sistemas de conhecimento - inf.ufrgs.br · 3 sumário sumÁrio .....3
TRANSCRIPT


2

3
Sumário SUMÁRIO ......................................................................................................................................................3
ÍNDICE DE FIGURAS .................................................................................................................................4
ÍNDICE DE TABELAS.................................................................................................................................5
1. INTRODUÇÃO....................................................................................................................................7 1.1. INTELIGÊNCIA ARTIFICIAL..........................................................................................................10 1.2. SISTEMAS DE CONHECIMENTO....................................................................................................12 1.3. APLICAÇÕES DOS SISTEMAS DE CONHECIMENTO .......................................................................14
2. ENGENHARIA DE CONHECIMENTO........................................................................................19 2.1. NÍVEIS DE CONHECIMENTO.........................................................................................................20 2.2. CATEGORIAS DE CONHECIMENTO...............................................................................................21 2.3. CONHECIMENTO TÁCITO E CONHECIMENTO EXPLÍCITO..............................................................21 2.4. A NOÇÃO DE NÍVEL DE CONHECIMENTO DE NEWELL................................................................24
2.4.1. Modelo do Domínio...............................................................................................................25 2.4.2. Modelo da Tarefa ..................................................................................................................26 2.4.3. Métodos de Solução de Problemas .......................................................................................27
2.5. A MODELAGEM DE CONHECIMENTO NO NÍVEL DO CONHECIMENTO.........................................28 3. METODOLOGIA COMMONKADS..............................................................................................31
3.1. O CONJUNTO DE MODELOS.........................................................................................................32 4. O MODELO DO CONHECIMENTO.............................................................................................43
4.1. CONCEITOS DE ABSTRAÇÃO.......................................................................................................43 4.1.1. Classificação/Instanciação ...................................................................................................45 4.1.2. Generalização/Especialização..............................................................................................45 4.1.3. Associação-conjunto/Associação-elemento..........................................................................46 4.1.4. Agregação de elemento/Agregação de componentes ...........................................................47 4.1.5 Raciocínio associado aos conceitos de abstração ...............................................................48
4.2. CONHECIMENTO DO DOMÍNIO ....................................................................................................49 4.3. CONHECIMENTO DE INFERÊNCIA ................................................................................................50
4.3.1. Conhecimento de Tarefa .......................................................................................................55 5. AQUISIÇÃO DE CONHECIMENTO ............................................................................................57
5.1. ENTREVISTAS ..............................................................................................................................57 5.2. ANÁLISE DE PROTOCOLOS ..........................................................................................................59 5.3. CLASSIFICAÇÃO DE TERMOS.......................................................................................................60 5.4. FOCALIZANDO CONTEXTOS OU CENÁRIOS .................................................................................61 5.5. OBSERVAÇÃO..............................................................................................................................62 5.6. RECUPERAÇÃO DE EVENTOS.......................................................................................................62 5.7. GRAFOS DE CONHECIMENTO ......................................................................................................62 5.8. ANÁLISE DE CASOS.....................................................................................................................64
6. CONSTRUÇÃO DO MODELO.......................................................................................................65 6.1. IDENTIFICAÇÃO DO CONHECIMENTO...........................................................................................65 6.2. ESPECIFICAÇÃO DO CONHECIMENTO ..........................................................................................65 6.3. VALIDAÇÃO DO CONHECIMENTO................................................................................................66
7. PROJETO DO SISTEMA.................................................................................................................67
ANEXO I......................................................................................................................................................71
REFERÊNCIAS...........................................................................................................................................95

4
Índice de Figuras Figura 1.1: O argumento da similaridade baseia-se no fato de que o computador, por seus
próprios meios, realiza funções inteligentes do homem. ..................................................... 10 Figura. 2.1: A Espiral do conhecimento...................................................................................... 23 Figura. 2.2: O nível do conhecimento e o nível simbólico são modelos do comportamento, ou
seja, da interação observada entre o agente e o ambiente. (Adaptado de [Velde, 1993]). ... 25 Figura. 3.1: O conjunto de modelos da metodologia Common KADS [Schreiber; Akkermans;
Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000]: ..................................................... 32 Figura 3.2: Visão geral do Modelo da Organização (modificado de [Schreiber; Akkermans;
Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000] ...................................................... 34 Figura 4.1: Categorias de conhecimento do modelo do conhecimento de Common KADS. ..... 43 Figura 4.2: Relacionamentos de classificação e instanciação para um exemplo de modelagem de
tipos de automóveis.............................................................................................................. 45 Figura 4.3: Relacionamentos de generalização e especialização para um exemplo de modelagem
de tipos de automó ............................................................................................................... 46 Figura 4.4: Representação gráfica dos relacionamentos de associação-conjunto e associação-
elemento............................................................................................................................... 47 Figura 4.5: Representação gráfica dos relacionamentos de agregação de elemento e agregação
de componentes.................................................................................................................... 47 Figura 7.2 – Arquitetura de referência de Common KADS........................................................ 68 Figura A.1: Estrutura de inferência para o método de classificação (extraído de [Schreiber,
2000])................................................................................................................................... 72 Figura A.2: Esquema de domínio para o método de classificação (extraído de [Schreiber,
2000])................................................................................................................................... 73 Figura A.3: Estrutura de inferência para o método de avaliação (extraído de [Schreiber, 2000]).
............................................................................................................................................. 74 Figura A.4: Esquema de domínio para o método de avaliação (extraído de [Schreiber, 2000]). 75 Figura A.5: Estrutura de inferência para o método de diagnóstico (extraído de [Schreiber,
2000])................................................................................................................................... 76 Figura A.6: Esquema de domínio para o método de diagnóstico (extraído de [Schreiber, 2000]).
............................................................................................................................................. 77 Figura A.7: Estrutura de inferência para o método de monitoração (extraído de [Schreiber,
2000])................................................................................................................................... 79 Figura A.9: Estrutura de inferência para o método de configuração (extraído de [Schreiber,
2000])................................................................................................................................... 83 Figura A.10: Esquema de domínio para o método de configuração (extraído de [Schreiber,
2000])................................................................................................................................... 84 Figura A.11: Estrutura de inferência para o método de atribuição (extraído de [Schreiber,
2000])................................................................................................................................... 86 Figura A.12: Estrutura de inferência para o método de planejamento (extraído de [Schreiber,
2000])................................................................................................................................... 88 Figura A.13: Estrutura de inferência para o método de escalonamento (extraído de [Schreiber,
2000])................................................................................................................................... 89 Figura A.14: Esquema de domínio para o método de escalonamento (extraído de [Schreiber,
2000])................................................................................................................................... 91

5
Índice de Tabelas
Tabela 1.1: Práticas tradicionais e de gestão de conhecimento........................................ 9
Tabela 1.2 - Diferenças entre a Inteligência Artificial e Computação Convencional .... 11
Tabela 1.3: Evolução da Engenharia de Conhecimento. ................................................ 13
Tabela 2.1: Dois tipos de conhecimento......................................................................... 22
Tabela 2.2: Comparação da análise de sistemas para construir software convencional e da análise de conhecimento para desenvolver sistemas especialistas...................... 29
Tabela 3.1: MO-1 ........................................................................................................... 34
Tabela 3.2: MO-2 ........................................................................................................... 35
Tabela 3.3: MO-3 ........................................................................................................... 35
Tabela 3.4: MO-4 ........................................................................................................... 36
Tabela 3.5: MO-4a.......................................................................................................... 36
Tabela 3.6: MO-5 ........................................................................................................... 37
6. Tabela 4.1: Primitivas de inferência de Common KADS. ...................................... 51
Tabela 4.2: Tarefas de análise. ....................................................................................... 54
Tabela 4.3: Tarefas de síntese. ....................................................................................... 55

6

7
1. Introdução Por décadas, as fórmulas para medir o patrimônio de uma determinada empresa consideravam aspectos como o patrimônio físico e humano desta empresa. Eram contabilizados prédios, instalações, equipamentos, estoques e, secundariamente, número de funcionários. Os anos recentes mostraram que determinados patrimônios, ditos voláteis, podem ter mais valor agregado do que todas as instalações físicas de uma determinada empresa. Quanto vale uma marca como a Coca-Cola ou Chanel? Essas marcas passaram a ser contabilizadas juntamente com os equipamentos e instalações das suas respectivas empresas, no momento do cálculo do valor de suas ações ou patrimônio.
A revolução tecnológica levou a um novo impasse na avaliação de patrimônio das empresas de tecnologia de ponta. A distribuidora de livros Amazon Books, que não possui sede, instalações, equipamentos e trabalha com um número reduzido de funcionários, representou o conjunto de ações mais valorizadas em 1999 na Bolsa de Nova York, embora seu patrimônio medido pelos métodos tradicionais seja insignificante. No que se constitui exatamente a riqueza de instituições como a Amazon Books, Microsoft, Sound Blaster e outras empresas que vivem graças ao desenvolvimento contínuo de novos produtos de tecnologia de ponta? É o que chamamos de capital intelectual, o conhecimento tratado como uma commodity [Spek e Spijkervet, 1997]. O conhecimento de uma empresa de tecnologia de ponta, disperso em seus funcionários, bancos de dados, relatórios, arquivos e projetos, se constitui em um patrimônio muito maior do que toda a instalação física que possa possuir.
Tom Stewart, da Revista Fortune, explicou a transformação dos insumos com a modificação da economia:
“A matéria prima essencial da Revolução Industrial era óleo e aço. Bem, mais de 50% do custo de extrair petróleo da terra atualmente é obter e processar informação. Assim como para o aço... grandes produtores precisavam de quatro horas-homem de trabalho para fazer uma tonelada de aço. Agora, como uso de sofisticados computadores, precisam apenas de 45 minutos de trabalho por tonelada. O componente intelectual cresceu e o físico encolheu. Se o aço foi o produto essencial da industrialização, o produto da Idade da Informação é o circuito integrado (CI). O valor de todos os CIs produzidos excede o valor do aço produzido. O que faz com que tenham esse valor? Certamente não são seus componentes físicos. Um CI é feito basicamente de silício, ou seja, de areia e em pouca quantidade. O valor está principalmente no projeto do circuito, e no projeto das complexas máquinas que o fazem. Esse ingrediente principal é conhecimento. A soma disto tudo nos leva a uma conclusão: mais e mais do que nós compramos e vendemos é conhecimento. Conhecimento é a principal matéria prima.”
O desafio nessa Idade do Conhecimento da Administração de Empresas é como tornar esse patrimônio volátil, não-registrável, em algo que possa ser capturado, tornado independente das pessoas que o retém e, em algum grau, medido [Lebowitz, 1987; Liebowitz e Wilcox, 1997]. A motivação crescente pelo domínio do conhecimento e a capacidade de gerenciá-lo é garantida por diversos fatores [Spek; Spijkervet, 1997], listados a seguir.

8
• O percentual de conhecimento envolvido nos produtos e serviços está crescendo
rapidamente e se reflete na estrutura dos custos de produção; • o conhecimento necessário para implementar processos de negócios muda
subitamente como resultado de desenvolvimentos científicos e tecnológicos, ou modificações nas relações econômicas;
• a pressão crescente do tempo cada vez menor no qual as decisões gerenciais devem ser feitas;
• a mobilidade dos profissionais vem aumentando devido às modificações nas relações de trabalho e possibilidades tecnológicas, o que pode levar a transferência do conhecimento direto para a concorrência.
A busca de instrumentos que permitam às organizações reter, organizar e otimizar a utilização do conhecimento é objeto de estudo da área chamada Gestão do Conhecimento [Liebowitz; Wilcox, 1997].A Gestão do Conhecimento busca organizar os processos nos quais [Spek; Spijkervet, 1997]:
• Novo conhecimento é produzido;
• o conhecimento é distribuído para aqueles que necessitam dele;
• o conhecimento é tornado acessível tanto para uso por toda a organização como para uso futuro;
• diferentes áreas do conhecimento são combinadas.
Um conceito de Gestão do Conhecimento é descrito em [Boff, 2001].
“Gestão do Conhecimento é um conjunto de estratégias para: − criar, adquirir, compartilhar e utilizar ativos de conhecimento; − estabelecer fluxos que garantam a informação necessária no tempo e formato
adequados, a fim de auxiliar na geração de idéias, solução de problemas e tomada de decisão. “
A Revolução Industrial revolucionou o trabalho braçal. No processo, surgiram novas disciplinas, como as Engenharias Mecânica, Elétrica, Química que incorporam a base científica dessa revolução. Da mesma forma, a Sociedade da Informação está agora revolucionando o trabalho intelectual. Cada vez maior número de pessoas estão se tornando trabalhadores de conhecimento [Boff, 2000] e, ao mesmo tempo, sua forma de trabalho sofre transformações profundas. Novas disciplinas estão surgindo para fornecer o suporte científico deste processo, sendo que uma delas é a engenharia de conhecimento. Exatamente como a engenharia mecânica fornece as teorias métodos e técnicas para construir máquinas, a engenharia de conhecimento fornece a metodologia científica para extrair, analisar e construir sistemas que apliquem conhecimento.
As próximas seções irão analisar quais são as técnicas adequadas para reconhecer e extrair conhecimento de suas fontes, representá-lo em um formato computacional e selecionar a ferramenta adequada para aplicar esse conhecimento na solução de problemas. As ferramentas computacionais para suporte a gestão de conhecimento vão desde a simples comunicação via intranet ou internet até sofisticadas ferramentas de suporte ao cliente, avaliação financeira ou análise de crédito. Este curso dará ênfase as
9
ferramentas que extraem e/ou utilizam conhecimento organizacional para a tomada de decisão.
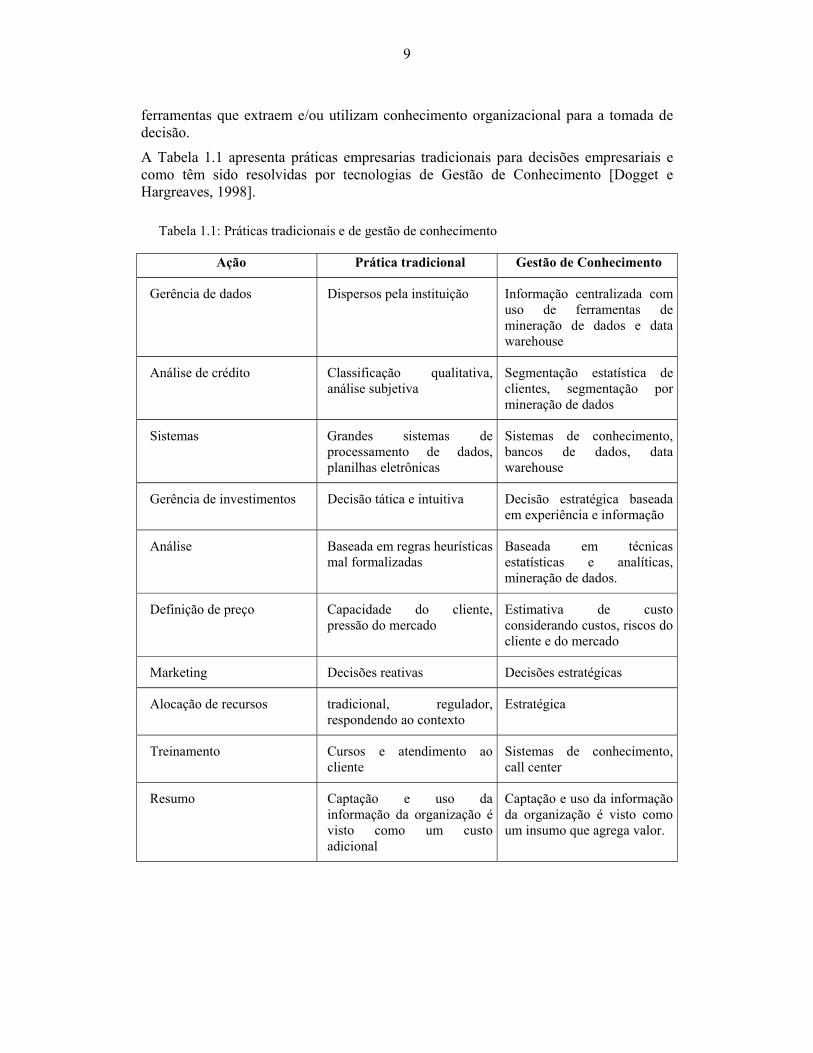
A Tabela 1.1 apresenta práticas empresarias tradicionais para decisões empresariais e como têm sido resolvidas por tecnologias de Gestão de Conhecimento [Dogget e Hargreaves, 1998].
Tabela 1.1: Práticas tradicionais e de gestão de conhecimento
Ação Prática tradicional Gestão de Conhecimento
Gerência de dados Dispersos pela instituição Informação centralizada com uso de ferramentas de mineração de dados e data warehouse
Análise de crédito Classificação qualitativa, análise subjetiva
Segmentação estatística de clientes, segmentação por mineração de dados
Sistemas Grandes sistemas de processamento de dados, planilhas eletrônicas
Sistemas de conhecimento, bancos de dados, data warehouse
Gerência de investimentos Decisão tática e intuitiva Decisão estratégica baseada em experiência e informação
Análise Baseada em regras heurísticas mal formalizadas
Baseada em técnicas estatísticas e analíticas, mineração de dados.
Definição de preço Capacidade do cliente, pressão do mercado
Estimativa de custo considerando custos, riscos do cliente e do mercado
Marketing Decisões reativas Decisões estratégicas
Alocação de recursos tradicional, regulador, respondendo ao contexto
Estratégica
Treinamento Cursos e atendimento ao cliente
Sistemas de conhecimento, call center
Resumo Captação e uso da informação da organização é visto como um custo adicional
Captação e uso da informação da organização é visto como um insumo que agrega valor.

10
1.1. Inteligência Artificial
Historicamente, o aquisição e processamento de conhecimento têm sido uma área de pesquisa da Inteligência Artificial (IA). O estudo dos aspectos cognitivos do trabalhador do conhecimento tem fornecido subsídio para a proposta de formas computacionais para reproduzir a inteligência por computador. Neste contexto, serão introduzidos os conceitos e áreas da Inteligência Artificial, incluindo a dos Sistemas de Conhecimento.
O termo Inteligência Artificial foi introduzido pelo Dr. John McCarty (STANFORD AI Lab.), em 1956, no Massachusetts Institute of Technology como título de uma conferência sobre as possibilidades de fornecer inteligência à máquina.
Segundo McCarty: “Inteligência Artificial é a capacidade de uma máquina de realizar funções que se fossem realizadas pelo ser humano seriam consideradas inteligentes.”
O conceito é definido a partir da noção de SIMILARIDADE, ou seja, utilizando seu conjunto de programas e sua arquitetura, a máquina realiza a mesma função que o Homem utilizando sua mente e seu organismo (Figura 1.1).
Figura 1.1: O argumento da similaridade baseia-se no fato de que o computador, por seus próprios meios, realiza funções inteligentes do homem.
A Inteligência Artificial no seu conceito mais moderno corresponde a um conjunto de técnicas interdisciplinares que busca implementar sistemas e processos em domínios
Mente
Organismo Arquitetura
Programas

11
que não possuem tratamento algorítmico. Sistemas que utilizam técnicas de IA são normalmente mais flexíveis, adaptáveis ao usuário e capazes de processar informações simbólicas (Tabela 1.2).
Tabela 1.2 - Diferenças entre a Inteligência Artificial e Computação Convencional
Computação Convencional Inteligência Artificial
É possível construir um algoritmo para definir os passos de solução do problema.
Tratamento de problemas que não possuem soluções algorítmicas
O processamento é principalmente numérico.
Solução de problemas que dependem de informação simbólica
Os métodos de solução são codificados no programa e dificilmente modificados posteriormente.
Processamento flexível, métodos de solução adaptáveis
O processo de solução do problema é determinístico.
Soluções por busca (geração e teste) informada
As abordagens para resolver o problema de reproduzir a inteligência humana na máquina são as mais diversas:
• Conexionista: busca reproduzir o mecanismo que gera a inteligência humana, ou seja, os neurônios e a forma estão conectados, através da construção das redes neurais. As redes são classificadores capazes de aprender o padrão de informação de um determinado conjunto de dados. Após esse aprendizado, as redes são capazes de classificar novas informações. São utilizadas para reconehcimento de caracteres e outros padrões de imagens, descoberta de conhecimento em bases de dados, entre outros usos.
• Lógica: busca implementar os aspectos racionais da inteligência simbólica, através da implementação de representações que são manipuladas através de raciocínios lógicos, como os sistemas baseados em modelos (regras, frames, redes bayesianas).
• Multiagentes: subdividem o problema e especializam agentes para resolver cada uma das partes do problema. A solução final será obtida pela interação entre esses agentes e integração de suas soluções. Por exemplo, um sistema de interpretação de imagens, onde cada agente reconhece alguma das feições da imagem: florestas, cidades, estradas, etc.
• Aprendizado de máquina: uma ampla classe de métodos numéricos para extrair padrões da informação, aprender algo com eles e reutilizar na solução de novos problemas. Entre esses se incluem os algoritmos indutivos, C 4.5, entre outros.

12
1.2. Sistemas de Conhecimento
A Inteligência Artificial permite construir sistemas para processamento simbólico, o que de muitas formas reproduz a forma como o ser humano resolve problemas. A partir dos anos 60 foram construídos sistemas para resolver problemas simbólicos complexos como solução de equações simbólicas diferenciais (Sistema Macsyma 1), ou proposição de fórmulas químicas estruturais (Sistema Dendral). A experiência dessa primeira fase ensinou que a qualidade de solução desses sistemas não era determinada pelos mecanismos de raciocínio neles embutidos, mas sim pelo conhecimento extraído de especialistas humanos e codificado no programa.
A partir dessa constatação, parte do esforço na construção de sistemas de inteligência artificial voltou-se, na segunda fase, para técnicas de extração do conhecimento de especialistas e codificação em diversos formalismos de representação. Assim nasceu a Engenharia de Conhecimento e os primeiros sistemas especialistas (numa alusão à origem do conhecimento que esses sistemas aplicavam), dos quais os representantes mais conhecidos desta época são os sistemas MYCIN [Buchanan e Shortliffe, 1984]que fazia diagnóstico de doenças infecciosas, e PROSPECTOR [Duda et al., 1978], que auxiliava na prospeção de minérios metálicos. Esses sistemas, onde o conhecimento de um indivíduo (o especialista) era representado em uma base de conhecimento para ser utilizado exclusivamente por uma mecanismo de inferência, respondendo consultas na forma de um “oráculo” sem integração com outros sistemas, estabeleceram as bases para a engenharia de sistemas especialistas que orientou a área até o final dos anos 80. Assim foram definidos os sistemas especialistas nesta fase:
• Um programa de computador inteligente que usa conhecimento e inferência para resolver problemas que são difíceis o suficiente para requerer perícia humana significativa para sua solução. [Feigenbaum, 1979]
• Sistema de computação que executa funções semelhantes àquelas normalmente executadas por um especialista humano. [Beyon-Davis, 1991]
• Sistema de computação que usa representação de conhecimento ou perícia humana num domínio particular de forma a executar funções semelhantes às de um especialista humano naquele domínio. [Beyon-Davis, 1991]
• Sistema de computação que opera aplicando um mecanismo de inferência a um “corpo” de conhecimento ou perícia de especialista representado em algum formalismo de representação de conhecimento. [Beyon-Davis, 1991]
• São uma classe de sistemas de Inteligência Artificial desenvolvidos para servirem como consultores na tomada de decisões que envolvam áreas restritas da Ciência, normalmente apenas dominadas por especialistas humanos. São sistemas que utilizam o conhecimento de um ou mais especialista codificado em um programa que o aplica na resolução de problemas. [Abel, 1988].
Uma nova revolução na Engenharia de Conhecimento aconteceu com o surgimento dos modelos administrativos de gestão de conhecimento e das plataformas distribuídas de sistemas (Tabela 1.3). O modelo tradicional de sistemas especialistas restringe-se hoje a aplicações de pequeno porte. Na moderna engenharia de conhecimento, os sistemas de 1 As descrições desse e de outros sistemas especialistas desenvolvidos nas décadas de 60 e 70 podem ser encontrada no livro Building Expert Systems, de Hayes-Roth e colegas [Hayes-Roth, Waterman e Lenat, 1983].

13
conhecimento têm como função implementar um processo de solução de problemas que foi racionalizado e padronizado por uma organização, e não apenas reproduzir o conhecimento de um especialista.
Sistemas de conhecimento referem-se a qualquer sistema de informação que gerencie, armazene e/ou aplique conhecimento organizacional explicitamente representado. O conhecimento pode ser de fonte humana, de outros sistemas, de livros, etc. O termo inclui sistemas especialistas, sistemas baseados em conhecimento, bancos de dados inteligentes ou sistemas de informação intensivos em conhecimento, que possuem em comum o fato de modelarem conhecimento de forma explícita (não embutido ou disperso no algoritmo do sistema) e aplicá-lo no suporte à solução de problemas. Os sistemas de conhecimento permitem extrair o conhecimento de suas diferentes fontes, tornando-o independente das pessoas, organizá-lo, distribuí-lo e multiplicá-lo.
Tabela 1.3: Evolução da Engenharia de Conhecimento.
Fase Nome Característica Exemplos
1ª.
Sistemas Simbólicos
Conhecimento extraído de um ou mais indivíduos de modo empírico.
Sistemas de processamento simbólico.
Regras embutidas no código do programa.
Sistema Macsima
Sistema Dendral
Sistema Puff
2ª.
Sistemas Especialistas
Conhecimento extraído de um indivíduo com técnicas de aquisição de conhecimento.
Base de conhecimento separada do mecanismo de inferência.
Sistema Mycin
Sistema Propector
3ª.
Engenharia de Conhecimento
Conhecimento organizacional, racionalizado a partir da experiência de muitos e padronizado de acordo com os objetivos da organização.
Método de inferência também modelado na base de conhecimento.
Base de conhecimento pode estar distribuída e o sistema é integrado aos demais da organização.
Metodologia CommonKADS
Metodologia Protege
Metodologia Vital

14
Formalmente, pode-se distinguir as seguintes definições:
• Sistemas de IA Sistemas simbólicos, não algorítmicos que utilizam técnicas de IA para solução de
problemas • Sistemas baseados em conhecimento Sistemas de IA que otimizam a busca da solução pela aplicação de conhecimento
explicitamente representado • Sistemas Especialistas Sistemas baseados em conhecimento que resolvem problemas que necessitam de
altos níveis de perícia para sua solução. O conhecimento é extraído de um especialista humano
• Sistemas de conhecimento Termo mais atual. Refere-se a qualquer sistema de informação que gerencie,
armazene e/ou aplique conhecimento explicitamente representado. O conhecimento pode ser de fonte humana, da organização, disperso, etc.
Os benefícios do ponto de vista da organização acontecem em diferentes áreas [Schreiber et al., 2000]:
1. Produtividade: tomada de decisão mais rápida, aumento da produtividade, melhora no processo de solução de problemas, solução de problemas complexos, confiabilidade das decisões, automatização na operação de equipamentos.
2. Preservação do conhecimento organizacional: captura da perícia, organização do conhecimento disperso, reuso do conhecimento.
3. Disseminação do conhecimento organizacional: possibilidade de utilização do conhecimento longe de suas fontes, padronização das soluções aplicadas em qualquer ponto da organização.
4. Qualidade da decisão: aumento de qualidade das decisões, possibilidade de tratar com incertezas.
5. Treinamentos: melhora da qualidade dos treinamentos de funcionários e clientes pelo uso do conhecimento preservado (casos, acesso a informação, entre outros).
1.3. Aplicações dos Sistemas de Conhecimento
Sistemas de conhecimento são aplicados na solução de problemas em diferentes classes de tarefas intensivas em conhecimento [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000], listadas na Tabela 1.4.
Tarefas intensivas em conhecimento podem ser caracterizadas por:
1. Para a organização, o conhecimento técnico estratégico dominado por um ou poucos profissionais impõe um risco muito grande. Limita a capacidade de difusão da informação, aumenta os risco de perda do conhecimento e gera discussões intermináveis a respeito de propriedade industrial (de quem é o conhecimento? Do profissional que o detém ou da empresa que investiu em sua formação e treinamento?). Nesse caso, os sistemas são utilizados para tornar o conhecimento independente das pessoas (e portanto, propriedade da empresa) e permitir que seja distribuído.

