o processador: caminho de dados e controle › eduardo_barrere › files › 2013 › 03 ›...
TRANSCRIPT

O Processador: Caminho de Dados e Controle

Implemtação Monociclo

Implementação Multiciclo: Passos1. Busca de instrução2. Decodificação da instrução e busca do
registrador3. Execução, cálculo do endereço de memória ou
efetivação do desvio condicional4. Final da execução das instruções de acesso à
memória e do tipo R5. Final do passo de leitura de memória

1° Passo: busca da instrução
IR=Memória[PC]PC=PC+4
• Envio do PC para a memória como endereço, realização da leitura e escrita da instrução no registrador de instruções.

2° Passo: decodificação da instrução e busca do registradora) Executa algumas operações que podem depois ser
descartadas após a decodificação da instrução (ainda não se sabe qual instrução está no IR)
b) São executadas para evitar a perda de tempo durante a execução (ler rs e rt)
c) Carga de:– Registradores de entrada da ULA– Endereço de desvio condicional (salvo em UALSaída)
d) A = Reg[IR[25-21]];e) B = Reg[IR[20-16]];f) UALSaída = PC + extensão de sinal (IR[15-0] << 2);

3° Passo: Execução, cálculo do endereço de memória ou efetivação do desvio condicionala) Referência à memória
UALSaída = A + extensão de sinal IR[15-0]b) Instrução aritmética ou lógica (tipo R)
UALSaída = A op Bc) Desvio condicional
Se (A == B) PC = UALSaídad) Desvio incondicional
PC = PC [31-28] || (IR[25-0]<<2)

4° Passo: Final da execução das instruções de acesso à memória e do tipo Ra) Referência à memória
MDR = Memória [UALSaída];ouMemória = [UALSaída] = B;
b) Instruções aritméticas ou lógicas (tipo R)Reg[IR[15-11]] = UALSaída;

5° Passo: Final de leitura da memória• Load word:
– Reg[IR[20-16]] = MDR
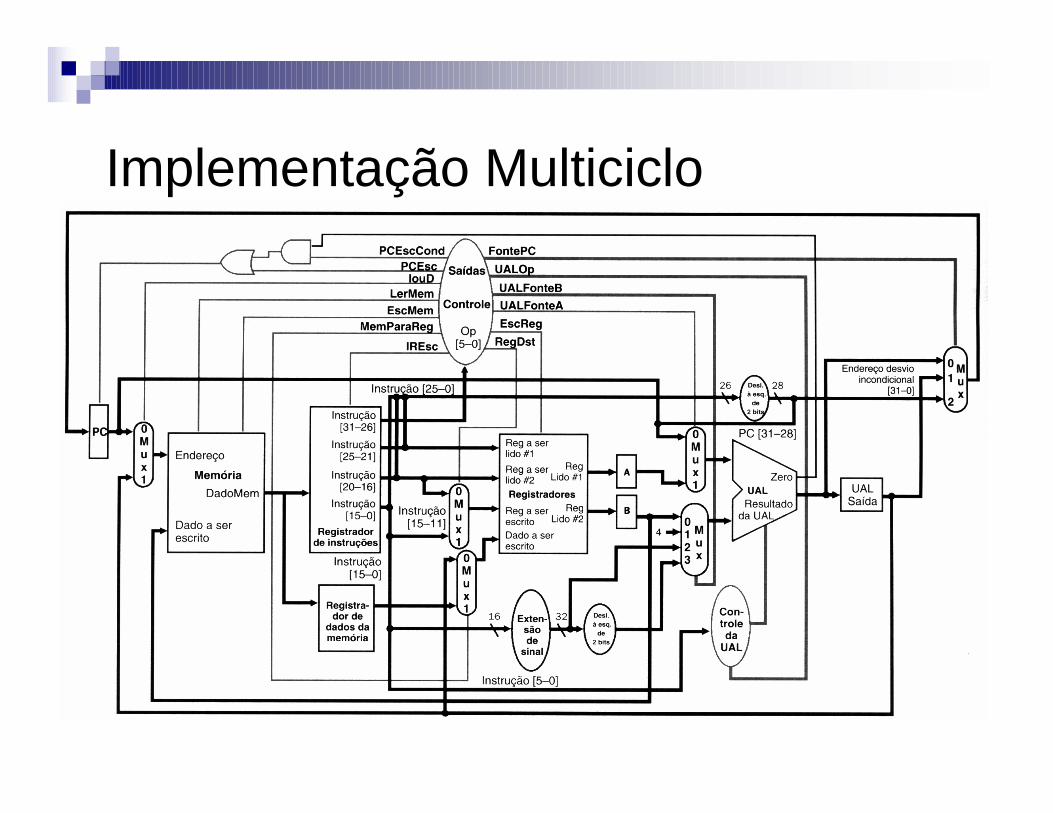
Implementação Multiciclo

Como melhorar o desempenho ?
Pipelining Técnica de implementação em que várias instruções
são sobrepostas na execuçãoPipelining não diminui o tempo para concluir uma
instrução, mas aumenta a vazão, reduzindo o tempo para concluir a aplicação
Instruções MIPS normalmente exigem cinco etapas: busca, decodificação/leitura de registradores, cálculo de operação/endereço; acesso a operando na memória, escrita de resultado em registradorPipelining de cinco estágios

Desempenho de ciclo único X desempenho com pipelining
500200100200Branch
700200200100200sw
800100200200100200lw
600100200100200Tipo R
TotalEscrita em Registrador
Acesso a Dados
Operação de ALU
Leitura de Registrador
Busca de Instruções
Classe

Desempenho de ciclo único X desempenho com pipelining
Busca instrução ALU Acesso
à dadosReg Reg
Busca instrução ALU Acesso
à dadosReg Reg
Busca instrução
200 400 600 800 1000 1200 1400 1600 18000
800ps
800ps
Ordem de execução doprograma (em instruções)
Tempo

Desempenho de ciclo único X desempenho com pipelining
Busca instrução ALU Acesso
à dadosReg Reg
Busca instrução ALU Acesso
à dadosReg Reg
Busca instrução ALU Acesso
à dadosReg Reg
200 400 600 800 1000 1200 1400 1600 18000
Ordem de execução doprograma (em instruções)
Tempo
200
200
200 200 200 200 200