universidade federal de viçosa -...
TRANSCRIPT

Universidade Federal de Viçosa
Disciplina: EST 631
Introdução à Metodologia de Superfície
Universidade Federal de Viçosa Departamento de Estatística
Disciplina: EST 631 – Métodos Estatísticos II
Apostila
Introdução à Metodologia de Superfícies de Resposta
Paulo Roberto Cecon
Anderson Rodrigo da Silva
Viçosa, MG
2011
de Resposta
Paulo Roberto Cecon
Anderson Rodrigo da Silva

ii
Introdução à Metodologia de Superfícies de Resposta

iii
Sumário
1. Introdução.................................................................................................................. 1
2. Modelo de Primeira Ordem ....................................................................................... 4
3. Delineamentos Experimentais para Ajuste de Modelos de Primeira Ordem ............ 9
3.1. Fatorial Completo .............................................................................................. 9
3.2. Delineamento Composto Central (DCC) ........................................................... 9
3.3. Delineamento Composto Central Rotacionado (DCCR) ................................. 10
3.4. Delineamento de Box-Behnken (DBB) ........................................................... 10
4. Teste de Significância do Modelo ........................................................................... 12
5. Medidas e Adequação de Modelos.......................................................................... 13
6. Teste para Falta de Ajuste ....................................................................................... 14
7. Método da Inclinação Ascendente .......................................................................... 15
8. Exemplo de Aplicação para o Modelo de Primeira Ordem .................................... 15
9. Modelo de Segunda Ordem ..................................................................................... 21
10. Localização do Ponto Estacionário ......................................................................... 28
11. Caracterizando a Superfície de Resposta ................................................................ 29
Referências ..................................................................................................................... 35

1
1. Introdução
No contexto da estatística experimental há constante interesse em caracterizar a
possível relação entre uma ou mais variáveis resposta e um conjunto de fatores de
interesse. Isso pode ser executado através da construção de um modelo que descreva a
variável resposta em função dos níveis aplicáveis desses fatores.
Certos tipos de problemas científicos envolvem a expressão de uma variável
resposta, tal como o rendimento de um produto, como uma função empírica de um ou
mais fatores quantitativos, tais como a temperatura de reação e a pressão. Isso pode ser
efetuado utilizando-se uma metodologia que permita modelar a relação: Rendimento em
função de temperatura de reação e pressão. O conhecimento da forma funcional de f,
frequentemente obtida com a modelagem de dados provenientes de experimentos
planejados, permite tanto sumarizar os resultados do experimento quanto predizer a
resposta para níveis dos fatores quantitativos. Assim, a função f define a superfície de
resposta, que em sua essência, consiste em estimar coeficientes da regressão polinomial
para a geração de um modelo empírico, por meio do qual é possível aproximar uma
relação (inicialmente desconhecida ou conhecida) entre os fatores e as respostas do
processo.
Podemos então definir a Superfície de Resposta como sendo a representação
geométrica obtida quando uma variável resposta é plotada como uma função de dois ou
mais fatores quantitativos. A função pode ser assim definida:
1 2 kY f (X ,X ,...,X )= + ε
Em que: Y é a resposta (variável dependente); 1 2 kX ,X ,...,X são os fatores (variáveis
independentes); e ε é o erro aleatório.
Denota-se a resposta esperada por:
1 2 kE(Y) f (X ,X , ,X )= = η…
então,
1 2 kf (X ,X , ,X )η = …

2
é chamada de superfície de resposta.
A metodologia de superfície de resposta, ou MSR, é uma coleção de técnicas
matemáticas e estatísticas que são úteis para modelagem e análise nas aplicações em
que a resposta de interesse seja influenciada por várias variáveis e o objetivo seja
otimizar essa resposta. Por exemplo, suponha que um engenheiro químico deseje
encontrar os níveis de temperatura (X1) e concentração da alimentação (X2) que
maximizem o rendimento (Y) de um processo. O rendimento de um processo é uma
função dos níveis de temperatura e concentração de alimentação, como
1 2Y f (x ,x )= + ε , em que ε representa o erro observado na resposta esperada
1 2E(Y) f (x ,x )= = η, então a superfície representada por 1 2f (x ,x )η = é chamada de
superfície de resposta (Montgomery e Runger, 2008).
Segundo Montgomery (2001), as equações definidas de superfície de resposta
podem ser representadas graficamente e utilizadas de três formas:
• Descrever como as variáveis em teste afetam as respostas;
• Determinar as inter-relações entre as variáveis em teste; e
• Para descrever efeitos combinados de todas as variáveis em teste sobre a
resposta.
Algumas considerações devem ser feitas quando utilizamos superfície de
resposta, a saber:
a) O uso efetivo da superfície de resposta deve considerar cinco pressupostos:
i. Os fatores que são críticos ao processo são conhecidos;
ii. A região em que os fatores influem o processo é conhecida;
iii. Os fatores variam continuamente ao longo da faixa experimental escolhida;
iv. Existe uma função matemática que relaciona os fatores à resposta medida;
v. A resposta que é definida por essa função é uma superfície lisa.

3
b) A técnica também apresenta algumas limitações que devem ser consideradas:
i. Grandes variações dos fatores podem resultar em conclusões falsas;
ii. Os fatores críticos não foram especificados corretamente;
iii. A região de ótimo pode não ser determinada devido ao uso de uma faixa muito
estreita ou ampla;
iv. Como em qualquer experimento, resultados destorcidos podem ser obtidos se os
princípios clássicos da experimentação não forem seguidos (casualização,
repetição e controle local); e
v. Superestimar a computação: o pesquisador dever utilizar de bom senso e seu
conhecimento sobre o processo para chegar a conclusões apropriadas a seus
dados.
A aplicação dessa metodologia foi realizada inicialmente na indústria química,
tendo sido seus fundamentos formalizados por Box e Draper (1987). No campo
agronômico, o uso concentrou-se no estudo do rendimento de cultivares, como efeito de
níveis de nutrientes aplicados ao solo, incluindo-se outros fatores, como: densidade de
plantio e lâminas de irrigação.
A superfície de resposta é útil quando o pesquisador não conhece a relação exata
entre os fatores. Mas, geralmente quando a expressão analítica da função é conhecida, a
metodologia pode ser útil em alguns casos: freqüentemente podem-se encontrar funções
descontínuas, e em muitos casos se trabalha com valores discretos das variáveis de
projeto ou fatores, sendo assim o uso da metodologia de superfície de resposta apresenta
uma ampla aplicação na pesquisa, porque ela considera vários fatores em níveis
diferentes e as interações correspondentes entre esses fatores e níveis.
Dentre as vantagens da metodologia de superfície de resposta, a principal é que
seus resultados são resistentes aos impactos de condições não ideais, como erros
aleatórios e pontos influentes, porque a metodologia é robusta. Outra vantagem é a
simplicidade analítica da superfície de resposta obtida, pois a metodologia gera
polinômios. Em geral, polinômios de duas ou mais variáveis, são funções contínuas.

