute o vetor de forças coesivas
Se o passo de tempo é múltiplo de n
A3. Sincronize atributos de nós proxies
A4. Sincronize atributos de nós ghosts
5 - Atualize as acelerações e velocidades nodais
6 - Atualize as forças externas e energias nos nós
7 - Aplique as condições de contorno aos nós
8 - Atualize os deslocamentos nodais
Figura 36 - Estrutura da simulação numérica paralela baseada em
computações replicadas. A sincronização de nós proxies ocorre
esporadicamente, em intervalos de n passos de tempo.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 88
Na etapa inicial de cada passo de tempo da simulação, as tensões nodais
são computadas (linha 2.1). Para isso, os valores temporários de um elemento
volumétrico são calculados a partir dos atributos dos nós adjacentes, o que
corresponde ao padrão nós-a-elemento. Assim, os resultados obtidos no
elemento são naturalmente simétricos, se apresentando consistente entre
partições diferentes. Na segunda etapa, entretanto, a contribuição do elemento é
adicionada aos nós adjacentes, segundo o padrão elementos-a-nó. Nesse caso,
a aplicação calcula os resultados nodais da forma tradicional, percorrendo os
elementos da partição corrente, e adicionando a contribuição de cada elemento
aos nós adjacentes.
Assumindo-se que nenhuma ordenação global é imposta ao percorrimento
de elementos, resultados numéricos ligeiramente divergentes para um mesmo
nó podem ser obtidos por partições diferentes, o que requer a sincronização
esporádica de nós proxies para se manter a consistência dos dados (linha A1).
Se a sincronização fosse completamente eliminada, as divergências numéricas
se propagariam para passos de tempo subsequentes, o que poderia afetar a
convergência correta da simulação. Por outro lado, divergências que não alterem
significativamente a simulação poderiam ser ignoradas (ou toleradas). Assim,
como forma de se remover o custo de sincronização, mas ao mesmo tempo
mitigar o acúmulo de divergências numéricas, a sincronização de proxies é
realizada em intervalos determinados de n passos de tempo. Nesta pesquisa,
executaram-se simulações numéricas com sincronização de nós proxies em
intervalos de 100 passos, com base na aplicação numérica Modo I considerada
como exemplo. Nenhuma diferença significativa foi observada quanto aos
resultados obtidos.
A determinação de facetas (linha 2.2) pode ser representada pelo padrão
de computação nós-a-elemento. Assim, considerando-se que os nós de cada
faceta encontram-se consistentes, a computação é naturalmente simétrica. Com
isso, a sincronização de conjuntos locais de facetas fraturadas pode ser
eliminada se a determinação de fraturas em cada partição incluir também facetas
do tipo proxy. Entretanto, as divergências numéricas da computação de tensões,
mesmo pequenas, podem afetar decisões binárias, como a do critério de fratura,
fazendo com que os conjuntos de facetas fraturadas fiquem inconsistentes entre
as partições. Dessa forma, para garantir a consistência dos dados, a
determinação de facetas permanece sendo feita com base em facetas locais
apenas, seguida pela sincronização dos conjuntos de facetas (linha A2).
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 89
Assim como a computação de tensões nodais, o vetor de forças internas
(linha 3) é computado em uma etapa baseada no padrão nós-a-elemento,
seguida de outra do tipo elementos-a-nó. Por sua vez, a computação do vetor de
forças coesivas (linha 4) corresponde aos padrões nós-a-elemento, elemento-a-
elemento e elementos-a-nó. As computações nós-a-elemento e elemento-a-
elemento são simétricas e dependem de atributos nodais (ex. deslocamentos e
materiais) não alterados no passo corrente. As computações elemento-a-
elemento alteram e dependem de atributos de elementos coesivos calculados no
passo anterior. Porém, como essas computações são também simétricas, os
resultados não precisam ser sincronizados para se garantir a consistência do
passo seguinte. Finalmente, as computações elementos-a-nó se baseiam nos
resultados das anteriores, e assim dependem de dados já consistentes. Os
resultados são tratados de maneira similar às tensões nodais. Assim, a
sincronização de nós proxies é também realizada em intervalos de n passos de
tempo, e apenas atributos de nós ghosts devem ser sincronizados antes de
serem usados nas computações seguintes, ou ao final do passo de tempo
(linhas A3 e A4).
As computações restantes (acelerações e velocidades, forças externas e
energias, condições de contorno e deslocamentos nodais) (linhas 5 a 8) seguem
o padrão nó-a-nó. Logo, ocorrem de forma simétrica para todos os nós.
4.6.3. Abordagem baseada em computações simétricas
A sincronização esporádica de nós proxies da abordagem anterior pode
ser eliminada de forma transparente à aplicação numérica através do uso de
iteradores estáveis (Seção 4.4.1) para o percorrimento de elementos em
computações elementos-a-nó. Nesse caso, os iteradores da aplicação original
são diretamente substituídos pelas versões estáveis correspondentes. Com
consequência, resultados de tensões nodais e forças internas e coesivas, por
exemplo, passam a ser computados de maneira simétrica, produzindo resultados
numericamente consistentes para nós locais e proxies de cada partição, sem a
necessidade de sincronização. Com a determinação de fraturas realizada
também para facetas proxies, além das locais, a sincronização de conjuntos de
facetas é removida. Por outro lado, facetas proxies podem ser adjacentes a nós
ghosts, e, assim, esses nós devem ser sincronizados antes da determinação de
facetas. O código paralelo baseado nessa estratégia é ilustrado na Figura 37, e
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 90
requer apenas sincronização de nós ghosts (linhas A1 e A2). Uma vantagem da
redução de pontos de sincronização através de computações estáveis é a
simplificação significativa da estrutura da simulação paralela.
Inicialize o modelo de elementos finitos
Para cada passo de tempo
1 - Compute o valor das condições de contorno
2 - Verifique a inserção de novos elementos coesivos
2.1 - Compute as tensões nodais
A1. Sincronize atributos de nós ghosts
2.2 - Determine as facetas fraturadas
2.3 - Insira elementos coesivos
2.4 - Atualize os valores das massas nodais
3 - Compute o vetor de forças nodais internas
4 - Compute o vetor de forças coesivas
A2. Sincronize atributos de nós ghosts
5 - Atualize as acelerações e velocidades nodais
6 - Atualize as forças externas e energias nos nós
7 - Aplique as condições de contorno aos nós
8 - Atualize os deslocamentos nodais
Figura 37 - Estrutura da simulação paralela utilizando iteradores
estáveis de elementos.
4.6.4. Abordagem mista
Com o emprego de computações simétricas, os pontos de sincronização
de atributos da simulação numérica são reduzidos em relação à abordagem
convencional baseada apenas em computações locais. Contudo, dependendo da
aplicação, a combinação de abordagens diferentes pode se tornar mais
vantajosa.
No caso da simulação numérica analisada, a sincronização de conjuntos
de facetas fraturadas não é necessária quando computações simétricas são
empregadas. Por outro lado, isso requer que atributos de nós ghosts sejam
sincronizados antes da determinação de fraturas. Porém, um volume menor de
dados é, em geral, esperado na sincronização de conjuntos de facetas em
comparação com atributos de nós ghosts. Assim, uma abordagem mais
compacta utiliza computações simétricas, mas mantém a determinação de
fraturas a partir de facetas locais, com a sincronização dos conjuntos de facetas
correspondentes. A estrutura da simulação paralela resultante é apresentada na
Figura 38.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

4 Simulações de fraturas extrínsecas em ambientes paralelo 91
Inicialize o modelo de elementos finitos
Para cada passo de tempo
1 - Compute o valor das condições de contorno
2 - Verifique a inserção de novos elementos coesivos
2.1 - Compute as tensões nodais
2.2 - Determine as facetas fraturadas
A1. Sincronize o conjunto de facetas fraturadas
2.3 - Insira elementos coesivos
2.5 - Atualize os valores das massas nodais
3 - Compute o vetor de forças nodais internas
4 - Compute o vetor de forças coesivas
5 - Atualize as acelerações e velocidades nodais
6 - Atualize as forças externas e energias nos nós
7 - Aplique as condições de contorno aos nós
8 - Atualize os deslocamentos nodais
A2. Sincronize os atributos de nós ghosts
Figura 38 - Estrutura da simulação paralela segundo a abordagem
mista, com iteradores estáveis e sincronização dos conjuntos de facetas
fraturadas.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais
Experimentos computacionais foram realizados com o objetivo de testar e
validar o sistema ParTopS. Primeiramente, avaliou-se a representação
topológica de fraturas e fragmentação; os resultados obtidos são analisados na
Seção 5.1. Em seguida, simulações numéricas em paralelo foram executadas de
forma a validar o sistema ParTopS para o tratamento de problemas reais de
larga escala. A escalabilidade das simulações numéricas foi medida com relação
a um grande número de processadores, através da execução em um ambiente
massivamente paralelo de memória distribuída. Os resultados são discutidos na
Seção 5.2.
5.1. Representação topológica de fraturas e fragmentação em paralelo
Com o objetivo de avaliar a corretude, eficiência e escalabilidade da
representação topológica de fraturas de ParTopS e o algoritmo de inserção
paralela de elementos coesivos, foram realizados experimentos computacionais
desacoplados da análise numérica. Os experimentos foram executados para
malhas bidimensionais (2D) e tridimensionais (3D), de diferentes tipos de
elementos, lineares (T3 e Tet4) e quadráticos (T6 e Tet10).
Os modelos básicos utilizados nos experimentos são ilustrados na Figura
39, considerando-se uma discretização de malha baseada em elementos
quadráticos. A topologia do modelo bidimensional (Figura 39a) corresponde a
uma grade regular de nx x ny células quadrilaterais decompostas em quatro
triângulos cada. O modelo tridimensional (Figura 39b) consiste em uma grade
regular de nx x ny x nz células hexahédricas decompostas em seis tetraedros
cada. Os modelos são divididos em um número de partições distintas, e cada
partição é atribuída a um processador diferente.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 93
Figura 39 - Exemplos de modelos básicos, 2D (a) e 3D (b) utilizados
nos experimentos computacionais.
Em cada experimento, elementos coesivos são inseridos aleatoriamente
em aproximadamente 50% do número total de facetas internas (interfaces entre
elementos volumétricos) de cada partição de malha, o que resulta na ocorrência
de padrões de fraturas arbitrários e complexos. A inserção é realizada de
maneira incremental, ao longo de 50 passos de iteração. Para cada passo, os
elementos são inseridos em 1% das facetas internas. Isso é feito com o objetivo
de se reproduzir o comportamento de simulações de fragmentação reais, na
quais o número de elementos coesivos criados em cada passo é geralmente
pequeno em relação ao número total de elementos volumétricos.
5.1.1. Corretude e eficiência
Os experimentos para a verificação da corretude e eficiência foram
executados em um conjunto (cluster) de até 14 máquinas conectadas por uma
rede Gigabit Ethernet. Cada máquina possui processador Intel(R) Pentium(R) D,
com dois núcleos (cores) de 3.40 GHz, e 2GB de memória RAM. O sistema
operacional é Red Hat Linux 3.4.6-9, com kernel de 32 bits. O compilador usado
é gcc v. 3.4.6.
