xii workshop de computação em clouds e aplicações wcga 2014 · luciano paschoal gaspary (ufrgs)...
TRANSCRIPT

Anais XII Workshop de Computação em
Clouds e Aplicações WCGA 2014

XXXII Simpósio Brasileiro de Redes de Computadores e
Sistemas Distribuídos
5 a 9 de Maio de 2014
Florianópolis - SC
Anais
XII Workshop de Computação em Clouds e
Aplicações (WCGA 2014)
Editora
Sociedade Brasileira de Computação (SBC)
Organizadores
Bruno Schulze (LNCC)
Danielo G. Gomes (UFC)
Luiz Bittencourt (UNICAMP)
Carlos André Guimarães Ferraz (UFPE)
Joni da Silva Fraga (UFSC)
Frank Siqueira (UFSC)
Realização
Universidade Federal de Santa Catarina (UFSC)
Promoção
Sociedade Brasileira de Computação (SBC)
Laboratório Nacional de Redes de Computadores (LARC)

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
i
Copyright ©2014 da Sociedade Brasileira de Computação
Todos os direitos reservados
Capa: Vanessa Umbelino (PostMix)
Produção Editorial: Roberto Willrich (UFSC)
Cópias Adicionais:
Sociedade Brasileira de Computação (SBC)
Av. Bento Gonçalves, 9500- Setor 4 - Prédio 43.412 - Sala 219
Bairro Agronomia - CEP 91.509-900 -Porto Alegre- RS
Fone: (51) 3308-6835
E-mail: [email protected]
Workshop de Computação em Clouds e Aplicações (12: 2014: Florianópolis,
SC)
Anais / XII Workshop de Computação em Clouds e Aplicações; organizado por
Bruno Schulze... [et al.] - Porto Alegre: SBC, c2014
118 p.
WCGA 2014
Realização: Universidade Federal de Santa Catarina
ISSN: 2177-496X
1. Redes de Computadores - Congressos. 2. Sistemas Distribuídos Congressos.
I. Schulze, Bruno. II. Sociedade Brasileira de Computação. III. Título.

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
ii
Promoção
Sociedade Brasileira de Computação (SBC)
Diretoria
Presidente
Paulo Roberto Freire Cunha (UFPE)
Vice-Presidente
Lisandro Zambenedetti Granville (UFRGS)
Diretora Administrativa
Renata de Matos Galante (UFRGS)
Diretor de Finanças
Carlos André Guimarães Ferraz (UFPE)
Diretor de Eventos e Comissões Especiais
Altigran Soares da Silva (UFAM)
Diretora de Educação
Mirella Moura Moro (UFMG)
Diretor de Publicações
José Viterbo Filho (UFF)
Diretora de Planejamento e Programas Especiais
Claudia Lage Rebello da Motta (UFRJ)
Diretor de Secretarias Regionais
Marcelo Duduchi Feitosa (CEETEPS)
Diretor de Divulgação e Marketing
Edson Norberto Caceres (UFMS)
Diretor de Relações Profissionais
Roberto da Silva Bigonha (UFMG)
Diretor de Competições Científicas
Ricardo de Oliveira Anido (UNICAMP)
Diretor de Cooperação com Sociedades Científicas
Raimundo José de Araujo Macêdo (UFBA)
Diretor de Articulação de Empresas
Avelino Francisco Zorzo (PUC-RS)

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
iii
Promoção
Sociedade Brasileira de Computação (SBC)
Conselho
Mandato 2013-2017
Alfredo Goldman (IME/USP)
José Palazzo Moreira de Oliveira (UFRGS)
Maria Cristina Ferreira de Oliveira (ICMC/USP)
Thais Vasconcelos Batista (UFRN)
Wagner Meira Junior (UFMG)
Mandato 2011-2015
Ariadne Carvalho (UNICAMP)
Carlos Eduardo Ferreira (IME - USP)
Jose Carlos Maldonado (ICMC - USP)
Luiz Fernando Gomes Soares (PUC-Rio)
Marcelo Walter (UFRGS)
Suplentes - 2013-2015
Alessandro Fabrício Garcia (PUC-Rio)
Aline Maria Santos Andrade (UFBA)
Daltro José Nunes (UFRGS)
Karin Koogan Breitman (PUC-Rio)
Rodolfo Jardim de Azevedo (UNICAMP-IC)

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
iv
Promoção
Laboratório Nacional de Redes de Computadores (LARC)
Diretoria 2012-2014
Diretor do Conselho Técnico-Científico
Elias P. Duarte Jr. (UFPR)
Diretor Executivo
Luciano Paschoal Gaspary (UFRGS)
Vice-Diretora do Conselho Técnico-Científico
Rossana Maria de C. Andrade (UFC)
Vice-Diretor Executivo
Paulo André da Silva Gonçalves (UFPE)
Membros Institucionais
SESU/MEC, INPE/MCT, UFRGS, UFMG, UFPE, UFCG (ex-UFPB Campus Campina
Grande), UFRJ, USP, PUC-Rio, UNICAMP, LNCC, IME, UFSC, UTFPR, UFC, UFF,
UFSCar, CEFET-CE, UFRN, UFES, UFBA, UNIFACS, UECE, UFPR, UFPA,
UFAM, UFABC, PUCPR, UFMS, UnB, PUC-RS, UNIRIO, UFS e UFU.

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
v
Realização
Comitê de Organização
Coordenação Geral
Joni da Silva Fraga (UFSC) Frank Augusto Siqueira (UFSC)
Coordenação do WCGA
Bruno Schulze (LNCC) Danielo G. Gomes (UFC)
Luiz Bittencourt (UNICAMP)
Coordenação de Workshops
Carlos André Guimarães Ferraz (UFPE)

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
vi
Realização
Organização Local
Carlos Barros Montez (UFSC)
Edison Tadeu Lopes Melo (UFSC)
Guilherme Eliseu Rhoden (PoP-SC)
Leandro Becker (UFSC)
Mário A. R. Dantas (UFSC)
Michelle Wangham (Univali)
Ricardo Felipe Custódio (UFSC)
Roberto Willrich (UFSC)
Rodrigo Pescador (PoP-SC)
Rômulo Silva de Oliveira (UFSC)
Secretaria do SBRC 2014
Juliana Clasen (UFSC)
Jade Zart (UFSC)

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
vii
Mensagem do Coordenador de Workshops do SBRC 2014
Confirmando a consolidação nos últimos anos, este ano o Simpósio Brasileiro de Redes
de Computadores e Sistemas Distribuídos (SBRC 2014) apresenta mais uma série de
workshops, visando a discussão de temas novos e/ou específicos, como Internet do
Futuro e Tolerância a Falhas. Os workshops envolvem comunidades focadas e oferecem
oportunidades para discussões mais profundas e ampliação de conhecimentos,
envolvendo pesquisadores e muitos estudantes em fase de desenvolvimento de seus
trabalhos em andamento. Neste ano tivemos novas submissões, além dos workshops já
considerados tradicionais parceiros do SBRC, o que representa o dinamismo da
comunidade de Redes de Computadores e Sistemas Distribuídos no Brasil. Infelizmente,
estas novas submissões não puderam ainda ser acomodadas, mas certamente serão
consideradas para próximas edições do SBRC.
Neste SBRC 2014, temos a realização de workshops já consolidados no circuito
nacional de divulgação científica nas várias subáreas de Redes de Computadores e
Sistemas Distribuídos, como o WGRS (Workshop de Gerência e Operação de Redes e
Serviços), o WTF (Workshop de Testes e Tolerância a Falhas), o WCGA (Workshop de
Computação em Clouds e Aplicações), o WP2P+ (Workshop de Redes P2P, Dinâmicas,
Sociais e Orientadas a Conteúdo), o WRA (Workshop de Redes de Acesso em Banda
Larga), o WoCCES (Workshop of Communication in Critical Embedded Systems), o
WoSiDA (Workshop on Autonomic Distributed Systems) e o WPEIF (Workshop de
Pesquisa Experimental da Internet do Futuro). Há que se mencionar a importante
parceria com o WRNP (Workshop da Rede Nacional de Ensino e Pesquisa), que em sua
15a edição, cumpre o importante papel de fazer a ponte entre as comunidades técnica e
científica da área. Não tenho dúvida que a qualidade técnica e científica dos workshops
se manterá em alta compatível com o SBRC.
Agradeço aos Coordenadores Gerais, Joni da Silva Fraga e Frank Siqueira (UFSC), pelo
convite para coordenar os workshops do SBRC 2014 e por todo o apoio recebido.
Desejo muito sucesso e excelente participação nos Workshops do SBRC 2014!
Carlos André Guimarães Ferraz (UFPE)
Coordenador de Workshops do SBRC 2014

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
viii
Mensagem dos Coordenadores do WCGA 2014
Sejam bem-vindos ao XII Workshop de Computação em Clouds e Aplicações (WCGA
2014), evento realizado em Florianópolis-SC em conjunto com o 32º Simpósio
Brasileiro de Redes de Computadores e Sistemas Distribuídos (SBRC 2014). O WCGA
tem se consolidado como um workshop que agrega um conjunto interessante de
trabalhos envolvendo os mais diversos temas dentro da computação em nuvem e,
historicamente, em grade. Como resultado, este fórum apresenta-se como um ambiente
para discussões de técnicas de pesquisas em andamento e atividades relevantes nas áreas
de infraestrutura real e virtualizada, serviços e diversas aplicações em nuvens
computacionais, congregando pesquisadores e profissionais que atuam ativamente
nestas áreas. O workshop também procura estabelecer redes colaborativas multi-
institucionais e grupos de competência técnico-científica, bem como fomentar a
discussão de tópicos incipientes ainda sem rumos definidos dentro do escopo do
WCGA.
O workshop iniciou a evolução de grades computacionais para clouds em 2010, e tem
dessa forma atraído submissões de grupos de pesquisa em todas as regiões do Brasil.
Com essa evolução, o WCGA consolidou-se como um importante workshop em redes e
sistemas distribuídos no país, alcançando em 2014 sua décima segunda edição.
As primeiras edições do WCGA (2003 - 2004 - 2005) foram realizadas no LNCC, em
Petrópolis-RJ. As edições de 2006, 2007, 2008, 2009, 2010, 2011, 2012 e 2013 foram
realizadas em conjunto com o Simpósio Brasileiro de Redes de Computadores e
Sistemas Distribuídos - SBRC em Curitiba (PR), Belém (PA), Rio de Janeiro (RJ),
Recife (PE), Gramado (RS), Campo Grande (MS), Ouro Preto (MG) e Brasília-DF. Os
anais destas edições anteriores do WCGA apresentam ampla combinação de diferentes
áreas de computação em grades e nuvens, como infraestrutura, middleware e aplicações,
com apresentações técnicas fomentando discussões em vários tópicos relevantes.
Nesta décima segunda edição do WCGA, de um total de 17 artigos submetidos, 8
artigos completos foram aceitos para publicação e apresentação no evento. Os tópicos
abordados nos artigos aceitos têm acompanhado a evolução da pesquisa em clouds, e
neste ano não é diferente: trabalhos envolvendo áreas importantes como elasticidade e
análise de desempenho, além de gerência e alocação de recursos, consolidam-se como
tópicos de interesse da comunidade de pesquisa em nuvem. Além disso, virtualização e
escalabilidade também aparecem como temas fortes no contexto do workshop. Por
último, mas não menos importante, arquiteturas para provisão de serviço em diferentes
níveis, incluindo questões de acessibilidade, são propostas e discutidas no workshop.

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
ix
Mensagem dos Coordenadores do WCGA 2014
A coordenação do WCGA agradece aos autores de todas as submissões recebidas e aos
autores de artigos aceitos pela apresentação do trabalho e contribuições para evolução da
pesquisa em computação em nuvem. Agradecemos especialmente a todos os revisores e
aos membros do comitê de programa pelo compromisso de realizar um excelente
trabalho de revisão dos artigos. Destacamos aqui, também, o apoio dos coordenadores
gerais do SBRC 2014, Joni da Silva Fraga (UFSC) e Frank Siqueira (UFSC), do
coordenador de workshops do SBRC 2014, Carlos André Guimarães Ferraz (UFPE) e
do comitê de organização local na pessoa de Roberto Willrich (INE/UFSC),
agradecendo seu trabalho e colaboração. Por fim, agradecemos as entidades que
acolhem e apoiam os organizadores do WCGA e SBRC: Unicamp, UFC, LNCC, UFSC
e SBC.
Luiz Fernando Bittencourt, co-coordenador e co-editor
Instituto de Computação
Universidade Estadual de Campinas - Unicamp
Danielo Gonçalves Gomes, co-coordenador e co-editor
Grupo de Redes de Computadores, Engenharia de Software e Sistemas (GREat)
Universidade Federal do Ceará - UFC
Bruno Schulze, co-coordenador e co-editor
ComCiDis – Computação Científica Distribuída,
Laboratório Nacional de Computação Científica - LNCC

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
x
Comitê de Programa do WCGA 2014
Alba Melo (UnB)
Antônio Tadeu Azevedo Gomes (LNCC)
Antonio Mury (LNCC)
Artur Ziviani (LNCC)
Carlos Ferraz (UFPE)
Cesar De Rose (PUCRS)
Claudio Geyer (UFRGS)
Cristina Boeres (UFF)
Daniel Batista (USP)
Daniel de Oliveira (UFF)
Edmundo Madeira (UNICAMP)
Fabio Costa (UFG)
Fabricio da Silva (CETEX)
Fernando Koch (IBM Research)
Hélio Guardia (UFSCar)
Hermes Senger (UFSCAR)
José Neuman de Souza (UFC)
Luis Carlos de Bona (UFPR)
Luis Veiga (INESC-ID, PT)
Marco Netto (IBM Research)
Marcos Assunção (IBM Research)
Nabor Mendonça (Unifor)
Nelson Fonseca (UNICAMP)
Noemi Rodrigues (PUC-Rio)
Paulo Ferreira (INESC-ID, PT)
Philippe Navaux (UFRGS)
Raphael Camargo (UFABC)
Rossana Andrade (UFC)
Wagner Meira Jr. (UFMG)
Walfredo Cirne (Google)

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
xi
Sumário
Sessão Técnica 1 – Desempenho.................................................................................. 1
Análise do Desempenho de Sistemas Operacionais Hospedeiros de Clusters
Virtualizados com o VirtualBox
David W. S. C. Beserra (UFRPB), Rubens K. P. da Silva, Kádna Camboim,
Alexandre W. T. Borba, Jean C. T. de Araujo, Alberto E. P. de Araujo............... 3
Análise de Escalabilidade de Aplicações Hadoop/MapReduce por meio de
Simulação
Fabiano da G. Rocha (UFSCar) e Hermes Senger................................................ 16
Análise de Desempenho do Virtualizador KVM com o HPCC em Aplicações de
CAD
Rubens K. P. da Silva (UPE), David Willians S. C. Beserra, Patricia T. Endo e
Sergio Galdino....................................................................................................... 28
Sessão Técnica 2 – Elasticidade................................................................................... 41
Uma Proposta de Framework Conceitual para Análise de Desempenho da
Elasticidade em Nuvens Computacionais
Emanuel F. Coutinho (UFC), Danielo G. Gomes e José Neuman de Souza......... 43
Métricas para Avaliação da Elasticidade em Computação em Nuvem Baseada
em Conceitos da Física
Emanuel F. Coutinho (UFC), Paulo A. L. Rego, Danielo G. Gomes e
José Neuman de Souza.......................................................................................... 55
Gerenciamento de Elasticidade em Nuvens Privadas e Híbridas
Rhodney Simões (UFAL) e Carlos A. Kamienski................................................. 67
Sessão Técnica 3 – Arquitetura e Gerência................................................................ 79
Alocação de Máquinas Virtuais em Ambientes de Computação em Nuvem
Considerando o Compartilhamento de Memória
Fernando J. Muchalski (UTFPR), Carlos A. Maziero........................................... 81

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
xii
Sumário
Deaf Accessibility as a Service: uma Arquitetura Elástica e Tolerante a Falhas
para o Sistema de Tradução VLIBRAS
Eduardo L. Falcão (UFPB), Tiago Maritan e Alexandre N. Duarte.................... 93
Índice por Autor......................................................................................................... 105

32º Simpósio Brasileiro de Redes de Computadores e
Sistemas Distribuídos
Florianópolis - SC
XII Workshop de Computação em
Clouds e Aplicações (WCGA)
Sessão Técnica 1
Desempenho


Análise do Desempenho de Sistemas Operacionais
Hospedeiros de Clusters Virtualizados com o VirtualBox
David Beserra1, Rubens Karman
2, Kádna Camboim
1, Jean Araujo
1, Alexandre
Borba1, Alberto Araújo
1
1Unidade Acadêmica de Garanhuns – Universidade Federal Rural de Pernambuco
(UFRPE)
Garanhuns – PE – Brasil
2Departamento de Computação Inteligente – Universidade de Pernambuco (UPE)
Recife – PE – Brasil
[email protected], [email protected], {kadna, jean, alexandre,
aepa}@uag.ufrpe.br
Abstract. The Cloud Computing has applications in High Performance
Computing (HPC) and the virtualization is its basic technology, being
necessary analyze its overheads on performance of HPC applications. In this
work, was analyzed the performance of virtualized clusters with VirtualBox for
HPC applications in function of the Operating System (OS) chosen for host.
Linux presented best scalability performance and better resource distribution
between Virtual Machines (VMs) that share the same host, being more suitable
as OS host for virtualized clusters.
Resumo. A Computação em Nuvem tem aplicações em Computação de Alto
Desempenho (CAD) e a virtualização é sua tecnologia básica, sendo
necessário determinar suas sobrecargas no desempenho de aplicações de
CAD. Neste trabalho foi analisado o desempenho de clusters virtualizados
com o VirtualBox em aplicações CAD em função do Sistema Operacional (SO)
adotado como hospedeiro. O Linux apresentou maior escalabilidade de
desempenho e melhor distribuição de recursos entre Máquinas Virtuais (VMs)
que compartilham o mesmo hospedeiro, sendo mais adequado como SO
hospedeiro de clusters virtualizados.
1. Introdução
Atualmente, de acordo com [Younge et al. 2011], a Computação em Nuvem é o
paradigma dominante em sistemas distribuídos e a virtualização é sua tecnologia básica
mais destacada. A virtualização é um mecanismo que provê abstração de recursos de um
SO hospedeiro a um SO convidado, permitindo que mais de um SO convidado seja
instalado em VMs, executando concorrentemente sobre um SO hospedeiro [Ye et al.
2010]. Se a virtualização modifica o SO hospedeiro diz-se paravirtualização (PV), caso
contrário, virtualização total (VT). Os virtualizadores são as ferramentas que
implementam e gerenciam VMs e estão uma camada abaixo das ferramentas que
implementam nuvens [Younge et al. 2011].
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
3

A Computação em Nuvem oferece benefícios para CAD, como alta
disponibilidade, customização de SO e redução de custos com manutenção [Ye et al.
2010] [Napper e Bientinesi. 2009] A Computação em Nuvem obteve destaque em CAD
com o advento de nuvens científicas [Keahey et al. 2008] e aglomerados de
computadores (Clusters Beowulf) virtualizados [Foster et al. 2006]. Como os
virtualizadores são a tecnologia básica da computação em nuvem, é necessário avaliar
seu desempenho para aplicações CAD, das quais as mais tradicionais são as aplicações
que fazem uso da Interface de Passagem de Mensagens (MPI) executando em Clusters
Beowulf [Ye et al. 2010][Mello et al. 2010].
Neste trabalho, foi analisado o desempenho do virtualizador VirtualBox para
aplicações de CAD e como a escolha do SO hospedeiro influi no desempenho de um
ambiente virtualizado para CAD. Em continuação a este trabalho, a Seção 2 introduz o
VirtualBox no contexto de CAD. A Seção 3 descreve os objetivos a serem alcançados e
os procedimentos metodológicos adotados. A Seção 4 apresenta os resultados obtidos e
a Seção 5 encerra o trabalho com os resultados e as considerações finais.
2. A Computação de Alto Desempenho, os Virtualizadores e o VirtualBox
Alguns requisitos devem ser atendidos ao empregar virtualização em CAD: A
sobrecarga da virtualização não deve ter impactos significativos no desempenho do
sistema, deve melhorar a administração do ambiente, permitindo a criação e destruição
rápida de VMs e distribuição flexível de recursos de hardware. Também deve isolar
aplicações em VMs e prover migração automática de VMs de um servidor a outro
quando necessário, para aumentar a confiabilidade e a segurança do ambiente [Ye et al
2010].
Alguns trabalhos já abordaram o uso do VirtualBox para CAD, como o de
[Younge et al. 2011], que analisou a viabilidade da virtualização para CAD. Foram
analisados os virtualizadores de código aberto Xen, KVM e VirtualBox e elaborada uma
tabela-resumo de suas características principais, sendo a Tabela 1 uma versão
atualizada. Em relação a original verifica-se o aumento na capacidade de endereçamento
de memória do VirtualBox de 16 GB para 1 TB. O desempenho dos virtualizadores foi
medido com o High Performance Computing Benchmark (HPCC) e o Standard
Performance Evaluation Corporation (SPEC) aplicado em clusters virtuais. A partir dos
resultados obtidos foi elaborada uma classificação de virtualizadores para CAD,
concluindo que KVM e VirtualBox são os melhores em desempenho global e facilidade
de gerenciamento.
Dentre os virtualizadores analisados em [Younge et al. 2011], apenas o
VirtualBox suporta um SO não unix-like como hospedeiro. Sabe-se que o desempenho
da rede de comunicação afeta o desempenho de processamento do cluster quando o
mesmo aumenta de tamanho [Ye et al. 2010]. Todavia, não foram realizados testes de
escalabilidade, onde em larga escala o melhor desempenho de rede do VirtualBox pode
implicar que o mesmo também supere o KVM em processamento.
Em [Mello et al. 2010] foi avaliado o desempenho de distribuições Linux de 32
e 64 bits como hospedeiros de clusters virtualizados com o VirtualBox, concluindo que
distribuições de 32 bits tem melhor desempenho. Foram avaliados também os efeitos do
compartilhamento de recursos em um mesmo hospedeiro, que foi incapaz de distribuir
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
4

igualmente os recursos entre as VMs. O trabalho é limitado por não avaliar o
desempenho do VirtualBox nos dois SOs hospedeiros possíveis. Avalia apenas o
desempenho de processamento e de rede, quando outros atributos, como taxa de leitura
e escrita em memória principal também são importantes [Johnson et al 2011][Ye et al.
2010]. A escalabilidade do ambiente também não foi avaliada.
[Beserra et al. 2012] avalia o desempenho de virtualizadores (VMWare
Workstation, Virtual PC e VirtualBox) para implementação de clusters virtualizados em
hospedeiros Windows. O VirtualBox obteve o melhor desempenho global. Tem as
mesmas limitações do trabalho de [Mello et al. 2010], além de utilizar apenas um núcleo
de processamento de quatro disponíveis.
Tabela 1. Resumo das características dos virtualizadores de código aberto.
Xen KVM VirtualBox
Ultima versão 4.3
Embutido no Kernel
Linux mais recente. 4.3.6
Para-virtualization Sim Não Sim
Full virtualization Sim Sim Sim
CPU hospedeira x86, x86-64, IA-64 x86, x86-64, IA-64, PPC x86, x86-64
CPU convidada x86, x86-64, IA-64 x86, x86-64, IA-64, PPC x86, x86-64
SO hospedeiro Linux, Unix Linux Windows, Linux,
OS X, Solaris, Unix
SO convidado Linux, Windows,
NetBSD Windows, Linux, Unix
Windows, Linux,
Unix, Solaris
VT-x / AMD-v Opcional Requerido Opcional
Núcleos suportados 128 64 128
Memória suportada 5TB 4TB 1TB
Aceleração 3d Xen-GL VMGL Open-GL, Direct3D
Live Migration Sim Sim Sim
Licença GPL GPL GPL/Proprietária
Diferentemente dos trabalhos citados, este verifica o desempenho do VirtualBox
para aplicações de CAD em ambos os SOs suportados para hospedeiro. Também
verifica o efeito das instruções de para-virtualização de rede e avaliam a escalabilidade
do desempenho. O objetivo desse trabalho foi determinar qual SO hospedeiro tem
melhor desempenho para CAD virtualizada com o VirtualBox. Por ser multiplataforma,
o VirtualBox pode ser utilizado para a criação de nuvens baseadas tanto em Linux
quanto em Windows, sendo necessário verificar a adequabilidade dos SOs hospedeiros
em cada contexto de aplicação.
3. Mensurando o Desempenho do VirtualBox para CAD
Esta seção trata da metodologia da pesquisa. Descreve o ambiente de provas, as
ferramentas de avaliação de desempenho empregadas e os testes executados. Todos os
testes foram executados dez vezes. Para cada teste foram descartados o maior e o menor
valor obtidos e calculadas a média e o desvio padrão dos demais, similarmente a [Ye et
al. 2010]. Obter o desvio padrão é importante, uma vez que, em um ambiente de nuvem
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
5

o serviço ofertado deve ser estável, confiável. Grandes oscilações de desempenho não
são bem vindas pelos clientes [Younge et al. 2011] [Napper e Bientinesi. 2009].
3.1. Ambiente de Testes
Os experimentos foram executados em oito computadores HP Compaq 6005, equipados
com processadores AMD Athlon II X2 220 operando em frequência de 2.8 GHz. Esse
processador tem um conjunto de instruções específicas para virtualização, o AMD-v. Os
computadores tem 8 GB de memória principal, do tipo DDR 3 com frequência de
operação de 1066 MHz.
A interconexão entre os computadores foi realizada com adaptadores de rede
Realtek RTL 8169 e um comutador de rede Intelbras SG 8000. Ambos funcionando em
conformidade com o padrão Gigabit Ethernet 10/100/1000. A ferramenta de
virtualização utilizada para a criação de todas as VMs usadas no experimento foi o
VirtualBox 4.3.6. Para a construção dos clusters foi utilizado o SO Rocks Clusters 6.1
64bit. O Rocks Clusters é um SO baseado em Linux desenvolvido para simplificar o
processo de criação de clusters de alto desempenho [Papadopoulos, Katz e Bruno.
2003]. Os hospedeiros de VMs utilizaram o Microsoft Windows 7 e o Kubuntu 13.04
como SO, ambos 64bit.
3.2. Ferramentas de Avaliação de Desempenho
Para comparar o desempenho dos diferentes ambientes testados foi utilizado o HPCC
[Luszczek et al. 2006]. O HPCC é o conjunto de testes padrão da comunidade de
pesquisa em CAD [Ye et al. 2010]. O HPCC avalia o desempenho do processador, da
memória, da comunicação inter-processos e da rede de comunicação. É constituído
pelos seguintes testes:
HPL – O High Performance Linpack mede a quantidade de operações de ponto
flutuante por segundo (FLOPS) realizadas por um sistema computacional
durante a resolução de um sistema de equações lineares. É o teste mais
importante para CAD [Young et al. 2011];
DGEMM – Mede a quantidade de FLOPS durante uma multiplicação de
matrizes de números reais de ponto flutuante de precisão dupla;
STREAM – Mede a largura de banda de memória principal (em GB/s).
PTRANS – O Parallel matrix transpose mede a capacidade de comunicação de
uma rede. Ele testa as comunicações onde pares de processadores comunicam-se
entre si simultaneamente transferindo vetores de dados da memória;
RandomAccess – Mede a taxa de atualizações aleatórias na mémoria (GUPs).
FFT – O Fast Fourier Transform mede a quantidade de operações com números
complexos de precisão dupla em GFlops durante a execução de uma
Transformada Rápida de Fourier unidimensional.
Communication Latency/Bandwidth – Mede a largura de banda (em MB/s) e a
latência da rede durante a comunicação inter-processos MPI utilizando padrões
de comunicação não simultânea (ping-pong) e simultânea (Anel de processos
Aleatoriamente Ordenados (ROR) e Anel Naturalmente Ordenado (NOR)).
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
6

O HPCC possui três modos de execução: single, star e mpi. O modo single
executa o HPCC em um único processador. No modo star todos os processadores
executam cópias separadas do HPCC, sem comunicação inter-processo. No modo mpi
todos os processadores executam o HPCC em paralelo, empregando comunicação
explícita de dados [Ye et al. 2010]. O HPCC requer a instalação de uma versão do MPI
e do Basic Linear Algebra System (BLAS). Para a realização dos experimentos deste
trabalho foram utilizados o OpenMPI (OMPI 1.4.1) e o AMD Core Math Library
(ACML 4.4.0).
3.3. Método Experimental
O objetivo geral deste trabalho é determinar qual SO hospedeiro tem melhor
desempenho em ambientes de cluster virtualizados com o VirtualBox. Portanto, todos
os testes foram executados para ambos os SOs hospedeiros admitidos pelo VirtualBox,
de forma a verificar como o desempenho varia em função da escolha do SO hospedeiro.
Os seguintes objetivos específicos foram utilizados na estruturação dos testes
realizados:
1. Determinar a sobrecarga provocada pela virtualização no desempenho de uma
única VM;
2. Determinar a sobrecarga provocada pela virtualização no desempenho de um
cluster virtual, em função da quantidade de nós do cluster (medição de
escalabilidade);
a. Verificar se o desempenho do cluster melhora ou piora ao usar as
instruções de paravirtualização de rede do VirtualBox.
3. Determinar os efeitos no desempenho de clusters virtuais durante o uso
concorrente de recursos de um mesmo hospedeiro físico por esses clusters.
3.3.1. Sobrecarga em uma única VM
Para alcançar o objetivo específico 1 o HPCC foi executado em dois ambientes
virtualizados, cada um com um SO hospedeiro diferente e com uma única VM por
hospedeiro físico. Cada VM com duas v-CPUs e 4GB alocados para uso como memória
principal e 4GB para uso exclusivo do SO hospedeiro. Seus desempenhos foram
comparados ao obtido pelo ambiente sem uso de virtualização (hardware nativo). Para
igualar os recursos entre todos os ambientes, o ambiente sem virtualização também
estava com 4GB de memória principal durante a execução dos testes.
3.3.2. Desempenho em Ambiente de Cluster
Para alcançar o objetivo específico 2 foram testados ambientes de cluster virtualizados,
nomeados EVA-01 e EVA-02. O ambiente EVA-01 tem como SO hospedeiro o
Kubuntu e o EVA-02 o Windows. Ambos os clusters foram configurados com uma VM
por hospedeiro físico, com configurações idênticas as descritas na subseção anterior. Os
clusters virtuais foram comparados a um ambiente de cluster instalado em hardware
nativo, nomeado EVA-00. Para igualar os recursos entre todos os ambientes, foi adotada
medida similar a descrita na subseção anterior.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
7

Para verificar a escalabilidade dos clusters em aplicações MPI, o HPCC foi
executado em quantidade variável de elementos de processamento (nodos), com o
parâmetro N do HPCC (tamanho do sistema linear a ser resolvido pelo HPL) ajustado a
cada quantidade, conforme Tabela 2. Após a execução desses testes, as instruções de
paravirtualização de rede foram desabilitadas e os testes reexecutados; para verificar o
efeito de tais instruções no desempenho de clusters virtualizados com o VirtualBox. Em
[Ye et al. 2010] é realizado um teste similar em um cluster virtualizado com o Xen, e o
uso de tais instruções refletiu em melhora do desempenho de rede e global do cluster.
Tabela 2. Valores utilizados para o parâmetro N do HPCC.
Nós 1 2 4 8
N 20664 29232 41328 58496
3.3.3. Efeitos do Compartilhamento de Recursos.
Foram instanciados dois clusters virtuais em um mesmo servidor para verificar como o
compartilhamento de recursos afeta o desempenho individual de cada cluster (objetivo
específico 3). Cada cluster foi configurado com dois nós e cada nó com uma vCPU e 1,5
GB de memória principal, de forma a não esgotar os recursos de processamento e
memória do sistema. O desempenho de ambos foi aferido simultaneamente com o
HPCC, com N = 17080. Os testes foram conduzidos em ambos os SOs suportados como
hospedeiro pelo VirtualBox.
É importante garantir que dois usuários que contratam um determinado serviço o
recebam com desempenho similar. Se o serviço, neste caso instâncias de VMs, é
fornecido em um mesmo hospedeiro, o SO do hospedeiro tem que distribuir os recursos
igualmente entre as VMs. Se isto não ocorre, então não se provê uma boa qualidade de
serviço, o que implica em impactos negativos para os usuários [Younge et al. 2011].
4. Resultados Obtidos
Esta seção apresenta os resultados obtidos dos testes e o que foi verificado em cada um.
4.1. Sobrecarga de uma única VM
As médias e desvios padrão dos resultados obtidos em cada teste são apresentados como
uma fração dos obtidos pelo sistema nativo. A Figura 1 apresenta o desempenho médio
das amostras obtidas pelo HPCC no modo mpi, exceto para os testes DGEMM e
STREAM, que não dispõe deste modo, sendo então apresentados seus resultados para o
modo star. Como em alguns testes os valores obtidos para o desvio padrão são muito
elevadas, não foi possível inclui-los na Figura 1, sendo exibidos a parte na Figura 2.
A capacidade de computação dos sistemas virtualizados, medida com HPL,
DGEMM e o FFT, é similar, embora para hospedeiros Linux seja 21% menor que a do
sistema nativo para o HPL, 30% para o DGEMM e 9,5% para o FFT. A diferença do
Windows para o Linux é de aproximadamente 1% para os três testes. Estes resultados
indicam que aplicações computacionais são sensíveis a virtualização em graus distintos.
A variação no desempenho de processamento dos ambientes virtualizados é pequena
quando comparada ao nativo. A capacidade de leitura e escrita em memória principal
dos ambientes virtualizados também é similar entre si.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
8

Por não estar conectado a uma rede, todos os processos executam localmente e o
desempenho dos testes em modo mpi não reflete o desempenho de rede e sim o da
comunicação inter-processo local. Neste item, ambos os ambientes virtualizados
apresentam desempenho similar em largura de banda. Entretanto, percebe-se grande
diferenciação em latência de comunicação, a qual é muito maior no ambiente hospedado
sob o Windows, sendo 4x superior a do ambiente nativo e 2x a do ambiente hospedado
sob Linux, para todos os padrões de comunicação testados.
Figura 1. Desempenho médio
Figura 2. Variação do desempenho
O desempenho da largura de banda de comunicação dos ambientes virtualizados
varia pouco entre si. Varia menos que o ambiente nativo para padrões de comunicação
em anel e mais para a comunicação ping-pong. A latência da comunicação, por outro
lado, apresenta grande variação em relação a si próprio e a variação do ambiente nativo,
com o Windows variando mais em padrões de comunicação do tipo anel que o Linux e
menos em comunicação ping-pong.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
9

4.2. Sobrecargas em ambiente de cluster
As Figuras 3, 4 e 5 apresentam respectivamente a escalabilidade do desempenho médio
de computação, de memória e de capacidade de comunicação dos ambientes testados.
As barras sobre os pontos representam o desvio padrão obtido sobre as médias.
Na Figura 3 verifica-se que o desempenho do ambiente EVA-01 para o HPL
aumenta em escala, embora degrade em relação ao ambiente EVA-00. O ambiente
EVA-02 não consegue aumentar o desempenho em escala. O uso de instruções de para-
virtualização de rede implicou em melhor desempenho de processamento para todos os
ambientes virtualizados. O desempenho no DGEMM, por não usar de comunicação
inter-processos, variou pouco em todos os ambientes e manteve-se similar ao obtido em
uma única VM. O desempenho com o FFT escala bem em EVA-00; pouco em EVA-01
e não escala em EVA-02. As instruções de para-virtualização pouco acrescentaram ao
desempenho com o FFT. A variação no desempenho foi pequena para todos os
ambientes em todos os testes de computação.
Figura 3. Escalabilidade da capacidade de computação
Na Figura 4 observa-se que o desempenho dos ambientes virtualizados no acesso
a memória é bastante inferior ao nativo, tanto em nível local (STREAM), quanto global
(RandomAccess). O desempenho obtido com o STREAM oscila muito nos ambientes
EVA-01 e EVA-02, enquanto o obtido com o RandomAcess apresenta poucas
oscilações. Para o teste RandomAcess verifica-se que o ambiente nativo apresenta boa
escalabilidade, ao contrario dos virtualizados, mesmo quando empregam instruções de
paravirtualização de rede. Problema similar foi verificado em [Ye et al. 2010] ao medir
a escalabilidade deste teste em um ambiente de cluster virtualizado com o Xen. A
justificativa apontada em [Ye et al. 2010] foi que o RandomAcess requer mais
comunicação entre processos que os outros testes, o que degrada o desempenho.
Figura 4. Escalabilidade do desempenho de memória
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
10

Da parte superior da Figura 5 percebe-se que a largura de banda de comunicação
de todos os ambientes apresenta escalabilidade similar ao ambiente nativo para todos os
padrões de comunicação testados. A queda de desempenho ao passar de 1 para 2 nodos
é devida ao emprego de recursos de rede em lugar de apenas barramentos locais aos
servidores. Da parte central da Figura 5 percebe-se que a latência de rede do ambiente
EVA-01 escala similarmente a de EVA-00, enquanto a do ambiente EVA-02 é muito
maior que a dos outros ambientes, além de apresentar maior variação de desempenho.
Essa grande latência na comunicação observada explica porque o ambiente
EVA-02 apresenta desempenho muito inferior em quase todos os testes. Excetuando-se
os testes DGEMM e STREAM, que operam em modo star, todos os demais testes
fazem uso intensivo da rede de comunicação. Logo, tem-se que a latência de rede é o
grande gargalo para a escalabilidade do desempenho do ambiente EVA-02 em todos os
aspectos que dela demandem.
A parte inferior da Figura 5 apresenta os resultados obtidos para o teste
PTRANS. A variação nos resultados foi pequena em todos os ambientes. O ambiente
EVA-01 escala e o EVA-02 não. As instruções de paravirtualização não melhoraram
consideravelmente o desempenho de nenhum dos ambientes virtualizados. Todavia, o
ambiente EVA-00 apresenta estouro de capacidade para este teste em 8 VMs quando
não usa as instruções de paravirtualização de rede.
Figura 5. Escalabilidade da capacidade de comunicação
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
11

