tÉcnicas para projeto de s - lsi.usp.brdmpsv/download/tesenavarro.pdf · 2.2.3.1 estratégia com...
TRANSCRIPT

JOÃO NAVARRO SOARES JUNIOR
TÉCNICAS PARA PROJETO DE ASICS CMOS
DE ALTA VELOCIDADE
Tese apresentada à Escola Politécnica da Universidade de São Paulo para obtenção do título de Doutor em Engenharia.
São Paulo 1998

JOÃO NAVARRO SOARES JUNIOR
TÉCNICAS PARA PROJETO DE ASICS CMOS
DE ALTA VELOCIDADE
Tese apresentada à Escola Politécnica da Universidade de São Paulo para obtenção do título de Doutor em Engenharia.
Área de concentração: Microeletrônica
Orientador: Wilhelmus A.M. Van Noije
São Paulo 1998

Navarro Soares Jr., João Técnicas para Projeto de ASICs CMOS de Alta
Velocidade. São Paulo, 1998. 196p.
Tese (Doutorado) - Escola Politécnica da Universidade de São Paulo. Departamento de Engenharia Elétrica.
1. Microeletrônica 2. Circuitos Integrados 3. CMOS 4. Circuitos de alta velocidade - Projetos I. Universidade de São Paulo. Escola Politécnica. Departamento de Engenharia Elétrica II. t

Agradecimentos
A conclusão deste trabalho só foi possível devido a colaboração de diversas pessoas e instituições.
Dessa forma, gostaria de tornar publico meus agradecimentos
ao Prof. Dr. Wilhelmus A.M. Van Noije pela orientação, pelo exemplo de trabalho que sempre deu,
e sobretudo pelo incentivo e confiança;
ao Laboratório de Sistemas Integráveis da USP (LSI), onde foi desenvolvida a quase totalidade
deste trabalho, ao CNPq/Protem e à Fundação Banco do Brasil, que apoiaram a aquisição dos
equipamentos usados nos testes, à FAPESP, que possibilitou a fabricação dos protótipos via projeto
PMU-FAPESP, e ao Laboratório de Microeletrônica da USP (LME), onde foram realizados alguns dos
testes necessários;
aos colegas do LSI, pela ajuda e paciência;
aos amigos Pedro L.P. Sanchez e Sandra Abib pelo apoio que sempre deram;
aos meus pais, a quem devo o que sou;
e à Priscila, de cuja paciência e amor abusei, e a quem espero pagar com maior amor.
Por fim, minha gratidão à Deus, origem e fim de tudo.

Sumário
1
Sumário
Sumário ..........................................................................................................................................................................1
Lista de Figuras .............................................................................................................................................................5
Lista de Tabelas ...........................................................................................................................................................10
Lista de Símbolos .........................................................................................................................................................11
Resumo .........................................................................................................................................................................17
Abstract ........................................................................................................................................................................19
1. Introdução ...................................................................................................................................................................21
1.1 História das tecnologias MOS ...............................................................................................................................21
1.2 Motivações e objetivos ...........................................................................................................................................22
1.3 Desenvolvimento da pesquisa ................................................................................................................................25
1.4 Capítulos: descrição ..............................................................................................................................................27
2. Implementação de Register Transfer Systems (RTS) de Alta Velocidade ...............................................................29
2.1 Introdução ..............................................................................................................................................................29
2.2 Register Transfer Systems (RTS) ............................................................................................................................29
2.2.1 Lógica Combinatorial .....................................................................................................................................30
2.2.1.1 Lógica Estática Complementar CMOS...................................................................................................30
2.2.1.2 Lógica Estática Pseudo NMOS...............................................................................................................32
2.2.1.3 Lógica Estática com Transistores de Passagem......................................................................................33
2.2.1.4 Lógica Dinâmica CMOS.........................................................................................................................34
2.2.1.5 Lógica Dinâmica Clocked CMOS (C2MOS) ..........................................................................................37
2.2.2 Registradores ..................................................................................................................................................37
2.2.2.1 Registradores Estáticos ...........................................................................................................................38
2.2.2.2 Registradores Dinâmicos ........................................................................................................................39
2.2.3 Políticas de clock ............................................................................................................................................40
2.2.3.1 Estratégia com duas fases de clock NORA.............................................................................................40
2.2.3.2 Estratégia com uma fase de clock TSPC.................................................................................................42
2.2.3.2.1 Portas Lógicas e Registradores .......................................................................................................42
2.2.3.2.2 Regras de Composição....................................................................................................................44
2.2.3.2.3 Conclusões sobre o TSPC ...............................................................................................................46
2.3 Estratégia E-TSPC .................................................................................................................................................47
2.3.1 Blocos da E-TSPC..........................................................................................................................................47
2.3.2 Regras de composição ....................................................................................................................................47

Sumário
2
2.3.2.1 Definições............................................................................................................................................... 47
2.3.2.2 Descrição das Regras.............................................................................................................................. 52
2.3.2.2.1 Regras r1 a r5................................................................................................................................... 53
2.3.2.2.2 Blocos Dps e data chains do circuito ............................................................................................. 55
2.3.3 Teorema fundamental da estratégia E-TSPC ................................................................................................. 60
2.3.3.1 Propriedades dos blocos do E-TSPC...................................................................................................... 61
2.3.3.2 Demonstração do Teorema fundamental ................................................................................................ 63
2.3.4 Blocos N-MOS like......................................................................................................................................... 74
2.3.5 Regra de Exceção........................................................................................................................................... 77
2.3.6 Comparações e conclusões sobre o E-TSPC.................................................................................................. 81
3. Otimização de Tapered Buffers para altas taxas de operação................................................................................. 83
3.1 Introdução.............................................................................................................................................................. 83
3.2 Critérios clássicos para otimização de Tapered Buffers ....................................................................................... 84
3.3 Novo critério para otimização de Tapered Buffers para altas taxas ..................................................................... 88
3.3.1 Novo critério: sinal de teste e definição de passagem do sinal....................................................................... 89
3.3.2 Modelo teórico para o novo critério de otimização........................................................................................ 90
3.3.3 Simulação dos Tapered Buffers...................................................................................................................... 93
3.3.3.1 Condições para as simulações ................................................................................................................ 94
3.3.3.2 Resultados das Simulações..................................................................................................................... 97
3.3.3.2.1 Modelamento dos Tapered Buffers com as expressões analíticas (14) ......................................... 101
3.3.3.2.2 Modelamento dos Tapered Buffers com o uso de tabelas empíricas ............................................ 103
3.3.4 Mismatch do Atraso ..................................................................................................................................... 108
3.3.4.1 Atraso do Tapered Buffer ..................................................................................................................... 109
3.3.4.2 Modelos estatísticos para os parâmetros variáveis ............................................................................... 112
3.3.4.2.1 Parâmetro Li .................................................................................................................................. 113
3.3.4.2.2 Parâmetro Wi................................................................................................................................. 113
3.3.4.2.3 Parâmetros VTni e VTpi.................................................................................................................... 114
3.3.4.2.4 Parâmetro Coxi ............................................................................................................................... 115
3.3.4.2.5 Parâmetros µni e µpi ....................................................................................................................... 115
3.3.4.3 Expressões para as derivadas e sua avaliação nos valores médios ....................................................... 116
3.3.4.4 Cálculo da variância do atraso de um Tapered Buffer .......................................................................... 120
3.3.4.5 Análise da variância em função do fator de aumento ........................................................................... 121
3.3.4.5.1 Primeiro e segundo termo............................................................................................................. 121
3.3.4.5.2 Terceiro termo .............................................................................................................................. 122
3.3.4.5.3 Quarto termo................................................................................................................................. 123
3.3.4.5.4 Quinto termo................................................................................................................................. 123
3.3.4.5.5 Sexto a nono termos...................................................................................................................... 124
3.3.4.5.6 Décimo termo ............................................................................................................................... 124

Sumário
3
3.3.4.5.7 Décimo primeiro a décimo quarto termos.....................................................................................124
3.3.4.5.8 Resultados Numéricos...................................................................................................................125
3.3.4.6 Considerações finais sobre o estudo do Mismatch do Atraso ...............................................................130
3.4 Conclusões sobre a otimização de Tapered Buffers.............................................................................................131
4. Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers .............................................................133
4.1 Introdução ............................................................................................................................................................133
4.2 Circuitos Multiplexador e Demultiplexador.........................................................................................................133
4.2.1 Projeto do Multiplexador e do Demultiplexador (primeira versão)..............................................................134
4.2.1.1 Circuitos de entrada/saída conversores ECL-CMOS e CMOS-ECL ....................................................134
4.2.1.2 Principais células TSPC........................................................................................................................136
4.2.1.3 Multiplexador 8:1 .................................................................................................................................137
4.2.1.4 Demultiplexador 1:8 .............................................................................................................................139
4.2.2 Projeto do Multiplexador e do Demultiplexador (nova versão)....................................................................141
4.2.2.1 Novo circuito conversor ECL-CMOS [Na98b] ....................................................................................142
4.2.2.2 Células com blocos N-MOS like ...........................................................................................................142
4.2.2.3 Novo Multiplexador 8:1 .......................................................................................................................144
4.2.2.4 Novo Demultiplexador 1:8 ...................................................................................................................145
4.2.3 Resultados Experimentais do Multiplexador 8:1 e do Demultiplexador 1:8................................................149
4.2.3.1 Testes dos conversores ECL-CMOS e CMOS-ECL.............................................................................153
4.2.3.2 Testes do Circuito Multiplexador 8:1 ...................................................................................................155
4.2.3.3 Testes do Circuito Demultiplexador 1:8 ...............................................................................................157
4.2.4 Multiplexador e Demultiplexador: conclusões .............................................................................................159
4.3 Circuito Dual-Modulus Prescaler........................................................................................................................160
4.3.1 Circuito Dual-Modulus Prescaler (divide por 128/129)...............................................................................161
4.3.2 Estudo preliminar dos contadores síncronos ................................................................................................162
4.3.3 Resultados Experimentais do Dual-Modulus Prescaler ...............................................................................165
4.3.4 Dual-Modulus Prescaler: conclusões...........................................................................................................168
5. Conclusões e futuros trabalhos ................................................................................................................................171
5.1 Futuros trabalhos sobre o E-TSPC ......................................................................................................................172
5.2 Futuros trabalhos sobre otimização de tapered buffers.......................................................................................172
APÊNDICE A .............................................................................................................................................................175
APÊNDICE B .............................................................................................................................................................177
APÊNDICE C.............................................................................................................................................................181
APÊNDICE D.............................................................................................................................................................185
Referências Bibliográficas .........................................................................................................................................189

Sumário
4

Lista de Figuras
5
Lista de Figuras Figura 1. Número de transistores em função do ano de lançamento para os principais microprocessadores da Intel (não
estão no gráfico os processadores 8088, 386SX e 486SX pois eles são versões econômicas do 8086, do 386DX e do
486DX, respectivamente)..............................................................................................................................................23
Figura 2. Esquemático de sistema para transmissão e recepção por meio de fibra óptica; E/O é um conversor
elétrico/óptico (foto-emissor) e O/E, um conversor óptico/elétrico (foto-receptor). As taxas de operação indicadas são
do padrão SONET STS24/CCITT STM8 [St92]...........................................................................................................26
Figura 3. Representação genérica de um Register Transfer System (RTS). ..........................................................................30
Figura 4. Porta lógica estática complementar CMOS para a função ( )d a b c= + : (a), representação com transistores e
(b), sua representação simplificada. ..............................................................................................................................31
Figura 5. Porta lógica estática pseudo NMOS para a função e a b c d= + + + : (a), representação com transistores e (b),
sua representação simplificada......................................................................................................................................33
Figura 6. Portas lógicas estáticas com transistores de passagem para a função c a b= ⊕ : (a), porta simples com
transistores N e (b), Complementary Pass-Transistor Logic (CPL)..............................................................................34
Figura 7. Portas lógicas dinâmicas para a função ( )d a b c= + : (a), representação com transistores da porta n-dinâmica e
(b), sua representação simplificada; (c), representação com transistores da porta lógica p-dinâmica e (d), sua
representação simplificada. ...........................................................................................................................................35
Figura 8. Ligação de portas lógicas dinâmicas; (a), ligação sujeita a descarga indevida, (b), estilo de projeto dominó e (c),
estilo de projeto np-CMOS. ..........................................................................................................................................36
Figura 9. Porta/registrador dinâmico C2MOS para a função ( )d a b c= + : (a), representação com transistores e (b), sua
representação simplificada. ...........................................................................................................................................38
Figura 10. Registradores estáticos: (a), latch pseudo-estático com transistores de passagem e (b), D-flip-flop com lógica
diferencial......................................................................................................................................................................39
Figura 11. Registrador latch dinâmico com transistor de passagem: (a), porta de passagem com um transistor N e (b), com
transistores N e P...........................................................................................................................................................40
Figura 12. Latches dinâmicos TSPC: (a), armazena o dado quando o clock é baixo e (b), armazena o dado quando o clock é
alto.................................................................................................................................................................................40
Figura 13. Exemplo de circuito NORA. ................................................................................................................................41
Figura 14. Circuitos n-latch e p-latch: (a), representação com transistores e (b), representação simplificada do n-latch; (c),
representação com transistores e (d), representação simplificada do p-latch................................................................42
Figura 15. Transformação de uma porta estática complementar CMOS (a) em portas data pre-charged Dp: (b), portas PH e
(c), portas PL.................................................................................................................................................................44
Figura 16. Gráfico de conexões para o TSPC de acordo com [La95]. As portas e circuitos são representados pelos
quadrados. O fluxo de dados permitido é indicado pelo sentido das setas. # indica ligações onde atrasos diferenciados
do clock nos blocos não causam problemas (skew safe communication); * indica pontos de latch depois dos quais
portas estáticas complementar CMOS podem ser inseridas; ◊ indica ligações onde há problemas potenciais de
violação de holding time. ..............................................................................................................................................45
Figura 17. Ligação de dois D-flip-flops TSPC. .....................................................................................................................46

Lista de Figuras
6
Figura 18. Circuito com possibilidade de violação de holding time usando blocos data precharged................................... 46
Figura 19. Circuito E-TSPC com exemplos de data chains. ................................................................................................. 52
Figura 20. Conversão de blocos para blocos N-MOS like: (a), bloco n-dinâmico e (b), bloco n-dinâmico N-MOS like; (c),
bloco p-dinâmico e (d), bloco p-dinâmico N-MOS like; (e), bloco n-latch e (f), bloco n-latch N-MOS like; (g), bloco
p-latch e (h), bloco p-latch N-MOS like........................................................................................................................ 76
Figura 21. Ilustração de um tapered buffer com N inversores. O nó de saída tem uma capacitância de carga CL................ 83
Figura 22. Gráfico mostrando o fator de aumento que minimiza o atraso total de um tapered buffer como função da razão
KLC
DS
ox........................................................................................................................................................................... 88
Figura 23. Demultiplexador 1:8 com tapered buffers para o dado e para o clock [Ro95b]................................................... 89
Figura 24. Sinais de entrada e saída de um tapered buffer com um número par de inversores............................................. 90
Figura 25. Gráfico de Kα como função de Tt
N
N
∆
0
. ............................................................................................................. 93
Figura 26. Configuração em pente dos transistores N e P para simulações. ......................................................................... 95
Figura 27. Diagrama de decisões para determinação da máxima taxa em que opera um tapered buffer qualquer (εrf é o erro
relativo da freqüência). ................................................................................................................................................. 96
Figura 28. Gráfico da máxima taxa de operação, Gbit/s, em função do fator de aumento do tapered buffer. São
simulados buffers com 2, 3, 4, 5, 6 e 7 inversores. A carga final em todos eles é 0,2pF e a tecnologia é 0,8µm. ........ 98
Figura 29. Gráfico da máxima taxa de operação, Gbit/s, em função do fator de aumento do tapered buffer. São
simulados buffers com 2, 3, 4, 5 e 6 inversores. A carga final em todos eles é 0,2pF e a tecnologia é 0,35µm. .......... 99
Figura 30. Gráfico da largura mínima de um pulso que passa pelo tapered buffer em função da carga capacitiva CL da
saída. São simulados buffers com 2, 3, 4 e 5 inversores. O fator de aumento usado é χ=2 e a tecnologia é de 0,8µm.100
Figura 31. Gráfico da largura mínima de um pulso que passa pelo tapered buffer em função da carga capacitiva CL da
saída. São simulados buffers com 2, 3, 4 e 5 inversores. O fator de aumento usado é χ=2 e a tecnologia é de 0,35µm.100
Figura 32. Gráfico da largura mínima de um pulso que passa por um inversor em função da sua carga capacitiva. As
larguras de canal dos trans.P/trans.N são: 8/5µm; 12/7,5µm; 16/10µm; 20/12,5µm; 24/15µm; 28/17,5µm; 32/20µm;
36/22,5µm; 40/25µm. O comprimento do canal é L=0,8µm. A tecnologia é de 0,8µm. ............................................ 102
Figura 33. Gráfico da largura mínima de um pulso que passa por um inversor em função da sua carga capacitiva. As
larguras de canal dos trans.P/trans.N são: 8/5µm; 12/7,5µm; 16/10µm; 20/12,5µm; 24/15µm; 28/17,5µm; 32/20µm;
36/22,5µm; 40/25µm. O comprimento do canal é L=0,35µm. A tecnologia é de 0,35µm. ........................................ 102
Figura 34. Gráfico da largura mínima de um pulso que passa pelo tapered buffer em função do número de inversores.
Curvas para diversos valores de fator de aumento são apresentadas (fator de aumento de 1, 2, 3, 4 e 5). O primeiro
inversor, em todos os exemplos, tem 5µm para largura de canal do transistor N, e 8µm para o transistor P. O
comprimento de canal para todos é de 0,8µm. A carga na saída é de 1fF e a tecnologia CMOS de 0,8µm. .............. 105
Figura 35. Gráfico do largura mínimo de um pulso que passa pelo tapered buffer em função do número de inversores.
Curvas para diversos valores de fator de aumento são apresentadas (fator de aumento de 1, 2, 3, 4 e 5). O primeiro
inversor, em todos os exemplos, tem 5µm para largura de canal do transistor N, e 8µm para o transistor P. O
comprimento de canal para todos é de 0,35µm. A carga na saída é de 1fF e a tecnologia CMOS de 0,35µm. .......... 106

Lista de Figuras
7
Figura 36. Comparação entre os pontos obtidos por simulação (o buffer com dois inversores é apresentado com ‘x’, três
com ‘+’, quatro com ‘o’ e cinco com ‘*’) e equações dadas por (16) (linhas contínuas). A tecnologia é de 0,8µm e a
capacitância de carga de 0,2pF....................................................................................................................................106
Figura 37. Comparação entre os pontos obtidos por simulação (o buffer com dois inversores é apresentado com ‘x’, três
com ‘+’, quatro com ‘o’, cinco com ‘*’, seis com 'x', sete com '+' e oito com '*') e equações dadas por (16) (linhas
contínuas). A tecnologia é de 0,8µm e a capacitância de carga de 1pF. .....................................................................107
Figura 38. Comparação entre os pontos obtidos por simulação (o buffer com dois inversores é apresentado com ‘x’, três
com ‘+’, quatro com ‘o’ e cinco com ‘*’) e equações dadas por (16) (linhas contínuas). A tecnologia é de 0,35µm e a
capacitância de carga de 0,2pF....................................................................................................................................107
Figura 39. M Tapered buffers usados para a distribuição de clock......................................................................................109
Figura 40. Processos básicos que geram os desvios nos parâmetros: (a) eventos que ocorrem aleatoriamente no circuito
como ruído branco (nonuniform arrangement of events), (b) rugosidade das bordas (edge roughness), e (c) acurácia
de repetição no processo de geração de formas (repetition accuracy of pattern generation process)[Oe93]. ............113
Figura 41. Atraso de um inversor em função do fator de aumento do buffer para as tecnologias 0,8µm e 0,35µm............127
Figura 42. Comportamento dos fatores de análise, Fac3 ..., Fac14, em função do fator de aumento do buffer. Os valores
apresentados são relativos ao valor encontrado para χ=3. A tecnologia é 0,8µm. ......................................................128
Figura 43. Comportamento dos fatores de análise, Fac3 ..., Fac14, em função do fator de aumento do buffer. Os valores
apresentados são relativos ao valor encontrado para χ=3. A tecnologia é 0,35µm. ....................................................128
Figura 44. Gráfico do desvio padrão normalizado do atraso do buffer determinado por simulações de "Monte Carlo", em
função do fator de aumento do buffer (tecnologia 0,35µm). Também são apresentadas as curvas teóricas para
comparação dos resultados..........................................................................................................................................129
Figura 45. Circuito conversor de alta velocidade ECL-CMOS (a) e seu circuito de polarização (b). .................................135
Figura 46. Circuito conversor de alta velocidade CMOS-ECL (a) e seu circuito de polarização (b). .................................136
Figura 47. Células básicas empregadas no projeto do Multiplexador 8:1 e do Demultiplexador 1:8. Estão representados
tanto o diagrama de transistores como o símbolo de cada célula. Os blocos hachurados avaliam quando o sinal de
clock (Cl) é baixo; os outros blocos, quando o sinal de clock é alto. Todos os transistores usados aqui têm
comprimento de canal L=0,8µm. A largura de canal, para a maioria, é W=2,4µm; para os transistores onde isso não é
verdade, o valor da largura do canal, em µm, está indicado na figura. .......................................................................137
Figura 48. Diagrama esquemático da primeira versão do circuito Multiplexador 8:1.........................................................139
Figura 49. Diagrama esquemático do núcleo do circuito Demultiplexador 1:8 da primeira versão. ...................................140
Figura 50. Circuito para gerar sinais de alinhamento de byte. .............................................................................................140
Figura 51. Circuito para gerar o clock que sincroniza a saída (CA). ...................................................................................141
Figura 52. Circuito para gerar sinais de seleção para os multiplexadores 2:1 da saída. ......................................................141
Figura 53. Circuito modificado conversor de alta velocidade ECL-CMOS (a) e seu circuito de polarização (b). ..............142
Figura 54. Novas células básicas que empregam blocos N-MOS like. Estão representados tanto o diagrama de transistores
como o símbolo de cada célula. Os blocos hachurados avaliam quando o sinal de clock (Cl) é baixo; os outros blocos,
quando o sinal de clock é alto. Todos os transistores usados aqui têm comprimento de canal L=0,8µm. A largura de
canal, para a maioria, é W=2,4µm; para os transistores onde isso não é verdade, o valor da largura do canal, em µm,
está indicado na figura. ...............................................................................................................................................143
Figura 55. Diagrama esquemático do novo circuito Multiplexador 8:1. .............................................................................144

Lista de Figuras
8
Figura 56. Diagrama esquemático do núcleo do novo circuito Demultiplexador 1:8. Os blocos hachurados são aqueles que
foram alterados. .......................................................................................................................................................... 146
Figura 57. Modificações no circuito para gerar sinais para alinhamento de byte. Os blocos hachurados são aqueles que
foram alterados. .......................................................................................................................................................... 146
Figura 58. Modificações no circuito gerador do clock CA. Os blocos hachurados são aqueles que foram alterados. ........ 147
Figura 59. Configuração dos tapered buffers para a distribuição do sinal de clock no Demultiplexador 1:8..................... 147
Figura 60. Sinal DadoM e clock, no primeiro Multiplexador fabricado, após passarem pelo circuito conversor ECL-CMOS
da entrada e tapered buffers (ver Figura 49). Os sinais na entrada têm freqüência de 625MHz, tempo de
subida/descida de 0,2ns e níveis de tensão de 4,0V/3,2V. Os resultados são obtidos a partir de simulação SPICE, level
2 e parâmetros slow. ................................................................................................................................................... 148
Figura 61. Sinal DadoM e clock, no novo Multiplexador, após passarem pelo circuito conversor ECL-CMOS da entrada e
tapered buffers (ver Figura 56). Os sinais na entrada têm freqüência de 625MHz, tempo de subida/descida de 0,2ns e
níveis de tensão de 4,0V/3,2V. Os resultados são obtidos a partir de simulação SPICE, level 2 e parâmetros slow.. 149
Figura 62. Layout do novo circuito Multiplexador 8:1. As dimensões deste circuito (incluindo os PADs) são 1,68mm por
0,94 mm. ..................................................................................................................................................................... 150
Figura 63. Layout do novo circuito Demultiplexador 1:8. As dimensões deste circuito (incluindo os PADs) são 1,90mm
por 1,08mm................................................................................................................................................................. 151
Figura 64. Fotografias dos C.I.s fabricados (nova versão). Em (a) está o circuito Multiplexador 8:1 e em (b), o circuito
Demultiplexador 1:8. .................................................................................................................................................. 152
Figura 65. Resultado do teste nos conversores ECL-CMOS e CMOS-ECL. É mostrado o sinal na entrada do PAD InTest,
INPUT, que está a taxa de 2,4Gbit/s, e no PAD OuTest, OUTPUT. Os sinais INPUT e OUTPUT são invertidos. A
seqüência que aparece na figura, sinal de entrada, é "1111010000000100101010". .................................................. 153
Figura 66. Diagrama de olho para avaliação dos conversores ECL-CMOS e CMOS-ECL. O sinal de entrada é Pseudo-
Randon-Bit-Sequence 223-1 (HP Pulse Generator 8133A). Em (a) o sinal aplicado tem taxa de
622,1Mbit/s(STS12/STM4 [St92]) em (b), taxa de 1244,12Mbit/s (STS24/STM8 [St92]) e em (c), taxa de 1,6Gbit/s.154
Figura 67. Diagrama de olho do sinal na entrada do C.I.: (a) para o sinal com taxa de 1244,1Mbit/s e (b), para o sinal a
1,6Gbit/s. O sinal é Pseudo-Randon-Bit-Sequence 223-1. ........................................................................................... 155
Figura 68. Sinal de clock e da saída do Multiplexador 8:1 funcionando a taxa de 1,7Gbit/s. O sinal de saída é "01100101".
A posição relativa no tempo, entre o clock e o sinal de saída, foi ajustada para facilitar a visualização. ................... 156
Figura 69. Sinal de dados, DADO, e sinal de clock nas entradas do circuito Demultiplexador 1:8 (versão nova). O sinal de
dados tem valor "101011" e taxa de 1,38Gbit/s. ......................................................................................................... 158
Figura 70. Diagrama de blocos de sintetizador de freqüência RF empregando PLL e Prescaler. ...................................... 160
Figura 71. Diagrama esquemático do Dual-Modulus Prescaler (divide por 128/129). ...................................................... 162
Figura 72. Diagrama de transistores e layout dos quatro projetos do contador síncrono 4/5: em (a) está o projeto DG1; em
(b), DG2; em (c), DG3; em (d), DG4. Na representação de transistores também estão indicados a largura e, quando
diferente de 0,8µm, o comprimento do canal de cada transistor (largura/comprimento). No layout, a moldura em
torno do circuito tem dimensões de 100µm X 70µm (praticamente as dimensões de DG1), para os quatro casos. .... 163
Figura 73. Fotografia do C.I. fabricado. Em (a) aparece o C.I. completo, com três diferentes Prescalers; também são
mostradas as conexões do C.I. com placa de teste. Em (b), estão detalhes do Prescaler que foi testado em alta
freqüência (implementação 1)..................................................................................................................................... 166

Lista de Figuras
9
Figura 74. Resultados experimentais do Prescaler. A curva (*), eixo à esquerda, fornece a máxima freqüência de operação
em função da tensão de alimentação (VDD); a curva (o), eixo à direita, fornece a corrente consumida na freqüência
máxima........................................................................................................................................................................167
Figura 75. Estrutura para caracterizar mismatch em buffers com fator de aumento χ. Wn indica a largura de canal do
transistor N. .................................................................................................................................................................173
Figura C1. Modelo de primeira ordem para um inversor.....................................................................................................181
Figura D1. Comparação entre os pontos obtidos por simulação (o buffer com dois inversores é apresentado com ‘x’, três
com ‘+’, quatro com ‘o’, cinco com ‘*’, seis com 'x', sete com 'o') e equações dadas por (16) (linhas contínuas). A
tecnologia é CMOS 0,8µm da AMS e a capacitância de carga de 1pF.........................................................................186

Lista de Tabelas
10
Lista de Tabelas Tabela 1. Processadores produzidos pela Intel e suas características básicas [Bo98]. .......................................................... 22
Tabela 2. Características das gerações tecnológicas apresentadas no NTRS/97 ([Se97], [Br98]). ....................................... 24
Tabela 3. Condições que determinarão o dimensionamento dos transistores dos blocos N-MOS like. ................................. 76
Tabela 4. Número de blocos estáticos e Dps (estes pertencendo a SE) entre o bloco BF e o bloco Bi para o data chain SE. 78
Tabela 5. Relações para cálculo da área e do perímetro de dreno. W é a largura de canal do transistor considerado........... 94
Tabela 6. Condições para obtenção dos resultados de simulação para as tecnologias 0,8µm e 0,35µm. .............................. 98
Tabela 7. Valores de χmax para vários valores de N. .............................................................................................................. 99
Tabela 8. Valores das constantes K1 e K2 das equações dadas por (14)............................................................................... 103
Tabela 9. Condições para geração de curvas/tabelas T0 x CL para modelamento dos tapered buffers. ............................... 105
Tabela 10. Taxa máxima para o buffer com fator de aumento χ=3, taxa máxima possível (qualquer χ) e aumento relativo
da taxa de operação (valor em χ=3 tomada como referência). É também indicado o valor do fator de aumento que
maximiza a taxa de operação do buffer (χot)............................................................................................................... 108
Tabela 11. Descrição, expressão e fator para análise de cada termo da equação (28). ........................................................ 125
Tabela 12. Atraso de um inversor como função do fator de aumento do buffer, para as tecnologias 0,8µm e 0,35µm. ..... 127
Tabela 13. Valores dos níveis lógicos ECL utilizados pelo Multiplexador e pelo Demultiplexador. ................................. 134
Tabela 14. PADs de entrada/saída do novo circuito Multiplexador 8:1 e sua descrição. .................................................... 150
Tabela 15. PADs de entrada/saída do novo circuito Demultiplexador 1:8 e sua descrição. ................................................ 151
Tabela 16. Resultados experimentais da primeira versão do circuito Multiplexador 8:1 e de sua nova implementação.
Também são apresentadas as diferenças entre eles..................................................................................................... 156
Tabela 17. Tecnologia, potência consumida e máxima taxa de operação de diversas implementações de Multiplexadores.157
Tabela 18. Resultados experimentais da primeira versão do circuito Demultiplexador 1:8 e de sua nova implementação.
Também são apresentadas as diferenças entre eles..................................................................................................... 158
Tabela 19. Tecnologia, potência consumida e máxima taxa de operação de diversas implementações de Demultiplexadores.159
Tabela 20. Resultados de máxima velocidade e potência consumida para os quatro contadores síncronos 4/5 projetados
(simulação SPICE com parâmetros slow). .................................................................................................................. 164
Tabela 21. PADs de entrada/saída do Prescaler testado e sua descrição (Figura 73(b)). .................................................... 166
Tabela 22. Resultados de área, velocidade e potência para cinco diferentes implementações do Prescaler....................... 168
Tabela A1. Número de blocos que pode haver entre as entradas e saídas de blocos adjacentes dentro de um data chain..175 Tabela D1. Condições para obtenção dos resultados de simulação para a tecnologia CMOS 0,8µm da AMS....................185

Lista de Símbolos
11
Lista de Símbolos ACox: parâmetro do processo que relaciona σCoxi com variações de curta distância; AL: parâmetro do processo que relaciona σLi com o edge roughness; Asdf: valor default para área de fonte; AVTn: parâmetro do processo que relaciona σVTn com variações de curta distância; AVTp: parâmetro do processo que relaciona σVTp com variações de curta distância; AW: parâmetro do processo que relaciona σWi com o edge roughness; Aµn: parâmetro do processo que relaciona σµni com variações de curta distância; Aµp: parâmetro do processo que relaciona σµpi com variações de curta distância; B(CE): conjunto dos blocos que compõe o circuito CE; CCoxi,Coxj: covariância entre Coxi e Coxj; Cdni e Cdpi: capacitâncias de junção de dreno dos transistores N e P, respectivamente, do i-ésimo inversor do tapered buffer; Cgpi e Cgpi: capacitâncias de gate dos transistores N e P, respectivamente, do i-ésimo inversor do tapered buffer; CL: carga capacitiva na saída do tapered buffer; CLi: capacitância de carga do i-ésimo inversor do tapered buffer; CLj,i: capacitância de carga do i-ésimo inversor do j-ésimo buffer; CLV: capacitância cujo valor é dado pela expressão ( )C C W W LLV ox n p
N= +1 1 χ ; Cox: capacitância, por unidade de área, no gate do transistor N ou P; Coxi: capacitância, por unidade de área, no gate dos transistores P e N do i-ésimo inversor do tapered buffer; C oxi : valor médio da variável Coxi; Coxj,i: capacitância, por unidade de área, no gate dos transistores P e N do i-ésimo inversor do j-ésimo buffer; CVTni,VTnj: covariância entre VTni e VTnj; CVTpi,VTpj: covariância entre VTpi e VTpj; Cxi,xj: covariância entre xi e xj; C ni njµ µ, : covariância entre µni e µnj; C pi pjµ µ, : covariância entre µpi e µpj; D: entrada digital com valor entre 0 e (2m-1); Distance: distância do transistor a uma referência; Fac3: fator para análise da variância de tD devido à acurácia do pattern generation process em Li; Fac4: fator para análise da variância de tD devido ao edge roughness em Li; Fac5: fator para análise da variância de tD devido ao nonuniform arrangement of events em Coxi; Fac6: fator para análise da variância de tD devido ao nonuniform arrangement of events em VTni; Fac7: fator para análise da variância de tD devido ao nonuniform arrangement of events em VTpi; Fac8: fator para análise da variância de tD devido ao nonuniform arrangement of events em µni; Fac9: fator para análise da variância de tD devido ao nonuniform arrangement of events em µpi; Fac10: fator para análise da variância de tD devido às variações de longa distância em Coxi; Fac11: fator para análise da variância de tD devido às variações de longa distância em VTni; Fac12: fator para análise da variância de tD devido às variações de longa distância em VTpi; Fac13: fator para análise da variância de tD devido às variações de longa distância em µni; Fac14: fator para análise da variância de tD devido às variações de longa distância em µpi; fdiv : freqüência média do sinal fdiv;

Lista de Símbolos
12
fG: termo cujo valor é fG =−χ
χ 1;
Fmax: máxima freqüência de operação do circuito, em MHz; fout: freqüência do sinal fout, saída do sintetizador de RF; G: indica quantas vezes o inversor é maior que 8,0/5,0µm (largura de canal do trans. P/trans. N); Hdif: parâmetro do modelo do transistor (ver modelos HSPICE no APÊNDICE B); hEE: hipótese das entradas externas estáveis; hTC: hipótese do timming correto; ID: corrente de dreno do transistor; ID0i: correntes de dreno dos transistores do i-ésimo inversor do tapered buffer para V V VGS DS DD= = ; ID0nj,i e ID0pj,i: correntes de dreno dos transistores N e P, respectivamente, do i-ésimo inversor do j-ésimo buffer para V V VGS DS DD= = ; ID0n0 e ID0p0: corrente de dreno do transistores N e P, respectivamente, do inversor 0 para V V VGS DS DD= = ; IM: índice de mérito; I(BQ): conjunto das entradas do bloco BQ; I(CE): conjunto das entradas externas do circuito CE; Kci: parâmetro do transistor P ou N, no i-ésimo inversor; KCn: valor de Kcni; KCni: parâmetro Kci para o transistor N; KCp: valor de Kcpi; KCpi: parâmetro Kci para o transistor P; KDSn e KDSp: parâmetros que dependem do processo e do layout e relacionam as capacitâncias de dreno com a largura dos canal do transistor N e P, respectivamente;
K∆: constante dada pela expressão KTt∆∆=
exp
0;
K1: constante que depende dos parâmetros da tecnologia, do layout e das dimensões do primeiro inversor do tapered buffer; K1 , K2, K3 e K4: constantes que dependem dos parâmetros da tecnologia e do layout do tapered buffer; Kα: constante que relaciona TN-1 com t0N; L: comprimento de canal do transistor N ou P; Ld: parâmetro do modelo do transistor (ver modelos HSPICE no APÊNDICE B); Ldif: parâmetro do modelo do transistor (ver modelos HSPICE no APÊNDICE B); Li: valor de Lni e Lpi; Li : valor médio da variável Li; Lj,i: valor de Lnj,i e Lpj,i; Lni e Lpi: comprimento de canal dos transistores N e P, respectivamente, do i-ésimo inversor do tapered buffer; Lnj,i e Lpj,i: comprimentos de canal dos transistores N e P, respectivamente, do i-ésimo inversor do j-ésimo buffer; L(CE): conjunto das ligações do circuito CE; L
O(CE): conjunto de pares ordenados que representam as ligações do circuito CE
m: número inteiro; M: número de tapered buffers; N: número de inversores do tapered buffer;

Lista de Símbolos
13
NA: número de inversores de cada buffer da implementação A; NB: número de inversores de cada buffer da implementação B; ND: número inteiro que indica fator de divisão do Prescaler; OBQ: saída do bloco BQ; O(CE): conjunto das saídas externas do circuito CE; PCi: parâmetro do transistor P ou N ( P K CCi Ci i oxi= µ ) do i-ésimo inversor PCnj,i e PCpj,i: parâmetros PC para os transistores N e P, respectivamente, do i-ésimo inversor do j-ésimo buffer; Pot: potência consumida pelo circuito por MHz, em µW/MHz; pri: i-ésima propriedade dos blocos usados no E-TSPC; Psdf: valor default para perímetro de fonte; RD: parâmetro do modelo do transistor (ver modelos HSPICE no APÊNDICE B); Rddf: valor default para resistência série de dreno; rE: regra de exceção; ri: regra de composição i; Rinv: resistência equivalente ao transistor; rG: regra geral; RS: parâmetro do modelo do transistor (ver modelos HSPICE no APÊNDICE B); Rsdf: valor default para resistência série de fonte; RSH: parâmetro do modelo do transistor (ver modelos HSPICE no APÊNDICE B); SCox: parâmetro do processo que relaciona σCoxi com variações de longa distância; SVTn: parâmetro do processo que relaciona σVTn com variações de longa distância; SVTp: parâmetro do processo que relaciona σVT com variações de longa distância; Sµn: parâmetro do processo que relaciona σµni com variações de longa distância; Sµp: parâmetro do processo que relaciona σµpi com variações de longa distância; tD: atraso do tapered buffer; td : atraso do i-ésimo inversor quando não há mismatch; t da : atraso médio de um inversor da implementação A; t db: atraso médio de um inversor da implementação B; tdi: atraso do i-ésimo inversor do tapered buffer; tDj: atraso do tapered buffer j; tdj,i: atraso médio do i-ésimo inversor do j-ésimo tapered buffer; TE: teorema da estabilidade; Tec: comprimento mínimo de canal para a tecnologia, em µm; Ti: largura do pulso na saída do i-ésimo inversor do tapered buffer; tpHLi: atraso da transição de alto-para-baixo (descarga) na saída do i-ésimo inversor do tapered buffer; tpLHi: atraso da transição de baixo-para-alto (carga) na saída do i-ésimo inversor do tapered buffer; tTi: tempo de transição efetivo do sinal na saída do i-ésimo inversor; T∆: valor de T∆i para os N-1 primeiros inversores do tapered buffer; T∆i: constante do i-ésimo inversor do tapered buffer; t0: valor de t0i para os N-1 primeiros inversores do tapered buffer;
t0: constante dada pela expressão ttK0
0
3= ;
t0i: constante de tempo do i-ésimo inversor do tapered buffer; VDD: tensão mais alta aplicada ao circuito (5V, por exemplo); VDS: tensão dreno-fonte; VD0i: tensão de dreno de saturação, quando |VGSi|=VDD, para o transistor (P ou N); VD0n: tensão de dreno de saturação, quando VGS=VDD, para o transistor N;

Lista de Símbolos
14
VD0nj,i e VD0pj,i: tensões VD0 para os transistores N e P, respectivamente, do i-ésimo inversor do j-ésimo buffer. VD0p: tensão de dreno de saturação, quando |VGS|=VDD, para o transistor P; VGS: tensão gate-fonte; VGSi: tensão entre gate e fonte do i-ésimo inversor do tapered buffers; VSS: tensão mais baixa aplicada ao circuito, normalmente terra; VTi: tensão de limiar do transistor utilizado (N ou P), no i-ésimo inversor do tapered buffer; VTn: tensão de limiar do transistor N; VTni e VTpi: tensão de limiar dos transistores N e P, respectivamente, do i-ésimo inversor do tapered buffer; V Tni : valor médio da variável VTni; VTp: tensão de limiar do transistor P; V Tpi: valor médio da variável VTpi; VTnj,i e VTpj,i: tensões de limiar dos transistores N e P, respectivamente, do i-ésimo inversor do j-ésimo buffer; W: comprimento de canal do transistor; Wef: largura efetiva de canal do transistor; Wi: valor de Wni; W i : valor médio da variável Wi; Wj,i: valor de Wnj,i; Wni e Wpi: largura de canal dos transistores N e P, respectivamente, do i-ésimo inversor do tapered buffer; Wnj,i e Wpj,i: larguras de canal dos transistores N e P, respectivamente, do i-ésimo inversor do j-ésimo buffer; W0: largura de canal do inversor 0;
Z1: termo cujo valor é ( ) ( ) ( )[ ]ZV
L F V V V K F V V V KDDD Tn Tp D n n Cn D Tp Tn D p p Cp1
20 01
2= + +θ µ θµ, , , , , , ;
Z2: termo cujo valor é ( )( ) ( )
ZV
LF z V V K
zF V z V K
zDD D Tp D n n Cn D Tp D p p Cp
22 0 0
12
= + +
θ∂ µ
∂∂ θµ
∂, , , , , ,
;
Z3: termo cujo valor é ( )( ) ( )
ZV
LF z V V K
zF V z V K
zDD D Tn D p p Cp D Tn D n n Cn
32 0 01
2= + +
θ∂ θµ
∂∂ µ
∂, , , , , ,
;
Z4: termo cujo valor é ( )( )
ZV
LF V V V zK
zDD D Tn Tp D n Cn
42 01
2= +
θ∂
∂, , ,
;
Z5: termo cujo valor é ( )( )
ZV
LF V V V zK
zDD D Tp Tn D p Cp
52 0
12
= +
θ∂ θ
∂, , ,
;
α: constante que está entre 1 e 2.
βn: constante do transistor N dado por β µn n oxn
nC
WL
=
;
θ: constante que relaciona Wpi e Wni; µi: mobilidade dos portadores do transistor; µn: mobilidade dos elétrons para o transistor N;

Lista de Símbolos
15
µni e µpi: mobilidade dos elétrons e das lacunas nos transistores N e P, respectivamente, do i-ésimo inversor do tapered buffer; µ ni: valor médio da variável µni; µnj,i e µpj,i: mobilidades dos elétrons e das lacunas nos transistores N e P, respectivamente, do i-ésimo inversor do j-ésimo buffer; µp: mobilidade das lacunas para o transistor P; µ pi: valor médio da variável µpi;
σCoxi: desvio padrão da variável Coxi; σLi: desvio padrão da variável Li; σL0: parâmetro do processo que relaciona σLi com a acurácia do pattern generation process; σtD: desvio padrão de tD; σWi: desvio padrão da variável Wi; σW0: parâmetro do processo que relaciona σWi com a acurácia do pattern generation process; σVTni: desvio padrão da variável VTni; σVTpi: desvio padrão da variável VTpi; σµni: desvio padrão da variável µni; σµpi: desvio padrão da variável µpi; νTi=|VTi/VDD|; χ: fator de aumento entre inversores do tapered buffer; χA: fator de aumento de cada buffer da implementação A; χB: fator de aumento de cada buffer da implementação B; χmax: fator de aumento que maximiza a taxa de operação para tapered buffers com N inversores.


Resumo
17
Resumo
A redução nas dimensões dos transistores CMOS e a demanda crescente por circuitos rápidos fizeram da velocidade um importante fator de desempenho dos circuitos integrados (C.I.) modernos. O objetivo deste trabalho é o estudo e desenvolvimento de técnicas para projeto de ASICs (Application-Specific Integrated Circuits) CMOS de alta velocidade.
Uma estratégia para o projeto de Register Transfer Systems os quais usam um único clock no sincronismo é inicialmente proposta. Essa estratégia foi denominada Extended True Single Phase Clock (E-TSPC). Nela são utilizadas portas lógicas complementar CMOS, CMOS dinâmicas e data precharged (onde os dados de entrada fazem a pré-carga), blocos n-latches e blocos p-latches. Ainda, são permitidas modificações em algumas destas portas e blocos, formando novos blocos N-MOS like que aumentam a velocidade dos circuitos. Um conjunto de regras de composição, que regulam as ligações entre blocos e portas, é criado. Tais regras, quando obedecidas, garantem que problemas referentes ao funcionamento das portas e dos blocos usados não ocorrerão. Isso é provado por meio de vários teoremas.
O estudo da otimização de tapered buffers, para obter máxima taxa de operação, é apresentado em seguida. A partir de simulações com diferentes tecnologias verificamos que a minimização do atraso de um buffer (desde sua entrada à saída) não proporciona a máxima taxa de operação necessariamente. Os resultados apontaram que valores de fator de aumento entre inversores inferiores a 2,0 proporcionam maiores taxas. Tais fatores, por outro lado, levam a atrasos maiores que o mínimo que pode ser conseguido. Incrementos superiores a 20% na máxima taxa de operação foram alcançados com o uso de pequenos fatores de aumento.
Para verificação das técnicas propostas, foram projetados e implementados os seguintes circuitos: uma versão de alta performance de um Multiplexador 8:1, uma versão de alta performance de um Demultiplexador 1:8 com byte alignment e um Dual Modulus Prescaler (contador 128/129). A tecnologia empregada foi CMOS 0,8µm (comprimento de canal efetivo de 0,7µm). Nos circuitos Multiplexador e Demultiplexador foram aplicados os resultados do estudo da otimização de tapered buffers e os novos blocos N-MOS like introduzidos no E-TSPC. Resultados experimentais apontaram que o Multiplexador opera a taxas de 1,7Gbit/s e o Demultiplexador, a 1,38Gbit/s. O ganho de velocidade conseguido em relação a primeira versão destes mesmos circuitos, efeito do emprego das técnicas aqui propostas, foi de 62% para o Multiplexador e de 29% para o Demultiplexador. Adicionalmente, a comparação dos resultados com os de outros circuitos da literatura indica que velocidade e o consumo de potência alcançados são excelentes.
No Dual Modulus Prescaler a estratégia E-TSPC foi amplamente explorada, mostrando ser vantajosa para atingir tanto altas freqüências de operação como baixos consumos de potência. O protótipo caracterizado do Prescaler operou a 1,58GHz. O índice de mérito utilizado para comparações entre diferentes implementações de Prescalers (Tec3.Fmax/Pot), índice que leva em conta a freqüência máxima de operação (Fmax), o consumo de potência (Pot) e a tecnologia utilizada (Tec), foi, para nosso circuito, quase duas vezes superior ao melhor resultado encontrado nas implementações dos outros trabalhos.


Abstract
19
Abstract
The dimension reduction of the CMOS transistors and the increasing demand for fast circuits have made the speed an important performance factor of the modern integrated circuits (I.C.). The main goal of this work is the study and development of design techniques for high speed CMOS ASICs (Application-Specific Integrated Circuits).
A design strategy for Register Transfer Systems which use a single clock for synchronization is initially proposed. This strategy was called Extended True Single Phase Clock (E-TSPC). Complementary CMOS, dynamic CMOS, and Data Precharged (where the input data does the precharge) logic gates, n-latch blocks, and p-latch blocks are accepted in the E-TSPC. In addition, modifications in some of these gates and blocks are allowed, building new N-MOS like blocks which increase the circuit speed. A set of composition rules, regulating the connections between gates and blocks, is also laid down. Such rules guarantee that problems concerning the operation of the used gates and blocks will not occur, whenever the rules are followed. It is proved through some theorems.
The study of the tapered buffer optimization, to reach maximum operation rates, is next presented. From simulations with different technologies, we verified that the delay minimization of a buffer (from its input to the output) does not provide necessarily the maximum operation rate. The results have pointed out that tapering factors lower than 2.0 will lead to higher operation rates. Such factors, on the other hand, enlarge the buffer delay, which will be higher than the possible minimum. Employing small tapering factors, we have achieved increases larger than 20% in the maximum operation rate.
To verify the proposed techniques, the following circuits were designed and implemented: a high performance version of an 8:1 Multiplexer, a high performance version of an 1:8 Demultiplexer with byte alignment, and a Dual Modulus Prescaler (128/129 counter). The employed technology was a 0.8µm CMOS (0.7µm effective channel length). In the Multiplexador and Demultiplexer circuits, the results of the tapered buffer optimization study and the new N-MOS like blocks were applied. Experimental measurements showed that the Multiplexer and the Demultiplexer operate at 1.7Gbit/s and at 1.38Gbit/s rates, respectively. The speed gain, in relation to the first version of these same circuits, effect of our proposed techniques, was of 62% for the Multiplexer and 29% for the Demultiplexer. Additionally, the comparison of the results with the ones from the literature indicates that the achieved speed and power consumption are excellent.
In the Dual Modulus Prescaler, the E-TSPC strategy was widely explored, showing to be advantageous to reach both a high frequency and a low power consumption. The characterized Prescaler prototype operated at 1.58GHz frequency. In addition, the index of merit used for comparing different Prescaler implementations (Tec3.Fmax/Pot), which takes the clock frequency (Fmax), the power consumption (Pot), and the technology (Tec) into account, has, for our circuit, a value which is almost twice the best result found in the other work implementations.


Introdução
21
1. Introdução
1.1 História das tecnologias MOS
Os princípios por trás dos transistores de efeito-campo Metal Oxide Silicon (MOS) são
primeiramente propostos em 1925 por J. Lilienfeld, professor de física da Universidade de Leipzig
[Sa88]. Lilienfeld usou apenas a eletrostáticos para prever a modulação da condutividade (a física
quântica estava em sua infância) ([Sa88]). Em 1935 o alemão O. Heil faz, na Inglaterra, pedido de
patente para uma estrutura similar aos transistores MOS modernos ([We93], [Ra96], [Sa88]); nele, a
descrição da operação do transistor faz já uso de conceitos de elétrons e lacunas derivados da teoria
dos semicondutores ([Sa88]). Não obstante as previsões teóricas, os transistores construídos fracassam
em apresentar amplificações de corrente. Para explicar isso, Bardeen propõe que estados de superfície
bloqueiam o campo elétrico e impedem a formação e modulação do canal no transistor. Ele, Brattain e
Schockley, tentado contornar esta dificuldade nos transistores de efeito-campo, acabam por inventar o
transistor bipolar no Bell Telephone Laboratories em 1948 ([Me98], [Rs98]). Com o estudo e
explicação dos fenômenos que ocorrem no transistor bipolar é que, por fim, a física básica por trás do
transistor é compreendida [Sa88].
A invenção do transistor bipolar faz com que os transistores de efeito campo sejam quase
esquecidos. No fim da década de 50, surgem várias importantes contribuições tanto para o
desenvolvimento da microeletrônica como para a volta dos transistores de efeito-campo:
• em 1959 , J. Hoerni, Fairchild, inventa o processo planar para fabricação de transistores;
• em 1959, Atalla e Kahng, Bell Labs., fabricam e conseguem a operação de um transistor MOS
[Me98]. Ele é tido como uma curiosidade pois sua performance é bastante inferior aos bipolares;
• em 1958, J. Kilby, Texas Instruments, desenvolve o primeiro circuito integrado (C.I.); este é
aperfeiçoado com os trabalhos de Noyce, Farchaild, 1959, que usa o processo planar e alumínio
evaporado para as interconexões [Me98].
Observemos que a fabricação dos primeiros C.I.s marca uma importante transição na concepção da
aplicação dos transistores; eles deixam de ser encarados como meros substitutos de válvulas para
serem vistos como dispositivos que possibilitam o desenvolvimento de circuitos muito mais complexos
do que até então eram possíveis.
Estando resolvidos os principais problemas na compreensão e na fabricação dos transistores, a
indústria da microeletrônica começa então a ser estabelecida.
Devido à sua estrutura mais simples, adequada para os circuitos integrados complexos, o transistor
MOS passa a ser encarado como um dispositivo viável na década de 60. Em 1964, Fairchild e RCA
introduzem no mercado os primeiros transistores MOS [Sa88]. Problemas com estados de interface e

Introdução
22
impurezas mantém, no entanto, restrito o uso do MOS até o fim da década. Entre 1964 e 1969
desenvolvem-se técnicas para redução dos estados de interface, identifica-se o sódio como principal
impureza no MOS e apresentam-se soluções para evitar problemas com esta impureza. A
confiabilidade do transistor MOS, em vista disso, melhora e aumenta a gama de suas aplicações
comerciais.
Nos primeiros anos a tecnologia MOS é dominada pelo PMOS (MOS onde só há transistores canal
P), mais robusta aos problemas com impurezas, embora o conceito de Complementary Metal Oxide
Silicon (CMOS) já houvesse sido introduzido por Weimer, RCA, em 1962 e por Wanlass, Fairchild,
em 1963. Em 1970 a primeira memória em semicondutor com produção em massa é anunciada pela
Intel: DRAM (Dynamic Random Access Memory) de 1-Kbit na tecnologia PMOS com três transistores
por bit. Por volta de 1971, superados os problemas com impurezas e estados de superfície, emergem as
primeiras tecnologias NMOS (MOS onde só há transistores canal N) que permitem maiores
velocidades e, ao mesmo tempo, maior nível de integração. Como conseqüência, surgem memórias
maiores (DRAM de 4-Kbit começam a ser produzidos em 1972) e o primeiro microprocessador, o
4004 da Intel (ver Tabela 1 [Bo98]).
O domínio das tecnologias NMOS se estende até fim da década de 70. Com o aumento das
densidades e velocidades começa a haver problemas com o consumo de potência, o que dá
oportunidade as tecnologias CMOS. Esta tecnologia, não obstante apresentar mais etapas na fase de
fabricação, tem um desempenho, no que tange ao consumo de potência, bem superior as outras
tecnologias. Tem início então o domínio do CMOS e que dura até hoje (Tabela 1).
Nos últimos anos a base de cerca de 98% da produção de circuitos semicondutores (tanto por
número de componentes como por valor) é o silício, sendo que mais de 75% destes circuitos são
produzidos com tecnologias CMOS ([Br98], [Se97]). Isso não deve se alterar significativamente nos
próximos anos. Dessa forma, o CMOS continuará a ser a tecnologia mais importante dentro da
indústria de microeletrônica.
1.2 Motivações e objetivos
Encontramos na indústria de microeletrônica certas tendências históricas de avanços. Uma delas é a
redução do preço por função entre 25% a 30% por ano [Se97]. Outra, conhecida como lei de Moore, é
a duplicação da complexidade de integração a cada 18 meses ([Mo65], [Ra96], [Sh98]). A Figura 1,
que apresenta o número de transistores dos microprocessadores da Intel em função do ano do seu
lançamento, confirma esta lei.
Tabela 1. Processadores produzidos pela Intel e suas características básicas [Bo98].