Os resultados obtidos são apresentados na Tabela 1 e Tabela 2. A Tabela
1 descreve as diversas discretizações de malha utilizadas e os tempos totais
sequenciais correspondentes à inserção de elementos coesivos em 50% das
facetas internas de cada modelo utilizado, em 50 passos de interação de 1% de
facetas. Os modelos de tamanho maior não puderam ser representados na
memória de apenas uma máquina (apresentados como n/a nas tabelas). A
Tabela 2 mostra os resultados da inserção paralela de elementos coesivos com
um número variável de máquinas e duas partições de malha por máquina (uma
(a) (b)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 94
partição por núcleo de processamento). Os tempos totais apresentados
correspondem à média dos tempos totais obtidos para cinco execuções de cada
experimento. Ao final de uma execução em paralelo, o número total de
elementos coesivos inseridos é aproximadamente igual ao experimento
sequencial correspondente. A consistência da malha final é verificada após cada
experimento, a fim de garantir a corretude da representação topológica.
Tabela 1 - Tempos, em segundos, para a inserção sequencial de
elementos coesivos em várias discretizações de malha. Os campos
indicados com n/a correspondem às discretizações que não puderam ser
representadas na memória de apenas uma máquina.
Tipo de
elemento
Discretização
de malha
Núm. de
elementos
volumétricos
Núm. de
nós
Núm. de
elementos
coesivos
inseridos
Tempo
total (s)
T3 256x256 262.144 131.585 196.352 1,20
512x512 1.048.576 525.313 785.920 4,99
1024x1024 4.194.304 2.099.201 3.144.704 21,24
1536x1536 9.437.184 4.721.665 7.076.352 58,43
2048x2048 16.777.216 8.392.705 12.580.864 n/a
T6 256x256 262.144 525.313 196.352 1,42
512x512 1.048.576 2.099.201 785.920 5,99
1024x1024 4.194.304 8.392.705 3.144.704 30,19
1536x1536 9.437.184 18.880.513 7.076.352 n/a
2048x2048 16.777.216 33.562.625 12.580.864 n/a
Tet4 16x16x16 24.576 4.913 23.808 0,80
32x32x32 196.608 35.937 193.536 5,39
64x64x64 1.572.864 274.625 1.560.576 45,87
96x96x96 5.308.416 912.673 5.280.768 161,52
128x128x128 12.582.912 2.146.689 12.533.760 n/a
Tet10 16x16x16 24.576 35.937 23.808 0,93
32x32x32 196.608 274.625 193.536 6,21
64x64x64 1.572.864 2.146.689 1.560.576 53,55
96x96x96 5.308.416 7.189.057 5.280.768 n/a
128x128x128 12.582.912 16.974.593 12.533.760 n/a
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
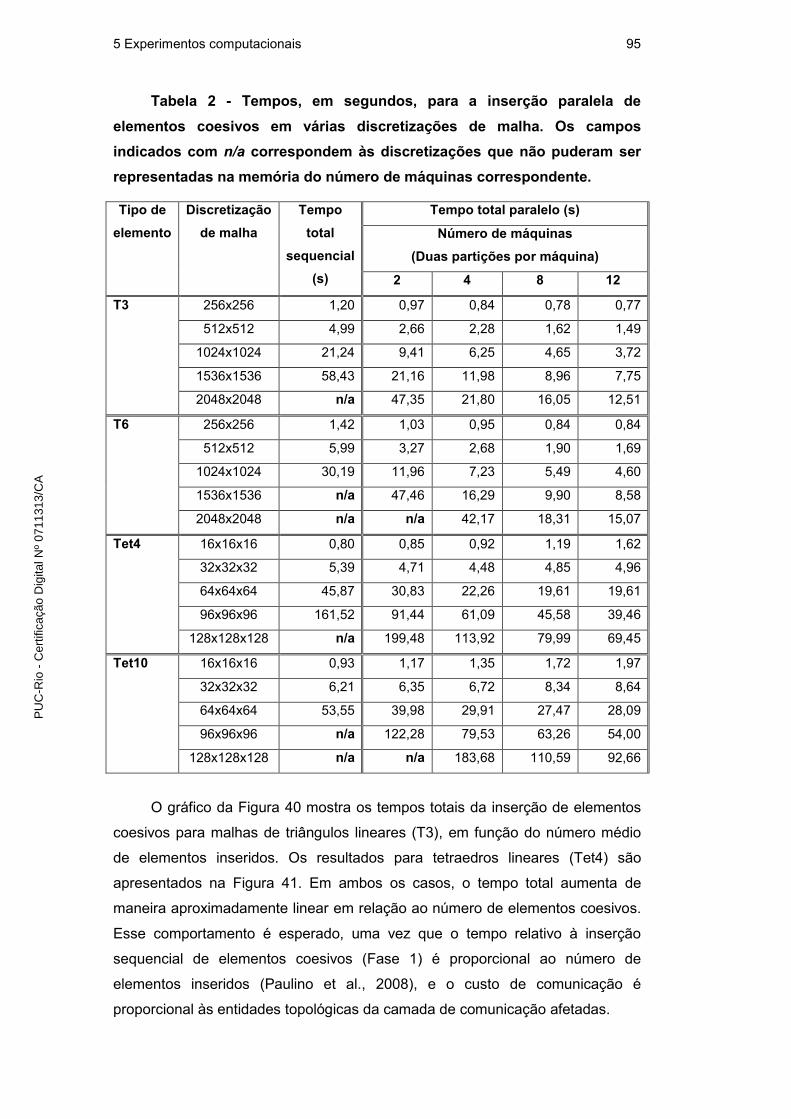
5 Experimentos computacionais 95
Tabela 2 - Tempos, em segundos, para a inserção paralela de
elementos coesivos em várias discretizações de malha. Os campos
indicados com n/a correspondem às discretizações que não puderam ser
representadas na memória do número de máquinas correspondente.
Tipo de
elemento
Discretização
de malha
Tempo
total
sequencial
(s)
Tempo total paralelo (s)
Número de máquinas
(Duas partições por máquina)
2 4 8 12
T3 256x256 1,20 0,97 0,84 0,78 0,77
512x512 4,99 2,66 2,28 1,62 1,49
1024x1024 21,24 9,41 6,25 4,65 3,72
1536x1536 58,43 21,16 11,98 8,96 7,75
2048x2048 n/a 47,35 21,80 16,05 12,51
T6 256x256 1,42 1,03 0,95 0,84 0,84
512x512 5,99 3,27 2,68 1,90 1,69
1024x1024 30,19 11,96 7,23 5,49 4,60
1536x1536 n/a 47,46 16,29 9,90 8,58
2048x2048 n/a n/a 42,17 18,31 15,07
Tet4 16x16x16 0,80 0,85 0,92 1,19 1,62
32x32x32 5,39 4,71 4,48 4,85 4,96
64x64x64 45,87 30,83 22,26 19,61 19,61
96x96x96 161,52 91,44 61,09 45,58 39,46
128x128x128 n/a 199,48 113,92 79,99 69,45
Tet10 16x16x16 0,93 1,17 1,35 1,72 1,97
32x32x32 6,21 6,35 6,72 8,34 8,64
64x64x64 53,55 39,98 29,91 27,47 28,09
96x96x96 n/a 122,28 79,53 63,26 54,00
128x128x128 n/a n/a 183,68 110,59 92,66
O gráfico da Figura 40 mostra os tempos totais da inserção de elementos
coesivos para malhas de triângulos lineares (T3), em função do número médio
de elementos inseridos. Os resultados para tetraedros lineares (Tet4) são
apresentados na Figura 41. Em ambos os casos, o tempo total aumenta de
maneira aproximadamente linear em relação ao número de elementos coesivos.
Esse comportamento é esperado, uma vez que o tempo relativo à inserção
sequencial de elementos coesivos (Fase 1) é proporcional ao número de
elementos inseridos (Paulino et al., 2008), e o custo de comunicação é
proporcional às entidades topológicas da camada de comunicação afetadas.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
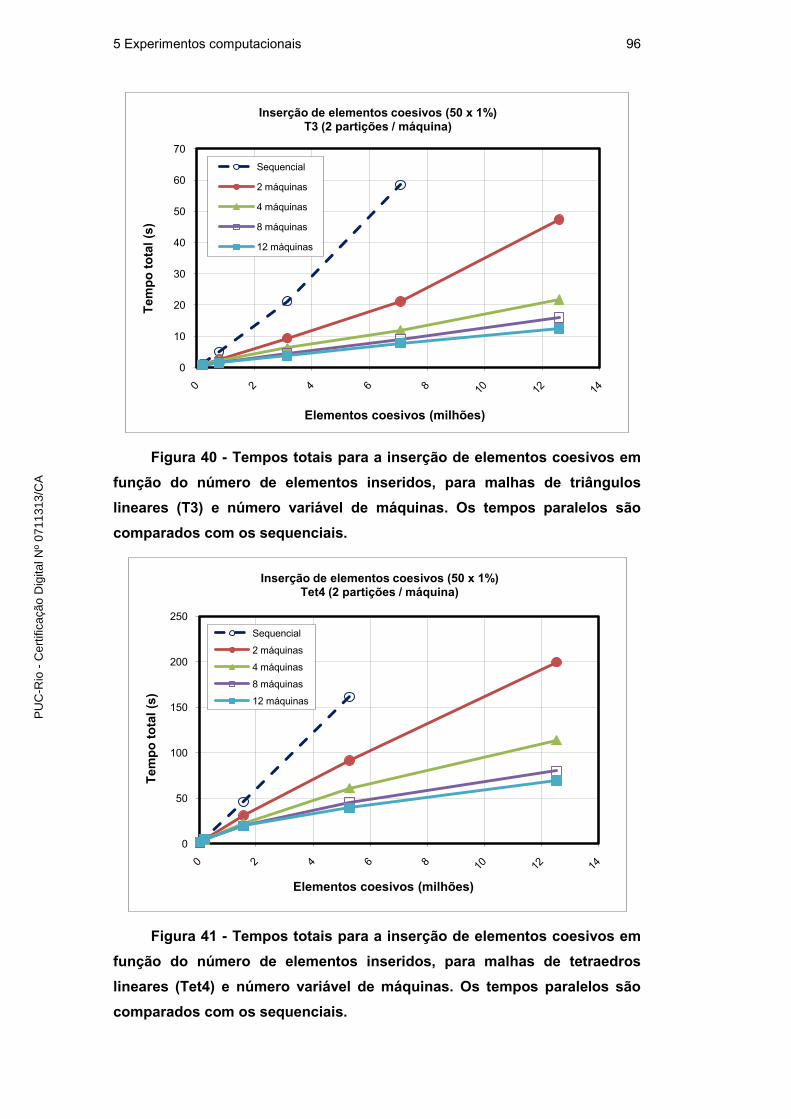
5 Experimentos computacionais 96
Figura 40 - Tempos totais para a inserção de elementos coesivos em
função do número de elementos inseridos, para malhas de triângulos
lineares (T3) e número variável de máquinas. Os tempos paralelos são
comparados com os sequenciais.
Figura 41 - Tempos totais para a inserção de elementos coesivos em
função do número de elementos inseridos, para malhas de tetraedros
lineares (Tet4) e número variável de máquinas. Os tempos paralelos são
comparados com os sequenciais.
0
10
20
30
40
50
60
70T
em
po
to
tal
(s)
Elementos coesivos (milhões)
Inserção de elementos coesivos (50 x 1%)T3 (2 partições / máquina)
Sequencial
2 máquinas
4 máquinas
8 máquinas
12 máquinas
0
50
100
150
200
250
Te
mp
o t
ota
l (s
)
Elementos coesivos (milhões)
Inserção de elementos coesivos (50 x 1%)Tet4 (2 partições / máquina)
Sequencial
2 máquinas
4 máquinas
8 máquinas
12 máquinas
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 97
A Figura 42 mostra uma malha distribuída de tetraedros lineares, usada
nos experimentos, após a inserção de elementos coesivos em aproximadamente
10% do total de facetas internas da malha original (10 passos de iteração).
