mw consultoria científica - mwc.com.brmwc.com.br/files/slides-rebb2016.pdfobjetivos do curso...
TRANSCRIPT

Curso de Revisão de Tópicos de Epidemiologia, Bioestatística e
Bioética
Regente
Dr. Mário B. Wagner, MD PhD DLSHTM
Prof. FAMED/UFRGS e PUCRS
2016Porto Alegre, RS
MW Consultoria CientíficaA diferença significativa

Informações
• ProfessoresMário B. Wagner, MD PhD DLSHTMBruna P. Genro, Biol PhD
• ContatoFone: (51) 3330-8560 email: [email protected]
• Sites de referência para este cursowww.mwc.com.br/bibliotecawww.mwc.com.br/rebb2016www.bioetica.ufrgs.br

Objetivos do curso
• Revisar os princípios fundamentais da Epidemiologia, da Bioestatística e da Bioética
• Auxiliar no desenvolvimento de um raciocínio crítico apontando os campos de atuação dessas disciplinas na área biomédica.
• Apresentar de forma resumida tópicos frequentemente abordados no Exame Fundação Médica

Método de trabalho
• Aulas expositivas
• Exercícios aplicados com correção
• Discussão em grande grupo
Espera-se que os alunos leiam o material solicitado

Leitura recomendada
Callegari-Jacques, SM. Bioestatística: Princípios e Aplicações. Porto Alegre: ArtMed, 2003.
Fletcher R et al.Epidemiologia Clínica. 5a. Ed.Porto Alegre: ArtMed, 2014.
Veja sites e links disponibilizados
Haynes RB et al. Epidemiologia Clínica: Como realizar pesquisa clínica na prática. 3ª Ed. Porto Alegre: ArtMed, 2008.
Hulley SW et al. Delineando a Pesquisa Clínica: Uma Abordagem Epidemiológica.4ª Ed. Porto Alegre: ArtMed, 2015.

Tópicos
• Definição e aplicações da Epidemiologia e da Bioestatística na clínica, pesquisa e saúde pública
• Medidas descritivas e de associação
• Delineamentos de pesquisa
• Vieses mais comuns em estudos epidemiológicos
• Medidas de desempenho de testes diagnósticos
• Fundamentos de Bioestatística (distribuição Normal, DAM, significância, teste t, proporções, qui-quadrado, correlação e regressão)
• Elementos de Bioética

Conceitos Básicos em Epidemiologia e Bioestatística

Bioestatística
Estatística: Ramo do conhecimento que consta de processos que tem por objeto a observação, a classificação e a análise de fenômenos coletivos com a finalidade de obter inferências indutivas a partir dos dados.
Bioestatística: Aplicação da Estatística nas ciências biológicas e da saúde.
A Bioestatística é essencial nas pesquisas epidemiológicas uma vez que possibilita a avaliação da probabilidade e do papel do acaso nas observações que são feitas nos estudos.

Epidemiologia
A Epidemiologia representa o braço da Metodologia Científica aplicada à área da saúde e com a qual é possível avaliar a credibilidade das pesquisas médicas.
Quem não sabe Epidemiologia e Bioestatística não tem condições de adquirir novos conhecimentos por conta própria e nem de avaliar a qualidade da informação que recebe.
Ciência da saúde que estuda a distribuição, os determinantes e o controle das doenças nas populações.

Epidemiologia
• Descrever a ocorrênciapor estatísticasdescritivas
• Tentar a explicação com estatísticas de associaçãoe método científico
• Para poder prevenir …
Como assim, prevenir a gravidez?! Nós nem sequer sabemos qual é sua causa.
Conhecimento

Artigos científicos publicados
nas áreas das ciências biológicas
e da saúde freqüentemente
apresentam termos do domínio da
Epidemiologia e da Bioestatística.
O papel da Epidemiologia eda Bioestatística

Para entender adequadamente
artigos científicos desta área o leitor
deve estar familiarizado com os
princípios fundamentais da
Epidemiologia e da Bioestatística.

Na grande maioria dos casos este
conhecimento não é de nível profundo e
nem envolve cálculos complicados.
Para o usuário comum é mais importante
conhecer as indicações e as limitações
dos procedimentos utilizados em
Epidemiologia e Bioestatística do que
saber exatamente como executá-los.

Medidas de Sumário(Estatísticas Descritivas)

Objetivos
• Entender os conceitos de variável, nível de medida, amostra e população.
• Apresentar medidas descritivas
• Média e mediana
• DP e AIQ
• Prevalência e incidência

Bioestatística: Princípios Fundamentais
• Resumir a informação (p.e., média, %)
• Resumir as relações (p.e., ES, RR)
• Estimar a magnitude das relações (p.e., IC95%)

Relações
Tanto a Epidemiologia como a Bioestatística essencialmente estudam as relações entre as variáveis.
Ex: Relação entre fumo e câncer, idade e PA.
Assim, se busca
• Verificar se há ou não relação
• Estimar a magnitude da relação (estimar o tamanho do efeito e seu IC)

Variáveis e seus níveis de medida
• Qualitativas ou categóricas
- Nominal (grupo sangüíneo, gênero)
- Ordinal (grau de dor, escores)
• Quantitativas
- Discretas (número de filhos)
- Contínuas (colesterol total)

Vantagens da variável quantitativa
• Nível de informação é superior
• Pode ser transformada em qualquer outro tipo de variável
• Aceita transformações matemáticas (log, raiz quadrada, inversão, etc.)
• Estudos com este tipo de variável necessitam tamanhos amostrais menores

População e Amostra
Média () = ?
X Inferência

Parâmetro: valor que resume, em uma população, a informação relativa a uma variável. Ex: média, porcentagem
Estatística: quantidade que descreve a informação estatística obtida em um conjunto de dados amostrais. Ex: média, porcentagem calculadas em uma amostra
As estatísticas estimam os parâmetros.

Duas variáveis importantes
• Desfecho: Aquilo que se supõe ser o resultado, ou seja, acontecerá durante uma investigação na mensuração da condição de saúde-doença. Sinônimo: variável dependente. (Ex: câncer de pulmão)
• Exposição: O fator que precede o desfecho, suposta causa. Sinônimos: fator em estudo, v. preditora, v. independente. (Ex: fumo)

Procedimentos Descritivos
• Distribuição de freqüências (tabelas e gráficos)
• Medidas-resumo ou medidas descritivas
– de tendência central (média, mediana e moda)
– de dispersão (amplitude, variância/desvio padrão, amplitude interquartil, CV)
– de freqüência (prevalência, incidência)

PAS (mm Hg) nº %
55 59 3 3,1
59 63 5 5,2
63 67 40 41,7
67 71 24 25,0
71 75 15 15,6
75 79 8 8,3
79 83 1 1,0
Total 96 100,0
Pressão arterial sistólica em 96 recém-nascidos ( primeiras 24 horas de vida)

Pressão arterial sistólica (PAS) em mm Hg nas primeiras 24 horas de vida em
96 recém-nascidos
Histograma

Características da distribuição de freqüências
• A forma da distribuição determina
- o tipo de medida descritiva mais adequada
- a técnica estatística correta para as inferências
• Uma distribuição de freqüências é muitas vezes descrita apenas por:
tendência central (média)dispersão (desvio padrão)

Distribuição de freqüências
• Toda variável (seja ela qualitativa ou quantitativa) quando avaliada em um grupode indivíduos apresenta uma distribuição de freqüências.
• Sempre que possível os dados devem ser examinados graficamente para que possamos identificar valores extremos e a forma da distribuição.

Medidas de Tendência Central
• Média: Indicação de uso em distribuições simétricas. Possui o maior poder matemático e é a medida descritiva mais utilizada (e preferida). No entanto, é afetada por valores extremos e em distribuições
Curva de distribuição de freqüênciascom representação pictórica da nuvem de dispersão de pontos.
n
xx
assimétricas pode apresentar uma informação distorcida.

• Mediana: Medida de posicionamento repre-sentando o valor que ocupa o meio da série, ou seja, em tese 50% dos valores estão abaixo e 50% acima da mediana. Não é afetada por valo-res extremos, daí ser preferida em séries com distribuição assimétrica.
• Moda: medida maisfrequente
Distribuição de freqüências com assimetria positiva

Medidas de Dispersão
• Amplitude: Máximo - Mínimo, simples e pouco informativa, pois refere-se a apenas dois valores. Além disso, é sensível a valores extremos.
• Variância: Promédio dos desvios quadrados em relação à média. Como a unidade é expressa ao quadrado, é comum utilizar-se o desvio padrão (DP), pois este é a raiz quadrada da variância.

• Desvio padrão: Em palavras simples, o desvio padrão (DP) representa o padrão de oscilações que os valores da série apresentam em relação à média. É fundamental em Estatística, sendo um importante marcador de variação. É freqüentemente usado em conjunto com a média e, como esta, também é afetado por valores extremos.
1
)( 2
2
n
n
xx
DP
1
)( 2
n
xxDP

• Coeficiente de variação: Representa qual o tamanho do DP em relação à média
100x
DPCV

Curva de distribuição de freqüências com representação pictórica da nuvem de dispersão de pontos.