4
Após o ajuste do modelo aos dados, é possível estimar a sensibilidade da
resposta aos fatores, além de determinar os níveis dos fatores nos quais a resposta é
ótima (por exemplo, máxima ou mínima).
2. Modelo de Primeira Ordem
Na maioria dos problemas em superfície de resposta, a forma do relacionamento
entre as variáveis dependentes e independentes é desconhecida. Assim, o primeiro passo
é encontrar uma aproximação para o verdadeiro relacionamento entre a variável
resposta (y) e as variáveis independentes (fatores). Geralmente utiliza-se de uma
regressão polinomial de baixo grau em alguma região das variáveis independentes. A
forma geral para o modelo de primeira ordem (ou modelo de grau um) em k variáveis de
entrada (independentes) pode ser representado por:
k
0 i ii 1
Y X=
= β + β + ε∑
Onde Y é uma variável resposta observada, 0 1 k, , ...,β β β são parâmetros desconhecidos,
e ε é o termo do erro aleatório. Se ε tem média zero, então a porção não aleatória do
modelo geral de primeira ordem representa a verdadeira resposta média, η , que é,
k
0 i ii 1
E(Y) X=
η = = β + β∑
e ε é tido como erro experimental. Se, entretanto, o modelo descrito é inadequado para
representar a verdadeira resposta média, então ε contém, adicionalmente ao erro
experimental, um erro não aleatório (sistemático). Este último erro é atribuído a omissão
de termos em 1 2 kX , X ,...,X de grau superior a um que podem ser entendidas como
outras variáveis as quais tem alguma influência sobre a variável resposta. Este erro
adicional (excluindo o erro experimental) é chamado falta de ajuste.
Escrevendo o modelo em notação matricial, considerando N observações, temos:
= +Y Xβ ε

5
Em que Y é um vetor de N (N ≥ k+1) observações, [ ]0 1 k` ...= β β ββ é um vetor (k+1)
x 1 de parâmetros desconhecidos, [ ]1 2 N` ...= ε ε εε é um vetor N x 1 de erros, e X é
uma matriz N x (k+1) de coeficientes dos parâmetros que compreende os níveis das
variáveis independentes. Assume-se que os erros aleatórios são 2NID(0, )σ , isto é,
independentemente distribuídos com distribuição Normal de média zero e variância
comum. Quando a matriz X é de posto coluna completo, então o estimador de mínimos
quadrados ordinários de β pode ser obtido por:
1ˆ ( )−=β X`X X`Y
E a matriz de variâncias e covariâncias de β é dada por:
1 2ˆV( ) ( )−= σβ X`X
Na maioria dos casos, os cálculos para estimação dos parâmetros podem ser
simplificados codificando os níveis das k variáveis independentes iX por meio de:
iu iiu
i
2(X X )x i 1,2,...,k e u 1,2,...,N
R−= = =
Em que N
i iuu 1X X / N
==∑ e iR é a diferença entre o maior e o menor valor dos níveis.
A codificação apresenta a característica:
N
iuu 1
x 0 i 1,2,...,k=
= =∑
Exemplo: Os dados a seguir referem-se ao peso de alimentos ingeridos em experimento
com alimentação de ratos em relação a duração do tempo entre inoculação de dosagens
de uma droga e a alimentação (horas).

6
Droga (X1) Dosagem (mg kg-1)
Tempo (X2) Peso observado
0,3 1 5,63 0,3 1 6,42 0,7 1 1,38 0,7 1 1,94 0,3 5 11,57 0,3 5 12,16 0,7 5 5,72 0,7 5 4,69 0,3 9 12,68 0,3 9 13,31 0,7 9 8,28 0,7 9 7,73
Utilizando variáveis codificadas, tem-se:
( ) ( )1u 1 1u 1u1u
1
2 X X 2 X 0,5 X 0,5x
R 0,7 0,3 0,2
− − −= = =−
( ) ( )2u 2 2u 2u2u
2
2 X X 2 X 5 X 5x
R 9 1 4
− − −= = =−
Então, o modelo de primeira ordem para u 0 1 1u 2 2u uY X X= β + β + β + ε , em notação
matricial = +Y Xβ ε , utilizando as variáveis codificadas é
0
1
23 1
12 1 12 3
5,63 1 1 1
6,42 1 1 1
1,38 1 1 1
1,94 1 1 1
11,57 1 1 0
12,16 1 1 0
5,72 1 1 0
4,64 1 1 0
12,68 1 1 1
13,31 1 1 1
8,28 1 1 1
7,73 1 1 1
− − − − − − −
β − = β +
β − −
11
12
21
22
31
32
41
42
51
52
61
6212 1
ε ε ε ε ε ε ε ε ε ε ε ε

7
YX'XX'β1)(ˆ −=
=
=
∑∑∑
∑∑∑
∑∑
===
===
==
800
0120
0012
xxxx
xxxx
xxn
n
1u
22u
n
1u2u1u
n
1u1u
n
1u2u1u
n
1u
21u
n
1u1u
n
1u2u
n
1u1u
XX'
n
uu 1
n
u 1uu 1
n
u 2uu 1
Y
Y x
Y x
=
=
=
=
∑
∑
∑
X'Y
−=
−
=32875,3
67333,2
62166,7
63,26
08,32
46,91
8
100
012
10
0012
1
β
Equação ajustada:
u2**
u1**
u2**u1**
u2**
u1**
X83212875,0X3665,131440,10Y
4
5X32875,3
2,0
5,0X67333,262166,7Y
x32875,3x67333,262166,7Y
+−=
−+
−−=
+−=
Hipóteses:
zerodedifereβdosummenospelo:H
0ββ:H
1
210 ==

8
Quadro da análise de variância:
FV GL SQ QM F
Regressão 2 174,1380 87,0690 84,28**
Resíduo 9 9,2980 1,0331
Total 11 183,4360
9493,04360,183
1380,174R2 ==
Teste para cada um dos parâmetros:
0β:H
0β:H
11
10
≠=
**10,9
)0331,1(12
1
0-2,67333-t −==
0β:H
0β:H
21
20
≠=
**26,9
)331(1,08
1
032875,3t =−=
** significativo pelo teste t a 5% de probabilidade.