Introdução
23
início freqüência do clock (MHz)
bus width número de transistores (tecnologia)
4004 15/nov./71 0,108 4 2300 (NMOS 10µm)
8008 1/abr./72 0,108 8 3500 (NMOS)
8080 1/abr./74 2 8 6000 (NMOS 6µm)
8086 8/jun./78 5; 8; 10 16 29000 (NMOS 3µm)
8088 1/jun./79 5; 8 8 29000 (NMOS 3µm)
80286 1/jan./82 6; 8; 10; 12,5 16 134000 (NMOS 1,5µm)
386 DX 17/out./85 16; 20; 25; 33 32 275000 (CMOS 1µm)
386 SX 16/jun./88 16; 20; 25; 33 16 275000 (CMOS 1µm)
486 DX 10/abr./89 25; 33; 50 32 1,2 milhões (CMOS 1µm e 0,5µm)
486 SX 22/abr./91 16; 20; 25; 33 32 1,185 milhões (CMOS 1µm)
Pentium 22/mar./93 60; 66; 75; 90; 100; 120; 133; 150; 166
32 3,1 milhões (BiCMOS 0.8µm)
Pentium Pro 1/nov./95 150; 166; 180; 200 64 5,5 milhões (0,6µm)
Pentium II 7/maio/97 200; 233; 266; 300 333; 350; 400
64 7,5 milhões (CMOS 0,35µm e 0,25µm)
1 9 7 0 1 9 7 5 1 9 8 0 1 9 8 5 1 9 9 0 1 9 9 5 2 0 0 01 0 0
1 0 1
1 0 2
1 0 3
1 0 4
1 0 5
a n o d e la n ç a m e n t o
n ú m e r o d et r a n s is t o r e s ( k )
4 0 0 48 0 0 8
8 0 8 0
8 0 8 6
8 0 2 8 6
I n t e l 3 8 6
I n t e l 4 8 6
P e n t iu mP e n t iu m P r o
P e n t iu m I I
Figura 1. Número de transistores em função do ano de lançamento para os principais
microprocessadores da Intel (não estão no gráfico os processadores 8088, 386SX e 486SX pois eles
são versões econômicas do 8086, do 386DX e do 486DX, respectivamente).
A partir dessas tendências, as características das próximas gerações tecnológicas CMOS podem ser
extrapoladas, um trabalho que foi desenvolvido no National Technology Roadmap for Semiconductors
(NTRS) produzido pelo Semiconductor Industry Association ([Se92], [Se94], [Se97]). A Tabela 2

Introdução
24
apresenta algumas das características das próximas gerações CMOS como apontado no NTRS de
1997.
Tabela 2. Características das gerações tecnológicas apresentadas no NTRS/97 ([Se97], [Br98]).
Ano do início de produção 1997 1999 2001 2003 2006 2009 2012 linhas densas (DRAM half
pitch) (nm)* 250 180 150 130 100 70 50
linhas isoladas (gates lenght de microprocessador) (nm)*
200 140 120 100 70 50 35
Memória bits/cm2 96M 270M 380M 770M 2,2G 6,1G 17G Microprocessador
transistor/cm2 3,7M 6,2M 10M 18M 39M 64M 100M
chip to packge Pads (alta performance) #
1450 2000 2400 3000 4000 5400 7300
freqüência on-chip-local (alta performance) (MHz)♣
750 1250 1500 2100 3500 6000 10000
freqüência on-chip-across chip (alta performance) (MHz)♣
750 1200 1400 1600 2000 2500 3000
freqüência chip to board (alta performance) (MHz)
750 1200 1400 1600 2000 2500 3000
área do chip (mm2) DRAM 280 400 445 560 790 1120 1580 área do chip (mm2) microprocessador
300 340 385 430 520 620 750
número de níveis de metal 6 6-7 7 7 7-8 8-9 9 número mínimo de máscaras 22 22-24 23 24 24-26 26-28 28
VDD para lógica (V) 1,8-2,5 1,5-1,8 1,2-1,5 1,2-1,5 0,9-1,2 0,6-0,9 0,5-0,6 dissipação de potência (alta
performance) (W) 70 90 110 130 160 170 175
dissipação de potência (equipamentos c/ bateria) (W)
1,2 1,4 1,7 2,0 2,4 2,8 3,2
* o NTRS/97 divide as tecnologias de fabricação em duas classes: aquelas usadas para implementação de DRAMs e aquelas usadas em circuitos lógicos. Para as primeiras, é usado o half pitch do primeiro nível de interconexão, linhas mais densas, como característica mais representativa da geração tecnológica. No caso das tecnologias usadas para lógica, é usado o comprimento do canal (L);
# os circuitos projetados para alcançar a máxima velocidade são chamados de circuitos de alta performance; ♣ duas classes de clocks são discriminadas no NTRS/97: o clock global, que deve ser distribuído por todo o C.I., e o
clock local, gerado a partir do global e que será usado em porções menores do C.I., normalmente em C.I.s de alta performance.
É importante lembrar que os dois NTRS anteriores, de 1992 e de 1994 ([Se92], [Se94]), ficaram
aquém do progresso real verificado na indústria ([Br98]).
Também foram discutidas as dificuldades que devem ser superadas para tornar realidade as
extrapolações feitas (não previsões [Br98]), e as implicações disso. As maiores dificuldades esperadas
para o futuro são [Se97]1:
• habilidade em continuar a redução de custos;
• habilidade em desenvolver litografia com custos razoáveis para tecnologias abaixo de 100nm;
1 Cada um destes itens é explicado em detalhe na referência. Aqui, como estamos preocupados apenas com operações
em altas freqüências, não faremos isso.

Introdução
25
• introdução de novos materiais e estruturas;
• operação em GHz, tanto internamente como chip-to-board;
• metrologia e testes;
• desafios na pesquisa e desenvolvimento.
Destes desafios, a operação em GHz é o que nos interessa. A Tabela 2 nos mostra que a barreira do
1GHz já está sendo ultrapassada e que maiores velocidades são esperadas para o clock local, para o
clock global e mesmo para a comunicação chip-to-board.
O aumento na velocidade dos circuitos, conseqüência direta da redução nas dimensões mínimas das
tecnologias, tem sido útil em duas grandes classes de aplicações. A primeira classe é composta pelos
circuitos que eram apenas realizáveis com outras tecnologias mais velozes (Bipolar, GaAs); uma vez
que as tecnologias CMOS oferecem grandes vantagens com relação a custos, níveis de integração e
consumo de potência, sua utilização no lugar das tecnologia concorrentes, quando possível, é sempre
vantajosa. Exemplos destes são circuitos para comunicação em fibras ópticas ([Ku96], [Oh97]) e
telefonia celular ([Ro98a], [Ro98b], [Le97]). Lembremos que freqüências muito elevadas são somente
alcançadas com circuitos Bipolares ou, principalmente, GaAs ([Ot98]). Em particular, no caso de
fibras ópticas, com sua banda superior a 50000Gbit/s (50Tbit/s [Ta96]), os circuitos CMOS permitem
a utilização de uma pequena fração da capacidade.
A segunda classe de circuitos, onde o aumento das velocidades é importante, é composta por
microprocessadores e Digital Signal Processors (DSPs), que estão sob constante pressão para
melhoras no desempenho devido à demanda crescente por maiores capacidades de processamento
([Gr98], [Gu96], [Ga96]).
A implementação de circuitos CMOS trabalhando em GHz enfrenta um número enorme de
problemas. Entre eles podemos citar a escolha dos blocos que serão usados, portas lógicas e latches, a
distribuição de sinais no C.I., por exemplo o clock, o aumento do consumo de potência, os sinais de
entrada e saída, encapsulamento, linhas de interconexão, testabilidade entre outros.
Neste trabalho propomos algumas novas técnicas que permitem a implementação de ASICs
(Application-Specific Integrated Circuits) CMOS digitais de alta velocidade, aproveitando ao máximo
a tecnologia usada. Um exemplo disso, apresentado nesse trabalho, é um circuito Prescaler, fabricado
com uma tecnologia CMOS 0,8µm, funcionando a 1,6GHz [Na99].
1.3 Desenvolvimento da pesquisa
Este trabalho foi iniciado durante o desenvolvimento de circuitos Multiplexadores 8:1 e
Demultiplexadores 1:8 com byte alignment ([Ko91], [Vi89]), para serem utilizados na transmissão de
dados por fibras ópticas ([Ro95a], [Ro95b], [Ro96], [No98])(Figura 2). Neste caso, tanto o

Introdução
26
Multiplexador como o Demultiplexador devem trabalhar com freqüências tão altas quanto aquela que é
utilizada na transmissão (na figura, 1,244Gbit/s). Os outros circuitos do sistema, como por exemplo os
responsáveis pela montagem de frames, funcionam com taxas bem menores (na figura, 155,5Mbit/s).
Por esta razão estes dois circuitos são críticos no desempenho do sistema completo.
O objetivo do projeto era atingir taxas de 622Mbit/s (STS12/STM4) e, se possível, de 1,244Gbit/s
(STS12/STM8), utilizando uma tecnologia CMOS de 0,8µm e alimentação de 5V (CMOS da
ES2/ATMEL [Es94]). Foram empregados no projeto D-flip-flops do tipo True Single Phase Clock
(TSPC)([Yu87], [Yu89], [Af90]).
E/O O/E
Multiplexador8:1
Demultiplexador1:8
Entradade dados
Saída dedados
Fibra óptica
1,244Gbit/s
155,5Mbit/s 155,5Mbit/s
Figura 2. Esquemático de sistema para transmissão e recepção por meio de fibra óptica; E/O é um
conversor elétrico/óptico (foto-emissor) e O/E, um conversor óptico/elétrico (foto-receptor). As taxas
de operação indicadas são do padrão SONET STS24/CCITT STM8 [St92].
Uma primeira dificuldade para a realização dos circuitos acima foram os sinais de alta freqüência
que chegam ou saem do C.I. (no Multiplexador, o clock e a saída de dados; no Demultiplexador, o
clock e a entrada de dados). Para permitir altas velocidades, menor ruído e menor consumo de
potência, convém utilizar, para estes sinais, níveis lógicos com excursão de tensão pequena. Um
padrão adequado para isto é o ECL ([Ch88], [Sc90], [St91], [Is92], [Aa93]) no entanto, para seu uso,
são necessários circuitos de entrada e saída que façam a conversão dos níveis ECL para os níveis
usados internamente no C.I. e vice-versa (internamente no C.I. são usados níveis CMOS). Os circuitos
de conversão projetados para essas tarefas são descritos em [Na95], [Na96] e [Na97a].
Na primeira versão dos circuitos Multiplexador e Demultiplexador, os resultados experimentais
apontaram que podiam operar com taxas próximas de 1,1Gbit/s, na tecnologia CMOS 0,8µm.
Estando as taxas alcançadas próximas ao padrão SONET STS24, novos estudos foram feitos para
melhorar o desempenho dos circuitos. Da análise dos blocos internos, portas lógicas e latches, e suas
conexões resultaram as idéias que desenvolvidas e organizadas formaram o que chamamos de
Extended True Single Phase Clock (E-TSPC) ([Na97b], [Na97c], [Na99]).
Ainda foram feitos estudos sobre os tapered buffers, usados nos circuitos tanto para a distribuição

Introdução
27
do sinal de clock como dos sinais de dados. Foi observado que o uso do atraso para otimização não
resultava no melhor desempenho. A partir daí foram feitas análises para obter um critério mais
apropriado para otimização de tapered buffers [Na98a].
Os resultados dos estudos referidos acima foram empregados no projeto de novas versões dos
circuitos Multiplexador e Demultiplexador com bons resultados [Na98b]. Ainda um circuito Dual-
Modulus Prescaler (128/129) ([Ch96], [Cr96], [Le97]) foi fabricado e testado para avaliar melhor a
estratégia E-TSPC, que havia sido parcialmente aplicada nos outros dois circuitos [Na99].
Nestes três tópicos, a estratégia E-TSPC, a otimização de tapered buffers e os resultados
experimentais obtidos com a aplicação destes, é que está constituída esta tese.
1.4 Capítulos: descrição
O trabalho é apresentado em cinco capítulos. No segundo capítulo são discutidas algumas formas de
implementação de Register Transfer Systems (RTL). Posteriormente é introduzida a estratégia E-
TSPC, com seus blocos e regras de conexão. Finalmente, a função destas regras é explicada e são
demonstrados teoremas que provam que elas são suficientes para evitar os problemas que as
motivaram.
No capítulo três é apresentado e discutido um novo critério para otimização de tapered buffers.
Através de simulações é mostrado que com a minimização do atraso total, critério mais usado para
otimização de buffers, não são alcançadas as maiores taxas de operação. Ganhos na velocidade entre
20% e 30% são conseguidos com outra forma de otimização. Por fim é feita uma análise do
comportamento do atraso, devido ao mismatch entre os inversores, em função do fator de aumento
entre inversores usado no buffer.
Os circuitos projetados aplicando-se as técnicas estudadas, Multiplexador, Demultiplexador e
Prescaler, são apresentados no capítulo quatro. Também são apresentados os testes experimentais
feitos nos protótipos fabricados. O novo circuito Multiplexador foi quase 70% mais veloz que a versão
anterior; no circuito Demultiplexador, a melhora na velocidade foi de apenas 30%, quando comparado
a primeira versão (sempre utilizando a mesma tecnologia). O circuito Prescaler, por sua vez, apresenta
freqüências de operação tão altas quanto outros já publicados e consumo de potência bem inferior.
No capítulo cinco, de conclusão, são sumariados os principais aspectos do trabalho e futuras etapas
da pesquisa.


Implementação de Register Transfer Systems (RTS) de Alta Velocidade
29
2. Implementação de Register Transfer Systems (RTS) de Alta Velocidade
2.1 Introdução
Neste capítulo apresentaremos a estratégia Extended True Single Phase Clock, E-TSPC, usada para
implementação de circuitos RTS (Register Transfer Systems) digitais. Ela foi desenvolvida a partir da
técnica True Single Phase Clock (TSPC)([Yu87], [Yu89], [Af90], [La95]); acrescentamos a esta novas
regras, que permitem uma maior variedade de combinações das portas lógicas e registradores, além de
novos blocos, tornando-a mais veloz. O E-TSPC visa especialmente à implementação de circuitos
rápidos dentro da tecnologia CMOS.
Antes de entrarmos no E-TSPC, falaremos dos Register Transfer Systems e apresentaremos vários
circuitos usados para implementação tanto das portas lógicas como dos registradores. Também
falaremos sobre algumas políticas de sincronização ou de clock para os RTS. Nos deteremos um pouco
na técnica TSPC e apontaremos alguns problemas dela. Por fim trataremos do E-TSPC: seus blocos,
regras e os problemas, referentes ao funcionamento destes blocos, que as regras evitam. Provaremos,
que, obedecidas a tais regras, os blocos operam corretamente.
2.2 Register Transfer Systems (RTS)
Como apontado em [Go84], o armazenamento de informações em registradores e a transferência
destas de um registrador para outro, com a manipulação lógica das informações durante a
transferência, são operações fundamentais em qualquer sistema digital complexo. Chamaremos aqui
genericamente de Register Transfer Systems, ou simplificadamente de RTS, qualquer conjunto de
registradores e portas lógicas que executam estas funções. Na Figura 3 é apresentado um RTS com
suas partes principais. As máquinas de estados finitos e os pipelined systems são exemplos de RTS, o
que mostra sua importância pois, em grande extensão, os sistemas VLSI (Very-Large-Scale of
Integration) são combinações de máquinas de estados finitos e pipelined systems [We93].
No RTS, os sinais de clock ou relógio servem para sincronizar transferências dos dados de um
registrador para outro e a unidade de controle, para permitir operações condicionais. A política de
clock empregada determina como serão implementados os circuitos, que tipos de registradores serão
usados, latches, D-flip-flops, etc., e quantos diferentes sinais de relógio haverá. Os diferentes sinais de
relógio também são chamados de fases de clock. Veremos mais adiante alguns exemplos de políticas
de clock.
Várias são as famílias de circuitos utilizadas para a construção da lógica combinatorial e dos
registradores. Nas próximas seções apresentaremos aquelas mais conhecidas nas tecnologias CMOS.
Daqui por diante chamaremos de VDD a tensão mais alta aplicada ao circuito, por exemplo 5V, 3V, e

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
30
de VSS a mais baixa, normalmente terra. O nível lógico baixo será indicado por “0” e o nível lógico
alto, por “1”; a transição de “0” para “1”, será indicada por “0”→”1”, e de “1” para “0”, por “1”→”0”.
Registrador
Registrador
Registrador
clocks clocks clocks
Lógicacombinatorial
Lógicacombinatorial
Lógicacombinatorial
Unidade de Controle
Sinais decontrole
Figura 3. Representação genérica de um Register Transfer System (RTS).
2.2.1 Lógica Combinatorial
Podemos, como feito em [Ra96], separar as portas lógicas que implementam a lógica combinatorial
em estáticas e dinâmicas. As portas estáticas têm como característica que a todo instante, exceto talvez
durante a transição, a saída está conectada a VDD, a VSS, ou a ambas via um caminho de baixa
impedância (transistores conduzindo). O valor na saída é uma função lógica das entradas da porta. As
portas lógicas dinâmicas, ao contrário, têm a saída desconectada tanto de VDD como de VSS durante
fases de sua operação. O sinal da saída fica armazenado na capacitância do próprio nó de saída. As
portas dinâmicas apresentam a vantagem de serem mais simples e rápidas mas sofrem com ruído.
As portas lógicas mostradas nas próximas seções são:
estáticas: complementar CMOS dinâmicas: CMOS dinâmicos
pseudo NMOS C2MOS
com transistores de passagem
2.2.1.1 Lógica Estática Complementar CMOS
Uma porta lógica estática complementar CMOS, como apresentada na Figura 4 ([Go84], [We93],
[Ra96]), é um combinação de duas estruturas, uma chamada pull-up network (PUN) e outra, pull-down
network (PDN). A estrutura PUN é uma conexão condicional da saída da porta para VDD,
implementada com transistores P; a estrutura PDN, uma conexão condicional da saída da porta para
VSS, implementada com transistores N. Estas duas estruturas devem ser projetadas para operar de forma
complementar, ou seja, quando uma delas conduz a outra está cortada e vice-versa. Desta forma,

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
31
qualquer que seja o valor dos sinais de entrada, a saída estará ligada ou a VDD, tendo nível lógico alto,
ou a VSS, tendo nível lógico baixo.
Uma característica determinante das portas estáticas complementar CMOS é que o seu correto
funcionamento não depende da relação entre as dimensões dos transistores P e N (ratioless). Apenas
velocidade e margens de ruído dependem destas. Devido a isto, o projeto com portas complementar
CMOS é bastante simplificado.
As vantagens das portas lógicas complementar CMOS são:
• altas margens de ruído;
• baixa potência estática: neste tipo de porta, quando não há transições nos valores de entrada, a
potência dissipada, potência estática, é devido a apenas correntes de fuga, sendo praticamente
zero;
• tempos de subida e descida comparáveis se a porta for bem projetada;
• baixa sensibilidade a variações de processo e facilidade de projeto (ratioless).
Por outro lado, como podemos observar na Figura 4, a função lógica do circuito é executada duas
vezes, uma na estrutura PUN e outra na estrutura PDN. Esta redundância acarreta desvantagens para
esta família de circuitos:
• há gasto maior com área;
• funções lógicas complexas têm degradadas a velocidade do circuito.
PDN
a b
c
a
d=a(b+c)
d
VSS
cb
VDD
PUN( )d a b c= + ⋅
( )d a b c= +
transistor P
transistor N
PUNtrans. P
PDNtrans. N
entradasaída
b)
VDD
VSS
a)
Figura 4. Porta lógica estática complementar CMOS para a função ( )d a b c= + : (a), representação
com transistores e (b), sua representação simplificada.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
32
2.2.1.2 Lógica Estática Pseudo NMOS
A porta lógica pseudo NMOS, Figura 5 ([We93], [Ra96], [Gu96]), é semelhante as portas lógicas
utilizadas nas tecnologias NMOS, onde existem apenas transistores N, o de enriquecimento e o de
depleção [Me80]. Na lógica pseudo NMOS, o transistor P é usado como carga ao invés do de
depleção. O transistor P de carga tem seu gate2 ligado a VSS ou a alguma outra tensão de polarização
(como VL na Figura 5). Comparando a porta pseudo NMOS com a complementar CMOS vemos que
apenas a estrutura PDN está presente. Quando esta conduz, a saída do circuito é levada para próximo
de VSS. Veja que isto deve ocorrer mesmo estando o transistor P conduzindo, o que exige um correto
dimensionamento do circuito. Por outro lado, se a estrutura PDN não conduz, o transistor P de carga
leva a saída para VDD. Esta é uma lógica com relação, ratioed, onde a razão entre as dimensões dos
transistores N e P é fundamental para o funcionamento do circuito (não apenas velocidade e margens
de ruído).
Duas características importantes estão presentes nesta configuração de portas: a carga capacitiva de
entrada da porta é reduzida em relação a complementar CMOS; os transistores P, normalmente mais
lentos, não são usados para a função lógica. A conseqüência destas características é que a velocidade
do pseudo NMOS é maior, principalmente para portas lógicas mais complexas. A maior dificuldade
nestes circuitos, como nas tecnologias NMOS em geral, é o consumo de potência estática que ocorrerá
sempre que a saída da porta tenha valor lógico baixo.
Considerando os aspectos comentados acima, o uso de portas pseudo NMOS é aconselhado em
pequenos subcircuitos onde a velocidade é de grande importância ou, também, onde é sabido que as
saídas das portas ficam na maior parte do tempo em nível alto.
Sumariando as vantagens dos pseudo NMOS, temos:
• maiores velocidades principalmente para funções lógicas complexas;
• ocupação de menores áreas.
Três problemas importantes com estas portas são:
• o consumo de potência estática;
• a maior dificuldade no projeto pois as dimensões do circuito são importantes para o
funcionamento (ratioed);
• os tempos de subida e descida, em geral, diferentes.
2 A palavra gate é mantida em inglês quando tratamos da porta do transistor; com isso procuramos evitar qualquer
confusão entre as expressões "porta lógica" e "porta do transistor".

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
33
PDN
V L
e=a+b+c+d
e
e a b c d= + + +
PDNtrans. N
entrada
saída
b)
V DD
V SS
a)
cba d
VDD
V SS
V L
Figura 5. Porta lógica estática pseudo NMOS para a função e a b c d= + + + : (a), representação com
transistores e (b), sua representação simplificada.
2.2.1.3 Lógica Estática com Transistores de Passagem
Uma das formas de construir funções lógicas é através de chaves ou transistores de passagem. Neste
caso, um pequeno número de elementos é empregado, resultando um circuito simples e rápido.
Diferentes famílias lógicas são construídas desta maneira ([We93], [Ra96], [Gu96]). Na Figura 6(a)
está uma porta ou exclusivo feita com transistores de passagem. Neste caso apenas transistores N
foram usados na função de chave, o que causa a degradação do nível alto após o transistor de
passagem; seu valor máximo será (VDD-VTn), onde VTn é a tensão de limiar do transistor N. Para
contornar este problema é acrescido um transistor P de pull-up. As chaves podem ser também
construídas com dois transistores, um P e outro N. Como conseqüência disso, haverá o aumento da
área, a redução da velocidade e a necessidade de se fornecer, para cada sinal, o seu negado.
O circuito da Figura 6(b) apresenta uma outra alternativa no uso de transistores de passagem; é a
chamada Complementary Pass-Transistor Logic (CPL) [Ya90]. Aqui os circuitos são sempre
duplicados para fornecer o sinal e seu negado.
Portas lógicas com transistores de passagem são rápidas e simples para certas funções mas, quando
são necessários em série vários transistores de passagem, elas sofrem drástica redução na velocidade.
Acrescenta-se a isto que a degradação do nível alto pode ser um sério problema para circuitos com VDD
pequeno, acarretando a diminuição da velocidade.
Quando ao consumo de potência estática, as duas configurações apresentadas na figura não sofrem
problemas com isso.
Com exceção do transistor P de pull-up, as dimensões dos transistores apenas afetam a velocidade
do circuito (ratioless).

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
34
c=a⊕b
c
V D D
V SS
b
a
a
b
V D D
V SS
a⊕b
V D D
V SS
b
a
a
b
V D D
V SS
V D D
V SS
a
a
V D D
V SS
a⊕b
a) b)
Figura 6. Portas lógicas estáticas com transistores de passagem para a função c a b= ⊕ : (a), porta
simples com transistores N e (b), Complementary Pass-Transistor Logic (CPL).
2.2.1.4 Lógica Dinâmica CMOS
Na porta lógica dinâmica CMOS está presente apenas a estrutura PUN ou a PDN ([Go84], [We93],
[Ra96]). A operação do circuito tem duas fases: uma fase onde é feita a pré-carga da saída e outra onde
é feita a avaliação. A Figura 7(a) mostra um circuito n-dinâmico, onde a estrutura PDN, construída
com transistores N, é que está presente. Durante a fase de pré-carga, quando o sinal de clock é baixo, a
saída é levada para VDD. Durante a avaliação, quando o sinal de clock é alto, dependendo dos valores
das entradas, a saída é ou não descarregada via transistores N. Observe que, uma vez descarregado o
nó de saída, não há mais a possibilidade de carregá-lo durante a mesma fase de avaliação. Assim,
transições do tipo “1”→”0” na entrada desta porta podem ser causa de erros nos valores da saída. Por
exemplo, considere a porta da Figura 7(a) em avaliação e com os seguintes valores nas entradas:
a=”1”, b=”1” e c=”1”. Durante a avaliação a saída será descarregada. Pois bem, mesmo ocorrendo em
a uma transição “1”→”0”, a saída permanecerá em “0”, que não é o valor esperado.
A saída de uma porta n-dinâmica apresentará, na avaliação, apenas transições “1”→”0”. Veja
também que ela poderá, ainda na avaliação, estar desconectada tanto de VSS como de VDD,
característica dos circuitos dinâmicos.
A porta lógica p-dinâmica, Figura 7(c), tem sua pré-carga para "0" quando o sinal de clock é alto e
sua avaliação quando o sinal de clock é baixo. Nela, podem causar erros as transições do tipo “0”→”1”
na entrada. A saída, por sua vez, apresentará apenas transições do tipo “0”→”1” na avaliação.
As vantagens das portas dinâmicas são descritas abaixo:

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
35
• a carga capacitiva de entrada da porta é pequena, aumentando a velocidade dos circuitos;
• haverá consumo de potência na pré-carga, caso o valor pré-carregado anteriormente tenha sido
modificado, mas não haverá na avaliação;
• nas portas n-dinâmicas a função lógica é executada por transistores N, tornando o circuito mais
rápido.
• o funcionamento correto não depende das dimensões dos transistores (ratioless);
• o número de transistores é reduzido implicando em menores áreas.
Durante a fase de avaliação, diferentes problemas podem surgir que acabam por reduzir as margens
de ruído nas portas dinâmicas. Alguns deles são:
• charge leakage: perda da carga armazenada na saída devido às correntes de fuga;
• charge sharing: redistribuição da carga armazenada na saída pelos vários nós internos do PDN ou
do PUN;
• acoplamento capacitivo entre entradas e saída: quando uma das entrada tem seu valor alterado, a
saída sofre variações. No caso do acoplamento entre o clock e a saída chamamos de clock-
feedthrough.
É importante dizer que todos estes problemas têm como causa o fato que a saída pode ficar, na fase
de avaliação, em “alta impedância” ou seja, desconectada tanto do VDD como do VSS.
PDN a b
cc
a
d=a(b+c)
d
VSS
b
VDD
PUN( )d a b c= + ⋅( )d a b c= + PUN
trans. PPDN
trans. N
c)
VDD
VSS
a)
VDD
clock
clock
clock
clock
VSS
entrada
saída
b)
VDD
VSS
clock
clock
clock
clock
saída
d)
entrada
d
Figura 7. Portas lógicas dinâmicas para a função ( )d a b c= + : (a), representação com transistores da
porta n-dinâmica e (b), sua representação simplificada; (c), representação com transistores da porta
lógica p-dinâmica e (d), sua representação simplificada.
O uso de portas dinâmicas requer alguns cuidados para evitar a destruição da carga pré-carregada.
Por exemplo, duas portas n-dinâmicas não podem ser ligadas diretamente como feito na Figura 8(a),

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
36
pois o nó Si, levado para VDD durante a pré-carga, poderá, na fase de avaliação, descarregar
indevidamente a segunda porta dinâmica. O erro aparecerá quando a entrada a da primeira porta n-
dinâmica tiver nível alto, causando uma transição “1”→”0” em Si.
Apresentamos dois estilos de projeto para associações de portas dinâmicas em cascata e que evitam
tais problemas. A primeira é a lógica dominó [Kr82]. Ela consiste na colocação de inversores entre
duas portas dinâmicas (Figura 8(b)). Como “1”→”0” é a única transição possível na saída de um n-
dinâmico, durante a avaliação, o inversor garante que o sinal na entrada da segunda porta dinâmica
nunca tenha transições “1”→”0”, a que causa problemas. Outro estilo possível é o np-CMOS, que faz
parte da técnica NORA ([Go83], [Go84]), e consiste no uso alternado de uma porta n-dinâmica e outra
p-dinâmica (Figura 8(c)). Como a porta n-dinâmica não tem, na fase de avaliação, transições “0”→”1”
na saída, não haverá a descarga errônea na porta p-dinâmica seguinte; analogamente, como a porta p-
dinâmica não tem, na fase de avaliação, transições “1”→”0” na saída, não haverá a descarga errônea
na porta n-dinâmica seguinte.
Para que as duas portas lógicas, a p-dinâmica e a n-dinâmica, façam a avaliação ao mesmo tempo, é
necessário o uso do sinal de clock e do seu inverso, ou seja, o uso de duas fases para o sinal de clock. O
NORA, que veremos mais adiante, é uma técnica que emprega duas fases de clock.
a
VSS
PDNtrans. N
a)
VDD
clock
clock
clock
clock
entradasaída
b)
VDD
VSS
Si saída
c)
VDD
VSSVSS
PDNtrans. N
VDD
PUNtrans. P
VDD
VSS
saída
VSS
PDNtrans. N
clock
clock
entrada
VDD
clock
clock
Figura 8. Ligação de portas lógicas dinâmicas; (a), ligação sujeita a descarga indevida, (b), estilo de
projeto dominó e (c), estilo de projeto np-CMOS.
Comparações entre a potência consumida pelas portas dinâmicas e a consumida pelas portas
estáticas complementar CMOS, indicam vantagens para os circuitos dinâmicos [Ma96]. Uma análise
mais detalhada deve levar em conta, no entanto, a atividade da porta e de como suas entradas estão
sendo alteradas [Cha95].
Os problema com margens de ruído são a maior desvantagem das portas dinâmicas e exigem um
maior esforço de projeto.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
37
2.2.1.5 Lógica Dinâmica Clocked CMOS (C2MOS)
As portas/registradores C2MOS ([Go84], [We93], [Ra96]) têm, como as portas complementar
CMOS, tanto a estrutura PDN como a PUN (Figura 9). Além disso, o circuito apresenta um transistor
P entre PUN e a saída, cujo gate está ligado ao clock invertido, e um transistor N entre PDN e a saída,
cujo gate está ligado ao clock. Existem duas fases de operação no circuito: a fase de avaliação, clock
no nível alto, onde ambos os transistores ligados ao clock conduzem e o circuito opera como uma porta
complementar CMOS; a fase de holding, clock no nível baixo, onde ambos os transistores ligados ao
clock estão cortados e a saída retém a informação avaliada na fase anterior, funcionando como um
registrador. Assim o circuito C2MOS tem dupla função, uma como porta lógica e outra como
registrador latch.
Na fase de holding a saída do circuito fica em alta impedância e, por esta razão, o C2MOS tem
problemas semelhantes aos que aparecem na porta dinâmica: problemas de charge leakage e
acoplamento capacitivo entre entradas e saída. Caso os transistores ligados ao clock sejam deslocados
para junto do VDD, transistor P, e do VSS, transistor N, o circuito ficará mais veloz mas também passará
a sofrer de problemas de charge sharing.
As vantagens da porta/registrador C2MOS são:
• baixo consumo de potência;
• tem dupla função, operando como porta lógica e como registrador;
• o circuito é ratioless.
As desvantagens, em contrapartida, são:
• menor velocidade;
• maior área;
• problemas com margens de ruído.
Dada a dupla função do circuito, comparações de área, velocidade e potência são de fato um pouco
arbitrárias.
2.2.2 Registradores
Também aqui acompanharemos [Ra96] e classificaremos os circuitos registradores em estáticos e
dinâmicos. Nos circuitos registradores estáticos o que garante o armazenamento da informação é a
realimentação entre entrada e saída (feedback). Nos registradores dinâmicos, a informação fica
armazenada como carga em capacitores, necessitando ser periodicamente reforçada devido às correntes
parasitas. Este tipo de armazenamento é comum dentro das tecnologias MOS.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
38
P D N
a b
c
c
a
d = a (b + c )
d
V S S
b
V D D
P U N( )d a b c= + ⋅
( )d a b c= +
P U Ntr a n s . P
P D Ntr a n s . N
e n tra d a s a íd a
b )
V D D
V S S
a )
c lo c k
c lo c kc lo c k
c lo c k
M C PM C P
M C NM C N
Figura 9. Porta/registrador dinâmico C2MOS para a função ( )d a b c= + : (a), representação com
transistores e (b), sua representação simplificada.
2.2.2.1 Registradores Estáticos
Um dos exemplos mais simples de registrador estático é o latch pseudo-estático com transistores de
passagem da Figura 10(a). Neste circuito, quando o clock está alto, o sinal da entrada passa para a
saída Q. Quando está baixo, ocorre a realimentação da saída por meio dos dois inversores. Para o
correto funcionamento deste latch, não pode haver sobreposição dos sinais clock e clock . Isto é muitas
vezes difícil de ser garantido. Também neste circuito, como nas lógicas com transistores de passagem,
podemos utilizar apenas um transistor ou o par de transistores P e N para a função de chave. Um único
transistor nos fornece uma configuração mais simples mas o circuito sofrerá a degradação do nível
lógico alto. Isto é evitado com o par de transistores que, em contrapartida, necessita de dois sinais para
seu controle.
Outro exemplo de registrador estático está na Figura 10(b); um D-flip-flop formado por um circuito
diferencial associado a um flip-flop RS. Este registrador é sensível a borda do clock. Quando o sinal de
clock é alto, o nó R é forçado ao mesmo valor lógico da entrada e S, ao seu inverso. Estes valores são
então passados para a saída do flip-flop RS, com Q S= e Q R= . Estando o clock baixo, os nós R e S
vão para VDD, e o valor anterior da saída é armazenado na saída do flip-flop RS. Este tipo de registrador
foi usado no microprocessador Alpha 21264 da Digital [Gr98], que deve operar a 600MHz numa
tecnologia CMOS de 0,35µm.
Um aspecto interessante nos registradores estáticos é que o ruído os afeta menos. Outro aspecto
vantajoso, explorado no microprocessador Alpha 21264, é que a informação continua armazenada,

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
39
quase indefinidamente, mesmo quando o clock não é aplicado. Isto possibilita a utilização de clocks
condicionais para diferentes porções do circuito, sendo apenas ativados os sinais de clock das porções
que devem operar. Este recurso pode ser aplicado para redução do consumo de potência, tendo, como
custo, o aumento adicional nas dimensões do circuito.
a)
VDD
clockentrada
b)
VDD
VSSclock
entrada
clock
Q
Q
S
R
flip-flopRS
Figura 10. Registradores estáticos: (a), latch pseudo-estático com transistores de passagem e (b), D-
flip-flop com lógica diferencial.
2.2.2.2 Registradores Dinâmicos
O principal atrativo na utilização de registradores dinâmicos, que exigem um número menor de
transistores, é o aumento na densidade dos circuitos. Já apontamos que um circuito C2MOS, além de
fazer operação lógica, pode atuar como registrador latch. Este é um exemplo de registrador dinâmico e
nele são necessárias duas fases de clock para o funcionamento. Outros exemplos são os latches com
transistores de passagem da Figura 11. No latch da figura (a) é usado apenas um transistor N como
chave, estando sujeito a degradação do nível lógico; para evitar este problema pode-se usar dois
transistores em paralelo, um P e outro N, como na figura (b). Latches dinâmicos com dois transistores
de passagem foram empregados no microprocessador Alpha 21164 [Gr98]. Ambas as configurações
necessitam de apenas uma fase de clock.
Por fim, como último exemplo de registrador, mostraremos certos circuitos propostos por [Yu89]
para a técnica TSPC. Mais tarde daremos mais exemplos de latches aplicados nesta técnica. O latch da
Figura 12(a) é transparente para a entrada quando o clock é alto e armazena a saída quando ele é baixo.
O outro latch, Figura 12(b), tem a operação inversa.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
40
clock
entrada Q
entrada Q
clock
VSS
a) b)
Figura 11. Registrador latch dinâmico com transistor de passagem: (a), porta de passagem com um
transistor N e (b), com transistores N e P.
Q
V S S
V D D
e n tr a d a
b )a )
c lo c k Q
V S S
V D D
e n tr a d a
c lo c k
Figura 12. Latches dinâmicos TSPC: (a), armazena o dado quando o clock é baixo e (b), armazena o
dado quando o clock é alto.
2.2.3 Políticas de clock
Várias políticas de clock foram propostas ao longo do tempo. Políticas com múltiplas fases
permitem uma utilização do tempo mais eficiente, resultando em desempenho melhor [Ra96]. O
problema surge com a distribuição destas múltiplas fases, normalmente com restrições quanto a
sobreposição delas. A tendência em circuitos de alta velocidade CMOS VLSI é a utilização de um
único clock ([We93], [Ra96]), simplificando a tarefa da distribuição deste.
Mostraremos aqui duas estratégias de clock indicadas para circuitos de alto desempenho; o NORA e
o TSPC.
2.2.3.1 Estratégia com duas fases de clock NORA
A técnica NORA, No-Race CMOS Technique ([Go83], [Go84]), permite a utilização de portas
lógicas estáticas complementar CMOS, portas dinâmicas e portas C2MOS. Para registrador é
empregado apenas o C2MOS. São usadas duas fases complementares de clock no NORA, φ1 e φ2.
Devido a isto são possíveis 4 diferentes configurações de portas lógicas dinâmicas: duas configurações
de portas n-dinâmicas, uma controlada pela fase φ1 e outra pela φ2; duas configurações de portas p-
dinâmicas, analogamente. Também são disponíveis duas configurações diferentes para os latches
C2MOS. Regras de composição para as portas e registradores completam a estratégia. Elas foram

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
41
criadas para evitar os problemas de race: os delay race errors e os clock skew race errors. O delay dos
sinais que chegam aos blocos dinâmicos pode causar a perda do valor pré-carregado na sua saída e, em
conseqüência, a incorreta avaliação do bloco. Este é o chamado delay race error. O clock skew entre as
duas fases do clock de um circuito NORA pode, por sua vez, causar avaliação incorreta tanto em
circuitos dinâmicos como em C2MOS latches, o chamado clock skew race error.
O estilo np-CMOS é usado aqui. Uma vez obedecidas às regras de composição, o circuito projetado
tolerará sobreposição das fases, podendo ser, dessa forma, empregadoφ1 = clock e φ2 = clock . Por esta
razão, muitas vezes, o NORA é dito ser uma estratégia de uma única fase de clock [We93].
As regras do NORA são aplicadas sobre os chamados data chains, φ1-data chains e φ2-data chains.
Um φ1-data chain é um caminho de propagação de dados, signal propagation path, onde, durante a
fase φ1 1=" " , todas as portas e registradores estão em avaliação e, durante a fase φ1 0=" " , todas as
portas e registradores estão em pré-carga ou em holding. Um φ2-data chain faz avaliação durante a
fase φ2 1=" " e pré-carga/holding quando φ2 0=" " . A Figura 13 apresenta um exemplo de circuito
NORA com data chains assinalados, um φ1-data chain e um φ2-data chain.
VDD
φ2
φ1
VSS
PUNtrans. P
VDD
VSSVSS
PDNtrans. N
entrada
VDD
φ1
φ1 φ2
φ2
saída
VSS
PDNtrans. N
VDD
φ2
φ2
φ2
φ1
VSS
VDD
φ1-data chain
φ2-data chain
Figura 13. Exemplo de circuito NORA.
A técnica NORA permite melhora na velocidade, menores áreas e consumo de potência além de
evitar disputa de sinais. Em contrapartida, a utilização de elementos dinâmicos, portas lógicas e
registradores, traz problemas de charge sharing, charge leakage, acoplamento capacitivo e
sensibilidade ao ruído. Isto dificulta o projeto, devendo a técnica ser aplicada somente quando máxima
performance é procurada.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
42
2.2.3.2 Estratégia com uma fase de clock TSPC
O True Single Phase Clock, TSPC, é uma estratégia que utiliza de fato um único clock. Um dos
primeiros trabalhos sobre o TSPC é [Yu87]. Mais tarde, novos aspectos foram abordados e
aprofundados em [Yu89] e [Af90]. Em [La95], por fim, um enfoque mais geral foi desenvolvido.
Apresentaremos aqui, com um pouco de detalhes, o TSPC como elaborado em [La95].
2.2.3.2.1 Portas Lógicas e Registradores
As portas lógicas que podem ser usadas no TSPC são as portas estáticas complementar CMOS,
dinâmicas e portas data precharged (Figura 15), que serão vistas mais adiante. São introduzidos
também novos tipos de circuitos que podem executar operações lógicas e ajudam como registrador;
não são, no entanto, registradores completos. Chamaremos estes circuitos de n-latch e p-latch (Figura
14). Ambos circuitos apresentam as estruturas PUN e PDN e são ratioless. A diferença entre eles está
no tipo de transistor cujo gate está ligado ao clock. Para o n-latch é um transistor N e durante a fase
clock=”1” sua saída será função lógica dos sinais de entrada; diremos que está na avaliação. Quando o
clock é baixo, por outro lado, apenas transições “1”→”0” na entrada poderão alterar a saída; diremos
que o circuito está em holding. Observemos que o nome holding é aqui empregado apenas por
analogia pois a saída do n-latch não retém necessariamente seu valor durante esta fase.
O p-latch tem a fase de avaliação quando clock=”0” e holding quando clock=”1”, ao contrário do n-
latch. No holding destes circuitos, as transições “0”→”1” é que poderão afetar a saída.
a
VSS
PDNtrans. N
clock clock
VDD
saída
VDD
VSS
PUNtrans. P
entradad
b
a
clock
VDD
VSS
b
VSS
PDNtrans. N
clock
VDD
saída
PUNtrans. P
entrada
d ab= d ab=
d
a) b) c) d)
Figura 14. Circuitos n-latch e p-latch: (a), representação com transistores e (b), representação
simplificada do n-latch; (c), representação com transistores e (d), representação simplificada do p-
latch.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
43
A posição indicada na Figura 14 para os transistores ligados ao clock, próximo ao VSS no n-latch e
ao VDD no p-latch, segue a sugestão de [Hu93]. Esta configuração apresenta vantagens em termos de
velocidade do circuito mas sofre maiores problemas de charge sharing. A colocação destes transistores
mais próximo da saída do circuito é uma opção que reduz o charge sharing, não obstante afeta a
velocidade.
As portas data pre-charged, Dp, são pouco conhecidas e utilizadas. Daremos, em vista disso, alguns
detalhes sobre a sua construção. Tais portas são apresentadas em [Yu93] e elas dão maior flexibilidade
à técnica TSPC. A idéia aqui é obter uma porta que é um misto entre a estática complementar e a
dinâmica; neste caso a pré-carga não é executada pelo sinal de clock mas sim por alguns dos sinais de
entrada da própria porta. Aqueles sinais de entrada responsáveis pela pré-carga serão por nós
chamados de pc-entradas (pre-charging entradas). Podemos ainda dividir as portas Dps em duas
classes: uma formada pelas portas em que a pré-carga é feita quando as pc-entradas estão no nível alto,
portas PH (pre-charged in high), e outra formada pelas portas em que a pré-carga é feita quando as pc-
entradas estão no nível baixo, portas PL (pre-charged in low).
A Figura 15 exemplifica a formação de portas PH e PL para a função lógica d a(b c)= + . Elas são
formadas a partir de uma porta estática complementar (Figura 15(a)) que executa a mesma função
lógica. Tratemos com detalhes a porta PH. Nela a estrutura implementada pelos transistores P é igual a
aquela da porta estática; apenas a estrutura com os transistores N é modificada. Na pré-carga da porta
PH sua saída dever ir para o nível lógico baixo o que é conseguido forçando-se todas as entradas
ligadas aos transistores N para o nível alto. Durante a avaliação, tem-se que os transistores P, da
mesma forma que na porta estática, fazem a avaliação lógica das entradas, ligando ou não a saída do
circuito a VDD. Pois bem, no caso da saída ter valor alto, não deverá surgir nenhuma ligação entre esta
e VSS. Assim, a função da estrutura implementada com transistores N é descarregar a saída na pré-carga
e evitar o aparecimento de um curto entre VDD e VSS na avaliação. Essa estrutura N não executa,
necessariamente, uma função lógica igual a da porta. Pare obter a nova configuração dos transistores
N, podemos partir daquela encontrada na porta estática e, para cada conjunto de k ramos em paralelo aí
encontrados, cortarmos k-1 deles. O processo está exemplificado na Figura 15. É livre a escolha de
quais ramos são cortados, possibilitando o surgimento de diferentes circuitos, como é visto na figura.
Para as portas PL, será modificada, em contraposição, a estrutura formada pelos transistores P. O
raciocínio é, no entanto, análogo.
Observemos que as pc-entradas de uma porta PH são todas aquelas ligadas a transistores N; as pc-
entradas de uma porta PL são todas aquelas ligadas a transistores P. A Figura 15 indica também as pc-
entradas em cada configuração.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
44
Para o funcionamento destas portas devemos garantir que as pc-entradas tenham valores corretos
durante a pré-carga. Isto é feito através do emprego de outros circuitos convenientemente associados
as portas Dps.
Chamaremos de blocos n-Dps aos blocos PH ou PL que fazem a pré-carga quando clock=”0”, ao
menos no fim dessa fase, e de blocos p-Dps aos blocos PH ou PL que fazem a pré-carga quando
clock=”1” (ao menos no fim dessa fase).
a b
c
c
d
a b
c
b )
a
bd
aa b
c
c
a
d = a (b + c )
d
a )
a
c
a
d
b
b
b
c
c
a
d
b
p c -e n tra d a : a , bn ã o -p c -e n tra d a : c
p c -e n tra d a : a , cn ã o -p c -e n tra d a : b
p c -e n tra d a : an ã o -p c -e n tra d a : b , c
p c -e n tra d a : b , cn ã o -p c -e n tra d a : a
c )
O U
O UV D D
V D D V D D
V D D V D D
V S S V S S
V S S V S S
Figura 15. Transformação de uma porta estática complementar CMOS (a) em portas data pre-
charged Dp: (b), portas PH e (c), portas PL.
Para simplificação, tanto aqui como quando estivermos falando do E-TSPC, chamaremos
genericamente de blocos tanto as portas lógicas usadas na técnica como os latches. No texto esses
blocos serão designados pela letra B e, quando necessário, mais um índice será acrescido; os índices
poderão conter indicações do tipo de bloco (St para estático, Nd para n-dinâmico, Pd para p-dinâmico,
Dp para data precharged, NL ou PL para os latches, etc.), números e letras. Exemplos de nomes de
blocos são: BST1, BHDpA e BF.
2.2.3.2.2 Regras de Composição
As ligações permitidas no TSPC, de acordo com [La95], estão sumariadas no diagrama da Figura
16. Observemos que os latches apontados na Figura 12, apesar de não poderem ser construídos com os
blocos considerados acima, também fazem parte da técnica TSPC. A introdução deles no circuito, uma
vez que são latches verdadeiros com uma fase de holding que retém a informação, é uma tarefa
simples.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
45
O diagrama fornece adicionalmente informações sobre problemas que podem ocorrer devido aos
atrasos diferenciados nos sinais de clock que chegam a blocos interligados, clock skew. Para entender
este ponto considere uma porta n-dinâmica com saída ligada a um n-latch. Se o sinal de clock chegar
antes no bloco que no n-latch, devido aos atrasos diferenciados no circuito de distribuição de clock,
teremos que o bloco dinâmico estará em pré-carga e o n-latch em avaliação. Isto poderá causar erros.
Atrasos diferenciados no clock aparecem devido às dissimetrias no seu circuito de distribuição e são
inevitáveis. O melhor que pode ser feito é o controle do valor dos atrasos por meio de um projeto
cuidadoso de buffers ([Do92], [Gr98]).
##
#◊
#
◊
PL
PL
PH
PH
N-latch *
P-latch *
N-latch P-latchN-dinâm. P-dinâm.
Figura 16. Gráfico de conexões para o TSPC de acordo com [La95]. As portas e circuitos são
representados pelos quadrados. O fluxo de dados permitido é indicado pelo sentido das setas. # indica
ligações onde atrasos diferenciados do clock nos blocos não causam problemas (skew safe
communication); * indica pontos de latch depois dos quais portas estáticas complementar CMOS
podem ser inseridas; ◊ indica ligações onde há problemas potenciais de violação de holding time.
Outra questão assinalada são as configurações onde há o perigo de violação de hold time. O caso
mais comum de possível violação surge no D-flip-flop clássico do TSPC, apresentado na Figura 17.
Para examinar tal violação consideremos um estado inicial onde clock=entrada=saída_a=”0”. Neste
instante os blocos BL1 e BL4 estão avaliando. No fim da fase de avaliação ambas as saídas, a1 e b1,
estão no nível alto. Na seqüência, quando o clock muda para nível alto, os outros blocos irão para a
avaliação. Suponha que a1 funcione propriamente e retenha o valor alto. Neste caso, o nó a2 vai para
baixo, a saída_a, para alto e b1 vai para nível baixo. Em conseqüência o transistor N1 é cortado e o
valor na saída do bloco BL5, b2, dependerá do holding time deste bloco. Assim, caso a mudança em b1
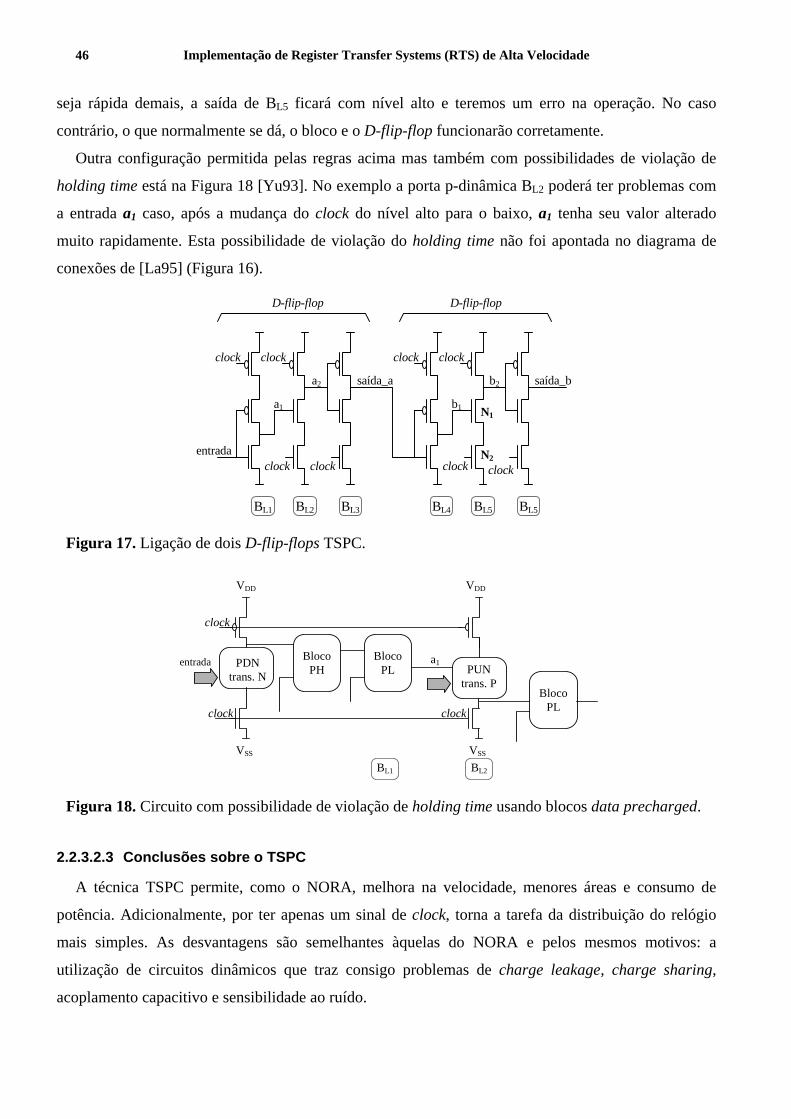
Implementação de Register Transfer Systems (RTS) de Alta Velocidade
46
seja rápida demais, a saída de BL5 ficará com nível alto e teremos um erro na operação. No caso
contrário, o que normalmente se dá, o bloco e o D-flip-flop funcionarão corretamente.
Outra configuração permitida pelas regras acima mas também com possibilidades de violação de
holding time está na Figura 18 [Yu93]. No exemplo a porta p-dinâmica BL2 poderá ter problemas com
a entrada a1 caso, após a mudança do clock do nível alto para o baixo, a1 tenha seu valor alterado
muito rapidamente. Esta possibilidade de violação do holding time não foi apontada no diagrama de
conexões de [La95] (Figura 16).
clock
a1
BL1 BL2
clock
clock clock
entrada
a2
BL3
clock
b1
BL4 BL5
clock
clock clock
b2
BL5
saída_a saída_b
N1
N2
D-flip-flop D-flip-flop
Figura 17. Ligação de dois D-flip-flops TSPC.
PDNtrans. N
VDD
VSS VSS
PUNtrans. P
entrada
VDD
clock
clock
clock
BlocoPH
BlocoPL
BlocoPL
BL1
a1
BL2
Figura 18. Circuito com possibilidade de violação de holding time usando blocos data precharged.
2.2.3.2.3 Conclusões sobre o TSPC
A técnica TSPC permite, como o NORA, melhora na velocidade, menores áreas e consumo de
potência. Adicionalmente, por ter apenas um sinal de clock, torna a tarefa da distribuição do relógio
mais simples. As desvantagens são semelhantes àquelas do NORA e pelos mesmos motivos: a
utilização de circuitos dinâmicos que traz consigo problemas de charge leakage, charge sharing,
acoplamento capacitivo e sensibilidade ao ruído.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
47
Uma outra dificuldade é normalmente apontada em circuitos TSPC ([Do92], [Ra96]): caso os
tempos de subida e descida do sinal de clock sejam grandes, poderá haver ocasiões quando todos os
transistores ligados ao clock, tanto os transistores P como os N, conduzirão; a conseqüência será o race
no circuito.
O estudo deste problema feito por [La94] mostra que as condições para evitar este race são simples
de serem implementadas (o fan out do buffer de clock deve ser inferior a 10). Também em [Do92] tal
dificuldade é analisada e tida como facilmente superável.
2.3 Estratégia E-TSPC
Esta seção é dedicada a descrição da estratégia E-TSPC. Serão apresentados os blocos nela
permitidos, as regras de composição, a função destas e a prova do funcionamento correto dos circuitos.
Uma apresentação simplificada do E-TSPC, principalmente no que diz respeito aos teoremas e suas
demonstrações, é apresentada em [Na97c]. O trabalho desenvolvido nesta seção é mais longo e
rigoroso. [Na97c] poderá servir, então, como uma introdução para o estudo desta seção.
2.3.1 Blocos da E-TSPC
Os blocos que são usados na técnica E-TSPC são:
i. portas lógicas estáticas complementar CMOS (chamada de estática simplesmente) (Figura 4);
ii. portas lógicas CMOS dinâmicas, tanto n-dinâmicas como p-dinâmicas (Figura 7);
iii. blocos latches, tanto n-latches como p-latches (Figura 14);
iv. portas data pre-charged CMOS n-Dp ou p-Dp, tanto PH como PL (Figura 15).
Cada um dos blocos usados tem uma única saída e um número finito de entradas.
O conjunto das entradas de um bloco BQ qualquer será denotado por I(BQ), não sendo considerado
o clock como entrada. A saída deste bloco será denotada por OBQ. Serão usadas letras minúsculas
handwriting, mais um índice quando necessário, para denotar uma entrada ou a saída de um bloco, por
exemplo: a, k0.
2.3.2 Regras de composição
Nesta seção serão apresentadas as regras de composição e sua finalidade.
2.3.2.1 Definições
Estabeleceremos preliminarmente algumas definições, tanto de nomenclatura como de simbologia.
Apesar de monótona, tanto para quem escreve como para quem lê, a tarefa não pode deixar de ser feita
sob o risco de causar dificuldades na compreensão do texto.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
48
Definição 1: Ligação elétrica é um meio físico qualquer que une eletricamente dois pontos que
podem ser: entradas de blocos, saídas de blocos.
Uma ligação entre i1 e OBSt1 será denotada por (i
1, OBSt1).
Para os blocos considerados aqui, a saber, portas estáticas complementar CMOS, dinâmicos, Dps e
latches, certas ligações não devem ser permitidas. Por exemplo, dois blocos quaisquer não podem ter
suas saídas ligadas uma a outra. Em vista disto vamos definir o que entendemos por circuito.
Definição 2: Um circuito E-TSPC é um conjunto finito de blocos (complementar CMOS, n ou p
dinâmicos, n ou p “latches”, ou CMOS Dps) e um conjunto ligações entre eles. Estas são sempre
entre uma entrada e uma saída de bloco. As entradas de “clock” de todos os blocos são ligadas
entre si e genericamente chamadas de “clock” do circuito. As entradas de blocos são chamadas de
entradas do circuito quando não participam de nenhuma ligação; dentre estas algumas são
definidas como entradas externas do circuito. Algumas das saídas de blocos são definidas como
saídas externas do circuito.
Usaremos a letra C e mais um índice, se necessário, para nomear os circuitos E-TSPC. Indicaremos
por B(CE) o conjunto dos blocos que compõem CE, por L(CE) o conjunto das ligações do circuito, por
I(CE) o conjunto das entradas externas e por O(CE) o conjunto das saídas externas. Um sinal aplicado
a uma entrada externa é chamado de sinal externo. Se a entrada ou saída i1 do bloco BQ faz parte de
alguma ligação do circuito CE, ou do seu conjunto de entradas externas ou do seu conjunto de saídas
externas, então diremos que CE passa por i1; também diremos, neste caso, que i
1 é um ponto do
circuito e que BQ pertence ao circuito. Por simplicidade vamos admitir que os pontos do circuito
podem estar apenas ou no nível lógico baixo ou no nível lógico alto. Notemos que quando (a, b) ∈
L(CE), os pontos a e b têm o mesmo comportamento. Quando o clock do circuito está com nível
lógico zero, diremos que o circuito está na fase φ=”0”; quando o clock está com nível lógico um,
diremos que está na fase φ=”1”.
Para representar as ligações de um circuito podemos usar alternativamente o conjunto de pares
ordenados LO(CE) definido abaixo.
Definição 3: Seja o circuito E-TSPC CE. O conjunto de pares ordenados LO(CE) é definido como:
(a, b) ∈ LO(CE) ⇔ ((a, b) ou (b, a) é uma ligação de CE e a é entrada de bloco).
Por sua vez b é a saída de algum bloco de CE.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
49
Se CE é um circuito, poderemos escrever as três propriedades abaixo:
• BA ∈ B(CE) ⇒ BA é (bloco estático, ou bloco dinâmico, ou bloco Dp ou latch);
• (a, b) ∈ L(CE) ⇒ (∃BA e BC ∈ B(CE)) t.q. (((a ∈ I(BA)) ∧ (b = OBC)) ∨ ((b ∈ I(BA)) ∧ (a =
OBC))).
• i ∈ I(CE) ⇒ (∃BA ∈ B(CE) t.q. (i∈I(BA))) ∧ (∀(a, b) ∈ LO(CE), (a≠i)).
Vamos precisar usar o conceito de subcircuito mais adiante. Damos a definição abaixo.
Definição 4: O circuito E-TSPC CS é um subcircuito de CE se:
i. B(CS) ⊆ B(CE);
ii. L(CS) ⊆ L(CE);
iii. para todo i ∈ I(CS) ⇒ ((i ∈ I(CE)) ∨ (∃(a, b ) ∈ LO(CE) t.q. (a =i )));
iv. para todo o ∈ O(CS) ⇒ ((i ∈ O(CE)) ∨ (∃(a , b ) ∈ LO(CE) t.q. (b =o ))).
Sendo CS um subcircuito de CE, indicaremos por CS⊆CE. A definição abaixo trata da acessibilidade
de um bloco a outro.
Definição 5: Sejam Bi e Bj dois blocos de um circuito CE. Diremos que Bj é acessível a partir de Bi
se existe uma seqüência de blocos B1, B2, ...,Bs, tal que
B1=Bi, BS=Bj
e existe (OBi, t ) ∈ LO(CE) t.q. t ∈ I(Bi+1) para todo i=1, 2,, ..., s-1.
Vamos definir agora o que é um caminho de propagação de dados. Procuramos colocar nessa
definição exatamente aquilo que temos na intuição sobre tal conceito.
Definição 6: Um “signal propagation path”, spp, de CE é um subcircuito Cspp, com uma única
entrada e uma única saída, o qual obedece às condições:
i. contém ao menos um bloco BE a partir do qual todos os blocos do circuito Cspp são acessíveis;
ii. contém um bloco BO que é acessível a partir de qualquer bloco do circuito Cspp;
iii. a saída de todo bloco de B(Cspp), exceção do bloco B0, está ligada a apenas um bloco de Cspp; a
saída de BO pode estar ligada ou não a um bloco;
iv. uma das entradas de BE é a única entrada de Cspp;
v. a saída do bloco BO é a única saída do Cspp.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
50
Os spps serão nomeados com a letra S mais um índice, quando necessário.
Seja o spp Si. Este é também um circuito, logo podemos falar dos conjuntos B(Si), L(Si), LO(Si),
I(Si), ou simplesmente ISi, e O(Si) ou OSi. Ainda são aplicáveis aqui os conceitos de Si passando por i
e de ponto de Si. Se um bloco pertence ao spp diremos que este passa por aquele. As definições de
subcircuitos e de acessibilidade de blocos podem ser estendidos aos spps (definições 4 e 5).
Definição 7: Diremos que um bloco BA antecede um bloco BB no spp se:
i. ambos os blocos pertencem ao mesmo spp;
ii. o bloco BB é acessível a partir do bloco BA.
Diremos também que um bloco é o último de um spp se todos os outros antecedem a ele; será o
primeiro caso anteceda todos os outros.
Definição 8: Diremos que o spp é não cíclico quando nenhum bloco do spp é atingível a partir de si
mesmo.
Apresentaremos a definição de data chain que é fundamental para a compreensão das regras de
composição. Um n-data chain é um spp onde, durante a fase φ=”1”, todos os blocos estão em
avaliação e, durante a fase φ=”0”, parte do seus blocos está em holding (os latches) e parte em pré-
carga (os blocos dinâmicos e Dps). O p-data chain tem os blocos em avaliação na fase contrária ao n-
data chain.
Definição 9: Um n-data chain do circuito CE é um spp não cíclico SNC que obedece às seguintes
condições:
i. contém ao menos um n-latch, um n-dinâmico ou um bloco n-Dp;
ii. a entrada do SNC deve estar ligada a uma entrada externa de CE ou a saída de algum bloco p-
latch, p-dinâmico ou p-Dp;
iii. contém apenas blocos estáticos, n-dinâmicos, n-Dps e n-latches;
iv. a saída do SNC deverá estar ligada a entrada de algum bloco p-latch, p-dinâmico ou p-Dp ou a
nenhum outro bloco de CE.
Notemos que os blocos estáticos no início de um data chain podem pertencer também ao data chain
anterior, sendo este e aquele de tipos diferentes. A definição desta forma não causa maiores problemas
e simplifica a apresentação de algum teoremas.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
51
Definição 10: Um p-data chain do circuito CE é um spp SPC que obedece à condições equivalentes à
(i), (ii), (iii) e (iv) da Definição 9. Neste caso substituem-se "n" por "p" e "p" por "n" em todas as
denominações de blocos que aparecem.
Usaremos a letra D e mais um índice, quando necessário, para nomear os data chains. Normalmente
se o índice inicia com N, teremos um n-data chain, por exemplo DN1; quando inicia com P, teremos
então um p-data chain.
Tudo quanto foi dito para os spps, sobre conjunto de blocos, conjunto de pares ordenados, etc.,
também vale para data chains, visto que data chains são um tipo especial de spp.
Definição 11: Diremos que um n-data chain está na fase de “holding” quando o “clock” tem valor
“0” (φ=”0”). Quando o “clock” tem valor “1” (φ=”1”), é dito que o n-data chain está na
avaliação. Para o p-data chain, o “holding” acontece quando φ=”1” e a avaliação, quando φ=”0”.
Veja que o estado de operação de um bloco Dp não depende diretamente do clock e, a princípio,
nada garante que estes blocos façam a pré-carga no momento certo. Isto dependerá sim dos blocos que
estão ligados a ele.
A Figura 19 fornece alguns exemplos de data chains. Com entrada no nó ia existem dois n-data
chains: um passando pelos blocos BA, BC, BE, BG, BJ e BM, sendo a saída deste último a saída do data
chain; outro passando pelos blocos BA, BC, BE, BK, e BH, sendo a saída deste último a saída do data
chain. Com entrada no nó ih aparece um p-data chain passando pelos blocos BH, BF e BD, sendo a
saída deste último bloco a saída do data chain.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
52
c lo c k
P D Ntr a n s . N
c lo c k
c lo c k
P D Ntr a n s . N
P U Ntr a n s . P
P D Ntr a n s . N
c lo c k
P U Ntr a n s . P
P D Ntr a n s . N
c lo c k
P U Ntr a n s . P
P D Ntr a n s . N
c lo c k
c lo c k
c lo c k
c lo c k
c lo c k
B A
B B
B D
B E
B G
B I
B L
B J
B K
B M
B Ci
a
ic 2
ii
B H
B F
ih
ic 1
Figura 19. Circuito E-TSPC com exemplos de data chains.
2.3.2.2 Descrição das Regras
Os blocos utilizados no E-TSPC exigem uma série de cuidados para o correto funcionamento.
Abaixo descreveremos tais cuidados:
• as entradas dos blocos n-dinâmicos e dos blocos PL não devem nunca sofrer transições “1”→”0”
durante sua avaliação. Observe que, se uma das entradas de um destes blocos tiver valor “1”
durante a avaliação, poderá haver a descarga da saída. Neste caso, se esta entrada muda para “0”,
ainda na mesma avaliação, não poderemos garantir que a saída volte para “1”, se for necessário.
Para exemplificar um funcionamento faltoso considere na Figura 15(c) o circuito PL mais a
esquerda. Inicialmente sejam os seguintes valores para as entradas: a=”1”, b=”0” e c=”1” (a porta
em avaliação); então a saída terá valor d=”0”. Havendo uma transição “1”→”0” em c, a saída
permanecerá em “0”, que não é o valor desejado. Na seção 2.2.1.4 foi discutido o mesmo
problema para as portas dinâmicas;
• as entradas dos blocos p-dinâmicos e dos blocos PH não devem nunca sofrer transições “0”→”1”
durante sua avaliação. As razões são similares as apresentadas acima;
• as pc-entradas dos blocos PH devem ir para “1” durante a fase de pré-carga; as pc-entradas dos
blocos PL devem ir para “0” durante a fase de pré-carga. Como vimos na descrição do
funcionamento dos blocos Dps, isto é necessário para a pré-carga;