Amplitude interquartil: A distância entre o percentil 75 e o percentil 25. É geralmente apresentada junto com a mediana na descrição de séries assimétricas. Há outros percentis...
Distribuição de freqüências com assimetria positiva

Medidas de freqüência: Conceitos Básicos
• Razão: Relação (divisão) entre duas quantidades quaisquer (ratio em Inglês).
• Proporção: Tipo de razão onde o numerador é de mesma natureza e esta contido no denominador (proportion em Inglês).
• Odds: razão de eventos/não-eventos
• Taxa: Termo que refere-se a razões especiais nas quais necessariamente temos no denominador uma unidade de tempo (rate em Inglês).

A distorção do termo “taxa”
Infelizmente o termo taxa (rate) ao longo do tempo (e do mau uso) foi perdendo seu verdadeiro sentido, sendo freqüentemente utilizado em proporções e razões.
Assim alguns epidemiologistas quando querem referir-se a taxa original apelam para a expressão “taxa verdadeira” ou “true rate”.

Prevalência e Incidência
• A ocorrência da doença (desfecho) é freqüentemente categorizada como presente/ausente.
• Variável categórica (nível de medida nominal): descrita com razões, proporções e taxas.
• Em Epidemiologia as razões, proporções e taxas (verdadeiras) recebem nomes especiais

Prevalência
• Definição: Proporção de indivíduos que apresentam o desfecho em um determinado momento no tempo.
• Apesar de ser uma medida com lógica de instantâneo, a coleta de dados pode levar dias ou até meses.

Prevalência
• Medida estática análoga ao momento capturado por uma fotografia.
estudados indivíduos
de total número
tempo no momento odeterminad um em
desfecho o com indivíduos de número
revalênciaP

Incidência
• Refere-se ao número de casos novos (do desfecho) em um grupo em risco durante um período específico de tempo (período de observação).
• Pode ser expressa de duas formasIncidência cumulativa (proporção)Densidade de incidência (taxa verdadeira)

Incidência cumulativa (IC)
• Definição: IC é a proporção de pessoas em um grupo definido (em risco) que desenvolveram o desfecho durante o período de observação. O período sempre deve ser referido nos relatórios (p.e. semanal, mensal, anual).
• A IC é usada para medir/estimar o risco (probabilidade) de um indivíduo sem o desfecho vir a desenvolvê-lo durante o período de observação.

Incidência cumulativa (IC)
• Para o cálculo da IC é assumido que todos os indivíduos são seguidos até manifestarem o desfecho ou até o final do período de observação.
observação de período do início no
risco em indivíduos de total número
observação de período o durante
novos casos de número
IC

Prevalência/Incidência cumulativa:Representação esquemática
caso 1caso 2
caso 3
caso 5caso 6
caso 7
caso 8
caso 9caso 10
caso 4
1º Jann=100
31 Dez

Densidade de Incidência (ID)
• Definição: Refere-se a taxa de surgimento de novos casos de doença por unidade de tempo.
• O termo “densidade” é utilizado pois a ocorrência dos casos depende do número de indivíduos em risco e o tempo de observação de cada um.
• Apresenta relação com o conceito de velocidade.

Densidade de Incidência (ID)
• Os indivíduos estudados são acompanhados por períodos de tempo variáveis, de modo semelhante às condições da vida real.
• Para considerar os tempos de seguimento variáveis, o denominador da ID é pessoa-tempo em risco, ou seja, o tempo total que cada pessoa ficou no estudo sem apresentar o desfecho (tempo livre de desfecho).

Densidade de Incidência (ID)
• Pessoa-tempo é freqüentemente denominado paciente-tempo e pode ser expresso em diversas unidades de tempo (paciente-dia, paciente-mês, paciente-ano, etc)
risco em tempo-pessoas
de total número
observação de período o durante
novos casos de número
ID

Escolhendo a medida descritiva
• Nominal: usar freqüências e proporções (P/I).
• Ordinal: freqüências e proporções, mediana e amplitude interquartil. A média e o desvio padrão também podem ser utilizados.
• Quantitativa: Depende da distribuição de freqüências.
– D. simétrica: média e desvio padrão
– D. assimétrica: mediana e amplitude interquartil. Com n pequeno (n<20) pode-se usar mínimo e máximo.
Tipo de variável

Observações Importantes
• É importante consultar o estatístico antes do início da coleta de dados, para calcular o tamanho de amostra e planejar as medidas
• Devemos utilizar a estatística para apoiar nossas conclusões e não como fonte de respostas as nossas perguntas.
• A melhor análise estatística não consegue corrigir erros no planejamento e na condução de um estudo.
• As variáveis em estudo devem ser definidas pelo pesquisador, nunca pelo estatístico
• Deve-se evitar o uso exclusivo de variáveis categóricas na coleta de dados no lugar de variáveis quantitativas, pois há perda de informação.

Resumo
• Epidemiologia e Bioestatística auxiliam a compreender a literatura científica na área biomédica e estão estreitamente relacionadas com a MBE.
• A Epidemiologia e a Bioestatística passam pela descrição dos dados para chegar à relação entre as variáveis e a consequente estimativa da magnitudedestas relações.

• As variáveis são classificadas de acordo com seu nível de mensuração em categóricas (nominal e ordinal) e quantitativas (discretas/contínuas).
• Em Epidemiologia (e Bioestatística) é importante distinguir entre variável preditora (exposição) e desfecho.

• As medidas descritivas clássicas usadas em Bioestatística (e Epidemiologia) são:
média e desvio padrãomediana e amplitude interquartilprevalência/incidência

Medidas de Associaçãoe Impacto

Objetivos• Conhecer as principais medidas de associação (relativas)
• Risco relativo (RR) e RRR
• Odds ratio (OR)
• Razão de prevalências (RP)
• Diferença de médias padronizada (ES)
• Conhecer as principais medidas de impacto (absolutas)
• Risco atribuível (RA)
• NNT/NNH

Risco relativo
• Definição: Compara a probabilidade de ocorrência do desfecho entre os expostos (Tx[E]) com a probabilidade de ocorrência nos não-expostos (Tx[n-E]).
• É a razão da incidência do desfecho nos expostos pela incidência do desfecho nos não-expostos.
• O desfecho nos expostos apresenta uma incidência que é RR vezes a incidência observada nos não-expostos.

)/(
)/(
dcc
baa
I
IRR
EXPOSTOS
EXPOSTOS
Tabela de contingência 2 x 2
Desfecho
Exposição Presente Ausente Total
Presente a b a + b
Ausente c d c + d
Total a + c b + d n

• RR > 1 indica risco aumentado de desfecho entre expostos e quanto maior o RR mais forte é a associação entre a exposição e o desfecho.
• RR próximo de 1 indica que não há associação da exposição com o desfecho.
• RR < 1 indica associação negativa, ou seja, expostos apresentam menor incidência (fator de proteção).

• Redução de risco relativo: RRRQuando o RR < 1 a exposição protege e pode-se calcular a redução de ocorrer o desfecho (muito comum em ECR).
– Tx[E] = 7,3%
– Tx[n-E] = 26,9%; RR=7,3/26,9 = 0,27
– RRR = 1 – 0,27 = 0,73 ou 73%

Odds ratio
• O que é odds?Tal como a probabilidade, o odds é também uma medida de ocorrência de desfecho.
• O odds é bastante utilizado nos EUA e no Reino Unido, para expressar a possibilidade de ocorrência de um evento, principalmente em jogos e corridas.
• Em português já foi sugerida a palavra “chance” ou “chances” no lugar de odds, mas há controvérsias na tradução.

Odds ratio
• O que é odds?
Ainda pode-se dizer que a expressão matemática para o odds é
desfecho) (não eventos não
(desfecho) eventosodds

Odds ratio
• Definição: É a razão de odds, ou seja, compara o odds de ocorrência do desfecho entre os expostos com o odds de ocorrência nos não-expostos.
• Com o mesmo resultado numérico o odds ratio (OR) expressa também o odds de exposição entre os que tem o desfecho (casos) pelo odds de ocorrência nos livres de desfecho (controles).

• Sua interpretação indica que o odds de desfecho entre expostos é OR vezes o oddsde desfecho entre os não-expostos.
• Conseqüentemente pode-se também dizer que o odds de exposição entre casos é OR vezes o odds de exposição entre os controles.

dc
ba
odds
oddsOR
EXPOSTOS
EXPOSTOS
/
/
Tabela de contingência 2 x 2
Desfecho
Exposição Presente Ausente Total
Presente a b a + b
Ausente c d c + d
Total a + c b + d n
cb
da
db
ca
controles os entre
exposição de odds
casos os entre
exposição de odds
OR
/
/

50,360/30
40/70
EXPOSTOS
EXPOSTOS
odds
oddsOR
Tabela de contingência 2 x 2
Desfecho
Exposição Presente Ausente Total
Presente 70 40 110
Ausente 30 60 90Total 100 100 200
50,34030
6070
60/40
30/70
controles os entre
exposição de odds
casos os entre
exposição de odds
OR

• OR > 1 indica odds aumentado de desfecho entre expostos e quanto maior o OR mais forte é a associação entre a exposição e o desfecho.
• OR próximo de 1 indica que não há associação da exposição com o desfecho.
• OR < 1 indica associação negativa, ou seja, expostos apresentam menor incidência (fator de proteção).

Razão de prevalências
• Definição: Tem o mesmo princípio das duas medidas anteriores e como o risco relativo, a razão de prevalências (RP) compara a prevalência do desfecho entre os expostos com a prevalência do mesmo nos não-expostos.
)/(
)/(
dcc
baa
aPrevalênci
aPrevalênciRP
EXPOSTOS
EXPOSTOS

Risco Atribuível (RA)
• Definição: É a medida do excesso ou acréscimo absoluto de risco que pode ser atribuído a uma exposição.
• Com o RA é possível estimar o número de casos que podem ser prevenidos se a exposição for eliminada e assim estimar a magnitude do impacto em termos de saúde pública imposto por esta exposição.