4.3. Efeitos do compartilhamento de recursos
As Figuras 6 e 7 apresentam o desempenho obtido por dois clusters, nomeados Cluster
A e Cluster B, executando concorrentemente em um mesmo servidor hospedeiro, tendo
como SOs hospedeiros Linux (Figura 6) e Windows (Figura 7). A Tabela 3 exibe o
desvio padrão obtido em todos os testes, para todos os ambientes.
Na Figura 6 observa-se que o Linux foi capaz de prover boa distribuição dos
recursos de computação e memória local. Ambos os clusters virtuais apresentaram
desempenho similar, exceto para o teste FFT, que sofre queda brusca de desempenho no
Cluster B. Os recursos da rede de comunicação, por outro lado, são mal divididos, com
a largura de banda e a latência variando muito do Cluster A para o B.
Figura 6. Desempenho de clusters que compartilham hospedeiro Kubuntu
É provável que o mau desempenho na divisão dos recursos de rede de
comunicação ocorra devido as VMs de ambos os clusters utilizarem a mesma interface
de rede física. Enquanto que, os recursos de processamento e memória são distintamente
alocados pelo SO e estão dentro da capacidade do servidor hospedeiro (4 CPUs físicas –
4 vCPUs; 8 GB RAM total instalados no servidor – 6 GB RAM alocados as VMs).
Como o FFT é bastante afetado pelo desempenho da rede, é possível que esta seja a
causa de seu mau desempenho no Cluster B, que apresenta desempenho de rede muito
inferior ao Cluster A.
Na figura 7 nota-se que o Windows é incapaz de distribuir equivalentemente os
recursos compartilhados de rede entre os dois clusters, provendo distribuição de
recursos menos proporcional que o Linux. Por não utilizarem recursos de rede, o
DGEMM e o STREAM apresentaram desempenho mais compatível entre si, o que
indica que os recursos locais de processamento e memória são bem divididos pelo
Windows, embora não obtenha o mesmo desempenho do Linux.
A variação no desempenho individual de cada cluster é maior nos testes que
demandam pela rede de comunicação, em ambos os ambientes. De uma maneira geral o
desempenho do Cluster A sofre mais variação do que o do Cluster B em hospedeiros
Windows, para todos os testes.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
12
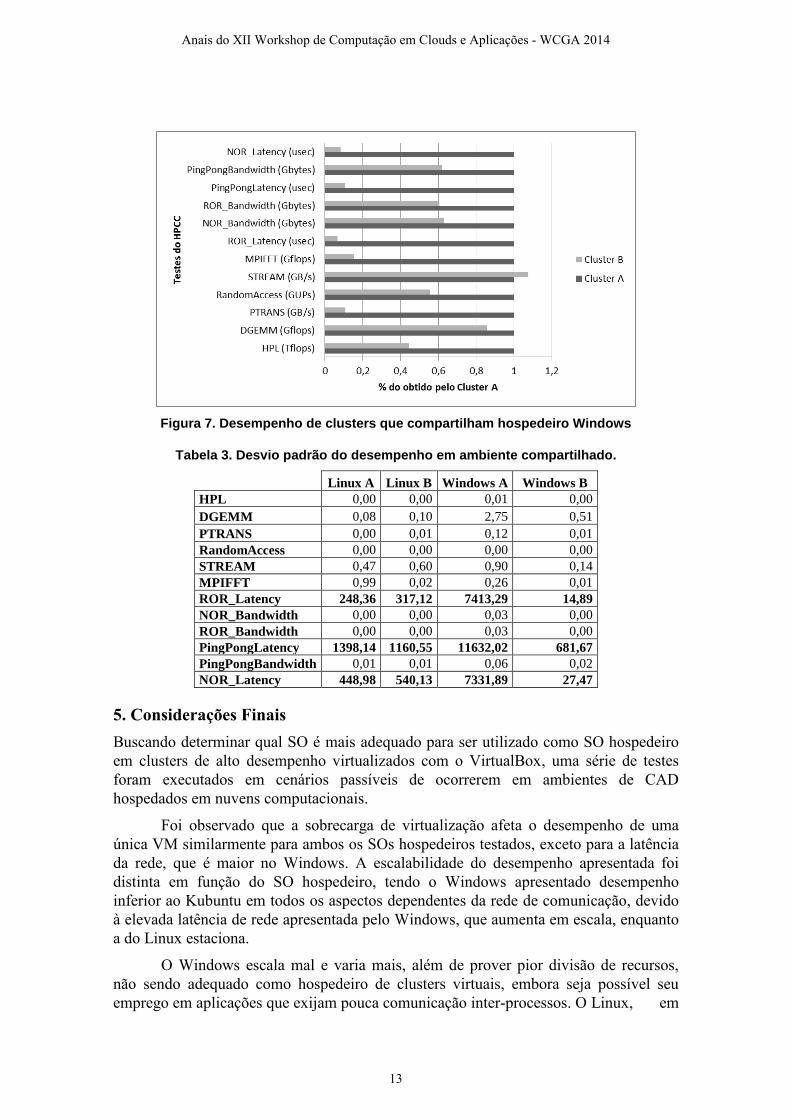
Figura 7. Desempenho de clusters que compartilham hospedeiro Windows
Tabela 3. Desvio padrão do desempenho em ambiente compartilhado.
Linux A Linux B Windows A Windows B
HPL 0,00 0,00 0,01 0,00
DGEMM 0,08 0,10 2,75 0,51
PTRANS 0,00 0,01 0,12 0,01
RandomAccess 0,00 0,00 0,00 0,00
STREAM 0,47 0,60 0,90 0,14
MPIFFT 0,99 0,02 0,26 0,01
ROR_Latency 248,36 317,12 7413,29 14,89
NOR_Bandwidth 0,00 0,00 0,03 0,00
ROR_Bandwidth 0,00 0,00 0,03 0,00
PingPongLatency 1398,14 1160,55 11632,02 681,67
PingPongBandwidth 0,01 0,01 0,06 0,02
NOR_Latency 448,98 540,13 7331,89 27,47
5. Considerações Finais
Buscando determinar qual SO é mais adequado para ser utilizado como SO hospedeiro
em clusters de alto desempenho virtualizados com o VirtualBox, uma série de testes
foram executados em cenários passíveis de ocorrerem em ambientes de CAD
hospedados em nuvens computacionais.
Foi observado que a sobrecarga de virtualização afeta o desempenho de uma
única VM similarmente para ambos os SOs hospedeiros testados, exceto para a latência
da rede, que é maior no Windows. A escalabilidade do desempenho apresentada foi
distinta em função do SO hospedeiro, tendo o Windows apresentado desempenho
inferior ao Kubuntu em todos os aspectos dependentes da rede de comunicação, devido
à elevada latência de rede apresentada pelo Windows, que aumenta em escala, enquanto
a do Linux estaciona.
O Windows escala mal e varia mais, além de prover pior divisão de recursos,
não sendo adequado como hospedeiro de clusters virtuais, embora seja possível seu
emprego em aplicações que exijam pouca comunicação inter-processos. O Linux, em
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
13

contrapartida, apresenta desempenho escalável, com poucas oscilações e melhor
distribuição de recursos, sendo mais adequado para aplicações de CAD. Temos que, por
maioria de casos vencedores e pela importância dos mesmos em CAD, o Linux
apresenta maior adequação para a implementação de clusters virtualizados com o
VirtualBox direcionados a CAD. Como trabalho futuro, verificar-se-ão os efeitos da
adição de uma segunda interface de rede no desempenho de clusters virtualizados que
compartilham o mesmo hospedeiro.
Referências
Beserra, D.W.S.C., Borba, A., Souto, S.C.R.A., de Andrade, M.J.P, e de Araújo, A.E.P.
(2012) "Desempenho de Ferramentas de Virtualização na Implementação de Clusters
Beowulf Virtualizados em Hospedeiros Windows." Em: X Workshop em Clouds,
Grids e Aplicações-SBRC 2012. SBC, Ouro Preto, pp. 86-95.
Foster, I., Freeman, T., Keahy, K. Scheftner, D., Sotomayor, B. e Zhang, X. (2006)
“Virtual clusters for grid communities,” International Symposium on Cluster
Computing and the Grid, IEEE, vol. 0, pp. 513–520.
Johnson, E., Garrity, P., Yates, T., e Brown, R. (2011) “Performance of a Virtual Cluster
in a General-purpose Teaching Laboratory”, In: 2011 IEEE International Conference
on Cluster Computing. Pp. 600-604. IEEE.
Keahey, K., Figueiredo, R., Fortes, J., Freeman, T. e Tsugawa, M. (2008) “Science
clouds: Early experiences in cloud computing for scientific applications,” Cloud
Computing and Applications.
Kejiang, Y., Jiang, X., Chen, S., Huang, D. e Wang, B. (2010) "Analyzing and modeling
the performance in xen-based virtual cluster environment." High Performance
Computing and Communications (HPCC), 2010 12th IEEE International Conference
on. IEEE.
Luszczek, P. R., Bailey, D. H., Dongarra, J. J., Kepner, J., Lucas, R. F., Rabenseifner,
R., & Takahashi, D. (2006). The HPC Challenge (HPCC) benchmark suite. In
Proceedings of the 2006 ACM/IEEE conference on Supercomputing pp. 213-225.
ACM.
Mello, T. C. Schulze, B. Pinto, R. C. G. e Mury, A. R. (2010) “Uma análise de recursos
virtualizados em ambiente de HPC”, Em: Anais VIII Workshop em Clouds, Grids e
Aplicações, XXVIII SBRC/ VIII WCGA, SBC, Gramado, pp. 17-30.
Napper, J. e Bientinesi, P. (2009) “Can cloud computing reach the TOP500?”, Em:
Proc. Combined Workshops on UnConventional High Performance Computing
Workshop Plus Memory Access Workshop, UCHPC-MAW '09, , pp. 17-20.
Papadopoulos, P. M., Katz, M. J., e Bruno, G. (2003). NPACI Rocks: Tools and
techniques for easily deploying manageable linux clusters. Concurrency and
Computation: Practice and Experience, 15(7‐8), 707-725.
Ye, K., Jiang, X., Chen, S., Huang, D., e Wang, B. "Analyzing and modeling the
performance in xen-based virtual cluster environment." High Performance
Computing and Communications (HPCC), 2010 12th IEEE International Conference
on. IEEE, 2010.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
14

Younge, A. J., Henschel, R., Brown, J. T., von Laszewski, G., Qiu, J., Fox, G. C.,
(2011) "Analysis of virtualization technologies for high performance computing
environments." 2011 IEEE International Conference on Cloud Computing
(CLOUD). IEEE.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
15

ANÁLISE DE ESCALABILIDADE DE APLICAÇÕES
HADOOP/MAPREDUCE POR MEIO DE SIMULAÇÃO
Fabiano da Guia Rocha1,2
, Hermes Senger2
1 Instituto Federal de Educação, Ciência e Tecnologia de Mato Grosso
Campus Cáceres – Mato Grosso, Brasil
2 Programa de Pós-Graduação em Ciência da Computação
Universidade Federal de São Carlos (UFSCAR)
[email protected], [email protected]
Abstract. MapReduce is a programming model for the execution of applications that
manipulate large data volumes in machines composed of several (potentially hundreds
or thousands) of processors/cores. Currently, Hadoop is the most widely adopted free
implementation of MapReduce. In this work we study the scalability of MapReduce
applications running on Hadoop adopted a combined approach involving both
experimentation and simulation. The experimentation has been carried out in a local
cluster of 32 nodes, and for the simulation we employed MRSG (MapReduce over
SimGrid). As main contributions, we present a scalability analysis method that allows
us to identify main performance bottlenecks and to improve the scalability of
MapReduce applications on larger clusters with thousands of nodes.
Resumo. MapReduce é um modelo de programação para a execução de aplicações que
manipulam grandes volumes de dados em máquinas compostas por até centenas ou
milhares de processadores ou núcleos. Atualmente Hadoop é o framework MapReduce
mais largamente adotado. Este trabalho descreve um estudo sobre a escalabilidade de
aplicações MapReduce executadas na plataforma Hadoop utilizando um método que
combina experimentação e simulação. A experimentação foi realizada em um cluster
local de 32 nós e para a simulação foi empregado o simulador MRSG (MapReduce
over SimGrid). Como principais contribuições, este artigo mostra como a abordagem
combinada pode ser empregada para identificar os principais gargalos em termos de
escalabilidade de aplicações reais em diferentes cenários, melhorando
significativamente a sua escalabilidade em plataformas com milhares de nós.
1. Introdução
MapReduce é um modelo de programação e um framework desenvolvido para
processamento paralelo de grandes volumes de dados em clusters com milhares de
processadores [Dean and Ghemawat 2004]. O modelo tem sido amplamente utilizado
por diversas empresas e mais recentemente pela comunidade de pesquisa em diversas
áreas como bioinformática, processamento de linguagem natural, aprendizagem de
máquina, análise de imagens e diversos outros segmentos.
No modelo MapReduce as tarefas de processamento são distribuídas entre os nós
implementando uma arquitetura mestre-escravo, na qual existe um único nó mestre
gerenciando um determinado número de nós escravos. A execução das tarefas ocorre em
duas etapas denominadas map e reduce. O nó mestre escalona as tarefas aos nós
escravos, determinando se o nó deve realizar uma tarefa map ou uma tarefa reduce.
Sempre que um nó escravo completar a execução de uma tarefa, ele sinaliza ao nó
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
16

mestre, para que esse possa escalonar uma nova tarefa ao escravo que está disponível. A
fase map manipula os dados na forma de lista de pares chave-valor, produzindo dados
intermediários que passam pela fase shuffle, são recombinados e posteriormente
consumidos e processados pela fase reduce [White 2009, Dean and Ghemawat 2004].
Hadoop é uma das mais conhecidas e difundidas implementações de MapReduce.
Foi desenvolvida pela Apache Software Foundation para executar aplicações em clusters
com milhares de nós, utiliza um sistema de arquivos distribuído denominado HDFS
(Hadoop Distributed File System) e conta com a implementação de mecanismos de
tolerância a falhas, balanceamento de cargas e distribuição de dados. Em ambientes
distribuídos, a plataforma Hadoop é capaz de gerenciar a arquitetura distribuída,
realizando, de forma automática, atividades como o escalonamento de tarefas, a
interação com o sistema de arquivos distribuídos e a troca de mensagens entre os nós
permitindo que o usuário se preocupe apenas com a lógica da aplicação [White 2009,
Dean and Ghemawat 2004]. Há relatos do uso do Hadoop/MapReduce na execução de
aplicações em um mesmo cluster com até 4.000 processadores, 40 mil tarefas
concorrentes, manipulando um total de até 20 petabytes [O’Maley 2011].
No Hadoop MapReduce, os dados de entrada são inicialmente divididos em N
partes (chunks), sendo N o número de tarefas map. Esses chunks são distribuídos e
replicados aos nós da arquitetura e representam os dados de entrada para as tarefas map.
O nó mestre aloca as tarefas map que efetuam o processamento dos dados de entrada e o
resultado intermediário é enviado às tarefas reduce. A função reduce efetua a
computação dos dados intermediários recebidos e grava os dados de saída no HDFS. No
ambiente de execução, uma tarefa reduce somente inicia após o término de todas as
tarefas map [White 2009].
SimGrid é um projeto de código aberto (open source) implementado em
linguagem C e utiliza arquivos XML (Extensible Markup Language) como entrada.
Nesses arquivos são definidas as características da simulação, tais como a topologia de
rede e as características e responsabilidades dos nós. No simulador, as aplicações são
modeladas pela manipulação de tarefas que são divididas em “tarefas de computação”,
que utilizam os recursos de processamento (CPU), ou “tarefas de transmissão”, que
utilizam o canal de comunicação [Casanova et al. 2008].
O MRSG (MapReduce Over SimGrid) foi desenvolvido sobre o SimGrid para
simular o ambiente e o comportamento do MapReduce em diferentes plataformas. Por
meio de uma descrição simplificada dos dados de entrada, tais como o tamanho e o custo
das tarefas, o MRSG consegue de maneira determinística simular o gerenciamento, o
escalonamento e a execução de tarefas de uma aplicação MapReduce, enquanto que a
computação dos nós e a simulação do ambiente são realizadas pelo SimGrid [Kolberg et
al. 2013].
Este artigo trata da análise de escalabilidade de aplicações MapReduce em
clusters com centenas ou muitos milhares de nós. Devido ao número limitado de
processadores disponíveis, nossa abordagem combina experimentação e simulação. A
experimentação permite uma primeira análise e a coleta de informações sobre o
desempenho de uma aplicação real, e a calibração do simulador torna possível a
reprodução do comportamento da aplicação real.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
17

Uma vez calibrado e validado, o simulador permite extrapolar a análise para
diversos cenários onde tanto o problema quanto a plataforma podem escalar
significativamente. Dessa forma, é possível identificar gargalos que irão aparecer em tais
cenários, e a criação de estratégias que podem auxiliar na melhoria tanto das aplicações
quanto da plataforma na busca por maior escalabilidade. Os experimentos foram
realizados em um cluster local de 32 nós e o simulador utilizado foi o MRSG. Os
experimentos mostram como seria possível elevar o limite de escalabilidade de uma
aplicação, de algumas centenas para até 10 mil nós com speedups quase lineares.
O artigo está assim organizado: a seção 2 apresenta os experimentos e resultados
obtidos na execução da plataforma real; a seção 3 descreve os testes de escalabilidade
com o simulador calibrado e os experimentos realizados com objetivo de minimizar os
gargalos identificados; na seção 4 expõe as conclusões do trabalho seguido pelo
referencial bibliográfico utilizado.
2. Análise de Escalabilidade de Aplicações MapReduce
Para estudar a escalabilidade de sistemas computacionais é necessário realizar
experimentos de larga escala, na ordem de muitos milhares de processadores, o que se
torna inviável em plataformas reais/experimentais devido à limitação de recursos, tempo
e dificuldades na reprodutibilidade dos experimentos. Neste trabalho buscamos
contornar a limitação em termos de recursos computacionais disponíveis e, para isso,
fez-se uso da combinação de experimentação real e de simulação. A metodologia
utilizada pode ser útil para prever a escalabilidade de aplicações sem depender da
disponibilidade de uma plataforma real, podendo avaliar uma grande variedade de
cenários com diferentes parâmetros e que não seria possível via experimentação real.
Para a experimentação em ambiente real, utilizou-se uma aplicação de índices
reversos, bastante eficiente e otimizada, conhecida por Per-Posting list [McCreadie et al.
2011]. Esse método de construção de índices reversos está presente no sistema de
recuperação de informações denominado Terrier1. Tal aplicação foi executada em um
ambiente real composto de 32 nós (cluster DC-UFSCar), que possibilitou a coleta de
dados necessários para calibrar do simulador.
A calibração foi necessária para que o simulador pudesse reproduzir com maior
acurácia o comportamento da aplicação escolhida para a plataforma de 32 nós
disponível. Uma vez calibrado, o simulador permite extrapolar o número de nós da
plataforma e avaliar a escalabilidade da aplicação-alvo para plataformas de grande porte,
da ordem de milhares de nós. Com a simulação das diferentes plataformas, é possível
identificar, ainda que de maneira aproximada, qual seria o comportamento esperado em
termos de escalabilidade da aplicação nessas plataformas.
2.1 Primeiro Experimento
Inicialmente, foram executados experimentos em um cluster do Departamento de
Computação (DC-UFSCar), composto por 32 nós conectados por um switch Gigabit
Ethernet. Cada nó de processamento possui 2 processadores AMD Opteron 246, 8
1 http://terrier.org
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
18

Gigabytes de memória RAM, 4 discos de 250 Gigabytes cada e sistema operacional
Linux CentOS. O desempenho de cada nó foi de 6.393254 Gflops, medido através do
benchmark Linpack [Dongarra et al. 2003]. A velocidade de transmissão da interface de
rede entre nós no mesmo switch foi medida através do software Iperf que indicou largura
de banda de 392 Mbps e latência de 1e-4
segundos. No cluster está instalado o Hadoop
versão 1.0.4, com 4 slots para a execução concorrente de tarefas map e reduce. O valor
padrão para o tamanho do chunks de dados foi de 64 Megabytes, fator de replicação
igual a 3 e o intervalo entre os heartbeats gerados por cada nó escravo foi de 3 segundos.
A aplicação utilizada nos testes foi a ferramenta de recuperação de informações
Terrier¹, que implementa a indexação Per-Posting list. Trata-se de um sistema
desenvolvido em Java voltado ao processamento de documentos em larga escala. Para a
composição de índices invertidos, o Terrier analisa um corpus de texto de forma
sequencial ou paralela, gerando um job, submetido para execução no cluster com
Hadoop. Por fim, o Terrier produz como resultado índices invertidos contendo dados
estatísticos sobre a incidência de cada termo encontrado nos documentos da coleção. Os
testes de indexação distribuída foram realizados utilizando-se a base de dados da coleção
Clueweb09_English_1 que é um subconjunto do corpus ClueWeb09 composto por mais
de 50 milhões de documentos. Esse conjunto de dados já foi largamente estudado e
otimizado, sendo utilizado em diversas trilhas na TREC 2009 [McCreadie et al. 2011].
A base de dados vem originalmente gravada compactada (formato tar.gz) de
forma a minimizar o tempo de E/S (entrada e saída). O Hadoop possui classes nativas
que lêem dados compactados nesse formato. A base de dados foi gerada replicando-se
dois arquivos até gerar 192 arquivos, totalizando aproximadamente 34 Gigabytes no
HDFS sendo composta por:
Número de Documentos: 4.169.664;
Número de Tokens: 4.287.926.208;
Número de Termos: 565.557;
Total de bytes lidos do HDFS: 35.810.457.876 bytes (aprox. 34 GB).
Por se tratar de uma base de dados voltada à recuperação de informações da
língua natural, os experimentos foram conduzidos com número fixo de 26 tarefas reduce
em que cada tarefa reduce trata de uma letra do alfabeto. Em todos os experimentos foi
fixado o número de 192 tarefas map, correspondente aos 192 arquivos de entrada.
2.2 Resultados do Primeiro Experimento (Makespan)
Cada experimento foi replicado duas vezes para plataformas com 32, 28, 24, 20, 16, 12,
8, 4 e 1 nó. Na Tabela 1 são descritos os tempos médios (em segundos) de execução das
fases map, reduce e o makespan (tempo total de execução da aplicação). Com base nos
tempos de execução das fases map, reduce e makespan calculamos o speedup
representado na Tabela 1, e ilustrado na forma gráfica na Figura 1.
Analisando o gráfico de speedup (Figura 1), observa-se que no caso do map há
um comportamento sublinear, ou seja, linear a menos de uma constante. O speedup
sublinear encontrado pode ser justificado pelos atrasos gerados pela sobrecarga do
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
19
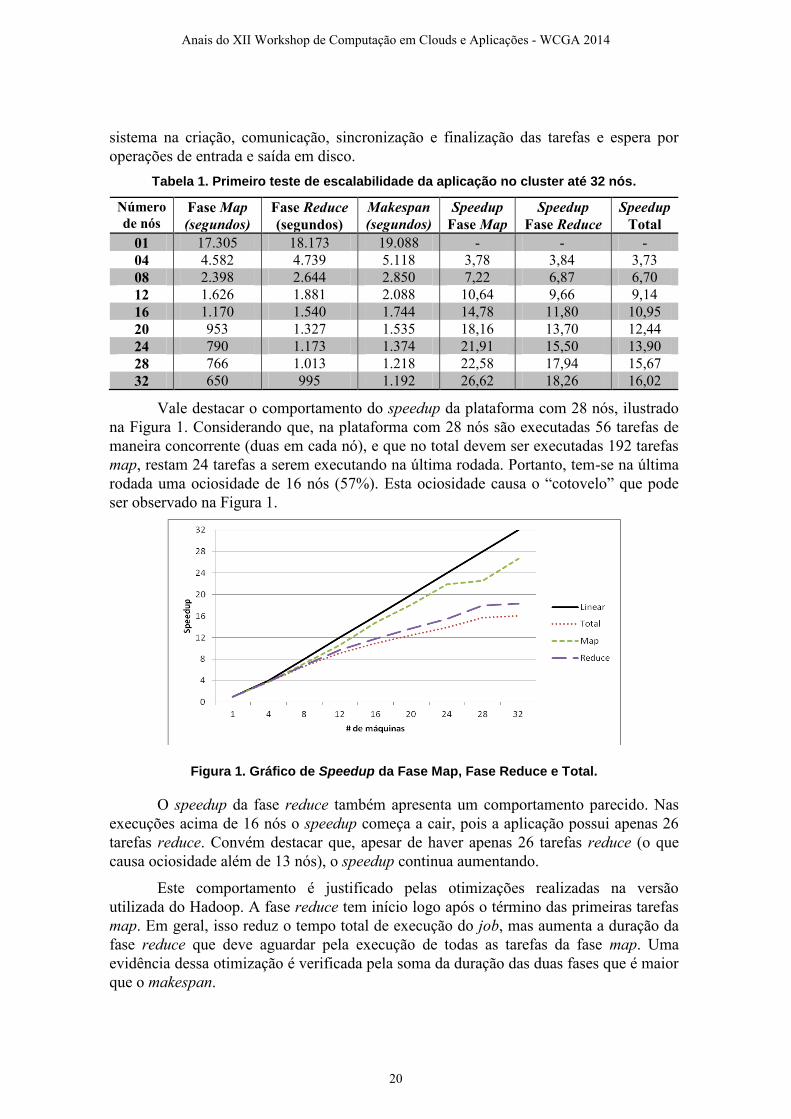
sistema na criação, comunicação, sincronização e finalização das tarefas e espera por
operações de entrada e saída em disco.
Tabela 1. Primeiro teste de escalabilidade da aplicação no cluster até 32 nós.
Número
de nós Fase Map
(segundos)
Fase Reduce
(segundos)
Makespan
(segundos)
Speedup
Fase Map
Speedup
Fase Reduce
Speedup
Total
01 17.305 18.173 19.088 - - -
04 4.582 4.739 5.118 3,78 3,84 3,73
08 2.398 2.644 2.850 7,22 6,87 6,70
12 1.626 1.881 2.088 10,64 9,66 9,14
16 1.170 1.540 1.744 14,78 11,80 10,95
20 953 1.327 1.535 18,16 13,70 12,44
24 790 1.173 1.374 21,91 15,50 13,90
28 766 1.013 1.218 22,58 17,94 15,67
32 650 995 1.192 26,62 18,26 16,02
Vale destacar o comportamento do speedup da plataforma com 28 nós, ilustrado
na Figura 1. Considerando que, na plataforma com 28 nós são executadas 56 tarefas de
maneira concorrente (duas em cada nó), e que no total devem ser executadas 192 tarefas
map, restam 24 tarefas a serem executando na última rodada. Portanto, tem-se na última
rodada uma ociosidade de 16 nós (57%). Esta ociosidade causa o “cotovelo” que pode
ser observado na Figura 1.
Figura 1. Gráfico de Speedup da Fase Map, Fase Reduce e Total.
O speedup da fase reduce também apresenta um comportamento parecido. Nas
execuções acima de 16 nós o speedup começa a cair, pois a aplicação possui apenas 26
tarefas reduce. Convém destacar que, apesar de haver apenas 26 tarefas reduce (o que
causa ociosidade além de 13 nós), o speedup continua aumentando.
Este comportamento é justificado pelas otimizações realizadas na versão
utilizada do Hadoop. A fase reduce tem início logo após o término das primeiras tarefas
map. Em geral, isso reduz o tempo total de execução do job, mas aumenta a duração da
fase reduce que deve aguardar pela execução de todas as tarefas da fase map. Uma
evidência dessa otimização é verificada pela soma da duração das duas fases que é maior
que o makespan.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
20

Com a execução real do Terrier na plataforma Hadoop e a base de dados de
entrada ClueWeb foi possível extrair os tempos de execução bem como os demais
parâmetros necessários para a etapa de calibração do simulador.
3. Calibração do Simulador MRSG
Para reproduzir adequadamente o comportamento de um sistema real, é necessário que
diversos parâmetros do simulador sejam configurados e calibrados, ou seja, deve ser
realizado o ajuste correto dos custos e demais parâmetros de aplicação permitindo que o
simulador reproduza o comportamento real da aplicação. Uma vez calibrado, pode-se
realizar simulações e verificar a acurácia do simulador validando a simulação com êxito.
Neste trabalho, o processo de calibração consiste em procurar valores de custo
das tarefas map e reduce (map_cost e reduce_cost) do simulador, para que a diferença
entre o tempo total simulado e o tempo total real seja minimizada. O custo de
computação por byte lido na fase map e na fase reduce está relacionado à quantidade de
trabalho que a tarefa deverá executar, possibilitando ao simulador estimar o tempo de
duração dessas tarefas.
Diversas execuções foram realizadas, até ajustar o custo das tarefas e calibrar o
simulador. A cada execução manual da plataforma simulada foram realizados ajustes
(aumentar ou diminuir o valor de custo) no parâmetro map_cost e reduce_cost de
maneira que o tempo de simulação corresponda o mais próximo possível do tempo real.
O erro percentual médio da fase map simulada ficou em torno de 2,43% em relação aos
testes reais e, na fase reduce o erro percentual médio foi de aproximadamente 2,06% em
relação à execução real.
Com o objetivo de obter uma maior acurácia entre o makespan simulado e o real,
buscamos ajustar os custos de map e reduce para execuções paralelas utilizando o valor
do custo médio obtido da experimentação real (1 a 24 nós) descontando-se os outliers
(valor mínimo e o máximo) e o custo para um nó (execução sequencial). Uma vez
calculado o custo médio de map e reduce, repetimos os testes no MRSG de 01 a 24 nós
conforme ilustrado na Tabela 2. Analisando o makespan obtido nos testes, observa-se
que o percentual de erro calculado entre o makespan real e o makespan da simulação foi
inferior a 1% com o erro percentual médio de aproximadamente 0,41%.
Tabela 2. Comparação entre o Makespan Real e o Makespan da Simulação.
Número de
nós
Makespan Real
(segundos)
Makespan Simulado
(segundos)
Erro (%)
01 19.088 19.248 0,83
04 5.118 5.127 0,17
08 2.850 2.871 0,73
12 2.088 2.095 0,33
16 1.744 1.739 0,28
20 1.535 1.528 0,45
24 1.374 1.373 0,07
Para validar o modelo de calibração ora executado, modelamos no MRSG um
cenário com 28 e 32 utilizando o custo médio de map e reduce calculado. O makespan
obtido da simulação foi comparado com o makespan extraído da execução real de 28 e
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
21

32 nós executada no cluster DC-UFSCar e calculado o percentual de erro inferior a 1%
em relação aos testes reais que pode ser observado na Tabela 3.
Tabela 3. Comparação entre o Makespan Real e o Makespan da Simulação.
Número de nós Makespan Real (seg) Makespan Simulado (seg) Erro (%)
28 1.218 1.207 0,91
32 1.192 1.188 0,33
Comparando a Tabela 2 com a Tabela 3, observa-se que o comportamento de
ambos os experimentos se assemelham e que a margem de erro foi relativamente baixa.
Assim, pode-se considerar que o simulador apresenta boa acurácia, podendo representar
com certo grau de confiabilidade o ambiente real desta aplicação específica em uma
plataforma pequena. Convém ressaltar que, para todos os experimentos, na simulação da
plataforma sequencial (um nó) utilizou-se o valor de custo obtido nos experimentos de
execução real.
3.1 Segundo Experimento: Teste de Escalabilidade com o Simulador Calibrado
Com o simulador calibrado, foi possível realizar diversos experimentos com plataformas
compostas por milhares de nós com o objetivo de avaliar a escalabilidade da aplicação.
Na realização dos testes de escalabilidade, modelamos plataformas com 1, 2, 5, 10, 20,
50, 100, 200, 500, 1.000, 2.000, 5.000 e 10.000 nós. Eis alguns parâmetros que foram
medidos na execução real e utilizados na configuração do simulador:
Map output gerado por cada tarefa map: 13343376 bytes;
Map cost: 1.22867E+12 (número de operações a serem executadas, por byte
de entrada da função map);
Reduce cost: 2.68667E+12 (número de operações a serem executadas, por
byte de entrada da função reduce);
Número de tarefas reduce: 26;
Chunk Size: 178 MB;
Input Chunks (tarefas map): 100.000;
Dfs réplicas: 3;
Map Slots e Reduce Slots: 2;
Tabela 4. Resultado Simulado das Fases Map, Reduce e do Makespan.
Número de nós Fase Map Fase Reduce Makespan Speedup Total Eficiência
01 8.707.546 8.158.951 9.029.708 1,000 1,000
02 4.879.228 4.554.412 5.042.337 1,791 0,895
05 1.951.695 1.819.932 2.015.104 4,481 0,896
10 975.849 905.803 1.003.390 8,999 0,900
20 487.926 439.568 488.363 18,490 0,924
50 195.173 176.107 195.626 46,158 0,923
100 97.589 88.309 98.070 92,074 0,921
200 48.797 44.448 49.330 183,047 0,915
500 19.519 28.829 30.785 293,315 0,587
1.000 10.015 28.642 29.652 304,523 0,305
2.000 5.029 28.551 29.155 309,714 0,155
5.000 2.087 28.545 28.816 313,357 0,063
10.000 1.181 28.556 28.822 313,292 0,031
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
22

