livro criptografiaemhwesw isbn85 7522 069-1-121124093411 phpapp01
TRANSCRIPT



3
Dedicatória
Agradeço à minha familia pelo apoio, incentivo e compreensão nos momentos de ausência e, em especial, por terem sempre paciência e muito amor. À minha familia da Colômbia por seu eterno amor.
Edward
Dedico este livro à minha esposa Ednéia, e ao meu filho, Pedro Luís, que iluminam o meu caminho. Aos meus pais que sempre me apoiaram, e aos meus amigos, que sempre me incentivaram em todos os sentidos.
Fábio
Ofereço este livro aos meus pais Alcides e Marta, e à minha irmã Josiane, que sempre estiveram ao meu lado, apoiando-me e incentivando. Aos meus familiares pela compreensão e atenção em todos os momentos.
Rodolfo

4
Agradecimentos
A DEUS pois, sem Ele, não estaríamos aqui e não fariamos nada daquilo que fazemos.
À Mantenedora do UNIVEM, Fundação de Ensino Eurípides Soares da Rocha, pelo comprometimento com a educação de ensino superior, formando profissionais com excelência acadêmica e responsabilidade social, e principalmente, por oferecer condições acadêmicas integradas à realização de pesquisas, pois entendem que é um dos caminhos para se alcançar excelência acadêmica, universitária e profissional.
Aos amigos e colegas do UNIVEM (Centro Universitário Eurípides de Marília, S.P.) que trabalham no LAS – Laboratório de Arquitetura e Sistemas Computacionais. Em especial a Cesar Giacomini Penteado e Rodrigo de Almeida Pericini que dividiram momentos de dificuldade e sucesso nos projetos e na vida.
Aos amigos Paulo Henrique Trecenti, Luis Fernando Ruivo Gatti, Eduardo Elias Laíno de Oliveira, Thiago Albuquerque Pinto; cujos trabalhos de Conclusão de curso apresentado no curso de Bacharelado em Ciência da Computação do UNIVEM auxiliaram e, muito, a realização deste livro.
Aos profissionais da área de computação e informática: Emiliano da Silva Alves, Vivian Patricia Mascarin e Everson Luiz Vilela Tescaro, que fizeram a sua especialização em engenharia de software, nos cursos lato-sensu do UNIVEM.
Aos alunos do Mestrado em Ciência da Computação e alunos da especialização em redes de computadores e segurança da informação do UNIVEM.
A todas as outras pessoas que, mesmo não citadas aqui, deram muito apoio e incentivo, que, sem os quais, esse livro não chegaria à sua conclusão.

5
Sobre os autores
Edward David Moreno é professor Doutor no UNIVEM (Centro Universitário Eurípides de Marília), e atua tanto no programa de mestrado stricto-sensu em ciência da computação quanto no curso de BCC (Bacharelado em Ciência da Computação). Também é Professor credenciado no programa de Pós-graduação da Universidade de São Paulo (USP, São Paulo) e membro do grupo HPCAC (High Performance Computer Architecture and Communications) da POLI-USP.
O Prof. Moreno finalizou seu Pós-Doutorado na UFSCar (Universidade Federal de São Carlos), São Carlos/SP, 2000 na área de Aplicações em Computação de Alto Desempenho, o seu Doutorado em Eng. Elétrica/POLI-USP, 1998 na área de Computação de Alto Desempenho e Arquiteturas Avançadas de Computador e o seu Mestrado em Eng. Elétrica/POLI-USP, 1994 na área de Arquitetura de Computadores. Finalmente, a Graduação foi em Eng. Elétrica/Universidad del Valle, Cali,Colômbia,1991, com o projeto de Microcontroladores em Gate Arrays CMOS. No ano de 1999, fez uma especialização em Gestão de Projetos, na PUC-Paraná.
As áreas de interesse do Prof. Moreno são: Arquitetura de Computadores, Computação de Alto Desempenho, Avaliação de Desempenho, Computação Reconfigurável e Prototipação de Sistemas Digitais.
O Prof. Moreno tem escrito e publicado, como autor principal e co-autor, aproximadamente 100 artigos em eventos nacionais e internacionais. Experiência internacional trabalhando como pesquisador convidado em projetos tais como “NUMAchine Multiprocessor” desenvolvido na universidade de Toronto, Canadá, e no projeto “Large Databases for Multiprocessors” desenvolvido em Chalmers University of Technology, Gotebörg, Suécia. Ele participa ativamente na comunidade internacional, tendo já colaborado como membro de comitê de programa em aproximadamente 50 eventos de renome internacional.
Fábio Dacêncio Pereira é bacharel e Mestre em Ciência da Computação pelo UNIVEM (Centro Universitário Eurípides de Marília). O projeto do mestrado foi na área de processadores para Segurança. Foi monitor do Laboratório de Arquitetura e Sistemas Computacionais (LAS) e Bolsista de IC da FAPESP (Fundação de Amparo à Pesquisa do Estado de São Paulo), no período de Agosto 2000 a Dezembro 2002, e bolsista CAPES no ano de 2004. Atualmente professor do UNIVEM. As áreas de interesse são: Circuitos e Sistemas Digitais em FPGAs, Avaliacao de Desempenho e Projeto de Processadores em FPGAs. Tem publicado alguns trabalhos em eventos nacionais e internacionais na área com ênfase no livro recente: Projeto, Implementação e Desempenho de Sistemas Digitais em FPGAs.

6
Rodolfo Barros Chiaramonte é bacharel em Ciência da Computação pelo UNIVEM. Atualmente mestrando na mesma instituição, no projeto “Sistemas Inteligentes de Segurança”, com bolsa da CAPES. O Rodolfo foi monitor do Laboratório de Realidade Virtual (LRV) do UNIVEM e Bolsista de Iniciação Científica, durante 3 anos, da FAPESP (Fundação de Amparo à Pesquisa do Estado de São Paulo), no período de Março 2001 a Dezembro 2003. As áreas de interesse são: Segurança de dados, Algoritmos de Criptografia, Circuitos e Sistemas Digitais em FPGAs, Avaliação de Desempenho. Tem publicado alguns trabalhos em eventos nacionais na área de criptografia e segurança da informação. Além disso, tem participado em algumas palestras e workshops sobre os assuntos acima mencionados.

7
Prefácio
Objetivos:
• Apresentar os principais algoritmos de criptografia utilizados na área de segurança e respectiva implementação em software (linguagem C e Java) e hardware (VHDL e FPGAs);
• Explicar alguns códigos em C, enfatizando nas similaridades e diferenças de se programar usando linguagem C e VHDL (amplamente usada em projetos de hardware);
• Comparar o desempenho desses algoritmos, tanto na implementação em software quanto em hardware. A análise comparativa é realizada através de parâmetros tais como: desempenho (velocidade, utilização de memória, impacto provocado pelo tamanho das chaves, etc.), nível de segurança, flexibilidade e facilidade de implementação e utilização;
• Mostrar a importância da criptografia implementada em hardware (usando-se de circuitos programáveis tais como FPGAs e equipamentos modernos tais como HSM e Smart Cards);
• Facilitar o aprendizado de segurança da informação usando-se de algoritmos de criptografia e a existência de algumas bibliotecas tais como CryptoAPI, JCA, OpenSSL e JCA;
• Motivar o aprendizado de projeto de sistemas digitais próprios da área de segurança de dados, usando-se de técnicas de prototipação rápida de sistemas de segurança em hardware.
Dessa maneira, o livro oferece ao leitor uma ferramenta de aprendizagem sobre os diferentes algoritmos de criptografia atualmente utilizados, enfatizando em aspectos de desempenho, a qual está amplamente relacionada com a forma de implementação. O livro ensina os aspectos teóricos, relacionando-os com a parte prática (implementação e utilização), e pode ser lido tanto por iniciantes quanto por profissionais e acadêmicos que queiram se aprofundar mais no assunto.
Resumo:
O texto está composto de 17 capítulos, organizados em quatro partes:
Parte I: Conceitos Básicos de Segurança, Software e Hardware
Parte II: Algoritmos Clássicos de Criptografia

8
Parte III: Algoritmos Modernos de Criptografia
Parte IV: Ferramentas e Dispositivos Modernos de Segurança
Em termos gerais, a proposta do livro apresenta de maneira clara os principais algoritmos de criptografia (tanto simétricos e assimétricos), explicando de maneira simples o respectivo funcionamento, sem necessidade de aprofundamentos nos conceitos matemáticos.
O livro destaca a implementação de alguns algoritmos de criptografia utilizando principalmente a linguagem C, assim como, a liguagem JAVA e VHDL, enfatizando a analise de desempenho de cada algoritmo, permitindo que o leitor saiba quando um algoritmo é melhor do que outro e porque. Isto é, apresenta, pela primeira vez, detalhes de performance (desempenho) desses algoritmos. Além de apresentar os níveis de segurança e aplicações, apresenta-se a velocidade com que cada algoritmo pode executar para diferentes tipos de arquivos de diferentes aplicações.
Mais uma grande diferença, é a apresentação das potencialidades oferecidas por implementações em hardware desses algoritmos. Assim, ele apresenta uma nova técnica de projetar sistemas digitais em uma tecnologia moderna chamada de circuitos programáveis (FPGAs). Para isso se mostram os conceitos da linguagem própria para hardware (VHDL) e como se projetam esses circuitos específicos de criptografia a partir das respectivas implementações em software (a maioria em linguagem C e alguns outros algoritmos em Java). Finalmente, se faz uma comparação entre as respectivas implementações em Software e Hardware.
Finalmente, no último capítulo, o décimo sétimo (17) se oferecem informações de uma ferramenta, chamada pelos autores de WEBCRY, e se disponibiliza um site na Internet com algumas informações públicas para que os leitores se atualizem a respeito dos algoritmos discutidos no livro, assim como a possibilidade de acessar alguns códigos e exemplos fornecidos no livro e a utilização da ferramenta WEBCRY criada pelos autores. Dessa maneira, os leitores e usuários podem exercitar a parte prática do livro e vivenciar por si mesmos os conhecimentos, experiências, resultados e os efeitos de desempenho desses algoritmos.
Público alvo:
Estudantes e Professores da área da Computação e Informática (tais como Ciência da Computação, Sistemas de Informação, Engenharia da Computação, Engenharia Elétrica, Engenharia Eletrônica), interessados em adquirir e aprofundar os conhecimentos na área de segurança, do ponto de vista de algoritmos, sistemas digitais e desempenho.
Profissionais que estejam realizando pós graduação lato sensu ou stricto sensu, nas áreas de segurança de dados e da informação.

9
Engenheiros e profissionais atuando na área de segurança de dados e da tecnologia da informação, com interesse em programação, no projeto de circuitos e sistemas digitais, e principalmente, no desempenho de sistemas de segurança.
Informações adicionais, tais como códigos da maioria dos algoritmos apresentados no livro podem ser acessados no link http://www.novateceditora.com.br/downloads.php, assim como detalhes da ferramenta WEBCRY.

10
Parte I Conceitos Básicos de Criptografia, Software e Hardware
A primeira parte divide-se em cinco capítulos, e é é feita uma introdução sobre o que será abordado no livro, como ele está estruturado e como pode ser lido. Este capítulo apresenta o assunto e motiva a necessidade do estudo de VHDL e a possível inserção de FPGAs como alternativa de projeto de circuitos e sistemas digitais, enfatiza principalmente os aspectos de implementação e desempenho de algoritmos de criptografia tanto em software quanto em hardware. Apresenta um algoritmo de criptografia, criado pelos autores e denominado de ALPOS, o qual visa, fundamentalmente, mostrar aos leitores com pouca experiência na área, como é possível criar soluções criptográficas. Esse algoritmo não é muito seguro, mas é uma versão didática que facilita o entendimento de vários conceitos relacionados à segurnaça de dados.

11
Capítulo 1 Conceitos de Segurança de Dados e Criptografia
Neste primeiro capítulo, Conceitos de Segurança de Dados e Criptografia, se apresenta e enfatiza a necessidade da segurança de dados nos tempos modernos, focalizando principalmente o papel dos algoritmos de criptografia e as vantagens de se ter conhecimento dos conceitos, implementação e, principalmente, do seu desempenho.
1.1 A Criptografia A criptografia pode ser entendida como um conjunto de métodos e técnicas para cifrar ou codificar informações legíveis através de um algoritmo, convertendo um texto original em um texto ilegível, sendo possível através do processo inverso recuperar as informações originais (SIMON, 1999), ver processo na figura 1.1.
Figura 1.1 – Esquema geral para cifragem de um texto.
Pode-se criptografar informações basicamente através de códigos ou de cifras. Os códigos protegem as informações trocando partes da informação por códigos predefinidos. Sendo que todas as pessoas autorizadas a ter acesso à uma determinada informação devem conhecer os códigos utilizados.
As cifras são técnicas nas quais a informação é cifrada através da transposição e/ou substituição das letras da mensagem original. Assim, as pessoas autorizadas podem ter acesso às informações originais conhecendo o processo de cifragem. As cifras incluem o conceito de chaves, que será apresentado em outra seção.
Os principais tipos de cifra são: as cifras de transposição que é a mistura dos caracteres da informação original. Por exemplo, pode-se cifrar a palavra "CRIPTOGRAFIA" e escrevê-la "RPORFACITGAI"; e as cifras de substituição que através de uma tabela de substituição predefinida é possível trocar ou substituir um caractere ou caracteres de uma informação.

12
1.1.1 Uma Breve História da Criptografia A criptografia é tão antiga quanto a própria escrita, já estava presente no sistema de escrita hieroglífica dos egípcios. Os romanos utilizavam códigos secretos para comunicar planos de batalha. Com as guerras mundiais e a invenção do computador, a criptografia cresceu incorporando complexos algoritmos matemáticos.
A criptologia faz parte da história humana porque sempre houve fórmulas secretas e informações confidenciais que não deveriam cair no domínio público ou na mão de inimigos.
Segundo Kahn (1967), o primeiro exemplo documentado da escrita cifrada aconteceu aproximadamente no ano de 1900 a.C, quando o escriba de Khnumhotep II teve a idéia de substituir algumas palavras ou trechos de texto. Caso o documento fosse roubado, o ladrão não encontraria o caminho que o levaria ao tesouro e morreria de fome perdido nas catacumbas da pirâmide.
Em 50 a.C, Júlio César usou sua famosa cifra de substituição para cifrar (criptografar) comunicações governamentais. Para compor seu texto cifrado, César alterou letras desviando-as em três posições; A se tornava D, B se tornava E, e etc. Às vezes, César reforçava seu método de criptografar mensagens substituindo letras latinas por gregas. O código de César é o único da antigüidade que é usado até hoje. Atualmente qualquer cifra baseada na substituição cíclica do alfabeto denomina-se de código de César. Apesar da sua simplicidade (ou exatamente devido a ela), esta cifra foi utilizada pelos oficiais sulistas na Guerra de Secessão americana e pelo exército russo em 1915.
Em 1901, iniciou-se a era da comunicação sem fio. Apesar da vantagem de uma comunicação de longa distância sem o uso de fios ou cabos, o sistema é aberto e aumenta o desafio da criptologia. Em 1921, Edward Hugh Hebern funda a Hebern Electric Code, uma empresa produtora de máquinas de cifragem eletro-mecânicas baseadas em rotores que giram a cada caracter cifrado (TKOTZ, 2003).
Entre 1933 e 1945, a máquina Enigma que havia sido criada por Arthur Scherbius foi aperfeiçoada até se transformar na ferramenta criptográfica mais importante da Alemanha nazista. O sistema foi quebrado pelo matemático polonês Marian Rejewski que se baseou apenas em textos cifrados interceptados e numa lista de chaves obtidas através de um espião (KAHN, 1967).
A seguir, outros acontecimentos relacionados à utilização da criptografia (TKOTZ, 2003):
1943 - Máquina Colossus projetada para quebrar códigos.
1969 - James Ellis desenvolve um sistema de chaves públicas e chaves privadas separadas.
1976 – Diffie-Hellman é um algoritmo baseado no problema do logaritmo discreto, é o criptosistema de chave pública mais antigo ainda em uso.

13
1976 - A IBM apresenta a cifra Lucifer ao NBS (National Bureau of Standards) o qual, após avaliar o algoritmo com a ajuda da NSA (National Security Agency), introduz algumas modificações (como as Caixas S e uma chave menor) e adota a cifra como padrão de criptografia de dados nos EUA (FIPS46-3, 1999), conhecido hoje como DES (Data Encryption Standard). Hoje o NBS é chamado de National Institute of Standards and Technology, NIST.
1977 - Ronald L. Rivest, Adi Shamir e Leonard M. Adleman começaram a discutir como criar um sistema de chave pública prático. Ron Rivest acabou tendo uma grande idéia e a submeteu à apreciação dos amigos: era uma cifra de chave pública, tanto para confidencialidade quanto para assinaturas digitais, baseada na dificuldade da fatoração de números primos grandes. Foi batizada de RSA, de acordo com as primeiras letras dos sobrenomes dos autores (TKOTZ, 2003).
1978 - O algoritmo RSA é publicado na ACM (Association for Computing Machinery), um dos melhores meios de divulgação de pesquisas científicas. Maiores detalhes desta organização podem ser obtidos no link www.acm.org.
1990- Xuejia Lai e James Massey publicam na Suiça "A Proposal for a New Block Encryption Standard" ("Uma Proposta para um Novo Padrão de Encriptação de Bloco")(LAI, 1990), o assim chamado IDEA (International Data Encryption Algorithm), para substituir o DES. O algoritmo IDEA utiliza uma chave de 128 bits e emprega operações adequadas para computadores de uso geral, tornando as implementações em software mais eficientes (SCHNEIER, 1996).
1991- Phil Zimmermann torna pública sua primeira versão de PGP (Pretty Good Privacy) como resposta ao FBI, o qual invoca o direito de acessar qualquer texto claro da comunicações entre usuários que se comunicam através de uma rede comunicação digital. O PGP oferece uma segurança alta para o cidadão comum e, como tal, pode ser encarado como um concorrente de produtos comerciais como o Mailsafe da RSADSI. Entretanto, o PGP é especialmente notável porque foi disponibilizado como freeware e, como resultado, tornou-se um padrão mundial enquanto que seus concorrentes da época continuaram absolutamente desconhecidos (BROWN, 2000).
1994- Novamente o professor Ronald L. Rivest, autor dos algoritmos RC2 e RC4 incluídos na biblioteca de criptografia BSAFE do RSADSI, publica a proposta do algoritmo RC5 na Internet. Este algoritmo usa rotação dependente de dados como sua operação não linear e é parametrizado de modo que o usuário possa variar o tamanho do bloco, o número de estágios e o comprimento da chave.
1994- O algoritmo Blowfish, uma cifra de bloco de 64 bits com uma chave de até 448 bits de comprimento, é projetado por Bruce Schneier (SCHNEIER, 1993).
1997- O PGP 5.0 Freeware é amplamente distribuído para uso não comercial.
1997- O código DES de 56 bits é quebrado por uma rede de 14.000 computadores (CURTIN, 1998).

14
1998 - O código DES é quebrado em 56 horas por pesquisadores do Vale do Silício (DESKEY, 2001).
1999 - O DES é quebrado em apenas 22 horas e 15 minutos, através da união da Electronic Frontier Foundation e a Distributed.Net, que reuniram em torno de 100.000 computadores pessoais ao DES Cracker pela Internet (MESERVE, 1999).
2000 - O NIST (National Institute of Standards and Technology) anunciou um novo padrão de uma chave secreta de cifragem, escolhido entre 15 candidatos. Este novo padrão foi criado para substituir o algoritmo DES, cujo tamanho das chaves tornou-se insuficientes para conter ataques de força bruta (MESERVE, 1999). O algoritmo Rijndael cujo o nome é uma abreviação dos nomes dos autores Rijmen e Daemen - foi escolhido para se tornar o futuro AES (Advanced Encryption Standard) (FIPS197, 2001).
2000 – 2004 – Muitos professores e profissionais da computação com vínculo em centros de pesquisa, universidades e empresas motivam-se e começam a pesquisar novas formas de implementar algoritmos e soluções de segurança. Surge assim, uma “onda” de pesquisas e desenvolvimentos voltados a realizar otimizações dessas primeiras implementações e uma dessas tendências é a implementação em hardware. Assim, este livro, mostra a importância de se implementar alguns desses algoritmos criptográficos em hardware, em especial, através do uso da tecnologia de circuitos programáveis (FPGAs), a qual é acessível e diminui de forma significativa os tempos e custos associados à realização de projetos e protótipos.
Os computadores são a expressão maior da era digital, marcando presença em praticamente todas as atividades humanas. Da mesma forma com que revolucionaram a informação, também influenciaram na criptologia: por um lado ampliaram seus horizontes, por outro, tornaram a criptologia quase que indispensável. Na próxima seção apresenta-se a importância da criptografia.
1.1.2 A Importância da Criptografia Nesta seção é discutida a importância da criptografia, a segurança dos sistemas operacionais e porque se deve utilizar este recurso contra intrusos que desejam acessar informações alheias.
A segurança eletrônica nunca foi tão amplamente discutida: casos de violação de contas bancárias, acesso a informações sigilosas, invasão e destruição de sistemas são cada vez mais comuns. Informações são transmitidas com mais eficiência e velocidade, mas como se sabe, nem sempre de forma segura.
A privacidade é importante para pessoas e para as empresas. Muitos problemas podem acontecer se uma pessoa não autorizada tiver acesso a dados pessoais como: contracheque, saldo bancário, faturas do cartão de crédito, diagnósticos de saúde e senhas bancárias ou de credito automático. No caso de empresas, os danos podem ser de maior magnitude, atingindo a organização e os próprios funcionários. Dados estratégicos da empresa, previsão de venda, detalhes técnicos de produtos, resultados

15
de pesquisas e arquivos pessoais são informações valiosas que caso alguma empresa concorrente tiver acesso de forma indevida, pode acarretar em sérios problemas.
A Internet é um ambiente que viabiliza principalmente a comunicação, a divulgação, a pesquisa e o comercio eletrônico. Em 1999 havia mais de 100 milhões de usuários da Internet nos Estados Unidos. No final de 2003 esse número alcançou 177 milhões nos Estados Unidos e 502 milhões no mundo todo (BURNETT, 2002). O comércio eletrônico emergiu como um novo setor da economia norte-americana, sendo responsável por cerca de U$100 bilhões em vendas durante 1999, em 2003 o comércio eletrônico excedeu a U$1 trilhão. Ao mesmo tempo, o Computer Security Institute (CSI) constatou um aumento de crimes cibernéticos, 55% dos entrevistados na pesquisa informaram atividades maliciosas relacionadas com pessoas da própria organização. Ciente disso pode-se ter certeza que as empresas em expansão precisam de produtos, mecanismos e soluções de segurança (BURNETT, 2002).
Não muito tempo atrás a segurança era uma questão de se trancar uma porta ou um cofre. Atualmente as informações geralmente não estão armazenadas somente em papéis e sim em banco de dados. Como proteger essas informações? O que os sistemas operacionais (SO) oferecem para essa proteção ?
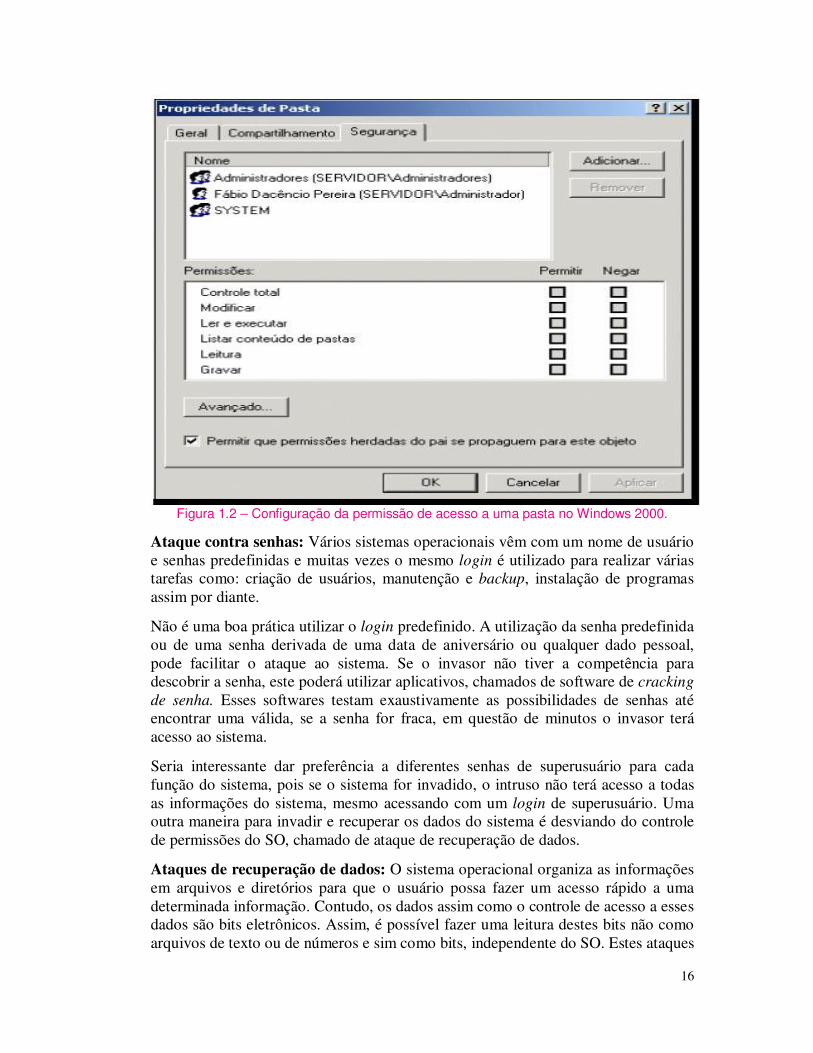
Os sistemas operacionais oferecem um sistema de proteção através de permissões (ver figura 1.2). Isto é, através do SO é possível criar usuários com diferentes níveis de acesso para as informações contidas em um computador. Tal acesso é implementado via procedimento de login. Assim quando um determinado usuário fazer login em um computador terá acesso às pastas e arquivos designados pelo seu nível de permissão, isto é, se um usuário tiver restrições para o acesso de pasta, arquivos e programas, este não conseguirá acessar.
Os cadastros de usuários e as permissões são concedidos pelo superusuário ou administrador do sistema. Este é responsável pelo gerenciamento do sistema, inclusive pode permitir que outros usuários possam alterar algumas permissões, como de uma pasta pessoal. Independente das restrições impostas, com o login de superusuário pode-se ter acesso a todas as funções do sistema.
A questão é como o sistema operacional sabe que a pessoa que está acessando o sistema é realmente o superusuário? O SO concede a permissão através de um nome de usuário e senha, normalmente os nomes de usuários administradores são “root”, “su” ou “administrador” e infelizmente sabe-se que as técnicas para superar essas defesas são amplamente conhecidas (BURNETT, 2002). A seguir são descritos alguns dos principais ataques.
16
Figura 1.2 – Configuração da permissão de acesso a uma pasta no Windows 2000.
Ataque contra senhas: Vários sistemas operacionais vêm com um nome de usuário e senhas predefinidas e muitas vezes o mesmo login é utilizado para realizar várias tarefas como: criação de usuários, manutenção e backup, instalação de programas assim por diante.
Não é uma boa prática utilizar o login predefinido. A utilização da senha predefinida ou de uma senha derivada de uma data de aniversário ou qualquer dado pessoal, pode facilitar o ataque ao sistema. Se o invasor não tiver a competência para descobrir a senha, este poderá utilizar aplicativos, chamados de software de cracking de senha. Esses softwares testam exaustivamente as possibilidades de senhas até encontrar uma válida, se a senha for fraca, em questão de minutos o invasor terá acesso ao sistema.
Seria interessante dar preferência a diferentes senhas de superusuário para cada função do sistema, pois se o sistema for invadido, o intruso não terá acesso a todas as informações do sistema, mesmo acessando com um login de superusuário. Uma outra maneira para invadir e recuperar os dados do sistema é desviando do controle de permissões do SO, chamado de ataque de recuperação de dados.
Ataques de recuperação de dados: O sistema operacional organiza as informações em arquivos e diretórios para que o usuário possa fazer um acesso rápido a uma determinada informação. Contudo, os dados assim como o controle de acesso a esses dados são bits eletrônicos. Assim, é possível fazer uma leitura destes bits não como arquivos de texto ou de números e sim como bits, independente do SO. Estes ataques

17
desviam do SO e capturam os bits brutos, reconstituindo-os em arquivos originais, burlando os controles de permissão do SO.
Ataque de reconstrução de memória: Freqüentemente, o material sigiloso está armazenado na memória do computador. Quando executar um programa, este será armazenado em uma área da memória principal e o SO marca esta área como indisponível. Quando o programa é finalizado, o SO apenas disponibiliza a área sem sobrescrevê-la. O invasor simplesmente aloca a memória liberada e examina o que sobrou (BURNETT, 2002).
Como impedir que um invasor tenha acesso a informações privadas?
Para impedir o acesso a informação privada pode-se utilizar a proteção por criptografia. A proteção por criptografia é uma solução prática para proteger informações sigilosas, independente do algoritmo criptográfico utilizado sempre ocorrerá uma transformação de um texto legível em um ilegível. Mesmo que o invasor obtenha o conteúdo de um arquivo, este será ilegível. Para ter acesso à informação original, o invasor terá que resolver um problema matemático de difícil solução. A criptografia pode adicionar também maior segurança ao processo de identificação de pessoas, criando identidades digitais fortes.
De modo algum a criptografia é a única ferramenta necessária para assegurar a segurança de dados, nem resolverá todos os problemas de segurança. É um instrumento entre vários outros. Além disso, a criptografia não é à prova de falhas. Toda criptografia pode ser quebrada e, sobretudo, se for implementada incorretamente, ela não agrega nenhuma segurança real (BURNETT, 2002).
1.1.3 Alguns Termos utilizados na Criptografia Junto com o conceito de criptografia, tem-se alguns termos oficiais comumente utilizados, que são conceituados nesta seção.
O ato de transformar um texto legível (texto claro, texto original, texto simples) em algo ilegível (cifra, texto cifrado, texto código) é chamado de “encriptar” (codificar, criptografar, cifrar). A transformação inversa é chamada de “decriptar” (decodificar, decriptografar, decifrar).
O algoritmo de criptografia é uma seqüência de procedimentos que envolvem uma matemática capaz de cifrar e decifrar dados sigilosos. O algoritmo pode ser executado por um computador, por um hardware dedicado e por um humano. Em todas as situações o que diferencia é a velocidade de execução e a probabilidade de erros. Existem vários algoritmos de criptografia, neste livro apresenta-se especificamente o DES, AES, RC5, IDEA e RSA, MD5 e SHA-1, pois são os mais utilizados atualmente, além do ALPOS (um algoritmo didático criado pelos autores).
Além do algoritmo, utiliza-se uma chave. A chave na criptografia computadorizada é um número ou um conjunto de números. A chave protege a informação cifrada. Para decrifrar o texto cifrado o algoritmo deve ser alimentado com a chave correta,

18
que é única. Na figura 1.3 tem-se a ilustração do esquema geral de cifragem utilizando chave.
Figura 1.3 – Esquema geral de cifragem com chave.
Na história da criptografia sempre ficou evidente que não existe um algoritmo que não possa ser quebrado (descoberto ou solucionado). Com a criptografia computadorizada, atualmente, os algoritmos são divulgados à comunidade e o sigilo das informações é garantido apenas pela chave. Isto significa que se alguém descobrir a chave para decifrar uma determinada informação, todas as outras informações cifradas com este algoritmo ainda estarão protegidas, por terem chaves diferentes.
Já um algoritmo criptográfico que não utiliza o recurso de chaves para cifrar as informações pode levar a um efeito cascata perigoso. Se este algoritmo for quebrado, todas as informações cifradas com ele estarão desprotegidas, pois o que garante o sigilo das informações seria o próprio algoritmo. Assim, toda criptografia moderna e computadorizada opera com chaves.
A criptografia desde seu inicio, foi desenvolvida para impedir que um invasor ou intruso, alguém que está tentando acessar informações sigilosas tivesse sucesso. Há pouco tempo a criptografia era amplamente utilizada para proteger informações militares. Atualmente protege uma gama maior de diferentes informações. Os invasores não necessariamente só querem acessar informações sigilosas, mas também desativar sites, excluir informações de uma pessoa ou empresa, danificar sistemas em geral.
O estudo sobre a quebra de sistemas criptográficos é conhecido como análise criptográfica. Semelhante ao invasor, o criptoanalista procura as fraquezas dos algoritmos. O criptógrafo desenvolve sistemas de criptografia. É importante que a comunidade de criptografia conheça as fraquezas, pois os invasores também estão procurando por elas. É quase certo que os invasores não irão publicar suas descobertas para o mundo (BURNETT, 2002).

19
1.1.4 Algoritmos de Bloco e Fluxo Pode-se classificar os algoritmos de criptografia através tratamento dado as informações que serão processadas assim, tem-se os algoritmos de bloco e os algoritmos de fluxo.
A cifra de blocos opera sobre blocos de dados. O texto antes de ser cifrado é dividido em blocos que variam normalmente de 8 a 16 bytes que serão cifrados ou decifrados. Quando o texto não completa o número de bytes de um bloco, este é preenchido com dados conhecidos (geralmente valor zero “0”) até completar o número de bytes do bloco, cujo tamanho já é predefinido pelo algoritmo sendo usado.
A forma mais comum de preenchimento é determinar o número de bytes que deve ser preenchido e utilizar este valor para preencher o bloco. Por exemplo: Suponha que o tamanho do bloco em um determinado algoritmo seja de 16 bytes e foi utilizado apenas 9. Deve-se preencher os 7 bytes restantes com o valor 07.
Um problema na cifra de bloco é que se o mesmo bloco de texto simples aparecer mais de uma vez, a cifra gerada será a mesma facilitando o ataque ao texto cifrado. Para resolver este problema são utilizados os modos de realimentação.
O modo mais comum de realimentação é a cifragem de blocos por encadeamento (Cipher Block Chaining - CBC). Neste modo é realizada uma operação de XOR do bloco atual de texto simples com o bloco anterior de texto cifrado. Para o primeiro bloco não há bloco anterior de texto cifrado assim, faz-se uma XOR com um vetor de inicialização. Este modo não adiciona nenhuma segurança extra. Apenas evita o problema citado da cifra de bloco.
Portanto, os algoritmos de blocos processam os dados como um conjunto de bits, são os mais rápidos e seguros para a comunicação digital. Tem ainda como vantagem que os blocos podem ser codificados fora de ordem, o que é bom para acesso aleatório, além de ser resistente a erros, uma vez que um bloco não depende do outro. Entretanto, possuem como desvantagem que se a mensagem possui padrões repetitivos nos blocos, o texto cifrado também o apresentará, o que facilita o serviço do criptoanalista. Outra desvantagem é que um bloco pode ser substituído por outro modificando a mensagem original.
Os algoritmos de fluxo criptografam (cifram) a mensagem bit a bit, em um fluxo contínuo, sem esperar que se tenha um bloco completo de bits. É também chamado de criptografia em Stream de dados, onde a criptografia se dá através de uma operação XOR entre o bit de dados e o bit gerado pela chave.
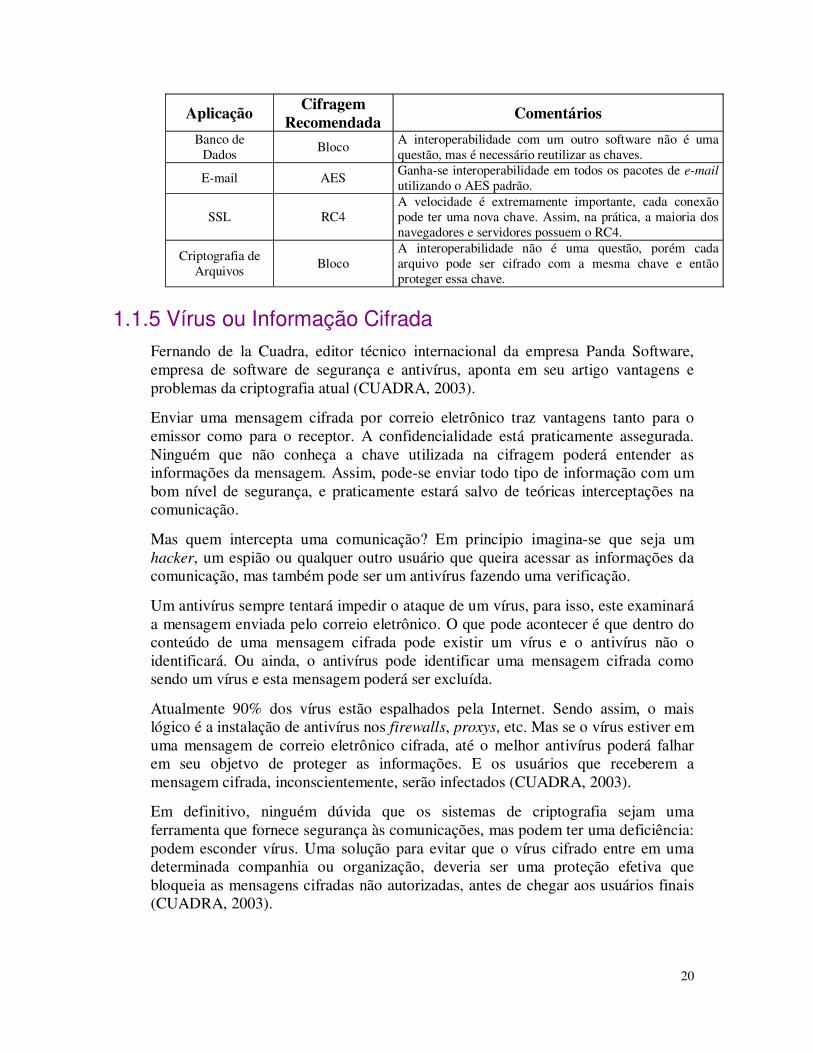
A tabela 1.1 mostra algumas recomendações para selecionar o tipo de algoritmo que deverá ser usado em uma determinada aplicação.
Tabela 1.1 - Escolhendo um algoritmo por aplicação (BURNETT, 2002)
20
Aplicação Cifragem
Recomendada Comentários
Banco de Dados
Bloco A interoperabilidade com um outro software não é uma questão, mas é necessário reutilizar as chaves.
E-mail AES Ganha-se interoperabilidade em todos os pacotes de e-mail utilizando o AES padrão.
SSL RC4 A velocidade é extremamente importante, cada conexão pode ter uma nova chave. Assim, na prática, a maioria dos navegadores e servidores possuem o RC4.
Criptografia de Arquivos
Bloco A interoperabilidade não é uma questão, porém cada arquivo pode ser cifrado com a mesma chave e então proteger essa chave.
1.1.5 Vírus ou Informação Cifrada Fernando de la Cuadra, editor técnico internacional da empresa Panda Software, empresa de software de segurança e antivírus, aponta em seu artigo vantagens e problemas da criptografia atual (CUADRA, 2003).
Enviar uma mensagem cifrada por correio eletrônico traz vantagens tanto para o emissor como para o receptor. A confidencialidade está praticamente assegurada. Ninguém que não conheça a chave utilizada na cifragem poderá entender as informações da mensagem. Assim, pode-se enviar todo tipo de informação com um bom nível de segurança, e praticamente estará salvo de teóricas interceptações na comunicação.
Mas quem intercepta uma comunicação? Em principio imagina-se que seja um hacker, um espião ou qualquer outro usuário que queira acessar as informações da comunicação, mas também pode ser um antivírus fazendo uma verificação.
Um antivírus sempre tentará impedir o ataque de um vírus, para isso, este examinará a mensagem enviada pelo correio eletrônico. O que pode acontecer é que dentro do conteúdo de uma mensagem cifrada pode existir um vírus e o antivírus não o identificará. Ou ainda, o antivírus pode identificar uma mensagem cifrada como sendo um vírus e esta mensagem poderá ser excluída.
Atualmente 90% dos vírus estão espalhados pela Internet. Sendo assim, o mais lógico é a instalação de antivírus nos firewalls, proxys, etc. Mas se o vírus estiver em uma mensagem de correio eletrônico cifrada, até o melhor antivírus poderá falhar em seu objetvo de proteger as informações. E os usuários que receberem a mensagem cifrada, inconscientemente, serão infectados (CUADRA, 2003).
Em definitivo, ninguém dúvida que os sistemas de criptografia sejam uma ferramenta que fornece segurança às comunicações, mas podem ter uma deficiência: podem esconder vírus. Uma solução para evitar que o vírus cifrado entre em uma determinada companhia ou organização, deveria ser uma proteção efetiva que bloqueia as mensagens cifradas não autorizadas, antes de chegar aos usuários finais (CUADRA, 2003).

21
1.2 Importância da Chave ou “senha” O termo “chave” vem do fato de que o número secreto, a famosa senha usada nos nos sistemas computacionais, funciona da mesma maneira que uma chave convencional usada nas portas e entradas a lugares fechados de residências, empresas e etc. de modo a proteger o patrimônio de um determinado usuário.
Assim, de forma similar acontece com a criptografia, onde para proteger a informação de um determinado usuário (armazenada em arquivos de computador), se deve instalar uma fechadura (algoritmo de criptografia). Para operar a fechadura precisa-se da famosa chave ou senha (número secreto), a qual permite cifrar ou decifrar a informação desejada.
O algoritmo realiza seus passos utilizando a chave para alterar o texto simples (mensagem original) e convertê-lo em texto cifrado. Para recuperar a informação em forma legível, é necessário inserir a mesma chave ou alguma que esteja relacionada com aquela que foi usada no processo anterior, e executar a operação inversa. O algoritmo inverte os passos e converte o texto cifrado de volta no texto simples original.
Assim como apenas a chave correta de um determinado prédio pode abrir sua entrada, apenas a chave correta usada em criptografia pode cifrar ou decifrar os dados. Na criptografia de chave simétrica, a chave que é utilizada para criptografar os dados é a mesma chave que é utilizada para decifrá-los. Na criptografia assimétrica, usa-se outra chave que possui um valor relacionado com essa primeira chave, na seção 1.3 apresenta-se mais detalhes sobre criptografia simétrica e assimétrica.
Toda criptografia moderna e computadorizada opera com chaves. Por que uma chave é necessária? Por que não criar um algoritmo que não necessite de uma chave?. Se os invasores podem entender o algoritmo, eles podem recuperar os dados secretos simplesmente executando o algoritmo.
Uma primeira solução seria manter o algoritmo em segredo, mas essa abordagem tem vários problemas. Um deles é, supondo que não seja possível manter o algoritmo em segredo, os invasores sempre quebram o algoritmo. Isso não seria possível se houvesse especialistas em criptografia que desenvolvem seus próprios algoritmos, mas neste caso também deve-se confiar que a empresa ou usuário que escreveu o algoritmo nunca o revele.
Neste ponto aparece um aspecto relevante em criptografia: o que é mais importante, um algoritmo que deve ser mantido em segredo ou um algoritmo que pode fazer seu trabalho de cifrar informações mesmo que os usuários de sistemas computacionais saibam como ele funciona. Neste segundo aspecto, aparece a importância dos algoritmos com chave, e principalmente, a relevância da chave.
As chaves aliviam a preocupação com o algoritmo utilizado no esquema de criptografia. Em termos computacionais para proteger os dados com uma chave, é necessário proteger apenas a chave, algo que é mais fácil de ser feito do que proteger

22
um algoritmo. Além disso, se utilizar chaves para proteger os segredos, é possível utilizar diferentes chaves para proteger diferentes segredos. Isso significa que se alguém descobrir (“quebrar”) uma das chaves, os outros segredos ainda poderão estar seguros. Se alguma informação depender somente de um algoritmo secreto, algum invasor que quebre esse segredo obterá acesso a todas as informações contidas em um determinado sistema computacional.
Assim, as chaves são muito importantes em criptografia. Esse é o princípio de Kerckhoffs, que diz da relevância do espaço de chaves, é muito mais seguro um sistema onde se conhece o algoritmo de criptografia, do que o espaço de chaves. Manter em segredo as chaves, e supondo conhecer o algoritmo usado, gera-se um sistema incondicional e computacionalmente seguro.
Esse princípio ainda é válido, por várias razões (KERCKHOFFS, 1983). Os invasores podem deduzir um algoritmo sem ajuda nenhuma. Na história da criptografia nunca alguém foi capaz de manter um algoritmo criptográfico em segredo. Eles sempre o descobrem.
Um exemplo disso é que durantes as guerras, os espiões sempre encontraram maneiras de descobrir o algoritmo, seja ele originado de uma operação matemática ou de uma máquina. Eles o roubam ou fazem com que alguém o revele (por meio de chantagem, extorsão ou pelo uso de técnicas de análise criptográfica). Agentes sempre descobriam o algoritmo ou obtinham uma cópia da máquina.
Por exemplo, na Segunda Guerra Mundial, os soldados poloneses capturaram a máquina alemã Enigma, logo no início da guerra. A Enigma era uma máquina de criptografia que o exército alemão utilizava. Os aliados (isto é, os britânicos) foram capazes de quebrar o código mais facilmente porque tinham a posse dessa máquina.
Alternativamente, os analistas criptográficos descobrem o algoritmo. Na Segunda Guerra Mundial, decifradores de código dos Estados Unidos foram capazes de determinar o funcionamento interno das máquinas codificadas japonesas sem ter a posse de uma dessas máquinas.
Um caso mais recente, refere-se ao exemplo do algoritmo RC4, um algoritmo inventado em 1987, mas nunca publicado. Os analistas de criptografia e outros especialistas o estudaram e determinaram que o RC4 era uma boa maneira de manter os dados em segredo. Atualmente o RC4 é utilizado como parte do Secure Sockets Layer (SSL), o protocolo de comunicação segura da WEB (World Wide Web).
Mas a empresa que o criou, a RSA Data Security, nunca tornou público o funcionamento interno do algoritmo RC4. Esse segredo tinha interesses financeiros e não de segurança. A empresa esperava que mantendo-o em segredo ninguém mais o implementaria e o comercializaria. Em 1994, hackers anônimos divulgaram o algoritmo na Internet. Acredita-se que eles provavelmente o descobriram usando um depurador de linguagem assembly, após terem tido acesso a uma cópia do código-objeto.
Se um sistema criptográfico estiver baseado no hardware, os engenheiros abrem-no e examinam as partes internas. Em 1998, David Wagner e Ian Goldherg, nessa época

23
alunos graduados da Universidade da Califórnia em Berkeley, abriram um telefone celular digital, supostamente seguro, e quebraram seu código.
Às vezes é possível manter um algoritmo em segredo por um período suficientemente longo para que ele seja eficaz, mas após certo tempo alguém acaba descobrindo-o.
A segunda razão de relevância da senha, mais do que o algoritmo usado refere-se à assuntos comerciais. Empresários e usuários sempre desejam saber como um determinado software de interesse foi realizado. Caso a empresa não revele os segredos de implementação e construção, através de técnicas de reengenharia reversa sobre um software pode-se conhecer detalhes da sua criação e respectiva implementação.
Soma-se a isso o fato que somente pessoas que adquiriram o produto podem se comunicar entre si. Isso enviabiliza a comunicação com pessoas que não adquiriram ou compraram o algoritmo de um mesmo fornecedor. Dessa maneira, como resultado, os algoritmos devem ser padronizados e isso significa que eles devem ser públicos.
Se alguém quiser utilizar a criptografia, é necessário empregar um dispositivo de hardware ou um programa de software. Portanto, se faz necessário adquirir o produto em algum lugar. Assim, como os usuários podem ter acesso a ele, os invasores também têm. Desse modo, possíveis invasores podem ir à mesma fonte e conseguir suas próprias cópias. Isso faz com que os algoritmos devem ser disponibilizados, e melhor então, deve-se cuidar da chave.
Uma outra razão para cuidar da chave e não do algoritmo refere-se ao fato que é possível construir sistemas criptográficos no qual o algoritmo é completamente conhecido, mas é seguro pois os possíveis invasores precisam conhecer a chave para descobrir as informações. Estes sistemas são mais seguros do que aqueles que não tem chave, e somente confiam no segredo de não se conhecer o algoritmo.
Quando os algoritmos se tornam públicos, os analistas criptográficos e os profissionais da área de computação têm uma chance de examinar suas fraquezas. Se um algoritmo for vulnerável, pode optar por não utilizá-lo. Caso contrário, pode ter certeza de que os dados estão seguros. Por outro lado, se um algoritmo for mantido em segredo, os analistas não serão capazes de encontrar nenhuma fraqueza que ele possa ter, assim não se sabe se ele é ou não é vulnerável.
1.2.1 Como Gerar a Chave
Em um sistema criptográfico de chave simétrica, a chave é formada por um conjunto de caracteres. Ele pode ser um número qualquer, ou uma seqüência de caracteres

24
alfanuméricos (letras e símbolos especiais) contanto que tenha um tamanho correto e adequado àquele que o algoritmo criptográfico selecionado permitir.
Geralmente, aconselha-se que a chave seja formada por números ou caracteres alfanuméricos sem coerência nenhuma entre si, pois assim fica mais díficil descobrí-la (ou em termos criptográficos, quebrá-la). A chave deve ser, dentro do possível, selecionada de forma aleatória. Para os criptógrafos, valores aleatórios são simplesmente conjuntos de números que passam em testes estatísticos de aleatoriedade e não são repetíveis.
Com esse intuito, de gerar chaves, há várias técnicas usadas. Entre elas destaca-se a utilização de sistema geradores de número aleatórios (GNA) ou RNG (Random Number Generator). Esses dispositivos funcionam agrupando números de diferentes tipos de entradas imprevisíveis como a medição da desintegração espontânea de radioatividade, o exame das condições atmosféricas ou o cálculo de minúsculas variâncias na corrente elétrica. Esses números passam por testes de aleatoriedade. Se solicitar um segundo grupo de números, a nova seqüência será completamente diferente, isto é, nunca receberá a mesma seqüência novamente. Isso ocorre porque a saída é baseada em uma entrada que sempre está mudando.
Esses números podem ser obtidos utilizando algoritmos chamados de GNPA geradores de números pseudo-aleatórios (pseudo-random number generators - PRNGs). Se um desses algoritmos for utilizado para gerar alguns milhares de números e aplicar testes estatísticos, os números passariam no teste de aleatoriedade. O que torna esses números pseudo-aleatórios, e não aleatórios, é que eles são repetíveis. Se for instalado o mesmo GNPA em um outro computador, os mesmos resultados poderão vir a ser obtidos. Se o programa for executado um tempo depois, os mesmos resultados podem ser obtidos.
Para evitar esse problema, costuma-se usar GNPA com uma entrada diferente em cada evento de utilização (chamada de semente). Assim, gerar-se-á dados diferentes, pois alterando a entrada, a saída será alterada. A geração aleatória dessa chave está associada a dois parâmetros importantes: velocidade de geração e entropia, as quais estão intimamente relacionadas com o tamanho da chave.
1.2.2 Importância do Tamanho da Chave
Se os invasores puderem descobrir qual é a chave usada na cifragem dos dados, eles podem decifrar a mensagem enviada e obter os dados contidos nela.
Um método, conhecido como ataque de força bruta, consiste em tentar todas as possíveis chaves até que a correta seja identificada. Ele funciona dessa maneira. Suponha que a chave seja um número entre 0 e 1.000.000 (um milhão). O invasor pega o texto cifrado e alimenta o algoritmo de criptografia junto com a “suposta chave” de valor “0”. O algoritmo realiza seu trabalho e produz um resultado. Se os dados resultantes parecerem razoáveis, “0” provavelmente é a chave correta. Se for um texto sem sentido, “0” não é a verdadeira chave. Nesse caso, ele tenta outro valor, por exemplo “1” e em seguida “2”, “3”, “4” e assim por diante.

25
Um algoritmo simplesmente realiza os passos, independentemente da entrada. Ele não tem nenhuma maneira de saber se o resultado que ele produz é o correto. Mesmo se o valor for um próximo da chave, talvez errado em apenas “1”, o resultado será um texto sem sentido.
Assim, é necessário examinar o resultado e compará-lo para identificar algum sentido e assim informar se o valor usado como chave pode ser a chave realmente usada para cifrar as mensagens.
Como isso depende de uma seqüência de entrada e saída, com valores supostos de chaves, um método consiste em criar programas que façam esses passos até descobrirem alguma informação.
Normalmente, esse processo requer pouco tempo para testar uma chave. Assim, pode-se escrever um programa que verifique várias chaves por segundo. Computacionalmente isso torna possível descobrir qualquer chave, somente precisa-se de tempo.
Interessante perceber que esse tempo de procura está fortemente associado ao tamanho da chave. Chaves criptográficas são medidas em bits. O intervalo de possíveis respostas para identificar uma chave está em correspondência ao número 2TC, onde “TC” é o Tamanho da Chave em bits.
Assim, tendo-se uma chave de 2 bits significa que o intervalo de possíveis valores é de 0 até 22 = 4. Uma chave de 40 bits significa que o intervalo dos possíveis valores é de 0 até aproximadamente 1 trilhão (240). Uma chave de 56 bits é de 0 até aproximadamente 72 quatrilhões (256). O intervalo de uma chave de 128 bits é tão grande que é mais fácil apenas dizer que ela é uma chave de 128 bits (número de possibilidades igual a 2128).
Cada bit adicionado ao tamanho da chave dobrará o tempo requerido para um ataque de força bruta. Se uma chave de 40 bits levasse três horas para ser quebrada, uma chave de 41 bits levaria seis horas, uma chave de 42 bits, 12 horas e assim por diante. Isso acontece pois cada bit adicional da chave dobra o número de chaves possíveis, (lembrar que esse número está em função de 2TC). Assim ao adicionar um bit o número de chaves possíveis é dobrado. Dobrando o número de chaves possíveis, o tempo médio que um ataque de força bruta leva para encontrar a chave correta também é dobrado.
Portanto, para se ter maior segurança, isto é tornar o trabalho de um determinado invasor mais difícil, deve-se escolher uma chave maior. Chaves mais longas significam maior segurança. A tabela 1.2 mostra o impacto de se aumentar o tamanho da chave e o respectivo tempo de quebrar a chave usando ataque por força bruta, assim como a respectiva estimativa de custo (em doláres) da tecnologia necessária para encontrar a chave. Pode-se ver que tendo mais recursos disponíveis (em tecnologia e portanto maior custo em doláres) é possível diminuir o tempo de se encontrar uma determinada chave. Não obstante seja possível achar a chave, há tamanhos de chave que inviabilizam esse fato, pois demandaria muito tempo.

26
Nessa tabela, o termo 2s significa 2 segundos; 200ms siginifica que o tempo é dado em milisegundos (10-3 segundos); 200 us significa que o tempo é dado em microsegundos (isto é, 10-6 segundos).
Tabela 1.2 – Tempo gasto para quebra de chaves por força bruta (SCHNEIER, 1996)
Tamanho da Chave (bits) Custo U$ 40 56 64 80 112 128
100000 2s 35 horas 1 ano 70000 anos 10 e 14 10 e 19 1 Milhão 200 ms 3,5 h 37 dias 7000 anos 10 e 13 10 e 18 10M Milhões 20s 21 m 4 dias 700 anos 10 e 12 10 e 17 100 M 2 ms 2m 9 h 70 anos 10 e 11 10 e 16 1G 200 us 13 s 1 h 7 anos 10 e 10 10 e 15 10G 20 us 1 s 5,4 m 245 anos 10 e 9 10 e 14 100G 2 us 100 ms 32 s 24 anos 10 e 8 10 e 13 1T 0,2 us 10 ms 3 s 2,4 anos 10 e 7 10 e 12 10T 0,02 us 1 ms 300 ms 6 horas 10 e 6 10 e 11
Importante lembrar que o poder computacional dobra a cada 1.5 anos, e que o tempo de existência do universo, segundo os últimos estudos científicos, está em torno de 10 10e10 anos. Assim, chega-se à conclusão que sempre é possível decrifrar uma determinada mensagem, pois sempre será possível descobrir a chave: basta testar todas as chaves possíveis –é somente uma questão de tempo. Mas pode demorar mais que o tempo de duração do Universo (SCHNEIER, 1996).
Então, qual o tamanho máximo que uma chave deve ter? Com o passar dos anos, o RSA Laboratories propôs alguns desafios. A primeira pessoa ou empresa a quebrar uma mensagem em particular ganharia um prêmio em dinheiro. Alguns desafios foram testes do tempo de um ataque de força bruta. Em 1997, uma chave de 40 bits foi quebrada em três horas e uma chave de 48 bits durou 280 horas. Em 1999, a Electronic Frontíer Foundation encontrou uma chave de 56 bits em 24 horas. Em cada um dos casos, pouco mais de 50% do espaço de chave foi pesquisado antes de a chave ser encontrada.
Em todas essas situações, centenas ou até milhares de computadores operavam conjuntamente para quebrar as chaves. Na realidade, com o desafio de 56 bits de DES que a Electronic Frontier Foundation quebrou em 24 horas, um dos computadores era um cracker especializado em DES. Esse tipo de computador faz apenas uma coisa: verifica as chaves de DES.
Um invasor que trabalhe secretamente, provavelmente não seria capaz de reunir a força de centenas de computadores e talvez não possua uma máquina especificamente construída para quebrar um algoritmo em particular. Para a maioria dos invasores, essa é a razão pela qual o tempo que leva para quebrar a chave quase certamente seria significativamente mais alto. Por outro lado, se o invasor fosse uma agência governamental de inteligência com grandes recursos, a situação seria diferente.

27
Pode-se pensar em situações ainda mais críticas. Suponha que examinar 1% do espaço de chave de uma chave de 56 bits leva 1 segundo e examinar 50% leva 1 minuto. Todas as vezes que se adicionar um bit ao tamanho de chave dobra-se então o tempo de pesquisa. Os resultados são mostrados na tabela 1.3, onde se percebe que o impacto e observações realizadas para os dados da tabela 1.2, são também aplicavéis.
Tabela 1.3 – Tempo gasto para quebra de chaves (BURNETT, 2002)
Bits 1% do Espaço da Chave 50% do Espaço da Chave
56 1 segundo 1 minuto
57 2 segundos 2 minutos
58 4 segundos 4 minutos
64 4,2 minutos 4,2 horas
72 17,9 horas 44,8 dias
80 190,9 dias 31,4 anos
90 535 anos 321 séculos
108 140.000 milênios 8 milhões de milênios
128 146 bilhões de milênios 8 trilhões de milênios
Atualmente, 128 bits é o tamanho de chave simétrica mais comumente utilizado. Se a tecnologia avançar e os invasores de força bruta puderem melhorar esses números (talvez eles possam reduzir para alguns anos o tempo das chaves de 128 bits), então precisar-se-á de chaves de 256 bits ou ainda maiores.
Assim, considerando que a tecnologia sempre está avançando, então teremos de aumentar repetidas vezes o tamanho das chaves. Então, com o passar do tempo sempre será necessário aumentar o tamanho das chaves. É bom lembrar que aumentar a chave significa também em aumentar o tempo cifragem e decifragem. Por isso é recomnedável ter cuidados com a escolha do tamanho da chave. Assim, é possível pensar que pode chegar um um momento quando precisaremos de uma chave tão grande que ela se tornará muito difícil de lidar. No momento atual, e considerando os conhecimnentos adquiridos na área de segurança, quase certamente nunca precisaremos de uma chave mais longa do que 512 bits (64 bytes). Supondo que cada átomo no universo conhecido (há aproximadamente 2300) fosse um computador e que cada um desses computadores pudesse verificar 2300 chaves por segundo, isso levaria cerca de 2162 milênios para pesquisar 1% do espaço de chave de uma chave de 512 bits. De acordo com a teoria do Big Bang, o tempo decorrido desde a criação do universo é menor de 224 milênios. Em outras palavras, é

28
altamente improvável que a tecnologia vá tão longe para forçar a utilizar chaves que sejam “muito grandes” (BURNETT, 2002).
Apesar do ataque de força bruta precisar de muito tempo, principalmente quando a chave possui um tamanho razoável, há outros ataques que exploram as fraquezas nos algoritmos criptográficos, e tendem a diminuir o tempo do ataque. Por esse motivo, no momento recomenda-se usar chaves relativamente longas, superiores a 128 bits. Já aplicações comerciais e financeiras (por exemplo, transações bancárias), é necessário que a chave seja maior que 128 bits. Isso significa que usuário comum que tente fazer um ataque de força bruta, precisará de muito tempo para ter uma invasão considerada bem sucedida.
1.3 Criptografia de Chave Simétrica e Assimétrica Na criptografia de chave simétrica os processos de cifragem e decifragem são feitos com uma única chave, ou seja, tanto o remetente quanto o destinatário usam a mesma chave. Em algoritmos simétricos, como por exemplo o DES (Data Encription Standard), ocorre o chamado "problema de distribuição de chaves". A chave tem de ser enviada para todos os usuários autorizados antes que as mensagens possam ser trocadas. Isso resulta num atraso de tempo e possibilita que a chave chegue a pessoas não autorizadas.
A criptografia assimétrica contorna o problema da distribuição de chaves através do uso de chaves públicas. A criptografia de chaves públicas foi inventada em 1976 por Whitfield Diffie e Martin Hellman a fim de resolver o problema da distribuição de chaves. Neste novo sistema, cada pessoa tem um par de chaves chamadas: chave pública e chave privada. A chave pública é divulgada enquanto que a chave privada é deixada em segredo. Para mandar uma mensagem privada, o transmissor cifra a mensagem usando a chave pública do destinatário pretendido, que deverá usar a sua respectiva chave privada para conseguir recuperar a mensagem original.
Atualmente, um dos mecanismos de segurança mais usados é a assinatura digital, a qual precisa dos conceitos de criptografia assimétrica. A assinatura digital é uma mensagem que só uma pessoa poderia produzir, mas que todos possam verificar. Normalmente autenticação se refere ao uso de assinaturas digitais: a assinatura é um conjunto inforjável de dados assegurando o nome do autor que funciona como uma assinatura de documentos, ou seja, que determinada pessoa concordou com o que estava escrito. Isso também evita que a pessoa que assinou a mensagem depois possa se livrar de responsabilidades, alegando que a mensagem foi forjada. Um exemplo de criptossistema de chave pública é o RSA (Rivest-Shamir-Adelman). Sua maior desvantagem é a sua capacidade de canal limitada, ou seja, o número de bits de mensagem que ele pode transmitir por segundo (BURNETT, 2002).
A figura 1.4 ilustra o funcionamento da criptografia simétrica e assimétrica. Observa-se que existem duas chaves na criptografia assimétrica.

29
Figura 1.4 – Modelo simétrico e assimétrico de criptografia.
Após analisar o exposto acima, pode-se ficar em dúvida de qual modelo utilizar: simétrico ou assimétrico. Pois bem, devido a isso foi desenvolvido um modelo híbrido, ou seja, que aproveitasse as vantagens de cada tipo de algoritmo. O algoritmo simétrico, por ser muito mais rápido, é utilizado no ciframento da mensagem em si, enquanto o assimétrico, embora lento, permite implementar a distribuição de chaves e alguns a assinatura digital.
Então, os algoritmos criptográficos podem ser combinados para a implementação dos três mecanismos criptográficos básicos: o ciframento, a assinatura digital e o hashing, sendo que estes últimos dois conceitos ainda serão descritos e analisados em capítulos posteriores. Estes mecanismos são componentes de protocolos criptográficos, embutidos na arquitetura de segurança dos produtos destinados ao comércio eletrônico. Estes protocolos criptográficos, portanto, provêm os serviços associados à criptografia que viabilizam o comércio eletrônico.
Descreve-se abaixo alguns exemplos de protocolos que empregam sistemas criptográficos híbridos.
O IPSec é o padrão de protocolos criptográficos desenvolvidos para o IPv6. Realiza também o tunelamento de IP sobre IP. Prometido como futuro padrão para todas as formas de VPN – Virtual Private Network(MAIA, 1999).
O SSL e TLS oferecem suporte de segurança criptográfica para os protocolos NTTP, HTTP, SMTP e Telnet. Permitem utilizar diferentes algoritmos simétricos, message digest e métodos de autenticação e gerência de chaves para algoritmos assimétricos (MAIA, 1999). O SSL, que significa Security Socket Layer, é o protocolo mais

30
conhecido em transações via WEB e hoje domina esse mercado, estando presente principalmente em vendas on-line envolvendo cartão de crédito. Foi criado pela Netscape, sendo o padrão livre para uso pessoal e empresarial. Ressalte-se novamente o nível de segurança deste protocolo, o qual assegura a inviolabilidade das vendas on-line com cartão de crédito (GEEK, 2002).
Pode-se citar também como exemplo o PGP, já descrito anteriormente, lembrando-se de que se trata de um programa de criptografia famoso e bastante difundido na internet, destinado a criptografia de e-mail. Suporta os algoritmos hashing MD5 e SHA-1.
O S/MIME (Secure Multipurpose Internet Mail Extensions) consiste em um esforço de um consórcio de empresas, tendo inclusive como um dos líderes a Microsoft, para adicionar segurança a mensagens eletrônicas no formato MIME. Acredita-se que o S/MIME deverá se estabelecer no mercado corporativo, enquanto que o PGP atuará no mundo do e-mail pessoal (MAIA, 1999).
Já o SET é um conjunto de padrões e protocolos para realizar transações financeiras seguras, como as realizadas com cartões de crédito na internet. Oferece um canal seguro entre todos os envolvidos na transação, bem como autenticidade e privacidade entre as partes envolvidas.
A especificação X.509 define o relacionamento entre as autoridades de certificação. Baseado em criptografia de chave pública e assinatura digital (MAIA,1999).
Pode-se então traçar um comparativo entre os modelos vistos (criptografia simétrica e assimétrica), conforme se mostra na Tabela 1.4.
Tabela 1.4 Comparação entre os Tipos de Algoritmos de Criptografia
Criptografia Simétrica Criptografia Assimétrica
Rápida Lenta
Gerência e distribuição das chaves é complexa
Gerência e distribuição é simples
Não oferece assinatura digital. Oferece assinatura digital
A tabela 1.5, mostra detalhes dos algoritmos simétricos mais conhecidos pela comunidade da área de segurança da informação e criptografia.
Tabela 1.5 Características dos Algoritmos Simétricos mais Conhecidos

31
Algoritmo Tipo Tamanho Chave Tamanho Bloco DES Bloco 56 64
Triple Des (2 chaves) Bloco 112 64 Triple DES (3 chaves) Bloco 168 64
IDEA Bloco 128 64 Blowfish Bloco 32 a 448 64
RC5 Bloco 0 a 2040 32, 64, 128 CAST-128 Bloco 40 a 128 64
RC2 Bloco 0 a 1024 64 RC4 Stream (fluxo) 0 a 256 --
Rijndael (AES) Bloco 128, 192, 256 128, 192, 256 MARS Bloco Variável 128 RC6 Bloco Variável 128
Serpent Bloco Variável 128 Twofish Bloco 128, 192, 256 128
Nessa tabela é possível observar que a maioria dos algoritmos criptográficos modernos, os mais usados na atualidade, são baseados no sistema de cifrar as informações por bloco, cujo tamanho de bloco mais usado é de 64 bits e possuem chaves de tamanho relativamente grande, superior a 56 bits. Outro aspecto que merece destaque, é o fato de alguns algoritmos possuem tamanhos de chave e/ou de bloco variável (ver situação dos algoritmos blowfish, RC5, CAST, RC2, RC4, Rijndael - AES, MARS, RC6, Serpent e Twofish, que casualmente foram os algoritmos que fizeram parte do projeto AES) (BIHAM, 1999).
1.4 Assinatura Digital Alguns algoritmos criptográficos de chave-pública permitem a sua utilização para gerar o que se denomina de assinaturas digitais. O algoritmo RSA é um destes algoritmos, assim, além da operação normal de cifrar com a chave-pública e decifrar com a chave-privada, permitir que, cifrando-se com a chave-privada, o processo de decifrar com a chave-pública resulta na recuperação da mensagem (BUCHMANN, 2001).
Obviamente esta forma de uso não assegura o sigilo da mensagem, uma vez que qualquer um pode decifrar a mensagem, dado que a chave-pública é de conhecimento público. Entretanto, se esta operação resulta na mensagem esperada pode-se ter a certeza de que somente o detentor da correspondente chave-privada poderia ter realizado a operação de cifragem.
Assim, uma assinatura digital é o criptograma resultante da cifração de um determinado bloco de dados (documento) pela utilização da chave-privada de quem assina em um algoritmo assimétrico. A verificação da assinatura é feita decifrando-se o criptograma (assinatura) com a suposta chave-pública correspondente. Se o resultado for válido, a assinatura é considerada válida, ou seja, autêntica, uma vez que apenas o detentor da chave privada, par da chave pública utilizada, poderia ter gerado aquele criptograma. Na figura 1.5 ilustra-se este procedimento.

32
Figura 1.5 – Geração de Assinatura Digital de um documento (BURNETT, 2002).
Nesta figura um usuário de nome Fábio assina um documento, cifrando-o com sua chave-privada e enviando tanto o documento original quanto a assinatura para um outro usuário chamado de Edward. Este usuário verifica a assinatura decifrando-a com a chave-pública de Fábio (de conhecimento público), e comparando o resultado com o documento recebido. Se estiverem de acordo, a assinatura confere, caso contrário a assinatura é considerada inválida, significando que ou não foi Fábio quem assinou, ou o documento foi adulterado após a assinatura. Interessante observar que este procedimento é capaz de garantir tanto a origem (autenticação do emissor), tendo em vista que supostamente somente Fábio conhece sua chave privada e portanto somente ele é capaz de gerar uma assinatura que possa ser verificada com sua chave-pública, como também a integridade do documento, já que, se o mesmo for alterado, a verificação da assinatura irá indicar isto, caso tenha vindo efetivamente do pretenso emissor.
Usualmente, face à ineficiência computacional dos algoritmos assimétricos, os métodos para assinatura digital empregados na prática não assinam o documento que se deseja autenticar em si, mas uma súmula deste, obtida pelo seu processamento através do que se denomina uma função de Hashing. Uma função de hashing é uma função criptográfica que gera uma saída de tamanho fixo (geralmente 128 a 256 bits) independentemente do tamanho da entrada. A esta saída se denomina de hash da mensagem (ou documento ou o que quer que seja a entrada). Segundo Burnett (BURNETT, 2002), para ter utilidade criptográfica, a função de hashing deve ser:
• Simples (eficiente, rápido) se computar o hash de dada mensagem;
• Impraticável se determinar a entrada a partir de seu hash;
• Impraticável se determinar uma outra entrada que resulte no mesmo hash de uma dada entrada;
• Valores de hash possíveis são estatisticamente equiprováveis.
33
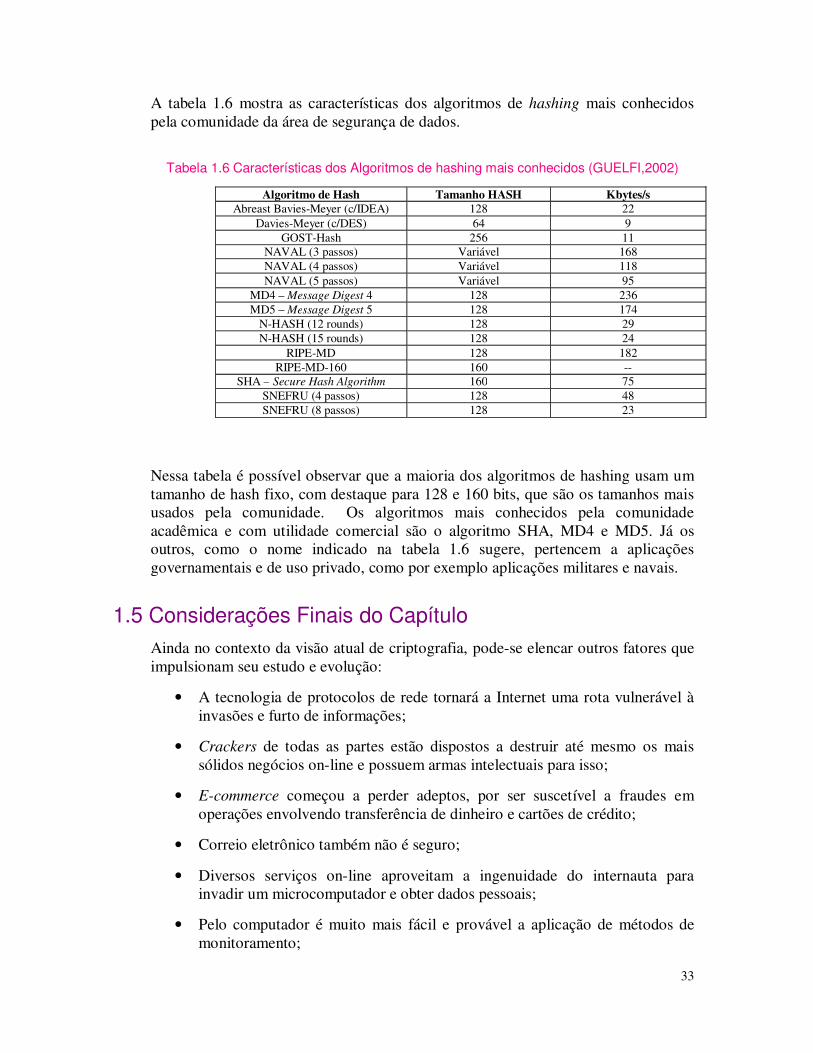
A tabela 1.6 mostra as características dos algoritmos de hashing mais conhecidos pela comunidade da área de segurança de dados.
Tabela 1.6 Características dos Algoritmos de hashing mais conhecidos (GUELFI,2002)
Algoritmo de Hash Tamanho HASH Kbytes/s Abreast Bavies-Meyer (c/IDEA) 128 22
Davies-Meyer (c/DES) 64 9 GOST-Hash 256 11
NAVAL (3 passos) Variável 168 NAVAL (4 passos) Variável 118 NAVAL (5 passos) Variável 95
MD4 – Message Digest 4 128 236 MD5 – Message Digest 5 128 174
N-HASH (12 rounds) 128 29 N-HASH (15 rounds) 128 24
RIPE-MD 128 182 RIPE-MD-160 160 --
SHA – Secure Hash Algorithm 160 75 SNEFRU (4 passos) 128 48 SNEFRU (8 passos) 128 23
Nessa tabela é possível observar que a maioria dos algoritmos de hashing usam um tamanho de hash fixo, com destaque para 128 e 160 bits, que são os tamanhos mais usados pela comunidade. Os algoritmos mais conhecidos pela comunidade acadêmica e com utilidade comercial são o algoritmo SHA, MD4 e MD5. Já os outros, como o nome indicado na tabela 1.6 sugere, pertencem a aplicações governamentais e de uso privado, como por exemplo aplicações militares e navais.
1.5 Considerações Finais do Capítulo Ainda no contexto da visão atual de criptografia, pode-se elencar outros fatores que impulsionam seu estudo e evolução:
• A tecnologia de protocolos de rede tornará a Internet uma rota vulnerável à invasões e furto de informações;
• Crackers de todas as partes estão dispostos a destruir até mesmo os mais sólidos negócios on-line e possuem armas intelectuais para isso;
• E-commerce começou a perder adeptos, por ser suscetível a fraudes em operações envolvendo transferência de dinheiro e cartões de crédito;
• Correio eletrônico também não é seguro;
• Diversos serviços on-line aproveitam a ingenuidade do internauta para invadir um microcomputador e obter dados pessoais;
• Pelo computador é muito mais fácil e provável a aplicação de métodos de monitoramento;

34
• Ainda existe um sentimento de insegurança quando se realiza alguma transação comercial via internet, fazendo com que não seja aproveitado todo o potencial neste tipo de comércio;
• A invasão de máquinas/sistemas e roubo de informação é uma realidade, deixando de lado a imagem fictícia e cinematográficas;
• Os algoritmos de criptografia ainda são um conceito distante da grande massa de usuários, se apresentado como algo abstrato e intangível.
Por esse motivo, este livro além de apresentar de forma clara os algoritmos criptográficos mais usados no momento, preocupa-se em apresentar dados de desempenho: tempos de execução do processo de cifragem e decifragem, tempo de processamento de alguns algoritmos simétricos (DES, AES, IDEA, RC5) e assimétricos como o RSA e funções de hashing (MD5 e SHA-1), quando implementados em software (usando-se da linguagem C e alguns deles em Java) e hardware (em circuitos programáveis – FPGAs através da linguagem especial para descrição de sistemas digitais, conhecida como VHDL).
Um dos pontos de interesse ao leitor é destacar que ao aumentar o tamanho da chave aumenta o nível de segurança, mas aumenta-se também o tempo de processamento do processo de cifragem e decifragem. Neste livro mostra-se qual é o real impacto desse processo, tais como impacto do algoritmo no tempo de processamento, impacto do sistema operacional (Windows, Linux), impacto do processador e etc.

35
Capítulo 2 Conceitos de Circuitos Programáveis FPGAs e VHDL e VHDL
Neste capítulo, apresentam-se conceitos básicos de circuitos programáveis FPGAs e da linguagem de descrição de hardware VHDL. Inicialmente é apresentada a estrutura interna e roteamento dos circuitos FPGAs, discutindo conceitos de reconfiguração. Posteriormente tem-se a definição das formas de descrever um circuito utilizando VHDL, exemplificando cada metodologia de descrição de hardware, onde a sintaxe da linguagem é baseada no padrão VHDL’93. Além de descrever os principais elementos que compõem a estrutura da linguagem como: operadores, expressões, atributos, tipos da linguagem, declaração de entidades e arquiteturas, expressões concorrentes, expressões seqüenciais, processos, comando seqüenciais e outros.
2.1 Estrutura Interna de um FPGA Como ponto de partida para este capítulo, faz-se necessário apresentar a estrutura interna de circuitos programáveis FPGAs, mostrando algumas arquiteturas desta tecnologia, bem como discutir os conceitos de reconfiguração e roteamento desses circuitos. Não é objetivo deste livro explorar em profundidade detalhes da tecnologia FPGA, mas apenas alguns conceitos básicos quse serão importantes para entender o projeto e desempenho dos algoritmos criptográficos implementados através desta tecnologia.
A figura 2.1 apresenta quatro principais arquiteturas internas utilizadas em circuitos programáveis: matriz simétrica, sea-of-gates, row-based e PLD hierárquico. Já a figura 2.2 mostra que um FPGA (Field Programmable Gate Arrays) são circuitos programáveis compostos de CLBs, switch boxes, IOBs e canais de roteamento.

36
Figura 2.1 – Arquiteturas interna de circuitos programáveis FPGA.
A arquitetura sea-of-gates é um circuito composto por transistores ou blocos lógicos de baixa complexidade. A vantagem dessa arquitetura é a grande disponibilidade de portas lógicas por área. Porém, como não há uma área dedicada para o roteamento, é necessário que o mesmo seja feito sobre as células, muitas vezes inutilizando áreas disponíveis para implementação de uma determinada lógica.
Nos circuitos de arquitetura row-based os blocos lógicos estão dispostos horizontalmente. Existe uma área dedicada de roteamento localizada entre as linhas de blocos lógicos. As arquiteturas row-based e sea-of-gates originaram-se das metodologias de projeto de ASICs, standard-cells e gate-array.
A arquitetura tipo PLD hierárquico é constituído por uma matriz de blocos lógicos, denominados logic arrays blocks, sendo interligados através do recurso de roteamento conhecido como matriz programável de interconexão (PIA). Esse tipo de dispositivo é dito hierárquico, porque os blocos lógicos podem ser agrupados entre si.
A arquitetura tipo matriz simétrica é flexível no roteamento, pois possui canais verticais e horizontais.

