estatística exploratóriacin.ufpe.br/~psb/ead/estatistica exploratoria - volume 1 v11.pdf · 6...
TRANSCRIPT

Recife, 2010
Estatística Exploratória
UNIVERSIDADE FEDERAL RURAL DE PERNAMBUCO (UFRPE)
COORDENAÇÃO GERAL DE EDUCAÇÃO A DISTÂNCIA (EAD/UFRPE)
Marco Domingues Jeísa Domingues
Volume 1

Universidade Federal Rural de Pernambuco
Reitor: Prof. Valmar Corrêa de AndradeVice-Reitor: Prof. Reginaldo BarrosPró-Reitor de Administração: Prof. Francisco Fernando Ramos CarvalhoPró-Reitor de Extensão: Prof. Paulo Donizeti SiepierskiPró-Reitor de Pesquisa e Pós-Graduação: Prof. Fernando José FreirePró-Reitor de Planejamento: Prof. Rinaldo Luiz Caraciolo FerreiraPró-Reitora de Ensino de Graduação: Profª. Maria José de SenaCoordenação Geral de Ensino a Distância: Profª Marizete Silva Santos
Produção Gráfica e EditorialCapa e Editoração: Rafael Lira, Italo Amorim e Arlinda TorresRevisão Ortográfica: Rita BarrosIlustrações: Allyson Vila NovaCoordenação de Produção: Marizete Silva Santos

Sumário
Apresentação ................................................................................................................. 5
Conhecendo o Volume 1 ................................................................................................ 6
Capítulo 1 – Introdução à Estatística............................................................................... 8
1.1. Tipos de Dados .........................................................................................................9
1.2. Planejamento de Experimentos..............................................................................11
1.3. Estudos Observacionais e Experimentos Aleatórios ...............................................14
Capítulo 2 – Resumo de Dados e Gráficos ..................................................................... 21
2.1. Distribuição de Frequências ...................................................................................21
2.2. Regras Gerais para elaborar uma Distribuição de Frequência ................................24
2.3. Histograma e Polígonos de Frequência ..................................................................24
2.4. Distribuições de Frequência Acumulada ................................................................26
2.5. Gráficos Estatísticos ................................................................................................31
2.5.1. Gráfico de Pontos ...........................................................................................31
2.5.2. Diagrama de Ramo e Folhas ...........................................................................32
2.5.3. Gráfico de Pareto ...........................................................................................33
2.5.4. Diagrama de Barras ........................................................................................34
2.5.5. Gráfico de Setores - Pizza ...............................................................................34
2.5.6. Gráfico de Dispersão ......................................................................................35
2.5.7. Gráfico de Séries Temporais ...........................................................................37
Capítulo 3 – Medidas Resumo ...................................................................................... 39
3.1. Medidas de Posição ................................................................................................39
3.1.1. Moda ..............................................................................................................40
3.1.2. Média .............................................................................................................41

3.1.3. Mediana .........................................................................................................42
3.1.4. Ponto Médio ..................................................................................................43
3.2. Assimetria ...............................................................................................................43
3.3. Medidas de Variação (dispersão) ............................................................................45
3.3.1. Amplitude ......................................................................................................45
3.3.2. Variância (σ2) e desvio padrão (σ) ..................................................................45
3.3.3. Escore z ..........................................................................................................49
3.3.4. Quartis e Percentis .........................................................................................49
3.3.5. Boxplot (diagrama de caixa) ...........................................................................50
Considerações Finais .................................................................................................... 52
Conheça os Autores ..................................................................................................... 54

5
Estatística Exploratória
Apresentação
Caro(a) aluno (a),
Seja bem-vindo (a) ao primeiro volume do curso de Estatística Exploratória. Neste primeiro volume, vamos estudar os conceitos introdutórios em estatística necessários para a compreensão do assunto que será estudado durante toda a disciplina.
O objetivo principal deste primeiro volume é proporcionar ao estudante uma ampla visão do tratamento estatístico de dados, desde sua coleta através dos estudos observacionais e experimentos, passando pela sua análise através de gráficos e medidas-resumo.
Bons estudos!
Marco Domingues e Jeísa Domingues
Autores

6
Estatística Exploratória
Conhecendo o Volume 1
Neste primeiro volume, você terá os conteúdos de estatística exploratória. A seguir, você pode entender a organização deste primeiro volume.
Planejamento de experimentos estatísticos de análise exploratória dos dados.
Carga horária: 15 h/aula
Objetivo do volume 1: Ao final do módulo, o aluno terá condições de iniciar o planejamento de experimentos e estudos estatísticos, analisando os dados através de medidas-resumo e por meio de gráficos e tabelas.
Assuntos
» Introdução à estatística e tipos de dados;
» Estudos observacionais e experimentos aleatórios;
» Planejamento de experimentos;
» Resumo de dados;
» Distribuições de frequências e gráficos;
» Medidas de posição e dispersão.
Dicas de Estudo
» O Capítulo 1 é tipicamente conceitual e por isso precisa de mais empenho e dedicação. Destine cinco horas de estudo para esse capítulo. Você deve organizar uma metodologia de estudo que possibilite contato diário com o material didático.
» Para o Capítulo 2, você também precisará dedicar cinco horas estudo. Nesse capítulo você precisará de muita dedicação nos exercícios. São eles que farão com que o conteúdo seja assimilado de forma duradoura.
» O Capítulo 3 engloba o tratamento gráfico e o estudo das medidas de posição e dispersão tão importantes para a compreensão da natureza dos dados.

7
Estatística Exploratória
Capítulo 1
Metas
Ao final do capítulo, esperamos que você consiga:
» Entender as características dos estudos estatísticos observacionais e experimentais;
» Conduzir experimentos estatísticos.
Assuntos
» Introdução à estatística;
» Tipos de dados;
» Planejamento de experimentos
› Estudos observacionais;
› Experimentos aleatórios.

8
Estatística Exploratória
Capítulo 1 – Introdução à Estatística
Vamos conversar sobre o assunto?
E afinal, para que serve a Estatística? Onde a estatística pode ser utilizada? Por que eu devo estudar estatística? É importante estudar estatística para trabalhar com desenvolvimento de sistemas de software? Para responder a essas perguntas vamos discutir duas situações que aconteceram recentemente.
Você deve ter observado que nas semanas que antecedem as eleições no Brasil, a maioria dos veículos de comunicação fala sobre pesquisas de intenções de voto. No Brasil, várias empresas de pesquisas estatísticas trabalham nas eleições. Por falar nisso, você já foi entrevistado por alguma dessas empresas? Conhece alguém que já tenha sido? Nas eleições presidenciais de 2010, foram registrados mais de 100 milhões de eleitores, não é intrigante que essas pesquisas de intenção de voto sejam realizadas com pouco mais de 2000 eleitores? Como será que eles escolhem os eleitores para serem entrevistados?
Em 2010 também aconteceu o recenseamento da população brasileira. Em cada censo, praticamente todas as residências brasileiras recebem a visita do representante do IBGE (Instituto Brasileiro de Geografia e Estatística) para uma rápida conversa. Essa entrevista consiste em um grupo de perguntas relativas à religião, composição de renda, escolaridade, quantidade de pessoas que moram na mesma residência, idade e quantidade de homens e mulheres etc. Ao final do processo, o IBGE realizará a análise com todos os dados coletados, elaborando um “raio-X” detalhado da sociedade brasileira. Essas informações são usadas pelo governo no desenvolvimento de políticas públicas para os estados da federação. Atualmente no Brasil, o CENSO ocorre a cada 10 anos e o primeiro aconteceu no ano de 1872, segundo dados do IBGE (http://www.ibge.gov.br/ibgeteen/censo2k/brasil.html).
Você pode ter observado que no primeiro exemplo apenas uma pequena porção (amostra) dos eleitores é entrevistada em cada pesquisa, enquanto que no censo, os dados são coletados de toda a população. Amostra e população são termos muito importantes em estatística. O quadro a seguir apresenta as definições desses e de outros termos básicos.
Definições
Dados São observações coletadas (por exemplo, idade, sexo, medidas).
População É o conjunto completo de todos os elementos a serem estudados.
Censo É um conjunto de dados obtidos de todos os membros de uma população.
Amostra É um subconjunto de membros selecionados de uma população.
Para realizar o censo 2010, o IBGE precisou contratar cerca de 190.000 recenseadores, cada um deles recebeu por mês entre R$ 800,00 e R$ 1.600,00 . Percebe-se claramente que a realização de um censo é muito dispendiosa, e estamos falando apenas dos salários dos recenseadores. Existem outros custos inerentes à realização do censo. Por outro lado, nas pesquisas de intenções de voto, são escolhidos, em média, 3000 eleitores em cada pesquisa. Você consegue se lembrar que na divulgação dessas pesquisas, sempre
Saiba Mais
1 Fonte – Instituto Brasileiro de Geografia e Estatística.

9
Estatística Exploratória
é citada uma margem de erro no resultado? Pois bem, um dos objetivos mais importantes da estatística é utilizar dados amostrais para tirar conclusões sobre populações. A grande vantagem é o baixo custo no processo de coleta e análise dos dados. Porém, a obtenção de dados amostrais representativos de uma população é um fator extremamente crítico. Observa-se facilmente que, quanto maior o tamanho da amostra, menor o erro da pesquisa e maior é o custo do processo. Daí, para que os dados coletados da amostra sejam verdadeiramente representativos da população, os elementos amostrais devem ser selecionados de modo aleatório e não tendencioso. Se os dados não forem coletados de modo apropriado, os resultados da análise estatística serão inválidos.
O objetivo desse módulo é fornecer a base conceitual para que você compreenda todas as possibilidades de aplicações da estatística. E não pense que você precisa ser um especialista em matemática. Você verá que, com dedicação, será muito fácil dominar os princípios básicos sem muita dificuldade.
1.1. Tipos de Dados
O Dicionário Aurélio define “estatística” como sendo “a parte da matemática em que se investigam os processos de obtenção, organização e análise de dados (características) sobre uma população ou sobre uma coleção de seres quaisquer, e os métodos utilizados para estabelecer conclusões e fazer inferências ou predições com base nesses dados”. E por falar em dados, é importante que você saiba reconhecer a natureza dos dados que serão analisados. Como exemplo, vamos utilizar alguns dados (características) solicitados pelos entrevistadores no censo/2010:
Para a característica “Sexo”, são dois os casos possíveis: masculino e feminino;
Para a característica “Estado Civil”, os casos possíveis são: casado, solteiro, divorciado, separado, viúvo;
Para a característica “Grau de Instrução”, os casos possíveis são: ensino fundamental, ensino médio e ensino superior;
Para a característica “Número de Pessoas na Família”, há um número de resultados possíveis, expresso através dos números naturais: 0, 1, 2, 3, 4,..., n;
Para a característica “Renda Familiar” a situação é diferente. Os resultados podem assumir um número infinito de valores numéricos dentro de um determinado intervalo;
Para a característica “CEP – Código de Endereçamento Postal” que representa uma localização geográfica, os possíveis valores assumem qualquer combinação de oito números. Ex: 50741-100.
O conjunto de valores que uma característica pode assumir é chamado de variável. Nos exemplos citados anteriormente, os dados da variável “Sexo” e os dados da variável “Estado Civil” são chamados de dados qualitativos, categóricos ou atributos. Perceba que para o atributo sexo, os valores masculino e feminino determinam uma categoria ou qualidade do indivíduo pesquisado, o mesmo ocorrendo para o atributo “Estado Civil”.
Os possíveis valores que uma variável pode assumir também são chamados de realizações. Para o caso da variável “Sexo”, os valores “masculino” e “feminino” também são chamados de realizações da variável “Sexo”.
As variáveis qualitativas ainda podem ser classificadas em dois tipos: variável qualitativa nominal, para a qual não existe nenhuma ordenação nas possíveis realizações,

10
Estatística Exploratória
e variável qualitativa ordinal, para a qual existe uma ordem nos seus valores. Os dados da variável “CEP”, apesar de numéricos, não são quantidades. O CEP não identifica medidas ou contagem de coisa alguma, por isso, não faz sentido realizar cálculos com eles. A variável “CEP” é um caso de variável qualitativa nominal, enquanto “Grau de Instrução” é um exemplo de variável qualitativa ordinal, porque ensino fundamental, ensino médio e ensino superior correspondem a uma ordenação relacionada com o número de anos completos de escolaridade de um indivíduo.
Definições
Dados qualitativos, ou categóricos ou de atributos
Podem ser classificados em diferentes categorias que se distinguem por alguma característica.
Dados quantitativosConsistem em números que representam contagens ou medidas.
De modo semelhante, as variáveis quantitativas podem ser classificadas em discretas e contínuas. A variável “Número de Pessoas na Família” é um exemplo de variável com dados discretos, uma vez que não podem ocorrer valores fracionados para essa variável. Por outro lado, a variável “Renda Familiar” é um exemplo de variável quantitativa com dados contínuos, cujos valores pertencem a um intervalo de números reais. A figura 1 apresenta um esboço da classificação das variáveis.
Figura 1 – Classificação de uma variável.
Os dados quantitativos descrevem medidas e é importante utilizarmos as unidades de medida apropriadas para cada variável. Por exemplo, suponha que você está desenvolvendo um sistema médico para controle de exames, como o teste ergométrico (teste de esforço). Esse exame pode auxiliar no diagnóstico de doenças cardíacas através do monitoramento do coração e da pressão arterial relacionada com o nível de esforço físico ao qual o paciente é submetido. Nesse exame são coletados vários dados do paciente: peso (medido em Kg), pressão arterial (medida em mmHg – milímetros de mercúrio), atividade elétrica do coração (corrente elétrica – medida em Ampere, tensão elétrica – medida em Volt, resistência elétrica – medida em Ohm), frequência cardíaca (bpm – medida em batimentos por minuto) etc. Todas essas variáveis são quantitativas e a utilização de unidades de medida inadequadas pode tornar os diagnósticos imprecisos e/ou inválidos.