Risco Atribuível
• Diferentemente das medidas relativas, o RA possui características de medida de impacto. Sinônimo: redução absoluta de risco (RAR), diferença de risco.
• O RA, ao invés de concentrar-se na associação em si refere-se mais às conseqüências e as repercussões da exposição sobre a ocorrência do desfecho.

Risco atribuível
• O risco de desenvolver o desfecho (incidência)
é aumentado em RA nos indivíduos expostos
em comparação com os não expostos.
EXPOSTOSEXPOSTOS IIRA

Grupo n eventos Incid. RR RA
Expostos 1000 8 0,008 0,008/0,002 = 4 0,008 – 0,002 = 0,006ou <1%
Risco Relativo vs Risco Atribuível
Ñ-Exp. 1000 2 0,002
Expostos 1000 400 0,4 0,4/0,1 = 4 0,4 – 0,1 = 0,3ou 30%Ñ-Exp. 1000 100 0,1

NNT
• Definição: Significa “number needed to treat” ou “número necessário a tratar”. É uma medida de impacto de intervenções, também utilizada em conjunto com o RA e RRR em Experimentos Controlados Randomizados e estima quantos indivíduos precisam receber a intervenção para evitarmos um desfecho indesejável como, por exemplo, morte ou infarto.

NNT
• Quanto menor o NNT melhor, ou seja, maior o impacto da interveção.
• NNT = 1/|RA|– Tx(E) = 7,3%– Tx(n-E) = 26,9%; RA=0,073 – 0,269 = – 0,196– NNT = 1 / 0,196 = 5,1, ou seja, aprox 6 pacientes
necessitam receber o tto p/ evitarmos um desfecho.
• Lembrar que também é possível utilizar o análogo NNH (number needed to harm) em situações que a exposição aumenta a ocorrência do desfecho.

Uma escala de magnitudes
Adaptada de Will Hopkins, http://www.sportsci.org/resource/stats/effectmag.html
trivial small moderate large
very
large
nearly
perfectperfect
r 0.0 0.1 0.3 0.5 0.7 0.9 1
ES 0.0 0.2 0.6 1.2 2.0 4.0 infinite
Freq. diff. 0 10 30 50 70 90 100
RR 1.0 1.2 1.9 3.0 5.7 19 infinite
OR 1.0 1.5 3.5 9.0 32 360 infinite

Resumo
• Tanto a Epidemiologia e como a Bioestatística tem como princípio obter uma descrição dos dados para em seguida chegar à relação entre as variáveis e a conseqüente estimativa da magnitude destas relações.
• Variável pode ser considerada uma característica mensurável que pode apresentar valores diferentes nos sujeitos do estudo.

• As variáveis são classificadas de acordo com seu nível de mensuração em qualitativas (nominal e ordinal) e quantitativas (intervalar/razão).
• Em Epidemiologia é importante distinguir entre variável preditora (exposição) e desfecho.

• medidas descritivasmédia e desvio padrãomediana e amplitude interquartilprevalência/incidência
• medidas de associaçãoRR e RRR, OR, RP
• medidas de impactoRA e suas frações; NNT e NNH

Delineamentos de Pesquisa mais comuns na área da Saúde

Objetivo
Conhecer os delineamentos mais
comuns usados nas pesquisas na área
da saúde.

Delineamento
Estrutura teórica ou esquema utilizado pelo pesquisador para atingir os objetivos da pesquisa. Constitui-se na abordagem teórica desenvolvida para o teste das hipóteses propostas na investigação

Elementos Básicos
• Variáveis componentes
– desfecho
– variável Preditora
• Temporalidade
• Enfoques
– diagnóstico, etiologia, prognóstico e tratamento

Delineamentos de pesquisa mais comuns
Primários• Observacionais
– estudo/série de casos– estudo transversal
(ecológico)– estudo de coorte– estudo de caso-controle
• Experimentais– experimento
laboratorial– experimento
(seres humanos)
Secundários
• Revisão sistemática (metanálise)
• Diretrizes (guidelines)
• Outros
– análise decisória
– análise econômica

Estudo transversal
População em risco
Amostra representativa
Com
doença
Sem
doença
Avalia os casos e não-casos de uma doença ou condição clínica em uma população de indivíduos em um determinado momento (“fotografia”).

Estudo transversal
• Desfecho e exposição avaliados no mesmo momento no tempo.
• Não há seguimento.
• Apresenta medidas de prevalência.

Estudo transversal
• Vantagens– útil para descrições e “levantamentos”– rápido e de baixo custo
• Desvantagens– inadequado em desfechos raros ou de curta
duração– potencial para viés na seleção da amostra– potencial para causalidade reversa
(dilema ovo/galinha)– baixo poder para testar hipóteses– falácia em estudo ecológico

Seguimento de pessoas livres de doença, por determinado período, aferindo-se os fatores de risco e buscando uma relação temporal entre causa e efeito. Ex.: seguimento de fumantes e não fumantes e comparando as taxas de infarto do miocárdio nestes dois grupos (controlando para outras variáveis – “ajuste”).
População
Exposição a determinado(s) fator(es) de risco
Desfecho
tempoAmostra
Sim/Não
Sim/Não
Estudo de coorte
Expostos
Não-Expostos

Estudo de coorte
• Um grupo de indivíduos é identificado, e classificado segundo a exposição (+ ou –)
• É realizado um seguimento no tempo para manifestação do desfecho.
• Gera medidas de incidência, comparando E x nE
• A coorte pode ser controlada ou não controlada (sem grupo exposto: est. incidência)
• A coorte pode ser contemporânea ou histórica

Estudo de coorte
Os elementos básicos são:
– identificação dos grupos (E/nE)
– definição da exposição e sua medida
– medir variáveis de confusão
– definir desfecho e sua medida
– análise e interpretação (I e RR)

Estudo de coorte
• Vantagens– adequado para exposições raras
– bom poder para testar hipóteses
– importante em estudos etiológicos e prognósticos
– salienta os múltiplos desfechos de uma exposição
• Desvantagens– inadequado em desfechos raros
– perdas no seguimento levam a viés de seleção
– demorado/elevado custo

Estudo de caso-controle
Comparam a freqüência de um fator de risco (ou exposição) em um grupo de casos (com determinado desfecho) com a de um grupo de controles (sem o desfecho). Ex.: pessoas com e sem câncer de pulmão e sua exposição ao fumo (controlando outras variáveis).
População em risco
Grupo COM desfecho(CASOS)
Grupo SEM desfecho
(CONTROLES)
pesquisa
tempo
Exposição ao fator de risco
Sim/Não
Sim/Não

Estudo de caso-controle
• Envolve a comparação das características de um grupo de indivíduos com o desfecho (casos) e outro sem desfecho (controles).
• O objetivo da comparação é identificar fatores que são mais (ou menos) comuns entre os casos do que entre os controles. Associação.

Estudo de caso-controle
Os elementos básicos são:
– propósito claro
– definir casos (prevalente/incidentes)
– definir exposição (início, tempo, intensidade)
– medir potenciais confundidores
– seleção controles (hosp: div diags/com: friends)
– mensuração (quest/registros/met. objetivos/blind)
– análise via OR como estimador de RR

Estudo de caso-controle• Vantagens
– útil em doenças raras
– mais barato que estudo de coorte
– poder moderado para testar hipóteses
– importante em estudos etiológicos
– investiga os múltiplos FRs para um desfecho
• Desvantagens– potencial a viés de seleção/aferição (recall)
– inadequado em exposições raras
– não estima incidência nem prevalência

• Delineamento no qual o investigador determina a exposição, ao contrário de ocorrer naturalmente. A exposição em experimentos (ensaios clínicos) é chamada de tratamento.
• Geralmente o propósito é comparar um grupo tratado e um de controles.
Experimentos (seres humanos)

Experimentos (seres humanos)
Os elementos básicos são:
– definir sujeitos (critérios i/o; consentimento)
– alocação (ant/dep; controles: hist; nrand; rand)
– condução/avaliação (temp seg; perdas; adesão; co-intervenções; mascaramento)
– análise: preferir intenção de tratarRRR = 1-RR e NNT=1/RA

Experimento Controlado Randomizado
– Explanatório x “de manejo”
– Eficácia x Efetividade
– Condições ideais x Condições usuais
– per protocol x intenção de tratar

Ensaio clínico - Fases• I: voluntários para determinar a segurança e o perfil
farmacocinético (n10).
• II: Estudo terapêutico piloto - para demonstrar atividade e segurança em curto prazo (n20 a 40).
• III: Estudo terapêutico ampliado - Avaliar risco/benefício a curto e longo prazo. Reações adversas, interções e fatores modificadores. Estudos controlados (n grande segundo hipótese).

