Área temÁtica - cienciapolitica.org.br · mediana, ou seja, o parâmetro que divide a...
TRANSCRIPT

ÁREA TEMÁTICA
Ensino e Pesquisa em Ciência Política e Relações Internacionais
O OUTLIER QUE PERTUBA O SEU SONO:
COMO IDENTIFICAR CASOS EXTREMOS?
DALSON BRITTO FIGUEIREDO FILHO
Universidade Federal de Pernambuco (UFPE)
LUCAS EMANUEL DE OLIVEIRA SILVA
Universidade Federal de Pernambuco (UFPE)

2
Resumo A presença de outliers é um dos problemas mais antigos da Estatística e afeta todos os ramos do conhecimento científico que utilizam testes de hipóteses como mecanismo de tomada de decisão. O principal problema dos casos extremos é que eles afetam a consistência das estimativas. Essas inconsistências podem se manifestar de várias formas: dificuldade de visualização gráfica, problemas na magnitude das estimativas, inversão de sinal dos coeficientes, erros do tipo 1 e 2, violação de pressupostos, etc. Este artigo apresenta uma introdução intuitiva sobre como identificar outliers. O foco repousa sobre cinco diferentes técnicas: (1) escores padronizados; (2) diferença interquartílica; (3) resíduos padronizados; (4) distância de Mahalanobis e (5) distância de Cook. O desenho de pesquisa utiliza simulação básica e replica dados secundários para ilustrar o passo a passo de cada procedimento. Defendemos que importante progresso pode ocorrer na Ciência Política brasileira se os pesquisadores checarem seus dados em busca de observações desviantes utilizando os procedimentos apresentados neste artigo.
Palavras-chave: outliers; casos extremos;
“Outliers: They will eat your results for lunch. Take them out before they do”.
Desconhecido
Nosso resumo foi inspirado no artigo “Understanding Interaction Models: Improving Empirical Analyses” de Brambor, Clark e Golder (2005), publicado na Political Analysis.

3
INTRODUÇÃO
Em 1778, Daniel Bernoulli se posicionou criticamente sobre a tendência de alguns
astrônomos em descartar observações destoantes e analisar os casos remanescentes como
se eles constituíssem a amostra original (HAWKINS, 1980). Nesse sentido, a presença de
outliers é um dos problemas mais antigos da Estatística e afeta todos os ramos do
conhecimento científico que utilizam testes de hipóteses como mecanismo de tomada de
decisão (GRUBBS, 1969; BARNET e LEWIS, 1994; HODGE, 2004).
O principal problema dos outliers é que eles afetam a qualidade das estimativas. As
inconsistências podem se manifestar de várias formas: dificuldade de visualização gráfica
(ATKINSON e MULIRA, 1993), violação de pressupostos (ATKINSON, 1994), problemas na
magnitude e na variabilidade das estimativas (SEO, 2002), inversão de sinal dos coeficientes
(FOX, 1991; VERARDI e CROUX, 2009), entre outros. Por essa razão, é essencial que os
pesquisadores saibam identificar e lidar com casos atípicos (DAVIES e GATHER, 1993;
OSBORNE e OVERBAY, 2004). Apesar dos esforços da comunidade estatística, os métodos
de detecção e tratamento de casos extremos raramente são utilizados por outras disciplinas
(IGLEWICZ e BANERJEE, 2001; WEBER, 2010). É o caso da Ciência Política brasileira.
Com o objetivo de preencher essa lacuna, este artigo apresenta um guia prático sobre
como identificar e tratar outliers. O foco repousa sobre a compreensão intuitiva de cinco
diferentes técnicas: (1) escores padronizados; (2) diferença interquartílica; (3) resíduos
padronizados; (4) distância de Mahalanobis e (5) distância de Cook. Metodologicamente,
utilizamos simulação e replicamos diferentes dados secundários para ilustrar o passo a passo
de cada procedimento.
O restante do artigo está organizado da seguinte forma. A próxima seção apresenta
uma discussão conceitual sobre outliers. Depois disso, apresentamos as cinco técnicas para
detectar casos extremos. A quarta seção discute diferentes estratégias sobre como lidar com
observações atípicas. A última seção sumariza as conclusões.
OUTLIERS: conceito, origem e efeitos
Neste artigo, adotamos a concepção de Hawkins (1980) que define outlier como uma
observação que se distancia tanto das demais ao ponto de gerar desconfiança se ela foi
gerada por um mecanismo diferente. O Quadro 1 sumariza diferentes definições encontradas
na literatura.
Quadro 1 – Diferentes definições de outliers
AUTOR (ANO) DEFINIÇÃO
4
Grubbs (1969) An outlying observation, or outlier, is one that appears to deviate markedly from other members of the sample in which occurs
Hawkins (1980) An observation that deviates so much from other observations as to arouse suspicion that it was generated by a different mechanism
Fox (1991) An outlier is an observation whose dependent variable value is unusual given the value of the independent variable
Johnson (1992) An observation in a data set which appears to be inconsistent with the remainder of that set of data
Mendenhall et al (1993) Observations whose values lies very far from the middle of the distribution in either direction
Ross (1996) Outlier are data points that do not appear to follow the pattern of the other cases
Pyle (1999) An outlier is a single, or very low frequency, occurrence of the value of a variable that is far away from the bulk of the values of the variable
Moore e McCabe
(1999) An outlier is an observation that lies outside the overall pattern of a distribution
Ramasmawy, Rastogi e
Shim (2000)
An outlier in a set of data is an observation or a point that is considerably dissimilar or inconsistent with the remainder of the data
Bluman (2000) An “outlier” is an extremely high or an extremely low data value when compared with the rest of the data values
Fonte: elaborado pelos autores (2016).
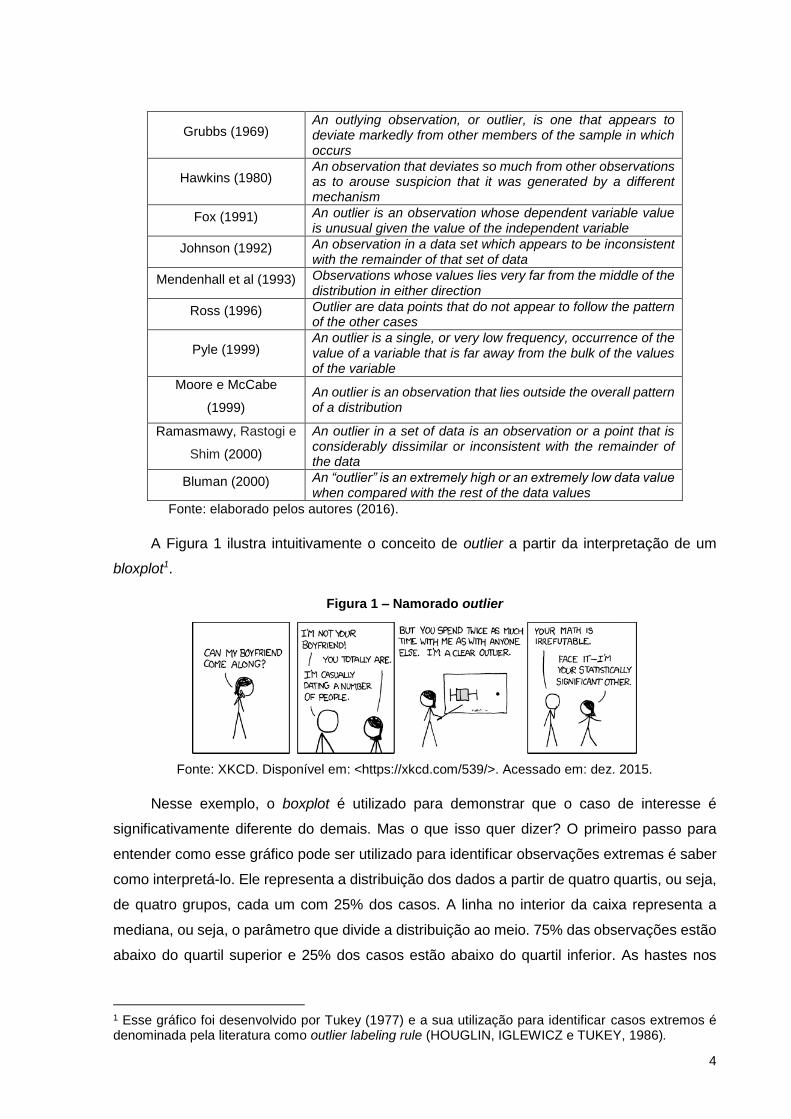
A Figura 1 ilustra intuitivamente o conceito de outlier a partir da interpretação de um
bloxplot1.
Figura 1 – Namorado outlier
Fonte: XKCD. Disponível em: <https://xkcd.com/539/>. Acessado em: dez. 2015.
Nesse exemplo, o boxplot é utilizado para demonstrar que o caso de interesse é
significativamente diferente do demais. Mas o que isso quer dizer? O primeiro passo para
entender como esse gráfico pode ser utilizado para identificar observações extremas é saber
como interpretá-lo. Ele representa a distribuição dos dados a partir de quatro quartis, ou seja,
de quatro grupos, cada um com 25% dos casos. A linha no interior da caixa representa a
mediana, ou seja, o parâmetro que divide a distribuição ao meio. 75% das observações estão
abaixo do quartil superior e 25% dos casos estão abaixo do quartil inferior. As hastes nos
1 Esse gráfico foi desenvolvido por Tukey (1977) e a sua utilização para identificar casos extremos é denominada pela literatura como outlier labeling rule (HOUGLIN, IGLEWICZ e TUKEY, 1986).