11
Estatística Exploratória
1.2. Planejamento de Experimentos
Você estudou nas seções anteriores que a estatística lida com a coleta, a apresentação, a análise e o uso dos dados como ferramentas auxiliares na tomada de decisões e resolução de problemas. Você também pôde observar que o desenvolvimento de sistemas trabalha, na prática, com a manipulação de dados e, obviamente, algum conhecimento de estatística é importante para esse profissional. O campo da engenharia de software encontra na estatística as ferramentas essenciais para o planejamento de novos sistemas, análise de código, análise de erros, levantamento de custos e orçamento.
As técnicas e métodos estatísticos são úteis para nos ajudar a entender a variabilidade de um determinado fenômeno observado. Por variabilidade, queremos dizer que sucessivas observações de um fenômeno não produzem exatamente o mesmo resultado. Por exemplo, considere que você é o gerente de um projeto com 10 programadores. Considere o desempenho diário de um dado programador em relação à produção de linhas de código e a quantidade de erros nesse código. Esse programador sempre atinge as mesmas metas de produção diária de código? Com as mesmas quantidades de erros? Naturalmente, não. Na verdade, algumas vezes o desempenho varia consideravelmente. Essa variabilidade observada no desempenho do programador depende de muitos fatores, tais como problemas pessoais, relacionamento com a equipe, experiência prévia com soluções semelhantes, habilidade com a linguagem de programação utilizada, apenas para citar alguns fatores. Esses fatores representam fontes potenciais de variabilidade na produção de software.
A compreensão da variabilidade também é importante quando consideramos, por exemplo, o desempenho diário de vários programadores com as mesmas características (experiência prévia, habilidade com a linguagem, bom entrosamento com a equipe etc.). Se a empresa que você trabalha também tem outros projetos, cada um deles contando com grupos de programadores, e você foi convidado para apresentar um estudo sobre o desempenho global dos programadores para a diretoria, como você faria o levantamento das medidas de desempenho dos programadores da empresa? Faria o estudo com toda a população de programadores da empresa para o levantamento de parâmetros de desempenho? Faria o estudo com uma amostra de programadores da empresa para o levantamento de estatísticas de desempenho e estenderia as conclusões para toda a população através da inferência estatística?
Definições
ParâmetroUm parâmetro é uma medida numérica que descreve alguma característica de uma população.
EstatísticaUma estatística é uma medida numérica que descreve alguma característica de uma amostra.
A estratégia baseada nas medidas de desempenho de alguns programadores para estabelecer conclusões sobre medidas de desempenho de todos os programadores da empresa pode resultar em erros (ou riscos). Esses erros são conhecidos como erros de amostragem. No entanto, se a amostra for selecionada adequadamente, esses riscos poderão ser quantificados e um tamanho apropriado de amostra poderá ser determinado.
Infelizmente, alguns estudos utilizam experimentos estatísticos baseados em amostras ruins (coletadas por métodos viesados2). Uma amostra é considerada ruim
Atenção
2 Viés é um termo muito comum em estatística. Uma medida viesada é uma medida tendenciosa, distorcida.

12
Estatística Exploratória
ou tendenciosa quando o método de amostragem não gera amostras representativas da população da qual foram obtidas. Vamos analisar dois exemplos de estudos estatísticos cujas amostras foram geradas por processos de coleta de dados tendenciosos:
Ao cursar uma disciplina de estatística aplicada na pós-graduação de uma universidade brasileira, um grupo de alunos realizou um experimento visando mapear o perfil salarial dos profissionais de TI em todo o Brasil, por regiões e pelas capitais. O método de coleta de dados consistiu no preenchimento voluntário de um formulário web contendo perguntas sobre as condições de trabalho, características do trabalho e salários dos profissionais de TI no Brasil. Esses profissionais de TI tomaram conhecimento da pesquisa através de um e-mail-convite enviado a eles por meio das redes sociais. Respostas voluntárias a questionários, apesar de ser um método muito comum de coleta de dados, é um dos piores, porque são os entrevistados que decidem se querem participar ou não da pesquisa;
Outro exemplo interessante de coleta de dados do tipo resposta voluntária ocorreu quando a revista Newsweek (http://www.newsweek.com/) realizou uma sondagem sobre o sítio Napster (www.napster.com) que, no início, oferecia livre acesso à cópia de CDs de músicas. Perguntou-se aos leitores se eles continuariam a usar o Napster se tivessem que pagar uma taxa. Os leitores poderiam dar suas respostas através do sítio da revista. Entre as 1873 respostas recebidas, 19% diziam sim, ainda é mais barato do que comprar CDs. Outros 5% diziam sim, sentiam-se mais confortáveis pagando uma taxa.
Nos dois estudos, a Internet foi o veículo escolhido para obtenção das amostras, e nesse caso, cabe às pessoas decidirem se querem ou não participar da pesquisa, de modo que constituem uma amostra de resposta voluntária. Sabe-se que as pessoas com opiniões mais contundentes têm mais tendência a participar, de maneira que as respostas não são representativas de toda a população.
É muito importante que você desenvolva o senso crítico em relação aos procedimentos para coleta de dados nos experimentos. Com as amostras coletadas através de respostas voluntárias, apenas conclusões relacionadas com o grupo específico que escolheu participar do experimento podem ser tiradas. Infelizmente tem sido prática comum estenderem-se as conclusões a uma população maior. Esse tipo de amostra é tipicamente tendenciosa e não deveria ser usada para se fazer afirmações sobre uma população maior.
A seguir serão apresentados alguns aspectos que devem ser considerados no planejamento de experimentos:
Pequenas Amostras
Como vimos nas seções anteriores, um dos principais objetivos da estatística é poder inferir sobre características de uma população a partir da análise de suas amostras. Você também percebeu que, se o tamanho dessas amostras cresce na direção do tamanho da população, mais precisas são as conclusões obtidas. Contudo, experimentos com amostras muito grandes se aproximam de um CENSO e podem se tornar bastante dispendiosos. Além disso, mesmo amostras grandes precisam ser coletadas por processos adequados. Mas por outro lado, amostras muito pequenas, mesmo sendo coletadas corretamente, podem não ser representativas da população. Resumindo, embora seja importante trabalharmos com amostras suficientemente grandes, é do mesmo modo importante que os dados amostrais tenham sido coletados de forma apropriada, de modo aleatório. Em outras palavras, mesmo amostras grandes podem ser ruins.
Questões Orientadas
Um problema fundamental na coleta de dados através de entrevistas ocorre quando

13
Estatística Exploratória
as questões são direcionadas para provocar a resposta desejada. Observe as questões a seguir e avalie qual seria a sua resposta nos dois cenários:
» “A CPMF deve voltar a vigorar no Brasil?”
» “A CPMF deve voltar a vigorar no Brasil para resolver definitivamente os problemas do sistema de saúde?”
Outra característica das entrevistas (também conhecidas como questões de sondagem) que pode causar impacto na qualidade dos dados coletados diz respeito à ordem das questões. Observe as duas questões a seguir e analise a sua resposta em comparação com as respostas de alguns de seus colegas de curso. Verifique se a ordem das palavras-chave (Jogos de computador e drogas leves) altera as respostas.
» “Você diria que os jogos de computador têm mais ou menos potencial de causar dependência em jovens do que as chamadas drogas leves?”
» “Você diria que as chamadas drogas leves têm mais ou menos potencial de causar dependência em jovens do que os jogos de computador?”
Claro que esse estudo é muito simples para estabelecer conclusões definitivas sobre o contexto das drogas, jogos digitais e jovens, mas é muito valioso para que você construa a percepção de que a ordem das palavras-chave nas entrevistas pode influenciar nas respostas.
Não-resposta
No final de 2010, um pesquisador do IPEA (Instituto de Pesquisa Econômica Aplicada), órgão ligado à Presidência da República, utilizou uma lista de discussão de pesquisadores da SBC (Sociedade Brasileira de Computação) para solicitar que os seus assinantes preenchessem um questionário com dados referentes às suas áreas de atuação e competências, dentre outras informações. No último dia disponível para envio do questionário, o pesquisador do IPEA responsável pela pesquisa, emitiu um e-mail informando que apenas 60 pesquisadores haviam respondido o questionário, um número muito pequeno se considerarmos a quantidade de pesquisadores nas instituições brasileiras.
Hoje em dia, cada vez mais as pessoas se recusam a responder esse tipo de questionário quando são abordadas. Alguns entrevistados se recusam porque já perceberam que vendedores tentam negociar bens e serviços começando com uma conversa que soa como se fosse parte de uma pesquisa de opinião, outras pessoas têm receio de perder a privacidade.
Dados Ausentes ou Faltantes
Os resultados de pesquisas podem ser fortemente afetados por dados não fornecidos. Isso acontece porque algumas perguntas podem causar constrangimento e as pessoas tendem a não responder esse tipo de pergunta. Em alguns casos, perguntas relacionadas com renda salarial, opção religiosa, opção sexual e experiências profissionais podem inibir as pessoas a fornecerem esses dados.
Estudos Tendenciosos (Interesse Próprio)
Você já deve ter visto em propagandas ou listas de e-mail sobre os benefícios de um determinado produto ou medicamento. Devemos tomar muito cuidado com estudos que são financiados por empresas e cujos resultados são “podados” para apresentar apenas as

14
Estatística Exploratória
virtudes de um determinado produto. Algumas vezes, pode acontecer o contrário. Grupos concorrentes podem custear pesquisas de opinião ou mesmo pesquisas científicas para denegrir a imagem dos produtos e serviços dos seus concorrentes, apresentando apenas os seus efeitos nocivos.
Outros cuidados devem ser tomados no tratamento estatístico dos dados. Por exemplo:
Estabelecer que duas variáveis são correlacionadas implica que seus valores de certa forma são proporcionais (direta ou inversamente), mas pode não haver causalidade entre elas, ou seja, uma variável pode não afetar a outra. Ex.: Altura e QI;
Descartar deliberadamente alguns dados para favorecer apenas os aspectos positivos da pesquisa. Ex.: Efeitos colaterais em medicamentos;
Fornecer dados tecnicamente corretos que conduzem o leitor a conclusões enganosas. Ex.: O desmatamento na Amazônia caiu 14% em 2010 na comparação com 2009 e atingiu a taxa de 6.450 km² desmatados por ano3 . O leitor desavisado pode entender que a área que já havia sido desmatada em 2009 foi replantada e no ano de 2010 outros 6.450 km² foram desmatados, quando na verdade, a floresta amazônica é continuamente desmatada, ano após ano, mas em 2010 ela foi menos desmatada. Isso significa que a floresta vai demorar um pouco mais a ser completamente extinta.
1.3. Estudos Observacionais e Experimentos Aleatórios
Na seção anterior, você aprendeu que antes de iniciar os estudos envolvendo experimentos estatísticos, é importante realizar um planejamento dos experimentos. Você também pôde observar que devemos procurar escapar de algumas armadilhas que podem aparecer quando estamos coletando dados amostrais. Nunca esqueça que, se os dados amostrais não forem coletados de maneira apropriada, eles podem não servir para estabelecer conclusões coerentes sobre a população estudada.
Vou convidá-lo a observar dois estudos com perfis diferentes. Acho que você será capaz de analisá-los e determinar a natureza de cada um deles.
Um laboratório farmacêutico está desenvolvendo uma nova droga para tratamento de um tipo de câncer (carcinoma). Foram selecionados 100 pacientes para com diagnóstico de carcinoma para receber tratamento com a nova droga. Os pacientes foram acompanhados durante seis meses para verificar os estágios da doença durante a administração da nova droga. Após esse período, verificou-se que em 75% dos pacientes houve redução no tamanho do tumor.
Uma universidade brasileira encomendou um estudo para avaliar o efeito das políticas públicas antitabagistas (especialmente as propagandas antitabagistas nos maços de cigarro) entre os universitários daquela instituição de ensino. A equipe responsável pelo estudo iniciou a pesquisa entre os universitários escolhendo aleatoriamente os estudantes e agrupando-os em “fumantes”, “ex-fumantes” e “não fumantes”. Para o grupo dos “fumantes” foi perguntado: as propagandas antitabagismo obrigatórias nos maços de cigarro influenciam ou não a quantidade de cigarros consumidos? Para o grupo de “ex-fumantes” foi perguntado: as propagandas antitabagismo obrigatórias nos maços de cigarro influenciaram a sua decisão de parar de fumar? Finalmente, para o grupo de “não-fumantes” foi perguntado: Você acha que as propagandas antitabagismo obrigatórias dos maços de cigarro podem influenciar ou não a decisão de parar de fumar?
Hiperlink
3 http://blog.planalto.gov.br/desmatamento-na-amazonia-tem-queda-historica/

