conceitos bÆsicos de estatística aula 2 - cm.de.iscte.ptcm.de.iscte.pt/aula2vi.pdf · intervalos...
TRANSCRIPT

Conceitos Básicos de Estatística
Aula 2
ISCTE - IUL, Mestrados de Continuidade
Diana Aldea Mendes
13 de Setembro de 2011
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 1 / 65

Estatística Aplicada
(Revisões)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 2 / 65

Programa
Introdução
Estatística Aplicada
Medidas de estatística descritiva com destaque para as medidas deassimetria e de curtose.Variáveis aleatórias.Distribuições: Normal, Qui-quadrado, t-Student e F-Snedecor.Intervalos de confiança e testes de hipóteses.
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 3 / 65

Estatística Descritiva
A Estatística Descritiva consiste na apresentação, análise einterpretação de um conjunto de dados (amostra), através da criaçãode instrumentos adequados:
representação gráfica (séries temporais, dispersão, caixas de bigodes,etc)distribuições de frequênciascálculo de valores numéricos que caracterizam os dados de uma formaglobal: medidas de estatística descritiva.
Essas medidas designam-se por parâmetros, quando os dados sereferem a uma população e por estatísticas, quando os dados dizemrespeito a uma amostra
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 4 / 65

Estatística Descritiva
A estatística incide sobre as características relevantes dos elementosque constituem as amostras e as populações. Cada característica égeralmente representada por uma variável, pois os elementos podemter diferentes posicionamentos relativamente a essa característica.
Variáveis
DiscretasContínuas
A escolha da técnica mais adequada para o tratamento estatísticoestá condicionada pela natureza das variáveis: dados qualitativos equantitativos.
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 5 / 65

Estatística Descritiva
Distribuições de frequências (gráficos de barras) para uma variáveldiscreta e para uma variável contínua
0
4
8
12
16
20
24
28
10 15 20 25 30 35 40
Series: PETROLEOSample 1986M01 2003M11Observations 215
Mean 20.94995Median 19.96000Maximum 39.53000Minimum 10.25000Std. Dev. 5.271820Skewness 0.823380Kurtosis 3.524400
JarqueBera 26.75686Probability 0.000002
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 6 / 65

Medidas de Estatística Descritiva
Medidas de tendência central (posição, localização): identificam ocentro de uma distribuição
Média (mean, average)Mediana (median)Moda (mode)
Medidas de tendência não-central (posição, localização): apontampara outras posições da distribuição
Quartis (Qi, i = 1, 2, 3, 4)Decis (Di, i = 1, 2, ..., 10)Percentis (Pi, i = 1, 2, ..., 100)
Medidas de dispersão (variabilidade)
variância (variance)desvio padrão (standard deviation)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 7 / 65

Medidas de tendência central
A média denota-se por µ para uma população e por x para umaamostra
Média de uma amostra (x1, x2, ..., xn) onde n é o tamanho da amostrae xi é o valor da observação i na amostra, é dada por
x =x1 + x2 + ...+ xn
n=
n∑
i=1xi
n,
Exemplo: Dada uma amostra de 5 observações 90, 95, 80, 60, 75, amédia é:
x =90+ 95+ 80+ 60+ 75
5=
4005= 80.
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 8 / 65
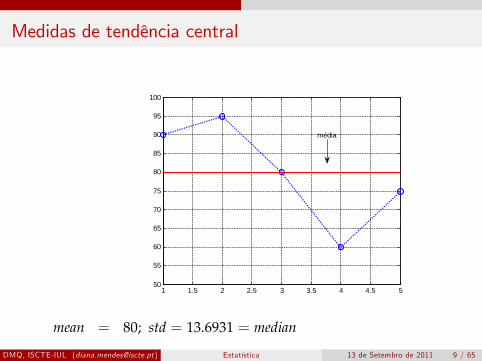
Medidas de tendência central
1 1.5 2 2.5 3 3.5 4 4.5 550
55
60
65
70
75
80
85
90
95
100
média
mean = 80; std = 13.6931 = median
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 9 / 65
Medidas de tendência central
0 10 20 30 40 50 60 70 80 90 1002.5
2
1.5
1
0.5
0
0.5
1
1.5
2
2.5
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 10 / 65

Medidas de tendência central
4
2
0
2
4
6
8
0 100 200 300 400 500T
LOG
VOL
LOGVOL vs. T
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 11 / 65

Medidas de tendência central
Mediana: Me - é um outro nome atribuido ao percentile 50% erepresenta o centro posicional da distribuiçãoCálculo da mediana de um amostra
ordenar os dados em ordem crescente: do mais pequeno para o maiorse n (o número de dados na amostra) é ímpar, então a mediana é onúmero do meio (central)
Me = x n+12
se n é par, então a mediana é a média dos dois números do meio(centrais)
Me =x n+2
2+ x n
2
2Exemplo 1: amostra com um número ímpar de dados: 2, 8, 3, 4, 1
ordenar os dados: 1, 2, 3, 4, 8, logo Me = 3
Exemplo 2: amostra com um número par de dados: 2, 8, 3, 4, 1, 8ordenar os dados: 1, 2, 3, 4, 8, 8 logo Me = (3+ 4)/2 = 3.5
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 12 / 65