5
extremos indicam os valores mínimo e máximo e valores localizados fora desses limites são
considerados potenciais casos extremos. Quanto maior a distância entre o caso e as hastes,
mais atípica é a observação em relação ao restante da amostra.
A literatura diferencia outliers univariados e multivariados (FOX, 1991; BARNETT e
LEWIS, 1994). Os univariados são casos destoantes em uma única variável enquanto os
multivariados representam combinações incomuns em um conjunto de variáveis. Por
exemplo, para Walfish (2006), o caso extremo univariado é aquela observação muito
destoante da média da distribuição e dos demais casos da amostra. Por outro lado, o outlier
em uma regressão é aquele que tem um valor muito atípico em Y, condicionado ao seu valor
em X. Tecnicamente, um caso extremo tem uma probabilidade muito pequena de ter sido
produzido pela mesma distribuição estatística responsável pela geração das demais
observações (HAWKINS, 1980; WALFISH, 2006). Portanto, é importante compreender a
origem de casos atípicos. Chandola, Banerjee e Kumar (2007) identificam quatro principais
hipóteses para explicar o surgimento de observações destoantes: (1) atividade maliciosa; (2)
erro de instrumento; (3) mudança abrupta no meio ambiente e (4) erro humano.
A atividade maliciosa diz respeito às ações ilegais que produzem padrões diferentes do
esperado. O exemplo típico de atividade maliciosa é quando a operadora de crédito entra em
contato com o titular do cartão para verificar a veracidade de uma determinada compra. Por
exemplo, imagine que um dia você resolve comprar uma Mitsubishi Pajero Rally Dakar2. Ao
chegar na concessionária o atendente indaga sobre a forma de pagamento e você responde:
“débito”. É natural receber uma ligação do banco com o objetivo de verificar a legalidade da
transação, já que o valor observado é bastante atípico em relação à média de gasto do cartão
de crédito3.
O erro de instrumento é mais comum nas Ciências Naturais, já que a mensuração dos
fenômenos de interesse geralmente depende de dispositivos específicos. Por exemplo, um
físico interessado em mensurar o nível de radiação pode utilizar o contador de Geiger-Muller4.
Um químico interessado em mensurar a temperatura de evaporação da água pode utilizar um
termômetro. Em qualquer caso, no entanto, se o instrumento não for adequado, corre-se o
risco de produzir medidas não confiáveis e inválidas5 (BLALOCK, 1979; ZELLER e
CARMINES, 1980; WALFISH, 2006).
2 Valor estimado em R$ 208.990,00. Ver: < http://mitsubishimotors.com.br/wps/portal/mit/areas/veiculos/familiapajero/pajerofull> 3 Agradecemos a Geovanes Neves pelo exemplo. 4 Ver <http://www.tecnologiaradiologica.com/materia_deteccao.htm> e http://www.analyticsvidhya.com/blog/2016/01/guide-data-exploration/ 5 A validade diz respeito ao nível de correspondência entre o conceito de interesse e o que foi de fato mensurado. A confiabilidade refere-se à consistência da mensuração. Uma balança bem calibrada é um instrumento válido e confiável para mensurar a massa de um determinado objeto. No entanto, se toda vez que a mensuração for realizada o instrumento informar pesos diferentes, tem-se um instrumento não confiável.