15
Estatística Exploratória
E então? Quais as características que você observou em cada estudo? Muito bem, vamos juntos tentar identificar essas características.
O primeiro estudo é normalmente chamado de experimento estatístico. Você pode notar que o interesse do estudo consiste na verificação do efeito da droga nos tumores dos pacientes. Os pacientes são também chamados de unidades experimentais. Somente após o início do tratamento é que os dados sobre o paciente são coletados. Portanto, há uma interferência direta sobre os indivíduos. Falaremos mais sobre as características dos experimentos estatísticos ao final desta seção.
O segundo estudo consiste em uma entrevista e é conhecido como estudo observacional. Nesse tipo de estudo, observam-se características específicas sem a intenção de modificar os sujeitos objetos do estudo. Existem basicamente três tipos de estudos observacionais, diferentes entre si pelo período do tempo onde o estudo é realizado.
Estudo retrospectivoOs dados são coletados do passado através de verificação em registros, entrevistas e documentos.
Estudo transversalOs dados são observados, medidos e coletados em um momento no tempo.
Estudo prospectivoOs dados são coletados no futuro a partir de grupos que compartilham fatores comuns.
Tudo bem, eu sei que essas definições parecem muito obscuras sem os respectivos exemplos. Então, vamos aos exemplos:
Estudo retrospectivo - Suponha que você está desenvolvendo um estudo para mapear os impactos na qualidade do software na segunda metade da década de 90. Esse estudo deve analisar os registros das empresas fabricantes de software, comparando projetos que empregaram a UML – Unified Modeling Language4 com projetos que utilizaram exclusivamente as técnicas estruturadas, como análise essencial e análise estruturada, no desenvolvimento de artefatos computacionais.
Estudo transversal - Suponha que você é o CIO (Chief Information Officer) de uma empresa e deseja investigar o desempenho de duas ferramentas de segurança utilizadas na empresa. Você deseja obter a resposta para as seguintes questões: qual a prevalência de ocorrências de ataques por vírus e spyware no parque de máquinas da empresa e qual a relação entre a quantidade de ocorrências desses ataques e as respectivas ferramentas de segurança? Para realizar esse estudo, você deverá selecionar duas amostras de computadores, cada uma delas com uma das ferramentas de segurança. Em seguida, é necessário realizar a quantificação e qualificação dos ataques em cada amostra, em um dado período de tempo.
Estudo prospectivo - Suponha que você foi contratado para coordenar uma grande equipe de desenvolvimento de projetos de software. Uma das suas tarefas é mensurar o desempenho dos times de projeto que utilizam metodologias ágeis de desenvolvimento, particularmente SCRUM e programação extrema (XP - eXtreme Programming). Para isso, você vai utilizar algumas métricas para avaliação de desempenho e analisar o comportamento da equipe ao longo do cronograma. Ao final do projeto, você terá elementos para avaliar se os times alcançaram os resultados esperados.
O fluxograma da figura 2 pode ajudar a identificar os tipos de estudos observacionais e também serve para relacionar algumas particularidades que merecem ser consideradas no planejamento de experimentos.
Hiperlink
4 http://www.uml.org/

16
Estatística Exploratória
Figura 2 – Tipos de estudos observacionais.
Por falar em planejamento de experimentos, eu acho que você já está preparado para fornecer uma boa definição para experimento estatístico. Não? Quer uma ajuda? Então vamos lá:
Experimento Estatístico é um procedimento planejado partindo de uma hipótese que visa provocar fenômenos em condições controladas, observar e analisar os seus resultados.
Vamos tentar entender melhor essa definição. Um procedimento planejado é aquele em que o pesquisador mantém o controle do procedimento através da previsão das ações que ocorrem sobre o experimento. Para provocar os tais fenômenos em condições controladas, o pesquisador tem a opção de escolher a técnica mais adequada para aplicar o “tratamento” nas unidades experimentais. Já o tratamento é qualquer procedimento ou conjunto de procedimentos cujo efeito será avaliado e comparado com outras unidades experimentais. Não esqueça que além do conjunto de unidades experimentais que recebem o tratamento, também há um conjunto de unidades experimentais que não recebem o tratamento e que são utilizadas para realizar as comparações. Esse conjunto é chamado de grupo de controle.
Quando você se deparar com a necessidade de realizar experimentos estatísticos, não se esqueça de considerar três fatores importantes (apresentados na figura 2): controlar o efeito das variáveis, realizar replicações do experimento e utilizar a aleatoriedade na escolha das amostras. Vamos considerar cada um desses fatores individualmente.
Controlando os Efeitos das Variáveis
Alguns métodos estão disponíveis para serem aplicados no controle dos efeitos das variáveis no experimento. Você vai observar que eles têm vantagens e desvantagens. A nossa intenção é que ao final da seção você seja capaz de reconhecer o método mais adequado para cada tipo de experimento. Vamos analisar alguns deles:

17
Estatística Exploratória
» Experimento cego - Você já ouviu falar em “efeito placebo”? Esse efeito ocorre quando, em um experimento, um grupo de pacientes recebe um tratamento (vacinas, comprimidos etc.) sem nenhum efeito farmacológico e outro grupo recebe o tratamento que está sendo testado. O efeito placebo ocorre quando um sujeito não tratado relata melhora nos sintomas (há estudos que atestam que a melhora pode ser real). No experimento cego, os pacientes (unidades experimentais) não devem saber se estão recebendo placebo ou o tratamento sob teste. Dessa maneira, é possível determinar se o efeito do tratamento é significativamente diferente do efeito placebo. O experimento cego também pode ser estendido para os técnicos que aplicam o tratamento e realizam as análises. Em resumo, os pacientes não sabem se estão recebendo placebo ou tratamento, e os técnicos não sabem se estão aplicando placebo ou tratamento. Isso faz com que não haja influência sobre os pacientes. Isso mesmo, a expressão facial, tom de voz ou atitude podem influenciar os pacientes. Esse tipo de técnica é chamado de experimento duplamente cego.
» Blocos - Quando planejamos um experimento, sabemos que existem alguns fatores que podem influenciar fortemente os resultados da variável em consideração. Por exemplo, se desejamos avaliar a produtividade dos membros de uma equipe de desenvolvimento de software ao utilizarmos uma nova suíte de desenvolvimento durante um determinado período (uma semana), precisamos levar diversos fatores em consideração – experiência em desenvolvimento de software, familiaridade com o projeto e com a linguagem de desenvolvimento, problemas hormonais (algumas mulheres sentem fortes cólicas durante o ciclo menstrual), ambiente de trabalho, etc. Isso quer dizer que a produtividade dos membros da equipe de desenvolvimento pode ser afetada tanto pela utilização da nova suíte de desenvolvimento quanto por outros fatores. Em outras palavras, um bloco é um grupo de sujeito que são semelhantes, mas são diferentes nos modos como podem afetar o resultado do experimento. Dessa forma, o ideal é separar os grupos de indivíduos com características semelhantes (bloco), e aplicar aleatoriamente o tratamento (no caso do exemplo, solicitar que o membro da equipe de desenvolvimento utilize a nova suíte) a alguns membros de cada grupo.
» Experimento completamente aleatorizado - Suponha que desejamos, novamente, avaliar a produtividade dos membros de uma equipe de desenvolvimento de software ao utilizarmos uma nova suíte de desenvolvimento durante um determinado período (uma semana). No entanto, queremos que o experimento seja completamente aleatorizado. Nesse caso, os membros da equipe que utilizarão a nova suíte de desenvolvimento serão sorteados aleatoriamente. Esse sorteio é semelhante ao lançamento de uma moeda, por exemplo, para cada membro da equipe devemos realizar o lançamento de uma moeda, caso o resultado seja “cara”, esse desenvolvedor terá que utilizar a nova ferramenta de desenvolvimento; caso seja “coroa”, o desenvolvedor continuará com as mesmas condições de trabalho. Tente relacionar os problemas que podem acontecer ao utilizarmos essa abordagem.
» Experimento rigorosamente controlado - Num experimento rigorosamente controlado, os indivíduos que recebem tratamento são cuidadosamente selecionados de tal forma que haja outro indivíduo em condições semelhantes no grupo que não recebe o tratamento. Com essa abordagem os efeitos individuais afetarão minimamente a avaliação. Por exemplo, em um experimento que avalia o desempenho de servidores de aplicações, todos os computadores utilizados devem ter as mesmas características, incluindo hardware, sistema operacional e carga de background.

18
Estatística Exploratória
Replicação
Além do controle dos efeitos que as variáveis podem exercer sobre os experimentos, a replicação dos experimentos é muito importante no planejamento de experimentos para verificar e/ou confirmar os efeitos da aplicação dos tratamentos em diferentes cenários. Obviamente, as amostras utilizadas na replicação do experimento devem ter sido escolhidas através de processos aleatórios e devem ser grandes o suficiente para que os efeitos da aplicação do tratamento sejam nitidamente reconhecidos. Contudo, é importante lembrar que, embora seja importante termos amostras suficientemente grandes, é mais importante que essas amostras sejam compostas por dados escolhidos de modo apropriado.
Estratégias para Seleção de Amostras
Pergunta para o leitor: E o que é afinal uma amostra aleatória? Nós já falamos algumas vezes no texto sobre amostra aleatória, você seria capaz de nos fornecer uma definição? Vamos tentar juntos e, para isso, vamos fazer uso de uma ilustração. Imagine que queremos fazer um experimento com uma moeda não viciada. Desejamos lançá-la ao ar e queremos saber qual a probabilidade de dar “cara”. Intuitivamente você dirá que as chances são de 50%. Exatamente, você está certíssimo. Vamos ver outro exemplo. Deseja-se utilizar um dado não viciado em um experimento. Queremos saber quais são as chances de aparecer o número 3 em um único lançamento. Se você disse que é 1/6, seu pensamento está correto mais uma vez. Nesse caso, qualquer número (1, 2, 3, 4, 5 e 6) tem as mesmas chances de aparecer no sorteio. Dessa forma, em uma amostra aleatória, os membros de uma população são selecionados de tal modo que cada indivíduo tenha as mesmas chances de ser selecionado.
Também há o conceito de amostra aleatória simples de tamanho n, selecionada a partir de uma população de tamanho N. O processo consiste em selecionar um indivíduo sem reposição até que seja alcançado o número pré-determinado n. Um exemplo será útil para explicarmos esse processo.
Exemplo: Você é o gerente de redes em uma grande empresa e deseja analisar as tentativas de ataques nos computadores. Ao todo, a empresa tem 300 computadores, cada um deles com a sua respectiva numeração, começando com o computador número 001. Por questões de custo, você fará as verificações de ataques em 5 amostras de tamanho n=10. Para selecionar os computadores das amostras, você pode utilizar uma urna e 300 pedaços de papel com as mesmas características, e anotar em cada pedaço de papel os números dos computadores, iniciando em 001 até 300. A partir daí, você pode sortear os 10 números para cada amostra, repetindo o procedimento 5 vezes. Como o tamanho N da população é muito maior do que o tamanho n da amostra, o processo para seleção pode ser sem reposição. O método de seleção de indivíduos também pode utilizar tabelas com números aleatórios associadas a cada elemento da população .
Além da amostragem aleatória, há outras técnicas de amostragem probabilísticas que podem ser utilizadas. Vejamos as mais comuns:
» Amostragem Aleatória Sistemática - Os itens ou indivíduos da população são ordenados. Um ponto de partida aleatório é sorteado, e então cada k-ésimo (por exemplo, 30º) membro da população é selecionado para a amostra.
» Amostragem Aleatória Estratificada - A população é inicialmente dividida em subgrupos (estratos) de tal forma que os membros do mesmo subgrupo compartilhem as mesmas características (idade, sexo, altura) e uma subamostra é selecionada a partir de cada estrato da população.
» Amostragem por Conglomerados - A população é inicialmente dividida em
Atenção
5 Exemplo de gerador de números aleatórios - www.masoft.com.br/index. php?page= download&id=1185

19
Estatística Exploratória
subgrupos (estratos) e uma amostra de estratos é selecionada (por exemplo, com probabilidade proporcional ao tamanho de cada estrato). A seguir, amostras são selecionadas dos estratos selecionados previamente.
Mesmo realizando um excelente planejamento, levando em consideração todos os cuidados que aprendemos até agora, sempre haverá algum erro nos resultados. Em outras palavras, mesmo que a amostra seja representativa da população, ainda haverá uma diferença entre o valor da estimativa da amostra e o parâmetro populacional. Essa diferença é chamada de erro amostral ou variabilidade amostral. Por outro lado, quando o processo de amostragem foi tendencioso ou o processo de seleção da amostra utiliza instrumentos não calibrados, os erros provenientes são conhecidos por erros não-amostrais.

