avaliação preliminar do desempenho de redes neurais...
TRANSCRIPT

Avaliação preliminar do desempenho de redes neurais feedforward para a
previsão de preços de derivados da cana-de-açúcar
Amanda Delatorre1, Sérgio Okida
1, Flávio Trojan
1, José Carlos Alberto de Pontes
2,
Sergio L. Stevan Jr.1,3
, Hugo Siqueira1
1 Departamento Acadêmico de Engenharia Eletrônica, e
2 Departamento Acadêmico de
Matemática, Universidade Tecnológica Federal do Paraná, Ponta Grossa, Paraná, Brasil,
3 Programa de Pós Graduação em Computação Aplicada, Universidade Estadual de Ponta
Grossa, Ponta Grossa, Paraná, Brasil,
[email protected], [email protected], [email protected],
[email protected], [email protected], [email protected]
RESUMO
O Brasil é um dos maiores produtores mundiais de cana-de-açúcar o que impacta diretamente
a geração de empregos e o produto interno bruto do país. Neste sentido, esta investigação
propõe a aplicação de redes neurais feedforward - perceptron de múltiplas camadas (MLP) e
máquinas de aprendizado extremo (ELM) - para a previsão preços de derivados de cana:
açúcar, etanol hidratado e etanol anidro. As ELMs são caracterizadas por um processo de
treinamento simples e eficiência computacional, aliados a bons desempenhos. Os resultados
computacionais obtidos mostram que esta arquitetura é um candidato viável para a solução de
problemas de previsão.
PALAVRAS-CHAVE: Redes Neurais feedforward, MLP, ELM, previsão, Açúcar, Etanol.
ABSTRACT
Brazil is one of the largest producers of sugarcane which directly impacts job creation and
gross national product. In this sense, this research proposes the establishment of feedforward
neural network - multilayer perceptron (MLP) and extreme learning machines (ELM) - for the
forecast of cane derivatives pricing: sugar, hydrous and anhydrous ethanol. The ELMs are
characterized by a simple training process and computational efficiency, combined with good
performances. The computational results show that this architecture is a viable candidate for
the solution of forecasting problems.
KEYWORDS: Feedforward Neural Networks, MLP, ELM, Prediction, Sugar, Etanol.

INTRODUÇÃO
Atualmente, o Brasil é um dos maiores produtores mundiais de açúcar, conforme
Moraes e Bacchi (2014), e sua cadeia produtiva gera milhares de empregos diretos e indiretos,
além de uma quantidade elevada de divisas (Alves e Bacchi, 2004). Isto impacta diretamente
na economia e no produto interno bruto do país. A chamada “Economia do Açúcar” foi
responsável pela consolidação da colonização, através da ocupação de parte da costa
brasileira. Introduzida no Brasil ainda no período colonial, devido ao solo e clima favoráveis,
a produção cana-de açúcar foi o vetor de introdução do país no mercado internacional,
tornando-se durante séculos, o seu principal produto.
O açúcar e o etanol são alguns dos subprodutos mais relevantes da cana. O primeiro
teve, nas últimas décadas, seu consumo acelerado por diversos fatores: mudanças
socioeconômicas e demográficas, tais como a urbanização, composição das famílias e o
aumento da participação da mulher no mercado de trabalho (Souza et al., 2014). Produtos
altamente dependentes dessa matéria prima, como o iogurte, o refrigerante e alimentos
preparados tiveram seu consumo elevado na proporção de 7, 4 e 2 vezes entre 1974 e 2003
(Schlindwein e Kassouf, 2007), atingindo a marca mundial de produção de 155 milhões de
toneladas na safra 2010/11, aproximadamente (Souza et al, 2014). Há, portanto uma relação
direta entre a exportação desse bem com a balança comercial nacional (Alves e Bacchi, 2004),
fato que demonstra a importância do estudo de metodologias acuradas para previsão de seu
preço (Jati, 2013).
