mini-curso: grades e nuvens
TRANSCRIPT


31/07/2010 2
Curso baseado em material existente
● Curso Jai de 2008– Fabio Kon e Alfredo
● Curso SBAC de 2008– Raphael Camargo, Fabio Kon e Alfredo
● Seminário de Cloud Computing– Carlos Eduardo Moreira Santos
● Seminário de ferramentas de Cloud Computing
– Gustavo Ansaldi Oliva

31/07/2010 3
Roteiro
● Grades●
● Cluods●
● Ferramentas

31/07/2010 4
Grades Computacionais: Conceitos Fundamentais e
Casos Concretos
Fabio Kon e Alfredo GoldmanDepartamento de Ciência da Computação
IME – USP
Jornada de Atualização em Informática (JAI)
Congresso da SBC - Belém do Pará15 e 16 de julho de 2008

31/07/2010 5
Roteiro do minicurso1) Histórico e Motivação
2) Conceitos Básicos
* Tipos de Grades
* Principais Serviços
3) Modelos de Programação
4) Middleware de grades
5) Grades em funcionamento
6) Pesquisa Atual em Grades

31/07/2010 6
Pré-história das grades
● A necessidade de alto poder de processamento existe há várias décadas.
● Na verdade, nasceu com a Computação.
● Na última década, tornou-se obrigatório para várias ciências.
● All Science is Computer Science – The New York Times 2001

31/07/2010 7
Necessidades das ciências
● Problemas computacionalmente pesados são muito presentes em– Biologia– Medicina– Física– Química– Engenharia
● mas também são presentes em– Ciências Humanas– Economia– Arte (música, gráfica)

31/07/2010 8
Evolução das ciências
● Criou-se um círculo virtuoso que – expande e melhora a qualidade do
conhecimento humano e– testa os limites do que é possível realizar
computacionalmente.
● Lei de Moore implica que– O computador pessoal de hoje é o
supercomputador da década passada.– Segundo Jack Dongarra (30/06/10) em 2020:
● Celulares: teraflop● Laptops: 10 teraflops● Supercompuradores: hexaflop

31/07/2010 9
Máquinas paralelas
● Década de 1980: computação de alto desempenho era feita com caríssimas máquinas paralelas (às vezes chamadas de supercomputadores).
● Eram produzidas em quantidades pequenas (centenas ou milhares).
● Tinham custo altíssimo.
● Acesso muito difícil.

31/07/2010 10
Aglomerados (clusters)
● Década de 1990: computadores pessoais popularizaram-se.
● Lei de Moore continuou agindo e levou milhões de computadores potentes a universidades, empresas e à casa das pessoas.
● Clusters com hardware de baixo custo.– p.ex. Beowulf baseado em Linux.

31/07/2010 11
O nascimento das grades
● Meados da década de 1990:– Internet popularizou-se.
● Universidades e institutos de pesquisa com – conexões locais estáveis de vários Mbps– milhares de computadores– dezenas de clusters– conexões de longa distância estáveis.
● Necessidade de poder computacional sempre crescendo.

31/07/2010 12
A grande idéia● Por que não interconectar aglomerados de
diferentes instituições através da Internet?
● Dificuldades:– rede (Internet acadêmica)– software– protocolos– middleware– gerenciamento / administração– ferramentas– segurança– heterogeneidade

31/07/2010 13
Grade Computacional
● Nossa definição para Grade (cada um tem a sua):
– Coleção de aglomerados geograficamente distantes e interconectados através de uma rede de forma a permitir o compartilhamento de recursos computacionais e de dados.
– Esses aglomerados podem ser dedicados ou não e podem possuir desde 1 até centenas de computadores.

31/07/2010 14
União de comunidades
● Meados da década de 1990: Computação em Grade tornou-se uma área de pesquisa combinando aspectos de:– Sistemas Distribuídos– Computação de Alto Desempenho
● Não era um conceito novo, revolucionário.● Já se falava sobre isso há muitas décadas.
● O termo Computational Grid vem da analogia com Power Grid, rede elétrica.

31/07/2010 15
Precursores das grades
Desde a década de 1980, já se falava muito em Sistemas Operacionais Distribuídos:
● Sprite (UCB [Ousterhout et al. 1988])● NOW (UCB [Anderson et al. 1995])● Amoeba (Holanda [Tanenbaum et al. 1990])● Spring (Sun Microsystems, 1993)● The V System (Stanford [Cheriton 1988])

31/07/2010 16
The V System (1988)

31/07/2010 17
Já na comunidade Paralela
● Algoritmos paralelos [Leighton 1991]
● Máquinas paralelas [Leighton 1991]– dedicadas com centenas ou milhares de
processadores
● Algoritmos de escalonamento [Bazewicz et al. 2000]
● Memória compartilhada distribuída [Nitzberg and Lo 1991]

31/07/2010 18
Principais diferenças
● Recursos dedicados● Configuração estática● Gerenciamento central● Ambiente controlado● Máquinas homogêneas
Grades computacionaisComputação de alto desempenho tradicional
● Recursos compartilhados● Configuração dinâmica● Gerenciamento distribuído● Ambiente não controlado● Máquinas heterogêneas

31/07/2010 19
Principais diferenças
● Dezenas ou centenas de máquinas
● Máquinas localizadas no mesmo espaço físico
● Falhas pouco freqüentes
Grades computacionaisComputação de alto desempenho tradicional
● Dezenas de milhares de máquinas
● Máquinas geograficamente distribuídas
● Falhas constantes

31/07/2010 20
Principais Desafios
● Segurança– Para os donos dos recursos– Para os usuários da grade
● Tolerância a Falhas– Para os componentes da grade– Para as aplicações em execução na grade
● Escalonamento– Determinar onde uma aplicação deve executar
● Gerenciamento

31/07/2010 21
Tipos de grades computacionais
● Grade de Computação
● Grade de Computação Oportunista
● Grade de Dados
● Grade de Serviços– “Colaboratórios”
● Grades Móveis

31/07/2010 22
Grades Computacionais
● Foco principal: solução de problemas computacionalmente pesados
● Gerenciamento de recursos– Busca de recursos computacionais– Entrada e saída de recursos computacionais
● Gerenciamento de Aplicações– Escalonamento e ciclo de vida

31/07/2010 23
Grades de Dados
● Foco principal: gerenciamento e distribuição de dados.
● Física de Altas Energia– Dados gerados em um acelerador de partículas
são utilizados por pesquisadores do mundo todo.
– Precisam gerenciar Petabytes de dados● Armazenamento e transmissão dos dados● Tolerância a falhas (Replicação)● Serviços de busca e diretórios de dados

31/07/2010 24
Grades de Serviços
● Oferecem serviços viabilizados pela integração de recursos na grade:
– Ambiente de trabalho colaborativo– plataforma de aprendizado à distância– Colaboratórios para experiências científicas
● A longo prazo, a tendência é que todos esses tipos diferentes de grades serão reunidos em uma única plataforma.
31/07/2010 25
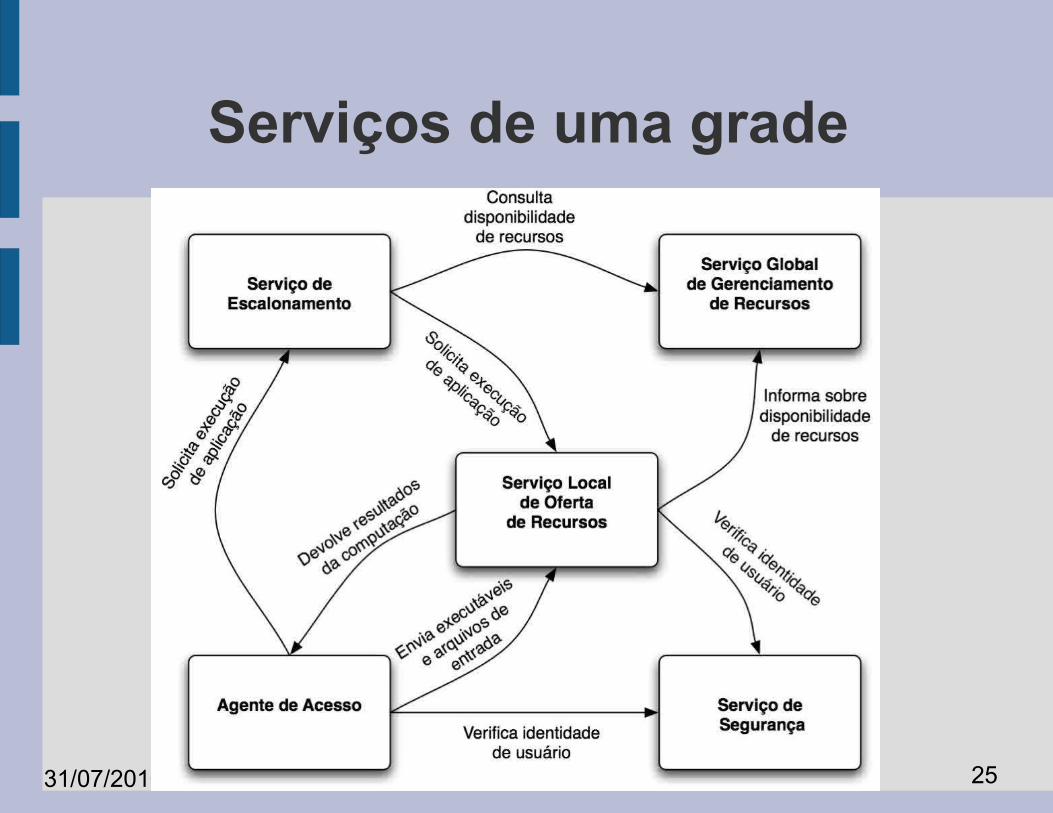
Serviços de uma grade

31/07/2010 26
Agente de acesso
● Ponto de acesso para os usuários interagirem com a grade.
● É executado na máquina do usuário da grade.
● Pode também ser um sistema Web acessado a partir de um navegador.
● Deve permitir que o usuário determine a aplicação a ser executada, os parâmetros da execução e os arquivos de entrada.

31/07/2010 27
Serviço local de oferta de recursos
● Executado nas máquinas que exportam seus recursos à Grade.
● Gerencia uso local de recursos.
● Responsável por executar aplicações nos nós da Grade. Precisa então – obter o arquivo executável– iniciar execução– coletar e apresentar eventuais erros– devolver os resultados da execução

31/07/2010 28
Serviço global de gerenciamento de recursos
● Monitora o estado dos recursos da grade.● Responde a solicitações por utilizações dos
recursos.● Para tanto, pode utilizar outros serviços, tais
como.– Serviço de informações sobre recursos
● coleta informações sobre recursos tais como capacidade total e capacidade corrente de processador, RAM, espaço em disco, largura de banda, etc.
– Serviço de escalonamento

31/07/2010 29
Serviço de escalonamento● Determina onde e quando cada aplicação
será executada.
➔ Recebe solicitações de execução.➔ Obtém informações sobre disponibilidade de recursos.
➔ Ordena a execução das aplicações

31/07/2010 30
Serviço de segurança
● Protege os recursos compartilhados, evitando ataques aos nós da grade.
● Autentica os usuários de forma a saber quem é responsável por cada aplicação e por cada requisição de execução.
● Fornece canais seguros de comunicação e de armazenamento de dados e aplicações garantindo confiabilidade e integridade.

31/07/2010 31
Serviços de uma grade

31/07/2010 32
Gerenciamento de recursos
● A principal tarefa de um SO é gerenciar e proteger os recursos de uma máquina.
● A principal tarefa de um middleware de grades é gerenciar e proteger os recursos de uma grade – i.e., um conjunto, potencialmente muito grande
de máquinas.
● O primeiro ponto é conhecer quais os recursos disponíveis em cada instante.

31/07/2010 33
Recursos mais comuns
● No contexto de alto desempenho, os recursos mais explorados são:– processador– memória principal
● Mas em alguns casos, também são fundamentais:– conexões de rede– armazenamento persistente (ex. discos)

31/07/2010 34
Outros recursos
● Placas de processamento de áudio● Compressores de vídeo● Monitores de altíssima qualidade● Telescópios eletrônicos● Radiotelescópios● Servidor de armazenamento com petabytes● Sensores de temperatura, pressão,
luminosidade● Et cetera.

31/07/2010 35
Informações estáticas de um recurso
● Processador– tipo: PowerPC G5, Pentium 4.– velocidade: 3,8 GHz.
● Sistema operacional– tipo: Linux, Windows, MacOS, Solaris, Irix– versão: Debian/kernel 2.6.20, NT, 10.5.3
● Memória principal e secundária– RAM total de 8GB– disco de 250GB

31/07/2010 36
Informações dinâmicas de um recurso
● Processador– utilização= 34%
● Memória principal e secundária– RAM disponível = 3,4 GB– memória virtual disponível = 8,7 GB – disco disponível = 232GB

31/07/2010 37
Heterogeneidade
● Mas as grades são heterogêneas.
● Onde uma aplicação será executada mais rapidamente?
1) Nó com PowerPC G5 de 2,0 GHz e 90% do processador livre e 1GB de RAM livre ou
2) Nó com Pentium 4 de 3,8 GHz e 80% do processador livre e 2GB de RAM livre.

31/07/2010 38
Comparações de desempenho em arquiteturas diferentes
● Pode-se usar ferramentas tais como bogomips ou outros benchmarks.
● Mas ainda é um problema não totalmente resolvido.
● O desempenho do processador também varia de acordo com a aplicação.– Há alguns anos processadores AMD eram mais
rápidos que os da Intel para processamento de texto e mais lentos para processamento numérico.

31/07/2010 39
Monitoramento
● Serviço local de oferta de recursos 1) monitora os recursos locais (ex. a cada 5 segundos)2) envia dados sobre a máquina local para o serviço global
(ex. a cada 5 minutos ou mudanças significativas).
● O serviço global agrega as informações em bancos de dados, potencialmente com informações sobre milhares de nós.
● Serviço global pode ser centralizado, ou estruturado de forma hierárquica, ou par-a-par, etc.

31/07/2010 40
Federação de aglomerados
● Um grande desafio é estruturar o mecanismo de monitoramento de forma que ele não se transforme em um gargalo quando o sistema cresce.
● Grades modernas são organizadas em federações de aglomerados estruturadas como árvores hierárquicas ou estruturas P2P.
● Cada aglomerado possui seus gerenciadores locais.
● A federação conta com protocolos inter-aglomerados para monitoramento e escalonamento.