20
Estatística Exploratória
Capítulo 2
Metas
Após o estudo deste capítulo, esperamos que você consiga:
» Analisar o comportamento dos dados através da distribuição de frequências;
» Construir gráficos e histogramas.
Assuntos
» Tipos de variáveis;
» Resumo de dados;
» Distribuições de frequências;
» Gráficos.

21
Estatística Exploratória
Capítulo 2 – Resumo de Dados e Gráficos
Vamos conversar sobre o assunto?
É um fato inquestionável – a incrível quantidade de informação gerada atualmente é muito maior do que a nossa capacidade de consumi-la. Alguns artigos6, 7 comentam que a informação que uma pessoa adquire em uma semana nos dias de hoje é equivalente a toda informação adquirida ao longo da vida de uma pessoa que vivia no século XVII.
E por falar em informação, você já ouviu o ditado popular – “quem tem a informação tem o poder”? Até pouco tempo, antes da popularização da internet, essa afirmativa era totalmente aplicável. Contudo, com a massificação dos mecanismos de busca de conteúdo na internet, qualquer pessoa pode localizar praticamente qualquer informação em alguns poucos segundos fazendo uma simples pesquisa no Google, se souber como procurar. Por isso, esse ditado nos dias atuais deveria ser reescrito – “Quem sabe garimpar a informação tem o poder”. O verbo garimpar é usado aqui de forma semelhante ao processo de extração de minério valioso entre os cascalhos de terra com minérios sem valor. Em outras palavras, a pessoa terá poder se ela souber escolher a informação realmente relevante. E essa informação “garimpada”, “limpa”, “pura” é um dos bens mais valiosos das organizações. É ela que orienta o processo de tomada de decisão, aumenta a produtividade e reduz custos e riscos.
Atualmente, existem muitos estudos com o objetivo de “descobrir” conhecimento em grandes bases de dados, como Data Mining, Information Retrieval9 e Machine Learning10. Em todas essas técnicas, a estatística tem um papel fundamental no processo de tratamento da informação. Neste capítulo, estudaremos alguns recursos da estatística para facilitar a análise de um conjunto de dados.
2.1. Distribuição de Frequências
Vamos iniciar os nossos estudos sobre tratamento de dados considerando a Tabela 1, extraída do sítio do Denatran, que apresenta o número de óbitos por acidente de trânsito nas capitais brasileiras entre os anos de 2000 e 2007. O tema da tabela foi propositalmente escolhido para servir de reflexão para todos nós. É importante salientar que a tabela contabiliza apenas os óbitos no local do acidente. Isto quer dizer que os números são ainda maiores.
Quando se deseja estudar o comportamento de um conjunto de dados (variáveis), o nosso maior interesse é conhecer como essas variáveis se comportam, e para alcançarmos esse objetivo, precisamos analisar as ocorrências das suas possíveis realizações. Algumas características dessas realizações são muito úteis para que você compreenda o comportamento dos dados:
» Medidas de centro - é um valor que representa o meio do conjunto de dados. Ex.: Em 2005, aconteceram em média 280 óbitos por acidente de trânsito nas capitais
Hiperlink
6 http://www.mettodo.com.br/pdf/O%20Excesso%20de%20Informacao.pdf
Hiperlink
7 http://www.thenewatlantis.com/publications/the-myth-of-multitasking
Hiperlink
8 http://www.intelliwise.com/reports/i2002.htm
Hiperlink
9 http://pt.wikipedia.org/wiki/Recuperação_de_informação
Hiperlink
10 http://ai.stanford.edu/~nilsson/mlbook.html

22
Estatística Exploratória
brasileiras.
» Medidas de variação - indica o quanto os valores dos dados variam entre eles. Ex.: Em oito anos do estudo, os dados apresentados na Tabela 1 mostram que o número de óbitos por acidente de trânsito na cidade de Curitiba, variou entre 358 e 432 óbitos.
» Valores discrepantes ou outliers - Valores amostrais que se localizam longe da grande maioria dos outros valores amostrais. Geralmente ocorrem por erros na alimentação dos dados, porém, em alguns casos, podem indicar algum fenômeno específico. Ex.: Na cidade de Belém, ocorreram 139 óbitos em 2004, enquanto a média ficou em 162 óbitos. Em 2006, a cidade de Curitiba apresentou 721 óbitos, enquanto a média estava próxima de 400.
» Distribuição dos dados - Representa a forma da distribuição dos dados. Características como a simetria e o volume nas extremidades da distribuição são importantes na análise dos dados. Vamos utilizar a distribuição de frequências como ferramenta para entender a distribuição dos dados.
Tabela 1. Mortes por acidentes de trânsito nas capitais
Número total de óbitos por acidentes de trânsito nas capitais - 2000 - 2007
Cidade 2000 2001 2002 2003 2004 2005 2006 2007
Aracaju 92 99 86 91 104 93 95 97
Belém 163 164 152 187 139 167 173 149
Belo Horizonte 381 417 382 393 410 400 491 451
Boa Vista 77 92 103 53 42 74 72 107
Brasília 520 488 519 587 505 527 471 555
Campo Grande 137 175 203 194 212 236 203 224
Cuiabá 125 94 153 125 129 127 137 142
Curitiba 425 372 358 371 425 432 721 427
Florianópolis 95 77 78 82 93 94 107 80
Fortaleza 329 384 485 465 444 519 405 383
Goiânia 346 309 339 400 381 341 315 330
João Pessoa 109 125 147 132 107 131 109 107
Macapá 79 86 98 84 91 76 91 79
Maceió 159 202 175 139 163 192 156 152
Manaus 253 219 235 247 261 278 328 281
Natal 62 66 82 59 85 72 62 65
Palmas 57 45 57 59 50 53 59 79
Porto Alegre 214 174 241 215 219 221 192 156
Porto Velho 122 89 117 99 113 91 104 109
Recife 245 218 243 213 227 230 207 234
Rio Branco 70 71 72 64 58 61 55 72
Rio de Janeiro 910 962 1020 924 974 930 1000 709
Salvador 103 126 114 126 103 292 290 294
São Luís 90 109 140 124 131 140 137 139
São Paulo 846 1604 1002 1465 1432 1544 1614 1651
Teresina 151 160 196 172 157 174 187 175
Vitória 64 56 56 62 59 60 51 51
23
Estatística Exploratória
A Tabela 2 apresenta a distribuição de frequência da variável número de óbitos nas capitais brasileiras no ano de 2005.
Tabela 2. Distribuição de frequências – nº de óbitos nas capitais em 2005
Nº óbitos nas capitais Frequência Proporção Porcentagem
0 – 200 15 =15/27=0,55 55%
201 – 400 7 =7/27=0,28 28%
401 – 600 3 =3/27=0,11 11%
601 – 800 0 =0 0%
801 – 1000 1 =1/27=0,037 3,7%
1001 – 1200 0 =0 0%
1201 – 1400 0 =0 0%
1401 – 1600 1 =1/27=0,037 3,7%
Total 27 1,0 100%
Observando os resultados da segunda coluna, você pode perceber que em 15 capitais aconteceram até 200 óbitos em 2005, em 3 capitais ocorreram entre 401 e 600 óbitos, em uma capital ocorreram entre 1401 e 1600 óbitos por acidentes de trânsito em 2005 e assim por diante. Tente continuar com essa análise para cada classe da Tabela 2.
Outra medida bastante útil na interpretação de tabelas de frequência é a proporção de cada realização em relação ao total de ocorrências. Por exemplo, aconteceram na cidade de São Paulo 1544 óbitos, um valor muito acima da média das cidades. Contudo, em termos proporcionais, podemos observar que isso representa 3,7% do total de óbitos nas capitais do país naquele ano.
As proporções também são úteis para comparar resultados de pesquisas com valores de frequências muito diferentes entre si. Por exemplo, segundo o Instituto de Pesquisa e Cultura Luiz Flávio Gomes11, no ano de 1996, o número de mortes no trânsito no Brasil foi de 35.281, e em 2008 foram 36.666 vítimas fatais. Em números absolutos o aumento foi de 1385 mortes, ou 3,92%. Porém, considerando o número de habitantes no Brasil em 1996 (156 milhões) e em 2008 (183 milhões), em termos proporcionais (óbitos/habitante) houve uma sensível redução do número de mortes por habitantes (veja Tabela 3). O mérito dessa redução é dado à promulgação do Código de Trânsito Brasileiro em 1998 e à famosa “lei seca” de 2008. Infelizmente, a eficiência dessas leis foi reduzida assim que a fiscalização diminuiu e os números voltaram aos patamares de 37 mil mortes por ano.
Tabela 3. Variação percentual do número de óbitos por habitantes ocorridos no Brasil entre os anos de 1996 e 2008.
Ano Nº de óbitos População Proporção de óbtos por habitante
1996 35.281 156 milhões 1 óbito para 4422 hab
2008 36.666 183 milhões 1 óbito para 4990 hab
Esse grande número de mortes no trânsito coloca o Brasil em 5º lugar no ranking mundial de acordo com as estatísticas da OMS – Organização Mundial de Saúde12. Os dados
Hiperlink
11 http://www.ipcluizflaviogomes.com.br
Hiperlink
12 OMS: http://www.who.int/en/

24
Estatística Exploratória
são de 2007 e os primeiros colocados são a Índia com 105,7 mil mortes por ano, a China 96,6 mil, os EUA 42,6 mil, a Rússia 35,9 e o Brasil com 35,1 mil mortes.
2.2. Regras Gerais para elaborar uma Distribuição de Frequência
Antes de começarmos a estudar as diferentes possibilidades de representação gráfica dos dados, vamos voltar à Tabela 2 para entender como ela foi construída. Os passos a seguir facilitarão o entendimento:
Definição do número de classes – a escolha do número de classes é arbitrária e depende muito da familiaridade do pesquisador com os dados. Contudo, lembre-se de que com um número pequeno de classes, perde-se informação, e com um número grande de classes, o objetivo de resumir dados fica prejudicado. O mais comum é que o número de classes deva estar entre 5 e 20. No caso da Tabela 2, os dados foram agrupados em 8 classes.
» O cálculo da amplitude da classe pode ser feito através da fórmula abaixo:
Amplitude da classe =
Arredonde o valor para obter um número mais conveniente. Para o caso da Tabela 2, por simplicidade, escolhemos 8 classes com amplitude igual a 200. Outra boa sugestão seria definirmos 10 classes, com amplitude 160, começando a partir de 40 até 1640.
» Cálculo dos limites da classe – adicione a amplitude da classe ao limite inferior da primeira classe para obter o limite inferior da segunda classe. Siga este procedimento até a última classe.
» Preenchimento da tabela – percorra o conjunto de dados incrementando o valor da classe apropriada para cada valor de dado.
» Ponto médio de uma classe – é o ponto médio do intervalo da classe e é obtido somando-se o limite inferior ao superior e dividindo-se a soma por 2. Dessa forma, o ponto médio da primeira classe (0-200) da Tabela 2 é 100; da segunda classe (200-400) é 300, e assim por diante.
2.3. Histograma e Polígonos de Frequência
O agrupamento dos dados em tabelas de frequência e frequência relativa (Tabela 2) é uma maneira bastante eficiente para analisar um conjunto de dados. Esses agrupamentos também podem ser representados graficamente através dos histogramas e polígonos de frequência.
Um histograma ou histograma de frequência consiste em um conjunto de retângulos que representam as classes cujas bases são iguais às suas amplitudes e são centradas no ponto médio de cada classe. As áreas de cada retângulo são proporcionais às frequências das classes e o número de classes deve variar entre 5 e 20 classes.
Um polígono de frequência é um gráfico de linha passando pelos pontos médios dos topos dos retângulos de um histograma. Para uma visualização mais ampla do polígono de frequências, costuma-se prolongar a linha até o eixo das abscissas, considerando classes com frequência zero. A Figura 3 apresenta um histograma e um gráfico de polígonos de frequências referentes aos dados da Tabela 2.

25
Estatística Exploratória
Figura 3 – Histogramas gerados a partir dos dados da Tabela 2.
O formato da curva do gráfico de polígonos de frequência dá uma boa ideia da distribuição dos dados em termos de assimetria. Veja outras formas de curvas de frequência na Figura 5.
As frequências relativas calculadas na Tabela 2 também podem ser utilizadas para a construção do histograma. Na verdade, os gráficos são exatamente os mesmos, basta para isso modificar os valores absolutos pelos valores relativos no eixo das ordenadas.

