probabilidade novo - ime.uerj.brmrubens/cursos/calculodasprobabilidades/... · ... de tal forma que...
TRANSCRIPT

1
Universidade do Estado do Rio de Janeiro – UERJ Instituto de Matemática e Estatística
Departamento de Estatística Disciplina: Processos Estocásticos I
Professor: Marcelo Rubens REVISÃO DE PROBABILIDADE E ALGUNS RESULTADOS IMPORT ANTES 1 - PROBABILIDADE E VARIÁVEIS ALEATÓRIAS 1.1 - CONCEITOS E DEFINIÇÕES E OPERAÇÕES PRELIMINARES Experimento aleatório e suas características: a) É um tipo de experimento no qual não é possível prever um resultado particular com
certeza absoluta, portanto, sujeito às leis do acaso; b) Pode-se descrever ou definir a lista de todos os seus resultados possíveis; c) Pode ser repetido indefinidamente sob condições inalteradas. População ou espaço amostral - Conjunto ou lista de todos os resultados possíveis de um experimento aleatório. O espaço amostral é usualmente denotado por Ω. Exemplos: Lançamento de uma moeda: Ω=cara, coroa Lançamento de um dado: Ω=1, 2, 3, 4, 5, 6 Renda média familiar anual: Ω=ℜ+ (conjunto dos números reais positivos) Tempo que um trabalhador leva da sua casa para o trabalho. Ponto amostral - Cada membro ou elemento indivisível pertencente a população ou espaço amostral. Evento - Qualquer subconjunto do espaço amostral. Eventos mutuamente exclusivos - Eventos são mutuamente exclusivos quando a ocorrência de um desses eventos exclui a possibilidade de ocorrência dos outros. Eventos exaustivos - Eventos são (coletivamente) exaustivos quando a união desses eventos eqüivale à população ou espaço amostral. A letra grega maiúscula Σ é usada para indicar somatório da seguinte forma:
X X X Xii
n
n=∑ = + + +
11 2 ...
Algumas propriedades:
1. k nki
n
=∑ =
1, em que k é uma constante. Assim 123433333
4
1i
==+++=∑=
.
2. kX k Xii
n
ii
n
= =∑ ∑=
1 1, em que k é uma constante.

2
3. ( )aX bY aX bY a X b Yi ii
n
ii
n
ii
n
ii
n
ii
n
+ = + = += = = = =∑ ∑ ∑ ∑ ∑
1 1 1 1 1, em que a e b são constantes
Seja o somatório duplo:
)X...XX(
)X...XX(
)X...XX(
)X...XX()X(X
m,n2,n1,n
m,22,21,2
m,12,11,1
n
1im,i2,i1,i
n
1i
m
1jj,i
n
1i
m
1jj,i
++++
+++++++++=
=+++== ∑∑ ∑∑∑== == =
M
Propriedades do somatório duplo:
1. ∑∑∑∑= == =
=m
1j
n
1ij,i
n
1i
m
1jj,i XX , ou seja, podemos trocar a ordem do somatório.
2. X Y X Yi jj
m
i
n
i jj
m
i
n
== ==∑∑ ∑∑=
11 11
3. ∑ ∑∑∑∑∑= = === =
+=+n
1i
n
1i
m
1jj,i
m
1jj,i
n
1i
m
1jj,ij,i YX)YX(
4.
∑∑
∑∑∑ ∑∑∑∑∑∑
≠=
<=
−
= +===≠===
+=
=+=+=+=
jiji
n
1i
2i
n
jiji
n
1i
2i
1n
1i
n
1ijji
n
1i
2i
n
1i
n
ij1j
ji
n
1i
2i
2n
1ii
XXX
XX2XXX2XXXX)X(
Note que na propriedade acima apresentamos diferentes notações algebricamente equivalentes para um determinado tipo de somatório duplo, pois:
∑∑∑ ∑∑∑≠<
−
= +==≠=
===ji
ji
n
jiji
1n
1i
n
1ijji
n
1i
n
ij1j
ji XXXX2XX2XX
Exemplo: ( ) ( )X X X X X X X X X X X X X X X X X X X X1 2 3 42
12
22
32
42
1 2 1 3 1 4 2 3 2 4 3 42+ + + = + + + + + + + + + 1.2 - PROBABILIDADE DE UM EVENTO NUM ESPAÇO EQUIPRO VÁVEL O conceito preliminar de probabilidade que iremos adotar refere-se a um número atribuído a um evento com valor no intervalo entre zero e um (∈ [0,1]), de tal forma que se tivermos um conjunto de eventos mutuamente exclusivos e exaustivos, então a soma da probabilidade desses eventos deve ter o valor de um. Se A é um evento de um espaço amostral Ω, denotamos probabilidade desse evento por P(A).
Nesta conceituação preliminar devemos observar que P(A) é uma função de valor real com as seguintes propriedades ou arcabouço axiomático:
• 0 ≤ P(A) ≤ 1 para todo A∈Ω;

3
• Se A, B, C, ... constituem uma coleção exaustiva de eventos, ou seja, Ω=A∪B∪C∪... então: P(A∪B∪C∪...)=1;
• Se A, B, C, ... são eventos mutuamente exclusivos, então: P(A∪B∪C∪...)= =P(A)+P(B)+P(C)+...;
• Se A, B, C, ... são eventos mutuamente exclusivos e exaustivos, então: P(A∪B∪C∪...)=P(A)+P(B)+P(C)+...=1
Seja Ω=a1, a2, ..., an, onde ai, i=1, 2, ..., n são pontos amostrais. Ω é um espaço
equiprovável se P(a1)=P(a2)=...=P(an)=p, ou seja, se todos os pontos amostrais de Ω tiverem mesma probabilidade. Como a soma das probabilidades deve ser um, então:
P(a1) + P(a2) + ... + P(an) = p + p + ... + p = np = 1 ⇒ p = P(ai) = 1 / n.
Se tivermos um total de N(Ω) resultados possíveis igualmente prováveis (não tendenciosos) de um experimento aleatório, e se N(A) dentre eles forem os resultados favoráveis à ocorrência do evento A, então a probabilidade de um evento num espaço equiprovável sera:
P(A) = N(A) / N(Ω) = (# casos favoráveis ao evento A) / (# casos possíveis do experimento)
Exemplo: Considere o experimento que consiste de lançar um dado numerado de 1 a 6. O espaço amostral consiste no conjunto de resultados Ω=1, 2, 3, 4, 5, 6. Estes seis pontos amostrais, portanto, esgotam todo o espaço amostral. A probabilidade de ocorrer qualquer um desses números é de 1/6 (supondo que cada ponto seja igualmente provável de ocorrer, ou seja, que o dado não seja viciado), já que, para cada evento existe somente um caso favorável dentre seis possíveis. Como Ω=1, 2, 3, 4, 5, 6 é formado pela união de um conjunto mutuamente exclusivo e exaustivo de eventos elementares, ou seja Ω=1 ∪2 ∪3 ∪4 ∪5 ∪6 então:
P(Ω)=P(1∪2 ∪3 ∪4 ∪5 ∪6)=P(1)+...+P(6)=1/6+1/6+1/6+1/6+1/6+1/6=1
Exemplo: Seja A=números primos de 1 a 6= 2, 3, 5 ⇒ P(A)=3/6=0,5 1.3 - DEFINIÇÃO FREQUENTISTA OU CLÁSSICA DE PROBABI LIDADE Seja A um evento de um espaço amostral. A probabilidade do evento A, P(A), é a proporção de vezes que o evento A ocorrerá se o experimento for repetido infinitas vezes. Se realizarmos uma amostra de tamanho n do experimento, e nesta amostra for observada nA (nA ≤ n) ocorrências do evento A, então a freqüência relativa do evento A será a razão nA / n. Para valores grandes de n, essa freqüência relativa fornecerá uma aproximação boa da probabilidade de A:
n
nlim)A(P A
n ∞→=

4
1.4 - DEFINIÇÃO BAYESIANA DE PROBABILIDADE Diferentemente do conceito clássico e freqüentista de probabilidade, o ponto de vista Bayesiano ou subjetivo "mapeia" a probabilidade em uma região de valores [0,1] que refletem a crença pessoal. Com respeito a crença pessoal na ocorrência de um evento A, sendo ele uma afirmação, podemos ter: P(A)=1 - Crença na verdade absoluta de uma afirmação; P(A)=0 - Crença na negação absoluta de uma afirmação; Valores Intermediários de P(A) - crenças parciais sobre afirmações. 1.5 – DEFINIÇÃO MATEMÁTICA DE PROBABILIDADE A partir de uma construção axiomática devido à Kolmogorov a Teoria da Probabilidade ganhou uma base matemática firme, onde um modelo matemático ou probabilístico pode ser formulado como um conceito matemático abstrato, sendo um espaço de probabilidade um trio ( )ΡΑΩ ,, ,onde:
Ω - Espaço Amostral; Α - coleção de subconjuntos de Ω , chamados de eventos aleatórios, ou σ - álgebra quando Α é ilimitado, de modo que a cada elemento de Α pode ser atribuído uma probabilidade Ρ, onde: P - probabilidade é uma função P : Α → +ℜ com as seguintes propriedades:
Sejam os elementos Α∈Αi
1. ( ) ( )ΑΡ−=ΑΡ 1 2. 0 ≤ Ρ(Α) ≤ 1 3. Se ( ) ( )2121 ΑΡ≤ΑΡ⇒Α⊂Α
4. ( )∑==
ΑΡ≤
Ρ
n
1ii
n
1iiAU
5. ( )∑∞
=
∞
=ΑΡ≤
Ρ
1ii
11iiiAU
6. (Continuidade de Probabilidade) A i seqüência crescente ou decrescente de conjuntos cujo limite é
( ) ( )ΑΡ →ΑΡ⇒Α∈Α ∞→ii
No caso, para seqüência crescente tem-se a seguinte notação:
( ) ( )ΑΡ↑ΑΡ⇒Α↑Α ii

