estatística aplicada - servicos.ulbra.br · “a estatística é uma ciência que estuda e...
TRANSCRIPT

Estatística Aplicada

Simone Echeveste
Estatística Aplicada

O grande avanço tecnológico das últimas décadas gerou a necessida-de de formação de profissionais capazes de acompanhar esse de-
senvolvimento com habilidades para gerar e analisar dados, produzindo informação útil a ser utilizada na resolução de problema. Neste contexto, as ferramentas estatísticas são imprescindíveis, e o conhecimento das mes-mas torna-se necessário para qualquer profissional.
A Estatística hoje se configura como uma das ciências que mais vem crescendo em termos de utilização e importância na Administração: pes-quisas de marketing, comportamento do consumidor, estudos de qualida-de, confiabilidade, desenvolvimentos de novos produtos, avaliação de sa-tisfação dos clientes etc. Estes são alguns exemplos da ampla utilização das ferramentas estatísticas para resolução de problemas e tomada de decisões nessa área.
A disciplina de Estatística Aplicada tem por objetivos: propiciar ao alu-no o estudo da estatística com vistas à análise de dados experimentais, cálculo e interpretação das medidas descritivas, utilização de testes estatís-ticos como ferramenta de análise de comparação e relação de dados no contexto das pesquisas realizadas na área de Administração.
Os conteúdos serão apresentados em 10 capítulos, contendo a ex-plicação teórica dos mesmos, bem como a apresentação de exemplos e aplicações em problemas na área da Administração. Em cada capítulo será destacado o objetivo de cada ferramenta estatística, bem como a interpre-tação dos resultados obtidos.
Introdução

Sumário
Introdução ................................................................................... iii
1 Conceitos Básicos de Estatística .............................................1
2 Apresentação de Dados ......................................................13
2.1 Tabelas de Frequência .....................................................014
2.2 Gráficos Estatísticos .........................................................018
3 Medidas de Tendência Central ............................................33
4 Medidas de Variabilidade ....................................................47
5 Distribuição de Probabilidade Normal .................................61
6 Amostragem .......................................................................85
7 Estimação .........................................................................101
8 Testes de Hipóteses ...........................................................117
9 Análise de Correlação ......................................................149
10 Análise de Regressão ........................................................169

Conceitos Básicos de Estatística
ÂÂNeste capítulo, será apresentado o contexto da pesqui-sa em que a estatística está inserida, bem como serão
destacados os principais conceitos básicos de estatística. O objetivo aqui é que o aluno compreenda o vocabulário pertinente à análise estatística e que compreenda os ele-mentos importantes no contexto dessa análise.
Ao final deste capítulo, espera-se que o aluno, dada uma situação problema, identifique corretamente a popu-lação e a amostra de estudo bem como as variáveis en-volvidas classificando-as de acordo com a sua natureza.
Capítulo 1
Simone Echeveste

2 Estatística Aplicada
O papel da estatística na ciência
A necessidade de analisar um conjunto de dados estatistica-mente está sempre inserida no contexto de uma pesquisa, ou seja, temos inicialmente uma situação problema a ser resol-vida, ou ainda uma hipótese a ser testada e, para isso, uma pesquisa deve ser realizada.
Com isso, em uma pesquisa, destaca-se a importância da utilização da estatística de acordo com os seguintes fatores:
a) Em uma pesquisa, muitas vezes são realizados estudos experimentais ou observacionais que culminam em uma coleção de dados numéricos que devem ser organizados e resumidos.
b) O padrão de variação nos dados faz com que a resposta não seja óbvia, ou seja, somente tratando os dados ade-quadamente é que poderemos verificar o comportamento das variáveis de estudo.
c) Uma análise estatística é composta por métodos para co-leta e descrição dos dados, viabilizando a verificação da força da evidência nos dados pró ou contra as hipóteses de pesquisa. A presença de uma variação não previsível nos dados faz disso, muitas vezes, uma tarefa pouco trivial.
Em toda a pesquisa realizada, almeja-se a resposta a um problema ou ainda uma situação-problema que está vinculada a uma tomada de decisão a ser realizada. Podemos considerar que nossa decisão pode ser tomada por meio de dois tipos de soluções: a primeira, que pode ser considerada uma solução empírica que se fundamenta na observação e na experiência,
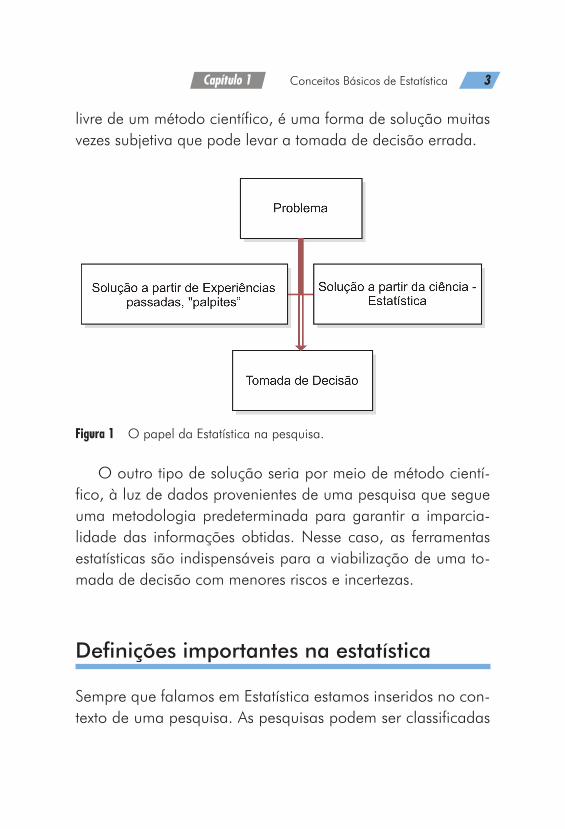
Capítulo 1 Conceitos Básicos de Estatística 3
livre de um método científico, é uma forma de solução muitas vezes subjetiva que pode levar a tomada de decisão errada.
Figura 1 O papel da Estatística na pesquisa.
O outro tipo de solução seria por meio de método cientí-fico, à luz de dados provenientes de uma pesquisa que segue uma metodologia predeterminada para garantir a imparcia-lidade das informações obtidas. Nesse caso, as ferramentas estatísticas são indispensáveis para a viabilização de uma to-mada de decisão com menores riscos e incertezas.
Definições importantes na estatística
Sempre que falamos em Estatística estamos inseridos no con-texto de uma pesquisa. As pesquisas podem ser classificadas

4 Estatística Aplicada
em duas grandes abordagens conforme demonstra a figura a seguir:
Figura 2 Tipos de Pesquisa.
Uma pesquisa quantitativa é composta por quatro etapas distintas. Dessas etapas, nas três últimas (planejamento, exe-cução e comunicação dos resultados), a estatística surge como uma importante ferramenta de suporte para o pesquisador (Fi-gura 3).
Na etapa Planejamento da pesquisa, a estatística tem im-portante participação na determinação do tamanho da amos-tra a ser estudada, na escolha do procedimento/processo de amostragem que deve ser utilizado para a coleta de dados, bem como na elaboração do instrumento de coleta e no esta-belecimento do tipo de variáveis a serem pesquisadas.

Capítulo 1 Conceitos Básicos de Estatística 5
Figura 3 Contribuição da Estatística para a pesquisa.
No momento da Execução da pesquisa, a estatística é im-prescindível, pois fornece as ferramentas necessárias para a análise dos dados e para a obtenção de conclusões sobre o objeto de estudo.
Na Comunicação dos resultados, a estatística auxilia a construção de tabelas e gráficos, facilitando a apresentação dos principais resultados obtidos.
A realização de todas essas etapas é importante, e elas fazem parte da elaboração de uma pesquisa científica que procure ser o mais fidedigna possível. O conhecimento dessas etapas também é importante para o julgamento da adequa-cidade de pesquisas realizadas por terceiros, ou seja, quando nos é apresentado oralmente ou por meio de artigos resultan-tes de uma pesquisa, precisamos ter um conhecimento mínimo do processo científico para que sejamos capazes de criticar e entender os resultados obtidos.

6 Estatística Aplicada
Na literatura, encontramos vários conceitos e definições para a Estatística, alguns autores a definem como um ramo da matemática, já outros defendem a ideia de que a Estatística representa por si só uma área única da ciência, desconside-rando ser esta uma subdivisão da matemática.
Rao (1999) define estatística como:
“A estatística é uma ciência que estuda e pesquisa sobre: o levantamento de dados com a máxima quantidade de informação possível para um dado custo; o processamento de dados para a quantificação da quantidade de incerteza existente na resposta para um determinado problema; a to-mada de decisões sob condições de incerteza, sob o menor risco possível. Finalmente, a estatística tem sido utilizada na pesquisa científica, para a otimização de recursos econô-micos, para o aumento da qualidade e produtividade, na otimização em análise de decisões.”
Esse conceito apresenta de forma clara e concisa todos os aspectos que envolvem as diversas formas de utilização da Estatística: levantamento de dados, processamento, análise e auxílio na tomada de decisões.
Ao iniciar uma análise estatística, deve-se também considerar alguns elementos relacionados à metodologia do estudo reali-zado, como as definições de População e Amostra da pesquisa:
Uma população (N) é conjunto de elementos de interesse em um determinado estudo, que podem ser pessoas ou resultados experimentais, com uma ou mais características comuns, que se pretende estudar.

Capítulo 1 Conceitos Básicos de Estatística 7
Uma amostra (n) é um subconjunto da população usado para obter informação acerca do todo. Obtemos uma amostra para fazer inferências de uma população. Nossas inferências são vá-lidas somente se a amostra é representativa da população.
Para ilustrar esses conceitos por meio de um exemplo, con-sidere a seguinte situação de pesquisa:
Situação de pesquisa
“Uma empresa operadora de TV a cabo deseja realizar uma pesquisa com seus clientes da cidade de Porto Alegre referente ao grau de satisfação dos mesmos com o serviço prestado. Ao todo, essa operadora possui, nessa cidade, 217.193 assinan-tes dos quais foram selecionados 620 para participar dessa pesquisa.”
População: 217.193 assinantes da operadora de TV a cabo de Porto Alegre.
Amostra: 620 assinantes da operadora de TV a cabo de Porto Alegre que participaram da pesquisa.
Outro conceito muito importante é o da Variável, que vem a ser a matéria prima de qualquer pesquisa, ou seja, quando se termina uma coleta de dados, em um primeiro momento, dispomos de um conjunto de valores ou ainda respostas perti-nentes às nossas variáveis de pesquisa.

8 Estatística Aplicada
Uma variável (x) é uma característica dos elementos investiga-dos que difere de um elemento para outro e do qual temos inte-resse em estudar. Cada unidade (elemento) da população que é escolhido como parte de uma amostra fornece uma medida de uma ou mais variáveis, também chamadas observações.
As variáveis podem ser classificadas em:
 Variáveis Quantitativas: são as características que podem ser medidas em uma escala quantitativa, ou seja, apresentam valores numéricos/quantidades. Podem ser contínuas ou discretas.
Discretas: características mensuráveis que podem as-sumir apenas um número finito ou infinito contável de valores e, assim, somente fazem sentido valores intei-ros. Exemplos: números de carros vendidos, número de filhos, número de reclamações recebidas por dia etc.
Contínuas: características mensuráveis que assumem valores em uma escala para as quais valores fracionais fazem sentido. Exemplos: renda mensal, tempo de en-trega da mercadoria, tamanho do imóvel em m2 etc.
 Variáveis Qualitativas: são as características que não possuem valores quantitativos, mas, ao contrário, são definidas por várias categorias, ou seja, represen-tam uma classificação dos elementos. Podem ser nomi-nais ou ordinais.
Nominais: não existe ordenação dentre as catego-rias. Exemplos: marca do carro, tipo de fornecedor, profissão etc.
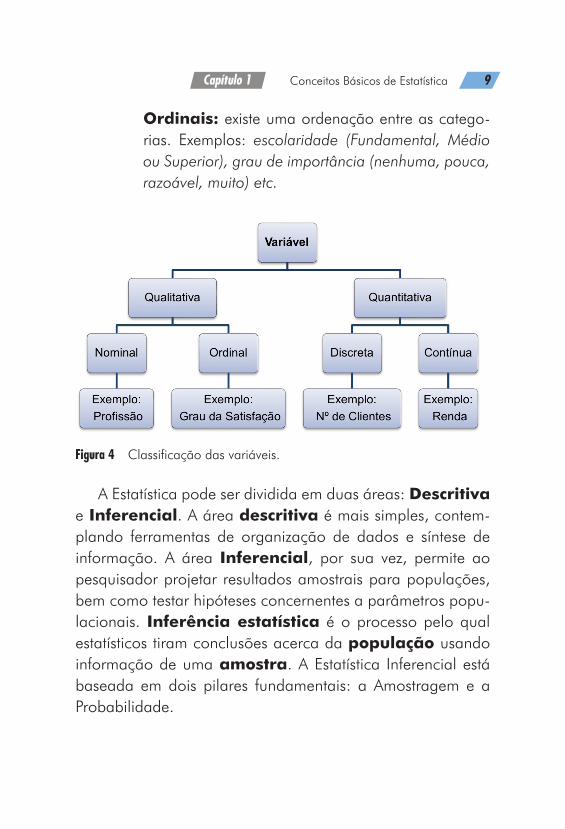
Capítulo 1 Conceitos Básicos de Estatística 9
Ordinais: existe uma ordenação entre as catego-rias. Exemplos: escolaridade (Fundamental, Médio ou Superior), grau de importância (nenhuma, pouca, razoável, muito) etc.
Figura 4 Classificação das variáveis.
A Estatística pode ser dividida em duas áreas: Descritiva e Inferencial. A área descritiva é mais simples, contem-plando ferramentas de organização de dados e síntese de informação. A área Inferencial, por sua vez, permite ao pesquisador projetar resultados amostrais para populações, bem como testar hipóteses concernentes a parâmetros popu-lacionais. Inferência estatística é o processo pelo qual estatísticos tiram conclusões acerca da população usando informação de uma amostra. A Estatística Inferencial está baseada em dois pilares fundamentais: a Amostragem e a Probabilidade.

10 Estatística Aplicada
Recapitulando
As ferramentas estatísticas são indispensáveis no trata-mento de dados provenientes de uma pesquisa. É pela análise e tratamento de dados que o pesquisador obtém todas as in-formações pertinentes ao objeto de estudo, propiciando uma tomada de decisão com menores riscos e incertezas.
Algumas definições importantes:
 População (N): é o conjunto de elementos de interes-se em um determinado estudo.  Amostra (n): parte da população selecionada é a quantidade de elementos investigada.  Variável (x): é a característica da amostra a ser inves-tigada, ou seja, o que desejamos saber com a pergunta realizada.
A Estatística pode ser dividida em duas áreas: Descritiva, que se refere à organização e síntese da informação, e Infe-rencial, destinada à projeção de resultados amostrais para toda a população.
Atividades: Conceitos básicos de estatística
Considere a seguinte situação de pesquisa:
“Uma pesquisa foi realizada com um grupo aleatoriamente se-lecionado de 400 clientes de um restaurante japonês. O objeti-vo dessa pesquisa era identificar o perfil do cliente em relação às características Bairro em que reside, Tempo que frequenta o restaurante, Gasto médio na refeição realizada e grau de

Capítulo 1 Conceitos Básicos de Estatística 11
satisfação com o serviço oferecido pelo restaurante (muito sa-tisfeito, satisfeito etc.).”
Questão 1. A população dessa pesquisa pode ser considerada como:
a) 400 clientes desse restaurante japonês. b) Todos os clientes desse restaurante japonês. c) Perfil do cliente. d) Características do cliente, como bairro, tempo que fre-
quenta, gasto e grau de satisfação. e) Todos os restaurantes japoneses.
Questão 2. A amostra dessa pesquisa pode ser considerada como:
a) Perfil do cliente. b) Características do cliente, como bairro, tempo que fre-
quenta, gasto e grau de satisfação. c) 400 clientes desse restaurante japonês. d) Todos os clientes desse restaurante japonês. e) Os restaurantes japoneses.
Questão 3. As variáveis dessa pesquisa são:
a) Identificação do Perfil do cliente. b) Os 400 clientes desse restaurante japonês. c) Todos os clientes desse restaurante japonês. d) Bairro em que reside, tempo que frequenta o restaurante,
gasto médio e grau de satisfação com o serviço. e) Os diferentes restaurantes japoneses existentes.
Questão 4. As variáveis quantitativas dessa pesquisa são: a) Bairro em que reside e grau de satisfação com o serviço. b) Bairro em que reside, gasto médio e grau de satisfação
com o serviço.

12 Estatística Aplicada
c) Tempo que frequenta o restaurante, gasto médio e grau de satisfação com o serviço.
d) Tempo que frequenta o restaurante e gasto médio. e) Todas as variáveis são quantitativas.
Questão 5. Marque V para verdadeiro e F para falso nas seguintes afirmativas: a) ( ) Em uma pesquisa, o padrão de variação nos dados
faz com que os resultados não sejam óbvios, por esse mo-tivo, os resultados obtidos devem receber um tratamento estatístico que permitirá a verificação do comportamento das variáveis de estudo.
b) ( ) As variáveis quantitativas são características que não pos-suem valores, mas, ao contrário, são definidas por catego-rias, ou seja, representam uma classificação dos elementos.
c) ( ) A necessidade da utilização da Estatística na análise de dados ocorre em pesquisas do tipo Quantitativas.
d) ( ) A Estatística dividi-se em duas partes: Estatística Des-critiva e Estatística Qualitativa.
Gabarito das atividades propostas
Questão 1. b) Todos os clientes desse restaurante japonês.
Questão 2. c) 400 clientes desse restaurante japonês.
Questão 3. d) Bairro em que reside, tempo que frequenta o restau-rante, gasto médio e grau de satisfação com o serviço.
Questão 4. d) Tempo que frequenta o restaurante e gasto médio.
Questão 5. a) V, b) F, c) V, d) F

Apresentação de Dados
Simone Echeveste
Capítulo 2

14 Estatística Aplicada
Tabelas de frequência
O primeiro contato do pesquisador com os seus dados é feito por meio da construção das tabelas de frequência. Podemos dizer que, neste momento, os dados recebem o seu primeiro tratamento. Nessa etapa de análise, o pesquisador identificará as possíveis respostas a uma determinada variável e o compor-tamento das mesmas no que se refere a sua frequência.
A tabela de frequência tem por objetivo apresentar os resul-tados de cada variável de uma forma organizada e resumida. Nessa tabela, encontramos o número de repetições de cada categoria de resposta de uma variável, bem como o seu per-centual no grupo investigado.
De acordo com as normas da ABNT (Associação Brasileira de Normas Técnicas) e do IBGE (Instituto Brasileiro de Geo-grafia e Estatística), as tabelas de frequência devem considerar os seguintes elementos:
a) Título: deve conter as informações necessárias para que se compreenda “o que” está sendo apresentado na tabela, “onde” os dados foram obtidos e “quando” esses dados foram coletados.
b) Cabeçalho: indica a natureza do conteúdo de cada co-luna da tabela.
c) Corpo da Tabela: é a parte composta por linhas e colu-nas com as informações observadas.
d) Rodapé: espaço logo abaixo da tabela que pode ser uti-lizado para a apresentação de notas ou observações de natureza informativa.

Capítulo 2 Apresentação de Dados 15
e) Fonte: refere-se à entidade que organizou ou forneceu os dados apresentados na tabela.
Exemplo de construção de uma tabela de frequência:
Considere uma pesquisa realizada com uma amostra de 20 clientes que compraram em um site de compras na Internet com o objetivo de investigar o tempo de atraso na entrega (em dias) das mercadorias adquiridas nesse site. Os dados obser-vados foram:
0 1 0 2 3 3 2 1 0 43 1 0 0 4 2 1 0 1 0
Para esses dados, podemos destacar as seguintes informações:
a) Variável de pesquisa: tempo de atraso na entrega das mercadorias.
b) Amostra investigada: 20 clientes.
Para a construção da tabela, precisamos das seguintes infor-mações:
c) Valores da variável que surgiram: correspondem aos tempos de atraso observados. Neste caso, encontra-mos 0, 1, 2, 3 e 4 dias.
d) Frequência (f) de cada valor da variável: corres-ponde ao número de vezes que cada valor se repetiu.
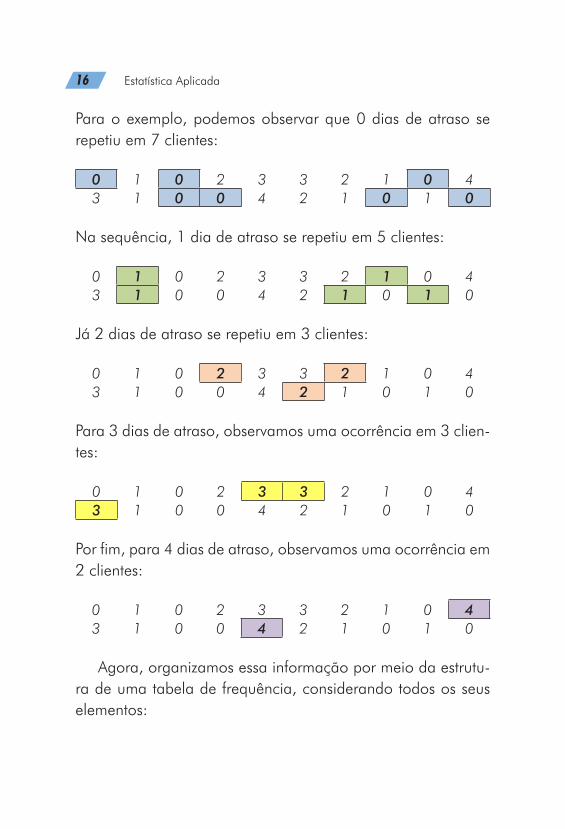
16 Estatística Aplicada
Para o exemplo, podemos observar que 0 dias de atraso se repetiu em 7 clientes:
0 1 0 2 3 3 2 1 0 43 1 0 0 4 2 1 0 1 0
Na sequência, 1 dia de atraso se repetiu em 5 clientes:
0 1 0 2 3 3 2 1 0 43 1 0 0 4 2 1 0 1 0
Já 2 dias de atraso se repetiu em 3 clientes:
0 1 0 2 3 3 2 1 0 43 1 0 0 4 2 1 0 1 0
Para 3 dias de atraso, observamos uma ocorrência em 3 clien-tes:
0 1 0 2 3 3 2 1 0 43 1 0 0 4 2 1 0 1 0
Por fim, para 4 dias de atraso, observamos uma ocorrência em 2 clientes:
0 1 0 2 3 3 2 1 0 43 1 0 0 4 2 1 0 1 0
Agora, organizamos essa informação por meio da estrutu-ra de uma tabela de frequência, considerando todos os seus elementos:

Capítulo 2 Apresentação de Dados 17
Tempo de atraso na entrega das mercadorias
Tempo de atraso Frequência %
0 7 35
1 5 25
2 3 15
3 3 15
4 2 10
Total 20 100
Fonte: Pesquisa Interna
Como calculamos a porcentagem da tabela de fre-quência?
Cálculo da Porcentagem:

18 Estatística Aplicada
IMPORTANTE!!!
De acordo com as normas, as tabelas de frequência não podem ser fechadas dos lados, nem ter linhas dividindo as categorias da variável. As únicas linhas permitidas são as que delimitam o cabeçalho e as que delimitam o total; no centro da tabela, é opcional colocar ou não o traço divisório das colunas.
Gráficos estatísticos
A utilização de gráficos como forma de apresentação de da-dos pode ser justificada por um ditado popular de que “uma imagem vale mais que 1000 palavras”
Técnicas gráficas são geralmente utilizadas, em vez de ta-belas, para descrever um conjunto de dados por meio de um “desenho”. Um gráfico estatístico é uma forma de apresen-tação dos dados estatísticos, cujo objetivo é o de reproduzir, no investigador ou no público em geral, uma impressão mais rápida e viva do fenômeno em estudo. (Crespo, 1996)
A representação gráfica deve ser utilizada levando-se em conta algumas qualidades essenciais básicas para a constru-ção destes conforme nos mostra a figura 2.
De acordo com Levin (1987), enquanto algumas pessoas parecem “desligar-se” ao serem expostas a informações esta-tísticas em forma de tabelas, elas podem prestar bastante aten-ção às mesmas informações apresentadas em forma gráfica. Esse fato justifica a grande utilização por parte dos pesquisa-dores e da mídia escrita e impressa dos gráficos em substitui-ção das tabelas.