Resultados em malhas de tetraedros genéricas são ilustrados na Figura 43. Os
elementos coesivos compartilhados por partições de malha diferentes são
representados de forma consistente em todas elas.
Figura 42 - Malha distribuída de tetraedros lineares correspondente à
discretização 16x16x16 do modelo básico tridimensional, decomposta em 8
partições. Elementos coesivos foram inseridos aleatoriamente em
aproximadamente 10% do número total de facetas internas, em 10 passos
de iteração, com 1% de facetas a cada iteração. As camadas de
comunicação e os elementos coesivos são enfatizados.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 98
(a)
(b)
Figura 43 - Dois exemplos de malhas distribuídas não estruturadas de
tetraedros lineares, (a) e (b), usadas para testar o suporte topológico de
fraturas. Elementos coesivos foram inseridos aleatoriamente em
aproximadamente 10% do número total de facetas internas, em 10 passos
de iteração, com 1% de facetas a cada iteração. As camadas de
comunicação e os elementos coesivos são enfatizados.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 99
5.1.2. Escalabilidade
Para avaliar a escalabilidade da representação topológica de fraturas e
fragmentação de ParTopS, foram realizados experimentos adicionas em um
ambiente computacional massivamente paralelo de memória distribuída. O
ambiente utilizado é o cluster Abe (Intel 64 Cluster), do National Center for
Supercomputer Applications (NCSA). Cada nó de computação (Dell PowerEdge
1955) é composto por dois processadores Intel 64, com quatro núcleos de
processamento (cores) de 2.33 GHz cada (8 núcleos por nó), front side bus de
1333 MHz por processador e cache L2 de 2x4 MB, e 1GB de memória RAM por
núcleo. O ambiente paralelo possui um total de 1200 nós de computação (9600
núcleos), interconectados por uma rede InfiniBand. O sistema de arquivos
paralelo Lustre (100TB) é utilizado, e o sistema operacional é Red Hat Enterprise
Linux 4 (Linux 2.6.18), com compilador gcc v. 3.4.6. Exatamente uma partição de
malha é atribuída a cada núcleo de processamento.
O experimento descrito a seguir demonstra a escalabilidade da
representação topológica de ParTopS com respeito à inserção de elementos
coesivos. A capacidade da representação topológica em paralelo de tratar
problemas maiores eficientemente é medida através da variação do número de
processadores em relação ao tamanho da malha utilizada, de forma a manter o
mesmo nível de eficiência. Isso corresponde à abordagem de isoeficiência
(Grama et al., 1993; Quinn, 2004), discutida na Seção 3.2.4. No caso ideal,
espera-se que o tempo de execução mantenha-se constante ao se aumentar o
número de processadores proporcionalmente ao tamanho da malha. No
experimento, utilizou-se a grade tridimensional da Figura 39b; o número de
elementos por partição de malha manteve-se em aproximadamente 50x50x50
células hexaédricas, decompostas em seis tetraedros lineares (Tet4) cada, o que
corresponde a um total de 750.000 elementos locais por partição. Assim como
nos experimentos anteriores, elementos coesivos são inseridos aleatoriamente
em aproximadamente 50% das facetas internas, em 50 passos de iteração, com
1% das facetas por passo.
Os resultados para várias discretizações de malha e números de núcleos
de processamento são resumidos na Tabela 3, e os tempos totais de execução
em função do número de núcleos são mostrados no gráfico da Figura 44. Para
um grande número de núcleos de processamento (e tamanhos de malha
correspondentes), os tempos de execução apresentam uma tendência próxima a
constante, com variação significativamente reduzida em função do número de
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 100
núcleos utilizados. Dessa forma, o algoritmo paralelo se aproxima dos resultados
de isoeficiência esperados e, assim, pode ser considerado escalável para os
tamanhos de problema considerados. A comparação com a execução sequencial
(Figura 44) mostra o custo paralelo introduzido à implementação sequencial
original. Para a execução em 1.000 núcleos de processamento, o tempo total em
paralelo é aproximadamente 1,9 vezes maior que o tempo sequencial. Porém, o
tamanho do problema tratado é aproximadamente 1.000 vezes maior.
Tabela 3 - Tempos totais da inserção paralela de elementos coesivos
para várias discretizações diferentes do modelo básico tridimensional.
Discretização
de malha
Elementos finitos
Núcleos de
processamento
Tempo
total (s)
50x50x50 750.000 1 (sequencial) 16,59
100x100x100 6.000.000 8 24,30
200x200x200 48.000.000 64 28,12
400x400x400 384.000.000 512 29,24
450x450x450 546.750.000 729 31,41
500x500x500 750.000.000 1.000 31,74
Figura 44 - Tempo total de 50 passos da inserção paralela de
elementos coesivos no modelo tridimensional, em função de núcleos de
processamento. A discretização do modelo é proporcional ao número de
núcleos. O tempo sequencial é mostrado como referência (linha tracejada).
0
5
10
15
20
25
30
35
Tem
po
to
tal (s
)
Núcleos de processamento
IsoeficiênciaInserção de elementos coesivos
750.000 elementos / núcleo
Paralelo
Sequencial
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 101
5.2. Simulações numéricas em paralelo
A interface fornecida por ParTopS para simulações de fraturas extrínsecas
em paralelo foi validada através de um conjunto de simulações numéricas
baseadas na aplicação paralela descrita no Capítulo 4. A escalabilidade das
simulações foi avaliada com os experimentos realizados. A propagação de
fraturas considerada é do tipo Modo I (Cook et al., 2001), com pequenas
deformações. A análise numérica utiliza um modelo de zona coesiva extrínseco
(Camacho & Ortiz, 1996; Ortiz & Pandolfi, 1999; Park et al., 2009), com modelo
constitutivo Park-Paulino-Roesler (PPR) (Park et al., 2009). O ambiente paralelo
usado para os experimentos é o mesmo das medições de escalabilidade da
seção anterior (cluster Abe (Intel 64 Cluster), do National Center for
Supercomputer Applications (NCSA)).
A geometria e condições de contorno (Park, 2009) dos modelos usados
nos experimentos são mostrados na Figura 45. O modelo 2D (Figura 45a)
consiste de um specimen retangular com uma falha inicial. O domínio geométrico
é discretizado em uma malha de elementos do tipo T6 (triângulo quadrático). Os
parâmetros iniciais de análise são: módulo elástico = 3,24 GPa; coeficiente de
Poisson = 0,35; densidade (density) = 1.190 kg/m3; energia de fratura do Modo I
(GI) = 352 N/m; tensão coesiva normal (cohesive strength) (σmax) = 324 MPa; e
parâmetros de forma (α) = 2. São impostas velocidades e acelerações nulas
( ) aos nós localizados ao longo das fronteiras superior e inferior do
modelo, além de deformação (strain) inicial 0 = 0,036, aplicada na direção
vertical. Os deslocamentos nodais iniciais correspondentes variam
proporcionalmente à distância vertical ao centro do modelo. O tempo total
simulado equivale a 2 s, em 10.000 passos de 0,2 ns. O domínio geométrico é
dividido em partições retangulares alinhadas com o sistema de coordenadas
cartesianas. O modelo 3D é mostrado na Figura 45b. A malha é composta de
elementos do tipo Tet4 (tetraedro linear), e as partições de malha foram criadas
utilizando-se o particionador de grafos METIS (Karypis & Kumar, 1995, 1998).
Os parâmetros iniciais do modelo 3D são equivalentes ao modelo 2D. O tempo
total simulado equivale a 2,4 s, em 12.000 passos de 0,2 ns. Tanto para o
modelo 2D como para o 3D, a verificação de facetas fraturadas é realizada em
todos os passos de tempo da simulação, e elementos coesivos são inseridos
conforme necessário.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
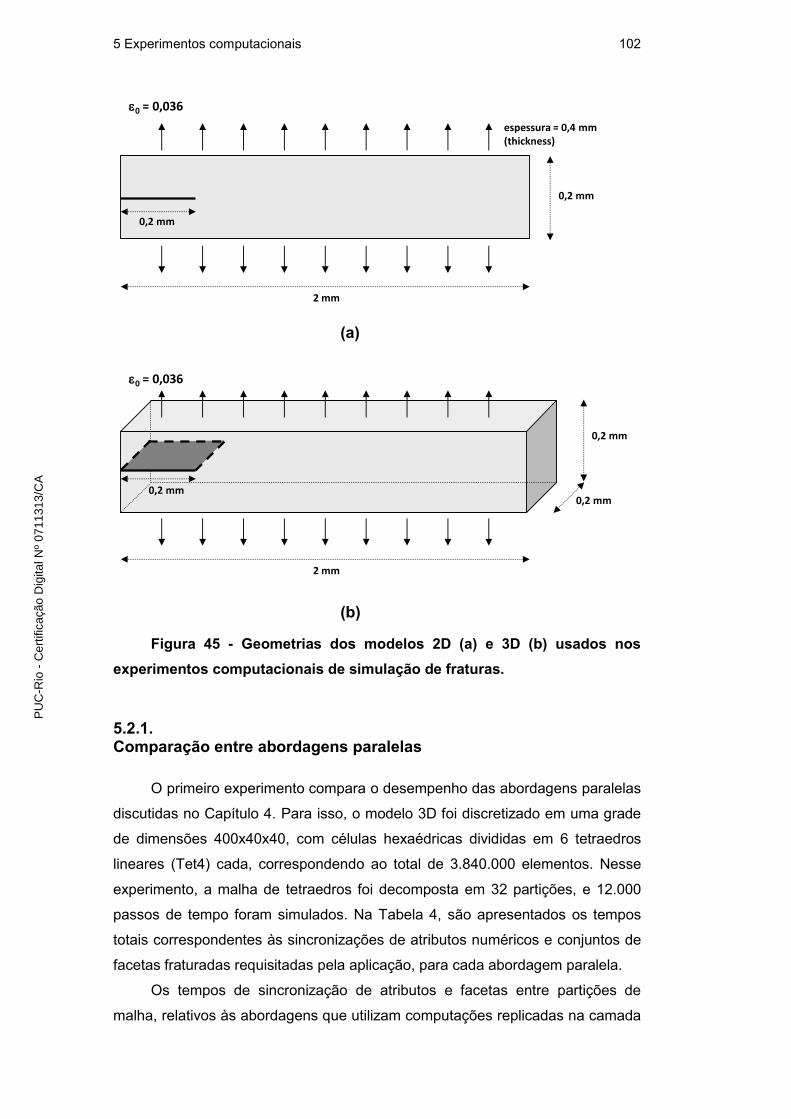
5 Experimentos computacionais 102
Figura 45 - Geometrias dos modelos 2D (a) e 3D (b) usados nos
experimentos computacionais de simulação de fraturas.
5.2.1. Comparação entre abordagens paralelas
O primeiro experimento compara o desempenho das abordagens paralelas
discutidas no Capítulo 4. Para isso, o modelo 3D foi discretizado em uma grade
de dimensões 400x40x40, com células hexaédricas divididas em 6 tetraedros
lineares (Tet4) cada, correspondendo ao total de 3.840.000 elementos. Nesse
experimento, a malha de tetraedros foi decomposta em 32 partições, e 12.000
passos de tempo foram simulados. Na Tabela 4, são apresentados os tempos
totais correspondentes às sincronizações de atributos numéricos e conjuntos de
facetas fraturadas requisitadas pela aplicação, para cada abordagem paralela.
