distribuições de frequências · isto indica que algum valor central é característica dos dados...
TRANSCRIPT

Distribuições de Frequências
Uma distribuição de frequência é uma tabela que reúne o conjunto de dados,
conforme as frequências ou as repetições de seus valores. No capítulo anterior, vimos
como são feitas essas tabelas quando a variável é qualitativa. Nesse capítulo, veremos
como montar essas tabelas quando a variável é quantitativa.
Podemos agrupar os dados segundo cada valor observado (distribuição de
frequências por intervalo) quando a variável é discreta e possui poucos valores
distintos, ou em classes de valores (distribuição de frequências por intervalo) quando a
variável é contínua ou discreta e possui muitos valores distintos.
Etapas para a construção de uma distribuição de frequências por ponto
Estabelecer o rol crescente (opcional)
Rol é uma lista, onde as observações são dispostas de forma ordenada crescente ou
decrescente. O objetivo da ordenação é tornar possível a visualização das variações
ocorridas, uma vez que os valores extremos são percebidos de imediato, e também
facilitar a construção da distribuição de frequências, entretanto essa etapa é opcional,
ou seja, a distribuição de frequências pode ser feita independente do rol.
1.1.1. Contar a ocorrência de cada valor
Deve-se contar a ocorrência de cada valor diferente dos dados brutos (valores
Originais). Essa contagem é chamada de frequência absoluta ( if ). Os diferentes
valores observados são colocados na primeira coluna, enquanto que as frequências
absolutas são colocadas na segunda coluna.
1.1.2. Calcular as frequências acumuladas, relativas e relativas acumuladas

Frequência absoluta acumulada ( iF ) é a soma de todas as frequências
anteriores até o valor observado atual. Essas frequências são colocadas na terceira
coluna.
A frequência relativa ( rf ) é calculada pela razão entre a frequência absoluta e
o número total de observações (n) e pode ser expressa em termos percentuais. Essas
frequências são colocadas na quarta coluna.
Frequência relativa acumulada ( riF ) é a soma de todas as frequências relativas
anteriores até o valor observado atual e pode ser expressa em termos percentuais.
Também pode ser calculada pela razão entre a frequência absoluta acumulada e o
número total de observações (n). Essas frequências são colocadas na quinta coluna.
1.2. Etapas para a construção de uma distribuição de frequências por intervalo
1.2.1. Estabelecer o rol crescente (opcional)
É realizado da mesma forma descrita anteriormente para o caso da distribuição
de frequências por ponto.
1.2.2. Calcular a Amplitude Total
A Amplitude Total (H) é a diferença entre entre o maior e o menor valor
observado da variável em estudo, ou seja, MINMAX xxH .
1.2.3. Calcular o número de classes
Classe é cada um dos grupos ou intervalos de valores em que se subdividirá a
amplitude total do conjunto de tamanho n. A classe i, onde i = 1, 2,..., k

Para a determinação do número de classes (k), não há uma fórmula exata e
existem diversos métodos, dentre os quais, destaca-se a regra de Sturges, que
estabelece que o número de classes (k) é calculado por:
nk log3,31 .
Outro método, chamado de Método da Raiz, estabelece que, se 25n , 5k ,
e se 25n , nk .
Esses métodos não necessariamente dão os mesmos resultados. não são
obrigatórias, ou seja, são apenas uma sugestão para se obter uma quantidade
adequada de classes. O pesquisador deverá ter em mente que a escolha do número de
classes dependerá da natureza dos dados e da unidade de medida em que eles forem
expressos, e poderá arredondar o valor calculado de k para cima ou para baixo,
conforme lhe convir. Em geral, recomenda-se considerar 124 k .
1.2.4. Calcular a amplitude das classes
A amplitude (h) de cada classe é calculada por:
kHh / .
Quando a distribuição de freqüências já existe, a amplitude (h) de cada classe é
obtida pela diferença entre o limite superior e o limite inferior da classe, ou seja:
ii lLh .
1.2.5. Estabelecer as classes
Os dois valores extremos de cada classe são: o limite inferior (Linf.), que é o
menor valor da classe considerada, e o limite superior (Lsup.), que é o maior valor da
classe considerada.