5
E para seqüência decrescente:
( ) ( )ΑΡ↓ΑΡ⇒Α↓Α ii
Na notação de James, B. R. (2a. ed. 1996 – projeto Euclides – IMPA) Essa formulação permite a aplicação dos resultados da Teoria da Medida aos Modelos Probabilísticos.
1.6 - VARIÁVEIS ALEATÓRIAS Uma variável cujo valor seja determinado pelo resultado de um experimento aleatório chama-se variável aleatória (va). As variáveis aleatórias são geralmente indicadas pelas letras maiúsculas X, Y, Z, etc..., e os valores assumidos por elas são indicados por letras minúsculas x, y, z, etc.
Uma variável aleatória pode ser discreta ou contínua. Uma VA discreta assume um conjunto de valores enumeráveis podendo ser finito ou infinito. Por exemplo, no experimento de lançamento de dois dados, cada um numerado de 1 a 6, se definirmos a variável aleatória X como a soma dos números que aparecem no lado superior dos dados, então X poderá assumir um dos seguintes valores: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ou 12. Portanto X é uma variável aleatória discreta.
Uma va continua, por outro lado, é a que pode assumir qualquer valor em algum intervalo de valores. Assim, a altura de uma pessoa é uma variável aleatória contínua, já que na faixa de, digamos, 1,60m a 2,00m ela pode assumir qualquer valor dependendo da precisão da medida, p.ex.: 1,876m.
Definindo matematicamente: uma V.A. é uma função que atribui um valor real a cada ponto pertencente ao espaço amostral (ou estados da natureza). Para o caso unidimensional temos que:
A função
→ωℜ→Ωx
:X é V.A. se o evento (X ≤ x) tiver probabilidade definida ℜ∈∀x .
Define-se função de distribuição de uma V.A. unidimensional X à função: ( ) ( )xxFX ≤ΧΡ= , que pela definição de V.A. está definida ℜ∈∀x .
Exemplos: Modelo de Bernoulli (exemplo de VA discreta)
X é dita uma v.a. de Bernoulli de parâmetro p (denota-se X ~ Bernoulli(p)), se X assume apenas as determinações 0 e 1, com respectivas probabilidades q = 1–p e p, onde: 0<p<1
=→→→Ω
pq
p
-1 adeprobabilid com ,0 "fracasso"
adeprobabilid com ,1 "sucesso" R
:Xx
Onde Ω=“sucesso”;”fracasso”, Rx=0; 1, então:
( ) ( )
≥=+<≤
<=≤ΧΡ=
1 xse 1,qp
1x0 se q,
0 xse ,0
xxFX

6
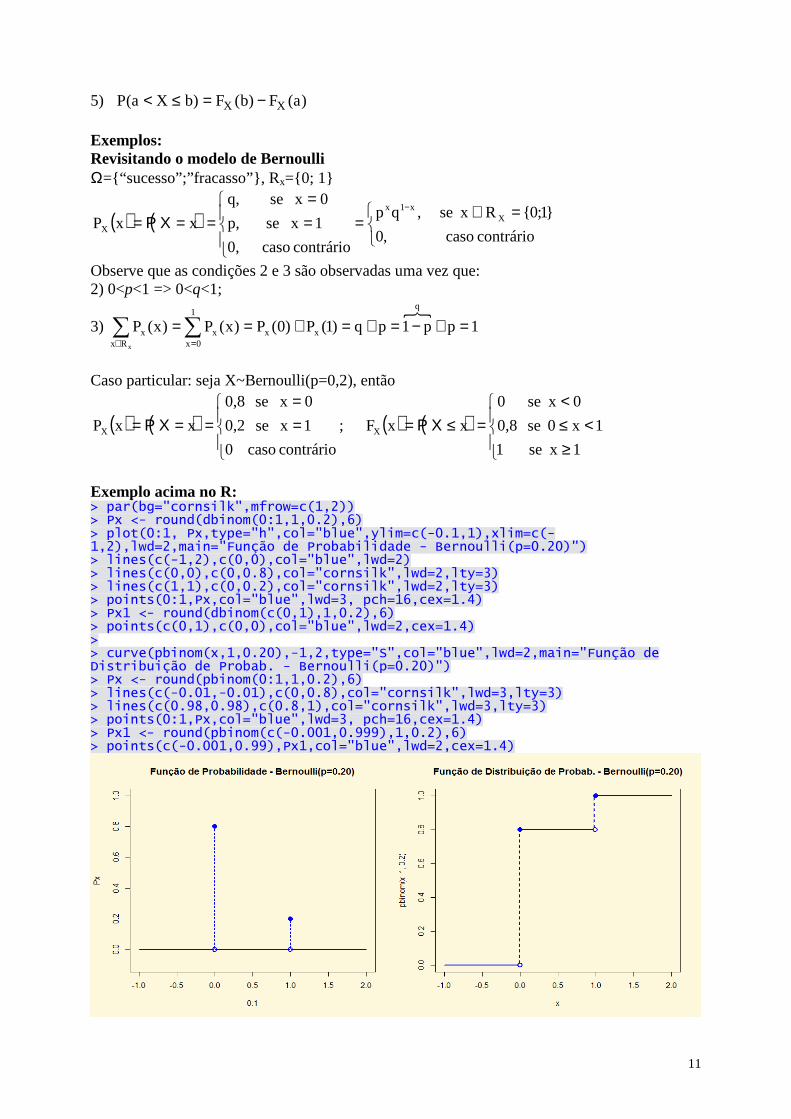
Exemplo de código em R para a função acima: > par(bg="cornsilk") > curve(pbinom(x,1,0.20),-1,2,type="S",col="blue",lwd=2,main="Função de Distribuição de Probab. - Bernoulli(p=0.20)") > Px<- round(pbinom(0:1,1,0.2),6) > lines(c(-0.01,-0.01),c(0,0.8),col="cornsilk",lwd=3,lty=3) > lines(c(0.98,0.98),c(0.8,1),col="cornsilk",lwd=3,lty=3) > points(0:1,Px,col="blue",lwd=3, pch=16,cex=1.4) > Px1<- round(pbinom(c(-0.001,0.999),1,0.2),6) > points(c(-0.001,0.99),Px1,col="blue",lwd=2,cex=1.4)
Obs.: no código em R usamos o fato de que a distribuição de Bernoulli é um caso particular da distribuição binomial, que será vista adiante. Modelo Exponencial (exemplo de VA contínua) X é dita uma VA Exponencial de parâmetro λ>0 (denota-se X~Exp(λ)), se X assume valores reais maiores o iguais a zero e tem a seguinte função de distribuição:
ℜ∈→ωℜ→Ω
+
+
x
:X
( )
≥−<
= λ− 0 xse ,e1
0 xse ,0xF
xX
Exemplo de código em R para a função acima com λλλλ=0,2: > curve(pexp(x,.2), -10, 30,col="blue",lwd=2,main="Função de Distribuição da VA Exp(lambda=0,2)", ylab="F(x)", xlab="x")

7
Dentre as propriedades de ( )xFX destaca-se (em geral decorrentes da definição de probabilidade):
1. ( )xFX ∈[0 ,1]
2. 1)(P)x|xX(P)x(Flim)(F Xx
X =Ω=+∞→≤=≡+∞+∞→
3. 0)(P)x|xX(P)x(Flim)(F X
xX =φ=−∞→≤=≡−∞
−∞→
4. ( )xFX é não decrescente
5. ( )xFX é contínua à direita em cada ponto x ∈ ℜ Observe que as funções de distribuição dos modelos de Bernouli e Exponencial atendem a estas propriedades acima. Para o caso multidimensional temos que:
A função :)X;...;X;X(X n21=
=→ℜ→
)x;...;(xxω
Ω
n1
n
é uma V. A. n-dimensional se o evento ( )nn11 x;...;x ≤Χ≤Χ tiver probabilidade definida nx ℜ∈∀ .
Mostra-se que cada Xi ∈ X é uma V.A. unidimensional e qualquer subconjunto de m
< n variáveis ∈ X é uma V.A. m-dimensional (Meyer, pg.110).
Define-se função de distribuição de uma V.A. n-dimensional X à função:
( ) ( )nn11X x;...;xxF ≤Χ≤ΧΡ= , que pela definição de V.A. está definida nx ℜ∈∀ .
Exemplos:

8
Exemplo de função de distribuição de uma VA bidimensional discreta:
Seja ( ) ( )
≥≥
≥>≥
≥>≥≥>≥>
<<
=≤≤ΧΡ=
1y e 1 xse 1,
0 x1 e 1y
ou
0y 1 e 1x
se 0,6,
0y 1 e 0 x1 se 0,36,
0y e 0 xse ,0
yY;xy,xFXY
Exemplo de código em R para a função acima: > Fxy <- function(x,y) + k<-length(x) + fxy <- numeric(k) + for(i in 1:k) + if(x[i]<0|y[i]<0)fxy[i]<-0 + if((x[i]<1&x[i]>=0)&(y[i]<1&y[i]>=0))fxy[i]<-0.36 + if((x[i]>=1&(y[i]<1&y[i]>=0))|(y[i]>=1&(x[i]<1&x[i]>=0)))fxy[i]<-0.6 + if(x[i]>=1&y[i]>=1)fxy[i]<-1 + + return(fxy) + > x <- seq(-1, 2, length.out = 50) > y <- x > z <- outer(x, y, Fxy) > oldpar <- par(bg = "white") > par(mfrow=c(1,1)) > persp(x, y, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue", + ltheta = 120, shade = 0.75, ticktype = "detailed", + xlab = "X", ylab = "Y", zlab = "Z") > title("Exemplo de Função de Distribuição de uma VA bidimensional discreta")

9
Exemplo de função de distribuição de uma VA bidimensional contínua:
( ) ( ) ( )( )
≥≥<<
=≤≤ΧΡ= λλ 0y e 0 xse ,e-1e-1
0you 0 xse ,0yY;xy,xF
y-x-XY
Exemplo de código em R para a função acima para λ=0,2: > Fxyl <- function(x,y) + lambda<-0.2 + k<-length(x) + fxy <- numeric(k) + for(i in 1:k) + if(x[i]<0|y[i]<0)fxy[i]<-0 + if(x[i]>=0&y[i]>=0)fxy[i]<-(1-exp(-lambda*x[i]))*(1-exp(-lambda*y[i])) + + return(fxy) + > x <- seq(-10, 30, length.out = 50) > y <- x > z <- outer(x, y, Fxyl) > oldpar <- par(bg = "white") > par(mfrow=c(1,1)) > persp(x, y, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue", + ltheta = 120, shade = 0.75, ticktype = "detailed", + xlab = "X", ylab = "Y", zlab = "Z",zlim=c(0,1)) > title("Exemplo de Função de Distribuição de uma VA bidimensional contínua")