37
Figura 2.2 – Dispositivos internos de um FPGA.
Já a figura 2.2 mostra que um FPGA (Field Programmable Gate Arrays) são circuitos programáveis compostos de CLBs, switch boxes, IOBs e canais de roteamento.
2.2 Roteamento e Configuração de um FPGA Nesta seção são discutidos conceitos básicos de roteamento e reconfiguração de circuitos programáveis e reconfiguráveis FPGAs.
O roteamento é a interconexão entre blocos lógicos através de uma rede de camadas de metal. As conexões físicas entre os blocos lógicos são feitas com transistores controlados por bits de memória (PIP) ou por chaves de interconexão (switch matrix).
Eis alguns elementos básicos utilizados na malha de roteamento da família XC4000 da Xilinx:
Conexões globais: estas formam uma rede de interconexão em linhas e colunas ligadas através de chaves de interconexão. Esta rede circunda os blocos lógicos (CLBs) e os blocos de E/S (IOBs).
Matriz de conexão (Switch Matrix): são chaves de interconexão que permitem o roteamento entre os blocos lógicos através das conexões globais.
Conexões diretas: interligam CLBs vizinhos e permitem conectar blocos com menor atraso, pois não utilizam recursos globais de roteamento.
Linhas longas: são conexões que atravessam todo o circuito sem passar pelas matrizes de conexão e são utilizadas para conectar sinais longos.
A exigência de alto poder de processamento e o surgimento de novas aplicações, promovem uma constante busca por alternativas e arquiteturas que visem melhorar a performance dos computadores, especialmente em aplicações de tempo real. Uma destas alternativas é a reconfiguração.

38
Acoplando um dispositivo programável FPGA a um processador de propósito geral (GPP), torna-se possível a exploração eficiente do potencial das chamadas arquiteturas reconfiguráveis.
Arquiteturas reconfiguráveis permitem ao projetista a criação de novas funções, e possibilita a execução de operações com um número consideravelmente menor de ciclos do que necessário em GPPs. Em uma arquitetura reconfigurável, são desnecessárias muitas das unidades funcionais complexas usualmente encontradas em processadores de propósito geral.
Os métodos de reconfiguração de um dispositivo programável e reconfigurável podem ser classificados como:
Reconfiguração total: é a forma de configuração, onde o dispositivo reconfigurável é inteiramente alterado. Também tratada apenas como configuração.
Reconfiguração parcial: é a forma de configuração que permite que somente uma parte do dispositivo seja reconfigurada. A reconfiguração parcial pode ser: não-disruptiva, onde as partes do sistema que não estão sendo reconfiguradas permanecem completamente funcionais durante o ciclo de reconfiguração; ou disruptiva, onde a reconfiguração parcial afeta outras partes do sistema, necessitando de uma parada no funcionamento do mesmo.
Reconfiguração dinâmica: também chamada de run-time reconfiguration (RTR), on-the-fly reconfiguration ou in-circuit reconfiguration. Todas essas expressões podem ser traduzidas também como reconfiguração em tempo de execução. Nesse tipo de reconfiguração não há necessidade de reiniciar o circuito ou remover elementos reconfiguráveis para programação.
Reconfiguração extrínseca: reconfigura parcialmente o sistema, mas somente considerando cada FPGA que o compõe como unidade atômica de reconfiguração.
Reconfiguração intrínseca: reconfigura parcialmente cada FPGA que compõe o sistema.
A partir desta seção apresentam-se conceitos básicos da linguagem VHDL utilizados nas implementações dos circuitos digitais básicos descritos no capítulo 3, os quais serão úteis para entender o projeto em hardware dos algoritmos criptográficos focados neste livro.
2.3 VHDL - Descrição Estrutural e Comportamental Na linguagem VHDL (VHSIC Hardware Description Language) existem duas formas para a descrição de circuitos digitais: a estrutural e a comportamental. A forma estrutural indica os diferentes componentes que constituem o circuito e suas respectivas interconexões. Desta maneira pode-se especificar um circuito e saber como é seu funcionamento.

39
A forma comportamental consiste em descrever o circuito pensando no seu comportamento e funcionamento e não na sua estrutura. Essa metodologia facilita a descrição de circuitos onde a estrutura interna não está disponível, mas o seu funcionamento e comportamento podem ser interpretados. Assim, esse tipo de descrição vem se desenvolvendo a cada dia. A descrição comportamental pode-se dividir em duas metodologias, dependendo do nível de abstração: a descrição algorítmica e de fluxo de dados.
Na descrição de um circuito utilizando a linguagem VHDL, é comum ter-se trechos implementados de maneira comportamental e estrutural, sendo de responsabilidade do projetista a utilização correta dos métodos de implementação de circuitos em VHDL.
2.4 Exemplo dos Estilos de Descrições em VHDL A figura 2.3 representa um comparador de 1 bit simplificado. Este será descrito nos dois estilos de descrição de circuitos digitais em VHDL, estrutural e comportamental. Onde U1, U2 são os componentes do circuito, L1 é uma linha de conexão entre os componentes, e E1, E2 e S são as portas de entrada e saída do circuito.
Figura 2.3 - Representação de um comparador de 1 bit
O funcionamento do comparador de 1 bit é simplificado, onde os valores lógicos da portas de entrada E1 e E2 serão comparados. Se E2 for menor que E1 a saída S recebe o valor lógico ‘1’, caso contrário, ‘0’. Este exemplo do comparador de 1 bit será utilizado para demostrar as formas de descrição de circuito digitais em VHDL nas seções 2.4.1, 2.4.2 e 2.4.3.
2.4.1 Descrição Algorítmica
A descrição algorítmica é um conjunto de passos que descreve de forma comportamental o circuito digital projetado. Em primeiro lugar, deve-se descrever a entidade do circuito, onde são definidas as portas de entrada e saída. A entidade (entity) independente do método de descrição de circuitos digitais sempre se mantém a mesma. Já a arquitetura (architecture) é responsável pela descrição do circuito de maneira estrutural ou comportamental. Neste caso, o comparador de 1 bit (figura 2.3) é descrito na seqüência, de maneira comportamental, aplicando o princípio algorítmico.

40
Comparador de 1 Bit (Descrição Algorítmica)
-- definição da entidade: portas de E/S
entity comp is
port port port port (e1,e2: inininin bit;
s: outoutoutout bit);
eeeend nd nd nd comp;
-- definição da arquitetura: descrição da lógica interna do circuito
architecture comp_alg of comp is
begin
process (e1,e2)
begin
if e2 < e1 then
s<=’1’;
else s<= ‘0’;
end if;
end process;
end comp_alg;
Nota-se que a comparação foi descrita de forma comportamental utilizando o comando seqüencial IF-THEN-ELSE, desprezando a lógica composta pelas portas lógicas XOR e AND do comparador de 1 bit representado na figura 2.3.
2.4.2 Descrição de Fluxo de Dados
A descrição de fluxo de dados pode ser visualizada como a transferência entre registradores possibilitando o paralelismo de instruções. Quando se tem várias instruções, estas tornam-se concorrentes entre si.
Comparador de 1 Bit (Descrição de Fluxo de Dados )
architecture architecture architecture architecture comp_fluxo_dados ofofofof comp isisisis
begin
s<= e1 whenwhenwhenwhen e2> e1
else else else else e2;
endendendend comp_fluxo_dados;
É interessante perceber que em ambas as descrições comportamentais não foi necessário utilizar os componentes do circuito descrito na figura 2.3, descrevendo apenas o comportamento em um alto nível de abstração.
2.4.3 Descrição Estrutural

41
Para descrever um circuito na forma estrutural, deve-se conhecer seus componentes e interconexões. Em sistemas onde não é possível visualizar a estrutura interna de maneira detalhada, torna-se difícil a descrição utilizando a metodologia estrutural.
Comparador de 1 bit (Descrição Estrutural)
architecture architecture architecture architecture comp_fluxo_dados ofofofof comp isisisis
signal signal signal signal l1: bit;
beginbeginbeginbegin
u1: entityentityentityentity xor2 port map port map port map port map (e1,e2,l1);
u2: entityentityentityentity and2 port map port map port map port map (e1,l1,s);
endendendend comp_fluxo_dados;
Interessante observar que sem a correta visualização dos componentes e as respectivas interconexões do comparador de 1 bit, conforme a descrição da figura 2.3, pode dificultar sua descrição estrutural em VHDL.
2.5 Elementos Sintáticos do VHDL Toda linguagem possui elementos sintáticos, tipos de dados e estruturas. A linguagem VHDL não é diferente, porém é uma linguagem de descrição de hardware, portanto deve oferecer suporte para a descrição de trechos concorrentes. A seguir os elementos sintáticos mais comuns:
Comentários: Qualquer linha precedida de -- não será compilada.
Símbolos especiais: Contendo apenas um caracter: + - / * ( ) . , : ; & ‘ “ < > = | # Contendo dois caracteres: ** => := /= >= <= <> --
Identificadores: Identificadores são usados para nomear objetos da linguagem como variáveis, sinais, rotinas, etc. Composto por letras, números e o símbolo “_”. Nunca pode conter símbolos especiais ou coincidir com palavras reservadas. Maiúsculas e minúsculas são consideradas iguais, assim VHDL, vhdl e VhDl são possibilidades que representam o mesmo objeto.
Números: Qualquer número que se encontra é considerado na base 10. Admite-se a notação científica convencional para números com ponto flutuante. É possível alterar a base de um número usando o simbolo “#”. Exemplo: 2#00001111, 16#0F ambos representam o número 15, respectivamente na base 2 e 16.
Caracteres: Qualquer caracter deve estar entre aspas simples: Exemplo ‘1’ ‘A’.
Cadeia de bits: Cadeia ou vetor de bits é uma seqüência de bits em uma determinada base Ex.: B “00001111”, X”0F”, onde B é binário e X Hexadecimal.
Palavras reservadas: São palavras que possuem um significado especial, são instruções e elementos que permitem definir sentenças. As palavras reservadas do padrão VHDL’93 são (ORDONEZ, 2003):
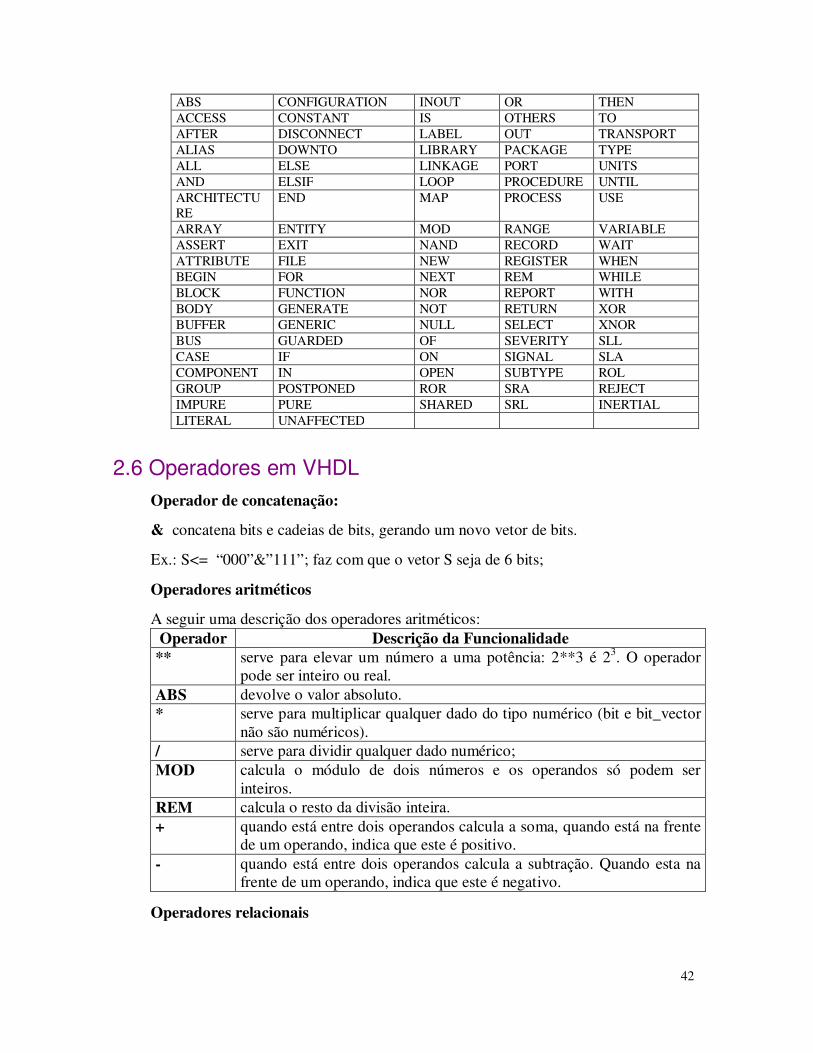
42
ABS CONFIGURATION INOUT OR THEN ACCESS CONSTANT IS OTHERS TO AFTER DISCONNECT LABEL OUT TRANSPORT ALIAS DOWNTO LIBRARY PACKAGE TYPE ALL ELSE LINKAGE PORT UNITS AND ELSIF LOOP PROCEDURE UNTIL ARCHITECTURE
END MAP PROCESS USE
ARRAY ENTITY MOD RANGE VARIABLE ASSERT EXIT NAND RECORD WAIT ATTRIBUTE FILE NEW REGISTER WHEN BEGIN FOR NEXT REM WHILE BLOCK FUNCTION NOR REPORT WITH BODY GENERATE NOT RETURN XOR BUFFER GENERIC NULL SELECT XNOR BUS GUARDED OF SEVERITY SLL CASE IF ON SIGNAL SLA COMPONENT IN OPEN SUBTYPE ROL GROUP POSTPONED ROR SRA REJECT IMPURE PURE SHARED SRL INERTIAL LITERAL UNAFFECTED
2.6 Operadores em VHDL Operador de concatenação:
& concatena bits e cadeias de bits, gerando um novo vetor de bits.
Ex.: S<= “000”&”111”; faz com que o vetor S seja de 6 bits;
Operadores aritméticos
A seguir uma descrição dos operadores aritméticos: Operador Descrição da Funcionalidade
** serve para elevar um número a uma potência: 2**3 é 23. O operador pode ser inteiro ou real.
ABS devolve o valor absoluto. * serve para multiplicar qualquer dado do tipo numérico (bit e bit_vector
não são numéricos). / serve para dividir qualquer dado numérico; MOD calcula o módulo de dois números e os operandos só podem ser
inteiros. REM calcula o resto da divisão inteira. + quando está entre dois operandos calcula a soma, quando está na frente
de um operando, indica que este é positivo. - quando está entre dois operandos calcula a subtração. Quando esta na
frente de um operando, indica que este é negativo.
Operadores relacionais

43
= ou /= O primeiro indica true, se os operandos forem iguais e false se forem diferentes. O segundo funciona justamente ao contrário, indicando o fato das relações sendo comparadas são diferentes ou não.
< , <= , > ou >= indicam respectivamente menor, menor igual, maior e maior igual.
Operadores lógicos
NOT , AND , NAND , OR , NOR , XOR ou XNOR atuam sobre os tipos bit, bit_vector e boolean. No caso de operações com vetores, a operação é realizada bit a bit.
2.7 Tipos de Dados em VHDL Há basicamente dois tipos de dados: escalares e compostos. A seguir, uma melhor descrição de cada um deles.
2.7.1 Tipos Escalares
Inteiros: São dados cujo conteúdo é um valor numérico inteiro. Pode definir um intervalo usando a palavra reservada RANGE, e os limites do intervalo são do tipo numérico inteiro.
Ex.: TYPETYPETYPETYPE integer IS RANGEIS RANGEIS RANGEIS RANGE 0 TOTOTOTO 255,
neste caso tem-se um tipo inteiro que pode variar dentro do intervalo de 0 a 255.
Reais: Conhecidos como numeração com ponto flutuante que define um número real. Pode-se utilizar intervalos do tipo numérico real.
Ex.: TYPETYPETYPETYPE real IS RANGEIS RANGEIS RANGEIS RANGE 0.0 TOTOTOTO 9.0;
Físicos: Como o próprio nome já diz, são dados que correpondem a fenômenos físicos e portanto expressam medidas físicas.
Ex.: TYPETYPETYPETYPE altitude IS RANGEIS RANGEIS RANGEIS RANGE 0 TOTOTOTO 1.0e6;
UNITSUNITSUNITSUNITS
um;
mm=1000um;

44
M=1000mm
Inch=25.4 mm;
END UNITSEND UNITSEND UNITSEND UNITS;
Enumerados: São dados que podem assumir qualquer valor especificado em um conjunto finito. Este conjunto é indicado através de uma lista entre parênteses onde os elementos estão separados por vírgula.
Ex.: TYPETYPETYPETYPE estados ISISISIS (reset, busca, executa);
2.7.2 Tipos Compostos Matrizes: É uma coleção de elementos do mesmo tipo acessados por um índice. Pode ser unidimensional e multidimencional.
Ex.: TYPETYPETYPETYPE positivo ISISISIS ARRAYARRAYARRAYARRAY (byte RANGERANGERANGERANGE 0 TOTOTOTO 127 ) OFOFOFOF integer;
Registro: É equivalente ao tipo registro (record) de outra linguagens. Ex.: TYPETYPETYPETYPE agenda IS IS IS IS
RECORDRECORDRECORDRECORD
Nome: string;
Rg: integer;
END RECORDEND RECORDEND RECORDEND RECORD;
Subtipos de dados : É um nome de um conjunto de tipos já definidos.
Ex.: SUBTYPESUBTYPESUBTYPESUBTYPE digitos ISISISIS integer RANGERANGERANGERANGE 0 TOTOTOTO 9,
neste caso o subtipo digitos representa os números inteiros entre 0 e 9.
2.8 Atributos em VHDL Os elementos como variáveis, sinais e outros podem ser acompanhados por atributos. Os atributos são utilizados para explorar as opções de cada elemento da linguagem. Os atributos estão associados a elementos da linguagem através da aspa simples. O tipo do elemento define os atributos herdados. Os atributos definidos neste tópico são os mais utilizados.
Se o elemento t é um tipo enumerado, inteiro, real, físico, herdará os seguintes atributos:
t’left. limite esquerdo do tipo t t’right limite direito do tipo t. t’low limite inferior do tipo t.

45
t’high limite superior do tipo t.
Supondo um tipo t como o anterior, um membro x desse tipo, e um n como valor inteiro, pode-se utilizar os seguintes atributos.
t’pos (x) posição de x dentro do tipo t. t’val (n) elemento n do tipo t.
t’leftof (x) elemento que está à esquerda de x em t. t’highof (x) elemento que está à direita de x em t. t’pred (x) elemento que está adiante de x em t t’succ (x) elemento que está atrás de x em t
Supondo que a é uma matriz e n é um inteiro desde 1 até o número de dimensão da matriz, então pode-se utilizar os seguintes atributos.
a’left (n) limite esquerdo do intervalo de dimensão n de a.
a’right (n) limite direito do intervalo de dimensão n de a. a’low (n) limite inferior do intervalo de dimensão n de a. a’high (n) limite superior do intervalo de dimensão n de a. a’range (n) intervalo do índice de dimensão n de a.
A’length (n) comprimento do índice de dimensão n de a.
Supondo que s é um sinal, pode-se utilizar os seguintes atributos:
s’event Devolve true, se acontecer uma troca de valores
do sinal s. s’stable (temp) Devolve true, se o sinal for estável durante o
último período de temp.
O atributo event é um dos atributos mais utilizados. Através dele é possível detectar a borda de subida de determinado sinal. Ex.: IF s’event AND s=’1’ THEN
2.9 Constantes, Variáveis e Sinais Um elemento em VHDL contém um valor de um tipo específico. Há três tipos de elemento em VHDL: constantes, variáveis e sinais. As variáveis e as constantes possuem um conceito semelhante ao de outras linguagem, enquanto que o conceito de sinais é diferente.
Constantes

46
Uma constante é um elemento iniciado com um determinado valor que não pode ser modificado depois de ter sido atribuído.
Ex.: CONSTANTCONSTANTCONSTANTCONSTANT zera: integer : = 0;
CONSTANTCONSTANTCONSTANTCONSTANT max: bit_vector ( 3 downto 0 ) : = “1010”;
Variáveis
Uma variável em VHDL é similar ao conceito de variável de outras linguagens. Toda variável deve ser declarada em um processo (PROCESS – que será explicado na seção 2.16) ou num subprograma. Seu escopo é válido apenas no processo ou subprograma em que foi declarada. As variáveis são elementos abstratos da linguagem e possuem uma concordância física real imediata, isto é, quando é atribuído algum valor para uma variável, a atualização é instantânea.
Ex.: VARIABLEVARIABLEVARIABLEVARIABLE flag: bit;
VARIABLEVARIABLEVARIABLEVARIABLE registrador: bit_vector (2 downto 0);
Sinais
Os sinais são declarados da mesma maneira que as constantes e variáveis com a diferença que os sinais podem ser, normal, register ou bus. Se na declaração não se especifica nada, o sinal é do tipo normal. Para utilizar os tipos register e bus, deve-se declarar explicitamente com as palavras reservadas REGISTER e BUS.
Os sinais devem ser declarados unicamente nas arquiteturas, pacotes ou nos blocos concorrentes. O conceito de sinais possui um significado físico. Representam conexões reais de um circuito. Isto na verdade não ocorre instantaneamente e sim quando o processo acaba ou encontra uma sentença WAIT.
Ex.: SIGNALSIGNALSIGNALSIGNAL teste: bit;
SIGNALSIGNALSIGNALSIGNAL byte: bit_vector ( 7 DOWNTODOWNTODOWNTODOWNTO 0) BUSBUSBUSBUS : = “00001111”;
2.10 Entidade e Arquitetura Entidade ( ENTITY )
A entidade é uma estrutura onde se define as entradas e saídas de um determinado circuito. Na declaração desta estrutura pode-se incluir outros elementos. A forma geral para declaração de uma entidade é:
ENTITYENTITYENTITYENTITY nome ISISISIS
[GENERICGENERICGENERICGENERIC (lista de parâmetros);]
[PORTPORTPORTPORT ( lista de portas);]
[declarações]
[BEGINBEGINBEGINBEGIN sentenças]
ENDENDENDEND [ENTITYENTITYENTITYENTITY] [nome];

47
Na declaração da entidade, observam-se os elementos como PORT e GENERIC. Após a instrução PORT, é declarada uma lista de portas de entrada e saída do circuito. Já a instrução GENERIC define uma lista de parâmetros que são instanciados com a instrução GENERIC MAP, assim como o PORT MAP instancia as portas de entradas e saídas do circuito, o GENERIC MAP instancia os parâmetros pré-definidos na entidade. A seguir um exemplo de utilização:
Ex.: ENTITYENTITYENTITYENTITY registrador ISISISIS
GENERICGENERICGENERICGENERIC (tamanho: integer);
PORTPORTPORTPORT (Clk: ININININ bit;
Enable: ININININ bit;
Din: ININININ bit_vector (tamanho-1 DOWNTODOWNTODOWNTODOWNTO 0);
Dout: OUTOUTOUTOUT bit_vector (tamanho-1 DOWNTODOWNTODOWNTODOWNTO 0));
ENDENDENDEND registrador;
Arquitetura ( ARCHITECTURE )
Na arquitetura implementa-se o funcionamento do módulo definido na entidade. Toda arquitetura faz referência a uma entidade especifica, mas uma entidade pode referenciar diferentes arquiteturas. A forma geral para declaração de uma arquitetura é:
ARCHITECTUREARCHITECTUREARCHITECTUREARCHITECTURE nome OFOFOFOF nome_entidade ISISISIS
[declarações]
BEGIN BEGIN BEGIN BEGIN
[sentenças concorrentes]
ENDENDENDEND [ARCHITECTUREARCHITECTUREARCHITECTUREARCHITECTURE] [nome];
2.11 Componentes em VHDL O componente é uma estrutura que referencia diretamente uma entidade e possibilita a instanciação e replicação da mesma sem a necessidade de descrevê-la novamente. A forma geral para declarar um componente é:
COMPONENTCOMPONENTCOMPONENTCOMPONENT nome [ISISISIS]
[GENERICGENERICGENERICGENERIC (lista de parâmetros);]
[PORTPORTPORTPORT (lista de portas);]
ENDENDENDEND COMPONENTCOMPONENTCOMPONENTCOMPONENT [nome];
Ex.: COMPONENTCOMPONENTCOMPONENTCOMPONENT inv
PORTPORTPORTPORT (e: ININININ bit; s: OUTOUTOUTOUT bit);
ENDENDENDEND COMPONENTCOMPONENTCOMPONENTCOMPONENT;
A forma geral para instanciar um componente é:

48
ref_id: [COMPONENT] nome_do_componente | ENTITY nome_da_entidade [(nome_da_arquitetura)] | CONFIGURATION nome_da_configuração [GENERIC MAP (parametros)] [PORT MAP (lista de portas)];
Onde, ref_id é uma referência ao componente que está sendo instanciado, possibilitando a réplica do mesmo componente, bastando mudar o identificador de referência.
Ex.: u1:inv PORTPORTPORTPORT MAPMAPMAPMAP (e=>, s => s1);
u2:inv PORTPORTPORTPORT MAPMAPMAPMAP (e=>, s => s1);
2.12 Pacotes em VHDL (Package) O pacote ou PACKAGE é uma coleção de tipos, constantes, subprogramas, etc. Esta é a maneira de agrupar elementos relacionados. Os pacotes estão divididos em duas partes, a declaração e corpo, onde o corpo contém definições de procedimentos e funções que podem ser omitidos, se não há nenhum desses elementos para declarar. A forma geral para a declaração de um pacote é:
PACKAGEPACKAGEPACKAGEPACKAGE nome ISISISIS
declarações
ENDENDENDEND [PACKAGEPACKAGEPACKAGEPACKAGE] [nome];
PACKAGEPACKAGEPACKAGEPACKAGE BOBOBOBODYDYDYDY nome ISISISIS
declarações , subprogramas, etc.
ENDENDENDEND [PACKAGEPACKAGEPACKAGEPACKAGE BODYBODYBODYBODY] [nome];
Uma vez declarado o pacote, os elementos podem ser referenciados através do nome do pacote. Pode-se referenciar apenas um elemento ou todos, bastando declarar no programa principal quais os elementos do pacote que estarão disponíveis.
A seguir, um exemplo utilizando PACKAGE.
PACKAGEPACKAGEPACKAGEPACKAGE cpu ISISISIS
SUBTYPESUBTYPESUBTYPESUBTYPE byte ISISISIS bit_vector (7 DOWNTODOWNTODOWNTODOWNTO 0);
FUNCTIONFUNCTIONFUNCTIONFUNCTION inc (valor: interger) RETURNRETURNRETURNRETURN interger;
ENDENDENDEND cpu;
PACKAGE BODYPACKAGE BODYPACKAGE BODYPACKAGE BODY cpu ISISISIS
FUNCTIONFUNCTIONFUNCTIONFUNCTION inc (valor: interger) RETURNRETURNRETURNRETURN interger ISISISIS
VARIABLEVARIABLEVARIABLEVARIABLE result: integer;
BEGINBEGINBEGINBEGIN
Result <= valor +1;
RETURNRETURNRETURNRETURN result;
ENDENDENDEND inc;
ENDENDENDEND cpu;

49
Ex.: Utilização do pacote declarado.
VARIABLEVARIABLEVARIABLEVARIABLE reg: work.cpu.byte;
pc <= work.cpu.inc(pc);
Ou ainda: quando é declarado o uso do pacote no início do programa, não é necessário apontar o caminho de referência.
Ex.: USEUSEUSEUSE work.cpu.ALLALLALLALL;
...
VARIABLEVARIABLEVARIABLEVARIABLE reg: byte;
pc <= inc(pc);
2.13 Configuração em VHDL (Configuration) A configuração é um bloco especial do VHDL que permite especificar os mínimos enlaces “componente-entidade”, através da parte declarativa de uma arquitetura. A forma geral para a declaração de uma configuração é:
CONFIGURATIONCONFIGURATIONCONFIGURATIONCONFIGURATION nome OFOFOFOF nome_entidade ISISISIS
{ sentenças | atributos }
ENDENDENDEND [CONFIGURATIONCONFIGURATIONCONFIGURATIONCONFIGURATION] [nome];
Outros elementos podem ser declarados na configuração, mas não são discutidos neste livro.
2.14 Procedimentos e Funções em VHDL Procedimentos e funções podem ser declarados nas partes declarativas de arquiteturas, blocos, pacote, etc. A forma geral para a declaração de procedimentos e funções é: PROCEDUREPROCEDUREPROCEDUREPROCEDURE nome [(parâmetros)] ISISISIS
[declarações]
BEGINBEGINBEGINBEGIN
[sentenças seqüenciais]
ENDENDENDEND [PROCEDUREPROCEDUREPROCEDUREPROCEDURE] [nome];
FUNCTIONFUNCTIONFUNCTIONFUNCTION nome [(parâmetros)] RETURNRETURNRETURNRETURN tipo ISISISIS
[declarações]
BEGINBEGINBEGINBEGIN

50
[sentenças seqüenciais]
ENDENDENDEND [FUNCTIONFUNCTIONFUNCTIONFUNCTION] [nome];
Com relação aos parâmetros nas funções, estes devem ser apenas do tipo IN (entrada) e podem ser CONSTANT e SIGNAL. Nos procedimentos, os parâmetros podem ser do tipo CONSTANT, IN, OUT e INOUT, sendo que CONSTANT é apenas do tipo IN. Ex.: PROCEDUREPROCEDUREPROCEDUREPROCEDURE inc_pc ISISISIS
BEGIN BEGIN BEGIN BEGIN
next_PC := PC + 1;
ENDENDENDEND;
2.15 Execução Concorrente em VHDL A execução de instruções concorrentes é feita através de atribuições entre sinais, utilizando o operador “<=”. Para facilitar algumas atribuições complexas, o VHDL possui alguns elementos de alto nível que são instruções condicionais, de seleção, e outras que auxiliam a implementação.
Atribuição condicional concorrente: WHEN...ELSE...
Toda expressão condicional descreve o hardware de forma concorrente. Deve incluir todas as possibilidades de variação de um sinal. A forma geral para declaração de uma atribuição condicional concorrente é: sinal <= {forma_de_onda WHENWHENWHENWHEN condição
ELSEELSEELSEELSE} forma_de_onda [ WHENWHENWHENWHEN condição];
Ex.: s <= ‘0’ WHENWHENWHENWHEN a>b ELSEELSEELSEELSE
‘1’ WHENWHENWHENWHEN a<b ELSEELSEELSEELSE
‘X’;
Atribuição com seleção concorrente: WITH...SELECT...WHEN
Este tipo de atribuição é semelhante a construções do case e do switch em Pascal e C. A atribuição é executada com base no valor da expressão em teste. A expressão deve sempre retornar um tipo discreto enumerado, inteiro ou um vetor de uma dimensão. A forma geral para declaração de uma atribuição com seleção concorrente é: WITHWITHWITHWITH expressão SELECTSELECTSELECTSELECT
sinal <= forma_de_onda WHENWHENWHENWHEN caso
{, forma_de_onda WHENWHENWHENWHEN caso};
Ex.: WITHWITHWITHWITH sel SELECTSELECTSELECTSELECT
s <= ‘1’ WHENWHENWHENWHEN “00”,
‘0’ WHENWHENWHENWHEN OTHERSOTHERSOTHERSOTHERS;

51
Estes são os principais e mais utilizados métodos para atribuições concorrentes. As atribuições em blocos concorrentes (BLOCK) não são discutidas neste livro. Para maiores informaçõs, verificar as aplicações e exemplos descritos em (ORDONEZ, 2003).
2.16 Execução Seqüencial
Processo ( PROCESS )
Os processos são, por definição, concorrentes, mas o conteúdo de cada processo é executado de forma seqüencial. A forma geral para declaração de um processo é: [id_proc:] [POSTPONEDPOSTPONEDPOSTPONEDPOSTPONED] PROCESSPROCESSPROCESSPROCESS [(lista sensível)] [ISISISIS]
Declarações
BEGIN BEGIN BEGIN BEGIN
Instruções seqüenciais
ENDENDENDEND [POSTPONEDPOSTPONEDPOSTPONEDPOSTPONED] PROCESSPROCESSPROCESSPROCESS [id_proc];
Onde id_proc é um rótulo ou uma etiqueta opcional, “lista sensível” é uma lista de sinais separados por vírgula que estão entre parênteses. Quando ocorre um evento de mudança em qualquer sinal da lista sensitiva, o processo é executado. Processos podem não possuir lista de sensibilidade, mas devem ser controlados pela sentença WAIT.
Na parte de declarações, podem ser criadas variáveis, tipos, subprogramas, atributos, etc. Não é possível declarar sinais. Declarar um processo e utilizar o elemento POSTPONED significa que este processo só será executado após a execução dos outros processos existentes na descrição de um determinado circuito digital. Ex.: PROCESSPROCESSPROCESSPROCESS (a,b);
BEGINBEGINBEGINBEGIN
a<= a ANDANDANDAND b;
END PROCESSEND PROCESSEND PROCESSEND PROCESS;
Comando condicional seqüencial: IF...THEN...ELSE
A partir do resultado de uma expressão booleana, decide-se qual sentença será executada. A forma geral para descrever um comando condicional seqüencial é: [id_if:] IFIFIFIF condição THENTHENTHENTHEN
sentença
{ELSIFELSIFELSIFELSIF condição THENTHENTHENTHEN sentença}
{ELSEELSEELSEELSE sentença}
ENDENDENDEND IFIFIFIF [id_if];
Note que há a possibilidade de utilizar IFs aninhados, utilizando a palavra reservada ELSIF, sendo que ELSIF não pede um END IF como finalização de comando.

52
Ex.: IFIFIFIF a>b THENTHENTHENTHEN
c <= a;
ELSIFELSIFELSIFELSIF a<b THENTHENTHENTHEN
c <= b;
ELSEELSEELSEELSE
c <= a ANDANDANDAND b;
ENDENDENDEND IFIFIFIF;
Comando de seleção seqüencial : CASE
Esta estrutura permite executar uma ou outra instrução, dependendo do resultado de uma expressão, esta deve ser do tipo discreto ou uma matriz de caracteres de uma dimensão. A forma geral para descrever um comando de seleção seqüencial é: [id_case:] CASECASECASECASE expressão ISISISIS
WHENWHENWHENWHEN caso => sentença;
{WHENWHENWHENWHEN caso => sentenças;}
[WHENWHENWHENWHEN OTHERSOTHERSOTHERSOTHERS => sentenças]
ENDENDENDEND CASECASECASECASE; [id_case]
O comando “case” exige que todas as possibilidades de casos sejam esgotadas. A palavra reservada OTHERS satisfaz todos os casos não previstos anteriormente. Ex.: CASECASECASECASE semaforo ISISISIS
WHENWHENWHENWHEN “00” => sinal <= “verde”;
WHENWHENWHENWHEN “01” => sinal <= “amarelo”;
WHENWHENWHENWHEN “10” => sinal <= “vermelho”;
WHEN OTHERSWHEN OTHERSWHEN OTHERSWHEN OTHERS => sinal <= “Erro”;
END CASEEND CASEEND CASEEND CASE;
Comandos de laço: FOR e WHILE
A definição dos laços FOR e WHILE segue a mesma estrutura e implementação de outras linguagens como C, Java, Fortran, C++ e etc., onde determinado trecho seqüencial é executado o número de vezes determinado em um intervalo. No caso do comando FOR ou WHILE, a sentença que irá repetir deve estar entre as palavras reservadas LOOP...END. A forma geral para descrever os comandos de laço FOR e WHILE é:
Comando FOR Comando WHILE [id_for:] FORFORFORFOR identificador ININININ intervalo LOOP LOOP LOOP LOOP
sentença
ENDENDENDEND LOOPLOOPLOOPLOOP [id_for];
[id_while:] WHILEWHILEWHILEWHILE condição LOOPLOOPLOOPLOOP
sentença
ENDENDENDEND LOOPLOOPLOOPLOOP [id_while];

53
Os comandos de laço possuem métodos auxiliares para a interrupção usando-se os comandos: NEXT e EXIT. O comando NEXT detém a execução do laço atual e passa para a próxima execução, enquanto que o comando EXIT finaliza o laço que está executando. Ex.: FORFORFORFOR I ININININ 0 TOTOTOTO 9 LOOPLOOPLOOPLOOP
A <= i+1;
EXITEXITEXITEXIT WHENWHENWHENWHEN a = 6;
ENDENDENDEND LOOPLOOPLOOPLOOP;
No próximo capítulo, estas definições e exemplos da linguagem VHDL serão usadas para implementar ciruitos digitais básicos, os quais serão usados nos capítulos seguintes, o que facilitará o entendimento da versão em hardware dos algoritmos criptográficos objeto de estudo neste livro.

54
Capítulo 3 Exemplos de Circuitos em VHDL
No terceiro capítulo, apresentam-se conceitos e a correspondente descrição em VHDL, no padrão VHDL´93, de alguns circuitos básicos tais como circuitos combinacionais (Ex. portas lógicas básicas, multiplexadores, demultiplexadores, somadores, subtratores, multiplicadores, divisores, decodificadores, codificadores e comparadores). Para cada circuito implementado, são gerados dados estatísticos de sua respectiva implementação em FPGA. As estatísticas geradas são: espaciais, como número de flip-flops, de LUTs de 4 e 3 entradas e de CLBs utilizadas; e temporais, relacionada aos atrasos para gerar a saída desejada de um determinado circuito. Este tempo é o resultado da soma do tempo de lógica mais o de roteamento do circuito digital. As estatísticas geradas são comparadas e analisadas.
3.1 Circuitos Combinacionais Um circuito combinacional é constituído por um conjunto de portas lógicas que determinam os valores das saídas diretamente, a partir dos valores atuais das entradas. Pode-se dizer que um circuito combinacional realiza uma operação de processamento de informação, a qual pode ser especificada por meio de um conjunto de equações booleanas. No caso, cada combinação de valores de entrada pode ser vista como uma informação diferente, e cada conjunto de valores de saída representa o resultado da operação. Na figura 3.1, observa-se a representação geral de um circuito combinacional com n entradas que passam por uma lógica combinacional até gerar m saídas.
Figura 3.1 - Diagrama genérico de um circuito combinacional.
O objetivo da análise de um circuito combinacional é determinar seu comportamento. Então, dado o diagrama de um circuito, deseja-se encontrar as

55
equações que descrevem suas saídas, a partir de um conjunto de entradas. Uma vez encontradas tais equações, pode-se obter a tabela verdade, caso esta seja necessária.
É importante certificar-se de que o circuito é combinacional e não seqüencial. Um modo prático é verificar se existe algum caminho (ou ligação) entre a saída e a entrada do circuito. Caso não exista, o circuito é combinacional.
Os circuitos combinacionais são responsáveis por operações lógicas e aritméticas dentro de um sistema digital. Além das operações lógicas e aritméticas como adição, subtração e complementação, existem ainda outras funções necessárias para a realização de conexões entre os diversos operadores. Dentre estas funções, estão a multiplexação e a decodificação. Os elementos que realizam estas duas últimas operações são denominados multiplexadores e decodificadores.
A maioria dos circuitos e sistemas digitais são implementados usando circuitos básicos, conhecidos como portas lógicas. Estes circuitos simples e básicos são estudados na seção 3.2.
3.2 Portas lógicas Básicas As portas lógicas básicas estão presentes em todos os circuitos lógicos, possuem estrutura e funcionamento simplificados e podem ser classificadas como portas: AND, OR, NOT, NAND, NOR e XOR e XNOR, adotando o padrão VHDL’93.
3.2.1 Porta AND
A função lógica da porta AND é combinar dois ou mais sinais de entrada de forma equivalente a um circuito em série, para produzir um único sinal de saída. A porta AND produz uma saída 1, se todos os sinais de entrada forem 1. Caso qualquer um dos sinais de entrada for 0, a porta AND produzirá um sinal de saída igual a 0. Na figura 3.2, visualiza-se a representação de uma porta AND de 2 entradas, a tabela verdade e um exemplo de funcionamento.
Figura 3.2 – (a) representação, (b) tabela verdade e (c) exemplo de funcionamento de uma
porta AND de duas entradas.
O exemplo de funcionamento da figura 3.2 (c), mostra duas portas AND, onde a saída de uma alimenta a entrada da outra. A resposta de cada operação AND está relacionada com a tabela verdade, figura 3.2 (b).

56
A linguagem VHDL tem como uma de suas primitivas a porta AND, assim como todas as outras portas lógicas básicas, facilitando a implementação de circuitos digitais. O código VHDL de uma porta AND de duas entradas, a e b e uma saída c é:
Porta AND de duas entradas de 1 bit
librarylibrarylibrarylibrary ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
-- declaração da entidade
entity and2 is
port (a,b: in std_logic;
c: out std_logic);
end and2;
-- declaração da arquitetura
architecture arch_and2 of and2 is
begin
c <= a and b;
end arch_and2;
3.2.2 Porta OR
A função lógica de uma porta OR consiste em combinar dois ou mais sinais de entrada, de forma equivalente a um circuito em paralelo, para produzir um único sinal de saída. A porta OR produz uma saída 1, se qualquer um dos sinais de entrada for igual a 1, ou produzirá um sinal de saída igual a 0 se todos os sinais de entrada forem 0. A figura 3.3, mostra a representação de uma porta OR de 2 entradas, a tabela verdade e um exemplo de funcionamento.
Figura 3.3 – (a) representação, (b) tabela verdade e (c) exemplo de funcionamento de
uma porta OR de duas entradas.
O código VHDL de uma porta OR de duas entradas a e b e uma saída c utilizando as primitivas que o VHDL’93 oferece é:
Porta OR de duas entradas de 1 bit
librarylibrarylibrarylibrary ieee;

57
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity or2 isisisis
portportportport (a,b: inininin std_logic;
c: outoutoutout std_logic);
endendendend or2;
architecturearchitecturearchitecturearchitecture arch_or2 ofofofof or2 isisisis
beginbeginbeginbegin
c <= a or b;
endendendend arch_or2;
3.2.3 Porta NOT
A função lógica implementada por uma porta NOT é inverter o sinal de entrada, ou seja, se o sinal de entrada for 0 ela produz uma saída 1, se a entrada for 1 produz uma saída 0. A representação de uma porta NOT, a tabela verdade e um exemplo de funcionamento é melhor visualizada na figura 3.4.
Figura 3.4 – (a) representação, (b) tabela verdade e (c) exemplo de funcionamento de uma
porta NOT.
O código VHDL de uma porta NOT utilizando as primitivas que o VHDL’93 oferece é:
Porta NOT de 1 bit
librarylibrarylibrarylibrary ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity inv isisisis
portportportport (a: inininin std_logic;
c: out std_logic);
end inv;
architecture arch_inv of inv is
begin
c <= not a;
end arch_inv;
3.2.4 Porta NAND
A função lógica implementada por uma porta NAND é eqüivalente a uma porta AND seguida de uma porta NOT, isto é, ela produz uma saída que é o inverso da saída produzida pela porta AND. Na figura 3.5 tem-se a representação de uma porta

58
NAND de duas entradas a e b e uma saída c, a tabela verdade e um exemplo de funcionamento.
Figura 3.5 – (a) Representação, (b) tabela verdade e (c) exemplo de funcionamento de
uma porta NAND de duas entradas.
O código VHDL de uma porta NAND de duas entradas a e b e uma saída c utilizando as primitivas que o VHDL’93 oferece é:
Porta NAND de duas entradas de 1 bit librarylibrarylibrarylibrary ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity nand2 iiiissss
portportportport (a,b: inininin std_logic;
c: outoutoutout std_logic);
endendendend nand2;
architecturearchitecturearchitecturearchitecture arch_nand2 ofofofof nand2 isisisis
beginbeginbeginbegin
c <= a nand b;
endendendend arch_nand2;
3.2.5 Porta NOR
A função lógica implementada por uma porta NOR é eqüivalente a uma porta OR seguida por uma porta NOT. Isto é, ela produz uma saída que é o inverso da saída produzida pela porta OR. Na figura 3.6, visualiza-se a representação de uma porta NOR de duas entradas a e b e uma saída c, a tabela verdade e um exemplo de funcionamento.
Figura 3.6 – (a) representação, (b) tabela verdade e (c) exemplo de funcionamento
respectivamente de uma porta NOR de duas entradas.

59
O código VHDL de uma porta NOR de duas entradas a e b e uma saída c utilizando as primitivas que o VHDL’93 oferece é:
Porta NOR de duas entradas de 1 bit
librarylibrarylibrarylibrary ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity nor2 isisisis
portportportport (a,b: inininin std_logic;
c: outoutoutout std_logic);
endendendend nor2;
architecturearchitecturearchitecturearchitecture arch_nor2 ofofofof nor2 isisisis
beginbeginbeginbegin
c <= a nor b;
endendendend arch_nor2;
3.2.6 Porta XOR
A função lógica implementada por uma porta XOR ou também conhecida como “ou exclusivo” é comparar os bits e produzir saída 0 quando todos os bits de entrada são iguais, e saída 1 quando pelo menos um dos bits de entrada é diferente dos demais. Na figura 3.7, tem a representação de uma porta XOR de duas entradas a e b e uma saída c, a tabela verdade e um exemplo de funcionamento.
Figura 3.7 – (a) representação, (b) tabela verdade e (c) exemplo de funcionamento
respectivamente de uma porta XOR de duas entradas.
O código VHDL de uma porta XOR de duas entradas a e b e uma saída c utilizando as primitivas que o VHDL’93 oferece é:
Porta XOR de duas entradas de 1 bit
librarylibrarylibrarylibrary ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entitentitentitentityyyy xor2 isisisis
portportportport (a,b: inininin std_logic;
c: outoutoutout std_logic);
endendendend xor2;
architecturearchitecturearchitecturearchitecture arch_xor2 ofofofof xor2 isisisis

60
beginbeginbeginbegin
c <= a xor b;
endendendend arch_xor2;
3.2.7 Porta XNOR
A função lógica da porta XNOR é eqüivalente a uma porta XOR seguida por uma porta NOT. Isto é, ela produz uma saída que é o inverso da saída produzida pela porta XOR. A representação de uma porta XNOR de duas entradas, a tabela verdade e um exemplo de funcionamento, pode ser visualizado na figura 3.8.
Figura 3.8 – (a) representação, (b) tabela verdade e (c) exemplo de funcionamento
respectivamente de uma porta XNOR de duas entradas.
O código VHDL de uma porta XNOR de duas entradas a e b e uma saída c utilizando as primitivas que o VHDL’93 oferece é:
Porta XNOR de duas entradas de 1 bit
librarylibrarylibrarylibrary ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity xnor2 isisisis
portportportport (a,b: inininin std_logic;
c: outoutoutout std_logic);
endendendend xnor2;
architecturearchitecturearchitecturearchitecture arch_xnor2 ofofofof xnor2 isisisis
beginbeginbeginbegin
c <= a xnor b;
endendendend arch_xnor2;
3.2.8 Estatísticas de Recursos Usados em FPGAs
Observa-se nos resultados da tabela 3.1 que as portas lógicas são implementadas basicamente com um único elemento, uma única LUT de 4 entradas, utilizando assim parte de uma CLB, com exceção da porta lógica NOT, onde não foi necessário a utilização de nenhum recurso listado na tabela 3.1.
Tabela 3.1 – Recursos utilizados do FPGAs – Portas lógicas básicas

61
Porta Lógica FF LUTs 4 LUTs 3 CLBs AND 0 1 0 1 OR 0 1 0 1
NOT 0 0 0 0 NAND 0 1 0 1 NOR 0 1 0 1 XOR 0 1 0 1
XNOR 0 1 0 1
Isto acontece, porque a lógica de inversão da porta NOT pode ser implementada por inversor que compõe uma das IOBs, não tendo a necessidade de utilizar nenhum outro recurso do FPGA. Isto justifica o atraso total de execução do circuito ser menor que das outras portas lógica (tabela 3.2).
Os tempos gerados representam o tempo levado para executar cada operação lógica listada na tabela 3.2. Esse tempo pode ser um dos elementos para medir o desempenho de um circuito. Neste caso, está-se medindo o tempo de propagação do sinal em operações lógicas básicas. Esse tempo é dado em: Tempo de Lógica (TL), o tempo que leva efetivamente para implementar a lógica do circuito; Tempo de Roteamento (TR), o tempo gasto no roteamento implementado pelo software. Sendo que a soma do TL com TR resulta no Atraso Total (AT). Esses tempos são dados em nanosegundos (10-9 segundos).
Tabela 3.2 – Temporização das portas lógicas básicas.
Porta Lógica TL (ns) TR (ns) AT (ns) AND 6.899 2.451 9.350 OR 6.899 2.472 9.371
NOT 5.709 0.194 5.903 NAND 6.899 2.472 9.371 NOR 6.899 2.472 9.371 XOR 6.899 2.472 9.371
XNOR 6.899 2.472 9.371
É interessante perceber que quase todas a funções lógicas possuem os mesmos tempos. Isso acontece, porque são circuitos básicos e simples, o tempo de roteamento deste circuitos é quase mínimo. Esses dados foram obtidos para portas lógicas mapeadas fisicamente em um FPGA simples, do modelo XC4000 da Xilinx.
3.3 Multiplexadores e Demultiplexadores A figura 3.9 (a) representa um circuito multiplexador 2x1 que possui algumas características como a presença de dois sinais lógicos de entrada e1 e e2, um de saída s e um de seleção sel. A função lógica do multiplexador é simplesmente selecionar um destes sinais de entrada e1 e e2 através do sinal de seleção sel, atribuindo à saída s o sinal de entrada desejado. Portanto, pode-se definir um multiplexador como um circuito que possui 2n entradas, n sinais de controle e uma saída.

62
Figura 3.9 – (a) representação, (b) tabela verdade e (c) descrição com portas lógicas.
Tem-se também os demultiplexadores, que implementam a lógica inversa dos multiplexadores. Portanto, são circuitos com um único sinal de entrada, 2n saídas e n sinais de controle, que tem a função de selecionar qual deve ser a saída desejada.
O VHDL permite descrever um mesmo circuito em inúmeras formas. Isto é, um circuito X pode ser descrito de várias maneiras, mantendo a sua função lógica original.
Seguindo e usando essas possibilidades a maioria dos circuitos descritos neste livro apresentam mais de uma descrição. A seguir apresentam-se quatro diferentes descrições em VHDL de um mesmo circuito multiplexador incluindo também suas respectivas estatísticas de desempenho espacial e temporal em um FPGA.
As implementações do circuito multiplexador 2x1 utiliza quatro diferentes estruturas disponíveis na linguagem VHDL, que são:
• Execução concorrente com WITH...SELECT.
• Execução seqüencial com IF...THEN...ELSE.
• Execução seqüencial com CASE
• Implementação com portas lógicas.
3.3.1 Multiplexador 2x1 – Códigos em VHDL
Código VHDL de um multiplexador 2x1 usando o comando de execução concorrente WITH SELECT:
Multiplexador 2x1
library library library library ieee;;;;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity mult2x1 isisisis
portportportport ( e1,e2,sel: inininin std_logic;
s: outoutoutout std_logic);

63
endendendend mult2x1;
architecturearchitecturearchitecturearchitecture arch_mult2x1 ofofofof mult2x1 isisisis
beginbeginbeginbegin
withwithwithwith sel selectselectselectselect
s <= e1 whenwhenwhenwhen '0',
e2 whenwhenwhenwhen othersothersothersothers;
endendendend arch_mult2x1;
Código VHDL de multiplexador 2x1 usando o comando de execução seqüencial IF...THEN...ELSE:
Multiplexador 2x1 library ieee;ieee;ieee;ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity mult2x1 isisisis
portportportport ( e1,e2,sel: inininin std_logic;
s: outoutoutout std_logic);
endendendend mult2x1;
architecturearchitecturearchitecturearchitecture arch_mult2x1 ofofofof mult2x1 isisisis
beginbeginbeginbegin
process (e1,e2,sel)(e1,e2,sel)(e1,e2,sel)(e1,e2,sel)
begin
if sel=’0’ sel=’0’ sel=’0’ sel=’0’ then
s <= e1;s <= e1;s <= e1;s <= e1;
else
s <= e2;s <= e2;s <= e2;s <= e2;
end if;;;;
end process;
end arch_mult2x1;arch_mult2x1;arch_mult2x1;arch_mult2x1;
Código VHDL de multiplexador 2x1 usando o comando de execução seqüencial CASE:
Multiplexador 2x1
library ieee;ieee;ieee;ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity mult2x1 isisisis
portportportport ( e1,e2,sel: inininin std_logic;
s: outoutoutout std_logic);
endendendend mult2x1;
architecturearchitecturearchitecturearchitecture arch_mult2x1 ofofofof mult2x1 isisisis
beginbeginbeginbegin
process (e1,e2,sel)(e1,e2,sel)(e1,e2,sel)(e1,e2,sel)
begin
case sel sel sel sel is
when '0' => s <= e1; '0' => s <= e1; '0' => s <= e1; '0' => s <= e1;

64
when others => s <= e2; => s <= e2; => s <= e2; => s <= e2;
end case;;;;
end process;;;;
end arch_mult2x1;arch_mult2x1;arch_mult2x1;arch_mult2x1;
Código VHDL de multiplexador 2x1 usando portas lógicas básicas:
Multiplexador 2x1
library ieee;ieee;ieee;ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity mult2x1 isisisis
portportportport ( e1,e2,sel: inininin std_logic;
s: outoutoutout std_logic);
endendendend mult2x1;
architecturearchitecturearchitecturearchitecture arch_mult2x1 ofofofof mult2x1 isisisis
beginbeginbeginbegin
s <= (e1 s <= (e1 s <= (e1 s <= (e1 and not (sel)) (sel)) (sel)) (sel)) or (e2 (e2 (e2 (e2 and sel);sel);sel);sel);
end end end end arch_mult2x1;;;;
Observa-se que usando os comandos IF-THEN-ELSE e CASE precisa-se definir um processo, pois são comando seqüenciais e são executados a partir de um evento predefinido.
3.3.2 Multiplexador 2x1 – Estatísticas em FPGAs Atavés dos dados apresentados na tabela 3.3, é possível observar que apesar dos códigos VHDL dos multiplexadores 2x1 serem diferentes, do ponto de vista das estatísticas de utilização de recursos do FPGA e dos tempos de funcionamento (tabela 3.4), são equivalentes, pois nem a estatística de elementos utilizados para implementação do circuito e a temporização foram alterados.
Tabela 3.3 – Recursos utilizados do FPGAs – Multiplexador 2x1
Multiplexador FF LUTs 4 LUTs 3 CLBs With Select 0 1 0 1 If-Then-Else 0 1 0 1
Case 0 1 0 1 Porta Lógica 0 1 0 1
Tabela 3.4 – Temporização dos multiplexadores 2x1.
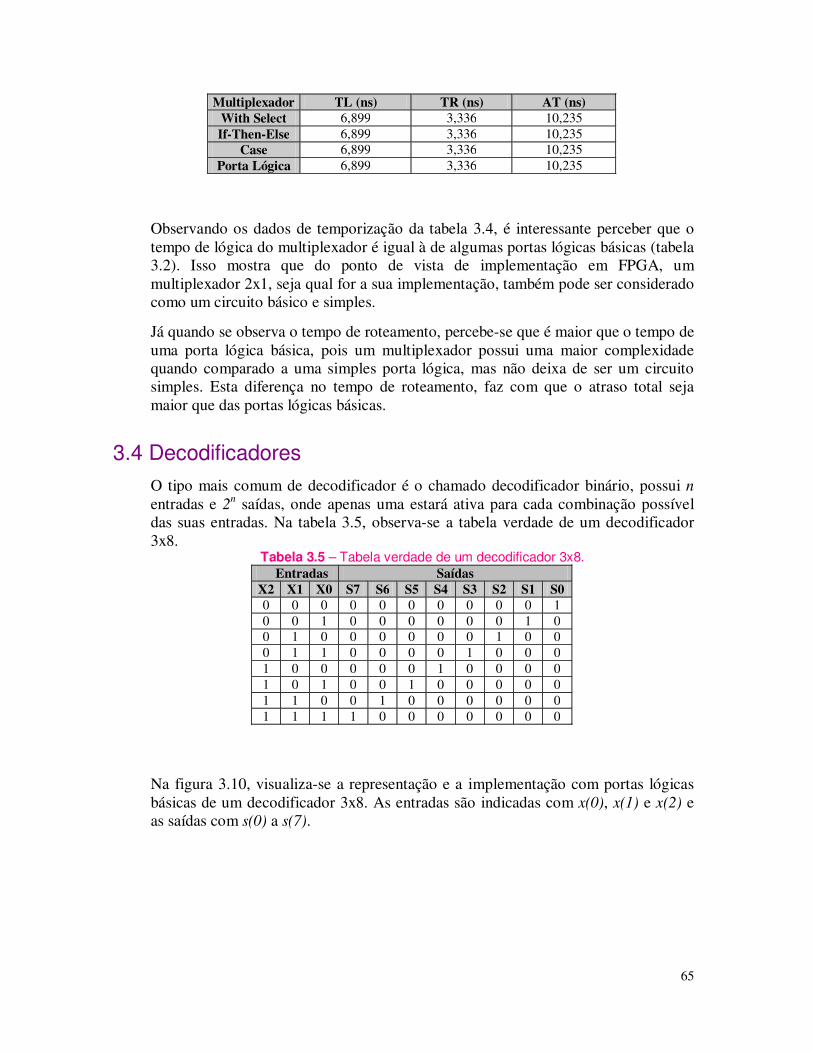
65
Multiplexador TL (ns) TR (ns) AT (ns) With Select 6,899 3,336 10,235 If-Then-Else 6,899 3,336 10,235
Case 6,899 3,336 10,235 Porta Lógica 6,899 3,336 10,235
Observando os dados de temporização da tabela 3.4, é interessante perceber que o tempo de lógica do multiplexador é igual à de algumas portas lógicas básicas (tabela 3.2). Isso mostra que do ponto de vista de implementação em FPGA, um multiplexador 2x1, seja qual for a sua implementação, também pode ser considerado como um circuito básico e simples.
Já quando se observa o tempo de roteamento, percebe-se que é maior que o tempo de uma porta lógica básica, pois um multiplexador possui uma maior complexidade quando comparado a uma simples porta lógica, mas não deixa de ser um circuito simples. Esta diferença no tempo de roteamento, faz com que o atraso total seja maior que das portas lógicas básicas.
3.4 Decodificadores O tipo mais comum de decodificador é o chamado decodificador binário, possui n entradas e 2n saídas, onde apenas uma estará ativa para cada combinação possível das suas entradas. Na tabela 3.5, observa-se a tabela verdade de um decodificador 3x8.
Tabela 3.5 – Tabela verdade de um decodificador 3x8. Entradas Saídas
X2 X1 X0 S7 S6 S5 S4 S3 S2 S1 S0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 1 1 0 0 0 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 0 1 0 0 1 0 0 0 0 0 1 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0
Na figura 3.10, visualiza-se a representação e a implementação com portas lógicas básicas de um decodificador 3x8. As entradas são indicadas com x(0), x(1) e x(2) e as saídas com s(0) a s(7).

66
Figura 3.10 – (a) Representação e (b) implementação com portas lógicas básicas de um
decodificador 3x8 (b).
A seguir, similar ao multiplexador, apresentam-se quatro diferentes descrições em VHDL de um circuito decodificador e suas estatísticas de desempenho espacial e temporal.
3.4.1 Decodificador 3x8 – Códigos em VHDL
Código VHDL de decodificador 3x8 usando o comando de execução concorrente WITH...SELECT:
Decodificador 3x8
library ieee;ieee;ieee;ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entity dec3x8 dec3x8 dec3x8 dec3x8 is
port ( x: ( x: ( x: ( x: in std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 downto 0);0);0);0);
s: s: s: s: out std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 downto 0));0));0));0));
end dec3x8;dec3x8;dec3x8;dec3x8;
architecture arch_dec3x8 arch_dec3x8 arch_dec3x8 arch_dec3x8 of dec3x8 dec3x8 dec3x8 dec3x8 is
begin
with x x x x select
s <= "00000001" s <= "00000001" s <= "00000001" s <= "00000001" when "000", "000", "000", "000",
"00000"00000"00000"00000010" 010" 010" 010" when "001","001","001","001",
"00000100" "00000100" "00000100" "00000100" when "010","010","010","010",
"00001000" "00001000" "00001000" "00001000" when "011","011","011","011",
"00010000" "00010000" "00010000" "00010000" when "100","100","100","100",

67
"00100000" "00100000" "00100000" "00100000" when "101","101","101","101",
"01000000" "01000000" "01000000" "01000000" when "110","110","110","110",
"10000000" "10000000" "10000000" "10000000" when "111","111","111","111",
"ZZZZZZZZ" "ZZZZZZZZ" "ZZZZZZZZ" "ZZZZZZZZ" when others;;;;
end arch_dec3x8;arch_dec3x8;arch_dec3x8;arch_dec3x8;
Código VHDL de decodificador 3x8 usando o comando de execução seqüencial IF...THEN...ELSE:
Decodificador 3x8
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity dec3x8 dec3x8 dec3x8 dec3x8 is
port (s: (s: (s: (s: out std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 downto 0);0);0);0);
x: x: x: x: in std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 downto 0));0));0));0));
end dec3x8;dec3x8;dec3x8;dec3x8;
architecture architecture architecture architecture arch_dec3x8 ofofofof dec3x8 is
begin
process (x)(x)(x)(x)
begin
if (x = "000") (x = "000") (x = "000") (x = "000") then s <= "00000001";s <= "00000001";s <= "00000001";s <= "00000001";
elsif (x = "001") (x = "001") (x = "001") (x = "001") then s <= "00000010";s <= "00000010";s <= "00000010";s <= "00000010";
elsif (x = "010") (x = "010") (x = "010") (x = "010") then s <= "00000100";s <= "00000100";s <= "00000100";s <= "00000100";
elsif (x = "011") (x = "011") (x = "011") (x = "011") then s <= "00001000";s <= "00001000";s <= "00001000";s <= "00001000";
elsif (x = "100") (x = "100") (x = "100") (x = "100") then s <= "00010000";s <= "00010000";s <= "00010000";s <= "00010000";
elsif (x = "101") (x = "101") (x = "101") (x = "101") then s <= "00100000";s <= "00100000";s <= "00100000";s <= "00100000";
elsif (x = "110") (x = "110") (x = "110") (x = "110") then s <= "01000000";s <= "01000000";s <= "01000000";s <= "01000000";
elsif (x = "111") (x = "111") (x = "111") (x = "111") then s <= "10000000";s <= "10000000";s <= "10000000";s <= "10000000";
else s <= "ZZZZZZZZ";s <= "ZZZZZZZZ";s <= "ZZZZZZZZ";s <= "ZZZZZZZZ";
end if;;;;
end process;;;;
endendendend arch_dec3x8 ;
Código VHDL de decodificador 3x8 usando o comando de execução seqüencial CASE:
Decodificador 3x8
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity dec3x8 dec3x8 dec3x8 dec3x8 is
port ( x: ( x: ( x: ( x: in std_logic_vector (2std_logic_vector (2std_logic_vector (2std_logic_vector (2 downto 0);0);0);0);
s: s: s: s: out std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 downto 0));0));0));0));
end dec3x8;dec3x8;dec3x8;dec3x8;
architecture arch_dec3x8 arch_dec3x8 arch_dec3x8 arch_dec3x8 of dec3x8 dec3x8 dec3x8 dec3x8 is
begin
process (x)(x)(x)(x)
begin

68
case x x x x is
when "000" => s <= "00000001"; "000" => s <= "00000001"; "000" => s <= "00000001"; "000" => s <= "00000001";
when "001" => s <"001" => s <"001" => s <"001" => s <= "00000010";= "00000010";= "00000010";= "00000010";
when "010" => s <= "00000100";"010" => s <= "00000100";"010" => s <= "00000100";"010" => s <= "00000100";
when when when when "011" =>=>=>=> s <= "00001000";
when "100" => s <= "00010000";"100" => s <= "00010000";"100" => s <= "00010000";"100" => s <= "00010000";
when "101" => s <= "00100000";"101" => s <= "00100000";"101" => s <= "00100000";"101" => s <= "00100000";
when "110" => s <= "01000000";"110" => s <= "01000000";"110" => s <= "01000000";"110" => s <= "01000000";
when "1"1"1"111" => s <= "10000000";11" => s <= "10000000";11" => s <= "10000000";11" => s <= "10000000";
when others => s <= "ZZZZZZZZ";=> s <= "ZZZZZZZZ";=> s <= "ZZZZZZZZ";=> s <= "ZZZZZZZZ";
end case;;;;
end process;;;;
endendendend arch_dec3x8;
Código VHDL de decodificador 3x8 usando portas lógicas básicas:
Decodificador 3x8
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity dec3x8 dec3x8 dec3x8 dec3x8 is
port ( x: ( x: ( x: ( x: in std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 downto 0);0);0);0);
s: s: s: s: out std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 downto 0));0));0));0));
end dec3x8;dec3x8;dec3x8;dec3x8;
architecture arch_dec3x8 arch_dec3x8 arch_dec3x8 arch_dec3x8 of dec3x8 dec3x8 dec3x8 dec3x8 is
begin
s(0) <= s(0) <= s(0) <= s(0) <= not (x(2)) (x(2)) (x(2)) (x(2)) and not(x(1)) (x(1)) (x(1)) (x(1)) and not(x(0));(x(0));(x(0));(x(0));
s(s(s(s(1) <= 1) <= 1) <= 1) <= not(x(2)) (x(2)) (x(2)) (x(2)) and not(x(1)) (x(1)) (x(1)) (x(1)) and x(0);x(0);x(0);x(0);
s(2) <= s(2) <= s(2) <= s(2) <= not(x(2)) (x(2)) (x(2)) (x(2)) and x(1) x(1) x(1) x(1) and not(x(0));(x(0));(x(0));(x(0));
s(3) <= s(3) <= s(3) <= s(3) <= not(x(2)) (x(2)) (x(2)) (x(2)) and x(1) x(1) x(1) x(1) and x(0);x(0);x(0);x(0);
s(4) <= x(2) s(4) <= x(2) s(4) <= x(2) s(4) <= x(2) and not(x(1)) (x(1)) (x(1)) (x(1)) and not(x(0));(x(0));(x(0));(x(0));
s(5s(5s(5s(5) <= x(2) ) <= x(2) ) <= x(2) ) <= x(2) and not(x(1)) (x(1)) (x(1)) (x(1)) and x(0);x(0);x(0);x(0);
s(6) <= x(2) s(6) <= x(2) s(6) <= x(2) s(6) <= x(2) and x(1) x(1) x(1) x(1) and not(x(0));(x(0));(x(0));(x(0));
s(7) <= x(2) s(7) <= x(2) s(7) <= x(2) s(7) <= x(2) and x(1) x(1) x(1) x(1) and x(0);x(0);x(0);x(0);
end arch_dec3x8;arch_dec3x8;arch_dec3x8;arch_dec3x8;
3.4.1 Decodificador 3x8 - Estatísticas em FPGAs
Observando os dados da tabela 3.6 e comparando-os àqueles obtidos para portas básicas é possível notar que um decodificador 3x8 é um circuito mais complexo que os anteriores. Um decodificador utiliza muito mais recursos do FPGA do que circuitos mais simples como portas lógicas básicas e multiplexadores e, mesmo sendo mais complexo, o atraso total destes circuitos não são muito maiores que os tempos de circuitos básicos.
Tabela 3.6 – Recursos utilizados do FPGAs – Decodificador 3x8
69
Decodificador FF LUTs 4
LUTs 3 CLBs
If-Then-Else 0 8 0 4 With-Select 0 8 0 4
Case 0 8 0 4 Porta Lógica 0 8 0 4
Na tabela 3.7 é possível observar o tempo de propagação de sinal para um decodificador 3x8, implementado de várias formas em VHDL, e mapeado em um FPGA simples XC4000 da empresa Xilinx. Neste caso, a implementação de um decodificador 3x8 com os comandos IF...THEN...ELSE, WITH...SELECT e CASE tiveram um melhor desempenho que a implementação do mesmo circuito com portas lógicas básicas. Nota-se que o tempo de lógica é igual para todos os decodificadores implementados, mas isso não acontece com o tempo de roteamento, pois o circuito implementado com portas básicas teve um pior desempenho.
Tabela 3.7 - Temporização dos decodificador 3x8
Decodificador TL (ns) TR (ns) AT (ns) If-Then-Else 6.899 5.079 11.978 With –Select 6.899 5.079 11.978
Case 6.899 5.079 11.978 Porta Lógica 6.899 7.872 14.771
É interessante perceber que o decodificador implementado apenas com portas lógicas teve o seu atraso total prejudicado em aproximadamente 18.9% quando comparado ao atraso total dos outros decodificadores. Esses dados são importantes para demonstrar a influência do tipo de implementação no desempenho final de um circuito. Observa-se que nem sempre a implementação com portas lógicas é a mais otimizada. Neste caso, esta implementação não obteve as melhores estatísticas de desempenho.
3.5 Codificadores em VHDL e FPGAs Os codificadores implementam a função inversa dos decodificadores, isto é, um codificador binário possui 2n entradas, codificadas em saídas de n bits. Na figura 3.11, nota-se a representação de um codificador 8x3.