Medidas de tendência central
A moda (Mo) é o valor ou categoria que ocorre com a maiorfrequência
Exemplo: a moda da amostra: 9, 2, 7, 11, 14, 7, 2, 7 é o 7, pois a suafrequência é 3As distribuições podem ser:
Unimodais —1 valor de MoBimodais —2 valores de MoMultimodais —vários valores de MoAmodais —Não regista qualquer valor de destaque
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 13 / 65

Medidas de dispersão
Variância:
σ2 = Var (x) = ∑ni=1 (xi − µ)2
npopulação
s2 = Var (x) = ∑ni=1 (xi − x)2
n− 1amostra
Desvio padrão (Standard Deviation): é a mais comum medida devariabilidade. Define-se para uma população (σ) e para uma amostra(s) como a seguir:
σ =
√∑n
i=1 (xi − µ)2
ne s =
√∑n
i=1 (xi − x)2
n− 1
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 14 / 65

Outras medidas
Momento Estatístico
Se x1, x2, ..., xn são os n valores assumidos pela variável X, definimos omomento de ordem t dessa variável como:
mt =∑n
i=1 xti
n
Note que se t = 1 temos a média aritmética.O momento de ordem t centrado em uma constante K, com K 6= 0 édefinido como:
mKt =
∑ni=1 (xi − K)t
n
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 15 / 65

Assimetria
Assimetria (skewness) é o grau de afastamento que uma distribuiçãoapresenta do seu eixo de simetria. Este afastamento pode acontecer dolado esquerdo ou do lado direito da distribuição, chamado de assimetrianegativa ou positiva respectivamente.
Coeficiente do momento de assimetria
sk =m3
s3 =1n ∑n
i=1 (xi − x)3√(1n ∑n
i=1 (xi − x)2)3
Temos entãosk = 0 distribuição simétricask > 0 distribuição assimétrica positivask < 0 distribuição assimétrica negativa
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 16 / 65
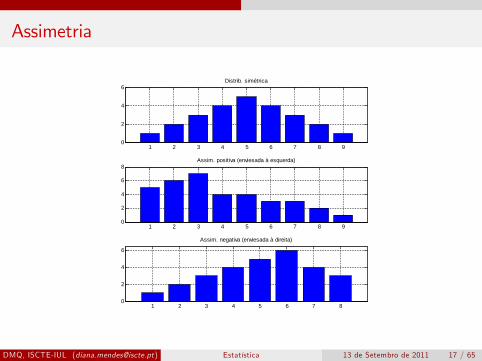
Assimetria
1 2 3 4 5 6 7 8 90
2
4
6Distrib. simétrica
1 2 3 4 5 6 7 8 90
2
4
6
8Assim. positiva (enviesada à esquerda)
1 2 3 4 5 6 7 80
2
4
6
Assim. negativa (enviesada à direita)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 17 / 65

Curtose
Curtose é o grau de achatamento da distribuição. Ou o quanto umacurva de frequência será achatada em relação a uma curva normal dereferência.
Para o cálculo do grau de curtose de uma distribuição utiliza-se ocoeficiente do momento de curtose
k =m4
s4 =1n ∑n
i=1 (xi − x)4(1n ∑n
i=1 (xi − x)2)2
Temos então k = 3 distribuição mesocúrticak > 3 distribuição leptocúrticak < 3 distribuição platicúrtica
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 18 / 65
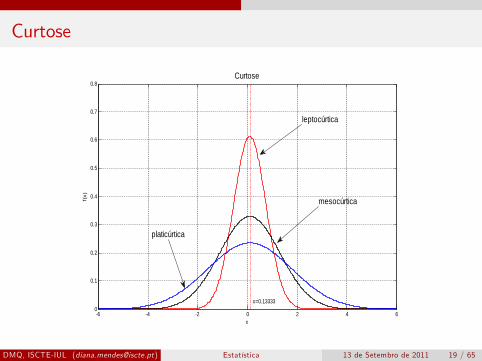
Curtose
6 4 2 0 2 4 60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
x
f(x)
Curtose
leptocúrtica
mesocúrtica
platicúrtica
x=0.13333
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 19 / 65
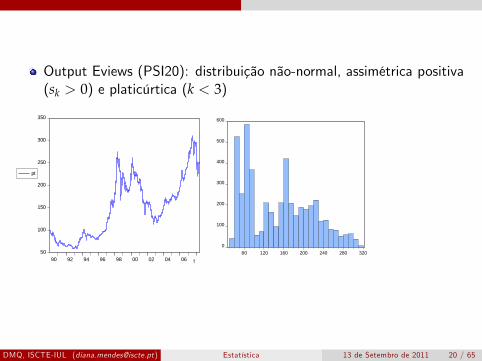
Output Eviews (PSI20): distribuição não-normal, assimétrica positiva(sk > 0) e platicúrtica (k < 3)
50
100
150
200
250
300
350
90 92 94 96 98 00 02 04 06
pt
PT
t
0
100
200
300
400
500
600
80 120 160 200 240 280 320
Series: PTSample 1/02/1990 5/12/2008Observations 4790
Mean 149.5132Median 151.5150Maximum 312.1800Minimum 58.83000Std. Dev. 66.51653Skewness 0.384446Kurtosis 2.054050
JarqueBera 296.5841Probability 0.000000
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 20 / 65