Ensaio clínico - Fases
• IV: Após a comercialização, usando as características primárias da droga
– vigilância pós-comercialização
– explorar outras aplicações

Experimento• Vantagens
– grande poder para testar hipóteses (ECR)
– importante em estudos terapêuticos
• Desvantagens
– demorado/elevado custo
– perdas no seguimento levam a viés na avaliação da terapia

Experimento Controlado Randomizado
População definida
MELHORA SEM MELHORA MELHORA SEM MELHORA
RANDOMIZAÇÃO
NOVO TRATAMENTO TRATAMENTO ATUAL

Revisão Sistemática/Metanálise
• Delineamento secundário no qual o investigador realiza uma revisão sistemática quantitativa dos achados de estudos semelhantes. Geralmente é realizado em ECR, mas pode também ser feita em estudos observacionais.
• Geralmente o propósito é obter uma melhor estimativa do tamanho do efeito.

Forest Plot

Quando as coisas podem dar errado...

Viés de publicação e publicação seletiva

Viés de publicação e publicação seletiva
a favor do placebo
Gráfico de funil paradetectar viés de publicação
Gráfico de funil paradetectar viés de publicação
sem viés
Estu
do
sm
aio
res
0
a favor da droga
Lod odds ratio
1 2-2 -1

Viés de publicação e publicação seletiva
a favor do placebo
Gráfico de funil paradetectar viés de publicação
Gráfico de funil paradetectar viés de publicação
sem viés
Estu
do
sm
aio
res
0
a favor da droga
Lod odds ratio
1 2-2 -1

Metanálise• Vantagens
– grande poder para resumir informação de diversos estudos
– aumenta a precisão de estimativas
• Desvantagem
– poder sofrer de viés de publicação (publication bias)

A hierarquia dos delineamentos de pesquisa
• metanálise
• ensaio clínico randomizado
• coorte contemporânea (est. incidência)
• coorte histórica
• ca-co (c. incidentes - aninhado)
• ca-co (c. prevalentes - aninhado)
• estudo transversal/est. prevalência/est. ecológico
• estudo de casos; série de casos
Cross-sectionalstudies

Erro aleatório e vieses nosestudos epidemiológicos

Objetivos
• Conhecer os erros mais comuns que ocorrem em estudos epidemiológicos
– Erro aleatório
– Erros sistemáticos: Seleção, aferição
– Confusão

Erros aleatórios e sistemáticos
• Em estudos epidemiológicos as medidas descritivas (média, prevalência, incidência) e as medidas de associação (TEP, r, RR, OR) podem diferir de seus valores verdadeiros (parâmetros) por dois tipos de erro
• aleatório
• sistemático

Erro aleatório
• Ocorre sempre que trabalhamos com amostras. Não pode ser eliminado, mas com o delineamento de pesquisa apropriado e o tamanho amostral adequado pode ser reduzido a níveis aceitáveis dentro dos recursos disponíveis.

Erro aleatório
• No teste de hipótese pode-se rejeitar Ho quando esta é verdadeira (I/a) ou não rejeitá-la quando falsa (II/b).
• Em estimação podemos obter valores errôneos ou imprecisos do parâmetro.

Erro aleatório
• O modo mais comum de reduzir o erro amostral é aumentando o tamanho amostral.
• Existem fórmulas disponíveis para o tamanho amostral mínimo segundo margens de erro toleráveis, efeito a testar, nível a e b (poder estatístico do estudo) desejados.

Erros sistemáticos (vieses)
• Estão relacionados com a própria validade do estudo. Esta depende do delineamento utilizado e da quantidade e intensidade dos viéses.
• Viéses são geralmente induzidos pelo pesquisador de forma não intencional (em algumas ocasiões o viés é altamente intencional).
• Tipos: seleção, aferição e confusão

Viés de seleção
• Distorção no processo de inclusão (seleção) ou manutenção dos grupos a serem comparados
• Problemático na montagem de estudos de caso-controle, mas pode ocorrer em estudos de coorte/ECR devido às perdas no seguimento.
• Variantes: viés de referência, viés de migração, viés de seguimento (perda)

Viés de seleção (exemplo)
• Estudo de ca-co para avaliar o papel do fumo no Ca de pulmão.
Casos: todos carcinomas de pulmão, s/exclusõesControles: pacientes do serviço de pneumologia que sofrem de afecções pulmonares não malignas
Como o fumo é um fator fortemente associado com bronquite, enfisema, etc, os controles superestimam o hábito tabágico. Assim, a força da associação fica prejudicada, ou seja, subestimada.

Viés de aferição
• Distorção da aferição/avaliação tanto da exposição como do desfecho nos grupos a serem comparados
• Ca-co: viés de re-lembrança (recall bias)
• Coorte: mudança não percebida no status de exposição (migração), avaliações diferenciadas (detection bias)
• ECR avaliação não cega dos desfechos

Confusão
• Envolve a possibilidade de uma terceira variável (fator de confusão) explicar em parte ou totalmente a relação entre um fator de risco e um desfecho.
• Exemplo: Ao comparar a ocorrência de Ca de pulmão entre trabalhadores de plataformas prerolíferas de alto mar e a população em geral (já ajustado para idade) esta ocupação mostrou-se associada com o D. Entretanto, isto pode ser devido em parte (ou totalmente) a um maior consumo de cigarros entre pessoas que trabalham em plataformas.

Confusão
• A confusão pode ser evitada durante o delineamento do estudo ou durante a análise de dados.
• Delineamento:
– restrição
– emparelhamento
– randomização
• Análise:
– análise estratificada
– análise multivariável (r. logística, Cox e outras).

Vieses de seleção e aferição x confusão
• Vieses de seleção e aferição, depois de introduzidos não podem ser remediados. O melhor a fazer é julgar de forma subjetiva o impacto na validade interna do estudo.
• A confusão, uma vez identificada, pode ser manejada.

O que significam e quais são os critérios de causalidade?
• A busca para identificação das etiologias das doenças depende de considerações sobre
– Pressupostos teórico-conceituais
– Unicausalidade
– Multicausalidade: combinação de fatores (biológicos, genéticos, socioeconômicos, ambientais, etc.) que interagem entre si e acabam desempenhando importante papel na gênese das doenças

Consumo de chocolate e Conquista de Prêmios Nobel
Chocolate Consumption, Cognitive Function, and Nobel Laureates N Engl J Med 2012; 367:1562-1564

Critérios de Hill (1965)
Austin Bradford Hill (1897 – 1991)Bioestatístico/Epidemiologista e professor da famosa London School of Hygiene & Tropical Medicine.
- Descobriu a relação entre fumo e Ca de Pulmão;
- Participou do planejamento e condução dos primeiros estudos clínicos randomizados em medicina;
- Descobriu a relação entre Rubéola na gravidez e malformação congênita;
- Propôs 9 critérios (em 1965) usados até hoje para reforçar a hipótese de uma relação causa-efeito;

Critérios de Hill (1965)
1. Força de Associação
2. Consistência (repetição)
3. Especificidade (introdução: causa; remoção: não ocorrência)
4. Temporalidade
5. Gradiente
6. Plausibilidade
7. Coerência (epidemiologia e lab concordam)
8. Experimentãção (ECR)
9. Analogia (mesmo efeito em fatores semelhantes)

Critérios de Hill (1965)
• À exceção do critério de temporalidade, nenhum outro critério de evidência epidemiológica de Hill deve ser exigido como condição sine qua non para julgar se uma associação é causal.
• Quando estão presentes, servem para reforçar a hipótese de causalidade; quando isto não ocorre, não se pode descartá-la.

• O uso de critérios para inferir causalidade deve ser visto como uma estratégia subjetiva para facilitar a abordagem de um problema altamente complexo.
Critérios de Hill (1965)

Erro aleatório e ViesesResumo
• O erro aleatório não pode ser evitado, mas pode ser exatamente quantificado.
• Vieses (seleção, aferição) e confusão podem ser evitados e manejados segundo sua natureza.

TestesDiagnósticos

Processo diagnóstico
• Incerteza da presença da doença: processo diagnóstico é imperfeito
• Essa incerteza pode ser expressa em termos probabilísticos
• Deve-se buscar apoio na literatura para tomada de decisões

Raciocínio Probabilístico
0 100

0 100
TratarTestarNãoTratarNem Testar
Raciocínio Probabilístico

0 100
Raciocínio Probabilístico
+-

Critérios para avaliação deum teste diagnóstico
1) Validade
2) Resultados (utilidade)
3) Aspectos práticos

1) Validade
• Houve comparação independente e mascarada (cega) em relação a um padrão-ouro?
• A amostra de pacientes representa o espectro de indivíduos que serão submetidos ao teste na prática clínica?

