capítulo 10 – testes não paramétricos – pg 273 · condições de peso (dentro ou fora das...
TRANSCRIPT

1
Capítulo 10 – Testes Não paramétricos – pg 273
O teste qui-quadrado são de grande aplicação devido ao fato dos mesmos não
dependerem de parâmetros populacionais e nem de suas estimativas. Esses testes não
exigem que a variável em análise seja numérica nem pressuposição a respeito da
distribuição dessa variável.
1 – Teste de Aderência - Dada uma amostra de tamanho n que pode ser dividida em
eventos E1, E2, ..., Ek. Sejam Fe1, Fe2, ..., Fek, as frequências esperadas e Fo1, Fo2, ...,
Fok, as frequências observadas. O teste visa comprovar a concordância entre freqüências
observadas e esperadas para um certo fenômeno. A realização do teste qui-quadrado:
1a) Enunciar as hipóteses
Ho: Não há discrepâncias entre as freq. observadas e esperadas.
H1: Há discrepâncias entre as freq. observadas e esperadas.
2a) Estabelecer o nível de significância .
Valor crítico: A variável teste adotada é (2 ) com grau de liberdade k – 1, onde k é
o número de eventos.
3a) Cálculo da variável teste. Avaliar as freqüências esperadas com base na hipótese
nula. Para facilitar esta avaliação convém distribuir as freqüências num quadro, da
seguinte forma:
Eventos E1 E2 E3 ... Ek Total
Freq. Observadas Fo1 Fo2 Fo3 ... Fok n
Freq. Esperadas Fe1 Fe2 Fe3 ... Fek n
k
i k
kk
i
ii
calFe
FeFo
Fe
FeFo
Fe
FeFo
Fe
FeFo
1
2
2
2
22
1
2
11
2
2 )(...
)()()(
Observação: Caso não existam eventos que não satisfaçam à condição Fe 5, estes
deverão ser somados aos eventos adjacentes, originando-se novas categorias.
4a) Conclusão: Se 22
cal
Rejeita-se Ho, isto é, as frequências observadas
diferem das esperadas ao nível de significância .
2. ANÁLISE DE ASSOCIAÇÃO - pg 287
Existe associação entre duas variáveis qualitativas quando as probabilidades de
eventos de uma delas são alteradas conforme a categoria da outra. O teste qui-quadrado
de independência serve para avaliar a significância de uma associação. O teste qui-
quadrado de homogeneidade verifica se diferentes populações apresentam as mesmas
proporções com respeito a variável qualitativa.

2
2a Teste de Independência - A finalidade deste teste é verificar se duas variáveis, que
podem ser divididas em categorias ou eventos, são estatisticamente independentes.
Consideram-se duas variáveis x e y que se dividem nos eventos x1, x2,..., xk e y1, y2,...,
yh, respectivamente, tem-se uma tabela de dupla entrada chamada de “Tabela de
Contingência LxC”, onde as freqüências observadas (F0) ocupam L- linhas e C-
colunas, ou seja:
EVENTO X
EVENTO Y X1 X2 ... Xk Totais
Y1 F011 F012 ... F01k L1
Y2 F021 F022 ... F02k L2
... ... ... ... ... ...
Yh F0h1 F0h2 ... F0hk Lh
Totais C1 C2 ... Ck n
Este teste é de 2 se baseia na comparação entre as (Fo) e as (Fe), cujas etapas
são:
1a) As hipóteses: Ho: As variáveis são independentes
H1: As variáveis não são independentes. As variáveis tem algum grau
de associação entre si.
2a) Nível de significância e Estabelecer os valores críticos:
Neste caso, a variável teste a ser adotada será a “ 2 ” com (L – 1).(C –1 ) graus de
liberdade.
3a) Cálculo da variável teste
L
i
C
j ij
ijij
calFe
FeFo
1 1
2
2)(
ij
ijij
Fe
FeFo
Fe
FeFo2
11
2
1111)(
...)(
F011 Fe11 = n
xCL 11 ; F012 Fe12 = n
xCL 21 ; ........... generalizando
F0ij Feij = n
TotalCxLTotal ji )()(
4a) Conclusão:
Se 22
cal Rejeita-se Ho ao nível de significância e conclui-se que as
variáveis são dependentes e apresentam algum grau de associação.
Correção de Yates Caso não existam eventos que não satisfaçam à condição Fe 5 ou
graus de liberdade igual a 1, aplicar o teste com correção de Yates ou optar pelo teste
Exato de Fisher.
h
i
k
j ij
ijij
calFe
FeFo
1 1
2
2)5,0(

3
O Coeficiente de Contingência - Quando a hipótese nula é rejeitada, conclui-se que as
variáveis são dependentes e apresentam algum grau de associação que pode ser medida
pelo coeficiente de contingência de Pearson (C), que é dado pela fórmula:
%100.n
C2
cal
2
cal
.
O Coeficiente de Contingência (C) possui intervalo de variação de: 0 < C < 1,
que é interpretado da seguinte forma:
- quanto mais próximo de “1” estiver o valor de C maior será o grau de dependência
entre as variáveis.
- quanto mais próximo de “0” estiver o valor de C menor será o grau de dependência
entre as variáves.
Teste de Homogeneidade - Este teste é aplicado para verificar se uma população se
distribui de forma homogênea em uma outra população. A metodologia deste teste é
semelhante ao do teste de independência, porém considerando as seguintes hipóteses:
Ho: A população X é homogênea em Y
H1: A população X não é homogênea em Y.
ATIVIDADE 10 A - Teste qui-quadrado 1) pg 275 - Determinado veículo está sofrendo críticas dos proprietários, com relação à grande freqüência de defeitos no pneu traseiro esquerdo. Para defender-se de indenizações, o fabricante
coletou 152 ocorrências de defeitos, classificando-as por posição de pneu. Sendo alfa 5%, há
razão para acreditar que a probabilidade de defeito é diferente para alguma posição?
Tabela 1 – Ocorrências de defeitos por posição do pneu de um veículo utilitário
Posição pneu Diant esq Diant. dir Tras. esq Tras dir Total
frequencia 35 32 57 28 152
2) pg 285- Uma empresa possui três laboratórios de pesquisa (A,B,C), cujos computadores estão
conectados a um servidor para onde enviam pacotes de dados para serem analisados em um
programa estatístico. Os usuários do laboratório A pediram prioridade ao gerente de rede, pois costumam enviar mais pacotes ao servidor. O gerente observou 500 pacotes de dados enviados e
classificou-os de acordo com origem, conforme a tabela a seguir:
Tabela 2 – Número de pacotes de dados analisados nos 3 laboratórios
Laboratórios A B C Total
Número de pacotes 165 179 156 500
Os dados constituem evidência suficiente para corroborar o pedido do laboratório A? Alfa 1%.
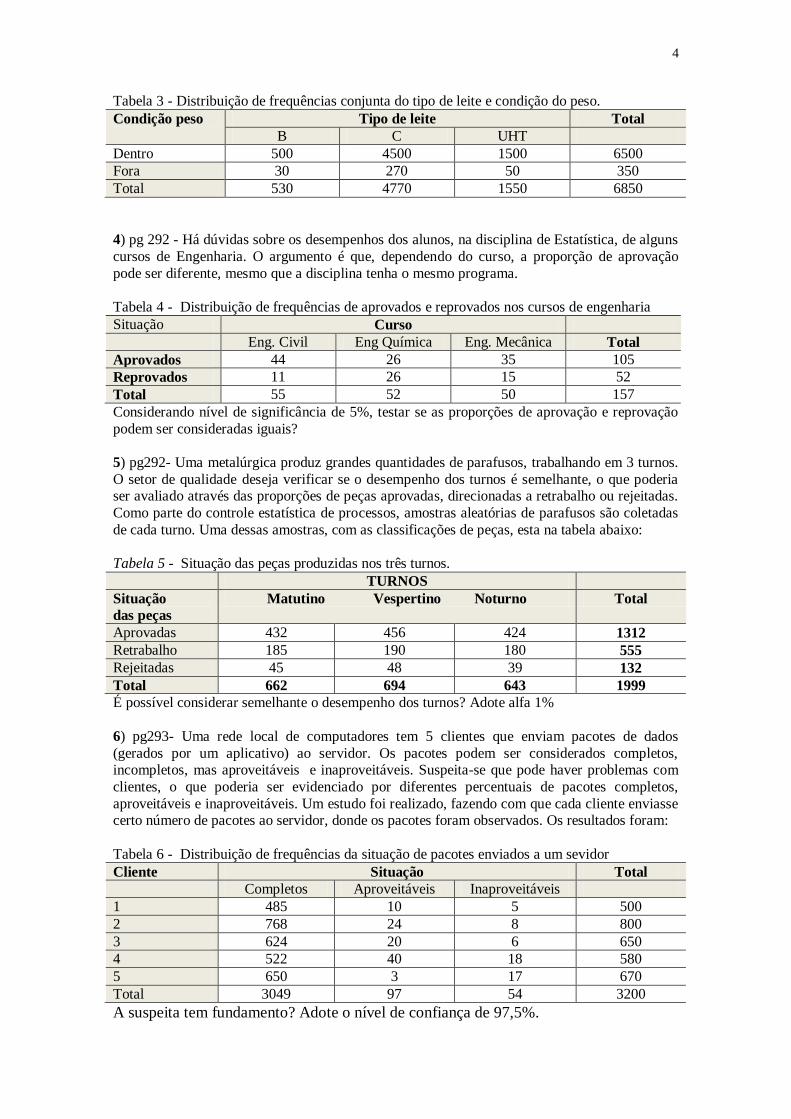
3) pg 287 - Determinado posto de qualidade de um laticínio retira uma amostra dos pesos dos
litros de leite produzidos em um dia, classificando-os de acordo com seu tipo ( B,C, UHT), e
condições de peso (dentro ou fora das especificações). A tabela abaixo mostra a distribuição de frequências conjunta de 6.850 unidades de leite, disposta numa tabela de contingência.
a) Testar se há associação entre tipo de leite e condições de peso, com alfa 5%.
b) Caso haja associação, encontre o coeficiente de contingência.
4
Tabela 3 - Distribuição de frequências conjunta do tipo de leite e condição do peso.
Condição peso Tipo de leite Total
B C UHT
Dentro 500 4500 1500 6500
Fora 30 270 50 350
Total 530 4770 1550 6850
4) pg 292 - Há dúvidas sobre os desempenhos dos alunos, na disciplina de Estatística, de alguns
cursos de Engenharia. O argumento é que, dependendo do curso, a proporção de aprovação
pode ser diferente, mesmo que a disciplina tenha o mesmo programa.
Tabela 4 - Distribuição de frequências de aprovados e reprovados nos cursos de engenharia
Situação Curso
Eng. Civil Eng Química Eng. Mecânica Total
Aprovados 44 26 35 105
Reprovados 11 26 15 52
Total 55 52 50 157
Considerando nível de significância de 5%, testar se as proporções de aprovação e reprovação
podem ser consideradas iguais?
5) pg292- Uma metalúrgica produz grandes quantidades de parafusos, trabalhando em 3 turnos.
O setor de qualidade deseja verificar se o desempenho dos turnos é semelhante, o que poderia ser avaliado através das proporções de peças aprovadas, direcionadas a retrabalho ou rejeitadas.
Como parte do controle estatística de processos, amostras aleatórias de parafusos são coletadas
de cada turno. Uma dessas amostras, com as classificações de peças, esta na tabela abaixo:
Tabela 5 - Situação das peças produzidas nos três turnos.
TURNOS
Situação
das peças
Matutino Vespertino Noturno Total
Aprovadas 432 456 424 1312
Retrabalho 185 190 180 555
Rejeitadas 45 48 39 132
Total 662 694 643 1999
É possível considerar semelhante o desempenho dos turnos? Adote alfa 1%
6) pg293- Uma rede local de computadores tem 5 clientes que enviam pacotes de dados
(gerados por um aplicativo) ao servidor. Os pacotes podem ser considerados completos, incompletos, mas aproveitáveis e inaproveitáveis. Suspeita-se que pode haver problemas com
clientes, o que poderia ser evidenciado por diferentes percentuais de pacotes completos,
aproveitáveis e inaproveitáveis. Um estudo foi realizado, fazendo com que cada cliente enviasse certo número de pacotes ao servidor, donde os pacotes foram observados. Os resultados foram:
Tabela 6 - Distribuição de frequências da situação de pacotes enviados a um sevidor
Cliente Situação Total
Completos Aproveitáveis Inaproveitáveis
1 485 10 5 500
2 768 24 8 800
3 624 20 6 650
4 522 40 18 580
5 650 3 17 670
Total 3049 97 54 3200
A suspeita tem fundamento? Adote o nível de confiança de 97,5%.

