criar um web spider no linux
TRANSCRIPT

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 1/17
Criar um Web Spider no Linux
Um spider e scraper simples coletam o conteúdo da Internet
M. Tim Jones, Consultant Engineer, Emulex Corp.
Resumo: Web spiders são agentes de software que passam pela coleta, filtragem e, potencialmente, agregação de informações da Internet para um usuário. Utilizandolinguagens de script comuns e suas coletas de módulos da Web, é possível desenvolver facilmente Web spiders. Este artigo mostra como criar spiders e scrapers para Linux ®
para efetuar crawl de um Web site e coletar informações e, neste caso, estocar dados.
Índice
• Motivação Biológica• Aplicativos de Spiders e Scrapers• Exemplo 1: Scraper Simples• Exemplo 2: Scraper com Cotações de Ações• Exemplo 3: Comunicação do Scraper com Cota de Estoque• Exemplo 4: Crawler de Web Site• Ferramentas de Geração de Spider do Linux• Questões Legais
• Indo Além• Recursos• Sobre o autor

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 2/17
Um spider é um programa que efetua crawl da Internet de um modo específico, com umobjetivo específico. O objetivo pode ser coletar informações ou entender a estrutura evalidade de um Web site. Spiders são a base para os mecanismos de procura modernos,como Google e AltaVista. Esses spiders recuperam automaticamente os dados da Web e
os transmitem para outros aplicativos que indexe os conteúdos do Web site para ummelhor conjunto de termos de procura.
Web Spiders como Agentes
Web spiders e scrapers são simplesmente outra forma de software robô ou agente (comofoi indicado por Alan Kay no início dos anos 1980). A ideia de Alan sobre um agente eracomo a de um proxy para o usuário no mundo da computação. O agente teria uma meta etrabalharia nela até chegar ao seu domínio. Caso ele parasse, pediria conselhos para ousuário e continuaria a buscar sua meta.
Hoje, os agentes são classificados com atributos como autonomia, adaptabilidade,comunicação e colaboração com outros agentes. Outros atributos, como mobilidade doagente e até mesmo personalidade, são metas da pesquisa do agente atual. Os Web spiderssão classificados neste artigo como Agentes Específicos de Tarefas na taxonomia deagente.
Semelhante a um spider, mas com questões legais mais interessantes, temos o Webscraper. Um scraper é um tipo de spider que destina conteúdo específico da Web, como ocusto de produtos ou serviços. Um uso do scraper é para preços concorrentes, paraidentificar o preço de um determinado produto para adequar seu preço ou anúncio
corretamente. Um scraper também pode agregar dados de diversas origens da Web efornecer essas informações a um usuário.
Motivação Biológica
Quando se pensa em uma aranha na natureza, pensa-se em sua interação com umambiente, não em seu isolamento. A aranha vê e sente o ambiente que a cerca, movendo-se de um lugar para outra de forma significativa. Web spiders operam de formasemelhante. Um Web spider é um programa escrito em uma linguagem de alto nível. Eleinterage com seu ambiente através do uso de protocolos de rede, como Protocolo deTransporte de Hipertexto (HTTP) para a Web. Se o spider deseja se comunicar com você,
ele pode usar o Protocolo Simples de Transporte de Correio (SMTP) para enviar umamensagem de e-mail.
Spiders são se limitam a HTTP ou SMTP. Alguns spiders usam serviços da Web, comoSOAP ou o Protocolo de Chamada de Procedimento Remoto para Linguagem deMarcação Extensível (XML-RPC). Outros spiders procuram grupos de notícias com o
Network News Transfer Protocol (NNTP) ou buscam itens de notícias nas alimentaçõesReally Simple Syndication (RSS). Enquanto a maioria das aranhas na natureza enxergamapenas a intensidade da escuridão e as mudanças de movimentos, os Web spiders podemver e sentir o uso de muitos tipos de protocolos.
Voltar para parte superior

