consenso distribuído › ~endler › courses › da › transp › consensus.pdf ·...
TRANSCRIPT

1
Consenso DistribuídoRoteiro:• Modelo de Sistema • O problema do Consenso• Sistemas Síncronos e o Acordo Bizantino• Consenso em Sistemas Assíncronos• Detectores de Falha e o Algoritmo de Chandra & Toueg• Consistência Interativa e relação entre os problemas
Referências:Li C l i S ã 11 5
© Markus Endler
Livro: Coulouris, Seção 11.5Livro: Pankaj Jalote: Fault Tolerance in Distributed Systems, seção 3.1Livro: Chow, Johnson, Cap. 11D. Dolev, C. Dwork, L. Stockmayer: On the minimal synchronization
needed for Distributed Consensus, Journal of the ACM, 35(2), 1997.T.D. Chandra, S.Toueg: Unreliable failure detectors for reliable
distributed systems, Journal of the ACM, 43(2), 1996.
O Consenso DistribuídoO Consenso é um problema fundamental em Sistemas Distribuídos pois é:p
• utilizado como módulo fundamental de vários algoritmos onde os processos precisam ter uma visão (ou ação) idêntica.Exemplos:
- para ordenação total de eventos (ou mensagens)- sobre o conjunto de processos não falhos/ativos de um grupo
© Markus Endler
- colaboração entre agentes em sistemas multi-agentes -...
• pode-se mostrar a sua equivalência com outros problemas tais como:
- multicast atômico (confiável + ordem total)- consistência interativa- acordo bizantino

2
Modelo do SistemaSistema:• conjunto de processos Pi (i= 1,2,..,N)
comunicação (por envio de mensagem) é confiável• comunicação (por envio de mensagem) é confiável• processos podem apresentar falhasTipos:
-falha de parada (crash) -falta arbitrária (bizantina)
• até f processos podem falhar simultaneamente
© Markus Endler
•em alguns casos assumiremos que mensagens recebem uma assinatura digital para garantir a autenticidade do remetente
impede-se que processos faltosos possam falsificar identidadedo remetente
O Problema de ConsensoDefinição do problema:
Existem N processos, dos quais f processos t f lhapresentam falhas.
cada processo Pi propõe um único valor vi ∈ Dtodos os processos interagem para a troca de valores entre síem algum momento, os processos entram no estado “decided” em que atribuem um valor para a variável de decisão di (que não é mais alterada)
© Markus Endler
de decisão di (que não é mais alterada)
Obs: O valor de di é uma função dos valores vifornecidos pelos N-f processos corretos.

3
Exemplo
P1 P2d1=OK d2=OK
Algorítmo de Consenso
v1=OK v2=OK
v2=NOK
© Markus Endler
P3
• P3 propõe NOK, mas falha durante o consenso• os processos corretos decidem por OK
Principais RequisitosTerminação:
Em algum momento, cada processo correto atinge o estado “decided” e atribui um valor à variavel de decisão di
Acordo:todos os processos corretos atribuemo mesmo valor para a variável de decisão
Integridadese todos os processos corretos propuseram o mesmo
© Markus Endler
valor vi =v, então qq processo correto em “decided” também terá decidido di =v
Integridade (alternativa mais fraca – depende da aplicação)o valor de di (i=1,2,..,N) deve ser necessariamente igual ao valor proposto por um Pi correto

4
Um Algoritmo simplesAssuma um Grupo de processos corretos não faltosos.Cada processo Pi :
usa multicast confiável para mandar o valor vi para os demaisdemaisespera até receber N-1 mensagensDefine o valor de di usando uma função deterministica:
maioria(v1,v2,..,vN), ou ⊥ se não houver maioria, máximo (v1,v2,..,vN) ou mínimo(v1,v2,..,vN)média (v1,v2,..,vN)
© Markus Endler
...Terminação é garantida pelo multicast confiável.Acordo e integridade garantidos pelo uso da mesma função (determinística) e do multicast confiável
Mas e se processos podem falhar (crash ou bizantinos)?
O Consenso com falhasSe processos podem ter falhas tipo crash (omissão), então a terminação não estará garantida, a menos que se detecte a falha. Se o sistema é assíncrono pode ser impossivelSe o sistema é assíncrono, pode ser impossivel distinguir um crash de uma mensagem que demora um tempo indeterminado.
Fischer, Lynch & Paterson(*) apresentaram um resultado teórico fundamental: é impossível garantir a obtenção de consenso em um sistema assíncrono com falhas tipo crash
Se processos podem apresentar falhas abitrárias
© Markus Endler
Se processos podem apresentar falhas abitrárias (bizantinas), então processos falhos podem comunicar valores aleatórios aos demais processos, evitando que os corretos tenham a mesma base de dados v1,v2,..,vN, para a tomada de uma decisão uniforme.
(*) Fischer, Lynch, Paterson: Impossibility of Distributed Consensus with one faulty process, Journal of the ACM, v.32 (2), 1985.