Capítulo 2 Apresentação de Dados 19
Figura 5 Qualidade de um bom gráfico.
Gráfico de setores
O gráfico de setores, também conhecido como gráfico pizza, torta, queijo ou bolacha, é um dos mais simples recursos gráfi-cos, sua construção é baseada no fato de que o círculo possui 360º, sendo que esse círculo é dividido em fatias de acordo com o percentual em cada categoria. É um gráfico útil para representar variáveis nominais ou apresentadas em categorias de respostas.

20 Estatística Aplicada
Figura 6 Exemplo de gráfico de setores.
Gráfico de colunas
O gráfico de colunas é um dos gráficos mais utilizados para representar um conjunto de dados, sendo a representação de uma série de dados por meio de retângulos dispostos verti-calmente. A altura desses retângulos é proporcional a suas respectivas frequências (ou porcentagens). Esse gráfico pode

Capítulo 2 Apresentação de Dados 21
ser utilizado para representar qualquer tipo de variável em qualquer nível de mensuração; por esse fato, é um recurso extremamente utilizado em pesquisas.
Figura 7 Exemplo de gráfico de colunas.
Gráfico de barras
O gráfico de barras é uma representação de uma série de dados por meio de retângulos dispostos horizontalmente. Os

22 Estatística Aplicada
comprimentos desses retângulos são proporcionais a suas res-pectivas frequências. Esse gráfico é semelhante ao gráfico de colunas, contudo, a posição da escala e da frequência é troca-da, ou seja, na linha horizontal temos a frequência (ou percen-tual) de casos observados e na linha vertical temos os valores (ou as categorias) da variável de estudo.
Figura 8 Exemplo de gráfico de barras.

Capítulo 2 Apresentação de Dados 23
Gráfico de linhas
Esse gráfico se utiliza de uma linha para representar uma série estatística. Seu principal objetivo é evidenciar a tendência ou a forma como o fenômeno está crescendo ou decrescendo em um período de tempo. Seu traçado deve ser realizado conside-rando o eixo “x” (horizontal), a escala de tempo, e o eixo “y” (vertical), frequência observada dos valores.
Figura 9 Exemplo de gráfico de linhas.

24 Estatística Aplicada
Como fazer gráficos no excel
Fazer gráficos no Excel é muito fácil e simples!
Para isso, precisamos inicialmente fazer as tabelas de frequências e calcular as porcentagens. Na confecção dos gráficos, devemos considerar que a informação percentual é sempre mais interessante de ser apresentada (essa regra só não se aplica no caso do gráfico de linhas, pois, nesse caso, muitas vezes desejamos acompanhar a evolução de uma determinada variável que não necessariamente é analisada em percentual).
Vamos considerar um exemplo de construção de um gráfi-co de barras apresentando os resultados para a variável Profis-são. Na planilha do Excel, precisamos colocar apenas duas informações: as categorias da variável que apareceram (no caso do exemplo apresentado abaixo, as profissões) e as suas respectivas porcentagens.

Capítulo 2 Apresentação de Dados 25
Marque com o mouse essas duas colunas na planilha e escolha a opção na barra de ferramentas Inserir Gráfico Barras.
Escolha o gráfico de barras dentre as opções fornecidas pelo Excel. Uma dica importante é que a primeira opção apre-sentada é sempre mais interessante e mais simples.

26 Estatística Aplicada

Capítulo 2 Apresentação de Dados 27
Após o gráfico pronto, você poderá formatar as cores, es-tilos, acrescentar título etc. utilizando a barras de ferramentas de Gráfico.
No item Design, você pode modificar as cores do gráfico.
No item Layout, você pode modificar os eixos do gráfico, acrescentar títulos, legendas e valores.
No item Formatar, você pode modificar os preenchimentos (cores) e os contornos do gráfico.

28 Estatística Aplicada
Recapitulando
 Variável (x): é a característica da amostra a ser inves-tigada, ou seja, o que desejamos saber com a pergunta realizada.  Categorias: representam as possíveis respostas para a variável investigada.  Frequência (f): é o número de vezes que cada cate-goria da variável se repetiu, ou ainda, quantos elemen-tos investigados optaram por determinada resposta da questão.
As tabelas de frequência correspondem a uma forma de apresentação de dados, seus elementos são: Título, Ca-beçalho, Corpo, Rodapé e Fonte. Sua estrutura é composta por linhas e colunas. As colunas são determinadas de forma que a variável a ser apresentada e suas respectivas catego-rias localizam-se na primeira coluna; já na segunda coluna, é apresentada a frequência (número de repetições) de cada ca-tegoria; e, por fim, a terceira coluna representa a porcentagem de cada categoria de resposta.
Os gráficos estatísticos são formas de apresentação dos dados cujo objetivo é o de reproduzir, no investigador ou no público em geral, uma impressão mais rápida e viva do fenômeno em estudo, levando-se em conta a simplicidade, clareza e veracidade das informações apresentadas.

Capítulo 2 Apresentação de Dados 29
Atividades: Apresentação de dados
Os dados a seguir referem-se ao tempo de espera na fila de uma casa lotérica, em minutos, considerando um grupo de 15 clientes. Os resultados obtidos foram:
6 5 6 7 88 8 8 5 78 7 6 8 6
Questão 1. A variável de pesquisa para esse exemplo é:
a) 15 clientes de uma casa lotérica. b) Clientes da casa lotérica. c) Tempo de espera na fila (em minutos). d) Contas pagas na fila da casa lotérica. e) Nenhuma das respostas anteriores.
Questão 2. A amostra de pesquisa para esse exemplo é:
a) 15 clientes de uma casa lotérica. b) Clientes da casa lotérica. c) Tempo de espera na fila (em minutos). d) Contas pagas na fila da casa lotérica. e) Nenhuma das respostas anteriores.
Questão 3. Construa uma tabela de frequência para repre-sentar esses dados.

30 Estatística Aplicada
Questão 4. Construa uma tabela para representar os dados abaixo que se referem ao número de viagens realizadas por 20 famílias nos últimos 5 anos:
0 1 2 5 2 3 4 2 2 44 0 0 2 3 2 1 5 2 1
Questão 5. “O desempenho do setor de Cartões de Crédito tem sido bastante satisfatório e tem crescido na medida em que a compensação de cheques vem diminuindo. Existe o incentivo por parte dos bancos para que seja impulsionado o uso de car-tões, tudo porque a transação com cheque custa 455% a mais que a eletrônica. Por parte dos estabelecimentos comerciais, o incentivo acontece por ser mais seguro e por reduzir as des-pesas financeiras. Atualmente, o potencial de crescimento de demanda é para o dobro de cartões que estão em circulação, hoje, pouco mais de 40 milhões. Nos últimos 8 anos, o uso do cartão de crédito aumentou 327%, enquanto que a utilização do cartão de débito, 562,5%.” Fonte: www.investnews.com.br
Os dados abaixo correspondem aos resultados de uma pesquisa realizada com 20 lojas de um shopping com o ob-jetivo de verificar o valor mensal de suas vendas (mil reais) pagas com cartão de débito:
12 15 10 5 10 10 5 12 2 210 15 10 15 10 5 10 10 10 10
Construa uma tabela de frequência para representar esses dados.
Capítulo 2 Apresentação de Dados 31
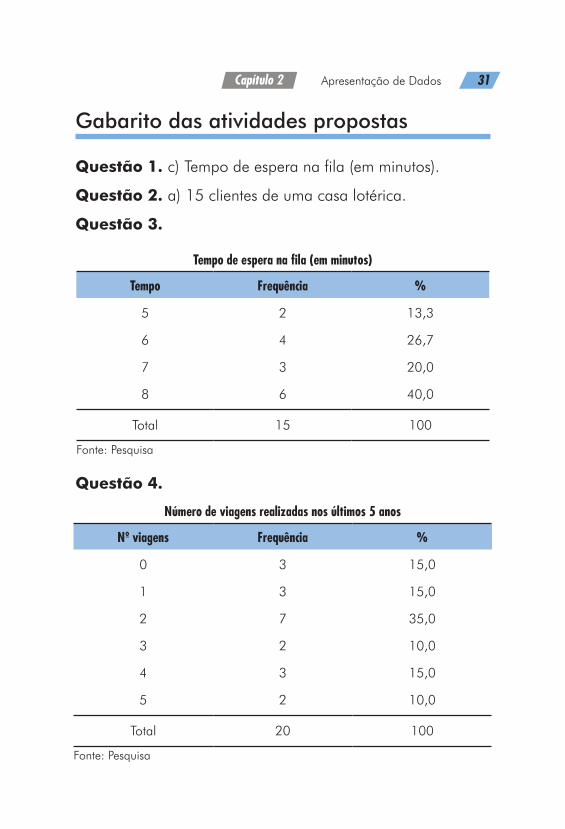
Gabarito das atividades propostas
Questão 1. c) Tempo de espera na fila (em minutos).
Questão 2. a) 15 clientes de uma casa lotérica.
Questão 3.
Tempo de espera na fila (em minutos)
Tempo Frequência %
5 2 13,3
6 4 26,7
7 3 20,0
8 6 40,0
Total 15 100
Fonte: Pesquisa
Questão 4.
Número de viagens realizadas nos últimos 5 anos
Nº viagens Frequência %
0 3 15,0
1 3 15,0
2 7 35,0
3 2 10,0
4 3 15,0
5 2 10,0
Total 20 100
Fonte: Pesquisa

32 Estatística Aplicada
Questão 5.
Valor mensal de suas vendas (mil reais) pagas com cartão de débito:
Valor (mil reais) Frequência %
2 2 10,0
5 3 15,0
10 10 50,0
12 2 10,0
15 3 15,0
Total 20 100
Fonte: Pesquisa

Medidas de Tendência Central
ÂÂNeste capítulo, iremos abordar as Medidas de Tendên-cia Central, que são medidas que têm por objetivo
representar todos os valores de uma variável por meio de um único valor. As medidas de tendência central são: Média, Mediana e Moda.
Simone Echeveste
Capítulo 3

34 Estatística Aplicada
Nosso objetivo aqui é a apresentação de cada uma dessas medidas no que se refere à aplicabilidade, ao cálculo e à in-terpretação dos resultados obtidos. O aluno, ao final deste capítulo, deverá ser capaz de calcular e interpretar as medidas estatísticas apresentadas.
Podemos ainda aprofundar um pouco mais a nossa análise estatística para o caso em que as variáveis analisadas sejam QUANTITATIVAS por meio das medidas estatísticas de ten-dência central.
Essas medidas têm por objetivo encontrar a “tendência central” de um conjunto de dados, ou seja, encontrar o valor do meio ou ainda os valores típicos de uma distribuição. São medidas úteis para caracterizar e representar um conjunto de dados por meio de um único valor utilizando critérios distintos para isso. As medidas de tendência central são: média, me-diana e moda.
Figura 10 Medidas de Tendência Central.

Capítulo 3 Medidas de Tendência Central 35
Média
A média é a medida de tendência central mais conhecida e mais utilizada de todas. Existem vários tipos de médias, a que utilizamos em pesquisas é a Média aritmética, obtida pela soma de todos os valores da variável investigada (valores de x) dividida pelo número total de valores no conjunto de dados (total da amostra – n). É representada pelos símbolos na amostra e por µ na população.
Notação:
µ – média populacional
– média amostral
Fórmula:
Onde:
S = somatório
x – variável (valores obtidos para a variável investigada)
n – tamanho da amostra
Exemplo
Os dados abaixo representam o tempo de relacionamento (em anos) de uma amostra de 7 clientes com a sua operadora de telefonia celular.
15 18 18 20 17 18 16

36 Estatística Aplicada
Elementos importantes:
Amostra (n): 7 clientes.
Variável (x): tempo de relacionamento com a operadora de telefonia celular.
Média:
= 17,4 anos
Interpretação: “Em média, o tempo de relacionamento dos clientes com sua operadora de telefonia celular é de 17,4 anos.”
Média para dados agrupados em tabelas de frequência
Quando os dados estão organizados na forma de uma tabe-la de frequências, devemos multiplicar os diferentes valores “x” pelas respectivas frequências “f”. A fórmula utilizada deve-rá ser nesse caso:

Capítulo 3 Medidas de Tendência Central 37
Onde:
S = somatório
x – variável
f – frequência de cada valor da variável
n – tamanho da amostra
Exemplo
Considere a seguinte tabela referente ao Número de faltas no período de um ano em uma amostra de 62 funcionários de uma empresa:
Número de faltas em um ano
Nº de faltas (x) Frequência (f) % x.f
0 5 8,0 0 x 5 = 0
2 25 40,3 2 x 25= 50
4 30 48,4 4 x 30= 120
6 2 3,2 6 x 2= 12
Total 62 (n) 100 182
= 2,9 faltas

38 Estatística Aplicada
Interpretação: “Em média, os funcionários tiveram 2,9 faltas em um ano.”
Mediana
Ordenados os elementos da amostra em ordem crescente, a mediana é o valor considerado o ponto do meio, que a divide ao meio, isto é, metade dos elementos da amostra é menor ou igual à mediana, e a outra metade é maior ou igual à mediana.
Notação:
Md ou Me
Como obter a Mediana:
1º) todos os valores do conjunto de dados devem ser colocados em ordem crescente, se houver algum valor que se repita mais de uma vez, deve ser repetido na ordenação também.
2º) devemos encontrar a posição da mediana considerando a seguinte regra: se o tamanho da amostra (n) é ímpar, a mediana é o valor central; se o tamanho da amostra (n) for par, a mediana será a média dos dois valores centrais.
EXEMPLO 1: Quando o tamanho da amostra “n” for ímpar.
Uma pesquisa foi realizada com o objetivo de verificar a renda, em salários mínimos, de uma amostra de 5 clientes de uma loja.
8,0 9,1 8,5 9,7 9,2

Capítulo 3 Medidas de Tendência Central 39
Amostra (n): 5 clientes de uma loja.
Variável (x): renda em salários mínimos.
Mediana (Md)
1º) Colocar os valores em ordem crescente.
8,0 8,5 9,1 9,2 9,7
2º) Encontrar o valor central no conjunto de dados.
8,0 8,5 9,1 9,2 9,7
Mediana
Interpretação: “Metade dos clientes dessa loja possuem renda de 9,1 salários mínimos ou menos, e metade dos clientes possui renda de 9,1 salários mínimos ou mais.”
EXEMPLO 2: Quando o tamanho da amostra “n” for par.
Uma pesquisa foi realizada com o objetivo de verificar a renda, em salários mínimos, de uma amostra de 6 clientes de uma loja.
8,0 8,8 8,5 9,7 9,5 9,2
Amostra (n): 6 clientes de uma loja.
Variável (x): renda em salários mínimos.

40 Estatística Aplicada
1º) Colocar os valores em ordem crescente.
8,0 8,5 8,8 9,2 9,5 9,7
2º) Encontrar os dois valores centrais no conjunto de dados.
8,0 8,5 8,8 9,2 9,5 9,7
Mediana
3º) Calcular o ponto médio entre esses dois valores centrais (somando os dois valores e dividindo por dois).
Md = 9,0 salários mínimos
Interpretação: “Metade dos clientes dessa loja possuem renda de 9 salários mínimos ou menos, e metade dos clientes possui renda de 9 salários mínimos ou mais.”
Moda
A moda de um conjunto de dados é simplesmente o valor do conjunto de dados que ocorreu com maior frequência, ou seja, que mais se repetiu.
Notação:
Mo

Capítulo 3 Medidas de Tendência Central 41
Exemplo
Os dados apresentados a seguir referem-se aos valores da diária (em reais) para um casal em uma amostra de 8 Hotéis na cidade de Porto Alegre:
200 210 200 210 210 250 230 210
Amostra (n): 8 Hotéis em Porto Alegre.
Variável (x): valor da diária para um casal (em reais).
Mo = 210 reais (este valor se repete quatro vezes na amos-tra, foi o valor de diária que mais se repetiu).
200 210 220 210 210 250 230 210
Interpretação: “O valor da diária para um casal que ocorreu com maior frequência foi de 210 reais.”
ATENÇÃO!!!
- Um conjunto de dados pode não ter moda, ou seja, nenhum valor se repetir.
Exemplo: Idade de 5 clientes:
34, 56, 23, 42, 38
Nenhum valor se repete – não tem moda!
- Um conjunto de dados pode ter mais que uma moda, ou seja, poderemos ter mais que um valor da variável se repetindo com frequências iguais.
Exemplo: Idade de 8 clientes:
35, 23, 35, 40, 51, 40, 32, 55
Duas modas: 35 e 40 peças!

42 Estatística Aplicada
Recapitulando
As Medidas de Tendência Central têm por objetivo representar todos os valores de uma variável por meio de um único va-lor. As medidas de tendência central são: Média, Mediana e Moda.
A Média representa a soma de todos os valores de uma variável dividida pela quantidade de valores existente; já a me-diana representa o valor central de um conjunto de dados de forma que metade dos valores observados é igual ou menor a ela, e metade igual ou superior a ela. A moda corresponde ao valor da variável que ocorreu com maior frequência, ou ainda, o que mais se repetiu.
Atividades: Medidas de tendência central
Questão 1. Uma pesquisa foi realizada com 12 empresas do ramo alimentício, com o objetivo de verificar o número de fun-cionários que estas possuem, os dados obtidos estão abaixo:
32 35 45 50 30 22 15 25 10 15 30 21
Calcule e interprete:
a) Média. b) Mediana. c) Moda.

Capítulo 3 Medidas de Tendência Central 43
Questão 2. A tabela abaixo representa os salários pagos a 100 operários da empresa GLT & Cia:
Salários GLT & Cia
Nº de salários mínimos Nº de operários %
0 40 40,0
2 30 30,0
4 10 10,0
6 15 15,0
8 5 5,0
Total 100 100,0
Fonte: Pesquisa
a) Quem é a variável de estudo? b) Qual foi a amostra pesquisada? c) Qual a média de salário dos operários da empresa GLT &
Cia?
Questão 3. Uma pesquisa levantou os dados sobre o mer-cado imobiliário de determinado centro urbano, do ano 2005 a 2012, e os valores obtidos sobre o número de lançamentos (em mil unidades) e o total em vendas (em milhões de Reais) estão dispostos abaixo:
Ano 2005 2006 2007 2008 2009 2010 2011 2012
Vendas 5,1 4,0 4,5 10,1 12,6 9,7 10,2 11,7Fonte: Pesquisa

44 Estatística Aplicada
a) Quem é a variável desse estudo? b) Quem é a amostra estudada? c) Calcule e interprete a média. d) Calcule e interprete a mediana. e) Calcule e interprete a moda.
Questão 4. A tabela abaixo apresenta os valores das diárias pagas por 40 turistas nos hotéis do balneário Beach Star:
Diárias pagas em Beach Star
Diária (em R$) Nº de turistas %
80 18 45,0
96 10 25,0
145 5 12,5
210 7 17,5
Total 40 100
Fonte: Rede hoteleira
a) Calcule e interprete a média para esses dados.
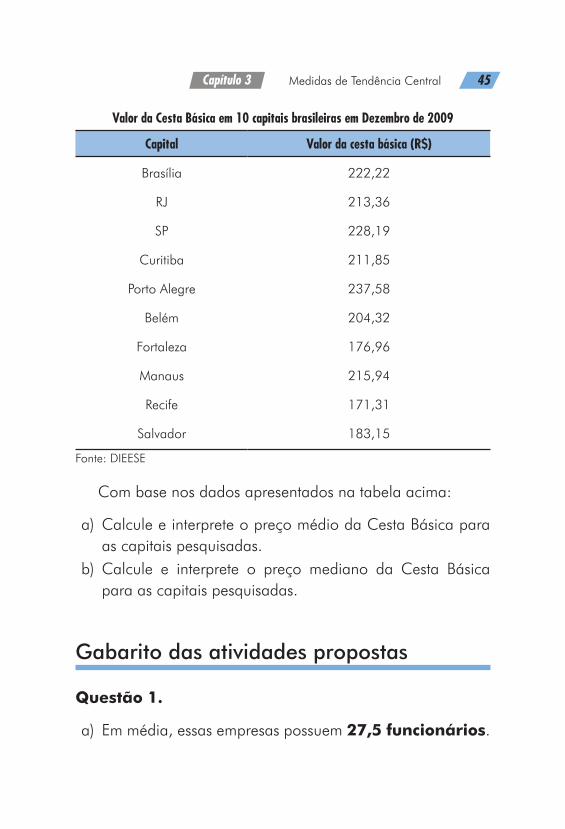
Questão 5. Segundo dados divulgados pelo DIEESE (Depar-tamento Intersindical de Estatísticas e Estudos Socioeconômi-cos), os valores da cesta básica em Dezembro de 2009, em 10 capitais brasileiras pesquisadas, estão na tabela abaixo:
Capítulo 3 Medidas de Tendência Central 45
Valor da Cesta Básica em 10 capitais brasileiras em Dezembro de 2009
Capital Valor da cesta básica (R$)
Brasília 222,22
RJ 213,36
SP 228,19
Curitiba 211,85
Porto Alegre 237,58
Belém 204,32
Fortaleza 176,96
Manaus 215,94
Recife 171,31
Salvador 183,15
Fonte: DIEESE
Com base nos dados apresentados na tabela acima:
a) Calcule e interprete o preço médio da Cesta Básica para as capitais pesquisadas.
b) Calcule e interprete o preço mediano da Cesta Básica para as capitais pesquisadas.
Gabarito das atividades propostas
Questão 1.
a) Em média, essas empresas possuem 27,5 funcionários.

46 Estatística Aplicada
b) Metade das empresas possui menos que 27,5 funcioná-rios, e metade mais que 27,5 funcionários.
c) Os números de funcionários que ocorrem com maior fre-quência são 15 e 30 funcionários.
Questão 2.
a) Variável: salários GLT&Cia. b) Amostra: 100 operários. c) 2,3 salários mínimos.
Questão 3.
a) Variável: total de vendas. b) Amostra: 8 anos. c) Em média, foram vendidos 8,5 milhões em reais nesse
período por ano. d) Metade do período foi vendida por menos que 9,9 mi-
lhões de reais, e metade por mais que 9,9 milhões de reais.
e) Não há moda, pois nenhum valor se repete.
Questão 4.
O valor médio das diárias é de 114,9 reais.
Questão 5.
a) O preço médio da cesta básica nessas capitais é de 206,5 reais.
b) Em metade das capitais, o preço da cesta básica é inferior a 212,6 reais, e em metade é superior a 212,6 reais.

Medidas de Variabilidade
ÂÂNeste capítulo, iremos abordar as Medidas de Variabi-lidade, que são medidas que têm por objetivo mensu-
rar variação de um conjunto de dados em torno da média.
Simone Echeveste
Capítulo 4

48 Estatística Aplicada
Nosso objetivo aqui é a apresentação de cada uma dessas medidas no que se refere à aplicabilidade, ao cálculo e à inter-pretação dos resultados obtidos. O aluno, ao final deste capítu-lo, deverá ser capaz de calcular e interpretar as medidas de va-riabilidade: variância, desvio-padrão e coeficiente de variação.
A média é extremamente útil como uma medida que obje-tiva representar/resumir um conjunto de dados, mas também é imprescindível ao pesquisador ter conhecimento da variação que ocorre em torno dessa média. Para isso, o cálculo das medidas de variabilidade contribui para uma melhor interpre-tação do comportamento de uma variável quantitativa (sua média e sua variação).
Tão importante quanto representarmos todos os valores de um conjunto de dados por meio das medidas de tendência central é ter o conhecimento da variação que ocorre em torno dessa medida. As medidas de variabilidade são extremamente úteis no tratamento de dados, pois estas indicam a variação existente em torno da média. As medidas de variabilidade que veremos em nossa disciplina são: Variância, Desvio-padrão e Coeficiente de variação.
Figura 11 Medidas de Variabilidade.

Capítulo 4 Medidas de Variabilidade 49
Variância
A variância de uma amostra corresponde à média dos qua-drados dos desvios dos valores em relação à média, Quanto maior for a variação dos valores do conjunto de dados, maior será a variância.
Notação:
σ2 – variância populacional
s2 – variância amostral
Fórmula:
Onde:
x – valores da variável investigada
– média da amostra
n – tamanho da amostra
S – somatório
Propriedades da Variância
1. Somando-se (ou subtraindo-se) a cada elemento de um con-junto de valores uma constante, a variância não se altera;
2. Multiplicando-se (ou dividindo-se) cada elemento de um con-junto de valores por um valor constante, a variância fica mul-tiplicada (ou dividida) pelo quadrado da constante.