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 3/17
Aplicativos de Spiders e Scrapers
Olhos e Pernas do Spider
O Web spider usa principalmente o HTTP para olhar e mover-se pela Internet. HTTP é
um protocolo orientado à mensagem no qual um cliente se conecta a um servidor e emite pedidos. O servidor fornece uma resposta. Cada pedido e resposta é composto decabeçalho e corpo, com o cabeçalho fornecendo informações de status e uma descrição doconteúdo do corpo.
O HTTP fornece três tipos básicos de pedidos. O primeiro é HEAD, que solicitainformações sobre um recurso no servidor. O segundo é GET, que solicita um recurso,como um arquivo ou uma imagem. Finalmente, POST permite que o cliente interaja com oservidor através de uma página da Web (geralmente através de um formulário da Web).
Web spiders e scrapers são aplicativos úteis e, portanto, é possível encontrar umavariedade de tipos diferentes de uso, tanto para o bem quanto para o mal. Vamos observar alguns dos aplicativos que utilizam essas tecnologias.
Web Crawlers de Mecanismos de Procura
Web spiders tornam a pesquisa na Internet fácil e eficiente. Um mecanismo de procurautiliza muitos Web spiders para efetuar crawl de páginas da Web na Internet, retornar seuconteúdo e o indexar. Depois que isso é feito, o mecanismo de procura pode pesquisar rapidamente o índice local para identificar a maioria dos resultados aplicáveis à sua
pesquisa. O Google também utiliza o algoritmo PageRank , no qual uma classificação de
páginas da Web nos resultados da procura tem como base a quantidade de páginas queestão vinculadas a ele. Ele serve como um voto, no qual páginas com votos mais altosobtêm o maior rank nos resultados.
Esse tipo de procura na Internet pode ser dispendiosa, em termos de largura de bandanecessária para comunicar o conteúdo da Web para o indexador e também de custoscomputacionais de indexação dos resultados. É necessário muito armazenamento, mas,aparentemente, isso não é um problema quando considera-se que o Google oferece 1.000megabytes de armazenamento para usuários do Gmail.
Os web spiders minimizam a exaustão da Internet utilizando um conjunto de políticas.
Para darmos uma idéia do escopo do desafio, o Google indexa mais de oito bilhões de páginas da Web. As políticas de comportamento definem quais páginas o crawler levaráao indexador, com qual frequência ele retornará a um Web site para verificá-lo novamentee algo denominado política de cortesia. Os servidores da Web podem excluir crawlersutilizando um arquivo chamado robot.txt que informa ao crawler o que pode ou não ter crawl efetuado.
Web Crawlers Corporativos
Como o spider do mecanismo de procura padrão, o Web spider corporativo indexaconteúdo que não está disponível ao público geral. Por exemplo, as empresas geralmente
possuem sites da Web internos que são utilizados pelos funcionários. Esse tipo de spider érestrito ao ambiente local. Como sua procura é restrita, geralmente há mais computação

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 4/17
disponível e especializada, e índices mais completos são possíveis. O Google se antecipoua isso fornecendo um mecanismo de procura de desktop para indexar o conteúdo de seucomputador pessoal.
Crawlers Especializados
Também há diversos usos não tradicionais para os crawlers, como o arquivamento deconteúdo ou geração de estatísticas. Um crawler de arquivamento simplesmente efetuacrawl de um Web site extraindo o conteúdo localmente para armazená-lo em um meio dearmazenamento de longo. Isso pode ser utilizado para backup ou, em casos maiores, parauma captura instantânea do conteúdo da Internet. As estatísticas podem ser úteis nacompreensão do conteúdo da Internet ou perda dele. Os crawlers podem ser usados paraidentificar quantos servidores da Web estão em execução, quantos servidores da Web deum determinado tipo estão executando, o número de páginas da Web disponíveis e atémesmo o número de links quebrados (são eles que retornam o erro HTTP 404, página nãoencontrada).
Outros crawlers úteis especializados incluem os verificadores de Web site. Esses crawlers procuram o conteúdo ausente, validam todos os links e garantem que sua Linguagem deMarcação de Hipertexto (HTML) seja válida.
Crawlers de Coleta de e-mail
Agora o lado ruim dos crawlers. Infelizmente, pessoas malintencionadas podem efetuar estragos na Internet por todos nós. Os crawlers de coleta de e-mail procuram por endereços de e-mail em Web sites que são então utilizados para gerar o spam em massa
que vemos diariamente. A Postini relata que, em agosto de 2005, 70% de todas asmensagens de e-mail processadas para os usuários dela eram spans indesejados.
A coleta de e-mail pode ser uma das atividades de crawl mais fáceis, como será visto noexemplo final de crawler neste artigo.
Agora que vimos alguns dos fundamentos dos Web spiders e scrapers, os próximos quatroexemplos mostram como é fácil criar spiders e scrapers para Linux com linguagens descript modernas, como Ruby e Python.
Voltar para parte superior
Exemplo 1: Scraper Simples
Este exemplo mostra como descobrir qual tipo de servidor da Web está sendo executado para um determinado Web site. Isso pode ser interessante e, se feito em uma amostragrande suficiente, pode fornecer algumas estatísticas intrigantes sobre a infiltração deservidores da Web no governo, em academias e na indústria.
A Lista 1 mostra um script Ruby que efetua scrap de um Web site para identificar oservidor HTTP. A classe Net::HTTP implementa um cliente HTTP e os métodos GET,HEAD e POST HTTP. Sempre que se faz um pedido para um servidor HTTP, parte da
resposta da mensagem HTTP indica o servidor do qual o conteúdo é servidor. Em vez defazer download de uma página do site, eu simplesmente uso o método HEAD para obter