6
A depender do problema, o instrumento pode produzir mensurações muito discrepantes
do que seria observado na presença de um dispositivo bem calibrado. É por esse motivo, por
exemplo, que você não deve comer uma feijoada antes de realizar um exame clínico para
avaliar o nível de triglicerídeos. Nas Ciências Sociais, um exemplo de instrumento é o
questionário. Se o questionário estiver mal formulado, as informações coletadas não serão
válidas para mensurar o fenômeno de interesse. Os resultados serão inconsistentes e, em
alguns casos, totalmente equivocados. Por exemplo, imagine um questionário que questiona
o peso dos entrevistados utilizando o sistema de quilogramas para respondentes norte-
americanos, acostumados com o peso em libras. As medidas reportadas apresentarão erros
de mensuração, o que por sua vez compromete a validade e a confiabilidade dos resultados
observados.
O outlier gerado por mudança abrupta no meio ambiente é típico de desastres naturais.
Uma chuva muito intensa e a cheia de um rio, por um lado, e a estiagem prolongada e a
consequente falta de água, por outro, representam exemplos de variações biológicas que
podem afetar a consistência das estimativas. Por exemplo, imagine um estudo sobre
segurança pública que mensura a quantidade de homicídios por dia. O padrão esperado é
que mais mortes ocorram durante os fins de semana. No entanto, a elevação abrupta do índice
pluviométrico tende a reduzir o número de mortes. Ao fim, tais variações podem afetar a
consistência das estimativas.
A última causa para explicar a presença de casos extremos é o erro humano (BELSLEY,
KUH e WELSCH, 1980). Esse problema é particularmente relevante para as Ciências Sociais,
já que a maior parte dos pesquisadores ainda coleta e codifica dados manualmente
(HOPKINS e KING, 2010). A coleta manual é mais lenta, onerosa e menos confiável do que
os procedimentos automatizados de extração de informações. Para Stevens (1984: 335),
“influential cases can occur because of recording errors (…) there are many possible sources
of error from the initial data collection to the final keypunching”. Um simples problema de
importação ou pontuação pode introduzir casos extremos na amostra, que, por sua vez,
podem ter consequências catastróficas sobre as inferências. Um exemplo conhecido de como
erros na manipulação de planilhas podem comprometer a consistência das inferências pode
ser encontrado em Reinhart e Rogoff (2010)6.
Depois de definir o conceito e indicar o seu processo de geração, o próximo passo é
identificar quais são os problemas produzidos por casos extremos. Fox (1991) argumenta que
outliers são problemáticos porque alteram os resultados observados e porque a sua presença
pode ser um sinal de que o modelo está falhando em identificar características importantes
da distribuição analisada. Osborne e Overbay (2004) argumentam que a presença de
6 Ver: <https://en.wikipedia.org/wiki/Growth_in_a_Time_of_Debt>. Acesso em março de 2016.

7
observações atípicas aumenta a variância e reduz o poder dos testes estatísticos. Além disso,
outliers podem violar a normalidade das distribuições, o que afeta a chance de cometer erros
do tipo 1 e do tipo 2, além da possibilidade de inversão do sinal e alteração da magnitude dos
coeficientes7.
Para ilustrar o impacto de casos atípicos sobre a consistência das estimativas, a
Tabela 1 sumariza a estatística descritiva do Índice de Desenvolvimento Humano (IDH) por
unidade da federação em 2010.
Tabela 1 – IDH por UF
Fonte: elaboração dos autores (2016) com base nos dados do Atlas Brasil
Enquanto a média do IDH com o Distrito Federal (DF) é de 0,704, sem ele é de 02,699.
Ao fim, a presença do DF garante que o Brasil se enquadre na categoria de Alto
Desenvolvimento Humano (0,7-0,8) ao invés de Médio Desenvolvimento Humano (0,55-0,7).
Ou seja, a presença de um único caso destoante muda a classificação do país no ranking.
Similarmente, a presença de casos extremos pode gerar problemas no sinal e na magnitude
das estimativas. Para ilustrar esse problema, a Figura 2 ilustra o efeito de observações
atípicas em uma análise de correlação bivariada.
Figura 2 – Comparação de correlações
7 O erro do tipo 1 é a rejeição incorreta da hipótese nula, ou seja, tem-se um resultado falso positivo. O erro do tipo 2 é incapacidade de rejeitar uma hipótese nula falsa, ou seja, tem-se um resultado falso negativo. Como os testes de significância são utilizados para julgar a plausibilidade da hipótese nula, as observações atípicas podem gerar um efeito de confusão e produzir inferências equivocadas.
N Média Mediana Desvio padrão
CV
Com DF 27 0,704 0,699 0,049 0,069
Sem DF 26 0,699 0,694 0,043 0,061
(com outlier)
r = 0,481
p-valor = 0,010 n = 28
(sem outlier)
r = 0
p-valor = 1,000 n = 27
Fonte: elaboração dos autores (2016) com base nos dados do Atlas Brasil

