elaboraÇÃo de mÓdulo de workflows … · fast science, produto da tese de doutorado que está...
TRANSCRIPT

ELABORAÇÃO DE MÓDULO DE WORKFLOWS BASEADO
EM COMPONENTES WEB REUTILIZÁVEIS PARA
PROJETOS DE CROWD SCIENCE
Daniel Souza RechtmanRafael Gonçalves dos Santos Quintanilha
Projeto de Graduação apresentado ao Curso de Engenharia de Computação e Informação da Escola Politécnica,
Universidade Federal do Rio de Janeiro, como parte dos requisitos necessários para à obtenção do
título de Engenheiro.
Orientador: Jano Moreira de Souza, Ph.D.Co-orientador: Maria Gilda Pimentel Esteves, M.Sc.
Rio de Janeiro
Abril de 2016

ELABORAÇÃO DE MÓDULO DE WORKFLOWS BASEADO
EM COMPONENTES WEB REUTILIZÁVEIS PARA
PROJETOS DE CROWD SCIENCE
Daniel Souza RechtmanRafael Gonçalves dos Santos Quintanilha
PROJETO DE GRADUAÇÃO SUBMETIDO AO CORPO DOCENTE DO CURSO DE
ENGENHARIA DE COMPUTAÇÃO E INFORMAÇÃO DA ESCOLA POLITÉCNICA
DA UNIVERSIDADE FEDERAL DO RIO DE JANEIRO COMO PARTE DOS
REQUISITOS NECESSÁRIOS PARA OBTENÇÃO DO GRAU DE ENGENHEIRO
DE COMPUTAÇÃO E INFORMAÇÃO.
Examinado por:
_____________________________________________
Jano Moreira de Souza, Ph.D. (Presidente)
_____________________________________________
Maria Gilda P. Esteves, M.Sc. (Co-orientadora)
_____________________________________________
Sergio Palma da Justa Medeiros, D.Sc.
RIO DE JANEIRO, RJ – BRASIL
ABRIL DE 2016

Agradecimentos
À professora Maria Gilda Pimentel Esteves pela inestimável colaboração e
parceria ao longo do desenvolvimento deste trabalho.
Ao professor Jano Moreira de Souza pela orientação ao longo deste trabalho.
Ao professor Sergio Palma da Justa Medeiros pela aceitação do convite para
compor a banca.
À Beatriz Prata, secretária da coordenação do curso de Engenharia de
Computação pela eficiência e dedicação.
À Universidade Federal do Rio de Janeiro pela formação acadêmica e pessoal
adquirida ao longo desses anos.
Daniel:
À minha família, especialmente, Wilma, Moyses, Mariana e Dirce e à minha
namorada Mariana pela paciência e apoio.
Rafael:
Ao apoio dado pelos meus pais, Sérgio e Rozely, e irmãos, Luisa e Ricardo.
ii

Resumo
Crowd Science é um tipo de pesquisa científica cuja premissa é contar com a
colaboração da multidão. Por permitir que um grande número de indivíduos participem
em etapas dessa pesquisa, torna-se extremamente versátil e importante para a ciência.
Uma consequência desse fato é que nem todos os participantes são
especialistas no tema científico a ser estudado. Com isso, torna-se necessário que as
etapas de um processo cientifico tradicional sejam subdivididas em etapas menores, de
fácil execução, e que as ferramentas desenvolvidas para a colaboração sejam intuitivas
e agradáveis de usar.
Projetar e gerenciar pesquisas desse porte não são tarefas triviais. A Plataforma
Fast Science, produto da tese de doutorado que está sendo desenvolvida pela
doutoranda Maria Gilda P. Esteves, sob a orientação do professor Jano Moreira de
Souza, busca preencher essa lacuna oferecendo um ambiente Web colaborativo para
cientistas interessados em usar o Crowd Science de forma acessível. A plataforma tem
o propósito de ser flexível o suficiente para abranger projetos de coleta, processamento
e validação de dados.
De posse dos requisitos e funcionalidades elencados por esse estudo de
doutorado, o objetivo deste projeto é propor uma solução e implementar um protótipo de
um módulo que facilite a criação e execução de workflows científicos em contextos de
Crowd Science. Esse protótipo deve ser capaz de se integrar ao projeto Fast Science.
iii

Abstract
Crowd Science is a scientific research whose premise is to have collaboration
from the crowd. By allowing a big number of individuals to take part in stages of this
research, it becomes extremely versatile and important for science.
One consequence of this fact is that you can't expect collaborators to be experts
in the subject to be studied. Tools developed for this matter must be intuitive and
pleasant to use.
Design and manage large-sized researches are not trivial tasks. The Fast
Science Platform, product of the doctoral thesis being developed by student Maria Gilda
P. Esteves, under the guidance from professor Jano Moreira de Souza, aims to fill this
gap offering a collaborative Web environment for scientists interested in using Crowd
Science in an accessible fashion. The platform has the purpose of being flexible enough
to embrace projects that include collecting, processing and validating data.
Having the requirements and features listed by this doctoral study, the goal of
this project is to propose a solution and implement a prototype able to manage a
scientific workflow in a Crowd Science context. This prototype must be capable of being
integrated to the Fast Science project.
iv

SumárioAgradecimentos................................................................................................................ ii
Resumo........................................................................................................................... iii
Abstract........................................................................................................................... iv
Sumário............................................................................................................................v
Índice de Figuras............................................................................................................vii
Introdução........................................................................................................................1
1.1. Objetivos................................................................................................................3
1.2. Metodologia...........................................................................................................3
1.3. Organização da Monografia...................................................................................4
2. Crowd Science.............................................................................................................5
2.1. Definição................................................................................................................5
2.2. A Ciência e as Multidões........................................................................................6
2.3 Tipologia.................................................................................................................7
3. Solução Proposta.........................................................................................................8
3.1. Módulo de Workflow para a Plataforma Fast Science............................................8
3.2. Requisitos..............................................................................................................8
3.3. Arquitetura.............................................................................................................9
3.4. Modelo de Dados.................................................................................................10
4. Protótipo.....................................................................................................................13
4.1. Ferramentas........................................................................................................13
4.2. Funcionalidades...................................................................................................15
4.3. Descrição da API.................................................................................................19
4.4. Integração com o Fast Science............................................................................19
4.5. Resultado............................................................................................................21
4.6. Limitações...........................................................................................................36
4.6.1. Componentes de Processamento Sofisticados.............................................36
v

4.6.2. Novos Parâmetros de Controle nos Componentes.......................................36
4.6.3. Leitura de Dados via EXIF.............................................................................36
4.6.4. Múltiplos Datasets.........................................................................................36
4.6.5. Workflow de Validação..................................................................................37
4.6.6. Multiplas Permissões de Edição por Projeto.................................................37
4.6.7. Exportação mais Sofisticada.........................................................................37
5. Avaliação do Protótipo................................................................................................38
6. Conclusão..................................................................................................................40
Referências....................................................................................................................41
vi

Índice de FigurasFigura 1 - Arquitetura simplificada da Plataforma Fast Science.(Comunicação pessoal,
ESTEVES, M.G.P., em elaboração).................................................................................2
Figura 2 - Modelo de dados simplificado........................................................................11
Figura 3 - MVC no módulo de workflow da Plataforma Fast Science.............................13
Figura 4 - ilustração da arquitetura em árvore do DOM. Fonte: W3Schools...................14
Figura 5 - Integração do módulo de workflow ao projeto Fast Science..........................20
Figura 6 - Projeto sem workflow cadastrado..................................................................22
Figura 7 - Tela de clonar workflow..................................................................................22
Figura 8 - Tela inicial de configurações do workflow.......................................................23
Figura 9 - Tela de configuração alterada e salva pelo usuário........................................24
Figura 10 - Tela inicial de tarefas inicialmente sem nenhuma tarefa cadastrada............25
Figura 11 - Tela de montagem de tarefas.......................................................................25
Figura 12 - Tarefa tem seu nome alterado e é reordenada.............................................26
Figura 13 - Componentes selecionados são visualizados na coluna mais à direita........27
Figura 14 - Edição de meta informações de um componente........................................28
Figura 15 - Pré-visualização de uma tarefa....................................................................29
Figura 16 - Preenchimento de um tutorial combinando markdown e HTML...................30
Figura 17 - Pré-visualização de um tutorial....................................................................31
Figura 18 - Tela de exportação das informações coletadas............................................31
Figura 19 - Início da tela de contribuição........................................................................32
Figura 20 - Preenchimento da tarefa pelo voluntário......................................................33
Figura 21 - Imagem emulada pelo Google Chrome ilustrando um smartphone típico.. . .34
Figura 22 - A última tarefa permite que o usuário finalize sua contribuição....................35
Figura 23 - Após finalizar, o usuário poderá repetir a experiência..................................35
vii

