boletim de anÁlises estatÍstico basta 2017 vol. 2 · do idh como medida do grau de...
TRANSCRIPT

PONTIFÍCIA UNIVERSIDADE CATÓLICA DE SÃO PAULO
Programas de Pós Graduação em
Economia e
Administração da
PUC-SP
BOLETIM DE ANÁLISES ESTATÍSTICO
BASTA 2017 Vol. 2
IDHEs ÍNDICE DE DESENVOLVIMENTO HUMANO ESTADUAL
ATLAS BRASIL
DISCIPLINA: MÉTODOS QUALITATIVOS E QUANTITATIVOS DA PESQUISA EMPÍRICA PROF. ARNOLDO JOSÉ DE HOYOS GUEVARA
Odair Gomes Salles
1º SEMESTRE
São Paulo – SP
2017
A Importância e Impacto da Esperança de Vida, Renda e Vulnerabilidade no País.

2
SUMÁRIO
INTRODUÇÃO ............................................................................................................ ...............4
CAPÍTULO I. DESENVOLVIMENTO HUMANO: IDHM, VARIÁVEIS E DADOS...............5
1.1 Conceito de Desenvolvimento Humano ..................................................................... ............5
1.2 Índice de Desenvolvimento Humano ......................................................................................5
1.3 Índice de Desenvolvimento Humano Municipal Brasileiro ....................................................6
CAPÍTULO II. ENTENDENDO OS DADOS .............................................................................7
2.1 Os Indivíduos .........................................................................................................................7
2.2 As Variáveis ...........................................................................................................................7
2.3 População ...............................................................................................................................8
2.4 As Variáveis em termos do significado ................................................................................ 10
2.5 O tipo de variável e sua unidade de medida.......................................................................... 14
CAPÍTULO III. ANÁLISE EXPLORATÓRIA DAS VARIÁVEIS .......................................... 15
3.1 As Variáveis dos IDHs: ........................................................................................................ 18
3.2 Variável Expectativa de Vida (ESPVIDA)............................................................................ 19
3.3 Variável Mortalidade Infantil (MORT1)............................................................................... 20
3.4 Taxa de analfabetismo - 25 anos ou mais (T_ANALF25M)................................................. 21
3.5 Variável % de 25 anos ou mais com fundamental completo (T_FUND25M)...................... 21
3.6 Variável Renda per capita (RDPC) ........................................................................................23
3.7 Variável Renda per capita média dos extremamente pobres (RIND).................................... 24
3.8 Variável Grau de formalização dos ocupados – 18 anos ou mais (P_FORMAL) .................25
3.9 Variável Rendimento médio dos ocupados – 18 anos ou mais (RENOCUP) .......................26
3.10 Variável % da População em domicílios com banheiro e água encanada
(T_BANAGUA) .............................................................................................................. ...........27
3.11 Variável % da População em domicílios com densidade>2 (T_DENS) .............................28
3.12 Variável % de 15 a 24 anos que não estudam, não trabalham e são vulneráveis à
pobreza (T_NESTUDA_NTRAB_MMEIO) .............................................................................29
3.13 Variável % de pessoas em domicílios vulneráveis à pobreza e em que ninguém tem
fun-damental completo (T_FUNDIN_TODOS_MMEIO) ........................................................30
3.14 Variável % de mães chefes de família sem fundamental completo e com filhos
menores de 15 anos (T_MULCHEFEFI014) ..............................................................................31
3.15 Variável PEA – 18 anos ou mais (PEA18M) ......................................................................32
CAPÍTULO IV. ANÁLISE COMPARATIVA DA ANÁLISE DESCRITIVA ......................... 33
CAPÍTULO V. CORRELAÇÃO DAS VARIÁVEIS ................................................................ 36
CAPÍTULO VI. GRÁFICOS DE DISPERSÃO ........................................................................ 40
CAPÍTULO VII. DENDROGRAMA ........................................................................................ 41
CAPÍTULO VIII. ANÁLISE DE TENDÊNCIAS ..................................................................... 42
8.1 Os Indivíduos ....................................................................................................................... 42

3
8.2 As Variáveis ......................................................................................................................... 42
8.3 A fonte e o tamanho da série de dados ................................................................................. 43
CAPÍTULO IX. ANÁLISE DAS VARIÁVEIS BANCO DE DADOS IBGE ........................ ...44
9.1 Variável: Taxa de analfabetismo de pessoas de 10 anos ou mais (%) ...................................43
9.1.1 Análise de tendência da variável .........................................................................................43
9.1.2 As previsões ........................................................................................................................44
9.2 Variável: Escolaridade de 15 anos ou mais – População ocupada ........................................46
9.2.1. Escolaridade de 15 anos ou mais – População ocupada.....................................................46
9.2.2 As previsões ........................................................................................................................47
9.3 Variável: Investimento ...........................................................................................................48
9.3.1 Investimento .......................................................................................................................48
9.3.2 As previsões........................................................................................................................ 49
CAPÍTULO X. ANÁLISE DE REGRESSÃO LINEAR MULTIVARIADA ............................ 52
10.1 Relações entre variáveis ..................................................................................................... 52
10.2 Apresentação de relações entre variáveis ........................................................................... 52
10.3 Regressão ........................................................................................................................... 53
CAPÍTULO XI. COMPARAÇÃO E TESTES DE HIPÓTESES ............................................... 58
CAPÍTULO XII. PESQUISA POR AMOSTRAGEM ............................................................... 66
CAPÍTULO XIII. ANÁLISE DOS COMPONENTES PRINCIPAIS ........................................ 74
CAPÍTULO XIV. COMPARAÇÃO DE MÉDIAS E ANÁLISE DE CLUSTER ...................... 84
14.1 Um Novo Mapa Do Brasil .................................................................................................. 92
CAPÍTULO XV. ANÁLISE DISCRIMINANTE ...................................................................... 92
CAPÍTULO XVI. OS DIFERENTES BRASIS........................................................................ 103
CAPÍTULO XVII. REGRESSÃO LOGÍSTICA ...................................................................... 113
CAPÍTULO XVIII. ANÁLISE DE CORRESPONDÊNCIA ................................................... 126
18.1 Preparação Dos Dados .......................................................................................................126
18.2 A Análise De Correspondência Por Estados Para As 7 Variáveis..................................... 127
18.3 Análise De Correspondência Por Região Para As 7 Variáveis.......................................... 129
18.4 Análise De Correspondência Por Novos Agrupamentos (3 Clusters) Para As 7
Variáveis ....................................................................................................................................134
18.5 Análise De Correspondência Por Estado Para As 3 Variáveis Analisadas No Trabalho
AnteriorDe Regressão Logística ...............................................................................................140
18.6 Comentários sobre a Análise de Correspondência............................................................. 142
APÍTULO XIX. RANKING POR ESTADOS..........................................................................148
CAPÍTULO XX. RANKING POR ESTADOS............................................... ......................... 148
20.1 Análise dos Principais Componentes ............................................... .................................146
20.2 Análise dos Principais Componentes................................................................................. 148
CONSIDERAÇÕES FINAIS ................................................................................................... 154
REFERÊNCIAS.................................................................................................................. .......156

4
INTRODUÇÃO
O Atlas do Desenvolvimento Humano no Brasil democratiza a informação no âmbito mu-
nicipal e metropolitano. Seu objetivo é instrumentalizar a sociedade. Fortalece as capacidades lo-
cais, o aprimoramento da gestão pública e o empoderamento dos cidadãos. É constituído pelo Atlas
do Desenvolvimento Humano nos Municípios e o Atlas do Desenvolvimento Humano nas Regiões
Metropolitanas. Local de consulta ao Índice de Desenvolvimento Humano Municipal (IDHM) de
5.565 municípios brasileiros, 27 Unidades da Federação (UF), 20 Regiões Metropolitanas (RM) e
suas respectivas Unidades de Desenvolvimento Humano (UDH). Além disso, fornece mais de 20
indicadores de demografia, educação, renda, trabalho, habitação e vulnerabilidade. Os dados dos
Censos Demográficos, dos anos de 1991, 2000 e 2010 (ATLAS BRASIL, 2017).
O Atlas consolida um diálogo informado e embasado sobre o desenvolvimento a partir de
uma referencia utilizada internacionalmente, o Índice do Desenvolvimento Humano (IDH). De-
senvolvimento Humano é o processo de ampliação das liberdades das pessoas, com relação às suas
capacidades e as suas oportunidades a seu dispor, para que elas possam escolher a vida que dese-
jam ter. Tanto o conceito como sua medida o IDH, foram apresentados em 1990 no Programa das
Nações Unidades para o Desenvolvimento (PNUD). Idealizado pelo o economista paquistanês
MahbubulHaq e colaboração do economista Amartya Sen (ATLAS BRASIL, 2017).
O Atlas permite transparência aos processos de desenvolvimento em importantes temas
sociais. Possibilita o acompanhamento dos caminhos trilhados nos últimos 20 anos e análises para
traçar o futuro. A audiência principal está organizada em cinco categorias: (1) gestores estaduais
e municipais, uma forma de identificar regiões que necessitam de intervenções, políticas e ações
especificas; (2) atores municipais, apoio ao diagnóstico aos principais desafios municipais; (3)
pesquisadores, nosso caso, estudo das políticas públicas, identificação de programas bem-sucedi-
dos e mapeamento de desafios e oportunidades; (4) sociedade civil e setor privado, orienta a alo-
cação de recursos e definição de público-alvo para as ações de desenvolvimento; e (5) cidadãos,
estimulo a participação social.
O presente trabalho tem por objetivo apresentar a análise dos Municípios Brasileiros, to-
mando como fonte de dados o Atlas de Desenvolvimento Humano no Brasil relativo aos índices
do ano de 2010 publicados em 2013. Inicia com uma análise exploratória de dados (AED), das
variáveis que compõem om IDHM em sete dimensões. O software estatístico utilizado é o MI-
NITAB (2016)

5
CAPÍTULO I. DESENVOLVIMENTO HUMANO: IDHM, VARIÁVEIS E DADOS
1.1 Conceito de Desenvolvimento Humano
O processo de expansão das liberdades inclui as dinâmicas sociais, econômicas, políticas e
ambientais. Dinâmicas necessárias para garantir oportunidades as pessoas. Além do ambiente pro-
pício para que cada uma exerça seu potencial. O desenvolvimento humano deve ser centrado nas
pessoas e na ampliação do seu bem-estar. Entendido como a ampliação do escopo das escolhas e
da capacidade e da liberdade de escolher. Nesta abordagem, a renda e a riqueza não são meios para
que as pessoas possam viver a vida que desejam (ATLAS BRASIL, 2017).
O crescimento econômico de uma sociedade não se traduz automaticamente em qualidade
de vida. Porém, observa-se em muitas vezes, as desigualdades. Este crescimento necessita ser
transformado em conquistas concretas para as pessoas: crianças mais saudáveis, educação univer-
sal e de qualidade, ampliação da participação política dos cidadãos, preservação ambiental, equi-
líbrio da renda e das oportunidades entre todas as pessoas, maior liberdade de expressão, entre
outras. Dessa forma as pessoas estão no centro da análise do bem-estar. Redefinindo a maneira
como pensamos sobre e lidamos com o desenvolvimento (ATLAS BRASIL, 2017).
A popularização da abordagem de desenvolvimento humano se deu com a criação e adoção
do IDH como medida do grau de desenvolvimento humano de um país, em alternativa ao Produto
Interno Bruto (PIB), hegemônico, à época, como medida de desenvolvimento (ATLAS BRASIL,
2017).
1.2 Índice de Desenvolvimento Humano
O IDH reúne três dos requisitos mais importantes para a expansão das liberdades das pes-
soas: a oportunidade de se levar uma vida longa e saudável (longevidade), de ter acesso ao conhe-
cimento (educação), e de poder desfrutar de um padrão de vida digno (renda), conforme Figura1.

6
Figura 1 – Desenvolvimento Humano: 3 Dimensões
Fonte: Atlas Brasil (2017)
O IDH obteve grande repercussão mundial devido principalmente à sua simplicidade, fácil
compreensão e pela forma mais holística e abrangente de mensurar o desenvolvimento. Transfor-
mando em um único número a complexidade de três importantes dimensões. A dimensão da lon-
gevidade, diz respeito a ampliação das oportunidades que as pessoas têm de evitar a morte prema-
tura, garantias de ambiente saudável, acesso à saúde de qualidade, para que possam atingir o pa-
drão mais elevado possível de saúde física e mental.A dimensão da educação, diz respeito ao
acesso ao conhecimento, é um determinante crítico para o bem-estar e é essencial para o exercício
das liberdades individuais, da autonomia e da autoestima. E a dimensão da renda, diz respeito ao
padrão de vida. Renda é essencial para acessarmos necessidades básicas como água, comida e
abrigo. A renda é um meio para uma série de fins, possibilita nossa opção por alternativas dispo-
níveis e sua ausência pode limitar as oportunidades de vida (ATLAS BRASIL, 2017).
Em 2012, o PNUD Brasil, o Ipea e a Fundação João Pinheiro assumiram o desafio de adap-
tar a metodologia do IDH Global para calcular o IDH Municipal (IDHM). Posterior ao IDHM dos
municípios brasileiros, as três instituições assumiram o novo desafio de calcular o IDHM a nível
intramunicipal das regiões metropolitanas do país (ATLAS BRASIL, 2017).
1.3 Índice de Desenvolvimento Humano Municipal Brasileiro
O IDHM brasileiro considera as mesmas três dimensões do IDH Global, mas, adequa a
metodologia global ao contexto brasileiro e à disponibilidade de indicadores nacionais. O IDHM
(três componentes: IDHM Longevidade; IDHM Educação; e IDHM Renda), conta um pouco da

7
história dos municípios, estados e regiões metropolitanas em três importantes dimensões do de-
senvolvimento humano durante duas décadas da história brasileira. O IDHM é um número que
varia entre 0 e 1. Quanto mais próximo de 1, maior o desenvolvimento humano de uma unidade
federativa, município, região metropolitana ou UDH (ATLAS BRASIL, 2017).
CAPÍTULO II. ENTENDENDO OS DADOS
Os dados são referentes ao ano de 2010. As variáveis são indicadores agregados que com-
põem o IDH_M e seus componentes IDH_E, IDH_L e IDH_R. Neste sentido, Desenvolvimento
Humano é definido como um conjunto de indicadores que tratam de Educação, Longevidade li-
gada à Saúde e Renda das populações nos municípios. As dimensões educação, longevidade e
econômica são capturadas pelas variáveis que serão discutidas na sequência deste trabalho.
2.1 Os Indivíduos
Os indivíduos desta análise são os 5565 municípios brasileiros que constam na base de
dados do Atlas de Desenvolvimento Humano no Brasil quanto a seus indicadores de Educação,
Longevidade e Renda e, os 232 indicadores disponíveis no portal Atlas Brasil, dados de 2010,
abertos em 08 categorias. Na análise por estados temos 27 estados da federação e, as oito categorias
são compostas por.
Demografia
Educação
Renda Trabalho
Habitação
Vulnerabilidade
População
IDHM
2.2 As Variáveis
A análise exploratória de dados emprega certa variedade de técnicas gráficas e quantitati-
vas. Consiste em organizar, resumir e apresentar os dados de uma determinada amostra. Antiga-
mente era apenas conhecida como estatística descritiva até que John Wilder Tukey (1915 – 2000)
publicou o livro Exploratory Data Analisysem 1977, popularizando o termo. A AED utiliza-se de
tabelas, gráficos e medidas descritivas como ferramentas, utilizadas na etapa inicial da análise para
obter informações que indicam possíveis modelos. Numa fase final estes modelos são utilizados
na inferência estatística.
As variáveis são as características estudas de um determinado fenômeno e, podem ter tipos
diferentes: qualitativas (não numéricas ou categóricas) e quantitativas (numéricas). As variáveis

8
quantitativas podem ser discretas, assumem apenas valores inteiros (ex.: número de irmãos, nú-
mero de filhos, etc.); ou contínuas, assumem qualquer valor no intervalo dos números reais (ex.:
peso, altura, etc.). As variáveis qualitativas podem ser nominais, quando as categorias não possuem
uma ordem natural (ex.: nomes, cores, sexo, etc.); ou ordinais, quando as categorias podem ser
ordenadas (ex.: tamanho – pequeno, médio, grande; grau de instrução – básico, médio, graduação,
entre outros).
Nosso estudo selecionou de forma aleatória 21 variáveis, incluindo a região, unidade da
federação e o nome dos municípios. Na sequência do trabalho descrevemos e explicamos cada
variável; ressalvando-se que os dados desta pesquisa se referem ao ano de 2010.
Dos 232 indicadores que compõem a base de dados disponibilizada no Atlas Brasil, por
metodologia previamente definida, foram escolhidas 02 variáveis de cada uma das 07 classifica-
ções que somadas aos 04 indicadores dos IDHM, incluindo unidade da federação, região e o nome
dos municípios, perfazem o total de 21 variáveis entre categóricas e quantitativas a serem aborda-
das, exploradas e analisadas neste estudo. ; na tabela 1 a seguir temos as dimensões versus indica-
dores e siglas correspondentes segundo definição do Atlas Brasil.
Na busca por esses indicadores procurou-se, mesmo que de forma empírica, uma provável
associação que possa nos levar a conhecer melhor a composição dos dados e, consequentemente,
ter mais subsídios em ações que possam ser adotadas.
2.3 População
População é o conjunto formado pelo total de indivíduos que representam pelo menos uma
característica comum, qual interessa inferir (analisar). Sendo o objetivo da generalização estatís-
tica, comunicar algo em relação as diversas características da população estudada. No nosso caso,
os indivíduos são os 5.565 municípios brasileiros contidos no Censo Demográfico do IBGE –
2010. O critério de seleção foi utilizar o banco de dados do Atlas de Desenvolvimento Humano no
Brasil que disponibiliza o IDHM e 232 indicadores de demografia, educação, renda, trabalho, ha-
bitação e vulnerabilidade. Os dados analisados de cada município são as variáveis tratadas no pró-
ximo tópico.
Tabela 1. Dimensões
DIMEN-
SÃO
TEMA INDICADORES SIGLA
IDHM
IDHM IDHM IDHM
IDHM Educa-
ção
IDHM Renda IDHM_R

9
IDHM Renda IDHM Longevidade IDHM_L
IDHM Longevi-
dade
IDHM Educação IDHM_ E
DEMO-
GRAFIA
Esperança de vida ao nas-
cer ESPVIDA
Mortalidade infantil MORT1
EDUCA-
ÇÃO
Analfabetismo Taxa de analfabetismo –
25 anos ou mais T_ANALF25M
Escolaridade % de 25 anos ou mais com
fundamental completo T_FUND25M
RENDA
Nível/Composi-
ção
Renda per capita RDPC
Pobreza Renda per capita média
dos extremamente pobres RIND
TRABA-
LHO
Posição na Ocu-
pação
Grau de formalização dos
ocupados - 18 anos ou mais P_FORMAL
Rendimento Rendimento médio dos
ocupados - 18 anos ou mais RENOCUP
HABITA-
ÇÃO
% da população em domi-
cílios com banheiro e água
encanada
T_BANAGUA
% da população em domi-
cílios com densidade > 2 T_DENS
VULNE-
RABILI-
DADE
Educação, Tra-
balho e Renda
% de 15 a 24 anos que não
estudam, não trabalham e
são vulneráveis à pobreza
T_NES-
TUDA_NTRAB_MMEIO
% de pessoas em domicí-
lios vulneráveis à pobreza
e em que ninguém tem
fundamental completo
T_FUNDIN_TO-
DOS_MMEIO
POPULA-
ÇÃO
População de
referência dos
indicadores
% de mães chefes de famí-
lia sem fundamental com-
pleto e com filhos menores
de 15 anos
T_MULCHEFEFIF014
PEA – 18 anos ou mais PEA18M
Fonte: Atlas do Desenvolvimento Humano do Brasil (Minitab 2016)
10
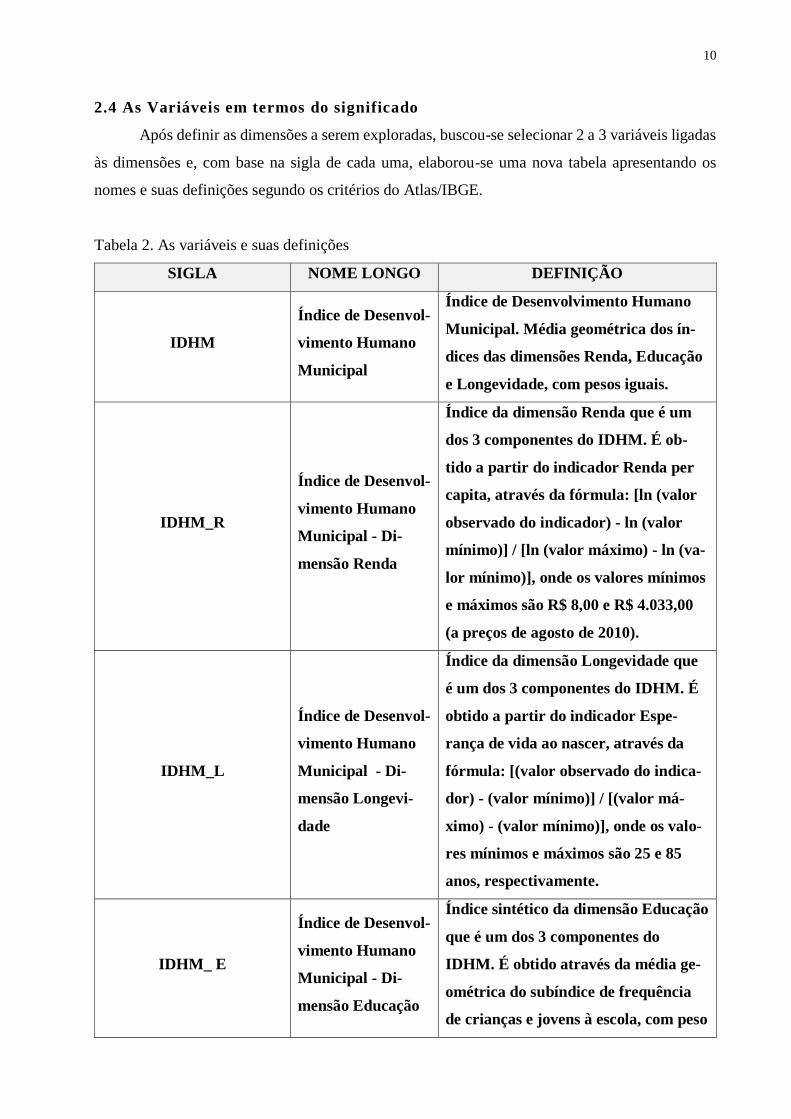
2.4 As Variáveis em termos do significado
Após definir as dimensões a serem exploradas, buscou-se selecionar 2 a 3 variáveis ligadas
às dimensões e, com base na sigla de cada uma, elaborou-se uma nova tabela apresentando os
nomes e suas definições segundo os critérios do Atlas/IBGE.
Tabela 2. As variáveis e suas definições
SIGLA NOME LONGO DEFINIÇÃO
IDHM
Índice de Desenvol-
vimento Humano
Municipal
Índice de Desenvolvimento Humano
Municipal. Média geométrica dos ín-
dices das dimensões Renda, Educação
e Longevidade, com pesos iguais.
IDHM_R
Índice de Desenvol-
vimento Humano
Municipal - Di-
mensão Renda
Índice da dimensão Renda que é um
dos 3 componentes do IDHM. É ob-
tido a partir do indicador Renda per
capita, através da fórmula: [ln (valor
observado do indicador) - ln (valor
mínimo)] / [ln (valor máximo) - ln (va-
lor mínimo)], onde os valores mínimos
e máximos são R$ 8,00 e R$ 4.033,00
(a preços de agosto de 2010).
IDHM_L
Índice de Desenvol-
vimento Humano
Municipal - Di-
mensão Longevi-
dade
Índice da dimensão Longevidade que
é um dos 3 componentes do IDHM. É
obtido a partir do indicador Espe-
rança de vida ao nascer, através da
fórmula: [(valor observado do indica-
dor) - (valor mínimo)] / [(valor má-
ximo) - (valor mínimo)], onde os valo-
res mínimos e máximos são 25 e 85
anos, respectivamente.
IDHM_ E
Índice de Desenvol-
vimento Humano
Municipal - Di-
mensão Educação
Índice sintético da dimensão Educação
que é um dos 3 componentes do
IDHM. É obtido através da média ge-
ométrica do subíndice de frequência
de crianças e jovens à escola, com peso

11
de 2/3, e do subíndice de escolaridade
da população adulta, com peso de 1/3.
ESPVIDA Esperança de vida
ao nascer
Número médio de anos que as pessoas
deverão viver a partir do nascimento,
se permanecerem constantes ao longo
da vida o nível e o padrão de mortali-
dade por idade prevalecentes no ano
do Censo.
MORT1 Mortalidade até
um ano de idade
Número de crianças que não deverão
sobreviver ao primeiro ano de vida em
cada 1000 crianças nascidas vivas.
T_ANALF25M
Taxa de analfabe-
tismo da população
de 25 anos ou mais
de idade
Razão entre a população de 25 anos
ou mais de idade que não sabe ler nem
escrever um bilhete simples e o total
de pessoas nesta faixa etária multipli-
cado por 100.
T_FUND25M
Percentual da po-
pulação de 25 anos
ou mais com fun-
damental completo
Razão entre a população de 25 anos
ou mais de idade que concluiu o en-
sino fundamental, em quaisquer de
suas modalidades (regular seriado,
não seriado, EJA ou supletivo) e o to-
tal de pessoas nesta faixa etária multi-
plicado por 100.
RDPC Renda per capita
média
Razão entre o somatório da renda de
todos os indivíduos residentes em do-
micílios particulares permanentes e o
número total desses indivíduos. Valo-
res em reais de 01/agosto de 2010.
RIND
Renda domiciliar
per capita média
dos extremamente
pobres
Média da renda domiciliar per capita
das pessoas com renda domiciliar per
capita igual ou inferior a R$ 70,00
mensais, a preços de agosto de 2010. O
universo de indivíduos é limitado
àqueles que vivem em domicílios par-
ticulares permanentes.

12
P_FORMAL
Grau de formaliza-
ção do trabalho
das pessoas ocupa-
das
Razão entre o número de pessoas de
18 anos ou mais formalmente ocupa-
das e o número total de pessoas ocupa-
das nessa faixa etária multiplicado por
100. Foram considerados como for-
malmente ocupados os empregados
com carteira de trabalho assinada, os
militares do exército, da marinha, da
aeronáutica, da polícia militar ou do
corpo de bombeiros, os empregados
pelo regime jurídico dos funcionários
públicos, assim como os empregadores
e trabalhadores por conta própria que
eram contribuintes de instituto de pre-
vidência oficial.
RENOCUP Rendimento médio
dos ocupados
Média dos rendimentos de todos os
trabalhos das pessoas ocupadas de 18
anos ou mais de idade. Valores em re-
ais de agosto de 2010.
T_BANAGUA
Percentual da po-
pulação que vive
em domicílios com
banheiro e água
encanada
Razão entre a população que vive em
domicílios particulares permanentes
com água encanada em pelo menos
um de seus cômodos e com banheiro
exclusivo e a população total residente
em domicílios particulares permanen-
tes multiplicado por 100. A água pode
ser proveniente de rede geral, de poço,
de nascente ou de reservatório abaste-
cido por água das chuvas ou carro-
pipa. Banheiro exclusivo é definido
como cômodo que dispõe de chuveiro
ou banheira e aparelho sanitário.
T_DENS
Percentual da po-
pulação que vive
em domicílios com
Razão entre a população que vive em
domicílios particulares permanentes

13
densidade superior
a 2 pessoas por
dormitório
com densidade superior a 2 e a popu-
lação total residente em domicílios
particulares permanentes multipli-
cado por 100. A densidade do domicí-
lio é dada pela razão entre o total de
moradores do domicílio e o número
total de cômodos usados como dormi-
tório.
T_NES-
TUDA_NTRAB_MMEIO
% de pessoas de 15
a 24 anos que não
estudam nem tra-
balham e são vul-
neráveis à pobreza.
Razão entre as pessoas de 15 a 24 anos
que não estudam nem trabalham e são
vulneráveis à pobreza e a população
total nesta faixa etária multiplicado
por 100. Define-se como vulneráveis à
pobreza as pessoas que moram em do-
micílios com renda per capita inferior
a 1/2 salário mínimo de agosto de
2010. São considerados apenas os do-
micílios particulares permanentes.
T_FUNDIN_TO-
DOS_MMEIO
% de pessoas em
domicílios vulnerá-
veis à pobreza e em
que ninguém tem
fundamental com-
pleto.
Percentual de pessoas que vivem em
domicílios vulneráveis à pobreza (com
renda per capita inferior a 1/2 salário
mínimo de agosto de 2010) e em que
ninguém tem o ensino fundamental
completo. São considerados apenas os
domicílios particulares permanentes.
T_MULCHEFEFIF014
Percentual de mães
chefes de família,
sem fundamental
completo e com
pelo menos um fi-
lho menor de 15
anos de idade
Razão entre o número de mulheres
que são responsáveis pelo domicílio,
não têm o ensino fundamental com-
pleto e têm pelo menos 1 filho de idade
inferior a 15 anos morando no domicí-
lio e o número total de mulheres che-
fes de família multiplicado por 100.
São considerados apenas os domicílios
particulares permanentes.

14
PEA18M
População econo-
micamente ativa de
18 anos ou mais de
idade
População economicamente ativa.
Corresponde ao número de pessoas
nessa faixa etária que, na semana de
referência do Censo, encontravam-se
ocupadas no mercado de trabalho ou
que, encontrando-se desocupadas, ti-
nham procurado trabalho no mês an-
terior à data da pesquisa.
Fonte: Atlas do Desenvolvimento Humano do Brasil (Minitab 2016)
2.5 O tipo de variável e sua unidade de medida
Selecionadas as variáveis, caracterizou-se o tipo e a unidade de medida para cada uma de-
las.
Tabela 3. O tipo de variáveis e sua unidade de medida
N VARIÁVEL SIGNIFICADO TIPO
UNIDADE
DE ME-
DIDA
1 REGIÃO Nome da Região do Brasil Texto NA
2 UF Unidade da Federação Texto NA
3 MUNICÍPIO Nome do Município Texto NA
4 IDHM IDH Município Quanti-
tativa Índice
5 IDHM_R IDHM Renda Quanti-
tativa Índice
6 IDHM_L IDHM Longevidade Quanti-
tativa Índice
7 IDHM_ E IDHM Educação Quanti-
tativa Índice
8 ESPVIDA Esperança de vida ao nascer Quanti-
tativa
Valor
Absoluto
9 MORT1 Mortalidade infantil Quanti-
tativa
Valor
Absoluto
10 T_ANALF25M Taxa de analfabetismo - 25
anos ou mais
Quanti-
tativa Percentual

15
11 T_FUND25M % de 25 anos ou mais com
fundamental completo
Quanti-
tativa Percentual
12 RDPC Renda per capita Quanti-
tativa
Valor
Absoluto
13 RIND Renda per capita média dos
extremamente pobres
Quanti-
tativa Índice
14 P_FORMAL Grau de formalização dos ocu-
pados - 18 anos ou mais
Quanti-
tativa Índice
15 RENOCUP Rendimento médio dos ocupa-
dos - 18 anos ou mais
Quanti-
tativa
Valor
Absoluto
16 T_BANAGUA
% da população em domicílios
com banheiro e água enca-
nada
Quanti-
tativa Percentual
17 T_DENS % da população em domicílios
com densidade > 2
Quanti-
tativa Percentual
18 T_NES-
TUDA_NTRAB_MMEIO
% de 15 a 24 anos que não es-
tudam, não trabalham e são
vulneráveis à pobreza
Quanti-
tativa Percentual
19 T_FUNDIN_TO-
DOS_MMEIO
% de pessoas em domicílios
vulneráveis à pobreza e em
que ninguém tem fundamental
completo
Quanti-
tativa Percentual
20 T_MULCHEFEFIF014
% de mães chefes de família
sem fundamental completo e
com filhos menores de 15 anos
Quanti-
tativa Percentual
21 PEA18M PEA – 18 anos ou mais Quanti-
tativa
Valor
Absoluto
Fonte: Atlas do Desenvolvimento Humano do Brasil (Minitab 16)
CAPÍTULO III. ANÁLISE EXPLORATÓRIA DAS VARIÁVEIS
Variáveis Qualitativas ou categórica
Este tipo de variável indica que o foco de concentração deve ser a análise de gráficos do
tipo pie chart e/ou barras.
Variável: “Município”

16
A amostra totaliza 5.565 municípios, que pode ser verificada na distribuição no território
nacional de acordo com a Unidade Federal no Gráfico 1
Gráfico 1 – Distribuição de Municípios por Região
Fonte: Elaborado pelo autor (Atlas Brail, 2016)
De acordo com o Gráfico 1, observa-se que as maiores concentrações de municípios brasi-
leiros estão nas regiões Nordeste (32%) e na região Sudeste (30%). Juntas somam mais de 60%
dos municípios pesquisados, totalizando 62%.
O Gráfico 2, apresenta a distribuição dos municípios brasileiros pelas Unidades da Federa-
ção do Brasil.

17
Gráfico 2 – Distribuição dos Municípios por Unidade da Federação
Fonte: Elaborado pelo Autor (Atlas Brasil, 2016)
Podemos observar no Gráfico 2, a Unidade Federativa mais populosa em números de mu-
nicípios é Minas Gerais (15%), seguida por São Paulo (12%) e Rio Grande do Sul (9%). As menos
populosas em número de municípios são Acre, Amazonas, Amapá, entre outras.
A Figura 2 apresenta o IDHM dos municípios brasileiros em 1999, 2000 e 2010. Com base
nesta representação topográfica, observa-se que os índices mais altos de IDHM, estão concentra-
dos na região centro-sul do Brasil. Nota-se também que a região Norte e Nordeste apresentava em
1999 índices muitos abaixo, nos 2000 e 2010 observa-se a significativa evolução dos índices nas
regiões.

18
Figura 2 - Mapa 1: IDHM do Brasil (1991, 2000, 2010)
Fonte: Atlas Brasil (2016)
Variáveis Quantitativas
A análise deste tipo de variável permite a utilização de uma maior gama de ferramentas de
análise como histogramas, curvas de densidade, gráfico de ramos, box-plot e dot-plot, além de
informações numéricas como média, desvio-padrão, mediana, quartis, 5 números, intervalo de
confiança e teste de normalidade de Anderson-Darling
3.1 As Variáveis dos IDHs:
IDHM – Índice de Desenvolvimento Humano Municipal (IDHM)
IDHM – Índice de Desenvolvimento Humano Dimensão Renda (IDHM_R)
IDHM – Índice de Desenvolvimento Humano Dimensão Longevidade (IDHM_L)
IDHM – Índice de Desenvolvimento Humano Dimensão Educação (IDHM_E)

19
Fonte: Elaborado pelo autor (Minitab 16)
Observações dos resultados do histograma:
• Forma: O Histograma O Histograma do IDH Municipal e IDH Renda apresentam uma
distribuição em 2 blocos de concentração na faixa entre os índices 0,5720 a 0,7180. O Box-
Plot demonstra a concentração na faixa citada, o posicionamento da mediana confirma essa
assertiva.
O Histograma do IDH Longevidade e IDH Educação apresenta uma distribuição concentrada;
sendo que, no IDH Longevidade a distribuição é mais à direita como se pode observar no Box-
Plot. Quanto ao IDH Educação das 4 variáveis é o que apresenta a distribuição mais normal de
todos em termos de concentração,.
• Valores Atípicos: Não se identifica valores atípicos; porém, o 9º município com pior IDH
M não aparece entre os 10 piores municípios no IDH R, IDH L e IDH E. (município de
Cachoeira do Piriá no estado do Pará), o que chama a atenção para uma pesquisa mais
pormenorizada.
• Centro e Dispersão: A mediana A mediana do IDH M mostra que há uma distribuição mais
a direita e seu valor é 0,66500 enquanto que o IDH M médio é 0,6591, tendo um desvio-
padrão de 0,0720. Com 95% de confiança podemos afirmar que a média encontra-se entre
os índices de 0,65727 a 0,66105.
A mediana do IDH L mostra que há uma distribuição mais à esquerda e seu valor é 0,80800
enquanto que o IDH L médio é 0,80156, tendo um desvio-padrão de 0,04468. Com 95% de confi-
ança podemos afirmar que a média encontra-se entre os índices de 0,80039 a 0,802874.

