crawleando a web feito gente grande com o scrapy
TRANSCRIPT

Construindo Crawler Na WebFeito Gente Grande
Apresentando o Scrapy
Bernardo Fontes@bbfontes

@bbfontes – bernardofontes.net – [email protected]


O que é um web crawler?

O que é um web crawler?
“Web crawler é um programa de computador que navega pela World Wide Web de uma forma
metódica e automatizada”
http://pt.wikipedia.org/wiki/Web_crawler

Estrutura básica de um web crawler

Estrutura básica de um web crawler
● Construção de requisições HTTP

Estrutura básica de um web crawler
● Construção de requisições HTTP● Tratamento da resposta
● Composição de objetos● Composição de novas requisições

Estrutura básica de um web crawler
● Construção de requisições HTTP● Tratamento da resposta
● Composição de objetos● Composição de novas requisições
● “Persistência” de dados
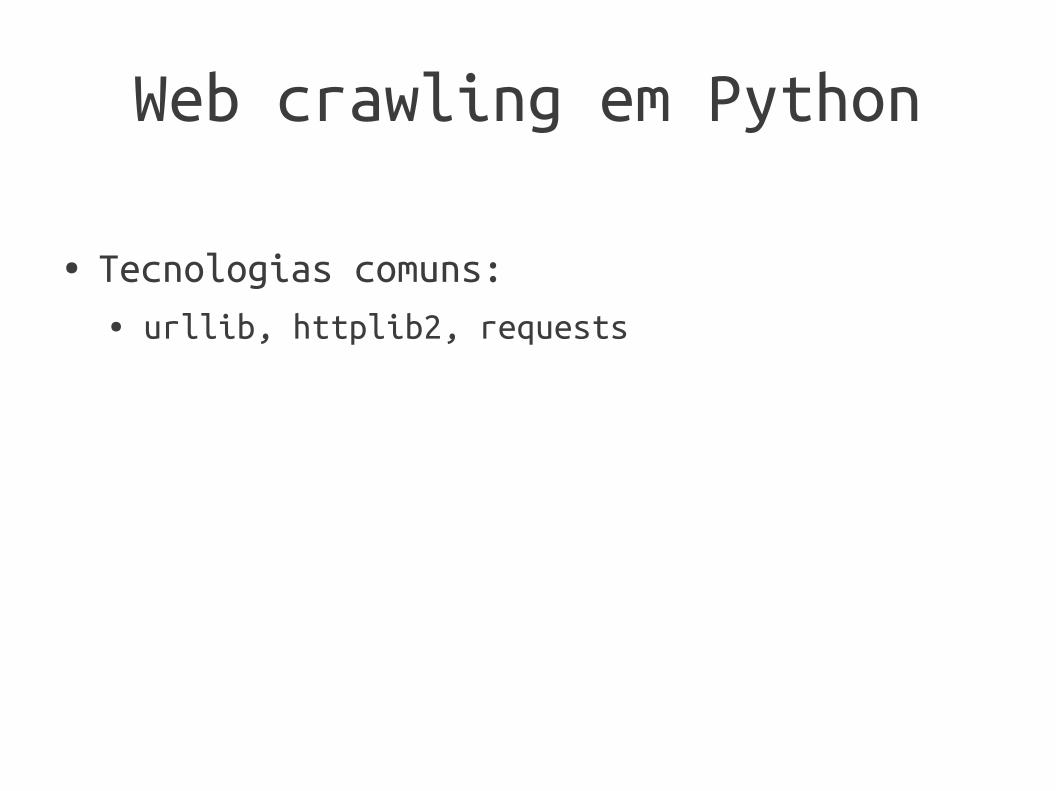
Web crawling em Python
● Tecnologias comuns:● urllib, httplib2, requests

Web crawling em Python
● Tecnologias comuns:● urllib, httplib2, requests● beautifulsoup ou lxml

Web crawling em Python
● Tecnologias comuns:● urllib, httplib2, requests● beautifulsoup ou lxml● json, pickle, yaml, sqlite3

Mas qual o problema?

