estudo e construção de uma cabeça artificial com audição e ... · ... para que os universos...
TRANSCRIPT

i
Faculdade de Engenharia da Universidade do Porto
Estudo e construção de uma cabeça artificial com audição e fala
Catarina Mendes Cruz
VERSÃO II
Dissertação realizada no âmbito do Mestrado Integrado em Engenharia Electrotécnica e de Computadores
Major Telecomunicações
Orientador: Prof. Diamantino Freitas
Abril 2018

ii
© Catarina Mendes Cruz, 2018

iii
Resumo
Os seres humanos têm a capacidade de identificar com alguma precisão as
características de um evento sonoro, desde o reconhecimento da fonte, o volume
sonoro, a sua direção, etc. A criação de tecnologias de realidade virtual cada vez mais
realistas, obriga a que o universo da acústica estude mais profundamente o som
binaural, para que os universos visuais virtuais se tornem imersivos também do ponto
de vista sonoro. Com este objetivo em mente têm vindo a ser estudados simuladores
de audição e fala humana que possam ser utilizados em situações de captura de sons
posteriormente usados para os fins acima mencionados. Contudo a audição humana é
bastante complexa, o que levanta a questão se será uma cabeça artificial capaz de nos
substituir a todos nesta situação? Ou será necessário que cada um de nós tenha uma
réplica da sua cabeça?
Até ao momento não foi encontrada uma forma fiável de realizar este processo
e garantir a generalização das funções de transferência da cabeça, este documento
apresenta o trabalho desenvolvido como contributo para responder às questões
colocadas, avaliando as diferenças encontradas entre a audição humana natural e a
audição mediada por uma cabeça artificial na tarefa de localização espacial da fonte
sonora, em particular no plano azimutal.

iv

v
Abstract
Humans have the ability to identify with some precision the characteristics of a sound
event, since the recognition of the source volume, direction, etc. The development of virtual
reality technologies is forcing the universe of acoustics to study in depth binaural hearing, so
that visual virtual universes become more immersive from an audio point of view. With this in
mind, there have been studies in human hearing and speech simulators that can be used in
sound acquisition, however human hearing is very complex and raises the question can one
artificial head replace all humans in this situations? Or should we all have a replica of our
head?
So far we haven’t found a way to accomplish this process in a reliable way and ensure the
generalization of the head related transfer functions. This document presents the work
developed as a contribution to respond to the questions asked, evaluating the differences
found between the natural human hearing and the hearing of an artificial head while
performing the task of spatial location of a sound source, particularly in the azimuthal plane.

vi

vii
Agradecimentos
Com a conclusão desta etapa da minha vida só tenho que agradecer a minha família, que
se manteve inamovível ao meu lado e que eu tenho confiança que isso nunca vai mudar.

viii

ix
Índice
Resumo ....................................................................................... iii
Abstract ....................................................................................... v
Agradecimentos ............................................................................ vii
Índice ......................................................................................... ix
Lista de figuras .............................................................................. xi
Lista de tabelas ........................................................................... xiv
Abreviaturas e Símbolos .................................................................. xv
Introdução ................................................................................... 1
1.1 Motivações para a dissertação .................................................................. 2
1.2 Objetivos da dissertação ......................................................................... 2
2 Audição Humana ....................................................................... 4
2.1 O som e as fontes sonoras ....................................................................... 5
2.2 O ouvido humano .................................................................................. 7
2.3 Fenómenos da audição humana ................................................................. 9
2.4 Audição Binaural .............................................. Error! Bookmark not defined.
2.5 Localização de uma fonte sonora ............................................................ 10
2.6 HRTF ............................................................................................... 14
3 Fala Humana ........................................................................... 16
3.1 Orgãos de produção da fala humana ......................................................... 16
3.2 A fisicalidade da fala humana ................................................................. 18
4 Simuladores com manequins e o manequim “Madalena” ..................... 20
4.1 K.E.M.A.R ......................................................................................... 20
4.2 Head and Torso Simulator (HTS) .............................................................. 21
4.3 O Manequim “Madalena” ....................................................................... 22
5 Opções binaurais já existentes ..................................................... 24
5.1 C.I.P.I.C Interface Laboratory ................................................................ 24
5.2 IRCAM Database .................................................................................. 25
5.3 ARI HRTF Database .............................................................................. 26
5.4 ATK for Reaper ................................................................................... 28
5.5 Oculus (Facebook) ............................................................................... 30

x
5.6 Daydream e Cardboard (Google) ............................................................. 31
6 Processos Eletroacústicos ........................................................... 32
6.1 Audição ........................................................................................... 32
7 Processo Experimental ............................................................... 35
7.1 Pistas Espectrais ................................................................................. 36
7.2 ITD ................................................................................................. 38
7.3 ILD ................................................................................................. 39
7.4 Interface .......................................................................................... 47
7.5 Testes e conclusões preliminares ............................................................ 49
8 Trabalhos Futuros..................................................................... 51
8.1 Realização de uma API ......................................................................... 51
8.2 Produção de fala ................................................................................ 51
8.3 User Interface / Experience ................................................................... 52
Referências ................................................................................. 54

xi
Lista de figuras
Figura 1: Onda sinusoidal com período 2*pi com 4 repetições ........................................ 6
Figura 2: Ilustração da capacidade de deslocamento de uma onda sonora através das ações de compressão e rarefação das partículas do meio. .............................................. 6
Figura 3: Divisão tripartida do ouvido nas partes relevantes e que influenciam acusticamente o sinal sonoro, assim como os elementos influenciadores da forma como um som é codificado [4] ........................................................................ 7
Figura 4: Sensibilidade do ouvido humano a sons [9].................................................... 9
Figura 5: Planos responsáveis por criar o espaço onde se localiza a fonte sonora e a cabeça do ouvinte. ............................................................................................. 11
Figura 6: Sistema de coordenadas para localização de uma fonte sonora, com origem no centro da cabeça e localizado no espaço definido na Figura 5. .............................. 11
Figura 7: Sinais recebidos por cada um dos ouvidos quando a fonte se encontra a 40º para a direita no plano mediano. ......................................................................... 13
Figura 8: (de cima para baixo e da esquerda para a direita) Sinal capturado à entrada de dos canais auditivos, as HRIR; Sinal capturado no canal direito após o uso de uma janela suficientemente pequena para não ser influenciada pela chegada do primeiro eco; Sinal do ouvido direito após uso da transformada de Fourier; Sinal capturado no canal esquerdo de forma idêntica); Sinal do ouvido esquerdo após uso da transformada de Fourier. ............................................................................................. 14
Figura 9: Representação do trato vocal [11] ............................................................ 17
Figura 10: Produção da fala humana [9] ................................................................. 18
Figura 11: Área de frequências da fala humana [9]. .................................................. 19
Figura 12: Exemplo do manequim KEMAR produzido pela G.R.A.S. visto de varias perspetivas, podem ainda ser observados os vários conectores e simuladores existentes. .............................................................................................. 21
Figura 13: Modelo 4128-C da Bruel&Kjaer com simuladores auditivos e bucal, este modelo é composto por dois microfones com pré-amplificador e um altifalante. .................. 22
Figura 14: Manequim "Madalena" visto de frente e de perfil ......................................... 23
Figura 15: Imagens do perfil do simulador "Madalena" e o pormenor do canal auditivo com o microfone utilizado na aquisição dos sons utilizados no estudo apresentado. .......... 23
Figura 16: Interface desenvolvida no laboratório C.I.P.I.C; permite escolher o sujeito o azimute e a elevação e são mostradas as HRTF e HRIR correspondentes. .................. 25
Figura 17: HRTFs para a experiência com o microfone montado por cima da pinna para o ouvido esquerdo [18] ................................................................................. 27

xii
Figura 18: HRTFs para a experiência com o microfone montado a entrada do canal auditivo para ambos os ouvidos [18].......................................................................... 28
Figura 19: Resultado das várias transformadas do ATK mencionadas. ............................. 29
Figura 20: Uma das cabeças disponíveis para realizar a descodificação binaural do ATK for Reaper .................................................................................................. 29
Figura 21: Imagem dos óculos de realidade virtual a serem desenvolvidos pelo Facebook. ... 30
Figura 22: Tecnologias de realidade virtual a serem desenvolvidas pelo Google. Do lado esquerdo a Cardboard e do lado direito os óculos Daydream. ................................ 31
Figura 23: Diagrama de blocos dos processos eletroacústicos constituintes do simulador ..... 32
Figura 24: Processo de aquisição dos sinais sonoros ................................................... 33
Figura 25: Resultados da primeira fase de processamento de sinal a) Visiveis as três ocorrências do sinal capturado pelos canais auditivos; b) Apenas uma ocorrência do sinal capturado onde se observam os efeitos combinados da ILD e da ITD. ................ 34
Figura 26: Interface criada para validar o uso do manequim ........................................ 36
Figura 27: HRIR e HRFT onde são visíveis as pistas espectrais de uma fonte colocada a 70° .. 37
Figura 28: Ilustração do espaço que contêm uma cabeça e uma fonte sonora a uma distância que tende para infinito. ............................................................................. 38
Figura 29: HRTFs dos sinais que chegam ao ouvido direito, após algum processamento de sinal. .................................................................................................... 39
Figura 30: HRTFs dos sinais adquiridos pelo ouvido esquerdo após algum processamento de sinal. .................................................................................................... 39
Figura 31: Diagrama de blocos do script de Matlab capaz de desenhar os gráficos das HRTFs ........................................................................................................... 41
Figura 32: Resultado da transposição do gráfico waterfall apresentado anteriormente para as HRTFs do ouvido direito .......................................................................... 42
Figura 33: Resultado da transposição do gráfico waterfall apresentado anteriormente para as HRTFs do ouvido esquerdo ....................................................................... 43
Figura 34: Dados da amplitude dependente apenas da posição da fonte sonora para podermos observar como esse comportamento altera quando a frequência for alterada. ................................................................................................ 43
Figura 35: Dados para a frequência de 6336 Hz Vs. Aproximação A*sen(θ) ....................... 45
Figura 36: Resultados da aproximação feita para os dados do canal do ouvido direito ......... 45
Figura 37: Resultado da aproximação A*sen(θ) feita para os dados do ouvido esquerdo ....... 46
Figura 38: Diagrama de blocos do banco de filtros desenhado para implementação das funções ILD artificiais. ............................................................................... 47
Figura 39: Diagrama de blocos da interface criada para a experiência ............................ 47

xiii
Figura 40: Diagrama de blocos do funcionamento da interface criado para a realização de experiência de validação dos simuladores ........................................................ 48
Figura 41: Resultados dos testes. ......................................................................... 50
Figura 42: Sugestão para a montagem do canal de saída do manequim [1] ....................... 52

xiv
Lista de tabelas
Tabela 1: Relação entre as variáveis utilizadas na criação do eixo que indica o ângulo da posição da fonte sonora .............................................................................. 40
Tabela 2: Correção da relação entre as variáveis utilizadas na criação do eixo que indica o ângulo da posição da fonte sonora ................................................................. 40

xv
Abreviaturas e Símbolos
Lista de abreviaturas (por ordem alfabética)
API Application Programming Interface
ARI Acoustics Research Institute
C.I.P.I.C Center for Image Processing and Integrated Computing
DEEC Departamento de Engenharia Electrotécnica e de Computadores
DFT Discrete Fourier Transform
FEUP Faculdade de Engenharia da Universidade do Porto
GUI Guide User Interface
HRIR Head Related Impulse Response
HRTF Head Related Transfer Functions
HTS Head and Torso Simulator
ILD Diferença Interaural de Nível
IRCAM Institut de Recherch et de Coordination Acoustique/Musique
ITD Diferença Interaural de Tempo
SDMD Sound Design para Medias Digitais
Lista de símbolos
θ Ângulo que representa o deslocamento horizontal de uma fonte sonora
Φ Ângulo que representa o deslocamento vertical de uma fonte sonora
r Distância entre o centro da cabeça e a fonte sonora


1
Introdução
O corpo humano tem vindo a ser motivo de estudo há muitos séculos, mas o que tem de
fácil e fascinante tem de difícil e complexo. A fala e a audição são dois exemplos perfeitos
deste equilíbrio. A capacidade humana em comunicação oral está bem documentada e há pouco
do seu funcionamento que não seja conhecido, facilmente compreendido e recriado. No verso
desta moeda, está a capacidade de ouvir, apesar de o funcionamento mecânico não ser difícil
de estudar e entender, reproduzir a audição humana é mais complexo e até ao momento desta
dissertação verifica-se que há muito por ser documentado. Mas do que já se conhece é que a
forma do corpo humano ser diferente para cada um de nós provoca diferenças na forma como
ouvimos um mesmo som.
Será então válido esperar que seja possível generalizar a audição humana com apenas um
simulador (na forma de um manequim) equipado com um sistema de audição? Ou as diferenças
serão de tal grandeza que tornam inválido substituir um ser humano por um manequim, em
certas situações?
Na área da comunicação acústica este tipo de simuladores têm bastante utilidade, uma vez
que se trata de um sistema autónomo e objetivo na captação e produção de sinais sonoros,
libertando desta forma o ser humano de tarefas que ocupam bastante tempo, como fazer testes
a aparelhos auditivos, auriculares e sistemas de comunicação (Bruel&Kjear 2014). Além disso
os manequins têm ainda a potencialidade de estabilizar a atividade de afinação de microfones,
pois é necessário que o som seja emitido sempre com o mesmo espectro de frequências, no
mesmo ponto do espaço e com a mesma intensidade, algo que um ser humano não é capaz de
fazer, mas atualmente estes manequins já se encontram no mercado, oferecidos por algumas
empresas com este propósito, mas o futuro poderá levar os simuladores a outras atividades.
Com o desenvolvimento das tecnologias de comunicação multimédia verifica-se a crescente
necessidade de registar a origem, simultaneamente, sonora e visual de um evento, colocando
assim os manequins no centro da captação binaural e 3D. Para que estas captações e futuras
utilizações das mesmas sejam fiáveis é necessário conhecer as funções de transferência da
cabeça (HRTF) e formas de manipulação, de maneira a fazer coincidir a posição aparente da
fonte sonora com a da fonte visual.

