anÁlise de dados categorizados
TRANSCRIPT

ANALISE DE DADOS
CATEGORIZADOS
Julio da Motta Singer
Universidade de Sao PauloSao Paulo, Brasil
Minicurso apresentado no
XIII Simposio de Estadistica”Estadıstica en Ciencias de la Salud”
3 a 7 de agosto de 2003Armenia, Quindio. Colombia

Prefacio
Estas notas de aula correspondem ao resumo de um texto sobre analise de dadoscategorizados em elaboracao por Carlos Daniel Paulino e Julio da Motta Singer.Elas tambem contem material extraıdo de um manual implementacao computa-cional das tecnicas aı desenvolvidas, preparado por Carine Savalli, Carlos DanielPaulino, Giovani Loiola Silva, Julio da Motta Singer, Maria Paula Chicarino,Mario de Castro e Rodrigo Andrade Tavares.
Julio da Motta SingerSao Paulo, julho de 2003.
2

1 Dados categorizados
Dados discretos relativos a uma ou mais variaveis definidas por meio de umnumero finito de nıveis ou categorias sao denominados dados categorizados.Alguns exemplos podem ser encontrados na Tabela 1. As variaveis correspon-dentes podem ser classificadas como ordinais ou nominais conforme suas cate-gorias sejam ordenadas ou nao.
Tabela 1. Exemplo de matriz com dados categorizados.
Dados de um estudo sobre EndometrioseDr. Maurício Simões Abrão (FMUSP)
Grupo Paciente Idade Gestação Partos Abortos Dismenorréia Dispareunia AFSrControle 1 26 3 3 0 L N 0Controle 2 37 4 3 1 N P 0Controle 3 37 4 4 0 N N 0Controle 4 35 3 3 0 L N 0Controle 5 34 4 3 1 N N 0Controle 6 38 5 5 0 L N 0Controle 7 30 5 4 1 N N 0Controle 8 38 11 7 4 N N 0Controle 9 36 7 6 1 N N 0Controle 10 41 4 3 1 N N 0Controle 11 36 7 4 3 N N 0Controle 12 38 3 3 0 N N 0Controle 13 32 3 3 0 L N 0Controle 14 37 3 3 0 M P 0Controle 15 32 6 6 0 N N 0Doente 1 31 0 0 0 M P 1Doente 2 32 0 0 0 M N 1Doente 3 27 0 0 0 I PRO 1Doente 4 28 1 1 0 L N 1Doente 5 34 2 1 1 M N 1Doente 6 38 9 6 4 I 2 1Doente 7 29 0 0 0 S/ N 1Doente 8 38 0 0 0 M 2 1Doente 9 20 0 0 0 M . 1Doente 10 38 0 0 0 L N 2Doente 11 34 5 3 2 M 2 2Doente 12 29 1 1 0 I PRO 2Doente 13 23 0 0 0 I PRO 2Doente 14 27 3 2 1 I PRO 2Doente 15 40 2 2 0 M N 2Doente 16 25 1 0 1 M P 2Doente 17 39 0 0 0 I PRO 2Doente 18 34 3 2 1 I PRO 2Doente 19 24 2 1 1 I PRO 2Doente 20 25 1 0 1 I PRO 2Doente 21 39 0 0 0 I N 3Doente 22 27 0 0 0 L PRO 3Doente 23 30 1 0 1 M PRO 3Doente 24 28 0 0 0 I N 3Doente 25 20 0 0 0 M . 3Doente 26 28 2 2 0 I N 3Doente 27 26 0 0 0 M 2 3Doente 28 32 1 1 0 I PRO 3Doente 29 37 0 0 0 M PRO 3
3

Essencialmente estes dados podem ser dispostos na forma de uma tabela (decontingencia) s × r onde as s linhas correspondem as combinacoes dos nıveis deuma ou mais variaveis explicativas (se existirem), e as r colunas as combinacoesdos nıveis de uma ou mais variaveis respostas. A distincao entre variaveisexplicativas e respostas e consequencia da definicao das questoes de interesse doestudo e da especificacao do planejamento amostral. Havendo apenas variaveisrespostas, consideramos s = 1. De uma forma generica, as tabelas de contingenciaenfocadas neste trabalho podem ser representadas segundo o modelo da Tabela1, em que nqm, q = 1, . . . , s , m = 1, . . . , r, denota a frequencia observada nacasela correspondente, nq. =
∑rm=1 nqm, q = 1, . . . s e o total da q-esima linha e
N e o tamanho da amostra.
Tabela 2. Forma bidimensional de uma tabela de contingencia generica
Categorias de respostaSubpopulacao 1 2 . . . m . . . r Total
1 n11 n12 . . . n1m . . . n1r n1·
2 n21 n22 . . . n2m . . . n2r n2·
· · ·· · ·q nq1 nq2 . . . nqm . . . nqr nq·
· · ·· · ·s ns1 ns2 . . . nsm . . . nsr ns·
Total N
Alguns exemplos ilustrativos seguem abaixo.
Exemplo 1 (Paulino e Singer (2003)). Os dados da Tabela 3 se referem aum estudo de suscetibilidade a carie dentaria em criancas. Os dois metodos deavaliacao dessa suscetibilidade determinam duas variaveis respostas, cada umacom 3 nıveis (neste caso s = 1 e r = 9).
4

Tabela 3. Frequencias observadas de 97 criancas de 11-13 anos de uma escolapublica.
Risco de carie segundoo metodo convencional
Baixo Medio AltoRisco de carie Baixo 11 5 0segundo o Medio 14 34 7metodo simplificado Alto 2 13 11
Exemplo 2 (Paulino e Singer (2003)). Os dados da Tabela 4 sao prove-nientes de um estudo envolvendo a avaliacao pulmonar pre-operatoria de 1162pacientes (classificados como tendo baixo, medio ou alto risco) e a ocorrenciade complicacao pulmonar no perıodo pos-operatorio de cirurgia geral (neste casos = 3 e r = 2).
Tabela 4. Numero de pacientes.
Avaliacao pre-operatoria Avaliacao pulmonardo grau de complicacao pos-operatoriapulmonar Sem complicacao Com complicacaoBaixo 737 48Moderado 243 74Alto 39 21
Exemplo 3 (Paulino e Singer (2003)). Estudo de fertilidade de ovelhas devarios rebanhos identificados pela raca e pela fazenda onde eram criadas, cuja in-fluencia no tamanho da ninhada se pretende averiguar (neste caso s = 9 e r = 4).
5