Grades Computacionais:
Conceitos Fundamentais e Casos Concretos
Algoritmos de escalonamento eescalonadores
Fabio Kon, Alfredo Goldman
Universidade de São Paulo{kon,gold}@ime.usp.br
SBC - JAI - Belém - 15 e 16/7/08

Roteiro
Definição de escalonamento
Nomenclatura e arquitetura
Algoritmos de Escalonamento
Exemplos de escalonadoresSLURMOAR
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores2/15

Escalonamento
Em inglês scheduling, corresponde ao estudo de comoalocar tarefas a recursos.
Tanto as tarefas como os recursos podem ser detipos diferentes ;a alocação otimiza uma função de custopreviamente definida ;mas, geralmente, esses problemas são difíceis.
Entre os vários tipos de tarefas podemos terprocessos, threads ou mesmo espaço em disco.
Recursos podem ser computacionais, dearmazenamento, de rede, etc,
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores3/15

Um problema difícil 1/2
Um exemplo simples da dificuldade do problema doescalonamento é o problema da partição, que éNP-Completo. Dados :
n e n inteiros I = {i1, . . . , in}
Queremos dividir o conjunto I em dois conjuntos I1 eI2, I1
⋃I2 = I e I1 ∩ I2 = ∅ tais que :∑
i∈I1
i =∑i∈I2
i
Dos problemas difíceis este é um dos mais fáceis(pseudo-polinomial).
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores4/15

Um problema difícil 2/2
No nosso contexto, os inteiros ij podem ser vistoscomo o tamanho de tarefas seqüenciais a seremalocadas para duas máquinas idênticas.
É fácil imaginar que com tarefas paralelas e ambientesdinâmicos, o problema fica bem mais difícil.
É interessante notar que existem problemas « ainda »mais difíceis como a 3-partição :Dados os inteiros positivos A = (a1, . . . , a3t) e B , existeuma partição (T1, . . . , Tt) de A tal que |Tj | = 3 e∑
ai∈Tjai = B para j = 1, .., t ?
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores5/15

O que fazer com problemas difíceis ?
Encontrar a solução exata de um problema difícil podelevar muito tempo.Quais as possíveis abordagens :
Aproximações : ao invés de buscar a solução ótimaprocura-se encontrar uma solução que esteja a umfator dela.(ex. : no máximo 2 vezes o tempo da solução ótima)Heurísticas : algoritmos que não fornecemnenhuma garantia em relação à solução, mas quepodem funcionar em diversas situações.
Em grades, onde o ambiente é geralmenteheterogêneo e dinâmico, o melhor é procuraraproximações e heurísticas.
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores6/15

Nomenclatura
Definições geralmente usadas em escalonamento paragrades :
tarefa : unidade indivisível a ser escalonadaaplicação : conjunto de tarefas e aplicaçõesrecurso : algo capaz de realizar alguma operação
sítio : unidade autônoma da grade, composta porrecursos
escalonamento de tarefas é um mapeamento, notempo, das tarefas para recursos.Conceito importante : escalonamento válido (atentarpara as capacidades)
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores7/15
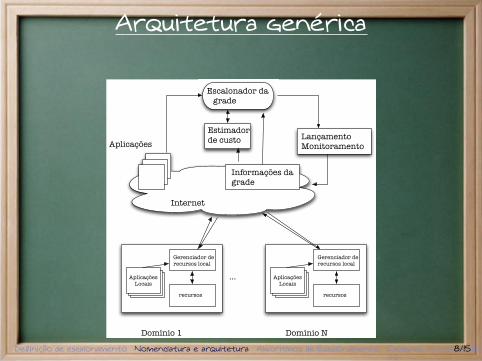
Arquitetura genérica
Escalonador da grade
Aplicações
Estimadorde custo
Informações dagrade
Lançamento Monitoramento
Internet
AplicaçõesLocais
Gerenciador derecursos local
recursos
Domínio 1
AplicaçõesLocais
Gerenciador derecursos local
recursos
Domínio N
...
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores8/15

Algoritmos
Enquadram-se em dois possíveis contextos :Estático : conhecimento total das aplicações a serem
submetidas antes do seu início.Dinâmico : as aplicações podem aparecer a qualquer
momento ; as próprias tarefas dasaplicações podem não ser conhecidas.
Algoritmos estáticos existem mas são poucoapropriados para grades :
recursos podem mudar ;o tempo previsto de uma tarefa pode nãocorresponder ao esperado ;para certas aplicações, não é possível prever o seutempo de execução ;o modelo estático pressupõe um conhecimentototal a priori.
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores9/15

Algoritmos dinâmicos
Conforme estimativas, as tarefas são alocadas arecursos.Podem ser alocadas no momento de sua criação.Para uma adaptação dinâmica usa-se balanceamentode carga :
tentativa de distribuir o trabalho entre osrecursos ;mais comum : roubo de trabalho (quem não tem,busca)
1. Adaptabilidade ao ambiente.2. Procura-se maximizar o uso dos recursos (ao invés
do tempo de término, que favorece um únicousuário).
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores10/15

Escalonadores de grades
Duas abordagens principais :Escalonadores completos (global + local).Meta-escalonadores que « conversam » comescalonadores locais.
Veremos dois :SLURM (Lawrence Livermore National Laboratory,início 2002)OAR (Mescal Project - INRIA/UJF, início 2002)
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores11/15

SLURM
Simple Linux Utility for Resource Management
aglomerados heterogêneos com milhares de nósLinuxprovê tolerância a falhasoferece
1. controle de estado das máquinas2. gerenciamento de partições3. gerenciamento de aplicações4. escalonador5. módulos para cópia de dados
slurmd - executado em cada nó do sistemaslurmctld - executado no nó de gerenciamento
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores12/15

SLURM (continuação)
Funções principais :alocar recursos, de forma exclusiva, ou não, porperíodos determinadosfornecer um arcabouço para lançar, executar emonitorar as aplicações nas máquinasgerenciar uma fila de trabalhos pendentes no casode pedidos de uso conflitantes
Escalonador simples do tipo FIFO com prioridadesDiferencial : Alto desempenho (usado no BlueGene/L),aceita plug-ins.
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores13/15

OAR
Escalonador para aglomerados e gradesPermite a reserva de máquinas de uma grade porusuários específicos.Para ele, os recursos são as máquinas.Possui comandos para :
1. submissão2. cancelamento3. consulta
Há controle de admissão e a aplicação é enfileirada.É executada quando os recursos tornam-sedisponíveis.
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores14/15

OAR (continuação)
Escalonamento modular, configurável peloadministrador :
filas de submissão diferentes (prioridades)casamento de recursosbackfilling (fura fila se não atrapalha)
Permite reservasExiste uma versão para ambientes oportunistas
Diferencial : Simplicidade e modularidade. É usado noGrid 5000.
Definição de escalonamento Nomenclatura e arquitetura Algoritmos de Escalonamento Exemplos de escalonadores15/15

31/07/2010 42
Segurança
● Com a popularização da Internet e a conexão dos mais variados sistema a ela, a Segurança se tornou um problema fundamental.
● Grandes empresas investem quantias vultosas para proteger seus sistemas de ataques externos (e internos).
● Por sua natureza, grades computacionais podem escancarar a porta de entrada aos sistemas. Portanto, segurança é fundamental.

31/07/2010 43
Múltiplos domínios
● Grades podem cobrir diferentes domínios administrativos.
● Isso dificulta o gerenciamento de– usuários– permissões– controle de acesso– contabilização de uso de recursos– auditoria– privacidade

31/07/2010 44
Objetivos do Serviço de Segurança
● Autenticação– processo de estabelecer a validade de uma
identidade reivindicada;– deve-se autenticar administradores, provedores
de recursos, provedores de aplicações, usuários da grade.
● Confidencialidade– impede que os dados sejam lidos ou copiados
por usuários que não têm esse direito.– ex.: grades entre empresas ou bancos.

31/07/2010 45
Objetivos do Serviço de Segurança
● Integridade de Dados– proteção da informação, evitando que ela seja
removida ou alterada sem a autorização de seu dono.
● Disponibilidade– proteção dos serviços, evitando que eles sejam
degradados a ponto de não poderem ser mais usados.
– proteção a ataques de negação de serviço.– ex.: usuário deve ser capaz de acessar o
resultado de suas computações e de executar novas aplicações na grade.

31/07/2010 46
Objetivos do Serviço de Segurança
● Controle de Acesso– permite que apenas usuários conhecidos, e com
os respectivos direitos de acesso, disponham dos recursos da grade;
– o gerenciamento de direitos de acesso de centenas de usuários em milhares de recursos deve ser realizado de forma viável.
– mecanismos utilizados● listas de controle de acesso● certificados de direitos● capacidades (capabilities)● controle de acesso baseado em papéis (RBAC)

31/07/2010 47
Objetivos do Serviço de Segurança
● Auditoria– registro de todas ações relevantes executadas
no sistema indicando quem fez o que e quando– sistemas de segurança falham; a auditoria provê
formas de detectar quando a falha ocorreu, qual falha ocorreu, etc.
– agentes inteligentes podem monitorar os registros de forma a detectar intrusos.
● Irretratabilidade (non-repudiation)– obtenção de provas (ou fortes indícios) das
ações de um usuário de forma que ele não as negue.

31/07/2010 48
Mecanismos de segurança
● Canais de comunicação seguros– criados entre os nós da grade de forma que
dados não sejam roubados ou corrompidos– atualmente, o meio mais comum é SSL (secure
socket layer) implementados por bibliotecas como OpenSSH
● Armazenamento seguro de dados– dados armazenados de forma persistente não
podem ser perdidos nem acessados por usuários não-autorizados.
– Criptografia e proteção do SO local ajudam.

31/07/2010 49
Mecanismos de segurança
● Sandboxing– como um areião onde crianças brincam,
isola as aplicações do ambiente exterior; as aplicações podem fazer a farra que quiserem pois o estrago estará limitado;
– limitam● uso de memória● uso de disco (quantidade e porção do disco)● uso do processador● uso da rede (banda e aonde se conectar)
– A máquina virtual Xen [Barham et al. 2003] tem sido muito usada para isso.

31/07/2010 50
Tolerância a Falhas
● Grades são um ambiente altamente dinâmico. Nós podem entrar e sair a qualquer momento.
● Aplicações pesadas podem demorar horas, dias, ou meses para serem executadas.
● Se um único nó de uma aplicação paralela falha, toda a computação pode ser perdida.
● Portanto, tolerância a falhas é essencial !

31/07/2010 51
Tolerância a falhas
● Além disso, os próprios nós que executam os serviços da grade podem falhar.
● Portanto, é necessário que haja replicação dos serviços essenciais da grade.
● Em ambos os casos, é necessário um bom mecanismo para detecção de falhas.
● Este mecanismo deve informar o middleware da grade em caso de falhas para que as aplicações sejam reiniciadas ou os serviços reestabelecidos.

31/07/2010 52
Checkpointing
● Consiste em tirar fotografias do estado de um processo de forma a constituir pontos de salvaguarda.
● Permite reiniciar a aplicação de um ponto intermediário de sua execução.
● Em aplicações seqüenciais é trivial.● Em aplicações paralelas com comunicação
entre os nós é mais complicado.

31/07/2010 53
Recuperação por Retrocesso
● Recuperação por retrocesso baseada em checkpointing:
– Checkpoints contendo o estado da aplicações são gerados periodicamente.
– Checkpoints são armazenados nas máquinas do aglomerado.
– Em caso de falha durante a execução, o middleware reinicia a aplicação a partir do último checkpoint gerado.

31/07/2010 54
Abordagens para checkpointing
● O estado de uma aplicação pode ser obtido de diferentes modos.
● Checkpointing no nível do sistema (ex. CryoPID)– Dados obtidos diretamente do espaço de memória
Transparente à aplicaçãoRequer uso de máquinas homogêneas
● Checkpointing no nível da aplicação– Aplicação fornece dados a serem salvos
Checkpoints portáteisPrecisa modificar código-fonte da aplicação
31/07/2010 55
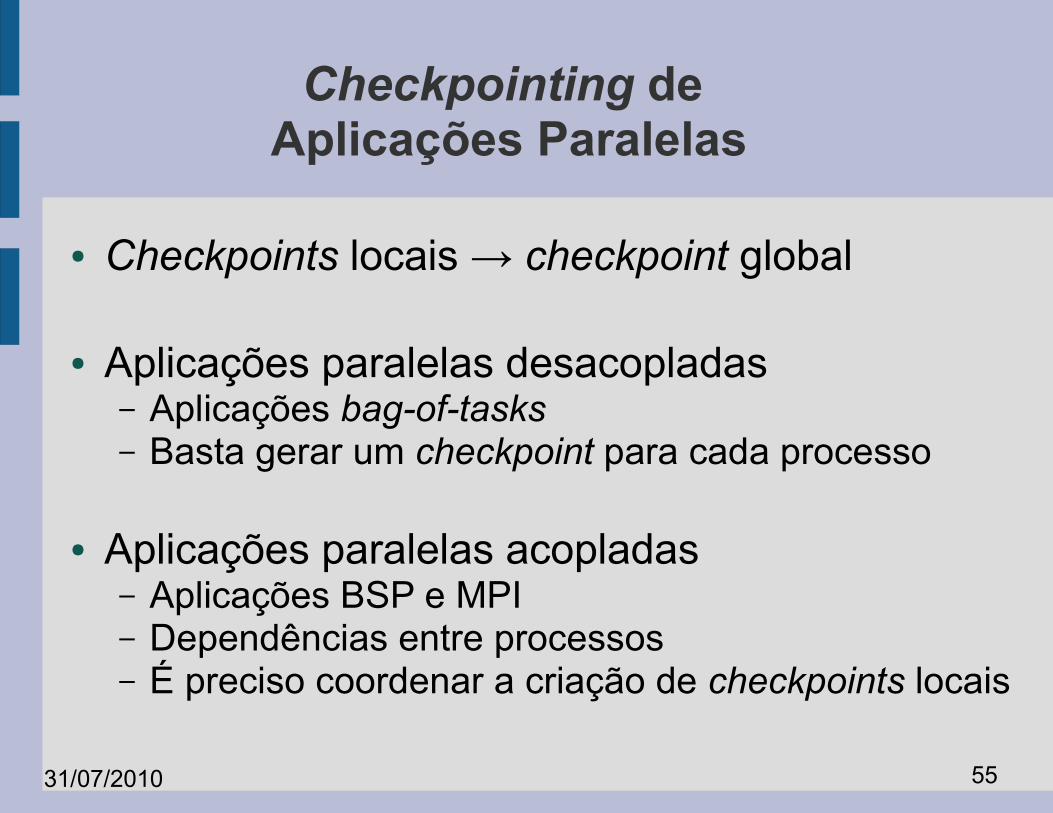
Checkpointing de Aplicações Paralelas
● Checkpoints locais → checkpoint global
● Aplicações paralelas desacopladas– Aplicações bag-of-tasks– Basta gerar um checkpoint para cada processo
● Aplicações paralelas acopladas– Aplicações BSP e MPI– Dependências entre processos– É preciso coordenar a criação de checkpoints locais
31/07/2010 56
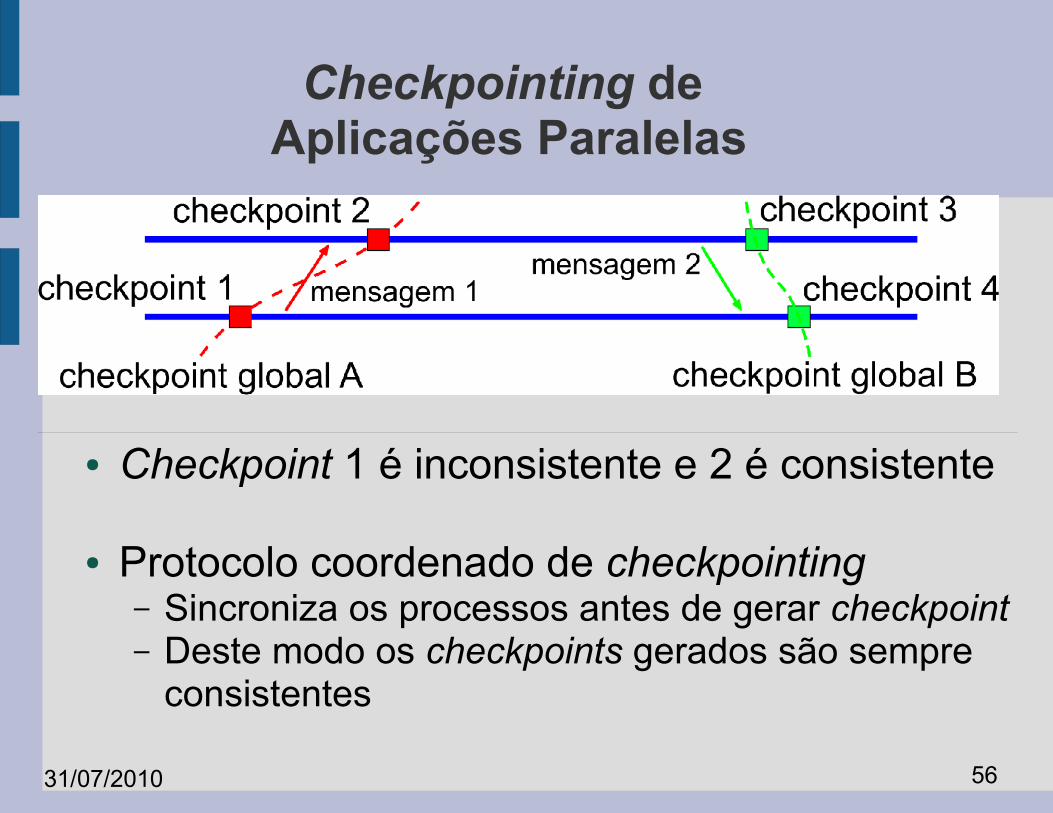
Checkpointing de Aplicações Paralelas
● Checkpoint 1 é inconsistente e 2 é consistente
● Protocolo coordenado de checkpointing– Sincroniza os processos antes de gerar checkpoint– Deste modo os checkpoints gerados são sempre
consistentes