5
TESTES PARA DUAS POPULAÇÕES
I - TESTE DOS SINAIS POR POSTOS – Teste de Wilcoxon pg298
O teste dos sinais por postos de Wilcoxon deve ser aplicado aos dados pareados.
Este teste é, portanto, uma alternativa ao teste t de Student no caso de amostras
dependentes, mas só deve ser aplicado quando as pressuposições exigidas pelo teste t
estiverem seriamente comprometidas. Trata-se de uma extensão do teste dos sinais e
deve ser aplicado aos dados pareados. É mais interessante que o teste do sinal, pois leva
em consideração a magnitude da diferença para cada par.
1a. Procedimento para pequenas amostras n≤ 20:
a) Determinar para cada par à diferença (di) entre os dois escores. b) Atribuir postos
(colocar em ordem crescente) todos os “dis”, desconsiderando-se os
sinais. No caso de empate, retire o par da análise e o tamanho da amostra se reduz.
c) Identificar cada posto pelo sinal “+” ou “-” do “di” que ele representa.
d) Definir a estatística s+ = soma dos postos das diferenças positivas.
e) Abater do “n” o número de zeros, isto é, di = 0.
Regra de decisão do teste de sinais por postos – “Wilcoxon”
Hipótese H1 Regra de decisão
Unilateral à direita P( S+ sc) = 1 - . Se s+ sc, rejeita-se Ho
Unilateral à esquerda P( S+ sc) = . S e s+ sc, rejeita-se Ho
Bilateral
P( S+ sc1 ) = /2.
P( S+ sc2) = 1 - /2.
Se s+ sc1 ou s+ sc2, rejeita-se Ho.
1b. Para grandes amostras - para n > 20
Para n > 20 a distribuição de S+ é aproximadamente igual a uma distribuição normal,
com média e variância especificadas.
ETAPAS:
1a - As hipóteses:
Ho: Não há diferença entre os grupos. A soma dos postos “+” não difere dos postos ”-“.
H1: Há diferença entre os grupos.
2a - Estabelecer o nível de significância .
Valores críticos – (Para grandes amostras) Quando H0 é verdadeira, os valores de Z
calculado têm distribuição assintoticamente normal com média zero e variância um.
Com auxílio da tabela normal padrão, determinam-se as regiões críticas.
3a - Cálculo da estatística teste
4a - Conclusão: Regra de decisão utilizando a distribuição normal padrão
4
24.
)1n2)(1n(n
)1n(ns4Zcal

6
Empates – 10 tipo- Caso os dois escores de algum par são iguais, di = 0 (não houve
diferença entre dois tratamentos), tais pares são retirados da análise e o tamanho n da
amostra é reduzido.
20 tipo - Dois ou mais d’s podem ser de mesma magnitude. Atribui-se o empate no
mesmo posto. O novo posto será a média dos postos que teriam sido atribuídos se os d i’s
tivessem diferido.
II - O Teste de Mann-Whitney - O teste de Mann-Whitney é utilizado para comparar a
posição central de duas populações. Esse teste é, portanto, uma alternativa para o teste t
no caso de amostras independentes. Mas você só deve aplicar o teste de Mann-Whitney
se sua amostra for pequena e/ou as pressuposições exigidas pelo teste t, estiverem
seriamente comprometidas.
2a. Para amostras pequenas n1, n2 ≤ 20
Considerar n1 = número de elementos da amostra 1 e n2 = número de elementos
da amostra 2. Considere todos os dados dos dois grupos e coloque-os em ordem
crescente. Atribua primeiro ao escore que algebricamente for menor e prossiga até N =
n1 + n2. As observações empatadas atribuir à média dos postos correspondentes:
Calcular W1 = soma dos postos do grupo n1, W2 = soma dos postos do grupo n2.
Verificar se W1 + W2 = 2
)1)(( 2121 nnnn
Para n1 e n2 ≤ 20 a tabela fornece valores críticos para U, para construir a regra de
decisão, em função da hipótese alternativa e do nível de significância alfa.
Regra de decisão do teste de Mann-Whitney
Hipótese H1 Regra de decisão
Unilateral direita H1: 21 P(U uc) = 1 - . Se u uc, rejeita-se Ho
Unilateral esquerda H1: 21 P(U uc) = . Se u uc, rejeita-se Ho
Bilateral H1: 21 P( U uc1) = /2.
P( U uc2) = 1 - /2.
Se u uc1 ou u uc2, rejeita-se Ho.
2b. Para grandes amostras - quando n1, n2 > 20.
ETAPAS:
1a - As hipóteses
Ho: Não há diferença entre os grupos.
H1: Há diferença entre os grupos.
2a - Estabelecer o nível de significância .
Valores críticos – (Para grandes amostras) - Quando H0 é verdadeira, os valores de Z
calculado têm distribuição assintoticamente normal com média zero e variância um.
Com auxílio da tabela normal padrão, determinam-se as regiões críticas.