70
Figura 3.11 – Representação de um codificador 8x3.
Na tabela 3.8 observa-se a tabela verdade de um codificador com 8 entradas e 3 saídas. As entradas são indicadas como x0 a x7 e as saídas como s0, s1 e s2.
Tabela 3.8 - Tabela verdade de um codificador 8x3 . Entradas Saídas
X7 X6 X5 X4 X3 X2 X1 X0 S2 S1 S0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 0 0 1 1 1
A seguir, quatro implementações em VHDL do mesmo circuito codificador 8x3 e suas respectivas estatísticas de desempenho espacial e temporal.
3.5.1 Codificador 8x3 – Códigos em VHDL
Código VHDL do codificador 8x3 usando o comando de execução concorrente WITH...SELECT:
Codificador 8x3
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity cod8x3 cod8x3 cod8x3 cod8x3 is
port ( x: ( x: ( x: ( x: in std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 downto 0);0);0);0);
s: s: s: s: out std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 downto 0));0));0));0));
end cod8cod8cod8cod8x3;x3;x3;x3;
architecture arch_cod8x3 arch_cod8x3 arch_cod8x3 arch_cod8x3 of cod8x3 cod8x3 cod8x3 cod8x3 is
begin
with x x x x select
s <= "000" s <= "000" s <= "000" s <= "000" when "00000001", "00000001", "00000001", "00000001",
"001" "001" "001" "001" when "00000010","00000010","00000010","00000010",
"010" "010" "010" "010" when "00000100","00000100","00000100","00000100",

71
"011" "011" "011" "011" when "00001000","00001000","00001000","00001000",
"100" "100" "100" "100" when "00010"00010"00010"00010000",000",000",000",
"101" "101" "101" "101" when "00100000","00100000","00100000","00100000",
"110" "110" "110" "110" when "01000000","01000000","01000000","01000000",
"111" "111" "111" "111" when "10000000","10000000","10000000","10000000",
"ZZZ" "ZZZ" "ZZZ" "ZZZ" when others; ; ; ;
end arch_cod8x3;arch_cod8x3;arch_cod8x3;arch_cod8x3;
Código VHDL do codificador 8x3 usando o comando de execução seqüencial IF...THEN...ELSE:
Codificador 8x3
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity cod8x3 cod8x3 cod8x3 cod8x3 is
port ( x: ( x: ( x: ( x: in std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 downto 0);0);0);0);
s: s: s: s: out std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 downto 0));0));0));0));
end cod8x3;cod8x3;cod8x3;cod8x3;
architecture arch_cod8x3 arch_cod8x3 arch_cod8x3 arch_cod8x3 of cod8x3 cod8x3 cod8x3 cod8x3 is
begin
process (x)(x)(x)(x)
begin
if (x= "00000001") (x= "00000001") (x= "00000001") (x= "00000001") then s <= "000"; s <= "000"; s <= "000"; s <= "000";
elsif (x= "00000010") (x= "00000010") (x= "00000010") (x= "00000010") then s <= "001";s <= "001";s <= "001";s <= "001";
elsif (x= "00000100") (x= "00000100") (x= "00000100") (x= "00000100") then s <= "010";s <= "010";s <= "010";s <= "010";
elsif (x= "00001000") (x= "00001000") (x= "00001000") (x= "00001000") then s <= "011";s <= "011";s <= "011";s <= "011";
elsif (x= "00010000") (x= "00010000") (x= "00010000") (x= "00010000") then s <= "100";s <= "100";s <= "100";s <= "100";
elsif (x= "00100000") (x= "00100000") (x= "00100000") (x= "00100000") then s <= "101";s <= "101";s <= "101";s <= "101";
elsif (x= "01000000") (x= "01000000") (x= "01000000") (x= "01000000") then s <= "110";s <= "110";s <= "110";s <= "110";
elsif (x= "10000000") (x= "10000000") (x= "10000000") (x= "10000000") then s <= "111";s <= "111";s <= "111";s <= "111";
else s <= "ZZZ";s <= "ZZZ";s <= "ZZZ";s <= "ZZZ";
end if;;;;
end process;;;;
endendendend arch_cod8x3;
Código VHDL do codificador 8x3 usando o comando de execução seqüencial CASE:
Codificador 8x3
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity cod8x3 cod8x3 cod8x3 cod8x3 is
port ( x: ( x: ( x: ( x: in std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 downto 0);0);0);0);
s: s: s: s: out std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 downto 0));0));0));0));
end cod8x3;cod8x3;cod8x3;cod8x3;
architecture arch_cod8x3 arch_cod8x3 arch_cod8x3 arch_cod8x3 of cod8x3 cod8x3 cod8x3 cod8x3 is
begin
process (x)(x)(x)(x)
begin
case x isx isx isx is
when "00000001" => s <= "000"; "00000001" => s <= "000"; "00000001" => s <= "000"; "00000001" => s <= "000";

72
when "00000010" => s <= "001";"00000010" => s <= "001";"00000010" => s <= "001";"00000010" => s <= "001";
when "00000100" => s <= "010";"00000100" => s <= "010";"00000100" => s <= "010";"00000100" => s <= "010";
when "00001000" => s <= "011";"00001000" => s <= "011";"00001000" => s <= "011";"00001000" => s <= "011";
when "00010000" => s <= "100";"00010000" => s <= "100";"00010000" => s <= "100";"00010000" => s <= "100";
when "00100000" => s <= "101";"00100000" => s <= "101";"00100000" => s <= "101";"00100000" => s <= "101";
when "01000000" => s <= "110";"01000000" => s <= "110";"01000000" => s <= "110";"01000000" => s <= "110";
when "10000000" => s <= "111";"10000000" => s <= "111";"10000000" => s <= "111";"10000000" => s <= "111";
when others => s <= "ZZZ";=> s <= "ZZZ";=> s <= "ZZZ";=> s <= "ZZZ";
end case;;;;
end process;;;;
endendendend arch_cod8x3;
Código VHDL de codificador 8x3 usando portas lógicas básicas:
Codificador 8x3
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity cod8x3 cod8x3 cod8x3 cod8x3 is
port ( x: ( x: ( x: ( x: in std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 std_logic_vector (7 downto 0);0);0);0);
s: s: s: s: out std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 std_logic_vector (2 downto 0));0));0));0));
end cod8x3;cod8x3;cod8x3;cod8x3;
architecture arch_cod8x3 arch_cod8x3 arch_cod8x3 arch_cod8x3 of cod8x3 cod8x3 cod8x3 cod8x3 is
begin
s(2)<= x(4) s(2)<= x(4) s(2)<= x(4) s(2)<= x(4) or x(5) x(5) x(5) x(5) or x(6) x(6) x(6) x(6) or x(7) x(7) x(7) x(7) or x(0);x(0);x(0);x(0);
s(1)<= x(2) s(1)<= x(2) s(1)<= x(2) s(1)<= x(2) or x(3) x(3) x(3) x(3) or x(6) x(6) x(6) x(6) or x(7) x(7) x(7) x(7) or x(0);x(0);x(0);x(0);
s(0)<= x(1) s(0)<= x(1) s(0)<= x(1) s(0)<= x(1) or x(3) x(3) x(3) x(3) or x(5) x(5) x(5) x(5) or x(7) x(7) x(7) x(7) or x(0x(0x(0x(0););););
endendendend arch_cod8x3;
3.5.2 Codificador 8x3 – Estatísticas em FPGAs
Através das tabelas 3.9 e 3.10 é possível observar como essas implementações de um codificador 3x8 demandam recursos especiais em um FPGA e os respectivos tempos quando mapeados em um FPGA do tipos XC4000.
Tabela 3.9 – Recursos utilizados do FPGAs – Codificador 2x1 Codificador FF LUTs 4 LUTs 3 CLBs If-Then-Else 0 3 0 2 With -Select 0 3 0 2
Case 0 3 0 2 Porta Lógica 0 3 0 2
Tabela 3.10 – Temporização dos codificadores 8x3 Codificador TL (ns) TR (ns) AT (ns) If-Then-Else 6.899 4.222 11.121 With -Select 6.899 4.222 11.121
Case 6.899 4.222 11.121 Porta Lógica 6.899 4.222 11.121

73
O codificador é um circuito mais simples que um decodificador percebe-se observando o número menor de componentes utilizados para implementa-lo e o menor tempo de atraso do seu funcionamento.
Neste caso a implementação do circuito codificador utilizando portas lógicas básicas não alterou o desempenho final do circuito implementado. Isto acontece pois o circuito codificador implementado não é complexo, utilizando apenas 2 CLBs. Já em um circuito que utilizam vários componentes e possui um roteamento mais complexo é possível visualizar esta diferença no desempenho final do circuito implementado.
3.6 Circuitos Combinacionais Aritméticos em VHDL Os circuitos combinacionais aritméticos são encontrados em todos os sistemas digitais que realizam operações lógicas e aritméticas. Existem circuitos aritméticos de baixa complexidade como, somadores, subtratores e outros. Existem também circuitos aritméticos que possuem maior complexidade, como operações com ponto flutuante.
Nesta seção se faz a descrição dos seguintes circuitos: comparadores simples e com múltiplas comparações, um somador completo de 1 e 4 bits, um subtrator completo de 4 bits , um multiplicador de 4 bits e um divisor também de 4 bits. Ao final tem-se estatísticas de desempenho e temporização das respectivas implementações em FPGAs, as quais são comparadas e analisadas.
3.6.1 Comparadores
Um comparador pode ser classificado como um comparador simples ou com múltiplas comparações. Independente do tipo de comparador, a comparação sempre é realizada bit a bit desde o menos significativo até o mais significativo ou vice-versa. No padrão VHDL’93 é possível realizar as comparações listadas na tabela 3.11.
Tabela 3.11 – Tabela de comparações possíveis.
Símbolo Significado Símbolo Significado = Igual >= Maior Igual != Diferente < Menor > Maior <= Menor Igual
A seguir apresenta-se três descrições VHDL, estas são: um comparador simples, um comparador simples utilizando portas lógicas e um comparador usando múltiplas comparações.
Código VHDL do comparador simples usando o comando de execução seqüencial IF...THEN...ELSE:

74
Comparador simples
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity comp_simp comp_simp comp_simp comp_simp is
port ( x , y : ( x , y : ( x , y : ( x , y : in std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0);0);0);0);
s : s : s : s : out std_logic);std_logic);std_logic);std_logic);
end comp_simp;comp_simp;comp_simp;comp_simp;
architecture arch_carch_carch_carch_comp_simp omp_simp omp_simp omp_simp of comp_simp comp_simp comp_simp comp_simp is
begin
process (x,y)(x,y)(x,y)(x,y)
begin
if x<y x<y x<y x<y then
s <='0';s <='0';s <='0';s <='0';
else
s <='1';s <='1';s <='1';s <='1';
end if;;;;
end process;;;;
endendendend arch_comp_simp;
Código VHDL do comparador simples usando portas lógicas básicas:
Comparador simples
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity comp_simp comp_simp comp_simp comp_simp is
port ( x, y: ( x, y: ( x, y: ( x, y: in std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0);0);0);0);
s: s: s: s: out std_logic);std_logic);std_logic);std_logic);
end comp_simp;comp_simp;comp_simp;comp_simp;
architecture arch_comp_simp arch_comp_simp arch_comp_simp arch_comp_simp of comp_simp comp_simp comp_simp comp_simp is
begin
process (x,y)(x,y)(x,y)(x,y)
variable aux : std_logic_vector(3 aux : std_logic_vector(3 aux : std_logic_vector(3 aux : std_logic_vector(3 downto 0);0);0);0);
variable vaium : std_logic;vaium : std_logic;vaium : std_logic;vaium : std_logic;
begin
vaium := '0';vaium := '0';vaium := '0';vaium := '0';
for i i i i in 0 0 0 0 to 3 3 3 3 loop
aux(i) := (x(i) aux(i) := (x(i) aux(i) := (x(i) aux(i) := (x(i) xor y(i) y(i) y(i) y(i) xor vaium);vaium);vaium);vaium);
vaium := (y(i) vaium := (y(i) vaium := (y(i) vaium := (y(i) and aux(i)) aux(i)) aux(i)) aux(i)) or (y(i) (y(i) (y(i) (y(i) and vaium) vaium) vaium) vaium) or
(vaium (vaium (vaium (vaium and aux(i));aux(i));aux(i));aux(i));
end loop;;;;
s <= s <= s <= s <= not vaium;vaium;vaium;vaium;
end process;;;;
end arch_comp_simp;arch_comp_simp;arch_comp_simp;arch_comp_simp;
Código VHDL de comparador com múltiplas comparações usando o comando de execução seqüencial IF...THEN...ELSE:
Comparador com múltiplas comparações

75
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity comp_mult comp_mult comp_mult comp_mult is
port ( x, y, z, w: ( x, y, z, w: ( x, y, z, w: ( x, y, z, w: in std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0);0);0);0);
s: s: s: s: out std_logic);std_logic);std_logic);std_logic);
end comp_mult;comp_mult;comp_mult;comp_mult;
architecture arch_comp_mult arch_comp_mult arch_comp_mult arch_comp_mult of comp_mult comp_mult comp_mult comp_mult is
begin
process (x,y,z,w)(x,y,z,w)(x,y,z,w)(x,y,z,w)
begin
if (x<=y (x<=y (x<=y (x<=y and (z<=w (z<=w (z<=w (z<=w or x=z)) x=z)) x=z)) x=z)) then
s <= '0'; s <= '0'; s <= '0'; s <= '0';
else
s <= '1';s <= '1';s <= '1';s <= '1';
end if;;;;
end process;;;;
end arch_comp_mult;arch_comp_mult;arch_comp_mult;arch_comp_mult;
3.6.2 Somadores e Subtratores
Os somadores e subtratores são circuitos combinatórios dedicados que executam, respectivamente, as operações de adição e subtração. Estes circuitos podem fazer parte de uma ULA (Unidade Lógica Aritmética), a qual está contida em calculadoras eletrônicas, microprocessadores e outros sistemas digitais.
Há várias formas de implementar somadores. Uma delas, bem conhecida, é o circuito “meio-somador”, que pode perfeitamente efetuar operações de 1 bit, mas em caso de palavras maiores, falha por não levar em conta o “estouro” da adição anterior. Para resolver este problema precisa-se de um somador completo ou full adder que considera o “estouro” da adição anterior. Para isso são implementados sinais de controle chamados de “vem-um” ou carry in e “vai-um” ou carry out.
O subtrator obedece ao mesmo raciocínio do circuito somador mudando apenas o tipo de operação a ser executada. A seguir são apresentadas descrições em VHDL de um somador completo de 1 e 4 bits e um subtrator completo de 4 bits.
A representação de um somador completo de 1 bit com portas lógicas pode ser visualizada na figura 3.12.
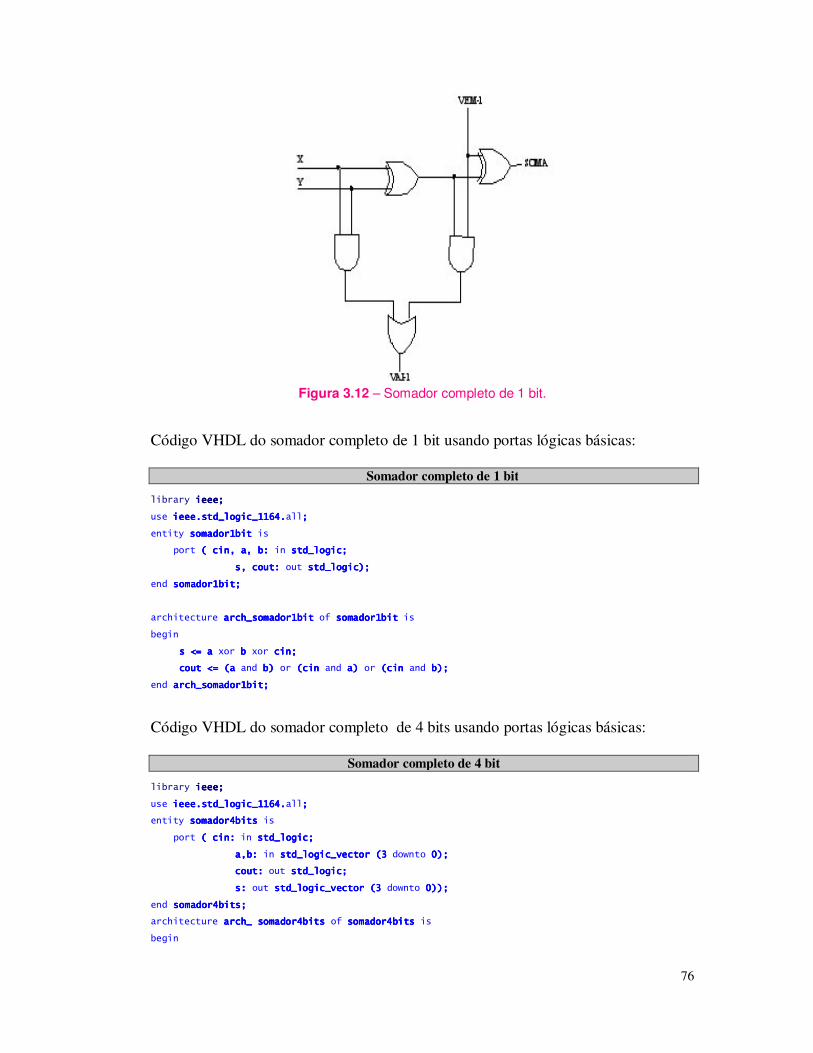
76
Figura 3.12 – Somador completo de 1 bit.
Código VHDL do somador completo de 1 bit usando portas lógicas básicas:
Somador completo de 1 bit
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity somador1bit somador1bit somador1bit somador1bit is
port ( cin, a, b: ( cin, a, b: ( cin, a, b: ( cin, a, b: in std_logic;std_logic;std_logic;std_logic;
s, cout: s, cout: s, cout: s, cout: out std_logic); std_logic); std_logic); std_logic);
end somador1bit;somador1bit;somador1bit;somador1bit;
architecture arch_somador1bit arch_somador1bit arch_somador1bit arch_somador1bit of somador1bit somador1bit somador1bit somador1bit is
begin
s <= a s <= a s <= a s <= a xor b b b b xor cicicicin;n;n;n;
cout <= (a cout <= (a cout <= (a cout <= (a and b) b) b) b) or (cin (cin (cin (cin and a) a) a) a) or (cin (cin (cin (cin and b); b); b); b);
end arch_somador1bit;arch_somador1bit;arch_somador1bit;arch_somador1bit;
Código VHDL do somador completo de 4 bits usando portas lógicas básicas:
Somador completo de 4 bit
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity somador4bits somador4bits somador4bits somador4bits is
port ( cin: ( cin: ( cin: ( cin: in std_logic;std_logic;std_logic;std_logic;
a,b: a,b: a,b: a,b: in std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0); 0); 0); 0);
cout: cout: cout: cout: out std_logic;std_logic;std_logic;std_logic;
s: s: s: s: out std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0)); 0)); 0)); 0));
end somador4bits;somador4bits;somador4bits;somador4bits;
architecture arch_ somador4bits arch_ somador4bits arch_ somador4bits arch_ somador4bits of somador4bits somador4bits somador4bits somador4bits is
begin

77
process(a, b, cin)(a, b, cin)(a, b, cin)(a, b, cin)
variable soma: std_logic_vector(3 soma: std_logic_vector(3 soma: std_logic_vector(3 soma: std_logic_vector(3 downto 0); 0); 0); 0);
variable c: std_logic;c: std_logic;c: std_logic;c: std_logic;
begin
c := cin;c := cin;c := cin;c := cin;
for i i i i in 0 0 0 0 to 3 3 3 3 loop
soma(i) := a(i) soma(i) := a(i) soma(i) := a(i) soma(i) := a(i) xor b(i) b(i) b(i) b(i) xor c;c;c;c;
c := (a(i) c := (a(i) c := (a(i) c := (a(i) and b(i)) b(i)) b(i)) b(i)) or ((a(i) ((a(i) ((a(i) ((a(i) xor b(i)) b(i)) b(i)) b(i)) and c);c);c);c);
end loop;;;;
cout <= c;cout <= c;cout <= c;cout <= c;
s <= soma;s <= soma;s <= soma;s <= soma;
end process;;;;
endendendend arch_somador4bits;
Código VHDL de um subtrator completo de 4 bits usando portas lógicas básicas:
Subtrator completo de 4 bit
library ieee;ieee;ieee;ieee;
use ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.ieee.std_logic_1164.all;;;;
entity sub4bits sub4bits sub4bits sub4bits is
port (a,b: (a,b: (a,b: (a,b: in std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0); 0); 0); 0);
s: s: s: s: out std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0)); 0)); 0)); 0));
end sub4bits;sub4bits;sub4bits;sub4bits;
architecture arch_ sub4bits arch_ sub4bits arch_ sub4bits arch_ sub4bits of sub4bits sub4bits sub4bits sub4bits is
begin
process(a, b)(a, b)(a, b)(a, b)
variable result: std_logic_vector(3 result: std_logic_vector(3 result: std_logic_vector(3 result: std_logic_vector(3 downto 0); 0); 0); 0);
variable vaium: std_logic;vaium: std_logic;vaium: std_logic;vaium: std_logic;
begin
vaium:='0'; vaium:='0'; vaium:='0'; vaium:='0';
for i i i i in 0 0 0 0 to 3 3 3 3 loop
result(i) := (a(i) result(i) := (a(i) result(i) := (a(i) result(i) := (a(i) xor b(i) b(i) b(i) b(i) xor vaium);vaium);vaium);vaium);
vaium := ( b(i) vaium := ( b(i) vaium := ( b(i) vaium := ( b(i) and result(i) ) result(i) ) result(i) ) result(i) ) or ( b(i) ( b(i) ( b(i) ( b(i) and vaium)vaium)vaium)vaium)
or (vaium (vaium (vaium (vaium and result(i) ) ;result(i) ) ;result(i) ) ;result(i) ) ;
end loop ;;;;
s<=result;s<=result;s<=result;s<=result;
end process; ; ; ;
end arch_ sub4bits;arch_ sub4bits;arch_ sub4bits;arch_ sub4bits;
3.6.3 Multiplicadores
Um multiplicador é um circuito mais complexo em nível de lógica de funcionamento. Existem muitos algoritmos para a sua implementação (KOREN, 1993). Neste caso, foi selecionado um algoritmo que talvez não seja o mais otimizado, mas é um algoritmo com passos simples e bem definidos, facilitando a compreensão do seu funcionamento. Este algoritmo pode ser implementado para multiplicadores de n bits.

78
Algoritmo do Multiplicador Inicio: Contador de bits recebe o numero de bits a ser multiplicado Inicializa produto com zero Para i de 0 até o número de bits da multiplicação faça deslocar (produto) Vaium recebe bit mais significativo do multiplicador Se vaium igual a 1 (um) então Soma (produto,multiplicando) deslocar (multiplicador) Resultado recebe produto Fim
A tabela 3.12 mostra uma multiplicação usando o algoritmo proposto, onde o resultado final é obtido quando o contador de bits for zero (“0”). Neste caso está fazendo a multiplicação de:
0011b � 3 (decimal - multiplicando)
x 0010b � 2 (decimal - multiplicador)
0110b � 6 (decimal - resultado)
Tabela 3.12 – Multiplicação aplicando o algoritmo. Vai-um Multiplicador Multiplicando Resultado Contador de bits
0 0010 0011 0000 04 0 0100 0011 0000 03 0 1000 0011 0000 02
1
0000
0011 0000
+0011 0011
01
0 0000 0011 0110 00
A seguir, mostra-se a descrição em VHDL de um multiplicador de 4 bits usando um somador e um deslocador de 4 bits.
Multiplicador de 4 bit
library ieee;ieee;ieee;ieee;
use ieee.std_logiieee.std_logiieee.std_logiieee.std_logic_1164.c_1164.c_1164.c_1164.all;;;;
entity mult4bits mult4bits mult4bits mult4bits is
port ( a, b: ( a, b: ( a, b: ( a, b: in std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0); 0); 0); 0);
s: s: s: s: out std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0)); 0)); 0)); 0));
end mult4bits;mult4bits;mult4bits;mult4bits;
architecture arch_mult4bits arch_mult4bits arch_mult4bits arch_mult4bits of mult4bits mult4bits mult4bits mult4bits is
-------- deslocamento de 1 bit para esquerda, zerando o bideslocamento de 1 bit para esquerda, zerando o bideslocamento de 1 bit para esquerda, zerando o bideslocamento de 1 bit para esquerda, zerando o bit menos significativot menos significativot menos significativot menos significativo
function deslocador (x : std_logic_vector (3 deslocador (x : std_logic_vector (3 deslocador (x : std_logic_vector (3 deslocador (x : std_logic_vector (3 downto 0))0))0))0))
return std_logic_vector isstd_logic_vector isstd_logic_vector isstd_logic_vector is
variable y : std_logic_vector (3 y : std_logic_vector (3 y : std_logic_vector (3 y : std_logic_vector (3 downto 0);0);0);0);
begin
for i i i i in 3 3 3 3 downto 1 1 1 1 loop
y(i) := x(iy(i) := x(iy(i) := x(iy(i) := x(i----1);1);1);1);

79
end loop ;;;;
y(0) :y(0) :y(0) :y(0) := '0';= '0';= '0';= '0';
return y;y;y;y;
end;;;;
-------- somador de 4 bits somador de 4 bits somador de 4 bits somador de 4 bits
function somador4bits (a : std_logic_vector (3 somador4bits (a : std_logic_vector (3 somador4bits (a : std_logic_vector (3 somador4bits (a : std_logic_vector (3 downto 0);0);0);0);
b : std_logic_vector (3 b : std_logic_vector (3 b : std_logic_vector (3 b : std_logic_vector (3 downto 0))0))0))0))
return std_logic_vector std_logic_vector std_logic_vector std_logic_vector is
variable vaium : std_logic;vaium : std_logic;vaium : std_logic;vaium : std_logic;
variable soma : soma : soma : soma : std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 std_logic_vector (3 downto 0);0);0);0);
begin
vaium := '0';vaium := '0';vaium := '0';vaium := '0';
for i i i i in 0 0 0 0 to 3 3 3 3 loop
soma(i) := a(i) soma(i) := a(i) soma(i) := a(i) soma(i) := a(i) xor b(i) b(i) b(i) b(i) xor vaium;vaium;vaium;vaium;
vaium := ( a(i) vaium := ( a(i) vaium := ( a(i) vaium := ( a(i) and b(i) ) b(i) ) b(i) ) b(i) ) or ( b(i) ( b(i) ( b(i) ( b(i) and vaium) vaium) vaium) vaium) or
(vaium (vaium (vaium (vaium and a(i) );a(i) );a(i) );a(i) );
end loop;;;;
return soma;soma;soma;soma;
end;;;;
begin
process(a,b)(a,b)(a,b)(a,b)
variable aux1 : std_logic_vector (3 aux1 : std_logic_vector (3 aux1 : std_logic_vector (3 aux1 : std_logic_vector (3 downto 0);0);0);0);
variable aux2 : std_logic_vector (3 aux2 : std_logic_vector (3 aux2 : std_logic_vector (3 aux2 : std_logic_vector (3 downto 0); 0); 0); 0);
variable vaium : std_logic;vaium : std_logic;vaium : std_logic;vaium : std_logic;
begin
-------- inicializacoesinicializacoesinicializacoesinicializacoes
aux1 := "0000"; aux1 := "0000"; aux1 := "0000"; aux1 := "0000";
aux2 := a; aux2 := a; aux2 := a; aux2 := a;
vaium := '0'; vaium := '0'; vaium := '0'; vaium := '0';
-------- implementacao doimplementacao doimplementacao doimplementacao do algoritmoalgoritmoalgoritmoalgoritmo
for i i i i in 0 0 0 0 to 3 3 3 3 loop
aux1 := deslocador( aux1 );aux1 := deslocador( aux1 );aux1 := deslocador( aux1 );aux1 := deslocador( aux1 );
vaium := aux2(3);vaium := aux2(3);vaium := aux2(3);vaium := aux2(3);
if vaium = '1' vaium = '1' vaium = '1' vaium = '1' then
aux1 := somador4bits( aux1, b );aux1 := somador4bits( aux1, b );aux1 := somador4bits( aux1, b );aux1 := somador4bits( aux1, b );
end if;;;;
aux2 := deslocador( aux2 );aux2 := deslocador( aux2 );aux2 := deslocador( aux2 );aux2 := deslocador( aux2 );
end loop; ; ; ;
s <= aux1; s <= aux1; s <= aux1; s <= aux1;
end process; ; ; ;
end arch_mult4bits;arch_mult4bits;arch_mult4bits;arch_mult4bits;

80
3.6.4 Divisores
Os divisores, assim como os multiplicadores, são circuitos relativamente complexos. Neste caso, o divisor descrito em VHDL consegue dividir números de 4 bits, apresentando ao final da operação o resultado e o resto. A seguir, o algoritmo principal da operação de divisão de n bits com ponto fixo.
Algoritmo do Divisor Inicio: Para i de 0 até o número de bits da divisão faça Vaium do quociente recebe o bit mais significativo do quociente. Deslocar (quociente). Bit menos significativo do quociente recebe sinal de resto maior que divisor. Deslocar (resto). Bit menos significativo do resto recebe sinal de Vaium do quociente.
Sinal de resto maior que o divisor recebe o resultado da comparação (divisor, resto). Se o sinal de resto maior for igual a um então Resto recebe o resto menos o divisor. Deslocar (quociente) Bit menos significativo do quociente recebe sinal de resto maior que divisor. Fim
A seguir a descrição em VHDL’93 do algoritmo aplicado para um divisor de 4 bits de ponto fixo.
Divisor de 4 bit
librarylibrarylibrarylibrary ieee;
useuseuseuse ieee.std_logic_1164.allallallall;
entityentityentityentity div4bits isisisis
portportportport(a, b : inininin std_logic_vector (3 downtodowntodowntodownto 0);
q, r : outoutoutout std_logic_vector (3 downtodowntodowntodownto 0));
endendendend div4bits;
architecturearchitecturearchitecturearchitecture arch_div4bits ofofofof div4bits isisisis
-- deslocamento de 1 bit para esquerda, zerando o bit menos significativo
function deslocadordeslocadordeslocadordeslocador (x : std_logic_vector (3(x : std_logic_vector (3(x : std_logic_vector (3(x : std_logic_vector (3 downto 0))0))0))0))
return std_logic_vector isstd_logic_vector isstd_logic_vector isstd_logic_vector is
variable y : std_logic_vector (3y : std_logic_vector (3y : std_logic_vector (3y : std_logic_vector (3 downto 0);0);0);0);
begin
for iiii in 3333 downto 1111 loop
y(i) := x(iy(i) := x(iy(i) := x(iy(i) := x(i----1)1)1)1);;;;
end loop ;
y(0) := '0';y(0) := '0';y(0) := '0';y(0) := '0';
return y;y;y;y;
end;
-- compara dois numeros
functionfunctionfunctionfunction comparador (x : std_logic_vector; y : std_logic_vector)
returnreturnreturnreturn std_logic is
variablevariablevariablevariable s : std_logic_vector (3 downtodowntodowntodownto 0);
variablevariablevariablevariable vaium : std_logic;
beginbeginbeginbegin

81
vaium := '0';
forforforfor i inininin 0 totototo 3 looplooplooploop
s(i) := (x(i) xorxorxorxor y(i) xorxorxorxor vaium);
vaium := ( y(i) andandandand s(i) ) orororor ( y(i) andandandand vaium) orororor (vaium andandandand s(i) ) ;
end loopend loopend loopend loop;
vaium := notnotnotnot vaium;
returnreturnreturnreturn vaium;
endendendend comparador;
-- subtracao de dois numeros
functionfunctionfunctionfunction sub4bits (x : std_logic_vector; y : std_logic_vector)
returnreturnreturnreturn std_logic_vector isisisis
variablevariablevariablevariable s : std_logic_vector (3 downtodowntodowntodownto 0);
variablevariablevariablevariable vaium : std_logic;
beginbeginbeginbegin
vaium := '0';
forforforfor i inininin 0 totototo 3 looplooplooploop
s(i) := (x(i) xorxorxorxor y(i) xorxorxorxor vaium);
vaium := ( y(i) andandandand s(i) ) orororor (y(i) andandandand vaium) orororor (vaium andandandand s(i) ) ;
end loopend loopend loopend loop;
return return return return s;
endendendend sub4bits;
beginbeginbeginbegin
processprocessprocessprocess (a,b)
variablevariablevariablevariable vq, vr : std_logic_vector (3 downtodowntodowntodownto 0);
variablevariablevariablevariable quoc, resto : std_logic;
beginbeginbeginbegin
vq := a;
quoc := '0';
resto := '0';
vr := "0000";
forforforfor i inininin 0 totototo 3 looplooplooploop
quoc := vq(3);
vq := deslocador(vq);
vq(0) := resto;
vr := deslocador(vr);
vr(0) := quoc;
resto := comparador(vr, b);
ifififif resto = '1' thenthenthenthen
vr := sub4bits (vr, b);
end ifend ifend ifend if;
end loopend loopend loopend loop;
vq := deslocador (vq);
vq(0) := resto;
q <= vq;
r <= vr;
eeeend processnd processnd processnd process;
endendendend arch_div4bits;

82
3.6.5 Estatísticas de Circuitos Aritméticos em FPGAs
O multiplicador e o divisor por apresentar um algoritmo complexo geram os maiores atrasos e utilização de recursos do FPGA (tabela 3.13 e 3.14). Normalmente algoritmos de implementação de multiplicadores e divisores são complexos. O tratamento da multiplicação e divisão com pontos flutuantes atingem níveis altos de complexidade.
Tabela 3.13 – Recursos utilizados do FPGA - Circuitos aritméticos.
Circuito Aritmético FF LUTs 4 LUTs 3 CLBs Comp. Simples 0 3 1 2
Comp. Porta lógica 0 3 1 2 Múltipla Comp. 0 10 2 6
Somador 1bit 0 2 0 1 Somador 4bit 0 9 1 5
Sub. 4bit 0 6 0 4 Mult. 4 bits 0 10 0 6 Div. 4 bits 0 45 5 25
Tabela 3.14 – Temporização dos circuitos aritméticos.
Circuitos Aritmético TL (ns) TR (ns) AT(ns) Comparador Simples 8,858 5,814 14,672
Comparador Porta lógica 8,858 5,183 14,041 Múltiplicador Complemento 10,048 7,925 17,973
Somador 1bit 6,899 3,234 10,133 Somador 4bit 10,048 6,938 16,557 Subtrator 4bit 8,089 6,025 14,114
Multiplicador 4 bits 9,279 8,515 17,794 Divisor 4 bits 18,378 30,664 49,042
Neste capítulo, foram apresentadas descrições em VHDL de circuitos combinacionais, ressaltando suas principais características, enfatizando o funcionamento, metodologias de descrição e estatísticas de desempenho espacial e temporal.
Importante ressaltar que os circuitos artiméticos implementados em VHDL e os respectivos dados de utilização de recursos em FPGAs são de grande utilidade para o nosso objetivo, qual é de apresentar dados e comparações de desempenho de algoritmos criptográficos implemenntados em software e hardware (FPGAs).
A maioria dos algoritmos criptográficos usam operações básicas do tipo soma, subtração, multiplicação e algumas outras operações especiais tais como substituições, permutações, deslocamentos, entre outras, como é possível de verificar através da tabela 3.15.
Tabela 3.15 – Freqüência de operações em algoritmos simétricos de criptografia.

83
Alg
oritm
o
Operações
XOR Deslocamento/Rotação S-BOX Permutação
DES X X X X
AES X X X
Serpent X X X
Cast-128 X X
MARS X X X
Twofish X X X X
Magenta X X X X
Frog X X X BlowFish X X X RC5 X X RC6 X X X IDEA X X

84
Capítulo 4 ALPOS: Um algoritmo Didático de Criptografia
No capítulo 4, apresenta-se um algoritmo criptográfico didático, criado e chamado pelos autores de ALPOS – algoritmo posicional. Esse algoritmo é relativamente simples e é baseado em cifras de substituição, considerando a posição do texto a ser cifrado. Esse algoritmo é útil para mostrar alguns conceitos básicos do processo de cifrar e decifrar mensagens. Apresenta-se e explica-se o código C e a respectiva implementação em VHDL, com destaque a aspectos de desempenho e segurança. Finalmente, se descrevem métodos para tentar quebrar o algoritmo, isto é a respectiva criptoanálise.
4.1 Conceitos e Exemplos O algoritmo de criptografia posicional ALPOS consiste em que a posição do byte interfere sobre a chave utilizada na criptografia (CHIARAMONTE, 2001). O ALPOS se baseia no bem conhecido algoritmos de Cifra de César (SCHNEIER, 1996). No algoritmo proposto pelos autores, o ALPOS, foi introduzida uma função sobre o algoritmo Cifra de César para que cada posição seja criptografada de forma diferente eliminando o problema de freqüência de letras.
Com o algoritmo posicional básico a seqüência AAABBB, por exemplo, poderia ser criptografada como BCDFGH, sem acrescer a ela nenhum bit. Para isso, admita-se o valor decimal dos bytes A, B, C ,D, E ,F ,G e H de acordo com a tabela ASCII (65, 66, 67, 68, 69, 70, 71 e 72 respectivamente). A esses valores são acrescidos os valores de sua posição. Agora vamos supor o exemplo da tabela 4.1 onde existe uma seqüência AAABBB. Como o primeiro A está na posição um, o seu valor decimal criptografado será 66 (que equivale na tabela ASCII ao caracter B), mas como o segundo A está na posição dois, deve-se acrescer 2 ao seu valor ASCII, assim o valor decimal do segundo byte será 67 (que equivale na tabela ASCII ao caracter C), e assim por diante.
Infelizmente esse modelo ainda é simples de ser quebrado. Por esse motivo, na proposta apresentada pelos autores, no algoritmo posicional é recomendável somar ao valor do byte original representado em ASCII um número gerado utilizando-se de uma expressão matemática que usa a posição do byte (variável x). Por exemplo: usando uma expressão do tipo a*x + b. Onde a e b são valores da chave; e x a posição.
85
Tabela 4.1 – Exemplo do Algoritmo Posicional Básico
Seqüência A A A B B B Valor decimal na tabela ASCII 65 65 65 66 66 66
Valor da posição 1 2 3 4 5 6 Valor decimal ASCII (código
criptografado) 66 67 68 70 71 72
Código em caracteres (criptografado) B C D F G H
Nesse tipo de criptografia, quanto maior o grau da expressão posicional, maior será a complexidade do algoritmo e por sua vez a segurança dos dados cifrados usando-se desse algoritmo. Por exemplo: Se a expressão posicional for uma equação do terceiro grau, terá uma segurança maior que um sistema com equação do segundo grau. Isto ocorre pois o número de valores que compõem a chave estão ligados ao grau da expressão posicional.
A seguir é apresentado um exemplo completo de criptografia utilizando grau 3. Neste exemplo ocorre o estouro de um byte, ou seja, o valor decimal do código criptografado é maior que 256 que é o valor máximo que pode ser armazenado em um byte (o código ASCII tem a capacidade de 28=256 possibilidades). No caso de estouro, nós assumimos que o valor do byte será “valor encontrado mod 256” onde mod retorna o resto da divisão.
A equação posicional utilizada será: f(x) = 23x3 + 26x2 - 45x1 - 63 onde os coeficientes 23,26,-45,-63 foram selecionados aleatoriamente.
Considerando o mesmo exemplo anterior cuja seqüência original é AAABBB, temos as seguintes fases.(ver tabela 4.2).
Tabela 4.2 – Exemplo Posicional Grau 3 (23x3 + 26x2 - 45x - 63)
Seqüência A A A B B B Valor decimal na tabela ASCII 65 65 65 66 66 66
Valor da posição 1 2 3 4 5 6 Resultado da expressão: 23x3 + 26x2 – 45x – 63
-59 135 657 1645 3237 5571
Valor da expressão + valor ASCII original 6 200 722 1711 3303 5637 Valor decimal na tabela (código
criptografado) 6 200 210 175 231 5
Código em caracteres (criptografado) � + Ê » Þ �
As colunas em destaque com sombra indicam aquelas onde ocorreu o estouro de um byte. Os valores 722, 1711, 3303 e 5637 ultrapassam 256 e não podem ser armazenados em apenas um byte. Para solucionar esse problema é realizada uma divisão e o resto da divisão é utilizado como o valor criptografado. Por exemplo:

86
dividindo o valor 722 por 256 o resto obtido é 210 que é utilizado na penúltima linha da tabela. Os outros valores são calculados do mesmo modo.
4.2 Descrição do Algoritmo A figura 4.1 mostra o esquema geral necessário para cifrar uma letra. O algoritmo necessário para cifrar uma letra é apresentado a seguir:
Inicio
soma = 0
Para i de 1 até grau_chave
Valor_chave = valores[i]
Soma = soma + valor_chave * exponencial(pos,i)
Fim Para
Nova_letra = (antiga_letra + soma) mod 256
O algoritmo acima descrito é capaz de processar uma chave de qualquer grau. O funcionamento dele consiste em calcular primeiro a soma que nas tabelas acima equivalem à “Resultado da expressão” e depois calcular a nova_letra que equivalem à “Valor decimal na tabela (código criptografado)”. Para o cálculo da nova_letra já é incluída a operação mod que retorna o resto da divisão para corrigir um eventual estouro de byte.

87
Figura 4.1 - Esquema Geral do ALPOS – Algoritmo Posicional
A função para o cálculo da soma pode ser expressa genericamente através de:
f(x) = a1 * xn + a2 * x n-1 + ... + an * x1;
onde a1, a2, ..., an são os valores da chave, x a posição do caracter e “n” o número de elementos da chave, também chamado de grau da chave.
Supondo que os valores a1, a2, ..., an estão armazenados em um vetor chamado “valores” como mostra a tabela 4.3. Calcular essa expressão seria executar repetidamente durante “n” vezes a seguinte operação:
valores[i] * posiçãoi
e acumular esses resultados em uma variável, no nosso caso: “soma”.
Tabela 4.3 – Vetor “valores” do ALPOS – Algoritmo Posicional
Índice 1 2 ... N “valores” a1 a2 ... an
O esquema para realizar os cálculos do vetor “valores” discutido anteriormente e “grau_chave”, que é o grau da chave utilizada, estão descritos e explicados a seguir.

88
Figura 4.2 – Cálculo do vetor valores no ALPOS – Algoritmo Posicional
O esquema na figura 4.2 responsável pelo cálculo do vetor “valores” recebe uma string chamada “chave” que está no formato (a1, a2, ..., an) e converte em um vetor com “n” elementos chamado “valores”.
Como a chave está em uma string e precisa ser transformada para o formato numérico é necessário o cálculo do valor de cada caractere dessa string. Levando em conta que os valores de cada elemento da chave estão na base 10 é necessário o cálculo:
(aux[ai]-48)*exponencial(10,j) = (aux[ai]-48)*10j
e acumular esse resultado em uma variável, no esquema acima chamada de “valor”. No cálculo acima, ai é a posição de uma string auxiliar que possui apenas um elemento da chave, por exemplo a1. O valor 48 é para realizar a transformação de uma string para um valor decimal, valor esse que deve ser multiplicado por 10j, onde 10j equivale ao valor real de um número naquela posição.
A figura 4.3 mostra o esquema necessário para o cálculo do grau da chave (grau_chave):

89
Figura 4.3 – Cálculo do Grau da Chave
Como a chave está no formato (a1, a2, ..., an), calcular o grau da chave significa percorrer a chave procurando por virgulas e incrementando o grau da chave a cada virgula encontrada. No algoritmo acima é utilizada uma variável auxiliar j para realizar essa contagem, no final é atribuído o valor de j à variável “grau_chave”.
4.3 Implementação em C do ALPOS O algoritmo posicional, ALPOS, foi implementado em linguagem C. Os leitores podem verificar a versão completa da implementação no link: http://www.editoranovatec.com.br/download.php, clicando na imagem correspondente ao livro de criptografia. Nesse site aparece também uma série de exemplos que facilitam o entendimento do funcionamento do algoritmo ALPOS e dos outros algoritmos decritos no livro.
A seguir são colocados exemplos de funcionamento do algoritmo com vários tipos de chaves diferentes. Os exemplos foram obtidos através da captura da tela de execução do algoritmo.
Os números utilizados para compor a chave podem ser gerados aleatoriamente, contudo, critérios para a formação das chaves estão sendo estudados para evitar a duplicidade das chaves, isto é, evitar que mais que uma chave possa decifrar determinada mensagem, como foi constatado através de uma criptoanálise por força bruta que será discutida em 4.6.
As figuras 4.4 e 4.5 mostram o algoritmo posicional implementado sendo executado. Inicialmente, o programa solicita o texto que deve ser cifrado, depois o programa solicita ao usuário a chave. Na figura 4.4 a chave digitada foi (1,1,1,1,1,1,1,1,1,1) o que significa que está se usando uma função de grau 10 na seguinte maneira:
f(x) = 1x10 +1x9 + 1x8 + 1x7 + 1x6 + 1x5 + 1x4 + 1x3 + 1x2 + 1x1
Similarmente na figura 4.5 solicita-se uma chave de entrada: (123,423,573,567,234) o que significa que:

90
f(x) = 123x5 + 423x4 + 573x3 + 567x2 + 234x1.
A função utilizada na figura 4.5 é, portanto, de grau 5.
Figura 4.4 – Exemplo do algoritmo utilizando a chave (1,1,1,1,1,1,1,1,1,1)
Figura 4.5 – Exemplo de algoritmo utilizando a chave (123,423,573,567,234)
A tabela 4.4 mostra como uma mesma mensagem fica cifrada utilizando-se de chaves diferentes. Nessa tabela, pode-se perceber mais uma vantagem do algoritmo posicional. Independentemente do grau do polinômio usado e dos coeficientes usados, a mensagem cifrada permanece do mesmo tamanho que a mensagem original.
Tabela 4.4 – Mensagens cifradas com chaves diferentes.
Mensagem \ Chave
(211,197) f(x) = 211x2 + 197x1
(223,239,251) f(x) = 223x3 + 239x2 +
251x1
(227,163,193,179) f(x) = 227x4 + 163x3 +
193x2 + 179x1 Algoritmo Posicional
Criptografia
Algumas mensagens criptografadas parecem ser menores que a original (ver tabela 4.4). No entanto, isso se deve à presença de caracteres invisíveis no final das mensagens.
4.4 Implementação em Hardware (VHDL)

91
Para a implementação em VHDL foi utilizada a ferramenta MAX PLUS II da Altera utilizando a FPGA EPF10K20RC240-4 (ALTERA, 2004). Todas as estatísticas e testes apresentados neste capítulo foram obtidos utilizando esse dispositivo.
Inicialmente, propomos um circuito para realizar a criptografia de um caracter. Para isso, estudaremos o algoritmo de criptografia de um caracter e os módulos necessários para a implementação em VHDL. O algoritmo para realizar a criptografia de um caracter é descrito a seguir:
PARA i DE 1 ATÉ grau_da_chave
soma = soma + (valor_da_chave * posiçãoi )
FIM PARA
caracter_cifrado = caracter_original + soma % 256;
Para a implementação desse algoritmo é necessário construir seis blocos digitais, conforme descrito a seguir:
(i) um módulo contador (CONTADOR_I) que será necessário para a execução do bloco “PARA”;
(ii) uma memória para armazenar o valor da chave
(iii) um contador para contar o grau da chave;
(iv) um módulo potência para realizar a operação posiçãoi;
(v) um módulo multiplicador e
(vi) um acumulador.
É necessário também um comparador para comparar os valores de i e grau_da_chave, pois se esses dois valores forem iguais significa que a criptografia de um caractere terminou e é necessário reiniciar alguns contadores.
Os contadores também precisam ser reiniciados quando há alguma alteração na chave, portanto, é necessário um módulo chamado de CTRL_CONT (Controlador Contadores) que é responsável pelo controle dos contadores.
Quando a criptografia de um caractere terminar, o resultado deve ser armazenado em um registrador para a sincronização. Há também a necessidade de atrasar o clock utilizado nesse registrador para indicar que a saída está disponível no momento exato. Portanto, também foi criado um módulo REGISTRADOR e um módulo CLK_D que é responsável pelo atraso do clock do registrador.
Os módulos acima podem ser melhor visualizados através da figura 4.6 que mostra a arquitetura total do sistema.

92
Figura 4.6 – Arquitetura total do sistema
4.5 Análise de Desempenho do ALPOS Nesta seção é realizada uma análise do desempenho em software e em hardware e uma comparação entre os resultados obtidos.
4.5.1 Desempenho em Software
Conhecendo a alta dependência de funcionamento em relação ao grau das expressões usadas, tem-se considerado mudar e avaliar o tempo de execução (necessário para cifrar as mensagens) para vários valores, considerando que o grau muda entre 1 e 10. Além disso, o desempenho depende também do tamanho da mensagem a ser cifrada. Por esse motivo, consideramos três exemplos: mensagens com 0,5; 1,0 e 1,5 Mbytes.
A tabela 4.5 mostra as estatísticas de desempenho obtidas em um computador Intel Celeron 466Mhz. A figura 4.7 mostra o desempenho do algoritmo posicional em seus vários graus de expressões e em relação a arquivos de diferentes tamanhos.
Tabela 4.5 – Estatísticas do algoritmo Posicional em software
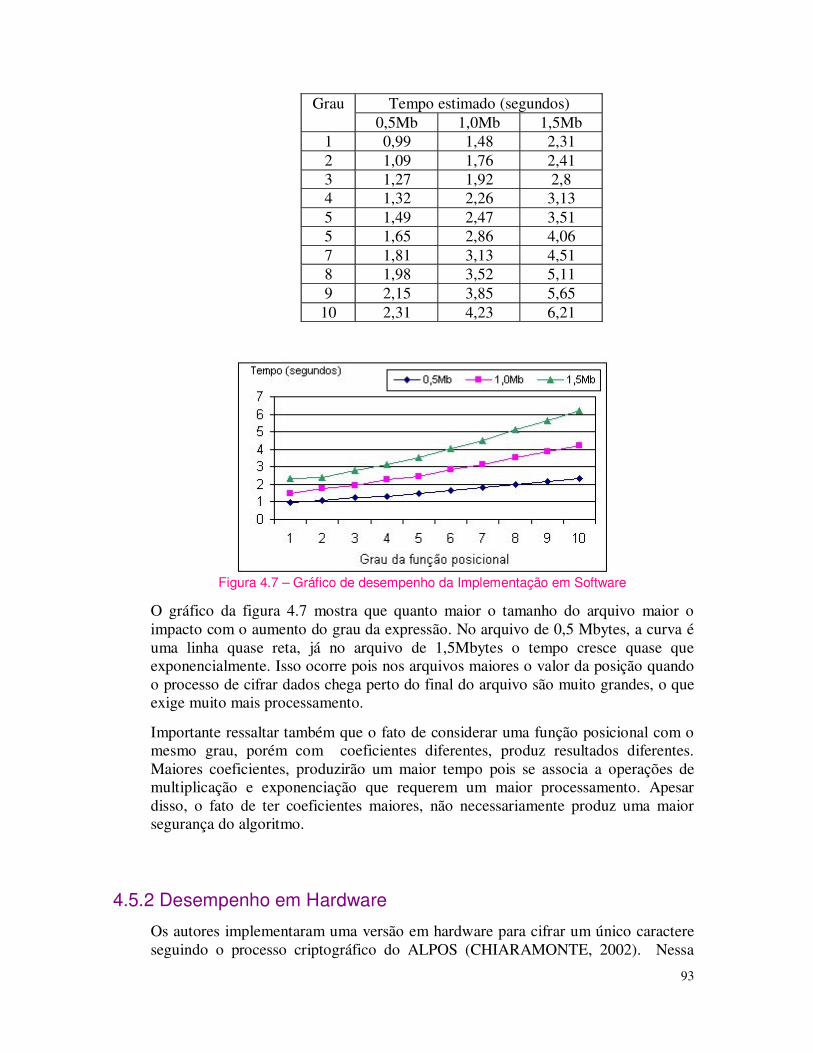
93
Grau Tempo estimado (segundos) 0,5Mb 1,0Mb 1,5Mb
1 0,99 1,48 2,31 2 1,09 1,76 2,41 3 1,27 1,92 2,8 4 1,32 2,26 3,13 5 1,49 2,47 3,51 5 1,65 2,86 4,06 7 1,81 3,13 4,51 8 1,98 3,52 5,11 9 2,15 3,85 5,65
10 2,31 4,23 6,21
Figura 4.7 – Gráfico de desempenho da Implementação em Software
O gráfico da figura 4.7 mostra que quanto maior o tamanho do arquivo maior o impacto com o aumento do grau da expressão. No arquivo de 0,5 Mbytes, a curva é uma linha quase reta, já no arquivo de 1,5Mbytes o tempo cresce quase que exponencialmente. Isso ocorre pois nos arquivos maiores o valor da posição quando o processo de cifrar dados chega perto do final do arquivo são muito grandes, o que exige muito mais processamento.
Importante ressaltar também que o fato de considerar uma função posicional com o mesmo grau, porém com coeficientes diferentes, produz resultados diferentes. Maiores coeficientes, produzirão um maior tempo pois se associa a operações de multiplicação e exponenciação que requerem um maior processamento. Apesar disso, o fato de ter coeficientes maiores, não necessariamente produz uma maior segurança do algoritmo.
4.5.2 Desempenho em Hardware
Os autores implementaram uma versão em hardware para cifrar um único caractere seguindo o processo criptográfico do ALPOS (CHIARAMONTE, 2002). Nessa

94
implementação, calculou-se que para realizar um acesso à memória precisam-se de 100ns (nanosegundos, lembrar que 1 ns = 10-9 segundos). No algoritmo ALPOS, a programação da chave requer somente acessos à memória para gravação de seus valores. Considerando que uma chave de grau n possui n valores e com isso requer n acessos à memória; o tempo de programação de uma chave pode ser calculado pela fórmula:
100ns * grau da chave.
No entanto, o tempo necessário para a criptografia é maior, uma vez que para a criptografia os dados devem percorrer o circuito consumindo vários ciclos de clock dependendo do tamanho das chaves.
Os tempos obtidos durante a criptografia de um caractere nos diversos graus possíveis para a chave são apresentados na tabela 4.6.
Tabela 4.6 – Tempos obtidos na criptografia de um caractere
Grau 1 2 3 4 5 6 7 8 9 10 Tempo (us) 0,3 0,6 1 1,5 2,1 2,8 3,6 4,5 5,5 6,6
Com base nesses tempos, podemos calcular o tempo necessário para criptografar textos com vários tamanhos e assim comparar os resultados com os obtidos na implementação em software.
A tabela 4.7 mostra o tempo estimado para a criptografia de textos com os tamanhos de 0,5; 1,0 e 1,5Mbytes.
A figura 4.8 mostra o gráfico de desempenho obtido através das estimativas calculadas na tabela 4.7. Nota-se que a implementação em hardware possui um desempenho muito parecido com a implementação em software, no entanto, ela é um pouco mais lenta. Isso ocorre pois os tempos obtidos são tempos estimados através da multiplicação do tamanho do arquivo pelo tempo necessário para a criptografia de um caractere. Uma otimização possível, é permitir que mais de um caractere possa ser criptografado em paralelo, o que melhora muito o desempenho.
A tabela 4.8 mostra as estatísticas de uso da FPGA, através dela podem ser verificados o número de células lógicas necessárias e o sintetizado bem como os tempos de atraso de cada módulo e da implementação da criptografia de um caractere (ALPOS.VHD).
Tabela 4.7 – Tempo estimado (segundos) para a criptografia de arquivos de 0,5Mb, 1,0Mb
e 1,5Mb
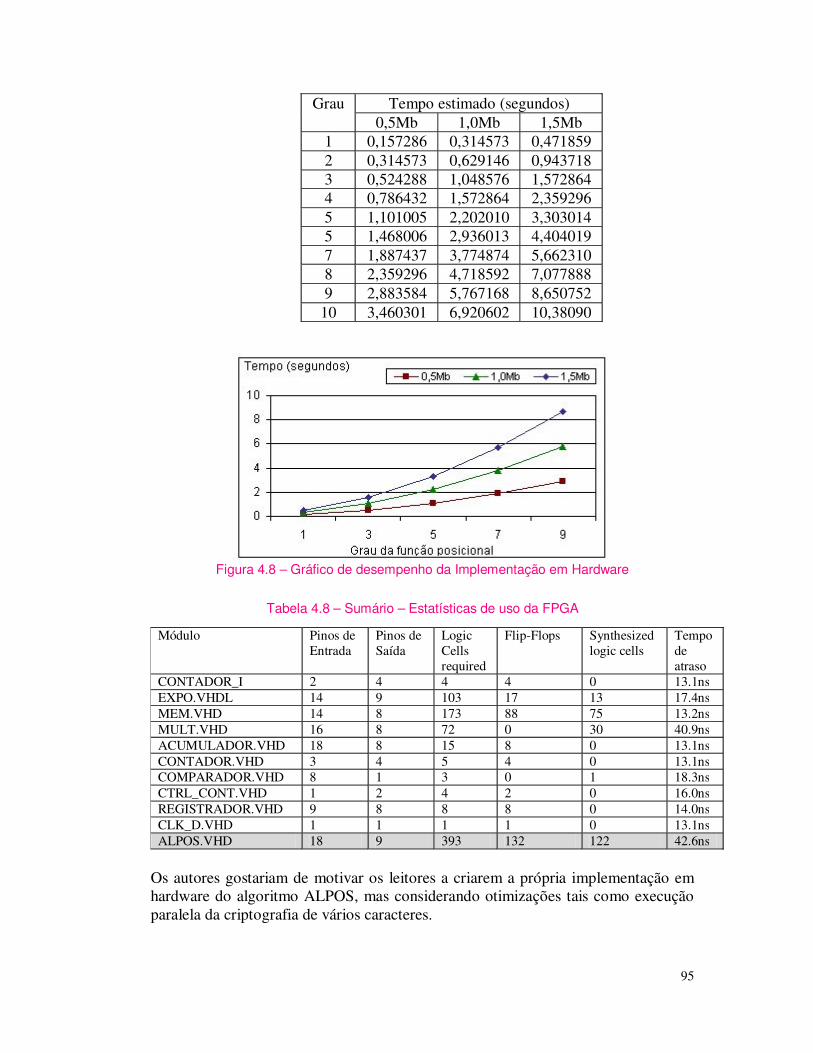
95
Grau Tempo estimado (segundos) 0,5Mb 1,0Mb 1,5Mb
1 0,157286 0,314573 0,471859 2 0,314573 0,629146 0,943718 3 0,524288 1,048576 1,572864 4 0,786432 1,572864 2,359296 5 1,101005 2,202010 3,303014 5 1,468006 2,936013 4,404019 7 1,887437 3,774874 5,662310 8 2,359296 4,718592 7,077888 9 2,883584 5,767168 8,650752
10 3,460301 6,920602 10,38090
Figura 4.8 – Gráfico de desempenho da Implementação em Hardware
Tabela 4.8 – Sumário – Estatísticas de uso da FPGA
Módulo Pinos de Entrada
Pinos de Saída
Logic Cells required
Flip-Flops Synthesized logic cells
Tempo de atraso
CONTADOR_I 2 4 4 4 0 13.1ns EXPO.VHDL 14 9 103 17 13 17.4ns MEM.VHD 14 8 173 88 75 13.2ns MULT.VHD 16 8 72 0 30 40.9ns ACUMULADOR.VHD 18 8 15 8 0 13.1ns CONTADOR.VHD 3 4 5 4 0 13.1ns COMPARADOR.VHD 8 1 3 0 1 18.3ns CTRL_CONT.VHD 1 2 4 2 0 16.0ns REGISTRADOR.VHD 9 8 8 8 0 14.0ns CLK_D.VHD 1 1 1 1 0 13.1ns ALPOS.VHD 18 9 393 132 122 42.6ns
Os autores gostariam de motivar os leitores a criarem a própria implementação em hardware do algoritmo ALPOS, mas considerando otimizações tais como execução paralela da criptografia de vários caracteres.

96
4.6 Criptoanálise O sistema posicional parece ser bem resistente contra um ataque testando-se todas as chaves possíveis (ataque de força bruta). Os autores implementaram um programa em C que testa varias chaves até conseguir descobrir a mensagem original a partir da mensagem já cifrada.
Testes foram realizados utilizando chaves até o grau 4, após esse grau de segurança o tempo utilizado para conseguir quebrar uma chave ultrapassa uma hora. A tabela 4.9 apresenta os tempos gastos para a quebra de chaves de diferentes graus de segurança. Além disso trabalhou-se na criação de um modelo matemático (KNUTH, 1997) onde conseguiu-se uma expressão para medir o tempo para quebrar uma chave de grau n.
Para obter o modelo, foi calculado o tempo médio do teste de força bruta em chaves de grau 3 utilizando um computador AMD K6-2 de 300Mhz, a média obtida foi 386 milesegundos. Considerando que cada parte da chave suporta um valor até 256, o tempo para o teste de força bruta para uma chave de grau 4 é igual a 256 vezes o tempo de uma chave de grau 3. Para uma chave de grau 5 o tempo é de 256 vezes o tempo de uma chave de grau 4. Sendo assim o tempo para uma chave de grau “n” é igual a 256 vezes o tempo de uma chave com grau “n-1”. Já que temos como base que uma chave de grau 3 demora 386 milessegundos, temos que uma chave de grau N demora (256^(N-3))*386 milesegundos para ser descoberta através de um teste de força bruta. Como o tempo mínimo para uma chave de grau 3 ser descoberta é 600 milesegundos (ainda com base no mesmo computador descrito acima) eles foram considerados obtendo assim o modelo:
600 + ((256^(N-3))*386).
Esses valores são mostrados na tabela 4.9. Foram realizados testes reais onde foi obtido um tempo de 0,6 segundos para uma chave de grau 3 e 98,920 segundos para uma chave de grau 4 (tempo mínimo). O tempo máximo para cada chave é igual ao tempo mínimo de uma chave com grau consecutivo. Por exemplo, o tempo máximo de uma chave de grau 3 é o mesmo que o tempo mínimo de uma chave de grau 4.
Para obter o modelo que estima o tempo necessário para encontrar as chaves utilizando uma máquina difirente é necessário recalcular o tempo médio e mínimo para uma chave de grau 3 na máquina desejada e substituí-los no modelo.
No entanto, durante esses testes, comprovou-se a existência de chaves equivalentes. Por exemplo, uma chave de grau 3 pode possuir uma chave de grau 2 equivalente, portanto, um possível melhoramento do algoritmo posicional proposto é criar regras para a composição da chave para que não ocorra esse problema.
Explorando esse problema um criptanalista pode conseguir obter uma chave em muito menos tempo. Existem alguns outros problemas conhecidos que serão discutidos e corrigidos no capítulo seguinte.
Tabela 4.9 – Tempo necessário para quebrar uma chave

97
Grau Mínimo (segundos) Máximo (segundos) 3 0,600 98,920 4 98,920 25.297,110β 5 25.297,110β 6.475.922,000β = 74,9 dias 6 6.475.922,000β = 74,9 dias 1,65786E+12β = 525 séculos 7 1,65786E+12β = 525 séculos 4,24411E+14β = 13457 milênios 8 4,24411E+14β = 13457 milênios 1,08649E+17β = 3445237 milênios 9 1,08649E+17β = 3445237
milênios 2,78142E+19β = 881982496
milênios 10 2,78142E+19β = 881982496
milênios 7,12044E+21β = 225787671232
milênios N 600 + ((256(Grau-3)) *386) 600 + ((256(Grau-2)) *386) Os dados indicados com β significa que o valor foi calculado de acordo com o
modelo estabelecido
4.7 Considerações Finais A figura 4.9 apresenta uma comparação das velocidades de cifrar dados obtidas com o ALPOS - algoritmo posicional. Através dela pode-se notar que a velocidade de para criptografar diminui a medida que o grau da chave aumenta. Pode-se notar também que a velocidade do algoritmo posicional em hardware é muito alta para chaves pequenas, entretanto, com o aumento do grau da chave o desempenho diminui bruscamente. Isso ocorre pois quando a chave é pequena, o número de ciclos necessários para criptografar um caractere é pequeno, mas com o aumento do grau da chave, o número de ciclos necessários cresce quase que exponencialmente.
Figura 4.9 – Comparação de desempenho do algoritmo Posicional(Software x Hardware)

98

99
Capítulo 5 Otimizações no ALPOS
No capítulo 5 apresentam-se algumas otimizações do algoritmo posicional, e faz-se uma comparação de desempenho com a versão anterior (desempenho e nível de segurança) finalizando com uma comparação de velocidade com alguns algoritmos de criptografia, considerados clássicos e discutidos nos próximos capítulos.
5.1 Motivação O algoritmo posicional apresentado no capítulo 4 obteve um nível de segurança significativamente maior que o algoritmo Cifra de César (que é o algoritmo no qual o ALPOS se baseia).
No entanto, o ALPOS ainda possui algumas falhas graves de segurança. Com isso são propostas algumas otimizações para fornecer um maior nível de segurança corrigindo os problemas conhecidos.
5.2 Criptografia Posicional usando Blocos Como descrito anteriormente, quando ocorre o estouro de um byte é calculado o resto da divisão do valor obtido por 256, ou seja,
valor criptografado = valor obtido (mod 256).
Isso faz com que a cifra tenha um período curto de 256 bytes, ou seja, o resultado da expressão (mod 256) vai coincidir a cada 256 bytes como mostra a tabela 5.1. O exemplo da tabela 5.1 foi gerado utilizando a chave (23,26,45,63):
Com isso um criptoanalista pode facilmente dividir o texto cifrado em blocos de 256 bytes e conseguir obter o texto legível. Para evitar esse ataque é necessário ampliar o período da cifra considerando blocos ao invés de bytes. Utilizando blocos de 32 bits (4 bytes) o período da cifra é alongado para 232, ou seja, a repetição dos valores só ocorrerá a cada 232 bytes (4.294.967.296 bytes – ou 4 giga bytes).
Tabela 5.1 – Repetição dos valores a cada 256 bytes

100
Posição Resultado da expressão Resultado (mod 256) 1 157 157 2 441 185 3 1053 29 4 2131 83
257 392144541 157 258 396733113 185 259 401357341 29 260 406017363 83 513 3111996573 157 514 3130217401 185 515 3148509213 29 516 3166872147 83
Para implementar esta operação em C basta fazer com que a função de leitura do arquivo leia 32 bits; e alterar o tipo de dados utilizado de “char” para “int”. Como blocos de 32 bits estão sendo utilizados, são cifrados 4 bytes ao mesmo tempo, o que melhorou significativamente o desempenho.
É possível realizar implementações com blocos maiores, no entanto, foi constatado que isso não oferece muitas vantagens. Dois motivos principais são:
1 – As mensagens que se desejam cifrar raramente excedem o limite de 4 giga bytes;
2 – Com blocos maiores, maior é a probabilidade de parte do bloco cifrado coincidir com o bloco original, pois o valor do resultado da expressão tende a ser pequeno no início das mensagens, principalmente quando a chave utilizada é pequena.
5.3 Inclusão de bits Aleatórios Como visto na seção anterior, realizar a criptografia em blocos alongando o período da cifra aumenta significativamente a segurança. No entanto, este algoritmo continua vulnerável a um ataque por texto legível conhecido, onde um criptanalista de posse de um texto legível e seu correspondente ilegível consegue obter a chave.
Veja a seguir um exemplo de como isso pode ocorrer com o ALPOS:
A função para cifrar os dados tem como entrada e saída um valor do tamanho do bloco que está sendo utilizado e as operações são realizadas mod (2t) onde t = tamanho do bloco.
Vamos supor que o criptanalista tem acesso à seguinte parte “ABCDEFGHIJKL” que começa na posição 111 de um texto que foi criptografado utilizando uma versão com blocos de 32 bits e com a chave “10,20,30”, no entanto o criptanalista não conhece a chave, apenas a mensagem ilegível correspondente àquela parte do texto.
101
A tabela 5.2 mostra como os dados foram criptografados e a tabela 5.3 mostra quais são os dados que o criptoanalista têm acesso.
Tabela 5.2 – Exemplo de criptografia
Texto ABCD EFGH IJKL Posição 111 112 113 Valor 65666768 69707172 73747576
Expressão 10x3+20x2+30x1 Resultado da
expressão 13926060 14303520 14687740
Criptografado 79592828 84010692 88435316
Tabela 5.3 – Dados em posse do criptanalista
Posição 111 112 113 Original 65666768 69707172 73747576
Criptografado 79592828 84010692 88435316
O criptoanalista em posse dos dados na tabela 5.3 calcula “Criptografado - (menos) Original” obtendo os valores equivalentes ao resultado da expressão na tabela 5.2. Com posse desses valores ele pode montar o sistema apresentado na figura 5.1:
Figura 5.1 – Sistema utilizado para criptoanalise
Para montar o sistema apresentado na figura 5.1. o criptoanalista utilizou o seguinte raciocínio: Para gerar o resultado da expressão para a posição 111 foi realizado o seguinte cálculo:
expr111 = chave1 * 1113 + chave2 * 1112 + chave3 * 1111
Como sobraram 3 incógnitas (chave1, chave2 e chave3) é necessário ter pelo menos 3 expressões para poder resolver o sistema. O criptanalista deve então gerar expressões utilizando os valores obtidos com as outras posições (112 e 113) para montar o sistema completo que foi apresentado.
No sistema da figura 5.1 as incógnitas chave1, chave2 e chave3 foram substituídas por a,b e c respectivamente.
Existem métodos matemáticos que permitem resolver rapidamente até os sistemas de grau 10 (grau máximo de segurança oferecido pelas implementações do algoritmo posicional).
Para solucionar esse problema a função para criptografar os dados foi alterada e passou a ter como entrada 3 caracteres de 8 bits (24 bits de entrada) e como saída um

102
inteiro de 32 bits. A função calcula internamente 8 bits aleatórios e acrescenta à entrada (formando o bloco completo de 32 bits) antes de realizar a criptografia do bloco (que ainda é de 32 bits). Isso dificulta ao criptoanalista a criação do sistema apresentado acima, pois não será possível a ele saber com certeza qual era o bloco original antes de ser criptografado, pois os bits aleatórios foram inseridos dentro da função de criptografia.
Para que o criptoanalista consiga gerar um sistema capaz de calcular a chave, ele terá que descobrir quais foram os bits acrescentados. Para uma chave de grau 1, como é necessário apenas um bloco para conseguir montar o sistema completo, ele terá de testar 256 possibilidades pra descobrir os 8 bits aleatórios acrescentados. Já para um sistema de grau 3, em que é necessário utilizar 3 blocos para montar o sistema, uma vez que um sistema com grau 3 existem três incógnitas, ele terá de testar 224 possibilidades para descobrir os 24 bits acrescentados, ou seja, 16777216 possibilidades. Em um sistema com grau 10, que é o que oferece o maior nível de segurança, é necessário testar 280 possibilidades, ou seja, 1.208.925.819.614.629.174.706.176 possibilidades; o que torna esse tipo de ataque inviável ao criptoanalista.
5.4 Desempenho das Otimizações
5.4.1 Desempenho da otimização em blocos
Como descrito anteriormente o desempenho melhorou significativamente. Na tabela 5.4 são apresentadas estatísticas de duas versões em blocos (blocos de 32 e de 64 bits) utilizando chaves de grau 1 até 10.
Os tempos foram obtidos com base em um computador com processador AMD – Duron 950 Mhz e 128 Mbytes de memória principal, RAM.
A figura 5.2 mostra um gráfico comparativo de desempenho sobre as implementações. O gráfico mostra a taxa de cifragem em Mbytes/s (Megabytes por segundo). Através dele pode-se observar que quanto maior o tamanho do bloco maior a taxa de cifragem (principalmente utilizando chaves pequenas como a de grau 1 ou 2), no entanto, o uso de blocos acima de 32 bits não é recomendável por questões de segurança.
Tabela 5.4 – Desempenho do algoritmo Posicional com blocos de 32 e 64 bits
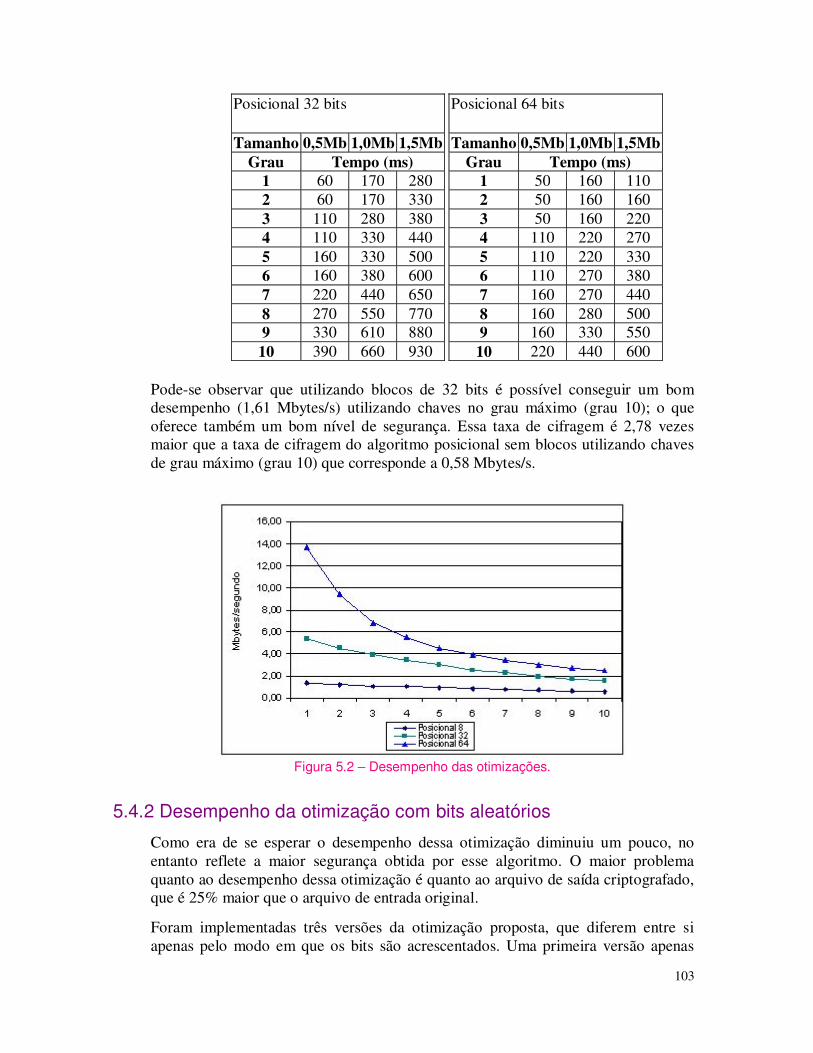
103
Posicional 32 bits Posicional 64 bits
Tamanho 0,5Mb 1,0Mb 1,5Mb Tamanho 0,5Mb 1,0Mb 1,5Mb Grau Tempo (ms) Grau Tempo (ms)
1 60 170 280 1 50 160 110 2 60 170 330 2 50 160 160 3 110 280 380 3 50 160 220 4 110 330 440 4 110 220 270 5 160 330 500 5 110 220 330 6 160 380 600 6 110 270 380 7 220 440 650 7 160 270 440 8 270 550 770 8 160 280 500 9 330 610 880 9 160 330 550 10 390 660 930 10 220 440 600
Pode-se observar que utilizando blocos de 32 bits é possível conseguir um bom desempenho (1,61 Mbytes/s) utilizando chaves no grau máximo (grau 10); o que oferece também um bom nível de segurança. Essa taxa de cifragem é 2,78 vezes maior que a taxa de cifragem do algoritmo posicional sem blocos utilizando chaves de grau máximo (grau 10) que corresponde a 0,58 Mbytes/s.
Figura 5.2 – Desempenho das otimizações.
5.4.2 Desempenho da otimização com bits aleatórios
Como era de se esperar o desempenho dessa otimização diminuiu um pouco, no entanto reflete a maior segurança obtida por esse algoritmo. O maior problema quanto ao desempenho dessa otimização é quanto ao arquivo de saída criptografado, que é 25% maior que o arquivo de entrada original.
Foram implementadas três versões da otimização proposta, que diferem entre si apenas pelo modo em que os bits são acrescentados. Uma primeira versão apenas
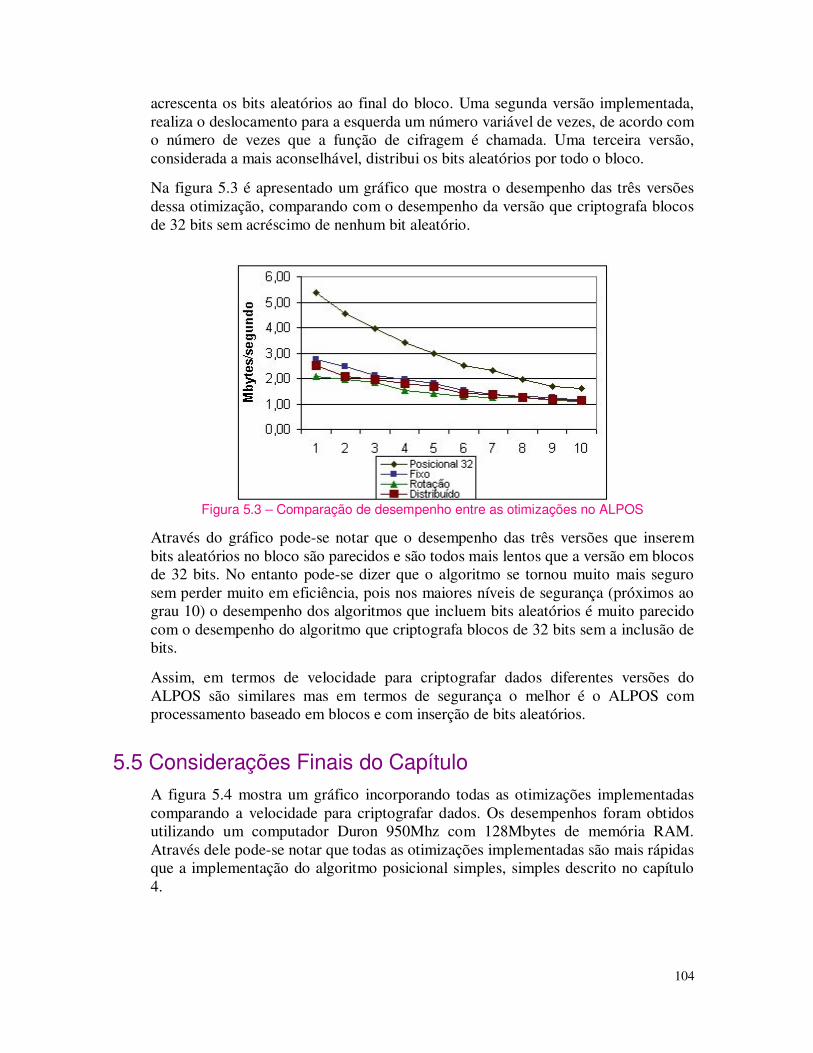
104
acrescenta os bits aleatórios ao final do bloco. Uma segunda versão implementada, realiza o deslocamento para a esquerda um número variável de vezes, de acordo com o número de vezes que a função de cifragem é chamada. Uma terceira versão, considerada a mais aconselhável, distribui os bits aleatórios por todo o bloco.
Na figura 5.3 é apresentado um gráfico que mostra o desempenho das três versões dessa otimização, comparando com o desempenho da versão que criptografa blocos de 32 bits sem acréscimo de nenhum bit aleatório.
Figura 5.3 – Comparação de desempenho entre as otimizações no ALPOS
Através do gráfico pode-se notar que o desempenho das três versões que inserem bits aleatórios no bloco são parecidos e são todos mais lentos que a versão em blocos de 32 bits. No entanto pode-se dizer que o algoritmo se tornou muito mais seguro sem perder muito em eficiência, pois nos maiores níveis de segurança (próximos ao grau 10) o desempenho dos algoritmos que incluem bits aleatórios é muito parecido com o desempenho do algoritmo que criptografa blocos de 32 bits sem a inclusão de bits.
Assim, em termos de velocidade para criptografar dados diferentes versões do ALPOS são similares mas em termos de segurança o melhor é o ALPOS com processamento baseado em blocos e com inserção de bits aleatórios.
5.5 Considerações Finais do Capítulo A figura 5.4 mostra um gráfico incorporando todas as otimizações implementadas comparando a velocidade para criptografar dados. Os desempenhos foram obtidos utilizando um computador Duron 950Mhz com 128Mbytes de memória RAM. Através dele pode-se notar que todas as otimizações implementadas são mais rápidas que a implementação do algoritmo posicional simples, simples descrito no capítulo 4.
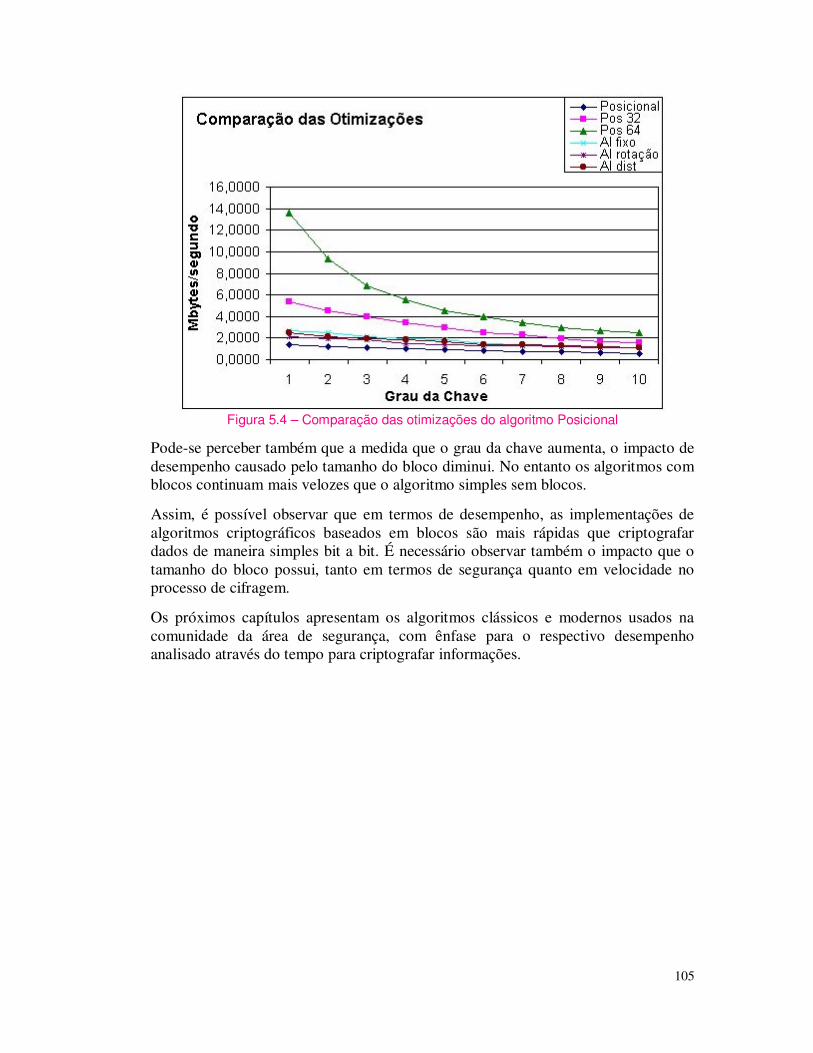
105
Figura 5.4 – Comparação das otimizações do algoritmo Posicional
Pode-se perceber também que a medida que o grau da chave aumenta, o impacto de desempenho causado pelo tamanho do bloco diminui. No entanto os algoritmos com blocos continuam mais velozes que o algoritmo simples sem blocos.
Assim, é possível observar que em termos de desempenho, as implementações de algoritmos criptográficos baseados em blocos são mais rápidas que criptografar dados de maneira simples bit a bit. É necessário observar também o impacto que o tamanho do bloco possui, tanto em termos de segurança quanto em velocidade no processo de cifragem.
Os próximos capítulos apresentam os algoritmos clássicos e modernos usados na comunidade da área de segurança, com ênfase para o respectivo desempenho analisado através do tempo para criptografar informações.

106
Parte II Algoritmos Clássicos de Criptografia
Nos capítulos 6 a 9, segunda parte do livro, se apresentam os conceitos relacionados com os algoritmos criptográficos clássicos, tais como o DES, IDEA, RSA e os baseados em Hashing. Oferecem-se exemplos, e depois a respectiva implementação, tanto em software (linguagem C e alguns deles em Java) e a respectiva implementação em hardware (usando-se da linguagem VHDL para criar o respectivo circuito que é mapeado em um FPGA). Cada algoritmo de interesse é estudado e apresentado seguindo a mesma estrutura, e é dedicado um capítulo a cada um deles. Cada capítulo faz ênfase nas questões de implementação e desempenho do algoritmo.

107
Capítulo 6 Algoritmo DES em Software e Hardware
Este capítulo apresenta o famoso algoritmo DES, com ênfase para o seu funcionamento e implementação em software e hardware, assim como dados de desempenho da sua implementação em C e FPGAs.
6.1 Um Breve Histórico do DES O algoritmo DES (Data Encryption Standard) é um dos algoritmos de cifragem mais usado no mundo. Durante muitos anos, e para muitas pessoas, criptografia e DES foram sinônimos. Apesar do recente grande feito da Electronic Frontier Foundation, criando uma máquina de US$ 220.000 para quebrar mensagens cifrados com DES, este algoritmo vai continuar sendo útil em governos e bancos pelos próximos anos através da versão chamada triple-DES (TKOTZ, 2003).
O triple-DES ou também conhecido como 3-DES faz o processo de cifragem idêntico ao algoritmo DES, só que é repetido três vezes, podendo usar sempre o mesmo valor da chave ou usando duas ou três chaves diferentes.
Em 15 de Maio de 1973, durante o governo de Richard Nixon, o National Bureau of Standards (NBS) publicou uma notícia solicitando formalmente propostas de algoritmos criptográficos para proteger dados durante transmissões e armazenamento. A notícia explicava porque a cifragem de dados era um assunto importante.
O National Bureau of Standards solicitava técnicas e algoritmos para a cifragem de dados por computador. Também solicitava técnicas para implementar as funções criptográficas de gerar, avaliar e proteger chaves criptográficas; manter arquivos cifrados com chaves que expiram; fazer atualizações parciais em arquivos cifrados e misturar dados cifrados com claros para permitir marcações, contagens, roteamentos, etc. O NBS, no seu papel de estabelecer padrões e de auxiliar o governo e a indústria no acesso à tecnologia, se encarregaria de avaliar os métodos de proteção para preparar as linhas de ação.
O NBS ficou esperando por respostas. Nenhuma apareceu até 6 de Agosto de 1974, três dias antes da renúncia de Nixon, quando a IBM apresentou um algoritmo candidato que ela havia desenvolvido internamente, denominado LUCIFER.

108
Horst Feistel um dos idealizadores do LUCIFER chegou como imigrante alemão aos Estados Unidos em 1934. Ele ia se tornar um cidadão americano quando os EUA entraram na segunda guerra mundial. Para Feistel, alemão, isto significou uma imediata prisão domiciliar, a qual se estendeu até 1944. Mesmo depois de alguns anos após o incidente, Feistel manteve-se distante da criptologia para evitar levantar suspeitas das autoridades. Porém, quando estava no Cambridge Research Center da Força Aérea Americana, ele não resistiu e começou a pesquisar cifras. Imediatamente começou a ter problemas com a National Security Agency, a NSA, organização americana responsável pela segurança das comunicações militares e governamentais, e que também tenta interceptar e decifrar mensagens estrangeiras. A NSA emprega um grande número de matemáticos e compra a maior quantidade de hardware e intercepta mais mensagens que qualquer outra organização no mundo.
A NSA não se importava com o passado de Feistel, queria apenas ter o monopólio da pesquisa em criptografia e conseguiu fazer com que o projeto de pesquisa de Feistel fosse cancelado. Em 1960, o pesquisador perseguido foi para a Mitre Corporation, mas a NSA continuou fazendo pressão e forçou-o a abandonar seu trabalho pela segunda vez. Feistel acabou indo para o Thomas J. Watson Laboratory da IBM, perto de Nova Iorque, onde, por alguns anos, conseguiu prosseguir com suas pesquisas sem ser caçado. Foi neste laboratório que, no início de 1970, ele desenvolveu o sistema LUCIFER. E foi este o sistema apresentado à NBS.
Após avaliar o algoritmo com a ajuda da National Security Agency, a NBS adotou o algoritmo LUCIFER com algumas modificações sob a denominação de Data Encryption Standard (DES) em 15 de Julho de 1977 (TKOTZ, 2003).
O DES foi rapidamente adotado na mídia não digital, como nas linhas telefônicas públicas. Depois de alguns anos, a International Flavors and Fragrances estava utilizando o DES para proteger as transmissões por telefone das suas preciosas fórmulas de sabores e fragrâncias.
Neste meio tempo, a indústria bancária, a maior usuária de criptografia depois do governo, adotou o DES como padrão para o mercado bancário atacadista. Os padrões do mercado atacadista da indústria bancária são estabelecidos pelo American National Standards Institute (ANSI). A norma ANSI X3.92, adotada em 1980, especificava o uso do algoritmo DES (TKOTZ, 2003).
6.2 O algoritmo DES O algoritmo DES é composto por operações simples como: permutações, substituições, XOR e deslocamentos. O DES criptografa informação através do processo de cifra de bloco com tamanho de 64 bits e retorna blocos de texto cifrado do mesmo tamanho usando uma chave de 56 bits.
O processo principal do algoritmo é executado 16 vezes, em cada iteração é utilizada uma subchave derivada da chave original.
Nesta seção apresenta-se o algoritmo DES e seus detalhes de funcionamento. O algoritmo foi dividido em duas partes, a geração de subchaves e o processamento

109
principal que inclui as 16 iterações do algoritmo (ver figura 6.1). A seguir tem-se a descrição do funcionamento da geração de subchaves.
Figura 6.1 –Descrição do Algoritmo DES (Visão top-level)
6.2.1 Chaves e Subchaves do DES
As chaves do DES são armazenadas com 64 bits (8 bytes), dos quais 8 bits são desprezados. É desprezado o último bit de cada byte reduzindo o tamanho da chave para 56 bits. A partir da chave original são geradas 16 subchaves, uma para cada iteração do processamento principal. Na figura 6.2 tem-se a ilustração da seqüência de passo para geração das subchaves.