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 5/17
informações sobre a página raiz ('/'). À medida que o servidor HTTP responde com êxito(indicado por um código de resposta "200"), eu faço a iteração de cada linha de resposta
procurando pela chave server e, se encontrada, imprimo o valor. O valor dessa chave éuma cadeia que representa o servidor HTTP.
Lista 1. Script Ruby para Scrap de Metadados Simples (srvinfo.rb)
#!/usr/local/bin/rubyrequer 'net/http'
# Obter o primeiro argumento da linha decomandos (a URL)url = ARGV[0]
begin
# Criar uma nova conexão HTTP
httpCon = Net::HTTP.new( url, 80 )
# Executar um pedido HEADresp, data = httpCon.head( "/", nil )
# Se bem-sucedido (200 é bem-sucedido)if resp.code == "200" then
# Iteragir através do hash de respostaresp.each {|key,val|
# Se a chave for o servidor, imprimir ovalor
if key == "server" then
print " The server at "+url+" is"+val+"\n"
end
}
end
end
Além de mostrar como utilizar o script srvinfo, a Lista 2 mostra alguns resultados devários Web sites do governo, de academias e de empresas. Há uma pequena variação daApache (68% infiltração) para a Sun e a Microsoft® Internet Information Services (IIS).Também é possível ver um caso no qual o servidor não é informado. É engraçado notar que os Estados Federados da Micronésia estão executando uma versão antiga da Apache(hora de atualizar) e a Apache.org utiliza tecnologia de ponta.
Lista 2. Exemplo do Uso de Scraper de Servidor
[mtj@camus]$ ./srvrinfo.rb www.whitehouse.govThe server at www.whitehouse.gov is Apache

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 6/17
[mtj@camus]$ ./srvrinfo.rb www.cisco.com The server at www.cisco.com is Apache/2.0
(Unix)[mtj@camus]$ ./srvrinfo.rb www.gov.ruThe server at www.gov.ru is Apache/1.3.29
(Unix)
[mtj@camus]$ ./srvrinfo.rb www.gov.cn[mtj@camus]$ ./srvrinfo.rb www.kantei.go.jpThe server at www.kantei.go.jp is Apache
[mtj@camus]$ ./srvrinfo.rb www.pmo.gov.toThe server at www.pmo.gov.to is
Apache/2.0.46 (Red Hat Linux)[mtj@camus]$ ./srvrinfo.rb www.mozambique.mzThe server at www.mozambique.mz is
Apache/1.3.27(Unix) PHP/3.0.18 PHP/4.2.3
[mtj@camus]$ ./srvrinfo.rb www.cisco.com The server at www.cisco.com is Apache/1.0
(Unix)
[mtj@camus]$ ./srvrinfo.rb www.mit.eduThe server at www.mit.edu is MIT Web ServerApache/1.3.26 Mark/1.5
(Unix) mod_ssl/2.8.9 OpenSSL/0.9.7c[mtj@camus]$ ./srvrinfo.rb www.stanford.eduThe server at www.stanford.edu is
Apache/2.0.54 (Debian GNU/Linux)mod_fastcgi/2.4.2 mod_ssl/2.0.54
OpenSSL/0.9.7e WebAuth/3.2.8[mtj@camus]$ ./srvrinfo.rb www.fsmgov.orgThe server at www.fsmgov.org is
Apache/1.3.27 (Unix) PHP/4.3.1[mtj@camus]$ ./srvrinfo.rb www.csuchico.edu
The server at www.csuchico.edu is Sun-ONE-Web-Server/6.1[mtj@camus]$ ./srvrinfo.rb www.sun.com The server at www.sun.com is Sun Java System
Web Server 6.1[mtj@camus]$ ./srvrinfo.rb www.microsoft.com The server at www.microsoft.com is
Microsoft-IIS/6.0[mtj@camus]$ ./srvrinfo.rb www.apache.orgThe server at www.apache.org is Apache/2.2.3(Unix)
mod_ssl/2.2.3 OpenSSL/0.9.7g
Estes dados são úteis e é interessante observar o que as instituições do governo eacadêmicas utilizam para seus servidores da Web. O próximo exemplo mostra algo um
pouco mais útil, um scraper com cotações de ações.
Voltar para parte superior
Exemplo 2: Scraper com Cotações de Ações
Neste exemplo, eu criei um Web scraper simples (também chamado scraper de tela) paracoletar informações de cota de estoque. Isso é feito de forma forçada, explorando-se um
padrão na página da Web de resposta, como a seguir:

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 7/17
Lista 3. Um Web Scraper Simples para Cotações de Ações
#!/usr/local/bin/rubyrequer 'net/http'
host = "www.smartmoney.com"link = "/eqsnaps/index.cfm?story=snapshot&symbol="+ARGV[0]
begin
# Criar uma nova conexão HTTPhttpCon = Net::HTTP.new( host, 80 )
# Executar um pedido HEADresp = httpCon.get( link, nil )
stroffset = resp.body =~ /class="price">/
subset = resp.body.slice(stroffset+14, 10)
limit = subset.index('<')
print ARGV[0] + " current stock price " +subset[0..limit-1] +
" (from stockmoney.com)\n"
end
Neste script Ruby, eu abro uma conexão com um cliente HTTP para um servidor (nestecaso, www.smartmoney.com) e crio um link que solicite especificamente uma cota deestoque como transmitida pelo usuário (via &symbol=<symbol>). Esse link é solicitadoutilizando-se o método HTTP GET (para recuperar a página de resposta completa) e depois
procurando-se por class="price">, que é imediatamente seguido pelo preço atual deestoque. Isso é imediatamente suprimido da página da Web e depois exibido para ousuário.
Para utilizar o scraper com cota de estoque, eu chamo o script com o símbolo de estoquedo meu interesse, como mostrado em Lista 4.
Lista 4. Exemplo de Uso do Scraper com Cota de Estoque
[mtj@camus]$ ./stockprice.rb ibm ibm current stock price 79.28 (fromstockmoney.com)[mtj@camus]$ ./stockprice.rb intlintl current stock price 21.69 (fromstockmoney.com)[mtj@camus]$ ./stockprice.rb ntnt current stock price 2.07 (fromstockmoney.com)[mtj@camus]$

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 8/17
Voltar para parte superior
Exemplo 3: Comunicação do Scraper com Cota de Estoque
O Web scraper para cotações de ações mostrado no exemplo 2 era tentador, mas seria
realmente útil se ele monitorasse com frequência o preço de estoque e lhe informassequando seu estoque favorito aumentasse a um determinado valor ou ficasse abaixo deoutro valor. Essa espera acabou. Na Lista 5, eu atualizei o Web scraper simples paramonitorar com frequência o estoque e enviar uma mensagem de e-mail quando esseestoque ficar fora de um intervalo de preço definido.
Lista 5. Scraper de Estoque que Pode Enviar um Alerta de e-mail
#!/usr/local/bin/rubyrequer 'net/http'requer 'net/smtp'
## Fornecidos um Web site e link, retornar o preçode estoque#def getStockQuote(host, link)
# Criar uma nova conexão HTTPhttpCon = Net::HTTP.new( host, 80 )
# Executar um pedido HEADresp = httpCon.get( link, nil )
stroffset = resp.body =~ /class="price">/
subset = resp.body.slice(stroffset+14, 10)
limit = subset.index('<')
return subset[0..limit-1].to_f
fim## Enviar uma mensagem (msg) para um usuário.# Nota: supõe-se que o servidor SMTP esteja nomesmo host.#def sendStockAlert( user, msg )
lmsg = [ "Subject: Stock Alert\n", "\n", msg ]Net::SMTP.start('localhost') do |smtp|smtp.sendmail( lmsg,
"[email protected]", [user] )end
fim## Nosso principal programa verifica o estoquedentro da faixa de preço a cada# dois minutos, manda e-mail e sai se as faixas depreço do estoque estiverem fora.