7
3a - Cálculo da estatística teste
U = W1 -
2
)1n(n 11
4a - Conclusão: Regra de decisão utilizando a distribuição normal padrão
ATIVIDADE 10 B - Teste de Wilcoxon, Mann-Whitney
Teste dos Sinais por postos –Wilcoxon (Pequenas amostras) – pg298
1) pg 295- Um sistema de alarme possui grande número de componentes. Há interesse em saber
se houve ou não aumento no tempo de falha dos componentes após a implementação de um
programa de manutenção. Usualmente, o tempo de falha segue distribuição exponencial. Observou-se uma amostra de dez componentes, antes e depois do programa de manutenção, e o
resultados (em horas) abaixo:
Tabela 1 – Tempo de falha de 10 componentes após o programa de manutenção
Comp 1 2 3 4 5 6 7 8 9 10
Antes 400 360 450 390 430 386 452 470 400 340
Depois 395 350 556 480 405 500 547 462 500 480
Sinal -5 -10 +106 +90 -25 +114 +95 -8 +100 +140
Testar se há diferença entre a mediana do tempo de falha dos dois momentos. Alfa 5%
Teste dos Sinais por postos - Wilcoxon (Grandes amostras)
2) pg 297- Uma empresa quer observar a viabilidade de utilizar um novo tipo de calibrador,
eletrônico, ao invés do modelo atual, mecânico, para medir dimensões de peças automotivas. Após treinamento, forma sorteados 26 funcionários para medir as peças, com calibrador
eletrônico e mecânico. Os tempos gastos em segundos foram registrados. Somente será viável a
introdução do novo calibrador se o tempo mediano de medição for menor do que obtido mecânico. Faça um teste unilateral com alfa 5%.
Tabela 2 – Tempo gasto (segundos) para medir dimensões de calibradores
Operário Eletrônico Mecânico Sinal Operário Eletrônico Mecânico Sinal
1 27 27 0 14 22 29 -7.0
2 25 30,1 -5.1 15 16 16 0
3 22 28 -6.0 16 22 20,6 +1.4
4 34 34 0 17 29,5 25 +4.5
5 23 24,5 -1.5 18 36 33 +3.0
6 22 28 -6.0 19 35 41 -6.0
7 25 28 -3.0 20 35 35 0
8 32,3 30 +2.3 21 27,5 28 -0.5
9 34 36 -2.0 22 29 31,8 -2.8
10 23,5 29 -5.5 23 27 28 -1.0
11 34,2 39 -4.8 24 24,3 29,3 -5.0
12 31,8 30 +1.8 25 30,1 30,8 -0.7
13 28,4 20 +8.4 26 29,3 35,6 -6.3
;
12
)1nn(n.n
2
n.nU
Z2121
21
cal
8
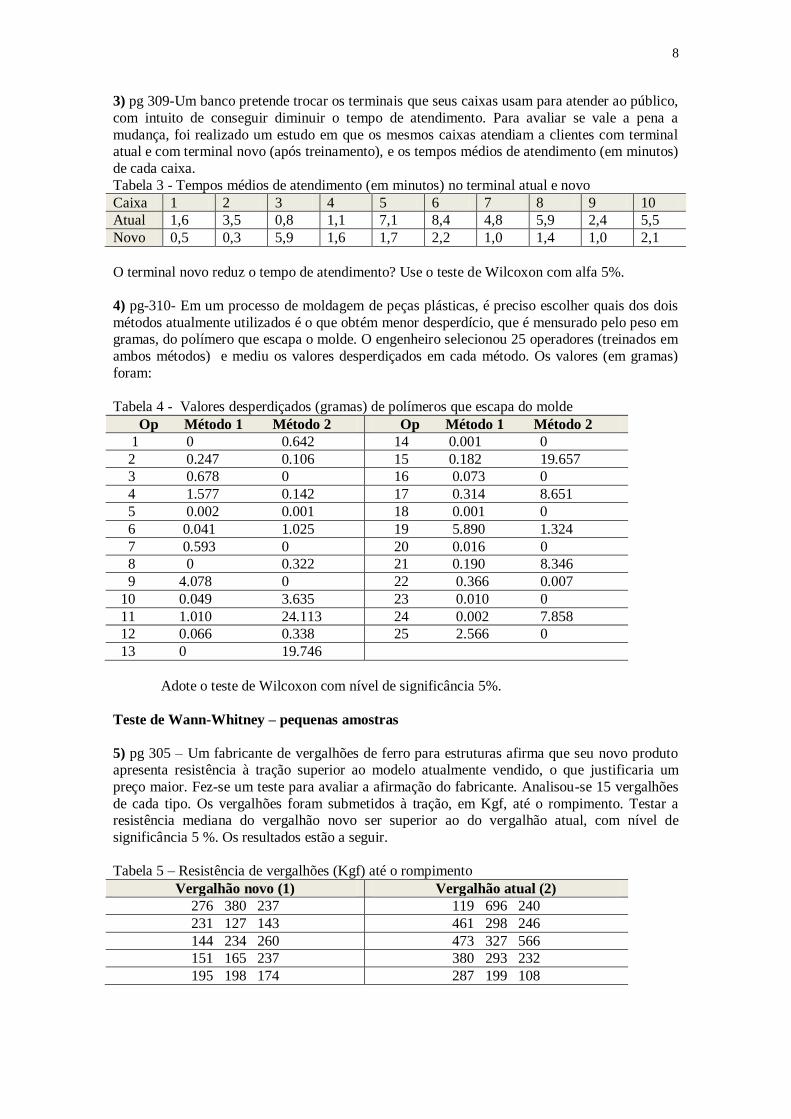
3) pg 309-Um banco pretende trocar os terminais que seus caixas usam para atender ao público,
com intuito de conseguir diminuir o tempo de atendimento. Para avaliar se vale a pena a
mudança, foi realizado um estudo em que os mesmos caixas atendiam a clientes com terminal atual e com terminal novo (após treinamento), e os tempos médios de atendimento (em minutos)
de cada caixa.
Tabela 3 - Tempos médios de atendimento (em minutos) no terminal atual e novo
Caixa 1 2 3 4 5 6 7 8 9 10
Atual 1,6 3,5 0,8 1,1 7,1 8,4 4,8 5,9 2,4 5,5
Novo 0,5 0,3 5,9 1,6 1,7 2,2 1,0 1,4 1,0 2,1
O terminal novo reduz o tempo de atendimento? Use o teste de Wilcoxon com alfa 5%.
4) pg-310- Em um processo de moldagem de peças plásticas, é preciso escolher quais dos dois
métodos atualmente utilizados é o que obtém menor desperdício, que é mensurado pelo peso em gramas, do polímero que escapa o molde. O engenheiro selecionou 25 operadores (treinados em
ambos métodos) e mediu os valores desperdiçados em cada método. Os valores (em gramas)
foram:
Tabela 4 - Valores desperdiçados (gramas) de polímeros que escapa do molde
Op Método 1 Método 2 Op Método 1 Método 2
1 0 0.642 14 0.001 0
2 0.247 0.106 15 0.182 19.657
3 0.678 0 16 0.073 0
4 1.577 0.142 17 0.314 8.651
5 0.002 0.001 18 0.001 0
6 0.041 1.025 19 5.890 1.324
7 0.593 0 20 0.016 0
8 0 0.322 21 0.190 8.346
9 4.078 0 22 0.366 0.007
10 0.049 3.635 23 0.010 0
11 1.010 24.113 24 0.002 7.858
12 0.066 0.338 25 2.566 0
13 0 19.746
Adote o teste de Wilcoxon com nível de significância 5%.
Teste de Wann-Whitney – pequenas amostras
5) pg 305 – Um fabricante de vergalhões de ferro para estruturas afirma que seu novo produto apresenta resistência à tração superior ao modelo atualmente vendido, o que justificaria um
preço maior. Fez-se um teste para avaliar a afirmação do fabricante. Analisou-se 15 vergalhões
de cada tipo. Os vergalhões foram submetidos à tração, em Kgf, até o rompimento. Testar a resistência mediana do vergalhão novo ser superior ao do vergalhão atual, com nível de
significância 5 %. Os resultados estão a seguir.
Tabela 5 – Resistência de vergalhões (Kgf) até o rompimento
Vergalhão novo (1) Vergalhão atual (2)
276 380 237 119 696 240
231 127 143 461 298 246
144 234 260 473 327 566
151 165 237 380 293 232
195 198 174 287 199 108
9
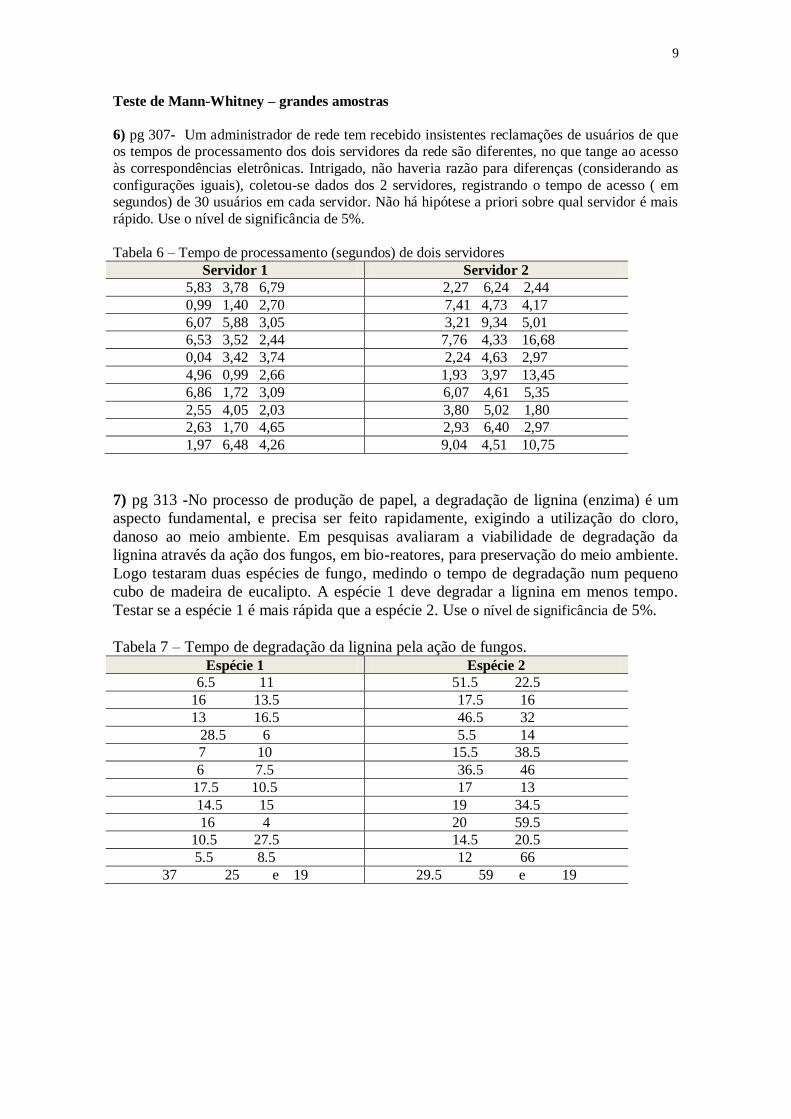
Teste de Mann-Whitney – grandes amostras
6) pg 307- Um administrador de rede tem recebido insistentes reclamações de usuários de que os tempos de processamento dos dois servidores da rede são diferentes, no que tange ao acesso
às correspondências eletrônicas. Intrigado, não haveria razão para diferenças (considerando as
configurações iguais), coletou-se dados dos 2 servidores, registrando o tempo de acesso ( em segundos) de 30 usuários em cada servidor. Não há hipótese a priori sobre qual servidor é mais
rápido. Use o nível de significância de 5%.
Tabela 6 – Tempo de processamento (segundos) de dois servidores
Servidor 1 Servidor 2
5,83 3,78 6,79 2,27 6,24 2,44
0,99 1,40 2,70 7,41 4,73 4,17
6,07 5,88 3,05 3,21 9,34 5,01
6,53 3,52 2,44 7,76 4,33 16,68
0,04 3,42 3,74 2,24 4,63 2,97
4,96 0,99 2,66 1,93 3,97 13,45
6,86 1,72 3,09 6,07 4,61 5,35
2,55 4,05 2,03 3,80 5,02 1,80
2,63 1,70 4,65 2,93 6,40 2,97
1,97 6,48 4,26 9,04 4,51 10,75
7) pg 313 -No processo de produção de papel, a degradação de lignina (enzima) é um
aspecto fundamental, e precisa ser feito rapidamente, exigindo a utilização do cloro,
danoso ao meio ambiente. Em pesquisas avaliaram a viabilidade de degradação da
lignina através da ação dos fungos, em bio-reatores, para preservação do meio ambiente.
Logo testaram duas espécies de fungo, medindo o tempo de degradação num pequeno
cubo de madeira de eucalipto. A espécie 1 deve degradar a lignina em menos tempo.
Testar se a espécie 1 é mais rápida que a espécie 2. Use o nível de significância de 5%.
Tabela 7 – Tempo de degradação da lignina pela ação de fungos.
Espécie 1 Espécie 2
6.5 11 51.5 22.5
16 13.5 17.5 16
13 16.5 46.5 32
28.5 6 5.5 14
7 10 15.5 38.5
6 7.5 36.5 46
17.5 10.5 17 13
14.5 15 19 34.5
16 4 20 59.5
10.5 27.5 14.5 20.5
5.5 8.5 12 66
37 25 e 19 29.5 59 e 19