Na Tabela 4 estão descritos, para cada experimento, os tempos de duração da fase
map, da fase reduce e o makespan. Com base nesses valores, foi calculado o speedup e a
eficiência do experimento conforme abaixo. O gráfico da Figura 2 ilustra o makespan
obtido na simulação para plataformas de 1 a 10.000 nós.
Figura 2. Gráfico de Makespan com 26 tarefas reduce e 100 mil tarefas map.
Como se pode observar, a partir de 200 nós os ganhos foram pouco significativos
e a partir de 500 nós o ganho é praticamente nulo. Isso ocorre devido ao baixo grau de
paralelismo da fase reduce, que possui apenas 26 tarefas. A fase reduce se tornou um
gargalo, porém, que pode ser facilmente melhorado aumentando-se o grau de
concorrência nesta fase.
Com a curva de speedup ilustrada no gráfico da Figura 3, percebe-se que a
aplicação não escala conforme o esperado a partir de 500 nós, ou seja, nota-se que a
escalabilidade aumenta sublinearmente até 500 nós, quando, então se estabiliza.
Figura 3. Gráfico de Speedup com 26 tarefas reduce e 100 mil tarefas map.
A eficiência da aplicação para a plataforma e as configurações ora simuladas
mantiveram constantes até 200 nós e, após esse valor, observa-se uma queda na
eficiência conforme ilustra a Figura 4. Com esses experimentos, é possível observar que
a fase map escala quase linearmente, desde que a quantidade de tarefas map seja
suficientemente grande para manter os nós ocupados. Alguns fatores podem contribuir
para que a fase map escale abaixo do linear, tais como a geração de uma grande
quantidade de tarefas não locais e o consequente aumento do tráfego de rede. Tais tarefas
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
23

têm impacto direto na aplicação, pois exigem a transmissão dos chunks antes da
execução.
Figura 4. Gráfico de Eficiência com 26 tarefas reduce e 100 mil tarefas map.
A implementação da aplicação faz com que a fase reduce não escale além de 26
núcleos (13 nós) devido à característica da aplicação que implementa 26 tarefas reduce,
em que cada tarefa é responsável por uma letra do alfabeto. Vale observar que a fase
reduce escala até 500 nós conforme a representação gráfica do speedup ilustrada na
Figura 3. Isso ocorre devido a uma otimização realizada no Hadoop, que antecipa o
início da fase reduce, logo que as primeiras tarefas map são finalizadas.
Na análise dos experimentos, observa-se que a fase reduce se mostrou um dos
principais limitantes da escalabilidade da aplicação (makespan). Isso ocorre, pois a fase
reduce atrasa a duração do job. Outro fator que pode ter influenciado o comportamento
observado da fase reduce é o gargalo ocasionado devido ao aumento dos tempos de
heartbeat. O simulador MRSG considera, por padrão, o intervalo de heartbeat como 3
segundos. Porém, se esse intervalo for muito longo os avanços na computação levarão
mais tempo para serem reportados, enquanto que intervalos muito curtos sobrecarregam
o nó mestre e a rede, o que pode também limitar a escalabilidade da aplicação.
Com objetivo de melhor adequar o valor do heartbeat ao tamanho da plataforma,
o MRSG ajusta o intervalo de heartbeat pela divisão do número de nós por 100. Caso
esse valor seja inferior a 3, utiliza-se o valor padrão, caso contrário, otimiza-se esse
intervalo. Nos experimentos realizados, o heartbeat foi de 3 segundos para plataformas
de 1 a 200 nós, de 5 segundos para 500 nós, de 20 segundos para 2.000 nós, de 50
segundos para 5.000 nós e de 100 segundos para 10.000 nós. Esse fato faz com que o nó
mestre (nó que executa o processo JobTracker) somente tenha ciência que a tarefa
terminou alguns instantes após e, consequentemente, o nó escravo (nó que executa o
processo TaskTracker) já estaria ocioso.
3.2 Terceiro Experimento: Redução do gargalo da fase Reduce
Uma possível estratégia para aumentar a escalabilidade da aplicação consiste em
modificar o seu código a fim de produzir um número maior de tarefas reduce,
aumentando o seu grau de paralelismo. Por exemplo, os dois primeiros caracteres de
cada termo poderiam ser verificados ao invés de apenas um (que resulta em apenas 26
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
24
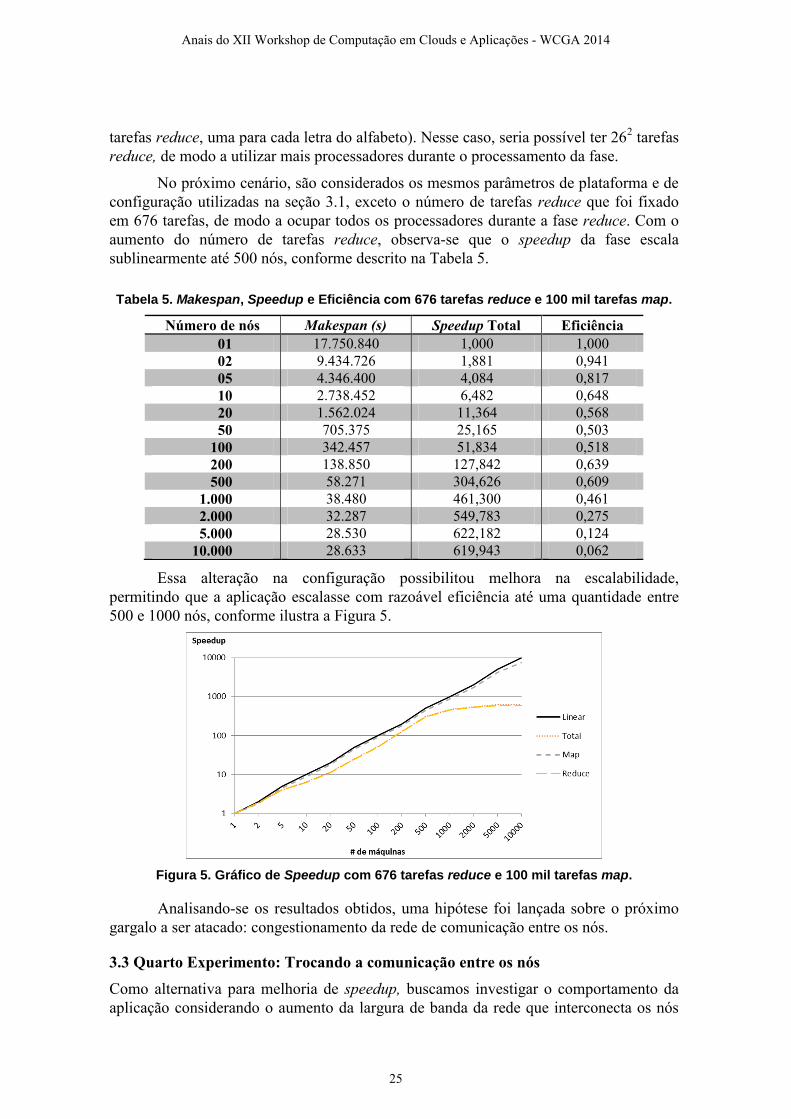
tarefas reduce, uma para cada letra do alfabeto). Nesse caso, seria possível ter 262 tarefas
reduce, de modo a utilizar mais processadores durante o processamento da fase.
No próximo cenário, são considerados os mesmos parâmetros de plataforma e de
configuração utilizadas na seção 3.1, exceto o número de tarefas reduce que foi fixado
em 676 tarefas, de modo a ocupar todos os processadores durante a fase reduce. Com o
aumento do número de tarefas reduce, observa-se que o speedup da fase escala
sublinearmente até 500 nós, conforme descrito na Tabela 5.
Tabela 5. Makespan, Speedup e Eficiência com 676 tarefas reduce e 100 mil tarefas map.
Número de nós Makespan (s) Speedup Total Eficiência
01 17.750.840 1,000 1,000
02 9.434.726 1,881 0,941
05 4.346.400 4,084 0,817
10 2.738.452 6,482 0,648
20 1.562.024 11,364 0,568
50 705.375 25,165 0,503
100 342.457 51,834 0,518
200 138.850 127,842 0,639
500 58.271 304,626 0,609
1.000 38.480 461,300 0,461
2.000 32.287 549,783 0,275
5.000 28.530 622,182 0,124
10.000 28.633 619,943 0,062
Essa alteração na configuração possibilitou melhora na escalabilidade,
permitindo que a aplicação escalasse com razoável eficiência até uma quantidade entre
500 e 1000 nós, conforme ilustra a Figura 5.
Figura 5. Gráfico de Speedup com 676 tarefas reduce e 100 mil tarefas map.
Analisando-se os resultados obtidos, uma hipótese foi lançada sobre o próximo
gargalo a ser atacado: congestionamento da rede de comunicação entre os nós.
3.3 Quarto Experimento: Trocando a comunicação entre os nós
Como alternativa para melhoria de speedup, buscamos investigar o comportamento da
aplicação considerando o aumento da largura de banda da rede que interconecta os nós
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
25

de modo a atender à demanda do tráfego de dados gerado principalmente na fase
intermediária.
O ambiente experimental utilizado se baseia em gigabit ethernet, contudo em
clusters de melhor qualidade faz-se uso de outras tecnologias, tais como Infiniband.
Neste experimento modelamos um cenário com uma rede Infiniband EDR (Enhanced
Data Rate) com taxa de largura de banda de 300Gb/s (37,5 GBps) e latência de 100
nanosegundos. Considerando o experimento com 10 mil nós e 676 tarefas reduce, o
speedup (vide Tabela 6) obtido foi de 5.739, conforme ilustra a Figura 6.
Tabela 6. Makespan, Speedup e Eficiência com 676 tarefas reduce e switch infiniband.
Número de nós Makespan (s) Speedup Total Eficiência
01 8.774.972 1,000 1,000
02 4.971.199 1,77 0,883
05 2.002.754 4,38 0,876
10 1.002.435 8,75 0,875
20 503.331 17,43 0,872
50 201.995 43,44 0,869
100 101.016 86,87 0,869
200 50.629 173,32 0,867
500 19.933 440,22 0,880
1.000 10.433 841,08 0,841
2.000 5.443 1.612,16 0,806
5.000 2.475 3.545,443 0,709
10.000 1.529 5.739,027 0,574
Observa-se que com o aumento do grau de paralelismo da fase reduce houve um
significativo ganho na escalabilidade da aplicação. A representação gráfica do speedup
ilustra o comportamento sublinear da fase map e reduce. Na plataforma de 10 mil, o
makespan resultante foi 18 vezes menor que o observado no experimento da seção 3.2.
Figura 6. Makespan, Speedup e Eficiência com 676 tarefas reduce e switch infiniband.
4. Conclusões
Neste trabalho, utilizamos o simulador MRSG para reproduzir o comportamento de
aplicações MapReduce sobre o ambiente de simulação SimGrid, com o objetivo de
avaliar a escalabilidade de aplicações. Foram realizados experimentos com uma
aplicação bem conhecida e relevante na área de processamento de informações, que é o
Terrier, indexando um corpus retirado do ClueWeb. Com os primeiros experimentos,
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
26

verificou-se que o simulador MRSG precisa ser calibrado para que reproduza com maior
acurácia o comportamento da aplicação cuja escalabilidade se quer avaliar.
Uma vez calibrado, o MRSG se mostra uma poderosa ferramenta que permite
avaliar os gargalos de escalabilidade de aplicações MapReduce em diversos cenários.
Dessa forma, usuários podem avaliar antecipadamente possíveis gargalos no caso de
aumento da base de dados e/ou da plataforma, e avaliar possíveis medidas e estratégias a
serem adotadas para se atingir o grau de escalabilidade desejado.
Como o MRSG é construído sobre o ambiente SimGrid, que por sua vez é
altamente escalável, é possível avaliar a escalabilidade de aplicações em grandes
plataformas de até 10 mil nós ou mais. Além de auxiliar no estudo sobre os limites de
escalabilidade, o simulador calibrado pode auxiliar a responder no futuro próximo uma
questão relevante, que é encontrar os limites assintóticos de escalabilidade de aplicações
MapReduce.
Agradecimentos
Os autores agradecem à CAPES pela concessão de bolsa de mestrado. Hermes Senger
agradece à FAPESP (contrato # 2014/00508-7) e ao CNPq pelo apoio recebido.
Referência
Casanova, H., Legrand, A., and Quinson, M. (2008). SimGrid: a Generic Framework for
Large-Scale Distributed Experiments. In 10th IEEE International Conference on
Computer Modeling and Simulation.
Dean, J. and Ghemawat, S. (2004). Mapreduce: Simplifed data processing on large
clusters. In 6th Symposium on Operating Systems Design and Implementation
(OSDI), pages 1–13.
Dongarra, J. J., Luszczek, P., and Petitet, A. (2003). The linpack benchmark:
Past,present, and future. Concurrency and computation: Practice and experience.
Concurrency and Computation: Practice and Experience, 15:2003.
Kolberg, W., de Marcos, P. B., dos Anjos, J. C. S., Miyazaki, A. K., Geyer, C. R., and
Arantes, L. B. (2013). MRSG – a MapReduce Simulator over Simgrid. Parallel
Computing, 39.
McCreadie, R., Macdonald, C., and Ounis, I. (2011). Mapreduce indexing strategies:
Studying scalability and efficiency. Information Processing and Management, (In
Press).
O’Maley, O (2011). In Next Generation of Apache Hadoop MapReduce.
White, T. (2009). Hadoop: the Definitive Guide. O’Reily.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
27

Análise de Desempenho do Virtualizador KVM com o
HPCC em Aplicações de CAD
Rubens Karman1, David Beserra
2, Patrícia Endo
3, Sergio Galdino
1
1Departamento de Computação Inteligente – Universidade de Pernambuco (UPE)
Recife – PE – Brasil
2Unidade Acadêmica de Garanhuns – Universidade Federal Rural de Pernambuco
(UFRPE)
Garanhuns – PE – Brasil
3Grupo de Estudos Avançados em Tecnologia da Informação e Comunicação –
Universidade de Pernambuco (UPE), Caruaru, Brasil
[email protected], [email protected], [email protected]
Abstract. Cloud Computing can support High Performance Computing (HPC)
applications, and the virtualization is its basic technology. Despite benefits
from virtualization, it is crucial to determine its overload on HPC applications
performance. This work analyzes the virtualized clusters performance over
KVM hypervisor for HPC applications, with the HPCC benchmark suite. We
also analyze the virtualized clusters performance when their virtual machines
are hosted in the same physical host, in order to realize the resource sharing
impact on the performance.
Resumo. A Computação em Nuvem pode oferecer suporte a aplicações de
Computação de Alto Desempenho (CAD) e a virtualização é sua tecnologia
básica. Apesar dos benefícios oriundos da virtualização, é de fundamental
importância determinar suas sobrecargas no desempenho de aplicações de
CAD. Este trabalho analisa o desempenho de clusters virtualizados com o
KVM executando aplicações de CAD, com a aplicação do conjunto de testes
HPCC. Também será avaliado o desempenho de clusters virtualizados quando
suas máquinas virtuais estão hospedadas em um mesmo servidor físico, para
determinar os efeitos do compartilhamento de recursos no desempenho.
1. Introdução
A Computação em Nuvem é considerada atualmente um dos paradigmas dominantes em
sistemas distribuídos [Younge et al. 2011]. Entre as diversas aplicações que podem ser
implementados na Nuvem, destaca-se a Computação de Alto Desempenho (CAD), que
necessita de clusters virtuais para execução de aplicações que utilizam Message Passing
Interface (MPI) ([Mello et al. 2010] e [Beserra et al. 2012]). Uma tecnologia que
permeia a infraestrutura de uma Nuvem é a virtualização, já bastante conhecida na área
de computação, e frequentemente identificada como uma forma de abstração de recursos
físicos com diferentes propósitos. De acordo com [Ye et al. 2010], a virtualização
proporciona benefícios como administração flexível e confiabilidade de sistemas.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
28

Todavia, apesar dos benefícios, ainda não são conhecidos em sua totalidade os
impactos da virtualização no desempenho de clusters virtualizados para CAD [Ye et al.
2010]. O objetivo principal deste trabalho é analisar o desempenho de um cluster
virtualizado com o virtualizador KVM ao executar aplicações de CAD. O intuito da
análise é determinar como a virtualização sobrecarrega o desempenho deste tipo de
estrutura computacional.
O presente artigo está estruturado da seguinte forma: a Seção 2 introduz o
virtualizador KVM no contexto de CAD; a Seção 3 descreve os objetivos a serem
alcançados e os procedimentos metodológicos adotados; a Seção 4 apresenta os
resultados obtidos; e por fim, a Seção 5 conclui o trabalho com as considerações finais e
trabalhos futuros.
2. Trabalhos Relacionados
Alguns requisitos fundamentais devem ser atendidos ao se empregar virtualização em
CAD, por exemplo, a sobrecarga da virtualização não deve ter impactos significativos
no desempenho do sistema, deve-se melhorar a administração do ambiente, permitindo a
criação e destruição rápida de VMs, e deve-se obter uma distribuição flexível de
recursos de hardware. Outro requisito importante é o isolamento das aplicações em
VMs e a migração automática de VMs de um servidor a outro quando necessário, para
aumentar a confiabilidade e a segurança do ambiente [Ye et al 2010].
Alguns trabalhos já abordaram o uso do KVM para CAD, como o de [Younge et
al. 2011], que analisou a viabilidade da virtualização para CAD. Foram analisados os
virtualizadores de código aberto Xen, KVM e VirtualBox e elaborada uma tabela-
resumo de suas características principais, sendo a Tabela 1 uma versão atualizada. O
desempenho dos virtualizadores foi medido com o High Performance Computing
Benchmark (HPCC) e o Standard Performance Evaluation Corporation (SPEC)
aplicado em clusters virtuais. A partir dos resultados obtidos foi elaborada uma
classificação de virtualizadores para CAD, concluindo que KVM e VirtualBox são os
melhores em desempenho global e facilidade de gerenciamento, com o KVM
sobressaindo-se em capacidade de computação e de expansibilidade de memória.
[Younge et al. 2011] também observou que, ao contrario do Xen, o KVM
apresenta poucas oscilações no desempenho, característica que é considerada um
componente chave em ambientes de Nuvem. Em um ambiente de Nuvem computacional o
serviço ofertado deve ser estável e confiável. Grandes oscilações de desempenho não são
bem vindas pelos clientes [Younge et al. 2011] [Napper e Bientinesi. 2009].
Em [Mello et al. 2010] foram avaliados os efeitos do compartilhamento de recursos
de um mesmo hospedeiro por múltiplos clusters virtualizados com VirtualBox. O SO do
servidor hospedeiro foi incapaz de distribuir igualmente os recursos entre clusters
virtualizados com o VirtualBox. Isto não é bem vindo, por não garantir que clientes que
paguem igualmente por um serviço de instancia de VMs com configurações iguais
obtenham desempenhos diferentes. Em um ambiente de cluster, o desempenho de toda a
estrutura em uma aplicação com carga de trabalho homogeneamente distribuída, com
barreiras de sincronização ativadas, é limitado pelo elemento computacional de menor
desempenho. Logo, é importante garantir distribuição justa de recursos entre VMs
hospedadas em um mesmo servidor hospedeiro.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
29

[Johnson et al. 2011] analisa o desempenho do KVM para aplicações de CAD,
todavia de cunho educacional, visando implementar um cluster virtualizado para prover
infraestrutura de ensino de programação paralela com MPI e o treinamento no uso de
sistemas de arquivos paralelos Hadoop. Todavia, não foram verificados os efeitos do
compartilhamento de recursos de um mesmo hospedeiro por múltiplas VMs no
desempenho dos clusters virtuais, e nem se o SO hospedeiro distribui os recursos de
maneira equipotente entre as VMs.
Este trabalho tem por objetivo verificar a ocorrência de sobrecargas no
desempenho de clusters virtualizados com o KVM e qual o efeito do compartilhamento
de recursos de um mesmo hospedeiro por clusters virtualizados com o KVM em seu
desempenho. Este trabalho está inserido no contexto de uma pesquisa, em nível de
mestrado, que estuda a aplicabilidade do paradigma da computação em nuvem em
aplicações cientificas biomédicas.
Tabela 1. Resumo das características dos virtualizadores de código aberto.
Xen KVM VirtualBox
Ultima versão 4.3
Embutido no Kernel
Linux mais recente. 4.3.6
Para-virtualização Sim Não Sim
Virtualização total Sim Sim Sim
CPU hospedeira x86, x86-64, IA-64 x86, x86-64, IA-64, PPC x86, x86-64
CPU convidada x86, x86-64, IA-64 x86, x86-64, IA-64, PPC x86, x86-64
SO hospedeiro Linux, Unix Linux Windows, Linux,
OS X, Solaris, Unix
SO convidado Linux, Windows,
NetBSD Windows, Linux, Unix
Windows, Linux,
Unix, Solaris
VT-x / AMD-v Opcional Requerido Opcional
Núcleos suportados 128 64 128
Memória suportada 5TB 4TB 1TB
Aceleração 3d Xen-GL VMGL Open-GL, Direct3D
Live Migration Sim Sim Sim
Licença GPL GPL GPL/Proprietária
3. Mensurando o Desempenho do KVM para CAD
Esta seção aborda a metodologia de pesquisa utilizada, descrevendo o ambiente de
provas, as ferramentas de avaliação de desempenho empregadas e os testes executados.
Todos os testes foram executados trinta vezes. Para cada teste foram descartadas as
amostras obtidas de maior e o menor valor e calculada a média das demais. Esta medida
foi adotada devido aos valores obtidos nestas amostras em particular estarem muito
afastadas da média das demais.
3.2. Ambiente de Testes
Os experimentos foram executados em quatro computadores equipados com
processadores Intel Core 2 Quad Q8200 operando em frequência de 2.8 GHz. Esse
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
30

processador tem um conjunto de instruções específicas para virtualização. Os
computadores tem 4 GB de memória principal, do tipo DDR 2 com frequência de
operação de 800 MHz. A interconexão entre os computadores foi realizada com
adaptadores e comutador de rede operando em conformidade com o padrão Gigabit
Ethernet 10/100/1000.
A ferramenta de virtualização utilizada para a criação de todas as VMs usadas
nos experimentos foi o KVM. A escolha do KVM como ferramenta de virtualização
deste estudo em relação a outros virtualizadores de código aberto é motivada por o
mesmo ser suportado por algumas das principais ferramentas para implementação de
nuvens computacionais, como Eucalyptus e Nimbus [Endo et al 2010]. Para a
construção dos clusters foi utilizado o SO Rocks Clusters 6.1 64bit. O Rocks Clusters é
um SO baseado em Linux desenvolvido para simplificar o processo de criação de
clusters para CAD [Papadopoulos, Katz e Bruno. 2003]. Os hospedeiros de VMs
utilizaram o CentOS 5.5 64bit como SO.
3.2. Ferramentas de Avaliação de Desempenho
Para comparar o desempenho global dos diferentes ambientes testados foi utilizado o
HPCC [Luszczek et al. 2006]. O HPCC é o conjunto de testes padrão da comunidade de
pesquisa em CAD [Ye et al. 2010]. O HPCC avalia o desempenho do processador, da
memória, da comunicação inter-processos e da rede de comunicação. É constituído
pelos seguintes testes:
HPL – O High Performance Linpack mede a quantidade de operações de ponto
flutuante por segundo (FLOPS) realizadas por um sistema computacional
durante a resolução de um sistema de equações lineares. É o teste mais
importante para CAD [Younge et al. 2011];
DGEMM – Mede a quantidade de FLOPS durante uma multiplicação de
matrizes de números reais de ponto flutuante de precisão dupla;
STREAM – Mede a largura de banda de memória principal (em GB/s).
PTRANS – O Parallel matrix transpose mede a capacidade de comunicação de
uma rede. Ele testa as comunicações onde pares de processadores comunicam-se
entre si simultaneamente transferindo vetores de dados da memória;
RandomAccess – Mede a taxa de atualizações aleatórias na mémoria (GUPs).
FFT – O Fast Fourier Transform mede a quantidade de operações com números
complexos de precisão dupla em GFlops durante a execução de uma
Transformada Rápida de Fourier unidimensional.
Communication Latency/Bandwidth – Mede a largura de banda (em MB/s) e a
latência da rede durante a comunicação inter-processos MPI utilizando padrões
de comunicação não simultânea (ping-pong) e simultânea (Anel de processos
Aleatoriamente Ordenados (ROR) e Anel Naturalmente Ordenado (NOR)).
O HPCC possui três modos de execução: single, star e mpi. O modo single
executa o HPCC em um único processador. No modo star todos os processadores
executam cópias separadas do HPCC, sem comunicação inter-processo. No modo mpi
todos os processadores executam o HPCC em paralelo, empregando comunicação
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
31

explícita de dados [Ye et al. 2010]. O HPCC requer a instalação de uma versão do MPI
e do Basic Linear Algebra System (BLAS). Para a realização dos experimentos deste
trabalho foram utilizados o OpenMPI (OMPI 1.4.1) e o ATLAS (ATLAS 3.8.0).
Os componentes do HPCC são classificados e agrupados pelo padrão em que
acessam a memória [Luszczek et al. 2006], conforme mostrado na Tabela 2. Outra
forma de classificar estes componentes leva em conta o tipo de recurso de hardware
mais requisitado [Zhao et al. 2010] (Tabela 3).
Tabela 2. Classificação de [Luszczek et al. 2006].
Local Global
DGEMM HPL
STREAM PTRANS
RandomAccess
(modo star)
RandomAccess
(modo mpi)
FFT (modo star) FFT (modo mpi)
Tabela 3. Classificação de [Zhao et al. 2010].
Computação Acesso a
Memória
Rede de Comunicação
HPL RandomAccess PingPongLatency
DGEMM STREAM PingPongBandwidth
FFT PTRANS HPL
STREAM PTRANS
PTRANS
Para este trabalho é proposta uma nova classificação, que leva em conta as duas
anteriores, sendo exibida na Tabela 4. Tal classificação é necessária, pois as anteriores,
quando utilizadas isoladamente, não cobrem todos os casos de aplicação desses testes.
Por exemplo, ao executar-se os testes PingPongBandwidth e PingPongLatency em um
único servidor, não se está medindo o desempenho da rede de comunicação e sim o
desempenho da comunicação inter-processos local ao servidor, aplicação não coberta
pelas classificações anteriores. O mesmo raciocínio pode ser aplicado a medidas de
acesso a memória com o RandomAccess em modo mpi. Como o STREAM e o DGEMM
apenas executam em modo star, podem obter apenas medidas de capacidade local.
Tabela 4. Nova Classificação Proposta.
Comp.
Local
Comp.
Global
Acesso a
Mem. Local
Acesso a
Mem. Global
Comunicação
Inter-processos
Local
Rede de
Comunicação
DGEMM HPL STREAM RandomAccess PingPongLatency PingPongLatency
HPL FFT RandomAccess PingPongBandwidth PingPongBandwidth
FFT ROR Latency ROR Latency
ROR Bandwidth ROR Bandwidth
NOR_Latency NOR_Latency
NOR_Bandwidth NOR_Bandwidth
PTRANS PTRANS
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
32

3.3. Método Experimental
O objetivo geral deste trabalho é verificar a adequabilidade do KVM para CAD. Os
seguintes objetivos específicos foram utilizados na estruturação dos testes realizados:
1. Determinar a sobrecarga provocada pela virtualização no desempenho de um
cluster virtual;
2. Determinar os efeitos no desempenho de clusters virtuais durante o uso
concorrente de recursos de um mesmo hospedeiro físico por esses clusters.
3.3.1. Desempenho em ambiente de cluster
Para alcançar o objetivo específico 1 foram testados e comparados os desempenhos de
dois clusters, nomeados Gilgamesh e Arthuria, com o HPCC. O cluster Gilgamesh foi
instalado em hardware nativo (sem uso de virtualização), com quatro CPUs disponíveis
por nó e quatro nós ao total. Para prover igualdade de condições com o cluster Arthuria,
um dos pentes de memória de 2GB foi removido de cada computador, ficando os nós de
Gilgamesh com 2 GB de capacidade de memória instalada. O cluster Arthuria, por sua
vez, é composto por VMs implementadas com o KVM, hospedadas em servidores
físicos e distribuição de uma VM por servidor hospedeiro. Cada VM do cluster Arthuria
conta com quatro v-CPUs e 2GB alocados para uso como memória principal. Os outros
2 GB de memória restantes nos servidores hospedeiros são destinados para o uso
exclusivo de seu SO.
3.3.2. Efeitos do compartilhamento de recursos.
Foram instanciados dois clusters virtuais (cluster A e cluster B) em um mesmo servidor
para verificar como o compartilhamento de recursos afeta o desempenho individual de
cada cluster (objetivo específico 2). Cada cluster foi configurado com dois nós escravos
e cada nó escravo com uma vCPU e 1 GB de memória principal, de forma a não esgotar
os recursos de processamento e memória do sistema. Os controladores centrais desses
clusters são computadores físicos. Esta medida é justificada para que seja necessário que
as VMs utilizem a rede de comunicação. Se assim não fosse, os testes de rede não
mediriam o desempenho da capacidade de comunicação em rede e sim a comunicação
inter-processos local, conforme exposto em subseção anteriormente.
Inicialmente foi medido o desempenho de um desses clusters virtuais com o
HPCC, o cluster A. Em seguida o desempenho de ambos foi aferido simultaneamente
com o HPCC e foram entre si, para verificar se o SO do hospedeiro é capaz de dividir
igualmente os recursos entre as VMs. O desempenho do cluster A executado em isolado
foi comparado ao desempenho do cluster A executado em uma situação de competição,
para determinar como a competição degenera o desempenho.
É importante garantir que dois usuários que contratam um determinado serviço o
recebam com desempenho similar. Se o serviço, neste caso instâncias de VMs, é
fornecido em um mesmo hospedeiro, o SO do hospedeiro tem que distribuir os recursos
igualmente entre as VMs. Se isto não ocorre, então não se provê uma boa qualidade de
serviço, o que implica em impactos negativos para os usuários [Younge et al. 2011].
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
33

4. Resultados Obtidos
Esta seção apresenta os resultados obtidos dos testes e o que foi verificado em cada um.
4.1. Sobrecargas da virtualização em ambiente de cluster
As médias dos resultados obtidos em cada teste são apresentadas como uma fração dos
obtidos pelo sistema nativo. A Figura 1 apresenta o desempenho médio das amostras
obtidas pelo HPCC no modo mpi, exceto para os testes DGEMM e STREAM, que não
dispõe deste modo, sendo então apresentados seus resultados para o modo star.
A capacidade de computação dos clusters Arthuria e Gilgamesh foi medida com
os testes HPL, DGEMM e FFT. Para o teste FFT, o cluster Arthuria tem desempenho
39% menor que o cluster Gilgamesh. O cluster Arthuria apresenta também desempenho
20% menor para o HPL e 22% para o DGEMM. Estes resultados indicam que
aplicações computacionais são sensíveis a virtualização em graus distintos. A
capacidade de leitura e escrita (E/S) em memória principal, em âmbito global
(RandomAccess), é bastante reduzida no cluster Arthuria, estando abaixo da metade da
obtida pelo Gilgamesh. A capacidade de E/S em memória, a nível local ao servidor, é
surpreendentemente favorável ao cluster virtualizado, o que, dado o resultado dos outros
testes e a condição de o acesso à memória principal do servidor pela VM sempre
necessitar passar pelo gerenciador de VMs antes, o que torna impossível de um sistema
virtual ser mais rápido que o nativo, indica uma possível falha do HPCC. O motivo
dessa anormalidade não é conhecido e volta a ocorrer nos demais testes.
Figura 1. Desempenho dos ambientes de cluster no HPCC.
Observando a Figura 1 percebe-se que a largura de banda de comunicação
cluster Arthuria é similar a apresentada pelo cluster Gilgamesh para o padrão de
comunicação PingPong e muito inferior para os padrões de comunicação inter-processo
NOR e ROR. Também pode-se observar na Figura 1 que a latência de rede do cluster
Arthuria é muito maior que a cluster Gilgamesh, para todos os padrões de comunicação
testados. Essa grande latência observada na comunicação pode explicar porque o cluster
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
34

Arthuria apresenta desempenho inferior em quase todos os testes. Excetuando-se os
testes DGEMM e STREAM, que operam em modo star, todos os demais testes fazem
uso intensivo da rede de comunicação. Logo, tem-se que a latência de rede é o grande
gargalo de desempenho do cluster Arthuria em todos os aspectos que dela demandem.
O desempenho obtido no teste PTRANS foi similar para ambos os clusters.
É possível que ao aumentar a escala dos clusters, os clusters virtualizados com o
KVM apresentem uma diferenciação de desempenho ainda maior em relação a clusters
instalados em hardware nativo, para as aplicações que façam uso intensivo da rede de
comunicação, assim como ocorre com clusters virtualizados com o Xen [Ye et al. 2010].
4.2. Efeitos do compartilhamento de recursos
A Figura 2 apresenta os resultados obtidos durante a execução de dois clusters virtuais
em um mesmo hospedeiro. Foi observado que a capacidade de computação de ambos os
clusters é bastante similar, o que indica boa distribuição dos recursos locais de
processamento entre as VMs pelo SO hospedeiro. A capacidade da rede de comunicação
obteve desempenho demasiadamente variável, possivelmente devido à existência de
uma única interface de rede no servidor hospedeiro. A largura de banda de comunicação
obtida pelo cluster B foi maior que a do cluster A, assim como a latência. Isso refletiu na
variação de desempenho entre os clusters em alguns dos testes que dependem da rede
comunicação, como o FTT, o RandomAccess e o PTRANS. Nos testes que demandam
mais por largura de banda, o cluster B foi superior, nos que demandam mais por menor
latência, apresentou-se inferior.
Figura 2. Desempenho de clusters virtuais que compartilham mesmo hospedeiro.
A Figura 3 Apresenta os resultados para os testes do HPCC no cluster A antes de
concorrer por recursos com o cluster B, e também durante a concorrência. Observa-se
claramente que o desempenho do cluster A cai durante o período que competiu por
recursos com o cluster B. A queda é maior nos testes de capacidade de comunicação,
por ter aumentado a quantidade de VMs que concorreram pela interface de rede, o que
refletiu na redução do desempenho dos testes que demandaram da rede.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
35

Figura 3. Comparativo do desempenho do cluster A isolado com o desempenho obtido
pelo cluster A em situação de competição por recursos.
Em paralelo a execução do HPCC nos clusters virtuais foi verificado o
percentual de utilização da CPU hospedeira por cada VM. Em uma situação ideal todas
as VMs utilizam um percentual igual de CPU durante toda a execução do HPCC,
chegando a um máximo de 25% de utilização por VM (um único núcleo de
processamento do servidor). A Figura 4 apresenta o consumo de CPU do hospedeiro
pelas VMs do cluster A, quando executado isoladamente. Cada PID na Figura 4 refere-
se a um identificador do processo que representa uma VM no SO hospedeiro. Observa-
se na Figura 4 que a utilização de CPU por ambas as VMs é similar durante a maioria do
tempo de execução do HPCC, sem extrapolar o limite de 25% dos recursos totais por
VM e 50% dos recursos globais para o cluster.
Figura 4. Utilização da CPU hospedeira pelo cluster A isolado.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
36
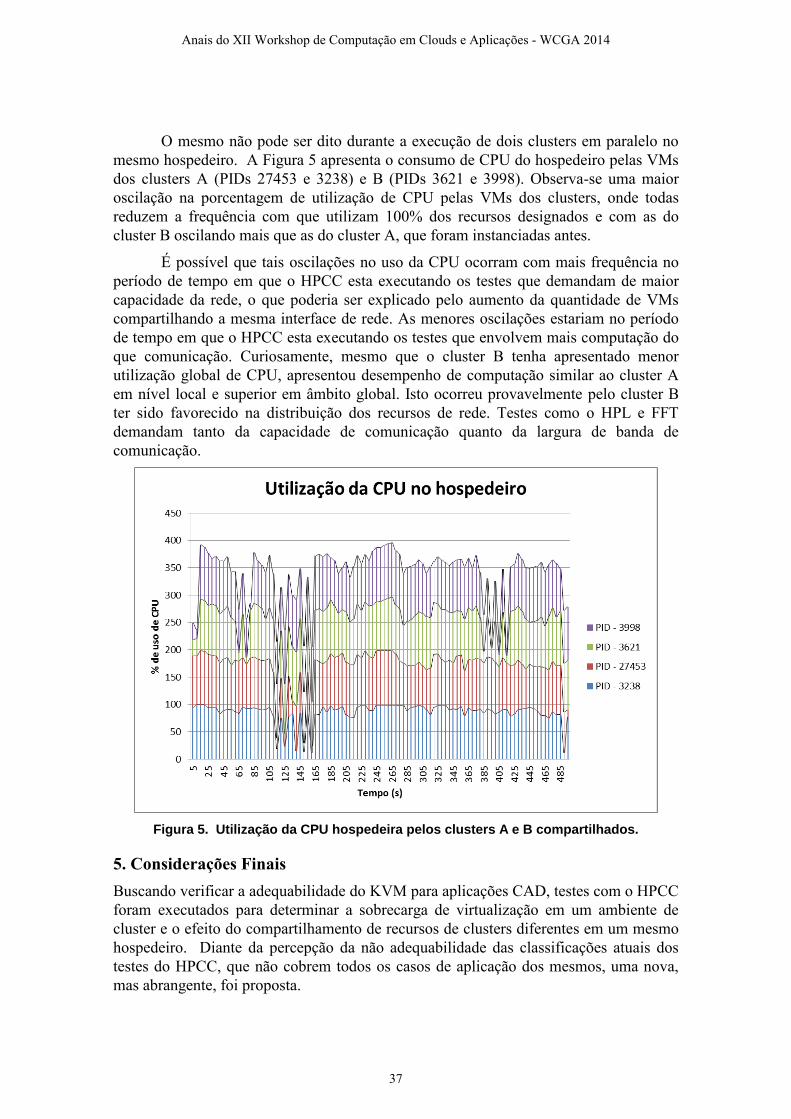
O mesmo não pode ser dito durante a execução de dois clusters em paralelo no
mesmo hospedeiro. A Figura 5 apresenta o consumo de CPU do hospedeiro pelas VMs
dos clusters A (PIDs 27453 e 3238) e B (PIDs 3621 e 3998). Observa-se uma maior
oscilação na porcentagem de utilização de CPU pelas VMs dos clusters, onde todas
reduzem a frequência com que utilizam 100% dos recursos designados e com as do
cluster B oscilando mais que as do cluster A, que foram instanciadas antes.
É possível que tais oscilações no uso da CPU ocorram com mais frequência no
período de tempo em que o HPCC esta executando os testes que demandam de maior
capacidade da rede, o que poderia ser explicado pelo aumento da quantidade de VMs
compartilhando a mesma interface de rede. As menores oscilações estariam no período
de tempo em que o HPCC esta executando os testes que envolvem mais computação do
que comunicação. Curiosamente, mesmo que o cluster B tenha apresentado menor
utilização global de CPU, apresentou desempenho de computação similar ao cluster A
em nível local e superior em âmbito global. Isto ocorreu provavelmente pelo cluster B
ter sido favorecido na distribuição dos recursos de rede. Testes como o HPL e FFT
demandam tanto da capacidade de comunicação quanto da largura de banda de
comunicação.
Figura 5. Utilização da CPU hospedeira pelos clusters A e B compartilhados.
5. Considerações Finais
Buscando verificar a adequabilidade do KVM para aplicações CAD, testes com o HPCC
foram executados para determinar a sobrecarga de virtualização em um ambiente de
cluster e o efeito do compartilhamento de recursos de clusters diferentes em um mesmo
hospedeiro. Diante da percepção da não adequabilidade das classificações atuais dos
testes do HPCC, que não cobrem todos os casos de aplicação dos mesmos, uma nova,
mas abrangente, foi proposta.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
37