8
As variáveis têm média zero e desvio padrão igual a 1 e foram simuladas de forma
ortogonal (correlação = 0). Com a inclusão de um único caso destoante (5,-5), a correlação
passa a ser moderada (r = 0,481) e significativa (p-valor<0,05). O coeficiente de determinação
(R2) passa para 0,231, ou seja, a variação na variável independente explica 23,10% da
variação da variável dependente. Aqui o pesquisador seria levado a cometer o erro do tipo 1:
rejeitar a hipótese nula quando ela não deveria ser rejeitada.
Outro problema gerado por casos atípicos é a dificuldade de visualização gráfica. A
Figura 3 ilustra um exemplo.
Figura 3 – Dificuldade de visualização da relação de interesse
(com oulier)
n = 666
r = 0,125 r2 = 0,012
p-valor<0,01
(sem outlier)
n = 666
r = 0,666 r2 = 0,444
p-valor<0,01
Fonte: elaboração dos autores (2016) com base nos dados do Atlas Brasil
Em virtude da magnitude do caso atípico em relação aos demais, não é possível
visualizar a relação de interesse. A correlação positiva de 0,666 passa para 0,125. A relação
continua significativa, mas o pesquisador chegaria a uma conclusão bastante diferente a
respeito do nível de associação entre as variáveis. Em resumo, esses exemplos ilustram como
a presença de casos extremos pode afetar a consistência das estimativas e produzir
inferências equivocadas sobre os fenômenos observados.
COMO DETECTAR OUTLIERS?
Depois de definir o conceito, discutir as suas origens e efeitos, o próximo passo é
apresentar os procedimentos de detecção de observações atípicas. Cateni, Colla e Vannuci
(2008) indicam diferentes métodos de identificação que incluem testes informais, análise
gráfica, teste de hipótese, medidas de distância, análise de cluster, inteligência artificial (redes
neurais, fuzzy inference system, support vector machine), entre outros. Os testes formais
comparam a distribuição observada com uma teoricamente esperada e utilizam teste de
hipótese para classificar uma observação como atípica (BARNETT e LEWIS, 1994; SEO,

9
2002). Por sua vez, os testes informais utilizam uma perspectiva indutiva a partir da análise
das características dos dados. Neste artigo, ilustraremos cinco diferentes procedimentos para
a identificação de outliers: (1) escores padronizados; (2) diferença interquartílica; (3) resíduos
padronizados; (4) distância de Mahalanobis e (5) distância de Cook.
1. Escores padronizados
Além de examinar as medidas de formato (curtose e assimetria) e variabilidade
(variância, desvio padrão, etc.), uma forma simples de identificar casos que se distanciam
excessivamente da média é analisar a distribuição padronizada da variável. Para tanto, deve-
se subtrair o valor de cada observação da média aritmética e dividir o resultado pelo desvio
padrão (Z = (xi – µ)/σ). A nova distribuição tem média zero e desvio padrão igual a um. Quanto
maior o escore Z, em módulo, maior é a distância entre uma determinada observação e a
média, mensurada em unidades de desvio padrão. A literatura indica que escores
padronizados superiores a 3 e inferiores a -3 podem ser classificados como atípicos
(ATIKSON E MULIRA, 1993; BARNETT e LEWIS, 1994; WALFISH, 2006). Isso porque, em
uma distribuição normal, cerca de 68%, 95% e 99% dos casos estão a um, dois e três desvios
padrão acima e abaixo da média, respectivamente. A Figura 4 ilustra essa propriedade.
Figura 4 – Distribuição normal
Fonte: <http://www.syque.com/quality_tools/tools/Tools63.htm>
Por exemplo, assumindo normalidade, é muito improvável observar um caso com escore
Z = 4. Isso porque menos de 1% das observações apresentariam um valor tão extremo: quatro
desvios padrão acima da média. Para os propósitos deste artigo, iremos ilustrar o passo a
passo desse método de identificação. A Figura 5 ilustra a estatística descritiva da taxa de
homicídios em 2010 no Brasil, tendo os estados como unidade de análise8.
8 Os dados originais estão disponíveis em: <http://www.mapadaviolencia.org.br/>

10
Figura 5 – Estatística descritiva (Taxa de homicídios, 2010)
Fonte: elaborado pelos autores (2016) com base em Waiselfisz (2015)
A linha contínua representa a média (21,68) e a linha pontilhada o desvio padrão
(11,24). Assumindo que não existe erro de mensuração e que os métodos de coleta são
iguais, observa-se que Alagoas (55,3), Espírito Santo (39,4) e Pará (34,6) são os estados
mais violentos, enquanto Santa Catarina (8,5), Piauí (8) e Roraima (7,1) os menos. O primeiro
passo para padronizar a distribuição, é subtrair o valor de cada caso da média (21,68) e dividir
o resultado pelo desvio padrão (11,24). Por exemplo, para a Paraíba que tem uma taxa de
32,8, o cálculo seria o seguinte: (32,8-21,68)/11,24, o que produz um escore Z de 1,13.
Interpretação: essa observação está a 1,13 desvio padrão acima da média. Tecnicamente,
uma forma intuitiva de observar casos destoantes é examinar graficamente a distribuição da
variável padronizada. A Figura 6 ilustra esse procedimento a partir de dois tipos de gráficos:
a) barra e b) boxplot.
Figura 6 – Taxa de homicídio padronizada9
Barra (descendente)
Boxplot
Fonte: elaborado pelos autores (2016) com base em Waiselfisz (2015)
No gráfico de barra, as linhas pontilhadas representam os limites de 3 e -3 desvio padrão
que é comumente utilizado para caracterizar potenciais outliers (WALFISH, 2006). Alagoas
apresentou um escore padronizado de 2,99, ou seja, está a aproximadamente três desvio
9 Os valores originais e padronizados para todos os casos estão listados nos anexos.