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
53
• se desejamos que certo n-latch mantenha o seu valor de saída durante a sua fase de holding, então
nenhuma de suas entradas poderá sofrer uma transição “1”→”0” durante o holding (ver seção
2.2.3.2.1);
• se desejamos que certo p-latch mantenha o seu valor de saída durante a sua fase de holding, então
nenhuma de suas entradas poderá sofrer uma transição “0”→”1” durante o holding (ver seção
2.2.3.2.1).
As regras de composição que serão apresentadas servirão para garantir que
durante a fase de avaliação do data chain:
e1. todas as entradas dos blocos n-dinâmicos e PL tenham apenas transições “0”→”1”;
e2. todas as entradas dos blocos p-dinâmicos e PH tenham apenas transições “1”→”0”.
e durante a fase de holding do data chain:
h1. todas as pc-entradas dos blocos PL estejam em “0”;
h2. todas as pc-entradas dos blocos PH estejam em “1”;
h3. todo n-data chain tenha ao menos um n-latch em cujas entradas, durante todo o holding, não
ocorrerem transições do tipo “1”→”0”;
h3. todo p-data chain tenha ao menos um p-latch em cujas entradas, durante todo holding, não
ocorrerem transições do tipo “0”→”1”.
2.3.2.2.1 Regras r1 a r5
Cinco regras de composição, r1 a r5, são descritas abaixo.
Regra de Composição 1 (r1): Se um bloco Dp for o primeiro bloco não estático do data chain, então
este data chain não pode passar por nenhuma de suas pc-entradas.
Os outros blocos e as entradas que não são as pc-entradas do bloco Dp estão livres de quaisquer
restrições. A regra é necessária para que h1 e h2 possam ser garantidos na fase de holding.
Regra de Composição 2 (r2): Um latch não deve anteceder a um bloco dinâmico ou a um bloco Dp
dentro do mesmo data chain.
Em outras palavras, a saída de um latch não pode ser ligada a um bloco dinâmico ou bloco Dp,
direta ou indiretamente, no data chain. Está regra é necessária para que e1 e e2 possam ser garantidos
na fase de avaliação.
Regra de Composição 3 (r3’): Dentro de um data chain o número de inversões lógicas entre:

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
54
r3a. dois blocos dinâmicos adjacentes deve ser ímpar;
r3b. dois blocos Dps adjacentes do mesmo tipo, sejam dois blocos PH ou PL, deve ser ímpar;
r3c. dois blocos Dps adjacentes de tipos diferentes, um PH outro PL, deve ser par;
r3d. um bloco PH (PL) adjacente a um bloco n (p) dinâmico, ou vice-versa, deve ser par;
r3e. um bloco PL (PH) adjacente a um bloco n (p) dinâmico, ou vice-versa, deve ser ímpar.
(os blocos serão chamados adjacentes se entre eles existirem apenas blocos estáticos).
Esta regra restringe quais blocos podem ser ligados a quais blocos dentro de um data chain. Ela
deve ser observada devido ao e1, e2, h1 e h2.
Podemos enunciar a regra r3’ de uma forma mais simples mas equivalente. Abaixo é dado esta
forma alternativa.
Regra de Composição 3 (r3): Dentro de um data chain o número de blocos entre:
r3a. dois blocos dinâmicos quaisquer deve ser ímpar;
r3b. dois blocos Dps do mesmo tipo, sejam dois blocos PH ou PL, deve ser ímpar;
r3c. dois blocos Dps de tipos diferentes, um PH outro PL, deve ser par;
r3d. um bloco PH (PL) e um bloco n (p) dinâmico, ou vice-versa, deve ser par;
r3e. um bloco PL (PH) e um bloco n (p) dinâmico, ou vice-versa, deve ser ímpar.
Desde que todos os blocos usados no E-TSPC são inversores, é fácil ver que se um data chain
obedecer à regra simplificada, r3, então também obedecerá ao que foi determinado na versão mais
completa. Também é fácil observar que o contrário é verdade: uma vez que o data chain obedece à r3’,
então r3 será satisfeita. Não obstante a forma r3 ser mais compacta e elegante, r3’ é mais simples de ser
aplicada.
Regra de Composição 4 (r4): Considere o último bloco dinâmico BDy de um data chain (se existir
algum). Deverá existir ao menos um latch BL neste data chain com um número par de blocos
(número par de inversões) entre BDy e BL.
Nesta regra obviamente BDy deve anteceder BL.
Está regra visa ao h3 e h4.
Regra de Composição 5 (r5): Em um data chain qualquer deve haver uma das duas configurações:
r5a. ao menos um bloco dinâmico e um latch;
r5b. ao menos dois latches e um número par de blocos (número par de inversões) entre eles.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
55
A regra r4 quando associada à r5a obriga que o data chain possua ao menos um bloco dinâmico e
um latch, com um número par de inversões entre eles. Novamente estas regras visam ao h3 e h4.
No APÊNDICE A, estas cinco regras são associadas em uma única regra geral.
Na Figura 19 aparecem sete n-data chains completos: dois deles com entrada em ia, dois com
entrada em ic1
, dois com entrada em ic2
e um n-data chain com entrada em ii. Todos eles obedecem às
cinco regras de composição.
As regras aqui colocadas são análogas àquelas apresentadas na técnica NORA ([Go83], [Go84]).
NORA, como vimos, utiliza duas fase de clock. Dois tipos de problemas enfrentados aí são os delay
race errors e os clock skew race errors. Regras muito semelhantes as regras r1, r2 e r3 aqui fornecidas
foram criadas no NORA para evitar os delay race errors. A motivação, portanto, para as três primeiras
regras da estratégia NORA e para r1, r2 e r3 é semelhante. Regras semelhantes a r4 e r5 são usadas para
evitar os clock skew race errors. Na E-TSPC, onde não há clock skew errors (ao menos com blocos
locais ([Af90], [La95]), estas duas regras servem para garantir que, durante o holding, haja em cada
data chain ao menos um latch que mantenha sua saída constante.
Vamos apresentar, por fim, o que chamamos de circuito RTS E-TSPC. Este é um circuito composto
de data chains, n ou p, e todos esses observam as regras de composição; também impomos que todas
as entradas de blocos que não estão ligadas a nenhuma saída de bloco sejam entradas externas do
circuito.
Definição 12: Um circuito CE será chamado de circuito RTS E-TSPC se para qualquer spp Sq de CE
ocorre que:
i. existirá um n-data chain DNi de CE tal que Sq ⊆ DNi, se o spp for formado por apenas blocos n-
dinâmicos, n-Dps e n-latches, ao menos um desses, e mais blocos estáticos;
ii. existirá um p-data chain DPi de CE tal que Sq ⊆ Dpi, se o spp for formado por apenas blocos p-
dinâmicos, p-Dps e p-latches, ao menos um desses, e mais blocos estáticos;
iii. existirá um p-data ou um n-data chain Di de CE tal que Sq ⊆ Di, se o spp for formado por apenas
blocos estáticos;
iv. as regras r1-r5 são observadas para todos os data chains;
v. todas as entradas do circuito são entradas externas.
2.3.2.2.2 Blocos Dps e data chains do circuito

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
56
As definições de data chains e, portanto, de circuitos RTS E-TSPC apresentam uma importante
dificuldade. Diz respeito ao uso dos blocos Dps e à distinção entre os n-Dps e os p-Dps, suposta
possível. Todos os blocos usados no E-TSPC podem ser classificados, quanto ao seu tipo, por meio de
inspeção direta, exceção aos blocos Dp. Neles a semelhança estrutural entre os n-Dps e os p-Dps
impede tal classificação.
Em vista disto, surgem duas dúvidas de caráter prático:
i. afinal como poderemos saber se o bloco que colocamos é um n-Dp ou um p-Dp? Como
poderemos saber se o data chain é n ou p? Será possível, em resumo, desenhar um circuito RTS
E-TSPC, obedecendo às regras de composição e utilizando blocos Dps?
ii. poderemos saber quem são os blocos p-Dps e os n-Dps de um circuito? Poderemos separar os n e
p data chains dele? Dado um circuito qualquer, será possível verificar se é ou não um circuito
RTS E-TSPC?
A primeira questão é de fácil resposta. Sim, é possível desenhar um circuito RTS E-TSPC com
blocos Dps. Para tal, durante a fase de projeto, cada bloco Dp manipulado deve ser marcado
antecipadamente como sendo n-Dp ou p-Dp; da mesma forma os data chain. Sendo obedecidas todas
as regras (em particular r1, r2 e r3), garantimos que os blocos são pré-carregados na fase correta
(conforme teoremas 2N e 2P abaixo), e que os data chains serão do tipo desejado.
Para verificar a aplicação das regras de composição em um circuito qualquer, a segunda questão
colocada, deveremos ser capazes de identificar todos os n e p data chains, pois as regras são aplicadas
sobre estes. Para esta identificação, a partir das definições de data chains, necessitamos saber quem
são os blocos n-Dps e p-Dps. Portanto necessitamos de um procedimento que permita tal identificação.
Abaixo descrevemos isso. Neste procedimento se usa o fato de ser possível identificar quais são os
blocos n e p dinâmicos, estáticos e Dps (sem distinguir entre n-Dp e p-Dp), quais são as entradas e
saídas desses blocos e quais são as pc-entradas dos blocos Dps3.
Procedimento 1- para classificação dos blocos Dps em RTS E-TSPC:
Seja o circuito CE e seu bloco Dp BDP (pode ser PH ou PL). O que será feito é recuar através das
ligações de CE, a partir de BDP, até encontrar um bloco dinâmico. Esse bloco dinâmico nos dirá que
tipo de bloco Dp temos. Iniciamos o processo com a escolha de uma das pc-entradas de BDP,
chamando-a de e0. Em e
0 estarão ligados vários blocos; tomemos um deles. Caso as regras r1, r2 e r3
3 As pc-entradas podem ser imediatamente separadas das outras entradas do bloco Dp: numa das porções do bloco,
aquela composta por transistores N ou aquela por P, o número de transistores será menor. As entradas que chegam a esta
porção são então as pc-entradas.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
57
sejam verificadas então o bloco poderá ser apenas um destes (caso apareça uma opção diferente então
saberemos que as regras não foram obedecidas):
i. um n-dinâmico;
ii. um p-dinâmico;
iii. um bloco estático complementar CMOS;
iv. um outro bloco Dp.
Para os casos (i) e (ii) a classificação de BDP estará terminada: n-Dp para (i), e p-Dp para (ii). Para
(iii) e (iv), não poderemos ainda decidir e deveremos recuar mais um bloco. Escolhemos para isto uma
das entradas do bloco estático (iii) ou uma das pc-entradas do bloco Dp (iv). Chamemos de e1 essa
entrada. Repetimos com e1 a análise feita com e
0 e, se não houver a possibilidade de decisão, faremos
mais um recuo determinando e2. Assim seguimos até cairmos em (i) ou (ii).
O teorema abaixo garante que, se estamos com um circuito RTS E-TSPC, o procedimento descrito
acima é efetivo, no sentido de fornecer sempre uma resposta, e correto, ou seja a resposta encontrada é
verdadeira.
Teorema da classificação dos blocos Dps. Considere um circuito RTS E-TSPC CE. Todos os seus
blocos Dps podem ser corretamente classificados como n-Dp ou p-Dp através do procedimento
descrito acima.
Dem.: Seja o bloco Dp BDp que desejamos classificar. O processo de ir recuando é finito desde que
todos os blocos aí encontrados pertencem ao mesmo data chain (pois um data chain nunca pode
iniciar por uma pc-entrada (r1)) e, dentro de um data chain, nenhum bloco é acessível a ele mesmo.
Assim, mais cedo ou mais tarde, devemos encontrar um bloco dinâmico. Desta forma chegaremos a
uma classificação de BDp, desde que as regras sejam obedecidas (caso contrário, ou encontraremos um
bloco não esperado ou ficaremos em um ciclo infinito). Assim o procedimento é efetivo.
Observe que o bloco BDP, não podendo ser n-Dp e p-Dp ao mesmo tempo, pertence a apenas um
dos tipos de data chain. Assim, qualquer caminho que seguirmos durante o recuo resultará na mesma
classificação. Também haverá apenas blocos estáticos e Dps entre BDp e o bloco dinâmico encontrado.
Desta forma, este e aquele devem pertencer ao mesmo data chain e a classificação feita é correta.
Uma vez separados os blocos n-Dps e p-Dps, poderemos encontrar os data chains do circuito. Isto é
feito com base nas definições de data chains, não importando se o circuito obedece ou não às regras de
composição.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
58
Procedimento 2- para determinação dos “data chains”:
Considere o circuito CE. Supomos que os blocos n e p dinâmicos, n e p latches, estáticos, n-Dp e p-
Dp já estejam identificados. Inicialmente vamos determinar os n-data chains. Tomemos todos os
blocos n-latches. Consideremos esses blocos numerados (desde que são finitos não há dificuldade para
enumerá-los). Sejam eles BnL1, BnL2, .....
Para cada bloco BnLi achemos o conjunto dos n-data chains a que o bloco pertence. Para isso
determinemos dois conjuntos de spps:
FI que possui os “pedaços iniciais” dos n-data chains que passam por BnLi;
FF que possui os “pedaços finais” dos n-data chains que passam por BnLi.
(como são esses dois conjuntos ficará mais claro a seguir)
Para construir FI começamos por formar o conjunto de spps
FI0= spp Si=(B(Si)=BnLi, L(Si)=∅, ISi=a, OSi= OBnLi) para todo a∈I(BnLi).
Para cada um dos elementos Si de FI0 são repetidos os passos abaixo até que FI0 acabe ficando
vazio:
i. retira-se Si de FI0;
ii. selecionam-se todos os blocos ligados a entrada de Si e, para cada um dos blocos selecionados,
acrescentam-se novos elementos a FI0 ou a FI de acordo com as regras:
a. se o bloco BS selecionado for estático, n-dinâmico, n-Dp ou n-latch então acrescentam-se a FI0
os novos spps:
spp Sj=B(Sj)=B(Si)∪BS, LO(Sj)=L
O(Si)∪(ISi, OBs), ISj=a, OSj=OSi para todo a∈I(BS);
b. se o bloco selecionado for p-dinâmico, p-Dp ou p-latch, então acrescenta-se Si a FI (caso ele
ainda não esteja lá).
A etapa acima é finita quando estivermos com um circuito RTS E-TSPC pois os blocos nos data
chains não são acessíveis a eles mesmos e o número de elementos de um circuito é finito.
O próximo passo será construir FF a partir do conjunto de spps FF0=spp Si=B(Si)=BP,
L(Si)=∅, I(Si)=a, OSi= OBP para todo a∈I(BP) tal que BP seja um bloco estático, n dinâmico, n-Dp
ou n-latch e (a , OBnLi) ∈ LO(CE).
Para cada um dos elementos Si de FF0 são repetidos os passos abaixo até que FF0 acabe ficando
vazio:
i. retire-se Si de FF0;
ii. selecionam-se todos os blocos ligados a saída de Si e, para cada um dos blocos selecionados,
acrescentam-se novos elementos a FF0 ou a FF de acordo com as regras:

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
59
a. se o bloco BS selecionado for estático, n-dinâmico, n-Dp ou n-latch então acrescenta-se à FF0 os
novos spps:
spp Sj=B(Sj)=B(Si)∪BS, LO(Sj)=L
O(Si)∪(a, OSi), I(Sj)=I(Si), OSj=OBS para todo
a∈I(BS) tal que a esteja ligado a OSi ;
b. se o bloco selecionado for p-dinâmico, p-Dp ou p-latch então acrescenta-se Si a FF (caso ele
ainda não esteja lá).
A combinação de um elemento Sa de FI com outro elemento Sb de FF formará um n-data chain Sc
que possui BnLi: Sc=B(Sc)=B(Sa)∪B(Sb), LO(Sc)=L
O(Sa)∪L
O(Sb)∪(I(Sb), OSa), I(Sc)=I(Sa), OSc=
OSb. O conjunto de todos os data chain que passam por BnLi é formado tomando-se todas as
combinações de um elemento de FI e um de FF.
O que foi feito com os n-latches é repetido para os blocos n-dinâmicos e n-Dp. Todos os n-data
chains do circuito serão identificados dessa maneira.
Passos similares são aplicados para identificar todos os p-data chains.
Teorema dos data chains: Considere um circuito RTS E-TSPC CE. O procedimento acima descrito é
efetivo e correto na determinação de todos os “data chains” de CE desde que a classificação dos
blocos Dps esteja correta.
Dem.: Primeiro observemos que os passos para geração dos conjuntos FI e FF são finitos pois:
a. nos spps formados por blocos estáticos, n-dinâmicos, n-Dps e n-latches, nenhum bloco é acessível a
si próprio;
b. nos spps formados por blocos estáticos, p-dinâmicos, p-Dps ou p-latches, nenhum bloco é acessível
a si próprio;
c. todos os blocos usados têm, por definição, um número finito de entradas;
d. um circuito é por definição um conjunto finito de blocos.
Como este procedimento está baseado na definição de data chain, sempre resultará na separação
correta dos data chains. Ainda, como todo n-data chain deve conter ao menos um n-latch, um bloco n-
dinâmico ou um bloco n-Dp, Definição 9, a conseqüência é que, uma vez analisados todos estes
blocos, teremos identificados todos os n-data chains de CE (idem para os p-data chains).
Voltemos agora a questão que pretendemos responder: dado um circuito CE qualquer, será possível
verificar se é ou não um circuito RTS E-TSPC? Um sim a esta questão representa a existência de um
procedimento aplicável sobre qualquer circuito CE, chamemo-lo de procedimento 3, tal que
procedimento 3 aponta CE como RTS E-TSPC ⇔ o circuito CE é RTS E-TSPC.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
60
Tal procedimento é descrito abaixo.
Procedimento 3- para verificar se um circuito é RTS E-TSPC
Considere o circuito CE. Devemos aplicar a CE o procedimento 1, para identificar os blocos n-Dps e
p-Dps, e, posteriormente, o procedimento 2 para obter todos os data chains. Uma vez que nenhum
problema seja encontrado durante a execução destes, a Definição 12 é usada para verificar se CE é ou
não um RTS E-TSPC. Particularmente, devemos investigar os itens iii, iv e v desde que os dois
primeiros foram aplicados no procedimento 2 e, portanto, são obedecidos necessariamente nos data
chains determinados.
Teorema da verificação: Seja CE um circuito qualquer. O procedimento 3 aponta CE como RTS E-
TSPC se e somente se o circuito CE é RTS E-TSPC.
Dem.: Primeiro mostraremos que (procedimento 3 aponta CE como RTS E-TSPC ⇐ CE é RTS E-
TSPC). Caso CE seja um circuito RTS E-TSPC, então, conforme os dois teoremas acima, teremos
classificados corretamente os blocos Dps e separados todos os data chain. Na aplicação da Definição
13 chegaremos a conclusão que o circuito é RTS E-TSPC. Portanto o procedimento 3 apontará CE
como RTS E-TSPC.
Mostraremos agora a segunda parte do teorema, que (procedimento 3 aponta CE como RTS E-
TSPC ⇒ CE é RTS E-TSPC).
Caso a identificação dos blocos n e p-Dps seja correta, então a separação dos n e p data chains pelo
procedimento 2, uma vez executada, será correta pois usa a própria definição de data chain. Também a
verificação do circuito, para determinar se é RTS E-TSPC, será correta pois novamente usa a
definição. Portanto qualquer erro na identificação de um circuito CE como RTS E-TSPC só pode ser
devido a algum erro na identificação dos blocos Dps. Por outro lado, se um bloco é dito ser n-Dp e os
data chains identificados pelo procedimento 2 obedecem às regras de composição r1-r3, então pode-se
mostrar que o bloco é realmente um n-Dp (a demonstração é igual a aquela do lema 3N, mostrada mais
para frente). O mesmo pode ser dito em relação a um p-Dp. Assim, se procedimento 3 aponta CE como
RTS E-TSPC ele será de fato um circuito RTS E-TSPC.
Observemos que toda esta seção tratou apenas do problema introduzido pelos blocos Dps. A
conclusão final é que é possível tanto o projeto como a identificação de um circuito RTS E-TSPC.
2.3.3 Teorema fundamental da estratégia E-TSPC
Para mostrar que, uma vez obedecidas às regras de composição, o circuito funciona corretamente,
enunciamos o seguinte teorema:

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
61
Teorema fundamental: Considere um circuito RTS E-TSPC CE. Se as entradas externas forem
convenientes, o “clock” tiver o período longo suficiente e se todo circuito estiver estável uma vez no
início de seu funcionamento, então:
i. a saída do último “latch” de um “data chain” ficará inalterada durante a fase de “holding”
deste;
ii. os blocos Dps farão a correta pré-carga durante a fase de “holding” do “data chain” a que
pertencem;
iii. os blocos dinâmicos e os blocos Dps não serão descarregados indevidamente durante a fase de
avaliação do “data chain” a que pertencem.
O teorema acima será provado separadamente por meio de 6 outros teoremas. Assim o item (i) é
tratado nos teoremas 1N e 1p, o item (ii), nos teorema 2N e 2P e o item (iii), nos teoremas 3N e 3P. Para
demonstração destes teoremas, todavia, serão necessários outros teoremas e lemas. Também será
explicado o que significa “entrada externa conveniente”, hipótese hEE vista adiante, e o que significa
“período longo suficiente”, hipótese hTC.
2.3.3.1 Propriedades dos blocos do E-TSPC
Antes de fazermos as demonstrações a que nos propomos, daremos uma lista das propriedades, dos
blocos usados, que aparecem implícita ou explicitamente nas demonstrações. Com isso desejamos
deixar claro o que depende das regras e o que depende dos próprios blocos.
Propriedade 1 (pr1): Transições na saída de um bloco qualquer somente poderão ocorrer quando
houver transições em alguma de suas entradas ou, para blocos dinâmicos e “latches”, no “clock”.
Para "latches", alterações na sua saída, devido ao "clock", podem apenas surgir quando o bloco
passa do "holding" para avaliação.
Essa propriedade diz que os blocos são causais, apresentando variações apenas quanto as entradas
(entrada aqui no sentido mais geral) são modificadas.
propriedade 2 (pr2): Para qualquer bloco, uma transição “1”→“0” na entrada somente poderá
causar uma transição “0”→“1” na saída. Analogamente, uma transição “0”→“1” somente poderá
causar uma transições “1”→“0”.
Em outras palavras, todos os blocos com que trabalhamos são blocos que causam inversão.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
62
propriedade 3 (pr3): A saída de um bloco n-dinâmico vai imediatamente para “1” logo que ocorre a
transição de “1”→“0” no "clock" (fase de “holding”). Permanece em “1” durante todo o intervalo
em que o "clock" é mantido em “0”.
Esta é a pré-carga do bloco e constitui uma etapa fundamental no funcionamento dele. O fato da
mudança de estado ser “imediata” é bastante importante, como veremos.
propriedade 4 (pr4): A saída de um bloco p-dinâmico vai imediatamente para “0” logo que ocorre a
transição de “0”→“1” no "clock" (fase de “holding”). Permanece em “0” durante todo o intervalo
em que o "clock" é mantido em “1”.
Como acima, esta característica é fundamental nos blocos p-dinâmicos.
propriedade 5 (pr5): A saída de um bloco n-dinâmico, na sua fase de avaliação ("clock" em “1”),
pode somente sofrer transições “1”→“0”.
Desde que os transistores p estão cortados na avaliação, não é possível que haja transições de
“0”→“1”.
propriedade 6 (pr6): A saída de um bloco p-dinâmico, na sua fase de avaliação ("clock" em “0”),
pode somente sofrer transições “0”→“1”.
Desde que os transistores n estão cortados na avaliação, não é possível que haja transições de
“1”→“0”.
propriedade 7 (pr7): Quando todas as pc-entradas de um bloco PH ("precharged in high") estão em
“1”, a saída do bloco vai para “0”. A mudança de estado na saída ocorre após as mudanças nas pc-
entradas que, por sua vez, podem vir imediatamente ou atrasadas com relação à transição no
"clock".
Nos blocos PH, a pré-carga é feita quando as pc-entradas estão em “1”. Por construção, a saída
deles deverá ir para “0”.
propriedade 8 (pr8): Quando todas as pc-entradas de um bloco PL ("precharged in low") estão em
“0”, a saída do bloco vai para “1”. A mudança de estado na saída ocorre após as mudanças nas pc-
entradas que, por sua vez, podem vir imediatamente ou atrasadas com relação à transição do
"clock".
Nos blocos PL, a pré-carga é feita quando as pc-entradas estão em “0”.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
63
propriedade 9 (pr9): Nos blocos n-latches, transições de “0”→“1” na entrada não afetam a saída
quando o "clock" está em “0” (fase de “holding”). Como conseqüência, nesta fase, a única
transição possível na saída será “0”→“1”.
Num bloco n-latch todos os transistores n, que formam a lógica n, estão em série com um transistor
n ligado ao clock. Estando este cortado, φ=“0”, não pode haver descarga na saída do latch. Em
conseqüência, transições de “0”→“1” não provocarão mudanças na saída.
propriedade 10 (pr10): Nos blocos p-latches, transições de “1”→“0” na entrada não afetam a saída
quando o "clock" está em “1” (fase de “holding”). Como conseqüência, nesta fase, a única
transição possível na saída será “1”→“0”.
Num bloco p-latch todos os transistores p, que formam a lógica p, estão em série com um transistor
p ligado ao clock. Estando este cortado, φ=“1”, não pode haver carga na saída do latch. Em
conseqüência, transições de “1”→“0” na entrada não provocarão mudanças na saída.
2.3.3.2 Demonstração do Teorema fundamental
Para garantir o funcionamento de um circuito RTS E-TSPC, são necessárias duas hipóteses: uma
delas trata de como devem ser as entradas externas do circuito, a outra, da duração das fases do clock.
Hipótese das entradas externas estáveis (hEE):
Apenas as entradas dos blocos dinâmicos, “latches” ou blocos Dps podem ser entradas externas do
circuito; adicionalmente, o sinal externo deve ser estável durante a fase de avaliação dos blocos a
ele ligados.
Assim, um sinal externo aplicado a um n-data chain deve ser estável quando φ=”1”; um sinal
externo aplicado a um p-data chain deve ser estável quando φ=”0”. Em vista de hEE não é possível
um sinal externo qualquer ser, ao mesmo tempo, aplicado as entradas de um n-data chain e de um p-
data chain.
A segunda hipótese só será apresentada após serem desenvolvidos alguns teoremas que servirão
para melhor esclarecê-la. O primeiro destes teoremas trata da estabilidade de um circuito.
Teorema da estabilidade (TE): Considere um circuito RTS E-TSPC CE onde o clock está fixo. Se as
entradas externas de CE forem fixas, então, após certo intervalo, todos os pontos do circuito CE
também ficarão fixos (ou estáveis).
Dem.: Vamos supor que o teorema não é correto e mostrar que isto nos levará a contradições. Não
estando todos os pontos do circuito CE estáveis, deverá haver então ao menos um bloco BA1 no circuito
cuja saída esteja sempre se modificando. Pois bem, para tal ocorrer deveremos ter que ao menos uma

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
64
das entradas de BA1 também esteja sempre se modificando (propriedade pr1). Tomemos uma destas
entradas; ela não poderá ser uma das entradas externas que são fixas e, portanto, deverá estar ligada a
saída de outro bloco. Chamaremo-lo de BA2. Aplicando o mesmo raciocínio encontraremos a seqüência
de blocos BA3, BA4, ..., que deve ser infinita. Como o número de blocos e de entradas em cada bloco é
finito, então dentro da seqüência anterior deveremos ter uma seqüência inicial BC1, BC2, ..., BCN com as
seguintes características:
a. a saída de cada um destes blocos está sempre sendo modificada;
b. a saída de BCi+1 está ligada a uma entrada de BCi;
c. BC1 é o próprio bloco BCN.
Uma vez que os blocos BCi podem formar um spp cíclico, não será permitido que eles pertençam a
apenas um dos seguintes conjuntos de blocos (Definição 12):
i. blocos estáticos;
ii. blocos n-dinâmicos, n-Dps, n-latches e estáticos;
iii. blocos p-dinâmicos, p-Dps, p-latches e estáticos.
Caso isto ocorresse, pela definição de circuito RTS E-TSPC, haveria um data chain, n ou p de
acordo com as circunstâncias, contendo tal spp cíclico. No entanto, os data chain são não cíclicos pela
definição.
Conseqüentemente, haverá ao menos um bloco BCH dinâmico ou um latch em holding (r5)4. Neste
caso, a saída do bloco poderá no máximo sofrer uma transição (se for um latch, pr3,4,9,10). Oras, isto é
uma contradição pois a saída de todos os blocos BCi estão sempre sendo modificadas. Portanto o
circuito CE deverá ficar todo estável após certo intervalo.
Uma importante aplicação do último resultado pode ser feita nos circuitos RTS E-TSPC onde
algumas das entradas não são estáveis. Consideremos um ponto n qualquer de um circuito RTS E-
TSPC com a seguinte propriedade: se i for uma das entradas não estáveis do circuito, nenhuma
alteração em i causa efeito em n. Sendo assim, o estado de n não depende destas entradas não
estáveis e, caso as fixemos, o ponto n terá o mesmo comportamento. A partir do teorema acima
conclui-se que, caso o clock esteja fixo, n atingirá ainda um valor estável após certo intervalo. De
forma mais geral, qualquer ponto do circuito que não depende das entradas externas que estão variando
deverá atingir a estabilidade após certo intervalo de tempo.
4 Na verdade, por r5 podemos garantir que há sempre um latch em holding. Com a aplicação de rE, visto mais a frente, é
que deverá haver ou um dinâmico ou um latch em holding. Assim este teorema continua a valer mesmo com rE.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
65
O que procuramos encontrar agora é quais blocos podem chegar a estabilidade em um circuito RTS
E-TSPC. Os dois lemas abaixo servem para responder a esta questão.
Lema 1N. Considere um circuito RTS E-TSPC onde hEE é válida. Se a saída do último “latch” de
qualquer p-data chain permanecer inalterada durante a fase φ=”1”, então, após certo intervalo
nesta fase φ=”1” (desde que ela seja longa suficiente), todos os blocos
i. n-Dps, n-dinâmicos, n-latches e
ii. estáticos que pertencem somente a n-data chains
terão sua saída fixa (estável).
Dem.: Considere o bloco BN como em (i) ou (ii). Para provar o lema basta mostrar que transições das
entradas externas não estáveis durante a fase φ=”1” não podem causar efeito algum na saída de BN.
Neste caso, para a saída de BN, é como se o circuito tivesse todas suas entradas fixas. Pelo teorema TE,
portanto, poderemos afirmar que a saída do bloco atingirá a estabilidade como afirma o lema.
Para provar que as transições nas entradas externas não causam efeitos na saída de BN, mostraremos
que tal hipótese nos levará a contradições. Suponha, então, que uma certa entrada i, não estável
durante a fase φ=”1”, tenha algum efeito sobre a saída de BN. Para que isto ocorra, deve existir ao
menos um spp Sx formado pelos blocos BP1, ..., BPT onde:
i. a saída de BPi está ligada a uma entrada de BPi+1;
ii. i está ligada a uma das entradas de BP1 e BPT é o próprio bloco BN;
iii. a saída de todos os blocos BPi, de BP1 até BN, dependem de alguma forma do sinal aplicado em i.
Caso não houvesse tal spp, modificações em i não causariam efeito na saída do bloco BN.
Considere o maior k tal que para todo bloco BPj, j≤k, BPj é estático, p-latch, p-dinâmico ou p-Dp.
Observe que k>0 por hEE. Pois bem, existirá um p-data chain SP contido em Sx e que passa pelos
blocos BP1, ..., BPk. Como o bloco BN não pode pertencer a nenhum p-data chain, teremos k<T. Os
blocos BP1, ..., BPk formam, portanto, o conjunto completo dos blocos do p-data chain Sp e o último p-
latch de Sp está naturalmente entre estes blocos. Por hipótese, a saída deste latch fica inalterada
durante toda a fase φ=”1”, o que contradiz o fato que as saídas dos blocos BPis devem ser de alguma
forma dependentes de i. Assim, fica demonstrado que a saída do bloco BN não pode ser modificada
por nenhuma das entradas não estáveis e, em conseqüência, ele atingirá a estabilidade.
Lema 1P. Considere um circuito RTS E-TSPC onde hEE é válida. Se a saída do último “latch” de
qualquer n-data chain permanecer inalterada durante a fase φ=”0”, então, após certo intervalo
nesta fase φ=”0” (desde que ela seja longa suficiente), todos os blocos

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
66
i. p-Dps, p-dinâmicos, p-latches e
ii. estáticos que pertencem somente a p-data chains
terão sua saída fixa (estável).
Dem.: Similar ao lema 1N.
Desde que a saída de um bloco esteja fixa (estável), qualquer mudança nela somente poderá ocorrer
quando uma das entradas do bloco ou o clock, no caso dos blocos dinâmicos e latches, for alterada
(pr1). Isto será usado mais tarde em algumas demonstrações.
Uma importante observação em relação a estes lemas é que o tempo que os blocos levam para
atingir a estabilidade depende apenas do estado inicial do circuito e do valor das entradas estáveis.
Chamemos de ∆1 ao período mínimo do clock para que os blocos definidos nos lemas acima, dentro
das hipóteses dadas, atinjam a estabilidade, para qualquer combinação de entradas e estados iniciais
(como estamos trabalhando com um caso simplificado, onde admitimos apenas valores “0” e “1” para
os pontos do circuito, existe um número finito de combinações de entradas e estados iniciais do
circuito. Desta forma também haverá um valor mínimo para o período do clock).
A estabilidade na saída do último latch dos data chains é uma das hipóteses usadas nestes lemas.
Os próximos dois lemas dão as condições para chegar a esta estabilidade.
Lema 2N. Considere um circuito RTS E-TSPC. A saída do último “latch” de qualquer n-data chain
permanecerá inalterada na passagem para, e durante toda a fase de “holding”, φ=”0”, se no fim da
fase φ=”1”, todos os blocos
i. n-Dps, n-dinâmicos, n-latches e
ii. estáticos que pertencem somente a n-data chains
tiverem sua saída fixa (estável).
Dem.: Primeiro lembremos que por r5 existe em cada data chain ao menos um latch. Seja BF o último
latch de um n-data chain qualquer. Pela hipótese do teorema a saída do bloco BF deve ser estável ao
fim da sua fase de avaliação. A transição do clock para "0" não causa, por sua vez, alteração no latch
(pr1). Para mostrar que o bloco BF permanecerá estável durante o holding, vamos supor que isto não
aconteça e chegar a um absurdo. Considere que a saída de BF sofreu uma transição após a mudança do
clock para “0”. Isto somente será possível se uma das entradas de BF sofrer uma transição de “1”→”0”
(pr1,9). Por r5, esta entrada deve estar ligada a um bloco BA1 do data chain, sendo este um bloco
estático, ou um n-Dp, ou um n-dinâmico ou um n-latch. Ainda, qualquer que seja o bloco ele é estável
no fim de φ=”1” (observe que se o bloco for estático, então ele não pode pertencer a nenhum p-data
chain). Sendo n-dinâmico ou n-latch, a única transição que ocorre no “holding” é “0”→“1” (pr3,9), que

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
67
não causa efeito algum em BF. Portanto, BA1 será estático ou n-Dp. Novamente alguma de suas
entradas deve sofrer uma transição de “0”→“1” (pr1,2). Seja BA2 o bloco ligado a esta entrada. Agora
este bloco somente pode ser estático, n-Dp ou n-latch. Estes chegaram a estabilidade durante a
avaliação e, portanto, somente uma transição “1”→”0” numa de suas entradas pode causar o resultado
desejado. Seja BA3 o bloco ligado a esta entrada. Da mesma forma que BA1, BA3 somente pode ser
estático ou n-Dp. Se continuarmos este processo, encontraremos blocos BA4, BA6, ..., estáticos, n-Dp ou
n-latches, e blocos BA5, BA7, ..., estáticos ou n-Dp, de forma que r5 nunca será satisfeito, o que é
absurdo. Assim, BF não poderá sofrer transições.
Lema 2P. Considere um circuito RTS E-TSPC. A saída do último latch de qualquer p-data chain
permanecerá inalterada na passagem para, e durante toda a fase de “holding”, φ=”1”, se no fim da
fase φ=”0”, todos os blocos
i. p-Dps, p-dinâmicos, p-latches e
ii. estáticos que pertencem somente a p-data chains
tiverem sua saída fixa (estável).
Dem.: Similar ao lema 2N.
Veja que os lemas 1N, 1P, 2N e 2P estão intimamente relacionados. Assim, num circuito RTS E-
TSPC onde hEE é válida, se no fim da fase φ=”1” todos os blocos
(a) n-Dps, n-dinâmicos, n-latches e
(b) estáticos que pertence somente a n-data chains
tiverem saída estável, então, por 2N, a saída do último latch de qualquer n-data chain permanecerá
inalterada na passagem e durante a fase φ=”0”. Neste caso, por 1P, após certo intervalo na fase
φ=”0”, todos os blocos
(c) p-Dps, p-dinâmicos, p-latches e
(d) estáticos que pertencem somente a p-data chains
ficarão com a saída estável. A estabilidade destes blocos garante que, lema 2P, a saída do último latch
de qualquer p-data chain permanecerá inalterada na passagem para, e durante a fase φ=”1”. Por fim, o
lema 1N assinala que, após certo intervalo na fase φ=”1”, os blocos em (a) e (b) têm a saída estável.
Voltamos ao início. Como conclusão, se o clock tiver período maior que ∆1 e em algum momento o
circuito todo estiver estável, então, pelos lemas 1N e 1P, teremos que, no fim de qualquer fase, serão
estáveis todos os blocos
(a) Dps, dinâmicos e latches em avaliação, e

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
68
(b) estáticos que pertencem somente ao data chain em avaliação.
Pelos lemas 2N e 2P, a saída do último latch de qualquer data chain permanecerá inalterada na
passagem para e durante toda a fase de holding deste mesmo data chain.
Os lemas 3N e 3P nos mostrarão que também os blocos Dps têm a saída estável após um intervalo
finito de tempo no holding.
Para a aplicação de indução nas próximas demonstrações, há a necessidade de que seja estabelecida
uma ordem para os blocos Dps. Vamos definir essa ordem abaixo.
Definição 13: Considere um bloco B0 e o conjunto F = (conjunto dos Γ-data chains DX tal que o
bloco B0 pertence a DX)(onde Γ é n ou p). O valor Θ(B0) = max (número de blocos Dps que
antecedem B0 no Γ-data chain Di) ∀Di∈F, será denominado ordem de B0.
A ordem de um bloco somente está bem definido para os blocos dinâmicos, Dps e latches, que
pertencem a apenas um tipo de data chain, n ou p-data chain. A ordem de um bloco será maior ou
igual a zero; seu valor máximo será inferior ao número total de blocos Dps do circuito. Veja que se BA
anteceder a BC, então Θ(BC)≥Θ(BA), desde que definida a ordem para eles. Desta forma, se houver um
bloco com ordem 5, haverá ao menos um bloco com ordem 4, outro com 3, ... e outro com zero, todos
eles no mesmo data chain.
Lema 3N. Considere um circuito RTS E-TSPC. Um bloco n-Dp deste circuito terá sua saída mudada
para
“1” nos blocos PL ou
“0” nos blocos PH,
aí permanecendo, após certo intervalo de tempo na fase de “holding”, φ=”0” (a fase de "holding"
deve ser longa suficiente).
Dem.: Vamos trabalhar com indução em relação à ordem dos blocos.
Primeiro mostraremos que o lema é válido para qualquer bloco n-Dp B0 com ordem zero (se existir
algum bloco n-Dp, então existirá um bloco com ordem zero). Suponha que B0 seja um bloco PL e que
sua saída esteja em “0” após longo tempo em holding. Mostremos que tal suposição nos levará a uma
contradição. Ao menos uma das pc-entradas do bloco B0 deverá ter valor “1” também após longo
tempo em holding (pr8). Por r1 e r2 esta entrada deverá estar ligada a saída de um bloco BA1 que é
estático ou n-dinâmico (como o bloco é de ordem zero não pode haver blocos n-Dps na sua entrada). A
regra r3e impede, por sua vez, que BA1 seja dinâmico. BA1 será, portanto, um bloco estático, com saída

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
69
em “1”. Ainda, uma das entradas deste bloco deverá estar em “0”. Esta entrada deverá ser ligada, por
sua vez, a um bloco BA2, sendo este estático ou n-dinâmico. Se BA2 fosse dinâmico sua saída estaria
em “1” após longo tempo em holding (pr3), o que é contrário ao que desejamos para a entrada de BA1.
Portanto, BA2 também é estático. Continuando a análise, encontraremos uma seqüência infinita de
blocos BA3, BA4, ... todos estáticos. Como não pode haver um spp cíclico com apenas blocos estáticos,
Definição 12, deveremos ter um número infinito de blocos, o que é uma contradição pois estamos
considerando circuitos finitos. Logo B0 deverá estar com sua saída em “1”. Para um bloco PH o
raciocínio é análogo. O teorema é assim válido para blocos de ordem zero.
O próximo passo para a prova por indução será mostrar que se o teorema for válido para todo bloco
n-Dp de ordem N ou menor, então será também válido para todo bloco n-Dp BN+1 de ordem N+1.
Suponha que o bloco BN+1 seja um bloco PL e que sua saída esteja em “0” após longo tempo em
holding. Mostraremos que tal suposição nos levará a uma contradição. Estando a saída do bloco em
“0”, ao menos uma das pc-entradas deverá ter valor “1” também após longo tempo em holding. Por r1
e r2 esta entrada deverá estar ligada a saída de um bloco BA1 que é estático, n-dinâmico, PL ou PH (no
caso dos blocos Dps, eles serão de ordem N ou menor). A regra r3e proíbe que BA1 seja dinâmico e
r3b, que seja PL. Caso BA1 seja um bloco PH, por hipótese de indução, sua saída ficará em “0” após
longo tempo em holding, não satisfazendo o que é desejado. BA1 será, portanto, um bloco estático com
uma de suas entradas em “0”, a fim de que sua saída esteja em “1”. Esta entrada deve ser ligada, por
sua vez, a um bloco BA2, sendo este estático, n-dinâmico, PL ou PH (estes com ordem N ou menor).
A regra r3c proíbe que BA2 seja PH. Por outro lado, se BA1 for dinâmico ou PL, sua saída ficará em “1”
após certo intervalo na fase de holding (pr3 e hipótese de indução), o que não é a situação desejada
para a entrada de BA1. Portanto, BA2 também é estático. Novamente a análise nos leva a uma seqüência
infinita de blocos BA3, BA4, ... todos estáticos o que é uma contradição, como acima. Logo BN+1 deverá
estar com sua saída em “1”. Para o caso do bloco BN+1 ser do tipo PH, o raciocínio é análogo e,
portanto, o lema vale para qualquer bloco de ordem (N+1). Por indução concluímos que o lema vale
para blocos de qualquer ordem.
Lema 3P. Considere um circuito RTS E-TSPC. Um bloco p-Dp deste circuito terá sua saída mudada
para
“1” nos blocos PL ou
“0” nos blocos PH ,
aí permanecendo, após certo intervalo de tempo na fase de “holding”, φ=”1” (a fase de "holding"
deve ser longa suficiente).
Dem.: Similar ao lema 3N.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
70
O tempo para que haja a pré-carga dos blocos Dps depende dos atrasos dos blocos, e seu pior caso
não depende dos sinais de entrada (este pior caso pode ser calculado/medido considerando os piores
atrasos dos blocos que estão entre os blocos dinâmicos e os blocos Dps). Chamaremos de ∆2 ao
período mínimo do clock que garante a pré-carga de todos os blocos dinâmicos e Dps durante a fase de
holding.
Os dois últimos lemas apontam mais alguns blocos que devem ficar fixos (estáveis) no fim de cada
fase.
Lema 4N. Considere um circuito RTS E-TSPC onde hEE é válida. Se a saída do último “latch” de
qualquer n-data chain permanecer inalterada na passagem para, e durante a fase φ=”0”, então,
após um intervalo finito nesta (desde que esta seja longa suficiente), os blocos estáticos que
pertencem a algum n-data chain e antecedem algum bloco n-dinâmico ou n-Dp deste “data chain”
terão sua saída fixa (estável).
Dem.: Considere o bloco BN que se enquadra na hipótese do lema. Após o tempo ∆2 os blocos n-
dinâmicos e n-Dps estão em pré-carga. Mostraremos que, após esta pré-carga, transições das entradas
externas não estáveis durante a fase φ=”0” não podem causar efeito algum na saída de BN. Neste caso,
para a saída de BN é como se o circuito tivesse todas suas entradas estáveis. Portanto, por TE, podemos
afirmar que a saída do bloco atingirá a estabilidade.
Para provar que as transições nas entradas não causam efeitos na saída de BN, mostraremos que tal
hipótese nos leva a contradições. Suponha então que uma certa entrada externa i do circuito, não
estável durante a fase φ=”0”, tenha algum efeito sobre a saída de BN . Para que isto ocorra, deve
existir ao menos um spp Sx formado pelos blocos BP1, ..., BPT onde:
i. a saída de BPi está ligada a uma entrada de BPi+1;
ii. i está ligada a uma das entradas de BP1 e BPT é o próprio bloco BN;
iii. a saída de todos os blocos BPi, de BP1 até BN, dependem de alguma forma do sinal aplicado em i.
Caso não houvesse tal spp, modificações em i não causariam efeito na saída do bloco BN.
Uma das duas situações abaixo descritas deve-se verificar:
i. algum bloco BPi é do tipo p-dinâmico, p-latch ou p-Dp: como i deve ser uma entrada de um n-
data chain (hEE) então haverá um n-data chain SN com início em i e fim na entrada do primeiro
bloco BPi p-dinâmico, p-latch ou p-Dp. O último n-latch de SN será naturalmente um dos blocos
BPi;