5
Consenso em sistemas síncronos[Dolev & Strong83] propuseram um algoritmo para o consenso entre N
processos que tolera até k falhas tipo “crash” em um sistema síncrono.
Ideia central: O algoritmo executa k+1 rodadas: Na rodada j todos os processos corretos difundem para todos os demais processos o conjunto de novos valores (propostos) v obtidos na rodada j-1. Inicialmente, difundem o próprio valor proposto.Ao final, executam uma função idêntica (p.ex. min/max) sobre o conjunto de valores coletados.
Observações:
© Markus Endler
ç• processos usam multicast não-confiável, mas sabe-se que a duração
máxima de cada difusão é ∆.• a variável Valuesj contém o conjunto de valores obtidos na rodada j• Os timers tem identificadores (que identificam a rodada corrente)
Consenso em sistemas síncronosAlgorítmo no processo Pi do grupo G:
Set_of_elem: Valuesj (0≤ j ≤ k+1); setV;Elem: vi di;Elem: vi, di;Inicialização:
Values0:=;Values1=vi; // próprio valor propostor = 1; // inicializa a rodada corrente
while (r ≤ k) set_timer(r, ∆); // timeout para rodada rmcast(G, Valuesr – Valuesr-1); // difunde a diferença dos conjuntos
1
© Markus Endler
Valuesr+1 = Valuesr;loop
receive(Pj,setV) => Valuesr+1 = Valuesr+1 ∪ setV;timeout(r) => r = r+1; exit; // incia nova rodada
di = min(Valuesr); // seta a variável de decisão

6
Consenso em sistemas síncronosCorretude do Algoritmo de Dolev&Strong:Terminação: obvio, pois algoritmo termina após ∆*(k+1)Acordo e Integridade: decorrem do uso da função min e se for mostrado
que ao terminar, todos os processos têm conjuntos Valuesk+1
idênticos
Proposição: Pi.Valuesk+1 = Pj.Valuesk+1 para ∀i,j ∈ NProva (contradição): Suponha v ∈ Pi.Valuesk+1 e v ∉ Pj.Valuesk+1. Então
existe um Pk, com v ∈ Pk.Valuesk e que falhou (crash) durante o multicast na rodada k, entregando v para Pi mas não para Pj. Mas se v ∈ Pk.Valuesk e v ∉ Pj.Valuesk, isto significa que existe um Pw, com v ∈ Pw.Valuesk-1 que falhou na rodada k-1, entregando v para Pk
ã Pj i di t
© Markus Endler
mas não para Pj, e assim por diante...Desta forma, conclui-se que houve uma falha (crash) por rodada, mas por suposição houve no máximo k falhas.
Dolev&Strong mostraram que qualquer algoritmo para obter o consenso na presença de k falhas requer pelo menos k+1 rodadas. Este limite inferior também vale para falhas arbitrárias (Problema do Acordo Bizantino)
Alguns artigos sobre ConsensoFrancisco Brasileiro et al,: Consensus in one communication step, Tech Report. Université Rennes 1, 2002.
Convergência rápida em “situações favoráveis”R G i A S hi C th Bi Mi d t di 6thR. Gerraoui, A. Schiper, Consensus: the Big Misunderstanding, 6th IEEE CS workshop on Future Trends of Distributed Computing Systems, 1997Badache, Hurfin, Macedo: Solving the consensus in a Mobile Environment, Relatório Técnico, IRISA, nov. 1997.
Consenso para redes móveis estruturadas (nós fixos da rede agregam votos)
M. Barborak, M. Malek, A. Dahbura, The Consensus Problem in Fault-Tolerant Computing, ACM Computing Surveys, vol. 25, no.2, 1993.
© Markus Endler
Tolerant Computing, ACM Computing Surveys, vol. 25, no.2, 1993.L.J Camargos, E. Madeira: DisCusS: desenvolvendo um serviço de consenso genérico, simples e modular. Dissertação de mestrado, IC/UNICAMPWei Ren, Beard, Atkins, A survey of Consensus problems in multi-agent coordination, American Control Conference, 2005

7
Acordo Bizantino“Problema dos Generais Bizantinos – PGB”
O PGB foi inicialmente proposto por L.Lamport (82) e equivale ao problema de consenso em um sistema com falhas arbitrárias.
Motivação:N generais (dentre eles, 1 comandante) devem concordar sobre esperar ou atacar uma cidade sitiada, que só conseguem conquistar se todos os batalhões atacarem conjuntamente.O comandante dá a ordem (atacar/esperar), e os generais devem ter certeza que receberam o mesmo. Alguns dos generais (ou o comandante) são traidores e tentam atrapalhar o consenso, divulgando para uns que receberam a ordem de atacar, e para outros a ordem de esperar.
© Markus Endler
, p p
A principal diferença entre o PGB e consenso: um dos processos fornece um valor que deve ser acordado entre todos os processos corretos (ao invés de um valor proposto por cada processo, como no consenso)
O Problema do Acordo BizantinoOs requisitos:
Terminação: Em algum momento, cada processo entra no estado “decidido” e atribui um valor à sua variável de decisão diAcordo: Se pi e pj são corretos e estão no estado “decidido” então diAcordo: Se pi e pj são corretos e estão no estado decidido , então di = djIntegridade: Se o comandante está correto, então todos os processos usam como valor de di o valor proposto pelo comandante.
Suposições:Possibilidade de falhas arbitrárias = envio de qualquer msg a qualquer momento, ou omissão de envioAté f processos (de N) podem falhar
© Markus Endler
Processos corretos conseguem detectar ausência de mensagem (usando timeouts), e neste caso assumem recebimento de um valor default mas são incapazes de detectar falha do processoCanais de comunicação são seguros: não é possível interceptar e modificar mensagens em trânsito
Idéia de solução: todos contam para todos o que receberam do comandante

