nosql: onde, como e por quê? - prodam.am.gov.br · universo digital em expansão fonte: idc white...
TRANSCRIPT


Quem aqui usabanco de dados?

Por que precisamos de SQL?

Onde usamos SQL (i.e. ACID)?

MAS...

Universo digital em expansão
Fonte: IDC White Paper, "The Diverse and Exploding Digital Universe", 2008.

Aplicações web modernas

Escalabilidade vertical écomplicada e/ou cara!

Os modelos transacionais
● ACIDpessimista, forçando consistência ao final de cada operação
● BASEotimista, aceitando que a consistência esteja em um “estado de fluxo”
Possibilita aescalabilidade
horizontal...
http://queue.acm.org/detail.cfm?id=1394128

distribuídosdistribuídos
NoSQL = Not Only SQLNoSQL = Not Only SQL
não relacionaisnão relacionais
horizontalmentehorizontalmenteescaláveisescaláveis
esquemasesquemasflexíveisflexíveis
replicáveisreplicáveis APIs simplesAPIs simples
http://nosql-database.org/

Key-Value Store
Zoologia dos bancos NoSQLZoologia dos bancos NoSQL
Wide Column Store / Column Families
Document Store
NoSQL Database

MAS...

Você precisa escolher 2!
Teorema de Brewer: CAP
● Consistência: visão única para os clientes
● Disponibilidade:toda operação temuma resposta
● Partição: sistema continua operante mesmo enfrentando partições na rede
ConsistênciaConsistency
DisponibilidadeAvailability
PartiçãoPartition
Tolerance

I. Consistência e Disponibilidade
● Limitações na escalabilidade (leitura e escrita)
C A

II. Consistência e Partição
● Completamente inacessível se qualquerum dos nós estiver fora!
CP

III. Disponibilidade e Partição
● Nem sempre lê a informação mais recente: futuramente consistente
A
P

“A high performance, scalable,distributed storage and processing system
for structured and unstructured data.”

Cassandra: um breve histórico
Bigtable Dynamo

Um novo modelo de dados
Row
schema-less
schema-optional

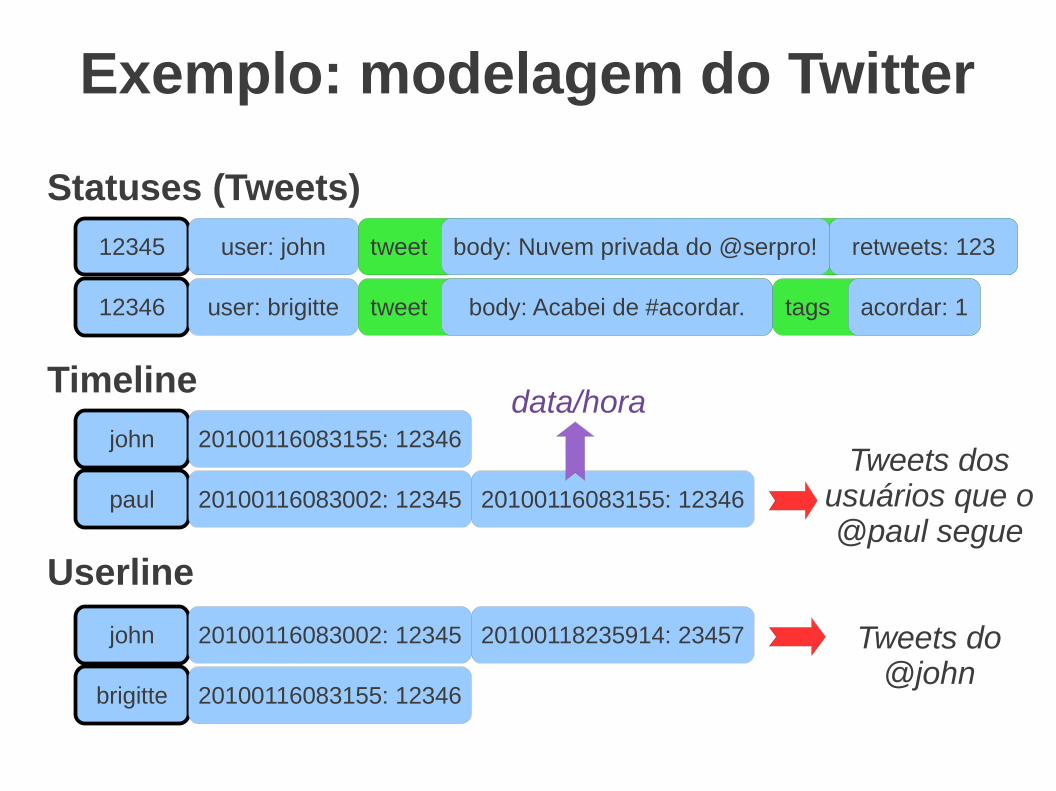
Exemplo: modelagem do Twitter
john name: John Doe pass: swordfish joined: 20091115
paul name: Paul Lane pass: thepass joined: 20091129
john paul: 20091204 brigitte: 20100815
paul john: 20091205 debora: 20100729 brigitte: 20100822
john tom: 20091128 paul: 20091205
brigitte john: 20100815 paul: 20100822
Users
Following
Followers
@paul segue @brigitte desde
22/08/2010
tweet
Exemplo: modelagem do Twitter
12345 user: john body: Nuvem privada do @serpro! retweets: 123
12346 user: brigitte
john 20100116083155: 12346
paul 20100116083002: 12345 20100116083155: 12346
john 20100116083002: 12345 20100118235914: 23457
brigitte 20100116083155: 12346
Statuses (Tweets)
Timeline
Userline
Tweets do @john
tweet body: Acabei de #acordar. tags acordar: 1
Tweets dos usuários que o @paul segue
data/hora