O etanol é um dos combustíveis mais utilizados para abastecimento de veículos no
Brasil. O advento do Proálcool em 1975 elevou consideravelmente a produção de cana no
país. Em tempos mais recentes, com a introdução no mercado dos carros flex fuel, esse
crescimento tornou-se ainda mais vertiginoso, chegando a uma produção de 520 milhões de
toneladas em 2007 (Figueira e Bacchi, 2014; Lima e Souza, 2014). Hoje cerca de 32% de toda
energia gerada no Brasil vai para o setor de transporte, sendo que deste montante, em 2013,
14,3% de toda energia gerada para o setor foi proveniente do Etanol, com um total consumido
de 3,67.109 l/dia (EPE, 2014).
O Balanço Energético Nacional de 2014 (EPE, 2014) aponta que, segundo o
Ministério da Agricultura, Pecuária e Abastecimento (MAPA), a produção de cana-de-açúcar
foi de 648,1 milhões de toneladas. Este valor é 9,2% superior ao ano anterior no qual
593,6 milhões de toneladas foram para moagem. De acordo com o documento, em 2013 a
produção nacional de açúcar foi de 37,3 milhões de toneladas. A fabricação de etanol, por sua
vez, atingiu o montante de 27.608,6 mil m³, sendo 56,5% referem-se ao etanol hidratado:

15.603,9 mil m³. Por conseguinte, a produção de etanol anidro, que é misturado à gasolina A
para formar a gasolina C, registrou acréscimo de 25,5%, totalizando 12.004,7 mil m³.
Nesse contexto é possível perceber que o estudo de metodologias de previsão do preço
de derivados de cana torna-se um campo de pesquisa relevante. Tarefas de previsão, em geral,
podem ser tratadas como mapeamento não-linear estático. Assim este trabalho propõe, para o
tratamento do problema abordado, a utilização das redes neurais feedforward (Haykin, 1999).
As arquiteturas de redes neurais artificiais podem ser classificadas quando a existência
ou não de laços de realimentação, que podem reinserir na entrada dos modelos informações de
saída. As redes feedforward não possuem realimentação e são adequadas a mapeamento não-
linear estático, desde que a função a ser aproximada seja contínua, limitada e totalmente
diferenciável (Haykin, 1999; Siqueira et al., 2014).
O principal representante dessa classe é o perceptron de múltiplas camadas (MLP - do
inglês multilayer perceptron), arquitetura que, com o trabalho de Rumelhart et al. (1986) que
reapresenta o algoritmo backpropagation para cálculo do vetor gradiente dos pesos da rede,
ganha destaque na literatura (Haykin, 1999). Esta rede é totalmente treinada e pode aproximar
qualquer mapeamento, sendo adequada a problemas de previsão, clusterização, equalização de
canais, dentre outros (Siqueira et al., 2012; 2014).
Recentemente, Huang et al. (2004) propuseram as máquinas de aprendizado extremo
(ELM – do inglês extreme learning machines). Os autores concluíram que com a inserção de
neurônios totalmente diferenciáveis é possível aproximar qualquer mapeamento com a
inserção de novos neurônios aleatoriamente gerados. Fica claro a relação direta entre as ELMs
e MLPs, sendo a primeira uma versão desorganizada da segunda, na qual a camada
intermediária não sofre nenhum tipo de ajuste (Huang et al., 2006; Siqueira et al., 2014).
O objetivo geral deste trabalho é investigar, comparar e propor uma metodologia para
as previsões do preço do açúcar na Brasil realizadas com a utilização de arquiteturas de redes
neurais do tipo máquinas de aprendizado extremo e perceptron de múltiplas camadas.
REDES NEURAIS ARTIFICIAIS (RNA)
O sistema nervoso dos organismos superiores é composto por neurônios conectados
entre si e por uma rede de sinapses que possuem como funções básicas receber as informações
pelos dendritos, processá-las e enviá-las de forma distribuída (Haykin, 1999).