20
A mediana do IDH R e IDH E mostra que há uma distribuição equilibrada entre os lados e
seus valores é respectivamente: 0,65400 e 0,56000; enquanto que o IDH R e IDH E médio respec-
tivamente é igual a 0,64287 e 0,55909. O desvio-padrão do IDH R e IDH E é respectivamente:
0,8066 e 0,09333.
Com 95% de confiança podemos afirmar que a média do IDH R encontra-se entre os índices
0,64075 a 0,64499 e, para o IDH E encontra-se entre os índices 0,55664 a 0,56155.
3.2 Variável Expectativa de Vida (ESPVIDA)
Observações dos resultados do histograma:
• Forma: O Através do histograma podemos verificar que se trata de uma distribuição simé-
trica. O teste de normalidade de Anderson- Darling demonstra normalidade na distribuição.
• Valores Atípicos: Não se identifica valores atípicos
• Centro e Dispersão: Podemos notar que a mediana indica que metades dos municípios es-
tudados possuem expectativa de vida menor que 73,47 anos e a outra metade da amostra
maior que 73,47. A média dos municípios é de 73,09 com desvio padrão de 2,681, o que
não é considerado um valor significativo para desvio padrão.
78767472706866
Median
Mean
73,673,573,473,373,273,173,0
1st Q uartile 71,150
Median 73,470
3rd Q uartile 75,160
Maximum 78,640
73,019 73,159
73,380 73,550
2,632 2,731
A -Squared 34,95
P-V alue < 0,005
Mean 73,089
StDev 2,681
V ariance 7,186
Skewness -0,409315
Kurtosis -0,486787
N 5565
Minimum 65,300
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for ESPVIDA

21
3.3 Variável Mortalidade Infantil (MORT1)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica de Mortalidade
infantil na faixa entre 13,8 a 16,9 para cada mil crianças nascidas vivas. O Box-Plot con-
firma a concentração na faixa citada com posicionamento da mediana à esquerda do refe-
rido intervalo.
• Valores Atípicos: O município com maior índice de mortalidade infantil é Roteiro no es-
tado de Alagoas, com índice de 46,8 para cada mil crianças nascidas vivas.
• Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem mortalidade infantil menor do que 16,9 e a outra metade maior que este valor. A mor-
talidade infantil média dos municípios é de 19,25, tendo um desvio-padrão de 7, 137 sendo
um valor expressivo considerando o número de crianças que não sobrevivem. Com 95%
de confiança, podemos afirmar que a média encontra-se entre os valores 19, 099 a 19, 435.
423630241812
Median
Mean
19,519,018,518,017,517,0
1st Q uartile 13,800
Median 16,900
3rd Q uartile 23,800
Maximum 46,800
19,059 19,435
16,700 17,173
7,006 7,272
A -Squared 158,86
P-V alue < 0,005
Mean 19,247
StDev 7,137
V ariance 50,932
Skewness 1,00629
Kurtosis 0,43243
N 5565
Minimum 8,490
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for MORT1

22
3.4 Taxa de analfabetismo - 25 anos ou mais (T_ANALF25M)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com 2 concentra-
ções sendo uma mais a esquerda e a taxa de analfabetismo de 25 anos ou mais, situa-se na
faixa entre 9,98% a 31,34%. O Box-Plot demonstra a concentração espaçada na faixa ci-
tada, o posicionamento da mediana está à esquerda do referido intervalo.
• Valores Atípicos: O município de Feliz no Rio Grande do Sul praticamente quase toda a
população nesta faixa de 25 anos ou mais, encontra-se alfabetizada com 98,9%.
• Centro e Dispersão: A mediana nos indica que metade dos municípios a taxa de analfabe-
tismo é maior do que 16,5%; portanto a outra metade é menor do que este valor. A taxa de
analfabetismo média dos municípios é de 20,5% da população; tendo um desvio-padrão de
12,8%. Com 95% de confiança, podemos afirmar que a média encontra-se entre os valores
20,2% a 20,9%.
56484032241680
Median
Mean
212019181716
1st Q uartile 9,980
Median 16,460
3rd Q uartile 31,335
Maximum 57,180
20,186 20,857
16,089 16,931
12,533 13,008
A -Squared 148,86
P-V alue < 0,005
Mean 20,522
StDev 12,766
V ariance 162,971
Skewness 0,588895
Kurtosis -0,830859
N 5565
Minimum 1,100
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for T_ANALF25M

23
3.5 Variável % de 25 anos ou mais com fundamental completo (T_FUND25M)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição simétrica com concentração
um pouco a esquerda e o percentual de municípios cuja população de 25 anos ou mais com
fundamental completo, situa-se na faixa entre 25,3% a 40,6%. O Box-Plot demonstra a
concentração espaçada na faixa citada e, o posicionamento da mediana está a esquerda do
referido intervalo.
• Valores Atípicos: Não apresenta valores atípicos. O município de São Francisco de Assis
do Piauí no estado do Piauí apresenta percentual da população na faixa de 25 anos ou mais,
encontra-se com apenas 9,4% com ensino fundamental completo.
• Centro e Dispersão: A mediana nos indica que metade dos municípios a taxa da população
com 25 anos ou mais e com fundamental completo é maior do que 32,3%; portanto a outra
metade é menor do que este valor. A taxa da população com idade igual ou maior que 25
anos e com fundamental completo média dos municípios é de 33,8%; tendo um desvio-
padrão de 11,1%. Com 95% de confiança, podemos afirmar que a média encontra-se entre
os valores 33,5% a 34,0%.
70605040302010
Median
Mean
34,033,533,032,532,0
1st Q uartile 25,340
Median 32,330
3rd Q uartile 40,610
Maximum 78,040
33,462 34,045
31,910 32,730
10,878 11,290
A -Squared 35,77
P-V alue < 0,005
Mean 33,753
StDev 11,080
V ariance 122,775
Skewness 0,618707
Kurtosis 0,133454
N 5565
Minimum 9,410
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for T_FUND25M
24
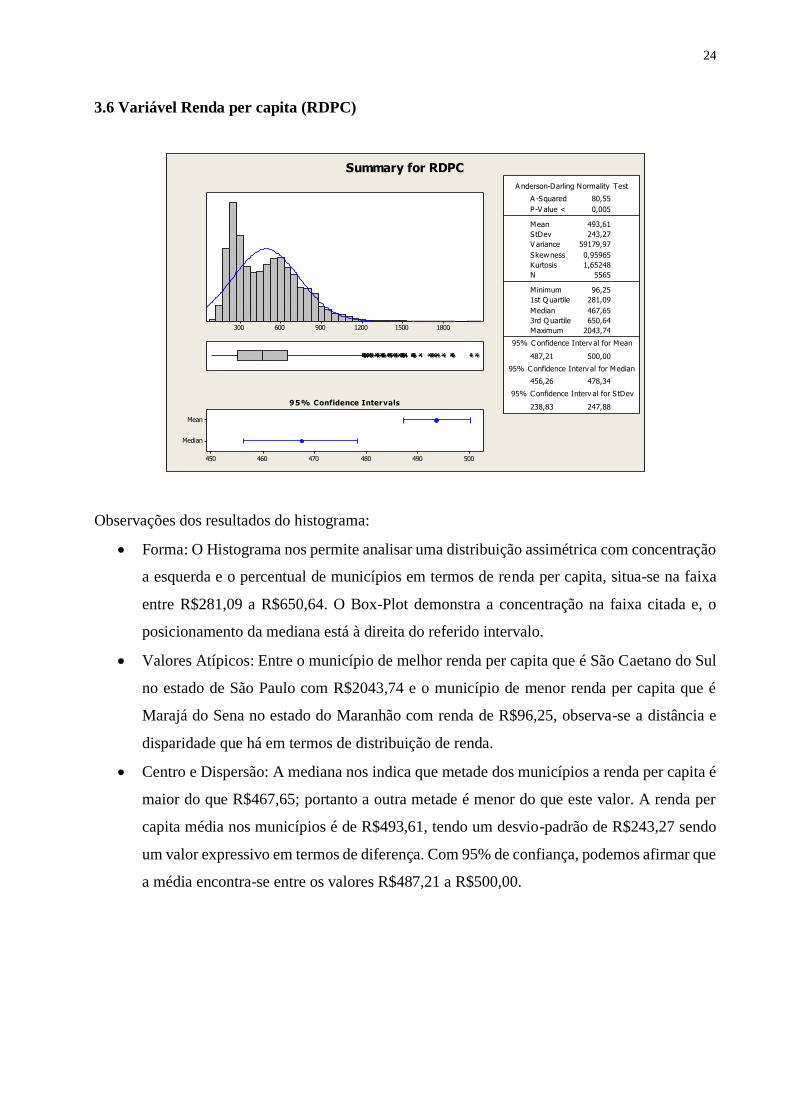
3.6 Variável Renda per capita (RDPC)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com concentração
a esquerda e o percentual de municípios em termos de renda per capita, situa-se na faixa
entre R$281,09 a R$650,64. O Box-Plot demonstra a concentração na faixa citada e, o
posicionamento da mediana está à direita do referido intervalo.
• Valores Atípicos: Entre o município de melhor renda per capita que é São Caetano do Sul
no estado de São Paulo com R$2043,74 e o município de menor renda per capita que é
Marajá do Sena no estado do Maranhão com renda de R$96,25, observa-se a distância e
disparidade que há em termos de distribuição de renda.
• Centro e Dispersão: A mediana nos indica que metade dos municípios a renda per capita é
maior do que R$467,65; portanto a outra metade é menor do que este valor. A renda per
capita média nos municípios é de R$493,61, tendo um desvio-padrão de R$243,27 sendo
um valor expressivo em termos de diferença. Com 95% de confiança, podemos afirmar que
a média encontra-se entre os valores R$487,21 a R$500,00.
180015001200900600300
Median
Mean
500490480470460450
1st Q uartile 281,09
Median 467,65
3rd Q uartile 650,64
Maximum 2043,74
487,21 500,00
456,26 478,34
238,83 247,88
A -Squared 80,55
P-V alue < 0,005
Mean 493,61
StDev 243,27
V ariance 59179,97
Skewness 0,95965
Kurtosis 1,65248
N 5565
Minimum 96,25
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for RDPC

25
3.7 Variável Renda per capita média dos extremamente pobres (RIND)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição simétrica e em termos de renda
per capita da população extremamente pobre, situa-se na faixa entre R$27,44 a R$37,51.
O Box-Plot demonstra a concentração na faixa citada e, o posicionamento da mediana está
à direita do referido intervalo.
• Valores Atípicos: Há 98 municípios cuja renda per capita da população extremamente po-
bre é ZERO, localizados nos estados de Goiás, Minas Gerais, Paraná, Pernambuco, Rio
Grande do Sul, Santa Catarina e São Paulo.
• Centro e Dispersão: A mediana nos indica que metade dos municípios a renda per capita
da população extremamente pobre é maior do que R$32,51; portanto a outra metade é me-
nor do que este valor. A renda per capita média nos municípios é de R$32,04, tendo um
desvio-padrão de R$9,60. Com 95% de confiança, podemos afirmar que a média encontra-
se entre os valores R$31,78 a R$32,29.
706050403020100
Median
Mean
32,832,632,432,232,031,8
1st Q uartile 27,435
Median 32,510
3rd Q uartile 37,090
Maximum 70,000
31,783 32,288
32,280 32,730
9,428 9,785
A -Squared 60,66
P-V alue < 0,005
Mean 32,036
StDev 9,603
V ariance 92,215
Skewness -0,28293
Kurtosis 2,37275
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for RIND

26
3.8 Variável Grau de formalização dos ocupados – 18 anos ou mais (P_FORMAL)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica e em termos do
grau de formalização dos ocupados e, situa-se na faixa entre 26,32% a 59,77%. O Box-Plot
demonstra a concentração na faixa citada e, o posicionamento da mediana confirma esse
dado.
• Valores Atípicos: Há uma elevada disparidade entre o município com o menor grau de
formalização que é Juruá no estado do Amazonas com 2,97% somente contra, o município
de Saudades no estado de Santa Catarina com 89,11%.
• Centro e Dispersão: A mediana nos indica que metade dos municípios o grau de formali-
zação é maior que 42,85% da população e metade é menor do que este valor. O grau de
formalização média nos municípios é de 43,51%, tendo um desvio-padrão de 19,27%
sendo significativo. Com 95% de confiança, podemos afirmar que o grau de formalização
médio nos municípios brasileiros encontra-se entre os valores de 43,00% a 44,01%.
84726048362412
Median
Mean
44,043,543,042,542,0
1st Q uartile 26,320
Median 42,850
3rd Q uartile 59,770
Maximum 89,110
42,999 44,012
41,846 43,980
18,923 19,640
A -Squared 65,23
P-V alue < 0,005
Mean 43,506
StDev 19,275
V ariance 371,525
Skewness 0,11438
Kurtosis -1,15796
N 5565
Minimum 2,970
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for P_FORMAL

27
3.9 Variável Rendimento médio dos ocupados – 18 anos ou mais (RENOCUP)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com concentração
à esquerda e em termos do rendimento médio dos ocupados de 18 anos ou mais, situa-se
na faixa entre R$488,59 a R$1008,08. O Box-Plot demonstra a concentração na faixa citada
e, o posicionamento da mediana confirma esse dado.
• Valores Atípicos: Há uma elevada disparidade entre o município com o menor rendimento
médio dos ocupados de 18 anos ou mais que é Fernando Falcão no estado do Maranhão
com R$135,42 somente; contra, o município com maior rendimento que é Santana de Par-
naíba no estado de São Paulo com R$3177,26.
• Centro e Dispersão: A mediana nos indica que metade dos municípios o rendimento médio
dos ocupados com 18 ou mais anos é maior que R$761,72 e metade é menor do que este
valor. O rendimento médio dos ocupados com 18 anos ou mais médio nos municípios é de
R$780,11, tendo um desvio-padrão de R$341,68 sendo significativo. Com 95% de confi-
ança, podemos afirmar que o grau de formalização médio nos municípios brasileiros en-
contra-se entre os valores de R$771,13 a R$789,09.
31502700225018001350900450
Median
Mean
790780770760750740
1st Q uartile 488,59
Median 761,72
3rd Q uartile 1008,08
Maximum 3177,26
771,13 789,09
745,23 776,58
335,45 348,15
A -Squared 35,59
P-V alue < 0,005
Mean 780,11
StDev 341,68
V ariance 116747,92
Skewness 0,72362
Kurtosis 1,27435
N 5565
Minimum 136,42
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for RENOCUP

28
3.10 Variável % da População em domicílios com banheiro e água encanada (T_BANA-
GUA)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com concentração
à direita e em termos do percentual da população residente em domicílios com banheiro e
água encanada, situa-se na faixa entre 67,77% a 98,00%. O Box-Plot demonstra a concen-
tração na faixa citada e, o posicionamento da mediana confirma esse dado.
• Valores Atípicos: O município de Santa Cecília no estado da Paraíba tem somente 3,26%
dos domicílios com banheiro e água encanada; ao passo que 73 municípios brasileiros têm
100% dos domicílios totalmente atendidos concentrando-se em sua maioria nos estados de
Minas Gerais e São Paulo.
• Centro e Dispersão: A mediana nos indica que metade dos municípios os domicílios com
banheiro e água encanada é de 91,25% e metade é menor do que este valor. A média de
municípios com domicílios com banheiro e água encanada é de 80,87%, tendo um desvio-
padrão de 21,7% sendo significativo. Com 95% de confiança, podemos afirmar que a mé-
dia de municípios com domicílios com banheiro e água encanada encontra-se entre 80,3%
a 81,4%.
98847056422814
Median
Mean
92908886848280
1st Q uartile 67,770
Median 91,250
3rd Q uartile 98,000
Maximum 100,000
80,301 81,442
90,449 91,930
21,316 22,124
A -Squared 358,72
P-V alue < 0,005
Mean 80,872
StDev 21,712
V ariance 471,431
Skewness -1,21327
Kurtosis 0,55699
N 5565
Minimum 3,260
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for T_BANAGUA

29
3.11 Variável % da População em domicílios com densidade>2 (T_DENS)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com concentração
à esquerda e em termos do percentual da população residente em domicílios com densidade
>2, situa-se na faixa entre 15,41% a 32,58%. O Box-Plot demonstra a concentração na
faixa citada e, o posicionamento da mediana a esquerda confirma esse dado.
• Valores Atípicos: O município de Três Arroios no estado do Rio Grande do Sul tem menos
de 1%; ou seja, 0,65% dos domicílios com densidade >2; ao passo que o município de
Uiramutã no estado de Roraima tem 88,64% dos domicílios com densidade >2.
• Centro e Dispersão: A mediana nos indica que metade dos municípios com densidade >2
é de 23,07% e metade é menor do que este valor. A média de municípios com domicílios
com densidade >2 é de 25,13%, tendo um desvio-padrão de 13,0% sendo significativo.
Com 95% de confiança, podemos afirmar que a média de municípios com domicílios com
densidade >2 encontra-se entre 24,79% a 25,47%.
847260483624120
Median
Mean
25,525,024,524,023,523,0
1st Q uartile 15,410
Median 23,070
3rd Q uartile 32,580
Maximum 88,640
24,785 25,468
22,689 23,551
12,761 13,245
A -Squared 60,82
P-V alue < 0,005
Mean 25,127
StDev 12,999
V ariance 168,961
Skewness 1,04504
Kurtosis 1,63411
N 5565
Minimum 0,650
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for T_DENS

30
3.12 Variável % de 15 a 24 anos que não estudam, não trabalham e são vulneráveis à po-
breza (T_NESTUDA_NTRAB_MMEIO)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com duas concen-
trações à esquerda e em termos do percentual da população de 15 a 24 anos que não estu-
dam, não trabalham e são vulneráveis à pobreza, situa-se na faixa entre 7,30% a 21,60%.
O Box-Plot demonstra a concentração na faixa citada e, o posicionamento da mediana a
esquerda confirma esse dado.
• Valores Atípicos: O município de Amajari no estado de Roraima tem 55,25% da população
na faixa de 15 a 24 anos que não estudam nem trabalham.
• Centro e Dispersão: A mediana nos indica que mais da metade dos municípios cuja popu-
lação de 15 a 24 anos que não estudam, não trabalham e são vulneráveis à pobreza é de
13,67% e um pouco menos da metade é menor do que este valor. A média de municípios
com percentual da população de 15 a 24 anos que não estudam, não trabalham e são vul-
neráveis à pobreza é de 14,78%, tendo um desvio-padrão de 8,57% sendo significativo.
Com 95% de confiança, podemos afirmar que a média de municípios com percentual da
população de 15 a 24 anos que não estudam, não trabalham e são vulneráveis à pobreza
encontra-se entre 14,55% a 15,01%.
56484032241680
Median
Mean
15,014,514,013,5
1st Q uartile 7,295
Median 13,670
3rd Q uartile 21,600
Maximum 55,250
14,546 15,006
13,299 14,340
8,592 8,917
A -Squared 61,38
P-V alue < 0,005
Mean 14,776
StDev 8,751
V ariance 76,588
Skewness 0,388117
Kurtosis -0,679693
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for T_NESTUDA_NTRAB_MMEIO

31
3.13 Variável % de pessoas em domicílios vulneráveis à pobreza e em que ninguém tem
fundamental completo (T_FUNDIN_TODOS_MMEIO)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com concentração
à esquerda e em termos do percentual de pessoas em domicílios vulneráveis à pobreza e
em que ninguém tem fundamental completo, situa-se na faixa entre 9,66% a 30,44%. O
Box-Plot demonstra a concentração na faixa citada e, o posicionamento da mediana a es-
querda confirma esse dado.
• Valores Atípicos: O município de Melgaço no estado do Pará tem 74,45% de pessoas em
domicílios vulneráveis à pobreza e em que ninguém tem fundamental completo.
• Centro e Dispersão: A mediana nos indica que metade dos municípios em que as pessoas
residentes em domicílios vulneráveis à pobreza e em que ninguém tem fundamental com-
pleto é de 18,75% e metade é menor do que este valor. A média de municípios com per-
centual de pessoas em domicílios vulneráveis à pobreza e em que ninguém tem fundamen-
tal completo é 20,71%, tendo um desvio-padrão de 12,72% sendo significativo. Com 95%
de confiança, podemos afirmar que a média de municípios com percentual de pessoas em
domicílios vulneráveis à pobreza e em que ninguém tem fundamental completo encontra-
se entre 20,38% a 21,04%.
706050403020100
Median
Mean
21,020,520,019,519,018,518,0
1st Q uartile 9,655
Median 18,750
3rd Q uartile 30,435
Maximum 74,450
20,376 21,044
18,200 19,301
12,492 12,965
A -Squared 78,24
P-V alue < 0,005
Mean 20,710
StDev 12,724
V ariance 161,900
Skewness 0,518829
Kurtosis -0,562870
N 5565
Minimum 0,210
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for T_FUNDIN_TODOS_MMEIO

32
3.14 Variável % de mães chefes de família sem fundamental completo e com filhos menores
de 15 anos (T_MULCHEFEFI014)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com concentração
à esquerda e em termos do percentual de mães chefes de família sem fundamental completo
e com filhos menores de 15 anos, situa-se na faixa entre 12,32% a 25,87%. O Box-Plot
demonstra a concentração na faixa citada e, o posicionamento da mediana a esquerda con-
firma esse dado.
• Valores Atípicos: O município de Cacimbas no estado da Paraíba o percentual de mães
chefes de família sem fundamental completo é de 77,59%.
• Centro e Dispersão: A mediana nos indica que metade dos municípios com percentual de
mães chefes de família sem fundamental completo e com filhos menores de 15 anos é de
18,09% e metade é menor do que este valor. A média de municípios com percentual de
mães chefes de família sem fundamental completo e com filhos menores de 15 anos é de
19,96%, tendo um desvio-padrão de 10,32% sendo significativo. Com 95% de confiança,
podemos afirmar que a média de municípios com percentual de mães chefes de família sem
fundamental completo e com filhos menores de 15 anos encontra-se entre 19,68% a
20,23%.
7260483624120
Median
Mean
20,520,019,519,018,518,0
1st Q uartile 12,320
Median 18,090
3rd Q uartile 25,865
Maximum 77,590
19,684 20,227
17,799 18,430
10,133 10,517
A -Squared 68,62
P-V alue < 0,005
Mean 19,956
StDev 10,321
V ariance 106,532
Skewness 0,99289
Kurtosis 1,37190
N 5565
Minimum 0,000
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for T_MULCHEFEFIF014

33
3.15 Variável PEA – 18 anos ou mais (PEA18M)
Observações dos resultados do histograma:
• Forma: O Histograma nos permite analisar uma distribuição assimétrica com concentração
à esquerda e em termos da população economicamente ativa de 18 anos ou mais, situa-se
na faixa entre 2386 a 10617 pessoas. O Box-Plot demonstra a concentração na faixa citada
e, o posicionamento da mediana a esquerda confirma esse dado.
• Valores Atípicos: O município de São Félix do Tocantins no estado do Tocantins tem 307
pessoas economicamente ativas na faixa de 18 anos ou mais.
• Centro e Dispersão: A mediana nos indica que a população economicamente ativa de 18
anos ou mais é 4933. A média da população economicamente ativa de 18 anos ou mais é
16863 pessoas; tendo um desvio-padrão de 107060 sendo significativo em termos de uso
dos dados como referência. Com 95% de confiança, podemos afirmar que a média da po-
pulação economicamente ativa de 18 anos ou mais se encontra entre 14049 a 19676.
CAPÍTULO IV. ANÁLISE COMPARATIVA DA ANÁLISE DESCRITIVA
Abaixo apresentamos uma tabela comparando Histograma, Box-Plot, Curva de Densidade
média, desvio-padrão, mediana e P-Value do teste de normalidade de Anderson-Darling, das vari-
áveis quantitativas analisadas.
540000045000003600000270000018000009000000
Median
Mean
200001750015000125001000075005000
1st Q uartile 2386
Median 4933
3rd Q uartile 10617
Maximum 6026212
14049 19676
4711 5140
105107 109087
A -Squared 1636,82
P-V alue < 0,005
Mean 16863
StDev 107060
V ariance 11461855390
Skewness 38,51
Kurtosis 1940,31
N 5565
Minimum 307
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for PEA

34
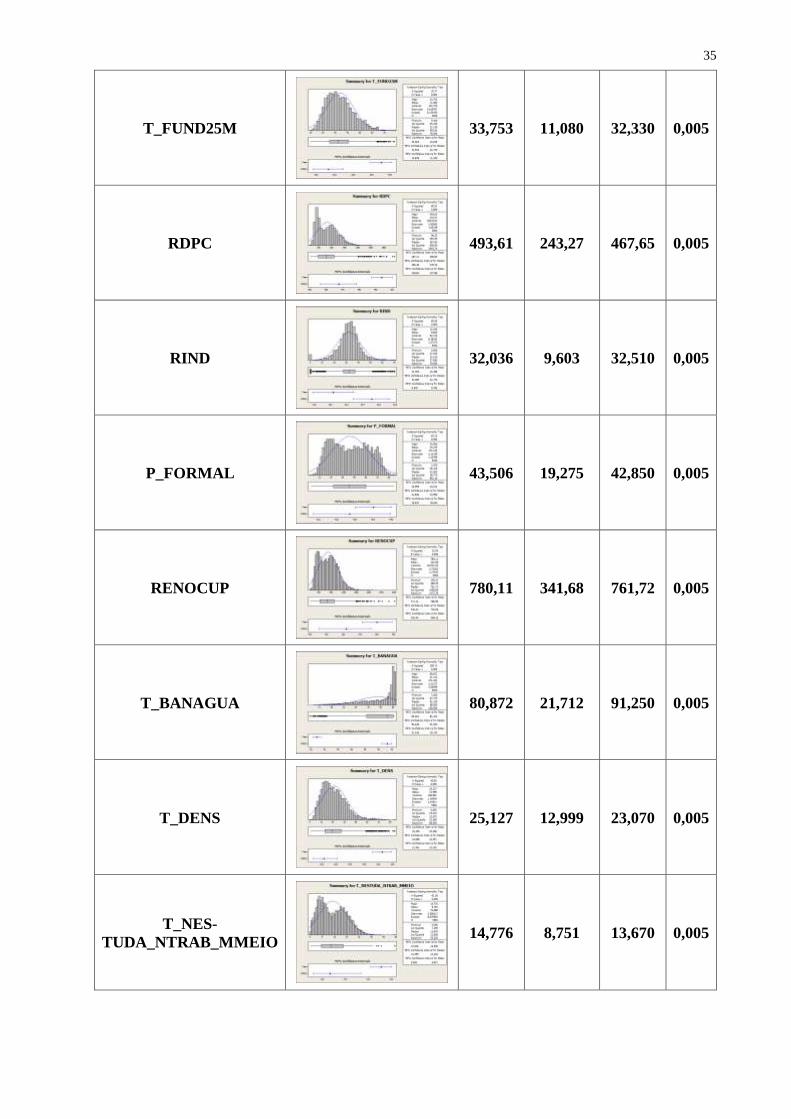
Tabela 4. Analise Comparativa das Variáveis (Dimensões Desenvolvimento Humano)
VARIÁVEL GRÁFICO MÉ-
DIA
DES-
VIO PA-
DRÃO
MEDI-
ANA
P-
VA-
LUE
IDHM
0,65916 0,07200 0,66500 0,005
IDHM_R
0,64287 0,08066 0,65400 0,005
IDHM_L
0,80156 0,04468 0,80800 0,005
IDHM_E
0,55909 0,09333 0,56000 0,005
ESPVIDA
73,089 2,681 73,470 0,005
MORT1
19,247 7,137 16,900 0,005
T_ANALF25M
20,522 12,766 16,460 0,005
35
T_FUND25M
33,753 11,080 32,330 0,005
RDPC
493,61 243,27 467,65 0,005
RIND
32,036 9,603 32,510 0,005
P_FORMAL
43,506 19,275 42,850 0,005
RENOCUP
780,11 341,68 761,72 0,005
T_BANAGUA
80,872 21,712 91,250 0,005
T_DENS
25,127 12,999 23,070 0,005
T_NES-
TUDA_NTRAB_MMEIO
14,776 8,751 13,670 0,005

36
T_FUNDIN_TO-
DOS_MMEIO
20,710 12,724 18,750 0,005
T_MULFHEFI014
19,956 10,321 18,090 0,005
PEA18M
16863 107060 4933 0,005
CAPÍTULO V. CORRELAÇÃO DAS VARIÁVEIS
Os dados a seguir representam a correlação entre as variáveis selecionadas e já trabalhadas
nas análises que antecederam. Destacaram-se aquelas que apresentaram correlação superior a 0,9
(assinaladas na tabela abaixo)
Correlations: IDHM; IDHM_E; IDHM_L; IDHM_R; ESPVIDA; MORT1;
T_ANALF25M; ...
IDHM IDHM_E IDHM_L
IDHM_E 0,951
0,000
IDHM_L 0,852 0,704
0,000 0,000
IDHM_R 0,948 0,820 0,834
0,000 0,000 0,000
ESPVIDA 0,852 0,704 1,000
0,000 0,000 0,000
MORT1 -0,829 -0,684 -0,967
0,000 0,000 0,000
T_ANALF25M -0,889 -0,790 -0,831
0,000 0,000 0,000
T_FUND25M 0,837 0,858 0,628
0,000 0,000 0,000
RDPC 0,908 0,791 0,784
0,000 0,000 0,000

37
RIND 0,072 0,098 -0,000
0,000 0,000 0,977
P_FORMAL 0,824 0,761 0,709
0,000 0,000 0,000
RENOCUP 0,869 0,764 0,741
0,000 0,000 0,000
T_BANAGUA 0,806 0,715 0,726
0,000 0,000 0,000
T_DENS -0,645 -0,555 -0,589
0,000 0,000 0,000
T_NESTUDA_NTRAB_ -0,837 -0,722 -0,753
0,000 0,000 0,000
T_FUNDIN_TODOS_M -0,961 -0,921 -0,802
0,000 0,000 0,000
T_MULCHEFEFIF014 -0,646 -0,602 -0,566
0,000 0,000 0,000
PEA 0,148 0,145 0,091
0,000 0,000 0,000
IDHM_R ESPVIDA MORT1
ESPVIDA 0,834
0,000
MORT1 -0,814 -0,967
0,000 0,000
T_ANALF25M -0,886 -0,831 0,833
0,000 0,000 0,000
T_FUND25M 0,755 0,628 -0,593
0,000 0,000 0,000
RDPC 0,962 0,784 -0,744
0,000 0,000 0,000
RIND 0,051 -0,000 0,005
0,000 0,981 0,736
P_FORMAL 0,810 0,709 -0,678
0,000 0,000 0,000
RENOCUP 0,915 0,741 -0,704
0,000 0,000 0,000

38
T_BANAGUA 0,807 0,726 -0,739
0,000 0,000 0,000
T_DENS -0,663 -0,589 0,594
0,000 0,000 0,000
T_NESTUDA_NTRAB_ -0,877 -0,753 0,741
0,000 0,000 0,000
T_FUNDIN_TODOS_M -0,906 -0,802 0,796
0,000 0,000 0,000
T_MULCHEFEFIF014 -0,620 -0,565 0,576
0,000 0,000 0,000
PEA 0,157 0,091 -0,073
0,000 0,000 0,000
T_ANALF25M T_FUND25M RDPC
T_FUND25M -0,743
0,000
RDPC -0,821 0,755
0,000 0,000
RIND -0,012 0,089 0,040
0,379 0,000 0,003
P_FORMAL -0,771 0,754 0,767
0,000 0,000 0,000
RENOCUP -0,795 0,816 0,929
0,000 0,000 0,000
T_BANAGUA -0,759 0,563 0,700
0,000 0,000 0,000
T_DENS 0,554 -0,270 -0,592
0,000 0,000 0,000
T_NESTUDA_NTRAB_ 0,808 -0,587 -0,826
0,000 0,000 0,000
T_FUNDIN_TODOS_M 0,885 -0,780 -0,843
0,000 0,000 0,000
T_MULCHEFEFIF014 0,574 -0,432 -0,571
0,000 0,000 0,000
PEA -0,112 0,247 0,220
0,000 0,000 0,000

39
RIND P_FORMAL RENOCUP
P_FORMAL 0,045
0,001
RENOCUP 0,020 0,801
0,142 0,000
T_BANAGUA 0,109 0,722 0,656
0,000 0,000 0,000
T_DENS -0,064 -0,470 -0,429
0,000 0,000 0,000
T_NESTUDA_NTRAB_ -0,061 -0,697 -0,720
0,000 0,000 0,000
T_FUNDIN_TODOS_M -0,069 -0,802 -0,791
0,000 0,000 0,000
T_MULCHEFEFIF014 -0,032 -0,469 -0,488
0,017 0,000 0,000
PEA 0,045 0,126 0,233
0,001 0,000 0,000
T_BANAGUA T_DENS T_NESTUDA_NTRAB_
T_DENS -0,750
0,000
T_NESTUDA_NTRAB_ -0,722 0,670
0,000 0,000
T_FUNDIN_TODOS_M -0,810 0,662 0,835
0,000 0,000 0,000
T_MULCHEFEFIF014 -0,617 0,634 0,579
0,000 0,000 0,000
PEA 0,058 0,021 -0,080
0,000 0,112 0,000
T_FUNDIN_TODOS_M T_MULCHEFEFIF014
T_MULCHEFEFIF014 0,661
0,000
PEA -0,105 -0,047
0,000 0,000
Cell Contents: Pearson correlation
P-Value
Fonte: Elaborado pelo autor (Minitab 16)

40
Com base nas informações constantes na matriz de correlação pode-se perceber que as va-
riáveis descritas na Tabela 5 apresentam forte relação, vale destacar que isto não significa que elas
apresentam causalidade, ou seja, um sentido direto entre elas. Ressalta-se ainda que para esta aná-
lise foram selecionadas aquelas com correlação maior que 0,9
Tabela 5. Correlação entre as variáveis
Variável Variável Grau de Correlação
RIND ESPVIDA 0,981
RIND IDHM_L 0,977
RDPC IDHM_R 0,962
IDHM_E IDHM 0,951
IDHM_R IDHM 0,948
RENOCUP RDPC 0,929
RENOCUP IDHM_R 0,915
RDPC IDHM 0,908
T_FUNDIN_TODOS_MMEIO IDHM_R -0,906
T_FUNDIN_TODOS_MMEIO IDHM_E -0,921
T_FUNDIN_TODOS_MMEIO IDHM -0,961
MORT1 IDHM_L -0,967
MORT1 ESPVIDA -0,967 Fonte: Elaborado pelo autor (Minitab 16)
CAPÍTULO VI. GRÁFICOS DE DISPERSÃO
Nos gráficos a seguir são apresentadas as relações entre as variáveis relacionadas na tabela 5.
0,80,60,4
2000
1000
0
0,80,60,4
0,9
0,6
0,3
0,80,60,4
0,8
0,6
0,4
200010000
3000
1500
0
0,80,60,4
3000
1500
0
0,80,60,4
2000
1000
0
50250
80
40
0
0,80,60,4
50
25
0
0,80,60,4
80
40
0
0,90,60,3
80
40
0
0,80,60,4
80
40
0
0,90,80,7
50
30
10
757065
50
30
10
RDPC*IDHM_R IDHM_E*IDHM IDHM_R*IDHM RENOCUP*RDPC
RENOCUP*IDHM_R RDPC*IDHM T_FUNDIN_TODOS_MMEIO*T_ANALF25M T_ANALF25M*IDHM_R
T_FUNDIN_TODOS_MMEIO*IDHM_R T_FUNDIN_TODOS_MMEIO*IDHM_E T_FUNDIN_TODOS_MMEIO*IDHM MORT1*IDHM_L
MORT1*ESPVIDA
Scatterplot of RDPC vs IDHM_R; IDHM_E vs IDHM; IDHM_R vs IDHM; RENOCUP

41
Gráficos de dispersão devem ser inicialmente analisados quanto a seu padrão geral e seus
desvios relativos ao padrão. A descrição do padrão geral pode ser feita pela verificação de sua
forma, direção e intensidade.
• Direção: Analisando as correlações acima percebemos que em todos os gráficos apresen-
tam-se associações positivas, ou seja, diretamente proporcional onde o crescimento de uma
variável é acompanhado do crescimento da outra, simultaneamente.
• Intensidade: Os gráficos acima indicam a existência de relações lineares nas sete compa-
rações apresentadas
• Forma: Todos os gráficos apresentam conglomerados que sugerem relações lineares.
• Valores Atípicos: Todos os gráficos indicam a existência de valores atípicos; ou seja, mu-
nicípios com índices distanciado dos demais.
CAPÍTULO VII. DENDROGRAMA
Um Dendrograma (dendr(o) = árvore) é um tipo específico de diagrama ou representação
icônica que organiza determinados fatores e variáveis. Isto quer dizer que sua representação apre-
senta um diagrama de similaridade.
A interpretação de um Dendrograma de similaridade entre amostras fundamenta-se na in-
tuição: duas amostras próximas devem ter também valores semelhantes para as variáveis medidas.
Ou seja, elas devem ser próximas matematicamente no espaço multidimensional.
Portanto, quanto maior a proximidade entre as medidas relativas às amostras, maior a simi-
laridade entre elas. O dendrograma hierarquiza esta similaridade de modo que podemos ter uma
visão bidimensional da similaridade ou dissimilaridade de todo o conjunto de amostras utilizado
no estudo.
Segue abaixo o Dendrograma das variáveis analisadas
Cluster Analysis of Variables: IDHM; IDHM_E; IDHM_L; IDHM_R; ESPVIDA; ...
Correlation Coefficient Distance, Single Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 17 99,9990 0,000021 3 5 3 2
2 16 98,0832 0,038336 4 9 4 2
3 15 97,5438 0,049125 1 2 1 2
4 14 97,4161 0,051679 1 4 1 4
5 13 96,4598 0,070805 1 12 1 5
6 12 94,2608 0,114783 7 16 7 2
7 11 92,9204 0,141592 1 8 1 6
8 10 92,6074 0,147851 1 3 1 8

42
9 9 91,7368 0,165263 7 15 7 3
10 8 91,6386 0,167228 6 7 6 4
11 7 91,1884 0,176232 1 11 1 9
12 6 90,3288 0,193424 1 13 1 10
13 5 83,4929 0,330143 6 14 6 5
14 4 83,0570 0,338860 6 17 6 6
15 3 62,3282 0,753435 1 18 1 11
16 2 55,4295 0,891411 1 10 1 12
17 1 51,0653 0,978694 1 6 1 18
T_MUL
CHEF
EFIF01
4
T_DE
NS
T_NE
STUD
A_NT
RAB_
MMEIO
T_FU
NDIN
_TOD
OS_M
MEIO
T_AN
ALF2
5M
MORT
1RI
NDPEA
T_BA
NAGU
A
P_FO
RMAL
ESPV
IDA
IDHM
_L
T_FU
ND25
M
RENO
CUP
RDPC
IDHM
_R
IDHM
_E
IDHM
51,07
67,38
83,69
100,00
Variables
Sim
ilari
ty
DendrogramSingle Linkage; Correlation Coefficient Distance
CAPÍTULO VIII. ANÁLISE DE TENDÊNCIAS
Neste capítulo procurou-se utilizar de outras fontes como estímulo à pesquisa em bases de
dados e propiciar uma análise de tendências; para isto, utilizaram-se como fonte, os dados dispo-
níveis no site do Instituto Brasileiro de Geografia e Estatística (IBGE).
8.1 Os Indivíduos
Os dados são séries históricas referentes ao Brasil, portanto, trata-se de séries temporais.
As séries vão de 2001 a 2011 para as 3 variáveis selecionadas: “Taxa de analfabetismo de pessoas
de 10 anos ou mais”, “Escolaridade de 15 anos ou mais da população ocupada” e, “Taxa de inves-
timento”.
8.2 As Variáveis
São 4 as variáveis desta pesquisa, incluindo o ano a que se referem os dados. As mesmas
são melhor explicadas na Tabela 6.