Introdução
O engajamento do publico em geral na pesquisa científica é uma pratica antiga. Inúmeros
exemplos são descritos na literatura e amplamente conhecidos como projetos de Ciencia Cidadã
ou “Citizen Science” (BONNEY, et al, 2009). Entretanto, devido ao amplo acesso à Internet e à
popularidade do uso de dispositivos móveis, cresce o número de projetos científicos que fazem
uso de plataformas de crowdsourcing para ampliar a capacidade, geralmente restrita, de
pequenos grupos de pesquisadores na realização de tarefas relacionadas a coleta e
processamento de dados científicos (Uchoa, 2013; Esteves et al, 2015). Através de uma chamada
aberta, um número indefinido de cidadãos (multidão) são convidados a resolver problemas ou
realizar tarefas científicas, fazendo assim parte de pesquisas científicas reais (HOWE, 2006;
DOAN et al., 2011).
Autores como FRANZONI & SAUERMANN (2014) e YOUNG, J.R. (2010) utilizam o termo
“Crowd Science” para rotular projetos de colaboração em larga escala. Para COOK, 2012 “... a
razão para o repentino olhar para Crowd Science é que ela oferece uma resposta criativa para um
problema central do século XXI: muita informação”. Crowd Science ou Citizen Science representa
uma nova ferramenta para a condução de estudos científicos.
A popularização da Crowd Science estimulou a criação de diversas plataformas
tecnológicas que permitem a exploração do potencial da multidão por pesquisadores. Até a
presente data nenhuma destas ferramentas apresenta a versatilidade necessária para que
pesquisadores com diferentes objetivos criem e disponibilizem seus experimentos para um grande
grupo de voluntários, de forma a abranger desde a coleta até processamento de dados em mídias
variadas.
Neste contexto, a doutoranda Maria Gilda Pimentel Esteves, do Programa de Engenharia
de Sistemas e Computação - PESC/COPPE/UFRJ, sob a supervisão do Prof. Jano Moreira de
Souza está desenvolvendo um estudo com o objetivo de compreender como o trabalho
cooperativo suportado por computador e a computação para multidões vem suportando e
impulsionando este novo paradigma de colaboração aberta na pesquisa cientícia.
Em sua tese de doutorado a aluna propõe uma plataforma alternativa de Crowd Science
denominada Fast Science, com o objetivo de facilitar e acelerar a criação e execução de projetos
de colaboração científica com multidões. A Plataforma Fast Science permitirá que qualquer
instituição ou pesquisador interessado em valer-se da participação das multidões, possa modelar
1

e executar projetos de Crowd Science prescindindo de conhecimento específico na área da
computação. Com foco na reutilização de componentes e compartilhamento de experiências e
lições aprendidas, a plataforma permitirá ao pesquisador reutilizar um experimento criado por seus
pares, alterando apenas os parâmetros e/ou componentes e criando novas atividades se desejar.
A fim de dar suporte à difícil tarefa de mobilizar a comunidade de voluntários em torno de cada
projeto o Fast Science contará também com ferramentas sociais e cadastro de voluntários e
parceiros.
A Figura 1 ilustra a dinâmica de uso da plataforma Fast Science para a criação, execução,
comunicação e divugação dos projetos:
Figura 1 - Arquitetura simplificada da Plataforma Fast Science.(Comunicação pessoal, ESTEVES,
M.G.P., em elaboração).
A partir das necessidades identificadas pelo estudo de doutorado da professora Maria
Gilda, foi proposto para este projeto de final de curso a elaboração do módulo de criação,
gerenciamento e colaboração em projetos de Crowd Science, denominado “Módulo de
Workflows”. Baseando-se nos requisitos elicitados pela professora, os autores investigaram as
2

melhores alternativas tecnológicas para a criação do módulo, realizaram o projeto de um protótipo
de solução, implementaram e integraram tal protótipo à plataforma Fast Science e realizaram uma
avaliação do resultado do trabalho.
A motivação para este trabalho foi a oportunidade de participar da elaboração de
ferramental para permitir a colaboração coletiva na realização de um projeto científico real.
1.1. Objetivos
Partindo de uma pesquisa para o entendimento do fenômeno da participação de muitidões
em projetos científicos e da colaboração com a professora Maria Gilda, o trabalho pretende propor
uma solução inovadora e de qualidade para a modelagem e execução de workflows.
1.2. Metodologia
Inicialmente foi feito um levantamento bibliografico sobre o tema e as principais soluções
tecnológicas existentes.
Utilizando os conhecimentos adquiridos na pesquisa sobre o tema e as diversas
entrevistas com a professora e seus colaboradores, foi possível identificar as características que a
solução pretendida deve apresentar.
Posteriormente foi elaborada uma lista de requisitos e proposta uma solução na forma de
um módulo para o projeto Fast Science. A solução proposta será desenhada tendo sua arquitetura
e modelo de dados definidos e validados junto ao professor Jano Moreira de Souza e demais
autores envolvidos.
Vencida esta etapa, foram escolhidas ferramentas computacionais que permitissem a
implementação com qualidade e respeitando as melhores práticas da solução proposta. Um
protótipo foi desenvolvido e integrado ao Fast Science para teste com um problema científico real
e para ser parte do objeto da tese de doutorado da professora Maria Gilda. Tanto o teste quanto a
avaliação de seus resultados fogem do escopo do presente trabalho. Ele se resumirá a apresentar
a ferramenta desenvolvida descrevendo e comentando suas características técnicas e
ergonômicas e apresentando as limitações e oportunidades de evolução.
3

1.3. Organização da Monografia
O trabalho tratará primeiro de contextualizar o leitor apresentando o conceito de Crowd
Science, aplicações e perspectivas. O conceito de crowdsourcing também será definidos de forma
a permitir um entendimento do valor e da importância deste tipo de colaboração na evolução e
mudança de paradigma da ciência, especialmente de alguns campos onde o uso de multidões
chegou mais cedo. Ainda no primeiro capítulo será explorada a história da colaboração de
multidões em projetos cientificos e seu impacto na difusão do conhecimento e interesse pela
ciência e nos próprios grupos que tradicionalmente lideram o avanço da fronteira do
conhecimento.
No capítulo “Solução Proposta” será apresentada uma solução modelada para ser
extremamente versátil e genérica sem perder a ergonomia e facilidade de uso. Esta solução tem o
objetivo de ser um módulo para a criação e reuso de workflows para projetos científicos e para a
colaboração da multidão em cada projeto. O módulo desenvolvido foi integrado ao projeto Fast
Science.
Ainda no mesmo capítulo serão apresentadas algumas das decisões técnicas tomadas
pelos autores deste trabalho de final de curso com argumentos que as sustentem. Será
comentada a arquitetura, escolhida com vistas à alta escalabilidade e flexibilidade do projeto.
Outra área desafiadora foi a modelagem de dados, uma vez que necessitou-se dar suporte a
diversos tipos de componentes já definidos e detentores do seu próprio conjunto de propriedades,
além de permitir a inclusão posterior de outros.
O capítulo seguinte é dedicado à descrição mais detalhada do protótipo implementado e
contém uma lista de suas funcionalidades. São apresentadas e descritas as ferramentas utilizadas
e as razões para sua escolha. Alguns elementos da abordagem arquitetural escolhida são
discutidos com suas limitações e pontos fortes. É também neste capítulo que a API de serviços
projetada para o módulo é descrita e a sua integração ao projeto Fast Science discutida. Na
sessão “Resultados” o protótipo desenvolvido é apresentado e sua ergonomia é discutida de
forma a ilustrar ao leitor as experiências na criação de um workflow e de colaboração com uma
pesquisa. Por fim, as limitações do protótipo são apresentadas como ponto de partida para futuros
desenvolvimentos.
O capítulo “Avaliação do Protótipo” dedica-se a comparar os resultados alcançados com os
requisitos originais e a solução proposta, comentando as discrepâncias entre ambos.
4