Tabela 5. Numero de ovelhas.
Numero de borregospor ninhada
Fazenda Raca 0 1 2 ≥ 3 TotalA 10 21 96 23 150
1 B 4 6 28 8 46C 9 7 58 7 81
A 8 19 44 1 722 B 5 17 56 1 79
C 1 5 20 2 28
A 22 95 103 4 2243 B 18 49 62 0 129
C 4 12 16 2 34
Exemplo 4 (Koch et al. (1985)). Os dados da Tabela 6 resultaram daavaliacao por um conjunto de homens de certos objetos culturalmente masculi-nos. Cada indivıduo classificava como masculino (M) ou feminino (F) objetos queeram mostrados durante perıodos variaveis de exposicao. Os indivıduos foramsubdivididos em dois grupos conforme o conhecimento (Grupo 2) ou nao (Grupo1) da finalidade da experiencia (neste caso s = 2 e r = 9).
Tabela 6. Frequencias observadas da avaliacao do simbolismo sexual deobjetos.
Categorias de resposta nos 3 perıodos de exposicaoGrupo MMM MMF MFM MFF FMM FMF FFM FFF
1 171 18 6 12 7 7 7 562 184 38 10 14 7 7 20 114
Exemplo 5. (Upton and Fingleton, 1985) Em ordem a detectar a eventualexistencia de interacao positiva (atracao ) ou negativa (repulsao) entre carvalhose nogueiras, uma dada zona florestal foi dividida em 576 areas de tamanho eforma fixos e registrou-se para cada uma delas a ocorrencia ou nao de cada tipo
6
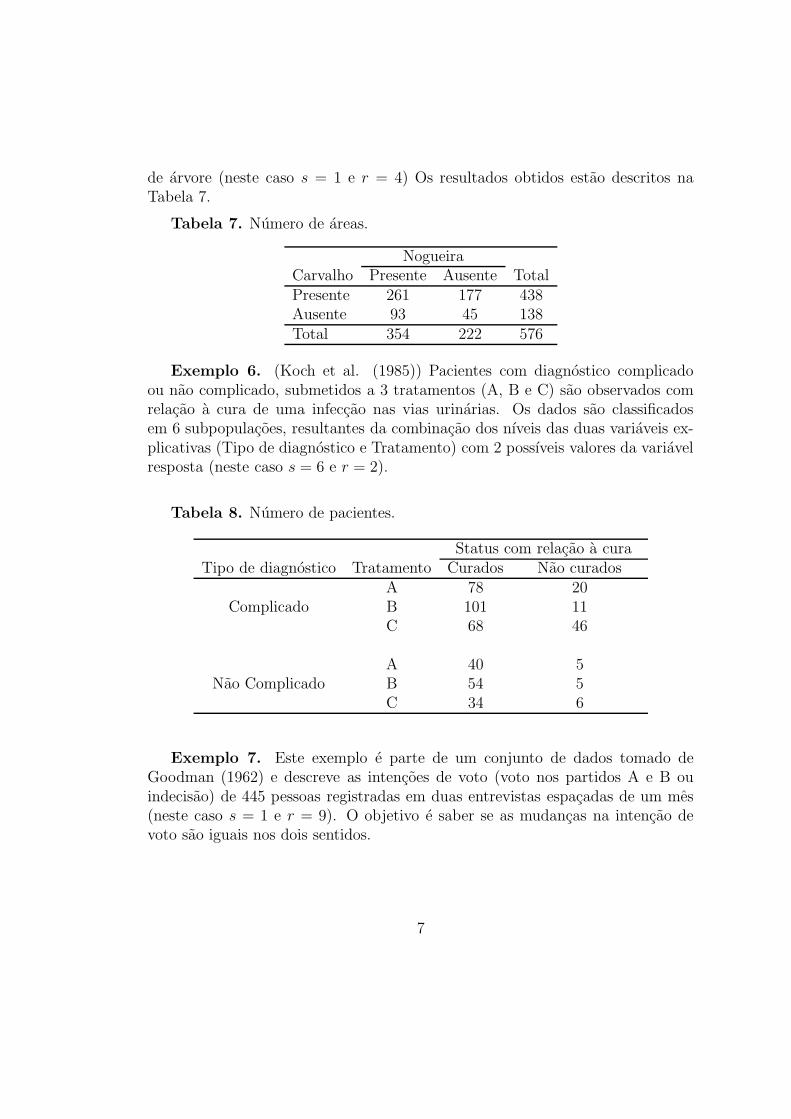
de arvore (neste caso s = 1 e r = 4) Os resultados obtidos estao descritos naTabela 7.
Tabela 7. Numero de areas.
NogueiraCarvalho Presente Ausente TotalPresente 261 177 438Ausente 93 45 138Total 354 222 576
Exemplo 6. (Koch et al. (1985)) Pacientes com diagnostico complicadoou nao complicado, submetidos a 3 tratamentos (A, B e C) sao observados comrelacao a cura de uma infeccao nas vias urinarias. Os dados sao classificadosem 6 subpopulacoes, resultantes da combinacao dos nıveis das duas variaveis ex-plicativas (Tipo de diagnostico e Tratamento) com 2 possıveis valores da variavelresposta (neste caso s = 6 e r = 2).
Tabela 8. Numero de pacientes.
Status com relacao a curaTipo de diagnostico Tratamento Curados Nao curados
A 78 20Complicado B 101 11
C 68 46
A 40 5Nao Complicado B 54 5
C 34 6
Exemplo 7. Este exemplo e parte de um conjunto de dados tomado deGoodman (1962) e descreve as intencoes de voto (voto nos partidos A e B ouindecisao) de 445 pessoas registradas em duas entrevistas espacadas de um mes(neste caso s = 1 e r = 9). O objetivo e saber se as mudancas na intencao devoto sao iguais nos dois sentidos.
7