31/07/2010 57
Coordenado vs. assíncrono
● Checkpointing coordenado é relativamente simples de implementar mas o desempenho é pior.
● Checkpointing assíncrono permite que se tire as fotografias sem interromper a execução dos processos.– mas é muito mais complexo.– ainda não são usados no contexto de grades.

Grades Computacionais:
Conceitos Fundamentais e Casos Concretos
Modelos de Programação
Fabio Kon, Alfredo Goldman
Universidade de São Paulo{kon,gold}@ime.usp.br
SBC - JAI - Belém - 15 e 16/07/08

Roteiro
Preliminares
Paramétricas e saco de tarefasSETI@homeMersenne Prime Search
MPIProgramação MPI
BSPProgramação BSP
Outros modelosOpenMPKAAPI
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 2/38

Modelos de Programação
Abstração da máquina de forma a simplificar arepresentação da realidade.
Modelos mais próximos da realidade são muitocomplexos.Modelos excessivamente simplificados podem estarlonge da realidade.É necessário um balanço entre a realidade e asimplicidade.
Veremos alguns modelos úteis para representaraplicações.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 3/38

Modelos de Programação (analogia)
Modelos paralelos : LogP (e variantes), PRAM, . . .Existem cursos específicos, como :
Topics in Parallel Algorithms using CGM/MPI -Song, Cáceres e Mongelli, SBAC 03.Modelos para Computação Paralela - Goldman,ERAD 03.
Analogia com seqüencialMais simples : Modelo de Von NeumanMais complexo : considerar os tempos de acesso àmemória, caches de diversos níveis, etc.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 4/38

Paramétricas e saco de tarefas
Aplicações paramétricas correspondem a uma classede aplicações idênticas que são executadas comdiferentes parâmetros.Aplicações do tipo saco de tarefas (bag-of-taks)correspondem a aplicações onde as tarefas a seremexecutadas são completamente independentes umasdas outras.A necessidade de comunicação entre tarefas émínima.
Duas comunicações1. uma no início, quando são passados os parâmetrosiniciais
2. e uma ao término, quando os resultados sãotransmitidos para serem combinados.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 5/38

Escalabilidade
Como quase não há comunicação, um grande númerode máquinas pode ser usado.
A paralelização é simples (embarrassingly parallel).
Algumas áreas de aplicação :mineração de dadossimulações de Monte Carlorenderização distribuídabuscas com BLAST em bioinformáticaaplicações em física de partículas
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 6/38

SETI@home
Projeto SETI@home (setiathome.berkeley.edu)computação voluntária387 TeraFLOPS (jan/08)busca de padrões em arquivospossui sofisticados mecanismos de controle
BOINCO sucessor deste projeto é o BOINC(boinc.berkeley.edu) para aplicações saco de tarefasgenéricas.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 7/38

Busca de Primos
Projeto de busca de número primos no formato 2n − 1
computação voluntáriawww.mersenne.org
maior primo 232,582,657 − 1 (9,808,358 dígitos)prêmio de 100 mil dólares para quem achar umprimo com 10 milhões de dígitos
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 8/38

MPI
Message Passing InterfacePadrão criado pelo MPI Forum (www.mpi-forum.org)
Define interfaces, protocolos e especificações para acomunicação paralela.Principais objetivos :DesempenhoEscalabilidadePortabilidade
Apesar de ser de « baixo nível », ainda é o padrão paracomputação paralela mais utilizado.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 9/38

Diferentes implementações
O MPI possui diferentes implementações, sendo asmais conhecidas :
MPICH - Argonne National LaboratoryOpen-MPI - (mantido por um consórcio) sucessordo mpi-lan
Para atingir alto desempenho, existem implementaçõesespecíficas para diversas placas de redeVersões principais :
MPI 1 (a partir de 1994) - troca de mensagens,ambiente de tamanho fixoMPI 2 (a partir de 1997) - criação dinâmica deprocessos, operações em memória remota
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 10/38

Troca de mensagens
É o principal modelo de comunicação em MPI.
Processos independentes com memórias locais trocaminformações através do envio de mensagens.
envio (MPI_Send())recepção (MPI_Recv())Existe a necessidade de sincronização
Existem sends e receives bloqueantes :a instrução bloqueia o fluxo de execução.Existem também instruções assíncronas :a verificação da transmissão pode ser feitaposteriormente (MPI_Wait())
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 11/38

Um programa
#include "mpi.h"#include <stdio.h>int main(int argc, char **argv) {
int rc;rc = MPI_Init (&argc, &argv);if (rc == MPI_SUCCESS) {
printf ("MPI iniciou corretamente.\n");}MPI_Finalize ();return 0;
}
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 12/38

Execução de um programa
Para compilar executar um programa existem comandoscomo o mpicc e o mpiexec.
No caso acima, após a compilação, temos o comandompirun [ -np X ] <program> que executa X cópias doprograma no ambiente.
O número de mensagens do programa anteriordepende de quantas cópias serão lançadas.Os processos são distribuídos (round-robin) entres asmáquinas disponíveis no ambente.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 13/38

Conceitos do MPI
Em MPI, é possível definir « comunicadores » quecorrespondem a abstrações que permitem a processosrelacionados trocar mensagens.O mais comum é o MPI_COMM_WORLD que é comum atodos os processos lançados através de mpiexecAs duas instruções seguintes são bem úteis :
MPI_Comm_size (comm, *number) dado umcomunicador, fornece sua quantidade deprocessadores.MPI_Comm_rank (comm, *id) devolve o número doprocesso corrente dentro do comunicador
Isso deve ficar claro com o próximo exemplo.Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 14/38

Um programa com « comunicador »
int main(int argc, char **argv) {int num_of_processes, rank, rc;rc = MPI_Init (&argc, &argv);if (rc == MPI_SUCCESS) {
MPI_Comm_size (MPI_COMM_WORLD, &num_of_processes);MPI_Comm_rank (MPI_COMM_WORLD, &rank);printf ("Sou o processo %d de %d\n", rank,
num_of_processes);}MPI_Finalize ();return 0;
}
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 15/38

Forma de programação
O modelo de programação em MPI é o SPMD SingleProgram Multiple Data.
Nesse modelo, existe um único programa e, conformeváriaveis locais, o comportamento muda.Uma das variáveis locais usadas é o id do processo.Com um simples esquema podemos definir que um« mestre » envia trabalho aos outros nós.
if(id == 0}// envia trabalho
else// recebe e executa
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 16/38

Sintaxe para o envio
Vejamos um programa onde um processador envia umamensagem a outro.Para isso, usaremos o MPI_Send (síncrono)
int MPI_Send(void *buf, int count, MPI_Datatype datatype,int dest, int tag, MPI_Comm comm )
Input Parametersbuf: initial address of send buffercount: number of elements in send bufferdatatype: datatype of each send buffer elementdest: rank of destinationtag: message tagcomm: communicator
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 17/38

Sintaxe para a recepção
Sintaxe do MPI_Recv (síncrono)
int MPI_Recv(void *buf, int count, MPI_Datatype datatype,int source, int tag, MPI_Comm comm,MPI_Status *status )
Output Parametersbuf: initial address of receive bufferstatus: status objectInput Parameterscount: maximum number of elements in receive bufferdatatype: datatype of each receive buffer elementsource: rank of sourcetag: message tagcomm: communicator
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 18/38

Sincronismo
No caso da recepção síncrona, o comando bloqueia ofluxo até a recepção completa da mensagem.Para o envio síncrono, o comando bloqueia o fluxo emum de três pontos :
Até o envio completo da mensagem.Isto é, a mensagem foi repassada para uma outracamada que não o MPI.Até a recepção da mensagem pelo nó destinatário.A mensagem é recebida pela máquina em que oprocesso destino se encontra.Até a recepção pelo processo destinatário.A mensagem é efetivamente recebida peloprocesso.
Não existe na especificação a determinação de ondeocorre o bloqueio.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 19/38

Uma troca de mensagensint main(int argc, char **argv) {
int numtasks, rank, dest, source, rc, count, tag = 1;char inmsg, outmsg; MPI_Status Stat;MPI_Init (&argc, &argv);...if (rank == 0) {
dest = 1;outmsg = ’x’;printf ("Enviando caractere %c para proc %d\n", outmsg, dest);rc = MPI_Send (&outmsg,1, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
}else if (rank == 1) {
source = 0;rc = MPI_Recv (&inmsg, 1, MPI_CHAR, source, tag,
MPI_COMM_WORLD, &Stat);printf ("Recebi o caractere: %c do proc %d\n", inmsg, source);
}MPI_Finalize ();
}
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 20/38

Comunicação em grupo
Além da possibilidade de troca de mensagens entrepares de processadores, o MPI oferece possibilidadespara a comunicação entre grupos de processadores.
As mais comuns são :Difusão - de um para todos os processos do grupoConcentração - de todos os processos para umRedução - aplica uma operação (ex. : soma) nosdados recebidos de todos os processosTroca completa - efetua uma troca completa demensagens entre todos os processos
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 21/38

Sintaxe da redução
int MPI_Reduce (void *sendbuf, void *recvbuf, int count,MPI_Datatype datatype, MPI_Op op, int root,MPI_Comm comm )
Input Parameterssendbuf: address of send buffercount: number of elements in send bufferdatatype: data type of elements of send bufferop: reduce operationroot: rank of root processcomm: communicator
Output Parameterrecvbuf: address of receive buffer
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 22/38

Primitivas de comunicação de grupo
int main(int argc, char **argv) {int rank, source = 0, dest = 0, rc;int value, totalValue;MPI_Init (&argc, &argv);MPI_Comm_rank (MPI_COMM_WORLD, &rank);if (rank == 0)
value = 10;MPI_Bcast (&value, 1, MPI_INT, source, MPI_COMM_WORLD);value *= rank + 1;MPI_Reduce (&value, &totalValue, 1, MPI_INT, MPI_SUM,
dest, MPI_COMM_WORLD);if (rank == 0)
printf ("Valor final calculado: %d\n", totalValue);MPI_Finalize();return 0;
}Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 23/38

MPI 2
Funcionalidades específicas de MPI 2 :Um processo pode criar sub-processosdinamicamente (em outras máquinas).Operações de acesso a memória remota(one-side-communications)
primeiro é necessário criar-se « janelas »MPI_PUT() e MPI_GET()além de outras primitivas de comunicação esincronização.
suporte para threads.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 24/38

BSP
Bulk Synchronous Parallel ModelModelo criado por Valiant [1990]
Objetivo : Portabilidade sem perder o desempenho.Idéia : Separação explícita da computação e dacomunicação.conceitos principais :
1. super-etapa2. sincronização
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 25/38
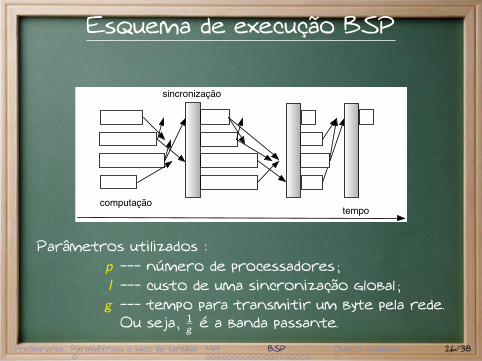
Esquema de execução BSP
computação
sincronização
tempo
Parâmetros utilizados :p --- número de processadores ;l --- custo de uma sincronização global ;g --- tempo para transmitir um byte pela rede.
Ou seja, 1g é a banda passante.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 26/38