Normalmente, a primeira classe inicia com o primeiro valor bruto observado,
mas o pesquisador pode iniciar com um valor anterior (mesmo que não existe), se lhe
for conveniente.
Cada classe deverá ter a mesma amplitude (h), entretanto, por causa dos
arredondamentos nos cálculos, a última classe poderá ser mais ampla que as demais, a
fim de contemplar todos os dados brutos.
Entre os limites inferior e superior, utiliza-se o símbolo |–, que significa que a
classe i contém o valor do limite inferior, mas não contém o valor do limite superior, o
qual entrará na última classe. A única exceção poderá ser a última classe, que poderá
utilizar o símbolo |–|, onde o valor do limite superior também estará incluído na
classe.
1.2.6. Contar as ocorrências em cada classe
Deve-se contar a ocorrência de todos os valores que estão contidos dentro de
cada classe. Essa contagem é chamada de frequência absoluta ( if ). Os diferentes
valores observados são colocados na primeira coluna, enquanto que as frequências
absolutas são colocadas na segunda coluna.
1.2.7. Calcular as frequências acumuladas, relativas e relativas acumuladas
É realizado da mesma forma descrita anteriormente para o caso da distribuição
de frequências por ponto.
1.3. Gráficos para distribuições de frequências
Existem gráficos adequados para apresentar as frequências de variáveis
quantitativas. São eles: o histograma, o polígono de frequências e a ogiva.
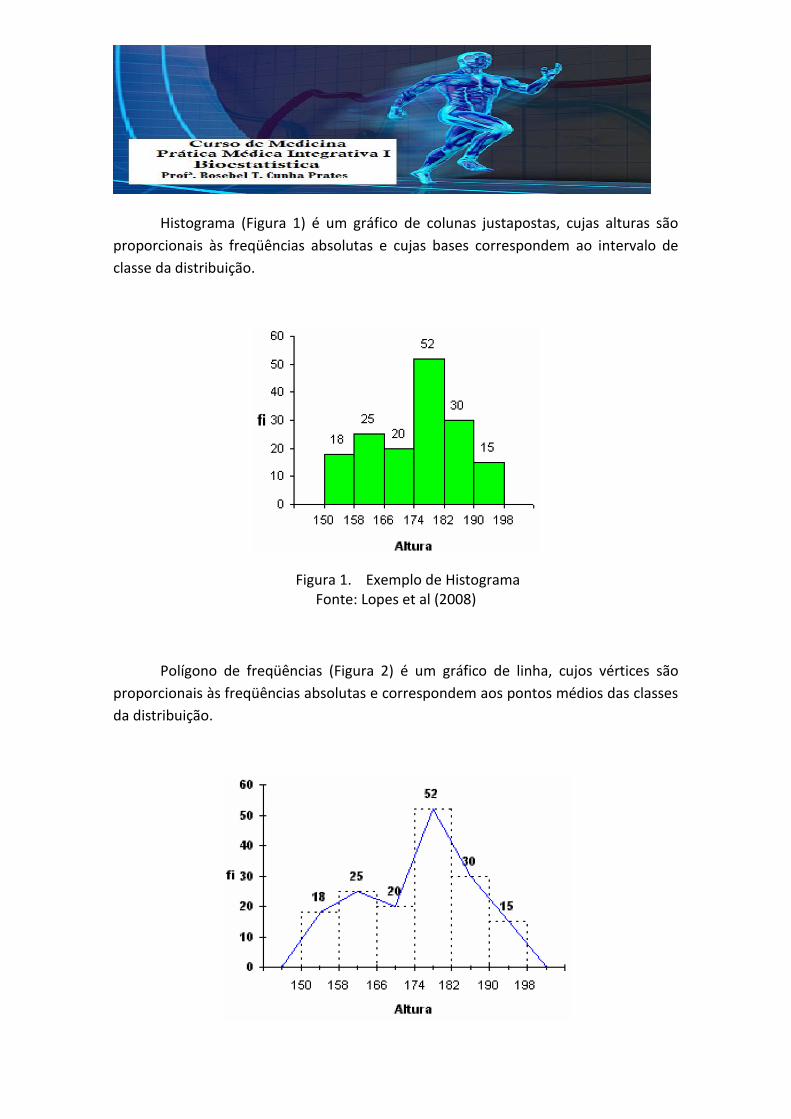
Histograma (Figura 1) é um gráfico de colunas justapostas, cujas alturas são
proporcionais às freqüências absolutas e cujas bases correspondem ao intervalo de
classe da distribuição.
Figura 1. Exemplo de Histograma Fonte: Lopes et al (2008)
Polígono de freqüências (Figura 2) é um gráfico de linha, cujos vértices são
proporcionais às freqüências absolutas e correspondem aos pontos médios das classes
da distribuição.
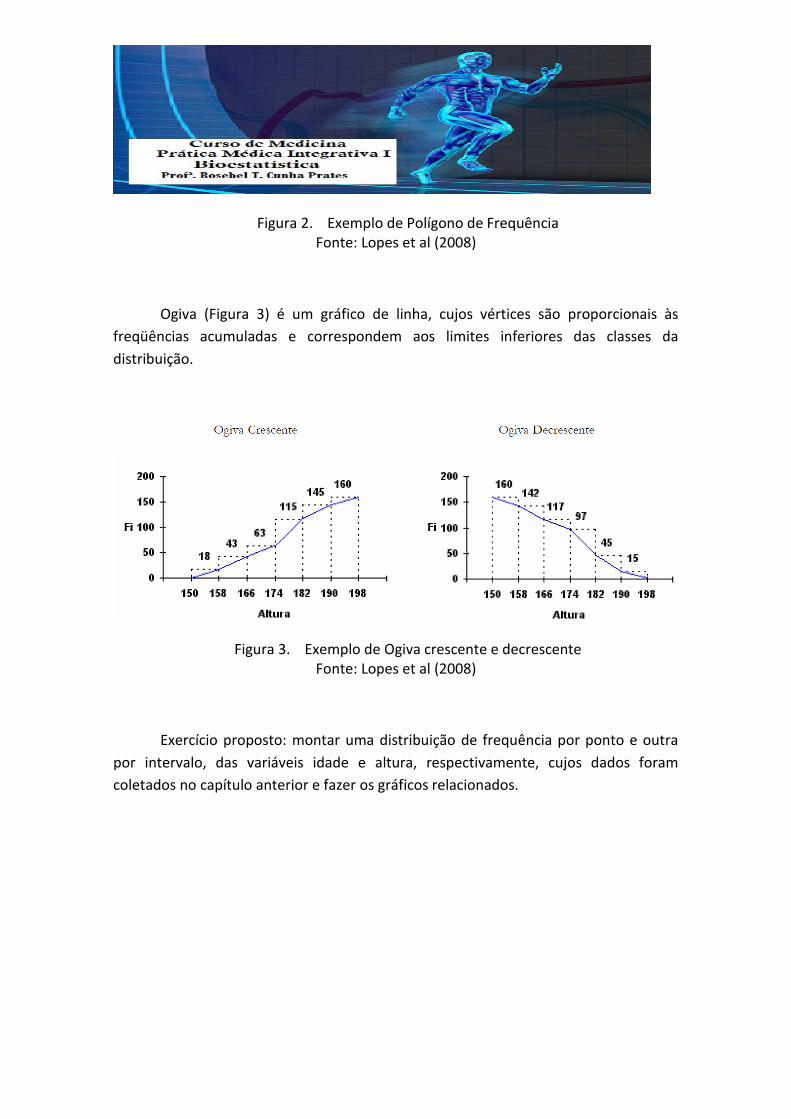
Figura 2. Exemplo de Polígono de Frequência Fonte: Lopes et al (2008)
Ogiva (Figura 3) é um gráfico de linha, cujos vértices são proporcionais às
freqüências acumuladas e correspondem aos limites inferiores das classes da
distribuição.
Figura 3. Exemplo de Ogiva crescente e decrescente Fonte: Lopes et al (2008)
Exercício proposto: montar uma distribuição de frequência por ponto e outra
por intervalo, das variáveis idade e altura, respectivamente, cujos dados foram
coletados no capítulo anterior e fazer os gráficos relacionados.

