universidade nove de julho -...
TRANSCRIPT

UNIVERSIDADE NOVE DE JULHO - UNINOVE
ELENICE DA CONCEIÇÃO CASTRO LOPES
APLICAÇÃO DA TRANSFORMADA DISCRETA WAVELET NO CONTROLE DA
DIVERSIDADE POPULACIONAL NOS ALGORITMOS GENÉTICOS EM
PROBLEMAS DE OTIMIZAÇÃO
São Paulo
2012

ELENICE DA CONCEIÇÃO CASTRO LOPES
APLICAÇÃO DA TRANSFORMADA DISCRETA WAVELET NO CONTROLE DA
DIVERSIDADE POPULACIONAL NOS ALGORITMOS GENÉTICOS EM
PROBLEMAS DE OTIMIZAÇÃO
Dissertação apresentada ao Programa de Mestrado em Engenharia da Produção da Universidade Nove de Julho - UNINOVE como requisito final para obtenção do grau de Mestre. Orientador: Prof. Dr. Fabio Henrique Pereira
São Paulo
2012

Lopes, Elenice da Conceição Castro.
Aplicação da transformada discreta wavelet no controle da diversidade
populacional nos algoritmos genéticos em problemas de otimização. / Elenice
da Conceição Castro Lopes. 2012.
70 f.
Dissertação (mestrado) – Universidade Nove de Julho - UNINOVE, São
Paulo, 2012.
Orientador (a): Prof. Dr. Fabio Henrique Pereira.
1. Algoritmos genéticos. 2. Diversidade populacional. 3. Convergência
prematura.
I. Fabio Henrique Pereira. II. Titulo
CDU 624

AGRADECIMENTOS
A Deus pela vida que me foi dada.
A minha família por todas às vezes em que me confortou e incentivou-me a
continuar em frente nesse projeto.
Agradeço imensamente ao Prof. Dr. Fabio Henrique Pereira por sua
perseverança no exercício da docência incitando em nós alunos, o desenvolvimento
da resiliência necessária para o desenvolvimento do trabalho científico e por toda a
generosidade em orientar-me nesse caminho.
À UNINOVE e ao corpo docente de Pós-Graduação dessa universidade por
toda generosidade e dedicação no desenvolvimento desse programa de mestrado.

LOPES, Elenice da Conceição Castro. Aplicação da transformada discreta wavelet no controle da diversidade populacional nos algoritmos genéticos em problemas de otimização. 2012. 75p. Dissertação (Mestre em Engenharia de Produção). Universidade Nove de Julho – UNINOVE, São Paulo.
RESUMO
Na sociedade moderna marcada pela globalização e pelo consumo, o uso racional e sustentável dos recursos naturais e a constante busca por maior qualidade e redução de custos nos processos de produção estão recebendo cada vez mais importância. Em ambos os aspectos a utilização de ferramentas de otimização é salutar. Nesse cenário se destaca a técnica dos algoritmos genéticos, que são algoritmos de busca baseado na teoria da evolução de Darwin e da mutação genética de Mendel. Os algoritmos genéticos trabalham com um conjunto de possíveis soluções (indivíduos) para o problema, que evoluem segundo alguns critérios genéticos para, idealmente, convergir para a melhor solução. Apesar de fornecerem soluções satisfatórias mesmo para problemas complexos e, talvez por isso, serem amplamente utilizados, essa técnica pode sofrer com problemas de convergência. Em muitas situações os indivíduos do conjunto podem se concentrar em determinadas regiões do espaço de busca que não contém a melhor solução, significando uma convergência prematura do método. Esse problema de concentração dos indivíduos no espaço de busca representa o que é chamado de perda de diversidade populacional. Este estudo aborda a questão da diversidade populacional do AG sob a perspectiva da escolha do tamanho do conjunto de possíveis soluções (a população) e do controle de sua diversidade ao longo do processo evolutivo. Para tal, propõe a aplicação da transformada discreta wavelet ao conjunto de indivíduos com vistas a criar uma aproximação desse conjunto por meio da eliminação da correlação entre seus indivíduos. A técnica de clusterização k-médias é usada para grupar os indivíduos que sofrerão conjuntamente a ação da transformada wavelet. A abordagem proposta, chamada de AGkW, foi testada em problemas benchmark usados comumente para avaliação de técnicas de busca global. Resultados obtidos mostram que, em geral, o método proposto se comportou de maneira eficiente para os problemas abordados, tendo apresentado resultados tão bons ou superiores em comparação ao AG. Em especial, para alguns dos problemas testados, o método AGkW apresentou um desempenho cerca de 50% superior com apenas 25% do número médio de avaliações da função objetivo, aproximadamente. Palavras-chave: Algoritmos Genéticos, Diversidade Populacional, Convergência Prematura, Problemas de Otimização, Transformada Discreta Wavelet, Clusterização k-médias

LOPES, Elenice da Conceição Castro. Application of discrete wavelet transform to control population diversity in genetic algorithms in optimization problems. 2012. 75p. Dissertation (Master in Production Engineers). Universidade Nove de Julho – UNINOVE, São Paulo.
ABSTRACT
In modern society marked by globalization and consumption, the rational and sustainable use of natural resources and the constant quest for higher quality and lower costs in production processes are getting more and more importance. In both aspects, the use of optimization tools is salutary. In this scenario highlights the technique of genetic algorithms, which are search algorithms based on Darwin's theory of evolution and genetic mutation of Mendel. Genetic algorithms work with a set of possible solutions (individuals) to the problem, which evolve according to some criteria for genetic ideally converge to the best solution. Despite provide satisfactory solutions even for complex problems and maybe therefore are widely used, this technique can suffer from convergence problems. In many situations, individuals can set the focus on certain regions of the search space that do not contain the best solution, meaning a premature convergence of the method. This problem of concentration of individuals in the search space represents what is called loss of population diversity. This study addresses the issue of population diversity of the AG from the perspective of the size of the choice set of possible solutions (the population) and the control of its diversity throughout the evolutionary process. To this end, proposes the use of discrete wavelet transform to a set of individuals in order to create a set of approximation by eliminating the correlation between its individuals. The technique of k-means clustering is used to group the individuals who suffer joint action of the wavelet transform. The proposed approach, called AGkW was tested on “benchmark” problems commonly used for evaluation of global search techniques. Results show that in general, the method proposed behave effectively to the problems addressed and tested as good as or superior as compared to the AG. In particular, a number of problems tested, the method AGkW performance was about 50% higher with only 25% of the average objective function evaluations, approximately. Keywords: Genetic Algorithms, Population Diversity, Optimization Problems, Discrete Wavelet Transform, k-means Clustering.

LISTA DE FIGURAS
Figura 1 - Quantidade de artigos das técnicas metaheurísticas nos últimos sete
anos. ......................................................................................................................... 10
Figura 2 - Quantidade de Artigos sobre técnicas metaheurísticas de otimização. .... 11
Figura 3 - Mínimos e máximos locais e globais de uma função de duas dimensões.
.................................................................................................................................. 17
Figura 4 - Estrutura de um Cromossomo. ................................................................. 21
Figura 5 - Estrutura do Diagrama de atividades de Funcionamento em um AG. ...... 22
Figura 6 - Exemplo de operador de mutação. Fonte: ................................................ 25
Figura 7 - Exemplo de operador de cruzamento em dois pontos. ............................. 25
Figura 8 - Exemplo da perda de diversidade no AG. ................................................. 27
Figura 9 - Exemplo de função wavelet: (a) Haar. ...................................................... 31
Figura 10 - Exemplo de função wavelet: (b) Mexican Hat. ........................................ 31
Figura 11 - de função wavelet: (c) Morlet. ................................................................. 32
Figura 12 - Exemplo de função wavelet: (d) Shannon.. ............................................. 32
Figura 13 - Resultado da aplicação da transformada discreta wavelet em um vetor
com oito elementos. .................................................................................................. 35
Figura 14 - Exemplo de aplicação da transformada discreta wavelet com um nível a
uma imagem. ............................................................................................................. 36
Figura 15 - Estrutura de Funcionamento do AGkW. .................................................. 44
Figura 16 - Função de teste Rastringin. .................................................................... 46
Figura 17 - Função Rastringin no domínio [-2,12; 2,12] e suas curvas de nível. ....... 47
Figura 18 - Comparação entre o AG e o AGkW para o número de avaliações da
Função Objetivo nos 16 cenários propostos para testes. .......................................... 50
Figura 19 - Percentual de convergências obtidas entre o AG X AgkW nos 16
cenários de teste. ...................................................................................................... 50
Figura 20 - Função teste Griewank, considerando o domínio [-10;10]. ..................... 52
Figura 21 - Função teste Branin. ............................................................................... 53
Figura 22 - Função teste Schwefel com mínimo global no ponto [-420,9687; -
420,9687]. ................................................................................................................. 55
Figura 23 - Diversidade populacional baseado no momento de inércia. ................... 57

LISTA DE TABELAS
Tabela 1: Valores de tamanho de população e número de gerações testadas ......... 47
Tabela 2: Resultados para AG usando a função teste Rastringin: desempenho x
número de avaliações ............................................................................................... 48
Tabela 3: Resultados para AGkW usando a função teste Rastringin: desempenho x
número de avaliações ............................................................................................... 49
Tabela 4: Comparativo de desempenho e número médio de avaliações .................. 51
Tabela 5: Resultados para a função Griewank: melhor solução encontrada, número
médio de avaliações (n) e desempenho (%) em 20 replicações ............................... 52
Tabela 6: Resultados para a função Branin: melhor solução encontrada, número
médio de avaliações (n) e desempenho (%) em 20 replicações. .............................. 54
Tabela 7: Resultados para a função Schwefel: melhor solução encontrada, número
médio de avaliações (n) e desempenho (%) em 20 replicações. .............................. 55

SUMÁRIO
1 INTRODUÇÃO ........................................................................................................ 8 1.1 JUSTIFICATIVA ................................................................................................. 11 1.2 O PROBLEMA DA PESQUISA .......................................................................... 13 1.3 MOTIVAÇÃO ...................................................................................................... 13 1.4 OBJETIVOS ....................................................................................................... 14
1.4.1 Objetivo Geral ................................................................................................. 14 1.4.2 Objetivos Específicos ...................................................................................... 14
1.5 Resultados Esperados ....................................................................................... 14 1.6 ESTRUTURA DESTA DISSERTAÇÃO .............................................................. 15 2 FUNDAMENTAÇÃO TEÓRICA ............................................................................ 16 2.1 PROBLEMAS DE OTIMIZAÇÃO NA ENGENHARIA DE PRODUÇÃO .............. 16
2.2 ALGORITMOS DE OTIMIZAÇÃO ...................................................................... 18 2.3 METAHEURÍSTICAS ......................................................................................... 19 2.4 ALGORITMO GENÉTICO .................................................................................. 20 2.4.1 Codificação do material genético no AG ......................................................... 21
2.5 PERDA DE DIVERSIDADE E CONVERGÊNCIA PREMATURA NO AG........... 26 2.6 TRANSFORMADA DISCRETA WAVELET ........................................................ 31
2.6.1 Wavelet e Algoritmo Genético ......................................................................... 36 2.7 CLUSTERIZAÇÃO K-MÉDIAS ........................................................................... 37
2.7.1 Alternativas ao k-médias ................................................................................. 38 3 MATERIAIS E MÉTODOS .................................................................................... 39 3.1 CARACTERIZAÇÃO METODOLÓGICA ............................................................ 39 3.2 DEFINIÇÃO DO OBJETO DE ESTUDO ............................................................ 39 3.3 FUNÇÕES OBJETIVO UTILIZADAS ................................................................. 40 3.3 AJUSTE DOS FATORES DE INFLUÊNCIA ....................................................... 41 3.4 FORMAS DE CONTROLE DOS EFEITOS DOS FATORES .............................. 41
3.5DESCRIÇÃO DA ABORDAGEM PROPOSTA .................................................... 42
4 RESULTADOS E DISCUSSÃO ............................................................................ 46 4.1 APLICAÇÃO AO PROBLEMA TESTE RASTRINGIN ........................................ 46
4.2 APLICAÇÃO AO PROBLEMA TESTE GRIEWANK ........................................... 52 4.3 APLICAÇÃO AO PROBLEMA TESTE BRANIN ................................................. 53 4.4 APLICAÇÃO AO PROBLEMA TESTE SCHWEFEL .......................................... 54 4.5 ANÁLISE DA DIVERSIDADE POPULACIONAL ................................................ 56 5 CONCLUSÕES ..................................................................................................... 58 REFERÊNCIAS BIBLIOGRÁFICAS ........................................................................ 60

8
1 INTRODUÇÃO
Na sociedade moderna marcada pela globalização e pelo consumo, dois
temas estão recebendo cada vez mais importância: o uso racional e sustentável dos
recursos naturais, e uma constante busca por maior qualidade e redução de custos
nos processos de produção. Em ambos os aspectos a utilização de ferramentas de
otimização é salutar. No que se refere à busca por maior qualidade e redução de
custos nos processos de produção, as ferramentas de otimização podem ser
aplicadas na busca de valores ideais para os fatores controláveis que interferem no
processo, visando, principalmente: a) uma redução da variação do processo e
melhor concordância entre os valores nominais obtidos e os valores pretendidos; b)
redução do tempo do processo; c) redução do custo operacional; d) melhoria no
rendimento do processo.
Portanto, acredita-se que o desenvolvimento de novas técnicas de
otimização, bem como o estudo das técnicas existentes, é plenamente justificado,
pois, conforme argumenta Harisson (1998), não há uma única técnica que resolva
todos os problemas e os diferentes métodos servem para diferentes propósitos;
cada um deles apresentando suas vantagens e suas desvantagens.
Especificamente no que diz respeito aos diversos ambientes de produção
industrial, há a necessidade de otimizar a análise das variáveis de controle de
processos. Essas variáveis, de acordo com o problema a ser analisado, podem
representar um conjunto de milhares de dados a serem tabulados e analisados a fim
de fornecer informações que, em muitos casos, se correlacionam de forma pouco
conclusiva quando não há uso de ferramentas para dar suporte a tomada de
decisões gerenciais.
Para análise desses dados vem sendo usado algoritmos que usam
estratégias de busca com informação (RUSSEL e NOVIG, 2004), com vistas a
minimizar os custos das análises necessárias, bem como a escolha do cenário mais
adequado a partir dos dados analisados. Esses algoritmos são métodos de
resolução de problemas de otimização de forma intuitiva, as heurísticas, estudadas
no campo da inteligência artificial. Quando esses métodos geram soluções além das
heurísticas de solução inicial, temos assim as técnicas metaheurísticas que se