26
Estatística Exploratória
2.4. Distribuições de Frequência Acumulada
A soma das frequências totais de todos os valores inferiores ao limite superior de uma dada classe é denominada frequência acumulada até e inclusive aquele intervalo de classe.
Tudo bem, eu também concordo. Essa definição está um pouco complicada. Vamos tentar entendê-la através de um exemplo. Observe na Tabela 2 que a frequência acumulada até, e inclusive, o intervalo de classe 801-1000 da Tabela 2 é 15 + 7 + 3 + 0 + 1 = 26, o que significa que das 27 capitais estudadas, em 26 delas ocorreram até 1000 fatalidades no trânsito. Ficou um pouco mais claro?
A Tabela 4 apresenta as frequências acumuladas por classe e, por isso, é chamada de tabela de frequência acumulada.
Tabela 4. Tabela de frequência acumulada
Nº óbitos nas capitais Frequência acumulada Frequência relativa acumulada
Abaixo de 200 15 0,55
Abaixo de 400 22 0,83
Abaixo de 600 25 0,94
Abaixo de 800 25 0,94
Abaixo de 1000 26 0,975
Abaixo de 1200 26 0,975
Abaixo de 1400 26 0,975
Abaixo de 1600 27 1,0
Da mesma forma, o gráfico da Figura 5 apresenta a frequência acumulada abaixo de qualquer limite superior de classe, plotada em relação a esse limite. Esse tipo de gráfico é chamado de polígono de frequência acumulada ou ogiva.

27
Estatística Exploratória
Figura 4 – Gráfico de frequência acumulada e frequência relativa acumulada.
A terceira coluna da Tabela 4 também apresenta a frequência relativa acumulada ou frequência percentual acumulada. Esse cálculo é realizado dividindo-se a frequência acumulada pela frequência total.
Uma característica importante a ser observada nos gráficos da Figura 3 é que a amplitude escolhida para as classes foi razoavelmente grande. Contudo, em muitos casos é possível escolhermos intervalos de classe relativamente pequenos e, além disso, obtermos amostras da população suficientemente grandes de tal forma que o “serrilhado” do polígono

28
Estatística Exploratória
de frequência fique muito semelhante a uma linha contínua.
Como já foi comentado, essas curvas de frequência são muito úteis para a compreensão do comportamento dos dados. A Figura 5 apresenta os tipos de curvas de frequência mais comuns. Os três primeiros gráficos representam curvas com assimetria à esquerda, curvas simétricas e curvas assimétricas à direita, respectivamente.

29
Estatística Exploratória

30
Estatística Exploratória
Figura 5 – Tipos de curvas de frequência.
Os outros gráficos da figura 5 representam curvas semelhantes a um “J”, curvas semelhantes a um “J” invertido e uma curva com distribuição dos dados uniforme.
De todas as curvas de distribuições apresentadas, sem dúvida alguma, a distribuição chamada de normal é a mais importante. Suas características marcantes são o formato de “sino” e a simetria em torno do valor com maior frequência. Em outras palavras, as frequências começam baixas, crescem até uma frequência máxima e depois decrescem para uma frequência baixa. Identifique a distribuição normal entre os gráficos da Figura 5.

31
Estatística Exploratória
Exemplo prático: Faça uma pesquisa entre os alunos (homens e mulheres separadamente) da sua turma, perguntando qual é a altura de cada um deles. Anote todos os valores, construa uma tabela com a distribuição das frequências e faça um histograma. Construa também um gráfico de polígono de frequências e observe se há alguma semelhança com a forma de um sino. Repita o mesmo procedimento para outras variáveis, como peso, notas dos alunos da disciplina banco de dados etc.
2.5. Gráficos Estatísticos
Nesta seção vamos estudar um pouco mais sobre os gráficos, você já foi apresentado a alguns deles? Lembra dos histogramas? Aquele gráfico de barras, comumente utilizado na análise estatística para entendermos o comportamento das frequências de ocorrência de um determinado fenômeno ou grandeza. E dos polígonos de frequência, você também lembra? Aquela ligação dos pontos médios dos topos das classes. A partir de agora, vamos aprender a construir outros tipos de gráficos e entender como as variáveis podem ser exploradas através deles.
Os gráficos são encontrados em todos os lugares, jornais, telejornais, livros, revistas, sítios diversos etc. Sua utilização traz vantagens como a capacidade de síntese de informações e a possibilidade de revelar características importantes das variáveis em estudo. Nessa seção vamos aprender a construir vários tipos de gráficos, dentre eles, o gráfico de pontos, o diagrama de ramo e folhas, o gráfico de Pareto, o gráfico de setores (pizza), o gráfico de barras, o diagrama de dispersão e o gráfico de séries temporais.
Existe atualmente um conjunto amplo de ferramentas computacionais para a análise estatística e construção de gráficos, muitas delas são pagas e bastante caras (ex.: Minitab, Spss, Excel etc.). No entanto, o meio acadêmico e muitas empresas estão migrando para ferramentas baseadas nas licenças de software livre. Quando esse tipo de software, além de gratuito, é estável e robusto, a decisão é quase unânime. É o caso do software utilizado em todo o contexto do livro – o R. Isso mesmo, o nome do aplicativo é apenas R e pode ser encontrado para download para sistemas Windows, Linux e Mac em http://cran.r-project.org/. Além disso, o código fonte do R está disponível para modificações, permitindo ainda a criação e integração de pacotes estatísticos desenvolvidos por qualquer usuário. Os gráficos gerados também são gerados com o R.
2.5.1. Gráfico de Pontos
O gráfico de pontos é um gráfico no qual cada valor é plotado como um ponto ao longo de uma escala de valores. Os pontos que representam valores iguais são empilhados. O gráfico de pontos da Figura 6 representa a distribuição das idades das deputadas federais eleitas para o mandato que começa a partir de 2011. Os dados foram extraídos do sítio da câmara dos deputados13. Esse tipo de gráfico é bastante útil, pois identifica a frequência a partir da contagem dos pontos. Por exemplo, na composição da câmara dos deputados com mandato no período entre 2011 - 2014, há 4 deputadas com 29 anos em 1º de janeiro de 2011.
Hiperlink
13 http://www2.camara.gov.br/deputados/pesquisa/arquivos/arquivo-formato-excel-com-informacoes-dos-deputados-1

32
Estatística Exploratória
Figura 6 – Gráfico de pontos referente às idades das deputadas federais eleitas em 2010 .
2.5.2. Diagrama de Ramo e Folhas
O diagrama de ramo e folhas é muito útil para obter uma apresentação visual informativa de um conjunto de dados. Neste tipo de gráfico, cada informação deve ter no mínimo dois dígitos. Para construir esse diagrama, dividimos cada número em duas partes; um ramo, consistindo em um ou mais dígitos iniciais, e uma folha, consistindo nos dígitos restantes. A figura 7 ilustra um gráfico de ramo e folhas para as mesmas idades das deputadas federais eleitas para o mandato que inicia a partir de 2011. As idades estão em ordem crescente e são 29, 29, 29, 29, 34, 36, 36, ...., 76. É fácil observar como o primeiro valor de 29 se separa em seu ramo, 2, e sua folha, 9. As folhas são sempre arranjadas em ordem crescente e não na ordem em que aparecem nas tabelas de dados.
2 9999
3 4
3 667777789
4 44
4 6899999
5 114444
5 777
6 1111
6 666666
7
7 66
Figura 6 – Diagrama de ramo e folhas para as idades das deputadas eleitas em 2010.
Virando-se a página de lado, 90º graus no sentido anti-horário, podemos ver a distribuição desses dados e ainda reconstruir todas as informações da tabela que originou o diagrama. Esse diagrama também é útil para a ordenação dos dados e para encontrar algumas de suas características como os quartis, percentis e mediana. Esses conceitos estatísticos serão abordados mais à frente.
Certamente você deve ter percebido a semelhança entre o diagrama de ramo e folhas e as barras de um histograma. Quando você aprendeu como construir histogramas, viu que uma das orientações para a construção de um histograma é que o número de classes deve ficar entre 5 e 20. Pode-se aplicar a mesma orientação para a construção de um diagrama de ramo e folhas. Além disso, um diagrama de ramo e folhas pode ser expandido ou condensado, podendo ter mais ou menos folhas.

33
Estatística Exploratória
2.5.3. Gráfico de Pareto
Para aprendermos a construir o gráfico de Pareto, vamos utilizar a Tabela 5. Essa tabela de dados apresenta o cenário partidário na câmara dos deputados a partir da eleição de 2010. Cada linha da tabela apresenta a frequência e a frequência relativa por partido.
Tabela 5. Deputados federais eleitos em 2010 agrupados por partido.
Partido Frequência Frequência relativa
DEM 57 0,11
PcdoB 12 0,02
PDT 23 0,04
PMDB 90 0,18
PMN 3 0,01
PP 38 0,07
PPS 14 0,03
PR 45 0,09
PRB 8 0,02
PSB 26 0,05
PSC 17 0,03
PSDB 56 0,11
PT 81 0,16
PSOL 3 0,01
PTB 22 0,04
PTC 2 0,00
Ptdo B 1 0,00
PV 14 0,03
TOTAL 512 1,00
Os dados foram extraídos do sítio da câmara dos deputados - http://www2.camara.gov.br/deputados/pesquisa.
Um gráfico de Pareto é um gráfico de barras para dados qualitativos, com as barras dispostas em ordem pela frequência. As escalas verticais nos gráficos de Pareto podem representar frequências ou frequências relativas. A barra mais alta fica à esquerda e as barras menores se afastam para a direita. O gráfico de Pareto é útil para destacar as categorias mais importantes. A Figura 7 ilustra a composição da câmara dos deputados a partir da eleição de 2010. Pode-se perceber claramente que os cinco partidos com maior representação na câmara dos deputados são aqueles que ocupam posições mais à esquerda no gráfico de pareto, e são PMDB, PT, DEM, PSDB e PR, respectivamente. Propositalmente os valores da escala vertical da Figura 7 foram omitidos. Experimente inserir esses valores a partir das frequências e usando as frequências relativas apresentadas na Tabela 5.

34
Estatística Exploratória
Figura 7 – Gráfico de Pareto apresentando a composição da câmara dos deputados a partir da eleição de 2010 agrupados por partido.
2.5.4. Diagrama de Barras
O gráfico de barras é muito semelhante ao gráfico de Pareto, exceto por não ser necessária seguir nenhuma ordem na distribuição dos retângulos do gráfico. Podem-se utilizar os valores para cada classe diretamente sobre os retângulos que representam as classes. A Figura 8 apresenta os dados da Tabela 5 através de um gráfico de barras.
Figura 7 – Gráfico de barras com a composição da câmara dos deputados por partido.
2.5.5. Gráfico de Setores - Pizza
O gráfico de setores ou pizza também é usado para apresentar dados qualitativos. No exemplo da Figura 9, foram utilizados os mesmos dados da Tabela 5 para elaborar um gráfico de setores. Observe que a construção de um gráfico de setores envolve a divisão de um círculo nas proporções das frequências das variáveis. Cada ocorrência assemelha-se a

35
Estatística Exploratória
uma fatia de pizza, daí o nome dado a esse tipo de gráfico.
Figura 9 – Gráfico de Setores descrevendo o número de deputados agrupados por partido – eleições/2010.
2.5.6. Gráfico de Dispersão
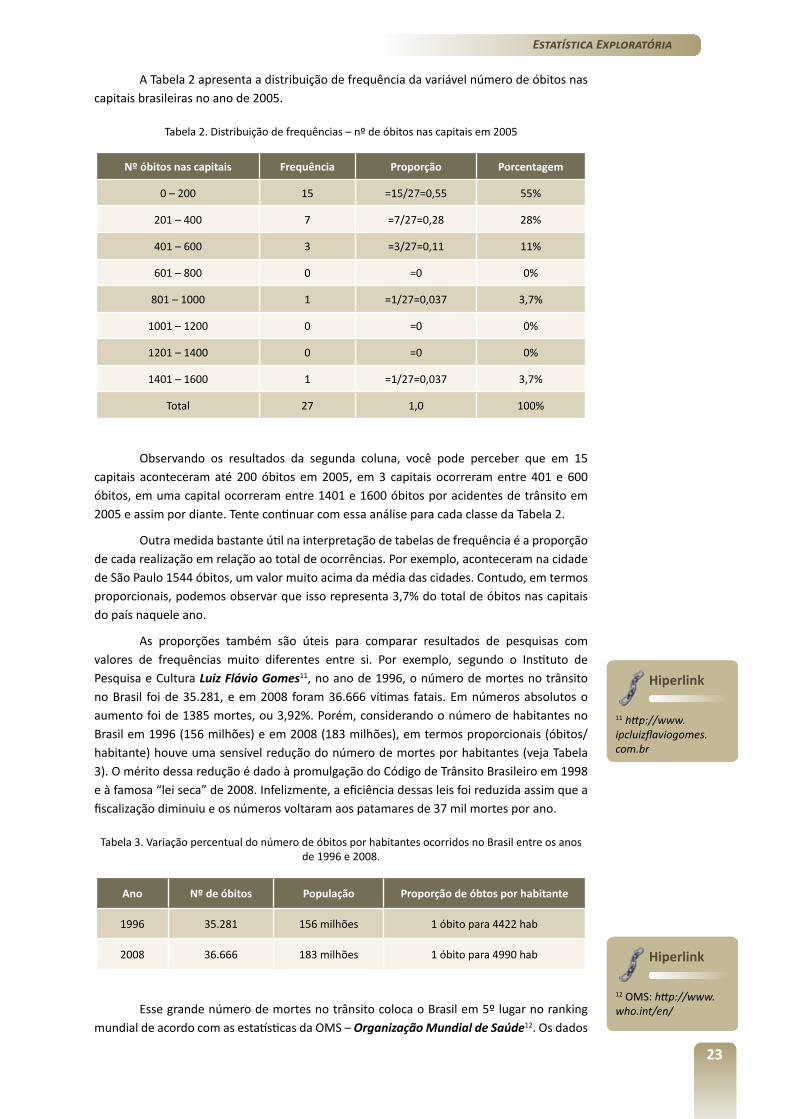
O diagrama de dispersão de dados emparelhados é um gráfico onde os pontos no espaço cartesiano XY são usados para representar simultaneamente os valores de duas variáveis quantitativas medidas em cada elemento do conjunto de dados. O diagrama de dispersão é usado principalmente para visualizar a relação/associação entre duas variáveis.
Para aprendermos a construir e analisar o gráfico de dispersão utilizaremos um conjunto de dados relativos ao gêiser Old Faithful14, que está localizado no Parque Nacional de Yellowstone, em Wyoming, nos Estados Unidos. Esse gêiser não é o mais alto desse parque, mas certamente suas erupções são as mais previsíveis. As erupções podem fazer jorrar entre 14.000 e 32.000 litros de água fervendo a uma altura entre 30 e 55 metros, com duração entre 1,5 a 5 minutos. A altura média das suas erupções é de 44 metros. A Tabela 6 apresenta um conjunto com 240 medidas relacionando o tempo de duração da erupção com o respectivo período de espera para a próxima erupção, ambos medidos em minutos.
Hiperlink
14 http://www.iis.uni-stuttgart.de/lehre/ws09-10/StatisticalDataMining/oldfaith.tab