2
Com estas possibilidades em mente já existem alguns desenvolvimentos neste tipo de
simuladores. Algumas empresas já criaram os seus próprios manequins que são atualmente
utilizados para atividades como as acima indicadas, por exemplo em automóveis. Estes
desenvolvimentos serão abordados em detalhe mais a frente.
Este documento apresenta todo o processo realizado no estudo da audição e fala humana,
assim como o trabalho desenvolvido para estudar a utilização de um manequim capaz de
libertar o ser humano durante a realização de algumas atividades exaustivas, longas e
repetitivas nomeadamente na concretização da audição espacial humana.
1.1 Motivações para a dissertação
O mundo da realidade virtual é cada vez mais realista e a componente do som tem que
acompanhar a evolução da imagem. Os simuladores abordados nesta dissertação, quando
revelados todos os seus segredos, podem ser utilizados para tornar universos de realidade
virtual ainda melhores e mais precisos. Quanto mais este simuladores forem desenvolvidos mais
pormenores se vão descobrir sobre o sistema auditivo humano, até ao ponto em que seremos
capazes de recriar a audição humana sem necessidade de recorrer a sinais capturados por
simuladores.
Em preparação para este trabalho foi concluída uma unidade curricular de Sound Design
para Media Digitais, o contacto com os materiais desta UC permitiu abrir uma linha de trabalho:
APIs e plugins para software utilizado no mundo da multimédia e entretenimento, como cinema
e jogos. No desenrolar da UC foram desenvolvidos vários trabalhos que me colocaram em
contacto com alguns plugins já em funcionamento, mas todos eles estão de alguma forma
dependentes do uso de uma cabeça humana, o processo proposto por esta dissertação para a
construção da audição binaural poderá ser o inicio para o melhoramento de APIs e plugins já
existentes.
1.2 Objetivos da dissertação
Partindo de um manequim já existente, constituído por cabeça e torso, será necessário
dotá-lo das capacidades humanas de audição e fala, integrando um subsistema de captação

3
binaural com dois microfones colocados à entrada de ambos os canais auditivos e um subsistema
de reprodução sonora através de um altifalante colocado na cavidade atrás da boca.
O primeiro objetivo será obter um manequim completamente funcional e independente,
isto é, com um canal duplo de entrada e um de saída adaptados para ligação a um computador
com uma interface analógica-digital de áudio apta a controlar o manequim de uma forma
simples e flexível em qualquer altura e por qualquer pessoa é o produto ideal que orienta o
presente estudo, contudo dada a dimensão do estudo possível na presente dissertação limitou-
se o tratamento do problema à audição direcional e ao estudo da produção da fala.
Para validar a utilização de ambos os subsistemas com a finalidade de libertar o ser humano
em certas funções de comunicação, é necessário utilizar algum processamento de sinal, sendo
desta forma fundamental criar o objetivo de uma formação mais profunda na área de
tratamento de sinais auditivos, com principal foco no estudo das pistas contidas no seu espectro
para determinação da direção de proveniência de um som e na relação complexa entre os sons
recebidos pelos dois ouvidos.
Com o domínio do conhecimento espectral e da audição binaural, é criado assim o segundo
objetivo que consiste em avaliar até que ponto o som ouvido por uma pessoa através das HRTF
de outra pessoa é indistinguível do som que é recebido pelas próprias HRTF, de tal forma, que
a pessoa possa conseguir uma boa noção da direccionalidade desse som.
O terceiro objetivo será o de produzir sons de fala com a mesma intensidade, espetro e
distribuição espacial da fala humana, para o que será necessário utilizar um processo de
equalização do som a reproduzir pelo altifalante colocado por trás da abertura da boca do
simulador para minimizar as influências da cavidade.

4
2 Audição Humana
A complexidade da audição torna-a de tão fascinante quanto robusta pois os seres humanos
são capazes de identificar com muita precisão a fonte sonora e muitas das suas características,
como por exemplo a diferença de timbre em notas musicais, instrumentos musicais
desafinados, presença de ruído, a direção de onde originou o som, etc..
Sons conhecidos são mais facilmente reconhecidos, quando ouvimos o nosso nome somos
capazes de identificar a sua direção e ficar a prestar atenção, mesmo que não seja uma voz
conhecida, e desta forma responder adequadamente na direção da fonte emissora. Mas como
é que esta capacidade funciona? Para dar resposta a esta pergunta é necessário compreender
o sistema auditivo humano e de que forma o cérebro processa a informação que lhe chega, pois
o som emitido e o som analisado no cérebro não são coincidentes.
Para darmos inicio ao estudo da audição humano temos primeiro que compreender em que
estado chega o evento sonoro ao sistema auditivo. A física é capaz de explicar as ações que
levam as alterações sofridas por um evento sonoro emitido por uma fonte durante o seu
percurso, desde o momento em que é produzido e o momento em que é captado pelo aparelho
auditivo para ser alvo de um processamento. Cada alteração que acontece é adicionada ao
sinal e transportada ao longo de toda a viagem, fornecendo ao cérebro toda a informação
necessária para a sua descodificação e, desta forma sermos capazes de reconhecer as várias
características tanto do som como da fonte, entre elas a sua posição no espaço. As deformações
da onda sonora que acontecem são devido a reflexões nos limites do meio onde viaja, refrações
e difrações em obstáculos e paredes, espalhamento do sinal. A estes fenómenos físicos
acrescentam-se ainda os fenómenos de modificação acústica que são causados pelo tronco e
cabeça do corpo humano, com o seus tamanhos e formas, que são diferentes de pessoa para
pessoa. Estes verificam-se principalmente para frequências mais elevadas, e as diferenças
levam a que cada pessoa ouça o mesmo som de forma diferente.

5
2.1 O som e as fontes sonoras
A física define o som como a propagação de uma frente de compressão mecânica em forma
de uma esfera, apenas em meios materiais. Todos os materiais têm massa e elasticidade
específicas o que vai limitar a velocidade de propagação, no entanto esta propagação não
acontece de forma espontânea, é sempre necessário existir uma quantidade de energia que dê
inicio a esta ação, a isto chamamos a ação da fonte sonora. O fenómeno físico do som está
sempre associado a uma sensação auditiva contudo os termos infrassons e ultrassons não nos
são estranhos e sabemos que querem dizer que se trata de sons que se encontram a frequências
impercetíveis ao ouvido humano (Mateus, Andrade et al. 1990).
Uma onda sonora tem algumas características que são importantes de nomear e relembrar,
comecemos pelo período, T (𝑠), o tempo que uma onda sonora demora a repetir valores
anteriores das características da forma de onda é o seu período. Algumas ondas sonoras
repetem-se de forma cíclica, se contabilizarmos o número de ciclos numa unidade tempo
falamos então de frequência, f (𝐻𝑧), que é inversamente proporcional ao período. Falemos
agora da amplitude, outra característica importante nos sistemas acústicos, numa
representação gráfica, a amplitude é o desvio máximo do valor em relação à linha do zero
convencionado. Nas ondas sonoras, a quantidade de maior interesse e para a qual se mede a
amplitude é a pressão, que é definida pela força que é exercida pelas moléculas de ar por
unidade de superfície, sendo o pascal (Pa) a unidade de medida usada em geral, embora por
vezes nos estudos de fala se possa encontrar o barye 𝑑𝑖𝑛𝑒 𝑐𝑚2⁄ .
É ainda importante fazer a distinção entre as terminologias altura e volume de um som.
Através da frequência pode definir-se uma escala de graves a agudos. Uma posição nesta escala
está associada à característica de um som que nos causa uma sensação que nós associamos à
altura de um som, quanto maior for a altura mais agudo é o som e a sua frequência. A variação
de pressão permite estabelecer uma escala entre fraco e forte. Uma posição nesta escala está
associada à característica que o ser humano chama volume (ou sonoridade), que aumenta com
a amplitude da variação da pressão (Mateus, Andrade et al. 1990).
Podem definir-se mais algumas quantidades acústicas que não estão relacionadas com a
psicologia humana, como a intensidade sonora (𝑤𝑎𝑡𝑡 𝑚2⁄ ) que se traduz na quantidade de
energia transmitida por unidade de tempo por unidade de superfície. O ouvido humano tem a
capacidade de ouvir uma gama de amplitudes com grandes variações e para podermos lidar
computacionalmente como esta gama dinâmica do ouvido humano foi criado o deciBel, dB,
uma décima parte do Bell, uma notação logarítmica utilizada para exprimir relações de
potências (Mateus, Andrade et al. 1990).
Uma onda sonora propaga-se no tempo mas também no espaço a uma velocidade
dependente do meio (𝑐 = 340𝑚/𝑠 no ar) e da sua temperatura, se a onda for periódica terá

6
periocidade temporal e espacial, a distância percorrida pela onda durante o espaço de tempo
de um período T à velocidade de propagação denomina-se comprimento de onda, 𝜆 = 𝑐 ∗ 𝑇 =
𝑐/𝑓, sendo o meio de propagação constante e mantendo-se as suas características inalteradas,
existe uma relação direta de proporcionalidade entre o período e o comprimento de onde e a
constante de proporcionalidade dessa relação é a velocidade c, quanto maior for o período
maior será o comprimento de onda.
Figura 1: Onda sinusoidal com período 𝟐 ∗ 𝒑𝒊 com 4 repetições
Infelizmente, a grande parte dos sons a que estamos expostos, incluindo a fala humana,
não apresenta estas características de uma forma explicita como as ondas sinusoidais, pois na
realidade sons como a fala são sons complexos, compostos pela combinação de várias ondas
sonoras com timbres, frequências, volumes e sensações sonoras diferentes.
Como referido acima, um sinal sonoro precisa de um meio de transporte para se propagar,
seja esse meio sólido, gasoso ou líquido. Para que a onda se possa propagar ela causa
compressão e rarefação sucessivas das partículas que constituem o meio onde o som está a ser
emitido, Figura 2, estas ações podem ocorrer mais próximas ou afastadas umas das outras
dependendo da densidade do material que constrói o meio de transporte.
Figura 2: Ilustração da capacidade de deslocamento de uma onda sonora através das ações
de compressão e rarefação das partículas do meio.
T
A

7
Após a emissão o som segue um caminho direto ao recetor, mas também segue em milhares
de caminhos diferentes em várias direções até chegar ao recetor através de reflexões nas
superfícies delimitadores do espaço, estas ondas chegam com atraso e com menor intensidade
em comparação ao som direto. A entrada do ouvido o som direto e todas as reflexões
combinam-se naturalmente.
2.2 O ouvido humano
O ouvido humano e todo o sistema auditivo influenciam a percepção da onda sonora
recebida, de tal forma que é necessário compreender o seu funcionamento antes de avançar.
A energia acústica do sinal é captada pelo ouvido externo e convertida para energia mecânica
que sofre uma transformação ao transitar no ouvido médio durante o percurso para o ouvido
interno onde é transformada em impulsos bioelétricos que são enviados para o sistema nervoso
auditivo central para serem processados e interpretados pelo córtex auditivo, Figura 3 (Nazaré
2009).
Figura 3: Divisão tripartida do ouvido nas partes relevantes e que processam
acusticamente o sinal sonoro, assim como os elementos influenciadores da forma como um som é codificado (Rowden 1992)
De forma mais detalhada, na chegada à pinna e concha o sinal sofre alterações influenciadas
pelas ressonâncias provocadas pela forma em concha do ouvido e ainda pela chegada das
reflexões vindas das várias direções o que provoca variações de pressão no tímpano.

8
Entre a concha e o tímpano situa-se o canal auditivo, que pode ser considerado um tubo
com comprimento constante, aberto numa ponta e fechado na outra pelo tímpano e as suas
paredes têm uma impedância elevada, desta forma pode ser interpretado como uma guia de
ondas unidimensional (Blauert 1983, Streicher and Everest 1998), o som que chega ao tímpano
já sofreu duas amplificações, a primeira ocorre devido a difração do sinal em torno da cabeça,
a segunda acontece devido a uma ressonância à frequência correspondente ao quádruplo do
comprimento do canal auditivo, o que provoca um aumento da pressão acústica. Juntos estes
fenómenos podem levar a um aumento de 20dB da pressão sonora junto ao tímpano (Streicher
and Everest 1998).
No ouvido médio encontramos três ossículos responsáveis pela transformação da energia
mecânica; ao serem excitados pelo tímpano, o movimento dos ossículos provoca, por sua vez,
a transmissão do movimento através da janela oval para o fluido no ouvido interno com
eficiência máxima (Streicher and Everest 1998).
No ouvido interno encontramos a cóclea que é um tubo em forma de espiral que vai
diminuindo de espessura, a base mais larga encontra-se junto a janela oval e é mais sensível
ás altas frequências, a outra extremidade termina de forma pontiaguda e é sensível ás baixas
frequências. Quando o sinal sonoro chega a esta fase do sistema auditivo provoca o movimento
do fluído no interior, que por consequência transporta esse movimento a duas membranas que
possuem de forma distribuída células ciliadas que estão ligadas a fibras do nervo auditivo por
sua vez ligado ao cérebro (Streicher and Everest 1998, Nazaré 2009).
Todas as alterações que o som sofre no seu trajeto acrescentam informação importante ao
sinal para que o cérebro possa realizar o processamento de toda a informação recebida, para
tal existem quatro mecanismos indispensáveis para a descodificação da localização de uma
fonte sonora, sendo o primeiro o tempo de atraso do sinal direto que existe entre as chegadas
do som aos dois ouvidos e é conhecido como ITD (Interaural time difference), o segundo, a
diferença de nível de pressão sonora entre os sinais que chegam a cada um dos ouvidos,
denominada ILD (Interaural level difference), o terceiro, o espetro do sinal recebido e, quarto,
os micro-movimentos da cabeça que ajudam em casos de ambiguidades (Blauert 1983, Zhong
and Xie 2014). Com a exceção da última pista que não é possível analisar matematicamente,
toda a informação apresentada está presente nas HRTF de uma pessoa.
A audição humana tem capacidades limitadas tanto no espetro das frequências como no
volume de um som que é capaz de ouvir. Começando pelas frequências, o ser humano é capaz
de ouvir sons que se estendam dos 20 Hz aos 20kHz. Contudo iremos limitar inferiormente a
banda de frequências aos 250Hz pois abaixo deste limite a literatura não é precisa sobre a
relevância dos conteúdos sonoros para a localização da fonte sonora. Este limite foi também
utilizado nas recolhas de sinais de respostas impulsionais binaurais da cabeça realizadas no
âmbito de um trabalho de dissertação anterior (Martinho 2015) que será mencionado adiante
quando for tratado o caso do manequim “Madalena”. A perceção da intensidade tem como
9
limite inferior de pico a pico uma vibração da ordem de grandeza de duas moléculas de ar, já
o limite superior será o que causar dor ao ser humano uma vez que o limiar da dor é um dos
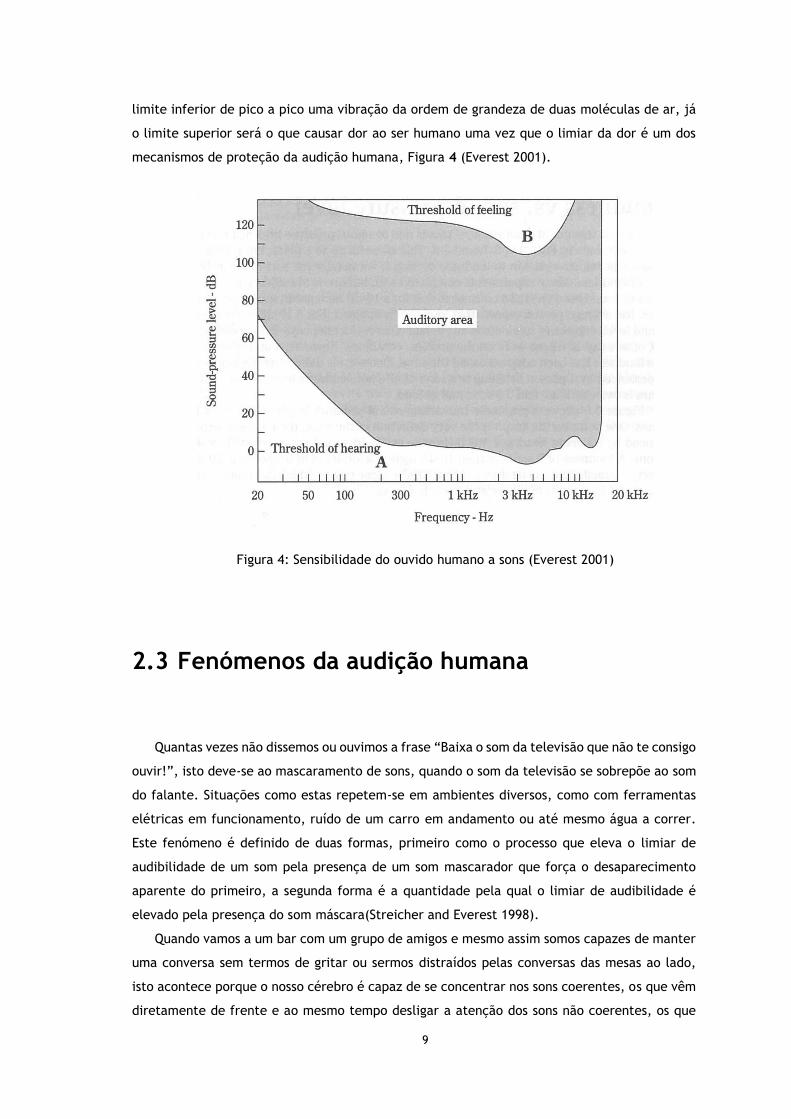
mecanismos de proteção da audição humana, Figura 4 (Everest 2001).
Figura 4: Sensibilidade do ouvido humano a sons (Everest 2001)
2.3 Fenómenos da audição humana
Quantas vezes não dissemos ou ouvimos a frase “Baixa o som da televisão que não te consigo
ouvir!”, isto deve-se ao mascaramento de sons, quando o som da televisão se sobrepõe ao som
do falante. Situações como estas repetem-se em ambientes diversos, como com ferramentas
elétricas em funcionamento, ruído de um carro em andamento ou até mesmo água a correr.
Este fenómeno é definido de duas formas, primeiro como o processo que eleva o limiar de
audibilidade de um som pela presença de um som mascarador que força o desaparecimento
aparente do primeiro, a segunda forma é a quantidade pela qual o limiar de audibilidade é
elevado pela presença do som máscara(Streicher and Everest 1998).
Quando vamos a um bar com um grupo de amigos e mesmo assim somos capazes de manter
uma conversa sem termos de gritar ou sermos distraídos pelas conversas das mesas ao lado,
isto acontece porque o nosso cérebro é capaz de se concentrar nos sons coerentes, os que vêm
diretamente de frente e ao mesmo tempo desligar a atenção dos sons não coerentes, os que

