modelando dados de contagem com inflaÇÃo de zeros
TRANSCRIPT

MODELANDO DADOS DE CONTAGEM COM INFLAÇÃO DE ZEROS,SOBREDISPERSÃO E DEPENDÊNCIA ESPACIAL
Carla Zeline Rodrigues Bandeira
Dissertação de Mestrado apresentada aoPrograma de Pós-graduação em Matemática,da Universidade Federal do Amazonas, comoparte dos requisitos necessários à obtenção dotítulo de Mestre em Matemática
Orientador: Max Sousa de Lima
ManausSetembro de 2015


Rodrigues Bandeira, Carla ZelineMODELANDO DADOS DE CONTAGEM COM
INFLAÇÃO DE ZEROS, SOBREDISPERSÃO EDEPENDÊNCIA ESPACIAL/Carla Zeline RodriguesBandeira. – Manaus: UFAM/ICE, 2015.
XIII, 67 p.: il.; 29,7cm.Orientador: Max Sousa de LimaDissertação (mestrado) – UFAM/ICE, Área de
Concentração: Estatística, 2015.Referências Bibliográficas: p. 64 – 67.1. Inflação de Zeros. 2. Sobredispersão. 3. Dependência
Espacial. 4. Quase Verossimilhança. 5. Equaçõesde Estimação Generalizadas. 6. Algoritmo Expectation-Solution. 7. Inferência Bootstrap. I. Sousa de Lima,Max. II. Universidade Federal do Amazonas, UFAM, Áreade Concentração: Estatística. III. Título.
iii

Este trabalho dedico à Deus, pois
sem Ele nada existiria.
iv

Agradecimentos
Agradeço primeiramente à Deus, criador de todas as coisas, pelo dom da vida, porconceder-me saúde, perseverança e capacidade para o desenvolvimento deste trabalho.
À toda minha família pelo amor, carinho e companheirismo cultivado entre nós. Emespecial, agradeço aos meus pais, Zeneide e Carlos, e ao meu padrasto, Aldenir, por todoensinamento, amor e educação dados à mim ao longo da vida, e por sempre me incentivaremnos estudos. À minha avó, Zulmira, por todo ensinamento de vida e fé. Às minhas irmãs,Caroline e Camila, e sobrinha (filha), Ana Celine, por todo o amor, companheirismo, carinhoe felicidade que me proporcionam todos os dias. Aos meus afilhados, Adrielle e Alberto, porexistirem em minha vida. Aos meus primos, Lucélia, Jean, Eduarda e Haroldo, Alberto eEdna, pelos momentos de alegria e descontração. Aos meus tios, em especial à tia Nilda, porentender esses três anos de ausência da sua casa, à tia Carminha por sempre orar por mim eao tio Nazareno, pelo amor e carinho que tem por mim como uma filha.
Aos membros da banca examinadora dessa defesa de dissertação, por aceitarem o convitepara avaliar este trabalho. Ao meu orientador, professor Max Sousa de Lima, pela paciência,dedicação, confiança e incetivo na busca por conhecimento, contribuindo significativamentecom o desenvolvimento deste e minha formação acadêmica.
Aos meus amigos e professores do Departamento de Estatística, que contribuíram diretae indiretamente na minha formação acadêmica, pelo apoio e pela consideração. Em especial,aos que foram meus professores do mestrado: James Dean, José Raimundo, Max Lima eCelso Rômulo, por todo conhecimento disseminado, ao professor José Cardoso, pela ami-zade e conselhos, aos professores e amigos Nelson Filho, Diego Souza, Camila Pinheiro,Carina Coelho, Márcia Brandão e Jocely Lopes, e amigas do mestrado, Renan, Vanessa,Renata e Regina, pelos momentos de descontração e trocas de conhecimento.
Finalmente, mas não menos importante, agradeço aos meus amigos Alessandra, Adriana,Adriano, Diana, Geane, Marcos, Patrícia e Raquel, por todos os momentos de alegria ediversão vividos, e por entenderem todas as minhas ausências.
À CAPES, pelo apoio financeiro em 10 meses de estudos.
v

”Com efeito, de tal modo Deus amou o mundo, que
lhe deu seu Filho único, para que todo o que Nele crer
não pereça, mas tenha a vida eterna.” (João 3:16).
vi

Resumo da Dissertação apresentada ao Programa de Pós-Graduação em Matemática, daUniversidade Federal do Amazonas, como parte dos requisitos necessários para a obtençãodo grau de Mestre em Matemática. (M.Sc.)
MODELANDO DADOS DE CONTAGEM COM INFLAÇÃO DE ZEROS,SOBREDISPERSÃO E DEPENDÊNCIA ESPACIAL
Carla Zeline Rodrigues Bandeira
Setembro/2015
Orientador: Max Sousa de Lima
Área de Concentração : Estatística
Neste trabalho foi proposto um novo modelo para dados de contagem com excesso dezeros, sobredispersão e dependência espacial. Para acomodar simultaneamente essas ca-racterísticas, utilizou-se uma quase verossimilhança inflacionada de zeros (QIZ), onde adependência espacial foi incorporada no processo de estimação através das equações de es-timação generalizadas (GEE). O algoritmo de estimação usado nesse processo foi o ES(Expectation-Solution); os intervalos de confiança para os parâmetros foram obtidos via In-ferência Bootstrap. Estudos de simulação foram realizados considerando-se vários cenários.Finalmente, o método proposto foi ilustrado usando dados de casos de Hanseníase no Estadodo Amazonas.
vii

Abstract of Dissertation presented to Postgraduate in Mathematics, of the Federal Universityof Amazonas, as a partial fulfillment of the requirements for the degree of Master ofMathematics. (M.Sc.)
MODELING COUNT DATA WITH ZEROS INFLATION, OVERDISPERSION ANDSPATIAL DEPENDENCE.
Carla Zeline Rodrigues Bandeira
September/2015
Advisor: Max Sousa de Lima
Research area: Statistics
This work proposes a new model for count data with excess zeros, overdispersion andspatial dependence. To accommodate these characteristics simultaneously, we used an zero-inflated quasi-likelihood (QIZ), where the spatial dependence is incorporated in the esti-mation process through generalized estimating equations (GEE). The estimation algorithmused in this process was the ES (Expectation-Solution); confidence intervals for the param-eters were obtained via Bootstrap Inference. Simulation studies have been performed invarious scenarios. Finally, the method is illustrated using data of leprosy cases in the Stateof Amazonas.
viii

Sumário
Lista de Figuras xi
Lista de Tabelas xiii
1 Introdução 11.1 Aspectos Gerais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Justificativa e Importância do Trabalho . . . . . . . . . . . . . . . . . . . . 31.3 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.4 Estrutura do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Fundamentação Teórica 52.1 O Modelo Inflacionado de Zeros . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Estimação via Algoritmo EM . . . . . . . . . . . . . . . . . . . . 82.2 Quase Verossimilhança . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1 Estimação de Parâmetros . . . . . . . . . . . . . . . . . . . . . . . 122.3 Quase Verossimilhança Estendida . . . . . . . . . . . . . . . . . . . . . . 132.4 Equações de Estimação Generalizadas . . . . . . . . . . . . . . . . . . . . 152.5 Dependência Espacial em Dados de Contagens . . . . . . . . . . . . . . . 162.6 Algoritmo Expectation-Solution (ES) . . . . . . . . . . . . . . . . . . . . . 172.7 Intervalos de Confiança Bootstrap . . . . . . . . . . . . . . . . . . . . . . 18
2.7.1 Intervalo de Confiança Bootstrap-t . . . . . . . . . . . . . . . . . . 18
3 Modelos de Quase-Verossimilhança Inflacionados de Zeros para Dados de Con-tagem Espacialmente Dependentes 203.1 Modelo QIZ para dados com Independência . . . . . . . . . . . . . . . . . 21
3.1.1 Modelo Quase-Poisson Inflacionado de Zeros . . . . . . . . . . . . 233.1.2 Modelo Quase-Binomial Inflacionado de Zeros . . . . . . . . . . . 243.1.3 Modelo Quase-Binomial Negativo Inflacionado de Zeros . . . . . . 25
3.2 Modelo QIZ para dados com Dependência Espacial . . . . . . . . . . . . . 263.2.1 Estimação dos parâmetros no modelo QIZDE . . . . . . . . . . . . 273.2.2 Estimação Geral dos parâmetros no modelo QIZDE . . . . . . . . . 31
ix

3.3 Distribuição dos Estimadores via Bootstrap . . . . . . . . . . . . . . . . . 31
4 Estudo de Simulação 334.1 Descrição do Estudo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 334.2 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5 Aplicação do Modelo em Dados Reais 465.1 Descrição dos Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 465.2 Modelo ZIP para os novos casos notificados de hanseníase no Amazonas . 485.3 Descrição do Modelo Proposto . . . . . . . . . . . . . . . . . . . . . . . . 515.4 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
6 Considerações Finais 616.1 Principais Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 616.2 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
Referências Bibliográficas 64
x

Lista de Figuras
4.1 Mapa do Estado do Amazonas, com seus 62 municípios. . . . . . . . . . . 344.2 Boxplot das estimativas de β0, com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi. . . . . . . . . . . . . 404.3 Boxplot das estimativas de β1, com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi. . . . . . . . . . . . . 404.4 Boxplot das estimativas de γ0, com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi. . . . . . . . . . . . . 414.5 Boxplot das estimativas de γ1, com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi. . . . . . . . . . . . . 414.6 Boxplot das estimativas de ρ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi. . . . . . . . . . . . . 424.7 Boxplot das estimativas de ρ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 22,5% da ∼ Ber e 22,5% da ∼ Poi. . . . . . . . . . . 424.8 Boxplot das estimativas de ρ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 15% da ∼ Ber e 30% da ∼ Poi. . . . . . . . . . . . . 434.9 Boxplot das estimativas de φ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi. . . . . . . . . . . . . 444.10 Boxplot das estimativas de φ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 22,5% da ∼ Ber e 22,5% da ∼ Poi. . . . . . . . . . . 444.11 Boxplot das estimativas de φ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para
45% de zeros, sendo 15% da ∼ Ber e 30% da ∼ Poi. . . . . . . . . . . . . 45
5.1 Distribuição espacial dos novos casos de Hanseníase, notificados no Estadodo Amazonas-Brasil, no período de 2009 a 2012. . . . . . . . . . . . . . . 47
5.2 Correlograma espacial dos resíduos do modelo ajustado para novos casos deHanseníase no Estado do Amazonas-Brasil, nos anos de 2009 a 2012. . . . 50
5.3 Histograma (a) e Boxplot (b) das estimativas de β2. . . . . . . . . . . . . . 565.4 Histograma (a) e Boxplot (b) das estimativas de β3. . . . . . . . . . . . . . 575.5 Histograma (a) e Boxplot (b) das estimativas de γ0. . . . . . . . . . . . . . 575.6 Histograma (a) e Boxplot (b) das estimativas de γ1. . . . . . . . . . . . . . 58
xi

5.7 Histograma (a) e Boxplot (b) das estimativas de γ2. . . . . . . . . . . . . . 585.8 Histograma (a) e Boxplot (b) das estimativas de γ3. . . . . . . . . . . . . . 595.9 Histograma (a) e Boxplot (b) das estimativas de γ4. . . . . . . . . . . . . . 595.10 Histograma (a) e Boxplot (b) das estimativas de ρ . . . . . . . . . . . . . . 605.11 Histograma (a) e Boxplot (b) das estimativas de φ . . . . . . . . . . . . . . 60
xii

Lista de Tabelas
4.1 Fórmula Geral para β0 e γ0 de acordo com o φ . . . . . . . . . . . . . . . . 364.2 Estudo de Simulação, para 45% de Zeros. . . . . . . . . . . . . . . . . . . 374.3 Mapa do AM, para 45% de Zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi. . . 384.4 Mapa do AM, para 45% de Zeros, sendo 22,5% da ∼ Ber e 22,5% da ∼ Poi. 384.5 Mapa do AM, para 45% de Zeros, com 15% da ∼ Ber e 30% da ∼ Poi. . . 39
5.1 Resultados para o modelo ZIP(µi, pi), gerados pela função "zeroinfl", paraos novos casos de hanseníase, notificados no Estado do Amazonas-Brasil-2009/2012. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.2 Resultados para o modelo proposto, para os novos casos notificados de han-seníase de 2009 a 2012, com valor estimado, erro padrão e intervalo de con-fiança Bootstrap-t. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
xiii

Capítulo 1
Introdução
1.1 Aspectos Gerais
Na época atual, em que a tecnologia se torna a cada dia mais avançada, o surgimentode dados com comportamentos mais complexos têm requerido modelos estatísticos mais ro-bustos, que consigam adequar-se a eles, ou seja, que modelem esses dados de forma correta.Com isso, a demanda por métodos mais sofisticados de análise e interpretação de dados comcaracterísticas mais completas crescem. Dentro desses novos tipos de dados, encontram-se os que estão geograficamente referenciados e correlacionados, que inspiraram a criaçãode novas técnicas para análise e modelagem, formando um campo da estatística, conhecidocomo análise de dados espaciais ou estatística espacial.
Em estatística espacial, os dados de contagem geralmente são modelados através dedistribuições convencionais, como a Poisson ou a Binomial, o que talvez não seja adequadoem muitos cenários. Por exemplo, em áreas como medicina, saúde pública ou epidemiologiaé comum, devido a heterogeneidade da população, a contagem de casos de doenças apre-sentar maior variabilidade do que a prevista pela distribuição usual, pois as contagens emdeterminadas áreas são bem maiores do que a predita pelo modelo. Esse excesso de vari-abilidade é chamado de sobredispersão, cuja variância é maior do que a média, e tem sidoamplamente considerado na literatura (Fahrmeir & Tutz (2001); Lima et al. (2013)). A faltade modelagem para a sobredispersão existente pode levar a uma subestimação do erro padrãoe com isso ocasionar em inferências distorcidas para os parâmetros do modelo (ver Zhanget al. (2012)).
Outro problema comum em dados de contagens é que muitas vezes estes apresentamum número excessivo de zeros que não são esperados pelo modelo usual. Por exemplo, emum ambiente de vigilância epidemiológica, onde se realiza a contagem de novos casos depessoas com hanseníase, pequenas áreas podem apresentar um menor número de casos deinfectados em relação ao valor esperado predito, em decorrência da distância desses lugaresem relação aos estabelecimentos de saúde. Além disso, a subnotificação de novos casos pode
1

ocorrer, em regiões subdesenvolvidas, devido à coleta de dados ineficiente ou à dificuldadede acesso a lugares remotos. Esses fatores geram contagens de casos com excesso de zeros,fazendo com que haja heterogeneidade no processo. Perumean-Chaney et al. (2013) veri-ficaram em seu estudo que, ignorando o excesso de zeros nos dados, as estimativas para omodelo usual Poisson são equivocadas, pois há uma violação no modelo estatístico usual e,por consequência, em problemas de teste de hipóteses, o erro tipo I é inflado, acarretando emperdas de resultados estatisticamente significativos.
Modelos para dados inflacionados de zeros (ZI), têm sido usados em diversas áreas(Hall (2000); Cheung (2002); Yau et al. (2004); Warton (2005)). Parâmetros estimadosusando ZI podem, também, ser severamente viciados se as contagens positivas forem subs-tancialmente dispersas, ou seja, se houver a sobredispersão na parte positiva dos dados. Si-multaneamente, dados de contagem podem apresentar essas duas fontes independentes deefeitos de sobredispersão. Se a sobredispersão é causada pela inflação de zeros, então o mo-delo Poisson inflacionado de zeros ZIP, introduzido por Lambert (1992), pode fornecer umajuste suficiente para os dados. Uma vez modelada a inflação de zeros, se os dados conti-nuam a sugerir sobredispersão adicional, devemos considerar um modelo de contagem queacomode também a sobredispersão nos valores positivos.
A não modelagem simultânea da sobredispersão e inflação de zeros pode causar umainferência enganosa. Por exemplo, em um estudo simulado, Perumean-Chaney et al. (2013)verificaram que, quando a inflação de zeros nos dados for ignorada, as estimativas para omodelo Poisson são equivocadas e os resultados estatisticamente significativos podem serperdidos. Quando a sobredispersão dentro do modelo inflacionado de zeros for ignorada, aestimativa do erro Tipo I é inflada. Nestes casos, os modelos inflacionados de zeros PoissonGeneralizado (ZIGP), Poisson Duplo (ZIDP) ou o Binomial Negativo (ZINB) podem serboas alternativas para a modelagem conjunta da inflação de zeros e sobredispersão nos dados(Lima & Duczmal (2014)).
Em processos de contagem geograficamente referenciados, os modelos ZIGP, ZIDPe ZINB são flexíveis para incorporar a inflação de zeros, a sobredispersão e o ajuste porcovariáveis, mas ao mesmo tempo são limitados por não assumirem dependência ou exis-tência de correlação espacial, o que sempre ocorre em problemas dessa natureza, pois dadoscoletados em áreas vizinhas tendem a ser mais similares (ou correlacionados) do que os ob-tidos em áreas mais distantes geograficamente. Um exemplo comum desta situação, ocorrena área de saúde pública, onde epidemiologistas estudam a variação geográfica dos casos dedoenças para gerar e refinar hipóteses testáveis sobre a sua etiologia. Neste contexto, mode-los hierárquicos têm sido propostos para utilizar localizações espaciais e seus vizinhos comosubstitutos para fatores de riscos desconhecidos ou não mensuráveis na análise dos casos dadoença.
Para acomodar simultaneamente os problemas de sobredispersão, inflação de zeros e
2

dependência espacial em processos espaciais de contagem, propomos uma nova modelagemutilizando uma quase verossimilhança inflacionada de zeros (QIZ). A função de quase veros-similhança (Q) ou, mais precisamente, a função de quase log-verossimilhança, foi propostapor Wedderburn (1974) e reexaminada por McCullagh & Nelder (1983). Essa função podeser usada para estimação de forma semelhante à função de verossimilhança. Sua grandevantagem é necessitar apenas da especificação da relação entre a média e a variância dasobservações, enquanto que na verossimilhança precisa-se especificar também a forma cor-reta da distribuição das observações. A quase verossimilhança foi estendida por Nelder &Pregibon (1987) para incluir termos da variância, comparar diferentes funções de variânciae, ainda, a possibilidade de modelar a dispersão (ou a sobredispersão) como uma funçãode covariáveis. A estimação dos parâmetros, neste caso, é realizada sobre a suposição deindependência estatística entre as observações.
Nesta dissertação, propomos que o excesso de zeros e a sobredispersão sejam mo-delados, respectivamente, por uma distribuição de Bernoulli e pela quase verossimilhançaestendida. O resultado é uma mistura de modelos representado por uma quase verossimi-lhança estendida inflacionada de zeros (QIZ). Para incorporar a dependência espacial, utili-zamos no processo de estimação as equações de estimação generalizadas (GEE), propostaspor Liang & Zeger (1986) , que construíram funções de estimação para os parâmetros deinteresse na ausência da verossimilhança totalmente especificada e presença de correlação,que é exatamente o nosso caso.
O algoritmo de estimação utilizado nesse processo foi o ES (Expectation-Solution)(ver Elashoff & Ryan (2004)), que consiste na substituição do passo de maximização (M) noalgoritmo EM por um passo que requer a solução (S) de uma equação de estimação genera-lizada. No contexto de mistura de GLM’s, Rosen et al. (2000) mostraram que se o algoritmoES convergir, ele convergirá para um estimador não-viciado, consistente e assintoticamenteNormal, sob suaves condições de regularidade.
1.2 Justificativa e Importância do Trabalho
Devido ao avanço tecnológico, surgiram várias estruturas de dados mais complexas,incluindo estes que englobam excesso de zeros, sobredispersão e dependência espacial. Es-sas novas estruturas exigem modelos compatíveis com seus comportamentos, que consigammodelar os dados da melhor forma, nos dando estimativas e interpretações corretas dos da-dos. A grande importância deste trabalho é por haver pouquíssimos trabalhos nessa área deestatística espacial, que englobe ao mesmo tempo aos dados de contagem o excesso de zeros,sobredispersão e dependência espacial, além da grande aplicabilidade do modelo em dadoscom essas características, como por exemplo dados epidemiológicos, de saúde pública e decriminalidade, podendo ajudar na vigilância epidemiológica e na análise de incidência de
3

crimes.
1.3 Objetivos
Este trabalho teve como principal objetivo a modelagem de processos de contagem,com excesso de zeros, sobredispersão e dependência espacial. Como metas e objetivos es-pecíficos tivemos:
1) A construção de modelos para processos de contagem distribuídos no espaço comexcesso de zeros, sobredispersão e correlação espacial;
2) O desenvolvimento e implementação do algoritmo ES para a estimação de parâmetrosdos modelos propostos;
3) A realização da análise dos modelos propostos com dados reais;
4) A realização de estudos com dados simulados para avaliar o desempenho do métodoproposto em vários cenários.
1.4 Estrutura do Trabalho
A dissertação está estruturada como segue: no Capítulo 2 descreveremos as princi-pais abordagens utilizadas no desenvolvimento deste trabalho, que são o modelo para dadosde contagem inflacionados de zeros (ZI), com sua representação estocástica e seu processode estimação via algoritmo EM, as funções de quase verossimilhança (Q) e quase verossi-milhança estendida Q+, com suas características e propriedades, as equações de estimaçãogeneralizadas GEE, o algoritmo ES e intervalos de confiança Bootstrap. No Capítulo 3introduziremos o modelo proposto, de quase-verossimilhança inflacionada de zeros (QIZ),para dados sem e com dependência espacial, suas caracterização, propriedades e estimaçãovia algoritmo ES, e também apresentaremos a inferência Bootstrap, com a definição de inter-valos de confiança gerados por este método. Estudos de simulação comparativos, realizadosem diversos cenários, a fim de comparar o desempenho do modelo são discutidos no Capí-tulo 4. Uma aplicação do modelo proposto em dados reais de hanseníase, da região nortedo Brasil, é apresentada no Capítulo 5. Finalmente, no Capítulo 6 discutimos os resultadosobtidos, as principais conclusões e propostas de trabalhos futuros.
4

Capítulo 2
Fundamentação Teórica
Neste capítulo faremos um breve levantamento da teoria utilizada no desenvolvi-mento deste trabalho. "Os principais tópicos abordados"são os modelos inflacionados dezeros, quase-verossimilhança, equações de estimação generalizada, modelos de regressãoespacial, algoritmo Expectation-Solution (ES) e intervalos de confiança Bootstrap, com suasrespectivas definições e propriedades.
2.1 O Modelo Inflacionado de Zeros
Eventualmente, é bem comum dados de contagem apresentarem um número exces-sivo de zeros. Esses zeros podem ser ocasionados por diferentes processos inerentes aosdados. Em diversas áreas, como por exemplo vigilância epidemiológica, saúde pública, bi-ologia, sociologia, engenharia, agricultura e criminalidade, dados com essa característicasurgem facilmente. Um exemplo, em vigilância epidemiológica, seria a contagem de novoscasos de hanseníase, em determinada localização (cidade, estado, região, país, etc.), apre-sentar uma quantidade de zeros acima do predito pelo modelo probabilístico proposto paraos dados, como por exemplo os modelos de Poisson ou Binomial. Esse excesso de zerospode ter ocorrido, por exemplo, pela subnotificação de casos, devido a dificuldade de acessoa lugares remotos para o registro de novos casos, ou pela não ocorrência de novos casosnessa localidade. Para esse problema, existem diversos modelos de regressão inflacionadosde zeros (ZI) que podem perfeitamente modelar esses tipos de dados.
Uma forma bastante simples de verificar se dados de contagem possuem ou não umexcesso de zeros é através da quantidade: zi = p0− P(Y = 0), a qual chamaremos de índicede inflação de zeros, em que Y é uma variável aleatória discreta, p0 é a proporção de zerosnos dados e P(Y = 0) é a probabilidade de ocorrer o zero segundo o modelo de contagemproposto. Se o valor de zi <= 0, diz-se que a variável aleatória Y segue a distribuição decontagem usual proposta, e se zi > 0, modelos ZI que acomodem a inflação de zeros sãomais adequados para os dados Lambert (1992).
5