Os tempos de sincronização de atributos e facetas entre partições de
malha, relativos às abordagens que utilizam computações replicadas na camada
0,2 mm
0,2 mm
2 mm
espessura = 0,4 mm(thickness)
0 = 0,036
0,2 mm
0,2 mm
2 mm
0 = 0,036
0,2 mm
(a)
(b)
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
5 Experimentos computacionais 103
de comunicação, se mostraram substancialmente menores que a abordagem
convencional baseada em computações apenas em entidades locais (Seção
4.6.1), como resultado da redução dos pontos de sincronização da aplicação
paralela. Os melhores tempos obtidos correspondem à abordagem mista (Seção
4.6.4), que requer apenas dois pontos de sincronização. Neste caso, os tempos
de sincronização da aplicação foram reduzidos em aproximadamente 27% em
relação à abordagem de computações em entidades locais. A abordagem
baseada em computações simétricas com iteradores estáveis (Seção 4.6.3)
também requer apenas dois pontos de sincronização de atributos. Porém, esta
apresentou tempos maiores em comparação com a mista, devido ao maior custo
de sincronização de atributos de nós ghosts em relação aos conjuntos de facetas
da mista. A abordagem baseada em computações replicadas e sincronizações
esporádicas de nós proxies (Seção 4.6.2) resultou em tempos de sincronização
mais próximos à mista. As duas abordagens apresentam pontos de
sincronização equivalentes, se desconsiderado o custo residual das
sincronizações esporádicas de nós proxies.
Tabela 4 - Tempos de execução, em segundos, das várias abordagens
paralelas, para 12.000 passos de simulação do modelo 3D discretizado em
3.840.000 tetraedros lineares (Tet4) e executado em 32 núcleos de
processamento (1 partição de malha por núcleo).
Abordagem paralela Sincronização (atributos + facetas)
Tempo (s) Ganho relativo (%)
Computações locais
(convencional) 1.516,39 –
Computações replicadas
(com sincronização esporáridica de nós proxies) 1.113,72 26,55
Computações replicadas simétricas
(com iteradores estáveis) 1.120,04 26,14
Mista
1.104,01 27,19
5.2.2. Desempenho em relação à simulação sequencial
O segundo experimento compara o desempenho de simulações paralelas
com a versão sequencial original, considerando-se apenas a variação no número
de núcleos de processamento utilizados. Para que a simulação numérica
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
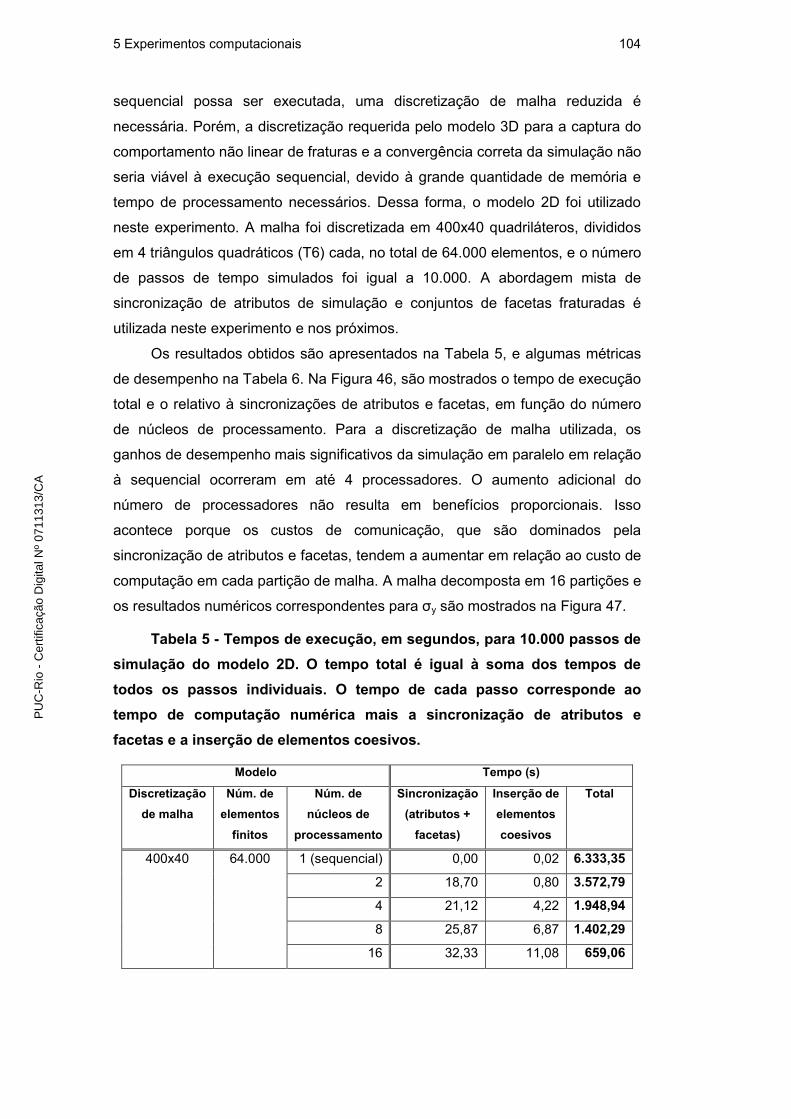
5 Experimentos computacionais 104
sequencial possa ser executada, uma discretização de malha reduzida é
necessária. Porém, a discretização requerida pelo modelo 3D para a captura do
comportamento não linear de fraturas e a convergência correta da simulação não
seria viável à execução sequencial, devido à grande quantidade de memória e
tempo de processamento necessários. Dessa forma, o modelo 2D foi utilizado
neste experimento. A malha foi discretizada em 400x40 quadriláteros, divididos
em 4 triângulos quadráticos (T6) cada, no total de 64.000 elementos, e o número
de passos de tempo simulados foi igual a 10.000. A abordagem mista de
sincronização de atributos de simulação e conjuntos de facetas fraturadas é
utilizada neste experimento e nos próximos.
Os resultados obtidos são apresentados na Tabela 5, e algumas métricas
de desempenho na Tabela 6. Na Figura 46, são mostrados o tempo de execução
total e o relativo à sincronizações de atributos e facetas, em função do número
de núcleos de processamento. Para a discretização de malha utilizada, os
ganhos de desempenho mais significativos da simulação em paralelo em relação
à sequencial ocorreram em até 4 processadores. O aumento adicional do
número de processadores não resulta em benefícios proporcionais. Isso
acontece porque os custos de comunicação, que são dominados pela
sincronização de atributos e facetas, tendem a aumentar em relação ao custo de
computação em cada partição de malha. A malha decomposta em 16 partições e
os resultados numéricos correspondentes para σy são mostrados na Figura 47.
Tabela 5 - Tempos de execução, em segundos, para 10.000 passos de
simulação do modelo 2D. O tempo total é igual à soma dos tempos de
todos os passos individuais. O tempo de cada passo corresponde ao
tempo de computação numérica mais a sincronização de atributos e
facetas e a inserção de elementos coesivos.
Modelo Tempo (s)
Discretização
de malha
Núm. de
elementos
finitos
Núm. de
núcleos de
processamento
Sincronização
(atributos +
facetas)
Inserção de
elementos
coesivos
Total
400x40 64.000 1 (sequencial) 0,00 0,02 6.333,35
2 18,70 0,80 3.572,79
4 21,12 4,22 1.948,94
8 25,87 6,87 1.402,29
16 32,33 11,08 659,06
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
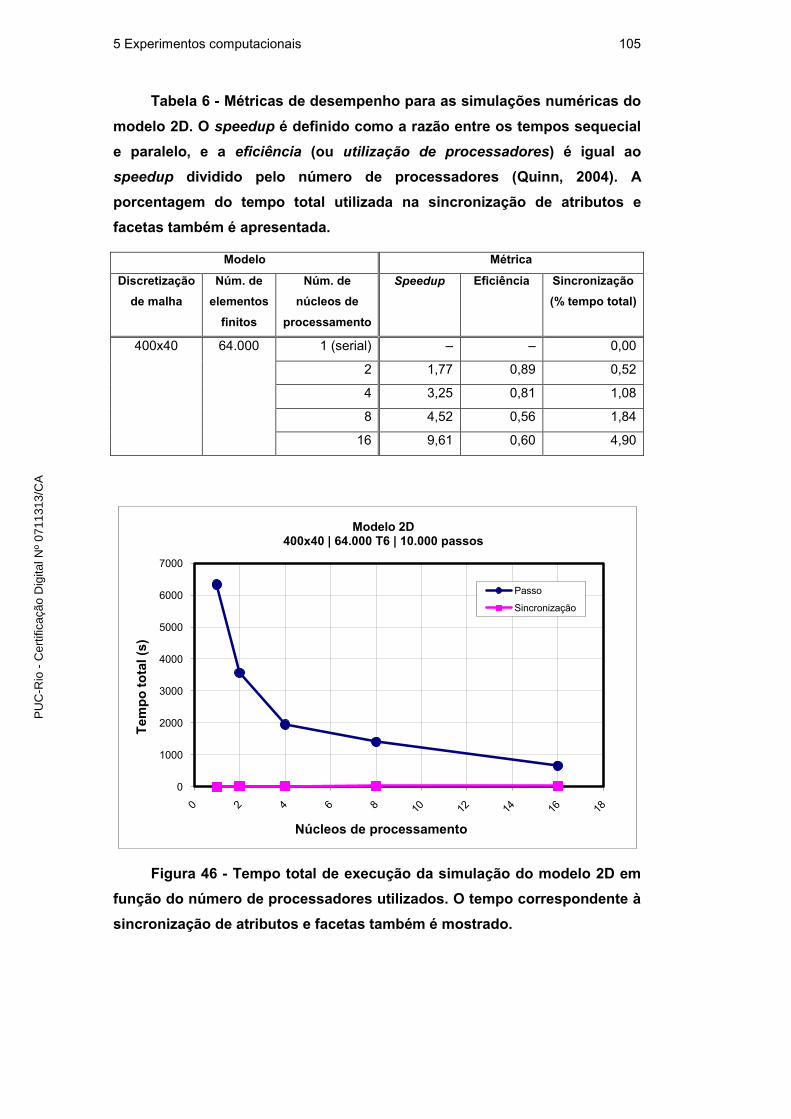
5 Experimentos computacionais 105
Tabela 6 - Métricas de desempenho para as simulações numéricas do
modelo 2D. O speedup é definido como a razão entre os tempos sequecial
e paralelo, e a eficiência (ou utilização de processadores) é igual ao
speedup dividido pelo número de processadores (Quinn, 2004). A
porcentagem do tempo total utilizada na sincronização de atributos e
facetas também é apresentada.
Modelo Métrica
Discretização
de malha
Núm. de
elementos
finitos
Núm. de
núcleos de
processamento
Speedup Eficiência Sincronização
(% tempo total)
400x40 64.000 1 (serial) – – 0,00
2 1,77 0,89 0,52
4 3,25 0,81 1,08
8 4,52 0,56 1,84
16 9,61 0,60 4,90
Figura 46 - Tempo total de execução da simulação do modelo 2D em
função do número de processadores utilizados. O tempo correspondente à
sincronização de atributos e facetas também é mostrado.
