o recursive partitioning algorith (rpa), um sistema de ... filedesenvolveu um sistema de...
TRANSCRIPT

1
O Recursive Partitioning Algorith (RPA), Um Sistema de Classificação Não-Paramétrico
Autoria: Luiz Carlos Jacob Perera, Herbert Kimura, Roberto Borges Kerr, Fabiano Guasti Lima
Resumo Leo Breiman (1984, 1998) foi um estatístico que gostava de aplicações práticas e isto o levou a desenvolver alguns estudos originais. A partir dos trabalhos iniciados por Friedman (1977) desenvolveu um sistema de classificação muito apurado e sem a necessidade dos pressupostos estatísticos, pois é uma metodologia não-paramétrica. O presente estudo busca apresentar o trabalho de Breiman conhecido como Recursive Partitioning Algorithm. O RPA será introduzido como uma técnica não-paramétrica para análise de crédito permitindo a incorporação dos custos de classificações erradas. Vários estudos como os de Novak e LaDue (1999) e Marais, Patais e Wolfson (1984) têm mostrado sua aplicabilidade na análise e concessão de crédito. Do trabalho inicial de Friedman (1977) ao modelo CART desenvolvido por Steinberg e Golovnya (2006) um longo caminho foi percorrido. O presente trabalho além de apresentar os fundamentos e possibilidades de emprego do RPA, pretende discutir em profundidade os aspectos de amostragem essenciais para o bom resultado de qualquer pesquisa. A amostragem na análise de crédito apresenta algumas peculiaridades que exigem cuidados específicos, sendo discutidas as técnicas de emparelhamento de dados, segmentação, bootstrap e problemas de oversampling. A metodologia utilizada buscou comparar o RPA com uma técnica paramétrica tradicionalmente utilizada na análise de crédito, a análise discriminante, que supõe populações com características de normalidade e homocedasticidade. Nos resultados verificados o RPA mostrou-se como uma técnica superior e de fácil intuição pelos analistas. A principal conclusão do trabalho é a técnica do RPA pouco conhecida e discutida por profissionais de mercado e acadêmicos brasileiros é uma poderosa ferramenta classificatória, com a vantagem de ser não-paramétrica, a disposição dos estudiosos.
1 Introdução O presente estudo procura mostrar uma alternativa para os modelos classificatórios, tradicionalmente em uso. Por tratar-se de um modelo não-paramétrico dispensa o uso de pressupostos tradicionais dos modelos classificatórios em uso como análise discriminante, regressão logística e outros. O estudo apresenta e discute, paralelamente ao modelo, a metodologia de análise de crédito considerando a aplicação do modelo. O trabalho está estruturado com uma breve introdução, segue-se o referencial teórico que pretende mostrar o desenvolvimento do RPA. Discute-se profundamente problemas de amostragem e os fundamentos do modelo. A metodologia compara o RPA com a análise discriminante com suporte de um banco de dados da Compustat. A amostra analisada possui 164 empresas, sendo 41 falidas. Os resultados são analisados comparando os modelos e finalmente faz-se as considerações finais.
2 Referencial Teórico 2.1 A metodologia de Brieman: Classification and Regression Trees (CART) Leo Breiman (1984, 1998) foi um estatístico que gostava de aplicações práticas e isto o levou a desenvolver alguns estudos originais. A partir dos trabalhos iniciados por Friedman (1977) desenvolveu um sistema de classificação muito apurado e sem a necessidade dos pressupostos estatísticos, pois é uma metodologia não-paramétrica. Este tópico procura mostrar a forma prática e objetiva como desenvolveu seus trabalhos, sem descurar o rigor científico. Breiman era professor emérito de estatística na Universidade da Califórnia, Berkeley desde 1980. Pouco antes de morrer em julho de 2005 foi distinguido com o SIGKDD Data Mining and Knowledge Discovery Innovation Award, o mais elevado reconhecimento nas áreas de análise de dados e descobertas inovadoras. Na Universidade da Califórnia, no San Diego Medical Center, quando um paciente com ataque cardíaco é admitido, 19 variáveis são medidas durante as primeiras 24 horas. Entre elas pressão do sangue, idade e 17 outras variáveis ordenadas e binárias, sumarizando os sintomas médicos considerados relevantes indicadores de pacientes naquelas condições (BREIMAN et al. 1984).

2
O objetivo do estudo médico desenvolvido por Breiman et al. (1984) foi criar um método para identificar os pacientes de alto risco (aqueles que não sobreviverão, no mínimo, por 30 dias) com base nos dados analisados nas primeiras 24 horas a partir da admissão do paciente. A Figura 1. mostra a árvore com a classificação estruturada que foi produzida a partir do referido estudo. As regras para a classificação indicam os pacientes classificados como F ou G , dependendo do sim/não em pelo menos três questões. A letra F significa que o paciente não apresenta alto-risco e a letra G que o paciente representa alto-risco. Sua simplicidade pode causar a suspeita de que padrões decorrentes de métodos estatísticos poderiam originar regras de classificação mais acuradas. No entanto, quando regras estatísticas foram tentadas, as regras produzidas foram consideravelmente mais intrincadas, porém menos acuradas (BREIMAN et al., 1984). Em sua obra, Breiman discute muitos problemas práticos de diversas naturezas, cujo objetivo é o mesmo: dado um conjunto de medidas seja um caso ou um objeto, encontrar um meio prático de predizer em que classe ele será classificado. Em qualquer problema, um classificador ou uma regra de classificação é um forma sistemática de predizer qual será a classe indicada. Considere um conjunto de medidas sobre um determinado caso x1 , x2 , ... xk, sendo, por exemplo, x1 a idade, x2 a pressão sanguínea, etc. Definidas as medidas feitas em um caso (x1 , x2 , ... xk) e a medida do vetor xC como o vetor de classificação. Considere o espaço X definido como o espaço de todos os possíveis vetores de medidas. Por exemplo, no caso do ataque cardíaco estudado, X é um espaço com 19-dimensões tal que a primeira coordenada x1 (idade) varia de 0 a 200; a segunda coordenada x2 (pressão sanguínea), pode ser definida como contínua de 50 a 150. Há também o vetor de classificação xC que indica se o paciente foi considerado de alto-risco ou não. Pode haver um número diferente de dimensões (k) para X, mas o importante é que qualquer definição de X sempre implicará em um vetor de medida correspondente a algum caso (xC) que pretende-se classificar como sendo um ponto no espaço X. Breiman admite que os casos ou objetos podem cair em mais de uma classe. Podem ser as classes 1, 2, ....., j e C o conjunto das classes, isto é, C = {1, 2, ..., j} (BREIMAN, 1984). Uma forma sistemática de predizer a classe de um elemento é uma regra que assinala uma determinada classe em C para cada vetor de medida xk no espaço X. Isto é, dado qualquer xk pertencente a X, a regra assinala uma das classes {1, 2, ..., j} para cada elemento a ser classificado. Definição 1: Um classificador ou uma regra de classificação é uma função f(x) definida em X de tal forma que para cada xk , f(x) é igual a um dos números 1, 2, ...., j.