CQL (Query Language)CQL (Query Language)
CREATE COLUMNFAMILY users (KEY varchar PRIMARY KEY,name varchar, pass varchar, joined bigint);
INSERT INTO users (KEY, name, pass)VALUES ('jsmith', 'John Smith', 'changeme')USING CONSISTENCY QUORUM;
SELECT * FROM users WHERE KEY = 'jsmith';u'jsmith' | u'pass',u'changeme'
SELECT name..pass FROM users WHERE KEY >= 'h' LIMIT 10;
CREATE INDEX users_joined_idx ON users (joined);
DELETE joined FROM users where KEY = 'jsmith';

“It took two weeks to perform ALTER TABLE on the statuses [tweets] table.”
01
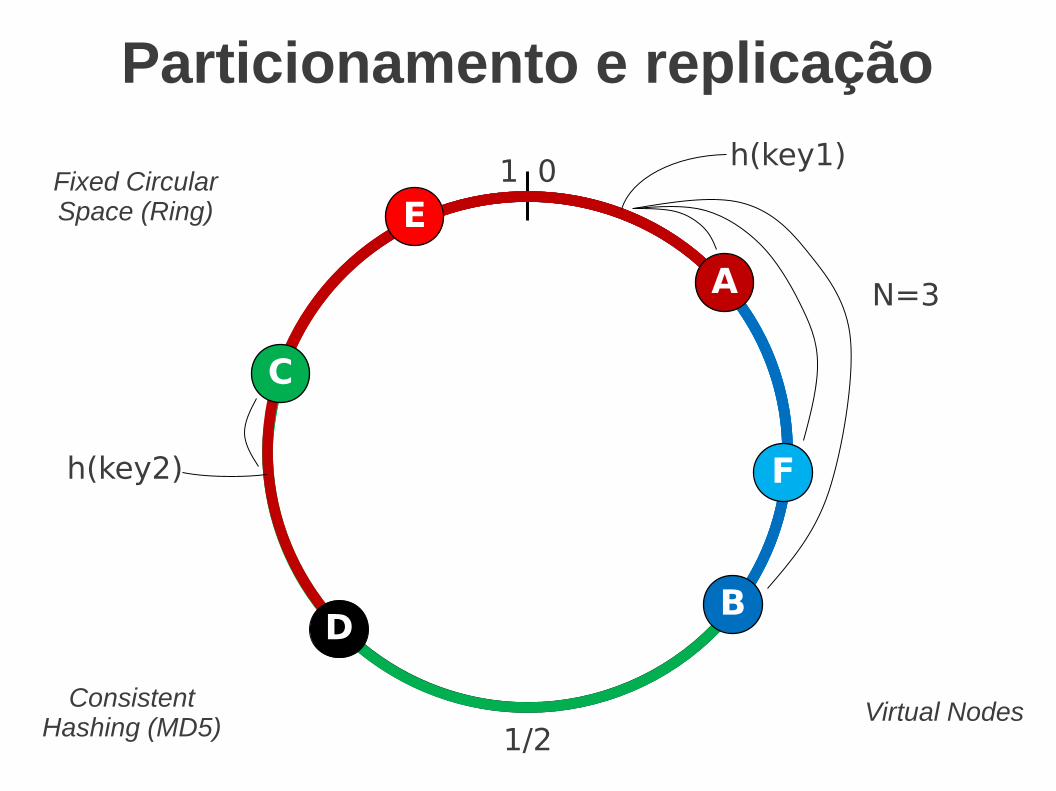
1/2
F
E
D
C
B
A N=3
h(key2)
h(key1)
Particionamento e replicação
Fixed CircularSpace (Ring)
Virtual NodesConsistentHashing (MD5)

