disciplina de processamento de imagens -...
TRANSCRIPT

Disciplina de Processamento de Imagens
Prof. Fabio Augusto Faria
Instituto de Ciencia e TecnologiaUNIFESPSala 106
[email protected]://fafaria.wix.com/fabiofaria
Segundo Semestre de 2015

Roteiro
1 Reconhecimento de Padroes
2 Tipos de Classificadores
3 Classificador K-Vizinhos Mais Proximos
4 Classificador Bayesiano
5 Redes Neurais Artificiais
6 Maquinas de Vetores de Suporte
7 Avaliacao dos Classificadores
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 2 / 62

Reconhecimento de PadroesFundamentos
I O reconhecimento de padroes visa determinar um mapeamento pararelacionar caracterısticas ou propriedades extraıdas de amostras com umconjunto de rotulos.
I Amostras com caracterısticas semelhantes devem ser mapeadas ao mesmorotulo.
I Quando se atribui um mesmo rotulo a amostras distintas, diz-se que taiselementos pertencem a uma mesma classe, esta caracterizada porcompreender elementos que compartilham propriedades em comum.
I Cada classe recebe um dentre os rotulos C1,C2, . . . ,Cm, em que m denota onumero de classes de interesse em um dado problema.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 3 / 62

Reconhecimento de PadroesAreas de aplicacao
I A tarefa de classificacao ocorre em uma variedade de atividades humanas:
I MedicinaI Sensoriamento RemotoI Biometria (reconhecimento de faces, ıris, impressoes digitais, voz)I Automacao IndustrialI BiologiaI AstronomiaI Meteorologia
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 4 / 62

Reconhecimento de PadroesComponentes
aquisição pré−processamentoextração
avaliação
características
de
x1
x2
xn
...classes
C1... Cm
problemapredição
resultado
bases de dados regressãoagrupamentodescrição
redução de dimensionalidade
normalização classificaçãoatenuação de ruídoequipamentos matriz de confusãovalidação cruzada
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 5 / 62

Reconhecimento de PadroesCiclo de projeto para reconhecimento de padroes
I AquisicaoI Provavelmente o componente mais custosoI Quantas amostras sao suficientes?
I Pre-processamentoI Preparacao dos dados
I Extracao de caracterısticasI Crıtico para resolucao do problemaI Requer conhecimento previo
I PredicaoI Adaptacao do modelo para explicar os dadosI TreinamentoI Escolha do modelo: sintatico, estatıstico, estrutural, rede neural
I AvaliacaoI AcuraciaI Sobreajuste × generalizacao
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 6 / 62

Reconhecimento de PadroesCaracterısticas
I Uma caracterıstica e uma propriedade mensuravel de uma amostra.
I Caracterısticas devem ser idealmente discriminativas e independentes.
I O conjunto de caracterısticas normalmente e agrupado em um vetor oudescritor de caracterısticas, representado como
x =
x1
x2
...xn
em que xi denota o i-esimo descritor e n e o numero total desses descritores.
I O espaco n-dimensional definido pelo vetor de caracterısticas e chamado deespaco de caracterısticas.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 7 / 62
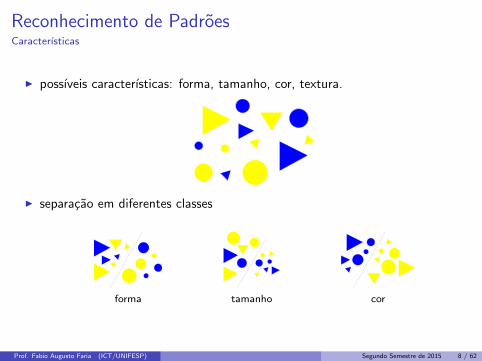
Reconhecimento de PadroesCaracterısticas
I possıveis caracterısticas: forma, tamanho, cor, textura.
I separacao em diferentes classes
forma tamanho cor
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 8 / 62

Reconhecimento de PadroesCaracterısticas
I dependencia do domınio / informacao a priori
I custo de extracao
I preferencialmente baixa dimensionalidade
I caracterısticas discriminativasI valores similares para padroes similares (baixa variabilidade intraclasse)I valores diferentes para padroes diferentes (alta variabilidade interclasse)
I caracterısticas invariantes com respeito a rotacao, escala, translacao, oclusao,deformacoes
I robustez em relacao a ruıdo
I nao correlacao entre caracterısticas
I normalizacao
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 9 / 62

Reconhecimento de PadroesPadroes
I Padrao e uma composicao de caracterısticas de amostras.
I Em tarefas de reconhecimento, um padrao e um par de variaveis {x, c}, talque
I x e uma colecao de observacoes ou caracterısticas (vetor de caracterısticas)I c e o conceito associado a observacao (rotulo)
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 10 / 62