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
71
ii. nenhum dos blocos BPis é do tipo p-dinâmico, p-latch ou p-Dp: por hEE e r2 algum dos blocos BPi
que antecedem a BN deve ser n-dinâmico ou n-Dp.
Teremos portanto que um dos blocos BPi é ou o último latch de um n-data chain ou um n-
dinâmico/n-Dp; em ambos os casos, este bloco terá sua saída fixa após o tempo ∆2. Isto contradiz o
fato que as saídas dos blocos BPis devem ser de alguma forma dependentes de i. Assim, fica
demonstrado que a saída do bloco BN não pode ser modificada por nenhuma das entradas não estáveis
e, em conseqüência, ela atinge a estabilidade.
Lema 4P. Considere um circuito RTS E-TSPC onde hEE é válida. Se a saída do último “latch” de
qualquer p-data chain permanecer inalterada na passagem para, e durante a fase φ=”1”, então,
após um intervalo finito nesta (desde que esta seja longa suficiente), os blocos estáticos que
pertencem a algum p-data chain e antecedem algum bloco p-dinâmico ou p-Dp deste “data chain”
terão sua saída fixa (estável).
Dem.: Similar ao lema 4N.
O tempo necessário para que os blocos estáticos referidos acima fiquem estáveis depende,
naturalmente, de ∆2, do valor das entradas estáveis e das condições iniciais do circuito. Novamente não
dependem das entradas que estão em transição. Chamaremos de ∆3 ao período mínimo do clock para
que os blocos definidos nos lemas 4N e 4P , dentro das condições dadas, atinjam a estabilidade, para
qualquer combinação de entradas e estados iniciais.
Agora se pudermos garantir que o período do clock seja maior que o máximo de ∆1, ∆2 e ∆3 e, além
disso, que em algum momento o circuito fique todo estável, então poderemos afirmar a estabilidade de
vários blocos ao fim de cada fase do clock. Esta será a nossa segunda hipótese. Ela trata da máxima
velocidade permitida ao circuito. Nossa intenção não é determinar esta máxima velocidade mas apenas
mostrar que existe um período de clock para o qual o circuito funciona.
Hipótese do “timming” correto (hTC)
No início do funcionamento, o circuito deve estar todo estável e o período do “clock” deve ser
superior ao máximo entre ∆1, ∆2 e ∆3.
Podemos então, a partir dos lemas acima, gerar os seguintes corolários e teoremas (serão chamados
de teoremas apenas os resultados mais importantes os quais queremos destacar).
Corolário 1N: Considere um circuito RTS E-TSPC onde hEE e hTC são válidas. No fim da fase φ=”1”,
todos os blocos

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
72
i. n-Dps, n-dinâmicos, n-latches e
ii. estáticos que pertences somente a n-data chains
terão sua saída fixa (estável).
Dem.: Aplicação dos lemas 1N, 1P, 2N e 2P.
Corolário 1P. Considere um circuito RTS E-TSPC onde hEE e hTC são válidas. No fim da fase φ=”0”,
todos os blocos
i. p-Dps, p-dinâmicos, p-latches e
ii. estáticos que pertencem somente a p-data chains
terão sua saída fixa (estável).
Dem.: Aplicação dos lemas 1N, 1P, 2N e 2P.
Teorema 1N. Considere um circuito RTS E-TSPC onde hEE e hTC são válidas. A saída do último
“latch” de qualquer n-data chain permanecerá inalterada na passagem para, e durante toda a fase
de “holding”, φ=”0”.
Dem.: Aplicação do corolário 1N e do lema 2N.
Teorema 1P. Considere um circuito RTS E-TSPC onde hEE e hTC são válidas. A saída do último
“latch” de qualquer p-data chain permanecerá inalterada na passagem para, e durante toda a fase
de “holding”, φ=”1”.
Dem.: Aplicação do corolário 1P e do lema 2P.
Teorema 2N. Considere um circuito RTS E-TSPC onde hTC é válida. Um bloco n-Dp deste circuito
terá sua saída mudada para
“1” nos blocos PL ou
“0” nos blocos PH,
aí permanecendo, antes do fim da fase de “holding”, φ=”0”.
Dem.: Aplicação do lema 3N e da hTC.
Teorema 2P. Considere um circuito RTS E-TSPC onde hTC é válida. Um bloco p-Dp deste circuito
terá sua saída mudada para
“1” nos blocos PL ou
“0” nos blocos PH,

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
73
aí permanecendo, antes do fim da fase de “holding”, φ=”1”.
Dem.: Aplicação do lema 3P e da hTC.
Corolário 2N. Considere um circuito RTS E-TSPC onde hEE e hTC são válidas. No fim da fase φ=”0”,
os blocos estáticos que pertencem a algum n-data chain e antecedem algum bloco n-dinâmico ou n-
Dp deste “data chain” terão sua saída fixa (estável).
Dem.: Aplicação do teorema 1N e lema 4N junto com hTC.
Corolário 2P. Considere um circuito RTS E-TSPC onde hEE e hTC são válidas. No fim da fase φ=”1”,
os blocos estáticos que pertencem a algum p-data chain e antecedem algum bloco p-dinâmico ou p-
Dp deste “data chain” terão sua saída fixa (estável)
Dem.: Aplicação do teorema 1P e lema 4P junto com hTC.
Os dois últimos teoremas tratam de garantir que não haja transições que incorretamente
descarreguem os blocos dinâmicos e Dps.
Teorema 3N. Considere um circuito RTS E-TSPC onde hEE e hTC são válidas. Em um n-data chain
qualquer na fase de avaliação, φ=”1”, serão possíveis apenas transições:
“0”→ “1” nas entradas dos blocos n-dinâmicos ou dos blocos PL;
“1”→ “0” nas entradas dos blocos PH.
Dem.: Seja o bloco B0 n-dinâmico ou PL. Vamos supor que haja na sua entrada uma transição do tipo
“1”→“0” na fase φ=”1”. Mostraremos que tal suposição nos levará a um absurdo. Esta entrada não
poderá ser uma entrada externa do circuito pois estas, por hEE, devem ser estáveis durante a fase
φ=”1”. Ela estará então ligada a saída de um bloco BA1. Este não poderá ser um bloco:
i. p-latch pois neste caso ele será o último bloco p-latch de um p-data chain e sua saída é fixa
(teorema 1P);
ii. p-dinâmico ou p-Dp, pois os p-data chain que passariam por BA1, terminando neste próprio bloco,
não podem possuir nenhum p-latch; r5 não será obedecida.
iii. bloco n-latch (r2);
iv. n-dinâmico ou PL (r3a e r3e).
As possibilidades são de um bloco estático ou PH (n-Dp). Estes dois blocos ficam estáveis no fim
da fase φ=”0”, corolário 2N e teorema 2N, e assim permanecerão na fase φ=”1”, a menos que haja
uma transição em uma de suas entradas (pr1). Assim para causar a transição “1”→“0” na saída de BA1

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
74
deveremos ter uma transição “0”→“1” em alguma de suas entradas. Novamente temos que esta entrada
deve estar ligada a um novo bloco BA2. Com análise similar à apresentada antes, chegamos que o novo
bloco poderá ser n-dinâmico, PL (n-Dp) ou estático. Um bloco n-dinâmico na avaliação, todavia,
somente apresentará transição “1”→“0”, (pr5), que não interessa aqui. Assim, restará para BA2 duas
possibilidades, o bloco estáticos ou o PL. Estes blocos estavam estáveis no fim da fase φ=”0”, e assim
permanecerão durante a fase φ=”1” se não houver uma transição em uma de suas entradas. Para o
resultado desejado devemos ter a transição “1”→“0”. Prosseguindo, será necessário um bloco BA3,
estático ou PH (n-Dp), ligado a uma entrada de BA2, um outro bloco BA4, estático ou PL (n-Dp), ligado
a uma entrada de BA3, etc. Este processo nunca chega a um fim o que é absurdo. Desta forma, é
impossível haver uma transição “1”→“0” na entrada de qualquer n-dinâmico ou PL (n-Dp), durante a
fase φ=”1”. Para os blocos PH (n-Dp), raciocínio similar nos leva a tese do teorema.
Teorema 3P. Considere um circuito RTS E-TSPC onde hEE e hTC são válidas. Em um p-data chain
qualquer na fase de avaliação, φ=”0”, serão possíveis apenas transições:
“1”→ “0” nas entradas dos blocos p-dinâmicos ou dos blocos PH;
“0”→ “1” nas entradas dos blocos PL.
Dem.: Similar ao teorema 3N.
O Teorema fundamental fica provado com os seis teoremas acima, teoremas 1N, 1P, 2N, 2P, 3N e 3P.
As hipóteses do Teorema fundamental são, na verdade, as hipóteses hEE e hTC.
2.3.4 Blocos N-MOS like
As regras apresentadas permitem uma grande flexibilidade na associação dos blocos, o que leva a
circuitos mais compactos e rápidos. Uma dificuldade pode ser apontada, no entanto, quando lidamos
com altas velocidades. Os blocos p-dinâmicos têm a função lógica executada pela estrutura PUN,
implementada com transistores P; os blocos p-latches, por sua vez, têm adicionado um transistor P,
com o gate ligado ao clock, em série com a estrutura PUN. Como os transistores P são tipicamente
mais lentos que os N, duas ou mais vezes, os p-data chains, onde encontramos os blocos p-dinâmicos e
p-latches, serão, em conseqüência, mais lentos que os n-data chains. Isto acaba por restringir a
velocidade máxima alcançada pelo circuito [Gu96]. Para contornar esta dificuldade, uma solução é
reduzir ao mínimo os p-data chains, deixando para os n-data chains toda a função de manipulação
lógica. Com isto ou se aumenta a profundidade lógica dos n-data chains, com a redução na velocidade,

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
75
ou se aumenta o número de data chains em série, a profundidade de “pipeline”, aumentando a área e o
consumo de potência do circuito.
Aqui propomos uma solução diferente que possibilita a melhor utilização dos p-data chains. Como
já observamos, nos blocos utilizados a porção implementada com transistores P e a porção
implementada com transistores N trabalham de forma complementar (quando uma conduz a outra está
cortada e vice-versa). Nos blocos p-dinâmicos isto é garantido através dos transistores com gates
conectados ao clock, Figura 7, e nos p-latches, através das estruturas PUN e PDN, Figura 14. Podemos
modificar estes blocos suprimindo o transistor P ligado ao clock, no p-dinâmico, e a estrutura PUN, no
p-latch. Os novos blocos resultantes terão o funcionamento correto garantido por meio do
dimensionamento dos transistores restantes (ratioed). No caso dos blocos p-dinâmicos basta aumentar
a largura de canal do transistor N de forma que, toda vez que o sinal de clock esteja em nível alto, a
saída será descarregada, independentemente dos valores aplicados às entradas do bloco. No caso dos p-
latches, o transistor P deve ser tal que sempre que a estrutura PDN conduza a saída será levada a VSS.
Uma técnica semelhante, mas limitada, foi utilizada em [Ch96].
As modificações sugeridas, com a retirada de transistores P, aumentam a velocidade dos blocos
obtidos pois diminui o número de transistores em série. Em particular no novo bloco p-latch restará
apenas um transistor P e a função lógica será executada por transistores N, redundando num aumento
considerável da velocidade. Um procedimento análogo pode ser aplicado também aos blocos n-
dinâmicos e n-latches, mas as vantagens aí não são sempre expressivas. Chamaremos estes novos
blocos de N-MOS like.
A Figura 20 mostra os blocos originais e os blocos N-MOS like que podem ser construídos. Como
dissemos, o correto funcionamento destes blocos N-MOS like depende essencialmente das dimensões
dos transistores. Na Figura 20 também é apontada qual porção do bloco deve predominar (elemento
em negrito nos blocos N-MOS like) quando existem caminhos ligando a saída tanto a VDD como a VSS.
A Tabela 3 resume as condições que devem ser obedecidas por estes blocos para que a sua operação
seja igual a dos blocos CMOS originais.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
76
c lo c k
c lo c k
P D Ntra n s . N
e n tra d a
s a íd ac lo c k
c lo c k
P U Ntra n s . P
sa íd a
P U Ntra n s . P
P D Ntra n s . N
e n tra d asa íd a
c lo c k
P U Ntra n s . P
P D Ntra n s . N
e n tra d asa íd a
c lo c k
a ) c )
e ) g )
e n tra d a
c lo c k
P D Ntra n s . N
e n tra d a
s a íd a
b )
c lo c k
P U Ntra n s . P
sa íd a
d )
e n tra d a
P U Ntra n s . P
e n tra d a
s a íd a
c lo c k
f )
P D Ntra n s . N
e n tra d a
s a íd a
c lo c k
h )
V S S V S S
V D D
V S S V S S
V D D V D D V D D
V S S V S S V S S V S S
V D D V D D V D D V D D
Figura 20. Conversão de blocos para blocos N-MOS like: (a), bloco n-dinâmico e (b), bloco n-
dinâmico N-MOS like; (c), bloco p-dinâmico e (d), bloco p-dinâmico N-MOS like; (e), bloco n-latch e
(f), bloco n-latch N-MOS like; (g), bloco p-latch e (h), bloco p-latch N-MOS like.
O ganho de velocidade que os novos blocos proporcionam é acompanhado de um aumento na
potência consumida. Este aumento ocorre devido à condução, ao mesmo tempo, das duas porções do
bloco. O quanto aumenta a potência depende da freqüência do clock e da atividade do bloco.
Agora consideremos as 10 propriedades listadas anteriormente e que são usadas nas demonstrações
dos teoremas. Os blocos N-MOS like, uma vez projetados conforme as condições da Tabela 3, têm as
mesmas propriedades dos blocos originais e, desta forma, nas regras dadas, podem substituir em
qualquer posição os blocos originais. Com isso ganhamos maior flexibilidade de projeto e ficamos
livres para usar os blocos N-MOS like apenas nos data chains onde há problemas com a velocidade.
Resultam então, a partir do uso conscencioso dos novos blocos, circuitos onde a velocidade é alta e
mesmo o consumo de potência é reduzido. Veremos isto nos circuitos de testes implementados e
expostos no capítulo quatro.
Tabela 3. Condições que determinarão o dimensionamento dos transistores dos blocos N-MOS like.
bloco clock= nível alto clock= nível baixo
N-MOS like n-dinâmico
nenhuma saída deve ser alta, independente das entradas
N-MOS like p-dinâmico
saída deve ser baixa, independente das entradas
nenhuma

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
77
N-MOS like n-latch
saída deve ser alta se a estrutura PUN está conduzindo; caso
contrário, baixa
nenhuma
N-MOS like p-latch
nenhuma saída deve ser baixa se a estrutura PDN está conduzindo; caso contrário,
alta
2.3.5 Regra de Exceção
As regras dadas acima impedem que haja certos erros no circuito que lhes obedece; elas são
suficientes. Por outro lado, pode haver circuitos, e há, que mesmo não obedecendo a algumas delas,
executam a função que deles é esperada. As regras dadas não são, portanto, necessárias. As
configurações apresentadas nas Figuras 17 e 18, quanto funcionam, são exemplos destes circuitos.
Consideremos a configuração da Figura 17. Aqui os p-data chain, um formado por BL1 e o outro
por BL4, têm apenas um bloco, uma violação de r5. Conseqüentemente não podemos assegurar h4, e as
saídas dos p-latches não são mantidas durante a fase de holding. Apesar disso, os n-data chains
funcionam perfeitamente.
Podemos introduzir uma regra de exceção que permita configurações semelhantes àquelas das
Figuras 17 e 18. Antes disso observemos mais atentamente o que ocorre nos dois exemplos. Três
características são essenciais para o funcionamento deles:
i. a saída do data chain que não segue as regras r1-r5 (chamaremos este data chain de SE) somente
pode ter um tipo de transição na fase de holding, seja a transição “0”→”1”, seja a transição
“1”→”0”;
ii. os blocos ligados à saída deste data chain devem ser insensíveis, durante a sua avaliação, a esta
transição;
iii. a saída do data chain SE deve permanecer fixa durante o início da sua fase de holding, ao menos
tempo suficiente para que os blocos ligados a esta saída possam ser corretamente avaliados.
Na Figura 17, por exemplo, a saída do bloco BL4, um p-latch, durante o holding só pode ter a
transição “1”→”0”; o bloco BL5, um bloco n-dinâmico, não tem, por sua vez, sua saída modificada
pela transição “1”→”0”. Ainda, o valor lógico do nó b1 deve ser mantido durante o início da fase de
holding, ao menos por tempo suficiente para que o bloco BL5 avalie corretamente. Na Figura 18, em a1
somente pode haver, na fase de holding dos n-data chains, transições “0”→”1” e esta transição não
afeta o bloco p-dinâmico BL2. Deve também ser mantido o valor lógico de a1, durante o holding, por
tempo suficiente para que BL2 avalie corretamente.

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
78
As duas primeiras destas características podem ser facilmente garantidas pois dependem apenas de
como são associados os blocos. Para este fim devemos ter as seguintes características:
a. SE possuir ao menos um bloco dinâmico ou um latch (o último bloco dinâmico ou latch de SE será
chamado de BF);
b. serem os blocos ligados a saída de SE, e pertencentes a um data chain de tipo diferente de SE, ou
Dp ou dinâmico (estes blocos serão chamados de blocos Bis);
c. haver entre BF e cada bloco Bi um número de inversões regido pela Tabela 4.
Veja que (a) garante que a saída do data chain SE tenha apenas um tipo de transição no holding
(pr3,4,9,10); (b), por sua vez, garante que o bloco ligado a saída do data chain não seja afetado por certo
tipo de transição; (c), finalmente, garante que a transição possível na saída do data chain SE e a
transição que não afeta os blocos aí ligados, (b), são as mesmas.
A terceira característica necessária para o data chain SE depende não só da associação dos blocos
mas também dos atrasos destes.
Tabela 4. Número de blocos estáticos e Dps (estes pertencendo a SE) entre o bloco BF e o bloco Bi
para o data chain SE.
BF
Bi
n-dinâmico n-latch p-dinâmico p-latch
PH par par ímpar ímpar
PL ímpar ímpar par par
n-dinâmico n.p. n.p. par par
p-dinâmico par par n.p. n.p.
n.p.: ligações que não são permitidas; par: deve haver um número par de blocos; ímpar: deve haver um número ímpar de blocos. Consideremos agora a regra chamada de regra de exceção.
Regra de Exceção (rE): Seja o data chain SE com as seguintes características:
i. SE possuir ao menos um bloco dinâmico ou um latch (o último bloco dinâmico ou latch de SE será
chamado de BF);

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
79
ii. serem os blocos ligados a saída de SE, e pertencentes a um data chain de tipo diferente de SE, ou
Dp ou dinâmico (estes blocos serão chamados de blocos Bis);
iii. haver entre BF e cada bloco Bi um número de inversões regido pela Tabela 4.
Neste caso, se a saída de SE permanecer fixa durante o início da sua fase de holding, ao menos tempo
suficiente para que todos os blocos Bis possam avaliar corretamente, então o data chain SE não
precisará obedecer à r4 e à r5.
Esta nova regra exige, antes de mais nada, que façamos uma nova definição para o circuito RTS que
analisamos. Para diferenciar da definição anterior falaremos agora de circuito RTS E-TSPC’.
Definição 14: Um circuito CE será chamado de circuito RTS E-TSPC’ se para qualquer spp Sq de CE
ocorre que:
i. existe um n-data chain DNi de CE tal que Sq ⊆ DNi, se o spp for formado por apenas blocos n-
dinâmicos, n-Dps e n-latches, ao menos um desses, e mais blocos estáticos;
ii. existe um p-data chain DPi de CE tal que Sq ⊆ Dpi, se o spp for formado por apenas blocos p-
dinâmicos, p-Dps e p-latches, ao menos um desses, e mais blocos estáticos;
iii. existe um p-data ou um n-data chain Di de CE tal que Sq ⊆ Di, se o spp for formado por apenas
blocos estáticos;
iv. as regras r1-r5 ou as regras r1-r3 e rE são observadas para todos os data chains;
v. todas as entradas do circuito são entradas externas.
Podemos provar para o circuito RTS E-TSPC’ um teorema similar ao teorema fundamental
mostrado anteriormente. Ele é enunciado abaixo.
Teorema fundamental para os circuitos RTS E-TSPC’: Considere um circuito RTS E-TSPC’ CE. Se
as entradas externas forem convenientes, o “clock” tiver o período longo suficiente e se todo circuito
estiver estável uma vez no início de seu funcionamento, então:
i. a saída do último “latch” de um “data chain” que obedece às regras r1-r5 fica inalterada durante
a fase de “holding” deste;
ii. os blocos Dps fazem a correta pré-carga durante a fase de “holding” do “data chain” a que
pertencem;
iii. os blocos dinâmicos e os blocos Dps não são descarregados indevidamente durante a fase de
avaliação do “data chain” a que pertencem.
Para a prova deste teorema são usados os mesmos passos que os dados acima. As diferenças que
aparecem são:

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
80
a. nos teoremas, lemas e corolários devemos dizer que a saída do último latch é estável no holding
apenas nos data chains que obedecem à r1-r5, seja isto usado na hipótese ou na tese destes;
b. as demonstrações dos lemas 1N e 1P devem levar em consideração os data chains que não
obedecem à r4 e r5. O mesmo para os teoremas 3N e 3P.
Procuremos agora determinar quais condições são necessárias para que os blocos Bis da regra de
exceção rE tenham tempo para avaliar corretamente. Consideremos inicialmente as definições abaixo.
Definição 15: Considere um bloco BΓ não estático complementar que pertence a um Γ-“data chain”
(deverá ser um bloco Dp, Γ-dinâmico ou Γ-"latch"). Sejam DΓ1, DΓ2, ..., DΓn todos os Γ-"data
chains" que passam por BΓ. Chamaremos de atraso de avaliação de BΓ, ∆EBΓ, ao máximo dos ∆is,
para i=1, ...n, onde
∆i=(máximo atraso entre a aplicação de um sinal na entrada do primeiro bloco não estático do
“data chain” DΓi e a mudança causada na saída de BΓ, estando o Γ-“data chain” em avaliação).
Definição 16: Considere um Γ-"data chain" qualquer que obedece às regras de composição (r1-r5).
Existirá ao menos um Γ-"latch" que é precedido por ou outro Γ-"latch" ou um Γ-dinâmico, havendo
entre este e aquele um número ímpar de inversões (r4 ou r5). O primeiro “latch”, considerado da
entrada para a saída do "data chain", que observa esta condição será chamado de "true-latch" do
"data chain".
Definição 17: Considere um Γ-"data chain" DΓ qualquer e o bloco BΓ, o primeiro bloco não estático
complementar que pertence ao “data chain” (deverá ser um bloco Dp, Γ-dinâmico ou Γ-"latch").
Considere todos os “data chains” que terminam na entrada de BΓ por onde passa DΓ (todos de tipo
diferente de Γ), DΓ1 , D
Γ2 , ..., D nΓ . Suponha que todos esses obedeçam as regras de composição (r1-
r5). Chamaremos de atraso de avaliação no data chain precedente a DΓ, ∆PDΓ, ao mínimo dos ∆is,
para i=0, ...n, onde
∆i=(mínimo atraso entre a aplicação de um sinal na entrada do "true-latch", se D iΓ obedece à r1-r5,
ou na entrada do último latch/porta dinâmica, se D iΓ obedece à rE, e a mudança causada na saída do
"data chain" D iΓ , estando o Γ -"data chain" em avaliação).
Pois bem, seja SE um data chain que não obedeça a r4 e r5 mas sim as condições (i), (ii) e (iii) de rE.
Sejam Bis os blocos ligados a saída de SE e que pertençam a um data chain de tipo diferente de SE.
Podemos garantir que os blocos Bis avaliam corretamente se para todo Bi

Implementação de Register Transfer Systems (RTS) de Alta Velocidade
81
i. (atraso entre a saída do bloco BD até a saída de SE) >> (atraso de avaliação de Bi), onde BD é
o último bloco dinâmico de SE, mais próximo a saída, para o caso de SE possuir um bloco
dinâmico;
ii. (atraso de avaliação no data chain precedente a SE) + (atraso entre a entrada do primeiro
bloco não estático complementar e a saída de SE) >> (atraso de avaliação de Bi), para o caso
contrário.
O uso da regra de exceção é delicada e só aconselhada para o caso do D-flip-flop da Figura 17. Foi
em razão deste circuito que procuramos introduzi-la.
2.3.6 Comparações e conclusões sobre o E-TSPC
Comparando as regras de composição aqui apresentadas com as de [La95], Figura 16, encontramos
as seguintes diferenças:
• em nosso trabalho fizemos a distinção entre dois tipos de entradas nos blocos Dps: as entradas que
ajudam na pré-carga da porta, chamadas de pc-entradas, e aquelas que não ajudam. As não pc-
entradas têm condições de conexão mais simples que as outras. A conexão entre os blocos BB e BD
na Figura 19 é um exemplo de ligação permitida por nós e proibida por [La95]. Esta diferença é
das menos importantes pois os blocos Dps são, no geral, de difícil aplicação;
• em nossas regras a colocação dos blocos estáticos é mais liberal: em [La95] estes blocos podem
estar apenas após certos latches (Figura 16). No exemplo da Figura 19, as ligações entre os blocos
BI e BG, entre BE e BG e entre os blocos BJ e BM são conexões aceitas em nosso trabalho e que
estão excluídos de [La95].
Por outro lado, todas as ligações permitidas em [La95] são também aceitas em nosso trabalho. Em
alguns casos a regra de exceção deve ser aplicada. Adicionalmente, propomos blocos modificados, as
versões N-MOS like dos blocos dinâmicos e latches, que não foram considerados anteriormente.
Quanto aos latches apontados na Figura 11, que fazem parte da técnica TSPC, podemos fazer os
mesmos comentários já apresentados: apesar de não poderem ser construídos com os blocos do E-
TSPC, sua introdução em um circuito é tarefa simples uma vez que são latches verdadeiros.
Concluindo, apresentamos aqui blocos e regras de composição para projeto de circuitos RTS de
uma única fase. Os blocos e as regras permitem configurações mais gerais do que aquelas já
apresentadas na literatura. Por esta razão chamamos a técnica de Extended-TSPC.
Um comentário final a respeito dos teoremas e demonstrações deste capítulo. Procuramos aqui
desenvolvê-los da forma mais rigorosa possível e a conseqüência disso foi a necessidade de um
número grande de teoremas, lemas e corolários.


Otimização de Tapered Buffers para altas taxas de operação
83
3. Otimização de Tapered Buffers para altas taxas de operação
3.1 Introdução
Tapered buffers, como apresentado na Figura 21, consistem de uma cadeia de inversores com um
fator de aumento, normalmente constante, entre um inversor e outro. Estas estruturas são empregadas
para diversas funções dentro dos circuitos integrados, servindo, sobretudo, para amplificar sinais
pequenos e drenar cargas capacitivas elevadas. Exemplos do primeiro tipo de aplicação são
apresentados no conversor A/D de [Ku86] e no circuito de entrada de [St91]; exemplos do segundo
tipo são os buffers para distribuição de sinais ([Fr95]), onde a carga capacitiva é interno ao C.I., e os
buffers de saída para sinais digitais, onde a carga capacitiva é externa ao C.I..
Os primeiros estudos sobre tapered buffers apareceram há mais de 20 anos [Li75]. Nos dias de hoje,
sua principal aplicação é, sem dúvida, a distribuição do sinal de clock dentro de circuitos integrados
[Fr95]. Em microprocessadores de alto desempenho, por exemplo, uma porção considerável da área e
da potência são consumidas nesta tarefa ([Gr98] e [Do92]). Seja qual for o emprego do tapered buffer,
um dos objetivos principais é, no geral, o aumento da velocidade dos sinais no C.I..
V0 V1
1 2 N-1 N CL
V2 VN-1 VN
entrada
saída
Figura 21. Ilustração de um tapered buffer com N inversores. O nó de saída tem uma capacitância de
carga CL.
Neste capítulo discutiremos a otimização de tapered buffers com o objetivo de atingir maiores
velocidades. Veremos que a minimização do atraso total do buffer, em certas aplicações, pode ser
deixada para segundo plano. Iremos então propor um novo critério para projeto de buffers, passagem
de pulsos o mais estreitos possível, e mostrar, por meio de simulações, que ele permite aumentos
consideráveis na velocidade, desde que seja possível aplicá-lo. Por fim discutiremos o problema do
casamento dos inversores e como variam, em conseqüência deste, os atrasos causados pelos tapered
buffers. Como veremos, o controle destes atrasos é importante para a utilização do critério aqui
proposto.

Otimização de Tapered Buffers para altas taxas de operação
84
3.2 Critérios clássicos para otimização de Tapered Buffers
O projeto de um tapered buffer envolve a determinação do fator de aumento entre os inversores
(tapering factor), que chamaremos de χ, e do número de inversores a ser empregado, dadas as
dimensões do primeiro inversor e a carga capacitiva da saída do buffer, CL.
Quando são examinados circuitos de alta velocidade, o principal critério para determinação do fator
de aumento é a minimização do atraso entre a entrada e a saída do buffer, ou simplesmente o atraso do
buffer. Este mesmo critério já era empregado em [Li75].
Podemos calcular o fator de aumento ótimo que minimiza este atraso. Antes de prosseguirmos,
porém, daremos o significado de alguns símbolos que serão usados neste capítulo. Chamaremos de:
N o número de inversores do tapered buffer (ver Figura 21);
Coxi a capacitância, por unidade de área, no gate dos transistores P e N do i-ésimo inversor;
Lni e Lpi o comprimento de canal dos transistores N e P, respectivamente, do i-ésimo inversor;
Wni e Wpi a largura de canal dos transistores N e P, respectivamente, do i-ésimo inversor;
CLi a capacitância de carga do i-ésimo inversor;
µni e µpi a mobilidade dos elétrons e das lacunas nos transistores N e P, respectivamente, do i-ésimo
inversor;
VTni e VTpi a tensão de limiar dos transistores N e P, respectivamente, do i-ésimo inversor.
Consideramos ainda válidas as seguintes relações:
L L Lni pi i= = ; W Wni i= ; W Wpi i= θ (1)
Para o cálculo do fator ótimo, o que minimiza o atraso do buffer, é necessário conhecer o atraso
causado por cada um de seus inversores. Usaremos, para este fim, as relações propostas por [Sa90],
que levam em consideração efeitos de canal curto, importantes para as tecnologias modernas. Assim
por [Sa90] temos que:
t t tC V
IpHLi pLHiTi
TiLi DD
D i
, = −−+
+−
12
11 21
0
να
(2)
tC V
IV
VV
eVTiLi DD
D i
D i
DD
D i
DD= +
0
0 00 908 08
10.. .
ln (3)
( )IWL
P V VD ii
iCi DD Ti0 = −
α (4)

Otimização de Tapered Buffers para altas taxas de operação
85
onde: tpHLi é o atraso na transição de alto-para-baixo (descarga) da saída do i-ésimo inversor; para o
cálculo de tpHLi os parâmetros do transistor N são aplicados na fórmula (2), e os parâmetros do P, na
fórmula (3);
tpLHi é o atraso na transição de baixo-para-alto (carga) da saída do i-ésimo inversor; para o cálculo de
tpLHi os parâmetros do transistor P são aplicados na fórmula (2), e os parâmetros do N, na fórmula
(3);
tTi é o tempo de transição efetivo do sinal na saída do i-ésimo inversor;
PCi é um parâmetro do transistor P ou N; usaremos aqui que P K CCi Ci i oxi= µ onde KCi é outro
parâmetro e µi, a mobilidade dos portadores do transistor;
VD0i é a tensão de dreno de saturação quando VGSi=VDD para o transistor utilizado na equação (P ou
N). VGSi é a tensão entre gate e fonte;
νTi=|VTi/VDD|. VTi é a tensão de limiar do transistor utilizado na equação (P ou N);
α é uma constante que está entre 1 e 2.
Para o caso ideal de tapered buffer, onde não há mismatch dos parâmetros e eles têm exatamente o
valor com que foram projetados, são válidas as seguintes relações:
Coxi=Cox Li=L VTni=VTn VTpi=VTp VD0ni=VD0n VD0pi=VD0p
W Wii= −χ 1 K KCni Cn= K KCpi Cp= µ µni n= µ µpi p= (5)
Para a aplicação das relações do atraso, devemos determinar o valor da capacitância de carga de
cada inversor, CLi. Para este fim faremos três hipótese:
i. as capacitâncias das conexões que ligam dois inversores são muito reduzidas (desprezíveis) em
comparação com as capacitâncias de gate e com as capacitâncias de junção de dreno dos
transistores;
ii. as capacitâncias de gate são constantes, não dependendo do estado do transistor;
iii. as capacitâncias de junção de dreno são constantes e diretamente proporcionais à largura de canal
do transistor.
Estas hipóteses servem para simplificar os resultados e são normalmente adotadas [He87]. Pela
hipótese i acima poderemos então escrever que
( ) ( )C C C C CLi gni dni gpi dpi= + + ++ +1 1 para 1≤ <i N e C C C CLN dnN dpN L= + +
onde: Cgni e Cgpi são as capacitâncias de gate dos transistores N e P, respectivamente, do i-ésimo
inversor;
Cdni e Cdpi são as capacitâncias de junção de dreno dos transistores N e P, respectivamente, do i-
ésimo inversor.

Otimização de Tapered Buffers para altas taxas de operação
86
As capacitâncias de gate e dreno são (hipótese iii):
C C W Lgni oxi ni i= C C W L C W Lgpi oxi pi i oxi ni i= = θ
C W Kdni ni DSn= C W K W Kdpi pi DSp ni DSp= = θ
onde KDSn e KDSp são parâmetros que dependem do processo e do layout.
Por simplicidade vamos usar que KDSn=KDSp=KDS. Por fim, a partir das relações acima, teremos que
( )( )C K W W L CLi DS i i i oxi= + + + + +1 1 1 1θ para 1≤i<N
( )C K W CLN DS N L= + +1 θ
Não havendo mismatch dos parâmetros então
( )C LC WKLCLi ox
i DS
ox
= + +
−1 1θ χ χ para 1≤i<N (6)
O atraso do i-ésimo (i>1) inversor do tapered buffer pode ser calculado pela relação abaixo:
tt t V C
IV
VVeV
CI
CI
VV
VeV
dipHLi pLHi DD Li
D ni
Tpi D ni
DD
D ni
DD
Li
D ni
Li
D pi
Tni D pi
DD
D pi
DD
=+
= −−+
+
+
+
−−+
+
−
−
− −
−
−
− −
2 212
11
0 90 8 0 8
102
12
11
0 90 8 0 8
10
1
0 1
0 1 0 1
0
1
0 1
0 1 0 1
να
να
.
. .ln
.
. .ln
+
CI
Li
D pi2 0
(7)
onde: tdi é o atraso do i-ésimo inversor;
o índice n é sempre relativo ao transistor canal N e p, ao transistor canal P.
Vamos definir novas funções que nos ajudarão a rescrever as fórmulas acima. Chamemos de:
( )F V V
VV V
VV
eVT D
T
DD D
DD
D
DD
,.. .
ln00 01
2
1
10 90 8 0 8
10= −
−
+
+
α
(8)
( ) ( ) ( )F V V V KK V V
F V VD a b D C
C DD a
b D, , , ,0 0
1 12
=−
+
α (9)
Aplicando então estas novas funções, escrevemos o atraso do i-ésimo, 1< ≤i N , inversor como:
( ) ( )tt t V C
IF V V
CI
CI
F V VCIdi
pHLi pLHi DD Li
D niTpi D ni
Li
D ni
Li
D piTni D pi
Li
D pi=
+= +
+
+
−
−−
−
−−2 2 2 2
1
0 10 1
0
1
0 10 1
0, , (10)
Para o caso onde não há mismatch dos parâmetros, podemos aplicar as relações de (5) e (6) na
expressão acima, obtendo

Otimização de Tapered Buffers para altas taxas de operação
87
( ) ( )t tV L K
LCF V V V K F V V V Kdi d
DD DS
oxD Tn Tp D n Cn D Tp Tn D p Cp= = + +
+1
2
2
0 0θ χ θ( , , , ) ( , , ) (11)
onde td é o atraso do i-ésimo inversor, 1<i<N, quando não há mismatch.
Observemos que KLC
DS
oxfornece a razão entre a capacitância de dreno de um inversor e sua
capacitância de gate. Esta razão depende tanto da tecnologia como do layout e tem, raramente, valor
superior a um.
Por fim, podemos calcular o fator de aumento ótimo que minimiza o atraso de um tapered buffer.
Para que a razão entre a carga na entrada e a carga na saída do N-ésimo inversor seja igual a aquela dos
N-1 primeiros inversores do buffer vamos assumir que
( )C C CL gn gpN= +1 1 χ ou
( )N
C
C CL
gn gp=
+
ln
ln1 1
χ
Também consideraremos que o atraso no primeiro inversor seja da forma dada pela expressão (11).
Assim o atraso num tapered buffer com N inversores será
( ) ( )t NV L K
LCF V V V K F V V V KD
DD DS
oxD Tn Tp D n Cn D Tp Tn D p Cp= + +
+1
2
2
0 0θ χ θ( , , , ) ( , , )
onde tD é o atraso do tapered buffer.
Substituindo o valor de N na última expressão teremos por fim
( ) ( ) ( )t
KLC C
C C
V LF V V V K F V V V KD
DS
ox L
gn gp
DDD Tn Tp D n Cn D Tp Tn D p Cp=
+
+
+ +
χ
χθ θ
lnln ( , , , ) ( , , )
1 1
2
0 012
Para determinar o fator de aumento que minimiza tD, devemos derivar a expressão acima, em
relação a χ, e igualar o resultado a zero. Abaixo temos em que condições a derivada de tD se anula:
∂∂χ
χ χχ
t KLC
D DS
ox
= ⇔ − +
0
1ln
O valor ótimo para χ será então
χ χχot
DS
oxot
ot
KLC
= +
exp
1
onde χot é o valor do fator de aumento que minimiza o atraso do tapered buffer.

Otimização de Tapered Buffers para altas taxas de operação
88
Na Figura 22 é mostrado χot em função da razão KLC
DS
ox. O fator de aumento ótimo para KDS=0,
situação em que as capacitâncias de dreno são desprezíveis, é χot=e=2,714, o mínimo valor para χot e
que coincide com o resultado clássico.
0 2,7180,2 2,910,4 3,090,6 3,2660,8 3,43
1 3,591,2 3,751,4 3,891,6 4,041,8 4,18
2 4,32
0
1
2
3
4
5
0 0,5 1 1,5 2razão entre capacitância de dreno e capacitância de
gate
fato
r de
aum
ento
ótim
o
Figura 22. Gráfico mostrando o fator de aumento que minimiza o atraso total de um tapered buffer
como função da razão KLC
DS
ox.
Em trabalhos mais recentes, não só o atraso mas também outros fatores, tais como potência
consumida, área do buffer e confiabilidade, são considerados para a otimização. Neste caso, pesos
diferentes são associados a cada um destes fatores. O valor ótimo do fator de aumento, então, varia de
acordo com os pesos e com a tecnologia analisada ([He87], [La88], [Ch95]).
3.3 Novo critério para otimização de Tapered Buffers para altas taxas
Vamos nos concentrar, daqui para frente, em circuitos onde a máxima taxa de operação é o aspecto
prioritário. Observemos que a minimização do atraso do buffer, para várias aplicações, não é de fato
importante para alcançar a máxima velocidade. Um exemplo destes é o demultiplexador de alta
velocidade indicado na Figura 23 [Ro95b]. Neste circuito, tapered buffers são usados na distribuição
do clock e também para o sinal de dado de entrada (o sinal a ser demultiplexado). Desde que os atrasos
destes buffers, o do dado e os do clock, sejam iguais, não importa o seu valor. O que se deseja é que os
buffers permitam a passagem de pulsos rápidos ou estreitos, que é a mesma coisa. Veja, portanto, que
não há verdadeiramente imposição alguma para a minimização do atraso e, além disso, o buffer com
mínimo atraso não é, necessariamente, o melhor para o circuito.

Otimização de Tapered Buffers para altas taxas de operação
89
d a d o
c lo c k
ta p e re d b u ffe r
ta p e re d b u ffe r
C .I. d e m u ltip le x a d o r
Figura 23. Demultiplexador 1:8 com tapered buffers para o dado e para o clock [Ro95b].
O que foi dito acima nos traz imediatamente duas questões: qual deve ser o critério para otimização
de tapered buffers para circuitos de alta velocidade onde o atraso total não é importante? Qual é o fator
de aumento ótimo resultante do uso deste novo critério?
Procuramos responder essas questões nesta seção.
3.3.1 Novo critério: sinal de teste e definição de passagem do sinal
Em aplicações onde o atraso não é importante, devemos usar um novo critério para alcançar a
máxima taxa de operação, como visto. O critério imediato é que o buffer permita a passagem de sinais
digitais de maior freqüência ou, que é o mesmo, que o buffer permita a propagação dos pulsos o mais
estreitos possível. Detalharemos melhor este novo critério de otimização.
Primeiro devemos definir qual o sinal de entrada a ser aplicado no buffer para avaliá-lo. A opção
mais simples é uma onda quadrada. Outra possibilidade é o uso de uma seqüência de pulsos “0s” e
“1s” previamente escolhida. Neste caso é recomendável que a seqüência tenha ao menos um pulso
isolado no nível alto, como em “000100”, e outro no nível baixo, como em “111011”. Estes pulsos
isolados são os que têm maior dificuldade de passagem e, portanto, servem melhor para avaliar o
buffer. Destas duas alternativas, a melhor escolha dependerá da aplicação destinada ao tapered buffer.
No caso dele ser usado apenas para a distribuição do clock, não temos razões para aplicar outro sinal
que não uma onda quadrada. No exemplo apresentado na Figura 23, onde por buffers iguais passam
tanto o sinal de clock como o de dados, uma seqüência de “1s” e “0s” na entrada será a melhor opção
de teste.
Devemos ainda esclarecer o que significa um sinal passar pelo buffer. Aqui também aparecem
diferentes possibilidades. Duas definições aplicáveis são:
i. diremos que o sinal de entrada passa pelo buffer se todos os pulsos que forem aplicados na entrada
chegam à saída e, ainda, atingem níveis mínimos tolerados de tensão. A Figura 24 ilustra esta
condição. O sinal aplicado à entrada do buffer, a seqüência “01001011”, é apresentado na parte
superior da figura e o sinal de saída, na parte inferior. Neste exemplo o tapered buffer é formado

Otimização de Tapered Buffers para altas taxas de operação
90
por um número par de inversores. Um pulso “1” é considerado ter passado com sucesso se ele
atinge na saída tensão VHM ou superior; um pulso “0”, por sua vez, se ele atinge na saída tensão
VLM ou inferior (para buffers com um número ímpar de inversores será o oposto). Por exemplo, o
segundo pulso “1” da entrada não passou para a saída segundo este critério;
ii. diremos que o sinal de entrada passa pelo buffer se todos os pulsos que forem aplicados na entrada
chegam a saída, atingem níveis mínimos de tensão e, ainda, a diferença entre as larguras do pulso
na entrada e do pulso na saída é menor que uma certa porcentagem da largura do pulso da entrada.
Na Figura 24 estão dadas as larguras dos pulsos. As relações abaixo fornecem as condições que
devem ser observadas pelos pulsos na saída, no que diz respeito a largura:
( ) ( )1 11 3 4− ≤ ≤ +ε εP P P P PW W W W W, , ,
12
2 12
22 5−
≤ ≤ +
ε εP P P PW W W W,
onde: ε é a constante de erro relativa (por exemplo ε=0,1);
Pwi é a largura do i-ésimo pulso da saída (Figura 24).
Uma vez mais a aplicação do buffer determinará qual definição é a mais adequada. Para buffers
onde passam apenas sinais de clock, por exemplo, é recomendável o uso da definição (ii) para que haja
maior simetria no sinal na saída.
PW 1
Sinal de entrada
Sinal de saída
falha
PW 2 PW 3 PW 4 PW 5
PW
VHM
VLM
Figura 24. Sinais de entrada e saída de um tapered buffer com um número par de inversores.
3.3.2 Modelo teórico para o novo critério de otimização
Nosso objetivo agora é encontrar expressões teóricas que auxiliem na determinação do fator de
aumento ótimo, permitindo a passagem dos pulsos o mais estreitos pelo tapered buffer, dadas as
dimensões do primeiro inversor e a carga capacitiva na saída do buffer. Para tal fim é necessário saber
calcular, dado um tapered buffer, qual a maior taxa que pode ter o sinal de entrada de forma que ele
ainda propague pelo buffer.

Otimização de Tapered Buffers para altas taxas de operação
91
Ao contrário do que acontece com o atraso de tapered buffers, onde diversos modelos são
disponíveis, não conhecemos, na literatura, relação que possa ser diretamente aplicada para o cálculo
da máxima taxa possível para o sinal que atravessa o buffer.
Para nosso problema, servindo como aproximação, utilizaremos uma expressão desenvolvida em
[Sh92] que trata do colapso de pulsos (collapse of pulses) em cadeias de inversores. Ela foi construída
a partir de um modelo bastante simplificado do transistor; abaixo fornecemos as equações da saturação
e da região tríodo do transistor N que foram aí aplicadas:
I V VV
VD n GS TnDS
DS= − −
β
2 se VDS<VGS-VTn (região tríodo)
( )I V VDn
GS Tn= −β2
2 se VDS>VGS-VTn (saturação)
onde: ID é a corrente de dreno do transistor;
VGS é a tensão gate-fonte;
VDS é a tensão dreno-fonte;
VTn é a tensão de limiar;
β µn n oxn
n
CWL
=
.
Wn é a largura do canal; Ln é o comprimento do canal; µn é a mobilidade dos elétrons.
(para o transistor P as relações são análogas)
Consideremos novamente o tapered buffer da Figura 21, com seus N inversores e fator de ganho χ.
Vamos supor que tanto as relações em (1) como em (5) são obedecidas. Ainda, que o valor de θ seja tal
que os transistores P e N de cada inversor tenham a mesma capacidade de drenar corrente, ou seja
( ) ( )1 1
β βni DD Tni pi DD TpiV V V V−
=−
=Rinvi
onde: o índice i é relativo ao i-ésimo inversor;
Rinv é uma resistência equivalente ao transistor.
Em [Sh92] é derivada a seguinte relação para o i-ésimo inversor do tapered buffer:
T T tT T
ti i ii i
i−
−− = −−
1 0
1
02 exp ∆ (12)
onde: Ti é a largura do pulso em Vi (ver Figura 21);
t0i é uma constante de tempo do i-ésimo inversor; seu valor é dado por t C Ri Li invi0 = ;
T∆i é uma constante do i-ésimo inversor; seu valor está em torno de 3t0i.

Otimização de Tapered Buffers para altas taxas de operação
92
Pelo exposto acima e pela relação (6) podemos escrever que
( )t
C
V V
CV V
L KLCi
Li
pi DD Tpi
Li
ni DD Tni n
DS
ox0
21=
−=
−=
++
β βθµ
χ( ) ( )
= constante para 1≤ <i N
Em [Sh92] é também mostrado que, para um número grande de inversores, a partir de (12)
chegamos a seguinte equação:
( )exp expTt
Tt
K NN0
0
1
02 1
−
= −−
∆
onde t0 é a constante de tempo dos (N-1) primeiros inversores;
KTt∆∆=
exp
0;
T∆ é a constante T∆i dos N-1 primeiros inversores.
Para o último inversor vale a equação abaixo:
T T tT T
tN N NN N
N−
−− = −−
1 0
1
02 exp ∆
Vamos supor que TN≈0 quando o pulso na saída não satisfaz o critério adotado; a equação acima
nos leva então ao seguinte resultado:
T t KTtN N N
N
N−
−= −
1 0
1
02 ∆ exp onde K
TtN
N
N∆
∆=
exp
0
Daí derivamos que T t KN N− =1 0 α , onde Kα é uma constante. O valor de Kα depende de K∆N, e portanto
da razão Tt
N
N
∆
0
. A Figura 25 mostra como Kα varia em função de
Tt
N
N
∆
0
, para esta razão variando de
0, mínimo valor que assume, até 6, valor superior ao que é normalmente encontrado.
Para determinar TN-1 escrevemos a expressão para t0N:
( ) ( )( )
( ) ( )tC
V VLC
C W V VLK
C V VL
C V VC
WconstN
LN
nN DD Tn
L
n ox nN DD Tn
DS
n ox DD Tn n ox DD Tn
L
nN0
1=
−=
−+
+−
=−
+
β µθ
µ µ.
Derivamos finalmente que
TK
WC K
KC KN
nNL N L− −= + = +1
12
11 2χ
(13)
onde: K1 e K2 são constantes que dependem dos parâmetros da tecnologia e do layout;
K1 é uma constante que depende dos parâmetros da tecnologia, do layout e das dimensões do
primeiro inversor do buffer.

Otimização de Tapered Buffers para altas taxas de operação
93
0 1 2 3 4 5 60
1
2
3
4
5
6
v a lo r e s d e ( T ∆ N / t 0 N )
V a lo r e sd e K α
Figura 25. Gráfico de Kα como função de Tt
N
N
∆
0
.
Resumindo os resultados obtidos, escrevemos as três expressões abaixo que fornecem a largura
mínima de um pulso que propaga pelo tapered buffer:
( )
( ) ( )
TK
C K
T t K NTt
tL K
LCK K
N N L
N
n
DS
ox
− −
−
= +
= − +
=+
+
= +
11
1 2
0 01
0
0
2
3 4
2 1
1
χ
θµ
χ χ
ln exp∆ (14)
onde K3 e K4 são constantes que dependem dos parâmetros da tecnologia e do layout.
Façamos, por fim, uma análise qualitativa do comportamento de T0 em função de CL, a usando as
expressões de (14). Quando a capacitância de carga CL é pequena teremos que TN-1=t0NKα<<t0 e, em
conseqüência, T0 é praticamente independente da carga da saída (equações (14)). Por outro lado,
quando a capacitância de carga CL é muito grande teremos que TN-1=t0NKα>>t0, e T0 será praticamente
igual a TN-1, sendo, portanto, função linear de CL. Um gráfico de T0 x CL terá, de acordo com as
equações em (14), o seguinte comportamento: para valores pequenos de CL a curva será horizontal e
para valores grandes, tenderá a uma reta. A inclinação desta reta dependerá diretamente da largura de
canal dos transistores do último inversor do tapered buffer. Veremos, mais adiante, que este
comportamento está perfeitamente em acordo com os resultados de simulações.
3.3.3 Simulação dos Tapered Buffers
Para avaliar o comportamento dos tapered buffers e as relações acima, várias simulações foram
feitas. As condições das simulações são apresentadas na próxima seção.

Otimização de Tapered Buffers para altas taxas de operação
94
3.3.3.1 Condições para as simulações
Os resultados apresentados neste capítulo são gerados a partir de duas tecnologias diferentes (no
APÊNDICE D, resultados de uma terceira tecnologia são dados):
• tecnologia CMOS 0,8µm da ES2/ATMEL [Es94];
• tecnologia CMOS 0,35µm do IMEC/Bélgica [Hu97].
obs.: neste trabalho chamamos a tecnologia da ES2 de tecnologia de 0,8µm pois esta é a dimensão
mínima de máscara para o comprimento de canal. O comprimento efetivo do canal é 0,7µm. A ES2,
por sua vez, chama a mesma de tecnologia 0,7µm CMOS.
Para a tecnologia da ES2 as simulações foram feitas com SPICE3d2, level 2 e parâmetros slow
([Vl80], [An88]). Para a tecnologia 0,35µm, foi utilizado o HSPICE, level 3 e também parâmetros
slow ([Me95a], [Me95b]). Os modelos dos transistores estão no APÊNDICE B. O layout de cada
transistor é imaginado como tendo a forma de um pente com dois ramos (Figura 26). Essa
configuração é a que dá os menores valores de perímetro e área de dreno. Considerando tal
configuração é possível o cálculo de perímetros e áreas de drenos e a sua inclusão nas simulações. A
Tabela 5 nos fornece as equações usadas para determinação da área e do perímetro de dreno. Para
áreas e perímetros de fonte e também para as resistências de dreno/fonte não foram fornecido os
valores, ficando assim o valor default do simulador. Notemos que no HSPICE estes valores default são
consideráveis e calculados pelas relações abaixo [Me95b]:
As Hdif Wdf ef= 2 . Ps Hdif Wdf ef= +4 2 ( )
RsHdif RSH Ld Ldif RS
Wdfef
=+ +.
( )Rd
Hdif RSH Ld Ldif RDWdf
ef=
+ +.
onde: Wef é a largura efetiva de canal do transistor;
Hdif, Ld, Ldif, RD, RS, e RSH são parâmetros do modelo do transistor (ver APÊNDICE B);
Asdf valor default para área de fonte;
Psdf valor default para perímetro de fonte;
Rddf valor default para resistência série de dreno;
Rsdf valor default para resistência série de fonte.
Tabela 5. Relações para cálculo da área e do perímetro de dreno. W é a largura de canal do transistor
considerado.
tecnologia área de dreno (µm2) perímetro de dreno (µm)

Otimização de Tapered Buffers para altas taxas de operação
95
0,8µm 1,2W W+4,8
0,35µm 0,5W W+2,2
Escolhidos o sinal de entrada para o teste e o critério para verificação da propagação do sinal, pode-
se determinar a máxima taxa de operação de qualquer tapered buffer. A Figura 27 apresenta o
procedimento usado para este fim. Ele é executado automaticamente por um programa em C que
prepara os arquivos para o simulador, inicia as simulações (SPICE ou HSPICE), analisa os resultados
desta e, com base na análise, decide se deve continuar ou não as simulações.
g a te
d r e n o
V D D o uV S S
V D D o uV S S
Figura 26. Configuração em pente dos transistores N e P para simulações.
Façamos algumas observações a respeito do diagrama da Figura 27:
• a taxa máxima, fmax, usada no início do procedimento é escolhida entre 5Gbit/s e 10Gbit/s,
dependendo da tecnologia;
• a taxa mínima, fmin, é determinada, por sua vez, através de simulações sucessivas. Começamos
com 1Gbit/s; caso não funcione é tentado 0,8Gbit/s, e assim por diante;
• as simulações são feitas com a seqüência escolhida e com a sua complementar. Foi observado,
durante as simulações, que o fato de haver um número par ou ímpar de inversores afeta os
resultados, introduzindo descontinuidades nos dados obtidos. O uso da seqüência e da sua
complementar reduz esta influência. O problema, no entanto, não é totalmente eliminado;
• as simulações são terminadas quando a diferença entre fmax e fmin for pequena. Tomamos, então,
como taxa máxima de operação o valor médio destas.
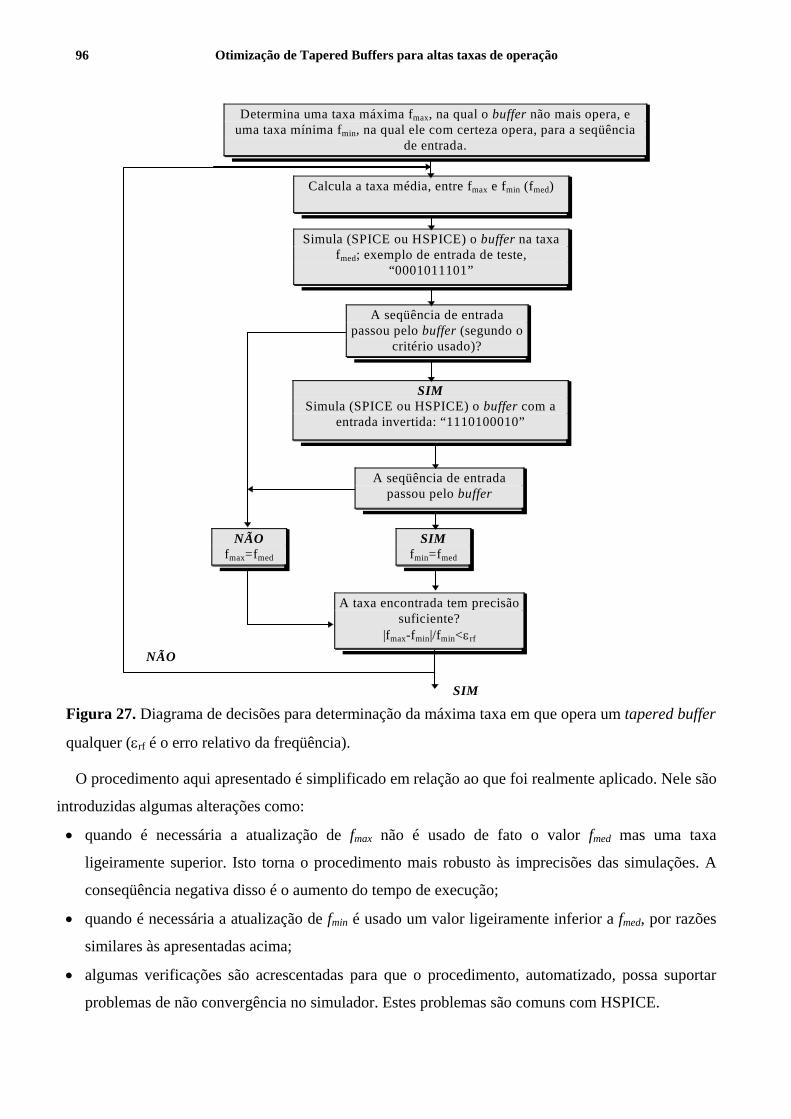
Otimização de Tapered Buffers para altas taxas de operação
96
Figura 27. Diagrama de decisões para determinação da máxima taxa em que opera um tapered buffer
qualquer (εrf é o erro relativo da freqüência).
O procedimento aqui apresentado é simplificado em relação ao que foi realmente aplicado. Nele são
introduzidas algumas alterações como:
• quando é necessária a atualização de fmax não é usado de fato o valor fmed mas uma taxa
ligeiramente superior. Isto torna o procedimento mais robusto às imprecisões das simulações. A
conseqüência negativa disso é o aumento do tempo de execução;
• quando é necessária a atualização de fmin é usado um valor ligeiramente inferior a fmed, por razões
similares às apresentadas acima;
• algumas verificações são acrescentadas para que o procedimento, automatizado, possa suportar
problemas de não convergência no simulador. Estes problemas são comuns com HSPICE.
Calcula a taxa média, entre fmax e fmin (fmed)
A taxa encontrada tem precisãosuficiente?
|fmax-fmin|/fmin<εrf
Determina uma taxa máxima fmax, na qual o buffer não mais opera, euma taxa mínima fmin, na qual ele com certeza opera, para a seqüência
de entrada.
Simula (SPICE ou HSPICE) o buffer na taxafmed; exemplo de entrada de teste,
“0001011101”
A seqüência de entradapassou pelo buffer (segundo o
critério usado)?
NÃOfmax=fmed
SIMSimula (SPICE ou HSPICE) o buffer com a
entrada invertida: “1110100010”
A seqüência de entradapassou pelo buffer
SIMfmin=fmed
SIM
NÃO

Otimização de Tapered Buffers para altas taxas de operação
97
Algumas vezes os problemas de convergência tornam difícil a obtenção de resultados significativos.
Nestes casos o programa implementado tem que abandonar o procedimento sem conseguir reduzir o
intervalo entre fmax e fmin ao nível desejado.
Os resultados que serão apresentados foram obtidos com:
• a seqüência de entrada “010001111011100101101”;
• tempos de subida e de descida iguais a 20% da largura de um pulso mínimo;
• verificação simples dos níveis dos pulsos na saída para garantir valores mínimos. Para a tecnologia
de 0,8µm, que tem VDD=5V, os níveis mínimos tolerados usados são VHM=4,0V e VLM=1,0V
(Figura 24). Para a tecnologia de 0,35µm, VDD=3V, os níveis usados são VHM=2,5V e VLM=0,5V.
Adotamos as seguintes dimensões para o primeiro inversor em todos os tapered buffers
examinados, tanto na tecnologias CMOS 0,8µm como na 0,35µm:
• Transistor N com largura de canal Wn1=5µm;
• Transistor P com largura de canal Wp1=8µm;
• L (comprimento de canal) com valor mínimo permitido para a tecnologia.
A Tabela 6 resume as condições em que foram obtidos os resultados para os tapered buffers.
3.3.3.2 Resultados das Simulações
As Figuras 28 e 29 mostram a máxima taxa de operação, em Gbit/s, de tapered buffers com 2, 3,
4, 5 e 6 (7 para Figura 28) inversores em função do fator de aumento χ. A carga capacitiva CL na
saída é 0,2pF. Note que a máxima taxa de operação não é obtida para χ=2,7 ou para valores maiores,
como apontam as análises baseadas no atraso, mas sim para o fator de aumento com valores pequenos.
Para um buffer com N inversores, podemos estimar o fator de aumento que fornece a máxima taxa de
operação com a seguinte relação:
( )χmaxN
ox n p LC W W L C1 1+ ≅
onde χmax é o fator de aumento que maximiza a taxa de operação para tapered buffers com N
inversores.
A Tabela 7 apresenta valores de χmax, calculados usando a expressão acima, como função de N para
uma carga CL=0,2pF. Compare estes valores com os resultados das Figuras 28 e 29.