Tabela 9: Intencoes de voto em duas sondagens
Segunda sondagemA B I
Primeira A 192 1 5sondagem B 2 146 5
I 11 12 71
Para a analise de dados com essas caracterısticas podemos seguir os seguintespassos:
i) definicao das questoes de interesse;
ii) especificacao do delineamento amostral;
iii) descricao dos dados amostrais;
iv) escolha de um modelo probabilıstico que se afigure adequado (pelo menos,na base do senso comum ...);
v) traducao das questoes de interesse em termos dos parametros do modeloprobabilıstico adotado, ou seja, especificacao de modelos estruturais;
vi) ajuste dos modelos especificados atraves de alguma metodologia estatıstica(e.g., metodologia de maxima verosimilhanca ou metodologia de mınimosquadrados generalizados);
vii) comparacao do(s) modelo(s) ajustado(s) com outros modelos alternativos;
viii) conversao das conclusoes em termos das questoes originais.
2 Medidas de associacao
Consideramos aqui algumas medidas importantes para a analise de dados cate-gorizados. Comecamos com o seguinte exemplo:
Fator Estado do pacientede risco Sem doenca Doente TotalNao 1 − π0 π0 1Sim 1 − π1 π1 1
8

• π0: Proporcao de pacientes nao expostos ao fator de risco que apresen-taram a doenca.
• π1: Proporcao de pacientes expostos ao fator de risco que apresentaram adoenca.
• Risco atribuıvel (d = π1−π0): aumento na proporcao de doentes atribuıvela exposicao ao fator risco.
• Risco relativo (r = π1/π0): proporcao de doentes entre indivıduos expos-tos ao fator de risco e r vezes a propocao de doentes entre os nao expostos.
• Comparacao
π0 = 0.42π1 = 0.44
}d = 0.02r = 0.44
π0 = 0.02π1 = 0.04
}d = 0.02r = 2.00
• log r = log π1 − log π0: genese dos modelos log-lineares
• Importancia do conhecimento de alguma medida de associacao entre fatorde risco e doenca mesmo sem conhecimento de π0 e π1. Em muitos estudos(caso/controle, por exemplo) nao se pode estimar π0 e π1.
• Chances (”odds”): medida de frequencia de ocorrencia de eventos
• π1/(1 − π1): chance de um indivıduo ser doente vs. nao doente quandoexposto ao fator de risco.
• π0/(1 − π0): chance de um indivıduo ser doente vs. nao doente quandonao exposto ao fator de risco.
• Razao de chances (”odds ratio”):
ω =π1/(1 − π1)
π0/(1 − π0)
• Estudos caso-controle
Estado do Exposicao ao fator de riscopaciente Nao Sim TotalSem doenca (controle) 1 − p0 p0 1Doente (caso) 1 − p1 p1 1
9

• p0: proporcao de controles (nao doentes) que tiveram exposicao ao fatorde risco (6= π0).
• p1: proporcao de casos (doentes) que tiveram exposicao ao fator de risco(6= π1).
• Utilizando o Teorema de Bayes pode-se demonstrar que
p1/(1 − p1)
p0/(1 − p0)=
π1/(1 − π1)
π0/(1 − π0)= ω
3 Modelos probabilısticos
A escolha de um modelo probabilıstico para os dados depende do planejamento edo objetivo do estudo. Vamos considerar tres estrategias de obtencao dos dadosde uma pesquisa de intencao de voto, cujo interesse era avaliar a relacao entrea opiniao de eleitores sobre um determinado candidato (X1) e sua faixa etaria(X2).
• Estrategia I: entrevistar tantas pessoas quanto possıvel, por exemplo, em4 horas. Poder-se-ao obter dados como os da Tabela 10.
Tabela 10: Frequencias hipoteticas dos resultados de entrevistas realizadasnum perıodo de tempo fixo.
Faixa etariaOpiniao < 40 ≥ 40 TotalFavoravel 43 25Desfavoravel 41 70Total 179
• Suposicoes sobre o numero de transeuntes com menos de 40 anos favoraveisao candidato que passa no sıtio em que se vai colher a amostra:
i) num determinado intervalo de tempo, o numero desses transeuntes eindependente do numero de transeuntes com as mesmas caracterısticasque passa em qualquer outro intervalo de tempo disjunto daquele;
10

ii) a distribuicao daquele numero de transeuntes so depende do compri-mento do intervalo de tempo considerado e nao do seu instante inicial;
iii) a probabilidade de passagem de um daqueles transeuntes num inter-valo de tempo suficientemente pequeno (um segundo, por exemplo)e aproximadamente proporcional ao comprimento do intervalo, comconstante de proporcionalidade λ11;
iv) a probabilidade de que dois ou mais daqueles transeuntes passem si-multaneamente num intervalo de tempo suficientemente pequeno e de-sprezavel.
• Essas suposicoes permitem demonstrar que o numero n11 de apoiantes commenos de 40 anos que passa num intervalo de tempo de comprimento m =14400s (= 4 × 3600s) tem uma distribuicao de Poisson com media µ11 =mλ11.
• Aplicando o mesmo argumento aos outros nij e admitindo a independenciaentre todas essas variaveis aleatorias (suposicao que, neste caso, pode geraralguma controversia), chegamos ao modelo Produto de distribuicoes dePoisson:
f (n | µ) =2∏
i=1
2∏
j=1
e−µij µnij
ij
nij!, (1)
para nij ∈ INo i, j = 1, 2 onde n = (n11, n12, n21, n22)′ , µ = (µ11, µ12, µ21, µ22)
′
com µij ∈ IR+, i, j = 1, 2.
• Hipotese de interesse: a proporcao de apoiantes entre os indivıduos maisjovens e a mesma que existe entre as pessoas menos jovens, ou seja,
HI :µ11
µ·1=
µ12
µ·2
(=
µ1·
µ··
)(2)
onde µ·j =∑
i µij, µi· =∑
j µij e µ·· =∑
i,j µij. Note-se que esta hipotese eequivalentemente expressavel por
HI : µij =µi· × µ·j
µ··
, (3)
para i, j = 1, 2.
11