2. Crowd Science
2.1. Definição
Crowd Science é toda pesquisa científica que se utiliza do poder das multidões para algum
propósito. Esta tendência, também conhecida como Citizen Science, foi primeiro observada no
início do século XX, quando o ornitólogo Frank Chapman promoveu censos de populações de
pássaros com a ajuda de grandes grupos de colaboradores (COOK, G, 2011). A área de
ornitologia sempre foi alvo de interesse do cidadão, pois além da necessidade do conhecimento
cientifico sobre a distribuição e ocorrência das aves, há atividades relacionadas ao cotidiano de
comunidades de avistadores, que já possuem o hábito de observar pássaros durante suas horas
livres como atividade de lazer (MILLER-RUSHING, 2011).
A partir da difusão do acesso à Internet trazida pelos dispositivos móveis e tecnologias de
comunicação sem fios, o uso da multidão para diversos fins tornou-se extremamente popular. No
que se convencionou chamar “crowdsourcing”, diversas organizações e indivíduos passaram a
lançar seus projetos na Web e solicitar colaborações de voluntários por todo o mundo (COOK, G,
2011 e FRANZONI & SAUERMANN, 2014). Outros tipos populares de aplicação do conceito são:
● Crowdfunding, quando um determinado projeto, científico, de caridade ou até comercial, é
financiado por contribuições de diversos indivíduos pelo mundo;● Crowdtesting, quando um produtor de software solicita à multidão que teste seu produto
colaborativamente;● Criação coletiva de conteúdo, quando a produção de conteúdo editorial de bases de
conhecimento como a Wikipedia, que é escrita, revisada e mantida por milhares de pessoas
espalhadas pelo mundo.
Não existe norma quanto à contrapartida oferecida aos voluntários. Alguns projetos de
crowdfunding, por exemplo, utilizam a multidão para financiar o desenvolvimento de produtos.
Quando do início da comecialização, colaboradores recebem as primeiras unidades ou
preferência e desconto para adiquirí-los. Em outros casos, como projetos de Crowd Science e
financiamento de ações de caridade, o colaborador geralmente recebe um agradecimento e
prestações de contas periódicas sobre o andamento do trabalho.
Autores como YOUNG, J.R. (2010) utilizam o termo Crowd Science para rotular projetos
de colaboração em larga escala como e-bird e Galaxy Zoo. Estes projetos se distinguem dos
projetos científicos tradicionais devido à participação aberta de um número grande e ilimitado de
5

indivíduos que participam com diferentes motivações. Tais motivações podem incluir
aprendizagem, lazer, altruísmo, ativismo e reconhecimento, bem como a possibilidade de
conhecer novas pessoas, lugares e contextos socio-ambientais diferentes (RADDICK et al., 2010;
NOV et al., 2011; CROWSTON,K. & PRESTOPNIK, 2011).
Plataformas de marketplace como o a “Amazon Mechanical Turk” e “Crowdflower”, apenas
citando algumas, promovem aos seus usuários infraestrutura para execução de micro tarefas
mediante retribuição financeira dos participantes. Embora a remuneração pecuniária não seja uma
prática comum aplicada a projetos cientificos, deve também ser considerada como uma forma de
reconhecimento e retribuição da partcipação em projetos de crowd science.
2.2. A Ciência e as Multidões
Em termos de pesquisa científica, o uso de multidões tem se tornado uma ferramenta
importante para projetos em um número crescente de áreas. A necessidade de analisar enormes
quantidades de informação sempre foi um problema para projetos científicos. A evolução da
computação, embora tenha permitido o processamento automático de parte destas informações,
também fez explodir a quantidade e qualidade dos dados colhidos e armazenados. Alguns
exemplos de disciplinas que passam por revoluções por causa das novas e imensas massas de
dados disponíveis são:
● Física e Astronomia, com radiotelescópios, aceleradores de particulas e outros equipamentos;● Biologia, com máquinas sequenciadoras de gens e redes de sensores sem fio coletando dados
ambientais em escala colossal;● Ciências sociais, com as redes sociais e sistemas de difusão de conteúdo sob demanda que já
contam com grafos da ordem de bilhões de nós.
Nem sempre é viável trabalhar computacionalmente os dados. Eventualmente o
pesquisador não conta com os meios necessários (equipamentos, expertise, recursos financeiros)
ou simplesmente (no atual estágio de desenvolvimento das técnicas de inteligência
computacional) não é possível desenvolver algoritmos capazes de realizar a tarefa. Neste
contexto, a utilização da Crowd Science tem se mostrado muito promissora com casos de sucesso
capazes de animar as comunidades científicas (SIMPSON, 2014).
A astronomia foi um dos campos pioneiros pela realização de projetos que lançaram as
bases para a Crowd Science através da iniciativa denominada Galaxy Zoo, descrita por
SIMPSON, (2014) e YOUNG, (2010). Apesar da grande difículdade encontrada pelos criadores
6

do Galaxy Zoo para engajar a comunidade astronômica, tão acostumada às visitas solitárias aos
telescópios e à proteção dos dados de seus experimentos como se fossem segredos comerciais,
o projeto foi um grande sucesso. Um dos resultados da iniciativa foi a descoberta de novos
exoplanetas, um fenômeno até então desconhecido (SIMPSON, 2014 e YOUNG, 2010).
Na Astronomia, como em diversos outros campos, a chegada da Crowd Science tem
oxigenado a comunidade acadêmica vencendo resistências e trazendo mudanças de paradigmas.
No modelo tradicional de fazer ciência, o mérito do pesquisador está na publicação de artigos e,
dessa forma, ele se ressente de compartilhar dados brutos e resultados preliminares. A
colaboração com as multidões traz a mudança de cultura para a valorização da autoria e
modelagem dos projetos e para o compartilhamento de informação (COOK, 2011 e YOUNG,
2010).
2.3 Tipologia
De acordo com a tipologia apresentada no exame de qualificação de doutorado de
ESTEVES (2013) os projetos de Crowd Science podem ser divididos em dois grupos, de acordo
com o tipo de trabalho realizado pelos colaboradores. Enquanto alguns projetos solicitam que os
voluntários processem os dados, outros desejam que eles contribuam com os próprios dados da
pesquisa.
Nos projetos de coleta de dados, os usuários da plataforma escolhida são incentivados a
contribuir com material para a pesquisa. Estes dados podem apresentar diversos tipos de mídias e
estar em diferentes domínios. Há projetos, por exemplo, que requisitam o envio de imagens, sons,
vídeo, e até coordenadas geográficas. Por sua vez, nos projetos de processamento de dados, os
voluntários tem a oportunidade de, após um rápido treinamento, realizar análise de imagens,
vídeos ou responder a questionários.
É natural que um projeto de coleta seja elaborado para formar uma grande base de dados,
a ser posteriormente objeto de um projeto de processamento. Neste projeto, os dados podem ser
validados, avaliados e classificados por voluntários.
7

3. Solução Proposta
3.1. Módulo de Workflow para a Plataforma Fast Science
Através do estudo do uso das multidões em projetos científicos e da colaboração com a
professora Maria Gilda os autores chegaram a uma proposta de solução para o módulo de
workflow do projeto Fast Science. Foram levados em conta diversos fatores e diretrizes que
nortearam o projeto e a implementação do módulo. Houve especial atenção à usabilidade e
ergonomia da interface para que fosse simples e prático para os pesquisadores, leigos em
computação, criarem seus projetos.
Outro princípio fundamental levado em conta foi a modularização e baixo acoplamento da
solução. Modelagem de dados, arquitetura e organização do código foram feitas de forma a
permitir fácil manutenção e evolução em direção a um produto ainda mais completo.
3.2. Requisitos
Através de entrevista semi-estruturada junto à prof. Maria Gilda P. Esteves, uma elicitação
dos principais requisitos e funcionalidades da plataforma foi realizada. Como o escopo deste
projeto restringe-se ao módulo de workflows, serão descritas nesta sessão apenas as
funcionalidades que o compõem.
Abaixo há uma lista das características que o projeto deverá apresentar:
● REQ1: Interface gráfica que permita ao pesquisador criar workflows de processamento, coleta e
validação de dados;● REQ2: No caso dos workflows de processamento deve ser possível fazer o upload de múltiplos
datasets, que consistem em um arquivo no formato ZIP com as mídias a serem processados pela
multidão;● REQ3: Para um dado workflow o pesquisador deve poder adicionar diversas tarefas, de maneira a
segmentar o trabalho do voluntário em etapas;● REQ4: Cada tarefa consistirá de um conjunto de componentes pré-definidos que poderão ser
adicionados, removidos, re-ordenados e ter parâmetros visuais customizados;● REQ5: O protótipo deverá permitir o reuso de informações a partir da possibilidade de clonar
workflows existentes, alterando-se apenas os parâmetros desejados; ● REQ6: Permitir ao pesquisador pré-visualizar e testar os workflows antes de serem abertos ao
público na Plataforma Fast Science;
8

● REQ7: Permitir que o pesquisador crie um tutorial explicativo sobre as tarefas de cada workflow
utilizando elementos básicos para formatação de texto;● REQ8: Criar interface gráfica para execução dos workflows, permitindo assim a contribuição de
múltiplos usuários tanto para tarefas de processamento quanto para coleta de dados;● REQ9: Tornar a tela de contribuição responsiva, possibilitando a colaboração em dispositvos
móveis;● REQ10: Possibilitar a exportação das informações adquiridas (resultados da execução dos
workflows);● REQ11: Permitir a inclusão de novos itens na biblioteca de componentes pré-definidos sem a
necessidade de alteração estrutural no código;● REQ12: Integrar o protótipo desenvolvido à plataforma Fast Science.
Essa lista será recuperada no capítulo 6 ao avaliar-se como o protótipo resolveu esses requisitos.
3.3. Arquitetura
A Plataforma Fast Science, ao qual o módulo deve ser integrado, foi concebida como um
sistema Web onde um software roda num servidor na nuvem e expões uma API de serviços que é
consumida por outro sistema rodando no navegador dos usuários. Esta abordagem apresenta
diversas vantagens no tratamento do problema de colaboração de multidões em projetos
científicos.
Como os tipos de projeto que mais se beneficiam da Crowd Science são intensivos tanto
em número de colaboradores quanto em necessidade de espaço de armazenamento, o Fast
Science precisa suportar acessos concorrentes e ser facilmente escalável. Adicionalmente, a
rápida evolução da Crowd Science exigirá da plataforma que adicione novos componentes e
comportamentos de forma rápida e barata para se manter útil. Outro fator essencial para o
sucesso do projeto é a capacidade de adicionar futuramente, sem muito custo, outros tipos de
interface tanto visual quando com outros sistemas.
A elaboração de uma API de serviços para o acesso ao core da plataforma Fast Science
permite que novas interfaces gráficas, por exemplo para dispositívos móveis, sejam elaboradas
sem a necessidade de modificação na base de código que implementa as principais regras de
negócios. Outra vantagem desta abordagem é a possibilidade de se expor futuramente uma API
pública, permitindo à comunidade criar extensões ao projeto.
A tecnologia de comunicação escolhida para a comunicação entre cliente e servidor foi o
protocolo HTTP, por sua simplicidade e por ser o padrão para a Web. Utilizamos a arquitetura
9

