aprendizagem por reforço profundo uma nova perspectiva
TRANSCRIPT

UNIVERSIDADE DO RIO GRANDE DO NORTEFEDERAL
UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE TECNOLOGIA
PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA E
DE COMPUTAÇÃO
Aprendizagem por reforço profundo uma novaperspectiva sobre o problema dos k-servos
Ramon Augusto Sousa Lins
Orientador: Prof. Adrião Duarte Dória Neto
Tese de Doutorado apresentada aoPrograma de Pós-Graduação em EngenhariaElétrica e de Computação da UFRN (área deconcentração: Engenharia de Computação)como parte dos requisitos para obtenção dotítulo de Doutor em Ciências.
Número de ordem PPgEEC: D267Natal, RN, dezembro de 2019

Lins, Ramon Augusto Sousa. Aprendizagem por reforço profundo uma nova perspectiva sobreo problema dos k-servos / Ramon Augusto Sousa Lins. - 2020. 93 f.: il.
Tese (Doutorado)-Universidade Federal do Rio Grande do Norte,Centro de Tecnologia, Programa de Pós-Graduação em EngenhariaElétrica e de Computação, Natal, 2020. Orientador: Prof. Dr. Adrião Duarte Dória Neto.
1. Problema de otimização online - Tese. 2. Otimizaçãocombinatória - Tese. 3. Localização de facilidades competitiva -Tese. I. Dória Neto, Adrião Duarte. II. Título.
RN/UF/BCZM CDU 621.3
Universidade Federal do Rio Grande do Norte - UFRNSistema de Bibliotecas - SISBI
Catalogação de Publicação na Fonte. UFRN - Biblioteca Central Zila Mamede
Elaborado por Raimundo Muniz de Oliveira - CRB-15/429





À minha Esposa e filha, Isabel eCecília, minhas fontes de inspiração.


Agradecimentos
Ao meu orientador e ao meu co-orientador, professores Adrião Duarte e Jorge Dantas,sou grato pela orientação.
Aos colegas do laboratório de sistemas inteligentes pelas sugestões que contribuíramimensamente na elaboração desta tese.
Aos demais professores, pelas críticas e sugestões de modelos de tese.
Aos meus pais Luciano e Sandra pelo apoio incondicional durante esta jornada, sem elesnada disso seria possível.
À CAPES, pelo apoio financeiro.


Resumo
O problema dos k-servos em um grafo ponderado (ou espaço métrico) é definido pelanecessidade de mover eficientemente k servos para atender uma sequência de requisiçõesque surgem de maneira online em cada nó do grafo. Este é talvez o problema mais influ-ente de computação online cuja solução continua em aberto servindo de abstração paradiversas aplicações, como a compra e venda de moedas, reatribuição de processos em pro-cessamento paralelo para balanceamento de carga, serviços de transporte online, geren-ciamento de sondas de produção de petróleo, dentre outros. Sua simplicidade conceitualcontrasta com sua complexidade computacional que cresce exponencialmente com o au-mento do número de nós e servos. Anteriormente a este trabalho, o algoritmo Q-learningfoi utilizado na solução de pequenas instâncias do problema dos k-servos. A solução ficourestrita à pequenas dimensões do problema pois sua estrutura de armazenamento cresceexponencialmente com o aumento do número de nós e servos. Este problema, conhecidocomo maldição de dimensionalidade, torna ineficiente ou até impossibilita a execução doalgoritmo para certas instâncias do problema. Para lidar com maiores dimensões, o Q-learning em conjunto com o algoritmo guloso foi aplicado a um número reduzido de nósseparados por um processo de agrupamento (abordagem hierárquica). A política local ob-tida em cada agrupamento, em conjunto com a política gulosa, foi utilizada na formaçãode uma política global, abordando de maneira satisfatória grandes instâncias do problema.Os resultados foram comparados a importantes algoritmos da literatura, o Work function,o Harmonic e o guloso. As soluções até então propostas dão ênfase ao aumento do nú-mero de nós, porém se analisarmos o crescimento da estrutura de armazenamento definidapor Cn,k ' O(nk), é possível perceber que o aumento do número de servos pode torná-larapidamente limitada pelo problema da maldição da dimensionalidade. Para contornaresta barreira, o problema dos k-servos foi modelado como um problema de aprendizagempor reforço profundo cuja a função de valor estado-ação foi definida por uma rede neuralperceptron de múltiplas camadas capaz de extrair as informações do ambiente a partirde imagens que codificam a dinâmica do problema. A aplicabilidade do algoritmo pro-posto foi ilustrada em um estudo de caso no qual diferentes configurações do problemaforam consideradas. O comportamento dos agentes foi analisado durante a fase de treina-mento e sua performance foi avaliada a partir de testes de desempenho que quantificarama qualidade das políticas de deslocamento dos servos geradas. Os resultados obtidos for-necem uma visão promissora de sua utilização como solução alternativa ao problema dosk-servos.
Palavras-chaves: Aprendizado por reforço profundo, Problemas online, O problemados k-Servos, Otimização combinatória, Localização competitiva.


Abstract
The k-server problem in a weighted graph (or metric space) is defined by the need toefficiently move k servers to fulfill a sequence of requests that arise online at each graphnode. This is perhaps the most influential online computation problem whose solutionremains open, serving as an abstraction for a variety of applications, as buying and sellingof currencies, reassign processes in a parallel processing for load balancing, online trans-portation service, probe management of oil production rigs, among others. Its conceptualsimplicity contrasts with its computational complexity that grows exponentially with theincreasing number of nodes and servers. Prior to this work, the Q-learning algorithmwas used to solve small instances of the k-server problem. The solution was restricted tosmall dimensions of the problem because its storage structure grows exponentially withthe increase in the number of nodes and servers. This problem, known as the curse ofdimensionality, makes the algorithm inefficient or even impossible to execute for certaininstances of the problem. To handle with larger dimensions, Q-learning together with thegreedy algorithm were applied to a small number of nodes separated into different clus-ters (hierarchical approach). The local policy obtained from each cluster, together withgreedy policy, were used to form a global policy satisfactorily addressing large instancesof the problem. The results were compared to important algorithms in the literature, as theWork function, Harmonic and greedy. The solutions proposed so far emphasize the incre-ase in the number of nodes, but if we analyze the growth of the storage structure definedby Cn,k ' O(nk) It can be seen that the increase in the number of servers can be quicklylimited by the problem of the curse of dimensionality. To circumvent this barrier, thek-server problem was modeled as a deep reinforcement learning task whose state-actionvalue function was defined by a multilayer perceptron neural network capable of extrac-ting environmental information from images that encode the dynamics of the problem.The applicability of the proposed algorithm was illustrated in a case study in which dif-ferent problem configurations were considered. The behavior of the agents was analyzedduring the training phase and their performance was evaluated from performance tests thatquantified the quality of the displacement policies of the servers generated. The resultsprovide a promising insight into its use as an alternative solution to the k-servers problem.
Keywords: Deep reinforcement learning, Online problem, The k-server problem,Combinatorial optimization, Competitive location.


Sumário
Sumário i
Lista de Figuras iii
Lista de Tabelas v
Lista de Símbolos e Abreviaturas vii
1 Introdução 11.1 Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 Estado da Arte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.4 Organização do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Problema dos k-servos 112.1 Problemas de otimização online e offline . . . . . . . . . . . . . . . . . . 112.2 Formulação do modelo dos k-servos . . . . . . . . . . . . . . . . . . . . 132.3 Aplicação prática . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3 Fundamentos de Aprendizagem Profunda 173.1 Conceitos Fundamentais . . . . . . . . . . . . . . . . . . . . . . . . . . 173.2 Visão Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.3 Modelo típico de aprendizagem . . . . . . . . . . . . . . . . . . . . . . . 213.4 Rede Neural de Múltiplas Camadas . . . . . . . . . . . . . . . . . . . . 23
3.4.1 Computação para frente . . . . . . . . . . . . . . . . . . . . . . 233.4.2 Computação para trás . . . . . . . . . . . . . . . . . . . . . . . . 253.4.3 Regularização . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4 Aprendizagem por Reforço 294.1 Visão Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304.2 Processo de Decisão de Markov . . . . . . . . . . . . . . . . . . . . . . 314.3 Função Valor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324.4 Diferença Temporal (Temporal Difference - TD) . . . . . . . . . . . . . . 34
4.4.1 Q-learning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.4.2 Semi-gradient Q-learning . . . . . . . . . . . . . . . . . . . . . 35
i

5 Aprendizagem por reforço profundo aplicado ao PKS 415.1 Visão geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415.2 Observações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 425.3 Ações e observações futuras . . . . . . . . . . . . . . . . . . . . . . . . 445.4 Rede neural perceptron de múltiplas camadas . . . . . . . . . . . . . . . 445.5 Recompensa e retorno . . . . . . . . . . . . . . . . . . . . . . . . . . . . 455.6 Interação agente-ambiente . . . . . . . . . . . . . . . . . . . . . . . . . 465.7 Algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
6 Resultados 496.1 Problema de emergência móvel online . . . . . . . . . . . . . . . . . . . 50
6.1.1 Conceito . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 506.1.2 Formalização . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
6.2 Estudo de casos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 516.2.1 Configurações iniciais . . . . . . . . . . . . . . . . . . . . . . . 516.2.2 Hiperparâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . 52
6.3 Análise de desempenho . . . . . . . . . . . . . . . . . . . . . . . . . . . 546.3.1 Curvas de aprendizagem Q-learning . . . . . . . . . . . . . . . . 546.3.2 Curvas de aprendizagem aproximada . . . . . . . . . . . . . . . 546.3.3 Testes de pontuação . . . . . . . . . . . . . . . . . . . . . . . . 56
6.4 Análise dos resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
7 Conclusões, discussões e perspectivas 637.1 Discussões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 647.2 Perspectivas futuras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 657.3 Publicação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
Referências bibliográficas 67

Lista de Figuras
2.1 Distribuição inicial dos servos e requisição no problema dos k-servos. . . 142.2 Nova distribuição após o servo ser deslocado e uma nova solicitação acon-
tecer. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1 Modelo de neurônio não linear . . . . . . . . . . . . . . . . . . . . . . . 193.2 Aprendizagem profunda aplicada a um problema de classificação. . . . . 203.3 Visão geral de sistemas inteligentes. . . . . . . . . . . . . . . . . . . . . 213.4 Visão simplificada de uma rede MLP. . . . . . . . . . . . . . . . . . . . 233.5 Computação para frente . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.6 Regra da cadeia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263.7 Retropropagação do erro . . . . . . . . . . . . . . . . . . . . . . . . . . 273.8 Método de regularização dropout . . . . . . . . . . . . . . . . . . . . . . 28
4.1 Interação do agente com ambiente na aprendizagem por reforço . . . . . 314.2 Diagrama de backup para V p e Qp . . . . . . . . . . . . . . . . . . . . . 33
5.1 Interação agente-ambiente em uma abordagem de aprendizagem por re-forço profundo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5.2 Exemplo de um problema com nós 4 e 2 servos. . . . . . . . . . . . . . . 435.3 Outro exemplo com 5 nós e 2 servos. . . . . . . . . . . . . . . . . . . . . 435.4 Espaço de ações para o exemplo da figura 5.2 . . . . . . . . . . . . . . . 445.5 Arquitetura da rede neural. . . . . . . . . . . . . . . . . . . . . . . . . . 455.6 Função de recompensa. . . . . . . . . . . . . . . . . . . . . . . . . . . . 465.7 O problema dos k-servos como uma tarefa de aprendizagem por reforço
profunda. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
6.1 Valor estado-ação (Q-learning). . . . . . . . . . . . . . . . . . . . . . . . 556.2 Valor estado-ação (rede neural). . . . . . . . . . . . . . . . . . . . . . . 556.3 Função custo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 566.4 Crescimento da estrutura de armazenamento dos algoritmos. . . . . . . . 61
iii


Lista de Tabelas
6.1 Tabela de hiperparâmetros I. . . . . . . . . . . . . . . . . . . . . . . . . 536.2 Tabela de hiperparâmetros II. . . . . . . . . . . . . . . . . . . . . . . . . 546.3 Comparação entre os algoritmos para cidade com 9 regiões e 2 ambulâncias. 576.4 Comparação entre os algoritmos para cidade com 9 regiões e 4 ambulâncias 576.5 Comparação entre os algoritmos para a cidade com 10 regiões e 2 ambu-
lâncias. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 586.6 Comparação entre os algoritmos para a cidade com 15 regiões e 2 ambu-
lâncias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 586.7 Comparação entre os algoritmos para a cidade com 20 regiões e 2 ambu-
lâncias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 596.8 Comparação entre os algoritmos para a cidade com 20 regiões e 3 ambu-
lâncias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 596.9 Comparação entre os algoritmos para a cidade com 20 regiões e 4 ambu-
lâncias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 606.10 Comparação entre os algoritmos para a cidade com 20 regiões e 5 ambu-
lâncias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
v


Lista de Símbolos e Abreviaturas
DCNN Deep Convolutional Neural Network
DL Deep Learning
DRL Deep Reinforcement Learning
DRL Deep Reinforcement Learning
KSP The K-Server Problem
MDP Markov Decision Process
ML Machine Learning
MLP Multilayer Perceptron
MSE Mean Square Error
OPT Optimal algorithm
Relu Rectified Linear Unit
SGD Stochastic Gradient Descent
SVM Support Vector Machine
TD Temporal Difference
TSP Traveling Salesman Problem
WFA Work Function Algorithm
vii


Capítulo 1
Introdução
Proposto por Manasse et al. [1988], o problema dos k-servos (KSP) pode ser definido
em termos de um grafo G (ou espaço métrico) no qual k servos são previamente iniciali-
zados em alguns de seus n nós. Ao longo do tempo requisições s aparecem de maneira
sequencial nos diferentes nós do grafo. Após uma requisição aparecer, um dos k servos
deve ser deslocado para atender a requisição. Este deslocamento é associado a um custo
que pode ser, por exemplo, a distância entre o nó do servo escolhido e o nó no qual a
requisição apareceu. O objetivo é minimizar o custo total envolvido no atendimento das
requisições, em outras palavras, tornar a soma dos custos dos deslocamentos dos servos a
menor possível ao longo do tempo.
Uma característica típica do problema dos k-servos é atender as requisições de ma-
neira online levando em consideração apenas a relação entre a requisição atual e a pas-
sada. Outra forma de abordar o problema é utilizar uma versão offline (determinística) no
qual uma sequência finita de requisições conhecidas devem ser atendidas. No contexto
online, não existe informações sobre o local no qual as requisições futuras irão acontecer;
o que torna a solução do problema complexa podendo acarretar custos maiores do que os
obtidos pelos métodos offlines [Bertsimas et al. 2019].
Os algoritmo online são tipicamente avaliados por meio da sua razão competitiva, que
leva em consideração a performance do algoritmo online em relação ao desempenho de
um algoritmo offline. Neste contexto, à medida que as requisições acontecem qualquer

2 CAPÍTULO 1. INTRODUÇÃO
algoritmo online deve produzir soluções sub-ótimas. Para medir o desempenho dos algo-
ritmos de forma apropriada Sleator & Tarjan [1985] sugeriram que a solução produzida
por um algoritmo online para uma entrada específica deveria ser comparada com a solu-
ção obtida por um algoritmo ótimo offline com a mesma sequência de entrada. Dentro
deste contexto, [Manasse et al. 1988] formalizou a ideia e introduziu a noção de competi-
tividade, que diz que um algoritmo é c-competitivo se existir constante c ≥ 1 de maneira
que a inequação CALG(s) c COPT (s) é válida para qualquer sequência de requisições s.
Nesta expressão CALG e COPT correspondem aos custos associados as algoritmos online
ALG e ao algoritmo ótimo OPT offline, respectivamente [Borodin & El-Yaniv 1998].
Em razão disso e diante da conjectura dos k-servos, que afirma existir um algoritmo
ótimo online k-competitivo [Manasse et al. 1988], diversos algoritmos vêm sendo de-
senvolvidos [Bartal & Koutsoupias 2004], [Grove 1991] ao longo dos anos com o in-
tuito de confirmar sua veracidade. Até agora nenhum algoritmo conseguiu provar ser
k-competitivo para todos os casos [Bansal et al. 2015]. Sua simplicidade conceitual
contrasta com sua complexidade computacional que cresce exponencialmente com o au-
mento do número de nós e servos, sendo talvez o mais influente dos problemas online
[Koutsoupias 2009], servindo de propulsor para o desenvolvimento de novos algoritmos
[Rudec et al. 2013], [Bansal et al. 2015], [Gupta et al. 2016], [Bertsimas et al. 2019].
1.1 Motivação
Inicialmente, os trabalhos relacionados ao problema dos k-servos se concentraram
em espaços métricos especiais, como o espaço métrico uniforme no qual algoritmos de
alto desempenho são conhecidos [Sleator & Tarjan 1985]. Isso levou a afirmação de que
um resultado semelhante deve valer para as métricas arbitrárias. Tal afirmação ficou co-
nhecida como a conjectura dos k-servos que afirma que para cada espaço métrico com
mais de k pontos distintos, a taxa competitiva do problema dos k-servos é exatamente k

1.1. MOTIVAÇÃO 3
[Bansal et al. 2015]. Para métricas gerais, Koutsoupias & Papadimitriou [1995] propôs o
algoritmo Work Function adequado a qualquer espaço métrico, cuja taxa de competitivi-
dade é 2k− 1. Apesar disso, os resultados obtidos por esse algoritmo é determinístico e
existe um grande interesse no estudo de algoritmos aleatórios pois eles tendem a ter um
desempenho melhor que os determinísticos [Bansal et al. 2015].
Um algoritmo aleatório tem a aleatoriedade como parte intrínseca de seu design,
e como dito anteriormente, existe um grande interesse em usá-los na solução do pro-
blema dos k-servos. Isso leva a outro desafio em aberto conhecido como a conjectura
dos k-servos aleatória que afirma existir um algoritmo online aleatório para o problema
dos k-servos com uma razão competitiva logk para cada espaço métrico. Qualquer pro-
gresso nesse problema pode abrir novos caminhos para atacar as conjecturas dos k-servos
[Koutsoupias 2009].
Em um problema dos k-servos online como a decisão depende apenas das informa-
ções disponíveis no momento, esse problema pode ser modelado como um Processo de
Decisão de Markov (MDP) e, consequentemente, definido como um problema de apren-
dizagem por reforço (RL).
A técnica de aprendizado por reforço é uma ferramenta de decisão sequencial baseada
na interação de um agente com um ambiente, fundamentada no conceito de programação
dinâmica introduzida por Bellman [1957]. O ambiente por sua vez é modelado como
um processo de decisão markoviano no qual a tomada de decisão é baseada apenas na
informação disponível em um instante de tempo t. Estas características tornam bastante
atrativo o uso da técnica de aprendizado por reforço na solução de problemas online como
o problema dos k-servos.
Anteriormente a este trabalho o problema do k-servos foi abordado como um pro-
blema de aprendizagem por reforço através da utilização do algoritmo Q-learning. O
seu uso em problemas práticos é naturalmente restrita a problemas de pequena dimensão.
Isso acontece porque o Q-learning precisa visitar todo o espaço de possibilidade "infi-

4 CAPÍTULO 1. INTRODUÇÃO
nitas"vezes para que sua política de decisão convirja para uma política ótima [Watkins
1989]. A medida que a dimensionalidade do problema aumenta a estrutura de armaze-
namento conhecida como função de valor estado-ação (função Q) aumenta exponenci-
almente. Bellman [1957] definiu este tipo de problema como o problema da maldição
de dimensionalidade, conceito que aborda a intratabilidade de problemas de grande di-
mensionalidade; a partir de certas instâncias o problema tem um número tão elevado de
possibilidades que é impossível de se obter computacionalmente uma resposta em tempo
hábil. Este problema foi abordado por meio de uma estratégia hierárquica, cuja solução
abordou grandes dimensões do problema. Apesar disso calcular a função de valor estado-
ação para instâncias maiores torna-se um processo computacional extremamente custoso,
mesmo em uma abordagem hierárquica, tendo talvez como principal fator limitante o nú-
mero de servos, uma vez que a complexidade computacional em espaço do algoritmo é
O(nk) [Costa et al. 2016] e o aumento de servos pode rapidamente levar o problema a
uma explosão de dimensionalidade.
1.2 Objetivos
Para lidar com esse tipo de problema, métodos de aprendizagem baseados em apro-
ximação de funções podem ser utilizados como uma alternativa à abordagem tradicional.
Neste trabalho, o problema dos k-servos foi definido como uma tarefa de aprendizagem
por reforço profundo através do uso do algoritmo Q-learning em conjunto com uma rede
neural de múltiplas camadas (MLP) . O método do gradiente descendente foi utilizado
para integrar a rede neural ao Q-learning [Lin 1993] [Tesauro 1995] [Riedmiller 2005].
Atualmente, o uso das técnicas de aprendizagem profunda (DL), em conjunto com o pa-
radigma da aprendizagem por reforço são impulsionados por avanços recentes [Mnih
et al. 2015] [Silver et al. 2017], bem como sua vasta aplicabilidade em diversas áreas
práticas [Mao et al. 2016] [Bello et al. 2016] [Araque et al. 2017] [Afify et al. 2019].