Otimização de Tapered Buffers para altas taxas de operação
98
Tabela 6. Condições para obtenção dos resultados de simulação para as tecnologias 0,8µm e 0,35µm.
tecnologia 0,8µm tecnologia 0,35µm
simulador SPICE HSPICE
modelo usado level 2 slow level 3 slow
alimentação do buffer (VDD)
5,0V 3,0V
sinal de entrada do buffer
“010001111011100101101” e o seu complemento (“101110000100011010010”)
tempos de subida e descida
iguais a 20% da largura de um pulso mínimo
critério de análise da saída
todas os pulsos da entrada chegam a saída e atingem níveis mínimos adotados
níveis mínimos da saída VHM=4,0V VLM=1,0V
VHM=2,5V
VLM=0,5V
comprimento de canal dos transistores
L=0,8µm
L=0,35µm
largura de canal dos trans. do primeiro
inversor
trans. P Wp1=8µm trans. N Wn1=5µm
2 inv 7,76E-10 6,68E-10 5,88E-10 5,28E-10 4,84E-10 4,50E-10 4,27E-10 4,06E-10 3,88E-10 3,88E-10 3,93E-103 inv 8,27E-10 6,13E-10 4,97E-10 4,27E-10 3,88E-10 3,67E-10 3,59E-10 3,62E-10 3,63E-10 3,81E-10 3,93E-104 inv 7,85E-10 4,92E-10 3,62E-10 3,25E-10 3,27E-10 3,35E-10 3,54E-10 3,72E-10 3,97E-10 4,14E-10 4,37E-105 inv 8,27E-10 4,77E-10 3,54E-10 3,30E-10 3,38E-10 3,59E-10 3,79E-10 4,06E-10 4,32E-10 4,63E-10 4,84E-106 inv 7,95E-10 3,84E-10 3,21E-10 3,32E-10 3,59E-10 3,76E-10 4,06E-10 4,34E-10 4,59E-10 4,89E-10 5,11E-107 inv 8,27E-10 3,88E-10 3,27E-10 3,49E-10 3,72E-10 3,98E-10 4,29E-10 4,63E-10 4,92E-10 5,21E-10 5,51E-10
1,0 1,2 1,4 1,6 1,8 2,0 2,2 2,4 2,6 2,8 3,0 2 inv 1,29 1,50 1,70 1,89 2,07 2,22 2,34 2,46 2,58 2,58 2,55 3 inv 1,21 1,63 2,01 2,34 2,58 2,72 2,79 2,77 2,75 2,63 2,55 4 inv 1,27 2,03 2,77 3,08 3,05 2,99 2,82 2,68 2,52 2,42 2,29 5 inv 1,21 2,10 2,83 3,03 2,96 2,79 2,64 2,46 2,32 2,16 2,07 6 inv 1,26 2,61 3,12 3,02 2,79 2,66 2,46 2,30 2,18 2,04 1,96 7 inv 1,21 2,58 3,05 2,86 2,68 2,51 2,33 2,16 2,03 1,92 1,82
-
0,50
1,00
1,50
2,00
2,50
3,00
3,50
- 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0
fator de aumento do tapered buffer
max
. tax
a (G
bit/s
)
2 inv3 inv4 inv5 inv6 inv7 inv
.
Figura 28. Gráfico da máxima taxa de operação, Gbit/s, em função do fator de aumento do
tapered buffer. São simulados buffers com 2, 3, 4, 5, 6 e 7 inversores. A carga final em todos eles é
0,2pF e a tecnologia é 0,8µm.

Otimização de Tapered Buffers para altas taxas de operação
99
2 inv 4,88E-10 4,12E-10 3,61E-10 3,25E-10 2,97E-10 2,73E-10 2,52E-10 2,36E-10 2,25E-10 2,13E-10 2,05E-103 inv 5,15E-10 3,79E-10 3,03E-10 2,53E-10 2,21E-10 2,04E-10 1,90E-10 1,84E-10 1,85E-10 1,86E-10 1,91E-104 inv 4,88E-10 3,02E-10 2,10E-10 1,62E-10 1,60E-10 1,64E-10 1,69E-10 1,79E-10 1,88E-10 1,96E-10 2,09E-105 inv 5,21E-10 2,87E-10 1,96E-10 1,66E-10 1,63E-10 1,71E-10 1,80E-10 1,93E-10 2,04E-10 2,17E-10 2,28E-106 inv 4,88E-10 2,25E-10 1,55E-10 1,58E-10 1,68E-10 1,79E-10 1,91E-10 2,04E-10 2,15E-10 2,28E-10 2,42E-10
1,0 1,2 1,4 1,6 1,8 2,0 2,2 2,4 2,6 2,8 3,0 2 inv 2,05 2,42 2,77 3,07 3,37 3,66 3,96 4,24 4,44 4,70 4,88 3 inv 1,94 2,64 3,30 3,95 4,53 4,91 5,28 5,45 5,40 5,37 5,24 4 inv 2,05 3,31 4,77 6,18 6,25 6,08 5,92 5,59 5,33 5,10 4,79 5 inv 1,92 3,48 5,09 6,01 6,13 5,84 5,54 5,18 4,90 4,61 4,40 6 inv 2,05 4,44 6,46 6,32 5,95 5,58 5,24 4,91 4,65 4,40 4,13
-
1,00
2,00
3,00
4,00
5,00
6,00
7,00
- 0,5 1,0 1,5 2,0 2,5 3,0 3,5 4,0 4,5 5,0fator de aumento do tapered buffer
max
. tax
a (G
bit/s
)
2 inv3 inv4 inv5 inv6 inv
Figura 29. Gráfico da máxima taxa de operação, Gbit/s, em função do fator de aumento do
tapered buffer. São simulados buffers com 2, 3, 4, 5 e 6 inversores. A carga final em todos eles é
0,2pF e a tecnologia é 0,35µm.
Tabela 7. Valores de χmax para vários valores de N.
Número de inversores (N)
χmax para a tecnologia 0,8µm
χmax para a tecnologia 0,35µm
2 3,22 3,16 3 2,18 2,15 4 1,79 1,78 5 1,59 1,58 6 1,48 1,47 7 1,4 -
As Figuras 30 e 31 mostram, por sua vez, a largura mínima de um pulso que passa pelo buffer em
função da capacitância de carga CL. O fator de aumento usado nessas figuras é χ=2.
Para cada uma das curvas pode-se distinguir duas regiões, com comportamento semelhante àquele
encontrado na análise do modelo teórico:
• uma região onde as capacitâncias de carga são relativamente pequenas quando comparadas com a
capacitância de entrada do último inversor; as curvas aí são quase horizontais;
• outra onde a capacitância de carga é bastante grande, e as curvas se aproximam de retas.
De forma intuitiva, sem a utilização de fórmulas, podemos facilmente entender este
comportamento: na primeira região, onde a capacitância de carga é pequena, o aumento da carga influi
pouco no desempenho do buffer, pois o último inversor consegue facilmente alimentar a carga de sua
saída. Neste caso são os (N-1) primeiros inversores que limitam a taxa máxima de operação.
Naturalmente, a medida que a capacitância de carga aumenta, a operação do último inversor vai se
tornando difícil e influência todo o buffer. Considere o valor
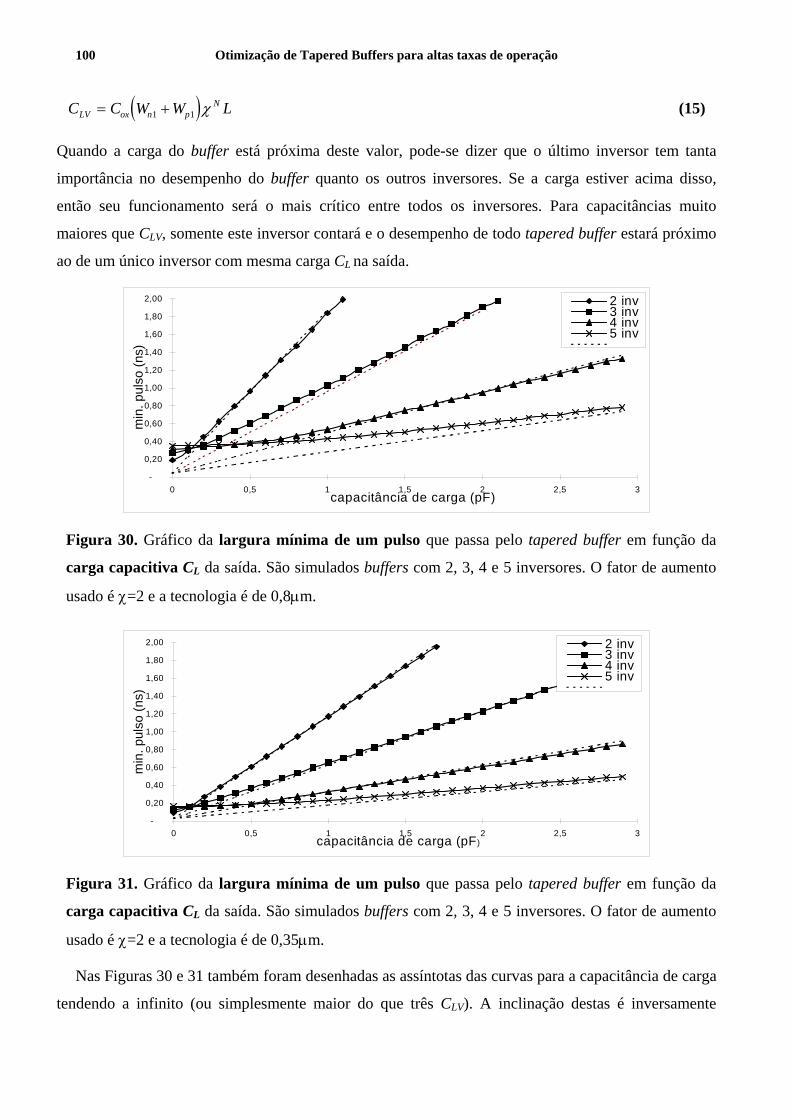
Otimização de Tapered Buffers para altas taxas de operação
100
( )C C W W LLV ox n pN= +1 1 χ (15)
Quando a carga do buffer está próxima deste valor, pode-se dizer que o último inversor tem tanta
importância no desempenho do buffer quanto os outros inversores. Se a carga estiver acima disso,
então seu funcionamento será o mais crítico entre todos os inversores. Para capacitâncias muito
maiores que CLV, somente este inversor contará e o desempenho de todo tapered buffer estará próximo
ao de um único inversor com mesma carga CL na saída.
0 0,1 0,2 0,3 0,4 0,5 0,6 0,72 inv 0,19 0,29 0,45 0,62 0,80 0,96 1,14 1,31 3 inv 0,27 0,31 0,37 0,44 0,52 0,60 0,69 0,78 4 inv 0,31 0,33 0,34 0,35 0,37 0,38 0,41 0,43 5 inv 0,35 0,36 0,36 0,37 0,37 0,38 0,39 0,40
0,05 0,23 0,41 0,60 0,78 0,96 1,14 1,33 0,05 0,14 0,23 0,32 0,41 0,50 0,60 0,69 0,05 0,09 0,14 0,18 0,23 0,28 0,32 0,37 0,05 0,07 0,10 0,12 0,14 0,17 0,19 0,21
-
0,20
0,40
0,60
0,80
1,00
1,20
1,40
1,60
1,80
2,00
0 0,5 1 1,5 2 2,5 3capacitância de carga (pF)
min
. pul
so (n
s)
2 inv3 inv4 inv5 inv
Figura 30. Gráfico da largura mínima de um pulso que passa pelo tapered buffer em função da
carga capacitiva CL da saída. São simulados buffers com 2, 3, 4 e 5 inversores. O fator de aumento
usado é χ=2 e a tecnologia é de 0,8µm.
0 0,1 0,2 0,3 0,4 0,5 0,6 0,72 inv 0,09 0,16 0,27 0,38 0,50 0,61 0,72 0,84 3 inv 0,13 0,16 0,20 0,26 0,31 0,37 0,42 0,48 4 inv 0,15 0,16 0,16 0,17 0,18 0,19 0,22 0,25 5 inv 0,16 0,17 0,17 0,17 0,18 0,19 0,20 0,20
0,03 0,14 0,26 0,37 0,49 0,60 0,72 0,83 0,03 0,09 0,15 0,21 0,27 0,33 0,39 0,45 0,03 0,06 0,09 0,12 0,15 0,18 0,21 0,24 0,03 0,04 0,06 0,07 0,09 0,10 0,12 0,13
-
0,20
0,40
0,60
0,80
1,00
1,20
1,40
1,60
1,80
2,00
0 0,5 1 1,5 2 2,5 3capacitância de carga (pF)
min
. pul
so (n
s)
2 inv3 inv4 inv5 inv
Figura 31. Gráfico da largura mínima de um pulso que passa pelo tapered buffer em função da
carga capacitiva CL da saída. São simulados buffers com 2, 3, 4 e 5 inversores. O fator de aumento
usado é χ=2 e a tecnologia é de 0,35µm.
Nas Figuras 30 e 31 também foram desenhadas as assíntotas das curvas para a capacitância de carga
tendendo a infinito (ou simplesmente maior do que três CLV). A inclinação destas é inversamente

Otimização de Tapered Buffers para altas taxas de operação
101
proporcional as dimensões do último inversor do buffer. Em conseqüência, a inclinação da assíntota do
buffer com 2 inversores é o dobro daquela do buffer com 3 inversores; esta, por sua vez, é o dobro
daquela do buffer com 4 e assim por diante (lembremos que o fator de aumento é de 2 nestes
exemplos).
As duas figuras anteriores apontam que o comportamento qualitativo dos tapered buffers se
aproxima bastante daquilo que foi previsto pelo modelo teórico. As assíntotas das curvas T0 x CL são
da forma expressa pela primeira equação de (14)(como já discutido, para CL grande, T0=TN-1). Tais
resultados mostram que as relações deduzidas a partir de [Sh92], se não são corretas estão próximas
disso.
3.3.3.2.1 Modelamento dos Tapered Buffers com as expressões analíticas (14)
As equações dadas em (14), como vimos, foram obtidas a partir de expressões bastante
simplificadas do comportamento dos transistores. Mesmo assim, elas se mostraram boas na descrição
qualitativa dos tapered buffers. Em vista disso podemos tentar aplicá-las no modelamento numérico.
Para este fim precisamos determinar o valor das cincos constantes que aí aparecem: K1, K2, K3, K4 e
K∆. Uma vez que as expressões foram construídas por meio de aproximações, o mais apropriado será
determinar o valor das constantes por meio de resultados obtidos por simulações.
As duas primeiras constantes estão relacionadas com as assíntotas das curvas T0 x CL quando CL é
muito grande. Assim elas podem ser obtidas por estas mesmas curvas (Figuras 30 e 31). Outra forma,
mais direta e precisa, é através das curvas largura mínima de um pulso que passa pelo buffer em
função da capacitância de carga, sendo o buffer formado por apenas um inversor. As Figuras 32 e 33
apresentam estas curvas, respectivamente para as tecnologias 0,8µm e 0,35µm. Para cada tecnologia,
vários inversores são simulados. Observe que: o sinal de entrada e o critério de propagação do sinal
são sempre os mesmos; a relação entre as larguras de canal do transistor N e do transistor P é sempre
igual.
A partir dos resultados das Figuras 32 e 33 são obtidas as equações abaixo para largura mínima do
pulso que passa pelo buffer com um inversor:
T CG
ns pF psL= +3 89
47 6,
/ , para tecnologia de 0,8µm;
T CG
ns pF psL= +2 46
29 7,
/ , para tecnologia de 0,35µm.
onde: T é a largura mínima de um pulso que passa pelo inversor;
G indica quantas vezes o inversor é maior que 8,0/5,0µm (largura de canal do trans. P/trans. N);
CL é a capacitância de carga em pF.

Otimização de Tapered Buffers para altas taxas de operação
102
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6Wn=5,0um 0,82 1,59 2,34 3,11 3,88 4,64 5,41 6,15 Wn=7,5um 0,56 1,06 1,57 2,08 2,58 3,09 3,60 4,12 Wn=10,0um 0,43 0,81 1,19 1,56 1,95 2,32 2,70 3,08 Wn=12,5um 0,35 0,66 0,95 1,26 1,57 1,86 2,16 2,46 Wn=15,0um 0,30 0,55 0,80 1,06 1,31 1,56 1,82 2,06 Wn=17,5um 0,27 0,48 0,69 0,91 1,13 1,34 1,55 1,77 Wn=20,0um 0,24 0,42 0,61 0,79 0,99 1,18 1,37 1,55 Wn=22,5um 0,21 0,38 0,55 0,72 0,88 1,06 1,22 1,38 Wn=25,0um 0,20 0,35 0,50 0,65 0,80 0,95 1,10 1,25
-
2,00
4,00
6,00
8,00
10,00
12,00
0 0,5 1 1,5 2 2,5 3capacitância de carga (pF)
min
. pul
so (n
s)
Wn=5,0umWn=7,5umWn=10,0umWn=12,5umWn=15,0umWn=17,5umWn=20,0umWn=22,5umWn=25,0um
Figura 32. Gráfico da largura mínima de um pulso que passa por um inversor em função da sua
carga capacitiva. As larguras de canal dos trans.P/trans.N são: 8/5µm; 12/7,5µm; 16/10µm;
20/12,5µm; 24/15µm; 28/17,5µm; 32/20µm; 36/22,5µm; 40/25µm. O comprimento do canal é
L=0,8µm. A tecnologia é de 0,8µm.
0,2 0,4 0,6 0,8 1 1,2 1,4 1,6W n=5,0um 0,52 1,00 1,49 1,98 2,48 2,98 3,45 3,93 W n=7,5um 0,36 0,69 1,01 1,34 1,67 2,00 2,33 2,66 W n=10,0um 0,28 0,53 0,76 1,01 1,26 1,50 1,76 2,00 W n=12,5um 0,23 0,42 0,62 0,81 1,02 1,21 1,40 1,61 W n=15,0um 0,20 0,36 0,53 0,69 0,86 1,02 1,18 1,34 W n=17,5um 0,17 0,31 0,45 0,59 0,73 0,88 1,02 1,16 W n=20,0um 0,16 0,28 0,40 0,53 0,65 0,77 0,90 1,02 W n=22,5um 0,14 0,25 0,36 0,47 0,58 0,69 0,80 0,90 W n=25,0um 0,13 0,23 0,33 0,43 0,53 0,62 0,72 0,82
-
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
4,50
0 0,5 1 1,5 2 2,5 3capacitância de carga (pF)
min
. pul
so (n
s)
W n=5,0umW n=7,5umW n=10,0umW n=12,5umW n=15,0umW n=17,5umW n=20,0umW n=22,5umW n=25,0um
Figura 33. Gráfico da largura mínima de um pulso que passa por um inversor em função da sua
carga capacitiva. As larguras de canal dos trans.P/trans.N são: 8/5µm; 12/7,5µm; 16/10µm;
20/12,5µm; 24/15µm; 28/17,5µm; 32/20µm; 36/22,5µm; 40/25µm. O comprimento do canal é
L=0,35µm. A tecnologia é de 0,35µm.
Lembrando que também o primeiro inversor dos buffers simulados tem as dimensões 8µm/5µm
(largura do canal), então chegamos aos valores da Tabela 8.
Para as outras constantes, K3, K4 e K∆, foram tentados vários caminhos para sua determinação,
todavia para nenhum dos valores encontrados foi possível um ajuste satisfatório entre as expressões de
(14) e os dados. O que se observou neste processo foi que o termo ( )2 1K N∆ − , na equação de T0, (14),
causa a maior parte das dificuldades. Como conclusão temos que as expressões usadas, apesar de se
aproximarem do desejado, não são suficientemente exatas para o modelamento (no APÊNDICE C é

Otimização de Tapered Buffers para altas taxas de operação
103
tentado um modelamento alternativo baseado em funções de transferência, considerando o inversor um
circuito linear invariante com um pólo).
Tabela 8. Valores das constantes K1 e K2 das equações dadas por (14).
tecnologia K1 (ns/pF) K2 (ps)
0,8µm 3,89 47,6
0,35µm 2,46 29,7
3.3.3.2.2 Modelamento dos Tapered Buffers com o uso de tabelas empíricas
Na impossibilidade de encontrar equações que descrevam os buffers, procuramos outra forma de
modelamento. O uso de tabelas foi o que melhor resultado apresentou. Nesta forma de modelamento,
através de uma ou mais tabelas, conseguimos determinar a máxima taxa de operação do tapered buffer.
Para entender esta solução, voltemos as equações dadas por (14). Como já dito, elas pecam devido ao
termo dependente de N. Sendo assim, supomos que as seguintes relações descrevam corretamente o
buffer:
( )
TK
C K
T t f NTt
t K
N N L
N
− −
−
= +
=
= +
11
1 2
0 01
0
0 4
χ
χ
, onde f( ) é uma função não conhecida. (16)
Comparando as relações de (16) com aquelas de (14), vemos que a primeira equação é a mesma e
que ttK0
0
3= . Em (16), se conhecermos a função f( ) poderemos então determinar T0 (é necessário
ainda o parâmetro K4). Não a conhecendo, podemos tabelá-la para diversos valores de N (2, 3, 4, 5, ...).
Isto pode ser feito a partir de curvas semelhantes às apresentadas nas Figuras 30 e 31. O exemplo
seguinte mostra como as Figuras(/Tabelas) 30 e 31 poderão ser usadas para encontrar os valores
mínimos da largura de pulso. Seja o seguinte problema:
Qual a largura mínima do pulso que passa por um tapered buffer com ganho χy, N inversores e
carga Cly (será chamado de buffer problema)? Como nos exemplos das Figuras 30 e 31, o primeiro
inversor tem transistores com larguras de canal de 8µm e 5µm. São conhecidos os valores de K1, K2 e
K4.
Solução:

Otimização de Tapered Buffers para altas taxas de operação
104
Pelas equações dadas em (16), podemos escrever que ( )
( )T
t
KC K
KN y
y
yN Ly
y
−−
=
+
+1
0
11 2
4
χ
χ, onde os termos
com índice y são relativos ao buffer problema.
Chamemos de CL2 a capacitância que faz valer a igualdade ( )
( )( )T
t
KC K
KT
tN N L N y
y
− − −=+
+=1 2
02
11 2 2
4
1
0
22
, onde
os termos com índice 2 são relativos ao buffer cujos resultados estão na Figura 30 ou na Figura 31
(χ2=2).
Como ( ) ( )Tt
Tt
N N y
y
− −=1 2
02
1
0
então ( ) ( )Tt
f NT
tf N
Tt
Tt
N N y
y
y
y
02
02
1 2
02
1
0
0
0
=
=
=
− −, , e, conseqüentemente,
( )( )T T
K
Kyy
0 024
42=
+
+
χ. Pois bem, o valor de T02 pode ser encontrado facilmente a partir do valor de CL2,
diretamente ou por interpolação, e das curvas apresentadas nas Figuras 30 e 31. Logo o valor de T0y
pode ser determinado.
Resumindo o procedimento, devemos primeiro determinar o valor de CL2 tal que ( ) ( )Tt
Tt
N N y
y
− −=1 2
02
1
0
;
posteriormente, consultando na Figura 30 ou na Figura 31 (dependendo da tecnologia utilizada) a
curva associada ao buffer com N inversores, determinar o valor de T02 e, por fim, calcular o valor de
T0y. Em vez do gráfico podemos ter tabelas de T0 em função de CL, para vários valores de N, e para
um fator de aumento pré-estabelecido qualquer. Estas tabelas, junto com as constantes K1, K2 e K4,
serão suficientes para fornecer o valor de T0 para um tapered buffer qualquer desde que:
• o sinal de teste aplicado na entrada e o critério de propagação do sinal sejam os mesmos
daqueles usados na determinação das tabelas e das constantes;
• a relação entre a largura de canal do transistor P e a do transistor N é igual àquela usada na
determinação destas tabelas e constantes.
Para um melhor aproveitamento dos dados das tabelas, dois cuidados devem ser tomados na sua
geração:
• utilizar um fator de aumento grande para evitar que, durante o cálculo de CL2, apareçam valores
negativos;
• tabelar T0 apenas para valores baixos de CL. As curvas T0 x CL, para valores grandes de CL,
aproximam-se bastante das assíntotas, sendo possível determiná-las a partir das constantes K1 e K2.

Otimização de Tapered Buffers para altas taxas de operação
105
A Tabela 9 apresenta as condições usadas para geração das curvas/tabelas T0 x CL para as duas
tecnologias aqui analisadas.
Tabela 9. Condições para geração de curvas/tabelas T0 x CL para modelamento dos tapered buffers.
tecnologia máximo valor usado para capacitância de carga
número de pontos em cada curva/tabela
0,8µm 2,5CLV (15) 20
0,35µm 3CLV (15) 30
Falta-nos ainda a determinação do parâmetro K4. Para este fim é utilizado o procedimento acima
descrito para determinação de T0 em um buffer qualquer, e o gráfico largura mínima de um pulso
que passa pelo buffer em função do número de inversores do buffer, com CL≈0, para diversos valores
de fator de aumento. As Figuras 34 e 35 apresentam estes gráficos. O valor escolhido para K4 é aquele
que minimiza, no sentido do mínimo quadrado, o erro entre os resultados fornecidos pelas equações
dadas em (16), aplicando o procedimento acima, e os dados da Figura 34/35. Foi utilizado o método de
busca SIMPLEX para encontrar K4 (MATLAB). Observemos que a utilização de CL≈0 equivale a
escolhermos, no procedimento acima, CLy igual a zero. Isto simplifica as expressões. Os valores
encontrados para K4 são 0,81 e 0,72, respectivamente, para as tecnologias de 0,8µm e de 0,35µm.
2,0 3,0 4,0 5,0 6,0 ft. aum.=5 0,34 0,55 0,65 0,74 0,80 ft. aum.=4 0,30 0,46 0,54 0,61 0,66 ft. aum.=3 0,24 0,37 0,43 0,49 0,52 ft. aum.=2 0,19 0,27 0,32 0,35 0,37 ft. aum.=1 0,14 0,19 0,21 0,24 0,25
-
0,10
0,20
0,30
0,40
0,50
0,60
0,70
0,80
0,90
- 1,0 2,0 3,0 4,0 5,0 6,0número de inversores
min
. pul
so (n
s)
ft. aum.=5ft. aum.=4ft. aum.=3ft. aum.=2ft. aum.=1
Figura 34. Gráfico da largura mínima de um pulso que passa pelo tapered buffer em função do
número de inversores. Curvas para diversos valores de fator de aumento são apresentadas (fator de
aumento de 1, 2, 3, 4 e 5). O primeiro inversor, em todos os exemplos, tem 5µm para largura de canal
do transistor N, e 8µm para o transistor P. O comprimento de canal para todos é de 0,8µm. A carga
na saída é de 1fF e a tecnologia CMOS de 0,8µm.

Otimização de Tapered Buffers para altas taxas de operação
106
2,0 3,0 4,0 5,0 6,0 ft.aum.=5 0,17 0,26 0,31 0,35 ft.aum.=4 0,14 0,21 0,25 0,29 ft.aum.=3 0,12 0,17 0,20 0,23 0,24 ft.aum.=2 0,09 0,13 0,15 0,17 0,18 ft.aum.=1 0,07 0,09 0,10 0,11
-
0,05
0,10
0,15
0,20
0,25
0,30
0,35
- 1,0 2,0 3,0 4,0 5,0 6,0número de inversores
min
. pul
so (n
s)
ft.aum.=5ft.aum.=4ft.aum.=3ft.aum.=2ft.aum.=1
Figura 35. Gráfico do largura mínimo de um pulso que passa pelo tapered buffer em função do
número de inversores. Curvas para diversos valores de fator de aumento são apresentadas (fator de
aumento de 1, 2, 3, 4 e 5). O primeiro inversor, em todos os exemplos, tem 5µm para largura de canal
do transistor N, e 8µm para o transistor P. O comprimento de canal para todos é de 0,35µm. A carga
na saída é de 1fF e a tecnologia CMOS de 0,35µm.
Por fim, as Figuras 36, 37 e 38 mostram a comparação entre os resultados de simulação e as
relações semi-empíricas dadas por (16) (as figuras foram geradas pelo MATLAB). Também nestas
figuras estão indicadas a máxima taxa que pode ser alcançada por um tapered buffer e o seu melhor
valor para χ=3.
1 1 , 5 2 2 , 5 3 3 , 5 4 4 , 5 51 , 2
1 , 4
1 , 6
1 , 8
2
2 , 2
2 , 4
2 , 6
2 , 8
3
3 , 2
f a t o r d e a u m e n t o d o t a p e r e d b u f f e r
m a x . t a x a( G b i t / s )
2 i n v .
3 i n v .
4 i n v .
5 i n v .
s i m u l a ç ã oC L = 0 , 2 p F0 , 8 µ m C M O S
Figura 36. Comparação entre os pontos obtidos por simulação (o buffer com dois inversores é
apresentado com ‘x’, três com ‘+’, quatro com ‘o’ e cinco com ‘*’) e equações dadas por (16) (linhas
contínuas). A tecnologia é de 0,8µm e a capacitância de carga de 0,2pF.

Otimização de Tapered Buffers para altas taxas de operação
107
s i m u l a ç ã o 2 i n v . 3 i n v . 4 i n v . 5 i n v . 6 i n v . 7 i n v . 8 i n v .
1 1 , 5 2 2 , 5 3 3 , 5 4 4 , 5 50
0 , 5
1
1 , 5
2
2 , 5
3
f a t o r d e a u m e n t o d o t a p e r e d b u f f e r
m a x . t a x a( G b i t / s )
C L = 1 p F0 , 8 µ m C M O S
Figura 37. Comparação entre os pontos obtidos por simulação (o buffer com dois inversores é
apresentado com ‘x’, três com ‘+’, quatro com ‘o’, cinco com ‘*’, seis com 'x', sete com '+' e oito
com '*') e equações dadas por (16) (linhas contínuas). A tecnologia é de 0,8µm e a capacitância de
carga de 1pF.
1 1 , 5 2 2 , 5 3 3 , 5 4 4 , 5 51 , 5
2
2 , 5
3
3 , 5
4
4 , 5
5
5 , 5
6
6 , 5
f a t o r d e a u m e n t o d o t a p e r e d b u f f e r
m a x . t a x a( G b i t / s )
2 i n v .3 i n v .4 i n v .5 i n v .
s i m u l a ç ã oC L = 0 , 2 p F0 , 3 5 µ m C M O S
Figura 38. Comparação entre os pontos obtidos por simulação (o buffer com dois inversores é
apresentado com ‘x’, três com ‘+’, quatro com ‘o’ e cinco com ‘*’) e equações dadas por (16) (linhas
contínuas). A tecnologia é de 0,35µm e a capacitância de carga de 0,2pF.
As relações semi-empíricas proporcionam uma boa aproximação para a tecnologia de 0,35µm, e
razoável para 0,8µm, onde foi usado o simulador SPICE. Neste último caso, a previsão do valor da
máxima taxa de operação deixa um pouco a desejar. Em contrapartida, em ambas tecnologias, o
método proposto é eficiente para apontar qual é o fator de aumento ótimo.
Notemos que as relações para cálculo da maior taxa do sinal que propaga pelo buffer foram
derivadas a partir de relações quadráticas para a corrente de dreno, Estas relações não são boas para
modelar transistores de canal pequeno ([Mu86], [Sa90]). Por outro lado, as expressões finais (relação

Otimização de Tapered Buffers para altas taxas de operação
108
(16)) mostraram-se boas mesmo para a tecnologia de 0,35µm. Acreditamos, baseados nos resultados
alcançados, que estas expressões podem ser usadas mesmo em tecnologias mais modernas.
Ainda no APÊNDICE D são apresentados os resultados obtidos com outra tecnologia CMOS
0,8µm, a tecnologia da AMS. São usados para simulação o HSPICE e o modelo BSIM3 (versão 2).
Um bom ajuste é conseguido também neste caso.
A Tabela 10, por sua vez, resume as informações de máximas taxas atingidas com χ=3 e para
qualquer valor de fator de aumento. Pelos resultados expostos, vemos que um ganho próximo a 20%
pode ser conseguido com o uso de χ diferente daquele que minimiza o atraso. Repare que os valores
para χot são sempre pequenos.
Tabela 10. Taxa máxima para o buffer com fator de aumento χ=3, taxa máxima possível (qualquer
χ) e aumento relativo da taxa de operação (valor em χ=3 tomada como referência). É também
indicado o valor do fator de aumento que maximiza a taxa de operação do buffer (χot).
Tecnologia(µm)/CL(pF) max. taxa (Gbit/s) χ=3
max. taxa (Gbit/s) aumento relativo da taxa (%)
0,8/0,2 2,54 3,08 (χot=1,6) 21,3
0,8/1,0 2,13 2,13 (χot=1,6) 27,7
0,35/0,2 5,24 6,24 (χot=1,8) 19,1
3.3.4 Mismatch do Atraso
Os resultados da seção anterior mostram que o critério proposto nos leva a tapered buffers que
utilizam um fator de aumento pequeno. Uma conseqüência disto é o aumento do número de inversores
do buffer. Como vimos, nosso critério é aplicável quando o valor do atraso não é importante para o
desempenho do circuito, como no exemplo da Figura 23. Neste circuito, por outro lado, os valores dos
atrasos no buffer do dado e nos vários buffers que distribuem o clock devem ser iguais ou muito
próximos. A igualdade destes valores é praticamente impossível, mesmo em buffers casados, devido a
dispersão dos parâmetros dos transistores no C.I.. A questão aqui levantada é o que ocorrerá com as
variações do atraso dos tapered buffers (mismatch do atraso), causadas pelas dispersões estatísticas dos
parâmetros dos transistores, quando o fator de aumento é diminuído ou elevado. Este problema é
estudado nesta seção. Veja que esta questão é importante pois se a redução do fator de aumento, com a
conseqüente elevação no número de inversores, acarreta um crescimento no mismatch do atraso, então
o critério proposto aqui terá seu uso reduzido.

Otimização de Tapered Buffers para altas taxas de operação
109
3.3.4.1 Atraso do Tapered Buffer
Para o estudo do mismatch do atraso, vamos considerar uma configuração bastante usada na
distribuição do sinal de clock dentro de circuitos integrados. Ela é mostrada na Figura 39. A
característica que nos interessa nesta aplicação é que todos os inversores enxergam, relativamente as
suas dimensões, uma mesma carga capacitiva, simplificando o tratamento do problema. Consideremos
os M tapered buffers da figura, cada um com N inversores, e o atraso total, t1D, t2D ... tMD, de cada dos
buffers. O que queremos é saber qual a variância destes atrasos e, principalmente, como esta se
comporta em relação ao fator de aumento utilizado no buffer.
M,1 M,2 M,N-1 M,N
2,1 2,2 2,N-1 2,N
1,1 1,2 1,N-1 1,N
tMD
t2D
t1D
clock
tapered bufferM
tapered buffer2
tapered buffer1
0
Figura 39. M Tapered buffers usados para a distribuição de clock.
Usaremos a seguinte notação para os M buffers:
Coxj,i é a capacitância, por unidade de área, no gate dos transistores P e N do i-ésimo inversor do j-
ésimo buffer (Figura 39);
Lnj,i e Lpj,i são os comprimentos de canal dos transistores N e P, respectivamente, do i-ésimo inversor
do j-ésimo buffer;
Wnj,i e Wpj,i são as larguras de canal dos transistores N e P, respectivamente, do i-ésimo inversor do j-
ésimo buffer;
CLj,i é a capacitância de carga do i-ésimo inversor do j-ésimo buffer;
µnj,i e µpj,i são as mobilidades dos elétrons e das lacunas nos transistores N e P, respectivamente, do i-
ésimo inversor do j-ésimo buffer;

Otimização de Tapered Buffers para altas taxas de operação
110
VTnj,i e VTpj,i são as tensões de limiar dos transistores N e P, respectivamente, do i-ésimo inversor do
j-ésimo buffer;
PCnj,i e PCpj,i são os parâmetros PC para os transistores N e P, respectivamente, do i-ésimo inversor do
j-ésimo buffer;
VD0nj,i e VD0pj,i são as tensões VD0 para os transistores N e P, respectivamente, do i-ésimo inversor do
j-ésimo buffer.
Consideraremos ainda que L L Lnj i pj i j i, , ,= = , W Wnj i j i, ,= e W Wpj i j i, ,= θ . Também, que a
capacitância de carga é dada por ( )( )C K W W L CLj i DS j i j i j i oxj i, , , , ,= + + + + +1 1 1 1θ para 1≤ <i N . Para a
situação ideal, quando não há mismatch dos parâmetros, será válido:
Coxj,i=Cox Lj,i=L VTnj,i=VTn VTpj,i=VTp VD0nj,i=VD0n VD0pj,i=VD0p
W Wj ii
, =−χ 1 K KCnj i Cn, = K KCpj i Cp, = µ µnj i n, = µ µpj i p, =
Estes também serão os valores médios dos parâmetros.
Vamos encontrar o atraso dos tapered buffers da Figura 39. Usaremos uma vez mais as relações de
atraso de inversor propostas por [Sa90]. O atraso do buffer j é dado por
t tDj dj ii
N
==∑ ,
1
onde tdj,i é o atraso médio do i-ésimo inversor do j-ésimo tapered buffer (relação (10)).
Resultará para o atraso o seguinte valor
( ) ( )[ ]
tV C
IF V V
CI
F V V
L CW C
F V V V K F V V V K
CI
C
DjDD L
D nTpj D pj
L
D pTnj D nj
j i Lj i
j i oxj iD Tnj i Tpj i D nj i nj i Cnj i D Tpj i Tnj i D pj i pj i Cpj i
i
N
Lj N
D nj N
Lj
=
+ +
+ +
+
+ +=
−
∑
2
2
0
0 01 0 1
0
0 01 0 1
1 0 1 01
1
0
( , ) ( , )
, , , , ,
, , , ,
, ,
, ,, , , , , , , , , ,
,
,
µ θµ
,
,
N
D pj NI2 0
onde: ID0n0 e ID0p0 são as correntes de dreno (equação (4)) dos transistores N e P, respectivamente, do
inversor 0 (ver Figura 39);
ID0nj,i e ID0pj,i são as correntes de dreno (equação (4)) dos transistores N e P, respectivamente, do i-
ésimo inversor do j-ésimo buffer;
( )C K W W L CL DS j j oxjj
M
0 0 1 1 11
1= + +
=∑θ , , , ;
W0 está relacionado com a largura de canal do inversor 0 (Wn0=W0 e Wp0=θW0 e W MW0χ = );
( )( )C K W LWCLj N DS NN
ox, = + +1 θ χ .

Otimização de Tapered Buffers para altas taxas de operação
111
Acrescentaremos a expressão de tDj o seguinte termo:
V CI
VV
VeV
CI
VV
VeV
DD Lj N
D nj N
Tpj N D nj N
DD
D nj N
DD
Lj N
D pj N
Tnj N D pj N
DD
D pj N
DD
212
11
0 908 08
10
12
11
0 908 08
10
0
1 0 0
0
1 0 0
,
,
, , ,
,
,
, , ,
.
. .ln
.
. .ln
−−+
+
+
−−+
+
+
+
να
να
(17)
onde: νTnj,N+1 será tomado como VTn/VD0n;
νTpj,N+1 será tomado como |VTp|/VD0p.
Este termo reflete a influência do último inversor do tapered buffer, o N-ésimo inversor, no atraso
dos inversores ligados a sua saída. A adição de (17) além de melhor avaliar os efeitos do mismatch no
buffer também torna mais simples a manipulação das derivadas, como veremos mais adiante.
Consideraremos como expressão do atraso do j-ésimo buffer a que é dada abaixo:
( ) ( )][ ]t
V CI
F V VCI
F V V
L CW C
F V V V K F V V V K
DjDD L
D nTpj D pj
L
D pTnj D nj
j i Lj i
j i oxj iD Tnj i Tpj i D nj i nj i Cnj i D Tpj i Tnj i D pj i pj i Cpj i
i
N
=
+
++ +=∑
20
0 01 0 1
0
0 01 0 1
1 0 1 01
( , ) ( , )
, , , , ,
, , , ,
, ,
, ,, , , , , , , , , ,µ θµ
(18)
onde: VTnj,N+1 será tomado como VTn;
VTpj,N+1 será tomado como VTp.
Para cálculo da variância dos tDs faremos uso do teorema abaixo [Pa91].
Teorema: Considere as variáveis aleatórias x1, x2, ..., xn, com média e variância ( )x x1 12,σ , ...
( )xn xn,σ 2 , respectivamente, e a variável aleatória y, y=g(x1, x2, ..., xn). Se a função g é
suficientemente suave ("smooth") perto de ( )x xn1,...., , então a variância de y pode ser estimada em
termos da média, variância e covariância de x1, x2, ..., xn:
σ∂∂
∂∂y
i jxi xj
i j
n gx
gx
C2 = ∑ ,,
(19)
onde: Cxi,xj é a covariância entre xi e xj;
a função g e suas derivadas são avaliadas em ( )x xn1,...., .
Observe que Cxi,xi=σxi2
Determinaremos, a partir de (18), a variância no atraso dos buffers causada pela dispersão dos
parâmetros Lj,i, Wj,i, Coxj,i, VTnj,i, VTpj,i, µnj,i e µpj,i, para 1≤ ≤i N . Os parâmetros VD0nj,i, VD0pj,i, KCnj,i e

Otimização de Tapered Buffers para altas taxas de operação
112
KCpj,i, por sua vez, são tomados como iguais a VD0n, VD0p, KCn e KCp, respectivamente. A restrição sobre
que parâmetros sofrem variações serve para manter os resultados tratáveis.
Na aplicação do teorema acima, para determinar a variância dos tDs, a função g será
( ) ( )][ ]t
V CI
F V VCI
F V V
L CWC
F V V V K F V V V K
DDD L
D nTp D p
L
D pTn D n
i Li
i oxiD Tni Tpi D n ni Cn D Tpi Tni D p pi Cp
i
N
=
+
++ +=∑
20
0 01 0
0
0 01 0
1 0 1 01
( , ) ( , )
, , , , ,µ θµ (20)
onde: ( )IMWK C
LV VD n
Cn ox nDD Tn0 0 = −
µχ
α e ( )I
M WK CL
V VD pCp ox p
DD Tp0 0 = −θ µ
χα
;
( ) ( )C KMW
M WLC W L CL DS ox ox0 1 1 11 1= + + − +
θ
χ
Li é uma variável aleatória que modela a variação do comprimento de canal no i-ésimo inversor;
Wi é uma variável aleatória que modela a variação da largura de canal no i-ésimo inversor;
Coxi é uma variável aleatória que modela a capacitância de porta dos transistores no i-ésimo inversor;
VTni e VTpi são variáveis aleatórias que modelam a variação da tensão de limiar dos transistores N e P,
respectivamente, no i-ésimo inversor;
µni e µpi são variáveis aleatórias que modelam a variação da mobilidade dos elétrons e lacunas nos
transistores N e P, respectivamente, no i-ésimo inversor.
Para a utilização de (19), é necessário saber a média, a variância e a covariância das variáveis
aleatórias, além das derivadas da equação (20) em relação a estas variáveis. Isto será determinado a
seguir.
3.3.4.2 Modelos estatísticos para os parâmetros variáveis
Como apontado em [Pe89], podemos separar os processos que geram variações nos parâmetros do
transistor em duas classes. Na primeira classe, estão os processos físicos que têm variações de curta
distância, short distance variations, podendo ser modelados como ruído branco espacial (Figura
40(a)). Chamaremos estas variações de short distance disturbances. Se o parâmetro é afetado por
apenas este tipo de problema, então sua variância é dependente de 1/WL, onde W e L são as dimensões
do canal do transistor. Na segunda classe, estão os processos físicos que têm variações de longa
distância ou long distance variations. O valor do parâmetro dependerá da posição do transistor na
lâmina, ou melhor, é função de D2, onde D é a distância a um ponto de referência na lâmina.
Chamaremos as variações desta classe de long distance disturbances.

Otimização de Tapered Buffers para altas taxas de operação
113
Os parâmetros W e L em particular são afetados por processos um pouco diferentes daqueles
discutidos no parágrafo anterior, como apontado em [La86] e [Oe93]. Eles sofrem basicamente de
efeitos de rugosidade das bordas, edge roughness, e problemas de acurácia de repetição no processo de
geração de formas, repetition accuracy of pattern generation process (Figura 40). Ambos os processos
têm variações de curta distância.
A causa das variações, a média e a variância dos parâmetros, além da covariância entre eles, são
fornecidas abaixo ([La86], [Pe89] e [Oe93]). No que segue, indicaremos por x eσ x respectivamente o
valor médio e a variância da variável x e por Cx,y a covariância entre as variáveis x e y.
W
L
WW
(a) (b) (c) Figura 40. Processos básicos que geram os desvios nos parâmetros: (a) eventos que ocorrem
aleatoriamente no circuito como ruído branco (nonuniform arrangement of events), (b) rugosidade
das bordas (edge roughness), e (c) acurácia de repetição no processo de geração de formas (repetition
accuracy of pattern generation process)[Oe93].
3.3.4.2.1 Parâmetro Li
O comprimento de canal do transistor, Li, sofre desvios devido à acurácia de repetição no processo
de geração de formas, durante a produção do transistor, e devido à rugosidade das bordas do canal
[Oe93], como já dito. Os dois problemas são locais, short distance disturbances. Os valores da média e
variância deste parâmetro são
L Li = e σ σLi L L
iL LA
L W
=
+
20
2 2
2 (o primeiro termo da direita é causado pelo pattern generation
process; o segundo, pela edge roughness).
onde σL0 e AL são parâmetros do processo.
O parâmetro Li é considerado como sendo independente de todos os outros parâmetros, mesmo os
outros Lis, pois é modificado apenas por variações de curta distância.
3.3.4.2.2 Parâmetro Wi
A largura de canal do transistor, Wi, sofre também de desvios devido à acurácia de repetição no
processo de geração de formas, durante a produção do transistor, e devido à rugosidade das bordas do

Otimização de Tapered Buffers para altas taxas de operação
114
canal [Oe93]. Os dois problemas são locais, short distance disturbances. Os valores da média e
variância deste parâmetro são
W Wii= −χ 1 e
σ σWi
i
W
i
W
iW WA
LW
=
+
20
2 2
2 (o primeiro termo da direita é causado pelo pattern
generation process; o segundo, pela edge roughness).
onde σW0 e AW são parâmetros do processo.
O parâmetro Wi, tal como Li, é considerado independente dos outros todos.
3.3.4.2.3 Parâmetros VTni e VTpi
A tensão de limiar do transistor N, VTni, sofre de desvios devido às short distance disturbances e
long distance disturbances. Os valores da média e variância deste parâmetro são [Pe89]
V VTni Tn= e σVTniVTn
iVTn is ce
AW L
S D22
2 2= + tan (o primeiro termo da direita é causado pelas variações de curta
distância; o segundo, pelas variações de longa distância).
onde AVTn e SVTn são parâmetros do processo;
Distance é a distância do transistor a uma referência.
Assumiremos que todos os inversores que fazem parte do mesmo tapered buffer sofrem do mesmo
desvio de longa distância. Também assumiremos que os processos de curta e de longa distância são
independentes. Em conseqüência, a covariância entre VTnis será
C S DVTni VTnj VTn is ce, tan= 2 2 .
As informações na literatura acerca da covariância entre VTni e os outros parâmetros, principalmente
Coxi e VTpi, são controversas. Em [La86] é sugerido que a covariância entre VT e Cox é mínima, quase
zero; em [Af92], todos os parâmetros do transistor são tomados como independentes. Por outro lado,
em [Ha96] é encontrado um coeficiente de correlação de 0,21 entre VTn e VTp, e um coeficiente de
correlação de 0,86 entre VTn e tox (espessura do óxido de porta). [Po94] aponta que a tensão de flat
band, tanto do transistor N como do P, tem coeficiente de correlação com tox não pequeno (0,42 e 0,2
respectivamente).
Em nosso trabalho vamos assumir covariância zero entre VTni e os outros parâmetros diferentes de
VTnj, principalmente por razões de simplicidade.
A tensão de limiar do transistor P, VTpi, tem as mesmas características que VTni. Sua média e
variância são
V VTpi Tp= e σVTpiVTp
iVTp is ce
AW L
S D22
2 2= + tan
onde AVTp e SVTp são parâmetros do processo;

Otimização de Tapered Buffers para altas taxas de operação
115
Distance é a distância do transistor a uma referência.
A covariância entre VTpis será
C S DVTpi VTpj VTp is ce, tan= 2 2 .
A covariância entre VTpi e outros parâmetros é assumida como sendo zero.
3.3.4.2.4 Parâmetro Coxi
A capacitância, por unidade de área, no gate do transistor, Coxi, sofre de desvios devido às short
distance disturbances e long distance disturbances. Os valores da média e variância deste parâmetro
são [Pe89]
C Coxi ox= e σCoxiCox
iCox is ce
AW L
S D22
2 2= + tan (o primeiro termo da direita é causado pelas variações de curta
distância; o segundo, pelas variações de longa distância).
onde ACox e SCox são parâmetros do processo;
Distance é a distância do transistor a uma referência.
Assumiremos que todos os inversores que fazem parte do mesmo tapered buffer sofrem do mesmo
desvio de longa distância. Também assumiremos que os processos de curta e de longa distância são
independentes. Em conseqüência, a covariância entre Coxis será
C S DCoxi Coxj Cox is ce, tan= 2 2 .
A covariância entre Coxi e outros parâmetros é assumida como sendo zero. As razões são as mesmas
expostas para o parâmetro VTni.
3.3.4.2.5 Parâmetros µni e µpi
A mobilidade dos elétrons no transistor N, µni, sofre de desvios devido às short distance
disturbances e long distance disturbances. Os valores da média e variância deste parâmetro são [Pe89]
µ µni n= e σµµ
µnin
in is ce
AW L
S D22
2 2= + tan (o primeiro termo da direita é causado pelas variações de curta
distância; o segundo, pelas variações de longa distância).
onde Aµn e Sµn são parâmetros do processo;
Distance é a distância do transistor a uma referência.
Assumiremos que todos os inversores que fazem parte do mesmo tapered buffer sofrem do mesmo
desvio de longa distância. Também assumiremos que os processos de curta e de longa distância são
independentes. Em conseqüência, a covariância entre µnis será
C S Dni nj n is ceµ µ µ, tan= 2 2 .