REST como inpiração para o desenvolvimento da API. Embora não possa ser chamada de
RESTful por não aproveitar-se dos verbos e códigos de resposta do protocolo HTTP para
padronizar e enriquecer a comunicação, a aplicação tenta manter-se fiel a filosofia por trás desta
do REST. As chamadas de API são simples, independentes, não guardam estados e foram
projetadas de maneira a reduzir o acoplamento no produto final.
Outra arquitetura que norteou o desenvolvimento do projeto foi a MVC (Model, View e
Controller), que propõe a separação dos sistemas em três camadas:
1. Apresentação de dados, a View, que é responsável apenas pela exibição ao usuário do conteúdo;2. Acesso a dados e implementação de regras de negócios, o Model, que é a única a acessar o
banco de dados e deve encapsular a inteligência de negócios do produto;3. E por fim o Controller, que deve fazer o meio de campo entre Models e Views.
No projeto, Models e Controllers estão localizados na aplicação do servidor, que expõe
uma API para ser consumida por um sistema isolado que fará o papel das Views.
3.4. Modelo de Dados
Tendo em vista a necessidade da disponibilidade da plataforma a um grande número de
pessoas, um sistema Web foi concebido. A simplicidade de uso para a montagem de workflows
científicos e a aquisição de dados através dos usuários foram requisitos importantes.
Na solução proposta, usuários podem cadastrar projetos de Crowd Science e criar
múltiplos workflows por projetos. Os responsáveis pelo projeto devem ser capazes de estabelecer
tarefas sequenciais para que os colaboradores voluntários realizem. A montagem de tais tarefas
será feita por componentes pré-determinados, que podem variar entre simples campos de
formulários HTML5 e complexos processamentos em imagens. Finalmente, cada componente
poderá ser customizado para refletir as necessidades da tarefa (por exemplo, editando um rótulo
descritivo ou cadastrando múltiplas opções numa caixa de seleção).
O diagrama a seguir ilustra parte do modelo entidade-relacionamento proposto:
10

Figura 2 - Modelo de dados simplificado.
Uma descrição de cada uma das entidades é a seguinte:
1. Project: informações gerais sobre o projeto.2. Workflow: entidade que representará os workflows pertencentes a um dado projeto.3. Task: entidade que representará as tarefas pertencentes a um dado workflow;4. Component: domínio de componentes disponíveis no sistema;5. TaskComponent: tabela intermediária entre Task e Component, indicando um componente
específico para aquela tarefa;6. TaskComponentMeta: meta-informações sobre o TaskComponent, ou seja, personalizações
feitas especificamente para o componente pertencente à tarefa;7. TaskComponentAnswer: resposta, quando aplicável, de um colaborador ao TaskComponent
elaborado. Inclui o id do colaborador e, se requerido pelo componente, o id da mídia associada;8. Media: qualquer tipo de mídia associada ao workflow (áudio, imagem, vídeo);9. User: usuário cadastrado no sistema, podendo ser o gerente do projeto ou um colaborador.
Observe que a modelagem proposta permite a inclusão futura de componentes, uma vez
que é agnóstica às suas propriedades.. No evento de associação entre Task e Component, o
gerente do projeto pode então adequar o componente às suas necessidades e essas informações
são armazenadas, chave e valor, sem a necessidade de prévio conhecimento das chaves
possíveis.
11

Através de TaskComponentMeta, cada componente pode definir parâmetros de
customização que também podem ser incrementados ao longo do tempo. A arquitetura prevê dois
campos: name e value. Em name, definimos qual atributo estamos customizando (por exemplo,
label). Já em value armazenamos o valor do atributo (por exemplo, “Digite seu nome”). Como
cada componente é personalizado em uma tarefa, é necessário passar o identificador da tarefa
para completar a associação.
As respostas coletadas nos componentes são armazenadas no campo value de
TaskComponentAnswer. Observe que se a resposta estiver atrelada a uma mídia ela é
referenciada através de media_id. Essa abordagem facilita a exportação e processamento dos
dados em uma etapa futura.
A utilização de múltiplos workflows por projeto visa dar a noção de "começo, meio e fim" a
uma pesquisa. Dessa forma, resultados utilizados em um workflow podem ser utilizados em
etapas posteriores. No próximo capítulo, mostraremos exemplos específicos de como
potencializar essa arquitetura e a abordagem utilizada na elaboração do protótipo.
12

4. Protótipo
4.1. Ferramentas
Baseado nos requisitos definidos para o módulo de criação e design de workflows para a
plataforma Fast Science, na avaliação das plataformas existentes e na solução proposta neste
trabalho, um protótipo que implementando os requisitos mais importantes foi desenvolvido.
O sistema foi dividido em dois softwares, um para o front-end e outro para o back-end,
interligados por uma API. Esta decisão facilita o reuso de código, futuras melhorias a divisão de
trabalho entre os autores. O paradigma Model-View-Controller (MVC) foi implementado utilizando
ferramentas disponíveis à comunidade, como pode ser visto no seguinte diagrama:
Figura 3 - MVC no módulo de workflow da Plataforma Fast Science.
React é uma biblioteca desenvolvida pelo Facebook que é comumente utilizada como o V
do modelo MVC, responsável pela camada de apresentação. Ela se encarrega de criar e mapear
componentes em elementos HTML através do chamado Virtual DOM, que é uma abstração do
Document Object Model (DOM). O DOM é uma representação estruturada em árvore onde os nós
(ou folhas) são elementos HTML reconhecidos pelo navegador. O seguinte exemplo ilustra sua
organização:
13

Figura 4 - ilustração da arquitetura em árvore do DOM. Fonte: W3Schools
No contexto do React, cada mudança no estado da aplicação altera o Virtual DOM, que
reflete suas mudanças apenas sobre os nós alterados e seus descendentes no DOM “real”. De
acordo com o exemplo acima, se os nós Text: “My title” e Element: <h1> mudam, a biblioteca se
encarrega de substituí-los pela suas novas versões e propagar as alterações aos nós-filhos
(nesse exemplo, Text: “My header”).
Uma aplicação típica utilizando o React é definida pela composição de componentes,
similar a forma como páginas HTML são desenvolvidas. Cada componente recebe como
parâmetro certas propriedades (props) e possui um estado (state) interno. Propriedades são
passadas de “pai pra filho”, ou seja, de componentes de ordem superior para componentes de
ordem inferior (esse comportamento explica a necessidade de mapear as mudanças de um nó
sobre seus filhos). Já o estado é controlado pelo próprio componente e pode ser utilizado para
reagir a uma ação do usuário ou a um evento externo.
De acordo com a arquitetura proposta, tarefas são compostas por componentes que
possuem atributos próprios a serem renderizados em tempo de execução. Uma vez que
componentes são o cerne do React, sua escolha para o projeto foi um caminho natural. Ao longo
das próximas seções veremos exemplos sobre como essa abordagem foi utilizada na prática.
O front-end foi desenvolvido na forma de uma Single Page Application (SPA) utilizando o
React. A necessidade de uma SPA, onde páginas são renderizadas sem a necessidade de
múltiplas chamadas ao servidor, deu-se tanto pela melhora da usabilidade do sistema, quanto pela
14

