bioestat´ıstica -...
TRANSCRIPT

Bioestatıstica
Valeska Andreozzi
2011
Probabilidade 2Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3Variavel Aleatoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4Funcao de probabilidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6Funcao de distribuicao. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8Binomial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12Funcao de densidade de probabilidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15Normal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17Exercıcios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Estimacao 23Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Definicao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25Elementos da estimacao. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26Propriedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29Modelo parametrico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30Metodos de Estimacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31Metodo dos momentos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32Mınimos quadrados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34Maxima Verossimilhanca . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Solucao Analıtica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38Solucao Grafica no R. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Exercıcio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43Outro Exemplo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45Calculo da EMV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46Met. Newton-Raphson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47Metodo Iterativo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48Pratica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
Correlacao Linear 50Conceitos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51Conceitos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52Propriedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53Coef. Correlacao. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54Padroes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55Desafio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Regressao linear 62Motivacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63Definicao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68Pressupostos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72Estimacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73No R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
1

Teste de Hipoteses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77Intervalo de confianca . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83Diagnostico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
Modelagem Estatıstica 87Modelagem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88Objetivos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90Construcao do modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
Regressao linear multipla 94Motivacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95Exemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96O modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109Pressupostos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117Interpret. dos β’s . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118Estimacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119Variaveis categoricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130Variaveis dummy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132Inferencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145IC para β. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158Multicolinearidade. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160Comparacao de modelos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167Selecao de variaveis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179Diagnostico do modelo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205Predicao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
Miscelanias 264Confundimento. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265Interacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266Interacao ou confundimento? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267Variancia nao constante. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 270Transformacoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273Modelos com efeitos aleatorios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279
2

Probabilidade slide 2
Introducao
Nesta secao serao revistos alguns conceitos importantes de probabilidade e as principais distribuicoes deprobabilidade para uma variavel aleatoria discreta ou contınua, tais como:
■ Variavel aleatoria
■ Funcao probabilidade
■ Funcao de distribuicao
■ Distribuicao Binomial
■ Distribuicao de Poisson
■ Distribuicao Normal
DEIO/CEAUL Valeska Andreozzi – slide 3
Variavel Aleatoria
Definicao
■ Considere um experimento para qual o espaco amostral e denotado por S. Uma funcao que e definida noespaco S e conhecida com uma variavel aleatoria.
■ Em outras palavras, num experimento em particular, a variavel aleatoria X e uma funcao que tomavalores reais X(s) para cada possıvel resultado s ∈ S.
■ Diferentes variaveis aleatorias podem ser definidas para um mesmo evento.
DEIO/CEAUL Valeska Andreozzi – slide 4
Variavel Aleatoria
Exemplo:
■ Para o evento lancar duas moedas, podemos definir, as seguintes variavels aleatorias:
◆ numero de caras
◆ numero de coras
sample space
head
s
01
2
TT TH HT HH
Variável aleatória: número de caras no lançamento de duas moedas
DEIO/CEAUL Valeska Andreozzi – slide 5
3

Funcao de probabilidade
■ A funcao de probabilidade de uma variavel aleatoria discreta X (tambem denominada funcao massa deprobabilidade) e definida como a funcao f tal que para qualquer valor real x,
f(x) = Pr(X = x)
■ Se o valor x nao e um valor possıvel da v.a. X, entao f(x) = 0
■ Se a sequencia x1, x2, . . . inclue todos os possıvel valores de v.a. X, entao∑∞
i=1 f(xi) = 1
DEIO/CEAUL Valeska Andreozzi – slide 6
Funcao de probabilidade
Exemplo:
■ Cada barra vertical no grafico abaixo representa o valor da probabilidade da v.a. X = numero de caras nolancamento de duas moedas.
■ Nota-se que a soma das alturas das barras verticais e igual a um.
Quantil x
Pro
babi
lidad
e
0.00
0.25
0.50
1.00
0 1 2
Função de Probabilidade da v.a. número de caras no lançamento de duas moedas
DEIO/CEAUL Valeska Andreozzi – slide 7
4

