centro de investigaÇÕes regionais e urbanas©todos de análise espacial.pdf · desequilíbrios...
TRANSCRIPT

UNIVERSIDADE TÉCNICA DE LISBOA
INSTITUTO SUPERIOR DE ECONOMIA E GESTÃO
CENTRO DE INVESTIGAÇÕES REGIONAIS E URBANAS
E C O N O M I A
R E G I O N A L E U R B A N A
Coordenação: Manuel Brandão Alves
4º ANO DO CURSO DE ECONOMIA
2001/2002
2. MÉTODOS DE ANÁLISE DA EVOLUÇÃO DO SISTEMA ESPACIAL
PORTUGUÊS: AS REGIÕES, AS CIDADES E OS FENÓMENOS
URBANOS
Manuel Brandão Alves
António Natalino Martins
Maria Luiza Vaz Pinto
Paulo Madruga
CIRIUSCentro de Investigações Regionais e Urbanas
SÉRIE DIDÁTICA
Documento de Trabalho nº 2 /2001


2. MÉTODOS DE ANÁLISE DA EVOLUÇÃO DO
SISTEMA ESPACIAL PORTUGUÊS: AS REGIÕES,
AS CIDADES E OS FENÓMENOS URBANOS
Manuel Brandão AlvesAntónio Natalino Martins
Maria Luiza Vaz PintoPaulo Madruga
Edição de Setembro de 1999


ÍNDICE
ÍNDICE 1
2. MÉTODOS DE ANÁLISE DA EVOLUÇÃO DO SISTEMA
ESPACIAL PORTUGUÊS: AS REGIÕES, AS CIDADES E
OS FENÓMENOS URBANOS 3
2.1. ANÁLISE ESTÁTICA DA ESTRUTURA REGIONAL 5
2.1.1 As medidas de especialização 8
2.1.2 As medidas de diversificação 14
2.2. ANÁLISE DINÂMICA 19
2.2.1 O método de Dunn e a análise de decomposição 19
2.2.2. A análise shift-share 23
2.3. INDICADORES DE SÍNTESE 29
2.3.1. A análise factorial 29
2.3.2. A distância económica 54
2.4. A IDENTIFICAÇÃO E A CLASSIFICAÇÃO DAS REGIÕES 56
2.4.1. A análise de clusters 65
2.4.2. Noções de densidade e de distância inter-grupal 76
2.4.3. A formação de agrupamentos homogéneos 79
2.4.4. A formação de agrupamentos polarizados 84


2. MÉTODOS DE ANÁLISE DA EVOLUÇÃO DO SISTEMA ESPACIAL PORTUGUÊS: AS
REGIÕES, AS CIDADES E OS FENÓMENOS URBANOS 3
2. MÉTODOS DE ANÁLISE DA EVOLUÇÃO DO SISTEMA
ESPACIAL PORTUGUÊS: AS REGIÕES, AS CIDADES E
OS FENÓMENOS URBANOS
Foi referido em ponto anterior que, o espaço económico é o
resultado de uma aplicação do espaço matemático no espaço
geográfico, em que as variáveis do espaço matemático assumem
significado económico.
O espaço matemático foi definido como sendo um espaço
abstracto de representação das relações entre variáveis, enquanto o
espaço geográfico o foi como sendo o espaço físico e o meio ambiente
em que vivemos. O espaço económico é, assim, o conjunto de espaços
concretos (lugares) de ocorrência dos fenómenos económicos, que
designaremos por espaços elementares. O que lhe dá consistência é a
unidade dos fenómenos económicos que aí ocorrem. Por isso, um
mesmo fenómeno pode dar unidade a diferentes espaços elementares.
Cada espaço elementar é, todavia, meio ambiente da ocorrência
de fenómenos diversos, protagonizados por múltiplos sujeitos. Duns e
doutros, resulta a coesão económica e social, que nos permite
distinguir os espaços entre si. Surge, assim, a região, produto da
agregação de espaços elementares dotados de determinadas
características e contíguos1 entre si.
A região, sendo uma entidade dotada de dinamismo próprio,
constitui uma dimensão privilegiada de actuação pública sobre os
fenómenos macro-económicos. A organização dessa actuação pelos
1A contiguidade significa que se pode passar de um espaço elementar a outro, sem
necessidade de transitar por um terceiro.
O espaço económico é umaaplicação do espaço deactividades sobre o espaçodos lugares.
A região é um tipo particulade espaço económico.
Os elementos que dãoidentidade à região, não seopõem à sua abertura aoexterior.

4 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
poderes públicos pressupõe, por isso, a delimitação das regiões, ou
seja, a identificação dos elementos que conferem unidade a vários
espaços elementares, o que permite tomá-los como região. A região,
conjunto de espaços elementares, é, por sua vez, parte do todo
nacional e, deste modo, enquanto subsistema do sistema económico
nacional, caracteriza-se por ser um sistema aberto, o que significa, que
são reduzidas as restrições à mobilidade de bens e factores produtivos,
quer no seu interior (mobilidade intra-espacial), quer nog seu
relacionamento com outras regiões (mobilidade inter-espacial), também
elas elementos do sistema nacional.
A abertura das regiões é fomentadora de relações de
interdependência, que podem ser de dominação ou de dependência,
consoante o papel que, no conjunto desse sistema de relações,
desempenha cada uma dessas regiões
As interdependências espaciais geradas resultam da estrutura
económica de cada região e, por esse motivo, tão importante se torna
estudar as relações interregionais, como conhecer o seu suporte
económico e o respectivo quadro organizativo, ou seja, as relações
intra-regionais.
À política regional interessará conhecer a estrutura económica de
cada região, não apenas em termos estáticos (caracterização), mas
também em termos dinâmicos (perspectivas de evolução), porque da
conjugação destes dois aspectos tanto podem resultar condições
propícias ao desenvolvimento como ao aprofundamento de
desequilíbrios regionais, que necessitem de correcção.
Este conjunto de problemas será abordado nos pontos seguintes,
onde iremos estudar, os instrumentos de caracterização e evolução das
estruturas económicas das regiões e as metodologias que permitem,
A abertura das regiões gerainterdependências espaciais.
A política económicaregional supõe análise
estática e dinâmica.

2.1.1 AS MEDIDAS DE ESPECIALIZAÇÃO 5
realizar comparações entre elas, determinar o seu posicionamento no
todo nacional, classificá-las e delimitá-las.
2.1. ANÁLISE ESTÁTICA DA ESTRUTURA REGIONAL
As regiões são sistemas abertos que se interrelacionam por várias
formas e em que assumem particular importância os fluxos de bens e
serviços. Há regiões que não produzem tudo o que consomem e outras
produzem mais do que necessitam. Aí está uma fonte da
interdependência entre as regiões, mas ela não se pode esgotar numa
visão que encara as relações das regiões apenas como dando origem a
fluxos de bens e serviços. A tecnologia, os recursos humanos, a
cultura, o lazer, etc, são outras tantas perspectivas através das quais
aquela interdependência pode ser encarada.
O tipo ou as características do relacionamento referido estão
ligados à composição da estrutura económica de cada região. Como os
recursos naturais e a capacidade do seu aproveitamento variam no
espaço, as relações interregionais podem gerar condições e situações
de desigualdade, acentuando dependências julgadas pouco aceitáveis.
As desigualdades traduzem-se em desequilíbrios e estes
constituem hoje um dos objectos marcantes, embora não exclusivo, da
política regional. A política supõe, no entanto, intervenção e esta
conhecimento. O conhecimento exige a identificação e a medição dos
referidos desequilíbrios.
A medição e avaliação dos desequilíbrios supõe a escolha de um
termo de comparação, que permita concluir sobre a existência de
desvios (detecção do problema) e da respectiva amplitude (gravidade
do problema). A este termo de comparação designaremos por padrão.
A interdependência dasregiões pode ser observadaatravés dos fluxos de bens eserviços que entre elas sãogerados.
Os fluxos deinterdependência podemgerar mecanismos dedesigualdade.
A existência dedesequilíbrios exige medidasde política económica e estaimpõem o conhecimentorigoroso da importânciadaqueles desequilíbrios.
Medir implica comparar enão há comparação sem aescolha de um padrão.

6 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
O padrão pode ser uma variável cuja distribuição espacial se
considera exemplar ou um espaço em que a sua distribuição sectorial
pode ser tomada como referência. A escolha do tipo de padrão
depende dos objectivos da análise, já que os indicadores a utilizar não
serão os mesmos, sendo, também distintas as suas potencialidades
informativas.
Contudo, para bem avaliar o significado dos desequilíbrios
importa que conheçamos a estrutura ou composição interna da
economia de cada um dos espaços.
Para a caracterização do que existe interessa conhecer a forma
como as actividades produtivas se distribuem, em termos espaciais e
sectoriais.
O comportamento espacial dos sectores de actividade permite
avaliar o grau de especialização de uma região ou a diversificação de
actividades que comporta.
Este aspecto reveste um interesse especial quando o objectivo de
política regional é o da correcção dos desequilíbrios, porque a
intervenção possível terá de ser diferenciada, consoante se verifique a
concentração sectorial da actividade económica regional
(especialização) ou, pelo contrário, a sua difusão mais ou menos
equilibrada, por vários sectores (diversificação).
Em qualquer caso, são pouco desejáveis graus excessivos, tanto
de especialização como de diversificação. A especialização
exagerada, em situações desfavoráveis, aumenta a vulnerabilidade da
região, embora, em situações favoráveis, .possa conferir-lhe
características de região dominante no relacionamento com as outras
regiões.
A escolha de um padrãovaria de acordo com os
objectivos da análise.
Os indicadores dediversificação permitem-nos
conhecer a estruturaeconómica das regiões.
A avaliação do grau deespecialização ou de
diversificação de umaregião…
…é importante em termos dedefinição de política
regional.

2.1.1 AS MEDIDAS DE ESPECIALIZAÇÃO 7
Apesar dos aspectos positivos que a especialização possa
apresentar, é preciso ter presente que se em determinadas
circunstâncias pode revelar uma capacidade específica de uma região,
indiciadora de potencialidades a desenvolver, noutras pode significar a
existência de bloqueamentos condicionadores do arranque para o
desenvolvimento.
A especialização implica, em geral, capacidade exportadora
significativa e, por isso, inserção da economia regional nas economias
que a envolvem. Em épocas de expansão da procura, a especialização é
um benefício para a região. No entanto, se a região não sabe
acompanhar o dinamismo da procura pode acontecer que, porque o
mercado exige novos produtos, ou produtos mais sofisticados, a sua
actividade económica venha a sofrer graves revezes.
Inversamente, uma elevada diversificação de actividades
protege com mais facilidade a região dos impactos negativos que
possam ter origem nas zonas de exportação, ou porque a dinâmica da
procura se orientou para outros produtos, ou porque aí se começam a
verificar tendências depressivas generalizadas. Contudo, um grau de
diversificação demasiado elevado, ou não convenientemente gerido,
pode impedir a região de participar do esforço de crescimento e
desenvolvimento que, a nível nacional e mundial, apresentam
determinados sectores de actividade. A diversificação excessiva pode,
ainda, significar dispersão de recursos susceptível de impedir a
obtenção das dimensões mínimas2 necessárias para tornar competitivas
determinadas actividades.
2Seja em termos de dimensão das próprias empresas, seja em termos de dimensão da
actividade, no primeiro caso, condicionada pelas economias de escala e, no segundo caso,pelas economias de aglomeração.
Vantagens e incoveninentesda especialização regional…
…e da diversificaçãoregional.

8 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Haverá que procurar beneficiar das vantagens, tentando evitar os
seus inconvenientes, tanto da especialização como da
diversificação.Em cada caso deverá procurar-se encontrar o que
poderíamos designar como a combinação óptima de especialização e
diversificação3.
2.1.1 As medidas de especialização
Como já foi salientado, se é importante que a estrutura
económica de uma região seja equilibradamente diversificada, também
é importante que a diversificação não seja tão extrema que elimine toda
a possibilidade de especialização4.
Somos, por isso, levados a estudar medidas de especialização,
apresentando em primeiro lugar, o coeficiente de localização.
O coeficiente de localização (CL ) pode ser interpretado como
um indicador de associação (distribuição) espacial entre duas
actividades (variáveis) ou como um indicador agregado das
disparidades na distribuição de uma variável num determinado espaço5,
recorrendo à comparação da sua distribuição com a de uma outra que é
tomada como termo de comparação e se chama variável padrão. Não
se pode dizer que o coeficiente de localização tem dois conteúdos
diferentes. Trata-se de duas leituras de um mesmo conteúdo.
Começamos por apresentar a primeira interpretação.
3Não basta contudo encontrar essa combinação num determinado momento. Haverá
que saber geri-la no tempo, porque uma combinação óptima hoje poderá não o ser amanhã.4Quer o ponto de vista seja o do peso de uma actividade no conjunto das actividades
de uma região, quer do da forma como uma actividade se distribui no conjunto das regiões,em comparação com um padrão pré-definido.
5 Em geral o espaço nacional.
Existem duas leituraspossíveis para o coeficiente
de localização.

2.1.1 AS MEDIDAS DE ESPECIALIZAÇÃO 9
O CL compara a distribuição espacial de uma variável x para
uma actividade j (x rj ) com a sua distribuição espacial para uma
actividade padrão (x rp)6.
A variável padrão pode ser o conjunto das actividades ou uma
qualquer outra variável considerada exemplar, ou que se quer tomar
como referência.
Para cada região r a proporção da actividade j e da actividade
padrão que lhe cabem são representadas por:
x
xr j
j
e x
xr p
p
O somatório dos desvios (positivos ou negativos) entre estas
duas relações, constitui a base do cálculo do Coeficiente de
Localização (CL j). A fim de evitar que os desvios se compensem, são
tomados em módulo.
A representação algébrica de CL j será dada por:
C L
x
x x
x
2 (0 CL 1)j
rj
j
rp
p rj
−
≤ <∑
(1)
onde:
x j é o valor da variável x, no conjunto dos espaços e para a
actividade j;
x rp é o valor da variável x na região r para a actividade padrão;
x p valor da variável x, no conjunto dos espaços, e para a
actividade padrão.
6Ao referir-se a distribuição espacial está-se a chamar a atenção para o facto de com
o CL j se considerarem, para além do espaço padrão, todas as regiões r.
A primeira leitura.
O cálculo do CLj.
=

10 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
O cálculo do CLj permite determinar até que ponto estão
associadas as distribuições espaciais de duas actividades que, teórica e
(ou) normativamente, o deveriam estar7 . Quanto maior for CLj ,
maiores são os desequilíbrios verificados nas distribuições daquelas
actividades. Se as distribuições da actividade j e da actividade padrão
forem iguais, CLj =0. À medida que as distribuições se afastam uma da
outra, CLj tenderá a aproximar-se da unidade, sem contudo conseguir
atingir esse valor.
O desequilíbrio pode ser interpretado como um indicador da
especialização da actividade j num certo espaço, ou conjunto de
espaços. Daí que o coeficiente de localização possa ser apresentado
como um indicador de especialização. Dá-nos informações, não sobre a
região que está especializada na actividade j, mas antes sobre o grau de
especialização do conjunto das regiões, na actividade j8.
Tem sido comum uma outra forma de apresentação do
coeficiente de localização em que a variável cuja distribuição se
compara com um padrão não está necessariamente associada à
distribuição de uma determinada actividade e que, por isso,
designaremos apenas por CL.
Pode, por ex., comparar-se a distribuição regional do produto
com a da superfície. Seja o produto representado pela variável x, e a
superfície pela variável y. Para cada região r , as proporções de produto
e de superfície que lhe cabem são representadas por:
xx
r e yy
r
7Por exemplo se admitíssemos que seria desejável que a transformação da cortiça se
processasse nas regiões florestalmente especializadas no sobreiro, este indicador permitir-nos-ia estimar os desvios em relação a esse objectivo.
Os limites de variação doCLj
A segunda leitura.

2.1.1 AS MEDIDAS DE ESPECIALIZAÇÃO 11
A representação algébrica de CL é, assim, dada por:
C L =
x x
yy
2 (0 CL 1)
r r
r
−≤ <
∑ (2)
Os comentários ao comportamento de CL são idênticos aos já
referidos para CL j .
A segunda medida de especialização que iremos estudar é o
quociente de localização.
O quociente de localização não é um indicador da especialização
de uma região9, mas antes do grau em que uma região pode ser
considerada, ou não, como especializada numa determinada actividade.
A estrutura sectorial de uma região pode ser identificada, como
se sabe, através do peso relativo que nela possuem as suas diferentes
actividades. Esse peso relativo constituir a base da construção do
quociente de localização. Seja:
xrj /xr - o peso da actividade j na região r (conjunto das
actividades), tendo as variáveis o significado que
anteriormente lhes foi atribuído.
Se se pretender comparar o peso de uma variável, para uma
determinada actividade, num determinado espaço, com o seu peso no
espaço padrão, podemos utilizar o indicador simples, acima referido
como Quociente de Localização (QL rj ).
8Uma outra leitura permitirá dizer que CL j é um indicador de dispersão da
actividade j , tanto maior quanto mais se aproximar de 0.9E para esse efeito pode ser utilizado o coeficiente de diversificação, embora com
uma leitura simétrica da que atrás foi apresentada.

12 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Escolhido um espaço padrão, que normalmente corresponde ao
conjunto das regiões em análise, o QLrj pode ser definido a partir da
seguinte expressão:
QLx
x x
x (0 QL )rj
rj
r
pj
prj= ≤ ≤ ∞
em que:
QL rj é o quociente de localização da actividade j na região r;
x pj é o valor da variável x, para a actividade j , no espaço
padrão;
x p é o valor da variável x, no espaço padrão, para o conjunto
das actividades.
Se tomarmos a distribuição sectorial da actividade produtiva da
região padrão como desejável, isso permite-nos tomar o QL como um
indicador de disparidades regionais, considerando-se como modelar, a
região que mais se aproxima do padrão. Esta proximidade será tanto
maior, quanto mais os QL das diversas actividades forem próximos da
unidade.
O recurso ao QL , como indicador de especialização sectorial de
uma região, tem, relativamente aos índices simples xrj /xr, a vantagem
de evitar a escolha arbitrária de um limiar de especialização.
Particularmente, se o espaço tomado como padrão, for o conjunto das
regiões (a nação), a importância do QL como medida de
especialização, torna-se evidente, já que, na prática, ele nos fornece
uma medida da importância de cada sector na região, tendo em conta a
respectiva dimensão nacional. Ou seja, permite-nos saber até que ponto
O quociente de localização.
É possível ler o quociente delocalização como um
indicador das disparidadesregionais na distribuição de
uma determinada actividade.

2.1.1 AS MEDIDAS DE ESPECIALIZAÇÃO 13
o sector é importante na região, por via da própria especialização
regional e não por via da especialização nacional10.
Quanto maior for QLrj maior é o grau de especialização da
região r na actividade j .
Se QLrj = 0, a região não possui a actividade j .
Se QLrj = 1, a região r tem um grau de especialização idêntico
ao do espaço padrão.
Se QLrj > 1, a actividade j é mais importante (isto é, está mais
localizada) na região r do que na região padrão, concluindo-se
que a região é especializada naquela actividade.
Os quocientes de localização (QL ) permitem comparar as
regiões entre si e com o padrão mas, apresentam limitações que
resultam de se ter que escolher um termo de comparação (o padrão
como situação ideal), e de utilizar uma única variável para realizar as
comparações interregionais.
Os valores obtidos para o QL dependem da nomenclatura de
actividades utilizada. Quanto mais agregada for, menos rica será a
informação produzida. Por isso, uma análise de especialização deverá
basear-se num número de sectores tão grande, quanto as
disponibilidades estatísticas o permitirem.
A utilização do QL como indicador de desequilíbrios é
discutível, na medida em que é difícil dizer o que é uma distribuição
sectorial óptima. A fragilidade da hipótese que consiste em considerar,
como referência, o conjunto das regiões é evidente. Tomar-se como
10Nesta óptica não terá sentido afirmar que uma região é especializada num sector
que corresponde a, por ex., 51% do conjunto da sua actividade, se a nível nacional o sectorrepresenta mais do que esses 51%.
Os limites de variação doquociente de localização.
O quociente de localizaçãopossui limitações,decorrentes, tanto da sualógica de construção, comonas utilizações que dele sãofeitas.

14 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
padrão uma qualquer outra região (nacional ou estrangeira) revela as
mesmas insuficiências. Nada garante que o que é uma especialização
frutuosa para uma dada região o seja também, dada a complexidade
dos factores em apreciação, para uma outra.
Acrescente-se ainda que o QL pode apresentar a desvantagem de
não se tratar de uma medida agregada para cada espaço. Existe um QL
para cada par actividade-região, pelo que, para cada espaço, se obtem
um número elevado de indicadores cuja apreciação de conjunto se
torna difícil11.
2.1.2 As medidas de diversificação
Um dos indicadores mais usados para estudar a diversificação
regional é o coeficiente de diversificação.
O coeficiente de diversificação (CD)12 para uma determinada região
r , pode ser explicitado através da seguinte expressão:
CD =2
(0 CD < 1)r r
x
x
x
xrj
r
pj
pj
−≤
∑
11No entanto, uma interpretação correcta não pode concluir que estamos na presença
de uma limitação do indicador, uma vez que, por esta via, se está a pretender acusar oquociente de localização de não fornecer elementos de interpretação que com ele nunca sepretendeu proporcionar.
12É por vezes também designado por índice de especialização, o que tem tambémjustificação, uma vez que a especialização de um espaço é tanto maior quanto menor for adiversificação. Consideramos, no entanto, que o indicador tem mais potencialidades em serutilizado como indicador de diversificação do que como indicador de especialização.
O coeficiente dediversificação.