50 Estatística Aplicada
Exemplo
Os dados apresentados abaixo correspondem ao número de reclamações (em mil reclamações) diárias recebidas pelo PROCON referentes às operadoras de TV a cabo no período de 5 dias:
17 18 16 20 22
Elementos importantes:
Variável (x): número de reclamações (em mil reclamações) diárias recebidas pelo PROCON referentes às operadoras de TV a cabo.
Amostra (n): 7 dias.
Média:
Variância:

Capítulo 4 Medidas de Variabilidade 51
s2 = 5,8 reclamações/dia2
No cálculo da variância, pode-se observar que a unidade da variável estudada é elevada ao quadrado, dificultando, as-sim, a interpretação de seu resultado final. A solução para esse problema é extrair a raiz quadrada da variância, permitindo, dessa forma, que se volte à unidade original da variável. Essa nova medida (a raiz quadrada da variância) é chamada de desvio-padrão.
Desvio-padrão
O desvio-padrão corresponde à raiz quadrada da variância. Essa medida expressa a variação média do conjunto de dados em torno da média, para mais ou para menos na mesma uni-dade de medida da média.
Notação:
σ – desvio-padrão populacional
s – desvio-padrão amostral
Fórmula:
52 Estatística Aplicada
Propriedades do Desvio-padrão
1. Somando-se (ou subtraindo-se) a cada elemento de um conjun-to de valores uma constante, o desvio-padrão não se altera;
2. Multiplicando-se (ou dividindo-se) cada elemento de um con-junto de valores por um valor constante, o desvio-padrão fica multiplicado (ou dividido) pela constante.
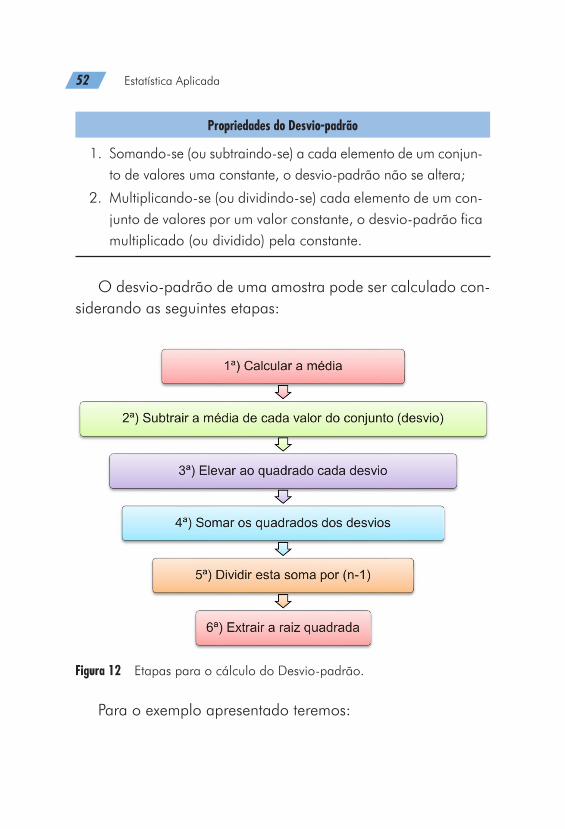
O desvio-padrão de uma amostra pode ser calculado con-siderando as seguintes etapas:
Figura 12 Etapas para o cálculo do Desvio-padrão.
Para o exemplo apresentado teremos:

Capítulo 4 Medidas de Variabilidade 53
Variância:
s2 = 5,8 reclamações/dia2
Desvio-padrão:
s = 2,4 reclamações/dia
Interpretação:
“Em média, o PROCON recebe diariamente 18,6 reclamações com uma variação em torno dessa média de 2,4 reclamações.”
Coeficiente de variação
Neste momento, poderemos questionar: quando um desvio--padrão é grande e quando ele é pequeno? Na verdade, um desvio padrão pode ser considerado grande ou pequeno de-pendendo da ordem de grandeza da variável.
Por esse motivo, quando desejamos comparar a variabili-dade entre métodos, ou ainda entre grupos de valores, é indi-cada a utilização do Coeficiente de Variação que representa o desvio-padrão expresso como uma porcentagem da média.
Notação:
C.V. – Coeficiente de variação.

54 Estatística Aplicada
Fórmula:
Onde:
– média da amostra
s – desvio-padrão
Para o exemplo...
Interpretação:
“Existe uma variação em torno da média de 12,9%.”
Figura 13 Interpretação Coeficiente de Variação.

Capítulo 4 Medidas de Variabilidade 55
Medidas de variabilidade para dados agrupados em tabelas de frequência
Os dados abaixo se referem ao tempo de espera na fila de um caixa de supermercado (em minutos):
Tempo de espera na fila (minutos)
Tempo de espera (x) Frequência (f) % x.f
0 5 8,0 0 x 5 = 0
2 25 40,3 2 x 25= 50
4 30 48,4 4 x 30= 120
6 2 3,2 6 x 2= 12
Total 62 (n) 100 182
Média:
Agora, vamos calcular a variância e o desvio-padrão. Nes-se caso, devemos considerar a frequência de cada valor da variável.

56 Estatística Aplicada
Variância:
Tempo de espera na fila (minutos)
Tempo de espera (x) Frequência (f) % (x– )2. f
0 5 8,0 (0 – 2,9)2. 5 = 42,05
2 25 40,3 (2 – 2,9)2. 25 = 20,25
4 30 48,4 (4 – 2,9)2. 30 = 36,3
6 2 3,2 (6 – 2,9)2. 2 = 19,22
Total 62 (n) 100 117,82
s2 = minutos2
Desvio-padrão:
s = 1,4 minutos

Capítulo 4 Medidas de Variabilidade 57
Interpretação:
“Em média, o tempo de espera na fila desse supermercado é de 2,9 minutos com uma variação em torno dessa média de 1,4 minutos.”
Recapitulando
As Medidas de Variabilidade (Variância, Desvio-padrão e Coefi-ciente de Variação) são extremamente úteis no tratamento de da-dos, pois estas indicam a variação existente em torno da média.
Quando realizamos o tratamento estatístico de dados pro-venientes de variáveis quantitativas, o cálculo e interpretação dessas medidas fornece informação detalhada e de extrema importância na tomada de decisão do pesquisador.
Atividades: Medidas de variabilidade
Questão 1. Os dados abaixo são referentes às taxas de de-semprego (em %) em alguns países selecionados da América do Sul e da América do Norte:
Brasil Uruguai Chile Argentina Canadá EUA Venezuela11.4 12.1 5.6 7.3 4.8 5.3 7.3
Calcule e interprete a Média e o desvio-padrão para esses dados.

58 Estatística Aplicada
Questão 2. A capacidade em litros dos porta-malas dos car-ros populares produzidos no Brasil foi investigada obtendo-se os seguintes dados:
Corsa: 240 litros Uno: 224 litros Hobby: 325 litros Gol: 146 litros
Calcule e interprete a média e o desvio-padrão para esses dados.
Questão 3. Um fabricante de molas está interessado em im-plementar um sistema de controle de qualidade para monitorar seu processo de produção. Para isto, foi registrado o número de molas fora da conformidade em cada lote de produção. Os dados apresentados na tabela de frequência abaixo se referem a 20 lotes selecionados, observando-se o número de molas fora de conformidade.
Número de molas fora de conformidade
Número de molas f %
6 3 15,0
7 6 30,0
8 4 20,0
9 3 15,0
12 4 20,0
Total 20 100,0
a) Calcule e interprete as medidas descritivas: média e des-vio-padrão para esses dados.

Capítulo 4 Medidas de Variabilidade 59
Questão 4. Considere a seguinte tabela:
Número de faltas no mês de uma amostra de 153 funcionários na empresa WK
Nº de faltas Nº funcionários %
0 85 55,5
1 20 13,1
2 40 26,1
3 8 5,3
Total 153 100,0
Calcule e interprete a média e o desvio-padrão para esses dados.
Questão 5. Duas turmas de Estatística apresentam as seguin-tes estatísticas para as notas na prova G1:
Turma A: média = 7,8 pontos e desvio-padrão = 1,4 pontos.
Turma B: média = 8,2 pontos e desvio-padrão = 2,5 pontos.
Qual das duas turmas teve um desempenho mais homogê-neo na prova G1? Justifique.
Gabarito das atividades propostas
Questão 1.A taxa média de desemprego é 7,7% com uma variação em torno dessa média de 2,9%.

60 Estatística Aplicada
Questão 2.Em média, a capacidade do porta-malas desses carros é de 233,8 litros com uma variação em torno dessa média de 73,4 litros.
Questão 3.Em média, são produzidas por lote 8,4 molas fora de confor-midade com uma variação de 2,2 molas.
Questão 4.Em média, os funcionários da empresa WK possuem 0,8 fal-tas, com uma variação em torno dessa média de 1 falta.
Questão 5.CVA = 17,9% CVB = 30,5% CVA < CVB
A turma A teve um desempenho mais homogêneo na prova G1, comparada com a turma B, pois tem um coeficiente de variação menor.

Distribuição de Probabilidade Normal
ÂÂ A distribuição Normal ou Gaussiana é, sem dú-vida, o modelo probabilístico mais conhecido. Várias
técnicas estatísticas necessitam da suposição de que os dados se distribuam normalmente para serem utilizadas. Na natureza, uma grande quantidade de variáveis apre-senta tal distribuição.
O objetivo desse capítulo é a apresentação dessa dis-tribuição por meio de exemplos de aplicações na área da administração; espera-se que o aluno compreenda as situações problema em que ela possa ser aplicada e as interpretações dos resultados fornecidos.
Simone Echeveste
Capítulo 5

62 Estatística Aplicada
A distribuição Normal é o modelo probabilístico mais utilizado no tratamento estatístico de dados, pois diversas ferramentas estatísticas necessitam da suposição de que os dados se distri-buam normalmente para serem utilizadas.
A sua função densidade de probabilidade da distribuição normal f(x) é dada por:
; para -∞ < x < ∞ , -∞ < µ < ∞ e σ2 > 0
Os parâmetros da Normal são a média ( µ ) e o desvio--padrão ( σ ), que permitem infinitas curvas normais com dife-rentes formatos (mas sempre simétricas). O gráfico da função densidade de probabilidade é apresentado a seguir:
Figura 14 Gráfico da Curva Normal.

Capítulo 5 Distribuição de Probabilidade Normal 63
Figura 15 Características da Distribuição Normal.
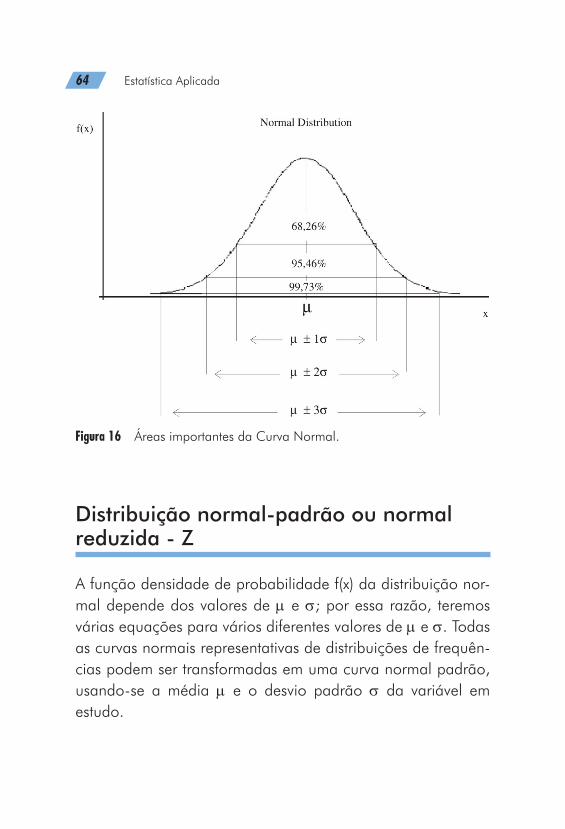
A distribuição Normal, independentemente dos valores dos parâmetros, apresenta sempre a seguinte relação (Fi-gura 11):
64 Estatística Aplicada
Figura 16 Áreas importantes da Curva Normal.
Distribuição normal-padrão ou normal reduzida - Z
A função densidade de probabilidade f(x) da distribuição nor-mal depende dos valores de µ e σ; por essa razão, teremos várias equações para vários diferentes valores de µ e σ. Todas as curvas normais representativas de distribuições de frequên-cias podem ser transformadas em uma curva normal padrão, usando-se a média µ e o desvio padrão σ da variável em estudo.

Capítulo 5 Distribuição de Probabilidade Normal 65
Para evitar cálculos com a integração, uma tabela única foi desenvolvida para uma variável aleatória agora chamada de “Z” com µ=0 e σ=1, e sua distribuição de probabilidades é definida como normal padronizada, ou ainda normal padrão.
Seja X uma variável aleatória normalmente distribuída com quaisquer parâmetros média µ e desvio-padrão σ. Para reali-zar o processo de padronização, devemos realizar a seguinte transformação:
Onde:
x = valor de interesse da variável
µ = média da variável
σ = desvio-padrão da variável
Após a padronização, poderemos obter as probabilidades associadas a cada área por meio da Tabela Normal padrão apresentada a seguir:
Tabela da Distribuição Normal Padrão P(Z < z) – VALORES POSITIVOS
z 0,0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,090,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,53590,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,57530,2 0,5793 0,5832 0,5871 0,5910 0,5948 0,5987 0,6026 0,6064 0,6103 0,61410,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,65170,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,68790,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,7224

66 Estatística Aplicada
0,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,75490,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,78520,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,81330,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,83891,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,86211,1 0,8643 0,8665 0,8686 0,8708 0,8729 0,8749 0,8770 0,8790 0,8810 0,88301,2 0,8849 0,8869 0,8888 0,8907 0,8925 0,8944 0,8962 0,8980 0,8997 0,90151,3 0,9032 0,9049 0,9066 0,9082 0,9099 0,9115 0,9131 0,9147 0,9162 0,91771,4 0,9192 0,9207 0,9222 0,9236 0,9251 0,9265 0,9279 0,9292 0,9306 0,93191,5 0,9332 0,9345 0,9357 0,9370 0,9382 0,9394 0,9406 0,9418 0,9429 0,94411,6 0,9452 0,9463 0,9474 0,9484 0,9495 0,9505 0,9515 0,9525 0,9535 0,95451,7 0,9554 0,9564 0,9573 0,9582 0,9591 0,9599 0,9608 0,9616 0,9625 0,96331,8 0,9641 0,9649 0,9656 0,9664 0,9671 0,9678 0,9686 0,9693 0,9699 0,97061,9 0,9713 0,9719 0,9726 0,9732 0,9738 0,9744 0,9750 0,9756 0,9761 0,97672,0 0,9772 0,9778 0,9783 0,9788 0,9793 0,9798 0,9803 0,9808 0,9812 0,98172,1 0,9821 0,9826 0,9830 0,9834 0,9838 0,9842 0,9846 0,9850 0,9854 0,98572,2 0,9861 0,9864 0,9868 0,9871 0,9875 0,9878 0,9881 0,9884 0,9887 0,98902,3 0,9893 0,9896 0,9898 0,9901 0,9904 0,9906 0,9909 0,9911 0,9913 0,99162,4 0,9918 0,9920 0,9922 0,9925 0,9927 0,9929 0,9931 0,9932 0,9934 0,99362,5 0,9938 0,9940 0,9941 0,9943 0,9945 0,9946 0,9948 0,9949 0,9951 0,99522,6 0,9953 0,9955 0,9956 0,9957 0,9959 0,9960 0,9961 0,9962 0,9963 0,99642,7 0,9965 0,9966 0,9967 0,9968 0,9969 0,9970 0,9971 0,9972 0,9973 0,99742,8 0,9974 0,9975 0,9976 0,9977 0,9977 0,9978 0,9979 0,9979 0,9980 0,99812,9 0,9981 0,9982 0,9982 0,9983 0,9984 0,9984 0,9985 0,9985 0,9986 0,99863,0 0,9987 0,9987 0,9987 0,9988 0,9988 0,9989 0,9989 0,9989 0,9990 0,99903,1 0,9990 0,9991 0,9991 0,9991 0,9992 0,9992 0,9992 0,9992 0,9993 0,99933,2 0,9993 0,9993 0,9994 0,9994 0,9994 0,9994 0,9994 0,9995 0,9995 0,99953,3 0,9995 0,9995 0,9995 0,9996 0,9996 0,9996 0,9996 0,9996 0,9996 0,99973,4 0,9997 0,9997 0,9997 0,9997 0,9997 0,9997 0,9997 0,9997 0,9997 0,99983,5 0,9998 0,9998 0,9998 0,9998 0,9998 0,9998 0,9998 0,9998 0,9998 0,99983,6 0,9998 0,9998 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,99993,7 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,99993,8 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,9999 0,99993,9 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000 1,0000

Capítulo 5 Distribuição de Probabilidade Normal 67
Tabela da Distribuição Normal Padrão P(Z < z) – VALORES NEGATIVOS
z 0,0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,090,0 0,5000 0,4960 0,4920 0,4880 0,4840 0,4801 0,4761 0,4721 0,4681 0,4641-0,1 0,4602 0,4562 0,4522 0,4483 0,4443 0,4404 0,4364 0,4325 0,4286 0,4247-0,2 0,4207 0,4168 0,4129 0,4090 0,4052 0,4013 0,3974 0,3936 0,3897 0,3859-0,3 0,3821 0,3783 0,3745 0,3707 0,3669 0,3632 0,3594 0,3557 0,3520 0,3483-0,4 0,3446 0,3409 0,3372 0,3336 0,3300 0,3264 0,3228 0,3192 0,3156 0,3121-0,5 0,3085 0,3050 0,3015 0,2981 0,2946 0,2912 0,2877 0,2843 0,2810 0,2776-0,6 0,2743 0,2709 0,2676 0,2643 0,2611 0,2578 0,2546 0,2514 0,2483 0,2451-0,7 0,2420 0,2389 0,2358 0,2327 0,2296 0,2266 0,2236 0,2206 0,2177 0,2148-0,8 0,2119 0,2090 0,2061 0,2033 0,2005 0,1977 0,1949 0,1922 0,1894 0,1867-0,9 0,1841 0,1814 0,1788 0,1762 0,1736 0,1711 0,1685 0,1660 0,1635 0,1611-1,0 0,1587 0,1562 0,1539 0,1515 0,1492 0,1469 0,1446 0,1423 0,1401 0,1379-1,1 0,1357 0,1335 0,1314 0,1292 0,1271 0,1251 0,1230 0,1210 0,1190 0,1170-1,2 0,1151 0,1131 0,1112 0,1093 0,1075 0,1056 0,1038 0,1020 0,1003 0,0985-1,3 0,0968 0,0951 0,0934 0,0918 0,0901 0,0885 0,0869 0,0853 0,0838 0,0823-1,4 0,0808 0,0793 0,0778 0,0764 0,0749 0,0735 0,0721 0,0708 0,0694 0,0681-1,5 0,0668 0,0655 0,0643 0,0630 0,0618 0,0606 0,0594 0,0582 0,0571 0,0559-1,6 0,0548 0,0537 0,0526 0,0516 0,0505 0,0495 0,0485 0,0475 0,0465 0,0455-1,7 0,0446 0,0436 0,0427 0,0418 0,0409 0,0401 0,0392 0,0384 0,0375 0,0367-1,8 0,0359 0,0351 0,0344 0,0336 0,0329 0,0322 0,0314 0,0307 0,0301 0,0294-1,9 0,0287 0,0281 0,0274 0,0268 0,0262 0,0256 0,0250 0,0244 0,0239 0,0233-2,0 0,0228 0,0222 0,0217 0,0212 0,0207 0,0202 0,0197 0,0192 0,0188 0,0183-2,1 0,0179 0,0174 0,0170 0,0166 0,0162 0,0158 0,0154 0,0150 0,0146 0,0143-2,2 0,0139 0,0136 0,0132 0,0129 0,0125 0,0122 0,0119 0,0116 0,0113 0,0110-2,3 0,0107 0,0104 0,0102 0,0099 0,0096 0,0094 0,0091 0,0089 0,0087 0,0084-2,4 0,0082 0,0080 0,0078 0,0075 0,0073 0,0071 0,0069 0,0068 0,0066 0,0064-2,5 0,0062 0,0060 0,0059 0,0057 0,0055 0,0054 0,0052 0,0051 0,0049 0,0048-2,6 0,0047 0,0045 0,0044 0,0043 0,0041 0,0040 0,0039 0,0038 0,0037 0,0036-2,7 0,0035 0,0034 0,0033 0,0032 0,0031 0,0030 0,0029 0,0028 0,0027 0,0026-2,8 0,0026 0,0025 0,0024 0,0023 0,0023 0,0022 0,0021 0,0021 0,0020 0,0019-2,9 0,0019 0,0018 0,0018 0,0017 0,0016 0,0016 0,0015 0,0015 0,0014 0,0014-3,0 0,0013 0,0013 0,0013 0,0012 0,0012 0,0011 0,0011 0,0011 0,0010 0,0010-3,1 0,0010 0,0009 0,0009 0,0009 0,0008 0,0008 0,0008 0,0008 0,0007 0,0007

68 Estatística Aplicada
-3,2 0,0007 0,0007 0,0006 0,0006 0,0006 0,0006 0,0006 0,0005 0,0005 0,0005-3,3 0,0005 0,0005 0,0005 0,0004 0,0004 0,0004 0,0004 0,0004 0,0004 0,0003-3,4 0,0003 0,0003 0,0003 0,0003 0,0003 0,0003 0,0003 0,0003 0,0003 0,0002-3,5 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002 0,0002-3,6 0,0002 0,0002 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001-3,7 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001-3,8 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001 0,0001-3,9 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Como utilizar a tabela normal padrão
Na tabela, desejamos saber a área correspondente a um de-terminado valor de “z”, devemos considerar duas informações importantes obtidas a partir do valor de “z” que são: a linha e a coluna em que devemos procurar o valor.
Por exemplo, para P(z < 1,35), lê-se “probabilidade de z ser inferior a 1,35”:
Devemos dividir esse número em duas partes: a primei-ra composta pela parte inteira do número e a primeira casa após a vírgula que representa os décimos; a segunda parte é composta pela segunda casa após a vírgula que representa o centésimo.

