mÉtodo variacional com uma estratÉgia de … · lizamos o critério de custo médio a longo prazo...
TRANSCRIPT

MÉTODO VARIACIONAL COM UMA ESTRATÉGIA DE OBSERVAÇÃO INDIRETA PARASISTEMAS LINEARES ESTOCÁSTICOS COM SALTOS NOS PARÂMETROS
Daiane C. Bortolin, Carlos A. Silva, Eduardo F. Costa
Universidade de São Paulo, São Carlos, Brasil,[email protected], [email protected], [email protected]
Resumo: Neste trabalho propomos um método variacionalpara o problema de custo médio a longo prazo para sistemaslineares com saltos Markovianos não-observados. O métodointroduz níveis intermediários de observação, partindo docenário de observação completa, o que permite iniciar ométodo com soluções de equações de Riccati.
Palavras-chave: Método variacional, controle ótimo, sis-temas lineares estocásticos.
1. INTRODUÇÃO
Sistemas lineares com saltos Markovianos (SLMS) for-mam uma importante classe de sistemas estocásticos, e sãoutilizados para modelar processos cuja dinâmica muda deforma abrupta em determinados instantes. Encontramos naliteratura resultados que remetem a noções de estabilidade[1], estabilizabilidade e detetabilidade [2], controle ótimocom normas H2, H∞ e outros critérios [3], detecção de fa-lhas [4], filtragem [5] e diferentes cenários de observação,incluindo observações completas e parciais [6].
Consideramos a presença de ruído no sistema, e uti-lizamos o critério de custo médio a longo prazo (CMLP) paraavaliar os SLSMs. No cenário de observação completa dosestados da cadeia de Markov, a solução ótima para o CMLPé obtida na forma de ganhos de realimentação linear, atravésde equações algébricas de Riccati (EAR), vide [7].
Quando a observação do estado da cadeia não é acessívelao controlador, temos poucos resultados na literatura sobreo CMLP para SLSM. No cenário de não-observação pode-mos citar [8], onde é proposto um algoritmo genético paraobter os ganhos MS-estabilizantes. O algoritmo utiliza umasolução inicial (ganho inicial) MS-estabilizante gerado porEAR, porém a mudança do cenário de observação acontecede maneira abrupta, afetando a qualidade das soluções pos-teriores. Em [9] é feita uma aproximação para o CMLPatravés de uma abordagem variacional para o custo de ho-rizonte finito quadrático, cujos controles estão na forma derealimentação linear. A convergência do custo médio de ho-
rizonte finito para o CMLP é demonstrada em [10], porémnão se pode garantir a convergência por realimentação de es-tados.
Neste artigo tratamos o problema como um conjunto desubproblemas associados a níveis de observação. Considera-mos a observação indireta da cadeia de Markov (θ ) via umavariável rk, tomando valores no conjunto finito S= {1, . . . ,S}e assumindo P(rk = θk|θk) = c, onde c representa o nívelde observação. A ideia é que esse nível de observaçãodiminua gradativamente a fim de se aproximar do cenáriode não-observação. No cenário inicial (observação com-pleta, c = c0 = 1), podemos empregar a solução dada porEAR. Para cada passo m consideramos c = cm < cm−1 ecalculamos os novos ganhos via uma adaptação/extensão dométodo variacional de [9].
Destacamos que uma vantagem do método é a inicializa-ção com solução da EAR, pois os métodos existentes normal-mente requerem um conjunto de ganhos MS-estabilizante, oque pode ser muito difícil de obter em certas aplicações. Nométodo presente, se a EAR não tiver solução, então o pro-blema de controle não tem solução.
O artigo está organizado da seguinte maneira: na Seção2 são apresentados alguns resultados preliminares, a formu-lação do problema e o propósito do trabalho. Na Seção 3é descrita a metodologia de observação indireta e o métodovariacional adaptado aplicado ao problema proposto. Umaanálise dos resultados originados do algoritmo implemen-tado são apresentados na Seção 4. Por fim, na Seção 5 éfeita a conclusão do trabalho.