1.2. OBJETIVOS 5
Para converter o Q-learning em um método baseado no gradiente, a modificação da
função Q foi substituída pela atualização do vetor de pesos sinápticos w através da função
de valor estado-ação aproximada, denotada como Q(s,a;w) ou Q(s,a) (parâmetro implí-
cito) e o cálculo de seu gradiente. Para adaptar o problema dos k-servos à esta abordagem,
a dinâmica do problema foi representada por imagens que codificam os estados do am-
biente, e recompensas definidas pelos caminhos de custo mínimo relacionadas às ações
executadas. Com o problema modelado como uma tarefa visual, a função Q, que remete a
todas as possibilidades, foi substituída por uma matriz de pesos cuja solução generalizada
depende do número de parâmetros da arquitetura da rede neural.
Nossa proposta de trabalho é aliar a capacidade de generalização da rede neural com
a ideia de aprendizagem por interação com o ambiente através do paradigma de apren-
dizagem por reforço, utilizando em particular o algoritmo Q-learning, como solução al-
ternativa a resolução do problema dos k-servos. Os principais objetivos deste trabalho
são:
• Propor um algoritmo menos suscetível à maldição da dimensionalidade, visto que o
processo de tomada de decisão é realizado de maneira generalizada, apresentando
maior escalabilidade para problemas de instâncias maiores, com foco no aumento
do número de servos;
• Transformar o modelo dos k-servos em um problema de imagem adequado aos
métodos de aproximação;
• Analisar o algoritmo proposto comparando seu desempenho com o Q-learning, um
algoritmo com forte prova de convergência [Watkins 1989]; e o algoritmo guloso
que apresenta bom desempenho quando as requisições são definidas por uma dis-
tribuição uniforme [Rudec et al. 2013];
• Analisar a robustez do algoritmo à aleatoriedade, uma propriedade intrínseca ao
problema dos k-servos;
• Fornecer uma visão de como esta abordagem pode ser utilizada em situações práti-

6 CAPÍTULO 1. INTRODUÇÃO
cas.
1.3 Estado da Arte
Nesta seção será feita uma breve discussão de importantes algoritmos (offline e online)
da literatura. Diversos algoritmos foram propostos na tentativa de resolver o problema
dos k-servos. Eles geralmente diferem em relação as taxas competitivas, tratabilidade e
quantidade de dados históricos que usam para a tomada de decisão. Em geral, quanto
mais informações são usadas, melhor o desempenho dos métodos.
Sleator & Tarjan [1985], em seu artigo sobre análise competitiva, deram exemplos
de alguns algoritmos com taxa de competitividade k para o problema de paginação de-
monstrando que nenhum algoritmo determinístico pode ser melhor. Isso levou Manasse
et al. [1988] a afirmar que um resultado semelhante deve valer para métricas arbitrárias,
definindo a conjectura dos k-servos.
Koutsoupias & Papadimitriou [1995], propuseram o algoritmo work function (WFA)
com taxa de competitividade de 2k − 1, valor próximo ao ideal, visto que a conjectura
define que qualquer algoritmo determinístico deve ser k-competitivo. O work function é
um dos algoritmos online mais importantes para o problema dos k-servos, tanto pela pers-
pectiva teórica de competitividade quanto do desempenho prático [Rudec et al. 2013].
Ele tem como base o conceito de função de trabalho, cujos valores são armazenados em
uma estrutura de dados de tamanho C(n,k).m, em que n representa o número de nós,
k a quantidade de servos e m a quantidade total de requisições existentes. A combina-
ção de nós e servos geram as colunas da tabela, as requisições as linhas e a função de
trabalho indica os valores inseridos na estrutura. Basicamente o algoritmo funciona da
seguinte maneira, define-se uma configuração inicial constituída do posicionamento dos
servos e da requisição, em seguida calcula-se os valores da função de trabalho. Estes va-
lores são computados de maneira recursiva, via programação dinâmica de tal forma que

1.3. ESTADO DA ARTE 7
os valores posteriores da tabela são calculados com base nos valores obtidos anteriores
[Leandro 2005]. Por fim, o menor valor de uma linha é selecionada na estrutura de dados
deslocando-se o servo que tiver a menor distância para a demanda.
Uma heurística natural de ser pensada é o algoritmo guloso que atende à requisição le-
vando em consideração o menor custo, levando em consideração as distâncias e ignorando
o histórico. Assim, a estratégia gulosa sempre desloca o servo mais próximo do local no
qual a requisição foi solicitada. Outra heurística simples é o algoritmo de balanceamento
que tenta manter a distância total percorrida por todos os servos o mais próximo possível.
Ele desloca o servo cuja distância cumulativa percorrida até o momento mais a distância
até o novo local da requisição é a menor [Manasse et al. 1988].
Ao contrário dos algoritmos determinísticos, algoritmos aleatórios contêm etapas ale-
atórias como parte de seu design. Nesse caso, a noção de uma razão competitiva pode ser
generalizada da perspectiva dos custos esperados produzidos pelos algoritmos [Borodin
& El-Yaniv 1998]. Raghavan & Snir [1994] propuseram o algoritmo Harmonic usando a
propriedade de aleatoriedade como uma estratégia de solução para diminuir o problema
de competitividade [Koutsoupias 2009]. O algoritmo é baseado na estratégia gulosa, po-
rém, a escolha do servo está associada a uma probabilidade cujo valor é inversamente
proporcional à distância ao nó requisitado. É de certa forma uma estratégia gulosa pro-
babilística no qual o servo escolhido é aquele cuja probabilidade é a maior em função da
menor distância que deve ser percorrida para atender a demanda [Leandro 2005].
A primeira vez que se tem conhecimento da utilização de aprendizado por reforço
como solução ao problema dos k-servos foi no trabalho de Manoel Leandro et al. [2005].
O autor modelou o PKS como um processo de tomada de decisão de múltiplos estágios e
utilizou o algoritmo Q-Learning, um método de diferença temporal que calcula a função
Q diretamente a partir dos dados (model-free) e de forma independente da política utili-
zada (off-policy) para resolução do problema. Como resultado foi feita uma comparação
entre o método proposto e os algoritmos Harmonic e Work function. Para adaptar o algo-

8 CAPÍTULO 1. INTRODUÇÃO
ritmo à grandes instâncias, foi utilizada uma abordagem hierárquica na qual os nós e os
servos foram separados em agrupamentos. A política local obtida em cada agrupamento
foi combinada e usada na formação de uma política global. Quando as requisições acon-
tecem em agrupamentos distintos gerando situações não treinadas pelo Q-learning (esta-
dos não visitados) a estratégia gulosa é utilizada no deslocamento do servo para atender
a requisição. Os resultados mostraram que a utilização do Q-Learning tanto de forma
direta, como na abordagem hierárquica, funcionam de forma competitiva (não compro-
vada), dada a comparação com métodos competitivos, percorrendo distâncias menores do
que a dos algoritmos Harmonic e WFA.
Dando continuidade a esta abordagem, Costa et al. [2016] propôs a utilização de uma
técnica de clusterização na tentativa de gerar agrupamentos melhores e paralelizou o pro-
blema. Neste trabalho os grupos de nós foram separados pelo método k-means a partir de
um critério de equilíbrio de carga, estabelecido por um parâmetro t usado para aumentar
a eficiência do método proposto. Os resultados mostram que a utilização do Q-Learning
hierárquico paralelizado com equilíbrio de carga pode ser uma opção viável na resolução
de problemas reais de dimensões práticas, como abordadas por [Rudec et al. 2013] and
[Bertsimas et al. 2019].
Recentemente o problema dos k-servos foi abordado sob a perspectiva de um modelo
de otimização inteira mista, robusta e adaptativa. Bertsimas et al. [2019] propuseram
uma nova formulação do PKS que incorpora informações do passado e incertezas sobre o
futuro conseguindo obter resultados superiores aos principais algoritmos da literatura.
Saindo um pouco dos problemas diretamente relacionados ao problema dos k-servos,
abordamos aqui alguns dos principais trabalhos relacionados a área de aprendizado por re-
forço com aproximadores de funções não lineares, em específico as redes neurais. Há um
pouco mais de uma década Riedmiller [2005] propôs o uso do Q-Learning em conjunto
com as redes perceptron de múltiplas camadas. A atualização dos pesos da rede foram
realizados de forma offline armazenando e repetindo as experiências das transições já con-

1.3. ESTADO DA ARTE 9
sideradas. O intuito foi evitar que o ajuste online dos pesos sinápticos para um certo par
estado-ação levasse a mudanças inesperadas em outros lugares do espaço estado-ação,
permitindo uma convergência mais rápida e confiável. O autor nomeou o algoritmo de
Neural Fitted Q (NFQ) e avaliou em problemas de benchmark, como por exemplo o cart-
pole [Sutton & Barto 1998]. De forma empírica, o algoritmo NFQ mostrou ser capaz de
gerar políticas de controle comparáveis a de controladores analiticamente projetados.
Em um trabalho recente Mnih et al. [2015] propôs a utilização do Q-Learning em con-
junto com uma rede neural convolucional profunda (DCNN) realizando a atualização dos
pesos sinápticos a partir de mini lotes. Com essa proposta, o algoritmo foi capaz de apren-
der a jogar diferentes jogos de Atari 2600 diretamente a partir de dados brutos (pixels). O
agente interage com o ambiente (imagens representativas de partes do problema) e toma
decisões (ações em um jostick), sem nenhum conhecimento prévio do problema. As Conv-
Nets, como também podem ser chamadas as redes DCNN, foram utilizadas para receber
como entrada os estados do problema, reduzindo sua dimensionalidade, tornando esta
abordagem um problema de aprendizagem tratável. O algoritmo foi denotado como Deep
Q-Network (DQN) dando origem ao termo aprendizagem por reforço profunda (DRL) .
Com intuito de minimizar a difícil tarefa de obter soluções heurísticas para problemas
de gerenciamento de recursos em sistemas e redes de computadores, Mao et al. [2016]
utilizou o método Policy Gradient [Sutton & Barto 2018], com política parametrizada por
uma rede neural profunda, como uma alternativa às heurísticas geradas pelo homem. A
abordagem teve performance comparável às heurísticas de ponta.
Em outro trabalho Bello et al. [2016] abordou o problema do caixeiro viajante (TSP),
outro problema de otimização combinatória, como um problema de aprendizado por re-
forço profundo. Neste trabalho o autor utilizou o paradigma de aprendizado por reforço
através do algoritmo ator-crítico em conjunto com uma rede neural recorrente atingindo
valores próximos ao resultado ótimo para grafos euclidianos com 100 nós.

10 CAPÍTULO 1. INTRODUÇÃO
1.4 Organização do Trabalho
Este texto está organizado da seguinte forma: no capítulo 2, serão introduzidas as no-
ções gerais de computação online e análise competitiva. No capítulo 3, serão apresentados
os aspectos básicos do paradigma de aprendizagem por reforço profundo. Em seguida no
capítulo 4, para possibilitar uma melhor compreensão da modelagem do problema, se-
rão definidos os principais conceitos de aprendizagem por reforço. No capítulo 5 será
apresentada a ideia central desse trabalho: o problema dos k-servos sob a perspectiva do
paradigma de aprendizagem por reforço profundo. Esse capítulo descreve a metodolo-
gia utilizada no trabalho, detalhando os casos de estudo investigados para se alcançar os
diferentes objetivos dessa tese. No capítulo 6 serão demonstradas a metodologia e os re-
sultados do trabalho. Finalmente, no capítulo 7 serão discutidas, com base nos resultados
obtidos, algumas conclusões a respeito do trabalho, como também algumas propostas de
ideias para trabalhos futuros.

Capítulo 2
Problema dos k-servos
O problema dos k-servos online definido por Manasse et al. [1988] é talvez o problema
mais influente da computação online [Koutsoupias 2009]. Este modelo serve como abstra-
ção para um grande números de problemas, como o problema de paginação de memória,
uma instância do KSP com espaço métrico unitário [Borodin & El-Yaniv 1998], locali-
zação de facilidades, localização de cabeças de leitura de discos rígidos, atendimento de
segurança e emergências, distribuição de transportadores em um sistema flexível de ma-
nufatura, dentre muitos outros [Goldbarg & Luna 2000]. Além disso, esse problema tem
aplicações na teoria dos grafos e em sistemas de tarefas métricas [Borodin et al. 1992]. A
conjectura dos k-servos continua como uma questão em aberto servindo de grande esti-
mulo para o desenvolvimento de novos algoritmos. Nas próximas seções serão abordadas
algumas das definições e notações básicas utilizadas neste trabalho.
2.1 Problemas de otimização online e offline
Os problemas computação onlines são caracterizados pela necessidade de decidir qual
ação deve ser tomada dada uma entrada específica sem conhecimento prévio das entra-
das futuras. Em geral, os problemas de computação online tem como principal objetivo
minimizar (maximizar) uma função custo dado um problema específico. Um problema
de otimização P de minimização de custo é constituído por um conjunto I de entradas e

12 CAPÍTULO 2. PROBLEMA DOS K-SERVOS
uma função custo C. Associado a cada entrada I tem-se um conjunto de possíveis soluções
F(I), e associado a cada solução possível O 2 F (I) existe um custo C(I,O) (positivo),
que representa o custo da saída O relacionado a entrada I. O objetivo é buscar um valor de
saída O possível associado ao valor de entrada I que minimize o valor de C(I,O) [Borodin
& El-Yaniv 1998].
Dada qualquer entrada I permitida, um algoritmo ALG em um problema de otimiza-
ção P computa uma possível solução ALG[I] 2 F(I). O custo associado com a possível
solução é denotada por ALG(I) =C(I,ALG[I]). Uma solução ótima OPT deve obedecer
para qualquer entrada I válida a equação:
OPT (I) = minO2F(I)
C(I,O) (2.1)
de maneira que o custo associado ao algoritmo ótimo deve ser menor ou igual ao custo
associado a qualquer outra solução possível em P . Um mesmo algoritmo pode ter vários
custos associados dependendo da entrada I. Para o problema dos k-servos um elemento I
do conjunto de entradas I corresponde a uma sequência de requisições definida como:
I ⌘ s = {s(1),s(2), . . . ,s(t), . . . ,s(T )} (2.2)
de modo que para atender a requisição st , 1 t m, um servo deve ser deslocado para
atendê-la [Manoel Leandro et al. 2005]. Para cada requisição, uma saída (ou nova confi-
guração dos servos) é produzida e tem-se um custo associado ao deslocamento do servo.
A maneira como as requisições são apresentadas define dois tipos de problemas de otimi-
zação. Se uma nova requisição só é conhecida após o acontecimento de uma anterior, o
problema é definido como um problema de otimização online. Mais precisamente, quando
s(t) acontece, não existe nenhuma informação sobre s(t+1). Comparado aos problemas
offline, que possuem conhecimento completo das requisições futuras, os problemas online
são mais complexos, tendo em vista que após uma decisão ser tomada, esta não pode ser

2.2. FORMULAÇÃO DO MODELO DOS K-SERVOS 13
revogada influenciado a solução como um todo.
2.2 Formulação do modelo dos k-servos
Formalizando o problema, considere que G = (N,E) represente um grafo ponderado,
conectado e não direcional, onde n = |N| é o número de nós e E, o conjunto de arestas
que se interconectam os nós. Cada aresta e 2 E está associada a um peso não negativo
e simétrico; e(u,v) representa o peso dos nós (u,v) 2 N unidos pela aresta; k(t) para
representar a distribuição dos servos (homogêneos) no grafo e k define o número de servos
que devem satisfazer as requisições que aparecem de maneira online nos n nós ao longo
do passo de tempo t.
Supondo que uma nova requisição apareça somente após a requisição atual ter sido
atendida, o problema do servidor k pode ser definido da seguinte maneira:
• A distribuição dos k servos no grafo é definida como k(t) =n
k(t)1,i ,k(t)2,i , . . . ,k
(t)l,i , . . . ,k
(t)k,i
o
onde l = {1,2, . . . ,k} especifica o servo na distribuição e i 2 N determina o nó no
qual o servo está localizado. O termo k(t)l,i significa que, a cada passo de tempo t, o
servo l está localizado no nó i de G.
• A sequência de requisições s =n
s(0)1 ,s
(1)2 , . . . ,s
(t)j
o
representa a requisição s(t)j
que aparece no nó j 2 N ao longo do tempo t = {0,1, . . . ,T − 1}, onde T é o
número total de requisições em uma sequência.
• O deslocamento de k(t)l,i para atender s(t)j a partir de k(t) =
n
k(t)1,i ,k(t)2,i , . . . ,k
(t)l,i , . . . ,k
(t)k,i
o
leva a uma nova distribuição k(t+1) =n
k(t+1)1,i ,k(t+1)
2,i , . . . ,k(t+1)l, j
o
.
Para uma melhor compreensão, o problema dos k-servos é demonstrado em um exem-
plo com n = 4 e k = 2 (ver figura 2.1). A configuração inicial (t = 0) deve ser conhe-
cida; para este exemplo o servo l = 1 está localizado no nó i = 2, o servo l = 2 no nó
i = 3 e a requisição aparece em j = 4 caracterizando a distribuição dos servos como
k(0) =n
k(0)1,2,k(0)2,3
o
e requisição como s(0)4 .