Mas qual o problema?
● Ter que resolver tudo na mão:● Se tiver autenticação?● Lidar com sessão, cookie...● HTML mal formatado● Crawlear outros recursos● Aumento de pontos de falha● Complexidade de testes● Encoding● Mais alguns outros

Ok... Então, #comofaz?


Quadrado mágico do Scrapy

Item

Item
● Objeto Python que herda da classe scrapy.item.Item que é dict-like

Item
● Objeto Python que herda da classe scrapy.item.Item que é dict-like
● ORM-like● Atributos são instâncias da classe scrapy.item.Field

Item
● Objeto Python que herda da classe scrapy.item.Item que é dict-like
● ORM-like● Atributos são instâncias da classe scrapy.item.Field
● Consegue separar a “modelagem” e tratamento dos dados do processamento do crawler:● Field(serializer=str)

scrapy.http.Request

scrapy.http.Request
● Classe que abstrai a requisição:

scrapy.http.Request
● Classe que abstrai a requisição:
● Request(url, callback=func)

scrapy.http.Request
● Classe que abstrai a requisição:
● Request(url, callback=func)● Outros argumentos:
● method● body● headers● ...

Spider

Spider
● Classe executora do crawler que herda de scrapy.spider.BaseSpider

Spider
● Classe executora do crawler que herda de scrapy.spider.BaseSpider
● Atributos chaves:● name● allowed_domains● start_urls