Reconhecimento de PadroesTipos de problemas de predicao
I ClassificacaoI Atribuicao de um objeto a uma classe.I O sistema retorna um rotulo inteiro.
I exemplo: classificar um produto como “bom” ou “ruim” em um teste decontrole de qualidade.
I RegressaoI Generalizacao de uma tarefa de classificacaoI O sistema retorna um numero real.
I exemplo: predizer o valor das acoes de uma empresa com base no desempenhopassado e indicadores do mercado de bolsas.
I AgrupamentoI Organizacao de objetos em grupos representativos.I O sistema retorna um grupo de objetos.
I exemplo: organizar formas de vida em uma taxonomia de especies.
I DescricaoI Representacao de um objeto em termos de uma serie de primitivas.I O sistema produz um descricao estrutural ou linguıstica.
I exemplo: rotular um sinal de eletrocardiograma em termos de seuscomponentes (P, QRS, T, U)
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 11 / 62

Reconhecimento de PadroesExemplo
I Classificacao automatica de objetos.
Figura : Visao superior de uma esteira de rolagem. Os objetos devem ser classificados deacordo com a forma apresentada.
I Neste exemplo, o objetivo do reconhecimento de padroes e encontrar ummapeamento, a partir da forma de cada objeto, para o conjuntoY = {C1,C2,C3}.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 12 / 62

Reconhecimento de PadroesClassificadores
I Os algoritmos que visam estabelecer o mapeamento entre as propriedades dasamostras e o conjunto de rotulos sao denominados classificadores.
I A determinacao da rotulacao para o conjunto de amostras pode ser realizadapor um processo de classificacao:
I supervisionadoI nao supervisionado
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 13 / 62

Classificacao de PadroesClassificacao supervisionada
I Quando o processo de classificacao considera classes previamente definidas,este e denotado como classificacao supervisionada.
I Uma etapa denominada treinamento deve ser executada anteriormente aaplicacao do algoritmo de classificacao para obtencao dos parametros quecaracterizam cada classe.
I O conjunto formado por amostras previamente identificadas (rotuladas)chama-se conjunto de treinamento, no qual cada elemento apresenta doiscomponentes, o primeiro composto de medidas responsaveis pela descricao desuas propriedades e o segundo representando a classe a qual ele pertence.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 14 / 62

Classificacao de PadroesClassificacao supervisionada
I Ilustracao da classificacao que utiliza classes definidas previamente.
1
? 2
3
(a)
1
2
3
?
(b)
Figura : Classificacao supervisionada. Atribuicao de amostras desconhecidas (indicadas pelas linhastracejadas) a classes previamente definidas.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 15 / 62

Classificacao de PadroesClassificacao supervisionada
I As classes sao definidas por meio de descritores capazes de resumir aspropriedades das amostras que as compoem.
I No exemplo da esteira rolante, o algoritmo de classificacao deve atribuir cadaobjeto a classe que apresentar caracterısticas mais proximas.
I No caso da figura (a), a atribuicao da-se de maneira direta, em razao daforma apresentada pela amostra em questao ser identica aquelasrepresentadas pela classe C2.
I Entretanto, na classificacao mostrada na figura (b), deve-se utilizar umamedida de similaridade que seja robusta a transformacao de rotacao para quea amostra seja classificada como pertencente a classe C1.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 16 / 62

Classificacao de PadroesClassificacao nao supervisionada
I Quando nao se dispoe de parametros ou informacoes coletadas previamente aaplicacao do algoritmo de classificacao, o processo e denotado como naosupervisionado.
I Todas as informacoes de interesse devem ser obtidas a partir das propriasamostras a serem rotuladas.
I Assim como na classificacao supervisionada, amostras que compartilhampropriedades semelhantes devem receber o mesmo rotulo na classificacao naosupervisionada.
I No entanto, diferentemente da classificacao supervisionada, as classes naoapresentam um significado previamente conhecido, associado aos rotulos.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 17 / 62

Classificacao de PadroesClassificacao nao supervisionada
I No exemplo da classificacao supervisionada, a classe C2 e composta deobjetos que apresentam formato retangular, entretanto, quando um conjuntode treinamento nao se encontra disponıvel, pode-se afirmar apenas que oselementos que compoem a classe C2 possuem propriedades semelhantes.
3
2
1
3
3
3
3
3
3
2
2
2
2
2
2
21
1
1
1
1
1
Figura : Classificacao nao supervisionada. Agrupamento de amostras que possuem propriedadessemelhantes.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 18 / 62

Classificacao de PadroesSuperfıcie de decisao
I Alguns modelos de classificacao utilizam medidas de similaridade paradeterminar a qual classe uma amostra deve ser atribuıda pela geracao de umasuperfıcie de decisao.
I As superfıcies de decisao podem ser obtidas a partir das amostras contidas noconjunto de treinamento.
I Utiliza-se o vetor de caracterısticas de cada amostra para determinar aposicao em relacao a essa superfıcie e, consequentemente, sua classificacao.
v1
v2
1
C
C1 C2
C
2
6 5 4 1 0 0
1
2
3
4
5
6
2 3
(a) separabilidade linear
v1
v2
C1
C2
C1 C2
6 5 4 1 0 0
1
2
3
4
5
6
2 3
(b) separabilidade nao-linear
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 19 / 62
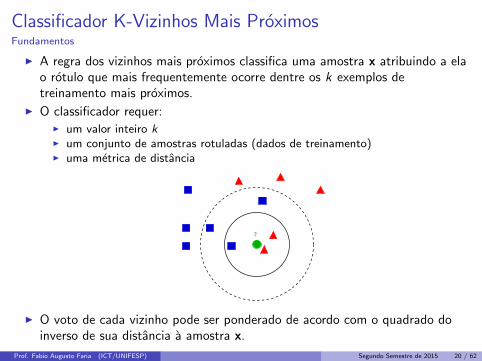
Classificador K-Vizinhos Mais ProximosFundamentos
I A regra dos vizinhos mais proximos classifica uma amostra x atribuindo a elao rotulo que mais frequentemente ocorre dentre os k exemplos detreinamento mais proximos.
I O classificador requer:I um valor inteiro kI um conjunto de amostras rotuladas (dados de treinamento)I uma metrica de distancia
?
I O voto de cada vizinho pode ser ponderado de acordo com o quadrado doinverso de sua distancia a amostra x.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 20 / 62