facilidade da integração da solução proposta em um site já existente. Nessa arquitetura, a
aplicação comunica-se com o servidor através de uma API HTTP e monta a interface de acordo
com os dados recebidos.
Para o back-end, o framework Django (escrito em Python) foi escolhido. Essa escolha deu-
se não só pela facilidade de integração com o projeto Fast Science, elaborado com esta
ferramenta, mas também pela sua capacidade de suportar o desenvolvimento de aplicações
escaláveis, flexíveis e modulares com alta qualidade.
O Django possui um Object-Relational Mapping (ORM) bastante completo, que facilita as
chamadas ao banco de dados tanto para gravação quanto para leitura dos dados. Além disso, ele
torna muito natural escrever aplicações utilizando uma arquitetura onde front-end e back-end são
sistemas separados. Embora este não seja o caso do protótipo, muito dessa arquitetura foi
aproveitado na sua modelagem.
O último pedaço da arquitetura é o banco de dados. Para essa função, foi escolhido o
PostgreSQL. Uma vez que existem muitos níveis de associação e dependências entre as
entidades, a escolha de um banco relacional tornou-se natural. A opção específica pelo
PostgreSQL se deu pela existência do banco na aplicação Fast Science.
4.2. Funcionalidades
De posse da solução proposta e da tecnologia escolhida para seu desenvolvimento, foi
feito um estudo para selecionar as funcionalidades a serem implementadas na primeira versão do
protótipo. Como critérios de escolha foram levados em consideração tempo de desenvolvimento,
tempo disponível e relevância para o tema.
A primeira etapa foi identificar quais características apresentadas de fato são
indispensáveis para uma prova de conceito e testes ainda em sua infância. A resposta foi a
necessidade de se criar um workflow, separá-lo em tarefas, apresentá-lo a voluntários e por fim
exportar os dados para análise.
Com base nas funcionalidades descritas, a etapa posterior foi identificar possíveis
refinamentos para melhorar a experiência do usuário. Nessa fase, foi levado em consideração um
dos principais objetivos do projeto, que é tornar fácil para o cientista leigo a criação de um
workflow científico capaz de gerar algum valor através da contribuição da massa. Sendo assim, a
15

interface foi projetada para ser user-friendly e dispensar conhecimentos de computação para sua
montagem.
A aplicação foi então projetada para cumprir duas funcionalidades: a montagem e
gerenciamento do workflow, e a captura de informações pelos voluntários. A tela de montagem
será disponibilizada somente aos gerentes do projeto (limitado a um usuário para fins de protótipo)
enquanto qualquer usuário poderá ser capaz de contribuir.
A tela de gerenciamento engloba todas as possíveis configurações previstas no protótipo. Um
requisito importante é que não será permitida a edição de um workflow uma vez que alguma
resposta já tenha sido coletada, caso contrário haveria parâmetros de comparação diferentes.
Ao criar um workflow, o usuário deve escolher entre diferentes propósitos. Na prova de
conceito implementada, dois foram cobertos: coleta e processamento. Um workflow é classificado
como coleta quando ele pede um recurso externo próprio ao voluntário (por exemplo, uma foto).
Já o workflow é dito de processamento quando ele utiliza o conhecimento do voluntário para
processar um conjunto de dados já obtido pelo gestor do projeto.
Com esses dois objetivos em mente, o próximo passo foi elencar quais componentes
seriam indispensáveis para a montagem de workflows capazes de realizá-los. Chegou-se a
seguinte lista:
1. Caixa de Texto: textos simples e curtos;2. Caixa de Seleção: seleção única entre múltiplas opções;3. Área de Texto: textos simples e maiores;4. Caixa de Combinação: seleção múltipla entre múltiplas opções;5. Imagem: exibição de imagem;6. Captura de Mídia: captura de mídia específica pelo usuário;7. Geolocalização: informação de latitude e longitude.
Tais componentes cobrem a maioria dos casos presentes em workflows de coleta e
processamento. Para fins de protótipo, suas personalizações (meta informações) foram mantidas
as mais simples possíveis. Por exemplo, todos os componentes possuem a possibilidade de
edição do label informativo.
Uma vez que os componentes foram decididos, foi necessário especificar como
efetivamente implementá-los em um workflow. Para isso, a tela de tarefas foi criada. Nessa tela, o
gerente do projeto poderá selecionar entre a lista de componentes disponíveis quais ele quer
16

adicionar na tarefa. Uma vez que o componente for selecionado, ele pode ser reordenado e
customizado. Por simplicidade de uso, uma abordagem drag and drop foi utilizada.
Como um workflow é constituído de múltiplas tarefas sequenciais, a mesma lógica dos
componentes foi aplicada em sua criação. Dessa forma, tarefas são criadas e reordenadas
utilizando o mesmo padrão drag and drop. Ao utilizar elementos de estilos semelhantes, o objetivo
é reforçar a associação e facilitar o uso da aplicação.
A última funcionalidade implementada nessa tela foi a possibilidade de pré-visualizar o
resultado da tarefa. Esse foi considerado um requisito importante pois dá ao gerente do projeto a
exata noção de como seus componentes serão exibidos ao voluntário. Essa funcionalidade
também é considerada chave pois aparecerá em outros momentos ao longo da aplicação.
Uma vez que o cerne da aplicação foi definido, o próximo passo foi elaborar a criação do
workflow. Informações básicas e descritivas devem ser cadastradas para que voluntários saibam
identificar o propósito da colaboração. Além disso, deve ser possível selecionar entre os tipos de
workflow definidos: coleta ou processamento.
No caso de workflow de processamento, um ponto chave é atribuir um conjunto de
imagens (dataset). Essas imagens serão recuperadas através do componente Imagem para
serem processadas pela multidão. Para tal, o usuário será capaz de enviar seu dataset através de
um arquivo compactado e que obedeça a uma regra de proporção (tipicamente 4:3). Essa regra é
necessária para evitar que dimensões não-usuais não sejam renderizadas corretamente no
momento da exibição ao usuário. Como algumas tarefas de processamento podem envolver
marcações em imagens (não implementadas nesse protótipo), fixar a proporção é importante para
que pontos sejam mapeados corretamente. Outra característica vital de um workflow de
processamento é definir um limite de respostas para cada imagem contida no dataset. Quando a
imagem atinge o limite especificado, ela não é mais exibida e dá a vez às outras, até que todas
sejam processadas.
Um workflow tipicamente envolve perguntas sobre conhecimentos específicos e o gerente
pode querer orientar a multidão. Para isso, a funcionalidade “Tutorial” foi implementada. Nela, será
possível escrever um texto de orientação a ser exibido aos voluntários no momento da
colaboração. Para enriquecer a experiência, a linguagem de markdown foi utilizada, permitindo
que ênfases e recursos como imagens sejam exibidos.
17

Finalmente, as informações obtidas pelo pesquisador podem ser exportadas e
processadas em outro ambiente. Para sanar esse problema, a funcionalidade “Exportação” foi
criada. Nela, o gerente poderá efetuar o download das colaborações até o momento em um
formato amigável para o Excel.
Uma vez que um dos objetivos principais da solução é promover a colaboração e o reuso,
o usuário pode ser capaz de clonar um workflow existente. Essa funcionalidade faz com que seja
possível começar um projeto de colaboração em tempo mínimo. Ao clonar-se um workflow, o
gerente do projeto carregará todas suas informações e tarefas associadas. Cabe a ele customizá-
lo de acordo com suas necessidades e aí sim levá-lo ao público.
Com a montagem dos workflows definida, o próximo passo foi estabelecer a tela para
coleta ou processamento dos dados. Cada workflow exibirá um link de contribuição aberto ao
público onde as tarefas serão renderizadas. A diferença para a tela de gerenciamento de tarefas é
que dessa vez o que for preenchido em cada componente será gravado no banco de dados.
O caso mais complexo dessa funcionalidade é como lidar com o processamento de mídias.
Uma vez que o gerente somente define um dataset, cabe à aplicação escolher qual imagem será
enviada ao colaborador e registrar sua identificação junto à resposta.
Para resolver o primeiro problema, a imagem com maior número de respostas que não
tenha atingido o limite nem tenha sido processada pelo usuário será exibida (em caso de mais de
uma mídia cumprindo os requisitos, a escolha será aleatória). Esse algoritmo visa completar a
colaboração em uma imagem antes de passar para a próxima, evitando distribuir as respostas
uniformemente e correr o risco de não atingir o limite em nenhuma delas.
Já o segundo problema é resolvido através do armazenamento do identificador da imagem
na tabela TaskComponentAnswer. Num evento de coleta de mídia, no entanto, esse campo será
preenchido com o caminho da mídia enviada ao servidor. Assim, é possível recuperar para cada
imagem quais foram as respostas associadas, sejam elas de processamento ou de coleta.
Uma vez que o usuário finalizar todo o fluxo de execução, sua resposta será registrada e
sua participação terá terminado. No caso de um workflow de processamento, onde as imagens
mudam de acordo com o algoritmo proposto, uma opção para colaborar novamente será
apresentada.
18