15
2. O custo de formação e a escassez dos profissionais capazes de realizar a tarefa com bom desempenho justificam a aplicação da técnica. Domínios altamente especializados utilizam um número muito pequeno de profissionais cuja performance na solução do problema é muito superior à média alcançada pelos demais técnicos da área. Esse comportamento é típico nos domínios ligados às ciências naturais, como a química, a medicina, a geologia. Os profissionais que se destacam possuem mais de dez ou vinte anos de experiência e são reconhecidos por toda comunidade científica. 3. Domínios onde os dados a serem avaliados são predominantemente simbólicos e não numéricos. A computação convencional não é apropriada para processar grandezas do tipo pequeno, escuro, inadequado, suficiente, quase, em cima, ao lado, utilizados em muitas áreas técnicas para descrever informações estratégicas. 4. A solução depende da avaliação de um número muito grande de variáveis que podem assumir ampla gama de valores. É o caso de sistemas de projeto, configuração e diagnóstico de falhas em equipamentos. Embora o conhecimento não seja necessariamente personalizado, o bom desempenho da tarefa é resultado de uma análise demorada e criteriosa de muitos fatores. Tabela 1.4: Classes de problemas intensivos em conhecimento.
Tarefas Analíticas Tarefas de Síntese
Classificação Projeto e/ou configuração
Aconselhamento Modelagem
Diagnóstico Planejamento
Monitoração Escalonamento
Previsão Atribuição
Sistemas de conhecimento vêm sendo amplamente utilizados em empresas de médio e grande porte. Alguns exemplos são aqui resumidamente descritos, mencionando a ferramenta utilizada para seu desenvolvimento.
• AT&T (EUA) utiliza um sistema especialista para planejamento e escalonamento da linha de produção, considerando disponibilidade de material, capacidade de armazenamento e alocação de equipamentos e mão de obra. (eGain)
• American Express Card (EUA) aplica um sistema especialista para autorização de crédito no CC. (eGain).
• Swiss Bank Corporation (Suíça) utiliza sistema especialista para reduzir o tempo da análise de risco e custo de capital no empréstimo para empresas. (eGain)
• Ford (EUA) desenvolveu um sistema especialista para avaliar as solicitações de reembolso sob garantia para seus produtos. (eGain).

16
• American Airlines (EUA) desenvolveu um sistema especialista para determinação dos roteiros aéreos com ociosidade de assentos, passíveis de serem incluídos em promoções da empresa. (eGain)
• United Kingdom Employment Department Group (Inglaterra) utiliza um sistema especialista para aconselhamento de planos de aposentadoria para trabalhadores civis. (eGain)
• Nippon Steel utiliza um sistema baseado em casos para reduzir o tempo de projeto e configuração de peças e equipamentos de acordo com as necessidades dos clientes. (eGain)
• Peugeot (França) utiliza uma suíte de produtos de IA para o projeto e cálculo de novos automóveis, considerando requisitos do novo projeto, informações vinda de diferentes fornecedores e reuso de projetos de sucesso anteriormente desenvolvidos. (Cognition e Acknosoft).
• CFM International (França e USA) utiliza raciocínio baseado em casos para diagnóstico de falhas nos motores de Boeings 737 (Acknosoft).
• Rue Du Commerce (França) possui um sistema de raciocínio baseado em casos para orientar a venda de produtos por comércio eletrônico (Acknosoft).
• Sextant Avionique (França) utiliza raciocínio baseado em casos para verificação de controle por horas voadas em aeronaves Airbus (Acknosoft).
• Analog Devices (USA) utiliza raciocínio baseado em casos para suporte de vendas para circuitos integrados (Acknosoft).
• Legrand (França) utiliza raciocínio baseado em casos para estimativa de custo de produção de peças em plástico (Acknosoft).
• Ericsson (França) utiliza raciocínio baseado em casos para análise de cartas de telecomunicação e sistemas eletrônicos de testes de dados (Acknosoft).
• Sepro Robotique (França) utiliza raciocínio baseado em casos para suporte após venda de robôs (Acknosoft).
• Alstom (França) utiliza raciocínio baseado em casos para otimização no escalonamento de trens (Acknosoft).
• Ansaldo Transporti (Itália) utiliza raciocínio baseado em casos para manutenção preventiva no metrô de Napoles (Acknosoft).
• Barclays Bank e Abbey Bank (Inglaterra) utilizam sistemas especialistas para avaliação de risco e segmentação de clientes
(*) eGain Co. (www.egain.com)dispõem de sistemas de conhecimento para suporte ao cliente: eGain Knowledge Central, eGain Knowledge Agent, eGain Knowledge Self-Service, eGain Knowledge Gateway que permite armazenar, indexar e distribuir documentos semi-estruturados (documentos, arquivos html, etc.) e faz suporte a clientes utilizando raciocínio baseado em casos. A empresa eGain incorporou a Inference Co. e junto com ela a tecnologia de ferramentas tradicionais, como o ART e ART-IM, que são sistemas híbridos de objetos e regras, com raciocínio progressivo e regressivo e a ferramenta CBR Express, para raciocínio baseado em casos.

17
(**) Cognition Europe (www.cognition.fr) dispõe das ferramentas Mechanical Advantage e Cost Advantage, para projeto de equipamentos considerando os requisitos de projeto e estimativa de custo integrado, e a ferramenta Knowledge Center para integração do conhecimento originados de diferentes fontes internas ou externas à organização.
(***) Acknosoft () dispõe das ferramentas KAIDARA Commerce para personalização da WEB e suporte ao comércio eletrônico e KAIDARA Adviser para suporte ao cliente (help desk) ambas de raciocínio baseado em casos. A Akcnosoft é também a proprietária da ferramenta KATE para raciocínio baseado em casos.
Outras empresas com soluções de sistemas de conhecimento podem ser encontradas em http://www.ai-cbr.org .

18
Exercício
1. Quais os argumentos utilizados pelos estudiosos de Inteligência Artificial para afirmar que o computador é inteligente, embora seja reconhecido que a máquina é determinística e tem suas decisões definidas através de um programa?
2. A tabela abaixo compara as principais características dos sistemas de conhecimento em cada uma das três fases da Engenharia de Conhecimento. Que diferenças essas características provocaram em termos de arquitetura de sistema (ou seja, em termos de componentes do sistema) nos sistemas de conhecimento?
Fase Nome Característica Exemplos
1ª.
Sistemas Simbólicos
Conhecimento extraído de um ou mais indivíduos de modo empírico.
Sistemas de processamento simbólico.
Regras embutidas no código do programa.
Sistema Macsima
Sistema Dendral
Sistema Puff
2ª.
Sistemas Especialistas
Conhecimento extraído de um indivíduo com técnicas de aquisição de conhecimento.
Base de conhecimento separada do mecanismo de inferência.
Sistema Mycin
Sistema Propector
3ª.
Engenharia de Conhecimento
Conhecimento organizacional, racionalizado a partir da experiência de muitos e padronizado de acordo com os objetivos da organização.
Método de inferência também modelado na base de conhecimento.
Base de conhecimento pode estar distribuída e o sistema é integrado aos demais da organização.
Metodologia CommonKADS
Metodologia Protege
Metodologia Vital
3. Sistemas de conhecimento possuem um custo e prazo de desenvolvimento bem
maiores do que os sistemas convencionais, bem como utilizam técnicas de desenvolvimento ainda não bem dominadas. Quais as vantagens competitivas obtidas pelas organizações com a utilização de sistemas de conhecimento?
4. Exemplifique e descreva uma aplicação (ou problema), distinta dos apresentados em aula, cuja solução implementada exigiria a utilização de técnicas de inteligência artificial. Justifique sua escolha de acordo com os critérios apresentados.
5. Todo sistema de computação incorpora conhecimento de solução de problemas de uma forma ou de outra. Sistemas de conhecimento, no entanto, utilizam conhecimento explicitamente representado, ou seja, conhecimento que pode ser verificado sem abrir o código do programa. Por que esse diferencial é importante?

19
2. Engenharia de Conhecimento
Engenharia de Conhecimento agrega um conjunto de metodologias, técnicas e formalismos que suportam a construção de sistemas de conhecimento. Peter Drucker nos permite compreender melhor o seu papel [Drucker, 1993] na citação abaixo.
“O conhecimento que é agora considerado conhecimento prova-se a si mesmo somente em ação. O significado intrínsico de conhecimento é a informação efetiva em ação, a informação focada nos resultados. Os resultados estão fora das pessoas, na sociedade e na economia, ou nos próprios avanços do conhecimento. Para realizar qualquer coisa este conhecimento deve ser altamente especializado... Ele não poderia ser aprendido ou ensinado. Nem implica em qualquer princípio genérico. Ele é experiência antes que aprendizado, treinamento antes que estudo. Mas hoje nós não falamos desse conhecimento especializado como habilidades. Nós falamos dele como uma disciplina. Essa é a grande mudança intelectual jamais registrada. Uma disciplina transforma uma habilidade em uma metodologia - como a engenharia, o método científico, o método quantitativo ou o diagnóstico diferenciado dos médicos. Cada uma dessas metodologias converte uma experiência ad hoc em um sistema. Converte anotações em informação. Converte habilidades em algo que pode ser ensinado e aprendido.”
Peter Drucker menciona as idéias básicas que norteiam a engenharia de conhecimento hoje:
- o conhecimento não é um bem estático a ser minerado, só existe quando se produz algo com ele ou a partir dele;
- o conhecimento não é individual, mas organizacional ou institucional;
- o conhecimento não é genérico, mas associado ou produzido pela solução de uma classe particular de problema ao qual está associado;
- conhecimento não é um conjunto de regras de solução, mas uma experiência que foi sistematizada e pode ser transmitida.
A engenharia de conhecimento lida com aquisição e representação de conhecimento e validação, inferência, explicação e manutenção de bases de conhecimento [Turban, 1992]. Aquisição de conhecimento refere-se a obtenção de conhecimento de suas diversas fontes: livros, documentos, computadores com principal ênfase, por sua dificuldade, a especialistas humanos. O conhecimento refere-se a solução de problemas em um domínio de aplicação e envolve os objetos do domínio, os procedimentos e a forma geral de como o conhecimento é aplicado. Representação de conhecimento refere-se a escolha de uma forma de representação que possa compor um modelo do domínio e a codificação da informação adquirida nessa forma. Refere-se habitualmente ao conhecimento declarativo. Validação do Conhecimento: Verificação da consistência da base de conhecimento.

20
Inferência: Definição dos procedimentos de manipulação e aplicação do conhecimento, com fins de implementação. Explicação e Justificativa: Envolve a recuperação do raciocínio do sistema ao atingir determinada conclusão e a definição da forma de apresentar esses caminhos de inferência para o usuário. Outras definições importantes para a Engenharia de Conhecimento: Conhecimento [Hayes-Roth; Waterman; Lenat, 1983] “consiste em (1) descrições simbólicas que caracterizam os relacionamentos empíricos e definicionais em um domínio e (2) os procedimentos para manipulação dessas descrições.” Conhecimento inclui a informação sobre o domínio e a forma como essa informação é utilizada para resolver problemas. Ex.: Maria tem mais de 18 anos. Maiores de 18 anos são responsáveis legais por seus atos. Maria será cobrada pelos danos. Informação: Reconhecimento dos objetos do domínio, suas características, suas restrições e seus relacionamentos com os outros objetos, sem ater-se a utilidade dessa informação. É o dado com o seu significado associado. Ex.: Idade de Maria = 20 anos Dado: Representação simbólica de um objeto ou informação do domínio sem considerações de contexto, significado ou aplicação. Ex.: 20 anos Domínio: Qualquer conjunto relativamente circunscrito de atividades. O objetivo geral da Engenharia de Conhecimento assemelha-se ao da Engenharia de Software: transformar o processo ad hoc de construir sistemas baseados em conhecimento em uma disciplina da Engenharia baseada em métodos, linguagens e ferramentas especializadas [Studer, Benjamins e Fensel, 1998] Em suas origens, o termo leva a supor em um processo passivo de extração de conhecimento, como se esse fosse um objeto inerte. A Engenharia de Conhecimento evoluiu, desde que surgiu nos anos 70, de um paradigma de transferência de conhecimento, ou enfoque humanístico. Nesta visão, a pesquisa buscava aperfeiçoar os métodos de transferir conhecimento de suas fontes para um programa, para um paradigma de modelagem que dirige a pesquisa atualmente.
2.1. Níveis de Conhecimento
[Harmon e Sawyer, 1990] Conhecimento superficial: Descrição de objetos do domínio; informações que se referem a problemas imediatos e a solução associada. Conhecimento do Domínio: Descreve a forma de resolver problemas no domínio na forma de descrições, heurísticas ou procedimentos, mesmo que muitos deles não sejam compreendidos teoricamente.

21
Conhecimento profundo: Estrutura interna e causal (relações de causa e efeito) dos objetos do domínio e suas interações. É o conhecimento teórico do domínio que pode ser aplicado a diferentes tarefas e em mais de uma situação utilizando mecanismos de transferência e analogia. Este tipo de conhecimento é de difícil aquisição e trato computacional.
2.2. Categorias de Conhecimento
Conhecimento declarativo: representação descritiva do domínio, declara os fatos do mundo, o quê as coisas são e como elas se associam. Descreve como os objetos são e como se relacionam no mundo, é um conhecimento superficial. Conhecimento procedural: descreve a forma como as coisas trabalham sob diferentes tipos de circunstâncias, descrita na forma de instruções passo a passo. Pode fornecer uma aplicação imediata para o conhecimento declarativo. Conhecimento semântico: refere-se às estruturas cognitivas dos objetos e a forma como eles são armazenados em memória. Inclui informação sobre: palavras e outros símbolos; significado dos símbolos e regras associadas; relacionamentos entre os símbolos e formas de manipulação dos símbolos e conceitos. Conhecimento episódico: descreve a ocorrência passada de problemas e suas soluções associadas, sendo armazenado de forma classificada e indexada, na memória de longa duração. Metaconhecimento: conhecimento sobre o conhecimento, ou seja, as leis básicas que regem o mundo e a forma como os demais tipos de conhecimento podem ser aplicados.
2.3. Conhecimento tácito e conhecimento explícito*
A criação do conhecimento organizacional deve ser entendida como um processo que amplia organizacionalmente o conhecimento criado pelos indivíduos, através de uma “comunidade de interação”, cristalizando-o como parte de uma rede de conhecimentos da organização. Essa “comunidade” pressupõe interação, tanto de indivíduos quanto das dimensões tácita e explícita do conhecimento.
Para Michael Polanyi, em seu livro “The Tacit Dimension”, o conhecimento tácito é pessoal, específico ao contexto e difícil de ser formulado e comunicado. Já o conhecimento explícito ou “codificado” refere-se ao conhecimento transmissível em linguagem formal e sistemática (ver Tabela 2.1). Polanyi observa que os seres humanos adquirem conhecimento criando e organizando ativamente suas próprias experiências.
* Adaptado de Nonaka, I. & Takeuchi, H. Criação de conhecimento na empresa: como
as empresas japonesas geram a dinâmica da inovação. São Paulo: Campus, 1997, por Boff, L.H.

22
Assim, o conhecimento que pode ser expresso em palavras e números representa apenas a ponta do iceberg, do conjunto do conhecimento como um todo. Em suas palavras “podemos saber mais do que podemos dizer”.
Tabela 2.1: Dois tipos de conhecimento
Conhecimento Tácito Conhecimento Explícito Subjetivo Objetivo Experiência (corpo) Racionalidade (mente) Simultâneo (aqui e agora) Seqüencial (lá e então) Analógico (prática) Digital (teoria)
Para Nonaka e Takeuchi, os conhecimentos tácito e explícito não são entidades totalmente separadas, e sim, mutuamente complementares. O pressuposto desses autores é de que o conhecimento humano é criado e expandido através da interação social entre o conhecimento tácito e o conhecimento explícito. Chamam essa interação de “conversão do conhecimento” e observam que essa conversão é um processo social entre indivíduos, e não confinada dentro de um indivíduo.
Esses autores estabelecem quatro tipos de conversão do conhecimento que eles denominam de socialização, externalização, combinação e internalização (Figura 2.1). Socialização - é um processo de compartilhamento de experiências e, a partir daí, da criação do conhecimento tácito, como modelos mentais ou habilidades técnicas compartilhadas. Sem alguma forma de experiência compartilhada é extremamente difícil para uma pessoa projetar-se no processo de raciocínio de outro indivíduo. Externalização - é um processo de articulação de conhecimentos tácitos em conceitos explícitos e é provocado pelo diálogo ou pela reflexão coletiva. Pode utilizar-se de métodos não analíticos, tais como analogias e metáforas, quando as expressões verbais não forem suficientes para expressar os insights, vivências ou percepções dos indivíduos. Combinação - é um processo de sistematização de conceitos em um sistema de conhecimento. Envolve a combinação de conjuntos diferentes de conhecimento explícito. Ocorre troca e combinação de conhecimentos através de meios como documentos, reuniões, ou redes de comunicação computadorizadas. Internalização - é o processo de incorporação do conhecimento explícito no conhecimento tácito. É intimamente relacionada ao “aprender fazendo”. Quando são internalizadas nas bases do conhecimento tácito dos indivíduos sob a forma de modelos mentais ou know-how técnico compartilhado, as experiências através da socialização, externalização e combinação tornam-se ativos valiosos. Esse conhecimento tácito acumulado precisa ser compartilhado com outros membros da organização, iniciando assim uma nova espiral de criação de conhecimento. Exemplos da transformação de conhecimento: Compartilhado: adquirir habilidades técnicas, observando o que os outros estão fazendo. Conceitual: descrever uma imagem ou fato através da linguagem escrita (fazer uso da metáfora, analogia) Operacional: aprender fazendo, seguindo os passos de um manual. Sistêmico: integração de informações de várias bases de dados.

23
Figura. 2.1: A Espiral do conhecimento
A interação e os níveis de criação do conhecimento produzem um processo em espiral, interativo, que leva à criação do conhecimento organizacional. A função da organização no processo de criação do conhecimento organizacional é fornecer o contexto apropriado para facilitação das atividades em grupo e para criação e acúmulo de conhecimento em nível individual. Para isso a organização necessita das seguintes condições: Intenção: a espiral do conhecimento é direcionada pela intenção organizacional, definida como a aspiração de uma organização às suas metas. Autonomia: amplia as chances de introduzir oportunidades inesperadas e a possibilidade de os indivíduos se automotivarem para criar novos conhecimentos. Possibilita aos indivíduos e equipes maior flexibilidade ao adquirir, interpretar e relacionar informações. Flutuação e caos criativo: estimulam a interação entre a organização e o ambiente externo. A organização que adota uma atitude aberta em relação aos sinais ambientais,

24
pode explorar a ambigüidade, a redundância ou os ruídos desses sinais para aprimorar seu próprio sistema de conhecimento. Redundância: a existência de informações que transcendem as exigências operacionais imediatas dos membros da organização. Diversos membros da organização possuindo as mesmas informações. Variedade de requisitos: diversidade interna de uma organização que lhe permita enfrentar os desafios impostos pelo ambiente. Pressupõe interligação orgânica entre as diversas unidades da organização que garanta o acesso rápido e flexível às informações em todos os níveis. A analogia é com um organismo vivo (organização tipo bio-funcional).
2.4. A Noção de Nível de Conhecimento de Newell
A noção de nível do conhecimento foi introduzida por Allen Newell nos anos 80 [Newell, 1982]. Desde então, tem proporcionado uma perspectiva comum para pesquisadores de Inteligência Artificial, especialmente estudiosos de sistemas baseados em conhecimento, quando permitiu tratar o nível do conhecimento como um nível em sistemas de computação, da mesma forma que o nível de arquitetura ou o nível simbólico. Nesta abordagem, desenvolver um sistema baseado em conhecimento é visto como a construção de um conjunto de modelos relacionados a algum comportamento de solução de problemas[Velde, 1993]. Em particular, um modelo no nível do conhecimento representa o conhecimento que racionaliza aquele comportamento. Um sistema baseado em conhecimento é visto como um agente que atua como se possuísse conhecimento sobre o mundo e utilizasse esse conhecimento de modo completamente racional para atingir seus objetivos. O nível do conhecimento permite a descrição do comportamento deste agente acima do nível simbólico, sem considerações sobre o quê exatamente é esse agente. Já o nível simbólico fornece a descrição do mecanismo que permite reproduzir esse comportamento e que atua sobre símbolos e estruturas de símbolos. O nível simbólico é orientado a sistema, enquanto o nível do conhecimento é orientado para o domínio. É importante notar que o objeto da modelagem no nível do conhecimento não é conhecimento, mas sim comportamento, ou seja a interação observada entre um agente e seu ambiente [Clancey, 1989] Essa noção, de fato, é que provocou a mudança de paradigma na Engenharia de Conhecimento. Um modelo no nível de conhecimento é um modelo de comportamento nos termos do conhecimento, exatamente como um modelo no nível simbólico é um modelo de interação em termos de símbolos e representações (Figura. 2.2). O que mantém esses modelos juntos é o fato de que eles modelam a mesma coisa, ou seja, a interação observada. Um modelo no nível do conhecimento e no nível simbólico são coerentes e consistentes na extensão do que se propõem a modelar e, em certo grau, devem levar à mesma classe de comportamentos. Essas idéias gerais norteiam as propostas feitas ao longo deste trabalho e serão retomadas no Capítulo 8, que descreve o modelo do domínio.

25
Figura. 2.2: O nível do conhecimento e o nível simbólico são modelos do comportamento, ou seja, da interação observada entre o agente e o ambiente. (Adaptado de [Velde, 1993]).
A evolução das noções apresentadas por Newell levaram ao surgimento de uma série de metodologias de aquisição e representação de conhecimento que tornaram-se tecnologias de sucesso. Entre as mais representativas cabe mencionar: Tarefas genéricas [Chandrasekaram, 1986]; Métodos de limitação de papéis [McDermott, 1988]; Componentes da perícia [Steels, 1990]; Ontologias [Wielinga e Schreiber, 1994] e OntoLíngua [Gruber, 1992]; VITAL [Stutt e Motta, 1994]; KADS [Schreiber, 1992] e Common KADS [Schreiber et al., 1994]. Todas essas metodologias têm em comum as noções básicas de Newell de que um modelo do conhecimento deveria ser definido em termos de conhecimento, objetivo e ações. Nos modelos baseados no Nível do Conhecimento há um consenso de que esses termos podem ser traduzidos em três conceitos relacionados: o de modelo do domínio, modelo da tarefa e métodos de solução de problemas.
2.4.1. Modelo do Domínio
Conjunto de declarações sobre o domínio que permite descrevê-lo de forma precisa e sistemática. Um modelo do domínio pode descrever, por exemplo, todas as particularidades da anatomia do coração humano, ou descrever o mapeamento entre problemas em um carro e suas causas. Um modelo, no entanto, é mais do que uma série de pedaços de conhecimento de um certo domínio, já que a descrição deve ser feita de modo coerente, segundo uma estrutura e terminologia previamente definida, a qual se atribui uma semântica não ambígua. Por exemplo, a associação entre causas e defeitos é vista como uma relação causal, com significado próprio e possibilidades de extrair novas informações por dedução e transitividade. Também a forma de descrever os objetos e entidades do domínio e restrições sobre suas propriedades permitem antever
Ambiente
Agente
Comportamento Observador
Nível do Conhecimento
Nível Simbólico
Racionalizar
Implementar

26
propriedades desse domínio. O modelo do domínio descreve o conhecimento estático e genérico (no sentido de que pode ser utilizado por mais de um agente) da aplicação.
No nível mais básico, o conhecimento do domínio é declarado por meio da ontologia do domínio, que descreve o conhecimento declarativo e estático daquele domínio, a ser acessado por todos os agentes que atuam sobre ele. O termo ontologia pode ser definido como “uma especificação formal e explícita de um conjunto de conceitos compartilhados” [Studer; Benjamins; Fensel, 1998]. Os conceitos, neste caso, referem-se àqueles selecionados como relevantes em um determinado domínio. Explícito significa que o conjunto de conceitos utilizados e as restrições aplicadas são previamente e explicitamente definidas. Formal refere-se ao fato de que espera-se que uma ontologia seja processável por computador, o que exclui definições em linguagem natural, por exemplo. Finalmente, uma ontologia é compartilhada porque descreve um conhecimento consensual, que é utilizado por mais de um indivíduo e aceito por um grupo. Uma ontologia de domínio é definida através de [Damski et al., 1993]: (i) um vocabulário de conceitos, ou termos do domínio; (ii) os tipos que esses conceitos podem ter, ou seja, a tipologia do domínio, que definem não só os tipos de dados, mas as restrições de valores que os termos devem respeitar; (iii) as relações de classe e subclasse ou de particionamento dos conceitos, que irão formar as taxonomias e partonomias daquele domínio. A definição de modelos de domínio tem sido objeto de intensa pesquisa em Ciência da Computação e novas propostas e definições surgem continuamente. Em especial, os trabalhos da metodologia CommonKADS [Schreiber, 1992; Schreiber; Wielinga; Hoog; Akkermans; Velde, 1994; Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 1999] têm servido como referência para diversos outros autores. Ontologias têm sido estudadas e propostas nos trabalhos de [Gruber, 1992; Wielinga et al., 1992; Erikssom et al., 1995; Guarino, 1995; Benjamins, 2000], entre outros autores. A importância desse tópico deve-se ao fato de que a formalização do conhecimento declarativo compartilhado de um domínio tem papel fundamental na definição de qual recursos são mais adequados para uma determinada aplicação, permitindo especificá-los nas fases iniciais de projeto. Ainda, modelos de domínio permitem o desenvolvimento de aplicações que representam conhecimento compartilhado e potencialmente reusável. Esse conhecimento potencialmente pode ser acessado e utilizado por diferentes aplicações desenvolvidas concomitantemente ao modelo do domínio, ou posteriormente ao longo de sua vida útil.
2.4.2. Modelo da Tarefa
O modelo da tarefa expressa os objetivos da aplicação de uma forma precisa e sistemática e as atividades necessárias para atingi-lo. Expressa como um objetivo pode ser atingido e como diversos objetivos são interrelacionados (relações de dependência ou prioridades, por exemplo). Um exemplo de tarefa pode ser a de achar o motivo da falha em um automóvel. O fato do problema ser de diagnóstico não define a forma de solução ou como a tarefa pode ser definida. Essa tarefa pode ser abordada como a tentativa de encontrar o componente responsável pela função que não está operando de acordo ou, alternativamente, por procurar a descrição dos defeitos e componentes responsáveis por eles até encontrar o

27
defeito que se assemelhe. Ambas abordagens são adequadas para diagnóstico, porém definem tarefas distintas. Uma tarefa é normalmente descrita através de dois componentes: a definição da tarefa, que expressa qual o objetivo a ser atingido (ou seja, tem um caráter declarativo), e o corpo da tarefa que especifica como atingir aquele objetivo (e tem um caráter procedimental) [Schreiber, 1992]. O modelo da tarefa descreve ainda como um objetivo pode contribuir para alcançar outro objetivo, permitindo a decomposição de uma tarefa em outras mais simples, construindo a estrutura de uma tarefa. O modelo da tarefa, ao contrário do modelo do domínio, é específico para uma aplicação e tipo de problema. Nele, são especificados os dados de entrada, as ações de inferência possíveis e as condições para que o objetivo seja atingido. A metodologia KADS é um recurso tipicamente orientado a tarefa e serve como exemplo de quais componentes são necessários para definir uma tarefa:
• objetivo: descrição de qual é o objetivo e como é atingido; • papéis de entrada e de saída dinâmicos, ou seja, são instanciados a cada
execução; • especificação da tarefa, que detalha as dependências entre os papéis envolvidos
(o que deve ser verdadeiro no final da execução, o que não muda, etc.); • O corpo da tarefa é descritos por suas sub-partes: • os sub-objetivos que a tarefa gera para ser realizada; • as sub-tarefas responsáveis por atingir cada um dos sub-objetivos; • a estrutura de controle da tarefa; que define como as sub-tarefas devem ser
realizadas para atingir o objetivo final. • Tarefas definem uma janela sobre o conhecimento do domínio voltada apenas
para as porções do domínio de uma aplicação em particular. É o formalismo de descrição menos genérico, que torna explícito os objetivos a serem alcançados por um sistema.
2.4.3. Métodos de Solução de Problemas
Os métodos de solução de problemas [Clancey, 1989; Benjamins e Fensel, 1998; Studer; Benjamins; Fensel, 1998] permitem modelar o componente dinâmico do conhecimento do domínio. É uma forma de relacionar uma tarefa e o modelo do domínio a fim de atingir determinado objetivo.
Métodos de solução de problemas foram inspirados no processo de solução de problema de especialistas humanos. Eles não refletem, por exemplo, o método dedutivo que permite executar uma regra, mas sim o conhecimento de controle que diz como selecionar a regra adequada a cada momento e como combinar as deduções de um conjunto de regras. Um método de solução de problemas é um modelo abstrato de inferência que pode ser reconhecido ou reaplicado em tarefas similares em diferentes domínios. Não é, porém, tão genérico ou equivalente aos métodos de inferência implementado nos sistemas especialistas de primeira geração, como encadeamento progressivo e regressivo ou resolução. Corresponde a uma generalização de um padrão de raciocínio específico, mas não é um raciocínio genérico que possa ser aplicado em diferentes classes de problemas [Benjamins; Fensel, 1998].