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 9/17
## Uso: ./monitor_sp.rb <símbolo> <alto> <baixo><endereço_de_email>#begin
host = "www.smartmoney.com"link = "/eqsnaps/index.cfm?story=snapshot&symbol="+ARGV[0]user = ARGV[3]
high = ARGV[1].to_flow = ARGV[2].to_f
while 1
price = getStockQuote(host, link)
print "current price ", price, "\n"
if (price > high) || (price < low) then
if (price > high) thenmsg = "Stock "+ARGV[0]+" has exceeded the
price of "+high.to_s+"\n"+host+link+"\n"
end
if (price < low) thenmsg = "Stock "+ARGV[0]+" has fallen below
the price of "+low.to_s+"\n"+host+link+"\n"
fimsendStockAlert( user, msg )
exit
fimsleep 120
fimfim
Este script Ruby é um pouco maior, mas é criado no script de scrap de estoque existenteda A Lista 3. Uma nova função, getStockQuote, encapsula a função de scrap de estoque.Outra função, sendStockAlert, envia uma mensagem para um endereço de e-mail(ambos são definidos pelo usuário). O programa principal não é nada mais que um loop
para obter o preço de estoque atual, verificar se esse preço está dentro da faixa e, se nãoestiver, enviar um alerta de e-mail para o usuário. Houve um atraso entre a verificação do
preço de estoque para não haver sobrecarga no servidor.
A Lista 6 é um exemplo de chamada do monitor de estoque com um estoque detecnologia popular. A cada dois minutos, o estoque é verificado e impresso. Quando esseestoque excede o limite máximo, um alerta de e-mail é enviado e o script sai.
5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 10/17
Lista 6. Demonstração de Script do Monitor de Estoque
[mtj@camus]$ ./monitor_sp.rb ibm 83.00 75.00 [email protected]
current price 82.06current price 82.32current price 82.75current price 83.36
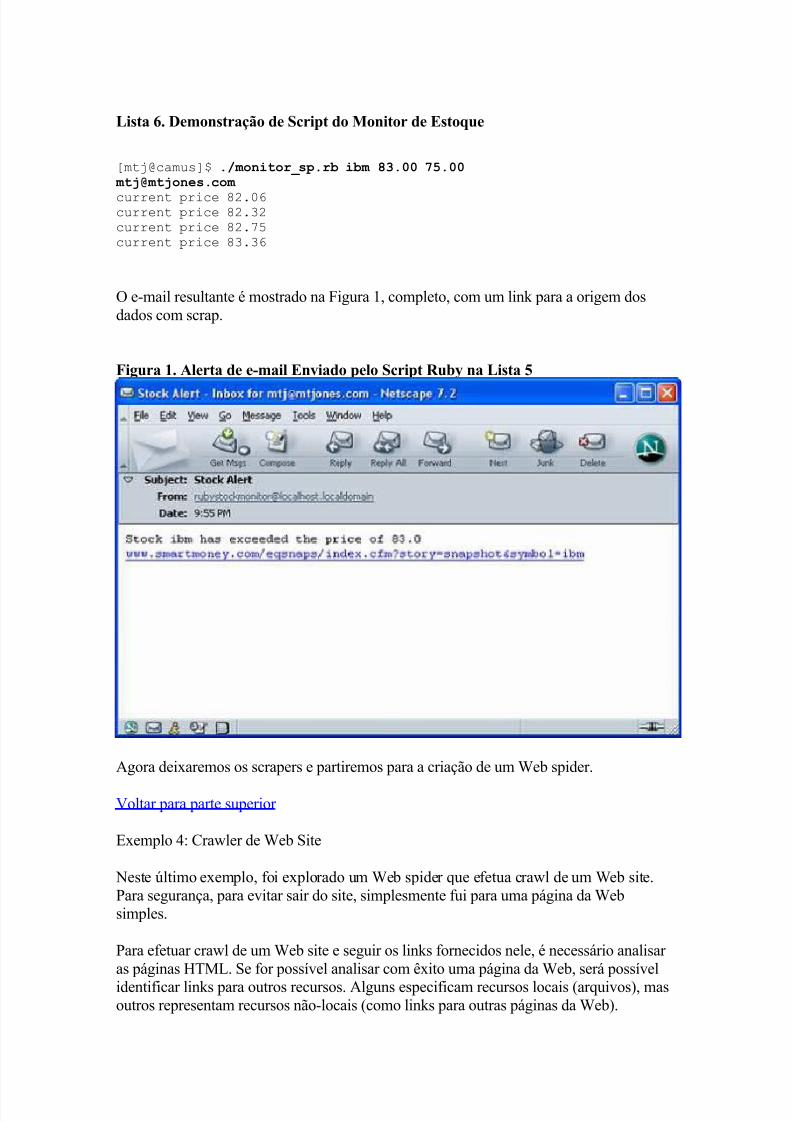
O e-mail resultante é mostrado na Figura 1, completo, com um link para a origem dosdados com scrap.
Figura 1. Alerta de e-mail Enviado pelo Script Ruby na Lista 5
Agora deixaremos os scrapers e partiremos para a criação de um Web spider.
Voltar para parte superior
Exemplo 4: Crawler de Web Site
Neste último exemplo, foi explorado um Web spider que efetua crawl de um Web site.Para segurança, para evitar sair do site, simplesmente fui para uma página da Websimples.
Para efetuar crawl de um Web site e seguir os links fornecidos nele, é necessário analisar as páginas HTML. Se for possível analisar com êxito uma página da Web, será possívelidentificar links para outros recursos. Alguns especificam recursos locais (arquivos), masoutros representam recursos não-locais (como links para outras páginas da Web).