14 CAPÍTULO 2. PROBLEMA DOS K-SERVOS
Figura 2.1: Distribuição inicial dos servos e requisição no problema dos k-servos.
Se k(0)2,3 for deslocado para atender a s(0)4 , uma nova distribuição denotada como k(1) =
n
k(1)1,2,k(1)2,4
o
é caracterizada e uma nova requisição aparece em algum nó, neste caso s(1)1
(ver figura 2.2).
Figura 2.2: Nova distribuição após o servo ser deslocado e uma nova solicitação acontecer.
O deslocamento do servo está sujeito à otimização de uma função de custo definida
de acordo com o problema. Um problema comum é minimizar o custo total envolvido no
deslocamento dos servos. Por uma questão de simplicidade, o problema dos k-servos é
modificado para que apenas um servo ocupe um nó e seja movido por vez. Embora sua
definição formal permita que vários servos sejam alocados no mesmo nó, essa situação
não é necessária, dessa maneira essa modificação não altera o custo da solução computada
[Borodin & El-Yaniv 1998].
2.3 Aplicação prática
O rápido aumento no número de veículos nas estradas, bem como o tamanho crescente
das cidades, levam a uma infinidade de desafios de gerenciamento de tráfego rodoviário
para as autoridades. Neste contexto, nós abordamos neste trabalho o problema particu-
lar do gerenciamento de tráfego para serviços de atendimento de urgências, para o qual
um atraso de alguns minutos pode causar riscos à vida humana, bem como perdas finan-
ceiras. O objetivo é reduzir a latência dos serviços de emergência para veículos como
ambulâncias e viaturas policiais.

2.3. APLICAÇÃO PRÁTICA 15
O problema dos k-servos pode servir de abstração para este tipo de problema, para isso
propomos uma modelagem para atender a população de uma cidade na situação de uma
urgência policial. As urgências podem ser caracterizadas por situações em que alguém é
vítima de uma ação criminosa, encontra-se em situação de risco ou faz uma denúncia. As
urgências são atendidas por viaturas policiais distribuídas em diferentes locais da cidade.
O objetivo é minimizar o tempo total associado ao atendimentos das requisições. Este
problema pode ser modelado da seguinte maneira: O grafo G representa a cidade, cada nó
n 2 G representa um diferente local (região) de urgência na cidade, k representa o número
de viaturas policiais V P (servos) e s a sequência de urgências (requisições) que podem
surgir em qualquer um dos locais da cidade é representada por s =n
s(0)1 ,s
(1)2 , . . . ,s
(t)j
o
.
O atendimento de uma requisição é caracterizado quando uma viatura k em um nó i é
deslocada para um nó j que representa o local de ocorrência de uma urgência (st). As-
sociado ao deslocamento de cada viatura tem-se um custo ct(i, j) proporcional ao tempo
gasto no atendimento de cada urgência. O objetivo é minimizar o custo totalmÂt
ct(i, j), ou
seja, atender uma sequência de urgências no menor tempo possível.
Do ponto de vista da Aprendizagem por Reforço, o problema pode ser modelado
como segue: o estado do ambiente é representado por uma configuração possível das k
viaturas, ou seja, por k-tuplas do tipo {V P1,V P2, . . . ,V Pk}. As ações correspondem aos
deslocamentos permitidos das V P em um estado válido. Em cada estado, e considerando o
surgimento de uma urgência s(t)i em um dos n locais, uma das k V P será deslocada. Deste
modo, tem-se que o número de ações permitidas para atender s(t)i é k. Será considerado
aqui o surgimento de uma urgência por vez, deixando a análise de múltiplas urgências
para trabalhos futuros.

16 CAPÍTULO 2. PROBLEMA DOS K-SERVOS

Capítulo 3
Fundamentos de Aprendizagem
Profunda
Aprendizagem profunda (DL) é um termo recente usado para definir o antigo conceito
conexionista da década de 80. O movimento começou com foco em técnicas de apren-
dizado não supervisionado [Hinton & Salakhutdinov 2006], [Y. Bengio & Larochelle
2007],[Ranzato et al. 2007], onde os modelos DL mostraram grande capacidade de ge-
neralização de modelos, o que despertou um novo interesse da indústria de tecnologia.
Atualmente as pesquisas realizadas nesta área seguem a todo vapor dada sua grande capa-
cidade de generalização [Goodfellow et al. 2016]. Nas próximas seções serão abordados
alguns dos principais conceitos fundamentais de DL, bem como os conceitos da rede de
múltiplas camadas (MLP), arquitetura utilizada neste trabalho.
3.1 Conceitos Fundamentais
A aprendizagem de máquinas (ML) consiste no processo de aprender através dos da-
dos a fazer predições e/ou tomar decisões. Usualmente o processo de aprendizado é
categorizado em supervisionado, não supervisionado e aprendizagem por reforço. No
aprendizado supervisionado existe um supervisor que conhece a saída desejada (rótulo)
para cada amostra dos dados de entrada, enquanto no aprendizado não supervisionado não

18 CAPÍTULO 3. FUNDAMENTOS DE APRENDIZAGEM PROFUNDA
existe a figura do supervisor, a meta é explorar ou descrever um conjunto de dados sem
uma saída de referência. No aprendizado por reforço não existe a ideia de pares de entrada
e saída, a aprendizagem acontece por meio da interação entre o agente e o ambiente afim
de maximizar (minimizar) um sinal de reforço ao longo do tempo.
As técnicas de aprendizagem de máquinas tradicionais, como por exemplo: regres-
são linear, Máquina de Vetores de Suporte (SVM) , árvores de decisão entre outras, têm
sido o motor de várias aplicações modernas, porém estas técnicas dependem fortemente
da forma como os dados são representados. Por décadas construir sistemas inteligentes
exigiu um esforço muito grande por parte dos profissionais de engenharia, no projeto
de sistemas capazes de representar dados brutos (como pixels por exemplo) em vetores
características de forma adequada [LeCun et al. 2015a]. Dentro dos métodos de apren-
dizagem de máquinas tradicionais podemos destacar as redes neurais artificiais base dos
principais modelos práticos [Goodfellow et al. 2016].
As redes neurais são formadas por unidades de processamento de informação conhe-
cidas como neurônios. O modelo neuronal é composto basicamente por três elementos
básicos (figura 3.1): Um sinal de entrada x j que conecta-se ao neurônio k multiplicando-
se por um peso sináptico wk j (sinapse), um somador responsável por fazer a combinação
linear das sinapses e uma função de ativação que define a amplitude do sinal e opera
tipicamente na faixa de [0,1] ou [−1,1]. Outro elemento que deve ser levado em conside-
ração é o bias bk, elemento que fornece ao neurônio um efeito de aumentar ou diminuir
(dependendo do sinal) a entrada da função de ativação, uma transformação que faz com
que a função não passe mais pela origem.
Como dito anteriormente, as funções de ativações são definidas em função do poten-
cial de ativação vk. Existem diversos tipos de função de ativação. Dentre as principais
funções utilizadas tem-se: a função de limiar, também conhecida como função de Heavi-
side f(vk) = 1 se vk ≥ 0 ou 0 caso contrário ; outra função utilizada (talvez a mais utili-
zada) é a função sigmóide, também conhecida como função logística f(vk) =1
1+exp(−av) ,

3.1. CONCEITOS FUNDAMENTAIS 19
Figura 3.1: Modelo de neurônio não linear[Haykin 1998].
onde os valores de saída assumem um intervalo contínuo de valores entre 0 e 1; A função
tangente hiperbólica, definida como f(vk) = tanh(vk) é usada quando os valores de saída
devem assumir um intervalo contínuo de valores entre −1 e 1, e as unidades retificadoras
lineares (ReLU) definida como f(vk) = max(0,vk).
Formalizando o modelo matemático dos conceitos ilustrados na figura 3.1, para cada
neurônio k tem-se as seguintes equações:
vk =m
Âj=1
wk jx j +bk (3.1)
yk = f(vk) (3.2)
de maneira que x representa os sinais de entrada; w os pesos sinápticos; v a saída do soma-
dor (combinação linear), conhecido como potencial de ativação ou campo local induzido;
b o bias; f(.) a função de ativação e y o sinal de saída do neurônio.
As redes neurais superficiais tradicionais dependem fortemente da forma como os
dados são representados. Dependendo da tarefa, extrair características importantes dos
dados de entradas pode se tornar uma tarefa complexa. Uma forma de contornar este
problema é aprender a representação sem a necessidade de projetar manualmente as ca-
racterísticas que devem ser extraídas dos dados.

20 CAPÍTULO 3. FUNDAMENTOS DE APRENDIZAGEM PROFUNDA
Os métodos de aprendizagem profunda atuam através de múltiplos níveis de represen-
tação, descobrindo automaticamente as representações necessárias para realização de uma
dada tarefa, como por exemplo detecção e classificação. Cada camada (nível) não linear
faz a representação dos dados hierarquicamente em níveis cada vez maiores de abstração
[LeCun et al. 2015a]. Em outras palavras, DL fornece ao computador a capacidade de
aprender hierarquicamente conceitos complexos a partir de conceitos mais simples, sem
a necessidade de projetar manualmente os vetores características.
Figura 3.2: Aprendizagem profunda aplicada a um problema de classificação.[Goodfellow et al. 2016].
Através das múltiplas camadas o sistema consegue implementar funções extrema-

3.2. VISÃO GERAL 21
mente complexas, que são ao mesmo tempo sensíveis a pequenos detalhes e insensíveis a
grandes variações como por exemplo plano de fundo, poses distintas, iluminação e obje-
tos vizinhos [LeCun et al. 2015a]. O conceito pode ser melhor visualizado na figura 3.3,
que mostra um exemplo de aprendizagem profunda aplicada a um problema de reconhe-
cimento de objetos em uma imagem.
3.2 Visão Geral
De maneira geral os sistemas inteligentes podem ser divididos em sistemas baseados
em regras, aprendizagem de máquinas e por aprendizagem profunda.
Figura 3.3: Visão geral de sistemas inteligentes.[Goodfellow et al. 2016].
3.3 Modelo típico de aprendizagem
Os algoritmos de aprendizagem profunda, assim como os algoritmos de aprendizado
de máquinas, são compostos (visão simplificada) por algumas etapas básicas: definição
dos dados, escolha da função custo, técnica de regularização, do algoritmo de otimização
e um modelo.

22 CAPÍTULO 3. FUNDAMENTOS DE APRENDIZAGEM PROFUNDA
Por exemplo, um problema de regressão linear pode ser definido a partir de dados
de entrada x 2 Rn e saída y 2 R, uma função custo J(w) qualquer, como por exemplo a
função de log-verossimilhança negativa
J(w) =−Ex,y⇠p [log p(y | x)] (3.3)
que representa o valor esperado de uma função p(y | x) (modelo) em relação a uma distri-
buição empírica p retirada dos dados x; a especificação de um modelo, como por exem-
plo o estimador de máxima verossimilhança p(y | x) = N (y; y(x;w,b),1) e, na maioria
dos casos, um algoritmo de otimização baseado no cálculo do gradiente [Goodfellow
et al. 2016].
A modificação destes componentes de forma independente leva a uma variedade de
algoritmos. Tipicamente a função custo inclui pelo menos um termo que proporciona uma
estimação estatística ao processo de aprendizagem. Ela pode ainda ser modificada com
a inserção de um termo de regularização. Por exemplo, um decaimento de peso pode ser
adicionado à função de custo
J(w) = l||w||22 −Ex,y⇠p [log p(y | x)] (3.4)
A regularização tem como objetivo aumentar o poder de generalização do modelo,
diminuindo o problema de overfitting. Ela pode ser realizada a partir de técnicas clássi-
cas como a norma-L2 (norma euclidiana), bem como as restrições impostas pela própria
arquitetura como por exemplos as camadas convolucionais. Podem ser também técni-
cas mais modernas como a Dropout [Srivastava et al. 2014] e métodos de regularização
variacional [Santana et al. 2016].
Essas etapas serão detalhadas mais a frente, dando-se ênfase às principais técnicas
utilizadas atualmente no desenvolvimento das redes neurais de múltiplas camadas.

3.4. REDE NEURAL DE MÚLTIPLAS CAMADAS 23
3.4 Rede Neural de Múltiplas Camadas
A rede neural de múltiplas camadas, também chamadas de Deep Feedforward Networks,
mapeia valores de entradas em valores de saída formando uma complexa função matemá-
tica a partir de funções simples camada a camada. Ela pode distorcer o espaço de entrada
transformando a classe de dados em uma região linearmente separável, como mostrado
na figura 3.4, que ilustra uma rede simples com duas unidades de entrada, uma camada
escondida com dois neurônios e um neurônio de saída.
Figura 3.4: Visão simplificada de uma rede MLP.[LeCun et al. 2015a].
3.4.1 Computação para frente
As unidades escondidas, que formam as camadas escondidas (l) (ocultas), são defini-
das pelas funções de ativação f(v(l)). Não existe uma função que seja definitiva, porém a
utilização das unidades retificadoras lineares (ReLU) tem se mostrado uma excelente es-
colha como função de ativação padrão, talvez pelo fato de ser facilmente otimizada pois
são similares as unidades lineares.
Posteriormente, as unidades de saídas l = L de uma rede MLP são definidas por um
conjunto de equações. Na camada de saída calcula-se um vetor de saída y(L) usando como
entrada a saída y(L−1) da camada anterior com parâmetros b(L) (bias) e w(L) (os pesos). A
camada de saída y(L) pode ser usada para fazer predições ou classificações em função da

24 CAPÍTULO 3. FUNDAMENTOS DE APRENDIZAGEM PROFUNDA
camada anterior y(L−1). Ela pode ser representada por diferentes funções como as citadas
anteriormente, em problemas de classificação as mais utilizadas são a softmax e a SVM.
Definido que y(L)j = y j representa os valores de saída da rede, o sinal de erro é dado por
e j = y j − y j, onde y j é o j-ésimo elemento da saída de referência (aprendizagem supervi-
sionada). Através do erro e j a função custo mede a diferença entre a saída de referência
y j e a estimada y j. Os passos descritos até aqui representam a etapa de computação para
frente ilustrada na figura 3.5.
Figura 3.5: Computação para frente
A função custo é um modelo paramétrico que em muitos casos definem uma distribui-
ção de probabilidade completa ou, em vez disso, predizem alguma estatística da saída y
condicionada aos dados de entrada x. A maioria das redes neurais modernas são treinadas
usando a máxima verossimilhança. Isso significa que a função de custo é simplesmente
o log-verossimilhança negativo (ver equação 3.3), equivalentemente descrito como a en-
tropia cruzada entre os dados de treinamento e a distribuição do modelo. Comparando a
entropia cruzada (equivalente ao log-verossimilhança negativa) com o erro médio quadrá-

3.4. REDE NEURAL DE MÚLTIPLAS CAMADAS 25
tico, se p(y | x) = N (y; y,I), então
J(w) =12Ex,y⇠p ||y− y||2 (3.5)
onde I representa uma matriz identidade com dimensão dada pelo contexto. A maxi-
mização da função log-verossimilhança em relação a w produz a mesma estimativa dos
parâmetros w que a minimização do erro quadrático médio (MSE) . Os dois critérios têm
valores diferentes, mas a mesma localização do ótimo. Isso justifica o uso do MSE como
um procedimento de estimador de máxima verossimilhança [Goodfellow et al. 2016].
Um tema recorrente em todo o projeto de redes neurais é que o gradiente da função de
custo deve ser grande e predizível o suficiente para servir como um bom guia para o al-
goritmo de aprendizagem. As funções que saturam (tornam-se muito planas) minam esse
objetivo porque tornam o gradiente muito pequeno (desaparecimento do gradiente). Em
muitos casos, isso acontece porque as funções de ativação usadas para produzir a saída
das unidades ocultas ou das unidades de saída saturam. A função log-verossimilhança
negativa ajuda a evitar esse problema para vários modelos. Muitas das unidades de saída
envolvem uma função exponencial que pode saturar quando seu argumento é muito nega-
tivo. A função log-verossimilhança negativa desfaz a exponencial de algumas unidades
de saída diminuindo o problema do desaparecimento do gradiente. Por essa razão o uso
da entropia cruzada como função custo tornou-se popular.
3.4.2 Computação para trás
Em um típico modelo de aprendizagem profunda existem milhões de parâmetros a
serem ajustados. Normalmente, o ajuste do peso é feito através do cálculo do gradiente,
que para cada peso, indica se o erro deve crescer ou diminuir em função do ajuste. Um
método de otimização bastante utilizado no ajuste dos pesos é o gradiente descendente

26 CAPÍTULO 3. FUNDAMENTOS DE APRENDIZAGEM PROFUNDA
determinístico que utiliza todo conjunto de dados sendo definido como:
—wJ = Ex,y⇠p —w[log p(y | x;w)] (3.6)
O cálculo do gradiente da função custo nada mais é do que uma aplicação da regra
da cadeia para derivadas. Tomando a figura 3.6 como exemplo definimos o conceito da
regra da cadeia. A derivada indica o quanto uma pequena mudança representada por Dx
influencia no comportamento de uma função y. Em uma composição de funções, a regra
da cadeia indica a relação entre as derivadas, ou seja o quanto Dx modifica y e o quanto
Dy modifica v.
Figura 3.6: Regra da cadeia
Através do algoritmo backpropagation o gradiente da função objetivo em relação a
entrada pode ser calculado em função do gradiente da saída (ou dos módulos subsequen-
tes). Este processo é melhor demonstrado na figura 3.7. Com isso os pesos são ajustados
na direção oposta ao vetor gradiente calculado. O vetor gradiente negativo indica a di-
reção de descida para um mínimo local, onde a saída média do erro é mínima [LeCun
et al. 2015a].
Calcular o gradiente dessa maneira é muito custoso pois requer uma avaliação do mo-
delo para todos os exemplos do conjunto de dados. Na prática o gradiente é calculado por
amostragens aleatórias de pequenos números de exemplos (mini lotes) {x(1), . . . ,x(m)} do
conjunto de treinamento com saídas de referência y em função da média destas amostras.
Este método é conhecido como o gradiente descendente estocástico (SGD) sendo definido

3.4. REDE NEURAL DE MÚLTIPLAS CAMADAS 27
Figura 3.7: Retropropagação do erro
como:
—qJ(q) = Exm,ym⇠p —q[logpmodelo(y|x;q)] (3.7)
Esse método é repetido para pequenos lotes de exemplos do conjunto de treinamento até
que o erro pare de decrescer. É chamado de estocástico porque cada pequeno conjunto de
exemplos fornece um ruído estimado da média do gradiente sobre todos os exemplos.
3.4.3 Regularização
A função custo pode ser modificada com a inserção de um termo de regularização.
Muitas das abordagens utilizadas para regularização são baseadas na capacidade de limi-
tar os modelos adicionando-se parâmetros de penalidade. Como foi dito anteriormente,
atualmente as redes mais modernas fazem uso da técnica de regularização denominada
dropout.
Esta técnica permite a criação de um conjunto constituído por várias sub-redes que
podem ser construídas removendo-se os neurônios das camadas ocultas da rede. Basica-

28 CAPÍTULO 3. FUNDAMENTOS DE APRENDIZAGEM PROFUNDA
mente as unidades e conexões são desconsideradas aleatoriamente (e temporariamente)
durante o processo de propagação e retropropagação do erro. Em seguida, esse processo
é repetido, primeiro os neurônios removidos são restaurados, novos neurônios e conexões
são removidos aleatoriamente, o gradiente é calculado para um novo mini-lote e os pesos
e bias são atualizados. O dropout fornece um pequeno esforço computacional mas é um
método poderoso para regularização de vários modelos [Srivastava et al. 2014].
Figura 3.8: Método de regularização dropout[Srivastava et al. 2014]
A esquerda uma rede neural padrão com duas camadas escondidas, a direita um exem-
plo de uma sub-rede produzida aplicando-se o método dropout na rede da esquerda. As
unidades cruzadas são as unidades desconsideradas.