2) Resultados
• Quais as medidas de desempenho obtidas (S/E/LR...)
3) Aspectos Práticos
• Custo
• Funcionamento (acurácia e precisão)
• Mudança no manejo (alteração probabilística)

Acurácia e Precisão

Acurácia
• Capacidade de identificar corretamente a presença ou ausência da doença
• Padrão-ouro– Indicador fiel da verdade
– Melhor marcador da doença
– Geralmente caro/arriscado

Precisão (Reprodutibilidade)
• Variabilidade Intra e Inter-observador
– Coeficientes de concordância
– Coeficiente de variação
– Estatística Kappa

• Todo teste diagnóstico é baseado na pressuposição de que indivíduos doentes e normais podem ser diferenciados pelo teste.
• Existem testes baseados em escalas dicotômicas e testes baseados em escalas semi-quantitativas (p.e. escores psiquiátricos) ou quantitativas.
Base teórica

O desempenho diagnóstico
• Para que possamos avaliar o desempenho diagnóstico de um teste primeiramente deve-se estabelecer um critério de positividade.
• Em seguida é necessário que tenhamos dois grupos de pacientes:
(a) um que sabidamente tenha a doença(b) um grupo sem a doença

O desempenho diagnóstico
• A diferenciação entre o grupo doente e o grupo controle é, geralmente, determinada por um teste ou procedimento de referência conhecido como padrão-ouro (gold standard).
– limitações do padrão-ouro: técnica complexa, inviabilidade, alto custo
– padrão-ouro imperfeito (p.e. cultura x PCR)

Representação tabular do desempenhode um teste diagnóstico
FP
VPLR )(
Tabela de contingência 2 x 2
Desfecho (Padrão Ouro)
Teste Presente Ausente Total
Positivo a b a + b
Negativo c d c + d
Total a + c b + d n
[S]
[E]
VP
VNFN
FP
)()(
)(
ca
a
D
TS
)()(
)(
db
d
D
TE
S1FN E1FP
)()(
)()(
ba
a
T
DVP
)()(
)()(
dc
d
T
DVP
Medidas Fixas Medidas Dependentesde Prevalência
VN
FNLR )(

Definições
• S(VP) = a/(a + c), entre quem tem a doença quem tem teste positivo
• E(VN) = d/(b + d), entre quem não tem a doença quem tem teste negativo

• LR(+) = VP/FP, likelihood ratio(+) ou razão de verossimilhança(+): proporção de testes positivos em doentes dividida pela proporção de testes positivos em não doentes
• LR() = FN/VN, likelihood ratio() ou razão de verossimilhança(): proporção de testes negativos em doentes dividida pela proporção de testes negativos em não doentes
Definições

• probabilidade pré-teste (ppre) = dado pela prevalência ou impressão diagnóstica
• odds pré-teste (opre) = ppre / (1 ppre)
• odds pós-teste (opos) = opre × LR
• probabilidade pós-teste (Valor preditivo) = opos / (opos + 1)
Definições

Regras gerais sobre as medidas de desempenho
• S (VP)– bom para rastreamento
– FN
– VP(-) (dep. prev.)
• E (VN)– bom para confirmação
– FP
– VP(+) (dep. prev.)

Apresentação de estimativas das medidas de desempenho
• sensibilidade
• especificidade
• VP(+) no grupo estudado:este achado depende de prevalência
Likelihood ratio

Como obter estimativas dos valores preditivos em diferentes prevalências
• simulação em tabelas 2 x 2
• teorema de Bayes
• Nomograma (Fagan)

Exemplo de simulação de tabela 2 x 2 na estimativa de valores preditivos
Investigar a habilidade preditiva do teste BCPF (B cell proliferation factor) em uma população com prevalência de Ca de mama de 5%, com sensibilidade = 95% e especificidadde = 85%.
Tabela de contingência 2 x 2
Câncer de mamaBCPF Presente Ausente Total
Positivo 304
Negativo 1296
Total 80 1520 1600
76
12924
228
Qual a probabilidade de D em uma mulher com T(+)?VP(+) = 76/304 =0,25 ou 25%
Qual a probabilidade de D em uma mulher com T(-)?1 VP(-) = 4/1296 = 0,003 ou 0,3%

Teorema de Bayes
• No teorema de Bayes o que se faz é multiplicar a probabilidade pré (expressa em odds) pelo LR, obtendo-se assim a probabilidade pós (odds probabilidade). Esta probabilidade pós chama-se também valor preditivo. O maior problema para o uso prático são os cálculos envolvidos e a transformação de odds em proporção e vice-versa.
FP
VPLR )(
VN
FNLR )(
LRodds(pré)odds(pós)
p
podds
11
odds
oddsp
Thomas Bayes1702 - 1761
Atualmente o teoremade Bayes é de longe ométodo mais utilizadopara o cálculo de valorespreditivos, mas com oauxílio de computadores.

Qual a probabilidade de D em uma mulher com T(+)?ppre = 0,05opre = ppre / (1 ppre) = 0,05 / 0,95 = 0,0526opos = opre × LR(+) = 0,0526 × (0,95/0,15) = 0,3331ppos = opos / (opos + 1) = 0,3331 / (0,3331 + 1) = 0,2499
O ppos é o VP(+) = 0,2499 ou 25%
Qual a probabilidade de D em uma mulher com T()?ppre = 0,05opre = ppre / (1 ppre) = 0,05 / 0,95 = 0,0526opos = opre × LR() = 0,0526 × (0,05/0,85) = 0,0031ppos = opos / (opos + 1) = 0,0031 / (0,0031 + 1) 0,0031
O ppos é o 1 VP() = 0,0031 ou 0,3%
Resolução do exemplo de BCPF pelo teorema de Bayes
LR(+) = 6,33
LR() = 0,0588

Nomograma
• Há uma maneira mais fácil de manipular todos esses cálculos, utilizando-se um nomograma.
• Cálculo da probabilidade pós-teste com o nomograma
Fagan TJ. Nomogram for Bayes' theorem. NEJM 1975; 293(5): 257

Bcpf
Bcpf +
1 VP(+) = 0,3%
VP(+) = 25%
Resolução do exemplo de BCPFcom o nomograma
Qual a probabilidade de D em uma mulher com T(+)?
Qual a probabilidade de D em uma mulher com T()?

Força relativa dos LRs
LR+
Interpretação
10 < 0,1 Grande variação do pré-teste para o pós-teste.
5 a 10 0,1 a 0,2 Moderada variação do pré-teste para o pós-teste.
2 a 5 0,2 a 0,5Pequena, mas algumas vezes importante, variação na probabilidade.
1 a 2 0,5 a 1 Pequena, raramente importante, variação na probabilidade.
1 1Probabilidade pré-teste = Probabilidade pós-teste.O teste é inútil.

Aspectos a considerar na avaliação de um teste diagnóstico
• Padrão ouro aceitável
• Avaliação “cega” do resultado do teste em teste
• Padrão ouro independente do teste em teste
• Medidas precisas e acuradas
• Amostra de espectro apropriado
• Descrição adequada do grupo em estudo
• O novo teste deve ser vantajoso

Testagem múltipla
• Os testes diagnósticos não são perfeitos
• É comum a utilização de mais de um teste no processo diagnóstico, seja em testagem paralela ou seriada

Testagem paralela
• testes realizados simultaneamente (no mesmo momento), ou seja, em situação na qual sua execução não depende dos resultados dos testes anteriores
• a testagem paralela é usada quando se deseja realizar uma investigação rápida ou em check-ups

Testagem seriada
• testes realizados de modo seqüencial, sendo a progressão, dependente de positividades anteriores.
• Geralmente envolve procedimentos complexos e invasivos. A sugestão é começar pelo mais específico, pois no caso de resultado positivo pode-se dispensar os demais (E e FP).

Testagem múltipla (vantagens e desvantagens)
• testes paralelos
– sensibilidade e FN
• testes seriados
– especificidade e FP

Referências
• Altman DG, Bland JM. Diagnostic tests 1: sensitivity and specificity. BMJ 1994; 308:1552
• Altman DG, Bland JM. (1994) Diagnostic tests 2: predictive values. BMJ 1994; 309, 102.
• Altman DG, Bland JM. (1994) Diagnostic tests 3: receiver operating characteristic plots. BMJ 1994; 309, 188.
• Deeks JJ and Altman DG. (2004) Diagnostic tests 4: likelihood ratios. BMJ 2004; 329, 168-169.
Artigos disponíveis emhttps://www-users.york.ac.uk/~mb55/pubs/pbstnote.htm

Fundamentos deBioestatística

Statistics should be usedas the drunken
man uses the lampost,for support ratherthan illumination.
Editorial, Lancet 1986 June 28;1478.

Objetivos
• Conhecer elementos essenciais da Bioestatística
– parâmetros e estatísticas (estimativas)
– distribuição Normal - escore z
– distribuição amostral de médias; erro padrão
– avaliação de desvios significativos
– teste de hipótese e valor P

População e Amostra
Média () = ?
X Inferência

Parâmetro: valor que resume, em uma população, a informação relativa a uma variável. Ex: média, porcentagem
Estatística: quantidade que descreve a informação estatística obtida em uma amostra. Ex: média ou porcentagem calculadas em uma amostra
As estatísticas estimam os parâmetros.

(média)
(desvio padrão)
Distribuição Normal (Curva Normal, Curva de Gauss)
• Modelo matemático de fundamental importância em estatística. Notar a forma de sino e o acúmulo central.