Estas características qualificam o comportamento neural à capacidade de adaptar-se
aos estímulos desconhecidos a partir de estímulos conhecidos para realizar tarefas inéditas. A

capacidade que o indivíduo tem de modificar seu comportamento em função de experiências
passadas caracteriza o processo de aprendizado (Castro, 2006).
Esta é a inspiração biológica que fez surgir a neurocomputação, ciência que se baseou
nos sistemas neurais biológicos de processamento de informação paralelo, distribuído e
adaptável, que autonomamente desenvolvem capacidade respostas ao ambiente
(Haykin, 1999).
Perceptron de múltiplas camadas
Uma rede neural artificial MLP, por sua vez, é capaz de aproximar qualquer função
não-linear, continua, limitada e diferenciável que possui entradas fixas em um espaço
compacto de precisão arbitrária, o que a torna um aproximador universal. Em uma MLP a
primeira camada transmite o sinal de entrada à camada. As camadas escondidas tem como
função mapear o sinal de entrada de forma não-linear em um outro espaço de acordo com a
particularidades de cada problema. Já a camada de saída recebe o sinal transformado, e
através de combinações lineares, fornece da resposta a rede. Na Figura 1 apresenta-se uma
rede MLP genérica (Haykin, 1999, Castro, 2006).
Na Figura, u representa o vetor de entradas da rede, b é vetor de bias (polarização), w
é o vetor de pesos sinápticos que, combinados com as entradas, formam um vetor do sinal de
saída x. Este passa por uma função de ativação não-linear f, geralmente a tangente
hiperbólica. Os neurônios da camada de saída possuem função de ativação linear fs. A
resposta da rede y será dada pela Equação (1):
K
k
N
n
n
i
kn
s
ks uwfwfy0 0
1 (1)
em que i
knw são os pesos, k=0,1,...,K a variável que referencia o neurônio e n=0,1,...,N a
entrada que chega até o mesmo. Os coeficientes s
kw1 são as conexões do neurônio de saída. As
demais indicações são: “ 1” representa a entrada de polarização, i
kx simboliza a ativação do
k-ésimo neurônio da camada intermediária, f é a função de ativação dos neurônios desta
camada e fs , em geral linear, da camada de saída.
Neurônios de camadas disjuntas se conectam, enquanto neurônios de camadas
coexistentes não se comunicam, o que atribui à rede condição feedforward, ou seja, a rede não
possui nenhum tipo de realimentação. Chama-se de “Treinamento de uma rede MLP” o
processo de ajuste de suas ponderações ou pesos sinápticos (Siqueira et al., 2012). Com base
em alguma métrica que represente o grau de adequação da resposta de cada interação, em

geral alguma métrica de erro, o objetivo é encontrar os pesos da rede neural e, eventualmente,
suas conexões, são alteradas durante o processo com vistas a encontrar o melhor conjunto de
pesos que realize o mapeamento desejado. Este procedimento pode ser visto como uma tarefa
de otimização linear irrestrita (Haykin, 1999).
Figura 1 – Rede Neural MLP.
Independente do modelo de otimização escolhido para realizar o treinamento é
necessário aplicar a RNA o algoritmo de retropropagação (backpropagation), pois é ele que
permite o cálculo do gradiente descendente da função custo formada pela saída da rede e o
sinal desejado. Uma decisão muito importante quando se está na etapa de treinamento de uma
rede neural é detectar quando se deve parar o processo. Um dos critérios mais utilizados é o é
determinar um erro de treinamento mínimo que, ao ser alcançado, interrompe o treinamento.
Aliado a este, a faz-se necessária a determinação do número máximo de iterações, já que há a
possibilidade do algoritmo de treinamento estacionar em um mínimo local. A técnica
conhecida como validação cruzada, na qual um conjunto de amostras desconhecidas da rede é
apresentado à mesma a cada iteração e, é muito utilizada para escolha do conjunto de pesos
ótimos. Na iteração em que o erro de saída de validação é mínimo, adotam-se as ponderações
que levaram a este comportamento como aquelas capazes de maximizar o poder de

generalização da rede (Haykin, 1999). Dessa maneira, a validação cruzada é capaz de auxiliar,
também, na definição da topologia mais adequada a determinado problema.