Capítulo 4
Aprendizagem por Reforço
O problema dos k-servos pode ser visto como um problema de tomada de decisão
sequencial sob incertezas. Nesse contexto, definimos que a evolução do sistema é influ-
enciada pelas decisões ou ações tomadas ao longo do tempo, de maneira que a decisão
tomada não pode ser revogada, influenciado a solução como um todo. O objetivo é deter-
minar um conjunto de regras de tomada de decisão (políticas de controle) que minimizem
(maximizem) um critério de desempenho. O paradigma de aprendizado por reforço é uma
ferramenta de decisão sequencial baseada na interação de um agente com um ambiente
adequada a estes tipos de problemas.
No paradigma de aprendizagem por reforço um agente mapeia situações (estados)
em ações de maneira que um sinal de retorno seja maximizado. Na prática, porém, o
aprendizado por reforço pode ficar restrito a pequenas aplicações dado o problema da
maldição de dimensionalidade encontrado em problemas reais. As redes neurais, bem
como outros aproximadores de funções, podem ser utilizadas para suprir essas limitações.
Utilizando uma rede neural como aproximador de função o aprendizado fica caracterizado
pelas modificações dos pesos sinápticos em função das recompensas obtidas pelo agente
após a interação com o ambiente.
A seguir serão discutidos os fundamentos básicos de aprendizado por reforço, dando
ênfase aos conceitos e definições do processo de decisão de Markov, método de iteração

30 CAPÍTULO 4. APRENDIZAGEM POR REFORÇO
de valor 1, algoritmo Q-learning, aproximadores de função e aprendizagem por reforço
profundo.
4.1 Visão Geral
O aprendizado por reforço é caracterizado por diversos tipos de desafios, como por
exemplo o problema da maldição de dimensionalidade, que representa a impossibilidade
de um algoritmo ser executado dado que os recursos computacionais sejam esgotados ou
inviabilidade do tempo. Outro importante desafio característico é a troca entre exploração
(diversificação) e explotação (intensificação). Para obter maiores recompensas o agente
deve preferir ações passadas que mostraram ter maior importância. Porém para descobrir
estas ações, deve-se procurar ações que ainda não foram selecionadas. O agente deve
intensificar as ações conhecidas, porém deve explorar novas ações que levem a possíveis
melhores recompensas no futuro, conhecido como o dilema da exploração-explotação. As
recompensas podem gerar o problema de atribuição de crédito. O que acontece é que cada
ação tomada em um dado estado do ambiente é caracterizada por um sinal de reforço. O
desafio é enxergar de que forma essas ações influenciam o retorno como um todo.
Além do agente e do ambiente, o sistema de aprendizado por reforço pode ser defi-
nido em quatro principais elementos, política, sinal de reforço, função de valor e opcio-
nalmente um modelo do ambiente. O agente observa o estado stß
A cada passo de tempo em que ações são tomadas um sinal de reforço rt é fornecido
ao agente. O objetivo do agente é aprender uma política ótima p⇤ (estratégia de controle)
que maximize o retorno esperado (acumulado). O grande desafio é aprender a mapear os
estados em ações por tentativa e erro. O processo de aprendizagem por reforço é ilustrado
na figura 4.1.
Este problema é formalizado matematicamente como um Processo de Decisão de Mar-
1Os métodos de iteração por política não serão abordados neste trabalho

4.2. PROCESSO DE DECISÃO DE MARKOV 31
AGENTE
AMBIENTE
Figura 4.1: Interação do agente com ambiente na aprendizagem por reforço[Sutton & Barto 2018].
kov (PDM) que será definido na seção seguinte, enquanto a função de valor será definida
mais adiante na seção 4.3.
4.2 Processo de Decisão de Markov
Uma tarefa de aprendizado por reforço que satisfaz a propriedade de Markov pode
ser definida por um PDM. A propriedade de Markov define que para um processo de
decisão sequencial os conjuntos de possíveis ações, retornos e probabilidades de transição
dependem apenas do estado e da ação no instante de tempo t.
Considere um PDM em um passo de tempo t 2 T , onde o agente recebe um con-
junto de estados st 2 S e seleciona um conjunto de ações at 2 A, seguido de uma política
p(at/st), que descreve o comportamento do agente, que por exemplo, mapeia st em at ,
recebe uma valor (escalar) de recompensa rt , e faz a transição para o próximo estado st+1,
de acordo com a dinâmica do ambiente, ou modelo (caso seja conhecido), com probabili-
dades de transição de estados P(st+1 = s0,rt+1 = r|st = s,at = a).
Se o PDM for episódico por exemplo, o estado pode ser reiniciado após um um es-
tado terminal ser alcançado. As sequências estados, ações e recompensas em um episódio

32 CAPÍTULO 4. APRENDIZAGEM POR REFORÇO
constitui o lançamento de uma política. Para cada política lançada são acumulados refor-
ços do ambiente, resultando em um retorno acumulado definido por: Rt = ÂT−1k=0 rt+1
Em alguns casos, o PDM pode ser considerado não episódico, onde T ! • e um
fator de desconto g 2 [0,1] é introduzido, resultando em um retorno acumulado definido
como: Rt = •k=0 gkrt+k+1 onde caso g = 0 representa um agente que maximiza apenas
os reforços imediatos; e caso g = 1, a visão do reforço abrange todos os estados futuros
dando a mesma importância para ganhos neste momento e qualquer ganho futuro [Lima
2009]. O objetivo é encontrar a política ótima p⇤ = argmaxpE[R|p], que maximiza o valor
esperado do retorno para todos os estados.
4.3 Função Valor
A função de valor é uma estimativa baseada no retorno futuro esperado (acumulado)
que associa um valor a um estado ou par de estado-ação. A função de valor reflete o qua-
lidade do agente estar em um estado (ou de realizar uma ação em um estado) associado
ao retorno esperado. Quando apenas o estado é levado em consideração, a função valor é
chamada de função valor-estado V (s), enquanto no caso em que a ação também é consi-
derada, a função valor é denominada de função valor estado-ação Q(s,a) (função-Q).
Para um PDM, a função de valor estado dada uma política p representada por V p(s) é
formalmente definida como
V p(s)⌘ Ep{Rt |st = s}= Ep
•
Âk=0
gkrt+k+1|st = s�
(4.1)
onde a função valor de estado ótimo, representado pelas políticas que maximizam o valor
esperado, é definida como V ⇤(s)⌘ maxp
V p(s).
De maneira similar, a função valor estado-ação 2 dada uma política p representada por
Qp(s,a) é definida como
2A função valor estado-ação será usada como modelo padrão neste trabalho.

4.3. FUNÇÃO VALOR 33
Qp(s,a)⌘ Ep{Rt |st = s,at = a}= Ep
•
Âk=0
gkrt+k+1|st = s,at = a�
(4.2)
onde a função valor de estado-ação ótimo, análogo a V ⇤, resulta em Q⇤(s,a)⌘maxp
Qp(s,a).
Rescrevendo a função de valor de estado-ação ótimo como uma equação de otimalidade
de Bellman (iteração de valor Q) [Sutton & Barto 2018] temos que
Q⇤(s,a) = E⇥
rt+1 + gmaxat+1
Q⇤(st+1,at+1)|st = s,at = a⇤
(4.3)
equação que expressa a relação entre o valor do estado-ação presente e o valor de estado-
ação sucessor [Sutton & Barto 2018]. Esta relação pode ser representada por meio de um
diagrama de backup como mostra a figura 4.2.
Figura 4.2: Diagrama de backup para V p e Qp
[Sutton & Barto 2018].
Existem diferentes métodos para resolver problemas de aprendizagem por reforço
como programação dinâmica, Monte Carlo, diferença temporal, semi-gradiente, gradi-
ente de políticas, ator crítico e etc. A maioria destes algoritmos envolve calcular a função
valor estado-ação (ou função valor estado). Resolver estes problemas consiste em defi-
nir uma política ótima p⇤ a partir de Q⇤(s,a) = E[rt+1 + gmaxa0Q⇤(s0,a0)|st = s,at = a]
(Equação de otimalidade de Bellman), onde a0 representa as possíveis ações que podem
ser tomadas a partir de um estado futuro st+1 denotado por s0 [Sutton & Barto 2018]. A
partir do cálculo de Q⇤ a política ótima é dada por p⇤(s) = argmaxa Q⇤(s,a).

34 CAPÍTULO 4. APRENDIZAGEM POR REFORÇO
4.4 Diferença Temporal (Temporal Difference - TD)
A aprendizagem por diferença temporal é um método central do aprendizado por re-
forço. No aprendizado T D a função de valor V (s) é calculada diretamente a partir do
erro T D, livre de modelo, de forma online e completamente incremental. A regra de atu-
alização da função de valor é dada por V (s) V (s)+a[Rt + gV (st+1)−V (s)], onde a
representa a taxa de aprendizagem e o termo Rt + gV (st+1)−V (s) é chamado de erro T D
[Sutton & Barto 2018].
4.4.1 Q-learning
Um dos principais algoritmos da classe TD utilizado em problemas de aprendizado
por reforço é o Q-learning [Watkins 1989], definido como
Q(st ,at) Q(st ,at)+a[rt+1 + gmaxat+1
Q(st+1,at+1)−Q(st ,at)] (4.4)
O algoritmo Q-learning é demonstrado em forma de pseudocódigo (ver algoritmo 1),
onde os termos (s,a) representam os valores de estado, ação em um passo de tempo t e
(a0,s0,r) representam o estado, a ação e o sinal de reforço em um passo de tempo t +1.
Algoritmo 1: Algoritmo Q-Learning1 início2 Inicialize Q(s,a) aleatoriamente3 repita4 Inicialize s5 repita6 Selecione a a partir de s utilizando p derivada de Q (por ex. e-gulosa)7 Receba a e observe os valores de r e s0
8 Q(s,a) Q(s,a)+a[r+ gmaxa0
Q(s0,a0)−Q(s,a)]
9 até o passo final do episódio ser atingido;10 até o episódio máximo ser atingido;11 fim

4.4. DIFERENÇA TEMPORAL (TEMPORAL DIFFERENCE - TD) 35
Uma de suas vantagens é a capacidade de aproximar-se diretamente de Q⇤, indepen-
dente da política seguida. A política continua a desempenhar um importante papel pois
determina quais pares estado-ação são visitados e atualizados. Porém, para garantir a con-
vergência é necessário apenas que todos os pares continuem sendo visitados e atualizados
[Sutton & Barto 2018]. A política e-gulosa citada no algoritmo 1 é uma estratégia que
permite que essa condição seja garantida sendo definida como
p(s,a) =
8
>><
>>:
1− e+ e|a(s)| ,se a = a⇤ = argmaxa q(s,a)
e|a(s)| ,se a 6= a⇤
(4.5)
A política e-gulosa seleciona a ação aleatória com probabilidade e, e a ação que re-
torna o maior valor esperado com probabilidade (1− e). Assim, o controle da gula (ale-
atoriedade) é estabelecido por e, enquanto |a(s)| corresponde ao número de ações que
podem ser executadas a partir de um estado s [Lima 2009].
Sabe-se que a dimensão da estrutura de armazenamento da função Q, necessária para
se obter uma política ótima, cresce em função do número de estados e de ações. Ao se
analisar esse crescimento, percebe-se que o mesmo ocorre de maneira exponencial (mal-
dição da dimensionalidade), o que implica a impossibilidade de execução de um algoritmo
para certas instâncias de um problema pelo esgotamento de recursos computacionais ou
inviabilidade do tempo na obtenção de sua saída [Costa 2017].
4.4.2 Semi-gradient Q-learning
O Q-learning é um método onde os valores de estado-ação ou as políticas precisam
estar armazenados em uma estrutura de dados em forma de tabela. Em vários problemas
em que o aprendizado por reforço pode ser utilizado o espaço de estado é combinacional
(muitas possibilidades).
Em problemas com um grande espaço de estados é inviável armazenar ou computar

36 CAPÍTULO 4. APRENDIZAGEM POR REFORÇO
em tempo hábil soluções de casos como este. Além disso, em diversas situações será
impossível visitar todos os estados, de maneira que as decisões em situações como esta
devem ser generalizadas a partir de estados visitados anteriormente e que de alguma forma
expressem um senso de similaridade ao estado em questão. A palavra chave deste pro-
blema é generalização e a questão principal é entender como a experiência obtida pelo
agente em um número limitado de estados pode produzir boas aproximações sobre um
grande espaço de estados.
Uma forma de lidar com este tipo de problema é utilizar aproximadores de função. O
aproximador de função tenta generalizar a partir de exemplos uma função completa. O
algoritmo online mais popular utilizado no cálculo de iteração de valor aproximado é o
Q-learning [Busoniu et al. 2010]. No Q-learning tradicional a atualização da função-Q é
feita segundo a equação Q(st ,at) Q(st ,at)+a[rt+1 + gmaxat+1
Q(st+1,at+1)−Q(st ,at)],
após observar o próximo estado st+1 e o reforço rt+1, resultante da escolha de uma ação
at em um estado st . Uma forma simples e direta de integrar o conceito de aproximadores
de função ao algoritmo Q-learning é utilizar o método gradiente descendente (Q-learning
baseado em gradiente) [Sutton & Barto 2018], wo que requer um aproximador diferen-
ciável em seus parâmetros .
A função-Q aproximada em um dado tempo t é representada pelo termo Q(st ,at ;qt)
ou Q(st ,at), colocando a dependência do parâmetro implícita. Com intuito de derivar o
Q-learning baseado no gradiente, assume-se por hora que após a tomada de uma ação at
em um dado estado st , é fornecido ao algoritmo um valor estado-ação ótimo verdadeiro
do par estado-ação atual Q⇤(st ,at), bem como o próximo estado st+1 e o reforço rt+1.
Sob estas circunstâncias, o algoritmo pode ter como objetivo minimizar o erro quadrático
entre o valor ótimo e o valor estimado
qt+1 = qt −12
at∂
∂qt
Q⇤(st ,at)− Q(st ,at)
�2
= qt +at
Q⇤(st ,at)− Q(st ,at)
�
∂
∂qtQ(st ,at)
(4.6)

4.4. DIFERENÇA TEMPORAL (TEMPORAL DIFFERENCE - TD) 37
entretanto, o valor Q⇤(st ,at) não é disponibilizado (livre de modelo), mas esse valor pode
ser substituído por um valor estimado rt+1 + gmaxat+1
Qt(st+1,at+1) oriundo da iteração de
valor (4.3), resultando na regra de atualização de parâmetros do Q-learning aproximado
qt+1 = qt +at
rt+1 + gmaxat+1
Qt(st+1,at+1)− Q(st ,at)
�
∂
∂qtQ(st ,at) (4.7)
onde o termo entre colchetes é na verdade uma aproximação da diferença temporal [Busoniu
et al. 2010].
Considerando por exemplo um aproximador linear, a regra de atualização é simplifi-
cada
qt+1 = qt +at
rt+1 + gmaxat+1
(fT (st+1,at+1)qt)−fT (st ,at)qt
�
f(st ,at) (4.8)
onde f(st ,at) representa o vetor de característica.
Assim como no Q-learning tradicional, aproximar uma função-Q requer a necessidade
de exploração. Como exemplo o algoritmo 2 apresenta em forma de pseudocódigo o Q-
learning baseado em gradiente com um aproximador linear e exploração e-gulosa.
Algoritmo 2: Algoritmo Q-Learning com aproximador de função linear1 início2 Inicialize o vetor de parâmetros, por ex. q0 03 repita4 Inicialize s5 repita6 Selecione a a partir de s utilizando p derivada de fT (s0,a0)qt (por ex. e-gulosa)7 Receba a e observe os valores de r e s0
8 qt+1 qt +at
r+ gmaxa0
(fT (s0,a0)qt)−fT (s,a)qt
�
f(s0,a0)
9 até o passo final do episódio ser atingido;10 até o episódio máximo ser atingido;11 fim
O Q-learning pode ser combinado com uma variedade de aproximadores, aproxi-
madores lineares, regras baseadas em fuzzy, redes neurais entre outros [Busoniu et al.

38 CAPÍTULO 4. APRENDIZAGEM POR REFORÇO
2010]. A utilização de redes neurais em conjunto com aprendizado por reforço remete
aos anos 90 [Lin 1993], [Tesauro 1995], [Bertsekas & Tsitsiklis 1996], [Riedmiller 2005],
[Schmidhuber 2015]. Sua utilização para estimar uma função-Q é instável e pode até di-
vergir [Riedmiller 2005]. Porém com as recentes conquistas dos métodos de deep lear-
ning [LeCun et al. 2015a], [Goodfellow et al. 2016], seja por conta da explosão de dados,
poder computacional e novos algoritmos, o paradigma de aprendizado por reforço está
cada vez mais em evidência [Li 2017].
Deep Reinforcement Learning é caracterizado quando técnicas de deep learning são
utilizadas para aproximar uma função de valor, V (s;q) ou Q(s,a;q). Neste caso os pa-
râmetros são pesos sinápticos w das redes. Para atualização dos pesos geralmente é uti-
lizado o método gradiente descendente estocástico que não garante convergência e pode
até mesmo tornar o aprendizado instável [Riedmiller 2005]. Entretanto, em conjunto
com a técnica de repetição de experiências [Lin 1993] os recentes trabalhos DQN [Mnih
et al. 2015] e AlphaGo [Silver et al. 2016] conseguiram demonstrar a estabilidade no
aprendizado das redes conseguindo atingir importantes resultados.
A técnica de repetição por experiência armazena o histórico et = (st ,at ,rt ,st+1) da
interação do agente com o meio a cada passo de tempo t em uma estrutura de dados
Dt = e1, . . . ,et . Durante o treinamento, as atualizações são feitas a partir de amostras ou
pequenos lotes (minibatch) da experiência (s,a,r,s0)⇠U(D), retiradas aleatoriamente de
uma distribuição uniforme da estrutura. Em seguida os parâmetros são atualizados a cada
iteração i em relação a função de custo
Li(wi) = E(s,a,r,s0)⇠(D)
✓
r+ gmaxa0
Q(s0,a0;w−i )−Q(s,a;wi)
◆2�
(4.9)
onde wi representa os parâmetros da rede na iteração i e w−i representa os parâmetros
fixados por uma constante C calculados na iteração/em iterações passada(s), usados para
computar o valor alvo Q na iteração i.

4.4. DIFERENÇA TEMPORAL (TEMPORAL DIFFERENCE - TD) 39
Algoritmo 3: Deep Q-Network com repetição por experiência1 início2 Inicialize a memória de repetição D com capacidade N3 Inicialize a função de valor estado-ação Q com pesos w aleatórios4 Inicialize a função de valor estado-ação alvo Q com pesos w− = w aleatórios5 repita6 Inicialize s e realize o pré processamento f(s)7 repita8 Selecione a em s utilizando p derivada de Q(s,a;w) (por ex. e-gulosa)9 Receba a e observe os valores de r e s0
10 Armazene (f,a,r,f0) em D11 Retire (fi,ai,ri,fi+1) aleatoriamente de D
12 yi
8
<
:
ri , se episódio terminar em i+1ri + gmax
a0Q(f0,a0;w−)
13 Calcule o gradiente de (yi −Q(f(s),a;w))2 em relação aos pesos w14 A cada passo C reinicie Q = Q15 até o passo final do episódio ser atingido;16 até o episódio máximo ser atingido;17 fim
A formalização matemática do algoritmo 3 é na verdade uma extensão das equações
4.6,4.7 do Q-learning aproximado demonstrada na subseção 4.4.2 [Sutton & Barto 2018].
Nossa proposta é utilizar estes conceitos de deep reinforcement learning no problema
dos k-servos na tentativa de reduzir o problema da maldição de dimensionalidade e tratar
problemas reais de grandes dimensões.