2.1.2 AS MEDIDAS DE DIVERSIFICAÇÃO 15
onde:
x r j - é o valor da variável x13, na região r e na actividade j;
x r - é o valor da variável x na região r, para o conjunto das
actividades;
x p j - é o valor da variável x, na região padrão (p), para a
actividade j;
xp - é o valor da variável x, na região padrão, para o conjunto
das suas actividades.
Quando CDr = 0, a diversificação é idêntica à do padrão; quanto
mais CDr se aproximar de 1 (o campo de variação é aberto à direita,
sem que o extremo 1 seja atingido), menor será a semelhança da
economia regional, em termos de diversificação, relativamente ao
padrão.
O recurso a um padrão implica condicionamentos na
interpretação dos resultados, nomeadamente, o facto de o padrão
poder estar sujeito a limitações. Os desvios em relação ao padrão, que
vierem a ser constatados, terão, por isso, que ser interpretados de
acordo com o significado normativo que se atribuir ao padrão. Os
juízos que a partir daí forem emitidos serão tanto mais válidos quanto
mais permanente for o padrão.
Assim, se o espaço padrão for diversificado, um CDr = 0 significa
que a região r é tão diversificada quanto o padrão, e se CDr se
aproximar de 1 então a região r será mais especializada que o padrão.
13Por ex., o emprego, os salários, a produção, etc.
Os limites de variação docoeficiente.
A escolha de um padrãosujeita a sua utilização alimitações.
Podem ser construídosindicadores que não estejamsujeitos às limitações daescolha de um padrão.

16 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Tem-se procurado superar os inconvenientes ligados à
necessidade de escolha de um padrão, construindo indicadores, ou
medidas, que não pressuponham essa escolha.
Um deles é o índice de diversificação (Dr), construído a partir
das relações xrj /xr .
Começa-se por colocar por ordem decrescente, as sucessivas
relações xrj /xr , com j = 1, 2, . . . , m.
Seguidamente, sejam pr1 , pr2 , . . . , prm, respectivamente, as
relações x rj /x r, para j = 1, 2, . . . , m, por ordem decrescente.
Teremos: pr1 > pr2 >... > prm
Construa-se a partir destas relações a seguinte sucessão:
dr1 = pr1
dr2 = pr1 + pr2
:
drm = pr1 + pr2 + . . . + prm
A soma dos diferentes drk, determinará o valor do índice de
diversificação para o espaço r :
Dr =∑d (k= 1,2, , m) rkk
!
Se a importância relativa de cada um dos sectores j for idêntica,
então:
pr1 = pr2 = ... = prm = 1m
pelo que:
O índice de diversificação.

2.1.2 AS MEDIDAS DE DIVERSIFICAÇÃO 17
dkmrk =
e o valor de Dr será:
D mm
r = + + + = +1m
( ... )1 21
2
No caso, também extremo, da actividade económica se
concentrar num único sector:
d r1 = d r2 = ... = d rm = 1
e teríamos:
D = mr
O índice de diversificação D r pode, assim, variar entre um valor
mínimo:
D =m + 1
2r , considerado a diversificação máxima (peso
igual de todos os sectores) e um valor máximo:
D = mr , que corresponde à ausência de diversificação.
Este índice também apresenta limitações relativamente à
apreensão das realidades espaciais. Uma delas é o facto de o valor do
índice Dr ser indiferente às actividades sobre que recai a
especialização. Duas regiões podem apresentar o mesmo valor para o
índice Dr , e possuírem composições sectoriais muito diferentes. Este
inconveniente tem a sua origem no facto de ter sido eliminada a
referência a um padrão, o que tem como consequência que se obtenha
um índice absoluto. A sua relativização pode ser obtida recuperando a
referência a um padrão. Só que o padrão, neste caso, vai ser escolhido
de acordo com o objectivo que se pretende prosseguir.
O valor mínimo do índice dediversificação
O valor máximo do índice dediversificação
A construção de índicesrelativos.
As limitações do índice dediversificação.

18 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Se o objectivo for a determinação da proporção de diversificação
relativamente ao índice de diversificação máxima, pode-se construir
o índice relativo:
a) D = D m +1
2
r' r
cujos valores extremos são 1, quando a diversificação é
máxima e 2mm +1 , quando é nula;
Ou, comparando com o índice correspondente à ausência de
diversificação.
b) D = Dmr
' ' r ,
com extremos iguais a 1 e m +12m , consoante há ausência
ou maximização da diversificação.
Quando haja interesse em comparações interregionais pode-se
utilizar como padrão, o índice relativo a uma região, ou conjunto de
regiões, e designado por DC .
c) D r' ' ' r C
r C
=D D
D - D
− ou D
D r' ' ' ' r C
r C
=D D
- D −
Os indicadores apresentados permitem-nos realizar um juízo
acerca do comportamento da estrutura económica da região. Estamos
no domínio da análise intra-regional.

2.2.1 O MÉTODO DE DUNN E A ANÁLISE DE DECOMPOSIÇÃO 19
2.2. ANÁLISE DINÂMICA
A informação obtida com a utilização dos indicadores anteriores
avalia a situação de uma região num dado momento e, por isso,
podemos dizer que não permite senão uma análise estática. Mas, as
estruturas espaciais evoluem no tempo e à política regional interessa
conhecer o sentido e a intensidade dessa evolução.
O diagnóstico de uma situação num dado momento não basta;
torna-se necessário determinar, para que a intervenção se justifique,
como é que tende a evoluir e, no caso concreto dos desequilíbrios
regionais, se possuem uma dinâmica divergente, agravando as
distâncias económicas entre regiões, ou se o processo de evolução
tende para a convergência, o que corresponde a uma atenuação dos
desequilíbrios.
A leitura estática de uma estrutura não pode, por isso, dispensar
a sua caracterização dinâmica, que constitui um elemento indispensável
de análise. Serão apresentados, a seguir, alguns indicadores de
evolução.
2.2.1 O método de Dunn e a análise de decomposição
O indicador de evolução mais vulgarizado é a taxa de
crescimento que compara os valores assumidos por uma variável em
dois momentos diferentes do tempo.
Para além da análiseestática que os indicadoresanteriores permitem realizar,necessitamos, também, deavaliar o comportamento, notempo, das estruturas.
Existe uma multiplicidade deindicadores de evolução.

20 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Representando simbolicamente por xo e x1 os valores assumidos
pela variável x (produto, emprego, etc.) em determinado espaço, nos
momentos inicial e final do período em análise, a taxa de crescimento ,
define-se pelo quociente:
δ = x - x
x
1 o
o(1)
A taxa de variação temporal ou de crescimento δ constitui um
instrumento básico, utilizado por diferentes métodos, para analisar e
explicar a evolução dos desequilíbrios.
Se tomarmos para espaço padrão um conjunto de regiões14 e se
δ, calculada em (1), for a evolução padrão, poderemos comparar a
evolução real da região com a evolução que teria se os valores iniciais
evoluíssem de acordo com a taxa de crescimento do espaço padrão.
Podemos estimar o valor assumido pela variável x, numa região
r e no momento 1, se porventura tivesse evoluído de acordo com a
taxa de crescimento do padrão, do seguinte modo:
�xr1 = x (1+ )r
0 δ (2)
�xr1 - dá o valor que assumiria a variável x no espaço r, se tivesse
evoluído segundo o ritmo do espaço padrão.
Comparando �xr1 com xr
1 (valor realmente observado pela
variável x na região r e no momento 1) - podemos concluir se a
situação da região se afastou ou aproximou da do conjunto de regiões.
Ao desvio ∆ r calculado como se segue:
∆ r r1
r1= x - x � (3)
A definição de taxa decrescimento.
A evolução da região deacordo com o espaço
padrão.
A definição de variaçãolíquida regional.

2.2.1 O MÉTODO DE DUNN E A ANÁLISE DE DECOMPOSIÇÃO 21
chama-se variação líquida regional e constituí uma primeira medida
de análise da atenuação ou acentuação dos desequilíbrios regionais
existentes. Embora no conjunto das regiões os desvios se compensem,
pois:
x x xr rrr
1 1 1= =∑∑ � ,
a análise individualizada dos ∆ r permite comparar a similaridade de
evoluções da região r e a do espaço padrão. Se ∆ r é positivo a
situação da região melhora, em relação ao padrão, deteriorando-se no
caso de ser negativo.
Pode chegar-se a uma conclusão equivalente trabalhando com
taxas de crescimento. Comecemos por definir xr1 .
x = x (1 + )r1
r0
rδ (4)
Substituindo em (3), xr1 por (4) e �xr
1 por (2) obtem-se
facilmente:
δ δ δ δr r= + ( - ) (5)
Esta expressão permite identificar, na taxa de evolução real da
região r, duas componentes: a primeira, associada ao comportamento
global, é constituída por δ (taxa de crescimento segundo a norma); a
segunda, (δ r - δ), representa um diferencial entre o comportamento da
região r e o comportamento correspondente do conjunto das regiões.
Quanto menor for este diferencial, maior será a semelhança do
comportamento evolutivo da região r com o do espaço padrão.
14Que pode ser uma nação ou um espaço de integração económica de nações, como
por ex., a União Europeia.
A análise em termos de taxasde crescimento.

22 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
A evolução dos desequilíbrios pode, assim, ser estudada, quer
através da análise dos desvios considerados em valor absoluto (as
variações líquidas ∆ r ), quer em termos relativos, através da diferença
de taxas de crescimento (δ r -δ).
À análise dos desvios, quer em termos absolutos, quer em termos
relativos, dá-se a designação de Método de Dunn. Trata-se de um
método de decomposição, que procura explicar a evolução regional
através da evolução nacional e dos desvios que a evolução da região
apresenta em relação àquela.
O método de Dunn pode ser objecto de decomposições mais
finas, por sectores de actividade e por regiões. Com elas pretende-se
aprofundar a explicação e a origem dos desequilíbrios.
Exemplificando, se retomarmos a variável x e caso seja possível
a sua desagregação por sectores j (j=1,2,...,J) e regiões
r (r=1, 2,...,R), teremos:
x = x = x rr=1
R
r jj =1
J
r=1
R
∑ ∑∑
Assim, a identidade expressa em (5) pode apresentar a seguinte
forma:
rj j rj j = +( - )+( - )δ δ δ δ δ δ , (6)
o que significa que a taxa de crescimento do sector j na região r pode
ser decomposta em três parcelas.
A primeira está associada ao crescimento segundo a norma, ou
seja, a taxa do crescimento nacional. A segunda, que relaciona o
comportamento do sector j com o comportamento do conjunto, é
constituída pelo diferencial (δj - δ). A terceira parcela associa o
A análise dos desvios ouMétodo de Dunn.
O Método de Dunn comométodo de decomposições.

2.2.2. A ANÁLISE SHIFT -SHARE 23
comportamento do sector j na região r com o comportamento do
mesmo sector no conjunto das regiões e é representada pelo diferencial
(δ rj -δ j).
Pode haver ainda vantagem na desagregação do sector j em k
sub-sectores. A identidade apresentada em (6) assume, então, a
seguinte forma:
rjk j jk j rjk jk= +( - )+( - ) +( - )δ δ δ δ δ δ δ δ , (7)
com significado semelhante.
A expressão apresentada em (6) pode ser objecto de outras
decomposições, conforme os objectivos do estudo. Assim, se se
pretende dar maior realce à perspectiva regional, a componente δ rj
pode apresentar a seguinte desagregação:
rj r rj r = + ( - ) + ( - ) δ δ δ δ δ δ , (8)
onde se procura destacar primeiro, o comportamento da região no
conjunto e, depois, o comportamento regional do sector j na estrutura
da região.
No ponto seguinte vai-se procurar aprofundar o significado do
diferencial (δr - δ), o que vai permitir obter resultados interessantes,
tanto do ponto de vista da análise, como do ponto de vista da
fundamentação de medidas de política económica.
2.2.2. A análise shift-share
Se se pretender aprofundar o significado dos desvios,
nomeadamente o do comportamento da região, em relação ao
comportamento nacional, pode-se analisar o diferencial (δr - δ) com
A análise shift-share abrepara a análise anterior novavirtualidades.

24 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
maior pormenor, procurando identificar nele elementos de análise que
aparentemente esconde.
A taxa de crescimento da região r pode ser representada da
seguinte forma:
rj rj rjrr
j jr r rj r
rjrj rj rj
j jr
x x x x = = = =
x x x x
x = =
x s
δ
δ δ
∆ ∆∆ ×∑ ∑
∑ ∑(9)
onde srj é o peso do sector j, no conjunto da actividade da região r, ou
seja uma componente estrutural da região.
De forma idêntica, a taxa de crescimento do conjunto de regiões
em que r se integra pode representar-se por:
j j j
j j j
jj j j
j j
x x x x = = = =
x x x x
x = =
x s
δ
δ δ
∆ ∆∆ ×∑ ∑
∑ ∑(10)
onde sj é uma componente estrutural, ou seja, o peso do sector j , no
conjunto da actividade do espaço global considerado. Se
multiplicarmos cada uma das componentes estruturais s rj pela taxa de
crescimento, segundo a norma, δj, obtém-se:
x
x s = =j
j rj j
jrj r
'∆∑ ∑ δ δs (11)
em que δ r' representa a taxa de crescimento da região r admitindo,
que cada sector tem comportamento idêntico na região e no espaço
global considerado.
De (9) e (10) resulta que:

2.2.2. A ANÁLISE SHIFT -SHARE 25
r rj rj j jj j
- = s - sδ δ δ δ∑ ∑ (12)
Somando e subtraindo δ r' tem-se uma nova representação para
aquele diferencial:
r rj rj j rj j rj j jj j j j
' 'r r r
rj j rj rj j jj j
- = s - + ( s - s )
= ( - ) + ( - ) =
= ( - ) s + ( s - s )
sδ δ δ δ δ δ
δ δ δ δδ δ δ
∑ ∑ ∑ ∑
∑ ∑(13)
O 2º membro desta expressão tem 2 componentes:
rj j rjj
rj j jj
( - ) s
e
( s - s )
δ δ
δ
∑
∑
A primeira é a soma de um conjunto de elementos, em que cada
um, é o resultado de se fazer evoluir o peso (estrutura) do sector j na
economia da região (s rj ), no ano base, segundo uma taxa, que é igual
à diferença entre o valor das taxas do sector, na região r (δrj ) e no
conjunto dos espaços (δj). A variação entre os ritmos de crescimento
da região r e do conjunto dos espaços, é explicada (nesta componente)
pela diferença de taxas de crescimento sectoriais (regionais e do país),
para uma estrutura constante. Por isso, se designa esta componente por
componente regional15.
Ainda que o peso relativo de cada sector na actividade
económica da região permanecesse constante, poderia haver um desvio
15Esta componente tanto pode ser positiva como negativa. Dado que o termo s rj é
sempre positivo, a primeira hipótese verifica-se quando, globalmente, os sectores têm naregião um dinamismo superior ao do país, verificando-se o contrário na segunda hipótese.Esta é a razão pela qual esta componente é , por vezes, também designado por componentedinâmica.
O significado dacomponente regional.

26 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
entre a taxa de crescimento regional e a taxa de crescimento no país,
com origem em desvios entre as taxas sectoriais de crescimento, na
região e no espaço global16.
Do mesmo modo que na componente regional também a
componente estrutural pode ser positiva ou negativa. Admitindo que
δj é positivo, o primeiro caso está presente quando os desvios positivos
entre os pesos de cada um dos sectores, multiplicados pelas taxas de
crescimento nacionais, mais do que compensam os desvios negativos,
multiplicados também pelas respectivas taxas nacionais. O segundo
caso acontece quando essa compensação não é possível.
A segunda componente é a soma de um conjunto de elementos
em que cada um é o resultado de se fazer evoluir a diferença entre os
pesos de um sector j , na actividade da região (srj ) e do país (sj),
segundo uma taxa que é igual à taxa de crescimento do sector no país
(δj). Como o elemento dinâmico é nesta componente a estrutura, ela é,
habitualmente designada por componente estrutural17. Pode haver um
desvio entre as taxas de crescimento da região e do país, mesmo
quando não há desvios entre as taxas sectoriais, da região e do país,
bastando para tanto que sejam diferentes os pesos de cada um dos
sectores no conjunto da actividade económica, da região e do país.
Resumindo, tem-se :
= + ( - )s + (s - s )r rjj
j rj rjj
j jδ δ δ δ δ∑ ∑ (14)
16O que não significa que não se tivesse modificado a sua importância em valor
absoluto. Assim também se compreende a importância que na análise deve ser atribuída acada um dos elementos do somatório.
17 Do mesmo modo que na componente regional também a componente estruturalpode ser positiva ou negativa. Admitindo que δ j é positivo, o primeiro caso está presentequando os desvios positivos entre os pesos de cada um dos sectores, multiplicados pelastaxas de crescimento nacionais, mais do que compensam os desvios negativos, multiplicados
O significado da componenteestrutural.
O crescimento regional podeser decomposto em três
componentes.

2.2.2. A ANÁLISE SHIFT -SHARE 27
isto é, o crescimento regional pode ser explicado através de três
componentes:
a) A primeira componente é o crescimento segundo a norma, δ
b) A segunda componente indica a dinâmica regional de
crescimento - r j jδ δ , para uma dada estrutura s rj .
c) A terceira componente explica o crescimento, por uma
variação estrutural (srj -sj) na região, dada uma taxa de
crescimento nacional para o sector j, δj .
Para além de ser conhecida pela designação de Análise Shift-
Share, este tipo de análise de decomposição tem também sido
divulgado com o nome de método de alteração-proporcional.
Tem sido frequentemente utilizado em estudos de economia
regional, como instrumento analítico de interpretação da evolução das
estruturas regionais, nomeadamente em estudos demográficos e de
estrutura industrial. Enquanto apoio à compreensão do significado da
dinâmica regional este tipo de estudos torna-se um excelente suporte à
formulação de medidas de política económica.
O instrumento de análise que acaba de ser apresentado é,
também, susceptível de representação gráfica, o que permite obter uma
imagem sugestiva do peso relativo de cada uma das componentes na
explicação do desvio total encontrado. Admitamos que se tinha
observado um valor de 0,05 para a componente regional e um valor de
0,10 para a componente estrutural. O desvio total seria igual a 0,15 e a
representação gráfica que daí resultaria seria a do gráfico da página
seguinte.
também pelas respectivas taxas nacionais. O segundo caso acontece quando essacompensação não é possível.

28 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
0-25 -20 -15 -10 -5 5 1 0 1 5 2 0 2 5
20
5
10
15
-20
-15
-10
-5
5
10
15
20
-5
-10
-15
-20
C O M P O N E N T E R E S I D U A LO U
D E S V I O T O T A L
C O M P O N E N T E R E G I O N A LC O M P O N E N T E E S T R U T U R A L
M É T O D O " S H I F T - S H A R E "
A interpretação do gráfico é quase imediata, pelo que se não
fazem comentários adicionais. Repare-se, apenas, que a projecção do
vértice obtido pela representação das componentes regional e
estrutural no eixo do desvio total, dá-nos exactamente o valor desse
desvio.

2.3.1. A ANÁLISE FACTORIAL 29
2.3. INDICADORES DE SÍNTESE
Ao analisarmos o espaço associado a um determinado território,
podemos considerá-lo, de forma diferenciada integrando projecções
de âmbito geográfico, social, cultural, económico ou físico, ou numa
perspectiva indiferenciada, enquanto espaço geométrico abstracto
que, como sabemos, é utilizado como ponto de partida das reflexões
teóricas da economia espacial.
Nesta perspectiva, cada ponto do espaço abstracto euclidiano
pode ser representado por coordenadas espaciais multidimensionais.
O facto de existirem inúmeras variáveis associadas a cada ponto
do espaço, leva-nos a procurar técnicas de redução da informação e a
construir indicadores de síntese que nos permitam ter em conta o
máximo de informação relevante e assim, mais fácil e correctamente,
estabelecer comparações entre as diferentes unidades em análise.
2.3.1. A análise factorial
A análise factorial é uma técnica estatística de simplificação da
informação, utilizada para representar as relações entre um conjunto de
variáveis, através de um menor número de características, designadas
por factores. Deste modo, procura-se salientar as dimensões
fundamentais (ou factores) que podem estar subjacentes a um
fenómeno de natureza complexa.
Com a análise factorial18 visam-se dois objectivos principais:
18 Esta técnica foi originalmente desenvolvida pelo psicólogo Spearman (1904) com
o objectivo de estudar o factor inteligência indirectamente, a partir de uma multiplicidadede variáveis.
A análise factorial é umatécnica estatística desimplificação da informação
Objectivos principais:

30 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
- Reduzir o número de variáveis iniciais, através do agrupamento
de variáveis, que estão altamente correlacionadas, eliminando
a informação que possa ser considerada como redundante,
garantindo, assim, que há uma perda mínima de informação;
- Evidenciar a estrutura fundamental implícita nos dados iniciais,
através de um menor número de factores independentes, que
representam as variações das observações originais num
espaço multidimensional.
A análise factorial desenvolve-se a partir de uma matriz inicial de
informação (X) que compreende J variáveis e R observações de cada
uma das J variáveis.
Ao longo desta secção a apresentação da análise factorial está
estruturada em torno de um exemplo, com base numa matriz de
informação regional, referente às 28 NUTS III do Continente (R=28),
ver Fig. 1, e com informação sobre um conjunto de 10 variáveis,
apresentadas no Quadro 1 (J=10).
- Reduzir o número devariáveis através do
agrupamento de variáveis,que estão altamente
correlacionadas.
- Evidenciar a estruturafundamental implícita nos
dados iniciais
A análise factorialdesenvolve-se a partir de
uma matriz inicial deinformação

2.3.1. A ANÁLISE FACTORIAL 31
Figura 1- Continente (NUTS III)
MINHO-LIMA
CAVADO
AVE
GRANDE PORTO
TAMEGA
ENTRE DOURO E VOUGA
DOURO
ALTO TRAS-OS-MONTES
BAIXO VOUGA
BAIXO MONDEGO
PINHAL LITORAL
PINHAL INT. NORTE
DAO-LAFOES
PINHAL INTERIOR SUL
SERRA DA ESTRELA
BEIRA INTERIOR NORTE
BEIRA INTERIOR SUL
COVA DA BEIRA
OESTE
GRANDE LISBOA
PENINSULA DE SETUBA
MEDIO TEJO
LEZIRIA DO TEJO
ALENTEJO LITORAL
ALTO ALENTEJO
ALENTEJO CENTRAL
BAIXO ALENTEJO
ALGARVE
Este texto procura seguir a apresentação dos resultados da
análise factorial, através da utilização dos outputs do software SPSS
for Windows19. Optou-se por ao longo do texto, mostrar apenas parte
do output gerado por este package estatístico, deixando para o fim a
referência aos procedimentos e opções do SPSS necessários à obtenção
da análise factorial. Em anexo, apresenta-se o output integral gerado
pelo SPSS (Anexo A.1.).
19 A exemplificação é efectuada sobre a versão 6.0 para ambiente Windows.