• Estrategia II: fixar antecipadamente o numero N de pessoas a entrevistare seleciona-las de um modo aleatorio. Por exemplo, fixando N = 200,poder-se-ao obter dados como os da Tabela 11.
Tabela 11: Frequencias hipoteticas dos resultados do numero fixado deentrevistas
Faixa etariaOpiniao < 40 ≥ 40Favoravel 50 26Desfavoravel 48 76Total 200
• θij: probabilidade de um indivıduo apresentar a caracterıstica (i, j), con-siderada constante para todo o indivıduo da populacao em estudo, i.e.θij = P (X1k = i, X2k = j), k = 1, . . . , N .
• Seja θ = (θ11, θ12, θ21, θ22)′ tal que 1′θ =
∑i,j θij = 1.
• Associemos ao indivıduo k da amostra selecionada o vetor Wk (com compo-nentes Wkij ordenadas lexicograficamente) definido de tal forma que Wkij =1 e Wki′j′ = 0, i′ 6= i ou j ′ 6= j, se para tal indivıduo se tem X1k = i eX2k = j. Isto significa que Wk e um vetor aleatorio cujos valores possıveissao
{(1, 0, 0, 0), (0, 1, 0, 0), (0, 0, 1, 0), (0, 0, 0, 1)}.
Deste modo, os vetores Wk, k = 1, . . . , N sao identicamente distribuıdossegundo a distribuicao de Bernoulli (trivariada) de parametro θ.
• Assumindo adicionalmente que esses vectores sao independentes, segue-seque o vetor das frequencias observaveis n =
∑Nk=1 Wk apresenta a dis-
tribuicao Multinomial
f (n | N, θ) = N !2∏
i,j=1
θnij
ij
nij !, (4)
com 1′n = N, 1′θ = 1.
12

• Hipotese de interesse: independencia estocastica entre X1 e X2.
HII : θij = θi· × θ·j , (5)
para i, j = 1, 2, onde {θi·} e {θ·j} representam as probabilidades marginaisde X1 e X2, respectivamente.
• Estrategia III: fixar antecipadamente o numero Nj de indivıduos de cadafaixa etaria. Fixando, por exemplo N1 = N2 = 100, poder-se-ao obterdados tais como aqueles dispostos na Tabela 12.
Tabela 12: Frequencias hipoteticas dos resultados do numero de entrevis-tas fixado para cada faixa etaria.
Faixa etariaOpiniao < 40 ≥ 40Favoravel 54 30Desfavoravel 46 70 TotalTotal 100 100 200
• Note-se que, enquanto na Estrategia II so o total geral da tabela e fixo,aqui, os totais marginais das colunas tambem sao fixos. A variavel fixa,X2, serve apenas para indicar as subpopulacoes de onde sao tomadas asobservacoes de X1.
• θi(j): probabilidade de qualquer indivıduo ser classificado na categoria i deX1 dado que esta classificado no nıvel j de X2, i.e.,
θi(j) = P (X1k = i | X2k = j) ,
para k = 1, . . . , N, j = 1, 2. Entao∑2
i=1 θi(j) = 1, j = 1, 2.
• Argumentos similares aos utilizados no caso anterior permitem concluir queum modelo probabilıstica adequado e o modelo Produto de distribuicoesMultinomiais
f (n | N, π) =2∏
j=1
Nj !
2∏
i=1
θnij
i(j)
nij !
(6)
onde N = (N1, N2)′ e π = (π′
1, π′2)
′ , com πj = (θ1(j), θ2(j))′, j = 1, 2.
13

• Hipotese de interesse: homogeneidade das distribuicoes Multinomiais
HIII : θ1(1) = θ1(2). (7)
• Relacao entre os modelos: A funcao de probabilidade do modelo Pro-duto de distribuicoes de Poisson admite as seguintes fatorizacoes :
f (n | µ) =e−µ·· µn··
··
n·· !× n·· !
2∏
i,j=1
(µij/µ··)nij
nij !(8)
=e−µ··µn··
··
n·· !× n·· !
2∏
j=1
(µ·j/µ··)n·j
n·j !×
2∏
j=1
{n·j!
2∏
i=1
(µij/µ·j)nij
nij!
}(9)
=2∏
j=1
{e−µ·j µ
n·j
·j
n·j !
}×
2∏
j=1
{n·j!
2∏
i=1
(µij/µ·j)nij
nij!
}(10)
• Como consequencia de (8), o modelo Multinomial com parametros θij =µij/µ·· pode ser obtido a partir do Modelo Produto de distribuicoes dePoisson por condicionamento no total da tabela, N.
• Como consequencia de (9) ou (10), o modelo Produto de distribuicoes Multi-nomiais com parametros θi(j) = µij/µ·j pode ser obtido a partir do ModeloProduto de distribuicoes de Poisson ou Multinomial por condicionamentonos totais marginais, Nj.
• Esses resultados permitem que a classificacao de algumas variaveis comofatores seja feita a posteriori, por condicionamento.
4 Modelos estruturais
Em geral estamos interessados na reducao do numero de parametros do modeloprobabilıstico, acarretando uma simplificacao de sua estrutura parametrica. Aexpressao matematica dessa reducao e chamada modelo estrutural. Em seguidaapresentamos modelos que surgem em diversas situacoes praticas. Lembramosque as restricoes naturais,
∑j θj = 1 sob o modelo Multinomial ou
∑j θi(j) = 1,
i = 1, · · · , s, sob o modelo Produto de distribuicoes Multinomiais devem serlevadas em conta. Essas restricoes podem ser expressas compactamente como(D′π = 1s) em que D e uma matriz conveniente.
14

4.1 Modelo linear geral
O chamado modelo linear geral tem formulacao dada por
Aπ = Xβ , (11)
onde A e uma matriz u × sr com posto r(A) = u ≤ sr tal que r([A′,D]) =u + s, X e a matriz u × p de constantes conhecidas especificadora do modelocom posto r(X) = p ≤ u e β e o vetor dos p parametros do modelo estrutural.Modelos de simetria e homogeneidade marginal, por exemplo, se enquadramna expressao (11). Em termos de restricoes, (11) e equivalente a
C A π = 0(u−p) (12)
onde C e uma matriz (u − p)×u de caracterıstica maxima, com linhas ortogonaisas colunas de X.
Exemplo 1 (continuacao). A hipotese de a distribuicao do grau de risco sera mesma para os dois metodos em analise (homogeneidade marginal), θi· = θ·i,i = 1, · · · 3, e expressavel por (11) com β = (θ1·, θ2·)
′,
A =
1 1 1 0 0 0 0 0 00 0 0 1 1 1 0 0 01 0 0 1 0 0 1 0 00 1 0 0 1 0 0 1 0
, (13)
X =
1 00 11 00 1
. (14)
Sob a formulacao (12), a hipotese de homogeneidade marginal pode ser expressacom A dada por (13) e
C =
(1 0 −1 00 1 0 −1
). (15)
Exemplo 7 (continuacao). A hipotese de simetria, i.e. θij = θji, i, j =1, · · ·3, i < j e expressavel por (11) com β = (θ12, θ13, θ23)
′,
15