40 CAPÍTULO 4. APRENDIZAGEM POR REFORÇO

Capítulo 5
Aprendizagem por reforço profundo
aplicado ao PKS
Neste capítulo o problema dos k-servos é modelado como um problema de imagem
inserido em uma abordagem de aprendizagem por reforço com solução aproximada por
uma rede neural perceptron de múltiplas camadas. O objetivo deste capítulo é apresentar
uma solução alternativa ao problema dos k-servos capaz de aliviar o problema da maldi-
ção da dimensionalidade, principalmente quando o número de servos é aumentado. Esta
característica torna os métodos tabulares rapidamente ineficientes, visto que o problema
apresenta uma complexidade computacional que cresce exponencialmente com o aumento
do número de servos. O algoritmo proposto aqui apresentado é de propósito geral e pode
ser aplicado em diferentes tipos de problemas como o problema de gerenciamento de ma-
nutenção de sondas de petróleo, logística de deslocamento de transportes de emergência,
localização competitiva de recursos entre outros problemas.
5.1 Visão geral
Em uma abordagem tradicional de aprendizagem por reforço, o agente observa o es-
tado st de um ambiente, executa uma ação at e recebe uma recompensa rt+1. Em uma
abordagem de aprendizagem por reforço profundo visual [Lange & Riedmiller 2010],

42CAPÍTULO 5. APRENDIZAGEM POR REFORÇO PROFUNDO APLICADO AO PKS
abordada neste trabalho, o agente percebe a dinâmica interna do ambiente a partir de
observações ot 2 O (imagem) com semântica desconhecida, como mostra a figura 5.1.
Figura 5.1: Interação agente-ambiente em uma abordagem de aprendizagem por reforçoprofundo.
5.2 Observações
O estado interno st do ambiente é definido por uma imagem ot 2 R+2 que codifica a
distribuição dos servos k(t) e da requisição s(t)j a cada passo de tempo t. O número de
pixels p deve satisfazer a condição de que n p, para que todas as distribuições possí-
veis possam ser codificadas. A codificação é feita por meio dos níveis de intensidade dos
pixels definidos em um intervalo [Lmin L Lmax] (escala de cinza), onde a cor branca é
utilizada (Lmax = 1) para definir os servos, o cinza médio (L = 0,5) a requisição e o preto
(Lmin = 0) os pixels não ocupados ou excedentes. Depois disso, a imagem é convertida
em um vetor de características xt 2 Rn⇥1 cujo valor numérico de requisição é convertido
em um valor negativo e os pixels excedentes são removidos. Essa representação é de-
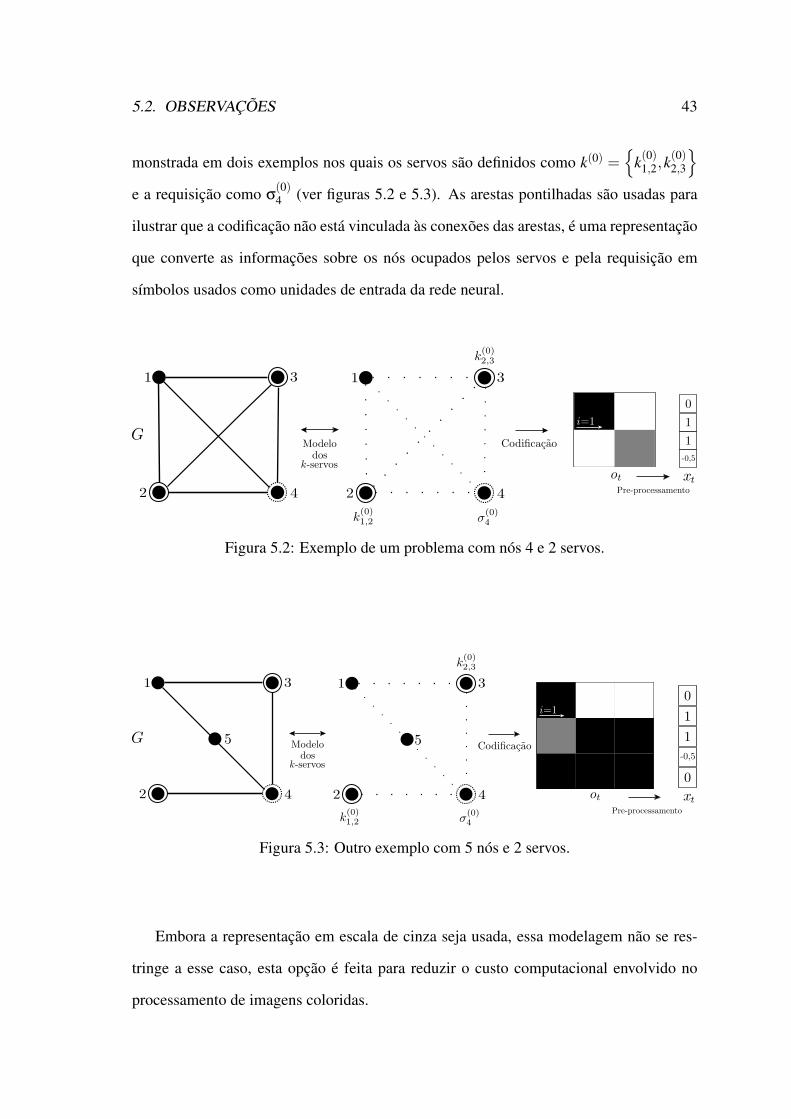
5.2. OBSERVAÇÕES 43
monstrada em dois exemplos nos quais os servos são definidos como k(0) =n
k(0)1,2,k(0)2,3
o
e a requisição como s(0)4 (ver figuras 5.2 e 5.3). As arestas pontilhadas são usadas para
ilustrar que a codificação não está vinculada às conexões das arestas, é uma representação
que converte as informações sobre os nós ocupados pelos servos e pela requisição em
símbolos usados como unidades de entrada da rede neural.
Figura 5.2: Exemplo de um problema com nós 4 e 2 servos.
Figura 5.3: Outro exemplo com 5 nós e 2 servos.
Embora a representação em escala de cinza seja usada, essa modelagem não se res-
tringe a esse caso, esta opção é feita para reduzir o custo computacional envolvido no
processamento de imagens coloridas.

44CAPÍTULO 5. APRENDIZAGEM POR REFORÇO PROFUNDO APLICADO AO PKS
5.3 Ações e observações futuras
Depois de definida a distribuição dos servos e da requisição, um dos servos k(t)l,i deve
ser movido para responder à solicitação s(t)j caracterizando uma ação at . Nessa situação,
o número de ações permitidas é igual a k, o número de servos, onde at 2 {1,2, . . . ,k}. A
distribuição dos servos e da requisição, associada a uma ação executada akl , caracteriza
uma instância do problema. Depois que a ação é executada, uma nova distribuição dos
servos k(t+1) é caracterizada e outra situação acontece quando uma solicitação está na
eminência de acontecer, nesse caso, a requisição s(t+1)j pode aparecer em um dos nós
não ocupados, caracterizando um número (nk)⇥ k de ações possíveis at+1 que define as
observações futuras xt+1.
Figura 5.4: Espaço de ações para o exemplo da figura 5.2
5.4 Rede neural perceptron de múltiplas camadas
A rede consiste de hn camadas ocultas composta por uma função de ativação sigmóide
ou retificadores lineares (mais de uma camada oculta) e uma camada de saída linear de-
finida em função do número de servos. A saída linear é usada para representar toda a
faixa de possíveis números reais de saída (ver figura 5.5). Como estamos usando o custo
envolvido no deslocamento dos servos como recompensa, mesmo que os limites da saída
não sejam conhecidos, há uma garantia de que seus valores serão representados.
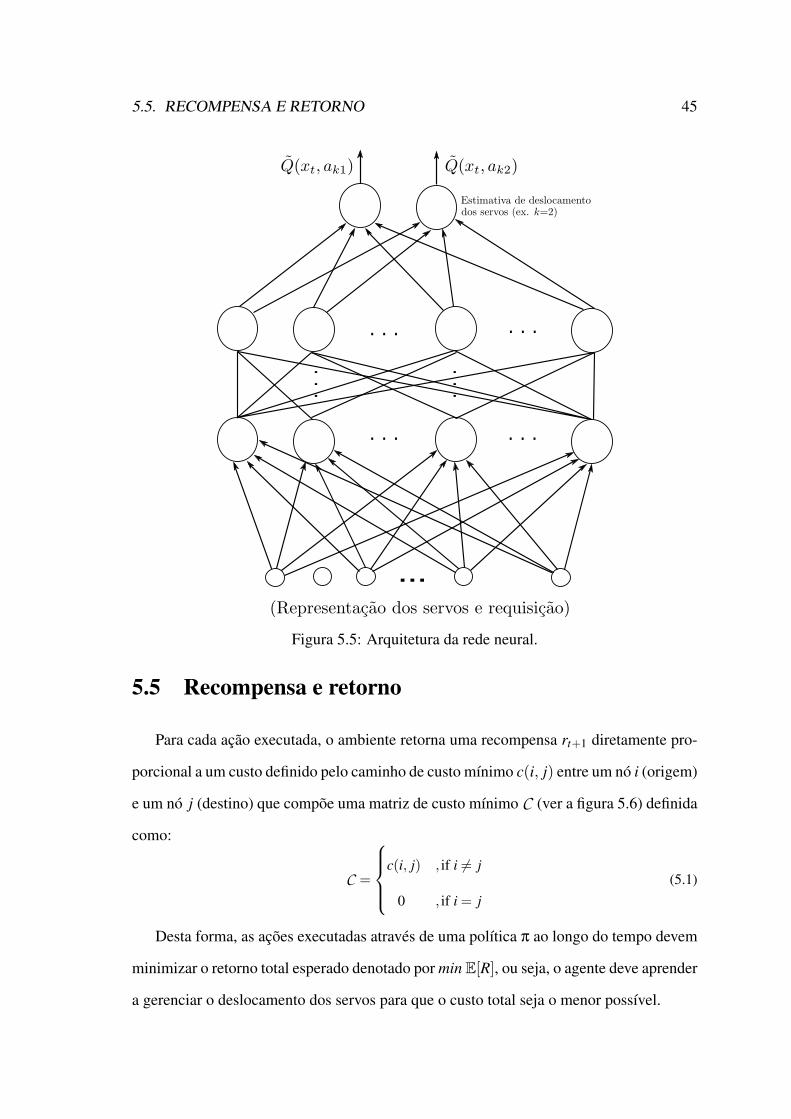
5.5. RECOMPENSA E RETORNO 45
. . .. . . . . .
. . .
. . .
. . . . . .
Figura 5.5: Arquitetura da rede neural.
5.5 Recompensa e retorno
Para cada ação executada, o ambiente retorna uma recompensa rt+1 diretamente pro-
porcional a um custo definido pelo caminho de custo mínimo c(i, j) entre um nó i (origem)
e um nó j (destino) que compõe uma matriz de custo mínimo C (ver a figura 5.6) definida
como:
C =
8
>><
>>:
c(i, j) , if i 6= j
0 , if i = j(5.1)
Desta forma, as ações executadas através de uma política p ao longo do tempo devem
minimizar o retorno total esperado denotado por min E[R], ou seja, o agente deve aprender
a gerenciar o deslocamento dos servos para que o custo total seja o menor possível.
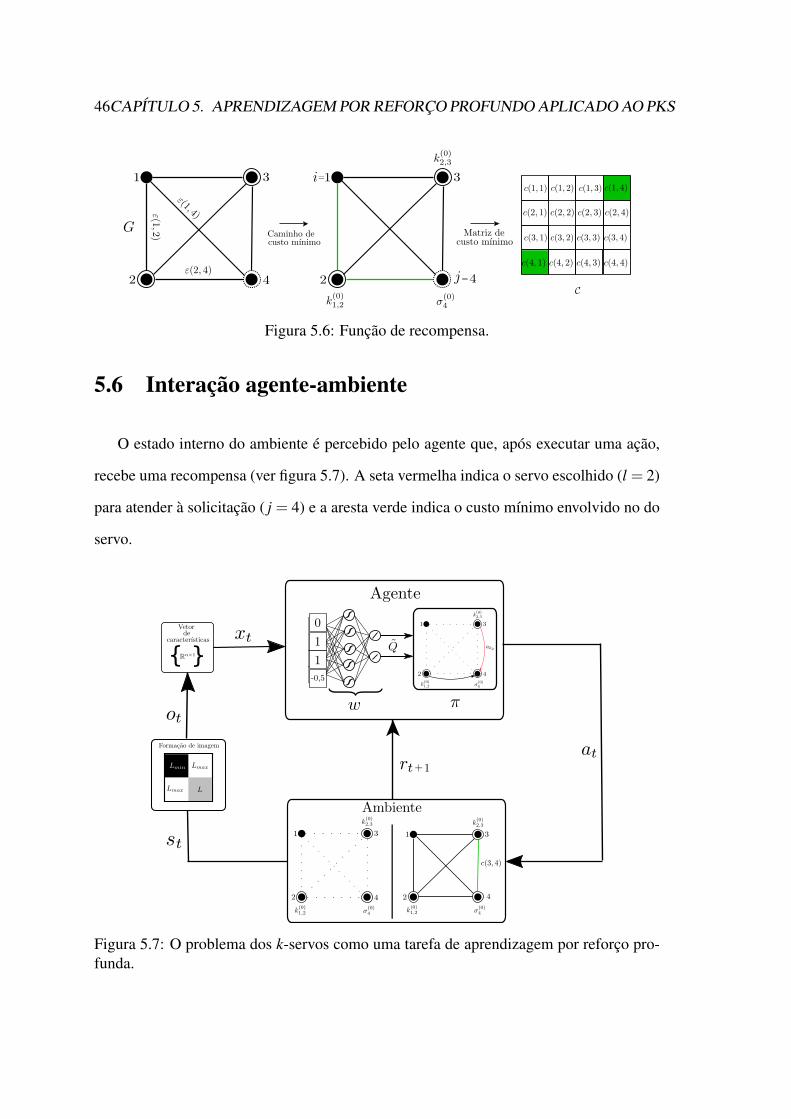
46CAPÍTULO 5. APRENDIZAGEM POR REFORÇO PROFUNDO APLICADO AO PKS
Figura 5.6: Função de recompensa.
5.6 Interação agente-ambiente
O estado interno do ambiente é percebido pelo agente que, após executar uma ação,
recebe uma recompensa (ver figura 5.7). A seta vermelha indica o servo escolhido (l = 2)
para atender à solicitação ( j = 4) e a aresta verde indica o custo mínimo envolvido no do
servo.
{ {
Figura 5.7: O problema dos k-servos como uma tarefa de aprendizagem por reforço pro-funda.

5.7. ALGORITMO 47
5.7 Algoritmo
A partir de G, o ambiente é codificado em ot e convertido em xt ; o vetor de entrada
é propagado para frente através dos neurônios da rede, aproximando-se da função Q. Em
seguida, a política p mapeia a ação akl através do algoritmo e-guloso definido por:
akl =
8
>><
>>:
argminat
Q(xt ,at ;wt) com probabilidade 1− e
aleatório (uniform) com probabilidade e
(5.2)
onde e representa o fator de aleatoriedade que garante o equilíbrio da estratégia de in-
tensificação de exploração de novas soluções, aumentando o poder de generalização da
rede. Depois que a ação é definida, a recompensa rt+1 é recebida e o próximo estado st+1
representado por xt+1 é observado. Desta forma, o sinal de erro, definido como:
DQ(xt ,at) =
Qalvo
z }| {�
c(i, j)+ gminat+1
Q(xt+1,at+1;w)| {z }
Q f uturo
�
−Q(xt ,at ;w) (5.3)
deve ser minimizado para que o valor previsto de Q, denotado por Q(xt ,at ;w), seja apro-
ximado ao valor Q de destino (Qtarget) de acordo para a função objetivo de Huber [Huber
& others 1964] definido como:
Ld(DQ) =
8
>><
>>:
12(Q
alvo −Q(xt ,at ;w))2 |DQ| d
d(|Qalvo −Q(xt ,at ;w)|− 12 .d) caso contrário
(5.4)
onde d = 1 representa o limite de comportamento da função objetivo. Para valores abaixo
de d, a função objetivo se comporta como uma função quadrática, enquanto que para
valores maiores se comporta como uma função linear. Essa característica fornece maior
capacidade de convergência do que um comportamento puramente quadrático (erro qua-
drado médio), pois a recompensa está diretamente ligada ao custo do deslocamento do

48CAPÍTULO 5. APRENDIZAGEM POR REFORÇO PROFUNDO APLICADO AO PKS
servo, impedindo assim que os outliers" tenham um grande impacto no aprendizado.
O vetor peso w, inicializado de acordo com Glorot & Bengio [2010] (normalizado em
relação as camadas anterior), é ajustado através do algoritmo de retropropagação para que
o erro possa ser minimizado [LeCun et al. 2015b]. Dessa maneira, diferenciando a função
objetivo em termos dos pesos, tem-se que seu gradiente é definido como:
—wLd(DQ) =
8
>><
>>:
(Qalvo −Q(xt ,at ;w))—wQ(xt ,at) |DQ| d
Qalvo−Q(xt ,at ;w)|Qalvo−Q(xt ,at ;w)|
caso contrário(5.5)
O algoritmo proposto pertence à família de algoritmos baseados em gradiente adap-
tado ao problema dos k-servos e seu pseudocódigo é mostrado no algoritmo 4.
Algoritmo 4: Q-learning com MLP para o problema dos k-servos1 G,a,e,g, t, M e B2 Inicialize w, w− = w3 Calcule C
4 repita5 Codifique s em o6 Faça o pré processamento de o em x7 Determine a ação (e-guloso)8 Receba r e observe s0
9 Armazene a experiência e em M10 Remova um conjunto de amostras eb ⇠U(M )11 Atualize w a partir das amostras reduzindo o erro de Huber:
Ld(DQ) =
⇢ 12 (Q
alvo − Q(xb,ab))2 |DQ| d
d(|Qalvo − Q(xb,ab)|−12 .d) caso contrário
onde Qalvo = c(i, j)+ gmina0b
Q(x0b,a0b;w−)−Q(xb,ab;w)
12 Após t passos w− = w13 até o passo final do episódio ser atingido;

Capítulo 6
Resultados
O objetivo deste capítulo é analisar a escalabilidade da abordagem de aprendizagem
por reforço tradicional definida por meio do algoritmo Q-learning comparando seu desem-
penho com o algoritmo proposto para diferentes configurações do problema dos k-servos.
O algoritmo guloso também foi considerado objeto de estudo deste trabalho pois possui
bom desempenho quando as requisições são geradas a partir de distribuições uniformes
[Rudec et al. 2013].
Para analisar o desempenho dos agentes, o problema dos k-servos foi definido em um
contexto de gerenciamento de tráfego inteligente denotado como o problema de emer-
gência móvel online. Desta forma, as políticas de decisões geradas pelos agentes foram
analisadas a partir de testes de desempenho que levaram em consideração o deslocamento
das ambulâncias para sequências de urgências de curto, médio e longo prazo. Além dos
testes de desempenho realizados, o comportamento de cada agente foi analisado durante
a fase de treinamento em uma configuração do problema de pequena dimensão.
Os códigos foram elaborados no Matlab e em Python e testados em um computa-
dor equipado com processadores de 4 gigahertz (4 núcleos), 32 gigabytes de memória e
sistema operacional Windows 10.