110
Figura 6.2 – Ilustração do algoritmo de geração de subchaves do DES.
Observa-se na figura 6.2 que a chave original de 64 bits sofre uma permutação de compressão inicial (PCI) de acordo com uma tabela predefinida (ver tabela 6.1). Além de ocorrer a troca de bits também é feita uma compressão, isto é, transforma-se uma chave de 64 bits em um vetor de 56 bits permutados (FIPS46-3, 1999).
Tabela 6.1 – Permutação de Compressão Inicial (PCI).
57 49 41 33 25 17 09 01 58 50 42 34 26 18
10 02 59 51 43 35 27 19 11 03 60 52 44 36
63 55 47 39 31 23 15 07 62 54 46 38 30 22
14 06 61 53 45 37 29 21 13 05 28 20 12 04
Observando a tabela 6.1, visualiza-se que a primeira entrada da tabela é "57", isto significa que o 57º bit da chave original torna-se o primeiro bit da chave permutada. O 49º bit da chave original transforma-se no segundo bit da chave permutada. O 4º bit da chave original é o último bit da chave permutada. Importante observar que apenas 56 bits da chave original aparecem na chave permutada.
Após a permutação de compressão inicial (PCI) é feito um desmembramento do vetor resultante de 56 bits em duas partes iguais de 28 bits. A parte C ficará com os 28 bits mais significativos e D ficará com os 28 bits menos significativos. Em

111
seguida é feita uma rotação à esquerda das duas partes C e D conforme a tabela 6.2. As partes C e D podem ser rotacionadas à esquerda um ou dois bits de acordo com a iteração que está sendo executada.
Tabela 6.2 – Vetor de rotação de chave (ROT).
1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 1
Na iteração 1 e 2 será rotacionado apenas 1 bit à esquerda (ver tabela 6.2). Na iteração 3, 4, 5, 6, 7 e 8 serão deslocados 2 bits e assim por diante. Depois de cada deslocamento é feita uma permutação de compressão (PC), ver tabela 6.3, que concatena C e D formando uma subchave de 48 bits. Ao final do processo são geradas 16 subchaves derivadas da chave original.
Tabela 6.3 – Permutação de Compressão (PC).
14 17 11 24 1 5 3 28
15 6 21 10 23 19 12 4
26 08 16 07 27 20 13 02
41 52 31 37 47 55 30 40
51 45 33 48 44 49 39 56
34 53 46 42 50 36 29 32
Basicamente há duas maneiras de se gerar as subchaves: uma já foi apresentada e utiliza rotação de bits e permutações de compressão. A outra forma seria a permutação direta bastante utilizada na descrição em hardware deste algoritmo. Sabe-se que todos os bits da subchave gerada são derivados da chave original, assim é possível gerar as subchaves através de uma permutação direta.
6.2.2 Processamento Principal
No processamento principal (PP) encontram-se operações como permutações, substituições, desmembramentos e a operação XOR. O PP utiliza as subchaves geradas pelo módulo gerador de subchaves. Para cada iteração do algoritmo principal é utilizada uma subchave diferente.
Para cifrar um determinado bloco de texto (64 bits) é necessário utilizar as subchaves na ordem crescente, isto é, na iteração 1 do PP será utilizada a subchave 1, na iteração 2 a subchave 2, na 3 a subchave 3 e assim por diante. Para decifrar um bloco de texto as subchaves são aplicadas na ordem inversa ou decrescente. Neste

112
contexto, para decifrar a iteração 1 utilizará a subchave 16, a iteração 2 a subchave 15, a 3 a subchave 14 e etc.
Observa-se que a seqüência de operações do processamento principal é a mesma sempre, o que muda para cifrar ou decifrar um bloco de texto é a ordem que as subchaves são aplicadas. Na figura 6.3 tem-se a representação do PP do algoritmo DES.
Elementos utilizados na figura 6.3.
Li � left block (bloco da esquerda), inicialmente armazena os 32 bits mais significativos resultantes da permutação inicial (PI)
Ri � right block (bloco da direita), inicialmente armazena os 32 bits menos significativos resultantes da permutação inicial (PI)
Ki � subchave correspondente a iteração i.
F � função que realiza operações como P-BOX e S-BOX. Utiliza a subchave Ki e o bloco Ri-1.
Observando a figura 6.3 é possível verificar que o processamento principal é divido em três etapas executadas em seqüência. A primeira etapa é a permutação inicial (PI), a segunda corresponde às iterações e a terceira e última etapa corresponde à permutação final (PF).
Permutação Inicial do Processamento Principal:
O processamento principal inicia-se com uma permutação inicial (PI) e em seguida são executadas as 16 iterações do algoritmo DES e por fim é realizada uma permutação final, através deste processo transforma-se o bloco de texto legível em algo ilegível ou vice-versa.
A permutação inicial é definida pelos valores da tabela 6.4. Nenhum bit é descartado ou adicionado nesta permutação, isto é, o vetor de bits resultante da PI contém os bits permutados do bloco de texto original.
Tabela 6.4 – Tabela de Permutação inicial (PI).
58 50 42 34 26 18 10 02
60 52 44 36 28 20 12 04
62 54 46 38 30 22 14 06
64 56 48 40 32 24 16 08
57 49 41 33 25 17 09 01
59 51 43 35 27 19 11 03
61 53 45 37 29 21 13 05
63 55 47 39 31 23 15 07
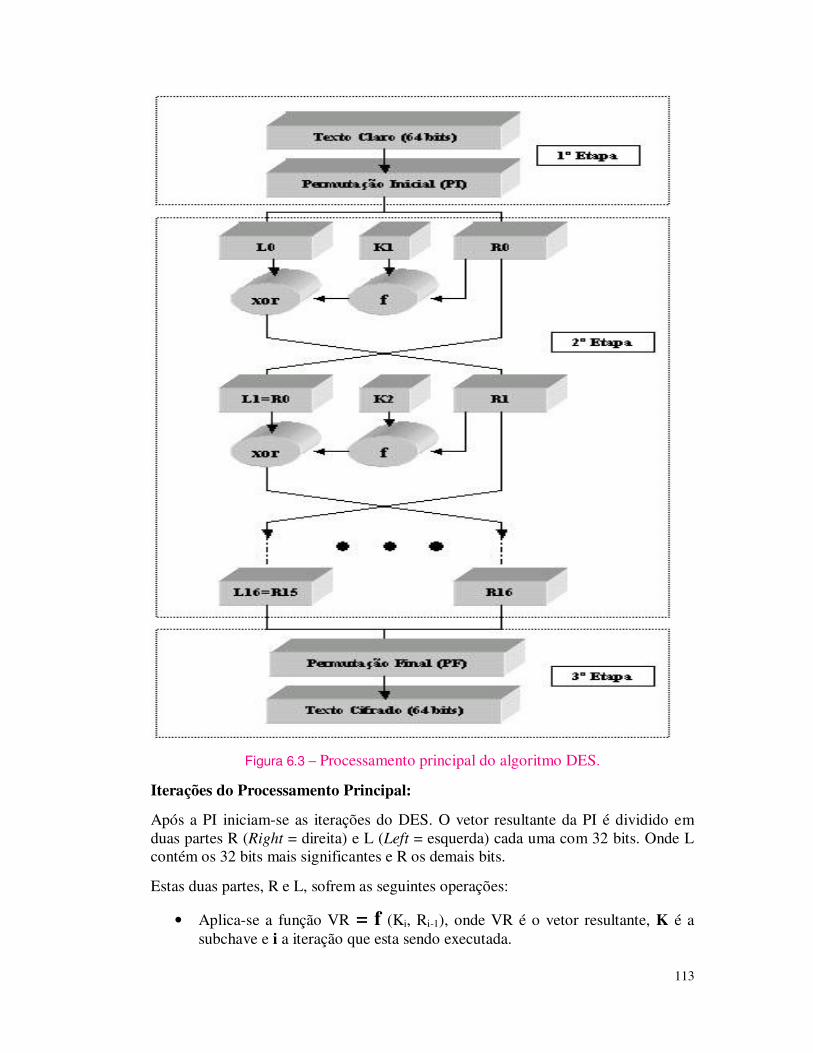
113
Figura 6.3 – Processamento principal do algoritmo DES.
Iterações do Processamento Principal:
Após a PI iniciam-se as iterações do DES. O vetor resultante da PI é dividido em duas partes R (Right = direita) e L (Left = esquerda) cada uma com 32 bits. Onde L contém os 32 bits mais significantes e R os demais bits.
Estas duas partes, R e L, sofrem as seguintes operações:
• Aplica-se a função VR = f (Ki, Ri-1), onde VR é o vetor resultante, K é a subchave e i a iteração que esta sendo executada.

114
• Realiza-se uma operação XOR de VR com Li (VR = VR xor Li).
• Li recebe Ri-1 (Li recebe Ri anterior)
• Ri recebe VR
Esta seqüência de operações é executada 16 vezes. Após as 16 iterações, R e L são concatenados formando novamente um vetor de 64 bits que passará pela última permutação (PF).
A função f (Ki, Ri-1): A função f realiza basicamente 4 operações:
(a) Operação de permutação de expansão,
(b) Operação XOR com a subchave correspondente a interação,
(c) Operação e Substituição S-BOX e,
(d) Operação de Permutação P-BOX.
A seguir a descrição destas operações.
(a) Permutação de expansão (PE): realiza uma permutação sobre Ri (32 bits), onde o vetor resultante terá 48 bits. A PE é definida pelos valores representados na tabela 6.5 (FIPS46-3, 1999).
Tabela 6.5 – Permutação de Expansão (PE).
32 01 02 03 04 05 04 05 06 07 08 09
08 09 10 11 12 13 12 13 14 14 16 17
16 17 18 19 20 21 20 21 22 23 24 25
24 25 26 27 28 29 28 29 30 31 32 01
(b) Xor com a subchave: é realizada uma operação de XOR entre o vetor resultante da PE com a subchave da iteração que está sendo executada.
(c) S-BOX: Esta operação realiza as substituições de bits. Para isso, utilizam-se 8 tabelas chamadas de caixas de substituição (ou melhor conhecidas como S-BOXES) que contém valores predefinidos (ver tabelas 6.6.1 a 6.6.8) (FIPS46-3, 1999).
Nesta fase tem-se um vetor de 48 bits ou oito grupos de 6 bits. Cada grupo atuará sobre uma S-BOX, obedecendo a seguinte ordem: os primeiros 6 bits (grupo 1) são substituídos por algum valor da S-BOX 1, o segundo grupo pela S-BOX 2, o terceiro grupo também de 6 bits pela S-BOX 3 e assim por diante.

115
Tabela 6.6.1 – S-BOX 1.
14 04 13 01 02 15 11 08 03 10 06 12 05 09 00 07
00 15 07 04 14 02 13 01 10 06 12 11 09 05 03 08
04 01 14 08 13 06 02 11 15 12 09 07 03 10 05 00
15 12 08 02 04 09 01 07 05 11 03 14 10 00 06 13
Tabela 6.6.1 – S-BOX 2.
15 01 08 14 06 11 03 04 09 07 02 13 12 00 05 10
03 13 04 07 15 02 08 14 12 00 01 10 06 09 11 05
00 14 07 11 10 04 13 01 05 08 12 06 09 03 02 15
13 08 10 01 03 15 04 02 11 06 07 12 00 05 14 09
Tabela 6.6.3 – S-BOX 3.
10 00 09 14 06 03 15 05 01 13 12 07 11 04 02 08
13 07 00 09 03 04 06 10 02 08 05 14 12 11 15 01
13 06 04 09 08 15 03 00 11 01 02 12 05 10 14 07
01 10 13 00 06 09 08 07 04 15 14 03 11 05 02 12
Tabela 6.6.4 – S-BOX 4.
07 13 14 03 00 06 09 10 01 02 08 05 11 12 04 15
13 08 11 05 06 15 00 03 04 07 02 12 01 10 14 09
10 06 09 00 12 11 07 13 15 01 03 14 05 02 08 04
03 15 00 06 10 01 13 08 09 04 05 11 12 07 02 14
Tabela 6.6.5 – S-BOX 5.
02 12 04 01 07 10 11 06 08 05 03 15 13 00 14 09
15 11 02 12 04 07 13 01 05 00 15 10 03 09 08 06
04 02 01 11 10 13 07 08 15 09 12 05 06 03 00 14
11 08 12 07 01 14 02 13 06 15 00 09 10 04 05 03

116
Tabela 6.6.6 – S-BOX 6.
12 01 10 15 09 02 06 08 00 13 03 04 14 07 05 11
10 15 04 02 07 12 09 05 06 01 13 14 00 11 03 08
09 14 15 05 02 08 12 03 07 00 04 10 01 13 11 06
04 03 02 12 09 05 15 10 11 14 01 07 05 00 08 13
Tabela 6.6.7 – S-BOX 7.
04 11 02 14 15 00 08 13 03 12 09 07 05 10 06 01
13 00 11 07 04 09 01 10 14 03 05 12 02 15 08 06
01 04 11 13 12 03 07 14 10 15 06 08 00 05 09 02
06 11 13 08 01 04 10 07 09 05 00 15 14 02 03 12
Tabela 6.6.8 – S-BOX 8.
13 02 08 04 06 15 11 01 10 09 03 14 05 00 12 07
01 15 13 08 10 03 07 04 12 05 06 11 00 14 09 02
07 11 04 01 09 12 14 02 00 06 10 13 15 03 05 08
02 01 14 07 04 10 08 13 15 12 09 00 03 05 06 11
A S-BOX é uma matriz 4x16. Para identificar qual será o valor utilizado na substituição deve-se visualizar cada grupo de 6 bits da seguinte forma: os bits 1 e 6 identificam a linha da matriz e os bits 2,3,4,5 a coluna da matriz. Desta forma pode-se determinar o valor para substituição.
(d) P-BOX: é uma permutação comum que segue os valores predefinidos pela tabela 6.7.
Tabela 6.7 – P-BOX.
16 07 20 21 29 12 28 17
01 15 23 26 05 18 31 10
02 08 24 14 32 27 03 09
19 13 30 06 22 11 04 25
Permutação Final do Processamento Principal:

117
Após as 16 iterações é realizada uma permutação final (PF) gerando o texto cifrado (FIPS46-3, 1999). As permutações finais e iniciais não influenciam muito do ponto de vista de segurança, pois não tem relação alguma com a chave criptográfica. A PF é realizada obedecendo a tabela 6.8.
Tabela 6.8 – Permutação final (PF).
40 08 48 16 56 24 64 32
39 07 47 15 55 23 63 31
38 06 46 14 54 22 62 30
37 05 45 13 53 21 61 29
36 04 44 12 52 20 60 28
35 03 43 11 51 19 59 27
34 02 42 10 50 18 58 26
33 01 41 09 49 17 57 25
6.3 Exemplo Preliminar de Funcionamento do DES O DES trabalha cifrando blocos de 64 bits de mensagem, o que significa 16 números hexadecimais, pois cada número hexadecimal representa 24 = 16, um grupo de 4-bits.
Para realizar o processo de cifrar dados, o DES utiliza chaves com comprimento aparente de 16 números hexadecimais (64 bits). Entretanto, no algoritmo DES, cada oitavo bit da chave é ignorado, de modo que a chave acaba tendo o comprimento de 56 bits.
A seguir um exemplo simples de como funciona a cifragem. Suponha a mensagem clara ou original "8787878787878787h" (apresentação hexadecimal) que cifrada com a chave DES "0E329232EA6D0D73h", obtem-se o texto cifrado "0000000000000000h". Assim, se o texto cifrado for decifrado com a mesma chave secreta DES "0E329232EA6D0D73h", o resultado deve ser o texto claro original "8787878787878787h" (KOCHER, 1999).
Este exemplo é simples e metódico porque nosso texto claro tinha o comprimento de exatos 64 bits. O mesmo seria verdade caso nosso texto claro tivesse um comprimento múltiplo de 64 bits. Mas a maioria das mensagens não necessariamente cairá nesta categoria, pois não necessariamente serão múltiplos exatos de 64 bits. Nestes casos, para cifrar a mensagem, seu comprimento precisa ser ajustado com a adição de alguns bytes extras no final. Depois de decifrar a mensagem, estes bytes extras são descartados. Existem vários métodos diferentes para adicionar bytes, um deles é o simples preenchimento com zeros.

118
6.4 Segurança do DES Antes que o DES fosse adotado como padrão internacional, durante o período em que o NBS estava solicitando comentários sobre o algoritmo proposto, os criadores da criptografia de chave pública, Martin Hellman e Whitfield Diffie, registraram algumas objeções quanto ao uso do DES como algoritmo de cifragem. Hellman escreveu: “Whitfield Diffie e eu ficamos preocupados com o fato de que o padrão de criptografia de dados proposto, enquanto provavelmente seguro em relação a assaltos comerciais, pode ser extremamente vulnerável a ataques efetuados por uma organização de inteligência" (carta ao NBS, 22 de Outubro de 1975) (TKOTZ, 2003).
Diffie e Hellman planejaram na mesma época um ataque de força bruta ao DES (lembrar que força bruta significa aplicar seqüencialmente as 256 chaves possíveis até encontrar a chave correta que decifra a mensagem cifrada) e propuseram o uso específico de computadores paralelos, usando um milhão de chips para testar um milhão de chaves por segundo e estimaram o custo de uma máquina deste tipo em US$ 20 milhões, com um custo diminuído para algumas centenas de milhares de dólares até o final da década de 80 (TKOTZ, 2003).
Sob a direção de John Gilmore do EFF (DESKEY, 2001), uma equipe gastou US$ 200.000 e construiu uma máquina que pode analisar todo o espaço de chaves de 56 bits do DES precisando em média 4,5 dias para completar a tarefa. Em 17 de julho de 1998 eles anunciaram que haviam quebrado uma chave de 56 bits em 46 horas. O computador, chamado de DES Key Search Machine (ver figura 6.4), usa 27 placas, cada uma com 64 chips, e é capaz de testar 90 bilhões de chaves por segundo (DESKEY, 2001). A única solução neste caso era propor um algoritmo com uma chave maior que não pudesse ser quebrado com facilidade, então surgiu o Triple-DES.
O algoritmo Triple-DES (FIPS46-3, 1999) é apenas o DES com duas chaves de 56 bits aplicadas. Dada uma mensagem em texto claro, a primeira chave é usada para cifrar a mensagem em DES. A segunda chave é usada para decifrar o DES da mensagem cifrada. Como a segunda chave não é a correta para decifrar, esta decifragem apenas embaralha ainda mais os dados. A mensagem duplamente embaralhada é, então, cifrada novamente com a primeira chave para se obter o texto cifrado final. Este procedimento em três etapas é chamado de triple-DES.
Assim, o triple-DES ou 3-DES é apenas o DES efetuado três vezes com duas chaves usadas numa determinada ordem. O triple-DES também pode ser feito usando-se três chaves diferentes, ao invés de apenas duas. Em qualquer um dos casos, o espaço de chaves resultante é de cerca de 2112, o que aumenta consideravelmente sua segurança.

119
Figura 6.4 – DES Key Search Machine (DESKEY, 2001).
6.5 Implementação em C e VHDL O DES é um algoritmo criptográfico possível de ser implementado em software e em hardware. Nesta seção apresentam-se detalhes da implementação em VHDL e em linguagem C do algoritmo DES. Os leitores podem encontrar detalhes dessa implementação no link www.novateceditora.com.br/downloads.php, onde também é possível executar o algoritmo para várias informações, conseguindo visualizar o funcionamento do algoritmo.
C é uma linguagem de programação seqüencial. Isto é, estabelecida uma determinada seqüência de instruções, estas são executadas uma após a outra obedecendo a uma lógica predefinida. Quem executa estas instruções é um processador genérico encontrado em PCs, estações de trabalhos, etc.
VHDL é uma linguagem padrão para descrição de hardware. Algumas ferramentas de síntese para FPGA transformam uma descrição VHDL em um circuito que pode conter ações executando em paralelo, ou seja, dois ou mais processos podem executar ao mesmo tempo.
Esta diferença de paradigmas entre as duas linguagens torna a implementação em software diferente da implementação em hardware em alguns pontos. Estas diferenças são mostradas nesta seção com a implementação dos principais módulos de execução do DES.
O DES inicia sua execução com uma permutação inicial (PI) e termina com uma permutação final (PF), que do ponto de vista de segurança não acrescenta muito. A permutação consiste em uma troca de bits. Para isso, existe uma tabela predefinida que informa para qual posição cada bit será deslocado conforme informações

120
contidas nas tabelas 6.4 e 6.8. A tabela 6.9 mostra a implementação em C da permutação final e inicial do DES e a respectiva implementação em VHDL.
Tabela 6.9 – Descrição dos módulos de permutação inicial e final.
Descrição dos módulos de permutação inicial e final Descrição em C Descrição em VHDL
//declaração da constante PI e
//PF
const unsigned char PI[64] =
{ 58,50,42,34,26,18,10,02,
60,52,44,36,28,20,12,04,
62,54,46,38,30,22,14,06,
64,56,48,40,32,24,16,08,
57,49,41,33,25,17,09,01,
59,51,43,35,27,19,11,03,
61,53,45,37,29,21,13,05,
63,55,47,39,31,23,15,07};
const unsigned char PF[64] =
{ 40,08,48,16,56,24,64,32,
39,07,47,15,55,23,63,31,
38,06,46,14,54,22,62,30,
37,05,45,13,53,21,61,29,
36,04,44,12,52,20,60,28,
35,03,43,11,51,19,59,27,
34,02,42,10,50,18,58,26,
33,01,41,09,49,17,57,25};
//... programa principal
//permutação inicial
for (i=0;i<=63;i++){
aux64[i]=E[PI[i]-1];
}
//iterações...
// permutação final
for (i=0;i<=63;i++){
S[i]=RL[PF[i]-1];
}
-- vetores para armazenar resultado das –
permutações
signal PI: std_logic_vector(0 to 63);
signal PF: std_logic_vector(0 to 63);
-- Programa principal
-- Permutação inicial
PI <=
E(06)&E(14)&E(22)&E(30)&E(38)&E(46)&
E(54)&E(62)&E(04)&E(12)&E(20)&E(28)&
E(36)&E(44)&E(52)&E(60)&E(02)&E(10)&
E(18)&E(26)&E(34)&E(42)&E(50)&E(58)&
E(00)&E(08)&E(16)&E(24)&E(32)&E(40)&
E(48)&E(56)&E(07)&E(15)&E(23)&E(31)&
E(39)&E(47)&E(55)&E(63)&E(05)&E(13)&
E(21)&E(29)&E(37)&E(45)&E(53)&E(61)&
E(03)&E(11)&E(19)&E(27)&E(35)&E(43)&
E(51)&E(59)&E(01)&E(09)&E(17)&E(25)&
E(33)&E(41)&E(49)&E(57);
-- permutação final
S <=
RL(39)&RL(07)&RL(47)&RL(15)&RL(55)&
RL(23)&RL(63)&RL(31)&RL(38)&RL(06)&
RL(46)&RL(14)&RL(54)&RL(22)&RL(62)&
RL(30)&RL(37)&RL(05)&RL(45)&RL(13)&
RL(53)&RL(21)&RL(61)&RL(29)&RL(36)&
RL(04)&RL(44)&RL(12)&RL(52)&RL(20)&
RL(60)&RL(28)&RL(35)&RL(03)&RL(43)&
RL(11)&RL(51)&RL(19)&RL(59)&RL(27)&
RL(34)&RL(02)&RL(42)&RL(10)&RL(50)&
RL(18)&RL(58)&RL(26)&RL(33)&RL(01)&
RL(41)&RL(09)&RL(49)&RL(17)&RL(57)&
RL(25)&RL(32)&RL(00)&RL(40)&RL(08)&
RL(48)&RL(16)&RL(56)&RL(24);
Observações E � texto de entrada
S � texto de saída
RL � vetor resultado das iterações
Aux64 � vetor para armazenar resultado da PI. (em C)
O processamento principal do algoritmo DES, como já foi dito, é composto por passos

121
simples tais como: permutações, substituições e a operação lógica XOR. Na seqüência são implementados os módulos P-BOX e S-BOX.
A P-BOX ou caixa de permutação tem seu funcionamento similar ao das permutações inicial e final. Dentro do algoritmo principal, a P-BOX é executada logo após a SBOX, isto é, o vetor resultante da SBOX alimenta a PBOX. Observa-se na tabela 6.10 que foi utilizada a troca direta de bits na implementação em VHDL.
Tabela 6.10 – Descrição da P-BOX.
Descrição da P-BOX Descrição em C Descrição em VHDL
// declaração da constante PBOX
const unsigned char PBOX[32] =
{16, 07, 20, 21, 29, 12, 28, 17,
01, 15, 23, 26, 05, 18, 31, 10,
02, 08, 24, 14, 32, 27, 03, 09,
19, 13, 30, 06, 22, 11, 04, 25};
//...
// programa principal
for (i=0;i<=31;i++){
PB[i]=SB[PBOX[i]-1];
}
-- vetor resultado da PBOX
signal PB: STD_LOGIC_VECTOR(0 to 31);
-- vetor de entrada da PBOX
signal SB: STD_LOGIC_VECTOR(0 to 31);
-- Programa principal
PB <=
SB(15)&SB(06)&SB(19)&SB(20)&SB(28)&
SB(11)&SB(27)&SB(16)&SB(00)&SB(14)&
SB(22)&SB(25)&SB(04)&SB(17)&SB(30)&
SB(09)&SB(01)&SB(07)&SB(23)&SB(13)&
SB(31)&SB(26)&SB(02)&SB(08)&SB(18)&
SB(12)&SB(29)&SB(05)&SB(21)&SB(10)&
SB(03)&SB(24);
Observações SB � vetor resultado da SBOX que alimenta a entrada da PBOX
PB � vetor resultado da PBOX
A S-BOX ou caixa de substituição, contêm valores que substituirão os bits resultantes da operação XOR com uma subchave. Na implementação em C deve-se identificar, através das coordenadas linha e coluna, o conjunto de bits que substituirão os bits originais. Nas tabelas 6.11 e 6.12 são apresentadas as descrições em C e VHDL da S-BOX 1
Tabela 6.11 – Descrição em C da S-BOX 1.

122
Descrição em C da S-BOX 1 // converte para decimal (no máximo 4 bits)
const unsigned char DEC[2][2][2][2][2] =
{0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15};
// declaração da constante SBOX1 (valores convertidos para binário)
const unsigned char SBOX1[4][16*4]=
{
1,1,1,0,0,1,0,0,1,1,0,1,0,0,0,1,0,0,1,0,1,1,1,1,1,0,1,1,1,0,0,0,
0,0,1,1,1,0,1,0,0,1,1,0,1,1,0,0,0,1,0,1,1,0,0,1,0,0,0,0,0,1,1,1,
0,0,0,0,1,1,1,1,0,1,1,1,0,1,0,0,1,1,1,0,0,0,1,0,1,1,0,1,0,0,0,1,
1,0,1,0,0,1,1,0,1,1,0,0,1,0,1,1,1,0,0,1,0,1,0,1,0,0,1,1,1,0,0,0,
0,1,0,0,0,0,0,1,1,1,1,0,1,0,0,0,1,1,0,1,0,1,1,0,0,0,1,0,1,0,1,1,
1,1,1,1,1,1,0,0,1,0,0,1,0,1,1,1,0,0,1,1,1,0,1,0,0,1,0,1,0,0,0,0,
1,1,1,1,1,1,0,0,1,0,0,0,0,0,1,0,0,1,0,0,1,0,0,1,0,0,0,1,0,1,1,1,
0,1,0,1,1,0,1,1,0,0,1,1,1,1,1,0,1,0,1,0,0,0,0,0,0,1,1,0,1,1,0,1};
//função sbox1
void sbox1 (bool E[6]){
int lin,col;
//identifica linha e coluna convertendo para decimal
lin = DEC[0][0][0][5]; -- bit 0 e 5
col = DEC[1][2][3][4]; -- bit 1,2,3 e 4
// realiza a substituição
E[0]=SBOX1[lin][col*4];
E[1]=SBOX1[lin][col*4+1];
E[2]=SBOX1[lin][col*4+2];
E[3]=SBOX1[lin][col*4+3];
}
Observações DEC � Converte para decimal números binários de até 4 bits SBOX1 � constantes que irão sibstituir os bits de entrada originais. lin, col � Valor linha e da coluna da SBOX1 para identificar o conjunto de bits de substituição
Importante destacar que na descrição VHDL não é necessário isolar os bits que identificam a linha e a coluna. Pode-se fazer o acesso direto através do vetor de localização (Pos). Tanto em C, como em VHDL, o valor resultante da S-BOX 1 deve ser o mesmo. De forma similar se implementam todas as outras S-BOXES.
Tabela 6.12 – Descrição em VHDL da S-BOX 1.

123
Descrição em VHDL da S-BOX 1
With Pos Select
Dado <=
"1110" when "000000", "0100" when "000010", "1101" when "000100",
"0001" when "000110", "0010" when "001000", "1111" when "001010",
"1011" when "001100", "1000" when "001110", "0011" when "010000",
"1010" when "010010", "0110" when "010100", "1100" when "010110",
"0101" when "011000", "1001" when "011010", "0000" when "011100",
"0111" when "011110", "0000" when "000001", "1111" when "000011",
"0111" when "000101", "0100" when "000111", "1110" when "001001",
"0010" when "001011", "1101" when "001101", "0001" when "001111",
"1010" when "010001", "0110" when "010011", "1100" when "010101",
"1011" when "010111", "1001" when "011001", "0101" when "011011",
"0011" when "011101", "1000" when "011111", "0100" when "100000",
"0001" when "100010", "1110" when "100100", "1000" when "100110",
"1101" when "101000", "0110" when "101010", "0010" when "101100",
"1011" when "101110", "1111" when "110000", "1100" when "110010",
"1001" when "110100", "0111" when "110110", "0011" when "111000",
"1010" when "111010", "0101" when "111100", "0000" when "111110",
"1111" when "100001", "1100" when "100011", "1000" when "100101",
"0010" when "100111", "0100" when "101001", "1001" when "101011",
"0001" when "101101", "0111" when "101111", "0101" when "110001",
"1011" when "110011", "0011" when "110101", "1110" when "110111",
"1010" when "111001", "0000" when "111011", "0110" when "111101",
"1101" when "111111", "ZZZZ" when others;
Observações Pos � Armazena a posição dos bits de substituição
Dado � Armazena os bits já alterados
Durante a descrição do algoritmo DES foram implementadas várias versões até alcançar uma versão otimizada deste algoritmo em VHDL, gerando um circuito de melhor performance temporal e espacial.
A maioria das descrições do DES em VHDL o processo de geração de subchaves e o processo principal executam em paralelo, isto significa que as subchaves do DES são geradas todas as vezes que um novo bloco de texto for cifrado ou decifrado. Portanto, a otimização de um destes processos, afetaria no desempenho final do sistema de forma positiva.
Com base nesta afirmação o processo de geração de subchaves foi otimizado. Realmente foi constatado que o circuito como um todo teve seu desempenho melhorado. Detalhes desta otimização podem ser vistos em (PEREIRA, 2003).
6.6 Estatísticas de Desempenho das Implementações do DES
O DES é um algoritmo criptográfico bastante explorado. Sua implementação em hardware e software atingem um bom nível de desempenho. Nesta seção apresentam-se algumas estatísticas de desempenho da descrição em C e VHDL do DES implementada pelos autores.
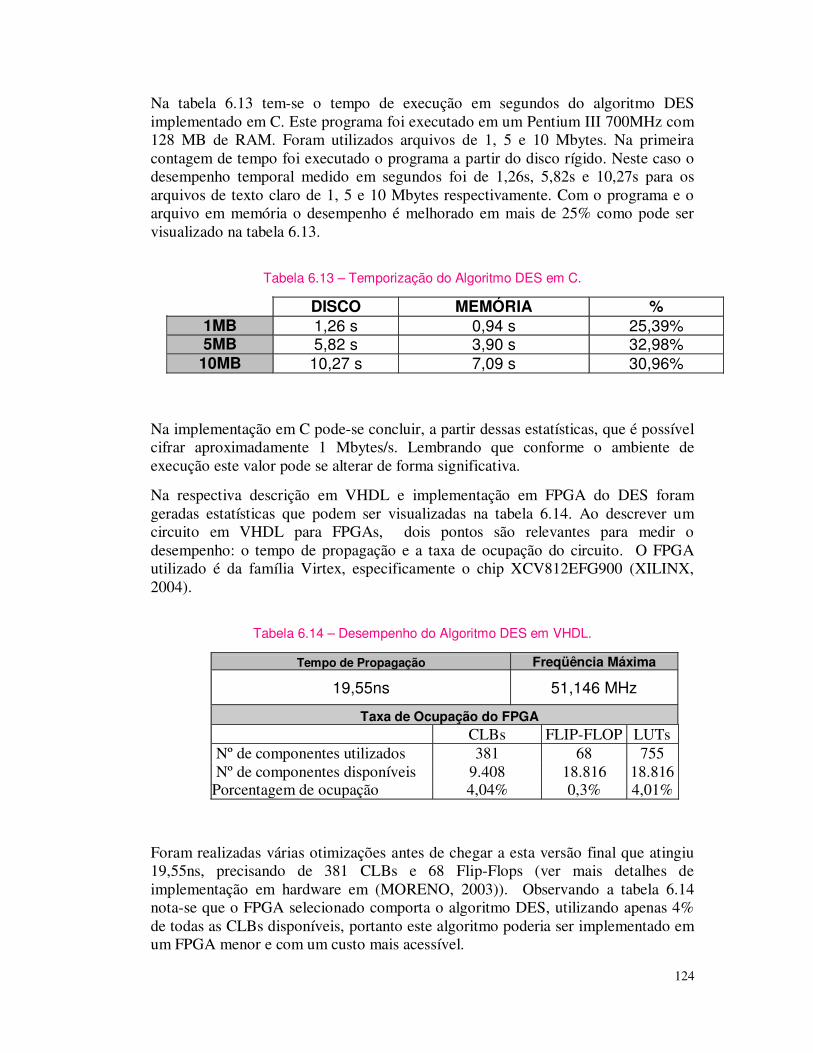
124
Na tabela 6.13 tem-se o tempo de execução em segundos do algoritmo DES implementado em C. Este programa foi executado em um Pentium III 700MHz com 128 MB de RAM. Foram utilizados arquivos de 1, 5 e 10 Mbytes. Na primeira contagem de tempo foi executado o programa a partir do disco rígido. Neste caso o desempenho temporal medido em segundos foi de 1,26s, 5,82s e 10,27s para os arquivos de texto claro de 1, 5 e 10 Mbytes respectivamente. Com o programa e o arquivo em memória o desempenho é melhorado em mais de 25% como pode ser visualizado na tabela 6.13.
Tabela 6.13 – Temporização do Algoritmo DES em C.
DISCO MEMÓRIA % 1MB 1,26 s 0,94 s 25,39% 5MB 5,82 s 3,90 s 32,98%
10MB 10,27 s 7,09 s 30,96%
Na implementação em C pode-se concluir, a partir dessas estatísticas, que é possível cifrar aproximadamente 1 Mbytes/s. Lembrando que conforme o ambiente de execução este valor pode se alterar de forma significativa.
Na respectiva descrição em VHDL e implementação em FPGA do DES foram geradas estatísticas que podem ser visualizadas na tabela 6.14. Ao descrever um circuito em VHDL para FPGAs, dois pontos são relevantes para medir o desempenho: o tempo de propagação e a taxa de ocupação do circuito. O FPGA utilizado é da família Virtex, especificamente o chip XCV812EFG900 (XILINX, 2004).
Tabela 6.14 – Desempenho do Algoritmo DES em VHDL.
Tempo de Propagação Freqüência Máxima
19,55ns 51,146 MHz
Taxa de Ocupação do FPGA CLBs FLIP-FLOP LUTs Nº de componentes utilizados 381 68 755 Nº de componentes disponíveis 9.408 18.816 18.816 Porcentagem de ocupação 4,04% 0,3% 4,01%
Foram realizadas várias otimizações antes de chegar a esta versão final que atingiu 19,55ns, precisando de 381 CLBs e 68 Flip-Flops (ver mais detalhes de implementação em hardware em (MORENO, 2003)). Observando a tabela 6.14 nota-se que o FPGA selecionado comporta o algoritmo DES, utilizando apenas 4% de todas as CLBs disponíveis, portanto este algoritmo poderia ser implementado em um FPGA menor e com um custo mais acessível.

125
Importante lembrar que os FPGAs são de baixo custo. Por exemplo, até final ddo ano de 2004, uma placa Digilent que contém capacidade suficiente para permitir o mapeamento dos algoritmos criptográficos discutidos no livro, devia custar em torno de R$ 50,00. Placas mais sofisticadas são mais custosas, por exemplo permitem mapear processadores complexos como o PowerPC. Para os algoritmos criptográficos, FPGAs menores de R$ 50,00 podem ser usados.
Em alguns testes realizados foi constatado que o algoritmo DES, implementado pelos autores, pode ser mapeado em um FPGA da família XC4010XLPC84. Este FPGA é aproximadamente 24 vezes menor que o Virtex utilizado na geração de estatísticas observadas na tabela 6.14.
Esta implementação em hardware é simples e básica pois não utiliza técnicas de pipeline, apesar disso, o desempenho atingido é considerando bom quando comparado a outras implementações como a encontrada no site mundial OPENCORES que contém cores abertos, isto é, disponíveis gratuitamente (OPENCORES, 2004).
Com um tempo de propagação de 19,55ns, o circuito dedicado poderá cifrar em 1s aproximadamente 25 Mbytes de texto claro. Essa taxa de execução é fixa, assim em 2 segundos será executado exatamente o dobro de informações, 50 Mbytes. Comparando com a implementação em software pode se dizer que o hardware neste caso é aproximadamente 25 vezes mais veloz. Pesquisas e dados estatísticos mostram que a implementação em hardware utilizando técnicas de pipeline chega a ser 400 vezes mais veloz que a versão em software (OPENCORES, 2004). A figura 6.5 ilustra esta comparação.
Figura 6.5 – Desempenho temporal do DES.
A versão implementada em hardware com pipeline pode ser encontrada no site de códigos abertos Opencores (OPENCORES, 2004). Na figura 6.6 ilustra-se como o algoritmo DES está mapeado no FPGA, destacando principalmente o roteamento físico do circuito.

126
Figura 6.6 – DES mapeado em um FPGA Virtex.

127
Capítulo 7 Algoritmo IDEA
Este capítulo apresenta o funcionamento do algoritmo IDEA, com ênfase na sua implementação em linguagem C e detalhes do seu desempenho.
7.1 Descrição do Algoritmo IDEA O algoritmo IDEA, inicialmente chamado de IPES, foi proposto por X. Lai e J. Massey em 1991. Foi projetado para ser eficiente em implementações por software (LAI, 1990).
O IDEA possuí chave secreta de 128 bits e tanto a entrada (texto legível) quanto a saída (texto ilegível) são de 64 bits. O mesmo algoritmo serve tanto para criptografar (cifrar) quanto para decriptografar (decifrar) e consiste de duas fases diferentes: (i) a primeira é baseada na realização de 8 iterações utilizando sub-chaves distintas e (ii) uma transformação final.
7.2 Operações no IDEA O algoritmo IDEA está baseado em três operações. Estas operações são todas sobre 16 bits conforme descrito a seguir (LAI, 1990):
Operação Descrição de Funcionamento ⊕ Ou exclusivo (XOR) sobre 16 bits
+ Soma mod 216, ou seja, somar dois valores de 16 bits desprezando o mais à esquerda, correspondente a 216.
� Esta operação consiste em vários passos: 1. Multiplicar dois valores de 16 bits obtendo um valor que chamaremos de Z,
sendo que antes de multiplicar, se um desses valores for 0 deve ser alterado para 216.
2. Se o resultado da operação acima for 216, então o resultado final da operação é 0, caso contrário é o valor obtido em 2 (Z mod (216 + 1)).
3. Calcular Z mod (216 + 1), ou seja, o resto da divisão de Z por 216 + 1.

128
7.2.1 Geração das Sub-Chaves
Como o mesmo algoritmo é utilizado tanto na criptografia quanto na decriptografia, o que define qual a operação a ser realizada é a forma de geração das sub-chaves.
Para a criptografia são geradas 52 subchaves de 16 bits a partir da chave secreta de 128 bits (chamadas em forma breve de K). A primeira subchave (K1) é gerada considerando os 16 bits mais significativos de K, a segunda (K2) é gerada considerando os próximos 16 bits, e assim são geradas as subchaves até K8 que será os 16 bits menos significativos de K.
Como a cada 8 subchaves geradas a próxima subchave inicia-se com um deslocamento de 25 bits a partir do início da chave K, a 9ª sub-chave é formada por 16 bits a partir do 25º bit a partir da direita de K, a K10 é formada pelos 16 próximos bits, e assim até gerar K14. Seguindo o mesmo raciocinio, a 15ª sub-chave (K15) será formada pelos 7 bits menos significativos de K e para completá-la são usados os primeiros 9 bits (os 9 bits mais significativos de K).
Lembrando que a cada 8 subchaves a próxima chave inicia-se acrescentando um deslocamento de 25 bits à chave inicial K, a K17 inicia-se a partir do 50º bit a partir da direita de K. Dessa forma são geradas as primeiras 48 subchaves.
A subchave K49 inicia-se a partir do 22º bit a partir da direita de K, a K50 é formada pelos próximos 16 bits, e assim até formar a K52.
A tabela 7.1 a seguir apresenta uma representação da criação das 52 subchaves:
Tabela 7.1 – Criação das subchaves
Bit de início em K (a partir da direita) K1..K8 0 16 32 48 64 80 96 112 K9..K16 25 41 57 73 89 105 121 9
K17..K24 50 66 82 98 114 2 18 34 K25..K32 75 91 107 123 11 27 43 59 K33..K40 100 116 4 20 36 52 68 84 K41..K48 125 13 29 45 61 77 93 109 K49..K52 22 38 54 70
7.2.2 Processamento das Iterações
Como descrito anteriormente, o algoritmo IDEA possui 8 iterações e uma transformação final. Cada iteração possui duas partes e utiliza 6 subchaves que chamaremos de Ka, Kb, Kc, Kd, Ke e Kf.
A primeira parte de cada iteração usa as quatro primeiras subchaves (Ka, Kb, Kc, Kd); e a segunda parte de cada iteração usa as subchaves Ke e Kf; e utilizam as operações descritas no início. As duas partes utilizam tanto entrada quanto saída de 64 bits dividida em quatro blocos de 16 bits que chamaremos de Xa, Xb, Xc e Xd

129
(para a entrada) e Xa’, Xb’, Xc’ e Xd’ (para a saída); e a saída da primeira parte é a entrada para a segunda parte.
O algoritmo para a primeira parte da iteração é:
Xa’ = Xa � Ka
Xd’ = Xd � Kd
Xb’ = Xc + Kc
Xc’ = Xb + Kb
O algoritmo para a segunda parte da iteração é:
Y1 = Xa ⊕ Xb
Z1 = Xc ⊕ Xd
Y2 = [(Ke � Y1) + Z1] � Kf
Z2 = (Ke � Y1) + Y2
Xa’ = Xa ⊕ Y2
Xb’ = Xb ⊕ Y2
Xc’ = Xc ⊕ Z2
Xd’ = Xd ⊕ Z2
A ultima transformação utiliza as últimas quatro subchaves (K49, K50, K51 e K52). Após 8 iterações descritas anteriormente, a saída Xa’, Xb’, Xc’ e Xd’ é fornecida como entrada da transformação final gerando o texto criptografado Xa’’, Xb’’, Xc’’ e Xd’’ como descrito a seguir.
Xa’’ = Xa’ � K49
Xd’’ = Xd’ � K52
Xb’’ = Xc’ + K50
Xc’’ = Xb’ + K51
O esquema da figura 7.1 mostra como é o processo completo realizado pelo algoritmo IDEA.
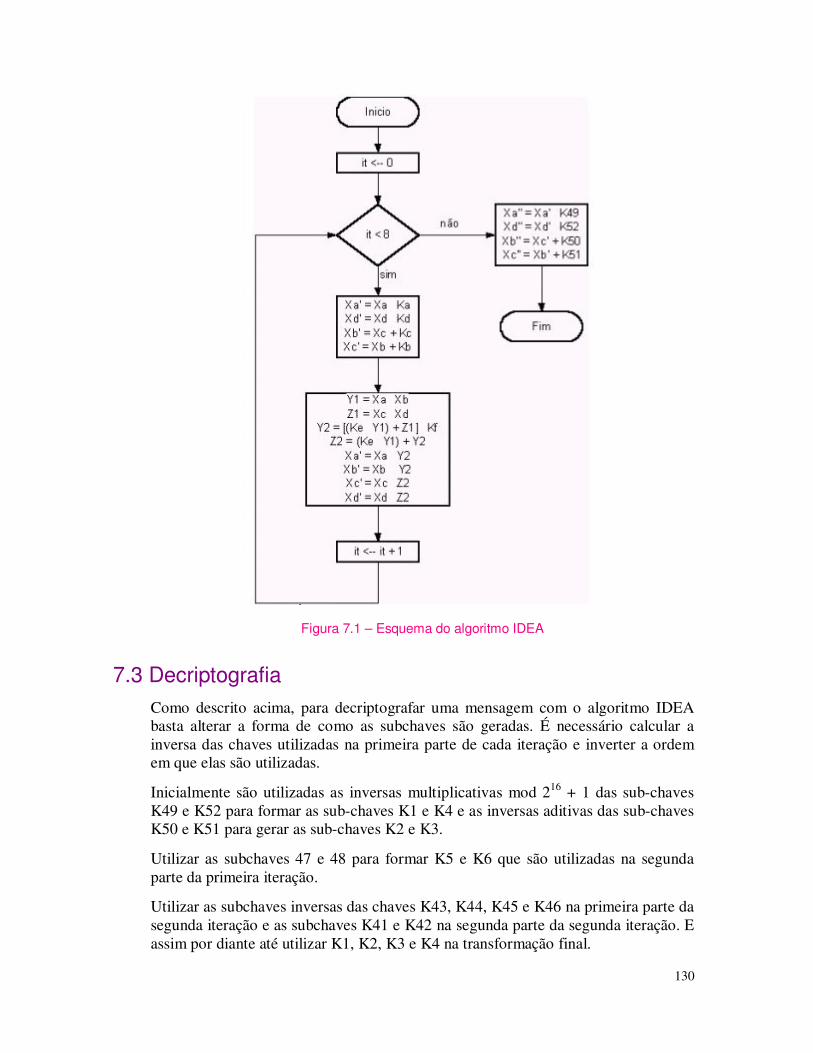
130
Figura 7.1 – Esquema do algoritmo IDEA
7.3 Decriptografia Como descrito acima, para decriptografar uma mensagem com o algoritmo IDEA basta alterar a forma de como as subchaves são geradas. É necessário calcular a inversa das chaves utilizadas na primeira parte de cada iteração e inverter a ordem em que elas são utilizadas.
Inicialmente são utilizadas as inversas multiplicativas mod 216 + 1 das sub-chaves K49 e K52 para formar as sub-chaves K1 e K4 e as inversas aditivas das sub-chaves K50 e K51 para gerar as sub-chaves K2 e K3.
Utilizar as subchaves 47 e 48 para formar K5 e K6 que são utilizadas na segunda parte da primeira iteração.
Utilizar as subchaves inversas das chaves K43, K44, K45 e K46 na primeira parte da segunda iteração e as subchaves K41 e K42 na segunda parte da segunda iteração. E assim por diante até utilizar K1, K2, K3 e K4 na transformação final.

131
7.4 Implementação em C Inicialmente foram implementadas as três operações básicas do algoritmo IDEA. O código da implementação das operações XOR e SOMA16; e uma implementação inicial de MULT16 são apresentados a seguir:
void XOR(int * A, int B, int C)
{
*A = B ^ C;
}
void SOMA16(int * A, int B, int C){
*A = (B + C) % v2_16;
}
void MULT16(int * A, int B, int C){
_int64 aux;
if (B == 0) B = v2_16;
if (C == 0) C = v2_16;
aux = BLAKLEY(B,C,(v2_16_1));
if (aux != v2_16)
*A = (int) aux;
else
*A = 0;
}
A constante v2_16 utilizada é equivalente a 216. A multiplicação implementada utiliza o algoritmo de BLAKLEY (KOÇ, 1994) para realizar multiplicações módulo 216+1 e a implementação desse algoritmo em linguagem C é apresentada a seguir:
int BLAKLEY(int a, int b, int n)
// entrada: a,b,n
// saída: R = (a * b) mod n
{
unsigned int aux;
int R; R = 0;
for (aux = 0x80000000; aux > 0; aux >>= 1)
{
R = (R << 1);
if((a & aux) != 0) R += b;
if (R > n) R -= n;
if (R > n) R -= n;
}
return R;
}
Após a implementação das operações básicas é possível implementar as iterações (primeira e segunda parte) e a transformação final. O código implementado possui uma função que implementa a primeira parte da iteração, uma função para a segunda parte da iteração, uma função que calcula uma iteração completa fornecendo a saída da primeira parte como entrada para a segunda parte como citado anteriormente na descrição do algoritmo e a transformação final. O código em linguagem C é apresentado a seguir:

132
void Iterac1(int Ka, int Kb, int Kc, int Kd,
int *Xa, int *Xb, int *Xc, int *Xd)
{
int Xal=*Xa, Xbl=*Xb, Xcl=*Xc, Xdl=*Xd;
MULT16(Xa,Xal,Ka);
MULT16(Xd,Xdl,Kd);
SOMA16(Xb,Xcl,Kc);
SOMA16(Xc,Xbl,Kb);
}
void Iterac2(int Ke, int Kf,
int *Xa, int *Xb, int *Xc, int *Xd)
{
int Xal=*Xa, Xbl=*Xb, Xcl=*Xc, Xdl=*Xd;
int Y1,Z1,Y2,Z2; int aux1,aux2;
XOR(&Y1,Xal,Xbl);
XOR(&Z1,Xcl,Xdl);
//calculo de Y2
MULT16(&aux1,Ke,Y1);
SOMA16(&aux2,aux1,Z1);
MULT16(&Y2,aux2,Kf);
//calcule de Z2
SOMA16(&Z2,aux1,Y2);
XOR(Xa,Xal,Y2);
XOR(Xb,Xbl,Y2);
XOR(Xc,Xcl,Z2);
XOR(Xd,Xdl,Z2);
}
void Iteracao(int Ka, int Kb, int Kc, int Kd, int Ke, int Kf,
int *Xa, int *Xb, int *Xc, int *Xd)
{
Iterac1(Ka,Kb,Kc,Kd,Xa,Xb,Xc,Xd);
Iterac2(Ke,Kf,Xa,Xb,Xc,Xd);
}
void TransformacaoT(int K49, int K50, int K51, int K52,
int *Xa, int *Xb, int *Xc, int *Xd)
{
int Xal=*Xa, Xbl=*Xb, Xcl=*Xc, Xdl=*Xd;
MULT16(Xa,Xal,K49);
MULT16(Xd,Xdl,K52);
SOMA16(Xb,Xcl,K50);
SOMA16(Xc,Xbl,K51);
}
Essa implementação utiliza como chave um vetor do tipo lógico (bool) de 128 posições. Para realizar a criptografia são utilizadas 52 subchaves de 16 bits que são geradas a partir da chave inicial de 128 bits.
As funções para gerar um vetor contendo as 52 subchaves a partir da chave inicial são apresentadas a seguir:

133
void GenSubKey(bool Key[], int K[])
{
//O vetor Pos possui as posições de início de cada subchave (ver Tabela 7.1)
const Pos[52] = { 0 , 16 , 32 , 48 , 64 , 80 ,
96 , 112, 25 , 41 , 57 , 73 ,
89 , 105, 121, 9 , 50 , 66 ,
82 , 98 , 114, 2 , 18 , 34 ,
75 , 91 , 107, 123, 11 , 27 ,
43 , 59 , 100, 116, 4 , 20 ,
36 , 52 , 68 , 84 , 125, 13 ,
29 , 45 , 61 , 77 , 93 , 109,
22 , 38 , 54 , 70
};
int i;
for (i = 0; i < 52; i++)
conv(Pos[i],&K[i],Key);
}
void conv(int Pos, int * K, bool Key[])
{
// gera uma subchave K a partir da posição Pos na chave Key
int i;
*K = Key[(Pos+15)%128];
for (i=14;i>=0;i--)
if (Key[(Pos+i)%128]!=0)
*K = *K + (int) pow(2,15-i);
}
Para criptografar com o algoritmo IDEA basta aplicar oito iterações e uma transformação final. A implementação da função de criptografia com o algoritmo IDEA é apresentada a seguir:
void CriptIDEA(int Key[], int *Xa, int *Xb, int *Xc, int *Xd)
{
int i;
for (i=0;i<8;i++)
{
Iteracao(K[i*6],K[i*6+1],K[i*6+2],K[i*6+3],K[i*6+4], \
K[i*6+5],Xa,Xb,Xc,Xd);
printf("%04x|%04x|%04x|%04x", *Xa,*Xb,*Xc,*Xd);
}
TransformacaoT(K[48],K[49],K[50],K[51],Xa,Xb,Xc,Xd);
}
Para decriptografar é necessário gerar as subchaves inversas e aplicar o mesmo algoritmo utilizado para a criptografia. Para isso é necessário calcular a inversa das operações básicas adição e multiplicação. A seguir são apresentadas as funções que calculam a inversa aditiva e a multiplicativa:
int InvSoma(int A){
return abs((v2_16 - A));
}
unsigned int InvMult(unsigned int A)
{

134
long n1,n2,q,r,b1,b2,t;
if(A==0)
b2=0;
else
{
n1=(v2_16_1);
n2=A;
b2=1;
b1=0;
do
{
r = (n1 % n2);
q = (n1-r)/n2;
if(r==0)
{
if(b2<0)
b2=(v2_16_1)+b2;
}
else
{
n1=n2;
n2=r;
t=b2;
b2=b1-q*b2;
b1=t;
}
} while (r!=0);
}
return b2 & 0xffff;
}
A seguir é apresentada a função de decriptografia, onde a medida que as subchaves inversas são geradas elas são aplicadas:
void DecriptIDEA(int Key[], int *Xa, int *Xb, int *Xc, int *Xd)
{
int i=8;
int Ka, Kb, Kc, Kd;
Ka = InvMult(K[i*6]);
Kd = InvMult(K[i*6+3]);
Kb = InvSoma(K[i*6+1]);
Kc = InvSoma(K[i*6+2]);
for(i=8;i>0;i=i)
{
Iteracao(Ka,Kb,Kc,Kd,K[i*6-2],K[i*6-1],Xa,Xb,Xc,Xd);
i--;
Ka = InvMult(K[i*6]);
Kd = InvMult(K[i*6+3]);
Kb = InvSoma(K[i*6+2]);
Kc = InvSoma(K[i*6+1]);
}
Ka = InvMult(K[0]);

135
Kd = InvMult(K[3]);
Kb = InvSoma(K[1]);
Kc = InvSoma(K[2]);
TransformacaoT(Ka,Kb,Kc,Kd,Xa,Xb,Xc,Xd);
}
7.5 Implementação de Otimizações É possível aumentar significativamente a performance do algoritmo IDEA apenas alterando a função de multiplicação (mod 216 + 1). Trocando a função de multiplicação utilizada pela função apresentada abaixo que utiliza o algoritmo Low-High, o desempenho melhora cerca de 2,4 vezes.
void MULT16(unsigned int * X, unsigned int a,unsigned int b)
{
long p;
unsigned int q;
if(a==0) p=65537-b;
else
{
if(b==0) p=65537-a;
else
{
q=(unsigned long)a*(unsigned long)b;
p=(q & 65535) - (q>>16);
if(p<=0) p=p+65537;
}
}
*X = (unsigned int)(p&65535);
}
Isso ocorre pois a função apresentada não utiliza cálculos matemáticos complexos como a operação “%” que equivale à operação (mod n). Essa função utiliza apenas uma multiplicação e operações lógicas que são muito mais rápidas que a operação (mod n), por exemplo.
7.6 Desempenho O algoritmo IDEA possui um bom desempenho chegando a atingir taxas para criptografar dados de até 500 Kbytes/s em um computador Duron 950 Mhz com 128 Mbytes de memória principal (RAM). O gráfico da figura 7.2 mostra uma comparação das duas versões (utilizando BLAKLEY como multiplicação modular, e utilizando o algoritmo Low-High para a multiplicação (mod 216 + 1) e qual o impacto gerado pelo uso dessas implementações).
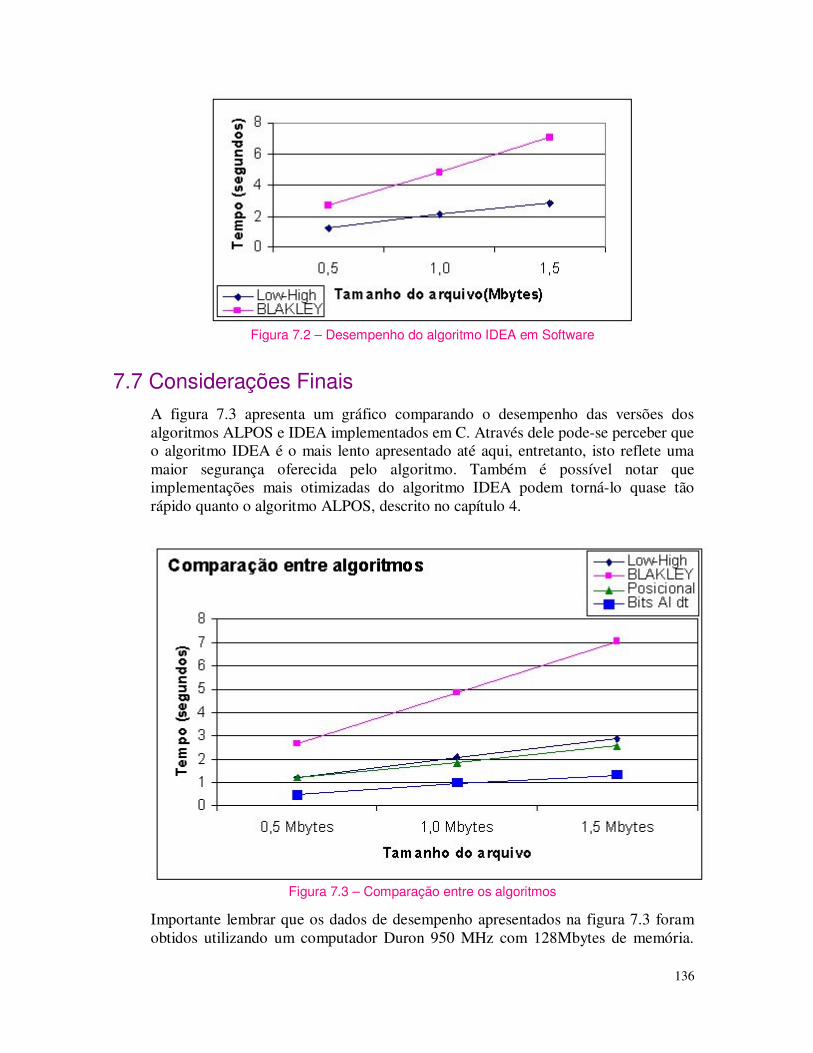
136
Figura 7.2 – Desempenho do algoritmo IDEA em Software
7.7 Considerações Finais A figura 7.3 apresenta um gráfico comparando o desempenho das versões dos algoritmos ALPOS e IDEA implementados em C. Através dele pode-se perceber que o algoritmo IDEA é o mais lento apresentado até aqui, entretanto, isto reflete uma maior segurança oferecida pelo algoritmo. Também é possível notar que implementações mais otimizadas do algoritmo IDEA podem torná-lo quase tão rápido quanto o algoritmo ALPOS, descrito no capítulo 4.
Figura 7.3 – Comparação entre os algoritmos
Importante lembrar que os dados de desempenho apresentados na figura 7.3 foram obtidos utilizando um computador Duron 950 MHz com 128Mbytes de memória.

137
Esses dados poderão ser diferentes quando executados em plataformas diferentes. Assim, o leitor poderá verificar mudanças nos valores apresentados. Não obstante, o comportamento da performance deverá seguir aquele da figura 7.3, o que valida as conclusões de velocidade até aqui apresentadas.

138
Capítulo 8 O Algoritmo Assimétrico - RSA
Este capítulo apresenta o funcionamento do algoritmo assimétrico RSA, assim como detalhes da sua implementação em software e hardware, e o respectivo desempenho da implementação em C e FPGAs.
8.1 Introdução ao RSA O RSA é um sistema de criptografia de chave assimétrica ou criptografia de chave pública que foi inventado por volta de 1977 pelos professores do MIT (Massachusetts Institute of Technology) Ronald Rivest, Adi Shamir e o professor da USC (University of Southern California) Leonard Adleman (RIVEST et al, 1978).
O sistema consiste em gerar uma chave pública (geralmente utilizada para cifrar os dados) e uma chave privada (utilizada para decifrar os dados) através de números primos grandes, o que dificulta a obtenção de uma chave a partir da outra.
Quanto maior os números primos utilizados para a criação da chave, maior é a segurança proporcionada por esse algoritmo. Hoje em dia os números primos que são utilizados têm geralmente 512 bits de comprimento e combinados formam chaves de 1024 bits. Em algumas aplicações, como por exemplo bancárias, que exigem o máximo de segurança a chave chega a ser de 2048 bits.
Com o passar do tempo, a tendência é que o comprimento da chave aumente cada vez mais. Esse fenômeno acontece, em grande parte, pelo avanço nos sistemas computacionais que acompanham o surgimento de computadores que são capazes de fatorar chaves cada vez maiores em um tempo muito baixo.
Os algoritmos para a geração da chave pública e privada usadas para cifrar e decifrar as mensagens são simples. Observe-os a seguir (RIVEST et al, 1978):
1. Escolhe-se dois números primos grandes (p e q);
2. Gera-se um número n através da multiplicação dos números escolhidos anteriormente (n = p . q);
3. Escolhe-se um número d, tal que d é menor que n e d é relativamente primo à (p-1).(q-1);

139
4. Escolhe-se um número e tal que (ed-1) seja divisível por (p-1).(q-1). Para realizar esse cálculo é necessário o algoritmo de Euclides Estendido (WIKIPEDIA, 2004).
5. Os valores e e d são chamados de expoentes público e privado, respectivamente. O par (n,e) é a chave pública e o par (n,d) é a chave privada. Os valores p e q devem ser mantidos em segredo ou destruídos.
Para cifrar uma mensagem com esse algoritmo é realizado o seguinte cálculo:
C = Te mod n,
onde C é a mensagem cifrada, T é o texto original, e e n são dados a partir da chave pública (n,e).
A única chave que pode decifrar a mensagem C é a chave privada (n,d) através do cálculo de:
T = Cd mod n.
8.2 Exemplos de Funcionamento O exemplo utilizado pelos autores para o algoritmo RSA realiza a criptografia da mensagem “ITS ALL GREEK TO ME” utilizada pelos autores do RSA no artigo A Method for Obtaining Digital Signatures and Public-Key Cryptosystems (RIVEST et al, 1978) utilizando-se de chaves diferentes.
Satisfazendo a etapa 1 de criação de chaves descrita acima, são selecionados dois números primos aleatórios p = 53, q = 61. No nosso exemplo utilizamos números pequenos para que possam ser representados facilmente.
Pela etapa 2 n = p . q, portanto n = 53 . 61 = 3233;
Pela etapa 3 escolher um número d tal que d seja menor que n e relativamente primo a (p-1).(q-1) para tanto basta escolher um número primo aleatório maior que p e q. Para o nosso exemplo escolhemos d = 193.
Pela etapa 4 escolhe-se um número e tal que (ed-1) seja divisível por (p-1).(q-1), para realizar tal calculo é utilizado o algoritmo de Euclides Estendido. Fazendo o uso desse algoritmo calculamos que e = 97.
Portanto, em nosso exemplo, os valores importantes do algoritmo RSA são:
p = 53, q = 61, n = 53 . 61 = 3233, d = 193 e e = 97.
No artigo (RIVEST et al, 1978) as chaves utilizadas foram:
p = 47, q = 59, n = 2773, d = 157, e = 17.

140
Para realizar a criptografia foi adotada uma tabela (ver tabela 8.1) para representar numericamente as letras maiúsculas do alfabeto. Em um algoritmo implementado em computador a tabela utilizada é a tabela ASCII que não será utilizada nesse exemplo para simplificar os cálculos.
Tabela 8.1 – Valores dos Caracteres para Exemplo do RSA.
A B C D E F G H I J K L 00 01 02 03 04 05 06 07 08 09 10 11 12
M N O P Q R S T U V W X Y Z 13 14 15 16 17 18 19 20 21 22 23 24 25 26
Usando a tabela 8.1 a frase “ITS ALL GREEK TO ME” seria representada numericamente como:
09 20 19 00 01 12 12 00 07 18 05 05 11 00 20 15 00 13 05 00
Como nosso n = 3233, a mensagem pode ser criptografada em blocos de duas letras pois o valor máximo que pode aparecer na frase original é o equivalente à seqüência “ZZ” = 2626 que é menor que n (3233). Portanto, agrupando a mensagem em grupos de duas letras temos:
0920 1900 0112 1200 0718 0505 1100 2015 0013 0500
Para cifrar cada bloco é realizado o cálculo:
C = Te mod n,
onde C é a mensagem cifrada e T é a mensagem original.
Para T = 0920, temos: C = 092097 mod 3233 = 2546;
Para T = 1900, temos: C = 190097 mod 3233 = 1728;
Para T = 0112, temos: C = 011297 mod 3233 = 0514;
Para T = 1200, temos: C = 120097 mod 3233 = 0210;
Para T = 0718, temos: C = 071897 mod 3233 = 2304;
Para T = 0505, temos: C = 050597 mod 3233 = 0153;
Para T = 1100, temos: C = 110097 mod 3233 = 2922;
Para T = 2015, temos: C = 201597 mod 3233 = 2068;
Para T = 0013, temos: C = 001397 mod 3233 = 1477;
Para T = 0500, temos: C = 050097 mod 3233 = 2726.
Assim temos a mensagem cifrada:

141
2546 1728 0514 0210 2304 0153 2922 2068 1477 2426
Para decifrar cada bloco é realizado o cálculo:
T = Cd mod n,
onde T é a mensagem original e C é a mensagem cifrada.
Para C = 2546, temos: T = 2546193 mod 3233 = 0920;
Para C = 1728, temos: T = 1728193 mod 3233 = 1900;
Para C = 0514, temos: T = 0514193 mod 3233 = 0112;
Para C = 0210, temos: T = 0210193 mod 3233 = 1200;
Para C = 2304, temos: T = 2304193 mod 3233 = 0718;
Para C = 0153, temos: T = 0153193 mod 3233 = 0505;
Para C = 2922, temos: T = 2922193 mod 3233 = 1100;
Para C = 2068, temos: T = 2068193 mod 3233 = 2015;
Para C = 1477, temos: T = 1477193 mod 3233 = 0013;
Para C = 2726, temos: T = 2726193 mod 3233 = 0500.
Assim temos a mensagem decifrada:
0920 1900 0112 1200 0718 0505 1100 2015 0013 0500,
que era a nossa mensagem original.
8.3 Descrição do Algoritmo Para a criação das chaves é necessário um gerador de números aleatórios para a escolha dos números p, q e d descritos nas etapas 1 e 3.
O gerador de números aleatórios utilizado na implementação foi inspirado no apresentado no livro de Knuth (KNUTH, 1997), seu esquema é apresentado na figura 8.1.

142
Figura 8.1 – Esquema do gerador de números aleatórios
Os valores atribuídos à MM, AA, QQ e RR são definidos para que os números gerados não se repitam facilmente, o valor X é o valor a partir do qual será calculado o próximo número.
Outro algoritmo necessário é o algoritmo de Euclides Estendido que é utilizado para o calculo de e na etapa 4, seu esquema é apresentado na figura 8.2.
Figura 8.2 – Esquema do algoritmo de Euclides Estendido

143
Para criptografar uma mensagem é realizado o cálculo C = Me mod n, onde C é a mensagem cifrada, M é a mensagem original, e é o expoente público e n é o módulo. Os valores e e n são os calculados de acordo com as etapas de 1 a 4. Para decifrar uma mensagem o cálculo realizado é: M = Cd mod n, sendo d o expoente privado.
Para realizar esses cálculos foi necessária a implementação dos algoritmos para exponenciação modular e para multiplicação modular (BLAKLEY). Esses algoritmos estão descritos em (KOÇ, 1994).
8.4 Implementação em C Para implementar o algoritmo RSA é necessário inicialmente um algoritmo para a geração de números aleatórios e um algoritmo para verificar se os números gerados são primos. Como esta implementação utilizará chaves entre 16 e 24 bits, que são chaves relativamente pequenas, não será necessário a implementação de algoritmos sofisticados para verificar se os números são primos. Em implementações que consideram chaves grandes (a partir de 512 bits) verificar se os valores utilizados na geração das chaves são primos é um problema, pois para valores grandes um teste utilizando algoritmos comuns demora um tempo impraticável. Em vez disto são utilizados algoritmos que comprovam que um número tem uma probabilidade alta de ser primo, mas não pode-se afirmar com certeza.
Desta forma esta implementação utilizará a função primo abaixo para determinar se um determinado valor é primo ou não. Como descrito anteriormente, esta função é uma função simples e não é adequada para o teste de números grandes.
int primo(unsigned int n)
{
int i;
i = (n / 2) + 1;
while(n % i != 0)
i--;
if (i==1)
return 1; // é primo
else
return 0; // não é primo
}
O algoritmo para a geração de números aleatórios utilizados é o que foi esquematizado na figura 8.1.
Desta forma, a função escolha(min,max) escolhe uma valor primo entre min e max. Importante lembrar que o valor de X é o valor a partir do qual serão calculados os outros valores. Este valor X é chamado de semente do gerador de números aleatórios.
#define MM 2147483647
#define AA 48271
#define QQ 44488
#define RR 3399
int X = 251;

144
int escolha(int min, int max)
{
int aux=0;
while(aux<min)
{
X=AA*(X%QQ)-RR*(long)(X/QQ);
if (X<0) X+=MM;
aux = X % max;
if (aux>min)
while (!primo(aux))
aux++;
}
return aux;
}
Outra função importante para a geração das chaves do algoritmo RSA é o algoritmo de Euclides Estendido. Esta função é utilizada para gerar o valor do expoente público.
int calc_e(unsigned int phi_n, unsigned int d)
{
int u[3];
int v[3];
int t[3];
int q;
u[0] = 1;
u[1] = 0;
u[2] = phi_n;
v[0] = 0;
v[1] = 1;
v[2] = d;
while (v[2] != 0)
{
q = (u[2] / v[2]);
t[0] = u[0] - (v[0] * q);
t[1] = u[1] - (v[1] * q);
t[2] = u[2] - (v[2] * q);
u[0] = v[0];
u[1] = v[1];
u[2] = v[2];
v[0] = t[0];
v[1] = t[1];
v[2] = t[2];
}
return u[1];
}
Para gerar as chaves basta executar os algoritmos conforme descrito nos cinco passos da seção 8.1. Desta forma, a implementação da função para gerar as chaves segue:
void criachave(int *a, int *b, int *c)
{

145
//p e q devem ser até 210 //65536
unsigned int p,q,d,e,n;
p = escolha(256,4000);
q = p;
while (p == q)
q = escolha(256,4000);
n = p * q;
d = escolha(50000,100000);
e = calc_e(((p-1)*(q-1)),d);
*a = e;
*b = d;
*c = n;
}
Após criadas as chaves, para realizar as operações de criptografia e decriptografia basta realizar as operações C = Me mod n e M = Cd mod n respectivamente. Para isto são necessários algoritmos específicos para a exponenciação modular. Os algoritmos utilizados foram escolhidos por sua performance e por não necessitar de variáveis maiores que 32 bits para esta implementação de 24 bits.
Maiores detalhes sobre estes algoritmos podem ser obtidos em (KOÇ, 1994). A seguir é apresentada a implementação destes algoritmos.
int BLAKLEY(int a, int b, int n)
// entradas: a,b,n
// saída: R = (a * b) mod n
{
int i,aux=1;
int a_[32];
int R;
for (i=0;i<32;i++)
{
a_[i] = (!((a & aux) == 0));
aux+=aux;
}
R = 0;
for (i=0;i<32;i++)
{
R = 2 * R + (a_[32-1-i] * b);
R = R % n;
}
return R;
}
int modexp(unsigned long m, unsigned long e, unsigned int n)
/* Algoritmo binário
m = base | e = expoente | n = modulo | t = nº de bits
*/
{
unsigned long temp=1;
int j,t;
int b[32]; //vetor de bits
int aux=1;

146
int achou;
for (j=0;j<32;j++) //converte o expoente em um vetor de bits
{
b[j] = !((e &aux) == 0);
aux += aux;
}
j = 31;
achou = 0;
while ((!achou) && (j >= 0)) // calcula o nº de bits do expoente (t)
{
if (b[j] == 1)
{
t = j+1;
achou = 1;
}
j--;
}
for (j=t;j>=0;j--)
{
temp = BLAKLEY(temp,temp,n);
if (b[j] == 1)
temp = BLAKLEY(temp,m,n);
}
return temp;
}
Ambos os algoritmos apresentados não estão em sua forma mais otimizada. Sugere-se que o leitor verifique pontos onde tais otimizações possam ser implementadas e realize implementações otimizadas.
8.5 Exemplos de Funcionamento do Algoritmo Implementado em C
O algoritmo RSA foi implementado em linguagem C. Embora a maioria das chaves utilizadas nos dias de hoje terem 1024 bits de comprimento, a nossa implementação do RSA terá apenas chaves que variam entre 16 e 24 bits, uma vez que o objetivo do livro é apresentar o algoritmo de forma didática, não sendo dessa forma, necessária uma implementação mais complexa do RSA. No entanto, considerando os principios e algoritmos aqui apresentados é possível realizar implementações completas que utilizem chaves de grandes tamanhos.
A tabela 8.2 apresenta exemplos de funcionamento do RSA. Nela aparecem três mensagens: “algoritmo”, “criptografia” e “RSA” e, as suas respectivas mensagens criptografadas para dois conjuntos diferentes de parâmetros e, d e n.

147
Tabela 8.2 – Exemplo de Funcionamento do RSA
Mensagem \ Chave e = 47453, d = 60077, n = 3269183 e = 54809, d = 88289, n = 787403 Algoritmo 2e0e420ac6bc1aa2db2994ae256cbb 08a5a00a35ff0a71a901a423054f79 Criptografia 0cca360c33e01967140243c313667419
54c9 094d7d0a8af409484a05281104ae8e01d55a
RSA 17f7fd2011e7 016c6e00b029
8.6 Implementação em Hardware (VHDL) Inicialmente será proposta a implementação dos módulos necessários para o cálculo de C = Me mod n; e M = Cd mod n.
A diferença entre a implementação da função para cifrar e a implementação da função para decifrar é apenas o tamanho de alguns sinais de entrada e saída. Portanto, basta implementar um módulo para calcular potência e um para calcular o módulo (resíduo).
Com isso podemos imaginar uma arquitetura simples que realize esse cálculo. Essa arquitetura é apresentada na figura 8.3.
Figura 8.3 – Arquitetura básica do RSA
Poderíamos implementar o RSA utilizando a arquitetura apresentada na figura 8.3, entretanto, o cálculo de Me resulta em um valor muito grande, que necessitaria de uma grande quantidade de bits para armazená-lo e seria necessário muito tempo para calcular o módulo (que é a próxima etapa). Com isso é necessário estudar alguns algoritmos que permitam calcular Me mod n sem que os valores intermediários sejam muito grandes, reduzindo assim o tempo necessário.
Os algoritmos utilizados para a implementação foram os algoritmos Binary Method – Modular Exponentiation e Blakley’s Method – Modular Multiplication descritos em (KOÇ, 1994).
//Binary Method – Modular Exponentiation
//Entradas: M, e, n;
//Saída temp = Me (mod n);
1. temp = 1;
2. PARA i DE número de bits do expoente e ATÉ 0 FAÇA
3. temp = temp * temp (mod n);

148
4. SE ei = 1 ENTÃO
5. temp = temp * M (mod n);
6. FIM SE;
7. FIM PARA;
Na linha 4, ei significa o bit i do expoente e.
Os cálculos realizados nas linhas 3 e 5 são realizados através do algoritmo Blakley’s Method, apresentado a seguir.
//Blakley’s Method – Modular Multiplication
//Entradas: A,B, n;
//Saída: R = A * B (mod n);
1. R = 0;
2. PARA i DE 0 ATÉ 32 FAÇA
3. R = R * 2 + (A31-i * B);
5. R = R (mod n);
6. FIM PARA;
Para simplificar os cálculos a linha 3 pode ser substituída por:
3.a. R = R << 1; //Desloca-se o R uma vez para a esquerda (equivale a multiplicar por 2)
3.b. SE A31-i = 1 ENTÃO R = R + B;
E a linha 5 pode ser substituída por:
5.a. SE R > n ENTÃO R = R – n;
5.b. SE R > n ENTÃO R = R – n;
Para implementar o RSA basta implementar os algoritmos descritos acima. O algoritmo principal é o Binary Method, que utiliza o algoritmo Blakley’s Method para realizar a multiplicação módulo n. Faremos isso propondo uma máquina de estados onde o algoritmo Blakley será representado por dois estados. A máquina de estados proposta é apresentada na figura 8.4.