2. Estatística Descritiva
A estatística descritiva tem o objetivo descrever os dados disponíveis da forma
mais completa. As medidas descritivas básicas mais importantes são as de posição, as
de dispersão ou variabilidade e as de forma. A ênfase aqui está sendo dada para o
cálculo das medidas para os dados brutos.
Às vezes, não conseguimos obter os dados brutos, mas os dados já tabelados.
Quando isso acontece, não é possível calcular algumas as medidas descritivas da
mesma forma que fazemos com os dados brutos. Nesses casos, algumas fórmulas
diferem da forma de calcular dos dados brutos. Quando isso acontecer, haverá um
destaque no texto (um quadro) para as fórmulas utilizadas no caso de dados já
tabelados.
2.1. Medidas de Posição
Quando se trabalha com dados numéricos, podemos calcular medidas
relacionadas com a posição dos dados. Podemos calcular medidas de posição central
(por exemplo, média, mediana, moda) ou de outras posições (por exemplo, quartis,
decis, percentis) observa-se uma tendência destes de se agruparem em torno de um
valor central. Isto indica que algum valor central é característica dos dados e que o
mesmo pode ser usado para descrevê-los e representá-los.
2.1.1. Média
A média aritmética (ou simplesmente média) á a mais utilizada das medidas de
tendência central. Consiste na soma de todas as observações dividida pelo total de
observações do grupo. Se esse grupo for uma amostra, o total de observações é dado
por n, porém se esse grupo for uma população, o total de observações é dado por N. A
média de uma amostra ( x ) é dada por:
n
x
n
xxxx
n
i
i
n
121 ...
,