Máquinas de aprendizado extremo
Recentemente uma nova abordagem de rede feedfrward vem ganhando destaque na
literatura, a qual procura aliar grande simplicidade no processo de treinamento com bons
desempenhos. Trata-se das máquinas de aprendizado extremo (ELM) propostas por Huang et
al. (2004), as quais possuem única camada intermediária. A ELMs são tem seus pesos gerados
de forma aleatória, mas apenas aqueles da camada de saída passam por um processo de ajuste.
Interessantemente, a forma de treinamento proposta resume-se a encontrar a solução para um
problema de mínimos quadrados, tarefa com solução determinística e de custo computacional
bastante reduzido. Além disso, os métodos de treinamento baseados em gradiente –
característicos das MLPs - sempre incorrem no risco de pararem em mínimos locais e podem
apresentar convergência lenta (Huang et al., 2006).
Assim como as MLPs, as ELMs são capazes de aproximar qualquer mapeamento não-
linear, continuo, limitado e diferenciável com precisão arbitrária, fato demonstrado por meio
de uma abordagem construtiva em Huang et al. (2006). A precisão está aliada ao fato de que a
inserção de novos neurônios na camada escondida eleva o potencial de aproximação da rede.
A Figura 2 apresenta esta arquitetura:
Figura 2 – Rede Neural ELM
Os neurônios da camada intermediária possuem ativações dadas pela expressão 2:
)( buWfxhhh
nn (2)
na qual T
11-nnn ][ Kn,...u,u uu é o vetor que contém o sinal de entrada, KNhh
W são os
coeficientes (pesos) da camada intermediária, b o bias de cada unidade da camada escondida

e fh(.) especifica as ativações dos neurônios da camada escondida. As saídas são geradas pela
expressão (3):
hout
xWy n , (3)
onde Wout
são os pesos da camada de saída.
Como mencionado, a principal vantagem das ELMs é que apenas a camada de saída é
treinada de acordo com um sinal de erro, por meio do cálculo de dos parâmetros de um
regressor linear. Um candidato bastante comum para resolver este tipo de tarefa é o operador
generalizado de Moore-Penrose, o qual minimiza a norma do vetor de pesos de saída, de
acordo com a expressão seguinte:
dXXXout
WTT -1
)( hhh (3)
na qual ks NT
hX é a matriz contendo as saídas da camada intermediária, T1T )( hhh XXX é
a pseudo inversa de hX , 1sT
d é o vetor com a resposta desejada e Ts o número de
amostras.
APLICAÇÃO, RESULTADOS E DISCUSSÃO
Nesta seção discute-se a aplicação das redes MLP e ELM para previsão do preço de
três importantes derivados da cana-de-açúcar: açúcar cristal, etanol hidratado e etanol anidro.
Os dados coletados para o estudo estão disponíveis no site do Centro de Estudos Avançados
em Economia Aplicada, da Escola Superior de Agronomia Luiz de Queiróz (ESALQ), da
Universidade de São Paulo (USP) (CEPEA, 2015).
Os dados relativos ao açúcar são referentes ao Indicador Açúcar Diário da
ESALQ/BVMF (bolsa de valores de mercadorias e futuros). O valor unitário, em reais,
corresponde à saca de 50 kg e expressa os preços efetivamente negociados no mercado à vista
do estado de São Paulo. A especificação do produto é: açúcar cristal especial, com mínimo de
99,7 graus de polarização, máximo de 0,08% de umidade, máximo de 150 cor ICUMSA,
máximo de 0,07% de cinzas. No dia de acesso haviam disponíveis amostras de 23 de janeiro
de 2013 a 18 de maio de 2015, totalizando 573 amostras. Os dados do etanol são referentes
ao Indicador Semanal Etanol Anidro/Hidratado CEPEA/ESAL Combustível – Estado de São
Paulo. O levantamento dos preços é diário, porém a sua divulgação é realizada através de uma
média semanal. Os valores coletados referem-se a negócios efetivados na modalidade
spot entre usinas e distribuidoras - preços ao produtor (usina). Cada dado corresponde ao
preço por litro. Os dados do etanol anidro foram coletados desde a semana de 29 de novembro

de 2002 até a de 15 de maio de 2015, totalizando 650 amostras. No caso do etano hidratado há
uma semelhança na forma de coleta, porém o preço apresentado é uma série diária com alguns
poucos valores faltantes. Neste caso, a unidade é Reais por metro cúbico (R$/m3), havendo
1321 amostras.