43
Tabela 6. As variáveis obtidas no site do IBGE
Variável Significado Tipo Unidade de
Medida
Ano É o ano a que se refere o dado de cada
variável
Variável Ca-
tegórica
Formato:
AAAA
Taxa de analfabe-
tismo de pessoas de
10 anos ou mais de
idade
É a percentagem de pessoas analfabe-
tas de um grupo etário em relação ao
total de pessoas do mesmo grupo etá-
rio
Variável
Quantitativa
Percentual
(%)
Escolaridade de 15
anos ou mais – Po-
pulação ocupada
Escolaridade em média de anos de es-
tudo. Classificação estabelecida em
função da série e do grau mais ele-
vado concluído das pessoas de 15 anos
e mais em relação às pessoas economi-
camente ativas (PEA)
Variável
Quantitativa
Percentual
(%)
Taxa de Investi-
mento
É o resultado da relação entre o valor
corrente da formação bruta de capital
fixo e o valor corrente do produto in-
terno bruto. É uma medida da capaci-
dade produtiva da economia
Variável
Quantitativa
Percentual
(%)
Fonte: Elaborado pelo autor (IBGE)
8.3 A fonte e o tamanho da série de dados
• Fonte:
Os dados desta pesquisa foram obtidos do site do Instituto Brasileiro de Geografia e Esta-
tística (IBGE); sendo que no ano de 2010 para a Taxa de analfabetismo de pessoas de 10
anos ou mais de idade e Escolaridade de 15 anos ou mais da População Ocupada foi obtido
através da média entre os anos 2009 e 2011.
As três séries de dados podem ser consideradas satisfatórias para a realização desta pes-
quisa, uma vez que todas possuem dados de 11 anos ou mais, sem interrupções.

44
Tabela 7. Dados do IBGE
Ano Taxa de analfabetismo de pes-
soas de 10 anos ou mais (%)
Escolaridade de 15 anos ou
mais - População ocupada (%)
Taxa de Inves-
timento (%)
2001 11,4 7,11 18,4
2002 10,9 7,41 18
2003 10,6 7,74 16,7
2004 10,4 7,84 17,4
2005 10,05 8,04 17,2
2006 9,41 8,67 17,3
2007 9,09 9,25 18,1
2008 9,2 9,8 19,5
2009 8,9 10,64 19,2
2010 8,4 11,15 20,6
2011 7,9 11,66 20,6
Fonte: Elaborado pelo autor (IBGE)
Os dados assinalados em vermelho foram atualizados pelo autor. Os demais têm origem
nas pesquisas no site do IBGE.
CAPÍTULO IX. ANÁLISE DAS VARIÁVEIS BANCO DE DADOS IBGE
Conforme mencionado acima, cada variável será analisada utilizando gráficos para de-
monstrar o comportamento histórico da série, linhas de tendência, funções, erros das funções, além
de extrapolações estatísticas.
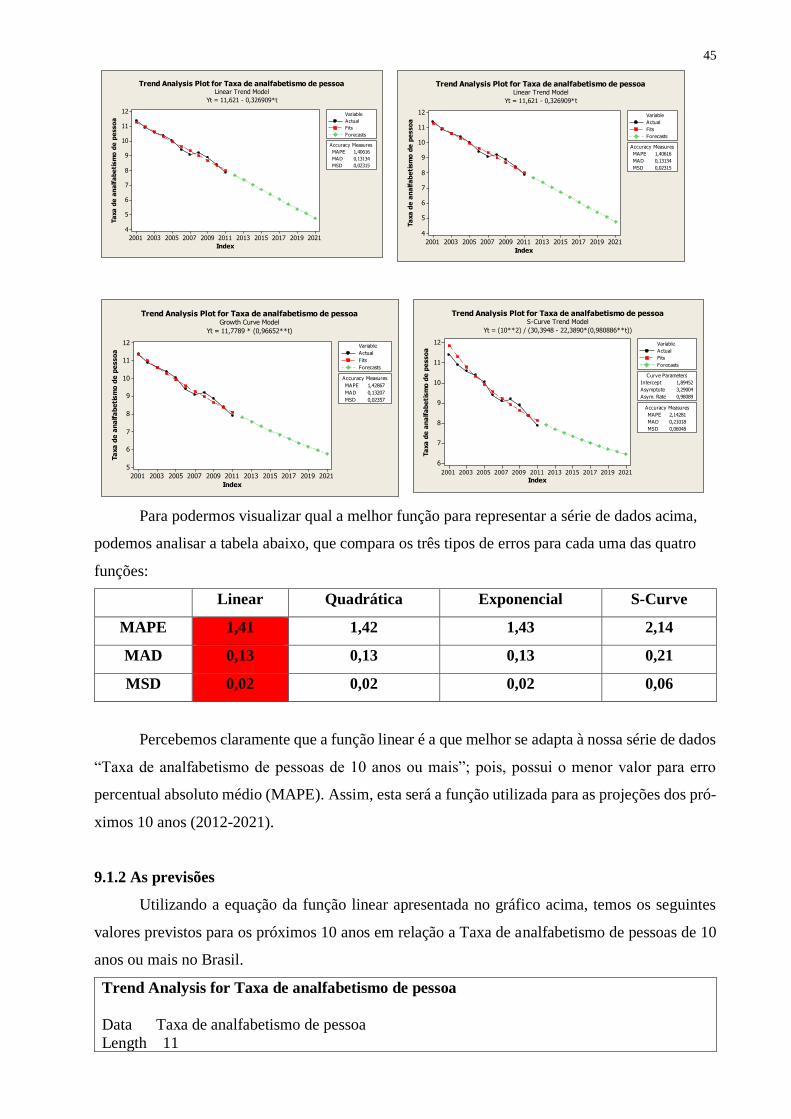
9.1 Variável: Taxa de analfabetismo de pessoas de 10 anos ou mais (%)
9.1.1 Análise de tendência da variável
Para análise do comportamento histórico da variável Taxa de Analfabetismo de pessoas de
10 anos ou mais utilizaremos, inicialmente, gráficos que permitem uma verificação visual.
Nesta seção analisaremos a tendência da série de dados, buscando encontrar a função (li-
near, quadrática, exponencial ou s-curve) que melhor a represente. Para medir a eficiência da fun-
ção ou da curva de tendência, analisaremos os erros: MAPE (Mean Average Percentual Error),
MAD (Mean Absolute Deaviation) e MSD (Mean Standard Deviation).
Segue abaixo gráficos incluindo a função, a linha de tendência que representa cada função
e os erros mencionados acima.
45
20212019201720152013201120092007200520032001
12
11
10
9
8
7
6
5
4
Index
Ta
xa
de
an
alf
ab
eti
sm
o d
e p
esso
a
MAPE 1,40616
MAD 0,13134
MSD 0,02315
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de analfabetismo de pessoaLinear Trend Model
Yt = 11,621 - 0,326909*t
20212019201720152013201120092007200520032001
12
11
10
9
8
7
6
5
4
Index
Ta
xa
de
an
alf
ab
eti
sm
o d
e p
esso
a
MAPE 1,40616
MAD 0,13134
MSD 0,02315
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de analfabetismo de pessoaLinear Trend Model
Yt = 11,621 - 0,326909*t
20212019201720152013201120092007200520032001
12
11
10
9
8
7
6
5
Index
Ta
xa
de
an
alf
ab
eti
sm
o d
e p
esso
a
MAPE 1,42867
MAD 0,13207
MSD 0,02357
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de analfabetismo de pessoaGrowth Curve Model
Yt = 11,7789 * (0,96652**t)
20212019201720152013201120092007200520032001
12
11
10
9
8
7
6
Index
Ta
xa
de
an
alf
ab
eti
sm
o d
e p
esso
a
Intercept 1,89452
Asymptote 3,29004
Asym. Rate 0,98089
Curve Parameters
MAPE 2,14281
MAD 0,21018
MSD 0,06048
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de analfabetismo de pessoaS-Curve Trend Model
Yt = (10**2) / (30,3948 - 22,3890*(0,980886**t))
Para podermos visualizar qual a melhor função para representar a série de dados acima,
podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das quatro
funções:
Linear Quadrática Exponencial S-Curve
MAPE 1,41 1,42 1,43 2,14
MAD 0,13 0,13 0,13 0,21
MSD 0,02 0,02 0,02 0,06
Percebemos claramente que a função linear é a que melhor se adapta à nossa série de dados
“Taxa de analfabetismo de pessoas de 10 anos ou mais”; pois, possui o menor valor para erro
percentual absoluto médio (MAPE). Assim, esta será a função utilizada para as projeções dos pró-
ximos 10 anos (2012-2021).
9.1.2 As previsões
Utilizando a equação da função linear apresentada no gráfico acima, temos os seguintes
valores previstos para os próximos 10 anos em relação a Taxa de analfabetismo de pessoas de 10
anos ou mais no Brasil.
Trend Analysis for Taxa de analfabetismo de pessoa
Data Taxa de analfabetismo de pessoa
Length 11

46
NMissing 0
Fitted Trend Equation
Yt = 11,621 - 0,326909*t
Accuracy Measures
MAPE 1,40616
MAD 0,13134
MSD 0,02315
Forecasts
Period Forecast
2012 7,69764
2013 7,37073
2014 7,04382
2015 6,71691
2016 6,39000
2017 6,06309
2018 5,73618
2019 5,40927
2020 5,08236
2021 4,75545
Os valores acima podem ser melhor ilustrados de forma gráfica, conforme abaixo:
20212019201720152013201120092007200520032001
12
11
10
9
8
7
6
5
4
Index
Ta
xa
de
an
alf
ab
eti
sm
o d
e p
esso
a
MAPE 1,40616
MAD 0,13134
MSD 0,02315
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de analfabetismo de pessoaLinear Trend Model
Yt = 11,621 - 0,326909*t
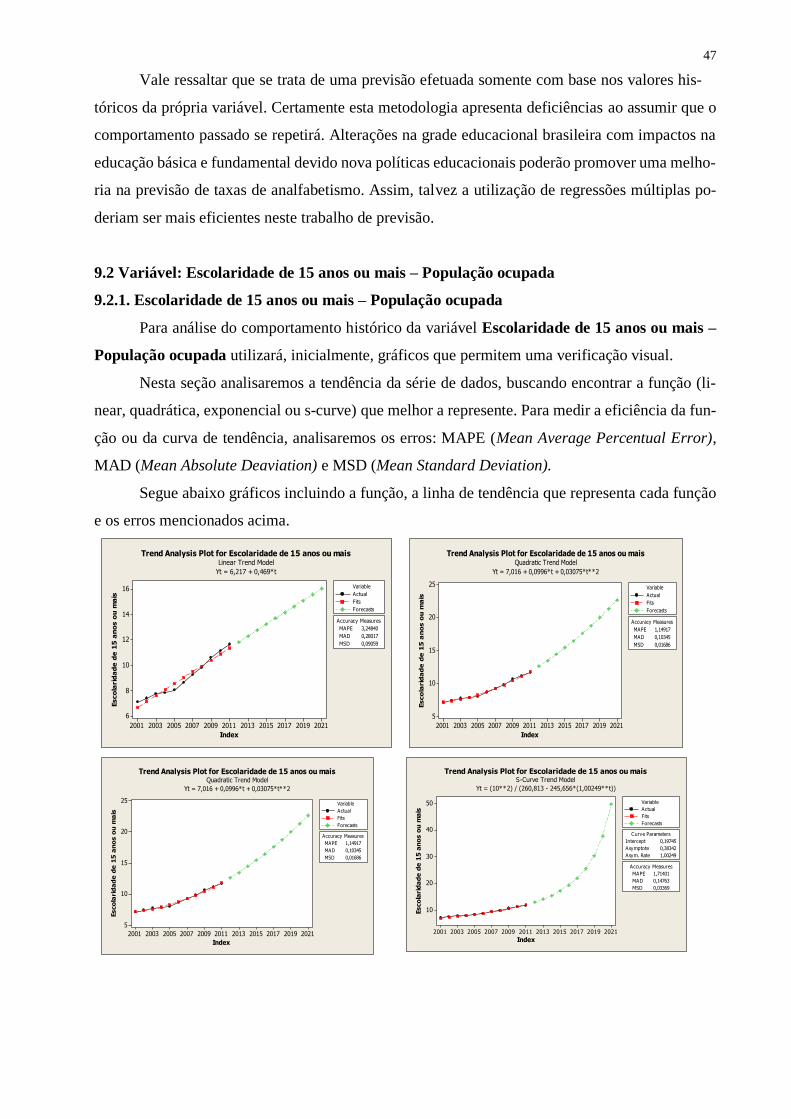
47
Vale ressaltar que se trata de uma previsão efetuada somente com base nos valores his-
tóricos da própria variável. Certamente esta metodologia apresenta deficiências ao assumir que o
comportamento passado se repetirá. Alterações na grade educacional brasileira com impactos na
educação básica e fundamental devido nova políticas educacionais poderão promover uma melho-
ria na previsão de taxas de analfabetismo. Assim, talvez a utilização de regressões múltiplas po-
deriam ser mais eficientes neste trabalho de previsão.
9.2 Variável: Escolaridade de 15 anos ou mais – População ocupada
9.2.1. Escolaridade de 15 anos ou mais – População ocupada
Para análise do comportamento histórico da variável Escolaridade de 15 anos ou mais –
População ocupada utilizará, inicialmente, gráficos que permitem uma verificação visual.
Nesta seção analisaremos a tendência da série de dados, buscando encontrar a função (li-
near, quadrática, exponencial ou s-curve) que melhor a represente. Para medir a eficiência da fun-
ção ou da curva de tendência, analisaremos os erros: MAPE (Mean Average Percentual Error),
MAD (Mean Absolute Deaviation) e MSD (Mean Standard Deviation).
Segue abaixo gráficos incluindo a função, a linha de tendência que representa cada função
e os erros mencionados acima.
20212019201720152013201120092007200520032001
16
14
12
10
8
6
Index
Esco
larid
ad
e d
e 1
5 a
no
s o
u m
ais
MAPE 3,24840
MAD 0,28017
MSD 0,09059
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Escolaridade de 15 anos ou maisLinear Trend Model
Yt = 6,217 + 0,469*t
20212019201720152013201120092007200520032001
25
20
15
10
5
Index
Esco
larid
ad
e d
e 1
5 a
no
s o
u m
ais
MAPE 1,14917
MAD 0,10345
MSD 0,01686
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Escolaridade de 15 anos ou maisQuadratic Trend Model
Yt = 7,016 + 0,0996*t + 0,03075*t**2
20212019201720152013201120092007200520032001
25
20
15
10
5
Index
Esco
larid
ad
e d
e 1
5 a
no
s o
u m
ais
MAPE 1,14917
MAD 0,10345
MSD 0,01686
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Escolaridade de 15 anos ou maisQuadratic Trend Model
Yt = 7,016 + 0,0996*t + 0,03075*t**2
20212019201720152013201120092007200520032001
50
40
30
20
10
Index
Esco
lari
da
de
de
15
an
os o
u m
ais
Intercept 0,19745
Asymptote 0,38342
Asym. Rate 1,00249
Curve Parameters
MAPE 1,71401
MAD 0,14763
MSD 0,03369
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Escolaridade de 15 anos ou maisS-Curve Trend Model
Yt = (10**2) / (260,813 - 245,656*(1,00249**t))

48
Para podermos visualizar qual a melhor função para representar a série de dados acima,
podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das quatro
funções:
Linear Quadrática Exponencial S-Curve
MAPE 3,25 1,15 2,24 1,71
MAD 0,28 0,10 0,19 0,15
MSD 0,09 0,02 0,05 0,03
Percebemos claramente que a função quadrática é a que melhor se adapta à nossa série de
dados “Taxa de escolaridade de pessoas de 15 anos ou mais da população ocupada”; pois, possui
o menor valor para erro percentual absoluto médio (MAPE) . Assim, esta será a função utilizada
para as projeções dos próximos 10 anos (2012-2021).
9.2.2 As previsões
Utilizando a equação da função quadrática apresentada no gráfico acima, temos os se-
guintes valores previstos para os próximos 10 anos em relação a Taxa de escolaridade de pessoas
de 15 anos ou mais da população ocupada no Brasil.
Trend Analysis Plot for Escolaridade de 15 anos ou mais
Trend Analysis for Escolaridade de 15 anos ou mais
Data Escolaridade de 15 anos ou mais
Length 11
NMissing 0
Fitted Trend Equation
Yt = 7,016 + 0,0996*t + 0,03075*t**2
Accuracy Measures
MAPE 1,14917
MAD 0,10345
MSD 0,01686
Forecasts
Period Forecast
2012 12,6388
2013 13,5071

49
2014 14,4368
2015 15,4281
2016 16,4808
2017 17,5950
2018 18,7707
2019 20,0079
2020 21,3066
2021 22,6667
Os valores acima podem ser melhor ilustrados de forma gráfica, conforme abaixo:
Vale ressaltar que se trata de uma previsão efetuada somente com base nos valores históri-
cos da própria variável. Certamente esta metodologia apresenta deficiências ao assumir que o com-
portamento passado se repetirá.
Alterações na grade educacional brasileira com impactos na educação básica e fundamental
devido nova políticas educacionais poderão promover uma melhoria na previsão de taxas de anal-
fabetismo; porém problemas decorrentes de emprego e renda atualmente em níveis desfavoráveis
irão exigir maiores investimentos em educação. Assim, talvez a utilização de regressões múltiplas
poderiam ser mais eficientes neste trabalho de previsão.
9.3 Variável: Investimento
9.3.1 Investimento
Para análise do comportamento histórico da variável Investimento utilizará, inicialmente,
gráficos que permitem uma verificação visual.
Nesta seção analisaremos a tendência da série de dados, buscando encontrar a função (li-
near, quadrática, exponencial ou s-curve) que melhor a represente. Para medir a eficiência da fun-
ção ou da curva de tendência, analisaremos os erros: MAPE (Mean Average Percentual Error),
MAD (Mean Absolute Deaviation) e MSD (Mean Standard Deviation).
20212019201720152013201120092007200520032001
25
20
15
10
5
Index
Esco
lari
da
de
de
15
an
os o
u m
ais
MAPE 1,14917
MAD 0,10345
MSD 0,01686
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Escolaridade de 15 anos ou maisQuadratic Trend Model
Yt = 7,016 + 0,0996*t + 0,03075*t**2

50
Segue abaixo gráficos incluindo a função, a linha de tendência que representa cada função e os
erros mencionados acima.
20212019201720152013201120092007200520032001
23
22
21
20
19
18
17
16
Index
Ta
xa
de
In
ve
sti
me
nto
MAPE 4,20078
MAD 0,76529
MSD 0,70711
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de InvestimentoLinear Trend Model
Yt = 16,600 + 0,309*t
20212019201720152013201120092007200520032001
40
35
30
25
20
Index
Ta
xa
de
In
ve
sti
me
nto
MAPE 1,98518
MAD 0,36898
MSD 0,20849
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de InvestimentoQuadratic Trend Model
Yt = 18,679 - 0,650*t + 0,0800*t**2
20212019201720152013201120092007200520032001
24
23
22
21
20
19
18
17
16
Index
Ta
xa
de
In
ve
sti
me
nto
MAPE 4,11102
MAD 0,75006
MSD 0,67787
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de InvestimentoGrowth Curve Model
Yt = 16,6871 * (1,01651**t)
20212019201720152013201120092007200520032001
100
90
80
70
60
50
40
30
20
10
Index
Ta
xa
de
In
ve
sti
me
nto
Intercept 13,2086
Asymptote 14,5237
Asym. Rate 1,1077
Curve Parameters
MAPE 3,22812
MAD 0,59687
MSD 0,71059
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de InvestimentoS-Curve Trend Model
Yt = (10**2) / (6,88532 - 0,685509*(1,10769**t))
Para podermos visualizar qual a melhor função para representar a série de dados acima,
podemos analisar a tabela abaixo, que compara os três tipos de erros para cada uma das quatro
funções:
Linear Quadrática Exponencial S-Curve
MAPE 4,20 1,99 4,11 3,23
MAD 0,77 0,37 0,75 0,60
MSD 0,71 0,21 0,68 0,71
Percebemos claramente que a função quadrática é a que melhor se adapta à nossa série de
dados “Taxa de Investimento”; pois, possui o menor valor para erro percentual absoluto médio
(MAPE) . Assim, esta será a função utilizada para as projeções dos próximos 10 anos (2012-2021).
9.3.2 As previsões
Utilizando a equação da função quadrática apresentada no gráfico acima, temos os seguin-
tes valores previstos para os próximos 10 anos em relação a Taxa de Investimento no Brasil.
Trend Analysis Plot for Taxa de Investimento

51
Trend Analysis for Taxa de Investimento
Data Taxa de Investimento
Length 11
NMissing 0
Fitted Trend Equation
Yt = 18,679 - 0,650*t + 0,0800*t**2
Accuracy Measures
MAPE 1,98518
MAD 0,36898
MSD 0,20849
Forecasts
Period Forecast
2012 22,3879
2013 23,7364
2014 25,2448
2015 26,9131
2016 28,7413
2017 30,7294
2018 32,8774
2019 35,1853
2020 37,6531
2021 40,2809
Os valores acima podem ser melhor ilustrados de forma gráfica, conforme abaixo:
20212019201720152013201120092007200520032001
40
35
30
25
20
Index
Ta
xa
de
In
ve
sti
me
nto
MAPE 1,98518
MAD 0,36898
MSD 0,20849
Accuracy Measures
Actual
Fits
Forecasts
Variable
Trend Analysis Plot for Taxa de InvestimentoQuadratic Trend Model
Yt = 18,679 - 0,650*t + 0,0800*t**2

52
Vale ressaltar que se trata de uma previsão efetuada somente com base nos valores históri-
cos da própria variável. Certamente esta metodologia apresenta deficiências ao assumir que o com-
portamento passado se repetirá. Alterações de natureza política e principalmente na condução da
política econômica brasileira podendo gerar cortes de investimentos poderão promover resultados
no médio prazo que venham a resultar em menores orçamentos em investimentos. Assim, talvez a
utilização de regressões múltiplas pudesse ser mais eficiente neste trabalho de previsão.
CAPÍTULO X. ANÁLISE DE REGRESSÃO LINEAR MULTIVARIADA
10.1 Relações entre variáveis
Ao se estudar a relação entre duas ou mais variáveis, devemos mensurá-las nos mesmos
indivíduos. Destaque-se a importância ao fato que a relação entre duas variáveis pode ser forte-
mente influenciada por outras variáveis ocultas em um determinado contexto. A associação entre
duas variáveis é encontrada quando, os valores de uma variável mensurada sobre os mesmos indi-
víduos, tendem a ocorrer com maior frequência juntamente com alguns valores de outra variável
e não simplesmente quaisquer outros valores.
Ao estudarmos a relação entre variáveis é importante ter clareza quanto ao objetivo. Este
pode ser entendido como apenas explorar a natureza da relação, ou também, demonstrar que uma
das variáveis pode explicar variações na outra. Isso nos remete a prever a possibilidade da exis-
tência de dois tipos de variáveis: (1) variável explanatória; (2) variável-resposta. A primeira ex-
plica as variáveis - resposta ou causa modificações nela, enquanto que a segunda, mede um resul-
tado de um estudo. Embora muitas pesquisas demonstrem que variações em uma ou mais variáveis
explanatórias causam variações em uma variável-resposta, nem todas as relações explanatórias -
respostas envolvem causa direta.
Costumeiramente as variáveis explanatórias são chamadas de variáveis independentes, e as
variáveis - respostas são chamadas de variáveis dependentes. Logo, entende-se que as variáveis -
respostas dependem das variáveis explanatórias. Uma consideração importante, é que, na estatís-
tica as palavras independentes e dependentes possuem outros significados não relacionados com a
distinção entre explanatória e resposta. Assim, julga-se necessário, certo cuidado com o emprego
das palavras.
10.2 Apresentação de relações entre variáveis
Hoje, com o aparecimento exponencial de tecnologias aplicadas a diversos fins, é comum
encontrar novas formas de apresentação de dados e informações. Talvez, não exista o melhor ca-
minho, mas um caminho melhor para demonstrar a relação entre variáveis quantitativas, o gráfico

53
diagrama de dispersão. Este mostra a relação entre duas variáveis quantitativas medidas sobre
os mesmos indivíduos.
No eixo horizontal aparecem os valores de uma das variáveis; logo, no eixo vertical estão
dispostos os valores da outra variável. O individuo é identificado
no gráfico definido pelos valores de ambas variáveis. No eixo horizontal (eixo x) usa-se sempre
variável explanatória, enquanto que no eixo vertical (eixo y) usa-se a variável-resposta. Caso não
haja distinção entre as variáveis elas podem ocupar quaisquer eixos.
Como em qualquer gráfico de dados, examinamos o diagrama de dispersão procurando o
padrão geral e os desvios. Podemos descrever o padrão geral enquanto sua forma, direção e inten-
sidade. Um outlier é um tipo importante de desvio, ou seja, um valor individual que se situa fora
do padrão geral. A associação entre as variáveis pode ser positiva ou negativa. Na primeira, os
valores acima de média de uma delas tendem a acompanhar valores acima da média da outra e
mesmo para os valores abaixo da média. Na segunda, os valores acima da média de uma delas
acompanham os valores abaixo da média da outra, e vice-versa.
A intensidade de uma relação em um diagrama de dispersão é determinada pela proximi-
dade dos pontos a uma forma definida. A intensidade é forte quando os pontos mostram uma dis-
persão modesta em relação ao padrão, neste caso temos uma relação linear moderadamente forte.
Ao contrario teríamos uma relação fraca.
10.3 Regressão
Para encontrar as relações entre variáveis, assumiu-se como variável - resposta o
“IDHM_E”, para as variáveis explanatórias utilizaram-se as demais variáveis deste estudo exceto
as seguintes variáveis “IDHM”, “IDHM_R”, e “IDHM_L”, para não permitir nenhum viés ao es-
tudo. Na Tabela 8 pode se observar a equação encontrada e nota-se que não houve exclusão de
nenhuma variável.
Tabela 8 – Analise de Regressão para variável-resposta “IDHM_E”
Regression Analysis: IDHM_E versus ESPVIDA; MORT1; ...
The regression equation is
IDHM_E = 0,489 + 0,000670 ESPVIDA + 0,000719 MORT1 + 0,00105 T_ANALF25M
+ 0,00399 T_FUND25M + 0,000018 RDPC + 0,000057 RIND - 0,000088 P_FORMAL
- 0,000028 RENOCUP - 0,000094 T_BANAGUA - 0,000663 T_DENS
+ 0,000497 T_NESTUDA_NTRAB_MMEIO - 0,00546 T_FUNDIN_TODOS_MMEIO
- 0,000203 T_MULCHEFEFIF014 - 0,000000 PEA
Predictor Coef SE Coef T P
Constant 0,48900 0,04661 10,49 0,000
ESPVIDA 0,0006696 0,0005907 1,13 0,257

54
MORT1 0,0007189 0,0002203 3,26 0,001
T_ANALF25M 0,00104957 0,00007567 13,87 0,000
T_FUND25M 0,00398749 0,00007608 52,41 0,000
RDPC 0,00001784 0,00000586 3,05 0,002
RIND 0,00005716 0,00003924 1,46 0,145
P_FORMAL -0,00008779 0,00003850 -2,28 0,023
RENOCUP -0,00002751 0,00000377 -7,29 0,000
T_BANAGUA -0,00009434 0,00003690 -2,56 0,011
T_DENS -0,00066312 0,00005723 -11,59 0,000
T_NESTUDA_NTRAB_MMEIO 0,00049673 0,00009360 5,31 0,000
T_FUNDIN_TODOS_MMEIO -0,00545630 0,00009455 -57,71 0,000
T_MULCHEFEFIF014 -0,00020335 0,00005098 -3,99 0,000
PEA -0,00000001 0,00000000 -2,57 0,010
S = 0,0272726 R-Sq = 91,5% R-Sq(adj) = 91,5%
Analysis of Variance
Source DF SS MS F P
Regression 14 44,3348 3,1668 4257,60 0,000
Residual Error 5550 4,1280 0,0007
Total 5564 48,4628
Source DF Seq SS
ESPVIDA 1 24,0459
MORT1 1 0,0072
T_ANALF25M 1 6,7443
T_FUND25M 1 7,7060
RDPC 1 0,3783
RIND 1 0,0779
P_FORMAL 1 0,0969
RENOCUP 1 0,9007
T_BANAGUA 1 0,7650
T_DENS 1 0,8428
T_NESTUDA_NTRAB_MMEIO 1 0,0684
T_FUNDIN_TODOS_MMEIO 1 2,6848
T_MULCHEFEFIF014 1 0,0118
PEA 1 0,0049 Fonte: Minitab (2016)
Em busca da melhor equação para definir as variáveis que mais explicam a variável
“IDHM_E”, realizou a análise de regressão passo a passo. A Tabela 9 demonstra os resultados. As
variáveis relevantes para explicar a variável-resposta são: “T_FUNDIN_TODOS_MMEIO”,
“T_FUND25M”, “T_ANALF25M”, “T_DENS”, “RENOCUP”.
Tabela 9 – Análise de Regressão Passo a Passo para a variável-resposta “IDHM_E”
Stepwise Regression: IDHM_E versus ESPVIDA; MORT1; ...

55
Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is IDHM_E on 14 predictors, with N = 5565
Step 1 2 3 4 5
Constant 0,6990 0,5552 0,5404 0,5262 0,5392
T_FUNDIN_TODOS_MMEIO -0,00676 -0,00472 -0,00594 -0,00525 -0,00529
T-Value -176,75 -94,33 -85,31 -60,62 -61,78
P-Value 0,000 0,000 0,000 0,000 0,000
T_FUND25M 0,00301 0,00325 0,00368 0,00409
T-Value 52,39 58,48 57,41 56,79
P-Value 0,000 0,000 0,000 0,000
T_ANALF25M 0,00156 0,00156 0,00134
T-Value 24,06 24,47 20,37
P-Value 0,000 0,000 0,000
T_DENS -0,00058 -0,00063
T-Value -12,94 -14,16
P-Value 0,000 0,000
RENOCUP -0,00003
T-Value -11,88
P-Value 0,000
MORT1
T-Value
P-Value
S 0,0363 0,0297 0,0283 0,0279 0,0275
R-Sq 84,88 89,88 90,83 91,10 91,32
R-Sq(adj) 84,88 89,88 90,83 91,09 91,31
Mallows Cp 4287,7 1035,6 415,9 243,3 101,8 Fonte: Minitab (2016)
Considerando que a análise de regressão passo a passo nos permitiu verificar as que as va-
riáveis relevantes para explicar a variável-resposta “IDHM_E” explicam 84,9% da variável. As-
sim na Tabela 10, os resultados da analise de regressão apenas com as variáveis explanatórias
mais relevante para explicar a variável-resposta.
Tabela 10 – Análise de Regressão para Variável - Resposta “IDHM_E” vs. Variáveis Explanató-
rias
Regression Analysis: IDHM_E versus T_FUNDIN_TODOS_MMEIO; T_FUND25M; ...

56
The regression equation is
IDHM_E = 0,539 - 0,00529 T_FUNDIN_TODOS_MMEIO + 0,00409 T_FUND25M
+ 0,00134 T_ANALF25M - 0,000634 T_DENS - 0,000026 RENOCUP
Predictor Coef SE Coef T P
Constant 0,539189 0,003112 173,28 0,000
T_FUNDIN_TODOS_MMEIO -0,00529107 0,00008564 -61,78 0,000
T_FUND25M 0,00408616 0,00007195 56,79 0,000
T_ANALF25M 0,00134139 0,00006586 20,37 0,000
T_DENS -0,00063362 0,00004473 -14,16 0,000
RENOCUP -0,00002570 0,00000216 -11,88 0,000
S = 0,0275065 R-Sq = 91,3% R-Sq(adj) = 91,3%
Analysis of Variance
Source DF SS MS F P
Regression 5 44,2568 8,8514 11698,74 0,000
Residual Error 5559 4,2060 0,0008
Total 5564 48,4628
Source DF Seq SS
T_FUNDIN_TODOS_MMEIO 1 41,1375
T_FUND25M 1 2,4204
T_ANALF25M 1 0,4624
T_DENS 1 0,1299
RENOCUP 1 0,1067 Fonte: Minitab (2016)
Nota-se que no resultado identificamos associações positivas e negativas. Para análise das
condições de inferência, observa-se na Figura 2 Neste caso as equações encontradas têm:
1. Os p-values menores do que 0,10 indicam que uma há significativa evidencia da existência
de uma relação.
2. A Figura 2 demonstra gráficos que permitem verificar se uma série de condições está sendo
atendidas.
Alguns apontamentos sobre os gráficos:
• O gráfico Normal PlotVs Residual nos demonstra uma distribuição praticamente
linear, o que é compatível com uma distribuição normal.
• O Histograma também parece demonstrar uma distribuição aproximadamente si-
métrica e normal.
• A forma de distribuição ao longo da reta parece ser igual ao longo da reta de re-
gressão, com exceção de alguns outliers no começo (0,2) e no final (1,0).