10
vêm de múltiplas direções e com níveis mais baixos, a esta capacidade chamamos o efeito
Cocktail Party.
Quando não temos deficiências no sistema auditivo somos todos capazes de reconhecer a
direção de um som que está a ser emitido por uma fonte, mas esta realidade torna-se mais
fácil quando o sinal sonoro a ser emitido já nos é conhecido, como a voz da nossa mãe ou o
nosso nome. Nestes casos, o erro de localização de uma fonte sonora é mais baixo quando
comparado com o de fontes que estão a emitir sons desconhecidos ou que estamos a ouvir pela
primeira vez. O volume e distância de uma fonte sonora não são quantidades lineares entre si
e desta forma podem influenciar de forma errada a nossa decisão em relação à localização de
uma fonte emissora, quando alguém está a falar muito alto a nossa interpretação é de que se
encontra a uma maior distância do que aquela a que poderá estar (Blauert 1983).
2.4 Localização de uma fonte sonora
Visualmente somos capazes de dizer ou apontar para a localização da fonte sem ser
necessário indicar as coordenadas geográficas no espaço, mas para trabalharmos e
compreendermos matematicamente as posições de uma fonte sonora é necessário definirmos
um sistema de três coordenadas no espaço centrado na cabeça do ouvinte, são elas um ângulo
no plano azimutal (θ), um ângulo de elevação (Φ) e a distância ao centro da cabeça (r), são
então criados três planos importantes que colocam a cabeça no centro dos eixos do sistema e
a fonte sonora num ponto no espaço bem definido, o plano horizontal composto pelos eixos x
e y, o plano frontal formado pelos eixos x e z e o plano medial criado pelos eixos y e z, como
é apresentado na Figura 5.

11
Figura 5: Planos estruturantes do espaço onde se localiza a fonte sonora e a cabeça do
ouvinte.
Para o cérebro esta informação passa na forma das HRTF que podem ser analisadas
matematicamente após a sua captura, juntamente com o valor do atraso Interaural (ITD) e
diferença de nível Interaural (ILD).
A Figura 6 mostra a localização de uma fonte no espaço tridimensional e como se posiciona
em relação a cabeça e órgãos auditivos.
Figura 6: Sistema de coordenadas para localização de uma fonte sonora, com origem no
centro da cabeça e localizado no espaço definido na Figura 5.
Estamos agora em condições de continuar o estudo da audição humana com as análises das HRTFs (head related transfer functions).
y
Plano Horizontal/Azimutal
Plano Medial/Sagital z
X
Y
z
X
Percurso entre fonte
e ouvidos
θ
Φ
Y
Fonte sonora
𝑆𝑧
𝑆𝑦 𝑆𝑥 𝑆
r – Distância entre o
centro de cabeça e a fonte
sonora

12
2.5 Audição Binaural
Os seres humanos devido a possuírem normalmente dois ouvidos funcionais são capazes de
ter uma audição binaural, pois esta é descrita como o resultado da existência de dois órgãos
sensíveis a sons separados e com um mecanismo de processamento neuronal com a capacidade
de combinar toda a informação acústica recebida e desta forma recolher a informação espacial
auditiva.
A audição binaural tem vindo a ser elemento de fascínio em várias áreas e durante muitos
anos. Inicialmente acreditava-se que a única pista ou, pelo menos, a mais importante no
fornecimento de informação direcional era a diferença de nível entre os dois ouvidos, a ILD,
com o decorrer do tempo e os estudos já realizados sabemos agora que isto não se verifica. A
ILD, apesar de ser uma das pistas direcionais mais complexas é também das mais estudadas e
por isso já existem algumas conclusões retiradas, por exemplo para provocar uma sensação de
lateralização é necessária uma ILD menor para frequências perto dos 2kHz, embora na
literatura seja também indicado o valore de 1,5 kHz, para a mesma diferença o grau de
deslocamento é maior para frequência mais baixas e mais pequeno para as altas frequências,
chegamos assim a conclusão que a ILD é dependente da frequência (Blauert 1983). Quanto
maior for a frequência do sinal maior será o obstáculo criado pela cabeça, por consequência
da diminuição do comprimento de onda, a este fenómeno dá-se o nome de Head Shadow. O
obstáculo criado pela cabeça e tronco é a razão da existência do fenómeno físico de difração
em torno da parte superior do corpo que por sua vez é a causa da diferença do nível de pressão
de sinal entre os dois ouvidos.
A ILD não é a única responsável por fornecer pistas espaciais ao cérebro, existe ainda a
diferença do tempo de chegada do sinal aos ouvidos direito e esquerdo. Para o ser humano, a
distância que separa externamente os dois órgãos é de aproximadamente 15 centímetros e é
responsável pela diferença no tempo de chegada do sinal acústico aos ouvidos, denominada
por ITD, contudo esta diferença não nos é percetível no momento de receção do sinal, mas o
nosso cérebro é capaz de a analisar, sendo as baixas frequências as mais afetadas pela ITD, isto
porque a diferença de fase não ultrapassa um período do sinal entre os dois ouvidos sendo, no
entanto, da mesma ordem de grandeza as amplitudes. A 7 mostra a diferença entre o sinal
recebido pelo ouvido esquerdo e o recebido pelo ouvido direito para uma fonte sonora frontal
deslocada de 40º para a direita no plano horizontal, pode ser observada tanto uma diferença
nos tempos de chegada como no nível de pressão acústica entre os dois ouvidos, o som direto
chega primeiro ao órgão direito, e com maior amplitude também, uma vez que a fonte se
encontra mais próxima deste lado, pois para chegar ao lado esquerdo o sinal acústico encontra
a cabeça como obstáculo o que quer dizer que tem uma maior distância para percorrer e vai

13
sofrer ainda alguma atenuação. Mais adiante será explicado o procedimento levado a cabo para
obter este resultado.
Figura 7: Sinais recebidos por cada um dos ouvidos quando a fonte se encontra a 40º para
a direita no plano mediano.
Blauert mencionou em 1983, que é necessário ter em atenção o tempo de exposição a um
som, pois um sistema estimulado por um longo período de tempo leva a que haja uma
habituação por parte do ser humano e, por consequência, uma diminuição da sensibilidade,
este fenómeno está dependente do tipo de som, do nível e do comprimento do sinal. Existem
dois motivos que provocam a dessensibilização, são eles a adaptação e a fadiga, contudo, psico-
-acusticamente estes fenómenos são difíceis de distinguir, mas influenciam a capacidade de
lateralização de uma fonte sonora. A primeira razão para a dessensibilização do sistema de
audição atua de forma rápida e inicia-se ao fim de alguns segundos, a readaptação demora
cerca de 1 a 2 minutos a acontecer, a segunda razão deve-se a sinais mais longos e intensos, o
regresso ao normal leva mais tempo nesta situação.
Com isto em mente é a altura de abordar um conceito introduzido por Cremer, a Lei da
primeira frente de onda (Streicher and Everest 1998), ou seja, o som que chega aos ouvidos é
composto pelo sinal que viaja da fonte para o individuo de forma direta e todas as reflexões
que chegam depois, vindas de várias direções, esta diferença nas chegadas é especialmente
importante em espaços pequenos que oferecem um grande número de reflexões, a primeira
frente de onda é o sinal direto e é este que será o ponto de interesse para a dissertação
apresentada. Como existem dois órgãos de audição vão existir duas frentes de onda quando
uma das fontes emissoras sofre um atraso superior a 1 ms o ouvinte sente que a localização do
som se deslocou no sentido da fonte que não sofreu atraso, este fenómeno mantém-se até aos
30 ms a partir daqui começam a ouvir-se ecos. Algo que vale a pena mencionar, quanto maior
for o atraso entre os sinais nos dois ouvidos mais baixo vai parecer o volume do sinal mais
atrasado, de tal forma que com um atraso de 15 ms é necessário um aumento de 10 dB do nível

14
do sinal no ouvido em atraso para que a diferença de volume seja contrariada (Streicher and
Everest 1998).
Nem todos os seres humanos têm os dois órgãos auditivos totalmente funcionais e como tal
o seu sistema auditivo não pode ser analisado da mesma forma como o de outra pessoa com
audição perfeita. Já têm sido realizadas algumas investigações sobre a audição binaural onde
participam indivíduos com os dois órgãos auditivos funcionais e indivíduos com funcionalidade
em apenas um dos órgãos sendo os resultados indicadores de que dispondo de apenas um ouvido
torna-se mais difícil focar a atenção numa só fonte sonora.
2.6 HRTF
Ao realizar uma experiência de captura de um sinal acústico a entrada dos canais auditivos
é rica em informação, para o trabalho realizado focamo-nos apenas na informação necessária
para indicar a localização da fonte sonora. Esta informação apresenta-se como uma função
recebida pelo cérebro com vários picos e vales criados pelas reflexões, refrações e difrações
que acontecem na viagem entre origem e destino, a transformada de Fourier é a ferramenta
usada para esta análise e, desta forma, obter os espectros dos sinais capturados, como pode
ser visto na Figura 8.
Figura 8: (de cima para baixo e da esquerda para a direita) Sinal capturado à entrada de
dos canais auditivos, as HRIR; Sinal capturado no canal direito após o uso de uma janela suficientemente pequena para não ser influenciada pela chegada do primeiro eco; Sinal do ouvido direito após uso da transformada de Fourier; Sinal capturado no canal esquerdo de forma idêntica); Sinal do ouvido esquerdo após uso da transformada de Fourier.
A partir dos gráficos da Figura 8 somos capazes de observar que a fonte se encontra do lado
direito, conclusão que pode ser obtida porque o sinal adquirido no canal auditivo direito está

15
adiantado em relação ao sinal capturado do lado esquerdo, existindo concomitantemente uma
diferença no nível entre os dois sinais; o sinal do lado direito (denominado ipsilateral) tem
maior energia do que o do lado esquerdo (denominado contra lateral). Em seguida são
analisados os espectros de ambos os sinais auditivos com o objetivo de encontrar os picos e
vales que fornecem informação ao cérebro, que, juntamente com o atraso e diferença de nível
de pressão entre os ouvidos, permitem a localização da fonte sonora, no que alcança bastante
precisão.
Os dados apresentados nos quatro gráficos inferiores da Figura 8 são os mesmos do gráfico
superior. O que distingue a coluna com os gráficos do lado esquerdo é serem as HRIR (head
related impulse response) enquanto que a coluna com os gráficos do lado direito apresenta as
respetivas HRTF (head related transfer functions) obtidas através da transformada de Fourier
(Zhong and Xie 2014).

16
3 Fala Humana
O corpo humano funciona como a combinação de vários sistemas em simultâneo e o
processo da fala humana é o exemplo perfeito do funcionamento em relativa harmonia de
funções com atividade simultânea, como comer e respirar, através do funcionamento dos
músculos e válvulas sem que ocorram erros, quando estamos com pressa e tentamos fazer tudo
ao mesmo tempo o resultado é que comida poderá seguir o percurso errado e entalamo-nos
demorando o sistema alguns segundos a recuperar. A capacidade de falar é o meio de
comunicação mais básico e eficaz de transmissão de informação e é ainda o mais rápido e
expressivo em comparação com outras formas de comunicação, como a língua gestual. Se
fizermos uma comparação rápida entre comunicação falada e a comunicação mediada pelo
telégrafo vemos que são dois métodos diferentes de transmitir a mesma mensagem, têm ainda
o mesmo débito de informação, contudo o que a mensagem falada transmite a mais é emoção,
personalidade, etc.(Gold and Morgan 2000).
3.1 Órgãos de produção da fala humana
O ser humano tem a aptidão de produzir fala de uma forma muito variável e momentânea,
sendo composta por energia distribuída em frequência, pressão sonora e tempo. Existem três
órgãos responsáveis pela produção da fala: (1) os pulmões e a traqueia, que podemos considerar
como sendo as fontes geradoras de energia, a traqueia é responsável por fazer chegar ao resto
do sistema o ar fornecido pelos pulmões, por norma não contribuem de forma audível para a
fala mas são responsáveis pela sua intensidade, (2) a laringe que é o mecanismo principal para
a geração de sons, é um sistema complexo de músculos e cartilagens, incluindo as cordas
vocais, que realizam, além de funções biológicas e acústicas entre as quais proteção de
processo respiratório e permitir a acumulação de pressão no tórax e abdómen, vibrações que
são o principal método de excitação da fonte sonora da fala e, (3) o trato vocal, representado
na figura 9, que engloba tudo acima das corda vocais e é composto por uma série de estruturas
e regiões que realizam várias funções biológicas e acústicas, à semelhança da laringe e pode
ser considerado um sistema acusticamente ressonante, com cerca de 17 cm desde as cordas
vocais até aos lábios. O trato vocal, Figura 9, é capaz de modular o som resultante, uma vez
que não é um tubo linear mas sim um tubo que vai mudando de forma ao longo do seu percurso
por causa da presença da língua e as suas ressonâncias são dependentes das várias formas que
este toma, o que torna a resposta em frequência dependente da sua forma. Algo que também

17
deve ser levado em consideração, é que a língua é um músculo com movimento, que provoca
não só alterações de forma da cavidade oral e da faringe mas também constrições quase
completas que produzem efeitos acústicos importantes e até oclusões temporárias (Parsons
1987, Everest 2001).
Figura 9: Representação do trato vocal (Parsons 1987)
O início do processo da fala reside no cérebro que, após ser decidido o que vai ser falado,
comanda os músculos do tórax e o diafragma para pressionarem os pulmões e desta forma dar
inicio aos processos mecânicos de produção da fala (Trujillo). A descrição mais básica deste
processo é que o ar forçado pelos pulmões, no momento de expiração, é a causa da vibração
das cordas vocais e o som emitido por este movimento viaja pelos tratos vocal e nasal, até sair
pela boca e/ou nariz, dependendo do tipo de som a produzir.
É possível identificamos três tipos de fontes sonoras para sons da fala, um deles são as
cordas vocais, responsáveis pelos sons vocálicos e vocálicos nasalados produzidos pela vibração
criado pela passagem do ar. São sons que têm normalmente uma duração elevada,
foneticamente são vogais orais e/ou nasaladas. Outro tipo de fontes de produção de sons de
fala são criadas pela língua, dentes ou lábios que pelo movimento que têm forçam o ar sob
pressão a passar pelos constrangimentos formados pelos elementos mencionados produzindo
turbulências na passagem do ar com produção associada de ruído, criando os sons de fonemas
denominados fricativos, que são representados pelas letras f, s, ch, v, z e j. Para completar a