Probabilidade de um Acontecimento
Um tratamento estatístico é sempre um tratamento numérico, mesmoque a natureza das variáveis envolvidas não o seja.Assim, torna-se necessário encontrar um processo que permita atribuirvalores reais aos resultados elementares de qualquer experiênciaaleatória. Fazer tais atribuições de valores, não é mais do que definirfunções reais no espaço de acontecimentos ΩNo entanto, não podem ser quaisquer funções.Têm que ser definidas de modo a que, ao trabalhar com elas, não seperca nenhuma informação sobre a forma como se distribuiam asprobabilidades, em relação aos acontecimentos da experiênciaaleatória inicial;Tem que se poder estar seguro em relação à interpretação dequalquer intervalo ou valor real, e ainda assegurar a validade dasoperações entre acontecimentos.
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 21 / 65

Probabilidade de um Acontecimento
Se uma experiência é repetida um número grande de vezes, n, e oacontecimento A é observado nA vezes, então a probabilidade de A é
P (A) ' nA
n, se n é suficientamente grande
onde nA é a frequência do acontecimento A e nAn é a frequência
relativa de A.Considere uma experiência aleatória cuja espaço de amostragem é S ecom pontos de amostragem E1, E2, .... Para cada acontecimentoEi ∈ S define-se um número P(Ei) (a probabilidade do Ei) quesatisfaz as seguintes três condições:
0 ≤ P(Ei) ≤ 1 para todo o iP(S) = 1Propriedade de aditividade ∑S P (Ei) = 1
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 22 / 65

Variáveis Aleatórias
Definição: uma variável aleatória (v.a.) é uma regra (função) queasigna um valor numérico (x) a cada resultado possível de umaexperiência aleatória (ω), isto é
X : Ω→ R
ω → X (ω) = x
Uma variável aleatória é discreta se só assume um número finito ouinfinito numerável de valores distintosUma variável aleatória diz-se contínua se assumir um número infinitonão numerável de valores distintosA função (densidade) de probabilidade de uma v.a. X é umafunção fX que associa a cada valor possível x de X a sua
probabilidade de ocorrência: fX (x) = P (X = x) . Tem-se que
0 ≤ fX (x) ≤ 1 e ∑xi
fX (xi) = 1.
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 23 / 65
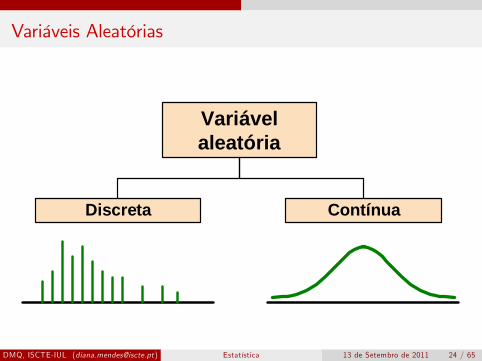
Variáveis Aleatórias
Variávelaleatória
Discreta Contínua
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 24 / 65

Variáveis Aleatórias
A distribuição de probabilidades pode ainda ser descrita através dafunção de distribuição cumulativa F(x), que, para cada x, dá aprobabilidade da v.a. assumir um valor inferior ou igual ax : F (x) = P (X ≤ x) (probabilidade acumulada até x), onde
0 ≤ F (x) ≤ 1, F (x) é não-decrescentelim
x→−∞F (x) = 0 e lim
x→+∞F (x) = 1
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 25 / 65

Variáveis Aleatórias
Se X é uma variável aleatória contínua, então, se existe uma funçãonão-negativa fX (x) ≥ 0, ∀x ∈ R e integrável com∫ +∞
−∞fX (x) dx = 1
tal que
P (a ≤ X ≤ b) =∫ b
afX (x) dx, ∀a, b ∈ R
então denotamos a função fX (x) por função densidade deprobabilidades (fdp) da v.a. X.Também podemos descrever a distribuição de probabilidades atravésda função de distribuição cumulativa
F (x) = P (X ≤ x) =∫ x
−∞fX (t) dt ⇒ F′ (x) = fX (x)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 26 / 65
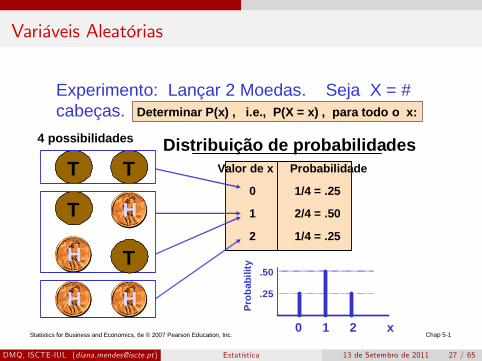
Variáveis Aleatórias
Statistics for Business and Economics, 6e © 2007 Pearson Education, Inc. Chap 51
Experimento: Lançar 2 Moedas. Seja X = #cabeças.
T
T4 possibilidades
T
T
H
H
H H
Distribuição de probabilidades
0 1 2 x
Valor de x Probabilidade
0 1/4 = .25
1 2/4 = .50
2 1/4 = .25
.50
.25
Prob
abili
ty
Determinar P(x) , i.e., P(X = x) , para todo o x:
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 27 / 65
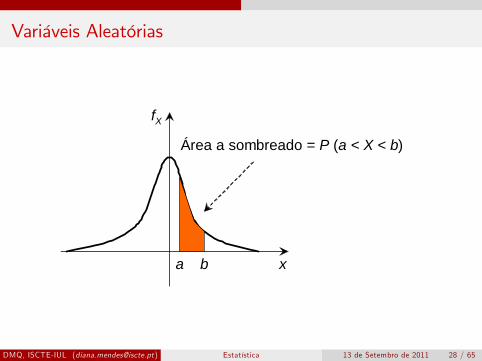
Variáveis Aleatórias
x
fX
a b
Área a sombreado = P (a < X < b)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 28 / 65