ou simplesmente:
n
xx
.
A média de uma população () é dada por:
N
x
N
xxx
N
i
i
N
121 ...
ou simplesmente:
N
x .
Propriedades da média1 (amostral ou populacional):
A soma dos desvios em relação à média é nula: 0xxi .
A média de uma constante é igual à constante: kkx )( .
A média do produto de uma constante por uma variável é igual ao produto da
constante pela média da variável: )()( ii xxkkxx ..
A soma dos quadrados dos desvios em relação à média é um mínimo:
xaaxxx ii ,22
.
No caso de dados tabelados por ponto, ix é o próprio valor da classe; porém
no caso de dados tabelados por intervalo ix é o ponto médio da classe i, e a média de
uma amostra ( x ) é dada por:
n
fx
n
fxfxfxx
k
i
ii
kk
12211 ).(...).().(
1 Representaremos aqui a média amostral, embora essas propriedades matemáticas sejam válidas também
para a média populacional.

ou simplesmente:
n
fxx
.
.
A média de uma população () é dada por:
N
fx
N
fxfxfx
k
i
ii
kk
12211
.).(...).().(
ou simplesmente:
N
fx
. .
2.1.2. Mediana
A mediana (Md ou x~ ) divide em duas partes (ao meio) o conjunto das
observações ordenadas (rol). Colocando-se os valores em ordem crescente ou
decrescente, a mediana é o elemento que ocupa o valor central. É utilizada quando o
conjunto de dados possui observações que se comportam de forma diferente dos
demais dados do conjunto ou quando os dados não seguem uma Distribuição Normal2.
Também pode ser utilizada no caso de variáveis qualitativas ordinais com escalas do
tipo likert.
Para encontrar a posição da mediana MdP , fazemos o seguinte cálculo:
Se o número de elementos3 (n ou N) for ímpar, a mediana será o elemento
central que ocupa a posição 2
1
nPMd do rol;
2 Em muitas situações práticas, os dados seguem uma Distribuição Normal, ou seja, eles podem ser
ajustados por essa distribuição. Essa distribuição será vista no capítulo de Probabilidades. 3 Utilizaremos nas fórmulas a simbologia n, que representa a quantidade total de observações de uma
amostra. As fórmulas são as mesmas para o caso em que a quantidade total de observações se refere à
população, N.

Se o número de elementos (n ou N) for par, a mediana será a média aritmética
entre os dois elementos centrais que ocupam as posições 2
1
nP Md e
12
2 n
P Md do rol.
Após encontrar a posição da mediana dMP , basta localizar essa posição e
encontrar o valor correspondente no rol, se n for impar. Se n for par, basta encontrar
os valores correspondentes no rol das duas posições calculadas dMP1 e
dMP2 e calcular
a média entre eles.
No caso de dados tabelados por ponto, a posição da mediana é calculada da
mesma forma que nos dados brutos e o rol é a própria tabela de frequências.
No caso de dados tabelados por intervalo, a posição da mediana é dada por:
2
nPMd .
A Mediana é calculada por:
Md
MdMdMd
f
FPhlMd 1
.
2.1.3. Moda
A moda (Mo) de um grupo de observações é definida como a medida de
freqüência máxima, ou seja, o valor que se repete com maior frequência. Pode ser
utilizada para variáveis qualitativas.
Há situações em que o conjunto de dados pode possuir mais de uma moda
(bimodal, trimodal, plurimodal ou multimodal), ou, ainda, não apresentar moda
(amodal).
No caso de dados tabelados por ponto, a moda é o valor da classe de maior