18
lista de tipos de fontes sonoras da fala humana é possível identificar ainda os sons produzidos
pela paragem completa do fluxo de ar por oclusão do trato vocal seguida de libertação
completa do ar de uma forma repentina formando os fonemas representados pelas letras p, t,
k, b, d e g a que chamamos os sons plosivos (Mateus, Andrade et al. 1990, Everest 2001). A
vibração das cordas vocais ou ausência da mesma divide ainda a fala em dois tipos de sons, os
vozeados, quando existe vibração, e os não-vozeados, no caso contrário. Para finalizar, ambos
os grupos exemplificados acima enquadram-se numa terceira categoria de sons, as consoantes
que contêm ainda as consoantes nasais, as líquidas, as rolantes e as africadas, mas estes sons
são muito dependentes da forma como a língua portuguesa é falada. Concluímos assim os vários
tipos de sons da fala humana e as suas respetivas fontes (Mateus, Andrade et al. 1990, Everest
2001).
Figura 10: Produção da fala humana (Everest 2001)
A Figura 10 resume então a produção da fala humana desde a fonte até a emissão pela
boca, mas este processo não é feito num só passo, vamos agora ver quais os mecanismos
necessários para que haja discurso audível a sair da nossa boca.
3.2 A fisicalidade da fala humana
Existem quatro mecanismos físicos que o corpo humano realiza para proceder a produção
do discurso: iniciação, fonação, processo oro-nasal e articulação.
O processo de iniciação é o momento em que o ar é expelido pelos pulmões passando pela
laringe através das cordas vocais, que se encontram com uma abertura pequena no caso de ser
um som vozeado. Se se encontrarem completamente abertas a vibração é mínima e temos
então os sons não-vozeados.
O comprimento das cordas vocais é maior para os homens em comparação com as mulheres,
sendo as frequências de vibração inversamente relacionadas. A este processo chama-se fonação
Sons Vocálicos
Sons Plosivos
Sons Fricativos
Trato Vocal Emissão da fala pela boca

19
de um som. Depois da laringe o ar passa pela faringe e daqui pode seguir pela cavidade oral ou
nasal. O palato identificado na figura 9, bloqueia a passagem do ar para o nariz direcionando-
o assim para a boca, sendo este o terceiro processo na fala identificado como o processo ora-
nasal. A fase de articulação acontece na boca e é o que nos permite produzir a maior parte dos
sons utilizados na fala humana, devido à contribuição de todos os elementos constituintes da
cavidade oral que juntamente com a garganta e a cavidade nasal criam os vários tipos de
ressonâncias. A língua é a maior responsável pela variedade de volume e forma que a cavidade
oral pode assumir (Trujillo). Esta combinação de formas e efeitos é capaz de alterar o som a
ser produzido através de uma filtragem dos seus harmónicos e desta forma modificar o timbre
produzido (Kinsler, Frey et al. 1982).
A vibração das cordas vocais produz uma sequência de frequências, chamados harmónicos
naturais, cada um com frequência múltipla da frequência fundamental. É nos nossos ouvidos
que o timbre de um som e a sua frequência fundamental são avaliados. Quanto às frequências
harmónicas, que têm amplitudes de valores inferiores à fundamental, não é possível ouvir
algumas frequências por impedimento das antirressonâncias e outras frequências são
privilegiadas porque ressoam bem na sua passagem pelo trato vocal (Rowden 1992).
Figura 11: Área de frequências da fala humana (Everest 2001).
A Figura 11 mostra a área de frequências que o ser humano produz no processo de produção
de fala (sombreado) em comparação com as frequências que é capaz de ouvir (tracejado), o
ouvido humano é sensível a uma quantidade muito superior de frequências aquelas que é capaz
de produzir.
A frequência fundamental da fala depende do orador, do seu estado de espirito, da ênfase
e da emoção que atribuir à mensagem que está a ser produzida e é a magnitude e a relação
entre as ressonâncias que faz com que os sons de discurso sejam facilmente reconhecidos
(Rowden 1992).

20
4 Simuladores com manequins e o manequim “Madalena”
Quando a audição humana começou a ser estudada era necessária a colaboração de seres
humanos no processo de captação, colocando microfones à entrada dos canais auditivos dos
indivíduos, mas era preciso que a cabeça se mantivesse imóvel durante todo o processo, algo
que o ser humano tem dificuldade de conseguir durante um período de tempo prolongado,
levando assim a alguns erros e incerteza em todo o processo e seus resultados. Com o tempo e
os desenvolvimentos alcançados na área, foram criados alguns substitutos artificiais para estas
tarefas, sob a forma de manequins, para utilizar, nomeadamente em testes de sistemas,
equipamentos e dispositivos de comunicação acústica.
A produção da fala por um simulador como o Madalena tem a grande vantagem de ter
características uniformes e bem controladas, emitidas pelo período de tempo necessário sem
alterações, algo que o ser humano não é capaz de fazer com a mesma qualidade.
4.1 K.E.M.A.R
Knowles Eletronic, atualmente pertencente á G.R.A.S., foi a primeira empresa em 1972 a
comercializar um manequim antropométrico, chamado Knowles Eletronics Manikin for Acoustic
Research, que permitiu realizar testes extensivos e repetitivos a aparelhos auditivos
minimizando desta forma o erro humano. Este manequim tem as dimensões de um adulto de
estatura média respeitando as normas ANSI S3.36/ASA58-2012 e IEC 60318-7:2011.
A Figura 12 mostra algumas perspetivas do K.E.M.A.R, do lado mais a esquerda pode ser
observado que todas as ligações por cabos, a amplificadores ou sound devices, ao simulador
são feitas na parte traseira. As duas perspetivas mais a direita do manequim mostram o canal
de saída pronto a ser utilizado, existe, contudo uma versão com a boca fechado caso o
utilizador esteja apenas interessado em utilizar o canal de entrada. A quando da aquisição de
um destes manequins o utilizador pode escolher a pinna que quiser de todas disponibilizadas
pela G.R.A.S, a empresa tem a disposição vários conjuntos de acessórios que se adaptam a
necessidade do utilizador (G.R.A.S 2017).

21
Figura 12: Exemplo do manequim KEMAR produzido pela G.R.A.S. visto de varias
perspetivas, podem ainda ser observados os vários conectores e simuladores existentes.
Nos últimos 45 anos foram desenvolvidos vários modelas do K.E.M.A.R, todos eles
completamente adaptáveis a situações desejadas. A G.R.A.S permite ainda que após a compra
inicial haja espaço para evolução do conjunto de acessórios adquiridos inicialmente, ou seja o
utilizador pode sempre comprar novos acessórios para modificar o manequim de base que
adquiriu readaptando-o assim as suas necessidades
Este produto é utilizado principalmente em teste de aparelhos auditivos, auriculares,
microfones e todo o tipo de aparelhos de comunicação que contenham um ou mais destes
elementos (G.R.A.S 2017).
4.2 Head and Torso Simulator (HTS)
A empresa Bruel&Kjaer, produtora de equipamentos acústicos, foi a criadora de manequim
mais famoso entre os vários simuladores que existem no mercado. Os modelos 4128-C e 4128-
D representam um adulto de estatura média, com pescoço ajustável de forma a melhorar
posição da cabeça e otimizar a situação para a qual está a ser utilizada, contêm ainda um
simulador bocal e dois simuladores dos órgãos auditivos que consistem em moldes de borracha
da pinna consistentes com a norma IEC 60318–4/ITU‐T Rec. P.57 Type 3.3 (Bruel&Kjear
2014).
A Figura 13 apresenta estes simuladores estilizados com o canal de entrada embutido no
interior da cabeça, não havendo uma solução sem produção de fala. Quanto ao canal de
entrada, possível ver do lado direito da figura, cada simulador auditivo consiste de uma pinna
de silicone em conjunto com um canal auditivo dentro das normas IEC 60318.

22
Figura 13: Modelo 4128-C da Bruel&Kjaer com simuladores auditivos e bucal, este modelo
é composto por dois microfones com pré-amplificador e um altifalante.
De acordo com a data sheet do manequim as suas aplicações variam entre testes precisos
a telefones, aparelhos mãos-livres, auriculares, aparelhos auditivos, análises de situações que
possam ocorrer em locais pequenos como o interior de um carro e calibração de microfones e
protetores auditivos.
4.3 O Manequim “Madalena”
O manequim utilizado como apoio ao estudo desta dissertação é o molde de uma dadora,
ex-aluna de Bioengenharia da FEUP, no decorrer de uma unidade curricular. O molde negativo
foi feito com silicone e o manequim realizado, posteriormente, com silicone e fibra de vidro
em seguida preenchido localizadamente por espuma de poliuretano. Ambos os canais auditivos
estão equipados com um microfone de eletrete de 6 mm colocado à entrada. As orelhas são
removíveis, o que permite fazer experiências que envolvam a comparação entre vários
tamanhos de ouvidos ou tipos de microfones. Para facilitar o transporte, foi colocada uma placa
de madeira na parte inferior do manequim com quatro espaçadores de plástico de alguns
centímetros de altura para permitir a inserção de uma mão.
Em comparação com os manequins apresentados anteriormente, o manequim tem a
particularidade de ser um molde de uma pessoa o que ainda não tinha sido feito entre nós,
como pode ser observado na Figura 14. Este processo tem a vantagem de aproximar o simulador
das medidas e formas do corpo humano o que por sua vez melhora o estudo das HRTFs. O
material com que são construídos estes manequins também vai influenciar o estudo da audição

23
binaural, não pode ser demasiado absorvente da energia sonora pois as reflexões do sinal no
corpo humano também são importantes para o cérebro processar a localização de uma fonte
sonora.
Na Figura 15 podemos observar o manequim de perfil e o microfone utilizado na captura
dos sinais alvos de análise durante dota esta dissertação.
Figura 15: Imagens do perfil do simulador "Madalena" e o pormenor do canal auditivo com
o microfone utilizado na aquisição dos sons utilizados no estudo apresentado.
Ambos os canais auditivos são removíveis no caso de se querer mudar os microfones ou até
mesmo estudar a influência da forma da concha para a audição binaural, nesse caso há a
possibilidade de fazer o molde dos ouvidos de outra pessoa e colocar no manequim e fazer um
novo estudo.
Figura 14: Manequim "Madalena" visto de frente e de perfil

24
5 Opções binaurais já existentes
O corpo humano é alvo de interesse há muitos anos e a audição humana não tem passado
despercebida, mas até recentemente não havia interesse por parte dos consumidores e o
resultado é que havia estudos e trabalhos fechados em gavetas. Alguns dos trabalhos sobre
audição binaural são agora apresentados. Desde bases de dados de HRTFs bastantes completas,
a API a serem desenvolvidas por empresas como a Google e plugins para software de sound
design, atualmente qualquer pessoa pode entrar em contacto com estas tecnologias.
5.1 C.I.P.I.C Interface Laboratory
Formado originalmente no Centro de Processamento de Imagem e Computação Integrada,
o laboratório de interface do C.I.P.I.C pesquisa a relação da perceção humana com as interfaces
entre humanos e máquinas e é constituído por especialistas de várias áreas da engenharia,
processamento de sinal e psicofísica. O trabalho de pesquisa encontra-se focado no som
espacial e síntese acústica 3D (Algazi 2001).
Usando 45 sujeitos e, duas cabeças KEMAR uma com pinna pequena e outra com pinna
grande, foram realizadas 25 capturas azimutais entre os −90° e 90°, 50 capturas em elevação
entre −90° e 270°, em 200 instantes no tempo e a partir destes sinais foram calculadas as HRIR.
A base de dados contém ainda aquisições adicionais com o manequim KEMAR nos planos
frontal e horizontal. Para a realização de uma captura foram levados em consideração dois
aspetos principais: a sua influência para as HRTF e se a sua realização era fiável e razoável.
Para completar a base de dados são ainda disponibilizados os dados antropométricos dos
indivíduos colaborantes para a experiência das aquisições, estes dados foram obtidos por
fotografias de alta resolução, medições e ferramentas digitais 3D. A interface foi desenvolvida
pela equipa do Professor V. R. Algazi (Algazi 1998, Algazi 2001) .
Um dos trabalhos de pesquisa desenvolvidos neste laboratório pelo Professor V. R. Algazi
foi uma interface que mostra as respetivas HRTF e HRIR para cada um dos indivíduos do grupo
participante na captura de sinais, a Figura 16 mostra interface deste trabalho.

25
Figura 16: Interface desenvolvida no laboratório C.I.P.I.C; permite escolher o sujeito o
azimute e a elevação e são mostradas as HRTF e HRIR correspondentes.
Qualquer um dos parâmetros pode ser alterado, o utilizador pode escolher uma cabeça
diferente e as HRFT serão calculadas de novo, pode ainda escolher qualquer uma das posições
captadas e os gráficos apresentados serão alterados para apresentar o resultado do novo
cálculo, correspondente as novas escolhas do utilizador.
5.2 IRCAM Database
Localizado no coração de Paris, o centro do IRCAM tem como principal objetivo desde a sua
abertura em 1977 aliar a investigação científica, o desenvolvimento tecnológico e a música
numa só criação artística.
Com o progresso em mente, não é então de estranhar que tenham realizado uma
investigação própria sobre aquisição de HRIR e composto uma base de dados pronta para
download e de utilização livre.
A experiência realizada para a captura dos sons foi realizada numa câmara anecoica de
324𝑚3, revestida por cunhas de lã de vidro de 1,1m de comprimento, capazes de absorver o
som com frequência acima dos 75 Hz. O equipamento de aquisição foi colocado num tabuleiro
metálico configurável.
A coluna de som emissora é montada numa grua com forma de “U”, os braços da grua são
cobertos por painéis de espuma de melanina para diminuir as reflexões e o motor que provoca
a elevação é controlado por um computador que escolhe o ângulo do passo da grua que suporta
a coluna.

26
O sujeito que servirá de base de aquisição encontra-se sentado numa cadeira rotativa, com
apoio para os pés e cabeça para ajudar o individuo a manter uma posição estável durante todo
o processo, o ângulo de azimute é escolhido pelo software e o feedback é enviado por um
sensor ótico. Para confirmação da posição da cabeça é utilizado um aparelho de controlo de
posição da cabeça ligado ao software e colocado no topo da cabeça do sujeito, o sinal é apenas
enviado quando a cabeça estiver na posição correta e é guardada a posição correta da
aquisição.
O par de microfones utilizado foi da Knowles o modelo miniatura FG3329, condensador de
eletrete omnidirecional, a cápsula do microfone foi colocada numa proteção de silicone
ajustável ao sujeito, inserida à entrada o canal auditivo impedindo desta forma ressonâncias
indesejadas, foi ainda desenhado um pré-amplificador com um ganho de 40 dB, o altifalante
usado foi da Tannoy modelo 600 com um amplificador da Yamaha. Todo o processo foi
controlado pela interface de áudio I/O box RME Multiface com 36 canais 24 bits/96 kHz.
Atualmente a base de dados é composta por medições feitas com 51 sujeitos em 187 pontos
de captura para cada um deles, mas a primeira vez que esta base de dados foi compilada
continha apenas 46 indivíduos. Em elevação são sempre usados os mesmos 10 ângulos a começar
nos −45° até 90° com um passo de 15° para cada valor de elevação o sujeito sofre também uma
rotação de 15°, daí os 187 pontos de captura para cada sujeito.
É possível fazer duas coisas com a base de dados: a primeira é uma experimentação online,
o IRCAM tem disponíveis demos das capturas azimutais, assim quem tiver curiosidade sobre
audição binaural pode ouvir um som modulado em movimento em torno da sua cabeça. A
segunda possibilidade é fazer o download dos ficheiros de todas as capturas da base de dados
no formato WAV e ainda, para cada sujeito, há apenas um ficheiro Matlab que contém uma
estrutura capaz de armazenar toda a informação relevante sobre o sujeito em causa. Junto
com o download são também disponibilizados dados equalizados de forma a garantir que os
dados possam ser alterados em alturas diferentes e por aparelhos diferentes (Warusfel 2003).
5.3 ARI HRTF Database
O Instituto de Investigação Acústica é um braço da Academia de Ciências Austríaca,
multidisciplinar e dedicado a aplicação de investigação acústica baseada em fundamentação
matemática. Integra as áreas da fonética, psico-acústica, física computacional e matemática
com o objetivo de cobrir todas as questões que possam surgir no processo de estudo da acústica
que envolve sempre vários passos desde a produção até à perceção do som. Contudo o instituto