149
Figura 8.4 – Máquina de estados para a implementação do RSA
Os módulos descritos acima foram implementados e simulados utilizando a ferramenta Xilinx Foundation (XILINX, 2004), versão 3.1 (XILINX, 1998). Ambos os módulos trabalham a uma freqüência de 50MHz e demoram cerca de 38.8us (1 microsegundo = 10-6 segundos) para cifrar/decifrar blocos de mensagem de dois caracteres.
A seguir é apresentada a descrição em VHDL para esta máquina de estados. Pode-se perceber através desta descrição que as portas de entrada são: M (16 bits – representa a mensagem), E (17 bits – representa o expoente público), n (24 bits – valor de n = p * q) e CLK; e as portas de saída são C (24 bits –mensagem cifrada) e PRONTO que indica que o bloco atual foi finalizado. A variável FLAG indica o estado em que a máquina se encontra.
LIBRARY ieee;
USE ieee.std_logic_1164.all;
USE ieee.std_logic_arith.all;
use IEEE.std_logic_unsigned.all;
ENTITY mod_exp is
port(
M : in std_logic_vector(15 downto 0);
E : in std_logic_vector(16 downto 0);
n : in std_logic_vector(23 downto 0);
CLK : in std_logic;
C : out std_logic_vector(23 downto 0);
PRONTO : out std_logic
);
end mod_exp;

150
architecture arc of mod_exp is
begin
process(clk)
variable temp: std_logic_vector(31 downto 0);
variable flag: std_logic_vector(2 downto 0);
variable A,B,R : std_logic_vector(31 downto 0);
variable i,j : integer;
begin
if clk'event and clk = '1' then
if flag = "000" then
j := 17;
temp := "00000000000000000000000000000001";
flag := "001";
elsif flag = "001" then
if j >=0 then
A := temp;
B := temp;
R := "00000000000000000000000000000000";
i := 0;
flag := "010";
else
PRONTO <= '1'; --Atribuição dos valores aos
C <= temp(23 downto 0); --sinais de saída.
end if;
elsif flag = "011" then
temp := R;
if E(j) = '1' then
A := temp;
B(15 downto 0 ) := M;
B(31 downto 16) := "0000000000000000";
R := "00000000000000000000000000000000";
i := 0;
flag := "100";
else
j := j - 1;
flag := "001";
end if;
elsif flag = "101" then
temp := R;
j := j - 1;
flag := "001";
elsif flag = "010" or flag = "100" then -- BLAKLEY
if i < 32 then
R := SHL(R,"1");
if A(31-i) = '1' then R := R + B; end if;
if R > n then R := R - n; end if;
if R > n then R := R - n; end if;
i := i + 1;
else
flag := flag + 1;
end if;

151
end if;
end if;
end process;
end arc;
A figura 8.5 apresenta a criptografia dos caracteres AB, que usando os respectivos valores da tabela ASCII são representados pelos valores em hexadecimal 4142. A chave utilizada é E=0B95Dh e N=31E23Fh. O valor criptografado aparece no sinal C=0C134Ah.
Figura 8.5 – Simulação de criptografia utilizando o RSA em Hardware
A figura 8.6 mostra como a mesma mensagem é decifrada. Na entrada C é colocado o valor da mensagem criptografada anteriormente (0C134Ah); a chave utilizada neste caso é a chave secreta D=0EAADh e N=31E23Fh. A mensagem decifrada aparece no sinal M. Note que o processo funcionou corretamente, pois a mensagem obtida após decifrar é a mesma do início (M=4142h).
Figura 8.6 – Simulação de decriptografia utilizando o RSA
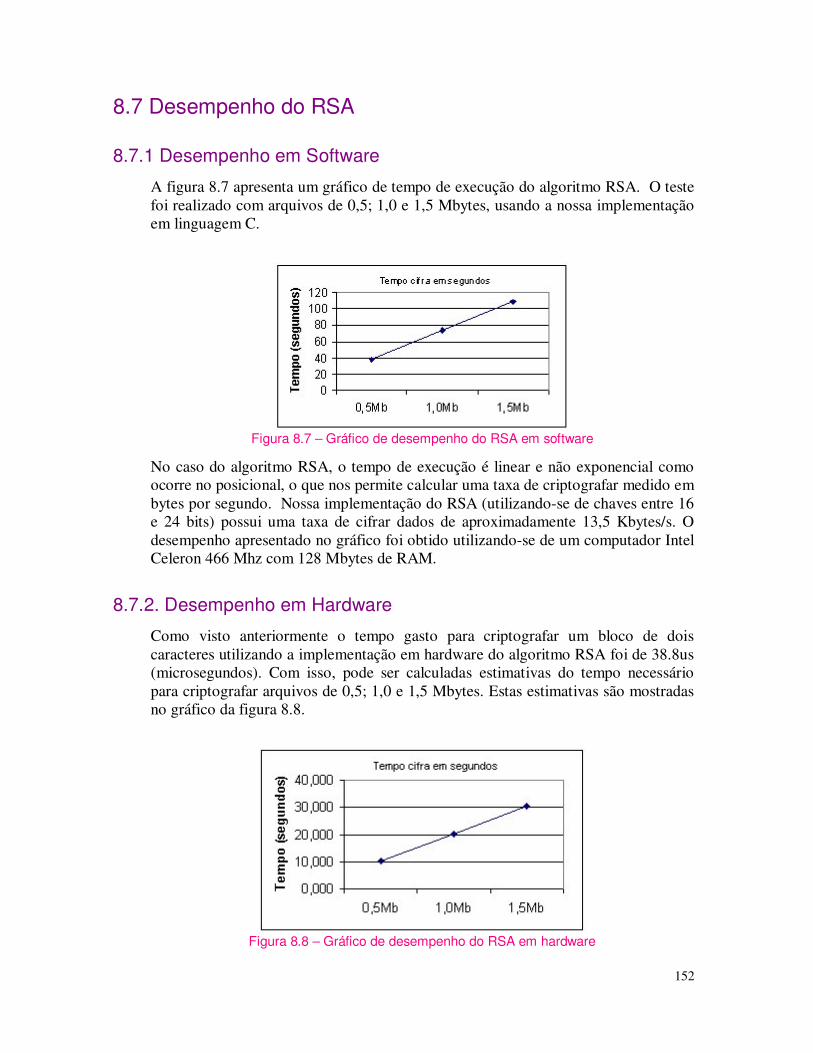
152
8.7 Desempenho do RSA
8.7.1 Desempenho em Software
A figura 8.7 apresenta um gráfico de tempo de execução do algoritmo RSA. O teste foi realizado com arquivos de 0,5; 1,0 e 1,5 Mbytes, usando a nossa implementação em linguagem C.
Figura 8.7 – Gráfico de desempenho do RSA em software
No caso do algoritmo RSA, o tempo de execução é linear e não exponencial como ocorre no posicional, o que nos permite calcular uma taxa de criptografar medido em bytes por segundo. Nossa implementação do RSA (utilizando-se de chaves entre 16 e 24 bits) possui uma taxa de cifrar dados de aproximadamente 13,5 Kbytes/s. O desempenho apresentado no gráfico foi obtido utilizando-se de um computador Intel Celeron 466 Mhz com 128 Mbytes de RAM.
8.7.2. Desempenho em Hardware
Como visto anteriormente o tempo gasto para criptografar um bloco de dois caracteres utilizando a implementação em hardware do algoritmo RSA foi de 38.8us (microsegundos). Com isso, pode ser calculadas estimativas do tempo necessário para criptografar arquivos de 0,5; 1,0 e 1,5 Mbytes. Estas estimativas são mostradas no gráfico da figura 8.8.
Figura 8.8 – Gráfico de desempenho do RSA em hardware
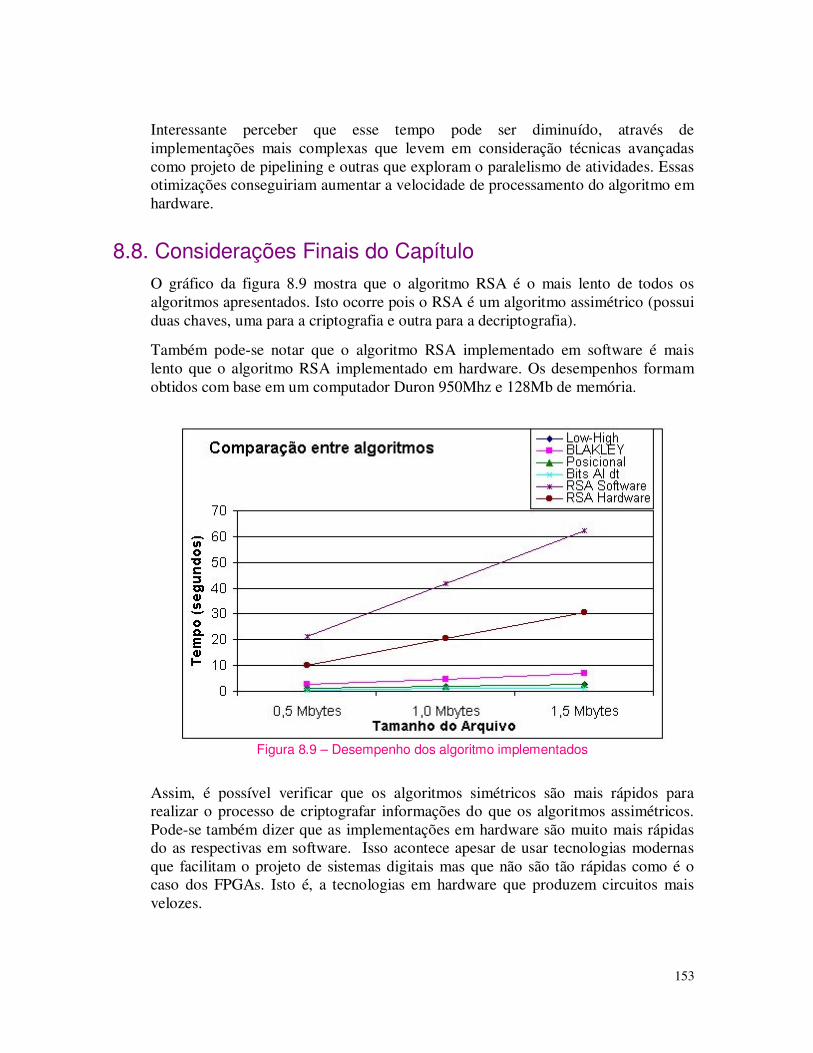
153
Interessante perceber que esse tempo pode ser diminuído, através de implementações mais complexas que levem em consideração técnicas avançadas como projeto de pipelining e outras que exploram o paralelismo de atividades. Essas otimizações conseguiriam aumentar a velocidade de processamento do algoritmo em hardware.
8.8. Considerações Finais do Capítulo O gráfico da figura 8.9 mostra que o algoritmo RSA é o mais lento de todos os algoritmos apresentados. Isto ocorre pois o RSA é um algoritmo assimétrico (possui duas chaves, uma para a criptografia e outra para a decriptografia).
Também pode-se notar que o algoritmo RSA implementado em software é mais lento que o algoritmo RSA implementado em hardware. Os desempenhos formam obtidos com base em um computador Duron 950Mhz e 128Mb de memória.
Figura 8.9 – Desempenho dos algoritmo implementados
Assim, é possível verificar que os algoritmos simétricos são mais rápidos para realizar o processo de criptografar informações do que os algoritmos assimétricos. Pode-se também dizer que as implementações em hardware são muito mais rápidas do as respectivas em software. Isso acontece apesar de usar tecnologias modernas que facilitam o projeto de sistemas digitais mas que não são tão rápidas como é o caso dos FPGAs. Isto é, a tecnologias em hardware que produzem circuitos mais velozes.

154
Para projetar circuitos ainda mais rápidos usam-se técnicas e tecnologias próprias para ASICs (Application Specific Integrated Circuits), as quais estão disponíveis em algumas universidades e centros de pesquisa brasileiros. Recentemente, em 2004, foi criado o CEITEC-Centro de Excelência em Tecnologia Eletrônica Avançada que está localizado em Porto Alegre, R.S. Brasil, e que visa estimular a criação de circuitos e sistemas digitais para prototipar produtos para o setor eletro-eletrônico brasileiro. Para mais informações, acessar http://www.sct.rs.gov.br/programas/ceitec.

155
Capítulo 9 Algoritmos Baseados em Hashing (MD5, SHA-1)
Este capítulo apresenta os conceitos relacionados a algoritmos de hashing, fortemente usados em aplicações de assinatura digital. O capítulo destaca os algoritmos SHA-1 e MD5.
9.1 Definição de MAC – Código de Autetincação de Mensagens
Funções de espalhamento são funções que calculam um valor “y” de comprimento relativamente menor que o comprimento de um texto x. Esse valor “y” é chamado de MAC (Message Authentication Code) ou Message Digest de “x”. Assim, o MAC define, em português, um código de autenticação de uma mensagem (FIPS180-1., 1995).
Essas funções são utilizadas para garantir a integridade da mensagem, já que o objetivo dessas funções é gerar um valor “y” diferente para cada mensagem. Com isso, caso a mensagem “x” for modificada para uma mensagem x’ quando o destinatário receber a mensagem x’ ele irá recalcular y para a mensagem que recebeu (x’). Como cada mensagem gera um “y” diferente ele irá detectar que “y” para a mensagem que ele recebeu é diferente do que ele esperava e, com isso detectar que a mensagem foi alterada.
No entanto, existe uma probabilidade de que ao calcular a função para mensagens diferentes o valor “y” obtido seja o mesmo. Essa situação é chamada de colisão. Portanto, um dos objetivos dos projetistas das funções de espalhamento é minimizar a probabilidade de ocorrer colisões, além de cuidar da velocidade de processamento.
9.2 Algoritmo MD5 O algoritmo MD5 foi proposto por Rivest e descrito no RFC1321 em Abril de 1992. Ele foi desenvolvido para executar rapidamente em máquinas de 32 bits e não requer longas tabelas de substituição, o que permite que seja codificado de forma compacta. (PINTO, 2004), (RFC1321, 1992).
O MD5 é uma extensão do algoritmo MD4, sendo cerca de 30% mais lento (TERADA, 2000), mas garantindo uma maior segurança. O algoritmo MD5 possui

156
probabilidade de colisão a cada 264 aplicações contra 220 aplicações do algoritmo MD4 (MENEZES, 1997).
No algoritmo MD5 a entrada pode ser de comprimento arbitrário e o processamento ocorre em blocos de 512 bits e a saída é de 128 bits.
Inicialmente, deve-se realizar o preenchimento da mensagem, para que ela fique de tamanho congruente a 448 (mod 512), ou seja, ao separar a mensagem em blocos de 512 bits no último bloco restará exatamente 448 bits. O formato do preenchimento a ser acrescentado é um bit ‘1’ seguido de bits ‘0’ até que o tamanho seja congruente a 448 (mod 512). Importante ressaltar que mesmo que a mensagem original seja de tamanho 448 (mod 512) é necessário realizar o preenchimento, com isto, no mínimo 1 e no máximo 512 bits serão acrescentados à mensagem.
Como descrito anteriormente, o algoritmo MD5 processa blocos de 512 bits, com isto é necessário que o tamanho da mensagem seja múltiplo de 512. Como após o preenchimento o tamanho do ultimo bloco é de 448 bits são necessários 64 bits para completar o bloco. Esses últimos 64 bits são preenchidos com o tamanho em bits da mensagem original. Caso o tamanho da mensagem não possa ser representado em 64 bits, apenas os bits menos significativos serão considerados.
Após realizar as operações descritas acima a mensagem está no formato correto para ser processada. Porém antes de iniciar o processamento é necessário inicializar os buffers do MD5. O algoritmo MD5 utiliza quatro buffers de 32 bits cada, aqui chamados de A, B, C e D, para realizar o processamento e o cálculo do hash. Os buffers do algoritmo MD5 devem ser inicializados com os valores descritos na tabela 9.1 (os valores estão em hexadecimal).
Importante salientar que o algoritmo MD5 foi criado para uma máquina little-endian, desta forma deve-se considerar primeiro os bytes menos significativos.
Tabela 9.1 – Valores para preencher os Buffers
A 01 23 45 67
B 89 AB CD EF
C FE DC BA 98
D 76 54 32 10
Para realizar o processamento, o bloco de entrada de 512 bits é dividido em 16 partes de 32 bits aqui chamadas de x0, x1,..., x15. Observe que 16 x 32 = 512, que é o tamanho do bloco usado no MD5.
Inicialmente é realizada a cópia dos valores antigos do buffer e então são realizadas operações sobre o texto de entrada alterando os valores armazenados no buffer (que está composto por quatro partes A, B, C e D).
As operações realizadas são divididas em quatro passos. Cada passo utiliza uma função auxiliar diferente e utiliza uma ordem diferente para aplicar as entradas x0, x1,..., x15. A tabela 9.2 sumariza quais são as funções auxiliares utilizadas em cada

157
passo bem como a ordem de aplicação das partes do texto de entrada (RFC1321, 1992).
Tabela 9.2 – Sumário das operações realizadas no MD5 (RFC1321, 1992).
Passo Função Auxiliar/Operação 1 F(X,Y,Z) = XY or not(X) Z
[abcd k s i] => a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s)
[ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4]
[ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8]
[ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12]
[ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16] 2 G(X,Y,Z) = XZ or Y not(Z)
[abcd k s i] => a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s)
[ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20]
[ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24]
[ABCD 9 5 25] [DABC 14 9 26] [CDAB 3 14 27] [BCDA 8 20 28]
[ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14 31] [BCDA 12 20 32] 3 H(X,Y,Z) = X xor Y xor Z
[abcd k s t] => a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s)
[ABCD 5 4 33] [DABC 8 11 34] [CDAB 11 16 35] [BCDA 14 23 36]
[ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40]
[ABCD 13 4 41] [DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44]
[ABCD 9 4 45] [DABC 12 11 46] [CDAB 15 16 47] [BCDA 2 23 48] 4 I(X,Y,Z) = Y xor (X or not(Z))
[abcd k s t] => a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s)
[ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52]
[ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56]
[ABCD 8 6 57] [DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60]
[ABCD 4 6 61] [DABC 11 10 62] [CDAB 2 15 63] [BCDA 9 21 64]
Importante ressaltar que o algoritmo MD5 utiliza 64 constantes, aqui chamadas de T[1], T[2],...,T[64]. Essas constantes são obtidas através do calculo: 232 * abs(sin(i)). Para evitar que a cada bloco seja necessário realizar tal operação é recomendável, em uma implementação, criar uma tabela onde os valores calculados estejam previamente armazenados e simplesmente utilizá-los. A tabela 9.3 apresenta os valores destas constantes.
Após o calculo de todas as operações de um determinado bloco é necessário realizar o somatório dos valores antigos contidos no buffer com os valores atuais antes de realizar o processo no próximo bloco. Após realizar o processamento de todos os blocos o valor de saída é o conteúdo do buffer do MD5 (A, B, C e D).
Tabela 9.3 – Constantes utilizadas pelo MD5

158
1 2 3 4
1 0xd76aa478 0xe8c7b756 0x242070db 0xc1bdceee
5 0xf57c0faf 0x4787c62a 0xa8304613 0xfd469501
9 0x698098d8 0x8b44f7af 0xffff5bb1 0x895cd7be
13 0x6b901122 0xfd987193 0xa679438e 0x49b40821
17 0xf61e2562 0xc040b340 0x265e5a51 0xe9b6c7aa
21 0xd62f105d 0x02441453 0xd8a1e681 0xe7d3fbc8
25 0x21e1cde6 0xc33707d6 0xf4d50d87 0x455a14ed
29 0xa9e3e905 0xfcefa3f8 0x676f02d9 0x8d2a4c8a
33 0xfffa3942 0x8771f681 0x6d9d6122 0xfde5380c
37 0xa4beea44 0x4bdecfa9 0xf6bb4b60 0xbebfbc70
41 0x289b7ec6 0xeaa127fa 0xd4ef3085 0x04881d05
45 0xd9d4d039 0xe6db99e5 0x1fa27cf8 0xc4ac5665
49 0xf4292244 0x432aff97 0xab9423a7 0xfc93a039
53 0x655b59c3 0x8f0ccc92 0xffeff47d 0x85845dd1
57 0x6fa87e4f 0xfe2ce6e0 0xa3014314 0x4e0811a1
61 0xf7537e82 0xbd3af235 0x2ad7d2bb 0xeb86d391
9.2.1 Implementação em C
O algoritmo MD5 foi implementado em linguagem C e Java. Nesta seção serão apresentados os principais aspectos e alguns exemplos de código da implementação em C deste algoritmo.
A primeira etapa apresentada na descrição do algoritmo MD5 define o processo de padding, ou seja, como preencher a mensagem para que seu tamanho seja múltiplo de 512 bits (que é o tamanho do bloco). No entanto, em uma implementação real, verificar o tamanho da mensagem e adicionar o preenchimento antes de começar a calcular o hash não é a maneira mais eficiente. Desta forma, inicialmente serão processados os primeiros blocos da mensagem calculando o hash, quando o processamento chegar ao ultimo bloco deve-se chamar uma função para realizar o padding e calcular o hash deste ultimo bloco.
Desta forma, seguindo o exemplo de algumas implementações existentes, serão definidas três funções principais:
• md5start() – responsável por inicializar o algoritmo MD5, definindo os valores iniciais utilizados pelo algoritmo.
• update(dados,numbytes) – acrescenta os dados em um buffer e quando o buffer estiver completo (512 bits) realiza a operação de hash neste bloco. O valor numbytes informa quantos bytes de dados devem ser considerados.
• doFinal() – realiza o padding e calcula o hash do ultimo bloco.

159
Considerando que os valores de A, B, C e D estão armazenados em variáveis do tipo inteiro, o tamanho da mensagem em um vetor do tipo inteiro não sinalizado (tamanho[]) e um contador (nc) do tipo inteiro para identificar quantos bytes foram utilizados no buffer que armazena os blocos que serão processados(buff[]); a seguir é apresentada a função necessária para inicializar o MD5.
void md5start(void)
{
A = 0x67452301;
B = 0xefcdab89;
C = 0x98badcfe;
D = 0x10325476;
tamanho[0] = 0;
tamanho[1] = 0;
nc = 0;
}
A função update() é responsável por realizar o controle do buffer (buff[]) e, quando algum bloco estiver completo (512 bits), chamar a função que realiza o cálculo do hash.
void update(unsigned char * bloco, int n) //
{
int i;
unsigned int nbits = n << 3;
tamanho[0] = tamanho[0] + nbits;
if (tamanho[0] < nbits)
{
tamanho[1]++;
}
tamanho[1] = tamanho[1] + (n >> 29);
for(i=0;i<n;i++)
{
buff[nc] = bloco[i];
nc++;
if(nc == 64)
{
md5();
nc = 0;
}
}
}
A função doFinal() verifica quantos bits é necessário adicionar ao buffer para que ele fique com 448 bits (56 bytes) e utiliza a função update para adicioná-los. Após esta etapa, é necessário apenas acrescentar o tamanho da mensagem em bits para completar este ultimo bloco e finalizar a operação de hash da mensagem. Ao acrescentar o tamanho da mensagem no buffer através da função update, o buffer passará a ter exatamente 512 bits (64 bytes) e com isto a função para calcular o hash

160
deste ultimo bloco será chamada pela função update() gerando o hash final para a mensagem.
void doFinal(void)
{
int idebug;
int i;
unsigned int npad;
unsigned int t[2];
unsigned char pad[64] = {
0x80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0
};
t[0] = tamanho[0];
t[1] = tamanho[1];
npad = 56 - nc;
if (npad == 0) npad = 64;
update(pad,npad);
update((char *)t,8);
}
Como pode-se notar, as funções apresentadas até aqui são funções responsáveis pelo controle dos blocos e do processamento da mensagem. Pode-se perceber também que a função que realiza a operação hash é a função md5() que é chamada através da função update().
Como apresentado na tabela 9.2, o algoritmo MD5 utiliza quatro funções diferentes chamadas de F, G, H e I, sendo uma em cada passo:
• F(X,Y,Z) = XY or not(X) Z
• G(X,Y,Z) = XZ or Y not(Z)
• H(X,Y,Z) = X xor Y xor Z
• I(X,Y,Z) = Y xor (X or not(Z))
Estas funções por serem baseadas em operações lógicas simples podem ser facilmente descritas como macros em C, de forma a obter um bom desempenho.
#define F(x,y,z) ((x&y)|(~x&z))
#define G(x,y,z) ((x&z)|(y&~z))
#define H(x,y,z) (x ^ y ^ z)
#define I(x,y,z) (y^(x|~z))
Também é necessário descrever as operações executadas em cada passo, para isto, também serão utilizadas macros em C. O uso destas macros facilitam o entendimento e permitem obter um bom desempenho.

161
#define ROL(reg,v) (reg << v) | (reg >> (32 - v))
#define R1(a, b, c, d, k, s, i) a = b + (ROL((a + F(b,c,d) + X[k] + T[i]), s))
#define R2(a, b, c, d, k, s, i) a = b + (ROL((a + G(b,c,d) + X[k] + T[i]), s))
#define R3(a, b, c, d, k, s, i) a = b + (ROL((a + H(b,c,d) + X[k] + T[i]), s))
#define R4(a, b, c, d, k, s, i) a = b + (ROL((a + I(b,c,d) + X[k] + T[i]), s))
A macro ROL apresentada é utilizada para realizar uma rotação, ou deslocamento circular à esquerda.
Importante lembrar que o vetor T[] armazena as constantes utilizadas pelo algoritmo MD5. O vetor X[] que também aparece na descrição das macros é um vetor utilizado localmente na função md5() para armazenar os dados do bloco no formato que o MD5 processa, ou seja, o bloco de dados é tratado como 16 partes de 32 bits.
A seguir é apresentada a função completa para realizar o cálculo do hash de um bloco. Esta função é baseada na utilização das macros descritas anteriormente utilizando os valores descritos na tabela 9.2.
void md5(void)
{
unsigned int X[16];
unsigned int AA,BB,CC,DD;
convert(X);
AA = A;
BB = B;
CC = C;
DD = D;
R1(A,B,C,D, 0, 7, 1);R1(D,A,B,C, 1,12, 2);R1(C,D,A,B, 2,17, 3);R1(B,C,D,A, 3,22, 4);
R1(A,B,C,D, 4, 7, 5);R1(D,A,B,C, 5,12, 6);R1(C,D,A,B, 6,17, 7);R1(B,C,D,A, 7,22, 8);
R1(A,B,C,D, 8, 7, 9);R1(D,A,B,C, 9,12,10);R1(C,D,A,B,10,17,11);R1(B,C,D,A,11,22,12);
R1(A,B,C,D,12, 7,13);R1(D,A,B,C,13,12,14);R1(C,D,A,B,14,17,15);R1(B,C,D,A,15,22,16);
R2(A,B,C,D, 1, 5,17);R2(D,A,B,C, 6, 9,18);R2(C,D,A,B,11,14,19);R2(B,C,D,A, 0,20,20);
R2(A,B,C,D, 5, 5,21);R2(D,A,B,C,10, 9,22);R2(C,D,A,B,15,14,23);R2(B,C,D,A, 4,20,24);
R2(A,B,C,D, 9, 5,25);R2(D,A,B,C,14, 9,26);R2(C,D,A,B, 3,14,27);R2(B,C,D,A, 8,20,28);
R2(A,B,C,D,13, 5,29);R2(D,A,B,C, 2, 9,30);R2(C,D,A,B, 7,14,31);R2(B,C,D,A,12,20,32);
R3(A,B,C,D, 5, 4,33);R3(D,A,B,C, 8,11,34);R3(C,D,A,B,11,16,35);R3(B,C,D,A,14,23,36);
R3(A,B,C,D, 1, 4,37);R3(D,A,B,C, 4,11,38);R3(C,D,A,B, 7,16,39);R3(B,C,D,A,10,23,40);
R3(A,B,C,D,13, 4,41);R3(D,A,B,C, 0,11,42);R3(C,D,A,B, 3,16,43);R3(B,C,D,A, 6,23,44);
R3(A,B,C,D, 9, 4,45);R3(D,A,B,C,12,11,46);R3(C,D,A,B,15,16,47);R3(B,C,D,A, 2,23,48);
R4(A,B,C,D, 0, 6,49);R4(D,A,B,C, 7,10,50);R4(C,D,A,B,14,15,51);R4(B,C,D,A, 5,21,52);
R4(A,B,C,D,12, 6,53);R4(D,A,B,C, 3,10,54);R4(C,D,A,B,10,15,55);R4(B,C,D,A, 1,21,56);
R4(A,B,C,D, 8, 6,57);R4(D,A,B,C,15,10,58);R4(C,D,A,B, 6,15,59);R4(B,C,D,A,13,21,60);
R4(A,B,C,D, 4, 6,61);R4(D,A,B,C,11,10,62);R4(C,D,A,B, 2,15,63);R4(B,C,D,A, 9,21,64);
A = A + AA;
B = B + BB;
C = C + CC;
D = D + DD;

162
}
A função convert(X) é utilizada para converter os dados contidos no buffer para o formato utilizado pelo MD5, que é de 16 partes de 32 bits. Nesta função é importante considerar que o formato que o MD5 utiliza é o formato little-endian.
9.2.2 Desempenho em Software
Com a finalidade de obter o desempenho da implementação do algoritmo MD5 foram realizados testes de desempenho em um computador AMD Duron de 1,2Ghz com 128 Mb de memória RAM utilizando o sistema operacional Windows XP.
Considerando implementações do algoritmo MD5 em linguagem C e em linguagem Java. Inicialmente a figura 9.1 apresenta o desempenho obtido após a execução de uma implementação em Java do algoritmo MD5 sobre três arquivos distintos:
(i) Imagem em vídeo com extensão MPG e um tamanho de 57,1 Mbytes;
(ii) Música Digital com Extensão MP3 e um tamanho de 6,43 Mbytes e;
(iii) Documento do tipo WORD, com extensão DOC e um tamanho de 346 Kbytes.
Figura 9.1 – Desempenho do algoritmo MD5 em Java (PINTO, 2004)
Os tempos apresentados na figura 9.1 estão descritos em milisegundos (ms). Como esperado, quanto maior seja um determinado arquivo, maior será o tempo de processamento.
A figura 9.2 apresenta uma comparação dos tempos em milisegundos utilizados para o processamento do algoritmo MD5 utilizando implementações em diferentes linguagens (C e Java). Através da figura pode-se notar que a implementação em Java é significativamente mais lenta que a implementação em C, sendo que em alguns arquivos o tempo gasto pela implementação em C é considerado insignificante.

163
Figura 9.2 – Comparação das implementações em C e Java do MD5 9PINTO, 2004)
9.3 Algoritmo SHA-1 O algoritmo SHA-1 foi desenvolvido pelo NIST em 1993 (RFC3174, 1994). A entrada pode ser de comprimento arbitrário e deve ser completada para que o comprimento se torne múltiplo de 512 bits (como ocorre com o MD5).
A saída deste algoritmo é de 160 bits sendo que blocos de 512 bits são processados a cada passo (RFC3174, 1994). Este algoritmo possui uma menor probabilidade de colisão quando comparado com o algoritmo MD5, sendo que no algoritmo SHA-1 existe a probabilidade de ocorrer colisões após 280 aplicações, contra 264 aplicações do MD5 (MENEZES, 1997).
A estrutura do algoritmo SHA-1 é parecida com a estrutura do algoritmo MD5. O algoritmo SHA-1, a exemplo do algoritmo MD5, possui um buffer que é atualizado a cada operação e que será o resultado final do hash. Neste caso como a saída é de 160 bits o buffer é composto por cinco partes de 32 bits aqui chamados de (A, B, C, D e E). O algoritmo SHA-1 utiliza também um segundo buffer de cinco partes de 32 bits que aqui serão chamadas de H0, H1, H2, H3 e H4.
O buffer do algoritmo SHA-1 deve ser iniciado com os valores contidos na tabela 9.4. (os valores estão em hexadecimal).
Tabela 9.4 – Valores para preencher o buffer do SHA-1
H0 67 45 23 01
H1 EF CD AB 89
H2 98 BA DC FE
H3 10 32 54 76
H4 C3 D2 E1 F0

164
No inicio de cada passo um bloco de entrada (X) de 512 bits é utilizado para criar um vetor W de 80 palavras de 32 bits. Inicialmente, o bloco de entrada X é dividido para formar as 16 primeiras palavras do vetor W (W0 a W15). As palavras de W16 até W79 são formadas obedecendo: Wi = (Wi-3 XOR Wi-8 XOR Wi-14 XOR Wi-16) <<< 1; onde a <<< b representa o deslocamento circular de a para esquerda b bits.
O algoritmo SHA-1 possui quatro funções e quatro constantes que são utilizadas de acordo com a iteração que estiver sendo processada; desta forma a tabela 9.5 apresenta as funções e constantes utilizadas e indica em quais iterações devem ser utilizadas.
Tabela 9.5 – Funções e Constantes utilizadas pelo SHA-1
Função Constante Iterações f(B,C,D) = (B AND C) OR ((NOT B) AND D) 5A827999 0 a 19 f(B,C,D) = B XOR C XOR D 6ED9EBA1 20 a 39 f(B,C,D) = (B AND C) OR (B AND D) OR (C AND D) 8F1BBCDC 40 a 59 f(B,C,D) = B XOR C XOR D CA62C1D6 60 a 79
Antes de executar as iterações necessárias para o processamento de um bloco com o algoritmo SHA-1, é realizada uma cópia dos valores contidos no buffer H0, H1, H2, H3 e H4 para o buffer A, B, C, D e E.
O processamento de um bloco com o algoritmo SHA-1 consiste de 80 iterações (de i=0 até i=79) onde são processadas as seguintes operações:
TEMP = (A<<<5) + fi(B,C,D) + E + Wi + Ki;
E = D; D = C; C = (B<<<30); B = A; A = TEMP;
Após a execução do laço principal é realizado o somatório dos dois buffers como segue:
H0 = H0 + A; H1 = H1 + B; H2 = H2 + C; H3 = H3 + D; H4 = H4 + E
Após processar todos os blocos da mensagem o valor do hash estará armazenado no buffer H0, H1, H2, H3 e H4.
9.3.1 Implementação em C
Assim como o algoritmo MD5, o algoritmo SHA-1 foi implementado nas linguagens C e Java. Nesta seção serão destacados os principais aspectos relativos a implementação do algoritmo SHA-1 em C.
O algoritmo SHA-1, assim como o MD5, trabalha com blocos de 512 bits. Desta forma, também é necessário realizar o preenchimento quando o tamanho da mensagem não for multiplo de 512 bits. A estrutura do preenchimento utilizada pelo SHA-1 é praticamente a mesma que a utilizada pelo algoritmo MD5, no entanto, ao contrário do MD5, o algoritmo SHA-1 utiliza o formato big-endian (o bit mais significativo é armazenado no endereço de memória mais baixo). Com isto, deve-se observar que o tamanho em bits da mensagem, que é acrescentado no final do último bloco, esteja no formato big-endian.

165
Isto faz com que as funções utilizadas para controlar o processamento da mensagem e acrescentar o preenchimento sejam praticamente as mesmas, com algumas pequenas alterações. Seguindo o exemplo do algoritmo MD5, são descritas três funções:
• sha1start() – responsável por inicializar o algoritmo SHA-1, definindo os valores iniciais utilizados pelo algoritmo.
• update(dados,numbytes) – acrescenta os dados em um buffer e quando o buffer estiver completo (512 bits) realiza a operação de hash neste bloco. O valor numbytes informa quantos bytes de dados devem ser considerados.
• doFinal() – realiza o padding e calcula o hash do último bloco.
Como descrito anteriormente, o algoritmo SHA-1 utiliza um buffer H0, H1, H2, H3 e H4 que deve ser iniciado com os valores contidos na tabela 9.4. Com isto, a seguir é apresentada a função sha1start() que realiza esta operação.
void sha1start(void)
{
H0 = 0x67452301;
H1 = 0xEFCDAB89;
H2 = 0x98BADCFE;
H3 = 0x10325476;
H4 = 0xC3D2E1F0;
tamanho[0] = 0;
tamanho[1] = 0;
nc = 0;
}
As funções update() e doFinal() são praticamente as mesas utilizadas pelo algoritmo MD5 com algumas pequenas alterações. Na função update(), onde existe a chamada para o algoritmo MD5 deve ser substituida por uma chamada ao algoritmo SHA-1. A alteração na função doFinal() está relacionada com o tratamento do formato com que o tamanho da mensagem em bits é acrescentado no final do bloco; esta alteração é uma alteração do vetor tamanho[] para o formato big-endian.
O algoritmo SHA-1 utiliza quatro funções e quatro constantes que são definidas a seguir.
#define f0(B,C,D) ((B&C)|((~B)&D))
#define f1(B,C,D) (B^C^D)
#define f2(B,C,D) ((B&C)|(B&D)|(C&D))
#define f3(B,C,D) (B^C^D)
#define K0 0x5A827999
#define K1 0x6ED9EBA1
#define K2 0x8F1BBCDC
#define K3 0xCA62C1D6
Outra função importante utilizada pelo algoritmo SHA-1 é um deslocamento circular para a esquerda em n bits. A função é definida a seguir.
#define S(reg,n) (reg << n) | (reg >> (32 - n))

166
A função principal do algoritmo SHA-1 para o cálculo do hash de um bloco é apresentada a seguir.
void sha1(void)
{
int i;
convert(W);
for(i=16;i<80;i++)
W[i]= S((W[i-3]^W[i-8]^W[i-14]^W[i-16]),1);
A=H0; B=H1; C=H2; D=H3; E=H4;
for (i=0;i<20;i++)
{
TEMP = (unsigned int)(S(A,5))+f0(B,C,D)+E+W[i]+K0;
E=D;D=C;C=S(B,30);B=A;A=TEMP;
}
for (i=20;i<40;i++)
{
TEMP = (unsigned int)(S(A,5))+f1(B,C,D)+E+W[i]+K1;
E=D;D=C;C=S(B,30);B=A;A=TEMP;
}
for (i=40;i<60;i++)
{
TEMP = (unsigned int)(S(A,5))+f2(B,C,D)+E+W[i]+K2;
E=D;D=C;C=S(B,30);B=A;A=TEMP;
}
for (i=60;i<80;i++)
{
TEMP = (unsigned int)(S(A,5))+f3(B,C,D)+E+W[i]+K3;
E=D;D=C;C=S(B,30);B=A;A=TEMP;
}
H0+=A;H1+=B;H2+=C;H3+=D;H4+=E;
}
Importante destacar que a função convert(W) que é utilizada para converter os dados contidos no buffer para o formato utilizado pelo SHA-1, que é de 16 partes de 32 bits deve considerar os dados no formato big-endian.
9.3.2 Desempenho em Software
De forma similar ao MD5, o algoritmo SHA-1 foi implementado usando-se da linguagem C e Java..
De maneira similar ao algoritmo MD5, foram realizadas implementações em C e em Java do algoritmo SHA-1. Os resultados são apresentados a seguir. Os testes apresentados consideram os mesmos arquivos utilizados nos testes com o MD5, sumarizando, estes arquivos são: Vídeo.MPG de 57,1 Mbytes; Música.MP3 de 6,43 Mbytes; e Documento.DOC de 346 Kbytes.
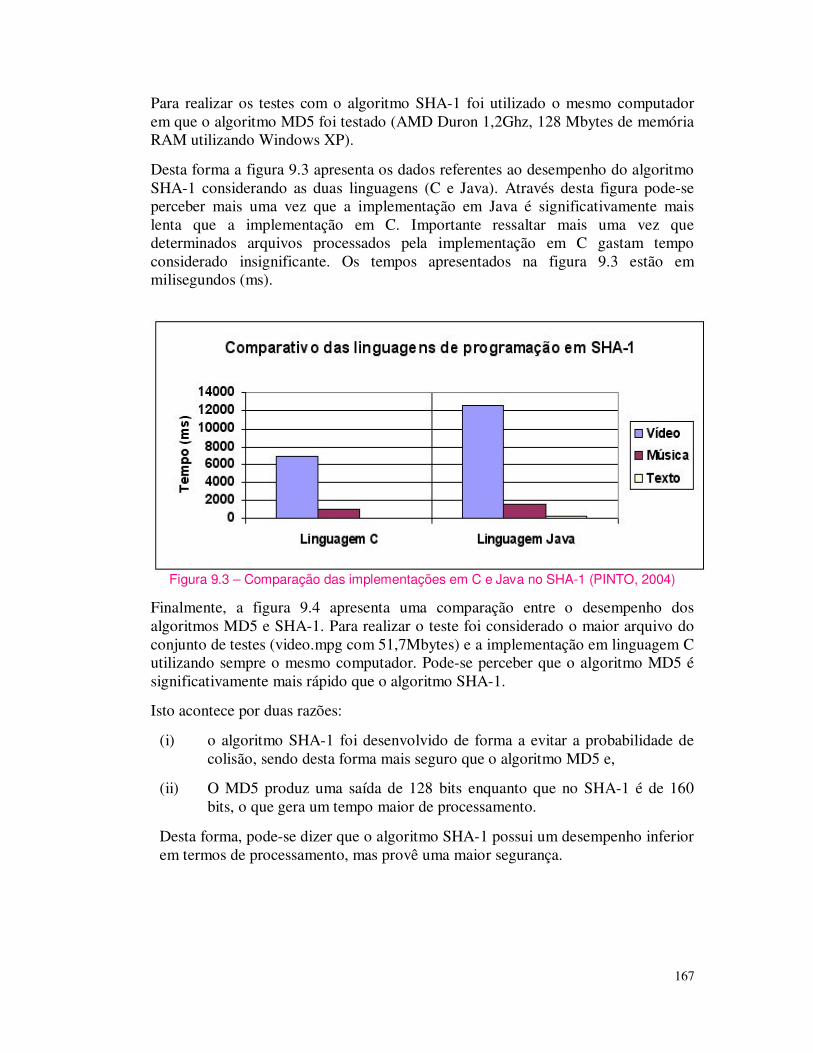
167
Para realizar os testes com o algoritmo SHA-1 foi utilizado o mesmo computador em que o algoritmo MD5 foi testado (AMD Duron 1,2Ghz, 128 Mbytes de memória RAM utilizando Windows XP).
Desta forma a figura 9.3 apresenta os dados referentes ao desempenho do algoritmo SHA-1 considerando as duas linguagens (C e Java). Através desta figura pode-se perceber mais uma vez que a implementação em Java é significativamente mais lenta que a implementação em C. Importante ressaltar mais uma vez que determinados arquivos processados pela implementação em C gastam tempo considerado insignificante. Os tempos apresentados na figura 9.3 estão em milisegundos (ms).
Figura 9.3 – Comparação das implementações em C e Java no SHA-1 (PINTO, 2004)
Finalmente, a figura 9.4 apresenta uma comparação entre o desempenho dos algoritmos MD5 e SHA-1. Para realizar o teste foi considerado o maior arquivo do conjunto de testes (video.mpg com 51,7Mbytes) e a implementação em linguagem C utilizando sempre o mesmo computador. Pode-se perceber que o algoritmo MD5 é significativamente mais rápido que o algoritmo SHA-1.
Isto acontece por duas razões:
(i) o algoritmo SHA-1 foi desenvolvido de forma a evitar a probabilidade de colisão, sendo desta forma mais seguro que o algoritmo MD5 e,
(ii) O MD5 produz uma saída de 128 bits enquanto que no SHA-1 é de 160 bits, o que gera um tempo maior de processamento.
Desta forma, pode-se dizer que o algoritmo SHA-1 possui um desempenho inferior em termos de processamento, mas provê uma maior segurança.
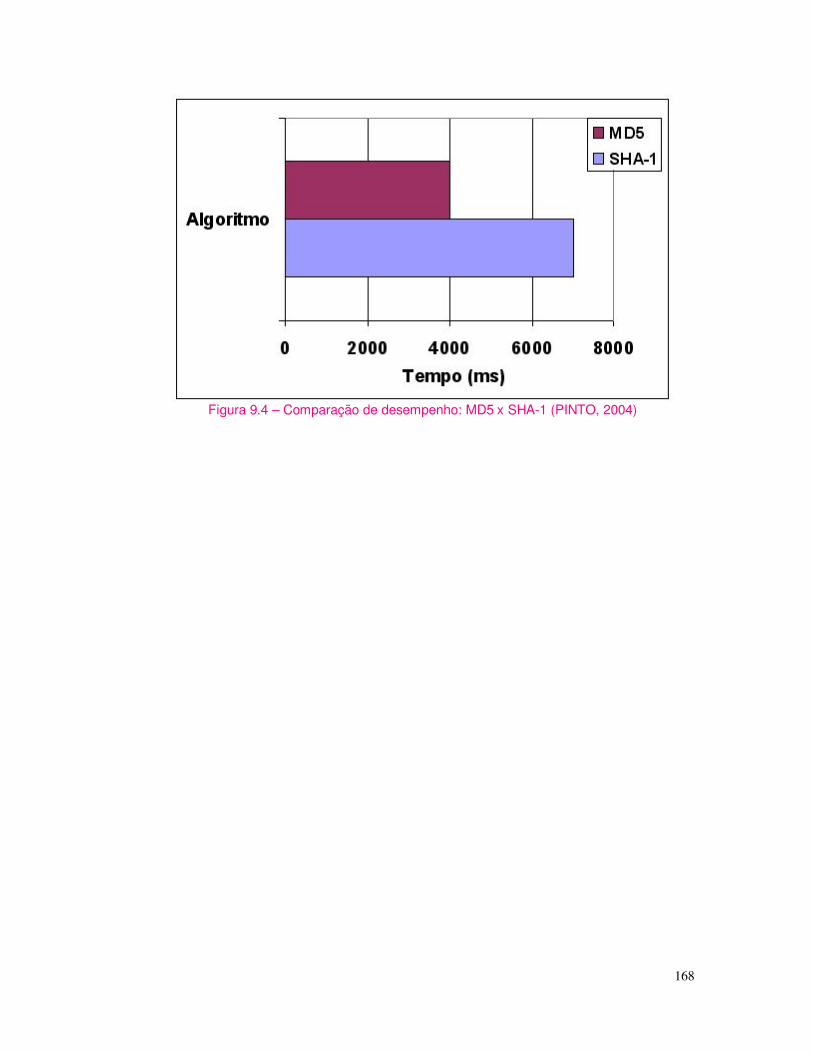
168
Figura 9.4 – Comparação de desempenho: MD5 x SHA-1 (PINTO, 2004)

169
Parte III Algoritmos Modernos de Criptografia
Nos capítulos 10 a 12, parte III do livro, três algoritmos modernos (AES, RC5/RC6 e Blowfish) são explicados do ponto de vista de implementação e desempenho, de forma similar ao explicado anteriormente na parte II do livro.

170
Capítulo 10 Algoritmo AES (Rindjael)
Este capítulo apresenta um breve histórico do projeto AES, e enfatiza nos detalhes de funcionamento, implementação e desempenho daquele que foi considerado o ganhador do concurso no ano 2000, o algoritmo Rindjael, conhecido comoAES.
10.1 Um Breve Histórico do Projeto AES Com a evolução das máquinas uma chave de 56 bits, como a usada pelo algoritmo DES, não poderia mais garantir a segurança desejada por muito tempo. Em 1997 iniciou-se o processo de escolha do sucessor do DES, o Advanced Encryption Standard (AES). O NIST especificou que os candidatos deveriam operar com tamanho de chave e bloco variável com tamanho mínimo de 128 bits.
O NIST colocou como requisitos fundamentais:
• Segurança Forte: O algoritmo projetado devia suportar os ataques futuros;
• Projeto Simples: Facilitando a análise e certificação matemática da segurança oferecida pelo algoritmo;
• Desempenho: Razoavelmente bom em uma variedade de plataformas, variando de smartcards a servidores;
• Não serem patenteados: Os algoritmos deviam ser de domínio público e deviam estar disponíveis mundialmente.
No primeiro congresso, chamado também de rodada, o NIST recebeu vinte e uma submissões, das quais quinze atendiam às exigências. Estes algoritmos foram testados e avaliados pela comunidade científica e empresas ligadas ao ramo de segurança durante o intervalo de tempo até a segunda rodada.
Para o segundo congresso foram escolhidos apenas cinco algoritmos (AESWINNER, 2003): MARS, RC6, Rijndael, Serpent e TwoFish. Esses algoritmos satisfaziam as principais condições, entre outras, de: cifrar e decifrar blocos de 128 bits; trabalhar com chaves de 128/192/256 bits; ser mais rápido que o 3DES.

171
Como todos os requisitos básicos foram supridos pelos concorrentes, a decisão foi tomada com base em certas características, tais como: segurança, eficiência em hardware e software, flexibilidade de implementação e modos de operação.
O algoritmo vencedor foi o Rijndael (AESWINNER, 2003), sendo a decisão informada oficialmente no dia 2 de outubro de 2000. Desse momento em diante o cifrador Rijndael passou a ser chamado de AES. A escolha do cifrador Rijndael contra os outros quatro finalistas do processo, os quais também foram classificados como altamente seguros pelo NIST, foi baseada na eficiência e baixa requisição de recursos. Os demais cifradores finalistas do concurso para AES podem ser utilizados em produtos específicos (MIERS, 2002).
10.2 Funcionamento do AES/Rindjael Várias operações do AES são definidas em nível de byte, com um byte representando um elemento no corpo finito GF(28), que em termos matemáticos define um campo de Galois ou melhor conhecido como Galois Field (GF). Outras operações são definidas com palavras de 4 bytes. Como AES trabalha sobre corpos finitos GF(28) pode-se definir uma operação binária em um conjunto, como um mapeamento de matrizes SxS para S. Isto é, uma regra pela qual associa-se cada par ordenado de elementos de S com um elemento de S. Para mais informações sobre corpos finitos consultar em (LIDL, 1994).
10.2.1 Corpo GF(28)
Os elementos de um corpo finito podem ser representados de várias maneiras diferentes. Para cada potência prima existe um corpo finito simples, de modo que todas as representações são isomórficas. Apesar desta equivalência, a representação possui considerável impacto na complexidade de implementação. A equipe de desenvolvimento do AES optou por uma representação clássica de polinômios.
Neste tipo de notação um byte “b” consiste dos bits: b7, b6, b5, b4, b3, b2, b1, b0.
considerados como um polinômio com coeficiente em {0,1}. Isso significa que sua interpretação como polinômio deve ser feita como: b7x
7, b6x6, b5x
5, b4x4, b3x
3, b2x
2, b1x1, b0.
10.2.1.1 Operação de Adição
Na representação polinomial, a soma de dois elementos é o polinômio com os coeficientes resultantes da operação de soma módulo 2 dos coeficientes dos dois termos.
Exemplo: Soma dos bytes 01010111 e 10000011.
01010111 = x6 + x4 + x2 + x1 + 1
10000011 = x7 + x + 1

172
(x6 + x4 + x2 + x1 + 1) + (x7 + x + 1) = x7 + x6 + x4 + x2
Através da notação hexadecimal 57h + 83h = D4h não consegue-se verificar nenhum procedimento simplificado para a operação. Porém analisando a operação em notação binária:
01010111
⊕ 10000011
11010100
Percebe-se que a soma corresponde à operação XOR em nível de bits.
10.2.1.2 Operação de Multiplicação
Na representação polinomial, a multiplicação em GF(28) corresponde a multiplicação modular de polinômios com um polinômio binário irredutível de grau 8. Um polinômio é irredutível caso não tenha nenhum divisor diferente de 1 e ele próprio. Para o AES, este polinômio é chamado de m(x) e é dado por:
m(x)= x8 + x4 + x3 + x + 1 ou 11Bh =100011011
Exemplo: Multiplicação de 57h por 83h.
(x6 + x4 + x2 + x1 + 1)( x7 + x + 1) = x13 + x11 + x9 + x8 + x7 +
x7 + x5 + x3 + x2 + 1 +
x6 + x4 + x2 + x1 + 1
= x13 + x11 + x9 + x8 + x6 + x5 + x4 + x3 + 1
Agora:
x13 + x11 + x9 + x8 + x6 + x5 + x4 + x3 + 1 módulo x8 + x4 + x3 + x + 1
é igual a: x7 + x6 + 1
Assim, a multiplicação de 57h por 83h é igual C1h
Devido à operação módulo com o polinômio irredutível m(x), o resultado sempre será um polinômio binário de grau inferior a 8. Diferente da operação de adição, não existe uma operação simples em nível de bits.
A multiplicação definida anteriormente é associativa e possui um elemento neutro (01h). Para qualquer polinômio binário b(x) de grau inferior a 8 esta operação de multiplicação pode ser feita através do algoritmo estendido de euclides para calcular:
173
b(x)a(x) + m(x)c(x)=1
Conseqüentemente, a(x)� b(x) mod m(x) = 1 ou b-1(x) = a(x) mod m(x).
Aplicando-se a propriedade distributiva tem-se
a(x) � (b(x) + c(x)) = a(x) � b(x) + a(x) � c(x).
Desta forma, tem-se um conjunto de 256 valores de bytes, utilizando XOR como adição e a multiplicação sendo definida como uma estrutura sobre um corpo finito GF(28) (FIPS197, 2001). As operações de multiplicação e similares (como a inversa) também podem ser realizadas através da utilização de uma tabela de logaritmos, ver tabela 10.1.
Tabela 10.1 – Tabela de logaritmos para multiplicação (FIPS197, 2001)
Exemplo. Multiplicação de 57h por 83h utilizando a tabela de logaritmos.
A partir dos valores originais em hexadecimal procura-se o valor do coeficiente de “g” na tabela 10.1, sendo que a ordem de busca é linha e depois coluna. Sendo o primeiro valor 57h, o valor do coeficiente de g estará na linha 5, coluna 7 e corresponde a 14. Para o valor 83h o valor do coeficiente g estará na linha 8, coluna 3 e corresponde a 230. Utilizando a tabela 10.1 obtém-se:
57h = g14 e 83h = g230
portanto, 57h + 83h = g14 + g230 = g244 = C1
Sendo os multiplicadores de mesma base (g), o resultado da operação é a mesma base e o coeficiente final consiste da soma dos coeficientes. Contudo o valor que se obtém no final da operação é o coeficiente de “g” resultante da multiplicação. Para transformar este coeficiente em um valor hexadecimal deve-se fazer uma busca nos elementos da tabela 10.1. A linha e coluna correspondentes ao valor do coeficiente são o valor em hexadecimal do resultado da operação.

174
10.2.2 Estrutura do Algoritmo AES
O AES é um cifrador de bloco com tamanho de bloco e chave variáveis entre 128, 192 e 256 bits. Isto significa que se pode ter tamanho de blocos com tamanhos de chaves diferentes. Em função do tamanho de bloco e chaves é determinada a quantidade de rodadas necessárias para cifrar/decifrar.
O AES opera desta forma com um determinado número de blocos de 32 bits, os quais são ordenados em colunas de 4 bytes, as quais são chamadas de Nb. Os valores de Nb possíveis são de 4, 6 e 8 equivalentes a blocos de 128, 192 e 256 bits.
Assim sempre que for referido Nb, significa que tem-se Nb x 32 bits de tamanho de bloco de dados. A chave é agrupada da mesma forma que o bloco de dados, isto é, em colunas, sendo representado pela sigla Nk. Com base nos valores que Nb e Nk podem assumir é que se determina a quantidade de rodadas a serem executadas, identificada pela sigla Nr. Através dos dados contidos na tabela 10.2 pode-se verificar as possíveis combinações e o número de rodadas necessárias na execução do algoritmo AES.
Tabela 10.2 – Nr em função do tamanho de bloco e chave no AES
Nr Nb=4
Nb=6 Nb=8
Nk=4 10 12 14 Nk=6 12 12 14 Nk=8 14 14 14
O processo de cifrar e decifrar no AES não são funções idênticas, como ocorre na maioria dos cifradores. A seguir apresentam-se as operações utilizadas nas iterações do AES.
10.2.3 Operações por Iteração
As operações a qual cada bloco (estado) é sujeitado durante o processo para cifrar em cada iteração são:
• SubByte: os bytes de cada bloco são substituídos por seus equivalentes em uma tabela de substituição (S-BOX).
• ShiftRow (Deslocamento de Linha): Nesta etapa os bytes são rotacionados em grupos de quatro bytes.
• MixColumn: Cada grupo de quatro bytes é sujeitado a uma multiplicação modular. Isto proporciona a cada byte do grupo a influenciar em todos os outros bytes.

175
• AddRoundKey (Adição da Chave de Rodada): nesta fase o bloco de dados é alterado através da subchave da rodada, a qual possui o mesmo tamanho do bloco, que realiza uma operação XOR com o bloco inteiro.
A seguir uma explicação mais detalhada de cada uma dessas quatro opoerações.
10.2.3.1 Transformação SubByte
A transformação SubBytes modifica cada byte através do uso de uma S-BOX. A S-BOX pode ser criada em tempo de execução visto que esta é construída através de uma operação matemática. A S-BOX é construída através da composição de duas transformações:
1. Realizando a inversa multiplicativa em GF(28), com a representação definida por um polinômio com coeficientes em {0,1}, sendo que o elemento 00h é mapeado em si mesmo.
2. Aplicando-se uma operação similar de transformação definida por:
b0 1 0 0 0 1 1 1 1 b0 1
b1 1 1 0 0 0 1 1 1 b1 1
b2 1 1 1 0 0 0 1 1 b2 0
b3 1 1 1 1 0 0 0 1 b3 0
b4 - 1 1 1 1 1 0 0 0 b4 + 0
b5 0 1 1 1 1 1 0 0 b5 1
b6 0 0 1 1 1 1 1 0 b6 1
b7 0 0 0 1 1 1 1 1 b7 0
A aplicação desta operação para cada byte do estado consiste na operação denotada por SubByte. Para realizar o processo de decifrar é necessário fazer a operação através da matriz inversa, que é obtida através da inversa multiplicativa da mesma sobre o corpo GF(28).
Através da figura 10.1 pode ser visualizada a forma de atuação da operação SubByte sobre o estado. Do lado esquerdo, um estado com Nb = 4, isto é um bloco de dados de 128 bits. Cada elemento do estado S é mapeado através da S-BOX em um novo elemento no estado novo S’, ocupando exatamente a mesma posição em S’.

176
Figura 10.1 – Transformação SubByte (FIPS197, 2001)
A transformação também pode ser implementada de uma forma eficiente através de uma S-BOX de dimensão 16x16 armazenada em memória. A Tabela 10.3 demonstra esta S-BOX em notação hexadecimal, onde a transformação da S-BOX inversa é feita através do emprego da mesma S-BOX.
Tabela 10.3 – Caixa de Substituição (S-BOX ) em Hexadecimal
10.2.3.2 Transformação ShiftRow
Nesta transformação, as linhas da matriz que representam o estado são rotacionadas de acordo com uma tabela de rotacionamento. A primeira linha do estado não sofre nenhum rotacionamento, sendo que as demais linhas sofrem um rotacionamento cíclico à esquerda. A quantidade de elementos que sofrem o rotacionamento é dada na tabela 10.4.

177
Tabela 10.4 – Deslocamento em função do tamanho de bloco
.
Nb C1 C2 C3 4 1 2 3 6 1 2 3 8 1 3 4
O emprego de rotacionamento cíclico tem por finalidade aumentar a difusão sobre os elementos do estado. Importante notar que de modo diferente ao que ocorre com os outros cifradores da atualidade onde o rotacionamento é feito em nível de bits, no AES o rotacionamento é realizado em nível de bytes.
Figura 10.2 – Operação de ShiftRow (FIPS197, 2001)
A motivação para esta operação ser feita em nível de bytes está relacionada ao fato de que o estado já sofreu uma alteração em nível de bits no processo de adição de chaves no início do processo de cifrar. Na figura 10.2 pode-se visualizar mais claramente a ação da transformação ShiftRow.
10.2.3.3 Transformação MixColumn
Na transformação MixColumn, as colunas do estado são consideradas como polinômios sobre GF(28), sendo feita uma multiplicação módulo x4 + 1 com um polinômio fixo a(x), dado por:
a(x) = {03}x3 + {01}x2 + {01} x + {02}
A transformação pode ser escrita através de uma matriz de multiplicação como:

178
S’(x) = a(x) ⊕ S(x)
S’0,x 02 03 01 01 S0,x
S’1,x 01 02 03 01 S1,x
S’2,x = 01 01 02 03 S2,x
S’3,x 03 01 01 02 S3,x
Em conseqüência desta multiplicação, os quatro bytes de cada coluna são substituídos pelo seguinte:
S’0,x = ({02} * S0,x ) ⊕ ({03} * S1,x) ⊕ S2,x ⊕ S3,x
S’1,x = S0,x ⊕ ({02} * S1,x) ⊕ ({03} * S2,x) ⊕ S3,x
S’2,x = S0,x ⊕ S1,x ⊕ ({02} * S2,x) ⊕ ({03} * S3,x)
S’2,x = ({03} * S0,x) ⊕ S1,x ⊕ S2,x ⊕ ({02} * S3,x)
Na ilustração 10.3 mostra-se a operação de Mixcolumn.
Figura 10.3 – Operação de MixColumn (FIPS197, 2001)
10.2.3.4 Tranformação AddRoundKey
A transformação realizada na adição de chaves é uma operação XOR byte a byte do estado com a subchave da rodada. O tamanho da chave de rodada é igual ao tamanho do bloco Nb.
Na figura 10.4 tem-se uma ilustração da matriz que representa o estado sobre a qual a operação XOR com a matriz da chave de rodada produz o resultado que será o próximo estado do cifrador (FIPS197, 2001).

179
Figura 10.4 – Transformação AddRoundKey (FIPS197, 2001)
10.2.4. Geração de Subchaves
O algoritmo de geração de chaves cria a partir da chave principal do AES uma quantidade de subchaves igual à quantidade de rodadas mais um, sendo que cada subchave possui o mesmo tamanho da chave principal.
O resultado produzido pelo processo de geração de chaves consiste em um vetor unidimensional com palavras (w) de 4 bytes (ou seja 32bits), sendo que a cada rodada é utilizada como subchave a quantidade de quatro palavras seqüencialmente (no caso de Nk=4 e Nb=4), caminhando progressivamente sobre os elementos do vetor. O processo de geração de subchaves também é conhecido como expansão de chave. Através da figura 10.5 pode-se visualizar o vetor que contém as chaves, na figura cada byte é nomeado wi de onde i é a posição do byte dentro do vetor.
Figura 10.5 – Vetor de chaves para Nk=4

180
Deve-se considerar que antes de realizar a expansão, as Nk palavras são preenchidas com a chave original do cifrador. O processo de expansão de uma chave no cifrador AES é definido pelo algoritmo mostrado nesta seção.
Para compreender corretamente o seu funcionamento e significado torna-se necessário compreender algumas funções utilizadas durante o processo de expansão de chaves:
• A constante cons(i) contém um valor resultante de (xi-1,00h,00h,00h) com xi-1 sendo uma potência de “x” (“x” é definido por 02h) no corpo GF(28);
• A operação rotação() faz um rotacionamento cíclico à esquerda de uma posição nos quatro bytes de “s”;
• A operação SubWord aplica a S-BOX do AES em cada um dos 4 bytes da palavra.
O algoritmo para expansão de chave para Nk=4 e Nk=6 representado em pseudocódigo é: KeyExpansion(byte key[4*Nk], word w[Nb*(Nr+1)], Nk)
Begin
word temp
i = 0
while (i < Nk)
w[i] = word(key[4*i], key[4*i+1], key[4*i+2], key[4*i+3])
i = i+1
end while
i = Nk
while (i < Nb * (Nr+1)]
temp = w[i-1]
if (i mod Nk = 0)
temp = SubWord(RotWord(temp)) xor Rcon[i/Nk]
else if (Nk > 6 and i mod Nk = 4)
temp = SubWord(temp)
end if
w[i] = w[i-Nk] xor temp
i = i + 1
end while
end
10.3 Algoritmo de Cifragem do AES O processo de cifrar do AES envolve uma aplicação seqüencial de funções explicadas anteriormente. Na figura 10.6 pode-se analisar a estrutura do processo de cifragem do AES.

181
Figura 10.6 – Algoritmo de cifragem do AES
Ao analisar essa visão macro do AES pode-se perceber os indicadores Nb, Nk e Nr que possuem seus valores de acordo com o tamanho de bloco e chave a serem utilizados. Observa-se que a última iteração é diferente das demais.
10.4 Algoritmo de Decifragem do AES

182
O processo de decifrar no AES consiste na execução de diferentes operações, devido a sua essência matemática. Ao contrário do DES que tem sua estrutura baseada em Feistel (FIPS46-3, 1999), que possui a característica de ser reversível apenas invertendo-se a seqüência das chaves para decifrar, o AES necessita de inversas matemáticas de suas transformações para realizar o processo de decifrar.
Observando o AES em uma visão macro, o algoritmo poderia ser considerado como uma seqüência de transformações matemáticas e o seu processo reverso consiste na aplicação da seqüência inversa a da original.
O processo de expansão de chaves continua sendo o mesmo, descrito anteriormente, porém as funções de SubByte, ShiftRow e MixColumn necessitam ser as suas inversas matemáticas para realizar o processo de decifrar.
Analisando o fluxo mostrado na figura 10.7 pode-se perceber as diferenças em nível de função do processo utilizado para cifrar.
Figura 10.7 – Algoritmo de decifragem do AES
A operação inversa da ShiftRow é realizada fazendo-se um rotacionamento cíclico à direita na mesma quantidade de bytes da operação de cifrar. A operação inversa mais complexa é a MixColumn. Do mesmo modo que o processo de cifrar, na

183
transformação InvMixColumn as colunas dos estados são considerados como polinômios sobre um corpo GF(28) e sofrem uma multiplicação módulo x4-1 com um polinômio fixo a-1(x), dado por:
a-1(x) = 0Bx3 + 0Dx2 + 09x + 0E
Da mesma forma que a operação MixColumn utilizada para cifrar, esta operação pode ser escrita como uma multiplicação de matrizes S’(x) = a-1(x) xor S(x):
S’0,x 0E 0B 0D 09 S0,x
S’1,x 09 0E 0B 0D S1,x
S’2,x = 0D 09 0E 0B S2,x
S’3,x 0B 0D 09 0E S3,x
Como resultado da multiplicação, os 4 bytes da coluna são substituídos por:
S’0,x = ({0E} * S0,x ) ⊕ ({0B} * S1,x) ⊕ ({0D} * S2,x) ⊕ ({09} * S3,x)
S’1,x = ({09} * S0,x ) ⊕ ({0E} * S1,x) ⊕ ({0B} * S2,x) ⊕ ({0D} * S3,x)
S’2,x = ({0D} * S0,x ) ⊕ ({09} * S1,x) ⊕ ({0E} * S2,x) ⊕ ({0B} * S3,x)
S’2,x = ({0B} * S0,x ) ⊕ ({0D} * S1,x) ⊕ ({09} * S2,x) ⊕ ({0E} * S3,x)
A operação inversa da adição de chave de rodada é a mesma operação utilizada para o processo de cifrar. A operação inversa de SubByte consiste no uso da inversa matemática da Caixa-S utilizada para cifrar. A Caixa-S invertida pode ser analisada usando a tabela 10.5.
Como pode ser observado, a seqüência de operações para cifrar e decifrar são diferentes, apesar do processo de expansão de chaves continuar sendo o mesmo para os dois processos. Porém através de algumas propriedades algébricas e matemáticas no algoritmo do AES pode-se obter o que se chama de Cifrador Equivalente Inverso. Em outras palavras, que utilize a mesma seqüência de operações utilizadas para cifrar (com as transformações substituídas pelas suas inversas). Contudo isso necessita que o processo de expansão de chaves seja alterado.
Tabela 10.5 – S-BOX invertida

184
As duas propriedades que possibilitam isso, são:
• A ordem das transformações SubByte e ShiftRow podem ser alteradas sem que com isso o resultado seja alterado. Isso ocorre devido ao fato dessas duas operações alterarem apenas a posição do byte dentro do estado, não fazendo nenhuma alteração em nível de bit. Sendo que o mesmo acontece com as inversas dessas duas operações.
• As transformações MixColumn e InvMixColumn são lineares relativas à coluna de entrada, o que significa:
InvMixcolumn(estado XOR ChaveRodada) = InvMixColumn(estado) XOR InvMixColumn(ChaveRodada)
Essas propriedades permitem que a ordem de InvSubytes e InvShiftRow sejam invertidas. As transformações de AddRoundKey e InvMixColumn também podem ser invertidas, prevendo-se que as colunas no processo de expansão de chave sejam alteradas por uma transformação InvMixColumn. Sendo que essa operação não deve ser realizada nas primeiras e últimas palavras Nb no processo de expansão de chave, visto que essas duas subchaves são utilizadas em rodadas que não possuem a transformação InvMixColumn.
Como resultado dessas operações obtém-se o Cifrador Equivalente Inverso, que possui uma estrutura mais similar à estrutura original do cifrador do que o algoritmo decifrador proposto anteriormente. Assim, o algoritmo para decifrar utilizando o Cifrador Equivalente Inverso do AES pode ser especificado em pseudocódigo da seguinte forma:
EqInvCipher(byte in[4*Nb], byte out[4*Nb], word dw[Nb*(Nr+1)])
begin
byte state[4,Nb]
state = in
AddRoundKey(state, dw[Nr*Nb, (Nr+1)*Nb-1])

185
for round = Nr-1 step -1 downto 1
InvSubBytes(state)
InvShiftRows(state)
InvMixColumns(state)
AddRoundKey(state, dw[round*Nb, (round+1)*Nb-1])
end for
InvSubBytes(state)
InvShiftRows(state)
AddRoundKey(state, dw[0, Nb-1])
out = state
end
Observando o pseudocódigo nota-se que a palavra dw contém as subchaves de cada iteração. A rotina modificada para expansão de chave consiste na adição do algoritmo abaixo no final do algoritmo padrão de expansão de chave do AES (RIJNDAEL, 1999).
for i = 0 step 1 to (Nr+1)*Nb-1
dw[i] = w[i]
end for
for round = 1 step 1 to Nr-1
InvMixColumns(dw[round*Nb, (round+1)*Nb-1])
end for
10.5 Estatísticas de Desempenho das Implementações Assim como o DES, o AES pode ser implementado em software e hardware. O AES é um algoritmo mais robusto quando comparado ao DES. Os processos de cifragem e decifragem são diferentes no AES, assim é necessária a implementação de funções de cifragem e decifragem separadamente. Esta característica, na implementação em hardware, leva a um aumento considerável do circuito implementado consumindo mais componentes e podendo aumentar o tempo de propagação do circuito. Na implementação em software aumenta a memória necessária para armazenar o algoritmo e isso pode trazer dificuldades em sistemas onde a memória é limitada como, por exemplo, PALM, PDA, celulares e etc.
Na proposta inicial do AES havia uma regra explícita solicitando que o algoritmo fosse robusto mas que tivesse um bom desempenho em hardware e software. Nesta seção apresentam-se as estatísticas de desempenho obtidas nas implementações dos autores (ver detalhes no link: www.novateceditora.com.br/downloads.php na página associada ao livro de criptografia), as quais permitem comprovar que o AES mesmo sendo um algoritmo complexo atinge um bom desempenho em ambos ambientes de implementação.
186
Na tabela 10.6 mostra-se o desempenho temporal da implementação em C do algoritmo AES de 128 bits. Da mesma forma como observado no DES, a diferença de desempenho do algoritmo em disco e em memória é significativo, acima de 20 %.
Tabela 10.6 – Temporização do Algoritmo AES em C
DISCO MEMÓRIA % 1MB 1,10 s 0,88 s 20,00% 5MB 4,98 s 3,35 s 32,73%
10MB 10,21s 5,77 s 43,48% O desempenho do algoritmo implementado em C não é continuo, isto é, conforme aumenta o tamanho do arquivo, a taxa de velocidade (medida em Mbytes/s) de texto cifrado não aumenta proporcionalmente. Uma das justificativas é quantidade de memória disponível para a execução da aplicação. Quanto mais memória disponível menos swaps (trocas) entre disco e memória serão realizados, assim a maior parte do arquivo ficará residente na memória em um determinado instante de tempo.
Quanto maior o arquivo e menor a área de memória disponível mais trocas serão necessárias, prejudicando o desempenho do processo de cifragem. Assim, pode-se afirmar que a memória que contém a plataforma onde os programas são executados é um fator decisivo para o desempenho de qualquer algoritmo de criptografia. Por esse motivo, pensar em criptografia em novos equipamentos como PDAs, PALM e celulares não é tão simples quanto parece, e pode sofrer prejuízos no desempenho final.
Na verdade todo ambiente de execução da aplicação influencia no desempenho, mas a memória destaca-se por participar de forma significativa. Na figura 10.8 mostra-se o desempenho ideal (não influenciado pelo ambiente) e o desempenho real em MB/s, obtido nas execuções de nossa implementação.
Figura 10.8 – Desempenho do AES em C
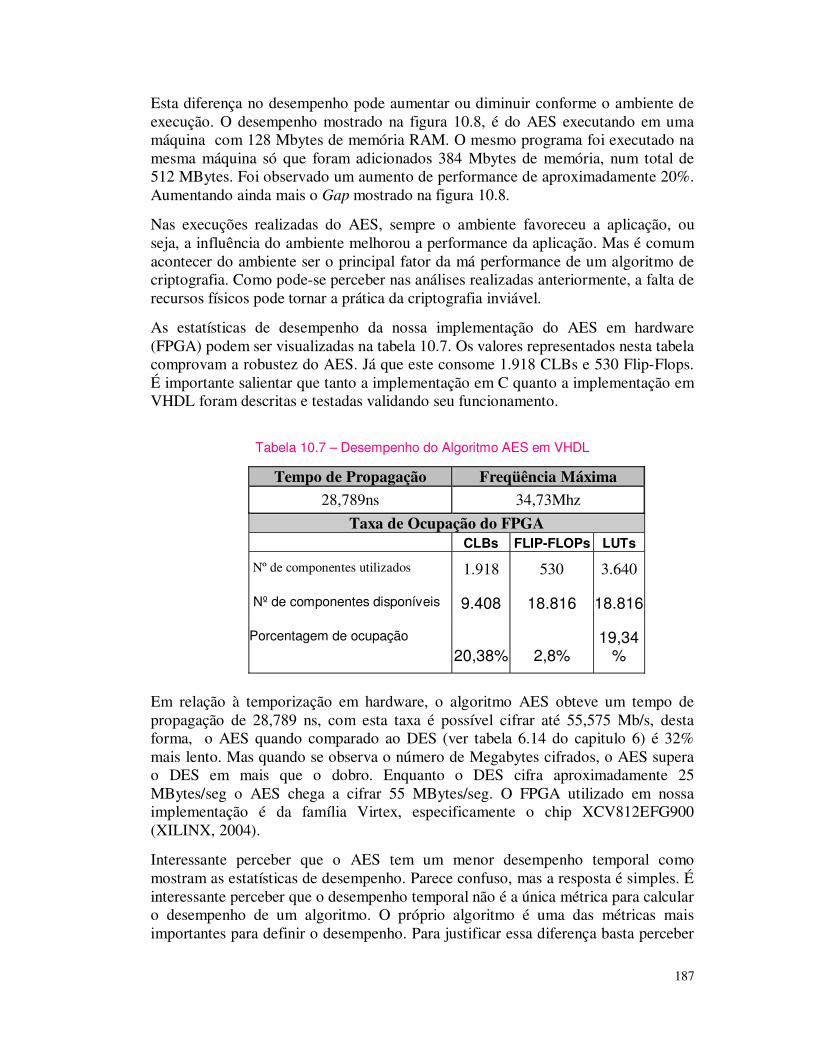
187
Esta diferença no desempenho pode aumentar ou diminuir conforme o ambiente de execução. O desempenho mostrado na figura 10.8, é do AES executando em uma máquina com 128 Mbytes de memória RAM. O mesmo programa foi executado na mesma máquina só que foram adicionados 384 Mbytes de memória, num total de 512 MBytes. Foi observado um aumento de performance de aproximadamente 20%. Aumentando ainda mais o Gap mostrado na figura 10.8.
Nas execuções realizadas do AES, sempre o ambiente favoreceu a aplicação, ou seja, a influência do ambiente melhorou a performance da aplicação. Mas é comum acontecer do ambiente ser o principal fator da má performance de um algoritmo de criptografia. Como pode-se perceber nas análises realizadas anteriormente, a falta de recursos físicos pode tornar a prática da criptografia inviável.
As estatísticas de desempenho da nossa implementação do AES em hardware (FPGA) podem ser visualizadas na tabela 10.7. Os valores representados nesta tabela comprovam a robustez do AES. Já que este consome 1.918 CLBs e 530 Flip-Flops. É importante salientar que tanto a implementação em C quanto a implementação em VHDL foram descritas e testadas validando seu funcionamento.
Tabela 10.7 – Desempenho do Algoritmo AES em VHDL
Tempo de Propagação Freqüência Máxima
28,789ns 34,73Mhz
Taxa de Ocupação do FPGA CLBs FLIP-FLOPs LUTs
Nº de componentes utilizados 1.918 530 3.640
Nº de componentes disponíveis 9.408 18.816 18.816
Porcentagem de ocupação
20,38% 2,8% 19,34
%
Em relação à temporização em hardware, o algoritmo AES obteve um tempo de propagação de 28,789 ns, com esta taxa é possível cifrar até 55,575 Mb/s, desta forma, o AES quando comparado ao DES (ver tabela 6.14 do capitulo 6) é 32% mais lento. Mas quando se observa o número de Megabytes cifrados, o AES supera o DES em mais que o dobro. Enquanto o DES cifra aproximadamente 25 MBytes/seg o AES chega a cifrar 55 MBytes/seg. O FPGA utilizado em nossa implementação é da família Virtex, especificamente o chip XCV812EFG900 (XILINX, 2004).
Interessante perceber que o AES tem um menor desempenho temporal como mostram as estatísticas de desempenho. Parece confuso, mas a resposta é simples. É interessante perceber que o desempenho temporal não é a única métrica para calcular o desempenho de um algoritmo. O próprio algoritmo é uma das métricas mais importantes para definir o desempenho. Para justificar essa diferença basta perceber

188
que enquanto o DES consome 19,55ns (nanosegundos, lembrar que 1ns = 10-9 segundos) em uma iteração para cifrar 64 bits, o AES consome 28,789ns para cifrar 128 bits.
Assim, mesmo que o tempo de propagação do AES seja maior, no final do processo este terá cifrado 128 bits enquanto que o DES apenas 64 bits. Outro fator importante é o número de iterações. Enquanto o AES executa em 10 ciclos, o DES processa em 16 rodadas, assim o DES cifra 64 bits em aproximadamente 312,8ns enquanto que o AES em 287,89ns cifra 128 bits. O algoritmo AES mapeado em um FPGA Virtex pode ser visualizado na figura 10.9.
Figura 10.9 – Algoritmo AES mapeado em um FPGA Virtex
10.6 Considerações Finais do Capítulo Com base nos resultados apresentados neste capítulo pode-se dizer que o algoritmo AES é efetivamente mais rápido que o algoritmo DES, além do seu maior nível de segurança. Até hoje não há nenhuma comunicação acadêmica e empresarial que tenha manifestado a quebra do sistema usando AES.
Finalmente, como o AES é um novo padrão que começa a ser divulgado e usado, há muitas pesquisas e estudos visando mostrar otimizações e novas formas de implementação tanto em software (linguagem C, Java e outras) como em hardware (em todas as tecnologias possíveis de projetos de sistemas digitais como VLSI, ASIC, FPGAs, entre outras). Nesse sentido, pode-se dizer que vários centros de pesquisa, universidades e até empresas possuem alguma implementação do AES. Essas pesquisas sempre visam otimizar a implementação, de modo a torná-lo mais rápido e com maior inserção em aplicações modernas.