2. PROPÓSITO
Consideramos o SLSM em tempo discreto na forma
ΦM :
{xk+1 = Aθk xk +Bθk uk +Gθk wk,
yk = x′kCθk xk +u′kDθk uk,(1)
com condição inicial x0 ∈ Rn, onde x ∈ Rn é o estado dosistema, u ∈ Rr é o controle, wk é uma variável aleatória
12
http://dx.doi.org/10.5540/DINCON.2011.001.1.0004

independente com distribuição gaussiana com média zero ematriz de covariância Σ e y ∈ Rn é a saída do sistema. Amatriz Aθk assume valores da coleção A = {A1, . . . ,AS} dematrizes conhecidas, de acordo com a cadeia de Markov{θ0,θ1, . . . θS}. Analogamente, o mesmo acontece para asmatrizes B,G,C e D, com C = C′ ≥ 0 e D = D′ > 0. Consi-deramos a função de custo parcial
JTk =
T
∑t=k
yt . (2)
As probabilidades de transição são P(θk+1 = j|θk = i) = pi j,com i, j ∈ S = {1, . . . ,S}, e a distribuição inicial é π =[P(θ0 = 1), . . . ,P(θ0 = S)] = [π1, . . . ,πS]. Assumimos quea matriz P = [pi j] e o vetor π são conhecidos. Sendo x umprocesso estocástico, o custo J como definido em (2) é umavariável aleatória, e consideramos seu valor esperado a sercalculado,
JT = E {JT}. (3)
Consideramos Mr,s o espaço linear formado por umnúmero S de matrizes de dimensão r × s, Mr,s = {U =(U1, . . . ,US)} e Mr ≡Mr,r. Seguindo a notação de [2] de-finimos, para U ∈Mn, V ∈Mn, o operador TU : Mn→Mn
por
TU,i(V ) :=S
∑j=1
p jiU jVjU ′j, ∀i ∈ S, (4)
e definimos por conveniência T0(V ) = V , e para t ≥ 1,Tt(V ) = T(Tt−1(V )).
A seguinte proposição é uma adaptação dos resultados em[7].
Proposição 1 Seja X ∈Mn, Q ∈Mn e Σ ∈Mn definidos porXi = x0x′0πi, Qi = Q e Σi = E, ∀i ∈ S. Então,
JT (X) =T
∑k=0
⟨Tk
A(X)+k−1
∑l=0
TlA(Σ) , Q
⟩. (5)
A coleção de matrizes X na Proposição 1 representa osegundo momento condicional da condição inicial, Xi =E {x0x′0|θ0 = i}P(θ0 = i).
2.1. Formulação do problema
O problema tratado neste trabalho assume que somentexk é acessível ao controlador a cada instante de tempo k eθk não é observado. Consideramos um controle na forma derealimentação linear na forma
uk = Kxk, (6)
onde K representa o ganho estático.Para um dado ganho K, temos a seguinte malha fechada
xk+1 =(Ak+BkK) compondo a coleção de matrizes de malhafechada AK = (A1 +B1K, . . . ,AS +BSK), o operador TAK e ocusto dado por (5), o qual pode ser reescrito como,
JTK(X) =
T
∑k=0
⟨Tk
AK(X)+
k−1
∑l=0
TlAK(Σ),Q
⟩. (7)
O problema de CMLP a ser calculado é dado por
minK limT→∞
supT
JTK(X)/T. (8)
3. MÉTODO
Nesta seção descrevemos a metodologia de observaçãoindireta empregada no problema de SLSM não-observado eo algoritmo variacional implementado para resolver o pro-blema de CMLP.
Consideramos que θk é observada via uma variável rkcom distribuição condicional,
P(rk = θk|θk) = c,
P(rk = j|θk) =1− cS−1
, quando j 6= θk. (9)
A variável c representa os níveis de observação. Para c = 1temos θk = rk, o que corresponde ao cenário de observaçãocompleta. Pode-se mostrar, conforme [11], que a distribuiçãode θ não depende de r quando c = 1/S, o que correspondeao cenário de não-observação. A seguir apresentamos umaformulação do problema levando em conta a observação in-direta de θ com a seguinte estrutura de controle,
uk = Frk,kxk. (10)
Ressaltamos que é possível usar o método descrito em [9]com uma cadeia de Markov aumentada, contudo a dimen-são do problema aumenta (a dimensão de P torna-se S2) ese torna inviável computacionalmente, motivando o desen-volvimento de uma formulação mais específica que preservaa dimensão de P. Seja a matriz de malha-fechada,
A j,`,k = A j +B jF ,k, j, ` ∈ S,k ≥ 0. (11)
Seja V ∈Mn; definimos os operadores Eθk ,Lθk,k : Mn→Mn
por
Li,k(V ) := ∑`∈S
∑j∈S
p jiA j`kVjA′j`k(
c 11{ j=`}+1− cS−1
11{ j 6=`}
),
(12)
e
Ei(φ) =S
∑j=1
pi jφ j, ∀i ∈ S, ∀φ ∈Mn. (13)
A probabilidade de transição para a observação indireta édefinida por
Pi,` = P(rk = `|θk = i) = c11{i=`}+1− cS−1
11{ j 6=`}. (14)
A seguir apresentamos uma definição e um lema para o custoparcial para a observação indireta.