Atualmente, existem diversos modelos (ZI), que são bastante utilizados na literaturapara modelar dados de contagem com excesso de zeros, como por exemplo os modelos:Poisson Inflacionado de Zeros (ZIP), Binomial Inflacionado de Zeros (ZIB), Poisson Gene-ralizado Inflacionado de Zeros (ZIGP) e Conway-Maxwell Inflacionado de Zeros (ZICM).Johnson & Kotz (1969) desenvolveram o modelo (ZIP) sem efeito de covariáveis, Lambert(1992) adicionou ao modelo ZIP o efeito de covariáveis, aplicando esse modelo em dados decontagem de defeitos de manufatura. Hall (2000) adaptou o modelo ZIP de Lambert (1992)e desenvolveu o ZIB incorporando efeitos mistos e sobredispersão, aplicando-o em dados dehorticultura. Podemos encontrar, ainda, aplicações dos modelos ZI nos contextos de estatís-tica espacial (Cancado et al. (2011); Lima et al. (2013)), séries temporais (Yang (2012)), nasáreas de medicina (Van den Broek (1995)), de biologia (Nie et al. (2006)) e em construçõesde novos modelos, como por exemplo o modelo de regressão Poisson inflacionado de zerosmultinível (Lee et al. (2006) e modelos marginais para dados agrupados inflacionados dezero Hall & Zhang (2004)).
A teoria sugere que os zeros excedentes são gerados por um processo separado dosvalores da contagem, e que estes podem ser modelados de maneira independente. Dessaforma, os modelos ZI são representados por uma mistura de duas distribuições. Seja Y =
(Y1, ...,Yn)T um vetor de observações de contagens independentes, dizemos que Yi segue um
modelo inflacionado de zeros ZI(pi,θ ), se sua distribuição é da forma:
Yi ∼ pi I{y=0}+(1− pi)Pθ (2.1)
em que pi é a probabilidade de ocorrer o zero estrutural, I é a função indicadora, (1− pi) é aprobabilidade de Yi seguir uma distribuição de contagem Pθ , parametrizada pelo vetor θ . Afunção de probabilidade de Yi é dada por:
f (yi; pi,θ) =
{pi +(1− pi)Pθ (Yi = yi), se yi = 0,(1− pi)Pθ (Yi = yi), se yi > 0.
(2.2)
Estocasticamente, o modelo admite a seguinte representação:
Yi|Ui = (1−Ui)Zi (2.3)
em que Ui é uma a variável latente, seguindo a distribuição de Bernoulli(pi) e Zi segueuma distribuição de contagem Pθ , com média µi, variância σ2
i e θ = (µi,σ2i ), com Ui e
Zi independentes. É fácil mostrar que, marginalmente, Yi segue um modelo ZI com valoresperado e variância, respectivamente, dados por:
E(Yi) = (1− pi)µi e Var(Yi) = (1− pi)σ2i + pi(1− pi)µ
2i . (2.4)
6

Por exemplo, se Pθ é uma Poisson, então o valor esperado e a variância desse modelosão da forma:
E(Yi) = (1− pi)µi e Var(Yi) = (1− pi)µi + pi(1− pi)µ2i ,
com função de probabilidade
f (yi) =
{0, com probabilidade pi +(1− pi)e−µi,
yi, com probabilidade (1− pi)e−µi µ
yii
yi!, yi = 1,2, . . . .
Usando a representação estocástica (2.3), a função de verossimilhança aumentada,f (y,u;p,θ), com dados observados y = (y1, . . . ,yn) e não observados u = (u1, . . . ,un), édescrita da seguinte forma:
f (y,u;p,θ) =n
∏i=1
puii [(1− pi)Pθ (Yi = yi)]
1−ui. (2.5)
Então, a log-verossimilhança completa do modelo ZI é dada por:
lc(p,θ ;y,u) =n
∑i=1
[ui log pi +(1−ui) log(1− pi)]+n
∑i=1
(1−ui) logPθ (Yi = yi)
= lc(p;u)+ lc(θ ;y,u) (2.6)
Note que em (2.6) temos a soma de duas log-verossimilhanças completas, umalc(p;u) que depende de dados não observados u e do vetor de parâmetros p e outra lc(θ ;y,u)que depende dos dados observados y e não observados u, e do vetor de parâmetros θ . Nocontexto de modelos lineares generalizados (GLM) isso pode ser interpretado como umamistura de dois GLM’s Nelder & Wedderburn (1972).
Um GLM (ver Nelder & Wedderburn (1972)) é formado por três componentes, comosegue:
(i) Componente Aleatório: composto pela variável resposta Yi, que é assumida pertencerà família exponencial com função de probabilidade ou função densidade de proba-bilidade f (yi;θi,φ), em que φ é o parâmetro de dispersão, fixo e conhecido, θi é oparâmetro que caracteriza a distribuição e Yi’s independentes.
(ii) Componente Sistemático: composto por p covariáveis X = (X1, ...,Xp) e por parâme-tros de regressão desconhecidos β = (β1, ...βp). Assim, podemos expressar a médiacomo uma função de ηi = XT
i β . O parâmetro η é chamado de preditor linear.
(iii) Função de Ligação: é uma função monotônica diferenciável que associa o compo-nente aleatório ao componente sistemático. Então, ao preditor linear teremos associ-
7

ada uma função da média g(µi) = ηi, em que o valor esperado de Yi é representado porµi e sua variância por φV (µi). A quantidade V (µi) é chamada de função de variânciado modelo.
Sendo assim, no modelo ZI, teremos dois GLM’s dados da seguinte forma:No primeiro GLM(p), para a modelagem do excesso de zeros, considerando G
uma matriz de covariáveis, γ um vetor de parâmetros de regressão e a função logit(pi) =
log( pi
1−pi
), teremos:
Ui = ui, τi = GTi γ e g(pi) = logit(pi) = τi (2.7)
E no segundo GLM(θ ), para a modelagem da média, considerando B uma matriz decovariáveis e β um vetor de parâmetros de regressão, teremos:
Yi = yi, ηi = BTi β e g(µi) = log(θi) = ηi (2.8)
A partir da descrição dos modelos, é preciso estimar seus parâmetros e avaliar aprecisão das estimativas. Na mistura de GLM’s, a estimação dos parâmetros é realizada viaalgoritmo EM.
2.1.1 Estimação via Algoritmo EM
Para encontrar os estimadores dos parâmetros desconhecidos p e θ , utiliza-se o mé-todo de máxima verossimilhança via algoritmo EM (Dempster et al. (1977)), o qual é in-dicado quando o conjunto de dados é incompleto ou envolve quantidades não observáveis(variáveis latentes). No último caso, as variáveis latentes podem ser incorporadas ao mo-delo propositalmente para facilitar a estimação dos parâmetros de interesse, tendo em vistaque com sua inserção no modelo, a log-verossimilhança completa pode ser reescrita comoa soma de duas log-verossimilhanças completas, como visto em (2.6). Em cada iteração, oalgoritmo EM alterna entre as operações de Esperança (passo E) e de Maximização (passoM).
Considere ϑ = (p,θ) o vetor de parâmetros do modelo. O algoritmo EM maximizaa função log-verossimilhança l(ϑ ;y,u) usando a verossimilhança completa (2.5) e a distri-buição condicional f (u|y,ϑ) de u dado y e ϑ . Assim, a maximização de (2.6) via algoritmoEM ocorre em dois passos.
Passo E: Inicialize o processo iterativo com ϑ(0) = (p(0),θ (0)) e na (k+1)-ésima
iteração a estimativa de u(k)i é a esperança condicional sobre y e a estimativa corrente ϑ(k).
Isto é, compute E{
lc(p,θ ;y,u)|y,ϑ (k)}
com respeito a distribuição condicional de u. Como
a lc é linear em u, a esperança condicional é dada por lc(ϑ (k);y,u(k)) = lc(p,θ ;y,u(k)), em
8

que na k-ésima iteração faremos u(k) = E(U|y,ϑ (k)) , com i-ésimo elemento
u(k)i = P(ui = 1|yi,ϑ(k)) =
P(Yi = yi|ui = 1,ϑ (k))p(k)i
P(Yi = yi|ui = 1,ϑ (k))p(k)i +P(Yi = yi|ui = 0,ϑ (k))(1− p(k)i ).
Usando (2.7) e (2.8), podemos encontrar a seguinte expressão para u(k)i :
u(k)i =
(
1+ exp{−logit(p(k)i )+ l(θ (k);yi)})−1
se yi = 0
0 se yi > 0
Passo M: Como temos uma mistura de GLM’s, maximizar lc(ϑ (k);y,u(k)) é equiva-lente a maximizar cada GLM, separadamente, em relação aos seus respectivos parâmetros,da seguinte maneira:
(i) Passo M para p: na (k+1)-ésima iteração, maximizar a lc(p,θ ;y,u(k)) com relação ap é equivalente a maximizar lc(p;u), considerando u = u(k).
(ii) Passo M para θ : na (k+1)-ésima iteração, maximizar a lc(p,θ ;y,u(k)) com relação aθ é equivalente a maximizar lc(θ ;y,u), considerando u = u(k).
A Informação de Fisher para a mistura de GLM’s é dada por:
I (ϑ) =−E
(∂S(ϑ)
∂ϑ
),
em que as funções escore, para cada GLM, são escritas da seguinte forma:
S(β ) =n
∑i=1
(∂ µ
∂β
)T[φV (µi)]
−1(yi−µi), (2.9)
e
S(γ) =n
∑i=1
(∂p∂γ
)T[φV (pi)]
−1(ui− pi), (2.10)
podemos maximizar a E{
lc(p,θ ;y,u)|y,ϑ (k)}
através do algoritmo de Newton Raphson-Scoring de Fisher (NR-SF). De acordo com os seguinte passos:
1. Inicializar a iteração com o valor de ϑ(0);
2. Para k −→ k+1 atualizar o valor de ϑ , via ϑ(k+1) = ϑ
(k)+(I (k))−1S(ϑ (k)).3. Repetir o passo 2 até que ‖ϑ (k+1)−ϑ
(k)‖< ε , ou seja, até se obter a convergência.Quando a função de ligação g(.) é canônica, teremos a seguinte expressão
∂θi
∂ µi=
∂ηi
∂ µi=V−1(µi).
9

Então, reescrevendo os GLM’s a partir dessa suposição, temos:
1. No GLM(p), fixando φ = 1, em que µ = p e a função de variância V (pi) = pi(1− pi).Definindo as seguintes expressões de forma matricial:
Wi =V−1(pi), ∆ = diag(g′(pi), ...,g′(pn)), h = η +∆(u− p),
em que a matriz de covariâncias W = diag(W1, ...,Wn) é diagonal (n×n), e o valor deui também obtido no passo E por
u(k)i =(
1+ exp{−logit(pi(γ(k)))+ li(θi(β
(k));0)})−1
I{yi=0},
o estimador para o parâmetro γ será obtido, também, via algoritmo NR-SF, pela ex-pressão:
γ(k+1) = (GT W(k)G)−1GW(k)h(k).
2. Da mesma forma, no GLM(θ ) definimos as expressões matriciais Wi = (1 −ui)
2V−1(µi), 4= diag(g′(µ1), ...,g′(µn)), h = η +4(y−µ) e W = diag(W1, ...,Wn).Assim, o estimador para o parâmetro β será obtido, via algoritmo NR-SF, através daexpressão:
β(k+1) = (FT W(k)F)−1FW(k)h(k).
Note que para se construir uma função de verossimilhança é necessário pressuporum modelo probabilístico, a partir do qual se especifica a função de probabilidade e define-se os intervalos de valores dos parâmetros do modelo. Essa especificação implica em quese detenha o conhecimento prévio do modelo, ou seja, saber através de qual mecanismo osdados foram gerados, ou basear-se em experiências anteriores significativas sobre dados se-melhantes. No entanto, algumas vezes, não queremos ou não podemos assumir previamentealgum modelo probabilístico para os dados. Neste caso, uma abordagem via função de quaseverossimilhança é mais adequada.
2.2 Quase Verossimilhança
Um conceito muito importante ao longo deste trabalho é o de quase verossi-milhança,que pode ser utilizado quando não queremos ou não podemos assumir um modelo probabi-lístico para os dados. Na função de verossimilhança é necessário pressupor o modelo pro-babilístico para os dados. Na quase verossimilhança, por outro lado, somente o primeiro e
10

segundo momentos da distribuição dos dados precisam ser definidos, além disso, a variân-cia de cada observação é especificada como sendo igual ou proporcional a alguma função damédia. A função de quase verossimilhança para modelos lineares generalizados, foi propostapor Wedderburn (1974), reexaminada por McCullagh & Nelder (1983) e é definida a seguir.
Definição 1. Considerando Yi, i = 1, ...,n, variáveis aleatórias independentes, com média
E(Yi) = µi e variância Var(Yi) = a(φ)V (µi), onde V é alguma função conhecida, denomi-
nada função de variância, e a(φ), que mede a dispersão do modelo, pode ser desconhecida.
Suponha que cada µi é uma função conhecida de um conjunto de parâmetros β1, ...,βp. E
ainda, suponha que a(φ) é uma constante, que não depende de β1, ...,βp. Então, para cada
observação, definimos a função de quase verossimilhança Q(yi,µi) pela relação:
∂Q(yi,µi)
∂ µi=
yi−µi
Var(Yi)(2.11)
ou de forma equivalente,
Q(y,µ) =n
∑i=1
Q(yi,µi) =n
∑i=1
∫µi
yi
yi− ta(φ)V (t)
dt (2.12)
Sob a suposição de independência dos componentes do vetor resposta Y, a matrizV (µ) deve ser diagonal. Assim, podemos escrevê-la da seguinte forma:
V (µ) = diag{V1(µ), ...,Vn(µ)}
Uma hipótese relevante sobre a função Vi(µ) é que ela deve depender apenas da i-ésimacomponente de µ .
Por analogia, a função quase-desvio (D), que mede a discrepância entre as obser-vações e seus valores esperados, é obtida de forma análoga à estatística da razão de log-verossimilhanças. Assim, para a i-ésima observação correspondente, essa função é escritada forma:
D(yi; µi) = 2a(φ)Q(µi;yi) =−2∫
µi
yi
yi− tV (t)
dt (2.13)
que é uma função estritamente positiva, exceto em yi = µi. O desvio total D(y; µ) é umafunção que não depende de a(φ), mas de y e de µ somente. Essa função é obtida de formaanáloga à estatística da razão de log-verossimilhanças.
A função Q tem muitas propriedades em comum com a função de log-verossi-milhança. De forma particular, se a distribuição de Y pertencer à família exponencial uni-paramétrica, podemos mostrar que Q é a função de log-verossimilhança. Em seu artigo,Wedderburn (1974) demonstrou que a quase-verossimilhança tem as seguintes propriedades,semelhantes as da log-verossimilhança:
11

(i) E(
∂Q∂ µ
)= 0;
(ii) E(
∂Q∂βi
)= 0;
(iii) E(
∂Q∂ µ
)2=−E
(∂ 2Q∂ µ2
)= 1
a(φ)V (µ) ;
(iv) E(
∂Q∂Q∂βi∂β j
)=−E
(∂ 2Q
∂βi∂β j
)= 1
a(φ)V (µ)∂ µ
∂βi
∂ µ
∂β j;
Assim, para estimarmos o parâmetro β , utilizaremos a função quase-escore (2.14),ou seja, resolveremos a seguinte equação S(β ) = 0, sendo que
∂Q∂β
= S(β ) =n
∑i=1
Si(β ) =n
∑i=1
(∂ µi
∂β
)T
Var−1(Yi;β ,φ)(yi−µi(β ))
=n
∑i=1
(∂ µi
∂β
)T
[a(φi)V (µi)]−1(yi−µi(β ))
=n
∑i=1
(Hi)T (Vi)
−1(yi−µi(β ))
= HT V−1(Y−µ), (2.14)
em que o componente V = diag(a(φ)V (µi)) é uma matriz diagonal (n×n) e H é uma matrizde derivadas (n× p), em que cada elemento dela corresponde à derivada ( ∂ µi
∂β j), com i =
1, ...,n e j = 1, ..., p.A função quase escore (2.14) é um caso bastante especial, pois ela tem a forma de
uma equação de estimação generalizada (GEE) de Liang & Zeger (1986), sob a suposição deindependência. Uma GEE, denotada por g(y;θ), é uma função dos dados y e dos parâmetrosθ , tendo média zero para todo o espaço paramétrico de θ , de forma que a E[g(y;θ)] = 0(McCullagh & Nelder (1989)).
2.2.1 Estimação de Parâmetros
Considerando a função quase escore (2.14), podemos definir sua matriz de covari-âncias, que é equivalente ao negativo do valor esperado da derivada de (2.14), dada por:
iβ = HTV−1H. (2.15)
No contexto de quase verossimilhança, essa matriz iβ desempenha o mesmo papelque a informação de Fisher nas funções de verossimilhança comuns. Então, se iniciarmoso processo de estimação com um valor arbitrário de β 0, suficientemente próximo de β , a
12

sequência de estimativas dos parâmetros, gerados pelo método NR-SF, obtidas pela iteraçãoaté a ocorrência de convergência, é dada por:
β(k+1)
= β(k)
+(HTV−1H)−1HTV−1(y−µ) (2.16)
onde β(0)
= β 0.Wedderburn (1974) e McCullagh (1983) mostraram que as funções de quase ve-
rossimilhança e seus estimadores de máxima quase verossimilhança (EMQV) têm muitaspropriedades análogas às da verossimilhança e seus estimadores de máxima verossimilhança(EMV). Em particular, o EMQV β é não-viesado e assintoticamente normal, com média β .E as matrizes de covariância assintóticas podem ser derivadas de forma usual da matriz dederivadas de segunda ordem de Q.
Um dos problemas da quase verossimilhança consiste na comparação de diferentesfunções de variância no mesmo conjunto de dados. Nelder & Pregibon (1987) notaram queuma distribuição com determinada função de variância pode existir, mas sem pertencer àclasse das distribuições necessárias para um modelo linear generalizado adequado. Então,para avaliar diferentes funções de variância, eles desenvolveram a quase verossimilhança es-tendida, que é uma generalização natural da quase verossimilhança e permite uma estimaçãoou modelagem do parâmetro de dispersão a(φ) ou parâmetros não lineares na variância.
2.3 Quase Verossimilhança Estendida
A quase verossimilhança foi estendida por Nelder & Pregibon (1987) para incluirtermos da variância, comparar diferentes funções de variância, preditores lineares e funçõesde ligação, e a possibilidade de modelar a dispersão como uma função de covariáveis, emque essa última abordagem nos interessa no desenvolvimento do modelo proposto. Fazendoa(φ) = φ , a quase verossimilhança estendida Q+, definida por McCullagh & Nelder (1989),é dada pela expressão:
Q+(µi,φ ;yi) =−1
2φD(yi,ui)−
12
log(φ), (2.17)
em que
D(yi,µi) =−2φ{Q(µi,yi)−Q(yi,yi)}=−2∫
µi
yi
yi− tV (t)
dt (2.18)
é chamada de função quase desvio do modelo estendido.Uma família bastante útil é obtida considerando potências de µi (Nelder & Pregibon
13

(1987)):Vλ (µi) = µ
λi , (2.19)
em que λ é conhecido e assume valores positivos como 0,1,2,3, que correspondem a fun-ções de variância associadas com as distribuições Normal, Poisson, Gama e Normal Inversa,respectivamente. Para a família de funções de variância (2.19), podemos escrever a funçãoquase desvio como:
D(yi;ui) =
2{
yi log( yiµi)− (yi−µi)
}se λ = 1
2{
yiµi
log( yiµi)−1
}se λ = 2
2{
y2−λ
i −(2−λ )yiµ1−λ
i +(1−λ )µ2−λ
i
}(1−λ )(2−λ ) caso contrário.
Essas são algumas formas para a função de variância com suas respectivas funçõesquase desvio. Neste caso, é possível definir uma função de ligação h, tal que h(φi) = Ziλ , emque Z representa a estratificação de variáveis ou covariáveis afetando somente a dispersão.Os estimadores dos parâmetros β obtidos pela maximização de Q+ são similares aos obtidospela maximização de Q, que são os EMQV. Isso acontece, porque Q+ é uma função linearde Q com coeficientes independentes de β . O estimador de φ obtido da maximização de Q+
é φ = ∑i=1 nD(yi; µi)/n, que é o quase-desvio médio.E, derivando a Q+, com relação aos parâmetros β e φ , obtemos os seguintes resulta-
dos:
1. ∂Q+(µi,φ ,yi)∂β
= [φV (µi)]−1(yi−µi)
(∂ µi∂β
).
2. ∂Q+(µi,φ ,yi)∂φ
= 12φ 2 D(yi,µi)− 1
2φ.
3. Se existe uma função de ligação h+ e a covariável Zi tais que: h+(φi) = ZTi λ . Então,
a função quase escore, em relação a λ , é dada como segue:
∂Q+(µi,yi)
∂λ=
D(µi,yi)−φi
2φ 2i
(∂φi
∂λ
)Nesse caso, o estimador do parâmetro de dispersão, desenvolvido por Nelder & Pregibon
(1987), tem a forma:
a(φ) =1
n− p ∑i
(Yi− µi)2
Vi(µi)=
χ2
n− p. (2.20)
A utilização da quase verossimilhança estendida Q+ nos permite a comparação demodelos, nos quais o componente aleatório é especificado somente em relação aos seus doisprimeiros momentos. Assim, as técnicas padrão para o ajuste e a comparação de modelos
14

podem, então, ser aplicadas nessa classe flexível de modelos, que são as quase verossimi-lhanças estendidas. Daí, o motivo de utilizarmos a Q+ na modelagem proposta por essetrabalho.
2.4 Equações de Estimação Generalizadas
Na teoria GLM, a suposição de independência entre os indivíduos deve ser satisfeitapara que, a partir daí, seja realizado o tratamento dos dados. Neste caso, esses modelos setornam limitados em estudos georreferenciados que levam em consideração uma estruturade dependência espacial natural entre indivíduos de um mesmo grupo ou que estejam emlocalizações mais próximas (vizinhas). Para acomodar a dependência na estrutura de umGLM, Zeger & Liang (1986) e Liang & Zeger (1986) desenvolveram as equações de esti-mação generalizadas (GEE). As GEE’s nada mais são que uma extensão dos GLM’s, coma inclusão de uma estrutura de correlação no processo de estimação. Em uma GEE, não énecessário assumir que a distribuição da variável resposta pertença à família exponencial dedistribuições, porém basta assumir que a média e a variância estejam caracterizadas comoem um GLM. A abordagem GEE foi aplicada inicialmente no contexto de dados longitu-dinais e medidas repetidas, mas pode ser considerada também para dados georreferenciados(Monod (2007)).
Usando a mesma notação de Liang & Zeger (1986), considere um vetor respostaYi = (Yi1, ...,Yimi)
T , de dimensão (mi× 1), e matriz de covariáveis Xi = (Xi1, ...,Ximi)T , de
dimensão (mi× p), para o i-ésimo indivíduo, i = 1, ...,n, da seguinte forma:
Vi(ρ) =V 1/2i Ri(ρ)V
1/2i φ
−1,
em que, Vi é uma matriz diagonal (mi×mi) com elementos da diagonal iguais a V (µi) que éa função de variância definida na quase verossimilhança, Ri(ρ) é uma matriz de correlaçãosimétrica (mi×mi) chamada de matriz de correlação de trabalho e ρ é um escalar e/ou vetorde parâmetros desconhecidos que caracterizam completamente Ri(ρ). Se Ri(ρ) é de fato averdadeira matriz de correlação para Yi, então define-se as GEE’s, como:
n
∑i=1
HTi V−1
i (ρ)(yi−µ i) = 0, (2.21)
em que Hi =∂ µi∂β j
é o vetor de derivadas e Vi(ρ) é a matriz de covariâncias para o i-ésimo
indivíduo. O vetor β solução da equação (2.21) é o estimador de β obtido através da aborda-gem GEE. Esses estimadores são consistentes, sob fracas suposições, e o modelo é robusto aerros, na especificação da estrutura da matriz de correlação Ri(ρ). Não é difícil perceber que
15