Otimização de Tapered Buffers para altas taxas de operação
116
Informações sobre a covariância entre µni e os outros parâmetros são poucas na literatura. Em
[Po94] podemos calcular o coeficiente de correlação entre µn e µp, que resulta ser baixo. Adotaremos,
portanto, covariância zero entre µni e os outros parâmetros diferentes de µnj.
A mobilidade das lacunas no transistor P, µpi, tem as mesmas características que µnj. Sua média e
variância são
µ µpi p= e σµµ
µpip
ip is ce
AW L
S D22
2 2= + tan
onde Aµp e Sµp são parâmetros do processo;
Distance é a distância do transistor a uma referência.
A covariância entre µpis será
C S Dpi pj p is ceµ µ µ, tan= 2 2 .
A covariância entre µpi e outros parâmetros é assumida como sendo zero.
3.3.4.3 Expressões para as derivadas e sua avaliação nos valores médios
Devemos encontrar as derivadas de tD (20) em função dos parâmetros Li, Wi, Coxi, VTni, VTpi, µni e
µni, 1≤ ≤i N e, posteriormente, avaliar estas derivadas no valor médio dos parâmetros. A dedução
destes segue-se.
Primeiro calculamos as derivadas com relação aos Wis. De (20) chegamos a
( ) ( ) ( )
( )
∂∂
θ µ µ
θµ
tW
V L L W CW C
F V V V K L L CW C
F V V V K
L L W CW C
F V V V K L L CW
D
i
DD i i i oxi
i oxiD Tni Tpi D n ni Cn
i i oxi
i oxiD Tni Tpi D n ni Cn
i i i oxi
i oxiD Tpi Tni D p pi Cp
i i oxi
= + − +
+
− +
+ + ++
−
− −− −
+ + ++
−
12
1 1 12 1 0
1
1 11 0 1
1 1 12 1 0
1
, , , , , ,
, , , ( )i oxi
n Tpi Tni D p pi CpCF V V V K
− −− −
1 11 0 1, , ,θµ
para 1< ≤i N .
As derivadas avaliadas no valor médio das variáveis serão:
( ) ( ) ( )
( ) ( ) ( )
∂∂
θχ
µ µ
θχ
θµ θµ
tW
V LW
F V V V KL
WF V V V K
V LW
F V V V KL
WF V V V K
D
ivalormediodas
iaveis
DD
iD Tn Tp D n n Cn
iD Tn Tp D n n Cn
DD
iD Tp Tn D p p Cp
iD Tp Tn D p p Cp
var
, , , , , ,
, , , , , ,
= + − +
+
+ − +
=
−
−
12
12
0
2
0
2
10
2
0
2
10
Logo as derivadas em relação aos Wis, para 1< ≤i N , têm valor zero quando avaliadas no valor
médio das variáveis. Para i=1 o resultado é ligeiramente diferente:

Otimização de Tapered Buffers para altas taxas de operação
117
( ) ( ) ( )
( ) ( )
∂∂
θ µ
θµ
tW
V L L W CW C
F V V V KL CI
F V V
L L W CW C
F V V V KL CI
F V V
D DD ox
oxD Tn Tp D n n Cn
ox
D nTp D n
ox
oxD Tp Tn D p p Cp
ox
D pTn D p
1
1 2 2 2
12
11 2 0 1
1 1
0 01 0
1 2 2 2
12
11 2 0 1
1 1
0 01 0
12
= + − +
+
− +
, , , ,
, , , ,
Quando M>>1 teremos no valor médio
( ) ( ) ( )[ ]∂∂
θ χ µ θµtW
V LW
F V V V K F V V V KDvalormediodas
iaveis
DDD Tn Tp D n n Cn D Tp Tn D p p Cp
1
2
0 012
var
, , , , , ,≈ − + + (21)
A dedução das derivadas com respeito aos Lis é feito abaixo.
( ) ( ) ( )
( )
( )
∂∂
θ µ µ
µ
θ
tL
V K WWC
F V V V KC L W
WCF V V V K
C L WW C
F V V V K
V K WWC
F V V V
D
i
DD DS i
i oxiD Tni Tpi D n ni Cn
oxi i i
i oxiD Tni Tpi D n ni Cn
oxi i i
i oxiD Tni Tpi D ni ni Cn
DD DS i
i oxiD Tpi Tni D
= + + +
+
+
++ + +
+
−
− −− − −
+
12
12
1 01 1 1
1 0
1
1 11 0 1 1
1 0
, , , , , ,
, , ,
, ,( ) ( )
( )
p pi Cpoxi i i
i oxiD Tpi Tni D p pi Cp
oxi i i
i oxiD Tpi Tni D p pi Cp
KC L W
WCF V V V K
C L WW C
F V V V K
, , , ,
, , ,
θµ θµ
θµ
+ +
+ + ++
−
− −− −
1 1 11 0
1
1 11 0 1
para 1< ≤i N .
Estas derivadas avaliadas no valor médio das variáveis darão:
( ) ( ) ( )( )∂∂
θ χ µ θµtL
LV KLC
F V V V K F V V V KD
ivalormediodas
iaveis
DD DS
oxD Tn Tp D n n Cn D Tp Tn D p p Cp
var
, , , , , ,= + +
+1
22 0 0 (22)
Para i=1 teremos
( ) ( ) ( )
( )
( ) ( )
∂∂
θ µ µ
θ θµ
tL
V K WW C
F V V V KC L W
W CF V V V K
C WI
F V V
V K WW C
F V V V KC L W
W CF
D DD DS
oxD Tn Tp D n n Cn
ox
oxD Tn Tp D n n Cn
ox
D nTp D n
DD DS
oxD Tp Tn D p p Cp
ox
ox
1
1
1 11 2 0 1
2 2 2
1 11 2 0 1
1 1
0 01 0
1
1 11 2 0 1
2 2 2
1 1
12
12
= + + +
+
+ +
, , , , , ,
, ,
, , , ( )
( )
D Tp Tn D p p Cp
ox
D pTn D p
V V V K
C WI
F V V
1 2 0 1
1 1
0 01 0
, , ,
,
θµ +
Esta derivada avaliada no valor médio das variáveis dará (para M>>1)

Otimização de Tapered Buffers para altas taxas de operação
118
( ) ( ) ( )( )∂∂
θ χ µ θµtL
LV KLC
F V V V K F V V V KDvalormediodas
iaveis
DD DS
oxD Tn Tp D n n Cn D Tp Tn D p p Cp
10 01
2var
, , , , , ,≈ + +
+
O próximo passo é encontrar as derivadas com relação às variáveis Coxis:
( ) ( )
( )
∂∂
θ µ µ
µ
θ
tC
V K L WW C
F V V V K L L W CW C
F V V V K
L L WW C
F V V V K
V K L WW C
F
D
oxi
DD DS i i
i oxiD Tni Tpi D n ni Cn
i i i oxi
i oxiD Tni Tpi D n ni Cn
i i i
i oxiD Tni Tpi D n ni Cn
DD DS i i
i oxi
= + − − +
+
+ −
++ + +
+
−
− −− −
( ) , , , , , ,
, , ,
( )
12
12
2 1 01 1 1
2 1 0
1
1 11 0 1
2 ( ) ( )
( )
D Tpi Tni D p pi Cpi i i oxi
i oxiD Tpi Tni D p pi Cp
i i i
i oxiD Tpi Tni D p pi Cp
V V V K L L W CW C
F V V V K
L L WW C
F V V V K
, , , , , ,
, , ,
++ + +
+
−
− −− −
− +
1 01 1 1
2 1 0
1
1 11 0 1
θµ θµ
θµ
para 1< ≤i N .
No valor médio das variáveis estas derivadas serão
( ) ( )
( ) ( )
∂∂
θχ χ
µ
θχ χ
θµ
tC
V K LC
LC
LC
F V V V K
V K LC
LC
LC
F V V V K
D
oxivalormediodas
iaveis
DD DS
ox ox oxD Tn Tp D n n Cn
DD DS
ox ox oxD Tp Tn D p p Cp
var
, , ,
, , ,
= + − − +
+
+ − − +
12
12
2
2 2
0
2
2 2
0
e por fim
( ) ( )[ ]∂∂
θ µ θµt
CV K L
CF V V V K F V V V KD
oxivalormediodas
iaveis
DD DS
oxD Tn Tp D n n Cn D Tp Tn D p p Cp
var
( ) , , , , , ,= − + +12 2 0 0 (23)
Para i=1 teremos
( ) ( )
( )
( )
∂∂
θ µ µ
θ θµ
tC
V K L WW C
F V V V KL L W C
W CF V V V K
L WI
F V V
V K L WW C
F V V V K
D
ox
DD DS
oxD Tn Tp D n n Cn
ox
oxD Tna Tp D n n Cn
D nTp D n
DD DS
oxD Tp Tn D p p Cp
1
1 1
1 12 1 2 0 1
1 2 2 2
1 12 2 0 1
1 1
0 01 0
1 1
1 12 1 2 0 1
12
12
= + − − +
+
+ − −
( ) , , , , , ,
,
( ) , , , ( )
( )
L L W CW C
F V V V K
L WI
F V V
ox
oxD Tp Tn D p p Cp
D pTn D p
1 2 2 2
1 12 1 2 0 1
1 1
0 01 0
, , ,
,
θµ +
No valor médio das variáveis esta derivada será (para M>>1)

Otimização de Tapered Buffers para altas taxas de operação
119
( ) ( ) ( )[ ]∂∂
θχ
µ θµt
CV K L
CL
CF V V V K F V V V KD
oxivalormediodas
iaveis
DD DS
ox oxD Tn Tp D n n Cn D Tp Tn D p p Cp
var
, , , , , ,≈ − + +
+1
2 2
2
0 0 .
As derivadas com respeito as variáveis Vtnis e Vtpis são determinadas para 1< ≤i N .
( ) ( )∂∂
∂ µ∂
∂ θµ∂
tV
V L CWC
F V V V KV
L CW C
F V V V KV
D
Tni
DD i Li
i oxi
D Tni Tpi D n ni Cn
Tni
i Li
i oxi
D Tpi Tni D p pi Cp
Tni
= +
+ − −
− −
− −
21 0 1 1
1 1
1 0 1, , , , , ,
( ) ( )∂∂
∂ θµ∂
∂ µ∂
tV
V L CWC
F V V V KV
L CW C
F V V V KV
D
Tpi
DD i Li
i oxi
D Tpi Tni D p pi Cp
Tpi
i Li
i oxi
D Tni Tpi D n ni Cn
Tpi
= +
+ − −
− −
− −
21 0 1 1
1 1
1 0 1, , , , , ,
( )( ) ( )∂
∂θ χ
∂ µ∂
∂ θµ∂
tV
VL
KLC
F z V V Kz
F V z V Kz
D
Tnivalormediodas
iaveis
DD DS
ox
D Tp D n n Cn D Tp D p p Cp
var
, , , , , ,= + +
+
12
2 0 0 (24)
( )( ) ( )∂
∂θ χ
∂ θµ∂
∂ µ∂
tV
VL
KLC
F z V V Kz
F V z V Kz
D
Tpivalormediodas
iaveis
DD DS
ox
D Tn D p p Cp D Tn D n n Cn
var
, , , , , ,= + +
+
12
2 0 0 (25)
Para i=1 encontraremos os mesmos valores para as derivadas.
Finalmente, as derivadas com respeito as variáveis µnis e µpis para 1≤ ≤i N são
( )∂∂µ
∂ µ∂µ
t V L CWC
F V V V KD
ni
DD i Li
i oxi
D Tni Tpi D n ni Cn
ni=
+
21 0, , ,
( )∂∂µ
∂ θµ∂µ
t V L CWC
F V V V KD
pi
DD i Li
i oxi
D Tpi Tni D p pi Cp
pi=
+
21 0, , ,
( )( )∂
∂µθ χ
∂∂
t VL
KLC
F V V V zKz
D
nivalormediodas
iaveis
DD DS
ox
D Tn Tp D n Cn
var
, , ,= + +
12
2 0 (26)
( )( )∂
∂µθ χ
∂ θ∂
t VL
KLC
F V V V zKz
D
pivalormediodas
iaveis
DD DS
ox
D Tp Tn D p Cp
var
, , ,= + +
12
2 0 (27)
Uma observação final deve ser feita. Pudemos tratar as derivadas para 1< ≤i N igualmente, em
todos os casos acima, devido ao termo (17) que foi adicionado para formar a expressão (18), que, por
sua vez, gerou (20).

Otimização de Tapered Buffers para altas taxas de operação
120
3.3.4.4 Cálculo da variância do atraso de um Tapered Buffer
Agora a equação (19) somada as relações das derivadas de (20), expressões de (21) a (27), e os
modelos estatísticos dos parâmetros variáveis, com as médias, variâncias e covariâncias, fornecerão
enfim a variância de tD. Por razões de simplicidade usaremos a expressão (22), válida apenas para
1< ≤i N , no cálculo da derivada ∂∂tL
D
1 e a expressão (23), válida apenas para1< ≤i N , no cálculo da
derivada ∂∂
tC
D
ox1
. Abaixo está a expressão de σtD:
( )σ χσ
χσ
χ
tDW W DS
ox
L L
ii
N
DS
ox
Cox
ii
N
CoxDS
ox
VTn
ZW
AW L
ZKLC
NL
AW L
ZKLC
ALW
N S D ZKLC
AL
21
2 02 2
2 1
2
02 2
21
1 2
2 2
1
2 2 22
2 2
2=
+
+ +
+
+
+
+ +
=
=
∑
∑ WN S D
ZKLC
ALW
N S D ZKLC
ALW
N S D
ZKLC
ALW
ii
N
VTn
DS
ox
VTp
ii
N
VTpDS
ox
n
ii
N
n
DS
ox
p
ii
N
=
= =
=
∑
∑ ∑
∑
+
+
+
+
+ +
+
+
+
+
1
2 2 2
3
2 2
1
2 2 24
2 2
1
2 2 2
5
2 2
1
χ χ
χ
µµ
µ N S Dp2 2 2
µ
onde: ( ) ( ) ( )[ ]ZV
L F V V V K F V V V KDDD Tn Tp D n n Cn D Tp Tn D p p Cp1
20 01
2= + +θ µ θµ, , , , , ,
( )( ) ( )
ZV
LF z V V K
zF V z V K
zDD D Tp D n n Cn D Tp D p p Cp
22 0 0
12
= + +
θ∂ µ
∂∂ θµ
∂, , , , , ,
( )( ) ( )
ZV
LF z V V K
zF V z V K
zDD D Tn D p p Cp D Tn D n n Cn
32 0 01
2= + +
θ∂ θµ
∂∂ µ
∂, , , , , ,
( )( )
ZV
LF V V V zK
zDD D Tn Tp D n Cn
42 01
2= +
θ∂
∂, , ,
e ( )( )
ZV
LF V V V zK
zDD D Tp Tn D p Cp
52 0
12
= +
θ∂ θ
∂, , ,
Notemos que Z1, Z2, Z3, Z4 e Z5 são independentes de W. Rescrevemos a equação da variância
eliminando todos os somatórios e separando os termos:

Otimização de Tapered Buffers para altas taxas de operação
121
( ) ( )
( ) ( )
σ χσ
χ χσ
χχ
χ χχ
χ χ
tDW W DS
ox
L
DS
ox
N
NL DS
ox
N
NCox
ZW
ZA
W LZ
KLC
NL
ZKLC
AWL
ZKLC
ALW
Z
21
2 02
1
22
2 1
2
02
1
2
1
2
2 1 2
2
1
2
2
21
11
1
=
+ + +
+
+
−−
+
−−
+− −
( ) ( )
( )
2
2
1
2
3
2
1
2
4
2
1
2
5
11
11
11
KLC
ALW
ZKLC
ALW
ZKLC
ALW
ZKLC
DS
ox
N
NVTn DS
ox
N
NVTp
DS
ox
N
Nn DS
ox
+
−−
+ +
−−
+
+
−−
+ +
− −
−
χχ
χ χχ
χχ χ
χχ
χ χχµ
( )
( )
−−
+
+ +
+ +
+
+
+ +
−
2
1
2
1 2
22 2 2
2
2
2 2 23
2
2 2 2
4
2
2 2 25
11
χχ χ
χ χ
χ χ
µ
µ
N
Np
DS
oxCox
DS
oxVTn
DS
oxVTp
DS
oxn
DS
ox
ALW
ZKLC
N S D ZKLC
N S D ZKLC
N S D
ZKLC
N S D ZKLC
2
2 2 2N S Dpµ
(28)
A expressão da variância, exposta acima, obtida considerando as variações nos parâmetros Li, Wi,
VTni, VTpi, Coxi, µni e µpi, apesar das simplificações discutidas, apresenta ainda quatorze termos.
3.3.4.5 Análise da variância em função do fator de aumento
Uma vez encontrada a expressão para a variância (28), podemos responder a questão original, a
saber, como a variância do atraso é afetada pelo fator de aumento usado no tapered buffer. Vamos
comparar a variância do atraso na configuração da Figura 39, para buffers com fatores de aumento
diferentes. Consideremos, portanto, duas implementações para a distribuição do clock; a
implementação A com M buffers, cada um deles com Na inversores e fator de aumento χa, e a
implementação B com M buffers com Nb inversores e fator de aumento χb. Para que a comparação
tenha sentido vamos ainda assumir que valem, para ambas implementações, as condições:
i. todos os buffers têm o mesmo valor de θ;
ii. as dimensões do primeiro inversor de todos os buffers são iguais;
iii. a carga na saída de cada buffers é a mesma, ou seja que χ χaN
bNa b= .
Para extrair algum resultado de (28), é feita a comparação termo a termo da expressão.
3.3.4.5.1 Primeiro e segundo termo
O primeiro e o segundo termos são os mais simples da expressão (28). Eles dependem diretamente
do fator de aumento, χ, e, portanto, serão maiores para valores maiores de χ.
Um comentário adicional é sobre a importância destes termos. É razoável supormos que σ σW L0 0≈
e A AW L≈ ; além disso normalmente W>>L. Em razão disso podemos ver que o primeiro termo é

Otimização de Tapered Buffers para altas taxas de operação
122
muito menor que o terceiro, ZKLC
NL
DS
ox
L1
2
02
2+
χ
σ, e o segundo, muito menor que o quarto
( ( )ZKLC
AWL
DS
ox
N
NL
1
2
1
2
221
1+
−−
−χ
χχ χ
). São, portanto, os dois primeiros termos da expressão pouco
relevantes.
3.3.4.5.2 Terceiro termo
A razão entre os terceiros termos das expressões da variância nas duas implementações é calculada
abaixo:
σ
σ
χσ
χσ
χ
χ
χ χ
χ
tD termobufferA
tD termobufferB
DS
oxa a
L
DS
oxb b
L
DS
oxa a
DS
oxb b
DS
oxa b
DS
oxb
o
o
ZKLC
NL
ZKLC
NL
KLC
N
KLC
N
KLC
KLC
23
23
1
2
02
1
2
02
2
2
2
2
2
2
2
2
2=
+
+
=+
+
=+
+
ln
2
ln χa
σ
σ
χ
χ
χχ
tD termobufferA
tD termobufferB
DS
oxa
DS
oxb
b
a
o
o
KLCKLC
3
3
2
2=
+
+
lnln
Do resultado acima, vemos que o comportamento relativo do terceiro termo da equação da
variância do atraso depende do fator
KLC
DS
ox
+
2χ
χln. Assim, estudando o comportamento deste fator
como função do fator de aumento, χ, podemos saber se o terceiro termo aumenta ou não com χ. Um
resultado mais conveniente para análises pode ainda ser derivado. Considere a desigualdade abaixo:
σ
σ
χ
χ
χχ
χ
χ
χχ
χχ
tD termobufferA
tD termobufferB
DS
oxa
DS
oxb
b
a
DS
oxa
DS
oxb
b
a
da
db
b
a
o
o
KLCKLC
KLCKLC
tt
3
3
2
2=
+
+
≥+
+
=lnln
lnln
lnln
*
* para χ χa b≥
onde t da é o atraso médio de um inversor da implementação A e t db é da implementação B (veja (11)).
A desigualdade mostra que se usarmos o fator Fact d
3 = ln χ para estudo do comportamento do
terceiro termo, estaremos “prejudicando” os buffers de menor fator de aumento. Como o valor de td
pode ser determinado facilmente por simulações, preferimos analisar Fac3.

Otimização de Tapered Buffers para altas taxas de operação
123
3.3.4.5.3 Quarto termo
A razão entre os quartos termos das expressões da variância nas duas implementações é calculada
abaixo:
( )
( )
σ
σ
χχ
χ χ
χχ
χ χ
χ
χ
χtD termo
bufferA
tD termobufferB
DS
oxa
L aN
a aN
DS
oxb
L bN
b bN
DS
oxa
DS
oxb
o
o
a
a
b
b
ZKLC
AWL
ZKLC
AWL
KLC
KLC
24
24
1
2 2
2 1
1
2 2
2 1
2
2
21
1
21
1
2
2=
+
−−
+
−−
=+
+
−
−
( )
( )
( )( )
aN
a aN
bN
b bN
DS
oxa
DS
oxb
b a
a b
DS
oxa
DS
oxb
Ga
Gb
a
a
b
b
KLC
KLC
KLC
KLC
ff
−−
−−
=
+
+
−
−=
+
+
−
−
11
11
2
2
11
2
2
1
1
2
2
2
2
χ χχ
χ χ
χ
χ
χ χχ χ
χ
χ
*
onde fG =−χ
χ 1;
* lembremos que χ χaN
bNa b= .
Ainda, como acima, podemos fazer as seguintes manipulações
σ
σ
χ
χ
tD buffera
tD bufferb
DS
oxa
DS
oxb
Ga
Gb
da
db
Ga
Gb
KLCKLC
ff
tt
ff
=+
+
≥2
2
*
* para χ χa b≥
O fator Fac t fd G4 = será usado para a análise do comportamento do quarto termo.
3.3.4.5.4 Quinto termo
A razão entre os quintos termos das expressões da variância nas duas implementações é calculada
abaixo:
( )
( )
( )( )
σ
σ
χχ χ
χχ χ
χ χχ χ
tD termobufferA
tD termobufferB
DS
ox
Cox aN
a aN
DS
ox
Cox bN
b bN
a b
b a
Ga
Gb
o
o
a
a
b
b
ZKLC
ALW
ZKLC
ALW
ff
25
25
1 2
2 2
1
1 2
2 2
1
11
11
11
=
−−
−−
=−
−=
−
−
σ
σ
tD termobufferA
tD termobufferB
Ga
Gb
o
o
ff
5
5= .

Otimização de Tapered Buffers para altas taxas de operação
124
O fator Fac fG5 = será usado para análise do comportamento do quinto termo. Notemos que não
foi usada nenhuma desigualdade aqui.
3.3.4.5.5 Sexto a nono termos
A razão entre os sextos termos das expressões da variância nas duas implementações é calculada
abaixo:
( )
( )
( )( )
σ
σ
χχ
χ χ
χχ
χ χ
χ χχ χ
tD termobufferA
tD termobufferB
DS
oxa
VTn aN
a aN
DS
oxb
VTn bN
b bN
da
db
a b
b a
da
db
Ga
Gb
o
o
a
a
b
b
ZKLC
ALW
ZKLC
ALW
tt
tt
ff
26
27
2
2 2
1
2
2 2
1
2
2
2
2
11
11
11
=
+
−−
+
−−
=−
−=
−
−
σ
σ
tD termobufferA
tD termobufferB
da
db
Ga
Gb
o
o
tt
ff
6
6= .
O fator Fac t fd G6 = será usado para análise do comportamento do sexto termo. Para o sétimo, o
oitavo e o nono termo, facilmente encontramos que Fac Fac Fac t fd G7 8 9= = = .
3.3.4.5.6 Décimo termo
A razão entre os décimo termos das expressões da variância nas duas implementações é calculada
abaixo:
( )
( )
σ
σ
tD termobufferA
tD termobufferB
DS
oxa Cox
DS
oxb Cox
a
b
o
o
ZKLC
N S D
ZKLC
N S D
NN
210
210
1 2
22 2 2
1 2
22 2 2
2
2=
= ; σ
σχχ
tD termobufferA
tD termobufferB
a
b
b
a
o
o
NN
10
10= =
lnln
.
O fator Fac10
1=
ln χserá usado para análise do comportamento do décimo termo.
3.3.4.5.7 Décimo primeiro a décimo quarto termos
A razão entre os décimos primeiros termos das expressões da variância nas duas implementações é
calculada abaixo:
σ
σ
χ
χ
tD termobufferA
tD termobufferB
DS
oxa a VTn
DS
oxb b VTn
da
db
a
b
o
o
ZKLC
N S D
ZKLC
N S D
tt
NN
211
211
2
2
2 2 2
2
2
2 2 2
2
2
2
2=
+
+
= ; σ
σχχ
tD termobufferA
tD termobufferB
da
db
a
b
da
db
b
a
o
o
tt
NN
tt
11
11= =
lnln
;

Otimização de Tapered Buffers para altas taxas de operação
125
O fator Fact d
11 = ln χserá usado para análise do comportamento do décimo primeiro termo. Para os
outros três termos, encontramos analogamente que Fac Fac Fact d
12 13 14= = =ln χ
.
Na Tabela 11 está um resumo dos resultados acima. Para cada um dos termos da equação (28) são
fornecidos a descrição daquilo que o causa, a sua expressão e que fator devemos analisar para
determinar seu comportamento.
Observe que os fatores ligados a Coxi, Fac5 e Fac10, são independentes da tecnologia.
3.3.4.5.8 Resultados Numéricos
Para que a comparação dos termos possa ser realizada, devemos conhecer os valores de t d em
função de χ. Eles foram obtidos com o HSPICE que tem comandos específicos para calcular esta
grandeza [Me95a] sem necessidade de simulações com osciladores em anel. Foram simulados
inversores tanto da tecnologia CMOS 0,8µm (level 6) como da tecnologia 0,35µm (level 3)
(APÊNDICE B). Parâmetros slow foram usados em ambos os casos. A Tabela 12 apresenta os
resultados. A Figura 41, por sua vez, mostra o gráfico do atraso de um inversor em função do fator de
aumento do buffer. Como era esperado, há uma relação linear entre atraso e fator de aumento.
Tabela 11. Descrição, expressão e fator para análise de cada termo da equação (28).

Otimização de Tapered Buffers para altas taxas de operação
126
Termo descrição do que causa o termo
expressão do termo fator para análise
primeiro accuracy of pattern generation process de Wi;
variações de curta dist. ( )Z
WW
1
2 02
χσ
χ (termo não significativo.)
segundo edge roughness de Wi; variações de curta dist. ( )Z
AW L
W1
22
2χ χ (termo não significativo.)
terceiro accuracy of pattern generation process de Li; variações de curta dist.
ZKLC
NL
DS
ox
L1
2
02
2+
χ
σ Fac
t d3 = ln χ
quarto edge roughness de Li; variações de curta dist. ( )Z
KLC
AL W
DS
ox
N
NL
1
2
1
2
221
1+
−−
−χχ
χ χ Fac t fd G4 =
quinto nonuniform arrangement of events para Coxi; variações
de curta dist. ( )ZKLC
ALW
DS
ox
N
NCox
1 2
2
1
211
−−
−
χχ χ
Fac fG5 =
sexto nonuniform arrangement of events para VTni; variações
de curta dist. ( )ZKLC
ALW
DS
ox
N
NVTn
2
2
1
211
+
−−
−χχ
χ χ
Fac t fd G6 =
sétimo nonuniform arrangement of events para VTpi; variações
de curta dist. ( )ZKLC
ALW
DS
ox
N
N
VTp3
2
1
211
+
−
−
−
χχ
χ χ
Fac t fd G7 =
oitavo nonuniform arrangement of events para µni; variações de
curta dist. ( )ZKLC
ALW
DS
ox
N
Nn
4
2
1
211
+
−−
−χ
χχ χ
µ Fac t fd G8 =
nono nonuniform arrangement of events para µpi; variações de
curta dist. ( )ZKLC
ALW
DS
ox
N
Np
5
2
1
211
+
−−
−χχ
χ χµ
Fac t fd G9 =
décimo variações de longa dist. para Coxi Z
KLC
N S DDS
oxCox1 2
2
2 2 2
Fac10
1=
ln χ
décimo primeiro
variações de longa dist. para VTni Z
KLC
N S DDS
oxVTn2
2
2 2 2+
χ Fac
t d11 = ln χ
décimo segundo
variações de longa dist. para VTpi Z
KLC
N S DDS
oxVTp3
2
2 2 2+
χ Fac
t d12 = ln χ
décimo terceiro
variações de longa dist. para µni Z
KLC
N S DDS
oxn4
2
2 2 2+
χ µ Fac
t d13 = ln χ
décimo quarto
variações de longa dist. para µpi Z
KLC
N S DDS
oxp4
2
2 2 2+
χ µ Fac
t d14 = ln χ

Otimização de Tapered Buffers para altas taxas de operação
127
Tabela 12. Atraso de um inversor como função do fator de aumento do buffer, para as tecnologias
0,8µm e 0,35µm.
fator de aumento
atraso do inversor para tecnologia de 0,8µm (ps)
atraso do inversor para tecnologia de 0,35µm (ps)
6 405,7 168,6 5,5 376,4 155,8 5 346,6 144,8
4,5 316,2 132,2 4 286,6 119,3
3,5 255,6 106,8 3 225,3 94,35
2,5 195,6 81,8 2 166 69,4
1,5 137 56,9 1,2 121 49,7
td(0,35) td (0,8)6 168,6 405,7
5,5 155,8 376,45 144,8 346,6
4,5 132,2 316,24 119,3 286,6
3,5 106,8 255,63 94,35 225,3
2,5 81,8 195,62 69,4 166
1,5 56,9 1371,2 49,7 121
0
50
100
150
200
250
300
350
400
450
0 1 2 3 4 5 6fator de aumento
atra
so (
ps)
td(0,35)td (0,8)
Figura 41. Atraso de um inversor em função do fator de aumento do buffer para as tecnologias
0,8µm e 0,35µm.
Podemos agora computar a variação dos Facs para estas tecnologias. As duas próximas figuras,
Figura 42 e Figura 43, apresentam o comportamento relativo destes fatores em função do valor de χ.
Foi usado como referência, para cada um dos fatores, o seu valor no ponto χ=3.

Otimização de Tapered Buffers para altas taxas de operação
128
Fac1 Fac2,4,5 Fac7,8 Fac3 Fac6 Fac3 Fac4,6,7,8,6 405,7 303,0855 444,4221 226,4255 1,095445 0,558111 1,410023 1,610604
5,5 376,4 288,2833 416,1259 220,7951 1,105542 0,586597 1,34116 1,5080585 346,6 273,2068 387,5106 215,3547 1,118034 0,621335 1,27102 1,404355
4,5 316,2 257,826 358,5371 210,2285 1,133893 0,664859 1,199465 1,2993534 286,6 243,4156 330,9372 206,7382 1,154701 0,721348 1,132425 1,19933
3,5 255,6 228,3633 302,43 204,029 1,183216 0,798236 1,062398 1,0960193 225,3 214,9508 275,935 205,0769 1,224745 0,910239 1 1
2,5 195,6 204,3394 252,5185 213,4694 1,290994 1,091357 0,950634 0,9151382 166 199,3863 234,7595 239,4874 1,414214 1,442695 0,92759 0,850778
1,5 137 215,1512 237,291 337,8836 1,732051 2,466303 1,000932 0,8599521,2 121 283,3781 296,3883 663,6626 2,44949 5,484815 1,31834 1,074123
0
1
2
3
4
5
6
7
0 1 2 3 4 5 6fator de aumento
valo
r rel
ativ
o do
fato
r de
anál
ise
Fac3Fac4,6,7,8,9Fac11,12,13,14Fac5Fac10
Figura 42. Comportamento dos fatores de análise, Fac3 ..., Fac14, em função do fator de aumento do
buffer. Os valores apresentados são relativos ao valor encontrado para χ=3. A tecnologia é 0,8µm.
Fac1 Fac2,4,5 Fac7,8 Fac3 Fac6 Fac3 Fac4,6,7,8,6 168,6 125,9557 184,692 94,09745 1,095445 0,558111 1,399259 1,598304
5,5 155,8 119,3266 172,2434 91,3918 1,105542 0,586597 1,325616 1,4905755 144,8 114,1383 161,8913 89,9693 1,118034 0,621335 1,267978 1,400989
4,5 132,2 107,7944 149,9007 87,89441 1,133893 0,664859 1,197503 1,2972244 119,3 101,3241 137,7558 86,05676 1,154701 0,721348 1,125623 1,192123
3,5 106,8 95,41943 126,3675 85,25156 1,183216 0,798236 1,060027 1,093573 94,35 90,01599 115,5547 85,88107 1,224745 0,910239 1 0,999997
2,5 81,8 85,45484 105,6033 89,27298 1,290994 1,091357 0,949329 0,913882 69,4 83,3579 98,14642 100,123 1,414214 1,442695 0,926034 0,849348
1,5 56,9 89,35843 98,55369 140,3327 1,732051 2,466303 0,992695 0,8528731,2 49,7 116,3958 121,7396 272,5953 2,44949 5,484815 1,293057 1,053521
0
1
2
3
4
5
6
7
0 1 2 3 4 5 6fator de aumento
valo
r rel
ativ
o do
fato
r de
anál
ise
Fac3Fac4,6,7,8,9Fac11,12,13,14Fac5Fac10
Figura 43. Comportamento dos fatores de análise, Fac3 ..., Fac14, em função do fator de aumento do
buffer. Os valores apresentados são relativos ao valor encontrado para χ=3. A tecnologia é 0,35µm.
Com o propósito de verificar as relações acima, foram realizadas simulações de "Monte Carlo",
considerando-se diferente buffers, com diferentes fatores de aumento, e, naturalmente, com χ N igual
para todos eles. Para cada um dos buffers foram variados aleatoriamente os seguinte parâmetros:
i. L, sendo considerado igual para os transistores P e N do mesmo inversor mas diferente para os
diversos inversores do buffer. Os resultados, neste caso, servem para verificar, indiretamente, as
derivadas ∂∂tL
D
ie, diretamente, o comportamento de Fac3;
ii. Cox, sendo considerado igual para todos os inversores do mesmo buffer. Os resultados aqui servem
para verificar, indiretamente, as derivadas ∂∂
tC
D
oxie, diretamente, o comportamento de Fac10;

Otimização de Tapered Buffers para altas taxas de operação
129
iii. VTn0, zero-bias threshold voltage, no modelo dos transistores N, sendo considerado igual para
todos os transistores N do buffer. Os resultados aqui servem para verificar, indiretamente, as
derivadas ∂tV
D
Tnie, diretamente, o comportamento de Fac11;
iv. µn0, mobilidade dos portadores no modelo dos transistores N, sendo considerada igual para todos
os transistores N do buffer. Os resultados aqui servem para verificar, indiretamente, as derivadas
∂∂µ
tD
noie, diretamente, o comportamento de Fac13.
Para determinar a variância do atraso, 1000 valores para cada parâmetro foram tomados. Com este
número podemos garantir que o desvio padrão correto está dentro de um intervalo inferior a ± 5% em
torno do valor do desvio padrão estimado a partir das simulações, com confiança de 90% (é
considerado que a distribuição de tD é normal e, portanto, seu desvio padrão tem distribuição qui
quadrado [Co77]).
A Figura 44 apresenta o desvio padrão normalizado do atraso do buffer para simulações
considerando variações em L, Cox, VTn0 e µn0, conforme explicado acima, para a tecnologia CMOS
0,35µm. Cada um dos parâmetros é considerado separadamente. Também na figura são apresentadas
as curvas de Fac3, Fac10, Fac11 e Fac13.
1 2 3 4 5 60
0 . 5
1
1 . 5
2
2 . 5
3 V a r i â n c i a c a u s a d a p o r L
V a r i â n c i a c a u s a d a p o r C o x
V a r i â n c i a c a u s a d a p o r V T n 0
V a r i â n c i a c a u s a d a p o r µ n 0
F a t o r d e a u m e n t o d o b u f f e r ( χ )
V a l o rn o r m a l i z a d o d o
d e s v i o p a d r ã od o a t r a s o d o
b u f f e r
F a c 1 1 e F a c 1 3
F a c 1 0
F a c 3
Figura 44. Gráfico do desvio padrão normalizado do atraso do buffer determinado por simulações de
"Monte Carlo", em função do fator de aumento do buffer (tecnologia 0,35µm). Também são
apresentadas as curvas teóricas para comparação dos resultados.
Pelos resultados vemos que as relações teóricas e os dados de simulação estão bastante próximos.
Uma observação a respeito das simulações feitas, para obter o desvio padrão do atraso, com variações
em Cox. O resultado mostrado no gráfico só foi conseguido após serem retiradas as resistências de

Otimização de Tapered Buffers para altas taxas de operação
130
dreno e de fonte dos transistores, resistências calculadas e incluídas automaticamente pelo HSPICE.
Esses resistores fazem com que o atraso do buffer tenda a aumentar quando o valor de Coxi aumenta e,
diminuir quando o valor de Coxi diminui. A expressão (23), calculada sem considerar tais resistores,
indica o comportamento inverso de tD com relação a Coxi. Desse modo, a presença dos resistores de
dreno e fonte faz com que o efeito da variação de Coxi em tD seja mitigado.
Dos resultados acima podemos tirar alguma conclusões. Primeiro, concentremos nossa atenção em
Fac5 e Fac10, ambos relacionados com Coxi. Note que como eles não dependem de t d , também não
dependerão da tecnologia. Fac5 e Fac10 diminuem continuamente com o aumento de χ. Deste modo, a
variância do atraso aumenta quando são utilizados valores baixos de χ, se estamos considerando
apenas as variações causadas por distúrbios em Coxi. Não obstante este resultado desfavorável,
devemos lembrar que Coxi é um dos parâmetros melhor controlados no processo de fabricação de
circuitos integrados CMOS. Deste modo, podemos esperar que a influência de Coxi seja de fato
pequena. Também a presença de resistências de dreno/fonte, não considerada nas relações teóricas,
reduz estes efeitos.
Fac3,Fac4, Fac6, ..., Fac9 são devidos às variações de curta distância em Li, VTni, VTpi, µni e µpi. Para
valores de χ maiores que 2, estes fatores vão aumentado a medida que χ aumenta; para valores de χ
entre 1,5 e 2, os fatores sofrem poucas variações; por fim, se χ tem valores inferiores a 1,5 então os
fatores aumentam bruscamente (Figuras 42 e 43). Segue destas observações que a redução do fator de
aumento, desde que este fique acima de 1,5, não traz conseqüências negativas para a variância do
atraso total, considerando as variações de curta distância em Li, VTni, VTpi, µni e µpi.
Fac11, ..., Fac14, que estão relacionados com variações de longa distância em VTni, VTpi, µni e µpi, têm
o seu valor mínimo em torno de χ=3,5 (Figuras 42 e 43). Para valores de χ menores que 1,5, Fac11, ...,
Fac14 aumentam rapidamente. Para χ=1,5 os valores de Fac11, ..., Fac14 são 70% maiores que os
valores mínimos que estes fatores assumem.
3.3.4.6 Considerações finais sobre o estudo do Mismatch do Atraso
A conclusão do estudo sobre a variância do atraso do tapered buffer é que seu comportamento
depende do tipo de distúrbio que é predominante na tecnologia utilizada. De forma geral, variações de
curta distância, exceto para Coxi, tendem a causar maiores problemas para buffers com fator de
aumento maior. Variações de longa distância, ao contrário, têm efeito mais acentuado nos buffers onde
χ é de valor menor. Podemos ainda esperar que, desde que variações no Coxi não sejam a principal

Otimização de Tapered Buffers para altas taxas de operação
131
fonte de mismatches em tD, e desde que o fator de aumento seja superior a 1,5, a utilização de maior ou
menor fator de aumento no tapered buffer não causará grandes diferenças na variância do atraso.
3.4 Conclusões sobre a otimização de Tapered Buffers
A aplicação do novo critério para otimização de tapered buffers permite, como vimos, um aumento
em torno de 20% da taxa máxima do sinal que propaga por eles. Este aumento, apesar de não ser
expressivo, pode, em certas aplicações, ser de fundamental importância para se alcançar os resultados
desejados. Veremos no próximo capítulo um exemplo destes.
O novo critério exige a utilização, no geral, de fatores de aumento pequenos o que acarreta o
aumento no número de inversores do buffer. Este maior número de inversores não piora
necessariamente as condições de matching entre buffers, como vimos. O comportamento do matching
dependerá da tecnologia e dos tipos de distúrbios nela predominantes.


Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
133
4. Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
4.1 Introdução
Nos dois capítulos precedentes apresentamos a estratégia E-TSPC e um novo critério para
otimização de tapered buffers. A tônica desses capítulos foi a apresentação teórica, sem comprovação
experimental dos resultados.
Durante a preparação do trabalho foram desenvolvidos alguns circuitos integrados que ajudaram na
elaboração e na verificação das idéias apresentadas. Dentre eles um circuito Multiplexador 8:1, um
Demultiplexador 1:8 com byte alignment e um circuito Dual-Modulus Prescaler (divide por 128/129).
O Multiplexador e o Demultiplexador foram implementados durante a fase inicial do trabalho para
aperfeiçoar versões anteriores destes mesmos circuitos ([Ro95a], [Ro95b], [Ro96]). Nestas novas
implementações foram empregados o critério de otimização de tapered buffers aqui tratado e flip-flops
usando blocos N-MOS like. O circuito Prescaler foi implementado com a finalidade específica de
comparar o E-TSPC com outras técnicas.
Apresentaremos neste capítulo estes três circuitos junto com os resultados experimentais obtidos. A
tecnologia utilizada nas implementações foi a CMOS 0,8µm (comprimento de canal efetivo de 0,7µm),
duplo metal, da ES2/ATMEL [Es94].
4.2 Circuitos Multiplexador e Demultiplexador
Umas das áreas mais promissoras para a aplicação de circuitos CMOS de alta freqüência é a de
transmissão digital de dados. No emprego de fibras óticas, que tem banda de transmissão superior a
50000Gbit/s [Ta96], vários são os circuitos necessários.
Circuitos Multiplexadores 8:1 e Demultiplexadores 1:8 para transmissão em padrão SONET/SDH
foram desenvolvidos e implementados dentro do Laboratório de Sistemas Integrados da USP ([Ro95a],
[Ro95b], [Ro96], [No98]). Duas características básicas destas implementações são:
i. a utilização de níveis compatíveis com os níveis lógicos ECL para os sinais de entrada/saída de
alta freqüência (sinais de clock e dados multiplexados, este último sendo sinal de saída no
Multiplexador e de entrada no Demultiplexador): os níveis ECL permitem que os circuitos possam
ser usados em ambientes de alta velocidade. Também é necessário, nestes ambientes, o casamento
de impedância das linhas que conduzem os sinais rápidos ECL, reduzindo as reflexões dos sinais.
Para isto são usados resistores de 50Ω externos ao C.I.. Com o emprego de sinais ECL, são
possíveis tanto altas velocidades como níveis baixos de ruído devido à excursão dos sinais ser
pequena (≈0,9V). A compatibilidade com ECL exige circuitos de entrada que façam a conversão
de níveis lógicos ECL para os níveis lógicos CMOS usados internamente, chamados conversores

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
134
ECL-CMOS, e circuitos de saída que façam a operação contrária, conversão dos níveis lógicos
CMOS para os ECL, chamados conversores CMOS-ECL. Os valores de tensão dos níveis lógicos
da família ECL 10KH, que são empregados no Multiplexador e no Demultiplexador, são
apresentados na Tabela 13 [Bl88]. Para trabalhar com estas tensões negativas, a alimentação dos
C.I.s deve ser VDD=0V e VSS=-5V. No entanto, para fins de testes, empregamos os valores
convencionais, VDD=5V e VSS=0V; os níveis ECL médios são então deslocados para 4,1V, nível
alto, e 3,2V, nível baixo;
Tabela 13. Valores dos níveis lógicos ECL utilizados pelo Multiplexador e pelo Demultiplexador.
níveis máximo (V) mínimo (V) médio (V)
alto (VH(ECL)) -0,81 -0,98 0,895
baixo (VL(ECL)) -1,63 -1,95 -1,79
ii. são usadas nos C.I.s células TSPC e nestas, empregados transistores com dimensões próximas das
mínimas, não só para o comprimento do canal, que é prática corrente, mas também para a sua
largura: uma das grandes vantagens do TSPC, como foi dito no capítulo dois, é a simplificação da
distribuição do sinal de clock que é único. Os transistores de pequenas dimensões permitem que a
potência consumida fique em níveis baixos. Também são explorados nestes projetos ambos os
níveis do clock, empregando-se D-flip-flops sensíveis à borda de subida e à borda de descida.
Na próxima seção detalhamos as implementações feitas originalmente para o Multiplexador e para
o Demultiplexador.
4.2.1 Projeto do Multiplexador e do Demultiplexador (primeira versão)
4.2.1.1 Circuitos de entrada/saída conversores ECL-CMOS e CMOS-ECL
Os circuito de entrada/saída conversores ECL-CMOS e CMOS-ECL foram desenvolvidos para
permitir testes nos C.I.s encapsulados. Na Figura 45(a) é mostrado o circuito de entrada para conversão
ECL-CMOS [Na95]. Ele é composto por um seguidor de fonte, transistores Mi1 e Mi2, e inversores. A
função do seguidor de fonte é assegurar que a entrada do primeiro inversor, OSF, tenha valor em torno
de -2,5V quando o sinal de entrada, in, tem valor de -1,22V (valor médio entre os níveis lógicos ECL).
Neste caso poderemos usar os inversores para amplificar os sinais da entrada.
Para manter a operação do circuito em quaisquer circunstâncias, independente das variações
normais que ocorrem nos parâmetros dos transistores, é necessário um circuito de polarização especial
[St91]. O circuito aqui empregado está apresentado na Figura 45(b). Neste circuito uma cópia do

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
135
seguidor de fonte, transistores M'i1 e M'i2, e uma cópia do primeiro inversor, M'i3 e M'i4, são utilizadas.
O inversor tem ligadas sua entrada e saída, fazendo com que ele vá estabilizar na região de transição,
caracterizada por ter alto ganho. Com auxílio do par diferencial MP1 e MP2, a tensão de polarização
VBiasI é ajustada para que a saída do seguidor de fonte M'i1/M'i2 seja igual a saída do inversor M'i3/M'i4.
Assim, aplicando-se em VREF -1,2V, garantimos que o seguidor de fonte desloca a entrada de -1,2V até
a região de alto ganho do primeiro inversor. O circuito de polarização funciona corretamente mesmo
com variações na tecnologia, desde que estas não sejam muito grandes.
in
VBiasI
Mi1
Mi2
Mi3
Mi4
Tapered buffernão faz parte do
conversor
out
VDD
VSS
a) b)
VDD
VSS
OSF
VREFM'i1
M'i2VBiasI
M'i3
M'i4
MP2MP1
Figura 45. Circuito conversor de alta velocidade ECL-CMOS (a) e seu circuito de polarização (b).
O circuito de saída para conversão CMOS-ECL é, por sua vez, apresentado na Figura 46(a)([Na96],
[Na97a]). Este circuito necessita uma carga resistiva de 50Ω externa ao C.I. (resistor de casamento). O
conversor é baseado em fontes de corrente chaveadas. A descrição do circuito segue: quando o sinal de
entrada é baixo, in=VSS (=-5V), o transistor MO1 é cortado. Neste caso, o nó de saída será puxado para
o nível VH(ECL) pelo resistor de casamento (resistor externo de 50Ω). Na entrada contrária, in=VDD
(=0V), MO1 estará conduzindo e uma corrente de valor fixo é forçada através do resistor de 50Ω pelo
transistor MO2. A tensão de polarização VBiasO é ajustada para assegurar, neste caso, o nível correto na
saída (VL(ECL)).
Também aqui é necessário um circuito especial de polarização para o conversor, de forma a garantir
que o nível baixo seja sempre correto, não dependendo das variações dos parâmetros dos transistores.
Ele é mostrado na Figura 46(b); seu funcionamento é baseado em comparações e realimentação
([Na96], [Na97a]), similarmente ao que acontece no conversor ECL-CMOS. É importante observar,
neste caso, que são necessários dois PADs para o circuito de polarização: um fornecendo a tensão
VH(ECL) (PAD extra 1) e outro fornecendo a tensão VL(ECL) (PAD extra 2).

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
136
in
R=50Ω
VBiasO
Trans. line
Externo ao CIVH(ECL)
CL
MO1 (120µm/1,0µm)
MO2 (280µm/1,0µm)
saída
VDD
R=50Ω
VBiasO
Externo ao CIVH(ECL)
CL
M'O1 (120µm/1,0µm)
M'O2 (280µm/1,0µm)+
-
nível baixo(referência)
-1,8V
PADextra 2
PADextra 1
a) b)
VSSVSS
Figura 46. Circuito conversor de alta velocidade CMOS-ECL (a) e seu circuito de polarização (b).
Encerrando esta seção sobre os circuitos de entrada/saída, façamos um último comentário: neles,
todos os resistores para casamento de impedância são externos. Foram desta forma projetados para
reduzir os riscos de erros na implementação. Resistores internos, por outro lado, apesar do consumo de
área, são melhores para os circuitos de entrada, resultando num casamento de impedância superior e,
como conseqüência, reduzindo as reflexões dos sinais.
4.2.1.2 Principais células TSPC
Na Figura 47 estão apresentadas as células TSPC usadas na construção do Multiplexador e do
Demultiplexador. Também estão indicados na figura quais os blocos que avaliam quando o clock tem
nível baixo, blocos hachurados, e quais avaliam quando o clock tem nível alto. A descrição das células
segue:
• circuitos D-flip-flops sensíveis à borda de subida: Figuras 47(a) e 47(c), este último com estágio
de saída duplicado;
• circuitos D-flip-flops sensíveis à borda de descida: Figuras 47(b) e 47(d), este último com estágio
de saída duplicado;
• circuitos D-flip-flops sensíveis à borda de subida, com atraso de meia fase: Figuras 47(f) e 47(e),
este último com estágio de saída duplicado;
• circuito D-flip-flop sensível à borda de descida, com atraso de meia fase: Figura 47(g).
A grosso modo podemos ver estas células como associações de p-data chains, blocos hachurados
que formam latches sensíveis ao clock baixo, com n-data chains, que formam latches sensíveis ao
clock alto (não hachurados). Assim, a célula da Figura 47(f) é um p-data chain + n-data chain + p-
data chain.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
137
Uma característica importante em todas células, explorada no circuito Multiplexador, é a presença
de um bloco dinâmico seguido de um bloco latch, formando o data chain n ou p dependendo do caso,
na saída. O último bloco latch, durante a fase de holding, fica com a saída em alta impedância.
Pela figura podemos observar ainda que as dimensões usadas para os transistores são pequenas,
próximas das mínimas permitidas pela tecnologia.
D
Cl Cl
Cl Cl
Qb
D
ClQb
a)
D
Cl
Cl
Cl
Cl
Qb
D
ClQb
b)
D
Cl
Cl
Cl
D
Cl
Qb
d)
Cl
Qb
Cl
Qb
Cl
Cl
D
Cl Cl
Cl Cl
f)
Cl
Cl
ClQb
D
ClQb
e)
Cl
Cl
Cl
D
Cl Cl
Cl Cl
Qb
Cl
Cl
ClD
Cl
Qb
Qb
Cl
Cl Cl
Qb
D
Cl
Cl
Cl
Cl
g)
D
Cl
Qb
D
Cl Cl
Cl
D
Cl
Qb
c)
Cl
Qb
Cl
Qb
Cl
Cl
4,8 4,8
4,8
4,8 4,8
4,8
4,8
4,8
4,8
4,8
4,8
4,8
4,8
4,8 4,8
4,8
4,8
4,8
4,8
4,8
VSS
VDD
Figura 47. Células básicas empregadas no projeto do Multiplexador 8:1 e do Demultiplexador 1:8.
Estão representados tanto o diagrama de transistores como o símbolo de cada célula. Os blocos
hachurados avaliam quando o sinal de clock (Cl) é baixo; os outros blocos, quando o sinal de clock é
alto. Todos os transistores usados aqui têm comprimento de canal L=0,8µm. A largura de canal, para
a maioria, é W=2,4µm; para os transistores onde isso não é verdade, o valor da largura do canal, em
µm, está indicado na figura.
4.2.1.3 Multiplexador 8:1
A arquitetura do circuito Multiplexador é baseada em células multiplexadoras 2:1 síncronas, como
indicado na Figura 48 [Ro96]. O sinal de clock da entrada do Multiplexador é dividido por 2 e por 4,

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
138
internamente, sendo posteriormente aplicado a estes multiplexadores 2:1. A primeira coluna de
multiplexadores, aquela que está mais à esquerda na figura, é sincronizada pelo sinal clock/4. Aí
chegam, numa taxa igual a freqüência do sinal clock/4, os oito dados de entrada, bit0, ..., bit7, que
devem ser multiplexados. A partir deles são gerados os sinais m1, ..., m4. Estes sinais têm taxa igual ao
dobro dos anteriores, sendo que m1 resulta da multiplexação de bit0 e bit1, m2, da multiplexação de bit2
e bit3 e assim por diante. A segunda coluna de multiplexadores é sincronizada por clock/2 e recebe os
sinais m1, ..., m4, gerando m5 e m6. A taxa destes últimos é igual ao dobro da taxa dos anteriores, ou
seja, igual a freqüência do clock que entra no circuito. Por fim, os sinais m5 e m6 são unidos no último
multiplexador 2:1, gerando o sinal de saída do Multiplexador 8:1. A taxa do sinal multiplexado final é
o dobro da freqüência do sinal de clock da entrada (aplicado externamente). Esta característica é
vantajosa pois facilita a distribuição do sinal de clock dentro do C.I. e reduz, também, o consumo de
potência.
Note que no último multiplexador 2:1, são utilizados três D-flip-flops. Com isso uma maior
velocidade foi atingida.
Os multiplexadores 2:1 são construídos com a união de dois D-flip-flops sensíveis à borda de
subida, um flip-flop convencional e outro que tem meia fase de atraso. No D-flip-flop convencional, o
dado de entrada, amostrado durante a borda de subida do clock, aparece na saída imediatamente após
esta borda; no D-flip-flop com meia fase de atraso, o dado, amostrado também durante a borda de
subida, vai aparecer na sua saída apenas meia fase após a amostragem. Como nestes D-flip-flops a
saída, ora de um ora de outro, está em alta impedância, podemos uni-las e assim obter o multiplexador
2:1 síncrono.
No Multiplexador são usados vários tapered buffers. Três deles, os mais críticos por onde passam
os sinais de maior freqüência, estão indicados no diagrama esquemático. Também está indicado
quantos inversores em série são usados em cada um destes buffers.
Um sinal externo para sincronização, select, está ainda presente no circuito. Ele servirá para inverter
o sinal clock/4 quando sua borda de subida estiver muito próxima da transição dos dados da entrada
(bit0, ...,bit7).