Definição 1 Seja F ={
Fr,k,r ∈ S,k ≥ 0}
uma sequência decoleções de ganhos. Denotamos o custo dado por (2) comcontrole definido em (10) por
JTF,k(x, i) = E
{T−1
∑t=k
(yt |xk = x,θk = i)
}, (15)
e também denotamos JTF,T = 0.
13

Lema 1 Considere uma sequência de coleções de ganhos Fcomo na Definição 1, e a seguinte sequência de coleções dematrizes, definida recursivamente por Li,T = 0, i = 1, . . . ,S,e
Li,k = ∑S`=1
(Qi +F ′`,kRiF ,k +A′i,`,kEi(Lk+1)Ai,`,k
)Pi,`.
Então o funcional (15) é equivalente à,
JTF,k(x, i) = x′Li,kx+wi,k, (16)
sendo Xi = xx′, X j = 0 para j 6= i.
Demonstração: A prova é feita por indução. Seja k = T ,então temos JT
F,T (x, i) = x′T Li,T xT = 0.Note que o custo parcial pode ser expresso por:
JTF,k(xk, i) =
S
∑`=1
E
{S−1
∑t=k
yt11{rk=`}|xk,θk = i
}
=S
∑`=1
ykP+S
∑`=1
E{
JTF,k+1(xk+1, j)|xk = x,θk = i
}P,
sendo P = P(rk = `|θk).Suponha que a expressão do funcional de custo seja válida
para k+1,
JTF,k+1(xk+1, j) = x′k+1L j,k+1xk+1 +w j,k+1,
então consideramos o custo no instante k,
JTF,k(xk, i) =
S
∑`=1
ykP+S
∑`=1
E{
JTF,k+1(xk+1, j)|xk,θk = i
}P
=S
∑`=1
yk +E{
x′k+1L j,k+1xk+1 +w j,k+1|xk,θk = i}
P
=S
∑`=1
(x′kQixk +u′kRiuk
)P+E
{x′k+1L j,k+1xk+1+
= w j,k+1|xk,θk = i},
usando o fato de que uk = F ,kxk têm-se que,
JTF,k(xk, i) =
S
∑`=1
{(x′kQixk + x′kF ′`,kRiF ,kxk
)E[x′k+1L j,k+1xk+1
+w j,k+1|xk,θk = i]}
P
Note que, E{
L j,k+1|xk,θk = i}= Ei(Lk+1), e
E{
w′kG′iL j,k+1Giwk|xk, θk = i}= Tr
[Ei(Lk+1)GiΣG′i
].
Finalmente, têm-se que
JTF,k(xk, i) =
S
∑`=1
[x′k{
Qi +F ′`,kRiF ,k +A′i,`,kEi(Lk+1)Ai,`,k}
xk
+Tr[Ei(Lk+1)GiΣG′i
]+Ei(wk+1)
]P
= x′kS
∑`=1
(Qi +F ′`,kRiF ,k +A′i,`,kEi(Lk+1)Ai,`,k
)Pxk
+S
∑`=1
(Tr[Ei(Lk+1)GiΣG′i
]+Ei(wk+1)
)P
= x′kLi,kxk +wi,k.
Analogamente a Seção 2, estendemos a definição de Jpara todo X ∈Mn como segue:
JTF,k(X) = 〈X ,Lk〉+π
′kwk. (17)
Lema 2 [11] Considere o SLSM (1) com observação indi-reta da cadeia de Markov via variável r e controle na forma(10). Então,
Xi,k+1 = LL,i (Xk)+ ϕi,k, (18)
sendo ϕ ∈Mn definido por,
ϕi := ∑`∈S
∑j∈S
p jiπ jG jΣG′j(
c 11{ j=`}+1− cS−1
11{ j 6=`}
).
O Algoritmo 1 descreve o método variacional aplicado aoproblema (16).
Algoritmo 11) Gere uma sequência inicial de ganhos F(0).2) Encontre X (η)
i,k conforme Lema 2, em seguida façaη = η +1 e k = T −1.3) Encontre F(η)
`,k definido porS∑
i=1
[(Ri +B′iEi(L
(η)k+1)Bi
)F(η)`,k +B′iEi(L
(η)k+1)Ai
]PX (η)−1
i,k = 0.
Faça k = k−1; se k ≥ 0, retorne a 3).4) Se |JF(η)(X0)− JF(η−1)(X0)|/JF(η)(X0) < ε , para ε dado,retorne a 2).