3
Breiman (1984) assume que a construção de um classificador é baseada numa amostra, na qual: Definição 2: Uma amostra de aprendizado com n elementos, consiste de uma matriz X de dados (n por k+1) sendo (x1,1, x2,1 , ... xk,1, xC,1) o primeiro elemento e (x1,n, x2,n, ..., xk,n, xC,n) o último elemento. Os vetores xk são vetores de medidas das variáveis do hiperplano e o vetor xC o vetor de classificação. Breiman (1984) explica que as regras de classificação são baseadas em experiências passadas. No caso do ataque cardíaco, por exemplo, os pacientes mais velhos com pressão baixa são geralmente de alto risco. Na construção dos classificadores, a experiência passada é sumarizada em um amostra de aprendizado. Na prática o projeto de diagnóstico médico consistiu de uma amostra de 215 pacientes admitidos no hospital com ataques cardíacos, todos eles sobreviveram ao período inicial de 24 horas. Os registros continham uma saída inicial de 19 medidas e a identificação daqueles que não tinham sobrevivido a um período de 30 dias. 2.2 O Recursive Partitioning Algorithm (RPA) Novak e LaDue (1999) apresentam o RPA como uma técnica computadorizada, baseada num método não-paramétrico de classificação, que não impõe a adoção de nenhuma distribuição a priori. A essência do RPA é desenvolver uma árvore de classificação particionando as observações baseada em divisões binárias de variáveis características. O processo de seleção e partição ocorre repetidas vezes até que mais nenhuma seleção ou divisão das variáveis características seja possível, ou o processo seja interrompido por algum critério pré-determinado. Finalmente, às observações dos nós terminais da árvore de classificação, são atribuídos a grupos classificatórios.
Para entender o processo de construção da árvore será utilizada a Figura 2. como referência. Os
grupos a serem classificados são designados como ( i ) e ( j ) e poderiam ser pagam/não pagam, empresas falidas/não falidas, etc. Neste caso estamos considerando uma classificação binária, porém poderiam ser mais de dois grupos. As variáveis características são indicadas por (A) e (B) e poderiam ser índices como Liquidez Corrente e Ativo Total/Débito Total. No processo de classificação, deve-se considerar a população representada pela amostra N com (k) variáveis características. Todos os (n) elementos da amostra N estão contidos no nó pai, o qual constitui a primeira sub-árvore T0 referida como a classificação inicial da árvore. Todas as

4
observações da amostra original N são alocadas para os grupos i ou j de acordo com uma determinada regra. A alocação de T0 para um dos grupos i ou j depende também das probabilidades estabelecidas a priori e do custo das classificações erradas. Quando as probabilidades a priori são iguais à proporção dos grupos na amostra e o custo das classificações erradas também é igual, T0 é alocada para o grupo com a maior proporção de observações, minimizando o custo das classificações erradas. Quando as probabilidades a priori não são iguais à proporção dos grupos na amostra e o custo das classificações erradas também não é igual, T0 é alocada para o grupo com o maior número de observações que minimiza os custos das classificações erradas. Para iniciar o processo de crescimento da árvore, o RPA metodicamente procura cada uma das variáveis características, ordenada por seu valor crescente ou decrescente, e divide esse vetor de acordo com a regra pré-estabelecida, direcionando parte da distribuição para a direita e parte para a esquerda. O algoritmo computadorizado seleciona então uma variável característica, neste caso A, e divide o valor da variável característica, neste caso a1 , baseado em uma regra que otimiza esta divisão univariada. A regra de otimização implica que nenhuma outra variável característica e valor da divisão podem minimizar a impureza ou, em outras palavras, as observações mal classificadas, levando em conta as probabilidades a priori e os custos da má classificação, nos dois nós descendentes resultantes. Na Figura 2, A é a variável característica selecionada é a1 a regra que minimiza o custo das classificações erradas, ou a valor ótimo da divisão selecionada pelo algoritmo computadorizado. Observações com valor da variável característica igual ou menor que a1 cairão no lado esquerdo do nó e as observações com valor da variável característica maior que a1 serão dirigidas para o lado direito. A subárvore resultante T1 , consiste de um nó pai à direita e um e um subnó terminal à esquerda. O subnó da direita é denominado de Subnó 1, porque ele continua. A subárvore T2 , por sua vez é composta de nó pai à esquerda e um nó terminal à direita. O nó pai toma o nome de subnó 1 para indicar sua origem. Os nós terminais tomam o nome do grupo predominante, i ou j. Por exemplo, se a amostra fosse de empresas falidas e não-falidas os nós terminais à esquerda tomariam o nome de falidas e os à direita de não-falidas. T0 e T1 são as subárvores iniciais de uma seqüência de árvores que termina em Tmax. Se a subárvore considerada não é Tmax o processo recursivo (RPA) continua. No processo considerado T1 não é o Tmax , logo o processo continua com B sendo a variável característica e b1 a regra que minimiza o custo das classificações mal feitas. O processo repete-se em T2 e finaliza com T3 com dois nós terminais sendo considerado o Tmax. Uma vez que Tmax seja determinada, o caminho de sua seqüência pode ser seguido e a árvore pode ser usada para efetuar classificações com outras populações semelhantes, além da amostra original. 2.3 O Algoritmo RPA O RPA, como explicado anteriormente, tem a forma de uma árvore binária de classificação que assinala os objetos em grupos selecionados a priori. As observações dos nós terminais da árvore de classificação, são atribuídos a grupos classificatórios de modo a minimizar o custo observado de classificação errônea. Considerando um nó terminal t, o risco de atribuir o nó t ao grupo 1 e ao grupo 2 é dado, respectivamente, por: R1 = C21 x π2 x n2/N2 R2 = C12 x π1 x n1/N1
Define-se a impureza do nó, dada por I, como sendo: I = {[C21 x π2 x n2/N2] x [(π1 x n1/N1)/ ((π1 x n1/N1) + (π2 x n2/N2))] + [C12 x π1 x n1/N1] x [(π2 x n2/N2)/ ((π1 x n1/N1) + (π2 x n2/N2))] ou I = {[C12 + C21] x [(π1 x n1/N1)/ ((π1 x n1/N1) + (π2 x n2/N2))] x [(π2 x n2/N2) /

5