36
Estatística Exploratória
Tabela 6. Duração das erupções e período de espera (em mintutos) do gêiser Old Faithful.
1 3,6 79 41 4,35 80 81 4,13 75 121 2,61 53 161 2,2 45 201 2,1 60
2 1,8 54 42 1,88 58 82 4,33 82 122 4,06 69 162 4,15 86 202 4,35 82
3 3,33 74 43 4,56 84 83 4,1 70 123 4,25 77 163 2 58 203 4,13 91
4 2,28 62 44 1,75 58 84 2,63 65 124 1,96 56 164 3,83 78 204 1,86 53
5 4,53 85 45 4,53 73 85 4,06 73 125 4,6 88 165 3,5 66 205 4,6 78
6 2,88 55 46 3,31 83 86 4,93 88 126 3,76 81 166 4,58 76 206 1,78 46
7 4,7 88 47 3,83 64 87 3,95 76 127 1,91 45 167 2,36 63 207 4,36 77
8 3,6 85 48 2,1 53 88 4,51 80 128 4,5 82 168 5 88 208 3,85 84
9 1,95 51 49 4,63 82 89 2,16 48 129 2,26 55 169 1,93 52 209 1,93 49
10 4,35 85 50 2 59 90 4 86 130 4,65 90 170 4,61 93 210 4,5 83
11 1,83 54 51 4,8 75 91 2,2 60 131 1,86 45 171 1,91 49 211 2,38 71
12 3,91 4,71 52 4,71 90 92 4,33 90 132 4,16 83 172 2,08 57 212 4,7 80
13 4,2 78 53 1,83 54 93 1,86 50 133 2,8 56 173 4,58 77 213 1,86 49
14 1,75 47 54 4,83 80 94 4,81 78 134 4,33 89 174 3,33 68 214 3,83 75
15 4,7 83 55 1,73 54 95 1,83 63 135 1,83 46 175 4,16 81 215 3,41 64
16 2,16 52 56 4,88 83 96 4,3 72 136 4,38 82 176 4,33 81 216 4,23 76
17 1,75 62 57 3,71 71 97 4,66 84 137 1,88 51 177 4,5 73 217 2,4 53
18 4,8 84 58 1,66 64 98 3,75 75 138 4,93 86 178 2,41 50 218 4,8 94
19 1,6 52 59 4,56 77 99 1,86 51 139 2,03 53 179 4 85 219 2 55
20 4,25 79 60 4,31 81 100 4,9 82 140 3,73 79 180 4,16 74 220 4,15 76
21 1,8 51 61 2,23 59 101 2,48 62 141 4,23 81 181 1,88 55 221 1,867 50
22 1,75 47 62 4,5 84 102 4,36 88 142 2,23 60 182 4,583 77 222 4,267 82
23 3,45 78 63 1,75 48 103 2,1 49 143 4,53 82 183 4,25 83 223 1,75 54
24 3,06 69 64 4,8 82 104 4,5 83 144 4,81 77 184 3,767 83 224 4,483 75
25 4,53 74 65 1,81 60 105 4,05 81 145 4,33 76 185 2,033 51 225 4 78
26 3,6 83 66 4,4 92 106 1,86 47 146 1,98 59 186 4,433 78 226 4,117 79
27 1,96 55 67 4,16 78 107 4,7 84 147 4,63 80 187 4,083 84 227 4,083 78
28 4,08 76 68 4,7 78 108 1,78 52 148 2,01 49 188 1,833 46 228 4,067 78
29 3,85 78 69 2,06 65 109 4,85 86 149 5,1 96 189 4,417 83 229 3,267 70
30 4,43 79 70 4,7 73 110 3,68 81 150 1,8 53 190 2,183 55 230 3,917 79
31 4,3 73 71 4,03 82 111 4,73 75 151 5,03 77 191 4,8 81 231 4,55 70
32 4,46 77 72 1,96 56 112 2,3 59 152 4 77 192 1,833 57 232 2,417 54
33 3,36 66 73 4,5 79 113 4,9 89 153 2,4 65 193 4,8 76 233 4,183 86
34 4,03 80 74 4 71 114 4,41 79 154 4,6 81 194 4,1 84 234 2,217 50
35 3,83 74 75 1,98 62 115 1,7 59 155 3,56 71 195 3,966 77 235 4,45 90
36 2,01 52 76 5,06 76 116 4,63 81 156 4 70 196 4,233 81 236 1,883 54
37 1,86 48 77 2,01 60 117 2,31 50 157 4,5 81 197 3,5 87 237 1,85 54
38 4,83 80 78 4,56 78 118 4,6 85 158 4,08 93 198 4,366 77 238 4,283 77
39 1,83 59 79 3,88 76 119 1,81 59 159 1,8 53 199 2,25 51 239 3,95 79
40 4,78 90 80 3,6 83 120 4,41 87 160 3,96 89 200 4,667 78 240 2,333 64
A Figura 10 apresenta um diagrama de dispersão relativo às observações das erupções do gêiser Old Faithful. Note que existe uma correlação entre medida de tempo de erupção do gêiser com o tempo de espera para a próxima erupção. Enfatizamos com uma linha a orientação dessa correlação.
37
Estatística Exploratória
Figura 10 – Diagrama de dispersão das erupções e tempos de espera de erupções relacionadas com o gêiser Old Faithful.
2.5.7. Gráfico de Séries Temporais
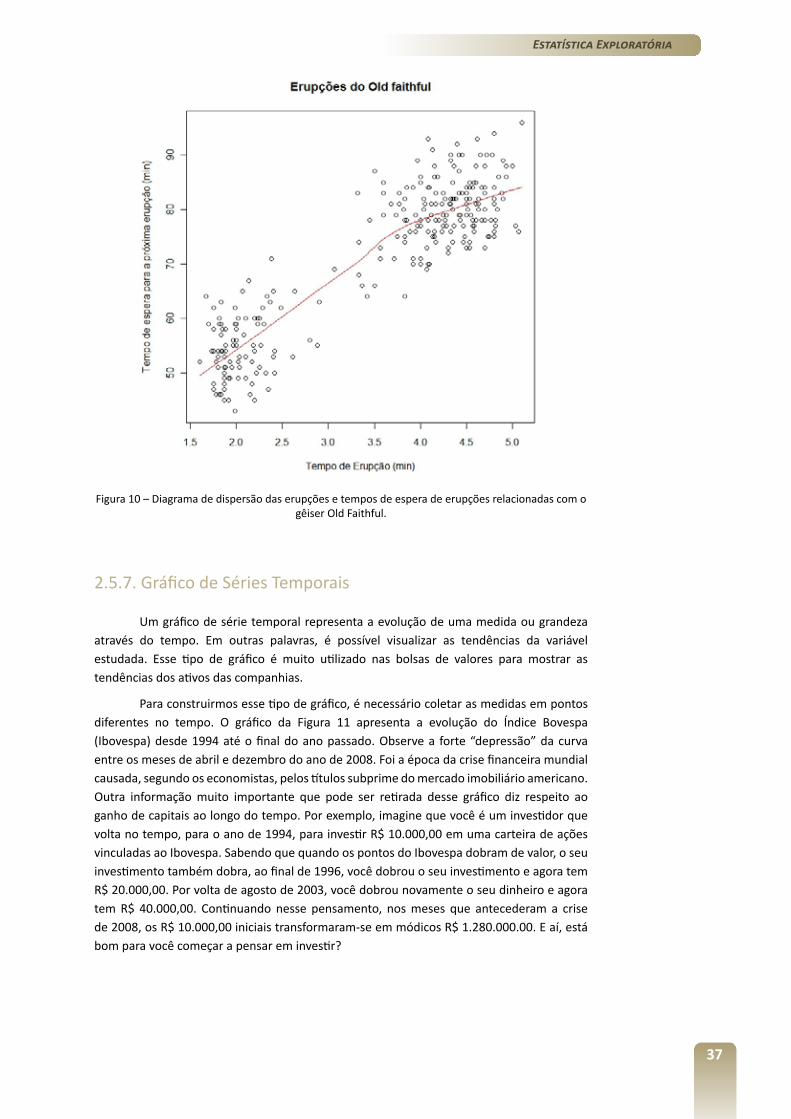
Um gráfico de série temporal representa a evolução de uma medida ou grandeza através do tempo. Em outras palavras, é possível visualizar as tendências da variável estudada. Esse tipo de gráfico é muito utilizado nas bolsas de valores para mostrar as tendências dos ativos das companhias.
Para construirmos esse tipo de gráfico, é necessário coletar as medidas em pontos diferentes no tempo. O gráfico da Figura 11 apresenta a evolução do Índice Bovespa (Ibovespa) desde 1994 até o final do ano passado. Observe a forte “depressão” da curva entre os meses de abril e dezembro do ano de 2008. Foi a época da crise financeira mundial causada, segundo os economistas, pelos títulos subprime do mercado imobiliário americano. Outra informação muito importante que pode ser retirada desse gráfico diz respeito ao ganho de capitais ao longo do tempo. Por exemplo, imagine que você é um investidor que volta no tempo, para o ano de 1994, para investir R$ 10.000,00 em uma carteira de ações vinculadas ao Ibovespa. Sabendo que quando os pontos do Ibovespa dobram de valor, o seu investimento também dobra, ao final de 1996, você dobrou o seu investimento e agora tem R$ 20.000,00. Por volta de agosto de 2003, você dobrou novamente o seu dinheiro e agora tem R$ 40.000,00. Continuando nesse pensamento, nos meses que antecederam a crise de 2008, os R$ 10.000,00 iniciais transformaram-se em módicos R$ 1.280.000.00. E aí, está bom para você começar a pensar em investir?

38
Estatística Exploratória
Figura 11 – Diagrama de série temporal apresentando o índice Ibovespa a partir de 1994.
Mas cuidado, o lucro do passado não significa lucro no futuro. Apenas a poupança tem correção garantida pelo governo – 0,5% ao mês mais a variação da TR(taxa referencial).
Você pode estudar mais sobre a crise econômica e os seus efeitos no mercado brasileiro de ações visitando o sítio da Bovespa - http://www.bmfbovespa.com.br.