Variáveis Aleatórias - Valor esperado e Variância
Definição: o valor esperado (média) de uma v.a. X denota-se porµ e é definida como a seguir:
µ = E (X) = ∑x
x fX (x) = ∑x
x P (x) , X discreta
µ = E (X) =∫ +∞
−∞x fX (x) dx, X contínua
Definição: Se X é uma variável aleatória com média µ, então avariância de X é definida por
σ2 = Var (X) = ∑x(x− µ)2 fX (x) = ∑ x2fX (x)−µ2 = E
((X− µ)2
)O desvio padrão de X define-se por
σ =√
Var (X) =√
∑x(x− µ)2 fX (x) =
√∑ x2fX (x)− µ2
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 29 / 65

Variáveis Aleatórias
Example
Continuação da experiência de lansamento de 2 moedas: temos a seguintetabela
x P (x)0 0.251 0.52 0.25
Calcular o valor esperado
E (X) = ∑x
x P (x) = ( 0︸︷︷︸x1
× 0.25︸︷︷︸P(x1)
) + ( 1︸︷︷︸x2
× 0.50︸︷︷︸P(x2)
) + (2× 0.25) = 1
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 30 / 65

Variáveis Aleatórias
Teorema: Se fX (x) é a função probabilidade de uma variávelaleatória X e g (X) é alguma função de variável X, então o valoresperado da função g é dado por
E (g (X)) = ∑x
g (X) fX (x)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 31 / 65

Variáveis Aleatórias
Propriedades
E (c) = cE (cX) = cE (X)E (aX+ bY) = aE (X) + bE (Y)E (XY) = E (X)E (Y) + cov(X, Y) (se X, Y são independentes, entãoE (XY) = E (X)E (Y))Var (X) = E
(X2)− (E (X))2
Var (c) = 0Var (aX+ b) = a2Var (X)Var(X± Y) = Var(X) +Var(Y)± 2cov(X, Y) (se X e Y sãoindependentes, então Var(X± Y) = Var(X) +Var(Y))
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 32 / 65

Variáveis Aleatórias Bidimensionais
Usa-se quando há interesse por dois resultados simultâneos (porexemplo, altura X e peso Y de duas pessoas)
Sejam E um experimento aleatório e Ω o espaço amostral associado aE e sejam X = X(ω) e Y = Y(ω) duas funções, cada umaassociando um número real a cada resultado ω ∈ Ω. Então o par(X, Y) designa-se variável aleatória bidimensional.Para (X, Y) variável aleatória bidimensional e para ∀ (x, y) ∈ R2
define-se a função de distribuição conjunta de (X, Y) por:
FX,Y (x, y) = P (X ≤ x, Y ≤ y) = ∑xi≤x
∑yj≤y
PX,Y(xi, yj
), (discreto)
FX,Y (x, y) = P (X ≤ x, Y ≤ y) =∫ x
−∞
∫ y
−∞PX,Y (x, y) dxdy, (contínuo)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 33 / 65

Variáveis Aleatórias Bidimensionais
Propriedades da função de distribuição conjunta
0 ≤ FX,Y (x, y) ≤ 1, ∀ (x, y) ∈ R2
FX,Y(x+4x, y+4y
)≥ FX,Y (x, y) , ∀4x,4y ≥ 0
limx,y→+∞
FX,Y (x, y) = 1
limx→−∞
FX,Y (x, y) = 0 e limy→−∞
FX,Y (x, y) = 0
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 34 / 65

Variáveis Aleatórias Bidimensionais
Seja (X, Y) uma variável aleatória bidimensional. Então
PX,Y (x, y) = P (X = x, Y = y) , ∀ (x, y) ∈ R2
diz-se a função (densidade) de probabilidade conjunta de (X, Y).PX,Y (x, y) ≥ 0, ∀ (x, y) ∈ R2
∑x ∑y PX,Y (x, y) = 1 (discreto)∫ +∞−∞
∫ +∞−∞ PX,Y (x, y) dxdy = 1 (contínuo)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 35 / 65