((π1 x n1/N1) + (π2 x n2/N2))] x [(π1 x n1/N1) + (π2 x n2/N2)] Onde: C12 = custo da classificação errada da empresa falida, como não falida e C21 = custo da classificação errada da empresa não falida como falida; π1 e π2 são as probabilidades a priori de a empresa falir ou não falir; n1 e n2 são os valores das empresas falidas e não falidas num nó terminal; N1 e N2 são os valores globais das empresas falidas e não falidas constantes da árvore; I (t) é a medida de impureza do nó (t)
I (t) = R1(t) p (1|t) + R2 (t) p(2|t) = 2 (C12 + C21) p(1|t) p(2|t) p(t)
Sendo p(i|t) = (πi ni (t)/Ni) / (Σ 2/k=1 πk nk (t)/Nk), a probabilidade condicional que um objeto do nó (t) pertença ao grupo (i) , e p(t) = Σ 2/k=1 p(k,t) = (Σ 2/k=1 πk nk (t)/Nk) a probabilidade de um objeto pertencer ao nó (t). Isto pode ser interpretado como o custo esperado da classificação errada quando objetos do nó (t) são aleatoriamente atribuídos a dois grupos, com a probabilidade p(i|t) de ser atribuído ao grupo (i). I (t) = 0 se e somente se é um nó puro, i.é., todos os objetos do nó (t) pertencem ao mesmo grupo. Alcança-se o maior valor em p(1|t) = p(2|t) = 0,5 que é simétrico em p(1|t) e p(2|t). A impureza da árvore T, denotada I (T), é definida como a soma das impurezas dos nós terminais. Considere uma árvore T e outra árvore T’ obtida a partir de T, através da divisão de uma amostra em um nó terminal (t) de T em duas sub-amostras as quais originam dois sub-nós à esquerda e à direita, (tL) e (tR) do nó (t). Então, a diminuição da impureza da árvore T’ sobre a árvore T é dada por:
ΔI (t) = I(T) – I (T’) = I(t) - I(tL) - I(tR)
ΔI (t) é não negativo e sua magnitude depende da escolha da divisão. A melhor divisão para o nó terminal considerado (t) é definido como a divisão que possibilita maximizar ΔI (t). 2.4 Uma regra para o RPA (classificações não-paramétricas) Em muitos problemas de classificação a densidade da probabilidade condicional das classes é parcial ou completamente desconhecida. Conseqüentemente, a lógica da classificação deverá ser desenhada com base nas informações obtidas a partir de amostras representativas de cada classe. O problema da classificação não-paramétrica pode ser colocado da seguinte maneira. Um vetor aleatório p-dimensional de partes observadas X
ré reconhecido como pertencente a uma das M
populações π1, π2 ... πM caracterizadas pela distribuição de densidade que são não-especificadas. Com base nessas características, é tomada uma decisão de qual função de distribuição caracteriza Xr
,usando para treinamento um conjunto de vetores retirado das populações π1, π2 ... πM (FRIEDMAN, 1977) Inicialmente será considerado o caso mais simples onde há apenas duas classes (M=2). A regra de decisão para o problema multiclasses será uma extensão deste caso mais simples. Sejam f1(x) e f2(x) as funções densidade de probabilidade de duas classes. Sejam F1(x) e F2(x) suas respectivas distribuições acumuladas. Supondo-se, por enquanto, que F1(x) e F2(x) sejam distribuições univariadas conhecidas, demonstra-se que se a linha real fosse cortada em um ponto e a região esquerda fosse atribuída a uma classe e a região direita à outra, o ponto x* que minimiza o risco de erro na classificação de Bayes é o ponto que maximiza a equação abaixo:
D(x) = [F1(x) – F2(x)]; Isto é, D(x*) = maxx D(x)
D (x*) é a conhecida distância de Kolmogorov-Smirnoff entre duas distribuições, apresentada na Figura 3. Em muitas situações, um único corte não forneceria a discriminação adequada. Neste

6
caso, o procedimento seria estendido reaplicando-o em cada um dos subintervalos definidos na primeira subdivisão, resultando em quatro cortes. Este método de partição pode ser recursivamente aplicado a cada intervalo definido na partição anterior, até que o intervalo atinja um critério de terminação e, neste ponto, o intervalo não é mais subdividido. O intervalo terminal é denominado uma célula de classe 1 (um) se F1(x) > F2(x), caso contrário é denominado uma célula de classe 2 (dois).
Uma extensão natural da partição univariada acima, para o caso multivariado, seria cortar naquela característica para a qual a distância Kolmogorov-Smirnoff entre as classes marginais de distribuições fosse máxima. Do mesmo modo que na partição univariada, poder-se-ia aplicar o partimento recursivo para cada subpopulação até que o critério de terminação fosse obtido e a subpopulação obtida fosse então atribuída a uma das duas classes. As distribuições cumulativas F1(x) e F2(x) não são conhecidas em aplicações não paramétricas, mas são facilmente estimadas a partir das distribuições cumulativas empíricas. O algoritmo de partição recursivo não paramétrico para discriminação entre duas classes continuaria até que uma subamostra atingisse o critério de terminação, quando então ela seria atribuída a uma das classes. Caso contrário a distância Kolmogorov-Smirnoff entre as distribuições empíricas marginais das duas classes seria calculada para cada uma das j características e aquela característica para a qual a distância D(x*) é máxima é escolhida para ser cortada. A atribuição das células terminais a uma das classes é feita com base na razão densidade estimada f1/f2 dentro da célula. A cardinalidade da subamostra dentro de cada célula deve ser grande o bastante para permitir uma estimativa razoável desta razão densidade. Portanto a partição de uma célula deve terminar quando ela não puder mais ser partida de modo a permitir pelo menos k subamostras remanecentes em cada uma das células filha, onde k é o tamanho mínimo absoluto da subamostra, prederminado para todas as células terminais. O valor de k é um parâmetro do algoritmo. 2.5 O Software CART (Classification and Regression Trees) O modelo original do CART (Classification and Regression Trees) foi desenvolvido por Bierman et al. (1984). Cart 6.0 para Windows é um modelo robusto para processar dados, o qual instrumentaliza árvores de decisão com fins preditivos. O CART automaticamente procura por modelos e relações, pesquisando relações complexas e estruturas não-aparentes. O modelo CART de árvores tem sido usado em muitos campos do conhecimento como previsão de abandono de contratos, modelos de credit scoring, descoberta de remédios, detecção de fraudes, controle de qualidade em manufatura, pesquisa de vida selvagem, entre outras. É um modelo fácil de ser usado com uma interface Windows (STEINBERG e GOLOVNYA, 2007).

7