0
1000
2000
3000
4000
5000
6000
7000
Tem
po
to
tal (s
)
Núcleos de processamento
Modelo 2D400x40 | 64.000 T6 | 10.000 passos
Passo
Sincronização
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
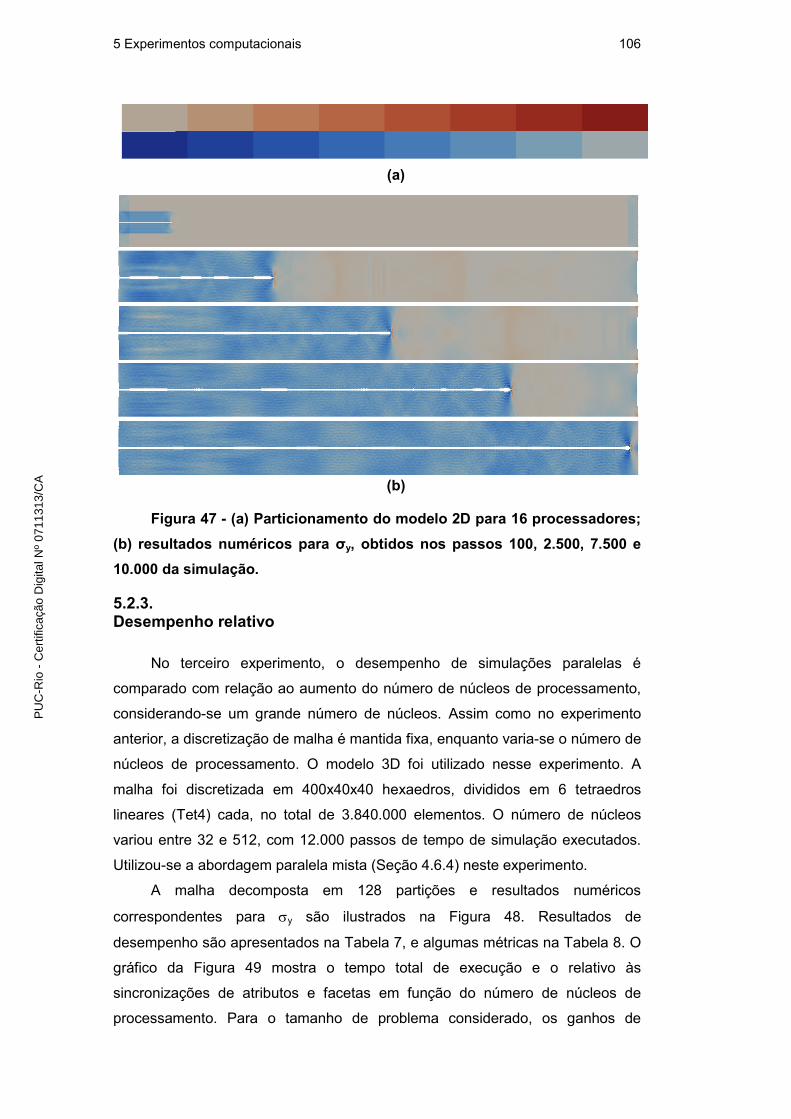
5 Experimentos computacionais 106
(a)
(b)
Figura 47 - (a) Particionamento do modelo 2D para 16 processadores;
(b) resultados numéricos para σy, obtidos nos passos 100, 2.500, 7.500 e
10.000 da simulação.
5.2.3. Desempenho relativo
No terceiro experimento, o desempenho de simulações paralelas é
comparado com relação ao aumento do número de núcleos de processamento,
considerando-se um grande número de núcleos. Assim como no experimento
anterior, a discretização de malha é mantida fixa, enquanto varia-se o número de
núcleos de processamento. O modelo 3D foi utilizado nesse experimento. A
malha foi discretizada em 400x40x40 hexaedros, divididos em 6 tetraedros
lineares (Tet4) cada, no total de 3.840.000 elementos. O número de núcleos
variou entre 32 e 512, com 12.000 passos de tempo de simulação executados.
Utilizou-se a abordagem paralela mista (Seção 4.6.4) neste experimento.
A malha decomposta em 128 partições e resultados numéricos
correspondentes para y são ilustrados na Figura 48. Resultados de
desempenho são apresentados na Tabela 7, e algumas métricas na Tabela 8. O
gráfico da Figura 49 mostra o tempo total de execução e o relativo às
sincronizações de atributos e facetas em função do número de núcleos de
processamento. Para o tamanho de problema considerado, os ganhos de
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 107
desempenho mais significativos foram obtidos em até 128 núcleos, ou 4 vezes o
valor inicial. Quando mais núcleos são utilizados, a proporção dos custos de
comunicação em relação ao tempo total aumenta, conforme esperado, o que faz
com que benefícios proporcionais não sejam mais alcançados.
(a)
(b)
Figura 48 - (a) Modelo 3D decomposto em 128 partições; (b)
resultados numéricos para σy, obtidos nos passos 500, 3.000, 6.000, 9.000 e
12.000 da simulação.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
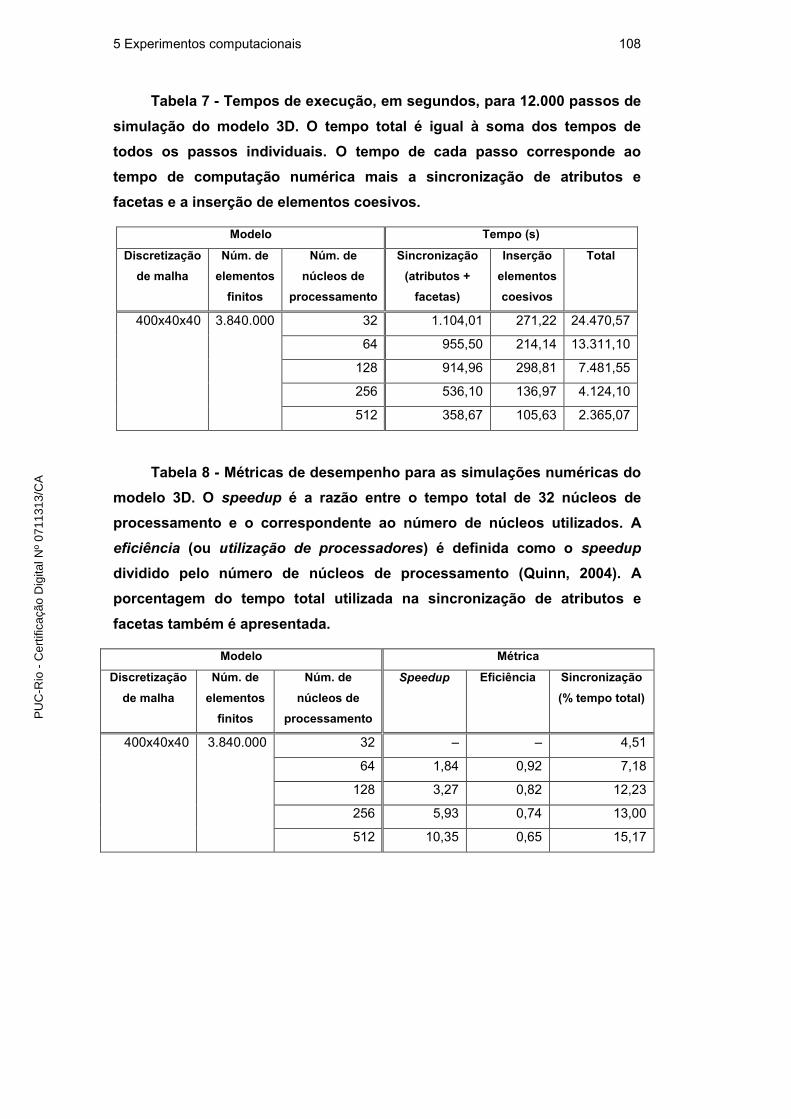
5 Experimentos computacionais 108
Tabela 7 - Tempos de execução, em segundos, para 12.000 passos de
simulação do modelo 3D. O tempo total é igual à soma dos tempos de
todos os passos individuais. O tempo de cada passo corresponde ao
tempo de computação numérica mais a sincronização de atributos e
facetas e a inserção de elementos coesivos.
Modelo Tempo (s)
Discretização
de malha
Núm. de
elementos
finitos
Núm. de
núcleos de
processamento
Sincronização
(atributos +
facetas)
Inserção
elementos
coesivos
Total
400x40x40 3.840.000 32 1.104,01 271,22 24.470,57
64 955,50 214,14 13.311,10
128 914,96 298,81 7.481,55
256 536,10 136,97 4.124,10
512 358,67 105,63 2.365,07
Tabela 8 - Métricas de desempenho para as simulações numéricas do
modelo 3D. O speedup é a razão entre o tempo total de 32 núcleos de
processamento e o correspondente ao número de núcleos utilizados. A
eficiência (ou utilização de processadores) é definida como o speedup
dividido pelo número de núcleos de processamento (Quinn, 2004). A
porcentagem do tempo total utilizada na sincronização de atributos e
facetas também é apresentada.
Modelo Métrica
Discretização
de malha
Núm. de
elementos
finitos
Núm. de
núcleos de
processamento
Speedup Eficiência Sincronização
(% tempo total)
400x40x40 3.840.000 32 – – 4,51
64 1,84 0,92 7,18
128 3,27 0,82 12,23
256 5,93 0,74 13,00
512 10,35 0,65 15,17
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
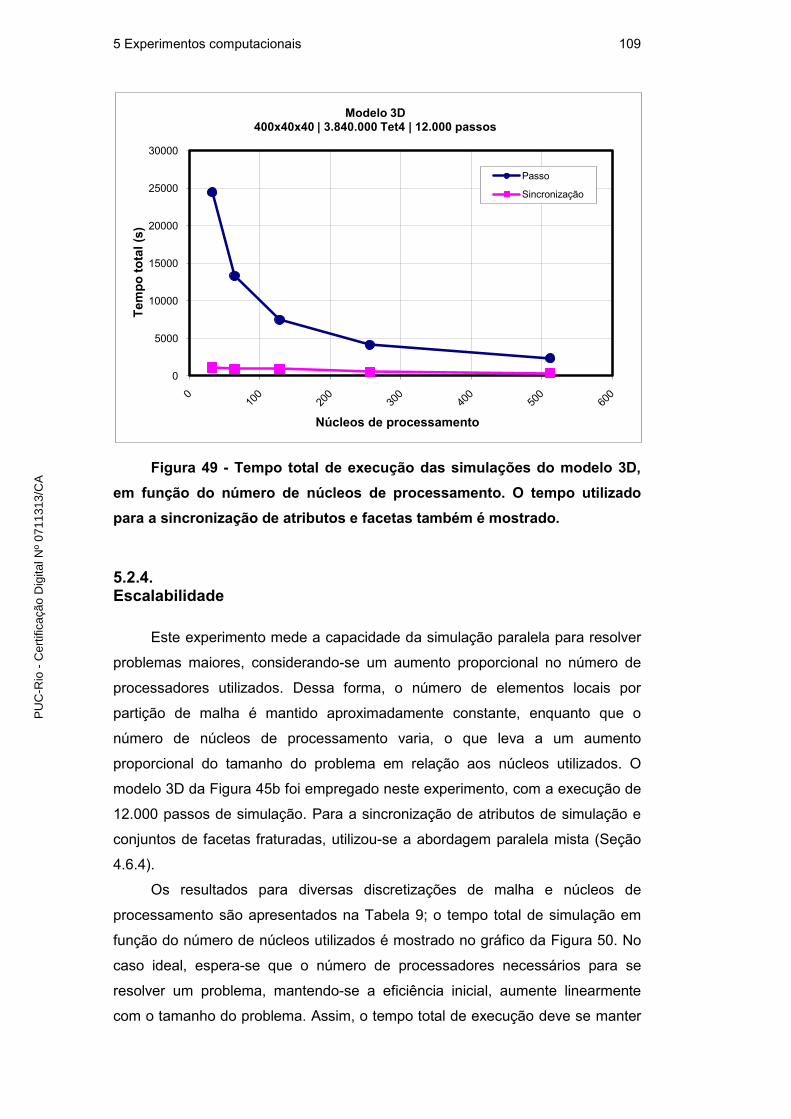
5 Experimentos computacionais 109
Figura 49 - Tempo total de execução das simulações do modelo 3D,
em função do número de núcleos de processamento. O tempo utilizado
para a sincronização de atributos e facetas também é mostrado.