Classificador K-Vizinhos Mais ProximosVantagens e desvantagens
I Algumas vantagensI implementacao simplesI usa informacao local, o que pode resultar em comportamento adaptativoI pode ser naturalmente paralelizadoI permite a criacao de superfıcie de decisao complexa
I Algumas desvantagensI sensıvel a ruıdo nas caracterısticasI sensıvel a alta dimensionalidade dos dadosI funcao de distancia deve ser calculada entre a amostra e todos os exemplos no
conjunto de treinamento, cujo processo torna-se custoso para conjuntos detreinamento compostos de um elevado numero de amostras.
I Complexidade para algoritmo basico (todas as n amostras de dimensao d emmemoria)
I O(d): complexidade para computar distancia para uma amostraI O(nd): complexidade para encontrar um vizinho mais proximoI O(knd): complexidade para encontrar k vizinhos mais proximosI complexidade pode ser reduzida com diagrama de Voronoi ou k-d tree
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 21 / 62

Classificador K-Vizinhos Mais ProximosAlgoritmo para k-vizinhos mais proximos
Dado o conjunto de treinamento T , o algoritmo visa encontrar um subconjuntoS ⊂ T composto de k amostras mais proximas de x no espaco de caracterısticas.O rotulo atribuıdo a x e aquele que apresenta maior frequencia dentre as amostrasem S .
Seja o conjunto de treinamento T = {< x1, y1 >,< x2, y2 >, . . . , < xn, yn >}, emque yi = {C1,C2, . . . ,Cm}. δ(x) = 1 quando x = 0 e δ(x) = 0, caso contrario.
1: // treinamento2: T = amostras no conjunto de treinamento3: // classificacao4: determinar as k amostras em T mais proximas de x5: para i de 1 ate m faca
6: ci =k∑
j=1
δ(yj − Ci )
7: Y = arg maxi
{ci}
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 22 / 62

Classificador Bayesiano
I Seja um conjunto de amostras rotuladas como pertencentes a uma dentre mclasses distintas, C1,C2, . . . ,Cm.
I Uma possıvel atribuicao dos rotulos e dada de modo que cada amostrapertenca a classe que maximize a probabilidade P(Ci |x), para i = 1, 2, . . . ,m,ou seja, dado o vetor de caracterısticas x, atribui-se a amostra a classe Ci queapresenta a maior probabilidade condicional.
I Conforme a descricao sobre a atribuicao dos rotulos, a classificacao de umaamostra especıfica segue a regra de decisao mostrada na equacao 1.
P(Ci |x) > P(Cj |x) j = 1, . . . ,m; i 6= j (1)
I Nessa regra, x e atribuıda a classe Ci caso P(Ci |x), denominadaprobabilidade a posteriori, seja maior que qualquer outra P(Cj |x).
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 23 / 62

Classificador Bayesiano
I Ambos os lados da regra de decisao da equacao 1 podem ser avaliados pormeio do teorema de Bayes, mostrado na equacao 2, em que P(x|Ci ) denota aprobabilidade de ocorrer x dado que a amostra pertence a classe Ci e P(Ci ) edenominada probabilidade a priori, ou seja, a probabilidade incondicional deocorrencia de uma determinada classe.
P(Ci |x) =P(x|Ci )P(Ci )
P(x)=
P(x|Ci )P(Ci )n∑
j=1
P(x|Cj)P(Cj)
(2)
I A substituicao da equacao 2 em 1 resulta na equacao mostrada em 3,conhecida como regra de Bayes para taxa mınima de erro.
I Essa regra particiona o espaco de caracterısticas nas regioes R1, R2, . . ., Rm,tal que, se x ∈ Ri , x deve ser atribuıdo a classe Ci .
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 24 / 62

Classificador Bayesiano
I Dado que a probabilidade P(x) do denominador da equacao 2 e termocomum para todas as classes, esse e removido da equacao 3.
P(x|Ci )P(Ci ) > P(x|Cj)P(Cj) j = 1, . . . ,m; i 6= j (3)
I Considerando a existencia de apenas duas classes, pode-se transformar aequacao 3 na razao mostrada na equacao 4, denominada razao deverossimilhanca.
Λ(x) =P(x|C1)
P(x|C2)>
P(C2)
P(C1)implica que x ∈ C1 (4)
I Utiliza-se essa equacao como funcao discriminante entre as duas classes, ouseja, a atribuicao de x passa a depender de sua localizacao espacial no espacode caracterısticas.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 25 / 62