28
Como exemplo [Velde, 1993], pode-se considerar o método de geração e teste para ser aplicado ao objetivo de diagnosticar uma falha em um sistema. O papel de gerar pode ser desempenhado por uma tarefa que seleciona os componentes candidatos a responsáveis pela falha, descritos no modelo do domínio. O papel de testar fica a cargo de outra tarefa que verifica se o componente selecionado está funcionando perfeitamente ou não, utilizando o modelo do domínio que descreve a função de cada componente. O método de solução de problema, portanto é responsável por propor a estratégia de solução para um determinado problema e aplicá-la até atingir a solução. Métodos de solução de problemas têm sido, isoladamente, o mais intenso tópico de pesquisa em Engenharia de Conhecimento recentemente. Consistem de um problema mal equacionado cientificamente, pela pobre compreensão dos mecanismos cognitivos de solução de problema [Sternberg, 1994]. Sua compreensão e a geração de um modelo formal pode levar ao desenvolvimento de um conjunto de metodologias mais maduras para construção de sistemas que utilizem conhecimento. A integração de ontologias e PSMs é uma área bastante promissora, especialmente quando ontologias e bancos de dados são integrados. Os PSMs podem então fornecer serviços de raciocínio no topo destes bancos de dados, que podem levar a bancos de dados ativos, dinamicamente configurados em vez de repositórios passivos de conhecimento estático esperando por serem consultados [Gómez-Pérez e Benjamins, 1999]. Para alcançar esse objetivo, têm-se pesquisado formas de definir e catalogar os métodos de solução de problemas em bibliotecas, com seu escopo e aplicabilidade completamente descritas. Ainda, métodos de solução de problemas, como componente de um modelo abstrato de aplicação de inferências, vêm sendo estudados por [McDermott, 1988] e [Clancey, 1985], ou como as Tarefas Genéricas de Chandrasekaran [Chandrasekaram, 1986]. Já KADS [Schreiber, 1992], desenvolveu uma biblioteca de métodos de solução de problemas que é considerada referência na área.
2.5. A Modelagem de Conhecimento no Nível do Conhecimento
O processo de modelagem utilizando a abordagem dos modelos KL (de Knowledge Level) deve considerar ainda [Studer; Benjamins; Fensel, 1998]:
• Um modelo é uma aproximação da realidade, logo o processo de modelagem é contínuo em busca de uma maior aproximação;
• O processo de modelagem é cíclico, novas observações podem causar modificações no modelo, enquanto que o próprio modelo dirige o processo de aquisição de conhecimento;
• O processo de modelagem é falho, uma vez que depende de interpretações subjetivas, logo, o modelo deve ser progressivamente validado em cada estágio de seu desenvolvimento.
O modelo do domínio, da tarefa e os métodos de solução de problemas tornaram independentes os tipos de conhecimentos com diferentes características, permitindo ainda uma sistematização no processo de modelagem de conhecimento. Por conta disso, têm se tornado uma unanimidade entre os pesquisadores de modelagem da Engenharia de Conhecimento. Os benefícios da utilização dessa abordagem podem ser medidos em diversos momentos do desenvolvimento de um sistema baseado em conhecimento:

29
O modelo do domínio permite dirigir o esforço de aquisição de conhecimento para a geração de grandes bases de conhecimento uniformes e compartilhadas, que podem atender a diversas aplicações. Isso minimiza dois grandes problemas no desenvolvimento de sistemas especialistas: a dificuldade de aquisição de conhecimento associada a pouca vida útil do sistema. O modelo da tarefa permite modelar particularidades do problema ou diferentes formas de solução sem desrespeitar o formalismo de modelagem. Nas abordagens convencionais isso acabava sendo feito na forma de inserção de código no sistema, dificultando enormemente a manutenção do sistema. A abordagem uniforme e flexível na construção de sistemas baseados em conhecimento e uma metodologia de desenvolvimento mais madura permitiu a definição de estratégias de integração desses sistemas com os demais sistemas de uma organização, sejam eles convencionais ou não. As novas metodologias, portanto, não abordam apenas a modelagem do conhecimento do especialista, mas também o conhecimento organizacional e do contexto onde se inserirá o sistema. Entre as mais conhecidas estão PROTÉGÉ II [Puerta et al., 1992], CommonKADS [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 1999] e VITAL [Stutt; Motta, 1994]. As bibliotecas dos métodos de solução do problema são as que, de fato, garantem a viabilidade de uma modelagem de conhecimento independente, ao permitir que a efetiva aplicação da inferência seja definida de forma abstrata. Tornar independente o método de resolução, tradicionalmente embutido no código do mecanismo de inferência a na própria organização da base de conhecimento (como a ordenação de regras de produção, por exemplo), permite definir componentes de software para desenvolvimento de sistemas baseados em conhecimento. Essa mudança de paradigma aproximou o processo de construção de sistemas baseados em conhecimento ao processo de desenvolvimento de um software convencional. As principais diferenças são listadas na Tabela 2.2 [Gardner et al., 1998]..
Tabela 2.2: Comparação da análise de sistemas para construir software convencional e da análise de conhecimento para desenvolver sistemas especialistas.
Comparação entre Análise de Sistemas e
Análise de Conhecimento
Análise de Sistema enfatiza Análise do Conhecimento enfatiza Necessidades do usuário Necessidades da perícia e do usuário Informações e dados factuais, processos e procedimentos
Aplicação cognitiva dos dados e da informação
Entradas, saídas e fluxo de dados Conceitos e estratégias de solução de problemas
Dados quantitativos Dados heurísticos e subjetivos Técnicas estruturadas Aquisição cognitiva do conhecimento e
técnicas de análise Aspectos sintáticos do domínio e seus processos
Riqueza semântica do domínio e raciocínio de solução de problemas

30
A expansão da abordagem de modelagem para a Engenharia de Conhecimento, não extinguiu, no entanto, a necessidade da aquisição de conhecimento de suas fontes ou da eliciação a partir de um especialista. Os métodos de aquisição devem servir às necessidades de modelagem e, normalmente, são ciclicamente incrementados por elas. A aquisição de conhecimento corresponde ao processo de coleta, eliciação, interpretação e formalização de dados sobre o funcionamento da perícia em um determinado domínio, com a finalidade de construir um sistema baseado em conhecimento. A aquisição de conhecimento busca extrair o conhecimento de suas diversas fontes, humanas ou artificiais, como livros, manuais, documentos ou sistemas. Ainda é visto como o gargalo no desenvolvimento de sistemas especialistas, em parte devido às dificuldades em compreender os mecanismos da perícia, em parte devido a falta de treinamento dos analistas de sistemas nas técnicas de eliciação. A eliciação de conhecimento é conhecido como o processo de extrair conhecimento de fontes humanas, particularmente, dos especialistas do domínio e por isso, alimenta-se de técnicas oriundas da Psicologia ou Ciência da Cognição.

31
3. Metodologia CommonKADS A abordagem de modelagem para desenvolvimento de sistemas especialistas tem produzido diversas metodologias de desenvolvimento. O objetivo comum de todas elas é estabelecer um padrão para o projeto de software baseado em conhecimento, desde a coleta de requisitos junto ao usuário e especialista, até a etapa de implementação do sistema. Por sua dificuldade e particularidade para projetos de sistemas baseados em conhecimento, a ênfase maior está na especificação formal do modelo da perícia como uma conseqüência natural da fase de aquisição de conhecimento. As estruturas de modelagem especificam o sistema no nível do conhecimento [Newell, 1982; Velde, 1993], sem uma definição antecipada de uma ou outra abordagem de implementação, eliminado vícios comuns do desenvolvimento por prototipação incremental, onde a forma de implementação (por exemplo, sistemas simbólicos baseados em regras ou frames) era definida antes da completa compreensão do problema. O conceito de reusabilidade garante que os modelos de conhecimento sejam definidos em termos de primitivas que resolvam não apenas uma tarefa em particular. É necessário que os conceitos modelados possam suportar outras tarefas no mesmo domínio. Assim, um sistema que modele doenças e sintomas, pode ser utilizado num momento para a tarefa de diagnóstico de doenças em pacientes e, posteriormente, para realizar planejamento estratégico de estoque de medicamentos. Para alcançar esse objetivo, as metodologias prevêem formas de modelar as tarefas de modo independente do conhecimento declarativo, ao contrário das abordagens baseadas em transferência. Como o padrão de modelagem mais conhecido, a metodologia KADS (mais especificamente sua última versão, Common KADS) será aqui descrita, baseada nas definições contidas em [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000]. O objetivo básico da metodologia KADS é dar suporte ao desenvolvimento de sistemas baseados em conhecimento em todas as suas fases e aspectos. Isso significa que a modelagem não se preocupa apenas com a aquisição e representação de conhecimento especialista, mas também com os aspectos organizacionais que definem onde esse conhecimento se insere e como é utilizado por usuários ou clientes. KADS parte de um conjunto de princípios que norteiam a aplicação da metodologia, dentre os quais, os principais são [Schreiber, 1992]:
• Princípio da Modelagem: o desenvolvimento de um sistema baseado em conhecimento é visto como a construção de um conjunto de modelos de comportamento para a solução de problemas em uma organização. Um sistema baseado em conhecimento é a realização computacional associada a esses modelos.
• Princípio da Limitação de Papéis: um agente inteligente pode ser modelado por atribuir-lhe um conjunto de estruturas de do conhecimento e os papéis que essas estruturas devem desempenhar no processo de solução de problemas.
• Princípio da Tipagem do Conhecimento: um modelo, no nível do conhecimento, pode ser visto como consistindo de três diferentes categorias de conhecimento (ou tipos): conhecimento do domínio, conhecimento da tarefa e conhecimento de inferência. Além desses, há também o conhecimento de solução de problemas, que compõe não uma quarta categoria, mas uma especificação de como as categorias acima são aplicadas para resolver problemas.
• Princípio da Interação Relativa: prevê diferentes níveis de interação entre as três categorias do conhecimento, que varia em função da aplicação modelada.

32
3.1. O Conjunto de Modelos
A construção de um sistema baseado em conhecimento segundo a metodologia KADS tem como produto um conjunto de seis modelos que especificam todos os aspectos ligados ao software a ser desenvolvido, incluindo a organização, os recursos humanos, os aspectos de implementação e a interação entre estes. O conjunto é formato por: Modelo da Organização, Modelo da Tarefa, Modelo de Agente, Modelo do Projeto, Modelo de Comunicação e Modelo do Conhecimento (Figura 3.1). Apesar de interdependentes, os modelos podem ser desenvolvidos em diferentes momentos do projeto e por diferentes equipes: O componente principal e mais complexo do conjunto de modelos é o Modelo da Perícia que detalha o conhecimento do domínio. O Modelo da Perícia descreve as capacidades de um agente, normalmente um sistema baseado em conhecimento, em resolver problemas utilizando conhecimento.
Figura. 3.1: O conjunto de modelos da metodologia Common KADS [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000]:
• O modelo da organização suporta a análise dos aspectos mais gerais da organização, de modo a identificar problemas e oportunidades para sistemas de conhecimento, estabelecendo sua viabilidade.
• O modelo da tarefa identifica as partes relevantes de um processo de negócio da instituição. Analisa a organização geral da tarefa, suas entradas e saídas, pré-condições e critérios de desempenho, bem como recursos e competências.
• O modelo de agentes são os executores da tarefa. Um agente pode ser uma pessoa ou um sistema de informação, ou qualquer entidade capaz de executar uma tarefa. O modelo de agentes descreve as características dos agentes envolvidos na execução de uma tarefa, definindo suas competências e restrições para atuar. Fazem parte do modelo ainda as comunicações existentes entre os agentes para executar a tarefa.
• O modelo de comunicação define como acontece a comunicação entre os agentes envolvidos em uma tarefa, na forma de transações permitidas.
• O modelo do conhecimento especifica em detalhe os tipos e estruturas do conhecimento utilizado para executar a tarefa. Garante uma descrição, independente da implementação, do papel que os diferentes componentes do
Modelo da Organização • Modelo da Tarefa • Modelo dos Agentes
Modelo de Comunicação
Modelo de Projeto
Modelo do Conhecimento
Especificações para funções de
raciocínio
Tarefa intensiva em
conhecimento
Especificação para interação
de funções

33
conhecimento desempenham na solução de problemas em um formato compreensível.
• O modelo de projeto define o sistema em termos de arquitetura, plataforma de implementação, módulos necessários de software, construtos de representação e mecanismos computacionais necessários para implementar as funções especificadas nos demais modelos.
O componente principal e mais complexo do conjunto de modelos é o modelo do conhecimento que detalha o conhecimento do domínio e descreve as capacidades de um agente, normalmente um sistema baseado em conhecimento, em resolver problemas utilizando conhecimento. O modelo da organização consiste no estudo de viabilidade do projeto, e permite situar o contexto de onde o conhecimento provêm, como e por quem ele é aplicado. Os modelos de comunicação e de projeto contemplam aspectos de implementação do sistema e integração no ambiente organizacional. O modelo da organização tem por objetivo descrever os elementos relevantes e as experiências de várias fontes - incluindo as teorias da organização, análise do processo de negócios e gerência da informação - e integrá-los, do ponto de vista do conhecimento, em um pacote coerente e compreensível. São descritos a estrutura da organização, os processos de negócio, pessoas, recursos e a forma como esses elementos interagem entre si.
A visão geral do modelo da organização é apresentada na Figura 3.2 e sua construção é dirigida pelas planilhas apresentadas da Tabela 3.1 à Tabela 3.6 [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000]2
O MO1 fornece uma visão geral do tipo de organização que será foco da análise, identificando áreas-chave que podem ser melhoradas por projetos de Gestão de Conhecimento. O MO2 descreve o principal PROCESSO da organização e os subprocessos que podem ser foco da análise.
O MO3 decompõe o processo em tarefas, identificando os aspectos envolvidos em sua execução. O MO4 tem como foco as tarefas identificadas como intensivas em conhecimento e quais os insumos de conhecimento que alimentam a tarefa. O MO4a descreve as ações de gestão de conhecimento propostas para a melhoria do processo/tarefa. O MO5 verifica a viabilidade de efetivação da ação.
2 Schreiber, G.; Akkermans, H.; Anjewierden, A.; Hoog, R.d.; Shadbolt, N.; Velde, W.v.d.; Wielinga, B. Knowledge engineering and management: the commonkads methodology. Cambridge: The MIT Press, 2000. 465p.

34
Figura 3.2: Visão geral do Modelo da Organização (modificado de [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000].
Tabela 3.1: MO-1
Identificando os problemas orientados ao conhecimento da organização
MO-1 Problemas e Oportunidades Organização (*) Identifique a organização e unidade no qual a análise se realiza.
Setor de atuação Descreva a área de atuação da empresa e seu principal foco de negócios.
Problemas e Oportunidades Faça uma lista resumida dos problemas e oportunidades percebidos, baseado em entrevistas, discussões de grupos, reuniões com gerentes, etc.
Contexto organizacional Indique os aspectos-chave do contexto organizacional, de modo a colocar os problemas e oportunidades na perspectiva correta. Considere: 1. Missão, visão e objetivos da organização 2. Crenças e valores da organização 3. Fatores externos importantes para a organização 4. Conduta estratégica da organização
Soluções Liste as possíveis soluções para os problemas e oportunidades identificados. (Podem ser obtidas a partir de entrevistas e discussões, análise do contexto organizacional, planos já desenvolvidos ou serem geradas a partir desta análise).
Modelo da Organização
MO-1 MO-2
MO-4 Problemas e
Oportunidades
Descrição da área foco na organização MO-3
Contexto (missão, estratégia,
ambiente...)
Estrutura Processo Pessoas
Cultura e Poder Recursos
Conhecimento
Soluções Potenciais
Decomposição do Processo
MO-4a Plano de ação
MO-5 Viabilidade de Execução
Insumos do Processo
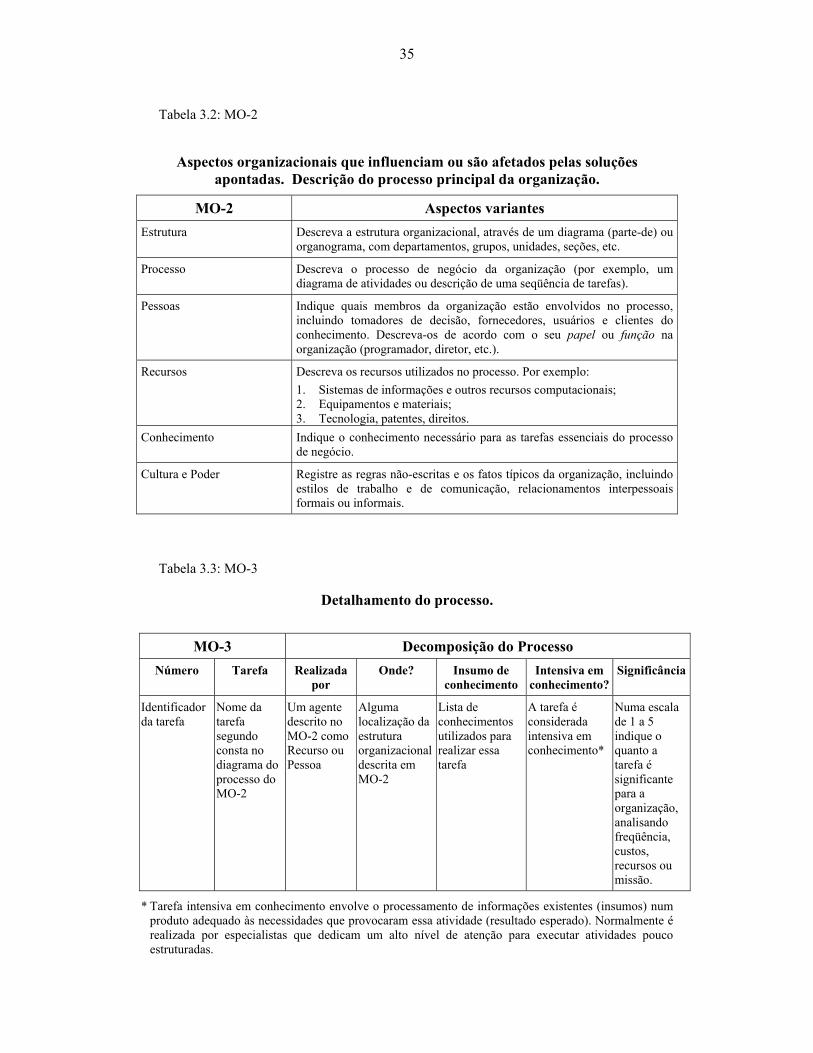
35
Tabela 3.2: MO-2
Aspectos organizacionais que influenciam ou são afetados pelas soluções
apontadas. Descrição do processo principal da organização.
MO-2 Aspectos variantes Estrutura Descreva a estrutura organizacional, através de um diagrama (parte-de) ou
organograma, com departamentos, grupos, unidades, seções, etc.
Processo Descreva o processo de negócio da organização (por exemplo, um diagrama de atividades ou descrição de uma seqüência de tarefas).
Pessoas Indique quais membros da organização estão envolvidos no processo, incluindo tomadores de decisão, fornecedores, usuários e clientes do conhecimento. Descreva-os de acordo com o seu papel ou função na organização (programador, diretor, etc.).
Recursos Descreva os recursos utilizados no processo. Por exemplo: 1. Sistemas de informações e outros recursos computacionais; 2. Equipamentos e materiais; 3. Tecnologia, patentes, direitos.
Conhecimento Indique o conhecimento necessário para as tarefas essenciais do processo de negócio.
Cultura e Poder Registre as regras não-escritas e os fatos típicos da organização, incluindo estilos de trabalho e de comunicação, relacionamentos interpessoais formais ou informais.
Tabela 3.3: MO-3
Detalhamento do processo.
MO-3 Decomposição do Processo
Número Tarefa Realizada por
Onde? Insumo de conhecimento
Intensiva em conhecimento?
Significância
Identificador da tarefa
Nome da tarefa segundo consta no diagrama do processo do MO-2
Um agente descrito no MO-2 como Recurso ou Pessoa
Alguma localização da estrutura organizacional descrita em MO-2
Lista de conhecimentos utilizados para realizar essa tarefa
A tarefa é considerada intensiva em conhecimento*
Numa escala de 1 a 5 indique o quanto a tarefa é significante para a organização, analisando freqüência, custos, recursos ou missão.
* Tarefa intensiva em conhecimento envolve o processamento de informações existentes (insumos) num produto adequado às necessidades que provocaram essa atividade (resultado esperado). Normalmente é realizada por especialistas que dedicam um alto nível de atenção para executar atividades pouco estruturadas.
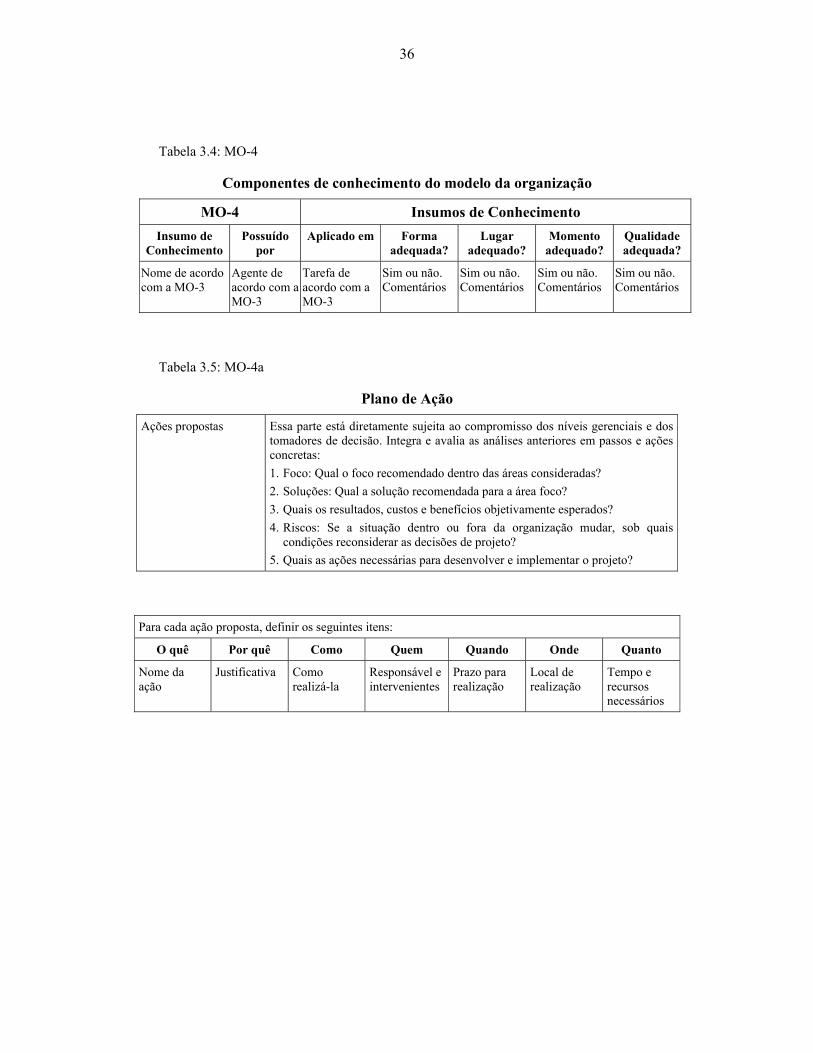
36
Tabela 3.4: MO-4
Componentes de conhecimento do modelo da organização
MO-4 Insumos de Conhecimento Insumo de
Conhecimento Possuído
por Aplicado em Forma
adequada? Lugar
adequado? Momento
adequado? Qualidade adequada?
Nome de acordo com a MO-3
Agente de acordo com a MO-3
Tarefa de acordo com a MO-3
Sim ou não. Comentários
Sim ou não. Comentários
Sim ou não. Comentários
Sim ou não. Comentários
Tabela 3.5: MO-4a
Plano de Ação
Ações propostas Essa parte está diretamente sujeita ao compromisso dos níveis gerenciais e dos tomadores de decisão. Integra e avalia as análises anteriores em passos e ações concretas: 1. Foco: Qual o foco recomendado dentro das áreas consideradas? 2. Soluções: Qual a solução recomendada para a área foco? 3. Quais os resultados, custos e benefícios objetivamente esperados? 4. Riscos: Se a situação dentro ou fora da organização mudar, sob quais
condições reconsiderar as decisões de projeto? 5. Quais as ações necessárias para desenvolver e implementar o projeto?
Para cada ação proposta, definir os seguintes itens:
O quê Por quê Como Quem Quando Onde Quanto
Nome da ação
Justificativa Como realizá-la
Responsável e intervenientes
Prazo para realização
Local de realização
Tempo e recursos necessários
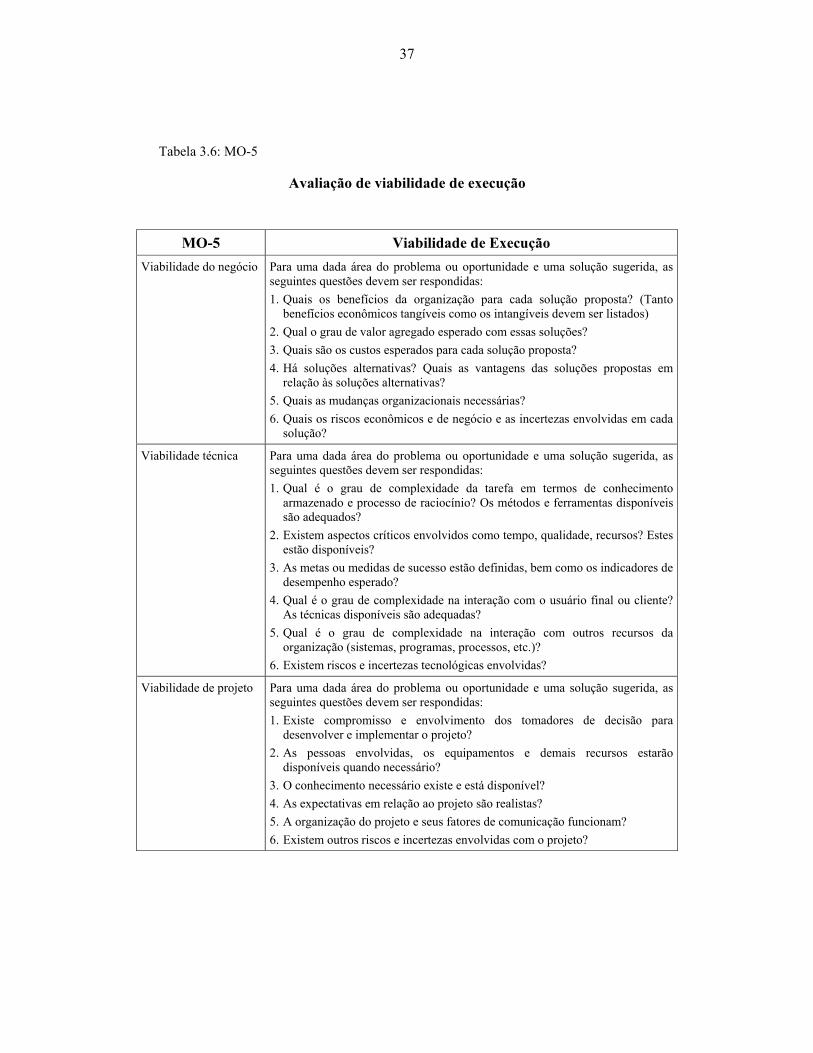
37
Tabela 3.6: MO-5
Avaliação de viabilidade de execução
MO-5 Viabilidade de Execução Viabilidade do negócio Para uma dada área do problema ou oportunidade e uma solução sugerida, as
seguintes questões devem ser respondidas: 1. Quais os benefícios da organização para cada solução proposta? (Tanto
benefícios econômicos tangíveis como os intangíveis devem ser listados) 2. Qual o grau de valor agregado esperado com essas soluções? 3. Quais são os custos esperados para cada solução proposta? 4. Há soluções alternativas? Quais as vantagens das soluções propostas em
relação às soluções alternativas? 5. Quais as mudanças organizacionais necessárias? 6. Quais os riscos econômicos e de negócio e as incertezas envolvidas em cada
solução?
Viabilidade técnica Para uma dada área do problema ou oportunidade e uma solução sugerida, as seguintes questões devem ser respondidas: 1. Qual é o grau de complexidade da tarefa em termos de conhecimento
armazenado e processo de raciocínio? Os métodos e ferramentas disponíveis são adequados?
2. Existem aspectos críticos envolvidos como tempo, qualidade, recursos? Estes estão disponíveis?
3. As metas ou medidas de sucesso estão definidas, bem como os indicadores de desempenho esperado?
4. Qual é o grau de complexidade na interação com o usuário final ou cliente? As técnicas disponíveis são adequadas?
5. Qual é o grau de complexidade na interação com outros recursos da organização (sistemas, programas, processos, etc.)?
6. Existem riscos e incertezas tecnológicas envolvidas?
Viabilidade de projeto Para uma dada área do problema ou oportunidade e uma solução sugerida, as seguintes questões devem ser respondidas: 1. Existe compromisso e envolvimento dos tomadores de decisão para
desenvolver e implementar o projeto? 2. As pessoas envolvidas, os equipamentos e demais recursos estarão
disponíveis quando necessário? 3. O conhecimento necessário existe e está disponível? 4. As expectativas em relação ao projeto são realistas? 5. A organização do projeto e seus fatores de comunicação funcionam? 6. Existem outros riscos e incertezas envolvidas com o projeto?