Nascido na Alemanha filho de pais humildes. Foi um brilhante matemático que por seus variados interesses estudou a teoria dos erros de observação e chegou, também, à
distribuição Normal. Segundo a lei de Stigler, Gauss é quem entrou para a história com o mérito da descoberta.
Aspectos Históricos da Distribuição Normal
Carl F. Gauss
(1777 – 1855)
Nascido na França passou a maior parte de sua vida na Inglaterra. Entre inúmeros trabalhos relacionou números complexos, trigonometria e foi o primeiro a mencionar a existência da distribuição Normal.
Abraham de Moivre
(1667 – 1754)

• Igualmente o comportamento de muitas medidas descritivas e de associação (média, %, RR e outras) pode ser estudado com o modelo da distribuição Normal ou de aproximações.
• Boa parte das variáveis não seguem diretamente o modelo gaussiano, mas aproximações bastante razoáveis podem ser obtidas com logaritmos, inversões (1/x), raiz quadrada e outras transformações.
Distribuição Normal

Distribuição Normal
• freqüências centrais
• freqüências caudais
• simetria e caudas assintóticas
• média, mediana e moda iguais.
• 68% (68,26%)
• 1,96 95% (1,96 freq. aprox. para 2 )
• 3 99,7% (99,7% freq. aprox. 99%)

• A linha suave é apenas teórica. Na prática as variáveis estudadas apresentam histogramas de distribuição que em maior ou menor grau aproximam-se da distribuição normal.
Distribuição Normal

Escore z
• Quantidade de unidades de desvio padrão que uma observação se encontra longe da média.
• Quando o z=0, o valor é igual a média
• z pequeno (|z| 1,0) indica prox. à média
• z grande (|z| > 1,5) indica afastamento e, conseqüentemente, observação pouco comum.
xz

Escore z
xz
Qual a proporção de indivíduos com alturaacima de 175 cm?
5010
170175z ,
h(z=0,5)=0,1915 (na tabela de z)
prop.(x>175)=0,5-0,1915=0,3085 ou 30,9%
175cm
0,3085
0,1915

Distribuição Amostral de Médias
• É uma distribuição normal formada por todas as médias de amostras de tamanho “n” possíveis de serem extraídas de uma população
• cada média é uma estimativa de
• a média de todas as médias amostrais é
• o desvio padrão da DAM (chamado de erro padrão) é uma medida de o quanto as médias são precisas ao estimarem
x
erro padrão
média

nx
• O teorema do limite central forma a base teórica para a DAM

Avaliação de desvio
• A avaliação da distância (desvio) de uma média de amostra em relação à média de uma população é um procedimento clássico no arsenal estatístico e forma a base do procedimento conhecido como teste de hipótese
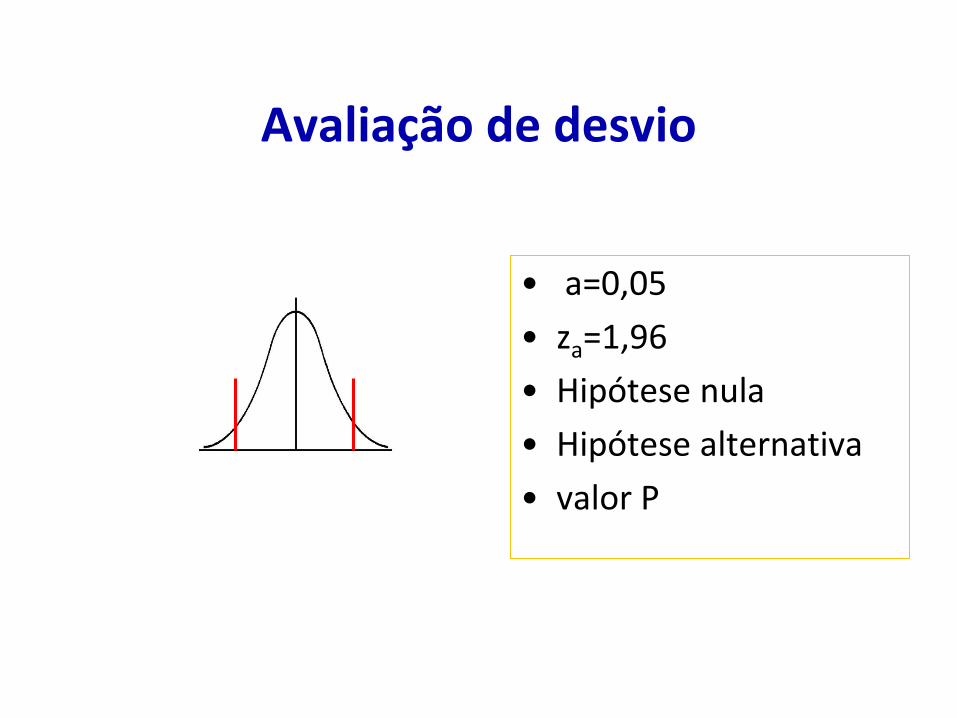
Avaliação de desvio
• a=0,05
• za=1,96
• Hipótese nula
• Hipótese alternativa
• valor P

O teste de hipótese
• É o procedimento clássico nas comparações em estatística. Quando dois grupos ou mais de indivíduos serão comparados geralmente realiza-se um teste de hipótese.

O teste de hipótese
• Hipótese nula (Ho): parte da igualdade (p.e. a=b)
• fixa-se o a (geralmente 0,05 ou 5%)
• busca-se o valor crítico segundo o teste a ser utilizado(p.e. za=1,96)
• realiza-se o teste estatístico (p.e. zcalc)
• pode-se obter o valor P referente ao teste executado
• compara-se o valor calculado com o valor crítico e rejeita-se ou não a Ho.
Os elementos básicos do teste de hipótese são:

Teste de hipótese
Dados populacionais
PAS: = 128mmHg e = 24mmHg
• Ho: o = m
• Ha: o m
• a = 0,05; za = 1,96
x
xz
26213
07
60
24
128135z ,
,
,
Como |zcalc| = 2,26 > zcalc = 1,96, rejeita-se Ho. A média amostral difere siginificativamente do parâmetro de referência (P=0,024).
Amostra (usando M)média = 135mmHg;
n = 60.

Erros de decisão do tipo I e II(e respectivas probabilidades)
Verdade
Ho Falsa Ho Verdadeira
Rejeita HoCorreto
(P = 1- )poder do teste
Erro tipo II(P = )
Ñ Rejeita Ho Correto(P = 1 - a)
Erro tipo I(P = a)

Poder de um teste
• Poder de um teste (1): probabilidade de detectar uma diferença (ou um efeito) que realmente existe.
• Utilizado para calcular que tamanho devem ter as amostras para se encontrar um efeito estatisticamente significante, caso exista este efeito.
• Quanto maior o poder desejado, maior deve ser o tamanho da amostra.

Obtendo-se o valor P
zcalc = 2,26
Procurando-se na tabela de valor críticos de z obtém-se que para este valor a área central é 0,4881.
0,4881
área caudal = 0,5 - 0,4881= 0,0119
P = 0,0119 x 2 = 0,0238 0,024zcalc = 2,26

Resumo
• Parâmetro população
• Estimativa amostra
• Curva normal modelo fundamental
• Ao apresentar resultados de estudos (amostras) devemos sempre que possível expressar a incerteza dos achados(p.e., IC95%)

Resumo
• Quanto maior o escore z de um evento, maior o desvio e menor a probabilidade de sua ocorrência na população de referência.
• Teste de hipótese: avalia a Ho. O valor P representa a probabilidade de observarmos um dado/evento quando a hipótese nula é verdadeira

Resumo
• Um achado estatisticamente significativo não representa obrigatoriamente algo importante, mas simplesmente que foi rejeitada a existência de um efeito zero.

Elementos básicosde inferência estatística
Comparação de grupose intervalos de confiança

Objetivos
• Apresentar os testes estatísticos mais corriqueiros
– t de Student
– r de Pearson
– b, regressão
– análise de proporções (IC)
– 2

Teste t de Student
• Como o s é desconhecido, este é substituído pelo DP amostral ficando o erro padrão expresso por
n
DPEP

Teste t de Student
• A confiabilidade de DP como um bom estimador de s depende essencialmente do n (usa-se o gl=n-1)
• Ao usarmos o t de Student o valor crítico za é substituído por um valor ajustável e que muda não só pelo a, mas também pelo tamanho amostral: ta;gl

Teste t de Student
• Caso de uma média amostral
– teste contra uma média populacional
– intervalo de confiança para m
EP
xt
EPtxμIC α;gl

W.S. Gosset era formado em química e trabalhou comopesquisador da cervejaria Guinness (Dublin, Irlanda) durantequase toda sua vida. Com o auxílio do notável Prof. Karl Pearson,Student escreveu sobre “o provável erro da média” e inventou ofamoso teste t, o qual é utilizado até hoje para analisar amostrascom n pequeno.
William Sealey Gosset (Student) 1876, Canterbury, Inglaterra 1937, Beaconsfield, Inglaterra
O pai do teste t

A distribuição t
• Tem forma de sino como a normal, mas é mais achatada.
• Quanto maior a amostra, mais próxima da curva normal é a curva t, porque quanto maior a amostra, melhor s estima .
• Valores críticos: obtidos da tabela conforme a e o tamanho da amostra (gl = n – 1).
Valor tabelado: t a ; gl

Teste de hipóteses com desconhecido: teste t
Pessoas saudáveis
Dados populacionais
= 6,1 = ??
• Ho: pac = saudáveis = 6,1
• Ha: pac saudáveis
• a = 0,05
• ta;gl = t0,05;14 = 2,145
EP
xt
n
sEP
Pacientes com a doença D:
Amostra:
n = 15; média = 6,5; s = 0,5
Título de anticorpos anti-A em pacientes com a doença D: difere do título nos indivíduos saudáveis?