27
mantém-se aberto a outras áreas de trabalho desde que estas sejam colaborativas com as já
existentes no espaço.
A experiência levada a cabo pelo ARI foi realizada numa sala semi-anecoica com 22
altifalantes colocados em posições de elevações fixas entre −30° e 80° ao longo de um arco
móvel, os altifalantes foram ligados a uma interface de áudio MA-5D da Edirol. Todo o
equipamento e suportes foram cobertos por materiais absorventes de som para reduzir as
reflexões. O par de microfones escolhidos para a captação foram Sennheiser KE-4-221-2. O
sujeito foi sentado no centro do arco com os microfones colocados a entrada dos canais
auditivos e ligados a pré-amplificadores que por sua vez foram ligados à interface de áudio
mencionada. O sinal sonoro utilizado foi um varrimento de frequências entre os 50Hz e os 20kHz
com uma duração de 1728,8ms.
As HRTFs foram recolhidas para cada valor de azimute com as suas várias elevações.
Concluídas todas as capturas para um ângulo de azimute o sujeito foi rodado com um passo de
2,5° para o próximo valor dentro da gama de valores ±45°. Para todos os outros valores de
ângulos de azimute o passo foi de 5°, totalizando assim 1550 HRTF para cada sujeito. Esta base
de dados contém informação de 150 sujeitos. Durante toda a experiência foi ainda controlado
o movimento da cabeça com um dispositivo próprio para este objetivo, de modo que se a
posição da cabeça não se encontrasse dentro dos parâmetros aceites a medição era repetida
de imediato. O procedimento de aquisição das HRTFs foi repetido mas desta vez com
microfones montados por cima da pinna no suporte de um aparelho auditivo. Os resultados são
apresentados para comparação e as grandes diferenças a olho nu entre os dois métodos de
aquisição das HRTF está na atenuação que o sinal sofre pelo forma da concha, como podemos
ver nas Figura 17 e Figura 18.
Figura 17: HRTFs para a experiência com o microfone montado por cima da pinna para o
ouvido esquerdo (INSTITUTE)
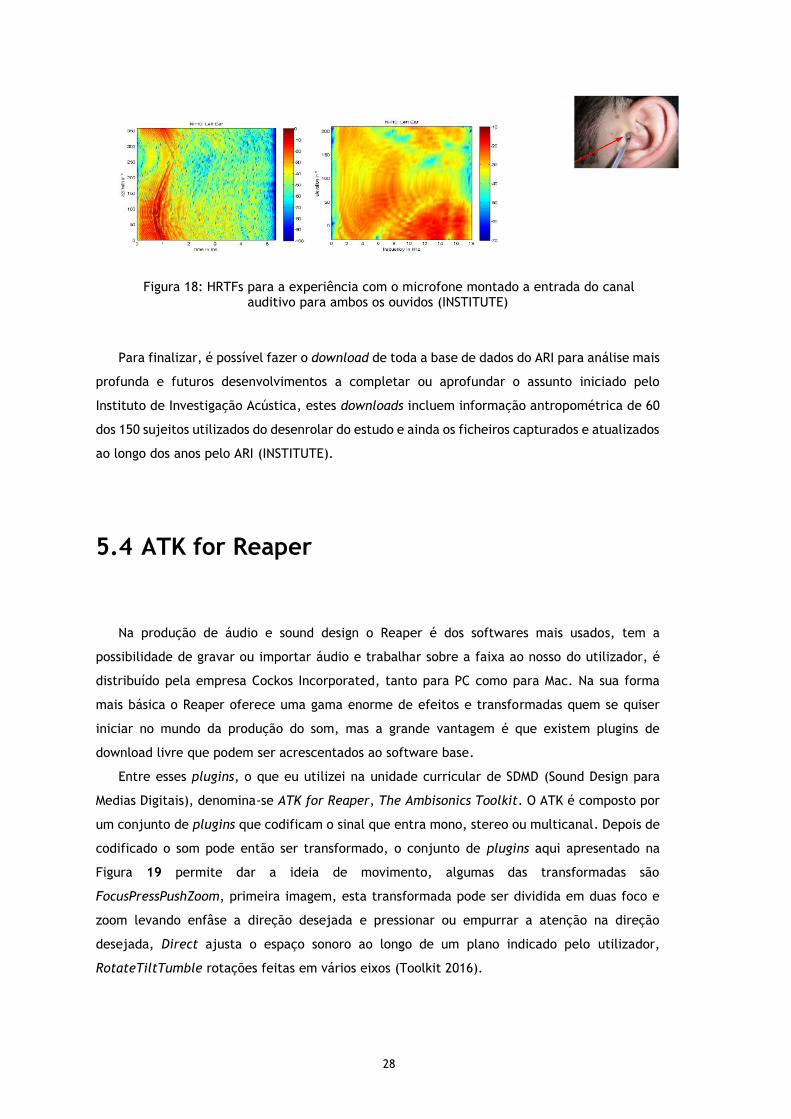
28
Figura 18: HRTFs para a experiência com o microfone montado a entrada do canal
auditivo para ambos os ouvidos (INSTITUTE)
Para finalizar, é possível fazer o download de toda a base de dados do ARI para análise mais
profunda e futuros desenvolvimentos a completar ou aprofundar o assunto iniciado pelo
Instituto de Investigação Acústica, estes downloads incluem informação antropométrica de 60
dos 150 sujeitos utilizados do desenrolar do estudo e ainda os ficheiros capturados e atualizados
ao longo dos anos pelo ARI (INSTITUTE).
5.4 ATK for Reaper
Na produção de áudio e sound design o Reaper é dos softwares mais usados, tem a
possibilidade de gravar ou importar áudio e trabalhar sobre a faixa ao nosso do utilizador, é
distribuído pela empresa Cockos Incorporated, tanto para PC como para Mac. Na sua forma
mais básica o Reaper oferece uma gama enorme de efeitos e transformadas quem se quiser
iniciar no mundo da produção do som, mas a grande vantagem é que existem plugins de
download livre que podem ser acrescentados ao software base.
Entre esses plugins, o que eu utilizei na unidade curricular de SDMD (Sound Design para
Medias Digitais), denomina-se ATK for Reaper, The Ambisonics Toolkit. O ATK é composto por
um conjunto de plugins que codificam o sinal que entra mono, stereo ou multicanal. Depois de
codificado o som pode então ser transformado, o conjunto de plugins aqui apresentado na
Figura 19 permite dar a ideia de movimento, algumas das transformadas são
FocusPressPushZoom, primeira imagem, esta transformada pode ser dividida em duas foco e
zoom levando enfâse a direção desejada e pressionar ou empurrar a atenção na direção
desejada, Direct ajusta o espaço sonoro ao longo de um plano indicado pelo utilizador,
RotateTiltTumble rotações feitas em vários eixos (Toolkit 2016).
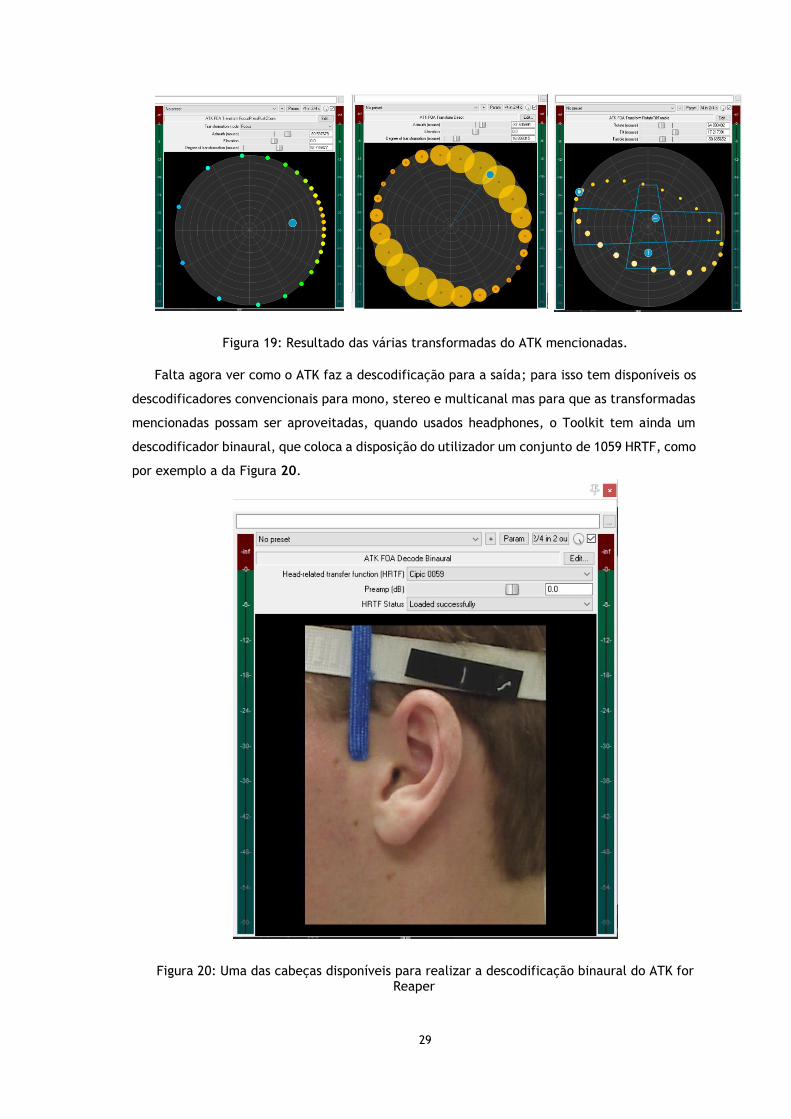
29
Figura 19: Resultado das várias transformadas do ATK mencionadas.
Falta agora ver como o ATK faz a descodificação para a saída; para isso tem disponíveis os
descodificadores convencionais para mono, stereo e multicanal mas para que as transformadas
mencionadas possam ser aproveitadas, quando usados headphones, o Toolkit tem ainda um
descodificador binaural, que coloca a disposição do utilizador um conjunto de 1059 HRTF, como
por exemplo a da Figura 20.
Figura 20: Uma das cabeças disponíveis para realizar a descodificação binaural do ATK for
Reaper

30
O plugins acede a base de dados disponível pelo CIPIC e utiliza as HRTF para fazer a
descodificação do trabalho realizado pelo utilizador.
5.5 Oculus (Facebook)
A serem desenvolvidos pelo Facebook os Oculus são uns óculos de realidade virtual
completamente imersivos com suporte para PC, mobile e até estações de jogos. Mas como tudo
o que o Facebook faz a ideia é ser partilhado e, por isso, qualquer pessoa que queira
desenvolver uma aplicação ou software e utilizar o sistema de realidade virtual do Oculus pode,
pois disponibilizam o SDK (software development kit) com toda a documentação e plugins
necessários para incorporar um sistema de realidade virtual no projeto, Figura 21 (Oculus
2018).
Figura 21: Imagem dos óculos de realidade virtual a serem desenvolvidos pelo Facebook.
No caso de ser um técnico de som que queira espacializar um projeto os programadores
tem disponíveis um software de produção de áudio, idêntico ao Reaper, mas focado na criação
de vídeos com áudio interativo denominado Facebook 360 Spatial Workstation.

31
5.6 Daydream e Cardboard (Google)
Tal como o Facebook o Google também tem tecnologias de realidade virtual disponíveis, a
Daydream idêntica aos Oculus, torna a experiência completamente imersiva, no caso da
Carboard é um acessório barato que pode ser montado junto ao telemóvel tornando a realidade
virtual simples e acessível, Figura 22.
Figura 22: Tecnologias de realidade virtual a serem desenvolvidas pelo Google. Do lado
esquerdo a Cardboard e do lado direito os óculos Daydream.
Esteja um programador a trabalhar em Android, Unity, IOS, ou outro sistema qualquer a
Google tem disponível tanto os SDK como os API para que o utilizador possa construir o seu
projeto com um mundo de realidade virtual. Um elemento importante será então o áudio, de
modo que a empresa disponibiliza um plugins de áudio para várias plataformas; é cabe ao
utilizador escolher qual a que prefere, Android Studio, Reaper e outros softwares do género,
Unity, IOS, WEB, etc..

32
6 Processos Eletroacústicos
Para dar início à parte prática deste trabalho foi necessário desenhar um diagrama de
blocos onde se define a cadeia dos processos objectivo, Figura 23.
O sistema de entrada do manequim são os dois microfones colocados nos canais auditivos,
responsáveis pela captura dos sons produzidos por uma fonte sonora próxima do simulador. O
sistema de saída é concretizado por um altifalante colocado numa cavidade aberta na boca do
manequim capaz de reproduzir voz humana de uma forma fiável, a realizar em trabalhos
futuros.
6.1 Audição
Em média uma cabeça humana tem um diâmetro de cerca de 15 centímetros, é possível
fazer capturas estéreo se colocarmos dois microfones isolados a 15 cm de distância, mas desta
forma não temos a riqueza de informação binaural proveniente da forma da cabeça e do tronco
humano. No âmbito de uma dissertação anterior (Martinho 2015) foi realizado um processo de
aquisição de HRIR usando o manequim Madalena, no qual foram utilizados varrimentos de
frequências e impulsos, á frequência de amostragem de 96 kHz. O simulador (manequim) foi
utilizado na captura dos varrimentos de frequências ou impulsos produzidos por um altifalante
colocado numa posição fixa, com o eixo principal horizontal e o manequim foi colocado num
suporte rotativo com motor. O suporte foi rodado até que o manequim completasse uma volta,
o passo do movimento causado pelo motor foi de 2º, como representa a Figura 24. O sinal foi
repetido três vezes em cada posição e o processamento foi realizado por Adobe Audition para
Amplificador Software Manequim
Fala
Manequim
Audição Pré-Amplificador Interface Áudio PC
Figura 23: Diagrama de blocos dos processos eletroacústicos constituintes do simulador

33
estimular, recolher as respostas e desconvolucionar as HRIR (head related impulse responses).
Foi utilizado um plugins do Audacity para gerar os estímulos(Martinho 2015).
Já no âmbito da presente dissertação o processamento foi principalmente realizado com o
objetivo de estudar as HRTF do manequim e colocar a questão: até que ponto são capazes de
ser generalizadas para todos os seres humanos?
Os sinais gerados (chirps logarítmicos) percorrem as frequências desde os 250 Hz até 20kHz
no intervalo de 2 segundos. A literatura é escassa no que diz respeito á relevância das
frequências abaixo dos 250 Hz para a espacialização e por isso não se deu valor a frequências
nesta gama. Por consequência o processo de aquisição foi acelerado devido a diminuição de
reverberações nas paredes da sala por eventuais sinais de baixa frequências (Martinho 2015).
Para que as HRTF possam ser analisadas corretamente é necessário realizar o subsequente
processamento de sinal, que consiste em convoluir e filtrar os sinais sonoros capturados. Os
resultados destas operações fornecem-nos as primeiras versões utilizáveis das funções
desejadas. A Figura 25 mostra o resultados obtidos para uma orientação do manequim
correspondente a 70° (portanto do lado direito do manequim).
Madalena
Figura 24: Processo de aquisição dos sinais sonoros

34
Figura 25: Resultados da primeira fase de processamento de sinal a) Visiveis as três
ocorrências do sinal capturado pelos canais auditivos; b) Apenas uma ocorrência do sinal capturado onde se observam os efeitos combinados da ILD e da ITD.
Uma vez que há duas repetições do sinal o primeiro passo a dar em seguida em termos de
processamento de sinal é sincronizar e fazer uma média das três ocorrências, para obter um
melhoramento da relação sinal/ruído total.