A metodologia do CART, ao procurar por modelos nas bases de dados, evita a armadilha do over fitting, isto é formular modelos que só se ajustam bem aos dados. A metodologia inclui o teste do modelo, assegurando que ele terá uma boa performance quando aplicado a novos dados da mesma população. O teste e a seleção da árvore ótima são partes integrantes do algoritmo CART. A validação cruzada, um dos testes internos do CART, permite modelar com um conjunto de dados relativamente pequeno ou maximizar o tamanho da amostra para treinamento. Isto é feito através da geração automática de um conjunto de números aleatórios com diferentes sementes. A validação cruzada permite a replicação dos resultados e a verificação da estabilidade do modelo. Pode-se extrair um relatório dos resultados médios. Srinivasan e Kim (1987) trazem alguns esclarecimentos sobre o RPA. Inicialmente revelam que a construção de uma árvore de classificação binária envolve três elementos: i) a definição das regras de partição; ii) a decisão de quando declarar um nó como terminal, e; iii) o aplicação de cada nó terminal a um determinado grupo. A performance do modelo criticamente depende dos dois primeiros elementos. A noção fundamental por trás do modelo é a de cada partição deve levar a subconjuntos mais puros. Impureza é considerada a mistura dos estados em um único nó. Com a finalidade de procurar a regra mais eficiente de partição o algoritmo primeiro procura pelo ponto mais adequado de partição para cada variável explicativa, e seleciona a melhor. O processo de partição se encerra quando não se verifica mais nenhuma redução da impureza da árvore considerada. Então a árvore é indicada como Tfin
. (SRIVASAN e KIM, 1987). O próximo passo é tornar árvore menos complexa devido aos problemas de overfitting que podem deixar a árvore muito ajustada à amostra e não à população. Geralmente os modelos procuram fazer a validação cruzada do modelo. A árvore final, considerada ótima é selecionada através de um critério de minimização do risco de re-substituição da validação cruzada. O processo é conhecido como V-fold; a amostra é dividida aleatoriamente em V grupos de tamanho igual ou semelhante. Os dados de (V – 1) grupos são usados para construir uma nova árvore considerando os critérios de custos de classificação definidos na árvore original. Nessa árvore são testados os demais (V – 1) grupos. O risco de re-substituição do teste de validação cruzada de uma particular árvore T será calculado pela média dos custos da validação cruzada. A árvore escolhida será a de menor custo de re-substituição. 3 Metodologia 3.1 O RPA e a distribuição amostral. O RPA é um método de classificação não paramétrico e não utiliza metodologia estatística, por isto não fica subordinado aos pressupostos comuns aos demais métodos que foram desenvolvidos ao longo dos anos, como análise discriminante, regressão logística (logit e probit) e análise fatorial entre outros. No entanto, com relação aos cuidados com a população e amostra a metodologia exige o mesmo rigor científico. Kmenta (1988) chama a atenção para o conceito de população que pode ser definida como a totalidade de todas as observações possíveis sobre medidas ou ocorrências. Como raramente o pesquisador pode desenvolver seu trabalho com o conjunto da população (censo), implica que este conheça os princípios de seleção das amostras. Supondo-se que infinitas amostras possam ser colhidas a partir de uma população, chegamos ao conceito de distribuição amostral. Tanto populações quanto amostras podem ser descritas através de suas características numéricas conhecidas como parâmetros. Conhecendo-se o tipo de distribuição e os parâmetros de uma população teoricamente teríamos condições de escolher uma amostra representativa, que permitisse ao pesquisador realizar análises probabilisticamente acuradas. Na prática, isto nem sempre ocorre, quer por desconhecimento dos parâmetros da população, quer por impossibilidade de acesso à distribuição amostral de populações infinitas. Geralmente o pesquisador está interessado em conhecer apenas algumas características da população, formando juízos sobre parâmetros populacionais e com eles realizar algum experimento prático. Kmenta (1988) afirma que: “Tais juízos são tentativas de adivinhação com certa base de segurança e podem
8
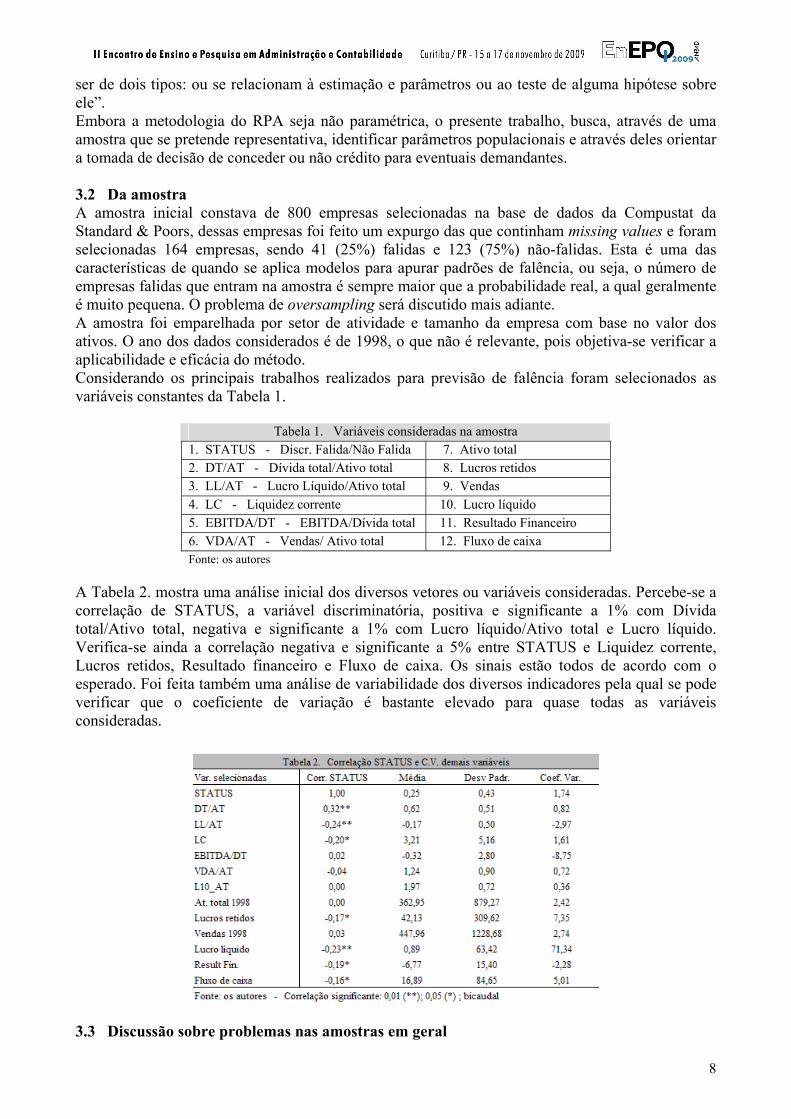
ser de dois tipos: ou se relacionam à estimação e parâmetros ou ao teste de alguma hipótese sobre ele”. Embora a metodologia do RPA seja não paramétrica, o presente trabalho, busca, através de uma amostra que se pretende representativa, identificar parâmetros populacionais e através deles orientar a tomada de decisão de conceder ou não crédito para eventuais demandantes. 3.2 Da amostra A amostra inicial constava de 800 empresas selecionadas na base de dados da Compustat da Standard & Poors, dessas empresas foi feito um expurgo das que continham missing values e foram selecionadas 164 empresas, sendo 41 (25%) falidas e 123 (75%) não-falidas. Esta é uma das características de quando se aplica modelos para apurar padrões de falência, ou seja, o número de empresas falidas que entram na amostra é sempre maior que a probabilidade real, a qual geralmente é muito pequena. O problema de oversampling será discutido mais adiante. A amostra foi emparelhada por setor de atividade e tamanho da empresa com base no valor dos ativos. O ano dos dados considerados é de 1998, o que não é relevante, pois objetiva-se verificar a aplicabilidade e eficácia do método. Considerando os principais trabalhos realizados para previsão de falência foram selecionados as variáveis constantes da Tabela 1.
Tabela 1. Variáveis consideradas na amostra 1. STATUS - Discr. Falida/Não Falida 7. Ativo total 2. DT/AT - Dívida total/Ativo total 8. Lucros retidos 3. LL/AT - Lucro Líquido/Ativo total 9. Vendas 4. LC - Liquidez corrente 10. Lucro líquido 5. EBITDA/DT - EBITDA/Dívida total 11. Resultado Financeiro 6. VDA/AT - Vendas/ Ativo total 12. Fluxo de caixa Fonte: os autores
A Tabela 2. mostra uma análise inicial dos diversos vetores ou variáveis consideradas. Percebe-se a correlação de STATUS, a variável discriminatória, positiva e significante a 1% com Dívida total/Ativo total, negativa e significante a 1% com Lucro líquido/Ativo total e Lucro líquido. Verifica-se ainda a correlação negativa e significante a 5% entre STATUS e Liquidez corrente, Lucros retidos, Resultado financeiro e Fluxo de caixa. Os sinais estão todos de acordo com o esperado. Foi feita também uma análise de variabilidade dos diversos indicadores pela qual se pode verificar que o coeficiente de variação é bastante elevado para quase todas as variáveis consideradas.