10
CAPÍTULO 11 - CORRELAÇÃO E REGRESSÃO -pg 316
O conceito de correlação refere-se a uma associação numérica entre duas
variáveis, não implicando numa relação de causa e efeito. Geralmente o estudo de
correlação é um passo intermediário na análise de um problema.
1. Diagrama de dispersão – È um gráfico para visualizar se as duas variáveis em
estudo estão correlacionadas. Os valores das variáveis são apresentados por pontos, num
sistema cartesiano.
2. Coeficiente de correlação linear (R)
O coeficiente de correlação linear tem por objetivo medir o grau de relação entre
duas variáveis (x, y) e é definido pela fórmula:
])(].[)([ 2222 yynxxn
yxyxnr ou
SYYSXX
SXYr
.
Onde -1 r 1. Se r = 1, a correlação é positiva perfeita;
Se r = - 1, a correlação é negativa perfeita;
Se r = 0, a correlação é nula.
3. Coeficiente de correlação populacional – pg321
A medida descritiva de correlação entre duas variáveis amostrais, pode-se testar
a correlação, em termos probabilísticos, o parâmetro correlação entre duas variáveis
aleatórias, X e Y. Dada uma amostra simples (x1,y1); (x2, y2);..... (xn, yn) de n
observações do par de variáveis aleatórias (x, y), o coeficiente (r) pode ser uma
estimativa do verdadeiro e desconhecido .
i) Testar as hipóteses: Ho: =0 vs H1: 0 ; >0; <0.
ii) Nível de significância
distribuição t para teste bilateral t (n-2; alfa)
iii) A estatística teste: t = 2r1
2n.r
iv) Conclusão. Sob a distribuição t de Student com (n-2) graus de liberdade, rejeita-se
adotando a regra habitual.
ATIVIDADE 11 A - CORRELAÇÃO
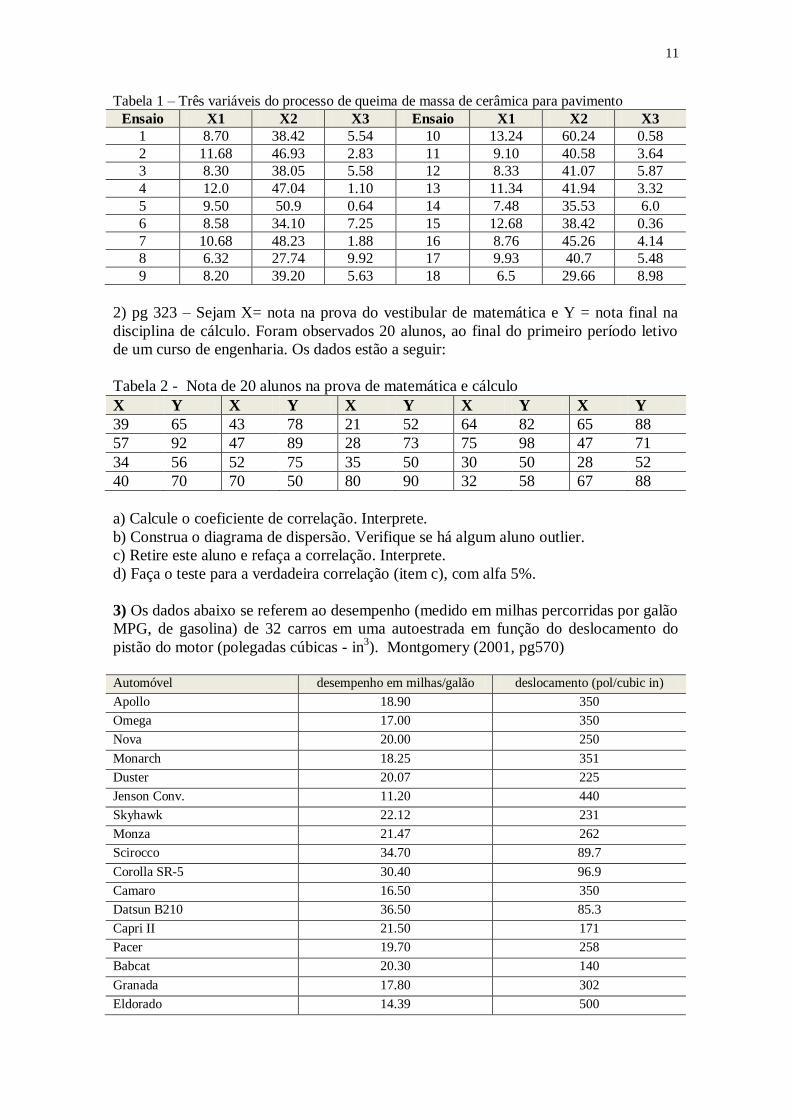
1) No processo de queima de massa de cerâmica para pavimento, corpos de prova foram analisados por 3 variáveis: X1: retração linear (%); X2: resistência mecânica (Mpa) X3:
absorção de água (%). Encontre a correlação entre as variáveis e construa o diagrama de
dispersão. Os resultados de 18 ensaios são apresentados a seguir:
11
Tabela 1 – Três variáveis do processo de queima de massa de cerâmica para pavimento
Ensaio X1 X2 X3 Ensaio X1 X2 X3
1 8.70 38.42 5.54 10 13.24 60.24 0.58
2 11.68 46.93 2.83 11 9.10 40.58 3.64
3 8.30 38.05 5.58 12 8.33 41.07 5.87
4 12.0 47.04 1.10 13 11.34 41.94 3.32
5 9.50 50.9 0.64 14 7.48 35.53 6.0
6 8.58 34.10 7.25 15 12.68 38.42 0.36
7 10.68 48.23 1.88 16 8.76 45.26 4.14
8 6.32 27.74 9.92 17 9.93 40.7 5.48
9 8.20 39.20 5.63 18 6.5 29.66 8.98
2) pg 323 – Sejam X= nota na prova do vestibular de matemática e Y = nota final na
disciplina de cálculo. Foram observados 20 alunos, ao final do primeiro período letivo
de um curso de engenharia. Os dados estão a seguir:
Tabela 2 - Nota de 20 alunos na prova de matemática e cálculo
X Y X Y X Y X Y X Y
39 65 43 78 21 52 64 82 65 88
57 92 47 89 28 73 75 98 47 71
34 56 52 75 35 50 30 50 28 52
40 70 70 50 80 90 32 58 67 88
a) Calcule o coeficiente de correlação. Interprete.
b) Construa o diagrama de dispersão. Verifique se há algum aluno outlier.
c) Retire este aluno e refaça a correlação. Interprete.
d) Faça o teste para a verdadeira correlação (item c), com alfa 5%.
3) Os dados abaixo se referem ao desempenho (medido em milhas percorridas por galão
MPG, de gasolina) de 32 carros em uma autoestrada em função do deslocamento do
pistão do motor (polegadas cúbicas - in3). Montgomery (2001, pg570)
Automóvel desempenho em milhas/galão deslocamento (pol/cubic in)
Apollo 18.90 350
Omega 17.00 350
Nova 20.00 250
Monarch 18.25 351
Duster 20.07 225
Jenson Conv. 11.20 440
Skyhawk 22.12 231
Monza 21.47 262
Scirocco 34.70 89.7
Corolla SR-5 30.40 96.9
Camaro 16.50 350
Datsun B210 36.50 85.3
Capri II 21.50 171
Pacer 19.70 258
Babcat 20.30 140
Granada 17.80 302
Eldorado 14.39 500
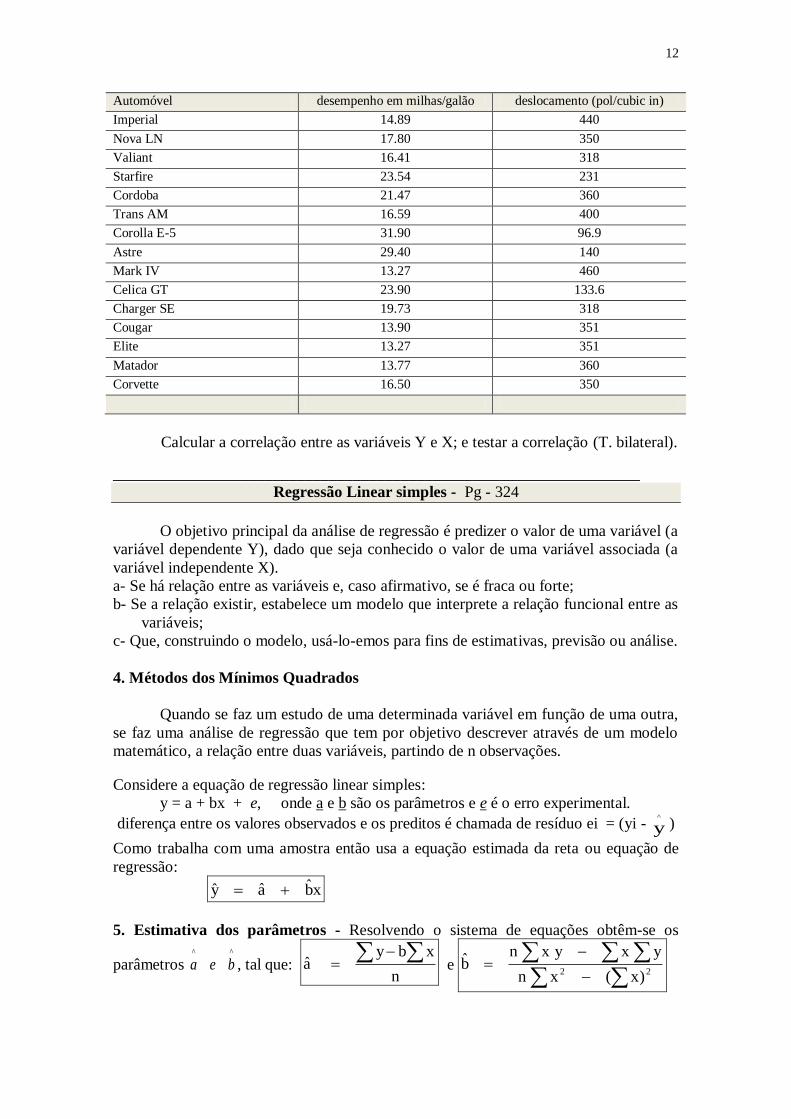
12
Automóvel desempenho em milhas/galão deslocamento (pol/cubic in)
Imperial 14.89 440
Nova LN 17.80 350
Valiant 16.41 318
Starfire 23.54 231
Cordoba 21.47 360
Trans AM 16.59 400
Corolla E-5 31.90 96.9
Astre 29.40 140
Mark IV 13.27 460
Celica GT 23.90 133.6
Charger SE 19.73 318
Cougar 13.90 351
Elite 13.27 351
Matador 13.77 360
Corvette 16.50 350
Calcular a correlação entre as variáveis Y e X; e testar a correlação (T. bilateral).
__________________________________________________________________
Regressão Linear simples - Pg - 324
O objetivo principal da análise de regressão é predizer o valor de uma variável (a
variável dependente Y), dado que seja conhecido o valor de uma variável associada (a
variável independente X).
a- Se há relação entre as variáveis e, caso afirmativo, se é fraca ou forte;
b- Se a relação existir, estabelece um modelo que interprete a relação funcional entre as
variáveis;
c- Que, construindo o modelo, usá-lo-emos para fins de estimativas, previsão ou análise.
4. Métodos dos Mínimos Quadrados
Quando se faz um estudo de uma determinada variável em função de uma outra,
se faz uma análise de regressão que tem por objetivo descrever através de um modelo
matemático, a relação entre duas variáveis, partindo de n observações.
Considere a equação de regressão linear simples:
y = a + bx + e, onde a e b são os parâmetros e e é o erro experimental.
diferença entre os valores observados e os preditos é chamada de resíduo ei = (yi - y^
)
Como trabalha com uma amostra então usa a equação estimada da reta ou equação de
regressão:
xbay
5. Estimativa dos parâmetros - Resolvendo o sistema de equações obtêm-se os
parâmetros ^^
bea , tal que: n
xbya
e
22 )x(xn
yxyxnb