Capítulo 5 Distribuição de Probabilidade Normal 69
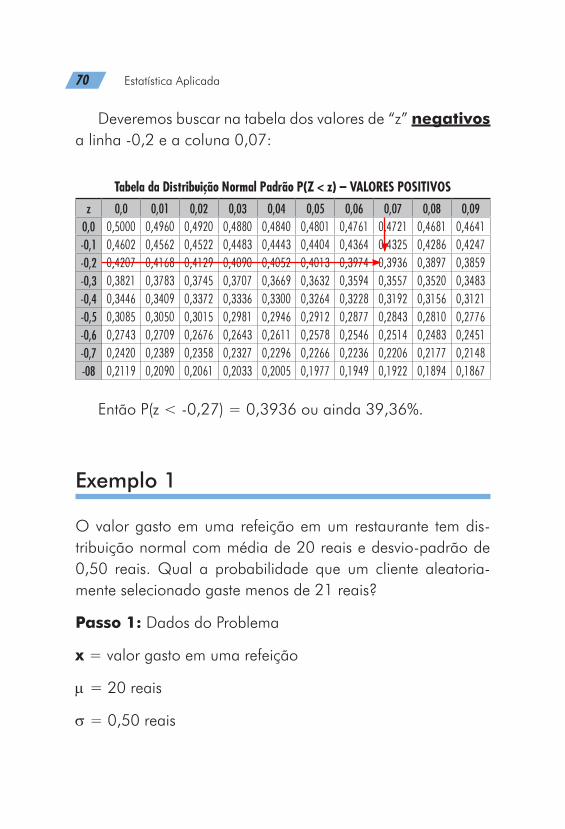
Para o nosso exemplo P(z < 1,35), deveremos buscar na ta-bela dos valores de “z” positivos a linha 1,3 e a coluna 0,05:
Tabela da Distribuição Normal Padrão P(Z < z) – VALORES POSITIVOSz 0,0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09
0,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,5359
0,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,5753
0,2 0,5793 0,5832 0,5871 0,5910 0,5948 0,5987 0,6026 0,6064 0,6103 0,6141
0,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,6517
0,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,6879
0,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,7224
0,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,7549
0,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,7852
0,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,8133
0,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,8389
1,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8557 0,8599 0,8621
1,1 0,8643 0,8665 0,8686 0,8708 0,8729 0,8749 0,8770 0,8790 0,8810 0,8830
1,2 0,8849 0,8869 0,8888 0,8907 0,8925 0,8944 0,8962 0,8980 0,8997 0,9015
1,3 0,9032 0,9049 0,9066 0,9082 0,9099 0,9115 0,9131 0,9147 0,9162 0,9177
1,4 0,9192 0,9207 0,9222 0,9236 0,9251 0,9265 0,9279 0,9292 0,9306 0,9319
1,5 0,9332 0,9345 0,9357 0,9370 0,9382 0,9394 0,9406 0,9418 0,9429 0,9441
Então P(z < 1,35) = 0,9115 ou ainda 91,15%.
Outro exemplo: P(z < -0,27)
70 Estatística Aplicada
Deveremos buscar na tabela dos valores de “z” negativos a linha -0,2 e a coluna 0,07:
Tabela da Distribuição Normal Padrão P(Z < z) – VALORES POSITIVOS
z 0,0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,090,0 0,5000 0,4960 0,4920 0,4880 0,4840 0,4801 0,4761 0,4721 0,4681 0,4641-0,1 0,4602 0,4562 0,4522 0,4483 0,4443 0,4404 0,4364 0,4325 0,4286 0,4247-0,2 0,4207 0,4168 0,4129 0,4090 0,4052 0,4013 0,3974 0,3936 0,3897 0,3859-0,3 0,3821 0,3783 0,3745 0,3707 0,3669 0,3632 0,3594 0,3557 0,3520 0,3483-0,4 0,3446 0,3409 0,3372 0,3336 0,3300 0,3264 0,3228 0,3192 0,3156 0,3121-0,5 0,3085 0,3050 0,3015 0,2981 0,2946 0,2912 0,2877 0,2843 0,2810 0,2776-0,6 0,2743 0,2709 0,2676 0,2643 0,2611 0,2578 0,2546 0,2514 0,2483 0,2451-0,7 0,2420 0,2389 0,2358 0,2327 0,2296 0,2266 0,2236 0,2206 0,2177 0,2148-08 0,2119 0,2090 0,2061 0,2033 0,2005 0,1977 0,1949 0,1922 0,1894 0,1867
Então P(z < -0,27) = 0,3936 ou ainda 39,36%.
Exemplo 1
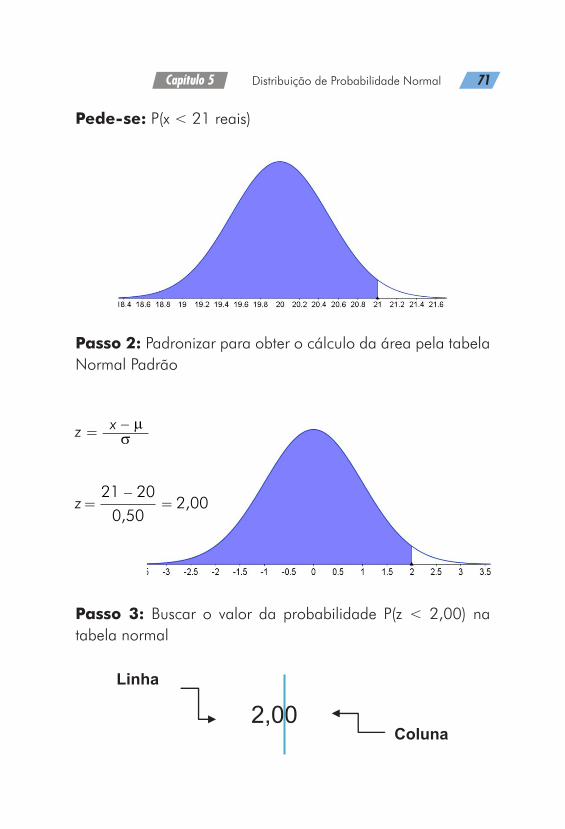
O valor gasto em uma refeição em um restaurante tem dis-tribuição normal com média de 20 reais e desvio-padrão de 0,50 reais. Qual a probabilidade que um cliente aleatoria-mente selecionado gaste menos de 21 reais?
Passo 1: Dados do Problema
x = valor gasto em uma refeição
µ = 20 reais
σ = 0,50 reais
Capítulo 5 Distribuição de Probabilidade Normal 71
Pede-se: P(x < 21 reais)
Passo 2: Padronizar para obter o cálculo da área pela tabela Normal Padrão
Passo 3: Buscar o valor da probabilidade P(z < 2,00) na tabela normal

72 Estatística Aplicada
Deveremos buscar na tabela dos valores de “z” positivos a linha 2,0 e a coluna 0,00:
Tabela da Distribuição Normal Padrão P(Z < z) – VALORES POSITIVOS
z 0,0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,090,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,53590,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,57530,2 0,5793 0,5832 0,5871 0,5910 ,05948 0,5987 0,6026 0,6064 0,6103 0,61410,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,65170,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,68790,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,72240,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,75490,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,78520,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,81330,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,83891,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,86211,1 0,8643 0,8665 0,8686 0,8708 0,8729 0,8749 0,8770 0,8790 0,8810 0,88301,2 0,8849 0,8869 0,8888 0,8907 0,8925 0,8944 0,8962 0,8980 0,8997 0,90151,3 0,9032 0,9049 0,9066 0,9082 0,9099 0,9115 0,9131 0,9147 0,9162 0,91771,4 0,9192 0,9207 0,9222 0,9236 0,9251 0,9265 0,9279 0,9292 0,9306 0,93191,5 0,9332 0,9345 0,9357 0,9370 0,9382 0,9394 0,9406 0,9418 0,9429 0,94411,6 0,9452 0,9463 0,9474 0,9484 0,9495 0,9505 0,9515 0,9525 0,9535 0,95451,7 0,9554 0,9564 0,9573 0,9582 0,9591 0,9599 0,9608 0,9616 0,9625 0,96331,8 0,9641 0,9649 0,9656 0,9664 0,9671 0,9678 0,9686 0,9693 0,9699 0,97061,9 0,9713 0,9719 0,9726 0,9732 0,9738 0,9744 0,9750 0,9756 0,9761 0,97672,0 0,9772 0,9778 0,9783 0,9788 0,9793 0,9798 0,9803 0,9808 0,9812 0,98172,1 0,9821 0,9826 0,9830 0,9834 0,9838 0,9842 0,9846 0,9850 0,9854 0,98572,2 0,9861 0,9864 0,9868 0,9871 0,9875 0,9878 0,9881 0,9884 0,9887 0,9890
Então a P(x < 21 reais) = 0,9772 ou 97,72%.

Capítulo 5 Distribuição de Probabilidade Normal 73
Exemplo 2
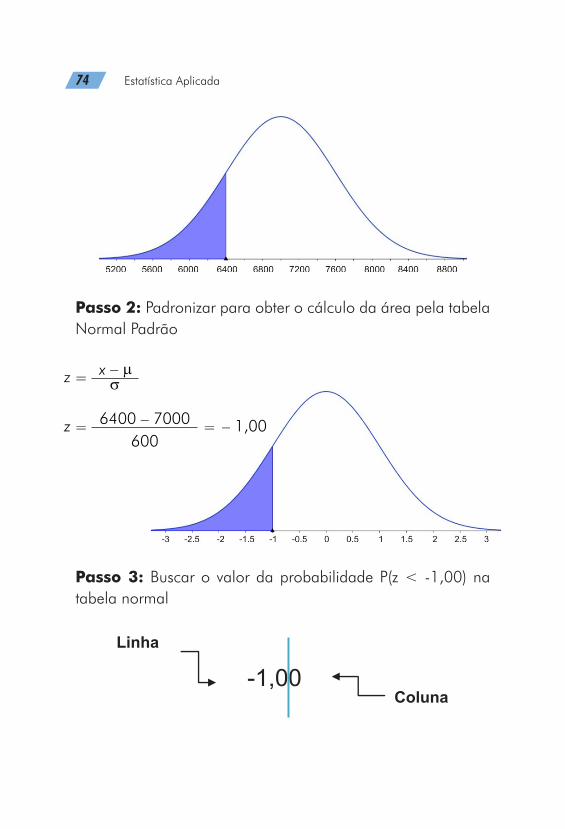
O número de unidades vendidas em uma loja de materiais es-portivos no período de um mês é normalmente distribuído com média de 7000 unidades e desvio-padrão de 600 unidades. Qual é a probabilidade de que em um determinado mês essa loja venda menos de 6400 unidades?
Passo 1: Dados do Problema
x = número de unidades vendidas em uma loja de materiais esportivos no período de um mês
µ = 7000 unidades
σ = 600 unidades
Pede-se:
P(x < 6400 unidades)
74 Estatística Aplicada
Passo 2: Padronizar para obter o cálculo da área pela tabela Normal Padrão
Passo 3: Buscar o valor da probabilidade P(z < -1,00) na tabela normal

Capítulo 5 Distribuição de Probabilidade Normal 75
Deveremos buscar na tabela dos valores de “z” negativos a linha -1,0 e a coluna 0,00:
Tabela da Distribuição Normal Padrão P(Z < z) – VALORES POSITIVOS
z 0,0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,090,0 0,5000 0,4960 0,4920 0,4880 0,4840 0,4801 0,4761 0,4721 0,4681 0,4641-0,1 0,4602 0,4562 0,4522 0,4483 0,4443 0,4404 0,4364 0,4325 0,4286 0,4247-0,2 0,4207 0,4168 0,4129 0,4090 0,4052 0,4013 0,3974 0,3936 0,3897 0,3859-0,3 0,3821 0,3783 0,3745 0,3707 0,3669 0,3632 0,3594 0,3557 0,3520 0,3483-0,4 0,3446 0,3409 0,3372 0,3336 0,3300 0,3264 0,3228 0,3192 0,3156 0,3121-0,5 0,3085 0,3050 0,3015 0,2981 0,2946 0,2912 0,2877 0,2843 0,2810 0,2776-0,6 0,2743 0,2709 0,2676 0,2643 0,2611 0,2578 0,2546 0,2514 0,2483 0,2451-0,7 0,2420 0,2389 0,2358 0,2327 0,2296 0,2266 0,2236 0,2206 0,2177 0,2148-0,8 0,2119 0,2090 0,2061 0,2033 0,2005 0,1977 0,1949 0,1922 0,1894 0,1867-0,9 0,1841 0,1814 0,1788 0,1762 0,1736 0,1711 0,1685 0,1660 0,1635 0,1611-1,0 0,1587 0,1562 0,1539 0,1515 0,1492 0,1469 0,1446 0,1423 0,1401 0,1379-1,1 0,1357 0,1335 0,1314 0,1292 0,1271 0,1251 0,1230 0,1210 0,1190 0,1170-1,2 0,1151 0,1131 0,1112 0,1093 0,1075 0,1056 0,1038 0,1020 0,1003 0,0985
Então a P(x < 6400 unidades) = 0,1587 ou 15,87%.
Nos exemplos anteriores, observe que as áreas/probabi-lidades solicitadas foram sempre áreas INFERIORES a um

76 Estatística Aplicada
valor “x” de interesse; observe que, na tabela normal padrão utilizada, as probabilidades que ali se encontram referem-se sempre a áreas inferiores:
Tabela da Distribuição Normal Padrão P(Z < z) – VALORES POSITIVOS
z 0,0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,090,0 0,5000 0,4960 0,4920 0,4880 0,4840 0,4801 0,4761 0,4721 0,4681 0,4641-0,1 0,4602 0,4562 0,4522 0,4483 0,4443 0,4404 0,4364 0,4325 0,4286 0,4247
Quando a probabilidade desejada for uma área SUPE-RIOR a algum valor de “x” ou ainda ENTRE dois valores de “x”, devemos utilizar a mesma tabela, porém observando as seguintes regras:
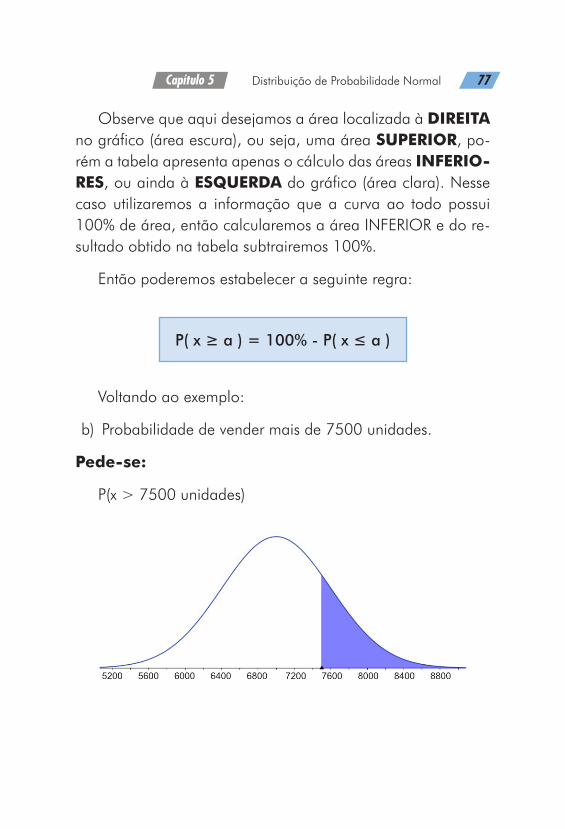
No mesmo exemplo anteriormente citado, vamos consi-derar agora que desejamos saber a probabilidade dessa loja vender mais de 7500 unidades:
Pede-se:
P(x > 7500 unidades)
Capítulo 5 Distribuição de Probabilidade Normal 77
Observe que aqui desejamos a área localizada à DIREITA no gráfico (área escura), ou seja, uma área SUPERIOR, po-rém a tabela apresenta apenas o cálculo das áreas INFERIO-RES, ou ainda à ESQUERDA do gráfico (área clara). Nesse caso utilizaremos a informação que a curva ao todo possui 100% de área, então calcularemos a área INFERIOR e do re-sultado obtido na tabela subtrairemos 100%.
Então poderemos estabelecer a seguinte regra:
P( x ≥ a ) = 100% - P( x ≤ a )
Voltando ao exemplo:
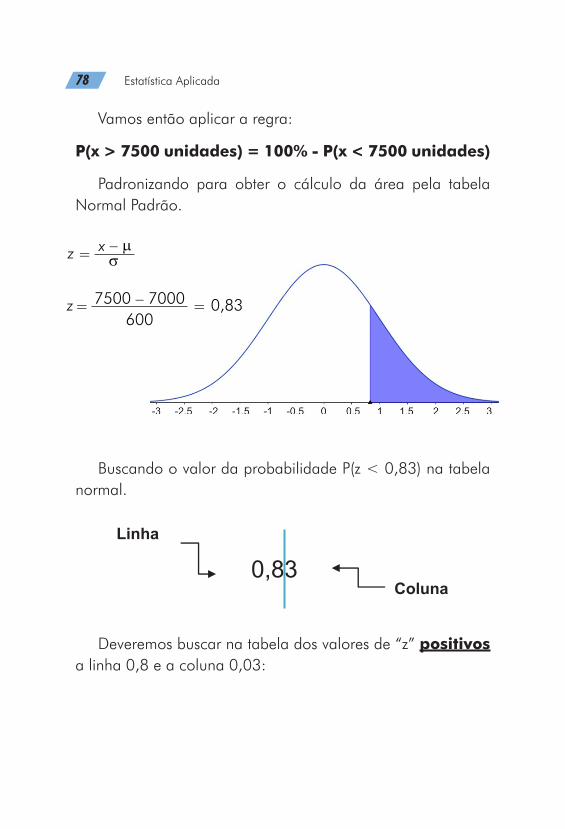
b) Probabilidade de vender mais de 7500 unidades.
Pede-se:
P(x > 7500 unidades)
78 Estatística Aplicada
Vamos então aplicar a regra:
P(x > 7500 unidades) = 100% - P(x < 7500 unidades)
Padronizando para obter o cálculo da área pela tabela Normal Padrão.
Buscando o valor da probabilidade P(z < 0,83) na tabela normal.
Deveremos buscar na tabela dos valores de “z” positivos a linha 0,8 e a coluna 0,03:
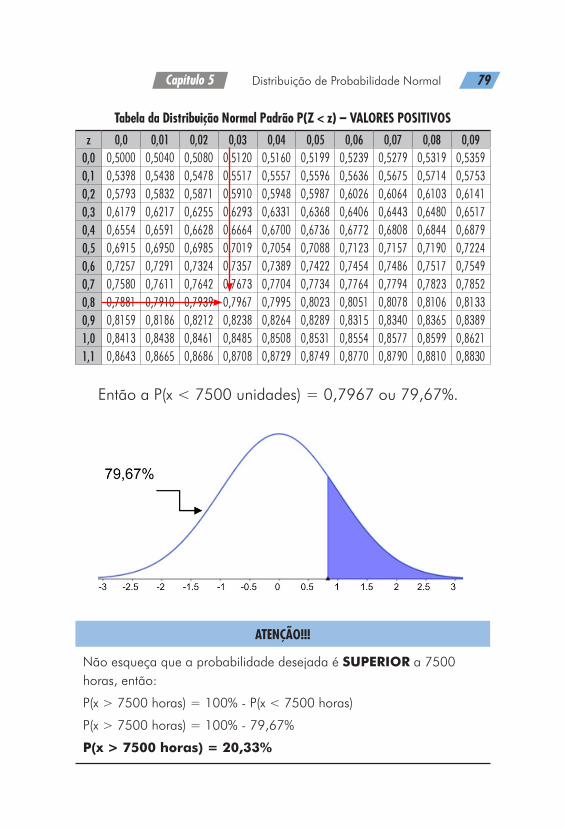
Capítulo 5 Distribuição de Probabilidade Normal 79
Tabela da Distribuição Normal Padrão P(Z < z) – VALORES POSITIVOS
z 0,0 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,090,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,53590,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,57530,2 0,5793 0,5832 0,5871 0,5910 0,5948 0,5987 0,6026 0,6064 0,6103 0,61410,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,65170,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,68790,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,72240,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,75490,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,78520,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,81330,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,83891,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,86211,1 0,8643 0,8665 0,8686 0,8708 0,8729 0,8749 0,8770 0,8790 0,8810 0,8830
Então a P(x < 7500 unidades) = 0,7967 ou 79,67%.
ATENÇÃO!!!
Não esqueça que a probabilidade desejada é SUPERIOR a 7500 horas, então:
P(x > 7500 horas) = 100% - P(x < 7500 horas)
P(x > 7500 horas) = 100% - 79,67%
P(x > 7500 horas) = 20,33%

80 Estatística Aplicada
Agora, vejamos o terceiro e último tipo de área/probabili-dade a ser calculada: ENTRE dois valores.
Qual é a probabilidade dessa loja vender entre 6300 uni-dades e 7400 unidades?
Pede-se:
P( 6300 ≤ x ≤ 7400 )
Nesse caso, teremos dois valores de “x” que deverão ser padronizados resultando em dois valores de probabilidade, uma referente à área inferior a 7400 e outra inferior a 6300.
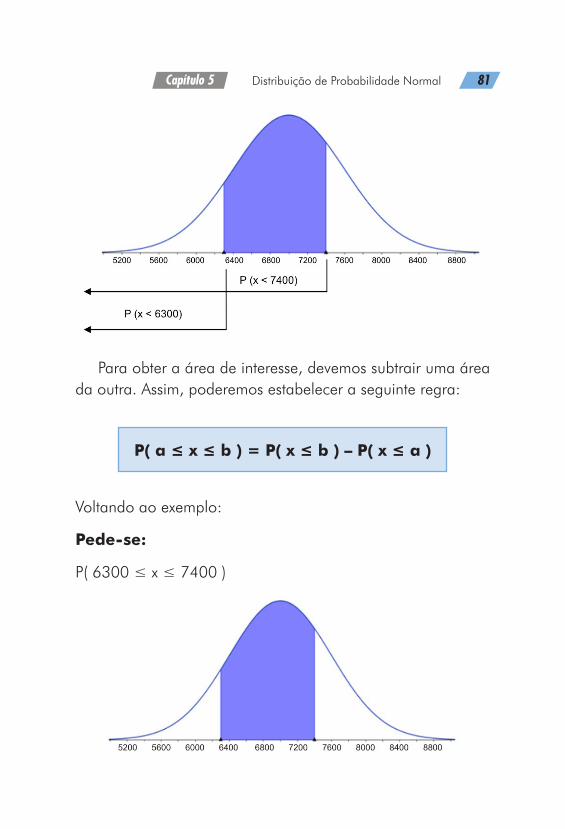
Capítulo 5 Distribuição de Probabilidade Normal 81
Para obter a área de interesse, devemos subtrair uma área da outra. Assim, poderemos estabelecer a seguinte regra:
P( a ≤ x ≤ b ) = P( x ≤ b ) – P( x ≤ a )
Voltando ao exemplo:
Pede-se:
P( 6300 ≤ x ≤ 7400 )

82 Estatística Aplicada
Vamos então aplicar a regra:
P( 6300 ≤ x ≤ 7400 ) = P(x ≤ 7400) – P(x ≤ 6300)
Padronizando para obter o cálculo da área pela tabela Normal Padrão.
Na tabela: linha 0,6 e coluna 0,07 0,7486 ou 74,86%
Na tabela: linha -1,1 e coluna 0,07 0,1210 ou 12,10%
Então:
P( 6300 ≤ x ≤ 7400 ) = 74,86% – 12,10%
P( 6300 ≤ x ≤ 7400 ) = 62,76%

Capítulo 5 Distribuição de Probabilidade Normal 83
Recapitulando
A distribuição de probabilidades para uma variável aleatória “X” é expressa por meio de um modelo matemático que repre-senta as probabilidades associadas aos possíveis valores que essa variável pode assumir.
A Distribuição Normal é o modelo probabilístico mais co-nhecido, no qual várias técnicas estatísticas necessitam da suposição de que os dados se distribuam normalmente para serem utilizadas. Seus parâmetros são a média e o desvio--padrão.
Atividades: Distribuição de probabilidade normal
Questão 1. Determinado atacadista efetua suas vendas por telefone. Após alguns meses, verificou-se que os pedidos se distribuem normalmente com média de 3.000 pedidos e des-vio-padrão de 180 pedidos. Qual a probabilidade de que em um mês selecionado ao acaso essa empresa venda menos de 2700 pedidos.
Questão 2. O conteúdo líquido das garrafas de 300 ml de um refrigerante é normalmente distribuído com média de 300 ml e desvio-padrão de 2 ml. Determine a probabilidade de uma garrafa selecionada ao acaso apresentar conteúdo líquido:
a) Inferior a 306 ml. b) Superior a 305 ml.