5.2.4. Escalabilidade
Este experimento mede a capacidade da simulação paralela para resolver
problemas maiores, considerando-se um aumento proporcional no número de
processadores utilizados. Dessa forma, o número de elementos locais por
partição de malha é mantido aproximadamente constante, enquanto que o
número de núcleos de processamento varia, o que leva a um aumento
proporcional do tamanho do problema em relação aos núcleos utilizados. O
modelo 3D da Figura 45b foi empregado neste experimento, com a execução de
12.000 passos de simulação. Para a sincronização de atributos de simulação e
conjuntos de facetas fraturadas, utilizou-se a abordagem paralela mista (Seção
4.6.4).
Os resultados para diversas discretizações de malha e núcleos de
processamento são apresentados na Tabela 9; o tempo total de simulação em
função do número de núcleos utilizados é mostrado no gráfico da Figura 50. No
caso ideal, espera-se que o número de processadores necessários para se
resolver um problema, mantendo-se a eficiência inicial, aumente linearmente
com o tamanho do problema. Assim, o tempo total de execução deve se manter
0
5000
10000
15000
20000
25000
30000
Tem
po
to
tal
(s)
Núcleos de processamento
Modelo 3D 400x40x40 | 3.840.000 Tet4 | 12.000 passos
Passo
Sincronização
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
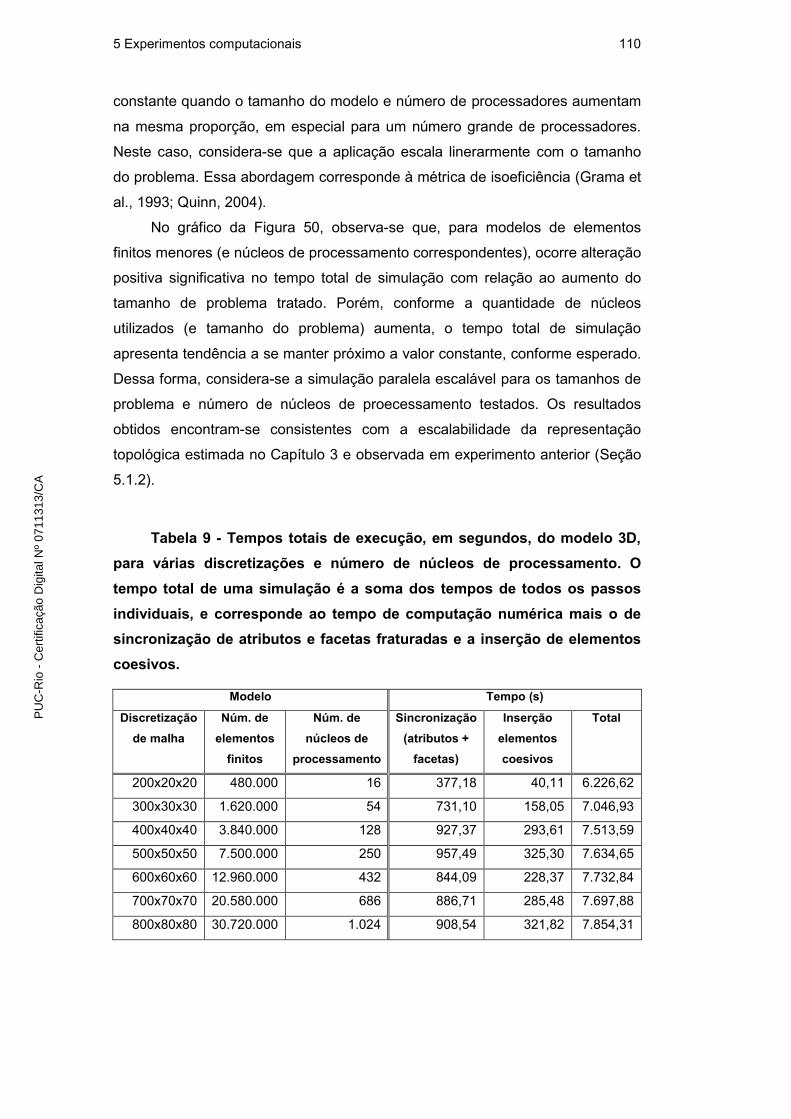
5 Experimentos computacionais 110
constante quando o tamanho do modelo e número de processadores aumentam
na mesma proporção, em especial para um número grande de processadores.
Neste caso, considera-se que a aplicação escala linerarmente com o tamanho
do problema. Essa abordagem corresponde à métrica de isoeficiência (Grama et
al., 1993; Quinn, 2004).
No gráfico da Figura 50, observa-se que, para modelos de elementos
finitos menores (e núcleos de processamento correspondentes), ocorre alteração
positiva significativa no tempo total de simulação com relação ao aumento do
tamanho de problema tratado. Porém, conforme a quantidade de núcleos
utilizados (e tamanho do problema) aumenta, o tempo total de simulação
apresenta tendência a se manter próximo a valor constante, conforme esperado.
Dessa forma, considera-se a simulação paralela escalável para os tamanhos de
problema e número de núcleos de proecessamento testados. Os resultados
obtidos encontram-se consistentes com a escalabilidade da representação
topológica estimada no Capítulo 3 e observada em experimento anterior (Seção
5.1.2).
Tabela 9 - Tempos totais de execução, em segundos, do modelo 3D,
para várias discretizações e número de núcleos de processamento. O
tempo total de uma simulação é a soma dos tempos de todos os passos
individuais, e corresponde ao tempo de computação numérica mais o de
sincronização de atributos e facetas fraturadas e a inserção de elementos
coesivos.
Modelo Tempo (s)
Discretização
de malha
Núm. de
elementos
finitos
Núm. de
núcleos de
processamento
Sincronização
(atributos +
facetas)
Inserção
elementos
coesivos
Total
200x20x20 480.000 16 377,18 40,11 6.226,62
300x30x30 1.620.000 54 731,10 158,05 7.046,93
400x40x40 3.840.000 128 927,37 293,61 7.513,59
500x50x50 7.500.000 250 957,49 325,30 7.634,65
600x60x60 12.960.000 432 844,09 228,37 7.732,84
700x70x70 20.580.000 686 886,71 285,48 7.697,88
800x80x80 30.720.000 1.024 908,54 321,82 7.854,31
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 111
Figura 50 - Tempo total de execução para o modelo 3D, em função do
número de processadores utilizados. A variação da discretização do
modelo é proporcional ao número de núcleo de processamento utilizados.
5.2.5. Simulação de fraturas com microrramificações
No experimento descrito a seguir, foram realizadas simulações em paralelo
de fraturas com microrramificações (microbranching) (Zhang et al., 2007; Park et
al., 2009). Resultados de uma simulação para um modelo bidimensional são
apresentados na Figura 51. A propagação de fraturas é do tipo Modo Misto
(Mixed Mode) (Park et al., 2009), sendo utilizado um modelo de zona coesiva
extrínseco (Camacho & Ortiz, 1996; Ortiz & Pandolfi, 1999; Park et al., 2009)
com modelo constitutivo Park-Paulino-Roesler (PPR) (Park et al., 2009). Esse
tipo de simulação é mais abrangente que o Modo I utilizado nos experimentos
anteriores (embora com a mesma estrutura do fluxo de controle da aplicação
numérica) e resulta em padrões complexos de fratura, como os avaliados na
Seção 5.1.1, demonstrando que o sistema proposto é geral para simulações de
fraturas e fragmentação.
Na simulação apresentada, utilizou-se um especimen retangular com falha
inicial, de geometria similar à Figura 45a, porém com domínio geométrico com
comprimento igual a 128 mm e largura igual a 32 mm; o comprimento da falha
inicial é igual a 32 mm. Um valor unitário é atribuído à espessura do modelo,
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
Te
mp
o t
ota
l (s
)
Núcleos de processamento
Isoeficiência - Modelo 3DDiscretização variável | 12.000 passos
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 112
para a computação de tensões planares. O specimen retangular corresponde ao
utilizado nas simulações sequenciais realizadas por Zhang et al. (2007) para a
investigação de fenômenos de microrramificações de fraturas. A propagação de
fraturas é do tipo Modo Misto (Mixed Mode) (Park et al., 2009), sendo utilizado
um modelo de zona coesiva extrínseco (Camacho & Ortiz, 1996; Ortiz &
Pandolfi, 1999; Park et al., 2009) com modelo constitutivo Park-Paulino-Roesler
(PPR) (Park et al., 2009).
O modelo de elementos finitos foi discretizado em uma malha
bidimensional de elementos do tipo T6 (triângulo quadrático), consistindo
inicialmente em 2.359.296 elementos e 4.722.817 nós. Para se reduzir o erro do
comprimento do caminho da fratura em relação ao esperado, devido à
dependência da discretização do domínio geométrico, as posições dos nós
internos da malha foram perturbadas ao longo de direções aleatórias, por um
fator de 0,3 vezes a distância mínima de um vértice de cada elemento aos
vértices adjacentes, conforme sugerido por (Paulino, Park, Celes & Espinha,
2010). Um operador de suavização Laplaciano foi empregado para garantir a
qualidade dos elementos da malha (Paulino, Park, Celes & Espinha, 2010).
O material do modelo simulado (Zhang et al., 2007) é PMMA
(Polymethylmethacrylate), com módulo elástico (E) = 3,24 GPa, coeficiente de
Poisson () = 0,35 e densidade (density) (ρ) = 1.190 kg/m3. Os parâmetros do
Modo I de fratura são: energia de fratura (GI) = 352,3 N/m; tensão coesiva
normal (cohesive strength) (Tnmax) = 129,6 MPa e parâmetro de forma (α) = 2. Os
valores dos parâmetros correspondentes do Modo II de fratura são idênticos ao
Modo I (GII = GI, Ttmax = Tn
max, β = α). São impostas velocidades e acelerações
nulas ( ) aos nós localizados ao longo das fronteiras superior e
inferior do modelo, além de deformação (strain) inicial 0 = 0,043, aplicada na
direção vertical. Os deslocamentos nodais iniciais correspondentes variam
proporcionalmente à distância vertical ao centro do modelo. O tempo total
simulado equivale a 22 s, em 220.000 passos de 0,1 ns. A ocorrência de
fraturas e a inserção correspondente de elementos coesivos são determinadas a
cada 10 passos de simulação.