Diferenciais do BSP
Vantagens :Conhecendo-se p, l e g é possível estimar o tempode execução em diferentes plataformas.Os pontos de sincronização criam estados globaisconsistentes.
Desvantagem : com sincronizações globaisfreqüentes, em alguns casos, os programas podemperder escalabilidade.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 27/38

Programando com BSP
Para obter um programa eficiente :a carga de cálculo deve estar balanceada,a comunicação deve ser limitada (quantidade dedados),deve-se usar poucas super-etapas.
Modelo semelhante : CGM Coarse Grained Multicomputers
Para a programação BSP pesquisadores (principalmenteda Oxford University) criaram a BSPlib em 1997.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 28/38

Formas de comunicação
Duas formas :acesso a memória remota -- Distributed RemoteMemory Addressing (DRMA)troca de mensagens -- Bulk Synchronous MessagePassing (BSMP)
1. as mensagens são enviadas para a fila local doprocesso remoto ;
2. cada processo pode acessar sua fila local.
Em DRMA para acessos à memória remota énecessário registrar as regiões a serem acessadasbsp_push_reg()
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 29/38

BSPlib
Comandos da BSPlib :bsp_begin (nprocs) --- inicia um programa BSP com
nprocs processosbsp_end() --- final da parte paralelabsp_pid() --- fornece o id do processo
bsp_nprocs() --- fornece o número total de processosbsp_sync() --- delimitador de super-passosLeitura e escrita em DRMA :bsp_put() recebe id do destino, offset local, endereço no
destino e offset remotobsp_get() é semelhante
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 30/38

Produto escalar 1/2
#include "BspLib.hpp"int main (int argc, char **argv) {
int pid, nprocs = 4;double produto,
*listaProdutos; // vetor local a cada processolistaProdutos = (double *)
malloc (nprocs * sizeof (double));bsp_begin (nprocs);// registra memória a ser compartilhabsp_push_reg (&listaProdutos, nprocs * sizeof(double));pid = bsp_pid ();
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 31/38

Produto escalar 2/2
// cálculo do produto com os pedaços de vetores locaisprod = calculaProdutoLocal (pid, nprocs);// envia os resultados a todos os outros processosfor (int proc = 0; proc < bsp_nprocs( ); proc++)
// coloca em proc um valor (double) em// listaProdutos usando pid como offsetbsp_put (proc, &produto, &listaProdutos,
pid, sizeof(double));bsp_sync ( ); // final do super-passocalculaProdutoEscalarFinal (listaProdutos);bsp_end( );
}
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 32/38

Troca de mensagens
Principais funções :bsp_send(int pid,void *tag,void *payload,intnbytes) -- envia uma mensagem de tamanho nbytescontida em payload e com o identificador tag para afila de mensagens do processo pid.bsp_set_tagsize(int *nbytes) -- define o tamanhoda tag como nbytes.bsp_get_tag(int *status, void *tag) -- se houvermensagens na fila, devolve o tamanho da próximamensagem em status e o conteúdo da tag damensagem em tag.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 33/38

Troca de mensagens (continuação)
bsp_move(void *payload, int nbytes) -- copia oconteúdo da primeira mensagem da fila em payload.A variável nbytes representa o tamanho do bufferapontado por payload.bsp_qsize(int *packets, int *nbytes) -- devolve onúmero de mensagens na fila em packets e otamanho total das mensagens em nbytes.
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 34/38

Produto escalar (troca de mensagens) 1/2
#include "BspLib.hpp"int main(int argc, char **argv) {
int pid, nprocs = 4;double produto;double *listaProdutos = (double *) malloc(nprocs *
sizeof(double));bsp_begin (nprocs);pid = bsp_pid ();produto = calculaProdutoLocal (pid, nprocs);int tagsize = sizeof(int);bsp_set_tagsize( &tagsize );// envio do produto escalar local a todos os outrosfor (int proc = 0; proc < bsp_nprocs( ); proc++)
bsp_send (proc, &pid, &produto, sizeof(double));bsp_sync ( );
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 35/38

Produto escalar (troca de mensagens) 2/2
for (int proc = 0; proc < bsp_nprocs( ); proc++) {int messageSize, source;bsp_get_tag (&messageSize, &source)
bsp_move( &listaProdutos[source], messageSize)}calculaProdutoEscalarFinal (listaProdutos);bsp_end( );
}
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 36/38

Modelo OpenMP
API proposta pela OpenMP Architecture Review Board (ARB)para sistemas com memória compartilhada.
Versão inicial proposta em 1997, atualmente versão 3.0(maio 2008).
Modelo de execução é baseado em fork-join.
Não existem instruções específicas para troca demensagens (a comunicação é baseada em memóriacompartilhada).
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 37/38

KAAPI
O Kernel for Asynchronous and Adaptive Parallel Interfacepermite o desenvolvimento e execução de aplicaçõesdistribuídas baseadas em fluxos de trabalho.Começou a ser desenvolvida no projeto MOAIS doLIG/INRIA em 2005, e é baseada em bibiotecasanteriores do mesmo grupo.
O escalonamento das tarefas aos processadoresalocados é realizado dinamicamente.
Utiliza um algoritmo do tipo roubo de trabalho(work-stealing).
Fornece tolerância a falhas através de checkpoints doestado do fluxo de trabalho (não dos processos em si).
Preliminares Paramétricas e saco de tarefas MPI BSP Outros modelos 38/38

31/07/2010 59
Middleware de grades
● Sistemas conhecidos internacionalmente– Condor– Legion– Globus– gLite
● Alguns sistemas brasileiros– OurGrid– InteGrade– EasyGrid

31/07/2010 60
Globus
● O middleware de grade mais conhecido atualmente.
● Ian Foster e Carl Kesselman
● Argonne National Lab., University of Chicago, NCSA, University of Illinois.
● Suas origens remontam o I-WAY– grade temporária composta por 17 instituições– apresentado no Supercomputing'95

31/07/2010 61
Evolução do Globus
● versão 1.0: 1998 (uso interno)versão 2.0: 2002 (disseminação mundial)
● versão 3.0: 2003 (comitê de padronização) ● versão atual: 4.0.5 pode ser baixada como software
livre de www.globus.org
● Padrão OGSA (Open Grid Services Architecture)– conjunto de Web Services definidos pelo Open
Grid Forum.

31/07/2010 62
Globus
● O middleware de grade mais conhecido atualmente– Pode ser baixado gratuitamento (Versão 4.0.5)– Padrão OGSA (Open Grid Services Architecture)
● Utiliza o conceito de Grid Services – Comunicação baseada em Web Services
● Baixo acoplamento entre os recursos● Desempenho ruim
– Adiciona funcionalidades a Web Services● Descoberta de serviços● Serviços nomeados● Serviços com estado

31/07/2010 63
Serviços do GT4
Serviços do Globus Toolkit 4:● Monitoring and Discovery Service (MDS)
– Trigger: coleta dados de uso de recursos e dispara um gatilho quando certas condições são satisfeitas.
– Index: agrega em um único índice centralizado um conjunto de informações sobre recursos espalhados pela rede
–
● Grid Resource Allocation and Management (GRAM)– responsável por localizar, submeter, monitorar e
cancelar a execução de tarefas

31/07/2010 64
Serviços do GT4
● GridFTP– permite a distribuição de arquivos na grade
● Replica Location Service– registro e recuperação de réplicas– mapeamento entre nomes lógicos e físicos
● Segurança– credenciais X.509 para identificação de usuários,
serviços e recursos– SSL para comunicação segura– OpenSAML para gerenciamento de autenticação,
atributos e autorizações.

31/07/2010 65
Serviços do GT4
● Bibliotecas de tempo de execução formam o Common Runtime
– XIO para entrada e saída usando vários protocolos– C Common Libraries unifica tipos e estruturas de dados
e chamadas ao sistema operacional– bibliotecas de suporte a C, Java e Python.

31/07/2010 66
OurGrid
● Um dos principais projetos brasileiros da área.
● Universidade Federal de Campina Grande.● Parceria e financiamento HP Labs.
● Middleware Java para execução de aplicações seqüenciais do tipo saco de tarefas (bag-of-tasks)

31/07/2010 67
OurGrid
● Principal motivação:– mecanismo simples para instalação e
configuração de grades– (infra-estruturas mais usadas, p.ex., Globus,
demandam um grande esforço de configuração)
● Para tanto desenvolveu-se um mecanismo simples baseados em redes par-a-par (P2P) para estruturação da federação de aglomerados.

31/07/2010 68
OurGrid: redes de favores
● Usa o conceito de “rede de favores” para determinar a prioridade dos usuários na utilização de recursos.
● Quem oferece muitos recursos à Grade, pode utilizar mais recursos da Grade.
● Essa abordagem facilita o gerenciamento, evitando configurações manuais.

31/07/2010 69
OurGrid: características
● Usa Xen para prover segurança mas não se preocupa com privacidade ou criptografia.
● Intencionalmente, não possui um escalonador global. O agente pessoal MyGrid é responsável pelo escalonamento das aplicações de um usuário.
● Está em produção desde dezembro de 2004 e reúne dezenas de laboratórios no Brasil e no exterior.
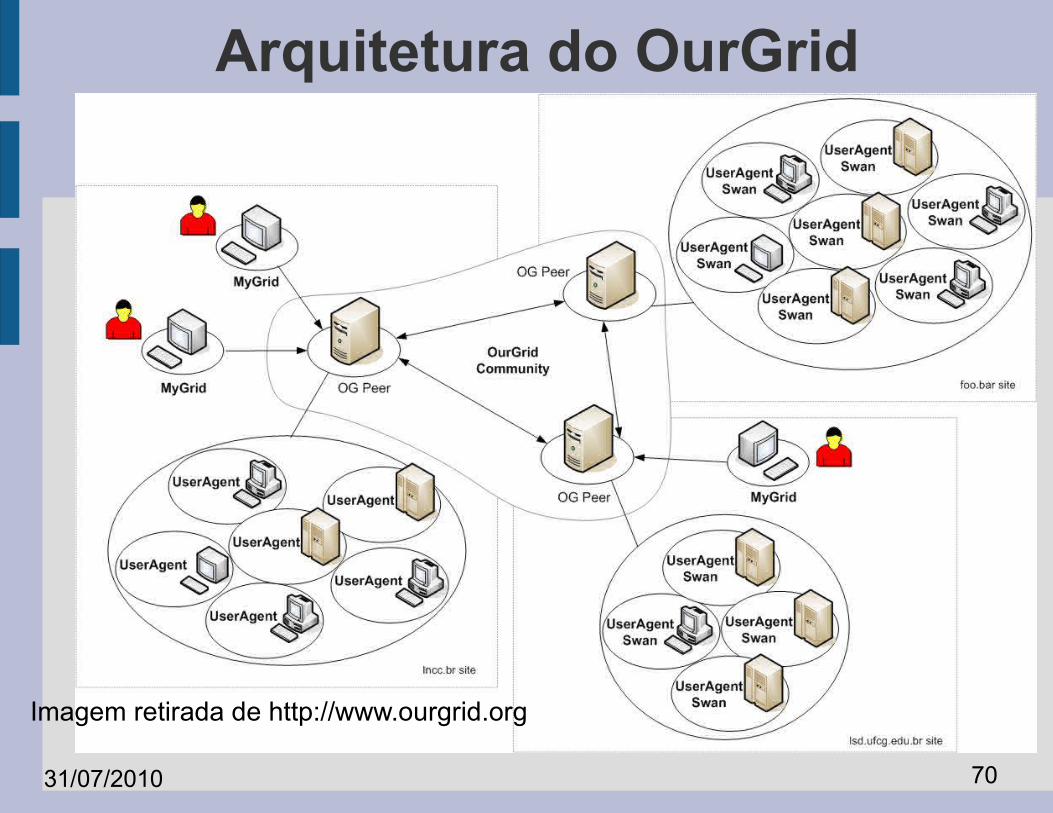
31/07/2010 70
Arquitetura do OurGrid
Imagem retirada de http://www.ourgrid.org

31/07/2010 71
Grades Oportunistas
● Foco na utilização ciclos computacionais ociosos estações de trabalho compartilhadas– Máquinas de laboratórios, professores, etc.
– Deve manter a Qualidade de Serviço dos donos das máquinas compartilhadas
– Máquina passa do estado ocioso para utilizada ● Aplicações da grade devem ser migradas para
outras máquinas

31/07/2010 72
Grades Oportunistas
● Vantagens✔ Baixo custo: utiliza hardware já existente✔ Economia de recursos naturais
✔ Eletricidade, refrigeração, espaço físico
● Desvantagens✗ Gerenciamento de recursos é mais complicado✗ Menor desempenho: Utiliza apenas períodos
ociosos das máquinas

31/07/2010 73
Exemplo: SETI@HOME
● Sistema de computação distribuída– Análise de sinais de rádio-telescópios– Objetivo é por procurar por padrões não-naturais
nos sinais obtidos
● Quebra o problema em blocos independentes– Não existe comunicação entre os nós
● Distribui grupos de blocos a cada computador– Computador realiza análise dos dados contidos nos
blocos recebidos– Dados são enviados de volta a um servidor central

31/07/2010 74
Exemplo: SETI@HOME
● Ótimo exemplo do poder computacional– Desempenho total até Janeiro de 2006
● 7.745.000.000.000 Gflops● Mais de 5 milhões de usuários
– Core 2 Duo (2.16GHz): ~ 3 Gflop/s (abril 2010)● 730.000 Gflops por dia● 5.100.000 Gflops por dia (Boinc)
– Computador mais rápido do mundo até 2007:● Blue Gene/L (212.992 processadores)● 478.200 GFlop/s● 187 dias no Blue Gene/L ↔ Seti@Home
– Hoje: Jaguar● 224.162 núcleos; pico: 2.331.000 GFlop/s

31/07/2010 75
Exemplo: Folding@home
● Folding@home – Sistema para realizar simulações computacionais
do enovelamento de proteínas
– Aplicações: cura de doenças, como o câncer, Alzheimer, Parkinson, etc.
– Possui versão que pode ser executada em Playstation 3.

31/07/2010 76
Condor: um sistema pioneiro● Grade oportunista
– Desenvolvido na University of Wisconsin-Madison desde o final da década de 1980.
– Permite utilizar ciclos ociosos de estações de trabalho compartilhadas.
● Condor pools: grupos de computadores– Condor pools podem ser conectados entre si
● Hoje em dia possui suporte a aplicações seqüencias, saco de tarefas e MPI.

31/07/2010 77
Exemplo: Condor
● Computadores fazem anúncios dos recursos disponibilizados– Estes recursos são então monitorados pelo Condor.
● Aplicação é submetida para execução– Match-maker repassa a execução a máquinas que
possuam os recursos necessários para executar a aplicação.
● Caso uma máquina seja requisitada pelo dono– Aplicação é migrada para outro nó.– Limitação: aplicações paralelas rodam em nós
dedicados.