9
utilizam de diferentes estratégias para exploração do espaço de busca (ARENALES
et al, 2007).
Essas técnicas metaheurísticas são inspiradas na natureza e visam
reproduzir padrões de comportamento nela observados. Como exemplo cita-se os
Algoritmos genéticos (AGs), que são algoritmos de otimização de busca baseado na
teoria da evolução de Darwin e da mutação genética de Mendel (ATMAR, 1994;
FOGEL, 1994); o Recozimento Simulado (Simulated Annealing, SA), baseado no
processo de recozimento dos metais (KIRKPATRICK et al, 1983); o Enxame de
Partículas – Particle Swarm Optimization (PSO), baseado no comportamento social
e formação de vôo de um bando de pássaros e seus meios de informações
(KENNEDY e EBERHART, 1995; SERAPIÃO, 2009), Colonia de Formigas (Ant
Colony System – ACS) (DORIGO et al, 1996), entre outros.
Esses métodos fornecem soluções aceitáveis para problemas complexos,
mesmo não garantindo a otimalidade de suas soluções, visto que não encontram
necessariamente a melhor resposta, mas sim um conjunto de soluções satisfatórias
aos problemas propostos. Outro ponto a ser considerado é a facilidade de
programação dessas técnicas numéricas quando comparadas aos métodos
determinísticos clássicos baseados em gradiente (BIRGIN et al, 2000).
As características acima citadas impulsionaram a utilização das técnicas
metaheurísticas nas mais diversas áreas, em especial no campo da engenharia de
produção. Em levantamento feito na base de dados de artigos científicos
ScienceDirect (2012), usando como critério de busca os termos mais comuns
relativos as essas técnicas (genetic algorithm, simulated annealing particle swarm,
swarm optimization, evolutionary algorithm) observa-se (Figura 1) uma quantidade
significativa de artigos que apresentam aplicação no campo da Engenharia de
Produção nos últimos 7 anos.
Foram considerados nessa pesquisa bibliográfica apenas os periódicos da
linha de Pesquisa Operacional e Engenharia Industrial: “European Journal of
Operational Research”, “Computers & Operations Research”, “Computers &
Industrial Engineering” e “Engineering Applications of Artificial Intelligence”.

10
Figura 1 - Quantidade de artigos das técnicas metaheurísticas nos últimos sete anos.
Fonte: (SCIENCEDIRECT, 2012).
Na fase de pesquisa bibliográfica tendo o site da Science Direct como
fonte, observou-se que a maior quantidade de artigos das áreas de pesquisa
operacional e engenharia industrial, abordam soluções usando o algoritmo genético.
Sendo o algoritmo genético, amplamente testado e utilizado no campo das
engenharias para pesquisa operacional, devido a sua facilidade de programação,
flexibilidade de aplicação em diversos cenários de resolução de problemas, há a
necessidade de lhe dar maior robustez.
Assim, com o crescente uso do AG em problemas de otimização cada vez
mais complexos, tem-se a necessidade de pesquisar as melhorias necessárias nos
pontos de desvantagens do AG, a fim de torná-lo um método cada vez mais robusto
e confiável. Para esse fim, optou-se em associá-lo a técnica matemática da
transformada discreta wavelet para otimizar os testes com grande quantidade de
dados, procurando preservar a diversidade desses dados, a fim de que assim possa
garantir uma maior possibilidade de encontrar valores ótimos.

11
Figura 2 - Quantidade de Artigos sobre técnicas metaheurísticas de otimização.
Fonte: (SCIENCEDIRECT, 2012).
Como exemplos de aplicação do AG na área de engenharia de produção,
citam-se os recentes trabalhos desenvolvidos no âmbito do Programa de Mestrado
em Engenharia de Produção da Universidade de Julho (COSTA e SASSI, 2012;
PEREIRA, PIRES e NABETA, 2012; LIBRANTZ et al., 2011; SILVA 2011; SANTANA
et al., 2010; ARAUJO et al, 2009). Destaca-se aqui a abordagem desenvolvida em
Silva (2011), na qual se tem a aplicação do AG para otimização dos parâmetros de
sequenciamento da produção em um ambiente de manufatura composto de diversas
máquinas e ordens a serem produzidas. O problema abordado naquele caso
envolve a busca de um sequenciamento ótimo em um espaço de busca composto
de, aproximadamente, 3,8x1014 possíveis soluções.
1.1 JUSTIFICATIVA
As diferentes implementações dos algoritmos genéticos variam em seus
detalhes, mas geralmente compartilham a mesma estrutura. Os AGs operam em um
espaço de busca de soluções candidatas, chamadas de indivíduos, que diferem uns
dos outros pela representação das variáveis do problema de otimização. Esse
problema de otimização é, em geral, representado pela minimização de uma função
matemática chamada de função objetivo, a qual pode ser usada para avaliar a

12
adequação (aptidão) de cada indivíduo para a solução do problema (PACHECO,
1999).
Um conjunto de indivíduos, chamado de população, é escolhido
aleatoriamente no início de um processo de evolução que tem como objetivo evoluir
para a melhor solução possível (solução ótima). A cada iteração do processo
evolutivo, também chamada geração, os indivíduos mais aptos são selecionados e
combinados por meio da troca de informação. Portanto, para criar novos indivíduos,
os membros combinados devem ser diferentes e a porção de diferença entre os
indivíduos da população é chamada de diversidade (MITCHELL, 1997). Uma maior
diversidade permite uma melhor exploração do espaço de busca e pode propiciar
uma maior probabilidade de encontrar os melhores valores dentro desse espaço
(valores ótimos globais).
De fato, a diversidade da população inicial é uma característica fundamental
para o bom desempenho de um Algoritmo Genético (HILL, 1999), pois está
diretamente ligada ao problema denominado de convergência prematura (CASTRO,
2001). Entende-se por convergência prematura quando a população converge para
uma solução que possui uma boa aptidão, mas que ainda não é a solução ótima, e
dela não conseguem sair por causa de sua baixa diversidade (LUCAS, 2002).
Na prática a diversidade da população deve ser suficiente para que o
processo evolutivo do AG seja capaz de produzir novos indivíduos no espaço de
busca por meio da combinação das características dos indivíduos existentes (POZO
et al. 2007). População com baixa diversidade pode gerar uma concentração de
indivíduos em uma determinada região do espaço de busca, que pode não
representar as melhores soluções (GAO, 2003), significando uma convergência
prematura do método (AZEVEDO, 1999).
O problema da perda de diversidade também está naturalmente ligado ao
tamanho da população inicial no AG (HIROYASU et al., 2008). A diversidade
decresce mais rapidamente para tamanhos menores de população, sendo o valor da
perda da diversidade é inversamente proporcional ao valor do tamanho da
população (GUDWIN e VON ZUBEN, 2002). Por outro lado, o uso de populações
com grande número de indivíduos, que poderia garantir uma maior exploração do
espaço de busca, pode ser computacionalmente inviável uma vez que o custo
computacional da aplicação dos algoritmos genéticos é governado pelo
procedimento de cálculo do valor de aptidão dos indivíduos.

13
1.2 O PROBLEMA DA PESQUISA
Diante do cenário exposto, este trabalho concentrou seus esforços na
seguinte questão:
Como definir uma estratégia que permita uma completa exploração do
espaço de busca amenizando (ou eliminando) a perda de diversidade populacional,
situação em que o algoritmo pode convergir prematuramente para as soluções
afastadas de valores ótimos globais?
A abordagem proposta neste trabalho considera que quaisquer adequações
no AG não devem comprometer a eficiência do método no que diz respeito ao tempo
de processamento.
1.3 MOTIVAÇÃO
Esse trabalho foi impulsionado pela vontade de verificar se seria possível
aplicar a transformada discreta wavelet como uma técnica que explorasse no
algoritmo genético, a correlação entre os indivíduos de sua população e que
simultaneamente promovesse uma redução na quantidade necessária de testes de
aptidão dessa população. Aplicar a transformada a fim de manusear o tamanho da
população por meio da construção do cálculo de uma aproximação da população
original, essa é justamente a tarefa realizada pela transformada discreta wavelet
quando aplicada a uma população. As wavelets são funções que possuem algumas
características especiais que permitem construir aproximações esparsas de um
conjunto de dados, conforme será apresentado no capítulo 2.
Durante o processo de testes, verificou-se a necessidade de potencializar o
desempenho da transformada discreta wavelet, pois os indivíduos semelhantes da
população precisam estar agrupados em colunas adjacentes na matriz populacional
para que seja adequadamente explorada a semelhança entre os indivíduos dessa
população.
Para auxiliar na solução desse impasse, foi escolhido trabalhar com a
técnica de agrupamento k-médias, por ser eficiente em resolver problemas de
agrupamentos, ou seja, organizar em clusteres quantidades significativas de dados.

14
Essa opção de uso também deve-se ao fato de a técnica K-médias, ser de fácil
implementação.
1.4. OBJETIVOS
1.4.1 Objetivo Geral
O objetivo principal deste trabalho é avaliar o desempenho do uso da
transformada discreta wavelet e do algoritmo de construção de agrupamentos
(clusteres) k-médias na exploração do tamanho e da diversidade populacional no
AG. Essa abordagem deu origem a uma versão do Algoritmo Genético chamada
aqui de AGkW.
1.4.2 Objetivos Específicos
Programar e testar o método AGkW em problemas de otimização
“benchmark” envolvendo funções matemáticas complexas;
Estudar o processo de escolha dos parâmetros de geração de
agrupamentos (número de clusteres) e da aplicação da transformada
discreta wavelet;
Estudar os efeitos do tamanho da população e do número de gerações
no desempenho do AG e do AGkW;
Avaliar o comportamento da diversidade populacional ao longo do
processo de evolução para o AG e o AGkW;
Comparar o métodos AG e AGkW em relação ao número de avaliações
da função objetivo e o desempenho de convergência para o ótimo global.
1.5 Resultados Esperados
Espera-se comprovar que o uso da transformada discreta wavelet,
associada ao k-médias e ao AG, possibilita uma exploração mais completa do

15
espaço de busca com um número aceitável de avaliações da função objetivo,
evitando a convergência para pontos que não são soluções ótimas globais.
Consequentemente, pretende-se que o método AGkW possa ser
eficientemente aplicado em problemas nos quais o AG tem dificuldades de preservar
a diversidade populacional e convergir para o ótimo global.
1.6 ESTRUTURA DESTA DISSERTAÇÃO
O trabalho está dividido em cinco capítulos, ordenados da seguinte forma:
Primeiro capítulo introdutório, apresentamos a justificativa do trabalho, o
problema da pesquisa, a motivação das técnicas utilizadas na pesquisa,
os objetivos geral e específico, bem como o resultado esperado.
O segundo capítulo apresenta a fundamentação teórica para a pesquisa,
com os conceitos de problema de otimização, algoritmos de otimização,
methaeuristica, o algoritmo genético ( AG) e suas características, a perda
de diversidade e convergência prematura no AG, a transformada discreta
wavelet ( TDW) e a clusterização k-médias.
No terceiro capítulo são descritos os materiais e métodos utilizados.
Aonde encontra-se a descrição do processo de pesquisa, o objeto de
estudo, as funções de teste utilizadas como funções objettivo, o ajuste
dos fatores de influência e suas formas de controle, a descrição da
estratégia proposta.
O quarto capítulo apresenta os resultados obtidos, os comentários e
discussão correspondente.
O Quinto capítulo apresenta a conclusão geral do trabalho.
No apêndice estão os anexos relativos aos artigos resultante dessa
dissertação.