a função quase escore dada em (2.14) é um caso particular de uma GEE com Ri(ρ) iguala matriz identidade. Por isso, nós utilizamos neste trabalho a abordagem de Liang & Zeger(1986) sob o cenário espacial, em que os dados serão modelados através de uma mistura dequase-verossimilhanças.
2.5 Dependência Espacial em Dados de Contagens
Nesse trabalho assumimos que {Yi ≡ Y (Si),Si ⊂ S, i = 1,2, . . . ,L} é a realização deprocesso espacial de contagens na área Si com S ⊂ R2. Mais especificamente, vamos as-sumir que S é um mapa particionado em n áreas Si, com yi representando uma contagemobservada em Si. A principal suposição deste tipo de processo é que as contagens observa-das em áreas mais próximas tendem a ser mais similares, isto é possuem uma correlação oudependência espacial maior do que contagens observadas em áreas mais distantes entre si.Formalmente essa dependência pode ser expressa em termos do argumento que a esperançacondicional de Yi dados todos Yj’s, dependem apenas dos Yj’s que ocorrem em áreas vizinhasde Si Besag (1974), ou seja,
E(Yi|Yj, j 6= i) = E(Yi|Y j, j ∼ i), (2.22)
em que j ∼ i denota o conjunto de todos os vizinhos da área Si. Uma forma de acomodara correlação espacial neste tipo de processo, é através da matriz de similaridade ou proxi-midade espacial, também chamada matriz de vizinhança e denotada por W, em que cadaelemento wi j representa uma medida de proximidade entre Si e S j. Esta medida de proximi-dade pode, por exemplo, ser calculada a partir de um dos seguintes critérios:
• wi j = 1, se o centroide de Si está a uma determinada distância de S j e caso contrário,wi j = 0;
• wi j = 1 se Si e S j compartilham fronteiras e wi j = 0 caso contrário.
Agora considere que temos um GLM espacial e queremos predizer os resíduos,ri = Yi−E(Yi), dado todos os outros r j’s. Se assumirmos que os ri’s são independentes,então a média global dos resíduos, E(ri) = 0 é o melhor preditor de ri. No entanto, se quere-mos utilizar as características locais do processo, devemos assumir que os ri’s vizinhos sãosimilares, de modo que uma média ponderada dos r j, j ∼ i, (∑ j∼i wi jr j/wi+), pode predizermelhor ri, em que wi+ = ∑ j∼i wi j. Dessa forma, combinando com (2.22) teremos que o pre-ditor de ri dado todos os outros r′s, pode ser visto como uma mistura dos preditores global elocal Yasui & Lele (1997). Especificamente,
E(ri|r j, j ∼ i) = (1−ρ)E(ri)+ρ ∑j∼i
wi j
wi+r j, (2.23)
16

em que, ρ é um parâmetro que representa o grau de dependência espacial e deve ser estimadodos dados. Usando a equação (2.23) podemos escrever que a esperança condicional de Yi
dado todos os outros Y ’s é,
E(Yi|Yj, j 6= i) = µi +ρ ∑j∼i
wi j(Y j−µ j)/wi+ (2.24)
com a esperança marginal E(Yi) = µi e matriz de correlação R(ρ) = (I−ρMW)−1M onde,I é a matriz identidade, M é uma matriz diagonal n×n com mii = 1/wi+ e W é uma matrizsimétrica n×n com wi j = 1 se j ∼ i wi j = 0 caso contrário Cressie (1992). No contexto deum GLM é mais natural escrevermos,
g(E(Yi|Yj, j 6= i)) = g(µi)+ρ ∑j∼i
wi j(g(Yj)−g(µ j))/wi+, (2.25)
com E(g(Yi)) ≈ g(µi). Como R−1(ρ) = M−1− ρW, teremos no contexto de GEE (veja,equação (2.21)) que V
−1é facilmente obtida, facilitando o cálculo dos estimadores do mo-
delo. Por isso, esta estrutura de correlação espacial será adota neste trabalho.
2.6 Algoritmo Expectation-Solution (ES)
Em um processo de estimação em mistura de modelos é comum utilizar o algoritmoEM (veja a Seção 2.1.1). No entanto, o algoritmo EM somente pode ser utilizado quandodispomos da função de verossimilhança para o modelo. Por exemplo, na estimação viamisturas de quase-verossimilhanças o algoritmo EM não pode ser utilizado, pois não conhe-cemos o modelo probabilístico gerador dos dados. No contexto de medidas repetidas, paraexplicar a correlação entre as observações repetidas em um mesmo indivíduo, Rosen et al.
(2000) inseriu as GEE no passo M do algoritmo EM, resultando em uma generalização dele,ao qual chamou de algoritmo Expectation-Solution (ES). Para ver a definição formal e provade algumas propriedades assintóticas do algoritmo ES, consultar Rosen et al. (2000).
O algoritmo ES, também, é executado em dois passos. O primeiro é similar aopasso de esperança E do algoritmo EM. O segundo consiste na substituição do passo demaximização (M) no algoritmo EM por um passo que requer a solução (S) de um sistemade GEE’s (2.14). No contexto de mistura de GLM’s, Rosen et al.(2000) mostraram quese o algoritmo ES convergir, ele convergirá para um estimador não-viciado, consistente eassintoticamente Normal, sob suaves condições de regularidade. Sendo assim, utilizaremosesse algoritmo no processo de estimação dos parâmetros da regressão do modelo proposto.
17

2.7 Intervalos de Confiança Bootstrap
A inferência em modelos complexos, é cada vez mais difícil por não se conseguirexpressões analiticamente tratáveis ou de fácil cálculo e interpretação na estimação dos pa-râmetros de interesse. Em nosso caso específico, não é possível garantir a convergênciados estimadores para uma distribuição normal, pois não assumimos qualquer distribuição.Sendo assim, optamos pela inferência via abordagem de intervalos de confiança Bootstrap
(ver Gentle (2009a)).
Intervalo de Confiança Bootstrap Percentil
Dada uma amostra aleatória (y1, ...,yn), cuja distribuição P é desconhecida, queremosestimar intervalos de confiança para um parâmetro θ a partir do estimador pontual T . Paraisso, podemos utilizar um estimador Bootstrap T ∗ baseado na amostra Bootstrap (y∗1, ...,y
∗n).
Se GT ∗(t) é a função de distribuição de T ∗, tal que GT ∗(t∗(1−α)) = 1−α , em que t∗(1−α) é olimite superior exato do intervalo de confiança (1−α) para o parâmetro θ . Então, o intervalode confiança Bootstrap Percentil (ICBP) é configurado da seguinte forma:
[t∗(α
2 ); t∗(1−α
2 ))]
(2.26)
em que t∗(π) é a (πm)th estatística de ordem de uma amostra de tamanho m de T ∗. O ICBP éum bootstrap empírico e pode ser estimado através de simulação de Monte Carlo.
2.7.1 Intervalo de Confiança Bootstrap-t
O intervalo de confiança Bootstrap-t (ICB-t) é um dos intervalos aproximados bas-tante útil para a estimação intervalar de parâmetros, ele pode geralmente ser construídousando como referência o intervalo de confiança para a média de uma distribuição normal,[
Y − t∗( 1−α
2 )
S√n
;Y − t∗(α
2 )
S√n
],
em que t(π) é o percentil da distribuição t-Student, Y é a média amostral e S2 é a variânciaamostral. Então, um ICB-t para qualquer parâmetro construído neste padrão é da forma:[
T − t( 1−α
2 )
√V (T );T − t(α
2 )
√V (T )
](2.27)
18

em que t(π) é o percentil estimado da estatística estudentizada:
T ∗−T0√V (T ∗)
em que T0 é o valor de T calculado a partir da amostra observada.Para diversos estimadores T , não existe uma expressão simples para a variância
V (T ∗). Por isso, podemos estimar a variância utilizando um bootstrap e a equação:
V (T ) = V (T ∗) =1
m−1
m
∑j=1
(T ∗j − T ∗)2
onde T ∗j é a j-ésima observação bootstrap de T . A vantagem dos ICB-t é que eles são maisprecisos do que os ICBP , porém a desvantagem é que eles são muito mais trabalhosos. Sea distribuição empírica é normal e T é uma medida amostral, o ICB-t (2.27) é um intervalode confiança exato (1−α)100% de menor tamanho, caso contrário ele pode não ter boaspropriedades.
19

Capítulo 3
Modelos de Quase-VerossimilhançaInflacionados de Zeros para Dados deContagem Espacialmente Dependentes
Como vimos no capítulo anterior (Seção 2.2), modelos de quase verossimilhança sãomuito úteis na ausência da especificação correta da distribuição dos dados, sendo necessáriaapenas a definição da relação entre a média e variância dos dados, como em um modelolinear generalizado. Essa abordagem faz-se interessante, no caso de dados que possuamestruturas complexas, como por exemplo apresentando inflação de zeros, sobredispersão edependência espacial, pois encontrar uma distribuição de probabilidade adequada, que mo-dele conjuntamente essas três características, pode se tornar uma tarefa árdua e talvez atémomentaneamente impossível.
Em processos de contagem já existem modelos como ZIGP, ZIDP e ZINB, que sãoflexíveis para incorporar a inflação de zeros, a sobredispersão e o ajuste por covariáveis.Entretando, tais modelos são limitados por não assumirem dependência ou existência de cor-relação espacial, fato este que é comum em problemas dessa natureza, pois dados coletadosem áreas vizinhas tendem a ser mais similares ou correlacionados do que os obtidos em áreasmais distantes geograficamente. Um exemplo comum desta situação ocorre na área de saúdepública, onde epidemiologistas estudam a variação geográfica dos casos de doenças para ge-rar e refinar hipóteses testáveis sobre a sua etiologia ou visualizar variáveis que possam estarinfluenciando no aparecimento da epidemia (Imbiriba et al. (2009a); Imbiriba et al. (2009b))
Descreveremos, a seguir, o modelo proposto (QIZ) quando as observações da variávelresposta forem independentes e, posteriormente, quando assumem dependência espacial.
20

3.1 Modelo QIZ para dados com Independência
Primeiramente, vamos considerar a descrição do modelo ZI (Capítulo 2, Seção 2.1),com representação estocástica
Y|U = (1−U)Z,
em que Y = (Y1, ...,YL)T é o vetor resposta de observações de contagem independentes, U =
(U1, ...,UL)T é o componente da mistura não observável e Z = (Z1, ...,ZL)
T é o componenteobservável, com representação estocástica (2.3), em que U e Z são independentes. E ainda,que Yi segue uma distribuição inflacionada de zeros (2.1), ou seja,
Yi ∼ pi I{yi=0}+(1− pi)P(θ),
em que I é a função indicadora, P(θ) é uma distribuição de contagem, pi é a probabilidadede Yi∼ 0 e (1− pi) é a probabilidade de Yi∼ P(θ). Assim, podemos escrever a probabilidademarginal de Yi (2.2) como sendo
P(Yi = yi) =
{pi +(1− pi)Pθ (Yi = yi), se yi = 0,(1− pi)Pθ (Yi = yi), se yi > 0,
ou ainda,
P(Yi = yi) = piI{yi=0}+(1− pi)Pθ (Yi = yi)
= piI{yi=0}+(1− pi)elogPθ (Yi=yi)
cuja probabilidade P(Yi = yi) depende de pi e da probabilidade Pθ (Yi = yi), que por sua vezvem da distribuição de contagem P(θ).
Então, a verossimilhança do modelo ZI é escrita como
l(θ) =L
∏i=1
P(Yi = yi)
=L
∏i=1
[piI{yi=0}+(1− pi)elogPθ (Yi=yi)] (3.1)
Uma das principais ideias deste trabalho foi a de substituir o logPθ (Yi = yi), em (3.1),pela quase-verossimilhança estendida Q+ (2.17), obtendo a aproximação
l(θ) ≈L
∏i=1
[piI{yi=0}+(1− pi)eQ+(yi;θi)] = Q(p,θ),
em que Q(p,θ) é a quase-verossimilhança.
21

A partir destas especificações, definiremos primeiramente o modelo QIZ sob a supo-sição de independência.
A construção do modelo QIZ foi baseada na log-verossimilhança completa do mo-delo ZI (2.6), dada no Capítulo anterior da seguinte forma:
lc(pi,θi;yi,ui) = [ui log pi +(1−ui) log(1− pi)]+(1−ui) logPθi(Yi = yi)
= lc(pi;ui)+ lc(θi;yi,ui),
Assim, o modelo QIZ é representado por uma quase verossimilhança inflacionada dezeros completa, considerando θi = (µi,φi), dada por:
Qc(pi,µi,φi;yi,ui) = ui log(pi)+(1−ui){log(1− pi)+Q+(µi,φi;yi)}, (3.2)
em que substituímos a lc(θi,yi,ui) em (2.6) pela quase verossimilhança estendida Q+ (2.17),a partir da qual poderemos modelar o parâmetro de dispersão como função de covariáveis,obtendo a quase verossimilhança inflacionada de zeros (3.2). Marginalmente, Qc (3.2) é aquase verossimilhança estendida para o modelo inflacionado de zeros. Através do modeloZI em (2.4), definimos a esperança e variância do modelo QIZ, representadas como:
E(Yi) = (1− pi)µi e Var(Yi) = (1− pi)φiV (µi)+ pi(1− pi)µ2i . (3.3)
em que µi é a esperança e φiV (µi) é a variância, ambas do componente da mistura referenteàs contagens positivas, e pi é a probabilidade de Yi vir do excesso de zeros. E, para a dife-renciação da Qc (3.2) com relação aos parâmetros de regressão que modelam a média β , adispersão λ e o excesso de zeros γ , são válidas as seguintes expressões:
(i) ∂Qc
∂γ= ui−pi
V (pi)
(∂ pi∂γ
), reescrevendo na forma matricial:
∂Qc
∂γ= ∑
Li=1
{∂ pi∂γ
}T[A1/2
i IA1/2i ]−1(u(k)i − pi),
com Ai = diag{p1(1− p1), ..., pL(1− pL)};
(ii) ∂Qc
∂β= (1−ui)
yi−µiφiV (µi)
(∂ µi∂β
), ou na forma matricial:
∂Qc
∂β= ∑
Li=1
{∂ µi∂β
}T[B1/2
i IB1/2i ]−1U(k)(yi−µi),
com Bi = diag{φ1V (µ1), ...,φLV (µL)} e U(k) = diag{(1−u(k)1 ), ...,(1−u(k)L )};
(iii) ∂Qc
∂λ= (1−ui)
D(yi,µi)−φi2φ 2
i
(∂φi∂λ
), e também na forma matricial:
∂Qc
∂λ= ∑
Li=1
{∂φi∂λ
}T[C1/2
i IC1/2i ]−1U(k)(D(yi,µi)−φi),
com Ci = diag{2φ 21 , ...,2φ 2
L} e U(k) = diag{(1−u(k)1 ), ...,(1−u(k)L )};
22

(iv) Eu
(∂Qc
∂γ
)= Ey
(∂Qc
∂β
)= Ey
(∂Qc
∂λ
)= 0.
As expressões (i), (ii) e (iii) são chamadas de funções quase escore, similar aquelasdefinidas no Capítulo 2 (equação 2.14) para seus respectivos parâmetros. A expressão (iv)é o valor esperado de cada função quase escore, que de forma similar às propriedades daquase verossimilhança definidas por Wedderburn (1974), são iguais a zero, pois tem a formade uma GEE.
A função quase desvio é dada de forma similar a descrita na seção sobre quase veros-similhança (2.13), no Capítulo 2. Agora, vejamos exemplos de modelos, com suas respecti-vas funções quase desvio, quase verossimilhança e outras.
3.1.1 Modelo Quase-Poisson Inflacionado de Zeros
O primeiro modelo que iremos exemplificar é o de Quase-Poisson Inflacionado de Ze-ros (QPIZ). Nesse modelo, para calcular a função quase desvio (2.13), considera-se V (t) = t.A partir daí, podemos então calcular a função quase desvio da seguinte forma:
D(yi; µi) = −2∫
µi
yi
yi− tV (t)
dt =−2∫
µi
yi
yi− tt
=−2[∫ µi
yi
yi
tdt−
∫µi
yi
dt]=−2
[yi ln t− t
]µi
yi
= −2[yi ln
(µi
yi
)− (µi− yi)
]= 2[yi ln
( yi
µi
)− (yi−µi)
]. (3.4)
Neste caso, a função de quase verossimilhança estendida é dada por:
Q+(µi,φi;yi) = −12
D(yi; µi)−12
log(φi) =−12
{2[yi ln
( yi
µi
)− (yi−µi)
]}− 1
2log(φi)
= yi
[1− ln
( yi
µi
)]−µi−
12
log(φi) (3.5)
Então, se yi > 0, a função de quase verossimilhança completa será da forma:
Qc(pi,µi,φi;yi,ui) = ui log(pi)+(1−ui){
log(1− pi)+Q+(µi,φi;yi)}
= ui log(pi)+(1−ui){
log(1− pi)+ yi
[1− ln
( yi
µi
)]−µi−
12
log(φi)}, (3.6)
e se yi = 0, em que assumimos yi ∗a = 0, com a assumindo qualquer valor, temos a
Qc(pi,µi,φi;yi,ui) = ui log(pi)+(1−ui){
log(1− pi)+Q+(µi,φi;yi)}
= ui log(pi)+(1−ui){
log(1− pi)−µi−12
log(φi)}. (3.7)
A esperança condicional de E(ui|yi; pi,µi,φi)≡ ui será descrita como:
23

ui =(
1+ exp{− logit(pi)+Q+(µi,φi;yi)
})−1I{yi=0}
=(
1+ exp{− logit(pi)−µi−
12
log(φi)})−1
,
3.1.2 Modelo Quase-Binomial Inflacionado de Zeros
Outro modelo, por exemplo, é o de Quase-Binomial Inflacionado de Zeros (QBIZ),no qual considera-se V (t) = t(ni−t)
ni, equivalente a µi = niπi da distribuição Binomial (ni,πi),
a função quase-desvio é dada por:
D(yi; µi) = −2∫
µi
yi
yi− tV (t)
dt =−2∫
µi
yi
yi− tt(ni−t)
ni
= −2ni
[∫ µi
yi
yi
t(ni− t)dt−
∫µi
yi
tt(ni− t)
dt]
= 2[yi ln
( yi
µi
)+(ni− yi) ln
( ni− yi
ni−µi
)](3.8)
Logo, a função de quase verossimilhança estendida desse modelo, pode ser escritacomo:
Q+(pi,µi,φi;yi,ui) = −12
D(yi; µi)−12
log(φi)
= −12
{2[yi ln
( yi
µi
)+(ni− yi) ln
( ni− yi
ni−µi
)]}− 1
2log(φi)
= (yi−ni) ln( ni− yi
ni−µi
)− yi ln
( yi
µi
)− 1
2log(φi) (3.9)
Então, se yi > 0, a função de quase verossimilhança completa, para esse modelo, seráda forma:
Qc(pi,µi,φi;yi,ui) = ui log(pi)+(1−ui){
log(1− pi)+Q+(µi,φi;yi)}
= ui log(pi)+(1−ui){
log(1− pi)+(yi−ni) ln( ni− yi
ni−µi
)−yi ln
( yi
µi
)− 1
2log(φi)
}, (3.10)
e se yi = 0, então a
Qc(pi,µi,φi;yi,ui) = ui log(pi)+(1−ui){
log(1− pi)+Q+(µi,φi;yi)}
= ui log(pi)+(1−ui){
log(1− pi)−ni ln( ni
ni−µi
)− 1
2log(φi)
},
(3.11)
24

A esperança condicional de E(ui|yi; pi,µi,φi)≡ ui pode ser expressa como:
ui =(
1+ exp{− logit(pi)+Q+(µi,φi;yi)
})−1I{yi=0}
=(
1+ exp{− logit(pi)−ni ln
( ni
ni−µi
)− 1
2log(φi)
})−1,
3.1.3 Modelo Quase-Binomial Negativo Inflacionado de Zeros
No modelo Quase-Binomial Negativo Inflacionado de Zeros (QBNIZ), consideramosV (t) = t
ri(t + ri), de forma equivalente a µi =
riπi
da distribuição Binomial Negativa (ri,πi),onde a função quase-desvio é dada por:
D(yi; µi) = −2∫
µi
yi
yi− tV (t)
dt =−2∫
µi
yi
yi− ttri(t + ri)
= −2ri
[∫ µi
yi
yi
t + ridt−
∫µi
yi
tt + ri
dt]
= 2[yi ln
( yi
µi
)− (yi + ri) ln
( yi + ri
µi + ri
)](3.12)
Então, a função de quase verossimilhança estendida para esse modelo, é escrita daforma:
Q+(µi,φi;yi) = −12
D(yi; µi)−12
log(φi)
= −12
{2[yi ln
( yi
µi
)− (yi + ri) ln
( yi + ri
µi + ri
)]}− 1
2log(φi)
= (yi + ri) ln( yi + ri
µi + ri
)− yi ln
( yi
µi
)− 1
2log(φi) (3.13)
Assim, se yi > 0, a função de quase verossimilhança completa, será descrita como:
Qc(pi,µi,φi;yi,ui) = ui log(pi)+(1−ui){
log(1− pi)+Q+(µi,φi;yi)}
= ui log(pi)+(1−ui){
log(1− pi)+(yi + ri) ln( yi + ri
µi + ri
)−yi ln
( yi
µi
)− 1
2log(φi)
}, (3.14)
e se yi = 0, então a
Qc(pi,µi,φi;yi,ui) = ui log(pi)+(1−ui){
log(1− pi)+Q+(µi,φi;yi)}
= ui log(pi)+(1−ui){
log(1− pi)+ ri ln( ri
µi + ri
)− 1
2log(φi)
},
(3.15)
25