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
139
m 6
m 5
m 4
m 3
m 2
m 1
C o n v e rs o rE C L -C M O S
c lo c k
C o n v e rs o rC M O S -E C L
s a íd a d oM u lt ip le x a d o r
D a d o M
c lo c k /2c lo c k /4
b u ffe r 25 in v e rs o re s
b u ffe r 14 in v e rs o re s
b i t0
b i t1
b i t2
b i t3
b i t4
b i t5
b i t6
b i t7
s e le c t
b u ffe r 33 in v e rs o re s
b u ffe r s d ee n tra d a
Figura 48. Diagrama esquemático da primeira versão do circuito Multiplexador 8:1.
4.2.1.4 Demultiplexador 1:8
As seguintes características marcam o circuito Demultiplexador ([Ro95a], [Ro95b]):
• o sinal de clock vem de fora do circuito e deve estar sincronizado com o meio do dado a ser
demultiplexado;
• é implementado um detetor para byte alignment [Ko91]. Desta forma toda vez que é recebido o
byte de alinhamento A1 (a seqüência "11110110" na entrada), se o detetor estiver habilitado, a
saída será resincronizada;
• trabalhou-se com as duas bordas do sinal de clock. Isto faz com que a taxa de operação dos flip-
flops seja reduzida a metade, facilitando o projeto e reduzindo o consumo de potência.
A Figura 49 mostra o núcleo do Demultiplexador. Nela não é mostrado como é feita a distribuição
do clock principal do circuito; também não são indicadas as entradas de clock dos D-flip-flops que
trabalham sincronizados com este clock principal. Para que haja atrasos iguais entre o sinal de dados,
DadoM, e o sinal clock, desde a entrada externa até as células internas, estes dois sinais passam por
circuitos, conversor ECL-CMOS e tapered buffers, similares e que têm as cargas casadas.
O Demultiplexador é composto por dois registradores de deslocamento, shift registers, um deles
trabalhando com a borda de subida do clock e outro, com a borda de descida. Assim o sinal de dados é
amostrado em ambas as bordas do clock. O flip-flop Lsinc, Figura 49, sincroniza os dois shift registers.
Dois blocos de circuitos, um na parte superior e outro na inferior, detectam a chegada do byte A1,

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
140
ativando os sinais fn1, fn2, fp1 e fp2. Os sinais fp1 e fn1 serão levados para nível alto se o A1 detectado
tem seu primeiro bit armazenado no registrador superior; por outro lado, fp2 e fn2 serão levados para
nível alto se o primeiro bit foi armazenado no registrador inferior. Não sendo encontrado o byte de
alinhamento, então fp1 ou fn1 e fp2 ou fn2 terão nível baixo.
A partir dos sinais fn1, fn2, fp1 e fp2 são gerados os sinais df1 e df2 (ver Figura 50); estes servirão, por
sua vez, para iniciar/reiniciar a geração do sinal CA (Figura 51), utilizado como clock nos D-flip-flops
da saída (Figura 49), e para gerar os sinais de seleção dos demultiplexadores 2:1 da saída (Figuras 49 e
52). O sinal CA é obtido a partir do clock principal do circuito, com a divisão deste por quatro em um
contador síncrono (Figura 51).
I1
D1
H1
C1
G1
B1
F1
A1
E1
bit0
bit1
bit2
bit3
bit4
bit5
bit6
bit7
S SB
Lsinc
clock/4CA
Registrador dedeslocamento
inferior
Registrador dedeslocamento
superior
fn1
fn2
F1
G1
H1
I1
E1
fp2
fp1 A1
B1
C1
D1
ConversorECL-CMOS
DadoM
ConversorECL-CMOS
clock
Taperedbuffer
Taperedbuffers
Din
clk1
clk2
clk27
clk26
Buffersde saída
Figura 49. Diagrama esquemático do núcleo do circuito Demultiplexador 1:8 da primeira versão.
fn1
fp1
enable enable
fp2
fn2df1
df2
Figura 50. Circuito para gerar sinais de alinhamento de byte.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
141
Se1
Se0
CA
df1
df2
Se0
Se1 Se1_i
Se0_i
Figura 51. Circuito para gerar o clock que sincroniza a saída (CA).
SB
Sdf1
df2 Se1_i
Se0_i
Figura 52. Circuito para gerar sinais de seleção para os multiplexadores 2:1 da saída.
Nos testes destes C.I.s, as taxas máximas de operação alcançadas pelos protótipos foram inferiores a
1,1Gbit/s, para alimentação de 5V.
4.2.2 Projeto do Multiplexador e do Demultiplexador (nova versão)
Analisando-se o desempenho dos circuitos anteriores, Multiplexador e Demultiplexador, verificou-
se que a velocidade máxima era limitada por três fatores:
• o circuito de entrada conversor ECL-CMOS (principalmente no caso do Demultiplexador);
• a velocidade de operação de certas células TSPC, principalmente aquelas onde se empregam p-
data chains com mais de um bloco (Figura 47, células b, d, e, f e g);
• a velocidade de operação dos tapered buffers que fazem a distribuição do clock e também por
onde passa o sinal DadoM, tanto na saída do Multiplexador como na entrada do Demultiplexador.
Para contornar estes fatores, foram tomadas as seguintes providências:
• melhora dos conversores ECL-CMOS;
• estudo e modificação das células TSPC;
• estudo e modificação dos tapered buffers.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
142
Do estudo das células TSPC resultou a teoria apresentada no capítulo dois, em suma, a estratégia
E-TSPC; do estudo dos tapered buffers resultaram as discussões apresentadas no capítulo três e o novo
critério de otimização. Vê-se, portanto, que esta tese originou-se do desenvolvimento e otimização de
circuitos Multiplexador e Demultiplexador.
Abaixo daremos detalhes do novo circuito de entrada conversor, das novas células empregadas e,
por fim, das modificações aplicadas ao Multiplexador e ao Demultiplexador.
4.2.2.1 Novo circuito conversor ECL-CMOS [Na98b]
A Figura 53 mostra o novo circuito conversor ECL-CMOS. A modificação mais significativa foi
feita no circuito de polarização. No circuito conversor propriamente dito foi introduzido apenas um
capacitor de acoplamento entre in e OSF, o capacitor CI com valor de 0,1pF (Figura 53(a)). A função
dele é fazer com que o sinal OSF siga a entrada mais rapidamente. No circuito de polarização, não é
mais utilizado o par diferencial para a realimentação mas sim inversores (Figura 53(b)). A tensão de
polarização VBiasI irá se ajustar de forma que o inversor formado por M'i3 e M'i4, transistores similares a
Mi3 e Mi4, esteja trabalhando em sua região de alto ganho, não dependendo dos valores assumidos
pelos parâmetros tecnológicos. Fazendo VREF=-1,22V, valor médio entre os níveis ECL alto e baixo,
teremos que o seguidor de fonte da entrada fornece o necessário deslocamento aos sinais para que os
inversores trabalhem como amplificadores. A capacitância CX é acrescentada para dar estabilidade ao
circuito de polarização (desloca os pólos para a esquerda).
in
V B iasI
M i1
M i2
M i3
M i4
T ap ered bu ffer
ou t
V D D
V S S
a ) b )
V R E F
V B iasI
M ’i1
M ’i2
M ’i3
M ’i4
C XV D D
V S S
C I
O S F
Figura 53. Circuito modificado conversor de alta velocidade ECL-CMOS (a) e seu circuito de
polarização (b).
4.2.2.2 Células com blocos N-MOS like
Das células originais, as que trabalhavam no limite da velocidade foram alteradas para os novos
circuitos. Basicamente as modificações ficaram restritas aos blocos p-latches e p-dinâmicos, sendo eles
substituídos por seus equivalentes N-MOS like. Os blocos p-latches substituídos são, sobretudo,

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
143
aqueles colocados na saída das células. Estes blocos, no geral, têm que trabalhar com capacitâncias de
carga maiores e são, em grande parte, responsáveis pelas limitações de velocidade.
Na Figura 54 estão apresentadas as novas células usadas na construção do Multiplexador e do
Demultiplexador. Os blocos hachurados, como antes, são aqueles que avaliam quando o clock tem
nível baixo.
e )
a )
D
C l C l
C l
D
C l
Q b
C l
Q b
C l
Q b
C l
C l
b )
D
C l
C l
C l
D
C l
Q b
C l
Q b
C l
Q b
C l
C l
c )
C l
C l
D
C l C l
C l C l
Q b
C l
C lD
C l
Q b
Q b
d )
C l
C l
D
C l C l
C l C l
Q b
C l
C lD
C l
Q b
Q b
D
C l C l
C l C l
C l
C l
C l
Q b
D
C lQ b
C l
C l C l
Q b
D
C l
C l
C l
C l
f )
D
C l
Q b
4 , 8
4 , 8
3 ,0
4 , 0
4 , 8
4 , 8
4 , 8
4 , 8
3 ,0
4 ,0
3 ,0
4 ,0
3 , 0
4 ,0
4 ,0
3 , 0
4 ,0
4 , 0
4 ,0
3 , 0 4 , 8
4 ,0
4 , 0
4 , 0
4 , 0
3 ,0
3 ,0
4 , 8
4 , 8 4 , 8
4 , 8
3 , 0
4 , 0
4 ,8
4 ,8
4 , 83 ,0
4 ,0
Figura 54. Novas células básicas que empregam blocos N-MOS like. Estão representados tanto o
diagrama de transistores como o símbolo de cada célula. Os blocos hachurados avaliam quando o
sinal de clock (Cl) é baixo; os outros blocos, quando o sinal de clock é alto. Todos os transistores
usados aqui têm comprimento de canal L=0,8µm. A largura de canal, para a maioria, é W=2,4µm;
para os transistores onde isso não é verdade, o valor da largura do canal, em µm, está indicado na
figura.
A descrição das células segue:
i. circuito D-flip-flop sensível à borda de subida: Figura 54(a), circuito com saída duplicada onde o
primeiro bloco foi modificado reduzindo a carga na entrada;
ii. circuito D-flip-flop sensível à borda de descida: Figura 54(b), circuito com saída duplicada onde
os últimos blocos foram modificados para aumentar a velocidade;

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
144
iii. circuitos D-flip-flops sensíveis à borda de subida, com atraso de meia fase: Figura 54(c), circuito
com saída duplicada e últimos blocos modificados; Figura 54(d), igual ao anterior mas com o
bloco de entrada também modificado; Figura 54(e), com apenas o último bloco modificado;
iv. circuito D-flip-flop sensível à borda de descida, com atraso de meia fase: Figura 54(f), onde o
bloco p-latch intermediário foi alterado.
Uma vez que as novas células usam blocos N-MOS like, é natural que tenham um consumo de
potência maior que as originais. Em vista disso, elas são aplicadas somente onde há necessidade. Por
outro lado, como pode ser visto na Figura 54, as dimensões dos transistores usados nestas células não
diferem muito daquelas dos transistores das originais. Isso faz com que as células modificadas e
originais tenham dimensões similares, tornando simples a substituição de umas pelas outras.
4.2.2.3 Novo Multiplexador 8:1
O novo Multiplexador tem a mesma arquitetura e princípio de funcionamento que a versão original,
como pode ser visto no seu diagrama esquemático, Figura 55. As mudanças feitas são de três tipos:
• uso do novo conversor ECL-CMOS;
• uso de novas células com blocos N-MOS like. Estas novas células, dado que têm um maior
consumo de potência, são empregadas apenas nos pontos críticos do Multiplexador;
• uso do novo critério, capítulo três, na otimização dos tapered buffers críticos usados com o sinal
de clock, buffer 1, buffer 2 e buffer 3 (Figura 55), e com o sinal multiplexado da saída (buffer 5).
m 6
m 5
m 4
m 3
m 2
m 1
n o v oC o n v e r s o r
E C L -C M O S
c lo c k
C o n v e r s o rC M O S - E C L
s a íd a d oM u l t ip le x a d o r
D a d o M
c lo c k /2c lo c k /4
b u f fe r 26 in v e r s o r e s
b u f fe r 11 in v e r s o r
s e le c tb u f fe r 4
2 in v e r s o r e s
b u f fe r 52 in v e r s o r e s
b u f fe r 34 in v e r s o r e s
b i t 0
b i t 1
b i t 2
b i t 3
b i t 4
b i t 5
b i t 6
b i t 7
b u f fe r s d ee n t r a d a
Figura 55. Diagrama esquemático do novo circuito Multiplexador 8:1.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
145
As células que foram alteradas aparecem hachuradas na figura (compare com Figura 48). Veremos
que estas três modificações permitiram uma melhora considerável na performance do Multiplexador.
4.2.2.4 Novo Demultiplexador 1:8
Da mesma forma que no Multiplexador, são aplicados neste circuito três tipos de mudanças, a saber,
o uso do novo conversor ECL-CMOS, o uso das células modificadas e, por fim, o uso do novo critério
para otimização dos tapered buffers utilizados na distribuição do sinal de clock e pelo sinal de dados
multiplexado (DadoM).
A arquitetura do Demultiplexador, embora mantendo as caraterísticas mais importantes, sofreu
várias alterações. A maior é feita no núcleo do circuito, Figura 56. Neste novo circuito, o registrador
de deslocamento inferior, que antes funcionava praticamente todo com a borda de descida do clock,
tem colocado, na sua entrada, um D-flip-flop sensível à borda de descida e com atraso de meia fase.
Ele executa a função que antes era feita pelo flip-flop Lsinc (Figura 49). Devido a este flip-flop na
entrada, todos os outros que o seguem são sensíveis à borda de subida. A causa desta alteração é
explicada: foi observado que os D-flip-flops sensíveis à borda de descida são os que maiores
problemas causaram para o funcionamento do circuito original. Desta forma, a melhora na
performance do circuito poderia ser conseguida ou com a troca deles por flip-flops modificados, ou
com a sua eliminação. Como as células modificadas aumentam o consumo de potência, a melhor
solução é a eliminação dos flip-flops sensíveis à borda de descida. Assim foi feito sempre que possível,
mantendo-se apenas aqueles flip-flops que não podem ser eliminados sem causar grandes alterações na
arquitetura do Demultiplexador. Na Figura 56, os D-flip-flops modificados/substituídos estão
hachurados (compare com Figura 49). Note que apenas uma célula com blocos N-MOS like foi usada
aí.
O circuito que gera sinais para alinhamento de byte sofreu uma pequena alteração, gerando um novo
sinal df1a, como pode ser visto na Figura 57. O bloco aí hachurado é o que foi modificado.
Os D-flip-flops sensíveis à borda de descida usados no circuito gerador do clock CA não puderam
ser eliminados. Foram, portanto, substituídos pelas versões modificadas que são mais velozes. A
Figura 58 mostra como ficou o novo circuito gerador de CA.
O circuito para gerar os sinais de seleção para os multiplexadores da saída, Figura 52, permaneceu
igual.
Junto com a modificação dos tapered buffers do sinal de clock e do sinal de dados, DadoM, foi
tomado o cuidado em manterem iguais os atrasos destes dois sinais.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
146
I1
D1
H1
C1
G1
B1
F1
A1
E1
S SB
clock/4CA
Registrador dedeslocamento
inferior
Registrador dedeslocamento
superior
fn1
fn2
F1
G1
H1
I1
E1
fp2
fp1 A1
B1
C1
D1
ConversorECL-CMOS
DadoM
ConversorECL-CMOS
clock
Taperedbuffer
Taperedbuffers
Din
clk1
clk2
clk29
bit0
bit1
bit2
bit3
bit4
bit5
bit6
bit7
Buffersde saída
Figura 56. Diagrama esquemático do núcleo do novo circuito Demultiplexador 1:8. Os blocos
hachurados são aqueles que foram alterados.
fn1
fp1
enable enable
fp2
fn2df1
df2
df1a
Figura 57. Modificações no circuito para gerar sinais para alinhamento de byte. Os blocos
hachurados são aqueles que foram alterados.
A Figura 59 mostra, de forma simplificada, a estrutura de tapered buffers usada na distribuição do
sinal de clock no Demultiplexador, na primeira e na nova versão. Há aí três níveis de tapered buffers: o
primeiro nível possui apenas um tapered buffer; o segundo, seis buffers; o terceiro, vinte e sete ou
vinte e nove buffers. A carga capacitiva para cada um dos sinais clki, Figuras 56 e 59, varia entre 88pF
a 140pF. Para determinação do fator de aumento dos buffers do novo multiplexador foi usada, como
entrada para os testes, uma seqüência de pulsos "0s" e "1s" e, como critério de análise da saída, a
verificação tanto dos níveis alcançados como da largura dos pulsos. Como resultado das análises, os
buffers foram implementados com fator de aumento de 1,4, em uma parte, e de 2, em outra. Estes

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
147
fatores garantem, dessa forma, a passagem de sinais rápidos e, também, a simetria entre os pulsos alto
e baixo.
Se1
Se0
CA
df1a
df2
Se0
Se1 Se1_i
Se0_i
Figura 58. Modificações no circuito gerador do clock CA. Os blocos hachurados são aqueles que
foram alterados.
clock
ckli
sinais para as célulasinternas do circuito
88pF<CL<140pF
Figura 59. Configuração dos tapered buffers para a distribuição do sinal de clock no
Demultiplexador 1:8.
O efeito da alteração do circuito de entrada, da melhora dos buffers de clock e dados, e da
equalização dos atrasos pode ser visto comparando as Figuras 60 e 61. Elas apresentam resultados de
simulação SPICE do circuito extraído a partir do layout; é usado o level 2 e parâmetros slow. São
mostrados nestas figuras os sinais
• Din: sinal de dados após passar pelo circuito de entrada (conversor ECL-CMOS) e pelo tapered
buffer (ver Figuras 49 e 56);

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
148
• clk1,2,..,27 e clk1,2,...29: sinais de clock após passarem pelo circuito de entrada (conversor ECL-
CMOS) e pelos tapered buffers (ver Figuras 49 e 56).
Na simulação é aplicada uma onda quadrada nos circuitos de entrada de dados e do clock, com as
seguintes características: freqüência de 625MHz, tempo de subida e descida de 0,2ns e níveis de tensão
de 4,0V a 3,2V (alimentação de 5V/0V).
O sinal de dados e o sinal de clock são aplicados em fase para melhor comparar os atrasos. Não é
esta, no entanto, a situação que deve ocorrer durante a operação do Demultiplexador (o dado deve ter
atraso de ¼ do período clock).
Na Figura 60 vemos que existem, na primeira versão do Demultiplexador, problemas de simetria no
clocks (não duty cycle) além de atrasos diferenciados entre estes e o sinal de dados. Os dois problemas
foram sensivelmente reduzidos na segunda implementação, como poder ser verificado pela Figura 61.
Antes de falarmos dos resultados experimentais, um último esclarecimento deve ser feito sobre as
novas implementações do Multiplexador e do Demultiplexador. As novas células, Figura 54, e o novo
conversor de entrada têm dimensões quase idênticas a dos circuitos originais; também os diagramas
esquemáticos, os das primeiras implementações e os das novas, são bastante similares. Isso permitiu
que o layout das novas implementações fosse feito a partir do layout das primeiras. Praticamente
houve apenas a substituição de algumas células. O posicionamento destas, tão bem como o roteamento
nos circuitos, permaneceu quase inalterado. Dessa forma, os ganhos em velocidade, conseguidos
nestes novos circuitos, devem pouco ou nada às melhoras de placement e de routing.
Din clk1,2,..,27
tempo (ns)
(V)
Figura 60. Sinal DadoM e clock, no primeiro Multiplexador fabricado, após passarem pelo circuito
conversor ECL-CMOS da entrada e tapered buffers (ver Figura 49). Os sinais na entrada têm
freqüência de 625MHz, tempo de subida/descida de 0,2ns e níveis de tensão de 4,0V/3,2V. Os
resultados são obtidos a partir de simulação SPICE, level 2 e parâmetros slow.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
149
Din
clk1,2,...,29
tempo (ns)
(V)
Figura 61. Sinal DadoM e clock, no novo Multiplexador, após passarem pelo circuito conversor
ECL-CMOS da entrada e tapered buffers (ver Figura 56). Os sinais na entrada têm freqüência de
625MHz, tempo de subida/descida de 0,2ns e níveis de tensão de 4,0V/3,2V. Os resultados são
obtidos a partir de simulação SPICE, level 2 e parâmetros slow.
4.2.3 Resultados Experimentais do Multiplexador 8:1 e do Demultiplexador 1:8
As novas versões do circuito Multiplexador 8:1 e do Demultiplexador 1:8 foram fabricadas na
tecnologia CMOS 0,8µm. Ambos os circuitos foram encapsulados em Quad Flat Packs (QFP) de 40
pinos. Na Figura 62 está o layout do circuito Multiplexador com seus PADs identificados. A Tabela 14
descreve a função dos sinais de cada um destes PADs. Na Figura 63, por sua vez, está o layout do
circuito Demultiplexador com seus PADs identificados. A Tabela 15 descreve a função dos sinais de
cada um destes PADs.
Duas características importantes na implementação destes dois circuitos são:
• vários PADs para alimentação do circuito (VDD e VSS) são empregados. Com isto procuramos
evitar que porções do circuito que geram maior ruído, tipicamente os circuitos de saída, causem
problemas nos circuitos digitais internos;
• toda a área livre do C.I. é aproveitada para a formação de capacitores de desacoplamento entre
o VDD e o VSS. Estes capacitores são formados com o polisilício e com as duas camadas de metal.
Capacitores internos desse tipo são ideais para desacoplamento por duas razões: primeiro porque
não apresentam resistências/indutâncias em série, como é o caso de qualquer capacitor externo;
segundo, que por serem internos, as indutâncias dos pinos do encapsulamento não interferem na
sua operação.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
150
Na Figura 62, podemos observar algumas linhas horizontais, logo abaixo dos PADs bit0 a bit7, que
parecem não ter função. Estas linhas servem para igualar a carga dos buffers de entrada (Figuras 48 e
55) e, em conseqüência, o atraso dos sinais de entrada (dados). Tal cuidado foi tomado em todas as
versões do Multiplexador.
bit0 bit1 bit2 bit3 bit4 bit5 bit6 bit7
VDD
VDD
VSSVSS
VSS
sw_selsw_sel
InTest
OuTest VH(ECL) DadoM selextVL(ECL) clock VREF
equalizaçãode atrasos
Figura 62. Layout do novo circuito Multiplexador 8:1. As dimensões deste circuito (incluindo os
PADs) são 1,68mm por 0,94 mm.
Tabela 14. PADs de entrada/saída do novo circuito Multiplexador 8:1 e sua descrição.
PADs de entrada/saída
Descrição
VSS terra do circuito (são três terras ao todo) VDD alimentação de 5V (duas entradas)
DadoM sinal multiplexado na saída sw_sel sinal para seleção de sincronismo (interno ou externo) selext sinal externo para sincronizar dados e clock. Este sinal é composto com
sw_sel para gerar o sinal select da Figura 48 clock sinal de clock do circuito
bit7-bit0 sinais de entrada para serem multiplexados VREF sinal de referência para ajuste da polarização do circuito conversor
ECL-CMOS (Figura 53(b)) VL(ECL) nível baixo ECL para ajuste da polarização do conversor CMOS-ECL
(Figura 46(b)) VH(ECL) nível alto ECL para ajuste da polarização do conversor CMOS-ECL
(Figura 46(b)) InTest, OuTest PADs para testes dos conversores de níveis ECL-CMOS e CMOS-ECL

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
151
VDD VSS bit7 bit6 bit5 bit4 bit3 bit2 bit1 bit0
VSS
VSS
VSS
VSS
VDD
VDD VDD
VDD
VDD
clockDadoM enable VREF
Figura 63. Layout do novo circuito Demultiplexador 1:8. As dimensões deste circuito (incluindo os
PADs) são 1,90mm por 1,08mm.
Tabela 15. PADs de entrada/saída do novo circuito Demultiplexador 1:8 e sua descrição.
PADs de entrada/saída
Descrição
VSS terra do circuito (são cinco terras ao todo) VDD alimentação de 5V (cinco entradas)
DadoM sinal de entrada para ser demultiplexado enable sinal de habilitação para o byte alignment (Figura 57) clock sinal de clock do circuito
bit7-bit0 sinais demultiplexados na saída VREF sinal de referência para ajuste da polarização do circuito conversor
ECL-CMOS (Figura 53(b))
Na Figura 64 estão apresentadas as fotografias dos dois novos circuitos, Multiplexador e
Demultiplexador, fabricados. O C.I. Multiplexador tem dimensões de 1,68mm X 0,94mm; o C.I.
Demultiplexador, dimensões de 1,90mm X 1,08mm.
Devido à importância dos circuitos conversores da entrada e da saída, foi colocado junto ao circuito
Multiplexador uma estrutura que permite a avaliação destes conversores. A estrutura é composta do
PAD InTest, Figura 62, de um conversor ECL-CMOS, ligado a este PAD, de um conversor CMOS-
ECL, que por sua vez tem sua entrada ligada a saída do conversor anterior, e do PAD OuTest que
recebe o sinal do conversor CMOS-ECL. Podemos, dessa forma, verificar a performance dos
conversores injetando no C.I. um sinal, pelo PAD InTest, e recuperando-o no PAD OuTest. A
comparação entre a entrada e a saída mostrará como eles estão funcionando.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
152
a)
b) Figura 64. Fotografias dos C.I.s fabricados (nova versão). Em (a) está o circuito Multiplexador 8:1 e
em (b), o circuito Demultiplexador 1:8.
Para o teste dos C.I.s encapsulados foi necessário o desenvolvimento de placas de PCB (Printed
Circuit Board). Usaram-se inicialmente placas de vibra de vidro, FR4, com 1,5mm de espessura e duas
camadas de metal. Para as linhas que transportam sinais de alta freqüência, por exemplo o sinal de
clock, foram usadas microlinhas com impedância característica de 50Ω ([Si96], [Jo93]), que é obtida
com o uso de trilhas de 2,8mm de largura. Tais trilhas, por serem muito largas, dificultaram bastante o
projeto destas placas.
Uma segunda placa foi desenvolvida com uma tecnologia que permitia quatro camadas de metal.
Neste caso, a primeira camada e a segunda ou a terceira camada e a quarta são isoladas por 0,4mm de
FR4. Com este valor de espessura de isolante, microlinhas com impedância característica de 50Ω são
construídas com trilhas de largura de apenas 0,7mm. O aumento no número de camadas de metal e a

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
153
redução da largura das trilhas simplificou bastante o projeto. Diferente das placas de duas camadas,
que foram confeccionada em nosso laboratório, as placas de quatro camadas foram fabricadas por uma
empresa especializada, elevando bastante seu custo. Os resultados experimentais, por outro lado,
mostraram que as duas soluções apresentam efeitos semelhantes.
Observemos que os C.I.s foram alimentados com 5V/0V durante os testes e, portanto, os valores
ECL nas entradas e saídas foram deslocados para 4,1V, para o nível alto, e 3,2V, para o nível baixo.
Estes níveis são os que deveriam ter sido aplicados nos testes mas, como pode ser visto nas figuras
abaixo, foram empregados, na realidade, valores inferiores. Duas são as razões para isto:
• o gerador de sinais usado tem como limite de valor na saída 4V (HP Pulse Generator 8133A);
• para o casamento de impedância foram usados resistores SMD (surface monted devices) de
47Ω, valores encontrados comercialmente, em vez de 50Ω. Isso fez com que as tensões na entrada
do C.I. fossem inferiores às fornecidas pelo gerador.
Resultou disso, para o circuito conversor de entrada, um comportamento inferior ao projetado.
4.2.3.1 Testes dos conversores ECL-CMOS e CMOS-ECL
Para avaliar o funcionamento destes dois circuitos foi aplicado um sinal no conversor de entrada e
observada a saída do conversor de saída. Duas classes de medidas foram feitas: determinação da
máxima velocidade em que os circuitos operavam (Figura 65); verificação, através de diagramas de
olho, do ruído/jitter introduzido pelo conversores (Figura 66).
Figura 65. Resultado do teste nos conversores ECL-CMOS e CMOS-ECL. É mostrado o sinal na entrada do
PAD InTest, INPUT, que está a taxa de 2,4Gbit/s, e no PAD OuTest, OUTPUT. Os sinais INPUT e OUTPUT
são invertidos. A seqüência que aparece na figura, sinal de entrada, é "1111010000000100101010".

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
154
Na Figura 65 é mostrado que os conversores de entrada/saída ainda operam com sinais a taxas de
2,4Gbit/s. Os sinais da figura são observados com osciloscópio Tektronix, modelo 11801B Digital
Sampling.
Na Figura 66 são apresentados os diagramas de olho em várias taxas de operação para avaliação dos
circuitos conversores. Vemos que para a taxa de 622,1Mbit/s (taxa de transmissão para STS12/STM4
[St92]) o sinal de saída quase não apresenta jitter; isso já não é verdade para a taxa de 1244,2Mbit/s
(ST24/STM8), e menos ainda para 1,6Gbit/s.
a) b)
c) Figura 66. Diagrama de olho para avaliação dos conversores ECL-CMOS e CMOS-ECL. O sinal de
entrada é Pseudo-Randon-Bit-Sequence 223-1 (HP Pulse Generator 8133A). Em (a) o sinal aplicado
tem taxa de 622,1Mbit/s(STS12/STM4 [St92]) em (b), taxa de 1244,12Mbit/s (STS24/STM8 [St92])
e em (c), taxa de 1,6Gbit/s.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
155
Contribui também para aumento do ruído/jitter a própria placa. O diagrama de olho do sinal na
entrada do C.I., vindo do gerador de sinais, está apresentado na Figura 67. Nota-se que existem várias
reflexões que deformam o sinal na entrada.
a) b) Figura 67. Diagrama de olho do sinal na entrada do C.I.: (a) para o sinal com taxa de 1244,1Mbit/s e
(b), para o sinal a 1,6Gbit/s. O sinal é Pseudo-Randon-Bit-Sequence 223-1.
4.2.3.2 Testes do Circuito Multiplexador 8:1
O circuito Multiplexador operou corretamente até a taxa de 1,7Gbit/s (sinal na saída). Na Figura 68
são apresentados o sinal de clock e o sinal de saída, "01100101", do circuito operando nessa taxa. Para
cada borda do sinal de clock um novo dado é colocado na saída uma vez que as duas bordas são
utilizadas na operação.
Os principais resultados obtidos com este circuito estão resumidos na Tabela 16, junto com os
dados referentes a primeira implementação do circuito. As diferenças entre os dois projetos são
indicadas na última coluna. Comparando os resultados, vemos que tanto a área como a potência
consumida são praticamente iguais. Por outro lado, o novo circuito teve um aumento de quase 70% na
velocidade, mostrando a importância das técnicas aplicadas.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
156
Figura 68. Sinal de clock e da saída do Multiplexador 8:1 funcionando a taxa de 1,7Gbit/s. O sinal
de saída é "01100101". A posição relativa no tempo, entre o clock e o sinal de saída, foi ajustada para
facilitar a visualização.
Tabela 16. Resultados experimentais da primeira versão do circuito Multiplexador 8:1 e de sua nova
implementação. Também são apresentadas as diferenças entre eles.
Circuito Área (apenas o núcleo do
Multiplexador) (103µm2)
Consumo de potência
(VDD=5V) (µW/Mbit/s)
Tecnologia Máxima taxa de
operação (Gbit/s)
Diferenças entre as duas implementações
primeira versão
60,0 41,85 0,8µm CMOS (ES2/ATMEL)
1,05 • conversor ECL-CMOS da Figura 45; • apenas flip-flops da Figura 47.
nova versão
70,0 51,6 0,8µm CMOS (ES2/ATMEL)
1,7 • uso de novo conversor ECL-CMOS (Figura 53);
• uso de novos flip-flops com blocos N-MOS like (Figura 54).
• otimização para máxima taxa de vários buffers do circuito (Figura 55).
Dados tecnológicos e resultados experimentais de implementações de Multiplexadores CMOS
recentemente publicados, junto com os resultados aqui obtidos, são apresentados na Tabela 17. Devido
às diferenças entre as tecnologias, principalmente entre aquela usada aqui e aquelas usadas nas outras
implementações, não é razoável a comparação direta dos resultados. Podemos, no entanto, usar a teoria
de escalonamento para estimar, ao menos em primeira ordem, os resultados que seriam obtidos com
nosso circuito em uma tecnologia mas avançada. Consideremos o Constant-Field Scaling [Mu86].
Para um fator de escala K temos que:
• as dimensões de superfície escalarão por 1/K;
• as tensões escalarão por 1/K;

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
157
• os atrasos do circuito escalarão por 1/K;
• a dissipação de potência escalará por 1/K2.
Na última linha da Tabela 17 são mostrados os resultados do escalonamento aplicado ao nosso
Multiplexador, para um fator K=2,5. Vemos que o "circuito" assim obtido tem desempenho bastante
superior as outras implementações tanto na potência consumida como na velocidade.
Naturalmente esta análise, via teoria de escalonamento, serve apenas como indicativo do que pode
acontecer. Por outro lado, o aumento da velocidade do circuito causa o aparecimento de uma série de
dificuldades, principalmente devido ao ruído e a propagação de sinais, que não foram nela
consideradas.
Tabela 17. Tecnologia, potência consumida e máxima taxa de operação de diversas implementações
de Multiplexadores.
Multiplexador Tecnologia (µm)
Alimentação(V)
Potência consumida
(µW/Mbit/s)
Máxima taxa de operação
(Gbit/s) [Ku96]5 (8:1) 0,15 (CMOS) 2,0 39,3 3,0 [Oh97] (16:2) 0,25
(CMOS/SIMOX) 2,0 68,0 (≈ 34,0 para
8:1) 2,5
este trabalho (nova versão) (8:1)
0,8 (CMOS; 0,7 efetivo)
5,0 42,6 1,7
este trabalho escalon. (constant-field scaling)
0,32 (CMOS; 0,28 efetivo)
2,0 6,8 4,25
4.2.3.3 Testes do Circuito Demultiplexador 1:8
O circuito Demultiplexador, por sua vez, operou corretamente até taxas de 1,38Gbit/s (velocidade
do sinal de entrada). Está máxima taxa é conseguida com alimentação VDD=4,7V e não com VDD=5V.
Para entender a razão disso devemos lembrar que, devido à limitação do gerador e aos resistores de
casamento de 47Ω usados, os valores ECL na entrada do C.I. são inferiores aos esperados. O circuito
conversor de entrada é bastante sensível a essa redução, principalmente o seguidor de fonte (Figura
53). Nele o transistor Mi1 trabalha com uma tensão gate-fonte pequena e que fica menor quando as
tensões de entrada são diminuídas, dificultando sua operação. Com a redução do valor de VDD, é
aumentado o deslocamento de nível necessário entre in e OSF (Figura 53), o que compensa a redução
dos níveis ECL da entrada. Dessa forma, o circuito funciona melhor com um valor de VDD menor.
Na Figura 69 estão mostrados o sinal de clock e o sinal de dados multiplexado, observados na
entrada do C.I., com o sinal DadoM a taxa de 1,38Gbit/s. Na figura são ainda indicados, com linhas
5 Este trabalho foi também apresentado no ISSCC de 1996, p.122-124.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
158
horizontais, os níveis de tensão 3,8V e 2,74V, mostrando que os sinais ECL de entradas estão longe de
atingir os valores que esperamos deles (4,1V e 3,2V). O valor de 3,3V foi usado para VREF no circuito
de polarização do conversor de entrada (Figura 53) neste caso.
É importante ter em mente que o Demultiplexador é mais sensível as entradas de alta velocidade, o
dado multiplexado e o clock, que o Multiplexador onde os dados de entrada são "lentos". Em vista
disso, acreditamos que os problemas com os níveis de entrada são, em boa parte, responsáveis pela
velocidade final alcançada neste Demultiplexador.
Os principais resultados obtidos com esta implementação estão resumidos na Tabela 18, junto com
os dados referentes a primeira implementação. Também são indicadas as diferenças entre elas. As
potências indicadas nessa tabela levam em consideração os buffers do dado e do clock. Comparando os
resultados vemos que o novo circuito é melhor que o anterior em todos os aspectos. Em particular, a
área foi reduzida em razão dos novos buffers usarem fator de ganho menor. O aumento da velocidade é
de 29%.
3,8V
2,74V
Figura 69. Sinal de dados, DADO, e sinal de clock nas entradas do circuito Demultiplexador 1:8
(versão nova). O sinal de dados tem valor "101011" e taxa de 1,38Gbit/s.
Dados tecnológicos e resultados experimentais de implementações de Demultiplexadores CMOS
recentemente publicados, junto com os resultados aqui obtidos, são apresentados na Tabela 19. Ainda,
a última linha da tabela apresenta estimativas de primeira ordem, usando teoria de escalonamento
(Constant-Field Scaling), dos resultados que seriam obtidos com uma tecnologia mais avançada. O
fator de escala usado é K=2,35.
Tabela 18. Resultados experimentais da primeira versão do circuito Demultiplexador 1:8 e de sua
nova implementação. Também são apresentadas as diferenças entre eles.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
159
Circuito Área (apenas o núcleo do
Demultiplexador) (103µm2)
Consumo de potência
(µW/Mbit/s)
Tecnologia Máxima taxa de
operação (Gbit/s)
Diferenças entre as duas implementações
primeira versão
602,0 395 (VDD=5V)
0,8µm CMOS (ES2/ATMEL)
1,06 • conversor ECL-CMOS da Figura 45;
• apenas flip-flops da Figura 47. Nova
versão 563,0 253
(VDD=4,7V) 0,8µm CMOS
(ES2/ATMEL)1,38 • uso de novo conversor ECL-CMOS
(Figura 53); • uso de novos flip-flops com blocos
N-MOS like (Figura 54); • otimização para máxima taxa de
vários buffers do circuito; • substituição de flip-flops sensíveis
à borda de descida por flip-flops sensíveis à borda de subida (Figura 56).
Os resultados previstos pelo escalonamento para nosso Demultiplexador são bastante favoráveis: é
ele que apresenta maior velocidade e, no que toca a potência, perde para o circuito em [Oh97],
fabricado com tecnologia SOI. Lembremos, por outro lado, que nosso circuito faz também a detecção
do byte alignment, e que boa parte dos D-flip-flops operando em alta freqüência estão presentes devido
a esta característica.
Tabela 19. Tecnologia, potência consumida e máxima taxa de operação de diversas implementações
de Demultiplexadores.
Demultiplexador Tecnologia (µm)
Alimentação (V)
Potência consumida
(µW/Mbit/s)
Máxima taxa de operação
(Gbit/s) [Tan96] (1:8) 0,35 (CMOS, 0,15
efetivo) 2,0 71,43 2,8
[Oh97] (2:16) 0,25 (CMOS/SIMOX)
2,0 43 (≈ 21,5 para 1:8)
2,5
este trabalho (nova versão) (1:8)
0,8 (CMOS; 0,7 efetivo)
4,7 253 1,38
este trabalho escalon. (constant-field scaling)
0,34 (CMOS; 0,30 efetivo)
2,0 45,8 3,22
4.2.4 Multiplexador e Demultiplexador: conclusões
O estudo, a implementação e os testes dos circuitos Multiplexador 8:1 e Demultiplexador 1:8
mostraram que a aplicação do E-TSPC, mais especificamente os blocos N-MOS like, e do novo critério
de otimização de tapered buffers trazem melhoras consideráveis. Em termos de velocidade de
operação, que tem sido a nossa maior preocupação, obtivemos ganhos de 62% no Multiplexador e 29%
no Demultiplexador, quando comparamos implementações onde tais técnicas foram ou não aplicadas.
Em termos de área e potência as variações são pequenas.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
160
Ainda, a análise das várias implementações de Multiplexadores e Demultiplexadores que aparecem
na literatura recente mostra que os resultados obtidos por nós são bastante bons: em termos de
velocidade os circuitos são superiores e em termos de potência, no mínimo, comparáveis.
4.3 Circuito Dual-Modulus Prescaler
Dual-Modulus Prescalers são, a grosso modo, divisores de freqüência programáveis. Um sinal de
controle seleciona se o sinal de entrada é dividido por ND ou por (ND+1). Estes circuitos, junto com
PLLs (phase-locked loop) são utilizados em sintetizadores de freqüência RF (Radio Frequency),
sobretudo, em telefonia celular ([Co88], [Fo95], [Ch96], [Cr96], [Hu96], [La96] e [Le97]).
C o m p a ra d o rd e fa se
L o o p F ilte rO scila d o r
co n tro la d o p o rten sã o (V .C .O .)
P resca ler/N D
/N D + 1
C o n tro la d o rd o m o d o
fo u t
Dm
F inF o u t
fre f
fd iv
S e leção (d iv id e p o rN D o u p o r N D + 1 )
Figura 70. Diagrama de blocos de sintetizador de freqüência RF empregando PLL e Prescaler.
Na Figura 70 está o diagrama de blocos de um sintetizador de freqüência RF que emprega PLL e
Prescaler. No diagrama o Prescaler tem seu modo de divisão dado pelo sinal Seleção: quando
Seleção="0" a freqüência do sinal Fout (do Prescaler) é igual a do sinal Fin dividida por ND; quando
Seleção="1" a freqüência do Fout é igual a do Fin dividida por (ND+1). A função do controlador de
modo é, para uma entrada D, gerar na saída um sinal que tem valor "1" durante D/2m do tempo e "0"
no restante. Em vista disso a freqüência média do sinal fdiv será dada por
ff
N Ddivout
D m
=+ 2
onde fdiv é a freqüência média do sinal fdiv;
fout é a freqüência do sinal fout, saída do sintetizador;
D é a entrada digital com valor entre 0 e (2m-1);
m é um número inteiro.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
161
O comparador de fase e o Loop Filter irão ajustar o V.C.O. (voltage-controlled oscillator) até que
fdiv se torne igual a freqüência do sinal fref. Como conseqüência, a freqüência na saída fout do
sintetizador terá valor
( )f N D fout D m ref= + 2
onde fref é a freqüência do sinal fref.
Conseguimos assim, através da entrada digital D, sintetizar 2m freqüências, desde NDfref, para D=0,
até N fD
m
m ref+−
2 12
, para D=(2m-1). Repare que apenas o V.C.O. e o Prescaler trabalham com
freqüências iguais à do sinal de saída. Os outros blocos trabalham com sinais bem mais lentos. Esta
característica torna a configuração da Figura 70 atraente para geração de sinais RF.
Não obstante a importância dos circuitos Prescalers, este não foi o principal motivo para a sua
implementação neste trabalho. Estes mesmos circuitos têm sido utilizados em várias implementações
de testes tanto de circuitos TSPC, ([Ch96], [Hu96]), como de outras técnicas ([Co88], [Fo95] [Cr96],
[La96], [Le97]). Portanto podemos, através da implementação do Prescaler com o emprego da
estratégia E-TSPC, comparar os resultados conseguidos com os de outros trabalhos, e melhor avaliar o
E-TSPC.
4.3.1 Circuito Dual-Modulus Prescaler (divide por 128/129)
O Prescaler que estudamos e implementamos faz a divisão por 128 ou 129 conforme o valor do
sinal de seleção de modo [Na99]. Seu diagrama esquemático está apresentado na Figura 71. Neste
circuito podemos distinguir duas porções: a porção hachurada compõe um contador síncrono que conta
até 4 ou 5, dependendo do valor do sinal div32; os outros D-flip-flops compõe um contador assíncrono
que conta até 32. O contador 4/5 gera o clock do primeiro D-flip-flop do contador assíncrono.
O sinal SM seleciona se o Prescaler irá dividir o sinal clock por 128 ou 129. Assim quando SM="0",
não será possível que o contador assíncrono modifique o sinal div32 e o contador 4/5 contará sempre
até 4. Resulta que a saída do Prescaler terá freqüência igual a do sinal clock dividida por 128. Por
outro lado, se SM="1", o valor do sinal div32 dependerá do estado do contador assíncrono. Como
conseqüência, a cada 32 ciclos o contador 4/5 contará 31 vezes até 4 e uma vez até 5. A saída do
Prescaler terá agora a freqüência do sinal de clock dividida por 129.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
162
D-FF
Q
D Q D-FF
Q
D Q D-FF
Q
D Q D-FF
Q
D Q D-FF
Q
D Q
D-FFD Q D-FF
D Q D-FFD Q
SM
div32
clock
saída128/129
Divide por 4/5 (contador)
Figura 71. Diagrama esquemático do Dual-Modulus Prescaler (divide por 128/129).
No circuito do Prescaler, apenas os blocos que compõe o contador 4/5, que recebem como clock o
próprio sinal a ser dividido, trabalham com a velocidade máxima. Os outros blocos recebem sinais
mais lentos. Em vista disto, o contador síncrono constitui-se no elemento crítico para o desempenho
em termos de velocidade.
4.3.2 Estudo preliminar dos contadores síncronos
Num estudo preliminar do Prescaler, tratamos de implementar o contador síncrono com estratégias
diferentes para compararmos os resultados. Quatro diferentes layouts foram projetados e desenhados
com a tecnologia 0,8µm CMOS; seus circuitos foram extraídos e então simulados no SPICE. Os
contadores síncronos projetados são enumerados e descritos abaixo:
DG1: projetado utilizando D-flip-flops convencionais sensíveis à borda de subida do clock;
DG2: projetado utilizando D-flip-flops sensíveis à borda de subida e otimizado através da aplicação
da estratégia E-TSPC;
DG3: projetado utilizando D-flip-flops sensíveis à borda de descida modificados conforme
apresentado em [Ch96];
DG4: projetado utilizando D-flip-flops sensíveis à borda de descida e otimizado através da aplicação
da estratégia E-TSPC.
A Figura 72 apresenta o diagrama de transistores e o layout para estes quatro projetos.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
163
c l k
d i v 3 2
c l o c k p a r a oc o n t a d o r
a s s í n c r o n o
4 , 0 4 , 0 4 , 0
4 , 0
4 , 0 4 , 04 , 0 2 , 4
C 1 C 2a )
c l k
2 , 42 , 4
c l k
2 , 42 , 4
c l k
2 , 42 , 4
c l k
2 , 4
2 , 4 2 , 4
2 , 4 2 , 4
2 , 4
4 , 8
2 , 4 2 , 4 2 , 4
2 , 4 2 , 4 2 , 4
c l k c l kc l k
c l k c l k
c l k
c l k
2 , 4
2 , 4 2 , 4
2 , 4
4 , 8
4 , 8
2 , 4
2 , 4
2 , 4
2 , 4
2 , 4
2 , 4
c l k
c l k
4 , 8
D G 1
c l k
d i v 3 2c l o c k p a r a o
c o n t a d o ra s s í n c r o n o
3 , 0
4 , 0 4 , 0 4 , 04 , 0
C 1 C 2
b )
c l k
2 , 43 , 0
c l k
2 , 43 , 8
c l k
2 , 4
c l k
2 , 4
2 , 4
2 , 4 2 , 4
2 , 4
4 , 8
2 , 4 2 , 4
4 , 0 2 , 4 2 , 4
c l k c l kc l k
c l k c l k
c l k
c l k
2 , 4
2 , 4 2 , 4
2 , 4
4 , 8
4 , 8
2 , 4
2 , 4
2 , 4
2 , 4
c l k
c l k
4 , 85 , 7
3 , 1
D G 2
c lk
d iv 3 2c lo c k p a ra o
c o n ta d o ra s s ín c ro n o
4 ,0 4 ,0 4 ,0
4 ,0
4 ,0 4 ,04 ,0
2 ,4
C 1 C 2
c )
c lk
3 ,02 ,4
c lk
3 ,02 ,4
c lk
2 ,42 ,4
c lk
3 ,0
2 ,44 ,0 4 ,0
3 ,0
2 ,4
2 ,4
4 ,0 4 ,0
c lk
c lk c lk
c lk
4 ,0 4 ,0
3 ,0
3 ,0
2 ,4
2 ,4
4 ,0 4 ,0
c lk
c lk3 ,0
D G 3
c l k c l k
c l k
c l k c l k
c l k
c l k c l k
c l k
d i v 3 2c l k
c l k
c l o c k p a r a oc o n t a d o r
a s s í n c r o n o
8 , 5 8 , 5 3 , 0 3 , 0 5 , 0 3 , 0 3 , 0 3 , 0 3 , 08 , 0 8 , 04 , 0
3 , 0 3 , 0
2 , 4 / 1 , 1 4 , 0 4 , 0 4 , 0 4 , 0
4 , 0 4 , 0
4 , 0 4 , 04 , 0 4 , 02 , 4 2 , 4 / 1 , 1 2 , 4 / 1 , 1
C 1 C 2d )
D G 4
Figura 72. Diagrama de transistores e layout dos quatro projetos do contador síncrono 4/5: em (a) está o projeto DG1; em (b), DG2; em (c), DG3; em (d), DG4. Na representação de transistores também estão indicados a largura e, quando diferente de 0,8µm, o comprimento do canal de cada transistor (largura/comprimento). No layout, a moldura em torno do circuito tem dimensões de 100µm X 70µm (praticamente as dimensões de DG1), para os quatro casos.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
164
Algumas observações acerca dos quatro projetos devem ser feitas para melhor compreensão das
comparações exibidas:
i. em todos os projetos foram usados transistores com pequenas dimensões, normalmente as
mínimas permitidas pela tecnologia;
ii. o diagrama esquemático da Figura 71 é alterado em cada uma das implementações visando ao
melhor aproveitamento de suas características. Apenas em DG1 é seguido o diagrama original;
iii. a porta lógica NOR, Figura 71, é implementada de forma semelhante a uma porta N-MOS, mas
com um transistor P como carga. A porta assim construída é mais veloz que uma porta estática
complementar CMOS. Esta configuração para o NOR aparece em DG1, DG3 e DG4;
iv. os blocos C1 e C2, Figura 72, geram o sinal de clock para o primeiro D-flip-flop do contador
assíncrono. Com esta configuração, as cargas ligadas a estes sinais de clock não interferem na
velocidade dos contadores. Ela foi usada nos quatro projetos.
Através dos layouts mostrados, podemos verificar que a área ocupada por cada um dos circuitos é
bastante próxima. A Tabela 20, por sua vez, mostra os resultados de velocidade e potência consumida,
para os diferentes projetos do contador 4/5. Estes dados foram obtidos a partir de simulações dos
netlists extraídos dos layouts (SPICE, parâmetros slow).
Tabela 20. Resultados de máxima velocidade e potência consumida para os quatro contadores
síncronos 4/5 projetados (simulação SPICE com parâmetros slow).
Projeto Velocidade (GHz) Potência consumida (µW/MHz)
DG1 0.98 3.27
DG2 1.28 4.45
DG3 1.39 4.85
DG4 1.67 5.62
Comparando os resultados vemos as vantagens do E-TSPC. Um aumento superior a 70% na
velocidade é conseguido do projeto DG1 para o DG4, e da ordem de 20% do DG3 para o DG4. Por outro
lado, a potência consumida aumenta 72% do DG1 para o DG4. Como o circuito DG4 utiliza apenas
blocos N-MOS like, este aumento não é surpreendente e confirma que tais blocos devem ser usados
apenas nas partes críticas das implementações. Desde que as regras de composição favorecem as trocas
entre os blocos convencionais e os blocos N-MOS like, os circuitos E-TSPC podem alcançar altas
velocidades mantendo o consumo de potência tão baixo quanto possível para o objetivo desejado.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
165
4.3.3 Resultados Experimentais do Dual-Modulus Prescaler
O Dual-Modulus Prescaler (divide por 128/129) completo foi implementado utilizando a
configuração de DG4. No contador assíncrono foram usados D-flip-flops convencionais TSPC (capítulo
dois) sensíveis à borda de subida. As dimensões usadas para estes blocos são iguais àquelas usadas
pelos D-flip-flops do projeto DG1, Figura 70(a). A área total ocupada pelo Prescaler é de 0,0126 mm2.
Uma alteração ainda foi acrescentada ao circuito: o sinal de clock gerado pelo contador síncrono é
invertido antes de ser ligado ao contador módulo 32. Este expediente permite maior tempo para a
preparação do sinal div32.
As simulações do circuito completo mostraram que ele deveria atingir freqüências de operação
superiores a 1,5GHz. Ainda, verificamos que o buffer para o clock (sinal de entrada de alta freqüência)
é um dos limitadores da velocidade final do circuito.
O C.I. foi projetado para testes com técnicas de chip-on-bord, pois, se fosse encapsulado, as
indutâncias e capacitâncias parasitas, associadas ao pino do sinal de clock, impossibilitariam que o
Prescaler alcançasse as velocidades previstas ([Ki93], [Ve95], [Li98]). Foram colocados no mesmo
C.I. três versões do Prescaler (Figura 73(a)): duas versões para serem testadas em alta freqüência e
que diferem no buffer do clock (implementação 1 e implementação 2, Figura 73(a)) e uma para ser
encapsulada para testes preliminares de baixa freqüência (implementação 3).
Foram utilizados, para a fabricação do C.I., os serviços do Circuits Multi-Projects (CMP) francês
que, para a tecnologia empregada, cobra, no mínimo, 2mm2 de área. Como as três implementações
juntas ocupam uma área pequena, grande parte do C.I. foi utilizada para a colocação de capacitores de
desacoplamento entre VDD e VSS que reduzem o ruído interno. As dimensões totais do C.I. são de
aproximadamente 1,6mm X 1,3 mm.
Para os testes aqui foi confeccionada uma placa em alumina e o C.I., colado sobre ela. Com exceção
do PAD de clock, e seus dois PADs de terra (Figura 73(b)), todos os outros, que não recebem sinais de
alta velocidade, são ligados diretamente a placa. Na Figura 73(a) estão mostrados os fios que ligam os
PADs do circuito a placa. O sinal de clock é injetado no C.I. por meio de ponta de prova RF coplanar
do tipo GSG, ground-signal-ground, com impedância característica de 50Ω. O resistor para casamento
de impedância é construído interno ao chip por meio da camada de difusão (dois resistores de 100Ω,
ver Figura 73(b)). Como o sinal de clock não passa por nenhum conversor de nível, deve, quando
possível, ter os mesmos níveis de tensão usados na lógica interna do C.I..

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
166
Implementação 1
Implemetação 2
Implementação 3
a)
output128/129
clockGnd Gnd
VSS
SM
VDD
VDD
b)
resistor de 100Ω resistor de 100Ω
Figura 73. Fotografia do C.I. fabricado. Em (a) aparece o C.I. completo, com três diferentes
Prescalers; também são mostradas as conexões do C.I. com placa de teste. Em (b), estão detalhes do
Prescaler que foi testado em alta freqüência (implementação 1).
Devido às dificuldades para execução dos testes (necessidade de confecção de placas) apenas a
implementação mais promissora, de acordo com as simulações, foi testada em alta freqüência. A
Figura 73(b) mostra em detalhes o circuito testado e a Tabela 21 dá a descrição de cada um de seus
PADs.
Tabela 21. PADs de entrada/saída do Prescaler testado e sua descrição (Figura 73(b)).
PADs de entrada/saída Descrição
clock sinal de alta freqüência para ser dividido pelo Prescaler
output 128/129 sinal de saída resultante da divisão do sinal de clock
SM sinal que determina se o circuito divide por 128 ou 129
VDD Alimentação do circuito (5V). São duas entradas de VDD, uma para o
Prescaler propriamente dito, e outra para o buffer do clock
VSS sinal de terra para o circuito Prescaler
Gnd terra para ponta de prova coplanar usada no sinal de clock
Na Figura 74 estão apresentadas a máxima freqüência de operação e a corrente consumida no
Prescaler como função da tensão VDD, medidas experimentalmente. Uma vez que o gerador de sinais
usado tem sua excursão de saída limitada a 3V (HP Pulse Generator 8133A), acreditamos que o
Prescaler funcione em velocidades um pouco superiores àquelas encontradas quando VDD é maior que
3V (veja linha tracejada na curva de máxima freqüência de operação, Figura 74).

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
167
2 2.5 3 3.5 4 4.5 50.4
0.6
0.8
1
1.2
1.4
1.6
VDD (V)
Máximafreqüência
deoperação
(GHz)
0
0.5
1
1.5
2
2.5
3
Correnteconsumidana máximafreqüência
(mA)
Figura 74. Resultados experimentais do Prescaler. A curva (*), eixo à esquerda, fornece a máxima
freqüência de operação em função da tensão de alimentação (VDD); a curva (o), eixo à direita, fornece
a corrente consumida na freqüência máxima.
Resultados de performance de nossa implementação, de três outras implementações recentemente
publicadas e que usam D-flip-flops TSPC e de uma nova arquitetura para Prescalers são sumariados na
Tabela 22. Em [Hu96], o Prescaler foi construído com D-flip-flops TSPC sensíveis à borda de subida e
que foram otimizados para atingir máxima velocidade; em conseqüência, tanto a velocidade como a
potência consumida são elevadas. D-flip-flops TSPC sensíveis à borda de descida com transistores de
pequenas dimensões e com alguns blocos N-MOS like foram empregados em [Ch96]. O circuito
resultante tem pequena área, baixo consumo de potência mas a máxima freqüência de operação não é
das maiores. No Prescaler proposto em [Ya98], um novo D-flip-flop TSPC sensível à borda de subida
é utilizado, resultando em alta velocidade e elevado consumo de potência (o que sugere o uso de
transistores grandes). Uma arquitetura alternativa é proposta e aplicada em [Cr96]; D-flip-flops
diferenciais substituem os TSPC nos pontos críticos. O resultado é uma altíssima velocidade e baixa
potência. Nossa implementação, com a estratégia E-TSPC e transistores de pequenas dimensões,
fornece a menor área e o menor consumo de potência, quando comparado com as versões anteriores;
adicionalmente, sua velocidade é comparável a [Cr96].
Por fim, para comparações entre as cinco implementações, foi empregado como índice de mérito
dos Prescalers o valor calculado pela relação
ITec F
PotM =3
max
onde IM é o índice de mérito;

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
168
Tec é o comprimento mínimo de canal para a tecnologia, em µm (Tabela 22, segunda coluna);
Fmax é a máxima freqüência de operação do circuito, em MHz (Tabela 22, quinta coluna);
Pot é a potência por MHz, em µW/MHz (Tabela 22, sexta coluna).
A última coluna da Tabela 22 apresenta o valor de IM. Observe que o expoente 3, para o parâmetro
Tec, é necessário para que o índice de mérito permaneça invariável quando é aplicado o Constant-
Field Scaling. O circuito aqui projetado é o que maior valor de IM apresenta6.
Tabela 22. Resultados de área, velocidade e potência para cinco diferentes implementações do
Prescaler.
Prescaler Tecnologia
(µm)
Tensão de
alimentação (V)
Área
(10-3mm2)
Velocidade
(GHz)
Potência
(µW/MHz)
IM
(µm3MHz2/ µW)
[Hu96] 1,0 5 39.1 1,6 31,2 51,3
[Ch96] 0,8 5 13,7* 1,22 20,9 29,9
[Cr96] 0,7 3 632** 1,75 13,7 43,8
[Ya98] 0,8 5 - 1,80 29,34 31,41
(este trabalho) 0,8 5 12,6 1,59 8,0 101,8
* unicamente o contador módulo 4/5 e o contador módulo 32 são considerados. ** inclui PADs e buffers.
4.3.4 Dual-Modulus Prescaler: conclusões
O estudo, a implementação e os testes do Dual-Modulus Prescaler confirmam algumas das
principais características da estratégia E-TSPC. São elas:
• as regras de composição permitem que o projetista utilize todo o potencial dos blocos
disponíveis;
• os blocos N-MOS like podem aumentar a velocidade em todos os pontos onde for necessário.
Ainda, desde que os blocos convencionais e os blocos N-MOS like devem seguir as mesmas regras
de composição, eles podem ser substituídos, uns pelos outros, com custos, em termos de tempo de
projeto, pequenos;
6 Podemos, a partir da Figura 74, determinar o valor de IM para várias tensões VDD. O menor valor é obtido quando
VDD=5V, que é o usado na Tabela 22.

Circuitos de testes para a estratégia E-TSPC e para os Tapered Buffers
169
• p-data chains usando predominantemente p-latches N-MOS like, onde a função lógica é
executada por transistores N, são mais velozes que os n-data chains. Em conseqüência, n e p-data
chains podem ser igualmente aplicados em circuitos de alta velocidade.