39
Estatística Exploratória
Capítulo 3 – Medidas Resumo
Vamos conversar sobre o assunto?
No Capítulo 2, aprendemos como construir gráficos e a partir deles, extrair as informações e características importantes de um conjunto de dados. Este capítulo também é importante porque aprenderemos a explorar e quantificar algumas dessas características dos dados, como medidas de posição e dispersão.
A utilização de gráficos e tabelas de frequências para resumir conjuntos de dados é uma maneira eficiente para extrair informações sobre o comportamento de uma variável, muito mais até do que a própria tabela original. Porém, em alguns casos é necessário resumir ainda mais estes dados através de valores ou medidas que sejam representativas de todo o conjunto de dados. Essas medidas são extraídas a partir do próprio conjunto de dados e podem ser classificadas em:
» Medidas de posição → média, mediana, moda e outras medidas de tendência central;
» Medidas de dispersão → amplitude, desvio padrão e variância;
» Medidas de posição relativa → escores z, quartis e percentis;
» Medidas relacionadas à forma → medidas de assimetria e curtose.
Encontrar os valores dessas medidas envolverá um conjunto de fórmulas e cálculos e a manipulação direta dos dados. Porém, é essencial que você tenha em mente que o mais importante nesta disciplina é o entendimento dos conceitos, sua interpretação e aplicação, mas que obviamente você deverá realizar/acompanhar algum cálculo para que esses conceitos sejam alcançados e fixados na sua memória.
Atualmente existem muitas ferramentas computacionais para cálculo estatístico e isso permite que a nossa atenção seja dedicada muito mais aos conceitos do que às contas.
Os métodos do Capítulo 2 e deste capítulo são, em geral, chamados de métodos de estatística descritiva, porque o objetivo é descrever as características importantes de um conjunto de dados.
3.1. Medidas de Posição
Antes de começarmos a trabalhar com as definições e fórmulas para cálculo das medidas de posição, vamos aprender um pouco sobre a notação matemática que será utilizada daqui para a frente.
Se você encontrar o símbolo Xj (leia-se “X índice j”) deve entender que ele representa qualquer um dos N valores, X1, X2, X3, X4,...XN, assumidos pela variável X. A letra j, em Xj, que pode representar qualquer dos números 1, 2, 3, ..., N, é denominada índice.
Notação de somatório → o Símbolo é usado para representar a soma de

40
Estatística Exploratória
todos os Xj desde j = 1 até j = N , isto é, por definição
= X1 + X2 + X3 + ... + XN
Quando não há possibilidade de confusão indica-se, frequentemente, o somatório,
de modo mais simples, por , ou O símbolo , é a letra grega Sigma.
Exemplo 1: Yj = X1 Y1 + X2 Y2 + X3 Y3 + ... + XN XN
Exemplo 2: aXj = aX1 + aX2 + aX3 + ... + aXN = (X1 + X2 + X3 + ... + XN) = a
a é uma constante.
Notação de produtório → o Símbolo é usado para representar o produto de
todos os Xj desde j = 1 até j= N, isto é, por definição
= X1 × X2 × X3 × ... × XN
Quando não há possibilidade de confusão indica-se, frequentemente, o somatório,
de modo mais simples, por X, Xj ou O símbolo , é a letra grega Pi.
3.1.1. Moda
A moda é definida como a realização mais frequente do conjunto de valores observados. Como exemplo, suponha que você entrevistou 25 professores do seu curso, casados, com relação ao número de filhos que eles têm. A pesquisa verificou que, ao todo, os casais têm 47 filhos. O resultado da pesquisa com a distribuição dos filhos entre os casais está resumido nas Tabelas 7 e 8.
Tabela 7. Dados dos professores da UAB-UFRPE segundo o número de filhos.
Casal Nº de filhos Casal Nº de filhos Casal Nº de filhos
1 2 10 3 19 1
2 4 11 2 20 4
3 0 12 1 21 0
4 1 13 5 22 2
5 3 14 1 23 3
6 2 15 0 24 2
7 1 16 2 25 1
8 0 17 3
9 3 18 1
Qual é a realização da variável “número de filhos” com maior frequência? Isso mesmo, a pesquisa mostrou que sete professores têm apenas um filho e essa é a moda da variável “número de filhos”.

41
Estatística Exploratória
moda(“nº de filhos”) = 1
Tabela 8. Frequência e porcentagens dos professores da UAB-UFRPE segundo o número de filhos.
Nº de filhos Frequência Frequência relativa
0 4 0,16
1 7 0,28
2 6 0,24
3 5 0,20
4 2 0,08
5 1 0,04
Total 25 1
Em certos casos pode haver mais de uma moda no conjunto de dados, e nesses casos, a distribuição dos valores é chamada de bimodal, trimodal etc. Quando nenhum valor se repete, dizemos que não há moda.
Particularmente, recorri ao conceito de moda relativa ao vestuário para fixar esse conceito na época de estudante. “Quando uma pessoa começa a usar uma determinada peça de vestuário porque está na moda, significa que muita gente está usando aquela peça, ou seja, a frequência de uso da peça é relativamente alta - a moda”.
3.1.2. Média
A média é uma das medidas de tendência central mais usadas e também a mais importante de todas as medidas numéricas usadas para descrever conjuntos de dados. Existem vários tipos de médias, no contexto deste livro, vamos estudar a média aritmética e a média ponderada:
Média aritmética → A média aritmética de um conjunto de dados é encontrada pela adição dos valores e divisão do total pelo número de valores. A média aritmética será usada em todo o contexto deste livro e será representada por uma barra sobre o nome da variável (no exemplo abaixo, pronuncia-se “x barra”). A partir deste momento vamos utilizar n minúsculo para denotar o tamanho da amostra ou tamanho amostral e vamos utilizar N maiúsculo para denotar o tamanho da população. Quando estivermos calculando a média populacional, então representaremos a média pela letra grega minúscula “mi” - µ. O cálculo da média aritmética é dado por:
Exemplo: Use os dados da Tabela 7 para calcular a média de filhos por casal.
Os casais entrevistados têm em média 1,88 filhos.
Média aritmética ponderada → Na média aritmética ponderada os componentes (ou conjunto de componentes) são tratados de modo diferente de acordo com a sua importância no cálculo da média. Para identificar esse grau de importância, atribui-se um

42
Estatística Exploratória
fator de ponderação ou peso para cada um dos componentes. O cálculo da média aritmética ponderada é dado por:
Onde wn é o peso relacionado com cada componente xn.
Exemplo: A coordenação do curso tecnológico em contabilidade da Faculdade de Ciências Contábeis - FACIC considera que os quatro bimestres da composição curricular têm diferentes graus de importância, aos quais atribui os respectivos pesos; w1=1, w2=2, w3=3, w4=4. Suponha que um aluno tenha tirado nos quatro bimestres de uma determinada disciplina as respectivas notas; x1=9, x2=6, x3=7, x4=6. Se a média para aprovação deve ser maior ou igual a 7,0, determine se esse aluno passou.
O aluno não passou na disciplina, sua nota foi inferior a 7,0. Como exercício, calcule a média aritmética desse aluno e analise o resultado.
3.1.3. Mediana
Você percebeu com o cálculo da média ponderada que, apesar de o aluno ter tirado um 9,0 no primeiro bimestre, ele não passou. Se a média da FACIC não considerasse o peso dado aos bimestres, a média do aluno seria 7,0 e ele passaria. A média também é muito sensível a qualquer valor discrepante (anormal), isto é, a presença de um único valor discrepante desloca a média na direção desse número. A mediana pode ser considerada como um “valor do meio”, no sentido de que cerca de metade dos valores no conjunto de dados está abaixo da mediana e metade está acima dela. A mediana também pode ser assim definida:
Mediana → A mediana de um conjunto de valores, organizados em ordem de grandeza, é o valor central ou a média aritmética dos dois valores centrais.
Exemplo 1: Considere os dados da Tabela 7 referente ao número de filhos dos casais entrevistados e determine a mediana dos valores.
O primeiro passo é separar o conjunto de valores:
Valores = {2,4,0,1,3,2,1,0,3,3,2,1,5,1,0,2,3,1,1,4,0,2,3,2,1}
O segundo passo é ordenar os valores em:
Valores = {0,0,0,0,1,1,1,1,1,1,1,2,2,2,2,2,2,3,3,3,3,3,4,4,5}
O número de elementos é impar (25), então a mediana é o valor que separa doze elementos à esquerda e doze elementos à direita dele, para esse exemplo a mediana é o valor 2.
Exemplo 2: Encontre a mediana do conjunto de valores a seguir.
Valores = {2,6,7,3,5,8,9,3,9,7}
Vamos ordenar o conjunto de valores:
Valores = {2,3,3,5,6,7,7,8,9,9}
O número de elementos é par (10), então o valor da mediana será encontrado pelo cálculo da média dos dois valores do meio do conjunto ordenado, para esse exemplo a mediana é vale:

43
Estatística Exploratória
É muito importante salientar que, geometricamente, a mediana é o valor da abcissa correspondente à uma reta vertical que divide o histograma em duas partes de áreas iguais. Muitas vezes a mediana recebe um til (~) sobre o nome da variável.
3.1.4. Ponto Médio
O ponto médio é a medida de centro que reprenta o valor central entre o menor e o maior valor de um conjunto de dados. Seu valor pode ser encontrado com a fórmula a seguir:
Não confunda o valor do ponto médio com o valor da mediana. Perceba que o ponto médio utiliza apenas os limites da amplitude do conjunto, e por isso mesmo, seu valor é muito sensível a esses extremos.
Exemplo: Encontre o ponto médio e a mediana do conjunto de valores a seguir.
Valores = {2,58,45,12,36,57,69,14,25,42}
O primeiro passo é ordenar os valores:
Valores = {2,12,14, 25, 36, 42, 45, 57, 58, 69}
Cálculo da Mediana → o conjunto possui 10 elementos e, por isso, a média é calculada a partir da média dos dois valores centrais do conjunto:
Cálculo do ponto médio → o limite inferior é 2 e o limite superior é 69. O ponto médio pode ser calculado, da seguinte forma:
3.2. Assimetria
As medidas de centro que estudamos na Seção 3.1, (média, moda, mediana e ponto médio) quando comparadas entre si, podem fornecer detalhes sobre a assimetria das distribuições de frequência. A Figura 12 apresenta três diferentes tipos de distribuições de frequências (suavização de histogramas) quanto à simetria.

44
Estatística Exploratória
Figura 12 – Curva de frequência assimétrica à esquerda (a). Curva de frequência assimétrica à direita(b). Curva de frequência simétrica(c).
Já comentamos anteriormente que uma distribuição é chamada de simétrica se a metade esquerda (cujo centro coincide com a média, mediana e moda) de seu histograma é praticamente uma imagem espelhada de sua metade direita.
Diz-se que a distribuição é assimétrica à esquerda ou negativamente assimétrica quando a média e a mediana estão à esquerda da moda e quando a cauda à esquerda é mais longa do que a cauda à direita (Figura 12(a)). Da mesma forma, diz-se que a distribuição é assimétrica à direita ou positivamente assimétrica quando a média e a mediana estão à direita da moda e quando a cauda à direita é mais longa do que a cauda à esquerda (Figura 12(b)). Na Figura 12(c), observe que a média, moda e mediana coincidem no mesmo ponto e ainda que, em torno da reta que vertical que passa por esse ponto, a cauda à esquerda é semelhante, em forma, que a cauda à direita, sendo por esse motivo, chamada de distribuição simétrica.
Essas medidas de centro ainda podem ser comparadas empiricamente através da seguinte relação:
Moda = média - 3 × média - mediana
Essa regra empírica fica mais precisa à medida que a distribuição dos dados for mais simétrica.
Exemplo: Verifique se as medidas de centro podem ser comparadas utilizando o conjunto de dados da Tabela 7:
Valores = { 1, 3, 6, 6, 6, 6, 7, 7, 8, 8, 10}
Média = 6,18
Mediana = 6
Moda = 6

45
Estatística Exploratória
Verificação da identidade
Moda = média - 3 × |média - mediana|
Moda = 6,18 - 3 × |6,18 - 6| = 5,64
3.3. Medidas de Variação (dispersão)
Você já aprendeu que a média, mediana, ponto médio e moda são medidas de posição que tendem a buscar o centro de uma distribuição de dados/valores. A partir de agora, você precisa também se preocupar como os outros valores estão distribuídos, dispersos, espalhados em torno dessa medida central. Essa dispersão é muito importante para a compreensão do comportamento dos dados. Nesta seção vamos estudar as principais medidas de dispersão: a amplitude, a variância e o desvio padrão.
3.3.1. Amplitude
Dado um conjunto de valores, a amplitude desse conjunto é medida através da diferença entre o maior e o menor valor do conjunto.
Amplitude = (valor Máximo) - (Valor Mínimo)
Exemplo → As notas da disciplina de banco de dados estão listadas no conjunto Notas a seguir. Calcule a média e a amplitude do conjunto de dados.
Notas = {3;7;2;5;7;5;5;5;6;5;1;5;5;9;4;5;5;5;8;5;8;6;6;4;4;5;3;2}
A média do conjunto de dados pode ser calculada por:
A amplitude total do conjunto pode ser calculada por:
Amplitude Total = 9 - 1,5 = 7,5
A amplitude também pode ser indicada pelo intervalo [1,5 - 9].
Essas medidas são interessantes para descrever as notas dos alunos de banco de dados. Sabemos agora que a média é 5,24, a menor nota é 1,5 e a maior nota é 9,0. Contudo, ainda não sabemos descrever como os dados estão espalhados em torno da média, ou seja, não temos como avaliar se as outras notas estão mais próximas das extremidades do conjunto (1,5 e 9,0) ou se estão próximas da média (5,24). Esse problema ocorre porque, para calcular a amplitude, utilizamos apenas dois valores. Precisamos de uma medida que indique a variabilidade (dispersão) de todos os valores em torno da média.
3.3.2. Variância (σ2) e desvio padrão (σ)
Esse é um dos conceitos que mais causa dúvida entre os estudantes de estatística e, por isso, vamos explicá-lo por partes.
A ideia básica é analisar os desvios (diferenças) dos valores individuais em relação à média de todas as observações. Dessa forma é possível avaliarmos o espalhamento dos dados em torno da média. A Tabela 9 será útil para você acompanhar os cálculos. Mas antes disso, vamos chamar o conjunto de notas apenas por x, cada nota individual será tratada por xi e a média por .