16
2 FUNDAMENTAÇÃO TEÓRICA
Este capítulo apresenta os principais conceitos necessários para
compreensão do trabalho desenvolvido: apresentação das definições de problemas
de otimização na engenharia de produção; definição dos conceitos de mínimo e
máximo, local e global; algoritmos determinísticos e algoritmos probabilísticos de
otimização, com destaque para as metaheurísticas; algoritmo genético e seus
operadores, e o problema da perda de diversidade; transformada discreta wavelet e
algoritmo de clusterização k-médias.
2.1 PROBLEMAS DE OTIMIZAÇÃO NA ENGENHARIA DE PRODUÇÃO
Problemas de otimização são objetos de estudo da pesquisa operacional, no
campo da engenharia de produção para auxiliar no gerenciamento de sistemas de
produção e logística, envolvendo problemas de planejamento, programação e
controle da produção, problema de distribuição de produtos, problemas de
localização de facilidades e instalações (ARENALES et al, 2007).
Na busca por soluções para problemas de otimização, a habilidade em
elaborar modelos matemáticos é fundamental (ARENALES et al, 2007). Em
matemática, o termo otimização, ou programação matemática, refere-se ao estudo
de problemas em que se busca minimizar ou maximizar uma função através da
escolha sistemática dos valores de variáveis reais ou inteiras dentro de um conjunto
viável (HOLDER, 2008). Essas funções, comumente chamadas de função objetivo,
podem representar qualquer tipo de elementos como números, listas, planos de
construção, e assim por diante (WEISE, 2008). Usualmente, o domínio da função é
definido de acordo com o problema a ser resolvido no processo de otimização. De
acordo com Weise (2008), funções objetivo não são necessariamente meras
expressões matemáticas, mas podem ser complexos algoritmos que, por exemplo,
envolvam simulações múltiplas.
Na otimização global, na qual se busca pelo valor ótimo global da função, é
uma convenção que os problemas de otimização sejam mais frequentemente
definidos como um problema de minimização. Assim, se um critério f(X) está sujeito
17
à maximização, assume-se simplesmente a minimização da sua função com sinal
oposto -f(X) (ARENALES et al., 2007).
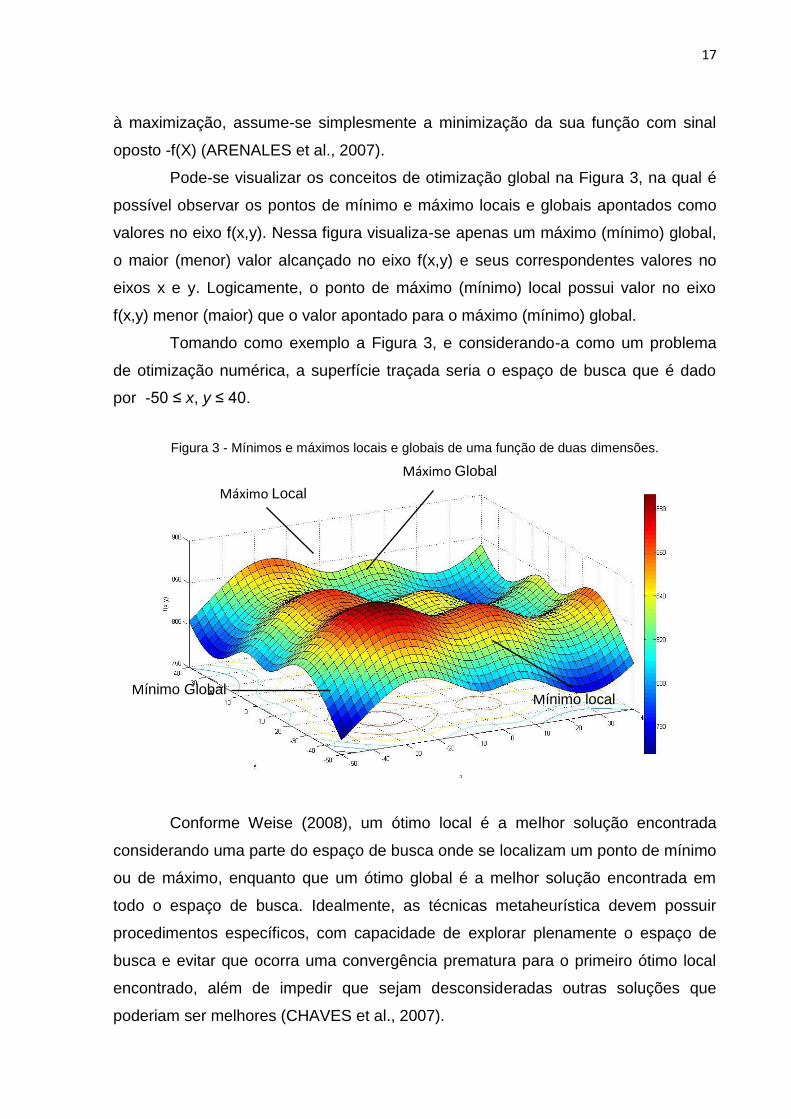
Pode-se visualizar os conceitos de otimização global na Figura 3, na qual é
possível observar os pontos de mínimo e máximo locais e globais apontados como
valores no eixo f(x,y). Nessa figura visualiza-se apenas um máximo (mínimo) global,
o maior (menor) valor alcançado no eixo f(x,y) e seus correspondentes valores no
eixos x e y. Logicamente, o ponto de máximo (mínimo) local possui valor no eixo
f(x,y) menor (maior) que o valor apontado para o máximo (mínimo) global.
Tomando como exemplo a Figura 3, e considerando-a como um problema
de otimização numérica, a superfície traçada seria o espaço de busca que é dado
por -50 ≤ x, y ≤ 40.
Figura 3 - Mínimos e máximos locais e globais de uma função de duas dimensões.
Conforme Weise (2008), um ótimo local é a melhor solução encontrada
considerando uma parte do espaço de busca onde se localizam um ponto de mínimo
ou de máximo, enquanto que um ótimo global é a melhor solução encontrada em
todo o espaço de busca. Idealmente, as técnicas metaheurística devem possuir
procedimentos específicos, com capacidade de explorar plenamente o espaço de
busca e evitar que ocorra uma convergência prematura para o primeiro ótimo local
encontrado, além de impedir que sejam desconsideradas outras soluções que
poderiam ser melhores (CHAVES et al., 2007).
Máximo Local
Máximo Global
Mínimo local Mínimo Global

18
Cumpre salientar, no entanto, que todas as técnicas metaheurísticas
populacionais sofrem com os problemas de perda de diversidade e convergência
prematura para ótimos locais (SERAPIÃO, 2009). A opção pelo AG deve-se a sua
popularidade, conforme apresentado no capítulo 1, mas a abordagem proposta pode
ser aplicada em outras técnicas com as mesmas características de estratégia de
busca local, no qual a solução do problema a ser resolvido é encontrada através de
testes das inúmeras soluções possíveis dentro da população ( RUSSEL e NORVIG,
2004).
2.2 ALGORITMOS DE OTIMIZAÇÃO
Existem na literatura diversas métodos numéricos para encontrar mínimos e
máximos de funções, conhecidos como algoritmos de otimização (PARDALOS,
ROMEIJN, 2002; GRAY, 1997; FLOUDAS, 1999; HORST e TUY, 1996). Na
pesquisa operacional em Engenharia de Produção, é estudado na programação
dinâmica que consiste na decomposição do problema original em uma sequência de
problemas menores e mais simples de serem resolvidos, esses métodos podem ser
classificados, em programação dinâmica (ARENALES et al., 2007):
Determinística
Estocástica:
Na programação dinâmica determinísticas, temos conhecimento completo do
estado para o qual o sistema evolui em cada estágio do sistema, Nos algoritmos
dessa programação existe uma relação clara e formal entre as variáveis
independentes (soluções candidatas) e a variável dependente (resposta) para o
problema abordado (HORST e TUY, 1996).
Se a relação entre uma solução candidata e a resposta correspondente não
é tão óbvia, não é explícita ou é demasiadamente complicada, ou ainda, a
dimensionalidade do espaço de busca é muito elevada, torna-se mais difícil resolver
um problema de forma determinística (AKASAWA, 2007; SANTA CATARINA, 2009;
DING, BENYOUCEF e XIE, 2006). Uma alternativa seria realizar uma exploração
exaustiva do espaço de busca, o que é inviável mesmo em um espaço de busca
relativamente pequeno, ou quando se tratam de problemas com múltiplos objetivos.

19
Algoritmos da programação estocástica são aplicados em situação em que
não temos conhecimento exato de todos os termos do problema. São aplicados a
problemas de engenharia de produção no qual a demanda em cada período não
com certeza, em investimento de capital em que o retorno de cada investimento não
é conhecido com certeza, em jogos em que as jogadas dos outros jogadores não
são conhecidas com certeza, etc ( AENALES et, 2007) .
2.3 METAHEURÍSTICAS
O termo metaheurística, introduzido por Glover (1986), é utilizado para
representar o conjunto de algoritmos estocásticos estudados no campo da
Inteligência Artificial (IA). Baseiam-se em métodos nos quais a solução retornada
pode não ser necessariamente a melhor para o problema, porém com resultados
que se mostram adequados para problemas complexos, nos quais não há uma
relação explícita entre as variáveis (SILVA, 2011; PEREIRA, PIRES e NABETA,
2012).
Por apresentarem maior grau de generalidade em relação a outros
algoritmos, os algoritmos estocásticos podem ser aplicados em diversos tipos de
problemas. Eles são especialmente adequados para problemas nos quais se busca
escolher o melhor subconjunto de um determinado conjunto discreto e finito de
dados, satisfazendo determinados critérios pré-definidos (MACULAN et al., 2003).
Esses são chamados de problemas de otimização combinatória que envolvem a
combinação de vários fatores e buscam o valor máximo ou mínimo de uma função,
cujas variáveis devem obedecer a um conjunto de restrições, em um determinado
domínio (BLUM e ROLI, 2008). Portanto, são problemas que não podem ser
resolvidos por técnicas de otimização determinísticas tradicionais como, por
exemplo, a programação Linear, programação dinâmica, programação não-linear,
principalmente porque a verificação de todas as soluções possíveis é muito lenta e
dispendiosa (ARENALES et al., 2007).
Essa classe de métodos de otimização combina funções numéricas a serem
atendidas e procedimentos heurísticos em uma representação abstrata que seja
eficiente, usualmente sem a necessidade de grande aprofundamento na estrutura do
problema, abordando-o como um procedimento caixa-preta (WEISE, 2008).

20
A modelagem dos métodos metaheurísticos é muitas vezes desenvolvida
experimentalmente pela utilização de ensaios estatísticos no espaço de busca ou
baseada na simulação de alguns fenômenos naturais ou processos físicos. A técnica
metaheurística do Simulated Annealing, por exemplo, escolhe a próxima solução
candidata a ser testada de acordo com o fator de probabilidade de Boltzmann da
configuração atômica da solidificação de um metal recozido (KIRKPATRICK et al.,
1983).
Algoritmos evolucionários copiam o comportamento da evolução natural e
tratam a solução candidata como indivíduos que competem em um ambiente virtual
(GOLDBERG, 1989; HOLLAND, 1975). Destaca-se aqui o algoritmo genético, tema
deste trabalho e assunto abordado na próxima seção.
2.4 ALGORITMO GENÉTICO
O Algoritmo genético (AG) provê um método de aprendizagem motivado
pela analogia com o processo de seleção natural, o qual simula a evolução das
espécies (NORVIG, 2004). Os AGs têm por base o princípio da sobrevivência “do
mais forte” ou “melhor adaptado”, conforme definição darwinista dos fenômenos
naturais sobre a origem das espécies e da herança genética na luta pela
sobrevivência (MITCHEL, 1997; MICHALEWICZ, 1996).
O AG gera uma população de indivíduos, também chamados cromossomos
ou hipóteses, que evoluem gerando hipóteses sucessoras, para encontrar a solução
de um dado problema (NEMAT et al., 2009). Cada indivíduo representa uma
possível solução para o problema, e o número de indivíduos determina o número de
pontos do espaço de busca que são considerados (MITCHELL, 1997).
Consequentemente, a definição do tamanho da população e o número de gerações
têm uma influência muito grande no desempenho do método. Em geral, a escolha
destes parâmetros é definida de acordo com a complexidade do problema e
depende da realização de um grande número de experimentos e testes.

21
2.4.1 Codificação do material genético no AG
O mecanismo de codificação do material genético no AG é definido segundo
os seguintes conceitos (LINDEN, 2006):
a) Cromossomo: é a representação de cada indivíduo do AG. É constituído
pelo conjunto de valores (Genes) que representam uma das possíveis
soluções para um parâmetro do problema em estudo. A codificação deve
se adaptar ao problema estudado.
b) Genes: subconjunto do cromossomo, representam cada parâmetro do
problema (as variáveis que influenciam na solução do problema).
c) Alelos: codificação usada de acordo com o problema. As mais comuns
são: binária e real.
A estrutura de um cromossomo na população pode ser observada na Figura
4. O número de genes em cada cromossomo depende do número de parâmetros do
problema e o valor atribuído a cada gene é chamado de alelo (NEMAT et al., 2009).
Figura 4 - Estrutura de um Cromossomo.
Fonte: (Silva, 2011)
Semelhante ao que ocorre na natureza, o processo de transmissão e
recombinação de material genético ocorre no nível das informações da estrutura do
cromossomo (genótipo) usadas para formar o conjunto de parâmetros (fenótipo).
Esse processo de transmissão é realizado por meio de operadores genéticos que
modificam e recombinam partes dos indivíduos mais aptos. A cada passo, a
população é atualizada pela substituição de alguns indivíduos através da
descendência dos indivíduos mais aptos. Esse processo é ilustrado pelo fluxo da
Figura 5. As diferentes formas do processo de geração e teste do conjunto de
gene 1 gene 2 gene 3 gene 4
Cromossomo
alelo

22
indivíduos, em que as variações do melhor indivíduo corrente são mais prováveis de
serem consideradas na próxima geração, são detalhadas e discutidas nas próximas
subseções.
Figura 5 - Estrutura do Diagrama de atividades de Funcionamento em um AG.
Para execução do fluxo ilustrado na Figura 5, as seguintes etapas são
necessárias:
a) Definir a representação da solução;
b) Definir os operadores genéticos;

23
c) Definir a função objetivo;
d) Definir o critério de parada.
A seguir são apresentados e discutidos brevemente essas etapas essenciais
e os operadores genéticos do AG..
A) Representação da solução
A escolha de uma forma de representar as soluções candidatas no AG é o
primeiro passo para a utilização efetiva do método e está intimamente ligada ao
problema a ser resolvido. Esse processo de codificação de variáveis (cromossomos)
permite representar cada possível solução no espaço de busca como uma
sequência de símbolos gerados a partir de um dado alfabeto finito. Cada
cromossomo é formado por vários genes que representam os parâmetros do
problema, e são codificados em uma cadeia de símbolos do alfabeto escolhido, os
alelos.
Algumas das principais codificações utilizadas com sucesso na literatura são
a seguir apresentadas:
Codificação binária: codificação clássica utilizada por Holland (1992),
na qual a lista de símbolos (alfabeto) usada é composta apenas dos
valores 0 e 1. Assim, nesta codificação, cada cromossomo é
representado por uma série de bits 0 ou 1. Trata-se de uma codificação
muito utilizada, especialmente por sua relativa simplicidade.
Codificação por permutação: geralmente usada em problemas que
envolvem a ordenação de tarefas, codifica cada cromossomo como uma
série de números que representa uma posição em uma seqüência.
Codificação de valores: usada em situações nas quais a codificação
binária seria muito difícil, a codificação de valores codifica diretamente os
valores relacionados ao problema, os quais podem ser caracteres,
números reais ou qualquer outro objeto.
Codificação em árvore: usada para representar programas ou
expressões, essa codificação cria cromossomos na forma de árvores de
objetos, tais como funções ou comandos de uma linguagem de
programação.