Ajuste de parâmetros (N, R, W)
● Consistência versus Escalabilidade● Ajuste por requisição (R, W)
● Zero● One● Quorum: N / 2 + 1● All
● N: réplicas● R + W > N● Read repair
réplica réplica réplica
coordenador
ack
cliente

Comunicação entre os nós
Gossip-Based Protocol
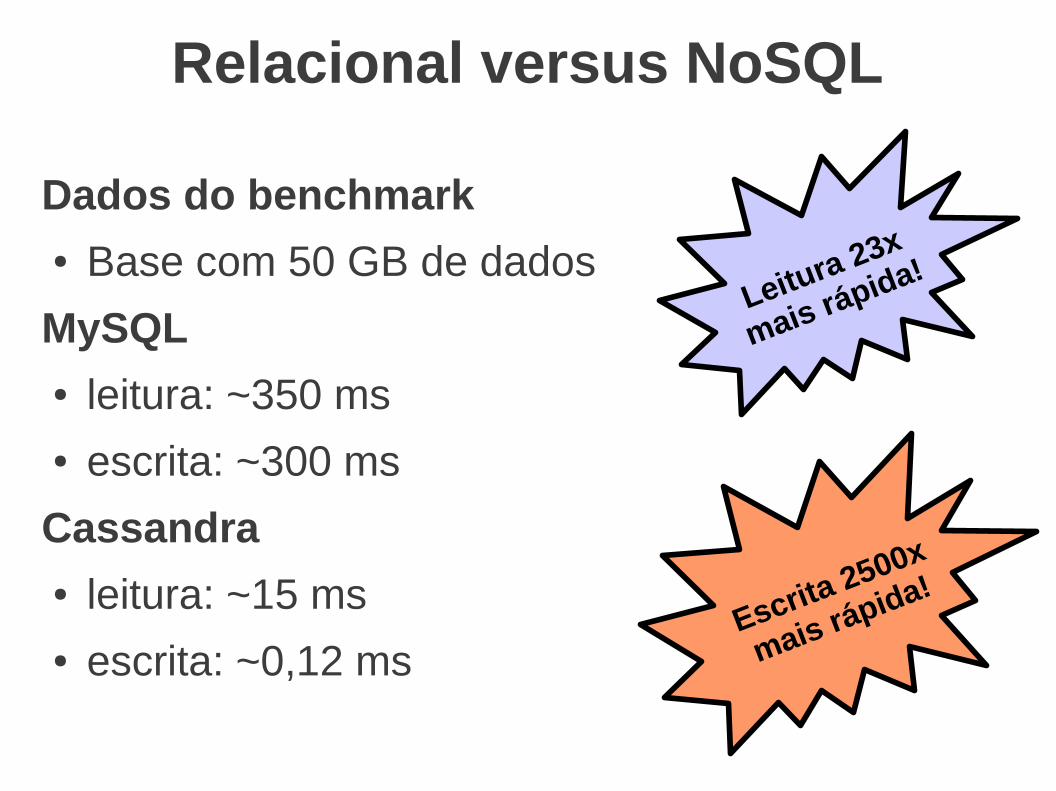
Relacional versus NoSQL
Dados do benchmark● Base com 50 GB de dados
MySQL● leitura: ~350 ms● escrita: ~300 ms
Cassandra● leitura: ~15 ms● escrita: ~0,12 ms
Leitura 23x
mais rápida!
Escrita 2500x
mais rápida!