A metodologia adotada para as previsões consistiu em separar todos os dados em três
conjuntos: treinamento, validação e teste. Os dois últimos foram selecionados com as 100
últimas amostras de cada série, sendo as 50 finais reservadas ao conjunto de testes. O restante
dos dados foi designado como conjunto de treinamento.
Em seguida, para selecionar as melhores variáveis (atrasos) utilizou-se a técnica de
filtragem conhecida como Informação mútua (MI) (Luna e Ballini, 2006). A Figura 3
apresenta o resultado gráfico da aplicação da MI à série etanol semanal.
Figura 3: Atrasos significativos calculados viaMI
É possível observar que até o 6º atraso há uma relação entre as amostras, uma vez que
esta é o último coeficiente que se encontra acima do limiar de confiança representado pelas
linhas horizontais, previamente calculado em ±0,78 por meio da técnica de bootstraping
(Luna e Ballini, 2006). Observa-se ainda que, com a metodologia utilizada, o 4º e 5º atrasos
têm pouca influência na previsão futura, Entretanto, considerou-se aproveitar até o último
atraso significativo, utilizando-os em ambas a redes. Para cada série discutida neste trabalho –
açúcar diário, etanol hidratado diário e etanol anidro semanal, o número de atrasos apontados
pela MI foi:

Tabela 1: Número de atrasos significativos calculados para cada série
De posse disso, a próxima etapa foi realizar a previsão com MLPs e ELMs. O
treinamento da MLP foi realizado por meio do algoritmo gradiente conjugado escalonado
modificado (Santos e Von Zuben, 2008), enquanto a ELM foi treinada pelo operador de
Moore-Penrose. O número de neurônios artificiais foi escolhido de forma empírica e, como
esperado, este número foi bastante variado com um mínimo de 10 e um máximo de 100.
Definida a melhor rede, os horizontes de previsão selecionados foram P = 1, 2 e 3 passos à
frente, com a previsão multipasso feita de forma direta (Sorjamaa et al., 2007). Para cada
caso, as redes foram executadas 50 vezes. As métricas de desempenho escolhidas foram o
erro quadrático médio (MSE) e erro absoluto médio (MAE) (Siqueira et al., 2014).
Os resultados computacionais são mostrados na Tabela 2, os quais apresentam como
medidas de erro a média aritmética dessas execuções. Nela, N. Neuron. denota o número de
neurônios na camada intermediária e MSE trein o erro de treinamento.
Tabela 2: resultados das previsões
Os resultados sumarizados mostram alguns comportamentos interessantes.