84 Estatística Aplicada
c) Entre 302 e 304 ml.
Questão 3. O lucro mensal obtido com ações de determi-nada empresa tem distribuição normal com média de 12 mil reais e desvio-padrão de 5 mil reais. Qual a probabilidade de que em determinado mês o lucro dessa empresa seja:
a) Superior a 18 mil reais. b) Inferior a 8 mil reais. c) Entre 10 e 15 mil reais.
Questão 4. Suponha que a renda média anual de uma grande comunidade tenha distribuição normal com média de 15 mil re-ais e com um desvio-padrão de 3 mil reais. Qual a probabilida-de de que um indivíduo aleatoriamente selecionado desse grupo apresente uma média salarial anual superior a 18 mil reais?
Questão 5. O escore de um estudante no vestibular é uma variável com distribuição normal com média de 550 pontos e desvio-padrão de 30 pontos. Se a admissão em certa faculda-de exige um escore mínimo de 575 pontos, qual é a probabi-lidade de um aluno ser admitido nessa faculdade?
Gabarito das atividades propostas
Questão 1. P(x < 2700 pedidos) = 4,75%
Questão 2. a) 99,87% b) 0,62% c) 13,59%
Questão 3. a) 11,51% b) 21,19% c) 38,12%
Questão 4. P(x > 18 mil reais) = 15,87%
Questão 5. P(x > 575 pontos) = 20,33%

Amostragem
ÂÂ Quando uma pesquisa/estudo analisa os dados de todo o Universo/grupo que ele tenta compreender,
dizemos que está trabalhando com a população. Entre-tanto, muitas vezes, o pesquisador trabalha com tempo, energia e recursos econômicos limitados, tornando possí-vel a análise de apenas parte do grupo de dados retirados da população. Esse grupo denomina-se amostra.
Neste capítulo, serão apresentados os elementos im-portantes relacionados ao processo de seleção da amos-tra que fará parte da pesquisa. Com o estudo da teoria da amostragem, espera-se que o aluno conheça as diferentes metodologias de seleção da amostra, bem como compre-enda os procedimentos do cálculo do tamanho mínimo de uma amostra em uma pesquisa.
Simone Echeveste
Capítulo 6

86 Estatística Aplicada
“Frederick Mosteller, estatístico e professor em Harvard, dis-se, certa vez, que é possível mentir usando estatísticas, mas que se mente mais, e melhor, sem estatísticas. É preciso en-tender que as amostras podem levar a conclusões erradas. Contudo, as opiniões pessoais, sem base em dados, levam, em geral, a conclusões muito mais erradas.”
Amostragem é o conjunto de procedimentos e técnicas para extração de elementos da população para compor a amostra. O objetivo da amostragem é obter amostras representativas das populações em estudo.
As técnicas de amostragem se dividem em: probabilísti-cas e não probabilísticas. As técnicas probabilísticas são aquelas em que todos os elementos da população têm uma probabilidade não nula de seleção. Nas técnicas não proba-bilísticas, não podemos garantir que todos os elementos têm probabilidade de serem selecionados para a amostra.
Técnicas de amostragem probabilísticas
 Amostra Aleatória SimplesUma amostra aleatória simples é selecionada tal que todos os elementos da população tenham a mesma chance de serem selecionados, por exemplo, por um sorteio.
 Amostra SistemáticaUma amostra sistemática poderá ser tratada como uma amostra aleatória simples se os elementos da população estiverem ordenados aleatoriamente, e a seleção será re-

Capítulo 6 Amostragem 87
alizada por meio da escolha sistemática, por exemplo, de uma a cada cinco elementos.
 Amostra EstratificadaEsta técnica consiste em dividir a população em subgrupos, que são denominados estratos. Esses estratos devem ser internamente mais homogêneos do que a população toda, com respeito às variáveis em estudo.
 Amostra por conglomeradosChamamos de conglomerado um agrupamento de elemen-tos da população. Por exemplo, numa população de alunos de uma escola, as turmas formam conglomerados de alunos.
Técnicas de amostragem não probabilísticas
 Amostra por cotasNesta técnica, a população é vista de forma segregada, dividida em diversos subgrupos. Numa pesquisa socioeco-nômica, por exemplo, a população pode ser dividida por faixas de renda, faixas de idade, nível de instrução etc.
 Amostra por julgamentoOs elementos escolhidos são aqueles julgados como típi-cos da população que se deseja estudar.
 Amostra por fluxoOs elementos são selecionados a partir do fluxo destes em determinado local. Por exemplo, considere uma pesquisa

88 Estatística Aplicada
referente à opinião das pessoas sobre a administração da cidade. A amostra pode ser selecionada considerando o fluxo das pessoas no centro de Porto Alegre.
As perguntas mais frequentes em relação ao tamanho mí-nimo da amostra podem ser resumidas em três questões apre-sentadas na figura 17.
Figura 17 Questões mais frequentes sobre o tamanho da amostra.
Nesse contexto, definir o tamanho mínimo da amostra é indispensável para garantir a capacidade de o estudo respon-der aos objetivos propostos considerando o rigor científico in-dispensável em qualquer pesquisa. É importante observar que não existe um tamanho de amostra predeterminado, ou seja, cada pesquisa deve ser realizada considerando sua população e seus objetivos.
A determinação do tamanho amostral é realizada mediante fórmulas estatísticas, conhecidas como fórmulas para cálculo de tamanho de amostra que consideram alguns elementos im-portantes apresentados na figura 18.

Capítulo 6 Amostragem 89
Figura 18 Elementos que devem ser considerados no cálculo do tamanho mínimo da amostra.
Determinação do tamanho mínimo da amostra
Quando desejamos coletar uma amostra aleatória de dados que será utilizada para estimar uma média populacional µ, quantos valores amostrais devem ser obtidos? De acordo com TRIOLA (2008), a determinação do tamanho de uma amostra é muito importante, pois amostras desnecessariamente gran-

90 Estatística Aplicada
des gastam tempo e dinheiro, e amostras muito pequenas po-dem levar a resultados pobres.
Não podemos evitar a ocorrência do ERRO AMOSTRAL, porém podemos limitar seu valor a partir da escolha de uma amostra de tamanho adequado. Obviamente, o ERRO AMOS-TRAL e o TAMANHO DA AMOSTRA seguem sentidos contrários (conforme apresentação da Figura 19, abaixo). Quanto maior o tamanho da amostra, menor o erro cometido e vice-versa.
Figura 19 Relação entre o erro amostral e o tamanho da amostra.
Cálculo do tamanho mínimo da amostra
A) PARA ESTIMAR UMA MÉDIA QUANDO A POPULA-ÇÃO É CONHECIDA
Para estimarmos uma média, o cálculo para o tamanho mínimo de amostra necessita das seguintes informações:
- Determinação do erro de estimação (e).

Capítulo 6 Amostragem 91
- Nível de confiança desejado nos resultados (normalmente, esse valor é estipulado em 95%).
Valores de z para níveis de confiança estabelecidos e o tamanho da amostra.
Nível de confiança Valor tabela Z
90% 1,645
95% 1,960
99% 2,575
- Tamanho da população de interesse do estudo (N).
A fórmula utilizada é:
Onde:
σ2 – desvio-padrão populacional elevado ao quadrado (vari-ância)
Z2 – valor da tabela normal padrão elevado ao quadrado
e2 – erro máximo de estimação estabelecido pelo pesquisador
N – tamanho da população

92 Estatística Aplicada
Exemplo
Deseja-se determinar o tamanho mínimo de uma amostra para estimar a média de gastos mensais em supermercado de clientes que possuem o cartão fidelidade, considerando um erro máximo de estimação de 15 reais e uma confiabilidade de 95%, o desvio-padrão desse gasto é sabido ser de 200 re-ais. Considere que, ao todo, 6500 clientes possuem o cartão fidelidade.
Informações do problema:
Deseja estimar a média de gastos mensais no supermercado.
N = 6.500 clientes (População)
Z = 1,96 (valor da tabela normal para uma confiança de 95%)
e = 15 reais (erro amostral)
σ = 200 reais (desvio-padrão)

Capítulo 6 Amostragem 93
Para o valor final, recomenda-se o arredondamento sempre para o próximo número inteiro.
n = 619
Para essa pesquisa, deve-se investigar no mínimo 619 clientes.
Para o caso do desvio-padrão ser desconhecido, deve-se utili-zar uma estimativa desse valor com base em dados amostrais, como por exemplo:
- A partir de um estudo piloto com base na primeira coleta de, pelo menos, 31 valores amostrais selecionados aleato-riamente, calcular o desvio-padrão amostral.
- Por meio da utilização do desvio-padrão obtido em outra pesquisa semelhante (características populacionais, men-suração das variáveis) da que está sendo realizada.
B) PARA ESTIMAR UMA MÉDIA QUANDO A POPULA-ÇÃO É DESCONHECIDA
Para o caso do tamanho total da população ser desconhecido, ou ainda naqueles casos em que a população é infinita, pode-remos utilizar a seguinte fórmula para determinar o tamanho mínimo da amostra:

94 Estatística Aplicada
Exemplo
Um Administrador de empresas deseja estimar a renda média para o primeiro ano de trabalho em sua área de atuação. Quantos administradores devem ser selecionados, desejando ter 95% de confiança em que a renda média amostral esteja a menos de 20 reais da verdadeira renda média populacional? Sabemos, por um estudo prévio, que o desvio-padrão é de 150 reais.
Devemos, portanto, obter uma amostra de, ao menos, 216 administradores que estejam no primeiro ano de trabalho, se-lecionados aleatoriamente.
C) PARA ESTIMAR UMA PROPORÇÃO QUANDO A PO-PULAÇÃO É CONHECIDA
Outro parâmetro estatístico cuja determinação afeta o ta-manho da amostra é a proporção populacional. A fórmula para cálculo do tamanho da amostra para uma estimativa da PROPORÇÃO POPULACIONAL (p) é dada por:

Capítulo 6 Amostragem 95
Onde:
Z – valor da distribuição normal (para 95% de confiança, z = 1,96)
p = proporção da característica a ser estudada (quando não sabemos essa proporção, utilizamos o valor de p = 50% ou ainda p = 0,50)
N = tamanho da população
e = erro máximo de estimação (normalmente, para pesquisas na área de administração, utilizamos 5% - 0,05)
Exemplo 1
Vamos supor uma pesquisa com uma população de 1450 as-sinantes da NET; qual o tamanho mínimo que a amostra deve ter considerando um erro máximo de estimação de 5%?
Informações do problema:
Z – 1,96 (para 95% de confiança, z = 1,96)
p = 0,50 (quando não sabemos essa proporção, utilizamos o valor de p = 0,50)
N = 1.450
e = 0,05

96 Estatística Aplicada
=
−+−−
=−+−
−=
)50,01(50,0.96,105,0).11450(1450).50,01(50,0.96,1
)1()1()1(
22
2
22
2
ppzNNppzn
e
86,3035829,4
58,392.19604,06225,3450.19604,0
25,084,30025,01449450.125,084,3
==+×
=
×+×××
=
n
n
Devemos, então, investigar uma amostra de 304 assinantes da NET.
D) PARA ESTIMAR UMA PROPORÇÃO QUANDO A PO-PULAÇÃO É DESCONHECIDA
Quando a população é desconhecida, utilizamos para es-timar uma proporção a seguinte fórmula:
Exemplo
Uma pequena indústria fabricante de gêneros alimentícios deseja realizar uma pesquisa em um supermercado de uma

Capítulo 6 Amostragem 97
região de São Leopoldo com o objetivo de estimar a propor-ção de consumidores que preferem o leite embalado em sacos plásticos. Qual deve ser o tamanho mínimo da amostra consi-derando um nível de confiança de 95% e um erro máximo de estimação de 5%?
Informações do problema:
Z – 1,96 (para 95% de confiança, z = 1,96)
p = 0,50 (quando não sabemos essa proporção, utilizamos o valor de p = 0,50)
e = 0,05
Devemos, então, investigar uma amostra de 385 consumi-dores.

98 Estatística Aplicada
Recapitulando
A determinação do processo de amostragem e do tamanho da amostra são decisões muito importantes em qualquer pes-quisa. Cabe sempre ao pesquisador procurar desenhar seu planejamento amostral procurando reduzir o máximo possível a fonte de erros.
Dependendo da variável principal a ser estimada e algu-mas informações a respeito da população alvo da pesquisa, podemos utilizar diferentes fórmulas para determinar o tama-nho mínimo da amostra.
Atividades: amostragem
Questão 1. Uma pesquisa é planejada para determinar as despesas médicas anuais das famílias dos empregados de uma grande empresa. A gerência da empresa deseja ter 95% de confiança de que a média da amostra está no máximo com uma margem de erro de 50 reais da média real das despe-sas médicas familiares. Um estudo-piloto indica que o desvio--padrão pode ser calculado como igual a 400 reais. Qual o tamanho de amostra necessário?
Questão 2. Um estudo deseja saber a proporção de eleitores que se declaram indecisos em relação a certo candidato. Qual

Capítulo 6 Amostragem 99
deverá ser o tamanho mínimo de amostra para uma confiança de 95% e um erro máximo de estimação de 5%?
Questão 3. Uma grande loja de departamentos deseja reali-zar uma pesquisa com seus clientes que possuem o cartão da loja. Ao todo, são 4500 clientes. Qual o tamanho da amostra que deve ser adotado com um erro máximo de estimação de 5% e um nível de confiança de 95%?
Questão 4. Um gerente de restaurante deseja estimar o tem-po médio que os clientes levam para realizar uma refeição. Com base em estudos anteriores, sabe-se que o desvio-pa-drão é de 15 minutos. Utilizando uma confiança de 95% e um erro máximo de 5 minutos, qual deve ser o tamanho mínimo da amostra para esse estudo?
Questão 5. Uma pesquisa deseja estimar a proporção de analfabetos em uma região do interior do Brasil com uma con-fiabilidade de 95% e com um erro de estimação máxi-mo de 2,5%. Qual o tamanho da amostra a ser utilizada?
Gabarito atividades propostas
Questão 1. n = 245,8 ≈ 246
Questão 2. n = 384,16 ≈ 385

100 Estatística Aplicada
Questão 3. n = 354,01 ≈ 355
Questão 4. n = 34,57 ≈ 35
Questão 5. n = 1.536,64 ≈ 1.537

Estimação
ÂÂNeste capítulo, serão trabalhados alguns conceitos im-portantes a respeito de estimação pontual e intervalar.
Será apresentado ao aluno a construção e a interpretação de um Intervalo de Confiança, bem como a importância da informação fornecida por ele.
Simone Echeveste
Capítulo 7

102 Estatística Aplicada
O aluno, ao final deste capítulo, deverá realizar estimações intervalares para parâmetros como a média e a proporção a partir da construção de intervalos de confiança, bem como realizar a correta interpretação dos mesmos.
Ao realizar uma pesquisa, na grande maioria das vezes, necessitamos conhecer algumas características da população por meio de informações amostrais, ou seja, uma amostra é extraída da população e, a partir da sua análise, as in-formações obtidas são inferidas para toda a população de interesse.
A estimação é o processo que consiste no uso de dados da amostra (dados amostrais) para estimar valores de parâ-metros populacionais desconhecidos, tais como média, desvio padrão, proporções etc.
Estimação é o processo pelo qual utilizamos um valor amostral (estimador) com o objetivo de inferir o seu respec-tivo valor populacional (parâmetro).
IMPORTANTE:
A média populacional µ é estimada por .O desvio-padrão populacional σ é estimado por s.A proporção populacional p é estimada por p.

Capítulo 7 Estimação 103
Estimação por ponto e por intervalos de confiança
A estimação pontual, ou por ponto de um parâmetro, ocorre sempre que calculamos alguma estatística utilizando apenas a aplicação da fórmula de seu estimador. Nesse tipo de estima-tiva a informação fornecida é composta por um único valor.
Quando calculamos, por exemplo, o salário médio de um grupo de pessoas e chegamos ao resultado = 3.250 reais, estamos estimando que, em média, essas pessoas tenham um salário de 3.250 reais. Observe que nossa estimativa é pontu-al, ou seja, feita utilizando apenas um único valor.
Já a estimação intervalar consiste na determinação de um intervalo de valores do qual, com certa confiança (probabilida-de), esteja contido o parâmetro desconhecido, utilizando, para isso, a informação obtida com o seu estimador. A utilização de intervalos de confiança é uma alternativa sempre muito in-teressante no processo de estimação, pois permite determinar o erro máximo de estimação cometido com certa confiança preestabelecida.
Intervalo de confiança para média µ
Ao construir um Intervalo de Confiança para uma média, de-sejamos estabelecer um intervalo de valores com uma proba-bilidade preestabelecida, considerando a estimativa da média ( ) corrigida pelo erro de estimação (e).

104 Estatística Aplicada
Destaca-se aqui que a variável analisada (x) deve apresen-tar distribuição aproximadamente normal para que se possa realizar esse procedimento de estimação intervalar.
Figura 20 Representação do Intervalo de Confiança 95% para a média.
Duas situações são consideradas quando desejamos estabe-lecer um Intervalo de Confiança para a média populacional µ:
1ª) Quando o desvio-padrão σ é conhecido. 2ª) Quando o desvio-padrão σ é desconhecido.
Seja “X” uma variável aleatória que apresenta distribuição normal com desvio-padrão desconhecido, o Intervalo de Confiança para a média µ pode ser assim determinado:
Onde:
Atenção!
= média amostrale = erro de estimaçãot = valor tabelado tabela t-students = desvio-padrão amostraln = tamanho da amostra
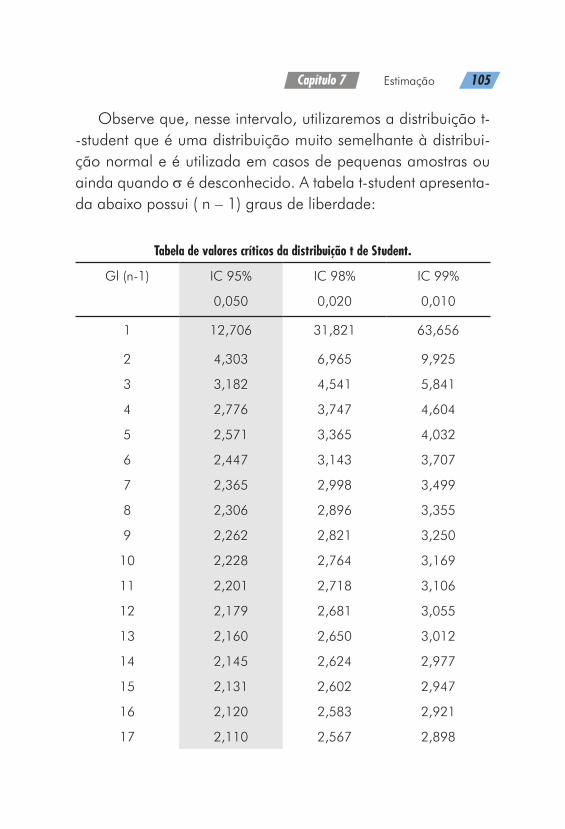
Capítulo 7 Estimação 105
Observe que, nesse intervalo, utilizaremos a distribuição t--student que é uma distribuição muito semelhante à distribui-ção normal e é utilizada em casos de pequenas amostras ou ainda quando σ é desconhecido. A tabela t-student apresenta-da abaixo possui ( n – 1) graus de liberdade:
Tabela de valores críticos da distribuição t de Student.
Gl (n-1) IC 95% IC 98% IC 99%
0,050 0,020 0,010
1 12,706 31,821 63,656
2 4,303 6,965 9,925
3 3,182 4,541 5,841
4 2,776 3,747 4,604
5 2,571 3,365 4,032
6 2,447 3,143 3,707
7 2,365 2,998 3,499
8 2,306 2,896 3,355
9 2,262 2,821 3,250
10 2,228 2,764 3,169
11 2,201 2,718 3,106
12 2,179 2,681 3,055
13 2,160 2,650 3,012
14 2,145 2,624 2,977
15 2,131 2,602 2,947
16 2,120 2,583 2,921
17 2,110 2,567 2,898
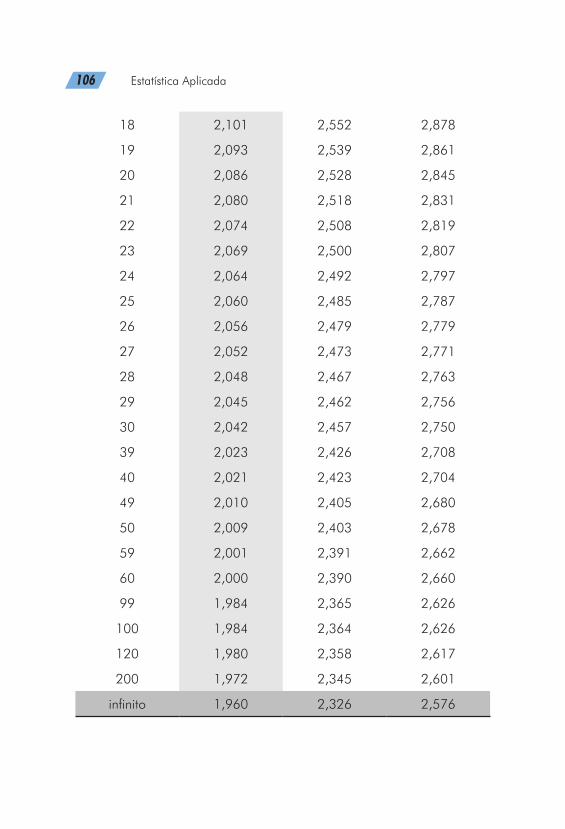
106 Estatística Aplicada
18 2,101 2,552 2,878
19 2,093 2,539 2,861
20 2,086 2,528 2,845
21 2,080 2,518 2,831
22 2,074 2,508 2,819
23 2,069 2,500 2,807
24 2,064 2,492 2,797
25 2,060 2,485 2,787
26 2,056 2,479 2,779
27 2,052 2,473 2,771
28 2,048 2,467 2,763
29 2,045 2,462 2,756
30 2,042 2,457 2,750
39 2,023 2,426 2,708
40 2,021 2,423 2,704
49 2,010 2,405 2,680
50 2,009 2,403 2,678
59 2,001 2,391 2,662
60 2,000 2,390 2,660
99 1,984 2,365 2,626
100 1,984 2,364 2,626
120 1,980 2,358 2,617
200 1,972 2,345 2,601
infinito 1,960 2,326 2,576

Capítulo 7 Estimação 107
Exemplo 1
Em um estudo realizado com uma amostra de 25 clientes in-vestidores de um banco, verificou-se uma idade média desses clientes de 54,7 anos com um desvio-padrão de 5,2 anos. Construa o Intervalo de Confiança (IC) 95% para a verdadeira idade média de todos os clientes investidores desse banco.
Dados do Problema:
Variável (x) – Idade (em anos)
Amostra (n) = 25 clientes
= 54,7 anos
s = 5,2 anos
t = 2,064 (veja na página a seguir como encontrar esse valor)
Intervalo de Confiança 95%

108 Estatística Aplicada
e = 2,1466
[ ± e]
[54,7 ± 2,15]
[54,7 – 2,15 a 54,7+ 2,15]
[52,55 a 56,85]
Interpretação: “Estima-se, com 95% de confiança, que a verdadeira idade média desses clientes seja um valor entre 52,55 anos e 56,85 anos.”
Como encontrar o valor de “T” na tabela T-student
Na tabela “t”, devemos considerar duas informações impor-tantes: a linha e a coluna em que o valor se encontra. Na linha, temos os graus de liberdade (gl) que correspondem sem-pre ao tamanho da amostra menos 1 (n-1), e na coluna deve-mos observar o nível de confiança do intervalo desejado.
No exemplo acima, o tamanho da amostra é 25 e o Inter-valo de Confiança solicitado é 95%, então devemos olhar na tabela a linha 25 – 1 = 24 e a coluna que corresponde ao IC 95%:
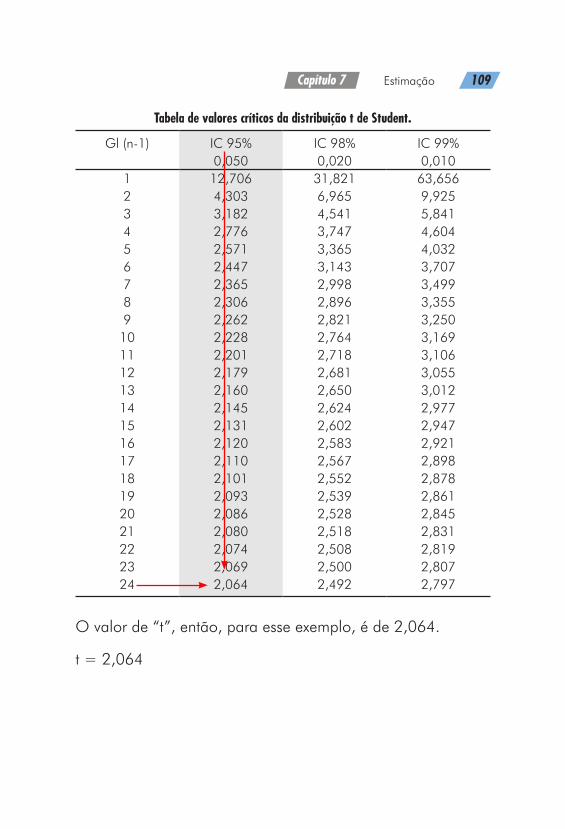
Capítulo 7 Estimação 109
Tabela de valores críticos da distribuição t de Student.
Gl (n-1) IC 95% IC 98% IC 99%0,050 0,020 0,010
1 12,706 31,821 63,6562 4,303 6,965 9,9253 3,182 4,541 5,8414 2,776 3,747 4,6045 2,571 3,365 4,0326 2,447 3,143 3,7077 2,365 2,998 3,4998 2,306 2,896 3,3559 2,262 2,821 3,250
10 2,228 2,764 3,16911 2,201 2,718 3,10612 2,179 2,681 3,05513 2,160 2,650 3,01214 2,145 2,624 2,97715 2,131 2,602 2,94716 2,120 2,583 2,92117 2,110 2,567 2,89818 2,101 2,552 2,87819 2,093 2,539 2,86120 2,086 2,528 2,84521 2,080 2,518 2,83122 2,074 2,508 2,81923 2,069 2,500 2,80724 2,064 2,492 2,797
O valor de “t”, então, para esse exemplo, é de 2,064.
t = 2,064

110 Estatística Aplicada
Exemplo 2
Em uma central 0800 de atendimento a dúvidas sobre os pro-dutos de um empresa, foi registrado, em uma amostra de 15 dias, uma média de 53 atendimentos ao dia com um desvio--padrão de 4 atendimentos. Obtenha o Intervalo de Confiança 95% para a verdadeira média de atendimentos diários recebi-dos por essa central.
Dados do Problema:
Variável (x) – Número de atendimentos realizados ao dia
Amostra (n) = 15 dias
= 53 atendimentos
s = 4 atendimentos
t = 2,145 (procurar na tabela - linha 14 e coluna IC95%)
Tabela de valores críticos da distribuição t de Student.
Gl (n-1) IC 95% IC 98% IC 99%0,050 0,020 0,010
1 12,706 31,821 63,6562 4,303 6,965 9,9253 3,182 4,541 5,8414 2,776 3,747 4,6045 2,571 3,365 4,0326 2,447 3,143 3,7077 2,365 2,998 3,4998 2,306 2,896 3,3559 2,262 2,821 3,250

Capítulo 7 Estimação 111
10 2,228 2,764 3,16911 2,201 2,718 3,10612 2,179 2,681 3,05513 2,160 2,650 3,01214 2,145 2,624 2,97715 2,131 2,602 2,94716 2,120 2,583 2,92117 2,110 2,567 2,898
Intervalo de Confiança 95%
e = 2,22
[53 ± 2,22]
[53 – 2,22 a 53 + 2,22]
[50,78 a 55,22]
Interpretação: “Estima-se, com 95% de confiança, que o verdadeiro número médio de atendimentos realizados por essa central seja um valor entre 50,78 e 55,22 atendimentos ao dia.”