13
6. Análise de variância do modelo - Uma maneira de testar a existência de regressão é
pela ANÁLISE DE VARIÂNCIA, que estuda o comportamento das variações totais
explicadas e residuais, cujo método é o seguinte:
i) Hipóteses: Ho: = 0 e H1: 0
ii) Nível de significância. Distribuição F [1; n-2; α]
iii) Variável teste Fcalc
FV GL SQ QM Fcal Ftab
Regressão 1 SQReg QMR = SQReg QMReg / QME [1; n – 2]
Erro n - 2 SQE QME = SQE / n-2 ... ...
Total n – 1 SQTo ... ...
A soma dos desvios satisfazem à equação:
()yy( 2
i y^
y )2 + 2y( )y
^
i
SQ total = SQReg + SQ Erro
Variação total = variação explicada + variação não explicada pela equação
ou SQTotal = ∑y2 – (∑y)
2∕n
SQReg = β1. Sxy
iv) Conclusão: Se (Fcal < Ftab), aceita-se Ho ao nível de significância e concluí-se que
não existe regressão, caso contrário, (Fcal > Ftab), concluí-se que existe regressão linear. 7. Coeficiente de determinação (R
2)
È uma medida descritiva da proporção da variação de Y que pode ser explicada por variações em X segundo o modelo especificado.
R2 =
TotSQ
gReSQ
8. Inferência sobre os parâmetros do modelo
Inferência sobre Coeficiente Angular ( b) Estimativa do desvio padrão dos resíduos
Se = 2n
xybyay2
Inferência sobre Coeficiente Escalar ( a) Estimativa do desvio padrão dos resíduos
Se = 2n
xybyay2
Estimativa do erro padrão de b
Sb = Se
22 )x(xn
n
Estimativa do erro padrão de a
Sa=Se
22
2
)(
)(
1
xxn
n
x
n
Teste de hipótese 0:10 Hvs
t =
b
0
s
b t (n-2; alfa) teste bilateral
Teste de hipótese 0:10 Hvs
t =
a
0
s
a t (n-2; alfa) teste bilateral
Intervalo de confiança para o coeficiente angular ( b )
IC (b) = [ b )
2,2(
nt Sb ]
Intervalo de confiança para o coeficiente escalar ( a )
IC (a) = [ a )
2,2(
n
t Sa ]