24
B) Operadores genéticos
Durante o processo de evolução, a população é avaliada e seus indivíduos
estão sujeitos aos processos de seleção e reprodução. Esses processos são
chamados de operadores genéticos e são chamados: seleção, combinação ou
cruzamento (crossover) e mutação. Conforme Holland (1992), os operadores
genéticos tornam possível reproduzir filhos diferentes dos pais proporcionando as
modificações necessárias nos genótipos de tal forma que os fenótipos mantenham
muitas das características herdadas dos pais, mas não sejam idênticos. Portanto
sua função básica é converter a população através de sucessivas gerações, até
encontrar um resultado satisfatório. Os operadores genéticos são imprescindíveis
para que a população se diversifique e conserve características de adaptação
obtidas pelas gerações anteriores
Seleção: Seleção é um processo em que os indivíduos são selecionados
com uma probabilidade proporcional à sua aptidão em representar uma
possível solução para o problema (MITCHELL, 1999). Como exemplos
de métodos de seleção podem-se citar o Torneio (tournament selection),
o qual é baseado em critérios de competição entre os indivíduos que
favorece a sobrevivência dos mais aptos; e a Roleta (Roulette Wheel) na
qual a probabilidade de seleção dos indivíduos é diretamente
proporcional ao seu valor da função de aptidão (SANTA CATARINA,
2009). Em geral, os métodos da roleta e do torneio são os mais
comumente usados no AG. Em especial, vem aumentando nos últimos
anos a popularidade da seleção por torneio pela sua adequação em
aplicações envolvendo a programação paralela do AG (FILIPOVIC,
2003). Entretanto, não há um conjunto de métodos definitivo, pois
diferentes abordagens de seleção vêm sendo propostas nos últimos anos
(KUMAR e JYOTISHREE, 2012; WINKLER, AFFENZELLER e WAGNER,
2008; OKABE, 2007; AFFENZELLER e WAGNER, 2004; SANCHEZ-
VELAZCO e BULLINARIA, 2003).
Mutação: Segundo Nemati et al. (2009), mutação é a alteração de partes
de um indivíduo com uma pequena probabilidade predefinida (coeficiente
de mutação). As alterações na estrutura do indivíduo se dão por meio de

25
trocas aleatórias de alguns de seus valores, visando manter a
diversidade da população e garantir que a probabilidade de se chegar a
qualquer ponto do espaço de busca seja sempre diferente de zero.
Entretanto, um coeficiente de mutação muito alto pode tornar a busca
aleatória, além de possibilitar que uma boa solução seja aniquilada. Um
exemplo de um operador de mutação em dois pontos aleatórios é
apresentado na Figura 6.
Figura 6 - Exemplo de operador de mutação. Fonte:
Fonte: (SILVA, 2011).
Cruzamento: é um processo no qual dois pais diferentes são
iterativamente selecionados, a partir do conjunto de pais, para trocar
informações entre si, com a finalidade de gerar dois novos indivíduos
(filhos). Isto é feito escolhendo aleatoriamente um (ou mais) ponto de
ruptura para os pais e trocando-se posições entre eles, conforme
ilustrado na Figura 7.
Figura 7 - Exemplo de operador de cruzamento em dois pontos.
Fonte: (SILVA, 2011).
Cromossomo Pai Filho 1
Cromossomo Pai Filho 2

26
O cruzamento tradicional gera 2 filhos de dois pais, e a mutação é
tipicamente aplicada a um individuo. Entretanto, é possível muitos outros tipos de
cruzamento e mutação, como o cruzamento usando três ou mais pais, cruzamento
assexuado ou mutação da população base (LINDEN, 2008).
C) Função objetivo
A função objetivo fornece uma medida de qualidade em relação a um
determinado problema em particular, e está limitado ao teste de um indivíduo por
vez, isto é, relaciona o indivíduo à solução do problema. O processo de calcular o
valor da função objetivo para um determinado indivíduo é chamado de avaliação da
função objetivo e o valor resultante é usado para determinar a aptidão daquele
indivíduo em relação aos demais membros da população. Em geral, o custo
computacional da avaliação da função objetivo governa o custo computacional do
AG (SCHWAAB, 2005).
D) Critérios de parada do algoritmo
Algoritmos genéticos têm sido aplicados com sucesso em uma ampla
variedade de problemas. Embora amplamente utilizado, há poucas diretrizes
teóricas para determinar quando parar a busca (HALDUN e GARY, 2000). Em geral,
a quantidade de gerações é usada como uma medida de parada, mas também pode
ser utilizado, se disponível, algum critérios de convergência da população
(MITCHELL, 1997).
2.5 PERDA DE DIVERSIDADE E CONVERGÊNCIA PREMATURA NO AG
A diversidade da população permite uma melhor exploração do espaço de
busca e, portanto, pode propiciar uma maior probabilidade de encontro de valores
ótimos globais nos testes da função objetivo. Porém, as aplicações de algoritmos
genéticos na resolução de problemas combinatórios frequentemente são
confrontadas com o problema da convergência precoce, fazendo com que os

27
processos evolutivos fiquem, muitas vezes, presos num ótimo local (PEI-CHANN et
al., 2010).
Quando a diversidade vai sendo perdida os indivíduos selecionados para
reprodução podem gerar filhos muito semelhantes, acentuando o processo de perda
de diversidade, conforme ilustrado na Figura 8 (MORRISON e DE JONG, 2002), na
qual se verifica a localização dos indivíduos nas gerações 1, 5 , 16 e 20 . Em uma
inspeção visual do gráfico, observa-se que a distribuição de indivíduos na primeira
geração é razoavelmente uniforme entre os quatro quadrantes. Entretanto, a partir
da quinta geração os indivíduos começam a se concentrar em torno dos pontos de x
= 0,5 e x = -0,5. Na décima sexta e na vigésima gerações os indivíduos já estão
totalmente concentrados no quadrante inferior esquerdo do plano x,y. Nessa
representação para as 4 gerações, podemos perceber a gradativa perda de
diversidade, caracterizada pela proximidade entre os pontos marcados no plano.
Figura 8 - Exemplo da perda de diversidade no AG.
GERAÇÃO 1

28
GERAÇÃO 5
GERAÇÃO 16
GERAÇÃO 20
Fonte: (MORRISON; DE JONG, 2002).
O grande problema é que em muitos casos os indivíduos se concentram em
regiões do espaço nas quais o verdadeiro ótimo global não está localizado,
conduzido a um ponto ótimo local. Diversos estudos tentam contornar essa
dificuldade. Em um estudo apresentado em (ZHU, 2003), é proposto o controle da
diversidade populacional por meio da adaptação das taxas de cruzamento e
mutação, obtendo resultados muito competitivos. Nessa técnica, a diversidade
populacional é medida por meio da distância de Hamming entre genótipos no
ambiente populacional. A distância de Hamming entre duas representações de
indivíduos é definida como o número de posições nas quais elas diferem entre si, ou
seja, corresponde ao menor número de substituições necessárias para transformar

29
um indivíduo em outro, ou o número de erros que transformaram uma na outra.
Apesar dos bons resultados produzidos, a abordagem tem a dificuldade de
determinar as formas de adaptação uma vez que isso não é feito automaticamente
pelo método (ZHU, 2003).
Em Pei-Chann et al. (2010) é adotado a verificação constante do progresso
do processo evolutivo e quando a diversidade da população fica abaixo de um
limiar, cromossomos artificiais com alta diversidade são introduzidos para aumentar
o nível médio de diversidade, e dessa forma garantir que o processo possa saltar
para um melhor local e continuar o processo evolutivo novamente.
O uso das estratégias de hipermutação e imigrantes aleatórios para
manutenção e aumento da diversidade populacional foi investigado por Tragante e
Tinós (2009), apresentando resultados satisfatórios em problemas de predição de
estruturas em proteínas. Apesar dos bons resultados obtidos, a determinação da
taxa de substituição para novos imigrantes não pode ser feita a priori, o que pode
dificultar a convergência do Algoritmo Genético. A aplicação de redes neurais
artificiais em mecanismos de manutenção de diversidade é objeto de estudo em
Hiroyasu et al., (2008). O mecanismo proposto produz soluções com alta
diversidade, mas sofrem com a grande quantidade de testes da função objetivo,
dessa abordagem.
A tentativa de superar o problema da convergência prematura foi uma
preocupação tratada em Subbaraj et al., (2011), ao abordar o problema de despacho
econômico usando um AG auto-adaptativo com codificação real. O método proposto
naquele trabalho combina o AG auto-adaptativo e a codificação real com o método
de Taguchi, para explorar o potencial da prole. A auto-adaptação foi conseguida por
meio de cruzamento binário e a capacidade de exploração melhorada foi alcançada
através da criação de torneios entre dois individuos. O individuo selecionado como
melhor solução era escolhido e colocado no grupo de acasalamento conduzindo a
uma melhor convergência.
De fato, a definição de operadores adequados ao problema tratado parece
ser uma boa solução. No trabalho de Pavez-Lazo e Soto-Cartes (2011), os
indivíduos pais selecionados foram submetidos a um operador de crossover anelar
onde o cromossomo é codificado na forma de um anel. Os resultados obtidos
mostraram que com a aplicação dos operadores propostos para o problema,
melhores convergências e soluções foram obtidos em relação a aplicação dos

30
operadores genéticos tradicionais. Nesse trabalho, os autores ainda afirmam a
importância da definição dos operadores para a manutenção da diversidade.
Segundo esses autores, o operador genético de seleção depende da qualidade do
indivíduo, visto que a informação genética dos melhores indivíduos tende a dominar
as características da população. Além disso, quando a representação do
cromossoma é linear, o cruzamento é sensível à codificação ou depende da posição
do gene. As extremidades deste tipo de cromossoma têm apenas uma probabilidade
muito baixa de mudar por mutação (PAVEZ-LAZO e SOTO-CARTES, 2011).
Vale ressaltar, no entanto, que o cálculo de diversidade não é uma das
tarefas mais simples na execução do algoritmo, uma vez que esses cálculos
requerem a comparação de cada indivíduo com todos os outros, tornando exaustiva
a possibilidade de gravação desta estatística (WALL, 1996). Assim, abordagens que
dependem de uma verificação constante da diversidade ao longo do processo, como
as apresentadas por Pei-Chann et al. (2010) e Zhu (2003), tendem a não ser as
mais adequadas do ponto de vista computacional.
Com vistas a reduzir essa limitação, diversas técnicas para medida da
diversidade populacional tem sido estudadas (BARKER e MARTIN, 2000; BURKE,
GUSTAFSON e KENDALL, 2002; MORRISON e DE JONG, 2001). Nesse sentido,
LACEVIC e AMALDI, (2011) testaram e comparam diversas medidas de diversidade
em um grande conjunto de populações de indivíduos gerados aleatoriamente. Os
autores concluíram que a medida baseada no conceito de árvore geradora mínima
euclidiana (GOIS, 2004) é a mais promissora em relação ao dilema entre a medida
de tendência da população e a complexidade computacional.
Também merece destaque aqui a medida de diversidade populacional
baseada no cálculo do momento de inércia da população, proposto por Morrison e
De Jong (2002). Trata-se da extensão do conceito de momento de inércia da medida
de distribuição de massa em um espaço arbitrário de dimensão elevada. A
vantagem desse método, em comparação as técnicas tradicionais de medida de
diversidade, é sua complexidade computacional linear em relação ao tamanho da
população (MORRISON e DE JONG, 2002).

31
2.6 TRANSFORMADA DISCRETA WAVELET
O termo wavelet é uma tradução para o inglês das palavras francesas
ondelettes ou petites ondes, ou seja, pequenas ondas. No português, recebem também
o nome de ondaletas (MORETTIN, 1999). Na verdade, esses termos são usados para
sugerir que se tratam de funções que são localizadas em torno de um valor central, são
diferentes de zero apenas em um intervalo limitado e nulas fora desse intervalo. A
Figura 9 ilustra alguns exemplos dos vários tipos de funções wavelet existentes
(FRASIER, 1999; SARKAR, SALAZAR-PALMA E MICHAEL, 2002).
Figura 9 - Exemplo de função wavelet: (a) Haar.
Figura 10 - Exemplo de função wavelet: (b) Mexican Hat.

32
Figura 11 - de função wavelet: (c) Morlet.
Figura 12 - Exemplo de função wavelet: (d) Shannon..
Uma característica das funções wavelet é o fato de serem facilmente obtidas
por meio de translações e dilatações de uma única função ( )t chamada wavelet mãe.
Introduzindo as dilatações por um fator de escalamento positivo a e as translações por
meio de uma variável b, ambas pertencentes ao conjunto dos números reais , a
forma geral de uma família dessas funções é dada pela equação (1), na qual o termo
1/ a é introduzido para preservar a norma da função no espaço ao qual ela pertence
(FRASIER, 1999; SARKAR, SALAZAR-PALMA E MICHAEL, 2002).
,
1( ) .a b
t bt
aa (1)

33
Outra importante característica das funções definidas pela equação (1) é que
elas formam uma base para o espaço de funções. Assim, qualquer função f(t) nesse
espaço pode ser aproximada por uma combinação das wavelets, usando
coeficientes ,a bc dados pela equação (2) (FRASIER, 1999; SARKAR, SALAZAR-
PALMA E MICHAEL, 2002 ),
, ,,a b a bc f , (2)
na qual , denota o produto interno nesse espaço.
O trabalho da transformada wavelet é decompor o espaço gerado pelas
funções definidas pela equação (1) em uma soma de dois subespaços V e W , tais
que a interseção entre eles seja nula e ortogonal.
Na prática, essa análise é empregada em problemas discretos que estão
definidos em um espaço vetorial 0V , onde as funções são representadas por vetores.
Nesse caso, isso significa que dado um vetor u em , os coeficientes 1,kc e 1,kd
podem ser calculados para representá-lo como uma combinação linear dos vetores
1,k e 1,k , bases dos subespaços 1V e 1W , usando-se a equação (3):
1, 1, 1, 1,u k k k k
k
c d . (3)
A grande vantagem da decomposição representada pela equação (3) é que
a maior parte da variação do vetor u fica concentrada nos coeficientes , enquanto
que a representação do vetor no subespaço é praticamente nula (valores dos
coeficientes são muito próximos de zero). Assim, os coeficientes 1,kc podem ser
considerados como uma aproximação de u no espaço 1V . Esse resultado ocorre em
função das características dos vetores , os quais estão associados às frequências
mais baixas do vetor. Os detalhes do vetor, relacionados aos componentes de alta
frequência e que não podem ser representados pelos vetores , são representados
pelos coeficientes . Todo esse processo é equivalente a filtragem do sinal por
0V
1,kc
1W
1,kd
1,k
1,k
1,kd