32 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Quadro 1. Lista dos indicadores utilizados20
Dpopul Densidade populacional (milhares de pessoas /km2)
VABpcap Valor Acrescentado Bruto per capita (em contos, ano de 1991)
Produtiv Produtividade do Emprego (em contos, 1991)
Celectr Consumo Doméstico de Electricidade (Kwh/Habit)
Lespec Peso do Emprego Especializado no Emprego Total
Sercom % do Emprego nos Sectores do Comércio e Turismo
Mortinf Taxa de mortalidade Infantil
Camhosp Número de camas de hospital por 1000 habit.
EmNOX Emissões de Nox (Kg/km2)
Abastag % população servida por água da rede publica
A. Operações prévias
As variáveis associadas a cada uma das unidades espaciais em
estudo fornecem, na generalidade dos casos, informações cuja
compatibilização não é imediata devido a questões ligadas, quer à
natureza das variáveis, quer às unidades de medida utilizadas.
Se em relação às limitações que decorrem da natureza das
variáveis não é possível eliminá-las, já em relação às que e são
consequência das unidades de medida utilizadas é possível a sua
correcção através das operações de relativização da dimensão
territorial e de normalização das variáveis.
A relativização da dimensão territorial21 é uma operação,
prévia à normalização, que visa transformar o valor de cada uma das
variáveis tendo em conta a dimensão do espaço considerado.
20 No anexo A.2 apresenta-se a base de dados com os valores das variáveis para
todas as regiões.21 Há autores, ver por exemplo PAELINCK e NIJKAMP(1975), que designam esta
transformação por estandardização das variáveis. No entanto, optou-se por esta designaçãopara diferenciar da operação de estandardização “estatística” que corresponde a uma formade normalização e por isso apresentada mais adiante.
Problemas decompatibilização das
variáveis
As operações prévias:
- a relativização da dimensãoterritorial ;
- normalização das variáveis
A relativização da dimensãoterritorial: a consideração
da dimensão das regiões.

2.3.1. A ANÁLISE FACTORIAL 33
Tomemos como ponto de partida a seguinte matriz:
Variáveis
1 ... j ... J
R 1
e
g ...
i r xrj X’r
õ ...
e R
s Xj
em que:
X’r é um vector (linha) que explicita a estrutura da região; e
Xj é um vector (coluna) que explicita a dispersão de uma dada
variável através das regiões.
O facto das regiões r e r' terem diferentes dimensões (por ex. em
termos de Km2, população residente, número de trabalhadores, etc.),
pode originar diferentes configurações estruturais cujos inconvenientes
se ultrapassam relativizando os indicadores, isto é, tomando a mesma
unidade relativa de medida em todas as regiões (por exemplo,
população por Km2, produto per capita, número de telefones por mil
habitantes, etc.). A superfície, a população e o emprego, são
geralmente os indicadores de dimensão mais utilizados.
Assim, se Drj for o indicador de dimensão apropriado para a
variável xrj , a relativização da dimensão territorial obtem-se da seguinte
forma:
xx
Drjrj
rj
* =
A escolha do indicador dedimensão.

34 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Esta operação não evita, contudo, resultados distorcidos, pois as
variáveis estão muitas vezes expressas em unidades de natureza
diferente (escudos per capita, percentagens, etc.), o que pode levar a
que uma delas domine outra ou as restantes. Para evitar este problema
e eliminar os efeitos de dominância de algumas variáveis em relação às
restantes, deverá proceder-se à operação de normalização.
Com a normalização homogeneízam-se as escalas de medida das
diferentes variáveis, mantendo-se, no entanto, as proporções
interregionais em cada variável. Deste modo, viabilizam-se as
comparações inter-variáveis em cada espaço. Das transformações
alternativas de normalização das variáveis, apresenta-se seguidamente
duas das hipóteses mais utilizadas:
i) Transformação, da variável (Xj*) de modo a que a média seja
igual a zero e o desvio padrão igual a 1.22
Neste caso, a variável normalizada (Xj** ) obtem-se,
transformando o valor da variável Xj* para cada uma das
regiões r, do seguinte modo:
XX X
srjrj j
x j
*** *
*
=−
.
em que X j* representa a média da variável Xj
*, ou seja:
X
X
Rj
rjr
R
*
*
= =∑
1
e sx j* o desvio padrão da variável Xj
*, que é dado por:
22 Também designada por operação de estandardização da variável.
As diferentes unidades demedida das variáveis: a
operação de normalização.
Diferentes métodos denormalização das variáveis
Estandardização davariável: Média zero e
desvio padrão igual a um.

2.3.1. A ANÁLISE FACTORIAL 35
s
X X
nx
rj jr
R
j*
( )* *
=−
−=
∑ 2
1
1
ii) Transformação das variáveis atribuindo a todos os vectores de
variáveis um mesmo comprimento.
A operação que conduz a um tal resultado consiste numa
transformação em que cada vector (Xj*) é dividido pela sua
norma (ou comprimento) ||Xj* ||.
O comprimento do vector (a sua norma) associa-se ao
conceito de distância do vector à origem. Assim o
comprimento, ou norma euclidiana de um vector x
representa-se por || Xj*|| e é dado por:
X X X Xj j j rjr
R* * * *=
′
=∑=
2
1
sendo, por convenção, tomado o valor positivo da raiz.
A variável normalizada, representa-se por Xj** e define-se
como:
XX
Xj
j
j
***
*=
B. O modelo da análise factorial
O modelo estatístico da análise factorial é em parte semelhante
ao modelo de regressão linear múltipla. Cada uma das variáveis é
expressa através de uma combinação linear dos factores que não são
observáveis, à partida. Por exemplo, a variável, VAB per capita
(VABpcap) pode ser expressa do seguinte modo:
VAB a rica b urban c socind Upcap VABpcap= + + +( ) ( ) ( ) (1)
Transformação das variáveisatribuindo a todos osvectores de variáveis ummesmo comprimento
As variáveis são expressaatravés de uma combinaçãolinear dos factores comuns(que não são observáveis, àpartida)

36 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Esta equação difere da equação de regressão linear múltipla uma
vez que os factores rica, urban e soeco não são variáveis
independentes simples, mas representam designações de agrupamentos
de variáveis23, determinados através da análise factorial.
Rica, urban e soeco são designados por factores comuns já que
todas as variáveis originais são expressas em função destes factores. A
variável UVABpcap é designada por factor único uma vez que representa
a parte do VABpcap que não pode ser explicada através dos factores
comuns, assumindo-se como uma variável residual de natureza
aleatória.
Em geral, a equação para j-ésima variável Xj apresenta-se do
seguinte modo:
X b F b F b F Uj j j jK K j= + + + +1 1 2 2 ... (2)
onde F1, F2, ...,FK são os factores comuns, Uj a variável residual e
bj1,..,bjK os coeficientes utilizados na combinação dos K factores.
Admite-se que os factores únicos (U1,U2,...,UJ) não estão
correlacionados, entre si, nem com os factores comuns.
Os factores comuns, determinados a partir das variáveis
originais, são estimados como combinações lineares destas variáveis.
Por exemplo, a estimação para o factor grau de riqueza (rica) pode ser
representada como
rica w Dpopul w VAB w Abastagpcap= + + +1 2 10... (3)
Em geral, a expressão para estimar o i-ésimo factor, Fi pode
escrever-se do seguinte modo:
23 Mais adiante teremos oportunidade de identificar as variáveis e os factores
comuns.
A expressão da j-ésimavariável X em função dos
factores

2.3.1. A ANÁLISE FACTORIAL 37
F w X w X w X w Xi ij jj
J
i i iJ J= = + + +=
∑1
1 1 2 2 ... (4)
Em que os wi,j representam os valores dos coeficientes das
variáveis e J o número de variáveis originais.
À partida todas as variáveis inicialmente consideradas devem
contribuir para a estimação dos diferentes factores. No entanto,
identificados os coeficientes (w) que apresentam maiores valores
absolutos já é possível encontrar subconjuntos de variáveis que
permitem caracterizar os factores comuns.
C. As Etapas da Análise Factorial
A análise factorial compreende fundamentalmente quatro etapas:
i) Na primeira, procura testar-se a possibilidade de utilização
desta técnica estatística; recorre-se às matrizes dos
coeficientes de correlação para verificar o grau de associação
entre variáveis e concluir em que medida é possivel a
utilização da análise factorial;
ii) A segunda, corresponde à extracção dos factores, ou seja,
escolha do modelo de ajustamento a utilizar e determinação
dos factores a serem considerados na representação da
informação inicial;
iii) Na terceira, procede-se à rotação dos factores com objectivo
de melhor evidenciar a estrutura fundamental dos dados
iniciais e interpretar o significado dos factores comuns
considerados;
A estimação dos factorescomuns
A caracterização dosfactores comuns em funçãodos coeficientes associadosàs variáveis
As etapas da análisefactoriali) Avaliação da possibilidadede utilização da análisefactorial.
ii) A extracção dos factores
iii) A interpretação dosfactores

38 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
iv) Na quarta, os valores dos factores são determinados para as
diferentes observações das variáveis (regiões); estes valores
podem ser utilizados em análises posteriores.
C.1. Análise da Matriz dos Coeficientes de Correlação
Com base na matriz X, com informação inicial referente às J
variáveis e aos R indivíduos (regiões), calculam-se vários indicadores e
constroem-se as matrizes dos coeficientes de correlação simples (C) e
das variâncias-covariâncias (S).
O coeficiente de correlação simples entre as variáveis Xj e Xk é
calculado do seguinte modo:
1
( )( )
( 1)
R
rj j rk kr
jkj k
X X X Xr
R s s=
− −=
−
∑�
Com base nos diferentes rjk, assim obtidos, constroi-se a matriz
dos coeficientes de correlação simples:
C
r r
r r
r r
p
p
p p
=
1
1
1
12 1
21 2
1 2
...
...
... ... ... ...
...
A covariância entre duas variáveis Xj e Xk representa-se por sjk e
é definida do seguinte modo:
s
X X X X
Rjk
rj j rk k
r
R
=
− −
−=
∑( )( )
( )1
1
iv) A determinação dosvalores dos factores
1ª Etapa
As matrizes dos coeficientesde correlação simples e das
variâncias-covariâncias
O coeficiente de correlaçãosimples.
A covariância.

2.3.1. A ANÁLISE FACTORIAL 39
No caso de j=k obtem-se a variância da variável Xj ,ou seja, sj2. É
igualmente possível contruir a matriz S das variâncias e covariâncias24:
S
s s s
s s s
s s s
p
p
p p pp
=
11 12 1
21 22 2
1 2
...
...
... ... ... ...
...
Da observação das definições dos coeficientes de correlação e
das covariâncias, conclui-se que os coeficientes de correlação podem
ser interpretados como covariâncias normalizadas, uma vez que é
possível expressar os coeficientes de correlação em função das
covariâncias. Com efeito:
rs
s sjkjk
j k
=
A matriz dos coeficientes de correlação entre as 10 variáveis,
acima referidas, é apresentada na Fig. 2. Tendo em conta que, um dos
principais objectivos da análise factorial é obter um conjunto de
factores que possam explicar as correlações entre as variáveis,
facilmente se conclui que, a utilização desta técnica estatística
pressupõe que as variáveis originais devam estar significativamente
correlacionadas entre si.
24 No sentido de facilitar a representação da matriz das variâncias e covariâncias
utiliza-se igualmente o simbolo sii como forma alternativa a si2 na representação da
variância.
Os coeficientes decorrelação podem serinterpretados comocovariâncias normalizadas
A análise factorial exige umaelevada correlação entre asdiversas variáveis iniciais

40 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Figura 2 - Matriz de correlações entre as variáveis
Correlation Matrix:
DPOPUL VABPCAP PRODUTIV CELECTR LESPEC SERVCOM ABASTAG
DPOPUL 1,00000VABPCAP ,63716 1,00000PRODUTIV ,40191 ,68317 1,00000CELECTR ,53785 ,62147 ,39207 1,00000LESPEC ,47605 ,27885 ,22480 ,25592 1,00000SERVCOM ,42376 ,66116 ,51687 ,62643 ,33645 1,00000ABASTAG ,28452 ,53012 ,48348 ,50281 ,07892 ,50948 1,00000CAMHOSP ,17519 ,14336 ,16880 ,34608 ,26599 ,09185 ,38710MORTINF ,01937 -,43109 -,39719 -,21592 -,30057 -,33680 -,24591EMNOX ,56675 ,54401 ,53214 ,42609 ,49516 ,44790 ,41424
CAMHOSP MORTINF EMNOX
CAMHOSP 1,00000MORTINF -,29996 1,00000EMNOX ,05382 -,16529 1,00000
Uma das formas de avaliar a possibilidade de utilização da análise
factorial faz-se através do recurso ao teste de Bartlett, em que se testa
a hipótese da matriz dos coeficientes de correlação ser uma matriz
identidade (todos os elementos da diagonal são iguais a 1 e os restantes
iguais a 0). Da observação da figura 3 verifica-se que o valor do teste
está associado a um nível de significância muito reduzido pelo que se
rejeita a hipótese de se estar perante uma matriz identidade.
Figura 3- Estatística de KMO e teste de Bartlett
Kaiser-Meyer-Olkin Measure of Sampling Adequacy = ,70768
Bartlett Test of Sphericity = 120,59010, Significance = ,00000
Outro indicador que deve ser tido em conta na avaliação da
possibilidade de utilização da análise factorial é o coeficiente de
correlação parcial. Este indicador de associação mede a intensidade
da relação entre duas variáveis após a exclusão dos efeitos de terceiras
variáveis.
Deste modo, como a análise factorial exige que as diferentes
variáveis estejam todas muito correlacionadas entre si, os coeficientes
de correlação parcial, entre pares de variáveis, excluindo os efeitos das
O teste de Bartlett.
O coeficiente de correlaçãoparcial

2.3.1. A ANÁLISE FACTORIAL 41
restantes variáveis, devem apresentar valores próximos de zero. Os
simétricos dos coeficientes de correlação parcial são apresentados na
matriz anti-imagem (ver figura 4).
Figura 4 - Matriz anti-imagem
DPOPUL VABPCAP PRODUTIV CELECTR LESPEC SERVCOM ABASTAG
DPOPUL ,65488VABPCAP -,57106 ,74020PRODUTIV ,01032 -,32848 ,86127CELECTR -,16577 -,19472 ,17122 ,81742LESPEC -,39475 ,23169 ,12399 ,15003 ,54764SERVCOM ,09163 -,19109 -,13223 -,41023 -,29493 ,79655ABASTAG ,15479 -,18820 -,06817 -,03069 ,26422 -,27438 ,74212CAMHOSP -,16749 ,23693 -,11695 -,34334 -,27267 ,31141 -,45389MORTINF -,54637 ,49365 ,12444 -,04932 ,35563 ,04185 -,11056EMNOX -,15951 -,01269 -,29393 -,12215 -,42013 ,10894 -,30271 CAMHOSP MORTINF EMNOXCAMHOSP ,40627MORTINF ,27804 ,49708EMNOX ,30262 -,05790 ,77509
Measures of Sampling Adequacy (MSA) are printed on the diagonal
Tendo por base os coeficientes de correlação simples e os
coeficientes de correlação parcial constroi-se o indicador KMO25 que
compara os valores dos coeficientes de correlação simples com os
coeficientes de correlação parcial:
KMO
r
r a
ijj ii j
ijj ii j
ijj ii j
=+
≠≠
≠≠ ≠≠
∑∑∑∑ ∑∑
2
2 2
onde rij é coeficiente de correlação simples entre as variáveis Xi e Xj, e
aij é coeficiente de correlação parcial entre as variáveis Xi e Xj.
Se o somatório dos quadrados dos coeficientes de correlação
parcial entre os diferentes pares de variáveis for pequeno, quando
comparado com o somatório dos quadrados dos coeficientes de
correlação simples, então, o indicador KMO está próximo de 1 e a
utilização da análise factorial não oferece grandes problemas.
25 Kaiser-Meyer-Olkin
O indicador KMO

42 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Segundo Kaiser(1974) é possível estabelecer a seguinte
classificação para o valor do indicador KMO:
Figura 5 - Estatística KMO e Utilização da Análise Factorial
KMO Utilização da
Análise Factorial
0.90-1.00 Muito Boa
0.80-0.90 Boa
0.70-0.80 Média
0.60-0.70 Medíocre
0.50-0.60 Muito má
< 0.50 Inaceitável
Utilizando o mesmo princípio é igualmente possível calcular
medidas de adequação da análise factorial para cada uma das variáveis
consideradas individualmente. Para a j-ésima variável a medida de
adequação (MSAj)26 obtem-se do seguinte modo:
MSA
r
r aj
iji j
iji j
iji j
=+
≠
≠ ≠
∑∑ ∑
2
2 2
Estas medidas são apresentadas ao longo da diagonal principal da
matriz anti-imagem (ver fig. 4), não devendo ser consideradas na
análise factorial as variáveis que apresentem valores muito próximos de
zero.
C.2. Extracção dos factores
Nesta etapa o principal objectivo é determinar os factores
comuns. Entre os vários métodos possíveis para proceder à estimação
dos factores normalmente, o mais utilizado é o método das
26 Measure of Sampling Adequacy.
2ª Etapa
Extracção dos factores

2.3.1. A ANÁLISE FACTORIAL 43
componentes principais27, que passaremos seguidamente a expor de
uma forma abreviada.
C.2.1. O método das componentes principais
O método das componentes principais28 é uma técnica de análise
estatística multivariada, independente da análise factorial, que tem por
objectivo fundamental transformar um conjunto J de variáveis
correlacionadas, num novo conjunto de J de variáveis (combinações
lineares das variáveis originais) não correlacionadas e que explicam,
igualmente, a variância das variáveis originais. As novas variáveis
denominam-se componentes principais e, na explicação da variância
das variáveis iniciais, vêm ordenadas por ordem decrescente da sua
importância.
Toma-se como primeira componente principal (F1) a combinação
linear das variáveis X1, X2 ,...,XJ, que for capaz de explicar a maior
percentagem da variância das variáveis originais, ou seja:
F w X w X w XJ J1 11 1 12 2 1= + + +...
que permita obter a maior variância possível para F1, Var(F1), sujeita à
restrição29:
w w w J2
112
122
1 1+ + + =...
A segunda componente principal (F2), é a combinação linear que
explica a segunda maior percentagem da variância das variáveis
originais de tal modo que:
F w X w X w XJ J2 21 1 22 2 2= + + +...
27 Para uma descrição sobre os diferentes métodos de extracção dos factores ver por
exemplo Norusis (1993).28 Primeiramente desenvolvido por Pearson (1901).29 Esta restrição tem o efeito de normalização porque, caso contrário, seria possível
aumentar Var(F1) através de um aumento proporcional dos valores de w1j.
método das componentesprincipais…
transformação das variáveisiniciais em variáveis nãocorrelacionadas - ascomponentes principais.
Primeira componenteprincipal: combinação linearque seja capaz de explicar amaior percentagem davariância das variáveisiniciais.