14
9. Análise de resíduo
A análise de resíduos desempenha papel fundamental na avaliação do ajuste de um
MRLS, investiga a adequação do modelo quanto às suposições básicas do modelo, bem como:
i) independência das variáveis erros, ei;
ii) homogeneidade das variâncias de ei;
iii) normalidade dos erros ei, i=1,2,.....n
iv) relação linear das variáveis x e y;
e assim, avalia-se a falta de ajuste do modelo proposto. Além dos testes de significância e
adequação, a análise de resíduo vem complementar o elenco de procedimentos que devem ser
realizados após o ajuste de qualquer modelo.
Tipos de resíduos
Resíduos padronizados são escalonados para reduzir uma variável aleatória a ter
esperança com média zero e seus desvios padrão seja aproximadamente igual a um.
Consequentemente di > 3 indica outliers.
di = 2ˆRe
ii e
sQM
e com i=1,2,....,n
Resíduo na forma de Student (Estudentizado) – os resíduos padronizados e estudentizado
são parecidos, mas em algumas situações os resíduos estudentizado é mais sensível para detectar
pontos influentes, dada por: ri = )1(ˆ 2
ii
ii
h
e
onde hii = (
xx
i
S
xx
n
2)(1 )
9.1 Gráficos de resíduos
Para o modelo de regressão, os termos dos erros ei são assumidos serem variáveis
aleatórias normais e independentes, com média zero e variância 2 . Se o modelo é adequado
para os dados, os resíduos observados, devem refletir as propriedades assumidas para os erros e.
Esta é a idéia básica da análise de resíduos, uma maneira útil de examinar a adequação de um
modelo estatístico. Análise gráfica é muito eficiente para verificar a adequação do modelo, e
checar violações do modelo (não independência dos erros, normalidade dos erros, variância
constante dos erros).
a. Gráfico dos Zi’s versus variável regressora ou valores estimados.
No gráfico plota-se os resíduos padronizados (Zi’s) no eixo das ordenadas e a variável
regressora (xi) ou o valor estimado da variável resposta no eixo das abscissas. Ambas os
gráficos nos dará mesmas informações. A característica do gráfico é que a faixa de variação dos
resíduos ao longo dos valores de X é constante, ou ainda, os pontos devem estar espalhados
aleatoriamente, não demonstrando nenhuma tendência. Isso indica a não violação do modelo.

15
b- Presença de Outliers
“Outliers” são observações extremas. Outliers residuais podem ser identificados no
gráfico de gráfico de caixa dos resíduos. O gráfico de resíduos padronizados é particularmente
útil, pois permite distinguir observações afastadas, uma vez que se torna fácil identificar
resíduos que se encontram muitos desvios padrão do zero. Embora a presença de outliers possa
criar dificuldades, só é recomendável retirá-lo da análise se há evidência direta que representa
um erro de coleta, um cálculo mal feito ou circunstância similar.
c- Normal Probability Plot
Pequenos afastamentos da normalidade não criam sérios problemas, o que não é
verdadeiro para grandes afastamentos. Uma forma de analisar a normalidade dos resíduos é
análise gráfica através do gráfico Normal Probability. Neste caso cada resíduo é plotado contra
seu valor esperado de normalidade. Um gráfico aproximadamente linear sugere concordância
com a normalidade, enquanto um gráfico que se afasta substancialmente da linearidade sugere
que a distribuição dos resíduos não seja aproximadamente normal.
Sempre é conveniente realizar um teste que verifique estatisticamente esta suposição. Dentre os
mais utilizados, citamos o de Shapiro-Wilk; Kolmogorov ou Lilliefors (Barbetta 2008).
ATIVIDADE 11 B - REGRESSÃO
1) Exemplo 11.2 - pg 325 - Considere um experimento em que se analisa a octanagem
(pureza/qualidade) da gasolina (Y) em função da adição de um novo aditivo (X). para
isso, foram realizados ensaios com os percentuais de 1,2,3,4,5,6% de aditivo. Os
resultados estão na tabela abaixo. Pede-se:
Tabela 1 – Octanagem da gasolina em função do aditivo
X Aditivo Y Octanagem
1 80,5
2 81,6
3 82,1
4 83,7
5 83,9
6 85,0
a) Diagrama de dispersão
b) Coeficiente de correlação linear entre as variáveis e testar a correlação
c) Ajuste o modelo de regressão
d) Trace a reta estimada no diagrama de dispersão
e) Estimar a octanagem da gasolina, quando o aditivo novo 3,5 %.
f) Estimar a porcentagem de aditivo, se a octanagem foi de 80,9.
g) Coeficiente de determinação, discuta.
h) testar a significância do modelo. Alfa 5%
i) qual a variância residual do modelo?
j) testar a hipótese e construir os intervalos de confiança dos parâmetros
k) realize uma análise de resíduo

16
2) pg 345 - Um estudo foi desenvolvido para verificar o quanto o comprimento de um
cabo serial de microcomputadores influencia na qualidade de transmissão de dados,
medida através do número de falhas em 10.000 lotes de dados transmitidos (taxa falha).
Os resultados foram:
Tabela 2 - Comprimento do cabo serial e taxa de falha na transmissão de dados.
Comp. Cabo (m) Taxa de falha Comp. Cabo (m) Taxa de falha
8 2,2 12 9,8
8 2,1 12 8,7
9 3,0 13 12,5
9 2,9 13 13,1
10 4,1 14 19,3
10 4,5 14 17,4
11 6,2 15 28,2
11 5,9
a) Determine o coeficiente de correlação linear de Pearson.
b) Testar a correlação com nível de significância de 5%
c) Estabeleça o modelo de regressão.
d) Determine o coeficiente de determinação e discuta.
e) Diagrama de dispersão
f) Ajustar a reta no diagrama de dispersão.
g) Testar a significância do modelo de regressão
h) Testar a hipótese e construir os intervalos de confiança dos parâmetros
i) Estimar a taxa de falha quando o comprimento do cabo for 20.
j) Estimar o comprimento do cabo, quando a taxa de falha for de 10,0.
k) Qual a variância residual do modelo?
l) realize uma análise de resíduo
#######################################################
#ATIVIDADE 10 A - TESTE QUI-QUADRADO - ADERÊNCIA
########################################################
# Exercício 1 - Pg 275
# Defeitos nos pneus traseiro esquerdo
##############-------------------------
# 1- Hipóteses: H0: Não há discrepância entre as fo e fe
H1: Há discrepância entre as fo e fe
# 2- alfa- 5%
# 3- qui-quadrado tabelado
qtab=qchisq(c(0.05), df=3,lower.tail=F);qtab

17
#-----------------------
# 4- Estatística teste
#-----------------------
X=c(35,32,57,28)
chisq.test(X)
sum(X)
chisq.test(X)$expected
barplot(X, xlab="Frequencias de defeitos no pneu T.E.", ylab="freq")
# 5- Conclusão: Rejeita-se H0
#---------------------
#Gráfico de caixas
#---------------------
pneus = c("DE","DE","DE","DE","DE","DE","DE","DE","DE","DE",
"DE","DE","DE","DE","DE","DE","DE","DE","DE","DE",
"DE","DE","DE","DE","DE","DE","DE","DE","DE","DE",
"DE","DE","DE","DE","DE",
"DD","DD","DD","DD","DD","DD","DD","DD","DD","DD",
"DD","DD","DD","DD","DD","DD","DD","DD","DD","DD",
"DD","DD","DD","DD","DD","DD","DD","DD","DD","DD",
"DD","DD",
"TE","TE","TE","TE","TE","TE","TE","TE","TE","TE",
"TE","TE","TE","TE","TE","TE","TE","TE","TE","TE",
"TE","TE","TE","TE","TE","TE","TE","TE","TE","TE",
"TE","TE","TE","TE","TE","TE","TE","TE","TE","TE",
"TE","TE","TE","TE","TE","TE","TE","TE","TE","TE",
"TE","TE","TE","TE","TE","TE","TE",
"TD","TD","TD","TD","TD","TD","TD","TD","TD","TD",
"TD","TD","TD","TD","TD","TD","TD","TD","TD","TD",
"TD","TD","TD","TD","TD","TD","TD","TD")
t1= table(pneus); t1
barplot(t1, xlab="Posição do Pneu", ylab="freq",
col=c("cyan","cornsilk","purple","violetred1"))
###############---------------------------------
# Exercicio 2 - Pg 285
# Pacotes de dados enviados para 3 laboratórios
###############---------------------------------
# 1- Hipóteses: H0: Não há discrepância entre as fo e fe
H1: Há discrepância entre as fo e fe
# 2- alfa- 1%
# 3- qui-quadrado tabelado

18
# 4- Estatística teste
# 5- Conclusão: Aceita-se H0
##################-----------------------------------
# Exercício 3 - pg 287 - Tabelas de Contigência
# TESTE QUI-QUADRADO - INDEPENDÊNCIA
##################------------------------------------
# 1- Hipóteses: H0: As variáveis são independentes
H1: As variáveis são dependentes
# 2- alfa- 5%
# 3- Qtab
qtab=qchisq(c(0.05), df=2,lower.tail=F);qtab
# 4- Estatística teste
Y=matrix(c(500,30,4500,270,1500,50),nc=3);Y
chisq.test(Y)
chisq.test(Y)$expected
# 5- Conclusão- Rejeita-se H0
#----------------------------------------------------------------------------------------------------
# COEFICIENTE DE CONTIGÊNCIA: # MEDE O GRAU DE ASSOCIAÇÃO
#-----------------------------------------------------------------------------------------------------
qcalc = 14.66; qcalc
n = 6850; n
denom = n+qcalc; denom
num = qcalc; num
CC= (num/denom)^0.5; CC
###############------------------------------------------
# Exercício 4 - situação final x cursos de engenharia
###############-----------------------------------------
# 1- Hipóteses: H0:As variáveis são homogêneas
H1: As variáveis não são dependentes
# 2- alfa- 5%
# 3- qui-quadrado tabelado com gl=2 e alfa 5%
# 4- Estatística teste
# 5- Conclusão: Rejeita-se H0.