083130
40
15
50
1656,
,
,
,
,,
n
s
xt
Como |tcalc| = 3,08 > t0,05;14 = 2,145, rejeita-se Ho. A média amostral (média = 6,5) difere significativamente do parâmetro de referência ( = 6,1).
Os pacientes com a doença D apresentam título de anti-A mais alto do que os indivíduos saudáveis.
Teste de hipótesescom desconhecido
2,145
3,08t0,05;14

m = ?
s = ?
média= 6,5
n = 15s = 0,5
Estimando a média populacional desconhecida: intervalo de confiança para a média
População de pacientes com D: qual o título verdadeiro
de anti-A?
Amostra de15 pacientes
Estimação:- por ponto- por intervalo

EPtx gl a;ˆ
Li = 6,5 ( 2,145 0,13) = 6,22
Intervalo de 95% confiança para a média
Ls = 6,5 + (2,145 0,13) = 6,78
então, IC 95% (): 6,2 a 6,8
t 0,05;14 = 2,145
EP = 0,13
ME = 0,28
Margem de erro ouerro de estimação

Teste t para duasamostras independentes
Dados de PAS (mmHg)
1(obesos): 150,611,1; n=13
0(não obesos): 140,910,1; n=14
• Ho: A = B
• Ha: A B
• a = 0,05;
• gl=nA+nB-2=25
• ta;gl = t0,05;25 = 2,060
Para avaliar a relação entre obesidade e
PAS foram estudados 27 indivíduos: 13 obesos (IMC ≥ 30 Kg/m2)
14 não obesos (IMC < 30 Kg/m2)

dif
BA
EP
xxt
B
2
o
A
2
odif
n
s
n
sEP
2
222
BA
BBAAo
nn
glsglss
Teste t para duas amostras independentes
média da variabilidadevariância ponderada (pooled var)
erro padrão da diferençausando a (SE difference)2
os
t calculado usado para obtermos o valor P

38,208,4
9,1406,150
t
08,414
19,112
13
19,112difEP
19,112
21413
1141,101131,1122
2
os
Teste t para duas amostras independentes

Teste t para duas amostras independentes
Usando SPSS
estatísticasdescritivas
teste estatístico com valor P e intervalo de confiança para as diferenças2,38 ~ 2,39

Teste t para duas amostras independentes
Usando SPSS
Dados de PAS (mmHg)
1(obesos): 150,611,1; n=13
0(não obesos): 140,910,1; n=14
homogeneidade
de variâncias
teste t P
Diferença de
médias (efeito)
intervalo de
confiança de 95%
pressupostos do t
de Student
- homocedasticidade
- normalidade
- var. quantitativa

Teste t para duasamostras independentes
Como |tcalc| = 2,394 > t0,05;25 = 2,060, rejeita-se Ho. As médias das duas amostras diferem significativamente entre si, sendo maior a PAS entre os obesos (P=0,025).
Esta conclusão é só o resultado de um teste de significância estatística (contra zero). Não se refere à importância clínica, magnitude do efeito ou se o mesmo é válido (questionar métodos do estudo e potenciais fatores de confusão).

difglBA EPtxx a;ˆ
Li = 9,76 2,060 4,08 = 1,36
Intervalo de confiançada diferença de médias
Ls = 9,76 + 2,060 4,08 = 18,17
IC95%(): 1,4 a 18,3 mm(Hg)

Pressupostos para o teste t entre duas amostras
• x normal ou aproximada. Na falha desse pressuposto é possível lançar mão de transformações matemáticas que ajudam a diminuir a assimetria e melhoram o desempenho do teste. Transformações: log é a mais usada (outras: 1/x, quadrado e raiz quadrada). A transformação rank quando usada faz com que os testes paramétricos tenham um desempenho semelhante aos não-paramétricos.
• variâncias homogêneas (Levene; t de Welch – “not pooled variances”)

Teste t de Student
• Caso de duas médias emparelhadas
– mesmo procedimento do caso de uma média
EP
xt
EPtxμIC α;gl

Efeito de variáveis externas na comparação de grupos
• Ao compararmos as médias de dois grupos outras variáveis podem influenciar os resultados.
• As variáveis que comprometem as comparações são freqüentemente denominadas variáveis de confusão.

Exemplo de efeito de confusão
PAS
Obesidade
Idade

Controle de confusão nodelineamento do estudo
• Randomização
• Restrição: critérios de inclusão/exclusão
• Emparelhamento

média
DP
t de Student: amostras emparelhadas
P idade: 0,44P PAS (empar): 0,59
n = 9 pares PAS (mmHg)

Teste de t emamostras emparelhadas
Amostra
dif média = 0,7
DP = 3,6
GL = n - 1
• Ho: o = 0
• Ha: o 0
• a = 0,05;
• ta;gl = t0,05;8 = 2,306
EP
xt
n
sEP
EP
xt

56,0202,1
67,0
9
61,3
67,0
t
Como |tcalc| = 0,56 < t0,05;8 = 2,306, não se rejeita Ho. Não há evidências com este estudo de que a PAS está associada com obesidade (P=0,59).
Teste de hipótesecom desconhecido

EPtxIC gl ;a
Li = 0,67 2,306 1,20 = 3,44
Intervalo de confiançapara a média das diferenças
Ls = 0,67 + 2,306 1,20 = 2,11
IC95%(): 3,4 a 2,1 mm(Hg)

t de Student: amostras emparelhadas
intervalode confiançada diferença
Diferença valor Pteste t
GL

Duas variáveis quantitativasCorrelação e Regressão
• No caso de duas variáveis quantitativas as estatísticas mais usadas são o coeficiente de correlação de Pearson (r) e a técnica de regressão linear simples.

Correlação linear
Karl Pearson
1857, Londres, Inglaterra
1936, Londres, Inglaterra
O desenvolvimento da correlação linear recebeu uma importante contribuição a partir de 1893 com os estudos de Karl Pearson.
Pearson formou-se em matemática em Cambridge, 1879 e atuou como professor de Matemática Aplicada no University College, London durante a maior parte do tempo de sua carreira acadêmica.

Correlação linear
n
yy
n
xx
n
yxxy
r2
2
2
2

0 10 20 30 40 50 60 70 80 90 100 110 120 130 140 1500.0
0.2
0.4
0.6
0.8
1.0
1.2
Gráficos de dispersão de pontos
r = 0,76 r = 0,42
r = - 0,82r = 0
relação não linear

Teste t de Student para o coeficiente de correlação
Dados da amostra
r = 0,58 e n=8
• Ho: r = 0
• Ha: r 0
• a = 0,05
• gl=nº de pares-2=6
• ta;gl = t0,05;6 = 2,447Estudo (horas)
0 1 2 3 4 5 6 7 8 9
No
ta n
a p
rova
0
1
2
3
4
5
6
7
8
9
10

2n
r1
r
EP
rt
2r
Como |tcalc| = 1,74 < t0,05;6 = 2,447, não há evidência de correlação uma vez que o desvio de r em relação a r=0 não foi significativo.
Teste t de Student para o coeficiente de correlação
741
28
5801
580t
2,
,
,
*
* É possível obter-se, também, o intervalo de confiança para o r

Uma escala de magnitudes
Adaptada de Will Hopkins, http://www.sportsci.org/resource/stats/effectmag.html
trivial small moderate large
very
large
nearly
perfectperfect
r 0.0 0.1 0.3 0.5 0.7 0.9 1
ES 0.0 0.2 0.6 1.2 2.0 4.0 infinite
Freq. diff. 0 10 30 50 70 90 100
RR 1.0 1.2 1.9 3.0 5.7 19 infinite
OR 1.0 1.5 3.5 9.0 32 360 infinite

Correlação linearCoeficiente de determinação
• O quadrado do coeficiente de correlação (r2) é conhecido como coeficiente de determinação e representa a “variância explicada”, ou seja, qual a proporção da variabilidade de y que pode ser explicada pela variabilidade de x.

Explorador e antropologista, Galton tornou-se famoso por seusestudos pioneiros sobre hereditariedade da inteligência. Galtondescobriu a regressão linear (a qual chamou inicialmente dereversão) estudando ervilhas, provavelmente influenciado por seunão menos famoso primo, o biólogo Charles Darwin. Apesar denão ser matemático, Galton influenciou o pensamento estatísticoda época tendo como um de seus seguidores o jovem matemáticoKarl Pearson.
Francis Galton1822, Birmingham, Inglaterra 1911, Surrey, Inglaterra
Galton e a reversão

Regressão linear
• Técnica de análise de dados que permite quantificar o efeito de x sobre y partindo de um modelo linear (reta).
• Com regressão linear é possível estimar o valor de y (variável dependente) a partir de um valor de x (variável independente).