A =
0 1 0 0 0 0 0 0 00 0 1 0 0 0 0 0 00 0 0 1 0 0 0 0 00 0 0 0 0 1 0 0 00 0 0 0 0 0 1 0 00 0 0 0 0 0 0 1 0
, (16)
X =
1 0 00 1 01 0 00 0 10 1 00 0 1
. (17)
Sob a formulacao (12), a hipotese de simetria pode ser expressa com A dada por(16) e
C =
1 0 −1 0 0 00 1 0 0 −1 00 0 0 1 0 −1
. (18)
Exemplo 3 (continuacao). A comparacao das subpopulacoes determinadaspela combinacao dos nıveis das variaveis definidoras da fazenda e raca podera serfeita em termos do tamanho medio da ninhada. Admitimos que as categoriasrepresentadas pelos inteiros ≥ 3 sao agrupadas tendo score comum igual a 3.O interesse no modelo de ausencia de interacao entre as variaveis explicativas(fazenda e raca) e obtido em (11) tomando A e X indicadas abaixo, com β
traduzindo a parametrizacao da casela de referencia na subpopulacao (1,1), ouseja correspondente a raca A na fazenda 1, i.e., β = (β1A, βB, βC , β2, β3)
′.
A = I9 ⊗ (0, 1, 2, 3)′ (19)
X′ =
1 1 1 1 1 1 1 1 10 1 0 0 1 0 0 1 00 0 1 0 0 1 0 0 10 0 0 1 1 1 0 0 00 0 0 0 0 0 1 1 1
(20)
16

4.2 Modelos log-lineares
Entre outras aplicacoes os modelos log-lineares sao uteis na descricao de padroesde associacao entre variaveis categorizadas. Exemplos tıpicos sao os modelos deindependencia. Os modelos log-lineares podem ser expressos na forma
logπq = 1rλq + Xqβ , q = 1, . . . , s
ou, de uma forma condensada, por
logπ = (Is ⊗ 1r)λ + Xβ , (21)
onde λ e um vetor de s componentes associados as restricoes naturais. A matrizX = (X1
′, . . . ,Xs′)′, de dimensao (sr × p), e tal que cada submatriz (r × p) de
X, gerando πq a partir de β, satisfaz r([1r,Xq]) = 1 + r(Xq) , q = 1, . . . , s er([Is ⊗ 1r,X]) = s + r(X) = s + p. A formulacao (21) equivale a
Alogπ = XLβ (22)
onde A e uma matriz s(r − 1) × sr tal que r(A) = s(r − 1) e AD = 0s(r−1)×s eXL e uma matriz s(r − 1) × p com as relacoes
XL = AX e X = A′(AA′)−1XL .
Na expressao acima 0s(r−1)×s representa uma matriz s(r − 1) × s de elementosiguais a 0. Tomando A = Is ⊗ [Ir−1,−1r−1] obtemos os chamados logitos dereferencia (relativos a categoria r).
Exemplo 5 (continuacao). O modelo Multinomial correspondente a esteproblema pode ser reparametrizado fazendo-se
log θij = λ + λXi + λY
j + λXYij
com as restricoes de identificabilidade
2∑
i=1
λXi =
2∑
j=1
λYj =
2∑
i=1
λXYij =
2∑
j=1
λXYij = 0.
O modelo estrutural de independencia corresponde a tomar λXY11 = 0 e poder ser
expresso sob a formulacao (21) com s = 1, r = 4, λ = λ, β = (λX1 , λY
1 )′ e
17

X =
1 11 −1−1 1−1 −1
. (23)
Sob a formulacao (22), basta tomar
A =
1 0 0 −10 1 0 −10 0 1 −1
(24)
XL =
2 22 00 2
. (25)
Exemplo 6 (continuacao). Neste caso, que pode ser adequadamente mode-lado por um produto de distribuicoes Multinomiais, o modelo log-linear saturadocorrespondente pode ser convenientemente expresso por (22) com
A = I6 ⊗ (1,−1) (26)
XL =
1 1 1 1 1 11 1 −1 0 −1 01 1 0 −1 0 −11 −1 1 1 −1 −11 −1 −1 0 1 01 −1 0 −1 0 1
. (27)
Aqui os elementos de β = (µ, α1, β1, β2, αβ11, αβ12)′ tem interpretacao similar
aquela dos parametros de uma ANOVA com restricoes de identificabilidade desoma zero.
Embora as formulacoes (21) e (22) sejam equivalentes, para efeito de inter-pretacao e implementacao computacional, a primeira e mais adequada para prob-lemas cujo modelo probabilıstico e Multinomial enquanto a segunda e mais ade-quada para problemas cujo modelo probabilıstico e um produto de distribuicoesMultinomiais.
18

Ainda em relacao aos modelos log-lineares pode-se considerar uma classe maisampla expressavel por
A∗logπ = X∗
Lβ , (28)
onde A∗ e uma matriz u × sr com r(A∗) = u ≤ s(r − 1) e a matriz u × p deespecificacao X∗
L e tal que r(X∗
L) = p ≤ u. Nesta classe, mais ampla que aqueladescrita acima, podemos ter u < s(r − 1) e A∗D 6= 0u×s. Tais modelos saoditos log-lineares generalizados. Quando A∗D = 0u×s o modelo (28) podeser escrito na forma (21); para detalhes ver Paulino e Singer (2003).
Em certas aplicacoes o modelo e mais facilmente concretizado via (22) e emoutras, via (28).
Exemplo 2 (continuacao). Um dos objetivos do estudo era compararos riscos relativos de ocorrencia de complicacoes pulmonares no perıodo pos-operatorio, tomando como referencia a categoria de baixo risco pre-operatorio.Assim, o modelo (28) reflete a igualdade dos dois riscos relativos ao fazermosβ = β,
A∗ =
(0 −1 0 1 0 00 −1 0 0 0 1
), (29)
X∗
L = (1, 1)′. (30)
4.3 Modelos funcionais lineares
Os modelos vistos anteriormente constituem casos particulares de modelos fun-cionais lineares definidos por
F(π) = Xβ , (31)
onde F(π) e um vetor de u ≤ s(r−1) funcoes parametricas de interesse e a matrizu × p de especificacao X tem r(X) = p ≤ u. A funcao vetorial F(·) : IRsr → IRu
deve satisfazer certas condicoes de regularidade (ver Paulino e Singer (2003), porexemplo).
Aqui, (31) corresponde a chamada formulacao em termos de equacoeslivres, sendo que (11), (22) e (28) configuram casos particulares. De formaequivalente temos a formulacao em termos de restricoes
19