10
Dentre as propriedades de ( )xFX destacam-se (em geral decorrentes da definição de
probabilidade):
1. ( )xFX ∈[0 ,1]
2. XF (+ ∞; + ∞; ...; + ∞) = 1 e XF (- ∞; - ∞; ...; - ∞) = P(∅) = 0 (operações com limites)
3. ( )xFX é não decrescente
4. A função de distribuição de cada subconjunto de m (1≤m<n) V.As m-dimensionais é obtida tornando-se o limite → +∞ das (n – m) V.As que não pertencem ao subconjunto na função de distribuição. Exemplo: seja n=6, logo )X;X;X;X;X;X(X 654321= , se quisermos obter a função de
distribuição de dimensão m=2 do vetor aleatório bidimensional )X;X( 52 a partir do vetor
aleatório n-dimensional )X;X;X;X;X;X(X 654321= , então:
( ) ( )( )
( )+∞+∞+∞∞+==+∞≤Χ≤Χ+∞≤Χ+∞≤Χ≤Χ+∞≤ΧΡ=
==+∞→+∞→+∞→+∞→
;x;;;x;F
;x;;;x;
xFlimx;xF
52X
65543221
Xx;x;x;x
52)X;X(6431
52
5. ( )xFX é contínua à direita em cada ponto xi ∈ x
A função de distribuição é bastante útil na definição formal única de uma variável ou vetor aleatório a despeito de a variável ou vetor aleatório ser discreto ou contínuo. Entretanto as variáveis e vetores aleatórios discretos e contínuos têm diferentes abordagens analíticas e definições matemáticas para o cálculo de probabilidades conforme abordaremos em seguida. 1.6.1 - FUNÇÃO DE PROBABILIDADE (VA discreta) 1.6.1.1 - FUNÇÃO DE PROBABILIDADE UNIVARIADA Assuma que o conjunto de valores que define o espaço amostral de uma variável aleatória discreta X, seja Rx=x 1, x2, .... Então a função de probabilidade de X será a função Px(x) que satisfaz as seguintes propriedades e condições:
1) Px(x)=P(X=x), se x ∈ Rx Px(x)=0 se x ∉ Rx; 2) 0 ≤ Px(x) ≤ 1 , para ∀ x;
3) 1)x(P
xRxx =∑
∈
4) ∑
≤=
axxX )x(P)a(F
11
5) )a(F)b(F)bXa(P XX −=≤<
Exemplos: Revisitando o modelo de Bernoulli Ω=“sucesso”;”fracasso”, Rx=0; 1
( ) ( ) =∈
=
==
==ΧΡ=−
contrário caso ,0
1;0R xse ,qp
contrário caso 0,
1 xse p,
0 xse ,q
xxP Xx1x
X
Observe que as condições 2 e 3 são observadas uma vez que: 2) 0<p<1 => 0<q<1;
3)
1pp1pq)1(P)0(P)x(P)x(P
q
xx
1
0xx
Rxx
x
=+−=+=+==∑∑=∈
Caso particular: seja X~Bernoulli(p=0,2), então
( ) ( )
==
==ΧΡ=contrário caso 0
1 xse 0,2
0 xse 0,8
xxPX ; ( ) ( )
≥<≤
<=≤ΧΡ=
1 xse 1
1x0 se 0,8
0 xse 0
xxFX
Exemplo acima no R: > par(bg="cornsilk",mfrow=c(1,2)) > Px <- round(dbinom(0:1,1,0.2),6) > plot(0:1, Px,type="h",col="blue",ylim=c(-0.1,1),xlim=c(-1,2),lwd=2,main="Função de Probabilidade - Bernoulli(p=0.20)") > lines(c(-1,2),c(0,0),col="blue",lwd=2) > lines(c(0,0),c(0,0.8),col="cornsilk",lwd=2,lty=3) > lines(c(1,1),c(0,0.2),col="cornsilk",lwd=2,lty=3) > points(0:1,Px,col="blue",lwd=3, pch=16,cex=1.4) > Px1 <- round(dbinom(c(0,1),1,0.2),6) > points(c(0,1),c(0,0),col="blue",lwd=2,cex=1.4) > > curve(pbinom(x,1,0.20),-1,2,type="S",col="blue",lwd=2,main="Função de Distribuição de Probab. - Bernoulli(p=0.20)") > Px <- round(pbinom(0:1,1,0.2),6) > lines(c(-0.01,-0.01),c(0,0.8),col="cornsilk",lwd=3,lty=3) > lines(c(0.98,0.98),c(0.8,1),col="cornsilk",lwd=3,lty=3) > points(0:1,Px,col="blue",lwd=3, pch=16,cex=1.4) > Px1 <- round(pbinom(c(-0.001,0.999),1,0.2),6) > points(c(-0.001,0.99),Px1,col="blue",lwd=2,cex=1.4)

12
Modelo Binomial
X é dita uma v.a. Binomial de parâmetros (n; p) (e denota-se X ~ Bin(n; p)), se X identifica-se ao número de sucessos ocorridos numa seqüência de n provas independentes de Bernoulli, onde a probabilidade de sucesso é igual a p, onde q=1–p. X pode assumir valores Rx=0; 1; 2; ...; n
∈
===−
contrário caso 0,
R xse ,qpx
n
)xX(P)x(P Xxnx
X
Observe que as condições 2 e 3 são observadas uma vez que:
xnxqpx
n −
são as parcelas positivas do binômio de Newton:
xnxn
0x
xnxn
0x
n qp)!kn(!k
!nqp
x
n)qp( −
=
−
=∑∑ −
=
=+ e estas parcelas positivas também precisam ser
menores que 1 pois este binômio de Newton totaliza 1, afinal: p+q=p+1–p=1=>
1)1()qp(qpx
n)x(P nn
n
0x
xnx
Rxx
x
==+=
=∑∑
=
−
∈
.
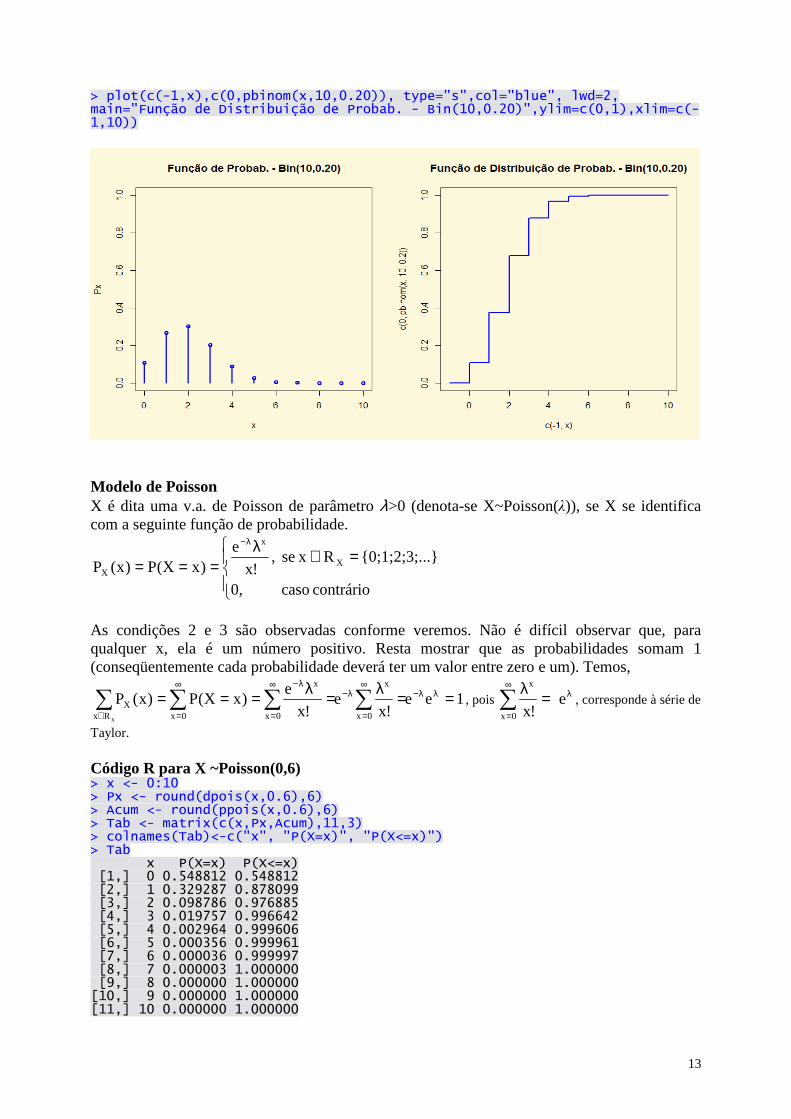
Observe também que o modelo de Bernoulli é um caso particular do modelo Binomial quando n=1. Exemplo: x ~ Bin(10; 0,2)
∈
=−
contrário caso 0,
10;...;2;1;0 xse ,8,02,0x
10
)x(Px10x
X
Código R para X ~ Bin(10; 0,2) > x <- 0:10 > Px <- round(dbinom(x,10,0.2),6) > Acum <- round(pbinom(x,10,0.2),6) > Tab <- matrix(c(x,Px,Acum),11,3) > colnames(Tab) <- c("x", "P(X=x)", "P(X<=x)") > Tab x P(X=x) P(X<=x) [1,] 0 0.107374 0.107374 [2,] 1 0.268435 0.375810 [3,] 2 0.301990 0.677800 [4,] 3 0.201327 0.879126 [5,] 4 0.088080 0.967207 [6,] 5 0.026424 0.993631 [7,] 6 0.005505 0.999136 [8,] 7 0.000786 0.999922 [9,] 8 0.000074 0.999996 [10,] 9 0.000004 1.000000 [11,] 10 0.000000 1.000000 > > par(bg="cornsilk",mfrow=c(1,2)) > plot(x,Px,type="h",col="blue",lwd=2, main="Função de Probab. - Bin(10,0.20)", ylim=c(0,1)) > points(x,Px,col="blue",lwd=2)
13
> plot(c(-1,x),c(0,pbinom(x,10,0.20)), type="s",col="blue", lwd=2, main="Função de Distribuição de Probab. - Bin(10,0.20)",ylim=c(0,1),xlim=c(-1,10))
Modelo de Poisson X é dita uma v.a. de Poisson de parâmetro λ>0 (denota-se X~Poisson(λ)), se X se identifica com a seguinte função de probabilidade.
=∈λ
===
λ−
contrário caso 0,
..0;1;2;3;.R xse ,!x
e)xX(P)x(P X
x
X
As condições 2 e 3 são observadas conforme veremos. Não é difícil observar que, para qualquer x, ela é um número positivo. Resta mostrar que as probabilidades somam 1 (conseqüentemente cada probabilidade deverá ter um valor entre zero e um). Temos,
1ee!x
e!x
e)xX(P)x(P
0x 0x
x
0x
x
RxX
x
==λ=λ=== λλ−∞
=
∞
=
λ−∞
=
λ−
∈∑ ∑∑∑ , pois ∑
∞
=
=λ0x
x
!x λe , corresponde à série de
Taylor. Código R para X ~Poisson(0,6) > x <- 0:10 > Px <- round(dpois(x,0.6),6) > Acum <- round(ppois(x,0.6),6) > Tab <- matrix(c(x,Px,Acum),11,3) > colnames(Tab)<-c("x", "P(X=x)", "P(X<=x)") > Tab x P(X=x) P(X<=x) [1,] 0 0.548812 0.548812 [2,] 1 0.329287 0.878099 [3,] 2 0.098786 0.976885 [4,] 3 0.019757 0.996642 [5,] 4 0.002964 0.999606 [6,] 5 0.000356 0.999961 [7,] 6 0.000036 0.999997 [8,] 7 0.000003 1.000000 [9,] 8 0.000000 1.000000 [10,] 9 0.000000 1.000000 [11,] 10 0.000000 1.000000