8
O Problema do Acordo BizantinoImpossibilidade de solução para N=3 e f=1 [Lamport,Pease,Shostak82]:Dois possíveis casos:
Comandante (iniciador) é traidorU l é t idUm general é traidor
Obs: mensagem “3:2:a” significa “P3 diz que P2 diz que comando é a(ttack)”mensagem “3:2:w” significa “P3 diz que P2 diz que comando é w(ait)”
C1:a 1:a
C1:a 1:w
© Markus Endler
p2 p32:1:a
3:1:wp2 p3
2:1:a
3:1:w
(A) General traidor (B) Comandante traidor
as duas configuração não são distinguíveis para P2.
O Problema do Acordo BizantinoEsboço da Prova:Em (A) C esta correto. Pelo Requisito de Integridade, P2 precisa
decidir o valor recebido de C. C P2 ã di ti d fi õ (B) i d idiComo P2 não distingue as duas configurações, em (B) vai decidir
também pelo valor recebido de CO mesmo se aplica ao P3 correto (que não sabe se C ou P2 é o
traidor). Logo P3 sempre decidiria pelo valor recebido de C.Mas então, no caso (B), P2 e P3 teriam decidido por valores
distintos (w e a), o que contradiz o Requisito de Acordo. Logo, não pode existir solução.
© Markus Endler
Note que o problema todo está no fato de que no caso (A), o processo P3 forjou a informação recebida de C, e que P2 é incapaz de distinguir os dois casos.
Obs: Se os generais usarem assinaturas digitais em suas mensagens (ou seja, as mensagens originais não puderem ser forjadas), então o PGB para N=3*f tem solução.
9
O Problema do Acordo BizantinoPease,Shostak,Lamport mostraram que o problema de
impossibilidade do PGB para qualquer N ≤ 3*f é redutível ao problema N=3 e f=1ao problema N=3 e f=1.
Idéia:Faça 3 processos P1,P2 e P3 simularem o comportamento
de n1, n2, n3 generais, respectivamente, tal que:n1+n2+n3 = N n1, n2, n3 ≤ N/3 + 1P t i l t t d
© Markus Endler
Processos corretos simulam o comportamento de generais corretosUm dos processos só simula generais traidores (possível, pois como no máximo f generais são traidores, N ≤ 3*f e n1, n2, n3 ≤ N/3 +1 )
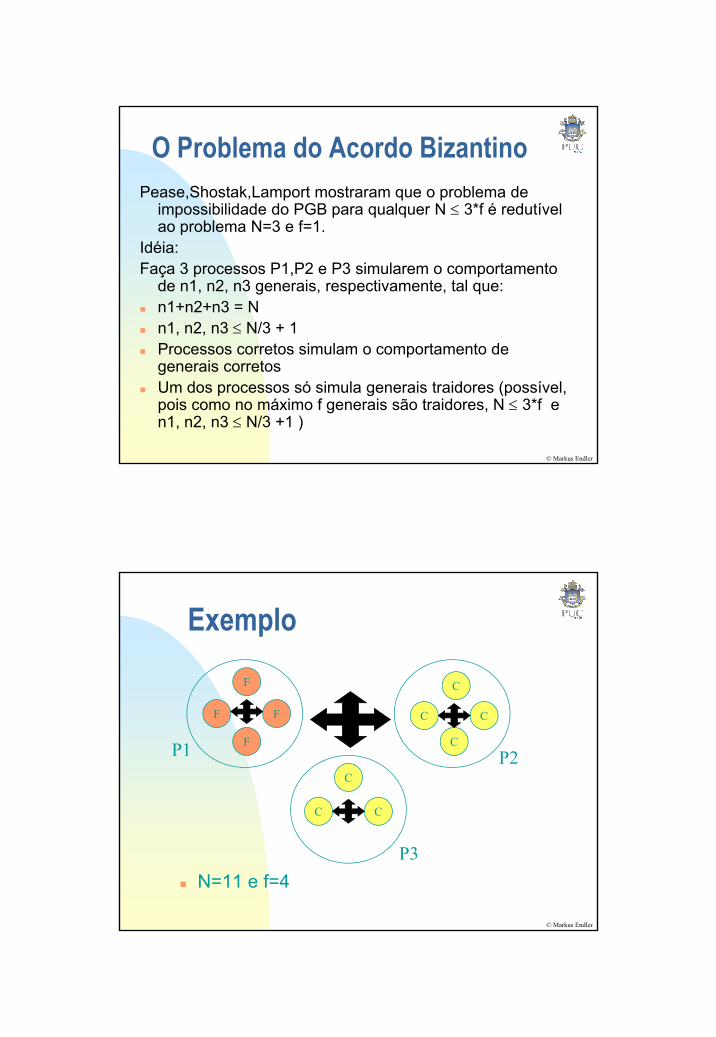
ExemploF C
F F
F
C
C
C
C
CC
P1 P2
© Markus Endler
N=11 e f=4
CC
P3

10
O Problema do Acordo Bizantino
Como supostamente o programa de simulação dos generais tá t i l ã t iestá correto, a simulação termina.
Suponha que os N – f generais corretos conseguissem chegar ao consenso.
Neste caso, os processos simuladores correspondentes teriam chegado ao consenso (pegando o valor decidido pelos seus generais simulados) o que contradiz o
© Markus Endler
pelos seus generais simulados), o que contradiz o resultado para N=3 com f=1.
O Problema do Acordo BizantinoA solução para N=4 e f=1 requer apenas 2 (e.g f+1) rodadas.
0a rodada: comandante difunde os comandos
C
p2 p3
1:a 1:a
2:1:a
3:1:u
C
p2 p3
1:u 1:w
2:1:u
3:1:w
1:a
4:1:a 4:1:a 4:1:a 4:1:a
1:a
1a rodada:
© Markus Endler
(A) General traidor (B) Comandante traidor
p42:1:a 3:1:w
p42:1:u 3:1:w