4.3. Descrição da API
Para o protótipo, ainda que todas as especificações da arquitetura REST não tenham sido
seguidas, front-end e back-end se comunicam como aplicações separadas através de uma
interface comum conhecida por ambos. O design dessa interface foi um dos pontos críticos do
projeto, uma vez que esse é o único ponto de comunicação entre as aplicações.
Com a arquitetura e as funcionalidades definidas, a API (Application Programming
Interface) pode ser projetada. A lista a seguir engloba todas as chamadas disponíveis na
comunicação entre front-end e back-end do protótipo:
1. get_all_workflows: recebe os nomes do usuário e do projeto e retorna todas as informações dos
workflows associados relevantes para a montagem da tela de gerenciamento;2. update_workflow: recebe os nomes do usuário, do projeto e o conjunto de dados que descreve o
workflow e grava no banco. Caso não seja passado o id de um workflow, um novo é criado;3. delete_workflow: recebe o nome do usuário e o id de um workflow e o deleta;4. list_workflows: lista os dados básicos de todos os workflows. Utilizado para exibir workflows
passíveis de serem clonados;5. clone_workflow: recebe o nome do usuário, o nome do projeto e o id de um workflow. Cria um
novo workflow dentro do projeto sob a responsabilidade do usuário copiando todas as
configurações do workflow passado;6. upload_dataset: recebe o nome do usuário, o id de um workflow e um arquivo .zip contendo
imagens em uma dada proporção;7. remove_dataset: recebe o nome do usuário e o id de um workflow e apaga todas as imagens
existentes no servidor;8. get_worker_tasks: recebe os nomes do usuário e do projeto e retorna as informações
necessárias para renderizar as tarefas;9. save_worker_answers: recebe o nome do usuário e as respostas de cada componente e
armazena no banco de dados;
4.4. Integração com o Fast Science
Um dos objetivos primários deste trabalho é integrar o “módulo de workflows” à Plataforma
Fast Science e, assim, poder contribuir com a aplicação da solução em um problema científico
real.
O Fast Science é desenvolvido utilizando AngularJS (ou simplesmente Angular) como
framework front-end e Django como framework back-end. A aplicação em Angular também
19

funciona como uma Single Page Application (SPA), embora apresente um maior acoplamento com
o resto do sistema. Através das rotas definidas pela SPA, páginas HTML são servidas ao cliente.
Para evitar que um novo back-end fosse desenvolvido e uma interface de comunicação
projetada, definiu-se que o back-end do Fast Science seria compartilhado entre as aplicações.
Assim, os pontos de entrada HTTP poderiam ser expostos a aplicações externas ainda que
mantivessem acesso ao banco de dados.
Uma vez que a solução proposta prevê uma nova SPA autocontida utilizando React, a
integração do front-end tornou-se muito direta. A solução encontrada foi carregar o novo módulo
dentro das telas de gerenciamento e contribuição do workflow.
De modo a manter a consistência da aparência do Fast Science, a nova aplicação foi
carregada dentro de um iframe. Iframes (abreviação para inline frames) é uma tag HTML que
possibilita um documento HTML ser embutido em outro documento. Dessa forma, a aplicação
existente escrita em Angular é capaz de carregar a nova aplicação quando apropriado.
A imagem a seguir descreve em alto-nível o sistema esquematizado. Itens em azul são
específicos do Fast Science, em verde são específicos do módulo workflow e em laranja são
comuns às duas aplicações.
Figura 5 - Integração do módulo de workflow ao projeto Fast Science.
20

A nova SPA desenvolvida foi hospedada no domínio .../workflow. No entanto, para que o
sistema saiba exatamente o que renderizar, fez-se necessário que a aplicação em Angular
expusesse identificadores a serem passados diretamente na URL. O interfaceamento disponível
foram os campos user_name e project_name.
Sendo assim, definiu-se que a chamada .../workflow?
project_name=nome+do+projeto&user_name=nome+do+usuario seria responsável por carregar
os dados do workflow pertencente ao projeto “nome do projeto” pelo usuário “nome do usuario”. A
aplicação então efetuará uma chamada ao back-end com esses parâmetros, sendo
responsabilidade do back-end validar se o projeto existe e se o usuário possui as credenciais para
editá-lo.
Para a tela de contribuição, a URL definida foi .../workflow/contribute?
project_name=nome+do+projeto&user_name=nome+do+usuario. Novamente, a aplicação faz
uma requisição ao back-end passando os parâmetros providenciados e procede de acordo com a
resposta recebida.
Assim, a integração foi finalizada carregando os iframes com as URLs definidas nos
pontos de entrada da SPA em Angular.
4.5. Resultado
Nessa seção apresentaremos o resultado do protótipo levando-se em conta as
ferramentas e funcionalidades descritas nesse capítulo.
Num fluxo de execução típico, após acessar a área de gerenciamento do projeto, o usuário
deseja criar um workflow. Como ainda não há nenhum cadastrado, ele terá como opções criar um
novo ou reutilizar um existente.
21

Figura 6 - Projeto sem workflow cadastrado.
Selecionando a opção Clonar, uma lista de workflows disponíveis será exibida. Nela, o
usuário poderá visualizar o projeto a qual ele pertence, pré-visualizar suas tarefas e finalmente
optar por cloná-lo. A ação de clonar copia todas as informações de um workflow para o outro e
redireciona o usuário pra tela de gestão (ilustrada na Figura 8).
Figura 7 - Tela de clonar workflow.
Uma vez que Novo Workflow é selecionado, o usuário é redirecionado à tela de gestão do
workflow. Nela, ele poderá navegar pelo menu superior através das ações Configurações (exibida
por padrão), Tarefas, Tutorial e Exportar.
22

Figura 8 - Tela inicial de configurações do workflow.
Todas as alterações realizadas pelo usuário só serão armazenadas no banco de dados no
momento que ele apertar o botão Salvar Alterações.
23
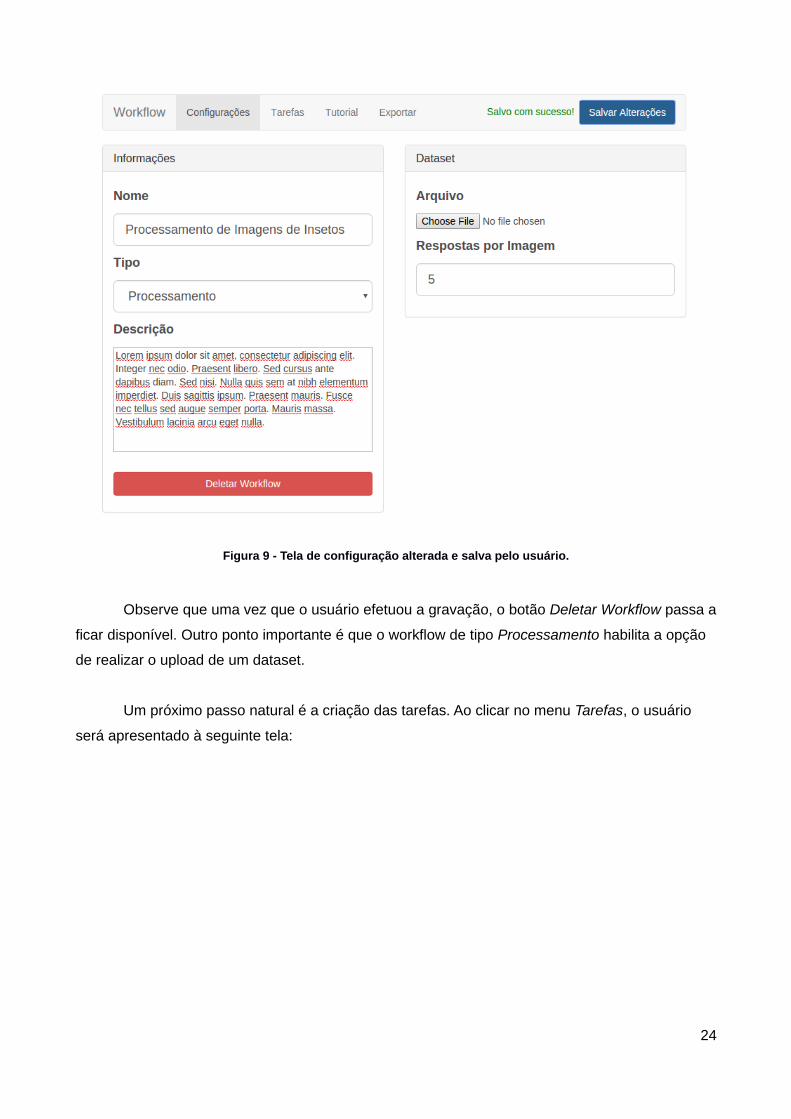
Figura 9 - Tela de configuração alterada e salva pelo usuário.
Observe que uma vez que o usuário efetuou a gravação, o botão Deletar Workflow passa a
ficar disponível. Outro ponto importante é que o workflow de tipo Processamento habilita a opção
de realizar o upload de um dataset.
Um próximo passo natural é a criação das tarefas. Ao clicar no menu Tarefas, o usuário
será apresentado à seguinte tela:
24

Figura 10 - Tela inicial de tarefas inicialmente sem nenhuma tarefa cadastrada.
Ao clicar no botão Nova Tarefa, o usuário poderá observar a ordem que as tarefas serão
apresentadas, além da lista de componentes disponíveis para serem selecionados e
customizados de acordo com as necessidades de cada projeto científico.
Figura 11 - Tela de montagem de tarefas.
25