14
> > par(bg="cornsilk",mfrow=c(1,2)) > plot(x,Px,type="h",col="blue",lwd=2, main="Função de Probab. - Poisson(0.6)") > points(x,Px,col="blue",lwd=2) > plot(c(-1,x),c(0,ppois(x,0.6)), type="s",col="blue", lwd=2, main="Função de Distribuição de Probab. - Poisson(0.6)",ylim=c(0,1),xlim=c(-1,10))
Variável Aleatória Geométrica Seja uma seqüência de quantidade indeterminada de realizações de experimentos independentes de Bernoulli. Defina a variável aleatória X por: número de realizações ou repetições de Bernoulli(p) até que o primeiro “fracasso” ocorra” X é dita uma v.a. Geométrica de parâmetro 0<p<1 (denota-se X~Geom(p)), e demonstra-se que X tem a seguinte função de probabilidade.
=∈⋅
===−
contrário caso 0,
1;2;3;...R xse ,qp)xX(P)x(P X
1x
X
As condições 2 e 3 são observadas conforme veremos. Não é difícil observar que, para qualquer x, ela é um número positivo. Resta mostrar que as probabilidades somam 1 (conseqüentemente cada probabilidade deverá ter um valor entre zero e um). Temos,
1p1
1qpqqp)xX(P)x(P
1 e 0 entre razão com infinita P.G. uma de Soma
1x
1x
1x 1x
1x
RxX
x
=−
⋅=⋅=⋅=== ∑∑ ∑∑∞
=
−∞
=
∞
=
−
∈
876
Código R para X ~Geom(0,6) > x <- 0:10 > Px <- round(dgeom(x,0.6),6) > Acum <- round(pgeom(x,0.6),6) > Tab <- matrix(c(x,Px,Acum),11,3) > colnames(Tab)<-c("x", "P(X=x)", "P(X<=x)") > Tab x P(X=x) P(X<=x) [1,] 0 0.600000 0.600000 [2,] 1 0.240000 0.840000

15
[3,] 2 0.096000 0.936000 [4,] 3 0.038400 0.974400 [5,] 4 0.015360 0.989760 [6,] 5 0.006144 0.995904 [7,] 6 0.002458 0.998362 [8,] 7 0.000983 0.999345 [9,] 8 0.000393 0.999738 [10,] 9 0.000157 0.999895 [11,] 10 0.000063 0.999958 > > par(bg="cornsilk",mfrow=c(1,2)) > plot(x,Px,type="h",col="blue",lwd=2, main="Função de Probab. - Geom(0.6)") > points(x,Px,col="blue",lwd=2) > plot(c(-1,x),c(0,pgeom(x,0.6)), type="s",col="blue", lwd=2, main="Função de Distribuição de Probab. - Geom(0.6)",ylim=c(0,1),xlim=c(-1,10))
1.6.1.2 - FUNÇÃO DE PROBABILIDADE CONJUNTA (BIVARIA DA) Suponha que o experimento que define a VA discreta X anterior ocorra em conjunto com o experimento que define a V.A. discreta Y, onde RY=y1, y2, ... é o conjunto que enumera todos os resultados possíveis da V.A. discreta Y, de maneira análoga definimos a função de probabilidade conjunta PXY(x,y) do vetor aleatório (X;Y) deve satisfazer as seguintes propriedades e condições:
1) PXY(x,y)=P(X=x ∩Y=y), se x ∈ RX e y ∈ RY PXY(x,y)=0 se x ∉ RX ou y ∉ RY;
2) 0 ≤ PXY(x,y) ≤ 1; 3) ∑ ∑
∈ ∈
=X YRx Ry
XY 1)y,x(P
4) ∑∑
≤ ≤=
ax byXYXY )y,x(P)b,a(F

16
Exemplos: a) Considere a seguinte função de probabilidade conjunta (bivariada):
∈∈
=−−+
contrário caso ,0
0;1y e 0;1 xse ,qp)y,x(P
yx2yx
XY , para 0<p<1 e q=1–p
Verifique que a condição 2 é observada e que a condição 3 é satisfeita, pois:
1)1()qp(qpq2pqpqpqpqp
qpqpqpqp)y,x(P
222202111120
Rx Ry
1
0x
x11xx2x1
0x
1
0y
yx2yx1
0x
1
0y
yx2yxXY
X Y
==+=++=+++=
=+=
==∑ ∑ ∑∑ ∑∑∑
∈ ∈ =
−+−
= =
−−+
= =
−−+
Caso particular para p=0,4:
∈∈
=−−+
contrário caso ,0
0;1y e 0;1 xse ,6,04,0)y,x(P
yx2yx
XY
Tabela 1 - Exemplo para p=0,4
0 10 0,36 0,241 0,24 0,16
X
Y
Pxy(x,y)
Código R para o gráfico do exemplo acima: > par(bg="cornsilk",mfrow=c(1,1)) > linhas <- 4 > x <- rep(NA,linhas) > y <- rep(NA,linhas) > Pxy <- rep(NA,linhas) > c <- 1 > for(i in 0:1) + for(j in 0:1) + x[c] <- i + y[c] <- j + Pxy[c] <- (0.4^(i+j))*(0.6^(2-i-j)) + c <- c+1 + + > par(bg="cornsilk") > library(scatterplot3d) # carrega o pacote scaterplot3d que precisa estar previamente instalado > scatterplot3d(x, y, Pxy, col.axis="blue", type="h", col.grid="lightblue", main="Exemplo de uma função de probabilidade bivariada", lwd=5, pch=" ", xlim=c(-1,2), ylim=c(-1,2))

17
b) Considere a seguinte função de probabilidade conjunta (bivariada):
ℵ=∈ℵ=∈λ
=
+λ−
contrário caso ,0
.0;1,2,3,..y e ..0;1,2,3,. xse ,!y!x
e)y,x(P
yx2
XY , para λ>0
Verifique que a condição 2 é observada e que a condição 3 é satisfeita, pois:
111
!y
e
!x
e
!y!x
ee
!y!x
e)y,x(P
X YRx Ry
1
0y
)Poisson(~Y .obPr .F
y
1
0x
)Poisson(~X .obPr .F
x
0x 0yy para .Const
y
y para .Const
x
0x 0y
yx2
XY
=⋅=
=λ⋅λ=λλ=λ=∑ ∑ ∑∑∑∑∑∑∈ ∈
=
∞
=
λ
λ−
=
∞
=
λ
λ−∞
=
∞
=
λ−λ−∞
=
∞
=
+λ−
44 344 21
876
44 344 21
876876
Caso particular para λ=0,5:
ℵ∈ℵ∈
=
+−
contrário caso ,0
y e xse ,!y!x
5,0e)y,x(P
yx1
XY
Código R para o gráfico do exemplo acima: > par(bg="cornsilk",mfrow=c(1,1)) > linhas <- 25 > x <- rep(NA,linhas) > y <- rep(NA,linhas) > Pxy <- rep(NA,linhas) > c <- 1
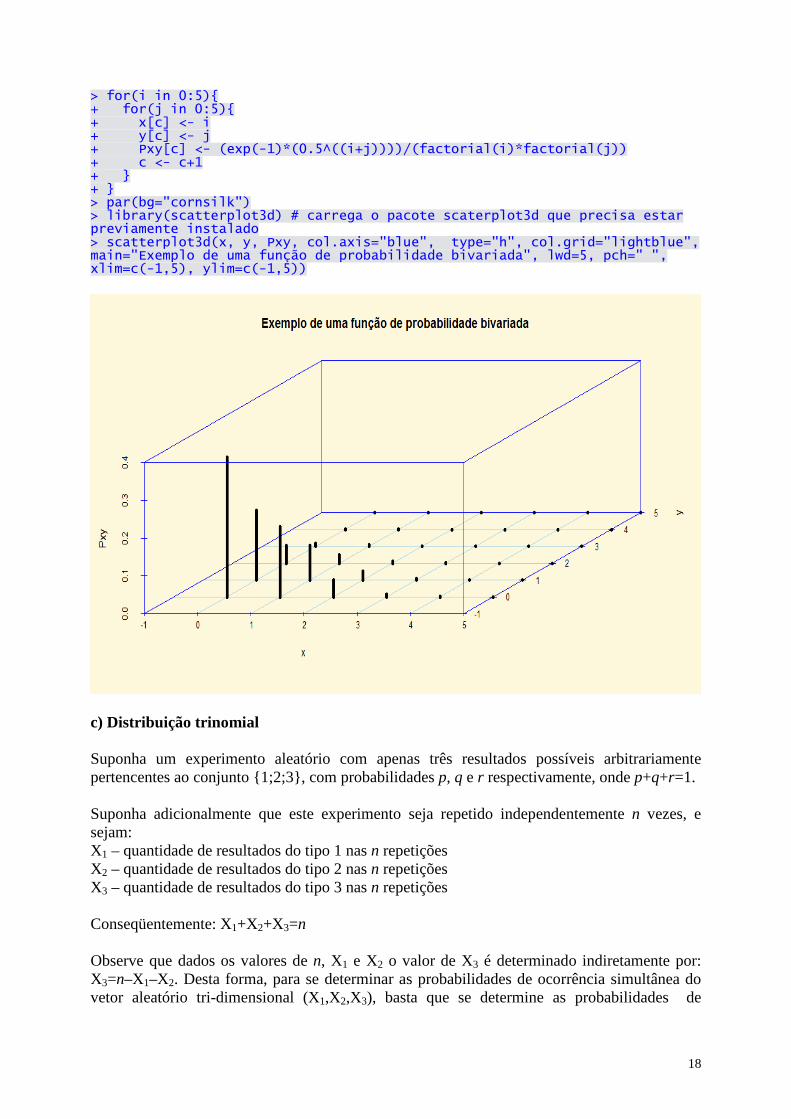
18
> for(i in 0:5) + for(j in 0:5) + x[c] <- i + y[c] <- j + Pxy[c] <- (exp(-1)*(0.5^((i+j))))/(factorial(i)*factorial(j)) + c <- c+1 + + > par(bg="cornsilk") > library(scatterplot3d) # carrega o pacote scaterplot3d que precisa estar previamente instalado > scatterplot3d(x, y, Pxy, col.axis="blue", type="h", col.grid="lightblue", main="Exemplo de uma função de probabilidade bivariada", lwd=5, pch=" ", xlim=c(-1,5), ylim=c(-1,5))
c) Distribuição trinomial Suponha um experimento aleatório com apenas três resultados possíveis arbitrariamente pertencentes ao conjunto 1;2;3, com probabilidades p, q e r respectivamente, onde p+q+r=1. Suponha adicionalmente que este experimento seja repetido independentemente n vezes, e sejam: X1 – quantidade de resultados do tipo 1 nas n repetições X2 – quantidade de resultados do tipo 2 nas n repetições X3 – quantidade de resultados do tipo 3 nas n repetições Conseqüentemente: X1+X2+X3=n Observe que dados os valores de n, X1 e X2 o valor de X3 é determinado indiretamente por: X3=n–X1–X2. Desta forma, para se determinar as probabilidades de ocorrência simultânea do vetor aleatório tri-dimensional (X1,X2,X3), basta que se determine as probabilidades de