Altura (cm)
Peso (Kg)
A reta de regressão linear
altura peso152 55153 56160 63163 60165 61171 64172 70178 71180 73181 85185 80186 89186 75

• y: peso (v. dependente)
• x: altura (v. independente)
• b: coeficiente angular. Efeito de x em y, ou seja, para cada alteração de uma unidade em x, y altera-se em b unidades.
• a: coeficiente linear. Ponto em y quando x for igual a zero.
Altura (cm)
Peso (Kg)
A reta de regressão linear
y = a + bx

Regressão linear
n
xx
n
yxxy
b2
2
xbya
y = a + bx

Regressão linear
Assim, no exemplo da altura (cm) e do peso (kg) temos
n
xx
n
yxxy
b2
2
xbya
x8105369y ,,
altura8105369peso ,,

Teste de significância do coeficiente angular (b)
B = 0

Teste t de Student para o coeficiente angular
• Ho: B = 0
• Ha: B 0
• a = 0,05
• gl=nº de pares-2=11
• ta;gl = t0,05;11 = 2,201
altura peso152 55153 56160 63163 60165 61171 64172 70178 71180 73181 85185 80186 89186 75

bb EP
b
EP
Bbt
Teste t de Student para o coeficiente angular (b)
2
2
2
2n
xxn
xybyayEPb
onde

Teste t de Student para o coeficiente angular (b)*
altura(x)8105369peso(y) ,,
C oeffic ientsa
-69.52719.070-3.646.004
.809.111.9107.301.000
(C onstant)
ALTU R A
M odel
1
BStd. Error
U nstandard ized
C oefficients
Beta
Standard ized
C oefficients
tS ig .
D ependent Variab le: PESOa.
SPSS output

Teste t de Student para o coeficiente angular (b)*
Como |tcalc| = 7,30 > t0,05;11 = 2,201, o “b” é significativamente diferente de zero, havendo regressão do peso sobre a altura.
* É possível obter-se o IC para o b.
C oeffic ientsa
-69.52719.070-3.646.004
.809.111.9107.301.000
(C onstant)
ALTU R A
M odel
1
BStd. Error
U nstandard ized
C oefficients
Beta
Standard ized
C oefficients
tS ig .
D ependent Variab le: PESOa.
SPSS output

Análise de proporções
• Caso de uma proporção amostral
– teste contra uma proporção populacional (via z/2)
– intervalo de confiança para p

Análise de proporções
• Caso de uma proporção amostral
– teste contra uma proporção populacional (via z/2)
n
PQ
nPp
z 2
10

Análise de proporções
• Caso de uma proporção amostral
– intervalo de confiança para p
n
qpPE p
)(
(p)α EPzpπIC

Exemplo para intervalode confiança de proporção
Dados da amostra
Produção de b-lactamase em isolados de H. influenzae
x(eventos)=75; n=300
p=x/n, p=75/300=0,25

Li = 0,25 1,96 0,025 = 0,30
Ls = 0,25 + 1,96 0,025 = 0,20
IC95%(): 0,2 a 0,3ou 25% (IC95%: 20 a 30)
Exemplo para intervalode confiança de proporção
)( pEPzpIC a

Análise de proporções
• Caso de duas proporções
– teste de uma proporção contra a outra (via z, 2, RR,OR).
ba
ba
nnqp
Cppz
1100
nbnaC
115,0
ba
ba
nn
xxp
0

A estatística qui-quadrado (2) foi criada por Karl Pearson para:
• Verificar se uma distribuição observada de dados se ajusta a uma distribuição teórica.
• Comparar as proporções de duas ou mais populações.
• Verificar se existe associação entre variáveis categóricas.
Qui-Quadrado

• 2 calculado: mede discrepância entre freqüências observadas (O) e freqüências esperadas segundo determinada lei (E).
• 2: valor entre 0 e infinito.
• Como saber se diferenças entre O e E podem ser aleatórias?
• Compara-se 2 calculado com valor tabelado, conforme a e gl.

A distribuição 2

Principais usos
• Adequação de ajuste (Goodness of fit)
• Associação entre variáveis categóricas

Procedimento do 2
• Depende da aplicação da fórmula
• GL é determinado por categorias
E
EO2
2

Valor calculado é comparado com valor de tabela segundo a distribuição e o GL
20,05;2 = 5,99
Não se rejeita H0
Rejeita-se H0
Valor calculado = 2,25
0

Teste de associação
Tipo de Pneumopatia
Eosinófilos
no escarro T1 T2 T3 T4 Total
Sim 142 26 32 28 228(59%)
Não 55 19 41 41 156(41%)
Total 197 45 73 69 384
Existe associação entre presença de eosinófilos no escarro e tipo de pneumopatia?

Teste de associação
• Não existe lei anterior que determine o número esperado em cada classe.
• Então, supõe-se que não há diferença entre os grupos e os E são calculados por “regra de três”, o que leva a
GeralTotal
LinhaTotalColunaTotalE

Teste de associação
• Ho: O = E (supondo independência)
HA: O E
E
)EO( 22
• 2 calculado = 30,44
• gl = (Linhas - 1)(Colunas -1)
2a;gl = 2
0,001;3 = 16,27
• 2 calculado = 30,44 > 20,001;3 = 16,27, rej. Ho.
• Freq. observadas diferem significativamente das esperadas.
Existe associação entre presença de eosinófilos no escarro e tipo de pneumopatia.
GeralTotal
LinhaTotalColunaTotalE

Teste de associação
Eosinófilos Tipo de Pneumopatia
no escarro T1 T2 T3 T4 Total
Sim 142 26 32 28 228
Não 55 19 41 41 156
Total 197 45 73 69 384
% com eosin. 72% 58% 44% 41% 59%no escarro

Exemplo
Investigar se existe associação entre artropatia e história familiar positiva para essa condição.
Foram estudados 114 pacientes com artropatia
Casos
Após entrevista 54 relataram ter parentes em 1º grau que também apresentavam queixas de artropatia
Foram estudados 334 pacientes sem nenhum sintoma de artropatia
Controles
Após a mesma entrevista 89 relataram ter parentes em 1º grau que apresentavam queixas de artropatia

Tabela de contingência 2 x 2
Artropatia
História familiar Presente Ausente Total
Positiva 54 (47,4) 89 (26,6) 143
Negativa 60 245 305
Total 114 334 448
Exemplo
Investigar se existe associação entre artropatia e história familiar positiva para essa condição.

Exemplo
Investigar se existe associação entre artropatia e história familiar positiva para essa condição.
48224589
6054OR ,
/
/ IC95%: 1,56 a 3,94

Tabelas 2 X 2: correção de Yates
Retinopatia
Pacientes Sim Não
C/proteinúria 33 4
S/proteinúria 23 13
E
EO 2
2)5,0(
Correção de Yates:


Exigências para aplicação do 2
1. gl=1: Correção de Yates
2. E < 5 deve ser menor que 20%
Na ruptura de pressupostos
- Simulações de Monte Carlo
- Teste exato de Fisher


Resumo
• O teste de hipótese é um procedimento comum e muito utilizado.
• Recomenda-se que seja complementado por intervalos de confiança, tanto para médias como para proporções.

Elementos de amostragem

Passos para a seleção dos sujeitos do estudo
PERGUNTADE PESQUISA
VERDADENO UNIVERSO
População-alvo
Especificar característicasclínicas, demográficas e
geográficas
PLANO DE ESTUDO
VERDADENO ESTUDO
Amostra Pretendida
Especificar populaçãoacessível e
abordagem paraseleção da amostra
Delineamento

Generalização dos Resultados
PERGUNTADE PESQUISA
VERDADENO UNIVERSO
População-alvoGENERALIZAÇÃO RAZOAVELMENTE
SEGURAMesma associação em
adultos brancos na classemédia dos EUA
GENERALIZAÇÃOMENOS SEGURA
Mesma associação existe:a) Outros adultos dos EUA
b) Pessoas moradoras em outros países
c) Pessoas que estarão vivendo em 2020
PLANO DE ESTUDO
ACHADOS NOESTUDO
Sujeitos doEstudo
Associação entreHipertensão e DAC
Observada em uma Amostra de adultos
De FraminghamInferência

Técnicas de amostragem
• Conveniência
• Probabilística
– Aleatória simples
– Aleatória estratificada
– Conglomerado
– Sistemática

Técnicas de amostragem
• Conveniência
• Probabilística
– Aleatória simples
– Aleatória estratificada
– Conglomerado
– Sistemática
Indivíduos que preenchem os critérios de inclusão e são de fácil acesso ao investigador. Melhor usada em processo de inclusão consecutivo para evitar viés de voluntarismo. Abordagem muito usada em pesquisa clínica.

Técnicas de amostragem
• Conveniência
• Probabilística
– Aleatória simples
– Aleatória estratificada
– Conglomerado
– Sistemática
Padrão-ouro na generalização. Baseada em sorteio.

Técnicas de amostragem
• Conveniência
• Probabilística
– Aleatória simples
– Aleatória estratificada
– Conglomerado
– Sistemática
Padrão-ouro na generalização. Baseada em sorteio.
Enumeram-se os todos indivíduos que compõem a população e seleciona-se aleatoriamente uma amostra. Ex: Listar todas as cirurgias do mês X e usar números aleatórios para selecionar 20 procedimentos que serão estudados detalhadamente.

Técnicas de amostragem
• Conveniência
• Probabilística
– Aleatória simples
– Aleatória estratificada
– Conglomerado
– Sistemática
Padrão-ouro na generalização. Baseada em sorteio.
Identifica estratos na população. (p.e.: sexo, raça) e realiza o sorteio dentro dos mesmos permitindo o controle da proporção desses estratos na amostra. Ex.: Estudar iguais proporções de mulheres negras e brancas na pré-eclâmpsia.

Técnicas de amostragem
• Conveniência
• Probabilística
– Aleatória simples
– Aleatória estratificada
– Conglomerado
– Sistemática
Padrão-ouro na generalização. Baseada em sorteio.
Parte de conglomerados ou agrupamentos naturais (p.e.: cidades, bairros, quarteiões) os quais são sorteados e re-amostrados. Ex: Estudo epidemiológico seleciona 5 quarteirões que são visitados por equipe que lista e sorteia as casas a compor a amostra.

Técnicas de amostragem
• Conveniência
• Probabilística
– Aleatória simples
– Aleatória estratificada
– Conglomerado
– Sistemática
Padrão-ouro na generalização. Baseada em sorteio.
Após enumer todos os indivíduos que compõem a população a seleção da amostra é feita por processo periódico. Ex: Listar todas as cirurgias do mês X e selecionar 1 de cada 10 para estudado detalhado.

A generalização abrangeum julgamento complexoe amplamente qualitativo