189
Capítulo 11 Algoritmo RC5 em Software e Hardware
Este capítulo apresenta um breve histórico do RC5, e enfatiza nos detalhes de funcionamento, implementação e desempenho daquele que é considerado um dos algoritmos mais utilizados mundialmente.
11.1 Introdução O algoritmo RC5 foi projetado pelo Professor Ronald Rivest do MIT, Estados Unidos, e a primeira publicação foi em dezembro de 1994 (RIVEST, 1995). Desde sua publicação, o RC5 chamou a atenção de muitos investigadores na comunidade científica em esforços para avaliar com precisão a segurança oferecida.
O algoritmo criptográfico simétrico RC5 é o sucessor do RC4 e apresenta significativas melhoras nos fatores segurança e velocidade. Ambos foram criados pela empresa americana RSA Data Security Inc (ver mais informações no link http://www.rsasecurity.com/) que foi criada pelos autores do sistema RSA, e é atualmente uma das mais importantes na área de sistemas de criptografia e proteção de dados (BURNETT, 2002).
Quando o RC5 foi desenvolvido, a empresa RSA tinha os seguintes objetivos em relação ao algoritmo:
• Cifra simétrica de bloco
• Apropriado para hardware e software
• Rápido
• Flexível para processadores com diferentes comprimentos de palavra
• Número variável de iterações
• Tamanho de chave variável
• Simples
• Baixa memória requerida
• Alto nível de segurança

190
O algoritmo RC5 foi projetado para qualquer computador de 16, 32 ou 64 bits. Possui uma descrição compacta e é adequado para implementações em software ou em hardware. Similarmente ao algoritmo DES, o RC5 possui várias iterações e cada iteração utiliza um par de subchaves. Ao contrário do DES, o número de iterações e o número de bytes na chave são variáveis.
O algoritmo baseia-se na operação de rotação (deslocamento circular) de um número variável de posições, e esse número depende de quase todos os bits resultantes da iteração anterior e do valor da subchave em cada iteração.
Após alguns anos de análise dos especialistas sabe-se que após 8 iterações todo bit da entrada legível afeta pelo menos uma rotação. A criptoanálise diferencial para o RC5 considera o algoritmo seguro após 16 iterações (RIVEST, 1995).
11.2 Parâmetros do RC5 O RC5 é um algoritmo parametrizado, isto é, possui flexibilidade quanto ao tamanho do bloco, da chave e número de iterações. Em particular estes parâmetros são designados como w, r, b. A seguir a descrição desses parâmetros(RIVEST, 1995).
w � tamanho do bloco em bits que será cifrado. O valor padrão é 32 bits; podendo ser 16, 32, ou 64 bits. RC5 codifica blocos de duas palavras de forma que o texto claro e o cifrado são de tamanho 2w.
r � O número de iterações. Valores permissíveis são 0, 1,..., 255.
b � O número de bytes da chave secreta K. valores permissíveis de b são 0, 1,..., 255.
O algoritmo genérico é representado por RC5-w/r/b. Na verdade é uma família de algoritmos, no RC5-32 o criador, Prof. Ronald Rivest, recomenda 12 iterações e para o RC5-64, 16 iterações.
11.3 Operações Básicas do RC5 O algoritmo RC5 consiste em três componentes básicos:
(i) um algoritmo de expansão fundamental,
(ii) um algoritmo de cifragem, e
(iii) um algoritmo de decifragem.
Estes algoritmos usam 5 operações primitivas, todas sobre operandos de tamanho “w” bits. Estas operações são (RIVEST, 1995):
1. v + u é a soma dos inteiros “v” e “u” de tamanho “w” bits, resultando um valor de “w” bits (soma mod 2w);

191
2. v – u é a subtração dos inteiros “v” e “u” de tamanho “w” bits, resultando um valor de “w” bits (subtração mod 2w);
3. v xor u é o ou-exclusivo (XOR) “v” e “u” de tamanho “w” bits, resultando um valor de “w” bits;
4. v << t é o deslocamento circular (rotação) de “t” posições para a esquerda dos bits em “v”. Se “t” exceder “w” bits, pode-se considerar os “w” bits menos significativos sem alterar o resultado;
5. v >> t é o deslocamento circular (rotação) de “t” posições para a direita dos bits em “v”. Se “t” exceder “w” bits, pode-se considerar os “w’ bits menos significativos sem alterar o resultado;
O texto claro no algoritmo RC5 consiste em duas palavras de tamanho “w” bits, denotadas por A e B. O primeiro byte ocupa as posições menos significativas do registro A, e assim por diante, de modo que o quarto byte ocupe o byte mais significativo de A, o quinto byte ocupa a posição menos significativa em B, e o oitavo (último) byte ocupa a posição mais significativa em B.
As duas metades de entrada (A, B) são alteradas a cada iteração. São usadas 2 subchaves antes da primeira iteração. E duas subchaves a cada iteração, tendo no total 2r+2 subchaves. A chave K é de b bytes, da qual são geradas as subchaves Kj de tamanho “w” bits cada, como descrito a seguir.
11.4 Geração de Subchaves do RC5 O algoritmo RC5 expande os b bytes da chave K para 2r+2 subchaves de w bits. Inicialmente este algoritmo descreve como a chave K é armazenada nas variáveis L[0], L[1], ....
Algoritmo de subchaves RC5
Entrada: r (número de iterações), chave K de “b” bytes armazenados em:
K[0], K[1], ... K[b-1];
Saída: 2r+2 subchaves de w bits K0,K1,K2 ... K 2r+1
1. Seja u = w/8 (número de bytes em cada variável de “w” bits. Para w = 32 bits, valor padrão do algoritmo, u = 32/8 = 4 para w igual a 32 bits ;
2. Seja c = [b/u] (número de posições de w bits ocupados por K. Considerando como exmplo um valor de b = 10 bytes, então tem-se c = [10/4] = 3;
3. Se necessário, preencher K à direita de K[b-1] até completar um comprimento total em bytes divisível por “u”, para
j = b, b+1, …c x u-1 faça: K[j] 0;

192
4. para j = 0,1,.... c-1 faça: w-1
Lj ∑ 28t K[j x u + t] t=0
preencher os “u” bytes, da direita para esquerda, de cada Lj com os bytes K[0], K[1], K[2], ... K[c x u -1];
5. K0 Pw (veja o valor de Pw na tabela 11.1)
6. Para j = 1,2,...2r+1 faça: Kj Kj-1 + Qw (veja o valor de Qw na tabela 11.1)
7. i 0; j 0; A 0; B 0; t Max[c,2r+2];
8. para s=1,2,3,...3t faça {
A Ki (ki + A + B) << 3; A Ki; i = (i +1) mod (2r +2);
B Lj (Lj + A + B) << (A + B); B Lj; j = (j +1) mod (c);
}
9. A saída é K0, K1, K2 K3 ... K 2r+1.
As constantes Pw e Qw são representações binárias das constantes matemáticas e e Φ (ver tabela 11.1), e foram escolhidas pelo criador do algoritmo por serem constantes que não foram definidas por ele, e portanto, não levantaria qualquer suspeita de incorporar algum conhecimento prévio que facilite a quebra do algoritmo.
Tabela 11.1 – Valores das constantes mágicas Pw e Qw no algoritmo RC5
w 16 32 64 Pw B7E1 B7E15163 B7E15163 8AED2A6B Qw 9E37 9E3779B9 9E3779B9 7F4A7C15
Valores em Hexadecimal
11.5 Algoritmos de Cifragem e Decifragem do RC5 Tanto na criptografia como na decriptografia este algoritmo supõe que o computador armazena os bytes em modo little-endian, ou seja tanto o texto legível como o ilegível são armazenados da seguinte forma nas variáveis A e B, para w=32: os primeiros quatro bytes do texto (i)legível (x0, x1, x2, x3 ) são armazenados em A na seqüência (x3, x2, x1, x0) e os quatro bytes seguintes do texto (i)legível (x4, x5, x6, x7) são armazenados em B na seqüência (x7, x6, x5, x4).

193
Algoritmo de Cifragem RC5
Entrada: Chave K de “b” bytes, texto legível de “2w” bits (A,B)
Saída: texto ilegível de “2w” bits (A,B)
1. Calcular 2r+2 subchaves K0, K1,K2, K3....K2r+1
2. A A + K0i; B B K1i;
3. para j = 1,2,3…r faça{
A ((A xor B) << B) + K2j;
B ((B xor A) << A) + K2j+1;
}
4. A saída é o valor (A, B)
Algoritmo de Decifragem RC5
Entrada: chave K de “b” bytes, texto ilegível de “2w” bits (A,B)
Saída: texto legível de “2w” bits (A,B)
1. Calcular 2r+2 subchaves K0, K1,K2, K3....K2r+1
2. para j = r, r-1, ....1 faça:
B ((B - K2j+1) >> A) xor A;
A ((A - K2j) >> B) xor B;
3. A saída é o valor (A – K0, B-K1)
11.6 O algoritmo RC5-64 O RC5 na sua versão de 64 bits, possui um bom nível de segurança. Esta segurança foi testada através do desafio RC5-64 (RC5-64, 2003). O desafio RC5-64 é uma dentre várias competições, organizadas para determinar a dificuldade de se achar a chave de algoritmos codificados, por meio de tentativa e erro. Os desafios anteriores incluíram DES, RC5-40 e RC5-56.
Depois de quatro anos, em 2003, a equipe de cientistas, programadores e usuários conhecida como "Distributed.Net", solucionou o desafio da chave secreta RC5-64, do laboratório RSA. O grupo formado por voluntários ganhou um prêmio de US$ 10 mil doláres.

194
O consórcio utilizou o momento inativo dos computadores distribuídos por todo o mundo para procurar todas as possibilidades da chave de 64 bits do algoritmo RC5, da RSA Security. O objetivo do grupo era achar a chave secreta usada pela corporação, e com isso, decifrar a mensagem corretamente. Isso foi conseguido utilizando um total de 331.252 máquinas em várias partes do mundo. O servidor, computador localizado em Tóquio, retornou o resultado correto para o algoritmo.
Criado em 1997, o desafio Chave Secreta dos laboratórios RSA visa verificar a força de algoritmos simétricos, tais como DES e RC5, com tamanhos variados de chaves. Ao patrocinar a competição, os laboratórios RSA ajudam a indústria a confirmar as estimativas teóricas, e com esta avaliação constante, os fabricantes são motivados a melhorar continuamente suas soluções de segurança.
11.7 Estatísticas de Desempenho do RC5 O RC5 é um algoritmo desenvolvido para ser veloz e seguro, ideal para ambientes onde o tempo de cifragem não pode ser o gargalo do processamento principal. Observando as estatísticas de temporização da nossa implementação em C (ver tabela 11.2) nota-se que a performance do RC5 pode ser considerada muito boa quando comparada a outros algoritmos como o DES e o AES.
Tabela 11.2 – Estatísticas de desempenho temporal do RC5 em C
Tamanho em Megabytes Tempo RC5 Tempo DES Tempo AES
1 Mb 0,141 s 0,94 s 0,88 s 5 Mb 0,703 s 3,90 s 3,35 s
10 Mb 1,403 s 7,09 s 5,77 s
Por ser veloz, o RC5 é utilizado em aplicações de transações on-line (OLTP – On Line Transactions Processing) onde o tempo é um fator crítico para se avaliar o desempenho. O RC5 pode ser encontrado nos protocolos para a segurança de correio eletrônico como PGP - Pretty Good Privacy (PGP) (BROWN, 2000) e S/MIME - Secure Multipurpose Internet Mail Extension.
Na tabela 11.3 apresentam-se as estatísticas de desempenho da nossa implementação em hardware (FPGA). É interessante notar que o mesmo bom desempenho observado na versão em software não é confirmado na nossa implementação em hardware. Nesta versão do RC5 a geração de subchaves e o processamento principal (iterações) são executados em paralelo. O hardware consumido para a implementação deste paralelismo foi de cerca de 236 CLBs e 54 Flip-Flops do FPGA XCV812EFG900, para nossa implementação RC5/32/16/64, que indica os parâmetros w=32, r=16 e b=64.
Tabela 11.3 – Estatísticas de desempenho do RC5 em FPGAs
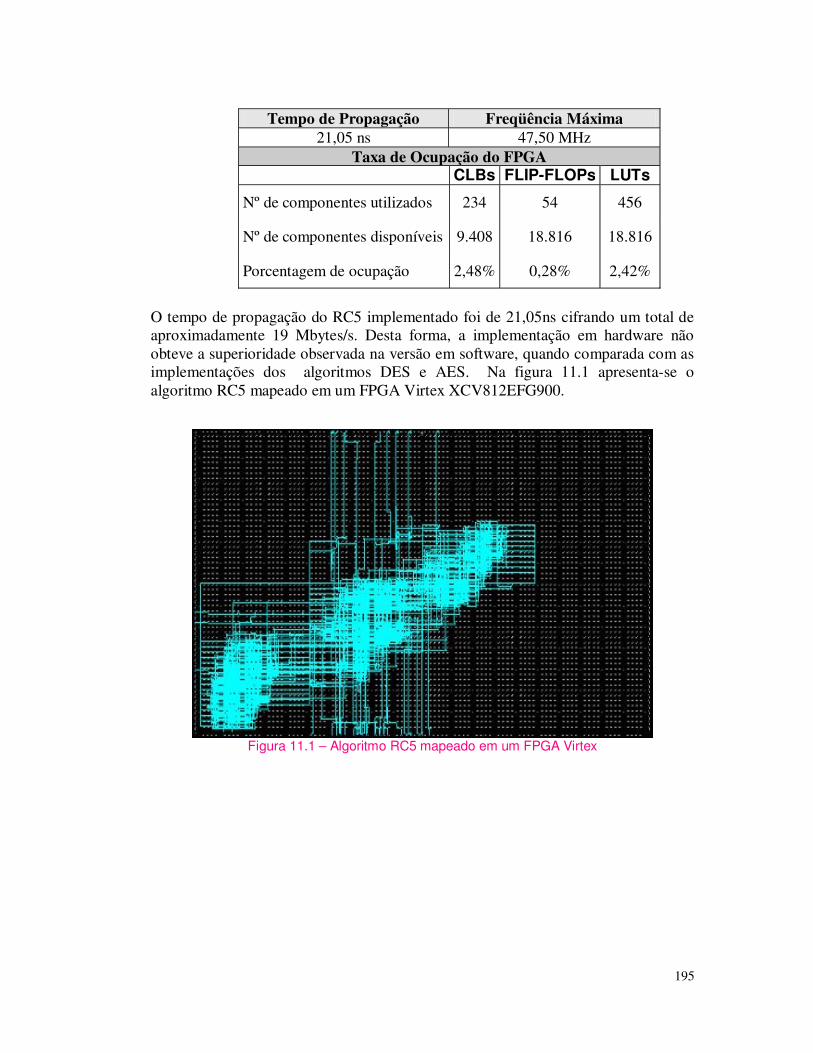
195
Tempo de Propagação Freqüência Máxima 21,05 ns 47,50 MHz
Taxa de Ocupação do FPGA CLBs FLIP-FLOPs LUTs
Nº de componentes utilizados 234 54 456
Nº de componentes disponíveis 9.408 18.816 18.816
Porcentagem de ocupação 2,48% 0,28% 2,42%
O tempo de propagação do RC5 implementado foi de 21,05ns cifrando um total de aproximadamente 19 Mbytes/s. Desta forma, a implementação em hardware não obteve a superioridade observada na versão em software, quando comparada com as implementações dos algoritmos DES e AES. Na figura 11.1 apresenta-se o algoritmo RC5 mapeado em um FPGA Virtex XCV812EFG900.
Figura 11.1 – Algoritmo RC5 mapeado em um FPGA Virtex

196
Capítulo 12 AES - Outros Candidatos
Este capítulo apresenta alguns critérios de projeto relativos ao concurso realizado para selecionar o novo padrão de criptografia simétrico mundial (AES). São apresentados também dados comparativos sobre os outros candidatos concorrentes do Rijndael.
12.1 Motivação Para um Novo Padrão de Criptografia Simétrica
O plano do NIST foi formalmente anunciado em 2 de janeiro de 1997, quando o órgão convidou qualquer pessoa a submeter um algoritmo como o novo padrão, que seria conhecido como AES. Como uma condição para entrar no processo do AES, os desenvolvedores tinham de abrir mão de quaisquer direitos quanto à propriedade intelectual do algoritmo selecionado. Várias pessoas e empresas responderam e, em 20 de agosto de 1998, o NIST nomeou 15 candidatos (BIHAM, 1999).
O passo seguinte era fazer com que os algoritmos fossem analisados mundialmente, O critério era a segurança (sem nenhuma fraqueza algorítmica), desempenho (teria de ser rápido em várias plataformas) e tamanho (não poderia ocupar muito espaço nem utilizar muita memória). Vários dos 15 algoritmos originais não duraram muito tempo. Fraquezas foram descobertas e alguns simplesmente se mostraram muito grandes ou muito lentos.
Em agosto de 1999, o NIST reduziu a lista a cinco candidatos: o Rijndael, Serpent, Twofish, MARS e RC6. No ano seguinte, pesquisadores, analistas de criptografia e fornecedores de hardware e de software para computadores testaram os cinco algoritmos finalistas para decidir qual deles era o preferido. Vários artigos foram publicados e números estatísticos eram distribuídos comparando esses cinco algoritmos finalistas. Cada um tinha suas forças e suas fraquezas.
Finalmente, em 2 outubro de 2000, o NIST anunciou o vencedor: um algoritmo chamado de Rijndael inventado por dois pesquisadores belgas: Vincent Rijmen e Joan Daemen.
A partir desse momento, o algoritmo de AES está livremente disponível para qualquer pessoa desenvolver, utilizar ou vender. Como o DES, é esperado que o

197
AES torne-se um padrão mundial. Pode-se esperar que isso aconteça em um curto período de tempo.
Apesar do algoritmo Rijndael ter sido o ganhador do concurso e se tornar o algoritmo AES, os outros algoritmos finalistas que também participaram e foram pré-selecionados merecem destaque. As próximas seções apresentam detalhes sobre os critérios utilizados no projeto AES apresentando também algumas características sobre os demais concorrentes.
12.2 Critérios para o Projeto AES Para poder definir o novo padrão para a criptografia simétrica foram estabelecidos um conjunto de critérios, a fim de permitir a seleção e classificação dos algoritmos concorrentes ao AES (REQUEST AES,1997).
12.2.1 Áreas de Aplicação
Um algoritmo padrão de criptografia deve ser satisfatório para diferentes aplicações como:
Criptografia do tipo Bulk: O algoritmo deve ser eficiente na codificação de dados de arquivos ou de fluxo contínuo de dados.
Gerador de bit aleatório: O algoritmo deveria ser eficiente na geração de bits aleatórios.
Criptografia de pacote: O algoritmo deveria ser eficiente na codificação de dados do tamanho do pacote. Por exemplo, um pacote de um Banco 24 Horas tem um campo de dados de 48 bytes, deveria tornar fácil a implementação em uma aplicação onde pacotes sucessivos podem ser cifrado ou decifrados com chaves diferentes.
Hash : O algoritmo deveria ser eficiente quando convertido a uma função hash única.
12.2.2 Plataformas
Um algoritmo de criptografia padrão deve ser fácil de implementar em uma variedade de plataformas diferentes, cada um com as suas próprias exigências. Isso inclui:
Hardware especial: O algoritmo deveria ser eficientemente implementado em hardware VLSI padrão.
Processadores de grande porte: Enquanto hardware dedicado sempre será usado para as aplicações mais rápidas, implementações de software são mais comuns. O algoritmo deveria ser eficiente em microprocessadores de 32-bits com 4 Kbytes de programa e cache de dados.

198
Processadores de médio porte: O algoritmo deveria funcionar em microcontroladores e outros processadores de médio porte, como os 68HC11.
Processadores de pequeno porte: Deveria ser possível implementar o algoritmo em cartões inteligentes (smartcards), mesmo que não fosse eficiente.
As exigências para processadores pequenos são os mais difíceis. Limitações de memória RAM e ROM são severas para esta plataforma. Também, eficientemente, são mais importantes nessas máquinas pequenas que começam a ganhar cada vez mais popularidade. Enquanto Workstations dobram sua capacidade quase que anualmente, pequenos sistemas embarcados (embedded systems) precisam otimizar os recursos que possuem e começam a ser grandemente usados em empresas de diferentes portes, de grandes, médias e até pequenas.
12.2.3 Exigências Adicionais
Com estas exigências adicionais deveria, se possível, ser criado um algoritmo de criptografia padrão. O algoritmo deveria ser simples para implementar também. Experiências com o DES mostram que os programadores freqüentemente cometem erros de implementação caso o algoritmo seja complicado. Se possível, o algoritmo deveria ser robusto contra estes erros.
O algoritmo deveria ter um grande espaço de chaves (keyspace), permitindo que qualquer conjunto de bits aleatórios do tamanho desejado possa ser uma chave possível. Não deveria haver nenhuma chave fraca.
O algoritmo deveria facilitar a administração da chave para a implementação de software. Implementações de software, como por exemplo a do DES, geralmente usam técnicas de controle de chave fracas. Em particular, em algumas aplicações, a senha que o usuário digita torna-se a chave. Isso significa que mesmo que o DES tenha um espaço para as chaves, teoricamente de 256, o espaço real é limitado a chaves construídas com os 95 caracteres que podem ser entrados diretamente pelo teclado. O algoritmo deveria ser facilmente modificado para diferentes níveis de segurança, com ambas necessidades, mínima e máxima.
Todas as operações deveriam manipular dados em blocos de tamanho do byte. Onde possível, operações deveriam manipular dados em blocos de 32-bits.
12.2.4 Decisões de Projeto
Baseado nos parâmetros acima, foram criadas essas decisões de projeto. O algoritmo deveria:
♦ Manipular dados em grandes blocos, preferencialmente 32 bits (e não em nível de bits, tal como o DES).
♦ Ter um bloco de 64 ou 128 bits.
♦ Ter uma chave escalável, de 32 a pelo menos 256 bits.

199
♦ Utilizar operações simples que sejam eficientes em microprocessadores: tipo OU-exclusivo, adição, substituições baseadas em procura de tabelas (table lookup) e etc.
♦ Não deveria utilizar mudanças de cumprimento variável ou permutações bit-wise, ou saltos condicionais.
♦ Ser possível de implementar em um processador de 8 bits com no mínimo 24 bytes de RAM (e que a RAM armazene a chave) e 1 Kbyte de ROM.
♦ Utilizar subchaves pré-computáveis. Em sistemas com grande memória, essas subchaves podem ser pré-calculadas para uma operação mais rápida. Não pré-calcular estas chaves resultará em uma operação mais lenta, mas ainda deveria ser possível cifrar dados sem qualquer pré-computação ou pré-cálculo.
♦ Consistir de um número variável de iterações. Para aplicações com chaves pequenas, a troca entre a complexidade de um ataque de força bruta e um ataque diferencial torna um grande número de iterações supérfluo. E deveria ser possível reduzir o número de iterações sem a perda de segurança (além da causada pelo tamanho reduzido da chave).
♦ Se possível, não ter nenhuma chave fraca. A proporção de chaves fracas deveria ser pequena o bastante para ser improvável a escolha de uma ao acaso. Também, qualquer chave fraca deveria ser conhecida explicitamente, e assim elas podem ser retiradas durante o processo de geração da chave.
♦ Utilizar subchaves que sejam uma hash única da chave. Isso permitiria a utilização de longas frases como chave sem comprometer a segurança.
♦ Não ter nenhuma estrutura linear (por exemplo, a propriedade de complementação do DES), uma vez que, as estruturas lineares reduzem a complexidade de procura exaustiva.
♦ Utilizar um projeto que seja simples de entender. Isto facilitaria a análise e aumentaria a confiança no algoritmo.
12.2.5 Processamento de Blocos
Existem várias maneiras de construir blocos e produzir cifras fortes. Muitas dessas podem ser implementadas eficientemente em microprocessadores de 32 bits.
Grandes S-boxes: S-boxes maiores são mais resistentes à criptoanálise diferencial. Um algoritmo com uma palavra de 32 bits pode utilizar S-boxes de 32 bits.
S-boxes dependentes de chaves: Enquanto S-boxes fixos devem ser desenvolvidos para serem resistentes à criptoanálise diferencial e linear, S-boxes dependentes de chaves são muito mais resistentes a esses ataques.

200
Combinação de operações de grupos algébricos diferentes: O processo de cifragem no algoritmo IDEA introduziu esse conceito, combinando o XOR mod 216, adição mod 216, e multiplicação mod 216+1.
Outra operação importante é a realização de permutações dependentes de chaves, similar ao realizado pelo algoritmo DES.
12.3 Comparação dos Candidatos ao AES Como descrito anteriormente, na primeira conferência sobre o AES foram selecionados quinze candidatos. Os concorrentes foram provenientes de vários grupos de pesquisas, incluindo universidades e empresas ligadas à área de segurança. A tabela 12.1 apresenta os algoritmos selecionados e seus respectivos países e autores.
Tabela 12.1 – Sumário dos algoritmos concorrentes ao AES (BIHAM, 1999)
Algoritmo País Autores LOKI97 Australia Lawrie Brown, Josef Pieprzyk, Jennifer Seberry RIJNDAEL Belgica Joan Daemen, Vincent Rijmen CAST-256 Canada Entrust Technologies, Inc. DEAL Canada Outerbridge, Knudsen FROG Costa Rica TecApro Internacional S.A. DFC França Centre National pour la Recherche Scientifique (CNRS) MAGENTA Alemanha Deutsche Telekom AG E2 Japão Nippon Telegraph and Telephone Corporation (NTT) CRYPTON Coréia Future Systems, Inc. HPC EUA Rich Schroeppel MARS EUA IBM RC6 EUA RSA Laboratories SAFER+ EUA Cylink Corporation TWOFISH EUA Bruce Schneier, John Kelsey, Doug Whiting, David
Wagner, Chris Hall, Niels Ferguson SERPENT Inglaterra,
Israel, Noruega
Ross Anderson, Eli Biham, Lars Knudsen
Tabela 12.2– Características gerais dos concorrentes ao AES (BIHAM, 1999)
201
Algoritmo Estrutura Iterações LOKI97 Feistel 16 RIJNDAEL Square 10,12,14 CAST-256 Feistel Estendido 48 DEAL Feistel 6,8 FROG Especial 8 DFC Feistel 8 MAGENTA Feistel 6,8 E2 Feistel 12 CRYPTON Square 12 HPC Omni 8 MARS Feistel Estendido 32 RC6 Feistel 20 SAFER+ SP Network 8,12,16 TWOFISH Feistel 16 SERPENT SP Network 32
A tabela 12.2 apresenta as estruturas utilizadas pelos algoritmos concorrentes do AES. Nela pode-se perceber a grande influência causada por Feistel, uma vez que, grande parte dos algoritmos utilizam a estrutura proposta por este pesquisador.
Segundo um trabalho apresentado por Biham (1999), a tabela 12.3 apresenta os dados de desempenho estimados para o algoritmo do AES. Neste mesmo trabalho, Biham destacou os critérios para obtenção das medidas de desempenho como sendo:
• Alguns algoritmos podem avaliados utilizando uma API disponibilizada pelo NIST (NIST API) (NISTAPI, 1999);
• Alguns algoritmos utilizam procedimentos em linguagem nativa para a avaliação de desempenho o que normalmente permite um desempenho entre 10% e 20% superior do que os utilizando a NIST API;
• Alguns algoritmos utlizam algumas otimizações de código as quais não são compatíveis com a NIST API. Estas otimizações incluem o uso de vetores estáticos para armazenamento das subchaves ou incluindo as subchaves em código assembly. Isto proporciona uma velocidade adicional de 20%.
Importante ressaltar que a tabela 12.3 apresenta dados de desempenho relativos a códigos compilados com o GCC-2.7.2.2 utilizando Linux em um computador Pentium 133Mhz MMX (BIHAM, 1999). Nela pode-se perceber que os algoritmos estão ordenados pelo número de ciclos na encriptação. Isto significa que o algoritmo Twofish utiliza um menor número de ciclos para realizar a encriptação, lembrando que para se avaliar um melhor algoritmo a velocidade é apenas um dos critérios, sendo importante também a segurança do algoritmo entre outros parâmetros. Desta forma, Biham (BIHAM, 1999) realiza uma comparação onde é destacado também o

202
número mínimo de iterações para tornar um algoritmo seguro contra criptoanálise. Com isto, cada algoritmo foi avaliado para determinar este número mínimo de iterações e uma nova análise de desempenho considerando este número de iterações foi realizada. Os dados desta análise são apresentados na tabela 12.4.
Tabela 12.3 – Comparação de desempenho dos concorrentes ao AES (BIHAM, 1999)
Encriptação Decriptação Geração de Subchaves Algoritmo (ciclos) (ciclos) Encriptação Decriptação
TWOFISH 1254 1162 18846 18634 RIJNDAEL 1276 1276 17742 18886 CRYPTON 1282 1286 758 824 RC6 1436 1406 5186 5148 MARS 1600 1580 1408 5548 SERPENT 1800 2102 13154 12648 E2 1808 1854 7980 7780
Com NIST API CAST-256 2088 2080 11412 11478 FROG 2182 2668 3857000 3817100 HPC 2602 2962 234346 248444 SAFER+ 4424 4620 4708 4668 DFC 5874 5586 23914 25616 LOKI97 6376 6118 22756 22490 DEAL 8950 8910 108396 107996 MAGENTA 23186 23230 1490 1622
Observa-se nas tabelas 12.3 e 12.4 que os algoritmos que foram selecionados para a fase final do AES (Rijndael, Serpent, Twofish, MARS e RC6) estão sempre bem colocados nas avaliações. Outros parâmetros como desempenho em hardware, em smartcards, entre outros, também foram considerados na avaliação que definiu os algoritmos finalistas em 1999 (REQUEST AES,1997).
Finalmente, em outubro de 2000 o algoritmo Rijndael foi selecionado para ser adotado como o novo padrão AES. Entretanto, foi destacado que os demais finalistas também obtiveram excelentes resultados durante a avaliação, sendo também recomendados para o uso em diversas aplicações AESWINNER, 2003).
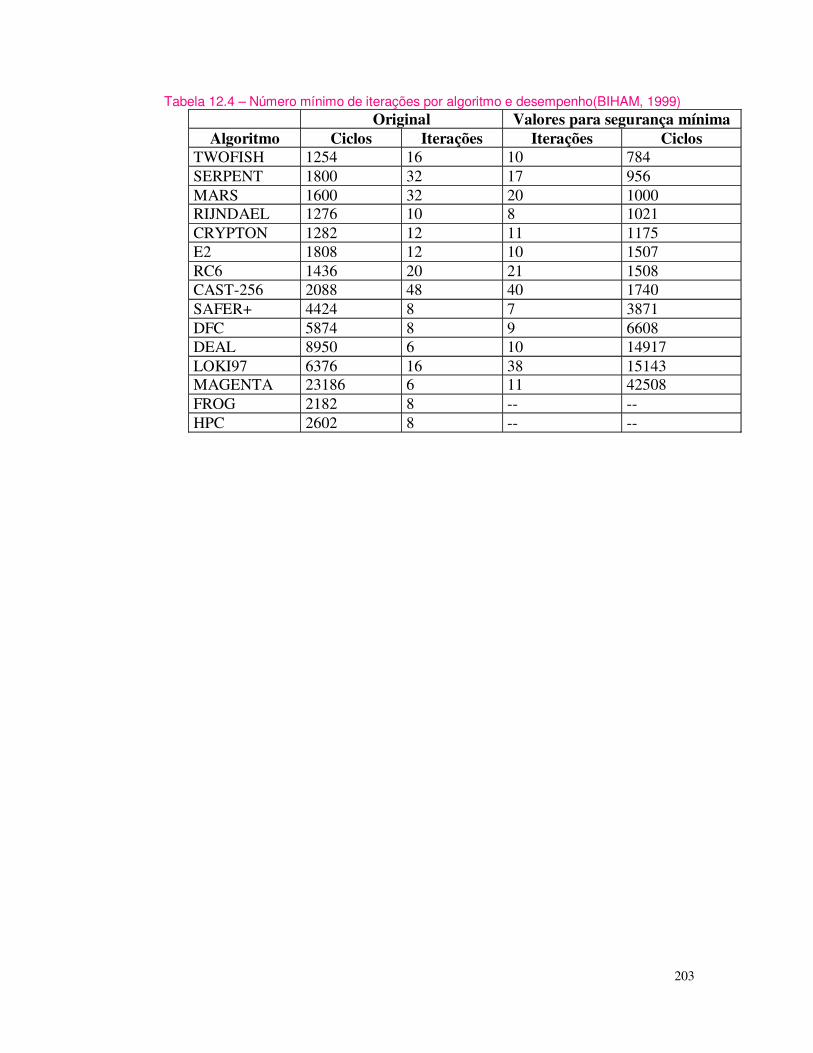
203
Tabela 12.4 – Número mínimo de iterações por algoritmo e desempenho(BIHAM, 1999) Original Valores para segurança mínima
Algoritmo Ciclos Iterações Iterações Ciclos TWOFISH 1254 16 10 784 SERPENT 1800 32 17 956 MARS 1600 32 20 1000 RIJNDAEL 1276 10 8 1021 CRYPTON 1282 12 11 1175 E2 1808 12 10 1507 RC6 1436 20 21 1508 CAST-256 2088 48 40 1740 SAFER+ 4424 8 7 3871 DFC 5874 8 9 6608 DEAL 8950 6 10 14917 LOKI97 6376 16 38 15143 MAGENTA 23186 6 11 42508 FROG 2182 8 -- -- HPC 2602 8 -- --

204
Parte IV Ferramentas e Dispositivos Modernos de Segurança
Os capítulos 13 a 16, da parte IV, apresentam conceitos e dados que permitem ao leitor o aprendizado de mecanismos avançados de segurança, tais como bibliotecas (compostas por um conjunto de algoritmos e protocolos de criptografia), dispositivos em hardware que aceleram as operações de criptografia e aumentam o nível de segurança das soluções implementadas. Nestes capítulos se apresentam conceitos e uma breve descrição das bibliotecas CryptoAPI, OpenSLL e JCA; e de alguns dispositivos tais como Smart Cards, HSM, e alguns processadores criptográficos.
Assim, esta parte do livro visa explicar o impacto que alguns parâmetros de arquitetura possuem no desempenho dos algoritmos estudados anteriormente. Também se discute qual é o impacto de usar plataformas com diferentes sistemas operacionais e mudanças nos parâmetros dos arquivos sendo cifrados e/ou decifrados.
Apresenta-se também o projeto de um processador criptográfico com arquitetura VLIW mapeado e analisado em FPGAs, ver capítulo 15. Os algoritmos RC5 e DES são executados nele, e dados de desempenho são discutidos no capítulo 16.
O capítulo 17, último capítulo do livro, apresenta uma ferramenta criada pelos autores, acessível via internet no site www.novateceditora.com.br/downloads.php. Através dessa ferramenta os leitores podem executar alguns exemplos selecionando os algoritmos e os parâmetros, e visualizar, de forma didática, o impacto em usar um outro algoritmo criptográfico. Assim, a ferramenta oferece possibilidade de visualização, para que os usuários vejam o desempenho e as características de execução de um determinado algoritmo implementado.

205
Capítulo 13 Bibliotecas Criptográficas em Software
De maneira breve, este capítulo apresenta as bibliotecas criptográficas CryptoAPI, JCA, e OpenSSL. Para exemplificar o desempenho dessas bibliotecas implementaram-se o algoritmo DES, Blowfish e mini-blowfish, analisando o impacto de mudar o sistema operacional, processador e tipos de arquivos. Além disso, apresenta-se resumidamente conceitos e aplicações de HSM (Hardware Security Module), Smartcards e de processadores específicos para realizar operações de criptografia.
13.1 Motivação
É bom lembrar que o ciframento de uma mensagem baseia-se em dois componentes: o algoritmo e a chave. O algoritmo é uma transformação matemática que combinada com uma chave converte uma mensagem clara em uma mensagem cifrada e vice-versa. Na figura 13.1 tem-se a representação do funcionamento geral da criptografia.
Dentro da modelagem criptográfica atual pode-se classificar os sistemas criptográficos em sistemas simétricos e assimétricos.
Figura 13.1 Funcionamento geral da criptografia
Como descrito anteriormente, a criptografia simétrica caracteriza-se por utilizar a mesma chave tanto para a cifragem como para a decifragem dos dados, esse método funciona em aplicações limitadas, onde o emissor e o receptor podem se preparar antecipadamente para trocar a chave. Os algoritmos mais conhecidos são o DES, 3DES, AES, RC4, RC5, RC6, Blowfish, entre outros.

206
Os sistemas assimétricos utilizam um par de chaves, uma chave pública e uma chave privada. As mensagens criptografadas com uma das chaves do par só podem ser decriptografadas com a outra chave correspondente. Alguns algoritmos que seguem o modelo assimétrico são: RSA, ElGamal, Diffie-Hellman, algoritmos baseados em curvas elípticas entre outros.
Desta forma existem diversos algoritmos, sendo que cada algoritmo possui suas características próprias de implementação. Para facilitar a utilização destes algoritmos, existem algumas bibliotecas criptográficas que implementam tais algoritmos e fornecem uma base para a utilização em diversas aplicações.
13.2 Bibliotecas Modernas de Criptografia Existem hoje várias bibliotecas de criptografia como CryptoAPI, JCA, e OpenSSL, sendo que cada uma delas é para um uso específico. Algumas empresas desenvolvem bibliotecas específicas para cada tipo de aplicação atendendo seus mais variados clientes, para isso, são utilizadas bibliotecas específicas que facilitam a implementação de aplicações e ambientes seguros .
Implementar segurança é complexo e difícil. Neste contexto, a utilização de bibliotecas criptográficas pode reduzir a complexidade e o tempo de desenvolvimento de projetos nesta área. Desta forma apresenta-se uma comparação das bibliotecas CryptoAPI e OpenSSL, através de dois algoritmos básicos e bem conhecidos: o DES e o Blowfish, apresentando alguns dados de desempenho das bibliotecas selecionadas em diferentes plataformas. Apresenta-se também os fundamentos da biblioteca JCA em Java.
13.2.1 Biblioteca OpenSSL
O projeto OpenSSL é composto por uma equipe de desenvolvimento, que consiste dos colaboradores ativos atuais e outros contribuintes principais. Adicionalmente um subconjunto dos colaboradores dá forma à equipe do núcleo de OpenSSL que controla o projeto global de OpenSSL. Qualquer um que queira se juntar ao esforço do desenvolvimento poderá fazê-lo desde que se inscreva na lista onde estão os colaboradores que se encontra no endereço virtual: [email protected], onde todos os esforços do desenvolvimento são coordenados (YOUNG, 2003).
OpenSSL é baseado na biblioteca SSLeay, desenvolvida por Eric A. Young e Tim J. Hudson, e pode ser usada livremente (TESCARO, 2003), (MENDES, 2003).
OpenSSL é uma versão aberta ao público mas eficaz de SSL/TLS, o protocolo mais extensamente usado como fonte para comunicações seguras da rede.
Criado pela Netscape, o SSL propicia transações seguras mediante a criptografia dos dados que trafegam entre a máquina do usuário e o servidor ao qual está conectado (YOUNG, 2003).

207
O projeto OpenSSL disponibiliza um toolkit em código livre (STEVENS, 2001), que implementa o protocolo SSL e vários algoritmos e primitivas criptográficas de uso comum, incluindo algoritmos de troca de chaves, funções de hash, algoritmos simétricos e assimétricos. O toolkit se apresenta na forma de duas bibliotecas e um conjunto de programas que implementam as rotinas por elas disponibilizadas. Os mecanismos do SSL estão implementadas na libssl, e os outros algoritmos estão implementados na libcrypto (PUTINI, 2004), (REGULY, 2001).
A parte que trata da criptografia dentro do projeto OpenSSL, chama-se de biblioteca CRYPTO – OpenSSL. Esta biblioteca implementa uma ampla variedade de algoritmos criptográficos, os quais são usados em vários padrões da internet. Assim, os serviços fornecidos pela biblioteca são usados por implementações OpenSSL de padrões tais como o SSL (Secure Sockets Layer), TLS (Transport Layer Security) e S/MIME (Secure Multipurpose Internet Mail Extensions); os quais também têm sido usados para implementar padrões criptográficos tais como SSH, OpenPGP e outros (BROWN, 2000).
O nome dessa biblioteca é denominada de libcrypto, e consiste de um número de sub-bibliotecas que implementam os algoritmos criptográficos de forma individual, conforme foi visto nos capítulos anteriores.
As funcionalidades incluem cifragem simétrica, criptografia de chave pública, autenticação de chaves, gerenciamento de certificados, funções de hashing, e gerador de números pseudo-aleatórios usados em aplicações de criptografia.
Uma descrição dos algoritmos que esta biblioteca implementa são:
• Algoritmos Simétricos: Blowfish, Cast, DES, IDEA, RC2, RC4 e RC5
• Criptografia de chave Pública e Certificação de Chaves: DSA, DH, RSA.
• Certificados Digitais: X509, X509v3
• Códigos de Autenticação e Funções Hashing: HMAC, MD2, MD4, MD5, MDC2, RipeMD, SHA.
Usando as bibliotecas OpenSSL: A biblioteca OpenSSL é escrita na linguagem C, e suporta uma vasta gama de algoritmos de criptografia, utilizados em vários padrões da Internet. Como SSL é uma camada, ela não implementa sockets, então o programador deve cuidar desta etapa. O suporte SSL se dá na seguinte maneira (mas não necessariamente nesta ordem):
• a biblioteca é iniciada com uma chamada para a função SSL_library_init()
• um contexto SSL é criado (SSL_CTX_new())
• um socket é criado
• um objeto SSL deve ser criado (SSL_new())
• socket é associado a um objeto SSL (SSL_set_fd() ou SSL_set_bio())

208
• handshake entre o cliente e o servidor é feito (SSL_accept() ou SSL_connect())
• cliente e o servidor trocam dados pela conexão SSL (SSL_read() ou SSL_write())
• e então a função SSL_shutdown é chamada para terminar a sessão
• socket é fechado para terminar a conexão
• objeto SSL é liberado (SSL_free())
• contexto SSL é liberado (SSL_CTX_free())
13.2.2 Biblioteca CryptoAPI
Conhecendo que a preocupação com a segurança em rede aumenta com o crescimento do número de usuários que a utilizam, há várias tecnologias emergentes para oferecer suporte a segurança de dados.
Atualmente não existe mais barreira para a interconexão e comunicação entre equipamentos e software de diferentes plataformas, viabilizando os ataques (invasão, destruição, roubo, espionagem, alteração, vírus etc.) a qualquer máquina conectada em uma rede. A preocupação existe há muito tempo e as técnicas para tentar garantir a segurança em rede têm evoluído de acordo com a necessidade.
Hoje, a maioria dessas tecnologias são baseadas no conceito de conjunto de serviços dispostos em camadas que oferece serviços de segurança para aplicações. A camada mais baixa oferece componentes fundamentais como algoritmos de criptografia, por exemplo. As camadas mais altas oferecem certificados digitais, mecanismos de gerenciamento de chaves e protocolos para transações seguras. A biblioteca CryptoAPI é baseada nesse conceito de camadas de serviços.
CryptoAPI é uma API desenvolvida pela Microsoft fornecendo algumas aplicações, não apenas programas baseados na Web, com características de segurança de fácil implementação. Uma tecnologia fornecida como parte do Windows 95, 98, Windows NT e Windows 2000 e, recentemente pelas novas versões XP, Millenium. A biblioteca fornece uma forma padrão para que os aplicativos obtenham serviços criptográficos, em especial cifragem/decifragem de dados, autenticação e assinatura digital, entre outras (MASCARIN,2003).
Nas plataformas base, no ambiente de Windows, há um conjunto de funções que traduzem este modelo teórico em chamadas de programação e formam a biblioteca CryptoAPI. Ela é implementada pelas funções definidas no arquivo de cabeçalho “wincrypt.h” implementado em “advapi32.dll”. Estas funções lhe permitem codificar e decifrar arquivos como também armazenar e verificar certificados digitais de documentos, através do creating/parsing na “crypt32.dll”.

209
É importante salientar que uma API (Application Programming Interface) é um conjunto de rotinas que um aplicativo utiliza para solicitar e conduzir serviços executados por um sistema operacional.
A biblioteca CryptoAPI fornece interfaces de funções para assinatura digital para utilização em aplicações Windows de 32 bits. A potencialidade desta API está na forma como foi implementada. São DLLs conhecidas como CSPs (Cryptographic Service Providers). Mudanças podem ser feitas nas DLLs sem ter que mudar a interface das funções.
A CryptoAPI da Microsoft oferece seis funções (CRYPTOAPI, 1998):
1. short DSPrepCrypEnv(void) – Carrega dinamicamente as DLLs da CryptoAPI.
2. void DSFreeCryptEnv(void) – Limpa a estrutura CryptFuncEnv.
3. short DSSignMessage(charP msg, long msgLen, charP csp, charP hashAlg, charP signer, charP *pSignature, long *pSignatureLen) – Captura um bloco de dados e verifica a identidade do assinante, gerando uma assinatura.
4. short DSVerifySignature(charP msg, long msgLen, charP csp, charP signature, long signatureLen, charP *pSigner, charP * pCertInfo, charP *pCertChain, short *pVerifyStatus) – Captura um bloco de dados e uma assinatura e, executa testes (Ex: compara o valor de hash).
5. short DSGetIdentityList(charP csp, charP subString, short OnlyValidCerts, charP **listPtr, short * listSizePtr) – Captura uma string que identifique o usuário (Ex: e-mail address) e gera uma lista identidades do assinante.
6. short DSGetCertList(charP csp, charP certStoreName, short wholeSubject, charP *theCertificatePtr) – Lista os certificados digitais armazenados.
Assim, a CryptoAPI oferece vários serviços criptográficos como: algoritmo RSA com chave de 512 bits, algoritmos RC2 e RC4 com chaves de 40 bits, e as funções de hashing MD5 e SHA-1. Os leitores interesssados em se aprofundar em detalhes de funcionamento desta biblioteca, podem encontrar informações atualizadas em www.cryptoapi.com e (ESPOSITO, 2004).
13.2.3 Biblioteca JCA
A biblioteca JCA (Java Cryptography Architecture) pode ser entendida como um framework que facilita a incorporação de funcionalidades criptográficas em aplicações Java.
Uma framework orientada por objetos é um conjunto de classes que interagem entre si para disponibilizar uma solução total ou parcial para um problema. As frameworks permitem criar aplicações com maior facilidade, sem exigir um grande conhecimento do domínio em que se aplicam, quando fornecem uma solução parcial para um problema permitem reduzir o esforço de desenvolvimento, pois é apenas

210
necessário acrescentar o código correspondente às particularidades da aplicação (JCA, 1999), (BURNETT, 2000), (JAVAROME, 2003).
13.2.3.1 Vantagens e Desvantagens da JCA
Existem várias vantagens em se utilizar a JCA, como: independência das implementações específicas e dos algoritmos, compatibilidade entre as implementações e possibilidade de extensão.
A JCA é definida como uma API base do Java, como tal, permite escrever aplicações com técnicas criptográficas com todas as vantagens inerentes a esta linguagem, por exemplo, a independência da plataforma. Sendo uma framework, permite disponibilizar novas técnicas criptográficas com o mínimo de esforço (JCA, 1999).
Algumas empresas de renome na área de segurança da informação (exemplo a RSA Data Security Inc.) já começam a desenvolver providers compatíveis com a JCA. Existem outras frameworks escritas em Java com aplicação em domínios de interesse para a criptografia.
Apesar das vantagens em se usar a JCA, esta biblioteca também possui algumas desvantagens, como: Pouco eficiente pois, inicialmente, as extensões contendo os mecanismos de cifragem/decifragem de dados não eram exportáveis para fora dos USA e Canadá. Hoje em dia estas restrições já não são tão severas (JCA, 1999), mas a integração de implementações na JCA passou a ser restrita aquelas que apresentam uma certificação da empresa Sun.
13.2.3.2 Objetivos da JCA
A biblioteca JCA foi criada com base em três objetivos:
(i) Independência das implementações específicas de técnicas criptográficas:
Implica que as aplicações possam usar um determinado algoritmo criptográfico sem se preocupar com as especificidades das suas várias implementações.
Na JCA esta independência é obtida através do conceito de provider, que permite a co-existência de diversas implementações de subconjuntos da API num sistema, sendo isto transparente (até certo ponto) para a aplicação, dado que a JCA normaliza a forma de nomear os diversos algoritmos criptográficos.
Quando uma aplicação requisita um determinado algoritmo ao framework, instancia-se uma implementação de qualquer um dos providers instalados, desta forma, se a mesma aplicação for executada em plataformas com diferentes providers instalados, desde que estes implementem o mesmo algoritmo, não existe qualquer problema.
Esta independência também permite que os providers possam ser atualizados transparentemente. Por questões de segurança, pode ser desejável não desenvolver aplicações independentes das implementações específicas. Ao requisitar um algoritmo pode-se, opcionalmente, indicar qual o provider a que a implementação deve pertencer.

211
(ii) Independência dos algoritmos:
A independência dos algoritmos significa que os usuários podem utilizar as diversas técnicas criptográficas independentemente do algoritmo que as implementa. Esta independência é conseguida à custa de classes abstratas que especificam cada uma das técnicas criptográficas (e.g. mecanismos de hash, cifras ou assinaturas digitais), estas classes são denominadas engine classes. As implementações concretas disponibilizadas nos providers devem respeitar a interface definida na engine class que especifica a técnica criptográfica do algoritmo implementado.
(iii) Compatibilidade entre implementações e possibilidade de extensão
A compatibilidade entre as implementações permite que, por exemplo, para o mesmo algoritmo, as chaves geradas por um provider possam ser utilizadas por outro; ou que as assinaturas geradas por um provider possam ser verificadas por outro. Isto é conseguido à custa de classes que especificam os diversos componentes dos algoritmos criptográficos.
A possibilidade de extensão significa que novos providers podem ser acrescentados ao framework. Estes providers devem disponibilizar implementações das engine classes já especificadas.
13.2.3.3 Arquitetura da JCA
Providers Criptográficos:
A JCA introduz o conceito de Provider Criptográfico: um pacote (ou conjunto de pacotes) que fornecem uma implementação concreta de um subconjunto dos serviços definidos na API. No JDK 1.1 (PALOS, 2004) um provider podia conter uma implementação de um ou mais algoritmos de assinatura digital, algoritmos de hash e algoritmos de geração de chaves. No Java 2 apareceram cinco tipos adicionais de serviços: fábrica de chaves (keyfactory), criação e gestão de armazenamento de chaves (keystores), geração e gestão de parâmetros de algoritmos e fábrica de certificados (certificatefactory), aparece também a possibilidade de implementar algoritmos de geração de números pseudo-aleatórios.
O provider “SUN” (PALOS, 2004)
O JDK inclui no seu pacote “Java.security” a implementação de um provider mínimo com o nome “SUN”, este provider inclui implementações de:
• Digital Signature Algorithm (DSA) ou algoritmos de assinatura digital.
• Algoritmos de hash MD5 e SHA-1.
• Gerador de pares de chaves para DSA.
• Geração e gestão de parâmetros para DSA.

212
• Key factory capaz de instanciar objetos com chaves DSA.
• Gerador de números pseudo-aleatórios "SHA1PRNG".
• Certificate factory capaz de lidar com certificados X.509.
• Keystore do tipo "JKS".
Outros providers
Todos os providers implementam uma classe derivada da classe Provider especificada no pacote Java.security, o construtor desta classe encarrega-se de registrar na JCA todas as implementações suportadas pelo pacote correspondente. Isto permite a JCA reconhecer quais são os serviços e as implementações que estão disponíveis no sistema, e quais as bibliotecas a que pertencem, de modo a poder instanciar os objetos correspondentes, quando necessário. A instalação de um novo provider consiste em tornar visível esta classe à framework.
13.2.3.4 Classes da JCA
Seguindo a linguagem Java, a JCA está baseada na utilização de classes. Destacam-se a classe de segurança (security) e as várias classes que fazem as operações desejadas pelo usuário, chamadas de classes engines (ALVES, 2003).
A classe security efetua a gestão dos providers instalados e as propriedades de segurança do sistema. Esta classe tem apenas métodos estáticos e como não é instanciada, pode ser utilizada para obter uma lista dos providers instalados. O método getProviders retorna um array com todas as sub-classes provider existentes no sistema, por ordem de preferência. O método getProviders permite obter um provider específico através do seu nome e as propriedades de segurança, esta classe mantém uma lista destas propriedades, lista esta que está acessível através dos métodos getProperty e setProperty.
As classes engine definem os tipos de serviços criptográficos de uma forma abstrata, independente do algoritmo e da implementação e define uma API para esses serviços. Um serviço está associado a uma operação ou a um tipo particular e pode efetuar operações criptográficas como a assinatura digital ou o hashing; gerar material criptográfico (chaves ou parâmetros) necessário para efetuar operações criptográficas; gerar objetos de dados (keystores ou certificados) que encapsulam chaves criptográficas de uma forma segura.
Associadas às Engine Classes existem as SPI - Service Provider Interfaces que são classes abstratas que definem métodos e as respectivas implementações desses serviços. O nome de uma classe SPI é o mesmo da Engine Class correspondente seguido de Spi Signature/SignatureSpi. Na implementação de um provider em que se pretenda fornecer um determinado serviço é necessário definir uma sub-classe da classe SPI correspondente e implementar todos os métodos virtuais.
Ao contrário das Engine Classes, as classes SPI estão relacionadas com algoritmos específicos. Esta informação é essencial e está acessível através da API da Engine

213
Class. Compete à classe principal do provider registrar as implementações que disponibiliza, de modo a que a engine.class correspondente as consiga invocar.
No que diz respeito às engine classes que efetuam a instanciação de objetos com material criptográfico, existem dois tipos:
• Factories – Instanciam objetos com base em informação já existente num formato qualquer.
• Generators – Criam novas unidades de informação criptográfica, por exemplo as chaves criptográficas.
Alguns exemplos de Engine Classes da JCA são as seguintes:
• MessageDigest – Utilizada para calcular o hash (message digest) dos dados que lhe são transferidos.
• Signature – Utilizada para assinar dados e verificar assinaturas.
• KeyPairGenerator – Utilizada para gerar pares de chaves públicas e privadas compatíveis com um algoritmo de cifra específico.
• KeyFactory – Utilizada para converter chaves criptográficas genéricas do tipo Key, em representações transparentes das mesmas chaves e vice-versa.
• CertificateFactory – Utilizada para lidar com certificados de chave pública e CRLs - Certificate Revocation Lists.
• KeyStore – Utilizada para gerar e gerenciar uma keystore. Uma keystore é uma base de dados de chaves. As chaves privadas são associadas com uma cadeia de certificados que autentica a chave pública associada. Uma keystore também contém certificados emitidos por entidades de confiança.
• AlgorithmParameters – Utilizada para gerar parâmetros de um determinado algoritmo (incluindo codificação e decodificação).
• AlgorithmParameterGenerator – Utilizada para gerar um conjunto de parâmetros compatíveis com um determinado algoritmo.
• SecureRandom – Utilizada para gerar números aleatórios ou pseudo-aleatórios.
A tabela 13.1 mostra os alguns dos algoritmos criptográficos e o respectivo provider usado pela JCA.

214
Tabela 13.1 Alguns Algoritmos Disponibilizados na biblioteca JCA (CUNHA, 1999).
Algoritmo Provider
DES SunJCE, Crypto-J, IAIK,ABA Cryptix, Entrust
DESede, 3DES SunJCE, Crypto-J, IAIK, ABA Cryptix, Entrust
RC2 Crypto-J, IAIK, Cryptix, Entrust RC4 Crypto-J, IAIK, ABA, Cryptix,
Entrust RC5 Crypto-J, IAIK, RSA Crypto-J, IAIK, ABA, Cryptix ElGamal Cryptix RPK Cryptix IDEA IAIK, ABA, Cryptix Blowfish IAIK, Cryptix Twofish ABA GOST IAIK CAST128 IAIK, Entrust CAST5, LOK191, SAFER Cryptix SPEED, Square Cryptix PBEWithMD5AndDES IAIK, ABA PbeWithSHAAnd40BitRC2 IAIK PBEWithSHA1And128BitRC4
ABA
13.2.3.5 JCE – Java Cryptography Extension
O JCE (Java Cryptography Extension) oferece extensões ao JCA. Este pacote (javax.crypto) estende a funcionalidade do Pacote Java.security. O JCE foi criado separadamente devido às restrições de exportação de tecnologias criptográficas em países como EUA e Canadá. Todas as tecnologias abrangidas por esta restrição são implementadas apenas neste pacote.
Tecnologias da JCE:
As tecnologias que são implementadas na JCE são as seguintes:
• Algoritmos de cifra simétrica como o RC4.
• Algoritmos de cifra simétrica por blocos como o DES, o RC2 e o IDEA.
• Algoritmos de cifra assimétrica como o RSA.
• Algoritmos de cifra baseados em passwords (password-based encryption PBE).
• Message Authentication Codes (MAC).
• Key Agreement (acordo de chaves).

215
Mais informações podem ser obtidas em www.jca.com O leitor poderá facilmente entender todas essas facilidades oferecidas por estas bibliotercas, uma vez que a maioria dos algoritmos foram estudados e apresentados nos capítulos anteriores.
13.3 Alguns dados de Desempenho Para testar e avaliar as bibliotecas OpenSSL e CryptoAPI foram implementados os algoritmo criptográficos Blowfish e DES (GATTI, 2003), (LAINO, 2003). Esses algoritmos foram implementados em linguagem C seguindo as especificações das bibliotecas CriptoAPI e OpenSSL, para que os testes pudessem ser executados e as comparações feitas.
13.3.1 Ambiente de Teste Na realização dos testes de alguns algoritmos pertencentes às bibliotecas OpenSSL e CryptoAPI, foi criado um sistema que facilitou a obtenção de dados e visualização do desempenho de alguns desses algoritmos. Assim, nesse sistema foram definidas várias classes (GATTI, 2003). A classe cryptoFrame, é responsável pela interface gráfica do programa.
Existe também uma classe chamada CifradorDes/Blowfish, que é a classe que é chamada para cifrar e decifrar os arquivos selecionados. Esta classe funciona de acordo com as opções selecionadas na execução do programa, ou seja ela cifrar ou decifra o arquivo selecionado na opção abrir e utilizará o algoritmo escolhido pelo usuário no momento da execução do programa.
Quando um arquivo é cifrado, além de sua extensão normal a ele, é adicionada uma outra extensão .crypt que significa que o arquivo foi cifrado. Se na hora da escolha do arquivo, este já possuir a extensão .crypt o programa automaticamente fará o processo inverso, decifrando assim o arquivo e adicionando a extensão .decrypt.
Após qualquer um dos processos, seja cifrar ou decifrar, o tempo de execução é mostrado na tela. O tempo é dado em milisegundos (ms).
Para cifrar ou decifrar utilizando ambos algoritmos é necessário uma chave, esta chave também está especificada nesta classe. Inicialmente, foi feita a escolha por uma chave fixa, pois apenas um dos testes executados leva em conta o tamanho da chave. Caso seja necessária a mudança da chave, será necessário somente a edição de duas linhas de código desta classe.
O sistema criado pelos autores também oferece informações dos arquivos que serão cifrados e/ou decifrados. Estas classes fazem parte da ferramenta JBCRI (GATTI, 2005). Uma outra ferramenta, que contém mais opções de teste é apresentada no capítulo 17 deste livro, onde se mostra como usar a ferramenta On-Line, chamada de WEBCRY.
Existe também a classe DialogError que é responsável pelo tratamento das exceções, ou seja ela é chamada toda vez que os campos necessários não forem

216
preenchidos corretamente. Por exemplo selecionar o algoritmo para cifrar e/ou decifrar, mas não abrir o arquivo, ou abrir o arquivo e não selecionar o algoritmo a ser utilizado.
A classe principal ou classe que contém o método main é chamada de CryptoManager. A classe CryptoManager é responsável pela validação dos frames. Ela também define a interface, a qual possui o tom de cinza escuro e azul para as janelas, e também faz a chamada para os outros métodos (GATTI, 2005).
13.3.2 Testes Preliminares Foram consideradas diferentes arquiteturas, (hardware disponível, quantidade de memória, e processadores), assim como sistemas operacionais modernos: Windows e Linux, considerando diferentes tipos e tamanho de arquivos para cifrar e decifrar.
Para realizar o teste foram utilizados três arquivos de tipos diferentes, porém com o mesmo tamanho, 1.56 Mbytes. Os arquivos utilizados foram:
• Arquivo de vídeo, extensão AVI;
• Arquivo de texto do Microsoft Word, com extensão DOC e
• Arquivo de áudio, extensão mp3.
Na maioria dos testes, o computador utilizado foi um AMD Athlon 900Mhz, com 512 Mbytes de RAM, utilizando o sistema operacional Windows XP Professional Edition.
Foi utilizada uma chave de 64 bits na criptografia dos arquivos. O primeiro teste teve como objetivo a comparação dos mesmos algoritmos, porém derivados de bibliotecas diferentes. As comparações foram feitas baseadas no tempo de execução (cifrar e decifrar os arquivos), dado em milisegundos (ms).
A figura 13.2 e 13.3 mostram os resultados de cifragem e decifragem dos algoritmos DES e Blowfish, respectivamente, para as especificações das duas bibliotecas em análise: CryptoAPI e OpenSSL.
Percebe-se que não há muita diferença entre as bibliotecas, para o caso do DES. Já para o Blowfish há um tempo maior para o OpenSSL. Outro aspecto, é que diferentes arquivos, ainda que do mesmo tamanho, podem ter tempo de cifrar e decifrar diferentes, o qual pode ser explicado pela diferente entropia em cada um deles, além da diferente estrutura dos algoritmos, entre outros.
Percebe-se que quando comparadas as duas versões do algoritmo DES provenientes de bibliotecas diferentes, a diferença entre eles é pouca.
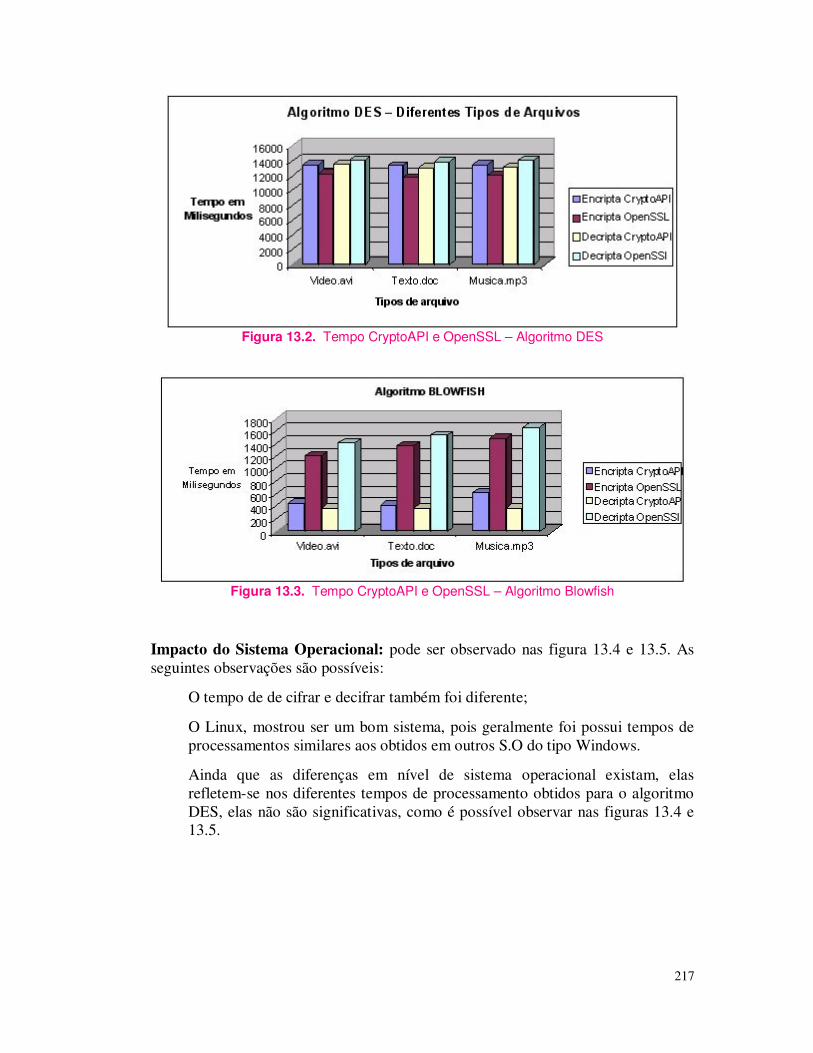
217
Figura 13.2. Tempo CryptoAPI e OpenSSL – Algoritmo DES
Figura 13.3. Tempo CryptoAPI e OpenSSL – Algoritmo Blowfish
Impacto do Sistema Operacional: pode ser observado nas figura 13.4 e 13.5. As seguintes observações são possíveis:
O tempo de de cifrar e decifrar também foi diferente;
O Linux, mostrou ser um bom sistema, pois geralmente foi possui tempos de processamentos similares aos obtidos em outros S.O do tipo Windows.
Ainda que as diferenças em nível de sistema operacional existam, elas refletem-se nos diferentes tempos de processamento obtidos para o algoritmo DES, elas não são significativas, como é possível observar nas figuras 13.4 e 13.5.
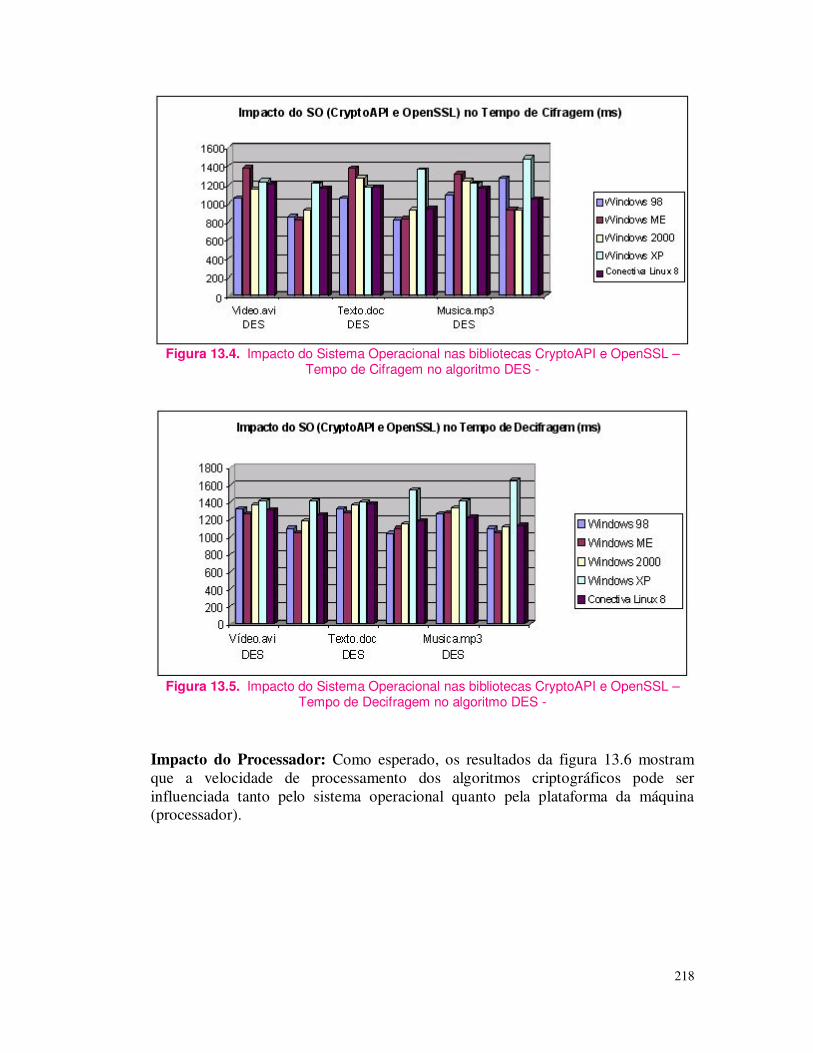
218
Figura 13.4. Impacto do Sistema Operacional nas bibliotecas CryptoAPI e OpenSSL –
Tempo de Cifragem no algoritmo DES -
Figura 13.5. Impacto do Sistema Operacional nas bibliotecas CryptoAPI e OpenSSL –
Tempo de Decifragem no algoritmo DES -
Impacto do Processador: Como esperado, os resultados da figura 13.6 mostram que a velocidade de processamento dos algoritmos criptográficos pode ser influenciada tanto pelo sistema operacional quanto pela plataforma da máquina (processador).

219
Figura 13.6 Impacto do Processador no DES e Blowfish
Observa-se no gráfico que os arquivos que foram cifrados no computador com o processador AMD Athlon XP 1800++ foram mais do que duas vezes mais rápidos tanto na criptografia quanto na decriptografia de arquivos. Lembrar que a velocidade não somente depende da relação entre as velocidades dos processsadores, pois há mais fatores que influcenciam tais como tamanhos das memórias, velocidades de acesso às memórias, arquitetura do processador e do sistema PC, entre outros.
Impacto de Simplificações dos Algoritmos:
A figura 13.7 mostra a comparação entre o algoritmo Blowfish e a implementação sugerida para melhorar a velocidade do algoritmo, chamada de MiniBlowfish que aproveita o funcionamento do Blowfih e faz as três seguintes simplificações:
(i) Menos e menores S-boxes. Pode ser possível reduzir o número de S-box de quatro para um. Adicionalmente, pode ser possível sobrepor entradas em um único S-box: entrada 0 consistiria de bytes 0 a 3, entrada 1 consistiria em bytes 1 a 4 e etc. A simplificação anterior reduz as exigências de memória para os quatro S-boxes de 4096 para 1024 bytes, o último reduz as exigências para um único S-box de 1024 bytes para 259 bytes. Assim, podem ser exigidos passos adicionais para eliminar as simetrias que estas simplificações criam.
ii) Menos iterações. É seguro reduzir o número de repetições de 16 para 8. O número de repetições necessárias para segurança pode depender do comprimento da chave.
(iii) Cálculo rápido de sub-chaves. O método atual de cálculo de sub-chaves exige calcular todas as sub-chaves antes de qualquer processo de cifrar dados. Uma alternativa é calcular cada sub-chave independente de cada outra.
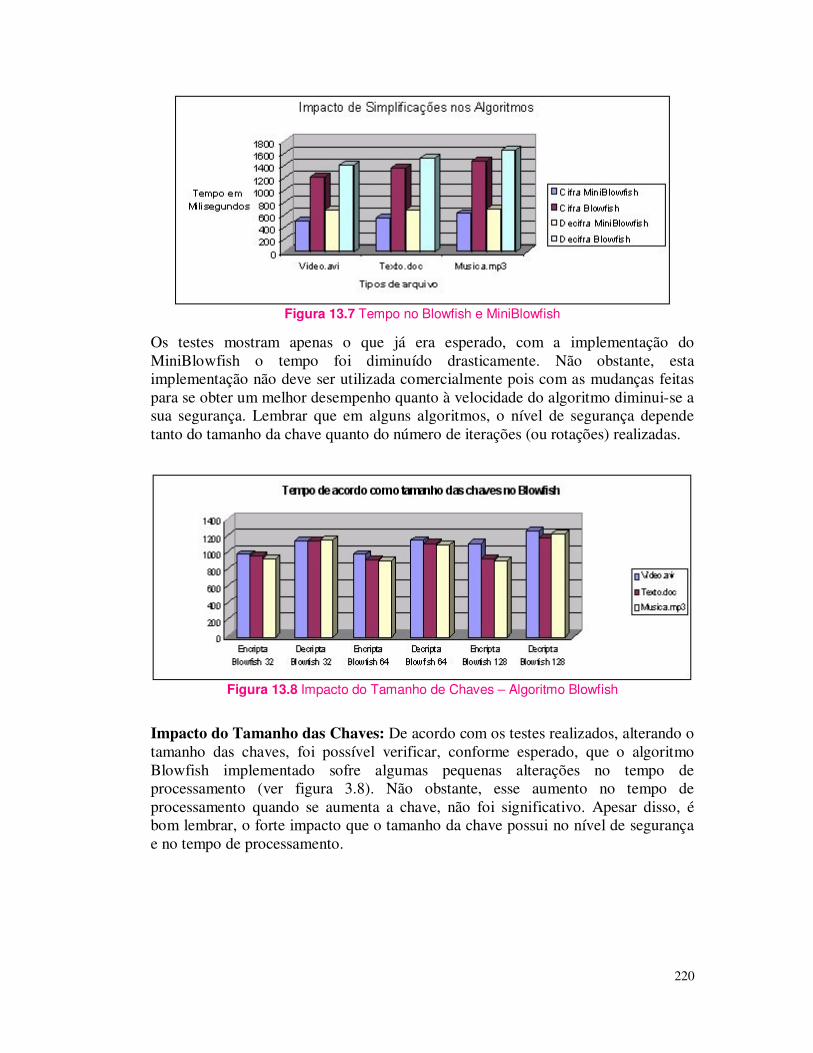
220
Figura 13.7 Tempo no Blowfish e MiniBlowfish
Os testes mostram apenas o que já era esperado, com a implementação do MiniBlowfish o tempo foi diminuído drasticamente. Não obstante, esta implementação não deve ser utilizada comercialmente pois com as mudanças feitas para se obter um melhor desempenho quanto à velocidade do algoritmo diminui-se a sua segurança. Lembrar que em alguns algoritmos, o nível de segurança depende tanto do tamanho da chave quanto do número de iterações (ou rotações) realizadas.
Figura 13.8 Impacto do Tamanho de Chaves – Algoritmo Blowfish
Impacto do Tamanho das Chaves: De acordo com os testes realizados, alterando o tamanho das chaves, foi possível verificar, conforme esperado, que o algoritmo Blowfish implementado sofre algumas pequenas alterações no tempo de processamento (ver figura 3.8). Não obstante, esse aumento no tempo de processamento quando se aumenta a chave, não foi significativo. Apesar disso, é bom lembrar, o forte impacto que o tamanho da chave possui no nível de segurança e no tempo de processamento.

221
13.4 Considerações Finais do Capítulo Após diferentes testes realizados é possível destacar algumas observações. O tempo gasto pelos algoritmos no processo de cifrar e decifrar arquivos, está ligado a vários fatores, entre eles, tipo de arquivo, quantidade de memória disponível na máquina onde se realizam os testes, processos rodando na máquina com maiores prioridades e também linguagem em que o algoritmo foi implementado.
Ao oposto de que se tinha imaginado, os testes também mostraram que em alguns algoritmos “didáticos”, o aumento da chave não influencia significativamente no tempo gasto na criptografia, mas é importante lembrar que uma chave pequena pode comprometer a segurança do sistema onde esse algoritmo esteja sendo usado.
Ficou estabelecido também que na tomada de tempo é necessário avaliar os processos que estão sendo executados na máquina e as suas prioridades e se não for possível desativar tais processos, é necessário que se aumente a prioridade do algoritmo ou se diminua a prioridade dos outros processos em execução na máquina.

222
Capítulo 14 Hardware Especializado para Segurança
Este capítulo apresenta alguns dispositivos específicos para segurança que vêm sendo muito usados nos últimos anos, e que cada dia ganham mais popularidade, como são os HSM, Smartcards e recentemente, processadores específicos para segurança conhecidos como criptoprocessadores.
14.1 Criptoprocessadores Existem várias aplicações onde os criptoprocessadores podem ser utilizados, entre elas roteadores com suporte a VPN, servidores de acesso remoto, bridges e outros dispositivos de redes que necessitem de algum tipo de criptografia.
Os criptoprocessadores podem ser utilizados para ampliar a velocidade dos sistemas que utilizam criptografia livrando o processador principal desta tarefa. O processdor principal é aquele que executa o programa principal de uma aplicação ou de um usuário e que solicitou realizar as operações criptográficas. Deste modo, enquanto os criptoprocessadores executam operações de criptografia e decriptografia o processador principal pode continuar seu processamento normal.
Esta seção apresenta dois criptoprocessadores que foram projetados utilizando abordagens diferentes. Os processadores da família S1 da Motorola realizam bem esta função, podendo até utilizar acessos diretos à memória para realizar as operações de criptografia.
Existem também aplicações onde, além de desempenho, é necessário um baixo consumo de energia. Estas aplicações são telefones celulares, dispositivos para redes wireless e computação móvel. Desta forma, uma das principais preocupações no desenvolvimento do criptoprocessador DSRCP foi o consumo de energia, o que fez com que este processador apresentasse o menor consumo de energia entre os processadores estudados.
O primeiro processador discutido é o DSRCP proposto por Goodman e Chandrakasan (GOODMAN, 2001) onde a arquitetura proposta contém um conjunto de instruções que permite a implementação de vários algoritmos de criptografia assimétricos.

223
O segundo criptoprocessador discutido é o MPC185 da família S1 da Motorola (MPC185TS, 2003). Este processador, bem como os outros processadores desta família, não possuí um conjunto de instruções. Eles possuem em suas arquiteturas implementações dedicadas dos algoritmos de criptografia mais comuns (tanto simétricos quanto assimétricos), tais como aqueles discutidos nos capítulos anteriores, e sua programação é feita por meio de gravações em seus registradores internos.
14.1.1 O Criptoprocessador DSRCP
O criptoprocessador DSRCP (Domain-specific Reconfigurable Cryptography Processor) é um processador de domínio específico para a execução de algoritmos criptográficos assimétricos. Ele foi proposto por James Goodman e Anantha Chandrakansan (GOODMAN, 2001) para prover segurança a sistemas portáteis que devem funcionar com um baixo consumo de energia.
Como o número de operações necessárias para a implementação dos algoritmos criptográficos assimétricos é pequena, o processador pôde ser projetado com hardware reconfigurável de modo que a sobrecarga que ocorre com dispositivos programáveis e reconfiguráveis genéricos fosse minimizado.
O conjunto de instruções do DSRCP foi definido de acordo com o padrão IEEE 1363 (IEEE 1363, 1999) que realiza a especificação de técnicas para a criptografia de chave pública e os parâmetros relacionados a este tipo de criptografia. Com isto, as funções aritméticas foram implementadas de acordo com as primitivas definidas no padrão.
O conjunto de instruções deste processador possuí 24 instruções divididas em 6 grupos de operação: Aritmética convencional, Aritmética modular, Aritmética GF(2n), Aritmética de curvas elípticas sobre GF(2n), Manipulação de registradores e Configuração do processador.
Estas instruções são particionadas em três níveis hierárquicos. O primeiro nível corresponde às instruções que são executadas diretamente pelo hardware. O segundo nível é composto por instruções microprogramadas que são compostas por seqüências de instruções correspondentes ao primeiro nível. Da mesma forma, o terceiro nível é composto por seqüências de instruções correspondentes ao primeiro e segundo nível.
O DSRCP possuí como elementos básicos de sua arquitetura um controlador global, uma unidade de microprograma (ROMs de µ-programa), um controlador para desligamento de parte do sistema para economia de energia (Controlador de Desligamento) e uma interface de entrada e saída (Interface de E/S) como mostra a figura 14.1 (GOODMAN, 2001).

224
Figura 14.1. – Arquitetura do DSRCP (GOODMAN, 2001)
A função do Controlador Global é realizar um controle de alto nível dentro do DSRCP. Ele utiliza três filas de controle que são necessárias para implementar os três níveis de instruções presentes no DSRCP.
A utilização de ROMs de µ-programa permite uma maior simplicidade e flexibilidade para que alterações no conjunto de instruções possam ser realizadas com o mínimo esforço.
Como o DSRCP foi desenvolvido para funcionar em ambientes portáteis, um elemento importante de sua arquitetura é o controlador de desligamento, que é responsável por desabilitar partes não utilizadas do datapath para reduzir o consumo de energia.
A interface de entrada e saída utiliza um barramento de 32 bits. Isto permite um bom mapeamento com os sistemas existentes além de permitir rápidas operações de entrada e saída que consomem no máximo 32 ciclos para o maior operando possível composto de 1024 bits (GOODMAN, 2001).
O principal componente do DSRCP é o Datapath Reconfigurável que é composto por quatro blocos funcionais: um register file de oito palavras, um somador, um comparador e a unidade lógica reconfigurável.
O tamanho do register file foi definido como oito palavras, uma vez que este é o tamanho mínimo necessário para implementar todas as funções do DSRCP. Ele foi implementado utilizando registradores do tipo TSPC (True-Single-Phase-Clock) (YUAN, 1989).
O somador é capaz de realizar somas e subtrações entre dois operandos de n bits, onde: 8 ≤≤≤≤ n ≤≤≤≤ 1024. Estas operações podem ser realizadas em até três ciclos.
A unidade comparador é capaz de realizar comparações em um único ciclo executando um XOR entre os dois operandos. Ao realizar a comparação, dois flags (gt e eq) são gerados de forma a decodificar todas as relações possíveis.