19
ocorrência simultânea do vetor aleatório bi-dimensional (X1,X2), conhecido como distribuição trinomial. Demonstra-se que:
( )
∈∈
⋅
−−= =
=
contrário caso ,0
x-n0;1,..., xe n0;1,..., xse ,q-p-1qp
! xxn!x!x
!n
)x,x(P
121
x-x-n
r
xx
x
212121XX
21
21
3
21
321
43421
Código R para o gráfico do exemplo acima para n=5, p=0,4, q=0,3 e r=0,3: > par(bg="cornsilk",mfrow=c(1,1)) > linhas <- 36 > x1 <- rep(NA,linhas) > x2 <- rep(NA,linhas) > Px1x2 <- rep(0,linhas) > c <- 1 > for(i in 0:5) + for(j in 0:5) + x1[c] <- i + x2[c] <- j + if(j<5-i|j==5-i)Px1x2[c] <- dmultinom(c(i,j,5-i-j),5,c(0.4,0.3,0.3)) + c <- c+1 + + > par(bg="cornsilk") > library(scatterplot3d) # carrega o pacote scaterplot3d que precisa estar previamente instalado > scatterplot3d(x1, x2, Px1x2, col.axis="blue", type="h", col.grid="lightblue", main="Exemplo de uma distribuição trinomial (n=5,p=0,4,q=0,3,r=0,3)", lwd=5, pch=" ", xlim=c(-1,6), ylim=c(-1,6),angle=70) > Tab <- matrix(Px1x2,6,6,byrow=T) > colnames(Tab)<-as.character(0:5) > rownames(Tab)<-as.character(0:5) > Tab 0 1 2 3 4 5 0 0.00243 0.01215 0.0243 0.0243 0.01215 0.00243 1 0.01620 0.06480 0.0972 0.0648 0.01620 0.00000 2 0.04320 0.12960 0.1296 0.0432 0.00000 0.00000 3 0.05760 0.11520 0.0576 0.0000 0.00000 0.00000 4 0.03840 0.03840 0.0000 0.0000 0.00000 0.00000 5 0.01024 0.00000 0.0000 0.0000 0.00000 0.00000 > sum(Tab) [1] 1
Obs.: utilizamos neste código-exemplo o fato de que a distribuição trinomial é um caso particular da distribuição multinomial, a qual é implementada através da função do R dmultinom(). Definiremos a distribuição multinomial adiante. Observe também que todas as probabilidades calculadas desta distribuição trinomial do exemplo somam 1.

20
1.6.1.3 - FUNÇÃO DE PROBABILIDADE MARGINAL De posse de uma distribuição de probabilidade conjunta bivariada de X e Y (V.A.s onde RX=x 1, x2, ... é o conjunto que enumera todos os resultados possíveis da V.A. discreta X e RY=y1, y2, ... é o conjunto que enumera todos os resultados possíveis da V.A. discreta Y) podemos definir as funções de probabilidade marginais de X e Y, respectivamente pelas expressões:
∑∈
=YRy
XYX )y,x(P)x(P e ∑∈
=XRx
XYY )y,x(P)y(P
A tabela a seguir fornece um exemplo de função de probabilidade conjunta (a qual não foi determinada por uma expressão matemática específica alguma) e de funções de probabilidades marginais de X e Y associadas.
Tabela 2 – Outro exemplo
-2 0 2 33 0,27 0,08 0,16 0 0,516 0 0,04 0,10 0,35 0,49
0,27 0,12 0,26 0,35 1Px(x)
Y
Pxy(x,y) Py(y)X

21
Observe-se que as funções de probabilidades marginais localizam-se nas margens da tabela de uma distribuição de probabilidades conjunta bivariada, onde se localizam os totais das linhas e das colunas, conforme preconiza a definição de função de probabilidade marginal. Aplicando as expressões das funções de probabilidade marginal ao exemplo a) da seção anterior usado para ilustrar a função de probabilidade conjunta bivariada, temos que as respectivas funções de probabilidade marginais serão:
Xx1x
1
x1x
Ry
x11xx2x1
0y
yx2yxXYX R xpara ,qpqpqpqpqpqp)y,x(P)x(P
Y
∈=
+=+=== −−
∈
−+−
=
−−+∑ ∑
Yy1y
1
y1y
Rx
y11yy2y1
0x
yx2yxXYY Ry para ,qpqpqpqpqpqp)y,x(P)y(P
x
∈=
+=+=== −−
∈
−+−
=
−−+∑ ∑
Ambas as funções de probabilidade marginais deste exemplo assumem a forma da função de probabilidade do modelo de Bernoulli de parâmetro p. Aplicando-se analogamente as definições de função de probabilidade marginal para a função de probabilidade conjunta do exemplo b) da seção anterior pode-se concluir que ambas as funções de probabilidade marginais associadas têm distribuição de Poisson com parâmetro λ. Quanto à distribuição trinomial apresentada no exemplo c) da seção anterior, demonstra-se que as funções de probabilidade marginais associadas têm distribuição binomial de parâmetros n e probabilidades de sucesso respectivamente p, q e r, assim X1 ~ Bin(n,p), X2 ~ Bin(n,q) e X3 ~ Bin(n,r) A tabela seguinte apresenta uma ilustração numérica destes fatos usando-se os dados do exemplo implementado anteriormente em R:
Tabela 3 – Exemplo da trinomial n=5, p=0,4, q=0,3 e r=0,3
0000 1 2 3 4 5
0000 0,00243 0,01215 0,02430 0,02430 0,01215 0,00243 0,07776 0,077761111 0,01620 0,06480 0,09720 0,06480 0,01620 0 0,25920 0,259202222 0,04320 0,12960 0,12960 0,04320 0 0 0,34560 0,345603333 0,05760 0,11520 0,05760 0 0 0 0,23040 0,230404444 0,03840 0,03840 0 0 0 0 0,07680 0,076805555 0,01024 0 0 0 0 0 0,01024 0,01024
0,16807 0,36015 0,30870 0,13230 0,02835 0,00243 1 1
0,16807 0,36015 0,30870 0,13230 0,02835 0,00243 1 -
P(X1=x1), onde X1~Bin(5;0,4)
Marginal P X2(x2)
P(X2=x2), onde X2~Bin(5;0,3)
PX1X2(x1,x2)X2
X1
Marginal PX1(x1)

22
1.6.1.4 - FUNÇÃO DE PROBABILIDADE CONDICIONAL As funções de probabilidade condicionais em X e Y são definidas respectivamente por:
)y(P
)y,x(P)yY|xX(P)x(P
Y
XYyY|X ≡====
)x(P
)y,x(P)xX|yY(P)y(P
X
XYxX|Y ≡====
Exemplos numéricos aplicados aos dados da Tabela 2 :
7143,0)6(P
)6;3(P)3(P
3137,0)3(P
)3;2(P)2(P
49,035,0
Y
XY6Y|X
51,016,0
Y
XY3Y|X
===
===
=
=
e
3846,0)2(P
)6;2(P)6(P
6667,0)0(P
)3;0(P)3(P
26,010,0
X
XY2X|Y
12,008,0
X
XY0X|Y
===
===
=
=
X PX|Y=3(x) PX|Y=6(x)-2 0,5294 0,00000 0,1569 0,08162 0,3137 0,20413 0,0000 0,7143
soma 1 1 Obs.: nos exemplos acima pudemos observar que:
XRx
yY|X R x todoarap ,1)x(PX
∈=∑∈
= e YRY
xX|Y Ry todoarap ,1)y(PY
∈=∑∈
=
Ou seja, as funções de probabilidade condicionais associadas a uma função de probabilidade
conjunta bivariada atendem às condições 2 e 3 de uma função de probabilidade univariada. Verifique também como exercício: 1) Que as expressões das funções de probabilidade condicionais associadas à função de
probabilidade conjunta bivariada tomada na exemplo a) da seção 1.6.1.2, assim como as funções de probabilidade marginais, também são as expressões da função de probabilidade univariada de um modelo de Bernoulli;
2) Que as expressões das funções de probabilidade condicionais associadas à função de probabilidade conjunta bivariada tomada na exemplo b) da seção 1.6.1.2, assim como as funções de probabilidade marginais, também são as expressões da função de probabilidade univariada de um modelo Poisson(λ);
3) Que as expressões das funções de probabilidade condicionais associadas à função de probabilidade conjunta da distribuição trinomial tomada no exemplo c) da seção 1.6.1.2 são diferentes das funções de probabilidade marginais (binomeiais). Para efeito de conferência observe que:
( ) ( )( )
( ) ( )( )2
211
221 xn211
xxnx2
1xX|Xq-1 ! xxn !x
q-p-1 p ! xn)x(P −
−−
= ⋅−−⋅⋅⋅−
= , uma expressão que depende de x1 e x2.
Y PY|X=-2(y) PY|X=0(y) PY|X=2(y) PY|X=3(y)3 1,0000 0,6667 0,6154 0,00006 0,0000 0,3333 0,3846 1,0000
soma 1 1 1 1

23
1.6.1.5 - FUNÇÃO DE PROBABILIDADE CONJUNTA (MULTIVA RIADA) Seja o vetor aleatório constituído de n variáveis aleatórias discretas X =(X1; X2; ...; Xn ) (vetor aleatório n-dimensional cujo conjunto que enumera todos os seus resultados possíveis é denotado por n
XR ℜ⊂ ). A função de probabilidade conjunta de X deve satisfazer as
seguintes condições e propriedades:
1) ( ) ( ) ( ) ∈=∩∩=∩=
==contrário caso ,0
Rx se ,xXxXxXPx;;x;xPxP
Xnn2211n21XX
LK
2) ( ) 1xP0 X ≤≤ ;
3) ( )∑ ∑ ∑
∈ ∈ ∈
=1X1 2X2 nXnRx Rx Rx
X 1xPL ;
4) ( )∑ ∑ ∑
≤ ≤ ≤
=11 22 nnax ax ax
Xn21X xP)a;...;a;a(F L ;
5) Seja n=6 e );;;;;( 654321 XXXXXXX = com função de probabilidade conjunta
( )xPX . Se quisermos obter a função de probabilidade conjunta de dimensão m=2 do
vetor aleatório );( 52 XX , então:
( ) ( )∑ ∑ ∑ ∑∈ ∈ ∈ ∈
=1x1 3x3 4x4 6x6
52Rx Rx Rx Rx
X52XX xPx;xP
Estas definições, condições e propriedades de um vetor aleatório n-dimensional constituem
uma extensão natural das definições análogas as de um vetor aleatório bi-dimensional. Exemplo: distribuição multinomial Suponha um experimento aleatório com k resultados possíveis arbitrariamente pertencentes ao
conjunto 1;2;...;k, com probabilidades p1, p
2 , ..., p
k respectivamente, onde 1p
k
1ii =∑
=
.
Suponha adicionalmente que este experimento seja repetido independentemente n vezes, e sejam: X1 – quantidade de resultados do tipo 1 nas n repetições X2 – quantidade de resultados do tipo 2 nas n repetições M Xk – quantidade de resultados do tipo k nas n repetições
Conseqüentemente: nXk
1ii =∑
=