A esperança condicional de E(ui|yi; pi,µi,φi)≡ ui pode ser descrita como:
ui =(
1+ exp{− logit(pi)+Q+(µi,φi;yi)
})−1I{yi=0}
=(
1+ exp{− logit(pi)+ ri ln
( ri
µi + ri
)− 1
2log(φi)
})−1,
3.2 Modelo QIZ para dados com Dependência Espacial
Para incorporar a dependência espacial, utilizamos no processo de estimação, domodelo QIZ com independência, as equações de estimação generalizadas (GEE), propostaspor Liang & Zeger (1986), que construíram funções de estimação para os parâmetros deinteresse na ausência da verossimilhança totalmente especificada e presença de correlação(Zeger & Liang (1986)), que é exatamente o nosso caso. Definimos o modelo de quaseverossimilhança inflacionado de zeros com dependência espacial (QIZDE), como segue.
Definição 2. Suponha que {Yi ≡ Y (Si),Si ⊂ S, i = 1,2, . . . ,L)} é a realização de processo
espacial de contagens na área Si com S ⊂ R2. Mais especificamente, vamos assumir que
S é um mapa particionado em L áreas Si com yi representando uma contagem observada
em Si com excesso de zeros. Assuma que Yi pertence à classe de modelos com quase veros-
similhança completa (dada na Seção 2.2), com vetor de parâmetros ϑi = (µi,φi, pi), dada
por:
Qc(ϑi;yi,ui) = ui log(pi)+(1−ui){log(1− pi)+Q+(µi,φi;yi)},
então, para acomodar a dependência espacial, no processo de estimação substitui-se a ma-
triz identidade I, nas funções quase escore, por uma matriz simétrica de covariância espa-
cial R(ρ), com ρ representando o parâmetro que mede o grau de dependência espacial. A
essa nova estrutura chamamos modelo de quase verossimilhança inflacionado de zeros com
dependência espacial QIZDE.
Sendo assim, partimos da definição do modelo QIZDE, em que substituímos a matrizidentidade I, nas funções quase escore definidas em (i), (ii) e (iii), pela matriz de covariân-cia espacial R(ρ), resultando nas seguintes funções quase escore para cada parâmetro de
26

regressão, respectivamente, dadas por:
∂Qc
∂γ=
L
∑i=1
{∂ pi
∂γ
}T[A1/2
i Rγ(ρ)A1/2i ]−1(ui− pi) = 0, (3.16)
∂Qc
∂β=
L
∑i=1
{∂ µi
∂β
}T[B1/2
i Rβ (ρ)B1/2i ]−1U(yi−µi) = 0, (3.17)
∂Qc
∂λ=
L
∑i=1
{∂φi
∂λ
}T[C1/2
i Rλ (ρ)C1/2i ]−1U(D(yi,µi)−φi) = 0, (3.18)
em que as matrizes de covariância espacial Rγ(ρ),Rβ (ρ) e Rλ (ρ) representam a estru-tura de dependência espacial na estimação dos parâmetros de regressão γ , β e λ , respectiva-mente, e U = diag{(1−u1), ...,(1−uL)} é uma matriz de valores não observados.
Como havíamos comentado anteriormente, essas funções quase escore têm uma es-trutura de equação de estimação generalizada. Por exemplo, no caso QIZDE Poisson:
a) Para o parâmetro de regressão γ , cuja função de ligação é logit(pi) =GTi γ , a função
quase escore é dada por:
∂Qc
∂γ=
L
∑i=1
{GT
i pi(1− pi)}T
[A1/2i Rγ(ρ)A
1/2i ]−1(ui− pi) = 0; (3.19)
b) Já para o parâmetro de regressão β , cuja função de ligação é log(µi) = XTi β , a
função quase escore será:
∂Qc
∂β=
L
∑i=1
{XT
i µi
}T[B1/2
i Rβ (ρ)B1/2i ]−1U(yi−µi) = 0; (3.20)
c) Finalmente, para o parâmetro de regressão λ , cuja função de ligação é log(φi) =
ZTi λ , a função quase escore será:
∂Qc
∂λ=
L
∑i=1
{ZT
i φi
}T[C1/2
i Rλ (ρ)C1/2i ]−1U(D(yi,µi)−φi) = 0. (3.21)
3.2.1 Estimação dos parâmetros no modelo QIZDE
Por simplicidade na estimação e sem perda de generalidade, assumimos que as matri-zes de dependência espacial que modelam a inflação de zeros e a sobredispersão são iguaisa matriz identidade, ou seja, Rγ(ρ) = Rλ (ρ) = I. E que a matriz de dependência espacialque modela a média das contagens positivas Rβ (ρ) é uma representação de um processocondicional autorregressivo (CAR), veja a Seção 2.5, especificada da seguinte forma:
Rβ (ρ) = (I−ρMW)−1M (3.22)
27

em que W é uma matriz (L× L) simétrica, que define a estrutura espacial de vizinhança,com elementos definidos por pesos adjacentes conhecidos, representados por wi j se i ∼ j
(lê-se: i e j são áreas vizinhas) e 0 caso contrário, M é uma matriz diagonal (L×L) comi-ésimo elemento na diagonal igual a wi+ = ∑ j∼i wi j, ρ é o parâmetro que mede o grau dedependência espacial e R−1
β(ρ) = M−1−ρW, se ρ ∈ (ρmin,ρmax), caso contrário R−1
β(ρ) é
singular, com ρmin = ι−11 e ρmax = ι−1
n , tal que ι1 < 0 < ιn, ι1 e ιn são, respectivamente, omenor e maior autovalor da matriz M−1/2MWM1/2 (ver Lawson et al. (1999), pg. 66).
Nessa estrutura de covariância, representada através de um modelo CAR, podemosescrever a esperança condicional da variável resposta Y de uma área i dada outra j, sendoi 6= j, como:
E[Yi|Y j, i 6= j] = µi(β )+ρ ∑j∼i
wi j
wi+(Yj−µ j(β )) (3.23)
em que o termo wi jwi+
é resultado da matriz de correlação espacial Rβ (ρ), descrita em (3.22).Então, o valor esperado marginal de Yi é calculado a partir da esperança de (3.23),
obtendo a expressão:E(Yi) = µi(β ) (3.24)
E, ainda, o valor esperado da função quase desvio é aproximado pelo valor do parâ-metro de sobredispersão φi, ou seja,
E[D(yi,µi)]≈ φi (3.25)
Os modelos CAR podem assumir que a resposta é uma função de ambas as variáveisexplicativas e os valores da resposta em locais vizinhos (equação 3.23) .
Estimação de β
Suponha que a sobredispersão é a mesma em todas as áreas, ou seja, φl = φ , l =
1,2, ...,L. Então, a estimação do vetor de parâmetros de regressão β é realizada via algoritmoES, em dois passos.
Passo E: defina Qc(ϑ ;y,u) = ∑Li=1 Qc(ϑi;yi,ui). Então, na k-ésima iteração, inici-
alizamos o processo com ϑ(k) = (γ(k),β (k),ρ(k),φ (k)) e calculamos a Eu|ϑ (k);y[Q
c(ϑ ;y,u)].Como a Qc(ϑ ;y,u) é linear em u, esta quantidade é dada por Qc(ϑ ;y, u(k)), com i-ésimoelemento dado por:
u(k)i =(
1+ exp{−logit(pi(γ(k)))+Q+(µi(β
(k)),φi(λ(k)),yi)}
)−1I{yi=0},
em que Q+(·) é a função de quase verossimilhança estendida, especificada de acordo com osmodelos da Seção 3.1.
28

Passo S: definimos V−1(ρ(k),β (k)) = [B1/2Rβ (ρ
(k))B1/2]−1U(k), em que a matrizB = diag(V (µ
(k)1 ), ...,V (µ
(k)L )), e estimamos o vetor de parâmetros de regressão β na k+1-
ésima iteração solucionando iterativamente a GEE (3.17), ou seja, calculando a expressãoabaixo, que é o estimador para β , dado por
β(k+1) = β
(k)+(
HTV−1(ρ(k),β (k))H
)−1HTV−1
(ρ(k),β (k))(y−µ(β (k))), (3.26)
em que H é a matriz de derivadas parciais [∂ µ
∂β]T , sendo estas matrizes avaliadas em β
(k).
Estimação de γ
A estimação de γ é realizada solucionando (3.16) de maneira similar a um GLM(p),com I = Rγ(ρ). Nesse caso teremos
γ(k+1) = (GT A−1(k)G)−1GA−1(k)h(k), (3.27)
com h(k) = Gγ(k)+∆(u(k)− p(k)) e ∆ = diag(g′(p1), ...,g′(pL)) avaliado em p(k) = p(γ(k)).
Estimação de ρ
Para estimar ρ utilizamos um procedimento via mínimos quadrados condicionais(Klimko & Nelson (1978)) minimizando a soma de quadrados dos desvios em relação afunção de ligação da esperança condicional dada em (2.25), somente com respeito aos yi
pertencentes ao conjunto
y = {yi : i = 1,2, . . . ,L}\{yi : yi = 0, pi > 0,05}, (3.28)
pois nesse caso específico a dependência espacial está sendo acomodada somente na distri-buição de contagem e consideramos que os zeros pertencentes ao conjunto {yi : yi = 0, pi >
0,05} são considerados como estruturais. Na prática, os valores de pi são desconhecidos,sendo substituídos pelos seus valores estimados com os dados observados. De modo que,dado β minimizamos, com relação a ρ , a seguinte expressão:
∑yi∈y
{g(yi)−g(µi(β ))+ρ ∑
j∼i
wi j
wi+[g(y j)−g(µ j(β ))]
}2
,
29

obtendo a expressão
∑yi∈y
{g(yi)−g(µi(β ))+ρ ∑
j∼l
wi j
wi+[g(y j)−g(µ j(β ))]
}
×
{∑j∼i
wi j
wi+[g(y j)−g(µ j(β ))]
}. (3.29)
Então, na (k+1)−ésima iteração, dado β(k+1), o valor de ρ é atualizado em (k+1)
através do estimador
ρ(k+1) =
∑y∈y
{∑ j∼i
wi jwi+
[g(yi)−g(µi(β(k+1)))][g(y j)−g(µ j(β
(k+1)))]}
∑y∈y
{∑ j∼i
wi jwi+
[g(y j)−g(µ j(β(k+1)))]
}2 , (3.30)
em que ρ(k+1) ∈ (ρmin,ρmax), ρmin e ρmin são o inverso do menor e maior autovalores, res-pectivamente, da matriz M1/2MWM1/2 (Lawson et al. (1999), pg. 66).
Se não existe a inflação de zeros, g é a função identidade (g(a) = a) e wi j é do tipo 0ou 1. Não é difícil verificar que ρ ∈ (−1,1) é um índice de Moran baseado nos resíduos domodelo (ver Druck et al. (2004), cap. 5), estimado por
ρ =∑
Li=1
1wi+
{∑ j∼i(yi−µi(β ))(y j−µ j(β ))
}∑
Li=1
1w2
i+
{∑ j∼i(y j−µ j(β ))
}2 (3.31)
Estimação de φ
Na estimação de φ , solucionamos iterativamente a GEE (3.18) condicionada ao valorde β
(k+1), com φl = φ , l = 1,2, ...,L e obtemos na (k+1)-ésima iteração,
φ(k+1) =
∑Ll=1(1−u(k)l )D(yl,µl(β
(k+1)))
∑Ll=1(1−u(k)l )
, (3.32)
em que D é a função quase desvio avaliada em β(k+1).
As estimativas dos parâmetros de regressão β e γ , do parâmetro que mede a sobredis-persão φ e do parâmetro de dependência espacial ρ , são obtidas solucionando iterativamenteas quatro equações (3.26), (3.27), (3.30) e (3.32), até obter-se a convergência. Em cada ite-ração, β é calculado dado φ e ρ , acima na expressão (3.31), em seguida φ e ρ são obtidos apartir do β calculado e γ é estimado a partir de p.
30

3.2.2 Estimação Geral dos parâmetros no modelo QIZDE
A partir das funções quase escore (3.16), (3.17) e (3.18), considerando que cadamatriz de correlação espacial é similar a definida como no modelo CAR, na expressão (3.22),obtemos os estimadores para os parâmetros de regressão do modelo proposto, de modo geral,no formato matricial. Assim, no passo S do algoritmo ES, teremos os seguintes estimadores:
(i) para γ:
γ(k+1) = γ
(k)+(
HTγ V γ
−1(ρ(k),γ(k))Hγ
)−1HT
γ V γ−1(ρ(k),γ(k))(u−p(γ(k))); (3.33)
(ii) para β :
β(k+1) = β
(k)+(
HTβ
V β
−1(ρ(k),β (k))Hβ
)−1HT
βV β
−1(ρ(k),β (k))(y−µ(β (k)));
(3.34)
(iii) para λ :
λ(k+1) = λ
(k)+(
HTλ
V λ
−1(ρ(k),λ (k))Hλ
)−1HT
λV λ
−1(ρ(k),λ (k))[D(y,µ)−φ(λ (k))];
(3.35)
(iv) para ρ:
ρ(k+1)=M−1(y−µ(β (k+1)))W(y−µ(β (k+1)))[M−1W(y−µ(β (k+1)))T (y−µ(β (k+1)))M−1]−1.
(3.36)
em que Hγ , Hβ e Hλ são as respectivas matrizes de derivadas parciais [∂p∂γ]T , [∂ µ
∂β]T e [ ∂φ
∂λ]T ,
avaliadas em γ(k), β(k) e λ
(k), e as matrizes V γ
−1(ρ(k),γ(k)) = [A1/2Rγ(ρ
(k))A1/2]−1, com
A = diag(p(k)1 (1− p(k)1 ), ..., p(k)L (1− p(k)L )), V β
−1(ρ(k),β (k)) = [B1/2Rβ (ρ
(k))B1/2]−1U(k),
com B = diag(V (µ(k)1 ), ...,V (µ
(k)L )) e V λ
−1(ρ(k),λ (k)) = [C1/2Rλ (ρ
(k))C1/2]−1U(k), comC = diag(2φ
2(k)1 , ...,2φ
2(k)L ).
3.3 Distribuição dos Estimadores via Bootstrap
Liang & Zeger (1986) mostraram que os estimadores GEE são consistentes e assin-toticamente normais, para qualquer escolha da matriz de correlação, desde que o modelo deregressão para a média esteja corretamente especificado. No entanto, o GEE padrão não en-volve qualquer variável latente. Em nosso modelo a variável latente (U) existe e o algoritmoES substitui essa variável pela média condicional dada a variável resposta e as estimativasdos parâmetros. Mas, ignorando a variação dessa substituição, de cada variável latente pela
31

média condicional, teremos para os estimadores variâncias estimadas menores do que asverdadeiras (Kong et al. (2015)). Por isso, optamos por uma abordagem Bootstrap em doisestágios para a realização de inferências sob os parâmetros do modelo.
Para descrever o processo de reamostragem a partir dos estimadores dos parâmetros,considere no primeiro estágio o vetor Z∗ = (Z∗1 , ...,Z
∗L) como sendo uma amostra de uma
distribuição de contagem proposta P(µi(β )), como por exemplo a Poisson, com média µi(β ),que é o estimador da média obtido através do processo de estimação, descrito na seçãoanterior, obtido através do processo de estimação com os dados reais, e
µ∗i (Z
∗) = µi(β )+ ρ ∑j∼l
wl j
wl+[Z∗j −µ j(β )]. (3.37)
No segundo estágio, para reamostrar valores do Modelo QIZDE usamos os seguintespassos,
1. gere si ∼ U(0,1);
2. se si ≤ pi(γ), Y ∗i = 0. Senão, gere Y ∗i ∼ φ ×Fi, com Fi ∼ Poisson(µ∗i (Z
∗)
φ
);
3. Na n-ésima reamostra, repetindo os passos 1. e 2. para i = 1,2, ...,L. Teremos o vetorreamostrado Y∗n = (Y ∗1 , ...,Y
∗L )n;
4. Repita o passo 3. para n = 1,2, ...,N e obtenha as amostras Bootstrap Y∗1,Y∗2, ...,Y
∗N .
Nota-se que a esperança condicional de cada componente do vetor de reamos-tras Y∗ proveniente do processo de contagem, é da forma E(Y ∗i |Z∗) = µ∗i (Z∗), sua espe-rança marginal é igual a E(Y ∗i ) = E[E(Y ∗i |Z∗)] = µi(β ). E, portanto, E(Y ∗i − µi(β )) = 0,E(D(Y ∗i ; µi(β )))∼= φ e ainda, a estrutura de dependência dada em (3.23) é preservada. Destaforma, sejam os estimadores (µi, pi)≡ (µi(β )pi(γ)), teremos que
L
∑i=1
{∂ pi
∂γ∗
}T[A1/2
i Rγ∗(ρ)A1/2i ]−1(u∗i − pi) = 0, (3.38)
L
∑i=1
{∂ µi
∂β∗
}T[B1/2
i Rβ ∗(ρ)B1/2i ]−1U∗(y∗i − µi) = 0, (3.39)
L
∑i=1
{∂ φi
∂λ∗
}T[C1/2
i Rλ ∗(ρ)C1/2i ]−1U∗(D(y∗i , µi)− φi) = 0, (3.40)
são GEE empíricas para obter os estimadores Bootstrap (β∗, γ∗, φ
∗) de (β ,γ,φ). Sendo
assim, testes de hipótese e intervalos de confiança Bootstrap podem ser realizados no modeloproposto através da sequência de estimadores Bootstrap (β
∗, γ∗, φ
∗)n,n = 1,2, ...,N.
32

Capítulo 4
Estudo de Simulação
4.1 Descrição do Estudo
Neste capítulo mostraremos diversos estudos de simulação realizados a fim de verifi-car o comportamento dos estimadores propostos pelo novo modelo (QIZDE). Consideramoscomo cenário o mapa do estado do Amazonas (ver Figura 4.1), com seus 62 municípios, eexecutamos esses estudos simulados para algumas variações dos parâmetros do modelo, queserão descritos posteriormente.
Seja a variável resposta Yi pertencente à classe de modelos com quase verossi-milhança completa, com Yi ∼ QIZDE(pi,µi,φi,ρ), i = 1,2...,62, em que pi é a probabi-lidade de ocorrer um zero estrutural, µi é a média de ocorrências, φi é a sobredispersão e ρ éo parâmetro que mede a dependência espacial entre as áreas. Em cada estudo, consideramosas covariáveis Xi ∼U(0,1) para modelar as contagens positivas e Gi ∼U(0,0.5) para mode-lar o zero estrutural (essas mesmas covariáveis foram utilizadas no estudo de simulação emNieto-Barajas & Bandyopadhyay (2013)), em que i é o índice que referencia a i-ésima área.Assim, os modelos de regressão são descritos por:
XTi β = β0 +β1Xi e GT
i γ = γ0 + γ1Gi. (4.1)
Para o componente do modelo de mistura, referente a modelagem da média da distri-buição de contagem, a função de ligação adotada foi a logarítmica (ηi = log(µi) = XT
i β ). E,para o componente referente ao zero estrutural, a função de ligação utilizada foi o logit(pi).Em todos os cenários, utilizamos uma matriz de vizinhança espacial W, considerando quewi j = 1 se i∼ j, ou seja, se a área i é vizinha da área j assume-se peso 1, e 0 caso contrário.Sob essas especificações, a variável resposta Yi, que é a contagem observada na i-ésima área,foi gerada da seguinte forma:
(i) se uma variável aleatória si ∼U(0,1)≤ pi(γ), então yi = 0;
33

Atalaia do Norte
Guajará Ipixuna
Benjamin Constant
Eirunepé
Envira
JutaíSão Paulo de Olivença
Japurá
São Gabriel da Cachoeira
Tabatinga
Santo Antônio do Içá
Pauini
Itamarati
Boca do Acre
Tonantins
Amaturá
Carauari
Tapauá
Santa Isabel do Rio Negro
Lábrea
Fonte Boa
Juruá
Tefé
Maraã
Uarini
Alvarães
Coari
Barcelos
Canutama
Codajás
Novo Airão
Humaitá
Anori
Beruri
Manicoré
Caapiranga
Anamã
Novo Aripuanã
Manacapuru
Borba
Manaquiri
Iranduba
Presidente Figueiredo
Manaus
Careiro
Apuí
Autazes
Urucará
Careiro da Várzea
Rio Preto da Eva
São Sebastião do Uatumã
Itacoatiara
Itapiranga
Nova Olinda do Norte
Nhamundá
Silves
Maués
Urucurituba
Boa Vista do RamosBarreirinha
Parintins
Figura 4.1: Mapa do Estado do Amazonas, com seus 62 municípios.
(ii) caso contrário, yi ∼ φ ∗Ti, com Ti ∼ Poisson(µ∗i /φ), em que:
µ∗i = µi(β )+ρ ∑
j∈∂i
wi j
wi+(Yj−µ j(β ))) (4.2)
é escrita de acordo com o modelo CAR (ver expressão 3.24), com a parametrização descritapela expressão (4.2).
Com a finalidade de garantir a comparabilidade entre os estudos de simulação paraos cenários propostos, foi necessário desenvolver uma fórmula geral que nos permitisse ma-nipular a proporção de zeros vindas do excesso e da distribuição de contagem. Sendo as-sim, consideramos a quase verossimilhança completa para o modelo proposto (QIZDE),definida em (3.7), em que Yi ∼ φ ∗ Ti é uma quase-Poisson inflacionada de zeros, comTi ∼ Poisson(µ∗i /φ), e y = 0, obtendo a relação da quase verosimilhança estendida, quecompõe a estrutura de (3.7), com o logaritmo da probabilidade de ocorrência do zero
34

(log[P(Yi = 0)]), dada da seguinte forma:
Q+(µi,φ ,yi = 0) =−µi
φ− 1
2log(φ), (4.3)
Aplicando a função exponencial a expressão (4.3), obtemos:
P(Yi = 0|Ti) ≈ exp{− µi
φ− 1
2log(φ)
}≈ e−
µiφ exp{log(φ−
12 )}
≈ φ− 1
2 e−µ∗iφ . (4.4)
Como a proporção de zeros, gerada para o modelo QIZDE, pode ser calculada comoa probabilidade da variável resposta ser igual a zero, quando ele vier do zero estrutural oudas contagens positivas, resultando em uma soma de probabilidades, dada pela seguinte ex-pressão:
P(Yi = 0) = P(Yi = 0|Ti ∼ 0)+P(Yi = 0|Ti ∼ φPoi(µ∗i /φ)) = pi +φ− 1
2 e−µiφ , (4.5)
em que pi é a probabilidade de ocorrer um zero estrutural.Assim, fixamos os valores de γ1 e β1, e obtemos uma fórmula geral para obtenção de
γ0 e β0, sob cada variação de φ , onde assumimos que a proporção de zeros pi = φ−12 e−
µiφ ,
se Yi ∼ φ ∗Ti, que representa a proporção de zeros proveniente da distribuição de contagem,e pi = pi, se Yi ∼ 0, que representa a proporção de zeros vinda do zero estrutural. Então,fixando β1, obtivemos que:
EX [log(µi)] = E[β0 +β1Xi] = β0 +β112, (4.6)
logo o log(µi)∼= β0 +β112 . Fixando γ1, tivemos que:
EG[logit(pi)] = E[γ0 + γ1Gi] = γ0 + γ114, (4.7)
logo o logit(pi)∼= γ0 + γ114 .
Fixando φ = 2 e utilizando as equações (4.6) e (4.7), desenvolvemos as seguintes
35

expressões, das quais para β0 obtivemos que:
log(pi) ∼= log(
φ− 1
2 e−µiφ
)=−1
2log(2)− µi
22log(pi) ∼= −µi− log(2)
µi ∼= − log(2)−2log(pi)
exp[β0 +β1
12
]∼= − log(2)−2log(pi)
β0 ∼= log{− log(2)−2log(pi)
}−β1
12, (4.8)
e para γ0 obtivemos:
logit(pi) = γ0 + γ1Zi
γ0 ∼= logit(pi)− γ114
(4.9)
Com esse mesmo procedimento, encontramos outras expressões para alguns valoresfixados de φ , que são apresentados na Tabela (4.1).
Tabela 4.1: Fórmula Geral para β0 e γ0 de acordo com o φ .
φ β1 (fixo) (pi, % de zeros da Poisson) γ1 (fixo) (pi, % de zeros da Bernoulli)1 β0 ∼= log(−log(pi))− β1
2γ0 ∼= logit(pi)− γ1
42 β0 ∼= log[−2log(pi)− log(2)]− β12
4 β0 ∼= log{−4[log(pi)+ log(2)]}− β12
Todos os estudos de simulação foram realizados através do software estatístico R,versão 3.0.2. E, ainda, para cada estudo, utilizamos os resultados da Tabela 4.1, na qual fixa-mos γ1 = 2, β1 = 1 e ρ = 0.5, para obter os respectivos valores de β0 e γ0. O valor fixado deρ = 0.5 é bastante comum na literatura (Yasui & Lele (1997)). Cada uma dessas simulaçõesforam realizadas com Bootstrap duplo, dos quais temos um Bootstrap externo de tamanho1.000, para calcular as probabilidades de cobertura, e um interno de tamanho 300, para ge-rar os intervalos de confiança, ou seja, foram gerados um total de 300.000 mapas distintosnesse processo de simulação. Fizemos alguns testes iniciais e percebemos que os resultadosobtidos com um bootstrap interno de 300 é equivalente ao obtido com tamanhos maiores,como por exemplo o de tamanho 500. Os valores de β0 e γ0 foram calculados, também,para cada valor fixado do parâmetro φ , mas escolhemos apenas φ = 2,4 que caracterizama sobredispersão. Desse modo, obtivemos os valores de β0 e γ0 para o estudo de simulação(Tabela 4.2), no qual a proporção de zeros total é igual a 45% .
Os Intervalos de Confiança Bootstrap-t (ICBt) (ver Seção 2.7) para a média das es-timativas dos parâmetros, foram criados ao nível de 95% de confiança, cujas médias foramcalculadas das 300 reamostras Bootstrap (Bootstrap interno), que por sua vez foram geradas
36