225
A unidade lógica reconfigurável contém seis registradores (Pc, Ps, A, B, Exp e N) e um bloco de lógica reconfigurável capaz de implementar todas as operações do datapath.
O datapath possui três barramentos separados para a distribuição dos dados entre suas unidades funcionais. Nem todos os registradores e barramentos são conectados, uma vez que foi observado por meio de uma análise que haviam conexões desnecessárias e estas foram removidas (GOODMAN, 2001).
A figura 14.2 apresenta o diagrama em blocos do datapth recofigurável do DSRCP onde podem ser visualizados suas unidades funcionais.
Figura 14.2. Diagrama em blocos do Datapath Reconfigurável (GOODMAN, 2001)
14.1.2 Processadores de Segurança da Motorola
A família S1 da Motorola disponibiliza uma série de processadores voltados para a segurança, chamados geralmente, de Motorola Security Processor. São eles: MPC180, MPC190, MPC185 e MPC184 (MPC180TS, 2003), (MPC184TS, 2003), (MPC185TS, 2003), (MPC190TS, 2003).
Esta família de processadores não possui um conjunto de instruções, mas sim implementações dedicadas de algoritmos criptográficos.
Alguns processadores desta família como o MPC184 e o MPC185 residem no espaço de endereçamento do processador. Desta forma quando uma aplicação requer funções criptográficas, ela simplesmente cria descritores para o criptoprocessador definindo qual função deve ser executada e a localização dos dados. Estes processadores também disponibilizam o funcionamento Master/Slave permitindo, desta forma, que o processador principal defina qual a operação a ser realizada escrevendo em alguns registradores do criptoprocessador e, desta forma, o criptoprocessador realiza as leituras e escritas diretamente na memória do sistema

226
para completar a tarefa requisitada. Outra maneira de realizar a comunicação entre o criptoprocessador e o processador principal é através do protocolo PCI.
Os processadores desta família possuem cinco blocos funcionais em suas arquiteturas: um módulo de interface do chip com o sistema (Master/Slave Interface), canais de criptografia (Crypto-channel), um módulo de controle (Control), unidades de execução e um gerador de números aleatórios. Os processadores MPC184 e MPC185 possuem ainda um módulo de memória RAM de 8 e 32 Kbytes respectivamente (MPC180TS, 2003), (MPC184TS, 2003), (MPC185TS, 2003), (MPC190TS, 2003).
Para exemplificar a arquitetura de um processador desta família será tomado como exemplo o diagrama de blocos funcionais do processador MPC185 apresentado na figura 14.3. O processador MPC185 foi escolhido como exemplo por ser o processador mais completo da família. Desta forma, todos os blocos funcionais discutidos a seguir fazem parte do processador MPC185 (MPC180TS, 2003), (MPC184TS, 2003), (MPC185TS, 2003), (MPC190TS, 2003).
Figura 14.3. MPC185 Blocos Funcionais (MPC185TS, 2003)
Como descrito anteriormente, o criptoprocessador pode se comunicar com o sistema de duas maneiras: por meio do protocolo PCI ou pelo espaço de endereçamento do sistema. Desta forma o módulo Master/Slave Interface é o responsável por esta comunicação.
O módulo de controle é responsável por gerenciar os recursos do chip. O controlador recebe as requisições de serviço por meio do barramento e dos canais de criptografia e realiza o escalonamento das atividades.
Os canais de criptografia são responsáveis por analisar os cabeçalhos dos pacotes e requisitar ao controlador os serviços criptográficos.
Os serviços criptográficos requeridos são processados pelas unidades de execução (Execution Units – EUs) que são blocos funcionais que realizam o processamento

227
dos algoritmos de criptografia. As unidades de execução apresentadas na figura 14.3 são:
• PKEU (Public Key Execution Unit) que é responsável pela execução dos algoritmos de chave pública;
• DEU (DES Execution Unit) que é responsável pela execução do algoritmo DES;
• AESU (AES Execution Unit) responsável pela execução do algoritmo AES;
• MDEU (Message Digest Execution Unit) responsável pela execução dos algoritmos do tipo Message Digest (MENEZES, 1997); importantes para realizar assinaturas digitais, motivo pelo qual usanm funções de hashing;
• AFEU (Arc Four Execution Unit) realiza a criptografia utilizando um algoritmo do tipo Stream (MENEZES, 1997) e;
• KEU (Kasumi Execution Unit) responsável pela execução de dois algoritmos criptográficos baseados no algoritmo de Kasumi.
Por meio da figura 14.3 pode-se observar que as unidades de execução PKEU, DEU, AESU e MDEU foram duplicados, uma vez que estas unidades são pelos algoritmos de criptografia mais utilizados e provavelmente deverão processar uma grande quantidade de dados (MPC185TS, 2003).
O módulo gerador de números aleatórios (Random Number Generator – RNG) é responsável por gerar números aleatórios de 32 bits, uma vez que vários algoritmos criptográficos necessitam de números aleatórios para a criação das chaves, conforme explicado no capítulo 1.
O módulo de memória RAM (General Purpose RAM – gpRAM) é utilizado para o armazenamento das chaves e dos dados.
14.1.3 Características das Arquiteturas e Desempenho
Nesta seção são apresentadas algumas principais características das arquiteturas, bem como, suas vantagens e desvantagens. Ao mesmo tempo será realizada uma análise de desempenho dos criptoprocessadores, vistos nas duas seções anteriores.
A principal diferença entre as arquiteturas apresentadas é o fato de possuir ou um conjunto de instruções para a implementação dos algoritmos, ou implementações dedicadas dos algoritmos em hardware.
Esta escolha influencia as características finais dos criptoprocessadores como a facilidade para o acréscimo de novos algoritmos e o desempenho final do sistema.
Como o DSRCP é um processador de domínio específico para execução de algoritmos assimétricos foi possível definir um conjunto de instruções comuns para a execução dos algoritmos desta classe. Isto conferiu ao DSRCP uma grande flexibilidade para o acréscimo de novos algoritmos assimétricos. Por outro lado, este
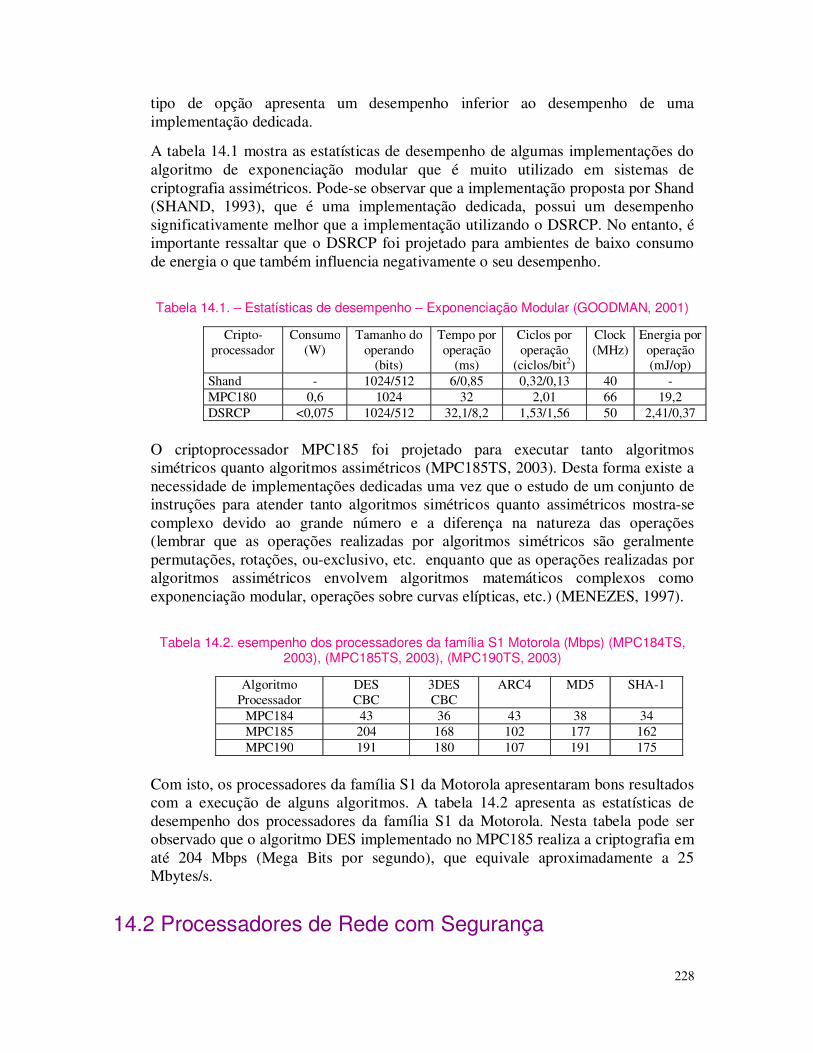
228
tipo de opção apresenta um desempenho inferior ao desempenho de uma implementação dedicada.
A tabela 14.1 mostra as estatísticas de desempenho de algumas implementações do algoritmo de exponenciação modular que é muito utilizado em sistemas de criptografia assimétricos. Pode-se observar que a implementação proposta por Shand (SHAND, 1993), que é uma implementação dedicada, possui um desempenho significativamente melhor que a implementação utilizando o DSRCP. No entanto, é importante ressaltar que o DSRCP foi projetado para ambientes de baixo consumo de energia o que também influencia negativamente o seu desempenho.
Tabela 14.1. – Estatísticas de desempenho – Exponenciação Modular (GOODMAN, 2001)
Cripto- processador
Consumo (W)
Tamanho do operando
(bits)
Tempo por operação
(ms)
Ciclos por operação
(ciclos/bit2)
Clock (MHz)
Energia por operação (mJ/op)
Shand - 1024/512 6/0,85 0,32/0,13 40 - MPC180 0,6 1024 32 2,01 66 19,2 DSRCP <0,075 1024/512 32,1/8,2 1,53/1,56 50 2,41/0,37
O criptoprocessador MPC185 foi projetado para executar tanto algoritmos simétricos quanto algoritmos assimétricos (MPC185TS, 2003). Desta forma existe a necessidade de implementações dedicadas uma vez que o estudo de um conjunto de instruções para atender tanto algoritmos simétricos quanto assimétricos mostra-se complexo devido ao grande número e a diferença na natureza das operações (lembrar que as operações realizadas por algoritmos simétricos são geralmente permutações, rotações, ou-exclusivo, etc. enquanto que as operações realizadas por algoritmos assimétricos envolvem algoritmos matemáticos complexos como exponenciação modular, operações sobre curvas elípticas, etc.) (MENEZES, 1997).
Tabela 14.2. esempenho dos processadores da família S1 Motorola (Mbps) (MPC184TS,
2003), (MPC185TS, 2003), (MPC190TS, 2003)
Algoritmo Processador
DES CBC
3DES CBC
ARC4 MD5 SHA-1
MPC184 43 36 43 38 34 MPC185 204 168 102 177 162 MPC190 191 180 107 191 175
Com isto, os processadores da família S1 da Motorola apresentaram bons resultados com a execução de alguns algoritmos. A tabela 14.2 apresenta as estatísticas de desempenho dos processadores da família S1 da Motorola. Nesta tabela pode ser observado que o algoritmo DES implementado no MPC185 realiza a criptografia em até 204 Mbps (Mega Bits por segundo), que equivale aproximadamente a 25 Mbytes/s.
14.2 Processadores de Rede com Segurança

229
14.2.1 Conceitos de NPs
Os processadores podem ter aplicações diferentes, desde a CPU da placa-mãe de um computador, até os sistemas embarcados, passando por placas de vídeo 3D, som, placas de rede até roteadores.
A demanda cada vez maior por poder de processamento e o surgimento de novas aplicações promovem uma constante busca por alternativas e arquiteturas que visem melhorar a performance dos computadores, especialmente em aplicações de tempo real.
Dentre os processadores existentes destacam-se os GPPs (General Purpose Processor), onde uma das preocupações básicas do projeto é com relação à sua performance genérica, não se importando com aplicações específicas, e os PDEs processadores especializados, que podem ser dedicados ou programáveis como por exemplo microcontroladores e os DSPs (Digital Signal Processor) (CROWLEY,2000), (LAPSLEY, 1997), (VILLASENOR, 1997 ), (PRADO, 2004).
Com relação aos projetos nota-se a produção de ASICs (Application Specific Integrated Circuit), circuitos integrados que se destinam a um único propósito dentro de alguma aplicação. Estes circuitos sob medida demandam muito tempo para sua produção, meses, até anos, e possuem custos elevados e manutenção onerosa. Ou ainda a implementação em FPGAs, os quais podem ser encontrados como unidades funcionais, co-processadores, unidades de processamento acoplado ao processador ou unidades de processamento isoladas.
Um Processador de Rede (NP - Network Processor) é um conjunto altamente integrado de micro-código ou mecanismos aceleradores embarcados, subsistema de memória, alta velocidade interconectada e interfaces para enfrentar o processamento de pacotes da rede. Pode fazer uso de pipeline, paralelismo e multi-threading para esconder a latência, tem um bom gerenciamento de fluxo de dados e suporta comunicações internas de alta velocidade (CROWLEY, 2000), (EZCHIP, 1999) (FREITAS, 2002), (FREITAS, 2001),(FREITAS, 2000). Como um processador para PC, espera-se de um NP funções como criptografia e segurança, manipulação de pacotes IP, reenvio de informações, armazenamento e capacidade de "auto aprendizado".
A Internet está no dia a dia das pessoas, empresas e instituições de ensino. Seu uso tem acarretado um congestionamento dos links de transmissão. Os principais responsáveis são os gateways (“roteadores”), Os quais confinam o tráfego entre redes. Os processadores de rede estão sendo objeto de estudo nas universidades e empresas.
Estes processadores surgiram para melhorar a qualidade de serviços (QoS: Quality of Services) (TANENBAUM, 1997). O tempo de processamento dos pacotes de rede é mais rápido usando os processadores de rede (TABEMBAUM, 1997). É necessário aumentar a capacidade de processamento dos pacotes para que não haja congestionamento e excessiva utilização da largura de banda. A segurança da informação é importante para que os pacotes não possam ser lidos por pessoas não
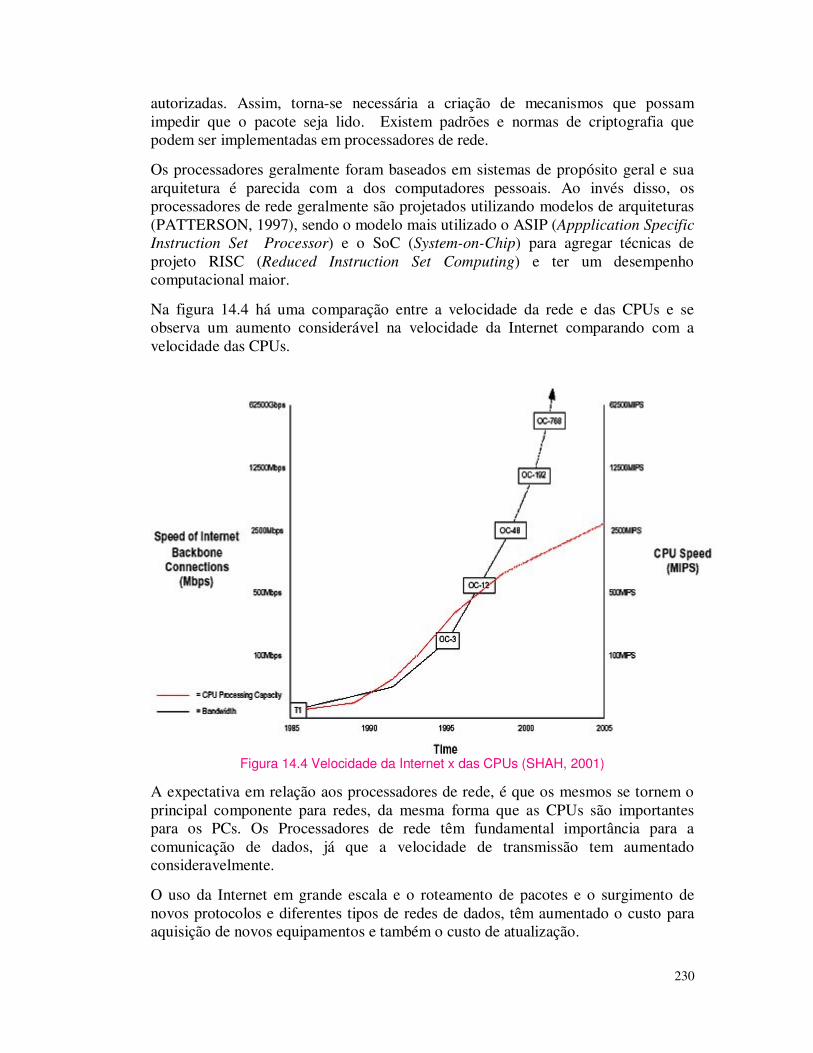
230
autorizadas. Assim, torna-se necessária a criação de mecanismos que possam impedir que o pacote seja lido. Existem padrões e normas de criptografia que podem ser implementadas em processadores de rede.
Os processadores geralmente foram baseados em sistemas de propósito geral e sua arquitetura é parecida com a dos computadores pessoais. Ao invés disso, os processadores de rede geralmente são projetados utilizando modelos de arquiteturas (PATTERSON, 1997), sendo o modelo mais utilizado o ASIP (Appplication Specific Instruction Set Processor) e o SoC (System-on-Chip) para agregar técnicas de projeto RISC (Reduced Instruction Set Computing) e ter um desempenho computacional maior.
Na figura 14.4 há uma comparação entre a velocidade da rede e das CPUs e se observa um aumento considerável na velocidade da Internet comparando com a velocidade das CPUs.
Figura 14.4 Velocidade da Internet x das CPUs (SHAH, 2001)
A expectativa em relação aos processadores de rede, é que os mesmos se tornem o principal componente para redes, da mesma forma que as CPUs são importantes para os PCs. Os Processadores de rede têm fundamental importância para a comunicação de dados, já que a velocidade de transmissão tem aumentado consideravelmente.
O uso da Internet em grande escala e o roteamento de pacotes e o surgimento de novos protocolos e diferentes tipos de redes de dados, têm aumentado o custo para aquisição de novos equipamentos e também o custo de atualização.

231
Assim, processadores de rede são parte de uma classe emergente de circuitos integrados programáveis baseados na tecnologia SOC (System On Chip), classificação essa por possuir vários blocos como memória, portas e interface de comunicação, que executam funções específicas de comunicação de forma mais eficiente que os GPPs (processadores de propósito geral) (CROWLEY, 2000).
Há uma tendência em relação aos processadores de rede, é que os mesmos se tornem o principal componente para redes, da mesma forma que as CPUs são importantes para os PCs. Com o processador de rede poderá se eliminar o gargalo existente na rede hoje.
As características típicas oferecidas por um NP são: o processamento em tempo real, segurança, store and forward, manipulação de pacotes IP devido à camada de rede no modelo OSI ser equivalente à camada inter-rede e rodar o protocolo IP (TANENBAUM, 1997). Nessa camada também é que se encontram os roteadores, outra aplicação dos NPs, que por sua flexibilidade e escalabilidade, permitem a troca de pacotes de tamanhos diferentes em redes com diferentes protocolos e topologias, e também a capacidade de aprendizado, como mostra a tabela 14.3.
Tabela 14.3 Representação de aplicações específicas de processamento de pacotes
(CROWLEY, 2000)
Aplicação Especificação
Classificação de pacotes e filtragem
Decisões, envio, estatísticas, proteção por firewall.
Reenvio de Pacotes IP Envio de pacotes IPs baseado em informação de roteamento Network Address Translation (NAT)
Tradução entre roteamento global e pacotes IP privados, mascaramento de IP, servidores web, etc.
Administração de fluxo Reduzir congestionamento, gargalos, forçar a distribuição da banda (pacotes).
TCP/IP Descarregar processamento TCP/IP dos webservers para as interfaces da rede
Web Switching Balanceamento de serviços web e monitoramento do cache do proxy. Virtual Private Network IP Security (IPSec)
Criptografia (3DES) e autenticação (MD5).
Transcodificação de dados
Conversão de dados de multimídia por demanda de um formato para outro dentro da rede
Supressão de dados duplicados
Reduz transmissão redundante de dados que gera custo alto na transmissão da rede.
Com o avanço da tecnologia, algumas empresas desenvolveram processadores de rede dedicados, capazes de serem mais velozes e com maior desempenho do que processadores de propósito geral. Esses processadores vieram para reduzir o gargalo das comunicações causado muitas vezes pelos roteadores, switches e hubs.
A tabela 14.4 mostra os principais processadores de rede existentes hoje na comunidade, e destaca as principais funcionalidades e características que eles possuem, em especial, a sua funcionalidade específica na visão de aplicaçoes de rede.
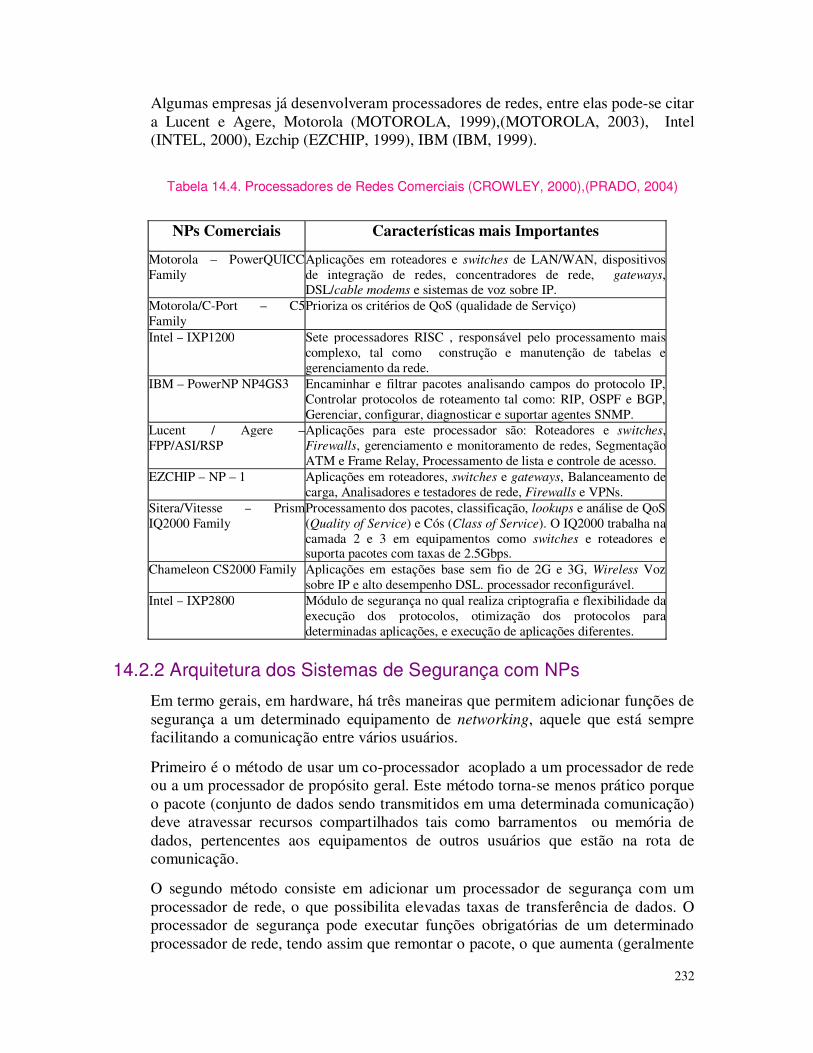
232
Algumas empresas já desenvolveram processadores de redes, entre elas pode-se citar a Lucent e Agere, Motorola (MOTOROLA, 1999),(MOTOROLA, 2003), Intel (INTEL, 2000), Ezchip (EZCHIP, 1999), IBM (IBM, 1999).
Tabela 14.4. Processadores de Redes Comerciais (CROWLEY, 2000),(PRADO, 2004)
NPs Comerciais Características mais Importantes
Motorola – PowerQUICC Family
Aplicações em roteadores e switches de LAN/WAN, dispositivos de integração de redes, concentradores de rede, gateways, DSL/cable modems e sistemas de voz sobre IP.
Motorola/C-Port – C5 Family
Prioriza os critérios de QoS (qualidade de Serviço)
Intel – IXP1200 Sete processadores RISC , responsável pelo processamento mais complexo, tal como construção e manutenção de tabelas e gerenciamento da rede.
IBM – PowerNP NP4GS3 Encaminhar e filtrar pacotes analisando campos do protocolo IP, Controlar protocolos de roteamento tal como: RIP, OSPF e BGP, Gerenciar, configurar, diagnosticar e suportar agentes SNMP.
Lucent / Agere –FPP/ASI/RSP
Aplicações para este processador são: Roteadores e switches, Firewalls, gerenciamento e monitoramento de redes, Segmentação ATM e Frame Relay, Processamento de lista e controle de acesso.
EZCHIP – NP – 1 Aplicações em roteadores, switches e gateways, Balanceamento de carga, Analisadores e testadores de rede, Firewalls e VPNs.
Sitera/Vitesse – Prism IQ2000 Family
Processamento dos pacotes, classificação, lookups e análise de QoS (Quality of Service) e Cós (Class of Service). O IQ2000 trabalha na camada 2 e 3 em equipamentos como switches e roteadores e suporta pacotes com taxas de 2.5Gbps.
Chameleon CS2000 Family Aplicações em estações base sem fio de 2G e 3G, Wireless Voz sobre IP e alto desempenho DSL. processador reconfigurável.
Intel – IXP2800 Módulo de segurança no qual realiza criptografia e flexibilidade da execução dos protocolos, otimização dos protocolos para determinadas aplicações, e execução de aplicações diferentes.
14.2.2 Arquitetura dos Sistemas de Segurança com NPs
Em termo gerais, em hardware, há três maneiras que permitem adicionar funções de segurança a um determinado equipamento de networking, aquele que está sempre facilitando a comunicação entre vários usuários.
Primeiro é o método de usar um co-processador acoplado a um processador de rede ou a um processador de propósito geral. Este método torna-se menos prático porque o pacote (conjunto de dados sendo transmitidos em uma determinada comunicação) deve atravessar recursos compartilhados tais como barramentos ou memória de dados, pertencentes aos equipamentos de outros usuários que estão na rota de comunicação.
O segundo método consiste em adicionar um processador de segurança com um processador de rede, o que possibilita elevadas taxas de transferência de dados. O processador de segurança pode executar funções obrigatórias de um determinado processador de rede, tendo assim que remontar o pacote, o que aumenta (geralmente

233
duplica) a área de trabalho do sistema, isto é, aumenta a necessidade de recursos de armazenamento (memória e etc.) no sistema de comunicação.
O terceiro método deve adicionar a funcionalidade da segurança no mesmo processador que se encarrega das funções de comunicação na rede, assim adiciona a funcionalidade de segurança no processador de rede, o que mantém ou aumenta a taxa de comunicação da rede e minimiza os recursos de hardware no sistema.
Com base nessas três possibilidades explicadas acima, os processadores atuais que contém mecanismos e funções de segurança requerem que um determinado pacote este disponível de forma inteira na memória antes de ser processado, sendo assim o pacote estará inteiro na memória antes de ser transmitido, o que aumenta a velocidade de comunicação em um sistema interconectado via rede, tipo internet, por exemplo.
Arquitetura Look-aside:
Como se pode observar na figura 14.5, entre um processador de rede e um processador de segurança na configuração look-aside, os dados do pacote devem tipicamente atravessar a memória quatro vezes, ao contrário de duas vezes, e o barramento entre o processador de rede e o processador de segurança deve ser capaz de fazer ao menos duas vezes a taxa desejada.
Figura 14.5 - Arquitetura look-aside
Arquitetura Flow-through:
A arquitetura Flow-through resolve os problemas de desempenho da arquitetura look-aside, mas requer que o processador de segurança seja capaz de fazer muitas das funções que o processador de rede precisaria e deveria fazer. Algumas destas tarefas incluem a remontagem dos pacotes, implementar o protocolo que processa os pacotes sendo transmitidos em uma comunicação, e a respectiva manipulação de exceção para evitar erros de comunicação.
É desejável poder usar a mesma arquitetura subjacente para múltiplas aplicações. Isto seria possível se a funcionalidade de segurança fosse adicionada ao processador de rede, responsável pela comunicação entre vários usuários interconectados.

234
Na Figura 14.6 pode-se observar o mecanimo da arquitetura Flow-through. Algumas aplicações requerem que o processador de rede esteja colocado antes do processador de segurança, outros requerem que o processador de segurança esteja colocado antes do processador de rede, e outros requerem um processador de rede antes e depois do processador de segurança. Por exemplo, uma aplicação do proxy do SSL requer a terminação de uma conexão do TCP, do SSL que processam, e então do estabelecimento de uma conexão nova do TCP (INTEL, 2000).
Figura 14.6 - Arquitetura Flow-through
Em um ambiente com segurança, é necessário que o processador de rede com segurança realize as operações de processamento normal a uma comunicação e processe também as ações e funções relacionadas com segurança, por exemplo execução de algoritmos criptográficos, e etc.
O processamento do protocolo inclui encapsular protocolo de segurança (ESP), encabeçamento de autenticação (AH), fixa a camada dos sockets (SSL), a segurança da camada de transporte (TLS), e realize as operações normais de outros protocolos que não conte´m ações de segurança tais como o Transmission Control Protocol (TCP) e processamento do Internet Protocol (IP).
O algoritmo de criptografia inclui a manipulação de dados que necessita ser feita na totalidade dos pacotes, mantendo a confiabilidade e a integridade.
A arquitetura Flow-through requer de um processador de segurança que deverá executar funções similares às funções de um processador de rede, o qual além de processar informações atende também às necessidades dos protocolos de comunicação. Isto pode ser feito com um processador dedicado ou talvez com vários processadores que integram e executam de forma integrada as funções de um processador de segurança.
Uma pergunta interessante é levantada: É melhor adicionar as funções necessárias a um processador de rede para permití-lo que faça e processe ações de segurança ou adicionar um processador especial que realize essas funções e trabalhe em conjunto com o processador de rede ?
Tentando resolver essa questão, várias processadores modernos de rede estão integrando ações e funções criptográficas e de segurança nos próprios processadores de rede. Um deles, e que na visão dos autores, merece destaque é o processador de rede da Intel, o IXP2800 (IXP2800, 2005).
foi adicionado a funcionalidade e a flexibilidade extensivas do processador de rede e adicionado os algoritmos criptografia necessários.

235
14.2.3 Processador IXP 2800
Existem diversos tipos de equipamento em hardware, que oferecem funções e serviços de criptografia e segurança, tais como: Processadores de Rede comerciais de diversos fabricantes, processadores especializados para segurança (Ex. o processador IXP 2800 visto na seção anterior) e coprocessadores (Ex. o IBM 4758).
Tabela 14.5. Processadores de Redes Comerciais
Processadores de Rede Comerciais
Características mais Importantes Segurança
Motorola – PowerQUICC Family
Aplicações em roteadores e switches de LAN/WAN, dispositivos de integração de redes, concentradores de rede, gateways, DSL/cable modems e sistemas de voz sobre IP.
Não
Motorola/C-Port – C5 Family
Prioriza os critérios de QoS (qualidade de Serviço) Não
Intel – IXP1200 Sete processadores RISC , responsável pelo processamento mais complexo, tal como construção e manutenção de tabelas e gerenciamento da rede.
Não
IBM – PowerNP NP4GS3
Encaminhar e filtrar pacotes analisando campos do protocolo IP, Controlar protocolos de roteamento tal como: RIP, OSPF e BGP, Gerenciar, configurar, diagnosticar e suportar agentes SNMP.
Não
Lucent / Agere – FPP/ASI/RSP
Aplicações para este processador são: Roteadores e switches, Firewalls, gerenciamento e monitoramento de redes, Segmentação ATM e Frame Relay, Processamento de lista e controle de acesso.
Não
EZCHIP – NP – 1 Aplicações em roteadores, switches e gateways, Balanceamento de carga, Analisadores e testadores de rede, Firewalls e VPNs.
Não
Sitera/Vitesse – Prism IQ2000 Family
Processamento dos pacotes, classificação, lookups e análise de QoS (Quality of Service) e Cós (Class of Service). O IQ2000 trabalha na camada 2 e 3 em equipamentos como switches e roteadores e suporta pacotes com taxas de 2.5Gbps.
Não
Chameleon CS2000 Family
Aplicações em estações base sem fio de 2G e 3G, Wireless Voz sobre IP e alto desempenho DSL. processador reconfigurável.
Não
Intel – IXP2800 Módulo de segurança no qual realiza criptografia e flexibilidade da execução dos protocolos, otimização dos protocolos para determinadas aplicações, e execução de aplicações diferentes.
Sim
Na tabela 14.5 pode-se observar que alguns fabricantes de processadores de redes modernos, comerciais, já começam a inserir serviços criprográficos. Exemplo disso, é o processador IXP2800(IXP2800, 2005).
Os projetos precedentes adicionaram funções e ações de segurança à rede através de um co-processador ou de um processador específico de segurança. Considerando as altas e crescentes necessidades de transferência de dados, essas duas possibildiades ainda que viáveis, em muitas aplicações não são viáveis.

236
Os processadores online da segurança podem realmente escalar a taxas de dados mais elevadas mas devem executar muitas das mesmas funções que o processador de rede faz para conseguir a taxa de dados elevada.
A integração de funções de segurança no IXP2800 torna possível uma velocidade em rede de até 10 Gigabits/s. Isto permite que o projeto ofereça as funcionalidades de segurança no equipamento da rede desde o começo de uma comunicação, providenciando também um sistema total de baixo custo nos termos do consumo de potência, e do investimento.
No IXP2800 adicionaram-se funcionalidades extensivas ao processador de rede através da inserção de uma unidade especial de segurança, chamada de unidade CRYPTO, a qual pode ser observada nos detalhes da sua arquitetura descritos na figura 14.7.
A unidade CRYPTO possibilita a execução dos algoritmos 3DES, AES, e SHA-1, e oferece também suporte para vários protocolos, tais como IPSec, SSL/TLS, ATM.
Figura 14.7 – Arquitetura do IXP2800 (IXP2800, 2005)

237
A figura 14.8 permite observar que é possível executar de forma paralela, ações de segurança em vários pacotes independentes. Através da figura, é possível executar até 5 operações em paralelo: uma para um pacote com ações do algoritmo 3DES, outra similar 3DES mas para outro pacote, um pacote pode ser tratado seguindo o algortimo AES. De forma similar, pode-se fazer tratamento de assinatura digital, usando o algoritmo hash SHA-1 para dois diferentes pacotes, os quais podem ser diferentes ou provenientes das unidades criptográficas 3DES ou AES.
Os algoritmos criptografia que são executados no chip IXP28xx faz com que seja possível conseguir taxas de dados seguras até de 10 Gigabits/s. Conseguir as exigências processando segurança em um processador de rede faz possível fornecer não somente uma velocidade elevada fixa a conexão mas também uma que é realziada em um custo relativamente baixo.
Devido à natureza flexível do processador de rede de IXP28xx, as gerações futuras integrarão mais funcionalidade da segurança. Estas funções poderão incluir a geração da chave pública, a geração do número aleatório, e até deteção de intrusão.
Figura 14.8 - Vista geral da unidade de criptografia do IXP 2800
14.3 Coprocessador IBM 4758 O coprocessador criptográfico 4758 da IBM é um subsistema seguro e avançado que pode ser instalado em sistemas de usuário para executar o DES e a criptografia de chave pública (IBM 4758, 2005).
Um coprocessador seguro é um ambiente computacional com um processador de propósito geral com suporte a ataques físicos e ataques lógicos. O dispositivo deve funcionar para os programas que se supõe serem programas de ataque. Um usuário deve poder (remotamente) distinguir entre o dispositivo real e a aplicação, e um “verificador” inteligente. O coprocessador deve manter a segurança mesmo se os adversários realizarem uma análise destrutiva de um ou mais dispositivos.
Muitos usuários costumam trabalhar nos ambientes distribuídos onde é difícil ou impossível fornecer a segurança física completa para processamento. E, em algumas

238
aplicações, o adversário é o usuário da outra extremidade. Portanto, se torna necessário um dispositivo em que se possa confiar mesmo que não possa controlar o ambiente.
O coprocessador IBM está qualificado para detectar tentativas de ataques , e para executar e processar com segurança, incluindo execução corretas de diversos algoritmos comercialmente significativos (IBM 4758, 2005).
Suas aplicações podem obter serviços de criptografia através do PKCS#11 que caracteriza a sustentação do DES, do triplo-DES (com chaves do triplo-comprimento), do RSA e do DSA, Sha-1, MD2, e serviços do hashing de MD5. Pode-se empregar múltiplos co-processadores, cada um que opere como unidade independente de PKCS #11. As aplicações são projetadas para suportar o múltiplo gerenciamento de chave, melhorando o throughput e/ou a disponibilidade com um co-processador adicional.
A arquitetura do co-processador IBM 4758 é ilustrada na figura 14.9.
Figura 14.9 – Arquitetura do Coprocessador IBM 4758 (IBM 4758, 2005)
14.4 Smart Cards Smartcards são cartões especiais que possuem processadores embutidos, similares àqueles apresentados na seção anterior, só que são projetados diferentemente, de modo a terem capacidade de processamento específica para a função qu estão realizando. De certa maneira, eles são muito mais simples do que aqules já discutidos, e são projetados em uma tecnologia diferente que oferece possibilidades de menor tamanho e relativo bom desempenho.
Atualmente há dois tipos de smart cards, aqueles chamados de cartão de memória e de microprocessador.

239
Cartão de Memória: armazenam informações e dependendo da tecnologia aplicada, podem ser descartáveis ou reutilizáveis. Nenhum processamento ocorre no cartão, toda a lógica do sistema está contida nas leitoras;
Cartão Microprocessador: tipo de cartão que realmente pode ser chamado de “Smart” ou inteligente. Cartões inteligentes possuem CPU com capacidade de
executar comandos e áreas de memória para armazenar informações.
Em termos gerais, os smart cards oferecem as seguinte vantagem: Armazenamento das chaves fora do servidor de criptografia. Não obstante, há uma desvantagem: Baixo poder computacional. Maiores informações em (PETRI, 2004).
14.4 HSM São equipamentos externos a um determinado servidor, e são dedicados exclusivamente a funções de criptografia e armazenamento de informações confidenciais.
O acesso lógico ao equipamento pode ser realizado por meio de: Rede Ethernet 10/100 Mbps - TCP/P ou de Interfaces proprietárias.
Eles possuem uma série de serviços, os quais são implementados em dependência da necessidade dos usuários. Por exemplo (GUELFI, 2002):
(1) Segmentação de funções, através da diferenciação de usuários:
- Em nível de Operador, pode oferecer funções tais como Configuração de parâmetros de rede (End. IP, Máscara, Gateway) e alguns mecanismos de Autenticação através de Chave físicas (implementadas em hardware).
(2) Segmentação de funções, através da diferenciação de usuários:
- Em nível de “Security Officer”, pode oferecer funções do tipo Ativação/Desativação das funções criptográficas, Backup/Restore das chaves e informações confidenciais. Assim como Mecanismo de Autenticação através de Smartcard + senha.
14.5 Considerações Finais do Capítulo Foram apresentados alguns conceitos relacionados à arquitetura de criptoprocessadores. Por meio destes conceitos foi possível realizar uma análise referente as diferentes abordagens utilizadas para o projeto de criptoprocessadores. Desta maneira foi possível observar que implementações dedicadas, apesar de obter um bom desempenho prejudicam a flexibilidade para o acréscimo de novos

240
algoritmos. Do mesmo modo, projetar criptoprocessadores que contenham conjuntos de instruções aumenta a flexibilidade e reduz o desempenho.
Outra linha de atuação que começa a se destacar é o projeto customizado de hardware para segunrança, através da utilização de uma nova tecnologia de prototipação de sistemas digitais, conhecida como FPGAs, a qual será alvo dos próximos capítulos.

241
Capítulo 15 Arquitetura e Implementação de um Criptoprocessador VLIW em FPGAs:
Este capítulo apresenta detalhes de projeto de um criptoprocessador que é um processador específico para criptografia, em especial, para algoritmos simétricos, prototipado em um FPGA seguindo o modelo e arquitetura VLIW (Very Long Instructions Word).
15.1 Introdução Neste capítulo apresenta-se a proposta e detalhes de implementação de um criptoprocessador VLIW, discutindo detalhes da arquitetura e especificando o seu conjunto de instruções. O criptoprocessador foi projetado para executar preferencialmente algoritmos de criptografia simétricos e para isso, foram descritos módulos especiais para aumentar a performance do Criptoprocessador e macro-instruções para auxiliar o programador.
O criptoprocessador foi descrito utilizando a linguagem VHDL. Posteriormente sua descrição foi sintetizada e implementada para um FPGA Virtex II Pro gerando dados estatísticos de ocupação e desempenho temporal, apresentados e discutidos neste capítulo.
Este criptoprocessador suporta uma série de algoritmos simétricos, inclusive algoritmos atuais, que utilizam chaves de 128 bits ou até maiores. É importante salientar que os módulos especiais, que diferenciam este criptoprocessador, não são específicos para um determinado algoritmo de criptografia. Estes foram projetados de forma a serem pré-configurados de acordo com as características do algoritmo que será executado. Esta característica ressalta uma das qualidades do criptoprocessador, a quantidade de algoritmos suportados.
A flexibilidade oferecida pelas instruções do Criptoprocessador VLIW permite que o usuário da área de segurança descreva algoritmos simétricos com relativa facilidade. Macro-instruções que realizam operações próprias de algoritmos de criptografia simétricos, como a permutação e substituição de bits, fazem uso destes módulos especiais.

242
A arquitetura VLIW proposta para o criptoprocessador pode ser definida a partir de dois conceitos: (i) o micro código horizontal e (ii) o processamento superescalar. Uma máquina VLIW típica tem palavras com centenas de bits (STALLINGS, 2002). Neste caso, o Criptoprocessador VLIW proposto tem 160 bits por palavra. Todas as unidades funcionais compartilham um grande banco de registradores comuns e as operações a serem executadas simultaneamente são armazenadas em uma palavra VLIW. O micro código horizontal de cada palavra VLIW é formado por opcodes e dados que especificam as operações a serem executadas em diferentes unidades funcionais (PEREIRA, 2004).
As técnicas superescalares e os processadores superpipeline exploram o paralelismo de instrução de forma a reduzir o número médio de ciclos por instrução e o tempo de ciclo, respectivamente. Em contrapartida, os processadores VLIW exploram o paralelismo em nível de instrução para reduzir o número de instruções e assim reduzir o tempo total de processamento. Apesar dessa sutil diferença, em função das três abordagens explorarem o mesmo tipo de paralelismo, elas compartilham algumas características e técnicas comuns que podem ser aplicadas para melhor explorar o paralelismo de instruções (STALLINGS, 2002).
A arquitetura VLIW busca uma palavra em um único endereço de memória e cada unidade funcional (UF) executa uma das diferentes operações contidas na palavra VLIW. Para tirar proveito dos recursos do processador é necessário um compilador eficiente para escalonar estaticamente as instruções independentes para não gerar conflitos estruturais e manter a semântica do programa durante a execução, em detrimento das dependências de dados existentes.
As principais caracteríticas de uma arquitetura VLIW são:
• Arquitetura altamente regular e exposta ao compilador. Portanto, há pouca restrição no acesso aos recursos do processador, permitindo o escalonamento de instrução com elevado grau de liberdade para explorar um vasto conjunto de possíveis otimizações;
• O compilador tem conhecimento prévio de todos os efeitos das operações sobre a arquitetura, como por exemplo, a latência de cada unidade funcional. Como a execução é regida por um clock global, o compilador está apto a resolver conflitos estruturais e de dados em tempo de compilação, dispensando mecanismos de sincronização em tempo de execução;
• Capacidade de despacho de múltiplas operações;
• Mantém o hardware de controle simples, permitindo teoricamente um ciclo de clock menor.
Essas são as principais características desta arquitetura. O fato de escalonar as instruções em nível de compilação torna esta arquitetura simples, pois o paralelismo das instruções não é definido em hardware (em tempo de execução). A simplificação da arquitetura, teoricamente, diminui o tempo do ciclo de clock, otimizando o processamento como um todo.

243
Duas das principais desvantagens do modelo VLIW são:
• A previsão incorreta do caminho tomado em desvios condicionais pode afetar consideravelmente sua performance. Como a previsão é feita estaticamente, informações importantes disponíveis em tempo de execução são completamente negligenciadas.
Importante salientar que no caso do nosso processador, que focaliza o impacto da carga de trabalho dos algoritmos criptográficos, esta desvantagem não afeta o desempenho, pois os algoritmos são códigos altamente estáticos e não são facilmente alterados em tempo de execução.
• Ineficiência em programas onde a dependência de dados é grande. Neste caso, grande parte das instruções não poderá executar em paralelo, prejudicando o desempenho do sistema. Uma maneira de identificar quando há muita dependência de dados é verificando a ocorrência de muitos NOPs no programa.
Esta desvantagem influência no desempenho do criptoprocesador de forma significativa. A dependência de dados nos algoritmos de criptografia pode ser classificada como média, sendo significativa, mas não predominante. Para otimizar a execução dos algoritmos criptográficos algumas técnicas foram estudas, uma delas é a técnica de looping pipeline destacada na seção 2 do capítulo 16.
A escolha do modelo de arquitetura VLIW justifica-se pela necessidade de atingir um desempenho diferenciado com um hardware composto por módulos independentes que em conjunto podem ser facilmente controlados e coordenados para a execução paralela de instruções. Diferente de outras arquiteturas que promovem estas características, a arquitetura VLIW não necessita de um hardware sofisticado para o controle do fluxo de informações, gerando um hardware relativamente enxuto quando comparado com outras arquiteturas como superescalar e superpipeline. Soma-se a isso o fato de considerar as possibilidades de usar circuitos programáveis (FPGAs), onde deve-se otimizar os recursos espaciais existentes.
O fato de que os algoritmos criptográficos simétricos são compostos por uma seqüência de operações estáticas, faz com que diminua de forma significativa a ocorrência de eventos aleatórios em tempo de execução que possam prejudicar o desempenho do Criptoprocessador, que não está preparado para tratar este tipo de exceção. Isto não quer dizer que ocorrerá um erro, mas apenas prejudicará o desempenho da execução.
A seguir destacam-se algumas das características deste criptoprocessador, que são discutidas no decorrer deste capítulo:
• Arquitetura VLIW composta modelo Harvard+Pipeline como um conjunto RISC de instruções.
• Palavra VLIW de 160 Bits

244
• Cache de dados e instrução (Harvard)
• 8 Unidades Funcionais de 128 Bits (UFs)
• 2 ULAs
• Deslocador de 1,2,4, 8 e 32 Bits (Logical Shifter)
• Rotacionador de 1,2,4, 8 e 32 Bits
• Permutação (P-BOX)
• Substituição (S-BOX)
• LOAD/STORE
• MOV/DESVIOS
• Paralelismo de Instruções (Estático)
• Até 4 instruções executando em um único ciclo
• 16 Permutações por ciclo
• Pipeline de 3 estágios globais
• 25 Instruções
• 24 Registradores
Estas características foram estabelecidas após realizar um breve estudo dos seguintes algoritmos criptográficos: RC6 (RIVEST, 2000), Serpent (ROSS, 1998), Cast-128 (CARLISLE, 1997), MARS (BURWICK, 1999), Twofish (SCHNEIER, 1998), Magenta (JACOBSON, 1998), Frog (GEORGOUDIS, 1998), BlowFish (SCHNEIER, 1994) e IDEA (LAI, 1990) com destaque para os algoritmos DES (FIPS46-3, 1999), AES (FIPS197, 2001) e RC5 (RIVEST, 1995), descritos nos capitulos 6, 10 e 11 respectivamente.
A palavra VLIW de 160 bits armazena até 4 instruções de 40 bits cada, que serão executadas em paralelo. O paralelismo acima de 4 instruções torna o hardware mais complexo, aumentando o tempo do ciclo de máquina. Além disso, a ocorrência de mais de 4 instruções sendo executadas em paralelo não seria comum, já que a dependência de dados inibiria esta possibilidade, prejudicando o desempenho geral do criptoprocessador, subutilizando suas unidades funcionais.
A ocorrência maior de algumas instruções como, deslocamento, rotação, permutação e substituição de bits torna importante a criação de módulos dedicados e diferenciados para atingir uma melhor performance. Os módulos de deslocamento e rotação de bits podem atuar tanto em um único bit quanto em blocos de até 32 bits. Esta propriedade diminui o número de instruções necessárias para execução destas operações.

245
As unidades funcionais de permutação e substituição foram projetadas para atingir um desempenho satisfatório e suportar o maior número de algoritmos criptográficos simétricos possíveis. A criação de módulos independentes de LOAD/STORE e de movimentação entre registradores e desvios (MOV/DESVIOS) são importantes, principalmente em processadores que adotam o modelo Harvard, que possui memórias distintas para instruções e dados.
15.2 Arquitetura do Criptoprocessador VLIW Nesta seção apresenta-se uma visão geral da arquitetura do criptoprocessador e detalhes de cada unidade funcional. A figura 15.1 ilustra a arquitetura top-level do criptoprocessador VLIW. O criptoprocessador é formado por quatro partes:
1) despachador de instruções;
2) as unidades funcionais;
3) banco de registradores e;
4) a unidade de controle.
Observa-se na figura 15.1 a presença de duas memórias Caches, uma de instruções (I-CACHE) e outra de dados (D-CACHE). Na cache de instruções devem estar armazenados os algoritmos de criptografia descritos em assembly do criptoprocessador. Na cache de dados são armazenadas informações como o conteúdo das S-BOXES de um determinado algoritmo, o texto claro e os resultados de operações realizadas.
A presença de duas memórias distintas, uma para instruções e outra para dados, caracteriza o modelo de arquitetura Harvard. Estas memórias têm endereçamento individual, isto permite a leitura e a escrita simultâneas em memórias distintas, diminuindo o número de ciclos nos estágios de busca e escrita de resultados.
A dimensão da I-CACHE é de 16x160 armazenando um total de 1.310.720 bytes, possibilitando o armazenamento de vários algoritmos criptográficos. A D-CACHE é de 16x128 armazenando um total de 1.048.576 bytes. Nesta memória são armazenados dados como o texto claro, o texto cifrado, resultados de operações e as S-BOXES.
Na figura 15.1 destacam-se as memórias como parte externa do criptoprocessador. Isto porque, neste protótipo as memórias não foram implementadas em FPGA. Visto que, seria pouco viável a descrição de memórias destas dimensões em dispositivos FPGAs.

246
Figura 15.1 – Arquitetura top-level do Criptoprocessador VLIW
O módulo despachador de instruções é responsável pelo direcionamento de cada instrução contida em uma palavra VLIW para a respectiva execução. A princípio, esta função exigiria um hardware sofisticado para tomar decisões, mas na arquitetura VLIW o despachador não engloba funções de decisão em tempo de execução. Isto é, a definição de qual instrução será executada e qual será a unidade funcional selecionada é de responsabilidade do compilador, simplificando o hardware e aumentando a velocidade de execução.
Na figura 15.1, mostra-se de forma simplificada as unidades funcionais presentes no sistema. No total são oito unidades funcionais. Estas podem executar um conjunto de operações selecionas pelo opcode da instrução. As unidades funcionais são:
• UF1 e UF2 - ULA, realiza operações lógicas e aritméticas básicas.
• UF3 - Deslocador de 1,2,4, 8 e 32 Bits
• UF4 - Rotacionador de 1,2,4,8 e 32 Bits
• UF5 - Permutação (P-BOX)
• UF6 - Substituição (S-BOX)
• UF7 - Load/Store, responsável pela busca e escrita em memória.
• UF8 - MOV/DESVIOS
As unidades funcionais (UFs) são responsáveis pela execução das instruções direcionadas pelo módulo despachador. Cada UF possui um registrador de instruções (RI). Assim, tem-se um total de oito registradores de instruções. Estes registradores armazenam a instrução que será executada.
Cada UF pode decodificar a instrução que irá executar. A execução entre as unidades funcionais pode ser realizada de forma paralela. Em um determinado ciclo

247
de execução até quatro unidades funcionais poderão estar em execução, já que o número máximo de instruções em uma palavra VLIW é de 4 instruções. A tabela 15.1 apresenta as unidades funcionais e os principais registradores que estas utilizam.
Tabela 15.1 – Principais Registradores utilizados pelas unidades funcionais
Unidade Funcional Principais Registradores ULA 1 A1 e B1 ULA 2 A2 e B2 Deslocador A3 Rotacionador A4 Permutação (P-BOX) A5, B5, X Substituição (S-BOX) A6, B6, SPC Load/Store DPC, IPC MOV/DESVIOS --
Os registradores A, B e X são de 128 bits, e armazenam operandos e resultados das unidades funcionais. Registradores e operações de 128 bits facilitam a descrição de algoritmos atuais que operam com chaves e blocos de texto de 128 bits ou mais.
Os registradores contadores (SPC, DPC e IPC) são de 16 bits, responsáveis por endereçar as memórias D-CACHE (16x128) e I-CACHE (16x160). Para todas as operações, o resultado será armazenado no registrador A. A tabela 15.2 mostra todos os registradores organizados por função.
Tabela 15.2 – Registradores organizados por função
Função Registradores Registradores de operandos e resultados
X, A1, B1, A2, B2, A3, A4, A5, B5, A6, B6
Registradores contadores PERAC, AC1, AC2, SPC, DPC, IPC Registradores de configuração
SBOXEND, SBOXCOL, SBOXQ, TBO, TBD, B
Observa-se na tabela 15.2 que o banco de registradores totaliza 24 registradores, cada unidade funcional utiliza um ou mais registradores distintos. Os registradores de configuração variam de 1 a 32 bits.
Toda a arquitetura é gerenciada pela unidade de controle, que organiza o fluxo de execução, inclusive o pipeline de três estágios. Detalhes de cada registrador e da arquitetura em geral são apresentados nas seções seguintes

248
15.3 Conjunto de instruções O conjunto de instruções do criptoprocessador segue o modelo RISC. Onde com apenas 25 instruções é possível descrever a maioria dos algoritmos de criptografia simétrica. As instruções podem ser divididas em quatro classes:
• Lógicas e Aritméticas (128 bits): AND,OR, XOR, ADD, SUB, SHL, SHR, ROL, ROR, INC, DEC, NOT, CLR e NOP.
• Movimentação: LOAD, STORE e MOV.
• Desvios: JMP, JZ, JL e JG.
• Especiais: PERINIC, PERBIT, SBOXINIC e SBOX.
As instruções especiais fazem acesso aos módulos especiais do criptoprocessador. Cada grupo de instruções é executado por uma unidade funcional especifica. Importante salientar, que das 8 unidades funcionais, há duas para execução de instruções especiais, tais como a permutação e a substituição. Também existem unidades funcionais próprias para instruções que merecem destaque do projeto do criptoprocessador relacionada a operações como o deslocamento e a rotação de bits, comuns em algoritmos de criptografia simétricos. A relação unidade funcional e instruções está descrita na tabela 15.3.
Tabela 15.3 – Instruções por unidades funcionais
Unidade Funcional Instruções ULA 1 e 2 AND,OR, XOR, ADD, SUB, INC, DEC, NOT E CLR Deslocador SHL E SHR Rotacionador ROR E ROL Permutação (P-BOX) PERINIC E PERBIT Substituição (S-BOX) SBOXINIC, SBOX Load/Store LOAD, STORE MOV/DESVIO MOV, JMP, JZ , JG, JL
Cada instrução possui um opcode diferente. Na tabela 15.4 tem-se uma descrição detalhada de cada instrução, apresentando seus opcodes e operando de cada uma das 25 instruções.
Tabela 15.4 – Descrição do conjunto de instruções do Criptoprocessador
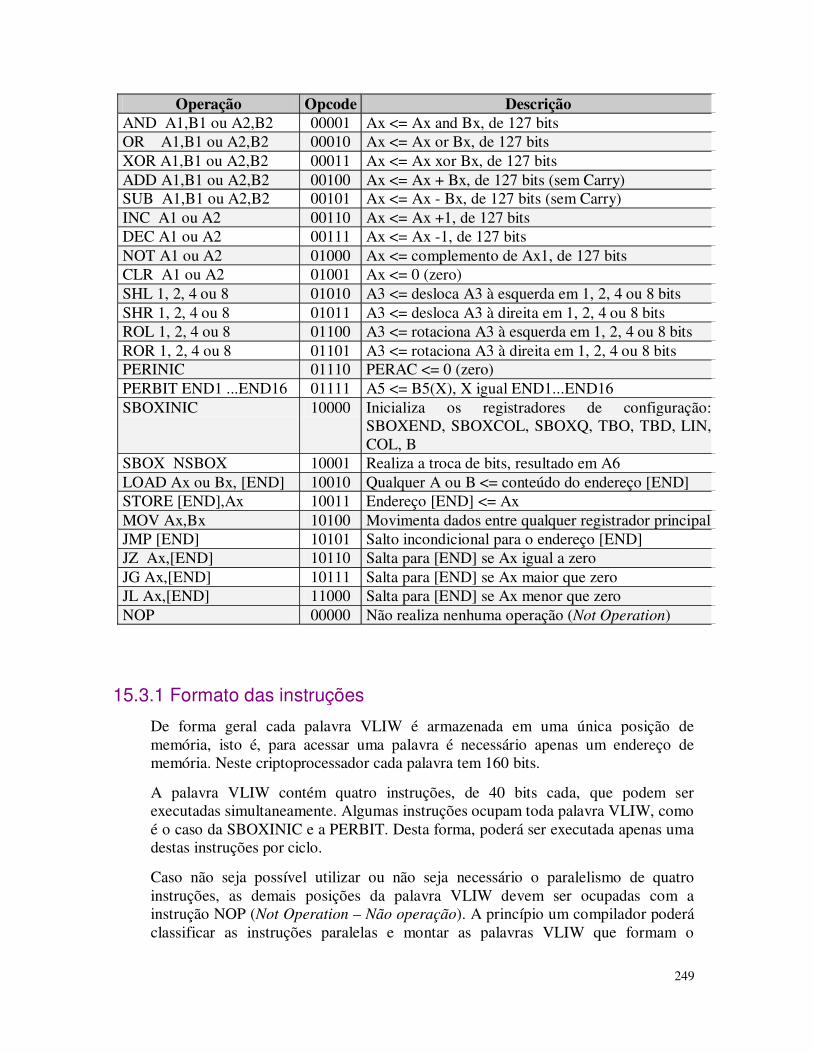
249
Operação Opcode Descrição AND A1,B1 ou A2,B2 00001 Ax <= Ax and Bx, de 127 bits OR A1,B1 ou A2,B2 00010 Ax <= Ax or Bx, de 127 bits XOR A1,B1 ou A2,B2 00011 Ax <= Ax xor Bx, de 127 bits ADD A1,B1 ou A2,B2 00100 Ax <= Ax + Bx, de 127 bits (sem Carry) SUB A1,B1 ou A2,B2 00101 Ax <= Ax - Bx, de 127 bits (sem Carry) INC A1 ou A2 00110 Ax <= Ax +1, de 127 bits DEC A1 ou A2 00111 Ax <= Ax -1, de 127 bits NOT A1 ou A2 01000 Ax <= complemento de Ax1, de 127 bits CLR A1 ou A2 01001 Ax <= 0 (zero) SHL 1, 2, 4 ou 8 01010 A3 <= desloca A3 à esquerda em 1, 2, 4 ou 8 bits SHR 1, 2, 4 ou 8 01011 A3 <= desloca A3 à direita em 1, 2, 4 ou 8 bits ROL 1, 2, 4 ou 8 01100 A3 <= rotaciona A3 à esquerda em 1, 2, 4 ou 8 bits ROR 1, 2, 4 ou 8 01101 A3 <= rotaciona A3 à direita em 1, 2, 4 ou 8 bits PERINIC 01110 PERAC <= 0 (zero) PERBIT END1 ...END16 01111 A5 <= B5(X), X igual END1...END16 SBOXINIC 10000 Inicializa os registradores de configuração:
SBOXEND, SBOXCOL, SBOXQ, TBO, TBD, LIN, COL, B
SBOX NSBOX 10001 Realiza a troca de bits, resultado em A6 LOAD Ax ou Bx, [END] 10010 Qualquer A ou B <= conteúdo do endereço [END] STORE [END],Ax 10011 Endereço [END] <= Ax MOV Ax,Bx 10100 Movimenta dados entre qualquer registrador principal JMP [END] 10101 Salto incondicional para o endereço [END] JZ Ax,[END] 10110 Salta para [END] se Ax igual a zero JG Ax,[END] 10111 Salta para [END] se Ax maior que zero JL Ax,[END] 11000 Salta para [END] se Ax menor que zero NOP 00000 Não realiza nenhuma operação (Not Operation)
15.3.1 Formato das instruções
De forma geral cada palavra VLIW é armazenada em uma única posição de memória, isto é, para acessar uma palavra é necessário apenas um endereço de memória. Neste criptoprocessador cada palavra tem 160 bits.
A palavra VLIW contém quatro instruções, de 40 bits cada, que podem ser executadas simultaneamente. Algumas instruções ocupam toda palavra VLIW, como é o caso da SBOXINIC e a PERBIT. Desta forma, poderá ser executada apenas uma destas instruções por ciclo.
Caso não seja possível utilizar ou não seja necessário o paralelismo de quatro instruções, as demais posições da palavra VLIW devem ser ocupadas com a instrução NOP (Not Operation – Não operação). A princípio um compilador poderá classificar as instruções paralelas e montar as palavras VLIW que formam o

250
programa. Assim, esse compilador será responsável por atribuir os NOPs necessários conforme a dependência de dados ou a lógica imposta pelo programador. Na figura 15.2 tem-se o formato da palavra VLIW.
Figura 15.2 – Formato da palavra VLIW
As instruções podem ser classificadas em dois tipos: instruções de 160 bits e de 40 bits. As instruções de 160 bits ocupam toda palavra VLIW e tem apenas um opcode. Neste caso, não é possível executar outras instruções em paralelo. As instruções de 160 bits são:
• PERBIT - executa 16 permutações por ciclo;
• SBOXINIC – inicialização da S-BOX.
As demais instruções são de 40 bits e podem ser executadas em paralelo, atingindo até quatro instruções por ciclo. Algumas instruções de 40 bits são exclusivas, isto é, não podem ocorrer na mesma palavra VLIW. A seguir mais detalhes dessas instruções exclusivas.
15.3.2 Instruções Exclusivas
Estas instruções acessam a Cache de dados e registradores de dados. Para manter a coerência e integridade do acesso a esses dispositivos, não é possível a execução de mais de uma instrução exclusiva na mesma palavra VLIW. Estas instruções são:
• LOAD – Carrega dado de um determinado endereço de memória (D-CACHE)
• STORE - Armazena dados na memória (D-CACHE)
• SBOX - Substitui n bits de bloco de entrada, por um valor localizado em uma tabela estática de substituições (D-CACHE).
Estas instruções são exclusivas, pois neste caso, fisicamente não é possível o acesso simultâneo à mesma memória (D-CACHE).
Caso especial: a instrução MOV movimenta dados entre registradores em um único ciclo. Dependendo do contexto, esta instrução pode gerar uma incoerência, prejudicando a integridade dos dados e do fluxo de execução. Assim, a instrução MOV pode ser considerada exclusiva em alguns casos, a seguir quatro exemplos:

251
Exemplo 1: Palavra VLIW [ADD A1, B1 | INC A2 | MOV A1,A3 | NOP ]
Esta palavra contém quatro instruções (ADD, INC, MOV e NOP) que são executadas simultaneamente em um único ciclo. Neste caso, existe uma incoerência, já que o valor de A1, após a execução, pode não ser o desejado. Isso acontece pois, tanto a instrução de ADD como a instrução de MOV, modificam o conteúdo de A1, sendo que, a predominância neste caso é da instrução de movimentação (MOV). Portanto A1, no final da execução armazenará o valor contido em A3 (MOV A1, A3).
Neste contexto, a instrução MOV pode ser considerada exclusiva. Sendo indicada sua execução em um ciclo anterior ou posterior à instrução de ADD, conforme o resultado que se deseja obter.
Exemplo 2: Palavra VLIW [ ADD A1,B1 | INC A2 | MOV A5,A3 | NOP ]
Neste caso, a instrução MOV não é exclusiva já que as operações ocorrem entre registradores que não estão sendo operados na mesma palavra VLIW.
Exemplo 3: Palavra VLIW [ ADD A1,B1 | INC A2 | MOV A5,A3 | LOAD A5,[1000] ]
Neste caso, ocorre uma instrução MOV e um LOAD que modificam o mesmo registrador (A5). Assim, da mesma forma como verificado no exemplo 1 pode existir uma incoerência. Quem estabelece a ordem de predominância é o projetista do sistema, neste caso, considera-se que a execução das instruções segue a seguinte ordem de predominância:
1º LOAD/STORE
2º MOV
3º Operações lógicas e aritméticas
Esta ordem foi estabelecida no projeto do criptoprocessador VLIW, para assegurar a integridade e coerência do valor armazenado em um determinado registrador, após a execução simultânea de instruções que modificam o mesmo registrador.
Assim, a instrução LOAD predomina sobre a instrução MOV. Portanto A5 armazenará o valor contido no endereço [1000] de memória (D-CACHE), e não o valor de A3 (instrução MOV A5,A3).

252
Exemplo 4: Palavra VLIW [ ADD A1,B1 | INC A2 | MOV A5,A3 | LOAD A6,[1000] ]
Neste caso, a instrução MOV não é exclusiva já que as operações ocorrem entre registradores distintos. Observa-se que mesmo com a presença de uma instrução exclusiva, o LOAD, é possível a execução paralela.
15.3.3 Instruções de Propósito Geral
Instruções de propósito geral são comuns em processadores de propósito geral (PPGs), ou seja, processadores implementados para suportar programas com características distintas. Estas realizam operações básicas como desvios, movimentações de dados, operações lógicas e aritméticas.
O Criptoprocessador proposto e implementado não é um PPG, pois suporta apenas uma classe específica de programas, os algoritmos de criptografia simétricos. Suas instruções consideradas de propósito geral possuem algumas características diferenciadas como:
• Operações lógicas e aritméticas de 128 bits
• Operações de deslocamento e rotação de 1,2,4, 8 2 32 bits em um único ciclo.
• Movimentação entre registradores em um único ciclo.
• Toda instrução de propósito geral tem 40 bits de opcode.
15.3.4 Instruções Especiais
As instruções especiais atendem as características próprias de algoritmos de criptografia simétricos como a permutação e substituição de bits. Estas são especiais por estarem presentes na maioria dos algoritmos criptográficos e possuir unidades funcionais dedicadas para executá-las no criptoprocessador VLIW. Além de não estarem presentes em processadores de propósito geral.
Para suportar o maior número de algoritmos possível foi necessário definir parâmetros de inicialização que configuram o modo de execução das instruções especiais. A seguir as instruções especiais:
Instruções de permutação Instruções de substituição
PERINIC - Inicialização da instrução de permutação
PERBIT* - Permutação de bits. (16 permutações por ciclo)
SBOXINIC* - Inicialização da instrução de substituição
SBOX – Substituição de bits.
* as instruções de SBOXINIC e PERBIT são de 160 bits.

253
Cada instrução especial pode ser considerada como uma macro-instrução, ou seja, elas são simples de serem utilizadas, mas executam uma tarefa complexa, composta por várias operações, tudo em um único ciclo de máquina. A implementação de macro-instruções no projeto do Criptoprocessador VLIW e não de várias instruções menos complexas pode ser justificada pela preocupação em facilitar a descrição destas operações. Nas seções 15.3.4.1 e 15.3.4.2 estas instruções são descritas em detalhes.
15.3.4.1 Operação de Permutação (PERBIT)
A operação de permutação realiza a troca de bits predefinidos em uma tabela de permutação estática. Esta operação é realizada por uma unidade funcional específica (UF5). A permutação utiliza quatro registradores A5, B5, X e PERAC.
• A5 – Armazena resultado da permutação (128 bits)
• B5 – Armazena os bits que serão permutados (128 bits)
• X – Armazena 16 endereços de permutação, de 8 bits cada. Estes endereços são oriundos da tabela de permutação estática do algoritmo em questão.
• PERAC – É um acumulador que aponta para os bits de A3 que serão alterados. A cada instrução de PERBIT, o acumulador PERAC é incrementado em 16 unidades inteiras, apontando para os próximos 16 bits que serão permutados.
Antes de iniciar um processo de permutação é necessário zerar o valor do acumulador PERAC, para este apontar para o bit inicial de A5. Para isso, utiliza-se a operação PERINIC. Na figura 15.3 tem-se a ilustração da instrução PERBIT e a seguir os passos para realizar esta operação:

254
Figura 15.3 – Operação de permutação (PERBIT)
• Inicializar registradores
o Inicializar PERAC, este irá apontar para o Bit inicial de A5.
o Carregar em B5 o vetor de bits que serão permutados.
o Carregar em X os endereços para onde os bits de B5 serão permutados. Cada endereço ocupa 8 bits, possibilitando o acesso a qualquer bit dentro de um vetor de 128 bits.
o Estes endereços de X representam qual bit de B5 será permutado para uma posição em A5 indexada por PERAC.
• Realizar permutação
o Observando a figura 15.3, deseja-se realizar a primeira permutação: Assim, PERAC aponta para o Bit 1 de A5.
o Em X tem-se os endereços de permutação definidos pela tabela de permutação estática de cada algoritmo, neste exemplo o primeiro endereço é 57, o segundo 49, num total de 16 endereços de 8 bits cada.
o B5 contém o vetor de dados que será permutado.
o O primeiro endereço de X aponta para posição 57 de B5.

255
o O conteúdo da posição 57, neste exemplo é 1, é permutado para o bit de A5 apontado por PERAC, neste caso o bit 1.
o A segunda permutação ocorre da mesma forma, mas utiliza-se o próximo endereço de X, neste exemplo o valor 49. O dado contido no endereço 49 de B5 será permutado para o Bit 2 de A5.
o Este processo se repete até que sejam realizadas as 16 permutações indicadas pelos endereços armazenados em X .
Exemplo: No algoritmo de criptografia DES (Data Encryption Standard) é realizada uma permutação inicial descrita pela tabela 15.5. Após realizar a permutação, o Bit 57 do vetor original será o Bit 1 do vetor permutado. O Bit 49 do vetor original será permutado para o Bit 2 e assim por diante.
Tabela 15.5 – Permutação inicial do algoritmo DES
57 49 41 33 25 17 09 01
59 51 43 35 27 19 11 03
61 53 45 37 29 21 13 05
63 55 47 39 31 23 17 07
56 48 40 32 24 16 08 00
58 50 42 34 26 18 10 02
60 52 44 36 28 20 12 04
62 54 46 38 30 22 14 06
O código assembly a seguir descreve uma forma de implementar a permutação inicial do algoritmo DES utilizando as instruções do criptoprocessador. PERINIC // inicializa permutação (PERAC=0)
PERBIT 57,49,41,33,25,17,09,01, // inicio da execução da permutação
59,51,43,35,27,19,11,03 //PERAC=0
PERBIT 61,53,45,37,29,21,13,05, //PERAC=16
63,55,47,39,31,23,15,07
PERBIT 56,48,40,32,24,16,08,00 //PERAC=32
58,50,42,34,26,18,10,02
PERBIT 60,52,44,36,28,20,12,04, //PERAC=48
62,54,46,38,30,22,14,06 // fim da execução da permutação
// resultado da per. em a5

256
15.3.4.2 Operação de Substituição (SBOX)
A S-BOX ou caixa de substituição é um conjunto de dados que forma um vetor ou uma matriz bidimensional. Toda S-BOX é composta por uma entrada de bits (Input S-BOX), que determina a localização do dado de substituição, e uma saída de bits (Output S-BOX), que retorna o valor do dado de substituição. O dado de substituição irá sobrescrever os bits utilizados na entrada da S-BOX.
A instrução SBOX realiza a substituição de bits predeterminados. Através de uma busca por linha e coluna, identifica-se o endereço onde está armazenado o dado de substituição. Este dado é recuperado e armazenado na posição adequada dentro do registrador resultante, realizando a substituição.
Este processo é executado baseado em alguns parâmetros configuráveis. Estes parâmetros são necessários para calcular o endereço de memória onde está localizado o dado de substituição.
Alguns parâmetros podem variar conforme o algoritmo criptográfico que está sendo descrito, por isso a necessidade de parâmetros configuráveis. Na tabela 15.6 tem-se o resultado de um estudo realizado que demonstra como as S-BOXs podem variar de algoritmo para algoritmo (PEREIRA, 2004).
Após um estudo preliminar realizado, os seguintes parâmetros foram considerados necessários para implementar qualquer S-BOX de algoritmos criptográficos simétricos:
• O número de SBOXES de um determinado algoritmo
• O número de bits de entrada da S-BOX
• O número de bits de saída da S-BOX
• Os bits que determinam a linha e bits que determinam a coluna da SBOX.
Observando a tabela 15.6 nota-se algumas características que diferenciam as S-BOXES apresentadas, como por exemplo:
• Alguns algoritmos não utilizam S-BOXES como o RC5, RC6 e IDEA.
• Em algoritmos como o DES e o AES, as S-BOXES são matrizes, portanto são endereçadas pelo par linha/coluna.
• Em algoritmos como Serpent, Mars, Magenta entre outros, as S-BOXES são vetores. Isto é, a busca é feita apenas por coluna. Observa-se na tabela 15.6 que não há bits que determinam a linha, apenas a coluna.
• Existem algoritmos com uma única S-BOX (como é o caso do algoritmo AES) e algoritmos com até oito S-BOXES (Exemplo, o algoritmo DES).
• As saídas das S-BOXES variam de 4 a 32 bits.
• As entradas das S-BOXES variam de 4 a 8 bits.

257
Tabela 15.6 – Comparação das SBOXES de diferentes algoritmos de criptografia
Algoritmo Nº de
S-BOX(ES) Nº de bits de entrada da
SBOX
Nº de bits de saída da SBOX
Bits que determinam a
linha
Bits que determinam
a coluna DES 8 6 4 1 e 6 2,3,4,5 AES 1 8 8 1,2,3,4 5,6,7,8 Serpent 8 4 4 -- 1,2,3,4 Cast-128 4 8 32 -- 1 a 8 MARS 2 8 32 -- 1 a 8 Twofish 8 4 4 -- 1 a 4 Magenta 1 8 8 -- 1 a 8 Frog 1 8 8 -- 1 a 8 BlowFish 4 8 32 -- 1 a 8 RC5 -- -- -- -- -- RC6 -- -- -- -- -- IDEA -- -- -- -- --
O algoritmo LOKI97 (BROWN, 1998) também foi avaliado, este é composto por duas S-BOXES vetoriais de tamanhos físicos distintos. Desta forma, a S-BOX1 tem 14 bits de entrada e 8 bits de saída e 14 bits que determinam a coluna. A SBOX2 do LOKI97 tem 12 bits de entrada e 8 bits de saída e 12 bits que determinam a coluna.
Esta diversificação quanto ao tamanho das SBOXES, dos bits de entrada e saída e da quantidade de S-BOXES tornam o projeto do hardware relativamente complexo. Um hardware dedicado para cada S-BOX descrita na tabela 15.6 pode tornar o circuito veloz, mas necessita de um elevado número de componentes para implementá-lo.
Desenvolver uma única S-BOX genérica que seja veloz e que atenda a maioria dos algoritmos simétricos pode ser considerado um desafio. Assim, no projeto e implementação do criptoprocessador foi proposto uma solução através de parâmetros de configuração por software (PEREIRA, 2004). Isto é, através de uma instrução, o programador poderá configurar o tamanho da S-BOX, bits de entrada e saída, bits que determinam linha e coluna e outros parâmetros necessários para configurar a S-BOX desejada.
Uma solução futura poderia ser através de reconfiguração, onde o hardware decide a necessidade de uma nova S-BOX e esta é reconfigurada em tempo de execução (RTR – Run Time Reconfiguration) (PAAR, 2004), (PAAR, 2000).
Os parâmetros de configuração são implementados através da instrução SBOXINIC. A seguir os parâmetros necessários e suas descrições:
• SBOXEND - Endereço de memória onde está localizada a S-BOX. Os dados da S-BOX estão armazenados na memória D-CACHE. Deve-se apenas indicar a partir de qual endereço inicia a S-BOX, independente do número de S-BOX que o algoritmo utiliza.

258
• SBOXCOL - Número de colunas de uma SBOX.
• SBOXQ – Quantidade de elementos de uma S-BOX.
• TBO - Tamanho do bloco origem, representa a quantidade em bits do bloco que será substituído. O bloco origem alimenta a entrada SBOX gerando o endereço do dado de substituição.
• TBD - Tamanho do bloco destino, representa a quantidade em bits do bloco de substituição. Ao final, o bloco origem será substituído pelo bloco destino, mesmo que forem de tamanhos diferentes. O bloco destino armazenará o resultado da substituição.
• LIN – Bits ou Bytes do bloco origem que determinam a linha de endereçamento da SBOX. Cada algoritmo tem uma forma específica para determinar qual os bits ou bytes que determinaram a linha e a coluna de uma S-BOX, onde está localizado o dado de substituição. Este parâmetro determina estes bits ou bytes para a linha.
• COL - Bits ou Bytes do bloco destino que determinam a coluna de endereçamento da SBOX, de forma similar ao LIN.
• B – Tipo Bit ou Byte, quando B=0 (zero) os valores de LIN e COL são considerados bits. Quando B=1 os valores de LIN e COL são considerados Bytes.
Todos os parâmetros são armazenados em registradores dedicados, assim há um limite físico de bits para a representação de cada parâmetro, os quais determinam os algoritmos suportados pelo criptoprocessador. Na tabela 15.7 tem-se a representação máxima de cada parâmetro.
Tabela 15.7 – Limites de representação dos parâmetros da operação de substituição
Parâmetro Nº de Bits Descrição SBOXEND 16 Endereça até 65535 posições de memória (D-CACHE) SBOXCOL 16 Configura S-BOXES até 65535 colunas SBOXQ 16 Configura S-BOXES até 65535 elementos TBO 6 Configura blocos origem com até 64 elementos TBD 6 Configura blocos destino com até 64 elementos LIN 32 Configura 8 bits para linha em modo bit (B=0);
Configura até 2 bytes em modo byte (B=1); COL 32 Configura 8 bits para coluna em modo bit (B=0);
Configura até 2 bytes em modo byte (B=1);
Alguns parâmetros podem representar um limite maior dos que os encontrados em algoritmos de criptografia simétricos atuais. Mas com o objetivo de adaptação a novos algoritmos, estes limites também foram propostos para suportar futuros algoritmos com S-BOXES diferenciadas.

259
A definição do número de bits de cada parâmetro foi baseada na tabela 15.6, onde se pode identificar e quantificar os bits necessários para representar o número máximo de colunas de uma S-BOX, o tamanho máximo do bloco origem e destino e outros parâmetros.
Por exemplo, os bits de saída definem o tamanho do bloco destino (TBD) de uma S-BOX, este tamanho varia de 4 a 32 bits (ver tabela 15.6), para representar este valor necessitaria de 5 bits (25 = 32), mas para atender futuros algoritmos, este registrador foi definido com 6 bits, podendo identificar um bloco destino de até 64 bits. Desta mesma forma, os demais parâmetros foram definidos. A sintaxe da instrução de inicialização e configuração da S-BOX é:
SBOXINIC SBOXEND, SBOXCOL, SBOXQ, TBO, TBD, LIN, COL, B
Exemplo: Este exemplo mostra a configuração da SBOX do algoritmo de criptografia DES. Detalhes desta S-BOX podem ser visualizados na tabela 15.6.
Define SBOXEND = 001Fh // endereço de inicio da S-BOX (D-CACHE)
Define SBOXCOL = Fh // 16 colunas
Define SBOXQ = 3Fh // 64 elementos
Define TBO = 6h // tamanho do bloco origem (bloco que será substituído)
Define TBD = 4h // tamanho do bloco destino (bloco de substituição)
Define LIN = BIT6, BIT1 // bits do bloco origem que definem a linha
Define COL = BIT5, BIT4, BIT3, BIT2 // bits do bloco origem que definem a coluna
Define B = 0 // modo bit de representação
SBOXINIC SBOXEND, SBOXCOL, SBOXQ, TBO, TBD, LIN, COL, B
Após a inicialização e configuração através da instrução SBOXINIC pode ser realizada a operação de substituição propriamente dita. A instrução SBOX realiza os cálculos necessários para localizar o dado de substituição armazenado na memória D-CACHE, baseando-se nos parâmetros configuráveis.
A instrução SBOX utiliza o parâmetro NSBOX que identifica qual S-BOX deve ser utilizada na substituição. Quando o algoritmo de criptografia utiliza-se de apenas uma S-BOX, o valor de NSBOX é zero. Para identificar um elemento dentro da memória, foi desenvolvida uma fórmula matemática que através de alguns dos parâmetros configuráveis pode identificar o endereço desejado, ver figura 15.4.
Figura 15.4 – Fórmula de endereçamento do dado de substituição

260
A memória é um vetor de N posições, em alguns algoritmos as S-BOXES são representadas por matrizes, como no DES e no AES. Em outros algoritmos por vetores, como no Serpent, Magenta e outros. Para identificar a posição de memória correspondente, independente do tipo de S-BOX, deve-se utilizar a fórmula da figura 15.4.
Figura 15.5 – Exemplo de funcionamento da operação de substituição
O valor contido em END após execução representa o endereço de memória onde está armazenado o dado de substituição. Na figura 15.5 tem-se a ilustração da operação de substituição, onde é possível verificar a utilização dos parâmetros configuráveis na operação de substituição.
A operação de substituição SBOX utiliza os seguintes registradores:
• A6 – armazena resultado final da substituição
• B6 – armazena bits que serão substituídos
• Registradores dos parâmetros configuráveis: SBOXEND, SBOXCOL, SBOXQ, TBO,TBD,LIN,COL.
• AC1 – Acumulador 1, aponta para o bloco origem que será substituído
• AC2 - Acumulador 2, aponta para o bloco destino de substituição
A cada substituição, o AC1 é incrementado com o valor do registrador TBO (Tamanho do Bloco Origem), apontando assim para o próximo bloco origem que será substituído. O mesmo acontece com AC2, mas este será incrementado com o valor de TBD (Tamanho do Bloco Destino), apontando para o próximo bloco destino de substituição. A instrução de inicialização e configuração da SBOX zera o valor de AC1 e AC2.
A figura 15.5 ilustra a instrução SBOX sendo executada. Uma seqüência de passos é executada até que a instrução finalize, estes passos estão indicados na figura 15.5 e descritos a seguir:
1º Passo – determinar os bits de entrada da S-BOX, (BO1 – Bloco Origem 1).