Variáveis Aleatórias Bidimensionais
A partir do conhecimento do comportamento conjunto de (X, Y) étambém possível analisar separadamente X e Y uma vez que
limx→+∞
FX,Y (x, y) = FY (y) e limy→+∞
FX,Y (x, y) = FX (x)
Função (densidade) de probabilidade marginal de X; pX (x)
pX (x) = P (X = x, Y qualquer) = ∑y
PX,Y (x, y)
pX (x) = P (X = x, Y qualquer) =∫ +∞
−∞PX,Y (x, y) dy
Função (densidade) de probabilidade marginal de Y; pY (y)
pY (y) = P (X qualquer, Y = y) = ∑x
PX,Y (x, y)
pY (y) = P (X qualquer, Y = y) =∫ +∞
−∞PX,Y (x, y) dx
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 36 / 65

Variáveis Aleatórias Bidimensionais
Dada uma variável aleatória bidimensional (X, Y), diz-se que as v.a.unidimensionais que a integram, X e Y, são independentes, se a suafunção de probabilidade conjunta, PX,Y (x, y), for igual ao produto dasfunções de probabilidade marginais correspondentes, isto é:
PX,Y (x, y) = pX (x)× pY (y) , ∀ (x, y) ∈ R2
Teorema: Se X e Y são variáveis aleatórias independentes então asvariáveis aleatórias U = g(X) e V = h(Y) são também independentes
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 37 / 65

Variáveis Aleatórias Bidimensionais
Sejam X e Y duas variáveis aleatórias discretas. A funçãoprobabilidade condicionada (condicional) da v.a. Y exprime aprobabilidade de Y assumir o valor y quando é especificado o valor xpara X. Define-se por
P (Y = y | X = x) =P (X = x, Y = y)
P (X = x)=
PX,Y (x, y)pX (x)
Tem-se analogamente
P (X = x | Y = y) =P (X = x, Y = y)
P (Y = y)=
PX,Y (x, y)pY (y)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 38 / 65

Variáveis Aleatórias Bidimensionais
Define-se a covariância entre X e Y, e denota-se por Cov(X, Y),como sendo
Cov(X, Y) = E[(X− µX)(Y− µY)]
= ∑x
∑y(x− µX)(y− µY)PX,Y (x, y)
= E (XY)− E (X)E (Y)
A covariância mede a intensidade da relação linear existente entreduas variáveis e assume valores reais.
Teorema: Se X e Y forem independentes então
Cov(X, Y) = 0
O recíproco não é, em geral, verdadeiro, isto é: Cov(X, Y) = 0 nãoimplica que X e Y sejam v.a. independentes
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 39 / 65
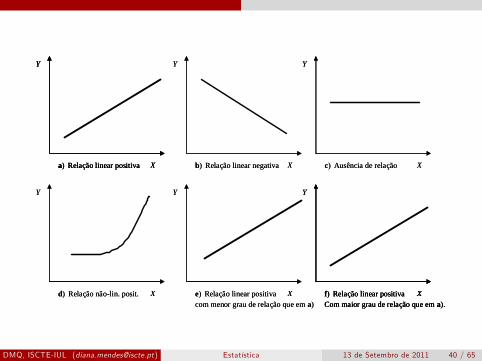
X
Y
a) Relação linear positiva X
Y
b) Relação linear negativa X
Y
c) Ausência de relação
X
Y
d) Relação nãolin. posit. X
Y
e) Relação linear positivacom menor grau de relação que em a)
X
Y
f) Relação linear positivaCom maior grau de relação que em a).
X
Y
a) Relação linear positiva X
Y
a) Relação linear positiva X
Y
b) Relação linear negativa X
Y
c) Ausência de relação
X
Y
d) Relação nãolin. posit. X
Y
e) Relação linear positivacom menor grau de relação que em a)
X
Y
f) Relação linear positivaCom maior grau de relação que em a).
X
Y
f) Relação linear positivaCom maior grau de relação que em a).
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 40 / 65

Distribuição normal: caracterizada por dois parâmetros: média µ edesvio-padrão σ e dada pela função densidade de probabilidades (fdp)
f (x) =1
σ√
2πe−(x−µ)2/2σ2
, −∞ < x < ∞
Uma v.a. normalmente distribuída com µ = 0 e σ = 1 diz-se que temuma distribuição normal padrão (standard). Denota-se por Z e asua fdp é dada por f (z) = 1√
2πe−z2/2, −∞ < z < ∞
Trata-se de uma função em forma de sino, simétrica em relação amédia com área abaixo do gráfico =1.
Notação: X ∼ N(µ, σ2) e Z ∼ N (0, 1)
Padronizar uma variável aleatória normal:
z-score Z =X− µX
σX⇔ X = µX + σXZ, µZ = 0, σ2
Z = 1.
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 41 / 65
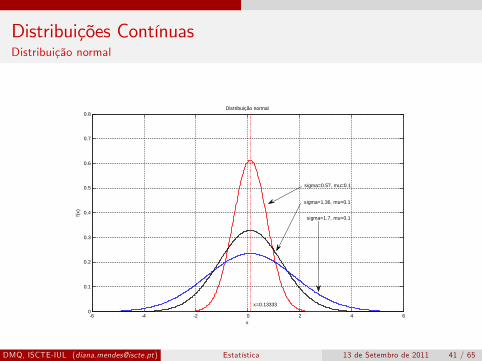
Distribuições ContínuasDistribuição normal
6 4 2 0 2 4 60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
x
f(x)
Distribuição normal
sigma=1.36, mu=0.1
sigma=0.57, mu=0.1
sigma=1.7, mu=0.1
x=0.13333
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 41 / 65