11
padrão acima da média. Ao se considerar o boxplot, novamente as linhas pontilhadas
representam os parâmetros para julgar em que medida uma determinada observação é
excessivamente diferente das demais. Todos os casos que ultrapassam os limites podem ser
considerados atípicos.
2. Diferença interquartílica
Assim como a técnica dos escores padronizados, o segundo método de identificação de
casos destoantes também é adequado para ouliers univariados e deve ser utilizado em
distribuições aproximadamente normais. A regra original é a seguinte:
DI = ((Q1-g(Q3-Q1), Q3+ g(Q3-Q1))
Q1 e Q3 representam os valores do primeiro e do terceiro quartis, respectivamente,
enquanto os valores de “g” são 1,5 para casos atípicos, 2,2 para observações mais extremas
e 3 para outliers de “tirar o sono”. Esse método é comumente denominado de outlier labeling
rule ou Inter-Quartile Range (IQR). Para ilustrar essa aplicação, simulamos uma distribuição
normal com média zero e desvio padrão igual a um, para uma amostra de 1.000 observações.
A Figura 7 ilustra esses dados.
Figura 7 – Distribuição normal (0,1)
Fonte: elaborado pelos autores (2016)
A linha vermelha representa o primeiro quartil (-0,562) e a preta representa o terceiro
(0,721). Esses parâmetros serão utilizados para calcular os limites mínimo e máximo para a
identificação de casos extremos. Originalmente, Tukey (1977) sugeriu a utilização de g igual
1,5. Aplicando a fórmula tem-se o limite inferior de -2,5 e o superior de 2,6. Por esse critério,
a amostra teria sete casos acima do limite superior e 12 observações extremas abaixo do
limite inferior. Posteriormente, Hoaglin, Iglewicz e Tukey (1986) atualizaram o valor de g para
2,2 para garantir resultados mais robustos, já que o limite de 1,5 tende a sobreestimar a
quantidade de casos verdadeiramente atípicos. Com o novo parâmetro, tem-se um outlier

12
acima do limite superior (3,5) e outro abaixo do limite inferior (-3,4). A Tabela 2 resume a
diferença interquartílica para dois níveis de g: 1,5 e 2,2.
Tabela 2 – Diferença interquartílica
Q1 Q3 G Inferior Superior
-0,562 0,721
1,5 -2,5 2,6
2,2 -3,4 3,5
Fonte: elaborado pelos autores (2016)
Para fixar a compreensão desse procedimento, replicamos os dados do Departamento
de Educação da Califórnia (API 2000 dataset)10. A Figura 8 ilustra o histograma do número de
estudantes.
Figura 8 – Número de estudantes
Fonte: elaborado pelos autores com (2016) com base no API 2000 dataset
Novamente a linha vermelha representa o primeiro quartil (320) e a preta o terceiro
(610). Aplicando o cálculo da diferença interquartílica tem-se os seguintes limites:
Tabela 3 – Diferença interquartílica
Q1 Q3 G Inferior Superior
320 610
1,5 -115 1.045
2,2 -318 1.248
Fonte: elaborado pelos autores com (2016) com base no API 2000 dataset
Por esse critério, não existe nenhum outlier abaixo do limite inferior. Em relação ao limite
superior, esse método de identificação detectou oito casos extremos quando g é igual a 1,5 e
quatro observações atípicas quando g é igual a 2,2. No entanto, antes de tirar conclusões
substantivas, deve-se observar em que medida a variável de interesse é normal já que a
diferença interquartílica assume esse pressuposto. A Figura 9 ilustra os testes de
normalidade.
10 Ver <http://www.ats.ucla.edu/stat/stata/webbooks/reg/chapter1/statareg1.htm>

13
Figura 9 – Diagnóstico de normalidade
Fonte: elaborado pelos autores com (2016) com base no API 2000 dataset
O Q-Q plot compara a distribuição observada com uma teoricamente esperada,
assumindo normalidade. Quanto maior a aderência dos pontos a linha diagonal, maior a
distribuição se aproxima da normalidade. Como pode ser observado, no entanto, a variável
não é normal (Kolmogorov-Smirnov Z = 1,941; p-valor = 0,001). Tem-se então um problema.
Isso porque para definir uma observação como destoante deve-se assumir uma distribuição
teoricamente esperada (DAVIES e GATHER, 1993). Tecnicamente, uma opção é transformar
a variável original. Dentre as diferentes transformações, optamos pelo logaritmo natural já que
é aquela que apresenta o melhor ajuste. A Figura 10 ilustra a nova distribuição.
Figura 10 – Histograma da variável transformada
Fonte: elaborado pelos autores com (2016) com base no API 2000 dataset
Como esperado, a variável transformada é normal (p-valor = 0,623). Ao aplicar o cálculo
da diferença interquartílica, observa-se que nenhum caso pode ser considerado como outlier.
Dessa forma, se o interesse do pesquisador for puramente descritivo, ele deve focalizar na
variável original. No entanto, se o objetivo for utilizar a variável como dependente ou
independente em algum modelo de regressão, recomendamos a versão transformada já que
esse procedimento reduz o impacto de casos extremos.

14
3. Resíduos padronizados
Diferente do escore padronizado e da diferença interquartílica, a técnica dos resíduos
padronizados é ideal para detectar outliers multivariados em modelos de regressão
(BELSLEY, KUH e WELSCH, 1980; FOX, 1991). Os resíduos (εi) representam a diferença
entre os valores observados da variável dependente (yi) e os valores preditos pelo modelo
(�̂�𝑖). Através da análise de resíduo é possível detectar problemas de heterocedasticidade,
autocorrelação, ausência de lineariedade, entre outros. Na verdade, a utilização dos resíduos
da regressão como ferramenta de diagnóstico é um dos procedimentos mais usualmente
empregados pelos analistas de dados. Isso porque o modelo de mínimos quadrados
ordinários apresenta diferentes pressupostos que devem ser satisfeitos para que as
estimativas produzidas sejam representativas dos parâmetros populacionais. Em particular,
no que diz respeito ao termo de erro, assume-se que ele tem média zero, variância constante,
é independente e normalmente distribuído.
A partir de agora é importante apresentar a diferença entre os conceitos de outlier,
leverage e influence. Em regressão, um outlier representa um caso com grande resíduo, ou
seja, forte diferença entre o valor predito pelo modelo e o valor observado11. A noção de
leverage refere-se a observações extremas na variável independente. Essa medida informa a
distância de uma determinada observação para a sua média e pode produzir uma
alavancagem danosa ao modelo. Por exemplo, a presença de casos extremos na variável
independente pode sobrestimar ou subestimar o valor do parâmetro populacional. Por fim, a
influence é uma medida síntese que informa a variação observada nos coeficientes na
presença e na ausência de uma determinada observação atípica. Quanto maior a variação
dos coeficientes, maior é o nível de influence do caso específico. A Figura 11 demonstra essas
ideias.
Figura 11 – Outlier, leverage e influence
Fonte: elaborado pelos autores (2016)
11 A presença desses casos não gera necessariamente viés, já que outros elementos podem minimizar o seu efeito, a exemplo do tamanho da amostra.