57
Nota-se que no resultado identificamos associações positivas e negativas. Para análise das
condições inferência, observa-se a Figura 3. Neste caso a equação encontrada temos:
3. Os p-values menores do que 0,10 indicam que uma há significativa evidencia da existência
de uma relação.
4. A Figura 22 demonstra os gráficos que permitem verificar se uma série de condições está
sendo atendidas.
Alguns apontamentos sobre os gráficos:
• O gráfico Normal PlotVs Residual nos demonstra uma distribuição praticamente
linear, o que é compatível com uma distribuição normal.
• O Histograma também parece demonstrar uma distribuição aproximadamente si-
métrica e normal.
• A forma de distribuição ao longo da reta parece ser igual ao longo da reta de re-
gressão, com exceção de alguns outliers no começo (0,2) e no final (0,8).
0,100,050,00-0,05-0,10
99,99
99
90
50
10
1
0,01
Residual
Pe
rce
nt
0,80,60,40,2
0,10
0,05
0,00
-0,05
-0,10
Fitted Value
Re
sid
ua
l
0,090,060,030,00-0,03-0,06-0,09
400
300
200
100
0
Residual
Fre
qu
en
cy
5500
5000
4500
4000
3500
3000
2500
2000
1500
100050
01
0,10
0,05
0,00
-0,05
-0,10
Observation Order
Re
sid
ua
l
Normal Probability Plot Versus Fits
Histogram Versus Order
Residual Plots for IDHM_E
Figura 3 – Análise das Condições de Inferência
Fonte: Elaborado pelo autor ( Minitab 16)
Para encontrar a melhor equação tanto para a explicação quanto para relação, foi realizada
uma serie de procedimentos. A melhor equação foi encontrada na Tabela 10, que utilizou a equa-
ção da Tabela 8. Com isso realizou-se outro procedimento de regressão linear para obter a seguinte
equação confirmando o R-Quadrado:
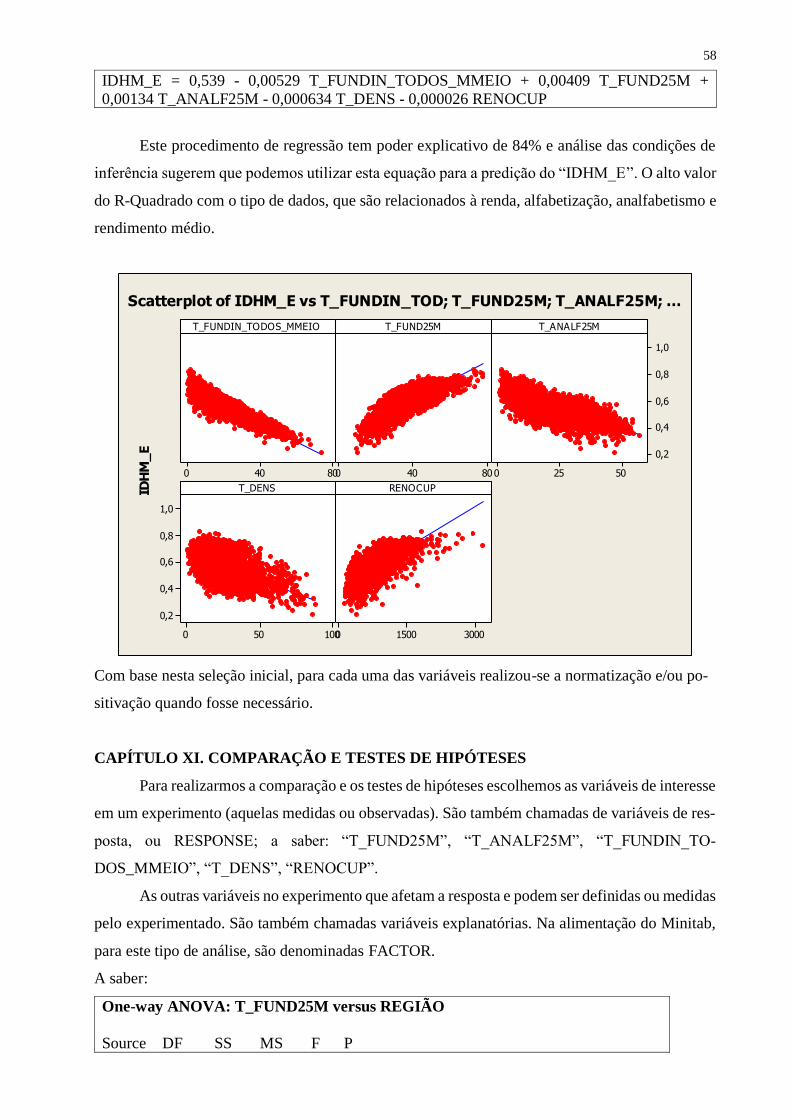
58
IDHM_E = 0,539 - 0,00529 T_FUNDIN_TODOS_MMEIO + 0,00409 T_FUND25M +
0,00134 T_ANALF25M - 0,000634 T_DENS - 0,000026 RENOCUP
Este procedimento de regressão tem poder explicativo de 84% e análise das condições de
inferência sugerem que podemos utilizar esta equação para a predição do “IDHM_E”. O alto valor
do R-Quadrado com o tipo de dados, que são relacionados à renda, alfabetização, analfabetismo e
rendimento médio.
80400 80400 50250
1,0
0,8
0,6
0,4
0,2
100500
1,0
0,8
0,6
0,4
0,2
300015000
T_FUNDIN_TODOS_MMEIO
IDH
M_
E
T_FUND25M T_ANALF25M
T_DENS RENOCUP
Scatterplot of IDHM_E vs T_FUNDIN_TOD; T_FUND25M; T_ANALF25M; ...
Com base nesta seleção inicial, para cada uma das variáveis realizou-se a normatização e/ou po-
sitivação quando fosse necessário.
CAPÍTULO XI. COMPARAÇÃO E TESTES DE HIPÓTESES
Para realizarmos a comparação e os testes de hipóteses escolhemos as variáveis de interesse
em um experimento (aquelas medidas ou observadas). São também chamadas de variáveis de res-
posta, ou RESPONSE; a saber: “T_FUND25M”, “T_ANALF25M”, “T_FUNDIN_TO-
DOS_MMEIO”, “T_DENS”, “RENOCUP”.
As outras variáveis no experimento que afetam a resposta e podem ser definidas ou medidas
pelo experimentado. São também chamadas variáveis explanatórias. Na alimentação do Minitab,
para este tipo de análise, são denominadas FACTOR.
A saber:
One-way ANOVA: T_FUND25M versus REGIÃO
Source DF SS MS F P

59
REGIÃO 4 151864,3 37966,1 398,25 0,000
Error 5559 529951,8 95,3
Total 5563 681816,1
S = 9,764 R-Sq = 22,27% R-Sq(adj) = 22,22%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ------+---------+---------+---------+---
CO 465 37,725 7,473 (--*-)
N 449 32,463 9,286 (--*-)
NE 1794 26,485 8,519 (-*)
S 1188 37,244 9,775 (*-)
SE 1668 38,303 11,536 (*-)
------+---------+---------+---------+---
28,0 31,5 35,0 38,5
Pooled StDev = 9,764
SESNENCO
80
70
60
50
40
30
20
10
0
REGIÃO
T_
FUN
D2
5M
Boxplot of T_FUND25M
Indicadores Expoente (+) SUDESTE, n=1668 Expoente (-) NORDESTE, n=1794
Q1 29,3625 20,9575
Mediana 37,825 25,08
Q3 45,8875 29,8625
Média 38,303 26,485
Desvio padrão 11,536 8,519
One-way ANOVA: T_ANALF25M versus REGIÃO

60
Source DF SS MS F P
REGIÃO 4 606142,6 151535,6 2804,56 0,000
Error 5559 300363,2 54,0
Total 5563 906505,8
S = 7,351 R-Sq = 66,87% R-Sq(adj) = 66,84%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -------+---------+---------+---------+--
CO 465 15,404 5,065 (*)
N 449 22,384 8,429 (*)
NE 1794 34,970 8,541 (*
S 1188 9,761 4,867 (*)
SE 1668 13,581 7,655 *)
-------+---------+---------+---------+--
14,0 21,0 28,0 35,0
Pooled StDev = 7,351
SESNENCO
60
50
40
30
20
10
0
REGIÃO
T_
AN
ALF2
5M
Boxplot of T_ANALF25M
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORDESTE,
n=1794
Q1 5,7425 29,835
Mediana 9,005 35,515
Q3 13,0275 40,6525
Média 9,761 34,970
Desvio padrão 4,867 8,541

61
One-way ANOVA: T_FUNDIN_TODOS_MMEIO versus REGIÃO
Source DF SS MS F P
REGIÃO 4 502391,4 125597,9 1753,51 0,000
Error 5559 398171,7 71,6
Total 5563 900563,1
S = 8,463 R-Sq = 55,79% R-Sq(adj) = 55,75%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
CO 465 15,223 6,759 (*-)
N 449 29,968 11,737 (*)
NE 1794 32,680 8,718 *)
S 1188 10,837 6,520 (*)
SE 1668 13,914 8,781 *)
---+---------+---------+---------+------
12,0 18,0 24,0 30,0
Pooled StDev = 8,463
SESNENCO
80
70
60
50
40
30
20
10
0
REGIÃO
T_
FUN
DIN
_TO
DO
S_
MM
EIO
Boxplot of T_FUNDIN_TODOS_MMEIO
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORDESTE,
n=1794
Q1 5,8 26,7975
Mediana 9,61 32,725
Q3 14,7275 38,48
Média 10,837 32,680
Desvio padrão 6,520 8,718
One-way ANOVA: T_DENS versus REGIÃO

62
Source DF SS MS F P
REGIÃO 4 489644,3 122411,1 1510,67 0,000
Error 5559 450452,4 81,0
Total 5563 940096,7
S = 9,002 R-Sq = 52,08% R-Sq(adj) = 52,05%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -------+---------+---------+---------+--
CO 465 20,779 8,877 (*)
N 449 45,136 17,489 (*)
NE 1794 33,068 8,606 *
S 1188 13,833 6,387 (*
SE 1668 20,456 7,575 *)
-------+---------+---------+---------+--
20 30 40 50
Pooled StDev = 9,002
SESNENCO
90
80
70
60
50
40
30
20
10
0
REGIÃO
T_
DEN
S
Boxplot of T_DENS
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORTE, n=449
Q1 9,06 30,935
Mediana 13,015 43,69
Q3 17,6775 58,265
Média 13,833 45,136
Desvio padrão 6,387 17,489

63
One-way ANOVA: RENOCUP versus REGIÃO
Source DF SS MS F P
REGIÃO 4 276629690 69157422 1039,86 0,000
Error 5559 369709458 66506
Total 5563 646339148
S = 257,9 R-Sq = 42,80% R-Sq(adj) = 42,76%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---------+---------+---------+---------+
CO 465 1015,2 241,6 (-*)
N 449 708,1 250,0 (*-)
NE 1794 473,7 192,1 (*
S 1188 980,1 257,3 (*)
SE 1668 920,0 319,2 *)
---------+---------+---------+---------+
600 750 900 1050
Pooled StDev = 257,9
SESNENCO
3500
3000
2500
2000
1500
1000
500
0
REGIÃO
REN
OC
UP
Boxplot of RENOCUP
Indicadores Expoente (+) CENTRO OESTE, n=465 Expoente (-) NORDESTE,
n=1794
Q1 848,43 351,48
Mediana 989,9 431,33
Q3 1144,63 551,08
Média 1015,2 473,7

64
Desvio padrão 241,6 192,1
One-way ANOVA: IDHM_E versus REGIÃO
Source DF SS MS F P
REGIÃO 4 18,83643 4,70911 884,60 0,000
Error 5559 29,59293 0,00532
Total 5563 48,42936
S = 0,07296 R-Sq = 38,89% R-Sq(adj) = 38,85%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --+---------+---------+---------+-------
CO 465 0,58380 0,05977 (-*-)
N 449 0,49043 0,09066 (-*-)
NE 1794 0,48842 0,06579 (*)
S 1188 0,61302 0,06520 (*)
SE 1668 0,60819 0,08287 (*)
--+---------+---------+---------+-------
0,490 0,525 0,560 0,595
Pooled StDev = 0,07296
SESNENCO
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
REGIÃO
IDH
M_
E
Boxplot of IDHM_E
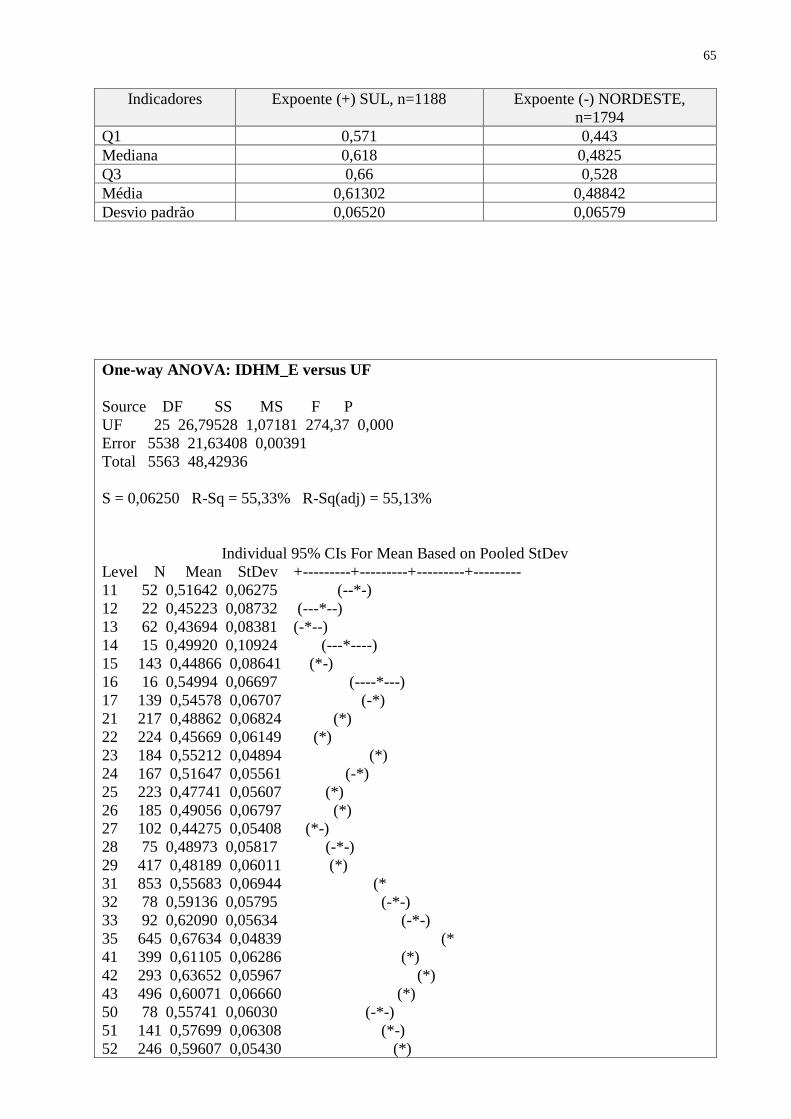
65
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORDESTE,
n=1794
Q1 0,571 0,443
Mediana 0,618 0,4825
Q3 0,66 0,528
Média 0,61302 0,48842
Desvio padrão 0,06520 0,06579
One-way ANOVA: IDHM_E versus UF
Source DF SS MS F P
UF 25 26,79528 1,07181 274,37 0,000
Error 5538 21,63408 0,00391
Total 5563 48,42936
S = 0,06250 R-Sq = 55,33% R-Sq(adj) = 55,13%
Individual 95% CIs For Mean Based on Pooled StDev
Level N Mean StDev +---------+---------+---------+---------
11 52 0,51642 0,06275 (--*-)
12 22 0,45223 0,08732 (---*--)
13 62 0,43694 0,08381 (-*--)
14 15 0,49920 0,10924 (---*----)
15 143 0,44866 0,08641 (*-)
16 16 0,54994 0,06697 (----*---)
17 139 0,54578 0,06707 (-*)
21 217 0,48862 0,06824 (*)
22 224 0,45669 0,06149 (*)
23 184 0,55212 0,04894 (*)
24 167 0,51647 0,05561 (-*)
25 223 0,47741 0,05607 (*)
26 185 0,49056 0,06797 (*) 27 102 0,44275 0,05408 (*-)
28 75 0,48973 0,05817 (-*-)
29 417 0,48189 0,06011 (*)
31 853 0,55683 0,06944 (*
32 78 0,59136 0,05795 (-*-)
33 92 0,62090 0,05634 (-*-)
35 645 0,67634 0,04839 (*
41 399 0,61105 0,06286 (*)
42 293 0,63652 0,05967 (*)
43 496 0,60071 0,06660 (*)
50 78 0,55741 0,06030 (-*-)
51 141 0,57699 0,06308 (*-)
52 246 0,59607 0,05430 (*)

66
+---------+---------+---------+---------
0,420 0,490 0,560 0,630
Pooled StDev = 0,06250
TOSPSESCRSRRRORNRJPRPIPEPBPAMT
MS
MG
MA
GOESCEBAAP
AMALAC
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
ESTADO
IDH
M_
EBoxplot of IDHM_E
Observando o boxplot do IDHM_E (Educação) e traçando uma linha aleatória, pratica-
mente dividindo o eixo vertical em duas partes, encontramos na parte superior (estados com me-
lhores índices educacionais) praticamente os estados das regiões SUL, SUDESTE e CENTRO
OESTE, e na parte inferior (estados com piores índices de educação), os da região NORTE e
NORDESTE.
Essa análise valida as hipóteses de relação existentes entre os responses escolhidos
T_FUND25M, T_ANALF25M, T_FUNDIN_TODOS_MMEIO, T_DENS, T_RENOCUP com
IDHM_E e os factors explorados, as regiões brasileiras.
CAPÍTULO XII. PESQUISA POR AMOSTRAGEM
A pesquisa por amostragem foi feita em três amostras, uma de 25 municípios, outra composta
por 100 municípios e uma terceira com 400 municípios. Para cada amostra foram efetuadas:
• Amostra Aleatória: foi feita através da funcionalidade “Calc, Random Data, Sample From
Columns” do Minitab16; estratificando-se em 3 seleções: 25, 100 e 400 municípios. Obti-
dos os resultados “colou-se” em uma coluna vazia no Minitab e também copiando os dados
apresentados para o trabalho.
• Anova: foi feita para cada uma das seleções sorteadas, através da funcionalidade “Stat,
Anova, One-Way (Unstacked)”. Inserindo a variável original e as 3 novas amostras a fim
de elaborar o Graphs Boxplots.

67
One-way ANOVA: IDHM_E; IDHE25; IDHE100; IDHE400
Source DF SS MS F P
Factor 3 0,00875 0,00292 0,34 0,797
Error 6085 52,39217 0,00861
Total 6088 52,40092
S = 0,09279 R-Sq = 0,02% R-Sq(adj) = 0,00%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
IDHM_E 5564 0,55906 0,09330 (-*)
IDHE25 25 0,57132 0,07381 (------------------*-----------------)
IDHE100 100 0,55237 0,09518 (--------*--------)
IDHE400 400 0,55780 0,08577 (----*---)
---+---------+---------+---------+------
0,540 0,560 0,580 0,600
Pooled StDev = 0,09279
Boxplot of IDHM_E; IDHE25; IDHE100; IDHE400

68
IDHE400IDHE100IDHE25IDHM_E
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
Da
ta
Boxplot of IDHM_E; IDHE25; IDHE100; IDHE400
A amostra de 400 municípios apresentou praticamente os mesmos valores na média e des-
vio padrão. Portanto, pode-se concluir que a amostra aleatória de 400 municípios representa muito
próximo da população do IDH_E original com 5564 municípios (considerando-se excluído o Dis-
trito Federal pois só tem 1 município). O Box-Plot confirma a hipótese nula de diferença de médias
para amostra aleatória de 400 indivíduos. O P-Value próximo de 1 que confirma a análise anterior:
a amostra aleatória é altamente representativa.
One-way ANOVA: T_FUND25M; FUND25M25; FUND25M100; FUND25M400
Source DF SS MS F P
Factor 3 441 147 1,19 0,313
Error 6085 752647 124
Total 6088 753088
S = 11,12 R-Sq = 0,06% R-Sq(adj) = 0,01%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
T_FUND25M 5564 33,75 11,07 *)
FUND25M25 25 30,52 7,99 (--------------*-------------)
FUND25M100 100 34,05 11,18 (------*-------)
FUND25M400 400 34,42 11,94 (---*--)
---+---------+---------+---------+------
27,0 30,0 33,0 36,0
Pooled StDev = 11,12

69
Boxplot of T_FUND25M; FUND25M25; FUND25M100; FUND25M40
FUND25M400FUND25M100FUND25M25T_FUND25M
80
70
60
50
40
30
20
10
0
Da
taBoxplot of T_FUND25M; FUND25M25; FUND25M100; FUND25M400
A amostra de 100 municípios apresentou praticamente os mesmos valores na média e des-
vio padrão. Portanto, pode-se concluir que a amostra aleatória de 100 municípios representa muito
próximo da população original com 5564 municípios (considerando-se excluído o Distrito Federal,
pois só tem 1 município). O Box-Plot confirma a hipótese nula de diferença de médias para amos-
tra aleatória de 100 indivíduos. O P-Value próximo de 1 que confirma a análise anterior: a amostra
aleatória é altamente representativa.
One-way ANOVA: T_ANALF25M; ANALF25M25; ANALF25M100;
ANALF25M400
Source DF SS MS F P
Factor 3 686 229 1,40 0,241
Error 6085 993744 163
Total 6088 994429
S = 12,78 R-Sq = 0,07% R-Sq(adj) = 0,02%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
T_ANALF25M 5564 20,52 12,77 (*-)
ANALF25M25 25 16,15 10,56 (----------------*----------------)
ANALF25M100 100 19,84 13,40 (-------*-------)
ANALF25M400 400 21,16 12,94 (----*---)
---+---------+---------+---------+------
12,0 15,0 18,0 21,0

70
Pooled StDev = 12,78
Boxplot of T_ANALF25M; ANALF25M25; ANALF25M100; ANALF25M40
ANALF25M400ANALF25M100ANALF25M25T_ANALF25M
60
50
40
30
20
10
0
Da
ta
Boxplot of T_ANALF25M; ANALF25M25; ANALF25M100; ANALF25M400
A amostra de 400 municípios apresentou praticamente os mesmos valores na média e des-
vio padrão. Portanto, pode-se concluir que a amostra aleatória de 400 municípios representa muito
próximo da população original com 5564 municípios (considerando-se excluído o Distrito Federal
pois só tem 1 município). O Box-Plot confirma a hipótese nula de diferença de médias para amos-
tra aleatória de 400 indivíduos. O P-Value próximo de 1 que confirma a análise anterior: a amostra
aleatória é altamente representativa.
One-way ANOVA: T_FUNDIN_TODOS_M; FUNDINTODOS25; FUNDINTO-
DOS100; FUNDINTODOS400
Source DF SS MS F P
Factor 3 192 64 0,40 0,755
Error 6085 981482 161
Total 6088 981674
S = 12,70 R-Sq = 0,02% R-Sq(adj) = 0,00%
Level N Mean StDev
T_FUNDIN_TODOS_MMEIO 5564 20,71 12,72
FUNDINTODOS25 25 21,20 13,59
FUNDINTODOS100 100 20,29 11,91
FUNDINTODOS400 400 20,04 12,51

71
Individual 95% CIs For Mean Based on
Pooled StDev
Level -----+---------+---------+---------+----
T_FUNDIN_TODOS_MMEIO (*)
FUNDINTODOS25 (-------------------*-------------------)
FUNDINTODOS100 (---------*---------)
FUNDINTODOS400 (----*----)
-----+---------+---------+---------+----
17,5 20,0 22,5 25,0
Pooled StDev = 12,70
Boxplot of T_FUNDIN_TODOS_MMEIO; FUNDINTODOS25; FUNDINTODOS100;
FUNDINTODOS400
FUNDINTODOS400FUNDINTODOS100FUNDINTODOS25T_FUNDIN_TODOS_MMEIO
80
70
60
50
40
30
20
10
0
Da
ta
t of T_FUNDIN_TODOS_MMEIO; FUNDINTODOS25; FUNDINTODOS100; FUNDINTOD
A amostra de 400 municípios apresentou praticamente os mesmos valores na média e des-
vio padrão. Portanto, pode-se concluir que a amostra aleatória de 400 municípios representa muito
próximo da população original com 5564 municípios (considerando-se excluído o Distrito Federal
pois só tem 1 município). O Box-Plot confirma a hipótese nula de diferença de médias para amos-
tra aleatória de 400 indivíduos. O P-Value próximo de 1 que confirma a análise anterior: a amostra
aleatória é altamente representativa.
One-way ANOVA: T_DENS; TDENS25; TDENS100; TDENS400
Source DF SS MS F P
Factor 3 584 195 1,15 0,328
Error 6085 1031936 170

72
Total 6088 1032519
S = 13,02 R-Sq = 0,06% R-Sq(adj) = 0,01%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -----+---------+---------+---------+----
T_DENS 5564 25,13 13,00 (*)
TDENS25 25 20,70 15,40 (-------------*--------------)
TDENS100 100 26,09 13,80 (-------*------)
TDENS400 400 25,09 12,99 (---*--)
-----+---------+---------+---------+----
17,5 21,0 24,5 28,0
Pooled StDev = 13,02
Boxplot of T_DENS; TDENS25; TDENS100; TDENS400
TDENS400TDENS100TDENS25T_DENS
90
80
70
60
50
40
30
20
10
0
Da
ta
Boxplot of T_DENS; TDENS25; TDENS100; TDENS400
A amostra de 400 municípios apresentou praticamente os mesmos valores na média e des-
vio padrão. Portanto, pode-se concluir que a amostra aleatória de 400 municípios representa muito
próximo da população original com 5564 municípios (considerando-se excluído o Distrito Federal,
pois só tem 1 município). O Box-Plot confirma a hipótese nula de diferença de médias para amos-
tra aleatória de 400 indivíduos. O P-Value próximo de 1 que confirma a análise anterior: a amostra
aleatória é altamente representativa.
One-way ANOVA: RENOCUP; RENCUP25; RENCUP100; RENCUP400
Source DF SS MS F P

73
Factor 3 240671 80224 0,68 0,563
Error 6085 716093532 117682
Total 6088 716334203
S = 343,0 R-Sq = 0,03% R-Sq(adj) = 0,00%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ----+---------+---------+---------+-----
RENOCUP 5564 779,8 340,9 (*-)
RENCUP25 25 736,1 334,1 (------------------*------------------)
RENCUP100 100 808,8 364,5 (---------*--------)
RENCUP400 400 797,2 367,6 (----*----)
----+---------+---------+---------+-----
630 700 770 840
Pooled StDev = 343,
Boxplot of RENOCUP; RENCUP25; RENCUP100; RENCUP400
RENCUP400RENCUP100RENCUP25RENOCUP
3500
3000
2500
2000
1500
1000
500
0
Da
ta
Boxplot of RENOCUP; RENCUP25; RENCUP100; RENCUP400
A amostra de 400 municípios não apresentou os mesmos valores na média e desvio padrão.
Portanto, pode-se concluir que a amostra aleatória de 400 municípios nos mostra que deveríamos
aumentar a amostragem aleatória a fim de identificar melhor aquela que representasse mais proxi-
midade com a variável original dos 5564 municípios (considerando-se excluído o Distrito Federal,
pois só tem 1 município). O Box-Plot confirma que a amostra não é tão representativa em termos
de média, mediana e desvio padrão.

74
CAPÍTULO XIII. ANÁLISE DOS COMPONENTES PRINCIPAIS
13.1 Correlações e Dendrograma
A seguir são apresentadas as matrizes de correlações e o dendrograma entre as variáveis
separadas por região, após normatização e positivação das mesmas.
Tabela 14 – Relação entre as variáveis selecionadas para o estudo
Correlations: ESPVIDAn; MORT1np; T_ANALF25Mnp; T_FUND25Mnp; RDPCn; ...
ESPVIDAn MORT1np T_ANALF25Mnp
MORT1np 0,967
0,000
T_ANALF25Mnp 0,831 0,833
0,000 0,000
T_FUND25Mnp -0,628 -0,593 -0,743
0,000 0,000 0,000
RDPCn 0,784 0,744 0,821
0,000 0,000 0,000
P_FORMALn 0,709 0,678 0,771
0,000 0,000 0,000
RENOCUPn 0,741 0,704 0,795
0,000 0,000 0,000
T_BANAGUAn 0,726 0,739 0,759
0,000 0,000 0,000
T_DENSnp 0,589 0,594 0,554
0,000 0,000 0,000
T_NESTUDA_NTRAB_ 0,753 0,741 0,808
0,000 0,000 0,000
T_FUNDIN_TODOS_M 0,802 0,796 0,885
0,000 0,000 0,000
T_MULCHEFEFIF014 0,565 0,576 0,574
0,000 0,000 0,000
PEAn 0,091 0,073 0,112
0,000 0,000 0,000
T_FUND25Mnp RDPCn P_FORMALn
RDPCn -0,755
0,000
P_FORMALn -0,754 0,767
0,000 0,000

75
RENOCUPn -0,816 0,929 0,801
0,000 0,000 0,000
T_BANAGUAn -0,563 0,700 0,722
0,000 0,000 0,000
T_DENSnp -0,270 0,592 0,470
0,000 0,000 0,000
T_NESTUDA_NTRAB_ -0,587 0,826 0,697
0,000 0,000 0,000
T_FUNDIN_TODOS_M -0,780 0,843 0,802
0,000 0,000 0,000
T_MULCHEFEFIF014 -0,432 0,571 0,469
0,000 0,000 0,000
PEAn -0,247 0,220 0,126
0,000 0,000 0,000
RENOCUPn T_BANAGUAn T_DENSnp
T_BANAGUAn 0,656
0,000
T_DENSnp 0,429 0,750
0,000 0,000
T_NESTUDA_NTRAB_ 0,720 0,722 0,670
0,000 0,000 0,000
T_FUNDIN_TODOS_M 0,791 0,810 0,662
0,000 0,000 0,000
T_MULCHEFEFIF014 0,488 0,617 0,634
0,000 0,000 0,000
PEAn 0,233 0,058 -0,021
0,000 0,000 0,112
T_NESTUDA_NTRAB_ T_FUNDIN_TODOS_M T_MULCHEFEFIF014
T_FUNDIN_TODOS_M 0,835
0,000
T_MULCHEFEFIF014 0,579 0,661
0,000 0,000
PEAn 0,080 0,105 0,047
0,000 0,000 0,000

76
Cell Contents: Pearson correlation
P-Value
O p-value de todas as correlações são significativos ao nível de 5%, o que indica que pode-
mos considerar os índices de correlação. Percebemos também que todas as correlações são relati-
vamente fortes, acima de 0,80. A maior correlações é entre as variáveis MORT1np e ESPVIDAn;,
agora, após positivação de MORT1 considera-se VIDA.
Tabela 15 - Correlação entre as variáveis
Variável (y) Variável (x) Grau de Correla-
ção
MORT1np ESPVIDAn 0,967
RENOCUPn RDPCn 0,929
T_FUNDIN_TODOS_MMEIOnp T_ANALF25Mnp 0,885
T_FUNDIN_TODOS_MMEIOnp RDPCn 0,843
T_FUNDIN_TODOS_MMEIOnp T_NESTUDA_NTRAB_MMEIOnp 0,835
T_ANALF25Mnp MORT1np 0,833
T_ANALF25Mnp ESPVIDAn 0,831
T_NESTUDA_NTRAB_MMEIOnp RDPCn 0,826
RDPCn T_ANALF25Mnp 0,821
T_FUNDIN_TODOS_MMEIOnp T_BANAGUAn 0,810
T_NESTUDA_NTRAB_MMEIOnp T_ANALF25Mnp 0,808
T_FUNDIN_TODOS_MMEIOnp ESPVIDAn 0,802
T_FUNDIN_TODOS_MMEIOnp P_FORMALn 0,802
RENOCUPn P_FORMALn 0,801
RENOCUPn T_FUND25Mnp -0,816
Fonte: Elaborado pelo autor
Vejamos abaixo o dendrograma que nada mais é do que as mesmas correlações acima,
porém em forma gráfica, nos indicando mais claramente quais as variáveis que poderiam ser uni-
das. O gráfico corrobora os comentários efetuados acima.

77
T_FU
ND25
Mnp
RIND
nPE
An
T_MUL
CHEF
EFIF01
4_np
T_DE
NSnp
P_FO
RMAL
n
T_BA
NAGU
An
T_NE
STUD
A_NT
RAB_
MMEIOnp
RENO
CUPn
RDPC
n
T_FU
NDIN_T
ODO
S_MMEIOnp
T_AN
ALF2
5Mnp
MOR
T1np
ESPV
IDAn
45,54
63,69
81,85
100,00
Variables
Sim
ilari
ty
DendrogramSingle Linkage; Correlation Coefficient Distance
Figura 7 – Dendrograma das Variáveis Selecionadas normatizadas e positivadas
Observa-se no Dendrograma que as variáveis com maior correlação são ESPVIDAn com
MORT1np e RDPCnp com RENOCUPn. As demais variáveis relacionam-se entre si confirmando
as análises anteriores.
13.2. Análise de Cluster das variáveis
Tabela 16 – Análise de Cluster das variáveis
Cluster Analysis of Variables: ESPVIDAn; MORT1np; T_ANALF25Mnp; ...
Correlation Coefficient Distance, Single Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 13 98,3543 0,03291 1 2 1 2
2 12 96,4598 0,07080 5 8 5 2
3 11 94,2608 0,11478 3 12 3 2 4 10 92,1453 0,15709 3 5 3 4
5 9 91,7368 0,16526 3 11 3 5
6 8 91,6386 0,16723 1 3 1 7
7 7 90,5147 0,18971 1 9 1 8
8 6 90,1076 0,19785 1 7 1 9
9 5 87,4796 0,25041 1 10 1 10
10 4 83,0570 0,33886 1 13 1 11
11 3 61,6572 0,76686 1 14 1 12
12 2 55,4295 0,89141 1 6 1 13

78
13 1 45,5368 1,08926 1 4 1 14
Final Partition
Cluster 1
ESPVIDAn MORT1np T_ANALF25Mnp RDPCn P_FORMALn RENOCUPn T_BA-
NAGUAn
T_DENSnp T_NESTUDA_NTRAB_MMEIOnp T_FUNDIN_TODOS_MMEIOnp
T_MULCHEFEFIF014_np PEAn
Cluster 2
T_FUND25Mnp
Cluster 3
RINDn
A tabela acima nos indica que há grande similaridade de todas as observações, apenas há
certo distanciamento no nível de similaridade 87,5 e 45,5. Se repararmos teremos 1 cluster com
muitas observações (12 variáveis) e os demais com apenas 1 observação.
Em geral, um cluster é mais compacto com um valor reduzido de sum of squares. Neste
caso o cluster tem um valor alto de sum of squares, o que significa que este cluster não é compacto,
tende a ser mais disperso.
13.3 Regressão e Stepwise
Para encontrar as relações entre variáveis, assumiu-se como variável - resposta ESPVIDAn,
para as variáveis explanatórias utilizaram-se as demais variáveis deste estudo exceto as seguintes
variáveis “IDHM”, “IDHM_R”, “IDHM_E” e “IDHM_L, para não permitir nenhum viés ao es-
tudo. Na Tabela 7 pode se observar a equação encontrada e nota-se que não houve exclusão de
nenhuma variável.
Tabela 17 – Análise de Regressão para as variáveis
General Regression Analysis: ESPVIDAn versus MORT1; T_ANALF25M; ...
Regression Equation
ESPVIDAn = 0,98042 - 0,0245129 MORT1 + 0,000221944 T_ANALF25M + 0,000199227
T_FUNDIN_TODOS_MMEIO + 0,000121451 RDPC + 8,09199e-006 RENOCUP +
2,16306e-005 T_NESTUDA_NTRAB_MMEIO
Coefficients
Term Coef SE Coef T P
Constant 0,980420 0,0052167 187,938 0,000
MORT1 -0,024513 0,0001661 -147,564 0,000
T_ANALF25M 0,000222 0,0001265 1,754 0,079

79
T_FUNDIN_TODOS_MMEIO 0,000199 0,0001252 1,592 0,112
RDPC 0,000121 0,0000091 13,419 0,000
RENOCUP 0,000008 0,0000054 1,509 0,131
T_NESTUDA_NTRAB_MMEIO 0,000022 0,0001550 0,140 0,889
Summary of Model
S = 0,0472141 R-Sq = 94,49% R-Sq(adj) = 94,48%
PRESS = 12,4209 R-Sq(pred) = 94,47%
Analysis of Variance
Source DF Seq SS Adj SS Adj MS F P
Regression 6 212,297 212,297 35,3828 15872,6 0,000000
MORT1 1 210,139 48,541 48,5406 21775,2 0,000000
T_ANALF25M 1 0,465 0,007 0,0069 3,1 0,079428
T_FUNDIN_TODOS_MMEIO 1 0,210 0,006 0,0056 2,5 0,111541
RDPC 1 1,477 0,401 0,4014 180,1 0,000000
RENOCUP 1 0,006 0,005 0,0051 2,3 0,131287
T_NESTUDA_NTRAB_MMEIO 1 0,000 0,000 0,0000 0,0 0,889002
Error 5558 12,390 12,390 0,0022
Total 5564 224,686
Em busca da melhor equação para definir as variáveis que mais explicam a variável “ES-
PVIDAn”, realizou a análise de regressão passo a passo. A Tabela 8 demonstra os resultados. As
variáveis relevantes para explicar a variável-resposta são: “MORT1np”, “RDPCn”, “P_FOR-
MALn”, “T_BANAGUAn”, “T_ANALF25Mnp” e “RENOCUPn”.
Tabela 18 – Regressão passo a passo das variáveis
Stepwise Regression: ESPVIDAn versus MORT1np; T_ANALF25Mnp; ...
Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is ESPVIDAn on 13 predictors, with N = 5565
Step 1 2 3 4 5 6
Constant -0,1664 -0,1302 -0,1319 -0,1226 -0,1224 -0,1207
MORT1np 1,0432 0,9265 0,9163 0,9356 0,9481 0,9478
T-Value 283,48 182,16 175,32 164,81 147,66 147,68
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
RDPCn 0,2341 0,1969 0,2063 0,2206 0,2516
T-Value 30,86 22,06 23,07 23,06 16,87
P-Value 0,000 0,000 0,000 0,000 0,000

80
P_FORMALn 0,0353 0,0488 0,0538 0,0592
T-Value 7,78 10,20 10,92 11,15
P-Value 0,000 0,000 0,000 0,000
T_BANAGUAn -0,0392 -0,0359 -0,0379
T-Value -8,41 -7,59 -7,92
P-Value 0,000 0,000 0,000
T_ANALF25Mnp -0,0262 -0,0251
T-Value -4,16 -3,98
P-Value 0,000 0,000
RENOCUPn -0,045
T-Value -2,71
P-Value 0,007
S 0,0511 0,0473 0,0470 0,0467 0,0466 0,0466
R-Sq 93,53 94,47 94,53 94,60 94,62 94,62
R-Sq(adj) 93,52 94,47 94,53 94,60 94,61 94,62
Mallows Cp 1179,9 196,6 136,7 67,3 51,8 46,4
Step 7 8 9 10 11
Constant -0,11253 -0,09287 -0,07663 -0,07247 -0,06818
MORT1np 0,9497 0,9524 0,9545 0,9540 0,9536
T-Value 147,27 146,33 146,05 146,09 146,05
P-Value 0,000 0,000 0,000 0,000 0,000
RDPCn 0,261 0,265 0,282 0,256 0,261
T-Value 17,10 17,30 17,47 14,53 14,71
P-Value 0,000 0,000 0,000 0,000 0,000
P_FORMALn 0,0582 0,0543 0,0576 0,0581 0,0574
T-Value 10,94 9,90 10,34 10,45 10,31
P-Value 0,000 0,000 0,000 0,000 0,000
T_BANAGUAn -0,0340 -0,0322 -0,0267 -0,0372 -0,0368
T-Value -6,83 -6,42 -5,07 -6,20 -6,13
P-Value 0,000 0,000 0,000 0,000 0,000
T_ANALF25Mnp -0,0242 -0,0296 -0,0218 -0,0183 -0,0190
T-Value -3,83 -4,49 -3,13 -2,60 -2,70
P-Value 0,000 0,000 0,002 0,009 0,007
RENOCUPn -0,051 -0,070 -0,086 -0,066 -0,066
T-Value -3,07 -3,92 -4,64 -3,41 -3,43
P-Value 0,002 0,000 0,000 0,001 0,001
T_MULCHEFEFIF014_np -0,0180 -0,0191 -0,0133 -0,0188 -0,0187
T-Value -2,85 -3,02 -2,02 -2,79 -2,78
P-Value 0,004 0,003 0,043 0,005 0,005

81
T_FUND25Mnp -0,0211 -0,0313 -0,0427 -0,0458
T-Value -2,89 -3,95 -5,02 -5,31
P-Value 0,004 0,000 0,000 0,000
T_FUNDIN_TODOS_MMEIOnp -0,037 -0,048 -0,050
T-Value -3,31 -4,15 -4,35
P-Value 0,001 0,000 0,000
T_DENSnp 0,0312 0,0303
T-Value 3,66 3,55
P-Value 0,000 0,000
PEAn -0,085
T-Value -2,27
P-Value 0,023
S 0,0466 0,0466 0,0465 0,0465 0,0464
R-Sq 94,63 94,64 94,65 94,66 94,67
R-Sq(adj) 94,63 94,63 94,64 94,65 94,66
Mallows Cp 40,2 33,9 24,9 13,5 10,3
Para reduzir o numero de variáveis realizamos o procedimento de análise de componentes
principais, ou seja, a análise nos permite perceber as relações entre as variáveis e a possibilidade
de agrupamento mediante sua similaridade. O procedimento realizado para análise das correlações
e dendograma já nos permitiu eliminar algumas variáveis e nos deu uma ideia dos possíveis agru-
pamentos. A Figura 4 apresenta as variáveis que compõe o primeiro e segundo componente.
0,40,30,20,10,0-0,1-0,2-0,3
0,75
0,50
0,25
0,00
-0,25
-0,50
First Component
Se
co
nd
Co
mp
on
en
t
PEAn
T_MULCHEFEFIF014_np
T_FUNDIN_TODOS_MMEIOnp
T_NESTUDA_NTRAB_MMEIOnp
T_DENSnp
T_BANAGUAn
RENOCUPn
P_FORMALn
RINDn
RDPCn
T_FUND25Mnp
T_ANALF25Mnp
MORT1npESPVIDAn
Loading Plot of ESPVIDAn; ...; PEAn
Figura 8 – Primeiro e Segundo Componentes
Fonte: Elaborado pelo autor (Minitab 16)

82
Abaixo a Tabela 19 e a Figura 9 apresentam respectivamente os resultados da análise dos
componentes principais e o gráfico eigenvalue.
Tabela 19 – Análise dos Componentes Principais
Principal Component Analysis: ESPVIDAn; MORT1np; T_ANALF25Mnp;
T_FUND25Mnp; RDP
Eigenanalysis of the Correlation Matrix
Eigenvalue 8,7597 1,2687 1,0278 0,8062 0,5097 0,4305 0,3440 0,2411
Proportion 0,626 0,091 0,073 0,058 0,036 0,031 0,025 0,017
Cumulative 0,626 0,716 0,790 0,847 0,884 0,914 0,939 0,956
Eigenvalue 0,2017 0,1568 0,1153 0,0710 0,0404 0,0270
Proportion 0,014 0,011 0,008 0,005 0,003 0,002
Cumulative 0,971 0,982 0,990 0,995 0,998 1,000
Variable PC1 PC2 PC3 PC4
ESPVIDAn 0,302 -0,060 -0,099 -0,037
MORT1np 0,297 -0,101 -0,097 -0,016
T_ANALF25Mnp 0,312 0,031 -0,072 -0,108
T_FUND25Mnp -0,265 -0,375 0,003 0,260
RDPCn 0,311 0,138 -0,026 -0,007
RINDn 0,020 0,055 0,959 -0,203
P_FORMALn 0,287 0,144 -0,029 -0,221
RENOCUPn 0,296 0,269 -0,074 -0,143
T_BANAGUAn 0,289 -0,193 0,116 0,095
T_DENSnp 0,234 -0,445 0,135 0,378
T_NESTUDA_NTRAB_MMEIOnp 0,296 -0,096 0,023 0,026
T_FUNDIN_TODOS_MMEIOnp 0,320 -0,021 0,023 -0,041
T_MULCHEFEFIF014_np 0,233 -0,274 0,072 0,355
PEAn 0,052 0,640 0,105 0,726
Loading Plot of ESPVIDAn; ...; PEAn

83
1413121110987654321
9
8
7
6
5
4
3
2
1
0
Component Number
Eig
en
va
lue
Scree Plot of ESPVIDAn; ...; PEAn
Figura 9 - Eigenvalue
Fonte: Elaborado pelo autor (Minitab 16)
Os resultados nos permitem observar que se agruparmos 11 variáveis em apenas uma (PC1)
teremos uma proporção de 62,6%, com duas (PC1 + PC2) chegamos a 71,3%, com três (PC1 +
PC2 + PC3) temos 79%, e com quatro (PC1 + PC2 + PC3 + PC4) chegamos 84,7%, seguindo com
o procedimento até chegar a 100%. Este resultado é significativo, pois, ao invés de trabalharmos
com 15 variáveis, podemos então reduzir para as três novas variáveis criadas “PC1”; “PC2”;
“PC3”, que explica quase 80% das variáveis. Na Figura 6 podemos observar a dispersão dos dados
em um gráfico em três dimensões das três novas variáveis criadas.