Foi observado que a virtualização provoca sobrecarga de desempenho, e que a
mesma é mais sentida em aplicações que demandem da rede de comunicação de que das
que demandam pelos recursos de computação locais. Além disso, também foi
observado que o compartilhamento de recursos nos hospedeiros degrada o desempenho
de ambos os ambientes que concorrem por tais recursos, e que maior é a degradação
quando mais VMs disputam os recursos. Isso ocorre devido a incapacidade do SO
hospedeiro de dividir seus recursos entres os hospedeiros.
De uma maneira geral, o KVM proporciona desempenho adequado a aplicações
de CAD que demandem pouca comunicação inter-processo e desempenho inadequado
para aplicações que demandem de maior quantidade de comunicação inter-processo.
Como trabalho futuro pretende-se adicionar mais interfaces de rede aos servidores
hospedeiros, em slots do tipo PCI Express, e reexecutados os testes com
compartilhamento de recursos. Isto será feito para verificar se, ao fornecer interfaces de
rede exclusivas para cada VM, seus desempenhos globais tornam-se mais similares.
Referências
Beserra, D.W.S.C., Borba, A., Souto, S.C.R.A., de Andrade, M.J.P, e de Araújo, A.E.P.
(2012) "Desempenho de Ferramentas de Virtualização na Implementação de Clusters
Beowulf Virtualizados em Hospedeiros Windows." Em: X Workshop em Clouds,
Grids e Aplicações-SBRC 2012. SBC, Ouro Preto, pp. 86-95.
Endo, P. T., Gonçalves, G. E., Kelner, J., e Sadok, D. (2010) “A Survey on Open-source
Cloud Computing Solutions”. Em: Anais do VIII Workshop em Clouds, Grids e
Aplicações, pp. 3-16.
Johnson, E., Garrity, P., Yates, T., e Brown, R. (2011) “Performance of a Virtual Cluster
in a General-purpose Teaching Laboratory”, In: 2011 IEEE International Conference
on Cluster Computing. Pp. 600-604. IEEE.
Kejiang, Y., Jiang, X., Chen, S., Huang, D. e Wang, B. (2010) "Analyzing and modeling
the performance in xen-based virtual cluster environment." Em: 12th IEEE
International Conference on High Performance Computing and Communications
(HPCC). IEEE.
Luszczek, P. R., Bailey, D. H., Dongarra, J. J., Kepner, J., Lucas, R. F., Rabenseifner,
R., & Takahashi, D. (2006). The HPC Challenge (HPCC) benchmark suite. In
Proceedings of the 2006 ACM/IEEE conference on Supercomputing pp. 213-225.
ACM.
Mello, T. C. Schulze, B. Pinto, R. C. G. e Mury, A. R. (2010) “Uma análise de recursos
virtualizados em ambiente de HPC”, Em: Anais VIII Workshop em Clouds, Grids e
Aplicações, XXVIII SBRC/ VIII WCGA, SBC, Gramado, pp. 17-30.
Napper, J. e Bientinesi, P. (2009) “Can cloud computing reach the TOP500?”, Em:
Proc. Combined Workshops on UnConventional High Performance Computing
Workshop Plus Memory Access Workshop, UCHPC-MAW '09, pp. 17-20.
Papadopoulos, P. M., Katz, M. J., e Bruno, G. (2003). NPACI Rocks: Tools and
techniques for easily deploying manageable linux clusters. Concurrency and
Computation: Practice and Experience, 15(7‐8), 707-725.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
38

Ye, K., Jiang, X., Chen, S., Huang, D., e Wang, B. (2010) "Analyzing and modeling the
performance in xen-based virtual cluster environment." High Performance
Computing and Communications (HPCC), 2010 12th IEEE International Conference
on. IEEE.
Younge, A. J., Henschel, R., Brown, J. T., von Laszewski, G., Qiu, J., Fox, G. C.,
(2011) "Analysis of virtualization technologies for high performance computing
environments." 2011 IEEE International Conference on Cloud Computing (CLOUD).
IEEE.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
39


32º Simpósio Brasileiro de Redes de Computadores e
Sistemas Distribuídos
Florianópolis - SC
XII Workshop de Computação em
Clouds e Aplicações (WCGA)
Sessão Técnica 2
Elasticidade


Uma Proposta de Framework Conceitual para Analise deDesempenho da Elasticidade em Nuvens Computacionais
Emanuel F. Coutinho1,2,4, Danielo G. Gomes1,3, Jose Neuman de Souza1,2
1Grupo de Redes de Computadores, Engenharia de Software e Sistemas (GREat)2Mestrado e Doutorado em Ciencia da Computacao (MDCC)3Departamento de Engenharia em Teleinformatica (DETI)
4Instituto UFC VirtualUniversidade Federal do Ceara
Fortaleza – CE – Brasil
[email protected], {danielo,neuman}@ufc.br
Abstract. Elasticity can be understood as how a computational cloud adaptsto variations in their workload by provisioning and de-provisioning resources.This article proposes a conceptual framework for conducting elasticity perfor-mance analysis in cloud computing in a systematic and reproducible way. Forverification and validation of the proposal, we performed a case study in theCloud UFC, a private cloud installed on Campus do Pici, Federal Universityof Ceara. As a result, two experiments were designed using microbenchmarksand a classic scientific application. Through these experiments, the frameworkwas validated in their activities, allowing systematization of an analysis of theelasticity through mechanisms of autonomic computing and a set of allocationtime and allocated resources oriented metrics.
Resumo. Elasticidade pode ser entendida como o quao uma nuvem computaci-onal se adapta a variacoes na sua carga de trabalho atraves do provisionamentoe desprovisionamento de recursos. Este artigo propoe um framework conceitualpara a realizacao de analise de desempenho da elasticidade em nuvens compu-tacionais de maneira sistematica e reproduzıvel. Para verificacao e validacaoda proposta, realizou-se um estudo de caso na Cloud UFC, uma nuvem pri-vada instalada no Campus do Pici da Universidade Federal do Ceara. Comoresultado, dois experimentos foram projetados utilizando microbenchmarks euma aplicacao cientıfica classica. Atraves destes experimentos, o frameworkfoi validado em suas atividades, permitindo a sistematizacao de uma analise daelasticidade por meio de mecanismos de computacao autonomica e um conjuntode metricas orientadas a tempos de alocacao e recursos alocados.
1. IntroducaoCom o aumento de acesso aos ambientes computacionais em nuvem e sua facilidade deutilizacao, baseada no modelo de pagamento por uso, e natural que a quantidade deusuarios e as respectivas cargas de trabalho tambem crescam. Como consequencia, osprovedores devem ampliar seus recursos e manter o nıvel de qualidade acordado com osclientes, sob pena de quebras do Service Level Agreement (SLA) e decorrentes multas.
O monitoramento de recursos computacionais, como CPU, memoria e banda, setorna essencial tanto para os provedores, os quais disponibilizam os servicos, quanto
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
43

para seus clientes. Uma maneira de monitorar aplicacoes em nuvem de modo maisefetivo e utilizar mecanismos de computacao autonomica, atraves dos quais recursossao adicionados e removidos do ambiente conforme limiares de uso pre-estabelecidos[Kephart e Chess 2003]. Esse tipo de estrategia de monitoramento esta diretamente asso-ciado a uma das principais caracterısticas da Computacao em Nuvem: a elasticidade.
Elasticidade pode ser definida como o quao um sistema computacional e capazde se adaptar a variacoes na carga de trabalho pelo provisionamento e desprovisiona-mento de seus recursos de maneira autonomica, de modo que em cada instante no tempoos recursos disponıveis atendam da melhor maneira possıvel a demanda da carga de tra-balho [Herbst et al. 2013]. Um estudo sobre elasticidade em nuvem foi realizado em[Coutinho et al. 2013b], com destaque para diversos aspectos como: definicoes, estadoda arte da elasticidade, analise de desempenho, metricas, estrategicas elasticas, bench-marks, desafios e tendencias na construcao de solucoes elasticas.
Diversas arquiteturas para solucoes de provisionamento e manutencao de SLAutilizando recursos de computacao autonomica tem sido propostas [Rego et al. 2011,Tordsson et al. 2012]. Porem, devido a pouca disponibilidade de informacao acerca desua instalacao e configuracao corretas, do ponto de vista experimental em geral nao etrivial implementar tais arquiteturas, muito menos aplica-las em ambientes de nuvem.Alem disso, nota-se uma carencia de trabalhos na literatura que avaliem o desempenhodestes ambientes de forma metodologica e sistematizada. Na tentativa de diminuir estalacuna, propomos um framework conceitual para a resolucao de um problema especıficode analise de desempenho da elasticidade no domınio das nuvens computacionais.
O objetivo geral deste artigo e analisar o desempenho da elasticidade em um am-biente de nuvem de maneira sistematica. Para alcanca-lo, tracamos tres objetivos es-pecıficos: (i) propor um framework conceitual com foco em elasticidade; (ii) realizarexperimentos para validacao do framework utilizando metricas orientadas a velocidade(tempo de resposta) e utilizacao de recursos; e (iii) implementar ferramentas para suportea analise de desempenho proposta (microbenchmarks, cargas de trabalho e visualizacao).Para a validacao da proposta, realizamos um estudo de caso na Cloud UFC1, uma nuvemprivada instalada no Campus do Pici da Universidade Federal do Ceara.
2. Proposta de um Framework Conceitual
Um framework ou arcabouco conceitual e um conjunto de conceitos utilizados para aresolucao de um problema de um domınio especıfico, sendo que existem dois tipos: fra-meworks verticais (ou especialistas, confeccionados atraves da experiencia obtida em umdeterminado domınio especıfico ou de um especialista, tentando resolver problemas deum determinado domınio de aplicacao), e frameworks horizontais (podem ser utilizadosem diferentes domınios) [Cruz 2013].
Sendo assim, o framework conceitual proposto neste trabalho e vertical. Nele pro-pomos um conjunto de atividades para a execucao de uma analise de desempenho da elas-ticidade em nuvem computacional de maneira sistematizada. As atividades relacionadasao planejamento da elasticidade foram elaboradas com base em princıpios de computacaoautonomica, na arquitetura definida em [Kephart e Chess 2003]. Basicamente, o fra-
1CloudUFC - http://www.lia.ufc.br/ cloud/
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
44
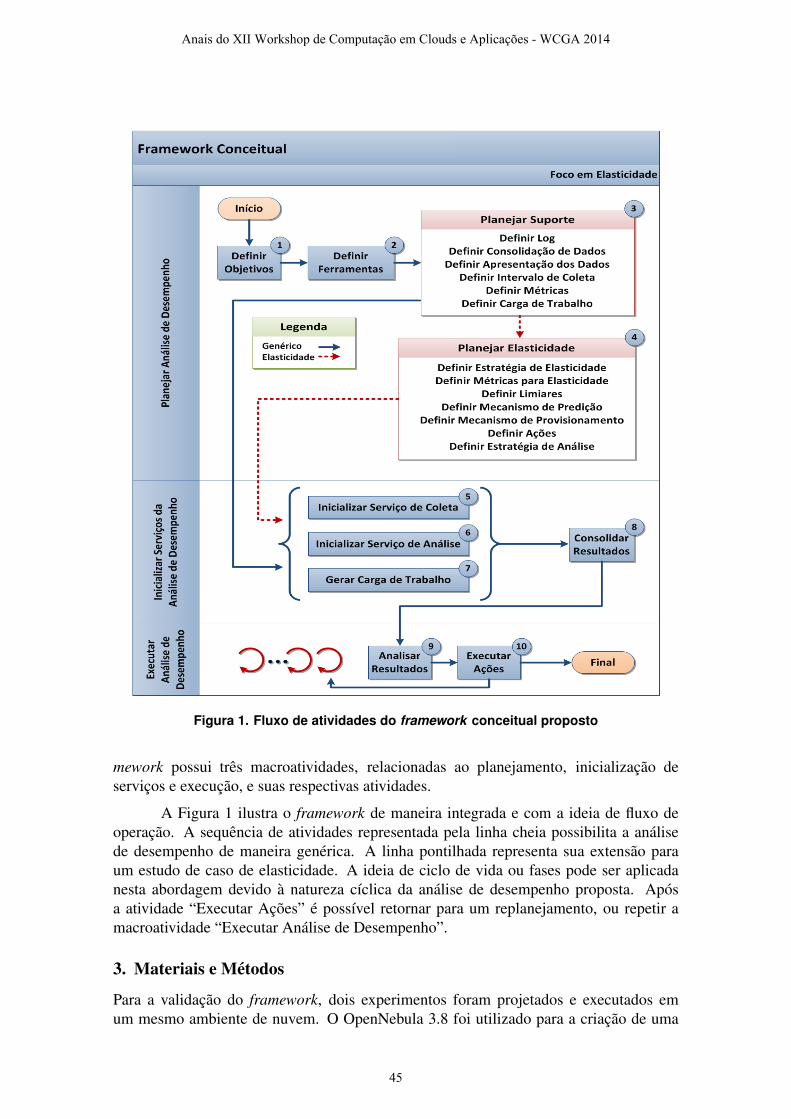
Figura 1. Fluxo de atividades do framework conceitual proposto
mework possui tres macroatividades, relacionadas ao planejamento, inicializacao deservicos e execucao, e suas respectivas atividades.
A Figura 1 ilustra o framework de maneira integrada e com a ideia de fluxo deoperacao. A sequencia de atividades representada pela linha cheia possibilita a analisede desempenho de maneira generica. A linha pontilhada representa sua extensao paraum estudo de caso de elasticidade. A ideia de ciclo de vida ou fases pode ser aplicadanesta abordagem devido a natureza cıclica da analise de desempenho proposta. Aposa atividade “Executar Acoes” e possıvel retornar para um replanejamento, ou repetir amacroatividade “Executar Analise de Desempenho”.
3. Materiais e Metodos
Para a validacao do framework, dois experimentos foram projetados e executados emum mesmo ambiente de nuvem. O OpenNebula 3.8 foi utilizado para a criacao de uma
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
45

nuvem privada. Nao foram utilizados neste trabalho nuvens publicas comerciais. Todas asmaquinas fısicas sao do tipo Ci5 e Ci7, 24 GB de memoria, sistema operacional UbuntuServer 12.04 64 bits e hipervisor KVM. Foram utilizadas quatro maquinas virtuais nosexperimentos, todas com 1 VCPU, 1 GB de memoria e sistema operacional Ubuntu Server12.04 64 bits. Foi utilizado como servidor web o Apache Tomcat, balanceador de carga oNGINX, e gerador de cargas de trabalho o HTTPERF. A instanciacao do framework foidesenvolvida em Java e shell script. A representacao do testbed esta descrita na Figura 2.
Figura 2. Arquitetura e ambiente experimental
3.1. Projeto dos ExperimentosO objetivo dos experimentos e avaliar o comportamento de aplicacoes web diante de car-gas de trabalho dinamicas, e como se comportam de maneira autonomica para adaptacaoa variacoes de demanda e manutencao do SLA. Para isso, o framework sera utilizado, eassim suas atividades serao instanciadas para o ambiente e para o projeto de experimentos.Dessa maneira, as atividades serao validadas, nao implementando solucoes otimas.
As ferramentas foram definidas na infraestrutura. Para a macroatividade “PlanejarSuporte”, arquivos texto registram o log das operacoes de coleta das maquinas virtuais.O log gerado para cada maquina virtual em arquivo texto contem a data da coleta, valoresde utilizacao de CPU, memoria, disco e rede. Tambem foi gerado um arquivo de logpara a media de utilizacao de CPU e alocacao de recursos, permitindo sua leitura em umaferramenta construıda especificamente para a visualizacao grafica de todas as metricas demaneira individual (metricas coletadas de cada maquina virtual) e em conjunto (metricascoletadas de todas as maquinas virtuais ao mesmo tempo). A consolidacao dos dados se dapor meio da leitura dos arquivos de log, onde a partir desses dados decisoes sao tomadas.O dados coletados sao apresentados sob a forma de graficos de linha, disponibilizadosatraves de uma aplicacao de visualizacao. O intervalo de coletas definido foi de 1 segundoadicionado do custo da coleta e analise dos resultados.
Para a avaliacao da elasticidade, utilizamos um conjunto de metricas proposto em[Coutinho et al. 2013a], divididas em dois grupos: tempo de execucao de operacoes e
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
46

utilizacao de recursos. As metricas relacionadas a tempo sao: Tempo de Alocacao So-breprovisionado (TASo), correspondente ao tempo utilizado em operacoes de remocao derecursos; Tempo de Alocacao Subprovisionada (TASu), utilizado para medir o tempo deoperacoes de adicao de recursos; Tempo de Alocacao Estabilizada (TAE), tempo no qualnao ha adicao ou remocao de recursos; e Tempo de Alocacao Transitoria (TAT), corres-pondente ao tempo em que os efeitos da adicao ou remocao de recursos ainda nao impac-taram no ambiente. As metricas relacionadas a recursos sao: Total de Recursos AlocadosSubprovisionados (TRASu), correspondente a quantidade de recursos alocados em umestado subprovisionado, mas nao estabilizado; Total de Recursos Alocados Sobreprovisi-onados (TRASo), indicando a quantidade de recursos alocados em um estado sobrepro-visionado, mas nao estabilizado; e o Total de Recursos Alocados Estabilizados (TRAE),que corresponde a quantidade de recursos em um estado estabilizado. As metricas Elasti-cidade de Scaling UP e Elasticidade de Scaling Down, propostas por [Herbst et al. 2013],serao utilizadas como analise complementar. Estas metricas avaliam a velocidade na qualum ambiente realiza essas operacoes. Demais metricas estao descritas na Tabela 1.
Cargas de trabalho foram utilizadas diretamente na maquina virtual do balan-ceador de carga, originadas de navegadores web e HTTPERF, distribuıdas entre as de-mais maquinas virtuais. Adicionalmente, utilizou-se cargas de trabalho diretamente nasmaquinas virtuais. A ideia e possibilitar a emulacao da concorrencia pelos recursos emdiferentes maneiras de se utilizar um ambiente de Computacao em Nuvem.
Para a macroatividade “Planejar Elasticidade”, um mecanismo baseado na arqui-tetura de Computacao Autonomica definida em [Kephart e Chess 2003] foi construıdoutilizando aspectos de auto-configuracao. Uma estrategia de elasticidade horizontal foiutilizada, atraves da qual a medida que recursos sao necessarios, novas instancias demaquinas virtuais sao adicionadas, por meio de um balanceador de carga, e retiradascaso nao sejam mais necessarias. A metrica utilizada para disparar acoes de elasticidadefoi a media do percentual de utilizacao de CPU das maquinas virtuais. Os limiares utili-zados para a execucao de acoes de elasticidade no ambiente foram: acima de 90% (alocauma nova maquina virtual), abaixo de 80% (desaloca uma maquina virtual), e entre 80%e 90% (mantem alocacao). Esses valores foram definidos considerando a premissa que asituacao ideal de consumo de CPU das maquinas virtuais do ambiente deveria ser quaseem sua totalidade, maximizando a utilizacao da capacidade de processamento.
Esse valor foi calculado como a media das 10 ultimas coletas de utilizacao de CPUnas maquinas virtuais. Como mecanismo de predicao foi utilizado regressao multilinearsobre valores de utilizacao de CPU, memoria, disco e rede, coletados em experimentosprevios, com cargas de trabalho semelhantes. Esse calculo e realizado para decidir se umaacao de alocacao ou desalocacao deve ser executada, antes mesmo do calculo da media.
Para o provisionamento dos recursos, a estrategia de um balanceamento de cargafoi utilizada, onde maquinas virtuais sao adicionadas conforme a necessidade. Um con-junto de scripts foi desenvolvido para promover acoes e estrategias de analise.
As macroatividades “Inicializar Servicos da Analise de Desempenho” e “Execu-tar Analise de Desempenho” foram implementadas atraves de scripts que inicializam osservicos de coleta, analise, geracao das cargas de trabalho (operacoes manuais com oHTTPERF), e consolidacao dos dados, alem de analisar e disparar acoes. A Tabela 1
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
47

Tabela 1. Projeto de experimentosCaracterısticas DescricaoSistema Ambiente privado de Computacao em Nuvem (OpenNebula)Metricas Tempo de resposta das aplicacoes, percentual de utilizacao de CPU, percen-
tual de utilizacao de memoria, pacotes recebidos e enviados em KB, KB li-dos e escritos em disco; TASo, TASu, TAE, TAT, TRASu, TRASo, TRAE[Coutinho et al. 2013a]; Elasticidade de Scaling UP e Elasticidade de ScalingDown [Herbst et al. 2013]
Parametros Fixos CPU, memoria, quantidade de maquinas virtuaisFatores Confi-guraveis
Configuracao do benchmark (repeticoes e tamanho da matriz), configuracaodo BLAST (tamanho do arquivo, tamanho da consulta), configuracao do HTT-PERF (quantidade de requisicoes, taxa de requisicoes, tempo)
Tecnica de Avaliacao MedicaoCarga de Trabalho Experimento 1: Executar multiplicacoes de matrizes (dimensao
200x200x200) atraves de um microbenchmark construıdo na linguagemde programacao Java, sob a forma de pequenas aplicacoes web, comrequisicoes disparadas atraves do HTTPERF, com taxas variando de 1 a 5requisicoes por segundo e quantidade de conexoes variando em 10, 30 e 50;Experimento 2: Executar uma aplicacao cientıfica, o BLAST, atraves deum microbenchmark construıdo na linguagem de programacao Java, sob aforma de pequenas aplicacoes web, com requisicoes disparadas atraves doHTTPERF, com taxas variando de 1 a 3 requisicoes por segundo e quantidadede conexoes variando em 3, 6 e 9
detalha itens do projeto experimental, tais como metricas e cargas de trabalho.
3.2. Experimento 1 - Microbenchmark
Neste experimento projetamos uma carga de trabalho sintetica orientada a CPU e memoriapara multiplicacao de matrizes. A duracao deste experimento foi de 12min58s. A Figura 3ilustra a utilizacao media de CPU, alocacao das maquinas virtuais, e o tempo de respostadas requisicoes.
Conforme observado na Figura 3, muitas variacoes no consumo de CPU ocorre-ram, e a medida em que a primeira maquina virtual executa requisicoes, a utilizacao deCPU aumenta ao longo do tempo. Ao violar o SLA estabelecido, novas instancias sao alo-cadas. Para memoria o comportamento foi quase constante, estando em todas as maquinasvirtuais quase sempre em 100% de utilizacao. O tempo de resposta do servidor teve gran-des picos na maquina virtual 1. Estes picos se devem ao fato de que muitas requisicoesestavam represadas no servidor da maquina virtual 1, e demoraram muito a serem finali-zadas. Nas demais maquinas virtuais o comportamento foi mais constante, o que implicaem uma distribuicao de requisicoes conforme a necessidade. A media de utilizacao deCPU e alocacao das maquinas virtuais, metricas diretamente associadas a elasticidade,coincidiram quando o SLA estabelecido era violado. Quando a carga de utilizacao daCPU era inferior ao limite estabelecido, havia uma desalocacao de maquinas virtuais.
3.3. Experimento 2 - BLAST
A carga de trabalho neste experimento foi projetada para executar uma aplicacao ci-entıfica, o BLAST, orientada a CPU, memoria e disco. O BLAST e uma ferramentade similaridade muito utilizada para sequencias de proteınas. A duracao do experimento
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
48

Figura 3. Utilizacao media de CPU, alocacao de maquinas virtuais, e tempo deresposta das requisicoes para o experimento 1
foi de 19 minutos. A Figura 4 ilustra a utilizacao media CPU, a quantidade de maquinasvirtuais alocadas, e o tempo de resposta das requisicoes.
Figura 4. Utilizacao media de CPU, alocacao de maquinas virtuais, e tempo deresposta das requisicoes para o experimento 2
O BLAST e uma aplicacao de computacao cientıfica, e seu consumo de CPU ealto, constatado na Figura 4. Logo que a primeira maquina virtual executava requisicoes,sua utilizacao de CPU aumentava, e ao superar o SLA estabelecido, novas instancias
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
49

foram alocadas. Para memoria e acesso a disco o comportamento foi quase constante,porem a memoria em todas as maquinas virtuais permaneceu quase sempre em 100%,semelhante ao experimento anterior. Espera-se que em aplicacoes melhores estruturadascom o BLAST, a leitura em disco seja maior devido a pesquisas em arquivos. O tempode resposta do servidor foi maior na maquina virtual 1, com aproximadamente picos noinıcio, na metade, e no final do experimento. Nas demais maquinas virtuais foi quaseconstante. Este pico se deve ao fato de que muitas requisicoes ficaram presas no servidorda maquina virtual 1, demorando mais tempo a finalizarem. Em picos de utilizacao deCPU as 3 maquinas virtuais foram alocadas, e em geral ha uma desalocacao logo apos.Isso se explica devido a carga de trabalho empregada, que parava de enviar requisicoespor um intervalo de tempo, perıodo em que as requisicoes alocadas eram finalizadas.
3.4. Discussao dos ResultadosO objetivo dos experimentos foi validar o framework. Todas as atividades definidasna Secao 2 foram executadas e atendidas. De maneira geral, o framework permitiu arealizacao de analise de desempenho em um ambiente de Computacao em Nuvem, comfoco em elasticidade.
Percebeu-se nos dois experimentos que em alguns momentos a media de utilizacaoda CPU ficou acima do limite. Caso existissem maquinas virtuais adicionais alocadas aobalanceador de carga, seria provavel que tais violacoes nao ocorressem tanto. Isso e umaspecto direto da atividade de mecanismos de provisionamento. Nesse caso, o ideal e queinstancias de maquinas virtuais fossem geradas dinamicamente sempre que necessario, efinalizadas quando nao mais necessario. Entretanto, este ja e um ponto de ajuste a serrealizado sobre o ambiente, alertado pela utilizacao do framework.
O tempo de resposta em geral e alto, mesmo quando novas maquinas virtuais saocriadas. Muitos deles devido a latencia das operacoes, e o ideal e que fosse evitada.Para minizar esses altos valores, possivelmente uma escolha de limiares diferentes seriasuficiente para manter a latencia sempre dentro de um limite aceitavel, alem da inclusao deuma regra que contemplasse o tempo de resposta como criterio para acoes de elasticidade.
A Tabela 2 contem as metricas calculadas para os dois experimentos. Em ambosexperimentos, TAE ocupa a maioria do tempo de alocacao, conforme esperado. Isto sedeve ao fato que grande parte dos experimentos a alocacao dos recursos e estavel, vari-ando apenas quando ha incremento ou reducao de recursos, refletidos nos tempos TASu,TASo e TAT. Apesar de experimentos com caracterısticas diferentes de cargas de trabalho,
Tabela 2. Metricas coletadas para os experimentos 1 e 2Metrica Experimento 1 Experimento 2Tempo Total do Experimento (minutos) 12:58 19:00Tempo de Alocacao Estabilizada (TAE) 11:01 16:51Tempo de Alocacao Subprovisionada (TASu) 00:26 00:37Tempo de Alocacao Sobreprovisionada (TASo) 00:27 00:31Tempo de Alocacao Transitoria (TAT) 01:03 00:59Total de Recursos Alocados (maquinas virtuais) 132 102Total de Recursos Alocados Estabilizado (TRAE) 54 42Total de Recursos Alocados Subprovisionados (TRASu) 47 36Total de Recursos Alocados Sobreprovisionados (TRASo) 31 24
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
50

todas as metricas de tempo possuıram valores percentuais em relacao ao tempo total doexperimento proximos para os dois experimentos: 84% e 88% (TAE), 3% e 2% (TASu),2% e 2% (TASo), e 8% e 5% (TAT). Isto indica uma similaridade nos experimentos.
Estabilidade nao necessariamente implica em atendimento do SLA. Um valor altopara TAE deve ser analisado em conjunto com outros aspectos. O limite superior definidopara SLA foi 90%, e ocorreram algumas violacoes. Isto indica que a capacidade de re-cursos atingiu o limite. Se houvessem mais recursos, os graficos de alocacao teriam maisdegraus, correspondendo a alocacoes e desalocacoes de maquinas virtuais. As metricasTRASu e TRASo aumentariam e TRAE diminuiria. Consequentemente TASu e TASoprovavelmente seriam maiores. Diferente da metrica TAE, cujo valor e maior que TASu,TASo e TAT, a metrica TRAE mostra que um ambiente pode ter grandes intervalos comalocacao estavel com poucos recursos. Quanto maior a variacao na media de consumo deCPU, maior a adicao ou remocao de recursos no ambiente. Apesar que no experimento1 foram alocados mais recursos as operacoes de scaling up e scaling down, na media osvalores foram bem proximos. O ideal e que quanto maior a quantidade de intervalos emestado de alocacao subprovisionada e sobreprovisionada, maior a capacidade do ambienteem se adaptar as demandas impostas. Os valores medios para TRASu, TRASo e TRAEforam bem proximos nos dois experimentos, indicando similaridade nos comportamentos.
Para uma avaliacao mais completa, as metricas Elasticidade de Scaling UP e Elas-ticidade de Scaling Down, propostas por [Herbst et al. 2013] foram calculadas. Estasmetricas avaliam a velocidade na qual um ambiente realiza essas operacoes. Os doisexperimentos obtiveram valores bem semelhantes. A velocidade de Scaling Up para osdois experimentos foi de 0,03 e 0,01 respectivamente, e de Scaling Down 0,04 e 0,02. Oexperimento 1 e um pouco mais veloz que experimento 2, sendo um pouco mais efici-ente. Porem na pratica a diferenca e numericamente quase insignificante. Observando osgraficos de alocacao percebe-se que os momentos em que ocorrem alocacao de recursossao bem parecidos em termos de duracao e utilizacao de recursos.
A analise de desempenho muitas vezes depende da carga de trabalho utilizada naaplicacao, tendo impacto direto sobre o ambiente. Um desafio para ambientes experimen-tais e projetar uma carga de trabalho que represente a realidade de um provedor, devidoa caracterıstica dinamica de cargas de trabalhos reais. Um estudo do comportamento dascargas de trabalho, atraves de metodos estatısticos, predicao, natureza das aplicacoes eusuarios pode auxiliar no projeto. Como os dois experimentos utilizaram o mesmo ambi-ente, a carga de trabalho foi o principal elemento a provocar a diferenca nos resultados.
4. Trabalhos RelacionadosAlguns trabalhos na literatura desenvolveram aplicacoes e frameworks para operacao emambientes de Computacao em Nuvem. Outros propuseram abordagens e metodologiaspara a realizacao de analise de desempenho em Computacao em Nuvem. Esta secaodiscute alguns trabalhos correlatos ao framework proposto. Aqui eles estao organizadosem (i) frameworks, (ii) benchmarks, e (iii) metodologias para avaliacao de desempenhoem nuvens computacionais.
No que concerne os frameworks e aplicativos para desempenho em nuvens, des-tacamos o C-METER [Yigitbasi et al. 2009], um framework portavel, extensıvel, comgeracao e submissao de cargas de trabalho sinteticas. Seguindo um princıpio de ciclo de
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
51

vida autoadaptavel com gerenciamento autonomico, outro framework que merece desta-que e o LoM2HiS [Emeakaroha et al. 2010], cujo objetivo e mapear metricas de infraes-trutura (IaaS) para metricas de usuario (SaaS), visando deteccao de quebras de SLA.
Dentre o conjunto de trabalhos sobre benchmarks, [Sobel et al. 2008] propu-seram CloudStone, um benchmark de aplicacoes web 2.0 para medir o custo mo-netario usuario/mes. O CloudGauge foi apresentado por [El-Refaey e Rizkaa 2010]para virtualizacao em Nuvens com o objetivo de medir cargas de trabalho dinamicas,enquanto o MalStone e voltado para desempenho em aplicacoes orientadas a CPU[Bennett et al. 2010]. [Li et al. 2010] compararam o desempenho entre provedores denuvem mediante o benchmark CloudCMP, considerando aspectos de elasticidade, rede,custo e armazenamento, avaliados de maneira sistematica.
Criterios a serem utilizados na avaliacao da elasticidade sao descritos em[Herbst et al. 2013], tais como: processos de adaptacao para escalabilidade autonomica;recursos escalaveis para o processo de adaptacao; variacao da quantidade de recursos alo-cados; e limite superior da quantidade de recursos que podem ser alocado. Alem disso,metricas foram propostas para a medicao da elasticidade baseadas em velocidade e pre-cisao. E um trabalho motivacional, nao havendo experimentos, porem propoe as metricasElasticidade de Scaling UP e Elasticidade de Scaling Down, especıficas para elasticidade,baseadas em tempos de operacoes e recursos.
Algumas propostas para quantificar elasticidade sao discutidas em[Islam et al. 2012], considerando SLA e penalidades em caso de nao antendimentodo servico, atraves de modelos matematicos. Uma abordagem para a medicao da elasti-cidade de uma nuvem e proposta em [Shawky e Ali 2012], baseada no conceito de stressda nuvem (taxa de recursos requerida pela quantidade de recursos alocados), e tensaoda nuvem (variacao nos recursos antes e depois de operacoes de escalonamento). Ummodelo matematico foi proposto em [Costa et al. 2011] para representar um provedorde IaaS, e seus experimentos simularam aplicacoes Bag of Tasks (BoT) em relacao aoslimites impostos por provedores na execucao deste tipo de aplicacao.
Em geral, o projeto de experimentos nao e claro. Muitos trabalhos nao infor-mam detalhes dos experimentos, que auxiliam em sua replicacao, assim como deta-lhes da instalacao e configuracao dos frameworks e benchmarks disponibilizados. Ou-tra deficiencia comum em trabalhos e que nao e disponibilizada uma metodologia para a
Tabela 3. Comparacao entre trabalhos relacionados e tecnica do experimentoutilizada (T): medicao (M), simulacao (S) e modelagem analıtica (MA)
Trabalho Objetivo TCloudStone [Sobel et al. 2008] Benchmark para aplicacoes web 2.0 MC-METER [Yigitbasi et al. 2009] Framework para analise de desempenho em nuvem MCloudGauge[El-Refaey e Rizkaa 2010]
Benchmark para virtualizacao em nuvem e medicaode cargas de trabalho dinamicas
M
LoM2HiS [Emeakaroha et al. 2010] Framework para mapear metricas de nıvel mais baixopara SLA para deteccao de violacoes
S
MalStone [Bennett et al. 2010] Benchmark para medir desempenho de computacaointensiva de dados
M/S
CloudCMP [Li et al. 2010] Comparar desempenho entre provedores deComputacao em Nuvem
M
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
52

utilizacao das ferramentas para experimentos. Muitas vezes existem poucos detalhes ounao ha uma abordagem sistematica para sua utilizacao, dificultando a analise de desem-penho. A Tabela 3 descreve alguns trabalhos com diferentes nıveis de detalhamento doprojeto de experimento, o que nao quer dizer que nao seguem uma metodologia ou naoha projeto de experimentos, sendo em geral muito bem escritos.
O framework proposto procura estabelecer uma metodologia para a realizacao deanalise de desempenho em ambientes de Computacao em Nuvem de maneira sistematica,com foco em elasticidade. Ele destaca o projeto dos experimentos, das cargas de tra-balho, coletas e medicoes. Nao define uma arquitetura, mas sugere fortemente aspectosferramentais que influenciam diretamente em seus componentes. Por ser um frameworkconceitual, ele e generico e independente de tecnologia. Como em alguns trabalhos rela-cionados, a ideia e ser extensıvel e adaptavel, porem projetando a avaliacao de maneiraflexıvel e reutilizavel.
5. ConclusaoEste trabalho teve como objetivo avaliar a elasticidade em ambientes de Computacao emNuvem de maneira metodologica atraves de um framework conceitual. De maneira geral,o framework permitiu a realizacao de analise de desempenho em uma nuvem computaci-onal satisafatoriamente atraves de dois experimentos, atendendo aos objetivos.
A contribuicao central deste artigo e possibilitar, que uma nuvem sob analise te-nha sua elasticidade avaliada de maneira sistematizada, considerando metricas de desem-penho. Como contribuicoes secundarias, propomos um conjunto de microbenchmarkspara geracao de cargas de trabalho sinteticas e uma ferramenta de visualizacao grafica demetricas coletadas de uma nuvem computacional. Mesmo nao sendo avaliado o real ga-nho proporcionado pela utilizacao do framework, entende-se que a organizacao e estruturaproporcionados sao uteis na avaliacao de desempenho.
Ainda e necessario o detalhamento de cada atividade do framework, para que sejamais intuitivo o objetivo e a importancia de cada atividade. A repeticao de sua utilizacaopermitira um refinamento das atividades, e consequentemente melhoria na sua execucao.
Como trabalhos futuros, pretendemos utilizar outros mecanismos de elasticidade(horizontal e vertical), outras metricas e estrategias de computacao autonomica, expandira ferramenta de visualizacao e os microbenchmarks. Tambem pretende-se realizar umprojeto da carga de trabalho que se aproxime de situacoes reais, e estender a validacao doframework em aplicacoes e ambientes com aplicacoes reais (e-science, web, aplicacoesbiomedicas), assim como provedores comerciais (por exemplo Amazon Web Services eHP Cloud), e nuvens computacionais hıbridas.
ReferenciasBennett, C., Grossman, R. L., Locke, D., Seidman, J., and Vejcik, S. (2010). Malstone:
towards a benchmark for analytics on large data clouds. In Proceedings of the 16thACM SIGKDD international conference on Knowledge discovery and data mining,KDD ’10, pages 145–152, New York, NY, USA. ACM.
Costa, R., Brasileiro, F., Lemos, G., and Mariz, D. (2011). Sobre a amplitude da elastici-dade dos provedores atuais de computacao na nuvem. In XXIX Simposio Brasileiro deRedes de Computadores e Sistemas Distribuıdos (SBRC 2011).
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
53