Uma vez que a tarefa foi criada, ela poderá ser selecionada clicando-se no pequeno
círculo ao seu lado (uma marcação em azul aparecerá). O usuário pode alterar o nome da tarefa
no campo Texto Principal e reordená-la através de drag and drop no menu à esquerda.
Figura 12 - Tarefa tem seu nome alterado e é reordenada.
Para começar a trabalhar nos componentes, o usuário deve selecionar o desejado na lista
da esquerda e arrastá-lo para o da direita. Os componentes também podem ser reordenados de
acordo com a conveniência.
26

Figura 13 - Componentes selecionados são visualizados na coluna mais à direita.
Os componentes selecionados apresentam dois ícones: um responsável pela edição e
outro pela deleção. A edição de um componente altera suas meta informações e é característica
de cada um.
27

Figura 14 - Edição de meta informações de um componente.
À medida que o usuário for realizando suas alterações ele poderá pré visualizá-las. Essa
funcionalidade exibe exatamente como o workflow será apresentado ao colaborador, mas não
permitirá que nenhuma resposta seja gravada. Para isso, basta apertar o botão Pré-visualizar.
28

Figura 15 - Pré-visualização de uma tarefa.
Observe que durante a execução do workflow um botão Tutorial é exibido. O objetivo é que
o gerente do projeto seja capaz de escrever um texto de orientação para o colaborador se guiar.
A edição de um tutorial é realizada clicando-se no item Tutorial do menu. O texto poderá
ser escrito utilizando markdown (uma sintaxe de formatação de textos) ou HTML.
29

Figura 16 - Preenchimento de um tutorial combinando markdown e HTML.
A qualquer momento o usuário pode clicar no ícone do olho no canto superior direito e pré-
visualizar o andamento do tutorial, que será renderizado da forma correta:
30

Figura 17 - Pré-visualização de um tutorial.
Todas as respostas que tenham sido coletadas podem ser posteriormente exportadas
numa tabela. Ao selecionar o menu Exportar o usuário será apresentado a um botão que realizará
essa função.
Figura 18 - Tela de exportação das informações coletadas.
A outra ponta do sistema é a execução do workflow pelo usuário. Ao clicar no link de
contribuição do projeto, a seguinte tela será exibida:
31

Figura 19 - Início da tela de contribuição.
Após o usuário optar por começar a contribuir, as tarefas serão exibidas sequencialmente
para serem preenchidas. Novamente os círculos no topo da página indicam a seleção a tarefa
(Figura 20).
32
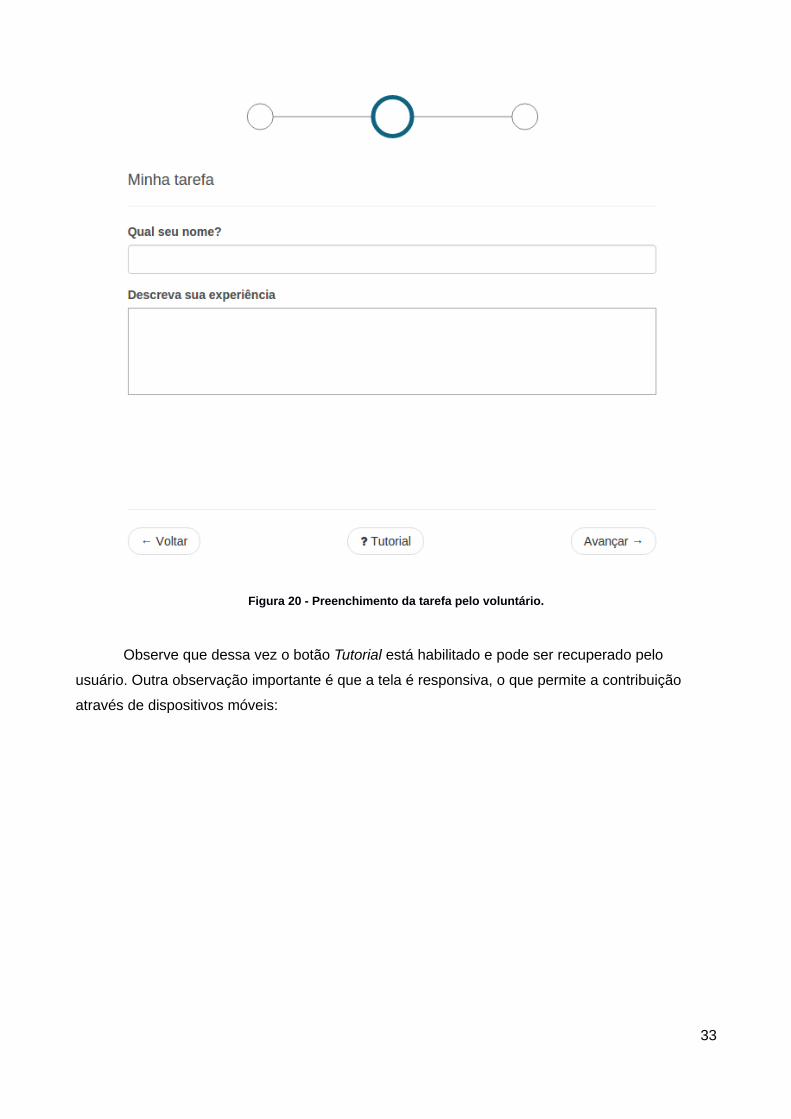
Figura 20 - Preenchimento da tarefa pelo voluntário.
Observe que dessa vez o botão Tutorial está habilitado e pode ser recuperado pelo
usuário. Outra observação importante é que a tela é responsiva, o que permite a contribuição
através de dispositivos móveis:
33

Figura 21 - Imagem emulada pelo Google Chrome ilustrando um smartphone típico.
Na última tarefa, o botão Avançar se transformará em Finalizar e o usuário gravará suas
respostas no banco de dados. A tela seguinte oferecerá a opção dele contribuir novamente.
34

Figura 22 - A última tarefa permite que o usuário finalize sua contribuição.
Figura 23 - Após finalizar, o usuário poderá repetir a experiência.
35

4.6. Limitações
Embora as funcionalidades propostas cubram grande parte da arquitetura descrita no
capítulo anterior, algumas limitações são encontradas e podem ser resolvidas em versões futuras.
Além disso, o processo considerado para desenvolvimento é iterativo e portanto a filosofia é
apresentar o mínimo necessário para uma experiência relevante e desenvolver melhorias
incrementais de acordo com o uso da plataforma.
Existe, portanto, uma lista (não-exaustiva) de melhorias a ser explorada em novas versões.
A saber:
4.6.1. Componentes de Processamento Sofisticados
Existem vários tipos de processamento a serem analisados em um workflow. Um
componente que existe em outras plataformas é o de marcação de polígonos em uma imagem.
Essa técnica permite que voluntários reconheçam padrões em fotos.
4.6.2. Novos Parâmetros de Controle nos Componentes
Uma vez que o React renderiza cada componente baseado em seu construtor, é possível
estendê-lo a partir de meta informações. Para efeitos do protótipo, apenas parâmetros básicos
foram passados (lista de opções, label, número de linhas). Para um produto mais robusto, pode
ser possível escolher entre um componente ser obrigatório ou não, adicionar um texto de ajuda ou
outros comportamentos mais dinâmicos.
4.6.3. Leitura de Dados via EXIF
Imagens digitais mais modernas possuem um padrão de especificação chamado
Exchangeable Image File Format (EXIF). Tal especificação adiciona metadados naturais à uma
imagem, a mais interessante delas sendo geolocalização. Dessa forma um usuário poderia
submeter uma imagem e automaticamente gravar suas coordenadas, sem a necessidade de
enviá-las novamente em um novo componente.
4.6.4. Múltiplos Datasets
Um caso de uso relevante no contexto da Crowd Science é comparar imagens
provenientes de diferentes datasets. O protótipo é limitado a um dataset onde a imagem é
36

escolhida segundo o algoritmo já descrito. Uma possível melhoria seria cadastrar vários datasets
e referenciar um componente imagem a um deles, possibilitando a comparação.
4.6.5. Workflow de Validação
O protótipo permite a criação de dois tipos de workflows. O de coleta de dados, onde a
multidão forma uma base de dados, no caso imagens, através de suas contribuições. E o de
processamento, onde o pesquisador fornece uma base de imagens e os voluntários trabalham em
tarefas relacionadas a cada uma delas, por exemplo categorizando-as.
Dessa forma, é natural unir as duas pontas, utilizando a multidão para gerar um banco de
imagens (coleta) e depois a utilizando novamente para validar, classificar ou realizar alguma
operação sobre estas imagens (processamento). Embora seja possível atingir este objetivo
exportando o conjunto de dados de um workflow de coleta e o re-importando em um workflow de
processamento, o protótipo não dispõe de ferramentas que facilitem ou automarizem este
processo.
4.6.6. Multiplas Permissões de Edição por Projeto
Um projeto colaborativo pode ser grande e complexo demais para que apenas uma pessoa
o gerencie. É natural propor que exista um time por trás. Em versões futuras, deve ser possível
atribuir a múltiplos usuários a capacidade de editar um projeto. Um refinamento ainda maior seria
definir níveis de permissão cada cada usuário na equipe.
4.6.7. Exportação mais Sofisticada
Uma premissa importante do sistema é ser capaz de processar os dados pela multidão.
Sendo esses dados potencialmente massivos, uma exportação mais refinada se faz necessária.
Possíveis melhorias nesses campos preveem a seleção de respostas a serem exportadas, filtros
(por exemplo, de data).
37