35
7 Processo Experimental
Para dar inicio ao trabalho desta dissertação foi desenhada uma experiência de localização
de uma fonte sonora. Para tal, foram consideradas algumas ideias para tornar mensurável ou
observável, a direção aparente da fonte sonora tal como é sentida pelo sujeito em teste. Uma
das idéias iniciais era colocar o sujeito sentado numa cadeira, com os olhos vendados,
auscultadores do tipo in-ear, para a reprodução da fonte sonora, e apontar com a mão na
direção aparente da fonte sonora, se esta metodologia de teste tivesse sido a selecionada seria
posteriormente desenvolvido um método de medição do ângulo apontado pelo individuo talvez
uma régua circular que circundasse a cabeça. A grande desvantagem deste teste seriam os
olhos vendados do sujeito que levariam a grandes incertezas da posição do corpo, isto levou à
exclusão da utilização deste método para a fase de testes. Uma segunda ideia foi pedir ao
sujeito que orientasse a cabeça para a fonte, o problema neste caso é que como são utilizados
auscultadores in-ear a fonte sonora não muda de posição com o movimento da cabeça no plano
azimutal. Outra idéia foi apontar para o som reproduzido pela fonte sonora com um segundo
som de direção ajustável, as vantagens deste método é que o sujeito consegue concentrar-se
mais na análise dos sons que está a ouvir e menos nos movimentos físicos que tem que realizar,
diminuindo assim o erro humano relativo à capacidade de interpretação espacial de cada
sujeito em testes. Revendo todas as idéias, a última apresentada é a que revela melhores
hipóteses de obter resultados rigorosos.
O conceito assenta na reprodução repetida do som de referência, cuja orientação espacial
aparente se pretende encontrar. Um segundo som, diferente, com a direção aparente
sintetizado com o modelo composto por processamento de ITD e ILD, é também reproduzido
mediante ação temporal do sujeito. O sujeito ouvinte recrutado com a condição de não ter
deficiências auditivas significativas, ouvirá os dois sons através de auscultadores do tipo in-ear.
Foi criada, em sequência desta escolha, uma interface em Matlab que permitisse ao
utilizador perseguir o sinal áudio de referência com o segundo som digital até que ambos fossem
coincidentes. A interface, representada na Figura 26, tem um botão de play que dá inicio à
reprodução de um dos sinais adquiridos pelo simulador, tem dois botões com setas responsáveis
por deslocar o som digital no sentido escolhido pelo utilizador. Quando este estiver satisfeito
com o resultado, este é guardado após ser pressionado o botão de stop.
Mediante a imagem mental recebida, o sujeito é convidado a utilizar os botões com as setas
de forma a deslocar o som sintetizado até este coincidir em direção aparente com o som de
referência. Os sons sintetizados assumem assim um carácter de perseguidores, sendo o som de
referência, o som perseguido.

36
Figura 26: Interface criada para validar o uso generalizado do manequim
Uma vez que o sinal perseguidor não é produzido por uma fonte sonora física, mas é, sim,
um sinal criado por um script Matlab, é necessário atribuir-lhe as características de um sinal
sonoro como se fosse reproduzido por uma fonte existente no espaço físico colocada numa
certa posição arbitrária e ajustável do espaço. Foram estudadas quais as características que o
sinal perseguidor deveria ter para que se verificasse uma correspondência de orientações física
e sensorial. Numa primeira versão da interface as setas de deslocação apenas atrasavam um
dos sinais enviados aos ouvidos um certo número de amostras, mas desta forma só era possível
gerar sinais com orientações aparentes entre os 90° e −90°, tornando-se por isso necessário
observar os espetros dos sinais capturados e alterar os espectros dos sinais perseguidores de
forma a conterem as pistas de orientação suficientes para criar uma imagem mental correta.
Foram observadas as pistas espectrais, a ITD e a ILD para dar a ilusão de movimento do sinal
perseguidor numa gama de 0° e 360°.
7.1 Pistas Espectrais
Para a análise mais detalhada dos sinais capturados são utilizados os espectros (HRTFs),
que contêm vales e picos ao longo de toda a gama de frequências que são fornecedores de
informação para o cérebro, dependendo da posição o número de vales e picos varia.
Processando as HRIR de um dos sinais por aplicação da Transformada de Fourier vamos
poder observar as HRTF. Analisando atentamente o resultado gráfico destas funções observam-

37
se os vales e picos ao longo do espetro das frequências, como pode ver-se na Figura 27 nos
gráficos do lado direito. Os sinais HRIR extraídos são transformados após janelamento Hamming
com extensão de 501 amostras.
Para se obterem resultados corretos o comprimentos da janela atrás definido teve em
consideração que é necessário excluir dos sinais o primeiro eco e seguintes captados pelos
microfones, pois tratando-se de repetições do sinal causam interferências problemáticas para
a análise desejada.
Figura 27: HRIR e HRFT onde são visíveis as pistas espectrais de uma fonte colocada a 70°
É por este processo que é segundo a literatura (Streicher, 1998) transportada alguma
informação espectral para o cérebro e estes vales e picos podem ser sintetizados por filtros
rejeita banda ou passa banda, respetivamente. Mas nem todos terão a mesma importância
quando descodificados pelo cérebro, os vales mais abertos, com maior largura de banda
rejeitada, serão os de maior relevância, pois acontecimentos de pequena largura de banda,
eventos visíveis por vales muito estreitos são registados pelo cérebro humano como eventos de
menor importância.
Propõe-se começar por replicar os vales mais abertos e com mais atenuação, criando uma
cascata de filtros rejeita banda para cada vale e aplicando o resultado ao sinal perseguidor.
Desta forma foi possível observar e ouvir que o sinal digital sofreu uma deslocação, mas ainda
não fica coincidente com a posição da fonte sonora.

38
7.2 ITD
Um passo essencial a dar na criação do sinal perseguidor é criar o atraso de chegada entre
os sinais que chegam aos dois ouvidos, para tal foi deduzida uma fórmula capaz de calcular a
ITD dependendo de θ, como mostra a Figura 28.
Figura 28: Ilustração do espaço que contêm uma cabeça e uma fonte sonora a uma
distância que tende para infinito.
Dedução da fórmula da ITD:
A distância percorrida pelo sinal entre a fonte e o ouvido direito:
𝐿𝑅 = 𝐿𝑅1 + 𝐿𝑅2
O comprimento do arco 𝐿𝑅2:
𝐿𝑅2 =𝑑
2∗ 𝜃
O comprimento do segmento de reta 𝐿𝑅3:
𝐿𝑅3 = 𝑑
2∗ sen (𝜃)
A ITD é a diferença do tempo de chegada do sinal aos ouvidos, logo podemos dizer,
tal como em (Rossi 1970, Viste and Evangelista 2004), é:
𝐼𝑇𝐷 = |𝐿𝑅 − 𝐿𝐿
𝑐| =
𝑑2 ∗ (sen(𝜃) + 𝜃)
𝑐
Sendo c a velocidade do som no ar de 340 m/s. Será então usada esta fórmula da
ITD para atrasar os sinais digitalmente gerados que chegam a cada um dos ouvidos.
θ
𝐿𝐿
𝐿𝑅1 = 𝐿𝑅3 + 𝐿𝐿
𝐿𝑅2
𝑑/2
𝐿𝑅3
𝐿𝑅3
𝑟 → ∞
y
x
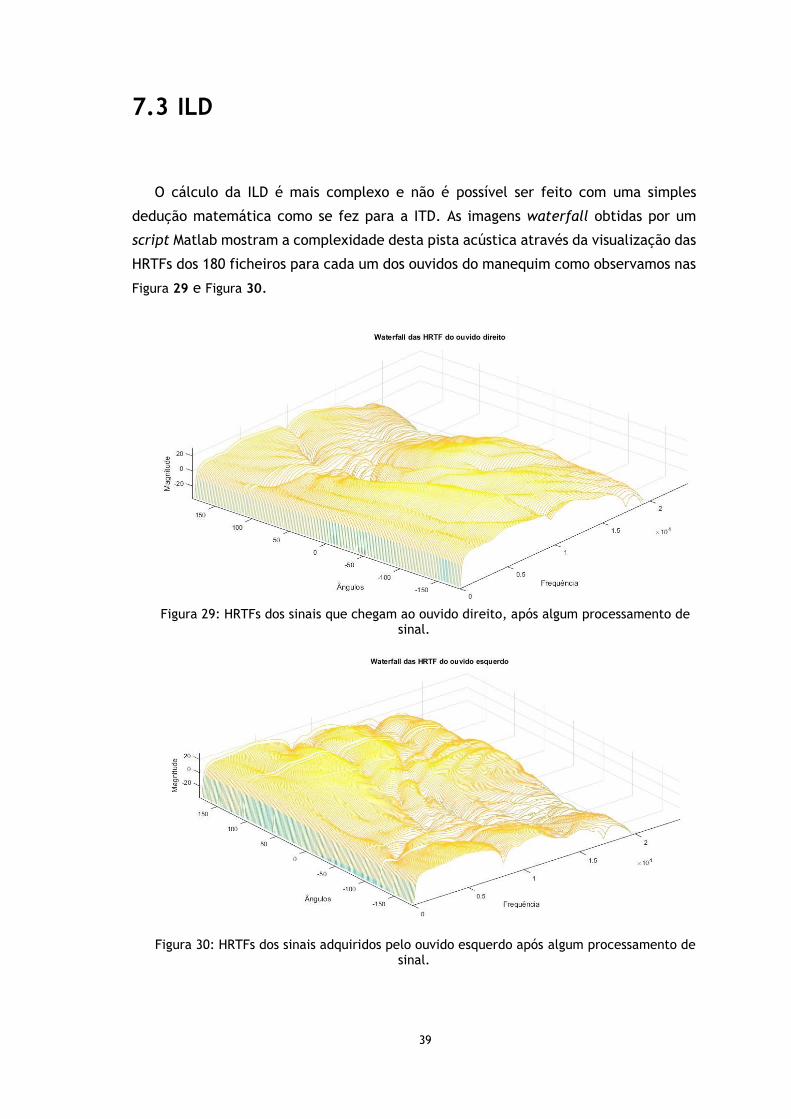
39
7.3 ILD
O cálculo da ILD é mais complexo e não é possível ser feito com uma simples
dedução matemática como se fez para a ITD. As imagens waterfall obtidas por um
script Matlab mostram a complexidade desta pista acústica através da visualização das
HRTFs dos 180 ficheiros para cada um dos ouvidos do manequim como observamos nas
Figura 29 e Figura 30.
Figura 29: HRTFs dos sinais que chegam ao ouvido direito, após algum processamento de
sinal.
Figura 30: HRTFs dos sinais adquiridos pelo ouvido esquerdo após algum processamento de
sinal.

40
A lista original dos ficheiros dos sinais adquiridos encontra-se organizada pela ordem na
qual os sinais foram adquiridos [0° a 358°], mas por uma questão de apresentação e
conveniência de leitura de dados foi necessário reorganizar os ficheiros [-180°a 180°]. Para tal,
foram criadas duas variáveis que se relacionam entre si de forma a construir o eixo das posições
desejado. Enquanto k indexa do número ficheiro que está a ler na ordem desejada e não na
ordem em que a lista foi guardada, k_2 guardará o valor do ângulo correspondente ao ficheiro
que está a ser lido e é este valor que será apresentado no eixo do gráfico. A variável k_1 será
a responsável por calcular o valor do ângulo de k_2, a fórmula usada foi:
𝑘2 = (1 − 𝑘1)𝑥2 + 180
Tabela 1: Relação entre as variáveis utilizadas na criação do eixo que indica o ângulo da
posição da fonte sonora
k k_2 k_1
90 180° 1
180 2° 90
1 0° 91
91 -178° 180
Mais à frente a fórmula teve que ser corrigida pois na realidade a tabela de equivalência
devia mostrar que para k_1 = 90 k_2 deviria ser 2°, mas como já tinha sido realizada uma
grande porção do processamento até este erro ser detetado e como não influencia os dados
apenas a apresentação, a correção apenas foi feita para a geração dos sinais perseguidores.
Tabela 2: Correção da relação entre as variáveis utilizadas na criação do eixo que indica o
ângulo da posição da fonte sonora
k k_2 k_1
90 -180° 1
180 -2 90
1 0° 91
91 178° 180
A fórmula corrigida passa a ser 𝑘2 = (𝑘1 − 1)𝑥2 − 180, os valores são todos simétricos dos
valores da primeira tabela.

41
for k=[91:180 1:90]
Figura 31: Diagrama de blocos do script de Matlab capaz de desenhar os gráficos das HRTFs
Sobrepor janela ao sinal: ylinha_esq e ylinha_dir, respetivamente
Calibrar alterações de amplitude
Lado esquerdo: y_esq
Lado direito: y_dir
Separar os componentes do sinal y
Ler Ficheiro e guardar sinal numa variável: y
Encontrar o máximo de y (max_y)
Usar posição do máximo para definir o centro da janela retangular
Definir os limites inferior e superior da janela
Definir janela de Hamming
Aplicar transformada de Hilbert
Aplicar transformada de Fourier
Definir eixos dos gráficos
end
Desenhar os gráficos

42
Encontrado o máximo do sinal capturado são localizados todos os picos superiores a metade
desse valor, o vetor resultante é ordenado de ordem crescente, desta forma garantindo que a
posição do máximo é facilmente conhecida pois será necessária para definir o centro da janela
retangular usada para evitar que o primeiro eco influencie o processamento de sinal que será
feito, apenas o sinal direto nos interessa. A janela menciona tem uma limite inferior, 𝑛1, e um
limite superior, 𝑛2, definidos de forma que, sendo 𝑛0 o centro da janela:
𝑛1 = 𝑛0 − 250
𝑛2 = 𝑛0 + 250
𝑛2 − 𝑛1 = 500 𝑎𝑚𝑜𝑠𝑡𝑟𝑎𝑠
Após uma primeira versão dos gráficos waterfall foi observado que de 60 em 60 ficheiros
exista um salto de alguns dB, durante o processamento atual foi feito o oposto, encontrando o
multiplicador que contrariasse a ação realizada inicialmente. Este processo foi feito
encontrando a diferença de nível entre dois ficheiros consecutivos que apresentassem um
desnível diferente a outros ficheiros consecutivos, localizando a outra extremidade do bloco
de ficheiros com necessidade de calibração foi inserido no código um pequeno if que elimina o
fenómeno adicionado durante o primeiro processamento de sinal, este processo foi repetido
até que os gráfico fossem os das Figura 29 e Figura 30.
Ainda no mesmo script do Matlab, foi feita uma análise de comportamento dos dados para
um valor dado de frequência e sendo a variável independente a posição da fonte sonora (𝜃),
de forma a tentar caracterizar como varia a ILD em função da orientação. O primeiro passo foi
transpor os gráficos waterfall, como se pode observer nas Figura 32 e Figura 33 e a opção
seguinte foi fazer uma observação individual dos dados.
Figura 32: Resultado da transposição do gráfico waterfall apresentado anteriormente para
as HRTFs do ouvido direito
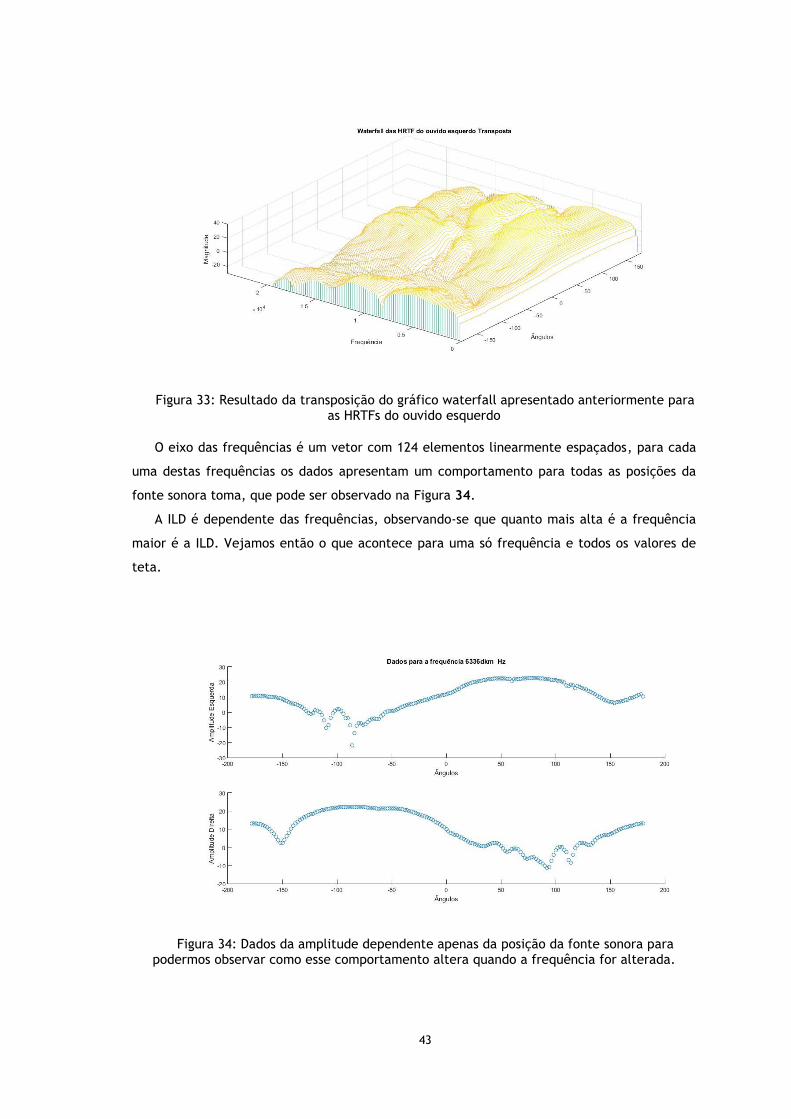
43
Figura 33: Resultado da transposição do gráfico waterfall apresentado anteriormente para
as HRTFs do ouvido esquerdo
O eixo das frequências é um vetor com 124 elementos linearmente espaçados, para cada
uma destas frequências os dados apresentam um comportamento para todas as posições da
fonte sonora toma, que pode ser observado na Figura 34.
A ILD é dependente das frequências, observando-se que quanto mais alta é a frequência
maior é a ILD. Vejamos então o que acontece para uma só frequência e todos os valores de
teta.
Figura 34: Dados da amplitude dependente apenas da posição da fonte sonora para
podermos observar como esse comportamento altera quando a frequência for alterada.