Distribuições ContínuasDistribuição Qui-Quadrado
Seja um conjunto de k variáveis Zi (i = 1, ..., k) tal que:cada variável Zi segue uma distribuição normal padronizada,Zi ∼ N(0, 1)as variáveis Zi são mutuamente independentes
A variável aleatória X = ∑i Z2i , segue uma Distribuição
Qui-quadrado com k graus de liberdade quando a sua funçãodensidade de probabilidades tem a forma
f (x) =1
2k/2Γ (k/2)e−x/2x(k/2)−1, Γ função gamma
Notação: X = ∑i Z2i ∼ χ2
(k)
Média: µ = k e Variância: σ2 = 2kÉ uma distribuição assimétrica, que se aproxima da distribuiçãonormal, à medida que k aumenta
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 42 / 65
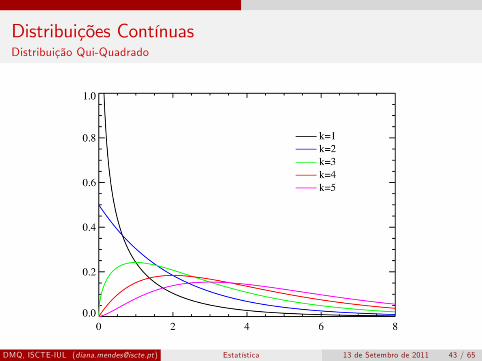
Distribuições ContínuasDistribuição Qui-Quadrado
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 43 / 65

Distribuições ContínuasDistribuição t-Student
Sejam duas variáveis independentes Z ∼ N (0, 1) e V ∼ χ2(k).
Define-se a nova variável
X =Z√V/k
.
A variável X tem uma distribuição t de Student com k graus deliberdade se a sua função densidade de probabilidades tem a forma
f (x) =Γ(
k+12
)√
kπΓ(
k2
) (1+x2
k
)− k+12
, −∞ < x < ∞, k > 0
Notação: X ∼ t(k)Média: µ = 0 para k > 1 e Variância: σ2 = k
k−2 para k > 2Distrib. simétrica em relação à origem, que se aproxima da distrib.normal à medida que k aumenta;
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 44 / 65
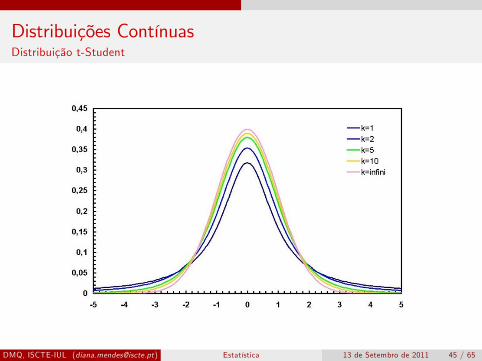
Distribuições ContínuasDistribuição t-Student
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 45 / 65

Distribuições ContínuasDistribuição F de Snedecor
Sejam duas variáveis independentes V1 ∼ χ2(k1)
e V2 ∼ χ2(k2)
.Define-se a nova variável
X =V1/k1
V2/k2.
A variável X segue uma distribuição F com k1 e k2 graus de liberdadese a sua função densidade de probabilidades tem a forma
f (x) =Γ(
k1+k22
)Γ(
k12
)Γ(
k22
)(
k1k2
) k12 x
k12 −1
(k2 + k1x)k1+k2
2
Notação: X ∼ F(k1,k2)
Média: µ = k2k2−2 para k2 > 2
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 46 / 65

Distribuições ContínuasDistribuição F de Snedecor
Variância: σ2 =2k2
2(k1+k2−2)k1(k2−2)2(k2−4)
para k2 > 4
É uma distribuição positiva e assimétrica e os seus valoresencontram-se em tabelas
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 47 / 65
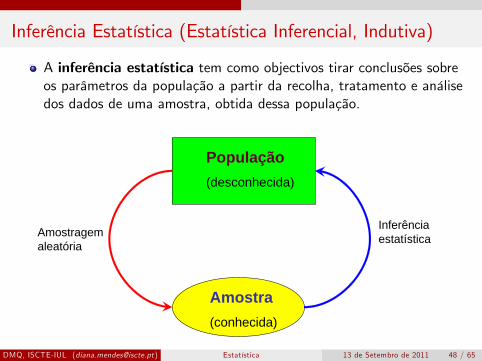
Inferência Estatística (Estatística Inferencial, Indutiva)
A inferência estatística tem como objectivos tirar conclusões sobreos parâmetros da população a partir da recolha, tratamento e análisedos dados de uma amostra, obtida dessa população.
População(desconhecida)
Amostra(conhecida)
Amostragemaleatória
Inferênciaestatística
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 48 / 65