44 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
continuando a ter-se:
w w w J2
212
222
2 1+ + + =...
e ainda a restrição de F1 e F2 não estarem correlacionados.
Do mesmo modo, é possível obter as sucessivas componentes
principais que progressivamente vão explicando menores percentagens
da variância do conjunto das variáveis iniciais, mantendo-se as
restrições de normalização e de não correlação entre as diferentes
componentes principais.
Demonstra-se30 que as componentes principais podem ser obtidas
a partir dos valores próprios e dos correspondentes vectores próprios
da matriz de variância-covariâncias (S) sendo que as variâncias das
componentes principais correspondem aos valores próprios da matriz S
e os ponderadores das variáveis aos respectivos vectores próprios.
Ordenando os valores próprios por ordem decrescente de tal
modo que, λ1≥ λ2≥ ...≥ λJ≥ 0, tem-se para o valor próprio λi,
correspondente à i-ésima componente principal (Fi):
F w X w X w Xi i i iJ J= + + +1 1 2 2 ...
Var(Fi)= λi
e wi1,wi2,...,wiJ os elementos do vector próprio correspondente.
Uma propriedade importante dos valores próprios de uma matriz
é que o seu somatório é igual à soma dos valores da diagonal da matriz
S (traço de S), ou seja,
λ λ λ1 2 11 22+ + + = + + +... ...J JJs s s
30 Os desenvolvimentos de alguns resultados seguidamente apresentados podem ser
encontradas em PAELINCK e NIJKAMP (1975) ou em JONHSON e WICHERN (1982).
As componentes principaisobtem-se a partir dos valores
próprios e doscorrespondentes vectores
próprios da matriz devariâncias-covariâncias

2.3.1. A ANÁLISE FACTORIAL 45
Este resultado permite concluir que as componentes principais
consideram toda a variância do conjunto das variáveis originais, uma
vez que a soma das variâncias das componentes principais é idêntica à
soma das variâncias das variáveis iniciais.
Como estas variáveis estão expressas em unidades diferentes e
por isso com valores da variância muito dispares, então deve proceder-
se, previamente, à sua normalização.
Esta transformação tem como resultado que, em vez da matriz
das variâncias e covariâncias (S), se considere a matriz dos coeficientes
de correlação simples (C) na determinação das componentes principais.
Neste caso, o somatório da diagonal principal da matriz, ou seja, do
conjunto dos valores próprios, equivale ao número de variáveis (J) da
matriz (X).
Na figura 6 apresentam-se os resultados da aplicação do método
das componentes principais. A variância total explicada por cada um
dos factores é apresentada na coluna com o título eigenvalue (valor
próprio). As colunas seguintes apresentam as percentagens (individuais
e acumuladas) da variância total atribuível aos factores.
Figura 6 - Estatísticas iniciais
Initial Statistics:
Variable Communality * Factor Eigenvalue Pct of Var Cum Pct *DPOPUL 1,00000 * 1 4,55322 45,5 45,5VABPCAP 1,00000 * 2 1,25539 12,6 58,1PRODUTIV 1,00000 * 3 1,08655 10,9 69,0CELECTR 1,00000 * 4 ,96735 9,7 78,6LESPEC 1,00000 * 5 ,64489 6,4 85,1SERVCOM 1,00000 * 6 ,52147 5,2 90,3ABASTAG 1,00000 * 7 ,34534 3,5 93,7CAMHOSP 1,00000 * 8 ,31696 3,2 96,9MORTINF 1,00000 * 9 ,18355 1,8 98,7EMNOX 1,00000 * 10 ,12529 1,3 100,0
A necessidade denormalização faz com que seconsidere a matriz doscoeficientes de correlaçãoem vez da matriz devariâncias-covariâncias

46 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Note-se que as duas primeiras colunas apresentam informação
sobre as variáveis iniciais e deverão ser consideradas isoladamente, não
existindo qualquer relação pelo facto de uma determinada variável se
encontrar na mesma linha de um qualquer factor. Na segunda coluna, é
explicitada a variância das variáveis iniciais considerada pelo conjunto
das componentes principais, designada por variância comum
(communality) e normalmente representada por h2.
Tendo em conta que a variância do conjunto das componentes
principais é idêntica ao somatório das variâncias das variáveis iniciais,
conclui-se que a variância de cada uma das variáveis originais é
totalmente distribuída pelas diferentes componentes principais, ou seja,
tem-se h2i=1, para i=1,2,...J.
C.2.2. O número de factores a considerar
Após a determinação das componentes principais coloca-se a
questão de saber qual o número de componentes principais a
considerar. Um dos critérios utilizados é o de considerar os factores
em que se verifique a condição Var(Fi)> 1. A justificação para esta
opção resulta do facto de se procurar que os factores consigam captar
uma variância superior à de cada uma das variáveis consideradas
individualmente31.
Alternativamente, a determinação do número de factores a
extrair pode, por exemplo, ser efectuada impondo que pelo menos
sejam considerados os primeiros k factores comuns.
31 Relembra-se que, pelo facto de se considerar as variáveis estandardizadas, a sua
variância é igual a 1.
A variância comum(communality).
O número de factores aconsiderar:
o critério dos valorespróprios maiores que 1.

2.3.1. A ANÁLISE FACTORIAL 47
Utilizando o critério do valor próprio superior a 1, a partir da
figura 6, observa-se que são considerados três factores comuns que no
seu conjunto retêm 69% da variância do conjunto das variáveis.
Com base nestes três factores comuns é igualmente calculada a
matriz dos ponderadores dos factores (factor loadings), ver figura 7,
que permitem expressar as variáveis iniciais estandardizadas em função
dos factores comuns.
Figura 7 - Matriz dos coeficientes dos factores
Factor Matrix: Factor 1 Factor 2 Factor 3
DPOPUL ,70053 ,48540 ,18164VABPCAP ,86711 ,04488 -,22687PRODUTIV ,74318 -,06834 -,24271CELECTR ,75841 -,02954 -,08089LESPEC ,51829 ,20585 ,73858SERVCOM ,77588 ,01907 -,22309ABASTAG ,67181 -,31865 -,30038CAMHOSP ,36037 -,60573 ,46895MORTINF -,45843 ,59430 -,15257EMNOX ,72188 ,38450 ,08915
Assim cada linha da figura 7 apresenta os coeficientes usados
para representar cada uma das variáveis iniciais estandardizadas através
da através dos factores comuns. Por exemplo, a variável VABpcap
estandardizada, representada por ZVABpcap, é expressa em função dos
factores comuns do seguinte modo:
ZVAB F F Fpcap = + + −0 86711 0 04488 0 226871 2 3. . .
No método utilizado na extracção dos factores implica que estes
sejam ortogonais (não estão correlacionados entre si) então os
ponderadores representam os coeficientes de correlação entre as
variáveis e os factores comuns.
Para avaliar a forma como os três factores comuns descrevem as
variáveis originais é possível calcular a proporção da variância de cada
uma das variáveis que é explicada pelo modelo baseado nos factores
A matriz dos ponderadoresdos factores
A representação dasvariáveis através dosfactores comuns.

48 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
comuns. Por exemplo, considerando a variável VABpcap, o primeiro
factor retem 75.188% da variância desta variável, que resulta da
elevação ao quadrado do coeficiente de correlação simples entre o
VABpcap e F1 (0.86711)2.
A percentagem total da variância da variável VABpcap retida pelos
modelo baseado nos três factores comuns é 80.537% e que é o
somatório das percentagens explicados pelos diferentes factores
(75.188%+.201%+5.147%).
Como todas as variáveis estão estandardizadas, a proporção da
variância considerada pelos factores comuns, corresponde à variância
comum, h2 de cada uma das variáveis, expressa em %. Assim, os
valores da variância comum para cada uma das variáveis(ver figura 8),
podem variar entre 0 e 1, em que 0 indica que os factores comuns não
retem nada da variância da variável e 1 corresponde à situação em que
toda a variância é explicada pelo conjunto dos factores comuns.
Figura 8 - Estatísticas finais
Final Statistics:
Variable Communality* Factor Eigenvalue Pct of Var Cum Pct *DPOPUL ,75935 * 1 4,55322 45,5 45,5VABPCAP ,80537 * 2 1,25539 12,6 58,1PRODUTIV ,61590 * 3 1,08655 10,9 69,0CELECTR ,58261 *LESPEC ,85649 *SERVCOM ,65212 *ABASTAG ,64310 *CAMHOSP ,71670 *MORTINF ,58663 *EMNOX ,67690 *

2.3.1. A ANÁLISE FACTORIAL 49
C.3. Rotação dos factores
A matriz dos ponderadores dos factores obtida na etapa anterior,
indica as relações entre os factores e as variáveis individuais mas,
normalmente, não permite uma identificação e uma interpretação clara
da associação entre os factores e as variáveis iniciais. Vários factores
estão correlacionados com as mesmas variáveis. Com esta etapa, da
rotação dos factores, pretende-se transformar a matriz dos
ponderadores numa outra que seja mais facilmente interpretável.
Refira-se desde já, que a rotação dos factores não altera os
valores da variância comum das variáveis, apenas redistribui a variância
explicada pelos diferentes factores comuns.
Existe um conjunto variado de algoritmos para proceder a uma
rotação ortogonal dos factores sendo o método mais utilizado o do
varimax32, que procura minimizar o número de variáveis que
apresentam elevados valores nos ponderadores associados a um
determinado factor comum.
O resultado da rotação dos factores é apresentado na figura 10 e
a sua interpretação deve ser efectuada tendo em conta que os
ponderadores representam as correlações entre as variáveis e os
factores. Assim, com base nos valores da matriz da figura 9 é possível
concluir que:
i) O primeiro factor apresenta fortes correlações positivas com as
variáveis VABpcap, Produtiv, Celectr, Sercom e Abastag; estas
variáveis estão todas relacionadas com grau de desempenho
económico conseguido pelas regiões, pelo que se pode falar
do factor relacionado com grau de riqueza regional (rica);
32 Para uma abordagem dos métodos alternativos de rotação ver, por exemplo,
Norusis (1993) ou Johnson e Wichern (1982).
3ª Etapa
A transformação da matrizdos ponderadores comobjectivo de facilitar ainterpretação dos factorescomuns.
O método varimax
A interpretação dos factores
O primeiro factor: o grau deriqueza regional

50 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Figura 9 - Matriz dos coefcientes dos factores após
rotação
VARIMAX converged in 10 iterations.
Rotated Factor Matrix:
Factor 1 Factor 2 Factor 3
DPOPUL ,44727 ,73992 -,10869VABPCAP ,84022 ,30072 ,09475PRODUTIV ,75353 ,16493 ,14451CELECTR ,67285 ,30116 ,19796LESPEC ,00026 ,85788 ,34717SERVCOM ,76434 ,24380 ,09200ABASTAG ,74178 -,05099 ,30044CAMHOSP ,06922 ,13933 ,83216MORTINF -,32730 ,01455 -,69231EMNOX ,52280 ,63181 -,06630
ii) O segundo factor está significativamente correlacionado
(correlação positiva) com Dpopul, Lespec, EmNOX; as três
estão de algum modo ligadas ao nível de urbanização das
regiões, pelo se pode relacionar este factor com o grau de
urbanização regional (urban);
iii) O terceiro apresenta uma forte correlação positiva com a
variável Camhosp e negativa com Mortinf; deste modo,
maiores valores deste factor são sinónimo de melhor
cobertura em termos de indicadores de conforto e de “bem
estar social”, melhor desempnho em termos de indicadores
sociais (socind).
C.4. Estimação dos valores dos factores para diferentes
observações
Como um dos principais objectivos da análise factorial é reduzir
o conjunto de variáveis inicialmente considerado a um pequeno número
de factores então deverá ser possível estimar os valores dos factores
para cada uma das observações (regiões). Estas estimativas podem ser
O segundo factor: o grau deurbanização regional
O terceiro factor: ascondições sociais.
4ª Etapa
A estimação dos valores dosfactores para cada uma das
regiões.

2.3.1. A ANÁLISE FACTORIAL 51
usadas em análises subsequentes para representar os valores assumidos
pelos factores nas diferentes regiões.
Como já anteriormente vimos (equação 4) os valores dos
factores podem ser estimados como combinação linear das variáveis
originais, existindo uma multiplicidade de métodos para estimar os
coeficientes dos factores associados a cada uma das variáveis33.
No caso do modelo de extracção dos factores se basear no
método das componentes principais, os três métodos disponíveis no
SPSS (Anderson-Rubin, regression e Bartlett) produzem os mesmos
resultados, verificando-se sempre que a média dos valores assumidos
por cada um dos factores é igual a 0.
Na figura 10 apresenta-se a matriz dos coeficientes dos valores
dos factores34, a partir da qual é possível determinar os valores dos
factores para cada uma das regiões.
Figura 10 - Matriz dos coeficientes das variáveis
Factor Score Coefficient Matrix:
Factor 1 Factor 2 Factor 3DPOPUL ,01023 ,40633 -,18950VABPCAP ,27238 -,02389 -,07987PRODUTIV ,26342 -,09834 -,02102CELECTR ,18064 ,01907 ,02909LESPEC -,29786 ,59718 ,23779SERVCOM ,25510 -,04315 -,06696ABASTAG ,29204 -,25488 ,11125CAMHOSP -,14901 ,04743 ,63317MORTINF -,03192 ,12864 -,48620EMNOX ,06667 ,30664 -,16493
Para se perceber o modo como os valores dos factores para as
diferentes regiões são calculados apresenta-se no Quadro 2 os valores
das dez variáveis estandardizadas, relativas a 4 NUTS III, e os valores
assumidos pelos três factores.
33 Ver Tucker (1974).
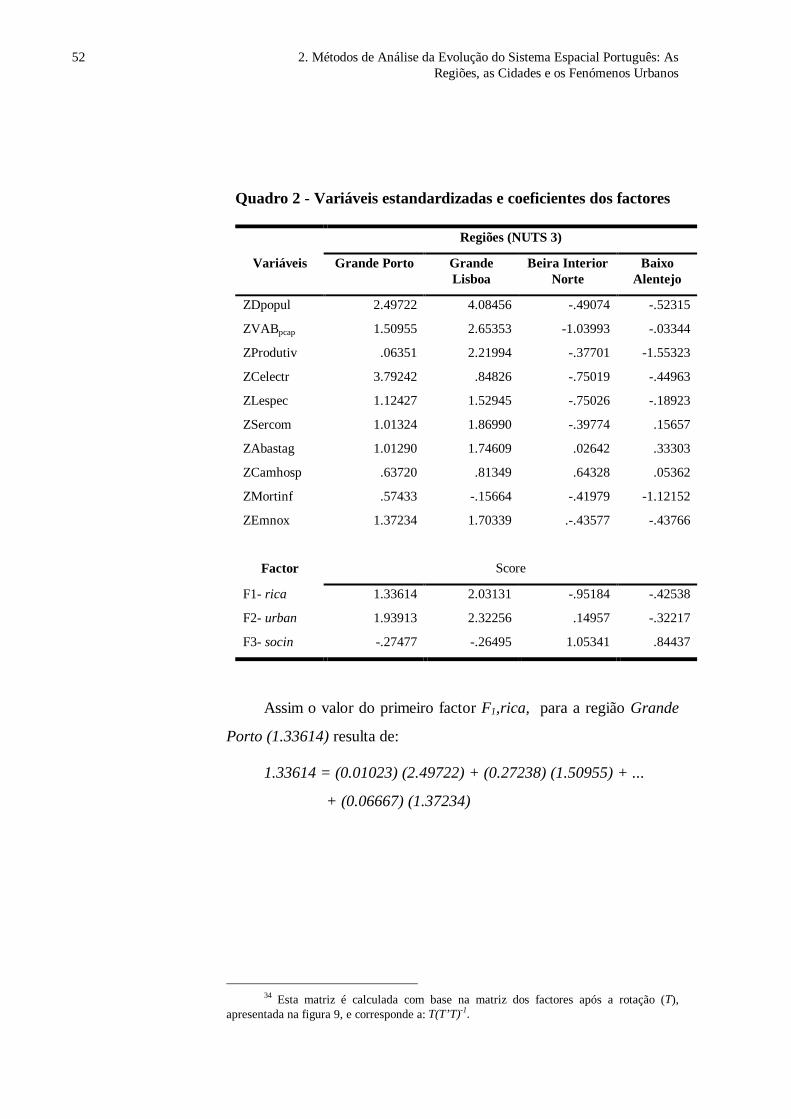
52 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Quadro 2 - Variáveis estandardizadas e coeficientes dos factores
Regiões (NUTS 3)
Variáveis Grande Porto GrandeLisboa
Beira InteriorNorte
BaixoAlentejo
ZDpopul 2.49722 4.08456 -.49074 -.52315
ZVABpcap 1.50955 2.65353 -1.03993 -.03344
ZProdutiv .06351 2.21994 -.37701 -1.55323
ZCelectr 3.79242 .84826 -.75019 -.44963
ZLespec 1.12427 1.52945 -.75026 -.18923
ZSercom 1.01324 1.86990 -.39774 .15657
ZAbastag 1.01290 1.74609 .02642 .33303
ZCamhosp .63720 .81349 .64328 .05362
ZMortinf .57433 -.15664 -.41979 -1.12152
ZEmnox 1.37234 1.70339 .-.43577 -.43766
Factor Score
F1- rica 1.33614 2.03131 -.95184 -.42538
F2- urban 1.93913 2.32256 .14957 -.32217
F3- socin -.27477 -.26495 1.05341 .84437
Assim o valor do primeiro factor F1,rica, para a região Grande
Porto (1.33614) resulta de:
1.33614 = (0.01023) (2.49722) + (0.27238) (1.50955) + ...
+ (0.06667) (1.37234)
34 Esta matriz é calculada com base na matriz dos factores após a rotação (T),
apresentada na figura 9, e corresponde a: T(T’T)-1.

2.3.1. A ANÁLISE FACTORIAL 53
D. Procedimentos e opções no SPSS
A obtenção do exemplo utilizado ao longo do texto requer os
seguintes procedimentos e opções seleccionados através do sistema de
menus:
1- Abertura do ficheiro com as variáveis originais:
FILE ...
OPEN...
DATA...
2- Selecção do Procedimento análise factorial
STATISTICS ...
DATA REDUCTION...
FACTOR.....
3- Selecção das variáveis a submeter à análise factorial
4- Selecção das seguintes opções na janela Descriptives:
INITIAL SOLUTION
COEFFICIENTS
KMO AND BARTLETT’S TEST OF SPHERICITY
ANTI-IMAGE
5- Selecção das seguintes opções na janela Extraction :
Method: PRINCIPAL COMPONENTS
Extract: EIGENVALUES OVER 1
Display: UNROTATED FACTOR SOLUTION;
6- Selecção das seguintes opções na janela Rotation:
Method: VARIMAX
Display: ROTATED SOLUTION;
7- Selecção das seguintes opções na janela Scores:
SAVE AS VARIABLES
Method: REGRESSION
DISPLAY FACTOR SCORE COEFFICENT MATRIX

54 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
2.3.2. A distância económica
O conceito de distância desenvolvido em análise vectorial é a
base de cálculo do indicador abstracto de distância económica entre as
regiões, desde que se considere que cada região r é caracterizada por
um vector cujos elementos representam um conjunto de características
regionais (por ex. indicadores do rendimento per capita, grau de
urbanização, grau de industrialização, etc.).
Um país composto por R regiões elementares (r = 1 … R) pode
ser morfologicamente caracterizado pela matriz X** . O elemento
genérico da matriz [ ] x rj** representa o valor da j -enésima variável
(relativizada e normalizada) na r-enésima Região.
Note-se que xr**' nos fornece indicações acerca da estrutura
económica da região r, enquanto x j** dá o quadro de distribuição
espacial da variável j .
Variáveis1 ... j ... J
R 1
eg ...i r x**
rj X**’r
õ ...e Rs X**
j
Cada vector xr**' pode ser representado por um ponto num
espaço euclidiano J-dimensional, enquanto cada vector x j** pode ser
representado através de um ponto num espaço R-dimensional.
Aplicação do conceito dedistância desenvolvido em
análise vectorial

2.3.2. A DISTÂNCIA ECONÓMICA 55
Atendendo a que num espaço vectorial linear J-dimensional a
distância de um ponto à origem deste espaço é igual a:
drr'2 = x = x xr j
**2
jr**
r**'∑
dro = ( x x ) = || x ||r**'
r**
r**
A distância económica em relação à origem pode, em certas
circunstâncias ser entendido como um índice sintético de
desenvolvimento de cada região. Haverá, contudo, que tomar a
precaução de que todas as variáveis consideradas na definição da
distância económica variam no mesmo sentido que o nível de
desenvolvimento (por ex., o nível de escolaridade, a taxa de
investimento, etc.).
O cálculo da distância económica entre duas regiões r e r' é
formalmente idêntico ao do cálculo da distância económica de uma
região em relação à origem.
drr'
rj**
jr' j** 2
r**
r'** '
r**
r'**
r**
r'** 2 = ( x - x ) = ( x - x ) ( x - x ) = || ( x - x ) ||2 ∑ −
com:
drr' = ( x - x ) ( x - x ) = || x - x ||r**
r'** '
r**
r'**
r**
r'**
A distância económica interregional pode, assim, interpretar-se
como um indicador da similaridade de estruturas socio-económicas de
regiões diferentes. Se existe alguma correspondência entre a estrutura
económica de duas regiões, os valores assumidos pelos indicadores
característicos dessas regiões não apresentam diferenças assinaláveis,
pelo que, a distância económica entre elas (obtida a partir da soma das
A distância à origem…
…como indicador sintéticode desenvolvimento de cadaregião…
…desde que todas asvariáveis variem no mesmosentido que o nível dedesenvolvimento.
O cálculo da distânciaeconómica entre duasregiões...
… a similaridade deestruturas sócio-económicasdas regiões.

56 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
diferenças quadradas dos valores que explicitam os diferentes
indicadores) será relativamente baixa.
O número total de distâncias interregionais calculáveis num
sistema de regiões é R(R-1)/2 e não R2, já que R(R-1)/2 são valores
repetidos (a matriz é diagonal) e os R valores da diagonal principal são
nulos35.
Os conceitos de similaridade e de distância económica são
úteis quando se pretende proceder à formação de agrupamentos
(clusters).
2.4. A IDENTIFICAÇÃO E A CLASSIFICAÇÃO DAS
REGIÕES
Se a caracterização da estrutura económica é indispensável para
basear decisões que se pretendem adequadas, torna-se necessária a
delimitação espacial como requisito à definição das políticas regionais.
A delimitação pode e deve apoiar-se em metodologias que tomam
como elemento de base a caracterização de espaços elementares
contíguos.
Como em qualquer metodologia de suporte ao estudo empírico
de fenómenos de natureza sócio-económica, as metodologias definidas
encontram o seu fundamento na teoria. Todavia, a sua aplicação
prática fica sujeita às restrições derivadas da disponibilidade de
informação estatística.
35A distância de r a r' é igual à distância de r' a r.
A delimitação espacial comorequisito à definição das
políticas regionais.