19
###############-----------------------------------------
# Exercício 5 - pg 292 - Situação da peças x turnos
###############-----------------------------------------
# 1- Hipóteses
# 2- alfa- 1%
# 3- Qtab; gl = 2 e alfa = 1%
qtab=qchisq(c(0.01), df= 2 , lower.tail=F);qtab
# 4 - Qcalc
M = matrix(c(432,185,45,456,190,48,424,180,39),nc=3);M
chisq.test(M)$expected
chisq.test(M)
# 5 - CONCLUSÃO:
##############----------------------------------------------
# Exercício 6 - pg 293 - Cliente x Situação dos pacotes
#############-----------------------------------------------
# 1- Hipóteses: H0:
H1:
# 2- alfa-
# 3- Qtab; gl = 8 e alfa =2.5%
# 4 - Qcalc
# 5 - CONCLUSÃO:
###################
# ATIVIDADES 10B
###################------------------------------------------------------------------
# Exercício 1 - TESTE DE WILCOXON - 2 AMOSTRAS PAREADAS n<20
# Tempo de falha de 10 componentes após o programa de manutenção
#----------------------------------------------------------------------------------------------
A = c(400,360,450,390,430,386,452,470,400,340)
D = c(395,350,556,480,405,500,547,462,500,480)
n= length(D); n # n= 10 componentes

20
wilcox.test(D,A, paired=TRUE, alternative = "greater",
exact = FALSE, correct = TRUE,conf.level = 0.95)
# S+= 45 (soma dos postos positivos)
###############-----------------------------------------------------------------------------
# Exercício 2 - TESTE DE WILCOXON - 2 AMOSTRAS PAREADAS - n>20
##############-------------------------------------------------------------------------------
# Tempo gasto(segundos) para medir dimensões de peças com
# calibradores eletronicos e mecânicos
#------------------------------------------------------------------------
Ele = c(27,25,22,34,23,22,25,32.3,34,23.5,34.2,31.8,28.4,22,
16,22,29.5,36,35,35,27.5,29,27,24.3,30.1,29.3)
Mec = c(27,30.1,28,34,24.5,28,28,30,36,29,39,30,20,
29,16,20.6,25,33,41,35,28,31.8,28,29.3,30.8,35.6)
n= length(Ele); n #n= 26 operários
wilcox.test(Ele,Mec, paired=TRUE, alternative = "less",
exact = FALSE, correct = TRUE,conf.level = 0.95)
# S+= 62.5 (soma dos postos positivos)
#################
# Exercício 3
#################--------------------------------------------------------
# TESTE DE WILCOXON - 2 AMOSTRAS PAREADAS
# Tempos médios de atendimento (em minutos) no terminal atual e T. novo
#------------------------------------------------------------------------
Atual=c(1.6,3.5,0.8,1.1,7.1,8.4,4.8,5.9,2.4,5.5)
Novo =c(0.5,0.3,5.9,1.6,1.7,2.2,1,1.4,1,2.1)
# resolver

21
##############
# Exercício 4
##############-----------------------------------------------------------------
# TESTE DE WILCOXON - 2 AMOSTRAS PAREADAS
# Valores desperdiçados (gramas) de polímeros que escapa do molde
#-----------------------------------------------------------------------------------
M1=c(0,0.247,0.678,1.577,0.002,0.041,0.593,0,4.078,0.049,1.01,0.066,
0,0.001,0.182,0.073,0.314,0.001,5.890,0.016,0.19,0.366,0.01,0.002,2.566)
M2=c(0.642,0.106,0,0.142,0.001,1.025,0,0.322,0,3.635,24.113,0.338,19.746,
0,19.657,0,8.651,0,1.324,0,8.346,0.007,0,7.858,0)
# resolver
############
# Exercício 5
#############------------------------------------------------------------------------------
# TESTE DE MANN WHITNEY - 2 AMOSTRAS INDEPENDENTES
# Resistência de vergalhões (Kgf) até o rompimento - Vergalhões novo e atual
#----------------------------------------------------------------------------------------------
VN =c(276,380,237,231,127,143,144,234,260,151,165,237,195,198,174)
VA =c(119,696,240,461,298,246,473,327,566,380,293,232,287,199,108)
wilcox.test(VN,VA,paired=F,alternative="two.sided",conf.level = 0.95)
wilcox.test(VA,VN,paired=F,alternative="two.sided",conf.level = 0.95)
##############
# Exercício 6
##############-----------------------------------------------------------
# TESTE DE MANN WHITNEY - 2 AMOSTRAS INDEPENDENTES
# Tempo de processamento (segundos) de dois servidores S1 e S2
#------------------------------------------------------------------------
# S1: Servidor 1 e S2: Servidor 2
S1 =c(5.83,0.99,6.07,6.53,0.04,4.96,6.86,2.55,2.63,1.97,
3.78,1.40,5.88,3.52,3.42,0.99,1.72,4.05,1.70,6.48,
6.79,2.70,3.05,2.44,3.74,2.66,3.09,2.03,4.65,4.26)
S2 =c(2.27,7.41,3.21,7.76,2.24,1.93,6.07,3.80,2.93,9.04,
6.24,4.73,9.34,4.33,4.63,3.97,4.61,5.02,6.40,4.51,
2.44,4.17,5.01,16.68,2.97,13.45,5.35,1.80,2.97,10.75)

22
boxplot(S1,S2)
# valor crítico Ztab= ??
ztab= qnorm(c( ?? ), mean=0, sd=1, lower.tail=TRUE); ztab
wilcox.test(S1,S2,paired=F,alternative="two.sided",conf.level = 0.95)
##############
# Exercício 7
##############------------------------------------------------------------
# TESTE DE MANN WHITNEY - 2 AMOSTRAS INDEPENDENTES
# Tempo de degradação da lignina pela ação de 2 espécies de fungos
#------------------------------------------------------------------------
Esp1 = c(6.5,11,16,13.5,13,16.5,28.5,6,7,10,6,7.5,17.5,10.5,
14.5,15,16,4,10.5,27.5,5.5,8.5,37,25,19)
Esp2 = c(51.5,22.5,17.5,16,46.5,32,5.5,14,15.5,38.5,36.5,46,17,13,
19,34.5,20,59.5,14.5,20.5,12,66,29.5,59,19)
boxplot(Esp1, Esp2)
# X: (tempo gasto para degradação de um cubo de madeira)
#1) Ho: Esp1 = Esp2
# Tempo mediano de degradação da espécie 1 é igual ao Tempo mediano
# de degradação da espécie 2
# H1: Esp1 < Esp2
# Tempo mediano de degradação da espécie 1 é menor ao Tempo mediano
# de degradação da espécie 2
#2) valor crítico Ztab= ??
# 3) Estatística teste
# 4) conclusão

23
#################################
# CAPÍTULO 11 - ATIVIDADE 11A -
#################################
#---------------------------------------------------------------------------------------------
# Exercício 1 - dados: X1 e X2 - Pedro Barbetta pg 317
# variáveis x1:retração linear, x2:resitencia mecânica, x3:absorção de água
#---------------------------------------------------------------------------------------------
rm(list=ls())
x1 = c(8.7,11.68,8.3,12,9.5,8.58,10.68,6.32,8.2,13.24,9.1,8.33,11.34,
7.48,12.68,8.76,9.93,6.5)
x2 = c(38.42,46.93,38.05,47.04,50.9,34.1,48.23,27.74,39.2,60.24,40.28,
41.07,41.94,35.53,38.42,45.26,40.7,29.66)
x3=c(5.54,2.83,5.58,1.1,0.64,7.25,1.88,9.92,5.63,0.58,3.64,5.87,3.32,6,0.36,
4.14,5.48,8.98)
#----------------------------------------------------------
# a1 - Gráfico de dispersão - pontos de x1 e x2
#--------------------------------------------------------
par(mai=c(1,1,0.2,0.2))
plot(x2~x1, las=1, bty='l', pch=19, col='blue',
xlab='RL(%)', ylab='Resistencia')
#-------------------------------------------------
# b1 - Cálculo do Coeficiente de Correlação
# e o teste de hipótese da correlação
#-------------------------------------------------
n=18
cor(x1,x2)
cor.test(x1,x2)
#valor tabela t de Student
gl = n-2; gl
ttab = qt(c(0.025, 0.975), df=gl, lower.tail=T); ttab
#--------------------------------------------------------
# a2 - Gráfico de dispersão - pontos de x1 e x3
#--------------------------------------------------------
#-------------------------------------------------
# b2 - Cálculo do Coeficiente de Correlação
# e o teste de hipótese da correlação
#-------------------------------------------------