Redes Neurais ArtificiaisFundamentos
I Uma rede neural artificial e um modelo inspirado na aprendizagem desistemas biologicos formados por redes complexas de neuroniosinterconectados.
I O modelo e um grafo orientado em que os nos representam neuroniosartificiais e as arestas denotam as conexoes entre as entradas e as saıdas dosneuronios.
I Redes neurais podem ser vistas como maquinas massivamente paralelas commuitos processadores simples e diversas interconexoes.
I A popularidade das redes neurais cresceu devido ao fato de que,aparentemente, elas possuem uma baixa dependencia a um domınioespecıfico, de forma que a mesma rede pode ser utilizada em problemasdistintos.
I As redes neurais sao capazes de aprender relacoes entre entradas e saıdascomplexas, bem como generalizar a informacao aprendida.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 26 / 62

Redes Neurais ArtificiaisUnidade perceptron
I O modelo mais simples de rede neural e composto de apenas uma unidadedenominada perceptron.
I Essa rede mapeia multiplas entradas, compostas de valores reais, para umasaıda representada por um valor binario com os estados normalmentedenotados como ativado ou nao-ativado.
I Obtem-se o valor da saıda pela aplicacao da funcao de ativacao mostrada naequacao 5, em que x = [x1 x2 . . . xn] e o vetor de caracterısticas e oselementos de w = [w0 w1 . . . wn] representam os pesos utilizados para otreinamento da rede neural.
s(x) =
{1 se w0 + w1x1 + . . .+ wnxn > 0
−1 caso contrario(5)
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 27 / 62
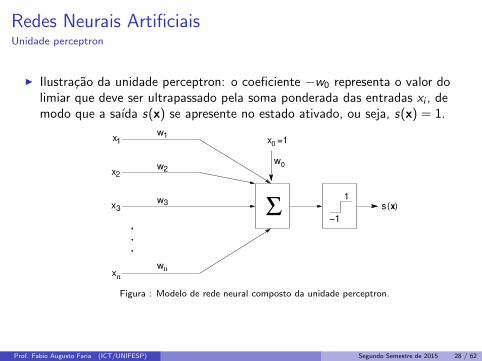
Redes Neurais ArtificiaisUnidade perceptron
I Ilustracao da unidade perceptron: o coeficiente −w0 representa o valor dolimiar que deve ser ultrapassado pela soma ponderada das entradas xi , demodo que a saıda s(x) se apresente no estado ativado, ou seja, s(x) = 1.
Σw
w2
w
1
−1
0x =1
w
s( )x
w1
3
1
2x
x
x
nx
3
n
0
Figura : Modelo de rede neural composto da unidade perceptron.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 28 / 62

Redes Neurais ArtificiaisRegras para treinamento
I O treinamento de uma rede neural da-se por meio da atualizacao iterativados pesos, ou seja, as variaveis w0,w1, . . . ,wn, com objetivo de encontraruma funcao que permita classificar corretamente todas as amostras contidasno conjunto de treinamento.
I Duas regras sao normalmente aplicadas para o treinamento da rede neuralcom camada unica:
I regra perceptron: encontra um hiperplano em um espaco n-dimensional deamostras que sejam linearmente separaveis.
I regra delta: permite boa adaptacao aos dados que compoem o conjunto detreinamento, mesmo que nao sejam linearmente separaveis.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 29 / 62

Redes Neurais ArtificiaisRegra perceptron
I A regra perceptron atualiza os pesos wi conforme a equacao 6, em que ydenota a classe a qual pertence a amostra sendo apresentada a rede neural es(x) o valor obtido em sua saıda.
wi ← wi + α(y − s(x))xi (6)
I A constante α e chamada de taxa de aprendizagem, que determina quaorapido os pesos wi devem ser alterados (normalmente, utiliza-se α = 0.1).
I Com essa regra, tem-se que o peso wi sofrera alteracoes quando a amostraem questao for classificada incorretamente, pois o valor de y e s(x) seraodistintos; por outro lado, wi nao sofrera alteracoes quando ocorrer aclassificacao correta, pois a segunda parte da equacao 6 resulta no valor zero.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 30 / 62

Redes Neurais ArtificiaisAlgoritmo de redes neurais com regra perceptron
I O algoritmo a seguir descreve os passos utilizados para efetuar o treinamentoe a classificacao com rede neural pela aplicacao da regra perceptron.
I Apos a convergencia dos valores dos pesos wi , a rotulacao de amostras queapresentam classificacao desconhecida pode ser efetuada.
I Uma amostra descrita pelo vetor de caracterısticas x, composto de nelementos, e apresentada na camada de entrada da rede e sua classificacao edada conforme o valor da saıda s(x).
I Como s(x) assume os valores −1 ou 1, a classificacao com rede neuralconstituıda de apenas uma unidade perceptron e binaria.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 31 / 62