112 Estatística Aplicada
Intervalo de confiança para proporção p
Seja “p” a proporção de ocorrência de algum evento de inte-resse em uma população, o Intervalo de Confiança para uma proporção da população p pode ser definido como:
Figura 21 Representação do Intervalo de Confiança 95% para a proporção.
Atenção!
p = proporção observada na amostra
e = erro de estimação
z = valor tabelado tabela normal
n = tamanho da amostra
Os valores de Z (normal-padrão) podem ser obtidos na tabela t com infinitos graus de liberdade. Valores típicos:

Capítulo 7 Estimação 113
z0,05= 1,645 (IC 90%)
z0,025 = 1,96 (IC 95%)
z0,005 = 2,576 (IC 99%)
Exemplo
Num depósito, uma amostra de 230 latas de certo produto ali-mentar armazenadas para serem distribuídas foram verificadas constatando-se que 12 já ultrapassaram o prazo de validade. Construa e interprete o Intervalo de confiança 95% para a pro-porção verdadeira de latas que já ultrapassaram o prazo de validade.
Dados do Problema:
Proporção investigada – proporção de latas com prazo de va-lidade vencido
Amostra (n) = 230 latas
Verifique que, de acordo com o enunciado do problema das 230 latas, 12 ultrapassaram o prazo de validade.
z = 1,96 (valor obtido a partir da normal padrão de acordo com os valores de z apresentada na página anterior)

114 Estatística Aplicada
Intervalo de Confiança 95%
Após o intervalo construído,
multiplique os valores obti-
dos por 100 para apresentar
o intervalo em percentual.
Interpretação: “Estima-se, com 95% de confiança, que a verdadeira proporção de latas que já ultrapassaram o prazo de validade seja um valor entre 2,35% a 8,09%.”
Recapitulando
A Estimação é o processo pelo qual utilizamos um valor amos-tral (estimador) com o objetivo de inferir o seu respectivo valor populacional (parâmetro), podendo ser realizada de duas for-mas: estimativa pontual ou estimativa intervalar.

Capítulo 7 Estimação 115
A estimação intervalar é construída a partir do cálculo do estimador de interesse ajustado a um erro de estimação, corresponde a uma alternativa sempre muito interessante no processo de estimação, pois permite ao pesquisador conside-rar em uma estimativa pontual o erro de estimação que pode ocorrer nesse valor.
Atividades: Estimação
Questão 1. Um determinado Instituto de Pesquisa investigou uma amostra de 400 Administradores a respeito do tempo que levaram para obter seus diplomas. A média obtida foi de 4,5 anos com um desvio-padrão de 0,5 anos. Com base nesses dados amostrais, construa um intervalo de 95% de confiança para o verdadeiro tempo médio gasto por todos os Adminis-tradores para obter seus diplomas.
Questão 2. Uma amostra de 539 lares de certa cidade foi selecionada e determinou-se que em 133 deles havia, pelo menos, uma arma de fogo. Usando um nível de confiança de 95%, calcule o Intervalo de Confiança para a verdadeira pro-porção de lares com, pelo menos, uma arma de fogo.
Questão 3. Para estimar o tempo médio de atendimento em um restaurante do tipo fast-food, um pesquisador anotou o tempo gasto por 40 garçonetes para completar um pedido--padrão (consistindo de 1 hambúrguer, uma porção de fritas e uma bebida). As garçonetes levaram, em média, 4,3 minutos com um desvio-padrão de 2,4 minutos para completar os pe-

116 Estatística Aplicada
didos. Construa o Intervalo de Confiança 95% para o verda-deiro tempo médio necessário para completar um pedido--padrão.
Questão 4. Quarenta e uma pessoas, de uma amostra alea-tória de 500 trabalhadores, estão desempregadas. Calcule um Intervalo de Confiança 95% para essa proporção.
Questão 5. Para avaliar o peso médio de uma nova safra de limões, o administrador de uma fazenda obteve os pesos de 50 limões novos, encontrando uma média de 115,5 gramas, com um desvio-padrão de 20,4 gramas. Construa e interprete confiança 95% para o verdadeiro peso médio dos limões.
Gabarito das atividades propostas
Questão 1. R: [4,45 anos a 4,51 anos].
Questão 2. R: [21,03% a 28,31%].
Questão 3. R: [3,56 minutos a 5,04 minutos].
Questão 4. R: [5,8% a 10,6%].
Questão 5. R: [109,85 gramas a 121,15 gramas].

Testes de Hipóteses
ÂÂNeste capítulo, estudaremos uma importante ferramen-ta de análise estatística muito utilizada na área da Ad-
ministração que é o Teste de Hipóteses. Essa ferramenta permite ao pesquisador verificar se uma afirmação sobre um parâmetro (média) pode ser aceita para toda a popu-lação ou não.
Ao final deste capítulo, o aluno deverá identificar os ti-pos de problemas que podem ser analisados por meio de um teste de hipóteses, compreender todos os passos que compõem a realização deste, bem como concluir sobre os resultados obtidos.
Simone Echeveste
Capítulo 8

118 Estatística Aplicada
Em algumas situações de pesquisa, existe um particular inte-resse em decidir sobre a verdade ou não de uma hipótese específica (se dois grupos têm a mesma média ou não, ou se o parâmetro populacional tem um valor em particular ou não). Na Estatística, quando falamos em hipóteses, referimo-nos a uma afirmação a respeito de um parâmetro, como a média ou o desvio-padrão, por exemplo.
Nesse caso, precisamos de ferramentas que permitam tes-tar se uma afirmação é aceita ou rejeitada, tendo como base as informações obtidas em uma amostra. O Teste de hipó-teses viabiliza uma estrutura para que façamos isto; ele é útil quando desejamos verificar a alegação (afirmação) feita sobre um parâmetro (média ou proporção).
Exemplos:
 O lucro médio mensal da empresa é de 500 mil reais.  As vendas médias da loja A são superiores às da loja B.  O tempo médio de entrega da mercadoria é de 7 dias.
Um teste de hipóteses deve considerar alguns passos im-portantes na sua realização. Iniciamos com a determinação da hipótese a ser investigada, ou ainda com o efeito que de-sejamos comprovar; este deve se referir a algum parâmetro populacional como a média ou a proporção, por exemplo.
A hipótese estabelecida é comparada aos resultados obti-dos considerando uma pesquisa realizada com uma amostra de “n” elementos. As informações obtidas com os estimadores dos parâmetros de interesse adicionadas a alguns elementos

Capítulo 8 Testes de Hipóteses 119
de probabilidade permitirão ao pesquisador decidir se a hipó-tese é verdadeira ou não.
Figura 22 Elementos de um Teste de Hipóteses.
Em geral, estipula-se um nível de 5%. O valor da proba-bilidade de se obter o efeito observado, dado que a hipótese nula é verdadeira, é chamado de p-valor. Se o valor do p-valor for menor que o nível de significância estipulado (normalmente de 5%), assume-se o erro tipo I e rejeita-se a hipótese nula. Ao contrário, se o p-valor for maior, não é assumido o erro tipo I e se aceita a hipótese nula.
Os testes podem rejeitar ou aceitar a hipótese nula e, nessa decisão, podem ocorrer dois possíveis tipos de erros conforme demonstra a Figura 20:
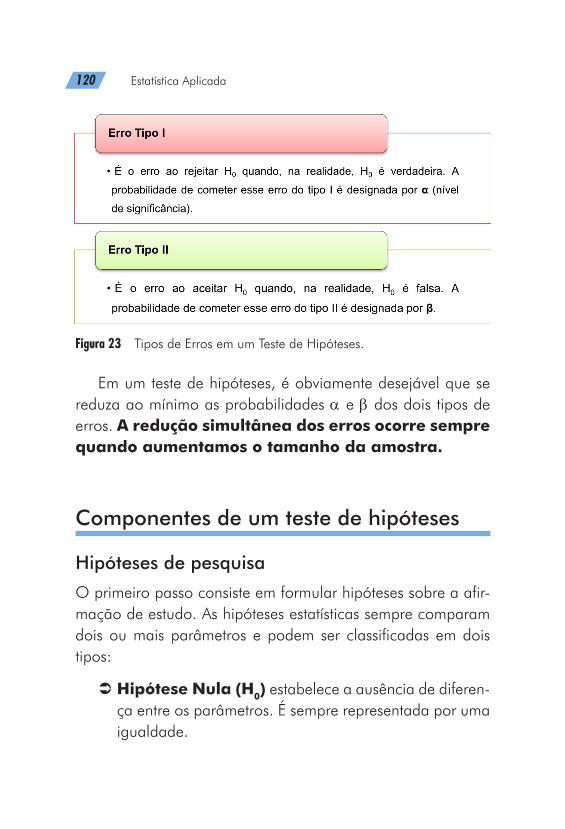
120 Estatística Aplicada
Figura 23 Tipos de Erros em um Teste de Hipóteses.
Em um teste de hipóteses, é obviamente desejável que se reduza ao mínimo as probabilidades α e β dos dois tipos de erros. A redução simultânea dos erros ocorre sempre quando aumentamos o tamanho da amostra.
Componentes de um teste de hipóteses
Hipóteses de pesquisa
O primeiro passo consiste em formular hipóteses sobre a afir-mação de estudo. As hipóteses estatísticas sempre comparam dois ou mais parâmetros e podem ser classificadas em dois tipos:
 Hipótese Nula (H0) estabelece a ausência de diferen-ça entre os parâmetros. É sempre representada por uma igualdade.

Capítulo 8 Testes de Hipóteses 121
 Hipótese Alternativa (H1) é a hipótese contrária à H0; geralmente, é a hipótese que o pesquisador quer ver confirmada. Pode representar simplesmente uma desi-gualdade, ou ainda a ideia de superioridade/inferiori-dade.
- O tempo médio de entrega da mercadoria é de 7 dias.
H0 : µ = 7 dias
H1 : µ ≠ 7 dias
- A quantidade média de peças defeituosas do fabricante A é superior a do fabricante B.
H0 : µ A = µ B
H1 : µ A > µ B
Estatística do teste
A estatística do teste é um valor calculado com as informações provenientes da amostra e, posteriormente, utilizado para se tomar a decisão sobre a aceitação ou rejeição da hipótese nula (H0).

122 Estatística Aplicada
Regra de decisão
Se o valor da estatística do teste localiza-se na região críti-ca, rejeitamos a hipótese (nula) H0, pois existe uma forte evi-dência amostral de sua falsidade. Ao contrário, aceitamos H0, concluindo que não existe evidência amostral significativa para sua rejeição.
Conclusão experimental
Após a regra de decisão, o teste deve ter uma conclusão expe-rimental na qual o pesquisador, de acordo com o contexto do problema, finalizará a sua análise descrevendo os resultados obtidos.
Figura 24 Etapas de um teste de hipóteses.

Capítulo 8 Testes de Hipóteses 123
Teste de hipóteses para uma média (Teste T – Student)
O objetivo desse teste é comparar os valores obtidos em uma amostra com uma média estabelecida como referência.
Hipóteses
Ho: µ = µ0 (referência)Ha: µ ≠ µ0 (referência)
Estatística do teste
ns
Xt ocal
µ−=
Onde: = média da amostra
µ0 = valor de referência
s = desvio-padrão da amostra
n = tamanho da amostra
Regra de decisão
Na regra de decisão, devemos considerar que a variável ana-lisada tenha distribuição aproximadamente normal. Nesse caso, a partir dos valores da tabela t-student, iremos definir os pontos de corte na regra de decisão, ou seja, a partir de que ponto inicia e termina a região crítica (região de rejeição).
A regra estabelece que, se o valor calculado na estatística do teste for um valor localizado na região de aceitação, de-veremos então aceitar a hipótese nula H0 que representa a decisão de que a diferença encontrada nos dados amostrais com os parâmetros populacionais NÃO é significativa.
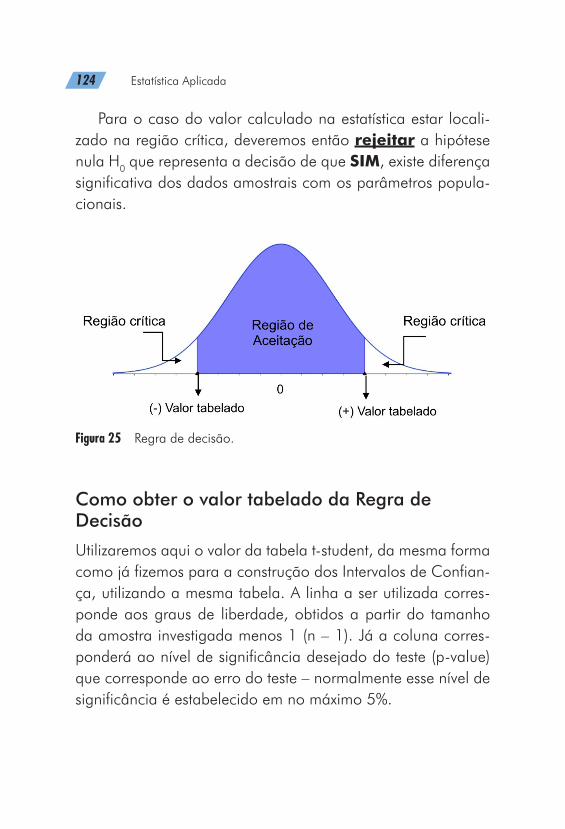
124 Estatística Aplicada
Para o caso do valor calculado na estatística estar locali-zado na região crítica, deveremos então rejeitar a hipótese nula H0 que representa a decisão de que SIM, existe diferença significativa dos dados amostrais com os parâmetros popula-cionais.
Figura 25 Regra de decisão.
Como obter o valor tabelado da Regra de Decisão
Utilizaremos aqui o valor da tabela t-student, da mesma forma como já fizemos para a construção dos Intervalos de Confian-ça, utilizando a mesma tabela. A linha a ser utilizada corres-ponde aos graus de liberdade, obtidos a partir do tamanho da amostra investigada menos 1 (n – 1). Já a coluna corres-ponderá ao nível de significância desejado do teste (p-value) que corresponde ao erro do teste – normalmente esse nível de significância é estabelecido em no máximo 5%.
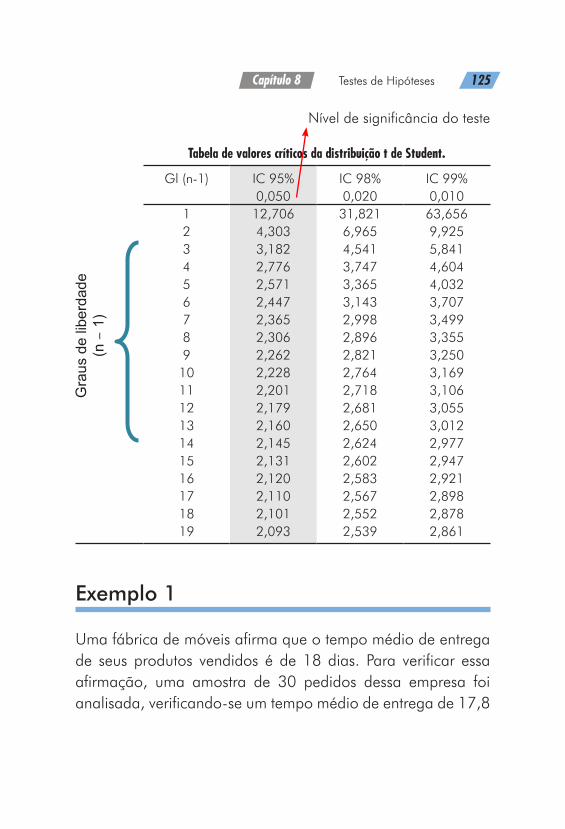
Capítulo 8 Testes de Hipóteses 125
Nível de significância do teste
Tabela de valores críticos da distribuição t de Student.
Gl (n-1) IC 95% IC 98% IC 99%0,050 0,020 0,010
1 12,706 31,821 63,6562 4,303 6,965 9,9253 3,182 4,541 5,8414 2,776 3,747 4,6045 2,571 3,365 4,0326 2,447 3,143 3,7077 2,365 2,998 3,4998 2,306 2,896 3,3559 2,262 2,821 3,250
10 2,228 2,764 3,16911 2,201 2,718 3,10612 2,179 2,681 3,05513 2,160 2,650 3,01214 2,145 2,624 2,97715 2,131 2,602 2,94716 2,120 2,583 2,92117 2,110 2,567 2,89818 2,101 2,552 2,87819 2,093 2,539 2,861
Exemplo 1
Uma fábrica de móveis afirma que o tempo médio de entrega de seus produtos vendidos é de 18 dias. Para verificar essa afirmação, uma amostra de 30 pedidos dessa empresa foi analisada, verificando-se um tempo médio de entrega de 17,8

126 Estatística Aplicada
dias com um desvio-padrão de 5,6 dias. Analise os dados e conclua ao nível de significância de 5%.
Passo 1 – Dados do Problema
Variável (x) = Tempo de entrega dos produtos (dias)
µ0 = 18 dias (valor de referência)
n = 30 pedidos (tamanho da amostra)
= 17,8 dias (média da amostra)
s = 5,6 dias (desvio-padrão da amostra)
α = 0,05 (nível de significância do teste: p = 5%)
Passo 2 – Hipóteses de Pesquisa
H0 : µ = 18 diasH1 : µ ≠ 18 dias
Passo 3 – Cálculo da Estatística do Teste
Passo 4 – Regra de DecisãoVamos agora identificar o valor tabelado a ser utilizado na Regra de Decisão: A amostra dessa pesquisa foi de 30 televi-sores, então o grau de liberdade (n-1) é 30 – 1 = 29 (linha 29 da tabela t). O nível de significância estabelecido no problema

Capítulo 8 Testes de Hipóteses 127
é de 5% – então a coluna a ser utilizada da tabela é a que corresponde 0,05.
Tabela de valores críticos da distribuição t de Student.
Gl (n-1) IC 95% IC 98% IC 99%
0,050 0,020 0,010
18 2,101 2,552 2,87819 2,093 2,539 2,86120 2,086 2,528 2,84521 2,080 2,518 2,83122 2,074 2,508 2,81923 2,069 2,500 2,80724 2,064 2,492 2,79725 2,060 2,485 2,78726 2,056 2,479 2,77927 2,052 2,473 2,77128 2,048 2,467 2,76329 2,045 2,462 2,75630 2,042 2,457 2,75039 2,023 2,426 2,70840 2,021 2,423 2,70449 2,010 2,405 2,68050 2,009 2,403 2,67859 2,001 2,391 2,66260 2,000 2,390 2,66099 1,984 2,365 2,626
100 1,984 2,364 2,626120 1,980 2,358 2,617200 1,972 2,345 2,601
infinito 1,960 2,326 2,576
O valor de “t” tabelado é então 2,045 – esse valor deter-minará na regra de decisão os limites da região crítica.

128 Estatística Aplicada
Regra de Decisão
A regra estabelecida é: se o valor da estatística do teste for SUPERIOR a +2,045 ou INFERIOR a -2,045, nossa deci-são será REJEITAR H0, ou seja, há diferença significativa entre os valores observados na amostra com o valor estabelecido como referência.
Já se o valor da estatística do teste estiver ENTRE -2,045 e +2,045, nossa decisão será de ACEITAR H0, o que implica na existência de uma diferença NÃO significativa entre os va-lores da amostra com a referência.
Para o nosso exemplo, o valor da estatística do teste foi de t = -0,196.

Capítulo 8 Testes de Hipóteses 129
Esse valor (t = -0,196) está localizado, na nossa regra de decisão, dentro da região de aceitação – então nossa decisão será ACEITAR H0.
Ao aceitar a hipótese nula H0, estaremos aceitando a se-guinte afirmação:
H0 : µ = 18 dias
No contexto do problema, estaremos então aceitando que o tempo médio de entrega dos produtos dessa fábrica de mó-veis não difere significativamente de 18 meses, ou seja, a dife-rença encontrada em relação a esse tempo médio na amostra NÃO FOI SIGNIFICATIVA.
Passo 5 – Conclusão
Na conclusão, escreveremos um parágrafo referente ao re-sultado final do teste de hipóteses:

130 Estatística Aplicada
“Verifica-se, a partir do teste estatístico realizado, ao nível de significância de 5%, que o tempo médio de entrega dos produtos não difere significativamente de 18 meses.”
Exemplo 2
Uma indústria alimentícia produz determinado tipo de pão, cujo peso médio deve ser de 190 gramas. Devido a mudan-ças na política cambial, que ocasionou aumento no preço do trigo, alguns ingredientes da receita foram substituídos. Uma equipe do controle de qualidade dessa indústria resolveu ve-rificar se o peso do produto aumentou e escolheu, aleatoria-mente, 200 unidades, medindo o peso de cada uma. O peso médio obtido da amostra foi de 182 gramas com um desvio--padrão de 12 gramas. Analise os dados e conclua ao nível de significância de 5%.
Passo 1 – Dados do Problema
Variável (x) = Peso do pão (gramas)
µ0 = 190 gramas (valor de referência)
n = 200 pães (tamanho da amostra)
= 182 gramas (média da amostra)
s = 12 gramas (desvio-padrão da amostra)
α = 0,05 (nível de significância do teste: p = 5%)
Passo 2 – Hipóteses de Pesquisa
H0 : µ = 190 gramasH1 : µ ≠ 190 gramas

Capítulo 8 Testes de Hipóteses 131
Passo 3 – Cálculo da Estatística do Teste
Passo 4 – Regra de Decisão
A amostra dessa pesquisa foi de 200 pães televisores, en-tão o grau de liberdade (n-1) é 200 – 1 = 199 (não temos na tabela a linha 199, então usaremos a mais próxima, nesse caso, a linha 200). O nível de significância estabelecido no problema é de 5% – então a coluna a ser utilizada da tabela é a que corresponde 0,05.
Tabela de valores críticos da distribuição t de Student.
Gl (n-1) IC 95% IC 98% IC 99%
0,050 0,020 0,010
18 2,101 2,552 2,87819 2,093 2,539 2,86120 2,086 2,528 2,84521 2,080 2,518 2,83122 2,074 2,508 2,81923 2,069 2,500 2,80724 2,064 2,492 2,79725 2,060 2,485 2,78726 2,056 2,479 2,77927 2,052 2,473 2,77128 2,048 2,467 2,76329 2,045 2,462 2,756

132 Estatística Aplicada
30 2,042 2,457 2,75039 2,023 2,426 2,70840 2,021 2,423 2,70449 2,010 2,405 2,68050 2,009 2,403 2,67859 2,001 2,391 2,66260 2,000 2,390 2,66099 1,984 2,365 2,626
100 1,984 2,364 2,626120 1,980 2,358 2,617200 1,972 2,345 2,601
infinito 1,960 2,326 2,576
O valor de “t” tabelado é então 1,972 – esse valor deter-minará na regra de decisão os limites da região crítica.
Regra de Decisão
Para o nosso exemplo, o valor da estatística do teste foi: t = -9,41.