Coutinho, E., Gomes, D. G., and Souza, J. D. (2013a). An analysis of elasticity in cloudcomputing environments based on allocation time and resources. In LATINCLOUD2013, Maceio, Brazil.
Coutinho, E., Sousa, F. R. C., Gomes, D. G., and Souza, J. D. (2013b). Elasticidade emcomputacao na nuvem: Uma abordagem sistematica. In XXXI Simposio Brasileiro deRedes de Computadores e Sistemas Distribuıdos (SBRC 2013) - Minicursos.
Cruz, F. (2013). Scrum e PMBOK unidos no Gerenciamento de Projetos. Brasport Livrose Multimıdia Ltda.
El-Refaey, M. and Rizkaa, M. (2010). Cloudgauge: A dynamic cloud and virtualiza-tion benchmarking suite. In Enabling Technologies: Infrastructures for CollaborativeEnterprises (WETICE), 2010 19th IEEE International Workshop on, pages 66–75.
Emeakaroha, V., Brandic, I., Maurer, M., and Dustdar, S. (2010). Low level metrics tohigh level slas - lom2his framework: Bridging the gap between monitored metrics andsla parameters in cloud environments. In High Performance Computing and Simulation(HPCS), 2010 International Conference on, pages 48–54.
Herbst, N. R., Kounev, S., and Reussner, R. (2013). Elasticity in cloud computing: Whatit is, and what it is not. In Proceedings of the 10th International Conference on Auto-nomic Computing(ICAC 2013), San Jose, CA, pages 23–27. USENIX.
Islam, S., Lee, K., Fekete, A., and Liu, A. (2012). How a consumer can measure elasticityfor cloud platforms. In Proceedings of the 3rd ACM/SPEC International Conferenceon Performance Engineering, ICPE ’12, pages 85–96, New York, NY, USA. ACM.
Kephart, J. O. and Chess, D. M. (2003). The vision of autonomic computing. Computer,36(1):41–50.
Li, A., Yang, X., Kandula, S., and Zhang, M. (2010). Cloudcmp: comparing publiccloud providers. In Proceedings of the 10th ACM SIGCOMM conference on Internetmeasurement, IMC ’10, pages 1–14, New York, NY, USA. ACM.
Rego, P., Coutinho, E., Gomes, D., and De Souza, J. (2011). Faircpu: Architecture for al-location of virtual machines using processing features. In Utility and Cloud Computing(UCC), 2011 Fourth IEEE International Conference on, pages 371–376.
Shawky, D. M. and Ali, A. F. (2012). Defining a measure of cloud computing elasticity.In Systems and Computer Science (ICSCS), 2012 1st International Conference on.
Sobel, W., Subramanyam, S., Sucharitakul, A., Nguyen, J., Wong, H., Klepchukov,A., Patil, S., Fox, O., and Patterson, D. (2008). Cloudstone: Multi-platform, multi-language benchmark and measurement tools for web 2.0.
Tordsson, J., Montero, R. S., Moreno-Vozmediano, R., and Llorente, I. M. (2012). Cloudbrokering mechanisms for optimized placement of virtual machines across multipleproviders. Future Generation Computer Systems, 28(2):358 – 367.
Yigitbasi, N., Iosup, A., Epema, D., and Ostermann, S. (2009). C-meter: A frameworkfor performance analysis of computing clouds. In Cluster Computing and the Grid,2009. CCGRID ’09. 9th IEEE/ACM International Symposium on, pages 472–477.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
54

Metricas para Avaliacao da Elasticidade em Computacao emNuvem Baseadas em Conceitos da Fısica
Emanuel F. Coutinho1,2,4, Paulo A. L. Rego1,2,Danielo G. Gomes1,3, Jose N. de Souza1,2
1Grupo de Redes de Computadores, Engenharia de Software e Sistemas (GREat)2Mestrado e Doutorado em Ciencia da Computacao (MDCC)
3Departamento de Engenharia em Teleinformatica (DETI)4Instituto UFC Virtual
Universidade Federal do CearaFortaleza – CE – Brasil
[email protected], {pauloalr,danielo,neuman}@ufc.br
Abstract. Currently many customers and providers are using resources of cloudcomputing environments, such as processing and storage, for their applicationsand services. With the increase in use of resources, a key feature of cloud com-puting has become quite attractive: elasticity. The elasticity can be defined ashow the cloud adapts to variations in their workload by provisioning and de-provisioning resources. This work aims to propose metrics for measuring CloudComputing elasticity based on Physics’ concepts, such as stress and tension.For validating the metrics, two experiments were designed in a private cloud,using workloads generated by microbenchmarks to evaluate the elasticity.
Resumo. Atualmente muitos clientes e provedores estao utilizando recursos deambientes de Computacao em Nuvem, tais como processamento e armazena-mento, para suas aplicacoes e servicos. Com o aumento na utilizacao dosrecursos, uma das caracterısticas principais da Computacao em Nuvem temse tornado bastante atrativa: a elasticidade. A elasticidade pode ser definidacomo o quanto uma nuvem computacional se adapta a variacoes na sua cargade trabalho atraves do provisionamento e desprovisionamento de recursos. Estetrabalho tem como objetivo propor metricas para a medicao da elasticidadeem Computacao em Nuvem baseada em conceitos da Fısica, como estresse etensao. Para a validacao das metricas, dois experimentos foram projetados emuma nuvem computacional privada, utilizando cargas de trabalho geradas pormicrobenchmarks para a avaliacao da elasticidade.
1. IntroducaoAtualmente muitos clientes e provedores estao utilizando recursos de ambientes deComputacao em Nuvem, tais como processamento e armazenamento, para a execucaode suas aplicacoes de disponibilizacao de servicos. Com o aumento na utilizacao dosrecursos, uma das caracterısticas principais da Computacao em Nuvem tem se tornadobastante atrativa: a elasticiade.
A elasticidade e uma caracterıstica essencial da Computacao em Nuvem. Con-forme o National Institute of Standards and Technology (NIST), a elasticidade e a ha-
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
55

bilidade de rapido provisionamento e desprovisionamento, com capacidade de recur-sos virtuais praticamente infinita e quantidade adquirıvel sem restricao a qualquer mo-mento [Mell e Grance 2009]. Uma definicao de elasticidade mais recente proposta por[Herbst et al. 2013] consiste no quanto um sistema e capaz de se adaptar a variacoes nacarga de trabalho pelo provisionamento e desprovisionamento de recursos de maneira au-tonomica, de modo que em cada ponto no tempo os recursos disponıveis combinem com ademanda da carga de trabalho o mais proximo possıvel. Considerando que a elasticidadeesta se tornando uma necessidade cada vez maior em ambientes de nuvens devido a ca-racterıstica dinamica das diversas cargas de trabalho impostas, diversos provedores estaodisponibilizando servicos de monitoramento de recursos e provimento da elasticidade.
Diversas estrategias para a avaliacao da elasticidade foram propostas na lite-ratura [Islam et al. 2012, Shawky e Ali 2012, Herbst et al. 2013, Coutinho et al. 2013].Porem, a maneira de se medir a elasticidade e bastante variada, nao havendo ainda umapadronizacao para tal tarefa. Um aspecto comum e a utilizacao de recursos do ambi-ente, como CPU e memoria, para indiretamente se avaliar a elasticidade, mesmo semter uma metrica especıfica para a elasticidade. O conceito de elasticidade e comum emalgumas areas de atuacao diferentes da Computacao, tais como a Fısica, Biologia e Mi-croeconomia. [Gambi et al. 2013] e [Shawky e Ali 2012] descrevem algumas analogiasda elasticidade de outras areas em comparacao a elasticidade em Computacao em Nuvem.
Este artigo tem como objetivo geral permitir que um usuario ou provedor possamedir e avaliar a elasticidade de uma nuvem computacional. Para seu atendimento,tres objetivos especıficos foram tracados: (i) identificacao de metricas na literatura paramedicao da elasticidade em Computacao em Nuvem; (ii) definicao de um conjuntode metricas para a medicao da elasticidade; e (iii) realizacao de experimentos para avalidacao das metricas. As principais contribuicoes deste artigo sao: metricas para aavaliacao da elasticidade em Computacao em Nuvem baseadas nos conceitos de tensaoe estresse da Fısica; e um estudo de caso com experimentos realizados em uma nuvemcomputacional para avaliacao da elasticidade, utilizando cargas de trabalho geradas pormeio de microbenchmarks.
O trabalho esta organizado da seguinte forma, alem desta introducao: a Secao 2apresenta os trabalhos relacionados; a Secao 3 descreve as metricas propostas; na Secao4 sao descritas a metodologia de avaliacao, os experimentos, e discussao do resultados;finalmente, a conclusao e trabalhos futuros sao apresentados na Secao 5.
2. Trabalhos RelacionadosDiversos trabalhos consideram multiplos aspectos do ambiente para alocacao de recursos,baseando-se nesses parametros para a tomada de decisao. A maioria dos trabalhos executaa coleta de informacoes dos ambientes e os utilizam para decidir a alocacao dos recursos.
Em [Zhang et al. 2010], uma abordagem para o gerenciamento de recursos da in-fraestrutura utilizando um loop de controle adaptativo foi proposta. Dois loops de controleforam utilizados, um para alocar os recursos e outro para otimizar o consumo. Seus expe-rimentos utilizaram o Xen e trabalharam no nıvel de PaaS (Platform as a Service). Estetrabalho e generico para se adequar a qualquer aspecto, como CPU e memoria, porque elemonitora metricas de desempenho e pode modifica-las sempre que necessario.
Maneiras de quantificar elasticidade sao discutidas em [Islam et al. 2012], con-
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
56

siderando aspectos de qualidade e penalidades em caso de nao antendimento do servico.Um modelo matematico baseado em penalidades, recursos e demandas foi descrito. Alemdisso, experimentos foram realizados na Amazon EC2 com o benchmark TPC-W e o apli-cativo JMeter para geracao de cargas de trabalho. No trabalho proposto, a diferenca e quecargas de trabalho foram geradas atraves de microbenchmarks projetados, e como geradorde carga foi utilizado o HTTPERF.
Uma abordagem para a medicao da elasticidade de uma nuvem foi proposta por[Shawky e Ali 2012], baseada nos princıpios da elasticidade definida na Fısica. Nestadefinicao e abordado o conceito de estresse da nuvem, definido como a taxa de recursosrequerida pela quantidade de recursos alocados, e o de tensao da nuvem, definido comoa variacao nos recursos antes e depois de operacoes de escalonamento. A diferenca entreesse trabalho e o proposto e que as metricas utilizadas sao calculadas de maneiras diferen-tes, apesar de seguir o mesmo princıpio. Para o calculo do estresse, [Shawky e Ali 2012]utilizaram o conceito de capacidade de computacao, que e estimada pela quantidade to-tal de dados processados em Gigabytes, enquanto que utilizamos apenas a quantidade derecursos manipulada. O foco de [Shawky e Ali 2012] para o calculo da tensao foi emlargura de banda, e nosso trabalho utilizou apenas o tempo.
Um conjunto de metricas para elasticidade e proposto em [Herbst et al. 2013],com a ideia de velocidade e precisao. E um trabalho motivacional, nao havendo expe-rimentos, porem propoe uma metrica especıfica para elasticidade baseada em tempos deoperacoes e recursos. As metricas Elasticidade de Scaling Up e Elasticidade de ScalingDown foram propostas, e levam em consideracao a quantidade de recursos alocadas e operıodo de tempo dispendido durante perıodos de subprovisionamento e sobreprovisiona-mento, e serao utilizadas nos experimentos como analise complementar.
No trabalho de [Rego et al. 2013], uma solucao foi apresentada para alocacaodinamica e autonomica de recursos em um ambiente de Computacao em Nuvem. Este tra-balho descreve estrategias, baseadas na criacao de maquinas virtuais e alocacao dinamicade recursos, para atender os requisitos de qualidade e garantir a qualidade de servico dasaplicacoes em um ambiente hıbrido de Computacao em Nuvem. A solucao aproveita aarquitetura FairCPU [Rego et al. 2011] para ajustar dinamicamente a quantidade de CPUconforme limites pre-estabelecidos pelo usuario. Alem disso, experimentos foram con-duzidos para comparar tres estrategias de alocacao de recursos. No trabalho proposto naoserao utilizadas nuvens publicas ou hıbridas.
Em [Coutinho et al. 2013], o comportamento da elasticidade foi analisado em umambiente de Computacao em Nuvem, baseado em metricas relacionadas a tempo deresposta e recursos utilizados. Um conjunto de metricas foi apresentado e um experi-mento utilizando medicao para a validacao da proposta foi executado, concluindo-se quee possıvel avaliar a elasticidade baseado em tempos de alocacao de recursos. As metricasdefinidas neste trabalho serao utilizadas como analise complementar nos experimentos.
Novas ideias relacionadas ao teste de sistemas computacionais elasticos foram in-troduzidas por [Gambi et al. 2013], onde foram identificados alguns desafios de pesquisae tendencias futuras. Neste mesmo trabalho foi sugerida uma analogia com conceitos deelasticidade definidos na Fısica (Elasticidade de Materiais) com sistemas computacionaiselasticos, tais como: deformacao, recuperacao, plasticidade e tensao. Tambem foi elabo-
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
57

rada uma analogia com testes mecanicos para a definicao de testes adequados a sistemascomputacionais. Porem neste trabalho nao foram discutidas metricas, apenas a metaforaentre as areas. Tambem nao foram realizados experimentos.
3. Metricas para a Medicao da Elasticidade em Computacao em Nuvem
O conceito de elasticidade e comum em areas de atuacao diferentes da Computacao, taiscomo Fısica (Fısica de Materiais, Pneumatica, Hidraulica), Biologia, Teoria do Controle eMicroeconomia. Na Fısica, segundo [Timoshenko e Goodier 1970], todo material possuiuma extensao da propriedade denominada elasticidade. Se forcas externas aplicadas aomaterial produzirem uma deformacao na estrutura, nao excedendo um determinado limite,a deformacao desaparece com a remocao das forcas. A ideia deste trabalho e definirmetricas para avaliacao da elasticidade em nuvens computacionais baseadas em conceitosda Fısica. Para isso, as metricas estresse e tensao foram identificadas, e suas respectivasversoes computacionais foram propostas.
A Tabela 1 descreve as variaveis relacionadas as metricas propostas, assim comoa nomenclatura a ser utilizada. As metricas associadas a recursos sao valores coletadosdo ambiente, como utilizacao de CPU e quantidade de maquinas virtuais alocadas. Avariavel t corresponde ao numero de iteracoes que sao coletados os diferentes parametrosutilizados, definido pelo intervalo de coleta.
Tabela 1. Lista de variaveis e nomenclaturaVariavel Descricao
RD Recursos Demandados: recursos necessarios para o atendimento do SLARA Recursos Alocados: recursos alocados ao ambientet Total de iteracoes (intervalos de coleta)
RDAtu Recursos Demandados Atuais: recursos demandados pelo ambiente no momento da co-leta para atendimento do SLA
RDAnt Recursos Demandados Anteriores: recursos demandados pelo ambiente em momentos decoleta anteriores
RAAtu Recursos Alocados Atuais: recursos alocados ao ambiente no momento da coletaRAAnt Recursos Alocados Anteriores: recursos alocados ao ambiente em momentos de coleta
anteriores∆RD RDAtu−RDAnt∆RA RAAtu−RAAntSQN Estresse da Qualidade na Nuvem: taxa na qual os recursos sao demandados em relacao
aos recursos alocadosTRD Tensao dos Recursos Demandados: taxa que mede a variacao dos recursos demandados
entre intervalos de coleta (∆RD) e os recursos demandados ao ambiente no momento dacoleta
TRA Tensao dos Recursos Alocados: taxa que mede a variacao dos recursos alocados entreintervalos de coleta (∆RA) e os recursos alocados ao ambiente no momento da coleta
ERDi Elasticidade dos Recursos Demandados: relacao entre SQN e TRD
ERAi Elasticidade dos Recursos Alocados: relacao entre SQN e TRA
ER Elasticidade Media dos Recursos: media aritmetica de todas as elasticidades calculadasem cada um dos intervalos de coleta t
Na Fısica, o estresse mede o quao forte e um material. Ele e definido como aquantidade de pressao que o material pode suportar, sem sofrer algum tipo de alteracaofısica [Timoshenko e Goodier 1970, Shawky e Ali 2012]. Considerando que o estresse na
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
58

Fısica e uma forca que age sobre a area da seccao transversal do material, fazendo a analo-gia com uma nuvem computacional, onde RD sao os recursos demandados impostos pelascargas de trabalho e RA sao os recursos alocados na atual configuracao da infraestrutra,temos que o Estresse da Qualidade da Nuvem (SQN ) pode ser medido pela Equacao 1:
SQN =
{0, se RA = 0RD
RA, caso contrario
(1)
Algumas situacoes especıficas devem ser tratadas. No caso em que os recursosdemandados e recursos alocados sao zero, considera-se que o estresse e zero. No caso emque recursos demandados sao diferentes de zero e os recursos alocados sao iguais a zero,o estresse tende a infinito. Esta situacao semanticamente significa que ha uma demandaonde nao ha recursos alocados e nada que foi demandado sera atendido, e para fim deinterpretacao, esta situacao tambem implicara no estresse igual a zero.
A tensao conforme a definicao na Fısica e o quanto um objeto esta sendo esten-dido ou distorcido [Timoshenko e Goodier 1970, Shawky e Ali 2012], e pode ser medidaatraves da divisao entre a extensao de um material e seu comprimento apos a distorcaoprovocada pela aplicacao de forcas externas. Fazendo a analogia com a nuvem computa-cional, a Tensao dos Recursos Demandados (TRD) pode ser medida pela Equacao 2 e aTensao dos Recursos Alocados (TRA) pode ser medida pela Equacao 3:
TRD =
{0, se RD = 0
∆RD
RDAtu, caso contrario
(2)
TRA =
{0, se RA = 0
∆RA
RAAtu, caso contrario
(3)
Conforme a Lei de Hook, a elasticidade pode ser medida pela divisao entre oestresse e a tensao [Timoshenko e Goodier 1970, Shawky e Ali 2012]. A elasticidade dosrecursos em um determinado ponto i pode ser calculada de duas maneiras diferentes,dependendo da formula de tensao utilizada (TRD ou TRA). A Equacao 4 considera osrecursos alocados, enquanto que a Equacao 5 considera os recursos demandados.
ERDi =
{0, se TRDi = 0SQNi
TRDi, caso contrario
(4)
ERAi =
{0, se TRAi = 0SQNi
TRAi, caso contrario
(5)
Por fim, a elasticidade media dos recursos ER pode ser calculada tanto para osrecursos alocados quanto para demandados por meio da Equacao 6.
ER =
∑ti=0 Ei
t(6)
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
59

4. Experimentos
Para a validacao das metricas propostas, dois experimentos foram projetados. Diferentesmetricas podem ser utilizadas para analisar o desempenho de um ambiente, dependendodo aspecto considerado. Essas metricas, geralmente associadas a recursos do ambiente,como percentual de utilizacao de CPU e memoria, tempo de resposta ou throughput,influenciam diretamente no desempenho da aplicacao. A carga de trabalho empregadatambem possui um papel importante nos resultados, e deve ser cuidadosamente projetada.
Para o experimento, uma suposicao considerada e que sempre havera recursosalocados inicialmente e nao ha momentos sem recursos alocados. Em um ambiente com-putacional e plenamente possıvel que situacoes sem recursos alocados ou sem recursosdisponıveis ocorram, como em uma situacao inicial onde os recursos ainda nao foramalocados, ou quando o ambiente esta sendo inicializado, mas ja existe demanda, ou aindaem uma situacao ao longo do tempo em que os recursos por algum motivo estao indis-ponıveis, por exemplo, provocado por uma queda de energia, mas a demanda continua.
4.1. Infraestrutura
Uma nuvem computacional privada foi construıda sobre o OpenNebula 3.8. Todasas maquinas fısicas envolvidas possuem processadores com 4 e 6 nucleos, 24 GB dememoria RAM e sistema operacional Ubuntu Server 12.04. Quatro maquinas virtuais fo-ram utilizadas nos experimentos, todas com 1 VCPU, 1 GB de memoria RAM e sistemaoperacional Ubuntu Server 12.04. Para a geracao de cargas de trabalho foi utilizada aferramenta HTTPERF, que gerava uma quantidade de requisicoes, sob uma determinadataxa, para pequenas aplicacoes web (servlets) gerenciadas no container Apache Tomcat.Para a adaptacao dos recursos as cargas de trabalho geradas, uma estrategia de elastici-dade horizontal foi utilizada atraves de uma balanceador de carga, o NGINX. A Figura 1descreve a infraestrutura projetada para o experimento.
Figura 1. Infraestrutura dos experimentos
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
60

4.2. Projeto dos Experimentos
Em ambos os experimentos, o objetivo e avaliar o desempenho da elasticidade (o quantoo sistema e elastico) do ambiente de Computacao em Nuvem diante de uma carga de tra-balho variada composta por aplicacoes web. Foi utilizado como estrategia de elasticidadebalanceadores de carga (elasticidade horizontal), onde novos recursos sao adicionadosquando necessario ao balanceador de carga, e removidos quando a carga de trabalho dimi-nui. A metrica utilizada para acionar acoes de elasticidade foi o percentual de utilizacaode CPU de cada maquina virtual utilizada no experimento. Os limites utilizados comoreferencia foram: acima de 90% (aloca uma nova maquina virtual), abaixo de 80% (desa-loca uma maquina virtual), e entre 80% e 90% (mantem a infraestrutura atual). Esse valorfoi obtido atraves do calculo da media das 10 ultimas amostras de utilizacao de CPU dasmaquinas virtuais, armazenadas em arquivos de log gerados a cada iteracao.
Para o calculo da elasticidade, foi utilizado apenas a Tensao dos Recursos Aloca-dos (TRA), e consequentemente calculada a Elasticidade dos Recursos Alocados (ERAi).A Tabela 2 descreve aspectos relacionados ao projeto de experimentos.
Tabela 2. Projeto de experimentosCaracterısticas DescricaoSistema Ambiente privado de Computacao em Nuvem (OpenNebula)Metricas Tempo de resposta das aplicacoes, percentual de utilizacao de CPU; TASo, TASu,
TAE, TAT, TRASu, TRASo, TRAE [Coutinho et al. 2013], Elasticidade de ScalingUP e Elasticidade de Scaling Down [Herbst et al. 2013], SQN , TRA, ERAi, ER
Parametros CPU, memoria, sistema operacional, quantidade de maquinas virtuaisFatores Confi-guraveis
Configuracao do benchmark (repeticoes e tamanho da matriz), configuracao doBLAST (tamanho do arquivo, tamanho da consulta), configuracao do HTTPERF(quantidade de requisicoes, taxa de requisicoes, tempo)
Carga de Tra-balho
Experimento 1: Executar multiplicacoes de matrizes (dimensao 200x200x200)atraves de um microbenchmark construıdo na linguagem de programacao Java, sob aforma de pequenas aplicacoes web, com requisicoes disparadas atraves do HTTPERF,com taxas variando de 1 a 5 requisicoes por segundo e quantidade de conexoes vari-ando em 10, 30 e 50; Experimento 2: Executar uma aplicacao cientıfica, o BLAST,atraves de um microbenchmark construıdo na linguagem de programacao Java, sob aforma de pequenas aplicacoes web, com requisicoes disparadas atraves do HTTPERF,com taxas variando de 1 a 3 requisicoes por segundo e quantidade de conexoes vari-ando em 3, 6 e 9
Analise dosDados
Interpretacao dos resultados descritos nos graficos de media do percentual de CPU,graficos de alocacao das maquinas virtuais, e tabelas com metricas coletadas
4.3. Carga de Trabalho
Destaca-se a geracao de cargas de trabalho diretamente na maquina virtual do balance-ador de carga, oriundas de navegadores web e do HTTPERF, que sao distribuıdas entreas demais maquinas virtuais, e tambem cargas de trabalho executadas diretamente nasmaquinas virtuais utilizadas pelas aplicacoes. A ideia e emular a concorrencia pelos re-cursos em diferentes maneiras de se utilizar um ambiente de Computacao em Nuvem. ATabela 2 detalha itens do projeto experimental, tais como metricas e cargas de trabalho.A Figura 2 ilustra a carga de trabalho empregada nos dois experimentos sobre a infraes-trutura construıda.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
61

Figura 2. Projeto da carga de trabalho aplicada aos experimentos
4.4. Experimentos - Microbenchmark e Aplicacao Cientıfica
A carga de trabalho para os dois experimentos foi descrita na Tabela 2. Os graficos apre-sentados nas Figuras 3 e 4 descrevem o comportamento do experimento no tempo, con-forme as requisicoes eram disparadas, atraves do consumo medio de CPU em todas asmaquinas virtuais envolvidas no experimento, e suas respectivas alocacoes.
Devido a caracterıstica do microbenchmark empregado no experimento 1, e de seesperar muitas variacoes no consumo de CPU. A carga de trabalho utilizada no experi-mento 2 foi projetada para executar uma aplicacao cientıfica, BLAST, com foco em CPU,memoria e acesso a disco. O BLAST e uma ferramenta de similaridade muito utilizadapara sequencias de proteınas [NCBI 2013].
Quando os limites estabelecidos eram superados, novas maquinas virtuais eramalocadas. Os graficos de utilizacao media de CPU e alocacao de maquinas virtuais des-crevem metricas diretamente relacionadas a eventos de elasticidade. Pode-se visualizarnos graficos de consumo medio de CPU e alocacao, descritos nas Figuras 3 e 4, quequando os limiares estabelecidos sao superados, novas maquinas virtuais sao adicionadasao balancedor de carga, e quando a utilizacao de CPU e menor que o limite inferior, haentao uma desalocacao de maquinas virtuais.
4.5. Discussao dos Resultados
Para uma melhor comparacao dos resultados, os graficos de utilizacao de CPU, alocacaode maquinas virtuais, tensao, estresse e elasticidade estao dispostos na mesma imagem ena mesma escala, conforme as Figuras 3 e 4.
O estresse respeita a carga de trabalho aplicada ao ambiente no sentido quevariacoes na carga que impliquem em um consumo de CPU proximas ao SLA estabele-cido influenciam no estresse. Ha a tendencia de aumentar seu valor se a carga de trabalhoimposta aumentar. Momentos curtos de variacao na carga de trabalho e no consumo deCPU nao impactam tanto no estresse, implicando em um estresse menor e mais constante.O estresse para o contexto definido sempre sera maior ou igual a 1 devido a suposicao desempre haver pelo menos uma maquina virtual alocada. A tensao tambem nao e muito
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
62
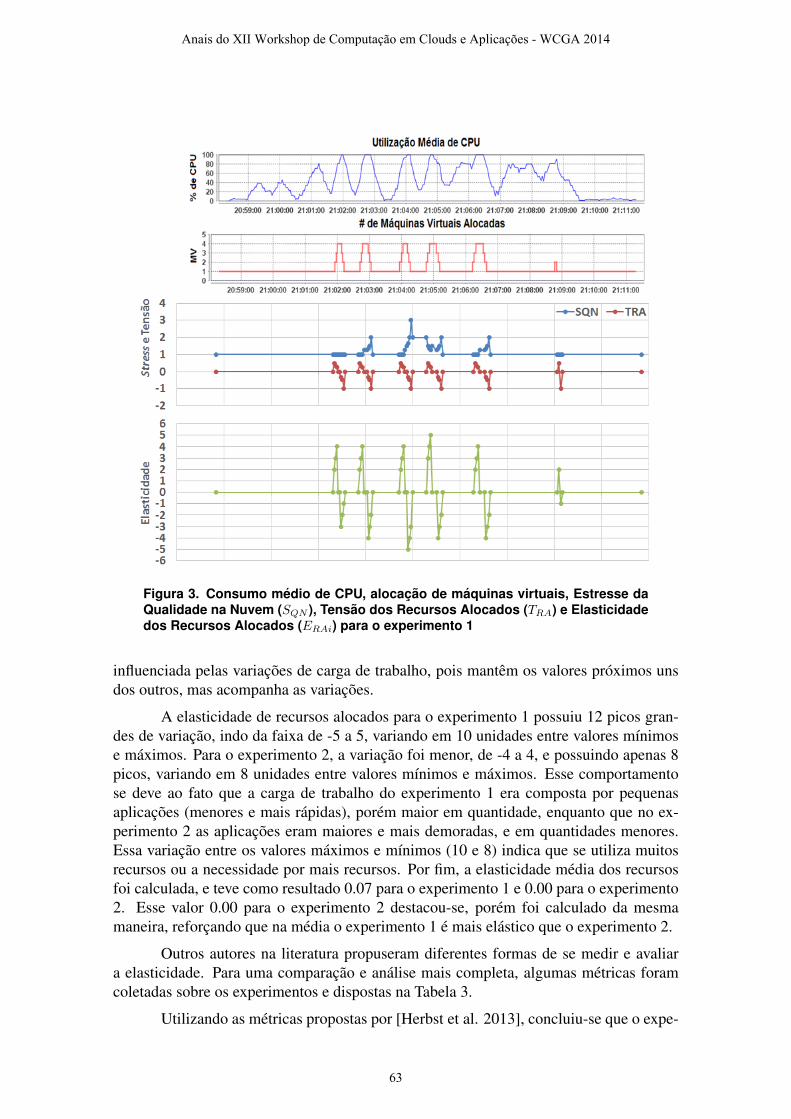
Figura 3. Consumo medio de CPU, alocacao de maquinas virtuais, Estresse daQualidade na Nuvem (SQN ), Tensao dos Recursos Alocados (TRA) e Elasticidadedos Recursos Alocados (ERAi) para o experimento 1
influenciada pelas variacoes de carga de trabalho, pois mantem os valores proximos unsdos outros, mas acompanha as variacoes.
A elasticidade de recursos alocados para o experimento 1 possuiu 12 picos gran-des de variacao, indo da faixa de -5 a 5, variando em 10 unidades entre valores mınimose maximos. Para o experimento 2, a variacao foi menor, de -4 a 4, e possuindo apenas 8picos, variando em 8 unidades entre valores mınimos e maximos. Esse comportamentose deve ao fato que a carga de trabalho do experimento 1 era composta por pequenasaplicacoes (menores e mais rapidas), porem maior em quantidade, enquanto que no ex-perimento 2 as aplicacoes eram maiores e mais demoradas, e em quantidades menores.Essa variacao entre os valores maximos e mınimos (10 e 8) indica que se utiliza muitosrecursos ou a necessidade por mais recursos. Por fim, a elasticidade media dos recursosfoi calculada, e teve como resultado 0.07 para o experimento 1 e 0.00 para o experimento2. Esse valor 0.00 para o experimento 2 destacou-se, porem foi calculado da mesmamaneira, reforcando que na media o experimento 1 e mais elastico que o experimento 2.
Outros autores na literatura propuseram diferentes formas de se medir e avaliara elasticidade. Para uma comparacao e analise mais completa, algumas metricas foramcoletadas sobre os experimentos e dispostas na Tabela 3.
Utilizando as metricas propostas por [Herbst et al. 2013], concluiu-se que o expe-
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
63
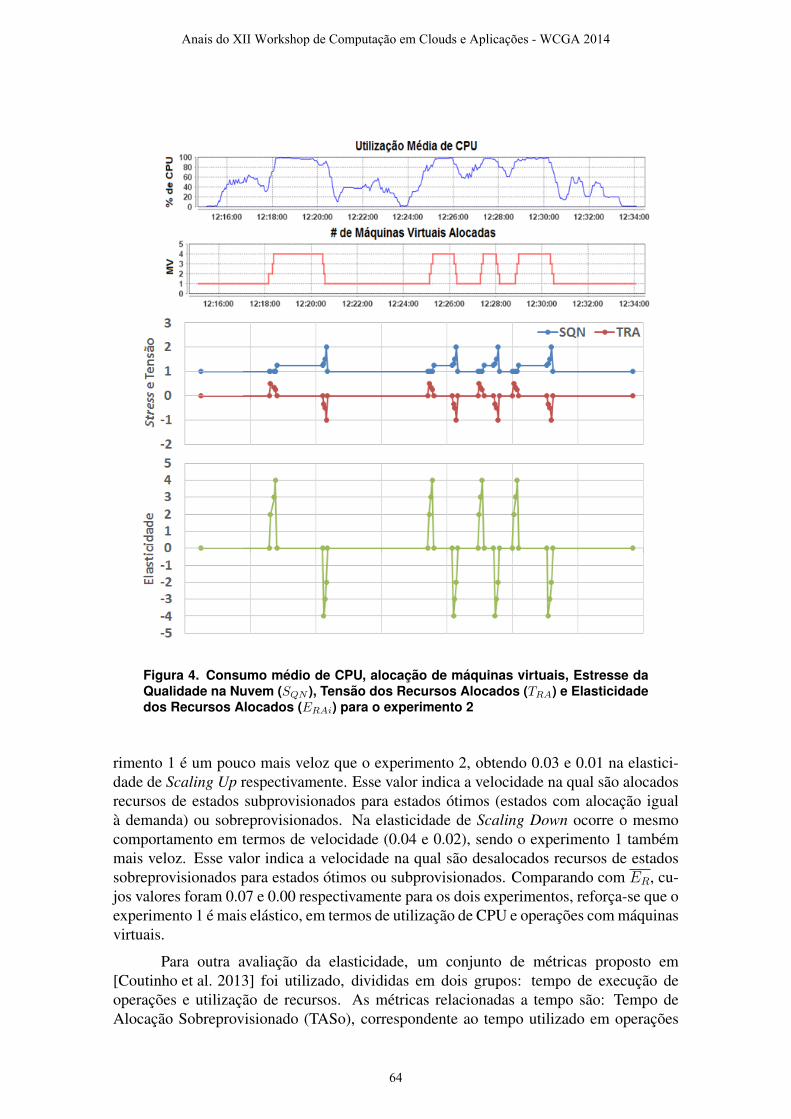
Figura 4. Consumo medio de CPU, alocacao de maquinas virtuais, Estresse daQualidade na Nuvem (SQN ), Tensao dos Recursos Alocados (TRA) e Elasticidadedos Recursos Alocados (ERAi) para o experimento 2
rimento 1 e um pouco mais veloz que o experimento 2, obtendo 0.03 e 0.01 na elastici-dade de Scaling Up respectivamente. Esse valor indica a velocidade na qual sao alocadosrecursos de estados subprovisionados para estados otimos (estados com alocacao iguala demanda) ou sobreprovisionados. Na elasticidade de Scaling Down ocorre o mesmocomportamento em termos de velocidade (0.04 e 0.02), sendo o experimento 1 tambemmais veloz. Esse valor indica a velocidade na qual sao desalocados recursos de estadossobreprovisionados para estados otimos ou subprovisionados. Comparando com ER, cu-jos valores foram 0.07 e 0.00 respectivamente para os dois experimentos, reforca-se que oexperimento 1 e mais elastico, em termos de utilizacao de CPU e operacoes com maquinasvirtuais.
Para outra avaliacao da elasticidade, um conjunto de metricas proposto em[Coutinho et al. 2013] foi utilizado, divididas em dois grupos: tempo de execucao deoperacoes e utilizacao de recursos. As metricas relacionadas a tempo sao: Tempo deAlocacao Sobreprovisionado (TASo), correspondente ao tempo utilizado em operacoes
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
64

Tabela 3. Metricas coletadas para os experimentos 1 e 2Metricas Experimento 1 Experimento 2Tempo Total do Experimento (minutos) 12:58 19:00Tempo de Alocacao Estabilizada (TAE) 11:01 16:51Tempo de Alocacao Subprovisionada (TASu) 00:26 00:37Tempo de Alocacao Sobreprovisionada (TASo) 00:27 00:31Tempo de Alocacao Transitoria (TAT) 01:03 00:59Total de Recursos Alocados Estabilizado (TRAE) 54 42Total de Recursos Alocados Subprovisionados (TRASu) 47 36Total de Recursos Alocados Sobreprovisionados (TRASo) 31 24Elasticidade de Scaling UP 0,03 0,01Elasticidade de Scaling DOWN 0,04 0,02
Elasticidade Media dos Recursos (ER) 0,07 0,00
de remocao de recursos; Tempo de Alocacao Subprovisionada (TASu), utilizado para me-dir o tempo de operacoes de adicao de recursos; Tempo de Alocacao Estabilizada (TAE),tempo no qual nao ha adicao ou remocao de recursos; e Tempo de Alocacao Transitoria(TAT), correspondente ao tempo em que os efeitos da adicao ou remocao de recursos aindanao impactaram no ambiente. As metricas relacionadas a recursos sao: Total de RecursosAlocados Subprovisionados (TRASu), correspondente a quantidade de recursos alocadosem um estado subprovisionado, mas nao estabilizado; Total de Recursos Alocados So-breprovisionados (TRASo), indicando a quantidade de recursos alocados em um estadosobreprovisionado, mas nao estabilizado; e o Total de Recursos Alocados Estabilizados(TRAE), que corresponde a quantidade de recursos em um estado estabilizado.
Em relacao a TAT, os valores foram muito proximos nos dois experimentos,reforcando operacoes de elasticidade executadas com comportamento e duracao seme-lhantes. Ambos experimentos possuıram TAE bem longos em relacao as demais metricas,ocupando grande parte do tempo total dos experimentos. Esse momento de alocacao es-tabilizada significa que, de certa forma, as alocacoes e desalocacoes estavam “estabili-zadas” ou “paradas” em termos de operacoes de elasticidade. Percebeu-se que TASu eTASo para o experimento 2 foram maiores que o experimento 1. Porem a duracao dosexperimentos e a quantidade de mudancas nos estados influencia na analise. Nao se podeafirmar com certeza que o experimento 2 foi pior que o experimento 1, ou menos elastico,pois em termos de duracao foi aproximadamente 6 minutos mais longo. Porem, TASu eTASo tiveram valores proximos, o que pode implicar em capacidades elasticas proximas.
TRAE, TRASu e TRASo, ao contrario da maioria das metricas de tempo, forammaiores para o experimento 1, implicando uma maior utilizacao de recursos durante acoesde alocacao e desalocacao (maquinas virtuais). E de se esperar que quanto maior seu va-lor, maior seja TAT. Essas metricas analisam indiretamente a elasticidade do ambiente.Se analisarmos os graficos de elasticidade das Figuras 3 e 4, verificamos que as variacoescoincidem com as alocacoes, consequentemente com os momentos onde sao mais utili-zados recursos, podendo ser empregados como analise complementar para a elasticidade.O experimento 1 teve em alguns pontos ERAi atingindo 5, e nesses momentos a alocacaoestava no maximo, necessitanto talvez de mais recursos, que o ambiente nao possuıa. Omesmo ocorreu para o experimento 2, mas com um pico menor, com ERAi igual a 4. Oequivalente ocorreu para ERAi negativos, indicando desalocacoes.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
65