38
Exercício
Organize grupos de trabalho. Selecione o local de trabalho de um dos membros do grupo e preencha os Modelos da Organização MO-1 a MO-5 abaixo, segundo as informações obtidas a partir dele.
Modelo da Organização Problemas e Oportunidades - MO-1
Organização
Setor de atuação
Problemas e Oportunidades
Contexto Organizacional
Soluções

39
Modelo da Organização Aspectos mutáveis - MO-2
Estrutura
Processo
Recursos
Conhecimento
Cultura e Poder
Pessoas
Modelo da Organização Decomposição do Processo – MO-3 Tarefa Nome Tarefa Feita por Onde? Insumos de
Conhecimento Intensiva Signific.

40
Modelo da Organização Insumos de Conhecimento – MO-4
Conhecimento Possuído por Usado em Foram correta? Lugar
correto? Momento correto?
Qualidade correta?
Modelo da Organização Plano de ação - MO-4a
Foco
Soluções
Resultados, custos e benefícios
Riscos
Ações necessárias

41
Plano de Ação
O quê Por quê Como Quem Quando Onde Quanto
Modelo da Organização Viabilidade de Execução - MO-5
Viabilidade do negócio
Viabilidade técnica
Viabilidade de projeto

42

43
4. O Modelo do Conhecimento A estrutura de KADS para o modelo do conhecimento separa o conhecimento da aplicação do conhecimento para solução de problemas (ou metaconhecimento da aplicação). São definidos utilizando-se das mesmas primitivas, porém enquanto o conhecimento da aplicação ser refere aos objetos do mundo sobre o qual se deseja raciocinar, o conhecimento para solução de problemas tem por objeto o próprio conhecimento da aplicação. Uma descrição da terminologia para modelar conhecimento do domínio em KADS e um exemplo de base de conhecimento está descrito no final desse capítulo. O modelo do conhecimento é descrito em três categorias epistemológicas (Figura 4.1):
• conhecimento do domínio, que descreve o conhecimento declarativo e inferencial do domínio da aplicação;
• conhecimento de inferência, que descreve os passos básicos de raciocínio que o sistema deve realizar para resolver o problema;
• conhecimento da tarefa, que descreve quais os objetivos que devem ser alcançados, que informações ou conhecimentos devem ser obtidos para alcançá-los e quais inferências devem ser feitas para atingir esse objetivo.
Figura 4.1: Categorias de conhecimento do modelo do conhecimento de Common KADS.
4.1. Conceitos de Abstração
[Mattos, 1988; Elmasri e Navathe, 1994; Maher e Garza, 1997] Uma abstração é uma descrição simplificada ou uma especificação de um sistema que enfatiza alguns detalhes ou propriedades enquanto suprime aqueles julgados irrelevantes
Conhecimento da Tarefa
Objetivos da tarefa Decomposição da
tarefa Controle da tarefa
Conhecimento de inferência
Inferências básicas Papéis
Conhecimento do Domínio
Tipos Regras Fatos
Diagnóstico (tarefa)
Hipótese Verificação
Sintoma Doença Teste

44
para o objetivo em questão. Uma boa abstração é aquela na qual a informação que é importante para o usuário é enfatizada e os detalhes não importantes são suprimidos. A tarefa de abstração refere-se à representação de conhecimento, cujo objetivo é o de modelar um “domínio do discurso” para armazenar e manipular conhecimento e realizar inferências, bem como à modelagem semântica de dados para a construção de bancos de dados. As diferenças entre os dois objetivos [Elmasri; Navathe, 1994] são sumariadas a seguir.
• Ambas as disciplinas usam um processo de abstração para identificar propriedades comuns e aspectos importantes dos objetos do domínio enquanto suprimem diferenças não significantes e detalhes sem importância.
• Ambas disciplinas fornecem conceitos, restrições, operações e linguagens para definir dados e representar conhecimento.
• Representação de conhecimento possui um escopo mais amplo do que modelos de dados semânticos. Diferentes formas de conhecimento como regras, conhecimento incompleto e default, e conhecimento espacial e temporal, são representados nos esquemas de representação de conhecimento. Modelos semânticos estão sendo expandidos para incluir alguns desses conceitos.
• Esquemas de representação de conhecimento incluem mecanismos de raciocínio que deduzem fatos adicionais daqueles armazenados no banco de dados, enquanto bancos de dados são capazes de responder apenas a perguntas diretas sobre as informações contidas em sua base. A tecnologia de BD está sendo expandida para incluir mecanismos de inferência, como nos bancos de dados dedutivos.
• Modelos de dados concentram-se na representação dos esquemas do banco de dados, ou meta-conhecimento, enquanto modelos de conhecimento misturam os esquemas com as próprias instâncias para obter maior flexibilidade na representação. Isso torna as implementações de bases de conhecimento ineficientes quando comparadas com bancos de dados, especialmente quando grandes quantidades de fatos necessitam ser armazenados.
Os modelos descrevem o mundo a partir de cinco construtos [Mattos, 1988]:
• Os conceitos, objetos ou entidades do domínio; • os atributos ou propriedades desses conceitos; • os relacionamentos entre os conceitos do domínio; • as operações sobre esses conceitos que resultam em mudanças nos conceitos ou
em seus relacionamentos; • as restrições que definem os conceitos e distinguem a realidade deste domínio
dos demais. A representação do domínio é realizada respeitando-se alguns axiomas de modelagem:
• Tudo o que existe no mundo real, incluindo as entidades utilizadas para descrever outras entidades são conceitos do modelo. Nesse caso, as diferenças entre os tipos do esquema de bancos de dados (meta-informação) e as instâncias do próprio banco não devem ser consideradas. As diferenças entre tipos e instâncias podem ser representadas como objetos distintos, mas deveriam ser tratados pelo modelo do mesmo modo.

45
• Deve ser mantida uma correspondência um para um entre as entidades do mundo e os conceitos do modelo, evitando que um conceito seja distribuído entre diversas entidades.
• Cada conceito do mundo pode ser simples ou composto (definido como uma abstração de outros conceitos). As abstrações são portanto expressas como relacionamentos entre conceitos com o objetivo de organiza-los de alguma forma.
• As abstrações podem ser feitas sobre um conjunto de conceitos simples de forma a construir um conceitos composto, sendo, nesse caso, uma abstração de um nível. Ou podem ser aplicadas recursivamente sobre objetos cada vez mais complexos, formando relacionamentos n-nível.
4.1.1. Classificação/Instanciação
Um objeto composto é definido como um conjunto de objetos simples que partilham do mesmo conjunto de propriedades, modificando apenas os valores dessas propriedades. Uma instância é um objeto simples que possui todas as propriedades de sua classe ou de mais de uma classe, com valores particulares para aquela ocorrência. É um relacionamento de um nível. Definido no modelo como os relacionamentos instância-de ou é-um.
Figura 4.2: Relacionamentos de classificação e instanciação para um exemplo de modelagem de tipos de automóveis.
4.1.2. Generalização/Especialização
Descreve as propriedades comuns de uma classe, omitindo os detalhes específicos que diferenciam suas instâncias ou subclasses (tanto estruturalmente, como em termos de valores de propriedades). A generalização pode definir relacionamentos entre classes cada vez mais especializadas, sendo uma relação n-nível. Definido no modelo como os relacionamentos subclasse-de ou é-um. Exemplo na Figura 4.3.
CONCEPT automóvel DESCRIPTION: “Objeto automóvel” ATTRIBUTES: cor: {branco, preto, vermelho}; proprietário : string; preço : real AXIOMS: 1.000 <= preço <= 100.000 END CONCEPT automóvel
INSTANCE a1 INSTANCE-OF: automóvel ATTRIBUTES: cor: branco
proprietário : Paul preço : 5.000 END INSTANCE
INSTANCE a2 INSTANCE-OF: automóvel ATTRIBUTES: cor: preto proprietário : Mary preço : 10.000 END INSTANCE

46
Figura 4.3: Relacionamentos de generalização e especialização para um exemplo de modelagem de tipos de automóveis.
4.1.2.1. 4.1.2.1 Hierarquia é-um e herança de atributos
A construção de estruturas de representação utilizando classificação/instanciação para definir os relacionamentos entre objetos e instâncias e generalização/especialização para relacionar classes e subclasses permite definir estruturas com hierarquias é-um e utilizar a herança de atributos para a dedução de informações que não estão explicitamente representadas. No exemplo acima, ao definir que um caminhão é um veículo, pode-se deduzir de imediato que ele poderá ter uma das três cores (branco, preto e vermelho), terá um proprietário e seu preço deverá ser definido entre os valores de 1.000 e 100.000 (no exemplo, esse intervalo foi ainda mais restrito na própria definição de caminhão).
4.1.3. Associação-conjunto/Associação-elemento
Permite associar objetos por alguma propriedade de interesse para que sejam manipulados como um único objeto. Normalmente é utilizado para obter outras propriedades associadas ao conjunto, como valores médios de atributos. A associação-elemento define o relacionamento 1-nível (i.e., entre instância e conjunto) enquanto a associação-conjunto, que é um relacionamento n-nível permite construir hierarquias entre conjuntos e subconjuntos. Definido no modelo como os relacionamentos subconjunto-de e elemento-de. Exemplo na Figura 4.4.
CONCEPT veículo DESCRIPTION: “Objeto veículo” ATTRIBUTES: cor: {branco, preto, vermelho}; proprietário : string; preço : real AXIOMS: 1.000 <= preço <= 200.000 END CONCEPT veículo
CONCEPT automóvel DESCRIPTION: “Objeto automóvel” SUB-TYPE-OF: veículo; ATTRIBUTES: cor: {branco, preto, vermelho}; proprietário : string; preço : real AXIOMS: 1.000 <= preço <= 100.000 END CONCEPT automóvel
CONCEPT caminhão DESCRIPTION: “Objeto caminhãol” SUB-TYPE-OF: veículo; ATTRIBUTES: cor: {branco, preto, vermelho}; proprietário : string; capacidade: integer; preço : real AXIOMS: 50.000 <= preço <= 200.000 50 <= capacidade <= 80 END CONCEPT caminhão
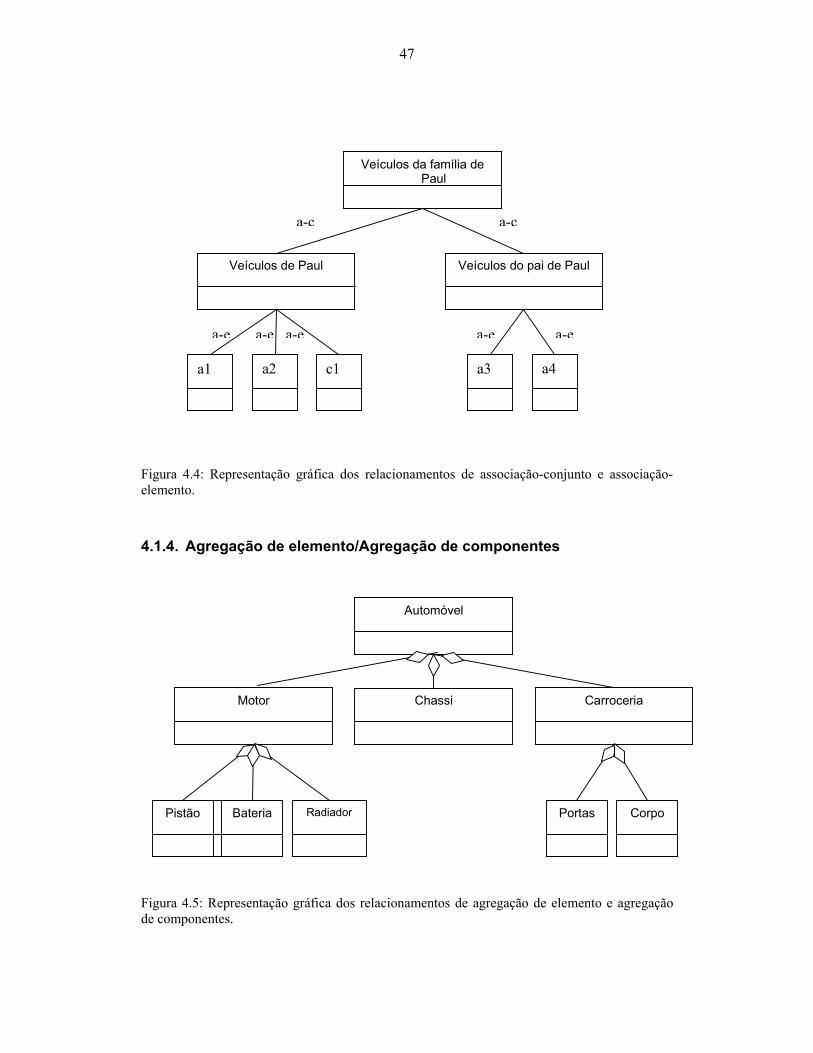
47
Figura 4.4: Representação gráfica dos relacionamentos de associação-conjunto e associação-elemento.
4.1.4. Agregação de elemento/Agregação de componentes
Figura 4.5: Representação gráfica dos relacionamentos de agregação de elemento e agregação de componentes.
Automóvel
Motor Chassi
a1 Pistão
Carroceria
Bateria Radiador Portas Corpo
a4
a-c
a-ea-ea-ea-ea-e
Veículos da família de Paul
Veículos de Paul Veículos do pai de Paul
c1 a1 a2 a3
a-c

48
Permite tratar objetos como uma composição de outros objetos mais simples. Ao contrário do relacionamento de associação de conjuntos, descrito acima, a agregação aplica o conceito de particionamento de conjuntos da Matemática, ou seja, um objeto é formado pela soma de suas partes, sendo que a ausência de qualquer dessas partes descaracteriza o objeto como tal. A agregação de elementos liga instâncias a objetos (1-nível) enquanto a agregação de componentes associa objetos compostos que são partes de outros objetos compostos. Definido no modelo como o relacionamento parte-de e subcomponente-de. Exemplo na Figura 4.5.
4.1.5 Raciocínio associado aos conceitos de abstração
A utilização de hierarquias é-um permite a utilização da herança de atributos como a forma de raciocínio mais imediata em estruturas de representação de dados ou conhecimento e garante a manutenção automática das restrições de integridade semântica [Mattos, 1988]. Com esse mecanismo, pode-se raciocinar de duas maneiras: sabendo-se a classe de uma determinada instância, pode-se obter a representação estrutural dessa instância (i.e., qual o conjunto de atributos suficiente para representar o objeto) e mesmo valores de propriedades da instância. Alternativamente, a partir da instância e de suas propriedades conhecidas, pode-se conhecer a que classe o objeto pertence. As associações de elementos e associações de conjuntos permitem, igualmente uma forma de herança de atributos, porém mais limitada. Ao se conhecer as propriedades que definem um conjunto, pode-se deduzir que essas propriedades são válidas para suas instâncias, embora o conjunto não permita determinar todas as propriedades de suas instâncias. Abstrações do tipo associação de conjuntos são utilizadas para determinar relacionamentos de propriedades. Por exemplo, determinar a idade média dos veículos de Paul, ou seu preço máximo. Representam visões particulares sobre o banco de informações. A agregação permite ao usuário ver um objeto alternativamente como uma unidade ou como suas partes componentes. O raciocínio é obtido a partir das propriedades estruturais comuns dos objetos, que podem crescer ou decrescer a medida em que se sobe ou desce na hierarquia. Por exemplo, o peso dos componentes será sempre menor do que o peso do objeto agregado, um cronograma de produção de uma parte componente deve terminar sempre antes do que o previsto para o objeto agregado. Esse comportamento permite fazer deduções ou impor restrições de integridade sobre valores de propriedades.
Exercício
Construa um modelo abstrato de uma Agência de Viagens demonstrando os conceitos de abstração estudados: classificação/instanciação, generalização/especialização, associação de elementos, associação de conjuntos e agregação. Construa uma hierarquia IS-A de objetos e demonstre as informações que podem ser obtidas por herança de atributos. Considere os seguintes objetos como relacionados a agência e sugira outros objetos ou instâncias necessários à demonstração dos conceitos.
Agência , viagem, cliente, contrato, roteiro, local turístico, meio de transporte, hospedagem, hotel, pousada, avião, ônibus, trem.

49
4.2. Conhecimento do Domínio
Descreve as informações estáticas do domínio e os objetos do conhecimento para uma determinada aplicação. O domínio do conhecimento é construído por dois componentes: as estruturas do domínio e as bases de conhecimento [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000]: As estruturas do domínios descrevem de forma esquemática os tipos abstratos do domínio e como eles se organizam através de hierarquias e relacionamentos. As bases de conhecimento contém as instâncias do conhecimento desses tipos abstratos que representam o problema particular a ser resolvido no contexto onde ele se insere. Diferentemente de modelos de dados, que representam unicamente tipos abstratos que serão instanciados unicamente pelo usuário, um modelo de conhecimento necessita representar determinadas porções do conhecimento que realmente correspondem a instâncias do modelo. Essas instâncias não são instâncias do usuário do sistema, mas instâncias do especialista. O conhecimento do domínio refere-se ao conhecimento estático do domínio, ou conhecimento declarativo (como definido na Introdução deste trabalho). Descreve os objetos, suas propriedades, e os relacionamentos que compõem a base sobre a qual uma tarefa raciocina. As estruturas do domínio são definidas através de três construtos: conceito, relação e tipo-regra.
• Os conceitos descrevem os objetos ou entidades do domínio da aplicação. São definidos através de seus atributos e valores, sendo que os valores de um atributos são definidos em termos de tipos e de domínio de valores.
• As relações definem a forma como os conceitos se associam, se agrupam, de dividem ou influenciam uns aos outros. As relações de especialização e generalização são utilizadas para construir a taxonomia do domínio. Em KADS, as relações têm cardinalidade e podem ter atributos associados.
• tipo-regra descreve um tipo especial de relação: aquela que descreve as dependências entre instâncias de conceitos com determinados atributos e valores, definindo os caminhos possíveis de inferência do modelo.
As instâncias dos conceitos do domínio, devidamente valoradas são descritas como expressões do domínio. São também expressões de domínio combinações dessas instâncias através de operadores lógicos (E, OU, NÃO) ou aritméticos (<, >, =, +, etc.). Uma forma usual de descrever esquemas de domínios é através de ontologias de domínio.
• Ontologia do domínio: são as definições básicas a respeito do domínio [Studer; Benjamins; Fensel, 1998], ou seja, (i) um vocabulário de conceitos, que são os termos do domínio; (ii) os tipos que esses conceitos podem ser e que valores podem assumir, ou a tipologia do domínio; (iii) a estrutura de relacionamento entre os termos, especialmente as relações de classe ou partes, ou seja, a taxonomia ou partonomia do domínio.
A ontologia do domínio permite definir formalmente um universo compartilhado, sobre o qual todas as operações vão acontecer. Num domínio fictício de conserto de aparelhos de som (o exemplo é clássico para KADS), a ontologia definiria os termos como: alto-falante, amplificador, dial, potência, voltagem, 220V. Os termos têm determinados papéis nesse domínio, como ser componente do aparelho de som, ou ser atributo do componente, ou valor do atributo, relacionamento, etc. Ontologias de domínio e métodos de solução de problemas parecem ser as ferramentas adequadas para introduzir funções de inferências em sistemas de gerência de bancos de

50
dados. A representação de ontologias em bancos de dados e a definição de métodos de solução de problemas como primitivas associadas por papéis a essa representação pode permitir a definição de inferências abstratas e independentes de domínio, implementáveis como bibliotecas nos sistemas de bancos de dados. Essas possibilidades vêm sendo discutidas por [Gómez-Pérez; Benjamins, 1999]. As bases de conhecimento contém as instâncias dos tipos do conhecimento de uma determinada aplicação, ou seja, dos conceitos, das relações e das regras. Ao contrário dos bancos de dados, as instâncias do conhecimento do domínio, não são instâncias do usuário do sistema, mas instâncias do próprio domínio, como nome de peças, de componentes, regras de diagnóstico, etc. As bases de conhecimento são construídas a partir das expressões do domínio, que descrevem o modelo de domínio, de uma forma potencialmente útil de ser aplicada pelos métodos de solução de problemas. São construídas com o vocabulário do domínio e respeitando as restrições definidas pela conhecimento do domínio. As expressões do domínio podem definir propriedades de objetos, relacionamentos, ou relações entre outras expressões.
4.3. Conhecimento de Inferência
Enquanto o conhecimento do domínio é descrito como uma estrutura de informação ou conhecimento estático da aplicação, o conhecimento de inferência descreve como essas estruturas estáticas podem ser utilizadas para suportar o processo de raciocínio. O conhecimento de inferência é descrito através da primitivas de inferência, papéis do conhecimento e funções de transferência [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000]. Uma primitiva de inferência corresponde a um passo atômico (no sentido de indivisível) de raciocínio, aplicado para derivar uma nova informação a partir das instâncias do conhecimento contidas na base de conhecimento e também das instâncias entradas pelo usuário. De acordo com a metodologia KADS, utilizada para descrever o conhecimento, "uma inferência é completamente descrita através de uma especificação declarativa de suas entradas e saídas. O processo interno de como essa inferência transforma aquela entrada na respectiva saída não é relevante no nível do conhecimento" [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000]. Na prática, o processo interno será definido no modelo do projeto. Uma inferência em KADS pode ser pensada como um mini-sistema baseado em conhecimento com uma finalidade bastante limitada e específica. Recebe uma porção do conhecimento do domínio ou do problema como entrada e gera uma saída, que é uma transformação desse conhecimento. As entradas e saídas das inferências são conhecidas como papéis, que são associados dinamicamente ao conhecimento do domínio. A Tabela 4.1 apresenta algumas da inferências da biblioteca de inferências de KADS [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000] com os respectivos significados.