Spider
● Classe executora do crawler que herda de scrapy.spider.BaseSpider
● Atributos chaves:● name● allowed_domains● start_urls
● Métodos chaves:● start_requests(self)● parse(self, response)
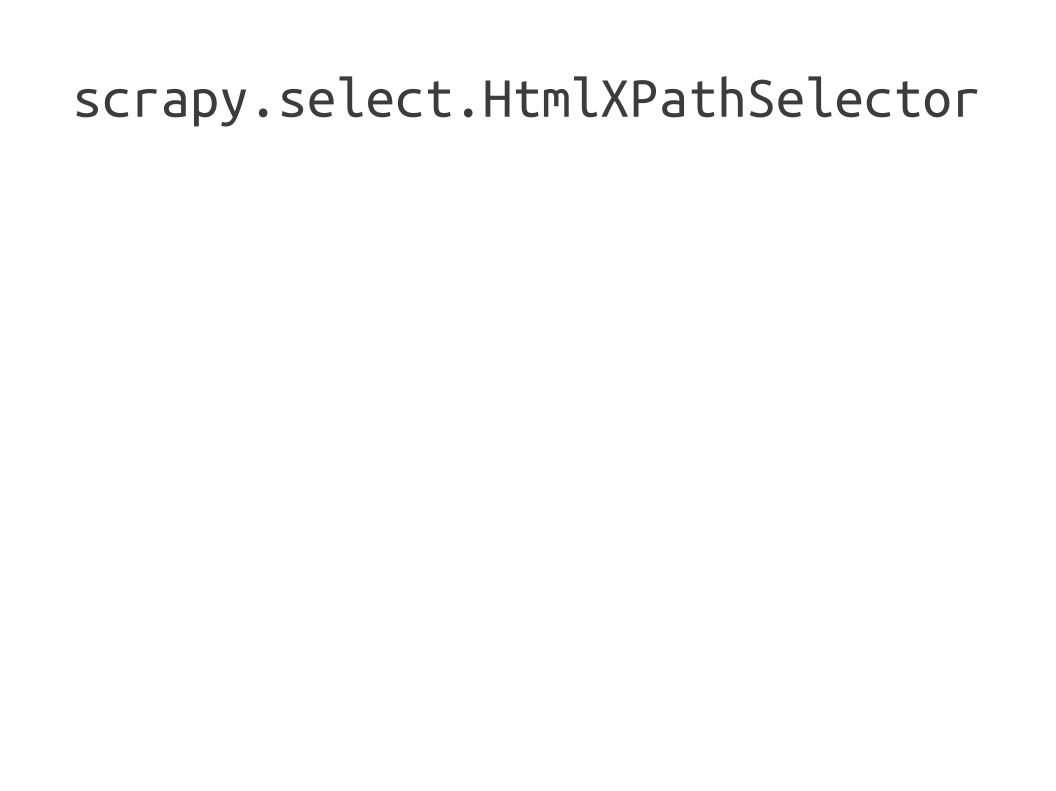
scrapy.select.HtmlXPathSelector
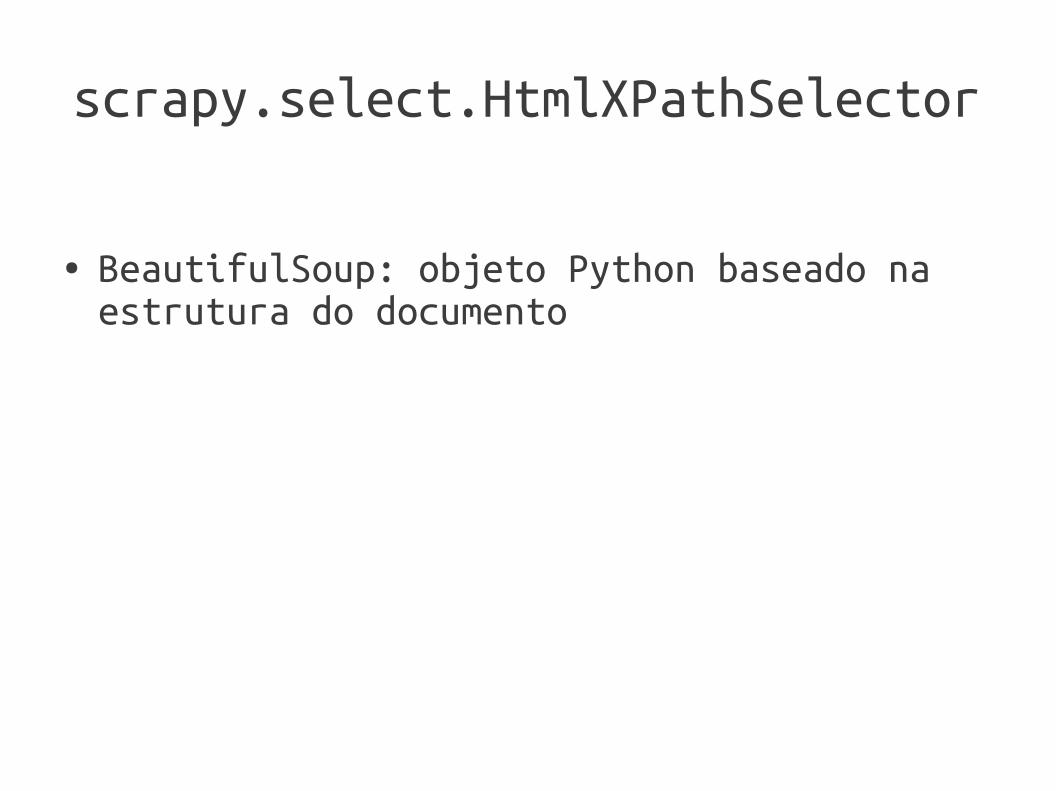
scrapy.select.HtmlXPathSelector
● BeautifulSoup: objeto Python baseado na estrutura do documento
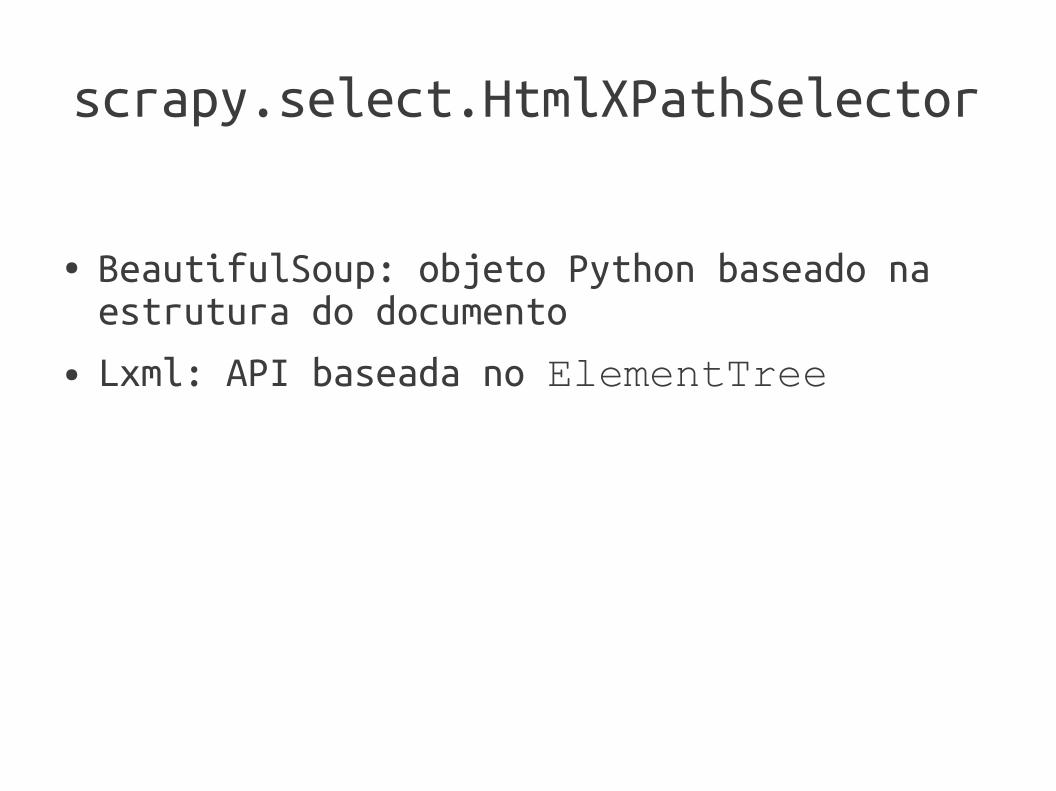