CF(π) = 0(u−p) ,
onde C′ e uma matriz u × (u − p) base do complemento ortogonal do espacoimagem de X, e portanto, CX = 0(u−p)×p.
Em muitas aplicacoes F(π) pode ser construıda atraves da composicao defuncoes lineares, logarıtmicas, exponenciais e adicao de um vetor de constantes.
Exemplo 1 (continuacao). Um dos objetivos do estudo era avaliar o graude concordancia entre os dois metodos de avaliacao. Para isto pode-se usar aestatıstica Kappa,
κ =
∑i θii −
∑i θi·θ·i
1 −∑
i θi·θ·i=
∑i θii −
∑i θi·θ·i
∑i θi·
(∑j 6=i θ·j
) .
que pode ser obtida atraves de
F(π) = κ = exp[A4 log{A3 exp{A2 log(A1π)}}] , com
A1 =
1 0 0 0 1 0 0 0 11 1 1 0 0 0 0 0 00 0 0 1 1 1 0 0 00 0 0 0 0 0 1 1 11 0 0 1 0 0 1 0 00 1 0 0 1 0 0 1 00 0 1 0 0 1 0 0 11 1 0 1 1 0 1 1 01 0 1 1 0 1 1 0 10 1 1 0 1 1 0 1 1
, (32)
A2 =
1 0 0 0 0 0 0 0 0 00 1 0 0 1 0 0 0 0 00 0 1 0 0 1 0 0 0 00 0 0 1 0 0 1 0 0 00 1 0 0 0 0 0 0 0 10 0 1 0 0 0 0 0 1 00 0 0 1 0 0 0 1 0 0
, (33)
A3 =
(1 −1 −1 −1 0 0 00 0 0 0 1 1 1
), (34)
20

A4 =(
1 −1). (35)
5 Estimacao por Maxima Verossimilhanca
Para estimar os parametros dos modelos estruturais apresentados consideramosum conjunto de dados com o paradigma da Tabela 2, para o qual assumimos ummodelo probabilıstico Produto de Multinomiais, em que, por razoes de simplici-dade notacional definimos πij = θi(j). Nosso interesse e ajustar modelos estrutu-rais da forma π = π(β) = (π1(β), . . . , πs(β))′ com πi(β) = (πi1(β), . . . , πir(β))′,i = 1, . . . , s em que β e um vector p-dimensional de parametros desconhecidos.
Sob essas condicoes, o logaritmo da funcao de verossimilhanca correspondentepode ser expresso como
ln Ln(β|n) = K +s∑
i=1
r∑
j=1
nij ln πij(β) (36)
em que K e uma constante que nao depende de β. O estimador de maximaverossimilhanca (MV) de β e a solucao βn das seguintes equacoes, obtidas quandoigualamos a zero as derivadas de (36)
Un(β) =s∑
i=1
r∑
j=1
nij
πij(β)
∂
∂βπij(β) = 0 sujeito a
r∑
j=1
πij(β) = 1, i = 1, . . . , s.
(37)Como a matriz hessiana correspondente,
Vn(β) =∂2
∂β∂β′ ln Ln(β|n)
=s∑
i=1
r∑
j=1
−nij
[πij(β)]2∂
∂βπij(β)
∂
∂β′πij(β)
+s∑
i=1
r∑
j=1
nij
πij(β)
∂2
∂β∂β′πij(β)
e negativa negativa, a solucao de (37) corresponde a um ponto de maximo.Embora existam solucoes explıcitas de (37) em alguns casos, geralmente e
preciso recorrer a metodos iterativos para resolver essas equacoes. Um dos maiscomum e o metodo de Newton-Raphson, que consiste em iterar
21

β(q) = β(q−1) − [Vn(β(q−1)]−1Un(β(q−1)), q = 1, 2, . . . (38)
iniciando o processo por uma aproximacao conveniente β(0) e terminando-o coma satisfacao de um criterio de convergencia previamente definido. Em situacoesparticulares, outros metodos iterativos podem ser mais convenientes.
5.1 Modelo linear geral
Para o modelo de simetria, existem solucoes explıcitas para as equacoes de verossim-ilhanca que sao dados por
θij =
{nij/N, i = j(nij + nji)/(2N), i 6= j.
(39)
Para outros modelos estruturais, o metodo do gradiente, proposto por Paulinoe Silva (2000) e uma alternativa adequada. O metodo e desenvolvido com basena formulacao (12). Partindo de uma estimativa inicial para π, novas estimativassao calculadas iterativamente ate que um criterio de convergencia seja satisfeito.Com a estimativa de π assim obtida, denotada por π (notacao tambem usadapara o estimador), segue de (11) que
β = (X′X)−1XA′π.
Para grandes amostras a matriz de covariancia aproximada do estimador MVde β e dada por
Vβ
= { J′ DN D−1
π(β)J }−1 , (40)
onde N = n∗. ⊗ 1r = (Is ⊗ 1r1′r) e DN e uma matriz diagonal sr × sr tendo
os componentes de N na diagonal. A matriz J, de dimensao sr × p, suposta deposto completo, e o jacobiano ∂π(β)/∂β′, e e calculada por
J = PA′(APA′)−1X , com P = Is ⊗ (Ir − r−11r1
′r).
A matriz de covariancia assintotica de Aπ e dada por
VAπ = X V
βX′. (41)
Substituindo β por β em (40) e (41) obtemos estimadores consistentes dasmatrizes de covariancias correspondentes.
22