Redes Neurais ArtificiaisAlgoritmo de redes neurais com regra perceptron
Dado o conjunto de treinamento T = {< x1, y1 >,< x2, y2 >, . . . , < xn, yn >}, emque yi = {−1, 1}. O vetor de pesos w = [w0,w1, . . . ,wn] e inicializadoaleatoriamente com valores proximos a zero. xi,j representa a j-esima medida dovetor de caracterıssticas da i-esima amostra.
1: // etapa de treinamento2: inicializar os pesos w3: enquanto houver alteracoes nos pesos w faca4: para cada amostra < xi , yi > ∈ T faca5: apresentar os valores de xi na entrada da rede neural6: w0 = w0 + α(yi − s(x))7: para j de 1 ate n faca8: wj = wj + α(yi − s(x))xi,j9: // etapa de classificacao
10: para cada amostra x a ser classificada faca11: apresentar os valores de x na entrada da rede neural12: atribuir x a classe obtida pela saıda s(x)
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 32 / 62

Redes Neurais ArtificiaisRegra delta
I A regra delta e utilizada quando as amostras nao sao linearmente separaveis.
I A regra aplica o metodo de otimizacao do gradiente descendente1 paraencontrar o hiperplano que melhor se adapta aos dados.
I Efetuando a minimizacao da funcao de erro mostrada na equacao 7, utiliza-sea regra de treinamento conhecida como regra delta
E (w0,w1, . . . ,wn) ≡ 1
2
∑<x,y>∈T
(y − s(x))2 (7)
em que T denota o conjunto de treinamento e s(x) representa a saıda darede quando se apresenta o vetor de caracterısticas x na sua entrada.
1O gradiente descendente e um algoritmo que aproxima o mınimo local de uma funcaotomando-se passos proporcionais ao negativo do gradiente da funcao como o ponto corrente.Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 33 / 62

Redes Neurais ArtificiaisRegra delta
I A atualizacao iterativa dos pesos w pela regra delta e efetuada por meio daequacao 8.
wi ← wi + α
n∑j=1
(yj − sj(x))xj,i (8)
I Ao contrario da regra perceptron, atualiza-se os pesos wi apenas aposconsiderar o resultado da classificacao para cada uma das amostras quecompoem o conjunto de treinamento.
I Quando se utiliza a regra delta, obtem-se a saıda sem a aplicacao dalimiarizacao como na regra perceptron, resultando, portanto, em uma funcaolinear, dependente da soma ponderada da multiplicacao dos pesos w e dasentradas x, como mostrado na equacao 9.
s(x) = w0 +n∑
i=1
xiwi (9)
I Diferentemente da regra perceptron, em que o valor de saıda s(x) e binario, asaıda na regra delta e um numero real no intervalo [0, 1].
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 34 / 62
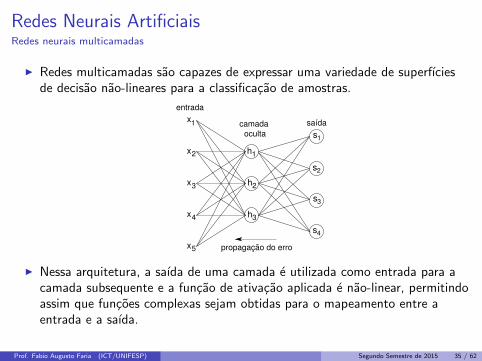
Redes Neurais ArtificiaisRedes neurais multicamadas
I Redes multicamadas sao capazes de expressar uma variedade de superfıciesde decisao nao-lineares para a classificacao de amostras.
x5
x4
x3
x2
x1
h3
h2
h1
s3
s4
s1
s2
camada
entrada
saída
propagação do erro
oculta
I Nessa arquitetura, a saıda de uma camada e utilizada como entrada para acamada subsequente e a funcao de ativacao aplicada e nao-linear, permitindoassim que funcoes complexas sejam obtidas para o mapeamento entre aentrada e a saıda.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 35 / 62

Redes Neurais ArtificiaisRedes neurais multicamadas
I Utiliza-se a funcao de ativacao sigmoide, mostrada na equacao 10, queapresenta a caracterıstica de ser nao-linear e diferenciavel.
I Diferentemente da saıda da unidade perceptron, que retorna valores binarios,essa funcao retorna valores reais entre 0 e 1.
s(x) =1
1 + exp
(−w0 −
n∑i=1
xiwi
) (10)
1)s(x
x1
−4 −2 0 2 4
0.8
1
0.6
0.4
0.2
0
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 36 / 62

Redes Neurais ArtificiaisAlgoritmo retropropagacao
I O treinamento e realizado por meio da retropropagacao do erro obtido pelaclassificacao.
I Esse algoritmo aplica a regra do gradiente descendente para minimizar umafuncao de erro que depende do resultado obtido na saıda e do valor corretopara a classificacao, contido no conjunto de treinamento.
I Uma vez que apenas o resultado da ultima camada e conhecido por meio doconjunto de treinamento, o erro das camadas intermediarias e minimizadocom a retropropagacao do erro obtido nas camadas posteriores.
I Durante a etapa de classificacao, atribui-se cada amostra a classe relacionadaao nodo da camada de saıda que apresenta o valor maximo.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 37 / 62