4. RESULTADOS E DISCUSSÕES
Consideramos um sistema em que cada modo é con-trolável e observável e a matriz de probabilidade P é tran-siente.
A1 =
[.7094 .0319.0646 .7962
], A2 =
[3.3276 2.2531−6.5302 −3.6410
],
A3 =
[.1057 .0614−.3748 .4090
],B1 =
[−.07112.4262
],
B2 =
[.2522−.3874
],B3 =
[.0157−.1292
],G1 =
[1.2052−.7724
],
G2 =
[.3738−.8129
],G3 =
[−.0043.2825
],
C1 =
[.0415 −.1678−.1678 .6781
],C2 =
[1.5628 .0577.0577 .0021
],
C3 = 103[
4.2419 −.2894−.2894 .0197
],x0 =
[−2.1707−.0592
]
P=
.2729 .7271 0.6907 .3093 0
0 .3534 .6466
,π0 = [.6516 .1805 .1678]
D1 = .3784, D2 = .8600, D3 = .8537, Σ = I.
A Figura 1 mostra o comportamento do CMLP ao longodos níveis de observação cm = {1, .9, .8, .7, .6, .5, .4, .3}. O
14
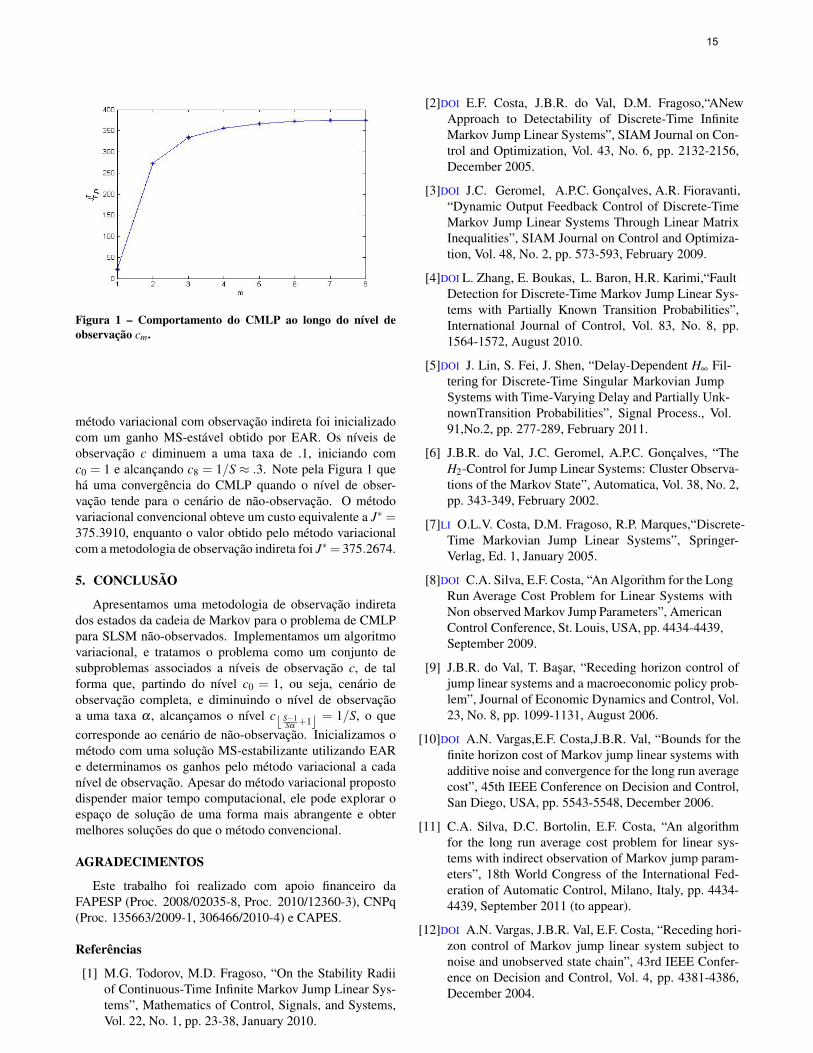
Figura 1 – Comportamento do CMLP ao longo do nível deobservação cm.
método variacional com observação indireta foi inicializadocom um ganho MS-estável obtido por EAR. Os níveis deobservação c diminuem a uma taxa de .1, iniciando comc0 = 1 e alcançando c8 = 1/S ≈ .3. Note pela Figura 1 quehá uma convergência do CMLP quando o nível de obser-vação tende para o cenário de não-observação. O métodovariacional convencional obteve um custo equivalente a J∗ =375.3910, enquanto o valor obtido pelo método variacionalcom a metodologia de observação indireta foi J∗= 375.2674.