261
2º Passo – determinar o valor da linha (LIN) e da coluna (COL) do dado de substituição desejado, (BO1 – Bloco Origem 1).
3º passo – Utilizando a formula da figura 15.4, gerar o endereço físico do dado de substituição, (D-CACHE).
4º passo – Determinar o bloco de destino e realizar a substituição, (BD1 – Bloco Destino 1).
15.4 Pipeline do Criptoprocessador VLIW) O criptoprocessador VLIW foi projetado para ter um pipeline de 3 estágios globais. Cada estágio é executado em um único ciclo de máquina, inclusive o estágio de execução de instruções. Os estágios são gerenciados por uma máquina finita de estados (unidade de controle) sincronizada pelo clock global. Os estágios são:
Estágio 1: Busca e despacho de instruções. Busca uma palavra VLIW de 160 bits. Esta palavra é recebida pelo despachador de instruções. O despachador realiza o direcionamento para as unidades funcionais predefinidas. Este estágio é realizado em um único ciclo de máquina.
Estágio 2: Decodificação e execução. Neste estágio as unidades funcionais decodificam as instruções que serão executadas e realizam-se as respectivas operações desejadas.
Estágio 3: Escrita em memória ou registradores. Os resultados são armazenados nos devidos registradores ou na memória D-CACHE. A arquitetura Harvard permite a leitura e escrita simultânea em memórias distintas.
Desta maneira, em três ciclos de máquina o pipeline está preenchido. Assim, a partir do terceiro ciclo podem ser executadas até 4 instruções por ciclo. Isto significa que o número de ciclos por instrução é de ¼ ou 0,25 ciclos por instrução, ou seja um CPI =0.25, o qual é menor que um, (CPI < 1), fazendo com que o processador seja considerado de alto desempenho. Lembrar que isso acontece em situação ideal, sem considerar dependência de dados e problemas de hazards.
O pipeline nunca é interrompido para o tratamento de instruções especiais ou de qualquer outra instrução. O fato de todas as instruções serem executadas em um único ciclo facilita a descrição do hardware que controla a transição entre estágios globais. Na tabela 15.8 mostram-se os estágios do pipeline.
Considerando que cada palavra VLIW possui até 4 instruções paralelas, é possível observar na tabela 15.8 que a partir do 3º ciclo tem-se a cada ciclo uma execução paralela de até quatro instruções. É bom lembrar que o pipeline diminui o número de ciclos necessários para executar uma instrução, mas aumenta de forma significativa a complexidade do hardware e o número de componentes utilizados para mapeá-lo em um FPGA.
Tabela 15.8 – Pipeline do Criptoprocessador VLIW
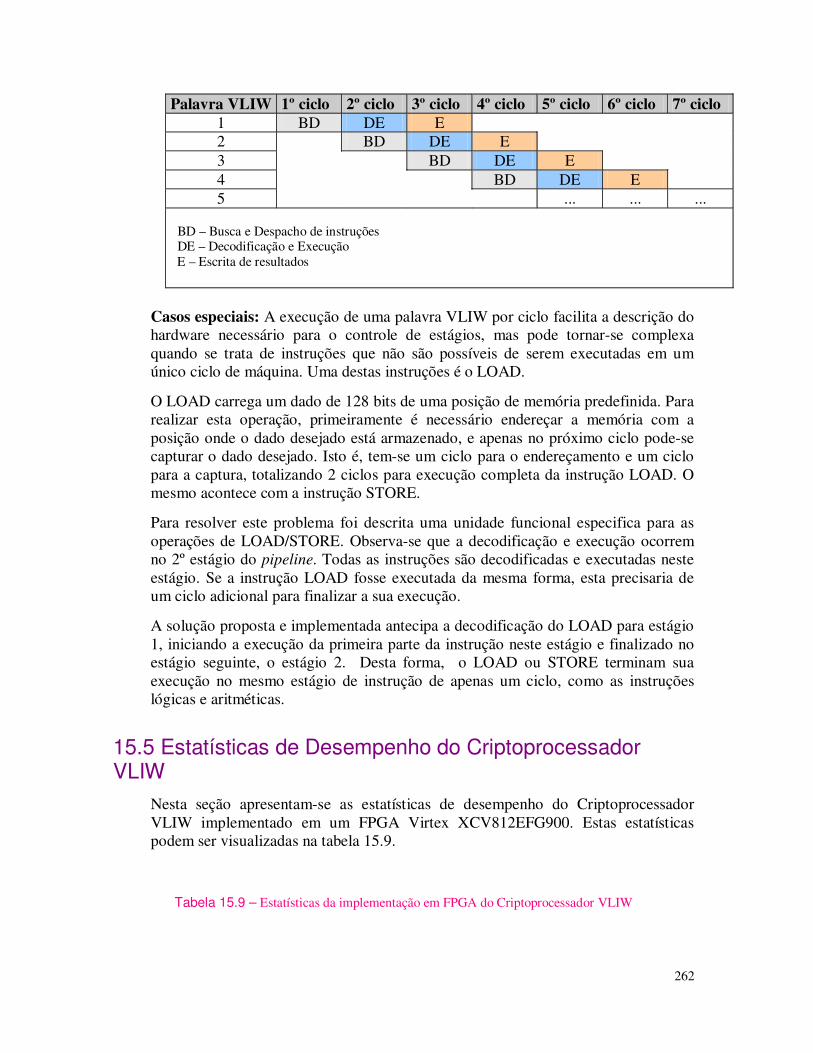
262
Palavra VLIW 1º ciclo 2º ciclo 3º ciclo 4º ciclo 5º ciclo 6º ciclo 7º ciclo 1 BD DE E 2 BD DE E 3 BD DE E 4 BD DE E 5 ... ... ...
BD – Busca e Despacho de instruções DE – Decodificação e Execução E – Escrita de resultados
Casos especiais: A execução de uma palavra VLIW por ciclo facilita a descrição do hardware necessário para o controle de estágios, mas pode tornar-se complexa quando se trata de instruções que não são possíveis de serem executadas em um único ciclo de máquina. Uma destas instruções é o LOAD.
O LOAD carrega um dado de 128 bits de uma posição de memória predefinida. Para realizar esta operação, primeiramente é necessário endereçar a memória com a posição onde o dado desejado está armazenado, e apenas no próximo ciclo pode-se capturar o dado desejado. Isto é, tem-se um ciclo para o endereçamento e um ciclo para a captura, totalizando 2 ciclos para execução completa da instrução LOAD. O mesmo acontece com a instrução STORE.
Para resolver este problema foi descrita uma unidade funcional especifica para as operações de LOAD/STORE. Observa-se que a decodificação e execução ocorrem no 2º estágio do pipeline. Todas as instruções são decodificadas e executadas neste estágio. Se a instrução LOAD fosse executada da mesma forma, esta precisaria de um ciclo adicional para finalizar a sua execução.
A solução proposta e implementada antecipa a decodificação do LOAD para estágio 1, iniciando a execução da primeira parte da instrução neste estágio e finalizado no estágio seguinte, o estágio 2. Desta forma, o LOAD ou STORE terminam sua execução no mesmo estágio de instrução de apenas um ciclo, como as instruções lógicas e aritméticas.
15.5 Estatísticas de Desempenho do Criptoprocessador VLIW
Nesta seção apresentam-se as estatísticas de desempenho do Criptoprocessador VLIW implementado em um FPGA Virtex XCV812EFG900. Estas estatísticas podem ser visualizadas na tabela 15.9.
Tabela 15.9 – Estatísticas da implementação em FPGA do Criptoprocessador VLIW
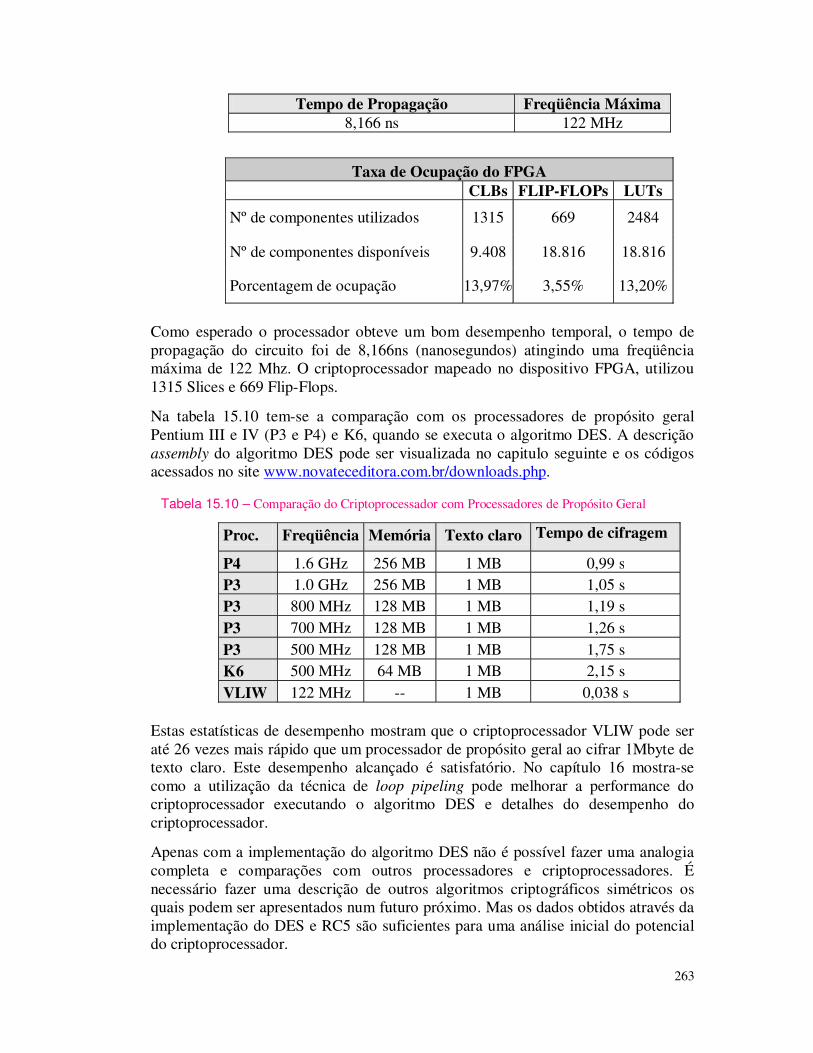
263
Tempo de Propagação Freqüência Máxima 8,166 ns 122 MHz
Taxa de Ocupação do FPGA CLBs FLIP-FLOPs LUTs
Nº de componentes utilizados 1315 669 2484
Nº de componentes disponíveis 9.408 18.816 18.816
Porcentagem de ocupação 13,97% 3,55% 13,20%
Como esperado o processador obteve um bom desempenho temporal, o tempo de propagação do circuito foi de 8,166ns (nanosegundos) atingindo uma freqüência máxima de 122 Mhz. O criptoprocessador mapeado no dispositivo FPGA, utilizou 1315 Slices e 669 Flip-Flops.
Na tabela 15.10 tem-se a comparação com os processadores de propósito geral Pentium III e IV (P3 e P4) e K6, quando se executa o algoritmo DES. A descrição assembly do algoritmo DES pode ser visualizada no capitulo seguinte e os códigos acessados no site www.novateceditora.com.br/downloads.php.
Tabela 15.10 – Comparação do Criptoprocessador com Processadores de Propósito Geral
Proc. Freqüência Memória Texto claro Tempo de cifragem
P4 1.6 GHz 256 MB 1 MB 0,99 s P3 1.0 GHz 256 MB 1 MB 1,05 s P3 800 MHz 128 MB 1 MB 1,19 s P3 700 MHz 128 MB 1 MB 1,26 s P3 500 MHz 128 MB 1 MB 1,75 s K6 500 MHz 64 MB 1 MB 2,15 s VLIW 122 MHz -- 1 MB 0,038 s
Estas estatísticas de desempenho mostram que o criptoprocessador VLIW pode ser até 26 vezes mais rápido que um processador de propósito geral ao cifrar 1Mbyte de texto claro. Este desempenho alcançado é satisfatório. No capítulo 16 mostra-se como a utilização da técnica de loop pipeling pode melhorar a performance do criptoprocessador executando o algoritmo DES e detalhes do desempenho do criptoprocessador.
Apenas com a implementação do algoritmo DES não é possível fazer uma analogia completa e comparações com outros processadores e criptoprocessadores. É necessário fazer uma descrição de outros algoritmos criptográficos simétricos os quais podem ser apresentados num futuro próximo. Mas os dados obtidos através da implementação do DES e RC5 são suficientes para uma análise inicial do potencial do criptoprocessador.

264
No próximo capítulo apresenta-se a implementação dos algoritmos DES e RC5 utilizando o assembly do criptoprocessador VLIW. Assim como, uma análise de desempenho e técnicas para melhoria de desempenho. Destaca-se também a implementação de uma interface simplificada em hardware e o primeiro protótipo do simulador do criptoprocessador VLIW. Em (PEREIRA, 2004) e no site do livro www.novateceditora.com.br/downloads.php, apresenta-se detalhes da microarquitetura do Criptoprocessador VLIW.

265
Capítulo 16 Desempenho do Criptoprocessador
Neste capítulo apresenta-se a implementação dos algoritmos simétricos DES, RC5 e da S-BOX do algoritmo AES utilizando o assembly do Criptoprocessador VLIW, discutindo técnicas para melhorar o desempenho. Também será apresentada uma interface em hardware para realização de testes físicos com o Criptoprocessador VLIW. Por fim, apresenta-se a primeira versão do simulador e montador assembler do Criptoprocessador VLIW.
16.1 Implementação do Algoritmo DES Nesta seção apresenta-se a implementação do algoritmo DES e o impacto da dependência de dados na execução deste algoritmo utilizando o Criptoprocessador VLIW.
Diferente da programação seqüencial, em processadores VLIW as instruções são representadas através de micro-códigos horizontais. A seguir, apresenta-se um trecho de micro-código horizontal segundo o assembly do criptoprocessador. Este código esboça o problema da dependência de dados.
P1: LOAD A2,[10] | SHL A3,32 | NOP | NOP
P2: XOR A2,B2 | MOV B1,A3 | NOP | NOP
P3: STORE [9],A2 | ADD A1,B1 | NOP | NOP
Observa-se que existem três palavras VLIW (P1, P2 e P3) que serão executadas em seqüência. Antes de realizar a operação de XOR foi necessário carregar um determinado valor em A2 (LOAD). Assim como, antes de armazenar A2 (STORE) foi necessário realizar a operação XOR. Desta forma, estas instruções devem estar em palavras VLIW diferentes, para que o fluxo de execução seja lógico.
Esta dependência de dados impede que o programador aproveite todo o hardware disponível, sub-utilizando o Criptoprocessador. Na tabela 16.1 tem-se a descrição completa do algoritmo de criptografia DES utilizando o assembly do criptoprocessador, onde foi necessário observar e evitar as possíveis dependências de dados existentes, como aquelas mostradas anteriormente.
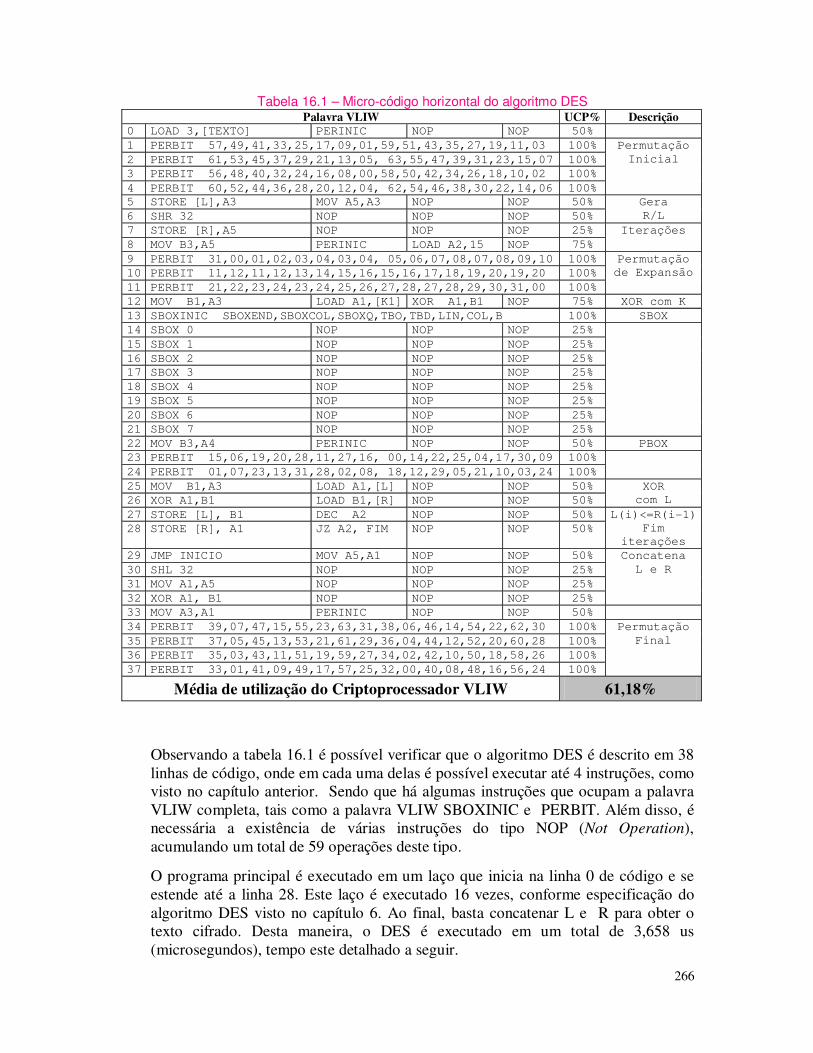
266
Tabela 16.1 – Micro-código horizontal do algoritmo DES Palavra VLIW UCP% Descrição
0 LOAD 3,[TEXTO] PERINIC NOP NOP 50%
1 PERBIT 57,49,41,33,25,17,09,01,59,51,43,35,27,19,11,03 100% Permutação
Inicial 2 PERBIT 61,53,45,37,29,21,13,05, 63,55,47,39,31,23,15,07 100%
3 PERBIT 56,48,40,32,24,16,08,00,58,50,42,34,26,18,10,02 100%
4 PERBIT 60,52,44,36,28,20,12,04, 62,54,46,38,30,22,14,06 100%
5 STORE [L],A3 MOV A5,A3 NOP NOP 50% Gera
R/L 6 SHR 32 NOP NOP NOP 50%
7 STORE [R],A5 NOP NOP NOP 25% Iterações
8 MOV B3,A5 PERINIC LOAD A2,15 NOP 75%
9 PERBIT 31,00,01,02,03,04,03,04, 05,06,07,08,07,08,09,10 100% Permutação
de Expansão 10 PERBIT 11,12,11,12,13,14,15,16,15,16,17,18,19,20,19,20 100%
11 PERBIT 21,22,23,24,23,24,25,26,27,28,27,28,29,30,31,00 100%
12 MOV B1,A3 LOAD A1,[K1] XOR A1,B1 NOP 75% XOR com K
13 SBOXINIC SBOXEND,SBOXCOL,SBOXQ,TBO,TBD,LIN,COL,B 100% SBOX
14 SBOX 0 NOP NOP NOP 25%
15 SBOX 1 NOP NOP NOP 25%
16 SBOX 2 NOP NOP NOP 25%
17 SBOX 3 NOP NOP NOP 25%
18 SBOX 4 NOP NOP NOP 25%
19 SBOX 5 NOP NOP NOP 25%
20 SBOX 6 NOP NOP NOP 25%
21 SBOX 7 NOP NOP NOP 25%
22 MOV B3,A4 PERINIC NOP NOP 50% PBOX
23 PERBIT 15,06,19,20,28,11,27,16, 00,14,22,25,04,17,30,09 100%
24 PERBIT 01,07,23,13,31,28,02,08, 18,12,29,05,21,10,03,24 100%
25 MOV B1,A3 LOAD A1,[L] NOP NOP 50% XOR
com L 26 XOR A1,B1 LOAD B1,[R] NOP NOP 50%
27 STORE [L], B1 DEC A2 NOP NOP 50% L(i)<=R(i-1)
Fim
iterações 28 STORE [R], A1 JZ A2, FIM NOP NOP 50%
29 JMP INICIO MOV A5,A1 NOP NOP 50% Concatena
L e R 30 SHL 32 NOP NOP NOP 25%
31 MOV A1,A5 NOP NOP NOP 25%
32 XOR A1, B1 NOP NOP NOP 25%
33 MOV A3,A1 PERINIC NOP NOP 50%
34 PERBIT 39,07,47,15,55,23,63,31,38,06,46,14,54,22,62,30 100% Permutação
Final 35 PERBIT 37,05,45,13,53,21,61,29,36,04,44,12,52,20,60,28 100%
36 PERBIT 35,03,43,11,51,19,59,27,34,02,42,10,50,18,58,26 100%
37 PERBIT 33,01,41,09,49,17,57,25,32,00,40,08,48,16,56,24 100%
Média de utilização do Criptoprocessador VLIW 61,18%
Observando a tabela 16.1 é possível verificar que o algoritmo DES é descrito em 38 linhas de código, onde em cada uma delas é possível executar até 4 instruções, como visto no capítulo anterior. Sendo que há algumas instruções que ocupam a palavra VLIW completa, tais como a palavra VLIW SBOXINIC e PERBIT. Além disso, é necessária a existência de várias instruções do tipo NOP (Not Operation), acumulando um total de 59 operações deste tipo.
O programa principal é executado em um laço que inicia na linha 0 de código e se estende até a linha 28. Este laço é executado 16 vezes, conforme especificação do algoritmo DES visto no capítulo 6. Ao final, basta concatenar L e R para obter o texto cifrado. Desta maneira, o DES é executado em um total de 3,658 us (microsegundos), tempo este detalhado a seguir.

267
Nº total de ciclos = Nº de ciclo de uma iteração * Nº de iterações Tempo total = Nº total de ciclos * Tempo de um Ciclo
Se, Nº de ciclos de uma iteração =29 Nº de iterações = 16
Tempo de um ciclo = 8,116 ns
Então,
Nº total de ciclos = 16 * 29 = 464 Tempo total = 464*8,166= 3789 ns = 3,789 us
Um dado muito importante e interessante é o aproveitamento da capacidade de processamento do Criptoprocessador VLIW, que indica qual a porcentagem efetiva de utilização de todo recurso de hardware disponível por um determinado programa. Nota-se no código apresentado que ocorrem vários NOPs (Not Operation), isto aponta que o criptoprocessador está sendo sub-utilizado, pois outras operações poderiam estar sendo executadas.
Para calcular este valor, é necessário quantificar qual a porcentagem de aproveitamento de cada palavra VLIW do algoritmo descrito. Isto é, se em uma palavra VLIW pode-se armazenar até 4 instruções que podem ser executadas em paralelo, o cálculo consiste em quantificar quantas instruções por palavra VLIW estão sendo efetivamente executadas.
Na linha 0 do código da tabela 16.1 observa-se que das 4 possíveis instruções que poderiam ser executadas, somente há duas que efetivamente serão executadas, as outras duas são instruções do tipo NOP. Assim, nesta linha de código é possível obter apenas 50% da capacidade total de processamento. Fazendo isso em cada linha de código, e dividindo o total da capacidade de processamento pelas 38 linhas de código, chega-se que, o algoritmo DES teve um aproveitamento de 61,18% da capacidade total do criptoprocessador que pode ser considerado aceitável, mas não ideal. O Ideal hipotético seria, de 100%. Mas sabe-se que não é comum esta taxa de aproveitamento, devido aos hazards (PATTERSON, 1997) que sempre existem, sejam de tipo estrutural, controle ou à dependência de dados inerentes aos programas.
O número de ciclos para a execução dessa primeira implementação do DES foi de 464 ciclos de clock. Cada algoritmo de criptografia simétrico tem um aproveitamento diferente, assim como diferentes descrições para o mesmo algoritmo também podem ter.
A dependência de dados foi o principal fator que influenciou no desempenho do algoritmo DES executado pelo criptoprocessador VLIW. Na seção 16.2 apresenta-se
Este valor foi obtido após a implemen- tação em FPGA do criptoprocessador VLIW. Mostrado no capítulo 15.

268
como a técnica de loop pipelining pode minimizar o impacto no desempenho causado pela dependência de dados do algoritmo DES, uma vez que a aplicação desta técnica pode aumentar o aproveitamento dos recursos disponíveis na arquitetura do criptoprocessador VLIW. Na figura 16.1 tem-se uma fotografia do sistema funcionando em hardware, Onde, pode-se notar que o texto “FABIO” foi criptografado pelo criptoprocessador VLIW, gerando uma cifra representada nesta figura.
Figura 16.1 – Cifrando um texto com o Criptoprocessador VLIW
16.2 Minimização do Impacto da Dependência de Dados do DES – Loop Pipelining
Arquiteturas horizontais, como a VLIW, são caracterizadas pela possibilidade de controlar independente e diretamente as diversas unidades funcionais, geralmente através de um único fluxo de controle. Assim, pode-se explorar apenas o paralelismo de grau mais fino, e dispor de um número elevado de unidades funcionais se torna inútil quando existem dependências de dados ou de controle.
O nível de desempenho pode ser maior, para um mesmo total de unidades funcionais, se estas forem divididas em grupos e existir técnicas de paralelismo que tenham efeito sobre a arquitetura destino. Através do estudo prévio de vários algoritmos simétricos, fica claro que a maioria desses algoritmos executa uma seqüência de operações com um grau de dependência elevado. Estas operações, são chamadas de iteração.
O número de iterações varia de algoritmo para algoritmo, sendo que estas são geralmente executadas em um laço principal. No caso de algoritmos criptográficos simétricos, as iterações atuam sobre um bloco de texto de tamanho fixo, com o

269
objetivo de cifrar ou decifrar as informações desejadas. O algoritmo DES, por exemplo, atua sobre blocos de 64 bits.
Neste contexto, pode-se aplicar de forma eficiente a técnica de Loop Pipelining (NEIL, 2000), onde operações de diferentes iterações podem ser executadas em um mesmo estado ou palavra VLIW. Assim, esta técnica permite uma melhor utilização dos recursos.
Em uma primeira implementação do algoritmo DES, usou-se a seguinte seqüência de passos: (i) captura bloco de 64 bits, (ii) processa as 16 iterações do DES, (iii) armazena texto cifrado. Este procedimento atingiu uma taxa de 61,18% de aproveitamento efetivo do hardware, conforme foi mostrado na seção 16.1.
Com a utilização da técnica de loop pipelining, o fluxo de execução torna-se mais complexo, mas o aproveitamento dos recursos de hardware disponíveis é maior e o desempenho geral da arquitetura é otimizado. Na figura 16.2 apresenta-se como aplicar esta técnica para atingir um paralelismo de grão médio ou também conhecido como mesoparalelismo.
Figura 16.2 - Ilustração da técnica de loop pipelining
Observa-se na figura 16.2 que o algoritmo DES descrito pode atuar sobre quatro blocos de texto em paralelo. Utilizando o loop pipelining, operações de diferentes iterações e blocos de texto, podem ser executados em um mesmo estado. O inicio do processamento de cada bloco é instanciado em tempos diferentes, indicados pelas setas da figura 16.2, evitando na maioria das vezes, a disputa entre duas ou mais instruções pela mesma unidade funcional. Na tabela 16.2 tem-se um trecho do algoritmo DES utilizando esta técnica.
Tabela 16.2 – Trecho de código do algoritmo DES com loop pipelining
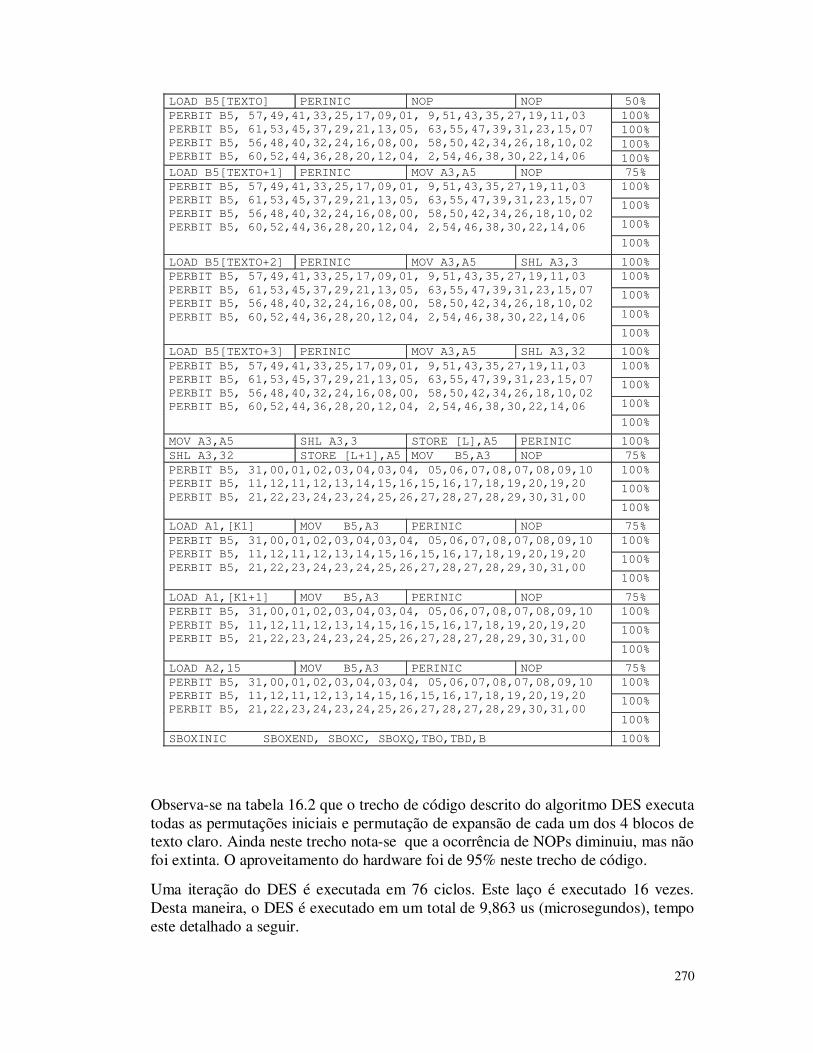
270
LOAD B5[TEXTO] PERINIC NOP NOP 50%
PERBIT B5, 57,49,41,33,25,17,09,01, 9,51,43,35,27,19,11,03
PERBIT B5, 61,53,45,37,29,21,13,05, 63,55,47,39,31,23,15,07
PERBIT B5, 56,48,40,32,24,16,08,00, 58,50,42,34,26,18,10,02
PERBIT B5, 60,52,44,36,28,20,12,04, 2,54,46,38,30,22,14,06
100%
100%
100%
100%
LOAD B5[TEXTO+1] PERINIC MOV A3,A5 NOP 75%
PERBIT B5, 57,49,41,33,25,17,09,01, 9,51,43,35,27,19,11,03
PERBIT B5, 61,53,45,37,29,21,13,05, 63,55,47,39,31,23,15,07
PERBIT B5, 56,48,40,32,24,16,08,00, 58,50,42,34,26,18,10,02
PERBIT B5, 60,52,44,36,28,20,12,04, 2,54,46,38,30,22,14,06
100%
100%
100%
100%
LOAD B5[TEXTO+2] PERINIC MOV A3,A5 SHL A3,3 100%
PERBIT B5, 57,49,41,33,25,17,09,01, 9,51,43,35,27,19,11,03
PERBIT B5, 61,53,45,37,29,21,13,05, 63,55,47,39,31,23,15,07
PERBIT B5, 56,48,40,32,24,16,08,00, 58,50,42,34,26,18,10,02
PERBIT B5, 60,52,44,36,28,20,12,04, 2,54,46,38,30,22,14,06
100%
100%
100%
100%
LOAD B5[TEXTO+3] PERINIC MOV A3,A5 SHL A3,32 100%
PERBIT B5, 57,49,41,33,25,17,09,01, 9,51,43,35,27,19,11,03
PERBIT B5, 61,53,45,37,29,21,13,05, 63,55,47,39,31,23,15,07
PERBIT B5, 56,48,40,32,24,16,08,00, 58,50,42,34,26,18,10,02
PERBIT B5, 60,52,44,36,28,20,12,04, 2,54,46,38,30,22,14,06
100%
100%
100%
100%
MOV A3,A5 SHL A3,3 STORE [L],A5 PERINIC 100%
SHL A3,32 STORE [L+1],A5 MOV B5,A3 NOP 75%
PERBIT B5, 31,00,01,02,03,04,03,04, 05,06,07,08,07,08,09,10
PERBIT B5, 11,12,11,12,13,14,15,16,15,16,17,18,19,20,19,20
PERBIT B5, 21,22,23,24,23,24,25,26,27,28,27,28,29,30,31,00
100%
100%
100%
LOAD A1,[K1] MOV B5,A3 PERINIC NOP 75%
PERBIT B5, 31,00,01,02,03,04,03,04, 05,06,07,08,07,08,09,10
PERBIT B5, 11,12,11,12,13,14,15,16,15,16,17,18,19,20,19,20
PERBIT B5, 21,22,23,24,23,24,25,26,27,28,27,28,29,30,31,00
100%
100%
100%
LOAD A1,[K1+1] MOV B5,A3 PERINIC NOP 75%
PERBIT B5, 31,00,01,02,03,04,03,04, 05,06,07,08,07,08,09,10
PERBIT B5, 11,12,11,12,13,14,15,16,15,16,17,18,19,20,19,20
PERBIT B5, 21,22,23,24,23,24,25,26,27,28,27,28,29,30,31,00
100%
100%
100%
LOAD A2,15 MOV B5,A3 PERINIC NOP 75%
PERBIT B5, 31,00,01,02,03,04,03,04, 05,06,07,08,07,08,09,10
PERBIT B5, 11,12,11,12,13,14,15,16,15,16,17,18,19,20,19,20
PERBIT B5, 21,22,23,24,23,24,25,26,27,28,27,28,29,30,31,00
100%
100%
100%
SBOXINIC SBOXEND, SBOXC, SBOXQ,TBO,TBD,B 100%
Observa-se na tabela 16.2 que o trecho de código descrito do algoritmo DES executa todas as permutações iniciais e permutação de expansão de cada um dos 4 blocos de texto claro. Ainda neste trecho nota-se que a ocorrência de NOPs diminuiu, mas não foi extinta. O aproveitamento do hardware foi de 95% neste trecho de código.
Uma iteração do DES é executada em 76 ciclos. Este laço é executado 16 vezes. Desta maneira, o DES é executado em um total de 9,863 us (microsegundos), tempo este detalhado a seguir.

271
Nº total de ciclos = Nº de ciclos de uma iteração * Nº de iterações Tempo total = Nº total de ciclos * Tempo de um Ciclo
Se, Nº de ciclos de uma iteração =76 Nº de iterações = 16
Tempo de um Ciclo = 8,116 ns
Então,
Nº total de ciclos = 16 * 29 = 1216 Tempo total = 1216*8,166= 9863 ns = 9,863 us
Aplicada a técnica de loop pipelining foi refeita a contagem de aproveitamento e foi contabilizada uma taxa de aproveitamento do hardware de 82,75%. Este aumento é considerado significativo e o impacto pode ser visto nos dados apresentados a seguir.
A implementação sem loop pipelining, pode executar um bloco de 64 bits em 464 ciclos de clock, então a relação de ciclos por bits cifrados é de 7,25. Já a implementação com loop pipelining pode executar até quatro blocos de 64, assim um total de 256 bits em 1216 ciclos, a taxa de ciclos por bits é de 4,75 ciclos/bit, isto quer dizer que são necessários menos ciclos para cifrar um bit em relação à implementação anterior.
O impacto dessa otimização no desempenho do criptoprocessador, medido em quantidade de Mbytes de texto cifrado por segundo (Mbytes/s), foi significativo. Onde, anteriormente era cifrado no máximo 17,5 Mbytes/s agora é cifrado 26 Mbytes/s. É importante salientar que não houve alteração na arquitetura do criptoprocessador VLIW.
Uma das características encontradas em algoritmos criptográficos simétricos que levou a escolha da técnica de loop pipelining para paralelizar instruções foi a presença freqüente de um laço principal de execução, chamado de iteração. A utilização da técnica de loop pipelining potencializou e otimizou a utilização do criptoprocessador VLIW. O ganho obtido no estudo de caso foi significativo, da ordem de 34% na quantidade de Mbytes cifrados por segundo (Mbytes/s).
Este estudo preliminar pode ser a base para o projeto de um compilador de alto nível para o criptoprocessador VLIW, onde um dos parâmetros críticos que pode ser tratado é a paralelização de laços através da técnica de loop pipelining
16.3 Implementação do algoritmo RC5
Este valor foi obtido após a implemen- tação em FPGA do criptoprocessador VLIW. Mostrado no capítulo 15.

272
O algoritmo RC5 não possui na sua especificação operações de substituição e permutação. O algoritmo RC5 implementado realiza 16 iterações no processo de cifragem de um bloco de texto. O pseudocódigo apresentado a seguir mostra um trecho do código assembler do processo de encriptação do RC5 utilizando as instruções do criptoprocessador VLIW.
LOAD A1,[TEXTO]
LOAD B1,[CHAVE]
ADD A1,B1 LOAD A2, [TEXTO +1]
LOAD B2[CHAVE +1]
ADD A2,B2
MOV B1,A2
XOR A1,B2 MOV A4,B1
ROT1 MOV A3,A1
JZ A4, [ROT2]
ROL 1
SHR 1
JMP ROT1
ROT2 MOV A2,A1
ADD A2,B2 MOV A3,A2
ROT3 JZ B4, ROT4
ROT 1
SHR 1
JMP ROT3
ROT4 DEC B2
JZ B2,FIM
JMP ROT1
FIM
Uma iteração do RC5 é executada em 19 ciclos. Este laço é executado 16 vezes. Desta maneira, o RC5 é executado em um total de 1,829 us, tempo este detalhado a seguir.
Nº total de ciclos = Nº de ciclos de uma iteração * Nº de iterações
Tempo total = Nº total de ciclos * Tempo de um Ciclo Se, Nº de ciclos de uma iteração =19 Nº de iterações = 16
Tempo de um Ciclo = 8,116 ns
Este valor foi obtido após a implemen- tação em FPGA do criptoprocessador VLIW. Mostrado no capítulo 15.

273
Então,
Nº total de ciclos = 16 * 19 = 304 Tempo total = 304*8,166= 2482 ns = 2,482 us
Desta forma o RC5 executado pelo criptoprocessador pode cifrar aproximadamente 26 Mbytes/s. Como esperado o RC5 teve um desempenho superior ao DES, cofirmando os dados obtidos nos respectivos capítulos dedicados a esses dois algoritmos, respectivamente, capítulo 6 e 11. A técnica de loop pipelining não foi aplicada para o RC5, a qual pode ser aplicada em trabalhos futuros, assim como, a implementação de outros algoritmos simétricos neste criptoprocessador.
16.4 Implementação da S-BOX do AES Nesta seção apresenta-se a implementação da S-BOX do algoritmo AES utilizando o assembly do Criptoproecssador VLIW. O AES possui apenas uma S-BOX, de dimensão 16x16, onde cada palavra de substituição é de 8 bits. Portanto, a S-BOX do AES ocupa um total de 2048 (16x16x8) bits de memória de dado (D-CACHE).
Para implementar a S-BOX do AES deve-se primeiramente configurar o Criptoprocessador VLIW. Para isso, utiliza-se a instrução S-BOXINIC. A SBOX do AES possui as seguintes características (detalhes no capítulo 10):
• 8 bits de entrada, dos quais, os 4 mais significativos endereçam a linha da SBOX e os 4 menos significativos endereçam a coluna da SBOX.
• 8 bits de saída. Estes irão substituir os 8 bits de entrada utilizados para endereçar a S-BOX.
• Existe apenas uma S-BOX de dimensão 16x16.
• vetor de entrada que alimenta a S-BOX é de 128 bits, portanto são necessárias 16 substituições (16 * 8 = 128 bits).
Neste exemplo a S-BOX está armazenada a partir do endereço 1F de memória.
Na figura 16.3 ilustra-se a instrução de substituição. Cada Sr,c é de 8 bits. Estes 8 bits endereçam a S-BOX, localizando o valor de substituição. O valor de substituição (S’r,c) sobreescreve o valor de endereçamento (Sr,c) realizando a operação de substituição. Esta operação é repetida até que toda a matriz S seja substituída por S’ através da S-BOX.

274
Figura 16.3 – Operação de substituição do AES
Extraindo estas características é possível descrever com facilidade a S-BOX do AES utilizando a instrução SBOXINIC e SBOX, como se nota no código assembly a seguir:
Define SBOXEND = 001Fh // endereço de inicio da S-BOX (D-CACHE)
Define SBOXCOL = Fh // 16 colunas (dimensão)
Define SBOXQ = FFh // 256 elementos (16x16)
Define TBO = 8h // tamanho do bloco origem (bloco que será substituído)
Define TBD = 8h // tamanho do bloco destino (bloco de substituição)
Define COL = BIT4, BIT3, BIT2, BIT1 // bits do bloco origem que definem a linha
Define LIN = BIT8, BIT7 BIT6, BIT5 // bits do bloco origem que definem a coluna
Define B = 0 // modo bit de representação
SBOXINIC SBOXEND, SBOXCOL, SBOXQ, TBO, TBD, LIN, COL, B
SBOX 0, SBOX 0, SBOX 0, SBOX 0
SBOX 0, SBOX 0, SBOX 0, SBOX 0
SBOX 0, SBOX 0, SBOX 0, SBOX 0
SBOX 0, SBOX 0, SBOX 0, SBOX 0
//Após executar a primeira instrução SBOX 0 automaticamente o criptoprocessador
//aponta para os próximos 8 bits que serão substituídos. Assim a última instrução SBOX 0
// estará realizando a substituição do último byte do vetor de entrada 128 bits.
16.5 - Interface em Hardware para Teste do Criptoprocessador VLIW)
O Criptoprocessador VLIW e os algoritmos DES, AES e RC5 descritos em assembly foram validados via simulação. Para realizar alguns testes físicos do criptoprocessador mapeado em um FPGA foi necessária a implementação de uma interface simplificada para ter uma entrada e saída básica, onde, através de comandos inseridos por um usuário o criptoprocessador realizará as operações de

275
cifragem, decifragem e troca de chave. Esta interface pode ser visualizada na figura 16.4. A interface é composta por três elementos principais:
• teclado, onde o usuário pode entrar com dados no sistema. Estes dados podem ser do tipo: texto, cifra, chave ou um comando para criptoprocessador.
• A placa de prototipação D2E da digelent (http://www.digilentinc.com) possui um FPGA Spartan200E, onde está mapeado o sistema principal, composto pelo Criptoprocessador VLIW e
• A interface de controle do teclado e do display LCD (16X2).
A placa de prototipação DIO2 da digilent (http://www.digilentinc.com) foi utilizada para fazer a interface física do teclado com o Criptoprocessador e do Criptoprocessador com o Display LCD.
Figura 16.4 – Interface em hardware do Criptoprocessador VLIW
Está é uma interface limitada, mas através dela é possível visualizar o funcionamento físico do criptoprocessador VLIW em um FPGA real. Como exemplo, apenas o algoritmo de criptografia DES está mapeado na memória do criptoprocessador VLIW. Através desta interface pode-se cifrar/decifrar apenas um bloco de 64 bits (8 caracteres) por vez. A seguir a seqüência de passos para utilizar este sistema:
1º Conectar o teclado na porta PS/2
2º Mapear o Criptoprocessador e a interface no FPGA Spartan200E (D2E).
3º Digitar 8 caracteres (texto, cifra ou chave).

276
4ºDigitar o operador “=”.
5ºDigitar o comando (“E”=Encriptar, “D”=Decriptar, “K”=Chave).
Nem todas as teclas do teclado PS/2 foram decodificadas. A princípio o teclado alfanumérico foi decodificado. As teclas não decodificadas geram o caracter “?” no LCD quando pressionadas. Algumas teclas têm função especial como:
ESC – Limpa todo o LCD e posiciona o cursor na linha 1 coluna 1.
F1 – Copia a linha de resposta, onde aparece o texto cifrado ou decifrado para a linha comando e posiciona o cursor para espera de um novo comando.
Backspace – Apaga caracter digitado.
A figura 16.5 apresenta fotos do sistema real implementado e testado no Laboratório de Arquitetura e Sistemas Computacionais do UNIVEM – Centro Universitário Eurípides de Marília http://www.fundanet.br.
Figura 16.5 – Fotos do Criptoprocessador integrado a interface em hardware.
É importante salientar que não foi utilizado nenhum componente eletrônico para o controle de teclado ou LCD. Toda a lógica necessária foi implementada utilizando a linguagem VHDL e integrada ao criptoprocessador VLIW. O sistema completo (Criptoprocessador + Interface) ocupa 89% do FPGA Spartan200E.
Assim, os autores gostariam de salientar que os leitores podem usar os códigos do livro, em especial, aqueles das implementações em hardware, da maioria dos algoritmos descritos no livro, assim como do projeto do criptoprocessador prototipado em FPGAs.
Esses códigos relacionados ao projeto do criptoprocessador específico para realizar operações criptográficas implementado em FPGAs ressalta a importância de se ter

277
hardware especializado para segurança, e o mais importante, que podem ser projetados no Brasil, com custo relativamente baixo.

278
Capítulo 17 WebCry – Uma Ferramenta Didática de Criptografia na WEB
Este capítulo apresenta uma ferramenta criada pelos autores, que facilita o entendimento e utilização dos algoritmos apresentados e discutidos no livro. Esta ferramenta pode ser acessada pelos leitores de modo on-line através da internet ou executado diretamente após download da ferramenta completa. Nessa ferramenta, os leitores poderão selecionar um algoritmo desejado para análise, assim como um arquivo que será cifrado ou decifrado. A ferramenta mostra o tempo que a operação leva, e o arquivo após a operação (cifrar/decifrar) desejada.
17.1 Motivação Existem hoje em dia um grande número de algoritmos criptográficos, sendo que eles se diferem em características como segurança, tipo (simétrico ou assimétrico) e performance. Com isto, o objetivo da ferramenta é integrar vários algoritmos, realizando uma distinção de tipo e aplicação para facilitar o entendimento destes algoritmos e detectar características importantes que algumas vezes recebem pouca atenção, como por exemplo, o desempenho. Desta forma, os algoritmos específicos como os didáticos, simétricos e assimétricos estão separados em categorias na ferramenta WebCry.
17.2 Apresentação da Ferramenta A ferramenta WebCry é uma ferramenta didática para auxiliar o aprendizado de criptografia, sendo que nela são incorporados diversos algoritmos, dentre eles destacam-se alguns que têm finalidade didática pela simplicidade na estrutura e a presença de falhas de segurança que podem ser exploradas pelo leitor para aprofundar os conhecimentos de como são realizados ataques em um algoritmo.
A ferramenta WebCry é composta por quatro partes básicas. A primeira parte é a parte de seleção de algoritmo, onde é possível escolher qual algoritmo será utilizado. A segunda parte permite a escolha da chave a ser utilizada; na terceira parte é possível realizar a criptografia de arquivos e a quarta parte permite a criptografia de textos pequenos como mostra a figura 17.1.
279
Na figura 17.1 que representa a tela inicial da ferramenta pode-se notar que os diversos algoritmos estão separados em categorias para facilitar o entendimento: simétricos, didáticos, sssimétricos e funções hash.
Figura 17.1 – Tela inicial da Ferramenta WebCry
17.3 Guia para usuários e Leitores A ferramenta WebCry está disponível em duas versões: uma versão em applet que pode ser acessada diretamente via WEB; e uma versão de aplicativo Java. Ambas as versões necessitam do pacote Java Runtime Environment (JRE) versão 1.4 ou superior. Recomenda-se o uso do JRE versão 1.4.2.
Para instalar o JRE é necessário fazer o download do programa de instalação através do site http://java.sun.com.
Para executar a versão em applet basta acessar o link http://www.novateceditora.com.br/downloads.php. Neste link é só clicar onde aparece a imagem do livro de criptografia. Localizando este site, acessar o link relacionado com a ferramenta WebCry.

280
Aparecerá uma janela como a apresentada na figura 17.2. onde é possível realizar a criptografia de pequenas quantidades de texto utilizando os diversos algoritmos implementados.
Importante ressaltar que a versão em applets é uma versão simplificada da ferramenta e pos isto não apresenta a opção para a criptografia de arquivos. Caso deseje realizar a criptografia de arquivos (texto, músicas, imagens, vídeos, etc) é necessário fazer o download da versão de aplicativo Java. O download pode ser realizado a partir do link anterior na seção que indica o arquivo WebCry.jar.
Figura 17.2 – Tela da Versão Applet da Ferramenta WebCry
Depois de realizado o download da ferramenta na versão aplicativo Java basta dar um clique duplo sobre o arquivo para executá-lo. No entanto, em algumas máquinas, devido à configuração do JRE, pode ser que a execução não se inicie com um clique duplo. Nestes casos será necessário realizar o download do arquivo WebCry.bat

281
(que é um arquivo em lote com o comando necessário para a execução da ferramenta) e executá-lo.
17.4 Exemplo de Funcionamento Para exemplificar o funcionamento da ferramenta inicialmente se apresenta a operação para criptografar e decriptografar um arquivo e posteriormente se apresenta um exemplo onde é realizada a criptografia e decriptografia de textos entrados diretamente pelo usuário.
O leitor pode seguir os seis seguintes passos:
I. Inicializar a ferramenta.
II. Selecione um algoritmo de interesse, entre as opções existentes na ferramenta. Exemplo, o algoritmo utilizado neste exemplo é o algoritmo didático chamado de posicional. Para isto, ao iniciar a ferramenta selecione o algoritmo Posicional como mostra a etapa 1 da figura 17.3.
III. Gerar uma chave. Após a seleção do algoritmo é necessário gerar uma chave, para isto, selecione o tamanho da chave desejada (etapa 2 da figura 17.3) e clique em “Gerar”, a chave gerada aparecerá em formato hexadecimal em uma caixa de texto.
IV. Escolher arquivos. Após a seleção da chave é necessário escolher os arquivos origem e destino que serão utilizados, para isto, clique em procurar e escolha o arquivo de origem e destino como mostra a etapa 3 da figura 17.3. Importante notar que caso já exista um arquivo destino com o mesmo nome que o selecionado, o arquivo escolhido para destino será sobrescrito com o arquivo origem criptografado, portanto, ao escolher o arquivo destino não é recomendável a seleção de arquivos existentes, mas sim que o usuário digite um novo nome de arquivo.
V. Selecionar Operação (cifrar/decifrar). Após escolher os arquivos é necessário escolher a operação desejada. Por padrão a operação selecionada é a operação de criptografia, caso o usuário deseje decriptografar o arquivo é necessário escolher a opção “Decriptografar” como mostra a etapa 4 da figura 17.3.
VI. Executar o algoritmo. Finalmente, depois de selecionados todos os dados necessários basta clicar em “Executar” para que a ferramenta realize a operação desejada.

282
Figura 17.3 – Etapas de Operação da Ferramenta
Outro exemplo considerado mostra como realizar a criptografia de textos entrados diretamente pelo usuário. Para isto é necessário escolher o algoritmo e a chave como descrito no exemplo anterior, no entanto, como o texto será digitado diretamente pelo usuário é necessário selecionar o painel apropriado para isto.
A etapa 1 da figura 17.4 mostra como selecionar o painel que permite a entrada do texto diretamente pelo usuário e como proceder para realizar a criptografia e sua decriptografia.
Após selecionar o painel, basta entrar com o texto na área de texto “Origem”, como mostra a etapa 2 da figura 17.4 e clicar em cifrar. O código cifrado aparecerá na caixa de texto abaixo como mostra a figura 17.5. Para decifrar o texto, copie o conteúdo da caixa de texto “Destino” e cole na caixa de texto origem para posteriormente clicar em decifrar. Note que o texto original é recuperado na caixa de texto “Destino”.
Um outro teste possível consiste em mudar a chave clicando em “Gerar” e tentar decifrar o texto, desta forma, pode-se notar que o texto original não é recuperado, uma vez que a chave utilizada na decriptografia é diferente da chave utilizada na criptografia.
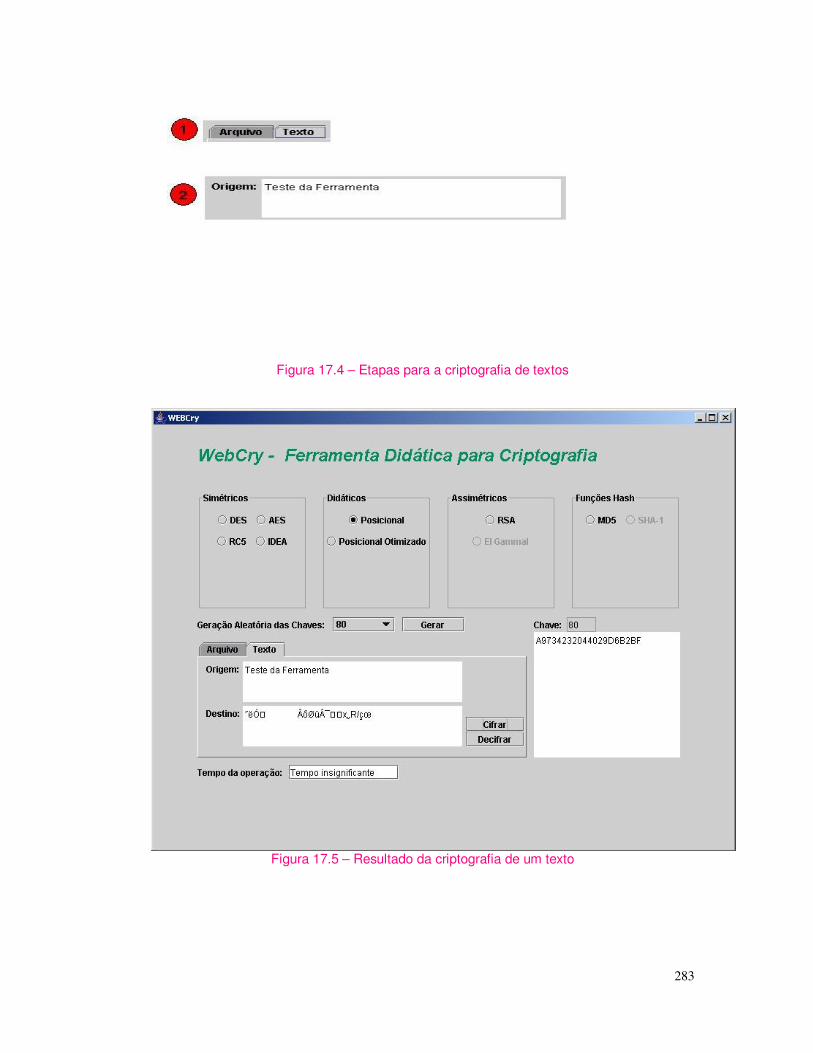
283
Figura 17.4 – Etapas para a criptografia de textos
Figura 17.5 – Resultado da criptografia de um texto

284
17.5 Considerações Finais Com a ferramenta, o leitor pode melhor entender o funcionamento dos algoritmos explicados no livro, uma vez que pode visualizar os efeitos de saída após realizar respectivo processamento relacionado com a cifragem ou decifragem de mensagens, além de conseguir ter uma idéia do tempo desse processamento.
O leitor pode executar o processo de criptografia escolhendo o algoritmo, e verificando as respectivas saídas, e compará-las com as obtidas com outros algoritmos, o que lhe oferece recursos para decidir qual algoritmo deseja usar para uma determinada aplicação.

285
Apêndice A Referências Bibliográficas
AESWinner. National Institute of Standards and Technology,NIST. http://www.nist.gov/public_affairs/releases/g00-176.htm., Acesso em 2003.
ALTERA, FPGA, CPLD & Structured ASIC Devices - http://www.altera.com/ - Acesso em Julho de 2004.
ALVES, E. S.., Biblioteca para Segurança de Dados: JCA – Um Estudo de Caso. Monografia de Especialização em Engenharia de Software, UNIVEM – Centro universitário Eurípides de Marília, Marília, S.P., Brasil, 2003.
BIHAM, E., A Note on Comparing the AES Candidates, Second AES conference. Technical report, Computer Science Department, Technion – Israel Institute of Technlogy, 1999. www.cs.technion.ac.il/~biham.
BROWN, I., BACK, A., LAURIE, B., Forward secrecy extentions for openPGP, internet-draft, 2000.
BROWN, L., PIEPRZYK, J., Introducing the new Loki97 Block Cipher. In Proceedings from the First Advanced Encryption Standard Candidate Conference, National Institute of Standards and Technology (NIST), August 1998.
BUCHMANN, Johannes A. Introduction to Cryptography, Springer Verlag,, EUA 2001.
BURNETT, S., PAINE S. Criptografia e Segurança - O guia oficial RSA, Editora Campus, 2002
BURNETT, S. Using the Java TM Cryptographic Architecture and Java TM
Cryptographic Extensions. Disponível em http://servlet.java.sun.com/javaone/javaone2000/pdfs/TS-1334.pdf., 2000.
BURWICK, C., COPPERSMITH, D., et al, MARS - a candidate cipher for AES, IBM Corporation, USA, 1999.
CARLISLE, A., "The CAST-128 Encryption Algorithm,",RFC 2144, May 1997.
CHIARAMONTE, R. B., MORENO, E.D. Criptografia Posicional em Hardware (VHDL e FPGAs)., Revista REIC-SBC, Dezembro, 2002.

286
CHIARAMONTE, R. B., MORENO, E.D. Criptografia Posicional – Uma Solução para Segurança de Dados. Revista REIC-SBC, Novembro, 2001.
CROWLEY, P., et al. Characterizing processor architectures for programmable network interfaces. Proc. of International Conference on Supercomputing, Santa Fé, 2000.
CRYPTOAPI, Digital Signatures with the Microsoft CryptoAPI - Dr.Dobb’s Journal, 1998.
CUADRA, Fernando de la, Criptografía explicada. http://www.baquia.com/com/20030317/art00014.print.html, Espanha, 2003.
CUNHA, Manuel Alcino Pereira da., Java Cryptography Architecture., Material do Curso, DI Universidade do Minho, Portugal, 1999.
CURTIN, M., DOLSKE, J., A Brute Force Search of DES Keyspace, the USENIX Association's journal, 1998.
DESKEY. Cryptography Research, DES Key Search Machine. http://www.cryptography.com/resources/whitepapers/DES.html, Acesso em 2001.
ESPOSITO, Dino. Supporting CryptoApi in Real-World Applications. Disponível em http://www.microsoft.com/mind/0697/crypto.asp, 2004.
EZCHIP, Network Processor Designs for Next-Generation Networking Equipment, 1999.
FIPS46-3. Federal Information Processing Standards Publication 46-3, DATA ENCRYPTION STANDARD, Dezembro, 1999.
FIPS197-2001. Federal Information Processing Standards Publication 197, ADVANCED ENCRYPTION STANDARD (AES), Novembro, 2001.
FIPS180-1. Secure Hash Standard. National Institute of Standards and Technology (NIST-1995). http://www.itl.nist.gov/fipspubs/fip180-1.htm.
FREITAS, H. C., C. A. P. S. Martins. R2NP: Processador de Rede RISC Reconfigurável. Anais do WSCAD (Workshop de Sistemas Computacionais de Alto Desempenho), 2002.
FREITAS, H. C., MARTINS, C. A. P. S., Projeto de Processador com Microarquitetura Dedicada para Roteamento em Sistemas de Comunicação de Dados. Anais do WSCAD (Workshop de Sistemas Computacionais de Alto Desempenho), 2000.
FREITAS, H. C., MARTINS, C. A. P. S., Processador de Rede com Suporte a Multi-protocolo e Topologias Dinâmicas. Anais do WSCAD (Workshop de Sistemas Computacionais de Alto Desempenho), 2001.

287
GATTI, Luis Fernando Ruivo; LAINO, Eduardo Elias; MORENO, E.D. JBCRI – Uma ferramenta para Analisar Bibliotecas Criptográficas. Proceedings of the GCETE/IEEE (Global Conference on Engineering and Technology for Education), Bertioga, S.P., Brasil, 2005.
GATTI, Luis Fernando Ruivo. Estudo e Comparação de Bibliotecas de Criptografia. Trabalho de Conclusão de Curso, Ciência da Computação, UNIVEM, Marília, 2003.
GEEK, Revista Geek, edição nº 09, Artigo: A Escrita Oculta, p.23-31, Editora Digerati., www.geek.com.br, 2002.
GEORGOUDIS, D., LEROUX, D., et al, Specification of the Algorithm THE "FROG" ENCRYPTION ALGORITHM,USA, 1998.
GOODMAN, J., CHANDRAKASAN, A. P. An Energy-Efficient Re-configurable Public-Key Cryptography Processor, IEEE Journal of Solid-State Circuits, Vol. 36, No. 11, Nov. 2001.
GUELFI, A. E.. Middleware de comunicação para prover o gerenciamento de serviços multimídia flexíveis e integrados em ambientes distribuídos e heterogêneos. 2002. Tese (Doutorado) - Escola Politécnica, Universidade de São Paulo, São Paulo, 2002.
IBM 4758, Coprocessador IBM 4758 http://www-3.ibm.com/security/cryptocards/ - Acesso em Janeiro de 2005.
IBM, The Network Processor – Enabling Technology for High-Performance Networking. 1999.
IEEE 1363, Standard Specifications for Public Key Cryptography—Draft 13, IEEE P1363, 1999.
INTEL, Intel Corporation – IXP 1200 Network Processor Datasheet, 2000.
IXP2800, The Intel® IXP2800 network processor - http://www.intel.com/design/network/products/npfamily/ixp2800.htm - Acesso em Janeiro de 2005.
JACOBSON, M.J., HUBERY, K., The MAGENTA Block Cipher Algorithm,GERMANY, 1998.
JCA, JavaTM Cryptography Architecture API Specification & Reference. Disponível em http://www.wedgetail.com/jcsi/provider/. Acesso em novembro de 2004.
JAVAROME. JCA. Disponível em http://javarome.free.fr/net/JCA.html., 2003.
KAHN, David., The Codebreakers. Macmillan, 1967.
KERCKHOFFS, A., La cryptographie militaire, Journal des sciences militaires, 1883.

288
KOCHER, P. C., Breaking DES, The technical newsletter of rsa laboratories, volume4, number2, 1999.
KOÇ, C. K., RSA Hardware Implementation., RSA Laboratories, U.S.A, 1995.
KOÇ, C.K., High Speed RSA Implementation., RSA Laboratories, USA, Nov., 1994.
KOREN, I. Computer Arithmetic Algorithms. Prentice Hall, 1993.
KNUTH, Donald E. Knuth, The Art of Computer Programming - Seminumerical Algorithms, Addison-Wesley, 1997.
LAI, X., MASSEY, J. L., A proposal for a new block encryption standard, 1990, apresentado no evento Eurocrypt 90, publicado pela Springer Verlag, 1991.
LAINO, E. Estudo, Comparação e Desempenho de Bibliotecas Criptográficas. Trabalho de Conculsão de Curso,Ciência da Computação, UNIVEM, 2003.
LAPSLEY, P. et al. DSP Processor Fundamentals: Architectures and Features. IEEE Press Series on Signal Processing, 1997.
LIDL, R., NIEDERREITER, H., Introduction to Finite Fields and Their Applications, Cambridge University Press, Cambridge, 1994.
MAIA, L. P., PAGLIUSI, P. S. Criptografia e Certificação Digital - http://www.training.com.br/lpmaia/pub_seg_cripto.htm - Acesso em: Dezembro de 1999.
MASCARIN, V. P., Bibliotecas para segurança de dados- CryptoAPI – Um estudo de caso. Monografia de Especialização em Engenharia de Software, UNIVEM – Centro universitário Eurípides de Marília, Marília, S.P., Brasil, 2003.
MENDES, Hammurabi das Chagas. Usando OpenSSL - Uma implementação livre do protocolo SSL. Trabalho da Disciplina Segurança de Dados 1/03, Universidade de Brasília - 13 de Julho de 2003 - http://www.cic.unb.br/docentes/pedro/trabs/hammurabi.htm
MENEZES, A., OORSCHOT, P.V., VANSTONE, S. Handbook of Applied Cryptography, CRC Press, New York, 1997.
MESERVE, J., DES code cracked in record time Network World, 1999.
MIERS, Charles Christian; CUSTODIO, Ricardo Felipe., Modelo Simplificado do Cifrador AES, UFSC, Florianópolis, 2002.
MORENO, E. D., PEREIRA, F., PENTEADO, C., PERICINI, R. Projeto, Desempenho e Aplicações de Sistemas Digitais em Circuitos Programáveis (FPGAs), Bless Gráfica e Editora, Marília/SP, 2003.
MOTOROLA, Motorola MPC680 PowerQUICC Processor, Hardware Specifications, 1999.

289
MOTOROLA, C-5™ Network Processor, 2002.
MPC180TS, MPC180 Security Processor Technical Summary, Motorola, 2003.
MPC184TS, MPC184 Security Processor Technical Summary, Motorola, 2003.
MPC185TS, MPC185 Security Processor Technical Summary, Motorola, 2003.
MPC190TS, MPC190 Security Processor Technical Summary, Motorola, 2003.
NISTAPI, National Institute of Standards and Technology, Advanced Encryption Standard (AES)-Development Effort, Cryptographic API Specifications and Reference Information, 1999.
NEIL, T. W., EDWIN H.-M., Minimizing Inter-Iteration Dependencies for Loop Pipelining, ISCA International Conference, 2000.
OPENCORES, OPENCORES.ORG - http://www.opencores.org/ - Acesso em Março de 2004.
PAAR,C. Cryptography and Data Security. Course Information. Electrical and Computer Engineering Department. Worcester Polytechnic Institute. http://ece.wpi.edu/People/faculty/cxp.html. http://ece.wpi.edu/~christof/578., 2004.
PAAR,C. Reconfigurable Hardware in Modern Cryptography. Technical Report, ECC 2000, Cryptography and Information Security Group, Electrical and Computer Engineering Department. Worcester Polytechnic Institute. http://www.ece.wpi.edu/Research/crypt., 2000.
PALOS, J. A., Seguridad en la Plataforma Java 2 JDK 1.2. http://www.programacion.com/java/tutorial/security1dot2/7/, Acesso em dezembro de 2004.
PATTERSON, D. A., HENNESSY J. L., Computer Organization and Design: The Hardware/Software Interface, Morgan Kaufmann Publisher, 1997.
PEREIRA, F. D., Um Criptoprocessador VLIW para algoritmos Criptográficos Simétricos: Projeto e Desempenho em FPGAs, Dissertação de mestrado em ciência da computação, UNIVEM, 2004.
PEREIRA, F., MORENO, E.D. Otimização em VHDL e Desempenho em FPGAs do Algoritmo de Criptografia DES. Quarto Workshop em Sistemas Computacionais de Alto Desempenho (WSCAD), São Paulo, Nov., 2003.
PETRI, Steve. Na Introduction to Smart Card. www.sspsolutions.com. Acesso em 2004.
PINTO, T. A. M.. Estudo e Comparação De Algoritmos De Função Hashing. Trabalho de Conclusão de Curso, Bacharelado em Ciência da Computação, UNIVEM (Centro Universitário Eurípides de Marília), Marília, S.P., Brasil, 2004.

290
PRADO, R. P., Proposta de Implementação em FPGA de um Processador de rede Reconfigurável, Dissertação de Mestrado, Ciência da Computçaão, UNIVEM, Brasil, 2004.
PUTINI, R., S.,. Material do curso de Pós-Graduação sobre Segurança de Redes Departamento de Engenharia Elétrica, Universidade de Brasilia. Link: http://www.redes.unb.br/security, 2004.
RC5-64, RSA Security Inc. The RSA Challenge Numbers (RC5-64), 2003.
REGULY, A., OpenSSL. Trabalho de Redes de Computadores, Universidade Federal do Rio Grande so Sul, Porto Alegre, 2001. http://reguly.net/alvaro/linux/security/openssl/rautu/OpenSSL_RauTu
REQUEST AES, National Institute of Standards and Technology, Announcing request for candidate algorithm nominations for the advanced encryption standard(aes), 1997.
RFC1321, Rivest, R., RFC 1321 - The MD5 Message Digest Algorithm., 1992.
RFC3174. RFC 3174 – US Secure Hash Algorithm 1 (SHA-1). NSA 1994.
RIJNDAEL, Daemen J., Rijmen, V., AES Proposal: Rijndael Block Cipher, 1999.
RIVEST, R., RC6 Block Cipher, RSA Security Inc, USA, 2000.
RIVEST, R., SHAMIR, A., ADLEMAN, L., A Method for Obtainig Digital Signatures and Public-Key Cryptosystems, Communications of the ACM, 1978.
RIVEST, R., The RC5 encryption algorithm, Fast Software Encryption. 2nd. International Workshop, Lec. Note in Comp. Sci. 1008, pp 86-96, Springer-Verlag, 1995.
ROSS, A., BIHAM, E., KNUDSEN, L., Serpent: A Proposal for the Advanced Encryption Standard., Cambridge University England, 1998.
SCHNEIER, B. Applied Cryptography: Protocols, Algorithms and Source in C. 2nd Ed. John Wiley and Sons, New York, 1996.
SCHNEIER, B. Description of a New Variable-Length Key, 64-Bit Block Cipher (Blowfish), Fast Software Encryption, Cambridge Security Workshop Proceedings (December 1993), Springer-Verlag, 1994, pp. 191-204.
SHAH, N., Understanding Network Processors. Dept. EECS, UC, Berkeley. 2001.
SHAND, M., VUILLEMIN, J., Fast implementations of RSA cryptography. Proc. 11th IEEE Symp. Computer Arithmetic, pp. 252–259,1993.
SIMON, S., "The Code Book", Anchor Books, EUA,1999.
SCHNEIER, B., Description of a New Variable-Length Key, 64-Bit Block Cipher (Blowfish), USA, 1994.

291
SCHNEIER, B., KELSEY, J., et al Twofish: A 128-Bit Block Cipher,USA, 1998.
STALLINGS, William. Cryptography and Network Security: Principles and Practice, 2002.
STEVENS, R., An Introduction to OpenSSL Programming (Part I). UNIX Netork Programming, Vol. 1, 2a. Edição, 2001.
TANENBAUM, A. S., Redes de Computadores. Editora Campus, 3a Edição – 1997.
TERADA, R., Segurança de Dados Criptografia em Redes de Computadores, Ed. Edgard Blücher, 1ª Edição, 2000.
TESCARO, E. L. V., BIBLIOTECA PARA SEGURANÇA DE DADOS: OPENSSL UM ESTUDO DE CASO. Monografia de Especialização em Engenharia de Software, UNIVEM – Centro universitário Eurípides de Marília, Marília, S.P., Brasil, 2003.
TKOTZ, V., Criptologia Numaboa. link: http://www.numaboa. com/criptologia. Acesso em dezembro de 2003.
VILLASENOR, J., MANGIONE, W. H.., Configurable Computing. Scientific American, June,1997.
YOUNG, E. A., HUDSON, T. J., The OpenSSL Project. Página oficial do Projeto OpenSSL, Suíça, http://www.openssl.org, 2003.
YUAN, J., SVENSSON, C., High-speed CMOS circuit technique. IEEE J. Solid-State Circuits, pp. 62–70, Feb. 1989.
WIKIPEDIA, Extended Euclidean algorithm - Wikipedia, the free encyclopedia. - http://en.wikipedia.org/wiki/Extended_Euclidean_algorithm - Acesso em Outubro de 2004.
XILINX, Xilinx: Programmable Logic Devices, FPGA & CPLD - http://www.xilinx.com/ - Acesso em Agosto de 2004.
XILINX Development Systems. Synthesis and Simulation Design Guide – Designing FPGAs with HDL, 1998.
Bibliografia Recomendada
AES_ALTERA2003. AES Cryptoprocessor, Altera Inc. www.altera.com/products/ip/ampp/cast/cast.html,Site consultado em julho de 2003.
BOK, Dong, LEE, Jong Su, PARK, Jong Sou, KIM, Sang Tae. The Simulation and Implementation of Next Generation Encryption Algorithm RIJNDAEL. In Proc. of MIC (Modelling Identification and Control), 2002.

292
BROWN, L. A Current Perspective on Encryption Algorithms. . Technical report, School of Computer Science, Australian Defense Force Academy, Canberra, Australia. www.adfa.oz.au/~lpb/papers. UniforumNZ´99, May, 1999. Also, UUG98, Sept., 1998.
BURKE J., MCDONALD, J., AUSTIN, T., Architectural Support for Fast Symmetric-Key Cryptography.. Advanced Computer Architecture Laboratory, Univ. of Michigan, U.S.A, In Proc. of ASPLOS IX, Cambridge, 2000.
BURNETT, Steve; PAINE, Stephen Paine. RSA Security's Official Guide to Cryptography, McGraw-Hill, EUA, 2002.
CHODOWIEC, P., GAJ, K. Implementations of the TWOFISH Cipher Using FPGA Devices. Technical Report, Electrical and Computer engineering, George Mason University, July, 1999.
DAEMEN, J., RIJMEN, V. AES Proposal: Rijndael Block Cipher. . 03/09/99.
DAHAB, R. Criptografia: Conceitos Básicos e Aplicações., UNICAMP. Palestra no Ibilce da UNESP, Ribeirão Preto, 2001.
DEALY, S. Cryptanalysis Study of RC5 with Emphasis on Exhaustive Key Search. Technical report, 1997. http://security.ece.orst.edu/koc/ece575/97Project/Dealy.txt.
DEHON, A. - Reconfigurable Architecture for General-Purpose Computing., Ph.D. thesis, Massachusetts Institute of Technology, 1996.
DES Cryptoprocessor Core, Cast Inc., http://www.cast-inc.com/cores/des/cast_des.pdf, Site consultado em julho de 2003.
DOUG, J. Architectural Synthesis from Behavioral Code to Implementation in a XILINX FPGA. , Business Development Manager, Forntier Design Inc. www.frontierd.com
ELBIRT, A.J., PAAR, C. An FPGA Implementation and Performance Evaluation of the Serpent Block Cipher. . In Proc.of FPGAs 2000.
GÓIS, M.C, A.; BEZERRA, H.M.A.; BARROS, P. G.; SANTOS, André. Tecnologia Java para Segurança de Sistemas. Revista REIC-SBC., Dezembro, 2003.
GONÇALVES, Leandro Salenave; RIBEIRO, Vinicius Gadis. Um estudo comparativo entre algoritmos de criptografia DES e AES. Trabalho desenvolvido na Universidade Luterana do Brasil. Canoas/RS, 2000.
HAUCK, S. The Roles of FPGAs in Reprogrammable Systems., Proceedings of the IEEE, Vol. 86, No. 4, pp.615-638, April, 1998.
HOLSCHUH, Henrique. Homepage do PGP Internacional. UNICAMP., http://www.dca.fee.unicamp.br/pgp/
LEE, B. K., JOHN, L.K. Implications of Programmable General Purpose Processors for Compression/Encryption Applications. In Proc. Of the IEEE 13th Intl. Conf. on

293
Application Specific Systems, Architectures and Processors (ASAP), San Jose, CA, USA, July, 2002.
MAARC: Models, Algorithms and Architectures for reconfigurable Computing. Technical report, University of Southern California - USC. http://maarc.usc.edu/
MARTINS, C.A.P.S.; MORENO, E. D.. Computação Reconfigurável: Conceitos, tendências e Aplicações. Minicurso no evento CORE-2000, Marilia, SP., Brasil, Ago., 2000.
MOREIRA, André. Documentos de Criptografia. Departamento de Engenharia Informática, Instituto Superior de Engenharia do Porto, Instituto Politécnico do Porto, Portugal. http://www.dei.isep.ipp.pt/~andre/
NUMABOA. Criptografia. Criptologia. Criptoanálise. Disponível em http://www.numaboa.com.br/criptologia/criptografia.php., 2003.
OPENSSL. Página Oficial do projeto OpenSSL: http://www.openssl.org.
ORLANDO, G., Efficient Elliptic Curve Processor Architectures for Field Programmable Logic. Tese de Doutorado em Engenharia Elétrica, Worcester Polytechnic Institute, Worcester - USA, , 2002.
PAAR, C.,CHETWYND, B., CONNOR, T., DENG, S. Y., MARCHANT, S., An Algorithm-Agile Cryptographic Coprocessor Based on FPGAs. ECE Department, Worcester Polytechnic Institute, Worcester, U.S.A, The SPIE´s Symposium on Voice and Data Communications, Sep. 1999, Bosto, U.S.A
PAAR,C. Implementations Options for Finite Field Arithmetic for Elliptic Curve Cryptosystems. Technical Report, ECC ´99, Cryptography and Information Security Group, Electrical and Computer Engineering Department. Worcester Polytechnic Institute. http://www.ece.wpi.edu/Research/crypt.
RAMALHO, D. G.. Estudo e desenvolvimento de uma plataforma Multi-FPGA para prototipação de Sistemas Digitais. Univ. Federal de Pernambuco - Centro de Informática, 2000.
ROSENSTIEL, W. Prototyping and Emulation, Hardware/Software Codesign: Principles and Practice. Kluwer Academic Publishers, pp. 75-112, 1997.
RSA. Empresa RSA Security. http://www.rsa.com/
SHS. SHS Communications Security. http://www.cs.hut.fi/ssh/crypto/
SPILLMAN, R. Cryptographic Analysis Program – CAP. . CAP - Software. Pacific Lutheran University. www.cs.plu.edu/pub/faculty/spillman/CAP/index.htm e www.plu.edu/~spillmrj/
SSH. Cryptography A-Z. Link: http://www.ssh.fi/support/cryptography/index.html, 2003.

294
SUN, Sun Microsystems – Fornecedora de classes e produtos Java. Link: www.sun.com
SUN-API. API Specification and Reference. Disponível em Setembro de 2003, http://java.sun.com/products/jdk/1.2/docs/guide/security/CryptoSpec.html..
TERADA, R., Criptografia e Cripto-Análises Diferencial e Linear., IME-USP, 1997.
VLSI Implementation of Cryptographic Functions. Tecnhical Report 1998. http://security.ece.orst.edu/koc/ece575/98Project/Ozdag.
WOLLINGER, T. J., Wang, M., Guajardo, J., Paar,C. How Well Are High-End DSPs Suited for the AES Algorithms ? AES Algorithms on the TMS320C6x DSP. . The Third Advance Encryption Standard (AES3) Candidate Conference, April, 2000, New York, U.S.A
WU, L., WEAVER, C., AUSTIN, T., CryptoManiac: A Fast Flexible Architecture for Secure Communication. Advanced Computer Architecture Laboratory, Univ. of Michigan, U.S.A, In Proc. of ISCA-2001 (Intl. Conf. On Computer Architecture), Goteborg, Sweden.
XIE, H., ZHOU L., BHUYAN, L., An Architectural Analysis of Cryptographic Applications for Network Processors. . Department of Computer Science and Engineering, Univ. of California, Riverside. IEEE First Workshop on Network Processors, with HPCA-8, Bosto, U.S.A., Feb., 2002.
YEOM, D. B., LEE, J. S., PARK, J. S., KIM, S. T., The Simulation and Implementation of Next Generation Encryption Algorithm RIJNDAEL. In Proc. of MIC-2002.
ZHUO, M. A Comparative Study of New Block Ciphers. . Technical report 1999. http://security.ece.orst.edu/koc/ece575/99Project/Zhuo.html.