3. Delineamentos ExperimenModelos de Primeira
3.1. Fatorial Completo
Caracteriza-se pela Combinação de todos os níveis de todos os fatores
escolhidos pelo pesquisador apresentando como desvantagem um número muito grande
de ensaios. Deste modo, um fatorial completo com p(níveis) e k(fatores) apresenta p
combinações distintas, se p = k
Exemplo 1: Em um ensaio onde se deseja contrastar temperatura (30, 35, 40), tempo (3,
5, 7) e pH (5, 6, 7) tentando otimizar uma determinada reação química, temos um
fatorial 33, onde k=3 fatores e
representação gráfica:
3.2. Delineamento Composto Central
Caracteriza-se pela Combinação de um fatorial 2
central. Sua vantagem é a de reduzir o número de ensaios, todavia sua utilização
restringe-se ao ajuste de modelos de primeira ordem.
Tomando-se como ilustração o exemplo
ficaria: 23+1 = 9, uma redução de 18 ensaios em relação ao fatorial completo.
9
Delineamentos Experimentais para Ajuste de Modelos de Primeira Ordem
Fatorial Completo
se pela Combinação de todos os níveis de todos os fatores
escolhidos pelo pesquisador apresentando como desvantagem um número muito grande
de ensaios. Deste modo, um fatorial completo com p(níveis) e k(fatores) apresenta p
s, se p = k.
m um ensaio onde se deseja contrastar temperatura (30, 35, 40), tempo (3,
5, 7) e pH (5, 6, 7) tentando otimizar uma determinada reação química, temos um
fatores e p=3 níveis. Ao todo serão 27 tratamentos
lineamento Composto Central (DCC)
se pela Combinação de um fatorial 2K (k fatores) mais o ponto
central. Sua vantagem é a de reduzir o número de ensaios, todavia sua utilização
modelos de primeira ordem.
se como ilustração o exemplo da seção 3.1, o número de tratamentos
+1 = 9, uma redução de 18 ensaios em relação ao fatorial completo.
tais para Ajuste de
se pela Combinação de todos os níveis de todos os fatores
escolhidos pelo pesquisador apresentando como desvantagem um número muito grande
de ensaios. Deste modo, um fatorial completo com p(níveis) e k(fatores) apresenta pk
m um ensaio onde se deseja contrastar temperatura (30, 35, 40), tempo (3,
5, 7) e pH (5, 6, 7) tentando otimizar uma determinada reação química, temos um
. Ao todo serão 27 tratamentos, conforme a
fatores) mais o ponto
central. Sua vantagem é a de reduzir o número de ensaios, todavia sua utilização
, o número de tratamentos
+1 = 9, uma redução de 18 ensaios em relação ao fatorial completo.

10
3.3. Delineamento Composto Central Rotacionado (DCCR)
É utilizado para experimentos onde k(fatores)2≥ . Este delineamento contém
pontos da parte cúbica codificados para (± 1), pontos axiais codificados para (± α ,
ondeα = (2k)1/4) para testar o modelo de segunda ordem e o ponto central codificado
para (0) que geralmente possui repetições. Assim, número de tratamentos passaria a ser:
fatorial 2k + ponto central + 2k pontos axiais. Para o exemplo da seção 3.1., 23+1+2*3=
15 tratamentos.
3.4. Delineamento de Box-Behnken (DBB)
É utilizado para experimentos com k ≥ 3. Tendo como principal vantagem a
redução do número de ensaios para estudar um maior número de fatores. De modo geral
os níveis dos fatores são escolhidos à partir das informações de seus limites inferiores e
superiores.
O número de tratamentos dá-se pela combinação dos níveis da parte cúbica +
ponto central.
A título de ilustração, seguem abaixo outros exemplos:
Exemplo 2. Um experimento com dois fatores de interesse (A e B), possuindo p = 4
níveis para ambos os fatores.

Exemplo 3.
Exemplo 4. Um planejamento experimental com 3 fatores e 4 níveis cada.
11
. Um planejamento experimental com 3 fatores e 4 níveis cada.. Um planejamento experimental com 3 fatores e 4 níveis cada.

12
4. Teste de Significância do Modelo
Este teste é realizado como um procedimento de ANOVA. Calculando-se a
razão entre a média quadrática dos termos de regressão e a média quadrática do erro,
encontra-se a estatística F, que comparada com o valor crítico de F para um dado nível
de significância, permite avaliar a significância do modelo. Se F for maior que F crítico
então o modelo é adequado (Montgomery, 2001).
Considerando o sistema de equações normais (SEN), dado por:
ˆ =X`Xβ X`Y
pode-se obter as somas de quadrados relativas a cada fonte de variação da ANOVA:
N2
Total jj 1
SQ C Y C=
= − = −∑Y`Y
ResíduoˆSQ = −Y`Y β`X`Y
RegˆSQ C= −β`X`Y
em que C é o termo de correção, dado por:
2N
jj 1
Y
CN
=
=∑
O teste para a significância da regressão determina se existe uma relação linear
entre a variável de resposta y um subconjunto de regressores. As hipóteses apropriadas
neste caso são:
0 1 2 k
1
H : ...
H : pelo menos um dos difere de zero
β = β = = ββ
O teste individual de significância de cada coeficiente pode conduzir a
otimização do modelo através da eliminação ou adição de termos. As hipóteses
utilizadas para testar qualquer um dos coeficientes de regressão são:
0 i
1 i
H : 0
H : 0
β =β ≠

13
O teste utilizado para realizar esse teste é:
ï ï
2iii
ˆ ˆt
ˆˆ ˆcV( )
β β= =σβ
Em que cii é o elemento da diagonal da matriz (X’X)-1 correspondente ao coeficiente em
teste. A estatística segue distribuição t com o número de graus de liberdade do resíduo.
Se o valor p do teste individual para os termos for inferior ao nível de
significância, então o termo é adequado ao modelo e deve, portanto, ser mantido. Ao
contrário, o termo deve ser excluído se tal procedimento conduzir a um aumento do
coeficiente de determinação R² conjuntamente com a diminuição do efeito residual e o
valor p referente à falta de ajuste do modelo for superior ao nível de significância. Além
disso, a retirada de qualquer termo deve obedecer ao princípio da hierarquia. Este
princípio, segundo Montgomery (2001), postula que quando um termo de ordem alta for
mantido no modelo, o de ordem baixa que o compõe também deve ser mantido.
5. Medidas e Adequação de Modelos
A medida de adequação mais comumente usada é o coeficiente de determinação
R², definido por:
2 2SQRegressão SQResíduoR 1 [0 R 1]
SQTotal SQTotal= = − ≤ ≤
e representa a proporção da variação total que é devida (explicada) pelo modelo
regressão.
Associado ao R² está o coeficiente de determinação ajustado 2R , que considera
o fato de que R² tende a superestimar a quantidade atual de variação contabilizada para
a população. Também é fato que a inclusão de muitos parâmetros no modelo de
regressão aumenta substancialmente o valor de R². Se o modelo recebeu parâmetros
desnecessários haverá um incremento em R² sem haver, necessariamente, melhoria de
precisão da resposta. Por isso o R² ajustado é mais indicado para comparar modelos com
números diferentes de parâmetros e, ainda, ajustados com número de observações
diferentes. O coeficiente de determinação ajustado para graus de liberdade e número de
parâmetros (p) é definido por:

14
22 R (n 1) p
Rn p 1
− −=− −
Nota: O R2 ajustado é sempre menor que o R2 e só será igual quando R2 = 1.
6. Teste para Falta de Ajuste
A adição de pontos centrais aos arranjos experimentais proporciona a obtenção
de uma estimativa do erro experimental. De acordo com Montgomery (2001), este
artifício permite que a soma de quadrados residual (SQRes) seja discriminada em dois
componentes: (i) a soma de quadrados devida ao erro puro (SQEP) e; (ii) a soma de
quadrados devido à falta de ajuste do modelo adotado (SQF.Aj). Assim, pode-se escrever:
Res EP F.Aj.SQ SQ SQ= +
Admitindo-se que existam ni observações de uma dada resposta Y de interesse
no i-ésimo nível dos regressores ix (i 1,2,...,k)= . Considere que ijY denote a j-ésima
observação da resposta no nível ix , com ij 1,2,...,n= e k
ii 1
n N=
=∑ , o total de
observações. Então, o ij-ésimo resíduo será:
ij ij ij i i ïˆ ˆY Y (Y Y ) (Y Y )− = − + −
Onde iY é a média da resposta para o nível ix . Elevando-se ao quadrado ambos os
lados e somando em relação a i e j, obtém-se:
i i
F.Aj.Res EP
n nk k k2 2 2
ij i ij i i i ii 1 j 1 i 1 j 1 i 1
SQSQ SQ
ˆ ˆ(Y Y ) (Y Y ) n (Y Y )= = = = =
− = − + −∑∑ ∑∑ ∑�������������� �������

15
7. Método da Inclinação Ascendente
O objetivo é auxiliar o pesquisador, de forma rápida e eficiente, a encontrar a
região de ótimo, isto é, determinar a melhor região de estudo. Encontrada a região de
ótimo, um modelo mais elaborado, por exemplo, um modelo de segunda ordem, pode
ser empregado, e uma análise pode ser feita para localizar o ponto de máximo ou de
mínimo (ponto ótimo).
Utiliza-se um conjunto de tratamentos em torno do ponto inicial e estimam-se
por Mínimos Quadrados as inclinações iβ . A partir das magnitudes e sinais destas
inclinações, calcula-se a direção do método da inclinação ascendente (MIA). Assim:
• Experimentos são conduzidos ao longo do caminho da MIA até que nenhum
incremento na resposta seja observado.
• Eventualmente, chega-se a vizinhança do valor ótimo e isto será indicado pela
falta de ajuste do modelo de 1ª ordem.
• A aproximação por um plano se torna insatisfatória pelo fato dos efeitos de
ordens mais elevadas, particularmente os de 2ª ordem (quadrático e de interação
linear), se tornarem relativamente mais importantes. Nesse caso usa-se o Modelo
Quadrático.
8. Exemplo de Aplicação para o Modelo de Primeira Ordem
Consideremos o seguinte exemplo: um experimento em esquema fatorial 2x2,
tempo e temperatura, com dois níveis cada, ou seja, um fatorial 22 para que os níveis
desses fatores maximizem a produção de um determinado processo. A região
experimental será (30, 40) min para o tempo de reação e (150, 160)°F para temperatura.
Normalmente, opera-se com um tempo de 35 minutos e temperatura de 155 ºF, que
resulta numa produção de 40% aproximadamente.

16
Como esta região provavelmente não contém o ótimo, um modelo de primeira
ordem será ajustado e aplicado o Método da Máxima Inclinação Ascendente. As
variáveis independentes serão codificadas para (-1, 1) para simplificar os cálculos.
Serão incluídos também cinco pontos centrais entre os valores máximos e mínimos do
tempo e temperatura. As repetições no ponto central são utilizadas para estimar o erro
experimental e para checar o ajuste do modelo de primeira ordem. Os pontos centrais do
delineamento são os correspondentes às condições de operação atual (35 min e 155 ºF).
Codificação:
Tabela 1. Variáveis originais e codificadas de um experimento fatorial 2x2 (tempo e
temperatura).
Variáveis originais Variáveis codificadas Resposta
1X 2X 1x 2x Y
30 150 -1 -1 39,3 30 160 -1 1 40,0 40 150 1 -1 40,9 40 160 1 1 41,5 35 155 0 0 40,3 35 155 0 0 40,5 35 155 0 0 40,7 35 155 0 0 40,2 35 155 0 0 40,6
Para realização do diagnóstico correto em relação ao modelo de primeira ordem
deveremos obter uma estimativa do erro experimental, verificar se a interação deve ser
incluída no modelo e finalmente verificar se os termos quadráticos devem ser
adicionados no modelo.
1 21 2
X 35 X 155x x
5 5− −= =

17
Tabela 2. Análise de variância do modelo de primeira ordem.
FV GL SQ QM F Valor p Regressão 2 2,8250 1,4125 47,8010 0,0002 Desvios 6 0,1773 0,0295 Total 8 3,0023
R² = 0,9409 R² Ajustado = 0,9212
Tabela 3. Estimativas dos parâmetros do modelo de regressão de primeira ordem.
Efeitos Estimativas Desvio t Valor p Constante 40,4444
Tempo ( 1x ) 0,7750 0,0859 9,0169 0,0002
Temperatura (2x ) 0,3249 0,0859 3,7811 0,0093
Equação ajustada:
39.0
39.5
40.0
40.5
41.0
41.5
42.0
-1.0
-0.50.0
0.51.0
-1.0-0.5
0.00.5
Y
x 1
x2
Figura 1. Superfície de Resposta do modelo de 1º Ordem.
Cálculo do erro experimental
A soma de quadrado do erro é obtida de forma tradicional, com 4 graus de
liberdade.
1 2y 40,440 0,775x 0,325x= + +

18
2 (40,3² 40,5² 40,7² 40,2² 40,6²) (202,3)² 5ˆ 0,0430
5 1+ + + + −σ = =
−
A interação entre os fatores pode ser obtida adicionando o termo x1x2 e é medida
pelo coeficiente β12. A estimativa é obtida (considerando as variáveis codificadas) por:
12 1 1 1 2 2 3 2 4o
1ˆ (x y x y x y x y )n trat
β = + + +
Extremos MeioInt o
Y YSQ
n trat
−= ∑ ∑
Para o exemplo em questão, temos:
Outra verificação da adequabilidade do modelo é obtida pela comparação da
resposta média dos quatro pontos do fatorial (40,425), com a resposta média do centro
do delineamento (40,46).
Se β11 e β22 são os coeficientes dos termos quadráticos 21χ e 2
2χ , então a diferença
das médias é uma estimativa de β11 + β22.
Assim, não existe nenhuma razão para questionar o modelo de primeira ordem.
Os próximos passos da (MIA) devem seguir.
Para andar (mover-se) do centro do delineamento (x1=0 e x2=0) no caminho da
inclinação ascendente, deveríamos mover 0,775 unidades na direção x1 para cada 0,325
( )12
1ˆ 1*39,3 ( 1* 40) ( 1* 40,9) 1* 41,55 0,0254
β = + − + − + = −
2
Int
[(39,3 41,5) (40 40,5)]SQ 0,0025
4+ − += =
Int
Erro
SQ 0,0025F 0,058
QM 0,043= = =
11 12 1 2ˆ ˆ y y 40,425 40,46 0,035β + β = − = − = −