“MongoDB (from "humongous") is a scalable,high-performance, open source, powerful,
document-oriented database written in C++.”

O modelo de dados
Relacional (Tabular) Orientado a Documentos
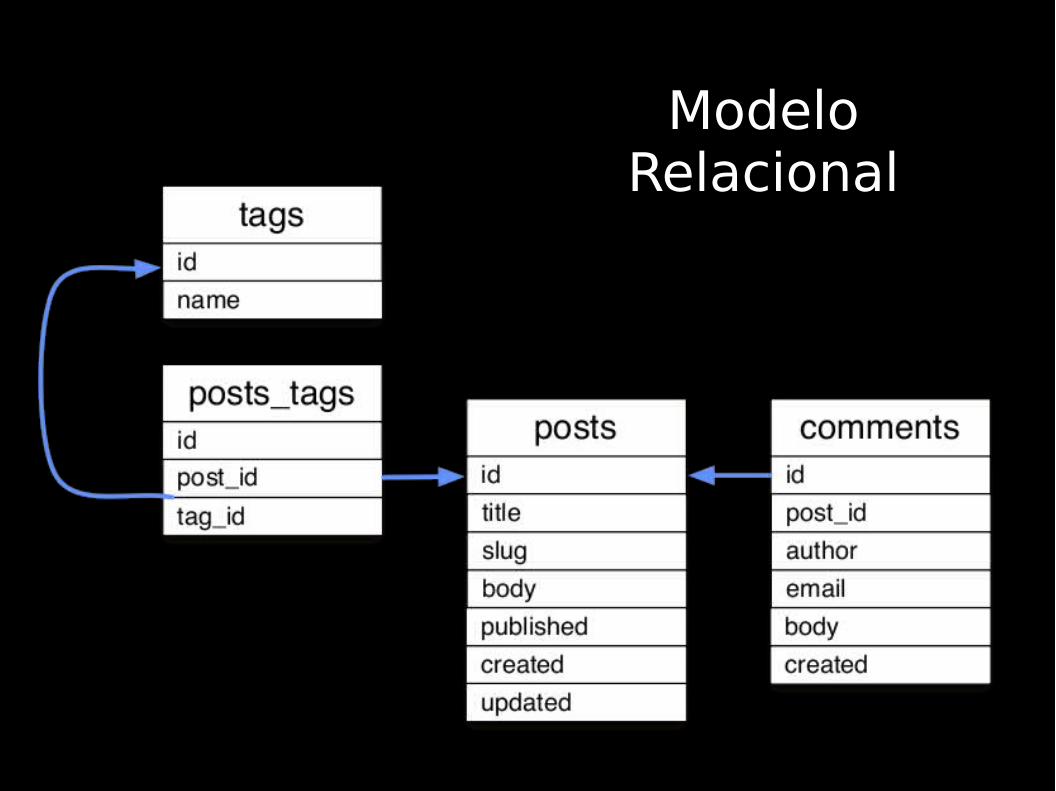
Modelo Modelo RelacionalRelacional

Modelo Modelo Orientado a Orientado a DocumentosDocumentos

{ _id : ObjectId("5ebf5e0fec5fab7db2b9b40e"), title : "Introdução ao MongoDB", slug : "introducao-ao-mongodb", body : "Este é o texto do post...", published : true, created : "Jun 28 2011 13:48:22 AMT", updated : "Jun 28 2011 17:01:15 AMT", comments : [ { author : "john", email : "[email protected]", body : "Caramba!", created : "Jun 28 2011 15:01:30 BRST" } ], tags : [ "databases", "MongoDB", "nosql" ]}
Array
Object ID
EmbeddedDocument
Um documento JSONUm documento JSON

Linguagem de ConsultaLinguagem de Consulta
SELECT * FROM usuarios> db.usuarios.find()
SELECT nome FROM usuarios> db.usuarios.find({}, {“nome”: 1})
SELECT * FROM usuarios WHERE idade = 29> db.usuarios.find({“idade”: 29})
SELECT * FROM usuarios WHERE idade = 29 AND ativo = true> db.usuarios.find({“idade”: 29, “ativo”: true})
SELECT * FROM usuarios WHERE idade >= 18 AND idade <= 30> db.usuarios.find({“idade”: {“$gte”: 18, “$lte”: 30}})
SELECT * FROM usuarios WHERE nome LIKE “%admin%”> db.usuarios.find({“nome”: /admin/i})