frequência (classe modal).
No caso de dados tabelados por intervalo, podemos estimar a moda de várias
formas diferentes. No Método Rudimentar, a moda é o ponto médio da classe de
maior frequência (classe modal), ou seja:
Mo
MoMo xlL
Mo
2
No Método de Czuber, que leva em consideração as frequências anteriores e
posteriores à classe modal, a moda é dada por:
11
1
2 MoMoMo
MoMo
Mofff
fflMo .
O método da Fórmula de Pearson é uma boa aproximação para a Moda
quando a distribuição apresenta razoável simetria em relação à média, e é dada por:
xxMo 2~3 .
2.1.4. Separatrizes
São valores de posição, que dividem o rol. As principais medidas separatrizes
são: mediana, quartis, decis e percentis (ou centis).
Os quartis dividem um conjunto de dados em quatro partes iguais. Assim:
0% 25% 50% 75% 100%
|--------------------|--------------------|--------------------|--------------------|
Q1 Q2 =Md Q3
onde:

1Q é o primeiro quartil, que separa os primeiros 25% dos 75% restantes;
2Q é o segundo quartil, que é a mediana (Md) vista anteriormente, e separa o
conjunto de dados em 2 partes iguais;
3Q é o terceiro quartil, que separa os primeiros 75% dos 25% restantes.
De forma análoga, Os decis dividem um conjunto de dados em dez partes
iguais. Assim:
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
|--------|--------|---------|--------|---------|---------|---------|---------|
D1 D2 D3 D4 D5=Md D6 D7 D8 D9
onde:
1D é o primeiro decil, que separa os primeiros 10% dos 90% restantes;
2D é o segundo decil, que separa os primeiros 20% dos 80% restantes;
9D é o nono decil, que separa os primeiros 90% dos 10% restantes.
Nota-se que o quinto decil é igual ao segundo quartil, que é igual à mediana.
De forma análoga, os percentis (ou centis) dividem um conjunto de dados em
cem partes iguais. Assim:
0% 1% 2% 99% 100%
|-------|-----------------------------------------------------------------|
P1 P2 P99

onde:
1P é o primeiro percentil, que separa os primeiros 1% dos 99% restantes;
2P é o segundo percentil, que separa os primeiros 2% dos 98% restantes;
99P é o nonagésimo nono percentil, que separa os primeiros 99% dos 1% restantes.
Nota-se que o qüinquagésimo percentil é igual ao quinto decil, que é igual ao
segundo quartil, e que é igual à mediana.
Há divergências entre os autores na forma de calcular as separatrizes. Alguns
consideram que a Separatriz será o elemento que ocupa a posição S
niP
iS
. do rol,
onde:
4S , e a separatriz for um quartil, e i indica a ordem do quartil;
10S , e a separatriz for um decil, e i indica a ordem do decil;
100S , e a separatriz for um percentil, e i indica a ordem do percentil.
do rol;
Outros consideram que a Separatriz será o elemento que ocupa a posição
S
niP
iS
)1( do rol. Essas duas formas de calcular entram em conflito com o cálculo
da mediana. A forma mais garantida é estabelecer o rol e procurar a Separatriz
diretamente ou utilizar softwares.
No caso de dados tabelados, a posição de uma separatriz é dada por:
S
niP
iS
. ,
onde:

4S , e a separatriz for um quartil, e i indica a ordem do quartil;
10S , e a separatriz for um decil, e i indica a ordem do decil;
100S , e a separatriz for um percentil, e i indica a ordem do percentil.
A separatriz é calculada por:
i
ii
i
S
SS
Sif
FPhlS 1
.
2.2. Medidas de dispersão
O objetivo das medidas de dispersão é descrever os dados no sentido de
informar o grau de dispersão ou afastamento dos valores observados em torno de um
valor central. Elas indicam se um conjunto é homogêneo (pouca ou nenhuma
variabilidade) ou heterogêneo (muita variabilidade). Há muitas aplicações dessas
medidas na estatística inferencial.
2.2.1. Amplitude
A amplitude (H) ou desvio extremo é a diferença entre o maior e o menor valor
do conjunto, é de grande instabilidade porque considera somente os valores extremos
do conjunto. Utiliza-se muito em gráficos de controle para monitorar a variabilidade
através da amplitude e para construir distribuições de frequências por intervalo.
Obtém-se por:
MINMAX XXH .