a partir do valor estimado em cada repetição (Boostrap externo), de forma similar ao pro-cedimento de estimação descrito na Seção 4.3. As probabilidades de cobertura Bootstrap
nada mais são que a proporção de intervalos ICBt que contiveram o valor estimado, em cadarepetição, para seus respectivos parâmetros.
No processo de reamostragem Bootstrap, um fato importante é que se a matrizV(ρ(k),β (k)) inserida no estimador de β (ver equação 3.26) for computacionalmente singu-lar (det(V(ρ(k),β (k)))→ 0), a amostra é descartada gerando-se uma nova, pois no processode estimação é necessário obter a inversa dessa matriz.
Tabela 4.2: Estudo de Simulação, para 45% de Zeros.
pi (% de zeros da Inflação) pi (% de zeros da Poisson) γ0 φ β0
22,5 22,5 -1.73681 -0.10012 0.32864 0.6613
30 15 -1.34731 0.14032 0.63174 1.0719
15 30 -2.23461 -0.31442 0.03934 0.2146
A partir dessas especificações iniciais, realizamos estudos de simulação sob três pers-pectivas a serem comparadas, nas quais a proporção de zeros estruturais é maior, menor ouigual a proporção de zeros vinda da distribuição de contagem. Em cada estudo, analisamosas qualidades dos estimadores dos parâmetros de regressão do modelo proposto, através desuas estimativas médias, vícios médios, erros padrão e probabilidades de cobertura baseadasem intervalos de confiança Bootstrap-t.
4.2 Resultados
O cenário deste estudo foi o mapa do estado do Amazonas-AM, com suas 62 áreas(municípios), ou seja, L = 62. Todos os 1000 intervalos ICBt dos parâmetros foram geradosa partir das reamostras bootstrap, para cada valor fixado do parâmetro de sobredispersão φ ,que no caso foram 2 e 4. Os resultados deste estudo estão dispostos nas tabelas 4.3, 4.4 e4.5.
No que tange a estimativa do vetor β , sob a perspectiva de que a proporção de zerosvinda do excesso é maior do que a da distribuição de contagem (Tabela 4.3), os estimadores(β0, β1) obtiveram em média estimativas razoáveis e vícios pequenos, evidenciando o nãoviés desses estimadores, com erros padrão pequenos. As probabilidades de cobertura estãoum pouco abaixo do esperado (95%), no entanto são maiores e mais próximas do esperadoquando φ = 2, sofrendo uma redução com o aumento da sobredispersão (φ = 4), sendo mais
37
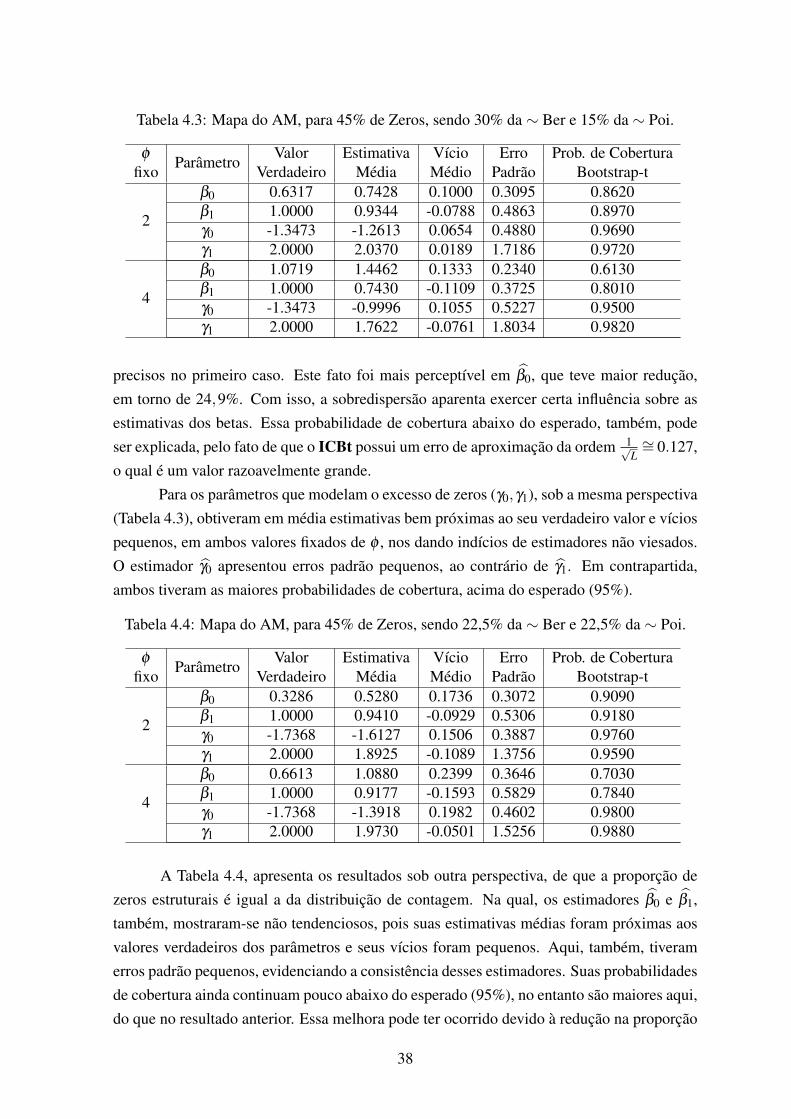
Tabela 4.3: Mapa do AM, para 45% de Zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi.
φParâmetro
Valor Estimativa Vício Erro Prob. de Coberturafixo Verdadeiro Média Médio Padrão Bootstrap-t
2
β0 0.6317 0.7428 0.1000 0.3095 0.8620β1 1.0000 0.9344 -0.0788 0.4863 0.8970γ0 -1.3473 -1.2613 0.0654 0.4880 0.9690γ1 2.0000 2.0370 0.0189 1.7186 0.9720
4
β0 1.0719 1.4462 0.1333 0.2340 0.6130β1 1.0000 0.7430 -0.1109 0.3725 0.8010γ0 -1.3473 -0.9996 0.1055 0.5227 0.9500γ1 2.0000 1.7622 -0.0761 1.8034 0.9820
precisos no primeiro caso. Este fato foi mais perceptível em β0, que teve maior redução,em torno de 24,9%. Com isso, a sobredispersão aparenta exercer certa influência sobre asestimativas dos betas. Essa probabilidade de cobertura abaixo do esperado, também, podeser explicada, pelo fato de que o ICBt possui um erro de aproximação da ordem 1√
L∼= 0.127,
o qual é um valor razoavelmente grande.Para os parâmetros que modelam o excesso de zeros (γ0,γ1), sob a mesma perspectiva
(Tabela 4.3), obtiveram em média estimativas bem próximas ao seu verdadeiro valor e víciospequenos, em ambos valores fixados de φ , nos dando indícios de estimadores não viesados.O estimador γ0 apresentou erros padrão pequenos, ao contrário de γ1. Em contrapartida,ambos tiveram as maiores probabilidades de cobertura, acima do esperado (95%).
Tabela 4.4: Mapa do AM, para 45% de Zeros, sendo 22,5% da ∼ Ber e 22,5% da ∼ Poi.
φParâmetro
Valor Estimativa Vício Erro Prob. de Coberturafixo Verdadeiro Média Médio Padrão Bootstrap-t
2
β0 0.3286 0.5280 0.1736 0.3072 0.9090β1 1.0000 0.9410 -0.0929 0.5306 0.9180γ0 -1.7368 -1.6127 0.1506 0.3887 0.9760γ1 2.0000 1.8925 -0.1089 1.3756 0.9590
4
β0 0.6613 1.0880 0.2399 0.3646 0.7030β1 1.0000 0.9177 -0.1593 0.5829 0.7840γ0 -1.7368 -1.3918 0.1982 0.4602 0.9800γ1 2.0000 1.9730 -0.0501 1.5256 0.9880
A Tabela 4.4, apresenta os resultados sob outra perspectiva, de que a proporção dezeros estruturais é igual a da distribuição de contagem. Na qual, os estimadores β0 e β1,também, mostraram-se não tendenciosos, pois suas estimativas médias foram próximas aosvalores verdadeiros dos parâmetros e seus vícios foram pequenos. Aqui, também, tiveramerros padrão pequenos, evidenciando a consistência desses estimadores. Suas probabilidadesde cobertura ainda continuam pouco abaixo do esperado (95%), no entanto são maiores aqui,do que no resultado anterior. Essa melhora pode ter ocorrido devido à redução na proporção
38
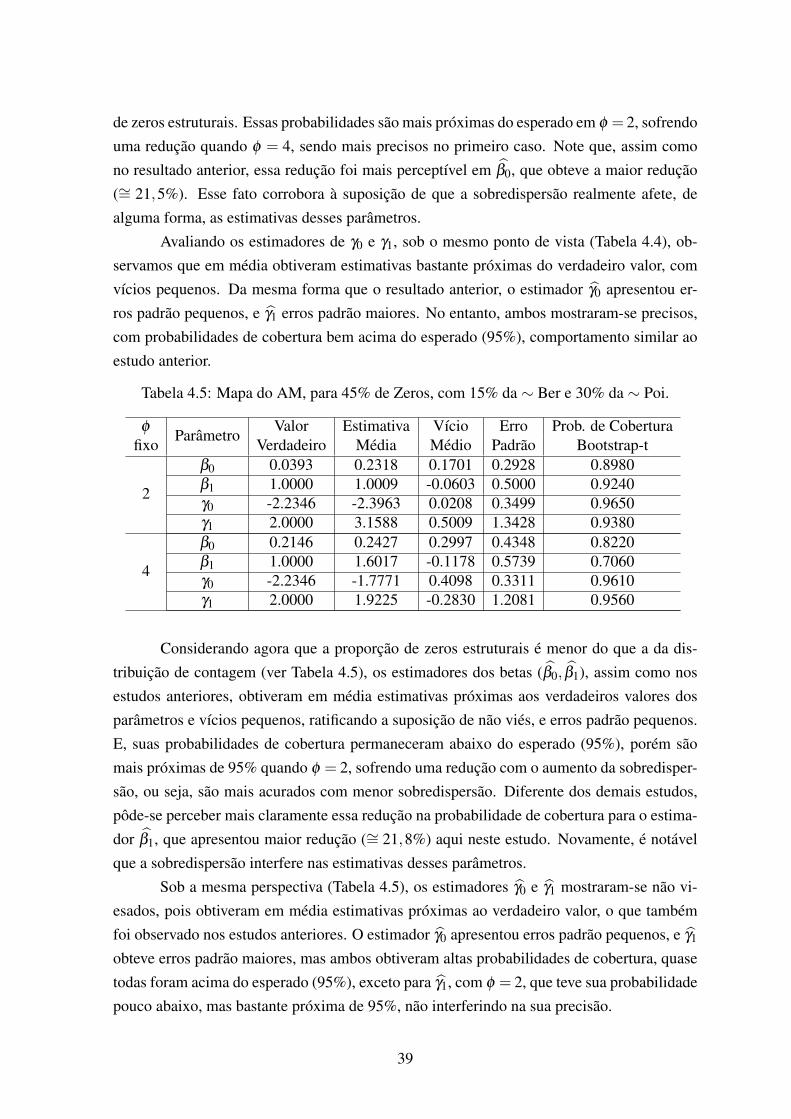
de zeros estruturais. Essas probabilidades são mais próximas do esperado em φ = 2, sofrendouma redução quando φ = 4, sendo mais precisos no primeiro caso. Note que, assim comono resultado anterior, essa redução foi mais perceptível em β0, que obteve a maior redução(∼= 21,5%). Esse fato corrobora à suposição de que a sobredispersão realmente afete, dealguma forma, as estimativas desses parâmetros.
Avaliando os estimadores de γ0 e γ1, sob o mesmo ponto de vista (Tabela 4.4), ob-servamos que em média obtiveram estimativas bastante próximas do verdadeiro valor, comvícios pequenos. Da mesma forma que o resultado anterior, o estimador γ0 apresentou er-ros padrão pequenos, e γ1 erros padrão maiores. No entanto, ambos mostraram-se precisos,com probabilidades de cobertura bem acima do esperado (95%), comportamento similar aoestudo anterior.
Tabela 4.5: Mapa do AM, para 45% de Zeros, com 15% da ∼ Ber e 30% da ∼ Poi.
φParâmetro
Valor Estimativa Vício Erro Prob. de Coberturafixo Verdadeiro Média Médio Padrão Bootstrap-t
2
β0 0.0393 0.2318 0.1701 0.2928 0.8980β1 1.0000 1.0009 -0.0603 0.5000 0.9240γ0 -2.2346 -2.3963 0.0208 0.3499 0.9650γ1 2.0000 3.1588 0.5009 1.3428 0.9380
4
β0 0.2146 0.2427 0.2997 0.4348 0.8220β1 1.0000 1.6017 -0.1178 0.5739 0.7060γ0 -2.2346 -1.7771 0.4098 0.3311 0.9610γ1 2.0000 1.9225 -0.2830 1.2081 0.9560
Considerando agora que a proporção de zeros estruturais é menor do que a da dis-tribuição de contagem (ver Tabela 4.5), os estimadores dos betas (β0, β1), assim como nosestudos anteriores, obtiveram em média estimativas próximas aos verdadeiros valores dosparâmetros e vícios pequenos, ratificando a suposição de não viés, e erros padrão pequenos.E, suas probabilidades de cobertura permaneceram abaixo do esperado (95%), porém sãomais próximas de 95% quando φ = 2, sofrendo uma redução com o aumento da sobredisper-são, ou seja, são mais acurados com menor sobredispersão. Diferente dos demais estudos,pôde-se perceber mais claramente essa redução na probabilidade de cobertura para o estima-dor β1, que apresentou maior redução (∼= 21,8%) aqui neste estudo. Novamente, é notávelque a sobredispersão interfere nas estimativas desses parâmetros.
Sob a mesma perspectiva (Tabela 4.5), os estimadores γ0 e γ1 mostraram-se não vi-esados, pois obtiveram em média estimativas próximas ao verdadeiro valor, o que tambémfoi observado nos estudos anteriores. O estimador γ0 apresentou erros padrão pequenos, e γ1
obteve erros padrão maiores, mas ambos obtiveram altas probabilidades de cobertura, quasetodas foram acima do esperado (95%), exceto para γ1, com φ = 2, que teve sua probabilidadepouco abaixo, mas bastante próxima de 95%, não interferindo na sua precisão.
39

(a) (b)0.
00.
51.
01.
5
Boxplot − Beta 0
0.5
1.0
1.5
2.0
Boxplot − Beta 0
Figura 4.2: Boxplot das estimativas de β0, com φ = 2 (a) e φ = 4 (b), mapa do AM, para45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi.
(a) (b)
−0.
50.
00.
51.
01.
52.
02.
5
Boxplot − Beta 1
−0.
50.
00.
51.
01.
52.
0
Boxplot − Beta 1
Figura 4.3: Boxplot das estimativas de β1, com φ = 2 (a) e φ = 4 (b), mapa do AM, para45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi.
Outro comportamento que podemos visualizar para o estimador β0 (ver Figura 4.2)é o de simetria no lado (a) e no lado (b), evidenciando uma distribuição assintoticamenteNormal, com a presença de outliers em ambos os lados da figura. O estimador β1 (verFigura 4.3) mostrou-se simétrico em ambos os lados (a) e (b), nos dando indícios de quepossuem distribuição Normal assintótica, com a presença de outliers.
O estimador γ0 apresentou comportamento levemente assimétrico à direita (ver Fi-gura 4.4), afastando-se da suposição de normalidade assintótica, e amplitudes equivalentesnos lados (a) e (b). E o estimador γ1 (ver Figura 4.5) apresentou simetria em (a) e (b),
40
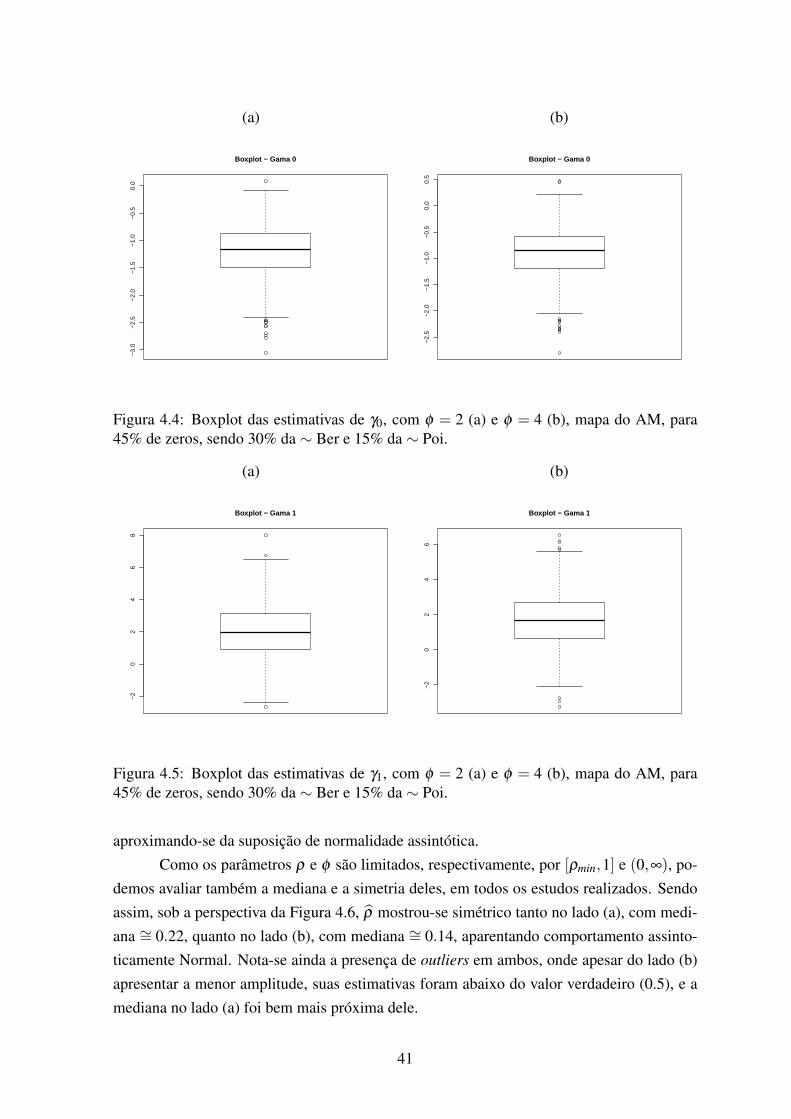
(a) (b)−
3.0
−2.
5−
2.0
−1.
5−
1.0
−0.
50.
0
Boxplot − Gama 0
−2.
5−
2.0
−1.
5−
1.0
−0.
50.
00.
5
Boxplot − Gama 0
Figura 4.4: Boxplot das estimativas de γ0, com φ = 2 (a) e φ = 4 (b), mapa do AM, para45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi.
(a) (b)
−2
02
46
8
Boxplot − Gama 1
−2
02
46
Boxplot − Gama 1
Figura 4.5: Boxplot das estimativas de γ1, com φ = 2 (a) e φ = 4 (b), mapa do AM, para45% de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi.
aproximando-se da suposição de normalidade assintótica.Como os parâmetros ρ e φ são limitados, respectivamente, por [ρmin,1] e (0,∞), po-
demos avaliar também a mediana e a simetria deles, em todos os estudos realizados. Sendoassim, sob a perspectiva da Figura 4.6, ρ mostrou-se simétrico tanto no lado (a), com medi-ana ∼= 0.22, quanto no lado (b), com mediana ∼= 0.14, aparentando comportamento assinto-ticamente Normal. Nota-se ainda a presença de outliers em ambos, onde apesar do lado (b)apresentar a menor amplitude, suas estimativas foram abaixo do valor verdadeiro (0.5), e amediana no lado (a) foi bem mais próxima dele.
41
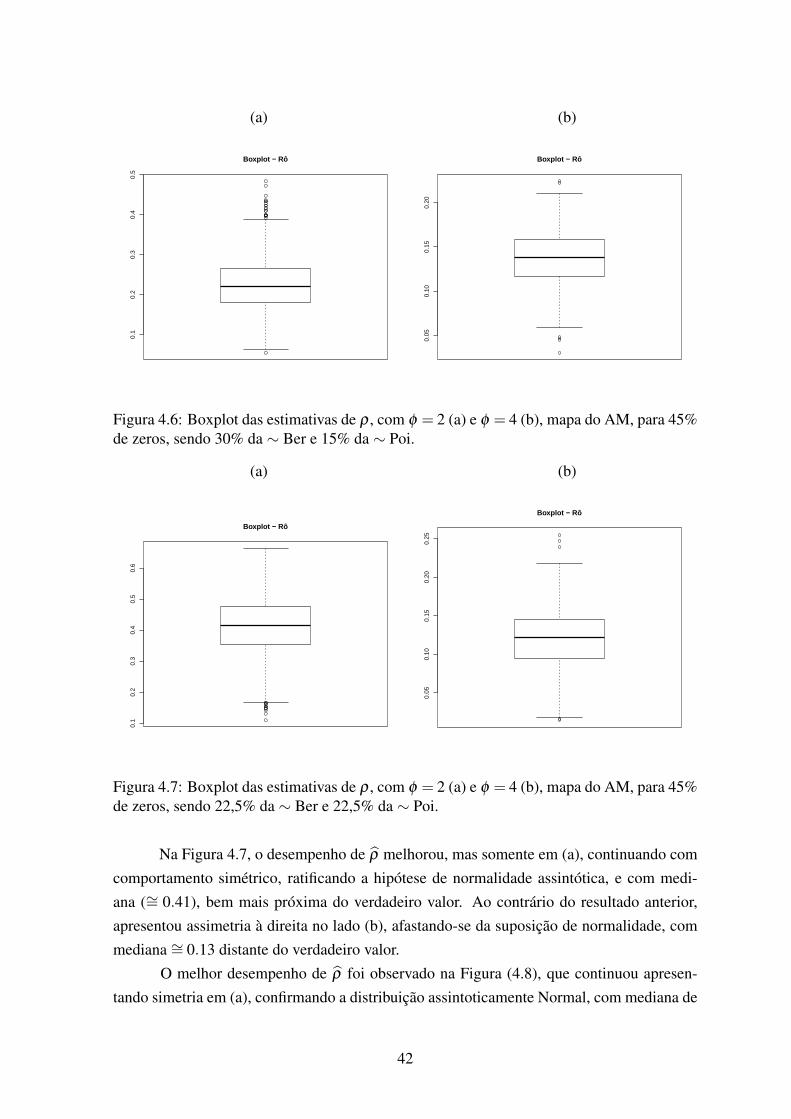
(a) (b)0.
10.
20.
30.
40.
5
Boxplot − Rô
0.05
0.10
0.15
0.20
Boxplot − Rô
Figura 4.6: Boxplot das estimativas de ρ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para 45%de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi.
(a) (b)
0.1
0.2
0.3
0.4
0.5
0.6
Boxplot − Rô
0.05
0.10
0.15
0.20
0.25
Boxplot − Rô
Figura 4.7: Boxplot das estimativas de ρ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para 45%de zeros, sendo 22,5% da ∼ Ber e 22,5% da ∼ Poi.
Na Figura 4.7, o desempenho de ρ melhorou, mas somente em (a), continuando comcomportamento simétrico, ratificando a hipótese de normalidade assintótica, e com medi-ana (∼= 0.41), bem mais próxima do verdadeiro valor. Ao contrário do resultado anterior,apresentou assimetria à direita no lado (b), afastando-se da suposição de normalidade, commediana ∼= 0.13 distante do verdadeiro valor.
O melhor desempenho de ρ foi observado na Figura (4.8), que continuou apresen-tando simetria em (a), confirmando a distribuição assintoticamente Normal, com mediana de
42
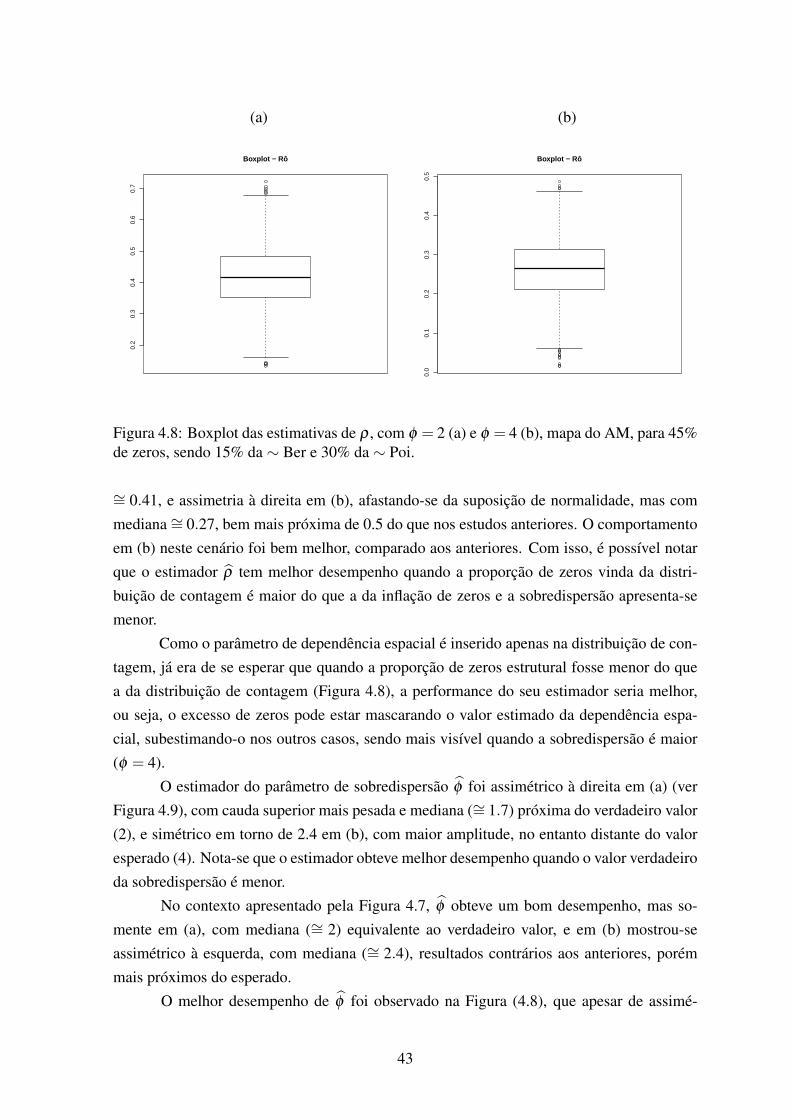
(a) (b)0.
20.
30.
40.
50.
60.
7
Boxplot − Rô
0.0
0.1
0.2
0.3
0.4
0.5
Boxplot − Rô
Figura 4.8: Boxplot das estimativas de ρ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para 45%de zeros, sendo 15% da ∼ Ber e 30% da ∼ Poi.
∼= 0.41, e assimetria à direita em (b), afastando-se da suposição de normalidade, mas commediana ∼= 0.27, bem mais próxima de 0.5 do que nos estudos anteriores. O comportamentoem (b) neste cenário foi bem melhor, comparado aos anteriores. Com isso, é possível notarque o estimador ρ tem melhor desempenho quando a proporção de zeros vinda da distri-buição de contagem é maior do que a da inflação de zeros e a sobredispersão apresenta-semenor.
Como o parâmetro de dependência espacial é inserido apenas na distribuição de con-tagem, já era de se esperar que quando a proporção de zeros estrutural fosse menor do quea da distribuição de contagem (Figura 4.8), a performance do seu estimador seria melhor,ou seja, o excesso de zeros pode estar mascarando o valor estimado da dependência espa-cial, subestimando-o nos outros casos, sendo mais visível quando a sobredispersão é maior(φ = 4).
O estimador do parâmetro de sobredispersão φ foi assimétrico à direita em (a) (verFigura 4.9), com cauda superior mais pesada e mediana (∼= 1.7) próxima do verdadeiro valor(2), e simétrico em torno de 2.4 em (b), com maior amplitude, no entanto distante do valoresperado (4). Nota-se que o estimador obteve melhor desempenho quando o valor verdadeiroda sobredispersão é menor.
No contexto apresentado pela Figura 4.7, φ obteve um bom desempenho, mas so-mente em (a), com mediana (∼= 2) equivalente ao verdadeiro valor, e em (b) mostrou-seassimétrico à esquerda, com mediana (∼= 2.4), resultados contrários aos anteriores, porémmais próximos do esperado.
O melhor desempenho de φ foi observado na Figura (4.8), que apesar de assimé-
43
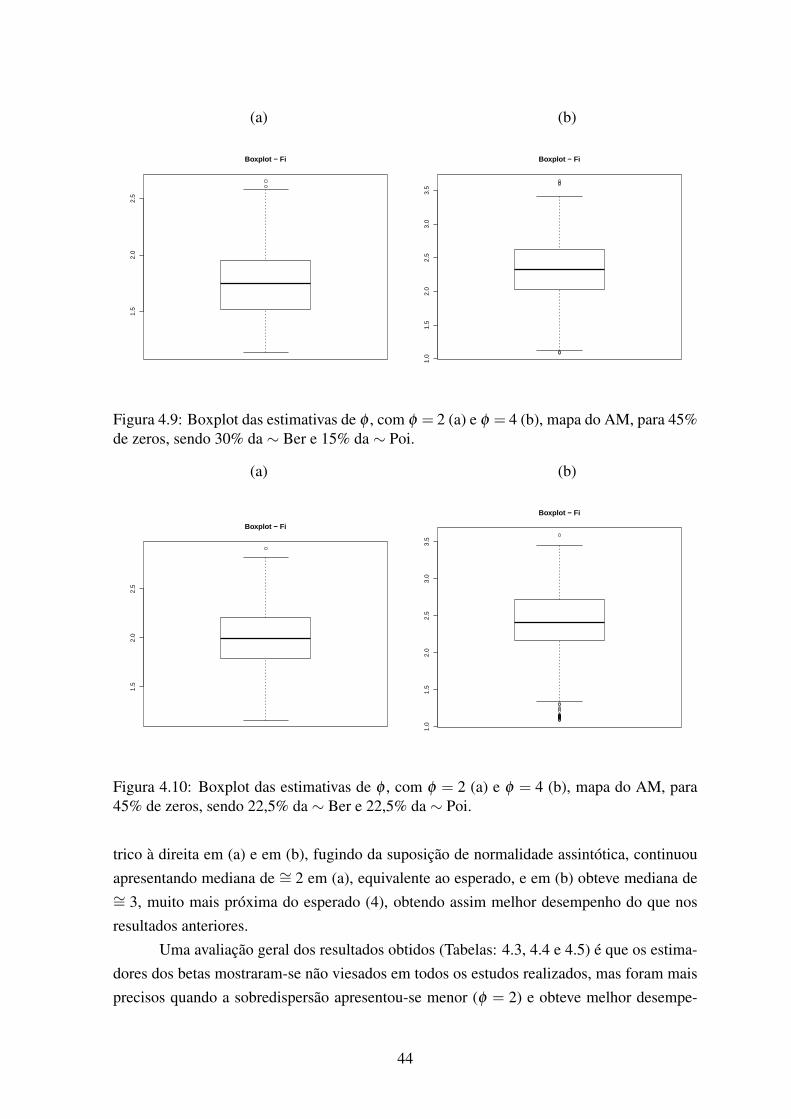
(a) (b)1.
52.
02.
5
Boxplot − Fi
1.0
1.5
2.0
2.5
3.0
3.5
Boxplot − Fi
Figura 4.9: Boxplot das estimativas de φ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para 45%de zeros, sendo 30% da ∼ Ber e 15% da ∼ Poi.
(a) (b)
1.5
2.0
2.5
Boxplot − Fi
1.0
1.5
2.0
2.5
3.0
3.5
Boxplot − Fi
Figura 4.10: Boxplot das estimativas de φ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para45% de zeros, sendo 22,5% da ∼ Ber e 22,5% da ∼ Poi.
trico à direita em (a) e em (b), fugindo da suposição de normalidade assintótica, continuouapresentando mediana de ∼= 2 em (a), equivalente ao esperado, e em (b) obteve mediana de∼= 3, muito mais próxima do esperado (4), obtendo assim melhor desempenho do que nosresultados anteriores.
Uma avaliação geral dos resultados obtidos (Tabelas: 4.3, 4.4 e 4.5) é que os estima-dores dos betas mostraram-se não viesados em todos os estudos realizados, mas foram maisprecisos quando a sobredispersão apresentou-se menor (φ = 2) e obteve melhor desempe-
44