15
O outlier na variável dependente ocorre quando o seu valor é muito próximo da média
de x, mas muito diferente do esperado para y (longe da reta de regressão). Como o método
de mínimos quadrados ordinários utiliza o quadrado dos resíduos, essas observações têm o
potencial de alterar a consistência das estimativas. Na presença da alavancagem inofensiva,
a correlação entre x e y é apenas marginalmente alterada. Isso quer dizer que uma
observação atípica que esteja próxima da reta de regressão não afeta a consistência dos
resultados. Por fim, na presença de pontos extremos na variável independente e distantes da
tendência da reta de regressão, tem-se uma variação significativa nos coeficientes estimados,
o que caracteriza uma alavancagem danosa. Ou seja, quanto maior a distância entre uma
determinada observação e a média da variável independente, maior o potencial de influência
sobre a consistência dos resultados (FOX, 1991).
Para ilustrar a utilização dos resíduos padronizados para detectar casos atípicos,
replicaremos os dados de Agresti e Finlay (1997) sobre criminalidade nos Estados Unidos12.
A base de dados original conta com 51 observações e possui as seguintes informações:
estado (state), taxa de crime (crime), taxa de homicídios (murder), pessoas vivendo em áreas
metropolitanas (pct metropolitan), proporção de brancos (pct whites), proporção de pessoas
com curso superior (pct graduates), pobreza (pct poverty) e proporção de pais solteiros (pct
single parent).
O objetivo é estimar um modelo de regressão linear de mínimos quadrados ordinários
para explicar a variação da taxa de homicídio (y) a partir da proporção de pessoas vivendo
em áreas urbanas (x1), da proporção de pessoas pobres (x2) e da proporção de pais solteiros
(x3). A Figura 12 ilustra a dispersão da taxa de homicídio a partir das três variáveis
independentes selecionadas com e sem o caso desviante.
Figura 12 – Correlações bivariadas
Com caso extremo Y vs X1 Y vs X2 Y vs X3
r = 0,316
p-valor = 0,024 N = 51
r = 0,566
p-valor <0,001 N = 51
r = 0,859
p-valor<0,001 N = 51
12 Ver: <http://www.ats.ucla.edu/stat/stata/webbooks/reg/crime>.

16
Sem caso extremo
Y vs X1 Y vs X2 Y vs X3
r = 0,331
p-valor = 0,019 N = 50
r = 0,629
p-valor < 0,001 N = 50
r = 0,728
p-valor < 0,001 N = 50
Fonte: elaborado pelos autores (2016) com base nos dados de Agresti e Finlay (1997)
A análise gráfica sugere que a observação dc apresenta um comportamento bastante
diferente das demais. Um primeiro procedimento é comparar o coeficiente de correlação com
e sem esse caso, assim como foi apresentado na Figura 2. Além disso, é possível estimar o
modelo e observar o que acontece com os coeficientes quando o caso extremo é excluído da
análise, conforme mostra a Tabela 5.
Tabela 5 – Modelo dos mínimos quadrados ordinários
Parâmetros Com caso extremo
Sem caso extremo
Constante -43,24*** (-9,98)
-17,06*** (-7,43)
Proporção de pessoas vivendo em áreas
metropolitanas
0,067 (1,83)
0,061*** (4,31)
Proporção de pessoas pobres
0,410* (2,02)
0,444*** (5,69)
Proporção de pais solteiros 3,672*** (8,08)
1,271*** (5,60)
R2 0,76 0,75
N 51 50
* p<0,05, ** p<0,01, *** p<0,001
Fonte: elaborado pelos autores (2016) com base nos dados de Agresti e Finlay (1997)
Observa-se que a constante varia bastante entre os dois modelos. Ainda, a variável
proporção de pessoas vivendo em áreas metropolitanas não é significativa no modelo com
todos os casos. Por fim, com a presença do caso extremo, o coeficiente da variável proporção
de pais solteiros aumentou significativamente. A Figura 13 ilustra a variação do resíduo
padronizado por estado.

17
Figura 13 – Resíduos por estado
Fonte: elaborado pelos autores (2016) com base nos dados de Agresti e Finlay (1997)
A literatura adverte que resíduos modulares maiores do que dois são preocupantes e
os maiores do que três podem ser considerados casos extremos (ATKINSON, 1994; SEO,
2002; WEBER, 2010). Em nosso exemplo, iremos examinar o caso do Distrito de Colúmbia
(id = 51), que apresenta resíduo padronizado de 4,318, ou seja, quatro desvios padrão acima
da média. Essa distância pode prejudicar a consistência das estimativas e, por esse motivo,
deve-se ter cuidado com a estimação dos próximos modelos. A Figura 14 ilustra a variação
da estatística Leverage por estado.
Figura 14 – Leverage por estado
Fonte: elaborado pelos autores (2016) com base nos dados de Agresti e Finlay (1997)
Os leverage values também são conhecidos como hat values. A média do leverage é
definida como (k+1)/n, em que k representa o número de variáveis independentes e n
representa o tamanho da amostra. Os valores variam entre zero (quando o caso não
apresenta nenhuma influência) até 1 (quando a observação distorce fortemente a capacidade
preditiva do modelo). Hoaglin e Welsch (1978) indicam que casos acima de (2(k+1)/n) devem