Maquinas de Vetores de SuporteFundamentos
I Seja um conjunto de treinamento com n amostras
I O objetivo e encontrar um hiperplano para separar amostras em diferentesregioes.
como escolher o hiperplano?
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 38 / 62
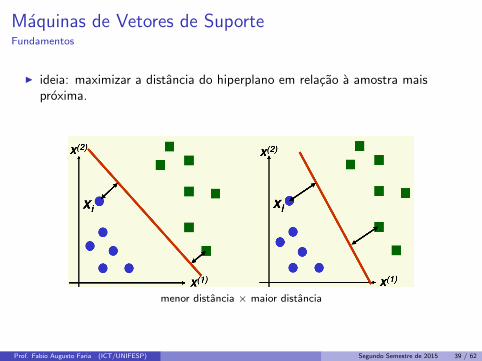
Maquinas de Vetores de SuporteFundamentos
I ideia: maximizar a distancia do hiperplano em relacao a amostra maisproxima.
menor distancia × maior distancia
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 39 / 62

Maquinas de Vetores de SuporteFundamentos
I SVM: procura maximizar a margem, que e o dobro do valor absoluto dadistancia d das amostras mais proximas ao hiperplano de separacao.
margem
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 40 / 62
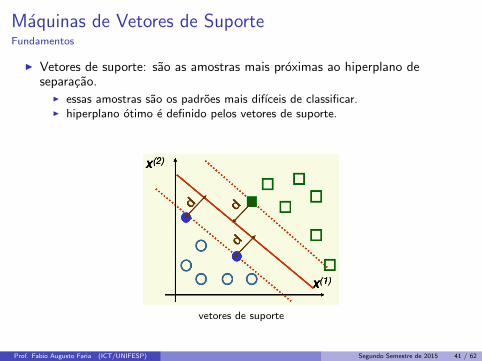
Maquinas de Vetores de SuporteFundamentos
I Vetores de suporte: sao as amostras mais proximas ao hiperplano deseparacao.
I essas amostras sao os padroes mais difıceis de classificar.I hiperplano otimo e definido pelos vetores de suporte.
vetores de suporte
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 41 / 62
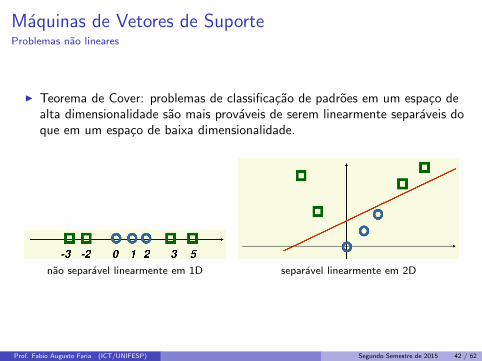
Maquinas de Vetores de SuporteProblemas nao lineares
I Teorema de Cover: problemas de classificacao de padroes em um espaco dealta dimensionalidade sao mais provaveis de serem linearmente separaveis doque em um espaco de baixa dimensionalidade.
nao separavel linearmente em 1D separavel linearmente em 2D
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 42 / 62

Maquinas de Vetores de SuporteProblemas nao lineares
I Qualquer classificador linear poderia ser utilizado em um espaco de altadimensionalidade.
I Entretanto, deve-se lidar com a “maldicao da dimensionalidade”:I generalizacao pobre aos dados de testeI caro computacionalmente
I SVM trata do problemaI garantir as maiores margens permite boa generalizacao.I computacao em casos de alta dimensionalidade e realizada por meio de
funcoes de kernel.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 43 / 62

Maquinas de Vetores de SuporteVantagens e Desvantagens
I VantagensI baseadas em formulacoes matematicas poderosas.I exibem propriedades de generalizacao.I podem ser utilizadas para encontrar funcoes discriminantes nao lineares.I complexidade do classificador e descrita pelo numero de vetores de suporte ao
inves da dimensionalidade do espaco transformado.
I DesvantagensI selecao da funcao de kernel nao e intuitiva.I tendem a ser lentas em comparacao com outras abordagens (caso nao linear).
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 44 / 62

Avaliacao dos ClassificadoresDesempenho da classificacao
I O desempenho dos metodos de classificacao esta estreitamente relacionadocom o conjunto de dados no qual estes serao aplicados.
I Os metodos de treinamento apresentam como objetivo encontrar uma funcaoque descreva de maneira satisfatoria as amostras contidas no conjunto detreinamento.
I Em outras palavras, dado um conjunto de dados formado pelas tuplas< xi , yi >, em que xi e yi representam o vetor de caracterısticas e o rotuloatribuıdo a i-esima amostra que compoe o conjunto de treinamento, tem-secomo objetivo encontrar uma funcao f (xi )→ yi , ∀i .
I Como a correta rotulacao esta disponıvel apenas para o conjunto detreinamento, as amostras nele contidas sao utilizadas para estimar odesempenho de um classificador para amostras que nao possuam umarotulacao conhecida, o qual se apresenta como objetivo primario daclassificacao de padroes.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 45 / 62