51
6. Tabela 4.1: Primitivas de inferência de Common KADS. .
Inferência Significado Abstrai A entrada é um conjunto de dados e a saída é um modelo abstrato
daqueles dados. Avalia A entrada é um conjunto de dados e uma norma e a saída é um valor-
verdade indicando se os dados se adeqúam a norma. Classifica A entrada é um conceito e a saída é a classe a qual o conceito
pertence. Cobre A entrada é um efeito e a saída é o estado do sistema que deve ter
causado esse defeito. Combina A entrada é um conjunto de dados e a saída é uma organização
coerente destes dados. Compara A entrada são dois valores e a saída é um valor verdade, definindo se
eles são iguais ou diferentes. Confronta A entrada são dois conjuntos de dados e a saída é uma medida de
similaridade entre os dois conjuntos de dados. Decompõe A entrada é um conceito único e a saída é o conjunto das partes que o
compõe. Especifica A entrada é um objeto e a saída é um novo objeto associado de
alguma maneira com o objeto da entrada. Gera A entrada é uma descrição (detalhes de um sistema, requisitos) e a
saída é uma solução, de acordo com um conjunto de normas. Ordena A entrada é um conjunto de dados e a saída são os dados ordenados
segundo algum critério. Seleciona A entrada é um conjunto de dados e a saída é um elemento ou
subconjunto desses dados. (*) Compilado de [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde;
Wielinga, 2000] e [Gardner; Rush; Crist; Konitzer; Teegarden, 1998] Além da primitivas de inferência, devem ser definidas também funções de transferência para modelar a interação com outros agentes, que recebem ou fornecem dados utilizados para a solução de problemas. Essas primitivas são:
• Obtém: O agente requisita uma informação do agente externo. O agente tem a iniciativa e o agente externo é quem detém a informação.
• Recebe: O agente recebe uma informação do agente externo. O agente externo tem a iniciativa e também retém a informação.
• Apresenta: O agente disponibiliza a informação para o agente externo. O agente tem a iniciativa e também retém a informação.
Fornece: O sistema fornece uma informação para o agente externo. O agente externo tem a iniciativa e o agente raciocinador retém a informação A tipologia das funções de transferência são apresentadas na Figura 4.6.

52
Figura 4.6: Tipologia das funções de transferência com base nas dimensões de iniciativa e agentes que retém a informação.
Os papéis do conhecimento são nomes de conceitos abstratos que indicam o seu papel no processo de raciocínio. Um determinado conhecimento pode exercer o papel de uma hipótese em uma determinada seqüência de raciocínio, ou de uma solução em outra seqüência, dependendo que qual forma de solução de problemas é utilizada. Os papéis do conhecimento podem ser estáticos ou dinâmicos. Os papéis dinâmicos do conhecimento referem-se as entradas e saídas das inferências, instanciadas no momento da execução, normalmente com os dados do usuário. Os papéis estáticos são mais estáveis ao longo do tempo. Definem quais as expressões de conhecimento do domínio aplicadas para realizar a inferência. Referem-se as regras ou taxonomias de domínio representadas no modelo e instanciadas de acordo com as necessidades da inferência. Juntas, as inferências formam os blocos construtores do raciocínio de uma sistema. O conjunto das inferências pode ser representado graficamente, de forma a explicitar as relações de dependência entre os passos de inferência. As estruturas de inferência assim construídas, quando definem métodos de solução abstratos e reusáveis em outros domínios, constituem-se em métodos de solução de problemas ou PSM. A Figura 4.6 descreve o método de solução de classificação heurística [Clancey, 1985] que especifica o processo de levantar uma hipótese e confrontá-la com os dados até alcançar uma conclusão. As elipses indicam as inferências primitivas. O diagrama pode ser percorrido usando uma estratégia de busca regressiva (as hipóteses definem a aquisição dos dados) ou progressiva, onde os dados definem a seleção das hipóteses. Os papéis do conhecimento, definidos genericamente no PSM e representados como retângulos no diagrama, são associados dinamicamente às expressões do conhecimento do domínio e aos dados do usuário durante o processo de inferência. Essa forma de utilização garante a reusabilidade do método para outros domínios que possuam a mesma classe de problemas. Métodos de solução de problemas têm atraído o foco da pesquisa em engenharia de conhecimento, por se mostrar um componente fundamental para o desenvolvimento de sistemas baseados em conhecimento eficientes e com componentes reusáveis [Fensel et al., 1997; Benjamins; Fensel, 1998; Musen, 1998; Gómez-Pérez; Benjamins, 1999]. A idéia básica da utilização de métodos de solução de problemas como componentes abstratos se opõem a abordagem tradicional onde a inferência sobre os dados era pré-
OBTÉM RECEBE
APRESENTA FORNECE
iniciativa iniciativa do sistema externa
informação externa
informação interna

53
definida e implementada no mecanismo de inferência do sistema. A possibilidade de reuso era condicionada a definição de mecanismos genéricos que não contemplavam as particularidades do problema para o qual foram originalmente desenvolvidos.
Figura 4.7: Estrutura de inferência que descreve o método de Classificação Heurística [Clancey, 1985].
O uso de métodos de solução de problemas associados a modelos declarativos, dos quais ontologias tem se mostrado o mais adequado, permite definir módulos de solução para diferentes problemas que utilizam conhecimento do mesmo domínio. O sistema pode ser desenvolvido de modo incremental e os métodos de solução podem migrar entre diferentes domínios. Assim, uma base de conhecimento que suporte diagnóstico de falhas em equipamentos utilizando um método de solução de problemas (de diagnóstico) pode também ser utilizada para projeto, com outro método de solução de problemas. Da mesma forma, métodos de diagnóstico, projeto ou planejamento podem ser aplicados a diferentes domínios, cujas ontologias baseiem-se nas mesmas primitivas. Os princípios que norteiam essa forma de desenvolvimento:
• base de conhecimento que contenha toda a informação do domínio, mesmo aquela não imediatamente necessária à inferência e
• métodos de solução propostos de forma abstrata e independente para diferentes problemas
• vêm de encontro às necessidades de bancos de dados inteligentes, de manter a independência entre o conhecimento e métodos de inferência, e a modularidade dos componentes de inferência.
Abstração de Dados
Hipóteses
Solução
Comparação Heurística
Especializar
Dados
Abstrair
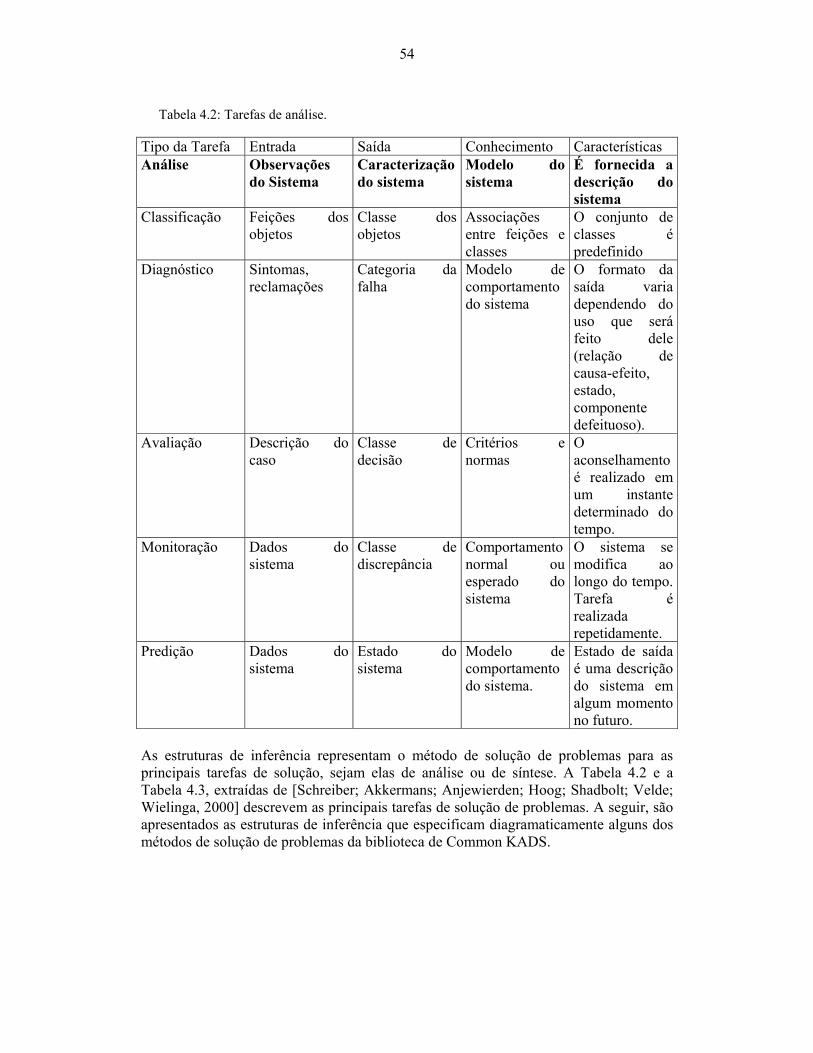
54
Tabela 4.2: Tarefas de análise.
Tipo da Tarefa Entrada Saída Conhecimento Características Análise Observações
do Sistema Caracterização do sistema
Modelo do sistema
É fornecida a descrição do sistema
Classificação Feições dos objetos
Classe dos objetos
Associações entre feições e classes
O conjunto de classes é predefinido
Diagnóstico Sintomas, reclamações
Categoria da falha
Modelo de comportamento do sistema
O formato da saída varia dependendo do uso que será feito dele (relação de causa-efeito, estado, componente defeituoso).
Avaliação Descrição do caso
Classe de decisão
Critérios e normas
O aconselhamento é realizado em um instante determinado do tempo.
Monitoração Dados do sistema
Classe de discrepância
Comportamento normal ou esperado do sistema
O sistema se modifica ao longo do tempo. Tarefa é realizada repetidamente.
Predição Dados do sistema
Estado do sistema
Modelo de comportamento do sistema.
Estado de saída é uma descrição do sistema em algum momento no futuro.
As estruturas de inferência representam o método de solução de problemas para as principais tarefas de solução, sejam elas de análise ou de síntese. A Tabela 4.2 e a Tabela 4.3, extraídas de [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000] descrevem as principais tarefas de solução de problemas. A seguir, são apresentados as estruturas de inferência que especificam diagramaticamente alguns dos métodos de solução de problemas da biblioteca de Common KADS.
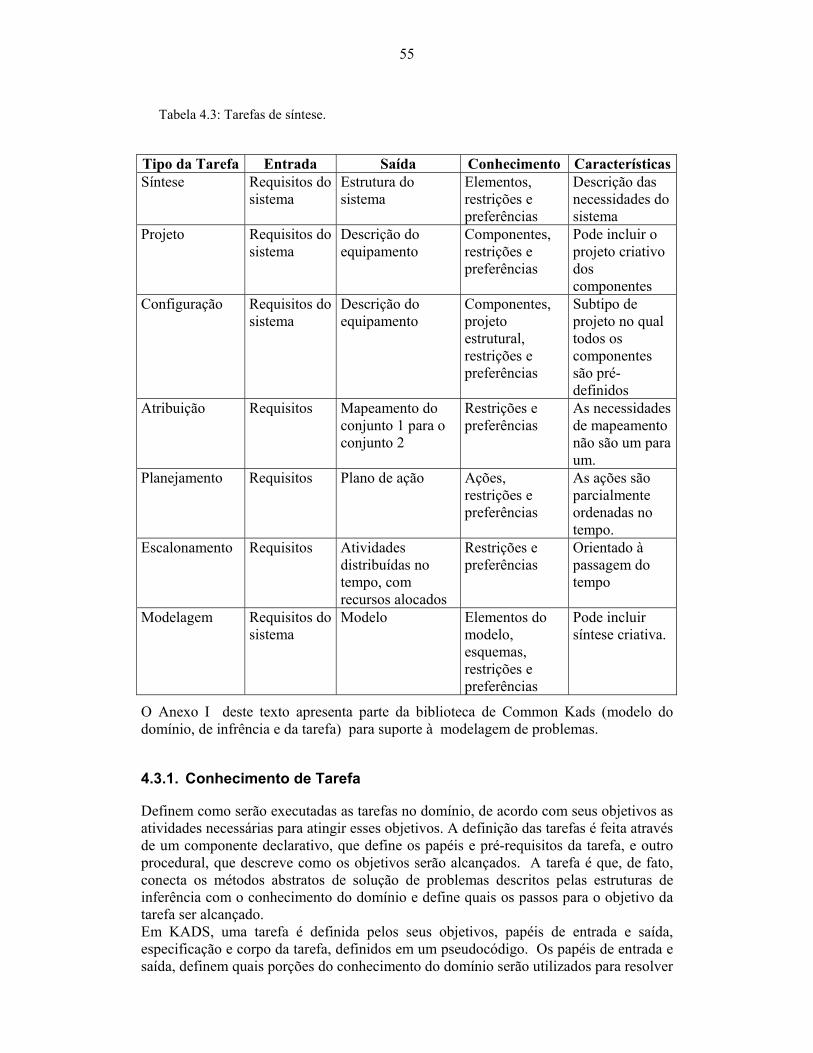
55
Tabela 4.3: Tarefas de síntese.
Tipo da Tarefa Entrada Saída Conhecimento CaracterísticasSíntese Requisitos do
sistema Estrutura do sistema
Elementos, restrições e preferências
Descrição das necessidades do sistema
Projeto Requisitos do sistema
Descrição do equipamento
Componentes, restrições e preferências
Pode incluir o projeto criativo dos componentes
Configuração Requisitos do sistema
Descrição do equipamento
Componentes, projeto estrutural, restrições e preferências
Subtipo de projeto no qual todos os componentes são pré-definidos
Atribuição Requisitos Mapeamento do conjunto 1 para o conjunto 2
Restrições e preferências
As necessidades de mapeamento não são um para um.
Planejamento Requisitos Plano de ação Ações, restrições e preferências
As ações são parcialmente ordenadas no tempo.
Escalonamento Requisitos Atividades distribuídas no tempo, com recursos alocados
Restrições e preferências
Orientado à passagem do tempo
Modelagem Requisitos do sistema
Modelo Elementos do modelo, esquemas, restrições e preferências
Pode incluir síntese criativa.
O Anexo I deste texto apresenta parte da biblioteca de Common Kads (modelo do domínio, de infrência e da tarefa) para suporte à modelagem de problemas.
4.3.1. Conhecimento de Tarefa
Definem como serão executadas as tarefas no domínio, de acordo com seus objetivos as atividades necessárias para atingir esses objetivos. A definição das tarefas é feita através de um componente declarativo, que define os papéis e pré-requisitos da tarefa, e outro procedural, que descreve como os objetivos serão alcançados. A tarefa é que, de fato, conecta os métodos abstratos de solução de problemas descritos pelas estruturas de inferência com o conhecimento do domínio e define quais os passos para o objetivo da tarefa ser alcançado. Em KADS, uma tarefa é definida pelos seus objetivos, papéis de entrada e saída, especificação e corpo da tarefa, definidos em um pseudocódigo. Os papéis de entrada e saída, definem quais porções do conhecimento do domínio serão utilizados para resolver

56
a tarefa e como essas porções serão modificadas para gerar as saídas. A especificação da tarefa descreve as dependências entre os papéis envolvidos (o que fica invariante, o que deve ser verdadeiro após a execução da tarefa, etc.). O corpo da tarefa é definido com base em sub-objetivos e estrutura de controle das subtarefas, ou seja, em que ordem e em que condições os sub-objetivos devem ser alcançados. A especificação de uma tarefa, usualmente contém:
• Um chamada de procedimento comum, como uma chamada de tarefa, de inferência ou uma função de transferência.
• Operações sobre os valores dos papéis do conhecimento, por exemplo, atribuir valor a um papel, adicionar valores a um papel, etc.
• Primitivas de controle usuais para iteração, como REPEAT-UNTIL, WHILE-DO, IF-THEN-ELSE.
• As condições usadas nas declarações de controle (UNTIL, IF...) são testes sobre valores dos papéis do conhecimento.
• Predicados para teste de condições produzidas durante a tarefa, como testar mais de uma solução para uma inferência (NEW-SOLUTION), ou se existe solução para um conjunto de parâmetros de inferência (HAS-SOLUTION).
Exercício Selecione um dos problemas e oportunidades detalhados no Modelo da Organização sobre o qual um dos membros do grupo tenha pleno conhecimento. Selecione UMA tarefa intensiva em conhecimento da OM-3. Detalhe os insumos de conhecimento necessários a solução da tarefa. Construa o modelo do conhecimento, com todos os subcomponentes detalhados, para esse problema. Entregue: 1. Modelo de Inferência para o problema específico selecionado para análise.O
modelo de inferência é composto de:
• diagrama da estrutura de inferência (inferências, papéis de conhecimento e fluxo de informação);
• descrição textual do diagrama de inferência utilizando a notação CML de CommonKADS. A descrição textual deve apresentar, assim como no exemplo do HousingApplication: (i) mapeamento dos papéis de domínio do diagrama para os conceitos do modelo do domínio (o qual é pedido a seguir) e (ii) descrição sucinta das ações executadas pelas inferências do diagrama (entradas, transformações e saídas).
2. Modelo do Domínio. Definição do conhecimento estático do domínio que suporta a tarefa escolhida. O modelo de domínio é composto de:
• esquema do domínio: descrição dos conceitos, atributos, relações, axiomas, tipos-regra que descrevem os objetos do domínio. O esquema deve ser representado visualmente (através da notação UML de CommonKADS) e textualmente, utilizando a notação CML 1.
• base de conhecimento: contém apenas as instâncias e regras necessárias para demonstração da inferência.
3. Modelo da Tarefa. Descrição de objetivos, papéis de entrada e saída, especificação da tarefa e detalhamento do controle, utilizando a notação CML 1.

57
5. Aquisição de Conhecimento [Motoda et al., 1991; Turban, 1992; Regoczei e Hirst, 1994] As técnicas de eliciação de conhecimento ajudam a reduzir os problemas de comunicação no processo de aquisição de conhecimento de fontes humanas. A seguir serão apresentadas e avaliadas as principais classes de técnicas de aquisição de conhecimento [Gardner; Rush; Crist; Konitzer; Teegarden, 1998]. Embora o especialista seja considerado a principal fonte de conhecimento por excelência, num projeto de sistema especialista, além do especialista, devem ser também entrevistados usuários potenciais do sistema, gerentes e outros profissionais detentores de partes do conhecimento envolvido na solução de problemas.
A aquisição de conhecimento é conduzida pelo engenheiro de conhecimento, que exerce o duplo papel de compreender o domínio da informação, para interagir com os detentores do conhecimento, e possuir o conhecimento necessário sobre computação, linguagens e ferramentas de inteligência artificial para selecionar o melhor ambiente e forma de implementar o sistema. As técnicas a seguir serão analisadas para o caso típico de construção de um sistema a partir do conhecimento obtido de um especialista, que possui reconhecidamente um desempenho superior na solução de problemas. Como o conhecimento desse tipo de profissional tende a ser mais tácito do que explícito, as técnicas de eliciação tendem a ser mais sofisticadas do que na coleta de requisitos para construção de sistemas de informação. Existem muitas outras técnicas além das descritas aqui, porém todas elas são construídas para extrair o componente declarativo do conhecimento e não o inferencial. Os métodos de solução de problemas e estruturas de inferência ainda são extraídos por métodos ad hoc, baseados em entrevistas e observação do comportamento do tomador de decisão ou, no caso de domínios complexos, através de experimentos que busquem evidenciar o comportamento cognitivo do especialista.
5.1. Entrevistas
É o método mais comum e tradicional para eliciar conhecimento. Corresponde à técnica inicial de qualquer projeto de Engenharia de Conhecimento, onde o engenheiro de conhecimento conversa diretamente com o especialista, questionando diversos aspectos envolvidos na solução de problemas naquele domínio. O processo de entrevista, no entanto, sempre fornece um conjunto incompleto de informações, independente dos cuidados com que é realizada. A qualidade dos resultados varia em função das habilidades de comunicação do entrevistado e da experiência e capacidade de compreensão do entrevistador, qualidades que raramente andam juntas.
Do ponto de vista cognitivo, as entrevistas têm por objetivo:
• alcançar alguma familiaridade com o especialista, de modo a conhecer seus métodos usuais de raciocínio, vocabulário e características pessoais que possam interferir na aquisição de conhecimento (timidez, falta de objetividade, comunicação obscura);
• obter compreensão sobre o funcionamento do domínio;
• coletar fatos do domínio.

58
As primeiras entrevistas são ditas não-estruturadas, onde questões muito gerais são perguntadas para o especialista que é deixado responder livremente. As questões comuns para esse tipo de entrevista são:
Quais as expectativas a respeito desse projeto?
Qual é o problema a ser resolvido? Como é reconhecido?
Como é resolvido?
A partir da compreensão inicial do problema, são realizadas as entrevistas dirigidas, Onde as perguntas referem-se a um assunto previamente definido, que é particularmente analisado. Exemplos de tópicos a serem estudados são:
• identificação dos processos principais envolvidos na aplicação;
• definição do nível do conhecimento esperado no usuário do sistema;
• definição do detalhamento (granularidade) das informações a serem modeladas;
• especificações gerais do sistema a ser proposto;
• expectativas de interface do sistema.
As entrevistas estruturadas são projetadas para eliciar fatos precisos da aplicação, em detalhes. Seguem um formato ou estrutura pré-definida. Exemplos das questões para esse tipo de entrevista podem ser:
Descreva os passos para a identificação do defeito mencionado.
Quais são as entradas necessárias nesse processo?
Quais desses termos estão relacionados ao equipamento X?
Entrevistas são inevitáveis num processo de aquisição de conhecimento e têm a vantagem de estabelecer rapidamente uma ligação entre o engenheiro de conhecimento e especialista. Não é possível, no entanto, basear todo o processo de eliciação em entrevistas, embora pareça ser possível nas etapas iniciais. Alguns dos problemas típicos da obtenção de informação por entrevistas são discutidos a seguir.
Descrições verbais sempre são tendenciosas e incompletas. O especialista explica o processo de solução de problema da forma como ele acha que acontece, ou da forma que seja mais fácil para o entrevistador compreender, não da forma como efetivamente acontece.
O processo de comunicação não depende apenas do emissor, no caso, do especialista, mas também da capacidade do receptor, o engenheiro de conhecimento, de decodificar a informação. Mesmo que se parta do princípio de que o engenheiro de conhecimento deve ser treinado a ser imparcial na captação do conhecimento, a completa isenção de julgamento é humanamente impossível de ser atingida.
Para grande parte dos domínios, uma parte do conhecimento simplesmente não tem tradução verbal, logo não é explicitado através de entrevistas. Essa dificuldade é tanto maior quanto mais sensório for o domínio. Nesse caso, o especialista desenvolve padrões de reconhecimento visual, táctil ou auditivo e os aplica de forma inconsciente para caracterizar o problema e identificar os caminhos de solução possíveis.
Entrevistas devem ser utilizadas nas fases iniciais da aquisição de conhecimento, nunca como técnica única. Com elas é possível identificar o escopo da aplicação, o tipo de

59
domínio do conhecimento e planejar os próximos passos no processo de aquisição, bem como apontar para as técnicas de eliciação mais adequadas para as etapas subsequentes.
5.2. Análise de Protocolos
É uma técnica que visa obter informações detalhadas a respeito do processo particular de solução de problemas. Considerando o problema em foco, por exemplo o diagnóstico de falha num equipamento, normalmente o processo é decomposto em subprocessos - analisar a possibilidade de falha em cada componente do equipamento - e a análise de protocolo é aplicada para cada uma das partes, devido a complexidade da informação obtida.
O especialista deve ter em mente as seguintes questões:
Qual meu objetivo nesse processo?
Quais são os métodos aplicados?
O que estou vendo/procurando com este processo?
O especialista executa o processo e, durante a solução, verbaliza seus pensamentos de forma a que sejam registrados. As entrevistas são gravadas e filmadas para posterior análise. A partir da análise de protocolos, as listas de termos do domínio são extraídas, as taxonomias de domínio são propostas e validadas pelo especialista, e algumas regras e fatos do domínio podem ser reconhecidos. A eficácia da análise de protocolos tem sido demonstrada em vários estudos [Ericsson e Simon, 1980] e é uma técnica onipresente no processo de aquisição de conhecimento ou análise cognitiva em diversos domínios.
As vantagens da aplicação dessa técnica devem-se principalmente a:
• processo real de solução é analisado, ao contrário das descrições estilizadas feitas posteriormente ao momento de solução de problema. [Abel, 1988] demonstrou que existem grandes diferenças entre o processo descrito pelo especialista e aquele efetivamente realizado por ele;
• registro da entrevista permite uma análise posterior mais cuidadosa, que permite reconhecer os termos mais utilizados ou com mais freqüência;
• ausência de um intervalo entre a solução de problema e posterior descrição pelo especialista, evitando distorções;
• a análise é feita com o nível de detalhe adequado à solução;
• as informações incompletas são facilmente identificadas;
• a utilização de informações não-verbalizáveis é evidenciada na seqüência do processo.
A análise de protocolos, no entanto, tem limitações significativas:
• nas as atividades que não seguem uma seqüência linear de solução;
• em algumas situações que simplesmente não permitem a verbalização durante o processo de solução;
• em aplicações que envolvam atividades motoras ou sensórias;

60
• pelo alto custo envolvido na aplicação da técnica e por ser altamente consumidora de tempo.
Uma característica da verbalização durante o processo de solução foi reconhecida em diversos experimentos que utilizaram análise de protocolos: o especialista interrompe a verbalização da solução quando a solução torna-se não trivial, ou quando há necessidade de buscar caminhos alternativos de solução. As heurísticas utilizadas nesses momentos são importantes e devem ser posteriormente investigadas através de entrevistas.
5.3. Classificação de Termos
Refere-se a um conjunto de técnicas que visa a identificação e organização de termos ou conceitos e seus relacionamentos num domínio particular, segundo a visão do especialista. Uma lista de termos do domínio é obtida a partir das entrevistas iniciais ou extraída da análise de protocolos.
A técnica mais conhecida, a de classificação de fichas [Wright e Ayton, 1987], consiste em escrever cada um desses termos num cartão e solicitar ao especialista que divida sucessivamente esses grupos de cartões em dois ou três grupos segundo o critério que desejar. O especialista deve incluir termos que deveriam estar presentes ou retirar aqueles que não tem utilidade para o raciocínio. Essa técnica evidencia a classificação dos objetos, as hierarquias e outras descrições estáticas dos objetos do domínio.
O engenheiro de conhecimento escreve os nomes dos objetos listados na análise preliminar em fichas separadas. Apresenta o conjunto das fichas ao especialista, solicitando que ele os separe em dois grupos, explicando o critério de separação. Na Figura 5.1, o especialista deveria separar os objetos carro, pardal, barco, gato, ônibus e trem. Une as fichas novamente e solicita que novamente que separe em dois grupos utilizando outro critério, até que não existam mais critérios de separação. Nesse caso, um dos grupos é selecionado, como na Figura 5.2, e reinicia o processo.
Figura 5.1: O especialista separa um conjunto de objetos em dois segundo o critério "veículos e animais".