19
unidades na direção de x2. Assim, a direção da inclinação ascendente passa pelo ponto
central (x1=0 e x2=0) e tem inclinação 0,325/0,775=0,42.
O engenheiro decide usar um tempo de reação de 5 minutos como tamanho do
passo inicial. Usando a relação entre 1X e x1, vimos que 5 minutos no tempo de reação
corresponde a um intervalo (passo), na variável codificada x1, de ∆x1=1. Os passos no
caminho da inclinação ascendente são:
∆x1=1
∆x2=(0,325/0,775) ∆x1=0,42
Os pontos experimentais são obtidos e a produção para estes pontos observados
até que se perceba um decréscimo na produção. Os resultados são mostrados na tabela a
seguir:
Tabela 4. Método da Inclinação Ascendente para o exemplo da tabela 1.
Passos Variáveis codificadas Variáveis originais
Resposta Y x1 x2 1X 2X
Origem 0 0 35 155
∆ 1,00 0,42 5 2 Não faz
Origem + ∆ 1,00 0,42 40 157 41,0
Origem + 2∆ 2,00 0,84 45 159 42,9
Origem +3∆ 3,00 1,26 50 161 47,1
Origem +4∆ 4,00 1,68 55 163 49,7
Origem +5∆ 5,00 2,10 60 165 53,8
Origem +6∆ 6,00 2,52 65 167 59,9
Origem + 7∆ 7,00 2,94 70 169 65,0
Origem + 8∆ 8,00 3,36 75 171 70,4
Origem + 9∆ 9,00 3,78 80 173 77,6
Origem + 10∆ 10,00 4,20 85 175 80,3
Origem + 11∆ 11,00 4,62 90 179 76,2
Origem + 12∆ 12,00 5,04 95 181 75,1
Incrementos na resposta são observados até o 10° passo; depois há um
decréscimo na produção.
Portanto, outro modelo de primeira ordem pode ser ajustado em torno do ponto
(85,175). A região de exploração para tempo seria (80,90) e de temperatura (170,180).
20
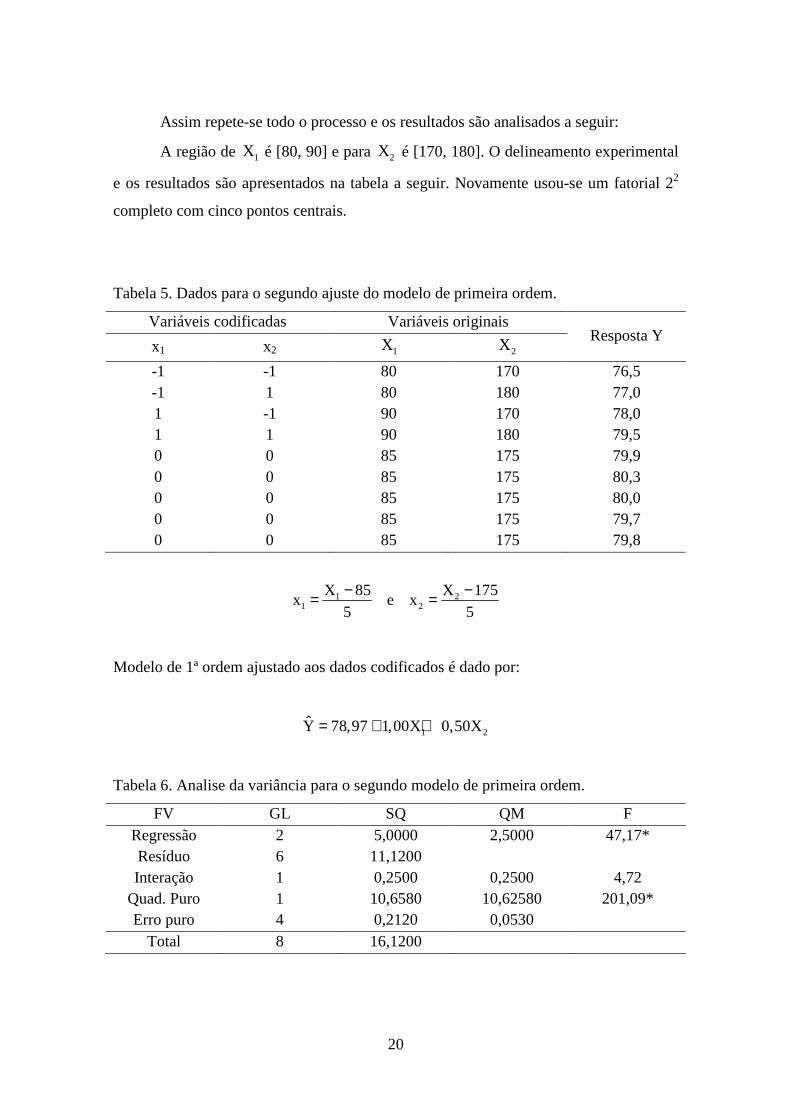
Assim repete-se todo o processo e os resultados são analisados a seguir:
A região de 1X é [80, 90] e para 2X é [170, 180]. O delineamento experimental
e os resultados são apresentados na tabela a seguir. Novamente usou-se um fatorial 22
completo com cinco pontos centrais.
Tabela 5. Dados para o segundo ajuste do modelo de primeira ordem.
Variáveis codificadas Variáveis originais Resposta Y
x1 x2 1X 2X
-1 -1 80 170 76,5 -1 1 80 180 77,0 1 -1 90 170 78,0 1 1 90 180 79,5 0 0 85 175 79,9 0 0 85 175 80,3 0 0 85 175 80,0 0 0 85 175 79,7 0 0 85 175 79,8
1 21 2
X 85 X 175x e x
5 5− −= =
Modelo de 1ª ordem ajustado aos dados codificados é dado por:
1 2Y 78,97 1,00X 0,50X= + +
Tabela 6. Analise da variância para o segundo modelo de primeira ordem.
FV GL SQ QM F Regressão 2 5,0000 2,5000 47,17* Resíduo 6 11,1200 Interação 1 0,2500 0,2500 4,72
Quad. Puro 1 10,6580 10,62580 201,09* Erro puro 4 0,2120 0,0530
Total 8 16,1200