5.2 Modelos log-lineares
Um exemplo de situacao em que existem solucoes explıcitas para as equacoesde verossimilhanca (37) e aquele para qual o modelo de independencia pode sercogitado. Nessas condicoes, para uma tabela I ×J , os estimadores MV de θij saodados por
θij = ni·n·j/N, i = 1, · · · , I, j = 1, · · · , J. (42)
Para outros casos, podemos adotar o procedimento de Newton-Raphson de-scrito em Reis (1989), por exemplo. O procedimento iterativo para maximizacaoda funcao de verossimilhanca e iniciado com uma estimativa β(0). A partir desta,π e β sao sucessivamente calculados ate que um criterio de convergencia sejaatendido. As matrizes de covariancias assintoticas de β e A log π sao dadas por
Vβ
= {s∑
q=1
nq. X′q[Dπq
− πqπ′q]Xq }−1 (43)
VAlogπ = X V
βX′ = X{J′ DN D−1
π(β)J }−1X′ (44)
Substituindo π por π em (43) e (44) obtemos estimadores consistentes para asrespectivas matrizes de covariancias.
6 Estimacao por Mınimos Quadrados General-
izados
Nas Secoes 5.1 e 5.2 o metodo MV foi particularizado para os modelos lineargeral e log-linear. Aqui nos dedicamos a tecnica MQG, aplicavel a toda a classede modelos funcionais lineares da Secao 4.3. Em particular, essa tecnica tambeme aplicavel aos modelos linear geral e log-linear. Referencias importantes sobreesse topico sao Grizzle, Starmer and Koch (1969), Landis et al. (1976) e Koch etal. (1985).
Seja p = D−1N n o vetor das sr proporcoes amostrais. A matriz de covariancia
de p e a matriz sr × sr diagonal em blocos dada por
Vp = D−1N diag(Dπq
− πqπ′q , q = 1, . . . , s). (45)
Substituindo π por p em (45) obtemos o seguinte estimador consistente para Vp :
23

Vp = D−1N diag(Dpq
− pqp′q , q = 1, . . . , s). (46)
Definindo F ≡ [F1(p), . . . ,Fu(p)]′ temos um estimador consistente de F(π). Umestimador consistente da matriz de covariancia de F e dado por
VF = H Vp H′ , (47)
em que H = ∂F(π)/∂π |π=p e a matriz u × sr das derivadas das funcoes F(·)calculadas em p.
Escrevendo
EA(F) = F(π) = Xβ , (48)
onde EA significa valor esperado assintotico e X e β tem o mesmo significadoindicado na Secao 4.3, o estudo das funcoes de interesse F(π) pode ser feitoanalisando (48) como um modelo de regressao linear. Minimizando
(F − Xβ)′VF
−1(F − Xβ) ,
obtemos o estimador de MQG
β = (X′VF
−1X)−1X′VF
−1F , (49)
cuja matriz de covariancia pode ser estimada de forma consistente por
Vβ
= (X′VF
−1X)−1. (50)
Valores preditos de F(π) sob o modelo (48) podem ser calculados como
F = Xβ . (51)
Um estimador consistente da matriz de covariancia correspondente e
VF
= X(X′VF
−1X)−1X′ (52)
Um estimador consistente para o vetor de probabilidades π e fornecido por
π = p − Vp H′ VF
−1(F − F)
24

Observacao 1. Mesmo quando o modelo Produto de Multinomiais nao e ad-equado as frequencias observadas, podemos realizar a analise das funcoes de in-teresse usando os resultados (49)—(52) se dispusermos de estimativas de F(π) eVF com as propriedades mencionadas.
Observacao 2. A existencia de frequencias observadas nulas (zeros amostrais)merece atencao especial neste caso. Ver Paulino e Singer (2003) para detalhes.
7 Testes de ajustamento dos modelos
Calculada uma estimativa π para o vetor de probabilidades, µ = DNπ forneceuma estimativa para as frequencias esperadas nas caselas. O ajustamento dosmodelos pode ser avaliado confrontando, por algum meio, as frequencias obser-vadas (n) com as frequencias esperadas sob o modelo (µ).
Para os modelos linear geral e log-linear com parametros estimados por MVpodemos usar a estatıstica da razao de verossimilhancas de Wilks
QV = −2n′(logµ − logn). (53)
As estatısticas de Pearson (QP ) e de Neyman (QN) definidas como
QP = (n − µ)′ D−1
µ(n − µ), (54)
QN = (n − µ)′ D−1n (n − µ) (55)
sao gerais na medida em que se aplicam aos dois metodos de estimacao (MV eMQG). O calculo de QP exige frequencias estimadas estritamente positivas,enquanto QV e QN exigem frequencias observadas com esta propriedade.
O teste de ajustamento do modelo dispensa a estimacao dos parametros, serecorrermos a estatıstica de Wald
QW = (CF)′ [CHVp(CH)′]−1 CF , (56)
onde F = Ap (F = Alogp), H = A ( H = AD−1p ) para o modelo linear geral
(log-linear) e Vp e dada em (46). A matriz C exerce o mesmo papel indicado naSecao 4.3, mas em relacao a matriz X em (11), XL em (22) e X∗
L em (28), con-soante o modelo em questao. No caso do modelo (28), a matriz A usada no calculode H acima e substituıda por A∗. Nos modelos log-lineares, as frequencias ob-servadas devem ser estritamente positivas. As estatısticas QN e QW sao identicasquando avaliadas com estimativas MQG.
25

Sob a validade do modelo estrutural em teste, a distribuicao limite comumdas estatısticas apresentadas e qui-quadrado com u − p graus de liberdade, comu = s(r − 1) nos modelos (21) e (22).
Na situacao da nota do final da Secao 6 o ajuste do modelo pode ser testadocom a estatıstica de Wald.
8 Hipoteses redutoras de modelos
Tendo conseguido um modelo satisfatoriamente ajustado aos dados pode haverinteresse em testar simplificacoes adicionais materializadas em hipoteses do tipo
H0 : Wβ = 0t×1 , (57)
onde W e uma matriz t × p de posto r(W) = t ≤ p. Essas hipoteses podem sertestadas atraves da estatıstica generalizada de Wald
QWG = (Wβ)′ (WVβW′)−1Wβ , (58)
onde β e Vβ
sao calculados de acordo com o modelo (ver expressoes apropriadas
nas Secoes 5.1, 5.2 e 6). Sob H0 a distribuicao limite de QWG e χ2t .
26