(a) (b)1.
52.
02.
5
Boxplot − Fi
1.5
2.0
2.5
3.0
3.5
4.0
Boxplot − Fi
Figura 4.11: Boxplot das estimativas de φ , com φ = 2 (a) e φ = 4 (b), mapa do AM, para45% de zeros, sendo 15% da ∼ Ber e 30% da ∼ Poi.
nho quando a proporção de zeros estruturais era menor ou igual do que a da distribuição decontagem. E, graficamente, apresentaram uma comportamento assintoticamente Normal.
Os gamas mostraram-se não viesados e precisos em todos os estudos e com melhordesempenho quando a proporção de zeros estruturais era maior ou igual do que a da distri-buição de contagem. No entanto, avaliando os gráficos, γ0 não apresentou comportamentoassintoticamente Normal, enquanto que γ1 mostrou seguir tal comportamento.
No que concerne ao estimador ρ , em geral obteve comportamento assintoticamenteNormal, apresentou melhor desempenho sob a perspectiva de que a proporção de zeros estru-turais é menor do que a da distribuição de contagem, principalmente quando a sobredispersãofoi fixada em 2. O que era esperado, pois a dependência espacial foi inserida na distribuiçãode contagem, então quando a quantidade de zeros vindos da inflação é maior do que a da dis-tribuição de contagem, percebemos que o excesso de zeros acaba mascarando a dependênciaespacial.
Por fim, o estimador φ apresentou comportamento assimétrico, fugindo da suposiçãode Normalidade. E, assim como observado no comportamento de ρ , obteve melhor desem-penho sob o aspecto de que a proporção de zeros estruturais é menor do que a da distribuiçãode contagem, com medianas muito mais próximas do verdadeiro valor.
45

Capítulo 5
Aplicação do Modelo em Dados Reais
5.1 Descrição dos Dados
Neste capítulo, realizamos uma aplicação do modelo proposto (QIZDE) em dados decontagem de novos casos de hanseníase em menores de 15 anos, notificados dentre os anosde 2009 a 2012, no estado do Amazonas, região norte do Brasil, para cada um dos seus 62municípios. Para uma visualização da distribuição espacial desses novos casos de hanseníaseveja a Figura 5.1.
A hanseníase, também conhecida como lepra, é uma doença infecto contagiosa cau-sada por uma bactéria chamada Mycobacterium leprae, que foi descoberta em 1873 por umcientista chamado Hansen. É uma doença curável, porém se não for devidamente tratadapode ser preocupante, devido à sua magnitude e seu alto poder incapacitante. Por isso, oacompanhamento epidemiológico e variação geográfica da hanseníase são de grande impor-tância à saúde pública, para seu controle e monitoramento.
O surgimento e desenvolvimento da hanseníase estão relacionados com as condiçõesde vida da população, e seu acompanhamento epidemiológico é realizado por meio do co-eficiente de detecção de novos casos, que é obtido dividindo-se o total de novos casos pelapopulação em risco e multiplicando o resultado por 10 mil habitantes. Os países com maiorincidência são os menos desenvolvidos ou com condições precárias de higiene e superpopu-lação.
O número de casos em menores de 15 anos é um indicador que reflete a gravidadedo nível endêmico da Hanseníase e a exposição precoce à doença, pois a detecção de casosnessa faixa etária tem relação com a doença detectada recente e focos de transmissão ativos.Por isso, o grupo com menores de 15 anos (grupo de risco) foi considerado o público alvodesta aplicação. Em geral, as taxas elevadas refletem baixos níveis de condições de vida,desenvolvimento socioeconômico e atenção à saúde.
Nos anos de 2009 a 2012 foram notificados 242 novos casos de hanseníase, do totalde 4.649.905 menores de 15 anos residentes no estado do AM, com uma taxa de 0,5204 casos
46

Cases Number to 2009−2012
Figura 5.1: Distribuição espacial dos novos casos de Hanseníase, notificados no Estado doAmazonas-Brasil, no período de 2009 a 2012.
para cada 10 mil habitantes, sendo classificada como hiperendêmica, segundo o Ministérioda Saúde do Brasil.
Cerca de 32,26% dos municípios não registraram ou não notificaram novos casos,evidenciando a existência de excesso de zeros nos dados. Na Figura 5.1, podemos notara existência de municípios sem notificações de casos durante 4 anos, que são as áreas embranco. Este fato nos sugeriu a hipótese de que estes zeros podem ter ocorrido estrutural-mente devido a subnotificação de casos causada, possivelmente, pelas condições de vidasocial e econômica destas populações. Por isso, inicialmente foi realizada uma análise preli-minar dos dados utilizando um modelo Poisson inflacionado de zeros (ZIP) com covariáveisque podem influenciar a ocorrência e o registro de novos casos de hanseníase. A descriçãodo modelo e resultados dessa análise serão apresentados na próxima seção.
47

5.2 Modelo ZIP para os novos casos notificados de hanse-níase no Amazonas
O banco de dados é composto por registros de novos casos de hanseníase, em me-nores de 15 anos, notificados no período de 2009 a 2012 nos 62 municípios do Estado doAmazonas (fonte: http://dtr2004.saude.gov.br/ sinanweb/index.php) e por outras variáveis:taxa padronizada de domicílios com saneamento inadequado de 2010, média de unidadesbásicas de saúde de 2009 a 2012, índice de desenvolvimento humano de 2010, quantidadede recursos humanos na área de saúde em 2010, distância padronizada dos municípios paraa capital (Manaus) e taxa de analfabetismo de 2010.
Inicialmente analisamos esses dados com um modelo para dados inflacionados dezeros, considerando que Yi ∼ ZIP(µi, pi), i = 1,2...,62, representa o número de novos casosde hanseníase registrados ou notificados no i-ésimo município do estado do Amazonas. Arepresentação do modelo é dada por:
log(µi) = β0 +β1Xi1 +β2Xi2 +β3Xi3 + log(ni), (5.1)
em que log(µi) é o preditor linear para a média das contagens positivas e,
logit(pi) = γ0 + γ1Gi1 + γ2Gi2 + γ3Gi3 + γ4Gi4 (5.2)
é o preditor linear para a probabilidade de ocorrer o zero estrutural, possivelmente devido asubnotificações. Essas covariáveis são descritas como:
Xi1: é a taxa padronizada de domicílios que possuem saneamento inadequado, dai-ésima área, dada por:
Xi1 =Xi1−min{Xi1 : i = 1, ...,62}
max{Xi1 : i = 1, ...,62}−min{Xi1 : i = 1, ...,62},
A diferença entre a capital do Estado do Amazonas, Manaus, e os demais municípios noque concerne a taxa de domicílioas com saneamento inadequado é muito grande, por issoadotamos os valores padronizados.
Xi2 = Gi3: é a quantidade média de unidades básicas de saúde, no período de 2009 a2012, da i-ésima área;
Xi3: é o índice de desenvolvimento humano (IDH), em 2010, da i-ésima área;Gi1: é a quantidade de recursos humanos na área de saúde, em 2010, da i-ésima área;Gi2: é a distância padronizada da i-ésima área para Manaus, dada por:
Gi2 =dim−min{dim : i = 1, ...,62}
max{dim : i = 1, ...,62}−min{dim : i = 1, ...,62},
48

em que dim é a distância da i-ésima área para Manaus-AM.Gi4: é a taxa de analfabetismo, em 2010, da i-ésima área;log(ni): é a variável (offset) utilizada para incorporar a heterogeneidade da popula-
ção, em que ni corresponde a população média projetada de menores de 15 anos de idade,residentes no estado do Amazonas, no período de 2009 a 2012, na i-ésima área (município).
As variáveis Gi1, Gi3 e Gi4 são consideradas covariáveis de registro ou notificaçõesno sentido de que inibem a ocorrência de zeros. A covariável Gi2 é considerada de subnotifi-cação, pois a capital Manaus concentra mais de 50% de toda população, apresenta condiçõesde recursos humanos e estrutura física (hospitais, clínicas, etc...) que favorecem o diagnós-tico da doença. No entanto, devido a extensão territorial do estado, Manaus é muito distantede algumas cidades, das quais o deslocamento só pode ser realizado através de embarca-ções. Tal fato, pode dificultar a busca pelo diagnóstico da doença gerando o não registro epossibilitando o surgimento de um zero estrutural.
Para análise do modelo, utilizamos no R a função "zeroinfl"do pacote "pscl"(Pa-
ckage ’pscl’) e os resultados obtidos para modelo ZIP(µi, pi) são apresentados na Tabela5.1. Como pode ser observado na Tabela 5.1, de acordo com essa modelagem, há apenasduas covariáveis significativas para a média do modelo de contagem, que são Xi2 (média deunidades básicas de saúde) e Xi3 (índice de desenvolvimento humano), e para a inflação dezeros nenhuma das covariáveis avaliadas foi significativas.
Note que há inconsistência de informação, por exemplo, a estimativa para Xi2 foinegativa, implicando na seguinte relação, de que quanto mais unidades básicas de saúdeexistirem em determinada área, espera-se que menor seja a média de novos casos notificadosde hanseníase, resultado este que é o oposto do esperado. Observa-se também, que nenhumadas covariáveis preditoras para o excesso de zeros, foram significativas. No entanto, o índicede inflação de zeros calculado com esse modelo ajustado, definido no Capítulo 2, foi esti-mado em zi = 0.189, o qual é maior que zero, implicando na presença da inflação de zerosnos dados. Podemos notar a existência de municípios sem notificação, o que não faz sentido,pois o esperado é que ao menos uma dessas covariáveis implicasse na inflação de zeros. Ba-seados na razão entre a soma de quadrados dos resíduos e os graus de liberdade do modeloZIP utilizado, obtivemos uma estimativa para sobredispersão igual a 8.67. O que nos levaa crer, que essa modelagem não consegue capturar adequadamente a inflação de zeros e asobredispersão, possivelmente porque não levam em consideração a existência da relação dedependência entre os municípios vizinhos.
Para verificar uma possível estrutura de dependência espacial no dados, utilizou-seno R o correlograma dos resíduos do modelo escolhido, gerado pela função "correlog"dopacote "ncf", que utiliza o Índice de Moran, para o caso univariado, e a estatística de Mantelcentrada, para o caso multivariado (Epperson (1993); Bjørnstad et al. (1999); Bjørnstad& Falck (2001)). O gráfico desses resíduos apresenta em sua estrutura o coeficiente de
49
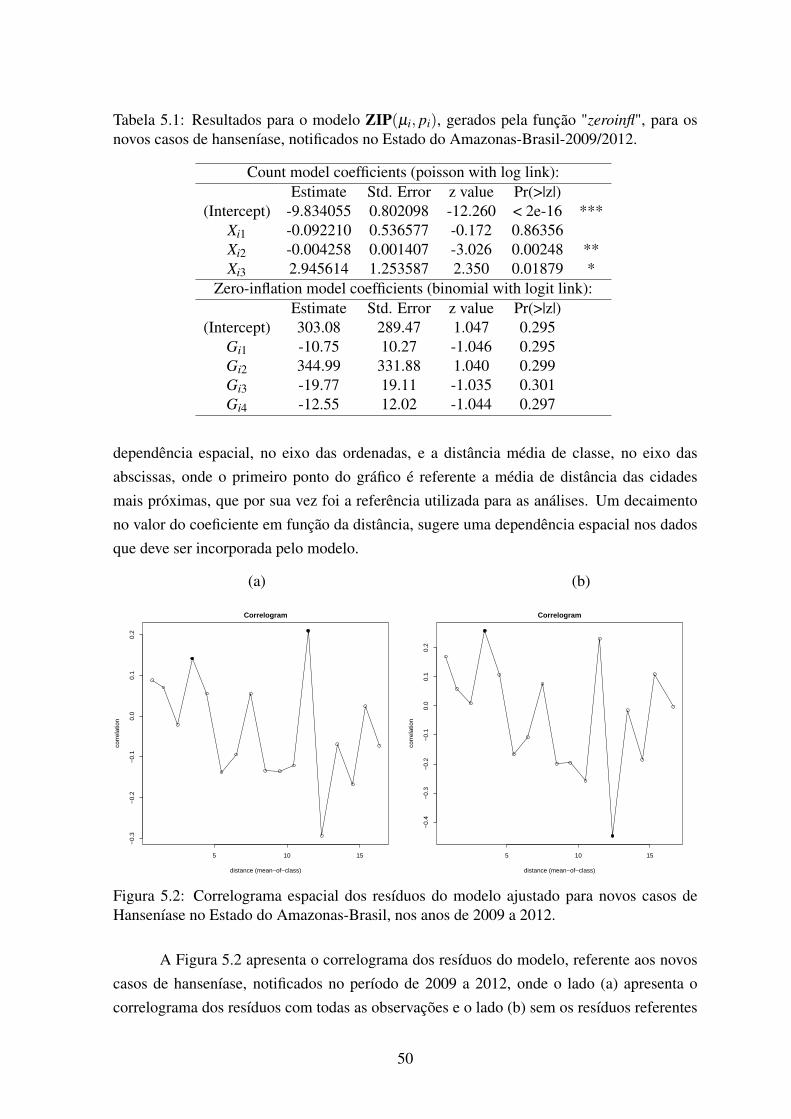
Tabela 5.1: Resultados para o modelo ZIP(µi, pi), gerados pela função "zeroinfl", para osnovos casos de hanseníase, notificados no Estado do Amazonas-Brasil-2009/2012.
Count model coefficients (poisson with log link):Estimate Std. Error z value Pr(>|z|)
(Intercept) -9.834055 0.802098 -12.260 < 2e-16 ***Xi1 -0.092210 0.536577 -0.172 0.86356Xi2 -0.004258 0.001407 -3.026 0.00248 **Xi3 2.945614 1.253587 2.350 0.01879 *
Zero-inflation model coefficients (binomial with logit link):Estimate Std. Error z value Pr(>|z|)
(Intercept) 303.08 289.47 1.047 0.295Gi1 -10.75 10.27 -1.046 0.295Gi2 344.99 331.88 1.040 0.299Gi3 -19.77 19.11 -1.035 0.301Gi4 -12.55 12.02 -1.044 0.297
dependência espacial, no eixo das ordenadas, e a distância média de classe, no eixo dasabscissas, onde o primeiro ponto do gráfico é referente a média de distância das cidadesmais próximas, que por sua vez foi a referência utilizada para as análises. Um decaimentono valor do coeficiente em função da distância, sugere uma dependência espacial nos dadosque deve ser incorporada pelo modelo.
(a) (b)
5 10 15
−0.
3−
0.2
−0.
10.
00.
10.
2
distance (mean−of−class)
corr
elat
ion
Correlogram
5 10 15
−0.
4−
0.3
−0.
2−
0.1
0.0
0.1
0.2
distance (mean−of−class)
corr
elat
ion
Correlogram
Figura 5.2: Correlograma espacial dos resíduos do modelo ajustado para novos casos deHanseníase no Estado do Amazonas-Brasil, nos anos de 2009 a 2012.
A Figura 5.2 apresenta o correlograma dos resíduos do modelo, referente aos novoscasos de hanseníase, notificados no período de 2009 a 2012, onde o lado (a) apresenta ocorrelograma dos resíduos com todas as observações e o lado (b) sem os resíduos referentes
50