2.2.2. Variância
A variância é uma medida de variabilidade quadrática. A variância populacional
( 2 ) é dada por:
N
xx
N
xxxxxx
N
i
i
N
1
2
22
2
2
12
)()(...)()(
e também pode ser calculada por:
N
N
xx
N
xi
ii
2
222
2
.
A variância populacional ( 2s ) é dada por:
1
)(
1
)(...)()( 1
2
22
2
2
12
n
xx
n
xxxxxxs
n
i
i
n
mas também pode ser calculada por:
11
2
222
2
n
n
xx
n
xxs
i
ii
.
Propriedades da variância4 (amostral ou populacional):
A variância de uma constante é zero: 0)(2 ks .
A variância da soma ou diferença de uma constante k com uma variável é igual
a variância da variável: )()( 22 xsxks .
A variância da soma de variáveis independentes é igual a soma das variâncias
das variáveis: )()()( 222 ysxsyxs .
4 Representaremos aqui a variância amostral, embora essas propriedades matemáticas sejam válidas
também para a média populacional.

A variância do produto de uma constante por uma variável é igual ao produto
do quadrado da constante pela variância da variável: )(.).( 222 xskxks .
No caso de dados tabelados, a variância populacional ( 2 ) é dada por:
N
fxx
N
fxxfxxfxx
k
i
ii
kk
1
2
2
2
2
21
2
12
)()(...)()(
e também pode ser calculada por:
N
N
fxfx
N
fxii
iiii
2
222
2
.
A variância populacional ( 2s ) é dada por:
1
)(
1
)(...)()( 1
2
2
2
2
21
2
12
n
fxx
n
fxxfxxfxxs
k
i
ii
kk
mas também pode ser calculada por:
11
2
222
2
n
n
fxfx
n
xfxs
ii
iiii
..
2.2.3. Desvio Padrão
O desvio padrão é a raiz quadrada da variância. O objetivo do desvio padrão é
remover o efeito quadrático da variância. O desvio padrão populacional () é dada por:
2 .
O desvio padrão populacional (s) é dada por:
2ss .

2.2.4. Coeficiente de Variação
O coeficiente de variação (CV) é uma medida de dispersão relativa. É útil
quando se deseja comparar a variação de conjuntos de dados que apresentem
diferentes unidades de medição e ou tamanhos diferentes, pois o coeficiente de
variação independe da unidade de medida dos dados. O coeficiente de variação (pode
também ser expresso como percentagem), para a amostra é dado por
x
sCV ou 100.%
x
sCV
e para a população
CV ou 100.%
CV .
2.3. Medidas de Forma
As medidas de assimetria e curtose complementam as medidas de posição e de
dispersão no sentido de proporcionar uma descrição e compreensão mais completa
das distribuições de freqüências. Estas distribuições não diferem apenas quanto ao
valor médio e à variabilidade, mas também quanto a sua forma (assimetria e curtose).
Existem várias formas de se calcular a assimetria e a curtose de um conjunto de dados.
2.3.1. Assimetria
Assimetria é o grau de desvio, afastamento da simetria ou grau de deformação
de um conjunto de dados. Se a curva de freqüências de uma distribuição tem uma
"cauda" mais longa à direita da ordenada máxima do que à esquerda, diz-se que a
distribuição é desviada para a direita ou que ela tem assimetria positiva. Se ocorrer o
inverso, diz-se que ela é desviada para a esquerda ou tem assimetria negativa. Se não
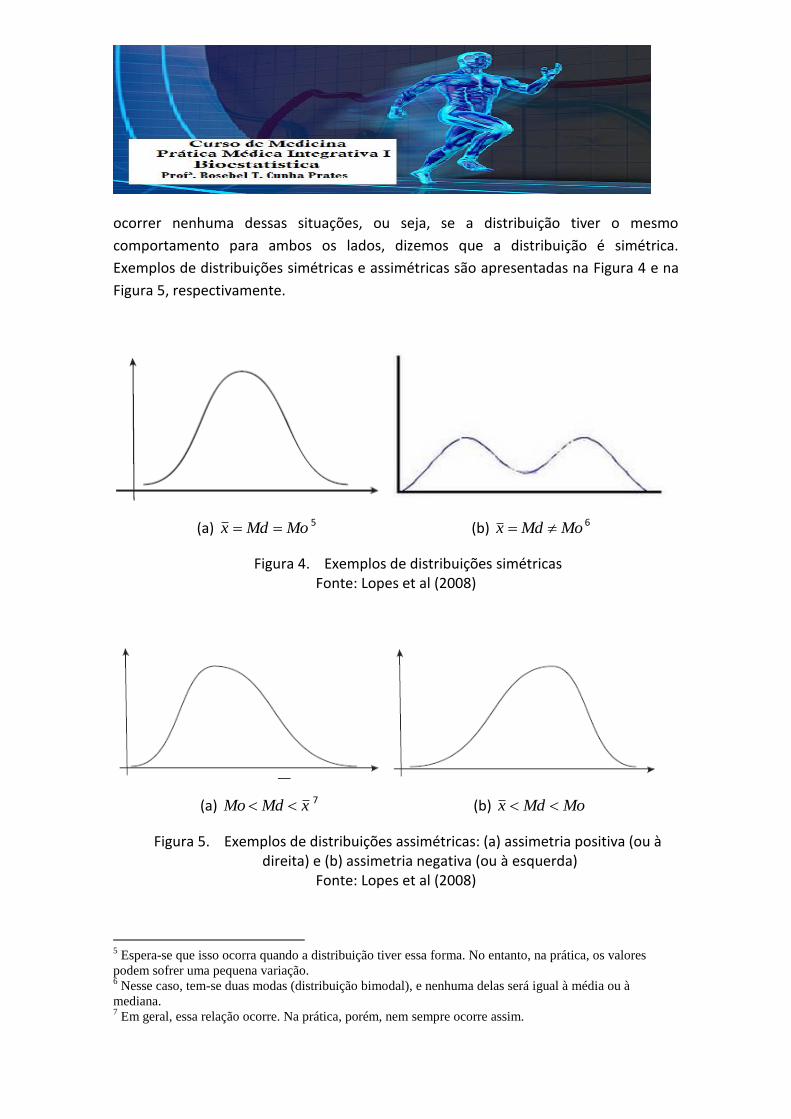
ocorrer nenhuma dessas situações, ou seja, se a distribuição tiver o mesmo
comportamento para ambos os lados, dizemos que a distribuição é simétrica.
Exemplos de distribuições simétricas e assimétricas são apresentadas na Figura 4 e na
Figura 5, respectivamente.
(a) MoMdx 5 (b) MoMdx 6
Figura 4. Exemplos de distribuições simétricas Fonte: Lopes et al (2008)
(a) xMdMo 7 (b) MoMdx
Figura 5. Exemplos de distribuições assimétricas: (a) assimetria positiva (ou à direita) e (b) assimetria negativa (ou à esquerda)
Fonte: Lopes et al (2008)
5 Espera-se que isso ocorra quando a distribuição tiver essa forma. No entanto, na prática, os valores
podem sofrer uma pequena variação. 6 Nesse caso, tem-se duas modas (distribuição bimodal), e nenhuma delas será igual à média ou à
mediana. 7 Em geral, essa relação ocorre. Na prática, porém, nem sempre ocorre assim.