Inicialmente, observa-se que o número selecionado de neurônios na camada escondida foi
bastante disperso, sem apresentar um padrão para nenhuma das redes, mas quase sempre
acima de 15 unidades processadoras. Além disso, para a série do etanol hidratado e P=3,
ambas as redes chegaram ao seu número máximo de neurônios, 70 para a ELM e 100 para a
MLP. Tratando-se apenas do conjunto de treinamento, observa-se que a ELM conseguiu
Açúcar diário 4
Etanol hidratado diário 7
Etanol anidro semanal 6
Açúcar diário Etanol hidratado diário Etanol anidro semanal
ELM
Horizonte 1 2 3 1 2 3 1 2 3
N. Neuron. 15 30 50 50 60 70 30 30 10
MSE Trein. 0,0883 0,1496 0,1938 63,414 191,26 386,2577 0,0008 0,0026 0,0095
MSE Teste 0,0382 0,0811 0,1249 31,414 84,043 142,4381 0,0006 0,0016 0,0038
MAE Teste 0,1628 0,2369 0,2970 4,3379 7,4233 9,3117 0,0189 0,0308 0,0456
MLP
Horizonte 1 2 3 1 2 3 1 2 3
N. Neuron. 30 50 15 20 15 100 20 20 50
MSE Trein. 0,0886 0,1686 0,2912 159,053 686,473 1011,07 0,0024 0,0076 0,0133
MSE Teste 0,0395 0,0954 0,1725 39,512 127,239 179,5932 0,0004 0,0010 0,0017
MAE Teste 0,1657 0,2487 0,3238 5,056 8,413 9,9975 0,0154 0,0253 0,0334

aproximar o mapeamento com maior precisão em todos os casos, embora, em termos de
desempenho final, deva-se considerar o erro do conjunto de testes.
Analisando os resultados dos conjuntos de testes arbitrou-se que, para ser considerado
o melhor desempenho, deve-se utilizar o MSE, uma vez que os algoritmos de treinamento
usam esta métrica para cálculo do erro e posterior ajuste dos pesos da rede. Nesse sentido,
nota-se que houve uma coincidência absoluta entre o melhor desempenho e os valores de
MAE e MSE. Outro comportamento verificado, e esperado, é que à medida que o horizonte
de previsão se eleva, o erro final aumenta. Isto ocorre porque a correlação entre as amostras
subsequentes acaba sendo menor do que em caso de dados temporalmente consecutivos. Para
as séries de dados diários, invariavelmente a ELM alcançou os menores erros finais, enquanto
para os dados semanais, o melhor desempenho favoreceu a MLP para todos os horizontes de
previsão propostos. Este resultado reflete um comportamento interessante, já que, neste
último caso, a MLP foi superior em dados com magnitude bastante reduzida em relação as
demais. Todavia, considerando a diferença de desempenho geral, e o esforço computacional
empregado para cada arquitetura ser treinada, é possível afirmar preliminarmente que a ELM,
com toda sua simplicidade tanto de implementação, quanto de ajuste se saiu melhor na
previsão de preços geral.
A Figura 4 apresenta os resultados para uma execução do melhor modelo de predição
utilizando P =1 para cada uma das três séries (ELM, ELM e MLP, respectivamente), com o
resultado sobreposto ao valor observado. Como é observável, os dados previstos conseguem
se aproximar dos valores desejados, apresentando um uma estimativa aceitável do valor real.
CONCLUSÕES
O presente artigo investigou a aplicação de redes neurais feedforward na previsão de
preços de derivados da cana-de-açúcar. As séries de preços selecionadas foram a de açúcar
cristal diário, etanol hidratado diário e etanol anidro semanal. As arquiteturas escolhidas
foram as redes perceptron de múltiplas camadas (MLP) e as recentemente desenvolvidas
máquinas de aprendizado extremo (ELM). As ELMs podem ser vistas como versões
desorganizadas das MLPs, uma vez que sua camada intermediária não passa por nenhum tipo
de ajuste, ficando o treinamento resumido a encontrar os melhores coeficientes de um
combinador linear, tarefa esta com solução determinística e reduzido custo computacional.