Capítulo 8 Testes de Hipóteses 133
Esse valor (t = -9,41) está localizado, na nossa regra de decisão, FORA da região de aceitação, ou ainda, ele se loca-liza na REGIÃO CRÍTICA – então nossa decisão será REJEI-TAR H0.
H0 : µ = 190 gramasH1 : µ ≠ 190 gramas
Ao rejeitar a hipótese nula H0, estaremos concordando com a afirmação feita em H1:
H1 : µ ≠ 190 gramas
No contexto do problema, estaremos então concluindo que os pães têm um peso médio DIFERENTE de 190 gramas, ou seja, a diferença encontrada em relação a esse peso médio na amostra FOI SIGNIFICATIVA. Como essa diferença foi signifi-cativa, poderemos observar, na amostra, que o peso encontra-do de 182 gramas é INFERIOR ao peso de referência 190 gramas.
Passo 5 – Conclusão
“Verifica-se, a partir do teste estatístico realizado, ao nível de significância de 5%, que o peso médio dos pães após a substituição de alguns ingredientes é significativamente DIFERENTE de 190 gramas. Observa-se, ao analisar os resultados da amostra, que esse peso é significativamente INFERIOR a 190 gramas.”

134 Estatística Aplicada
Teste de hipóteses para comparação entre duas médias (T-student para duas amostras)
Esse teste é muito semelhante ao anteriormente visto. Porém aqui não teremos um valor de referência a ser comparado, mas sim duas amostras provenientes de dois grupos distintos; e o objetivo aqui é comparar as médias dessas duas amostras independentes, verificando se existe ou não diferença signifi-cativa entre elas.
Cada um dos grupos investigados (ou amostras investiga-das) gera suas estatísticas descritivas que deverão ser utilizadas no cálculo da estatística do teste: tamanho da amostra (n), média amostral ( ) e desvio-padrão amostral (s).
Grupo 1 Grupo 2
Hipóteses:
As hipóteses são estabelecidas a partir da comparação da média dos grupos. Na hipótese nula H0, novamente teremos a ausência de diferença significativa, ou seja, a média do grupo 1 é igual a média do grupo 2. Já a hipótese alternativa H1

Capítulo 8 Testes de Hipóteses 135
indica que EXISTE diferença significativa entre as médias dos grupos 1 e 2.
Estatística do teste
Onde:
1 = Média do grupo 1
2 = Média do grupo 2
s12 = variância do grupo 1 (desvio-padrão ao quadrado)
s12 = variância do grupo 2 (desvio-padrão ao quadrado)
n1 = tamanho de amostra do grupo 1
n2 = tamanho de amostra do grupo 2
Regra de decisão
A regra de decisão para esse teste é praticamente a mesma do teste anterior. Porém, a única diferença refere-se aos graus de liberdade que agora, como teremos dois grupos, será: (n1 + n2 – 2), ou seja, deve-se somar os tamanhos de amostra dos dois grupos e subtrair dois.

136 Estatística Aplicada
Exemplo 1
Uma empresa fabricante de telefones celulares afirma que a duração média em horas (em stand by) da sua bateria é supe-rior à duração das concorrentes. Duas amostras formadas por 40 baterias desse fabricante e 40 do concorrente apresenta-ram médias iguais a 65 e 60 horas, com um desvio-padrão de 2 e 3 horas, respectivamente. Seria possível supor que a ba-teria da empresa do fabricante tenha significativamente maior duração? Considere um nível de significância de 5%.
Passo 1 – Dados do Problema
Variável (x) = Tempo de duração da bateria (horas)
Grupo 1 – Fabricante Grupo 2 – Concorrente
1 = 65 horas
2 = 60 horas
s12 = (2 horas)2
s12 = (3 horas)2
n1 = 40
n2 = 40
α = 0,05 (nível de significância do teste: p = 5%)
Passo 2 – Hipóteses de Pesquisa

Capítulo 8 Testes de Hipóteses 137
Passo 3 – Cálculo da Estatística do Teste
Passo 4 – Regra de Decisão
A tabela a ser utilizada é a mesma tabela do teste anterior. Na linha, vamos obter os graus de liberdade (gl), considerando a soma dos dois tamanhos de amostra dos grupos menos 2:
Gl: (n1+n2 – 2) = (40+40 - 2) = 78 (Na tabela, não temos linha 78, então iremos para a mais próxima que é a linha 60).
Tabela de valores críticos da distribuição t de Student.
Gl (n-1) IC 95% IC 98% IC 99%0,050 0,020 0,010
25 2,060 2,485 2,78726 2,056 2,479 2,77927 2,052 2,473 2,77128 2,048 2,467 2,76329 2,045 2,462 2,75630 2,042 2,457 2,75039 2,023 2,426 2,70840 2,021 2,423 2,704

138 Estatística Aplicada
49 2,010 2,405 2,68050 2,009 2,403 2,67859 2,001 2,391 2,66260 2,000 2,390 2,66099 1,984 2,365 2,626
100 1,984 2,364 2,626120 1,980 2,358 2,617200 1,972 2,345 2,601
infinito 1,960 2,326 2,576
O valor de “t” tabelado é então 2,000 – esse valor deter-minará na regra de decisão os limites da região crítica.
Regra de Decisão
Para o nosso exemplo, o valor da estatística do teste foi: t = 8,77.
Esse valor (t = 8,77) está localizado, na nossa regra de de-cisão, FORA da região de aceitação, ou ainda, ele localiza-se na REGIÃO CRÍTICA – então nossa decisão será REJEITAR H0.

Capítulo 8 Testes de Hipóteses 139
Ao rejeitar a hipótese nula H0, estaremos concordando com a afirmação feita em H1:
H1 : µ1 ≠ µ2
No contexto do problema, estaremos então concluindo que os grupos de celulares (fabricante e concorrente) têm um tem-po médio de duração da bateria DIFERENTE um do outro, ou seja, a diferença encontrada em relação a esse tempo mé-dio de duração na amostra investigada FOI SIGNIFICATIVA. Como essa diferença foi significativa, poderemos observar na amostra que o tempo médio de duração do fabricante (65 horas) é SUPERIOR ao tempo médio de duração do concor-rente (60 horas).
Passo 5 – Conclusão
“Verifica-se, a partir do teste estatístico realizado, ao nível de significância de 5%, que o tempo médio de duração da bateria é significativamente DIFERENTE entre os dois gru-pos de estudo (fabricante e concorrente). Observa-se, ao analisar os resultados da amostra, que esse tempo médio é significativamente SUPERIOR para o fabricante.”

140 Estatística Aplicada
Exemplo 2
Duas técnicas de venda são aplicadas em dois grupos de ven-dedores com o objetivo de verificar se alguma delas é mais efi-caz que a outra. Foi observado o Número de unidades vendi-das no período de uma semana. Os dados observados foram:
Técnica de venda Nº Vendedores Venda Diária Média Desvio-Padrão
Técnica A 20 76 unidades 9 unidades
Técnica B 25 78 unidades 8 unidades
Analise esses dados a um nível de significância de 5%.
Passo 1 – Dados do Problema
Variável (x) = venda diária (unidades)
Grupo 1 – Técnica de vendas A Grupo 2 – Técnica de vendas B
1 = 76 unidades
2 = 78 unidades
s12 = (9 unidades)2
s12 = (8 unidades)2
n1 = 20
n2 = 25
α = 0,05 (nível de significância do teste: p = 5%)

Capítulo 8 Testes de Hipóteses 141
Passo 2 – Hipóteses de Pesquisa
Passo 3 – Cálculo da Estatística do Teste
Passo 4 – Regra de Decisão
Gl: (n1+n2 – 2) = (20 + 25 - 2) = 43 (Na tabela, não te-mos linha 43, então iremos para a mais próxima que é a linha 40).
Tabela de valores críticos da distribuição t de Student.
Gl (n-1) IC 95% IC 98% IC 99%
0,050 0,020 0,010
18 2,101 2,552 2,87823 2,069 2,500 2,80724 2,064 2,492 2,79725 2,060 2,485 2,78726 2,056 2,479 2,77927 2,052 2,473 2,77128 2,048 2,467 2,763

142 Estatística Aplicada
29 2,045 2,462 2,75630 2,042 2,457 2,75039 2,023 2,426 2,70840 2,021 2,423 2,70449 2,010 2,405 2,68050 2,009 2,403 2,67859 2,001 2,391 2,662
200 1,972 2,345 2,601infinito 1,960 2,326 2,576
O valor de “t” tabelado é então 2,021 – esse valor deter-minará na regra de decisão os limites da região crítica.
Regra de Decisão
Para o nosso exemplo, o valor da estatística do teste foi: t = 0,78.
Esse valor (t = 0,78) está localizado, na nossa regra de decisão, DENTRO da região de aceitação, ou ainda, ele lo-

Capítulo 8 Testes de Hipóteses 143
caliza-se na REGIÃO DE ACEITAÇÃO – então nossa decisão será ACEITAR H0.
Ao aceitar a hipótese nula H0, estaremos concordando com a afirmação feita em H0:
H1: µ1 = µ2
No contexto do problema, estaremos então concluindo que não existe diferença significativa para as vendas médias entre as técnicas de venda A e B.
Passo 5 – Conclusão
“Verifica-se, a partir do teste estatístico realizado, ao nível de significância de 5%, que não existe diferença significativa para as vendas médias entre as técnicas de venda A e B.”
Recapitulando
Os Testes de hipóteses fornecem ao pesquisador uma fer-ramenta útil na comprovação ou não de hipóteses feitas sobre um parâmetro (média ou proporção). Trata-se de uma com-provação científica da existência de diferenças significativas a partir da análise de resultados provenientes de amostras com parâmetros populacionais.

144 Estatística Aplicada
Atividades: Testes de hipóteses
Questão 1. O tempo de deslocamento de Porto Alegre até São Leopoldo, antes das obras da copa, apresentava uma mé-dia de 40 minutos. Atualmente, devido às obras em andamen-to, uma amostra de 50 indivíduos que realizaram esse traje-to apresentou uma média de tempo de 70 minutos com um desvio-padrão de 5 minutos. Analise os dados e conclua ao nível de significância de 5% se houve um aumento significativo nesse tempo médio de deslocamento.
Questão 2. Foi feita uma comparação salarial entre profis-sionais de determinada categoria que atuam nos setores públi-co e privado. Foram investigados 45 profissionais do setor pú-blico, encontrando-se média de R$ 1220, com desvio-padrão de R$ 240. Entre 28 profissionais do setor privado, a média foi de R$ 1470, com desvio-padrão de R$ 270. Usando 5% de significância, analise e conclua sobre esses dados.
Questão 3. A industrial ABC S.A., fabricante de determina-do equipamento eletrônico, procedeu à substituição de cer-to componente importado pelo similar nacional. Um grande comprador da referida indústria supõe que tal substituição te-nha diminuído a duração do produto que antes era anunciada como sendo, em média, de 210 horas. Para julgar a aceita-bilidade de sua suposição, o comprador testou uma amostra de 100 unidades, verificando um tempo médio de duração de 197 horas com um desvio-padrão de 16 horas. Fixado o nível de significância de 5%, conclua sobre o caso.

Capítulo 8 Testes de Hipóteses 145
Automóvel n Média de consumo Desvio-padrão
Colossal 12 unidades 14 km/l 2 km/l
XP15 10 unidades Km/l 4 km/l
Questão 4. O dono de uma empresa de entregas e mudan-ças possui uma frota de automóveis e está interessando em testar duas marcas de pneus radiais. Os dados em km rodados até o desgaste do pneu para uma amostra de 25 unidades do pneu A e 25 unidades do pneu B são:
Pneu A : Média: 38500 km; Desvio-padrão: 1200 km
Pneu B : Média 36700 km; Desvio-padrão: 960 km
A partir desses dados, foi realizado o teste t-student de comparação de duas médias, resultando um valor de estatís-tica do teste t = 5,86. Ao analisar esses dados, ao nível de significância de 5%, você poderia concluir que:
A. ( ) Não existe diferença significativa para a quantidade de km rodados até o desgaste entre os pneus A e B.
B. ( ) Existe diferença significativa para a quantidade de km ro-dados até o desgaste entre os pneus A e B. Observa-se que quantidade é superior para o pneu B.
C. ( ) Não existe diferença significativa para a quantidade de km rodados até o desgaste entre os pneus A e B. Observa--se que quantidade é superior para o pneu A.

146 Estatística Aplicada
D. ( ) Existe diferença significativa para a quantidade de km ro-dados até o desgaste entre os pneus A e B, porém essa diferença é insignificante.
E. ( ) Existe diferença significativa para a quantidade de km ro-dados até o desgaste entre os pneus A e B. Observa-se que essa quantidade é significativamente superior para o pneu A.
Questão 5. O tempo médio gasto para profissionais da área de Ciências Contábeis realizarem uma determinada tarefa tem sido de 50 minutos. Um novo procedimento está sendo imple-mentado. Nesse novo procedimento, retirou-se uma amostra de 25 pessoas, com um tempo médio de execução dessa mes-ma tarefa de 48 minutos e um desvio-padrão de 11,9 minutos.
A partir desses dados, foi realizado o teste t-student, resul-tando um valor de estatística do teste t = 0,84. Ao analisar esses dados, ao nível de significância de 5%, você poderia concluir que:
A. ( ) Aceita-se H0, não existe diferença significativa para o tem-po de execução médio da tarefa com o novo procedimen-to.
B. ( ) Rejeita-se H0, existe diferença significativa para o tempo de execução médio da tarefa com o novo procedimento. Observa-se que esse tempo com o novo procedimento é significativamente inferior a 50 minutos.

Capítulo 8 Testes de Hipóteses 147
C. ( ) Aceita-se H0, existe diferença significativa para o tempo de execução médio da tarefa com o novo procedimento. Observa-se que esse tempo com o novo procedimento é significativamente superior a 50 minutos.
D. ( ) Rejeita-se H0, existe diferença significativa para o tempo de execução médio da tarefa com o novo procedimento. Observa-se que esse tempo com o novo procedimento é significativamente inferior a 48 minutos.
E. ( ) Aceita-se H0, existe diferença significativa para o tempo de execução médio da tarefa com o novo procedimento. Observa-se que esse tempo com o novo procedimento é significativamente inferior a 50 minutos.
Gabarito das atividades propostas
Questão 1. t = 42,25
Conclusão: Rejeita-se H0, logo, existe diferença significativa no tempo médio de deslocamento. Observa-se que ,com as obras em andamento, esse tempo de deslocamento de Porto Alegre a São Leopoldo é significativamente superior a 40 mi-nutos.
Questão 2. t = -4,01
Conclusão: Rejeita-se H0, logo, existe diferença significativa para o salário médio dos profissionais entre os setores público e privado. Observa-se que o salário médio dos profissionais

148 Estatística Aplicada
do setor privado é significativamente superior ao dos funcio-nários do setor público.
Questão 3. t = -0,77
Conclusão: Aceita-se H0, logo, não existe diferença significa-tiva na média de consumo entre os dois tipos de automóveis.
Questão 4. Letra “E”.
Existe diferença significativa para a quantidade de km rodados até o desgaste entre os pneus A e B. Observa-se que essa quantidade é significativamente superior para o pneu A.
Questão 5. Letra “A”.
Aceita-se H0, não existe diferença significativa para o tempo de execução médio da tarefa com o novo procedimento.

Análise de Correlação
ÂÂNeste capítulo, será abordada uma ferramenta estatís-tica com grande aplicabilidade em estudos da área
de Administração dos quais é necessário investigar o grau de relacionamento entre duas variáveis quantitativas. Será apresentado o cálculo do Coeficiente de Correlação de Pearson e a sua interpretação no contexto do problema.
Simone Echeveste
Capítulo 9

150 Estatística Aplicada
Espera-se que o aluno, após o término de estudo deste capítulo, possa identificar em quais situações aplica-se essa ferramenta, bem como realize os cálculos necessários para a mensuração da correlação entre duas variáveis, interpretando corretamente os resultados obtidos.
Muitas vezes, na prática, necessitamos estudar o relacio-namento de duas variáveis, coletadas como pares de valores, para resolver questões, como por exemplo:
Figura 26 Exemplos de correlações na área da Administração.
A existência de uma relação entre as variáveis e a men-suração desse grau de relação é o que caracteriza o objeto da Análise de Correlação. Essa ferramenta estatística indica a existência ou não de relacionamento entre duas variáveis e se esse relacionamento é fraco, moderado ou forte.
Os dados para a análise de correlação são provenientes de observações de variáveis aos pares, isso significa que cada

Capítulo 9 Análise de Correlação 151
observação da amostra é composta por dois valores (x e y), e com esses valores podemos, inicialmente, construir o digrama de dispersão que é uma forma de verificar o tipo de correlação existente entre duas variáveis.
Diagrama de Dispersão
Um dos métodos mais usados para a investigação de pares de dados é a utilização de diagramas de dispersão. Geometrica-mente, um diagrama de dispersão é considerado uma coleção de pontos num plano cujas duas coordenadas cartesianas são os valores de cada membro do par de dados. É um gráfico no qual cada ponto representa um par de valores observados, em que podemos visualizar a relação entre as variáveis, bem como, a partir da disposição dos pontos, podemos observar a existência ou não de um possível relacionamento entre as variáveis.
Gráfico 1 Diagrama de Dispersão para as variáveis: Renda X Aplicação Mensal na poupança.
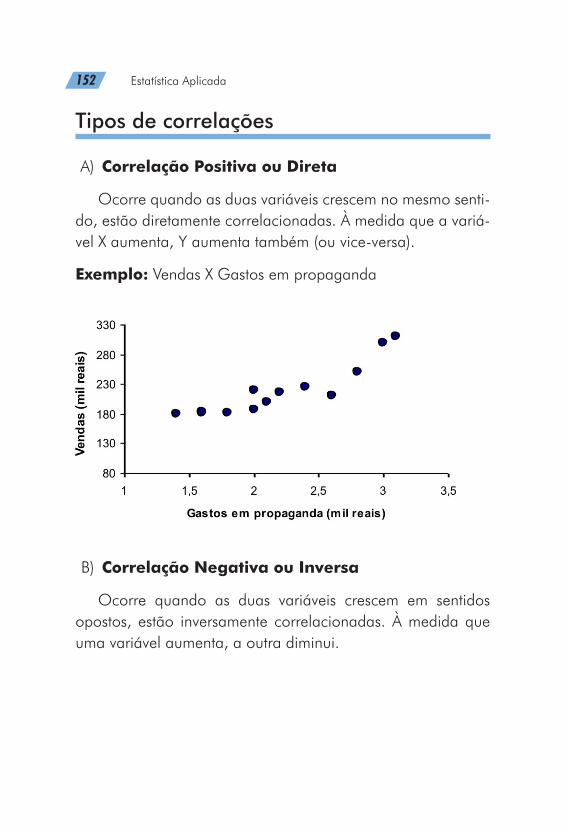
152 Estatística Aplicada
Tipos de correlações
A) Correlação Positiva ou Direta
Ocorre quando as duas variáveis crescem no mesmo senti-do, estão diretamente correlacionadas. À medida que a variá-vel X aumenta, Y aumenta também (ou vice-versa).
Exemplo: Vendas X Gastos em propaganda
B) Correlação Negativa ou Inversa
Ocorre quando as duas variáveis crescem em sentidos opostos, estão inversamente correlacionadas. À medida que uma variável aumenta, a outra diminui.
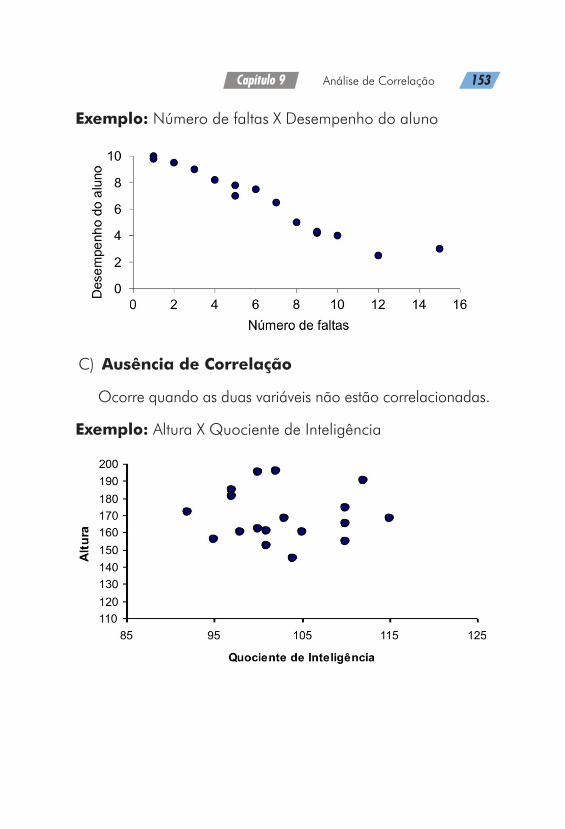
Capítulo 9 Análise de Correlação 153
Exemplo: Número de faltas X Desempenho do aluno
C) Ausência de Correlação
Ocorre quando as duas variáveis não estão correlacionadas.
Exemplo: Altura X Quociente de Inteligência

154 Estatística Aplicada
Coeficiente de correlação de pearson ( r )
O Coeficiente de correlação de Pearson é uma medida do grau e da direção de uma relação linear entre duas variáveis. O símbolo r representa o coeficiente de correlação popula-cional e o símbolo r representa o coeficiente de correlação amostral.
Figura 27 Condições importantes do Coeficiente de Correlação de Pearson.
Sua fórmula é:

Capítulo 9 Análise de Correlação 155
Como Calcular:
1º) Obtenha a soma dos valores de x : Sx
2º) Obtenha a soma dos valores de y: Sy
3º) Multiplique cada valor de x por seu valor y correspondente e obte-nha a sua soma: Sx.y
4º) Eleve ao quadrado cada valor de x e obtenha a sua soma: Sx2
5º) Eleve ao quadrado cada valor de y e obtenha a sua soma: Sy2
6º) Use essas cinco somas para calcular o coeficiente de correlação.
Interpretação do coeficiente de correlação de pearson ( r )
O Coeficiente de Correlação de Pearson foi desenvolvido de forma que seu resultado final será sempre um valor entre -1 e +1, ou seja: -1 ≤ r ≤ 1. A partir dos valores de r, podemos verificar o tipo da correlação existente entre as variáveis estu-dadas considerando as seguintes regras na interpretação de seu resultado:
 Se r > 0, indica uma correlação positiva ou direta en-tre as variáveis, um aumento na variável X provocará um aumento na variável Y.
 Se r < 0, indica uma correlação negativa ou inversa entre as variáveis, um aumento na variável X provoca-rá uma redução na variável Y.
 Se r = 0, indica a inexistência de qualquer relação ou tendência linear entre as variáveis X e Y.