scrapy.select.HtmlXPathSelector
● BeautifulSoup: objeto Python baseado na estrutura do documento
● Lxml: API baseada no ElementTree
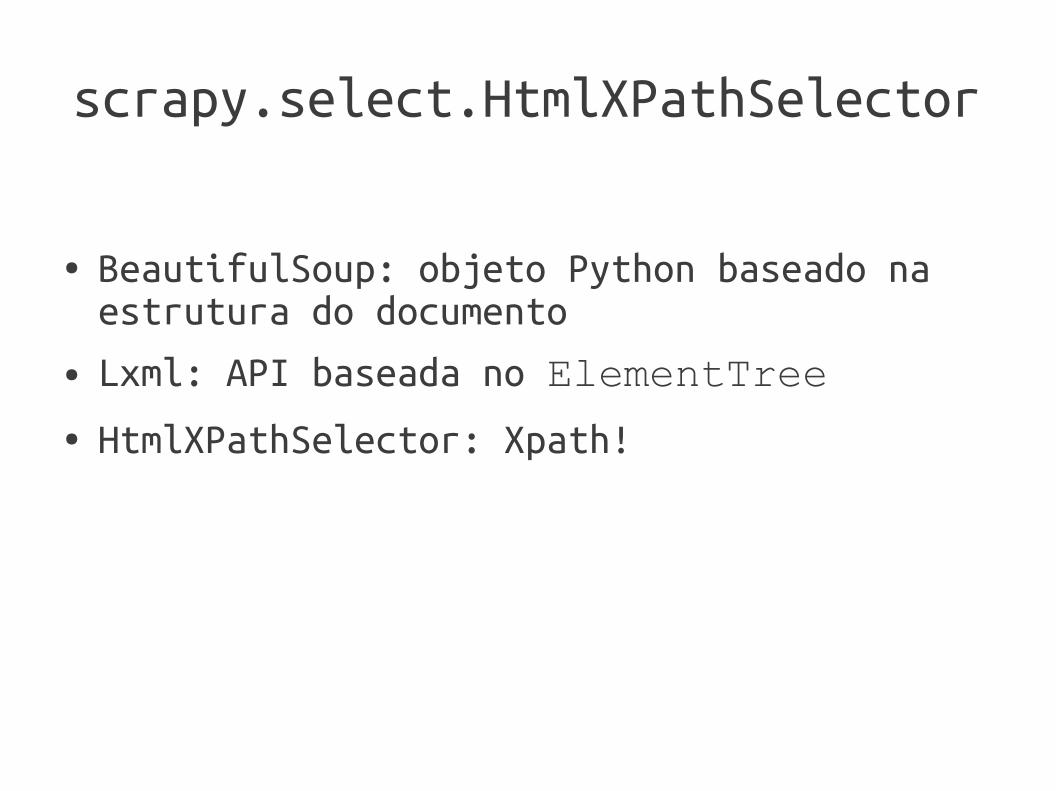
scrapy.select.HtmlXPathSelector
● BeautifulSoup: objeto Python baseado na estrutura do documento
● Lxml: API baseada no ElementTree● HtmlXPathSelector: Xpath!
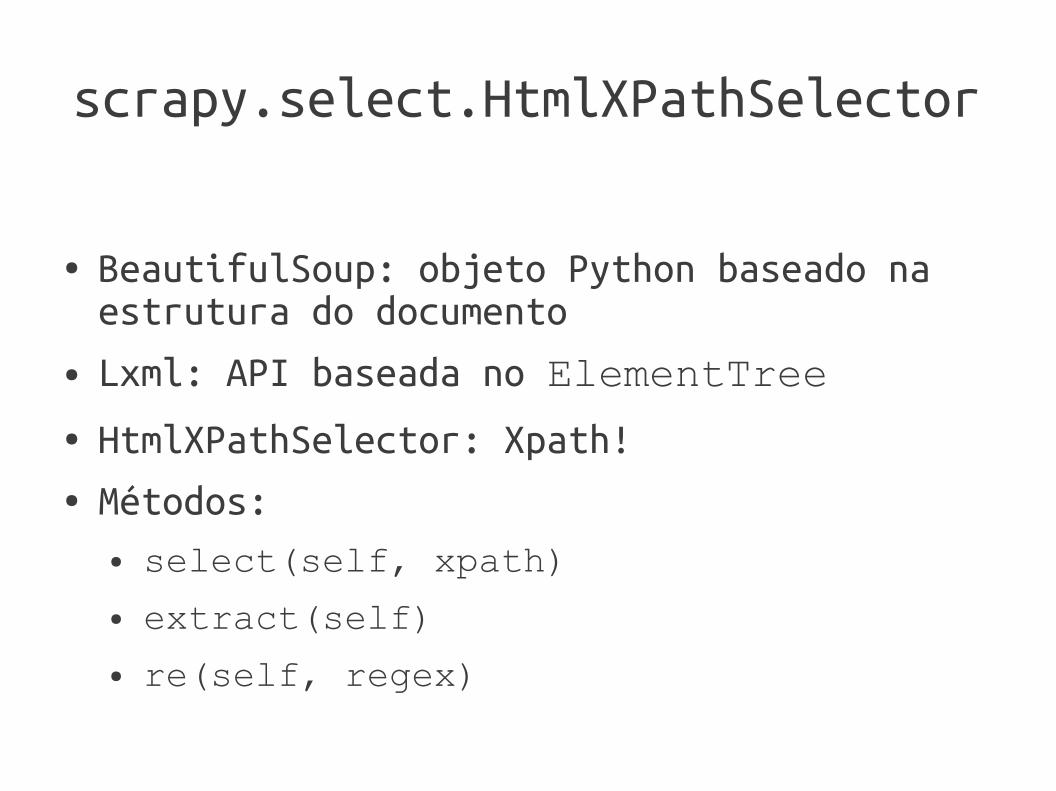
scrapy.select.HtmlXPathSelector
● BeautifulSoup: objeto Python baseado na estrutura do documento
● Lxml: API baseada no ElementTree● HtmlXPathSelector: Xpath!● Métodos:
● select(self, xpath)● extract(self)● re(self, regex)


$ scrapy startproject pybr8talks

github.com/berinhard/scrapy-pybr8

Item Pipeline

Scrapy Shell

Feed Exports

Logging

DjangoItem

Scrapyd

Perguntas?

Obrigado!
Bernardo [email protected]
http://bernardofontes.nethttp://twitter.com/bbfonteshttp://github.com/berinhard