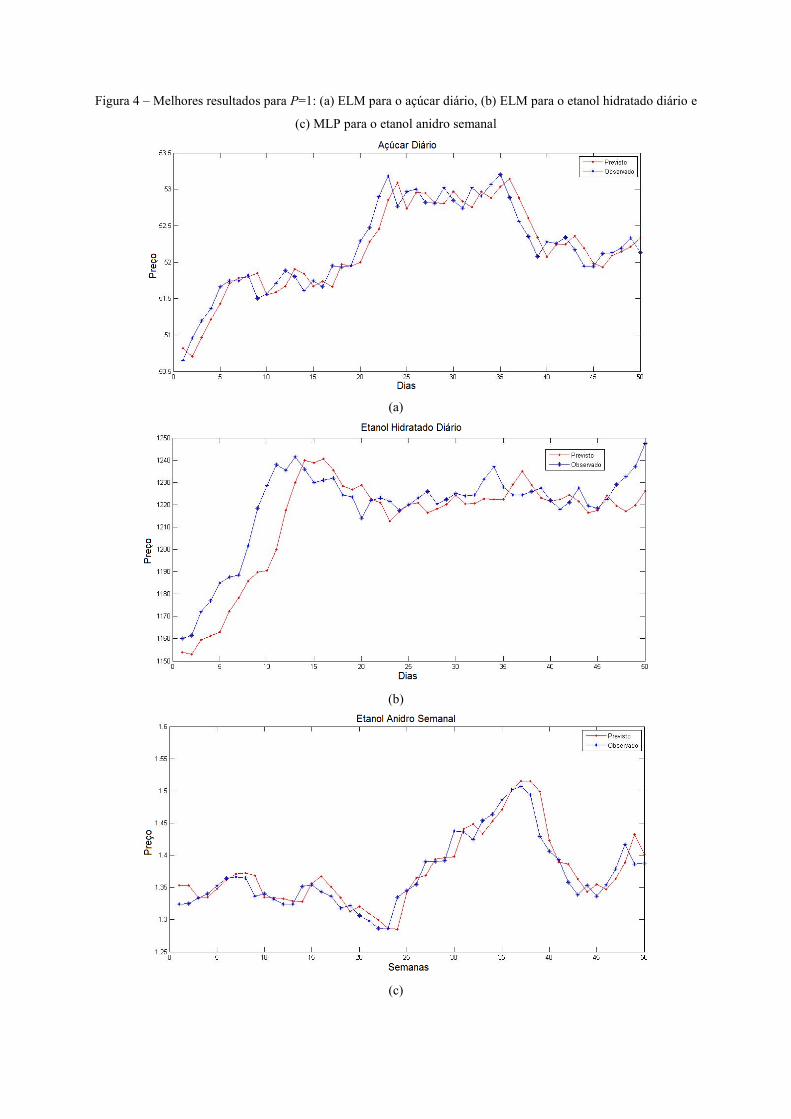
Figura 4 – Melhores resultados para P=1: (a) ELM para o açúcar diário, (b) ELM para o etanol hidratado diário e
(c) MLP para o etanol anidro semanal
(a)
(b)
(c)

O estudo foi baseado na previsão dos últimos 50 dados de cada série, com horizontes de 1, 2 e
3 passos à frente. O número de neurônios de cada rede foi determinado de forma empírica e a
seleção dos melhores atrasos foi feita por meio do cálculo da informação mútua entre as
amostras. Os resultados computacionais apresentaram desempenho superior para as ELMs nos
casos de séries diárias (e que possuem dados de maior magnitude), enquanto os dados
semanais foram de desempenho superior para a MLP. Tais resultados apontam que a ELM,
versão desorganizada da MLP, foi capaz de sobrepor a sua arquitetura totalmente treinada e
mostra que esta nova proposta é uma metodologia viável e de baixo custo computacional para
tratar previsões de séries de preços agrícolas e, possivelmente de séries temporais em geral.
Trabalhos futuros podem ser realizados no sentido de envolver outras arquiteturas de
redes neurais, como redes recorrentes e, também a aplicação a novas séries de preços. Além
disso, modelos lineares podem ser aplicados para um estudo comparativo.
REFERÊNCIAS
ALVES, L. R. A. ; BACCHI, M. R. P., Oferta de exportação de açúcar do Brasil. Revista de
Economia e Sociologia Rural, v. 42 (1), 2004.
BOX, G., JENKINS, G. E REINSEL, G. C., Time Series Analysis, Forecasting and Control,
3a. ed., Holden Day, Oakland, California, EUA, 1994.