5. Conclusao e Trabalhos FuturosEste trabalho propos metricas para a medicao da elasticidade em Computacao em Nuvembaseadas em conceitos da Fısica (estresse e tensao). Dois experimentos foram executadospara a avaliacao das metricas e da elasticidade em uma nuvem computacional privada.A utilizacao das metricas propostas neste trabalho permitira que outros pesquisadorespossam aplica-las em seus experimentos, possibilitando a comparacao e refinamento deexperimentos e solucoes elasticas. A intencao de sua utilizacao e ser mais simples e maisfacil de se aplicar na avaliacao da elasticidade de ambientes de nuvens computacionais.
Como trabalhos futuros, pretende-se realizar experimentos em ambientes deComputacao em Nuvem diversificados, com a utilizacao de nuvens publicas e hıbridas,com diferentes provedores de acesso, benchmarks e cargas de trabalho. Tambempretende-se desenvolver um mecanismo de escalonamento utilizando as metricas propos-tas. Por fim, para a validacao de alguns trabalhos futuros, e interessante a utilizacao desimuladores para os experimentos, e avaliar a elasticidade em grande escala.
ReferenciasCoutinho, E., Gomes, D. G., e Souza, J. D. (2013). An analysis of elasticity in cloud
computing environments based on allocation time and resources. In LATINCLOUD2013, Maceio, Brazil.
Gambi, A., Hummer, W., Truong, H.-L., e Dustdar, S. (2013). Testing elastic computingsystems. Internet Computing, IEEE, 17(6):76–82.
Herbst, N. R., Kounev, S., e Reussner, R. (2013). Elasticity in cloud computing: What itis, and what it is not. In Proceedings of the 10th International Conference on Autono-mic Computing(ICAC 2013), San Jose, CA, pages 23–27. USENIX.
Islam, S., Lee, K., Fekete, A., e Liu, A. (2012). How a consumer can measure elasticityfor cloud platforms. In Proceedings of the 3rd ACM/SPEC International Conferenceon Performance Engineering, ICPE ’12, pages 85–96, New York, NY, USA. ACM.
Mell, P. e Grance, T. (2009). The nist definition of cloud computing. National Institute ofStandards and Technology, 53(6):50.
NCBI (2013). Blast. National Center for Biotechnology Information (NCBI).
Rego, P., Coutinho, E., Gomes, D., e De Souza, J. (2011). Faircpu: Architecture for allo-cation of virtual machines using processing features. In Utility and Cloud Computing(UCC), 2011 Fourth IEEE International Conference on, pages 371–376.
Rego, P., Coutinho, E., e Souza, J. D. (2013). Estrategias para alocacao dinamica derecursos em um ambiente hıbrido de computacao em nuvem. In XII Workshop emClouds e Aplicacoes (WCGA2013).
Shawky, D. M. e Ali, A. F. (2012). Defining a measure of cloud computing elasticity. InSystems and Computer Science (ICSCS), 2012 1st International Conference on.
Timoshenko, S. P. e Goodier, J. (1970). Theory of Elasticity. McGraw-Hill Education,3rd edition.
Zhang, Y., Huang, G., Liu, X., e Mei, H. (2010). Integrating resource consumption andallocation for infrastructure resources on-demand. In Cloud Computing (CLOUD),2010 IEEE 3rd International Conference on, pages 75 –82.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
66

Gerenciamento de Elasticidade em Nuvens Privadas e Híbridas
Rhodney Simões £, Carlos Kamienski¥ £Universidade Federal de Alagoas (UFAL)
[email protected] ¥Universidade Federal do ABC (UFABC)
[email protected] Resumo. Computação em nuvem requer o gerenciamento da elasticidade para que recursos computacionais sejam alocados e liberados dinamicamente. Embora a adoção de serviços de nuvem esteja aumentando, o conhecimento disponível ainda não é suficiente para orientar o gerenciamento da elasticidade. Este artigo faz uma avaliação de elasticidade em nuvem privada e híbrida, usando o ambiente de laboratório, o PlanetLab e o serviço Amazon EC2. Os resultados mostram que a escolha de métricas e limiares é fundamental na manutenção da qualidade aliada ao controle de custos e que cloudburst pode ser usado para implementar uma nuvem híbrida mas a escolha do tipo de máquina virtual no provedor tem impacto significativo. Abstract. Cloud computing requires elasticity management for dynamically allocating and releasing computational resources. However, even though the adoption of cloud services has been growing, the available knowledge is not enough for guiding users when they need to manage elasticity. This paper analyzes elasticity in private and hybrid clouds, using a university lab, PlanetLab and Amazon EC2. Results show that the choice of metrics and thresholds plays a key role for keeping quality levels and controlling costs and that cloudburst can be effectively used for implementing a hybrid cloud but the choice of the type of virtual machine in the provider has a significant impact.
1. Introdução Computação em nuvem oferece a visão de computação como utilidade [Armbrust 2010], onde recursos computacionais são alocados e liberados dinamicamente e o usuário paga somente o que usar. Essa característica é provida através da elasticidade, que pode ser positiva, quando um novo recurso é criado para atender a um aumento de demanda, ou negativa, quando um recurso é liberado por estar ocioso. Computação em nuvem apresenta características únicas, além da elasticidade, como autosserviço sob demanda, amplo acesso via rede, recursos disponíveis e medição de uso de serviço [Mell & Grance, 2011].
Em geral as nuvens são classificadas em quatro categorias [Mell & Grance 2011]: públicas, privadas, híbridas e as comunitárias. Empresas que oferecem serviços de algum nível de computação em nuvem para os seus clientes são classificadas como nuvens públicas. Já nuvens privadas são construídas pelas organizações para atender necessidades específicas de sua empresa As nuvens híbridas surgem da composição de nuvens privadas e públicas, algo que geralmente ocorre quando uma empresa compra capacidade adicional num provedor de nuvem pública para atender picos de demanda na sua nuvem privada. Nuvens comunitárias são aquelas que permitem uso compartilhado

por usuários que colaboram para obter um ambiente computacional de maior capacidade. Este artigo faz uso das quatro categorias.
Embora existam vários provedores de nuvem pública que oferecem serviços pela Internet e a adoção de nuvem privada seja crescente nas organizações, há pouca informação disponível para orientar o gerenciamento da elasticidade de um ponto de vista prático. A principal questão é como e quando criar novos recursos computacionais para atender a demanda e liberá-los quando não mais são necessários para que o usuário não pague mais do que necessita. É necessária a definição de métricas e configuração de limiares para tomada de ações de elasticidade. No caso de IaaS o próprio usuário deve administrar o uso dos seus recursos computacionais, como máquinas virtuais. Provedores de nuvens públicas oferecem serviços adicionais para controlar a elasticidade, mas não há informações detalhadas sobre essas ações, inclusive pela dependência que existe de aplicações específicas. Por exemplo, pode-se usar métricas de nível de sistema operacional que são gerenciadas diretamente pelo provedor como uso de CPU e memória, ou então capturar métricas de aplicação e usá-las no gerenciamento da elasticidade. Por outro lado, também existe pouca informação e compreensão do funcionamento de nuvens híbridas, onde nuvens privadas direcionam parte da sua demanda para nuvens públicas através de cloudburst [Kim, H. et. al. 2009].
Este artigo apresenta resultados de avaliação de desempenho de elasticidade em nuvem privada e híbrida, usando o PlanetLab1 para geração de carga de trabalho dos clientes e o serviço Amazon EC22 de nuvem pública. Como cenário e motivação foi implementado um sistema que gerencia Smart Grid [Ipakchi, A., Albuyeh, F. 2009] na nuvem. Os resultados mostram que métricas e limiares devem ser cuidadosamente utilizados para obter o efeito desejado de manutenção da qualidade do serviço ao mesmo tempo que se controla os custos. Particularmente, descobrimos que as métricas de utilização de memória e CPU geram instabilidade na criação e liberação de máquinas virtuais e por isso passamos a usar uma métrica de aplicação, número de requisições, que gerou resultados estáveis. Os resultados evidenciam que a qualidade para o cliente e o custo são muito sensíveis aos limiares, ficando evidente que existem certos limites onde não vale a pena economizar ou gastar mais recursos computacionais. Além disso, a técnica de cloudburst pode ser usada para equalizar os recursos disponíveis com a demanda, mas a escolha do tipo de máquina virtual no provedor tem papel decisivo na obtenção de uma relação custo/benefício satisfatória. A principal contribuição desse artigo é apresentar resultados reais de experimentos executados em ambiente distribuído que podem efetivamente orientar administradores de ambientes de nuvem a melhor gerenciar os seus recursos.
Na sequência do artigo, a seção 2 trata do gerenciamento da elasticidade e apresenta trabalhos relacionais. A seção 3 apresenta a metodologia de avaliação e a seção 4 apresenta os resultados. A seção 5 discute os principais resultados e finalmente a seção 6 apresenta conclusões e trabalhos futuros.
2. Gerenciamento de Elasticidade em Nuvem O conceito de elasticidade em nuvem [Mell & Grance, 2011] [Leymann 2009] emprega a liberdade do cliente de alocar e liberar recursos diante da sua necessidade, sem que
1 http://planet-lab.org 2 http://aws.amazon.com/ec2

seja necessária a intervenção do provedor de serviço. Recursos de computação e de armazenamento são os que mais comumente podem ser alocados e liberados dinamicamente em um datacenter. Embora não seja uma condição essencial para caracterizar a computação em nuvem, já tornou-se padrão que os recursos de computação sejam oferecidos através de máquinas virtuais (VM).
Provedores comerciais de nuvens públicas oferecem serviços de elasticidade, como é o caso da Amazon AWS3, por meio do serviço CloudWatch4. O CloudWatch tem como principal funcionalidade monitorar métricas como a utilização de CPU e memória e quantidade de requisições que são efetuadas para uma determinada máquina virtual. Diante dessas métricas o usuário pode configurar limiares para que uma nova VM seja criada ou liberada para atender demandas flutuantes. Infelizmente este recurso não é oferecido diretamente por controladores de nuvem privada como OpenNebula5 e OpenStack6 e o administrador de nuvem privada quiser usufruir de tal funcionalidade ele terá de implementá-lo.
A utilização de nuvem híbrida pode fornecer um ambiente robusto o suficiente para suportar picos de demanda. Uma organização pode fazer um investimento em infraestrutura para suportar determinada demanda e tudo o que exceder a sua capacidade pode ser comprado da nuvem pública. A técnica de criar VMs em uma nuvem pública para atender a demandas que excedem a capacidade de uma nuvem privada é conhecida como cloudburst7 [Kim, H. et. al. 2009]. Cloudburst permite a redução do custo com infraestrutura sem ter a redução da qualidade do serviço, pois somente serão criadas novas máquinas virtuais na nuvem pública quando os recursos existentes na nuvem privada já tiverem sido exauridos. Desta forma, não haverá o uso da nuvem pública a menos que seja realmente necessária a sua utilização.
Existem trabalhos na literatura que tratam do gerenciamento da elasticidade, porém não com a abordagem desse artigo, que oferece informações úteis para configurar efetivamente os mecanismos de elasticidade. Muitos artigos apresentam resultados de simulação ou modelos matemáticos e outros focam em predição, mas não apresentam informações para auxiliar a configuração da elasticidade. Em [Morais et. al 2013] é apresentado um arcabouço para provisionamento automático de recursos em nuvem usando métricas que não dependem da aplicação (como CPU e memória) e são apresentados resultados de simulação. Neste artigo, com base em experimentos reais em ambiente distribuído, defendemos o uso de métricas de aplicação, por estarem mais próximas do usuário e portanto facilitarem a configuração efetiva dos níveis adequados para atender as demandas de SLA e fazer uso eficiente dos recursos. Em um ambiente real é possível perceber o comportamento efetivo de mecanismos que em um ambiente simulado podem ter um comportamento idealizado, devido às simplificações necessárias. CloudFlex (Seoung et al. 2011) é uma proposta para gerenciar os recursos na nuvem para atender demandas acima da capacidade instalada, mas que não se dedica a estudar especificamente os mecanismos de elasticidade. DEPAS (Calcavecchia et. al 2012) é um algoritmo decentralizado e probabilístico para elasticidade (chamado aqui de auto scaling) e que se integra um uma rede P2P. O artigo avalia o mecanismo por
3 http://aws.amazon.com 4 http://aws.amazon.com/pt/cloudwatch 5 http://opennebula.org 6 http://www.openstack.org 7 A tradução de cloudburst em português é aguaceiro. Dada a ausência de um termo adequado, usamos o original em inglês.

simulação e experimentação, mas os resultados não focam na escolha das métricas e dos limiares. Por último o trabalho apresentado em [Galante, G.; de Bona, L.C.E. 2012] categorizou a elasticidade em computação em nuvem.
Este artigo foca na avaliação e no efeito dos limiares, baseados na métrica de número de requisições simultâneas, que apresenta maior confiabilidade para evitar a ação da elasticidade de forma desnecessária.
3. Metodologia de avaliação
3.1. Ferramenta O cenário de avaliação da elasticidade ocorre no contexto de Smart Grid, a rede elétrica inteligente, para o qual foi desenvolvido o Smart Grid Autonomic Management System (SGAMS). O SGAMS possui três módulos (geração, distribuição e clientes), responsáveis por tarefas distintas, mas que se completam para compor o ambiente de redes inteligentes de energia elétrica. O módulo de geração simula a quantidade de carga elétrica a ser produzida para a rede pelas concessionárias e pelos consumidores, sendo este último apenas para aqueles que possuem meios para gerar tal carga. O módulo de distribuição é responsável por alocar e liberar automaticamente as máquinas virtuais diante do aumento e redução do número de requisições dos consumidores.
3.2. Ambiente O módulo de geração foi implementado utilizando a infraestrutura da nuvem privada da universidade com a linguagem Java. O módulo de distribuição também foi implantado na infraestrutura de nuvem privada usando o controlador de nuvem OpenNebula, para prover os recursos autonômicos necessários para o módulo de distribuição, como: elasticidade integrada com balanceamento de carga e o monitoramento tanto das máquinas virtuais existentes quanto das aplicações sendo executadas nestas máquinas. Foram utilizados recursos do próprio sistema operacional (Linux Debian) para evitar que o Tomcat fique indisponível. Por último foi utilizado o PlanetLab como um exemplo similar a nuvem comunitária para o módulo cliente, onde cada máquina representa um conjunto de consumidores de energia. A avaliação de cloudburst em nuvem híbrida foi implementada usando o Amazon Elastic Compute Cloud (EC2), que oferece alguns padrões de instâncias (máquinas virtuais, na terminologia da Amazon) a serem alocadas para o cliente. Neste trabalho foram utilizadas três tipos de instâncias com capacidades de processamento crescente (small, medium e large), com o intuito de analisar o impacto dos diferentes tipos na realização de elasticidade.
3.3. Cenário Um dos principais objetivos do trabalho é identificar os melhores valores para os limiares positivos e negativos para alocar e liberar VMs para oferecer um tempo de resposta adequado para os clientes do módulo de distribuição. Foram executados experimentos preliminares com intuito de definir qual seria o tempo de resposta mínimo (TRm), além de determinar o número máximo de requisições simultâneas que uma VM

pode suportar antes que o tempo de resposta ultrapasse um limite máximo, que para a aplicação de Smart Grid foi definido como 10 segundos8.
Dois experimentos preliminares foram realizados. O primeiro teve como foco determinar o TRm e para isto foram alocados 100 clientes do PlanetLab um após o outro sem que houvesse mais que um cliente gerando requisições simultaneamente. Este experimento foi utilizado também para identificar quais clientes do PlanetLab apresentavam tempos de resposta inferiores a 10 segundo, porque alguns demonstravam possuir recursos de rede insuficientes para a realização dos experimentos, resultando assim em valores excessivamente altos (outliers). O segundo experimento teve como foco determinar a quantidade máxima de requisições que uma VM consegue atender antes do TR superar o limite de 10 segundos. Para isso 100 clientes do PlanetLab foram alocados a cada 10 segundos gerando requisições simultâneas.
Para analisar o comportamento do tempo de resposta utilizando a técnica de cloudburst, foi usado o SGAMS com a arquitetura que emprega o uso da nuvem pública da Amazon quando os recursos da nuvem privada foram exauridos (Figura 1). Este experimento tem como objetivo estudar a viabilidade de uso de diferentes tipos de nuvem para compor um ambiente híbrido para atender as requisições existentes em Smart Grid. Nesta avaliação foram utilizados diferentes tipos de instâncias na Amazon a fim de identificar qual apresenta melhor custo benefício, tendo em vista que o uso de recursos da nuvem pública reflete no aumento do investimento na infraestrutura computacional para atender as requisições.
Figura 1 – Arquitetura do SGAMS com cloudburst
3.4. Métricas Para análise do comportamento dos tempos de resposta dos clientes que geram carga a partir do PlanetLab, foram definidas métricas a serem utilizadas.
• Tempo de resposta (TR): intervalo de tempo entre o cliente emitir uma requisição e receber a resposta do servidor. São calculadas três estatísticas (média, mediana e percentil 90) de todos os tempos de resposta a cada intervalo de 10 segundos.
8 Não existe bibliografia sobre o assunto e em se tratando de algo que ainda não existe definimos um limite de tempo (que poderia ser um valor ligeiramente diferente) para fins de avaliação do mecanismo de elasticidade.

• Recursos computacionais: comprometimento de recursos computacionais pelo provedor de nuvem, medido através do número de máquinas virtuais alocadas para o usuário.
• Carga de trabalho: número de requisições simultâneas existente na VM controladora que realiza o balanceamento de carga.
• Nós do PlanetLab: número de nós do PlanetLab alocados para gerar a carga de trabalho, onde cada nós no PlanetLab é usado para modelar o comportamento de um determinado número de clientes do Smart Grid. Por exemplo, cada nó envia uma requisição ao servidor a cada 3 segundos. Se considerarmos um ambiente onde cada cliente envia uma requisição a cada 2 minutos, então temos uma relação de 1:40, ou seja, um nó PlanetLab representa 40 clientes.
• Utilização de CPU: média de utilização de CPU de todas as máquinas virtuais alocadas, calculada a cada 30 segundos.
• Utilização da memória: média de utilização de memória de todas as máquinas virtuais alocadas, calculada a cada 30 segundos.
Tais métricas juntas viabilizam uma análise minuciosa do comportamento do TR no decorrer do experimento. O cálculo da média, mediana e percentil 90, proporciona a identificação de outliers, de modo a possibilitar a identificação de alguma instabilidade nos clientes alocados para a realização do experimento A partir da quantidade de clientes e a quantidade de requisições simultâneas existentes para a geração de carga é possível comprovar a necessidade ou não da realização da elasticidade. É importante notar que a elasticidade deveria ser idealmente realizada a partir de uma métrica de qualidade da experiência para o usuário, que nesse caso é o tempo de resposta. No entanto, em um ambiente real os valores das métricas dos usuários não necessariamente estão disponíveis para o provedor e nesse caso uma métrica disponível no provedor foi utilizada (requisições simultâneas), fazendo-se a comparação com os resultados do tempo de resposta para os clientes.
A métrica usada para efetuar a elasticidade positiva (criar VM) e negativa (liberar VM) é o número de requisições simultâneas, que foi dividida pelo número de máquinas virtuais existentes para elasticidade, resultando no número de requisições por VM. Tal métrica foi escolhida diante da comparação com a utilização de CPU e memória em uma série de experimentos preliminares. A taxa de utilização de CPU mostrou-se uma métrica muito sensível a pequenas oscilações na quantidade de requisições. Por outro lado, a taxa de utilização de memória apresentou diversos problemas, como excessiva lentidão na liberação de memória pela aplicação, que causava uma falsa impressão de falta de memória. A principal questão que levou à escolha do número de requisições como métrica para a elasticidade é a facilidade de compreensão para o desenvolvedor da aplicação e administrador de sistemas. Uma vez que se conhece o número de requisições simultâneas que determinada VM pode tratar com a qualidade desejada para o usuário, a configuração dos limiares da elasticidade se torna mais simples e direta.
4. Resultados Os resultados apresentados nessa seção consideram que cada cliente realiza uma requisição seguindo uma distribuição Exponencial com média de 3 segundos. Foram efetuadas 10 replicações de cada experimento e intervalos de confiança com nível de 99% foram calculados, sendo que em vários casos são apresentadas séries temporais dos
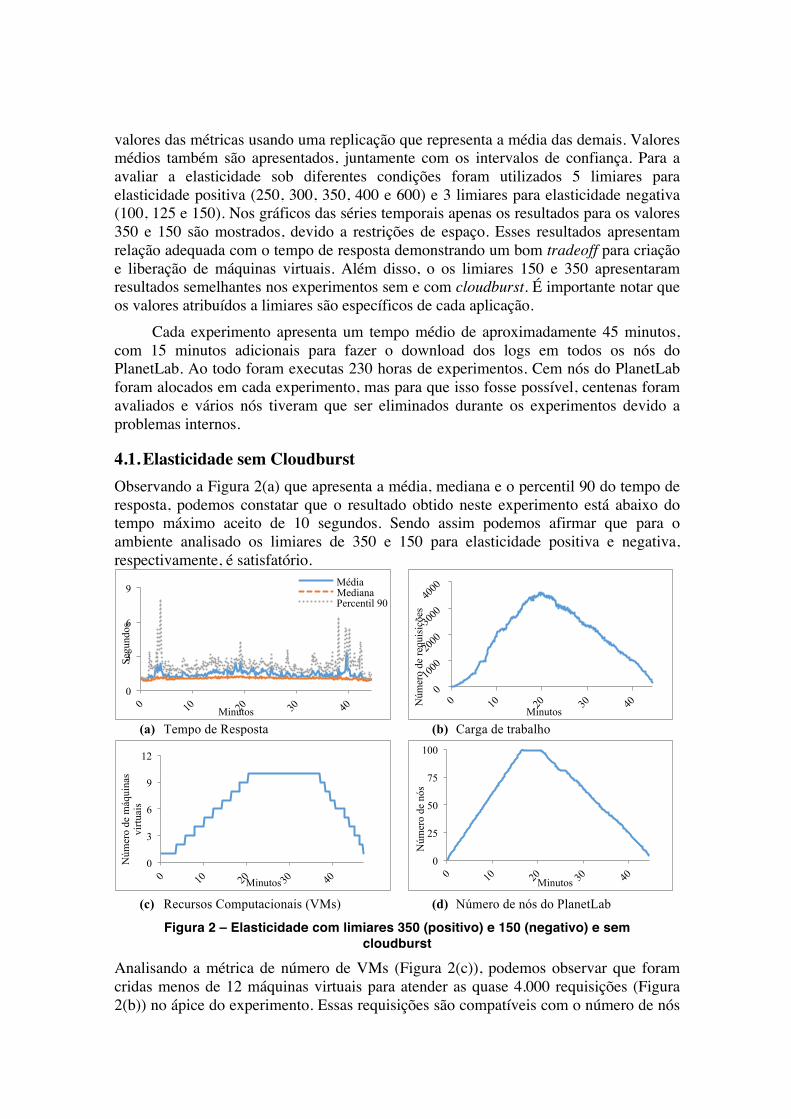
valores das métricas usando uma replicação que representa a média das demais. Valores médios também são apresentados, juntamente com os intervalos de confiança. Para a avaliar a elasticidade sob diferentes condições foram utilizados 5 limiares para elasticidade positiva (250, 300, 350, 400 e 600) e 3 limiares para elasticidade negativa (100, 125 e 150). Nos gráficos das séries temporais apenas os resultados para os valores 350 e 150 são mostrados, devido a restrições de espaço. Esses resultados apresentam relação adequada com o tempo de resposta demonstrando um bom tradeoff para criação e liberação de máquinas virtuais. Além disso, o os limiares 150 e 350 apresentaram resultados semelhantes nos experimentos sem e com cloudburst. É importante notar que os valores atribuídos a limiares são específicos de cada aplicação.
Cada experimento apresenta um tempo médio de aproximadamente 45 minutos, com 15 minutos adicionais para fazer o download dos logs em todos os nós do PlanetLab. Ao todo foram executas 230 horas de experimentos. Cem nós do PlanetLab foram alocados em cada experimento, mas para que isso fosse possível, centenas foram avaliados e vários nós tiveram que ser eliminados durante os experimentos devido a problemas internos.
4.1. Elasticidade sem Cloudburst Observando a Figura 2(a) que apresenta a média, mediana e o percentil 90 do tempo de resposta, podemos constatar que o resultado obtido neste experimento está abaixo do tempo máximo aceito de 10 segundos. Sendo assim podemos afirmar que para o ambiente analisado os limiares de 350 e 150 para elasticidade positiva e negativa, respectivamente, é satisfatório.
(a) Tempo de Resposta
(b) Carga de trabalho
(c) Recursos Computacionais (VMs)
(d) Número de nós do PlanetLab
Figura 2 – Elasticidade com limiares 350 (positivo) e 150 (negativo) e sem cloudburst
Analisando a métrica de número de VMs (Figura 2(c)), podemos observar que foram cridas menos de 12 máquinas virtuais para atender as quase 4.000 requisições (Figura 2(b)) no ápice do experimento. Essas requisições são compatíveis com o número de nós
0
3
6
9
Segu
ndos
Minutos
Média Mediana Percentil 90
Núm
ero
de re
quis
içõe
s
Minutos
0
3
6
9
12
Núm
ero
de m
áqui
nas
virtu
ais
Minutos
0
25
50
75
100
Núm
ero
de n
ós
Minutos

alocados no PlanetLab para representar os clientes (Figura 2(d)). A utilização de memória e CPU não apresentou resultados significativos e por esse motivo essas métricas não são apresentadas. Os valores das métricas de carga de trabalho e número de nós no PlanetLab também não serão mais apresentados porque os valores são semelhantes aos da Figura 2.
4.2. Elasticidade com Cloudburst Com o intuito de verificar a diferença entre utilizar ou não a técnica de cloudburst para suprir a necessidade de recursos computacionais oriundas dos picos de consumo, foram realizados experimentos variando o tipo de instância no serviço EC2 da Amazon. Desta forma foi possível identificar o impacto da utilização da nuvem da pública para a realização da elasticidade.
Nos experimentos com instâncias do tipo small, como pode ser observado na Figura 3(a), fica evidente a instabilidade gerada nos tempos de resposta quando o cloudburst é iniciado. Tal comportamento permanece até o momento em que estas VMs da nuvem pública são liberadas. Sendo assim podemos afirmar que para a nossa aplicação realizar cloudburst com instâncias do tipo small não apresenta resultados satisfatórios, devido à instabilidade de desempenho no atendimento das requisições.
Ao observamos Figura 3(b) e compararmos com a Figura 2(b) podemos afirmar que o número de máquinas virtuais criadas para elasticidade também não foi o motivo pela qual gerou a instabilidade. Desta forma é perceptível a razão pela qual ocorreu tal oscilação no tempo de resposta, ou seja, os recursos computacionais das instâncias small da Amazon não foram suficientes para suportar a carga gerada.
(a) Tempo de Resposta
(b) Recursos Computacionais (VMs)
Figura 3 – Experimento com limiares positivo e negativo 350, 150 respectivamente e com cloudburst utilizando instâncias do tipo small.
Nos experimentos com instâncias do tipo medium foi possível observar uma notável diferença no comportamento dos tempos de resposta (Figura 4(a)) em comparação com a Figura 3(a). Fica evidente que o incremento de recursos computacionais para cloudburst reflete diretamente nos tempos de resposta para os clientes. Utilizando instâncias do tipo medium ao invés de small o custo com a infraestrutura de nuvem para disponibilizar os serviços dobra de valor, mas o resultado é visivelmente melhor. Durante todo o tempo de duração do experimento os tempos de respostas permaneceram estáveis e na média não ultrapassaram o tempo de 4 segundos independentemente da quantidade de requisições existentes (Figura 4(b)).
0 10 20 30 40 50 60 70
Segu
ndos
Minutos
Média Mediana Percentil 90
0
2
4
6
8
10
12
Núm
ero
de V
Ms
Minutos
Amazon WS Nuvem Privada
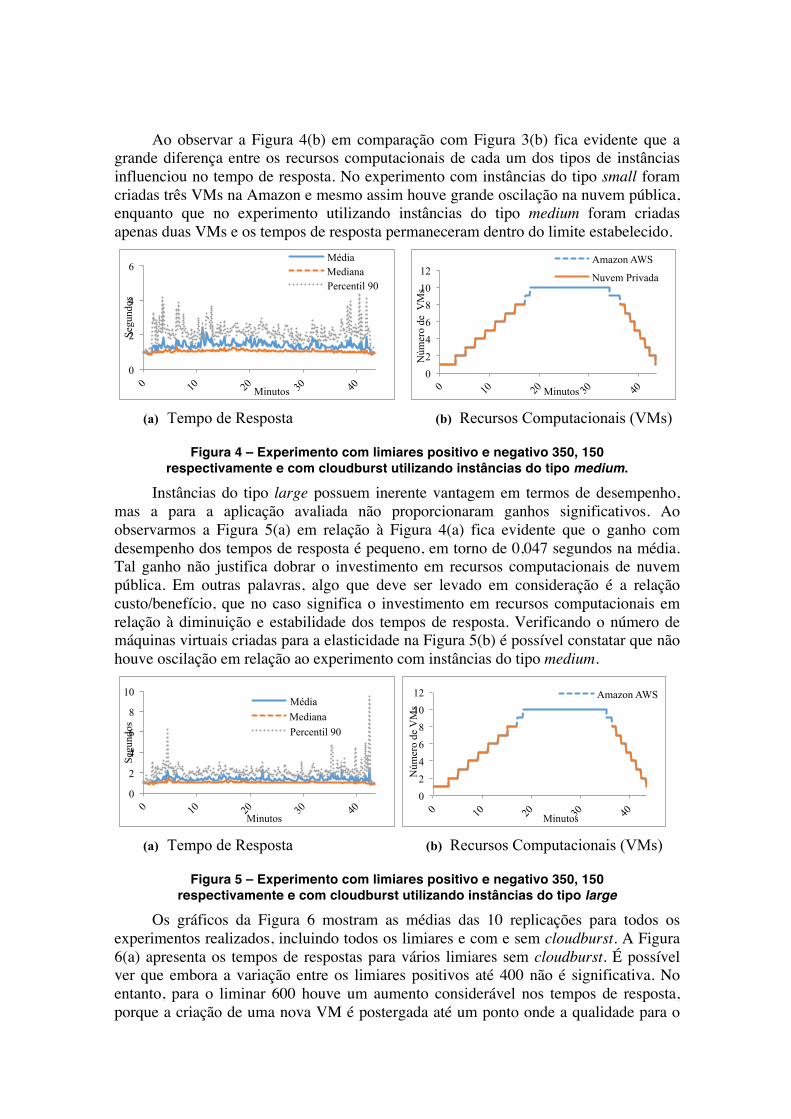
Ao observar a Figura 4(b) em comparação com Figura 3(b) fica evidente que a grande diferença entre os recursos computacionais de cada um dos tipos de instâncias influenciou no tempo de resposta. No experimento com instâncias do tipo small foram criadas três VMs na Amazon e mesmo assim houve grande oscilação na nuvem pública, enquanto que no experimento utilizando instâncias do tipo medium foram criadas apenas duas VMs e os tempos de resposta permaneceram dentro do limite estabelecido.
(a) Tempo de Resposta
(b) Recursos Computacionais (VMs)
Figura 4 – Experimento com limiares positivo e negativo 350, 150 respectivamente e com cloudburst utilizando instâncias do tipo medium.
Instâncias do tipo large possuem inerente vantagem em termos de desempenho, mas a para a aplicação avaliada não proporcionaram ganhos significativos. Ao observarmos a Figura 5(a) em relação à Figura 4(a) fica evidente que o ganho com desempenho dos tempos de resposta é pequeno, em torno de 0,047 segundos na média. Tal ganho não justifica dobrar o investimento em recursos computacionais de nuvem pública. Em outras palavras, algo que deve ser levado em consideração é a relação custo/benefício, que no caso significa o investimento em recursos computacionais em relação à diminuição e estabilidade dos tempos de resposta. Verificando o número de máquinas virtuais criadas para a elasticidade na Figura 5(b) é possível constatar que não houve oscilação em relação ao experimento com instâncias do tipo medium.
(a) Tempo de Resposta
(b) Recursos Computacionais (VMs)
Figura 5 – Experimento com limiares positivo e negativo 350, 150 respectivamente e com cloudburst utilizando instâncias do tipo large
Os gráficos da Figura 6 mostram as médias das 10 replicações para todos os experimentos realizados, incluindo todos os limiares e com e sem cloudburst. A Figura 6(a) apresenta os tempos de respostas para vários limiares sem cloudburst. É possível ver que embora a variação entre os limiares positivos até 400 não é significativa. No entanto, para o liminar 600 houve um aumento considerável nos tempos de resposta, porque a criação de uma nova VM é postergada até um ponto onde a qualidade para o
0
2
4
6
Segu
ndos
Minutos
Média Mediana Percentil 90
0 2 4 6 8
10 12
Núm
ero
de V
Ms
Minutos
Amazon AWS
Nuvem Privada
0
2
4
6
8
10
Segu
ndos
Minutos
Média Mediana Percentil 90
0 2 4 6 8
10 12
Núm
ero
de V
Ms
Minutos
Amazon AWS

usuário é afetada de maneira irreversível. Existe também variação de 50% no uso de recursos computacionais, de 8 a 12 VMs. Com o liminar positivo de 600 o custo é o menor possível, mas gerando perda de desempenho.
Como pode ser observado na Figura 6(c) comparando o comportamento do tempo de resposta na nuvem privada da UFABC com o da nuvem pública da Amazon, os resultados utilizando máquinas virtuais mais robustas são similares aos de sem cloudburst. No entanto, ao usar a infraestrutura da Amazon houve oscilação nos TRs refletindo no aumento do intervalo de confiança. Contudo as VMs com maior poder computacional demonstram ser mais estáveis que as demais. Na Figura 6(d) podemos constatar que mesmo sem utilizar a técnica de cloudburst o número de máquinas virtuais criadas para os experimentos com limiar positivo de 350 requisições simultâneas é próximo com os resultados usando a nuvem pública da Amazon.
a) Tempo de resposta (vários limiares, sem cloudburst) b) VMs (vários limiares, sem cloudburst)
c) Tempo de resposta (com e sem cloudburst)
d) VMs (com e sem cloudburst)
Figura 6 – Média do tempo de resposta e número de máquinas virtuais (sem e com cloudburst)
4.3. Custo vs. Benefício Com intuito de identificar relações de custo/benefício adequadas entre os diversos limiares utilizados nos experimentos, foi criada uma métrica que multiplica a média do número de máquinas virtuais de cada experimento pela média do tempo de resposta do mesmo experimento. Essa métrica não apresenta valores com significado específico, mas um valor que representa o custo/benefício dos diferentes experimentos realizados. Quanto menor o valor da métrica, mais adequada é a configuração usada. Embora em teoria seria possível um valor muito alto para custo em troca de um valor muito baixo para o benefício fica claro que os tempos de resposta tem tempos mínimos que não podem ser diminuídos mesmo com grandes investimentos.
0
5
10
15
20
25
Segu
ndos
0 2 4 6 8
10 12 14
Núm
ero
de V
Ms
0 2 4 6 8
10 12
Segu
ndos
8
9
10
11
12
13
Núm
ero
de V
Ms

A Figura 7(a) apresenta os resultados da métrica custo/benefício para os vários experimentos sem cloudburst. No geral, pequenas variações para baixo ou para cima no número de VMs (custo) são compensadas por variações na direção contrária do tempo de resposta (benefício). A exceção é o liminar positivo 600, mostrando que economizar a partir de um determinado ponto cobra um alto preço na redução da qualidade. Nos experimentos com cloudburst mostrados na Figura 7(b) em comparação a sem cloudburst com limiares 350 e 150, pode-se observar que o uso da nuvem híbrida é adequada para instâncias do tipo medium, mas não para instâncias small. No caso de instâncias large, embora o valor da métrica seja adequado, ela não computa o custo de aluguel cobrado pelo provedor. Isso torna as instâncias large inadequadas para o ambiente avaliado.
a) Custo/benefício sem cloudburst e vários limiares b) Custo/benefício com e sem cloudburst
Figura 7 – Relação custo/benefício
5. Discussão Nesse artigo alguns pontos a respeito da elasticidade foram discutidos e chegou-se a quatro pontos fundamentais: escolha da métrica, escolha dos limiares, viabilidade de uso de cloudburst e escolha da instância no provedor de nuvem pública. Embora provedores nuvem pública ofereçam serviços com elasticidade e métricas para o seu gerenciamento, não há conhecimento gerado e informações disponíveis sobre como escolher métricas e configurar limiares. Estes aspectos desempenham um papel importante no desempenho e no custo da computação em nuvem. O serviço CloudWatch da Amazon oferece utilização de memória e CPU como métricas principais mas também oferece a possibilidade de capturar métricas de aplicação. Seguindo essa linha, este trabalho foi iniciado fazendo elasticidade com memória e com CPU, mas os resultados foram muito insatisfatórios porque muito instabilidade era gerada. Uma métrica de aplicação, o número de requisições, apresenta resultados positivos e com boa relação com tempo de resposta (métrica relevante para o usuário).
Após a escolha da métrica, devem ser escolhidos valores de limiares positivos e negativos para aumentar ou diminuir os recursos alocados. Os resultados evidenciam que a qualidade para o cliente e o custo são muito sensíveis aos limiares. Fica evidente que economizar utilizando limiares positivos e negativos altos esbarram num limite onde passa a não mais valer a pena. A análise da métrica de busto/benefício mostra claramente essa questão.
A avaliação da técnica de cloudburst mostra que é possível utilizá-la como complemento para recursos da rede privada, que pode não possuir níveis médios de ociosidade de recursos compatíveis com as demandas de todos os seus usuários. Quando
0 20 40 60 80
100 120 140 160
Rel
ação
cus
to/b
enef
ício
0 10 20 30 40 50 60 70 80
Rel
ação
cus
to/b
enef
ício

se utiliza cloudburst, a escolha do tipo da instância na nuvem pública tem grande impacto na manutenção da qualidade e redução de custos. Por exemplo, a avaliação mostrou que o uso de instâncias small da Amazon prejudica muito o desempenho da aplicação avaliada. Por outro lado, instâncias large agregam pouco ao desempenho das instâncias médium mas com um custo significativamente maior. Ressalta-se que essa relação de desempenho de instâncias small, medium e large pode ser diferente para aplicações com características diferentes.
6. Conclusão O gerenciamento correto da elasticidade é fundamental para que usuários
obtenham o benefício da computação como utilidade num ambiente de nuvem. Pela pouca discussão que existe na literatura, fica claro que os usuários não tem informações precisas para lhes orientar na configuração de métricas e limiares para criar novos recursos para atender a demanda e liberá-los quando não mais são necessários. Os resultados mostram que a escolha de métricas e limiares é fundamental na manutenção da qualidade aliada ao controle de custos. Foi usada uma métrica de aplicação, o número de requisições, que trouxe estabilidade no gerenciamento da elasticidade. Ficou claro também que o uso de limiares muito altos ou baixos distorce a relação custo/benefício. Além disso, cloudburst pode ser usado para implementar uma nuvem híbrida mas a escolha do tipo de máquina virtual tem impacto significativo.
Como trabalhos futuros, serão realizados novos experimentos com padrões diferentes de envio de requisições pelos clientes. Serão também realizados estudos sobre o uso de técnicas estatísticas ou histerese para gerenciar o momento da realização da elasticidade positiva ou negativa. Referências Armbrust, M., Fox, A., Griffith, R., Joseph, A. D., Katz, R., Konwinski, A., Lee, G.,
Patterson, D., Rabkin, A., Stoica, I., Zaharia, M., (2010). “A View of Cloud Computing”, Communications of the ACM, 53(4), p. 50-58, Abril de 2010.
Calcavecchia, N., Caprarescu, B., Di Nitto, E., Dubois, D., and Petcu, D. (2012). DEPAS: a decentralized probabilistic algorithm for auto-scaling. Computing, 94:701–730.
Galante, G.; de Bona, L.C.E., (2012). "A Survey on Cloud Computing Elasticity," Utility and Cloud Computing (UCC), 2012 IEEE Fifth International Conference on , vol., no., pp.263,270, 5-8 Novembro de 2012.
Ipakchi, A., Albuyeh, F. (2009), “Grid of the Future: Are We Ready to Transition to a Smart Grid?”, IEEE Power & Energy Magazine, 7(2), p. 52-62, Março 2009.
Leymann, F. (2009). “Cloud Computing: The Next Revolution in IT,” in Proc. 52th Photogrammetric Week. W. Verlag, , pp. 3–12 Setembro de 2009.
Morais, F. et. al (2013). “Um Arcabouço para Provisionamento Automático de Recursos em Provedores de IaaS Independente do Tipo de Aplicação”, SBRC 2013, Maio.
Mell, P. and Grance, T. (2011). “The NIST Definition of Cloud Computing,” US Nat’l Inst. of Science and Technology, 2011.
Seung, Y., Lam, T., Li, L. E., Woo, T. (2011). Cloudflex: Seamless scaling of enterprise applications into the cloud. INFOCOM, páginas 211–215.