2.3.2. A DISTÂNCIA ECONÓMICA 57
Tais restrições, num estudo de economia espacial, referem-se não
apenas às variáveis, mas também, às próprias dimensões espaciais da
análise.
As implicações das primeiras, serão sentidas ao longo da própria
apresentação das metodologias. Das segundas resulta a necessidade de
uma extensão da definição de espaço elementar, o qual corresponderá
à escala espacial mínima, para a qual existe disponibilidade de
informação estatística.36
Não há uma metodologia única e exclusiva de delimitação de
regiões, há um conjunto de métodos com aplicação na delimit ação de
regiões. Tais métodos assentam numa taxinomia, cujo conhecimento
prévio é necessário antes de se proceder ao trabalho de delimitação das
regiões, isto é, ao trabalho de agrupamento de espaços elementares37.
A delimitação de regiões é um trabalho fundamentalmente
orientado pelos objectivos que se pretendem atingir com essa
delimitação, pois são esses objectivos que irão determinar as
características que interessa destacar nos espaços elementares a
agregar.
Consoante os objectivos, podem-se estabelecer vários tipos de
regiões e, a este propósito, já foram mencionados, anteriormente, as
regiões administrativas, como constituindo uma escala territorial de
intervenção permanente de determinados níveis funcionais da
Administração Pública.
Um critério possível a utilizar na delimitação de regiões
administrativas, para além do da coesão sócio-económica entre espaços
36No caso português corresponde ao concelho e, nalguns casos, à freguesia, ao
distrito ou às NUTS III.37Interessa ter presente alguns conceitos da teoria dos conjuntos: união, intersecção,
axioma da extensão, etc..
A delimitação de regiões éum trabalhofundamentalmente orientadopelos objectivos que sepretendem atingir.
Regiões Administrativas.
A coesão sócio económica eas acessibilidades entreespaços elementares.

58 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
elementares, poderia ser o das acessibilidades entre esses espaços. A
preocupação seria a de estabelecer uma administração localizada o
mais perto possível dos administrados: os espaços elementares seriam
assim agrupados de modo a minimizarem as distâncias físicas38 entre
eles.
Ao falarmos em regiões homogéneas, dissemos que se tratava
de regiões dotadas de um grau mínimo de uniformidade de
características entre os seus espaços elementares. Tais características
podem ser de natureza económica e social, e acrescentamos que a
delimitação deste tipo de regiões visava, fundamentalmente, objectivos
de equidade. Um critério possível na delimitação destas regiões poderá
ser o da minimização das distâncias económicas entre os respectivos
espaços elementares.
Referimos igualmente as regiões polarizadas, em que o critério
de agrupamento não incide já em características dos espaços
elementares, mas nas relações que os espaços estabelecem entre si.
Deste modo, a definição deste tipo de regiões pretende apoiar a
implementação de políticas de crescimento económico, já que se
procuram destacar os espaços que, por causa de uma maior
complementaridade e inter-relacionamento, são susceptíveis de
maximizar efeitos multiplicadores do investimento e de outras variáveis
macro-económicas.
As metodologias que vamos estudar servem, sobretudo, para a
definição de regiões homogéneas, e ainda de regiões administrativas, se
a sua delimitação assentar maioritariamente em critérios de
homogeneidade e de acessibilidade.
38Naturalmente que representadas pelas vias e meios de locomoção.
Regiões homogéneas
Regiões polarizadas

2.3.2. A DISTÂNCIA ECONÓMICA 59
A delimitação de regiões polarizadas tem sido inspirada pela
análise das matrizes de relações interregionais.
A delimitação de regiões homogéneas corresponde a uma
avaliação de afinidades ou similaridades existentes entre espaços
elementares e na sua subsequente classificação, na base das
similaridades, tendo em vista o seu agrupamento.
Tal classificação deve obedecer a vários critérios39 que
poderemos considerar como princípios operacionais da taxinomia, e
que passamos a mencionar40:
1) A classificação é função do objectivo pretendido; vimos já
que as características a obter para os agrupamentos (regiões)
a formar, dependem dos objectivos de política, e determinam
as características a destacar nos espaços elementares;
2) A classificação baseia-se em características de natureza
diferenciada, o que significa que nenhuma classificação se
deve fundamentar no comportamento de uma única variável.
3) Qualquer classificação, é sempre relativa, pois depende das
hipóteses iniciais e da informação disponível; vimos já que a
informação disponível condiciona o número e tipo de variáveis
a utilizar, bem como a determinação dos espaços elementares;
teoricamente, a delimitação de regiões homogéneas e
polarizadas deveria basear-se em espaços elementares
diferentes, exigindo-se, no primeiro caso, uma elevada
uniformidade interna, não forçosa no segundo caso;
normalmente as restrições de informação não o permitem;
39Aplicáveis também a definição de regiões polarizadas.40Baseando-nos em PAELINCK, J.H. e NIJKAMP, P. (1975).
A delimitação de regiõeshomogéneas corresponde auma avaliação dassimilaridades existentes entrespaços elementares.

60 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
4) A classificação deve basear-se nas características actuais41
dos espaços elementares, não havendo, por conseguinte, lugar
para a inclusão de factores históricos;
5) Exaustividade de classificação, ou seja, todos os espaços
elementares devem ser incluídos, ainda que isso signifique
perda de qualidade nos agrupamentos formados;
6) Classificação exclusiva, isto é, os agrupamentos devem ser
disjuntos;
7) Os princípios da classificação devem ser os mesmos em
todas as etapas da análise;
8) As características que separam grandes grupos devem
prevalecer sobre as referentes a pequenos grupos; na
selecção das variáveis; para além da arbitrariedade possível,
este tipo de selecção justifica-se, a nosso ver, por dois
motivos: os objectivos pretendidos que orientam a análise, na
qual a classificação de regiões não é mais do que um passo
intermédio e a necessidade de economia no número e
dimensão das regiões a obter;
9) Podem considerar-se elementos qualitativos, desde que seja
possível estabelecer uma escala de medida, por exemplo, uma
escala ordinal ou uma simples classificação binária;
10) A classificação deve conduzir a uma hierarquia de
classes, como veremos adiante.
A classificação dos espaços elementares, tendo em vista a sua
agregação em regiões, baseia-se na determinação de relações de
similaridade entre esses espaços.
41Com a actualidade que o atraso na produção estatística permite.

2.3.2. A DISTÂNCIA ECONÓMICA 61
A similaridade pode ser entendida como função inversa da
distância económica. Sendo d rr’ a distância económica entre duas
regiões r e r ', o grau de similaridade poderá então ser representado
por:
s rr' = (1 + d rr' ) -1
em que s rr' varia entre 1, valor correspondente à máxima
similaridade (mínima distância, drr' =0) e 0, mínima similaridade
(máxima distância, drr' → ∞.
Quando se dispõem de variáveis quantificadas, a distância
económica é obtida pelo método que vimos anteriormente. Quando se
dispõe apenas de informação qualitativa, a similaridade pode obter-se a
partir de uma matriz de características, em que a ocorrência ou
ausência de ocorrência de cada característica em cada região é
assinalada, respectivamente, com 1 e 0.
Característica
1 2. ... J
R 1 1 0 … 1
e 2 0 1 … 1
g . . .
i . . .
õ . . .
e R 1 1 … 0
s
Nos casos em que para a característica se pode estabelecer uma
escala de ocorrência, a classificação binária dependerá do
estabelecimento de um limiar (dj) de separação entre o que se
considerará como sendo 1 ou 0:
A similaridade pode serentendida como funçãoinversa da distânciaeconómica
A determinação dasimilaridade quando sedispõe apenas de informaçãode natureza qualitativa.
A construção de uma matrizde características.

62 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
1 se y
se y drj
rj j
≥
dj
0 E
em que y rj é o valor da característica j na região r .
Com base nesta matriz binária, pode-se estabelecer para cada par
de regiões:
Região r’
11rrJ ′
10rrJ ′
1rJ
Região r 01rrJ ′
00rrJ ′
0rJ
1rJ ′
0rJ ′ J
em que:
J r r'1 1 - número de características presentes, simultaneamente,
em r e r’ ;
J r r'0 0 - número de características ausentes, simultaneamente, em
r e r’ ;
J r r'1 0 - número de características presentes em r e ausentes em
r' ;
J r r'0 1 - número de características ausentes, em r e presentes em
r’ ;
J r 1 e J r'
1 - número total de características presentes em r e
em r' , respectivamente:

2.3.2. A DISTÂNCIA ECONÓMICA 63
1 11 10r rr' rr'=J +JJ ;
1 11 01r' rr' rr'J +JJ = ;
J r 0 e Jr'
0 - número total de características ausentes em r e em r' ,
ou seja :
0 01 00r rr' rr'+JJ J= ;
0 10 00r' rr' rr'J +JJ = ;
J - número total de características em análise.
Com os dados anteriores podem-se calcular índices de
similaridade, definidos como42:
* 11 00rr' rr' rr' s =(J +J ) /J )
a partir destes uma matriz de similaridades:
S* = [ * rr's ],
facilmente transformável numa matriz de distâncias económicas
entre regiões, na medida em que sendo:
1=rr' rr's (1+ ) d − ,
então:
d = (1 - s srr' rr'*
rr' * ) / ,
desde que se admita que srr' ≈srr'
* .
42Admite-se que a afinidade entre os espaços elementares tanto resulta da presença
comum de uma característica, como da sua ausência.
A determinação de umindicador de similaridade.

64 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Com base na matriz de similaridades, ou na matriz de distâncias
económicas é possível construir uma matriz de proximidade, onde
cada linha explicita a hierarquia de proximidade de cada região, em
relação às restantes. Para cada região, a proximidade com as outras
será tanto maior, quanto maior for a similaridade que lhes corresponde.
Se o ponto de partida for uma matriz de distâncias económicas,
para cada região, a sua proximidade com as outras variará em sentido
contrário ao valor das distâncias. Os números da matriz de
proximidade explicitam os valores das posições ocupadas, por cada
região, na hierarquia das suas relações com as restantes.
Exemplificando, se tivermos a seguinte matriz de distâncias
económicas43:
Regiões 1 2 3 4 5
1 0 1 8 10 6
2 1 0 7 9 5
3 8 7 0 2 3
4 10 9 2 0 4
5 6 5 3 4 0
A matriz de proximidade associada, é:
Regiões 1 2 3 4 5
1 1 2 4 5 3
2 2 1 4 5 3
3 5 4 1 2 3
4 5 4 2 1 3
5 5 4 2 3 1
43Com base em PAELINCK, J. H. e NIJKAMP, P., op. cit., 201. A metodologia de
cálculo da distância económica será explicitada no ponto seguinte
A construção da matriz deproximidade.
Um exemplo:

2.4.1. A ANÁLISE DE CLUSTERS 65
Será com base nesta matriz e na matriz de distâncias económicas
(ou de similaridades) que, segundo um processo iterativo, se procede à
escolha dos espaços elementares a agrupar.
2.4.1. A análise de clusters
A análise de clusters é uma técnica estatística de agrupamento de
observações de indivíduos baseada na similaridade das suas
características. O ponto de partida é, assim, uma matriz de similaridade
ou de distâncias entre os diferentes individuos.
Este texto procura seguir a apresentação dos resultados da
análise clusters, através da utilização dos outputs do software SPSS for
Windows. Optou-se por, ao longo do texto, mostrar apenas parte do
output gerado por este package estatístico, deixando para o fim a
referência aos procedimentos e opções do SPSS necessários à obtenção
da análise de clusters (no anexo A.3. apresenta-se o output integral
gerado pelo SPSS).
O exemplo apresentado tem por base uma matriz de informação
regional referente às 28 NUTS III do Continente com três indicadores
sobre os graus de riqueza (rica), urbanização (urban) e bem estar
social (socind), ver Anexo A.4., determinados através da aplicação da
análise factorial a um conjunto inicial de dez indicadores, efectuada em
7.2.6..
A análise de clusters é umatécnica de agrupamento deobservações baseada nasimilaridade das suascaracterísticas.

66 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
A. Os métodos de análise de clusters hierárquicos44
Os métodos de análise clusters hierárquicos processam-se através
de uma sucessão de aglomeração ou partição de indivíduos. No
primeiro caso, parte-se de uma situação em que o número de clusters é
idêntico ao número de espaços elementares (no exemplo presente, as
28 regiões NUTS III do Continente) e, através da aglomeração dos
espaços mais semelhantes, vai-se progressivamente diminuíndo o
número de clusters até que todas as regiões sejam agrupadas num
único cluster.
Os métodos hierárquicos de partição baseiam-se no princípio
oposto, ou seja, parte-se de uma situação em que todos os espaços
elementares estão agrupados num único cluster para uma situação de
partição em subgrupos, com base nas maiores distâncias entre regiões,
até que se formem tantos clusters quantos os espaços elementares
inicialmente considerados.
O algoritmo dos métodos de aglomeração hierárquica,
compreende fundamentalmente os seguintes passos:
1. Determinação de uma matriz das distâncias { }D dij= , em que
se consideram R clusters, cada um constituído por uma única
observação (região NUTIII)- cluster elementar; a matriz é
simétrica e de dimensão R x R, em que R é o número de
regiões inicialmente consideradas (28 no exemplo utilizado).
44 Para além dos métodos hierárquicos existem um outro conjunto de métodos que
não são objecto de referência neste texto. Entre os métodos não hierárquicos um dosalgoritmos mais utilizados é designado por K-means. Para uma apresentação deste algoritmover por exemplo Johnson e Wichern (1982).
Os métodos de análise declustes hierárquicos:
i) os métodos deaglomeração
ii) os métodos de partição.
O algoritmo dos métodos deaglomeração hierárquica.
1º A matriz das distâncias

2.4.1. A ANÁLISE DE CLUSTERS 67
2. Extracção na matriz das distâncias do menor dos valores (duv),
a que correspondem os clusters U e V.
3. Os clusters U e V são agregadas formando o cluster (UV); a
matriz das distâncias é actualizada, suprimindo-se as linhas e
as colunas referentes às regiões (U e V) e adicionando uma
nova linha e um nova coluna com as distâncias entre o
agrupamento (UV) e os restantes clusters.
4. Os procedimentos 2. e 3. são repetidos R-1 vezes, ou seja, o
processo termina quando todas as regiões estiverem
agrupadas, formando um único cluster.
Uma vez realizada a primeira iteração nos procedimentos 2. e 3.
coloca-se, em cada uma das seguintes, o problema da determinação da
distância entre clusters que não são constituídos por um único espaço
elementar. Diversos critérios podem estar subjacentes a essa
determinação. Normalmente os critérios mais utilizados são:
i) Vizinho mais próximo (nearest neighbor) ou single linkage: a
distância entre dois clusters corresponde à menor das
distâncias entre dois espaços elementares pertencentes a
clusters diferentes;
1.
2.
.3
.5
.4
C 1 C 2
Distância entre os clusters C1 e C2:
d24
2º A pesquisa da menordistância
3º A actualização da matrizde distâncias
4º A repetição dosprocedimentos 2 e 3.
Os critérios para adeterminação da distânciaentre dois clusters.
i) Vizinho mais próximo(nearest neighbor) ou singlelinkage

68 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
ii) vizinho mais afastado (furthest neighbor) ou complete
linkage: a distância entre dois clusters corresponde à maior
das distâncias entre dois espaços elementares pertencentes a
clusters diferentes;
1.
2.
.3
.5
.4
C 1 C 2
Distância entre os clusters C1
e C2: d15
iii) average linkage between groups, média entre todos os pares
de espaços elementares possiveis de serem formados, com
cada uma das regiões pertencentes a agrupamentos diferentes.
1.
2.
.3
.5
.4
C 1 C 2
Distância entre os clusters C1 e C2:
d d d d d d13 14 15 23 24 25
6
+ + + + +
O último critério difere substancialmente dos dois primeiros.
Utiliza informação sobre todos os pares de espaços elementares que
são possiveis constituir com os dois agrupamentos e não apenas a
distância entre os dois espaços mais próximos ou mais afastados.
Porque ao adoptar este critério se retêm um maior volume de
informação é normalmente preferível recorrer à sua utilização.
B. Análise dos resultados do SPSS
Como vimos na secção anterior, o ponto de partida da análise de
clusters é matriz das distâncias entre espaços elementares. Assim tendo
em conta os três indicadores atrás mencionados (ver anexo A2)
apresenta-se a matriz das distâncias euclidianas, calculada com recurso
ao SPSS, entre as 28 NUTS III, que constituem os espaços
elementares do exemplo proposto.
ii) vizinho mais afastado(furthest neighbor) ou
complete linkage
iii) average linkage betweengroups
2.4.1. A ANÁLISE DE CLUSTERS 69
Figura 2- Matriz das Distâncias* * * * * * * * * * * * * * * P R O X I M I T I E S * * * * * * * * * * * * * * * Data Information 28 unweighted cases accepted. 0 cases rejected because of missing value. Euclidean measure used.- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -Euclidean Dissimilarity Coefficient Matrix Case MINHO CÁVADO AVE G.PORTO TÂMEGA DOURO DOURO ALTO LIMA VOUGA T.MONTES CÁVADO ,5609 AVE ,8965 ,3491 G.PORTO 2,8505 2,6576 2,5240 TÂMEGA 1,6658 1,2358 1,1491 3,3334 DOURO VOUGA 1,5144 1,2100 1,0216 2,6245 1,9469 DOURO 1,1349 1,0676 1,1251 3,3533 1,7834 ,9874 ALTO T. MONTES 1,2756 ,8636 ,6797 2,9574 1,3111 ,7006 ,7482 BAIXO VOUGA 1,3398 1,2667 1,2231 2,3889 2,3356 ,6983 1,1758 1,2049 BAIXO MONDEGO 2,9539 3,4781 3,7589 4,2609 4,5924 3,8945 3,5509 4,0317 PINHAL LITORAL 1,5313 1,4466 1,3797 2,3619 2,4854 ,7412 1,3155 1,3270 PINHAL I.NORTE 2,0506 1,7762 1,5904 3,0618 2,3454 ,6184 1,2276 1,0797 DÃO-LAFÕES ,7620 ,6188 ,7215 3,0408 1,4930 ,9651 ,4495 ,6192 PINHAL I.SUL 2,0031 1,8684 1,7557 2,8733 2,7174 ,7906 1,3613 1,4228 SERRA ESTRELA 3,4416 3,0686 2,8179 4,1321 3,1119 2,0553 2,4939 2,2229 BEIRA I.NORTE ,7686 1,2915 1,5899 3,1940 2,3924 1,8627 1,3549 1,8006 BEIRA I.SUL 2,1203 2,5469 2,7553 3,5249 3,7426 2,5816 2,3449 2,8541 COVA DA BEIRA ,9201 1,4393 1,7284 3,1307 2,5749 1,9723 1,5452 1,9703 OESTE 2,0526 1,9622 1,8622 2,1869 2,9651 1,1623 1,8664 1,8243 GRANDE LISBOA 3,6214 3,4488 3,3172 ,7940 4,0935 3,3734 4,1307 3,7392 PENÍNS.SETÚBAL 2,8370 2,6450 2,5142 ,0575 3,3133 2,6374 3,3560 2,9581 MÉDIO TEJO 2,7281 2,7441 2,6955 3,3030 3,7165 1,8100 2,1853 2,4267 LEZIRIA DO TEJO 2,5892 2,5847 2,5216 2,8393 3,5991 1,6944 2,2165 2,3566 ALENTEJO LITORAL 2,7714 2,7231 2,6292 2,7935 3,6928 1,7709 2,3844 2,4562 ALTO ALENTEJO 2,3865 2,5121 2,5347 3,2082 3,5989 1,8171 2,0221 2,3688 ALENTEJO CENTRAL 3,2807 3,2887 3,2315 3,9047 4,1795 2,2918 2,5920 2,8694 BAIXO ALENTEJO 1,2105 1,5492 1,7343 3,0772 2,7186 1,5759 1,2869 1,7748 ALGARVE 2,9319 2,9403 2,8765 2,4126 4,0015 2,2187 2,8418 2,8829- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Case BAIXO BAIXO PINHAL PIN. I DÃO- PINH. I SERRA BEIRA I VOUGA MONDEGO LITORAL NORTE -LAFÕES SUL ESTRELA NORTE BAIXO MONDEGO 3,2732 PINHAL LITORAL ,1927 3,3475 PINHAL I.NORTE 1,1198 4,2531 1,0822 DÃO-LAFÕES 1,0990 3,4648 1,2724 1,4008 PINHAL I SUL ,7941 3,7857 ,6812 ,6428 1,5134 SERRA ESTRELA 2,6399 5,7488 2,5820 1,5326 2,7156 2,0430 BEIRA I. NORTE 1,4711 2,2837 1,6349 2,2960 1,2024 2,0717 3,7586 BEIRA I. SUL 1,9600 1,5267 2,0005 2,8360 2,3616 2,3245 4,2941 1,4391 COVA DA BEIRA 1,5101 2,0838 1,6612 2,4100 1,3898 2,1321 3,8984 ,2319 OESTE ,7526 3,5142 ,5709 1,3378 1,8392 ,8324 2,6792 2,1029 GRANDE LISBOA 3,1190 4,7244 3,0715 3,7659 3,8286 3,5468 4,7468 3,9191 PENÍN. SETÚBAL 2,4031 4,2550 2,3806 3,0826 3,0377 2,8988 4,1577 3,1864 MÉDIO TEJE 1,5240 3,6390 1,3756 1,6089 2,3816 1,0361 2,6619 2,5292 LEZIRIA TEJO 1,3191 3,5439 1,1470 1,6224 2,3231 1,0092 2,7838 2,4468 ALENTEJO LITORAL 1,4625 3,7864 1,2775 1,6616 2,4826 1,0985 2,7157 2,6790 ALTO ALENTEJO 1,3466 3,0419 1,2433 1,7910 2,1773 1,1696 3,0629 2,0673 ALENTEJO CENTRAL 2,1208 4,0763 1,9802 1,9454 2,8610 1,5052 2,6629 3,0547 BAIXO ALENTEJO 1,0541 2,3755 1,1604 1,8951 1,2891 1,5174 3,3895 ,7372 ALGARVE 1,7452 3,5356 1,5818 2,2875 2,8384 1,7137 3,4254 2,8015- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Case BEIRA I COVA OESTE GRANDE PENÍNS MÉDIO LEZIRIA ALENT.
SUL BEIRA LISBOA SETÚBAL EJO TEJO LITORAL COVA DA BEIRA 1,2701 OESTE 2,1579 2,0851 GRANDE LISBOA 4,0966 3,8341 2,8114 PENÍN.SETÚBAL 3,5333 3,1236 2,2175 ,8055 MÉDIO TEJO 2,1350 2,5162 1,1669 3,8494 3,3383 LEZIRIA TEJO 2,0912 2,4119 ,7833 3,3687 2,8760 ,4863 ALENTEJO LITORAL 2,3521 2,6475 ,8353 3,2900 2,8340 ,6268 ,2739 ALTO ALENTEJO 1,5370 2,0228 1,1537 3,7805 3,2369 ,5986 ,6752 ,9418 ALENTEJO CENTRAL 2,5833 3,0559 1,7897 4,4198 3,9428 ,6560 1,0941 1,1298 BAIXO ALENTEJO 1,0827 ,7193 1,5540 3,7763 3,0830 1,8096 1,7540 2,0022 ALGARVE 2,2905 2,7108 1,0621 2,7944 2,4557 1,2873 ,8526 ,7958- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Case ALTO ALENTEJO BAIXO ALENTEJO CENTRAL ALENTEJO ALENTEJO CENTRAL 1,1307 BAIXO ALENTEJO 1,3315 2,3374 ALGARVE 1,2986 1,7830 2,1813- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -

70 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Para exemplificar, tomemos a base de dados do anexo A2 e
consideremos a informação dos 3 indicadores referentes às regiões do
Minho-Lima e Cávado:
RICA URBAN SOCINDMinho-Lima -1.08147 0.61936 0.45908Cávado -1.03683 0.75803 -0.08258
então a distância entre as duas regiões vem dada por:
[ ] [ ]dMin Cav, , ( , ) ( , , ) , ( , )= − − − + − + − −108147 103683 0 61936 0 75803 0 45908 0 082582 2 2
Os resultados da análise de clusters utilizando o SPSS são
resumidos na output do SPSS apresentado na figura 3.
Figura 3- Resultados da Análise de Clusters
• * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * *• Agglomeration Schedule using Average Linkage (Between Groups)
Next Clusters Combined Stage Cluster 1st AppearsStage Cluster 1 Cluster 2 Coefficient Cluster 1 Cluster 2 Stage
1 4 21 .057463 0 0 15 2 9 11 .192670 0 0 9 3 16 18 .231904 0 0 12 4 23 24 .273936 0 0 7 5 2 3 .349071 0 0 13 6 7 13 .449477 0 0 10 7 22 23 .556573 0 4 14 8 6 12 .618444 0 0 11 9 9 19 .661742 2 0 17 10 7 8 .683687 6 0 16 11 6 14 .716672 8 0 17 12 16 27 .728222 3 0 20 13 1 2 .728687 0 5 16 14 22 25 .738552 7 0 18 15 4 20 .799743 1 0 26 16 1 7 .916534 13 10 21 17 6 9 .938814 11 9 22 18 22 26 1.002656 14 0 19 19 22 28 1.203453 18 0 22 20 16 17 1.263982 12 0 23 21 1 5 1.439690 16 0 23 22 6 22 1.526854 17 19 24 23 1 16 1.866338 21 20 24 24 1 6 2.165417 23 22 25 25 1 15 2.872076 24 0 26 26 1 4 3.215650 25 15 27 27 1 10 3.584466 26 0 0
Os títulos do output permitem identificar que se aplicou o
método hierárquico de aglomeração e que o critério de determinação
A leitura da figura 3

2.4.1. A ANÁLISE DE CLUSTERS 71
da distância entre clusters foi o da distância média entre os pares de
espaços elementares pertencentes a agrupamentos diferentes (average
linkage between groups).
A leitura das primeiras quatro colunas da figura 3 permite obter
informação sobre os clusters formados em cada uma das iterações e a
respectiva distância. Assim, da leitura da primeira linha e das colunas 2
(Clusters Combined - Cluster 1) e 3 (Clusters Combined - Cluster 2),
verifica-se que são as regiões 4 e 21, ou seja, as regiões que se
encontram na linha 4 e 21 da matriz de informação inicial
(respectivamente, Grande Porto e Península de Setúbal), aquelas que
apresentam um maior grau de proximidade (o valor distância é
apresentado no coluna coefficient) e passam a constituir
provisoriamente o primeiro cluster. Registe-se que este cluster é
identificado pelo menor número de ordem das regiões envolvidas,ou
seja, neste caso pelo indíce 4.
As três últimas colunas permitem obter informação
respectivamente sobre as iterações anteriores em que cada um dos
clusters tenha sido objecto de agrupamento e a próxima etapa em que
o cluster agora constituído vai de novo participar. No caso da iteração
1, verifica-se que as colunas 5 (Stage Cluster 1st Appears - Cluster 1)
e 6 (Stage Cluster 1st Appears - Cluster 2) têm o valor 0 uma vez que
estes clusters elementares (constituídos por uma única região) ainda
não tinham sido incluídos no processo de aglomeração. Finalmente a
coluna 7 (Next Stage) informa que o cluster resultante desta iteração é
de novo objecto de agrupamento na iteração 15.
Tomemos um outro exemplo, considerando ainda a figura 3,
analisando a iteração 7:

72 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
i) Através das colunas 2 e 3 conclui-se que os clusters agrupados
são o 22 (que inclui a região do Médio Tejo) e o 23 (que
inclui a Lezíria do Tejo);
ii) Da observação das colunas 5 e 6 que resulta que o cluster com
a região do Médio Tejo é a primeira vez objecto de
agrupamento (trata-se de um cluster elementar) e que o
cluster que inclui a região da Leziria do Tejo já foi objecto de
agregação na iteração 4;
iii)Recorrendo à informação da iteração 4 verifica-se que aí
foram agrupados os clusters 23 (Lezíria do Tejo) e 24
(Alentejo Litoral), não existindo para qualquer destes clusters
um envolvimento anterior à actual iteração (0 nas colunas 5 e
6).
Deste modo, tendo em conta que cada cluster constituido fica
identificado pelo indíce correspondente ao cluster elementar de ordem
mais baixa, o agrupamento constituído na iteração 7 passa a ser
identifcado pelo indíce 22 e resulta da agregação do cluster elementar
Médio Tejo ao cluster constituído pela regiões da Lezíria do Tejo e do
Alentejo Litoral.
Com base nas distâncias entre estas três regiões, retiradas da
matriz das distâncias apresentada na fig 2,
Médio Tejo Leziria doTejo
Lezíria do Tejo 0,4863Alentejo Litoral 0,6268 0,2739
a distância entre a região do Médio Tejo e o cluster constituído na
iteração 4, pelas regiões da Leziria do Tejo e do Alentejo Litoral, vem
dM Tejo Leziria A Litoral. ,( , . ), ,
,= + =0 4863 0 6268
20 5565

2.4.1. A ANÁLISE DE CLUSTERS 73
o que corresponde ao valor da coluna quatro (coefficient) referente à
iteração 7.
A observação da coluna coefficient permite igualmente observar
que à medida que o número de iterações aumenta procede-se à ligação
entre clusters com menores níveis de similaridade, ou seja, maiores
distâncias entre clusters. A informação sobre os valores das distâncias
entre os clusters pode fornecer um critério para a decisão sobre o
número de clusters que deverão ser considerados no caso de se
procurar formar agrupamentos com um certo grau de similaridade
entre os respectivos elementos. Com efeito, o processo de
aglomeração deverá ser interrompido quando se verificar um aumento
substancial na distância entre duas iterações consecutivas45.
No exemplo apresentado verifica-se que, entre a iteração 22 e a
iteração 23, existe um acréscimo na distância entre os clusters
agrupados bastante superior ao verificado na iteração anterior. Deste
modo, se fizermos a interrupção do processo de aglomeração no final
da iteração 22, obtêm-se 6 agrupamentos de regiões que de algum
modo confirmam uma certa ideia sobre a similaridade das
características económico-sociais das 28 regiões NUTS III do
Continente (ver figura 4).
45 Note-se que de acordo com o algoritmo de aglomeração alguns destes
agrupamentos podem ser constituidos por apenas um espaço elementar (NUTS III), bastando

74 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Figura 4 - Similaridades económico-sociais
das regiões portuguesas
M I N H O - L I M A
C A V A D O
A V E
G R A N D E P O R T O
T A M E G A
E N T R E D O U R O E V O U G A
D O U R O
A L T O T R A S - O S - M O N T
B A I X O V O U G A
B A I X O M O N D E G O
P I N H A L L I T O R A L
P I N H A L I N T . N O R T E
D A O - L A F O E S
P I N H A L I N T E R I O R S U L
S E R R A D A E S T R E L A
B E I R A I N T E R I O R N O R T E
B E I R A I N T E R I O R S U L
C O V A D A B E I R A
O E S T E
G R A N D E L I S B O A
P E N I N S U L A D E S E T Ú B A L
M E D I O T E J O
L E Z I R I A D O T E J O
A L E N T E J O L I T O R A L
A L T O A L E N T E J O
A L E N T E J O C E N T R A L
B A I X O A L E N T E J O
A L G A R V E
Para além do output apresentado na figura 3 é igualmente
possível obter com o SPSS várias representações gráficas do processo
de constituição dos clusters. Entre estas merece ser destacada a
representação através da construção de um dendrograma (figura 5).
O dendrograma permite não só identificar os clusters agrupados
ao longo de todo o processo (tracejado vertical), como ainda observar,
o incremento nos valores da distância entre os clusters (tracejado
horizontal).
para isso que esses espaços elementares apresentem características consideravelmentedistintas dos restantes.
O dendrograma.

2.4.1. A ANÁLISE DE CLUSTERS 75
Figura 5- Dendrograma
* * ** * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * *
Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+
GRANDE PORTO 4 -+---------+ PENÍNSULA DE SETÚB 21 -+ +---------------------------------+ GRANDE LISBOA 20 -----------+ | BAIXO VOUGA 9 -+-------+ | PINHAL LITORAL 11 -+ +---+ | OESTE 19 ---------+ +-------+ | ENTRE DOURO E VOUG 6 -------+-+ | | | PINHAL INTERIOR NO 12 -------+ +---+ | | PINHAL INTERIOR SU 14 ---------+ | | LEZIRIA DO TEJO 23 ---+---+ +-------+ | ALENTEJO LITORAL 24 ---+ +-+ | | +---+ MÉDIO TEJO 22 -------+ +---+ | | | | ALTO ALENTEJO 25 ---------+ +---+ | | | | ALENTEJO CENTRAL 26 -------------+ +---+ | | | ALGARVE 28 -----------------+ +---------+ | | BEIRA INTERIOR NOR 16 ---+-----+ | | | | COVA DA BEIRA 18 ---+ +-------+ | | | | BAIXO ALENTEJO 27 ---------+ +-------+ | | | | BEIRA INTERIOR SUL 17 -----------------+ | | | | | DOURO 7 -----+---+ | | | | | DÃO-LAFÕES 13 -----+ +---+ +---+ +-----+ | ALTO TRÁS-OS-MONTE 8 ---------+ +-----+ | | | CÁVADO 2 -----+---+ | | | | | AVE 3 -----+ +---+ +-----+ | | MINHO-LIMA 1 ---------+ | | | TÂMEGA 5 -------------------+ | | SERRA DA ESTRELA 15 ---------------------------------------+ | BAIXO MONDEGO 10 -------------------------------------------------+
C. Procedimentos e opções no SPSS
A obtenção do exemplo utilizado ao longo do texto requer os
seguintes procedimentos e opções seleccionados através do sistema de
menus:
1- Abertura do ficheiro com as variáveis originais:
FILE ...
OPEN...
DATA...

76 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
2- Selecção do Procedimento análise clusters
STATISTICS ...
CLASSIFY...
HIERARCHICAL CLUSTER.....
3- Selecção das variáveis a submeter à análise de clusters
4- Selecção das seguintes opções na janela Statistics:
AGGLOMERATION SCHEDULE
DISTANCE MATRIX
5- Selecção das seguintes opções na janela Plots:
DENDROGRAM
6- Selecção das seguintes opções na janela Method:
Cluster Method: BETWEEN-GROUPS LINKAGE
Measure: INTERVAL;
EUCLIDEAN DISTANCE;
2.4.2. Noções de densidade e de distância inter-grupal
Ao utilizar-se o conceito de distância económica na delimitação
de regiões, haverá que distinguir:
- As distâncias entre espaços elementares;
- As distâncias inter-grupais, ou seja, entre os agrupamentos que
se vão constituindo.
Se A é um território constituído por um conjunto de espaços
elementares r, temos que:
A = rr=1
R*
Os espaços elementares podem ser reunidos em agrupamentos
(ou clusters), que constituem subconjuntos de A e que designaremos
por c , de tal modo que
c = Ac=1
C*

2.4.2. NOÇÕES DE DENSIDADE E DE DISTÂNCIA INTER -GRUPAL 77
Se tomarmos rc como o elemento genérico do agrupamento c, a
soma dos elementos de cada agrupamento deverá ser igual ao
agrupamento:
r = ccrc=1c
Rc*
A densidade de um agrupamento c é um indicador da distância
económica média entre todos os espaços elementares que o compõem.
A densidade dos espaços elementares de um agrupamento será tanto
maior quanto mais pequena for essa distância média.
Assim, se dr c r c' for a distância económica entre dois espaços
elementares r c e r c' do agrupamento c, e Rc o respectivo número de
espaços elementares, o inverso da densidade do agrupamento será
dado por46:
DR
cc r
R
c
c
c
c
2 2
11
= d R - 1)
2
r r
rc c
rr
R
c c'
c'
c '
c
c (
⟨
==∑∑
Este indicador da densidade de um agrupamento define-se como
sendo igual ao somatório dos quadrados das distâncias económicas
entre os espaços elementares (pertencentes a um mesmo
agrupamento), dividido por metade do número de elementos da matriz
dessas distâncias, deduzidos dos elementos da diagonal principal, que
naturalmente são nulos. Daí o afirmar-se que a densidade corresponde
a uma distância média intra-grupal. Essas distâncias podem
representar-se numa matriz Dc c' , tal que:
Densidade de umagrupamento.
Densidade que correspondea uma distância média intra-grupal.

78 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
1c … Rc
1c
Dc c= dr rc c′
Rc
A distância inter-grupal é a distância económica média entre
espaços elementares rc e r c′ pertencentes a dois agrupamentos, c e c':
Dd
cc
rR
c
c
c
c
'
'
'
2
2
11
=R R
r
c crr
Rc'
'
c'c
c
==∑∑
Do mesmo modo, que para as distâncias intra-grupais, as
distâncias inter-grupais (entre espaços elementares pertencentes a
agrupamentos diferentes) podem representar-se numa matriz Dc c'
, tal
que:
1c’ … Rc’
1c
Dc ′c = dr rc c′
Rc’
Se tivéssemos um conjunto de espaços elementares agrupados
em três regiões, poderíamos continuar a calcular as distâncias inter-
grupais entre os elementos da várias regiões.
Do mesmo modo que anteriormente, temos agora, depois de
reordenadas as linhas e as colunas, uma matriz alargada, em que cada
elemento é uma matriz Dc ′c do tipo das anteriormente explicitadas.
46Tenhamos presente que a matriz de distâncias económicas é simétrica
Distância inter-grupal.

2.4.3. A FORMAÇÃO DE AGRUPAMENTOS HOMOGÉNEOS 79
11 1c cR. .. 1
2 2c cR... 13 3c cR.. .
11
1
c
cR... Dc1c1
Dc1c1Dc1c1
12
2
c
cR... Dc2c1
Dc1c1Dc1c1
13
3
c
cR... Dc1c1
Dc1c1Dc1c1
Posto isto, interessa ver como se processam as várias fases de
delimitação de regiões homogéneas.
2.4.3. A formação de agrupamentos homogéneos
Vamos abordar a questão da formação de agrupamentos
tomando como ponto de partida a informação reunida em matrizes de
similaridades, de proximidades ou de distâncias económicas. Os
espaços referidos nestas matrizes serão considerados como os espaços
elementares necessários para agregação. Através de um processo de
natureza iterativa, procuraremos proceder à escolha dos espaços
elementares que vão fazer parte de cada agrupamento.
As matrizes de proximidade permitem-nos estabelecer
hierarquias de proximidade, sem realizar a sua quantificação, enquanto
que as matrizes de distância económica dão-nos uma medida dessa
proximidade. No que se segue, referimo-nos sempre a matrizes de
distância económica. A utilização das matrizes de similaridades em
nada alteraria a metodologia a apresentar, apenas se deverá ter em
As matrizes de similaridade,distância e de proximidadecomo ponto de partida.
Os espaços referidos nessasmatrizes serão consideradoscomo os espaçoselementares.

80 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
conta que para qualquer elemento genérico de uma matriz de
similaridades se tem:
srr-1
rr= f (d )′ ′
Um critério básico a ser seguido na formação dos agrupamentos
será o de que a distância entre um agrupamento c de espaços
elementares e um novo espaço elementar r não deverá ser superior a
α Dc c 2 sendo α uma constante fixada à priori, embora, normalmente,
se possa admitir que se deva aproximar da unidade. Este critério tem
como fundamento o facto de se admitir que o alargamento de um
agrupamento inicial com novos espaços elementares, não se deve
realizar à custa da destruição da coerência interna entre os espaços
elementares que compõem o agrupamento inicial.
Tal critério corresponde a tomar-se como princípio genérico de
agregação, o de que as distâncias económicas entre os espaços
elementares de uma região devem ser inferiores às distâncias
económicas entre espaços elementares pertencentes a regiões
diferentes, o que está de acordo com a noção de regiões homogéneas.
O processo de agrupamento terá natureza iterativa, e cada
iteração é composta por 3 fases de análise e cálculo:
1) Com base na matriz de distâncias económicas entre espaços
elementares, procede-se à escolha dos espaços elementares
que apresentem menor distância económica entre si, e sejam
contíguos. Isto é, selecciona-se r i e r j , tais que:
d r jrr r r ri '
'= min d
sendo r, r’ = 1, ..., R e, r i e rj espaços contíguos.
Critério básico a ser seguidona formação dos
agrupamentos.
O processo de agrupamentoterá natureza iterativa, e
cada iteração é compostapor 3 fases de análise e
cálculo:
1ª Fase

2.4.3. A FORMAÇÃO DE AGRUPAMENTOS HOMOGÉNEOS 81
Com estes dois espaços elementares constitui-se um
primeiro agrupamento (provisório), que designaremos de c1147.
Um agrupamento só deixará de ser provisório quando já não for
possível acrescentar-lhe mais espaços elementares. É o que se
tentará nos passos que se seguem. Nesta iteração obtém-se:
c11
i j= r r*
2) Seguidamente, procede-se à reestimação das distâncias
económicas entre c11 e cada um dos restantes espaços
elementares, procedendo-se depois à anexação (que começa
por ser provisória) do espaço elementar rk que estiver mais
próximo do agrupamento c11 e lhe seja contíguo.
3) Para se verificar se o alargamento deve ou não ser mantido,
procede-se aos seguintes passos:
Tendo c1 sido provisoriamente definido, como:
c 11
i j= r r*
Hipótese 1:
SeD c r 2
c c2
11
k 11
11 D ≤ α , então rk ∈ c1 e c = r r r2
1i j k* * ,
retomando-se o passo 2) até que não seja possível encontrar
outro espaço elementar, contíguo ao espaço em formação que
verifique esta hipótese.
47Em que o índice superior é um indicador da iteração em curso e índice inferior umindicador de referência para o agrupamento
2ª Fase
3ª Fase

82 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Hipótese 2:
Se D c r 2
c c2
11
k 11
11 D ≥ αα , então r k ∉ c1 e c1 será definido apenas
como, c 1 1 2= r r* , já que outro espaço elementar que quiséssemos
acrescentar a c11 apenas contribuiria para um maior afastamento entre
os 2 termos da expressão anterior pois, como vimos em 2), r k era o
espaço elementar que mais próximo estava de c 11.
O parâmetro α surge aqui como estimado à priori e serve como
ponderador da importância relativa que se quer atribuir à
homogeneidade dos agrupamentos. Efectivamente, da condição de
retenção do alargamento do agrupamento (Hipótese 1) deduz-se que:
α D
Dc r 2
c c 211
k
11
11
≥
O valor a atribuir a α tem implicações no número de regiões a
obter e nas suas dimensões. Se se for muito exigente em termos de
homogeneidade, tornar-se-á mais difícil preencher as condições de
proximidade económica e, por conseguinte, obter-se-á um maior
número de regiões, de menor dimensão.
Este critério pode ser complementado com restrições adicionais
relativas, por exemplo, à dimensão territorial e (ou) à população
global. O critério anterior pode ser verificado mas, se uma das
restrições adicionais for violada, então o espaço elementar adicional
não deverá ser acrescentado ao agrupamento. Far-se-ão tantas
iterações, quantas as necessárias para que a formação de agrupamentos
esgote todos os espaços elementares (condição de exaustividade).
Como se pode verificar, a adopção desta metodologia para a
delimitação de regiões homogéneas constitui um processo
O parâmetro α, estimado àpriori, serve como indicador
da homogeneidade que sepretende atribuir aos
agrupamentos.
O valor a atribuir a α temimplicações no número deregiões a obter e nas suas
dimensões.
Este critério pode sercomplementado comrestrições adicionais
relativas, por exemplo, àdimensão territorial e (ou) à
população global.