O 1° coeficiente de assimetria de Pearson, para dados amostrais, é dado por:
s
MoxAs
,
e para dados populacionais, é dado por:
MoAs
.
O 2° coeficiente de assimetria de Pearson, para dados amostrais, é dado por:
13
31~2
xQQAs
.
Tanto para o primeiro quanto para o segundo coeficientes de assimetria, a
interpretação, segundo Fonseca e Martins (1996), é:
As < 0: distribuição Assimétrica Negativa;
As > 0: distribuição Assimétrica Positiva;
As = 0: distribuição Simétrica.
Coeficiente momento de assimetria ( 3 ) é o terceiro momento abstrato. O
momento abstrato r é dado por:
r
rr
s
M ,
onde rM é o momento de ordem r centrado na média, e é dado por:
n
xxM
r
i
r
)(.
No caso de dados tabelados, rM é dado por:
n
fxxM
i
r
i
r
)(.
Assim, o coeficiente momento de assimetria ( 3 ) é dado por:
3
33
s
M .
A interpretação para 3 é:
2,03 ⇒ distribuição Assimétrica Negativa;
2,03 ⇒ distribuição Assimétrica Positiva;
2,02,0 3 ⇒ distribuição Simétrica.
2.3.2. Curtose
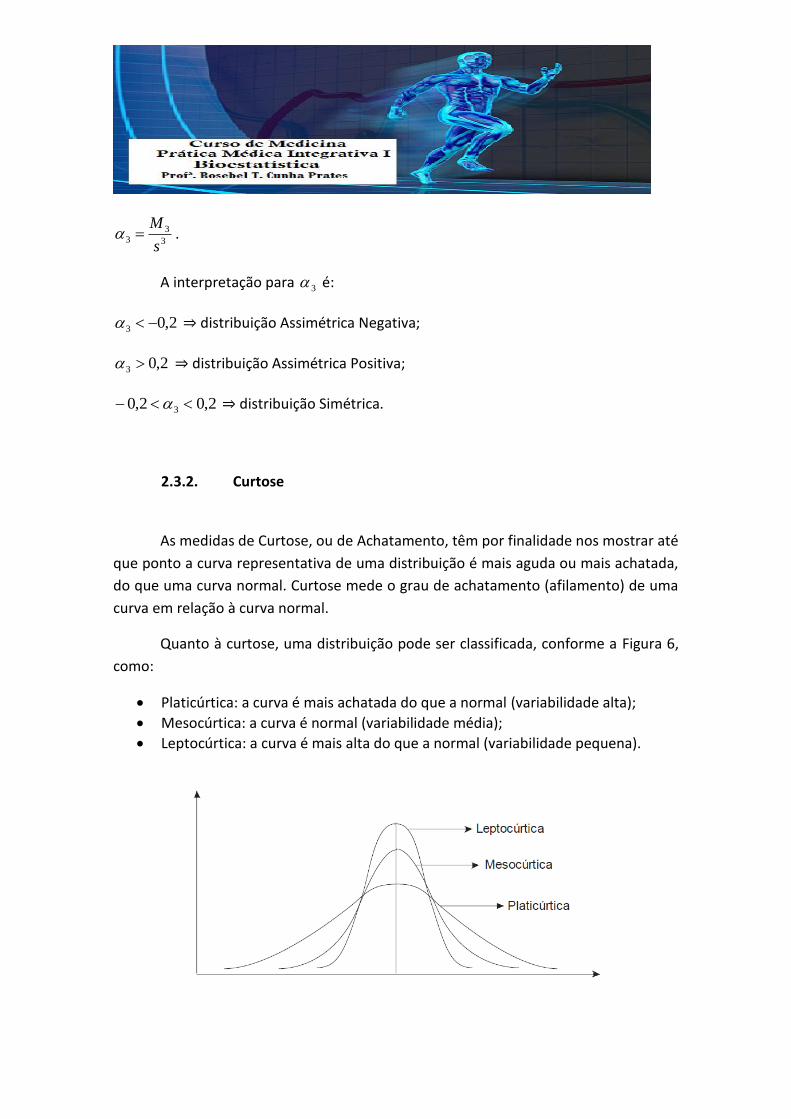
As medidas de Curtose, ou de Achatamento, têm por finalidade nos mostrar até
que ponto a curva representativa de uma distribuição é mais aguda ou mais achatada,
do que uma curva normal. Curtose mede o grau de achatamento (afilamento) de uma
curva em relação à curva normal.
Quanto à curtose, uma distribuição pode ser classificada, conforme a Figura 6,
como:
Platicúrtica: a curva é mais achatada do que a normal (variabilidade alta);
Mesocúrtica: a curva é normal (variabilidade média);
Leptocúrtica: a curva é mais alta do que a normal (variabilidade pequena).