34
filtros passa alta e passa baixas associados às funções wavelets. Na prática, o
procedimento é realizado realmente com um a utilização de filtros, como ilustrado no
seguinte exemplo numérico.
Exemplo 2.1: Considere o vetor u = (4, 6, 10, 12, 8, 6, 5, 5) e os coeficientes
dos filtros associados à wavelet de Haar:
Passa baixa (retém componentes de baixa frequência):
0 1
1 1[ , ] ,
2 2H h h
Passa alta (retém componentes de alta frequência):
0 1
1 1[ , ] ,
2 2G g g
O vetor u é decomposto em coeficientes c1,k e d1,k, conforme a função 4:
2 1 2 2 1 21, 1,
u u u u; , 1,...,8
2 2
k k k kk kc d k
(4)
que produz os seguintes vetores:
No exemplo, o vetor resultante 1c é uma aproximação, com a metade do
tamanho do vetor original u. Já os elementos de detalhes, vetor 1d , possuem valores
menores e representam os detalhes do sinal, associados às altas frequências. É
importante observar também a característica local dessa transformação. Se
elementos adjacentes no vetor tiverem valores muito próximos entre si, então a
aproximação gerada será muito próxima do valor original e o valor de detalhe será
muito pequeno. Em especial, se os valores de elementos vizinhos forem iguais, o
detalhe será nulo e a aproximação será exata, como ocorre com os dois últimos
valores do vetor u no exemplo. Os vetores resultantes do exemplo são apresentados
graficamente pela Figura 13.
1 1(5 2,11 2,7 2,5 2) e ( 2, 2, 2,0).c d

35
Figura 13 - Resultado da aplicação da transformada discreta wavelet em um vetor com oito elementos.
Segundo a teoria de multiresolução, o processo pode continuar decompondo
cada representação de u em jV no próximo par de subespaços 1jV e 1jW . Esse
processo de decomposição é denominado transformada discreta wavelet
(DAUBECHIES, 1988; FRASIER, 1999; SARKAR, SALAZAR-PALMA E MICHAEL,
2002).
No caso bidimensional, o procedimento descrito acima é aplicado nas linhas
e colunas da matriz, gerando um conjunto de coeficientes de aproximação e
detalhes em cada nível do processo. Essa técnica é muito utilizada no
processamento de imagens digitais, onde os detalhes capturados pelos filtros passa
alta são usados na reconstrução da matriz (imagem) (VO e ORAINTARA, 2010; AL-
HUDHUD, IBRAHIM E AL-AKAIDIB, 2010; PEREIRA et al., 2010; SCHEMPP, 1998).
Um exemplo dessa aplicação é ilustrado pela Figura 11, na qual são apresentadas a
imagem original e a imagem resultante da transformada wavelet em um nível.

36
Figura 14 - Exemplo de aplicação da transformada discreta wavelet com um nível a uma imagem.
2.6.1 Wavelet e Algoritmo Genético
As características das funções wavelets apresentadas resumidamente na
seção anterior fizeram surgir um grande número de aplicações, e não apenas na
área de processamento de sinais e imagens. Dessa forma, atualmente é possível
encontrar aplicações das funções wavelets nos mais diversos contextos, desde
problemas de cálculo de campos magnéticos (SARKAR, SALAZAR-PALMA E
MICHAEL, 2002; PEREIRA et al., 2008), até problemas de análises químicas
(LEUNG, CHAU e GAO, 1998) e de previsão de dados hidrológicos (MAHESWARAN
e KHOSA, 2012), e muitos outros.
Mais especificamente, o uso da transformada discreta wavelet em conjunto
com os algoritmos genéticos é também muito comum. Diversos trabalhos abordam
essa eficiente combinação das mais diversas formas. O que se observa, entretanto,
é que em geral essas duas técnicas são usadas formando algoritmos híbridos, com
a transformada wavelet sendo usada para o pré-processamento dos dados que

37
serão usados pelo AG (HAN e CHANG, 2012; WANG et al., 2011; AVCI e AVCI,
2009).
Destaca-se aqui o trabalho de Wang et al. (2011) no qual a integração
efetiva é realizada entre as funções wavelets e as redes neurais artificiais para,
apenas posteriormente, aplicar o AG. Nesse caso, aliás, a integração parece ser
mais natural e difundida (MUZHOU e XULI, 2011; ZAINUDDIN e ONG, 2011; LI e
KUO, 2008).
2.7 CLUSTERIZAÇÃO K-MÉDIAS
O Algoritmo k-médias (MACQUEEN, 1967) é um dos mais simples
algoritmos de aprendizado não supervisionado que resolvem o conhecido problema
de agrupamento, o qual consiste em separar objetos em grupos, baseando-se nas
características que estes objetos possuem, colocando em um mesmo grupo objetos
que sejam similares de acordo com algum critério pré-determinado (LINDEN, 2009).
O procedimento segue uma maneira simples e fácil de classificar um
determinado conjunto de dados por meio de certo número pré-estabelecido de
clusters (k clusteres).
A idéia principal do método é definir k centróides iniciais (um para cada
cluster) e associar cada ponto do conjunto de dados ao centróide mais próximo,
definindo assim um agrupamento inicial. Na sequência, k novos centróides são
calculados como os baricentros dos clusteres resultantes da etapa anterior. De
posse dos novos centróides, o processo de associação dos pontos ao centróide
mais próximo se repete gerando um processo iterativo. Como resultado desse ciclo,
pode-se notar que os centróides mudam a sua localização passo a passo até que
não haja mais mudanças a serem feitas. Em outras palavras, os centróides não se
movem mais.
Finalmente, esse algoritmo visa minimizar a função de erro quadrático dada
pela equação (5)
2( )
1 1
k nj
i j
j i
J x c , (5)

38
na qual, 2
( )j
i jx c é a medida da distância euclidiana entre um ponto xi do conjunto
de dados e o centro do cluster, cj. A função definida em (5) fornece um indicador da
distância dos n pontos do conjunto de dados aos centros de seus respectivos
clusteres.
2.7.1 Alternativas ao k-médias
Um aspecto que pode afetar a qualidade dos resultados do k-médias é que a
escolha do número de clusteres a serem gerados é feita pelo usuário. Segundo
Linden (2009), um número pequeno demais de clusteres pode causar a junção de
dois clusters naturais, enquanto que um número grande demais pode quebrar
artificialmente um cluster natural em dois.
Como uma alternativa, é possível usar outras técnicas de agrupamento que,
teoricamente, evitam esse problema como, por exemplo, o algoritmo X-médias ou
uma rede neural artificial que implementa os conceitos de auto-organização cerebral,
conhecidas como Redes Auto-Organizáveis ou redes de Kohonen (BIANCHI,
CALOGERO e TIROZZI, 2007).
A característica básica do X-médias é a procura no espaço pela localização
dos clusters, escolhendo o número ótimo de clusteres.(GEETHA et al., 2008).
Entretanto, uma dificuldade do método que limita sua utilização é a sua
característica de rápida convergência para mínimos locais.
Por outro lado, as redes de Kohonen têm a liberdade de descobrir os
clusteres (OJA et al, 2002), porém não possuem garantia de convergência para
redes de dimensões maiores, além do que o treinamento pode ser extremamente
longo para problemas grandes de classificação (LINDEN, 2009).

39
3 MATERIAIS E MÉTODOS
3.1 CARACTERIZAÇÃO METODOLÓGICA
Este trabalho caracteriza-se por sua abordagem quantitativa com natureza
de pesquisa aplicada, na medida em que visa gerar conhecimentos para aplicação
prática dirigidos especificamente à solução do problema da perda de diversidade
populacional do Algoritmo Genético em problemas de otimização.
A pesquisa visa descrever as características do fenômeno da perda de
diversidade populacional no AG e identificar os fatores que determinam ou
contribuem para sua ocorrência para, na sequência, propor uma abordagem
baseada no uso das funções wavelets para solução do problema. Assim sendo,
adotamos a classificação apresentada por Gil (1991), configura-se como uma
pesquisa descritivo-explicativa. Para atingir tais objetivos, o trabalho envolve os
procedimentos técnicos de pesquisa bibliográfica, em livros e artigos de periódicos,
e de pesquisa experimental.
A pesquisa bibliográfica de periódicos concentrou-se, principalmente, nas
bases de dados Scielo e Science Direct, com a busca pelos seguintes temas:
metaheurísticas populacionais, algoritmos genéticos, perda de diversidade, medidas
de diversidade, convergência prematura, transformada discreta wavelet e
clusterização k-médias.
As etapas da pesquisa experimental envolveram, conforme orientado
por Gil (1991), a definição do objeto de estudo (diversidade populacional no
algoritmo genético), a seleção dos fatores de influência (tamanho da população
inicial, tipo de função wavelet e número de clusteres), e as formas de controle e
observação dos efeitos dos fatores no objeto de estudo (medida de diversidade, taxa
de convergência do AG e número de avaliações da função objetivo). Essas etapas
são detalhadas a seguir.
3.2 DEFINIÇÃO DO OBJETO DE ESTUDO
A perda da diversidade populacional é um problema recorrente no AG, o
qual é influenciado pelo tamanho da população. Uma população pequena pode

40
comprometer a exploração do espaço de busca e conduzir o algoritmo a um ponto
do espaço que não é necessariamente o ótimo global, provocando a convergência
prematura do método. Por outro lado, uma população maior pode possibilitar uma
exploração mais eficiente, mas apresenta limitações computacionais. Portanto, este
estudo abordou a questão da diversidade populacional do AG sob a perspectiva da
escolha e do controle do tamanho da população e de sua diversidade ao longo do
processo evolutivo.
3.3 FUNÇÕES OBJETIVO UTILIZADAS
Com vistas a avaliar os efeitos do controle da perda de diversidade sobre a
convergência prematura, os métodos foram testados em problemas “benchmark”
usados comumente para avaliação de técnicas de busca global, os quais são
caracterizados pela existência de diversos ótimos locais ou superfícies suaves que
dificultam a convergência dos métodos de otimização (FLOUDAS e PARDALOS,
1990; SCHOEN, 1993).
As expressões matemáticas dessas funções são apresentadas a seguir:
a) Rastringin:
2 2( , ) 20 ( 10cos(2 )) ( 10cos(2 ))f x y x x y y (6)
b) Griewank
2
1 1( ) cos 1i
i i
if
i
22 XX( )
X4000
(7)
c) Branin
2 2
2
5,1 5 1( , ) ( 6) 10(1 )cos( ) 10
84f x y y x x x (8)
d) Schwefel
( , ) 837,9658 sin( ) sin( )f x y x x y y . (9)

41
3.3 AJUSTE DOS FATORES DE INFLUÊNCIA
Os fatores de influência foram determinados com base na literatura e seus
valores por experimentação. Um conjunto de experimentos foi realizado inicialmente
variando os parâmetros número de gerações e tamanho da população dentro de
intervalos considerados adequados para o problema, para os métodos AG e AGkW.
No que tange especificamente ao AGkW, o efeito dos fatores número de
gerações entre uma transformação wavelet e outra e o número de clusteres gerados
pelo k-médias também foram avaliados experimentalmente. Nesse caso, foram
avaliadas combinações de valores desses fatores após a fixação dos parâmetros
número de gerações e tamanho da população obtidos na etapa anterior.
A função wavelet utilizada foi definida com base na literatura (SARKAR,
SALAZAR-PALMA E MICHAEL, 2002), e considerando a premissa de preservar a
eficiência computacional do método. Assim, foi escolhida a wavelet de Daubechies
Db4 (DAUBECHIES, 1988). Essa função além de possuir excelentes propriedades
de aproximação que proporcionam resultados superiores em muitas aplicações
(PEREIRA at al., 2009; SOUZA et al., 2007), estão associadas a filtros mais curtos,
de comprimento 4 (quatro coeficientes passa baixa) o que reduz as operações
necessárias para o cálculo das aproximações em comparação com filtros mais
longos (JENSEN e la COUR-HARBO, 2001; GARCIA, ACEVEDO e VIDAL, 2008).
Os filtros passa baixa relacionados a essas wavelets e usados neste trabalho são
definidos conforme a equação (10):
[ , , , ] , , , .0 1 2 3
1 3 3 3 3 3 1 3
4 2 4 2 4 2 4 2H h h h h (10)
3.4 FORMAS DE CONTROLE DOS EFEITOS DOS FATORES
Três aspectos do algoritmo genético foram avaliados nos experimentos: a
capacidade de convergência para o ótimo global, o número de avaliações da função
objetivo e a capacidade de manutenção da diversidade populacional ao longo do
processo evolutivo.

42
Considerando a convergência, dois aspectos precisaram ser considerados: a
qualidade da solução encontrada e o número de réplicas do experimento. Os
problemas “benchmark” testados envolvem funções nas quais existem diversos
pontos com valores de aptidão muito bons, mas que não são o ótimo global. Assim,
o critério de convergência em alguns casos não considerou valores de aptidão, mas
sim a posição geométrica do ponto ótimo.
Por outro lado, é importante lembrar que o AG trabalho com geração de
números aleatórios (população inicial) e, portanto, não encontra sempre a(s)
mesma(s) solução(ões). Dessa forma, os resultados de convergência foram
avaliados considerando 20 replicações para cada caso. O número de replicações foi
definido estatisticamente visando garantir uma confiança para a proporção de
convergência e para o número médio de avaliações da função objetivo. A proporção
de convergência nas 20 replicações foi usada como critério de desempenho do
método.
No que diz respeito à capacidade de manutenção da diversidade
populacional, ambos os métodos foram avaliados igualmente. Nesse caso, foi
utilizado o cálculo do momento de inércia da população como medida de diversidade
populacional, conforme apresentado na seção 2.5. Como o cálculo da diversidade
populacional envolve uma varredura de todos os seus indivíduos, optou-se por
realizar essa medida a cada 5 gerações, após experimentações tanto no cálculo a
cada geração quanto a intervalos de 5 em 5 e de até 10 em 10 gerações.
3.5 DESCRIÇÃO DA ABORDAGEM PROPOSTA
Conforme já discutido, cada indivíduo no AG representa um vetor no espaço
de busca e o conjunto de vetores da população pode ser representado como uma
matriz populacional na qual cada indivíduo ocupa uma coluna. Nessa notação, a
perda da diversidade populacional pode ser interpretada como a geração de colunas
semelhantes na matriz. Se dois (ou mais) indivíduos da população são muito
semelhantes então haverá duas (ou mais) colunas na matriz populacional com
valores muito próximos uns dos outros e, portanto, que apresentarão grande
correlação. A correlação entre as colunas da matriz (indivíduos) será maior à medida
que a diversidade da população for sendo perdida.