31/07/2010 78
InteGrade: middleware para grades oportunistas
● Iniciativa de 6 universidades brasileiras– IME-USP, PUC-Rio, UFMS, UFG, UFMA e UPE
● Desenvolvido colaborativamente com o software livre disponível em www.integrade.org.br
● Implementado em Java, C++ e Lua.● Comunicação baseada em CORBA.
● Suporte a aplicações C, C++, Fortran e Java.

79
Motivação Desenvolver um middleware que permita
utilizar recursos ociosos de máquinas compartilhadas já existentes nas instituições.
Objetivo é realizar a execução de aplicações paralelas computacionalmente pesadas.
Armazenamento de dados de aplicações no espaço livre em disco das máquinas compartilhadas.
Importante para instituições com recursos financeiros escassos.
Ambientalmente mais responsável.

80
Características Foco na utilização de computadores pessoais
Suporte a aplicações seqüenciais e paralelas Saco de tarefas, BSP e MPI
Portal Web para submissão de aplicações Armazenamento distribuído de dados
Em desenvolvimento: Preservação da Qualidade de Serviço dos donos
de máquinas compartilhadas Segurança baseada em redes de confiança

81
Principais componentes
Global Resource Manager (GRM) gerencia os recursos de um aglomerado seleciona em quais máquinas cada aplicação
submetida será executada Local Resource Manager (LRM)
gerencia uma máquina provedora de recursos inicia a execução de aplicações na máquina
Application Repository (AR) armazena os executáveis das aplicações dos
usuários

82
Principais componentes
Application Submission and Control Tool (ASCT) permite a submissão de aplicações e a obtenção e
visualização de resultados Portal Web
versão Web da ferramenta ASCT Local Usage Pattern Analyser (LUPA)
analisa o padrão de uso das máquinas da grade permite ao escalonador realizar melhores escolhas
no momento de definir máquinas que executarão uma aplicação

83
Portal InteGrade

84
Federação de Aglomerados Federação de aglomerados
Aglomerados conectados em estrutura hierárquica Aglomerados possuem informações aproximadas sobre
recursos disponíveis em aglomerados filhos

85
Execução de Aplicações

86
Execução de Aplicações1. Usuário submete aplicações através do Portal
Pode ser executado a partir de qualquer máquina
2. GRM determina em quais máquinas a aplicação será executada (escalonamento)
3. Requisição é repassada para as máquinas selecionadas
4. Máquinas obtêm dados de entrada e os binários da aplicação e realizam sua execução
5. Após o término da execução, arquivos de saída são enviados à máquina executando o portal

87
Execução de Aplicações Paralelas
Cada processo é enviado a um LRM diferente

88
Execução Robusta de Aplicações
Aplicações executadas durante ciclos ociosos de máquinas não-dedicadas Podem ficar indisponíveis ou mudar de ociosa para
ocupada inesperadamente Execução da aplicação é comprometida
É preciso reiniciar a execução do início
Mecanismo de tolerância a falhas Reinicia automaticamente a aplicação de um ponto
intermediário de sua execução É totalmente transparente ao usuário

89
Aplicações da grade podem utilizar ou produzir grandes quantidades de dados Dados de aplicações podem ser compartilhados
Abordagem tradicional: servidores dedicados Grade oportunista
Máquinas com grandes quantidade de espaço livre Ambiente altamente dinâmico
Composto por dezenas de milhares de máquinas Utilizar somente períodos ociosos Máquina entram e saem do sistema continuamente
Armazenamento Distribuído

90
OppStore
Middleware que permite o armazenamento distribuído de dados da grade Provê armazenamento confiável e eficiente Utiliza o espaço livre de máquinas compartilhadas
Organizado como federação de aglomerados Similar à maioria das grades oportunistas
Aglomerados do OppStore são mapeados em aglomerados da grade oportunista
Facilita o gerenciamento do dinamismo do sistema Aglomerados conectados por uma rede par-a-par
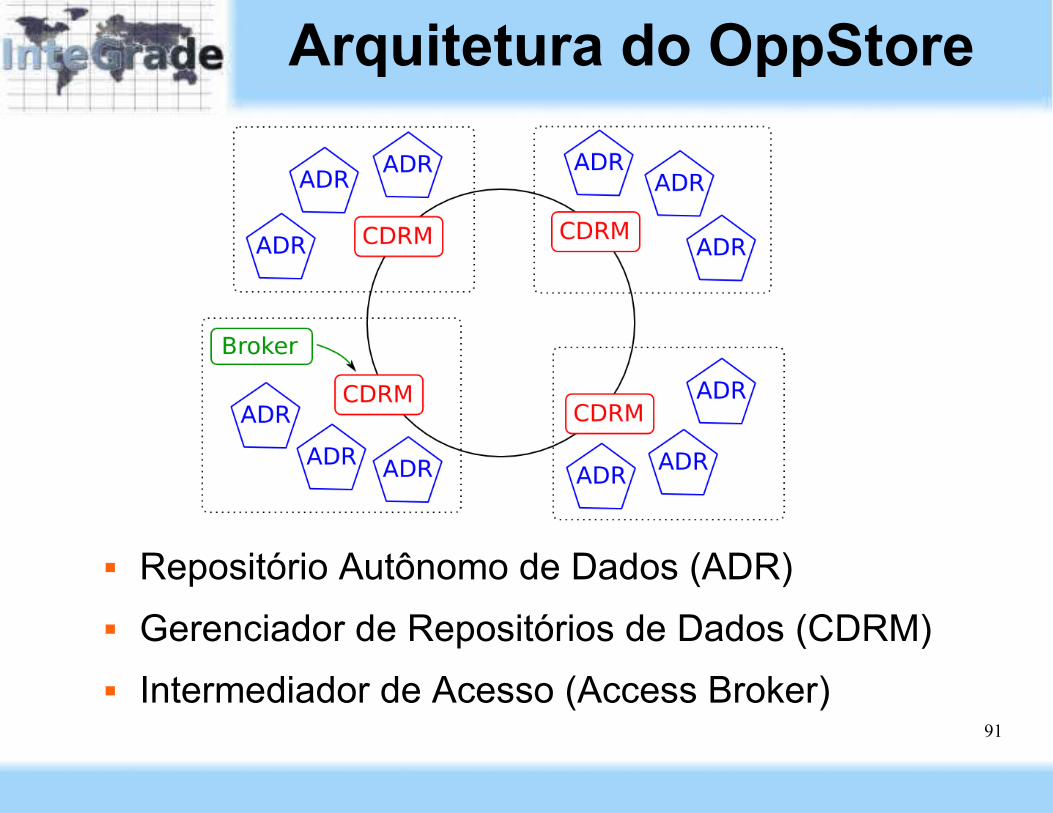
91
Arquitetura do OppStore
Repositório Autônomo de Dados (ADR) Gerenciador de Repositórios de Dados (CDRM) Intermediador de Acesso (Access Broker)

92
Armazenamento de arquivos
Arquivos codificados em fragmentos redundantes Fragmentos armazenados em aglomerados distintos
Vantagens Maior tolerância a falhas Bom desempenho, pois fragmentos são transferidos
em paralelo
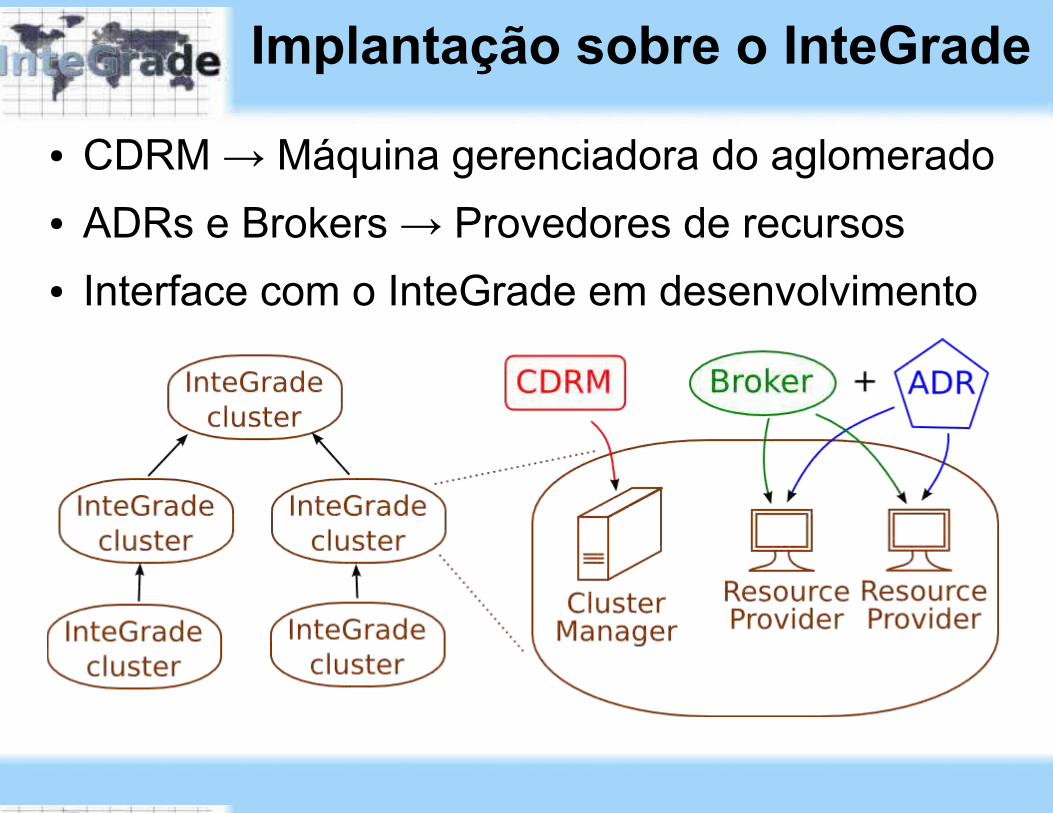
● CDRM → Máquina gerenciadora do aglomerado● ADRs e Brokers → Provedores de recursos ● Interface com o InteGrade em desenvolvimento
Implantação sobre o InteGrade

94
Estado Atual do InteGrade Atualmente na versão 0.4. Execução em 2 aglomerados e 2 laboratórios
compartilhados do IME-USP e em aglomerados de outras universidades.
Permite execução de aplicações paralelas MPI, BSP e paramétricas (saco de tarefas)
Precisam ser realizados mais testes Para tal, precisa-se de mais usuários e aplicações
Contato: [email protected] www.integrade.org.br

Grades Computacionais:
Conceitos Fundamentais e Casos Concretos
Grades em FuncionamentoPesquisa Atual em Grades
Fabio Kon, Alfredo Goldman
Universidade de São Paulo{kon,gold}@ime.usp.br
SBC - JAI - Belém - 15 e 16/07/08

Roteiro
Preliminares
Grid 5000
PlanetLab
EGEE
Pesquisa atual em grades
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 2/18

Grades em produção
Atualmente existem inúmeras grades emfuncionamento.
Escolhemos três tipos para ilustrar as possibilidades :acadêmicaplanetáriaalto desempenho
Mas, existem outras, principalmente baseadas emGlobus, como TeraGrid e Open Science Grid.
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 3/18

Grid 5000
Grade francesa para pesquisas em Ciência daComputação.Características principais :
INRIA, CNRS e vários outros orgãos financiadorescomposta por 9 aglomerados na Françainterligada por rede rápida e dedicadacada aglomerado tem de 256 a 1000processadoresambiente estanque
1. experimentos reprodutíveis2. segurança3. conexões completamente conhecidas
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 4/18
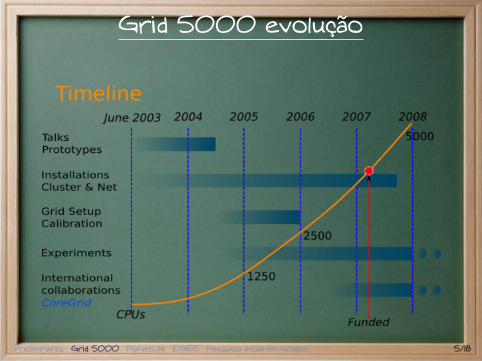
Grid 5000 evolução
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 5/18
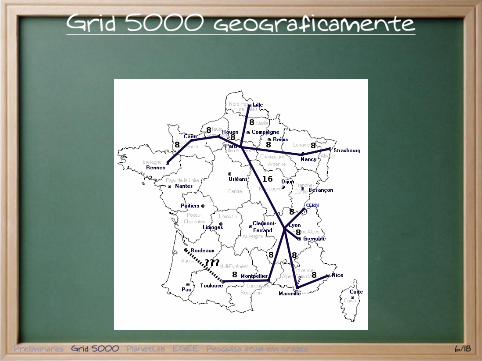
Grid 5000 geograficamente
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 6/18
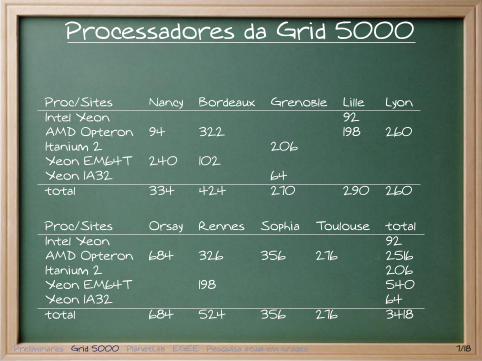
Processadores da Grid 5000
Proc/Sites Nancy Bordeaux Grenoble Lille LyonIntel Xeon 92AMD Opteron 94 322 198 260Itanium 2 206Xeon EM64T 240 102Xeon IA32 64total 334 424 270 290 260
Proc/Sites Orsay Rennes Sophia Toulouse totalIntel Xeon 92AMD Opteron 684 326 356 276 2516Itanium 2 206Xeon EM64T 198 540Xeon IA32 64total 684 524 356 276 3418
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 7/18

Características
Ambiente heterogêneoprocessadores AMD Opteron, Intel Itanium, Intel Xeon
e PowerPCrede de interconexão Myrinet 2G, Myrinet 10G e
Infinibandsistema operacional completamente configurável
O usuário pode escolher a imagem parainicializar as máquinas.
Várias ferramentas :injeção automática de falhasinjeção de tráfego na redemedida de consumo de energia (início 7/08)
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 8/18
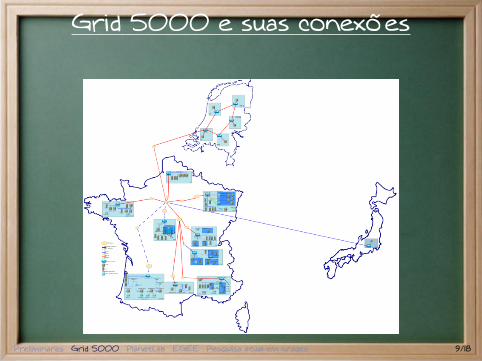
Grid 5000 e suas conexões
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 9/18