24
Observe que dados os valores de n, X1, X2, ..., Xk-1 o valor de Xk é determinado indiretamente
por: ∑−
=
−=1k
1iik XnX . Desta forma, para se determinar as probabilidades de ocorrência
simultânea do vetor aleatório k-dimensional X =(X1; X2; ...; Xk ), basta que se determine as probabilidades de ocorrência simultânea do vetor aleatório (k-1)-dimensional (X1; X2; ...; Xk-1), conhecido como distribuição multinomial. Demonstra-se que:
( )
=≥⋅⋅⋅⋅⋅⋅⋅= ∑
=
contrário caso ,0
nx que tais0, inteiros xse ,ppp!x!x!x
!n
xP
k
1iii
xk
x2
x1
k21X
k21 KK
A disttribuição trinomial é um caso particular da distribuição multinomial para k=3 1.6.2 - FUNÇÃO DE DENSIDADE DE PROBABILIDADE (VA contínua) 1.6.2.1 - FUNÇÃO DE DENSIDADE DE PROBABILIDADE UNIV ARIADA Seja X uma VA contínua. Então fX(x) é a função de densidade de probabilidade (fdp) se satisfizer as seguintes condições e propriedades:
1) ∫ ≤≤=b
aX )bXa(Pdx)x(f ;
2) fX(x) ≥ 0;
3) ∫∞
∞−
= 1dx)x(f X .
4) ∫∞−
=a
XX dx)x(f)a(F
Corolário: )x(Fdx
d)x(f XX =
5) )a(F)b(F)bXa(P XX −=≤<
Note que a função de densidade de probabilidade só permite o cálculo de probabilidades de intervalos de uma VA contínua, portanto não está definido o cálculo de probabilidades de pontos de uma variável aleatória contínua através do uso da função de densidade de probabilidade e nem por outra definição matemática. Desta forma a expressão
)xX(P)x(f X == é um equivoco e não condiz com a definição de uma fdp. Isto porque fX(x)
≥ 0 pela propriedade 2, porém )xX(P = é considerado desprezível ou em termos abstratos nulo para as VAs contínuas.
Uma forma entender esta restrição é considerar que o espaço amostral associado a uma VA contínua deve ser um conjunto de tamanho infinito, decorrente do fato de que o domínio das VAs contínuas é o conjunto dos números reais, onde qualquer intervalo, por menor que seja,

25
contém uma infinidade de elementos por definição. Intuitivamente é fácil imaginar que seria impossível o cálculo da probabilidade de um ponto de uma VA contínua (ou mesmo que esta probabilidade seria abstratamente nula) sob o paradigma dos espaços amostrais equiprováveis, pois o numerador deste cálculo seria 1, porém o denominador da fração de cálculo tenderia ao infinito. Já a probabilidade de uma VA contínua pertencer a um intervalo não padece da mesma restrição conceitual de nulidade.
Esta observação é a razão pela qual uma fdp apresenta o termo densidade em sua definição, termo inexistente quando tratamos de VAs discretas, onde uma função de probabilidade permite o cálculo de probabilidades de pontos de uma VA discreta. Uma função de densidade não mede probabilidade, apenas possibilita o cálculo de probabilidades para intervalos da variável aleatória contínua através de integrais desta função nos respectivos intervalos. Exemplos: Densidade do modelo Exponencial Podemos usar a propriedade 4 de uma VA contínua para determinar a função de densidade de uma VA X~Exp(λ). Esta VA foi previamente definida como exemplo de definição de uma VA contínua no início da seção 1.6, onde a expressão de sua função de distribuição foi apresentada:
X~Exp(λ) => ( )
≥λ<
==λ− 0 xse ,e
0 xse ,0xF
dx
d)x(f
xXX
Exemplo de código em R para a função acima com λλλλ=0,2: > curve(dexp(x,.2), 0, 30,col="blue",lwd=2,main="Função de Densidade da Exp(lambda=0,2)", ylab="f(x)", xlab="x", xlim=c(-10,30)) > curve(dexp(x,.2), -10, -0.01,col="blue",lwd=2, add=T) > lines(c(0,0),c(0,0.2),lwd=1,lty=3)
Verifique como exercício que as propriedades 2 e 3 são satisfeitas para a VA exponencial.

26
Distribuição Gama Diz-se que X é uma VA aleatória de distribuição Gama de parâmetros α e λ, X~Gama(α,λ) se:
≥
αΓλ
=λ−−α
α
contrário caso ,0
0 xse ,ex)()x(f
x1
X , onde ∫∞
−−α=αΓ0
x1 dxex)( (função Gama)
Aplicações: resultados analíticos da inferência estatística clássica. Algumas distribuições de probabilidade importantes são casos particulares da distribuição Gama, como a exponencial e a qui-quadrado. Exemplo de código em R para a função acima: > oldpar<-par() > par(mfrow=c(1,2),bg="white",mai=c(1.36,1.5,1.09,0.56)) > curve(dgamma(x,1,1), 0, 13,col=1,lwd=2,main="Função de Densidade da Distribuição Gama", ylab=expression(f[X](x)==frac(lambda^alpha,Gamma(alpha))*e^-lambda*x*x^alpha-1), xlab="x",xlim=c(0,13)) > curve(dgamma(x,1.5,1), 0, 13,col=2,lwd=2, add=T) > curve(dgamma(x,3,1), 0, 13,col=3,lwd=2, add=T) > curve(dgamma(x,5,1), 0, 13,col=4,lwd=2, add=T) > abline(v=0,h=0) > legenda <- expression(list(alpha==1.0,lambda==1),list(alpha==1.5,lambda==1),list(alpha==3,lambda==1),list(alpha==5,lambda==1)) > legend("center", legenda, col=1:4,lwd=2,bty="n") > > curve(dgamma(x,2,2), 0, 13,col=1,lwd=2,main="Função de Densidade da Distribuição Gama", ylab=expression(f[X](x)==frac(lambda^alpha,Gamma(alpha))*e^-lambda*x*x^alpha-1), xlab="x",xlim=c(0,13)) > curve(dgamma(x,2,1), 0, 13,col=2,lwd=2, add=T) > curve(dgamma(x,2,2/3), 0, 13,col=3,lwd=2, add=T) > curve(dgamma(x,2,1/2), 0, 13,col=4,lwd=2, add=T) > abline(v=0,h=0) > legenda <- expression(list(alpha==2,lambda==2),list(alpha==2,lambda==1),list(alpha==2,lambda==2/3),list(alpha==2,lambda==1/2)) > legend("center", legenda, col=1:4,lwd=2,bty="n") > par(oldpar)

27
Distribuição qui-quadrado É caso particular da fdp Gama: X~Gama(k/2,1/2)~2
kχ onde k é chamado de graus de liberdade da distribuição qui-quadrado. Apresenta importantes aplicações na inferência estatística clássica e na inferência não paramétrica. Alguns valores dessa distribuição encontram-se tabelados em livros sobre o assunto. Modelo Normal ou de Gauss Uma VA X tem distribuição Normal ou de Gauss de probabilidades com parâmetros µ e σ2>0 (denota-se X ~ Normal (µ,σ2)), se:
2
2
2
)x(
X e2
1)x(f σ
µ−−
πσ= , x é número real
Código R para X ~Normal(168;100) > curve(dnorm(x,168,10),130,210,col="blue",lwd=2,main="Função de Densidade da Normal(168,100)", ylab="f(x)", xlab="x") > polygon(x=c(158,seq(158,178,l=20), 178), + y=c(0,dnorm(seq(158,178,l=20),168,10),0), col="grey") > curve(dnorm(x,168,10),130,210,col="blue",lwd=2,add=T) # reforça a linha da densidade depois de poligon > abline(v=c(168,158,178),h=c(0,dnorm(168,168,10),dnorm(178,168,10)),lty=3) #traça as linha pontilhadas > text(167.9,-0.0008,expression(bold(mu==168))) > text(157.91,-0.0008,expression(bold(mu-sigma))) > text(177.91,-0.0008,expression(bold(mu+sigma))) > text(168,0.02,expression(paste(P,"(",mu-sigma,"<",X,"<",mu+sigma,")","="))) > text(168,0.015,expression(paste("=",integral(f[X](x)*dx, mu-sigma,mu+sigma),"="))) > text(168,0.015,expression(paste("=",integral(f[X](x)*dx, mu-sigma,mu+sigma),"="))) > text(168,0.01,"=68,27%")

28
Trata-se de uma das distribuições mais importantes do cálculo de probabilidades e da
inferência estatística. Isso porque além das observações empíricas, já foi demonstrado teoricamente através de alguns teoremas tal como o teorema central do limite que muitas das situações aleatórias do mundo real podem ser modeladas ou aproximadas por essa distribuição de probabilidades. No gráfico acima pudemos perceber a importante propriedade de simetria desta fdp.
Devido a sua grande importância, esta distribuição de probabilidades encontra-se tabelada em praticamente todos os livros que abordam este assunto. Para tanto, deve-se proceder a uma transformação linear que padroniza essa distribuição como uma Normal(0,1). Toda Normal(µ,σ2) pode ser convertida para a Normal(0,1). Propriedades da distribuição normal: 1. Sejam X1~Normal(µ1,σ1
2), X2~Normal(µ2,σ22), ..., Xn~Normal(µn,σn
2), e a1, a2, ..., an
constantes, então: ),a(Normal~XaG 2g
n
1ii1g
n
1iii σµ=µ= ∑∑
== (combinação linear de
v.as. Normais também tem distribuição Normal)
2. Se X ~ Normal(µ,σ2) então Zx
=− µσ
~ Normal(0,1) (padronização)
3. P(0<Z<a)=P(-a<Z<0) e P(Z>a)=P(Z<-a), onde a é constante. (simetria) Teorema Central do Limite (uma de suas versões)
Se X1, X2, ..., Xn são variáveis aleatórias independentes com médias µ1, µ2, ...,µn e
variâncias σ12, σ2
2, ..., σn2 respectivamente, então a distribuição de Y Xi
i
n
==∑
1 tende a uma
distribuição Normal com média E Y ii
n
( ) ==∑µ
1 e variância VAR Y i
i
n
( ) ==∑σ 2
1 quando n→∞.
Trata-se de um dos resultados mais importantes do cálculo de probabilidades, já que, toda vez que pudermos supor que a componente aleatória de um modelo seja provocado por uma grande quantidade de fatores causais independentes com distribuições desconhecidas, podemos modelar a distribuição de probabilidades da soma desses fatores pela distribuição Normal. Outros teoremas relacionados à distribuição normal 1) Sejam Z1, Z2, ..., Zk variáveis normais padronizadas (Normal(0,1)) independentes. Então, a
quantidade Z Z ii
k
==∑ 2
1 tem distribuição Qui-quadrado ( )χ k
2 com k graus de liberdade.
2) Sejam Z1 ~ Normal(0,1) e Z2 ~ χ k2 independentes, então a transformação t
Z
Z k= 1
2 / têm
distribuição t de Student (tk) com k graus de liberdade. Esta distribuição também é simétrica e converge para a distribuição Normal quando k→∞. Também a encontramos tabelada em muitos livros.