50 CAPÍTULO 6. RESULTADOS
6.1 Problema de emergência móvel online
O problema dos k-servos pode ter diferentes variantes, como por exemplo o problema
dos k-servos heterogêneos, no qual os servos podem desempenhar diferentes tarefas es-
pecíficas do problema. Em um problema de emergência móvel é comum existirem ambu-
lâncias com diferentes funcionalidades, entretanto, para simplificar o problema, neste tra-
balho as ambulâncias foram consideradas iguais caracterizando o problema dos k-servos
homogêneos.
6.1.1 Conceito
Para testar o algoritmo, definimos o problema dos k-servos em um contexto de ge-
renciamento de tráfego inteligente similar ao apresentado na seção 2.3, fornecendo uma
visão prática de como o algoritmo proposto pode ser aplicado. Com isso, o problema foi
definido da seguinte forma: a população de uma cidade deve ser atendida em casos de
emergência médica caracterizada por situações que podem levar a sofrimento, sequelas
ou morte. As emergências devem ser atendidas por unidades de serviço móvel (iguais),
denotadas por ambulâncias, distribuídas em diferentes locais da cidade. O objetivo do
problema é minimizar o tempo total associado ao atendimento das emergências. O trans-
porte do paciente para uma unidade de saúde não foi considerado, apenas a situação de
mover a ambulância para atender uma emergência.
6.1.2 Formalização
Formalizando em termos do problema dos k-servos, temos que G representa uma ci-
dade, cada nó n 2 G é um local (região) de emergência diferente na cidade, k representa
a quantidade de ambulâncias (servos) e S, a sequência de emergências (requisições) que
podem surgir em qualquer local da cidade. O atendimento de uma emergência é caracte-
rizado quando uma ambulância k(t)l,i é movida para o local da emergência s(t)j . Associado

6.2. ESTUDO DE CASOS 51
ao deslocamento de cada ambulância, existe um custo ct(i, j) definido aqui como sendo
o tempo gasto (unidade indefinida) no atendimento de cada emergência. O objetivo é
minimizar o tempo total de ÂTt ct(i, j) envolvido no atendimento de uma sequência de
emergências.
6.2 Estudo de casos
Para verificar o desempenho do algoritmo proposto dois diferentes casos foram con-
siderados: Em um dos casos, uma cidade, gerada aleatoriamente (distribuição uniforme),
foi definida como tendo 9 regiões e 2 ambulâncias disponíveis para atender as emergên-
cias que surgem de forma aleatória (distribuição uniforme) em cada região. Em seguida
o número de ambulâncias foi duplicado. Esta cidade foi definida por um número elevado
de conexões no qual aproximadamente 90% das regiões apresentaram ligações diretas en-
tre si, caracterizando um grafo de alta densidade. Em outro caso, uma cidade, também
gerada aleatoriamente (distribuição uniforme), foi definida com 10 regiões e 2 ambulân-
cias disponíveis para atender as emergências que surgem de forma aleatória (distribuição
uniforme) em cada região. Neste caso a cidade foi definida por um número de conexões
médio entre as regiões; aproximadamente 50% das regiões apresentaram conexão direta
entre si, caracterizando um grafo esparso. Em seguida, esta cidade foi expandida para um
número de 15 e 20 regiões; após a expansão em regiões foi feito um aumento gradativo
do número de ambulâncias de k = 2 até k = 5.
6.2.1 Configurações iniciais
A configuração com n = 9 e k = 2 teve a distribuição inicial das ambulâncias definida
de maneira aleatória por k(0) =n
k(0)1,8,k(0)2,9
o
e s(0)1 . Neste caso o agente observa uma
imagem o 2 [0,1]d com d = 3⇥ 3 = 9 pixeis mapeados em x 2 [−1,1]10⇥1. O custo
envolvido no deslocamento de uma das ambulâncias, como a ambulância l = 1, localizada

52 CAPÍTULO 6. RESULTADOS
em i = 8, para atender uma emergência em j = 1 define a recompensa rt+1 = c�
k(0)1,8,s(0)1�
.
Para o caso em que as ambulâncias foram aumentadas para k = 4 a distribuição inicial foi
definida por k(0) =n
k(0)1,3,k(0)2,7,k
(0)3,8,k
(0)4,9
o
.
Para as configurações com n = 10 e n = 15 foi considerada uma distribuição inicial
das ambulâncias (k = 2) definida de maneira aleatória por k(0) =n
k(0)1,2,k(0)2,8
o
e s(0)6 . A
partir dela o agente observa uma imagem o 2 [0,1]d com d = 4 ⇥ 4 = 16 pixeis ma-
peados em x 2 [−1,1]10⇥1. O custo envolvido no deslocamento de uma das ambulân-
cias, como a ambulância l = 1, localizada em i = 2, para atender uma emergência em
j = 6 define a recompensa rt+1 = c�
k(0)1,2,s(0)6
�
. Na configuração com 20 regiões o agente
observa inicialmente uma imagem o 2 [0,1]d com d = 5⇥ 5 = 25 pixeis mapeados em
x 2 [−1,1]20⇥1. Para esta configuração, a distribuição inicial das ambulâncias come-
çou em k(0) =n
k(0)1,2,k(0)2,8
o
e foi gradualmente aumentada em k(0) =n
k(0)1,2,k(0)2,8,k
(0)3,9
o
para
k = 3; k(0) =n
k(0)1,2,k(0)2,8,k
(0)3,9,k
(0)4,13
o
para k = 4; e k(0) =n
k(0)1,2,k(0)2,8,k
(0)3,9,k
(0)4,13,k
(0)5,19
o
para
k = 5, com s(0)6 para todos os casos.
Apesar de uma configuração inicial ser necessária a solução do problema não está
restrita a esta condição, a solução pode ser generalizada para diversos tipos de configura-
ções iniciais como será mostrado no teste de desempenho mais a frente. As configurações
iniciais também servem como referência para que os resultados possam ser replicados
6.2.2 Hiperparâmetros
Os hiperparâmetros foram definidos (ver tabelas 6.1 e 6.2) de forma empírica levando
em consideração algumas premissas. Para obter um menor custo esperado a longo prazo
utilizou-se a premissa de que o fator de desconto (g) deve dar mais importância às recom-
pensas futuras do que as imediatas [Sutton & Barto 2018]; Para o fator de aleatoriedade (e)
o intuito foi evitar que as soluções gulosas ficassem presas em mínimos locais, e evitar que
as ações aleatórias tornassem o processo de aprendizagem longo ou até divergente [Sutton
& Barto 2018]; Para a taxa de aprendizagem (a) da rede foi escolhido um valor que não

6.2. ESTUDO DE CASOS 53
aumentasse o potencial de divergência da rede [Haykin 1998], [Sutton & Barto 2018].
Para o Q-learning foi utilizado um valor prático padrão [Sutton & Barto 2018]; Enquanto
os parâmetros tamanho de memória (M), de lote (B) e do período de atualização dos pe-
sos (t) foram definidos em função de valores práticos [Mnih et al. 2015] levando-se em
consideração o aumento da dimensão do problema.
Foram testadas duas arquiteturas, uma profunda e outra rasa. A arquitetura rasa foi
definida por uma camada oculta e uma camada de saída denotada como hn : on, onde
hn representa o número de neurônios da camada oculta e on o número de neurônios da
camada de saída. A quantidade de neurônios utilizados na camada oculta foi definida
empiricamente. A medida que a dimensão do problema foi aumentada, o número de
neurônios utilizados também foram aumentados de tal forma que o modelo definido pela
rede neural conseguisse realizar tomadas de decisões adequadas. Em outro caso, a arqui-
tetura da rede foi definida por quatro camadas ocultas e uma camada de saída dada por
hn1:hn2:hn3:hn3:on, onde hni representa a quantidade de neurônios da i-ésima camada
oculta enquanto on representa o número de neurônios da camada de saída.
O fator de desconto e de aleatoriedade foram os mesmos utilizados tanto no treina-
mento da rede neural como no treinamento do Q-learning. O critério de parada foi de-
finido a partir do valor médio e do desvio padrão do erro de Huber, quando este valores
ficaram abaixo de um valor de referência (q) o treinamento da rede foi interrompido. O
mesmo número de requisições utilizados no treinamento da rede foi o mesmo utilizado
no treinamento do Q-learning.
n,k M B a g e t q w10,2
1000010
0.01 0.9 0.2
100.001 64 : 2
15,20.01
128 : 220,2
30
256 : 220,3
100000 100 0.051024 : 3
20,4 1024 : 420,5 1024 : 5
Tabela 6.1: Tabela de hiperparâmetros I.