PlanetLab
Grade com máquinas em todo o planeta.Projeto iniciado em 2002 e gerenciado pelasuniversidades de Princeton, Berkeley e Washington.Objetivo principal : desenvolvimento de serviços derede.Conta com 895 nós em 461 localidades (7/08).Conexão atraves da Internet pública.Todas as máquinas executam o mesmo pacote desoftware.
1. Mecanismos para reiniciar máquinas e distribuiratualizações.
2. Ferramentas para monitorar os nós.3. Gerenciamento de contas de usuários.4. Distribuição de chaves.
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 10/18
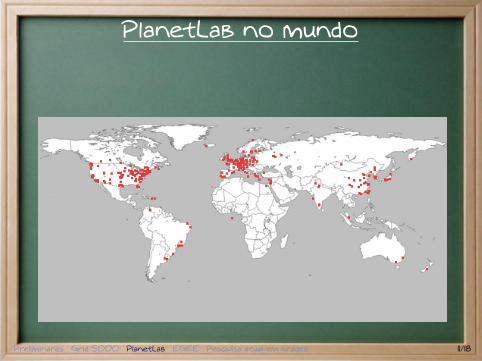
PlanetLab no mundo
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 11/18

Enabling Grids for E-science
Financiado pela união européiaSucessor do Data-GridEGEE I (março 04) encerrado, EGEE II(abril 06)Grade para aplicações científicasComposta por 68 mil processadores, em 250 sítiosde 48 países (7/08)8 mil usuários, processa mais de 150 mil aplicaçõespor dia20 Petabytes de armazenamentoDisponível permanentementeUsa o middleware gLite
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 12/18

Aplicações na EGEE
Física de alta energia1. maior utilização
2. vários projetos ligados ao Large Hadron Collider
Física de particulas espaciaisFusãoObservatório da grade (coleta da dinâmica e do usoda EGEE)Ciências da terra (principalmente geologia)Ciências da vida (imagens médicas, bioinfomática,descoberta de drogas)
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 13/18

www.eu-egee.orgEGEE-III is co-funded by the European Commission under contract number INFSO-RI-222667
The EGEE project is building a Grid infrastructure for the scientific community. Grids are networks of computers spread across many sites but able to act together to provide a range of large scale facilities, from incredible processing power and mass storage to a platform for international collaboration.
The 3d Grid monitor produced by GridPP. Downloads availaaable from http://gridportal.hep.ph.ic.ac.uk/rtm/
A cutaway of the proposed ITER fusion reactor (Pubaalished with the permission of ITER)
Left, the binding of the H5N1 virus to neuraminiaadase and below, the neuaaraminidase binding pocket.
Courtesy of YingaTa Wu,
Academia Sinica
The life sciences are a major application area for the EGEE project and have been used to guide the impleaamentation of the infrastructure from the start. With more than 30 applications deployed and being ported, the doaamain had more than 200,000 jobs executed per month in 2007. • The medical imaging domain works on a number of related systems, many of them in the computeaintensive area of image coaregistration. This enables techniques such as ‘virtual biopsies’ for cancer diagnosis that avoid invasive surgical procedures.• The bioinformatics domain studies genes, proteins, and all components of living organisms. These include enabling system biology on grid, oncology study at the molecular level, genome wide association studies of huaaman complex diseases, binding of protein and DNA in the cell nucleus, complete genome comparison, as well as portals or web services that enable grid access for users in areas such as protein sequence or genome level analaaysis.• The drug discovery domain uses the EGEE grid inaafrastructure to accelerate the search for candidate drug molecules against neglected diseases. The WISDOM iniaatiative has been successfully deployed against diseases such as malaria and avian flu, testing many thousands of potential drugs in short periods of time.
Life SciencesEarth Sciences EGEE supports two related communities in the area of Earth Sciences: Research (ESR) and Geosciences (EGEODE).
The applications of the ESR domain cover various disciplines. The most numerous applications are in seismology with the reaanalysis of the whole GEOSCOPE data set, the determination of the earthquake characterisaatics a few hours after the data arrival and numerical simulations of wave propagation in complex 3D geological models. Several applications are based on atmospheric modelling like the longarange air pollution transport over Europe, the regional el Niño climate, and the ozone in polar regions. In hydrology, applications include flood forecasting and the calculation of sea water intrusion into coastal aquifers, both related to risk management. Other applications are related to geomorphology, meteorology, or planetolaaogy.
Geoscluster, an industrial seismic processing solution, is the first industrial application successfully running on the EGEE Grid production infrastrucaa
ture. Operated by the French company CGGVeritas through the EGEODE Virtual organisation, Geocluster enables researchers to process seismic data and to exaaplore the composition of the Earth’s layers.
The community currently includes 17 institutes, all contributing with applications ported to EGEE. The most relevant among them are Planck, MAGaaIC, SWIFT/MERCURY, and LOFAR. All of them share problems of computation involving largeascale data acquisition, simulation, data storage, and data retrieval that the grid helps to resolve. Planck and MAGIC have been in EGEE since 2004. The ESA Planck satellite, to be launched in 2008, will map the sky using microwaves, with an unprecedented combination of sky and frequency coverage, accuracy, stability and sensitivity. The MAGIC telescope, on the island of La Palma in the Canary Islands, is an imaging atmospheric Cherenkov telescope that has been in operation since late 2004.
Astro-Particle PhysicsEGEE Applications and their support
The Enabling Grids for E-sciencE (EGEE) project began by working with two scientific groups, High Energy Physics (HEP) and Life Sciences, and has since grown to support foraamally astronomy, astrophysics, computational chemistry, earth sciences, fusion, and compuaater science. The full user community runs applications from research domains as diverse as multimedia, finance, archaeology, and civil protection. Researchers in these areas collabo-arate through Virtual Organisations (VOs) that allow them to share computing resources, comaamon datasets, and expertise via the EGEE grid infrastructure. End users can join existing VOs or create new VOs tailored to their needs. Those with existing computing resources can also federate them with the EGEE grid infrastructure to facilitate load balancing with other users and groups.
To help the user community take advantage of the benefits of grid computing, EGEE pro-avides a range of support services to its users: direct user support, Virtual Organisation (VO) support, and application porting support. Through other activities, the project also provides beginner and expert training on various topics
Fusion Commercial exploitation of fusion energy still needs to solve several outstanding problems, some of which reaaquire a strong computing capacity. The International Thermo nuclear Experimental Reactor (ITER), a joint inaaternational research and development project, aims to demonstrate the scientific and technical feasibility of fu-asion power and could potentially produce 500 MW of power by 2016. The exploitation of ITER requires a modaaelling capability that is at the limit of the present state of the art. Therefore, computing grids and high performance computers are basic tools for fusion research.Presently several applications are already running on the EGEE grid, namely Massive Ray Tracing, Global Kinetic Transport and Stellarator optimisation, that have helped to open new avenues of research. A number of new apaaplications devoted to ITER simulation will be ported to the grid in close collaboration with EUFORIA project. Data management in large international experiments and the development of complex workflows are the activities that will complement grid computing.
High-Energy PhysicsThe HighaEnergy Physics (HEP) commuaanity is one of the pilot application domains in EGEE, and is the largest user of its grid infrastructure.
At present, the major users are the four experiments (ALICE, ATLAS, CMS and LHCb) of the Large Hadron Collider (LHC), which will begin with the first proton-proton collisions in autumn 2008 and achieve the design luminosity in 2010.
These four experiments are using grid reaasources for largeascale production work inaavolving more than 150,000 jobs/day on the EGEE infrastructure and in collaboration with its sister projects OSG in the USA and NDGF in the Nordic countries.
Other major HEP experiments, such as BaBar, CDF, DØ, H1 and ZEUS have also adopted grid technologies and use the EGEE infrastructure for routine physics data processing.
Artist’s rendition of the ESA Planck Satellite (Copyright ESA 2002aIllustration Medialab)
The MAGIC telescope, La Palma
For all enquiries, contact [email protected]
The Computational Chemistry and Gaussian virtual organizations were established to alaalow access to chemical software packages on the EGEE infrastructure. At present both freely available (GAMESS, COLUMBUS, DL_POLY, RWAVEP or ABCtraj) and commercial software packages, including Gaussian, Turbomole and Wien2K, are used by chemists to understand better molecular properties, to model chemical reactions or to design new materials. The availaaability of chemical software is also beneficial for other communities as a source of molecular data parameters for their simulations.
Computational Chemistry
Grid ObservatoryThe application part of EGEE includes the Grid Observatory. Its aim is to develop a scientific view of the dynamics of grid behaviour and usaaage. The Grid Observatory will make available traces of users and middleware activity on the grid for study by computer scientists, based on the existing extensive monitoring facilities. These data will excite researchers in both the grid and machine learning areas and improve the connection between the EGEE project and computer science, with a specific impact sought to the emerging field of autonomic computing. Modelling the dynamics of both the grid and the user community will contribute to a better underaastanding of the areas of dimensioning and caaapacity planning, to performance evaluation, and to the design of selfaregulation and maintenance functionalities such as realatime fault diagnosis. Eventually, the improved understanding of grid activity may improve the reliability, stability, and performance of the grid itself.
Getting InvolvedDetails of how to join EGEE can be found on the User & Application portal at http://egeena4.lal.in2p3.fr/
Members of business and industry are also encouraged to join the project. EGEE runs an Industry Forum, hosts special Industry Days and works with industrial applications through an Industry Task Force, as well as collaboration with the commercial sector in the framework of the EGEE Business Associate Programme.For more details see the “EGEE and Business” section on www.euaegee.org.
The Collider Detector at Fermilab (CDF)
Simulation of a protonaproton collision at LHC energies
A magnet section from the 27km long LHC ring
A Muon detector in the ATLAS cavern, CERN
EGEE partner GridPP also produces a 3D (left) and 2D (right) visualisation of the infrastructure. Both are available from http://gridportal.hep.ph.ic.ac.uk/rtm/.
29/0
5/20
08
EGEE Applications
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 14/18

Pesquisa atual em grades 1/3
Abaixo listamos alguns dos tópicos « quentes » empesquisa sobre grades :
1. Contabilidade e Economia de GradeComo controlar a utilização dos recursoscomputacionais pelos usuários ;garantir justiça no compartilhamento ;pagamento pela utilização de recursos ;mercado de compra e venda de recursos.
2. Grades autônomasMecanismos adaptativos para gerenciamento eQoS ;Mecanismos para auto-otimização, auto-proteção,configuração automática e tolerância a falhasautomática.Segurança de fácil administração(auto-gerenciamento).
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 15/18

Pesquisa atual em grades 2/3
3. Protocolos e algoritmos inteligentes parafederação de aglomerados e escalonamento global
O que fazer quando a visão global do sistema não épossível ?O uso único e informações locais podem levar aodesperdício.Como maximizar a utilização dos recursos nestecontexto?
4. Escalonamento em gradesBuscar soluções que forneçam melhoras para todosos participantes.Para isso são necessárias regras de conduta.Atualmente existem duas linhas principais : rede defavores e teoria de jogos.
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 16/18

Pesquisa atual em grades 3/3
3. Melhor aproveitamento das novas arquiteturas dehardware.
Arquiteturas multi-processadas são uma realidade.Placas gráficas (GPUs) tem enormes capacidades deprocessamento.Como aproveitar melhor estes novos recursos emgrades ?
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 17/18

Onde obter mais informações ?
1. www.integrade.org.br Nosso projeto :-)2. www.ourgrid.org Outra iniciativa de origem
nacional3. www.globus.org The Globus Alliance4. www.grid5000.fr Grid’50005. www.planet-lab.org PlanetLab6. www.eu-egee.org Enabling Grids for E-sciencE7. www.cs.wisc.edu/condor The Condor Project8. www.legion.virginia.edu Legion : A Worldwide
Virtual Computer9. www.teragrid.org TeraGrid10. www.opensciencegrid.org Open Science Grid11. boinc.berkeley.edu Open-source software forvolunteer computing and grid computing
Preliminares Grid 5000 PlanetLab EGEE Pesquisa atual em grades 18/18