Inferência Estatística
Parâmetro —Medida usada para descrever a distribuição dapopulação
a média µ e a variância σ2 são parâmetros de uma distribuição Normal
Estatística —Função de uma amostra aleatória que não depende deparâmetros desconhecidos
Média amostral, Variância amostral
Num problema de inferência estatística a estimação dos parâmetrospode ser
pontual (estatística, estimador = é a v.a. que estima (pontualmente)um parâmetro (populacional) )por intervalos (intervalos de confiança)
Estimação pontual: procedimento que vai permitir obter um valorque seja o “melhor” (de acordo com algum critério) para umparâmetro desconhecido θ.Um estimador de θ é uma v.a. com uma dada distribuição.Chama-se estimativa de θ e representa-se por θ, um valor concretoassumido pelo estimador.DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 49 / 65

Inferência Estatística - Propriedades dos estimadores
O estimador Θ do parâmetro θ, diz-se centrado ou não enviesadose e só se E(Θ) = θ.Dados dois estimadores centrados para θ, Θ e Θ′ diz-se que Θ é maiseficiente do que Θ′ se
Var[Θ] ≤ Var[Θ′].
Um estimador diz-se suficiente, quando utiliza toda a informaçãodisponível na amostra.
Seja X1, ..., Xn uma amostra aleatória de dimensão n extraída de umapopulação com média µ e variância σ2. Então,
X = ∑ni=1 Xi
ne S2 =
∑ni=1(
Xi −X)2
n− 1
são estimadores centrados de µ e σ2, respectivamente.
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 50 / 65

Inferência Estatística - Estimação por Intervalos
Na estimação por intervalos, em vez de se indicar um determinadovalor estimado para certo parâmetro da população, constrói-se umintervalo que, com certo grau de certeza, previamente fixado, ocontenha.
Um intervalo de confiança para um parâmetro θ, a um grau deconfiança 1− α, é um intervalo aleatório (Linf , Lsup) tal que:
P(Linf < θ < Lsup) = 1− α, α ∈ (0, 1)
onde α deve ser um valor muito reduzido por forma a temosconfianças elevadas.
α é o nível de confiança (significância), ou seja o erro que estamosa cometer
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 51 / 65

Intervalo de confiançaIC para a média quando a variância é conhecida
Seja X1, ..., Xn uma amostra aleatória de dimensão n. Consideramosque a v. a. X tem um distribuiçao normal, i.e., X ∼ N
(µ, σ2) .
Se σ é conhecido, então considere-se a nova variável
Z =X− µ
σ/√
n∼ N (0, 1) .
Fixamos α (o nível de significância) e notamos por zα/2 o valor críticode Z tal que P (Z > zα/2) = α/2. Então
P (−zα/2 < Z < zα/2) = 1− α⇔ P(−zα/2 <
X− µ
σ/√
n< zα/2
)= 1− α
e portanto o intervalo a (1− α)× 100% de confiança para µ é
X− zα/2σ√n< µ < X+ zα/2
σ√n
(1)
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 52 / 65

Intervalo de confiançaIC para a média quando a variância é desconhecida
Se a variância σ é desconhecida e a amostra é grande, então podemossubstituir σ → SSe a amostra é pequena, a variável obtida no caso anterior já não énormal. Mas, se a população é normal, então a variável aleatória
T =(X− µ
)S/√
n∼ t(n−1)
tem distribuição t-Student com n− 1 graus de liberdade.Então, o intervalo a (1− α)× 100% de confiança para µ é
x− tα/2,(n−1)s√n< µ < x+ tα/2,(n−1)
s√n
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 53 / 65

Intervalo de confiança
Diminuindo o grau de confiança de 99% a 95%, aumentamos o riscode estar errados: de 1% de risco passamos a 5% de risco, ou sejatemos mais possibilidades (5/100 em vez de 1/100) de que o IC nãocontenha a média populacional.
Ao aumentar o risco, o intervalo deve ser mais preciso
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 54 / 65

Testes (ensaios) de hipóteses
Decisão estatística: tomar uma decisão baseando-nos numa amostraExemplos:
Verificar se mais de metade da população irá consumir um novoproduto lançado no mercado;Testar se um sistema educacional é melhor em média que outroDecidir se um novo medicamento cura ou não uma certa doença
Uma hipótese estatística é uma afirmação acerca dos parâmetros deuma ou mais populações (testes paramétricos) ou acerca dadistribuição da população (testes de ajustamento, não-paramétricos).
Os testes de hipóteses têm como objectivo decidir, com base nainformação fornecida pelos dados de uma amostra, sobre a aceitaçãoou não de uma dada hipótese (conjectura sobre aspectosdesconhecidos da(s) população(ões)).
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 55 / 65