46
Estatística Exploratória
Tabela 9. Notas dos alunos de banco de dados.
i Notas (xi) xi - |xi - | (xi - )2
1 3,0 -2,24 2,24 5,00
2 7,0 1,76 1,76 3,11
3 2,5 -2,74 2,74 7,49
4 7,5 2,26 2,26 5,12
5 5,5 0,26 0,26 0,07
6 6,5 1,26 1,26 1,60
7 1,5 -3,74 3,74 13,96
8 5,0 -0,24 0,24 0,06
9 9,0 3,76 3,76 14,16
10 4,5 0,74 0,74 0,54
11 5,5 0,26 0,26 0,07
12 8,5 3,26 3,26 10,65
13 8,0 2,76 2,76 7,64
14 6,0 0,76 0,76 0,58
15 6,0 0,76 0,76 0,58
16 4,0 -1,24 1,24 1,53
17 4,5 -0,74 0,74 0,54
18 3,0 -2,24 2,24 5,00
19 2,0 -3,24 3,24 10,48
99,5 0,00 34,26 88,18
Perceba que o somatório de (xi - ) = 0. Esse problema acontece com qualquer
conjunto de dados – “a soma dos desvios será sempre igual a zero”. Por esse motivo, a soma dos desvios não é uma boa medida de dispersão. Duas alternativas para contornar esse problema podem ser consideradas:
Utilizar o somatório dos valores absolutos dos desvios;
(xi - )2 = 34,26
Utilizar o somatório dos quadrados dos desvios;
(xi - )2 = 88,18
As duas alternativas são interessantes porque resolvem o problema do somatório dos desvios ser igual a zero, porém esses totais não são bons para realizar comparações entre conjunto de dados com tamanhos diferentes porque os totais serão discrepantes.
Certamente você chegou à solução desse impasse. Vamos calcular essas medidas de desvios como médias e, chamá-las, a partir de agora, como variância dos dados de uma população, cujo símbolo é designado pela letra grega sigma ao quadrado - σ2.
Considerando os dados da Tabela 9, a variância dos dados pode ser calculada por:

47
Estatística Exploratória
Nunca esqueça que a unidade de grandeza da variância é sempre elevada ao quadrado. Por exemplo, se os valores são fornecidos em metros, a variância será calculada em metros quadrados ou m2. Apesar de a variância ser muito utilizada em métodos estatísticos importantes, o fato de suas unidades serem diferentes das unidades dos dados originais causa frequentemente dificuldades no entendimento do seu valor em relação ao conjunto de dados original. No exemplo da Tabela 9, os alunos de banco de dados tiraram média = 5,24 pontos com variância σ2 = 4,64 pontos2. Para facilitar o entendimento dessa medida de espalhamento, utilizaremos o desvio padrão, que nada mais é do que a raiz quadrada da variância e, portanto, também considera todos os valores da população, designado pela letra grega sigma - σ.
Para o caso da Tabela 9, o desvio padrão é calculado da seguinte forma:
Desvio padrão de uma amostra → Quando desejamos calcular o desvio padrão de amostras de uma população, precisamos dividir o somatório dos quadrados dos desvios por (n - 1) , onde n é o tamanho da amostra. A variância amostral será designada por s2, e o desvio padrão amostral simplesmente por s. A equação torna-se:
Desvio padrão amostral =
Portanto, não esqueça! Se desejar calcular o desvio padrão amostral e/ou a variância amostral, divida a soma dos quadrados dos desvios por (n-1). Vamos utilizar outro exemplo para fixarmos os conceitos do desvio padrão.
Exemplo: O gerente de um banco deseja avaliar a satisfação dos seus clientes através do monitoramento do tempo de espera para atendimento nas filas dos caixas. Ele deseja saber se o atendimento é mais demorado pela manhã ou pela tarde para poder alocar mais funcionários nos horários mais críticos. Para isso ele coletou amostras dos tempos de espera (em minutos) de clientes aguardando atendimento durante a manhã e durante a tarde.
Tempo de espera (manhã)={ 7:43, 38:06, 25:10, 21:08, 14:10, 11:10, 7:17}
Tempo de espera (tarde)={ 11:14, 19:30, 12:55, 21:08, 35:25, 14:08, 9:56, 25:23}
O gerente do banco deseja analisar, não apenas a média dos tempos de espera, mas também o espalhamento dos dados em torno da média. Perceba que as duas amostras têm tamanho n diferentes e, portanto, temos que utilizar o desvio padrão para fazer a análise da dispersão dos dados em torno da média. A Tabela 10 nos ajudará nos cálculos:

48
Estatística Exploratória
Tabela 10. Análise dos tempos de espera em filas para atendimento para os clientes de um banco.
Manhã Tarde
iTempo
espera (xi)Tempo
espera (min)(xi - )2
Tempo espera (xi)
Tempo espera (min)
(xi - )2
1 7:43 7,72 102,01 11:14 11,23 55,88
2 38:06 38,1 411,28 19:30 19,5 0,63
3 25:10 25,17 54,02 12:55 12,92 33,47
4 21:08 21,13 10,96 21:08 21,13 5,88
5 14:10 14,17 13,32 35:25 35,42 279,39
6 11:10 11,17 44,22 14:08 14,13 20,93
7 7:17 7,28 111,09 9:56 9,93 77,00
8 25:23 25,38 44,56
124,74 746,90 149,64 517,73
» Análise dos períodos da manhã
» Análise dos períodos da tarde
Analisando os resultados dos desvios padrões15 dos tempos medidos pela manhã e pela tarde, observamos que no período da tarde o tempo médio de espera é maior e os valores medidos estão mais concentrados em torno da média (porque o desvio padrão foi menor) do que pela manhã. Portanto, é mais indicado alocar mais funcionários no período da tarde para minimizar o tempo médio de espera por atendimento.
Essa verificação é muito importante – valores próximos resultarão em desvios padrões pequenos, enquanto valores mais espalhados resultarão em desvios padrões maiores. Existe uma regra prática que se baseia no princípio de que, na maioria dos conjuntos de dados, a grande maioria (aproximadamente 95%) dos valores amostrais se localiza a dois desvios padrões da média.
Essa regra é mais precisa quando o histograma dos dados de uma população tem a forma de sino como na Figura 13. Observe que 68,2% dos valores estão a um desvio padrão da média µ, pouco mais de 95% dos valores estão a dois desvios padrões da média µ e pouco mais de 97% estão a três desvios padrões da média µ.
Atenção
15 Cuidado → Usando desvio padrão sem hífen, o plural é desvios padrões. Caso utilize desvio-padrão, o plural será desvios-padrão.

49
Estatística Exploratória
Figura 13 – Distribuição dos valores em torno da média considerando os desvios padrões.
3.3.3. Escore z
O escore z é uma medida padronizada que descreve o número de desvios padrões a que se situa determinado valor de x, acima ou abaixo da média. Os escores z permitem uma comparação entre duas medidas obtidas em escalas diferentes de mensuração. Para o caso de uma amostra, o escore z pode ser encontrado com a seguinte expressão:
»
»
Exemplo – Após a formatura, você foi contratado por uma empresa como programador para receber R$ 2500,00 mensais. Por outro lado, o seu chefe de departamento ocupa o cargo de arquiteto de software e recebe R$ 8.200,00 mensais. Sabendo que o salário médio dos recém graduados está em torno de R$ 2.200,00 com desvio padrão de R$ 250,00 e que os chefes de departamento ganham em média R$ 8.000,00 com desvio padrão de R$ 250,00. Quem você acha que ganha relativamente mais, você entre os recém formados? Ou o seu chefe de departamento, entre os demais chefes de departamento da sua empresa?
Observe que os salários dos recém graduados e dos chefes de departamento são provenientes de populações diferentes, de maneira que uma comparação requer a padronização dos salários em escores z;
» Seu salário
» Salário do seu chefe
Por incrível que pareça, o seu salário está 1,2 desvios padrões acima da média e o salário do seu chefe de departamento está a 0,8 desvios padrões acima da média. Obviamente o salário do seu chefe é muito maior que o seu, mas você ganha relativamente mais do que ele.
3.3.4. Quartis e Percentis
Quando estudamos a mediana como uma medida de tendência central, descobrimos que essa medida representa o valor do meio, de modo que 50% dos valores são iguais ou menores do que a mediana, e 50% dos valores são iguais ou maiores do que a mediana.

50
Estatística Exploratória
Dessa forma, assim como a mediana divide os dados de um conjunto em dois blocos iguais, os três quartis, chamados por Q1, Q2 e Q3, dividem os valores ordenados em quatro partes iguais. Como exemplo, considere os dados da Tabela 7 e encontre os quartis daquele conjunto de dados.
Da mesma forma que há três quartis que separam um conjunto de dados em quatro partes iguais, há também os percentis, representados por P1, P2,..., P99, que separam os dados em 100 grupos com aproximadamente 1% dos valores em cada grupo.
3.3.5. Boxplot (diagrama de caixa)
O boxplot é um gráfico que possibilita representar a distribuição de um conjunto de dados com base em alguns de seus parâmetros descritivos: a mediana (Q2), o quartil inferior (Q1), o quartil superior (Q3) e do intervalo interquartil (IQR = Q3 - Q1). Esse tipo de gráfico é muito útil para a comparação de conjuntos de dados diferentes, para isso é necessário que se utilize a mesma escala para os dois conjuntos de dados.
O gráfico da Figura 14 apresenta um boxplot com os dados contábeis de empresas coletados na junta comercial de um determinado estado. O conjunto de dados classifica a situação das empresas em “Solvente” e “Insolvente”, ou seja, empresas que podem honrar suas dívidas e empresas que não têm saúde financeira para honrar os seus compromissos. Os extremos dos dois gráficos representam os valores mínimos e máximos dos dois conjuntos de dados. A linha mais espessa ao centro da caixa representa o segundo quartil (Q2) ou mediana, a parte inferior da caixa representa o primeiro (Q1) quartil e a parte superior da caixa representa o terceiro quartil (Q3). Os círculos que, por acaso, estão acima nos gráficos representam os outliers. Os outliers são valores que estão no conjunto de dados, mas não seguem a mesmo padrão do resto do conjunto. Esses valores podem ter sido gerados por erros no processo de coleta de dados.
Figura 14 – Boxplot com os dados de empresas insolventes versus solventes.

51
Estatística Exploratória
Os boxplots também são úteis para descrever a simetria do conjunto de dados. Observe na Figura 15 como o boxplot acompanha a inclinação da distribuição.
Figura 15 – Boxplot usado para analisar a simetria de um conjunto de dados.

52
Estatística Exploratória
Considerações Finais
Até agora você estudou importantes fundamentos da estatística que serão muito úteis nos módulos posteriores. Analisar criticamente os dados, construir tabelas e gráficos, descrever os dados através de medidas de posição e dispersão foram alguns dos assuntos que você aprendeu neste módulo e que usará continuamente ao longo da sua carreira. Portanto, é essencial que você continue treinando esses conteúdos.
No próximo módulo estudaremos em detalhes os conceitos de probabilidade, as distribuições discretas e contínuas e, sobretudo, os fenômenos que geram esses tipos de conjuntos de dados – uma das mais belas áreas da estatística.
Até o próximo módulo e bons estudos!
Marco Domingues e Jeísa Domingues
Autores

53
Estatística Exploratória
Referências
BUSSAB, W., MORETTIN, P. A. Estatística Básica. 6. ed. São Paulo: Saraiva, 2010.
MORETTIN, Luiz Gonzaga. Estatística Básica. Probabilidade e Inferência. Volume Único. São Paulo. Pearson, 2009.
SPIEGEL, MURRAY R. Estatística. Bookman, 2009.
RUNGER, C., HUBELE, F., MONTGOMERY, C. Estatística aplicada à engenharia. 2ª Edição. LTC, 2004.
BORNIA, C., BARBETTA, A., REIS, M. Estatística para Cursos de Engenharia e Informática - 3ª Ed. 2010
TRIOLA, M. Introdução à Estatística. 10ª Edição. Rio de Janeiro: LTC, 2008

54
Estatística Exploratória
Conheça os Autores
Marco Antonio de Oliveira Domingues
O professor Marco Domingues é doutor em Ciência da Computação pelo Centro de Informática da UFPE, na área de inteligência computacional. Obteve o título de mestre em 2004, na área de redes de computadores no mesmo centro, atuou como engenheiro eletricista e também é graduado em Ciência da Computação pela Universidade Federal do Amazonas. Trabalhou na UFPE em diversos projetos de pesquisa na área de redes móveis e atualmente é professor e coordenador do curso superior de Tecnologia em Análise e Desenvolvimento de Sistemas no Instituto Federal de Pernambuco – IFPE.
Jeísa Pereira de Oliveira Domingues
A professora Jeísa defenderá a sua tese de doutorado em Ciência da Computação pelo Centro de Informática da UFPE, em março de 2011. Sua tese tem foco na área de redes de sensores e middleware. A professora Jeísa é graduada em Ciência da Computação pela Universidade Federal da Paraíba e obteve o título de mestre em 2004, na área de redes de computadores, também no Centro de Informática. Trabalhou como pesquisadora em diversos projetos de pesquisa na área de redes sensores e simulação e atualmente é professora no Departamento de Estatística e Informática na Universidade Federal Rural de Pernambuco – UFRPE.