43
Portanto, a transformada discreta wavelet pode ser usada para explorar as
possíveis correlações entre os indivíduos da população, evitando que indivíduos
muito próximos coexistam.
Esse processo tem o objetivo de eliminar redundâncias dentro da população
e, consequentemente, reduzir o número de avaliações da função objetivo
necessárias para a convergência. A aplicação da transformada considera, apenas os
filtros passa-baixa, capturando as aproximações necessárias para representar a
população em um nível com menos refinamento (um número menor de indivíduos).
Como os 50% dos indivíduos da população são eliminados a cada
aplicação da transformada em dois níveis, é possível iniciar o processo de busca
em população relativamente grande, população essa na ordem de milhares de
individuos, visando garantir uma diversidade inicial que permita uma completa
exploração do espaço de busca do problema. O processo de eliminação dos
indivíduos promovido pela transformada, reduz gradativamente o custo
computacional de cada geração, mas buscando manter a diversidade da
população inicial.
Os indivíduos sobreviventes desse processo são avaliados e submetidos às
operações convencionais do AG.
É importante observar que a transformada discreta wavelet possui um efeito
local nos dados de entrada (SARKAR, SALAZAR-PALMA E MICHAEL, 2002). Isso
significa que para que indivíduos semelhantes sejam envolvidos no mesmo cálculo,
como é ideal, eles devem estar posicionados de maneira adjacente na matriz
populacional. Dessa forma, foi utilizado um algoritmo de agrupamento antes de
aplicar a transformada discreta wavelet. Assim, são realizadas clusterizações
periódicas por meio da função k-médias para posterior uso da transformada wavelet
discreta.

44
Figura 15 - Estrutura de Funcionamento do AGkW.
A alteração de fluxo no AG provocada por esse processo de redução da
população é ilustrado na Figura 15, onde é aplicado a cada 10 gerações , no ponto
de decisão para verificar se o número que representa a geração é divisível por 10,

45
(mod (N,10) ==0). Caso seja divisível, é aplicado a clusterização k-média e a
transformada wavelet.
As simulações foram realizadas no MATLAB considerando o AG como
apresentado por Goldberg (1989). Pode-se afirmar que os resultados apresentados
podem ser considerados válidos mesmo para versões mais recentes do algoritmo,
visto que os métodos foram aplicados em condições semelhantes de mutação,
cruzamento e seleção.

46
4 RESULTADOS E DISCUSSÃO
Este capítulo apresenta os resultados obtidos com a aplicação do AGkW em
um conjunto de funções matemáticas tradicionais usadas como problemas teste de
otimização não linear (MICHALEWICZ, 1996). Tratam-se de funções frequentemente
usadas para testar métodos de otimização. Essas funções de teste possuem vários
mínimos locais e/ou superfícies suaves que dificultam a convergência para o único
mínimo global existente.
4.1 APLICAÇÃO AO PROBLEMA TESTE RASTRINGIN
A função de teste Rastringin, em duas dimensões, é dada matematicamente
pela equação (11),
2 2( , ) 20 ( 10cos(2 )) ( 10cos(2 ))f x y x x y y (11)
na qual, -2,12 ≤ x,y ≤ 2,12.
A função Rastringin com suas respectivas curvas de nível é apresentada nas
Figuras 16 e 17, com destaque para alguns dos mínimos locais (em azul) e máximos
locais ( vermelho).
Figura 16 - Função de teste Rastringin.

47
Figura 17 - Função Rastringin no domínio [-2,12; 2,12] e suas curvas de nível.
Primeiro foi realizado um conjunto de experimentos com vistas a estabelecer
os valores mais adequados dos parâmetros genéticos, tamanho da população e
número de gerações, tanto para o AG e quanto para o AGkW. Os valores
considerados para esses parâmetros variam segundo os níveis definidos na Tabela
1. É importante observar que como a transformada wavelet reduz pela metade o
tamanho da população, o método AGkW permite trabalhar com uma população
inicial maior. Por outro lado, o processo de dizimação realizado pela wavelet não
permite que a população evolua em muitas gerações, pois os indivíduos são
dizimados até que a população seja completamente eliminada. Logo, o processo de
evolução será interrompido em um reduzido número de gerações em comparação
ao AG.
No processo de escolha dos parâmetros de teste, para o tamanho da
população, confrontou-se o uso de valores na ordem de centenas de indivíduos para
o AG, dimensão utilizada na literatura pesquisada nesse trabalho para testes dessa
técnica ( Mitchell, 1997), com a proposta do AGkW de trabalhar com populações na
ordem de milhares de indivíduos em menor número de gerações.
Tabela 1: Valores de tamanho de população e número de gerações testadas
Método Tamanhos de população Números de gerações
AG 50, 100, 150, 200 100, 200, 300, 400
AGkW 500, 1000, 1500, 2000 20, 40, 60, 80

48
Os valores dos demais parâmetros genéticos, usados em todas as
aplicações deste trabalho, foram definidos com base na literatura (GOLDBERG,
1989) e estão apresentados a seguir:
Função de aptidão: é a própria função f(x) que caracteriza cada problema;
Operador de crossover: cruzamento em dois pontos de corte aleatórios;
Operadores de mutação: mutação heurística;
Taxa de crossover: 90% ;
Taxa de mutação: 5%;
Método de seleção: roleta
Quantidade de replicações: 20
Nas tabelas 2 e 3 são apresentados os resultados para as combinações de
20 replicações para cada combinação possível dos valores de tamanho da
população e número de gerações. São reportados valores médios do número de
avaliações (n) da função objetivo e o desempenho (%) o qual corresponde à
proporção de replicações convergentes.
Tabela 2: Resultados para AG usando a função teste Rastringin: desempenho x número de avaliações
População Gerações n %
50
100 3992 30
200 8167 25
300 11570 50
400 13537 45
100
100 8820 20
200 15055 45
300 21605 60
400 16220 85
150
100 9720 60
200 19402 65
300 17070 80
400 20790 100
200
100 11660 75
200 13120 90
300 16930 95
400 27290 95

49
Na tabela 2, observamos que nos testes do AG com a função Rastringin,
atingiu o valor de 100% de convergência para as 20 réplicas em uma população de
150 indivíduos e 400 gerações. Apresentou também o comportamento oscilatório em
relação ao desempenho de convergências para os inúmeros testes aplicados.
Tabela 3: Resultados para AGkW usando a função teste Rastringin: desempenho x número de avaliações
População Gerações N %
500
20 5450 40
40 7053 35
60 5432 60
80 8060 50
1000
20 9575 45
40 10125 80
60 6374 95
80 6784 85
1500
20 8063 80
40 9862 80
60 7705 90
80 7024 95
2000
20 4450 95
40 7425 95
60 8614 95
80 5231 95
Considerando as características do problema de possuir vários mínimos
locais, objetivou-se avaliar a capacidade do método de convergir para o mínimo
global da função que, nesse caso, é o ponto (x,y) = (0,0). Dessa forma, o critério de
convergência foi definido por meio da norma euclidiana da melhor solução obtida por
cada método nas diferentes combinações, considerando o ponto ótimo global da
função. Segundo esse critério foi considerado convergente uma replicação que
obtivesse uma solução X=(x,y) tal que (x2 + y2) ≤ 0,05. Como existem pontos
distantes do mínimo global nos quais o valor da função é muito próximo de zero, um
critério considerando o valor de aptidão da solução poderia não ser adequado.
Os resultados da Tabela 5 indicam a viabilidade do uso da clusterização e
da transformada discreta wavelet no AG para o caso teste, visto que o método
proposto apresenta, em geral, um desempenho semelhante com um menor número

50
de avaliações da função objetivo, o que representa um ganho em eficiência
computacional quanto à quantidade de avaliações realizadas, como pode ser visto
na figura 18, quando comparamos a quantidade média de avaliações nos 16
cenários propostos para cada técnica.
Figura 18 - Comparação entre o AG e o AGkW para o número de avaliações da Função Objetivo nos 16 cenários propostos para testes.
Ressaltamos também a maior tendência a estabilidade nos resultados
obtidos quando comparamos com o percentual de convergências obtidas entre o AG
e o AGkW.
Figura 19 - Percentual de convergências obtidas entre o AG X AgkW nos 16 cenários de teste.
Para os resultados apresentados na Tabela 3 – tamanho da população e
número de gerações, o algoritmo de clusterização k-médias foi aplicado a cada dez
gerações ao longo do processo iterativo, gerando dois clusteres e a transformada

51
discreta wavelet aplicada de forma independente dentro de cada cluster. A
configuração de parâmetros aqui apresentada, produziu resultados viáveis para a
escolha do intervalo de aplicação do k-médias, para o intervalo de aplicação da
transformada wavelet e do número de clusteres a serem gerados. Nesse sentido, foi
realizado um novo conjunto de experimentos variando o número de gerações entre
sucessivas clusterizações (5 e 10 gerações) e o número de clusteres gerados (2 e
4), num total de 80 replicações (vinte replicações para cada combinação possível
dos valores).
Nessa segunda etapa de experimentação, e em todos os testes subseqüentes,
foram aplicados os melhores valores de tamanho de população e número de gerações
segundo os resultados obtidos nos experimentos iniciais, população de 150 indivíduos e
400 gerações para cada réplica no AG e população de 1000 indivíduos e 60 gerações
para cada réplica no AGkW (em destaque na Tabela 4 e 5). Os resultados
correspondentes de desempenho (%) e número médio de avaliações (n), ainda
referentes a função Rastringin, são apresentados na Tabela 6.
Tabela 4: Comparativo de desempenho e número médio de avaliações
No de clusteres
Intervalo de gerações
5 gerações 10 gerações
2 clusteres 70%; n = 8110 95%; n = 6374
4 clusteres 65%; n = 7647 55%; n = 10746
A partir dos resultados apresentados nas Tabelas 3,4,5 e 6, foram definidos
os parâmetros a serem utilizados nos experimentos com as demais funções teste, os
quais são apresentados resumidamente a seguir:
Tamanho da população (AG): 150
Tamanho da população (AGkW): 1000
Número de gerações (AG): 400
Número de gerações (AGkW): 60
Intervalo de gerações: 10
No de clusteres: 2

52
4.2 APLICAÇÃO AO PROBLEMA TESTE GRIEWANK
A função Griewank em duas dimensões é definida para um vetor X=[X(1),
X(2)] = (x,y) conforme a função:
2
1 1( ) cos 1i
i i
if
i
22 XX( )
X4000
(12)
na qual, -10,0 ≤ X(i) ≤ 10,0.
Assim como a função Rastringin, a função Griewank possui vários mínimos
(e máximos) locais que dificultam a busca pelo ponto ótimo global X=[0;0] no qual
f(X) = 0, conforme ilustrado na Figura 20.
Figura 20 - Função teste Griewank, considerando o domínio [-10;10].
Os resultados de comparação dos métodos AG e AGkW para essa função
são apresentados na Tabela 7.
Tabela 5: Resultados para a função Griewank: melhor solução encontrada, número médio de avaliações (n) e desempenho (%) em 20 replicações
Método Melhor x Melhor y Melhor f(x,y) n %
AG -0,0636 -0,0114 0,0021 45645 35
AGkW -0,0719 0,0188 0,0027 18100 25

53
4.3 APLICAÇÃO AO PROBLEMA TESTE BRANIN
A função Branin também representa um problema teste de minimização
global, dada pela seguinte expressão,
2 2
2
5,1 5 1( , ) ( 6) 10(1 )cos( ) 10
84f x y y x x x (13)
Entretanto, ao contrário das funções anteriores, essa função possui
três diferentes mínimos globais nos pontos X1=[-π; 12,275], X2=[π; 2,275], X3 =
[9,42478; 2,475], nos quais o valor da função é f(Xi) = 0,397887. Além disso, a
função Branin não possui mínimo local e seu espaço de busca é tal que -5 ≤ x ≤10 e
0 ≤ y ≤15, conforme representação gráfica da Figura 21. A dificuldade dessa função
está no fato de representar uma superfície suave e com poucos pontos de mínimos
globais, fatores estes complicadores para qualquer método de busca de mínimos ou
máximos (MUNDIM e DELAVY, 2008).
Figura 21 - Função teste Branin.
Os resultados correspondentes são apresentados na Tabela 8. Nesse caso,
o critério de convergência foi definido usando o erro relativo gerado por uma
solução aproximada X, o qual é definido em função dos pontos de mínimo da função
Xi da seguinte forma:

54
3/ 10X X Xi i (14)
na qual ||X|| indica a norma euclidiana do vetor X, dada por ||X|| = (x2+y2)1/2.
Tabela 6: Resultados para a função Branin: melhor solução encontrada, número médio de avaliações (n) e desempenho (%) em 20 replicações.
Método Melhor x Melhor y Melhor f(x,y) n %
AG -3,1712 12,3241 0,4026 37283 50
AGkW 9,4042 2,5484 0,4081 7323 75
4.4 APLICAÇÃO AO PROBLEMA TESTE SCHWEFEL
O último problema abordado nos experimentos deste trabalho é a função de
Schwefel, também comumente usada em teste de algoritmos de busca de mínimos
globais. Assim como as duas primeiras funções, está possui diversos pontos de
extremos (mínimos locais) e um ponto de mínimo global X=[ -420,9687; -420,9687]
com f(X) = 0,0 sendo representada matematicamente pela equação (15),
( , ) 837,9658 sin( ) sin( )f x y x x y y . (15)
Uma dificuldade adicional desse problema é o tamanho do espaço de busca,
definido por -500 ≤ x, y ≤ 500. Uma representação gráfica dessa função pode ser
vista na Figura 22. Os resultados podem ser observados na Tabela 6. Foi adotado o
mesmo critério de convergência usado para o caso da função Branin.