24
#-------------------------------------------------
# a3 - Gráfico de dispersão - pontos de x2 e x3
#-------------------------------------------------
#-------------------------------------------------
# b3 - Cálculo do Coeficiente de Correlação
# e o teste de hipótese da correlação
#-------------------------------------------------
##############------------------------------
# Exercicio 2 - pg 323- Barbetta
##############------------------------------
x = c(39,57,34,40,43,47,52,70,21,28,35,80,64,75,30,32,65,47,28,67)
y = c(65,92,56,70,78,89,75,50,52,73,50,90,82,98,50,58,88,71,52,88)
#-------------------
# a - correlação
#-------------------
cor.test(x,y)
cor.test(x,y,method="pearson",alternative="two.sided")
#--------------------------------
# b- diagrama de dispersão
#--------------------------------
plot(x,y)
# cálculos
sum(x)
sum(y)
sum(x^2)
sum(y^2)
sum(x*y)
length(x)
# r= 0,69
# tcalc= 4,09; gl=18 p=0,00068
#-------------------------------------------------------
# c- Retirando o ponto (Sem Outlier:(70,50))
#-------------------------------------------------------
rm(list=ls())
x=c(39,57,34,40,43,47,52,21,28,35,80,64,75,30,32,65,47,28,67)
y=c(65,92,56,70,78,89,75,52,73,50,90,82,98,50,58,88,71,52,88)

25
length(x)
#------------------------
# nova correlação
#-----------------------
cor(x,y)
plot(x,y)
#----------------------------------
# d- teste da correlação
#----------------------------------
cor. test(x,y)
####################
# EXERCÍCIO 3
####################-------------------------------------------
# Y- Desempenho em milhas percorridas de 32 automóveis em função
# do X- deslocamento do pistão do motor em (polegadas cúbicas)
#--------------------------------------------------------------
rm(list=ls())
Y = c(18.90,17.00,20.00,18.25,20.07,11.20,22.12,21.47,34.70,30.40,
16.50,36.50,21.50,19.70,20.30,17.80,14.39,14.89,17.80,16.41,23.54,21.47,
16.59,31.90,29.40,13.27,23.90,19.73,13.90,13.27,13.77,16.50)
X = c(350,350,250,351,225,440,231,262,89.7,96.9,350,85.3,171,258,140,302,
500,440,350,318,231,360,400,96.9,140,460,133.6,318,351,351,360,350)
cbind(X)
sort(X)
ex2=as.data.frame(cbind(Y,X)); ex2
attach(ex2)
names(ex2)
dim(ex2)
cor(ex2)
#-------------------------------------------------
# Gráfico de dispersão - pontos de X e Y
#-------------------------------------------------
par(mai=c(1,1,0.2,0.2))
plot(Y~X, las=1, bty='l', pch=19, col='blue',
xlab='Deslocamento do motor', ylab='Desempenho em milhas')
#-------------------------------------------------
# Cálculo do Coeficiente de Correlação
# e o teste de hipótese da correlação
#-------------------------------------------------

26
########################
#ATIVIDADE 11 B
########################
#-----------------------------------------------------------------------
# Exercício 1 - ANÁLISE DE REGRESSÃO - pg 328 -
# Porcentagem de Aditivo (X) e Octanagem da gasolina (Y)
#------------------------------------------------------------------------
x = c(1,2,3,4,5,6)
y = c(80.5,81.6,82.1,83.7,83.9,85)
#------------------------------------------
# a- Diagrama de dispersão
#-----------------------------------------
plot(y~x,col='blue',xlab='Aditivo',ylab='Octanagem')
#----------------------------------------------
# b - Correlação e Teste para Correlação
#---------------------------------------------
cor(x,y)
cor.test(x,y)
#cálculos
sum(x)
sum(y)
sum(x^2)
sum(y^2)
sum(x*y)
length(x)
#-------------------------------------------------------------------------------
# c1 - ESTIMAÇÃO DOs PARÂMETROS - tipo I forma matricial
#Alguns cálculos matriciais (%*% - Multiplica matrizes)
#---------------------------------------------------------------------------------
n = length(x); n
X = as.matrix(cbind(1,x)); X #Matriz X
Y = as.matrix(cbind(y)); Y #Matriz Y
XtX = t(X)%*%X ; XtX #(X'X)
XtY = t(X)%*%Y ; XtY # X'Y
YtY = t(Y)%*%Y ; YtY # Y'Y
INV = solve(XtX) ; INV # inversa da matriz(X'X)
(Betas = INV%*%XtY) #Coeficientes Bj

27
#-----------------------------------
# c2 -Modelo de Regressão
#-----------------------------------
model=lm(y~x); model
#----------------------
# e - Estimar Y=?
#----------------------
#----------------------
# f- Estimar X=?
#-----------------------
#-----------------------------------------------------------------
# g- Coeficiente de determinação
#-----------------------------------------------------------------
summary(model)
#-----------------------------------------------------------------
# h - testar a hipótese da significância
#-----------------------------------------------------------------
anova(model)
#-----------------------------------------------------------------
# i - estimativa da variância residual - QMRes
#-----------------------------------------------------------------
anova(model)
#------------------------------------------------------------------------------
# j - Teste de hipótese e Intervalos de confiança dos parâmetros
#------------------------------------------------------------------------------
summary(model2)
confint(model2, conf.level=0.95)
#-----------------------------------------------------------------
# ANÁLISE DE RESÍDUOS
#-----------------------------------------------------------------------
# Tipos de residuos
#-------------------------------------------------------------------------
residuos = model$residuals #Resíduos Brutos
QMRes= 0.088
# Residuo padronizado dividido pelo Raiz do QMRes
respad = residuos / sqrt(QMRes); respad

28
cbind(respad) #Resíduos padronizados
# Restudent= residuos dividido pela Raiz do QMRes*(1-hii)
restudent = rstandard(model); restudent #Residuos estudentizados
#--------------------------------------------------------------------------------------------
# Figura 2.1 -
# ou o gráfico dos Resíduos Padronizados versus variáveis regressoras(X)
# ou o gráfico dos Resíduos Padronizados versus valores estimados
#------------------------------------------------------------------------------------------
par(mai=c(1,1,.2,.2))
plot(respad~x, las=1, pch=19, col='red', ylab='Resíduos Padronizados',
xlab='Concentrações', bty='l')
abline(h=0)
#ou
estimados=model$fitted.values; estimados
names(model)
par(mai=c(1,1,.2,.2))
plot(respad~estimados, las=1, pch=19, col='red', ylab='Resíduos Padronizados',
xlab='Valores Estimados',bty='l')
abline(h=0)
#-------------------------------------
# Figura 2.2 -
# Box plot dos resíduos padronizados
#-------------------------------------
par(mai=c(1,1,.2,.2))
boxplot(respad, horizontal=T, col='LightYellow', xlab='Resíduos Padronizados')
boxplot(respad, horizontal=F, col='LightYellow', xlab='Resíduos Padronizados')
#-----------------------------------------------------------------
# Figura 2.3 - Não Normalidade dos Erros
# Gráficos dos Resíduos Esperados com os Resíduos Ordenados
#-----------------------------------------------------------------
qqnorm(x)
qqline(x)
shapiro.test(residuos)
#-----------------------------------------------------------------
# Figura 2.4 - Resumindo todos gráficos
#-----------------------------------------------------------------
par(mfrow=c(2,2))
plot(model, which=c(1:4), pch=16, add.smooth=FALSE)

29
#################----------------------------------------------
# Exercício 2 - ANÁLISE DE REGRESSÃO - pg 345
#################-----------------------------------------------
rm(list=ls())
CA = c(8,8,9,9,10,10,11,11,12,12,13,13,14,14,15)
TF = c(2.2,2.1,3,2.9,4.1,4.5,6.2,5.9,9.8,8.7,12.5,13.1,19.3,17.4,28.2)
#--------------------------------------
# a; b - correlação e teste
#------------------------------------
#---------------------------------
# c- Modelo de regressão
#--------------------------------
#ou
#--------------------------------------------------------------------------------
# ESTIMAÇÃO DOA PARÂMETROS - tipo I forma matricial
#Alguns cálculos matriciais (%*% - Multiplica matrizes)
#------------------------------------------------------------------------------
#------------------------------------------------
# d- Coeficiente de determinação
#----------------------------------------------
#------------------------------------
# e- diagrama de dispersão
#-----------------------------------
#-------------------------
# g - Anova
#-------------------------
#-----------------------------
# h1 - Teste de hipóteses
#-----------------------------

30
#-----------------------------------
# h2 - Intervalos de confiança
#-----------------------------------
#-------------------
# i - Estimar Y=?
#-------------------
#-------------------
# j- Estimar X=?
#--------------------
#-------------------
# k- QMRes
#--------------------
#-----------------------------------------------------------------
# l - ANÁLISE DE RESÍDUOS
#-----------------------------------------------------------------
#-----------------------------------------------------------------------
# Tipos de residuos
#-------------------------------------------------------------------------
#-----------------------------------------------------------------------
# Figura 2.1 -
# ou o gráfico dos Resíduos Padronizados versus variáveis regressoras(X)
# ou o gráfico dos Resíduos Padronizados versus valores estimados
#-------------------------------------------------------------------------
#-------------------------------------
# Figura 2.2 -
# Box plot dos resíduos padronizados
#-------------------------------------

31
#-----------------------------------------------------------------
# Figura 2.3 - Não Normalidade dos Erros
# Gráficos dos Resíduos Esperados com os Resíduos Ordenados
#-----------------------------------------------------------------
#-----------------------------------------------------------------
# Figura 2.4 - Resumindo todos gráficos
#-----------------------------------------------------------------
######################### FIM DO CURSO ##########################