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 11/17
Para efetuar crawl da Web, comece com uma página da Web específica, identifique todosos links nessa página, enfilere-os em uma fila de visitas e depois repita esse processoutilizando o primeiro item dessa fila de visitas. Isso resulta em um comportamentotransversal de primeira largura (comparado com um comportamento de primeira
profundidade, quando se migra para o primeiro link encontrado).
Se você evita links não-locais e visita apenas páginas da Web locais, fornece um Webcrawler para um Web site simples, como mostrado na Lista 7. Neste caso, eu alterno doRuby para o Python para tirar proveito da classe útil HTMLParser do Python.
Lista 7. Crawler de Web Site Simples do Python ( minispider.py)
#!/usr/local/bin/python
import httplibimport sysimport refrom HTMLParser import HTMLParser
class miniHTMLParser( HTMLParser ):
viewedQueue = []instQueue = []
def get_next_link( self ):if self.instQueue == []:return ''
else:return self.instQueue.pop(0)
def gethtmlfile( self, site, page ):try:httpconn = httplib.HTTPConnection(site)httpconn.request("GET", page)resp = httpconn.getresponse()resppage = resp.read()
except:resppage = ""
return resppage
def handle_starttag( self, tag, attrs ):if tag == 'a':newstr = str(attrs[0][1])if re.search('http', newstr) == None:if re.search('mailto', newstr) ==
None:if re.search('htm', newstr) != None:if (newstr in self.viewedQueue) ==
False:print " adding", newstrself.instQueue.append( newstr )
self.viewedQueue.append( newstr)

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 12/17
else:print " ignoring", newstr
else:print " ignoring", newstr
else:print " ignoring", newstr
def main():
if sys.argv[1] == '':print "usage is ./minispider.py site link"sys.exit(2)
mySpider = miniHTMLParser()
link = sys.argv[2]
while link != '':
print "\nChecking link ", link
# Obter o arquivo do site e vincularretfile =
mySpider.gethtmlfile( sys.argv[1], link )
# Alimentar o arquivo no analisador HTMLmySpider.feed(retfile)
# Procurar pelo retfile aqui
# Obter o próximo link no pedido de nível
transversallink = mySpider.get_next_link()
mySpider.close()
print "\ndone\n"
if __name__ == "__main__":main()
O design básico desse crawler é carregar o primeiro link para verificar em uma fila. Estafila atua como a próxima fila a ser consultada. À medida que um link é verificado, todosos novos links encontrados são carregados na mesma fila. Isso fornece uma procura de
primeira largura. Eu também mantenho uma fila já visualizada e evito seguir qualquer link que vi anteriormente. Basicamente é isso; a maior parte do trabalho real é feita peloanalisador HTML.
Primeiro, derivo uma nova classe, chamada miniHTMLParser, da classe HTMLParser doPython. A classe faz algumas coisas. Primeiro, ela é meu analisador HTML, com ummétodo de retorno de chamada (handle_starttag) sempre que uma tag HTML de inícioé encontrada. Eu também uso a classe para acessar links encontrados no crawl(get_next_link) e recuperar o arquivo representado pelo link (neste caso, um arquivo
HTML).