21
Pela tabela de ANOVA, o componente do termo quadrático puro foi
significativo, isso implica que o modelo de 1ª Ordem não é uma aproximação adequada.
A curvatura na real superfície pode indicar que se está próximo do ótimo; assim,
análises adicionais devem ser feitas para localizar o ótimo com mais precisão. Nesse
ponto, uma análise adicional deve ser feita para localizar o ótimo com mais precisão.
9. Modelo de Segunda Ordem
Na falta de conhecimento suficiente acerca da forma da verdadeira superfície de
resposta, geralmente o experimentador tenta a aproximação pelo modelo de primeira
ordem. Quando, entretanto, o modelo de primeira ordem apresenta falta de ajuste para a
superfície, incorpora-se termos de ordem superior.
Quando o experimentador está relativamente próximo do “ótimo”, um modelo
que incorpora a curvatura é usualmente requerido para aproximar a resposta. Na maioria
dos casos o modelo de segunda ordem
k k k 1 k2
0 i i ii i ij i ji 1 i 1 i 1 j 2
i j
Y X X X X−
= = = =<
= β + β + β + β + ε∑ ∑ ∑∑
Em que 1 2 kX ,X ,...,X são as variáveis independentes que tem influência na resposta Y;
0 i ij, (i 1,2,...,k), ( j 1,2,...,k)β β = β = são parâmetros desconhecidos, e ε é um erro
aleatório.
Utilizando variáveis codificadas, ix ,obtidas por:
i
iu iiu
X
u 1,2,...., NX Xx
i 1,2,...,ks
=−==
Em que iuX é o u-ésimo nível da i-ésima variável independente, N
i iuu 1X X / N
==∑ é a
média dos valores iuX , i
1/2N 2X iu iu 1
s (X X ) / N=
= − ∑ é o desvio padrão, e N é o
número de observações. Sem perda de generalidade podemos considerar os valores de
iX sendo substituídos pelos correspondentes valores de ix (i 1,2,...,k)= . Os valores da

22
variável resposta obtidos com as variáveis codificadas podem, então, ser representados
como
k k k 1 k2
u 0 i iu ii iu ij iu ju ui 1 i 1 i 1 j 2
i j
Y x x x x−
= = = =<
=β + β + β + β + ε∑ ∑ ∑∑
Em que uε é o erro experimental em uY . Assume-se que os valores de uε sejam
independentemente distribuídos como variáveis aleatórias com média zero e variância
2σ .
O modelo pode ser escrito na forma de matriz da seguinte forma:
= +Y Xβ ε
Em que [ ]1 2 NY Y Y=Y` … , X é uma matriz N x p de coeficientes dos parâmetros que
compreende os níveis das variáveis independentes; p (k 1)(k 2) / 2= + + ; β é um vetor
p x 1 de parâmetros desconhecidos e [ ]1 2 N` ...= ε ε εε . O estimador de mínimos
quadrados para β no modelo é dado por:
1ˆ ( )−=β X`X X`Y
A matriz de variâncias e covariâncias de β é
1 2ˆV( ) ( )−= σβ X`X
10. Exemplo de Aplicação para o Modelo de Segunda Ordem
Considere um esquema fatorial 3 x 3, com 3 níveis de N (0, 50 e 100) e 3 níveis
de P (20, 40 e 60), de acordo com o modelo de segunda ordem:
i2i1i522i4
21i32i21i10i eXXβXβXβXβXββY ++++++=
O experimento dói instalado no delineamento em blocos casualizados com 3 repetições
e os dados obtidos encontram-se na tabela a seguir:

23
Trat. N P Bloco i1x i2x 12i1 xx − 2
2i2 xx − i2i1 xx Y
1 0 20 1 -1 -1 1/3 1/3 1 47 1 0 20 2 -1 -1 1/3 1/3 1 40 1 0 20 3 -1 -1 1/3 1/3 1 44 2 0 40 1 -1 0 1/3 -2/3 0 60 2 0 40 2 -1 0 1/3 -2/3 0 62 2 0 40 3 -1 0 1/3 -2/3 0 66 3 0 60 1 -1 1 1/3 1/3 -1 38 3 0 60 2 -1 1 1/3 1/3 -1 40 3 0 60 3 -1 1 1/3 1/3 -1 36 4 50 20 1 0 -1 -2/3 1/3 0 42 4 50 20 2 0 -1 -2/3 1/3 0 44 4 50 20 3 0 -1 -2/3 1/3 0 46 5 50 40 1 0 0 -2/3 -2/3 0 70 5 50 40 2 0 0 -2/3 -2/3 0 69 5 50 40 3 0 0 -2/3 -2/3 0 64 6 50 60 1 0 1 -2/3 1/3 0 45 6 50 60 2 0 1 -2/3 1/3 0 44 6 50 60 3 0 1 -2/3 1/3 0 46 7 100 20 1 1 -1 1/3 1/3 -1 45 7 100 20 2 1 -1 1/3 1/3 -1 46 7 100 20 3 1 -1 1/3 1/3 -1 44 8 100 40 1 1 0 1/3 -2/3 0 80 8 100 40 2 1 0 1/3 -2/3 0 70 8 100 40 3 1 0 1/3 -2/3 0 65 9 100 60 1 1 1 1/3 1/3 1 35 9 100 60 2 1 1 1/3 1/3 1 36 9 100 60 3 1 1 1/3 1/3 1 39
(0 100)1i 2 1i
1i 1i(100 0)2
X X 50x x { 1,0,1}
50
+
−
− −= = ∴ −
(20 60)2i 2 1i
2i 2i(60 20)2
X X 40x x { 1,0,1}
20
+
−
− −= = ∴ −
2i
2 i2i i
2 2 22 2i i
xP x
n( 1) (0) (1) 2
x X3 3
= −
− + += − = −
∑

24
1
2x
3=
6 6
27 0 0 0 0 0
0 18 0 0 0 0
0 0 18 0 0 0
0 0 0 6 0 0
0 0 0 0 6 0
0 0 0 0 0 12
=
X`X
6 1
1363
27
39`
47 / 3
455 / 3
8
−
= − −
−
X Y
6 1
1363 / 27
27 /18
39 /18ˆ47 /18
455 /18
8 /12
−
= − −
−
β
2 22 2
i 0 1 1i 2 2i 3 1i 3 4 2i 3 5 1i 2i iY β β x β x β (x ) β (x ) β x x e= + + + − + − + + 2
1i 2i 1ii
2
2i 1i 2i
X 50 X 40 X 501363 27 39 47 2Y
27 18 50 18 20 18 50 3
X 40 X 50 X 40455 2 818 20 3 12 50 20
− − − = + − − −
− − − − − −
21i 2i 1i 1i
i
22i 2i 1i 2i 2i 2i
27X 39X X 2X1363 27 78 47 2Y 1
27 18 18 900 360 18 2500 50 3
X 4X X X 2X X455 2 84 2
18 400 20 3 12 1000 50 20
= − + + − − − + +
− − + − − − − +
1ii
2 21i 1i 2i 2i 2i 1i 2i 1i 2i
27X1363 27 78 47 94 1820 910 36Y
27 18 18 18 54 18 54 12 90094X 16X 39X 1820X 8X 47X 455X 8X X
900 600 360 360 240 45000 7200 12000
= − + − + − + − + +
+ − + + − − −
2i 1i 2i 1i
22i 1i 2i
Y 34,8148 0,161111X 4,98055X 0,0010444X
0,0631944X 0,0006666X X
= − + + −− −