11
O Problema do Acordo BizantinoC
1:u 1:w1:a2a rodada:
p33:1:u
3:1:w
Msgs do traidor:
p2 p3
p4
4:3:1:w
2:3:1:u
2a rodada:2:4:1:ap2 p3
p4
4:3:1:w
2:3:1:w
4:2:1:u 3:2:1:u
3:4:1:a
P3 é traidor! C é traidor!
© Markus Endler
(A) General traidorp
P2 terá obtido:• 1:a• 3:1:u• 4:1:a• 4:3:1:w
P4 terá obtido:• 1:a• 3:1:w• 2:1: a• 2:3:1:u
(B) Comandante traidorp
P2 obterá:• 1:u• 3:1:w• 4:3:1:w• 3:4:1:a
P3 obterá:• 1:w• 4:1:a• 2:3:1:w• 4:2:1:u
P4 obterá:• 1:a• 2:1:u• 3:2:1:u• 2:3:1:w
O Problema do Acordo BizantinoVejamos os 2 casos:
(A): todos os corretos terão recebido N-2 versões do valor(A): todos os corretos terão recebido N 2 versões do valor proposto por C e terão recebido valores inconsistentes do processo traidor (P3).
(B): todos os corretos terão recebido valores inconsistentes do Comandante, concluindo que este é o traidor.
Em ambos os casos, aplicando-se a função maioria* sobre os valores originalmente propostos pelo Comandante, chega-se
© Markus Endler
g p p p g• ao mesmo valor ou • valor default quando não há valor majoritário, p.ex.
maioria(u,a,w) = w
• Portanto, cada um dos generais corretos irá tomar a mesma decisão (atacar ou esperar).

12
O Problema do Acordo BizantinoO Algorítmo Geral funciona em f+1 rodadas:1. Comandante C manda comando para todos2. Em cada rodada, um general P difunde os valores recebidos de Q
para todos demais, exceto C e Q3. Todos os generais executam maioria sobre todas as msgs recebidasObs: Se um processo deixar de enviar em uma rodada, considera-se que
enviou ⊥
A Eficiência de uma solução para o PGB é dada pelo:Número de rodadasQuantidade de mensagens (e seu tamanho) necessárias
© Markus Endler
O número de rodadas mínimo é f+1 [Fischer&Lynch82].no algorítmo acima o número de mensagens é O(Nf+1), mas existem otimizações, em especial, se as mensagens contém assinatura digital, pode-se obter número de mensagens = O(N2)O alto custo do algoritmo só se justifica em sistemas em que há problemas de segurança. Se defeitos são de hardware, então falhas não são realmente arbitrárias.
Consenso: Impossibilidade em Sistemas Assíncronos[Fischer,Lynch,Peterson85] mostraram que o consenso
em um sistema assíncrono (com a possibilidade de um único processo falho tipo “fail-stop”) não tem solução, isto é, não existe algoritmo que garanta o consenso em qualquer processamento.
Principal Razão:Consenso com falha (crash, arbitrária) requer que cada processo receba um conjunto completo de valores de todos os demais processos corretos só assim consegue criar uma base idêntica de valores
© Markus Endler
gpara a tomada de decisão comum.Devido a inexistência de um limite superior para o tempo de comunicação, não é possível distinguir uma falha de processo (fail-stop), de uma mensagem muito demorada (falha de temporização)

13
Consenso: Impossibilidade em Sistemas AssíncronosA idéia da prova da impossibilidade:Assume-se a existência de um adversário “muito
esperto” que seria capaz de perpetuar p q p p pindefinidamente a execução do protocolo através de:
Atraso imprevisível de mensagens em determinados momentosAceleração ou retardo da velocidade de um processo de forma que este permaneça sempre fora de sincronia com a atividade dos demais processos
Mesmo que seja muito improvável que exista uma rede
© Markus Endler
q j p q(ou usuário) que seja capaz de interferir no consenso de forma tão metódica e ágil o consenso não pode ser garantido...
... mesmo que (na maioria dos casos) o consenso possa ser alcançado.
Abordagens para lidar com a ImpossibilidadeLevando em conta que:
o consenso é um serviço fundamentala maioria dos sistemas são assíncronos
Como resolver? Possíveis abordagens:Eliminar a possibilidade de falhas “fail-stop”:
Idéia: Manter o estado atualizado de cada processo em memória persistente. Após uma falha, processo é reiniciado a partir do estado salvo. Os demais processos só percebem um atraso na execução do processo
Usar detectores de falha (a seguir...)Usar algoritmos randômicos
© Markus Endler
Usar algoritmos randômicosIdéia: Comportamento randômico do algoritmo impede que o adversário esperto consiga sistematicamenteimpedir o consensoObs: Não vai garantir que consenso seja sempre alcançado, mas com certa probabilidade (dependendo do sistema) e após tempo T, todos os processos saberão se consenso foi ou não atingido.