What Is It? Business Architecture Research Challenges Bibliography
Cloud ComputingResearch Challenges Overview
Carlos Eduardo Moreira dos Santos
IME-USP, Brazil
May 3, 2010
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Table of Contents I
1 What Is It?Related Technologies
Grid ComputingVirtualizationUtility ComputingAutonomic Computing
Is It New?Definition
2 BusinessBusiness ModelElasticityCommercial Solutions
Amazon EC2Google AppEngineMicrosoft Windows Azure
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Table of Contents II
3 ArchitectureService Categories
4 Research ChallengesAutomated Service ProvisioningAutomated Service ProvisioningEnergy ManagementServer ConsolidationVirtual Machine MigrationTraffic analysisData SecuritySoftware FrameworksNovel Cloud Architecture
5 Bibliography
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
What Is Cloud Computing?
Some technologies are often compared to Cloud Computing and, infact, they share some characteristics.
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Related Technologies
Grid Computing
Both make distributed resources available to an application.
A Cloud uses virtualization to
share resources,provision resources dynamically.
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Related Technologies
Virtualization
Abstracts details of hardware
Provides virtualized resources
Foundation of Cloud Computing
Virtualized resources are (re)assigned to applicationson-demand
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Related Technologies
Utility Computing
Charges customers based on usage, like electricity.
Cloud providers can
maximize resource utilization
minimize operating costs
using
utility-based pricing
on-demand resource provisioning
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Related Technologies
Autonomic Computing
IBM, 2001
Self-managing systemsInternal and external observationsNo human interventionAims to reduce complexity
Cloud Computing
Automatic resource provisioningServer consolidationAims to lower cost
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Is It New?
Is It New?
Cloud Computing is not a new technology, but a new operationsmodel that combines existing technologies.
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Definition
Definition
Cloud computing is a model for enabling convenient, on-demandnetwork access to a shared pool of configurable computing resources(e.g., networks, servers, storage, applications, and services) that canbe rapidly provisioned and released with minimal management effortor service provider interaction. [NIST, 2009]
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Business
Illusion of infinite resources on demand
No up-front commitment
Ability to pay on a short-term basis
Lower
risks (hardware failure)maintainance costshardware expenses (fabless companies)
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing
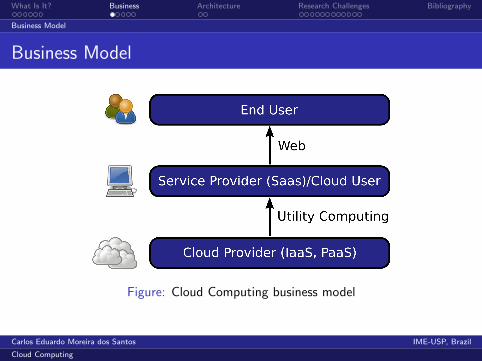
What Is It? Business Architecture Research Challenges Bibliography
Business Model
Business Model
Figure: Cloud Computing business model
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Elasticity
Elasticity
Datacenters utilization
average: 5% to 20%peak workload: 10% to 200%
Provisioning errors
Surges (Animoto - 50 to 3500 servers in 3 days)
DDoS example: 1 GB/s attack, 500 bots/EC2 instance
Attacker (week): 500, 000 bots × $0.03 = $15, 000Cloud (hour): $360 + $100 (32 hours)
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Commercial Solutions
Amazon EC2
Virtual Machines on top of Xen
Full control of software stack
Images can be used to launch other VMs
Conditions can trigger VM addition or removal
Multiple locations: US, Europe, Asia
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Commercial Solutions
Google AppEngine
Platform for traditional web applications
Supports python and java
Non-relational database
Scaling is automatic and transparent
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Commercial Solutions
Microsoft Windows Azure
Three components
1 Windows based environment (applications, data)2 SQL Azure based on SQL Server3 .NET Services for distributed infraestructure
Platform runs applications in the cloud or locally
Supports .NET, C#, VB, C++, etc
User must specify application needs to scale
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Service Categories
Service Categories
Infraestructure as a Service (IaaS)
On-demand resources, usually VMsAmazon EC2
Platform as a Service (PaaS)
Operating system supportSoftware development frameworksGoogle App Engine
Software as a Service (SaaS)
On-demand applications over the InternetSalesforce (CRM)
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing
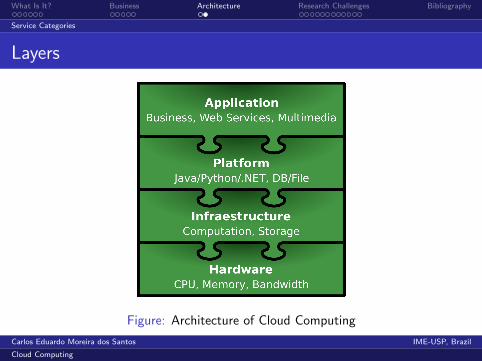
What Is It? Business Architecture Research Challenges Bibliography
Service Categories
Layers
Figure: Architecture of Cloud Computing
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing
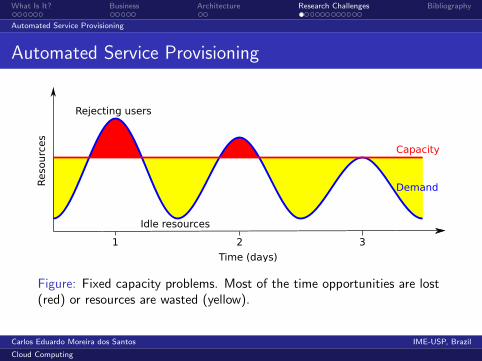
What Is It? Business Architecture Research Challenges Bibliography
Automated Service Provisioning
Automated Service Provisioning
Demand
Capacity
Rejecting users
Idle resources
Reso
urc
es
Time (days)
1 2 3
Figure: Fixed capacity problems. Most of the time opportunities are lost(red) or resources are wasted (yellow).
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Automated Service Provisioning
Automated Service Provisioning
Resource (de-)allocation to rapid demand flunctuations.
1 Predict number of instances to handle demand
Queuing theoryControl theoryStatistical Machine Learning
2 Predict future demand
3 Automatic resource allocation
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Energy Management
Energy Management
Problems:
Government regulations, environmental standards
53% of the cost is powering and cooling
Researches:
Energy-efficient hardware
Energy-aware job-scheduling
Server consolidation
Energy-efficient network protocols and infraestructures
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Energy Management
Figure: HP Performance-Optimized Dataceter (POD): 40 feet and acapacity of 3,520 nodes or 12,000 LFF hard drives.
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Energy Management
Figure: HP POD inside.
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing
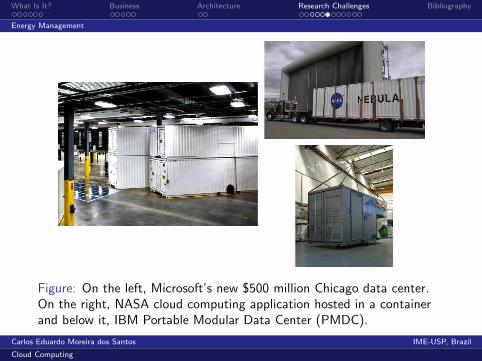
What Is It? Business Architecture Research Challenges Bibliography
Energy Management
Figure: On the left, Microsoft’s new $500 million Chicago data center.On the right, NASA cloud computing application hosted in a containerand below it, IBM Portable Modular Data Center (PMDC).
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Server Consolidation
Server Consolidation
Maximize servers in energy-saving state
VM dependencies (communication requirements)
Resource congestions
Variant of vector bin-packing problem (NP-hard)
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Virtual Machine Migration
Virtual Machine Migration
Xen and VMWare ”live” VM migration (<1 sec)
Detecting hotspots versus sudden workload changes
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Traffic analysis
Traffic analysis
Important for management and planning decisions
Much higher density of links
Most existing methods have problems here:
Compute only a few hundreds end hostsAssume flow patterns (MapReduce jobs)
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Data Security
Data Security
Confidentiality for secure data access and transfer
Cryptographic protocols
Auditability
Remote attestation (system state encrypted with TPM)With VM migration, it is not sufficientVirtualization platform must be trusted (SVMM)Hardware must be trusted using hardware TPMEfficient protocols are being designed
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Software Frameworks
Software Frameworks
Large-scale data-intensive applications usually leverage MapReduceframeworks.
Scalable
Fault-tolerant
Challenges:
Performance and resource usage depends on applicationBetter performance and cost can be achieved by:
Selecting configuration parameter valuesMitigating the bottleneck resourcesAdaptive scheduling in dynamic conditionsPerformance modeling of Hadoop jobs
Energy-aware:A node should sleep while waiting new jobsHDFS must be energy-aware, also
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Novel Cloud Architecture
Novel Cloud Architectures
Small data centers can be more advantageous
Less power (cooling)
Cheaper
Better geographically distributed (interactive gaming)
Using voluntary resources for cloud applications
Much cheaper
More suitable for non-profit applications
Must deal with heterogeneous resources
Machines can be turned on or off at any time
How to incentivate resource donations?
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

What Is It? Business Architecture Research Challenges Bibliography
Bibliography
Zhang, Q et al (2010)Cloud computing: state-of-the-art and research challengesJournal of Internet Services and Applications 1(1):7-18
Armbrust M et al (2009)Above the Clouds: A Berkeley View of Cloud ComputingUC Berkeley Technical Report
Mell, Peter and Grance, Tim (2009)The NIST Definition of Cloud Computing (v15)http://csrc.nist.gov/groups/SNS/cloud-computing/
Data Center Knowledgehttp://www.datacenterknowledge.com/archives/
category/technology/containers/
Carlos Eduardo Moreira dos Santos IME-USP, Brazil
Cloud Computing

TOOLS FOR CLOUD COMPUTING
Gustavo Ansaldi Oliva
Eucalyptus, OpenNebula and Tashi

Agenda
• Basic Concepts
• Eucalyptus
• OpenNebula
• Tashi
• Tools Comparison
• Extra: Amazon EC2 API
05/07/2010 2 Gustavo Ansaldi Oliva

Basic Concepts
• Virtualization – Hypervisor
• A.K.A Virtual Machine Monitor (VMM)
• Allows multiple operating systems to run concurrently on a host computer— a feature called hardware virtualization
• The hypervisor presents the guest OSs with a virtual platform and monitors the execution of the guest OSs
• Type 1/native/baremetal: Xen
• Type 2/hosted: VMWare Server, Sun VirtualBox
05/07/2010 3 Gustavo Ansaldi Oliva

Basic Concepts
• Virtualization – Hardware-assisted virtualization
• Processor instruction set extensions that provide hardware assistance to virtual machines
• These extensions address the parts of x86 that are difficult or inefficient to virtualize, providing additional support to the hypervisor.
• Enables simpler virtualization code and a higher performance for full virtualization.
• Intel VT-x, AMD-V
05/07/2010 4 Gustavo Ansaldi Oliva

Basic Concepts
• Virtualization
– KVM
• Kernel-based Virtual Machine
• Full virtualization solution for Linux on x86 hardware
• Requires processor with Intel VT or AMD-V
• KVM does not perform any emulation by itself.
• User-space program uses the /dev/kvm interface to set up the guest VM's address space, feeds it simulated I/O and maps its video display back onto the host's
• KVM uses QEMU for its device emulation
05/07/2010 5 Gustavo Ansaldi Oliva

Basic Concepts
• Clouds – Public/External Cloud
• Commercial cloud providers that offer a publicly-accessible remote interface to create and manage virtual machine instances within their proprietary infrastructure
– Private/Internal Cloud • Provides local users with a flexible and agile private
infrastructure to run service workloads within their administrative domain
– Hybrid Cloud • Supplements local infrastructure with computing capacity
from an external public cloud
05/07/2010 6 Gustavo Ansaldi Oliva

Eucalyptus
• Owner
– Eucalyptus Systems
• License
– GNU GPL v3
• Latest Version
– 1.6.2 (February, 2010)
05/07/2010 7 Gustavo Ansaldi Oliva

Eucalyptus
• Eucalyptus implements what is commonly referred to as Infrastructure as a Service (IaaS) – (Virtualization + Storage + Network) as a Service
• Eucalyptus is an open-source software infrastructure for the implementation of cloud computing on computer clusters which provides an interface that is compatible with the Amazon EC2 service
• Eucalyptus is not fault-tolerant – http://open.eucalyptus.com/forum/eucalyptus-specs-
scalability-fault-tolerance-and-slightl
05/07/2010 8 Gustavo Ansaldi Oliva

Eucalyptus
• Eucalyptus works with most of the currently available Linux distributions
• Eucalyptus can use a variety of Virtualization technologies including VMware, Xen and KVM
• Eucalyptus offers a community cloud (ECC) – Sandbox environment in which community
members can testdrive and experiment with Eucalyptus
05/07/2010 9 Gustavo Ansaldi Oliva

Eucalyptus
• Main features – Compatibility with Amazon Web Services API
– Installation and deployment from source or DEB and RPM packages.
– Secure communication between internal processes via SOAP and WS-Security
– Basic administration tools
– Able to configure multiple clusters as a single cloud
– Added support for elastic IP assignment
– Configurable scheduling policies and SLAs
05/07/2010 10 Gustavo Ansaldi Oliva

Eucalyptus
• Hybrid Cloud with Eucalyptus
05/07/2010 11 Gustavo Ansaldi Oliva

Eucalyptus API
• Eucalyptus uses Euca2ools • Euca2ools are command-line tools for interacting with
Web services that export a REST/Query-based API compatible with Amazon EC2 and S3 services.
• Euca2ools can be used with both Amazon's services and with installations of the Eucalyptus open-source cloud-computing infrastructure.
• Euca2ools were inspired by command-line tools distributed by Amazon (api-tools and ami-tools) and largely accept the same options and environment variables.
05/07/2010 12 Gustavo Ansaldi Oliva

Euca2ools
• Query of availability zones (i.e. clusters in Eucalyptus) • SSH key management (add, list, delete) • VM management (start, list, stop, reboot, get console
output) • Security group management • Volume and snapshot management (attach, list,
detach, create, bundle, delete) • Image management (bundle, upload, register, list,
deregister) • IP address management (allocate, associate, list,
release)
05/07/2010 13 Gustavo Ansaldi Oliva

Euca2ools
05/07/2010 14 Gustavo Ansaldi Oliva

Euca2ools
05/07/2010 15 Gustavo Ansaldi Oliva

Eucalyptus - UEC
• Core element of the Ubuntu Enterprise Cloud (UEC) cloud computing module
– Included in Ubuntu Server Edition
– Wizards to build private and public clouds
– http://www.ubuntu.com/cloud/why-ubuntu
05/07/2010 16 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
• All-in-one controller • One or more working nodes (run VM instances) • 1) Prerequisites
– Front end • Cloud controller (clc) • Cluster controller (cc) • Walrus (the S3-like storage service) • The storage controller (sc)
– One or more nodes • Node controller (nc)
• 2) Install the Cloud/Cluster/Storage/Walrus Front End Server
05/07/2010 17 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
05/07/2010 18 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
05/07/2010 19 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
05/07/2010 20 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
05/07/2010 21 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
05/07/2010 22 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
• 3) Install the Node Controller – Make sure that the node is connected to the network on
which the cloud/cluster controller is already running
– Boot from the same ISO on the node(s)
– Select “Install Ubuntu Enterprise Cloud”
– It should detect the Cluster and preselect “Node” install for you
– Confirm the partitioning scheme
– The rest of the installation should proceed uninterrupted; complete the installation and reboot the node
05/07/2010 23 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
• 4) Register the nodes – In Ubuntu 10.04 all registration is automatic with
the UEC CD Install • Public SSH keys have been exchanged properly
• The services are configured properly
• The services are publishing their existence
• The appropriate uec-component-listener is running
– Refer to the following link when doing a package install
• https://help.ubuntu.com/community/UEC/CDInstall
05/07/2010 24 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
• 5) Obtain credentials
– After installing and booting the Cloud Controller, users of the cloud will need to retrieve their credentials
– This can be done either through a web browser, or at the command line
• https://<cloud-controller-ip-address>:8443/
• Use username 'admin' and password 'admin' for the first time login
05/07/2010 25 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
• 6) Install an image from the store
– Image Store on the UEC web interface
05/07/2010 26 Gustavo Ansaldi Oliva

Setting Up Private Cloud in UEC
• 7) Run an Image
– There are multiple ways to instantiate an image in UEC:
• Use the command line
• Use one of the UEC compatible management tools such as Landscape
• Use the ElasticFox extension to Firefox
– More info on https://help.ubuntu.com/community/UEC/CDInstall
05/07/2010 27 Gustavo Ansaldi Oliva

OpenNebula
• Main Contributors
– DSA (Distributed Systems Architecture) Research at UCM (Universidad Complutense de Madrid)
– http://dsa-research.org/doku.php
• License
– Apache License v2 (2004)
• Latest Version
– 1.4 (December, 2009)
05/07/2010 28 Gustavo Ansaldi Oliva