156 Estatística Aplicada
Exemplo 1
Uma amostra de 6 residências selecionadas aleatoriamente foi observada quanto à idade do imóvel, em anos, e quanto ao preço de venda, em unidades monetárias. Os dados observa-dos foram:
Residência Idade do Imóvel (x) Preço de venda (y)
1 1 100
2 2 80
3 3 90
4 4 15
5 5 50
6 6 20
Para esse exemplo, temos as seguintes informações:
n = 6 residências
x = Idade do Imóvel
y = Preço de venda dos imóveis
Para calcular o Coeficiente de Correlação de Pearson, pre-cisaremos dos seguintes somatórios:
1º) Obtenha a soma dos valores de x: Sx 2º) Obtenha a soma dos valores de y: Sy 3º) Multiplique cada valor de x por seu valor y correspondente
e obtenha a sua soma: S x.y

Capítulo 9 Análise de Correlação 157
4º) Eleve ao quadrado cada valor de x e obtenha a sua soma: Sx2
5º) Eleve ao quadrado cada valor de y e obtenha a sua soma: Sy2
Tabela de cálculos:
Residência Idade (x) Preço de venda (y) x.y x2 y2
1 1 100 100 1 10000
2 2 80 160 4 6400
3 3 90 270 9 8100
4 4 15 60 16 225
5 5 50 250 25 2500
6 6 20 120 36 400
Totais 21 355 960 91 27.625
Cálculo do Coeficiente de correlação de Pearson

158 Estatística Aplicada
Interpretação:
“Como r apresenta um valor negativo, indica correlação inversa/negativa entre a idade do imóvel e o seu preço de venda, ou seja, quanto maior a idade do imóvel (mais antigo for) menor tende a ser o preço de venda.”
Interpretação da intensidade da correlação
Podemos, além de identificar a existência de correlação e o seu tipo (direta, inversa), analisar a sua intensidade da seguin-te forma: (Callegari-Jacques, 2003)
 Se 0,00 < r < ±0,30 – existe correlação fraca  Se ±0,30 ≤ r < ±0,60 – existe correlação moderada  Se ±0,60 ≤ r < ±0,90 – existe correlação forte  Se ±0,90 ≤ r < ±1,00 – existe correlação muito forte
Considere o símbolo “±” relacionado ao sinal da correla-ção – se negativo (-), inversa e, se positivo, direta (+).
Exemplo 2
Uma cadeia de supermercados financiou um estudo para ve-rificar a relação entre a renda mensal (salários mínimos) e as

Capítulo 9 Análise de Correlação 159
despesas semanais em supermercados de 8 famílias selecio-nadas aleatoriamente.
Renda mensal (salários mínimos) x Despesa semanal supermercado (reais)
Família Renda mensal (x) Despesa semanal supermercado (y)
1 3,5 280
2 3,8 360
3 2,6 200
4 1,9 110
5 3,1 230
6 2,8 210
7 4,2 330
8 4,0 350
Para esse exemplo, temos as seguintes informações:
n = 8 famílias
x = Renda mensal (salários mínimos)
y = Despesa semanal supermercado (reais)
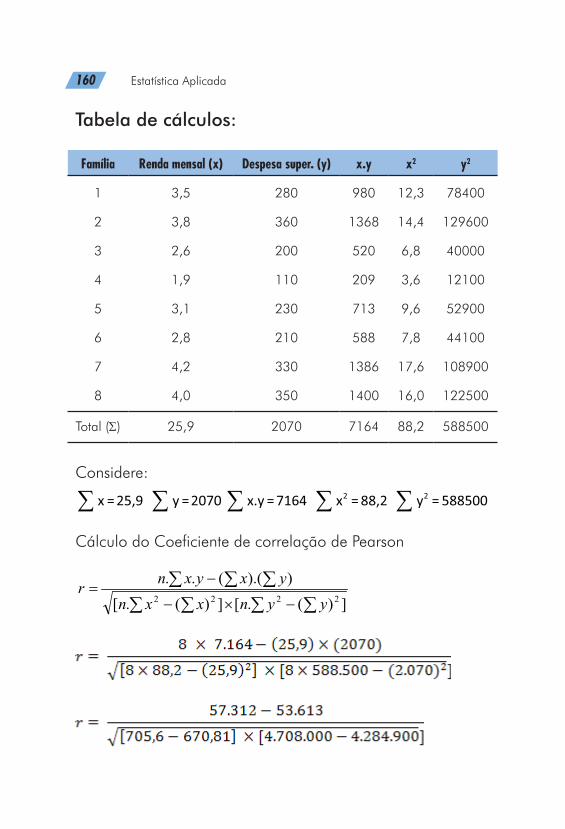
160 Estatística Aplicada
Tabela de cálculos:
Família Renda mensal (x) Despesa super. (y) x.y x2 y2
1 3,5 280 980 12,3 78400
2 3,8 360 1368 14,4 129600
3 2,6 200 520 6,8 40000
4 1,9 110 209 3,6 12100
5 3,1 230 713 9,6 52900
6 2,8 210 588 7,8 44100
7 4,2 330 1386 17,6 108900
8 4,0 350 1400 16,0 122500
Total (S) 25,9 2070 7164 88,2 588500
Considere:
Cálculo do Coeficiente de correlação de Pearson

Capítulo 9 Análise de Correlação 161
Interpretação:
“Como r apresenta um valor positivo, indica correlação dire-ta/positiva entre a renda mensal e as despesas semanais no supermercado, ou seja, quanto maior a renda, maior tende a ser a despesa semanal no supermercado. Podemos ainda destacar se essa correlação é muito forte.”
Recapitulando
Na Análise de Correlação, estamos interessados em mensurar o grau de associação entre duas variáveis por meio do cálculo do Coeficiente de Correlação de Pearson. Quando duas va-riáveis estão correlacionadas, essa relação pode ser direta (a medida que uma variável aumenta, a outra aumenta também ou vice-versa) ou inversa (a medida que uma variável aumen-ta, a outra diminui).

162 Estatística Aplicada
Atividades: Análise de correlação
Questão 1. Um comerciante de temperos está curioso sobre a grande variação nas vendas de loja para loja e acha que as vendas estão associadas com o espaço nas prateleiras dedica-dos a sua linha de produto em cada ponto de venda. Oito lo-jas foram selecionadas ao acaso, e as duas seguintes variáveis foram mensuradas: x: total de espaço de frente (comprimento x altura em cm2) dedicado a sua linha de produtos na loja e y = total das vendas dos produtos, em reais, no último mês. Os dados são apresentados na tabela a seguir:
Vendas x espaço dedicado aos produtos
Loja Loja 1 Loja 2 Loja 3 Loja 4 Loja 5 Loja 6 Loja 7 Loja 8 Totais (S)
Espaço
(x)
340 230 405 325 280 195 265 300 Sx = 2340
Vendas
(y)
71 65 83 74 67 56 57 78 Sy= 551
X.Y 24140 14950 33615 24050 18760 10920 15105 23400 Sx.y= 164940
X2 115600 52900 164025 105625 78400 38025 70225 90000 Sx2= 714800
Y2 5041 4225 6889 5476 4489 3136 3249 6084 Sy2= 38589
Calcule e interprete o Coeficiente de Correlação de Pear-son para esses dados.
Questão 2. Considere as seguintes informações referentes a 15 Municípios do Rio Grande do Sul:

Capítulo 9 Análise de Correlação 163
RELAÇÃO ENTRE O ÍNDICE DE POBREZA (%) E O PIB PER CAPTA (REAIS)
Município Índice de Pobreza (X) PIB per capta (Y) X.Y X2 Y2
Alegrete 30,9 14,2 438,8 954,8 201,6
Bagé 26,8 10,1 270,7 718,2 102,0
Bento Gonçalves 21,1 24,2 510,6 445,2 585,6
Camaquã 26,6 16,9 449,5 707,6 285,6
Canoas 29,5 49,5 1460,3 870,3 2450,3
Caxias do Sul 20,9 30,5 637,5 436,8 930,3
Erechim 26,3 21,4 562,8 691,7 458,0
Guaíba 31,4 20,1 631,1 986,0 404,0
Porto Alegre 23,7 26,3 623,3 561,7 691,7
Rio Grande 29,1 32,0 931,2 846,8 1024,0
Santa Maria 25,3 12,8 323,8 640,1 163,8
Sapucaia 31,4 14,0 439,6 986,0 196,0
Tramandaí 28,9 8,9 257,2 835,2 79,2
Vacaria 28,8 14,7 423,4 829,4 216,1
Viamão 33,1 7,0 231,7 1095,6 49,0
Totais (S) 413,8 302,6 8191,5 11605,3 7837,2
Ao realizar a Análise de Correlação de Pearson para esses dados, o valor do coeficiente foi r = -0,272. Sobre a interpre-tação desse valor, você diria que:

164 Estatística Aplicada
A. ( ) Pode-se concluir que existe uma correlação direta entre o Índice de Pobreza e o PIB per capta desses municípios, ou seja, quanto maior o Índice de Pobreza, menor tende a ser o PIB per capta.
B. ( ) Pode-se concluir que não existe diferença significativa entre o Índice de Pobreza e o PIB per capta desses muni-cípios, ou seja, o PIB não é superior em Municípios mais pobres.
C. ( ) Pode-se concluir que existe uma correlação inversa en-tre o Índice de Pobreza e o PIB per capta desses municí-pios, ou seja, quanto maior o Índice de Pobreza, menor tende a ser o PIB per capta.
D. ( ) Pode-se concluir que existe uma correlação inversa en-tre o Índice de Pobreza e o PIB per capta desses municí-pios, ou seja, quanto maior o Índice de Pobreza, maior tende a ser o PIB per capta.
E. ( ) Pode-se concluir que existe uma correlação inversa ex-tremamente forte entre o Índice de Pobreza e o PIB per capta desses municípios, ou seja, para todos os municí-pios, quanto maior o Índice de Pobreza, menor foi o PIB per capta.
Questão 3. Procurando quantificar os efeitos da escassez de sono sobre a capacidade de resolução de problemas simples, um agente tomou ao acaso 10 sujeitos e os submeteu a ex-perimentação. Deixou-os sem dormir por diferentes números de horas, após o que solicitou que os mesmos resolvessem os itens “contas de adicionar” de um teste. Obteve, assim, os seguintes dados:

Capítulo 9 Análise de Correlação 165
Amostra Horas sem dormir (x) Nº de erros (y) x.y x2 y2
1 8 8 64 64 64
2 8 6 48 64 36
3 12 6 72 144 36
4 12 10 120 144 100
5 16 8 128 256 64
6 16 14 224 256 196
7 20 14 280 400 196
8 20 12 240 400 144
9 24 16 384 576 256
10 24 12 288 576 144
Total (S) 160 106 1848 2880 1236
Calcule e interprete o coeficiente de correlação linear de Pearson para esses dados.
Questão 4. Em uma indústria de cervejas, realizou-se um estudo com o objetivo de correlacionar a temperatura do dia com as vendas de refrigerante. Realizou-se, para isso, uma Análise de Correlação entre essas variáveis resultando em um coeficiente de correlação de Pearson de r = 0,926. A partir da interpretação desse valor, podemos concluir que:
A ( )Existe uma correlação direta forte entre a temperatura do dia e as vendas de refrigerante.
166 Estatística Aplicada
B ( )Existe uma correlação inversa fraca entre a tempera-tura do dia e as vendas de refrigerante.
C ( )Existe uma correlação inversa forte entre a temperatu-ra do dia e as vendas de refrigerante.
D ( ) Essas variáveis não possuem nenhuma correlação.
E ( )Existe uma correlação direta muito forte entre a tem-peratura do dia e as vendas de refrigerante.
Questão 5. Um estudo de correlação foi realizado com o ob-jetivo de verificar a relação entre as variáveis Horas de estudo (x) e nota na prova de Estatística (y). Os dados observados em uma amostra de 8 alunos foram:
Aluno Horas de estudo (x) Nota na prova (y) x.y x2 y2
1 2 1 2 4 1
2 4 3 12 16 9
3 5 6 30 25 36
4 5 6 30 25 36
5 6 8 48 36 64
6 8 7 56 64 49
7 9 8 72 81 64
8 10 10 100 100 100
Total (S) 49 49 350 351 359

Capítulo 9 Análise de Correlação 167
Calcule e interprete o coeficiente de correlação linear de Pearson para esses dados.
Gabarito das atividades propostas
Questão 1. r = 0,857“Existe uma correlação forte direta entre total de espaço de frente dedicado a sua linha de produtos na loja e y = total das vendas dos produtos, em reais, no último mês, ou seja, quanto maior o espaço de frente dedicado à linha de produtos, maior tende a ser as vendas dos produtos.
Questão 2.C. ( x ) Pode-se concluir que existe uma correlação inversa entre o Índice de Pobreza e o PIB per capta desses muni-cípios, ou seja, quanto maior o Índice de Pobreza menor tende a ser o PIB per capta.
Questão 3. r = 0,801“Existe uma correlação forte direta entre o número de horas sem dormir e o número de erros, ou seja, quanto maior o número de horas sem dormir, maior tende a ser o número de erros cometidos.
Questão 4.
E. ( x )Existe uma correlação direta muito forte entre a tem-peratura do dia e as vendas de refrigerante.

168 Estatística Aplicada
Questão 5. r = 0,911
“Existe uma correlação muito forte direta entre o núme-ro de horas de estudo e a nota na prova, ou seja, quanto maior o número de horas de estudo, maior tende a ser a nota na prova.”

Análise de Regressão
ÂÂNeste capítulo, será apresentada uma ferramenta de análise estatística aplicada em estudos em que se de-
seja estabelecer um modelo matemático que represente a relação entre duas variáveis X e Y. Esse modelo é extrema-mente útil ao pesquisador, pois permitirá a ele a realiza-ção de previsões e estimativas.
Ao final desse estudo, o aluno deverá ser capaz de identificar as situações em que a Análise de Regressão pode ser utilizada na resolução de problemas na área de Administração de empresas, bem como interpretar cor-retamente os resultados obtidos com essa ferramenta de análise de dados.
Simone Echeveste
Capítulo 10

170 Estatística Aplicada
A relação linear entre duas variáveis X e Y pode ser inves-tigada de duas formas: pela Análise de Correlação, na qual quantificamos a intensidade dessa relação, e pela Análise de Regressão, na qual a forma dessa relação é explicitada por meio de um modelo matemático.
Usamos Análise de Regressão quando acreditamos que há relações entre as variáveis e desejamos expressar matematica-mente tais relações. A Regressão Linear nos fornece equações do primeiro grau para determinarmos estimativas dos valores médios de algumas variáveis em função dos valores das outras.
Modelo de regressão linear
Os Modelos de regressão simples são modelos matemáticos que relacionam o comportamento de uma variável Y com uma variável X a partir de uma função:
F(X) = Y = a + bX
Nesse modelo, a variável X é a variável independente da equação, enquanto Y = f(X) é a variável dependente das va-riações de X.
Figura 28 Denominação das variáveis no modelo de Regressão Linear.

Capítulo 10 Análise de Regressão 171
Poderemos utilizar seus resultados para os seguintes objetivos:
 Realizar previsões sobre o comportamento futuro de al-gum fenômeno por meio de uma coleta de dados.
 Simular os efeitos sobre uma variável Y em decorrência de alterações introduzidas nos valores de uma variável X.
Estimadores para o modelo de regressão linear
Os estimadores dos coeficientes angular (β) e linear (α) serão designados respectivamente por b e a. Assim, a estimativa do modelo adotado será dada por:
Y = a + bX
Os valores de a e b serão determinados pelo Método dos Mínimos Quadrados (MMQ), aplicado na amostra sele-cionada, utilizando-se as seguintes fórmulas:
onde e são as médias dos valores de Y e X.

172 Estatística Aplicada
INFORMAÇÕES IMPORTANTES
A inclinação (b) da regressão mede a direção e a magnitude da relação. Quando as duas variáveis estão correlacionadas positivamente, a inclinação (valor de b) também será positiva, enquanto, quando as duas variáveis estão correlacionadas negativamente, a inclinação (valor de b) será negativa.
A magnitude da inclinação da regressão pode ser lida como segue: para cada acréscimo unitário na variável (X), a variável dependente aumentará/diminuirá b unidades de y.
Exemplo 1
Certa empresa, estudando a variação da demanda de seu produto (unidades vendidas) em relação à variação de preço de venda (reais), obteve os dados que estão na tabela abaixo:
PREÇO DO PRODUTO X DEMANDA
Mês Preço (X) Demanda (Y)
1 35 350
2 40 325
3 50 290
4 55 270
5 60 250
6 65 240
7 70 235
8 80 220
9 95 215
10 110 205
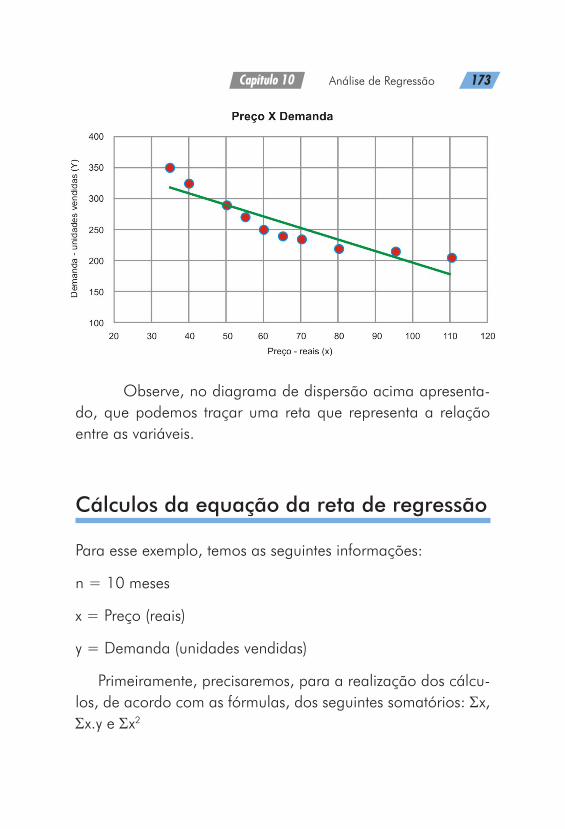
Capítulo 10 Análise de Regressão 173
Observe, no diagrama de dispersão acima apresenta-do, que podemos traçar uma reta que representa a relação entre as variáveis.
Cálculos da equação da reta de regressão
Para esse exemplo, temos as seguintes informações:
n = 10 meses
x = Preço (reais)
y = Demanda (unidades vendidas)
Primeiramente, precisaremos, para a realização dos cálcu-los, de acordo com as fórmulas, dos seguintes somatórios: Sx, Sx.y e Sx2

174 Estatística Aplicada
Mês Preço (x) Demanda (y) x . y x2
1 35 350 12250 1225
2 40 325 13000 1600
3 50 290 14500 2500
4 55 270 14850 3025
5 60 250 15000 3600
6 65 240 15600 4225
7 70 235 16450 4900
8 80 220 17600 6400
9 95 215 20425 9025
10 110 205 22550 12100
Total (S) 660 2.600 162.225 48.600
Cálculo das Médias

Capítulo 10 Análise de Regressão 175
Cálculo do Coeficiente b
Cálculo do Coeficiente a
Atenção ao sinal de negativa do coeficiente!!!

176 Estatística Aplicada
Equação da Reta de Regressão:
Equação da Reta para as variáveis:x: preço e y: demanda
Após a determinação da Equação da Reta, poderemos utili-zá-la agora com o objetivo de fazer previsões. Por exemplo, poderemos estimar qual será a demanda esperada para um preço de 100 reais.
Nesse caso, estamos determinando o valor de x = 100 reais e desejamos estimar qual será valor de y = demanda (unidades vendidas). Para isso, basta substituirmos os dados na Equação da Reta obtida:
Para x = 100 reais
Conclusão
Estima-se que, para um preço de 100 reais, sejam vendidas em torno de 196,76 unidades do produto.

Capítulo 10 Análise de Regressão 177
Exemplo 2
Os dados abaixo representam o x: tempo de experiência em anos, e os respectivos y: salários (em salários mínimos) de uma amostra de 8 Administradores:
Tempo de Experiência X Renda Mensal
Administrador X: Experiência (anos) Y: Salários Mínimos
1 2 5
2 5 6
3 10 11
4 8 9
5 6 7
6 12 10
7 15 14
8 11 10
Para esse exemplo, temos as seguintes informações:
n = 8 administradores
x = Tempo de experiência (anos)
y = Renda mensal (salários mínimos)

178 Estatística Aplicada
Tabela de cálculos:
Administrador X: Experiência (anos) Y: Salários Mínimos x.y x2
1 2 5 10 4
2 5 6 30 25
3 10 11 110 100
4 8 9 72 64
5 6 7 42 36
6 12 10 120 144
7 15 14 210 225
8 11 10 110 121
Total (S) 69 72 704 719
Cálculos para a construção da Equação da Reta
Cálculo das Médias

Capítulo 10 Análise de Regressão 179
Cálculo do Coeficiente b
Cálculo do Coeficiente a
Equação da Reta:
Equação da Reta para as variáveis:x: Tempo de experiência e y: Renda mensal

180 Estatística Aplicada
Questão:
Qual será a renda mensal estimada de um Administrador com 15 anos de experiência?
Nesse caso, estamos determinando o valor de x = 15 anos e desejamos estimar qual será valor de y = renda mensal (sa-lários mínimos). Para isso, basta substituirmos os dados na Equação da Reta obtida:
Para x = 15 anos
Conclusão
Estima-se que, para um tempo de experiência de 15 anos, o salário mensal de um Administrador seja em torno de 13,27 salários mínimos.
Recapitulando
A Análise de Regressão linear simples estuda o relacionamento entre uma variável dependente (y) e outra variável indepen-dente (x). Esse relacionamento é representado por um modelo

Capítulo 10 Análise de Regressão 181
matemático, por meio de uma equação que associa a variável dependente com a variável independente.
Após a determinação da Reta de Regressão, ou ainda Equação de Regressão, poderemos utilizá-la com o objetivo de realizar projeções ou simulações com as variáveis utilizadas no modelo.
Atividades: Análise de regressão
Questão 1. Uma amostra de funcionários de uma empresa foi observada quanto às variáveis: tempo de experiência na função (anos), e produtividade na realização da tarefa (núme-ro de relatórios produzidos). Para os dados obtidos com uma amostra de 20 funcionários, obteve-se a seguinte Equação da Reta de Regressão: y = 58,13 + 1,62x. A partir dessa equa-ção, responda às seguintes questões:
- Pelo valor do coeficiente “b” da reta, podemos dizer que a correlação entre o tempo de experiência na função e a produ-tividade é:
a. ( ) Inexistente
b. ( ) Direta/positiva
c. ( ) Inversa/Negativa
d. ( ) Direta/Negativa
e. ( ) Inversa/Positiva

182 Estatística Aplicada
- Para um funcionário com 10 anos de experiência, estima-se que este produza aproximadamente quantos relatórios?
a. ( ) 1,62 relatórios
b. ( ) 74 relatórios
c. ( ) 58 relatórios
d. ( ) 10 relatórios
e. ( ) 120 relatórios
Questão 2. Suponhamos que uma cadeia de supermercados tenha financiado um estudo dos gastos em alimentação para famílias de quatro pessoas. Obteve-se a seguinte equação de regressão linear: y = −200 + 0,10 x, onde y representa a despesa mensal estimada com alimentação e x a renda líquida mensal. A partir da Equação da Reta estabelecida, estime a despesa de uma família de quatro pessoas com renda mensal de R$ 15.000.
Questão 3. Foi feito um levantamento a respeito dos imóveis de dois dormitórios alugados por uma imobiliária da zona sul da cidade de Porto Alegre. Para verificar a relação entre o va-lor do aluguel cobrado (reais) e a sua distância em relação ao centro da cidade (metros), coletou-se os dados de 8 imóveis cadastrados nessa imobiliária.

Capítulo 10 Análise de Regressão 183
Valor do aluguel X Distância do centro
Imóvel Distância do centro (x) Valor do Aluguel (y)
1 5 950
2 4 980
3 6 1000
4 9 1100
5 6 1090
6 4 990
7 6 970
8 8 1030
a) Obtenha a Equação da Reta de regressão para esses da-dos.
b) Estime o valor do aluguel de um imóvel localizado a 10 metros.
Questão 4. Um corretor do mercado de ações, visando pre-ver o número de negócios fechados por dia, decidiu utilizar o número de chamadas telefônicas recebidas como variável independente. Os resultados obtidos para uma amostra de 10 dias foram:

184 Estatística Aplicada
Número de chamadas recebidas X Número de negócios fechados
Dia Nº chamadas recebidas Nº Negócios fechados
1 591 42
2 146 32
3 185 36
4 245 44
5 600 82
6 510 70
7 394 56
8 486 65
9 483 63
10 106 23
a) Obtenha a Equação da Reta de regressão para esses da-dos.
b) Estime o número de negócios fechados para um dia em que se recebam 500 chamadas.
Questão 5. Os dados abaixo representam o valor de um determinado mês da fatura do cartão de crédito (em reais) e a renda mensal (em salários mínimos) de uma amostra de 7 indivíduos:

Capítulo 10 Análise de Regressão 185
Indivíduo Renda Mensal (x) Gasto cartão (y)
1 3,5 520
2 5,0 850
3 2,8 310
4 4,5 800
5 5,2 860
6 5,8 910
7 6,9 900
a) Obtenha a Equação da Reta de regressão para esses da-dos.
b) Estime o gasto no cartão de uma família com renda de 7,5 salários mínimos.
Gabarito das atividades propostas
Questão 1.b. ( X ) Direta/positiva.
b. ( X ) 74 relatórios.
Questão 2.R: R$ 1.300,00

186 Estatística Aplicada
Questão 3.a) R: Y = 885,57 + 21,36 X
b) R: R$ 1.099,17
Questão 4.a) R: Y = 20,42 + 0,08 X
b) R: 60,42 negócios fechados.
Questão 5.a) R: Y = 15,20 + 149,66 X
b) R: 1.137,65 reais.
Referências Bibliográficas
BARBETTA, Pedro Alberto. Estatística Aplicada às Ciências So-ciais. Florianópolis: Ed. Da UFSC, 2001. 337 p.
CALLEGARI-JACQUES, S.M. Bioestatística: Princípios e Aplica-ções. ArtMed, Porto Alegre, 3a reimpressão, 2006.
CLARK, J. DOWNING, D. Estatística aplicada. São Paulo : Sa-raiva, 1998.
MOORE, D. A Estatística Básica e sua prática. Rio de Janeiro: Ed. LTC, 2000.
SIMON, Gary A. FREUND, John E. Estatística Aplicada. Porto Alegre : Bookman, 2000. 404 p.