44
Fazendo uma análise idêntica para as várias frequências podemos concluir que os dados se
comportam de uma maneira idêntica em torno dos 0°, com uma forma que se aproxima, a olho
nu, de um seno, tal como é sugerido na Figura 34 e segue o que consta da literatura (Viste,
2004). Vamos então tentar validar esta observação aproximando os dados de amplitude 𝑥(𝜃)
pela função 𝐴 ∗ 𝑠𝑒𝑛(𝜃), recorrendo ao método dos mínimos quadrados para calcular o valor de
A.
Com esta representação a observação e análise dos dados torna-se mais simples e estes
apresentam-se como uma onda sinusoidal, um seno na realidade centrado nos 0°.
Como a média de 𝑥(𝜃) é não-nula, removeu-se o seu valor
𝐴0 =1
𝑙𝑒𝑛𝑔𝑡ℎ(𝑒𝑖𝑥𝑜 Â𝑛𝑔𝑢𝑙𝑜𝑠)∑ 𝑥(𝜃)
𝜃
dos dados, antes do cálculo da aproximação, obtendo-se 𝑥′(𝜃) = 𝑥(𝜃) − 𝐴0. Aplicando-se o
método dos mínimos quadrados foi então realizado sobre 𝑥′(𝜃).
min𝐴 [∑[𝑥′(𝜃) − 𝐴𝑠𝑒𝑛(𝜃)]2
𝜃
] = min𝐴 𝐸
Para E ser mínimo então temos:
𝑑𝐸
𝑑𝐴= 0 ⇔ ∑
𝑑([𝑥′(𝜃)−𝐴𝑠𝑒𝑛(𝜃)]2)
𝑑𝐴𝜃 = ∑ 0 + 2𝐴𝑠𝑒𝑛2(𝜃) − 2𝑥′(𝜃)sen (𝜃)𝜃 = 0
𝑑2𝐸
𝑑𝐴2 > 0
Uma vez que podemos garantir que:
𝐴 > 0
𝑠𝑒𝑛2(𝜃) ≥ 0
2𝐴𝑠𝑒𝑛2(𝜃) ≥ 0
Estamos agora em condições para deduzir a amplitude necessária para a onda sinusoidal de
aproximação aos dados, 𝐴 ∗ 𝑠𝑒𝑛(𝜃), os resultados são apresentados na Figura 35.
∑ 2𝐴𝑠𝑒𝑛2(𝜃)
𝜃
− ∑ 2𝑥′(𝜃)sen (𝜃)
𝜃
= 0
𝐴 =∑ (𝑥(𝜃) − 𝐴0)sen (𝜃)𝜃
∑ 𝑠𝑒𝑛2𝜃 (𝜃)
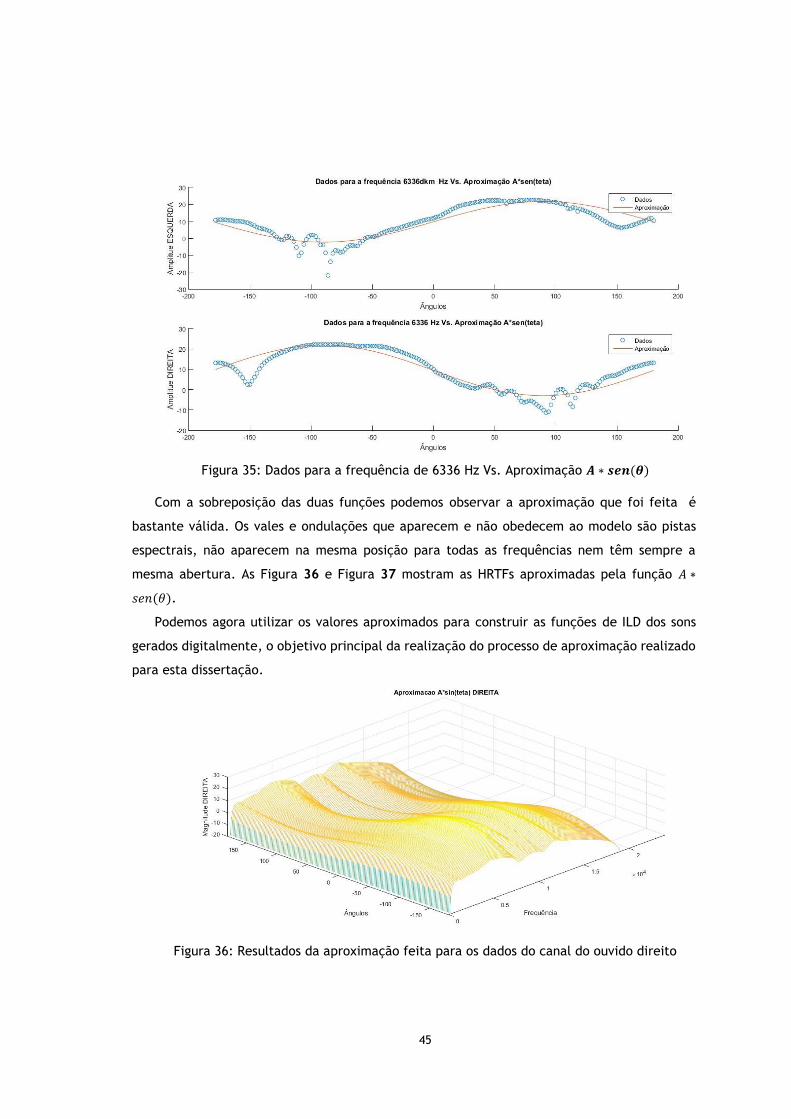
45
Figura 35: Dados para a frequência de 6336 Hz Vs. Aproximação 𝑨 ∗ 𝒔𝒆𝒏(𝜽)
Com a sobreposição das duas funções podemos observar a aproximação que foi feita é
bastante válida. Os vales e ondulações que aparecem e não obedecem ao modelo são pistas
espectrais, não aparecem na mesma posição para todas as frequências nem têm sempre a
mesma abertura. As Figura 36 e Figura 37 mostram as HRTFs aproximadas pela função 𝐴 ∗
𝑠𝑒𝑛(𝜃).
Podemos agora utilizar os valores aproximados para construir as funções de ILD dos sons
gerados digitalmente, o objetivo principal da realização do processo de aproximação realizado
para esta dissertação.
Figura 36: Resultados da aproximação feita para os dados do canal do ouvido direito

46
Figura 37: Resultado da aproximação A*sen(θ) feita para os dados do ouvido esquerdo
O passo seguinte na criação das funções ILD envolve a criação de um banco de filtros para
a sua implementação prática. Como a audição humana está limitada aos 20 kHz vamos apenas
utilizar os valores do eixo das frequências que se mantêm abaixo deste valor, temos então uma
gama de valores [192, 19968] Hz. A orientação da organização das sub-bandas foi inspirada na
distribuição das larguras de banda críticas da audição humana, começando por uma primeira
sub-banda até a gama de 500Hz, seguida de várias sub-bandas proporcionais daí para mais
elevadas frequências. Temos então um primeiro filtro entre as frequências 192 Hz e 576 Hz que
será então um filtro de 576
192= 3 ⟹ 𝑙𝑜𝑔2(3) = 1,6 𝑜𝑖𝑡𝑎𝑣𝑎𝑠. Já o resto do eixo tem
19968
576=
34,67 ⟹ 𝑙𝑜𝑔2(34,67) = 5,11 𝑜𝑖𝑡𝑎𝑣𝑎𝑠, podendo ser dividido em 5 filtros de 5,115⁄ = 1,022
oitavas cada um. No total teremos 6 sub-bandas.
Cada um destes filtros é responsável por filtrar apenas uma parte da função de aproximação
e terá como ganho a média de valores da função de aproximação dentro da sua banda, como
está ilustrado na Figura 38.
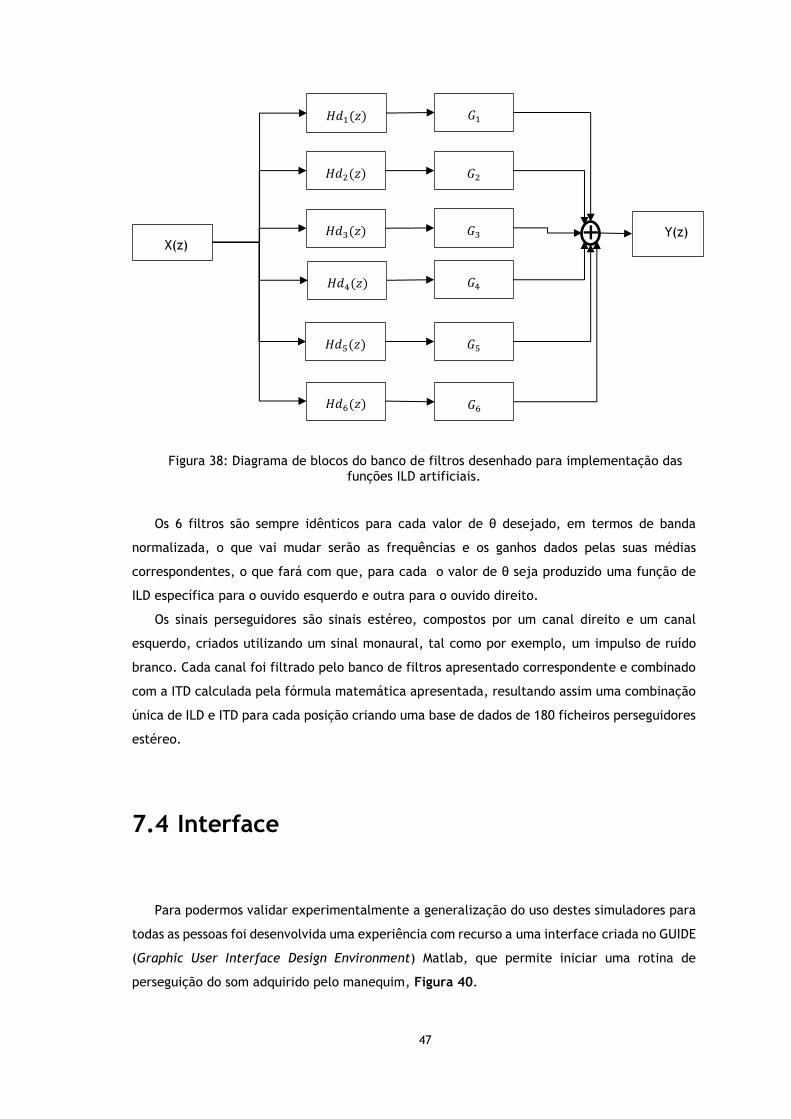
47
Figura 38: Diagrama de blocos do banco de filtros desenhado para implementação das funções ILD artificiais.
Os 6 filtros são sempre idênticos para cada valor de θ desejado, em termos de banda
normalizada, o que vai mudar serão as frequências e os ganhos dados pelas suas médias
correspondentes, o que fará com que, para cada o valor de θ seja produzido uma função de
ILD específica para o ouvido esquerdo e outra para o ouvido direito.
Os sinais perseguidores são sinais estéreo, compostos por um canal direito e um canal
esquerdo, criados utilizando um sinal monaural, tal como por exemplo, um impulso de ruído
branco. Cada canal foi filtrado pelo banco de filtros apresentado correspondente e combinado
com a ITD calculada pela fórmula matemática apresentada, resultando assim uma combinação
única de ILD e ITD para cada posição criando uma base de dados de 180 ficheiros perseguidores
estéreo.
7.4 Interface
Para podermos validar experimentalmente a generalização do uso destes simuladores para
todas as pessoas foi desenvolvida uma experiência com recurso a uma interface criada no GUIDE
(Graphic User Interface Design Environment) Matlab, que permite iniciar uma rotina de
perseguição do som adquirido pelo manequim, Figura 40.
+ Y(z)
𝐻𝑑1(𝑧)
𝐻𝑑2(𝑧)
𝐻𝑑3(𝑧)
𝐻𝑑4(𝑧)
𝐻𝑑5(𝑧)
𝐻𝑑6(𝑧)
𝐺1
𝐺2
𝐺3
𝐺4
𝐺5
𝐺6
X(z)
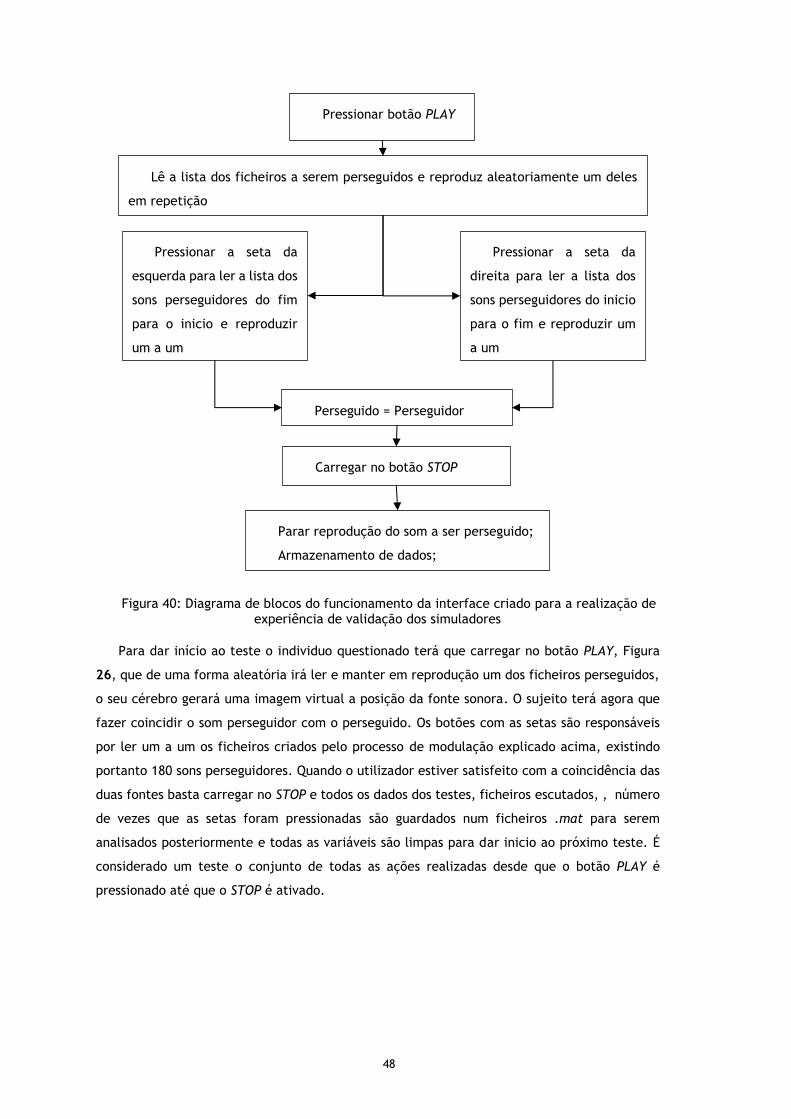
48
Figura 40: Diagrama de blocos do funcionamento da interface criado para a realização de
experiência de validação dos simuladores
Para dar início ao teste o individuo questionado terá que carregar no botão PLAY, Figura
26, que de uma forma aleatória irá ler e manter em reprodução um dos ficheiros perseguidos,
o seu cérebro gerará uma imagem virtual a posição da fonte sonora. O sujeito terá agora que
fazer coincidir o som perseguidor com o perseguido. Os botões com as setas são responsáveis
por ler um a um os ficheiros criados pelo processo de modulação explicado acima, existindo
portanto 180 sons perseguidores. Quando o utilizador estiver satisfeito com a coincidência das
duas fontes basta carregar no STOP e todos os dados dos testes, ficheiros escutados, , número
de vezes que as setas foram pressionadas são guardados num ficheiros .mat para serem
analisados posteriormente e todas as variáveis são limpas para dar inicio ao próximo teste. É
considerado um teste o conjunto de todas as ações realizadas desde que o botão PLAY é
pressionado até que o STOP é ativado.
Pressionar botão PLAY
Lê a lista dos ficheiros a serem perseguidos e reproduz aleatoriamente um deles
em repetição
Pressionar a seta da
esquerda para ler a lista dos
sons perseguidores do fim
para o inicio e reproduzir
um a um
Pressionar a seta da
direita para ler a lista dos
sons perseguidores do inicio
para o fim e reproduzir um
a um
Perseguido = Perseguidor
Carregar no botão STOP
Parar reprodução do som a ser perseguido;
Armazenamento de dados;