29
3) Sejam Z1 ~ χ k12 e Z2 ~ χk2
2 independentes , então a transformação F
Z k
Z k= 1 1
2 2
segue a
distribuição F de Fisher ( ),Fk k1 2 com k1 e k2 graus de liberdade. É comum encontrá-la
tabelada em livros. 1.6.2.2 - FUNÇÃO DE DENSIDADE DE PROBABILIDADE CONJUNTA (BIVARIADA) Quando o experimento que define a VA contínua X ocorre conjuntamente com o experimento que define a VA contínua Y, então fXY(x,y) é a função de densidade de probabilidade conjunta que satisfaz:
1) ∫ ∫ ≤<≤<=b
a
d
cXY )dYcebXa(Pdydx)y,x(f ;
2) fXY (x,y) ≥ 0;
3) ∫ ∫∞
∞−
∞
∞−
= 1dxdy)y,x(f XY
4) ∫ ∫∞− ∞−
=a b
XYXY dxdy)y,x(f)b,a(F
Exemplos: Verifique que as funções de densidade abaixo atendem às condições 2 e 3:
a) ≥≥
=+−
contrário caso 0,
0y e 0 xse ,e)y,x(f
)yx(
XY
b) ≥≥⋅
=+−
contrário caso 0,
0y e 0 xse ,ex)y,x(f
)1y(x
XY
c) (X,Y) com distribuição normal bivariada com parâmetros µ1,µ
2, σ
1
2, σ
2
2, ρ, se tem função
de densidade conjunta:
( ) 2
yx2
yx
12
1
21
XY y)(x, ,e12
1)y,x(f
2
2
1
12
2
22
1
12
ℜ∈ρ−σπσ
=
σµ−
σµ−
ρ−
σµ−
+
σµ−
ρ−−

30
Ilustração de exemplo:
Código R da ilustração acima: > par(mfrow=c(1,1),bg="white") > library(scatterplot3d) > library("mvtnorm") > x1 <- x2 <- seq(-5, 5, length = 51) > dens <- matrix(dmvnorm(expand.grid(x1, x2), + sigma = rbind(c(3, 2), c(2, 3))), + ncol = length(x1)) > z <- dens > z0 <- min(z) > z <- rbind(z0, cbind(z0, z, z0), z0) > x1 <- c(min(x1) - 1e-10, x1, max(x1) + 1e-10) > x2 <- c(min(x2) - 1e-10, x2, max(x2) + 1e-10) > > fill <- matrix("green3", nrow = nrow(z)-1, ncol = ncol(z)-1) > fill[ , i2 <- c(1,ncol(fill))] <- "gray" > fill[i1 <- c(1,nrow(fill)) , ] <- "gray" > fcol <- fill ; fcol[] <- terrain.colors(nrow(fcol)) > > zi <- dens[ -1,-1] + dens[ -1,-50] + + dens[-50,-1] + dens[-50,-50] ## / 4 > fcol[-i1,-i2] <- + terrain.colors(20)[cut(zi, + seq(min(zi),max(zi), length.out = 21), + include.lowest = TRUE)] > persp(x1, x2, + z, col=fcol, + theta = 110, phi = 30, + zlab = "f(x1, x2)", + xlab = "x1", ylab = "x2", + main = "Distribuição Normal Bivariada", + ticktype = "detailed", + zlim=c(0,0.085)) > text(0,0.25, + labels = expression(f[underline(X)](underline(x)) == frac(1, sqrt((2 * pi)^n * + phantom(".") * det(Sigma[underline(X)]))) * phantom(".") * exp * + bgroup("(", - scriptstyle(frac(1, 2) * phantom(".")) * + (underline(x) - underline(mu))^T * Sigma[underline(X)]^-1 * (underline(x) - underline(mu)), ")")))

31
> text(0.3, 0.15, + labels = expression("para" * phantom("m") * + underline(mu) == bgroup("(", atop(0, 0), ")") * phantom(".") * "," * + phantom(0) * + Sigma[underline(X)] == bgroup("(", atop(3 * phantom(0) * 2, + 2 * phantom(0) * 3), ")")))
1.6.2.3 - FUNÇÃO DE DENSIDADE DE PROBABILIDADE MARG INAL (BIVARIADA) De posse de uma função de densidade de probabilidade conjunta em X e Y (VAs contínuas) podemos calcular a funções de densidade de probabilidade marginais, respectivamente:
∫∞
∞−
= dy)y,x(f)x(f XYX e ∫∞
∞−
= dx)y,x(f)y(f XYY
Exemplos: Determinando as funções de densidades marginais a partir da função de densidade conjunta do exemplo a) da seção anterior.
( )
0 xpara ,edyeedyeedyedy)y,x(f)x(f x
1
0
)1exp( .dens ..funç
yx
0
y
y/p .const
x
0
)yx(XYX ≥===== −
=
∞−−
∞−−
∞+−
∞
∞−∫∫∫∫
44 344 21
(=> X ~ exp(1) e analogamente Y ~ exp(1)) Determinando as funções de densidades marginais a partir da função de densidade conjunta do exemplo b) da seção anterior.
( )
( ) exp(1) ~ X 0 xpara ,e10e
x
eexdyeexdyeexdyexdy)y,x(f)x(f
xx
xy
0
x
0
xyx
0
xy
y/p .const
x
0
)1y(xXYX
⇒≥=+
=/
−⋅/=⋅=⋅=⋅==
−−
−∞
−∞
−−∞
−−∞
+−∞
∞−
∫∫∫∫
876
Por outro lado,
( ) 0y para ,1y
1dxexdx)y,x(f)y(f
2
partespor integração da .aplic
0
)1y(xXYY ≥
+==⋅== ∫∫
∞+−
∞
∞−
L
1.6.2.4 - FUNÇÃO DE DENSIDADE DE PROBABILIDADE CONDICIONAL (BIVARIADA) As funções de densidade de probabilidade condicionais em X e Y (contínuas) são respectivamente:
)y(f
)y,x(f)x(f
Y
XYyY|X ≡= e
)x(f
)y,x(f)y(f
X
XYxX|Y ≡=

32
Exemplos: Para o exemplo a) temos que,
exp(1)~ Y pois ),y(f)y(f 0y para ,ee
e
)x(f
)y,x(f)y(f YxX|Y
yx
)yx(
X
XYxX|Y =⇒≥==≡ =
−−
+−
=
Analogamente, )x(f)x(f XyY|X ==
Para o exemplo b) temos que,
( ))x(f
1y
ex
)y(f
)y,x(f)x(f X2
)1y(x
Y
XYyY|X ≠
+⋅=≡ −
+−
=
Note que esta expressão depende dos valores de x e y, portanto ela é diferente da função de densidade marginal de X ~ exp(1) Analogamente as funções de densidade condicional e marginal em Y também são diferentes. 1.6.2.5 - FUNÇÃO DE DENSIDADE DE PROBABILIDADE CONJUNTA (MULTIVARIADA) Seja o vetor de variáveis aleatórias (contínuas) X =(X1, X2, ..., Xn )
A função de densidade de probabilidade conjunta ( )xf X deste vetor de variáveis aleatórias
deve satisfazer as seguintes condições e propriedades:
1. ( ) 0xf X ≥
2. ( )∫ ∫ ∫+∞
∞−
+∞
∞−
+∞
∞−
=1dx...dxdxxf... n21X
3. ( ) ( )∫ ∫ ∫∞− ∞− ∞−
µµµµµµ=1 2 nx x x
n21n21XX d...dd,...,f...xF
Obs.: ( ) ( )xFx...xx
xf Xn21
n
X ∂∂∂∂=
Exemplo: distribuição normal multivariada

33
1.6.3 - VETOR ALEATÓRIO BIDIMENSIONAL MISTO (DISCRE TO E CONTÍNUO) 1.6.3.1 - FUNÇÃO DE DENSIDADE DE PROBABILIDADE CONJUNTA DE UM VETOR BIDIMENSIONAL MISTO Há também a possibilidade de vetores aleatórios que misturam VAs discretas e contínuas integrantes no mesmo vetor aleatório. Quando o experimento que define uma VA discreta N ocorre conjuntamente ao experimento que define a VA contínua T, então fNT(n,t) é também uma função de densidade de probabilidade conjunta que deverá satisfazer:
1) )dTcebNa(Pdt)t,n(fb
ax
b
a
NT ≤<≤≤=∑∫=
;
2) fNT (n,t) ≥ 0;
3) 1dt)t,n(fNRn
NT =∑ ∫∈
∞
∞−
4) ∑ ∫≤ ∞−
=an
b
NYNT dt)y,n(f)b,a(F
Exemplo: Um processo de Poisson é um tipo de processo que serve para modelar a quantidade de ocorrências de eventos aleatórios ao longo do tempo. Neste tipo de processo, tanto a quantidade de ocorrências (variável discreta) quanto o tempo decorrido entre as ocorrências (variável contínua) podem ser considerados aleatórios, respectivamente com distribuições de probabilidade de Poisson e Exponencial. Sendo estas variáveis aleatórias independentes, então a função de densidade de probabilidade conjunta mista assumirá a seguinte expressão:
( )
ℵ∈>>λλλ
=
λ−
contrário caso ,0
n e 0 t,0 para ,!n
te)t,n(f
nt2
NT
1.6.3.2 - FUNÇÕES DE PROBABILIDADE E DE DENSIDADE DE PROBABILIDADE MARGINAIS ORIUNDAS DE UM VETOR ALEATÓRIO MISTO Considere o experimento que define uma VA discreta N a qual ocorre conjuntamente ao experimento que define a VA contínua T. De posse de uma função de densidade de probabilidade conjunta em N e T (respectivamente VAs discreta e contínua) podemos calcular a funções de probabilidade e de densidade de probabilidade marginais, respectivamente:
∫+∞
∞−
= dt)t,n(f)n(P NTN e ∑∈
=NRn
NTT )t,n(f)t(f