54 CAPÍTULO 6. RESULTADOS
n,k M B a g e t q w9,2
10000 10 0.01 0.9 0.2 1016 : 16 : 16 : 16 : 2
9,4 - 32 : 32 : 32 : 32 : 4
Tabela 6.2: Tabela de hiperparâmetros II.
6.3 Análise de desempenho
A solução proposta foi analisada de duas formas, durante a fase de treinamento e a
partir de testes de desempenho, onde o agente foi comparado aos algoritmos Q-learning
e guloso. A estratégia gulosa não requer treinamento e ilustra o comportamento de um
agente que visa um retorno a curto prazo. O algoritmo Q-learning tem a convergência
para a solução ótima garantida se todos os pares estado-ação forem visitados um número
"infinito"de vezes. Considerando o alto custo computacional necessário para atender este
critério, a análise da aprendizagem da rede neural foi realizada para a configuração n = 10
e k = 2.
6.3.1 Curvas de aprendizagem Q-learning
Para gerar a curva de aprendizagem quando os servos estavam localizados nos nós 3
e 5; a requisição surgiu no nó 4 e o servo 1 foi deslocado para atender a requisição, o
valor estado-ação, denotado por valor Q, foi registrado ao longo do tempo. A figura 6.1
demonstra a curva de aprendizagem obtida para os valores estado-ação predito e alvo da
instância�
k1,3,k2,5,s4,ak1
usando o Q-learning tradicional.
6.3.2 Curvas de aprendizagem aproximada
Os valores de Q, predito e alvo, da instância�
k1,3,k2,5,s4,ak1
usando o Q-learning
com rede neural são demonstrados na figura 6.2. A linha verde pontilhada (ver figura 6.2)
representa o valor predito de Q obtido através do algoritmo Q-learning. Ela é utilizada
para ilustrar o comportamento de aprendizagem semelhante entre os algoritmos.
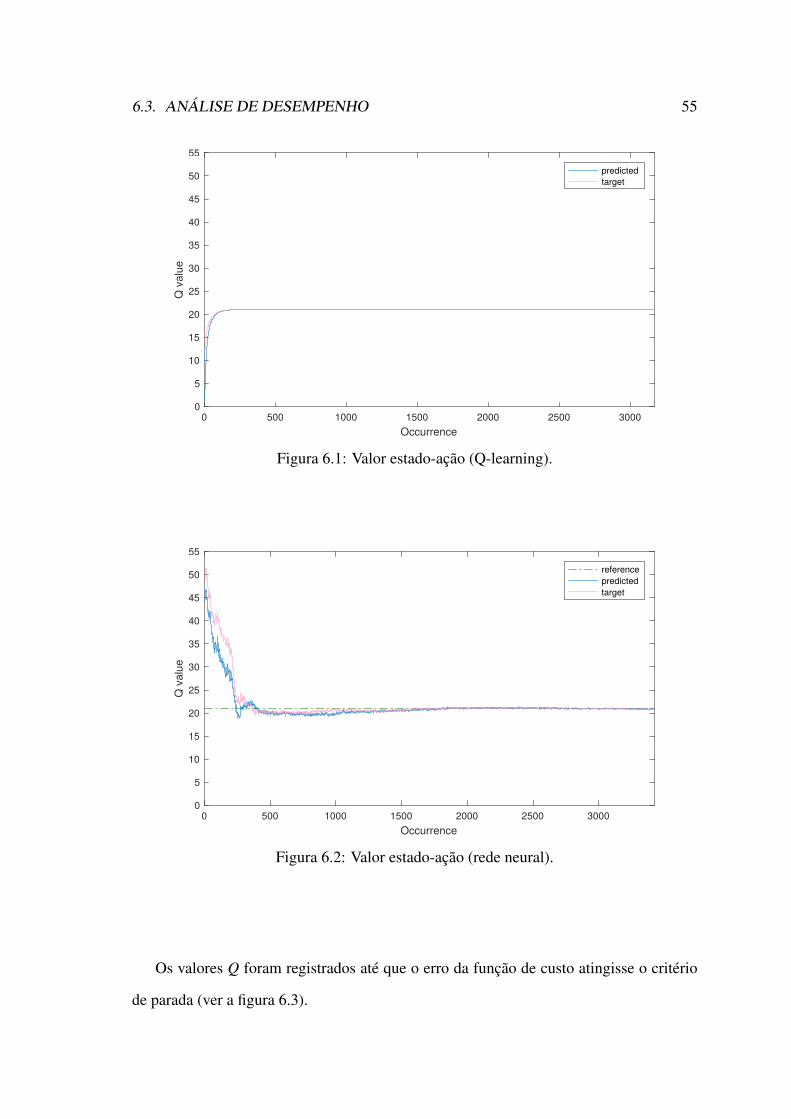
6.3. ANÁLISE DE DESEMPENHO 55
0 500 1000 1500 2000 2500 3000
Occurrence
0
5
10
15
20
25
30
35
40
45
50
55
Q v
alu
epredicted
target
Figura 6.1: Valor estado-ação (Q-learning).
0 500 1000 1500 2000 2500 3000
Occurrence
0
5
10
15
20
25
30
35
40
45
50
55
Q v
alu
e
reference
predicted
target
Figura 6.2: Valor estado-ação (rede neural).
Os valores Q foram registrados até que o erro da função de custo atingisse o critério
de parada (ver a figura 6.3).
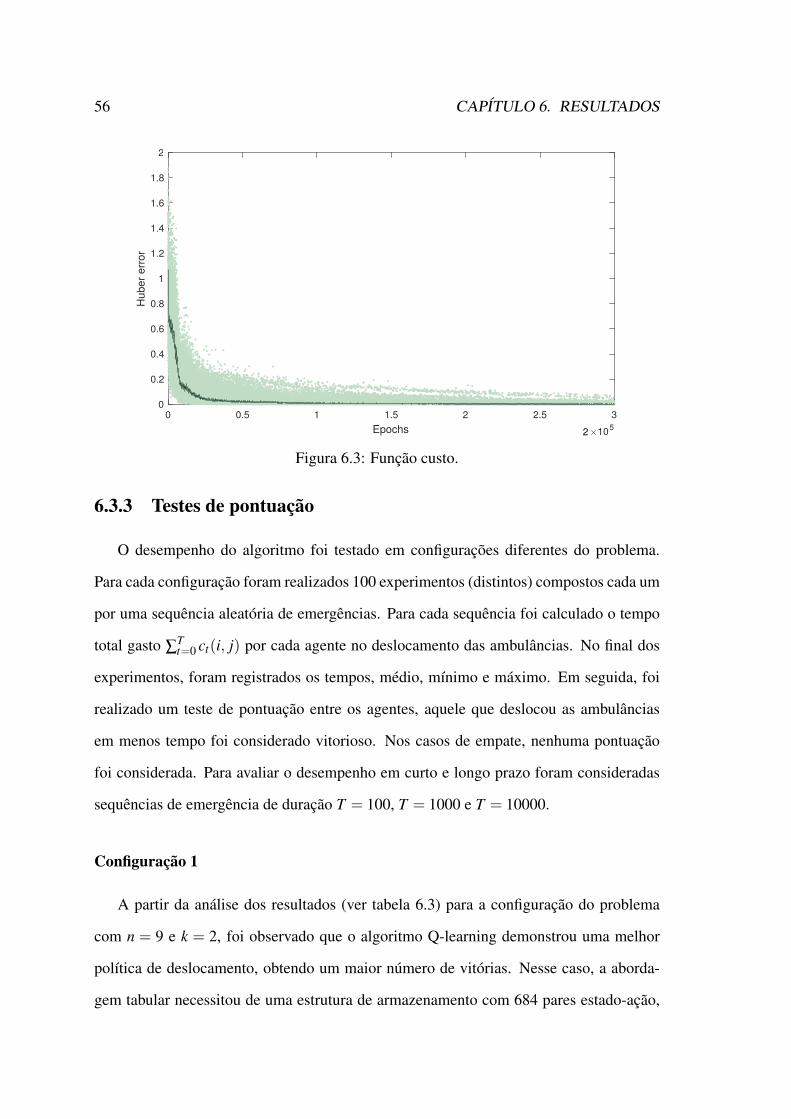
56 CAPÍTULO 6. RESULTADOS
0 0.5 1 1.5 2 2.5 3
Epochs 105
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
Huber
err
or
2
Figura 6.3: Função custo.
6.3.3 Testes de pontuação
O desempenho do algoritmo foi testado em configurações diferentes do problema.
Para cada configuração foram realizados 100 experimentos (distintos) compostos cada um
por uma sequência aleatória de emergências. Para cada sequência foi calculado o tempo
total gasto ÂTt=0 ct(i, j) por cada agente no deslocamento das ambulâncias. No final dos
experimentos, foram registrados os tempos, médio, mínimo e máximo. Em seguida, foi
realizado um teste de pontuação entre os agentes, aquele que deslocou as ambulâncias
em menos tempo foi considerado vitorioso. Nos casos de empate, nenhuma pontuação
foi considerada. Para avaliar o desempenho em curto e longo prazo foram consideradas
sequências de emergência de duração T = 100, T = 1000 e T = 10000.
Configuração 1
A partir da análise dos resultados (ver tabela 6.3) para a configuração do problema
com n = 9 e k = 2, foi observado que o algoritmo Q-learning demonstrou uma melhor
política de deslocamento, obtendo um maior número de vitórias. Nesse caso, a aborda-
gem tabular necessitou de uma estrutura de armazenamento com 684 pares estado-ação,
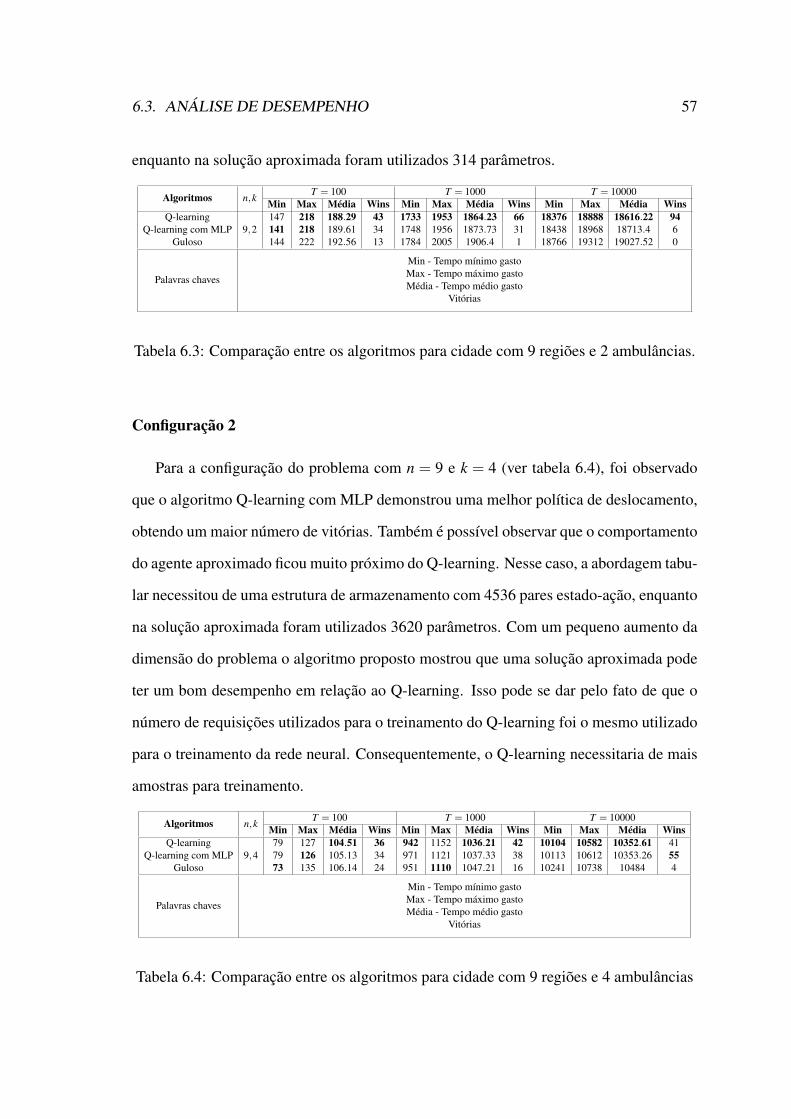
6.3. ANÁLISE DE DESEMPENHO 57
enquanto na solução aproximada foram utilizados 314 parâmetros.
Algoritmos n,kT = 100 T = 1000 T = 10000
Min Max Média Wins Min Max Média Wins Min Max Média WinsQ-learning
9,2147 218 188.29 43 1733 1953 1864.23 66 18376 18888 18616.22 94
Q-learning com MLP 141 218 189.61 34 1748 1956 1873.73 31 18438 18968 18713.4 6Guloso 144 222 192.56 13 1784 2005 1906.4 1 18766 19312 19027.52 0
Palavras chaves
Min - Tempo mínimo gastoMax - Tempo máximo gastoMédia - Tempo médio gasto
Vitórias
Tabela 6.3: Comparação entre os algoritmos para cidade com 9 regiões e 2 ambulâncias.
Configuração 2
Para a configuração do problema com n = 9 e k = 4 (ver tabela 6.4), foi observado
que o algoritmo Q-learning com MLP demonstrou uma melhor política de deslocamento,
obtendo um maior número de vitórias. Também é possível observar que o comportamento
do agente aproximado ficou muito próximo do Q-learning. Nesse caso, a abordagem tabu-
lar necessitou de uma estrutura de armazenamento com 4536 pares estado-ação, enquanto
na solução aproximada foram utilizados 3620 parâmetros. Com um pequeno aumento da
dimensão do problema o algoritmo proposto mostrou que uma solução aproximada pode
ter um bom desempenho em relação ao Q-learning. Isso pode se dar pelo fato de que o
número de requisições utilizados para o treinamento do Q-learning foi o mesmo utilizado
para o treinamento da rede neural. Consequentemente, o Q-learning necessitaria de mais
amostras para treinamento.
Algoritmos n,kT = 100 T = 1000 T = 10000
Min Max Média Wins Min Max Média Wins Min Max Média WinsQ-learning
9,479 127 104.51 36 942 1152 1036.21 42 10104 10582 10352.61 41
Q-learning com MLP 79 126 105.13 34 971 1121 1037.33 38 10113 10612 10353.26 55Guloso 73 135 106.14 24 951 1110 1047.21 16 10241 10738 10484 4
Palavras chaves
Min - Tempo mínimo gastoMax - Tempo máximo gastoMédia - Tempo médio gasto
Vitórias
Tabela 6.4: Comparação entre os algoritmos para cidade com 9 regiões e 4 ambulâncias
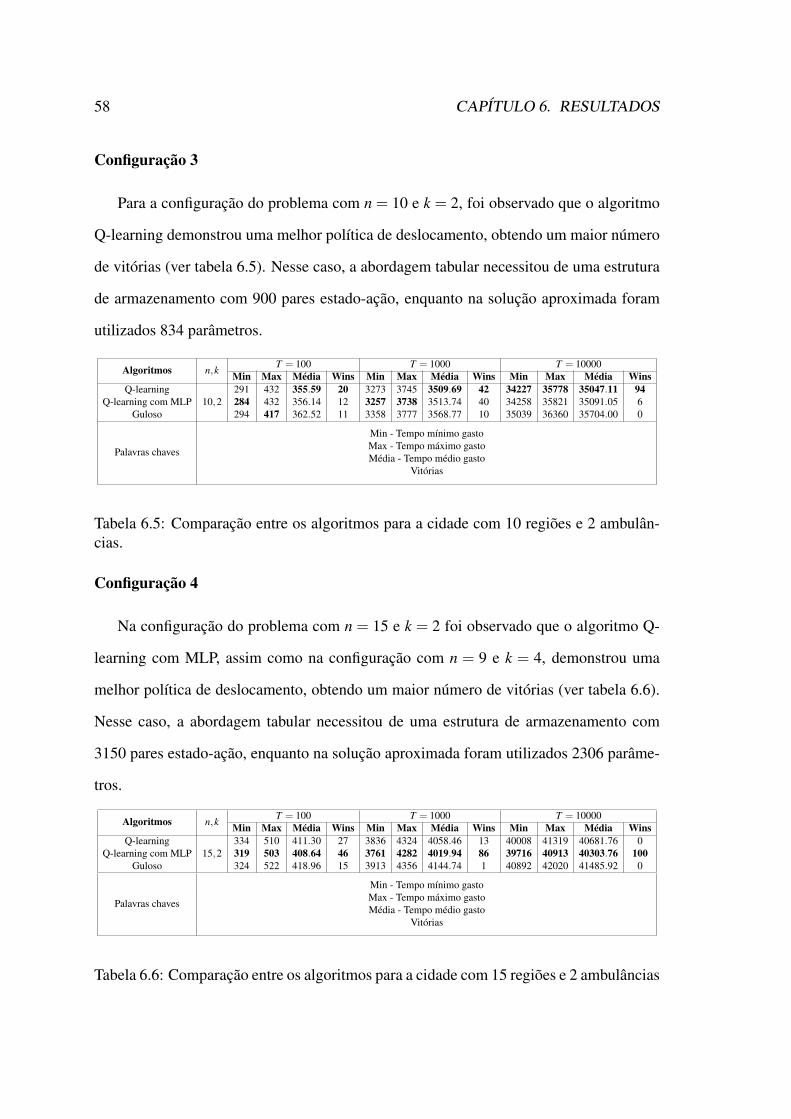
58 CAPÍTULO 6. RESULTADOS
Configuração 3
Para a configuração do problema com n = 10 e k = 2, foi observado que o algoritmo
Q-learning demonstrou uma melhor política de deslocamento, obtendo um maior número
de vitórias (ver tabela 6.5). Nesse caso, a abordagem tabular necessitou de uma estrutura
de armazenamento com 900 pares estado-ação, enquanto na solução aproximada foram
utilizados 834 parâmetros.
Algoritmos n,kT = 100 T = 1000 T = 10000
Min Max Média Wins Min Max Média Wins Min Max Média WinsQ-learning
10,2291 432 355.59 20 3273 3745 3509.69 42 34227 35778 35047.11 94
Q-learning com MLP 284 432 356.14 12 3257 3738 3513.74 40 34258 35821 35091.05 6Guloso 294 417 362.52 11 3358 3777 3568.77 10 35039 36360 35704.00 0
Palavras chaves
Min - Tempo mínimo gastoMax - Tempo máximo gastoMédia - Tempo médio gasto
Vitórias
Tabela 6.5: Comparação entre os algoritmos para a cidade com 10 regiões e 2 ambulân-cias.
Configuração 4
Na configuração do problema com n = 15 e k = 2 foi observado que o algoritmo Q-
learning com MLP, assim como na configuração com n = 9 e k = 4, demonstrou uma
melhor política de deslocamento, obtendo um maior número de vitórias (ver tabela 6.6).
Nesse caso, a abordagem tabular necessitou de uma estrutura de armazenamento com
3150 pares estado-ação, enquanto na solução aproximada foram utilizados 2306 parâme-
tros.
Algoritmos n,kT = 100 T = 1000 T = 10000
Min Max Média Wins Min Max Média Wins Min Max Média WinsQ-learning
15,2334 510 411.30 27 3836 4324 4058.46 13 40008 41319 40681.76 0
Q-learning com MLP 319 503 408.64 46 3761 4282 4019.94 86 39716 40913 40303.76 100Guloso 324 522 418.96 15 3913 4356 4144.74 1 40892 42020 41485.92 0
Palavras chaves
Min - Tempo mínimo gastoMax - Tempo máximo gastoMédia - Tempo médio gasto
Vitórias
Tabela 6.6: Comparação entre os algoritmos para a cidade com 15 regiões e 2 ambulâncias
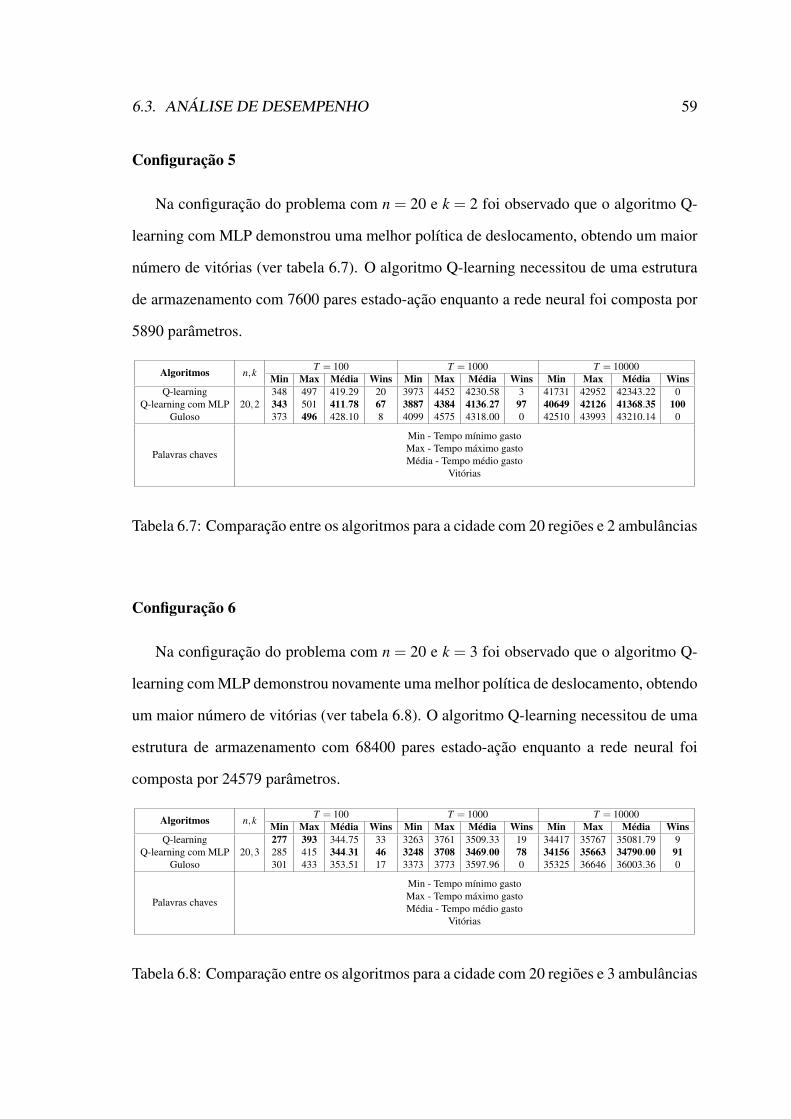
6.3. ANÁLISE DE DESEMPENHO 59
Configuração 5
Na configuração do problema com n = 20 e k = 2 foi observado que o algoritmo Q-
learning com MLP demonstrou uma melhor política de deslocamento, obtendo um maior
número de vitórias (ver tabela 6.7). O algoritmo Q-learning necessitou de uma estrutura
de armazenamento com 7600 pares estado-ação enquanto a rede neural foi composta por
5890 parâmetros.
Algoritmos n,kT = 100 T = 1000 T = 10000
Min Max Média Wins Min Max Média Wins Min Max Média WinsQ-learning
20,2348 497 419.29 20 3973 4452 4230.58 3 41731 42952 42343.22 0
Q-learning com MLP 343 501 411.78 67 3887 4384 4136.27 97 40649 42126 41368.35 100Guloso 373 496 428.10 8 4099 4575 4318.00 0 42510 43993 43210.14 0
Palavras chaves
Min - Tempo mínimo gastoMax - Tempo máximo gastoMédia - Tempo médio gasto
Vitórias
Tabela 6.7: Comparação entre os algoritmos para a cidade com 20 regiões e 2 ambulâncias
Configuração 6
Na configuração do problema com n = 20 e k = 3 foi observado que o algoritmo Q-
learning com MLP demonstrou novamente uma melhor política de deslocamento, obtendo
um maior número de vitórias (ver tabela 6.8). O algoritmo Q-learning necessitou de uma
estrutura de armazenamento com 68400 pares estado-ação enquanto a rede neural foi
composta por 24579 parâmetros.
Algoritmos n,kT = 100 T = 1000 T = 10000
Min Max Média Wins Min Max Média Wins Min Max Média WinsQ-learning
20,3277 393 344.75 33 3263 3761 3509.33 19 34417 35767 35081.79 9
Q-learning com MLP 285 415 344.31 46 3248 3708 3469.00 78 34156 35663 34790.00 91Guloso 301 433 353.51 17 3373 3773 3597.96 0 35325 36646 36003.36 0
Palavras chaves
Min - Tempo mínimo gastoMax - Tempo máximo gastoMédia - Tempo médio gasto
Vitórias
Tabela 6.8: Comparação entre os algoritmos para a cidade com 20 regiões e 3 ambulâncias
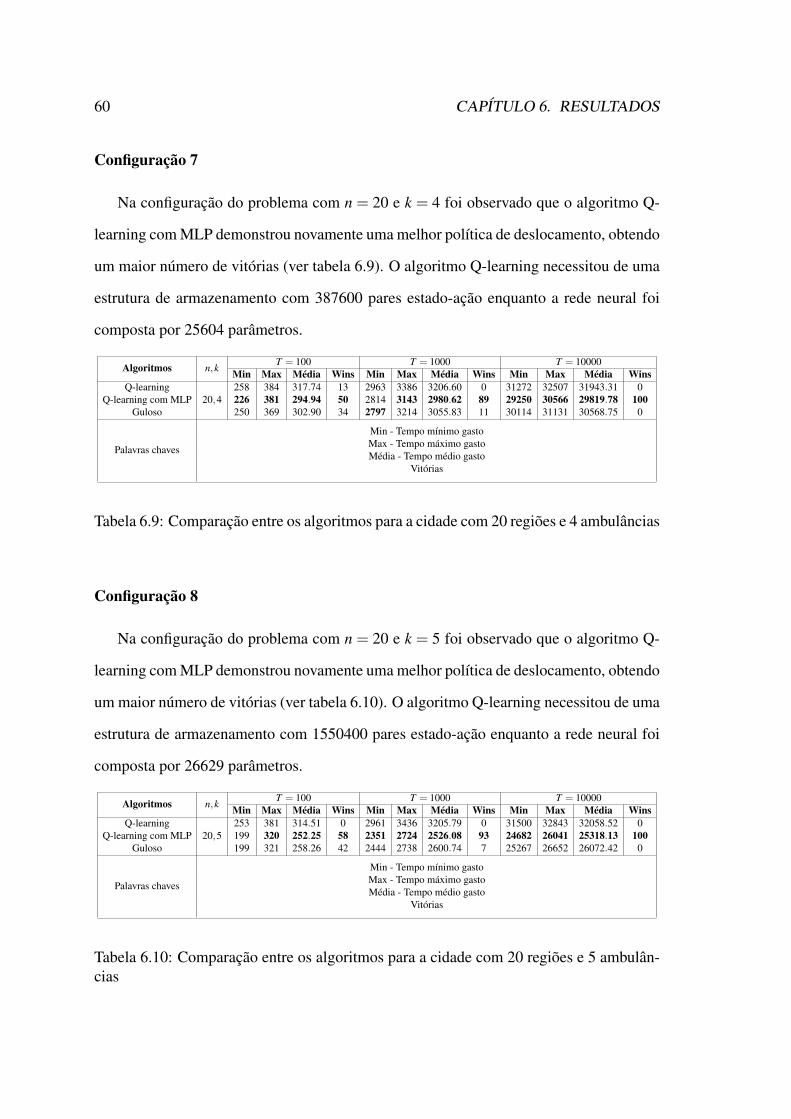
60 CAPÍTULO 6. RESULTADOS
Configuração 7
Na configuração do problema com n = 20 e k = 4 foi observado que o algoritmo Q-
learning com MLP demonstrou novamente uma melhor política de deslocamento, obtendo
um maior número de vitórias (ver tabela 6.9). O algoritmo Q-learning necessitou de uma
estrutura de armazenamento com 387600 pares estado-ação enquanto a rede neural foi
composta por 25604 parâmetros.
Algoritmos n,kT = 100 T = 1000 T = 10000
Min Max Média Wins Min Max Média Wins Min Max Média WinsQ-learning
20,4258 384 317.74 13 2963 3386 3206.60 0 31272 32507 31943.31 0
Q-learning com MLP 226 381 294.94 50 2814 3143 2980.62 89 29250 30566 29819.78 100Guloso 250 369 302.90 34 2797 3214 3055.83 11 30114 31131 30568.75 0
Palavras chaves
Min - Tempo mínimo gastoMax - Tempo máximo gastoMédia - Tempo médio gasto
Vitórias
Tabela 6.9: Comparação entre os algoritmos para a cidade com 20 regiões e 4 ambulâncias
Configuração 8
Na configuração do problema com n = 20 e k = 5 foi observado que o algoritmo Q-
learning com MLP demonstrou novamente uma melhor política de deslocamento, obtendo
um maior número de vitórias (ver tabela 6.10). O algoritmo Q-learning necessitou de uma
estrutura de armazenamento com 1550400 pares estado-ação enquanto a rede neural foi
composta por 26629 parâmetros.
Algoritmos n,kT = 100 T = 1000 T = 10000
Min Max Média Wins Min Max Média Wins Min Max Média WinsQ-learning
20,5253 381 314.51 0 2961 3436 3205.79 0 31500 32843 32058.52 0
Q-learning com MLP 199 320 252.25 58 2351 2724 2526.08 93 24682 26041 25318.13 100Guloso 199 321 258.26 42 2444 2738 2600.74 7 25267 26652 26072.42 0
Palavras chaves
Min - Tempo mínimo gastoMax - Tempo máximo gastoMédia - Tempo médio gasto
Vitórias
Tabela 6.10: Comparação entre os algoritmos para a cidade com 20 regiões e 5 ambulân-cias
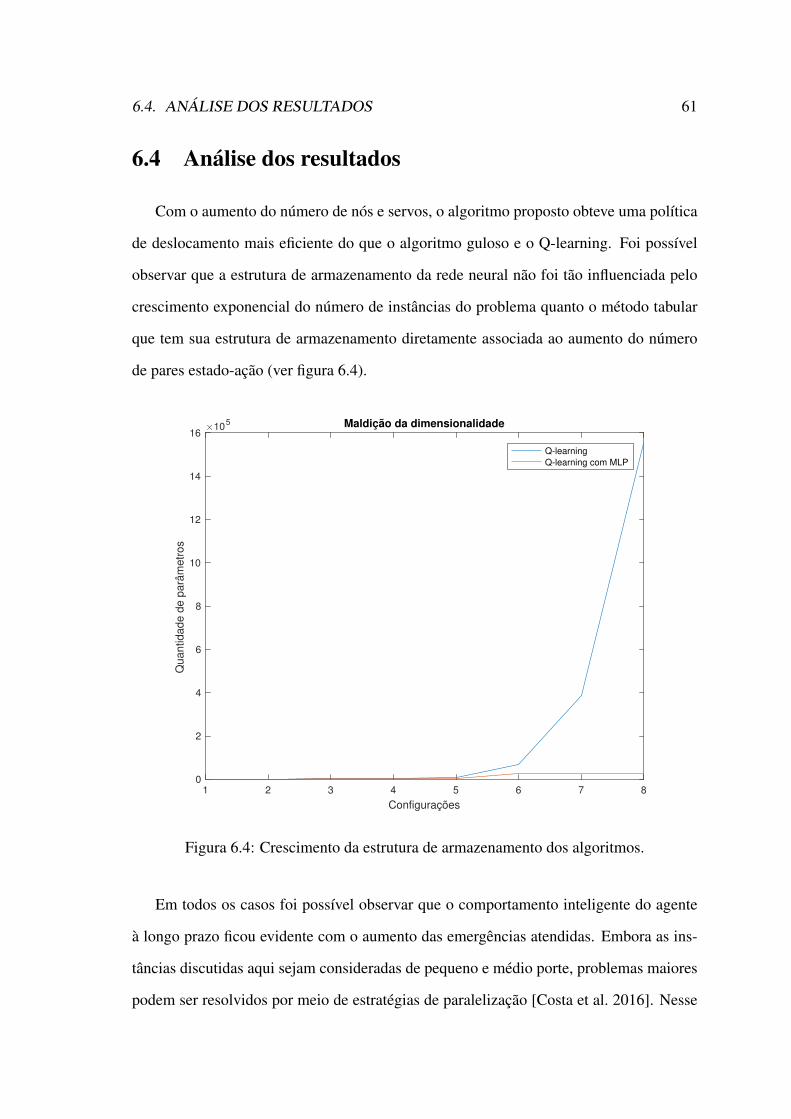
6.4. ANÁLISE DOS RESULTADOS 61
6.4 Análise dos resultados
Com o aumento do número de nós e servos, o algoritmo proposto obteve uma política
de deslocamento mais eficiente do que o algoritmo guloso e o Q-learning. Foi possível
observar que a estrutura de armazenamento da rede neural não foi tão influenciada pelo
crescimento exponencial do número de instâncias do problema quanto o método tabular
que tem sua estrutura de armazenamento diretamente associada ao aumento do número
de pares estado-ação (ver figura 6.4).
1 2 3 4 5 6 7 8
Configurações
0
2
4
6
8
10
12
14
16
Quantidade d
e p
arâ
metr
os
105 Maldição da dimensionalidade
Q-learning
Q-learning com MLP
Figura 6.4: Crescimento da estrutura de armazenamento dos algoritmos.
Em todos os casos foi possível observar que o comportamento inteligente do agente
à longo prazo ficou evidente com o aumento das emergências atendidas. Embora as ins-
tâncias discutidas aqui sejam consideradas de pequeno e médio porte, problemas maiores
podem ser resolvidos por meio de estratégias de paralelização [Costa et al. 2016]. Nesse