61
Figura 5.2: O especialista separa o conjunto 1 do exemplo 2.2 em dois conjuntos segundo o critério "veículos terrestres - veículos aquáticos".
Durante a classificação, o especialista irá retirar alguns objetos por serem sinônimos ou irrelevantes, e irá incluir outros que, segundo seu critério, estão ausentes. Ainda, ficará evidente a hierarquia dos objetos e a divisão dos objetos (conhecimento descritivo) e das regras (conhecimento procedimental), fornecendo subsídio para a organização das informações em uma das formas de representação de conhecimento disponíveis. Os resultados obtidos com as técnica de classificação de termos são o reconhecimento da hierarquia do domínio, a obtenção de termos não evidenciados através de entrevistas, o reconhecimento de conceitos que são sinônimos (um objeto mencionado com dois nomes diferentes) além de uma melhor compreensão global do domínio. A técnica é particularmente útil em domínios onde os métodos de solução de problemas são especialmente de classificação. Mesmo nesses casos, a aplicação torna-se difícil nos domínios muito complexos onde um número excessivamente grande de termos pode inviabilizar o uso de cartões. A prática aponta que os melhores resultados são obtidos quando a técnica é aplicada sobre menos do que uma centena de conceitos. Resultados medíocres são também obtidos em domínios excessivamente procedimentais, onde a explicitação das hierarquias de termos não parece fazer senso ao especialista.
5.4. Focalizando Contextos ou Cenários
Contextos ou cenários são casos de teste tanto reais quanto criados especialmente para enfatizar algum aspecto do problema. O engenheiro de conhecimento apresenta problemas definidos ao especialista e solicita que ele os resolva. As condições podem ser alteradas dinamicamente de forma a evidenciar os pontos essenciais do método aplicado. Quando os cenários refletem aspectos reais do domínios e são construídos para evidenciar particularidades dos processo de solução, esse método permite equacionar as necessidades de tratamento de incerteza nos métodos do especialista, definir prioridade de regras e tratamento de informações incompletas.

62
5.5. Observação
Observação corresponde a técnica de assistir o especialista enquanto este está executando uma tarefa, tanto real como simulada. A observação pode incluir ou não a possibilidade de interrupção. No primeiro caso, o engenheiro de conhecimento pode interromper o especialista durante o processo de solução para fazer perguntas ou tirar dúvidas. No segundo caso, irá apenas tomar notas ou filmar, sem nenhuma intervenção no processo. A experiência demonstra que a qualidade da observação é melhor no processo sem interrupção, desde que essa altera o caminho natural de raciocínio do especialista, que possivelmente prosseguirá na tarefa utilizando métodos mais compreensíveis ao observador, porem não os mais eficientes.
A técnica da observação tem a vantagem de garantir uma visão realista do processo de solução no ambiente onde ele ocorre, raramente obtida através de entrevistas. Nessa situação, o processo tende a mostrar-se mais simples (mas não mais claro) do que descrito pelo especialista. Nem sempre, no entanto, é possível realizar a observação direta. Outro problema é que assistir o processo de decisão não permite compreender porque as decisões foram tomadas, o que é essencial na aquisição de conhecimento. As razões devem ser questionadas posteriormente através de entrevistas.
5.6. Recuperação de Eventos
Essa técnica é utilizada para recuperar casos não triviais de solução de problemas. O especialista é convidado a descrever uma situação particular pela qual passou e qual a solução proposta. A recuperação de eventos só é efetiva para reconstruir situações de exceção, uma vez que os indivíduos tendem a esquecer situações que repetem-se diariamente e armazenar apenas aquelas que foram não usuais. Quando convidados a descrever uma situação do dia a dia, o especialista irá construir a ocorrência a partir do modelo (ou script) daquela situação construído pela experiência e não lembrar-se de uma situação já vivida. A técnica é adequada para complementar o modelo do conhecimento em relação a situações possíveis mais não usuais, ou ainda para identificar os limites do processo de solução.
5.7. Grafos de Conhecimento
A técnica de grafos de conhecimento, como uma técnica de eliciação de conhecimento foi proposta por [Leão, 1988; Leão e Rocha, 1990], para caracterização da perícia na identificação de cardiopatias congênitas.
Um grafo de conhecimento é uma árvore AND/OR com três tipos de nodos:
• nodos de hipóteses, que representam as hipóteses de interpretação consideradas no grafo;
• nodos de evidências, que representam as diferentes características que suportam a interpretação, propostas pelo engenheiro de conhecimento ou incluído pelo especialista e dispostos em ordem de importância no grafo;
• nodos intermediários que representam diferentes agrupamentos de evidências utilizados pelo especialista para resolver o problema.
A técnica de aquisição de conhecimento pode ser descritas através dos seguintes passos:

63
1. Coleta e definição de uma lista de evidências (sintomas, sinais, falhas, reclamações, etc.), obtidas da literatura e daqueles mencionados pelos especialistas, normalmente na ordem de uma centena de evidências.
2. Identificação do conjunto existente de soluções possíveis para o problema em estudo.
3. O especialista é solicitado a selecionar entre as evidências coletadas, aquelas associadas a cada uma das soluções. Novos evidências poder ser acrescidos à lista.
4. As evidências devem ser, por sua vez, ordenadas de acordo com sua ordem de importância decrescente para aquela solução.
5. A construção do grafo é realizada por colocar as evidências ordenadas na base do grafo e a solução no topo ou raiz do grafo.
6. O especialista deve mostrar graficamente as associações entre as evidências para suportar a solução, criando, se necessário, os nodos intermediários que representam essas associações. Se uma única evidência é capaz de suportar a solução, uma única linha ligará essa evidência à solução (como a evidência de peso 7 da Figura 5.3). Se esse evidência só for significativa se associada a outras evidências, essa associação será representada através de um nodo intermediário com conexões para cada uma das evidências e uma única conexão até o nodo de solução, como demonstrado pelas três primeiras evidências do grafo da Figura 5.4 (Extraído de [Leão, 1988]).
7. Após a construção do grafo, são atribuídos índices de significância, na escala de 0 a 10, para cada um dos nodos de evidência e nodos intermediários. Esses índices devem representar a confiança do especialista na solução representada, caso apenas a evidência ou as evidências representadas por aquele nodo fossem encontradas.
Os grafos de conhecimento possuem maior poder de expressão quando comparados com regras de produção, ao permitirem que sejam expressados, não apenas as evidências que levam às conclusões, mas também como essas evidências se combinam para indicar determinada conclusão e o quanto elas influenciam, individual ou coletivamente, para confirmar uma determinada hipótese.
Figura 5.3: Grafo de conhecimento representando como as evidências são combinadas para sugerir um diagnóstico clínico.
DIAGNÓSTICO
(9) (8) (8)
Evidência
Índice
Índice da combinação das
evidências

64
Assim como regras, não está implícito nos grafos de conhecimento a forma como eles serão aplicados para atingir uma determinada conclusão, ou seja, de que forma o raciocínio deve ser desenvolvido. Grafos expressam apenas como determinadas informações disponíveis no modelo do domínio estão relacionadas a uma determinada conclusão.
5.8. Análise de Casos
Casos são registros de problemas resolvidos no domínio, que contém uma descrição do problema e a solução proposta. Esse registro pode ser uma relação da reclamação de um cliente em um help desk, com a descrição de qual solução foi encaminhada. Pode ser um registro de falha em um sistema e a respectiva ação de correção. Um caso corresponde ainda aos dados financeiros de um cliente e o crédito que lhe foi disponibilizado, entre outros.
O estudo de casos resolvidos, quando eles estão disponíveis, permite obter uma série de informações sobre o problema: nível de conhecimento do usuário, recursos envolvidos, complexidade da solução, entre outros. Os casos são particularmente úteis para que sejam coletados os termos do domínio, pois refletem exatamente o vocabulário utilizado na solução de problemas. Ainda, os casos são instâncias reais do processo de solução de problema, permitindo antever quais informações suportam a inferência e de que forma essa é realizada.
Os casos coletados são divididos aleatoriamente em dois grupos. O primeiro grupo é utilizado para a análise, de onde serão extraídos os termos do domínio e formas de inferência. O segundo grupo será utilizado nos estágios finais de desenvolvimento para o teste e validação do sistema.
Se existirem casos corretos e completos em número suficiente para garantir uma boa cobertura do domínio, a abordagem de raciocínio baseado em casos [Watson, 1997], deve ser considerada como uma alternativa.

65
6. Construção do Modelo Não existe uma forma definida pela qual um modelo de conhecimento possa ser construído com sucesso. Cada área do conhecimento tem suas necessidades e particularidades e portanto irá necessitar de atividades adequadas às suas características. Qualquer modelo de conhecimento passa, no entanto, por alguns estágios na sua construção, que serão descritos a seguir.
6.1. Identificação do conhecimento
São identificadas as fontes de informação e é construído um glossário preliminar de termos. A construção do modelo da organização e a caracterização da tarefa da aplicação (diagnóstico, configuração, etc.) constituem o suporte para a identificação do conhecimento.
Atividades:
• Familiarização com o domínio: listas todas as fontes de conhecimento e caracterizá-las, resumo dos textos-chave a respeito do problema ou tarefa, seleção e ideentificação de cenários representativos do domínio, coleta de casos, se houverem.
• Listar componentes potenciais do modelo: identificar tipo da tarefa (diagnóstico, monitoração?) e do domínio (técnico, excessivamente simbólico, muitas heurísticas?)
6.2. Especificação do conhecimento
Esse estágio corresponde a especificação completa do modelo do conhecimento. Existem duas abordagens possíveis.
Em uma delas, uma tarefa detalhada no modelo da organização é escolhida e, a partir das necessidades de conhecimento para a estrutura de inferência, o esquema do conhecimento é especificado. Esse esquema irá partir dos conceitos coletados no glossário obtido na fase de identificação do conhecimento e será gradativamente completado através de aquisição de conhecimento. Outra abordagem possível é partir da especificação do conhecimento do domínio e da tarefa e identificar as estruturas de inferências capazes de relacioná-los. A escolha da melhor abordagem irá depender da qualidade da especificação da tarefa nos estágios anteriores e de sua compreensão.
O objetivo deste estágio é a construção do esquema do conhecimento, não da base de conhecimento. A especificação das instâncias do conhecimento será realizada no próximo estágio.
Atividades:
• Escolher a estrutura de inferência a partir de uma biblioteca disponível. Verificar se as entradas e saídas desta estrutura são adequadas ao problema. Coloque “anotações” nos papéis do conhecimento relacionando-os às instâncias da base de conhecimento. Adapte a estrutura para as necessidades do domínio, se necessário.
• Construção do esquema inicial do domínio. Defina os conceitos e termos do domínio e construa as hierarquias e partonomias desses conceitos necessárias a

66
solução da tarefa. Parta dos conceitos de abstração já definidos, especificando outros apenas quando a semântica for essencial.
• Completar a especificação do modelo do conhecimento. Pode-se partir da inferência e definir os conceitos (melhor), ou partir dos conceitos e identificar a inferência (possível quando casos foram obtidos na fase de aquisição).
6.3. Validação do Conhecimento
O estágio final volta-se à validação do conhecimento, tanto quanto possível, e a inclusão de instâncias do conhecimento na base de conhecimento. O processo de coleção das instâncias do conhecimento tende ser moroso e envolve outras fontes de informação alem de humanas, como bases de dados, manuais, catálogos, fontes oficiais e públicas, etc.
A validação do modelo é realizada através do teste do modelo e da base de conhecimento utilizando cenários (ou contextos) obtidos na fase de identificação do conhecimento. Outra forma possível é a utilização de casos já resolvidos coletados no estágio de identificação do conhecimento e previamente separados sem análise para teste. A validação pode exigir a construção de um protótipo para avaliar o comportamento de inferência e de interação do sistema, antes da coleta do número de instâncias necessárias ao seu funcionamento.
Atividades: • Validar o modelo do conhecimento através de uma simulação no papel, utilizando
casos previamente reservados para teste, ou através de um protótipo construído apenas para validar a base.
• Completar a base de conhecimento incluindo instâncias necessárias a execução da tarefa em questão.

67
7. Projeto do Sistema Os requisitos de solução de problemas coletados no modelo do conhecimento, associados ao modelo de comunicação e as restrições organizacionais e de ambiente definem o projeto do sistema, segundo a visão de Common KADS aqui descrita [Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000]. O Modelo do Projeto descreve a estrutura do sistema necessário para suprir esses requisitos, em termos de subsistemas, componentes de software e mecanismos computacionais, considerando o ponto de vista do software e não da aplicação, estes considerados na construção do modelo do conhecimento e de comunicação. Naturalmente, projetar um sistema de conhecimento segue as mesmas diretrizes da engenharia de software aplicadas ao projetar qualquer sistema complexo.
O projeto de um sistema de conhecimento é essencialmente um projeto de preservação da estrutura. Isso significa que a relação entre os construtos de comunicação e de conhecimento, coletados na fase de análise, devem ser facilmente recuperados nos componentes da arquitetura. Por exemplo, conceitos e inferências eliciados do domínio na fase de aquisição devem ter um seja possível mapear o modelo do conhecimento em uma arquitetura baseada em regras, como nos sistemas especialistas de primeira geração, tal projeto irá provocar a perda da distinção entre os diferentes tipos de conhecimento, o que reduz as possibilidades de manutenção e reuso do sistema.
A construção do projeto do sistema deve ser visto como um detalhamento sobre os demais modelos, adicionando detalhes de implementação. As decisões de projeto definem aspectos deixados em aberto durante a fase de análise, como definição de tipos e estruturas de dados, métodos computacionais para realizar as inferências, dinâmica do armazenamento de dados e meios de comunicação entre módulos e sistemas (redes, pessoas, arquivos, etc.). A vantagem dessa abordagem é que o modelo de comunicação e de conhecimento servem como uma documentação de alto nível da implementação, permitindo que os componentes do sistema sejam facilmente identificados, no caso de ser necessária uma modificação sobre algum dos componentes de modelo.
Os critérios de qualidade para um projeto de sistema são:
• Reusabilidade do código. Como o objetivo de cada um dos componentes do sistema é explícito e ligado a uma função do conhecimento, aumenta a possiblidade de reuso de código do sistema em futuras aplicações.
• Manutenção e adaptabilidade. A preservação da estrutura do modelo de análise, ou seja, a correspondência entre objetos do modelo (conceitos, regras, inferências) e objetos da implementação, permite recuperar inconsistências no modelo implementado. Isso facilita tanto a identificação de erros como a expansão por adição de novos componentes.
• Explicação. Uma feição típica de sistemas de conhecimento é a necessidade de fornecer explicações sobre o processo de tomada de decisão. A preservação da estrutura permite recuperar, para cada pedaço do conhecimento, quais os passos elementares de solução de problema são realizados e que papéis esse conhecimento cumpre na inferência, além de ser possível recuperar quando e porque esse conhecimento é utilizado para resolver um problema particular. Essas feições são normalmente suficientes para construir um sistema de explicação.
• Suporte à aquisição do conhecimento. A manutenção da relação entre componentes de software e do conhecimento facilita a construção de módulos de

68
suporte a aquisição de conhecimento. Por exemplo, podem ser contruídos editores específicos para a entrar instâncias de determinados tipos de conhecimento, ou depuradores semânticos que verifiquem a consistência da estrutura de representação.
A definição do projeto do sistema passa por uma seqüência de passos, em três etapas de especificação progressiva:
Etapa 1: Especificação dos componentes da arquitetura Aqui são detalhados os componentes da arquitetura do sistema, segindo a arquitetura de referência descrita na Figura 7.1, quais sejam:
- o módulo de controle: qual o componente de software controla os outros? No caso de um sistema desenvolvido em Java, qual a classe principal (main)? O módulo de controle deve evitar ao máximo as opções de interrupção e concorrência no desenvolvimento da aplicação;
- base de conhecimento: inclui a forma de definição dos tipos e regras (tabelas? arquivos?). Foram definidas funções de edição da base de conhecimento pelo usuário?
- base de dados: qual componente armazena as informações do usuário, entradas pelo usuário ou produzidas pelo sistema;
- visões e interfaces: componentes que realizam a interação com o usuário e com outros sistemas e como o sistema vai apresentar os dados gerados por inferência para os diferentes usuários e sistemas externos através de suas interfaces (interface visual? texto?)
Figura 7.2 – Arquitetura de referência de Common KADS.
Controle gerência das entradas dos
agentes externos e das funções dos agentes internos
Visões fornece as saídas para os agentes
externos (interface do
usuário e consultas de BD)
Modelo da Aplicação funções de raciocínio (tarefas,
inferências), esquema do domínio e bases de conhecimento
Entradas do usuário Sensores Bancos de
dados
Interface do usuárioInterface
do sistema externo
chamadas de funções
registro do resultado
atualizações acesso à informação
visões

69
Etapa 2: Definição da plataforma de desenvolvimento. Em princípio, uma aplicação pode ser completamente especificada sem que seja conhecida a plataforma onde será implementada. Porém, na prática, as restrições impostas por uma definição de plataforma podem dificultar o projeto do sistema. Se não houver restrições, a escolha da plataforma pode ser definida de acordo com as necessidades dos componentes da arquitetura. Alguns fatores devem ser considerados na plataforma escolhida:
- Facilidade para representação de conhecimento declarativo.
- Interfaces padrão para outros sistemas, como ODBC para banco de dados e CORBA para sistemas distribuídos.
- Linguagem tipada. Restrições de tipos, impostas pelas linguagens de programação, dificultam o trabalho inicial de programação, mas garantem a integridade dos dados na transferência entre os sistemas.
- Fluxo de controle. Facilidades como passagem de mensagens ou múltiplos threads de controle facilitam o desenvolvimento do sistema.
- Facilidades específicas para o desenvolvimento de sistemas de conhecimento
Alguns ambientes tradicionalmente utilizados para o desenvolvimento dos sistemas especialistas, como Lisp e Prolog, garantem facilidades de modelagem do conhecimento declarativo, mas a falta de tipagem dos dados dificulta a integração com outros sistemas e a manutenção de integridade desses dados. Ambientes orientados a objeto, como Java, fornecem bibliotecas para modelar os componentes do conhecimento, porém não permitem muita flexibilidade nas definições do projeto. Ambientes orientados a objeto e que disponibilizem componentes da arquitetura CommonKADS permitem um desenvolvimento rápido e com potencial reusabilidade de componentes, porém existem poucas opções desses ambientes e estes não foram ainda completamente testados.
Etapa 3: Detalhamento do projeto da aplicação - A definição de como os dados dinâmicos da aplicação são manipulados: entrada
do usuário por demanda do sistema? Todas entradas do usuário no início do programa? Entrada por arquivo?
- a implementação do conhecimento de tarefa: qual o componente de software vai implementar o conhecimento de tarefa, o qual basicamente, chama as inferências passando como parâmetro as informações dos papéis de conhecimento?
- a implementação das inferências: quais componentes de software vão representar as inferências definidas no conhecimento de inferência?
- a implementação do conhecimento de domínio: quais componentes de software vão representar os conceitos, tipos-regra, relações? Como são implementados os atributos desses objetos? Quais os tipos de dados usados? Qual o procedimento de acesso a esses dados?

70

71
ANEXO I
Biblioteca de Tarefas de CommonKads
Adaptado de [Schreiber, 2000]
1. Primitivas de Inferência de CommonKADS
Inferência Significado Abstrai A entrada é um conjunto de dados e a saída é um modelo abstrato
daqueles dados. Avalia A entrada é um conjunto de dados e uma norma e a saída é um valor-
verdade indicando se os dados se adeqúam a norma. Classifica A entrada é um conceito e a saída é a classe a qual o conceito
pertence. Cobre A entrada é um efeito e a saída é o estado do sistema que deve ter
causado esse defeito. Combina A entrada é um conjunto de dados e a saída é uma organização
coerente destes dados. Compara A entrada são dois valores e a saída é um valor verdade, definindo se
eles são iguais ou diferentes. Confronta A entrada são dois conjuntos de dados e a saída é uma medida de
similaridade entre os dois conjuntos de dados. Decompõe A entrada é um conceito único e a saída é o conjunto das partes que o
compõe. Especifica A entrada é um objeto e a saída é um novo objeto associado de alguma
maneira com o objeto da entrada. Gera A entrada é uma descrição (detalhes de um sistema, requisitos) e a
saída é uma solução, de acordo com um conjunto de normas. Ordena A entrada é um conjunto de dados e a saída são os dados ordenados
segundo algum critério. Seleciona A entrada é um conjunto de dados e a saída é um elemento ou
subconjunto desses dados.

72
2. Estruturas de Inferências [Schreiber, 2000]
2.1. Classificação Objetivo: A classificação estabelece a classe ou categoria correta de um objeto. O objeto deve estar disponível para inspeção, já que a classificação é baseada nas suas características. A classificação pode ser buscada dirigida por hipóteses ou por dados. Nesse exemplo, a descrição é dirigida por hipóteses. São geradas um conjunto de classes-candidatas, que são posteriormente “podadas” pelo raciocínio até restar a classe-solução.
Exemplo Típico: Classificação de uma maçã, classificação de minerais em uma rocha;
Entrada: O objeto com suas classes já estabelecidas;
Saída: As classes encontradas.
2.1.1. Estrutura de inferência
Figura A.1: Estrutura de inferência para o método de classificação (extraído de [Schreiber, 2000]).
candidato
valor verdade
objeto atributo
característica
gera
especifica
compara
obtém
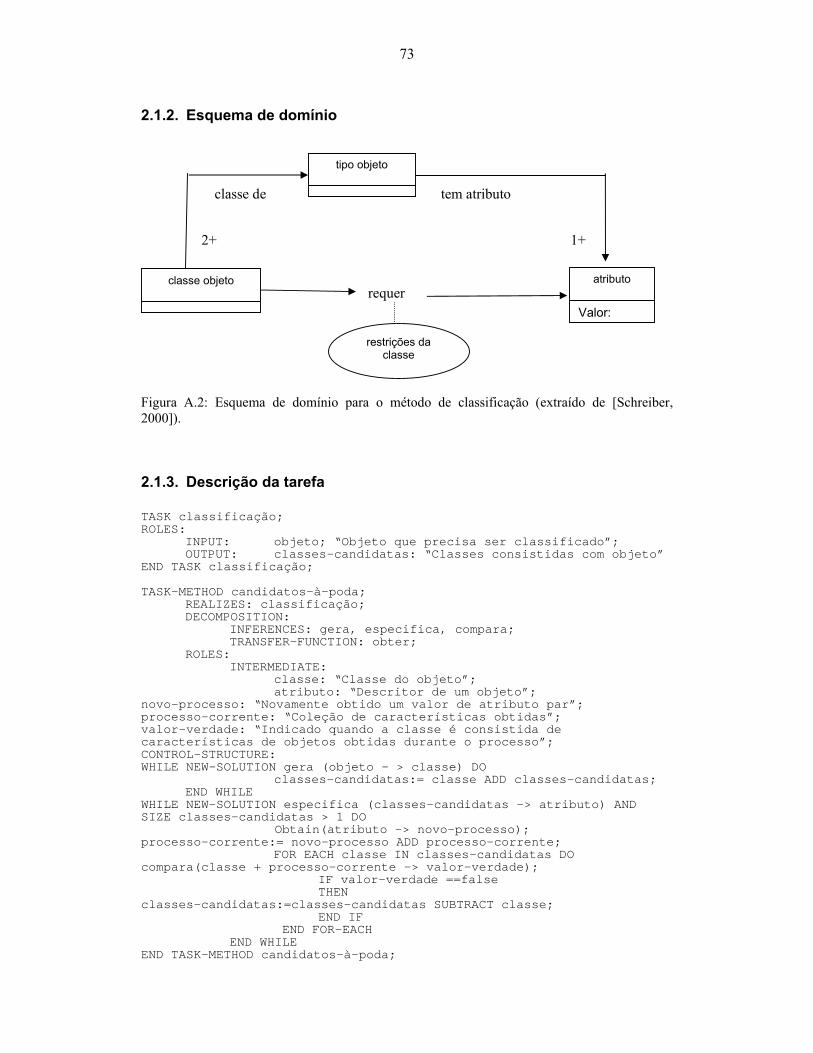
73
2.1.2. Esquema de domínio
Figura A.2: Esquema de domínio para o método de classificação (extraído de [Schreiber, 2000]).
2.1.3. Descrição da tarefa TASK classificação; ROLES: INPUT: objeto; “Objeto que precisa ser classificado”; OUTPUT: classes-candidatas: “Classes consistidas com objeto” END TASK classificação; TASK-METHOD candidatos-à-poda; REALIZES: classificação; DECOMPOSITION: INFERENCES: gera, especifica, compara; TRANSFER-FUNCTION: obter; ROLES: INTERMEDIATE: classe: “Classe do objeto”; atributo: “Descritor de um objeto”; novo-processo: “Novamente obtido um valor de atributo par”; processo-corrente: “Coleção de características obtidas”; valor-verdade: “Indicado quando a classe é consistida de características de objetos obtidas durante o processo”; CONTROL-STRUCTURE: WHILE NEW-SOLUTION gera (objeto - > classe) DO classes-candidatas:= classe ADD classes-candidatas; END WHILE WHILE NEW-SOLUTION especifica (classes-candidatas -> atributo) AND SIZE classes-candidatas > 1 DO Obtain(atributo -> novo-processo); processo-corrente:= novo-processo ADD processo-corrente; FOR EACH classe IN classes-candidatas DO compara(classe + processo-corrente -> valor-verdade); IF valor-verdade ==false THEN classes-candidatas:=classes-candidatas SUBTRACT classe; END IF END FOR-EACH END WHILE END TASK-METHOD candidatos-à-poda;
tipo objeto
atributo
Valor:
classe objeto
restrições da classe
tem atributo classe de
2+ 1+
requer
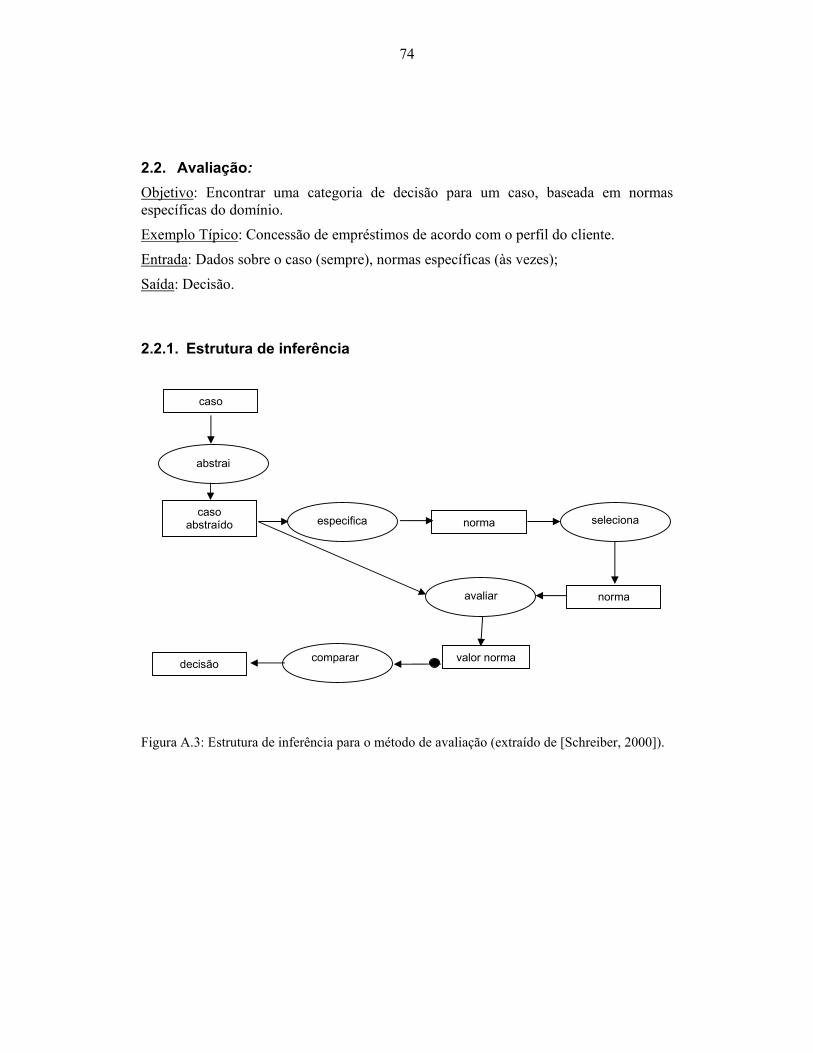
74
2.2. Avaliação: Objetivo: Encontrar uma categoria de decisão para um caso, baseada em normas específicas do domínio.
Exemplo Típico: Concessão de empréstimos de acordo com o perfil do cliente.
Entrada: Dados sobre o caso (sempre), normas específicas (às vezes);
Saída: Decisão.
2.2.1. Estrutura de inferência
Figura A.3: Estrutura de inferência para o método de avaliação (extraído de [Schreiber, 2000]).
caso abstraído
valor norma
caso
norma
norma
abstrai
especifica seleciona
avaliar
comparar decisão