84
40
20
-5
0
5
-5
10
0 0
5
PC1
PC2
PC3
CO
N
NE
S
SE
REGIÃO
3D Scatterplot of PC1 vs PC2 vs PC3
Figura 10 – Gráfico de dispersão 3 novas variáveis
Fonte: Elaborado pelo autor (Minitab 16)
De acordo com todas as análises acima, percebemos claramente o agrupamento das variá-
veis antes mesmo de aplicarmos o teste de componentes principais. Observamos que através dos
componentes principais o PC1 explica grande parte do comportamento das variáveis, sendo a re-
presentatividade de 63%, porém teremos representatividade de 94% apenas no sétimo componente
PC8. O gráfico de looding e o screen plot nos ajuda a enxergar com mais clareza esta afirmação.
CAPÍTULO XIV. COMPARAÇÃO DE MÉDIAS E ANÁLISE DE CLUSTER
Em sequência realizou-se a comparação de médias e a analise de cluster, buscando identi-
ficar após normalização e/ou positivação das 7 variáveis objetos de estudo como se comportou em
termos de clusterização por estados.
Antes de fazermos a nova análise em termos de estatística descritiva, realizou-se a norma-
lização e/ou positivação das variáveis tomando-se por base sempre o melhor resultado.
14.1 Uma Nova Análise Comparativa Das Variáveis Normalizadas E Positivadas
A seguir se apresenta na Tabela 20, a comparação do Histograma, Curva de Densidade,
Média, Desvio-Padrão, Mediana e P-Value do teste de normalidade de Anderson-Darling, das va-
riáveis quantitativas analisadas.
Tabela 20 - Análise Comparativa das Variáveis normalizadas e positivadas
VARIÁVEL GRÁFICO MÉ-
DIA
DES-
VIO
PA-
DRÃO
MEDI-
ANA
P-
VA-
LUE

85
ESPVIDAn 0,720,600,480,36
Median
Mean
0,650,600,550,500,450,40
1st Q uartile 0,39087
Median 0,51550
3rd Q uartile 0,67597
Maximum 0,78800
0,46675 0,59057
0,40706 0,65971
0,12021 0,21158
A -Squared 0,86
P-V alue 0,023
Mean 0,52866
StDev 0,15328
V ariance 0,02349
Skewness 0,17511
Kurtosis -1,46370
N 26
Minimum 0,30490
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for MeanESPVIDAn
0,5286
6
0,1532
8
0,5155
0
0,02
3
MORT1np 0,880,800,720,640,560,480,40
Median
Mean
0,800,750,700,650,60
1st Q uartile 0,54012
Median 0,69655
3rd Q uartile 0,82005
Maximum 0,89750
0,61206 0,73604
0,57219 0,78429
0,12037 0,21186
A -Squared 0,47
P-V alue 0,226
Mean 0,67405
StDev 0,15348
V ariance 0,02356
Skewness -0,19463
Kurtosis -1,11162
N 26
Minimum 0,38900
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for MeanMORT1np
0,6740
5
0,1534
8
0,6965
5
0,22
6
T_ANALF25Mnp 0,90,80,70,60,50,40,3
Median
Mean
0,750,700,650,600,550,500,45
1st Q uartile 0,41580
Median 0,61895
3rd Q uartile 0,75528
Maximum 0,87530
0,52849 0,68276
0,45124 0,74408
0,14978 0,26363
A -Squared 0,76
P-V alue 0,043
Mean 0,60562
StDev 0,19098
V ariance 0,03647
Skewness -0,16959
Kurtosis -1,40790
N 26
Minimum 0,27560
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for MeanT_ANALF25Mnp
0,6056
2
0,1909
8
0,6189
5
0,04
3
T_FUNDIN_TO-
DOS_MMEIOnp 0,90,80,70,60,5
Median
Mean
0,750,700,650,600,55
1st Q uartile 0,55107
Median 0,65850
3rd Q uartile 0,79520
Maximum 0,90480
0,61405 0,72625
0,56599 0,76528
0,10893 0,19173
A -Squared 0,59
P-V alue 0,113
Mean 0,67015
StDev 0,13889
V ariance 0,01929
Skewness 0,17206
Kurtosis -1,33526
N 26
Minimum 0,44500
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for MeanT_FUNDIN_TODOS_MMEIOnp
0,6701
5
0,1388
9
0,6585
0
0,00
5
RDPCn 0,320,240,160,08
Median
Mean
0,2500,2250,2000,1750,1500,1250,100
1st Q uartile 0,10117
Median 0,13061
3rd Q uartile 0,25163
Maximum 0,34440
0,13678 0,20987
0,10506 0,24699
0,07096 0,12491
A -Squared 1,33
P-V alue < 0,005
Mean 0,17333
StDev 0,09049
V ariance 0,00819
Skewness 0,56265
Kurtosis -1,19277
N 26
Minimum 0,06963
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for MeanRDPCn
0,1733
3
0,0904
9
0,1306
1
0,00
5
RENOCUPn 0,300,250,200,150,10
Median
Mean
0,270,240,210,180,15
1st Q uartile 0,12474
Median 0,20274
3rd Q uartile 0,27124
Maximum 0,31992
0,16935 0,23290
0,13110 0,26300
0,06170 0,10859
A -Squared 0,82
P-V alue 0,029
Mean 0,20112
StDev 0,07867
V ariance 0,00619
Skewness 0,04240
Kurtosis -1,56023
N 26
Minimum 0,09078
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for MeanRENOCUPn
0,2011
2
0,0786
7
0,2027
4
0,02
9
T_NES-
TUDA_NTRAB_MMEIOn
p
0,90,80,70,6
Median
Mean
0,800,750,700,650,60
1st Q uartile 0,57635
Median 0,62255
3rd Q uartile 0,79933
Maximum 0,91020
0,63197 0,73317
0,58877 0,78108
0,09824 0,17292
A -Squared 1,34
P-V alue < 0,005
Mean 0,68257
StDev 0,12527
V ariance 0,01569
Skewness 0,43748
Kurtosis -1,41357
N 26
Minimum 0,53360
A nderson-Darling Normality Test
95% C onfidence Interv al for Mean
95% C onfidence Interv al for Median
95% C onfidence Interv al for StDev
95% Confidence Intervals
Summary for MeanT_NESTUDA_NTRAB_MMEIOnp
0,6825
7
0,1252
7
0,6225
5
0,00
5
Fonte: Elaborado pelo autor (Minitab 2016)
Tabela 21. Estatística descritiva após normalização e/ou positivação
Descriptive Statistics: ESPVIDAn; MORT1np; T_ANALF25Mnp;
T_FUND25Mnp; ...
Variable N N* Mean SE Mean StDev Minimum
ESPVIDAn 5565 0 0,58388 0,00269 0,20095 0,00000
MORT1np 5565 0 0,71921 0,00250 0,18629 0,00000
T_ANALF25Mnp 5565 0 0,65368 0,00305 0,22764 0,00000
T_FUND25Mnp 5565 0 0,64530 0,00216 0,16145 0,00000
RDPCn 5565 0 0,20403 0,00167 0,12491 0,00000
RINDn 5565 0 0,45765 0,00184 0,13718 0,00000
P_FORMALn 5565 0 0,47058 0,00300 0,22376 0,00000

86
RENOCUPn 5565 0 0,21168 0,00151 0,11236 0,00000
T_BANAGUAn 5565 0 0,80227 0,00301 0,22444 0,00000
T_DENSnp 5565 0 0,72183 0,00198 0,14773 0,00000
T_NESTUDA_NTRAB_MMEIOnp 5565 0 0,73257 0,00212 0,15840 0,00000
T_FUNDIN_TODOS_MMEIOnp 5565 0 0,72387 0,00230 0,17139 0,00000
T_MULCHEFEFIF014_np 5565 0 0,74281 0,00178 0,13303 0,00000
PEAn 5565 0 0,00275 0,000238 0,01777 0,000000
Variable Q1 Median Q3 Maximum
ESPVIDAn 0,43853 0,61244 0,73913 1,00000
MORT1np 0,60037 0,78048 0,86139 1,00000
T_ANALF25Mnp 0,46086 0,72611 0,84165 1,00000
T_FUND25Mnp 0,54539 0,66604 0,76789 1,00000
RDPCn 0,09491 0,19071 0,28467 1,00000
RINDn 0,39193 0,46443 0,52986 1,00000
P_FORMALn 0,27107 0,46297 0,65939 1,00000
RENOCUPn 0,11581 0,20563 0,28665 1,00000
T_BANAGUAn 0,66684 0,90955 0,97933 1,00000
T_DENSnp 0,63712 0,74520 0,83225 1,00000
T_NESTUDA_NTRAB_MMEIOnp 0,60905 0,75258 0,86796 1,00000
T_FUNDIN_TODOS_MMEIOnp 0,59287 0,75027 0,87278 1,00000
T_MULCHEFEFIF014_np 0,66665 0,76685 0,84122 1,00000
PEAn 0,000345 0,000768 0,00171 1,00000
T_FU
ND25
Mnp
RIND
nPE
An
T_MUL
CHEF
EFIF01
4_np
T_DE
NSnp
P_FO
RMAL
n
T_BA
NAGU
An
T_NE
STUD
A_NT
RAB_
MMEIOnp
RENO
CUPn
RDPC
n
T_FU
NDIN_T
ODO
S_MMEIOnp
T_AN
ALF2
5Mnp
MOR
T1np
ESPV
IDAn
45,54
63,69
81,85
100,00
Variables
Sim
ilari
ty
DendrogramSingle Linkage; Correlation Coefficient Distance
Figura 11 – Dendrograma das Variáveis Selecionadas normatizadas e positivadas

87
Cluster Analysis of Observations: MeanESPVIDAn; MeanMORT1np;
MeanT_ANALF2; ...
Euclidean Distance, Single Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 26 95,5224 0,083642 8 9 8 2
2 25 94,0944 0,110317 15 16 15 2
3 24 94,0073 0,111943 5 15 5 3
4 23 93,1556 0,127852 23 24 23 2
5 22 92,7451 0,135522 8 11 8 3
6 21 92,6850 0,136645 5 6 5 4
7 20 92,5382 0,139386 5 17 5 5
8 19 92,3143 0,143568 12 13 12 2
9 18 92,1329 0,146957 8 18 8 4
10 17 91,8246 0,152717 5 20 5 6
11 16 91,4638 0,159456 5 25 5 7
12 15 90,6980 0,173761 8 23 8 6
13 14 90,4615 0,178178 19 26 19 2
14 13 90,3098 0,181013 8 12 8 8
15 12 89,4875 0,196374 8 19 8 10
16 11 87,0603 0,241713 1 14 1 2
17 10 86,8507 0,245629 2 5 2 8
18 9 86,8009 0,246559 1 3 1 3
19 8 86,5643 0,250978 8 21 8 11
20 7 85,6004 0,268985 8 27 8 12
21 6 85,5536 0,269859 1 22 1 4
22 5 85,1113 0,278121 2 10 2 9
23 4 84,1989 0,295164 2 8 2 21
24 3 83,6238 0,305907 1 2 1 25
25 2 82,7208 0,322774 1 4 1 26
26 1 54,4900 0,850126 1 7 1 27
Final Partition
Number of clusters: 1
Average Maximum
Within distance distance
Number of cluster sum from from
observations of squares centroid centroid
Cluster1 27 8,12645 0,507503 1,28570
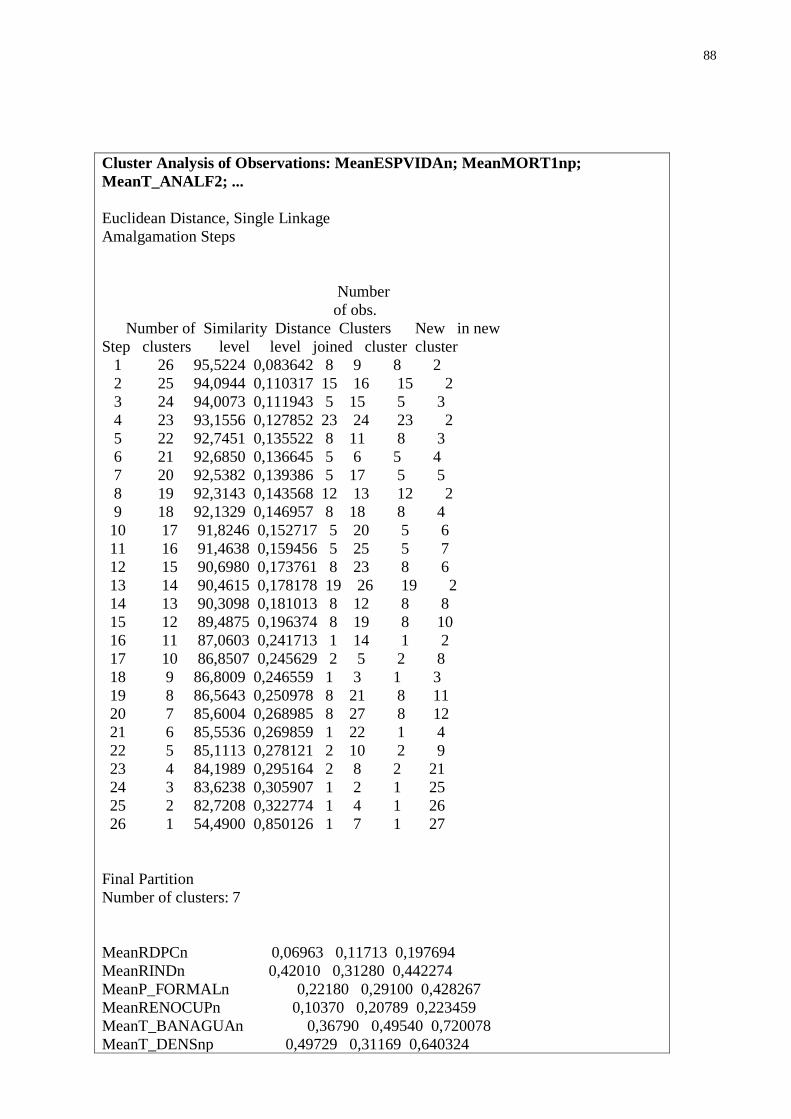
88
Cluster Analysis of Observations: MeanESPVIDAn; MeanMORT1np;
MeanT_ANALF2; ...
Euclidean Distance, Single Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 26 95,5224 0,083642 8 9 8 2
2 25 94,0944 0,110317 15 16 15 2
3 24 94,0073 0,111943 5 15 5 3
4 23 93,1556 0,127852 23 24 23 2
5 22 92,7451 0,135522 8 11 8 3
6 21 92,6850 0,136645 5 6 5 4
7 20 92,5382 0,139386 5 17 5 5
8 19 92,3143 0,143568 12 13 12 2
9 18 92,1329 0,146957 8 18 8 4
10 17 91,8246 0,152717 5 20 5 6
11 16 91,4638 0,159456 5 25 5 7
12 15 90,6980 0,173761 8 23 8 6
13 14 90,4615 0,178178 19 26 19 2
14 13 90,3098 0,181013 8 12 8 8
15 12 89,4875 0,196374 8 19 8 10
16 11 87,0603 0,241713 1 14 1 2
17 10 86,8507 0,245629 2 5 2 8
18 9 86,8009 0,246559 1 3 1 3
19 8 86,5643 0,250978 8 21 8 11
20 7 85,6004 0,268985 8 27 8 12
21 6 85,5536 0,269859 1 22 1 4
22 5 85,1113 0,278121 2 10 2 9
23 4 84,1989 0,295164 2 8 2 21
24 3 83,6238 0,305907 1 2 1 25
25 2 82,7208 0,322774 1 4 1 26
26 1 54,4900 0,850126 1 7 1 27
Final Partition
Number of clusters: 7
MeanRDPCn 0,06963 0,11713 0,197694
MeanRINDn 0,42010 0,31280 0,442274
MeanP_FORMALn 0,22180 0,29100 0,428267
MeanRENOCUPn 0,10370 0,20789 0,223459
MeanT_BANAGUAn 0,36790 0,49540 0,720078
MeanT_DENSnp 0,49729 0,31169 0,640324

89
MeanT_NESTUDA_NTRAB_MMEIOnp 0,54720 0,53730 0,690885
MeanT_FUNDIN_TODOS_MMEIOnp 0,52720 0,56620 0,679974
MeanT_MULCHEFEFIF014np 0,57800 0,64220 0,703233
MeanPEAn 0,00193 0,00213 0,011421
Distances Between Cluster Centroids
Cluster1 Cluster2 Cluster3 Cluster4 Cluster5 Cluster6 Cluster7
Cluster1 0,00000 0,47380 0,40817 1,70106 0,95380 0,34343 0,28803
Cluster2 0,47380 0,00000 0,66214 1,67189 0,82034 0,36890 0,57811
Cluster3 0,40817 0,66214 0,00000 1,42576 0,78478 0,66544 0,32277
Cluster4 1,70106 1,67189 1,42576 0,00000 1,03392 1,86800 1,55242
Cluster5 0,95380 0,82034 0,78478 1,03392 0,00000 1,09247 0,82120
Cluster6 0,34343 0,36890 0,66544 1,86800 1,09247 0,00000 0,58981
Cluster7 0,28803 0,57811 0,32277 1,55242 0,82120 0,58981 0,00000
Cluster Analysis of Observations: MeanESPVIDAn; MeanMORT1np;
MeanT_ANALF2; ...
Manhattan Distance, Centroid Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 26 96,2146 0,24423 8 9 8 2
2 25 95,3781 0,29820 15 16 15 2
3 24 95,6171 0,28278 5 15 5 3
4 23 95,0739 0,31783 8 18 8 3
5 22 95,0133 0,32174 23 24 23 2
6 21 94,7786 0,33688 5 6 5 4
7 20 94,7737 0,33720 5 20 5 5
8 19 94,2363 0,37187 5 25 5 6
9 18 93,9096 0,39295 12 13 12 2
10 17 93,7893 0,40071 8 12 8 5
11 16 93,9792 0,38846 8 11 8 6
12 15 91,5619 0,54443 5 17 5 7
13 14 91,4926 0,54889 19 26 19 2
14 13 91,6487 0,53882 19 23 19 4
15 12 92,7772 0,46601 8 19 8 10
16 11 89,7340 0,66236 1 14 1 2
17 10 91,8577 0,52534 1 3 1 3
18 9 89,0362 0,70738 2 5 2 8
19 8 88,4053 0,74808 1 22 1 4
20 7 87,9699 0,77618 2 10 2 9
21 6 87,7120 0,79282 1 2 1 13
22 5 87,1101 0,83165 21 27 21 2
23 4 84,5766 0,99511 1 21 1 15
24 3 81,2363 1,21062 1 4 1 16
25 2 70,3132 1,91538 1 8 1 26

90
26 1 46,5400 3,44921 1 7 1 27
Final Partition
Number of clusters: 7
Average Maximum
Within distance distance
Number of cluster sum from from
observations of squares centroid centroid
Cluster1 4 0,126185 0,174672 0,216025
Cluster2 9 0,314924 0,170439 0,327913
Cluster3 1 0,000000 0,000000 0,000000
Cluster4 1 0,000000 0,000000 0,000000
Cluster5 10 0,325879 0,174298 0,229105
Cluster6 1 0,000000 0,000000 0,000000
Cluster7 1 0,000000 0,000000 0,000000
Cluster Centroids
Variable Cluster1 Cluster2 Cluster3 Cluster4 Cluster5
MeanESPVIDAn 0,469725 0,367244 0,50440 0,90330 0,699930
MeanMORT1np 0,642975 0,505422 0,71730 0,85590 0,829420
MeanT_ANALF25Mnp 0,568050 0,385022 0,71010 0,94280 0,794710
MeanT_FUND25Mnp 0,675025 0,748500 0,50390 0,11930 0,570880
MeanRDPCn 0,105003 0,092327 0,15410 0,83125 0,275395
MeanRINDn 0,352625 0,477222 0,42670 0,53640 0,449870
MeanP_FORMALn 0,265800 0,294900 0,38680 0,79700 0,585320
MeanRENOCUPn 0,178290 0,112634 0,26133 0,80414 0,279694
MeanT_BANAGUAn 0,398625 0,615233 0,46780 0,95880 0,938010
MeanT_DENSnp 0,348243 0,622698 0,32171 0,74054 0,785206
MeanT_NESTUDA_NTRAB_MMEIOnp 0,576525 0,578056 0,61000 0,90710
0,824340
MeanT_FUNDIN_TODOS_MMEIOnp 0,527150 0,558611 0,69860 0,93550
0,821430
MeanT_MULCHEFEFIF014np 0,604225 0,649144 0,48670 0,81050 0,795710
MeanPEAn 0,002985 0,002063 0,00303 0,23367 0,003802
Grand
Variable Cluster6 Cluster7 centroid
MeanESPVIDAn 0,52660 0,53080 0,542537
MeanMORT1np 0,70390 0,68920 0,680785
MeanT_ANALF25Mnp 0,74830 0,60330 0,618111
MeanT_FUND25Mnp 0,68260 0,62700 0,632526
MeanRDPCn 0,20410 0,14339 0,197694
MeanRINDn 0,35950 0,41460 0,442274
MeanP_FORMALn 0,42780 0,38110 0,428267
MeanRENOCUPn 0,24579 0,19831 0,223459
MeanT_BANAGUAn 0,78920 0,71460 0,720078
MeanT_DENSnp 0,74051 0,63668 0,640324
MeanT_NESTUDA_NTRAB_MMEIOnp 0,75400 0,63080 0,690885

91
MeanT_FUNDIN_TODOS_MMEIOnp 0,70470 0,67010 0,679974
MeanT_MULCHEFEFIF014np 0,76900 0,70480 0,703233
MeanPEAn 0,00243 0,00070 0,011421
Distances Between Cluster Centroids
Cluster1 Cluster2 Cluster3 Cluster4 Cluster5 Cluster6 Cluster7
Cluster1 0,00000 0,46305 0,36802 1,66047 0,983563 0,69048 0,49494
Cluster2 0,46305 0,00000 0,65228 1,69083 0,918352 0,61127 0,41547
Cluster3 0,36802 0,65228 0,00000 1,42576 0,842548 0,64974 0,49117
Cluster4 1,66047 1,69083 1,42576 0,00000 0,989736 1,24639 1,36022
Cluster5 0,98356 0,91835 0,84255 0,98974 0,000000 0,37825 0,54374
Cluster6 0,69048 0,61127 0,64974 1,24639 0,378255 0,00000 0,26898
Cluster7 0,49494 0,41547 0,49117 1,36022 0,543744 0,26898 0,00000
Dendrograma por estados
DFSCRSSPRJMGMT
MSPRGOESAPTOROMAPISERNCEPEPBBAALRRAMPAAC
46,54
64,36
82,18
100,00
Observations
Sim
ilari
ty
Média por estados
Podemos observar no gráfico que corresponde ao dendrograma usando o método centroide
distância Manhattan temos no Brasil 7 agrupamentos dos estados com mesma similaridade de mé-
dia das variáveis selecionadas. Os grupos cujos estados são mais similares entre si está no grupo
5 e, os estados com maior similaridade são ES e GO, composto pelos demais estados que são: PR,
MS, MT, MG, RJ, SP, RS, SC.

92
14.2 Um Novo Mapa Do Brasil
Dada a similaridade dos dados entre alguns estados foi possível realizar o agrupamento das
vinte e sete unidades federativas do Brasil em 7 grandes grupos.
Através da formação destes clusters foi possível a sintetização dos dados de 5.565 municí-
pios em estados e grupos mostrando a grande diferença de realidade nos diferentes estados e regi-
ões do Brasil conforme demonstramos através do mapa acima. Esta análise apenas corroborou a
ideia de termos “mais de um Brasil” já antes mencionadas nos tópicos anteriores.
CAPÍTULO XV. ANÁLISE DISCRIMINANTE
15.1 Análise discriminante método Euclidiano Completo agrupamento com 7 clusters
Tabela 22 – Análise discriminante pelo método euclidiano completo
Discriminant Analysis: euclidianaC7 versus MeanESPVIDAn; MeanMORT1np;
...
Linear Method for Response: euclidianaC7
Predictors: MeanESPVIDAn; MeanMORT1np; MeanT_ANALF25Mnp;
MeanT_FUNDIN_TODOS_MMEIOnp; MeanRDPCn; MeanRENOCUPn;
MeanT_NESTUDA_NTRAB_MMEIOnp

93
Group 1 2 3 4 5 6 7
Count 8 2 2 3 4 4 3
Summary of classification
True Group
Put into Group 1 2 3 4 5 6 7
1 8 0 0 0 0 0 0
2 0 2 0 0 0 0 0
3 0 0 2 0 0 0 0
4 0 0 0 3 0 0 0
5 0 0 0 0 4 0 0
6 0 0 0 0 0 4 0
7 0 0 0 0 0 0 3
Total N 8 2 2 3 4 4 3
N correct 8 2 2 3 4 4 3
Proportion 1,000 1,000 1,000 1,000 1,000 1,000 1,000
N = 26 N Correct = 26 Proportion Correct = 1,000
Squared Distance Between Groups
1 2 3 4 5 6 7
1 0,000 37,278 42,718 55,843 222,741 123,259 356,457
2 37,278 0,000 93,589 148,456 419,991 262,639 579,052
3 42,718 93,589 0,000 24,014 218,910 107,966 358,080
4 55,843 148,456 24,014 0,000 131,036 56,148 248,920
5 222,741 419,991 218,910 131,036 0,000 27,659 24,803
6 123,259 262,639 107,966 56,148 27,659 0,000 82,756
7 356,457 579,052 358,080 248,920 24,803 82,756 0,000
Linear Discriminant Function for Groups
1 2 3 4 5
Constant -630,4 -472,1 -688,1 -778,2 -1136,8
MeanESPVIDAn -236,5 -122,2 -160,8 -203,2 -329,6 MeanMORT1np 1011,5 734,1 1011,1 1154,0 1454,9
MeanT_ANALF25Mnp -186,5 -146,9 -13,0 -83,2 -185,9
MeanT_FUNDIN_TODOS_MMEIOnp 206,6 202,8 152,0 200,2 196,6
MeanRDPCn -1270,5 -1363,3 -1577,5 -1427,7 -845,2
MeanRENOCUPn 447,2 457,1 464,0 522,4 351,0
MeanT_NESTUDA_NTRAB_MMEIOnp 1415,3 1284,1 1408,5 1411,6 1696,8
6 7
Constant -972,0 -1245,3
MeanESPVIDAn -188,3 -309,7
MeanMORT1np 1213,9 1480,6
MeanT_ANALF25Mnp -117,0 -180,4
MeanT_FUNDIN_TODOS_MMEIOnp 200,6 181,7

94
MeanRDPCn -1148,3 -467,2
MeanRENOCUPn 415,2 207,0
MeanT_NESTUDA_NTRAB_MMEIOnp 1615,9 1707,5
15.2 Dendrograma de clusterização Euclidiano completo com 7 clusters
ROMT
MS
MGSPSCRSRJPRGOESRRTOAPPAAMM
AALPIPEPBRNCESEBAAC
0,00
33,33
66,67
100,00
Observations
Sim
ilari
ty
Média por estados
A similaridade entre os estados na distribuição com os 7 clusters está em torno de 85%;
sendo a maior similaridade entre os estados da Bahia e Sergipe
15.3 Análise discriminante método Euclidiano Completo agrupamento com 3 clusters
A partir da análise anterior com 7 clusters o objetivo foi realizar a clusterização em 3 agru-
pamentos, tomando-se como referência a distância entre os mesmos e procurando preservar os que
já tinham maior número de observações.
Com base no exposto, o próximo passo foi determinar como deveria ficar a nova composi-
ção uma vez que tínhamos a seguinte configuração anterior:
Summary of classification
True Group
Put into Group 1 2 3 4 5 6 7
1 8 0 0 0 0 0 0
2 0 2 0 0 0 0 0
3 0 0 2 0 0 0 0
4 0 0 0 3 0 0 0
5 0 0 0 0 4 0 0

95
6 0 0 0 0 0 4 0
7 0 0 0 0 0 0 3
Total N 8 2 2 3 4 4 3
N correct 8 2 2 3 4 4 3
Proportion 1,000 1,000 1,000 1,000 1,000 1,000 1,000
N = 26 N Correct = 26 Proportion Correct = 1,000
Squared Distance Between Groups
1 2 3 4 5 6 7
1 0,000 37,278 42,718 55,843 222,741 123,259 356,457
2 37,278 0,000 93,589 148,456 419,991 262,639 579,052
3 42,718 93,589 0,000 24,014 218,910 107,966 358,080
4 55,843 148,456 24,014 0,000 131,036 56,148 248,920
5 222,741 419,991 218,910 131,036 0,000 27,659 24,803
6 123,259 262,639 107,966 56,148 27,659 0,000 82,756
7 356,457 579,052 358,080 248,920 24,803 82,756 0,000
Desta forma, observando-se as distâncias entre os clusters, realizou-se o seguinte reagrupa-
mento:
Cluster 1 manteve-se
Cluster 2 tem maior proximidade com cluster 1
Cluster 3 e 4 tem maior proximidade entre si
Cluster 5, 6 e 7 tem maior proximidade entre si
Após essa análise de reagrupamento entre os clusters novamente foi realizada a análise
discriminante utilizando-se do método euclidiano completo; porém, agora com os 3 novos clusters
formados com base nas distâncias entre eles.
A tabela 23 apresenta a nova distribuição com o percentual de acerto entre os novos clusters
definidos; cujo resultado aponta para um grau de acerto da ordem de 100%.
Tabela 23 – Análise discriminante pelo método euclidiano completo com 3 clusters
Discriminant Analysis: euclidianaC3 versus MeanESPVIDAn; MeanMORT1np;
...
Linear Method for Response: euclidianaC3
Predictors: MeanESPVIDAn; MeanMORT1np; MeanT_ANALF25Mnp;
MeanT_FUNDIN_TODOS_MMEIOnp; MeanRDPCn; MeanRENOCUPn;
MeanT_NESTUDA_NTRAB_MMEIOnp
Group 1 4 5

96
Count 10 5 11
Summary of classification
True Group
Put into Group 1 4 5
1 10 0 0
4 0 5 0
5 0 0 11
Total N 10 5 11
N correct 10 5 11
Proportion 1,000 1,000 1,000
N = 26 N Correct = 26 Proportion Correct = 1,000
Squared Distance Between Groups
1 4 5
1 0,0000 45,9122 66,1727
4 45,9122 0,0000 34,6876
5 66,1727 34,6876 0,0000
Linear Discriminant Function for Groups
1 4 5
Constant -363,4 -417,8 -522,6
MeanESPVIDAn 269,6 353,9 410,5
MeanMORT1np -60,0 -51,0 -105,8
MeanT_ANALF25Mnp -9,6 158,4 120,5
MeanT_FUNDIN_TODOS_MMEIOnp 222,0 180,8 210,2
MeanRDPCn -2018,1 -2246,0 -2332,9
MeanRENOCUPn 566,5 603,3 649,8
MeanT_NESTUDA_NTRAB_MMEIOnp 1138,4 1085,6 1262,8
15.4 Dendrograma de clusterização Euclidiana completo com 3 clusters após agrupamento
Uma vez reorganizados os clusters, agora agrupados em 3 conglomerados, novo dendro-
grama é apresentado a seguir de como ficou a nova composição.