32º Simpósio Brasileiro de Redes de Computadores e
Sistemas Distribuídos
Florianópolis - SC
XII Workshop de Computação em
Clouds e Aplicações (WCGA)
Sessão Técnica 3
Arquitetura e Gerência


Alocação de Máquinas Virtuais em Ambientes de Computaçãoem Nuvem Considerando o Compartilhamento de Memória
Fernando José Muchalski1, Carlos Alberto Maziero1
1Universidade Tecnológica Federal do Paraná (UTFPR)Curitiba – PR – Brazil
[email protected], [email protected]
Resumo. Nos ambientes de computação em nuvem, é importante manter sobcontrole a alocação de máquinas virtuais nos servidores físicos. Uma alocaçãoadequada implica na redução de custos com hardware, energia e refrigeração,além da melhora da qualidade de serviço. Hipervisores recentes implementammecanismos para reduzir o consumo de memória RAM através do comparti-lhamento de páginas idênticas entre máquinas virtuais. Este artigo apresentaum novo algoritmo de alocação de máquinas virtuais que busca o equilíbriono uso dos recursos de CPU, memória, disco e rede e, sobretudo, considera opotencial de compartilhamento de memória entre máquinas virtuais. Através desimulações em três cenários distintos, verificou-se que o algoritmo é superiorà abordagem padrão na questão do uso equilibrado de recursos e que, con-siderando o compartilhamento de memória, houve um ganho significativo nadisponibilidade deste recurso ao final das alocações.
Abstract. In cloud computing environments it is important to keep under controlthe allocation of virtual machines in physical servers. A good allocation bringsbenefits such as reduction costs in hardware, power, and cooling, also improvingthe quality of service. Recent hypervisors implement mechanisms to reduce RAMconsumption by sharing identical pages between virtual machines. This paperpresents a new algorithm for virtual machines allocation that seeks the balanceduse of CPU, memory, disk, and network. In addition, it considers the potential forsharing memory among virtual machines. Simulations on three distinct scenariosdemonstrate that it is superior to the standard approach when considering thebalanced use of resources. Considering shared memory, there was an appreciablegain in availability of resources.
1. IntroduçãoA tecnologia de virtualização emergiu como uma das tecnologias-chave para a computa-ção em nuvem, pois permite a um datacenter servir múltiplos usuários de forma segura,flexível e eficiente, principalmente devido à sua capacidade de isolamento, consolidação emigração de cargas de trabalho na forma de máquinas virtuais (VMs). Essas característicaspossibilitam a criação de políticas para o gerenciamento da infraestrutura computacional,visando garantir a qualidade de serviço (QoS) e economia de recursos através do melhoruso da capacidade computacional disponível.
A alocação de máquinas virtuais (VMs) consiste em escolher o servidor físico(host) onde alocar cada VM, buscando otimizar alguma métrica como balanceamento
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
81

de carga, consumo de energia, etc. Para tal, deve-se conhecer a demanda de recursos decada VM, o ambiente de execução e as políticas específicas do datacenter para possíveisconflitos [Hyser et al. 2007]. De modo geral, a alocação de uma VM é dividida em duasetapas: inicialmente é estimada a demanda de recursos da máquina virtual; em seguida,escolhe-se o servidor onde essa máquina virtual será alocada [Mishra and Sahoo 2011].
A demanda de recursos de uma VM pode ser difícil de estimar, pois as neces-sidades de recursos podem variar durante sua execução. Uma abordagem comum é derealizar a estimativa com base no histórico de utilização de recursos da VM. Este artigoconsidera que as necessidades de recursos de uma VM são previamente conhecidas. Aalocação em si usa uma estratégia para definir onde alocar a VM de modo a alcançar umnível eficiente de utilização de recursos de um servidor físico. Tal estratégia pode utilizarrepresentações matemáticas ou métricas que representam o grau de utilização dos recursospelas diversas VMs e servidores físicos. Essas métricas devem levar em consideração asvárias dimensões de consumo de recursos, como as capacidades de processador, memória,disco e banda de rede [Hyser et al. 2007], bem como recursos não envolvidos diretamentecom as necessidades da máquina virtual, mas que afetam o datacenter, como o consumode energia decorrente da alocação [Buyya et al. 2010].
Nesse artigo é apresentado um algoritmo para alocação de máquinas virtuais, ondesão avaliados os recursos de CPU, memória, disco e banda de rede, que busca equili-brar o uso dos recursos nos servidores físicos. Como diferencial, o algoritmo propostofaz uso da capacidade de compartilhamento de páginas de memória presente em algunshipervisores [Wood et al. 2009, Barker et al. 2012], buscando explorar o potencial de com-partilhamento de memória que uma VM terá quando alocada em determinado servidor.
As seções 2 e 3 apresentam os fundamentos necessários à compreensão deste tra-balho, a seção 4 apresenta o algoritmo de alocação e suas característica de funcionamento,a seção 5 apresenta o ambiente de simulação utilizado, os cenários testados e os resultadosatingidos, e por fim a seção 6 apresenta as considerações finais do trabalho.
2. Máquinas virtuaisA virtualização, técnica surgida na década de 60 no IBM S/370 [Creasy 1981], permitedividir os recursos computacionais de um computador físico em partições autônomas eisoladas chamadas máquinas virtuais (VM). Uma máquina virtual funciona como umacópia exata de uma máquina real, incluindo seus recursos de hardware. A virtualização éconstruída através de um hipervisor, uma camada de software de baixo nível que provêo suporte de execução necessário às máquinas virtuais. O hipervisor abstrai parcialmenteos recursos de hardware subjacentes, tornando possível a execução simultânea de váriasmáquinas virtuais autônomas e isoladas sobre um mesmo computador.
Uma das principais funcionalidades do hipervisor consiste em abstrair os recursosda máquina real e oferecê-los às máquinas virtuais. Assim, cada máquina virtual “enxerga”sua própria interface de rede, seus discos rígidos, seus processadores e suas áreas dememória RAM. Esses recursos virtuais usados pelas máquinas virtuais são mapeadospelo hipervisor nos recursos reais presentes no hardware subjacente, de forma eficientee controlada. Pode-se afirmar que o hipervisor constitui um “sistema operacional parasistemas operacionais”, pela flexibilidade que introduz na gestão dos recursos de hardware.A possibilidade de instanciar máquinas virtuais sob demanda e a relativa independência
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
82

do hardware são essenciais para os ambientes de computação em nuvem.
A abstração de recursos construída pelo hipervisor abre a possibilidade de trans-ferir uma máquina virtual em execução de um servidor físico para outro, mantendo seuestado interno. Esse procedimento, denominado migração de máquinas virtuais, deu muitaflexibilidade à gerência de datacenters [Grit et al. 2006]. Migrar máquinas virtuais entreservidores físicos permite balancear a carga de trabalho entre eles ou mesmo concentraras VMs em poucos servidores, hibernando os restantes e assim diminuindo o consumo deenergia, de refrigeração e o ruído no ambiente [Buyya et al. 2010, Lago et al. 2011].
Recentemente, alguns hipervisores têm explorado a possibilidade de reduzir oconsumo de memória RAM pelas máquinas virtuais através do compartilhamento depáginas de memória idênticas, como CBPS - Content-Based Page Sharing, disponível emhipervisores como VMWare ESX, Xen, e KSM - Kernel Samepage Merging, disponívelno KVM [Barker et al. 2012]. Nessas técnicas, o hipervisor identifica páginas de memóriacom conteúdo idêntico e as compartilha usando a estratégia copy-on-write, de formatransparente para as máquinas virtuais: caso uma das máquinas virtuais tente alterar oconteúdo de uma página compartilhada, o compartilhamento é desfeito pelo hipervisor euma cópia da página é alocada à máquina virtual solicitante. Essencialmente, existem duascategorias de compartilhamento: o auto-compartilhamento, quando as páginas duplicadasestão dentro da própria VM e o compartilhamento inter-VM, que ocorre entre máquinasvirtuais distintas [Sindelar et al. 2011]. O compartilhamento de memória entre máquinasvirtuais permite diminuir o consumo de memória RAM do servidor host, influenciandopositivamente no desempenho do sistema.
3. Alocação de máquinas virtuais
Considerando um conjunto de servidores físicos em um datacenter, a alocação de VMsconsiste em, dada uma VM, encontrar um servidor que seja adequado para instanciá-la.O servidor deve possuir recursos suficientes para garantir a execução da VM sem afetaros acordos de nível de serviço. Esse problema representa um desafio algorítmico porsua característica combinatória, onde um conjunto de n máquinas virtuais com requisitosdistintos de processamento, memória e outros recursos deve ser alocado em m servidorescom diferentes disponibilidades de recursos.
De forma geral, o problema de alocação de VMs pode ser visto como uma gene-ralização do problema de múltiplas mochilas (multiple knapsack problem - MKP), ondecada mochila representa um servidor físico, sua capacidade corresponde aos recursos dis-poníveis no servidor e os itens são as VMs a serem alocadas. Cada VM tem um peso,representado pela quantidade de recursos necessários e um preço, que pode significar ocusto que essa alocação representará no ambiente. Esse custo pode ser computacional,energético ou monetário. O objetivo é encontrar a melhor alocação das VMs em cadaservidor, de modo a minimizar o custo [Grit et al. 2006]. Os algoritmos de alocação deVMs também podem se apresentar como variações do problema Bin Packing: dado umconjunto de n itens, onde cada item possui um peso w associado, e um conjunto de mrecipientes (bins), cada um com uma capacidade c, encontrar o número mínimo de reci-pientes necessários para armazenar os itens tal que a soma dos itens em cada recipientenão ultrapasse sua capacidade. Comparando-se com o problema de alocação de VMs,tem-se os recipientes como sendo os servidores físicos, sua capacidade como os recursos
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
83

disponíveis no servidor e os itens seriam as VMs a alocar.
Na literatura há vários trabalhos relacionados à alocação de recursos virtuais emservidores físicos. Por se tratar de um problema combinacional do tipo NP-difícil, o assuntodesperta o interesse de pesquisadores em busca de estratégias algorítmicas eficientes parasolução desse tipo de problema [Singh et al. 2008].
O artigo [Grit et al. 2006] propôs estratégias para a chamada orquestração autô-noma, onde o datacenter se auto-gerencia, independente de interferência humana. Nessetrabalho, os autores estabeleceram que a estratégia para alocação de máquinas virtuaispode estar presente nos processos de provisionamento de VMs, colocação de VMs nosservidores físicos e migração de VMs entre os servidores para consolidação e balance-amento de carga. Para [Hyser et al. 2007] uma boa colocação inicial não é suficiente, jáque as cargas de trabalho das máquinas virtuais mudam com o passar do tempo. Consi-deram então ser necessário alterar dinamicamente a localização das máquinas virtuais deacordo com as condições do datacenter. Seu algoritmo considera os recursos de memória,processador, banda de rede e banda de disco disk bandwidth para estabelecer as máquinasvirtuais que deverão ser migradas e realocadas para estabilizar o ambiente. Em outro traba-lho, [Yen Van et al. 2009] criaram um módulo de decisão global para garantir a eficiênciado sistema em termos de qualidade de serviço e gerenciamento dos custos dos recursos,desacoplando os processos de provisionamento e de alocação de VMs. Seus algoritmoslevam em consideração as capacidades de recursos de processamento e de memória.
Dentro do contexto da computação em nuvem verde [Buyya et al. 2010] tratoudo problema de alocação de máquinas virtuais objetivando o uso eficiente de recur-sos, de modo que a dimensão analisada como critério para alocação se baseia na aná-lise do potencial consumo de energia do servidor físico após a alocação. O trabalho de[Chen et al. 2011] trata especificamente da consolidação de servidores, onde se objetivaliberar os servidores físicos que estejam subutilizados, migrando as máquinas virtuais eestabelecendo uma nova alocação. Sua abordagem, chamada effective sizing consiste emdeterminar as novas alocações através do menor número possível de migrações.
O trabalho [Wood et al. 2009] foi o primeiro a abordar o mecanismo de comparti-lhamento de páginas de memória entre máquinas virtuais, existente em alguns hipervisores,para estabelecer uma estratégia para alocação de máquinas virtuais. Sua solução baseia-seno cálculo de uma “impressão digital” para cada máquina virtual do sistema e através dacomparação com a “impressão digital” gerada para a nova máquina virtual é estabelecidouma probabilidade de compartilhamento de páginas de memórias entre elas. O compartilha-mento de páginas de memórias também é abordado no trabalho de [Sindelar et al. 2011],mas sua proposta baseia-se em dois modelos, que buscam estabelecer as maiores probabi-lidades de compartilhamento de memória de acordo com as características das máquinasvirtuais. Essa nova abordagem torna mais eficiente o processo de alocação, tendo emvista que não são necessários o cálculo contínuo das “impressões digitais” de todas asVMs do sistema. No entanto, tais algoritmos consideram apenas a probabilidade de com-partilhamento como fator de decisão para alocação, ignorando os demais recursos comoprocessamento, memória, disco e banda de rede.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
84

4. O Algoritmo VectorAllocEste trabalho propõe um algoritmo para a alocação online de máquinas virtuais nos ser-vidores de um datacenter, considerando as demandas de recursos das máquinas virtuais,os recursos disponíveis nos servidores e o compartilhamento de memória entre as máqui-nas virtuais alocadas em um mesmo servidor. Nosso algoritmo, denominado VectorAlloc,foi inspirado no VectorDot [Singh et al. 2008], um algoritmo de balanceamento de carga(VMs) que busca minimizar o grau de desequilíbrio de carga dos servidores físicos, le-vando em conta os vários tipos de recursos em uma representação vetorial.
No algoritmo VectorDot, os servidores que estão acima de um certo limite decarga são considerados em “desequilíbrio”; calcula-se então o IBScore (Imbalance Score)de cada servidor e um IBScoreTotal, para determinar o nível de desequilíbrio global dosistema. O algoritmo então busca outros servidores para alocar as máquinas virtuais dosservidores sobrecarregados. O produto escalar entre a carga do servidor e as necessidadesda máquina virtual determina a “atratividade” de um servidor. Além disso os vetores sãoajustados para refletir os custos de migração das VMs.
Nosso algoritmo também expressa a utilização de recursos de cada servidor eas demandas das VMs como vetores, nos quais cada elemento corresponde a um tipode recurso (memória, CPU, disco e rede) e seu valor corresponde ao grau de utilizaçãodo recurso em relação à sua capacidade total. Contudo, enquanto o VectorDot visa obalanceamento de carga, nosso algoritmo trata de alocações online, ou seja, sem um pré-conhecimento do conjunto de máquinas virtuais; a alocação ocorre à medida em que estaschegam. Além disso, nosso algoritmo considera a possibilidade de compartilhamento dememória entre máquinas virtuais.
O algoritmo VectorAlloc usa quatro vetores: Resource Utilization Vector RUV(u),grau de utilização dos recursos de um servidor físico u; Resource Requirement VectorRRV(u, v), recursos requeridos por uma VM v em relação a um servidor físico u; Re-source Threshold Vectors RTVmin e RTVmax, definem os limites mínimos e máximosde uso de cada um dos recursos em um servidor, em percentagem (notação adaptada de[Mishra and Sahoo 2011]). Esses vetores são expressos por:
RUV(u) =
[MemUse(u) − MemS hared(u)
MemCap(u),
CPUUse(u)CPUCap(u)
,DiskUse(u)DiskCap(u)
,NetUse(u)NetCap(u)
]RRV(u, v) =
[(1 − α(v, u))
MemReq(v)MemCap(u)
,CPUReq(v)CPUCap(u)
,DiskReq(v)DiskCap(u)
,NetReq(v)NetCap(u)
]RTVmin = [MemTmin,CPUTmin,DiskTmin,NetTmin]
RTVmax = [MemTmax,CPUTmax,DiskTmax,NetTmax]
Cada elemento do vetor representa um tipo de recurso e possui um valor real nointervalo [0, 1]. Pela ordem, os recursos analisados são: memória, CPU, disco e rede. Oelemento memória tem um tratamento diferenciado dos demais, pois deve considerar ocompartilhamento de páginas entre máquinas virtuais.
RUV(u) é calculado realizando-se o quociente entre os valores do recurso já alo-cado pela capacidade total do recurso. O elemento memória considera a quantidade dememória compartilhada entre as VMs. Por exemplo, um servidor físico que hospede duasmáquinas virtuais vm1 e vm2, onde vm1 demanda 100 MB de memória e vm2 demanda 200
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
85

MB, utilizaria 300 MB de memória. Todavia, se 50 MB de memória estiverem comparti-lhados entre vm1 e vm2, o total de memória realmente utilizada será de 250 MB.
O vetor RRV(u, v) representa a razão entre a demanda de recursos de uma VM ve os recursos disponíveis em um servidor físico u. O cálculo do recurso memória usa umfator de compartilhamento α(v, u). Este fator representa o potencial de compartilhamentode memória que uma VM v possui em relação ao servidor u. Por exemplo, uma VMque tenha um fator de compartilhamento de 20%, precisará alocar somente 80% de suademanda de memória. O cálculo de α será discutido na próxima seção.
Os vetores RTVmin e RTVmax indicam os limites mínimos e máximos de uso dosrecursos em cada servidor. Seu objetivo é garantir que a alocação de uma nova VM nãodesequilibre o uso de recursos, sobrecarregando ou subutilizando algum servidor. Assim,uma VM v só poderá ser alocada no servidor u se o uso de seus recursos se mantiver entreos limites inferior e superior, ou seja, se RTVmin ≤ RUV(u) + RRV(u, v) ≤ RTVmax.
Considerando o conjunto de servidores U do datacenter e uma máquina virtualv a ser alocada em um servidor u ∈ U, determina-se o conjunto D(v, γ, δ) de servidoresdisponíveis para alocar v como:
D(v, γ, δ) = {u ∈ U | γ ≤ RUV(u) + RRV(u, v) ≤ δ }
Com γ = RTVmin e δ = RTVmax, D(v, γ, δ) contém os servidores de U ondea alocação de v respeita os limites RTVmin e RTVmax. Caso D(v, γ, δ) = ∅, calcula-se D(v, 0, δ); caso este seja vazio, calcula-se D(v, 0, 1); caso este também seja vazio, aalocação não é possível. Do conjunto D(v) , ∅ escolhe-se um servidor ua que satisfaça:
ua = arg minu∈D(v)
(RUV(u) · RRV(u, v))
Em outras palavras, a máquina virtual v será alocada no servidor ua ∈ D(v) com omenor produto escalar entre RUV(u) e RRV(u, v), buscando respeitar os limites de alocação.A ideia subjacente é alocar a VM em um servidor para o qual RRV seja complementara RUV , resultando em um produto escalar mínimo, o que induz um uso balanceado dosrecursos. Por exemplo, uma VM com baixa demanda de CPU e alta demanda de memóriaserá alocada em um servidor com alto uso de CPU mas baixo uso de memória.
4.1. O Fator de Compartilhamento α(v, u)
O fator de compartilhamento α(v, u) é usado pelo algoritmo proposto para estabelecero potencial de compartilhamento de memória que uma VM v possui em relação a umservidor u. É um valor que varia entre 0 e 1, sendo 0 quando não há nenhuma chance de vcompartilhar memória com as demais VMs presentes em u, e 1 caso toda a memória de vpossa ser compartilhada.
O valor de α corresponde a uma estimativa, já que a memória efetivamente compar-tilhada só poderá ser determinada após a alocação da VM. Este trabalho não se aprofundano cálculo preciso de α, pois foge do seu escopo. Aqui, inclusive, abre-se uma possibili-dade de pesquisa para o estabelecimento de métodos para o cálculo de α, que poderiamfazer uso do histórico de alocações para determinar índices mais próximos da realidade.Alguns trabalhos como [Wood et al. 2009] e [Sindelar et al. 2011] apresentaram formas de
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
86

Figura 1. Modelo hierárquico em árvore [Sindelar et al. 2011]
capturar a memória compartilhada entre as máquinas virtuais e utilizaram tal informaçãopara criação de algoritmos de alocação, otimização e balanceamento de carga.
Neste trabalho, o fator de compartilhamento é calculado usando uma representaçãohierárquica de máquinas virtuais, similar à apresentada em [Sindelar et al. 2011]. Cadaservidor referencia as máquinas virtuais nele alocadas usando uma árvore similar à apre-sentada na Figura 1. Nessa árvore, cada nível representa um novo grau de especializaçãodas informações das VMs. Partindo da raiz, o próximo nível representa o sistema opera-cional (SO), em seguida vem a versão do SO e então a arquitetura do SO (32 ou 64 bits).As folhas da árvore representam as máquinas virtuais alocadas no servidor.
[Sindelar et al. 2011] utiliza essa árvore para capturar as páginas de memória dasVMs alocadas. Em seu modelo, a raiz da árvore contém todas as páginas de memóriacompartilhadas entre as VMs, os nós no nível do SO contêm as páginas compartilhadaspelo mesmo SO e o mesmo ocorre nos nós para a versão do SO e para a arquitetura doSO. As folhas contêm as páginas de memória que não são compartilhadas, ou seja, sãoexclusivas de cada VM. Nosso trabalho adotou uma interpretação diversa: cada nívelindica o potencial de compartilhamento para uma dada VM. Conforme aumenta o grau desimilaridade entre as VMs, também aumenta a probabilidade dessas VMs compartilharempáginas de memória comuns entre si. Dessa forma, ao realizar-se uma busca na árvore porVMs semelhantes a uma dada VM, quanto maior a profundidade alcançada, maior será aprobabilidade de compartilhamento de memória.
A Figura 2(a) ilustra um exemplo da árvore de alocação em um servidor físico u.Nesse exemplo existem quatro VMs alocadas: vm1 é uma máquina Windows 7 32 bits,vm2 é Windows 8 32 bits e vm3 e vm4 são Windows 8 64 bits. Supondo que uma VMLinux Ubuntu 13.10, 64 bits (vm5) deva ser alocada em u. Como vm5 não é similar anenhum nó da árvore, α(vm5, u) = 0. Se mesmo assim vm5 for alocada em u, uma novaramificação será criada na árvore (Figura 2(b)). Caso a vm5 fosse Windows 7 64 bits,seriam encontrados dois níveis de similaridade (SO e versão), portanto α(vm5, u) > 0.Caso vm5 seja alocada em u, sua árvore ficaria conforme a Figura 2(c).
Para a realização da simulação, foram estabelecidos pesos fixos de 0,1 para cadanível hierárquico da árvore. O fator α é calculado somando-se esse peso até o últimonível comum entre as VMs. Assim, uma VM que tenha dois níveis de similaridade comoutras terá α = 0, 2. O valor de 0,1 por nível foi escolhido de forma empírica, apenas paraavaliar o algoritmo proposto; em servidores reais o compartilhamento de memória é muitovariável, sofrendo oscilações durante o ciclo de vida das VMs.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
87

(a) Cenário original (b) Alocação de uma VMUbuntu 13.10 64 bits
(c) Alocação de uma VMWindows 7 64 bits
Figura 2. Exemplo de árvore de alocação em um servidor
5. Experimentos RealizadosPara a validação do algoritmo proposto optou-se pela realização de experimentos emum ambiente de simulação. Alguns fatores que contribuíram para essa escolha incluema dificuldade de acesso a um ambiente de larga escala real, a dificuldade em generalizarresultados de testes em ambientes de pequena escala para ambientes maiores, a dificuldadede reprodução de testes em ambientes reais decorrente do caráter dinâmico do problema e,não menos importante, a existência de muitos trabalhos de pesquisa que usam o mesmosimulador, atestando a qualidade de seus resultados e os benefícios de sua utilização.
Esta seção apresenta o ambiente de simulação utilizado para os experimentos,os ajustes necessários para adaptá-lo ao algoritmo proposto, os experimentos e cenáriostestados e os resultados obtidos.
5.1. Ambiente de SimulaçãoPara a avaliação do algoritmo foi usado o simulador CloudSim [Calheiros et al. 2011], umframework extensível feito em Java que permite a modelagem e simulação de um ambientede computação em nuvem. O CloudSim foi desenvolvido pelo The Cloud Computing andDistributed Systems (CLOUDS) Laboratory da Universidade de Melbourne, Austrália.Com o CloudSim é possível modelar vários aspectos do funcionamento de uma nuvem,como a configuração de um datacenter, nuvens federadas, cargas de trabalho dinâmicas,consumo de energia e políticas de alocação de máquinas virtuais.
O CloudSim apresenta uma arquitetura multi-camadas: na base fica a camada desimulação, que oferece suporte para modelagem e simulação de ambientes virtualizados,inclui interfaces para gerenciamento de máquinas virtuais, memória, armazenamento e lar-gura de banda. Dispõe de recursos para o gerenciamento de aplicações e monitoramentodinâmico do estado da nuvem. Nessa camada são estabelecidas as políticas de provisiona-mento e alocação de VMs. A camada do topo representa o código do usuário, que expõeas entidades básicas para definição dos hosts (número de máquinas e suas especificações),aplicações (número de tarefas e seus requisitos), máquinas virtuais, número de usuários epolíticas de escalonamento. É nessa camada que são construídos os cenários de simulaçãoe onde os experimentos são realizados.
Para que o CloudSim atendesse os requisitos do algoritmo proposto, foram neces-sárias algumas modificações no framework. A Figura 3 apresenta parte do diagrama de
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
88

classes do framework, sendo visíveis apenas as classes de maior relevância; as classes emfundo cinza foram incluídas ao framework neste trabalho, para dar suporte à simulação docompartilhamento de memória.
Figura 3. Diagrama simplificado de classes do CloudSim, com modificações
As classes Host e Vm, que modelam, respectivamente, as características de umservidor físico e as características de uma máquina virtual, foram estendidas para Sha-redHost e SharedVm, incluindo as informações necessárias para o tratamento da memóriacompartilhada. Foi criada uma nova classe chamada SharedTree, que modela a árvorede alocações de VMs em um SharedHost. Através dessa estrutura é possível calcular ofator de compartilhamento α para cada servidor físico. Por fim, a classe VmAllocationPo-licyVectorAlloc foi estendida de VmAllocationPolicy; ela contém a política de alocaçãoe distribuição das máquinas virtuais nos servidores físicos. Ao iniciar a simulação, essaclasse é a responsável por receber cada VM e encontrar o melhor servidor para alocá-la.
5.2. ExperimentosPara a realização dos experimentos foram criados três cenários distintos, simulando ambi-entes de datacenter de diferentes portes (inpirado de [Lago et al. 2011]). O datacenter depequeno porte contém 10 servidores onde devem ser alocadas 30 máquinas virtuais. Demédio porte contém 100 servidores para alocação de 300 máquinas virtuais e o datacenterde grande porte com 1000 servidores para 3000 máquinas virtuais.
As configurações de CPU, banda de rede e armazenamento nos servidores foramfixadas em 10.000 MIPS, 1 Gbps e 1 TB. Para a memória adotou-se uma distribuição cir-cular do conjunto {12, 16, 20 e 24 GB}, simulando servidores com diferentes capacidades.Para as máquinas virtuais, as configurações de banda de rede e de armazenamento ficaramfixas em 100 Mbps e 5 GB, com distribuição circular para a CPU em {1.000, 1.500, 2.000e 2.500 MIPS e para a memória em 512 MB, 1, 2, 4 e 8 GB. O sistema operacional decada VM pode ser Windows 7, Windows 8, Ubuntu 10.4 ou Ubuntu 12.4, todos podendoassumir a plataforma de 32 ou 64 bits. Adotou-se RTVmin = 0, 1 e RTVmax = 0, 9.
Para cada cenário foram executados três algoritmos de alocação: a) um algoritmode alocação usando a técnica First-Fit, onde uma VM é simplesmente alocada no pri-meiro servidor que tiver recursos suficientes disponíveis; b) o algoritmo VectorAlloc semo compartilhamento de memória, ou seja, com α = 0; e c) o algoritmo VectorAlloc consi-derando o compartilhamento de memória. A alocação das VMs ocorre de forma online,ou seja, não há um pré-conhecimento do conjunto a ser instanciado. As VMs são alocadasem sequência, à medida que entram na fila de alocação. Isto se torna interessante paragarantir a eficiência de alocação em sistemas onde os usuários chegam continuamente[Zaman and Grosu 2012].
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
89
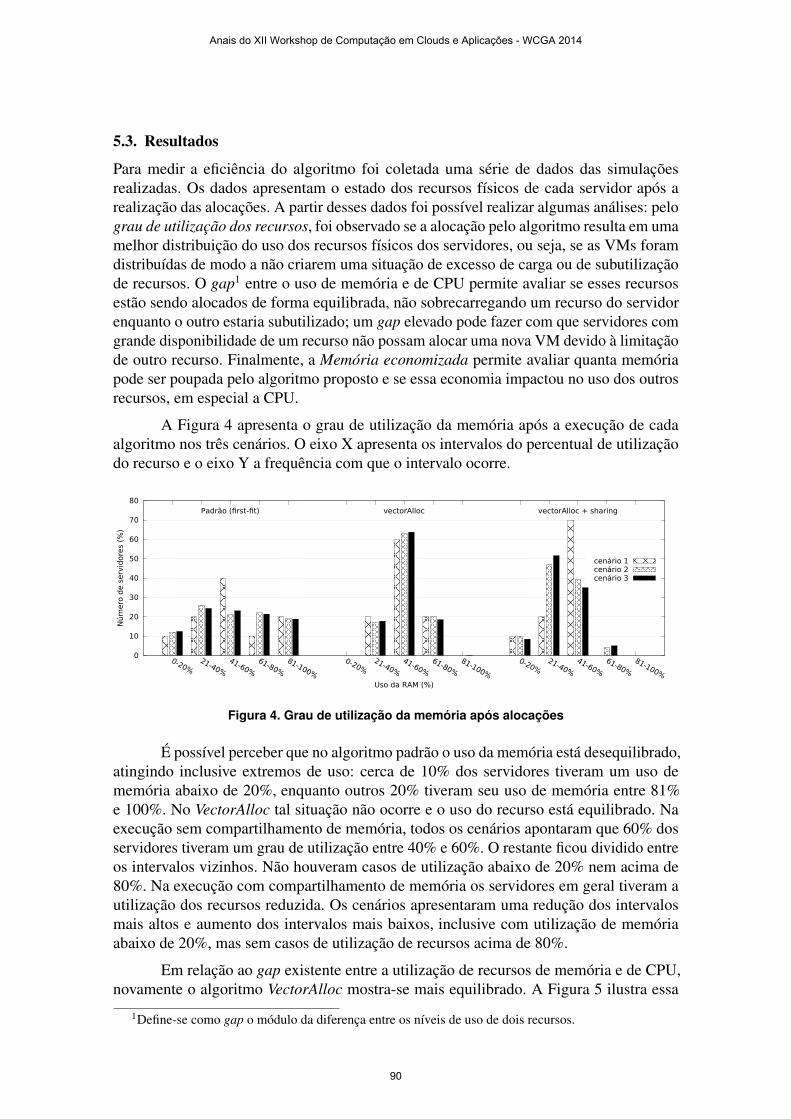
5.3. Resultados
Para medir a eficiência do algoritmo foi coletada uma série de dados das simulaçõesrealizadas. Os dados apresentam o estado dos recursos físicos de cada servidor após arealização das alocações. A partir desses dados foi possível realizar algumas análises: pelograu de utilização dos recursos, foi observado se a alocação pelo algoritmo resulta em umamelhor distribuição do uso dos recursos físicos dos servidores, ou seja, se as VMs foramdistribuídas de modo a não criarem uma situação de excesso de carga ou de subutilizaçãode recursos. O gap1 entre o uso de memória e de CPU permite avaliar se esses recursosestão sendo alocados de forma equilibrada, não sobrecarregando um recurso do servidorenquanto o outro estaria subutilizado; um gap elevado pode fazer com que servidores comgrande disponibilidade de um recurso não possam alocar uma nova VM devido à limitaçãode outro recurso. Finalmente, a Memória economizada permite avaliar quanta memóriapode ser poupada pelo algoritmo proposto e se essa economia impactou no uso dos outrosrecursos, em especial a CPU.
A Figura 4 apresenta o grau de utilização da memória após a execução de cadaalgoritmo nos três cenários. O eixo X apresenta os intervalos do percentual de utilizaçãodo recurso e o eixo Y a frequência com que o intervalo ocorre.
0
10
20
30
40
50
60
70
80
0-20%21-40%
41-60%61-80%
81-100%
0-20%21-40%
41-60%61-80%
81-100%
0-20%21-40%
41-60%61-80%
81-100%
Núm
ero
de s
erv
idore
s (%
)
Uso da RAM (%)
cenário 1cenário 2cenário 3
vectorAlloc + sharingvectorAllocPadrão (first-fit)
Figura 4. Grau de utilização da memória após alocações
É possível perceber que no algoritmo padrão o uso da memória está desequilibrado,atingindo inclusive extremos de uso: cerca de 10% dos servidores tiveram um uso dememória abaixo de 20%, enquanto outros 20% tiveram seu uso de memória entre 81%e 100%. No VectorAlloc tal situação não ocorre e o uso do recurso está equilibrado. Naexecução sem compartilhamento de memória, todos os cenários apontaram que 60% dosservidores tiveram um grau de utilização entre 40% e 60%. O restante ficou dividido entreos intervalos vizinhos. Não houveram casos de utilização abaixo de 20% nem acima de80%. Na execução com compartilhamento de memória os servidores em geral tiveram autilização dos recursos reduzida. Os cenários apresentaram uma redução dos intervalosmais altos e aumento dos intervalos mais baixos, inclusive com utilização de memóriaabaixo de 20%, mas sem casos de utilização de recursos acima de 80%.
Em relação ao gap existente entre a utilização de recursos de memória e de CPU,novamente o algoritmo VectorAlloc mostra-se mais equilibrado. A Figura 5 ilustra essa
1Define-se como gap o módulo da diferença entre os níveis de uso de dois recursos.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
90

situação. No algoritmo padrão, entre 70% e 80% das alocações criaram um gap de até40%, mas nos ambientes de médio e grande porte, quase 10% dos servidores atingiramuma diferença entre 61% e 80%. Percebe-se que nessas situações um recurso está sendomuito sobrecarregado em relação ao outro. O VectorAlloc sem compartilhamento reduziumuito essa diferença, deixando em torno de 90% dos servidores com um gap inferior a20%, o que indica uso equilibrado dos recursos. Com o compartilhamento de memóriaesse gap volta a ter um aumento, mas isso é explicado pelo fato do uso de CPU se manter omesmo, enquanto o uso de memória foi reduzido pela possibilidade de compartilhamento.
0
10
20
30
40
50
60
70
80
90
100
0-20%21-40%
41-60%61-80%
81-100%
0-20%21-40%
41-60%61-80%
81-100%
0-20%21-40%
41-60%61-80%
81-100%
Núm
ero
de s
erv
idore
s (%
)
Gap entre CPU e RAM (%)
cenário 1cenário 2cenário 3
vectorAlloc + sharingvectorAllocPadrão (first-fit)
Figura 5. Gap entre uso da memória e de CPU
Os últimos resultados obtidos aparecem na Tabela 1 e mostram o uso médio dememória nos servidores, para cada algoritmo executado. Dos três algoritmos, o VectorAlloccom compartilhamento de memória gerou os melhores resultados, resultando numa médiade utilização de memória em torno de 38%, cerca de 15% menor que o algoritmo padrãoe 12,5% menor que o VectorAlloc sem compartilhamento de memória (coluna ganho).
Tabela 1. Média e desvio padrão de uso da memória dos servidorescenário First-Fit VectorAlloc VectorAlloc + mem sharing
média desvio média desvio ganho média desvio ganho1 58,7% 27,9% 53,5% 12,0% 5.2% 43,9% 12,9% 14.8%2 53,5% 27,2% 50,7% 12,6% 2.8% 38,2% 13,3% 15.3%3 53,6% 27,1% 50,8% 12,4% 2.8% 38,0% 13,3% 15.6%
6. Conclusão
Este artigo apresentou o algoritmo VectorAlloc para alocação online de máquinas virtu-ais em ambientes de computação em nuvem. O algoritmo faz uso de uma representaçãovetorial para a análise dos múltiplos recursos físicos e leva em consideração o compar-tilhamento de memória entre máquinas virtuais. Comparado a uma abordagem padrãode alocação, os resultados dos testes comprovaram que o algoritmo faz um melhor usodos recursos físicos dos servidores, distribuindo as máquinas virtuais de uma modo maisequilibrado, eliminando cenários de sobrecarga ou subutilização. Nos testes considerandoa possibilidade de compartilhamento de memória, o consumo médio de memória dosservidores foi reduzido em cerca de 15% em relação à abordagem padrão.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
91