14
Outros ModelosO modelo síncrono é muito restrito (e.g. muito “otimista”),
o modelo assíncrono é muito geral (“pessimista”)Isto levou pesquisadores a definirem modelosIsto levou pesquisadores a definirem modelos
intermediários entre os dois, e que não estão sujeitos ao teorema da impossibilidade de FLP, por fazerem hipóteses sobre as falhas de temporização (delays arbitrários na execução ou comunicação).
São eles:Modelo de sincronia parcial (partially synchronous
© Markus Endler
Modelo de sincronia parcial (partially synchronous model)Modelo de assincronia temporal (timed asynch. model)Modelo assíncrono com detectores de falha(*)(*) um detector de falhas pode suspeitar da falha de um processo, e pode errar se esse estiver correto
Outros Modelos
Modelo de sincronia parcial (partially synchronous)“...existe um momento t a partir do qual não existem mais falhas de temporização”
Modelo de assincronia temporal (timed asynchonous model)“...a execução do sistema alterna entre períodos de estabilidade e instabilidade, sendo que no primeiro não correm falhas de temporização.”
© Markus Endler
Modelo assíncrono com detectores de falha“... existe um momento t a partir do qual um processo correto nunca mais é suspeito de estar faltoso, por qualquer outro processo correto.”

15
Detectores de FalhaUm Detector de Falha (DF) é um serviço que pode ser consultado
para informar sobre o estado de qualquer processo P.Retorna um de dois possíveis valores:
DF(P) = Suspected(P), Unsuspected(P), onde:DF(P) Suspected(P), Unsuspected(P), onde:Suspected(P) :: há indícios de que P esteja falho (“crashed”)Unsuspected(P):: há indícios de que P esteja correto (ativo)
A maioria dos DF não fornece quaisquer garantias sobre a informação fornecida, isto é, são não-confiáveis (“Unreliable FD”), podendo ser:Imprecisos: podem suspeitar de processos ainda ativos (falso positivo)
© Markus Endler
positivo)Incompletos: podem deixar de identificar processos falhos
Definição: DF confiáveis (DFC) são completos, e cujos valores retornados são:
DFC(P) = Failed(P), Unsuspected(P), onde:Failed(P):: significa que o DFC definiu que P está falho (mesmo que de fato esteja correto)Unsuspected(P):: como no caso de DF
Detectores de Falha: ImplementaçãoDF geralmente são implementados através de processos
(threads) monitores executando em cada nóa cada T unidades de temp, difunde uma mensagem “heartbeat” para todos os demais monitores do grupo“heartbeat” para todos os demais monitores do grupoSe um monitor não recebe um sinal de vida de um outro monitor P após T+ k*D desde a última mensagem recebida, então este retorna Suspected(P)O processo de aplicação consulta o DF local, e recebe uma lista dos processos suspeitos.
© Markus Endler
DF
Appl. P alive?
DFheartbeat

16
Detectores de Falha: ImplementaçãoEm sistemas assíncronos, não há nenhuma garantia de que
mensagens serão transmitidas em D unidades de tempo.Se T for pequeno demais:
Aumenta a probabilidade de suspeitas falsasAumenta a probabilidade de suspeitas falsasAumenta o tráfego na rede
Se T for grande demais:Processos falhos podem demorar para serem descobertosFalhas transientes podem permanecer desapercebidas
Na prática usa se um ajuste dinâmico do timeout:
© Markus Endler
Na prática, usa-se um ajuste dinâmico do timeout:p.ex. Se heartbeat chega após T+D(mas antes de T+2D) ajusta-se proximo timeout para T+2D, até um certo limite, de T+ n*D.
Obs: Em sistemas síncronos, os DF são sempre confiáveis: usa-se D = tempo máximo de transmissão de msgs
Detectores de Falha & ConsensoOs algoritmos mais populares para consenso usam um
DF.
A idéia central:Desconsiderar as mensagens de um membro do grupo suspeito de ter falhado (“fail-silent”). Desvantagem: se DF é impreciso, então pode-se ter suspeitas falsas, e possivelmente reduz-se desnecessariamente o número de processos
© Markus Endler
Usando um DF embute-se todo tratamento temporal no DF e simula-se um sistema síncrono.
Esta abordagem é usada em alguns serviços para comunicação de Grupo (p.ex. ISIS/Cornell)

17
Detectores de Falha & Consenso[Chandra,Hadzilacos,Toueg96] desenvolveram um
algoritmo para consenso em sist. assíncronos que usa um DF não-confiável e que permite que processos suspeitos (erroneamente) continuemprocessos suspeitos (erroneamente) continuem participando do grupo, e:mostraram que o consenso em um sist. assíncrono pode ser atingido com estes DF, contanto que f < N/2 e que a comunicação seja confiávele definiram 8 classes de DF, segundo as propriedades de Completude e Precisão.
© Markus Endler
Referências:[Chandra,Toueg,94]. Chandra, Toueg: Unreliable Failure Detectors for Reliable Distributed Systems (1994), Journal of the ACM, 1994.[Chandra,Hadzilacos,Toueg,96] The weakest failure detector for solving Consensus, (1996), http://citeseer.ist.psu.edu/chandra96weakest.html
Detectores de Falha & ConsensoCompletude (Completeness):
Forte: Qualquer processo falho em algum momento é suspeitado permanentemente por todos os processos corretos.Fraca: Qualquer processo falho em algum momento é suspeitado permanentemente por algum processo correto.
Precisão (Accuracy) Fraca, Forte, Eventualmente Fraca e Eventualmente Forte:
Forte: Qualquer processo correto nunca é apontado (suspeito) de falha por algum outro processo. Fraca: Algum processo correto nunca é suspeito de falha.
© Markus Endler
Fraca: Algum processo correto nunca é suspeito de falha.Event. Forte: Depois de certo tempo, qualquer processo correto não é apontado (suspeito) de falha por algum outro processo.Event. Fraco: Depois de certo tempo, algum processo correto não será suspeito por algum outro processo.