97
ROMT
MS
MGSPSCRSRJPRGOESRRTOAPPAAMM
AALPIPEPBRNCESEBAAC
0,00
33,33
66,67
100,00
Observations
Sim
ilari
ty
Média por estados
A similaridade entre os estados na distribuição com os 3 clusters está em torno de 85%;
sendo as maiores similaridades entre os estados da Bahia com Sergipe, Ceará com Rio Grande
do Norte, Espírito Santo com Goiás e, Rio Grande do Sul com Santa Catarina.
15.5 Análise discriminante método Manhattan Completo agrupamento com 7 clusters
Tabela 24 – Análise discriminante pelo método manhattan completo
Cluster Analysis of Observations: MeanESPVIDAn; MeanMORT1np;
MeanT_ANALF2; ...
Manhattan Distance, Complete Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 25 96,5711 0,09802 15 24 15 2
2 24 96,1947 0,10878 7 8 7 2 3 23 95,6108 0,12547 6 19 6 2
4 22 95,2946 0,13451 22 23 22 2
5 21 95,1848 0,13765 11 12 11 2
6 20 95,1676 0,13814 5 15 5 3
7 19 94,2154 0,16536 14 16 14 2
8 18 92,1519 0,22435 3 13 3 2
9 17 92,1176 0,22533 22 25 22 3
10 16 91,9577 0,22990 7 17 7 3
11 15 91,3567 0,24708 2 9 2 2

98
12 14 90,0537 0,28433 4 26 4 2
13 13 89,4215 0,30240 1 5 1 4
14 12 89,2036 0,30863 10 11 10 3
15 11 87,6802 0,35218 7 18 7 4
16 10 84,9918 0,42903 10 20 10 4
17 9 84,9138 0,43126 1 6 1 6
18 8 83,6912 0,46621 1 14 1 8
19 7 82,4784 0,50088 3 21 3 3
20 6 76,8131 0,66283 7 22 7 7
21 5 74,7114 0,72291 1 2 1 10
22 4 73,7606 0,75009 3 4 3 5
23 3 61,0248 1,11416 7 10 7 11
24 2 47,0755 1,51292 1 3 1 15
25 1 0,0000 2,85864 1 7 1 26
Final Partition
Number of clusters: 7
Average Maximum
Within distance distance
Number of cluster sum from from
observations of squares centroid centroid
Cluster1 8 0,0596342 0,079129 0,126415
Cluster2 2 0,0101466 0,071227 0,071227
Cluster3 3 0,0328437 0,100751 0,137183
Cluster4 2 0,0091120 0,067498 0,067498
Cluster5 4 0,0177370 0,063480 0,094509
Cluster6 4 0,0364575 0,092338 0,130127
Cluster7 3 0,0069788 0,047581 0,058720
Cluster Centroids
Variable Cluster1 Cluster2 Cluster3 Cluster4 Cluster5
MeanESPVIDAn 0,389663 0,30730 0,484067 0,517600 0,675475
MeanMORT1np 0,540650 0,39455 0,668800 0,703250 0,841125
MeanT_ANALF25Mnp 0,407612 0,33255 0,603800 0,656700 0,778825
MeanT_FUNDIN_TODOS_MMEIOnp 0,569000 0,48610 0,537300 0,684350 0,817325
MeanRDPCn 0,099945 0,07460 0,100730 0,148745 0,263153
MeanRENOCUPn 0,123459 0,10947 0,173420 0,229820 0,271833
MeanT_NESTUDA_NTRAB_MMEIOnp 0,590888 0,54040 0,566900 0,620400
0,815350
Grand
Variable Cluster6 Cluster7 centroid
MeanESPVIDAn 0,634650 0,761800 0,528662
MeanMORT1np 0,749650 0,878333 0,674050
MeanT_ANALF25Mnp 0,744725 0,867067 0,605623
MeanT_FUNDIN_TODOS_MMEIOnp 0,749450 0,883967 0,670146
MeanRDPCn 0,227965 0,331193 0,173327

99
MeanRENOCUPn 0,264950 0,298533 0,201125
MeanT_NESTUDA_NTRAB_MMEIOnp 0,768600 0,887200 0,682569
Distances Between Cluster Centroids
Cluster1 Cluster2 Cluster3 Cluster4 Cluster5 Cluster6 Cluster7
Cluster1 0,000000 0,20982 0,260578 0,364310 0,685910 0,563824 0,85717
Cluster2 0,209816 0,00000 0,433742 0,557028 0,883948 0,756482 1,05189
Cluster3 0,260578 0,43374 0,000000 0,187302 0,522661 0,399160 0,69418
Cluster4 0,364310 0,55703 0,187302 0,000000 0,359709 0,239402 0,53252
Cluster5 0,685910 0,88395 0,522661 0,359709 0,000000 0,138835 0,17768
Cluster6 0,563824 0,75648 0,399160 0,239402 0,138835 0,000000 0,30272
Cluster7 0,857174 1,05189 0,694180 0,532522 0,177677 0,302719 0,00000
15.6 Dendrograma de clusterização Manhattan completo com 7 clusters após agrupamento
ROMT
MS
MGSPSCRSRJPRGOESTOAPRRPAAMM
AALPIPBRNCESEPEBAAC
0,00
33,33
66,67
100,00
Observations
Sim
ilari
ty
Média por estados
A similaridade entre os estados na distribuição com os 7 clusters está em torno de 85%;
sendo as maiores similaridades entre os estados de Pernambuco com Sergipe; e, Espírito Santo
com Goiás.

100
15.7 Análise discriminante método Manhattan Completo agrupamento com 3 clusters
A partir da análise anterior com 7 clusters o objetivo foi realizar a clusterização em 3 agru-
pamentos, tomando-se como referência a distância entre os mesmos e procurando preservar os que
já tinham maior número de observações.
Com base no exposto, o próximo passo foi determinar como deveria ficar a nova composi-
ção uma vez que tínhamos a seguinte configuração anterior; conforme recorte a seguir:
Final Partition
Number of clusters: 7
Average Maximum
Within distance distance
Number of cluster sum from from
observations of squares centroid centroid
Cluster1 8 0,0596342 0,079129 0,126415
Cluster2 2 0,0101466 0,071227 0,071227
Cluster3 3 0,0328437 0,100751 0,137183
Cluster4 2 0,0091120 0,067498 0,067498
Cluster5 4 0,0177370 0,063480 0,094509
Cluster6 4 0,0364575 0,092338 0,130127
Cluster7 3 0,0069788 0,047581 0,058720
Distances Between Cluster Centroids
Cluster1 Cluster2 Cluster3 Cluster4 Cluster5 Cluster6 Cluster7
Cluster1 0,000000 0,20982 0,260578 0,364310 0,685910 0,563824 0,85717
Cluster2 0,209816 0,00000 0,433742 0,557028 0,883948 0,756482 1,05189
Cluster3 0,260578 0,43374 0,000000 0,187302 0,522661 0,399160 0,69418
Cluster4 0,364310 0,55703 0,187302 0,000000 0,359709 0,239402 0,53252
Cluster5 0,685910 0,88395 0,522661 0,359709 0,000000 0,138835 0,17768
Cluster6 0,563824 0,75648 0,399160 0,239402 0,138835 0,000000 0,30272
Cluster7 0,857174 1,05189 0,694180 0,532522 0,177677 0,302719 0,00000
Desta forma, observando-se as distâncias entre os clusters, realizou-se o seguinte reagrupa-
mento:
Cluster 1 manteve-se
Cluster 2 tem maior proximidade com cluster 1
Cluster 3 e 4 tem maior proximidade entre si
Cluster 5, 6 e 7 tem maior proximidade entre si
Após essa análise de reagrupamento entre os clusters novamente foi realizada a análise
discriminante utilizando-se do método manhattan completo; porém, agora com os 3 novos clusters
formados com base nas distâncias entre eles.
A tabela 25 apresenta a nova distribuição com o percentual de acerto entre os novos clusters
definidos; cujo resultado aponta para um grau de acerto da ordem de 100%.

101
Tabela 25 – Análise discriminante pelo método manhattan completo com 3 clusters
Discriminant Analysis: manhattancom versus MeanESPVIDAn;
MeanMORT1np; ...
Linear Method for Response: manhattancompleta3
Predictors: MeanESPVIDAn; MeanMORT1np; MeanT_ANALF25Mnp;
MeanT_FUNDIN_TODOS_MMEIOnp; MeanRDPCn; MeanRENOCUPn;
MeanT_NESTUDA_NTRAB_MMEIOnp
Group 1 4 5
Count 10 5 11
Summary of classification
True Group
Put into Group 1 4 5
1 10 0 0
4 0 5 0
5 0 0 11
Total N 10 5 11
N correct 10 5 11
Proportion 1,000 1,000 1,000
N = 26 N Correct = 26 Proportion Correct = 1,000
Squared Distance Between Groups
1 4 5
1 0,0000 45,9122 66,1727
4 45,9122 0,0000 34,6876
5 66,1727 34,6876 0,0000
Linear Discriminant Function for Groups
1 4 5 Constant -363,4 -417,8 -522,6
MeanESPVIDAn 269,6 353,9 410,5
MeanMORT1np -60,0 -51,0 -105,8
MeanT_ANALF25Mnp -9,6 158,4 120,5
MeanT_FUNDIN_TODOS_MMEIOnp 222,0 180,8 210,2
MeanRDPCn -2018,1 -2246,0 -2332,9
MeanRENOCUPn 566,5 603,3 649,8
MeanT_NESTUDA_NTRAB_MMEIOnp 1138,4 1085,6 1262,8

102
15.8 Dendrograma de clusterização Manhattan completo com 3 clusters após agrupa-
mento
ROMT
MS
MGSPSCRSRJPRGOESTOAPRRPAAMM
AALPIPBRNCESEPEBAAC
0,00
33,33
66,67
100,00
Observations
Sim
ilari
ty
Média por estados
A similaridade entre os estados na distribuição com os 3 clusters está em torno de 85%;
sendo as maiores similaridades entre os estados de Pernambuco com Sergipe e, Espírito Santo
com Goiás. Observa-se que o estado de Roraima aparece com os estados predominantemente das
regiões Sul e Sudeste; a fim de tentar identificar quais seriam as características e possíveis simi-
laridades das variáveis, elaborou-se a tabela 26.
Tabela 26 – Variáveis com os dados por estados
ES-
TADO
Mu-
nicí-
pios
ES-
PVI-
DAn
MORT1np T_ANALF25Mnp RDPCn RE-
NOCUPn
T_NES-
TUDA_NTRAB_MMEIOnp
T_FUNDIN_TO-
DOS_MMEIOnp
ES 78 0,6924 0,8367 0,7418 0,2463 0,24342 0,7971 0,781
GO 246 0,6914 0,8577 0,735 0,2498 0,27576 0,806 0,8162
PR 399 0,669 0,8556 0,7881 0,2639 0,26611 0,8487 0,8304
RJ 92 0,6491 0,8145 0,8504 0,2926 0,30204 0,8096 0,8417
RS 496 0,7587 0,8975 0,8753 0,332 0,26973 0,8858 0,8606
SC 293 0,788 0,893 0,8735 0,3444 0,30595 0,9102 0,8865
SP 645 0,7387 0,8445 0,8524 0,3172 0,31992 0,8656 0,9048
MG 853 0,684 0,7941 0,7161 0,2025 0,20717 0,755 0,7481
MS 78 0,6733 0,7216 0,7612 0,257 0,302 0,7773 0,7568
MT 141 0,6547 0,779 0,7533 0,2483 0,30484 0,7881 0,7882
RO 52 0,5266 0,7039 0,7483 0,2041 0,24579 0,754 0,7047
TO-
TAL 3373

103
CAPÍTULO XVI. OS DIFERENTES BRASIS
Podemos observar no gráfico 3, que corresponde ao dendrograma usando o método cen-
troide distância manhattan temos no Brasil 7 agrupamentos dos estados com mesma similaridade
de média das variáveis selecionadas. Os grupos cujos estados são mais similares entre si está no
grupo 5 e, os estados com maior similaridade é ES e GO, composto pelos demais estados que são:
PR, MS, MT, MG, RJ, SP, RS, SC.
16.1 Os 2 Brasis comparando-se com 7 clusters e agrupando-os em 3 conglomerados – mé-
todo euclidiano completo
16.2 Os 2 Brasis comparando-se com 7 clusters e agrupando-os em 3 conglomerados - mé-
todo manhattan completo

104
16.3 Os Brasis agrupados com 3 conglomerados
Dada a similaridade dos dados entre alguns estados foi possível realizar o agrupamento das
vinte e seis unidades federativas do Brasil em 3 grandes grupos; excluindo-se por conveniência o
Distrito Federal em função de representar um outlier; pois, só tem um município (Brasília).
Através da formação destes clusters foi possível a sintetização dos dados de 5.564 municí-
pios em estados e grupos mostrando a grande diferença de realidade nos diferentes estados e regi-
ões do Brasil conforme demonstramos através do mapa acima. Esta análise apenas corroborou a
ideia de termos “mais de um Brasil” já antes mencionadas em trabalhos anteriores.
Destaca-se a existência de 3 Brasis quase que separado ao meio; onde temos 2 clusters
compostos pelo Norte e Nordeste; exceção feita ao estado de Roraima já observado no dendro-
grama neste trabalho e complementado com a tabela 9.
Na sequência fica “um degrau” para subsidiar as próximas análises, elaborando-se a análise
Anova e gráficos Boxplots das variáveis objetos do estudo; bem como, um quadro comparativo
entre as regiões baseando-se nas variáveis já normalizadas e/ou positivadas (lado direito nas tabe-
las) versus resultados anteriores (lado esquerdo nas tabelas).
Variável: Esperança de vida ao nascer (ESPVIDA)
One-way ANOVA: ESPVIDA versus
REGIÃO N 5564
Source DF SS MS F
P
One-way ANOVA: ESPVIDAn versus
REGIÃO N 5564
Source DF SS MS F
P

105
REGIÃO N 5564 4 24990,54 6247,63
2319,16 0,000
Error 5559 14975,49 2,69
Total 5563 39966,03
S = 1,641 R-Sq = 62,53% R-Sq(adj) =
62,50%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev --+--------
-+---------+---------+-------
CENTRO OESTE 465 74,334 1,100
(*)
NORDESTE 1794 70,255 1,809 *)
NORTE 449 71,818 1,724
(*)
SUDESTE 1668 74,686 1,604
(*
SUL 1188 75,116 1,570
(*
--+---------+---------
+---------+-------
70,5 72,0 73,5
75,0
Pooled StDev = 1,641
REGIÃO N 5564 4 140,4313 35,1078
2319,16 0,000
Error 5559 84,1530 0,0151
Total 5563 224,5843
S = 0,1230 R-Sq = 62,53% R-Sq(adj) =
62,50%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev ---+-------
--+---------+---------+------
CENTRO OESTE 465 0,6772 0,0825
(*)
NORDESTE 1794 0,3714 0,1356 *)
NORTE 449 0,4886 0,1292
(*)
SUDESTE 1668 0,7036 0,1202
*)
SUL 1188 0,7358 0,1177
(*
---+---------+--------
-+---------+------
0,40 0,50
0,60 0,70
Pooled StDev = 0,1230
SULSUDESTENORTENORDESTECENTRO OESTE
80,0
77,5
75,0
72,5
70,0
67,5
65,0
REGIÃO N 5564
ES
PV
IDA
Boxplot of ESPVIDA
SULSUDESTENORTENORDESTECENTRO OESTE
1,0
0,8
0,6
0,4
0,2
0,0
REGIÃO N 5564
ES
PV
IDA
n
Boxplot of ESPVIDAn
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORDESTE,
n=1794
Q1 0,6539 0,2811
Mediana 0,7384 0,3857
Q3 0,8147 0,4640
Média 0,7358 0,3714
Desvio padrão 0,1177 0,1356

106
Variável: Mortalidade infantil até 1º ano (MORT1)
One-way ANOVA: MORT1 versus
REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 190952,7 47738,2
2871,93 0,000
Error 5559 92403,7 16,6
Total 5563 283356,4
S = 4,077 R-Sq = 67,39% R-Sq(adj) =
67,37%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev --------+---
------+---------+---------+-
CENTRO OESTE 465 15,731 2,705
(*)
NORDESTE 1794 27,188 5,856
(*
NORTE 449 21,578 4,713
(*)
SUDESTE 1668 15,512 2,700 (*
SUL 1188 12,999 2,138 *)
--------+---------+----
-----+---------+-
16,0 20,0
24,0 28,0
Pooled StDev = 4,077
One-way ANOVA: MORT1np versus
REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 130,1073 32,5268
2871,93 0,000
Error 5559 62,9600 0,0113
Total 5563 193,0673
S = 0,1064 R-Sq = 67,39% R-Sq(adj) =
67,37%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev ---------+-
--------+---------+---------+
CENTRO OESTE 465 0,8110 0,0706
(*)
NORDESTE 1794 0,5119 0,1529 *)
NORTE 449 0,6584 0,1230
(*)
SUDESTE 1668 0,8167 0,0705
(*
SUL 1188 0,8823 0,0558
*)
---------+---------+--
-------+---------+
0,60 0,70
0,80 0,90
Pooled StDev = 0,1064
SULSUDESTENORTENORDESTECENTRO OESTE
50
40
30
20
10
REGIÃO N 5564
MO
RT1
Boxplot of MORT1
SULSUDESTENORTENORDESTECENTRO OESTE
1,0
0,8
0,6
0,4
0,2
0,0
REGIÃO N 5564
MO
RT1
np
Boxplot of MORT1np
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORDESTE,
n=1794
Q1 0,8457 0,4196
Mediana 0,8875 0,5351
Q3 0,9214 0,6212

107
Média 0,8823 0,5119
Desvio padrão 0,0558 0,1529
Variável: Taxa de analfabetismo pessoas com 25 anos ou mais (T_ANALF25M).
One-way ANOVA: T_ANALF25M ver-
sus REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 606142,6
151535,6 2804,56 0,000
Error 5559 300363,2 54,0
Total 5563 906505,8
S = 7,351 R-Sq = 66,87% R-Sq(adj) =
66,84%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev -------+----
-----+---------+---------+--
CENTRO OESTE 465 15,404 5,065
(*)
NORDESTE 1794 34,970 8,541
(*
NORTE 449 22,384 8,429
(*)
SUDESTE 1668 13,581 7,655 *)
SUL 1188 9,761 4,867 (*)
-------+---------+-----
----+---------+--
14,0 21,0
28,0 35,0
Pooled StDev = 7,351
One-way ANOVA: T_ANALF25Mnp
versus REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 192,7342 48,1835
2804,56 0,000
Error 5559 95,5060 0,0172
Total 5563 288,2402
S = 0,1311 R-Sq = 66,87% R-Sq(adj) =
66,84%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev --------+--
-------+---------+---------+-
CENTRO OESTE 465 0,7449 0,0903
(*)
NORDESTE 1794 0,3960 0,1523 (*)
NORTE 449 0,6205 0,1503
(*)
SUDESTE 1668 0,7774 0,1365
(*
SUL 1188 0,8456 0,0868
*)
--------+---------+---
------+---------+-
0,48 0,60
0,72 0,84
Pooled StDev = 0,1311
SULSUDESTENORTENORDESTECENTRO OESTE
60
50
40
30
20
10
0
REGIÃO N 5564
T_
AN
ALF2
5M
Boxplot of T_ANALF25M
SULSUDESTENORTENORDESTECENTRO OESTE
1,0
0,8
0,6
0,4
0,2
0,0
REGIÃO N 5564
T_
AN
ALF2
5M
np
Boxplot of T_ANALF25Mnp
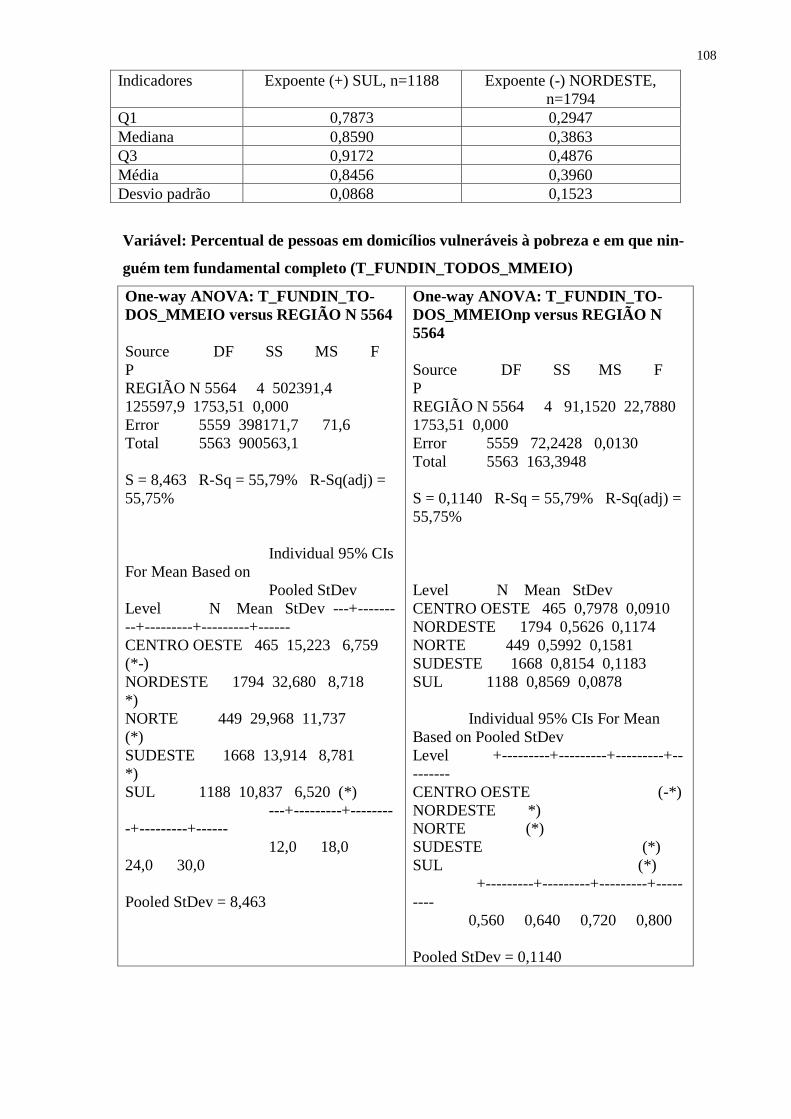
108
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORDESTE,
n=1794
Q1 0,7873 0,2947
Mediana 0,8590 0,3863
Q3 0,9172 0,4876
Média 0,8456 0,3960
Desvio padrão 0,0868 0,1523
Variável: Percentual de pessoas em domicílios vulneráveis à pobreza e em que nin-
guém tem fundamental completo (T_FUNDIN_TODOS_MMEIO)
One-way ANOVA: T_FUNDIN_TO-
DOS_MMEIO versus REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 502391,4
125597,9 1753,51 0,000
Error 5559 398171,7 71,6
Total 5563 900563,1
S = 8,463 R-Sq = 55,79% R-Sq(adj) =
55,75%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev ---+-------
--+---------+---------+------
CENTRO OESTE 465 15,223 6,759
(*-)
NORDESTE 1794 32,680 8,718
*)
NORTE 449 29,968 11,737
(*)
SUDESTE 1668 13,914 8,781
*)
SUL 1188 10,837 6,520 (*)
---+---------+---------+---------+------
12,0 18,0
24,0 30,0
Pooled StDev = 8,463
One-way ANOVA: T_FUNDIN_TO-
DOS_MMEIOnp versus REGIÃO N
5564
Source DF SS MS F
P
REGIÃO N 5564 4 91,1520 22,7880
1753,51 0,000
Error 5559 72,2428 0,0130
Total 5563 163,3948
S = 0,1140 R-Sq = 55,79% R-Sq(adj) =
55,75%
Level N Mean StDev
CENTRO OESTE 465 0,7978 0,0910
NORDESTE 1794 0,5626 0,1174
NORTE 449 0,5992 0,1581
SUDESTE 1668 0,8154 0,1183
SUL 1188 0,8569 0,0878
Individual 95% CIs For Mean
Based on Pooled StDev
Level +---------+---------+---------+--
-------
CENTRO OESTE (-*)
NORDESTE *) NORTE (*)
SUDESTE (*)
SUL (*)
+---------+---------+---------+-----
----
0,560 0,640 0,720 0,800
Pooled StDev = 0,1140

109
SULSUDESTENORTENORDESTECENTRO OESTE
80
70
60
50
40
30
20
10
0
REGIÃO N 5564
T_
FUN
DIN
_TO
DO
S_
MM
EIO
Boxplot of T_FUNDIN_TODOS_MMEIO
SULSUDESTENORTENORDESTECENTRO OESTE
1,0
0,8
0,6
0,4
0,2
0,0
REGIÃO N 5564
T_
FUN
DIN
_TO
DO
S_
MM
EIO
np
Boxplot of T_FUNDIN_TODOS_MMEIOnp
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORDESTE,
n=1794
Q1 0,8045 0,4845
Mediana 0,8734 0,5620
Q3 0,9247 0,6419
Média 0,8569 0,5626
Desvio padrão 0,0878 0,1174
Variável: Renda Per Capita (RDPC)
One-way ANOVA: RDPC versus
REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 166364376
41591094 1432,31 0,000
Error 5559 161420628 29038
Total 5563 327785004
S = 170,4 R-Sq = 50,75% R-Sq(adj) =
50,72%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev --------+----
-----+---------+---------+-
CENTRO OESTE 465 584,2 153,4
(-*)
NORDESTE 1794 276,9 97,7 (*)
NORTE 449 345,1 141,1 (-*)
SUDESTE 1668 590,6 214,9
*)
SUL 1188 704,2 200,0
(*
--------+---------+-----
----+---------+-
360 480
600 720
Pooled StDev = 170,4
One-way ANOVA: RDPCn versus
REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 43,86416
10,96604 1432,31 0,000
Error 5559 42,56068 0,00766
Total 5563 86,42484
S = 0,08750 R-Sq = 50,75% R-Sq(adj)
= 50,72%
Individual 95%
CIs For Mean Based on
Pooled StDev
Level N Mean StDev -----+----
-----+---------+---------+----
CENTRO OESTE 465 0,25056 0,07875
(-*)
NORDESTE 1794 0,09277 0,05019
*)
NORTE 449 0,12778 0,07244
(*-)
SUDESTE 1668 0,25385 0,11035
*)
SUL 1188 0,31219 0,10269
(*)
-----+---------+-----
----+---------+----
0,120 0,180
0,240 0,300

110
Pooled StDev = 0,08750
SULSUDESTENORTENORDESTECENTRO OESTE
2000
1500
1000
500
0
REGIÃO N 5564
RD
PC
Boxplot of RDPC
SULSUDESTENORTENORDESTECENTRO OESTE
1,0
0,8
0,6
0,4
0,2
0,0
REGIÃO N 5564
RD
PC
n
Boxplot of RDPCn
Indicadores Expoente (+) SUL, n=1188 Expoente (-) NORDESTE,
n=1794
Q1 0,2385 0,0646
Mediana 0,2972 0,0838
Q3 0,3733 0,1057
Média 0,3122 0,0928
Desvio padrão 0,1027 0,0502
Variável: Rendimento médio dos ocupados com 18 anos ou mais (RENOCUP)
One-way ANOVA: RENOCUP versus
REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 276629690
69157422 1039,86 0,000
Error 5559 369709458 66506
Total 5563 646339148
S = 257,9 R-Sq = 42,80% R-Sq(adj) =
42,76%
Individual 95% CIs
For Mean Based on
Pooled StDev
Level N Mean StDev ---------+--
-------+---------+---------+ CENTRO OESTE 465 1015,2 241,6
(-*)
NORDESTE 1794 473,7 192,1 (*
NORTE 449 708,1 250,0
(*-)
SUDESTE 1668 920,0 319,2
*)
One-way ANOVA: RENOCUPn versus
REGIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 29,91656 7,47914
1039,86 0,000
Error 5559 39,98282 0,00719
Total 5563 69,89938
S = 0,08481 R-Sq = 42,80% R-Sq(adj)
= 42,76%
Level N Mean StDev
CENTRO OESTE 465 0,28898 0,07945
NORDESTE 1794 0,11091 0,06318
NORTE 449 0,18801 0,08223 SUDESTE 1668 0,25770 0,10497
SUL 1188 0,27744 0,08463
Individual 95% CIs For Mean
Based on Pooled StDev
Level ---------+---------+---------+-----
----+
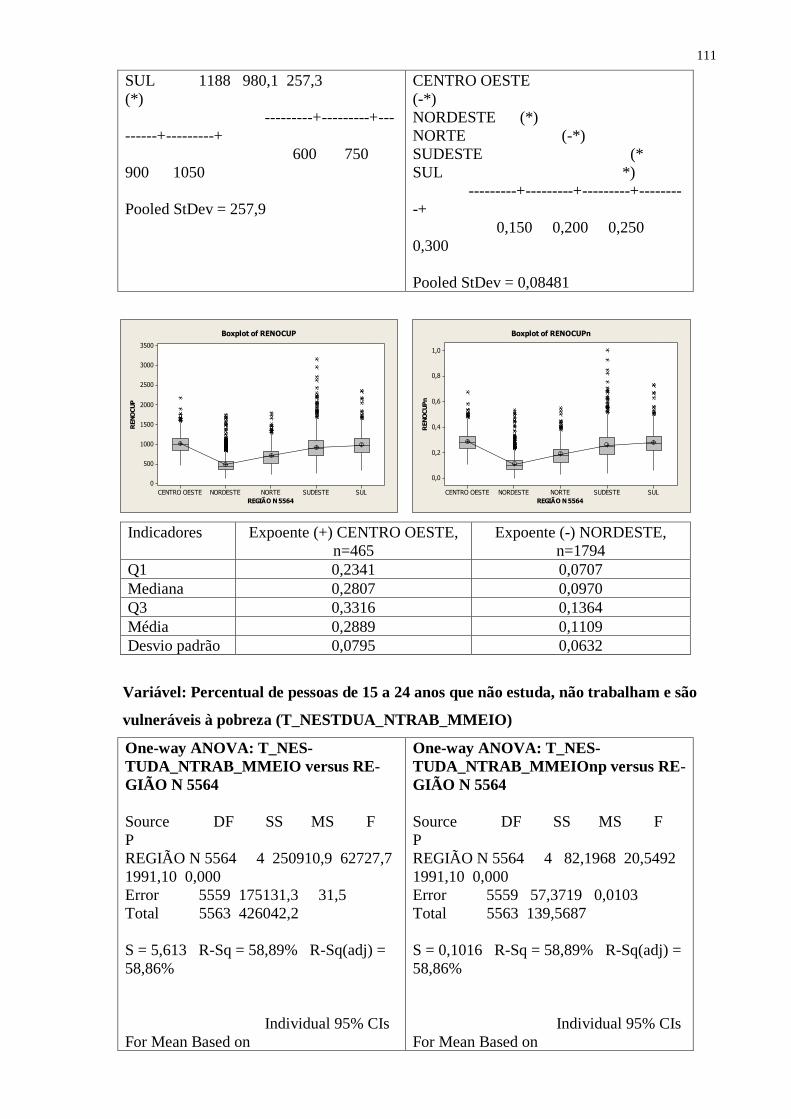
111
SUL 1188 980,1 257,3
(*)
---------+---------+---
------+---------+
600 750
900 1050
Pooled StDev = 257,9
CENTRO OESTE
(-*)
NORDESTE (*)
NORTE (-*)
SUDESTE (*
SUL *)
---------+---------+---------+--------
-+
0,150 0,200 0,250
0,300
Pooled StDev = 0,08481
SULSUDESTENORTENORDESTECENTRO OESTE
3500
3000
2500
2000
1500
1000
500
0
REGIÃO N 5564
REN
OC
UP
Boxplot of RENOCUP
SULSUDESTENORTENORDESTECENTRO OESTE
1,0
0,8
0,6
0,4
0,2
0,0
REGIÃO N 5564
REN
OC
UP
n
Boxplot of RENOCUPn
Indicadores Expoente (+) CENTRO OESTE,
n=465
Expoente (-) NORDESTE,
n=1794
Q1 0,2341 0,0707
Mediana 0,2807 0,0970
Q3 0,3316 0,1364
Média 0,2889 0,1109
Desvio padrão 0,0795 0,0632
Variável: Percentual de pessoas de 15 a 24 anos que não estuda, não trabalham e são
vulneráveis à pobreza (T_NESTDUA_NTRAB_MMEIO)
One-way ANOVA: T_NES-
TUDA_NTRAB_MMEIO versus RE-
GIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 250910,9 62727,7
1991,10 0,000
Error 5559 175131,3 31,5
Total 5563 426042,2
S = 5,613 R-Sq = 58,89% R-Sq(adj) =
58,86%
Individual 95% CIs
For Mean Based on
One-way ANOVA: T_NES-
TUDA_NTRAB_MMEIOnp versus RE-
GIÃO N 5564
Source DF SS MS F
P
REGIÃO N 5564 4 82,1968 20,5492
1991,10 0,000
Error 5559 57,3719 0,0103
Total 5563 139,5687
S = 0,1016 R-Sq = 58,89% R-Sq(adj) =
58,86%
Individual 95% CIs
For Mean Based on

112
Pooled StDev
Level N Mean StDev -------+----
-----+---------+---------+--
CENTRO OESTE 465 11,283 5,202
(*)
NORDESTE 1794 23,134 5,615
*)
NORTE 449 20,874 6,596
(*)
SUDESTE 1668 10,900 6,107
(*
SUL 1188 6,665 4,532 *)
-------+---------+-----
----+---------+--
10,0 15,0
20,0 25,0
Pooled StDev = 5,613
Pooled StDev
Level N Mean StDev --------+--
-------+---------+---------+-
CENTRO OESTE 465 0,7958 0,0941
(*-)
NORDESTE 1794 0,5813 0,1016 (*
NORTE 449 0,6222 0,1194 (*)
SUDESTE 1668 0,8027 0,1105
*)
SUL 1188 0,8794 0,0820
(*)
--------+---------+---
------+---------+-
0,640 0,720
0,800 0,880
Pooled StDev = 0,1016
SULSUDESTENORTENORDESTECENTRO OESTE
60
50
40
30
20
10
0
REGIÃO N 5564
T_
NES
TU
DA
_N
TR
AB
_M
MEIO
Boxplot of T_NESTUDA_NTRAB_MMEIO
SULSUDESTENORTENORDESTECENTRO OESTE
1,0
0,8
0,6
0,4
0,2
0,0
REGIÃO N 5564
T_
NES
TU
DA
_N
TR
AB
_M
MEIO
np
Boxplot of T_NESTUDA_NTRAB_MMEIOnp
Indicadores Expoente (+) SUDESTE,
n=1668
Expoente (-) NORDESTE,
n=1794
Q1 0,8281 0,5152
Mediana 0,8948 0,5885
Q3 0,9450 0,6505
Média 0,8794 0,5813
Desvio padrão 0,0820 0,1016
Ao executar a análise Anova com as variáveis normalizadas e/ou positivadas, observa-se
que segue a mesma distribuição da análise anterior; ou seja, temos predominantemente em todas
as variáveis selecionadas para este estudo, a região SUL apresentando as melhores médias e a re-
gião Nordeste as menores médias.
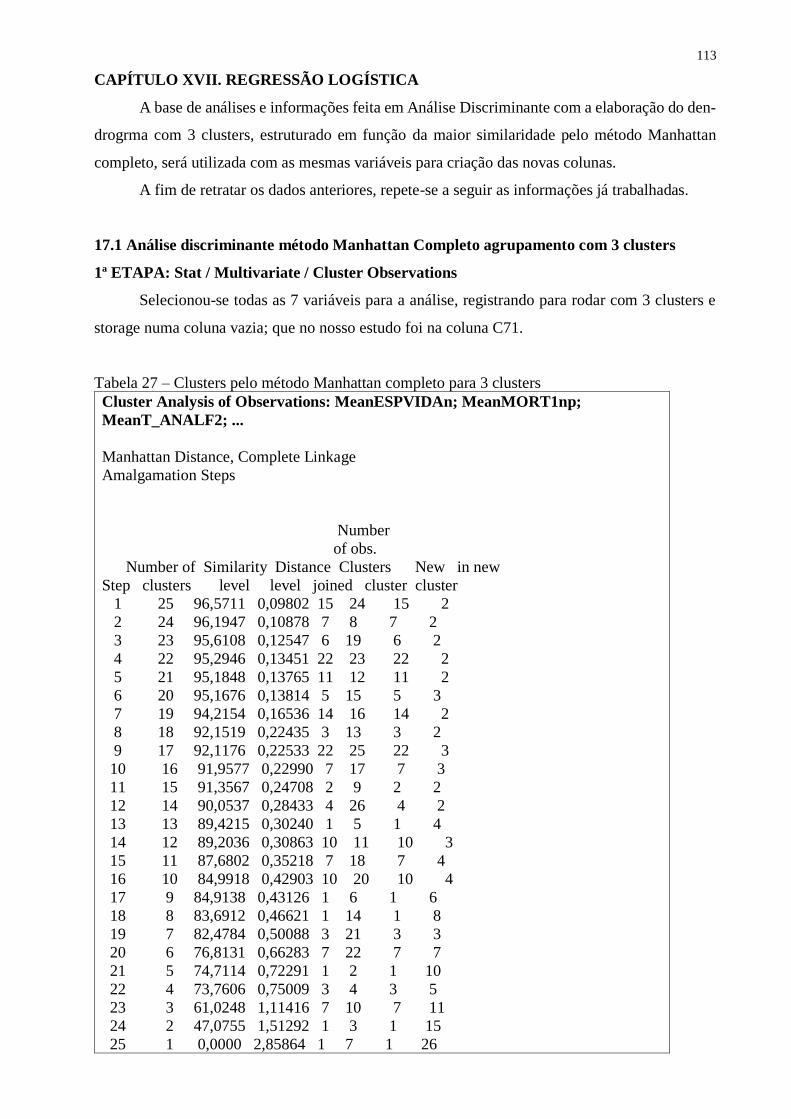
113
CAPÍTULO XVII. REGRESSÃO LOGÍSTICA
A base de análises e informações feita em Análise Discriminante com a elaboração do den-
drogrma com 3 clusters, estruturado em função da maior similaridade pelo método Manhattan
completo, será utilizada com as mesmas variáveis para criação das novas colunas.
A fim de retratar os dados anteriores, repete-se a seguir as informações já trabalhadas.
17.1 Análise discriminante método Manhattan Completo agrupamento com 3 clusters
1ª ETAPA: Stat / Multivariate / Cluster Observations
Selecionou-se todas as 7 variáveis para a análise, registrando para rodar com 3 clusters e
storage numa coluna vazia; que no nosso estudo foi na coluna C71.
Tabela 27 – Clusters pelo método Manhattan completo para 3 clusters
Cluster Analysis of Observations: MeanESPVIDAn; MeanMORT1np;
MeanT_ANALF2; ...
Manhattan Distance, Complete Linkage
Amalgamation Steps
Number
of obs.
Number of Similarity Distance Clusters New in new
Step clusters level level joined cluster cluster
1 25 96,5711 0,09802 15 24 15 2
2 24 96,1947 0,10878 7 8 7 2
3 23 95,6108 0,12547 6 19 6 2
4 22 95,2946 0,13451 22 23 22 2
5 21 95,1848 0,13765 11 12 11 2
6 20 95,1676 0,13814 5 15 5 3
7 19 94,2154 0,16536 14 16 14 2
8 18 92,1519 0,22435 3 13 3 2
9 17 92,1176 0,22533 22 25 22 3
10 16 91,9577 0,22990 7 17 7 3
11 15 91,3567 0,24708 2 9 2 2
12 14 90,0537 0,28433 4 26 4 2
13 13 89,4215 0,30240 1 5 1 4
14 12 89,2036 0,30863 10 11 10 3
15 11 87,6802 0,35218 7 18 7 4
16 10 84,9918 0,42903 10 20 10 4
17 9 84,9138 0,43126 1 6 1 6
18 8 83,6912 0,46621 1 14 1 8
19 7 82,4784 0,50088 3 21 3 3
20 6 76,8131 0,66283 7 22 7 7
21 5 74,7114 0,72291 1 2 1 10
22 4 73,7606 0,75009 3 4 3 5
23 3 61,0248 1,11416 7 10 7 11
24 2 47,0755 1,51292 1 3 1 15
25 1 0,0000 2,85864 1 7 1 26