55
Figura 22 - Função teste Schwefel com mínimo global no ponto [-420,9687; -420,9687].
Tabela 7: Resultados para a função Schwefel: melhor solução encontrada, número médio de avaliações (n) e desempenho (%) em 20 replicações.
Método Melhor x Melhor y Melhor f(x,y) n %
AG -419,2340 -421,5991 -0,4296 47498 30
AGkW -421,2787 -419,4781 -0,2923 12633 50
É possível observar claramente que os dois métodos produziram resultados
superiores para a função Rastringin, o que é compreensível visto que os valores dos
parâmetros foram definidos em experimentos realizados com essa função. Novas
combinações de tamanho de população e número de gerações podem produzir
resultados melhores para outros problemas, especialmente considerando que as
complexas funções matemáticas apresentadas possuem como características o fato
de possuírem comportamentos muito diferentes, como pode ser visto nas Figuras de
1 a 4. Destaca-se aqui a função Griewank, para a qual ambos os métodos tiveram o
pior desempenho. Apesar de apresentar um comportamento graficamente
semelhante ao da função Rastringin, a função Griewank tem um comportamento
numérico muito mais suave (todos os valores da função estão entre 0 e 2) o que
dificulta a convergência do algoritmo.
Cumpre destacar também que os métodos testados foram desenvolvidos
com base no algoritmo proposto por Goldberg (1989). Considerando que tanto o AG
quanto o AGkW foram avaliados em condições semelhantes os resultados obtidos

56
podem ser considerados válidos. A consideração desses fatos é importante para
avaliar os limites de aplicação e desempenho do algoritmo desenvolvido neste
trabalho.
Feitas essas considerações é possível perceber através dos resultados
obtidos que, em geral, o método proposto se comportou de maneira eficiente para os
problemas abordados, tendo apresentado resultados tão bons ou superiores em
comparação ao AG. Em especial, para as funções Branin e Schwefel, o método
AGkW apresentou um desempenho cerca de 50% superior com aproximadamente
apenas 25% do número médio de avaliações da função objetivo.
4.5 ANÁLISE DA DIVERSIDADE POPULACIONAL
Por fim, visando compreender melhor os resultados obtidos para os
problemas testados, foi avaliado o efeito do uso da transformada discreta wavelet na
diversidade populacional do AG. Como medida de diversidade populacional foi
utilizado o cálculo do momento de inércia da população, proposto por Morrison e De
Jong (2002), o qual é baseado na extensão do conceito de momento de inércia da
medida de distribuição de massa em um espaço arbitrário de dimensão elevada. A
vantagem desse método, em comparação as técnicas tradicionais de medida de
diversidade, é sua complexidade computacional linear em relação ao tamanho da
população (MORRISON e DE JONG, 2002).
Os resultados de diversidade em função do número de gerações, para a
função Rastringin, são apresentados na Figura 23, na qual é possível observar uma
vantagem da abordagem proposta sobre o método tradicional. É importante destacar
que, conceitualmente, o momento de inércia é uma medida da distribuição da massa
de um objeto em relação ao seu centro de gravidade, e representa no AG um efeito
de diminuição da probabilidade de convergência do algoritmo para o ótimo global da
função-objetivo (TAKAHASHI et al., 2005).

57
Figura 23 - Diversidade populacional baseado no momento de inércia.
Nos testes de avaliação dos parâmetros tamanho da população e número de
gerações, considerando a função teste Rastringin, o AGkW apresentou, em geral, o
mesmo desempenho de convergência com cerca de apenas 30% do número médio
de avaliações da função objetivo. Resultados semelhantes foram obtidos para as
funções teste Branin e Schwefel.
Em relação aos experimentos para determinar a melhor escolha dos
parâmetros do AGkW, os resultados foram melhores quando a população foi dividida
em dois clusteres a cada 10 gerações. Essa combinação apresentou um
desempenho de 95% para a função Rastringin, e foi fixada nos demais testes,
mesmo não sendo, necessariamente, a melhor combinação de valores para os
outros casos testados. A combinação ótima de valores para cada caso não foi
investigada.

58
5 CONCLUSÕES
De acordo com o que foi apresentado, o uso de uma população inicial com
um número elevado de indivíduos pode fornecer a diversidade necessária para uma
adequada exploração do espaço de busca para o AG. Porém, o cálculo dos valores
de aptidão para um grande número de indivíduos, em várias gerações, pode
comprometer o desempenho computacional do método (LIMA, 2011). Considerando
esse cenário, a solução apresentada foi iniciar o processo de busca com uma
população maior, e, portanto com maior diversidade e aplicando uma redução
gradual dessa população ao longo do processo evolutivo. Uma proposta de como
promover essa redução de forma a preservar a diversidade inicial, sem comprometer
não apenas o custo computacional devido a quantidade de testes da função objetivo,
mas a própria convergência do AG, foi apresentada com o desenvolvimento do
AGkW.
A fim de avaliar os efeitos do controle da perda de diversidade sobre a
convergência prematura, o método proposto foi testado em problemas “benchmark”
usados comumente para avaliação de técnicas de busca global, os quais são
caracterizados pela existência de diversos ótimos locais ou superfícies suaves que
dificultam a convergência dos métodos de otimização. Os resultados obtidos foram
comparados aos resultados do AG.
Apesar de não usar a combinação ótima em cada caso, foi possível perceber
que, em geral, o método proposto se comportou de maneira eficiente para os
problemas abordados, tendo apresentado resultados tão bons ou superiores em
comparação ao AG. Em especial, para as funções Branin e Schwefel, o método
AGkW apresentou um desempenho cerca de 50% superior com aproximadamente
apenas 25% do número médio de avaliações da função objetivo.
Por fim, na análise do efeito do uso da transformada discreta wavelet no
controle da diversidade populacional o método AGkW se mostrou muito superior ao
AG. Os resultados mostram que enquanto o AG tende a reduzir a diversidade da
população ao longo do processo evolutivo o AGkW promove uma significativa
ampliação dessa característica. É importante lembrar que, conceitualmente, o
aumento na diversidade, avaliada como momento de inércia da população,

59
representa um efeito de diminuição da probabilidade de convergência para o ótimo
global da função objetivo.

60
REFERÊNCIAS BIBLIOGRÁFICAS
AFFENZELLER, M.; WAGNER, S. Reconsidering the selection concept of genetic algorithms from a population genetics inspired point of view. In: CYBERNETICS AND SYSTEMS, v. 2, p. 701-706, 2004. Austrian Society for Cybernetic Studies, 2004.
AKASAWA, A. Aplicação da Simulação de Eventos Discretos como ferramenta integrada ao planejamento e programação da produção na manufatura ágil. 2007, 118p. Dissertação (Mestrado em Ciências em Engenharia de Produção), Universidade Federal de Itajubá, Minas Gerais, 2007.
AL-HUDHUD, G.; IBRAHIM, M. K.; AL-AKAIDIB, M. Automatic production of quantisation matrices based on perceptual modelling of wavelet coefficients for grey scale images. Image and Vision Computing, v. 28, n. 4, p. 644–653, 2010.
ARAUJO, S. A. de; LIBRANTZ, A. F.; WONDER, A. L. A. Uso de Algoritmos Genéticos em Problemas de Roteamento de Redes de Computadores. Exacta, v. 5, n. 2, p. 321, 2007.
ARAUJO, S. A.; LIBRANTZ, A. F. H.; WONDER, A. L. A. Algoritmos Genéticos aplicados na estimação de parâmetros em gestão de estoque. São Paulo, Exacta, v. 7, p. 9-21, 2009.
ARENALES, M. et al. Pesquisa Operacional. Rio de Janeiro: Elsevier, 2007.
ATMAR, W. Notes on the simulation of evolution. IEEE Transaction on Neural Networks, v. 1, n. 5, p. 130-47, 1994.
AVCI, E.; AVCI, D. The speaker identification by using genetic wavelet adaptive network based fuzzy inference system. Expert Systems with Applications. v. 36, n. 6, p. 9928–9940, 2009.
AZEVEDO, F. M. Algoritmos Genéticos em Redes Neurais Artificiais. Relatório técnico sobre Algoritmos Genéticos e Redes Neurais Artificiais. Universidade Federal de Santa Catarina, 1999.
BARKER, A. L.; MARTIN, W. N. Dynamics of a distance-based population diversity measure. In: PROCEEDINGS OF THE 2000 CONGRESS ON EVOLUTIONARY COMPUTATION, 2000, Piscataway, NJ, pag. 1002-1009, 2000..
BIANCHI, D.; CALOGERO, R.; TIROZZI, B. K. Neural networks and genetic classification. Mathematical and Computer Modelling, v. 1-2, n. 45, p. 34-60, 2007.
BIRGIN E. G.; MARTINEZ, J. M.; RAYDAN M. Nonmonotone, spectral projected gradient methods on convex sets, SIAM Journal on Optimization n. 10, p. 1196-1211, 2000.

61
BLUM, C.; ROLI, A. Metaheuristics in Combinatorial Optimization: Overview and Conceptual Comparison. ACM Computing Surveys, v. 35, n. 3, 2008.
BURKE, E.; GUSTAFSON, S.; KENDALL, G. A survey and analysis of diversity measures in genetic programming. In: GECCO 2002: PROCEEDINGS OF THE GENETIC AND EVOLUTIONARY COMPUTATION CONFERENCE. Morgan Kaufmann Publishers, v. 1, p. 716-23, 2002.
CASTRO, R. E. Otimização de Estruturas com Multi-Objetivos Via Algoritmos Genéticos. 2001. Tese (Doutorado em Ciências e Engenharia Civil). Universidade Federal do Rio de Janeiro, 2001.
CHANG , P.; HUANG, W. ; TING, C. Dynamic diversity control in genetic algorithm for mining unsearched solution space in TSP problems. Expert Systems with Applications, v. 37, p. 1863–1878, 2010.
CHAVES, A. A. et al. Metaheurísticas híbridas para resolução do problema do caixeiro viajante com coleta de prêmios. Produção, v. 17, n. 2, p. 263-272, 2007.
CHENG M. Y.; HUANG, K. K-means clustering and Chaos Genetic Algorithm for Nonlinear Optimization. INTERNATIONAL SYMPOSIUM ON AUTOMATION AND ROBOTICS IN CONSTRUCTION _ ISARC. Dept. of Construction Engineering, National Taiwan, University of Science and Technology, Taipei, Taiwan; 2009..
COSTA, F. M.; SASSI, R. J. Application of an hybrid bio-inspired meta-heuristic in the optimization of two-dimensional guillotine cutting in an Glass Industry. Lecture Notes in Computer Science. IDEAL'12 Proceedings of the 13th international conference on Intelligent Data Engineering and Automated Learning Pages 802-809. 2012
DAUBECHIES, I. Orthonormal bases of compactly supported wavelets. Comm. Pure and Appl. Math., n. 41, p. 909-96, 1988.
DING, H.; BENYOUCEF, L.; XIE, X. A simulation-based multi-objective genetic algorithm approach for networked enterprises optimization, Engineering Applications of Artificial Intelligence, v. 19, p. 609-23, 2006.
DORIGO M.; MANIEZZO, V.; COLORNI, A. The Ant System: Optimization by a colony of cooperating agents. IEEE Transactions on Systems, Man, and Cybernetics-Part B, v. 26, n. 1, p. 29-41, 1996.
FILIPOVIC, V. Fine-Grained Tournament Selection Operator in Genetic Algorithms. Computing and Informatics, v. 22, n. 2, p. 143-161, 2003.
FLOUDAS, C. A.; PARDALOS, P.M. A Collection of Test Problemsfor Constrained Global Optimization Algorithms, Springer-Verlag, Berlin / Heidelberg / New York, Lecture Notes in Computer Science v. 455, 1990.

62
FLOUDAS, C.A. Deterministic Global Optimization: Theory, Algorithms and Applications. Kluwer Academic Publishers, Dordrecht /Boston / London, 1999.
FOGEL, D. B. An Introduction to Evolutionary Computation, Australian Journal of Intelligent Information Processing, v. 1, n. 2, p. 34-42, 1994.
FRASIER, M. W. An Introduction to Wavelets Through Linear Algebra. Springer-Verlag, New York, 1999.
GAO, Y. Population size and sampling complexity in genetic algorithms. In: PROCEEDINGS OF THE BIRD OF A FEATHER WORKSHOPS (GECCO2003), 2003.
GARCIA, V. M.; ACEVEDO, L.; VIDAL, A. M. Variants of algebraic wavelet-based multigrid methods: Application to shifted linear systems. Appl. Math. Comput, v. 1, n. 202, p. 287-99, 2008.
GEETHA, S. et al. StegoHunter: Passive Audio Steganalysis using Audio Quality Metrics and its realization through Genetic Search and X-Means Approach, 2008.
GIL, A. C. Técnicas de pesquisa em economia. São Paulo, 1991.
GLOVER, F. Future paths for integer programming and links to artificial intelligence, Computer Operational Research, n. 13, p. 533 -49, 1986.
GOLDBERG, D. E. Genetic Algorithms in Search and Optimization. Addison-Wesley Pub. Co., 1989.
GRAY, P. et al. A Survey of Global Optimization Methods. Sandia National Laboratories, 1997.
GUDWIN; ZUBEN, V. Estudo de diversidade populacional: efeito da taxa de mutação. Relatório técnico sobre Diversidade Populacional, Universidade Estadual de Campinas, 2002.
HALDUN, A.; GARY J. K., New stopping criterion for genetic algorithms. European Journal of Operational Research, n. 126, p. 662-74, 2000.
HAN, X.; CHANG, X. An intelligent noise reduction method for chaotic signals based on genetic algorithms and lifting wavelet transforms. Information Sciences. Available online 6 July 2012. In Press.
HARRISON, T. H. Intranet Data Warehouse. São Paulo: Berkeley, 1998.