18
ser observados com mais cautela e Stevens (1984) sugere três vezes acima da média
(3(k+1)/n) como patamar para identificar casos com uma influência desproporcional.
Novamente os resultados indicam que o distrito de Colúmbia é um caso estranho. Ele
apresentou grande resíduo e agora demonstra forte influência (lev = 0,517). Em conjunto,
esses elementos sugerem que a inclusão desse caso pode afetar a consistência das
estimativas.
Por fim, é possível observar a relação entre grandes resíduos e forte alavancagem.
Observações com ambas as características são consideradas pontos de influência e podem
ter efeitos devastadores sobre a consistência das estimativas. A Figura 15 ilustra essa ideia.
Figura 15 – Resíduos, Leverage, valores previstos e razão de covariância
(A)
Resíduos x Leverage
(B)
Valores previstos x resíduos
(C)
Resíduos x razão de covariância
Fonte: elaborado pelos autores (2016) com base nos dados de Agresti e Finlay (1997)
Quanto maior o leverage, pior. Quanto maior o resíduo, pior. Em conjunto, observações
com altos resíduos e forte alavancagem afetam a consistência dos coeficientes estimados
(gráfico A). Os resíduos também podem ser examinados em função dos valores previstos pelo
modelo (gráfico b). O ideal seria observar uma distribuição aleatória com a maior parte dos
casos perto do zero. Como pode ser observado, no entanto, tem-se uma observação bastante
destoante das demais (dc). Por fim, podemos observar a relação entre os resíduos e a razão
de covariância13. Quanto menor essa razão, mais atípica é a observação e maior é a variação
esperada nos coeficientes de regressão.
4. Distância de Mahalanobis14
O quarto procedimento para detectar observações atípicas é a distância de
Mahalanobis. Essa medida foi introduzida em 1936 por Prasanta Chandra Mahalanobis no
13 Essa estatística é calculada a partir do determinante da matriz de covariância quando um determinado caso é excluído da análise. Quanto mais perto de 1, menor é o efeito de um caso específico. 14 Existem outras medidas de distância como a Euclidiana, a Euclidiana generalizada, a distância de Minskowski, a distância de Hellinger, entre outras. Se a matriz de covariância é uma matriz identidade, distância de Mahalanobis é igual à distância Euclidiana. Caso a matriz de covariância seja diagonal, a ela se iguala à distância Euclidiana normalizada.

19
artigo “On the generalised distance in statistics” e é uma das estatísticas mais utilizadas para
mensurar casos extremos em distribuições multivariadas. Ela informa a distância entre o caso
e o centroide das variáveis independentes. Em outras palavras, como o centroide representa
a média das médias em um espaço multidimensional, a distância de Mahalanobis mensura a
similaridade entre uma determinada observação e a média de várias distribuições. De acordo
com Islam (2003: 2), “Mahalanobis distances provide a powerful method of measuring how
similar some set of conditions is to an ideal set of conditions, and can be very useful for
identifying which regions in a landscape are most similar to some “ideal” landscape”.15. A
Figura 16 ilustra a lógica subjacente a essa medida.
Figura 16 – Representação gráfica da distância de Mahalanobis
Fonte: <http://www.jennessent.com/arcview/mahal_poster.htm>.
Em termos práticos, essa medida é amplamente utilizada em análise de conglomerados
para classificar observações a partir do nível de similaridade entre os casos. Diferente da
distância euclidiana, a de Mahalanobis também considera a correlação entre as variáveis, o
que elimina eventuais problemas de escala. Quanto maior a distância, maior é a diferença
entre um determinado caso e o centro do cluster. Logo, menos provável é o seu pertencimento
a um grupo ou distribuição. Para os propósitos deste artigo, apresentaremos dois exemplos
sobre como aplicar essa técnica para identificar casos extremos. O primeiro refere-se à
utilização de um modelo de regressão robusta (robust regression) para os dados de Agresti e
Finlay (1997). O segundo diz respeito a detecção de escolas outliers a partir dos dados do
INEP (ANO).
15 Algebricamente, essa medida pode ser representada da seguinte maneira:
𝐷2 = (𝑥 − 𝑚)𝑇𝐶−1(𝑥 − 𝑚)
Onde x representa o vetor de uma determinada variável, m a matriz com a média de todas as variáveis, C-1 a matriz de covariância inversa entre x e m. O termo T indica que a matriz diferença (x - m) é transposta.

20
5. Distância de Cook16
Por fim, a última técnica para identificar casos atípicos é a distância de Cook. Ela é uma
medida da variação esperada dos coeficientes de regressão na ausência dos casos extremos.
Ou seja, ela informa o que aconteceria com as estimativas do modelo se a observação atípica
fosse excluída da análise (STEVENS, 1984). A distância de Cook é sensível a casos
destoantes na variável dependente e no conjunto de variáveis explicativas e identifica quais
são os outliers que podem perturbar o seu sono. Cook e Weisberg (1982) indicam que valores
acima de 1 devem ser observados com cautela. Esquematicamente, a literatura indica
diferentes critérios para classificar um caso como desviante:
a) Cook>1 (STEVENS, 1984);
b) Cook> 4/n, em que n = número de casos.
c) Cook > 4/(n-k-1), em que n = número de casos e k = número de variáveis17
d) Examinar o valor dos casos via análise gráfica
CONCLUSÃO
A presença de observações destoantes é um dos fenômenos mais antigos da
Estatística e afeta todas as áreas do conhecimento científico que utilizam análise de dados
para testar hipóteses teoricamente orientadas. Isso porque estimativas como média, desvio
padrão, correlação e coeficientes de regressão geralmente são afetadas pela presença de
casos atípicos. No entanto, é raro encontrar artigos que reportam a checagem de casos
extremo na Ciência Política brasileira.
Este trabalho apresentou um guia prático sobre como identificar outliers. Adotamos uma
perspectiva intuitiva para apresentar cinco diferentes técnicas: (1) escores padronizados; (2)
diferença interquartílica; (3) resíduos padronizados; (4) distância de Mahalanobis e (5)
distância de Cook. Apesar do nosso público alvo ser estudantes de graduação e pós-
graduação em Ciência Política, este artigo pode ser útil para analistas de dados em diferentes
disciplinas.
Depois de identificados, como lidar com casos extremos? Sugerimos três abordagens.
Em primeiro lugar, deve-se checar a base de dados já que uma das fontes de casos atípicos
16 Ver: <http://www.ats.ucla.edu/stat/spss/examples/ara/foxch11.html>. Existem outras medidas semelhantes. Por exemplo, o valor predito ajustado (predicted adjusted value) informa o valor esperado da variável dependente para uma determinada observação se ela fosse excluída da análise. Quanto maior a distância entre o valor esperado e o valor esperado ajustado, maior é a influência do caso em particular. A diferença entre o valor esperado e o valor esperado ajustado é chamado de DFFIT. No entanto, essa medida não informa a mudança observada na capacidade geral do modelo. 17 Ver: <http://www.utexas.edu/courses/schwab/sw388r7/Tutorials/IllustrationofRegressionAnalysis_doc_html/052_Identifying_Influential_Cases___Cook_s_Distance.html>.