75
2.2.2. Esquema de domínio
Figura A.4: Esquema de domínio para o método de avaliação (extraído de [Schreiber, 2000]).
2.2.3. Descrição da tarefa TASK avaliação; ROLES: INPUT: descrição-caso: “O caso para ser avaliado”; OUTPUT: decisão: “o resultado da avaliação do caso ” END TASK avaliação; TASK-METHOD avaliação-com-abstração; REALIZES: avaliação; DECOMPOSITION: INFERENCES: abstrai, especifica, seleciona, avalia, compara; ROLES: INTERMEDIATE: caso-abstraído: “Os dados brutos mais as abstrações”; normas: “Conjunto de normas para avaliação”; norma: “Uma única norma de avaliação” valor-norma: “Valor verdade da norma para este caso”; avaliação-resultados: “Lista da normas avaliadas”; CONTROL-STRUCTURE: WHILE HAS-SOLUTION abstrai( descrição-caso -> caso-abstraído) DO descrição-caso:= caso-abstraído; END WHILE especifica (Caso-abstraído -> normas); REPEAT seleciona(normas-> norma) ; avalia (Caso-abstraído +norma -> Valor-Norma); resultados-da-avaliação:= valor-norma ADD resultados-da-avaliação; UNTIL HAS-SOLUTION compara(Resultados-da-avaliação -> decisão); END REPEAT END TASK-METHOD avaliação-com-abstração;
Caso Padrão
Decisão
Caso
Caso padrão Valor:
Regra de abstração
Requisitos
tem
indica
implica
norma valor-verdade:
boolean
Regra de decisão
1+
1+
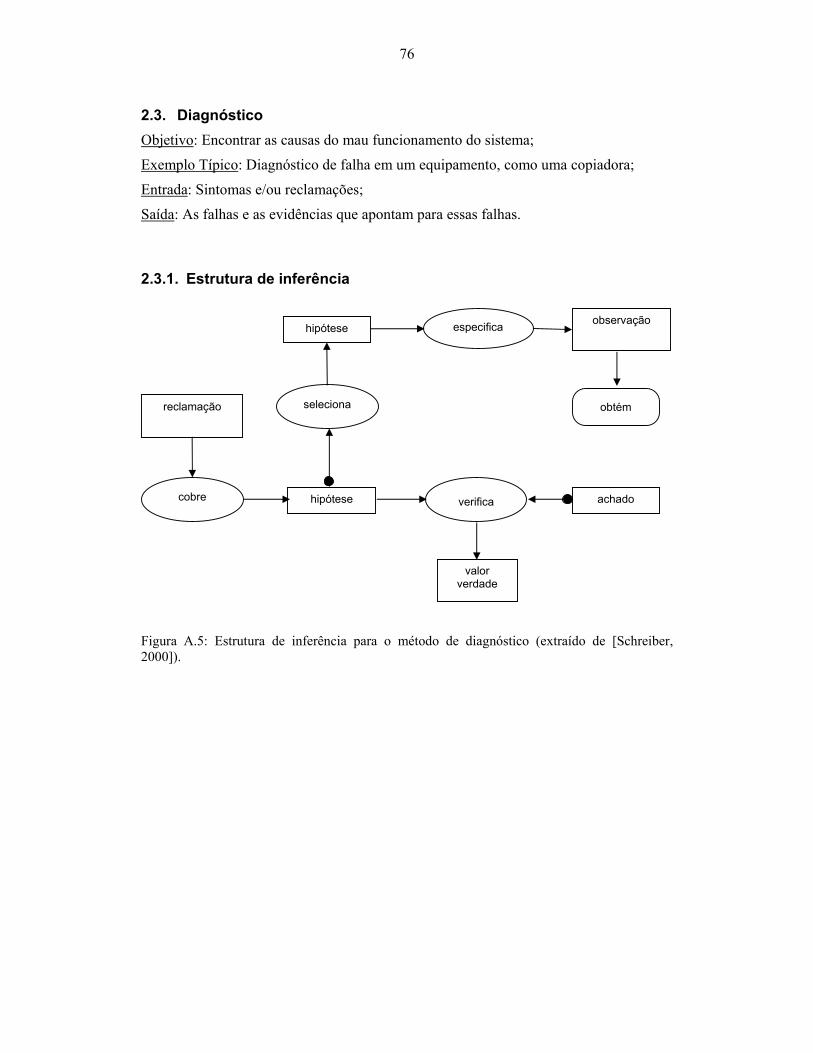
76
2.3. Diagnóstico Objetivo: Encontrar as causas do mau funcionamento do sistema;
Exemplo Típico: Diagnóstico de falha em um equipamento, como uma copiadora;
Entrada: Sintomas e/ou reclamações;
Saída: As falhas e as evidências que apontam para essas falhas.
2.3.1. Estrutura de inferência
Figura A.5: Estrutura de inferência para o método de diagnóstico (extraído de [Schreiber, 2000]).
hipótese
valor verdade
reclamação
observação
achado cobre
especifica
verifica
obtém
hipótese
seleciona

77
2.3.2. Esquema de domínio
Figura A.6: Esquema de domínio para o método de diagnóstico (extraído de [Schreiber, 2000]).
características do sistema
características observáveis
falhas
estado do sistema
estado do sistema
características do sistema
pode causar
dependência causal

78
2.3.3. Descrição da tarefa TASK diagnóstico; ROLES: INPUT: reclamação:”Encontrar o processo de diagnóstico para introduzir”; OUTPUT: falhas: “As falhas que causaram reclamações”; evidência: “As evidências reunidas durante o diagnóstico”; END TASK diagnóstico; TASK-METHOD cobertura-causal; REALIZES: diagnóstico; DECOMPOSITION: INFERENCES: cobre, seleciona, especifica, verifica; TRANSFER-FUNCTIONS: obtém; ROLES: INTERMEDIATE: Diferença: “soluções candidatas a serem ativas”; Hipótese: “Solução candidata”; Resultado: “Boolean indica o resultado do teste”; Expectativa-encontrada: “Um dado esperado no final”; Atual-estado: “O dado atualmente observado” CONTROL-STRUCTURE: WHILE NEW-SOLUTION cobre(reclamação -> Hipótese) DO Diferença:= Hipótese ADD Diferença; END WHILE REPEAT seleciona(Diferença -> Hipótese); especifica (Hipótese -> observação); obtém (observação -> achado); Evidência := achado ADD Evidência; FOR EACH Hipótese IN Diferença DO verifica (Hipótese + Evidência -> resulta); IF resultado ==falso THEN Diferença:= Diferença SUBTRACT Hipótese; END IF END FOR-EACH UNTIL SIZE Diferença <= 1 ou “não existem mais diferenças observáveis”; END REPEAT Falhas:= Diferença; END TASK-METHOD cobertura-causal;
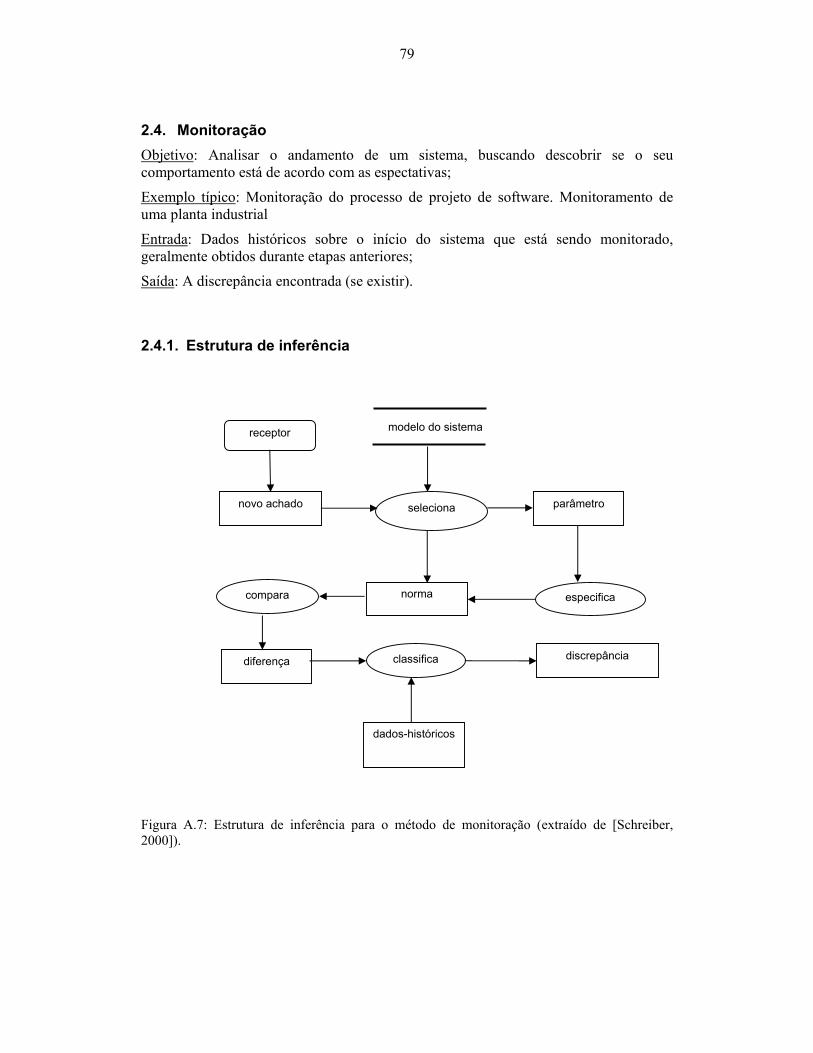
79
2.4. Monitoração Objetivo: Analisar o andamento de um sistema, buscando descobrir se o seu comportamento está de acordo com as espectativas;
Exemplo típico: Monitoração do processo de projeto de software. Monitoramento de uma planta industrial
Entrada: Dados históricos sobre o início do sistema que está sendo monitorado, geralmente obtidos durante etapas anteriores;
Saída: A discrepância encontrada (se existir).
2.4.1. Estrutura de inferência
Figura A.7: Estrutura de inferência para o método de monitoração (extraído de [Schreiber, 2000]).
receptor
novo achado parâmetro
diferença discrepância
dados-históricos
seleciona
compara especifica
classifica
norma
modelo do sistema

80
2.4.2. Descrição da tarefa TASK monitoração; ROLES: INPUT: dados-históricos: “Dados de etapas de monitoramento anteriores.”; OUTPUT: discrepância: ”indicação dos desvios de comportamento do sistema”; END TASK monitoração; TASK-METHOD dados-conduzem-monitoração; REALIZES: monitoração; DECOMPOSITION: INFERENCES: seleciona, especifica, compara, classifica; TRANSFER-FUNCTIONS: receptor; ROLES: INTERMEDIATE: encontra: “Alguns dados sobre o sistema são observados”; parâmetro: “Variável para checar a irregularidade do comportamento”; norma: “Valor esperado para o parâmetro”; diferença: “uma indicação para o desvio”; CONTROL-STRUCTURE: recebe (novo-achado); seleciona (novo-achado -> parâmetro); especifica(parâmetro -> norma); compara (norma + achado -> diferença); classifica (diferença + dados-históricos -> discrepância); dados-históricos := achado ADD dados-históricos; END TASK-METHOD dados-conduzem-monitoração;

81
2.5. Síntese Objetivo: Fornece um conjunto de requerimentos para construir a estrutura de um sistema que satisfaça estes requisitos;
Entrada: Um conjunto de requerimentos;
Saída: Uma (lista de) descrição(ões) de estrutura(s) de sistema(s).
2.5.1. Estrutura de inferência
Figura A.8: Estrutura de inferência para o método de síntese (extraído de [Schreiber, 2000]).
conhecimento composição
sistema
operacionaliza requisitos
estruturas sistemas possíveis
lista estruturas sistemas
requisitos essenciais
requisitos desejáveis
gera
seleciona sub-conjunto
estruturas sistemas válidas
ordena
preferências
restrições
conhecimento da ordenação das
preferências

82
2.5.2. Descrição da tarefa TASK síntese; ROLES:
INPUT: requisitos: “Os requisitos que necessitam ser utilizados no produto final”;
OUTPUT: lista-estruras-sistemas:”Uma lista de estruturas de sistemas, parcialmente ordenada”
END TASK síntese; TASK-METHOD método-síntese; REALIZES: síntese; DECOMPOSITION: INFERENCES: operacionaliza, gera, seleciona-subconjunto, classifica;
ROLES: INTERMEDIATE:
requisitos-essenciais: “Requisitos que precisam ser encontrados obrigatoriamente”; requisitos-desejáveis: “Requisitos tratados com preferência, não obrigatórios”; estruturas-sistemas-possíveis: “Todas possíveis estruturas de sistemas”; estruturas-sistemas-válidas: “Todas as estruturas do sistemas que consistem com as restrições”;
CONTROL-STRUCTURE: operacionaliza( requisitos -> requisitos-essenciais + requisitos-desejáveis) gera (requisitos -> estruturas-sistemas-possíveis); seleciona-subconjunto (estruturas-sistemas-possíveis + requisitos-essenciais -> estruturas-sistemas-válidas); classifica (estruturas-sistemas-válidas + requisitos- desejáveis> lista-estruras-sistemas);
END TASK- METHOD método-síntese;
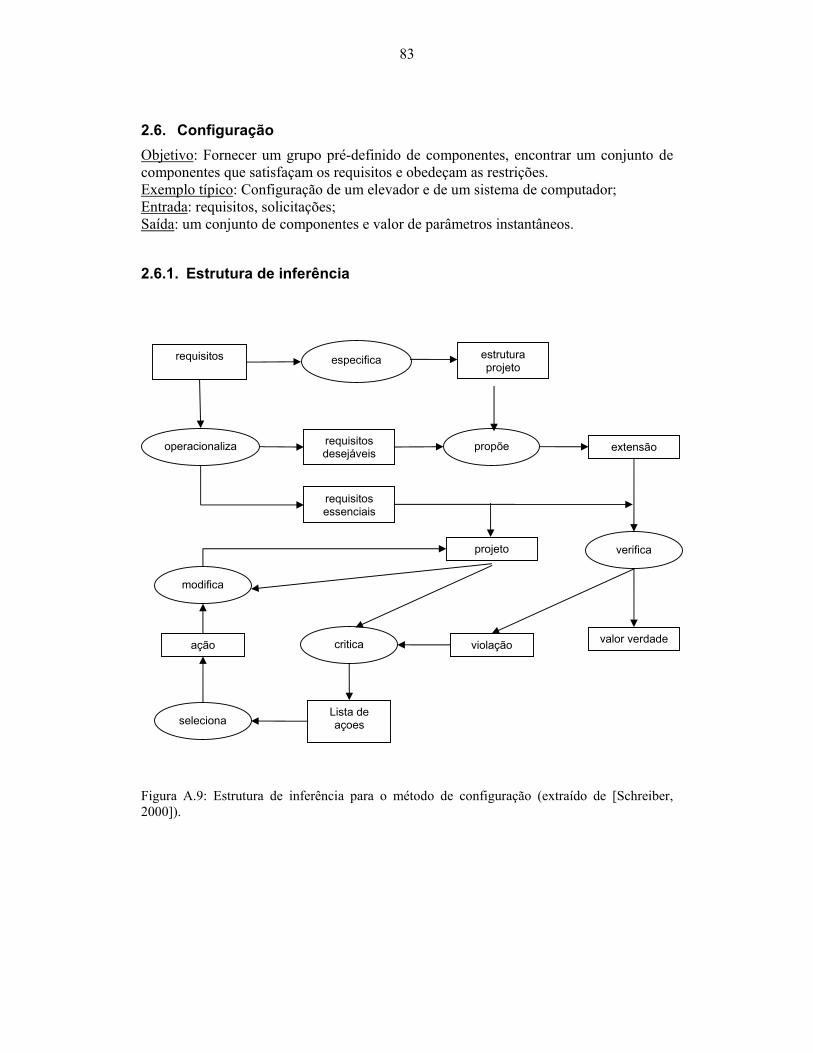
83
2.6. Configuração Objetivo: Fornecer um grupo pré-definido de componentes, encontrar um conjunto de componentes que satisfaçam os requisitos e obedeçam as restrições. Exemplo típico: Configuração de um elevador e de um sistema de computador; Entrada: requisitos, solicitações; Saída: um conjunto de componentes e valor de parâmetros instantâneos.
2.6.1. Estrutura de inferência
Figura A.9: Estrutura de inferência para o método de configuração (extraído de [Schreiber, 2000]).
requisitos essenciais
violação
projeto
estrutura projeto
valor verdadecritica
especifica
verifica
requisitos
modifica
extensão propõe requisitos desejáveis operacionaliza
ação
seleciona Lista de açoes
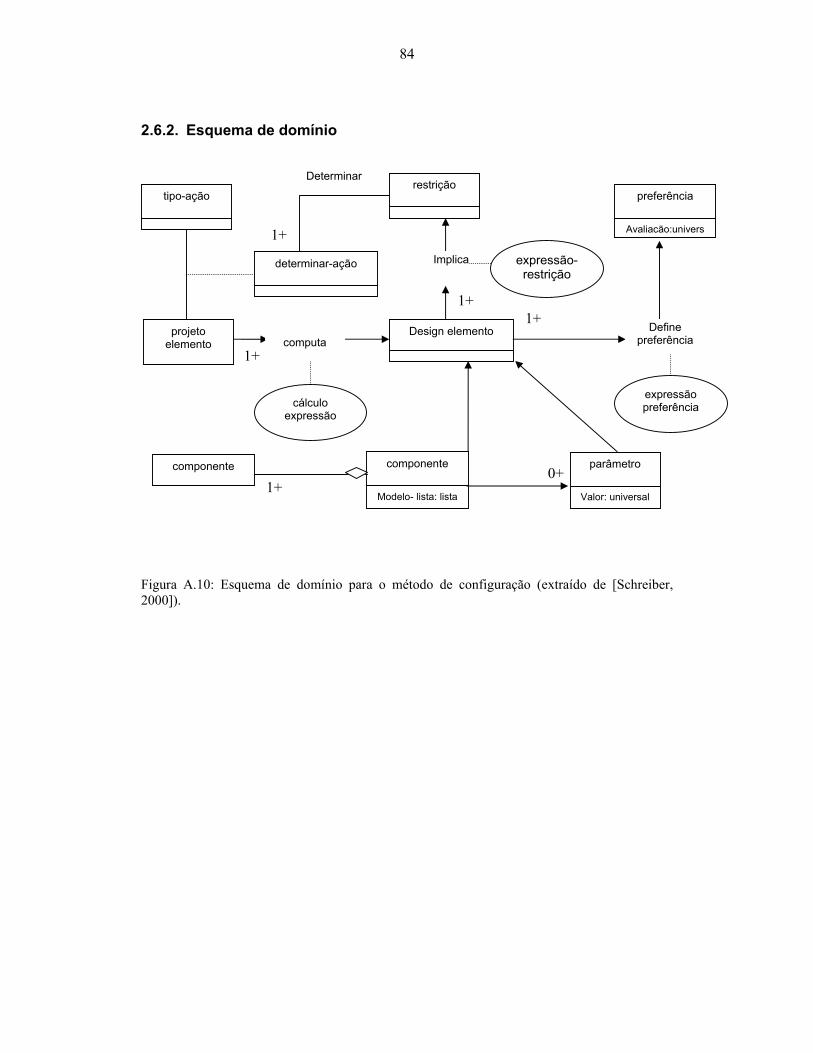
84
2.6.2. Esquema de domínio
Figura A.10: Esquema de domínio para o método de configuração (extraído de [Schreiber, 2000]).
tipo-ação
determinar-ação
restrição
Design elemento projeto elemento
preferência
Avaliação:univers
parâmetro
Valor: universal
componente
Modelo- lista: lista
componente
expressão-restrição
cálculo expressão
expressão preferência
computa
1+
Determinar
Implica
Define preferência
1+ 1+
1+
1+
0+

85
2.6.3. Descrição da tarefa TASK configuração-projeto; ROLES: INPUT: requisitos: “Requesitos para o projeto”; OUTPUT: projeto:”O projeto proposto”; END TASK configuração-projeto; TASK-METHOD propor-revisar; REALIZES: configuração-projeto; DECOMPOSITION:
INFERENCES: operacionaliza, especifica, propõe, verifica, seleciona, modifica;
ROLES: INTERMEDIATE:
requisitos-desejáveis: “Requisitos que são utilizados como preferências”; requisitos-essenciais: “Requisitos que são importantes restrições”; estrutura-projeto: “grupo dos elementos do projeto”; extensão: “um único novo valor para o elemento do projeto”; violação: “Restrições violadas pelo projeto corrente”; valor-verdade: “boolean indicando o resultado da verificação”; lista-ações: “lista ordenada de possíveis ações para reparação”; ação: “uma única ação de reparação”;
CONTROL-STRUCTURE: operacionaliza(requisitos -> requisitos—essenciais + requisitos-desejáveis) especifica (requisitos -> estrutura-projeto);
WHILE NEW-SOLUTION propõe (estrutura-projeto + projeto + requisitos-desejaveis -> extensão) DO
projeto:= extensão ADD projeto; verifica (projeto + requisitos-essenciais
-> valor-verdade + violação); IF valor-verdade ==false THEN critica (violação + projeto -> lista-ações);
REPEAT seleciona (lista-ações -> ação); modifica (projeto + ação -> projeto); verifica (projeto + requisitos-essenciais -> valor-verdade + violação);
UNTIL valor-verdade == true; END REPEAT
END IF
END WHILE END TASK- METHOD propor-revisar;
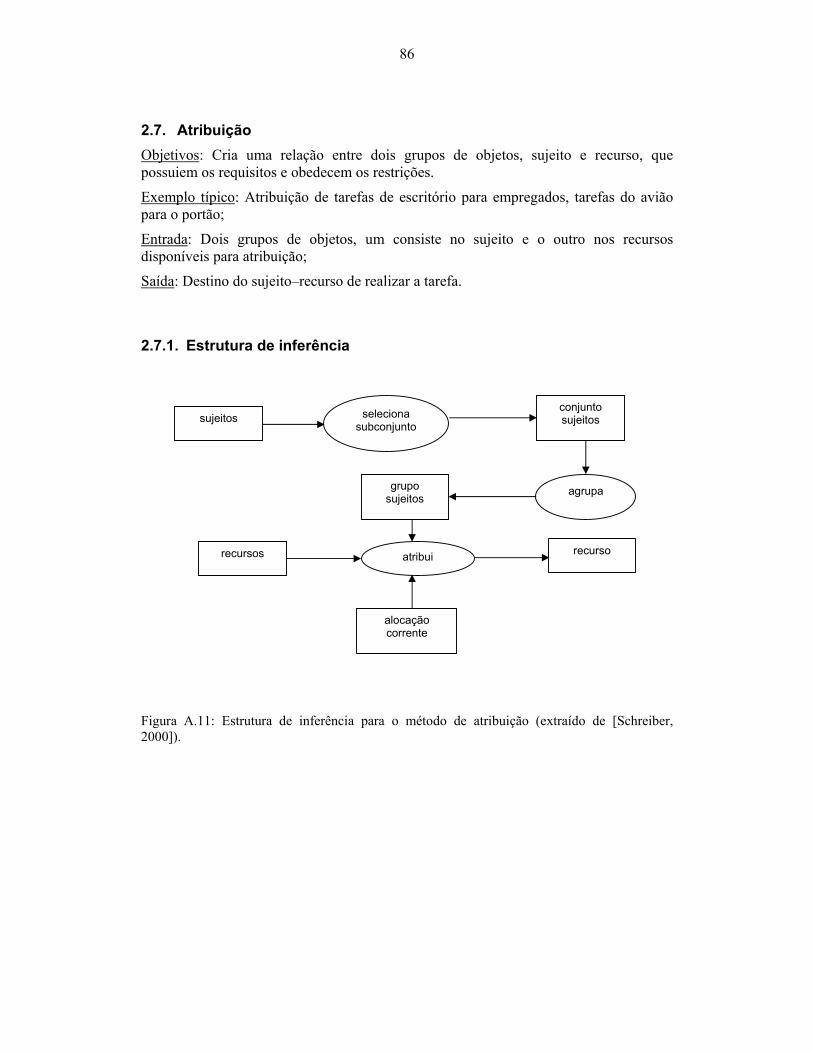
86
2.7. Atribuição Objetivos: Cria uma relação entre dois grupos de objetos, sujeito e recurso, que possuiem os requisitos e obedecem os restrições.
Exemplo típico: Atribuição de tarefas de escritório para empregados, tarefas do avião para o portão;
Entrada: Dois grupos de objetos, um consiste no sujeito e o outro nos recursos disponíveis para atribuição;
Saída: Destino do sujeito–recurso de realizar a tarefa.
2.7.1. Estrutura de inferência
Figura A.11: Estrutura de inferência para o método de atribuição (extraído de [Schreiber, 2000]).
sujeitos conjunto sujeitos
grupo sujeitos
recurso recursos
alocação corrente
seleciona subconjunto
agrupa
atribui