3.3 Discussão sobre problemas nas amostras em geral

9
Zmijewski ( 1984) discutiu os problemas que ocorrem com as amostras utilizadas para modelagem de problemas de crédito e falência. A falta de pagamento dos compromissos assumidos, felizmente é um evento raro, daí a dificuldade de se conseguir uma amostra de tamanho adequado para este tipo de modelagem. Estimando um índice de inadimplência de 3%, verifica-se que de cada 100 indivíduos/empresas que tomam empréstimos apenas 3 deixariam de honrar seus pagamentos. Um pesquisador desenvolvendo um experimento no qual necessitasse uma amostra de 50 não pagantes deveria contar uma amostra de aproximadamente 1.700 indivíduos/firmas. Considerando este tipo de dificuldade é comum na grande maioria dos experimentos o pesquisador trabalhar com uma amostra emparelhada de bons e maus pagadores, evidente que se a amostra não representa adequadamente a população alguns problemas podem ocorrer. Zmijewski ( 1984) abordou os problemas de seleção de amostras, considerando dois principais vieses de estimação: i) o primeiro viés resulta do oversampling ou da superamostragem das empresas falidas ou viés da amostra baseado na escolha; ii) o segundo resulta da falta de dados das empresas falidas e a conseqüente seleção da amostra, denominado viés de seleção de amostra. Em um levantamento de 17 estudos sobre empresas falidas Zmijewski verificou que apenas 3 estudos trabalharam com amostras de empresas falidas representando menos de 40% do total da amostra; 11 trabalharam com as empresas falidas representando 50% da amostra. Fica claro que as amostras tiveram composição completamente diferentes das populações representadas. Com relação à estimação dos modelos, que pressupõem técnicas randômicas de amostragem, conclui que os parâmetros e as probabilidades serão assintoticamente viesadas. Em seu experimento Zmijewski verificou que apesar de a existência dos viéses ficar bem clara, as inferências estatísticas e as taxas de classificação aparentemente não são afetadas. O problema maior ocorre quando são realizados os testes de validação, aparentemente ambos os vieses não afetam as inferências estatísticas, no entanto, as taxas de erro de classificação dos grupos são significativamente afetadas. Isto pode sugerir alguns efeitos corretivos. 3.4 Da amostra Scott (1981) comenta que a maioria das pesquisas utiliza amostras emparelhadas de firmas falidas e não falidas, considerando um determinado número de índices selecionados, calculados com base em dados coletados antes da falência. Acrescenta que os pesquisadores cuidadosos também treinam os modelos e os testam com uma amostra previamente separada (holdout) que não tenha sido utilizada para derivar o modelo. Em alguns casos como Altman (1968) os modelos são revalidados com testes em observações extra modelagem. Scott (1981) ainda chama a atenção que não existe uma fundamentação teórica em suporte ao uso de índices nem quanto à sua seleção, no entanto argúe que o assunto é bastante complexo para ser analisado com um único índice.
Amostra Grande A amostra inicial constava de 8419 empresas selecionadas na base de dados da Compustat da Standard & Poors, dessas empresas foi feito um expurgo das que continham missing values e foram selecionadas 4475 empresas das quais 41 eram falidas. O pequeno número de falidas representa uma realidade do mercado, cujo número de empresas falidas não chega a 1%. Ocorreu outra limitação na pesquisa que foi o número de casos permitido pelos programas, em versão demonstração ou estudante. Esta última limitação condicionou o formato final de uma amostra, selecionada com base em geração de números aleatórios, porém mantidas as empresas falidas. A amostra final ficou com 1481 empresas sendo 41 (2,8%) falidas e 1440 (97,2) não falidas, esta amostra foi chamada de Grande, dada a sua proximidade com as proporções de mercado e o número de elementos. Embora a amostra não mantenha a proporção original da população, procurou-se minimizar o viés de oversampling ou de super-amostragem de empresas falidas (Vide Tabela 1.). Lennox (1999) em sua amostra de 6.416 empresas teve 90 empresas falidas, uma taxa de 1,4% a.a., no entanto,em um período de sete anos essa taxa variou entre 0% e 3,1%, o que evidencia a dependência dos processos de falência em relação aos ciclos econômicos.
10
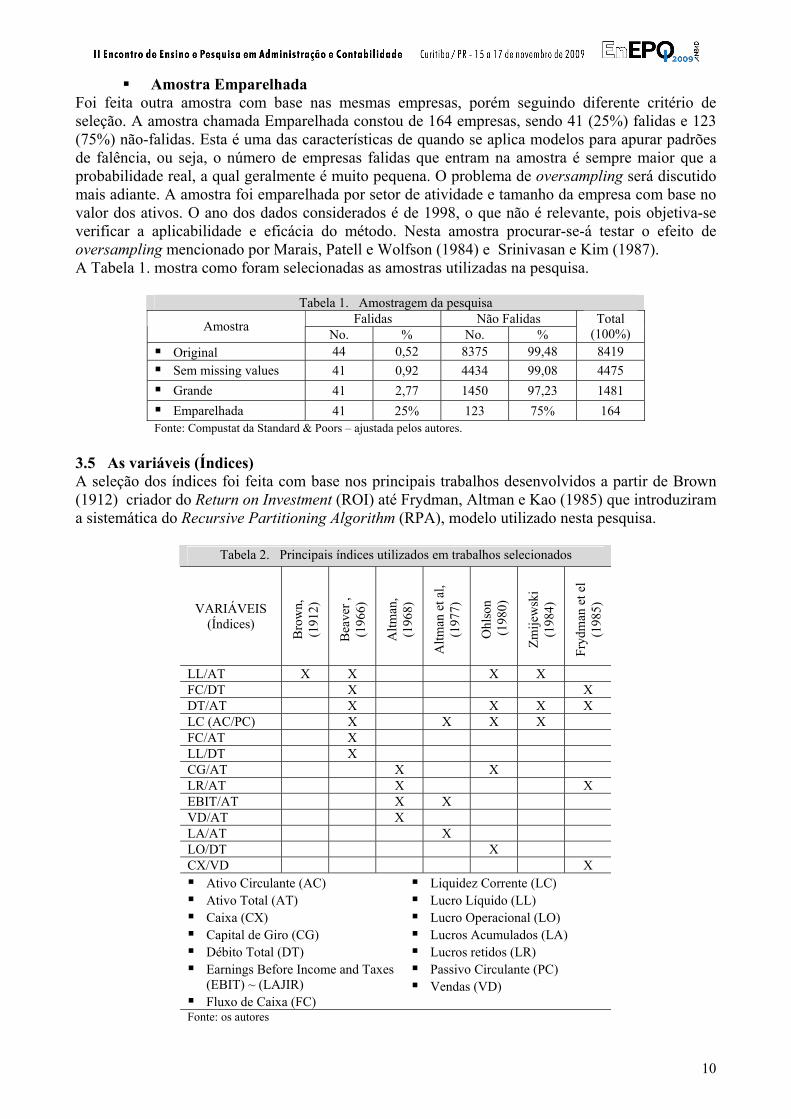
Amostra Emparelhada Foi feita outra amostra com base nas mesmas empresas, porém seguindo diferente critério de seleção. A amostra chamada Emparelhada constou de 164 empresas, sendo 41 (25%) falidas e 123 (75%) não-falidas. Esta é uma das características de quando se aplica modelos para apurar padrões de falência, ou seja, o número de empresas falidas que entram na amostra é sempre maior que a probabilidade real, a qual geralmente é muito pequena. O problema de oversampling será discutido mais adiante. A amostra foi emparelhada por setor de atividade e tamanho da empresa com base no valor dos ativos. O ano dos dados considerados é de 1998, o que não é relevante, pois objetiva-se verificar a aplicabilidade e eficácia do método. Nesta amostra procurar-se-á testar o efeito de oversampling mencionado por Marais, Patell e Wolfson (1984) e Srinivasan e Kim (1987). A Tabela 1. mostra como foram selecionadas as amostras utilizadas na pesquisa.