63
HILL, R. R. A Monte Carlo Study of Genetic Algorithm Initial Population Generation Methods. In: PROCEEDINGS OF THE 1999 WINTER SIMULATION CONFERENCE. Air Force Institute of Technology, 1999.
HIROYASU, T. et al. Diversity Maintenance Mechanism for Multi-Objective Genetic Algorithms Using Clustering and Network Inversion. In: PROCEEDINGS OF THE 10TH INTERNATIONAL CONFERENCE ON PARALLEL PROBLEM SOLVING FROM NATURE, Dortmund, Germany, n. 1 p. 722-32, 2008.
HOLDER, A. Mathematical programming glossary. Informs Computing Society, 2008. Disponível em: <http://glossary.computing.society.informs.org>.
HOLLAND, J. H. Adaptation in Natural and Artificial Systems. Ann Arbor: The University of Michigan Press, 1975.
HOLLAND, J. H. Genetic Algorithms. Scientific American, p. 66-72, 1992.
HORST, R.; TUY, H. Global Optimization – Deterministic Approaches. 3.ed. Springer, Berlin / Heidelberg / New York: Springer, 1996.
JENSEN, A.; COUR-HARBO, A. la. The Discrete Wavelet Transform, Ripples in Mathematics. Berlin: Springer, 2001.
KENNEDY, J.; EBERHART, R. Particle Swarm Optimization. IEEE International Conference on Neural Network. Perth, Australia, pp. 1942-1948, 1995.
KIRKPATRICK, S.; GELATT JR., C. D.; VECCHI, M. P. Optimization by Simulated Annealing, Science 13, v. 220 n. 4598 p. 671-80, 1983.
KUMAR, R.; JYOTISHREE. Effect of Annealing Selection Operators in Genetic Algorithms on Benchmark Test Functions, International Journal of Computer Applications, v. 40, n. 3, p. 38-46, 2012.
LACEVIC, B; AMALDI, E. Ectropy of diversity measures for populations in Euclidean space. Journal Information Sciences: an International Journal archive, v. 181 n. 11, p. 2316-39, 2011.
LEUNG, A. K.; CHAU, F.; GAO, J. A review on applications of wavelet transform techniques in chemical analysis: 1989–1997. Chemometrics and Intelligent Laboratory Systems, v. 43, n. 1-2, p. 165–184, 1998.
LI, S.; KUO, S. Knowledge discovery in financial investment for forecasting and trading strategy through wavelet-based SOM networks. Expert Systems with Applications, v. 34, n. 2, p. 935–951, 2008.

64
LIBRANTZ, A. F. H. et. al. Genetic Algorithm Applied to Investigate Cutting Process Parameters Influence on Workpiece Price Formation. Materials and Manufacturing Processes, v. 26, p. 550-7, 2011.
LIMA, M. P. Planejamento Multiobjetivo de Redes WLAN utilizando Algoritmos Genéticos. 2011. Dissertação (Mestrado em Engenharia Elétrica), Universidade Federal de Minas Gerais, 2011.
LINDEN, R. Algoritmos Genéticos: Uma importante ferramenta da Inteligência Computacional. 2.ed. Rio de Janeiro: Brasport, 2008.
LINDEN, R. Técnicas de Agrupamento. Revista de Sistemas de Informação da FSMA, n. 4, p. 18-36, 2009.
LUCAS, C. D. Algoritmos Genéticos: uma Introdução. 2002.
MACQUEEN, J. B. Some Methods for classification and Analysis of Multivariate Observations, Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press, 1967.
MACULAN, N.; PLATEAU, G.; LISSER A. V. Pesquisa Operacional, v. 1, n. 23, p. 161-8, 2003.
MAHESWARAN, R.; KHOSA, R. Comparative study of different wavelets for hydrologic forecasting. Computers & Geosciences, v. 46, p. 284–295, 2012.
MICHALEWICZ, Z. Genetic Algorithms + Data Structures = Evolution Programs. 3rd revised and extended. Berlim, Springer-Verlag, 1996.
MITCHELL, M. An Introduction to Genetic Algorithms. MIT Press, 1999.
MITCHELL, T. Machine Learning. McGraw Hill, 1997.
MORETTIN, P. A., Ondas e Ondaletas: da Análise de Fourier à Análise de Ondaletas. São Paulo: Edusp, 1999.
MORRISON, R.; DE JONG, K. A. A Test Problem Generator for Non-stationary Environments. In: PROCEEDINGS OF CONGRESS ON EVOLUTIONARY COMPUTATION. IEEE, p. 2047-53, 1999.
MORRISON, R. W.; DE JONG, K. A. Measurement of population diversity. In: INTERNATIONAL CONFERENCE, EVOLUTION ARTIFICIELLE, 5TH. 2001, Le Creusot, France, v. 1, p. 31-41.

65
MUNDIM, K. C.; DELAVY, V. C. T. Otimização Global de Processos usando o Método Generalized Simulated Annealing. Revista Processos Químicos, v. 2, n. 4, p. 9-23, 2008.
MUZHOU, H.; XULI, H. The multidimensional function approximation based on constructive wavelet RBF neural network. Applied Soft Computing, v. 11, n. 2, p. 2173–77, 2011.
NEMATI, S. et al. A novel ACO-GA hybrid algorithm for feature selection in protein function prediction”. Expert Syst. Appl, v. 10, n. 36, 2009.
OJA, M.; NIKKILA, J.; TORONEN, P. Exploratory clustering of gene expression profiles of mutated yeast strains. In: Computational and Statistical Approaches to Genomics. ZHANG, W; SHMULEVICH, I. (eds.). Kluwer Press, 2002.
OKABE, T. Theoretical Analysis of Selection Operator in Genetic Algorithms. In: IEEE CONGRESS ON EVOLUTIONARY COMPUTATION (CEC'2007), p. 4676-4683, IEEE Press, Singapore, September 2007.
PACHECO, M. A. Algoritmos Genéticos: Princípios e Aplicações. In: INTERCON 99: V CONGRESO INTERNACIONAL DE INGENIERÍA ELECTRÓNICA, ELÉTRICA Y SISTEMAS. Anais. Lima, Peru, 1999.
PARDALOS, P. M.; ROMEIJN, H. E. Handbook of Global Optimization, 2002, Gainesville, Kluwer.
PAVEZ-LAZO, B.; SOTO-CARTES, J. A deterministic annular crossover genetic algorithm optimisation for the unit commitment problem. Expert Syst. Appl., v. 38, n. 6, p. 6523-6529, 2011.
PEREIRA, F. H. et al. Low-loss image compreession techniques for cutting tool images: a comparative study of compression quality measures. Exacta. São Paulo, v. 8, p. 225-35, 2010.
PEREIRA, F. H.; PIRES, C. L.; NABETA, S. I. Optimal theoretical placement of rectifier substations on DC traction systems. IET Electrical Systems in Transportation, 2012. [No prelo].
PEREIRA, F.H. et al. Solution of nonlinear magnetic fiel problems by Krylov-subspace methods with eta-cycle wavelet based algebraic multigrid preconditioning. IEEE Transactions on Magnetics, v. 44, p. 950-53, 2008.
POZO, et al. Computação Evolutiva. Curitiba: Grupo de Pesquisas em Computação Evolutiva da Universidade Federal do Paraná, 2009. Disponível em: <http://www.inf.ufpr.br/aurora/tutoriais/Ceapostila.pdf>.

66
RUSSEL, S.; NORVIG, P. Inteligência Artificial. Rio de Janeiro: Campus. 2004.
SADRZADEH, A. 2012. A genetic algorithm with the heuristic procedure to solve the multi-line layout problem. Comput. Ind. Eng., v. 4, n. 62, maio 2012. Disponível em: <http://dx.doi.org/10.1016/j.cie.2011.12.033>.
SANCHEZ-VELAZCO, J.; BULLINARIA, J. A. Sexual Selection with Competitive/Co-operative Operators for Genetic Algorithms, PROCEEDINGS OF NCI’2003, Cancun, Mexico, p. 308 – 316, 2003.
SANTA CATARINA, A. SAHGA Um algoritmo genético híbrido com representação explicita de relacionamentos espaciais para análise de dados geoespaciais. 2009. 112p. Tese (Doutorado do Curso de Pós-Graduação em Computação Aplicada) Instituto Nacional de Pesquisas Espaciais - INPE, São José dos Campos, 2009.
SANTA CATARINA, A; BACH, S. L. Estudo do efeito dos parâmetros genéticos sobre a solução otimizada e sobre o tempo de convergência em algoritmos genéticos com codificações binárias e reais. Acta Scientiarum. Technology, v. 25, n. 2, p. 147-52, Jul./Dez. 2003.
SANTANA, J. C. C. et al. Optimization of the corn malt drying by use of genetic algorithm. Drying Technology, v. 28, p. 1-22, 2010.
SARKAR, T. K.; SALAZAR-PALMA, M.; MICHAEL, C. W. Wavelet Applications in Engineering Electromagnetics. Boston: Artech House, 2002.
SCHEMPP, W. Non-commutative affine geometry and symbol calculus: Fourier transform magnetic resonance imaging and wavelets. Wavelet Analysis and Its Applications, v. 7, p. 71–119, 1998.
SCHOEN, F. A wide class of test functions for global optimization. Journal of Global Optimization, v. 3, p. 133-8, 1993.
SCHWAAB, M. Avaliação de Algoritmos Heurísticos de Otimização em Problemas de Estimação de Parâmetros. 2005. Dissertação (Mestrado em Engenharia Química). Universidade Federal do Rio de Janeiro, COPPE.
SCIENCEDIRECT, http://www.sciencedirect.com, acessado em 20 de agosto de 2012.
SEAN L., Essentials of Metaheuristics, online version. March, 2010. Disponível em: <http://cs.gmu.edu/~sean/book/metaheuristics/>.
SERAPIAO, A. B. de S. Fundamentos de otimização por inteligência de enxames: uma visão geral. Sba Controle & Automação. v. 20, n.3, p. 271-304, 2009.

67
SILVA, M. F. de. Abordagem para Otimização Multiobjetivo de Regras Heurísticas de Sequenciamento em Sistemas de Manufatura Job Shop por meio de simulação computacional acoplada ao algoritmo genético. 2011. Dissertação, Universidade Nove de julho – Uninove, 2011.
SOUZA, E. M.; PAGAMISSE, A.; MONICO, J. F. G.; POLEZEL, W. G. C. Comparação das Bases de Wavelets Ortonormais e Biortogonais: Implementação, Vantagens e Desvantagens no Posicionamento com GPS. TEMA Tend. Mat. Apl. Comput., v. 8, n. 1, p. 149-158, 2007.
SUBBARAJ, P.; RENGARAJ, R.; SALIVAHANAN, S. Enhancement of Self-adaptive real-coded genetic algorithm using Taguchi method for Economic dispatch problem. Appl. Soft Comput., v. 11, n. 1, p. 83-92, 2011.
SWELDENS, W. The lifting scheme: A custom-design construction of biorthogonal wavelets, Appl. Comput. Harmon. Analysis, v. 3, n. 2, p. 186-200, 1996.
TAKAHASHI, R. H. C.; MARTINS, F.V.C. Sobre a inércia de populações de algoritmos genéticos, 2005.
TRAGANTE, V.; TINÓS, R., Diversity Control in Genetic Algorithms for Protein Structure Prediction. In: VII ENCONTRO NACIONAL DE INTELIGÊNCIA ARTIFICIAL (ENIA 2009), VII, 2009, Bento Gonçalves. Anais do XXIX Congresso da Sociedade Brasileira de Computação (CSBC), 2009, v. 1 p. 727-37.
TRAHAN, M.; WAGNER, J. F. Deterministic Global Optimization: Theory, Algorithms and Applications. Boston, London: Kluwer Academic Publishers, 1999.
VO, A.; ORAINTARA, S. A study of relative phase in complex wavelet domain: Property, statistics and applications in texture image retrieval and segmentation. Signal Processing: Image Communication, v. 25, n. 1, p. 28–46, 2010.
WALL, M. GALIB: A C++ library of genetic algorithm components. Mechanical Engineering Departament, Massachussetts Institute of Technology, 1996.
WANG, Y. et al. Flood simulation using parallel genetic algorithm integrated wavelet neural networks. Neurocomputing, v. 74, n. 17, p. 2734–44, 2011.
WEISE, T. Global Optimization Algorithms: Theory and Application. 2. ed. 2008. Disponível em: <http://www.it-weise.de>.
WINKLER, S.; AFFENZELLER, M.; WAGNER, S. Offspring selection and its effects on genetic propagation in genetic programming based system identification. In: CYBERNETICS AND SYSTEMS, v. 2, p. 549-554, 2008. Austrian Society for Cybernetic Studies, 2008.

68
ZAINUDDIN, Z.; ONG, P. Reliable multiclass cancer classification of microarray gene expression profiles using an improved wavelet neural network. Expert Systems with Applications, v. 38, n. 11, p. 13711–13722, 2001.
ZHAO, J.; LI, F.; ZHANG, X. Parameter adjustment based on improved genetic algorithm for cognitive radio networks. The Journal of China Universities of Posts and Telecommunications, v. 3, n. 19, 2012.
ZHU, K.Q. A Diversity-Controlling Adaptive Genetic Algorithm for the Vehicle Routing Problem with Time Windows. In: PROCEEDINGS OF THE 15TH IEEE INTERNATIONAL CONFERENCE ON TOOLS WITH ARTIFICIAL INTELLIGENCE. ICTAI. Washington: IEEE Computer Society, 2003.

69
ARTIGOS RESULTANTES DESTA DISSERTAÇÃO
Trabalhos publicados em anais de congressos oriundos desta dissertação:
LOPES, Elenice da Conceição Castro; NABETA, Silvio Ikuyo; PEREIRA, Fabio Henrique. Population Diversity Control in Genetic Algorithm Method using the Discrete Wavelet Transform and the k-means clustering. In: Compumag 2011, Sydney. Proceedings of Compumag, 2011.
LOPES, Elenice da Conceição Castro; PEREIRA, Fabio Henrique; CALARGE, Felipe Araújo. Controle da diversidade populacional em algoritmos genéticos pela clusterização usando a função k-médias e transformadas discreta wavelet. In: MECON 2010 - CILANCE 2010 - XXXI Iberian-Latin_American Congress on Computational Methods in Engineering, IX Argentinian Congress on Computational Mechanics, II South American Congress on Computational Mechanics, Buenos Aires. Anais do CILAMCE, 2010.
PEREIRA, Fabio Henrique; LOPES, Elenice da Conceição Castro. Population Diversity Control in Metaheuristic Techniques Using the Discrete Wavelet Transform. In: EngOpt 2010 - 2nd International Conference on Engineering Optimization, Lisboa. Books of Abstracts, 2010.