18
Detectores de Falha & ConsensoStrong Accuracy
WeakAccuracy
Eventual Strong Acc.
Eventual WeakAccuracy
Strongcompleteness
Perfect P
Strong S P S
O “Eventually Weak FD (EWFD)”, W é aquele que têm as propriedades mínimas necessárias para o consenso:
Completude Fraca: após um certo tempo, cada processo falho será suspeito por algum processo correto Precisão EW: após um certo tempo pelo menos um
p
Weak Completeness
Q Weak W Q W
© Markus Endler
Precisão EW: após um certo tempo, pelo menos um processo correto não é suspeito de falha por qualquer processo correto
Chandra&Toueg também mostraram que não é possível implementar um EWFD em sistemas assíncronos apenas com o envio de mensagens.Mas mostraram que o DF com time-outs adaptativos é uma ótima aproximação para o EWFD
O Algorítmo de Chandra&TouegEm vez de W, vamos mostrar o algoritmo que
funciona para um FD um pouco mais forte, o S (Eventual-weak Accuracy & Strong Completeness)
Completude Forte: Qualquer processo falho em algum momento é suspeitado permanentemente por todos os processos corretos.Precisão Eventualmente Fraca: Depois de certo tempo, algum processo correto não será suspeito por algum outro processo
© Markus Endler
por algum outro processo.

19
O Algorítmo de Chandra&TouegPrincípio (para cada consenso):
Executa um número indefinido de rodadas assíncronas r, onde em cada rodada um dos N processos faz o papel de coordenador (usa Paradigma do Coordenador Rotativo)coordenador (usa Paradigma do Coordenador Rotativo)Todos os processos sabem qual processo será o coordenador na rodada r. Exemplo: c = (r mod N) +1Em vez de executar uma função comum f(v1,v2,..,vN), o coordenador da rodada corrente sugere como valor de decisão d um dos vis recebidos (estimativa g) e difunde-os para os demais, Cada Pi que recebe valor do coordenador “muda de
© Markus Endler
Cada Pi que recebe valor do coordenador muda de opinião”, re-setando o seu valor proposto vi ← g e envia uma confirmação.O coordenador tenta coletar (n+1)/2 confirmações, e se conseguir, congela g como novo valor de decisão e difunde de forma confiável o g como resultado do consenso para todos.
O Algorítmo de Chandra&TouegCada consenso consiste de 4 etapas (que podem demorar
várias rodadas):1) Cada processo Pi envia o seu vi com o seu número de
rodada atual para o “coordenador da vez” Crodada atual para o coordenador da vez C2) C recolhe (n+1)/2 mensagens, escolhe o valor g com
o maior time-stamp, e difunde este valor para todos Pi i∈[1,N]
3) Em cada Pi pode acontecer:1) Recebe g de C ⇒ adota g como seu valor e retorna
ack para C2) Seu DF notifica: Suspected(C) ⇒ envia um NACK
© Markus Endler
2) Seu DF notifica: Suspected(C) ⇒ envia um NACK para C
4) Se C receber (n+1)/2 ACKS, faz multicast confiável(1)
para todos indicando o valor escolhido
(1) Garante que se um processo correto entregou m, então todos os processos corretos em algum momento entregam m.
20
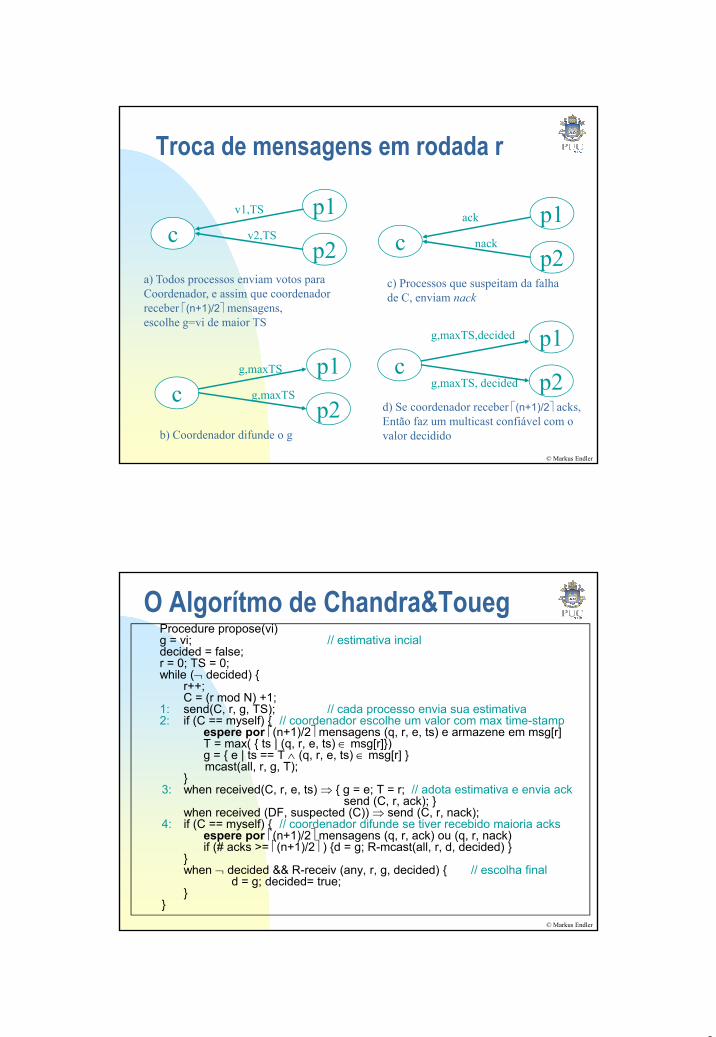
Troca de mensagens em rodada r
p1v1,TS p1ack
cp2
v2,TS
a) Todos processos enviam votos para Coordenador, e assim que coordenador receber (n+1)/2 mensagens, escolhe g=vi de maior TS
cp2
pnack
c) Processos que suspeitam da falha de C, enviam nack
p1g,maxTS,decided
© Markus Endler
cp2
p1g,maxTS
g,maxTS
b) Coordenador difunde o g
cp2
p1
g,maxTS, decided
d) Se coordenador receber (n+1)/2 acks, Então faz um multicast confiável com o valor decidido
O Algorítmo de Chandra&TouegProcedure propose(vi)g = vi; // estimativa incialdecided = false;r = 0; TS = 0;while (¬ decided)
r++;;C = (r mod N) +1;
1: send(C, r, g, TS); // cada processo envia sua estimativa2: if (C == myself) // coordenador escolhe um valor com max time-stamp
espere por (n+1)/2 mensagens (q, r, e, ts) e armazene em msg[r] T = max( ts | (q, r, e, ts) ∈ msg[r])g = e | ts == T ∧ (q, r, e, ts) ∈ msg[r] mcast(all, r, g, T);
3: when received(C, r, e, ts) ⇒ g = e; T = r; // adota estimativa e envia ack
send (C, r, ack); when received (DF suspected (C)) ⇒ send (C r nack);
© Markus Endler
when received (DF, suspected (C)) ⇒ send (C, r, nack); 4: if (C == myself) // coordenador difunde se tiver recebido maioria acks
espere por (n+1)/2 mensagens (q, r, ack) ou (q, r, nack)if (# acks >= (n+1)/2 ) d = g; R-mcast(all, r, d, decided)
when ¬ decided && R-receiv (any, r, g, decided) // escolha final
d = g; decided= true;