Tabela 1. Amostragem da pesquisa Falidas Não Falidas Amostra No. % No. %
Total (100%)
Original 44 0,52 8375 99,48 8419 Sem missing values 41 0,92 4434 99,08 4475 Grande 41 2,77 1450 97,23 1481 Emparelhada 41 25% 123 75% 164
Fonte: Compustat da Standard & Poors – ajustada pelos autores. 3.5 As variáveis (Índices) A seleção dos índices foi feita com base nos principais trabalhos desenvolvidos a partir de Brown (1912) criador do Return on Investment (ROI) até Frydman, Altman e Kao (1985) que introduziram a sistemática do Recursive Partitioning Algorithm (RPA), modelo utilizado nesta pesquisa.
Tabela 2. Principais índices utilizados em trabalhos selecionados
VARIÁVEIS (Índices)
Bro
wn,
(1
912)
Bea
ver ,
(1
966)
Altm
an,
(196
8)
Altm
an e
t al,
(197
7)
Ohl
son
(1
980)
Zmije
wsk
i (1
984)
Fryd
man
et e
l (1
985)
LL/AT X X X X FC/DT X X DT/AT X X X X LC (AC/PC) X X X X FC/AT X LL/DT X CG/AT X X LR/AT X X EBIT/AT X X VD/AT X LA/AT X LO/DT X CX/VD X Ativo Circulante (AC) Ativo Total (AT) Caixa (CX) Capital de Giro (CG) Débito Total (DT) Earnings Before Income and Taxes
(EBIT) ~ (LAJIR) Fluxo de Caixa (FC)
Liquidez Corrente (LC) Lucro Líquido (LL) Lucro Operacional (LO) Lucros Acumulados (LA) Lucros retidos (LR) Passivo Circulante (PC) Vendas (VD)
Fonte: os autores

11
A tabela 2. mostra a seleção das variáveis índices e na parte inferior são identificadas as variáveis financeiras que compõem os índices. Os trabalhos foram selecionados de acordo com sua importância para a análise de falências. Dos 30 índices trabalhados por Beaver (1966) três foram selecionados como os melhores preditores: Fluxo de Caixa/Total de Ativos, Renda Líquida / Débito Total e Fluxo de Caixa / Débito Total. Scott (1981) observa que os preditores selecionados envolvem uma variável de fluxo (renda ou caixa) dividido por uma variável de estoque (total de ativos ou de débito), alerta ainda que tais índices considerados individualmente podem ser considerados bons preditores de falência. As variáveis indicadas por Beaver foram testadas e mostraram-se não correlacionadas significativamente com Status, a variável indicativa do estado falida (1) não-falida (0). O resultado encontra-se na Tabela 2. A tabela 2 mostra que, das doze variáveis testadas, apenas AT/Log10, Logaritmo base 10 de Ativo Total, uma variável transformada, mostrou-se correlacionada significativamente ao nível de 5% com Status. Na seqüência, os índices CG/AT, FC/DT e LL/AT mostram-se correlacionados com Status, mas não-significativamente. Fazendo uma análise da Tabela 3. e considerando que a variável Status está indicada como zero para empresas não-falidas e um para empresas falidas, a correlação positiva indicaria que variações sobre a média, no mesmo sentido sinalizariam maior probabilidade de falência, e a correlação negativa menor probabilidade de falência. Considerando os ativos com correlação negativa, verifica-se variação de sinal contrário a de STATUS nos índices AT/Log10, EBIT/AT, FC/DT, LC, LL/AT, LR/AT, VD/AT, CX/VD, FC/AT e LL/DT sinalizando menor probabilidade de falência. O único índice de sinal positivo, CG/AT, apesar de não-significativo, permanece coerente, pois a teoria indica que necessidades elevadas de capital de giro podem indicar facilidades de crédito para atingir vendas ou manutenção de estoques elevados, com os conseqüentes custos financeiros.
4 Do Experimento 4.1 Definindo os parâmetros Para realizar o experimento de classificação de empresas falidas e não-falidas, além das amostras selecionadas, foi preciso considerar os demais elementos necessários à modelagem do RPA. Das estatísticas constantes no Boletim do Banco Central de abril de 2008 (BCB, 2008) foi calculada a média das taxas de juros pessoas físicas para 2007 que alcançou 12,8% a.a. e em 2008 houve uma pequena elevação para cerca de 14%; a taxa de inadimplência alcançou 2,5%. Tais dados foram confrontados com os quadros de decomposição de spread bancário de Costa e Nakane (2004) e FIPECAFI (2005), chegando-se a valores discrepantes. Decidiu-se manter uma postura conservadora e trabalhar com as seguintes taxas: taxa de juros para pessoa jurídica de 14%; taxa de

12
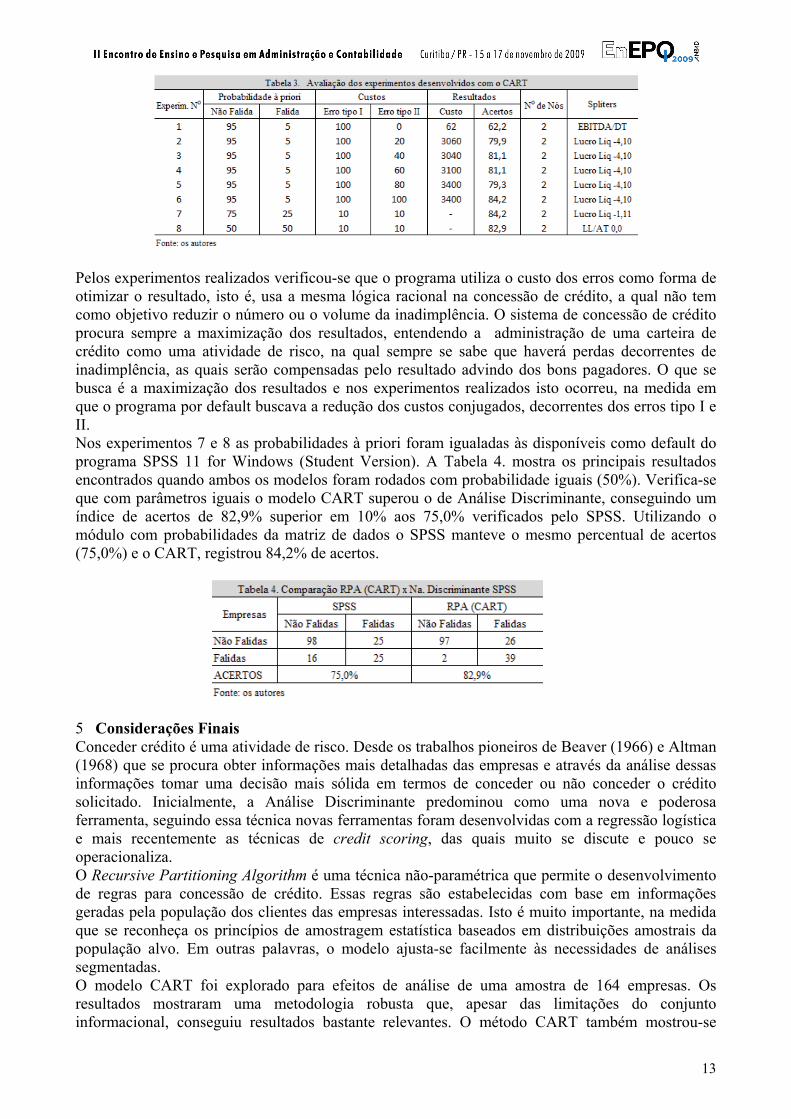
inadimplência de 2,5%; spread livre do banco de 4%. Estas seriam taxas vigentes no final de 2007, início de 2008. 4.2 Da distribuição amostral e o bootsrap Manski (1996) analisando a obra de Efron e Tibshirani: An introduction to the bootstrap lembra que “Um problema básico é que um analista usando uma amostra de dados para comparar um estimador não pode conhecer sua distribuição amostral”. Em quase todas as situações, a distribuição amostral de um estimador é uma função dos verdadeiros parâmetros que estão sendo estimados assim como de outras influências desconhecidas. Por isso, a inferência clássica exige que o analista estime não somente o parâmetro de interesse, mas também a distribuição amostral deste estimador (MANSKI, 1996). Manski comenta ainda que algumas contribuições para a ciência demandam algum tempo para serem entendidas e aplicadas, enquanto o surgimento do bootstrap foi muito oportuno. Avanços contemporâneos e procedimentos computacionais permitiram a comparação entre a acurácia do bootstrap e das estimativas normais assintóticas das distribuições amostrais. Essas estimativas mostraram o bootstrap tão acurado (no sentido das taxas de convergência) quanto estimativas normais assintóticas e, em alguns aspectos, até mais acurado. Diversos autores como Marais, Patell e Wolfson (1984), Frydman, Altman e Kao (1985) e Srinivasan e Kim (1987) têm usado a técnica do bootstrap para apurar os custos relativos de re-substituição, que pode ser entendido como os custos de classificações erradas ao usar a amostra de aprendizado para classificar as amostras de teste (YOHANNES E HODDINOTT, 1999). O método de bootstrap utilizado foi baseado em Marais, Patell e Wolfson (1984), Frydman, Altman e Kao (1985) os quais se orientaram em trabalho de Efron (1983). Considere uma população, com uma distribuição amostral de tamanho n, com custos definidos de má especificação de um determinado parâmetro que admite, por exemplo dois estados (falida, não falida). A esta amostra pode-se chamar de amostra original e ela funcionará como se fosse a população que representa. A estimativa do risco de re-substituição da árvore T, a partir da amostra original será definida da seguinte forma: i) a partir da amostra original obtém-se outra amostra com reposição e do mesmo tamanho, pode-se chamá-la de amostra bootstrap; ii) usando a amostra bootstrap constrói-se a árvore correspondente, considerando os mesmos custos de má classificação da amostra original; pode-se chamá-la de árvore bootstrap; iii) classifica-se a amostra bootstrap pela árvore bootstrap, fazendo o mesmo com a amostra original; iv) a diferença entre os custos de má classificação podem ser interpretados como o custo de re-substituição; tipicamente os custos da amostra bootstrap são inferiores; v) a operação se repete para as demais amostras bootstrap e o resultado final corresponderá à média das diferenças de custo de re-substituição. 