A simulação de fraturas foi executada no conjunto de máquinas (cluster)
disponível no laboratório Tecgraf/PUC-Rio, que consiste atualmente de até 14
máquinas conectadas por rede Gigabit Ethernet. Cada máquina possui
processador Intel(R) Pentium(R) D, com dois núcleos (cores) de 3.40 GHz, e
2GB de memória RAM, sistema operacional Red Hat Linux Red Hat 4.3.2-7,
kernel de 64 bits (versão 2.6.27) e compilador gcc v. 4.3.2. A malha de
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A
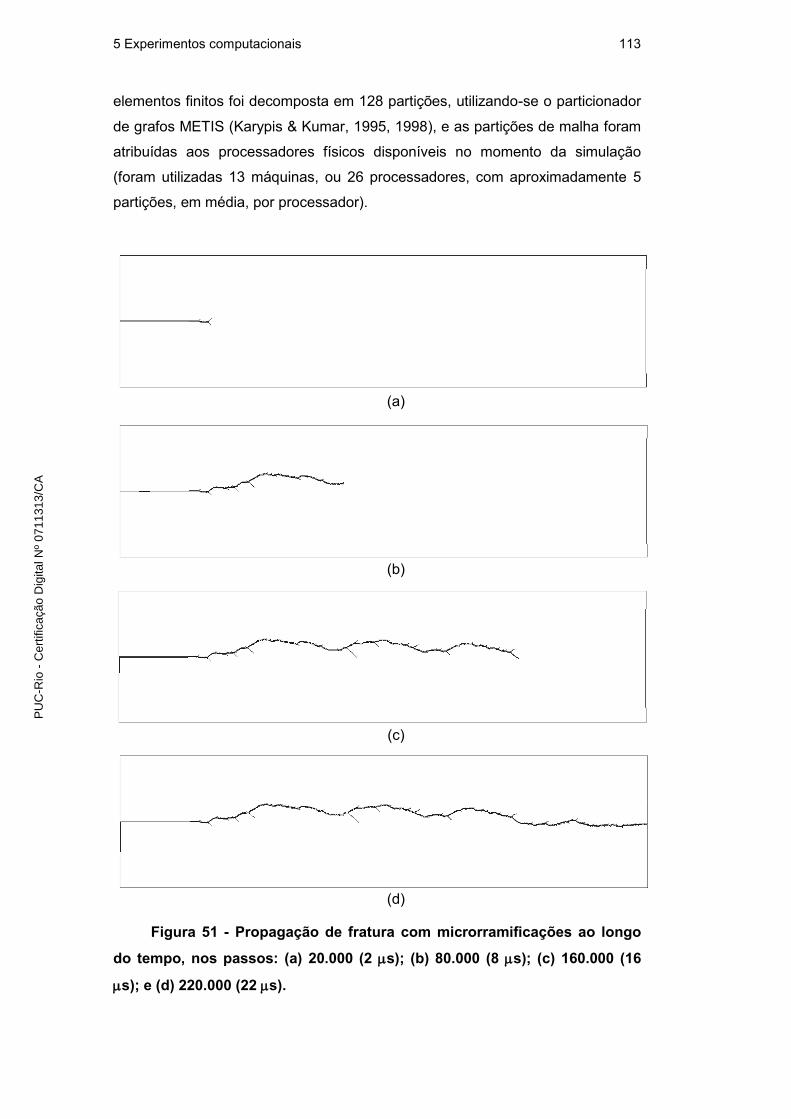
5 Experimentos computacionais 113
elementos finitos foi decomposta em 128 partições, utilizando-se o particionador
de grafos METIS (Karypis & Kumar, 1995, 1998), e as partições de malha foram
atribuídas aos processadores físicos disponíveis no momento da simulação
(foram utilizadas 13 máquinas, ou 26 processadores, com aproximadamente 5
partições, em média, por processador).
(a)
(b)
(c)
(d)
Figura 51 - Propagação de fratura com microrramificações ao longo
do tempo, nos passos: (a) 20.000 (2 s); (b) 80.000 (8 s); (c) 160.000 (16
s); e (d) 220.000 (22 s).
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

5 Experimentos computacionais 114
O padrão de propagação de fratura mostrado na Figura 51 encontra-se
consistente com os resultados sequenciais obtidos por (Zhang et al., 2007;
Paulino, Park, Celes & Espinha, 2010). A fratura principal se desenvolve próxima
à direção horizontal central do modelo. Ao longo do caminho da fratura, um
grande número de microrramificações do ramo principal ocorre livremente,
conforme ditado pela física do problema. Na Figura 52, uma região do modelo
simulado é ampliada para mostrar as ramificações do ramo principal. A
frequência e tamanho das ramificações tende a aumentar em conjunto com a
deformação inicial do modelo, conforme observado por Zhang et al. (2007). As
partições do modelo são mostradas na Figura 53.
Figura 52 - Microrramificações em uma região ampliada ao redor do
ramo de fratura principal.
Figura 53 - Modelo de elementos finitos decomposto em 128
partições.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

6 Conclusão
Esta tese propõe o suporte topológico ParTopS, para simulações, em
ambientes paralelos, de fraturas e fragmentação dinâmicas baseadas em
modelos coesivos extrínsecos. Esse suporte topológico fornece a representação
de fraturas necessária à viabilização de simulações escaláveis de modelos
tridimensionais, visando o tratamento de problemas de fraturas e fragmentação
em escala real.
Algumas contribuições são apresentadas por este trabalho. Uma
representação compacta de malhas distribuídas é fornecida por ParTopS;
diferentemente de abordagens anteriores, elementos coesivos são
explicitamente representados e tratados de maneira consistente, assim como os
outros elementos da malha de elementos finitos. Um novo tratamento para a
representação de cópias de entidades remotas em cada partição (camada de
comunicação) é proposto, com a classificação de entidades em proxies e ghosts.
Esse tratamento fornece um suporte topológico consistente para a
representação de elementos coesivos em malhas distribuídas. Com base na
representação de malhas distribuídas de ParTopS, propõe-se um algoritmo para
a inserção adaptativa de elementos coesivos em paralelo. O algoritmo
demonstra a viabilidade da representação paralela de fraturas extrínsecas.
Operações topológicas simétricas são exploradas pela inserção de elementos
coesivos, a fim de se reduzir a comunicação necessária entre partições de
malha. Esse conceito é também empregado no contexto de simulações
numéricas, com o uso de computações replicadas simétricas. Como
consequência, o número de pontos de sincronização de atributos da simulação é
reduzido, e a estrutura do fluxo de controle da aplicação numérica paralela é
significativamente simplificada em relação à abordagem convencional.
Para avaliar a aplicação de ParTopS em problemas reais, uma aplicação
sequencial existente de simulação de fraturas paralelizada. Um pequeno número
de modificações foi necessário para permitir a execução da aplicação em um
ambiente paralelo.
Experimentos computacionais desacoplados de simulações numéricas
foram realizados para verificar o suporte topológico proposto e medir o
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

6 Conclusão 116
desempenho e a escalabilidade do algoritmo de inserção de elementos coesivos.
A escalabilidade e a corretude de simulações numéricas de fraturas foram
demonstradas através de simulações de modelos bidimensionais e
tridimensionais. Os resultados obtidos sugerem que o sistema ParTopS pode ser
aplicado de maneira eficaz para viabilizar simulações de fraturas e fragmentação
de modelos em escala real.
Alguns aspectos relativos a simulações numéricas de elementos finitos não
foram abordados aqui. Assume-se que a malha inicial é bem balanceada pelos
algoritmos de particionamento utilizados, e que a inserção de elementos
coesivos não altera significativamente essa condição, uma vez que o número
esperado desses elementos é tipicamente muito menor que o de volumétricos.
Com isso, eventuais desbalanceamentos de carga são ignorados. Esses
aspectos serão investigados por pequisas futuras.
6.1. Trabalhos futuros
Algumas sugestões de trabalhos futuros são apresentadas a seguir:
Refinamento e simplificação adaptativa de malhas de fraturas e
fragmentação dinâmicas. A implementação atual de ParTopS
cobre os aspectos relativos à representação distribuída de malhas
de elementos finitos de fraturas, com as operações necessárias
para o tratamento de elementos coesivos. Uma extensão natural
deste trabalho está relacionada ao suporte a técnicas de
refinamento e simplificação adaptativa de malhas. Essas técnicas
são importantes para se aumentar a eficiência da simulação, uma
vez que o nível de refinamento requerido para a corretude da
simulação pode variar de acordo com a região de malha
considerada. Um desafio relativo à representação de malhas
adaptativas em paralelo é a propagação eficiente de modificações
topológicas entre partições de malha.
Balanceamento dinâmico de carga de malhas de fraturas e
fragmentação. Com o emprego de técnicas de refinamento e
simplificação adaptativas de malhas de elementos finitos, um
suporte para balanceamento dinâmico de carga entre partições de
malha torna-se fundamental à manutenção do ganho de
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

6 Conclusão 117
desempenho obtido com essas técnicas. O suporte ao
balanceamento dinâmico de carga deve incluir a migração eficiente
de entidades topológicas entre partições e considerar a topologia
de malhas contendo elementos coesivos.
Abordagem paralela híbrida. Esta pesquisa considerou o
problema de propagação de fraturas em ambientes paralelos de
memória distribuída. Com a disponibilidade de estações de trabalho
multiprocessadas, e crescente o emprego de placas gráficas
(GPUs) programáveis na aceleração de computações numéricas,
surge uma demanda para o aproveitamento desses recursos. Essa
é uma área de pesquisa bastante ativa atualmente, com diversas
questões ainda em aberto. Enquanto os ambientes de memória
distribuída atuais fornecem a escalabilidade necessária para o
tratamento de problemas maiores, os ambientes locais permitem
melhorar a eficiência da simulação dentro dos limites de cada nó de
processamento individual. Dessa forma, é interessante estender o
suporte topológico de malhas a fim de permitir uma integração
eficiente e transparente de ambas as abordagens paralelas na
computação numérica.
Visualização interativa de fraturas dinâmicas. Para permitir a
análise de resultados correspondentes a eventos de fratura
dinâmicos, métodos de visualização eficientes e escaláveis são
importantes. A visualização de fraturas apresenta desafios devido à
topologia dinâmica das malhas e ao grande volume de dados
resultantes de simulações paralelas.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

7 Referências bibliográficas
ANDREWS, G. Foundations of Multithreaded, Parallel, and Distributed Programming. Addison Wesley, 2000.
BATHE, K. J. Finite Element Procedures. Prentice Hall, New Jersey, 1996.
BEALL, M. W.; SHEPHARD, M. S. A general topology-based mesh data structure. Int J Numer Methods Eng, 40(9):1573–1596, 1997.
BELYTSCHKO, T.; LIU, W. K.; MORAN, B. Nonlinear Finite Elements for Continua and Structures. Wiley, New York, 2000.
CAMACHO, G. T., ORTIZ, M. Computational modelling of impact damage in brittle materials. International Journal of Solids and Structures 33 (20-22), 2899–2938, 1996.
CELES, W.; PAULINO, G. H.; ESPINHA, R. A compact adjacency-based topological data structure for finite element mesh representation. Int J Numer Methods Eng, 64(11):1529–1565, 2005a.
CELES, W.; PAULINO, G. H.; ESPINHA, R. Efficient handling of implicit entities in reduced mesh representations. J Comput Inf Sci Eng, 5(4):348–359 (Special Issue on Mesh-Based Geometric Data Process), 2005b.