25
2
ˆSQ Reg C
1363
27
391363 27 39 47 455 8 (1363)47 / 327 18 18 18 18 12 27
455 / 3
8
72811,2963 68806,2593
4005,0370
= −
− = − − − − − − −
−
= −=
βX`Y
SQTotal 73179 68806,2593 4372,7407= − =
Quadro da ANOVA
FV GL SQ QM F
Blocos 2 9,8518 --
(Tratamentos) (8) (4163,407) --
Regressão 5 4005,037 801,0074 64,24**
Falta de ajuste 3 158,370 52,7900 4,23*
Resíduo puro 16 199,4815 12,4675
Total 26 4372,7403
5% 1%F (3,16) 3,24 F (3,16) 5,29= =
2
2
SQ Reg 4005,037R 0,9159
SQTotal 4372,7403
SQ Reg 4005,037R 0,9619
SQTrat. 4163,407
= = =
= = =
Teste para as hipóteses:
0 1
1 1
H : 0
H : 0
β =β ≠
1% 5% 10%t (16) 2,92 t (16) 2,12 t (16) 1,75= = =
2718
118
0t 1,8023
(12,4675)
−= =

26
Utilizando : QM Res 18,8342
GLRes 19
= =
2718
118
0t 1,4664
(18,8342)
−= =
1% 5% 10%t (19) 2,86 t (19) 2,09 t (16) 1,73= = =
0− λ =B I
1 2
1
2 1
2
Y0,161111 0,0020888X 0,0006666X 0
X
Y4,98055 0,126388X 0,0006666X 0
X
∂ = − − =∂∂ = − − =∂
1 2
21
22
2 2
2
2
0,0020888X 0,0006666X 0,161111
0,161111 0,0006666XX
0,0020888
0,161111 0,0006666X4,98055 0,126388X 0,0006666 0
0,0020888
4,98055 0,126388X 0,0514154 0,000212732X 0
0,126175X 4,9291346
X 3
− = −−=
− − − =
− − + =− = −
= 9,06
1
0,161111 0,0006666(39,06)X 64,66
0,0020888−= =
Ponto crítico ( 1 2X 64,66;X 39,06= = ).
Matriz da segunda derivada:
2 2
2 21 2
2
1 2
Y Y0,0020888 0,126388
X X
Y0,0006666
X X
∂ ∂= − = −∂ ∂
∂ = −∂ ∂

27
Estudo da natureza da superfície de resposta: este pode ser realizado considerando o ponto estacionário e os sinais e magnitudes dos iλ .
0− λ =B I
22 12
21 1 2
2 212
21 2 2
YYX X X 1 0
0 1Y YX X X
∂∂ ∂ ∂ ∂ = = ∂ ∂ ∂ ∂ ∂
B I
Suponha que o ponto estacionário esteja dentro da região de estudo na qual foi ajustado o modelo de segunda ordem.
Conclusão:
i) Se todos os valores de iλ são positivos, então sX é um ponto de resposta
mínima. ii) Se todos os valores de iλ são negativos, então sX é um ponto de resposta
máxima. iii) Se os valores de iλ tem sinais positivos e negativos, então sX é um ponto
de sela.
0,0020888 0,0003333
0,0003333 0,126388
− = − B , então:
0,0020888 0,0003333 00
0,0003333 0,126388 0
− λ − λ = − = − λ
B I
0,0020888 0,00033330
0,0003333 0,126388
− − λ=
− − λ
2
2
1 2
( 0,0020888 )( 0,126388 ) (0,0003333) 0
0,126388 0,1284768 0,000263787 0
0,1284768 0,016506288 0,000133358
2(0,126388)
1,0144 0,00205
− − λ − − λ − =λ + λ + =
− ± −λ =
λ = − λ = −

28
11. Localização do Ponto Estacionário
Suponha que nosso interesse é encontrar os níveis 1 2 kx ,x ,...,x , que otimize a
resposta predita. Este ponto, se existir, será dado pelo conjunto 1 2 kx ,x ,...,x para o qual
as derivadas parciais são iguais são iguais à zero, isto é
1 2 k
ˆ ˆ ˆY Y Y... 0
x x x∂ ∂ ∂= = = =∂ ∂ ∂
Este ponto é chamado de ponto estacionário e pode representar um ponto de
máximo, de mínimo ou um ponto de sela.
Para obtenção de uma solução matemática geral para localização do ponto
estacionário, escrevemos o modelo de segunda ordem na seguinte notação matricial
ˆˆ = + +0Y β x`b x`Bx
onde
1 11 12 1k1
2 2 22 2k
k k kk
ˆ ˆ ˆ ˆ/ 2 / 2xˆ ˆ ˆx / 2
x ˆ ˆsim.
β β β β β β β = = = β β
x b B
…
…
⋮ ⋮ ⋱ ⋮
Em que b é um vetor (k x 1) dos coeficientes de regressão de primeira ordem e B é uma
matriz simétrica (k x k) onde na diagonal têm-se os coeficientes de regressão de
segunda ordem e fora da diagonal os coeficientes da interação.
As derivadas parciais dos valores preditos da resposta Y em relação aos
elementos do vetor x igualadas a zero são dadas por:
Y2 0
∂ = + =∂
b Bxx
O ponto estacionário é a solução das equações, ou seja,
1s
12
−= −x B b
O valor predito da variável resposta no ponto estacionário é:

29
s 0 s
1ˆY2
= β + x` b
12. Caracterizando a Superfície de Resposta
Uma vez encontrado o ponto estacionário, é necessário caracterizar a superfície
de resposta. Esta caracterização significa determinar se o ponto estacionário é um ponto
de máximo, de mínimo ou de sela.
Um modo de fazer isto é examinar o gráfico de contorno do modelo ajustado.
Entretanto nem sempre temos poucas variáveis e, nesses casos, uma análise mais formal
pode ser aplicada, chamada de análise canônica.
Considere uma translação (novo sistema de coordenadas) da superfície de
resposta da origem para o ponto estacionário sx e então rotacione os eixos desse
sistema até que eles fiquem paralelos aos eixos principais da superfície de resposta
ajustada. Esta transformação é ilustrada na Figura 3.
Figura 3. Forma canônica para o modelo de segunda ordem.
Pode-se mostrar que o modelo ajustado é
2 2 2s 1 1 2 2 k k
ˆ ˆY Y w w ... w= + λ + λ + + λ
x1
x2
x1,S
x1,S
w
w1