4.3 Resultados Lennox (1999) declara que a ocorrência dos erros tipo I e tipo II depende criticamente dos critérios de seleção das amostras. Relata que estudos com igual tamanho de empresas falidas e não falidas têm menor taxa de erro do que estudos com amostras proporcionais às populações representadas. Considerando que os erros do tipo I e do tipo II têm custos bem diferenciados sugere-se que os modelos sejam testados para os problemas de má especificação. O software da CART foi baixado e utilizado no módulo demonstração, o qual aparentemente não apresenta restrições de uso. O modelo foi rodado com as seguintes características: probabilidades a priori de 95% e 5%, o que significa aceitar uma taxa de inadimplência de 5%. O custo do erro tipo I, ou seja a empresa falida ser classificada como não falida foi mantido constante. O valor do erro tipo II variou de 0 a 100 e foram registrados o percentual de acertos e o custo dos erros. A Tabela 3. mostra os resultados encontrados.
13
Pelos experimentos realizados verificou-se que o programa utiliza o custo dos erros como forma de otimizar o resultado, isto é, usa a mesma lógica racional na concessão de crédito, a qual não tem como objetivo reduzir o número ou o volume da inadimplência. O sistema de concessão de crédito procura sempre a maximização dos resultados, entendendo a administração de uma carteira de crédito como uma atividade de risco, na qual sempre se sabe que haverá perdas decorrentes de inadimplência, as quais serão compensadas pelo resultado advindo dos bons pagadores. O que se busca é a maximização dos resultados e nos experimentos realizados isto ocorreu, na medida em que o programa por default buscava a redução dos custos conjugados, decorrentes dos erros tipo I e II. Nos experimentos 7 e 8 as probabilidades à priori foram igualadas às disponíveis como default do programa SPSS 11 for Windows (Student Version). A Tabela 4. mostra os principais resultados encontrados quando ambos os modelos foram rodados com probabilidade iguais (50%). Verifica-se que com parâmetros iguais o modelo CART superou o de Análise Discriminante, conseguindo um índice de acertos de 82,9% superior em 10% aos 75,0% verificados pelo SPSS. Utilizando o módulo com probabilidades da matriz de dados o SPSS manteve o mesmo percentual de acertos (75,0%) e o CART, registrou 84,2% de acertos.
5 Considerações Finais Conceder crédito é uma atividade de risco. Desde os trabalhos pioneiros de Beaver (1966) e Altman (1968) que se procura obter informações mais detalhadas das empresas e através da análise dessas informações tomar uma decisão mais sólida em termos de conceder ou não conceder o crédito solicitado. Inicialmente, a Análise Discriminante predominou como uma nova e poderosa ferramenta, seguindo essa técnica novas ferramentas foram desenvolvidas com a regressão logística e mais recentemente as técnicas de credit scoring, das quais muito se discute e pouco se operacionaliza. O Recursive Partitioning Algorithm é uma técnica não-paramétrica que permite o desenvolvimento de regras para concessão de crédito. Essas regras são estabelecidas com base em informações geradas pela população dos clientes das empresas interessadas. Isto é muito importante, na medida que se reconheça os princípios de amostragem estatística baseados em distribuições amostrais da população alvo. Em outras palavras, o modelo ajusta-se facilmente às necessidades de análises segmentadas. O modelo CART foi explorado para efeitos de análise de uma amostra de 164 empresas. Os resultados mostraram uma metodologia robusta que, apesar das limitações do conjunto informacional, conseguiu resultados bastante relevantes. O método CART também mostrou-se

14
superior ao de Análise Discriminante, embora este tipo de comparação não fosse este objetivo do trabalho. Pode-se concluir que o Recursive Partitionig Algorithm, é mais uma ferramenta a disposição dos analistas de crédito. Independente de ser usado com apoio da metodologia CART ou desenvolvimento interno na empresa, graças a sua facilidade de aplicação pode se tornar uma ferramenta muito útil na análise e concessão de crédito. O reconhecimento, quase intuitivo da sua funcionalidade, pode ser de grande valia para conquistar a confiabilidade dos analistas do mercado. As limitações do trabalho decorrem da amostra utilizada. Resultados mais robustos poderiam ser verificados com amostras de tamanho maior que permitiriam uma identificação mais adequada da população focada. No entanto, considerando o aspecto experimental do presente trabalho, pode-se afirmar que seus objetivos de mostrar a adequação da técnica empregada, foram alcançados. Um aspecto importante do presente trabalho é que a metodologia utilizada em uma análise de crédito, possibilitando evidenciar os recursos do modelo, pode ser utilizada em outras aplicações. Objetiva-se, em experimentos futuros, uma segmentação mais adequada da amostra e a análise a partir desses segmentos mais homogêneos. Outro aspecto a considerar é a dinâmica de mercado que exige modelos com resposta a dados que variam continuamente. Como continuação da presente linha de pesquisa segure-se também o aprofundamento dos estudos na linha de partição das variáveis, considerando já haver a constatação de alguns trabalhos como o de Utgoff e Sracuzzi (1999) que conseguem resultados semelhantes com aproximações simplificadas da metodologia.