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 13/17
Duas variáveis de instância estão contidas na classe, viewedQueue, que contém os linksque foram investigados até aqui, e instQueue, que representa os links que ainda serãointerrogados.
Como é possível ver, os métodos de classe são simples. O método get_next_link faz
uma verificação para saber se instQueue está vazio e retorna ''. Caso contrário, o próximo item é retornado através do método pop. O método gethtmlfile utilizaHTTPConnectionK para se conectar a um site e retornar o conteúdo da página definida.Finalmente, handle_starttag é chamado para cada tag de início em uma página da Web(alimentada no analisador HTML através do método feed). Nessa função, eu faço averificação para saber se o link é um link não-local (se contiver http), se é um endereço dee-mail (via mailto) e também se o link contém 'htm', indicando (com grande
probabilidade) que é uma página da Web. Eu também faço a verificação para garantir quenão fiz a visita antes e, nesse caso, carrego o link em minhas filas visualizadas e parainterrogar.
O método main é simples. Eu crio uma nova instância miniHTMLParser e começo com osite definido pelo usuário (argv[1]) e link (argv[2]). Obtenho os conteúdos do link, osalimento no analisador HTML e visito o próximo link, se existir. O loop então continuaenquanto houver links para visitar.
Para chamar o Web spider, é necessário fornecer um endereço de Web site e um link:
./minispider.py www.fsf.org /
Neste caso, estou solicitando o arquivo raiz do Free Software Foundation. Este comando
resulta na Lista 8. É possível ver os novos links incluídos na fila para interrogar e os quesão ignorados, como os links não-locais. Na parte inferior da lista, é possível ver ointerrogatório dos links encontrados na raiz.
Lista 8. Saída do Script Minispider
[mtj@camus]$ ./minispider.py www.fsf.org /
Checking link /ignoring hiddenStructureignoring http://www.fsf.org
ignoring http://www.fsf.orgignoring http://www.fsf.org/newsignoring http://www.fsf.org/eventsignoring http://www.fsf.org/campaignsignoring http://www.fsf.org/resourcesignoring http://www.fsf.org/donateignoring http://www.fsf.org/associateignoring http://www.fsf.org/licensingignoring http://www.fsf.org/blogsignoring http://www.fsf.org/aboutignoring https://www.fsf.org/login_formignoring http://www.fsf.org/join_formignoring http://www.fsf.org/news/fs-award-2005.html
ignoring http://www.fsf.org/news/fsfsysadmin.htmlignoring http://www.fsf.org/news/digital-communities.html

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 14/17
ignoring http://www.fsf.org/news/patents-defeated.htmlignoring /news/RSSignoring http://www.fsf.org/newsignoring http://www.fsf.org/blogs/rms/entry-
20050802.htmlignoring http://www.fsf.org/blogs/rms/entry-
20050712.htmlignoring http://www.fsf.org/blogs/rms/entry-20050601.htmlignoring http://www.fsf.org/blogs/rms/entry-
20050526.htmlignoring http://www.fsf.org/blogs/rms/entry-
20050513.htmlignoring
http://www.fsf.org/index_html/SimpleBlogFullSearchignoring documentContentignoring http://www.fsf.org/index_html/sendto_formignoring javascript:this.print();adding licensing/essays/free-sw.html
ignoring /licensing/essaysignoring http://www.gnu.org/philosophyignoring http://www.freesoftwaremagazine.comignoring donateignoring join_formadding associate/index_htmlignoring http://order.fsf.orgadding donate/patron/index_htmladding campaigns/priority.htmlignoring http://r300.sf.net/ignoring
http://developer.classpath.org/mediation/OpenOffice2GCJ4ignoring http://gcc.gnu.org/java/index.html
ignoring http://www.gnu.org/software/classpath/ignoring http://gplflash.sourceforge.net/ignoring campaignsadding campaigns/broadcast-flag.htmlignoring http://www.gnu.orgignoring /fsf/licensingignoring http://directory.fsf.orgignoring http://savannah.gnu.orgignoring mailto:[email protected] http://www.fsf.org/Members/rootignoring http://www.plonesolutions.comignoring http://www.enfoldtechnology.comignoring http://blacktar.com
ignoring http://plone.orgignoring http://www.section508.govignoring http://www.w3.org/WAI/WCAG1AA-Conformanceignoring http://validator.w3.org/check/refererignoring http://jigsaw.w3.org/css-
validator/check/refererignoring http://plone.org/browsersupport
Checking link licensing/essays/free-sw.htmlignoring mailto:webmaster
Checking link associate/index_htmlignoring mailto:webmaster
Checking link donate/patron/index_htmlignoring mailto:webmaster