5. CONCLUSÃO
Apresentamos uma metodologia de observação indiretados estados da cadeia de Markov para o problema de CMLPpara SLSM não-observados. Implementamos um algoritmovariacional, e tratamos o problema como um conjunto desubproblemas associados a níveis de observação c, de talforma que, partindo do nível c0 = 1, ou seja, cenário deobservação completa, e diminuindo o nível de observaçãoa uma taxa α , alcançamos o nível cb S−1
Sα+1c = 1/S, o que
corresponde ao cenário de não-observação. Inicializamos ométodo com uma solução MS-estabilizante utilizando EARe determinamos os ganhos pelo método variacional a cadanível de observação. Apesar do método variacional propostodispender maior tempo computacional, ele pode explorar oespaço de solução de uma forma mais abrangente e obtermelhores soluções do que o método convencional.
AGRADECIMENTOS
Este trabalho foi realizado com apoio financeiro daFAPESP (Proc. 2008/02035-8, Proc. 2010/12360-3), CNPq(Proc. 135663/2009-1, 306466/2010-4) e CAPES.
Referências
[1] M.G. Todorov, M.D. Fragoso, “On the Stability Radiiof Continuous-Time Infinite Markov Jump Linear Sys-tems”, Mathematics of Control, Signals, and Systems,Vol. 22, No. 1, pp. 23-38, January 2010.
[2]DOI E.F. Costa, J.B.R. do Val, D.M. Fragoso,“ANewApproach to Detectability of Discrete-Time InfiniteMarkov Jump Linear Systems”, SIAM Journal on Con-trol and Optimization, Vol. 43, No. 6, pp. 2132-2156,December 2005.
[3]DOI J.C. Geromel, A.P.C. Gonçalves, A.R. Fioravanti,“Dynamic Output Feedback Control of Discrete-TimeMarkov Jump Linear Systems Through Linear MatrixInequalities”, SIAM Journal on Control and Optimiza-tion, Vol. 48, No. 2, pp. 573-593, February 2009.
[4]DOI L. Zhang, E. Boukas, L. Baron, H.R. Karimi,“FaultDetection for Discrete-Time Markov Jump Linear Sys-tems with Partially Known Transition Probabilities”,International Journal of Control, Vol. 83, No. 8, pp.1564-1572, August 2010.
[5]DOI J. Lin, S. Fei, J. Shen, “Delay-Dependent H∞ Fil-tering for Discrete-Time Singular Markovian JumpSystems with Time-Varying Delay and Partially Unk-nownTransition Probabilities”, Signal Process., Vol.91,No.2, pp. 277-289, February 2011.
[6] J.B.R. do Val, J.C. Geromel, A.P.C. Gonçalves, “TheH2-Control for Jump Linear Systems: Cluster Observa-tions of the Markov State”, Automatica, Vol. 38, No. 2,pp. 343-349, February 2002.
[7]LI O.L.V. Costa, D.M. Fragoso, R.P. Marques,“Discrete-Time Markovian Jump Linear Systems”, Springer-Verlag, Ed. 1, January 2005.
[8]DOI C.A. Silva, E.F. Costa, “An Algorithm for the LongRun Average Cost Problem for Linear Systems withNon observed Markov Jump Parameters”, AmericanControl Conference, St. Louis, USA, pp. 4434-4439,September 2009.
[9] J.B.R. do Val, T. Basar, “Receding horizon control ofjump linear systems and a macroeconomic policy prob-lem”, Journal of Economic Dynamics and Control, Vol.23, No. 8, pp. 1099-1131, August 2006.
[10]DOI A.N. Vargas,E.F. Costa,J.B.R. Val, “Bounds for thefinite horizon cost of Markov jump linear systems withadditive noise and convergence for the long run averagecost”, 45th IEEE Conference on Decision and Control,San Diego, USA, pp. 5543-5548, December 2006.
[11] C.A. Silva, D.C. Bortolin, E.F. Costa, “An algorithmfor the long run average cost problem for linear sys-tems with indirect observation of Markov jump param-eters”, 18th World Congress of the International Fed-eration of Automatic Control, Milano, Italy, pp. 4434-4439, September 2011 (to appear).
[12]DOI A.N. Vargas, J.B.R. Val, E.F. Costa, “Receding hori-zon control of Markov jump linear system subject tonoise and unobserved state chain”, 43rd IEEE Confer-ence on Decision and Control, Vol. 4, pp. 4381-4386,December 2004.
15