114
Final Partition
Number of clusters: 3
Average Maximum
Within distance distance
Number of cluster sum from from
observations of squares centroid centroid
Cluster1 10 0,140217 0,107216 0,217649
Cluster2 5 0,084054 0,126656 0,159401
Cluster3 11 0,223619 0,129572 0,245216
Cluster Centroids
Grand
Variable Cluster1 Cluster2 Cluster3 centroid
MeanESPVIDAn 0,373190 0,497480 0,684173 0,528662
MeanMORT1np 0,511430 0,682580 0,818009 0,674050
MeanT_ANALF25Mnp 0,392600 0,624960 0,790491 0,605623
MeanT_FUNDIN_TODOS_MMEIOnp 0,552420 0,596120 0,810818 0,670146
MeanRDPCn 0,094876 0,119936 0,268914 0,173327
MeanRENOCUPn 0,120661 0,195980 0,276612 0,201125
MeanT_NESTUDA_NTRAB_MMEIOnp 0,580790 0,588300 0,817945 0,682569
Distances Between Cluster Centroids
Cluster1 Cluster2 Cluster3
Cluster1 0,000000 0,327106 0,725700
Cluster2 0,327106 0,000000 0,456206
Cluster3 0,725700 0,456206 0,000000 Fonte: Elaborado pelo autor (Minitab 2016)

115
Dendrograma
ROMT
MS
MGSPSCRSRJPRGOESTOA
PRRPAAMMAALPIPBRNCESEPEBAA
C
2,86
1,91
0,95
0,00
Observations
Dis
tan
ce
Média por estados
2ª ETAPA: Stat / Multivariate / Discriminant Analysis
Com o objetivo de verificar se os agrupamentos tiveram 100% de acerto
Tabela 28 – Análise discriminante pelo método manhattan completo
Discriminant Analysis: 3 novos agru versus MeanESPVIDAn; MeanMORT1np;
...
Linear Method for Response: 3 novos agrupamentos
Predictors: MeanESPVIDAn; MeanMORT1np; MeanT_ANALF25Mnp;
MeanT_FUNDIN_TODOS_MMEIOnp; MeanRDPCn; MeanRENOCUPn;
MeanT_NESTUDA_NTRAB_MMEIOnp
Group 1 2 3
Count 10 5 11
Summary of classification
True Group Put into Group 1 2 3
1 10 0 0
2 0 5 0
3 0 0 11
Total N 10 5 11
N correct 10 5 11
Proportion 1,000 1,000 1,000
N = 26 N Correct = 26 Proportion Correct = 1,000

116
Squared Distance Between Groups
1 2 3
1 0,0000 45,9122 66,1727
2 45,9122 0,0000 34,6876
3 66,1727 34,6876 0,0000
Linear Discriminant Function for Groups
1 2 3
Constant -363,4 -417,8 -522,6
MeanESPVIDAn 269,6 353,9 410,5
MeanMORT1np -60,0 -51,0 -105,8
MeanT_ANALF25Mnp -9,6 158,4 120,5
MeanT_FUNDIN_TODOS_MMEIOnp 222,0 180,8 210,2
MeanRDPCn -2018,1 -2246,0 -2332,9
MeanRENOCUPn 566,5 603,3 649,8
MeanT_NESTUDA_NTRAB_MMEIOnp 1138,4 1085,6 1262,8 Fonte: Elaborado pelo autor (Minitab 2016)
3ª ETAPA: Stat / Anova / One-Way
Fazer a Anova de uma por uma das Variáveis tendo como response a variável analisada e
o fator corresponde à coluna com os 3 novos agrupamentos
Variável: Expectativa de vida (dados normalizados) – ESPVIDAn
One-way ANOVA: MeanESPVIDAn versus 3 novos agrupamentos
Source DF SS MS F P
3 novos agrupamentos 2 0,51260 0,25630 78,87 0,000
Error 23 0,07474 0,00325
Total 25 0,58734
S = 0,05701 R-Sq = 87,27% R-Sq(adj) = 86,17%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ------+---------+---------+---------+---
1 10 0,37319 0,04059 (--*---)
2 5 0,49748 0,05747 (-----*----)
3 11 0,68417 0,06834 (--*---)
------+---------+---------+---------+---
0,40 0,50 0,60 0,70
Pooled StDev = 0,05701

117
Variável: Mortalidade Infantil até 1 ano (dados normalizados e positivados - MORT1np
One-way ANOVA: MeanMORT1np versus 3 novos agrupamentos
Source DF SS MS F P
3 novos agrupamentos 2 0,49278 0,24639 58,96 0,000
Error 23 0,09611 0,00418
Total 25 0,58890
S = 0,06464 R-Sq = 83,68% R-Sq(adj) = 82,26%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
1 10 0,51143 0,06764 (---*---)
2 5 0,68258 0,06027 (-----*-----)
3 11 0,81801 0,06356 (---*---)
---+---------+---------+---------+------
0,50 0,60 0,70 0,80
Pooled StDev = 0,06464
Variável: Taxa de Analfabetismo de pessoas com 25 anos ou mais (dados normalizados
e positivados) - T_ANALF25Mnp
One-way ANOVA: MeanT_ANALF25Mnp versus 3 novos agrupamentos
Source DF SS MS F P
3 novos agrupamentos 2 0,83160 0,41580 119,21 0,000
Error 23 0,08022 0,00349
Total 25 0,91182
S = 0,05906 R-Sq = 91,20% R-Sq(adj) = 90,44%
Individual 95% CIs For Mean Based on Pooled StDev
Level N Mean StDev -+---------+---------+---------+-------- 1 10 0,39260 0,06069 (---*--)
2 5 0,62496 0,05136 (---*----)
3 11 0,79049 0,06043 (--*--)
-+---------+---------+---------+--------
0,36 0,48 0,60 0,72
Pooled StDev = 0,05906

118
Variável: Percentual de pessoas em domicílios vulneráveis à pobreza e em que ninguém
tem fundamental completo (dados normalizados e positivados) - T_FUNDIN_TO-
DOS_MMEIOnp
One-way ANOVA: MeanT_FUNDIN_TODOS_MMEIOnp versus 3 novos agru-
pamentos
Source DF SS MS F P
3 novos agrupamentos 2 0,38367 0,19183 44,75 0,000
Error 23 0,09861 0,00429
Total 25 0,48227
S = 0,06548 R-Sq = 79,55% R-Sq(adj) = 77,78%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---------+---------+---------+---------+
1 10 0,55242 0,06003 (---*----)
2 5 0,59612 0,08404 (-----*-----)
3 11 0,81082 0,06158 (---*---)
---------+---------+---------+---------+
0,60 0,70 0,80 0,90
Pooled StDev = 0,06548
Variável: Renda Per Capita (dados normalizados) - RDPCn
One-way ANOVA: MeanRDPCn versus 3 novos agrupamentos
Source DF SS MS F P
3 novos agrupamentos 2 0,17630 0,08815 71,43 0,000
Error 23 0,02839 0,00123
Total 25 0,20469
S = 0,03513 R-Sq = 86,13% R-Sq(adj) = 84,93%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --------+---------+---------+---------+-
1 10 0,09488 0,01556 (---*---)
2 5 0,11994 0,02983 (----*----)
3 11 0,26891 0,04759 (---*--)
--------+---------+---------+---------+-
0,120 0,180 0,240 0,300
Pooled StDev = 0,03513
Variável: Rendimento médio dos ocupados com 18 anos ou mais (dados normalizados)
- RENOCUPn

119
One-way ANOVA: MeanRENOCUPn versus 3 novos agrupamentos
Source DF SS MS F P
3 novos agrupamentos 2 0,12756 0,06378 54,02 0,000
Error 23 0,02716 0,00118
Total 25 0,15471
S = 0,03436 R-Sq = 82,45% R-Sq(adj) = 80,92%
Individual 95% CIs For Mean Based on Pooled StDev
Level N Mean StDev +---------+---------+---------+---------
1 10 0,12066 0,02913 (---*----)
2 5 0,19598 0,04377 (-----*------)
3 11 0,27661 0,03443 (---*----)
+---------+---------+---------+---------
0,100 0,150 0,200 0,250
Pooled StDev = 0,03436
Variável: Percentual de pessoas de 15 a 24 anos que não estudam, não trabalham e são
vulneráveis à pobreza (dados normalizados e positivados) - T_NES-
TUDA_NTRAB_MMEIOnp
One-way ANOVA: MeanT_NESTUDA_NTRAB_MMEIOnp versus 3 novos agru-
pamentos
Source DF SS MS F P
3 novos agrupamentos 2 0,34962 0,17481 94,23 0,000
Error 23 0,04267 0,00186
Total 25 0,39229
S = 0,04307 R-Sq = 89,12% R-Sq(adj) = 88,18%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
1 10 0,58079 0,03129 (---*--)
2 5 0,58830 0,03964 (----*----)
3 11 0,81795 0,05251 (--*---)
-+---------+---------+---------+--------
0,560 0,640 0,720 0,800
Pooled StDev = 0,04307
4ª ETAPA: Construir a tabela com os resultados obtidos das Anovas

120
Tabela ANOVA das variáveis, tomando como base o valor “F” de cada uma, entendo
que quanto maior esse valor, maior a representatividade da variável na amostra estudada, bem
como suas médias e intervalos de confiança
Tabela 29 – Comparação entre os 3 novos grupos versus as variáveis e seus intervalos de
confiança
Fonte: Elaborado pelo autor
Observa-se que, pelo valor de F, as variáveis com maior representativi-dade no estudo
são, respectivamente, “T_ANALF25Mnp”, “T_NESTUDA_NTRAB_MMEIOnp”, “ESPVI-
DAn” e “RDPCn’.
Porém, observa-se uma sobreposição dos intervalos de confiança entre as variáveis
“RDPCn”, “T_FUNDIN_TODOS_MMEIOnp” e “T_NESTUDA_NTRAB_MMEIOnp”.
5ª ETAPA: Stat / Regression / Ordinal Logistic Regression
Utilizou-se dessa ordenação em função de identificar a ordem lógica dos clusters em termos
da maior importância
A response será a coluna com os 3 novos agrupamentos; que neste trabalho, foi a coluna
C71 versus todas as variáveis no campo model. A regressão logística tem como objetivo calcular
a probabilidade de uma variável pertencer a um grupo.
Ordinal Logistic Regression: 3 novos agru versus MeanESPVIDAn;
MeanMORT1np; ...
* WARNING * Algorithm has not converged after 20 iterations.
* WARNING * Convergence has not been reached for the parameter estimates
criterion.
* WARNING * The results may not be reliable.
* WARNING * Try increasing the maximum number of iterations.
Link Function: Logit
Response Information

121
Variable Value Count
3 novos agrupamentos 1 10
2 5
3 11
Total 26
Logistic Regression Table
Predictor Coef SE Coef Z P Odds Ratio
Const(1) 288,850 157907 0,00 0,999
Const(2) 344,677 163063 0,00 0,998
MeanESPVIDAn -91,0187 133753 -0,00 0,999 0,00
MeanMORT1np -32,6172 172041 -0,00 1,000 0,00
MeanT_ANALF25Mnp -306,214 64541,3 -0,00 0,996 0,00
MeanRDPCn 331,055 814822 0,00 1,000 5,96055E+143
MeanRENOCUPn 17,0818 298694 0,00 1,000 26213405,10
MeanT_NESTUDA_NTRAB_MMEIOnp -273,952 273199 -0,00 0,999 0,00
MeanT_FUNDIN_TODOS_MMEIOnp 102,589 111368 0,00 0,999
3,58107E+44
95% CI
Predictor Lower Upper
Const(1)
Const(2)
MeanESPVIDAn 0,00 *
MeanMORT1np 0,00 *
MeanT_ANALF25Mnp 0,00 *
MeanRDPCn 0,00 *
MeanRENOCUPn 0,00 *
MeanT_NESTUDA_NTRAB_MMEIOnp 0,00 *
MeanT_FUNDIN_TODOS_MMEIOnp 0,00 *
Log-Likelihood = -0,000
Test that all slopes are zero: G = 54,521, DF = 7, P-Value = 0,000
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 0,0000002 43 1,000
Deviance 0,0000003 43 1,000
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 215 100,0 Somers' D 1,00
Discordant 0 0,0 Goodman-Kruskal Gamma 1,00
Ties 0 0,0 Kendall's Tau-a 0,66
Total 215 100,0

122
Fonte: Elaborado pelo autor (Minitab 2016)
Comentários: Apesar de a concordância ser de 100%, o que viabilizaria o estudo, todos os
“P” das variáveis estão entre 99 e 100%, o que descaracteriza o estudo.
6ª ETAPA: Stat / Regression / Ordinal Logistic Regression
Nesta etapa, selecionou-se as 3 variáveis correlacionando os 3 maiores valores de F e o
intervalo de confiança (sempre olhando os f e os intervalos de confiança) e excluindo-se as variá-
veis sobrepostas
2ª Análise: As 3 variáveis que ficaram foram: ESPVIDAn, T_ANALF25Mnp e RENOCUPn
Ordinal Logistic Regression: 3 novos agru versus MeanESPVIDAn;
MeanT_ANALF2; ..
* WARNING * Algorithm has not converged after 20 iterations.
* WARNING * Convergence has not been reached for the parameter estimates
criterion.
* WARNING * The results may not be reliable.
* WARNING * Try increasing the maximum number of iterations.
Link Function: Logit
Response Information
Variable Value Count
3 novos agrupamentos 1 10
2 5
3 11
Total 26
Logistic Regression Table
95% CI
Predictor Coef SE Coef Z P Odds Ratio Lower Upper
Const(1) 287,829 22615,4 0,01 0,990
Const(2) 352,275 24894,3 0,01 0,989
MeanESPVIDAn -233,243 42515,3 -0,01 0,996 0,00 0,00 *
MeanT_ANALF25Mnp -497,358 47394,8 -0,01 0,992 0,00 0,00 *
MeanRENOCUPn 515,799 59449,9 0,01 0,993 1,01996E+224 0,00 *
Log-Likelihood = -0,000
Test that all slopes are zero: G = 54,521, DF = 3, P-Value = 0,000
Goodness-of-Fit Tests

123
Method Chi-Square DF P
Pearson 0,0000003 47 1,000
Deviance 0,0000006 47 1,000
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 215 100,0 Somers' D 1,00
Discordant 0 0,0 Goodman-Kruskal Gamma 1,00
Ties 0 0,0 Kendall's Tau-a 0,66
Total 215 100,0
Nesta nova análise, o percentual de concordância continuou de 100%, considerado como
aceitável, houve melhora nos indicadores “P”, mas ainda apresenta problemas.
Nas 3 variáveis os percentuais ficaram em 98% a 99%, lembrando que os valores aceitáveis
restringem-se ao limite de 10%. Desta forma, iremos restringir a 2 variáveis
7ª ETAPA: Stat / Regression / Ordinal Logistic Regression
Nesta etapa, selecionou-se as 2 variáveis correlacionando os maiores valores de F e o in-
tervalo de confiança (sempre olhando os f e os intervalos de confiança)
3ª Análise: As 2 variáveis que ficaram foram: ESPVIDAn e T_ANALF25Mp
Ordinal Logistic Regression: 3 novos agru versus MeanESPVIDAn; MeanT_ANALF2
* WARNING * Algorithm has not converged after 20 iterations.
* WARNING * Convergence has not been reached for the parameter estimates
criterion.
* WARNING * The results may not be reliable.
* WARNING * Try increasing the maximum number of iterations.
Link Function: Logit
Response Information
Variable Value Count
3 novos agrupamentos 1 10
2 5
3 11
Total 26
Logistic Regression Table
Odds 95% CI

124
Predictor Coef SE Coef Z P Ratio Lower Upper
Const(1) 438,785 22494,3 0,02 0,984
Const(2) 578,043 26940,0 0,02 0,983
MeanESPVIDAn -169,670 71630,4 -0,00 0,998 0,00 0,00 *
MeanT_ANALF25Mnp -672,756 53876,4 -0,01 0,990 0,00 0,00 *
Log-Likelihood = -0,000
Test that all slopes are zero: G = 54,521, DF = 2, P-Value = 0,000
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 0,0000008 48 1,000
Deviance 0,0000016 48 1,000
Measures of Association:
(Between the Response Variable and Predicted Probabilities)
Pairs Number Percent Summary Measures
Concordant 215 100,0 Somers' D 1,00
Discordant 0 0,0 Goodman-Kruskal Gamma 1,00
Ties 0 0,0 Kendall's Tau-a 0,66
Total 215 100,0
8ª ETAPA: Stat / Regression / Ordinal Logistic Regression
Nesta etapa, realizou-se a análise individual das 2 variáveis a fim de identificar qual a mais
representativa em termos de regressão logística.
4ª Análise: As 2 variáveis da análise individual são: ESPVIDAn e T_ANALF25Mp
Ordinal Logistic Regression: 3 novos
agrupamentos versus MeanESPVIDAn
Link Function: Logit
Response Information
Variable Value Count
3 novos agrupamentos 1 10
2 5
3 11
Total 26
Logistic Regression Table
Odds
95% CI
Ordinal Logistic Regression: 3 novos
agrupame versus
MeanT_ANALF25Mnp
* WARNING * Algorithm has not con-
verged after 20 iterations.
* WARNING * Convergence has not been
reached for the parameter estimates
criterion.
* WARNING * The results may not be re-
liable.
* WARNING * Try increasing the maxi-
mum number of iterations.
Link Function: Logit
Response Information
Variable Value Count
3 novos agrupamentos 1 10

125
Predictor Coef SE Coef Z P
Ratio Lower Upper
Const(1) 23,7440 10,4337 2,28
0,023
Const(2) 30,4049 13,5323 2,25
0,025
MeanESPVIDAn -54,4193 24,6912 -
2,20 0,028 0,00 0,00 0,00
Log-Likelihood = -5,661
Test that all slopes are zero: G = 43,198,
DF = 1, P-Value = 0,000
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 11,4896 49 1,000
Deviance 11,3229 49 1,000
Measures of Association:
(Between the Response Variable and Pre-
dicted Probabilities)
Pairs Number Percent Summary
Measures
Concordant 212 98,6 Somers' D
0,97
Discordant 3 1,4 Goodman-Krus-
kal Gamma 0,97
Ties 0 0,0 Kendall's Tau-a
0,64
Total 215 100,0
2 5
3 11
Total 26
Logistic Regression Table
Odds
95% CI
Predictor Coef SE Coef Z P
Ratio Lower Upper
Const(1) 2281,28 34477,8 0,07
0,947
Const(2) 2860,09 41862,1 0,07
0,946
MeanT_ANALF25Mnp -4010,66
58683,2 -0,07 0,946 0,00 0,00 *
Log-Likelihood = -0,000
Test that all slopes are zero: G = 54,521,
DF = 1, P-Value = 0,000
Goodness-of-Fit Tests
Method Chi-Square DF P
Pearson 0,0000119 49 1,000
Deviance 0,0000239 49 1,000
Measures of Association:
(Between the Response Variable and Pre-
dicted Probabilities)
Pairs Number Percent Summary
Measures
Concordant 215 100,0 Somers' D
1,00
Discordant 0 0,0 Goodman-Krus-
kal Gamma 1,00 Ties 0 0,0 Kendall's Tau-a
0,66
Total 215 100,0
Como a Regressão logística ordinal tem a finalidade de modelar a relação entre preditoras
e respostas, para estas variáveis escolhidas nesta base de dados; entende-se que a variável que
melhor atende às características probabilísticas desta análise é a “ESPVIDAn”, esperança de vida
com uma concordância de 98,6% e um valor de “P” na ordem de 0,028.

126
CAPÍTULO XVIII. ANÁLISE DE CORRESPONDÊNCIA
A análise de correspondência simples decompõe uma tabela de contingência de forma si-
milar à análise de componentes principais em relação a dados contínuos multivariáveis. A análise
de correspondência simples faz uma autoanálise dos dados, decompõe a variabilidade em dimen-
sões subjacentes e associa variabilidade a linhas e/ou colunas.
http://support.minitab.com/pt-br/minitab/17/topic-library/modeling-statistics/multivariate/ba-
sics/multivariate-analyses-in-minitab/#correspondence-analysis, acesso em 28/05/2017
O primeiro passo para esta análise foi resgatar a base de dados utilizada no trabalho anterior
(sem os dados de Brasília), ou seja, REGRESSÃO LOGÍSTICA, e as variáveis naquele estudo
consideradas e suas médias por Estado, a seguir, reforçando que já foram normalizadas e positiva-
das.
18.1 Preparação Dos Dados
1ªs ATIVIDADES
Preparar as 2 colunas; ou seja, Estado registrar em minúsculo os nomes e, numa coluna que
esteja vazia, registrar em minúsculo, na direção vertical com um nome curto as 7 variáveis seleci-
onadas nos trabalhos anteriores
N VARIÁVEL SIGNIFICADO ANALI-
SAR
UNIDADE
DE ME-
DIDA
1 REGIÃO Nome da Região do Brasil NÃO NA
2 UF Unidade da Federação NÃO NA
3 ESPVIDAn Esperança de vida ao nas-
cer
Quantita-
tiva
Valor Ab-
soluto
4 MORT1np Mortalidade infantil Quantita-
tiva
Valor Ab-
soluto
5 T_ANALF25Mnp Taxa de analfabetismo - 25
anos ou mais
Quantita-
tiva Percentual
6 T_FUNDIN_TO-
DOS_MMEIOnp
% de pessoas em domicílios
vulneráveis à pobreza e em
que ninguém tem funda-
mental completo
Quantita-
tiva Percentual
7 RDPCn Renda per capita Quantita-
tiva
Valor Ab-
soluto

127
8 RENOCUPn Rendimento médio dos ocu-
pados - 18 anos ou mais
Quantita-
tiva
Valor Ab-
soluto
9
T_NES-
TUDA_NTRAB_MMEIOn
p
% de 15 a 24 anos que não
estudam, não trabalham e
são vulneráveis à pobreza
Quantita-
tiva Percentual
18.2 A Análise De Correspondência Por Estados Para As 7 Variáveis
STAT / MULTIVARIATE / SIMPLE CORRESPONDENCE / CAMPO CATEGORICAL VARI-
ABLES: REGISTRAR A COLUNA ONDE ESTÃO OS ESTADOS (em minúsculo; neste traba-
lho ficou na coluna C46-T) / COLUMNS OF A CONTINGENCY: REGISTRAR AS 7 VARIÁ-
VEIS SELECIONADAS NOS TRABALHOS ANTERIORES E QUE SÃO OBJETO DE ES-
TUDO / ROW NAMES: REGISTRAR A COLUNA ONDE ESTÃO OS ESTADOS / COLUMN
NAMES: REGISTRAR A COLUNA ONDE ESTÃO OS ESTADOS (em minúsculo; neste traba-
lho ficou na coluna C46-T) / NUMBER OF COMPONENTS: 2 (equivale graficamente aos eixos
X e Y) / GRAPHS: MARCAR SIMMETRIC PLOT SHOWING ROWS AND COLUMNS / OK
Simple Correspondence Analysis: MeanESPVIDAn; MeanMORT1np;
MeanT_ANALF2; MeanRD
Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0074 0,6144 0,6144 ******************************
2 0,0023 0,1945 0,8089 *********
3 0,0010 0,0853 0,8942 ****
4 0,0006 0,0480 0,9422 **
5 0,0005 0,0451 0,9873 **
6 0,0002 0,0127 1,0000
Total 0,0121
Row Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 ac 0,082 0,031 0,019 -0,019 0,052 0,002 -0,015 0,030 0,003
2 al 0,835 0,023 0,063 -0,145 0,648 0,066 0,078 0,188 0,060
3 am 0,900 0,032 0,048 -0,038 0,077 0,006 -0,122 0,823 0,202
4 ap 0,588 0,040 0,041 0,047 0,182 0,012 -0,071 0,406 0,085
5 ba 0,881 0,031 0,030 -0,103 0,881 0,044 -0,000 0,000 0,000
6 ce 0,777 0,030 0,077 -0,155 0,777 0,097 -0,003 0,000 0,000
7 es 0,532 0,047 0,011 0,039 0,520 0,010 0,006 0,012 0,001
8 go 0,614 0,048 0,012 0,041 0,581 0,011 0,010 0,034 0,002
9 ma 0,751 0,026 0,063 -0,147 0,724 0,074 0,028 0,027 0,009
10 mg 0,147 0,045 0,013 0,013 0,046 0,001 -0,019 0,101 0,007
11 ms 0,852 0,046 0,041 0,091 0,781 0,052 0,028 0,071 0,015
12 mt 0,816 0,047 0,024 0,069 0,773 0,031 0,016 0,043 0,005
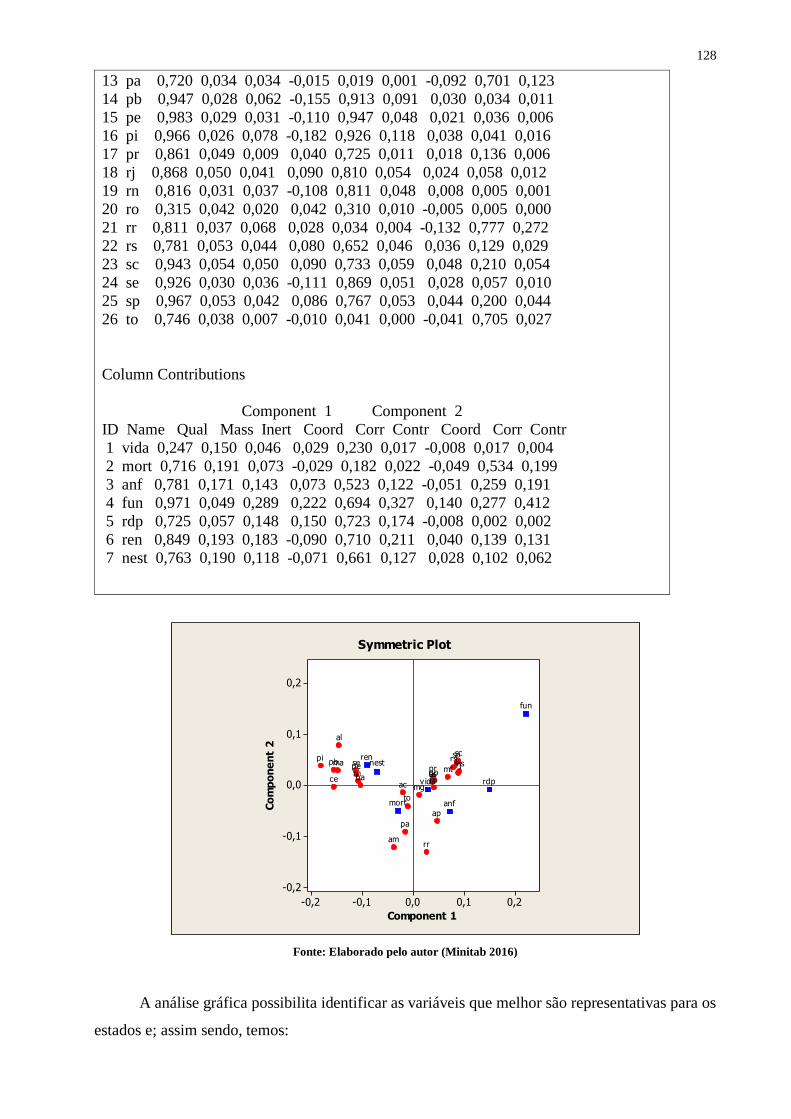
128
13 pa 0,720 0,034 0,034 -0,015 0,019 0,001 -0,092 0,701 0,123
14 pb 0,947 0,028 0,062 -0,155 0,913 0,091 0,030 0,034 0,011
15 pe 0,983 0,029 0,031 -0,110 0,947 0,048 0,021 0,036 0,006
16 pi 0,966 0,026 0,078 -0,182 0,926 0,118 0,038 0,041 0,016
17 pr 0,861 0,049 0,009 0,040 0,725 0,011 0,018 0,136 0,006
18 rj 0,868 0,050 0,041 0,090 0,810 0,054 0,024 0,058 0,012
19 rn 0,816 0,031 0,037 -0,108 0,811 0,048 0,008 0,005 0,001
20 ro 0,315 0,042 0,020 0,042 0,310 0,010 -0,005 0,005 0,000
21 rr 0,811 0,037 0,068 0,028 0,034 0,004 -0,132 0,777 0,272
22 rs 0,781 0,053 0,044 0,080 0,652 0,046 0,036 0,129 0,029
23 sc 0,943 0,054 0,050 0,090 0,733 0,059 0,048 0,210 0,054
24 se 0,926 0,030 0,036 -0,111 0,869 0,051 0,028 0,057 0,010
25 sp 0,967 0,053 0,042 0,086 0,767 0,053 0,044 0,200 0,044
26 to 0,746 0,038 0,007 -0,010 0,041 0,000 -0,041 0,705 0,027
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 vida 0,247 0,150 0,046 0,029 0,230 0,017 -0,008 0,017 0,004
2 mort 0,716 0,191 0,073 -0,029 0,182 0,022 -0,049 0,534 0,199
3 anf 0,781 0,171 0,143 0,073 0,523 0,122 -0,051 0,259 0,191
4 fun 0,971 0,049 0,289 0,222 0,694 0,327 0,140 0,277 0,412
5 rdp 0,725 0,057 0,148 0,150 0,723 0,174 -0,008 0,002 0,002
6 ren 0,849 0,193 0,183 -0,090 0,710 0,211 0,040 0,139 0,131
7 nest 0,763 0,190 0,118 -0,071 0,661 0,127 0,028 0,102 0,062
0,20,10,0-0,1-0,2
0,2
0,1
0,0
-0,1
-0,2
Component 1
Co
mp
on
en
t 2
nestren
rdp
fun
anfmort
vida
to
spse
scrs
rr
rorn
rjpr
pipe
pb
pa
mtms
mg
magoes
ce ba
ap
am
al
ac
Symmetric Plot
Fonte: Elaborado pelo autor (Minitab 2016)
A análise gráfica possibilita identificar as variáveis que melhor são representativas para os
estados e; assim sendo, temos:

129
a) Variável T_FUNDIN_TODOS_MMEIO (fund) com o maior distanciamento em to-
dos os estados e, os que menos se distanciam são os 3 estados do sul
b) Variável RDPC (rdpc) Mato Grosso com maior proximidade
c) Variável T_ANALF25M (anaf) explica com maior representatividade o estado do
Amapá
d) Variável ESPVIDA (vida) com maior proximidade dos estados de São Paulo e Minas
Gerais
e) Variável MORT1 (mort) com maior proximidade para o estado do Tocantins
f) Variável RENOCUP (reno) com maior proximidade para os estados do Maranhão, Per-
nambuco e Sergipe
g) Variável T_NESTUDA_NTRAB_MMEIO (nest) com maior proximidade dos estados
de Pernambuco e Sergipe.
18.3 Análise De Correspondência Por Região Para As 7 Variáveis
Para esta análise foi necessário criar as médias das sete variáveis por Região, a seguir:
One-way ANOVA: MeanESPVIDAn versus REGIÃO M
Source DF SS MS F P
REGIÃO M 4 0,54443 0,13611 66,61 0,000
Error 21 0,04291 0,00204
Total 25 0,58734
S = 0,04520 R-Sq = 92,69% R-Sq(adj) = 91,30%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --+---------+---------+---------+-------
CO 3 0,67313 0,01835 (---*----)
N 7 0,49153 0,05601 (--*--)
NE 9 0,36724 0,03815 (--*-)
S 3 0,73857 0,06200 (----*---)
SU 4 0,69105 0,03689 (---*---)
--+---------+---------+---------+-------
0,36 0,48 0,60 0,72
Pooled StDev = 0,04520
One-way ANOVA: MeanMORT1np versus REGIÃO M
Source DF SS MS F P
REGIÃO M 4 0,51163 0,12791 34,76 0,000
Error 21 0,07727 0,00368
Total 25 0,58890
S = 0,06066 R-Sq = 86,88% R-Sq(adj) = 84,38%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---------+---------+---------+---------+

130
CO 3 0,78610 0,06833 (---*----)
N 7 0,66890 0,06755 (---*--)
NE 9 0,50542 0,06886 (--*-)
S 3 0,88203 0,02300 (----*----)
SU 4 0,82245 0,02278 (---*---)
---------+---------+---------+---------+
0,60 0,75 0,90 1,05
Pooled StDev = 0,06066
One-way ANOVA: MeanT_ANALF25Mnp versus REGIÃO M
Source DF SS MS F P
REGIÃO M 4 0,81070 0,20268 42,09 0,000
Error 21 0,10111 0,00481
Total 25 0,91182
S = 0,06939 R-Sq = 88,91% R-Sq(adj) = 86,80%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --------+---------+---------+---------+-
CO 3 0,74983 0,01344 (-----*-----)
N 7 0,61913 0,09352 (--*---)
NE 9 0,38502 0,05914 (---*--)
S 3 0,84563 0,04983 (----*-----)
SU 4 0,79018 0,07148 (----*---)
--------+---------+---------+---------+-
0,45 0,60 0,75 0,90
Pooled StDev = 0,06939
One-way ANOVA: MeanRDPCn versus REGIÃO M
Source DF SS MS F P
REGIÃO M 4 0,18187 0,04547 41,85 0,000
Error 21 0,02282 0,00109
Total 25 0,20469
S = 0,03296 R-Sq = 88,85% R-Sq(adj) = 86,73%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
CO 3 0,25170 0,00464 (---*----)
N 7 0,13166 0,04018 (--*---)
NE 9 0,09233 0,01411 (--*-)
S 3 0,31344 0,04334 (----*----)
SU 4 0,26463 0,05079 (---*---)
-+---------+---------+---------+--------

131
0,080 0,160 0,240 0,320
Pooled StDev = 0,03296
One-way ANOVA: MeanRENOCUPn versus REGIÃO M
Source DF SS MS F P
REGIÃO M 4 0,13339 0,03335 32,84 0,000
Error 21 0,02132 0,00102
Total 25 0,15471
S = 0,03187 R-Sq = 86,22% R-Sq(adj) = 83,59%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -------+---------+---------+---------+--
CO 3 0,29420 0,01603 (----*----)
N 7 0,20266 0,04050 (---*---)
NE 9 0,11263 0,01516 (--*--)
S 3 0,28060 0,02203 (----*-----)
SU 4 0,26814 0,05215 (---*----)
-------+---------+---------+---------+--
0,140 0,210 0,280 0,350
Pooled StDev = 0,03187
One-way ANOVA: MeanT_NESTUDA_NTRAB_MMEIOnp versus REGIÃO M
Source DF SS MS F P
REGIÃO M 4 0,34631 0,08658 39,54 0,000
Error 21 0,04598 0,00219
Total 25 0,39229
S = 0,04679 R-Sq = 88,28% R-Sq(adj) = 86,05%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -----+---------+---------+---------+----
CO 3 0,79047 0,01450 (-----*-----)
N 7 0,61441 0,06983 (--*---)
NE 9 0,57806 0,03189 (--*--)
S 3 0,88157 0,03097 (----*-----)
SU 4 0,80683 0,04562 (----*----)
-----+---------+---------+---------+----
0,60 0,70 0,80 0,90
Pooled StDev = 0,04679

132
One-way ANOVA: MeanT_FUNDIN_TODOS_MMEIOnp versus REGIÃO M
Source DF SS MS F P
REGIÃO M 4 0,38568 0,09642 20,96 0,000
Error 21 0,09659 0,00460
Total 25 0,48227
S = 0,06782 R-Sq = 79,97% R-Sq(adj) = 76,16%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -------+---------+---------+---------+--
CO 3 0,78707 0,02972 (------*-----)
N 7 0,59743 0,09121 (----*---)
NE 9 0,55861 0,06019 (---*--)
S 3 0,85917 0,02808 (------*-----)
SU 4 0,81890 0,06916 (-----*-----)
-------+---------+---------+---------+--
0,60 0,72 0,84 0,96
Pooled StDev = 0,06782
Novas médias por região
regiões vida mort anf rdp ren nest fun
CO 0,67313 0,78610 0,74983 0,25170 0,29420 0,79047 0,78707
N 0,49153 0,66890 0,61913 0,13166 0,20266 0,61441 0,59743
NE 0,36724 0,50542 0,38502 0,09233 0,11263 0,57806 0,55861
S 0,73857 0,88203 0,84563 0,31344 0,28060 0,88157 0,85917
SU 0,69105 0,82245 0,79018 0,26463 0,26814 0,80683 0,81890
Após elaborar a tabela com as novas médias por região, rodou-se a análise de correspon-
dência por Região, seguindo a sequência conforme descrito:
STAT / MULTIVARIATE / SIMPLE CORRESPONDENCE / CAMPO CATEGORICAL VARI-
ABLES: REGISTRAR A COLUNA ONDE ESTÃO AS REGIÕES (em minúsculo; neste trabalho
ficou na coluna C75-T) / COLUMNS OF A CONTINGENCY: REGISTRAR AS 7 VARIÁVEIS
SELECIONADAS NOS TRABALHOS ANTERIORES E QUE SÃO OBJETO DE ESTUDO (co-
luna C72-T) / ROW NAMES: REGISTRAR A COLUNA ONDE ESTÃO AS REGIÕES / CO-
LUMN NAMES: REGISTRAR A COLUNA ONDE ESTÃO AS REGIÕES (em minúsculo; neste
trabalho ficou na coluna C75-T) /NUMBER OF COMPONENTS: 2 (equivale graficamente aos
eixos X e Y) / GRAPHS: MARCAR SIMMETRIC PLOT SHOWING ROWS AND COLUMNS
/ OK

133
Observar que as novas regiões são resultantes das anovas realizadas para obter as médias para
cada uma das variáveis e, portanto; devemos utilizar a nova coluna que se formou com “região
nova”.
Simple Correspondence Analysis: expvidaregia; mort1regiao; analf25Mregi;
rpdreg
Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0044 0,7487 0,7487 ******************************
2 0,0012 0,2053 0,9541 ********
3 0,0002 0,0417 0,9958 *
4 0,0000 0,0042 1,0000
Total 0,0059
Row Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 CO 0,642 0,222 0,078 0,037 0,641 0,067 0,001 0,000 0,000
2 N 0,989 0,170 0,174 -0,026 0,113 0,026 -0,073 0,877 0,745
3 NE 1,000 0,133 0,589 -0,159 0,963 0,757 0,031 0,037 0,107
4 S 0,898 0,246 0,119 0,043 0,659 0,104 0,026 0,239 0,138
5 SU 0,906 0,229 0,040 0,030 0,855 0,045 0,007 0,051 0,010
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 vida 0,956 0,152 0,026 0,031 0,934 0,032 0,005 0,022 0,003
2 mort 0,904 0,188 0,047 -0,025 0,441 0,027 -0,026 0,463 0,105
3 anf 0,938 0,174 0,114 0,046 0,536 0,082 -0,040 0,402 0,223
4 fun 0,994 0,054 0,381 0,179 0,766 0,390 0,098 0,229 0,425
5 rdp 0,821 0,059 0,145 0,100 0,693 0,134 -0,043 0,128 0,091
6 ren 0,990 0,188 0,163 -0,068 0,898 0,196 0,022 0,091 0,073
7 nest 0,972 0,186 0,123 -0,057 0,838 0,138 0,023 0,134 0,081

134
0,20,10,0-0,1-0,2
0,2
0,1
0,0
-0,1
-0,2
Component 1
Co
mp
on
en
t 2
nestren
rdp
fun
anfmort
vidaSU
SNE
N
CO
Symmetric Plot
A análise gráfica possibilita identificar as variáveis que melhor são representativas para os
estados e; assim sendo, temos:
a) Variáveis RENOCUP (reno) e T_NESTUDA_NTRAB_MMEIO (nest) com maior
proximidade na região Nordeste
b) Variável MORT1 (mort) com maior proximidade para a região Norte
c) Variáveis T_ANALF25M (anaf) e RDPC (rdp) com maior proximidade com as regiões
Sudeste e Centro Oeste
d) Variável ESPVIDA (vida) com maior proximidade das regiões Centro Oeste, Sudeste
e Sul.
e) Variável T_FUNDIN_TODOS_MMEIO (fund) também em termos de regiões se apre-
senta com um grande distanciamento de todas as regiões, ficando somente no mesmo
quadrante que contém as regiões Centro Oeste, Sudeste e Sul.
18.4 Análise De Correspondência Por Novos Agrupamentos (3 Clusters) Para As 7 Variáveis
Para esta análise foi necessário criar as médias das sete variáveis por Nova Região criada
(quando da divisão pelos 03 clusters nos trabalhos anteriores). Resgatando as análises anteriores,
as novas regiões estão assim subdivididas:
Região 01: Acre, Bahia, Pernambuco, Sergipe, Ceará, Rio Grande do Norte, Paraíba, Piauí, Ala-
goas e Maranhão.
Região 02: Amazonas, Pará, Roraima, Amapá e Tocantins.
Região 03 : Espírito Santo, Goiás, Paraná, Rio de Janeiro, Rio Grande do Sul, Santa Catarina, São
Paulo, Minas Gerais, Mato Grosso do Sul, Mato Grosso e Rondônia.