34
Exemplos: As marginais do exemplo anterior serão:
( ) ℵ∈λ===λ−+∞
∫ n para ,!n
tedt)t,n(f)n(P
nt
0
NTN K , ou seja, N~Poisson(λt)
0 tpara ,e)t,n(f)t(f t
0nNTT >λ=== λ−
+∞
=∑ K , ou seja, T~Exp(λ)
1.7 - CARACTERÍSTICAS DAS VARIÁVEIS ALEATÓRIAS 1.7.1 - INDEPENDÊNCIA ESTATÍSTICA
Sendo X ∈ nℜ uma V.A. n-dimensional com Função distribuição ( )xFX . Diz-se que as
V.As Xi , i = 1, ..., n são mutuamente independentes se, e somente se:
( ) ( ) ( ) ( )nX2X1X
indep. mut. X de comp. se
X xF...xFxFxFn21
= , ∀ x ∈ nℜ
Decorre que X e Y são independentes se e somente se (caso bivariado):
)y(P)x(P)y,x(P YX
indep. Y,X se
XY ⋅= , ∀ (x,y) ; x ∈ RX e y ∈ RY - VAs discretas
)y(f)x(f)y,x(f YX
indep. YX, se
XY ⋅= , ∀ (x,y) ∈ 2ℜ - VAs contínuas Note ainda que X e Y são independentes se e somente se (caso bivariado):
1) )x(P)y(P
)y(P)x(P
)y(P
)y,x(P)x(P X
Y
YXindep. YX, se
Y
XYyY|X =
⋅=≡= , analogamente:
)y(P)y(P Y
indep. YX, se
xX|Y === L , ou seja, quando duas variáveis aleatórias discretas são
independentes as respectivas funções de probabilidades marginais e condicionais são iguais. Através deste critério verificamos que as variáveis aleatórias dos exemplos a) e b) da seção 1.6.1.2 são independentes e também que as variáveis aleatórias do exemplo c) da seção 1.6.1.2 não são independentes porque não atendem à esta exigência de igualdade entre as funções de probabilidades condicionais e marginais.
2) )x(f)y(f
)y(f)x(f
)y(f
)y,x(f)x(f X
Y
YXindep. YX, se
Y
XYyY|X =
⋅=≡= , analogamente: )y(f)y(f Y
indep. YX, se
xX|Y === L ,
ou seja, quando duas variáveis aleatórias contínuas são independentes as respectivas funções de densidade marginais e condicionais são iguais. Através deste critério verificamos que as variáveis aleatórias do exemplo a) da seção 1.6.2.2 são independentes e também que as variáveis aleatórias do exemplo b) da seção 1.6.2.2 não são independentes porque não

35
atendem à esta exigência de igualdade entre as funções de densidade condicionais e marginais.
Verifica-se pela definição acima que as variáveis X e Y da Tabela 2 apresentada anteriormente não são independentes, pois 0588,049,012,0)6(P)0(P04,0)6;0(P YXXY =⋅=⋅≠= . Em termos literais verificamos que apenas uma das probabilidades conjuntas da tabela não é igual ao produto de suas respectivas probabilidades marginais e isso foi suficiente para a negação da condição de independência entre duas variáveis aleatórias a partir dos dados de uma tabela de dupla entrada, pois pela definição de independência a condição igualdade entre conjunta e o produto das marginais precisa ser verificada para todos os valores possíveis do vetor aleatório (para toda a tabela), para que as variáveis aleatórias sejam independentes. Na tabela seguinte temos um exemplo de VAs independentes, pois nela a condição de igualdade entre função de probabilidade conjunta e produto das funções de probabilidade marginais verifica-se para todos os valores possíveis das probabilidades conjuntas:
Tabela 4
1 2 3 Py(y)Y 1 1/6 1/6 1/6 1/2
2 1/6 1/6 1/6 1/21/3 1/3 1/3
XPxy(x,y)
Px(x) 1.7.2 - VALOR ESPERADO OU MÉDIA É uma medida que fornece a tendência central dos valores de uma variável aleatória (caso univariado), definida como:
E X x P xxx Rx
( ) . ( )=∈∑ - va discreta
E X xf x dx( ) ( )=−∞
∞
∫ - va contínua
Exemplos: Com os dados da tabela 1 temos: E(X)=(-2)(0,27)+(0)(0,12)+(2)(0,26)+(3)(0,35)=1,03 Com os dados da tabela 2 temos: E(X)=(1)(0,33...)+(2)(0,33...)+(3)(0,33...)=2
Generalizando a definição para o caso multivariado aplicado à função
→ℜ→ℜ
)x(gx:)X(g
n
∑ ∑ ∑∈ ∈ ∈
=1x1 2x2 nxnRx Rx Rx
X )x(P)x(g)]X(g[E L para o caso discreto
( )∫ ∫ ∫+∞
∞−
+∞
∞−
+∞
∞−
= n21X dx...dxdxxf)x(g...)]X(g[E para o caso contínuo

36
1.7.2.1 – ALGUMAS PROPRIEDADES DO VALOR ESPERADO 1) Se a for uma constante numérica , então:
E(a)=a;
2) Se a for uma constante numérica e X uma variável aleatória: E(aX)=aE(X);
3) Se a1, a2, ..., an forem constantes numéricas e X1, X2, ..., Xn variáveis aleatórias: E(a1X1+a2X2+...+anXn)=a1E(X1)+a2E(X2)+...+anE(Xn);
4) Se X1, X2, ..., Xn variáveis aleatórias independentes ⇒ E(X1X2 ... Xn)= E(X1)E(X2)...E(Xn)
OBS.: A volta não é necessariamente verdadeira. Há exemplos onde E(X1X2)=E(X1)E(X2)⇒/ X1, X2 VAs indep
1.7.3 - VARIÂNCIA E DESVIO-PADRÃO Seja X uma variável aleatória e E(X)=µ. A variância é uma medida que indica a dispersão dos valores da va X em torno da média, definida como:
VAR(X)=σx2=E[(X-µ)2]
A raiz quadrada positiva de σx2, σx é definida como o desvio-padrão de X
1.7.3.1 – ALGUMAS PROPRIEDADES DA VARIÂNCIA 1) VAR(X)=E(X2)-E(X)2≥0; 2) Se a for uma constante numérica , então:
VAR(a)=0;
3) Se a for uma constante numérica e X uma variável aleatória: VAR(aX)=a2VAR(X) VAR(a+X)=VAR(X);
4) Se a1, a2, ..., an forem constantes numéricas e X1, X2, ..., Xn variáveis aleatórias independentes: VAR(a1X1+a2X2+...+anXn)=a1
2VAR(X1)+a22VAR(X2)+...+an
2VAR(Xn) 1.7.4 - COVARIÂNCIA A covariância entre duas variáveis aleatórias X e Y com médias µx e µy indica o tipo de relacionamento entre essas variáveis pelo seu sinal, é definida como a seguir:
COV(X,Y)=E[(X-µx)(Y-µy)]

37
Quando seu sinal e positivo podemos afirmar que, na média, existe uma tendência para que quando os valores de X estiverem acima da sua média (µx) - valores grandes -, Y também estará acima da sua média (µy) e quando valores de X estiverem abaixo da sua média - valores pequenos -, Y também estará abaixo da sua média. Quando seu sinal é negativo, a conclusão será invertida, ou seja, valores grandes de X acontecem quando Y tende a ser pequeno e vice versa. Quando seu valor é nulo, se X é grande ou pequeno, nada podemos concluir com relação a Y. 1.7.4.1 – ALGUMAS PROPRIEDADES DA COVARIÂNCIA 1) COV(X,Y)=COV(Y,X)=E(XY)-µxµy; 2) COV(aW+bX,dY)=adCOV(W,Y)+bdCOV(X,Y), onde a,b,d constantes numéricas; 3) COV(a+bX,c+dY)=bdCOV(X,Y), onde a,b,c,d constantes numéricas; 4) COV(a,X)=0, onde a é uma constante; 5) Se X e Y são independentes: COV(X,Y)=0; 6) VAR(X+Y)=VAR(X)+VAR(Y)+2COV(X,Y); 7) VAR(X-Y)=VAR(X)+VAR(Y)-2COV(X,Y); 8) Se a1, a2, ..., an forem constantes numéricas e X1, X2, ..., Xn variáveis aleatórias, então:
∑∑
∑∑∑ ∑∑
∑∑∑ ∑
≠=
<=
−
= +==
=≠== =
+=
=+=+=
=+=
jijiji
n
1ii
2i
n
jijiji
n
1ii
2i
1n
1i
n
1ijjiji
n
1ii
2i
n
1i
n
ij1j
jiji
n
1i
n
1ii
2iii
)X,X(COVaa)X(VARa
)X,X(COVaa2)X(VARa)X,X(COVaa2)X(VARa
)X,X(COVaa)X(VARa)Xa(VAR
Novamente exploramos na propriedade acima diferentes notações algébricas equivalentes para um determinado tipo de somatório duplo aplicado às covariâncias. Exemplos: Sejam duas populações (ou variáveis aleatórias) X e Y com N elementos cada. Se cada elemento dessas populações tiver igual probabilidade (1/N), então:
XN
X
XN
1)X()X(E
N
1iiN
1ii
N
1iN1
ix ===⋅=µ=∑
∑∑ =
==
YN
Y
)Y(E
N
1ii
y ==µ=∑=

38
N
YX
)XY(E
N
1iii∑
==
2x
N
1i
2in
1iN12
i22
N
)XX(
])XX[(])XX[(E])X[(E)X(VAR σ=−
=⋅−=−=µ−=∑
∑ =
=
VAR Y
Y Y
N
ii
N
y( )
( )
=−
==∑ 2
1 2σ
)Y(E)X(E)XY(EN
)YY)(XX(
)]Y)(X[(E)Y,X(COV
N
1iii
yx −==−−
=µ−µ−=∑= L
1.7.5 - COEFICIENTE DE CORRELAÇÃO LINEAR O coeficiente de correlação linear entre as variáveis aleatórias X e Y é definido como:
ρσ σxy
x y
COV X Y=
( , )
É uma medida da associação linear entre duas variáveis e se encontra entre -1 e +1, onde ρxy=-1 indica uma associação linear negativa perfeita (Y = a - bX), ρxy=+1 indica uma associação linear positiva perfeita (Y = a + bX) e ρxy=0 indica a ausência completa de relação linear entre X e Y.