30
onde iw são as variáveis independentes transformadas e os iλ são constantes. A
equação acima é chamada de forma canônica do modelo. Os iλ são os autovalores ou
raízes características da matriz B. Assim, tem-se que:
i. Se todos os valores de (iλ ) são positivos, então, sx é um ponto de resposta
mínima;
ii. Se os ( iλ ) são todos negativos, então, sx é um ponto de resposta máxima;
iii. Se os valores de (iλ ) tem sinais positivos e negativos, então, sx é um ponto de
sela.
Além disso, a superfície tem inclinação na direção de iw para o qual o valor de
iλ é maior.
Consideremos novamente o exemplo: segunda fase do estudo. Para ajustar um
modelo de segunda ordem é necessário aumentar o delineamento com pontos adicionais.
Para ser possível estimar os parâmetros do modelo o engenheiro obteve mais 4
observações, mais ou menos no mesmo tempo em que executou os 9 tratamentos
anteriores. Os 4 tratamentos adicionais foram:(x1=0; x2=± 1,414) e (x1=± 1,414; x2=0).
Este é o Delineamento Composto Central.
Tabela 7. Delineamento composto central para avaliação do exemplo.
Variáveis originais Variáveis codificadas Resposta
1X 2X x1 x2 Y (produção)
80 170 -1 -1 76.5 80 180 -1 1 77 90 170 1 -1 78 90 180 1 1 79.5 85 175 0 0 79.9 85 175 0 0 80.3 85 175 0 0 80 85 175 0 0 79.7 85 175 0 0 79.8
92.07 175 1.414 0 78.4 77.93 175 -1.414 0 75.6
85 182.07 0 1.414 78.5 85 167.93 0 -1.414 77

31
Tabela 8. Análise da variância de dados referentes à produção no delineamento
composto central.
FV GL SQ QM F Valor p
Intercepto 1 31951.98 31951.98 450595.9 0.000000*
Tempo 1 7.92 7.92 111.7 0.000015*
Tempo² 1 13.17 13.17 185.8 0.000003*
Temperatura 1 2.12 2.12 29.9 0.000934*
Temperatura² 1 6.97 6.97 98.3 0.000023*
Tempo x Temperatura 1 0.25 0.25 3.5 0.102519
Resíduo 7 0.50 0.07
Os efeitos do modelo de segunda ordem ajustado aos dados codificados bem
como sua significância estatística são apresentados na Tabela 9.
Tabela 9. Estimativa dos parâmetros do modelo de segunda ordem.
Efeitos Estimativas Valor p
Intercepto 79.93995 0.000000
Tempo 0.99505 0.000015
Tempo² -1.37645 0.000003
Temperatura 0.51520 0.000934
Temperatura² -1.00134 0.000023
Tempo x Temperatura 0.25000 0.102519
Tem-se a não significância do efeito da interação Tempo x Temperatura, assim o
modelos ajustado pode ser expresso por:
2 21 1 2 2Y 79,93995 0,99505x 1,37645x 0,5152x 1,00134x= + − − −

32
Tabela 10. Análise de variância para falta de ajuste.
FV GL SQ QM F Valor p
Falta de ajuste 3 0.2843 0.0947 1.7885 0.2885
Erro puro 4 0.2120 0.0530
(Resíduo) (7) (0.4963) 0.0709
Pela Tabela 10 verifica-se a não significância da falta de ajuste, isto é, o modelo
de segunda ordem é adequado para descrever o comportamento da variável resposta e
tanto o F.AjQM quanto o ResíduoQM podem ser utilizados como estimativa da variância
residual.
As figuras 4 e 5 representam a superfície de resposta e o gráfico de contorno,
respectivamente, para a resposta (produção) em função da temperatura e do tempo. É
relativamente fácil ver por estas figuras que a resposta é realmente o máximo global.
74
75
76
77
78
79
80
81
-1.0-0.5
0.00.5
1.0
-1.0-0.5
0.00.5
1.0
Y
x 1
x2
Figura 4. Superfície de Resposta do modelo de 2º Ordem.

33
x1
-1.0 -0.5 0.0 0.5 1.0
x 2
-1.0
-0.5
0.0
0.5
1.0
75 76 77 78 79 80
Figura 5. Gráfico de contorno do modelo de 2º Ordem.
Sabendo que o modelo é apropriado para descrever os dados, podemos então
encontrar a localização do ponto estacionário usando a solução geral apresentada.
O ponto estacionário é a solução das equações, ou seja,
1s
12
0,73972 0,09234 0,99505 0,7836410,09234 1,01018 0,51520 0,612332
−= −
− − − = − = − − −
x B b
Em termos das variáveis originais, o ponto estacionário é dado por:
11
22
X 850,78364 X 81,0818
5X 175
0,61233 X 171,93835
−− = ∴ =
−− = ∴ =
O valor da resposta estimada no ponto estacionário é:
0,99505 1,37645 0,12500
0,51520 0,12500 1,00134
− = = −
b B

34
[ ]
's 0
s
1ˆY2
0,995051Y 79,94 0,78364 0,61233 79,39
0,515202
= β +
= + − − ≅
sx b
Análise canônica
Vamos expressar o modelo ajustado na forma canônica. Primeiramente
precisamos encontrar os autovalores, 1 2eλ λ , que são as raízes do determinante da
equação:
0
1,37645 0,125000
0,12500 1,00134
− λ =
− − λ=
− − λ
B I
Resolvendo a equação:
2 2,3777 1,3626 0λ + λ + =
Temos:
1 0,9635λ = − e 2 1,4143λ = −
A forma canônica do modelo ajustado fica:
2 21 2Y 80,21 0,9635w 1,4143w= − −
Visto que as raízes iλ são todas negativas, conclui-se então que sx é um ponto de
resposta máxima.

35
Referências
BOX, G. E. P.; DRAPER, N. R. Empirical model buiding and response surfaces.
New York: John Wiley & Sons, 1987.
KHURI, A. I.; CORNELL, J. A. Response Surfaces: designs and analysis. New York:
Marcel Dekker Inc., 1987.
MONTGOMERY, D. C. Design and analysis of experiments. John Wiley & Sons,
New York, 2001.
MONTGOMERY, D. C.; RUNGER, G. C. Estatística aplicada e probabilidade para
engenheiros; tradução Verônica Calado. 2 ed. Rio de Janeiro: LTC, 2008.