CHOUDHURY, N. Parallel Incremental adaptivity for Unstructured Meshes in Two Dimensions. MSc. Dissertation, Department of Computer Science, Univesity of Illinois at Urbana-Champaign, 2006.
COOK, R. D. et al. Concepts and Applications of Finite Element Analysis. 4th ed. John Wiley & Sons, 2001.
DESOUZA, J.; KALÉ, L. V. MSA: Multiphase Specifically Shared Arrays. Proceedings of the 17th International Workshop on Languages and Compilers for Parallel Computing, West Lafayette, Indiana, USA, 22-25 set. 2004
DEVINE, K. et al. Zoltan data management services for parallel dynamic applications. In: Comput Sci Eng 4(2):90–97, 2002.
DEVINE, K. D. et al. New challanges in dynamic load balancing. In: Appl. Numer. Math., vol. 52(2-3): 133—152, 2005.
DOOLEY, I. et al. Parallel Simulations of Dynamic Fracture Using Extrinsic Cohesive Elements, J Sci Comput 39(1): 144-165, 2009.
ESPINHA, R.; CELES, W.; RODRIGUEZ, N.; PAULINO, G. H. ParTopS: compact topological framework for parallel fragmentation simulations. In: Eng with Comput, 25(4): 345-365, 2009.
FOSTER, I. Designing and building parallel programs: concepts and tools for parallel software engineering. Addison–Wesley, Boston, 1995.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

7 Referências bibliográficas 119
GARIMELLA, R. V. Mesh data structure selection for mesh generation and FEA applications. In: Int J Numer Methods Eng, 55(4):451–478, 2002.
GRAMA, A. Y.; GUPTA, A.; KUMAR, V. Isoefficiency: measuring the scalability of parallel algorithms and architectures. In: IEEE Parallel Distrib Technol, 1(3):12–21, 1993.
HEATH, M. Scientific Computing: An Introductory Survey. 2nd ed. McGraw-Hill, 2002.
HENDRICKSON, B.; DEVINE, K. Dynamic load balancing in computational mechanics. In: Comput Methods Appl Mech Eng, 184(2–4):485–500, 2000.
HUANG, C.; LAWLOR, O.; KALE, L. V. Adaptive MPI. In: Proceedings of the 16th international workshop on languages and compilers for parallel computing (LCPC 2003), Lecture Notes in Computer Science, v. 2958, p. 306–322, 2003.
KALÉ, L. V.; KRISHNAN, S. CHARM++: a portable concurrent object oriented system based on C++. In: Paepcke A (ed), Proceedings of OOPSLA’93, ACM Press, p. 91–108, Sep. 1993.
KALÉ, L. V.; KRISHNAN, S. Charm++: Parallel Programming with Message-Driven Objects. In: WILSON, G. V.; LU, P. (eds) Parallel Programming using C++. MIT Press, London, p. 175–213, 1996.
KARYPIS, G.; KUMAR, V. METIS—Serial Graph Partitioning and Fill-reducing Matrix Ordering Library, Department Computer Science Engineering, University of Minnesota, 1995. Disponível em: <http://www.cs.umn.edu/~karypis/metis>. Acesso em: 9 jan. 2011.
KARYPIS, G.; KUMAR, V. Multilevel k-way partitioning scheme for irregular graphs. J Parallel Distrib Comput, 48(1):96–129, 1998a.
KARYPIS, G.; KUMAR, V. A parallel algorithm for multilevel graph partitioning and sparse matrix ordering. J Parallel Distrib Comput, 48(1):71–95, 1998b.
KERNINGHAN, B. W.; RITCHIE, D. M. The C programming language. Prentice Hall Press. Upper Saddle River, NJ, USA, 1988.
KLEIN, P. A. et al. Physics-based modeling of brittle fracture: cohesive formulations and the applications of meshfree methods. Sandia National Laboratory, Technical Report, SAND 2001-8009, 2001.
KIRK, B. S. et al. libMesh: a C++ library for parallel adaptive mesh refinement/coarsening simulations. Eng Comput, 22(3):237–254, 2006.
LAWLOR, O. S. et al. ParFUM: a parallel framework for unstructured meshes for scalable dynamic physics applications. Eng Comput 22 (3-4), 215–235, 2006.
MANGALA, S. et al. Parallel adaptive simulations of dynamic fracture events. Eng. with Comput. 24(4): 341-358, 2008.
MÄNTYLÄ, M. An Introduction to Solid Modeling. Computer Science Press: Rockville, MD, 1988.
MATTSON, T.; SANDERS, B.; MASSINGILL, B. Patterns for parallel programming. 1st ed. Addison-Wesley Professional, 2004.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

7 Referências bibliográficas 120
MOTA, A.; KNAP, J.; ORTIZ, M. Fracture and fragmentation of simplicial finite element meshes using graphs. Int. J. Numer. Methods Engrg. 73(11): 1547-1570, 2008.
MPI FORUM. MPI: A Message-Passing Interface Standard. Disponível em: <http://www.mpi-forum.org>. Acesso em: 23 fev. 2011.
NOELS, L.; RADOVITZKY, R. A general discontinuous Galerkin method for finite hyperelasticity. Formulation and numerical applications Int. J. Numer. Methods Engrg. 68(1): 64-97, 2006.
NOELS, L.; RADOVITZKY, R. An explicit discontinuous Galerkin method for non-linear solid dynamics: Formulation, parallel implementation and scalability properties. Int. J. Numer. Methods Engrg. 74(9): 1393-1420, 2008.
ORTIZ, M.; PANDOLFI, A. Finite-deformation irreversible cohesive elements for three-dimensional crack-propagation analysis. Int J Numer Methods Engrg 44 (9), p. 1267–1282, 1999.
OWEN, S. J.; SHEPHARD, M. S. Editorial: special issue on trends in unstructured mesh generation. Int J Numer Methods Engrg 58:159–160, 2003.
OZTURAN, C. Distributed environment and load balancing for adaptive unstructured meshes. PhD Thesis, Comput Sci Department, Rensselaer Polytechnic Institute, 1995.
OZTURAN, C. et al. Parallel adaptive mesh refinement and redistribution on distributed memory computers. Comp Methods Appl Mech Eng 119(1–2):123–127, 1994.
PANDOLFI, A.; ORTIZ, M. Solid modeling aspects of three-dimensional fragmentation. Engineering with Computers 14(4), 287-308, 1998.
PANDOLFI, A.; ORTIZ, M. An efficient adaptive procedure for three-dimensional fragmentation simulations. Eng Comput 18(2):148–159, 2002.
PAPOULIA, K. D.; VAVASIS, S. A.; GANGULY, P. Spatial convergence of crack nucleation using a cohesive finite-element model on a pinwheel-based mesh. Int J Numer Methods Eng 67(1):1–16, 2006.
PARK, K. Potential-Based Fracture Mechanics Using Cohesive Zone and Virtual Internal Bond Modeling, PhD Dissertation, Department of Civil and Environmental Engineering, University of Illinois at Urbana-Champaign, 2009.
PARK, K.; PAULINO, G. H.; ROESLER, J. R. A unified potential-based cohesive model of mixed-mode fracture. Journal of the Mechanics and Physics of Solids 57 (6), 891–908, 2009.
PARK, K.; PAULINO, G. H.; CELES, W.; ESPINHA, R. Cohesive zone modeling of dynamic fracture: An adaptive mesh refinement and coarsening strategy. Int. J. Numer. Meth. Engng., 2011 (aceito para publicação)
PAULINO, G. H.; CELES, W.; ESPINHA, R.; ZHANG, Z. A general topology-based framework for adaptive insertion of cohesive elements in finite element meshes. Eng Comput 24(1):59–78, 2008.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

7 Referências bibliográficas 121
PAULINO, G. H.; PARK, K.; CELES, W.; ESPINHA, R. Adaptive dynamic cohesive fracture simulation using nodal perturbation and edge-swap operators. Int. J. Numer. Meth. Engng 84:1303–1343, 2010. (DOI: 10.1002/nme.2943)
QUINN, M. J. Parallel Programming in C with MPI and OpenMP. McGraw-Hill, New York, 2004.
KUMAR, V.; GUPTA, A. Analyzing scalability of parallel algorithms and architectures. J Parallel Distrib Comput 22(3):379–391, 1994.
RADOVITZKY, R. et al. A scalable 3D fracture and fragmentation algorithm based on a hybrid, discontinuous Galerkin, cohesive element method. Computer Methods in Applied Mechanics and Engineering, 200(1-4), p. 326-344, jan. 2011
REMACLE, J-F. et al. Parallel algorithm oriented mesh database. Eng Comput 18(3):274–284, 2002.
REMACLE, J-F.; KARAMETE, B. K.; SHEPHARD, M. S. Algorithm oriented mesh database. Proceedings, 9th International Meshing Roundtable, Sandia National Laboratories, p.349-359, Oct. 2000.
REMACLE, J-F.; SHEPHARD, M. S. An algorithm oriented mesh database. Int J Numer Methods Eng 58(2):349–374, 2003.
SEOL, E. S.; SHEPHARD, M. S. Efficient distributed mesh data structure for parallel automated adaptive analysis. Eng Comput 22(3–4):197–213, 2006.
STEWART, J. R.; EDWARDS, H. C. A framework approach for developing parallel adaptive multiphysics applications. Finite Elem Anal Des 40(12):1599–1617, 2004.
STROUSTRUP, B. The C++ Programming Language, Third Edition. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1997.
UNIVERSITY OF ILLINOIS. Department of Computer Science. Parallel Programming Laboratory. Threaded CHARM++ Manual. Disponível em: <http://charm.cs.uiuc.edu/manuals/html/tcharm/manual-1p.html>. Acesso em: 1 mai. 2011.
WALTZ, J. Derived data structure algorithms for unstructured finite element meshes. Int.J Numer Methods Eng 54(7):945–963, 2002.
WEILER, K. Topological structures for geometric modeling. Ph.D. Thesis, Rensselaer Polytechnic Institute, New York, 1986.
WEILER, K. The radial edge structure: a topological representation for non-manifold geometric boundary modeling. Geometric Modeling for CAD Applications. WOZNY, M. J.; MCLAUGHLIN, H. W.; ENCARNAÇÃO, J. L. (eds) p. 3–36, 1988.
XU, X. P.; NEEDLEMAN, A. Numerical simulations of fast crack growth in brittle solids. Journal of the Mechanics and Physics of Solids 42(9):1397–1434, 1994.
ZHANG, Z. Extrinsic Cohesive Modeling of Dynamic Fracture and Microbranching Instability Using A Topological Data Structure, PhD Thesis, Department of Civil and Environmental Engineering, University of Illinois at Urbana-Champaign, 2007.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A

7 Referências bibliográficas 122
ZHANG, Z.; PAULINO, G. H. Cohesive zone modeling of dynamic failure in homogeneous and functionally graded materials. International Journal of Plasticity 21 (6), 1195–1254, 2005.
ZHANG, Z.; PAULINO, G. H.; CELES, W. Extrinsic cohesive modelling of dynamic fracture and microbranching instability in brittle materials. Int J Numer Methods Eng 72(8):893–923, 2007.
ZIENKIEWICZ, O. C.; TAYLOR, R. L.; ZHU, J. Z. The Finite Element Method: Its Basis & Fundamentals. Butterworth-Heinemann, Oxford, UK, 2005.
PU
C-R
io -
Cer
tific
ação
Dig
ital N
º 07
1131
3/C
A