49
7.5 Testes e conclusões preliminares
A amostra de indivíduos utilizada para os testes foi 8 pessoas, todas sem dificuldades
auditivas conhecidas, 2 do sexo masculino e 6 do sexo feminino, com média de idades de 25
anos, todos estudantes ou investigadores, mas apenas 3 estavam familiarizados com a área da
acústica, os restantes têm áreas de estudo bastante variadas, entre artes, design gráfico,
relações internacionais, enfermagem e engenharia. Cada elemento da amostra realizou 4
testes.
A metodologia para a realização dos testes foi explicada de igual forma para toda a amostra
usando a metáfora do som perseguido, para o som capturado pelo manequim, e do som
perseguidor, para o som manipulado artificialmente pelo processamento de sinal desenvolvido.
Chegados ao fim dos testes podemos concluir que a metáfora foi correta, pois foi facilmente
compreendida por todos os indivíduos da amostra.
Para os sinais perseguidores foram utilizados impulsos de ruído branco com 20000 amostras
processados pelo método de ILD e ITD abordados atrás, ficando para ser implementado em
trabalhos futuros o processo de introdução das pistas espectrais estudadas que irão eliminar
ambiguidades existentes entre sinais localizados nos hemisférios frontal e traseiro, por
exemplo, mas mesmo sem a informação espectral é possível ouvir a circunvolução da cabeça
realizada pela reprodução dos sinais perseguidores de forma consecutiva.
Os sinais perseguidos utilizados foram as próprias HRIR, contudo o plano inicial foi construir
uma base de dados de sinais de várias fontes sonoras convoluidas com as respostas impulsionais
do manequim utilizando a riqueza de informação das HRTF criadas digitalmente no decorrer
desta dissertação, contudo ao calcular a convolução entre as HRIR e as outras fontes sonoras,
os ficheiros originais de captura revelaram alguns problemas de consistência a nível de análise
de frequências, causando inconsistências nos sinais, o que impediu o uso eficaz do resultado
da operação nos testes.
Ficando a base de dados dos testes limitada as HRIR foram escolhidos com um passo de 30°
em 30°, todos os dados foram guardados em ficheiros .mat para serem analisados a posteriori.
Ainda foi realizada uma tentativa de utilizar ficheiros convoluidos, mas os resultados
desencadearam uma análise mais profunda da base de dados e por isso todos os testes
realizados com estes ficheiros foram eliminados da fase de interpretação dos dados.
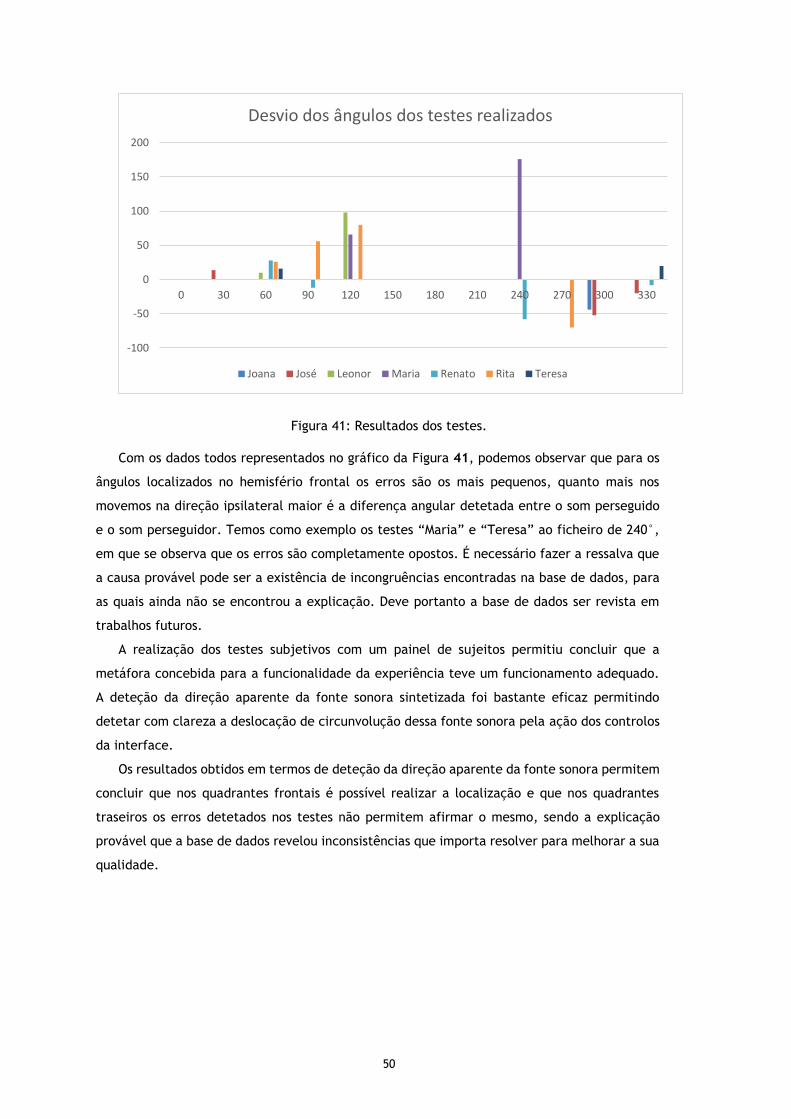
50
Figura 41: Resultados dos testes.
Com os dados todos representados no gráfico da Figura 41, podemos observar que para os
ângulos localizados no hemisfério frontal os erros são os mais pequenos, quanto mais nos
movemos na direção ipsilateral maior é a diferença angular detetada entre o som perseguido
e o som perseguidor. Temos como exemplo os testes “Maria” e “Teresa” ao ficheiro de 240°,
em que se observa que os erros são completamente opostos. É necessário fazer a ressalva que
a causa provável pode ser a existência de incongruências encontradas na base de dados, para
as quais ainda não se encontrou a explicação. Deve portanto a base de dados ser revista em
trabalhos futuros.
A realização dos testes subjetivos com um painel de sujeitos permitiu concluir que a
metáfora concebida para a funcionalidade da experiência teve um funcionamento adequado.
A deteção da direção aparente da fonte sonora sintetizada foi bastante eficaz permitindo
detetar com clareza a deslocação de circunvolução dessa fonte sonora pela ação dos controlos
da interface.
Os resultados obtidos em termos de deteção da direção aparente da fonte sonora permitem
concluir que nos quadrantes frontais é possível realizar a localização e que nos quadrantes
traseiros os erros detetados nos testes não permitem afirmar o mesmo, sendo a explicação
provável que a base de dados revelou inconsistências que importa resolver para melhorar a sua
qualidade.
-100
-50
0
50
100
150
200
0 30 60 90 120 150 180 210 240 270 300 330
Desvio dos ângulos dos testes realizados
Joana José Leonor Maria Renato Rita Teresa

51
8 Trabalhos Futuros
Chegados agora ao fim do trabalho vemos que é um ponto intermédio e não o fim, fica
assim a porta aberta para a realização de projetos que tenham a presente dissertação como
ponto de arranque.
8.1 Realização de uma API
Atualmente, vivemos num mundo onde gostamos de ter toda a informação disponível onde
quer que estejamos e em várias aplicações sem ser preciso estar a passar os dados a mão, é
aqui que os API entre em jogo. De uma forma geral, APIs são as regras que permitem duas
aplicações comunicarem e transmitem dados entre si, tornando públicas algumas e partes das
suas funções internas.
Seguindo a linha de trabalho da Google, será possível que com as conclusões retiradas do
trabalho realizado e apresentado neste documento levem á concretização de uma API a ser
utlizado por qualquer pessoa a desenvolver uma aplicação multimédia que necessite de recriar
a audição binaural humana.
8.2 Produção de fala
O manequim não tem trato vocal, para a produção de fala ser realizada seria colocado um
altifalante no interior da boca, a artista que realizou o manequim foi contactada para dar a
sua opinião de aula melhor maneira proceder, a sua sugestão foi fazer um corte transversal
como mostra a Figura 42 e colocar o sistema de produção numa posição idêntica ao HTS da
Bruel&Kjaer.

52
Foi feito ainda algum trabalho de pesquisa sobre o tipo de altifalante a ser utilizado, terá
que ter uma resposta em frequência boa para a fala humana, ou seja, entre os 100Hz e os 5kHz,
as dimensões do altifalante não devem ultrapassar 8cm, dado que esse é o comprimento
permitido pelas dimensões do manequim.
8.3 User Interface / Experience
Com o objetivo de tornar este manequim completamente independente e funcional pode
ser desenvolvida uma User Interface simples de ser utilizada por qualquer pessoa, que incluirá
uma fonte de alimentação e um sound device. Os microfones deverão ter uma fonte de
alimentação de 9V, o altifalante vai depender da tecnologia escolhida, a fonte deverá ainda
ter um pré-amplificador para ambos os sinais. Deverão ainda ser feitas as ligações necessárias
a um sound device que controlará os sinais a entrar e a sair do manequim, o que está disponível
no momento no laboratório é da Edirol e foi utilizada na aquisição dos sons perseguidos
(Martinho 2015).
A aliar-se à interface a ser desenvolvida pode ainda ser criada uma User Experience, onde
o utilizador tem a sua disposição uma base de dados de sons perseguidos e perseguidores e
pode fazer vários testes, são-lhe apresentados as HRIR e HRTFs respetivas dos sons escolhidos
e ainda ouvir os sons a circundar a cabeça.
Figura 42: Sugestão para a montagem do canal de saída do manequim (Bruel&Kjear 2014)

53
8.4 Pistas espectrais
O estudo das pistas espectrais realizado nesta dissertação, onde se analisaram os vales e
os picos das HRTF e se propôs construir filtros rejeita banda ou passa banda, respetivamente,
com a ferramenta de desenho de filtros do Matlab, fica para implementar no futuro para cada
uma das orientações dos sons perseguidores e combinar com a ITD e o banco de filtros
construído para a ILD já implementados.

54
Referências
Algazi, P. V. R. (1998). Documentation for the UCD HRIR FIles. University of California at
Davis.
Algazi, P. V. R. (2001). "The CIPIC HRTF Database." from
http://www.ece.ucdavis.edu/cipic/.
Blauert, J. (1983). Spatial Hearing. Cambridge, MIT Press.
Bruel&Kjear (2014). Head and Torso Simulator Types 4128‐C and 4128‐D. B. K. S. V. M. A/S.
Denmark, Brüel & Kjær Sound & Vibration Measurement A/S.
Everest, F. A. (2001). Master Handbook of Acoustics. United States of America, McGraw-
Hill.
G.R.A.S (2017). G.R.A.S. 45BB KEMAR Head and Torso. G.R.A.S, G.R.A.S.
Gold, B. and N. Morgan (2000). Speech and Audio Signal Processing: Processing and
Perception of Speech and Music. United States of America, Jonh Wiley & Sons.
INSTITUTE, A. R. "ARI HRTF Database." from
https://www.kfs.oeaw.ac.at/index.php?option=com_content&view=article&id=608:ari-
hrtf-database&catid=158:resources-items&Itemid=606&lang=en.
Kinsler, L. E., A. R. Frey, A. B. Coppens and J. V. Sanders (1982). Fundamentals of
Acoustics. United States of America
Canada, John Wiley & Sons, Inc.
Martinho, J. (2015). Optimizing Head Related Impulse Responses for High Order Ambisonics
Decoding in Virtual Immersive Environments., Faculdade de Engenharia da Universidade do
Porto.
Mateus, M. H. M., A. Andrade, M. d. C. Viana and A. Villalva (1990). Fonética, Fonologia e
Morfologia do Português. Lisboa, Universidade Aberta.
Nazaré, C. J. (2009). Testes Temporais para Estudo do Processamento Auditivo Central.
Master, Faculdade de Engenharia da Universidade do Porto.
Oculus. (2018). "Oculus VR." from https://developer.oculus.com/.
Parsons, T. (1987). Voice and Speech Processing, McGraw-Hill Book Company.
Rossi, M. (1970). Acoustics and Eletroaoustics, Artech House.
Rowden, C. (1992). Speech Processing, McGraw-Hill Book Company Europe.
Streicher, R. and F. A. Everest (1998). The New Stereo Sound Book. United States of
America, Audio Engineering Associates.

55
Toolkit, T. A. (2016). "ATK for Reaper." from
http://www.ambisonictoolkit.net/documentation/reaper/.
Trujillo, F. The Production of Speech. English Phonetics and Phonology.
Viste, H. and G. Evangelista (2004). BINAURAL SOURCE LOCALIZATION. 7th th Int.
Conference on Digital Audio Effects (DAFx’04), Naples, Italy.
Warusfel, O. (2003, 25/05/2003). "LISTEN HRTF DATABASE." from
http://recherche.ircam.fr/equipes/salles/listen/index.html.
Zhong, X.-l. and B.-s. Xie (2014). Head-Related Transfer Functions and Virtual Auditory
Display. Soundscape Semiotics - Localization and Categorization. D. H. Glotin, InTech.