135
A exemplo do que foi elaborado para as regiões; também, para esta análise foi necessário
criar as médias das sete variáveis por 3 Novos Clusters formados, agora denominados Regiões 1,
2 e 3. O procedimento consistiu em novamente realizar a Anova tomando-se como base os grupos
anteriormente formados para os 26 estados e as médias que já haviam sido calculadas para os
estados versus as 7 variáveis; calculando-se desta forma novas médias e nova nomenclatura dos
grupos (respeitando-se a formação dos 3 clusters); a seguir temos os valores da Anova por variável:
One-way ANOVA: MeanESPVIDAn versus 3 novos grupos
Source DF SS MS F P
3 novos grupos 2 0,51260 0,25630 78,87 0,000
Error 23 0,07474 0,00325
Total 25 0,58734
S = 0,05701 R-Sq = 87,27% R-Sq(adj) = 86,17%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ------+---------+---------+---------+---
REGIAO1 10 0,37319 0,04059 (--*---)
REGIAO2 5 0,49748 0,05747 (-----*----)
REGIAO3 11 0,68417 0,06834 (--*---)
------+---------+---------+---------+---
0,40 0,50 0,60 0,70

136
Pooled StDev = 0,05701
One-way ANOVA: MeanMORT1np versus 3 novos grupos
Source DF SS MS F P
3 novos grupos 2 0,49278 0,24639 58,96 0,000
Error 23 0,09611 0,00418
Total 25 0,58890
S = 0,06464 R-Sq = 83,68% R-Sq(adj) = 82,26%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---+---------+---------+---------+------
REGIAO1 10 0,51143 0,06764 (---*---)
REGIAO2 5 0,68258 0,06027 (-----*-----)
REGIAO3 11 0,81801 0,06356 (---*---)
---+---------+---------+---------+------
0,50 0,60 0,70 0,80
Pooled StDev = 0,06464
One-way ANOVA: MeanT_ANALF25Mnp versus 3 novos grupos
Source DF SS MS F P
3 novos grupos 2 0,83160 0,41580 119,21 0,000
Error 23 0,08022 0,00349
Total 25 0,91182
S = 0,05906 R-Sq = 91,20% R-Sq(adj) = 90,44%
Individual 95% CIs For Mean Based on Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
REGIAO1 10 0,39260 0,06069 (---*--)
REGIAO2 5 0,62496 0,05136 (---*----)
REGIAO3 11 0,79049 0,06043 (--*--)
-+---------+---------+---------+--------
0,36 0,48 0,60 0,72
Pooled StDev = 0,05906
One-way ANOVA: MeanRDPCn versus 3 novos grupos
Source DF SS MS F P
3 novos grupos 2 0,17630 0,08815 71,43 0,000
Error 23 0,02839 0,00123
Total 25 0,20469
S = 0,03513 R-Sq = 86,13% R-Sq(adj) = 84,93%

137
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev --------+---------+---------+---------+-
REGIAO1 10 0,09488 0,01556 (---*---)
REGIAO2 5 0,11994 0,02983 (----*----)
REGIAO3 11 0,26891 0,04759 (---*--)
--------+---------+---------+---------+-
0,120 0,180 0,240 0,300
Pooled StDev = 0,03513
One-way ANOVA: MeanRENOCUPn versus 3 novos grupos
Source DF SS MS F P
3 novos grupos 2 0,12756 0,06378 54,02 0,000
Error 23 0,02716 0,00118
Total 25 0,15471
S = 0,03436 R-Sq = 82,45% R-Sq(adj) = 80,92%
Individual 95% CIs For Mean Based on Pooled StDev
Level N Mean StDev +---------+---------+---------+---------
REGIAO1 10 0,12066 0,02913 (---*----)
REGIAO2 5 0,19598 0,04377 (-----*------)
REGIAO3 11 0,27661 0,03443 (---*----)
+---------+---------+---------+---------
0,100 0,150 0,200 0,250
Pooled StDev = 0,03436
One-way ANOVA: MeanT_NESTUDA_NTRAB_MMEIOnp versus 3 novos gru-
pos
Source DF SS MS F P
3 novos grupos 2 0,34962 0,17481 94,23 0,000
Error 23 0,04267 0,00186
Total 25 0,39229
S = 0,04307 R-Sq = 89,12% R-Sq(adj) = 88,18%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev -+---------+---------+---------+--------
REGIAO1 10 0,58079 0,03129 (---*--)
REGIAO2 5 0,58830 0,03964 (----*----)
REGIAO3 11 0,81795 0,05251 (--*---)
-+---------+---------+---------+--------
0,560 0,640 0,720 0,800

138
Pooled StDev = 0,04307
One-way ANOVA: MeanT_FUNDIN_TODOS_MMEIOnp versus 3 novos grupos
Source DF SS MS F P
3 novos grupos 2 0,38367 0,19183 44,75 0,000
Error 23 0,09861 0,00429
Total 25 0,48227
S = 0,06548 R-Sq = 79,55% R-Sq(adj) = 77,78%
Individual 95% CIs For Mean Based on
Pooled StDev
Level N Mean StDev ---------+---------+---------+---------+
REGIAO1 10 0,55242 0,06003 (---*----)
REGIAO2 5 0,59612 0,08404 (-----*-----)
REGIAO3 11 0,81082 0,06158 (---*---)
---------+---------+---------+---------+
0,60 0,70 0,80 0,90
Pooled StDev = 0,06548
Novas médias por Grupos
Região vida mort anf rdp ren nest fun
Região1 0,37319 0,51143 0,39260 0,09488 0,12066 0,58079 0,55242
Região2 0,49748 0,68258 0,62496 0,11994 0,19598 0,58830 0,59612
Região3 0,68417 0,81801 0,79049 0,26891 0,27661 0,81795 0,81082
STAT / MULTIVARIATE / SIMPLE CORRESPONDENCE / CAMPO CATEGORICAL VARI-
ABLES: REGISTRAR A COLUNA ONDE ESTÃO OS NOVOS AGRUPAMENTOS (em mi-
núsculo; neste trabalho ficou na coluna C84-T) / COLUMNS OF A CONTINGENCY: REGIS-
TRAR AS 7 VARIÁVEIS SELECIONADAS NOS TRABALHOS ANTERIORES E QUE SÃO
OBJETO DE ESTUDO já calculadas com as Anovas / ROW NAMES: REGISTRAR A COLUNA
ONDE ESTÃO OS NOVOS AGRUPAMENTOS (coluna C84-T) / COLUMN NAMES: REGIS-
TRAR A COLUNA ONDE ESTÃO OS NOVOS AGRUPAMENTOS (em minúsculo; neste tra-
balho ficou na coluna C72-T) / NUMBER OF COMPONENTS: 2 (equivale graficamente aos ei-
xos X e Y) / GRAPHS: MARCAR SIMMETRIC PLOT SHOWING ROWS AND COLUMNS /
OK
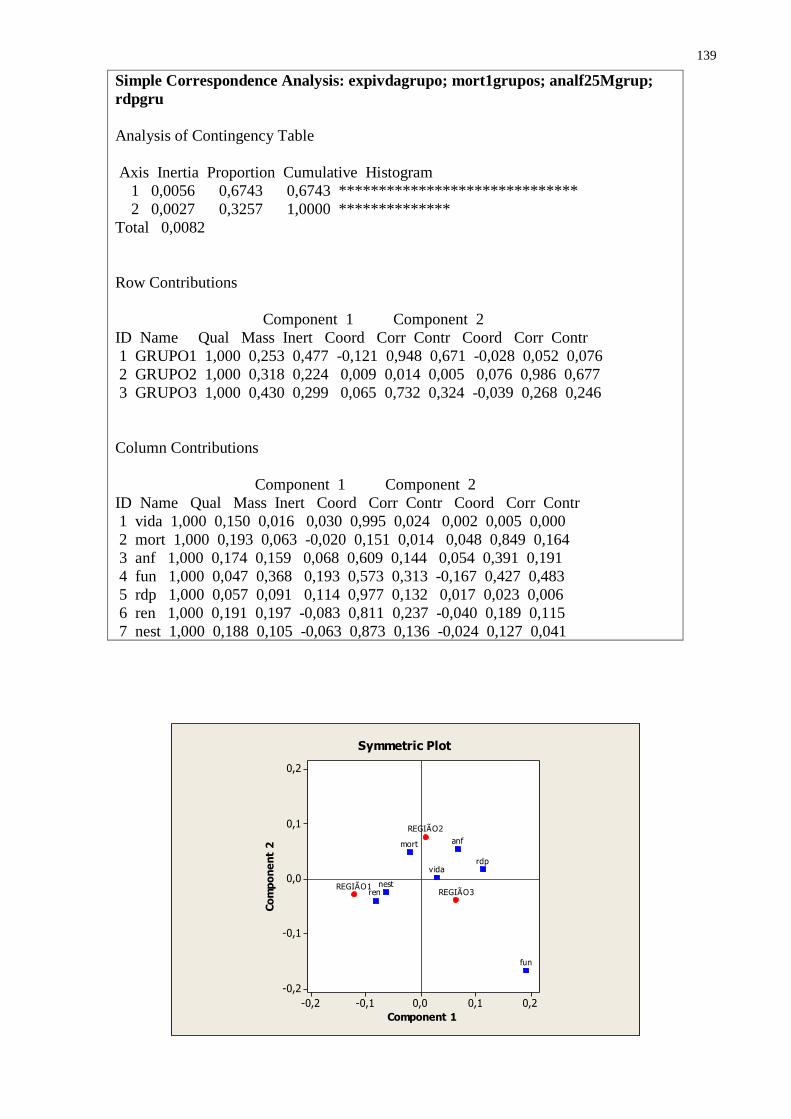
139
Simple Correspondence Analysis: expivdagrupo; mort1grupos; analf25Mgrup;
rdpgru
Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0056 0,6743 0,6743 ******************************
2 0,0027 0,3257 1,0000 **************
Total 0,0082
Row Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 GRUPO1 1,000 0,253 0,477 -0,121 0,948 0,671 -0,028 0,052 0,076
2 GRUPO2 1,000 0,318 0,224 0,009 0,014 0,005 0,076 0,986 0,677
3 GRUPO3 1,000 0,430 0,299 0,065 0,732 0,324 -0,039 0,268 0,246
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 vida 1,000 0,150 0,016 0,030 0,995 0,024 0,002 0,005 0,000
2 mort 1,000 0,193 0,063 -0,020 0,151 0,014 0,048 0,849 0,164
3 anf 1,000 0,174 0,159 0,068 0,609 0,144 0,054 0,391 0,191
4 fun 1,000 0,047 0,368 0,193 0,573 0,313 -0,167 0,427 0,483
5 rdp 1,000 0,057 0,091 0,114 0,977 0,132 0,017 0,023 0,006
6 ren 1,000 0,191 0,197 -0,083 0,811 0,237 -0,040 0,189 0,115
7 nest 1,000 0,188 0,105 -0,063 0,873 0,136 -0,024 0,127 0,041
0,20,10,0-0,1-0,2
0,2
0,1
0,0
-0,1
-0,2
Component 1
Co
mp
on
en
t 2
nestren
rdp
fun
anfmort
vida
REGIÃO3
REGIÃO2
REGIÃO1
Symmetric Plot

140
Observando-se a disposição no gráfico, percebe-se que as regiões com maiores correspon-
dências, são:
a) Região1 as variáveis T_NESTUDA_NTRAB_MMEIO (nest) e RENOCUP (ren) são as
que mais proximidade têm
b) Região2 as variáveis MORT1(mort), T_ANALF25M(anf) são as com maior proximidade
e
c) Região3 a variável EXPVIDA(vida) é a que tem maior proximidade
d) A variável T_FUNDIN_TODOS_MMEIO(fun) também na análise de correspondência por
Região (Novos Clusters) continua distante das regiões formadas.
18.5 Análise De Correspondência Por Estado Para As 3 Variáveis Analisadas No Trabalho
Anterior De Regressão Logística
Para esta análise utilizou-se das variáveis: ESPVIDA, MORT1 e RENOCUP resultante da
análise feita anteriormente para escolha das mais representativas dentre as 7 variáveis objeto de
estudo
Novamente buscou-se as médias por estados para as 3 variáveis, realizando-se as Anovas
para cada uma delas; uma vez calculadas as novas médias, foi possível realizar a análise de cor-
respondências conforme segue o passo a passo abaixo;
STAT / MULTIVARIATE / SIMPLE CORRESPONDENCE
CAMPO CATEGORICAL: ESTADOS (em minúsculo; neste trabalho ficou na coluna C80-T)
COLUMNS OF A CONTINGENCY: AS 3 VARIÁVEIS SELECIONADAS NOS TRABALHOS
ANTERIORES E QUE SÃO OBJETO DE ESTUDO (ESPVIDA, MORT1 e RENOCUP)
ROW NAMES: REGISTRAR A COLUNA ONDE ESTÃO OS ESTADOS (coluna C80-T)
COLUMN NAMES: A NOVA COLUNA ONDE ESTÃO OS NOMES DAS 3 VARIÁVEIS (em
minúsculo; neste trabalho ficou na coluna C84-T) / NUMBER OF COMPONENTS: 2 (equivale
graficamente aos eixos X e Y) / GRAPHS: MARCAR SIMMETRIC PLOT SHOWING ROWS
AND COLUMNS / OK
Simple Correspondence Analysis: expvid; morte1; renocupa
Analysis of Contingency Table
Axis Inertia Proportion Cumulative Histogram
1 0,0051 0,8419 0,8419 ******************************
2 0,0010 0,1581 1,0000 *****
Total 0,0061

141
Row Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 ac 1,000 0,032 0,018 0,046 0,617 0,013 0,036 0,383 0,044
2 al 1,000 0,022 0,000 -0,002 0,948 0,000 -0,001 0,052 0,000
3 am 1,000 0,033 0,037 -0,070 0,718 0,031 0,044 0,282 0,066
4 ap 1,000 0,041 0,074 0,071 0,449 0,040 0,078 0,551 0,259
5 ba 1,000 0,029 0,044 -0,096 1,000 0,052 0,001 0,000 0,000
6 ce 1,000 0,030 0,115 -0,154 1,000 0,137 0,001 0,000 0,000
7 es 1,000 0,049 0,007 -0,007 0,053 0,000 -0,029 0,947 0,043
8 go 1,000 0,050 0,005 0,025 0,980 0,006 -0,004 0,020 0,001
9 ma 1,000 0,022 0,008 -0,044 0,948 0,009 -0,010 0,052 0,003
10 mg 1,000 0,046 0,040 -0,038 0,276 0,013 -0,062 0,724 0,185
11 ms 1,000 0,046 0,120 0,120 0,915 0,131 -0,037 0,085 0,065
12 mt 1,000 0,048 0,073 0,096 0,998 0,086 0,004 0,002 0,001
13 pa 1,000 0,034 0,012 -0,045 0,931 0,014 0,012 0,069 0,005
14 pb 1,000 0,027 0,085 -0,137 0,996 0,101 -0,008 0,004 0,002
15 pe 1,000 0,028 0,027 -0,073 0,907 0,029 0,023 0,093 0,016
16 pi 1,000 0,025 0,076 -0,135 0,995 0,089 -0,009 0,005 0,002
17 pr 1,000 0,049 0,002 0,014 0,805 0,002 0,007 0,195 0,002
18 rj 1,000 0,048 0,050 0,077 0,925 0,055 0,022 0,075 0,024
19 rn 1,000 0,031 0,042 -0,090 0,972 0,048 0,015 0,028 0,007
20 ro 1,000 0,040 0,032 0,054 0,611 0,023 0,043 0,389 0,079
21 rr 1,000 0,042 0,007 -0,029 0,843 0,007 0,013 0,157 0,007
22 rs 1,000 0,053 0,011 0,004 0,012 0,000 -0,036 0,988 0,070
23 sc 1,000 0,054 0,034 0,048 0,597 0,024 -0,039 0,403 0,087
24 se 1,000 0,028 0,015 -0,054 0,890 0,016 0,019 0,110 0,010
25 sp 1,000 0,052 0,063 0,084 0,944 0,071 -0,020 0,056 0,022
26 to 1,000 0,039 0,001 -0,012 0,889 0,001 0,004 0,111 0,001
Column Contributions
Component 1 Component 2
ID Name Qual Mass Inert Coord Corr Contr Coord Corr Contr
1 vida 1,000 0,377 0,099 0,004 0,010 0,001 -0,040 0,990 0,622
2 mort 1,000 0,480 0,254 -0,052 0,833 0,252 0,023 0,167 0,268
3 ren 1,000 0,143 0,646 0,164 0,973 0,747 0,027 0,027 0,110

142
0,20,10,0-0,1-0,2
0,2
0,1
0,0
-0,1
-0,2
Component 1
Co
mp
on
en
t 2
renmort
v ida
to
sp
se
scrs
rr
ro
rn rjpr
pi
pe
pb
pamt
ms
mg
mago
es
ce ba
ap
am
al
ac
Symmetric Plot
Podemos observar através da representação gráfica, que:
a) Variável RENOCUP (ren) tem menor relevância nos estados, ficando com maior proximi-
dade dos estados do Mato Grosso e Rio de Janeiro.
b) Variável ESPVIDA (vida) tem maior proximidade com os estados do Rio Grande do Sul e
Espírito Santo, ficando distante de Amapá.
c) Variável MORT1 (mort) tem proximidade com os estados do Pará, Maranhão, Roraima,
Amazonas, Pernambuco e Tocantins. Ficando totalmente distante de Mato Grosso do Sul.
18.6 Comentários sobre a Análise de Correspondência
Esta análise praticamente corrobora as análises anteriores, mostrando os Brasis dentro do
mesmo Brasil e pertencentes ao sistema Federativo; pois, a análise de correspondência simples
decompôs uma tabela até chegarmos às 3 variáveis que melhor explicam (dentre as que foram
selecionadas pelo pesquisador) as condições nos estados brasileiros. Os resultados reafirmam o
que já havia sido diagnosticado em exercício anterior; ou seja, uma grande disparidade em termos
sociais quando comparamos as regiões Sul e Norte se pudermos traçar uma linha divisória entre
os 2 Brasis que predominam, ficando a região acima dessa linha divisória com indicadores mais
preocupantes do ponto de vista econômico-social. Se pensarmos que se trata de uma nação com as
dimensões e características do Brasil e um regime de União Federativo, muito há que se fazer para
minorar essas diferenças entre sul e o norte.

143
CAPÍTULO XIX. ÁRVORE DE CLASSIFICAÇÃO
Para elaboração desta análise foi utilizado o software estatístico SPSS que possibilita indi-
car qual a variável que melhor separa os grupos e classifica as variáveis por ordem de importância
na separação dos grupos. A seguir é demonstrado o teste desse modelo.
Analysis Case Processing Summary
Unweighted Cases N Percent
Valid 26 100,0
Exclu-
ded
Missing or out-of-
range group codes
0 ,0
At least one missing
discriminating variable
0 ,0
Both missing or out-of-
range group codes and
at least one missing
discriminating variable
0 ,0
Total 0 ,0
Total 26 100,0

144
Group Statistics
Grupos de estados Valid N (listwise)
Unweighte
d
Weighte
d
1,00 MeanMORT1np 8 8,000
Me-
anT_ANALF25Mnp
8 8,000
MeanRDPCn 8 8,000
MeanRENOCUPn 8 8,000
MeanT_NES-
TUDA_NTRAB_MM
EIOnp
8 8,000
MeanT_FUNDIN_TO-
DOS_MMEIOnp
8 8,000
2,00 MeanMORT1np 8 8,000
Me-
anT_ANALF25Mnp
8 8,000
MeanRDPCn 8 8,000
MeanRENOCUPn 8 8,000
MeanT_NES-
TUDA_NTRAB_MM
EIOnp
8 8,000
MeanT_FUNDIN_TO-
DOS_MMEIOnp
8 8,000
3,00 MeanMORT1np 10 10,000
Me-
anT_ANALF25Mnp
10 10,000
MeanRDPCn 10 10,000
MeanRENOCUPn 10 10,000
MeanT_NES-
TUDA_NTRAB_MM
EIOnp
10 10,000
MeanT_FUNDIN_TO-
DOS_MMEIOnp
10 10,000
Total MeanMORT1np 26 26,000
Me-
anT_ANALF25Mnp
26 26,000
MeanRDPCn 26 26,000
MeanRENOCUPn 26 26,000
MeanT_NES-
TUDA_NTRAB_MM
EIOnp
26 26,000
MeanT_FUNDIN_TO-
DOS_MMEIOnp
26 26,000

145
Eigenvalues
Func-
tion
Eigenva-
lue
% of Vari-
ance
Cumulative
%
Canonical
Correlation
d
i
m
e
n
s
i
o
n
0
1 1,023a 62,8 62,8 ,711
2 ,607a 37,2 100,0 ,615
a. First 2 canonical discriminant functions were used in the analy-
sis.
Standardized Canonical Discriminant
Function Coefficients
Function
1 2
MeanMORT1np -,097 ,953
Me-
anT_ANALF25Mnp
,425 -,377
MeanRDPCn -,163 -,624
MeanRENOCUPn ,029 ,807
MeanT_NES-
TUDA_NTRAB_MM
EIOnp
,532 ,381
MeanT_FUNDIN_TO-
DOS_MMEIOnp
,840 -,262

146
Structure Matrix
Function
1 2
MeanT_FUNDIN_TO-
DOS_MMEIOnp
,705* -,087
Me-
anT_ANALF25Mnp
,589* ,098
MeanT_NES-
TUDA_NTRAB_MM
EIOnp
,422* ,110
MeanRDPCn ,406* -,081
MeanMORT1np ,138 ,561*
MeanRENOCUPn ,456 ,480*
Pooled within-groups correlations between
discriminating variables and standardized
canonical discriminant functions
Variables ordered by absolute size of corre-
lation within function.
*. Largest absolute correlation between each
variable and any discriminant function
Functions at Group Centroids
Grupos de esta-
dos
Function
1 2
dimen-
sion0
1,00 -1,269 ,502
2,00 -,020 -1,099
3,00 1,031 ,477
Unstandardized canonical discriminant
functions evaluated at group means

147

148
Classification
Observed Predicted
1,00 2,00 3,00
Percent Cor-
rect
1,00 7 0 1 87,5%
2,00 0 5 3 62,5%
3,00 0 0 10 100,0%
Overall Percen-
tage
26,9% 19,2% 53,8% 84,6%
Growing Method: CHAID
Dependent Variable: Grupos de estados
Foi possível observar que tanto pelo software Minitab 16 (através da Regressão Logística
Nominal), quanto pela ferramenta SPSS (Árvore de Classificação e Regressão), a variável que
apresenta maior importância na separação dos estados é T_FUNDIN_TODOS_MMEIO.
CAPÍTULO XX. RANKING POR ESTADOS
Recordando o procedimento para normalização e/ou positivação das variáveis seleciona-
das; neste capítulo praticamente de finalização do estudo, descrevemos os passos que foram reali-
zados.
Fórmulas utilizadas
Passos no Minitab: CALC / CALCULADORA
Para normalização
Construir equação selecionando na caixa de opções funções a opção MINIMO e MAXIMO.
A equação: (c9-MIN(c9))/(MAX(c9)-MIN(c9))
Para positivação
Para os dados que representam valores
A Equação: 1-((c8-MIN(c8))/(MAX(c8)-MIN(c8)))
20.1 Análise dos Principais Componentes
Dando sequência em relação às variáveis objetos do trabalho, realizou-se nova análise dos
principais componentes para determinar o número de componentes que serão trabalhados:
A sequência de operações foi: STAT/Multivariate/Principal Components/Variables (as 7
selecionadas)/ Number of componentes = 5 / Sorage: as 5 colunas vazias onde serão registrados
os PC1 a PC5

149
Tabela 30. Principais componentes
Principal Component Analysis: MeanESPVIDAn; MeanMORT1np;
MeanT_ANALF2; MeanRDPC
Eigenanalysis of the Correlation Matrix
Eigenvalue 6,4851 0,2322 0,1376 0,0677 0,0497 0,0167 0,0111
Proportion 0,926 0,033 0,020 0,010 0,007 0,002 0,002
Cumulative 0,926 0,960 0,979 0,989 0,996 0,998 1,000
Variable PC1 PC2 PC3 PC4 PC5
MeanESPVIDAn 0,385 -0,124 0,308 0,299 0,459
MeanMORT1np 0,376 -0,385 0,557 0,060 0,066
MeanT_ANALF25Mnp 0,379 -0,391 -0,132 0,089 -0,761
MeanRDPCn 0,384 0,344 -0,189 0,112 0,171
MeanRENOCUPn 0,371 -0,359 -0,683 -0,230 0,358
MeanT_NESTUDA_NTRAB_MMEIOnp 0,374 0,559 -0,119 0,453 -0,198
MeanT_FUNDIN_TODOS_MMEIOnp 0,377 0,352 0,247 -0,793 -0,100 Fonte: Elaborado pelo autor (Minitab 2016).
O ideal é utilizar os componentes com Eigenvalue maior que 1. Com esta base, obtivemos
somente um componente (PC1) e, no caso a variável com maior representatividade foi “Mea-
nESPVIDAn”.
20.2 Análise dos Principais Componentes
O passo seguinte foi rodar a regressão Stepwise com os dados das 7 variáveis que compu-
seram o PC1, gerando uma nova coluna no Minitab e, desta forma possibilitou conhecer as variá-
veis que mais influenciam os componentes (R-Sq)
A sequência de operações foi: STAT/Regression/Stepwise/Response = PC1/Predictors (as
7 variáveis)

150
Tabela 31. Regressão das 7 variáveis
Stepwise Regression: PC1 versus MeanESPVIDAn; MeanMORT1np; ...
Alpha-to-Enter: 0,15 Alpha-to-Remove: 0,15
Response is PC1 on 7 predictors, with N = 26
Step 1 2 3 4 5 6
Constant -8,607 -6,922 -7,104 -8,210 -8,319 -9,559
MeanESPVIDAn 16,28 8,56 5,03 4,52 4,53 4,67
T-Value 24,08 6,64 5,54 6,89 8,55 11,63
P-Value 0,000 0,000 0,000 0,000 0,000 0,000
MeanRDPCn 13,8 11,9 8,5 7,1 2,8
T-Value 6,33 9,22 7,23 6,99 2,13
P-Value 0,000 0,000 0,000 0,000 0,047
MeanT_ANALF25Mnp 3,93 3,85 3,00 2,75
T-Value 6,83 9,41 7,27 8,65
P-Value 0,000 0,000 0,000 0,000
MeanT_FUNDIN_TODOS_MMEIOnp 3,01 3,35 3,38
T-Value 4,73 6,40 8,55
P-Value 0,000 0,000 0,000
MeanRENOCUPn 3,11 4,33
T-Value 3,49 5,86
P-Value 0,002 0,000
MeanT_NESTUDA_NTRAB_MMEIOnp 2,64
T-Value 4,01
P-Value 0,001
S 0,518 0,320 0,185 0,132 0,106 0,0804
R-Sq 96,03 98,55 99,54 99,78 99,86 99,92
R-Sq(adj) 95,86 98,42 99,47 99,73 99,83 99,90 Fonte: Elaborado pelo autor (Minitab 2016).
Ao rodar novamente a análise dos principais componentes com as 7 variáveis e agora com
apenas um componente; visto que, identificou-se que a proporção já representava 96,03% e com
somente uma variável (MeanESPVIDAn) para compor a fórmula que irá indicar a nova coluna dos
componentes por Estados; obteve-se os resultados apresentados na tabela a seguir:
A sequência de operações foi: STAT/Multivariate/Principal Components/Variables (as 7
selecionadas)/ Number of componentes = 1

151
ESTA-
DOS PC1
ac -1,78415
al -3,77314
am -1,92969
ap 0,315559
ba -2,07167
ce -2,27306
es 2,231413
go 2,556544
ma -3,3412
mg 1,483005
ms 2,137355
mt 2,309331
pa -1,29062
pb -2,70558
pe -2,32833
pi -3,09925
pr 2,780591
rj 2,95888
rn -1,97672
ro 0,99936
rr -0,59793
rs 3,780273
sc 4,205869
se -2,11803
sp 3,78832
to -0,25713
Uma vez realizada a análise dos principais componentes foi possível conhecer os dados que
iriam compor a fórmula com estes novos dados; considerando-se que a proporção é de 92,6% e a
variável com maior influência (MeanESPVIDAn) *também teve um alto impacto, onde R-Sq ficou
em 96,03%, foi possível determinar a expressão conforme descrito a seguir:
A sequência de operações foi: CALC/Calculator/Store result (definir coluna vazia)/Expres-
sion: 0,926 (proportion obtido em principais componentes) *(0,9603 que corresponde ao R-Sq de
MeanESPVIDAn*MeanESPVIDAn)
A tabela a seguir apresenta os Componentes versus Estados

152
ESTA-
DOS Comp.BR
ac 0,379438
al 0,271129
am 0,374903
ap 0,448532
ba 0,351338
ce 0,358274
es 0,615708
go 0,614819
ma 0,275397
mg 0,608239
ms 0,598724
mt 0,582184
pa 0,410917
pb 0,335865
pe 0,335598
pi 0,311233
pr 0,5949
rj 0,577204
rn 0,363965
ro 0,468273
rr 0,505532
rs 0,674665
sc 0,700719
se 0,33631
sp 0,65688
to 0,472007
O próximo passo foi criar uma nova coluna para normalização das variáveis tomando-se
como base a coluna Componentes BR e, aplicando a fórmula: 100* (xx-MIN(xx))/(MAX(xx)-
MIN(xx)), onde xx é a nova coluna criada no passo anterior.
A sequência de operações foi: CALC/Calculator/Store result (definir coluna vazia)/Expres-
sion: 100* (xx-MIN(xx))/(MAX(xx)-MIN(xx)), onde xx é a nova coluna criada no passo anterior

153
ESTA-
DOS
Normaliza-
ção
ac 25,21
al 0,00
am 24,16
ap 41,30
ba 18,67
ce 20,29
es 80,21
go 80,00
ma 0,99
mg 78,47
ms 76,26
mt 72,41
pa 32,54
pb 15,07
pe 15,01
pi 9,34
pr 75,37
rj 71,25
rn 21,61
ro 45,89
rr 54,56
rs 93,94
sc 100,00
se 15,17
sp 89,80
to 46,76
O próximo passo é a ordenação do ranking, utilizando a nova coluna normalizada com a
variável categórica ESTADO, do maior para o menor.
A sequência de operações foi: DATA/Sort/Sort Column: colunas onde estão os dados dos
Estados e os valores normalizados/By Column: Onde estão os valores normalizados e marcar des-
cending/Columns of current worksheet: 2 novas colunas onde serão ranqueados os estados versus
resultados.

154
Esta-
dos.BR Ranking
sc 100,00
rs 93,94
sp 89,80
es 80,21
go 80,00
mg 78,47
ms 76,26
pr 75,37
mt 72,41
rj 71,25
rr 54,56
to 46,76
ro 45,89
ap 41,30
pa 32,54
ac 25,21
am 24,16
rn 21,61
ce 20,29
ba 18,67
se 15,17
pb 15,07
pe 15,01
pi 9,34
ma 0,99
al 0,00
CONSIDERAÇÕES FINAIS
Mesmo trabalhando com um componente principal, sendo a variável com maior influência
nesta análise MeanESPVIDAn, Esperança de Vida ao nascer, o resultado deste estudo apresenta
muita similaridade com todas as análises anteriores, ou seja, os Estados do Sul, Sudeste e Centro-
Oeste apresentam os melhores indicadores e os Estados do Norte e Nordeste os piores indicadores.
Podemos constatar com os dados expostos nestas análises, o que já de certa forma havíamos
identificado nos levantamentos anteriores; ou seja, a disparidade social entre os dois Brasis, o
composto pelos Estados na parte de “cima” do mapa e os estados que compõem a parte de “baixo”
do mapa.
Desta forma podemos atestar que os problemas municipais brasileiros não são meramente
regionais e sim a discrepância em termos de políticas nacionais; uma vez que, o sistema brasileiro
é Federativo e portanto, deveria conduzir ao atendimento de toda a população do Brasil.
Nesta análise específica os três Estados com melhores indicadores foram; lembrando sem-
pre que excluímos por conveniência o Distrito Federal:

155
Santa Catarina (Sul) – 1º
Rio Grande do Sul (Sul) – 2º
São Paulo (Sudeste) - 3º
Já os três Estados com os piores indicadores foram:
Piauí (Norte) - 24º
Maranhão (Norte) – 25º
Alagoas (Nordeste) – 26º

156
REFERÊNCIAS
ANDERSON, David R.; SWEENEY, Dennis J.; WILLIAMS, Thomas A. Estatística aplicada
à administração e economia. 2. ed. São Paulo: Thomson Learning, 2007.
ATLAS DO DESENVOLVIMENTO HUMANO NO BRASIL. Disponível em: <http://www.atlas
brasil.org.br/2013/>. Acessado em: 17 mar. 2017.
IBGE, Instituto Brasileiro de Geografia e Estatística. Séries Históricas e Estatísticas. Dispo
nível em: <http://seriesestatisticas.ibge.gov.br/apresentacao.aspx>. Acessado em: 30 mar.
2017.
LAS CASAS A., DE HOYOS A. Pesquisa de Marketing. São Paulo, Ed. Atlas, 2010.