21
Terminação de Chandra&TouegProposição: Cada processo correto eventualmente chega ao estado
decided.
Dois Casos:a) Se um Pi correto decide, então este executou R-receive
(..,decided). Pela propriedade de R-mcast, todos decidem.b) Nenhum processo correto em algum momento decide. Precisa-
se mostrar que isto não ocorre: 1. Que nenhum processo correto fica indefinidamente
bloqueado em qualquer comando “espere”.2 Que existe um processo coordenador que recebe (n+1)/2
© Markus Endler
2. Que existe um processo coordenador que recebe (n+1)/2acks
Terminação de Chandra&TouegProva de 1: • Seja r a menor rodada em que um processo correto fica
bloqueado. Logo todos os processos corretos executaram etapa 1 da rodada r e enviaram ((n+1)/2) estimativas para C. (pois etapa 1 não é afetada pelo bloqueio)etapa 1 não é afetada pelo bloqueio).Como comunicação é confiável, em algum momento C recebe todas as estimativas e executa mcast(all, r, e, T), que faz com que todos os corretos eventualmente recebam a mensagem e não fiquem bloqueados. Se C falhar, devido a completude forte de S, para todos os processos corretos, existe um momento em que a falha de C é permanentemente detectada (suspected(C))Portanto nenhum processo correto fica bloqueado na etapa 3 e
© Markus Endler
Portanto, nenhum processo correto fica bloqueado na etapa 3, e todos enviam ACK ou NACK para C. Como existem ((n+1)/2) corretos, C também não pode ficar bloqueado na fase 4.Logo, todos os processos corretos irão completam a rodada r.

22
Terminação de Chandra&TouegProva de 2: Existência de um Pi que decide:
Como DF satisfaz Precisão EW, existe um processo Q e um instante de tempo τ, de forma que nenhum processo correto suspeita da falha de Q. Seja t’ > τ tal que todos os processos falhos já falharam (e Q não foi suspeitado).Então deve existir uma rodada r tal que:
Todos os processos corretos chegam à rodada r > t’Q é o coordenador de r, ou seja Q = (r mod N) +1
Nesta rodada r, todos os processos corretos enviam suas estimativas para Q, que difunde a de maior TS. Como nenhum suspeita de Q em r, (n+1)/2 mandam um ack para Q, que
© Markus Endler
p ( ) p qexecuta o R-mcast para todos. Devido às propriedades do R-mcast, em algum momento todos irão executar o R-receive, e vão chegar ao estado “decided”.
Chandra & Toueg em Rede MóvelSolving The consensus problem in a Mobile Environment, N.
Badache, M. Hurfin, R. Macedo, Publication Interne 1146, IRISA FrançaIRISA, França
Modelo de Rede móvel estruturada (MHs e MSSs)Cada um dos N MHk propõem um valor vk e todos os MHs precisam concordar sobre mesmo conjunto de valores MSSs são os representantes de todos os MHs em sua área de cobertura (isto pode mudar handover)
© Markus Endler
MSSs vão coletando os votos dos MHs, executam o algoritmo de consenso, e assim que o conjunto de valores propostos fica estável entram no estado decided , e notificam os MHs do resultado