87
2.7.2. Descrição da tarefa TASK atribuição ROLES:
INPUT: sujeitos: “Sujeito que precisa de um recurso para realizar a tarefa”;
recursos: “Os recursos que podem ser atribuídos”; OUTPUT: Alocação: “Conjunto de sujeito-recurso abribuído”; END TASK atribuição; TASK-METHOD método-atribuição; REALIZES: atribuição; DECOMPOSITION: INFERENCES: seleciona-subconjunto, agrupa, atribui;
ROLES: INTERMEDIATE:
conjunto-sujeitos: “Sub-conjunto de sujeitos com a mesma prioridade de atribuição”; grupo-sujeitos: “Conjunto de sujeitos (ou um sujeito) que podem ser atribuídos a um mesmo recurso.”; recurso: “Recurso atribuído”; alocação-corrente: “Sujeito-recurso atribuídos no momento.”;
CONTROL-STRUCTURE: WHILE NOT EMPTY sujeitos DO
seleciona-subconjunto (sujeitos -> conjunto-sujeitos);
WHILE NOT EMPTY conjunto-sujeitos DO agrupa(conjunto-sujeitos -> grupo-sujeitos); abribui (grupo-sujeitos + recursos
+ alocação-corrente -> recurso); alocação-corrente := < grupo-sujeitos, recurso > ADD alocação-corrente; conjunto-sujeitos:= conjunto-sujeitos DELETE grupo-sujeitos; recursos:= recursos DELETE recurso;
END WHILE sujeitos:= sujeitos DELETE conjunto-sujeitos;
END WHILE END TASK- METHOD atribuição-método;
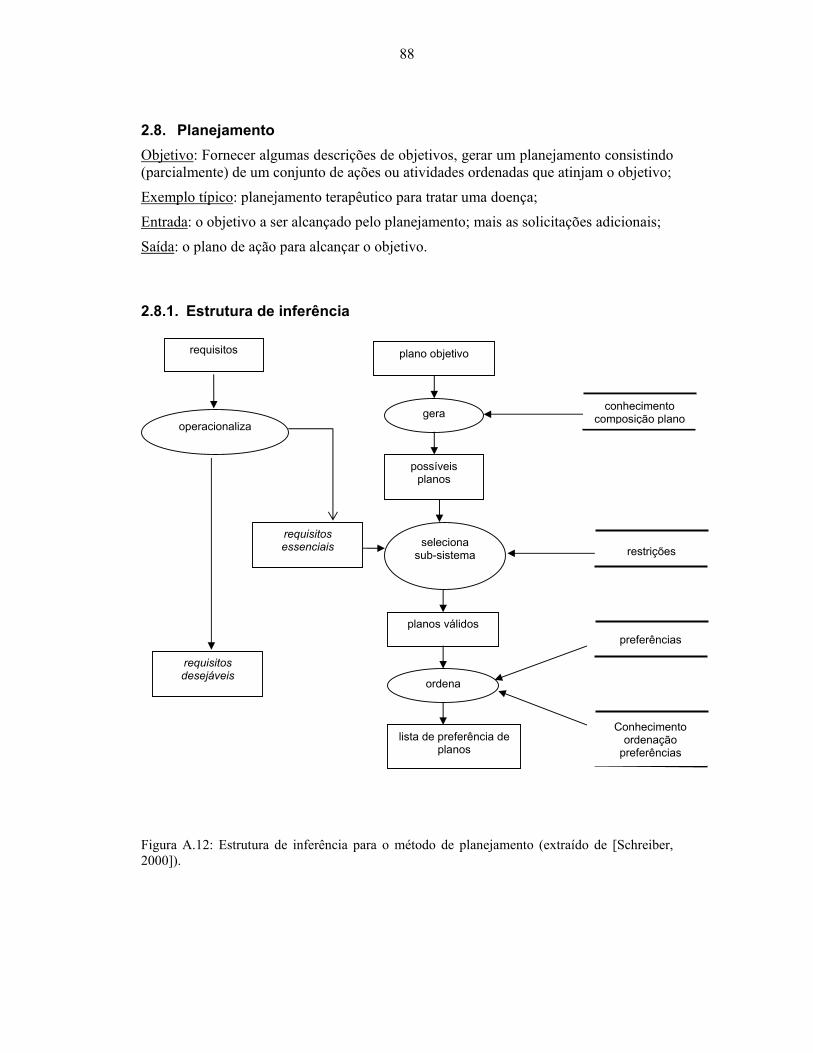
88
2.8. Planejamento Objetivo: Fornecer algumas descrições de objetivos, gerar um planejamento consistindo (parcialmente) de um conjunto de ações ou atividades ordenadas que atinjam o objetivo;
Exemplo típico: planejamento terapêutico para tratar uma doença;
Entrada: o objetivo a ser alcançado pelo planejamento; mais as solicitações adicionais;
Saída: o plano de ação para alcançar o objetivo.
2.8.1. Estrutura de inferência
Figura A.12: Estrutura de inferência para o método de planejamento (extraído de [Schreiber, 2000]).
requisitos plano objetivo
possíveis planos
planos válidos
lista de preferência de planos
operacionaliza
requisitos desejáveis
gera
seleciona sub-sistema
ordena
conhecimento composição plano
Conhecimento ordenação
preferências
restrições
preferências
requisitos essenciais
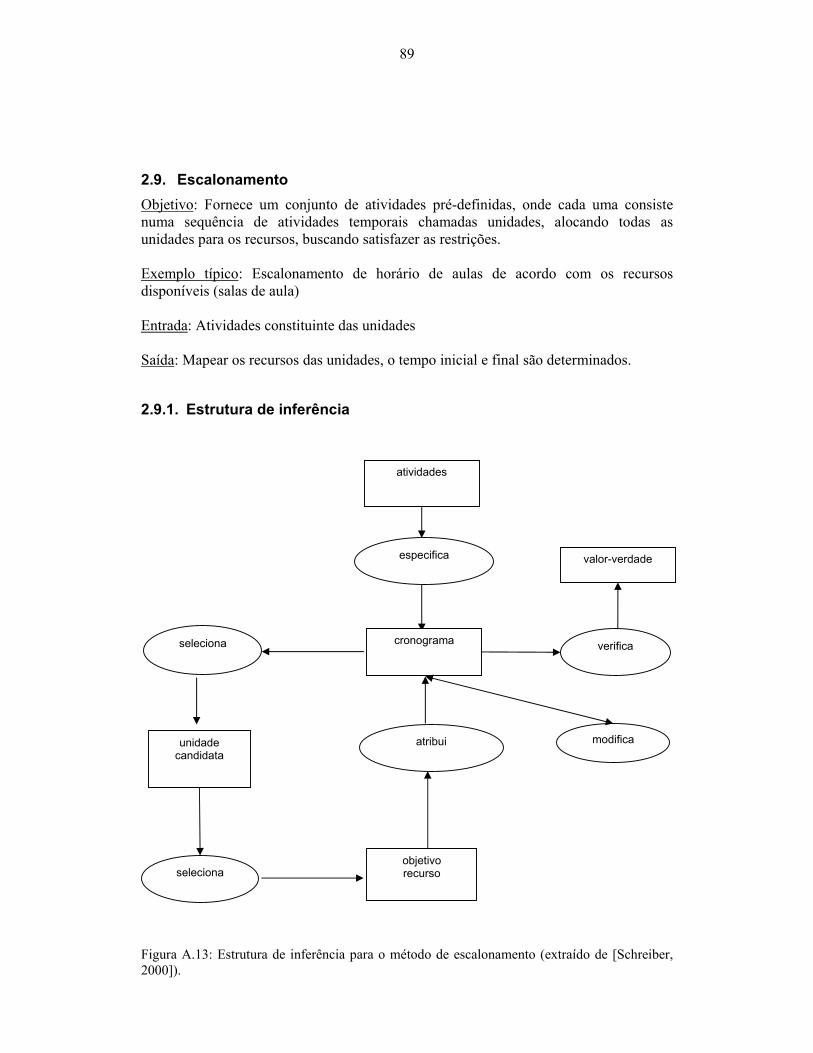
89
2.9. Escalonamento Objetivo: Fornece um conjunto de atividades pré-definidas, onde cada uma consiste numa sequência de atividades temporais chamadas unidades, alocando todas as unidades para os recursos, buscando satisfazer as restrições. Exemplo típico: Escalonamento de horário de aulas de acordo com os recursos disponíveis (salas de aula) Entrada: Atividades constituinte das unidades Saída: Mapear os recursos das unidades, o tempo inicial e final são determinados.
2.9.1. Estrutura de inferência
Figura A.13: Estrutura de inferência para o método de escalonamento (extraído de [Schreiber, 2000]).
atividades
cronograma
unidade candidata
valor-verdade
objetivo recurso
especifica
verifica seleciona
atribui modifica
seleciona

90
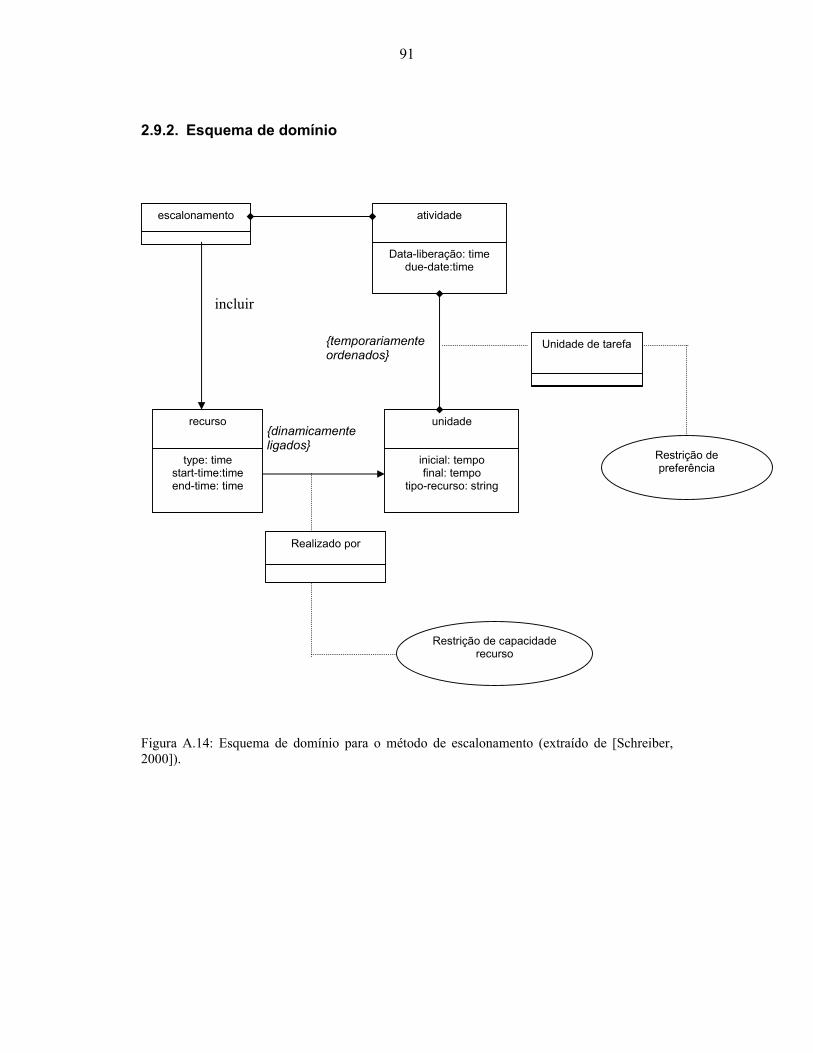
91
2.9.2. Esquema de domínio
Figura A.14: Esquema de domínio para o método de escalonamento (extraído de [Schreiber, 2000]).
escalonamento atividade
Data-liberação: time due-date:time
Unidade de tarefa
unidade
inicial: tempo final: tempo
tipo-recurso: string
recurso
type: time start-time:time end-time: time
Realizado por
Restrição de capacidade recurso
Restrição de preferência
{temporariamente ordenados}
{dinamicamente ligados}
incluir

92
2.9.3. Descrição da tarefa TASK escalonamento; ROLES: INPUT: atividades: “Atividades que precisam ser agendadas.”;
OUTPUT: cronograma: “Atividades alocadas para um determinado recurso em um determinado tempo”;
END TASK escalonamento; TASK-METHOD despache-temporário; REALIZES: escalonamento; DECOMPOSITION:
INFERENCES: especifica, seleciona, aloca, modifica, verifica;
ROLES: INTERMEDIATE:
unidade-candidata: “Atividade selecionada para a próxima alocação”; objetivo-recurso: “recurso selecionado para a próxima alocação”; valor-verdade: “Boolean indica o resultado da verificação”;
CONTROL-STRUCTURE: especifica (atividades -> cronograma); WHILE HAS-SOLUTION select (cronograma -> unidade-candidata) DO
seleciona (unidade-candidata + cronograma -> objetivo-recurso); aloca (unidade-candidata + objetivo-recurso -> cronograma);
verifica (cronograma -> valor-verdade); IF valor-verdade == false THEN modify (cronograma -> cronograma); END IF
END WHILE END TASK- METHOD despache-temporário;

93
TRABALHO FINAL – ESTUDO DE CASO
Objetivo: Exercitar as técnicas da engenharia de conhecimento, para identificação do conhecimento organizacional, aquisição e modelagem desse conhecimento com a finalidade de desenvolver um sistema de conhecimento baseado na Metodologia CommonKADS.
Desenvolvimento: Cada uma das etapas será desenvolvida em aula e completada como trabalho extra-classe.
♦ Organizem-se em grupos de trabalho e selecionem uma unidade de trabalho (setor, departamento) para ser o foco da análise, garantindo que um dos colegas do grupo possui pleno domínio do conhecimento utilizado no desenvolvimento do processo dessa unidade.
♦ Utilizem os modelos de CommonKADS como suporte a seqüência que deve ser seguida para Análise, Modelo e Projeto de Sistema.
♦ Todos os modelos devem ser entregues descritos na notação CML de CommonKADS 3.
Como o objetivo do trabalho é conhecer e treinar uma metodologia para gestão e engenharia de conhecimento, restrinjam e simplifiquem o problema a ser analisado de forma a que seja possível, no desenrolar da disciplina, executar todas as etapas esperadas. Guiem-se pela “Chave de Conceitos” disponível no Claroline para o desenvolvimento do trabalho.
Produto do trabalho:
1. Descrição sucinta (textual) da aplicação selecionada, com a caracterização do tipo de tarefa (classificação, diagnóstico, interpretação, etc) e do problema particular que será modelado.
2. (2 pontos) Modelo da Organização (MO-1 a MO-5) preenchendo cada uma das tabelas com os detalhes relativos à organização escolhida e ao problema em questão.
3. (2 pontos) Modelo de Inferência para o problema específico selecionado para análise. O problema deve ter sido identificado como uma tarefa intensiva em conhecimento dentro do processo analisado no MO. O modelo de inferência é composto de:
• diagrama da estrutura de inferência (inferências, papéis de conhecimento e fluxo de informação);
• descrição textual do diagrama de inferência utilizando a notação CML de CommonKADS. A descrição textual deve apresentar, assim como no exemplo do HousingApplication: (i) mapeamento dos papéis de domínio do diagrama para os conceitos do modelo do domínio (o qual é pedido a seguir) e (ii) descrição sucinta das ações executadas pelas inferências do diagrama (entradas, transformações e saídas).
3 A sintaxe da linguagem CML de CommonKADS está no Claroline. Um exemplo completo de modelagem utilizando a linguagem CML está disponível no Claroline, no diretório HousingApplication

94
4. (2 pontos) Modelo do Domínio. Definição do conhecimento estático do domínio que suporta a tarefa escolhida. O modelo de domínio é composto de:
• esquema do domínio: descrição dos conceitos, atributos, relações, axiomas, tipos-regra que descrevem os objetos do domínio. O esquema deve ser representado visualmente (através da notação UML de CommonKADS) e textualmente, utilizando a notação CML 1.
• base de conhecimento: contém apenas as instâncias e regras necessárias para demonstração da inferência.
5. (1 ponto) Modelo da Tarefa. Descrição de objetivos, papéis de entrada e saída, especificação da tarefa e detalhamento do controle, utilizando a notação CML 1.
6. (1 ponto) Modelo do Projeto, composto de: (i) especificação dos componentes de software (classes Java, tabelas de banco de dados, arquivos texto, etc.) e qual a função desses componentes; (ii) mapeamento dos objetos do modelo de conhecimento para os componentes de software (que classe representa que conceito? Que método representa que inferência? Que tabela representa que instâncias?).
7. (2 pontos) Protótipo do Sistema. Visa apenas expor os conceitos apresentados em aula, relacionados à construção do modelo e a execução da inferência, evidenciando a preservação da estrutura do modelo de conhecimento no modelo de projeto.
Dúvidas sobre o trabalho?
Enviar e-mail para a monitora Laura Mastella ([email protected]), com o assunto:
[MBA-Ferram-2004]

95
Referências
[Abel, 1988]Abel, M. Um sistema especialista para identificação e classificação de turbiditos. Porto Alegre: CPGCC da UFRGS, 1988. 202p. Dissertação de Mestrado.
[Benjamins, 2000]Benjamins, R. Knowledge Engineering and Ontologies. Disponível em: <http://www.swi.psy.uva.nl/usr/richard/home.html>. Acesso em: 12 Oct. 2000.
[Benjamins; Fensel, 1998]Benjamins, V.R.; Fensel, D. Editorial: problem-solving methods. International Journal of Human-Computer Studies, [S.l.], v. 49, n. 4, p.305-313, 1998.
[Beyon-Davis, 1991]Beyon-Davis, P. Expert database systems - a gentle introduction. London: McGraw-Hill, 1991.
[Boff, 2000]Boff, L.H. O processo cognitivo de trabalho de conhecimento: um estudo exploratório sobre o uso da informação no ambiente de análise de investimentos. Porto Alegre: Programa de Pós-Graduação em Administração da UFRGS, 2000. 179p. Tese de doutorado.
[Boff, 2001]Boff, L.H. Gestão do Conhecimento. Porto Alegre: Programa de Pós-Graduação em Computação, 2001. Notas de Aula.
[Buchanan; Shortliffe, 1984]Buchanan, B.; Shortliffe, E. Rule-based expert systems: the MYCIN experiments. Reading: Addison-Wesley, 1984. 748p.
[Chandrasekaram, 1986]Chandrasekaram, B. Generic tasks in knowledge-based reasoning: high level building blocks for expert system design. IEEE Expert, Los Alamitos, v. 1, n. 3, p.23-30, 1986.
[Clancey, 1985]Clancey, W.J. Heuristic classification. Artificial Intelligence, Amsterdam, v. 27, n. 3, p.289-350, 1985.
[Clancey, 1989]Clancey, W.J. The knowledge level reinterpreted: modeling how systems interact. Machine Learning, Boston, n. 4, p.285-291, 1989.
[Damski; Lima; Giorno; Valente, 1993]Damski, J.C.B.; Lima, J.G.M.d.; Giorno, F.d.G.; Valente, A.d.S.M. Sistemas Especialistas no Brasil: Um Enfoque Pragmático. Brasília: SUCESU, 1993. 118p.
[Dogget; Hargreaves, 1998]Dogget, P.; Hargreaves, J. Survival and profitability in the corporate lending market. Chartered Banker, p.28 a 31, 1998.
[Drucker, 1993]Drucker, P.F. Sociedade Pós-Capitalista. São Paulo: Pioneira, 1993.
[Duda; Hart; Barret; Gaschnig; Konolige; Reboh; Slocum, 1978]Duda, R.O.; Hart, P.E.; Barret, P.; Gaschnig, J.; Konolige, K.; Reboh, R.; Slocum, J. Development of the PROSPECTOR consultation system for mineral exploration. Menlo Park: Stanford Research Institute International, 1978. Final Report SRI Projects.
[Elmasri; Navathe, 1994]Elmasri, R.; Navathe, S.B. Fundamentals of Database Systems. Menlo Park (CA): The Benjamin/Cummings Pub., 1994.

96
[Ericsson; Simon, 1980]Ericsson, K.A.; Simon, H.A. Verbal reports as data. Psychology Review, [S.l.], v. 87, p.215-251, 1980.
[Erikssom; Shahar; Tu; Puerta; Musen, 1995]Erikssom, H.; Shahar, Y.; Tu, S.W.; Puerta, A.R.; Musen, M.A. Task modeling with reusable problem solving methods. Artificial Intelligence, Amsterdam, v. 79, n. 2, p.293-326, 1995.
[Feigenbaum, 1979]Feigenbaum, E.A. Themes and case studies of knowledge engineering. In: Michie, D. Expert Systems in the Micro_Eletronic Age. Edinburg: Edinburg Univ. Press, 1979. p.3-25.
[Fensel; Motta; Decker; Zdrahal, 1997]Fensel, D.; Motta, E.; Decker, S.; Zdrahal, Z. Using ontologies for definig tasks, problem-solving methods and their mappings. In: European Workshop in Knowledge Acquisition, Modeling and Management (EKAW'97), 10., 1997, Saint Felin de Guixols, Catalonia, Spain. Proceedings... Berlin: Springer-Verlag, 1997. v. 1319, p. 113-128.
[Gardner; Rush; Crist; Konitzer; Teegarden, 1998]Gardner, K.M.; Rush, A.; Crist, M.; Konitzer, R.; Teegarden, B. Cognitive patterns: problem-solving framework for object technology. Cambridge: Cambridge University Press, 1998. 237p.
[Gómez-Pérez; Benjamins, 1999]Gómez-Pérez, A.; Benjamins, V.R. Overview of knowledge sharing and reuse components: Ontologies and problem-solving methods. In: International Joint Conference on Artificial Intelligence(IJCAI-99), Workshop on Ontologies and Problem-Solving Methods (KRR5), 1999, Stockolm, Sweden. Proceedings... Disponível em: <http://sunsite.inforamtik.rwth-aachen.de/Publications/CEUR-WS/Vol-18/>. Acesso em: 03 Feb. 2001.
[Gruber, 1992]Gruber, T. Ontolingua: a mechanism to support portable ontologies. Stanford: Knowledge System Laboratory, Stanford University, 1992. Technical Report.
[Guarino, 1995]Guarino, N. Formal ontology, conceptual analysis and knowledge representation. International Journal Human-Computer Studies, [S.l.], v. 43, n. 2/3, p.625-640, 1995.
[Harmon; Sawyer, 1990]Harmon, P.; Sawyer, B. Creating Expert-systems for Business and Industry. New York: John Wiley &Sons, 1990. 329p.
[Hayes-Roth; Waterman; Lenat, 1983]Hayes-Roth, F.; Waterman, D.A.; Lenat, D.B. Building expert systems. Reading, MA: Addison-Wesley, 1983. 444p.
[Leão, 1988]Leão, B.d.F. Contrução de uma base de conhecimento de um sistema especialista de apoio ao diagnóstico de cardiopatias congênitas. São Paulo: Pós-Graduação em Cardiologia da Escola Paulista de Medicina, 1988. 230p. Tese de doutorado.
[Leão; Rocha, 1990]Leão, B.F.; Rocha, A.F. Proposed methodology for knowledge acquisition: a study on congenital heart disease diagnosis. Methods of Information in Medicine, [S.l.], n. 29, p.30-40, 1990.
[Lebowitz, 1987]Lebowitz, M. Experimental with incremental concept information:UNIMEM. Machine Learning p.103-138, 1987.
[Liebowitz; Wilcox, 1997]Liebowitz, J.; Wilcox, L.C. Knowledge Management and its Integrative Elements. Boca Raton: CRC Press, 1997. 205p.

97
[Maher; Garza, 1997]Maher, M.; Garza, A. Case-based reasoning in design. IEEE Expert, p.34-41, 1997.
[Mattos, 1988]Mattos, N.M. Abstraction Concepts: the basis for data and knowledge modeling. Roma, Italy: University of Kaiserslautern, 1988. p.331-350. ZRI.
[McDermott, 1988]McDermott, J. Preliminary steps towards a taxonomy of problem-solving methods. In: Marcus, S. Automating knowledge acquisition form expert systems. Netherlands: Kluwer Academic Publishers, 1988. p.225-255.
[Motoda; Mizoguchi; Boose; Gaines, 1991]Motoda, H.; Mizoguchi, R.; Boose, J.; Gaines, B. Knowledge acquisition for knowledge-based systems. Tokyo: OHMSHA, 1991.
[Musen, 1998]Musen, M. Modern architectures for intelligent systems: reusable ontologies and problem-solving methods. In: Amia Annual Symposium, 1998, Orlando. Proceedings... Disponível em: <http://smi-web.stanford.edu/pubs/SMI_Abstracts/SMI-98-0734.html>. Acesso em: 11 Jan. 2000.
[Newell, 1982]Newell, A. The knowledge level. Artificial Intelligence, Amsterdam, v. 18, n. 1, p.87-127, 1982.
[Puerta; Egar; Tu; Musen, 1992]Puerta, A.R.; Egar, J.W.; Tu, S.W.; Musen, M.A. A multiple-method knowledge-acquisition shell for the automatic generation of knowledge-acquisition tools. Knowledge Acquisition, [S.l.], v. 4, n. 2, p.171-196, 1992.
[Regoczei; Hirst, 1994]Regoczei, S.B.; Hirst, G. Knowledge and knowledge acquisition in the computational context. In: Hoffman, R. The psychology of expertise cognitive research and empirical AI. New York: Spring-Verlag, 1994. p.12-25.
[Schreiber, 1992]Schreiber, A.T. The KADS approach to knowledge engineering. Knowledge Acquisition, [S.l.], v. 4, n. 1, p.1-4, 1992.
[Schreiber; Akkermans; Anjewierden; Hoog; Shadbolt; Velde; Wielinga, 2000] Schreiber, G.; Akkermans, H.; Anjewierden, A.; Hoog, R.d.; Shadbolt, N.; Velde, W.v.d.; Wielinga, B. Knowledge engineering and management: the commonkads methodology. Cambridge: The MIT Press, 2000. 465p.
[Schreiber; Wielinga; Hoog; Akkermans; Velde, 1994] Schreiber, G.; Wielinga, B.; Hoog, R.d.; Akkermans, H.; Velde, W.v.d. CommonKADS: a comprehensive methodology for KBS development. IEEE Expert, Los Alamitos, v. 9, n. 6, p.28-37, 1994.
[Spek; Spijkervet, 1997]Spek, R.v.d.; Spijkervet, A. Knowledge management: dealing intelligently with knowledge. In: Liebowitz, J.; Wilcox, L. C. Knowledge Management and its Integrative Elements. Boca Raton: CRC Press, 1997. p.31-59.
[Steels, 1990]Steels, L. Components of expertise. AI Magazine, [S.l.], v. 11, n. 2, p.28-49, 1990.
[Sternberg, 1994]Sternberg, R.J. Thinking and problem solving. London: Academic Press, 1994. 461p.

98
[Studer; Benjamins; Fensel, 1998]Studer, R.; Benjamins, V.R.; Fensel, D. Knowledge engineering: principles and methods. Data & Knowledge Engineering, Amsterdam, v. 25, n. 1/2, p.161-197, 1998.
[Stutt; Motta, 1994]Stutt, A.; Motta, E. VITAL - A methodology-based workbench for KBS life cycle support. [S.l.]: ESPRIT II, 1994. Project Report.
[Turban, 1992]Turban, E. Expert Systems and Applied Artificial Intelligence. New York: Macmillan Publishing Company, 1992. 804p.
[Turban, 1992]Turban, E. Knowledge acquisition and validation. In: Turban, E. Expert Systems and Applied Artificial Intelligence. New York: Macmillan Publishing, 1992. p.117-166.
[Velde, 1993]Velde, W.V. Issues in knowledge level modeling. In: David, J. M.et al. Second generation expert systems. Berlin: Springer Verlag, 1993.
[Watson, 1997]Watson, I. Applying case-based reasoning: techniques for enterprise system. San Francisco: Morgan Kaufmann, 1997.
[Wielinga; Schreiber, 1994]Wielinga, B.J.; Schreiber, A.T. Conceptual modeling on large reusable knowledge bases. In: Von Luck, K.; Marburger, H. Management and processing of complex data structures. Berlin: Springer -Verlag, 1994. p.181-200. (Lecture Notes in Computer Science v.777).
[Wielinga; Velde; Schreiber; Akkermans, 1992]Wielinga, B.J.; Velde, W.V.d.; Schreiber, G.; Akkermans, H. The KADS knowledge modeling approach. In: Japanese Knowledge Acquisition for Knowledge-Based Systems Workshop, 2., 1992, Hatoyama, Saitama, Japan. Proceedings... [S.l]: Advanced Research Laboratory, 1992. p. 23-42.
[Wright; Ayton, 1987]Wright, G.; Ayton, P. Eliciting and modeling expert knowledge. North Holland: Elsevier Science Publ., 1987. 26p.