Figura 6. Comparação entre três distribuições com mesma média, porém diferente variabilidade.
Fonte: Lopes et al (2008)
O Coeficiente centílico de curtose é dado por:
)(2 19
13
DD
QQK
.
A interpretação para K é:
263,0K , curva leptocúrtica;
263,0K , curva mesocúrtica;
263,0K , curva platicúrtica.
Coeficiente momento de curtose ( 4 ) é o quarto momento abstrato. Assim, o
coeficiente momento de curtose ( 4 ) é dado por:
4
44
s
M
A interpretação para 4 é:
34 ⇒curva platicúrtica;
34 ⇒curva mesocúrtica;
34 ⇒curva leptocúrtica.

BIBLIOGRAFIA
FONSECA, J.S. da.; MARTINS, G.A. Curso de Estatística. 6ª Ed. São Paulo: Atlas, 1996
MOTTA,Valter T.Bioestatística. Caxias do Sul, RS:Educs,2006
PAGANO, Marcello.Princípios de Bioestatística São Paulo: Pioneira Thomson Learning 2004
TRIOLA, M. F. Introdução à Estatística. 7a Ed. Rio de Janeiro: LTC, 1999.
W. de O.; MORETIN, P.A. Estatística Básica. 5ª Ed. São Paulo: Saraiva, 2004.
COSTA NETTO, P. L.O. Estatística. 2a. Ed. São Paulo: Edgard Blücher LTDA, 2002.
MORETTIN, L.G. Estatística Básica: Inferência. São Paulo: Pearson Makron Books, 2000