ReferênciasBarker, S., Wood, T., Shenoy, P., and Sitaraman, R. (2012). An empirical study of memory
sharing in virtual machines. In Usenix Annual Technical Conference.
Buyya, R., Beloglazov, A., and Abawajy, J. (2010). Energy-efficient management of datacenter resources for cloud computing: A vision, architectural elements, and open chal-lenges. arXiv preprint arXiv:1006.0308, pages 1–12.
Calheiros, R., Ranjan, R., Beloglazov, A., De Rose, C., and Buyya, R. (2011). CloudSim:a toolkit for modeling and simulation of cloud computing environments and evaluationof resource provisioning algorithms. Software: Practice and Experience, 41(1):23–50.
Chen, M., Zhang, H., Su, Y.-Y., Wang, X., Jiang, G., and Yoshihira, K. (2011). Effective VMsizing in virtualized data centers. In IFIP/IEEE International Symposium on IntegratedNetwork Management, pages 594–601.
Creasy, R. J. (1981). The origin of the VM/370 time-sharing system. IBM Journal ofResearch and Development, 25(5):483–490.
Grit, L., Irwin, D., Yumerefendi, A., and Chase, J. (2006). Virtual machine hosting fornetworked clusters: Building the foundations for autonomic orchestration. In 1st Inter-national Workshop on Virtualization Technology in Distributed Computing. IEEE.
Hyser, C., Mckee, B., Gardner, R., and Watson, B. (2007). Autonomic virtual machineplacement in the data center. Technical Report HPL-2007-189, HP Labs, Palo Alto CA.
Lago, D., Madeira, E., and Bittencourt, L. (2011). Power-aware virtual machine schedulingon clouds using active cooling control and DVFS. In 9th International Workshop onMiddleware for Grids, Clouds and e-Science, New York USA. ACM Press.
Mishra, M. and Sahoo, A. (2011). On theory of VM placement: Anomalies in existingmethodologies and their mitigation using a novel vector based approach. In IEEE 4thInternational Conference on Cloud Computing, pages 275–282. IEEE.
Sindelar, M., Sitaraman, R. K., and Shenoy, P. (2011). Sharing-aware algorithms forvirtual machine colocation. In 23rd ACM Symposium on Parallelism in Algorithms andArchitectures, page 367, New York USA. ACM Press.
Singh, A., Korupolu, M., and Mohapatra, D. (2008). Server-storage virtualization: Integra-tion and load balancing in data centers. In ACM/IEEE Conference on Supercomputing,pages 1–12. IEEE Press.
Wood, T., Tarasuk-Levin, G., Shenoy, P., Desnoyers, P., Cecchet, E., and Corner, M. D.(2009). Memory buddies: Exploiting page sharing for smart colocation in virtualizeddata centers. Operating Systems Review, 43(3):27–36.
Yen Van, H., Dang Tran, F., and Menaud, J.-M. (2009). Autonomic virtual resource ma-nagement for service hosting platforms. In ICSE Workshop on Software EngineeringChallenges of Cloud Computing, pages 1–8, Washington DC. IEEE Computer Society.
Zaman, S. and Grosu, D. (2012). An online mechanism for dynamic VM provisioningand allocation in clouds. In 5th IEEE International Conference on Cloud Computing,pages 253–260. IEEE.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
92

Deaf Accessibility as a Service: uma Arquitetura Elastica eTolerante a Falhas para o Sistema de Traducao VLIBRAS
Eduardo Falcao, Tiago Maritan e Alexandre Duarte
1Digital Video Applications Lab - LAVIDFederal University of Paraiba - UFPB
Joao Pessoa, Paraıba, Brazil{eduardolf, tiagomaritan, alexandre}@lavid.ufpb.br
Abstract. When designed, Information and Communication Technologies rarelytake into account the barriers that deaf people face. Currently, there are toolsfor automatic translation from spoken languages to sign languages, but, un-fortunately, they are not available to third parties. To reduce these problems, itwould be interesting if any automatic translation service could be publicly avail-able. This is the general goal of this work: use a preconceived machine trans-lation from portuguese language to Brazilian Sign Language (LIBRAS), namedVLIBRAS, and provide Deaf Accessibility as a Service publicly. The idea is toabstract inherent problems in the translation process between the portugueselanguage and LIBRAS by providing a service that performs the automatic trans-lation of multimedia content to LIBRAS. VLIBRAS was primarily deployed as acentralized system, and this conventional architecture has some disadvantageswhen compared to distributed architectures. In this paper we propose a dis-tributed architecture in order to provide an elastic service and achieve faulttolerance.
1. IntroducaoA lıngua que um indivıduo usa para se comunicar depende de sua natureza alem do grupode indivıduos com o qual ele convive. Os ouvintes, por exemplo, comunicam-se porintermedio de lınguas oralizadas. Ja os surdos, por outro lado, encontram na linguagemgestual-corporal um meio eficaz de comunicacao como alternativa a falta de capacidadeauditiva. Portanto, a lıngua na qual o surdo consegue perceber e produzir de maneiranatural e a lıngua de sinais (LS), ao passo que as lınguas orais, utilizadas cotidianamentepela maioria das pessoas, representam apenas “uma segunda lıngua” [de Goes 1996].
Segundo o censo demografico realizado em 2010 pelo Instituto Brasileiro deGeografia e Estatıstica (IBGE), 5,1% da populacao brasileira possui deficiencia audi-tiva. Deste total, 1,7 milhoes tem grande dificuldade para ouvir e 344,2 mil sao surdos[Instituto Brasileiro de Geografia e Estatıstica 2010]. Normalmente, nos diferentes con-textos da sociedade atual brasileira, a informacao e transmitida atraves da lıngua por-tuguesa. Mas o nıvel de proficiencia dos surdos na lıngua portuguesa pode tornar a leiturauma tarefa ardua e limitada [Gomes and Goes 2011], fazendo deste fator uma barreira amais na inclusao digital.
A LIBRAS e dotada de uma gramatica propria, diferente da gramatica da lınguaportuguesa. Com relacao a ordem das palavras, por exemplo, existem diferencas en-tre as duas lınguas [de Araujo 2012]. Na maioria dos casos, a lıngua portuguesa utiliza
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
93

sentencas no formato sujeito-verbo-objeto (SVO), enquanto que a LIBRAS geralmenteutiliza sentencas no formato topico-comentario [Brito 1995]. Araujo (2012) utilizou osseguintes exemplos para explicar esta diferenca:
• O urso (S) matou (V) o leao (O).• Eu (S) nao vi (V) o acidente na rua (O).
As sentencas supracitadas seriam representadas em LIBRAS da seguinte forma:
• URSO (Topico), LEAO MATAR (Comentario).• RUA ACIDENTE (Topico) NAO ENXERGAR (Comentario).
E de extrema importancia a existencia da traducao de LIBRAS para a lınguaportuguesa, com objetivo de “reorganizar” as frases alterando a ordem das palavras, aspalavras em si (e.g., verbos em LIBRAS sao sempre no infinitivo) e eliminando partesdesnecessarias (e.g., artigos). Caso contrario, a sinalizacao realizada resultaria apenas em“portugues sinalizado”, de dificuldade ainda elevada por nao constituir a LIBRAS.
A acessibilidade para surdos requer primordialmente a traducao para LIBRAS.Esta traducao e de extrema importancia mas traz consigo alguns problemas:
1. Alto custo do servico: segundo SINTRA (2010) , a traducao de 60 minutos de umaudio em lıngua portuguesa para a LIBRAS custa 585 reais;
2. Grande dinamismo de conteudos nas tecnologias de informacao e comunicacao(TICs).
Para sistemas de Video on Demand - VoD, prover acessibilidade para surdostambem e uma tarefa complicada. Ao analisar o Youtube, por exemplo, e possıvel notar ainviabilidade da traducao de seus vıdeos por interpretes, devido aos milhoes de usuariosdo servico, e a grande quantidade de vıdeos que sao enviadas ao sistema.
Uma das solucoes para sistemas de VoD seria a utilizacao de um servico detraducao automatica da lıngua portuguesa para a LIBRAS. Para tanto, este trabalho uti-liza o sistema VLIBRAS [de Araujo 2012] para oferecer este servico. Atualmente, oVLIBRAS e implantado em uma arquitetura centralizada, e, portanto, pode ser apri-morado utilizando uma arquitetura distribuıda. Para uma nocao inicial da performancedo VLIBRAS implantado em uma arquitetura centralizada1, foi medido o tempo de pro-cessamento para 1, 10, 20, e 40 requisicoes simultaneas, apresentado na Tabela 1. Taisrequisicoes foram compostas por textos com 324 palavras.
Tabela 1. Media de tempo de processamento para requisicoes concorrentes
No de requisicoes Tempo medio Pior tempo Desvio padrao Falhas1 21.369s 21.369s 0 0
10 109.618s 118.023s 21.682 0
20 206.45106 223.023s 49.490 0
40 279.612s 281.016s 2.153 7
1Instancia da Amazon c3.large, Ubuntu 12.04 - 64 bits, 2 vCPU (CPUs virtuais) e 7 ECUs (unidade deprocessamento elastico), 3.75GB RAM
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
94

Com esses testes, foi possıvel constatar que o sistema falha ao atender um numerode requisicoes igual ou superior a 40. Deste modo, fica mais claro entender a necessidadede uma arquitetura distribuıda e dinamica. Como o servico sera disponibilizado de formapublica, em momentos de pico o sistema podera receber cargas muito superiores a 40requisicoes, porem, em momentos de baixa demanda, tambem podera receber um numerode requisicoes inferior a 40. Uma das principais caracterısticas da arquitetura distribuıdaproposta e a capacidade de provisionamento dinamico de recursos. Com ela e possıveleconomizar financeiramente em momentos de baixa demanda, mas tambem prover umservico de qualidade mesmo quando submetidos a grandes cargas de requisicoes.
Uma vez demonstrada a problematica que os surdos enfrentam nas TICs, estetrabalho tem como objetivo geral a oferta de Deaf Accessibility as a Service (DAaaS) - umservico de acessibilidade para surdos. Para tanto, sera disponibilizado publicamente umservico automatizado de traducao de conteudos multimıdia para a LIBRAS. Essa ofertapublica demanda do VLIBRAS elasticidade para atender grandes cargas de requisicoes.Portanto, o principal objetivo deste trabalho e projetar um arquitetura distribuıda, elasticae tolerante a falhas. A ideia e utilizar a nuvem para prover o DAaaS a terceiros de formatransparente, e utilizar os recursos de modo eficiente. Apesar deste trabalho utilizar umsistema de traducao previamente concebido, avaliar o nıvel de acerto na traducao realizadapelo sistema nao entra no escopo dos objetivos.
2. Acessibilidade para Surdos Brasileiros nas TICsPara conceber o DAaaS foi preciso analisar as ferramentas de traducao automatica maisabrangente, considerando variedade de entradas e plataformas de disponibilizacao.
Diante dos sistemas de traducao portugues -> LIBRAS pesquisados, foram com-paradas as principais caracterısticas dos mesmos, com objetivo de justificar a escolha doVLIBRAS como nucleo da API DAaaS. As caracterısticas avaliadas sao:
1. formatos de entrada aceitos: texto, audio, vıdeo, legenda;2. plataformas de execucao: PC, Web, mobile, televisao digital;3. forma de traducao: se a representacao visual dos sinais e feita utilizando portugues
sinalizado, ou utilizando a glosa (representacao textual em LIBRAS);4. Dicionario expansıvel: se o projeto disponibiliza alguma ferramenta que permita
a expansao do dicionario de sinais por especialistas em LIBRAS.
A tabela 2 lista os trabalhos com suas respectivas caracterısticas.
A caracterıstica mais importante a ser avaliada e a forma de traducao. Os trabal-hos que convertem o texto em lıngua portuguesa para a glosa devem ser priorizados, umavez que o portugues sinalizado e insuficiente para a compreensao completa por parte dossurdos. Normalmente, o dicionario de sinais e expandido por uma equipe de especialis-tas em LIBRAS e TI pertencentes ao projeto, porem, sabe-se que a quantidade de sinaisa ser confeccionados e muito grande. Desse modo, pode-se perceber o quanto a fun-cionalidade de “Dicionario expansıvel” e importante, pois permite que pessoas externasao projeto possam contribuir com a criacao de novos sinais. Por fim, quanto mais opcoesde formatos de entrada e plataformas de execucao o projeto oferecer, mais formatos de
2T = texto, A = audio, V = vıdeo, L = legenda3W = Web, M = mobile
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
95

Tabela 2. Sistemas de Traducao Automatica Portugues -> LIBRAS. Adaptado de:[Pivetta et al. 2011]
Tradutor Entradas 2 Plataformas 3 Traducao Codigo Dic. expansıvelT A V L PC W M TV
F-LIBRAS X X glosa fechado X
FALIBRAS X X X X X glosa fechado
POLI-LIBRAS X X X glosa aberto X
ProDeaf X X X X glosa fechado
Rybena X X X X port. sinalizado fechado
TLIBRAS X X X X glosa fechado
VLIBRAS X X X X X X X glosa fechado X
VE-LIBRAS X X X port. sinalizado fechado
entrada e plataforma de execucao o servico DAaaS podera oferecer. Portanto, a partir dasinformacoes colhidas e projetadas na tabela 2, foi concluıdo que para o presente trabalhoa melhor opcao e o sistema de traducao automatica VLIBRAS. Nesse sentido, o codigodo VLIBRAS foi disponibilizado para a concepcao do DAaaS.
3. Deaf Accessibility as a Service
Sistemas centralizados apresentam varias desvantagens quando comparados a sistemasdistribuıdos. A solucao atual para o sistema de traducao automatica VLIBRAS e baseadaem um sistema centralizado, e, portanto, possui capacidade de tolerancia a falhas limitadaalem de nao ter capacidade de provisionamento dinamico de recursos. Adicionalmente,a nuvem permite pagamento de recursos exclusivamente perante uso, nao havendo ne-cessidade de manter maquinas ociosas, e facil implantacao e configuracao do servicoem diferentes lugares do mundo, nao impondo a necessidade de espaco fısico, energia,refrigeracao, e manutencao da infraestrutura.
A capacidade de provisionamento dinamico permitira o sistema alocar recursospara atender grandes cargas de requisicao e readaptar-se quando a demanda diminuir,economizando recursos [Radhakrishnan 2012]. Essa elasticidade automatica e uma dascaracterısticas que atenua a probabilidade de ocorrencia de falhas, atraves da alta disponi-bilidade dos recursos [Bala and Chana 2012]. Alem disso, o trabalho utiliza uma tecnicade tolerancia a falhas reativa (resubmissao de tarefas) e uma proativa (self-healing).
3.1. Arquitetura Distribuıda Proposta
A arquitetura proposta para o DAaaS foi projetada para ser implantada em uma infraestru-tura de nuvem. O objetivo desta arquitetura e incorporar as seguintes funcionalidades:
Descentralizacao do fluxo de rede: a existencia de varios nos de processamentoimplica em varios fluxos de rede entre os clientes e as instancias de processa-mento;
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
96

Provisionamento dinamico de recursos: quando em momentos de sobrecarga, aescalabilidade sob demanda permite que o DAaaS tenha recursos disponıveis paraprocessar as requisicoes atraves da inclusao de novas instancias de processamento;Tolerancia a falhas:
Alta disponibilidade dos recursos: os recursos sao sempre disponibiliza-dos com redundancia e em diferentes zonas de disponibilidade;Em nıvel de software: tolerancia a falhas reativa por resubmissao de tare-fas, e proativa por meio de self-healing;
Para tal, pretende-se utilizar o Broker e a Fila de Requisicoes. O Broker fun-ciona como um gerenciador de requisicoes, adicionando as novas requisicoes na Fila deRequisicoes, e notificando os nos de processamento. Como sera explicado na secao 3.2,a Fila de Requisicoes tem como principal objetivo a recuperacao de falhas utilizando ummecanismo de resubmissao.
Na arquitetura centralizada existe um unico canal para fluxo de rede para que osconteudos de entrada (vıdeo, legenda, ou texto) e de saıda (vıdeo de traducao) trafeguem.Tal fato converge para elevar a probabilidade de haver um gargalo de rede, aumentando otempo de resposta para as requisicoes. A arquitetura proposta (Figura 1) busca diminuiro gargalo de rede uma vez que existira um canal de rede para cada instancia de proces-samento, e, portanto, varios canais de trafego de vıdeos para o sistema como um todo.Ao inves do sistema de VoD, por exemplo, enviar primariamente o arquivo de vıdeo paratraducao (como acontece na arquitetura centralizada), envia apenas uma requisicao (ar-quivo XML/JSON) que contem o endereco daquele vıdeo, e entao a instancia de proces-samento estabelece uma conexao direta para realizar o download do vıdeo. Esta carac-terıstica do sistema evita a sobrecarga no canal de rede em que se insere o Broker, uma vezque os arquivos XML/JSON possuem carga extremamente inferior a arquivos de vıdeo.
Na Figura 1, e ilustrado o funcionamento da arquitetura proposta. Para explicar ofuncionamento desta arquitetura sera utilizado o exemplo em que o sistema de VoD e ocliente do DAaaS. O processo completo para que um sistema de VoD requisite a traducaode algum conteudo obedece a sequencia de passos ordenada e identificada pelos numerosna Figura 1.
1. O usuario escolhe um vıdeo do sistema de VoD para assistir e requisita a opcao deacessibilidade;
2. O sistema de VoD envia uma requisicao (arquivo JSON ou XML em conformidadecom a API do DAaaS) de traducao ao Broker do sistema DAaaS;
3. O Broker adiciona essa requisicao a uma fila de requisicoes, e notifica as instanciasde processamento para que elas saibam que existe uma nova requisicao na fila;
4. As instancias que possuırem recursos livres, irao competir para processar asrequisicoes na fila. Cada requisicao e alocada de forma atomica por uma unicainstancia, nesse caso, a instancia B;
5. A instancia B realiza o download do vıdeo e da inıcio a traducao automatica;6. Uma vez que a traducao para LIBRAS seja concluıda, o vıdeo de traducao e trans-
ferido para o servico de armazenamento de arquivos escalavel;7. A instancia envia um sinal para a Fila de Requisicoes remover aquela requisicao
especıfica, uma vez que tenha sido processada com sucesso;8. Uma mensagem contendo o endereco do vıdeo de traducao em LIBRAS e enviado
para o Broker;
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
97

Figura 1. DAaaS - Arquitetura Distribuıda Proposta
9. Essa mensagem e enviada para o sistema de VoD;10. O sistema de VoD realiza o download do vıdeo de traducao em LIBRAS e exibe
para o usuario final de maneira sincronizada com o vıdeo original.
A seguir, serao demonstradas as estrategias de tolerancia a falhas (3.2) e provision-amento dinamico de recursos (3.3), que visa prover resiliencia e elasticidade ao DAaaS.
3.2. Tolerancia a Falhas
3.2.1. Alta Disponibilidade dos Recursos
A existencia de redundancia de recursos em localizacoes geograficas diferentes provetolerancia a falhas por meio de alta disponibilidade. De acordo com a Figura 1, asinstancias de processamento estao situadas em diferentes locais fısicos. E possıvel con-figurar o provisionamento dinamico para criar novas instancias em diferentes localizacoesgeograficas, visando equilibrar a quantidade de instancia nestes locais (e.g., 2 instanciasno “local A”, 2 instancias no “local B”, e 2 instancia no “local C”). Se porventura al-guma unidade de processamento falhar, o DAaaS nao ficara indisponıvel, uma vez queoutros nos de processamento podem assumir a carga do no defeituoso ate que o problemaseja resolvido. Deste modo, evita-se que problemas com rede ou energia em determinadalocalizacao, ou ate mesmo falhas de hardware, interfiram na disponibilidade do DAaaS.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
98

3.2.2. Em Nıvel de Software
Na antiga arquitetura centralizada, as falhas eram irreversıveis, ou seja, se ocorressemnao eram passıveis de recuperacao. A tolerancia a falhas em nıvel de software permite arecuperacao de uma falha ocorrida, alem de sua prevencao por antecipacao.
Os componentes responsaveis pela tolerancia a falha em nıvel de software sao oBroker e a Fila de Requisicoes. Com relacao a tolerancia a falha, as principais atividadesdo Broker sao:
Gerenciamento de requisicoes: toda requisicao chega primeiro ao Broker, que eencarregado de envia-la para a Fila de Requisicoes. Se nao houvesse o gerencia-mento as requisicoes seriam escalonadas automaticamente para um no de proces-samento, tornando a recuperacao de uma eventual requisicao falha restrita aquelainstancia de processamento;Notificacao: assim que o Broker adiciona uma nova requisicao a Fila deRequisicoes, seu proximo passo e notificar todos os nos de processamento paraque eles saibam o momento correto de consumir a Fila de Requisicoes;Provisionamento dinamico de recursos: baseado na quantidade de requisicoesna Fila de Requisicoes, o Broker adiciona ou remove novos nos de processamento.O Broker tambem faz checagens periodicas para garantir que todos os nos de pro-cessamento estejam em pleno funcionamento, removendo os defeituosos e adicio-nando novos quando necessario.
O servico DAaaS usa uma tecnica de tolerancia a falha reativa por resubmissao detarefas. A tecnica reativa proposta consiste em resubmeter as requisicoes que falharema Fila de Requisicoes. Para tal, todas as requisicoes desta Fila de Requisicoes sao mar-cadas com uma tag “visıvel” ou “invisıvel”. Todas as requisicoes inseridas nesta filasao marcadas por padrao como visıvel, para que todas as instancias possam acessa-las.Quando o Broker adiciona novas requisicoes a essa Fila de Requisicoes, sua proximatarefa e notificar as instancias de processamento para avisar que a fila possui novos itens aserem consumidos. Assim que uma instancia comeca a processar uma requisicao da fila,a mesma e marcada como “invisıvel” ate que essa instancia termine seu processamento eexplicitamente a remova da fila.
Testes preliminares devem ser realizados para definir quantas requisicoes si-multaneas cada instancia consegue processar com sucesso, e qual o pior tempo para pro-cessamento em situacoes de . Consideramos como falha o caso em que uma instancianao conseguir processar a requisicao dentro desse pior tempo estipulado. Este pior tempoe utilizado como tempo de invisibilidade padrao, ou seja, se o processamento de algumarequisicao for maior do que o pior tempo pre-calculado a requisicao sera automaticamentemarcada como visıvel e sera reprocessada por outra instancia ou ate pela mesma. Por-tanto, ha a possibilidade de acontecer a “falha real”, onde o processamento da requisicaorealmente falhou, mas tambem ha a possibilidade da “falha falsa”, quando uma instanciademorar mais tempo para processar uma requisicao do que o “pior tempo” estipulado.Quando ocorrer a “falha falsa” a requisicao sera processada duas ou mais vezes, onde oprimeiro processamento pode ate ser concluıdo com sucesso, mas por demorar muito edesconsiderado pelo DAaaS, e o ultimo processamento terminara antes do pior tempo.
Quando uma requisicao falhar e tornar-se visıvel novamente, nao havera mais nen-
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
99

huma notificacao exclusiva do Broker as instancias avisando que aquela requisicao es-pecıfica esta mais uma vez visıvel. Contudo, as instancias podem consumir a requisicaoque falhou atraves de outras notificacoes do Broker para outras requisicoes, ou atraves deum laco de checagem de requisicoes (15 segundos) que as instancias de processamentoimplementam para consumir novas requisicoes independente da notificacao do Broker. Omodelo de processo de negocios para tolerancia a falhas reativa por meio de resubmissaode tarefas e detalho na Figura 2, atraves de um diagrama BPMN (Business Process Mod-eling Notation).
Figura 2. Modelo de Processos de Negocios para Tolerancia a Falhas Reativa
A tecnica proativa tambem e implementada no Broker, atraves do provisionadordinamico de recursos, que e encarregado de alocar ou desalocar recursos diante dasmetricas especificadas. Uma das funcoes deste provisionador e verificar se alguma dasinstancias nao esta mais em funcionamento, atraves de requisicoes HTTP as maquinassupostamente ativas, e as repor caso elas aparentem estar defeituosas.
3.3. Provisionamento Dinamico de RecursosA estrategia utilizada para provisionamento dinamico de recursos baseia-se na Fila deRequisicoes. Deste modo, testes preliminares devem ser realizados para definir quan-tas requisicoes simultaneas cada tipo de instancia utilizada consegue processar, e qual
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
100

o pior tempo para processamento em situacoes de sobrecarga. Baseado na quantidademaxima de requisicoes simultaneas, no tamanho da Fila de Requisicoes, e na quantidadede instancias de processamento ativas, e possıvel calcular se o DAaaS esta sobrecarregadoou subutilizado, para criar novas instancias ou remover algumas.
A tendencia e que as instancias de processamento estejam sempre sobrecarregadas(caso haja requisicoes na Fila), uma vez que o Broker sempre notifica todas as instanciasquando novas requisicoes sao inseridas na fila, alem da existencia do laco de checagem denovas requisicoes nas instancias de processamento, que independe do Broker. Portanto,as instancias de processamento estarao sempre “absorvendo” a Fila de Requisicoes setiverem recursos disponıveis, ou seja, sempre que nao estiverem processando a quantidademaxima de requisicoes delimitadas.
O diagrama ilustrado na Figura 3, detalha os passos do algoritmo de provi-sionamento dinamico para criar ou terminar as instancias de processamento VLIBRAS.Seguindo esse modelo de processo de negocios, e possıvel simular o que aconteceriase, por exemplo, a Fila de Requisicoes possuısse 1435 requisicoes, a instancia pudesseprocessar no maximo 15 requisicoes, e o pior tempo para processamento em situacoesde sobrecarga fosse 30 minutos. Lembrando que o DAaaS inicia com 2 instancias deprocessamento, que e a quantidade mınima, o algoritmo de escalonamento executaria osseguintes passos:
1. “O DAaaS possui menos instancias de processamento do que a quantidade mınimadelimitada?” Nao, o DAaaS tem 2 instancias disponıveis.
2. “O DAaaS possui a quantidade de instancias necessarias para processar a Fila deRequisicoes?” Nao, o DAaaS possui apenas 2 instancias, que nao tem capacidadepara atender todas as requisicoes em tempo habil.
3. “O DAaaS cria N instancias ate atingir a quantidade necessaria para processar aFila de Requisicoes.” Abaixo vamos calcular N a partir do codigo do DAaaS:
(a) int instancesRequired = (int) Math.ceil(requestsOnQueue/maxRequestsPerInstance);(b) int instancesRequired = (int) Math.ceil(1435/15);(c) int instancesRequired = (int) Math.ceil(95.66);(d) int instancesRequired = 96;
4. Sabendo que uma instancia leva de 90 a 120 segundos para iniciar, 3 minutos eum tempo com folga para que a instancia inicie e absorva a quantidade maximade requisicoes, nesse caso, 15.
5. “O DAaaS possui menos instancias de processamento do que a quantidade mınimadelimitada?” Nao, o DAaaS tem 96 instancias disponıveis.
6. Quando o algoritmo de escalonamento chegar neste ponto, “O DAaaS possui aquantidade de instancias necessarias para processar a Fila de Requisicoes?”, aresposta sera SIM, ja que as 96 instancias (94 recem criadas) absorveram toda aFila de Requisicoes. A menos que nesse meio tempo novas requisicoes tenhamchegado na fila, e que as instancias ativas nao as tenham processado.
Para reducao da quantidade de instancias, o chamado scaling in, o DAaaS esper-aria o pior tempo para processamento em situacoes de sobrecarga. No caso do exemploanterior, o DAaaS esperaria 50 minutos para calcular quantas instancias deveriam sereliminadas a partir do numero de requisicoes na Fila, e da quantidade de instancias ativas.Ja que o pagamento na AWS e por hora, nao faz sentido terminar instancias ja pagas por
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
101

um tempo distante de 60 minutos. Quando o Broker notifica uma instancia para ser re-movida ela nao e imediatamente excluıda, porem, a partir desta notificacao ela se preparapra encerrar, ignorando as novas requisicoes na Fila de Requisicoes notificadas pelo Bro-ker ou pelo laco de checagem. Uma thread e ativada para checar continuamente se asrequisicoes em andamento ja finalizaram, e em caso positivo, a thread encerra a instanciaatual. Um detalhe que pode ser melhorado nesse algoritmo e o monitoramento exatode quantas requisicoes cada instancia ativa possui, para ao notificar a remocao de algu-mas instancias, faze-lo de forma crescente, notificando primeiramente as instancias commenor numero de requisicoes.
Figura 3. Modelo de Processos de Negocios para Provisionamento Dinamico deRecursos
4. Cenarios de Uso
A API esta sendo disponibilizada na AWS, recebendo requisicoes na urlhttp://184.169.148.166/Broker/requests. O DAaaS esta implantado utilizando instanciasdo tipo m1.small e e financiado por meio de creditos da AWS para pesquisas cientıficas.Atualmente, a API possui dois usuarios: 1 - sıtio do SENAPES; 2 - aplicativo VLIBRASmobile.
O SENAPES e um evento que sera aberto ao publico e tem como objetivo principala apresentacao e discussao de experiencias no desenvolvimento e implantacao de tecnolo-gias assistivas para promocao da acessibilidade para pessoas surdas nas TICs. Portanto,havera grande acesso de pessoas surdas ao sıtio e o mesmo sera acessıvel a elas por meiodo DAaaS.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
102

Para obter a traducao de um texto no sıtio do SENAPES o usuario deve selecionaro texto, e clicar no botao “Traduzir”. Entao uma janela de carregamento aparecera, equando a traducao estiver disponıvel sera prontamente exibida ao usuario, como podeser observado na 4. O plugin de traducao para o sıtio SENAPES foi desenvolvido peloLAVID utilizando a API DAaaS.
Figura 4. Avatar traduzindo o texto selecionado
O aplicativo VLIBRAS mobile e disponibilizado para plataforma android, o quecomprova que o DAaaS pode ser utilizado de forma heterogenea em diferentes meios dedisponibilizacao. O aplicativo permite traducao a partir de texto, legenda, e tambem apartir do audio, aplicando um passo adicional de conversao para texto. As Figuras 5 e 6ilustram o processo de traducao do VLIBRAS mobile.
5. Consideracoes Finais
O presente trabalho propoe a disponibilizacao de um servico de traducao automatica, oDAaaS, a ser implantada em uma arquitetura distribuıda, elastica e tolerante a falhas. Paraeste fim, utilizamos o paradigma de computacao em nuvem e implantamos a arquiteturano provedor de infraestrutura AWS.
Figura 5. Opcoes
Figura 6. Avatar realizandotraducao
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
103

Trabalhos futuros envolvem a validacao da arquitetura proposta quanto a capaci-dade de provisionamento dinamico de recursos e de tolerancia a falhas com um projeto deexperimentos. Tambem e necessario a implementacao de um mecanismo de autenticacaopara o servico. Atualmente, o DAaaS possui dois clientes como estudo de caso, o sıtio doSENAPES e o aplicativo VLIBRAS mobile.
O servico ainda apresenta um ponto crıtico passıvel de falhas que futuramentedeve ser corrigido, o Broker. Se, porventura, o Broker falhar, o DAaaS para de funcionar.Um modo rapido e facil de consertar essa vulnerabilidade no provedor de IaaS AWS, eutilizar o AutoScaling aliado ao Elastic Load Balancing. Para tal, basta configurar o Au-toScaling com um “gatilho” para detectar sempre que nao houver instancia com a AmazonMachine Image - AMI do Broker ativa, e configurar uma polıtica de escalonamento paracriar uma nova instancia com a AMI do Broker cada vez que o gatilho for disparado. OELB seria utilizado para redirecionar as requisicoes para a instancia recem criada. Outraforma de utilizacao seria utilizar o AutoScaling e o ELB para manter sempre as duasinstancias do Broker ativas, o que aumentaria a disponibilidade do Broker mas tambemelevaria os gastos.
Por fim, agradecemos a Amazon Web Services pelos creditos para pesquisa quepossibilitaram a realizacao deste trabalho.
6. Referencias
ReferencesBala, A. and Chana, I. (2012). Fault tolerance-challenges, techniques and implementation
in cloud computing. International Journal of Computer Science Issues, 9(1):288–293.
Brito, L. (1995). Por uma gramatica de lınguas de sinais. Tempo Brasileiro, Rio deJaneiro, Brasil.
de Araujo, T. M. U. (2012). Uma Solucao para Geracao Automatica de Trilhas em LınguaBrasileira de Sinais em Conteudos Multimıdia. PhD thesis, Universidade Federal doRio Grande do Norte, Natal, Brasil.
de Goes, M. (1996). Linguagem, surdez e educacao. Colecao Educacao contemporanea.Autores Associados.
Gomes, R. C. and Goes, A. R. S. (2011). E-acessibilidade para Surdos. Revista Brasileirade Traducao Visual, 7(7).
Instituto Brasileiro de Geografia e Estatıstica (2010). Censo demografico 2010: Carac-terısticas gerais da populacao, religiao e pessoas com deficiencia. Technical report.
Pivetta, E. M., Ulbricht, V., and Savi, R. (2011). Tradutores automaticos da linguagemportugues oral e escrita para uma linguagem visual-espacial da lıngua brasileira desinais. V CONAHPA - Congresso Nacional de Ambientes Hipermıdia para Aprendiza-gem.
Radhakrishnan, G. (2012). Adaptive application scaling for improving fault-tolerance andavailability in the cloud. Bell Labs Technical Journal, 17(2):5–14.
Sindicato Nacional dos Tradutores (2013). Valores de Referencia Praticados a Partir deJaneiro de 2013.
Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
104

Anais do XII Workshop de Computação em Clouds e Aplicações - WCGA 2014
105
Índice por Autor
A
Araujo, A.E.P. ...................................................................................................................3
Araujo, J.C.T. ...................................................................................................................3
B
Beserra, D.W.S.C. ......................................................................................................3, 28
Borba, A.W.T. ..................................................................................................................3
C
Camboim, K. .....................................................................................................................3
Coutinho, E.F. ...........................................................................................................43, 55
E
Endo, P.T. .......................................................................................................................28
G
Galdino, S. ......................................................................................................................28
Gomes, D.G. .............................................................................................................43, 55
K
Kamienski, C.A. .............................................................................................................67
M
Maziero, C.A. .................................................................................................................81
Muchalski, F.J. ................................................................................................................81
R
Rego, P.A.L. ...................................................................................................................55
Rocha, F.G. .....................................................................................................................16
S
Senger, H. .......................................................................................................................16
Silva, R.K.P. ...............................................................................................................3, 28
Simões, R. .......................................................................................................................67
Souza, J.N. ................................................................................................................43, 55