2.4.3. A FORMAÇÃO DE AGRUPAMENTOS HOMOGÉNEOS 83
relativamente complexo e algo exigente em meios de cálculo. Não se
pense, contudo, que qualquer outra metodologia alternativa permite
facilitar substancialmente a tarefa. Uma forma de diminuir a carga de
cálculo associada ao processo, será a de tomar como critério
alternativo, de inclusão de espaços elementares, ao anteriormente
explicitado, o seguinte:
β d2 em lugar de α Dc c 2 ,
em que β é um parâmetro constante estabelecido à priori, tal
como o α, mas em que d 2 . à média dos quadrados das distâncias entre
espaços elementares, da matriz inicial de distâncias económicas. Evita-
se, assim, a necessidade de reestimação dos Dc c 2 em cada iteração.
A delimitação de regiões homogéneas não tem de, forçosamente,
basear-se neste método, como já se referiu.
O recurso a indicadores estatísticos mais vulgares, como o
desvio padrão ou o coeficiente de variação pode constituir uma
alternativa. Tratar-se-ia, neste caso, de formar agrupamentos que
permitissem minimizar os desvios padrão ou os coeficientes de
variação respectivos.
A dificuldade está em que, ou se trabalha com uma só variável, o
que pode inviabilizar uma delimitação de regiões, aceitável em termos
do número e da dimensão, ou então, quando se pretende trabalhar com
mais variáveis, tem de estabelecer-se ponderadores que permitam
passar para um indicador sintético.48
48O cálculo consistiria em minimizar a soma dos desvios padrão ou dos coeficientes
de variação referentes às diversas variáveis em cada agrupamento. Os ponderadoresforneceriam os critérios de ligação entre as diferentes variáveis

84 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
O estabelecimento destes ponderadores representa um acto
subjectivo, o qual pode, no entanto, considerar-se como uma
vantagem, se tivermos em conta que esses ponderadores poderão
servir para representar a importância atribuída pelos agentes
económicos, sociais e políticos às diferentes variáveis a ter em conta na
análise. Este método será bastante útil se se pretender fazer da
delimitação de regiões um processo participado. Não esquecer, no
entanto, que a escolha das variáveis relevantes para a determinação das
distâncias económicas, pode igualmente ser objecto de consenso entre
as principais entidades interessadas.
Uma outra alternativa é-nos oferecida pela análise factorial. É um
método útil no trabalho de delimitação de regiões, na medida em que
permite uma redução do número de variáveis de trabalho, sem que haja
perdas de informação. O leitor é aqui remetido para o ponto do texto
em que se abordou explicitamente a análise factorial.
2.4.4. A formação de agrupamentos polarizados
Como vimos anteriormente, a delimitação de regiões polarizadas
não se baseia em valores assumidos por características internas aos
espaços elementares, mas sim em valores que tomam as relações
entre esses espaços. Por isso se diz que as regiões homogéneas
constituem um conceito estático, enquanto as regiões polarizadas
constituem um conceito dinâmico.
Para a delimitação deste tipo de regiões poderiam utilizar-se as
metodologias anteriormente referidas com adaptações metodológicas e
analíticas. Não estaríamos nesse caso perante matrizes de distâncias,
A delimitação de regiõespolarizadas baseia-se novalor das relações entre
espaços elementares.

2.4.4. A FORMAÇÃO DE AGRUPAMENTOS POLARIZADOS 85
cujos valores intra-grupais interessaria minimizar, mas sim, perante
matrizes de fluxos inter-espaços cujos valores interessaria maximizar.
Independentemente da metodologia a utilizar, uma das principais
dificuldades da delimitação de regiões polarizadas, está na
determinação dos fluxos (de bens e serviços e de factores) entre
espaços elementares. Estatisticamente tal determinação é difícil, senão
mesmo impossível, pelo que, se tem procurado soluções alternativas.
Uma, muito vulgar, consiste na utilização de um modelo que
encontra o seu fundamento na lei da atracção, de Newton e segundo o
qual modelo a atracção entre duas massas M i e M j é igual a:
y = kM M
di j
i j
ijα
em que k e α são parâmetros a estimar e dij a distância que
separa as massas.
A transposição deste modelo para o domínio dos fenómenos
económicos, é feita no pressuposto de que os espaços económicos
exercem, como os físicos, mútua atracção, a qual seria função dos seus
potenciais económicos (medidos por exemplo pelos PIB) e das
distâncias que os separam. Naturalmente, que se trata de uma hipótese
de trabalho restritiva, já que a capacidade de atracção e de difusão de
uma região não depende apenas da sua massa produtiva, mas de
múltiplos outros factores, ao mesmo tempo que a distância física é
apenas um dos elementos da distância económica entre regiões.
O modelo tornar-se-á ainda mais restritivo se tivermos em conta
que, na impossibilidade de determinação estatística dos seus
parâmetros, a prática habitual é a de extrapolar para a economia que
estudamos, os valores estabelecidos para o próprio modelo de Newton
A dificuldade nadeterminação dos fluxos debens, serviços e factoresentre espaços elementares.
Um solução alternativabaseada na lei da atracçãode Newton.

86 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
(K=1 e α=2), ou para outras economias cujo comportamento se julga
comparável.
Uma segunda hipótese de trabalho consiste na utilização de uma
matriz binária em que, cada cela, representando os fluxos inter-
espaços, terá o valor 1 ou 0, consoante os fluxos entre esses espaços
ultrapassem ou fiquem aquém de um determinado limiar. Teríamos,
assim, uma matriz:
F = [f rr' ]
em que f rr' = 1 ou f rr' = 0.
Em qualquer dos casos um método vulgarmente utilizado na
delimitação das regiões polarizadas, assenta no conceito de
decomponibilidade das matrizes. Diz-se que uma matriz é
decomponível se, através de um processo de permutação de linhas e
colunas, for passível de transformação numa matriz diagonal
(decomponibilidade forte) ou numa matriz triangular
(decomponibilidade fraca). Quer a diagonalidade, quer a
triangularidade podem ser por elementos ou por blocos.
No primeiro caso teremos:
x xx x x
. . . .. . . .
. . . .x x x . . . x
Matriz diagonal porelementos
Matriz triangularpor elementos
Uma segunda alternativa aconstrução de matrizes
binárias de fluxos inter-regionais.
O método utilizado nadelimitação das regiõespolarizadas, assenta no
conceito dedecomponibilidade das
matrizes

2.4.4. A FORMAÇÃO DE AGRUPAMENTOS POLARIZADOS 87
No segundo caso teremos:
xxx … xxx …xxx … xxx …xxx … xxx …. . .. . .. . . …
. . .
. . .
. . . …
… xxx xxx … xxx… xxx xxx … xxx… xxx xxx … xxx
Matriz diagonalpor blocos
Matriz triangularpor blocos
x - valores significativos ( ≠ 0)
Se tivermos uma matriz de fluxos inter-espaços elementares,
quantitativos ou qualitativos, e se essa matriz for aproximadamente
diagonizável por blocos, então, a identificação de espaços polarizados
é imediata. Efectivamente cada bloco da matriz diagonal, preenchido
com valores significativos, corresponde a um espaço polarizado.
No caso de uma matriz de fluxos quantitativos, a matriz diagonal
permitirá, por exemplo, determinar dois agrupamentos polarizados A e
B:
A B
A x ≈ 0
B ≈ 0 x
cujos fluxos internos são maioritariamente positivos AA e BB,
enquanto os fluxos inter-blocos AB e BA são maioritariamente nulos
ou pouco significativos.
No caso de uma matriz de fluxos qualitativos, os blocos
polarizados são preenchidos maioritariamente por 1, enquanto os
fluxos inter-blocos são maioritariamente preenchidos com 0.