Testes de hipóteses
Formular duas hipóteses:
hipótese nula H0 (aqui se especifica o valor do parâmetro ou adistribuição a verificar)hipótese alternativa H1
A resposta num teste de hipóteses é dada na forma rejeição ou nãorejeição de H0
Os pontos de fronteira chamam-se valores críticos
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 56 / 65

Testes de hipóteses
A tomada de decisões no processo de inferência posui riscos, o quedetermina a aparição dos erros de decisão
Tipos de erros:
Erro do tipo I: rejeitar H0 sendo H0 verdadeira (erro de rejeição);Erro do tipo II: não rejeitar H0 sendo H0 falsa (erro de não-rejeição).
Definem-se
α = P(erro do tipo I) = P (Rejeitar H0|H0 é verdadeira), onde αchama-se nível de significância do teste. Em geral, atribuir-se umvalor muito baixo à probabilidade do erro do tipo I (0.05 ou 0.01)β = P(erro do tipo II) = P(Não-rejeitar H0|H0 é falsa), onde 1− βchama-se potência do teste
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 57 / 65

Testes de hipóteses
Procedimento Geral dos Testes de Hipóteses (Testes deSignificância ou Teste Estatístico)
Pelo contexto do problema identificar o parâmetro de interesseEspecificar a hipótese nula H0 e a hipótese alternativa apropriada H1Escolher o nível de significância, αEscolher uma estatística de teste adequada (variável aleatória utilizadapara decidir: por exemplo média amostral)Definir a região crítica ou região de rejeição —RCDeterminar o valor real da estatística de testeDecidir sobre a rejeição ou não de H0
Se o valor calculado ∈ RC rejeita-se H0Se o valor calculado /∈ RC não se rejeita H0
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 58 / 65

Testes de hipóteses
5 4 3 2 1 0 1 2 3 4 50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
Não rejeitar H0
Rejeitar H0 Rejeitar H0
Região críticaRegião crítica
Região de aceitação
Valor crítico Valor crítico
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 59 / 65

Testes de hipóteses
Teste bilateral:
H0 : µ = µ0
H1 : µ 6= µ0
Teste unilateral à direita:
H0 : µ = µ0
H1 : µ > µ0
Os valores da estatística de teste que nos levarão a rejeitar H0 econcluir que µ > µ0, também nos levarão a rejeitar qualquer valormenor do que µ0.Teste unilateral à esquerda
H0 : µ = µ0
H1 : µ < µ0
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 60 / 65

Testes de hipóteses
5 4 3 2 1 0 1 2 3 4 50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
5 4 3 2 1 0 1 2 3 4 50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
Região crítica
Rejeitar H0
Região de aceitação
Não rejeitar H0
Região de aceitação
Não rejeitar H0
Valor crítico
Região crítica
Rejeitar H0
Valor crítico
H1: mu < mu0H1: mu > mu0
Testes unilaterais
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 61 / 65

Testes de hipóteses
A indicação do valor observado da estatística do teste, seguido daconsulta de uma tabela para a procura de um valor crítico, tem sidorecentemente “substituído”pelo cálculo de: a probabilidade de seobservar um valor igual ou mais extremo do que o observado, se ahipótese nula é verdadeira —chama-se a isto valor de prova; valor p( p-value, possível calcular com ajuda do qualquer software )Podemos interpretar o valor do p-value como o maior nível designificância que levaria à não rejeição da hipótese nula (ou o menorque levaria à rejeição).Assim, quanto menor for o p-value, menor é a consistência entre osdados e a hipótese nula (Quanto mais baixo for o valor-p maior é aevidência contra a hipótese nula.)Habitualmente adopta-se como regra de decisão:
rejeitar H0 se p-value ≤ α
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 62 / 65

Testes de hipóteses
Examples
Máquina de encher pacotes de açúcar. O peso de cada pacote deve ser ≈8g (isto é, µ = 8). Será que a máquina está a funcionar correctamente?
SolutionTemos então a hipótese nula
H0 : µ = 8
contra a hipótese alternativa H1 : µ 6= 8. Seja X - variável aleatória querepresenta o peso de um pacote de açúcar, com E (X) = µ e Var (X) = 1.Vamos considerar que numa amostra aleatória de 25 observações:X1, ..., X25 observou-se x = 8.5. Quer-se saber se, ao nível de significânciade 5%, se pode afirmar que a máquina continua afinada.
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 63 / 65

Testes de hipóteses
Estatística do teste:
Z0 =X− 8
1/√
25e para α = 0.05→ a = 1.96 donde se obtem a região crítica:
Z0 < −1.96 ou Z0 > 1.96.
Com x = 8.5 obtém-se
z0 =8.5− 81/√
25= 2.5.
Como z0 > 1.96 rejeita-se H0, ou seja existe evidência (ao nível designificância considerado) de que a máquina está desafinada.Considerando agora um valor-p, temos que: quando z0 = 2.5, para estevalor H0 não é rejeitada se
α ≤ 2 (1−Φ (2.5)) = 0.0124
ou seja, p = 0.0124.DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 64 / 65
DMQ, ISCTE-IUL ([email protected]) Estatística 13 de Setembro de 2011 65 / 65