BIBLIOGRAFIA
ALTMAN, E., HALDERMAN, R. e NARAYANAN, P. Zeta analysis: A new model toidentify bankruptcy risk of corporations. Journal of Banking and Finance, Vol.1(1), 1977, p.29-54.
ALTMAN, Edward I. Corporate financial distress and bankruptcy. New York: Wiley, 1993. ALTMAN, Edward I. Financial ratios, discriminant analysis and the prediction of corporate
bankruptcy. Journal of Finance Vol.23(4), 1968, p.589-609 BCN, Banco Central do Brasil. Boletim de Abril de 2008, v. 44, n. 4. Disponível em:
http://www.bcb.gov.br/?BOLETIMEST; Acesso em: 25 maio 2008 BEAVER, W. Financial Ratio as Predictors of Failure. Empirical Research in Accounting:
Selected Studies 1966”, Journal of Accounting Research, Supplement to vol.4, 1967, p.71-111 BLUM, Mark P. The failing company doctrine. Boston College Industrial and Commercial
Review. Vol. 16. 1974 BREIMAN, Leo, FRIEDMAN, J.H., OLSHEN R.A. e STONE, C.J. Classification and
regression trees. Wadsworth International Group, Belmont, California. 1984. BREIMAN, Leo, FRIEDMAN, Jerome, STONE, Charles e OLSHEN, R.A. Classification and
Regression Trees. – (CART) Reedição. USA: First CRC Press, 1998. BROWN, Frank Donaldson. Índice Dupont. 1912. Disponível em:
http://heritage.dupont.com/floater/fl_brown /floater.shtml. Acesso em: 24 Março 2008. COSTA, Ana C.A. e NAKANE, Márcio I. A decomposição do spread bancário no Brasil. In
Seminário de Economia Bancária e Crédito do Banco Central do Brasil. Dezembro, 2004. EDMISTER, R. O. An empirical test of ratio analysis for small business failure prediction.
Journal of Financial and Quantitative Analysis, (March), 1972, p. 1477- 1493. EFRON, Bradley. Estimating the error rate of a prediction rule: improvement on cross-
validation. Journal of the American Statistical Association. v. 78, n. 382, (Jun) p. 316-31, 1983. FIPECAFI, Fundação Instituto de Pesquisas Contábeis, Atuariais e Financeiras. Estudo sobre
a apuração do spread da indústria bancária. Base 1º. Semestre de 2005. Disponível em www.institutoassaf.com.br/downloads/fipecafi_port_net.pdf ; Acesso em: 18 de maio de 2008.

15
FRIEDMAN, J. H. A Recursive Partitioning rule for nonparametric classification. IEEE Transactions on Computers. (April), p. 404-409, 1977
FRYDMAN, Halina, ALTMAN, Eward I. e KAO, Duen-Li. Introducing Recursive Partitioning for financial classification: the case of financial distress. The Journal of Finace. V. XI, n. 1 (march), p. 269-291, 1985.
KMENTA, Jan. Elementos de econometria. São Paulo: Atlas, 1988 LEVINE, David M., RAMSEY, Patricia p. e BERENSON, Mark L. Business statistics for
quality and productivity. USA: Prentice Hall, 1995. MANSKI, Charles F. Reviewed work: An introduction to bootstrap. Efron b. e Tibshirani,
Robert J. Journal of Economic Literature, v. 34 n. (Sep) p.1340-1342, 1996. MARAIS, M. Laurentius, PATELL, James M., WOLFSON, Mark A. The experimental
design of classification models: an application of Recursive Partitioning and bootstrapping to commercial bank loan classifications. Journal of Accounting Research Vol. 22 Supplement, U.S.A. , 1984
MERTON R.C. On the pricing of corporate debt: the risk structure of interest rates. Journal of Finance, v. 29, n. 2, (May) p. 449-470, 1974.
MILLER, Merton H. e MODIGLIANI, Franco. Dividend Policy, Growth, and the Valuation of Shares. The Journal of Business, v. 34, n. 4 (Oct), p. 411-433, 1961
MIN, Jae H. e LEE, Young-Chan. Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters. Expert Systems with Applications 28 p. 603–614, 2005.
MYERS, S. Determinants of Corporate Borrowing. Journal of Financial Economics 9 (November), p. 147-76, 1977
NOVAK, Michael P. e LaDUE, Eddy. Application of Recursive Partitioning to agricultural credit scoring. Journal of Applied Economics, 31, 1 (April), p. 109-122, 1999.
PERERA, L. C. Jacob. Títulos de longo prazo. In Cálculo financeiro das Tesourarias. SECURATO, José Roberto (Org.). 2ª. ed. São Paulo: Saint Paul, 2003.
PERERAa , L. C. Jacob. Quantificação e precificação de risco de crédito através do modelo de opções. Revista de Administração de Empresas da FGV, v. 37, nº. 3, 1997, p. 42-55.
PERERAb, L. C. Jacob. Administrando risco de crédito com o CreditMetrics. In: II SEMEAD, 1997, São Paulo, SP. Anais do II SEMEAD. São Paulo : FEA - USP, 1997.
REILLY, Frank K. e BROWN, Keith C. Investment analysis and portfolio management. 6th. ed. USA: Dryden, 2000.
SAUNDERS, Anthony. Credit Risk Measurement. USA: Wiley, 1999. SHARPE, William F. , ALEXANDER, Gordon J e BAILEY, Jeffery V. Investments. 5th. ed.
Usa: Prentice Hall, 1995. SRINIVASAN, Venkat e KIM, Yong H. Credit granting: a comparative analysis of
classification procedures. The Journal of Finance, v.42, n. 3 (Jul), p. 665-681, 1987. STEINBERG, Dan e GOLOVNYA, Mikhail. Cart 6.0 Users Guide. USA: Salford Systems,
2007. Disponível em: www.salford-systems.com Acesso em 26 Abr 2008. UTGOFF, Paul E. e CLOUSE, Jeffery A. A Kolgomorov-Smirnoff metric for decision tree
induction. Tec. Report 96-3, University of Massachusetts, 1996. UTGOFF, Paul E. e SRACUZZI, David J. Approximation Via Value Unification. Procedings
of the SixteenthInternational Conference on Machine Learning (PP. 425-432). Ljubljana: Morgan Kaufmann, 1999.
WILCOX, J. W. A simple theory of financial ratios as predictors of failure. Journal of Accounting Research (Autumn), 1971, p. 389-395.

16
WILLIAMS, John Burr. The Theory of Investment Value. USA: Harvard University Press, 1938.
YOHANNES, Yisehac e HODDINOTT, John. Classification and regression trees: an introduction. Technical Guide #3. International Food Policy Research Institute. USA: March, 1999.
ZMIJEWSKI, Mark E. Methodological Issues Related to the Estimation of Financial Distress Prediction Models. Journal of Accounting Research Vol. 22 Supplement U.S.A., 1984, p. 59-82