88 2. Métodos de Análise da Evolução do Sistema Espacial Português: AsRegiões, as Cidades e os Fenómenos Urbanos
Bibliografia
JOHNSON, R. e WICHERN, D. (1982), Multivariate Statistical Methods,
Englewood Cliffs: Prentice-Hall (3ª edição, 1992).
KAISER, H. (1974), An index of factor simplicity, Psychometrika, 39:31-36.
NÖRUSIS, M. (1993), SPSS for Windows: Professional Statistics, Release 6.0,
Chicago: SPSS Inc.
PAELINCK, J. e NJKAMP, P. (1975), Operational Theory and Method in
Regional Economics, Saxon House.
PEARSON, K. (1901), On lines and planes of closest fit to a system of points in
space, Philosophical Magazine, 2:557-72.
SPEARMAN, C. (1904), General intelligence, objectively determined and
measured, American Journal of Psychology, 15:201-93.
SPSS Inc. (1991) SPSS Statistical Algorithms, Chicago: SPSS Inc. (2ª edição).
2.4.4. A FORMAÇÃO DE AGRUPAMENTOS POLARIZADOS 89
ANEXO A1: OUTPUT DO PROCEDIMENTO FACTOR DO SPSS
- - - - - - - - - - - F A C T O R A N A L Y S I S - - - - - - - - - - -
Analysis number 1 Listwise deletion of cases with missing values
Correlation Matrix:
DPOPUL VABPCAP PRODUTIV CELECTR LESPEC SERVCOM ABASTAGDPOPUL 1.00000VABPCAP .63716 1.00000PRODUTIV .40191 .68317 1.00000CELECTR .53785 .62147 .39207 1.00000LESPEC .47605 .27885 .22480 .25592 1.00000SERVCOM .42376 .66116 .51687 .62643 .33645 1.00000ABASTAG .28452 .53012 .48348 .50281 .07892 .50948 1.00000CAMHOSP .17519 .14336 .16880 .34608 .26599 .09185 .38710MORTINF .01937 -.43109 -.39719 -.21592 -.30057 -.33680 -.24591EMNOX .56675 .54401 .53214 .42609 .49516 .44790 .41424
CAMHOSP MORTINF EMNOXCAMHOSP 1.00000MORTINF -.29996 1.00000EMNOX .05382 -.16529 1.00000
Kaiser-Meyer-Olkin Measure of Sampling Adequacy = .70768
Bartlett Test of Sphericity = 120.59010, Significance = .00000
Anti-image Covariance Matrix:
DPOPUL VABPCAP PRODUTIV CELECTR LESPECDPOPUL .30234VABPCAP -.14433 .21129PRODUTIV .00379 -.10082 .44586CELECTR -.05826 -.05721 .07307 .40852LESPEC -.14701 .07213 .05608 .06495 .45876SERVCOM .03158 -.05506 -.05535 -.16437 -.12523ABASTAG .05784 -.05879 -.03093 -.01333 .12162CAMHOSP -.06813 .08057 -.05777 -.16234 -.13662MORTINF -.20549 .15521 .05684 -.02156 .16476EMNOX -.05742 -.00382 -.12848 -.05111 -.18629
SERVCOM ABASTAG CAMHOSP MORTINF EMNOX
SERVCOM .39299ABASTAG -.11689 .46181CAMHOSP .14442 -.22818 .54726MORTINF .01794 -.05139 .14069 .46786EMNOX .04471 -.13467 .14655 -.02592 .42855
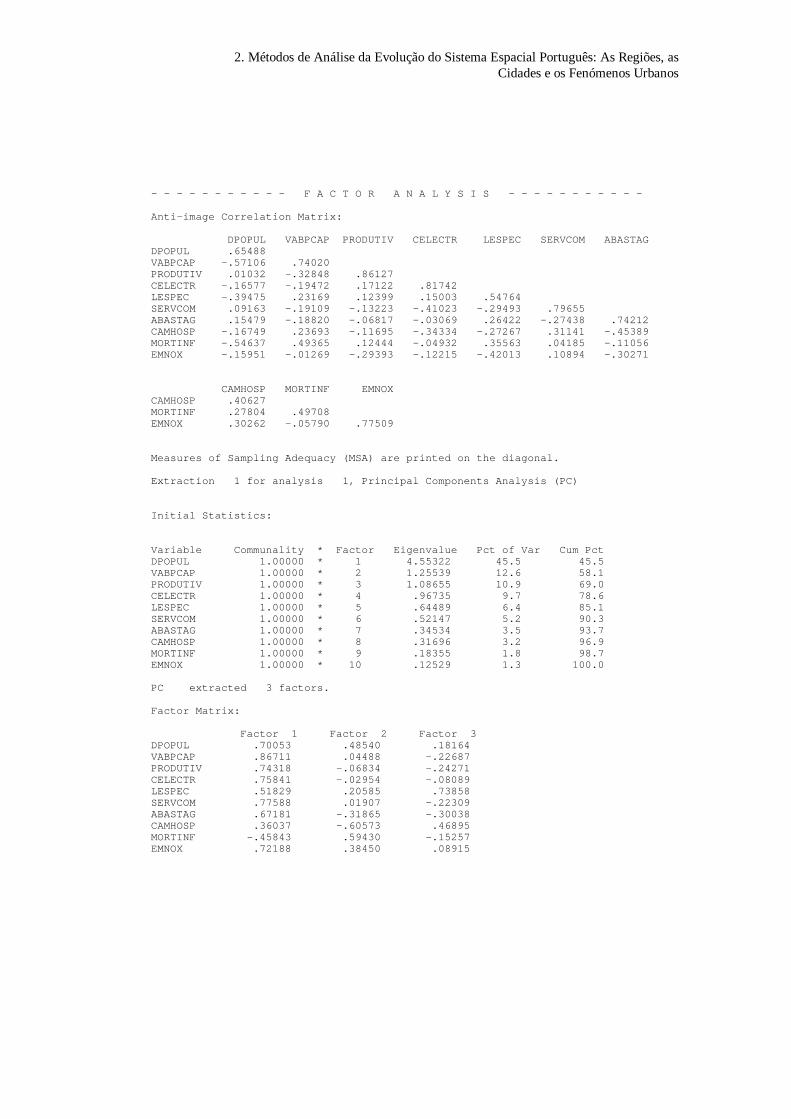
2. Métodos de Análise da Evolução do Sistema Espacial Português: As Regiões, asCidades e os Fenómenos Urbanos
- - - - - - - - - - - F A C T O R A N A L Y S I S - - - - - - - - - - -
Anti-image Correlation Matrix:
DPOPUL VABPCAP PRODUTIV CELECTR LESPEC SERVCOM ABASTAGDPOPUL .65488VABPCAP -.57106 .74020PRODUTIV .01032 -.32848 .86127CELECTR -.16577 -.19472 .17122 .81742LESPEC -.39475 .23169 .12399 .15003 .54764SERVCOM .09163 -.19109 -.13223 -.41023 -.29493 .79655ABASTAG .15479 -.18820 -.06817 -.03069 .26422 -.27438 .74212CAMHOSP -.16749 .23693 -.11695 -.34334 -.27267 .31141 -.45389MORTINF -.54637 .49365 .12444 -.04932 .35563 .04185 -.11056EMNOX -.15951 -.01269 -.29393 -.12215 -.42013 .10894 -.30271
CAMHOSP MORTINF EMNOXCAMHOSP .40627MORTINF .27804 .49708EMNOX .30262 -.05790 .77509
Measures of Sampling Adequacy (MSA) are printed on the diagonal.
Extraction 1 for analysis 1, Principal Components Analysis (PC)
Initial Statistics:
Variable Communality * Factor Eigenvalue Pct of Var Cum PctDPOPUL 1.00000 * 1 4.55322 45.5 45.5VABPCAP 1.00000 * 2 1.25539 12.6 58.1PRODUTIV 1.00000 * 3 1.08655 10.9 69.0CELECTR 1.00000 * 4 .96735 9.7 78.6LESPEC 1.00000 * 5 .64489 6.4 85.1SERVCOM 1.00000 * 6 .52147 5.2 90.3ABASTAG 1.00000 * 7 .34534 3.5 93.7CAMHOSP 1.00000 * 8 .31696 3.2 96.9MORTINF 1.00000 * 9 .18355 1.8 98.7EMNOX 1.00000 * 10 .12529 1.3 100.0
PC extracted 3 factors.
Factor Matrix:
Factor 1 Factor 2 Factor 3DPOPUL .70053 .48540 .18164VABPCAP .86711 .04488 -.22687PRODUTIV .74318 -.06834 -.24271CELECTR .75841 -.02954 -.08089LESPEC .51829 .20585 .73858SERVCOM .77588 .01907 -.22309ABASTAG .67181 -.31865 -.30038CAMHOSP .36037 -.60573 .46895MORTINF -.45843 .59430 -.15257EMNOX .72188 .38450 .08915
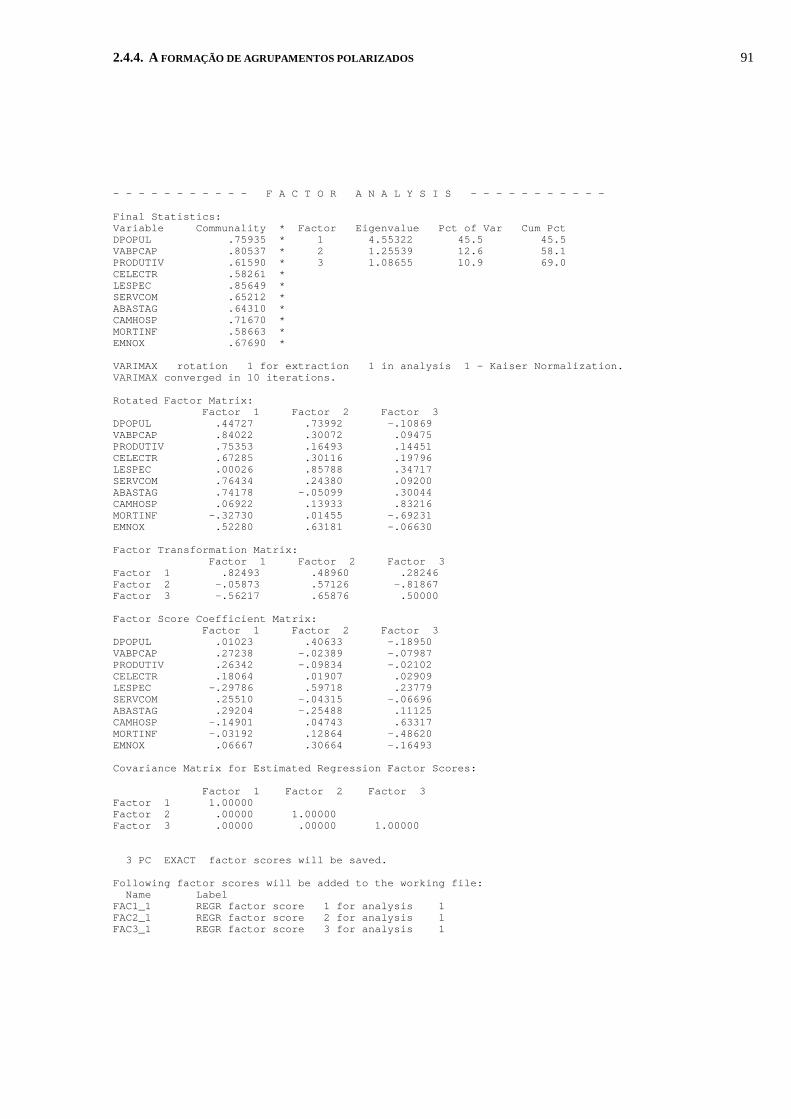
2.4.4. A FORMAÇÃO DE AGRUPAMENTOS POLARIZADOS 91
- - - - - - - - - - - F A C T O R A N A L Y S I S - - - - - - - - - - -
Final Statistics:Variable Communality * Factor Eigenvalue Pct of Var Cum PctDPOPUL .75935 * 1 4.55322 45.5 45.5VABPCAP .80537 * 2 1.25539 12.6 58.1PRODUTIV .61590 * 3 1.08655 10.9 69.0CELECTR .58261 *LESPEC .85649 *SERVCOM .65212 *ABASTAG .64310 *CAMHOSP .71670 *MORTINF .58663 *EMNOX .67690 *
VARIMAX rotation 1 for extraction 1 in analysis 1 - Kaiser Normalization.VARIMAX converged in 10 iterations.
Rotated Factor Matrix: Factor 1 Factor 2 Factor 3DPOPUL .44727 .73992 -.10869VABPCAP .84022 .30072 .09475PRODUTIV .75353 .16493 .14451CELECTR .67285 .30116 .19796LESPEC .00026 .85788 .34717SERVCOM .76434 .24380 .09200ABASTAG .74178 -.05099 .30044CAMHOSP .06922 .13933 .83216MORTINF -.32730 .01455 -.69231EMNOX .52280 .63181 -.06630
Factor Transformation Matrix: Factor 1 Factor 2 Factor 3Factor 1 .82493 .48960 .28246Factor 2 -.05873 .57126 -.81867Factor 3 -.56217 .65876 .50000
Factor Score Coefficient Matrix: Factor 1 Factor 2 Factor 3DPOPUL .01023 .40633 -.18950VABPCAP .27238 -.02389 -.07987PRODUTIV .26342 -.09834 -.02102CELECTR .18064 .01907 .02909LESPEC -.29786 .59718 .23779SERVCOM .25510 -.04315 -.06696ABASTAG .29204 -.25488 .11125CAMHOSP -.14901 .04743 .63317MORTINF -.03192 .12864 -.48620EMNOX .06667 .30664 -.16493
Covariance Matrix for Estimated Regression Factor Scores:
Factor 1 Factor 2 Factor 3Factor 1 1.00000Factor 2 .00000 1.00000Factor 3 .00000 .00000 1.00000
3 PC EXACT factor scores will be saved.
Following factor scores will be added to the working file: Name LabelFAC1_1 REGR factor score 1 for analysis 1FAC2_1 REGR factor score 2 for analysis 1FAC3_1 REGR factor score 3 for analysis 1
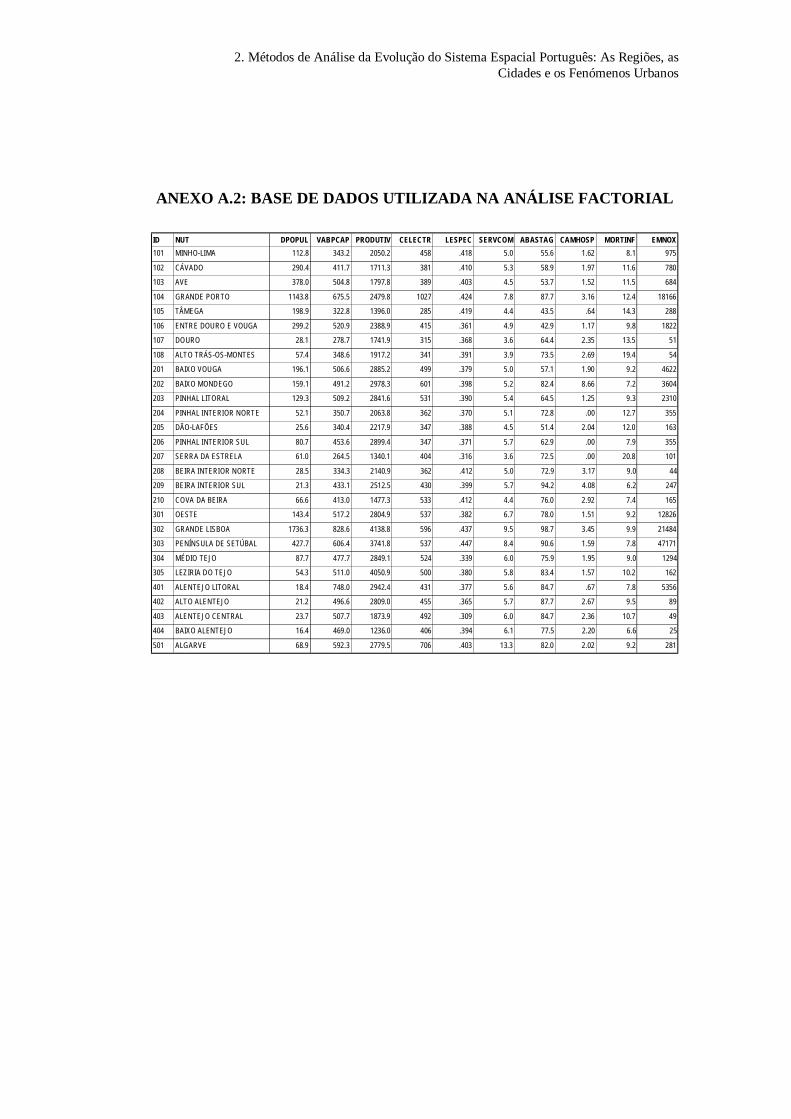
2. Métodos de Análise da Evolução do Sistema Espacial Português: As Regiões, asCidades e os Fenómenos Urbanos
ANEXO A.2: BASE DE DADOS UTILIZADA NA ANÁLISE FACTORIAL
ID NUT DPOPUL VABPCAP PRODUTIV CELECTR LESPEC SERVCOM ABASTAG CAMHOSP MORTINF EMNOX
101 MINHO-LIMA 112.8 343.2 2050.2 458 .418 5.0 55.6 1.62 8.1 975
102 CÁVADO 290.4 411.7 1711.3 381 .410 5.3 58.9 1.97 11.6 780
103 AVE 378.0 504.8 1797.8 389 .403 4.5 53.7 1.52 11.5 684
104 GRANDE PORTO 1143.8 675.5 2479.8 1027 .424 7.8 87.7 3.16 12.4 18166
105 TÂMEGA 198.9 322.8 1396.0 285 .419 4.4 43.5 .64 14.3 288
106 ENTRE DOURO E VOUGA 299.2 520.9 2388.9 415 .361 4.9 42.9 1.17 9.8 1822
107 DOURO 28.1 278.7 1741.9 315 .368 3.6 64.4 2.35 13.5 51
108 ALTO TRÁS-OS-MONTES 57.4 348.6 1917.2 341 .391 3.9 73.5 2.69 19.4 54
201 BAIXO VOUGA 196.1 506.6 2885.2 499 .379 5.0 57.1 1.90 9.2 4622
202 BAIXO MONDEGO 159.1 491.2 2978.3 601 .398 5.2 82.4 8.66 7.2 3604
203 PINHAL LITORAL 129.3 509.2 2841.6 531 .390 5.4 64.5 1.25 9.3 2310
204 PINHAL INTERIOR NORTE 52.1 350.7 2063.8 362 .370 5.1 72.8 .00 12.7 355
205 DÃO-LAFÕES 25.6 340.4 2217.9 347 .388 4.5 51.4 2.04 12.0 163
206 PINHAL INTERIOR SUL 80.7 453.6 2899.4 347 .371 5.7 62.9 .00 7.9 355
207 SERRA DA ESTRELA 61.0 264.5 1340.1 404 .316 3.6 72.5 .00 20.8 101
208 BEIRA INTERIOR NORTE 28.5 334.3 2140.9 362 .412 5.0 72.9 3.17 9.0 44
209 BEIRA INTERIOR SUL 21.3 433.1 2512.5 430 .399 5.7 94.2 4.08 6.2 247
210 COVA DA BEIRA 66.6 413.0 1477.3 533 .412 4.4 76.0 2.92 7.4 165
301 OESTE 143.4 517.2 2804.9 537 .382 6.7 78.0 1.51 9.2 12826
302 GRANDE LISBOA 1736.3 828.6 4138.8 596 .437 9.5 98.7 3.45 9.9 21484
303 PENÍNSULA DE SETÚBAL 427.7 606.4 3741.8 537 .447 8.4 90.6 1.59 7.8 47171
304 MÉDIO TEJO 87.7 477.7 2849.1 524 .339 6.0 75.9 1.95 9.0 1294
305 LEZIRIA DO TEJO 54.3 511.0 4050.9 500 .380 5.8 83.4 1.57 10.2 162
401 ALENTEJO LITORAL 18.4 748.0 2942.4 431 .377 5.6 84.7 .67 7.8 5356
402 ALTO ALENTEJO 21.2 496.6 2809.0 455 .365 5.7 87.7 2.67 9.5 89
403 ALENTEJO CENTRAL 23.7 507.7 1873.9 492 .309 6.0 84.7 2.36 10.7 49
404 BAIXO ALENTEJO 16.4 469.0 1236.0 406 .394 6.1 77.5 2.20 6.6 25
501 ALGARVE 68.9 592.3 2779.5 706 .403 13.3 82.0 2.02 9.2 281
2.4.4. A FORMAÇÃO DE AGRUPAMENTOS POLARIZADOS 93
ANEXO A3: OUTPUT DO PROCEDIMENTO CLUSTER DO SPSS
* * * * * * * * * * * * * * * * * * * P R O X I M I T I E S * * * * * * * * * * * * * * * * * * *
Data Information 28 unweighted cases accepted. 0 cases rejected because of missing value. Euclidean measure used.- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Euclidean Dissimilarity Coefficient Matrix
Case MINHO-LI CÁVADO AVE GRANDE P TÂMEGA ENTRE DO
CÁVADO .5609 AVE .8965 .3491 GRANDE 2.8505 2.6576 2.5240 TÂMEGA 1.6658 1.2358 1.1491 3.3334 ENTRE DO 1.5144 1.2100 1.0216 2.6245 1.9469 DOURO 1.1349 1.0676 1.1251 3.3533 1.7834 .9874 ALTO TRÁ 1.2756 .8636 .6797 2.9574 1.3111 .7006 BAIXO VO 1.3398 1.2667 1.2231 2.3889 2.3356 .6983 BAIXO MO 2.9539 3.4781 3.7589 4.2609 4.5924 3.8945 PINHAL L 1.5313 1.4466 1.3797 2.3619 2.4854 .7412 PINHAL I 2.0506 1.7762 1.5904 3.0618 2.3454 .6184 DÃO-LAFÕ .7620 .6188 .7215 3.0408 1.4930 .9651 PINHAL I 2.0031 1.8684 1.7557 2.8733 2.7174 .7906 SERRA DA 3.4416 3.0686 2.8179 4.1321 3.1119 2.0553 BEIRA IN .7686 1.2915 1.5899 3.1940 2.3924 1.8627 BEIRA IN 2.1203 2.5469 2.7553 3.5249 3.7426 2.5816 COVA DA .9201 1.4393 1.7284 3.1307 2.5749 1.9723 OESTE 2.0526 1.9622 1.8622 2.1869 2.9651 1.1623 GRANDE L 3.6214 3.4488 3.3172 .7940 4.0935 3.3734 PENÍNSUL 2.8370 2.6450 2.5142 .0575 3.3133 2.6374 MÉDIO TE 2.7281 2.7441 2.6955 3.3030 3.7165 1.8100 LEZIRIA 2.5892 2.5847 2.5216 2.8393 3.5991 1.6944 ALENTEJO 2.7714 2.7231 2.6292 2.7935 3.6928 1.7709 ALTO ALE 2.3865 2.5121 2.5347 3.2082 3.5989 1.8171 ALENTEJO 3.2807 3.2887 3.2315 3.9047 4.1795 2.2918 BAIXO AL 1.2105 1.5492 1.7343 3.0772 2.7186 1.5759 ALGARVE 2.9319 2.9403 2.8765 2.4126 4.0015 2.2187
Case DOURO ALTO TRÁ BAIXO VO BAIXO MO PINHAL L PINHAL I ALTO TRÁ .7482 BAIXO VO 1.1758 1.2049 BAIXO MO 3.5509 4.0317 3.2732 PINHAL L 1.3155 1.3270 .1927 3.3475 PINHAL I 1.2276 1.0797 1.1198 4.2531 1.0822 DÃO-LAFÕ .4495 .6192 1.0990 3.4648 1.2724 1.4008 PINHAL I 1.3613 1.4228 .7941 3.7857 .6812 .6428 SERRA DA 2.4939 2.2229 2.6399 5.7488 2.5820 1.5326 BEIRA IN 1.3549 1.8006 1.4711 2.2837 1.6349 2.2960 BEIRA IN 2.3449 2.8541 1.9600 1.5267 2.0005 2.8360 COVA DA 1.5452 1.9703 1.5101 2.0838 1.6612 2.4100 OESTE 1.8664 1.8243 .7526 3.5142 .5709 1.3378 GRANDE L 4.1307 3.7392 3.1190 4.7244 3.0715 3.7659 PENÍNSUL 3.3560 2.9581 2.4031 4.2550 2.3806 3.0826 MÉDIO TE 2.1853 2.4267 1.5240 3.6390 1.3756 1.6089 LEZIRIA 2.2165 2.3566 1.3191 3.5439 1.1470 1.6224 ALENTEJO 2.3844 2.4562 1.4625 3.7864 1.2775 1.6616 ALTO ALE 2.0221 2.3688 1.3466 3.0419 1.2433 1.7910 ALENTEJO 2.5920 2.8694 2.1208 4.0763 1.9802 1.9454 BAIXO AL 1.2869 1.7748 1.0541 2.3755 1.1604 1.8951 ALGARVE 2.8418 2.8829 1.7452 3.5356 1.5818 2.2875
2. Métodos de Análise da Evolução do Sistema Espacial Português: As Regiões, asCidades e os Fenómenos Urbanos
Case DÃO-LAFÕ PINHAL I SERRA DA BEIRA IN BEIRA IN COVA DA PINHAL I 1.5134 SERRA DA 2.7156 2.0430 BEIRA IN 1.2024 2.0717 3.7586 BEIRA IN 2.3616 2.3245 4.2941 1.4391 COVA DA 1.3898 2.1321 3.8984 .2319 1.2701 OESTE 1.8392 .8324 2.6792 2.1029 2.1579 2.0851 GRANDE L 3.8286 3.5468 4.7468 3.9191 4.0966 3.8341 PENÍNSUL 3.0377 2.8988 4.1577 3.1864 3.5333 3.1236 MÉDIO TE 2.3816 1.0361 2.6619 2.5292 2.1350 2.5162 LEZIRIA 2.3231 1.0092 2.7838 2.4468 2.0912 2.4119 ALENTEJO 2.4826 1.0985 2.7157 2.6790 2.3521 2.6475 ALTO ALE 2.1773 1.1696 3.0629 2.0673 1.5370 2.0228 ALENTEJO 2.8610 1.5052 2.6629 3.0547 2.5833 3.0559 BAIXO AL 1.2891 1.5174 3.3895 .7372 1.0827 .7193 ALGARVE 2.8384 1.7137 3.4254 2.8015 2.2905 2.7108
Case OESTE GRANDE L PENÍNSUL MÉDIO TE LEZIRIA ALENTEJO GRANDE L 2.8114 PENÍNSUL 2.2175 .8055 MÉDIO TE 1.1669 3.8494 3.3383 LEZIRIA .7833 3.3687 2.8761 .4863 ALENTEJO .8353 3.2900 2.8340 .6268 .2739 ALTO ALE 1.1537 3.7805 3.2369 .5986 .6752 .9418 ALENTEJO 1.7897 4.4198 3.9428 .6560 1.0941 1.1298 BAIXO AL 1.5540 3.7763 3.0830 1.8096 1.7540 2.0022 ALGARVE 1.0621 2.7944 2.4557 1.2873 .8526 .7958
Case ALTO ALE ALENTEJO BAIXO AL ALENTEJO 1.1307 BAIXO AL 1.3315 2.3374 ALGARVE 1.2986 1.7830 2.1813- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
* * * * * * * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * * * * * *
Agglomeration Schedule using Average Linkage (Between Groups) Clusters Combined Stage Cluster 1st Appears Next Stage Cluster 1 Cluster 2 Coefficient Cluster 1 Cluster 2 Stage 1 4 21 .057463 0 0 15 2 9 11 .192670 0 0 9 3 16 18 .231904 0 0 12 4 23 24 .273936 0 0 7 5 2 3 .349071 0 0 13 6 7 13 .449477 0 0 10 7 22 23 .556573 0 4 14 8 6 12 .618444 0 0 11 9 9 19 .661742 2 0 17 10 7 8 .683687 6 0 16 11 6 14 .716672 8 0 17 12 16 27 .728222 3 0 20 13 1 2 .728687 0 5 16 14 22 25 .738552 7 0 18 15 4 20 .799743 1 0 26 16 1 7 .916534 13 10 21 17 6 9 .938814 11 9 22 18 22 26 1.002656 14 0 19 19 22 28 1.203453 18 0 22 20 16 17 1.263982 12 0 23 21 1 5 1.439690 16 0 23 22 6 22 1.526854 17 19 24 23 1 16 1.866338 21 20 24 24 1 6 2.165417 23 22 25 25 1 15 2.872076 24 0 26 26 1 4 3.215650 25 15 27 27 1 10 3.584466 26 0 0

2.4.4. A FORMAÇÃO DE AGRUPAMENTOS POLARIZADOS 95
* * * * * * * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * * * * * *
Dendrogram using Average Linkage (Between Groups)
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+
GRANDE PORTO 4 -+---------+ PENÍNSULA DE SETÚBAL 21 -+ +---------------------------------+ GRANDE LISBOA 20 -----------+ | BAIXO VOUGA 9 -+-------+ | PINHAL LITORAL 11 -+ +---+ | OESTE 19 ---------+ +-------+ | ENTRE DOURO E VOUGA 6 -------+-+ | | | PINHAL INTERIOR NORT 12 -------+ +---+ | | PINHAL INTERIOR SUL 14 ---------+ | | LEZIRIA DO TEJO 23 ---+---+ +-------+ | ALENTEJO LITORAL 24 ---+ +-+ | | +---+ MÉDIO TEJO 22 -------+ +---+ | | | | ALTO ALENTEJO 25 ---------+ +---+ | | | | ALENTEJO CENTRAL 26 -------------+ +---+ | | | ALGARVE 28 -----------------+ +---------+ | | BEIRA INTERIOR NORTE 16 ---+-----+ | | | | COVA DA BEIRA 18 ---+ +-------+ | | | | BAIXO ALENTEJO 27 ---------+ +-------+ | | | | BEIRA INTERIOR SUL 17 -----------------+ | | | | | DOURO 7 -----+---+ | | | | | DÃO-LAFÕES 13 -----+ +---+ +---+ +-----+ | ALTO TRÁS-OS-MONTES 8 ---------+ +-----+ | | | CÁVADO 2 -----+---+ | | | | | AVE 3 -----+ +---+ +-----+ | | MINHO-LIMA 1 ---------+ | | | TÂMEGA 5 -------------------+ | | SERRA DA ESTRELA 15 ---------------------------------------+ | BAIXO MONDEGO 10 -------------------------------------------------+
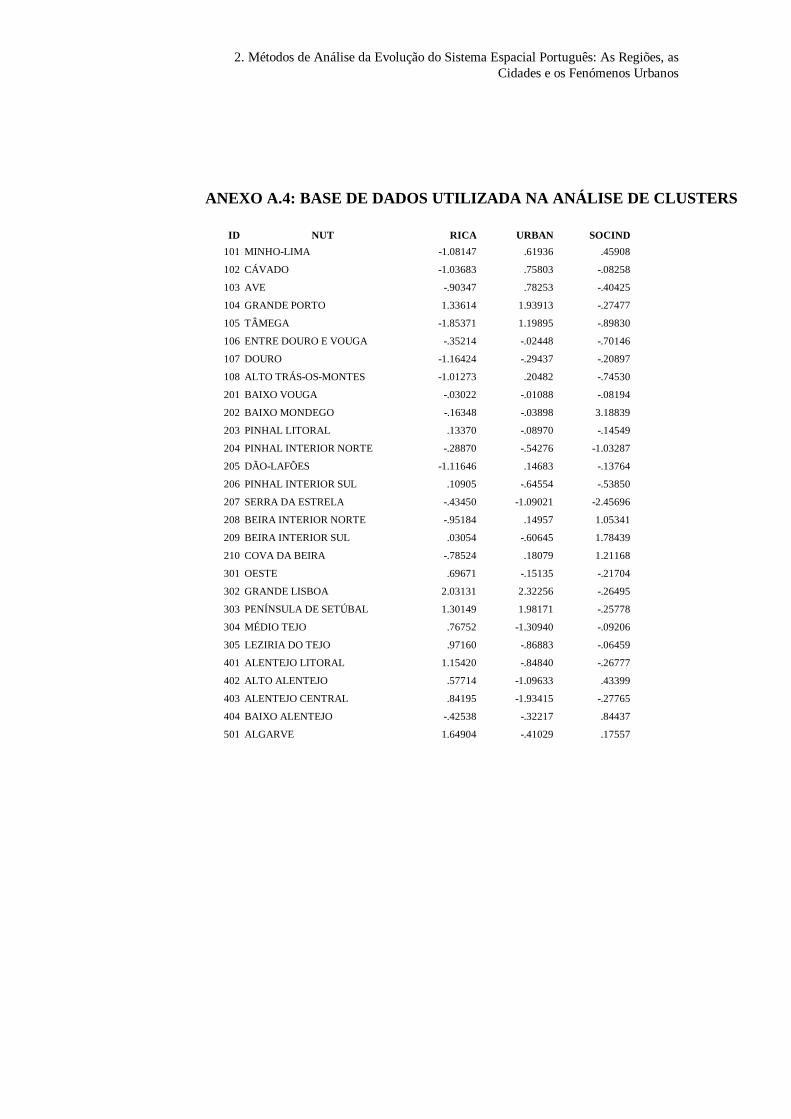
2. Métodos de Análise da Evolução do Sistema Espacial Português: As Regiões, asCidades e os Fenómenos Urbanos
ANEXO A.4: BASE DE DADOS UTILIZADA NA ANÁLISE DE CLUSTERS
ID NUT RICA URBAN SOCIND
101 MINHO-LIMA -1.08147 .61936 .45908
102 CÁVADO -1.03683 .75803 -.08258
103 AVE -.90347 .78253 -.40425
104 GRANDE PORTO 1.33614 1.93913 -.27477
105 TÂMEGA -1.85371 1.19895 -.89830
106 ENTRE DOURO E VOUGA -.35214 -.02448 -.70146
107 DOURO -1.16424 -.29437 -.20897
108 ALTO TRÁS-OS-MONTES -1.01273 .20482 -.74530
201 BAIXO VOUGA -.03022 -.01088 -.08194
202 BAIXO MONDEGO -.16348 -.03898 3.18839
203 PINHAL LITORAL .13370 -.08970 -.14549
204 PINHAL INTERIOR NORTE -.28870 -.54276 -1.03287
205 DÃO-LAFÕES -1.11646 .14683 -.13764
206 PINHAL INTERIOR SUL .10905 -.64554 -.53850
207 SERRA DA ESTRELA -.43450 -1.09021 -2.45696
208 BEIRA INTERIOR NORTE -.95184 .14957 1.05341
209 BEIRA INTERIOR SUL .03054 -.60645 1.78439
210 COVA DA BEIRA -.78524 .18079 1.21168
301 OESTE .69671 -.15135 -.21704
302 GRANDE LISBOA 2.03131 2.32256 -.26495
303 PENÍNSULA DE SETÚBAL 1.30149 1.98171 -.25778
304 MÉDIO TEJO .76752 -1.30940 -.09206
305 LEZIRIA DO TEJO .97160 -.86883 -.06459
401 ALENTEJO LITORAL 1.15420 -.84840 -.26777
402 ALTO ALENTEJO .57714 -1.09633 .43399
403 ALENTEJO CENTRAL .84195 -1.93415 -.27765
404 BAIXO ALENTEJO -.42538 -.32217 .84437
501 ALGARVE 1.64904 -.41029 .17557