Linguagem de ConsultaLinguagem de Consulta
SELECT * FROM usuarios ORDER BY nome> db.usuarios.find().sort({“nome”: 1})
SELECT * FROM usuarios ORDER BY idade DESC, nome> db.usuarios.find().sort({“idade”: -1, “nome”: 1})
SELECT * FROM usuarios LIMIT 3> db.usuarios.find().limit(3)
SELECT * FROM usuarios OFFSET 5> db.usuarios.find().skip(5)
SELECT * FROM usuarios LIMIT 3 OFFSET 5> db.usuarios.find().limit(3).skip(5)
SELECT * FROM usuarios ORDER BY nome LIMIT 3> db.usuarios.find().sort({“nome”: 1}).limit(3)

Map ReduceMap Reduceíndicesíndices
cappedcappedcollectionscollections
Server-SideServer-SideScriptingScripting
GridFSGridFS ad hoc queriesad hoc queries
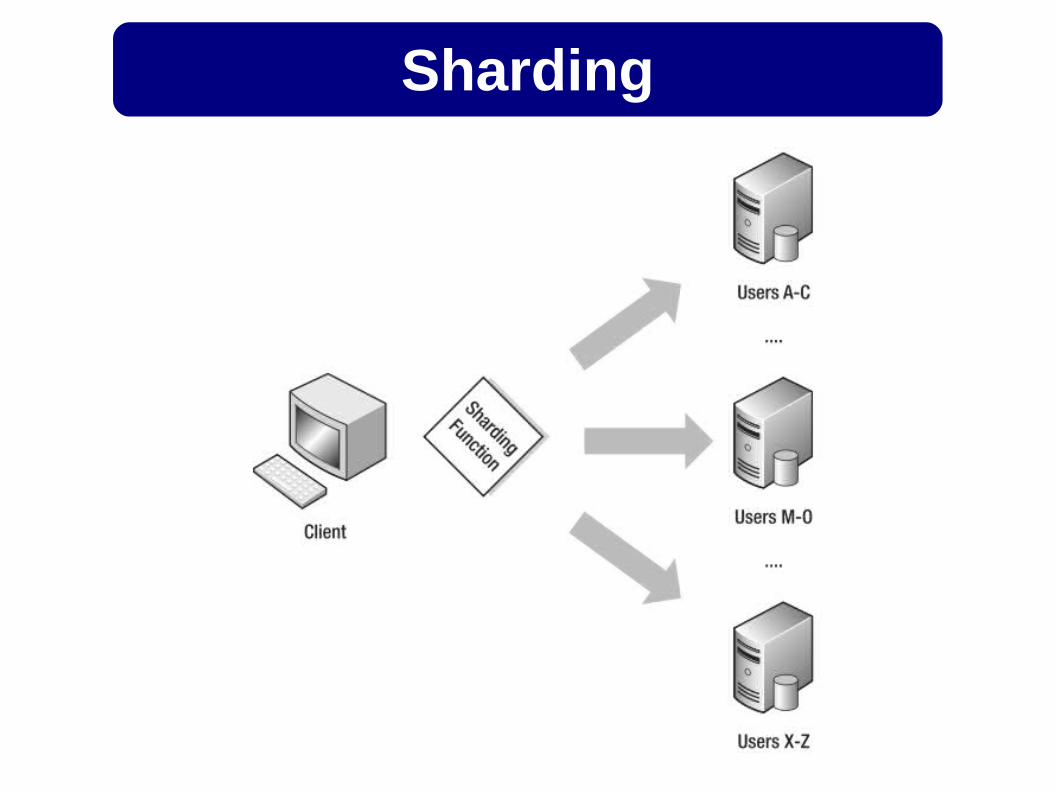
Sharding

Auto-Sharding + Replicação

A grande ruptura

A segunda ruptura

“NoSQL adoption is inevitable because,just as in every other walk of life, there are different tools for different jobs” – Stephen
O'Graddy (RedMonk)
Rodrigo [email protected]
http://www.hjort.co