62 CAPÍTULO 6. RESULTADOS
caso o atendimento a cada região pode ser considerado um subproblema localizado, em-
bora seja permitido possíveis deslocamentos dos servos entre as regiões. Desta forma
maiores dimensões do problema podem ser abordadas.

Capítulo 7
Conclusões, discussões e perspectivas
Este trabalho apresentou um estudo do paradigma de aprendizagem por reforço pro-
fundo como uma solução alternativa ao problema dos k-servos que foi modelado como
uma tarefa por imagem.
Para verificar o desempenho da solução proposta, o algoritmo foi aplicado a um pro-
blema (simulado) de serviço de emergência móvel. Inicialmente o problema dos k-servos
foi definido como um problema de pequena dimensão. Neste caso, os comportamen-
tos dos agentes, definidos por suas funções de valores estado-ação, foram comparados
apresentando resultados similares. Esses indicadores demonstraram que a codificação
foi capaz de fornecer informações suficiente para que a rede neural fosse capaz de gerar
uma política de decisão satisfatória. Em seguida novos experimentos foram realizados
aumentando-se de forma gradativa a complexidade do problema. Através dos resulta-
dos obtidos, o novo algoritmo demonstrou de maneira satisfatória ser capaz de realizar
o deslocamento das unidades de saúde em diferentes configurações de problemas. A es-
calabilidade do algoritmo proposto ficou evidente com o aumento da complexidade do
problema, dando-se ênfase ao incremento do número de servos.
Embora seja necessário um estado inicial para inicializar o problema, a solução pro-
posta não está restrita a esta condição. Seu desempenho foi avaliado considerando di-
ferentes estados iniciais possíveis, uma condição que aumenta o grau de incerteza do
problema e torna a solução ainda mais generalista.

64 CAPÍTULO 7. CONCLUSÕES, DISCUSSÕES E PERSPECTIVAS
De maneira geral, o algoritmo proposto apresentou melhor desempenho nos testes
que os demais, reduzindo o tempo de resposta as emergências. Os resultados obtidos
aqui, indicam que o algoritmo proposto pode ser uma abordagem eficaz na solução do
problema dos k-servos de pequeno e médio porte.
7.1 Discussões
Com o advento de novos métodos capazes de extrair informações de forma autônoma a
partir de imagens [Mnih et al. 2015] [Silver et al. 2017], a representação do problema dos
k-servos por imagens pode ser adaptado a diversas variantes do problema. Por exemplo,
o problema dos k-servos heterogêneos, definido por servos com diferentes funcionalida-
des, poderia ter os servos ou grupo de servos representados por diferentes cores; em um
outro caso denotado como problema dos k-servos estocástico [Dehghani et al. 2017], a
cada passo de tempo as requisições são retiradas de uma distribuição de probabilidade
diferente. Neste caso a representação do problema poderia ser a mesma mudando apenas
a forma como as requisições podem surgir nas imagens ao longo do tempo; Problemas
de grafos dinâmicos no qual as atualizações incluem inserções e remoções de vértices
(nós) e arestas podem ser representados de forma semelhante, observando-se a provável
necessidade de retreinamento da rede neural.
Um outro ponto relevante que pode ser modificado é a codificação utilizada neste tra-
balho que não leva em consideração, pelo menos não de forma direta, a estrutura espacial
dos nós nos grafos. Uma codificação mais complexa pode fornecer mais informações
para a rede neural e aumentar seu poder de generalização. A matriz de adjacência por
exemplo, pode fornecer a informação da conexão entre os nós conectados, e os elementos
da diagonal principal podem representar a mesma codificação apresentada neste trabalho.
Um problema intrínseco ao paradigma de aprendizagem por reforço é o problema da
maldição da dimensionalidade que dificulta a aplicação para os problemas de k-servos

7.2. PERSPECTIVAS FUTURAS 65
com instâncias elevadas. As redes neurais, pela sua capacidade de generalização tem se
mostrado uma forma de contornar este problema como buscou-se mostrar neste trabalho
de tese. Entretanto o aumento da complexidade da rede neural utilizada pode levar ao
problema de overfitting e um maior esforço computacional no processo de aprendizagem.
Para reduzir o problema do overfitting o uso de técnicas da teoria da regularização podem
ser aplicadas, possibilitando o emprego de redes neurais perceptrons múltiplas camadas
(MLP) com maior complexidade, denominadas de Deep MLP. Este trabalho buscou estu-
dar o problema do k-servos nesta perspectiva mas ressalta a necessidade de mais estudos
no sentido de avaliar redes neurais mais complexas e do esforço computacional necessário
para encontrar uma política de bom desempenho.
7.2 Perspectivas futuras
No futuro pretende-se explorar instâncias ainda maiores em um contexto de cidades
inteligentes, envolvendo o deslocamento inteligente de viaturas de saúde e segurança.
Outro caso prático a ser analisado é a utilização desta abordagem na indústria de varejo
online que utilizam robôs autônomos para fazer a armazenagem e retirada de produtos
que serão enviados para clientes.
Para instâncias maiores podem ser utilizadas outras redes neurais profundas como as
redes convolucionais [Krizhevsky et al. 2012], redes especiais projetadas para tratar ima-
gens; Também podem ser utilizadas as redes neurais de grafos [Wu et al. 2019], redes
projetadas para tratar problemas em grafos; Em conjunto com as redes convolucionais,
redes de grafos ou de forma separada, as redes recorrentes [Schmidhuber 2015], proje-
tadas para tratar sequências de dados, podem fazer uso de eventos anteriores fornecendo
um melhor gerenciamento no deslocamento dos servos em uma sequência de requisições.
Ademais, o paradigma de aprendizagem não supervisionado também pode ser utili-
zado previamente para extrair características do modelo. Por exemplo, uma rede neu-

66 CAPÍTULO 7. CONCLUSÕES, DISCUSSÕES E PERSPECTIVAS
ral Autoencoder [Lange & Riedmiller 2010] pode ser utilizada em uma fase de pré-
treinamento para reduzir uma imagem de alta dimensionalidade em características re-
presentativas compactas diminuindo o problema da maldição da dimensionalidade.
7.3 Publicação
O desenvolvimento desta tese de doutorado originou a seguinte publicação: Lins, R.
A. S., Neto, A. D. D., Melo, J. D.. "Deep reinforcement learning applied to the k-server
problem."Expert Systems with Applications, 2019.

Referências Bibliográficas
Afify, Badr, Sujoy Ray, Andrei Soeanu, Anjali Awasthi, Mourad Debbabi & Mohamad
Allouche [2019], ‘Evolutionary learning algorithm for reliable facility location un-
der disruption’, Expert Systems with Applications 115, 223–244.
Araque, Oscar, Ignacio Corcuera-Platas, J Fernando Sanchez-Rada & Carlos A Iglesias
[2017], ‘Enhancing deep learning sentiment analysis with ensemble techniques in
social applications’, Expert Systems with Applications 77, 236–246.
Bansal, Nikhil, Niv Buchbinder, Aleksander Madry & Joseph Seffi Naor [2015], ‘A
polylogarithmic-competitive algorithm for the k-server problem’, Journal of the
ACM (JACM) 62(5), 40.
Bartal, Yair & Elias Koutsoupias [2004], ‘On the competitive ratio of the work function
algorithm for the k -server problem’, Theoretical Computer Science pp. 337–345.
Bellman, Richard [1957], Dynamic Programming, Princeton University Press.
Bello, Irwan, Hieu Pham, Quoc V Le, Mohammad Norouzi & Samy io [2016], ‘Neu-
ral combinatorial optimization with reinforcement learning’, arXiv preprint ar-
Xiv:1611.09940 .
Bertsekas, Dimitri P. & John N. Tsitsiklis [1996], Neuro-Dynamic Programming, Athena
Scientific.
Bertsimas, Dimitris, Patrick Jaillet & Nikita Korolko [2019], ‘The k-server problem via a
modern optimization lens’, European Journal of Operational Research 276(1), 65–
78.
67

68 REFERÊNCIAS BIBLIOGRÁFICAS
Borodin, Allan, Nathan Linial & Michael E. Saks [1992], ‘An optimal online algorithm
for metrical task system’, Journal of the ACM pp. 745–763.
Borodin, Allan & Ran El-Yaniv [1998], Online Computation and Competitive Analysis,
Cambridge University Press.
Busoniu, Lucian, Robert Babuska, Bart De Schutter & Damien Ernst [2010], ‘Reinforce-
ment learning and dynamic programming using function approximators’, p. 260.
Costa, M L, C A A Padilha & J D Melo [2016], ‘Hierarchical Reinforcement Learning
and Parallel Computing Applied to the K-Server Problem’, IEEE Latin America
Transactions pp. 4351–4357.
Costa, Mademerson Leandro [2017], Uma Abordagem Utilizando Aprendizagem por Re-
forço Hierárquica e Computação Paralela para o Problema dos K-Servos., Tese de
doutorado.
Dehghani, S., S. Ehsani, M. Hajiaghayi, V. Liaghat & S. Seddighin [2017], ‘Stochastic k-
Server: How should uber work?’, Leibniz International Proceedings in Informatics,
LIPIcs pp. 1–18.
Glorot, Xavier & Yoshua Bengio [2010], Understanding the difficulty of training deep
feedforward neural networks, em ‘Proceedings of the thirteenth international confe-
rence on artificial intelligence and statistics’, pp. 249–256.
Goldbarg, Marco Cesar & Henrique Pacca L Luna [2000], ‘Otimização combinatória e
programação linear’, Editora Campus 2.
Goodfellow, Ian, Yoshua Bengio & Aaron Courville [2016], Deep Learning.
Grove, E. F. [1991], The harmonic online k-server algorithm is competitive, em ‘Pro-
ceedings of the Twenty-third Annual ACM Symposium on Theory of Computing’,
ACM, pp. 260–266.

REFERÊNCIAS BIBLIOGRÁFICAS 69
Gupta, Sushmita, Shahin Kamali & Alejandro López-Ortiz [2016], ‘On the advice com-
plexity of the k-server problem under sparse metrics’, Theory of Computing Systems
59(3), 476–499.
Haykin, Simon [1998], Neural Networks: A Comprehensive Foundation, 2ndª edição,
Prentice Hall PTR.
Hinton, G E & R R Salakhutdinov [2006], ‘Reducing the Dimensionality of Data with
Neural Networks’, Science pp. 504–507.
Huber, Peter J et al. [1964], ‘Robust estimation of a location parameter’, The annals of
mathematical statistics 35(1), 73–101.
Koutsoupias, Elias [2009], ‘The k-server problem’, Computer Science Review pp. 105–
18.
Koutsoupias, Elias & Christos H. Papadimitriou [1995], ‘On the k-server conjecture’, J.
ACM 42(5), 971–983.
Krizhevsky, Alex, Ilya Sutskever & Geoffrey E Hinton [2012], ‘ImageNet Classification
with Deep Convolutional Neural Networks’, Advances In Neural Information Pro-
cessing Systems pp. 1–9.
Lange, S. & M. Riedmiller [2010], Deep auto-encoder neural networks in reinforce-
ment learning, em ‘The 2010 International Joint Conference on Neural Networks
(IJCNN)’, pp. 1–8.
Leandro, Manoel [2005], Uma contribuição à solução do problema dos k-servos usando
aprendizagem por reforço, Dissertação de mestrado.
LeCun, Yann, Yoshua Bengio & Geoffrey Hinton [2015a], ‘Deep learning’, Nature .

70 REFERÊNCIAS BIBLIOGRÁFICAS
LeCun, Yann, Yoshua Bengio & Geoffrey Hinton [2015b], ‘Deep learning’, nature
521(7553), 436.
Li, Yuxi [2017], ‘Deep Reinforcement Learning: An Overview’, pp. 1–70.
Lima, Francisco Chagas [2009], Algoritmo Q-learning como Estratégia de Exploração e
/ ou Explotação para as Metaheurísticas GRASP e Algoritmo Genético ., Tese de
doutorado.
Lin, Long-ji [1993], Reinforcement Learning for Robots Using Neural Networks, Tese de
doutorado.
Manasse, M., L. McGeoch & D. Sleator [1988], ‘Competitive algorithms for on-line pro-
blems’, Proceedings of the twentieth annual ACM symposium on Theory of compu-
ting pp. 322–333.
Manoel Leandro, L., Adrião D.Dória Neto & Jorge D. Melo [2005], The k-server pro-
blem: A reinforcement learning approach, em ‘Proceedings of the International Joint
Conference on Neural Networks’.
Mao, Hongzi, Mohammad Alizadeh, Ishai Menache & Srikanth Kandula [2016], ‘Re-
source Management with Deep Reinforcement Learning’, Proceedings of the 15th
ACM Workshop on Hot Topics in Networks - HotNets ’16 pp. 50–56.
Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness,
Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg
Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen
King, Dharshan Kumaran, Daan Wierstra, Shane Legg & Demis Hassabis [2015],
‘Human-level control through deep reinforcement learning’, Nature pp. 529–533.
Raghavan, P. & M. Snir [1994], ‘Memory versus randomization in on-line algorithms’,
IBM J. Res. Dev. pp. 683–707.

REFERÊNCIAS BIBLIOGRÁFICAS 71
Ranzato, Marc Aurelio, Christopher Poultney, Sumit Chopra & Yann Lecun [2007], ‘Ef-
ficient Learning of Sparse Representations with an Energy-Based Model’, Advances
In Neural Information Processing Systems .
Riedmiller, Martin [2005], ‘Neural fitted Q iteration - First experiences with a data effi-
cient neural Reinforcement Learning method’, Lecture Notes in Computer Science
(including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in
Bioinformatics) pp. 317–328.
Rudec, Tomislav, Alfonzo Baumgartner & Robert Manger [2013], ‘A fast work function
algorithm for solving the k-server problem’, Central European Journal of Operati-
ons Research 21(1), 187–205.
Santana, Eder, Matthew Emigh & José C. Príncipe [2016], ‘Information theoretic-learning
auto-encoder’, arXiv:1603.06653 .
Schmidhuber, Jürgen [2015], ‘Deep Learning in neural networks: An overview’, Neural
Networks .
Silver, David, Aja Huang Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den
Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc
Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya
Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel
& Demis Hassabis [2016], ‘Mastering the game of Go with deep neural networks
and tree search’, Nature .
Silver, David, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang,
Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian
Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore
Graepel & Demis Hassabis [2017], ‘Mastering the game of Go without human kno-
wledge’, Nature pp. 354–359.

72 REFERÊNCIAS BIBLIOGRÁFICAS
Sleator, Daniel D. & Robert E. Tarjan [1985], ‘Amortized efficiency of list update and
paging rules’, Communications of the ACM pp. 202–208.
Srivastava, Nitish, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever & Ruslan Sa-
lakhutdinov [2014], ‘Dropout : A Simple Way to Prevent Neural Networks from
Overfitting’, Journal of Machine Learning Research (JMLR) pp. 1929–1958.
Sutton, Richard S. & Andrew G. Barto [1998], Introduction to Reinforcement Learning,
MIT Press.
Sutton, Richard S & Andrew G Barto [2018], Reinforcement learning: An introduction,
MIT press.
Tesauro, Gerald [1995], ‘Temporal difference learning and TD-Gammon’, Communicati-
ons of the ACM pp. 58–68.
Watkins, Christopher J C H [1989], Learning from Delayed Rewards, Tese de doutorado.
Wu, Zonghan, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang & Philip S
Yu [2019], ‘A comprehensive survey on graph neural networks’, arXiv preprint ar-
Xiv:1901.00596 .
Y. Bengio, P. Lamblin, D. Popovici & H. Larochelle [2007], ‘Greedy layer-wise training
of deep networks’, NIPS .