Avaliacao dos ClassificadoresProblemas de ajuste na aprendizagem
I Sobreajuste (overfitting): classifica perfeitamente os dados de treinamento,entretanto, generaliza mal.
I grande quantidade de ruıdos.I dados de treinamento nao representativos.I poucas amostras de treinamento.
I Subajuste (underfitting): nao se ajusta aos dados de treinamentoI dados nao representativos ou esparsos.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 46 / 62

Avaliacao dos ClassificadoresHoldout
I Este estimador divide as amostras em uma porcentagem fixa de exemplos ppara treinamento e (1− p) para teste, considerando normalmente p > 1/2.
Treinamento Teste
Número Total de Amostras
I Uma vez que uma hipotese construıda utilizando todas as amostras, emmedia, apresenta desempenho melhor do que uma hipotese construıdautilizando apenas uma parte das amostras, este metodo tem a tendencia desuperestimar o erro verdadeiro.
I De forma a tornar o resultado menos dependente da forma de divisao dosexemplos, pode-se calcular a media de varios resultados de holdout pelaconstrucao de varias particoes obtendo-se, assim, uma estimativa media doholdout.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 47 / 62

Avaliacao dos ClassificadoresAmostragem Aleatoria
I Na amostragem aleatoria, L hipoteses (L << n) sao induzidas a partir decada um dos L conjuntos de treinamento.
I O erro final e calculado como sendo a media dos erros de todas as hipotesesinduzidas e calculados em conjuntos de teste independentes e extraıdosaleatoriamente.
I Amostragem aleatoria pode produzir melhores estimativas de erro que oestimador holdout.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 48 / 62

Avaliacao dos ClassificadoresValidacao Cruzada
I Este estimador e um meio termo entre os estimadores holdout eleave-one-out.
I Na validacao cruzada com k particoes, as amostras sao aleatoriamentedivididas em k particoes mutuamente exclusivas de tamanhoaproximadamente igual a n/k exemplos.
I Os exemplos nas (k − 1) particoes sao usadas para treinamento e a hipoteseinduzida e testada na particao remanescente.
I Este processo e repetido k vezes, cada vez considerando uma particaodiferente para teste.
I O erro na validacao cruzada e a media dos erros calculados em cada um dask particoes.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 49 / 62
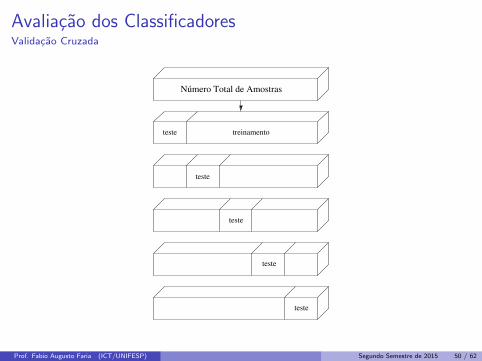
Avaliacao dos ClassificadoresValidacao Cruzada
Número Total de Amostras
teste treinamento
teste
teste
teste
teste
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 50 / 62

Avaliacao dos ClassificadoresValidacao Cruzada
I Este procedimento de rotacao reduz tanto o bias inerente ao metodo deholdout quanto o custo computacional do metodo leave-one-out.
I Entretanto, deve-se observar, por exemplo, que na validacao cruzada com 10particoes, cada par de conjuntos de treinamento compartilha 80% deexemplos.
I A medida que o numero de particoes aumenta, esta sobreposicao pode evitarque os testes estatısticos obtenham uma boa estimativa da quantidade devariacao que seria observada se cada conjunto de treinamento fosseindependente dos demais.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 51 / 62

Avaliacao dos ClassificadoresLeave-One-Out
I O estimador leave-one-out e um caso especial de validacao cruzada.
I E computacionalmente dispendioso e frequentemente e usado em amostraspequenas.
I Para uma amostra de tamanho n, uma hipotese e induzida utilizando (n − 1)exemplos; a hipotese e entao testada no unico exemplo remanescente.
I Este processo e repetido n vezes, cada vez induzindo uma hipotese deixandode considerar um unico exemplo.
I O erro e a soma dos erros em cada teste dividido por n.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 52 / 62

Avaliacao dos ClassificadoresLeave-One-Out
Número Total de Amostras
...
teste treinamento
teste
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 53 / 62

Avaliacao dos ClassificadoresBootstrap
I No estimador bootstrap, a ideia basica consiste em repetir o processo declassificacao um grande numero de vezes.
I Diferentemente da validacao cruzada (que usa amostragem sem reposicao), atecnica de bootstrap usa amostragem com reposicao para formar o conjuntode treinamento
I Estimam-se entao valores, tais como o erro ou bias, a partir dosexperimentos replicados, cada experimento sendo conduzido com base em umnovo conjunto de treinamento obtido por amostragem com reposicao doconjunto original de amostras.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 54 / 62