23
O Algoritmo PaxosPaxos [Lamport, 98] é outro algoritmo para consenso de
N processos baseado no paradigma do líder.Usa o detector de falha Ω, que retorna somente um valor -Usa o detector de falha Ω, que retorna somente um valor
o de um processo correto, e garante:Existe um momento t a partir do qual existe extamente um processo correto PL que nunca é suspeito por qualquer outro processo correto.
Idéia basica do Paxos: A cada momento cada processo considera um processo correto (PL) como líder
© Markus Endler
p ( )(escolhido por Ω) , e é este líder que tenta chegar ao consenso. Se PL falha, em algum momento Ω vai selecionar outro processo correto como líder.
L. Lamport, The Part-Time Parliament, ACM Transactions on Computer systemsNr. 16, 2, May 1998. começa: “Recent archeological discoveries on the island of Paxos reveal that the parliament functioned ...”
PaxosSe um processo Pi se considera líder, inicia um novo
“round”, que pode assumir valores(*):RoundNumber (RN): i, i+n, i+2n, i+3n, ... etc.
Desta forma, cada número de rodada será único. Isto é necessário, pois vários processos podem se considerar líderes simultaneamente, e portanto, vários consensos podem estar acontecendo concomitantemente.
Cada rodada consiste de 2 fases:1 Líder verifica se os participantes ainda não participaram de um
© Markus Endler
1.Líder verifica se os participantes ainda não participaram de um consenso com número de rodada maior ,e espera por confirmação da maioria (se recebe um NACK, aborta e passa para nova rodada).2. Líder envia um accept_req para os participantes com o valor de consenso proposto, e espera por confirmação da maioria, Se recebeu, confirma para todos.

24
PaxosFase 1:
Líder difunde “prepare(RN)” para todosParticpante aceita, i.e. responde com ACK (v, RN) (*) sse:
RN é i d t d itRN é maior do que qq proposta de consenso aceita eainda não aceitou a nenhuma proposta com número de rodada > RN
Senão,responde com NACK, e rejeita o (*) o ACK vem com o RN do momento em que a proposta foi aceitaLíder espera a resposta de pelo menos N+1/2. Se só recebeu ACK, decide qual é o valor a ser porposto, senão aborta o processo
© Markus Endler
q p p pe recomeça Fase 1 com RN+n.
Fase 2:Líder difunde msg “accept (d)”, e espera resposta da maioria com ACK. Se for o caso, difunde a msg decided, senão aborta o consenso e redefine o RN
Paxos
PL prepareACKConfirmed accept ACK -Voted Succeed
Propose(v) Decided(d))
PL
P2
P3
© Markus Endler
P4Fase 1 Fase 2

25
Consistência InterativaÉ uma variante do problema do consenso.Para N processos, todos os processos corretos devem entrar
em acordo sobre um vetor de valores v[N], onde cada l d [i] d lelemento do vetor v[i] corresponde ao valor proposto por
processo Pi. Exemplo: v[i] poderia conter o estado de Pi (correto ou
faltoso)
Requisitos da Consistência Interativa CI(v1,v2,..,vN):Terminação: em algum momento todo processo correto h t d “d id d”
© Markus Endler
chega ao estado “decided”;Acordo: O vetor de todos os processos corretos no estado “decided” é idêntico;Integridade: Se Pi está correto e vP[i]=x, então todos os processos Q tem vQ[i]=x.
Equivalência dos ProblemasDe fato, Consenso (C),o PGB e a CI são equivalentes.
Assuma que existem algoritmos que resolvam:
Ci(v1 v2 vN) retorna o valor de decisão de Pi ondeCi(v1,v2,..,vN) retorna o valor de decisão de Pi, onde v1,v2,..,vN são os valores propostos pelos processos
PGBi(j,v) retorna o valor de decisão de Pi para a proposta de Pj (o comandante)
CIi(v1,v2,..,vN)[j] retorna o j-ésimo valor do vetor de decisão de Pi, onde v1,v2,..,vN são os valores propostos pelos
© Markus Endler
de Pi, onde v1,v2,..,vN são os valores propostos pelos demais processos
Sem perda de generalidade, pode-se assumir que um processo incorreto/traidor propõem um único valor possível (mas incorreto1) para todos, em vez de diferentes valores para cada um.
(1) incorreto = que impede a decisão coordenada

26
Equivalência dos ProblemasConstruindo uma solução a partir de outra conhecida:
CI usando PGB:Execute PGB N vezes uma vez para cada processo noExecute PGB N vezes, uma vez para cada processo no papel de comandante, e use
CIi(v1,v2,..,vN)[j] = PGBi(j,vj)
Consenso usando CI:Execute CI e calcule o valor de decisão usando maioria dos elementos do vetor acordados, ou sejaCi(v1,v2,..,vN)= maioria(CIi(v1,v2,..,vN)[1], .. CIi(v1,v2,..,vN)[N])
© Markus Endler
i 1 2 N i 1 2 N i 1 2 N
PGB usando Consenso:O comandante Pj envia o seu valor para os demais e para sí próprio, e todos executam o consenso para os valores v1,v2,..,vN que receberam, e cada Pi decide:
PGBi(j,v) = Ci(v1,v2,..,vN) para i=1,..N
Segundo Trabalho de AD’08Relatório de simulações: 23/06Demonstração: 30/06
Tarefa:Implementar o algoritmo de Chandra, Hadzilacos & Toueg para consenso em sistemas assíncronosSistema simulado:
Comunicação confiável (não há perda de mensagens)No envio de qualquer mensagem p/outro processo escolhe-se um atraso arbitrárioP it té /2 f lh t d
© Markus Endler
Permite-se até n/2 falhas permanentes de processos (pe.x. sorteie quais processos poderão falhar)Ativação de consenso simultânea em todos os processos (por comunicação ou mecanismo sem atraso)