5. Avaliação do Protótipo
Dadas as especificidades do projeto, o desenvolvimento e integração do protótipo à
plataforma Fast Science podem ser considerados um sucesso. A tabela 1 lista as funcionalidades
implementadas em atendimento a cada item inicialmente especificado na seção de Requisitos.
Requisito Implementado? Comentários
REQ1 Parcialmente O workflow de validação não foi implementado
REQ2 Parcialmente O protótipo limitou-se a um dataset por workflow.
REQ3 Totalmente -
REQ4 Totalmente -
REQ5 Totalmente -
REQ6 Totalmente O usuário pode pré-visualizar na tela de gestão de tarefas.
REQ7 Totalmente A formatação utilizada foi markdown e HTML.
REQ8 Totalmente -
REQ9 Totalmente -
REQ10 Não Como o protótipo não foi testado com o público, essa
funcionalidade não foi implementada.
REQ11 Totalmente Cada componente adicionado precisa definir seu próprio
construtor, sem interferir em nenhuma outra parte do
código.
REQ12 Totalmente Foram utilizadas tags iframes para carregar o módulo
dentro da Plataforma Fast Science.
A arquitetura prevista foi capaz de cobrir casos de uso relevantes de uma plataforma de
Crowd Science além de preparar o terreno para melhorias incrementais. Já na primeira versão o
pesquisador é capaz de criar um workflow, promover um projeto de Crowd Science e analisar os
dados externamente.
Mesmo o projeto do Fast Science apresentando uma estrutura complexa e fora do escopo
dos autores, a solução encontrada foi suficiente para habilitar uma interface de comunicação entre
38

as duas aplicações. A API HTTP cobriu a maior parte das ações previstas e o uso do iframe fez
com que a integração ocorresse sem maiores problemas.
Uma etapa futura envolveria reescrever o módulo de criação e edição de projetos dentro
da aplicação em React. Essa melhoria possibilitaria maior controle sobre os parâmetros passados
via API (por exemplo, utilizar o id do projeto em vez do nome) e outras adaptações (por exemplo,
gerenciamento de múltiplos workflows). Um caminho natural seria desenvolver atividades
“utilitárias” no Fast Science ao passo de encorpar o módulo previsto neste trabalho.
Como consideração final, as tecnologias escolhidas mostraram-se efetivas e podem ser
consideradas adequadas para projetos de sistemas web de alto grau de complexidade.
39

6. ConclusãoO trabalho realizado pode ser dividido em duas partes: na primeira os autores tiveram a
oportunidade de aprender sobre Crowdsourcing e Crowd Science entendendo os requisitos e o
contexto de aplicação de ambos. Em seguida os autores puderam utilizar os conhecimentos
técnicos de Engenharia de Computação adquiridos ao longo da graduação para desenhar e
implementar uma solução para a criação e execução de workflows no projeto Fast Science.
A arquitetura escolhida para a construção do módulo de workflows da Plataforma Fast
Science mostrou-se eficiente no tocante à facilidade de manutenção e colaboração no
desenvolvimento do código bem como na elaboração do produto. A separação do módulo em dois
sistemas independentes, um para o front-end e outro para o back-end, com uma API entre eles,
permitiu uma integração suave com o Fast Science sem prejuízo da qualidade do módulo.
O isolamento da camada de acesso aos dados (model) deu consistência e ajudou a
garantir a qualidade da informação gravada no banco de dados e apresentada aos usuários. Em
termos de comunicação o uso do protocolo HTTP, mesmo com custo relativamente alto em termos
de dados de controle trafegados, favoreceu o uso de componentes prontos. Por ainda ser o
padrão para a comunicação na Web, este protocolo é implementado por um enorme gama de
ferramentas de código aberto. Algumas dessas foram utilizadas reduzindo consideravelmente o
tempo de desenvolvimento.
O modelo de dados baseado em armazenamento de meta-informação sobre componentes
de interface em colunas do tipo texto foi crucial para atingir a desejada facilidade para a inclusão
de novos componentes sem alteração da base de código. O back-end do sistema é totalmente
agnóstico quanto a componentes permitindo sua criação apenas no código da interface e no
banco de dados.
A elaboração do protótipo atingiu os objetivos esperados, embora não tenha implementado
todos os requisitos estabelecidos para o problema. Em futuras versões, funcionalidades relativas à
exportação, importação e validação dos dados coletados pela multidão podem ser desenvolvidas.
A evolução deste trabalho poderá se dar através da implementação dos requisitos já
mapeados não incluídos neste protótipo. Há também oportunidades de evolução na criação de
uma API pública. Este tipo de interface poderá permitir a criação de componentes de terceiros
para inclusão em projetos de Crowd Science que tenham propósitos mais específicos.
40

ReferênciasBONNEY, R.; COOPER, C. B.; DICKINSON, J.; KELLING, S.; PHILLIPS, T.; ROSENBERG, K. V.
and J. SHIRK, “Citizen Science: A Developing Tool for Expanding Science Knowledge and
Scientific Literacy,” BioScience, vol. 59, no. 11, pp. 977–984, Dec. 2009.
COOK, G. How crowdsourcing is changing science. The Boston Globe, Boston. November 11,
2011. Disponível em <humanfaceofbigdata.com>
CROWSTON,K. and PRESTOPNIK, N. R.Motivation and Data Quality in a Citizen Science Game:
A Design Science Evaluation. In 46th Hawaii International Conference on System Sciences
(HICSS), 2013, pp. 450–459.
DOAN, A., RAMAKRISHNAN, R. and HALEVY. A.Y. Crowdsourcing systems on the World-Wilde
Web. Communications of ACM, 54(4), 2011, pp. 86–96.
ESTEVES, M.G.P., Ambiente para concepção e execução de projetos científicos com a
participação de multidões “crowd science”. Exame de qualificação de doutorado apresentado ao
Programa de Pós-graduação em Engenharia, COPPE, da Universidade Federal do Rio de Janeiro,
2013.
ESTEVES, M. G. P., SOUZA, J. M., PEREIRA, C. V., UCHOA, A. P., ANTELIO, M. “Ciência Cidadã
– Oportunidades e Desafios para a Pesquisa e o Monitoramento de Ambientes Costeiros e
Marinhos,” in Anais do V Congresso Brasileiro de Biologia Marinha, Porto de Galinhas, PE, 2015.
ESTEVES, M.G.P. Ambiente para concepção e execução de projetos científicos com a
participação de multidões “crowd science”, Tese de Doutorado, Programa de Pós-graduação em
Engenharia, COPPE, da Universidade Federal do Rio de Janeiro, (em elaboração).
FRANZONI, C. and SAUERMANN, H. “Crowd Science: The organization of scientific research in
open collaborative projects,” Research Policy, vol. 43, no. 1, pp. 1–20, Fevereiro 2014.
HOWE, J. The rise of crowdsourcing. Wired, 2016. Disponível em:
<http://www.wired.com/wired/archive/14.06/crowds.html>.
NOV, O., ARAZY, O., and ANDERSON, D. (2010). Crowdsourcing for science: understanding and
enhancing SciSourcing contribution, Position paper: ACM CSCW 2010 Workshop on the Changing
Dynamics of Scientific Collaborations.
RADDICK, M. J., BRACEY, G., GAY, P. L., LINTOTT, C. J., MURRAY, P., SCHAWINSKI, K.,
SZALAY, A. S. and VANDENBERG, J. (2010). Galaxy Zoo: Exploring the Motivations of Citizen
Science Volunteers. Astronomy Education Review, 9 (1).
UCHOA, A. P., ESTEVES, M. G. P., e SOUZA, J. M. Mix4Crowds - Toward a framework to design
crowd collaboration with science, in 2013 IEEE 17th International Conference on Computer
Supported Cooperative Work in Design (CSCWD), 2013, pp. 61–66.
41

YOUNG, J. R. Crowd Science Reaches New Heights. The Rise of Crowd Science - Technology -
The Chronicle of Higher Education, 2010.
MILLER-RUSHING, A., PRIMACK, R. e BONNEY, R., The history of public participation in
ecological research, Front Ecol Environ, 2012.
SIMPSON, R., PAGE, K. R., DE ROUTE, D., Zooniverse: Observing the World’s Largest Citizen
Science Platform, Proceedings of the 23rd International Conference on World Wide Web, p. 1049-
1054, Seoul, South Korea, 2014.
42