9 Exemplo de analise
Tabela 13: Distribuicao de lesao obstrutiva coronariana expressiva para pa-cientes com e sem hipertensao arterial, controlando sexo e idade.
Hipert Grau de lesaoSexo Idade arterial LO<50% LO≥50% TotalFem <55 Nao 31 (65%) 17 (35%) 48 (100%)
Sim 42 (61%) 27 (39%) 69 (100%)≥55 Nao 55 (57%) 42 (43%) 97 (100%)
Sim 94 (47%) 104 (53%) 198 (100%)Subtotal 222 (51%) 190 (49%) 412 (100%)
Masc <55 Nao 80 (42%) 112 (58%) 192 (100%)Sim 70 (35%) 130 (65%) 200 (100%)
≥55 Nao 74 (28%) 188 (72%) 262 (100%)Sim 68 (18%) 314 (82%) 382 (100%)
Subtotal 292 (22%) 744 (78%) 1036 (100%)Total 514 (35%) 934 (65%) 1448 (100%)
• Variaveis explicativas: Sexo (M, F), Idade (< 55,≥ 55%), HAS (nao, sim)
• Variavel resposta: grau de lesao obstrutiva (< 50%,≥ 50%)
• Modelo probabilıstico: Produto de distribuicoes Binomiais
• Parametros:
• p(F, < 55, H): proporcao (populacional) de pacientes com lesao ob-strutiva ≥ 50% entre as mulheres com < 55 anos hipertensas
• p(M,≥ 55, NH): proporcao (populacional) de pacientes com lesaoobstrutiva ≥ 50% entre os homens com ≥ 55 anos nao hipertensos.
• Definicao analoga para os demais parametros
Um modelo estrutural saturado para esse problema pode ser expresso por (22)com
A = I8 ⊗ (1,−1)
27

XL =
1 1 1 1 1 1 1 11 1 1 −1 1 −1 −1 −11 1 −1 1 −1 1 −1 −11 1 −1 −1 −1 −1 1 11 −1 1 1 −1 −1 1 −11 −1 1 −1 −1 1 −1 11 −1 −1 1 1 −1 −1 11 −1 −1 −1 1 1 1 −1
.
O modelo aditivo, i.e., sem as interacoes de primeira ou segunda ordem entre asvariaveis explicativas pode ser escrito na mesma formulacao; nesse caso a matrizXL e obtida da matriz acima com a eliminacao das ultimas quatro colunas. Ovetor de parametros correspondente e β = (intercepto, sexo, idade, HAS)′.
Os resultados sugerem um bom ajuste e as estimativas (exponenciadas) dosparametros correspondentes estao indicadas na Tabela 14.
Tabela 14: Estimativas das razoes de chances sob um modelo log-linearaditivo
Parametro Estimativa IC (95%)exp(idade) 1.95 1.54 - 2.48exp(HAS) 1.50 1.19 - 1.90exp(Sexo) 3.41 2.58 - 4.35
Caso os 1448 pacientes avaliados puderem ser considerados como uma amostraaleatoria simples da populacao de interesse, podemos concluir que a chance (odds)de pacientes do sexo feminino com idade < 55 anos e sem hipertensao arterial terlesao obstrutiva ≥ 50% contra nao te-la e de 0.40 (IC(95%) = 0.40; 0.55). Inde-pendentemente dessa suposicao (isto e, mesmo que essa chance tenha um valor Rdiferente desse), a chance correspondente fica multiplicada por 3.41 (IC(95%) =2.58; 4.35) para pacientes do sexo masculino, por 1.95 (IC(95%) = 1.54; 2.48)para pacientes com idade ≥ 55 e por 1.50 (IC(95%) = 1.19; 1.90) para pacienteshipertensos. Dessa forma temos:
28

Tabela 15: Chances ajustadas atraves de modelo log-linear aditivo
Sexo Idade Hipertensao arterial ChanceLO ≥ 50%/LO < 50%
Fem < 55 Nao RFem ≥ 55 Nao 1.95 x RFem < 55 Sim 1.50 x RFem ≥ 55 Sim 1.95 x 1.50 x RMasc < 55 Nao 3.41 x RMasc ≥ 55 Nao 3.41 x 1.95 x RMasc < 55 Sim 3.41 x 1.50 x RMasc ≥ 55 Sim 3.41 x 1.95 x 1.50 x R
Se a suposicao de que os 1448 pacientes constituem uma amostra aleatoria dapopulacao de interesse, basta substituir R por 0.40 na tabela acima, para termosas chances correspondentes. Os termos que multiplicam a chance R sao as razoesde chances (odds ratios).
Referencias
[1] EMBRAPA (1996). Centro Nacional de Pesquisa Tecnologica em Informaticapara a Agricultura. Software NTIA, versao 4.2.1 : manuais. 2 disquetes3 1/2”. Campinas.
[2] Grizzle, J.E., Starmer, C.F. and Koch, G.G. (1969). The analysis of categor-ical data by linear models. Biometrics, 25, 489–504.
[3] Koch, G.G., Imrey, P.B., Singer, J.M., Atkinson, S.S. and Stokes, M.E.(1985). Lectures Notes for Analysis of Categorical Data. Montreal: LesPresses de l’Universite de Montreal.
[4] Landis, R., Stanish, W. Freeman, J. and Koch, G.G. (1976). A computerprogram for the generalized chi-square analysis of categorical data usingweighted least squares (GENCAT). Computer Programs in Biomedicine, 6,196-231.
[5] Paulino, C.D.M. e Singer, J.M. (2003). Analise de Dados Categorizados(Versao preliminar parcial). Sao Paulo: IME/USP.
29

[6] Paulino, C.D.M. e Silva, G.L. (2000). On the maximum lilkelihood analysisof the general linear model in categorical data. Computational Statistics andData Analysis, 30, 197-204.
[7] Reis, I.M. (1989). Modelos Log-lineares para Analise de Dados Categoriza-dos. Departamento de Estatıstica, Dissertacao de mestrado. Sao Paulo:IME/USP.
[8] Savalli, C., Paulino, C.D.M., Silva, G.L., Singer, J.M., Chicarino, M.P.Z.,Castro, M. e Tavares, R.A. (1999). Analise de Dados Categorizados no Sis-tema EMBRAPA-CNPTIA-NTIA, Versao 1.0. Sao Paulo: IME/USP.
[9] Upton, G. and Fingleton, B. (1985). Spatial data analysis by example, Vol1.. London: Wiley.
30