21
é o erro de mensuração das variáveis. Uma vez detectado o erro, deve-se recodificar o caso
ou excluí-lo.
A segunda opção é verificar o que acontece com as estimativas ao se excluir o caso.
Se os resultados não mudam substantivamente, o pesquisador pode excluir e informar o
critério de supressão. Contudo, muitas vezes a presença/exclusão do caso destoante afeta
fortemente a consistência das estimativas. Nesse cenário, a exclusão não é adequada. Um
procedimento viável é a utilização de técnicas de acomodação como a imputação do valor da
média ou o segundo valor mais extremo. Além disso, é possível transformar a escala dos
dados (logaritmo, raiz quadrada, inversa, etc.) ou aumentar a quantidade de observações com
o objetivo de reduzir a influência dos casos extremos. Independentemente do procedimento
escolhido é importante reportar exatamente o que foi feito para garantir a transparência e
replicabilidade dos resultados.
Por fim, nossa terceira e mais importante sugestão é realizar um estudo de caso
aprofundado da observação destoante. Como outliers representam situações incomuns,
identificar as variáveis explicativas pode ajudar a compreender melhor os fenômenos de
interesse. Defendemos que os pesquisadores devem checar seus dados em busca de
observações desviantes antes de interpretarem substantivamente os resultados. Caso
contrário, corre-se o risco de transformar o trabalho dos sonhos em seu terrível pesadelo.
REFERÊNCIAS
AGRESTI, A.; FINLAY, B. Statistical Methods for Social Sciences. 3ª Edição. 1997.
ATKINSON, A. C. Fast very robust methods for the detection of multiple outliers. Journal of the American Statistical Association, v. 89, n. 428, p. 1329-1339, 1994.
ATKINSON, A. C.; MULIRA, H.-M. The stalactite plot for the detection of multivariate outliers. Statistics and Computing, v. 3, n. 1, p. 27-35, 1993.
BAMNETT, V.; LEWIS, T. Outliers in statistical data. 1994.
BELSLEY, David A.; KUH, Edwin; WELSCH, Roy E. Detecting and assessing collinearity. Regression diagnostics: Identifying influential data and sources of collinearity, p. 85-191, 1980.
BLUMAN, Allan. Elementary Statistics, brief version, New York: McGraw-Hill, 2000.
BRAMBOR, Thomas; CLARK, William Roberts; GOLDER, Matt. Understanding interaction models: Improving empirical analyses. Political analysis, v. 14, n. 1, p. 63-82, 2006.
CHANDOLA, Varun; BANERJEE, Arindam; KUMAR, Vipin. Outlier detection: A survey. ACM Computing Surveys, 2007.
COOK, R. Dennis; WEISBERG, Sanford. Residuals and influence in regression. 1982.
DAVIES, Laurie; GATHER, Ursula. The identification of multiple outliers. Journal of the American Statistical Association, v. 88, n. 423, p. 782-792, 1993.
FOX, John. Regression diagnostics: An introduction. Sage, 1991.

22
GRUBBS, Frank E. Procedures for detecting outlying observations in samples. Technometrics, v. 11, n. 1, p. 1-21, 1969.
MOORE, David S.; MCCABE, George P. Introduction to the Practice of Statistics. WH Freeman/Times Books/Henry Holt & Co, 1989.
HAWKINS, Douglas M. Identification of outliers. London: Chapman and Hall, 1980.
HOAGLIN, David C.; IGLEWICZ, Boris; TUKEY, John W. Performance of some resistant rules for outlier labeling. Journal of the American Statistical Association, v. 81, n. 396, p. 991-999, 1986.
ISLAM, Saiful. Mahanalobis Distance, 2003. Disponível em: <http://www.jennessent.com/arcview/mahalanobis_description.htm>.
HODGE, Victoria J.; AUSTIN, Jim. A survey of outlier detection methodologies. Artificial Intelligence Review, v. 22, n. 2, p. 85-126, 2004.
HOPKINS, Daniel J.; KING, Gary. A method of automated nonparametric content analysis for social science. American Journal of Political Science, v. 54, n. 1, p. 229-247, 2010.
IGLEWICZ, Boris; BANERJEE, Sharmila. A simple univariate outlier identification procedure. In: Proceedings of the Annual Meeting of the American Statistical Association. 2001.
OSBORNE, Jason W.; OVERBAY, Amy. The power of outliers (and why researchers should always check for them). Practical assessment, research & evaluation, v. 9, n. 6, p. 1-12, 2004.
PYLE, Dorian. Data preparation for data mining. Morgan Kaufmann, 1999.
RAMASWAMY, Sridhar; RASTOGI, Rajeev; SHIM, Kyuseok. Efficient algorithms for mining outliers from large data sets. In: ACM SIGMOD Record. ACM, 2000. p. 427-438.
REINHART, Carmen M.; ROGOFF, Kenneth S. Growth in a time of debt (digest summary). American Economic Review, v. 100, n. 2, p. 573-578, 2010.
SEO, S. A review and comparison of methods for detecting outliers in univariate data sets (master’s thesis). 2002.
STEVENS, James P. Outliers and influential data points in regression analysis. Psychological Bulletin, v. 95, n. 2, p. 334, 1984.
TUKEY, John W. Exploratory data analysis. 1977.
VERARDI, Vincenzo; CROUX, Christophe. Robust regression in Stata. The Stata Journal 9 (3): 439-453. 2009.
WAISELFISZ, Julio Jacobo. Mapa da violência: mortes matadas por arma de fogo, v. 9, 2015.
WALFISH, Steven. A review of statistical outlier methods. Pharmaceutical technology, v. 30, n. 11, p. 82, 2006.
WEBER, Sylvain et al. bacon: An effective way to detect outliers in multivariate data using Stata (and Mata). Stata Journal, v. 10, n. 3, p. 331, 2010.