CASTRO, L. N., Fundamentals of natural computing: basic concepts, algorithms and
applications. Chapman & Hall, 2006.
CEPEL, CENTRO DE ESTUDOS AVANÇADOS EM ECONOMIA APLICADA -
ESALQ/USP - disponível em: <http://cepea.esalq.usp.br>, acesso em: 01 de junho de 2015.
EPE, Empresa de Pesquisa Energética, Balanço energético nacional 2014 (ano base 2013).
Ministério de Minas e Energia, 2014
FIGUEIRA, S. R., BACCHI, M. R. P., BURNQUIST, H. L., Forecasting fuel ethanol
consumption in Brazil by time series models: 2006-2012. Applied Economics (Print), v. 42, p.
865-874, 2010.
HAYKIN, S., Neural Networks: A Comprehensive Foundation, 2a. ed., Prentice-Hall, Upper
Saddle River, NJ, 1999.
HUANG, G.-B., ZHU, Q.-Y., SIEW, C.-K., Extreme learning machine: A new learning
scheme of feedforward neural networks, Proc. Int. Joint Conf. Neural Networks, p. 985–990,
2004.
HUANG, G.-B., ZHU, Q.-Y., SIEW, C.-K., Extreme learning machine: Theory and
applications, Neurocomputing 70(1–3), p. 489–501, 2006.
JATI, K., Sugar Price Analysis in Indonesia International Journal of Social Science and
Humanity, Vol. 3 (4), 2013.

LIMA, N. C., SOUZA, G. H. S., A demanda do etanol e sua caracterização no mercado
brasileiro de combustíveis, Organizações Rurais & Agroindustriais, Lavras, v. 16 (4) (edição
especial), p. 532-544, 2014.
LUNA, I. BALLINI, R., Top-Down Strategies Based on Adaptive Fuzzy Rule-Based Systems
for Daily Time Series Forecasting, International Journal of Forecasting, p. 708-724. 2011.
MORAES, M. L., BACCHI, M. R. P., Etanol: do início às fases finais de produção, Revista
de Politica Agricola, v. 4, p. 5-22, 2014.
RUMELHART, D., G. HINTON, AND R. WILLIAMS, Learning Representations by
Backpropagation Errors, Nature, p. 533–536, 1986.
SANTOS E. P., VON ZUBEN, F. J., Improved second-order training algorithms for globally
and partially recurrent neural networks, in IEEE Proc. Int. Joint Conf. Neural Networks, p.
1501–1506, 1999.
SCHLINDWEIN, M. M. e KASSOUF, A. L., Mudanças no padrão de consumo de alimentos
tempo-intensivos e de alimentos poupadores de tempo, por região no Brasil. In: SILVEIRA,
F. G., SERVO, L. M. S., MENEZES, T. e PIOLA, S. F. (Org.). Gasto e consumo das famílias
brasileiras contemporâneas. Vol. 2. Brasília: IPEA – Instituto de Pesquisa Econômica
Aplicada, p. 423-462, 2007.
SIQUEIRA, H. V., BOCCATO, L., ATTUX, R., LYRA, C., Echo state networks and extreme
learning machines: A comparative study on seasonal streamflowseries prediction, Lecture
Notes in Computer Science 7664(2), p.491–500, 2012.
SIQUEIRA, H. V., BOCCATO, L., ATTUX, R., LYRA, C., Unorgnized Machines for
Seasonal streamflow series forecasting, International Journal of Neural Systems, v. 24, p.
1430009-1430016, 2014.
SORJAMAA, A., HAO, J., REYHANI, N., JI Y., LENDASSE, A., Methodology for long-
term prediction of time series, Neurocomputing 70, p. 2861–2869, 2007.
SOUZA, M. J. P., OLIVEIRA, P. R., BURNQUIST, H. L., Lar 'Doce' Lar: uma análise do
consumo de açúcar e de produtos relacionados no Brasil. Revista de Economia e Sociologia
Rural, v. 51, p. 785-796, 2013.