Conclusões e futuros trabalhos
171
5. Conclusões e futuros trabalhos Nossa atenção, neste trabalho, esteve voltada para o projeto de circuitos de alta velocidade em
tecnologias CMOS. Como vimos, o aumento das freqüências de operação dos C.I.s, (NTRS-97
[Se97]), e a demanda crescente, em diversas áreas de aplicação, por circuitos mais rápidos, fizeram
com que a velocidade se tornasse um importante fator de desempenho mas criaram, todavia, novas
dificuldades para os projetos de C.I.s.
No capítulo dois, desenvolvemos uma estratégia para o projeto de Register Transfer Systems os
quais utilizam um único clock para sincronismo (True Single Phase Clock). A estratégia foi
denominada Extended-TSPC. Nela são utilizadas portas lógicas complementar CMOS, CMOS
dinâmicas e data pre-charged, blocos n-latches e blocos p-latches. Ainda, são permitidas
modificações em algumas destas portas e blocos, formando os blocos N-MOS like. Um conjunto de
regras de composição é fornecido, r1 a r5 (ou apenas rG) além de rE, para determinar como estes blocos
podem ou não ser ligados. Uma vez obedecidas a tais regras, garantimos, como mostram os teoremas
apresentados e provados no capítulo dois, que diferentes problemas, referentes ao funcionamento das
portas e dos blocos usados, não ocorrerão.
A otimização de tapered buffers, para obter máxima taxa de operação, foi então tratada no capítulo
três. A partir de simulações com diversas tecnologias verificamos que com a minimização do atraso do
buffer não obtemos, necessariamente, a máxima taxa de operação para ele. Os resultados mostraram
que valores pequenos de fator de aumento entre inversores, inferiores a dois, é que proporcionam as
maiores taxas. Como conseqüência, o uso de valores pequenos do fator de aumento, para aplicações
onde atrasos maiores no buffer podem ser suportados, é recomendado para melhora do desempenho.
Aumentos superiores a 20% na máxima taxa de operação têm sido alcançados dessa forma.
A estratégia E-TSPC, parcialmente, e os novos critérios para otimização de tapered buffers foram
empregados no desenvolvimento de versões de alta performance de dois circuitos: um Multiplexador
8:1 e um Demultiplexador 1:8 com byte alignment. Os resultados obtidos com testes nestes circuitos
foram descritos em detalhes no capítulo quatro. O novo Multiplexador operou a taxas de 1,7Gbit/s e o
novo Demultiplexador, a 1,38Gbit/s, valores excelentes para a tecnologia utilizada (CMOS 0,8µm). O
ganho de velocidade conseguido em relação a primeira versão destes mesmos circuitos, efeito do
emprego das técnicas aqui propostas, foi de 62% para o Multiplexador e de 29% para o
Demultiplexador.
Um outro circuito, um Dual Modulus Prescaler, foi também desenvolvido. Nele, a estratégia E-
TSPC foi empregada de forma mais ampla, mostrando-se vantajosa para se atingir tanto altas
freqüências de operação como baixos consumos de potência. O protótipo caracterizado do Prescaler

Conclusões e futuros trabalhos
172
operou na freqüência de 1,58GHz (tecnologia CMOS 0,8µm). O índice de mérito utilizado para
comparação de diferentes implementações de Prescalers, índice que leva em conta a freqüência de
operação, o consumo de potência e a tecnologia utilizada, foi, para nosso circuito, quase duas vezes
superior ao melhor resultado encontrado nas implementações de outros trabalhos.
5.1 Futuros trabalhos sobre o E-TSPC
O trabalho apresentado aqui é a base para futuros desenvolvimentos. Para sua utilização em
circuitos de média e grande complexidade, ele precisa ser complementado com bibliotecas de células e
com uma série de ferramentas de auxílio a projetos (ferramentas de CAD).
A biblioteca de células deve possuir vários blocos da estratégia, em todas as suas variantes, para as
funções lógicas mais comuns. Ainda, é essencial que cada bloco esteja devidamente caracterizado em
termos de velocidade e consumo de potência. Dessa forma, o projetista, ou a ferramenta de CAD,
poderá estimar o custo, em termos de potência, da substituição de um bloco mais lento por outro mais
veloz. Também é interessante que estejam disponíveis várias células D-flip-flops otimizadas para
atingir máxima taxa de operação. Nessa direção, alguns trabalhos estão sendo executados ([Gri98]).
A aplicação com sucesso do E-TSPC em circuitos maiores dependerá, em parte, da existência de
ferramentas que possam ser empregadas com ele. A ferramenta mais simples que pode ser concebida é
para verificação das regras de composição. Essa verificação será trivial uma vez identificados os data
chains do circuito, sendo esta identificação, por sua vez, uma tarefa fácil (no capítulo dois é sugerido
como). Outra ferramenta, mais sofisticada, pode ser construída para determinação dos caminhos
críticos de um circuito, esteja ele descrito por meio de conexões entre células de uma biblioteca, esteja
ele descrito na forma de layout. Tal ferramenta seria bastante útil para otimizações de velocidade e
consumo de potência, pois permitiria identificar as posições onde blocos N-MOS like são mais
necessários.
Para tirar maior proveito das potencialidades do E-TSPC, uma ferramenta completa para síntese
lógica é desejável. Esse é, por sua vez, o objetivo do Ambiente de Síntese de Circuitos de Alto
Desempenho (ASCAD) que vem sendo estudado dentro do LSI/USP [Rom98].
5.2 Futuros trabalhos sobre otimização de tapered buffers
Para aprofundamento do trabalho sobre tapered buffers, várias questões devem ser investigadas. A
primeira diz respeito aos problemas de mismatch entre inversores. Foi feita, no capítulo três, uma
análise teórica sobre a questão no entanto faltam resultados experimentais relativos a diferentes
tecnologias. Para isso várias estruturas com osciladores em anel, formados por inversores, devem ser

Conclusões e futuros trabalhos
173
fabricadas e caracterizadas. Na Figura 75 está exemplificado um oscilador para testes de um buffer
com fator de aumento χ.
Também estudos sobre a área ocupada e a potência consumida pelo tapered buffer, em função do
fator de aumento empregado, devem ser acrescentados àqueles efetuados no capítulo três.
Inv. 1Wn=W
Inv. 2Wn=χW
Inv. 3Wn=χ2W
Inv. NWn=χN-1W
Inv. N+1Wn=(χN-1)W
Figura 75. Estrutura para caracterizar mismatch em buffers com fator de aumento χ. Wn indica a
largura de canal do transistor N.
Por fim, como exemplificado no APÊNDICE C, novos modelos para determinação da largura
mínima do pulso que atravessa um buffer devem ser tentados. O desejável é obter relações fechadas
que possam ser usadas para a previsão desta.

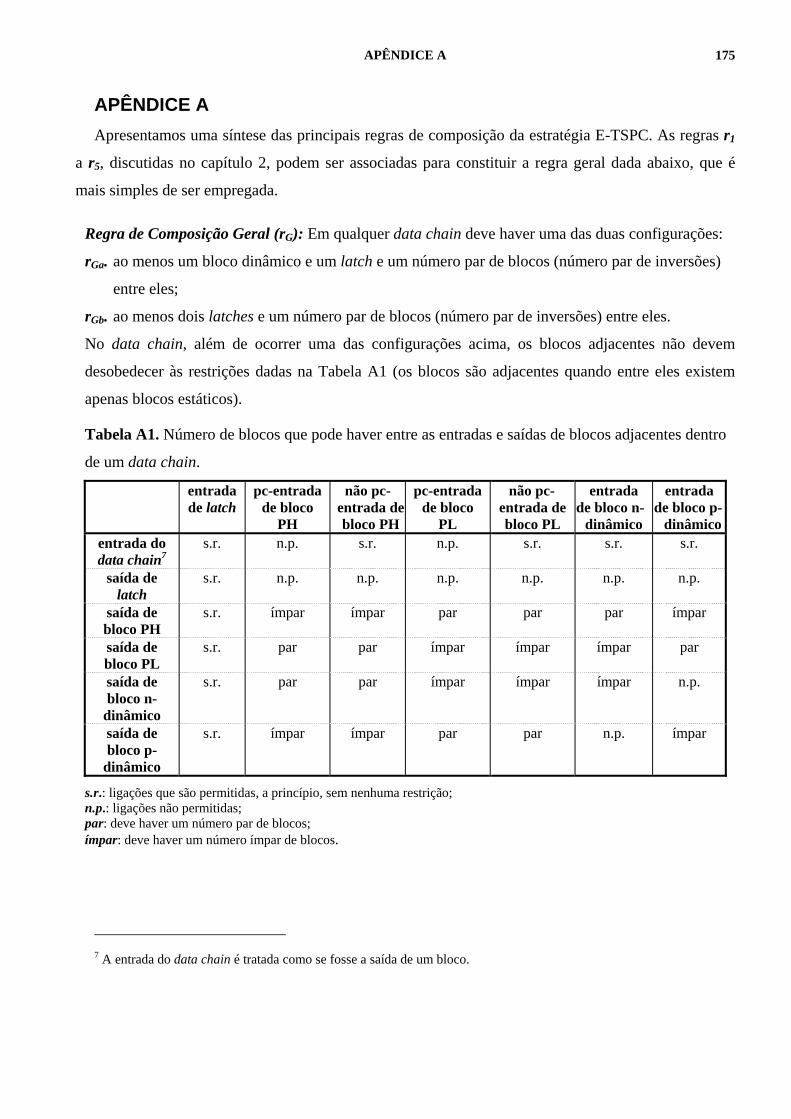
APÊNDICE A
175
APÊNDICE A Apresentamos uma síntese das principais regras de composição da estratégia E-TSPC. As regras r1
a r5, discutidas no capítulo 2, podem ser associadas para constituir a regra geral dada abaixo, que é
mais simples de ser empregada.
Regra de Composição Geral (rG): Em qualquer data chain deve haver uma das duas configurações:
rGa. ao menos um bloco dinâmico e um latch e um número par de blocos (número par de inversões)
entre eles;
rGb. ao menos dois latches e um número par de blocos (número par de inversões) entre eles.
No data chain, além de ocorrer uma das configurações acima, os blocos adjacentes não devem
desobedecer às restrições dadas na Tabela A1 (os blocos são adjacentes quando entre eles existem
apenas blocos estáticos).
Tabela A1. Número de blocos que pode haver entre as entradas e saídas de blocos adjacentes dentro
de um data chain.
entrada de latch
pc-entrada de bloco
PH
não pc-entrada de bloco PH
pc-entrada de bloco
PL
não pc-entrada de bloco PL
entrada de bloco n-
dinâmico
entrada de bloco p-
dinâmicoentrada do data chain7
s.r. n.p. s.r. n.p. s.r. s.r. s.r.
saída de latch
s.r. n.p. n.p. n.p. n.p. n.p. n.p.
saída de bloco PH
s.r. ímpar ímpar par par par ímpar
saída de bloco PL
s.r. par par ímpar ímpar ímpar par
saída de bloco n-
dinâmico
s.r. par par ímpar ímpar ímpar n.p.
saída de bloco p-
dinâmico
s.r. ímpar ímpar par par n.p. ímpar
s.r.: ligações que são permitidas, a princípio, sem nenhuma restrição; n.p.: ligações não permitidas; par: deve haver um número par de blocos; ímpar: deve haver um número ímpar de blocos.
7 A entrada do data chain é tratada como se fosse a saída de um bloco.


APÊNDICE B
177
APÊNDICE B Apresentamos abaixo os modelos para transistores da tecnologia CMOS 0,8µm da ES2/ATMEL e
da tecnologia CMOS 0,35µm do IMEC/Bélgica ([Es94] e [Hu97]), usados nas simulações.
B.1 Modelos para a tecnologia 0,8µm da ES2/ATMEL
B.1.1 Modelo level 2 para SPICE3d2 Modelo Típico para Transistores (0,8)
.Model NT0.7 NMOS (LEVEL=2 TOX=1.50E-08 VTO=0.906 LD=0.075U NSUB=2.35E16 + GAMMA=0.807 UO=554 UEXP=0.195 UCRIT=50K VMAX=68.15K DELTA=3.8 RSH=178.4 + NEFF=50 NFS=3.1 XJ=0.055U CJ=486U MJ=0.43 + CJSW=223P MJSW=0.43 PB=0.675 CGDO=200P CGSO=200P JS=2U) .Model PT0.7 PMOS(LEVEL=2 TOX=1.50E-08 VTO=-0.92 LD=0.021U NSUB=20E16 + GAMMA=0.62 UO=220 UEXP=0.217 UCRIT=17.6K VMAX=70K DELTA=2.85 RSH=220 + NEFF=1.0 NFS=1.0 XJ=0.5U CJ=600U MJ=0.51 + CJSW=820P MJSW=0.51 PB=0.70 CGDO=200P CGSO=200P JS=20U)
Modelo Slow para Transistores
.Model NS0.7 NMOS (LEVEL=2 TOX=1.65E-08 VTO=1.056 LD=0.075U NSUB=2.35E16 + GAMMA=0.93 UO=530 UEXP=0.195 UCRIT=50K VMAX=68.15K DELTA=3.8 RSH=120 + NEFF=50 NFS=3.1e11 XJ=0.055U CJ=535U MJ=0.43 + CJSW=245P MJSW=0.43 PB=0.675 CGDO=180P CGSO=180P JS=2U) .Model PS0.7 PMOS(LEVEL=2 TOX=1.65E-08 VTO=-1.07 LD=0.021U NSUB=20E16 + GAMMA=0.67 UO=208 UEXP=0.217 UCRIT=17.6K VMAX=70K DELTA=2.85 RSH=253 + NEFF=1.0 NFS=1.0e11 XJ=0.5U CJ=640U MJ=0.51 + CJSW=900P MJSW=0.51 PB=0.70 CGDO=180P CGSO=180P JS=20U)
Modelo Fast para Transistores
.Model NF0.7 NMOS (LEVEL=2 TOX=1.35E-08 VTO=0.756 LD=0.075U NSUB=2.35E16 + GAMMA=0.68 UO=580 UEXP=0.195 UCRIT=50K VMAX=68.15K DELTA=3.8 RSH=155 + NEFF=50 NFS=3.1 XJ=0.055U CJ=437U MJ=0.43 + CJSW=200P MJSW=0.43 PB=0.675 CGDO=220P CGSO=220P JS=2U) .Model PF0.7 PMOS (LEVEL=2 TOX=1.35E-08 VTO=-0.77 LD=0.021U NSUB=20E16 + GAMMA=0.56 UO=232 UEXP=0.217 UCRIT=17.6K VMAX=70K DELTA=2.85 RSH=190 + NEFF=1.0 NFS=1.0 XJ=0.5U CJ=440U MJ=0.51 + CJSW=740P MJSW=0.51 PB=0.70 CGDO=220P CGSO=220P JS=20U) B.1.2 Modelo level 6 para HSPICE
Modelo Típico para Transistores (0,8)
.Model NT08 NMOS (LEVEL = 6.0 UPDATE=1.0 NSUB=1.965e+16 TOX=150.0 BETA=97e-6 + XJ=0.25u RSH=65 MOB=2 F1=372k F2=200m UTRA=563m XL=0.04u LD=0.1u + XW=0.9u WD=0.45u VTO=815m NSS=0.0 NWE=193.7n UFDS=99.5m VFDS=0.2 FDS=84m + VB0=1.50 GAMMA=764m LGAMMA=705m VSH=650m NWM=-197m SCM=1.733

APÊNDICE B
178
+ WIC =2 NFS=5E11 WEX=17 LAMBDA=10.63u NU=1 KU=1.405 ECRIT=87k MBL=555m + KA=974m MAL=295m CLM=3 KCL=1.08 MCL=4.63 TLEV=1 BEX=-1.5 TCV=-2m + CAPOP=2.0 ACM=2.0 CJ=503u MJ=0.43 CJSW=109p MJSW=0.43 PB=0.675 + CGDO=200p CGSO=200p JS=2u) .Model PT08 PMOS (LEVEL=6.0 UPDATE=1.0 NSUB=2.5e+16 TOX=150.0 BETA=30.16e-6 + XJ=0.5u RSH = 80 MOB=2 F1=483k F2=320m UTRA=-197m XL=0.042u LD=0.1u + XW=0.9u WD=0.45u VTO=-1 NWE=56.1n UFDS=331m VFDS=0.5 FDS=286m + VB0 =1.5 GAMMA=587m LGAMMA=653m VSH=-116m NWM=-442m SCM=1.01 + WIC=2 NFS=6E11 WEX=14.3 LAMBDA=14u NU=1 KU=9.871 ECRIT=486k MBL=803m + KA=1.082 MAL=0 CLM=3 KCL=41.91m MCL=6.97 TLEV=1 BEX=-1.0 TCV=1.52m + CAPOP=2.0 ACM=2.0 CJ=776u MJ=0.51 CJSW=572p MJSW=0.51 PB=0.7 + CGDO=200p CGSO=200p JS=20u)
Modelo Fast para Transistores
.Model NF08 NMOS (LEVEL=6.0 UPDATE=1.0 NSUB=1.965e+16 TOX=135.0 BETA=107e-6 + XJ=0.25u RSH=55 MOB=2 F1=372k F2=200m UTRA=563m XL=-0.08u LD=0.1u + XW=1.08u WD=0.45u VTO=715m NSS=0.0 NWE=193.7n UFDS=99.5m VFDS=0.2 FDS=84m + VB0=1.50 GAMMA=714m LGAMMA=655m VSH=650m NWM=-197m SCM=1.733 + WIC=2 NFS=5E11 WEX=17 LAMBDA=10.63u NU=1 KU=1.405 ECRIT=87k MBL=555m + KA=974m MAL=295m CLM=3 KCL=1.08 MCL=4.63 TLEV=1 BEX=-1.5 TCV=-2m + CAPOP=2.0 ACM=2.0 CJ=453u MJ=0.43 CJSW=90p MJSW=0.43 PB=0.675 + CGDO=220p CGSO=220p JS=2u) .Model PF08 PMOS (LEVEL=6.0 UPDATE=1.0 NSUB=2.5e+16 TOX=135.0 BETA=33.4e-6 + XJ=0.5u RSH=70 MOB=2 F1=483k F2=320m UTRA=-197m XL=-0.078u LD=0.1u + XW=1.08u WD=0.45u VTO=-0.9 NWE=56.1n UFDS=331m VFDS=0.5 FDS=286m + VB0=1.5 GAMMA=537m LGAMMA=603m VSH=-116m NWM=-442m SCM=1.01 + WIC=2 NFS=6E11 WEX=14.3 LAMBDA=14u NU=1 KU=9.871 ECRIT=486k MBL=803m + KA=1.082 MAL=0 CLM=3 KCL=41.91m MCL=6.97 TLEV=1 BEX=-1.0 TCV=1.52m + CAPOP=2.0 ACM=2.0 CJ=706u MJ=0.51 CJSW=522p MJSW=0.51 PB=0.7 + CGDO=220p CGSO=220p JS=20u)
Modelo Slow para Transistores
.Model NS08 NMOS (LEVEL=6.0 UPDATE=1.0 NSUB=1.965e+16 TOX=165.0 BETA=88e-6 + XJ=0.25u RSH=75 MOB=2 F1=372k F2=200m UTRA=563m XL=0.16u LD=0.1u + XW=0.72u WD=0.45u VTO=915m NSS=0.0 NWE=193.7n UFDS=99.5m VFDS=0.2 FDS=84m + VB0=1.50 GAMMA=814m LGAMMA=755m VSH=650m NWM=-197m SCM=1.733 + WIC=2 NFS=5E11 WEX=17 LAMBDA=10.63u NU=1 KU=1.405 ECRIT=87k MBL=555m + KA=974m MAL=295m CLM=3 KCL=1.08 MCL=4.63 TLEV=1 BEX=-1.5 TCV=-2m + CAPOP=2.0 ACM=2.0 CJ=553u MJ=0.43 CJSW=130p MJSW=0.43 PB=0.675 + CGDO=180p CGSO=180p JS=2u) .Model PS08 PMOS (LEVEL=6.0 UPDATE=1.0 NSUB=2.5e+16 TOX=165.0 BETA=27.4e-6 + XJ=0.5u RSH=90 MOB=2 F1=483k F2=320m UTRA=-197m XL=0.162u LD=0.1u + XW=0.72u WD=0.45u VTO=-1.1 NWE=56.1n UFDS=331m VFDS=0.5 FDS=286m + VB0=1.5 GAMMA=637m LGAMMA=703m VSH=-116m NWM=-442m SCM=1.01

APÊNDICE B
179
+ WIC=2 NFS=6E11 WEX=14.3 LAMBDA=14u NU=1 KU=9.871 ECRIT=486k MBL=803m + KA=1.082 MAL=0 CLM=3 KCL=41.91m MCL=6.97 TLEV=1 BEX=-1.0 TCV=1.52m + CAPOP=2.0 ACM=2.0 CJ=846u MJ=0.51 CJSW=622p MJSW=0.51 PB=0.7 + CGDO=180p CGSO=180p JS=20u)
B.2 Modelos para a tecnologia 0,35µm do IMEC/Bélgica
B.2.1 Modelo level 3 para HSPICE Modelo Slow para Transistores (0,35)
.Model NS035 NMOS (level=3 VT0=0.733 Kp=218.2u Kappa=0.16 tox=7.5n Vmax=132.16K + Ld=0.01u Ldif=0.15u Hdfi=0.4u ACM=2 Xj=0.1u Wd=-0.01u Theta=0.24 U0=426.98 + Delta=-0.5 ETA=0 Gamma=0.629 NSUB=2.9e17 PHI=0.905 TPG=+1 JS=0.34e-6 + JSW=3.3e-13 N=1.05 CJ=102E-5 CJSW=4.1E-10 MJ=0.364 MJSW=0.255 PB=0.776 + PHP=0.757 RSH=2.0 RDC=0 RSC=0 RD=1990 RS=1990) *+ RDC=2.6 RSC=2.6 RD=1990 RS=1990) .Model PS035 PMOS (level=3 VT0=-0.726 Kp=46.3u Kappa=2 tox=7.5n Vmax=104.47K + Ld=0.01u Ldif=0.15u Hdif=0.4u ACM=2 Xj=0.1u Wd=-0.06u Theta=0.199 U0=100 + Delta=-0.56 ETA=0 Gamma=0.618 NSUB=2.8e17 PHI=0.895 TPG=+1 JS=0.29e-6 + JSW=2.8e-13 N=1.05 CJ=111E-5 CJSW=3.6E-10 MJ=0.453 MJSW=0.267 PB=0.894 + PHP=0.616 RSH=1.8 RDC=0 RSC=0. RD=4960 RS=4960) *+ RDC=2.4 RSC=2.4 RD=4960 RS=4960)


APÊNDICE C
181
APÊNDICE C Tentaremos aqui um modelamento alternativo para determinar a largura mínima do pulso que
propaga por um tapered buffer. Vamos considerar, para o problema, que os inversores são sistemas
lineares invariantes, com uma entrada que é VGS (tensão gate-fonte) e uma saída (tensão dreno-fonte),
sendo a fonte, a do transistor N. Poderemos então escrever a função de transferência do buffer ([Or85],
[De79]):
H s H sii
i N
( ) ( )==
=
∏1
onde H(s) é a função de transferência do buffer;
N é o número de inversores do buffer;
Hi(s) é a função de transferência do i-ésimo inversor do buffer.
Chamaremos a máxima taxa de transmissão de dados possível no buffer, em bit/s, de fm. Vamos
supor que, nessa freqüência máxima, o ganho da função de transferência seja KA, ou seja
H H Kc i ci
i N
A( ) ( )ω ω= ==
=
∏1
e fmc= 2
2ωπ
onde ωc será chamada de freqüência angular de corte do buffer;
KA é uma constante onde 0 0< <K HA ( ) .
O modelo aceitável mais simples para o inversor é dado na Figura C1. Neste modelo há um circuito
RC na saída que será responsável pelo único pólo da função de transferência. Para o i-ésimo inversor
será válido então
H s GsR Ci Ai
Ei Li( ) = −
+1
1
onde GAi é o ganho DC do inversor, GAi≥1;
REi é a resistência equivalente do i-ésimo inversor (Figura C1);
CLi é a capacitância de carga do i-ésimo inversor (Figura C1). REi
VGS
CLi
GAiVGSVDSVDSVDS
Figura C1. Modelo de primeira ordem para um inversor.
Por fim, a função de transferência do buffer será
H s GsR CAi
Ei Lii
i N
( ) = −+
=
=
∏ 111

APÊNDICE C
182
e, portanto, a freqüência angular de corte ωC será aquela que satisfaz a relação
111
1
ωc Ei Lii
i NA
Aii
i NR CK
G+
=
=
=
=
=∏∏ ( )
; observe que K
G
A
Aii
i N
( )=
=
∏<
1
1.
As seguintes simplificações serão ainda aplicadas:
• os ganhos GAis iguais para todos os inversores e com valor de GA. Observemos que o ganho do
inversor, quando os dois transistores estão na saturação, depende da relação entre gm,
transcondutância do transistor, e gd, a condutância de dreno. Pode ser mostrado que esta relação é
independente da largura do canal do transistor, ao menos em uma análise de primeira ordem
[Gr86]. De forma semelhante, supomos ser GAi;
• R Ct
Ei LiI= 0
π para todo 1≤i<N. As razões para justificar isso são similares àquelas apresentadas
para mostrar que t0i, expressão (12), capítulo 3, é constante para todo 1≤i<N;
• R C
KC K
EN LN
IN L I
=+
−
11 2χπ
,
onde KI1 é uma constante que depende dos parâmetros da tecnologia, do layout e das dimensões
do primeiro inversor do buffer;
KI2 é uma constante que depende dos parâmetros da tecnologia e do layout;
CL é a capacitância de carga do buffer.
As razões para justificar tal relação são similares àquelas usadas com toN, expressão (12), capítulo
3, que também é função linear de CL.
A partir das expressões acima podemos obter, para o buffer, o resultado:
1
1
1
1
02
1
11 2
2
2
2tt
KC K
t
KG
I
m
N
IN L I
m
A
AN
+
+
+
=
−
−χ
(C1)
onde tm é a mínima largura de um pulso que passa pelo buffer (tm=1/fm).
Vejamos se esta equação serve para modelar os resultados obtidos. Primeiro lembremos que,
conforme encontrado no capítulo 3, as assíntotas do gráfico largura mínima de um pulso que passa
pelo tapered buffer em função da carga capacitiva CL da saída, para valores grandes de CL, são retas

APÊNDICE C
183
cujas inclinações são inversamente proporcionais as dimensões do último inversor do buffer. Por (C1),
fazendo CL tender a infinito, determinamos que GA=1 é necessário para tal.
Por outro lado, quando CL=0 e adotando GA=1, podemos escrever
1
102
1
2
22
tt
KG
KI
m
N
A
AN A
+
≈ =
−
o que implica tt
Km
I
AN
≈
−−
−
02
12 1
.
A derivada de tm em relação a N pode ser calculada a partir dessa relação. Podemos verificar que
∂∂tNm
CL=0
tende a infinito quando N cresce. Os gráficos largura mínima de um pulso que passa pelo
tapered buffer em função do número de inversores, que são apresentados no capítulo 3, indicam que
isso não está correto. As derivadas devem sim tender a zero.
Essas considerações indicam que a expressão (C1) não é adequada para o modelamento.
Podemos escolher outras funções de transferência para o inversor e examinar os resultados. Em
[Pa97], para determinação do atraso do inversor, foi usada uma função de transferência cuja resposta
ao impulso é um sinal trapezoidal.
Este estudo, no entanto, será feito em futuros trabalhos.


APÊNDICE D
185
APÊNDICE D A comparação entre os resultados de simulação e as relações semi-empíricas para a tecnologia
CMOS 0,8µm da AMS, [Am95], é apresentada aqui.
D.1 Condições para a simulação
As condições para as simulações executadas com a tecnologia da AMS são semelhantes às usadas
nos exemplos do capítulo 3. Elas são resumidas na tabela D1.
Tabela D1. Condições para obtenção dos resultados de simulação para a tecnologia CMOS 0,8µm da
AMS.
Condições de simulação simulador HSPICE
modelo usado level 47, típico (BSIM3, versão 2) alimentação do buffer 5,0V
sinal de entrada do buffer “010001111011100101101” e o seu complemento (“101110000100011010010”)
tempos de subida e descida iguais a 20% da largura de um pulso mínimo critério de análise da saída todas os pulsos da entrada chegam a saída e atingem níveis
mínimos adotados níveis mínimos da saída VHM=4,0V
VLM=1,0V comprimento de canal dos
transistores L=0,8µm
largura de canal dos trans.
do primeiro inversor trans. P Wp1=8µm trans. N Wn1=5µm
configuração do transistor em pente com dois ramos dimensões de dreno
empregadas área=1,3Wµm2
perímetro= W+5,2µm
Dadas estas condições, as constantes necessárias para a expressão (16), capítulo 3, são determinadas
e seus valores são indicados abaixo:
K1=3,45ns/pF, K2=46ps e K4=0,62.
Na Figura D1 são mostrados os resultados simulados e a aproximação das equações semi-empíricas.
Para fator de ganho χ=3,0, a máxima taxa de operação é de 2,05Gbit/s; para χ=1,8, a máxima taxa é
de 2,53 Gbit/s que também é a máxima possível com o buffer (seis inversores). O aumento entre um e
outro caso é de 23%.

APÊNDICE D
186
1 1 . 5 2 2 . 5 3 3 . 5 4 4 . 5 50
0 . 5
1
1 . 5
2
2 . 5
3
f a t o r d e a u m e n t o d o t a p e r e d b u f f e r
m a x . t a x a ( G b i t / s )
C L = 1 p F0 , 8 µ m C M O SA M S
2 i n v .3 i n v .4 i n v .5 i n v .6 i n v .7 i n v .
s i m u l a ç ã o
Figura D1. Comparação entre os pontos obtidos por simulação (o buffer com dois inversores é
apresentado com ‘x’, três com ‘+’, quatro com ‘o’, cinco com ‘*’, seis com 'x', sete com 'o') e
equações dadas por (16) (linhas contínuas). A tecnologia é CMOS 0,8µm da AMS e a capacitância de
carga de 1pF.
D.2 Modelos para a tecnologia 0,8µm da AMS
Abaixo estão descritos os parâmetros do modelo level 47 para o HSPICE, BSIM3, versão 2
(Berkeley Short-Channel IGFET Model), usado. Lembramos que este modelo é o melhor entre os
empregados neste trabalho.
Modelo Típico para Transistores (0,8).
.MODEL nmos NMOS (LEVEL=47 * ---------------------------------------------------------------------- * format : HSPICE * model : MOS BSIM3v2 * extracted : CYB J010JR00; 1995-12; ese (-487) * doc# : 9933006 REV_A * created : 1995-12-19 * *** Flags *** + SUBTHMOD=2.000e+00 SATMOD =2.000e+00 BULKMOD =1.000e+00 * *** Threshold voltage related model parameters *** + K3 =2.849e+00 K3B =1.503e+00 NPEAK =1.021e+17 VTH0 =8.089e-01 + VOFF =-5.599e-02 DVT0 =4.668e-01 DVT1 =2.826e-01 + DVT2 =-3.650e-01 KETA =-7.230e-03 PSCBE1 =1.894e+08 PSCBE2 =9.574e-07 * *** Mobility related model parameters *** + UA =4.621e-10 UB =1.000e-22 UC =7.399e-03 U0 =4.789e+02 * *** Subthreshold related parameters *** + DSUB =1.000e+00 ETA0 =1.000e-02 ETAB =-9.720e-03 + NFACTOR =9.000e-01 VGHIGH =1.500e-01 VGLOW =-1.200e-01 * *** Saturation related parameters *** + ETA =3.000e-01 PCLM =1.236e+00 + PDIBL1 =1.012e-02 PDIBL2 =5.930e-04 DROUT =6.838e-02 + A0 =6.471e-01 A1 =0.000e+00 A2 =1.000e+00 + PVAG =1.964e-01 VSAT =8.981e+06

APÊNDICE D
187
* *** Geometry modulation related parameters *** + W0 =1.069e-12 * *** Temperature effect parameters *** + AT =3.300e04 UTE =-1.763 KT1 =-0.385 KT2 =0.013 KT1L =0.000 + UA1 =1.460e-09 UB1 =-7.610e-18 UC1 =-0.056 * *** Overlap capacitance related and dynamic model parameters *** + CGDO =0.350e-09 CGSO =0.350e-09 CGBO =0.150e-09 + XPART =1.000e+00 * *** Parasitic resistance and capacitance related model parameters *** + RDS0 =0.000e+00 RDSW =9.178e+02 + CDSC =2.065e-05 CDSCB =0.000e+00 CIT =0.000e+00 * *** Process and parameters extraction related model parameters *** + TOX =1.557e-08 NSUB =72.74e+15 NLX =0.000e+00 * *** Noise effect related model parameters *** + AF =1.451e-00 KF =0.233e-25 NLEV =0 * *** Common extrinsic model parameters *** + ACM =2 RD =0.000e+00 RS =0.000e+00 RSH =2.400e+01 + RDC =0.000e+00 RSC =0.000e+00 LD =1.137e-07 WD =5.290e-07 + LDIF =0.000e+00 HDIF =0.000e+00 WMLT =1.000e+00 + LMLT =1.000e+00 XJ =4.000e-07 + JS =0.010e-03 JSW =0.000e+00 IS =0.000e+00 + N =1.000e+00 NDS =1.000e+12 VNDS =-1.00e+00 + CBD =0.000e+00 CBS =0.000e+00 CJ =0.29e-03 + CJSW =0.230e-09 FC =0.000e+00 + MJ =0.460e-00 MJSW =0.330e-00 TT =0.000e+00 PB =0.88 PHP =0.88)
.MODEL pmos PMOS (LEVEL=47 * ---------------------------------------------------------------------- * format : HSPICE * model : MOS BSIM3v2 * extracted : CYB J010JR00; 1995-12; ese (-487) * doc# : 9933006 REV_A * created : 1995-12-19 * NOTE: Only for use in AMS-approved simulators. * *** Flags *** + SUBTHMOD=2.000e+00 SATMOD =2.000e+00 BULKMOD =2.000e+00 * *** Threshold voltage related model parameters *** + K3 =4.504e+01 K3B =-1.998e+01 NPEAK =2.933e+16 VTH0 =-7.736e-01 + VOFF =-7.207e-02 DVT0 =9.784e+00 DVT1 =7.501e-01 + DVT2 =1.102e-01 KETA =-5.641e-03 PSCBE1 =6.321e+09 PSCBE2 =1.081e-08 * *** Mobility related model parameters *** + UA =2.220e-09 UB =1.000e-23 UC =-2.055e-03 U0 =2.170e+02 * *** Subthreshold related parameters *** + DSUB =2.095e-01 ETA0 =6.638e-02 ETAB =-3.357e-03 + NFACTOR =1.864e+00 VGHIGH =1.500e-01 VGLOW =-1.200e-01 * *** Saturation related parameters *** + ETA =3.000e-01 PCLM =2.439e+00 + PDIBL1 =4.354e+00 PDIBL2 =6.428e-03 DROUT =9.730e-01 + A0 =4.858e+00 A1 =8.543e-01 A2 =1.648e-02 + PVAG =-2.390e-01 VSAT =4.204e+06

APÊNDICE D
188
* *** Geometry modulation related parameters *** + W0 =1.553e-05 * *** Temperature effect parameters *** + AT =3.300e+04 UTE =-1.040 KT1 =-0.482 KT2 =0.013 KT1L =0.000 + UA1 =6.990e-09 UB1 =-7.610e-18 UC1 =-0.056 * *** Overlap capacitance related and dynamic model parameters *** + CGDO =0.350e-09 CGSO =0.350e-09 CGBO =0.150e-09 XPART =1.000e+00 * *** Parasitic resistance and capacitance related model parameters *** + RDS0 =0.000e+00 RDSW =2.119e+03 + CDSC =1.102e-02 CDSCB =1.000e-04 CIT =0.000e+00 * *** Process and parameters extraction related model parameters *** + TOX =1.557e-08 NSUB =2.764e+16 + NLX =4.846e-07 * *** Noise effect related model parameters *** + AF =1.279 KF =6.314e-29 NLEV =0 * *** Common extrinsic model parameters *** + ACM =2 RD =0.000e+00 RS =0.000e+00 RSH =4.200e+01 + RDC =0.000e+00 RSC =0.000e+00 LD =1.352e-08 WD =2.348e-07 + LDIF =0.000e+00 HDIF =0.000e+00 WMLT =1.000e+00 + LMLT =1.000e+00 XJ =4.000e-07 + JS =0.040e-03 JSW =0.000e+00 IS =0.000e+00 + N =1.000e+00 NDS =1.000e+12 VNDS =-1.00e+00 + CBD =0.000e+00 CBS =0.000e+00 CJ =0.490e-03 + CJSW =0.210e-09 FC =0.000e+00 + MJ =0.470e+00 MJSW =0.290e+00 TT =0.000e+00 + PB =0.800e+00 PHP =0.800e+00)

Referências Bibliográficas
189
Referências Bibliográficas [Aa93] AASERUD, O.; DANIELSEN, H. CMOS driver for 50Ω Load. Electronics Letters, v.29,
n.10, p.876-878, 1993.
[Am95] AUSTRIA MIKRO SYSTEME INTERNATIONAL AG (AMS). 0.8µm CMOS design
rules. revision A, Aústria, 1995.
[Af90] AFGHAHI, M.; SVENSSON, C. A unified single-phase clocking schema for VLSI systems.
IEEE J. Solid-State Circuits, v.25, n.1, p.225-235, 1990.
[Af92] AFGHAHI, M.; SVENSSON, C. Performance of synchronous and asynchronous schemes for
VLSI systems. IEEE Trans. Comput., v.41, n.7, p.858-872, 1992.
[An88] ANTOGNETTI, P.; MASSOBRIO, G., ed. Semiconductor device modeling with SPICE.
New York, McGraw-Hill, 1988.
[Bl88] BLOOD JR., W.R. MECL system design handbook. 4.ed., Motorola Inc., 1988.
[Bo98] BONDYOPADHYAY, P.K. Moore's Law Governs the silicon revolution. Proceedings of the
IEEE, v.86, n.1, p.78-81, 1998.
[Br98] BREWER, J.E. A new and improved roadmap. IEEE Circuits & Devices, v.14, n.2, p.13-18,
1988.
[Ch88] CHAPPELL, B.A. et al. Fast CMOS ECL receivers with 100-mV worst-case sensitivity. IEEE
J. Solid-State Circuits, v.23, n.1, p.59-67, 1988.
[Ch95] CHERKAUER, B.S.; FRIEDMAN, E.G. A Unified Design Methodology for CMOS Tapered
Buffers. IEEE Trans. Very Large Scale Integration (VLSI) Systems, v.3, n.1, p.99-111,
1995.
[Cha95] CHANDRAKASAN, A.P.; BRODERSEN, R.W. Low power digital CMOS design. Boston,
Kluwer Academic, 1995.
[Ch96] CHANG, B. et al. A 1.2 GHz CMOS dual-modulus prescaler using new dynamic D-type flip-
flops. IEEE J. Solid-State Circuits, v.31, n.5, p.749-752, 1996.
[Co77] COSTA NETO, P.L.O. Estatística. São Paulo, Edgard Blücher, 1977.
[Co88] CONG, H.-I. et al. Multigigahertz CMOS dual-modulus Prescaler IC. IEEE J. Solid-State
Circuits, v.23, n.5, p.1189-1194, 1988.
[Cr96] CRANINCKX, J.; STEYAERT, M.S.J. A 1.75-GHz/3-V dual-modulus divide-by-128/129
prescaler in 0.7-µm CMOS. IEEE J. Solid-State Circuits, v.31, n.7, p.890-897, 1996.
[De79] DESOER, C.A.; KUH, E.S. Teoria básica de circuitos. Rio de Janeiro, Guanabara Dois,
1979.
[Do92] DOBBERPUHL, D. et al. A 200-MHz 64-b dual-issue CMOS microprocessor. IEEE J.

Referências Bibliográficas
190
Solid-State Circuits, v.27, n.11, p.1555-1567, 1992.
[Es94] EUROPEAN SILICON STRUCTURES, MANUFACTURING TECHNOLOGY DIV.
ECPD07 Dual layer Metal 0.7 micron layout rules. rev. B, France, 30th Oct. 1994.
[Fo95] FOROUDI, N.; KWASNIEWSKI, T.A. CMOS high-speed dual-modulus frequency divider
for RF frequency synthesis. IEEE J. Solid-State Circuits, v.30, n.2, p.93-100, 1995.
[Fr95] FRIEDMAN, E.G., ed. Clock Distribution Networks in VLSI Circuits and Systems: a
selected reprint volume. Piscataway, IEEE, 1995.
[Ga96] GAYLES, E. Building high speed, energy efficient CMOS circuits using variations in
circuit techniques. EUA, 1996. Ph.D. Thesis - Department of Computer Science and
Engineering, The Pennsylvania State University.
[Go83] GONÇALVES, N.F.; DE MAN, H.J. NORA: A racefree dynamic CMOS technique for
pipelined logic structures. IEEE J. Solid-State Circuits, v.18, n.3, p.261-266, 1983.
[Go84] GONÇALVES, N.F. NORA: a racefree CMOS technique for register transfer systems.
Leuven, Bélgica, 1984. Ph.D. Thesis - Katholieke Universiteit Leuven.
[Gr86] GREGORIAN, R.; TEMES, G.C. Analog MOS integrated circuits for signal processing.
New York, John Wiley & Sons, 1986.
[Gr98] GRONOWSKI, P.E. et al. High-performance microprocessor Design. IEEE J. Solid-State
Circuits, v.33, n.5, p.676-686, 1998.
[Gri98] GRIMALD, M.; NAVARRO, J.; VAN NOIJE, W. Otimização em freqüência de circuitos
CMOS sincronizados por bordas de sinal de clock. São Paulo, LSI, Escola Politécnica
da USP, 1996. (Relatório interno)
[Gu96] GU, R.X. et al. High-performance digital VLSI circuit design. Boston, Kluwer Academic,
1996.
[Ha96] HANSON, D.A. et al. Analysis of mixed-signal manufacturability with statistical technology
CAD (TCAD). IEEE Trans. Semicond. Manufact., v.9, n.4, p.478-488, 1996.
[He87] HEDENSTIERNA, N.; JEPPSON, K. CMOS circuit speed and buffer optimization. IEEE
Trans. Computer-Aided Design, v.6, n.2, p.270-281, 1987.
[Hu93] HUANG, Q. Speed optimization of edge-triggered nine-transistor D-flip-flop for gigahertz
single-phase clocks. In: INTERNATIONAL SYMPOSIUM ON CIRCUITS AND
SYSTEMS, Chicago, 1993. Proceedings. Chicago, IEEE, 1993. p.2118-2121.
[Hu96] HUANG, Q. et al. Speed optimazation of edge-triggered CMOS circuits for gigahertz single-
phase clocks. IEEE J. Solid-State Circuits, v.31, n.3, p.456-465, 1996.
[Hu97] HUYLENBROECK, S.V.; LIETAER, N. Electrical Parameters CD035P and CA035P:
prototyping C035. Leuven, Bégica, IMEC, 12th Mar. 1997.

Referências Bibliográficas
191
[Is92] ISHIBE, M. et al. High-speed CMOS I/O buffer circuits. IEEE J. Solid-State Circuits, v.27,
n.4, p.671-673, 1992.
[Jo93] JOHNSON, H.W.; GRAHAM, M. High-speed digital design: a handbook of black magic.
Englewood Cliffs, Prentice-Hall, 1993.
[Ki93] KIM, O. et al. Settling time reduction technique for high speed DACs. Electronics Letters,
v.29, n.25, p.2191-2192, 1993.
[Ko91] KONG, D.T. 2.488 Gb/s SONET multiplexer/demultiplexer with frame detection capability.
IEEE J. Selected Areas in Comunications, v.9, n.5, p.726-731, 1991.
[Kr82] KRAMBECK, R.H. et al. High-speed compact circuits with CMOS. IEEE J. Solid-State
Circuits, v.17, n.3, p.614-619, 1982.
[Ku86] KUMAMOTO, T. et al. An 8-bit high-speed CMOS A/D converter. IEEE J. Solid-State
Circuits, v.21, n.6, p.976-982, 1986.
[Ku96] KURISU, M. et al. 2.8-Gb/s 176-mW byte-interleaved and 3.0-Gb/s 118mW bit-interleaved
8:1 multiplexers with a 0.15-µm CMOS technology. IEEE J. Solid-State Circuits, v.31,
n.12, p.2024-2029, 1996.
[La86] LAKSHMIKUMAR, K.R. et al. Characterization and modeling of mismatch in MOS
transistors for precision analog design. IEEE J. Solid-State Circuits, v.21, n.6, p.1057-
1066, 1986.
[La88] LAI, F.S. A generalized Algorithm for CMOS circuit delay, power and area optimization.
Solid-State Electronics, Pergamon Press, v.31, n.11, p.1619-1627, 1988.
[La94] LARSSON, P; SVENSSON, C. Impact of clock slope on true single phase clocked (TSPC)
CMOS circuits. IEEE J. Solid-State Circuits, v.29, n.6, p.723-726, 1994.
[La95] LARSSON, P. Skew safety and logic flexibility in a true single phase clocked system. In:
INTERNATIONAL SYMPOSIUM ON CIRCUITS AND SYSTEMS, Seattle, 1995.
Proceedings. IEEE Circuits and Systems Society, 1995. p.941-944.
[La96] LARSSON, P. High-Speed architecture for a programmable frequency divider and a dual-
modulus prescaler. IEEE J. Solid-State Circuits, v.31, n.5, p.744-748, 1996.
[Le97] LEE, S.-J. et al. A fully integrated low-noise 1-GHz frequency synthesizer design for mobile
communication application. IEEE J. Solid-State Circuits, v.32, n.5, p.760-765, 1997.
[Li75] LIN, H.C.; LINHOLM, L.W. An optimized output stage for MOS integrated circuits. IEEE J.
Solid-State Circuits, v.10, n.2, p.106-109, 1975.
[Li98] LIN, J. Chip-package codesign for high-frequency circuits and systems. IEEE Micro, v.18,
n.4, p.24-32, 1998.
[Ma96] MACII, E.; PONCINO, M. Power consumption of static and dynamic CMOS circuits: a

Referências Bibliográficas
192
comparative study. In: INTERNATIONAL CONFERENCE ON ASIC, 2., 1996. IEEE.
p.425-427.
[Me80] MEAD, C.; CONWAY, L. Introduction to VLSI systems. 2.ed. Reading, Addison-Wesley,
1980.
[Me95a] META-SOFTWARE, INC. Analysis and Methods: HSPICE user's manual. Campbell,
1995.
[Me95b] META-SOFTWARE, INC. Elements and Models: HSPICE user's manual. Campbell,
1995.
[Me98] MELLIAR-SMITH, C.M. et al. The transistor: an invention becomes a big business.
Proceedings of the IEEE, v.86, n.1, p.86-110, 1998.
[Mo65] MOORE, G.E. Cramming more components onto integrated circuits. Electronics, v.38, n.8,
p.114-117, 1965.
[Mu86] MULLER, R.S.; KAMINS, T.I. Device electronics for integrated circuits, 2.ed. New York,
John Wiley & Sons, 1986.
[Na95] NAVARRO, J. et al. A high speed CMOS ECL-compatible input circuit. In: CONGRESS OF
THE BRAZILIAN MICROELECTRONICS SOCIETY, 10.; IBERO AMERICAN
MICROELECTRONICS CONFERENCE, 1., Canela, 1995. Proceedings, Porto Alegre,
UFRGS/SBMICRO, 1995. v.1, p.197-204.
[Na96] NAVARRO, J. et al. Circuito "buffer"-conversor CMOS/ECL In: SIMPÓSIO BRASILEIRO
DE CONCEPÇÃO DE CIRCUITOS INTEGRADOS, 9., Recife, 1996. Anais. Recife,
SBC/SBMICRO/ UFPE, 1996. p.247-258.
[Na97a] NAVARRO, J. et al. A 1.4Gbit/s CMOS driver for 50Ω ECL systems. In: GREAT LAKES
SYMPOSIUM ON VLSI, 7., Urbana-Champaign, 1997. Proceedings. Los Alamitos, IEEE
Computer Society, 1997. p.14-18.
[Na97b] NAVARRO, J.; VAN NOIJE, W. E-TSPC: Extended True Single-Phase-Clock CMOS circuit
technique. In: IFIP TC10 WG10.5 INTERNATIONAL CONFERENCE ON VLSI.
Gramado, 1997 VLSI: Integrated Systems on Silicon. London, Chapman & Hall, 1997.
p.165-176.
[Na97c] NAVARRO, J.; VAN NOIJE, W. E-TSPC: Extended True Single-Phase-Clock CMOS circuit
technique for high speed applications. SBMICRO J. Solid-State Devices and Circuits,
v.5, n.2, p.21-26, 1997.
[Na98a] NAVARRO, J.; VAN NOIJE, W. CMOS tapered buffer design for small width clock/data
signal propagation. In: GREAT LAKES SYMPOSIUM ON VLSI, 8., Lafayette, 1998.
Proceedings. Los Alamitos, IEEE Computer Society, 1998. p.89-94.

Referências Bibliográficas
193
[Na98b] NAVARRO, J.; VAN NOIJE, W. Design of an 8:1 MUX at 1.7Gbit/s in 0.8µm CMOS
technology. In: GREAT LAKES SYMPOSIUM ON VLSI, 8., Lafayette, 1998.
Proceedings. Los Alamitos, IEEE Computer Society, 1998. p.103-107.
[Na99] NAVARRO, J.; VAN NOIJE, W. A 1.6GHz dual modulus prescaler using the Extended True
Single-Phase-Clock CMOS circuit technique (E-TSPC). IEEE J. Solid-State Circuits,
v.34, n.1, 1999. /No prelo/
[No98] VAN NOIJE, W.; NAVARRO, J. SDHGCMOS: Implementation of CMOS circuits for
SDH/SONET systems applications with GigaBits rates. In: WORKSHOP OF
INTERNATIONAL EVALUATION OF THE PROTEM-CC PROGRAM, Belo
Horizonte, 1998, Proceedings. Brasília, CNPq, 1998. p.118-137.
[Oe93] OEHM, J.; SCHUMACHER, K. Quality assurance and upgrade of analog characteristics by
fast mismatch analysis option in network analysis environment. IEEE J. Solid-State
Circuits, v.28, n.7, p.865-871, 1993.
[Oh97] OHTOMO, Y. et al. A 40Gb/s 8x8 ATM switch LSI using 0.25um CMOS/SIMOX. In:
INTERNATIONAL SOLID-STATE CIRCUITS CONFERENCE, 40., Sao Francisco,
1997. ISSCC Digest of Technical Papers. IEEE Solid-State Circuits Council, 1997.
p.154-155.
[Or85] ORSINI, L.Q. Introdução aos sistemas dinâmicos. Rio de Janeiro, Guanabara Dois, 1985.
[Ot98] OTSUJI, T. et al. An 80-Gbit/s multiplexer IC using InAlAs/InGaAs/Inp HEMT's. IEEE J.
Solid-State Circuits, v.33, n.9, p.1321-1327, 1998.
[Pa91] PAPOULIS, A. Probability, random variables, and stochastic process, 3.ed. New York,
McGraw-Hill, 1991.
[Pa97] PARK, H.-J.; SOMA, M. Analytical model for switching transitions of submicron CMOS
logics. IEEE J. Solid-State Circuits, v.32, n.6, p.880-889, 1997.
[Pe89] PELGROM, M.J.M. et al. Matching Properties of MOS transistors. IEEE J. Solid-State
Circuits, v.24, n.5, p.1433-1440, 1989.
[Po94] POWER, J.A. et al. Relating statistical MOSFET model parameter variabilities to IC
manufacturing process fluctuations enabling realistic worst case design. IEEE Trans.
Semicond. Manufact., v.7, n.3, p.306-318, 1994.
[Ra96] RABAEY, J.M. Digital Integrated Circuits: a design perspective. Upper Saddle River
Prentice Hall, 1996. (Electronics and VLSI series)
[Ro95a] ROMÃO, F.L.; NAVARRO, J.; SILVEIRA, R.; VAN NOIJE, W. Projeto do circuito
DEMUX 8:1 com byte align no padrão SONET/SDH a taxas de 1,25Gb/s Tecnologia
CMOS. In: THE PRIMER WORKSHOP IBERCHIP, Cartagena de Indias, Colombia,

Referências Bibliográficas
194
1995. Memórias. 1995. p.153-163.
[Ro95b] ROMÃO, F.L.; NAVARRO, J.; SILVEIRA, R.; VAN NOIJE, W. 1.2Gb/s SONET/SDH
Demux in CMOS Technology. In: INTERNATIONAL MICROWAVE AND
OPTOELECTRONICS CONFERENCE, Rio de Janeiro, 1995. Proceedings. Rio de
Janeiro, SBMO/IEEE MTT-S, 1995. v.1, p.52-57.
[Ro96] ROMÃO, F.L.; NAVARRO, J.; SILVEIRA, R.; VAN NOIJE, W. Projeto do circuito MUX
8:1 no padrão SONET/SDH a taxas de 1,25Gb/s na tecnologia CMOS 0.7µm. In:
SIMPÓSIO BRASILEIRO DE CONCEPÇÃO DE CIRCUITOS INTEGRADOS, 9.,
Recife, 1996. Anais. Recife, SBC/ SBMICRO/UFPE, 1996. p.201-211.
[Ro98a] ROFOUGARAN, A. et al. A single-chip 900-MHz spread-spectrum wireless transceiver in 1-
µm CMOS-Part I: Architecture and transmitter design. IEEE J. Solid-State Circuits,
v.33, n.4, p.515-534, 1998.
[Ro98b] ROFOUGARAN, A. et al. A single-chip 900-MHz spread-spectrum wireless transceiver in 1-
µm CMOS-Part II: Receiver design. IEEE J. Solid-State Circuits, v.33, n.4, p.535-547,
1998.
[Rom98] ROMÃO, F.L. Ambiente de síntese de circuitos de alto desempenho. São Paulo,
Departamento de Engenharia Eletrônica, EPUSP, ago. 1998. 79p. /exame de Qualificação
para doutorado/
[Rs98] ROSS, I.M. The invention of the transistor. Proceedings of the IEEE, v.86, n.1, p.7-28,
1998.
[Sa88] SAH, C.-T. Evolution of the MOS transistor-from conception to VLSI. Proceedings of the
IEEE, v.76, n.10, p.1280-1326, 1988.
[Sa90] SAKURAY, T.; NEWTON, R. Alpha-power law MOSFET model and its application to
CMOS inverter delay and other formulas. IEEE J. Solid-State Circuits, v.25, n.2, p.584-
594, 1990.
[Sc90] SCHUMACHER, H.-J. et al. CMOS subnanosecond true-ECL output buffer. IEEE J. Solid-
State Circuits, v.25, n.1, p.150-154, 1990.
[Se92] SEMICONDUCTOR INDUSTRY ASSOCIATION (SIA), The national technology
roadmap for semiconductors. EUA, 1994.
[Se94] SEMICONDUCTOR INDUSTRY ASSOCIATION (SIA), The national technology
roadmap for semiconductors. San Jose, Dec. 1994.
[Se97] SEMICONDUCTOR INDUSTRY ASSOCIATION (SIA), The national technology
roadmap for semiconductors. San Jose, Nov. 1997.

Referências Bibliográficas
195
[Sh92] SHOJI, M. Theory of CMOS digital circuits and circuit failures. Princeton, Princeton
University, 1992.
[Sh98] SHEU, B.J. et al. Higher education for the information age. IEEE Circuits & Devices, v.14,
n.3, p.23-28, 1998.
[Si96] SILVEIRA, R. Placa de teste para um circuito integrado de alta velocidade. São Paulo,
LSI, Escola Politécnica da USP, 1996. (Relatório interno)
[St91] STEYAERT, M.S.J. et al. ECL-CMOS and CMOS-ECL interface in 1.2-µm CMOS for 150-
MHz digital ECL data transmission systems. IEEE J. Solid-State Circuits, v.26, n.1,
p.18-24, 1991.
[St92] STALLINGS, W. ISDN and Broadband ISDN. 2.ed. New York, Macmillan, 1992.
[Ta96] TANENBAUM, A.S. Computer Networks. 3.ed. Upper Saddle River, Prentice Hall, 1996.
[Tan96] TANABE, A. et al High performance CMOS for GHz communication IC. In: SYMPOSIUM
ON VLSI TECHNOLOGY, Honolulu, 1996. Digest of Technical Papers. 1996. p.134-
135.
[Ve95] VERGHESE, N.K. Simulation techniques and solutions for mixed-signal coupling in
integrated circuits. Boston, Kluwer Academic, 1995.
[Vi89] VITESSE SEMICONDUCTOR CORPORATION 1989 product data book. Camarillo,
1989.
[Vl80] VLADIMIRESCU, A.; LIU, S. The simulation of MOS integrated circuits using SPICE2.
Berkeley, Col. of Eng., Univ. of California, 1980. (Memorandum UCB/ERL M80/7)
[We93] WESTE, N.H.E.; ESHRAGHIAN, K. Principles of CMOS VLSI design. 2.ed. Reading,
Addison-Wesley, 1993.
[Ya90] YANO, K. et al. A 3.8-ns CMOS 16X16-b Multiplier Using Complementary Pass-Transistor
Logic. IEEE J. Solid-State Circuits, v.25, n.2, p.388-395, 1990.
[Yu87] YUAN, J.-R. et al. A true single-phase-clock dynamic CMOS circuit technique. IEEE J.
Solid-State Circuits, v.22, n.5, p.899-901, 1987.
[Ya98] YANG, C.-Y. et al. New dynamic flip-flop for high-speed dual-modulus prescaler. IEEE J.
Solid-State Circuits, v.33, n.10, p.1568-1571, 1998.
[Yu89] YUAN, J.-R., SVENSSON, C. High speed CMOS circuit technique. IEEE J. Solid-State
Circuits, v.24, n.1, p.62-70, 1989.
[Yu93] YUAN, J.-R. et al. New domino logic precharged by clock and data. Electronics Letters,
v.29, n.25, p.2188-2189, 1993.