OpenNebula
• OpenNebula is an open-source toolkit to easily build any type of cloud
• OpenNebula has been designed to be integrated with any networking and storage solution and so to fit into any existing data center. – Private cloud with Xen, KVM and VMWare – Hybrid cloud with Amazon EC2 and ElasticHosts – Public cloud supporting EC2 Query, OGF OCCI and
vCloud APIs
• Apache License v2 (2004)
20/05/2010 29 Gustavo Ansaldi Oliva

OpenNebula
20/05/2010 30 Gustavo Ansaldi Oliva

OpenNebula
• Focus on the Virtual Infrastructure Management
20/05/2010 31 Gustavo Ansaldi Oliva

OpenNebula – Fault Tolerance
• Fault tolerance is managed by a persistent back-end database (sqlite3), that stores the hosts and their VM information
• All virtual machine images are stored in a Image Repository accessible from the OpenNebula front-end
• When a VM start request is made, the VM is copied (cloned) to the cluster node which will then run the VM. When the image is closed, its copied back to the front-end
05/07/2010 32 Gustavo Ansaldi Oliva

OpenNebula – Fault Tolerance
• /srv/cloud/one hold the OpenNebula installation and the clones for the running VMs
• /srv/cloud/images will hold the master images and the repository • http://www.opennebula.org/documentation:rel1.4:plan#storage
05/07/2010 33 Gustavo Ansaldi Oliva

OpenNebula – EC2 Query API
• Implements a subset of the EC2 Query interface, enabling the creation of public clouds managed by OpenNebula – upload image: Uploads an image to the repository manager
– register image: Registers an image (previously uploaded in the repository manager) in order to be launched
– describe images: Lists all registered images belonging to one particular user.
– run instances: Runs an instance of a particular image (that needs to be referenced)
– terminate instances: Shutdown a virtual machine(or cancel, depending on its state)
05/07/2010 34 Gustavo Ansaldi Oliva

OpenNebula – EC2 Query API
• Starting with a working installation of an OS residing on an .img file, with three steps a user can launch it in the cloud
• 1) Upload image to the cloud image repository
• 2) Register the image to be used in the cloud
• 3) Launch the registered image to be run in the cloud
05/07/2010 35 Gustavo Ansaldi Oliva

OpenNebula – EC2 Query API
• Additionally, the instance can be monitored with:
05/07/2010 36 Gustavo Ansaldi Oliva

OpenNebula – OCCI API
• The OpenNebula OCCI API is a RESTful service to create, control and monitor cloud resources based on the latest draftof the OGF OCCI API specification
• OCCI stands for “Open Cloud Computing Interface”
• Resources are: Storage, Network, Compute
05/07/2010 37 Gustavo Ansaldi Oliva

OpenNebula – OCCI API
• Storage: – Upload: using a multi-part HTTP POST. – Retrieve: using a HTTP GET.
• Network: – Upload: using a HTTP POST. – Retrieve: using a HTTP GET.
• Compute: – Upload: using a HTTP POST. – Update: using a HTTP PUT. – Retrieve: using a HTTP GET.
05/07/2010 38 Gustavo Ansaldi Oliva

OpenNebula – OCCI API
• Upload an image
• $ ./occi-storage --url http://localhost:4567 --username oneadmin --password opennebula create imagexml <DISK><ID>ab5c9770-7ade-012c-f1d5-00254bd6f386</ID><NAME>GentooImage</NAME><SIZE>1000</SIZE><URL>file://images/gentoo.img<URL></DISK>
05/07/2010 39 Gustavo Ansaldi Oliva

OpenNebula – OCCI API
• Create a network resource
• $ ./occi-network --url http://localhost:4567 --username oneadmin --password opennebula create vnxml <NIC><ID>23</ID><NAME>MyServiceNetwork</NAME><ADDRESS>192.168.1.1</ADDRESS><SIZE>200</SIZE></NIC>
05/07/2010 40 Gustavo Ansaldi Oliva

OpenNebula – OCCI API
• Create a compute resource (VM)
05/07/2010 41 Gustavo Ansaldi Oliva

OpenNebula – OCCI API
• $ ./occi-compute --url http://localhost:4567 --username tinova --password opennebula create ~/vmxml <COMPUTE><ID>17</ID><NAME>MyCompute</NAME><STATE>PENDING</STATE><STORAGE><DISK image="ab5c9770-7ade-012c-f1d5-00254bd6f386" dev="sda1"/><FS size="512" format="ext3" dev="sda3"/><SWAP size="1024" dev="sda2"/></STORAGE><NETWORK><NIC network="23" ip="192.168.0.9"/><NIC network="23" ip="192.168.1.1"/></NETWORK></COMPUTE>
05/07/2010 42 Gustavo Ansaldi Oliva

Setting Up Private Cloud with OpenNebula and Ubuntu
• Six steps
– 1) Front-end installation
– 2) Add the cluster nodes to the system
– 3) Configure ssh access
– 4) Install the nodes Done on working nodes
– 5) Setting authorization Done on working nodes
– 6) Prepare Virtual Network and Launch VMs
• Please refer to https://help.ubuntu.com/community/OpenNebula
20/05/2010 43 Gustavo Ansaldi Oliva

Tashi
• Key Contributors
– Intel Labs Pittsburgh
– Carnegie Mellon University
• License
– Apache License v2 (2004)
• Latest Version
– No formal release (code must be checked out from SVN)
05/07/2010 44 Gustavo Ansaldi Oliva

Tashi
• An infrastructure through which service providers are able to build applications that harness cluster computing resources to efficiently access repositories of “Big Data”
– Cluster management system for cloud computing on big data
• Project incubated at Apache
– Non-trivial installation and setup
05/07/2010 45 Gustavo Ansaldi Oliva

Tashi
• Tashi is primarily a system for managing Virtual Machines (VMs) – Request the creation, destruction, and manipulation of
VMs (Xen, KVM/QEMU)
• Tashi also has a web client interface that is compatible with a subset of Amazon Web Services
• Boot 100 copies of an operating system in 2 minutes
• Tashi is a key software component that enables the Big Data cluster to participate in the HP OpenCirrus cluster testbed as a Center of Excellence
05/07/2010 46 Gustavo Ansaldi Oliva

Tashi
• Main features – Provide high-performance execution over Big Data
repositories Enable multiple services to access a repository
concurrently – Enable low-latency scaling of services – Enable each service to leverage its own software
stack • Virtualization, file-system protections
– Enable slow resource scaling for growth – Enable rapid resource scaling for power/demand
• Scaling-aware storage
05/07/2010 47 Gustavo Ansaldi Oliva

Tashi – Example Applications
05/07/2010 48 Gustavo Ansaldi Oliva
Application Big Data Algorithms Compute Style
Video search Video data Object/gesture
identification, face
recognition, …
MapReduce
Internet library
search
Historic web
snapshots
Data mining MapReduce
Virtual world
analysis
Virtual world
database
Data mining To be defined
Earth study Ground model Earthquake
simulation, thermal
conduction, …
HPC (high
performance
computing)
Language
translation
Text corpuses,
audio archives,…
Speech recognition,
machine translation,
text-to-speech, …
MapReduce &
HPC

Tashi – Organization
• Each cluster contains one Tashi Cluster Manager (CM) • The CM maintains a database of:
– Available physical resources (nodes) – Active virtual machines – Pending requests for virtual machines – Virtual networks
• Users submit requests to the CM through a Tashi Client • The Tashi Scheduler uses the CM databases to invoke
actions, such as VM creation, through the CM • Each node contains a Node Manager that carries out
actions, such as invoking the local Virtual Machine Manager (VMM), to create a new VM, and monitoring the performance of VMs
05/07/2010 49 Gustavo Ansaldi Oliva

Tashi – Native API
• Users invoke Tashi actions through a Tashi client
• VM Life-cycle – createVm [--userId <value>] --name <value>
[--cores <value>] [--memory <value>] --disks <value> [--nics <value>] [--hints <value>]
– destroyVm --instance <value>
– shutdownVm --instance <value>
05/07/2010 50 Gustavo Ansaldi Oliva

Tashi – Native API
• VM Management Calls – suspendVm --instance <value>
– resumeVm --instance <value>
– pauseVm --instance <value>
– unpauseVm --instance <value>
– migrateVm --instance <value> --targetHostId <value>
– vmmSpecificCall --instance <value> --arg <value>
05/07/2010 51 Gustavo Ansaldi Oliva

Tashi – Native API
• “Bookkeeping” Calls
– getMyInstances
– getInstances
– getVmLayout
– getUsers
– getNetworks
– getHosts
05/07/2010 52 Gustavo Ansaldi Oliva
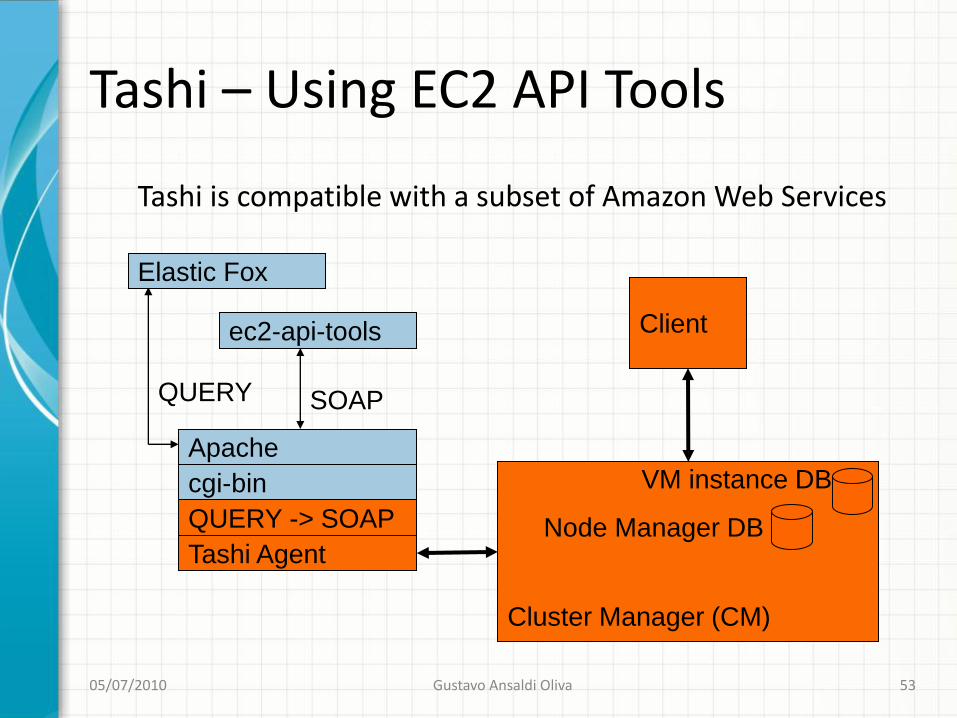
Tashi – Using EC2 API Tools
05/07/2010 53 Gustavo Ansaldi Oliva
Apache
cgi-bin
QUERY -> SOAP
Tashi Agent
QUERY SOAP
ec2-api-tools
Cluster Manager (CM)
Client
Node Manager DB
VM instance DB
Elastic Fox
Tashi is compatible with a subset of Amazon Web Services

Tashi
• More information
– Presentation: www.pittsburgh.intel-research.net/~rgass/projects/sc09/SC09-Tashi-CR.ppt
• Includes architecture diagrams of Tashi
– Tashi on a single test machine
• http://incubator.apache.org/tashi/documentation-single.html
05/07/2010 54 Gustavo Ansaldi Oliva

Tools Comparison
• Report done by Universiteit van Amsterdam
• Compares Cloud Computing Solutions and offers guidance according to specific scenarios
• http://staff.science.uva.nl/~delaat/sne-2009-2010/p31/report.pdf
05/07/2010 55 Gustavo Ansaldi Oliva

Eucalyptus vs OpenNebula
20/05/2010 56 Gustavo Ansaldi Oliva

Extra: Amazon EC2 API
• http://docs.amazonwebservices.com/AWSEC2/latest/APIReference/
– API Reference guide with usage examples
• EC2 Query API
• EC2 SOAP API
05/07/2010 57 Gustavo Ansaldi Oliva

Amazon EC2 API – Query API
05/07/2010 58 Gustavo Ansaldi Oliva

Amazon EC2 API – SOAP API
05/07/2010 59 Gustavo Ansaldi Oliva

References
• Eucalyptus – http://open.eucalyptus.com/
• Eucalyptus and Fault-Tolerance – http://open.eucalyptus.com/forum/eucalyptus-specs-
scalability-fault-tolerance-and-slightl
• Euca2ools User Guide – http://open.eucalyptus.com/wiki/Euca2oolsGuide_v1.1
• Euca2ools Blog Entry – http://blogs.plexibus.com/2010/06/17/eucalyptus-euca2ools/
• Ubuntu Enterprise Cloud – http://www.ubuntu.com/cloud/why-ubuntu
05/07/2010 60 Gustavo Ansaldi Oliva

References
• OpenNebula – http://www.opennebula.org/ – http://dsa-research.org/doku.php
• OpenNebula and Fault-Tolerance – http://www.opennebula.org/documentation:rel1.4:plan#storage
• Private Cloud with OpenNebula and Ubuntu – https://help.ubuntu.com/community/OpenNebula
• An Open Source Solution for Virtual Infrastructure Management in Private and Hybrid Clouds – IEEE Special Issue on Cloud Computing – http://www.mcs.anl.gov/uploads/cels/papers/P1649.pdf
• OGF OCCI Implementation on OpenNebula – http://62.149.240.97/uploads/Tutorials/ogf_occi_implementation_o
n_opennebula.pdf
05/07/2010 61 Gustavo Ansaldi Oliva

References
• Tashi – http://incubator.apache.org/tashi/index.html – http://www.pittsburgh.intel-
research.net/projects/tashi/
• Tashi Presentation by Michael Ryan (Intel) – www.pittsburgh.intel-
research.net/~rgass/projects/sc09/SC09-Tashi-CR.ppt
• SURFnet Cloud Computing Solutions – http://staff.science.uva.nl/~delaat/sne-2009-
2010/p31/report.pdf
05/07/2010 62 Gustavo Ansaldi Oliva

References
• Amazon EC2 API Reference – http://docs.amazonwebservices.com/AWSEC2/la
test/APIReference/
• Amazon EC2 API Tools – http://developer.amazonwebservices.com/conne
ct/entry.jspa?externalID=351&categoryID=88
• Elasticfox Firefox Extension for Amazon EC2 – http://developer.amazonwebservices.com/conne
ct/entry.jspa?externalID=609&categoryID=88
05/07/2010 63 Gustavo Ansaldi Oliva

That’s all
Questions?
05/07/2010 64 Gustavo Ansaldi Oliva