às cidades que não apresentaram nenhum caso. Note, que a inflação de zeros mascara umpouco dependência espacial em (a), mas os dados de contagem positiva possuem sim taldependência, como vemos claramente em (b), cuja correlação é interpretada como positivaentre áreas vizinhas. E ainda, o segundo correlograma (b) mostra que os vizinhos maispróximos possuem correlação espacial positiva de ∼= 0,2. Esse comportamento gráfico dotipo zig-zag para os resíduos, pode ser um indicador de que existam pequenos aglomeradosde municípios com excesso de zeros ou pequenos aglomerados de contagens positivas.
Portanto, como as três características abordadas: inflação de zeros, sobredispersão edependência espacial, foram identificadas nesses dados de hanseníase, os modelos tradicio-nais existentes, bem como os modelos para dados inflacionados de zeros, ambos no contextofrequentista, não ajustariam bem esses dados por não conseguirem modelar ao mesmo tempoas três características. Então, na próxima seção, aplicaremos o modelo (QIZDE) o qualpropõe-se a modelar essas três características conjuntamente, com abordagem frequentista,e discutiremos os resultados obtidos.
5.3 Descrição do Modelo Proposto
Considere a variável de interesse sendo Yi, i = 1, ...,62, que corresponde ao númerode novos casos de hanseníase notificados no i-ésimo município do estado do Amazonas,no período de 2009 a 2012, cujo mapa do estado é composto de 62 municípios. Comoobservado na seção anterior, os dados referentes a esses novos casos de hanseníase notifica-dos apresentam inflação de zeros, sobredispersão e as áreas vizinhas possuem dependênciaespacial. Vamos assumir, ainda, que Yi pertença à classe de modelos com quase verossimi-lhança completa. Sendo assim, pela definição 2 dada na Seção 3.2, podemos representarYi por um modelo quase inflacionado de zeros com dependência espacial QIZDE. Então,Yi ∼ QIZDE(pi,µi,φi,ρ), i = 1,2...,62, em que pi é a probabilidade de ocorrer um zeroestrutural, subnotificado, µi é a média de novos casos de hanseníase notificados, φi é a so-bredispersão e ρ é o parâmetro que mede o grau de dependência espacial entre municípiosvizinhos.
Para a modelagem dos dados, vamos adotar o modelo QIZDE Poisson, exemplifi-cado na Seção 3.1.1, com função de quase-verossimilhança completa dada pela expressão(3.6), se houverem casos notificados no i-ésimo município, e pela expressão (3.7), se nãohouver nenhum caso notificado. A partir dessas definições, para encontrarmos os estimado-res é necessário definir cada componente das funções quase-escore do modelo proposto (verexpressões (3.16), (3.17) e (3.18)), de acordo com os dados utilizados neste estudo.
Adotamos o modelo QIZDE Poisson, com as equações quase-escore descritas naSeção 3.2. Para a modelagem da inflação de zeros, utilizamos a função de ligação logit, emque logit(pi) = GT
i γ , com matriz de covariáveis Gi e vetor de parâmetros de regressão γ ,
51

resultando na equação quase-escore (3.19). Assumimos a relação de dependência espacialapenas na média de notificação de novos casos de hanseníase, para modelar a inflação dezeros, consideramos a matriz identidade I no lugar da matriz de correlação espacial Rγ(ρ),resultando na expressão definida no modelo para independência (ver Seção 3.1). Assimtemos que:
GTi γ = γ0 + γ1Gi1 + γ2Gi2 + γ3Gi3 + γ4Gi4, (5.3)
cujas covariáveis Gi· são exatamente as mesmas definidas anteriormente, na aplicação como modelo ZIP, Seção 5.2.
Para a modelagem da média de novos casos de hanseníase notificados, consideramos afunção logarítmica como sendo a de ligação, onde log(µi) =XT
i β , com matriz de covariáveisXi e vetor de parâmetros de regressão β , cuja função quase-escore é dada pela expressão(3.20). Assim temos que:
XTi β = β0 +β1Xi1 +β2Xi2 +β3Xi3 + log(ni), (5.4)
em que as covariáveis Xi·, também, foram definidas na aplicação com o modelo ZIP (Seção5.2).
Em sua composição, a função quase escore (3.20) conta com a matriz de correlaçãoespacial Rβ (ρ), definida em (3.22), em que a matriz W, que define a estrutura espacial devizinhança, será composta por elementos wi j = 1, se os municípios i e j forem vizinhos, ewi j = 0, caso contrário. E a matriz de pesos M, referente à essa estrutura de vizinhança, terácomo i-ésimo elemento da diagonal o wi+, que corresponde à soma de quantos vizinhos o i-ésimo município possui, ou seja, equivale à soma desses zeros e uns em cada linha da matrizW. Com isso, obtemos a esperança condicional da ocorrência de casos no i-ésimo municípiodada a sua vizinhança (ver expressão 3.23). Desta forma, substituindo adequadamente asmatrizes de covariáveis (X e G) e de correlação espacial (R), nas expressões (3.17), (3.16)e (3.18), os estimadores de (β ,γ,φ) são obtidos, respectivamente, a partir das seguintesGEE’s, em sua forma matricial:
XT (M−1−ρW)U(Y−µ) = 0, (5.5)
GT (U−p) = 0, (5.6)
diag((1−u)(D(y−µ)−φ)) = 0, (5.7)
Para os resíduos obtidos com os yi pertencente ao conjunto definido em (3.28), definao vetor de resíduos como:
r = [g(yi)−g(µi), ...,g(yL)−g(µL)]. (5.8)
52

Então, usando a expressão (3.29) a GEE para ρ pode ser escrita matricialmente daseguinte forma:
rT MW(I−ρMW)r. (5.9)
Com as funções quase-escore definidas, a estimação dos parâmetros de regressão érealizada de forma iterativa via algoritmo ES (ver seção 2.6), com dois passos de esperança(passo E) e solução (passo S) das funções quase-escore, definidas acima, que nada mais sãoque GEE’s. Todos os estimadores foram definidos na seção 3.2.1, onde os estimadores deβ , γ , φ e ρ são obtidos, respectivamente, pelas expressões (3.26), (3.27), (3.32) e (3.30).
A construção dos intervalos de confiança Bootstrap-t (ICBt) dos parâmetros, con-forme descrito na seção 2.7.1, foi realizada para verificar a significância dos estimadores nomodelo. Geramos 1000 reamostras Bootstrap do modelo QIZDE, a partir das estimativasde cada parâmetro do modelo proposto, com P(µi(β )) sendo uma Poisson(µi(β )), afim deavaliar a distribuição empírica desses estimadores (ver seção 3.3). As equações quase-escoreempíricas Bootstrap para β , γ , λ e ρ são, respectivamente, dadas por:
XT (M−1− ρW)U∗(Y∗− µ) = 0, (5.10)
GT (U∗− p) = 0, (5.11)
diag((1−u∗)(D(y∗− µ)− φ)) = 0, (5.12)
rT MW(I− ρMW)r = 0. (5.13)
Usando o modelo proposto, os resultados desta aplicação estão descritos na próximaseção.
5.4 Resultados
Aplicamos o modelo proposto aos dados de hanseníase, conforme descrito na seçãoanterior, para estimar os parâmetros de regressão. Foram consideradas 1000 reamostrasbootstrap, afim de construir os intervalos de confiança Bootstrap-t para cada parâmetro, cujosresultados estão apresentados na Tabela (5.2), e avaliar a qualidade desses estimadores.
Vale ressaltar que o algoritmo proposto foi bastante sensível a valores iniciais, noque se refere a β , pois foi por método de tentativa a escolha do valor inicial na exe-cução do processo de estimação, que no caso foi β
(0) = (0.01,0.01,0.01,0.01). Ten-tamos utilizar o valor estimado a partir da função "zeroinfl", mas não obtivemos êxito.Os gamas foram inicializados com as estimativas geradas pela função "zeroinfl", γ(0) =
(303.08,−10.75,344.99,−19.77,−12.55). O φ inicial (φ (0) = 8.6681) foi o deviance cal-culado do modelo ajustado pela mesma função e o ρ inicial (ρ(0) = 0.5) é o mesmo utili-
53
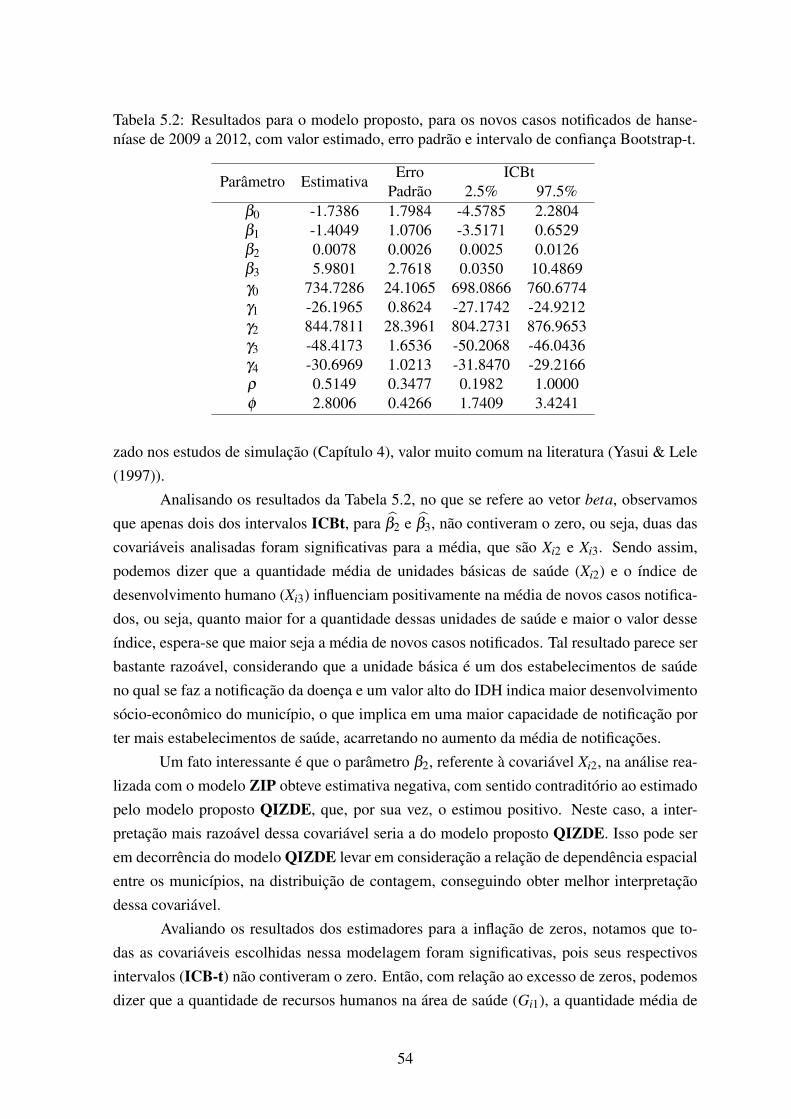
Tabela 5.2: Resultados para o modelo proposto, para os novos casos notificados de hanse-níase de 2009 a 2012, com valor estimado, erro padrão e intervalo de confiança Bootstrap-t.
Parâmetro EstimativaErro ICBt
Padrão 2.5% 97.5%β0 -1.7386 1.7984 -4.5785 2.2804β1 -1.4049 1.0706 -3.5171 0.6529β2 0.0078 0.0026 0.0025 0.0126β3 5.9801 2.7618 0.0350 10.4869γ0 734.7286 24.1065 698.0866 760.6774γ1 -26.1965 0.8624 -27.1742 -24.9212γ2 844.7811 28.3961 804.2731 876.9653γ3 -48.4173 1.6536 -50.2068 -46.0436γ4 -30.6969 1.0213 -31.8470 -29.2166ρ 0.5149 0.3477 0.1982 1.0000φ 2.8006 0.4266 1.7409 3.4241
zado nos estudos de simulação (Capítulo 4), valor muito comum na literatura (Yasui & Lele(1997)).
Analisando os resultados da Tabela 5.2, no que se refere ao vetor beta, observamosque apenas dois dos intervalos ICBt, para β2 e β3, não contiveram o zero, ou seja, duas dascovariáveis analisadas foram significativas para a média, que são Xi2 e Xi3. Sendo assim,podemos dizer que a quantidade média de unidades básicas de saúde (Xi2) e o índice dedesenvolvimento humano (Xi3) influenciam positivamente na média de novos casos notifica-dos, ou seja, quanto maior for a quantidade dessas unidades de saúde e maior o valor desseíndice, espera-se que maior seja a média de novos casos notificados. Tal resultado parece serbastante razoável, considerando que a unidade básica é um dos estabelecimentos de saúdeno qual se faz a notificação da doença e um valor alto do IDH indica maior desenvolvimentosócio-econômico do município, o que implica em uma maior capacidade de notificação porter mais estabelecimentos de saúde, acarretando no aumento da média de notificações.
Um fato interessante é que o parâmetro β2, referente à covariável Xi2, na análise rea-lizada com o modelo ZIP obteve estimativa negativa, com sentido contraditório ao estimadopelo modelo proposto QIZDE, que, por sua vez, o estimou positivo. Neste caso, a inter-pretação mais razoável dessa covariável seria a do modelo proposto QIZDE. Isso pode serem decorrência do modelo QIZDE levar em consideração a relação de dependência espacialentre os municípios, na distribuição de contagem, conseguindo obter melhor interpretaçãodessa covariável.
Avaliando os resultados dos estimadores para a inflação de zeros, notamos que to-das as covariáveis escolhidas nessa modelagem foram significativas, pois seus respectivosintervalos (ICB-t) não contiveram o zero. Então, com relação ao excesso de zeros, podemosdizer que a quantidade de recursos humanos na área de saúde (Gi1), a quantidade média de
54

unidades básicas de saúde (Gi3) e a taxa de analfabetismo (Gi4) influenciam negativamente,ou seja, quanto maior o quadro de recursos humanos na saúde, mais unidades básicas desaúde existirem e maior a taxa de analfabetismo, menor será o número de municípios semnotificação de novos casos de hanseníase, culminando na redução da inflação de zeros. Pois,se há mais recursos humanos e unidades básicas de saúde para realizar essas notificações,espera-se que aumente a quantidade de notificações, reduzindo o número de zeros estrutu-rais. Tendo em vista que a taxa de analfabetismo é uma variável que interfere na ocorrênciade novos casos, então se um município tiver maior taxa de analfabetismo, significa que elepossui maior vulnerabilidade à doença, com isso espera-se que ele tenha maior ocorrênciade novos casos de hanseníase, reduzindo a inflação de zeros.
Outra covariável significativa foi a distância padronizada para Manaus (Gi2), que in-fluencia positivamente na inflação de zeros, ou seja, quanto mais distante de Manaus for omunicípio maior será a probabilidade de ocorrência do zero estrutural. O que é razoável,tendo em vista que os municípios mais distantes da capital, Manaus, são menos desenvol-vidos, com maior dificuldade de acesso e deslocamento. Assim, quanto mais distante dacapital for esse município, espera-se que não ocorra a notificação dos casos, não pelo fatode que realmente não exista algum novo caso da doença, mas pela dificuldade de acessodos agentes de saúde à esses lugares ou pela dificuldade de deslocamento do portador dadoença à unidade de saúde notificadora, pois grande parte dos descolamentos no estado doAmazonas são realizados via fluvial.
Note que todas as covariáveis, consideradas na modelagem do excesso de zeros,obtiveram estimativas com o mesmo sinal em ambos modelos ZIP e QIZDE, culminandoem interpretações similares, pois ambos referem-se à inflação de zeros. No entanto, essascovariáveis foram significativas apenas para o modelo proposto QIZDE, cujos erros padrãode γ foram bem menores do que os do modelo ZIP.
O parâmetro que mede a dependência espacial (ρ) foi estimado em 0.5149, impli-cando em correlação espacial positiva entre as áreas vizinhas, ou seja, é esperado que mu-nicípios próximos a outros, que apresentem grande quantidade de casos, tenham mais casostambém.
A sobredispersão (φ ) foi estimada em 2.8006, apontando a existência de sobredis-persão nos dados. A sobredispersão em dados referentes a processos espaciais de contagemé muito comum, quando existe uma grande heterogeneidade populacional, o que de fatoocorre.
Portanto, o modelo de regressão estimado, com as covariáveis significativas, para osgamas correspondentes à inflação de zeros (5.3), é dado por:
GTi γ = 734.7286−26.1965Gi1 +844.7811Gi2−48.4173Gi3−30.6969Gi4,
55
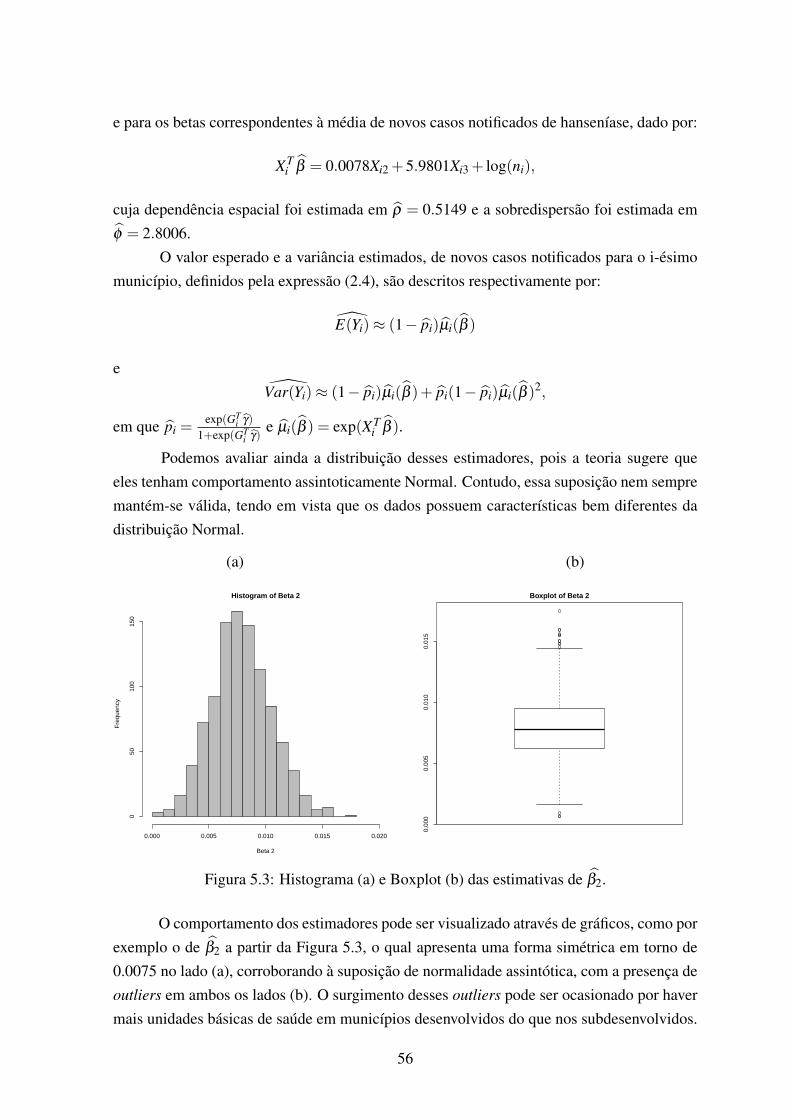
e para os betas correspondentes à média de novos casos notificados de hanseníase, dado por:
XTi β = 0.0078Xi2 +5.9801Xi3 + log(ni),
cuja dependência espacial foi estimada em ρ = 0.5149 e a sobredispersão foi estimada emφ = 2.8006.
O valor esperado e a variância estimados, de novos casos notificados para o i-ésimomunicípio, definidos pela expressão (2.4), são descritos respectivamente por:
E(Yi)≈ (1− pi)µi(β )
eVar(Yi)≈ (1− pi)µi(β )+ pi(1− pi)µi(β )
2,
em que pi =exp(GT
i γ)
1+exp(GTi γ)
e µi(β ) = exp(XTi β ).
Podemos avaliar ainda a distribuição desses estimadores, pois a teoria sugere queeles tenham comportamento assintoticamente Normal. Contudo, essa suposição nem sempremantém-se válida, tendo em vista que os dados possuem características bem diferentes dadistribuição Normal.
(a) (b)
Histogram of Beta 2
Beta 2
Fre
quen
cy
0.000 0.005 0.010 0.015 0.020
050
100
150
0.00
00.
005
0.01
00.
015
Boxplot of Beta 2
Figura 5.3: Histograma (a) e Boxplot (b) das estimativas de β2.
O comportamento dos estimadores pode ser visualizado através de gráficos, como porexemplo o de β2 a partir da Figura 5.3, o qual apresenta uma forma simétrica em torno de0.0075 no lado (a), corroborando à suposição de normalidade assintótica, com a presença deoutliers em ambos os lados (b). O surgimento desses outliers pode ser ocasionado por havermais unidades básicas de saúde em municípios desenvolvidos do que nos subdesenvolvidos.
56
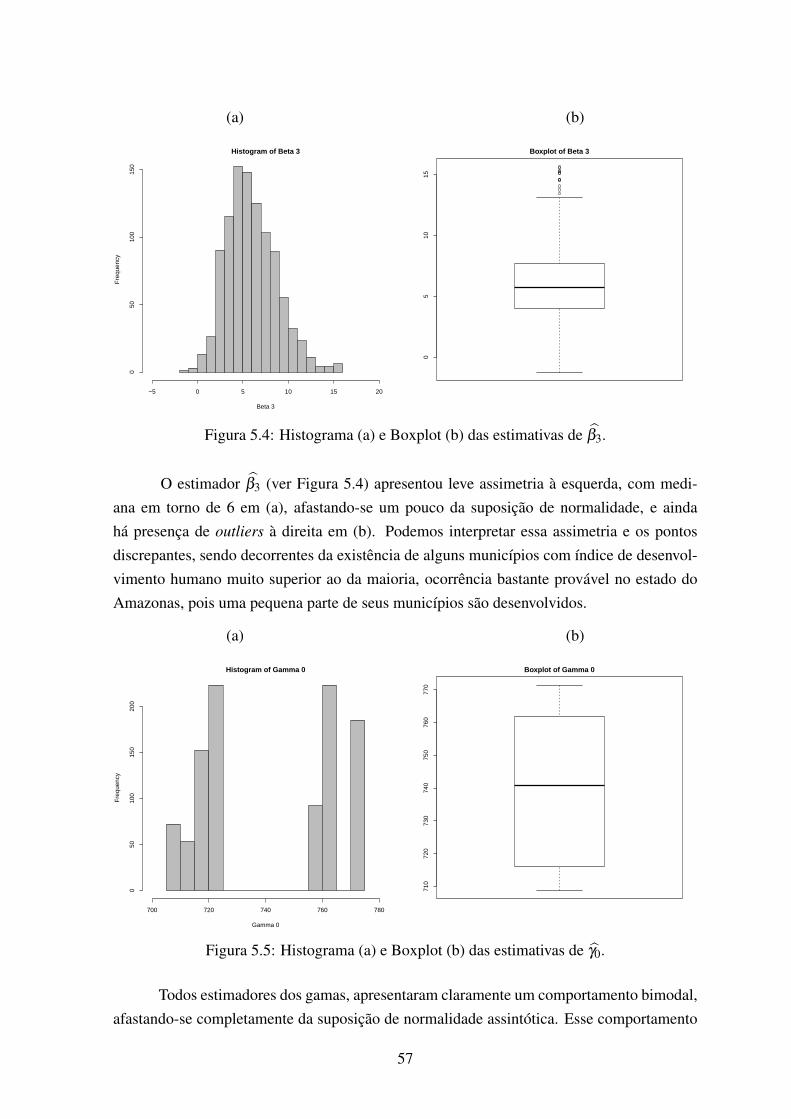
(a) (b)
Histogram of Beta 3
Beta 3
Fre
quen
cy
−5 0 5 10 15 20
050
100
150
05
1015
Boxplot of Beta 3
Figura 5.4: Histograma (a) e Boxplot (b) das estimativas de β3.
O estimador β3 (ver Figura 5.4) apresentou leve assimetria à esquerda, com medi-ana em torno de 6 em (a), afastando-se um pouco da suposição de normalidade, e aindahá presença de outliers à direita em (b). Podemos interpretar essa assimetria e os pontosdiscrepantes, sendo decorrentes da existência de alguns municípios com índice de desenvol-vimento humano muito superior ao da maioria, ocorrência bastante provável no estado doAmazonas, pois uma pequena parte de seus municípios são desenvolvidos.
(a) (b)
Histogram of Gamma 0
Gamma 0
Fre
quen
cy
700 720 740 760 780
050
100
150
200
710
720
730
740
750
760
770
Boxplot of Gamma 0
Figura 5.5: Histograma (a) e Boxplot (b) das estimativas de γ0.
Todos estimadores dos gamas, apresentaram claramente um comportamento bimodal,afastando-se completamente da suposição de normalidade assintótica. Esse comportamento
57
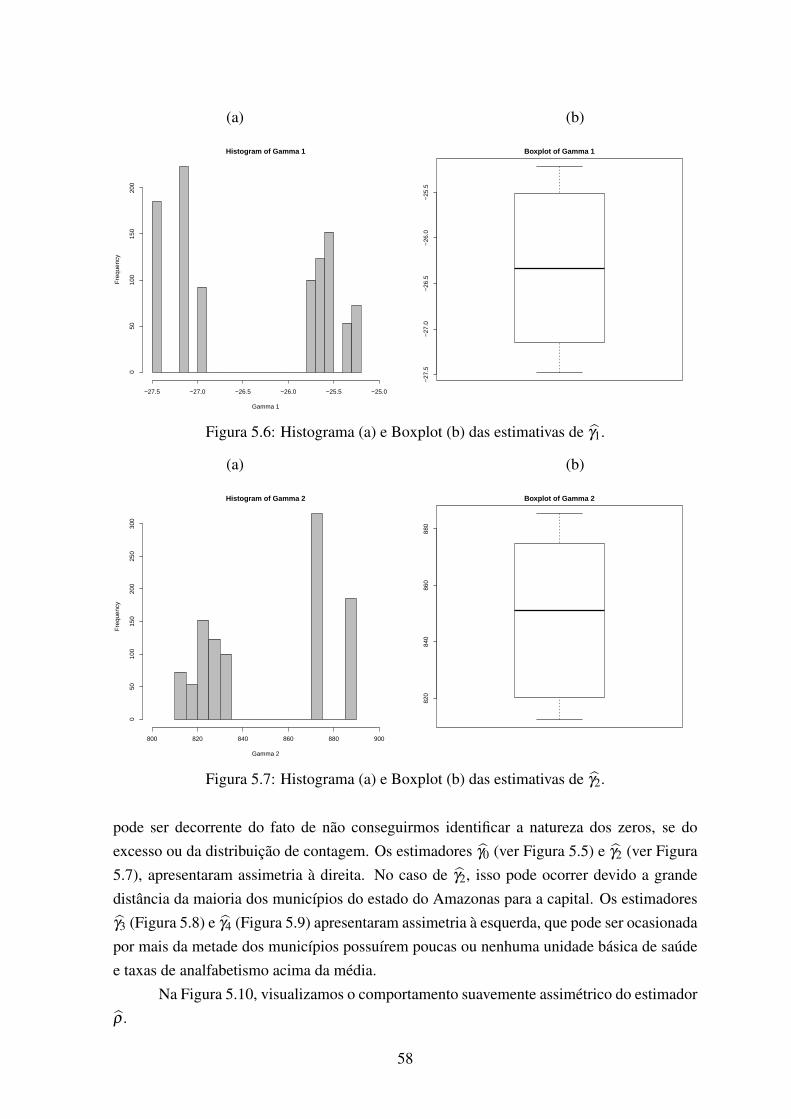
(a) (b)
Histogram of Gamma 1
Gamma 1
Fre
quen
cy
−27.5 −27.0 −26.5 −26.0 −25.5 −25.0
050
100
150
200
−27
.5−
27.0
−26
.5−
26.0
−25
.5
Boxplot of Gamma 1
Figura 5.6: Histograma (a) e Boxplot (b) das estimativas de γ1.
(a) (b)
Histogram of Gamma 2
Gamma 2
Fre
quen
cy
800 820 840 860 880 900
050
100
150
200
250
300
820
840
860
880
Boxplot of Gamma 2
Figura 5.7: Histograma (a) e Boxplot (b) das estimativas de γ2.
pode ser decorrente do fato de não conseguirmos identificar a natureza dos zeros, se doexcesso ou da distribuição de contagem. Os estimadores γ0 (ver Figura 5.5) e γ2 (ver Figura5.7), apresentaram assimetria à direita. No caso de γ2, isso pode ocorrer devido a grandedistância da maioria dos municípios do estado do Amazonas para a capital. Os estimadoresγ3 (Figura 5.8) e γ4 (Figura 5.9) apresentaram assimetria à esquerda, que pode ser ocasionadapor mais da metade dos municípios possuírem poucas ou nenhuma unidade básica de saúdee taxas de analfabetismo acima da média.
Na Figura 5.10, visualizamos o comportamento suavemente assimétrico do estimadorρ .
58
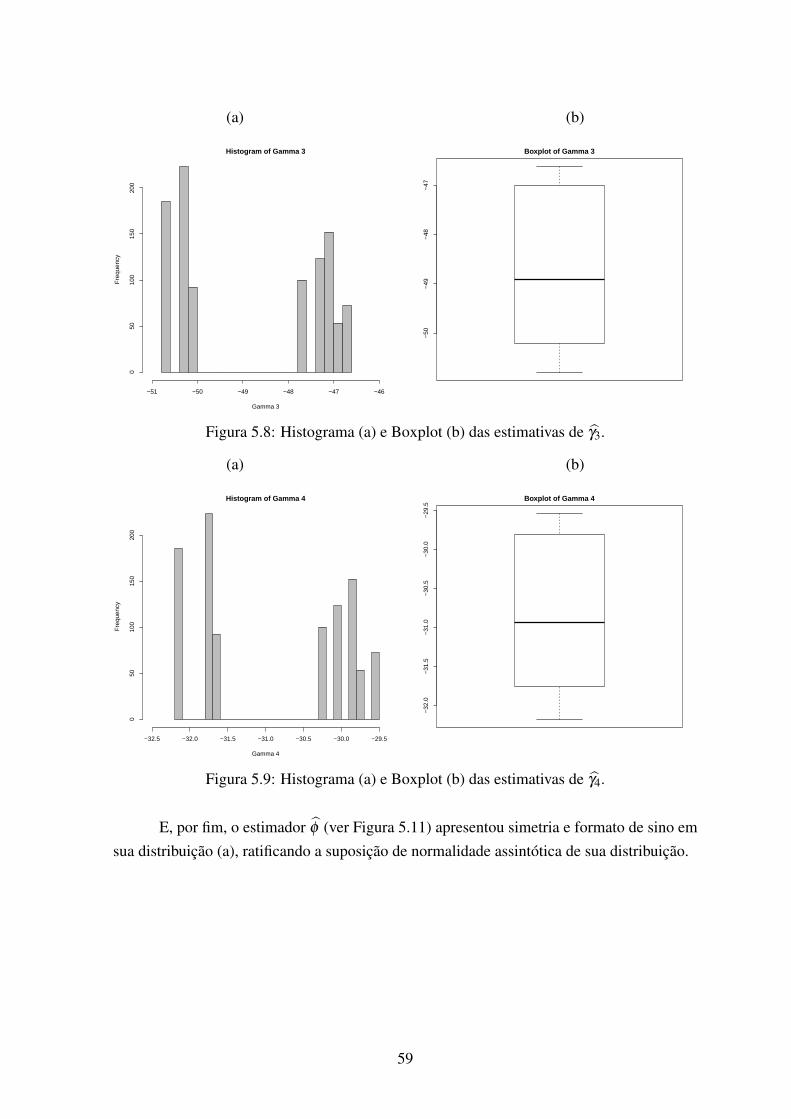
(a) (b)
Histogram of Gamma 3
Gamma 3
Fre
quen
cy
−51 −50 −49 −48 −47 −46
050
100
150
200
−50
−49
−48
−47
Boxplot of Gamma 3
Figura 5.8: Histograma (a) e Boxplot (b) das estimativas de γ3.
(a) (b)
Histogram of Gamma 4
Gamma 4
Fre
quen
cy
−32.5 −32.0 −31.5 −31.0 −30.5 −30.0 −29.5
050
100
150
200
−32
.0−
31.5
−31
.0−
30.5
−30
.0−
29.5
Boxplot of Gamma 4
Figura 5.9: Histograma (a) e Boxplot (b) das estimativas de γ4.
E, por fim, o estimador φ (ver Figura 5.11) apresentou simetria e formato de sino emsua distribuição (a), ratificando a suposição de normalidade assintótica de sua distribuição.
59
(a) (b)
Histogram of Rho
Rho
Fre
quen
cy
−0.5 0.0 0.5 1.0
020
4060
8010
0
−0.
50.
00.
51.
0
Boxplot of Rho
Figura 5.10: Histograma (a) e Boxplot (b) das estimativas de ρ .
(a) (b)
Histogram of Phi
Phi
Fre
quen
cy
1.5 2.0 2.5 3.0 3.5 4.0 4.5
050
100
150
200
2.0
2.5
3.0
3.5
4.0
Boxplot of Phi
Figura 5.11: Histograma (a) e Boxplot (b) das estimativas de φ .
60