Avaliacao dos ClassificadoresBootstrap e0
I Ha muitos estimadores bootstrap, sendo o mais comum denominadobootstrap e0.
I Um conjunto de treinamento bootstrap consiste em n amostras (mesmotamanho do conjunto original) amostradas com reposicao a partir doconjunto original de amostras.
I Isto significa que algumas amostras Ai podem nao aparecer no conjunto detreinamento bootstrap e algumas Ai podem aparecer mais de uma vez.
I As amostras remanescentes (aquelas que nao aparecem no conjunto detreinamento bootstrap) sao usadas como conjunto de teste.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 55 / 62

Avaliacao dos ClassificadoresBootstrap e0
A2 A4 A5A1
A2 A4
A4
A3
A3 A4
A3 A3 A5
...
A3 A1 A3 A3 A5
A4A1A4 A4 A4
A1
A2A1A3A5A5
A5 A1 A5 A2
...
testetreinamento
Conjunto Completo de Amostras
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 56 / 62

Avaliacao dos ClassificadoresBootstrap e0
I Para uma dada amostra bootstrap, uma amostra de treinamento temprobabilidade 1− (1− 1/n)n de ser selecionada pelo menos uma vez em cadauma das n vezes nas quais as amostras sao aleatoriamente selecionadas apartir do conjunto original de amostras. Para n alto, isto e aproximadamente1− 1/e = 0.632.
I Portanto, para esta tecnica, a fracao media de amostras nao repetidas e63.2% no conjunto de treinamento e 36.8% no conjunto de teste.
I Geralmente, o processo de bootstrap e repetido um numero de vezes, sendoo erro estimado como a media dos erros sobre o numero de iteracoes.
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 57 / 62

Avaliacao dos ClassificadoresMatriz de Confusao
I A matriz de confusao apresenta o numero de linhas e colunas equivalente aonumero de classes do problema, em que um elemento aij indica o numero deamostras atribuıdas a classe Ci dado que a classe correta e a Cj . Dessamaneira, os elementos contidos na diagonal principal da matriz denotam onumero de amostras classificadas corretamente.
a11 a12 . . . a1m
a21 a22 . . . a2m
......
......
am1 am2 . . . amm
I Exemplo: resultado da classificacao de 300 amostras pertencentes a seis
classes diferentes.40 4 0 0 7 03 45 0 0 1 00 0 29 1 3 180 0 4 43 0 147 1 1 0 39 00 0 16 6 0 18
taxa de erro = 1 −214
300≈ 0.287
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 58 / 62

Avaliacao dos ClassificadoresTabela de Contingencia
I Estrutura construıda com:
I verdadeiros positivos (VP): valores positivos que o sistema julgou positivos(acerto).
I falsos negativos (FN): valores positivos que o sistema julgou negativos (erro).I verdadeiros negativos (VN): valores negativos que o sistema julgou como
negativos (acerto).I falsos positivos (FP): valores negativos que o sistema julgou positivos (erro).
positivo
negativo
verdadeiropositivo
positivofalso
negativo
negativo
verdadeironegativo
falso
classe predita
classe real
positivo
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 59 / 62

Avaliacao dos ClassificadoresMedidas derivadas da tabela de contingencia
I Acuracia: proporcao de predicoes corretas, sem levar em consideracao o que epositivo e o que e negativo. Esta medida e altamente suscetıvel adesbalanceamentos do conjunto de dados e pode facilmente induzir a umaconclusao errada sobre o desempenho do sistema.
Acuracia =Total de Acertos
Total de Dados no Conjunto=
VP + VN
P + N
I Sensibilidade: proporcao de verdadeiros positivos, ou seja, a capacidade dosistema em predizer corretamente a condicao para casos que realmente a tem.
Sensibilidade =Acertos Positivos
Total de Positivos=
VP
P=
VP
VP + FN
I Especificidade: proporcao de verdadeiros negativos, ou seja, a capacidade dosistema em predizer corretamente a ausencia da condicao para casos querealmente nao a tem.
Especificidade =Acertos Negativos
Total de Negativos=
VN
N=
VN
VN + FP
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 60 / 62

Avaliacao dos ClassificadoresI Exemplo: resultado da classificacao de 27 animais (8 gatos, 6 cachorros e 13
coelhos), cuja matriz de confusao e:
gato
cachorro
coelho
gato cachorro coelho
classe predita
classe real
5
2
0
3
3
2
1
11
0
I Dos 8 gatos, 3 foram classificados como cachorros;I Dos 6 cachorros, 2 foram classificados como gato e 1 como coelho;I Dos 13 coelhos, 2 foram classificados como cachorros.
I Matriz de confusao para a classe gato:
5 verdadeiros positivos 3 falsos negativos(gatos que foram corretamente (gatos que foram incorretamente
classificados como gatos) classificados como cachorros)2 falsos positivos 17 verdadeiros negativos
(cachorros que foram incorretamente (animais restantes, corretamenteclassificados como gatos) classificados como nao gatos)
Prof. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 61 / 62

Exercıcios
I Implementar os descritores GCH e LCH;
I Escolha de forma aleatoria 5 imagens da base Corel2 para serem as consultasdo sistema de CbIR;
I Calcule a curva Precision x Recall para cada descritor implementado;
2www.ic.unicamp.br/ ffaria/Corel3906.tgzProf. Fabio Augusto Faria (ICT/UNIFESP) Segundo Semestre de 2015 62 / 62