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 15/17
Checking link campaigns/priority.htmlignoring mailto:webmaster
Checking link campaigns/broadcast-flag.htmlignoring mailto:webmaster
done
[mtj@camus]$
Este exemplo demonstra a fase de crawl de um Web spider. Depois que um arquivo é lido pelo cliente, a página também deve ser varrida quanto ao conteúdo, como no caso de umindexador.
Voltar para parte superior
Ferramentas de Geração de Spider do Linux
Foi observado como implementar dois scrapers e um spider. As ferramentas Linuxtambém podem fornecer essa funcionalidade para você.
O comando wget, que significa Web get, é um comando útil para trabalhar de modorecursivo através de um Web site e obter conteúdo de seu interesse. É possível especificar um Web site, o conteúdo no qual está interessado e algumas outras opçõesadministrativas. O comando obtém então os arquivos para seu host local. Por exemplo, oseguinte comando se conectará à sua URL definida e percorrerá de forma recursiva não
mais que três níveis e obterá todos os arquivos com a extensão mp3, mpg, mpeg ou avi.wget -A mp3,mpg,mpeg,avi -r -l 3 http://<some URL>
O comando curl opera de modo semelhante. Sua vantagem é que ele é ativamentedesenvolvido. Outros comandos semelhantes que é possível utilizar são snarf, fget efetch.
Voltar para parte superior
Questões Legais
Existiram processos judiciais para a mineração de dados na Internet utilizando Webspiders e eles não foram bem-sucedidos. A Farechase, Inc. foi recentemente processada
pela American Airlines por efetuar scrap de tela (em tempo real). Primeiro, o processo judicial alegou que a coleta de dados violava o contrato dos usuários da AmericanAirlines (localizado nos Termos e Condições). Quando tal processo não teve êxito, aAmerican Airlines alegou como um tipo de infração e teve êxito. Outros processos
judiciais alegam que a largura de banda obtida pelos spiders e scrapers interfere nalegitimidade dos usuários. Todas essas alegações são válidas e torna as políticas decortesia mais importantes. Consulte a seção Recursos para obter informações adicionais.
Voltar para parte superior

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 16/17
Indo Além
Efetuar crawl e scrap da Web pode ser divertido e, para alguns, extremamente eficaz.Mas, como discutimos anteriormente, há questões legais. Ao criar spider ou scrap, sempreobedeça as regras do arquivo robots.txt disponível no servidor e as incorpore em sua
política de cortesia. Protocolos mais novos, como SOAP, tornam a criação de spidersmuito mais fácil e menos intromissiva em operações da Web normais. Esforços futuros,como a Web semântica, tornarão a criação de spiders ainda mais simples, para quesoluções e métodos de criação de spiders continuem a crescer.
Recursos
Aprender
• A página Web crawler da wikipedia é uma ótima fonte de informações sobre Webcrawlers, inclusive sobre seu histórico e sobre as políticas de crawl da Web.
• Email Spiders oferece uma visão interessante sobre spiders de e-mail e sobrecomo combatê-los.
• Web Robots Pages é um dos Web sites mais antigos sobre robôs na Web e temótimas informações sobre o protocolo de exclusão de robôs (para sua política decortesia).
• "Scrapers, Robots and Spiders: The Battle Over Internet Data Mining" (Gesmer
Updegrove LLP, 2006) fornece uma visão geral interessante sobre questões legaise técnicas de Web scrapers, inclusive uma discussão do processo judicial daAmerican Airlines e da Farechase, Inc.
• Na zona Linux do developerWorks, encontre mais recursos para desenvolvedoresLinux.
• Fique atualizado com eventos técnicos e Webcasts do developerWorks.
Obter produtos e tecnologias
• Source Code for Web Robot Spiders de Searchtools.com fornece código deorigem para robôs de software livre em várias linguagens para diversas tarefas.
• Solicite o SEK para Linux, um conjunto de dois DVDs que contém o software de período experimental IBM mais recente para Linux a partir do DB2®, Lotus®,Rational®, Tivoli®e WebSphere®.
• Com o Software de período experimental IBM, disponível para downloaddiretamente do developerWorks, construa seu próximo projeto dedesenvolvimento em Linux.
Discutir

5/16/2018 Criar Um Web Spider No Linux - slidepdf.com
http://slidepdf.com/reader/full/criar-um-web-spider-no-linux 17/17
• Verifique blogs do developerWorks e envolva-se com a comunidade dodeveloperWorks.
Sobre o autor
M. Tim Jones é um arquiteto de firmwares embarcados e autor de Inteligência Artificial:Sistemas de Abordagem, GNU/Linux, Programação de Aplicativos AI (atualmente emsua segunda edição), Programação de Aplicativos AI (em sua segunda edição) e BSDSockets Programming from a Multilanguage Perspective. Sua formação em engenhariavai desde o desenvolvimento de kernels para nave espacial geossincrônica até a
arquitetura de sistema embarcado e o desenvolvimento de protocolos de interligação deredes. Tim é um Engenheiro Consultor para a Emulex Corp. em Longmont, Colorado.
http://www.ibm.com/developerworks/br/library/l-spider/