Capítulo 6
Considerações Finais
6.1 Principais Conclusões
A abordagem proposta nesta dissertação é interessante e inovadora, do ponto de vistaclássico, por oferecer a possibilidade da modelagem conjunta de três características muitocomuns: inflação de zeros, sobredispersão e dependência espacial. Sendo de grande relevân-cia, no que se refere a aplicabilidade em dados espaciais de contagem reais. Principalmentena atualidade, com o surgimento de diversos dados com essa natureza devido ao avançotecnológico.
Desenvolvemos a modelagem para dados de contagem que possuem inflação de zeros,sobredispersão e dependência espacial, através de uma quase verossimilhança inflacionadade zeros capaz de acomodar a dependência espacial, e aplicamos essa nova metodologiaem dados reais, realizamos estudos de simulação Bootstrap para avaliar a qualidade dosestimadores propostos e discutimos todos os resultados obtidos.
No que diz respeito à aplicação do modelo proposto QIZDE em dados reais (Capítulo5), ele conseguiu evidenciar todas as características abordadas como pertinentes aos dadosde novos casos de hanseníase, notificados entre 2009 e 2012, mostrou-se mais adequado namodelagem desses dados do que o modelo para dados inflacionados de zeros (ZIP), pois esteúltimo não conseguiu evidenciar tais características.
Um dos problemas levantados na aplicação, consistiu em identificar se realmente oproblema de subnotificação estaria ocasionando a inflação de zeros, pois as covariáveis uti-lizadas na modelagem estão associadas à tal problema. Nenhuma dessas covariáveis foramavaliadas como significativas pelo modelo ZIP, porém o modelo proposto QIZDE detec-tou que todas eram significativas na modelagem do excesso de zeros, concluindo-se que asubnotificação está causando o surgimento desses zeros excedentes. Além disso, o modeloproposto (QIZDE) ratificou a presença da sobredispersão e da dependência espacial positivaentre os municípios vizinhos, o que foi evidenciado na análise preliminar dos dados.
Na modelagem da média de novos casos notificados de hanseníase, o modelo proposto
61

(QIZDE) foi mais coerente que o modelo ZIP, no que refere-se à influência da média deunidades básicas de saúde na notificação, seus resultados mostraram que com o aumento damédia de unidades básicas a média de notificações também aumentaria, conclusão inversaapresentada pelo modelo ZIP.
À luz da aplicação em dados reais (Capítulo 5) e do estudo de simulação (Capítulo4), no que diz respeito à qualidade dos estimadores dos parâmetros do modelo proposto(QIZDE), obtivemos excelentes resultados no que tange a não tendenciosidade e precisãodeles. Percebemos, também, que a estimação dos parâmetros, principalmente a dos betas,são muito sensíveis a valores iniciais.
Um comentário importante a ser feito é a respeito dos estimadores de β , φ e ρ que, noestudo simulado, apresentaram melhor desempenho na ocasião em que a proporção de zerosestruturais era menor do que a vinda da distribuição de contagem, podendo ser decorrente dofato de que a inflação de zeros esteja mascarando de certa forma o verdadeiro valor dessesparâmetros. E os gamas apresentaram sempre maior precisão em quaisquer aspectos. Por-tanto, o modelo QIZDE aparenta melhor desempenho quando os dados possuem proporçãode zeros estruturais menor do que a da distribuição de contagem.
Um detalhe importante do modelo QIZDE é que a dependência espacial foi inseridano processo de estimação, através de uma GEE e pela configuração de um modelo CAR namatriz de correlação espacial Rβ (ρ), simplificando o processo de estimação. Outro pontointeressante foi a utilização do algoritmo ES no processo de estimação, que resulta na soluçãodas GEE’s.
Uma das mais importantes vantagens dessa abordagem é a possibilidade de modelarconjuntamente essas três características: dependência espacial, excesso de zeros e sobredis-persão, tendo em vista que não há trabalhos similares na literatura, no contexto clássico.Porém, há um trabalho recente com abordagem similar, mas sob o ponto de vista bayesiano(Monod (2012)). Outra, é a facilidade no tratamento dos dados por causa da quase veros-similhança, que não exige a definição de uma função de probabilidade, bastando apenasdefinir os dois primeiros momentos como em um GLM, em que as funções quase escorenada mais são que GEE’s, definidas no processo de estimação. E, ainda, a modelagem damatriz de correlação espacial como um modelo CAR, evitando difíceis inversas de matrizes,facilitando o cálculo dos estimadores e o processo de estimação, com uma forma simples dematriz inversa.
Algumas desvantagens, também, foram percebidas no desenvolvimento deste traba-lho. Como por exemplo, não termos a garantia de que o algoritmo ES convirja para um esti-mador não-viesado, consistente e assintoticamente Normal, sendo apenas uma possibilidade.A dificuldade na escolha do valor para inicializar o processo de estimação, pois dependendodessa escolha o algoritmo tende a não convergir. E, o fato de não conseguirmos estimar bemos gamas, tendo em vista que as estimativas são bastante dispersas e assimétricas, com a
62

presença de outliers, nos remetendo a ideia de que esse estimador não seja robusto.
6.2 Trabalhos Futuros
Diante dessas discussões, temos algumas propostas para trabalhos futuros, conside-radas interessantes na continuação deste, que são:
1. A substituição do algoritmo ES pelo Robust Expectation-Solution (RES) (ver Hall &Shen (2010)), aprimorando o processo de estimação, utilizando estimadores robustos.Inicialmente, essa substituição é sugerida apenas para os gamas, que apresentaramestimativas assimétricas.
2. Podemos realizar estudos de simulação comparativos com outros cenários, que pos-suam mais áreas, a fim de avaliar o desempenho dos estimadores quanto à eficiência.E comparar os ICB-t com outros intervalos de confiança empíricos, como por exem-plo o obtido através do método BCa (bias-corrected and acelerated), para correção deviés (ver Gentle (2009b)).
3. Utilizar um critério de seleção de modelos, para auxiliar na escolha de covariáveis eaté mesmo da matriz de correlação mais adequada. Uma sugestão seria o QIC (ver Pan(2001)), que é um critério de seleção de modelos que substitui a log-verossimilhança,usada na definição do critério AIC, pela quase verossimilhança.
4. E, ainda, estender o modelo proposto (QIZDE) para a modelagem de dados espaço-temporais, com as características tratadas neste trabalho, porém avaliando a correlaçãoespaço-temporal.
63

Referências Bibliográficas
Besag, J. (1974). Spatial interaction and the statistical analysis of lattice systems. Journal
of the Royal Statistical Society. Series B (Methodological), pages 192–236.
Bjørnstad, O. N. & Falck, W. (2001). Nonparametric spatial covariance functions: estima-tion and testing. Environmental and Ecological Statistics, 8(1), 53–70.
Bjørnstad, O. N., Ims, R. A. & Lambin, X. (1999). Spatial population dynamics: analyzingpatterns and processes of population synchrony. Trends in Ecology & Evolution,14(11), 427–432.
Cancado, A., da Silva, C. & da Silva, M. (2011). A zero-inflated poisson-based spatial scanstatistic. Emerging Health Threats Journal, 4.
Cheung, Y. B. (2002). Zero-inflated models for regression analysis of count data: a studyof growth and development. Statistics in medicine, 21(10), 1461–1469.
Cressie, N. (1992). Statistics for spatial data. Terra Nova, 4(5), 613–617.
Dempster, A. P., Laird, N. M. & Rubin, D. B. (1977). Maximum likelihood from incompletedata via the em algorithm. Journal of the Royal Statistical Society. Series B
(Methodological), pages 1–38.
Druck, S., Carvalho, M. S., Câmara, G., Monteiro, A. M. V. et al. (2004). Spatial analysis
of geographic data.. Embrapa Cerrados.
Elashoff, M. & Ryan, L. (2004). An em algorithm for estimating equations. Journal of
Computational and Graphical Statistics, 13(1), 48–65.
Epperson, B. K. (1993). Recent advances in correlation studies of spatial patterns of geneticvariation. In Evolutionary biology, pages 95–155. Springer.
Fahrmeir, L. & Tutz, G. (2001). Random effect model.
Gentle, J. E. (2009a). Computational statistics, volume 308. Springer.
64

Gentle, J. E. (2009b). Monte carlo methods for statistical inference. In Computational
Statistics, pages 417–433. Springer.
Hall, D. B. (2000). Zero-inflated poisson and binomial regression with random effects: acase study. Biometrics, 56(4), 1030–1039.
Hall, D. B. & Shen, J. (2010). Robust estimation for zero-inflated poisson regression.Scandinavian Journal of Statistics, 37(2), 237–252.
Hall, D. B. & Zhang, Z. (2004). Marginal models for zero inflated clustered data. Statistical
Modelling, 4(3), 161–180.
Imbiriba, E. B., Basta, P. C., Pereira, E. d. S., Levino, A. & Garnelo, L. (2009a). Hanseníaseem populações indígenas do amazonas, brasil: um estudo epidemiológico nosmunicípios de autazes, eirunepé e são gabriel da cachoeira (2000 a 2005). Cad
Saude Publica, 25(5), 972–84.
Imbiriba, E. N. B., Silva Neto, A. L. d., Souza, W. V. d., Pedrosa, V., Cunha, M. d. G. &Garnelo, L. (2009b). Social inequality, urban growth and leprosy in manaus: aspatial approach. Revista de Saúde Pública, 43(4), 656–665.
Johnson, N. L. & Kotz, S. (1969). Distribution in statistics: Discrete distribution. Wiley.
Klimko, L. A. & Nelson, P. I. (1978). On conditional least squares estimation for stochasticprocesses. The Annals of Statistics, pages 629–642.
Kong, M., Xu, S., Levy, S. M. & Datta, S. (2015). Gee type inference for clustered zero-inflated negative binomial regression with application to dental caries. Computa-
tional Statistics & Data Analysis, 85(0), 54–66.
Lambert, D. (1992). Zero-inflated poisson regression, with an application to defects inmanufacturing. Technometrics, 34(1), 1–14.
Lawson, A., Biggeri, A., Böhning, D., Lesaffre, E., Viel, J.-F., Bertollini, R. et al. (1999).Disease mapping and risk assessment for public health.. John Wiley & Sons.
Lee, A. H., Wang, K., Scott, J. A., Yau, K. K. & McLachlan, G. J. (2006). Multi-levelzero-inflated poisson regression modelling of correlated count data with excesszeros. Statistical Methods in Medical Research, 15(1), 47–61.
Liang, K.-Y. & Zeger, S. L. (1986). Longitudinal data analysis using generalized linearmodels. Biometrika, 73(1), 13–22.
65

Lima, M. S. d. & Duczmal, L. H. (2014). Abordagem bayesiana adaptativa para vigilânciaonline de cluster espaciais (pp. 6-10). Revista da Estatística da Universidade
Federal de Ouro Preto, 3(3).
Lima, M. S. d., Duczmal, L. H. & Pinto, L. P. (2013). Spatial scan statistics for models withexcess zeros and overdispersion. Online Journal of Public Health Informatics,5(1).
McCullagh, P. (1983). Quasi-likelihood functions. The Annals of Statistics, pages 59–67.
McCullagh, P. & Nelder, J. (1983). Generalised linear modelling. Chapman and Hall,
London. Negro, JJ & Hiraldo, F.(1992) Sex ratios in broods of the lesser kestrel
Falco naumanni. Ibis, 134, 190–191.
McCullagh, P. & Nelder, J. (1989). Quasi-likelihood functions. In Generalized Linear
Models, pages 323–356. Springer.
Monod, A. (2007). An analysis on count panel data using a zero-inflated poisson model.Ph.D. thesis, Université de Neuchâtel-Faculté des sciences économiques-Institutde statistique.
Monod, A. (2012). A Quasi-Likelihood Approach to Zero-Inflated Spatial Count Data.Ph.D. thesis, ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE.
Nelder, J. & Wedderburn, R. (1972). General linearized models. J. Roy. Stat. Soc. Ser. A,135, 370–384.
Nelder, J. A. & Pregibon, D. (1987). An extended quasi-likelihood function. Biometrika,74(2), 221–232.
Nie, L., Wu, G., Brockman, F. J. & Zhang, W. (2006). Integrated analysis of transcripto-mic and proteomic data of desulfovibrio vulgaris: zero-inflated poisson regres-sion models to predict abundance of undetected proteins. Bioinformatics, 22(13),1641–1647.
Nieto-Barajas, L. & Bandyopadhyay, D. (2013). A zero-inflated spatial gamma processmodel with applications to disease mapping. Journal of Agricultural, Biological,
and Environmental Statistics, 18(2), 137–158.
Pan, W. (2001). Akaike’s information criterion in generalized estimating equations. Bio-
metrics, 57(1), 120–125.
Perumean-Chaney, S. E., Morgan, C., McDowall, D. & Aban, I. (2013). Zero-inflatedand overdispersed: what’s one to do? Journal of Statistical Computation and
Simulation, 83(9), 1671–1683.
66

Rosen, O., Jiang, W. & Tanner, M. A. (2000). Mixtures of marginal models. Biometrika,87(2), 391–404.
Van den Broek, J. (1995). A score test for zero inflation in a poisson distribution. Biome-
trics, pages 738–743.
Warton, D. I. (2005). Many zeros does not mean zero inflation: comparing the goodness-of-fit of parametric models to multivariate abundance data. Environmetrics, 16(3),275–289.
Wedderburn, R. W. (1974). Quasi-likelihood functions, generalized linear models, and thegaussânewton method. Biometrika, 61(3), 439–447.
Yang, M. (2012). Statistical models for count time series with excess zeros.
Yasui, Y. & Lele, S. (1997). A regression method for spatial disease rates: an estimatingfunction approach. Journal of the American Statistical Association, 92(437), 21–32.
Yau, K. K., Lee, A. H. & Carrivick, P. J. (2004). Modeling zero-inflated count serieswith application to occupational health. Computer methods and programs in
biomedicine, 74(1), 47–52.
Zeger, S. L. & Liang, K. Y. (1986). Longitudinal data analysis for discrete and continuousoutcomes. Biometrics, pages 121–130.
Zhang, T., Zhang, Z. & Lin, G. (2012). Spatial scan statistics with overdispersion. Statistics
in medicine, 31(8), 762–774.
67