Funcao de distribuicao
■ A funcao de distribuicao (tambem conhecida como funcao de distribuicao acumulada) F associa osvalores da variavel aleatoria X no domınio da probabilidade tal queF (x) = Pr[X ≤ x] = α
■ No exemplo da v.a. X numero de caras no lancamento de duas moedas, temos:
x
F(x
)
0.25
0.75
1.00
0 1 2
Função distribuição v.a. número de caras
DEIO/CEAUL Valeska Andreozzi – slide 8
Distribuicao Binomial
■ A distribuicao binomial e derivada de uma sequencias de eventos (ensaios) denominado Bernoulli
■ Ensaio Bernoulli e caracterizado por resultar em apenas dois resultados mutuamente exclusivos: vivo oumorto, doente ou sadio, masculino ou feminino.
■ Uma sequencias de ensaios Bernoulli forma um processo Bernoulli sob as seguintes condicoes:
◆ Arbitrariamente, um dos resultados do evento e chamado de sucesso e o outro de falha.
◆ p e a probabilidade sucesso do evento e permanece constante durante o processo. (A probabilidadede falha e q = 1 − p)
◆ Os eventos sao independentes, isto e, o resultado de um evento em particular nao afeta o resultadode um outro evento.
DEIO/CEAUL Valeska Andreozzi – slide 9
Distribuicao Binomial
■ Temos entao que uma v.a. discreta Y possui distribuicao binomial com parametros n e p (Y ∼ Bin(n, p)), em que n e o numero de ensaios e p e a probabilidade sucesso com funcao deprobabilidade dada por:
f(y) =
(ny
)py(1 − p)n−y
■ Outras caracterısticas importantes da distribuicao binomial sao o valor esperado e a variancia dada,respectivamente, por:
E(Y ) = np
V ar(Y ) = np(1 − p)
DEIO/CEAUL Valeska Andreozzi – slide 10
5

Distribuicao Binomial
Exemplo
■ Numa populacao em que 52% dos registros de nascimento sao masculinos, qual a probabilidade de, aoselecionar aleatoriamente 4 registros, sairem 2 femininos e 2 masculinos?p = Pr(M) = 0, 52,logo q = Pr(F ) = 1 − p = 0, 48Pr(MMFF ) = p × p × q × q = p2q2 = 0, 062
■ Outras possibilidades de combinacao: MFMF, MFFM, FMFM, FFMM, FMMF e cada uma delas com amesma probabilidade
■ Logo a Pr(M,M,F, F ) = 6 × 0, 062 = 0, 37
■ v.a. Y = numero nascimento masculinos em 4 registros com Y ∼ Bin(n = 4, p = 0, 52)
f(y) =
(ny
)py(1 − p)n−y
DEIO/CEAUL Valeska Andreozzi – slide 11
Distribuicao Poisson
■ Utilizada para dados de contagem de um evento.
■ Se y e o numero de ocorrencias de algum evento aleatorio ocorrido em algum intervalo de tempo ouespaco, a probabilidade de y ocorrer e dada por:
f(y) =µye−µ
y!
■ o parametro µ e igual ao numero medio de ocorrencias do evento no intervalo de tempo
■ A distribuicao de Poisson e caracterizada por ter media e variancia iguais (E(Y ) = V ar(Y ) = µ)
DEIO/CEAUL Valeska Andreozzi – slide 12
Distribuicao Poisson
■ Um processo de Poisson e caracterizado por
◆ Ocorrencia de eventos independentes. A ocorrencia de um evento num intervalo de tempo ou espaconao afeta a probabilidade da segunda ocorrencia do evento, no mesmo, ou em qualquer outrointervalo
◆ Teoricamente, um numero infinito de ocorrencias do evento em um dado intervalo deve ser possıvel
◆ A probabilidade da ocorrencia de um simples evento em um dado intervalo e proprocional aotamanho do intervalo
◆ Numa proporcao infinitesimal do intervalo, a proporcao de ocorrencia de mais de um evento einsignificante
DEIO/CEAUL Valeska Andreozzi – slide 13
6

Poisson
Exemplo:
■ Um estudo sobre suicıdios nos EUA reportou uma media mensal de 2,75 suicıdios de adolescentes, entre1977 e 1987. Assumindo que a distribuicao mensal de suicıdios segue uma distribuicao de Poisson,encontre a probabilidade de que em um mes selecionado aleatoriamente tenham ocorrido 3 suicıdios.
Y ∼ Poi(µ = 2, 75)
Pr(Y = 3) =µye−µ
y!=
2, 753e−2,75
3!= 0, 22
DEIO/CEAUL Valeska Andreozzi – slide 14
Funcao de densidade de probabilidade
■ Uma v.a. contınua tem uma funcao de probabilidade, tambem conhecida por funcao de densidade deprobabilidade (f.d.p.), se existe uma funcao nao negativa f , definida na reta real, tal que para qualquerintervalo A,Pr(X ∈ A) =
∫A
f(x)dx
■ Toda f.d.p. deve satisfazer:f(x) ≥ 0
e ∫ ∞
−∞f(x)dx = 1
■ Podemos tambem definir a f.d.p. f(x) como sendo igual a primeira derivada da funcao de distribuicaoF (x)
DEIO/CEAUL Valeska Andreozzi – slide 15
Funcao de densidade de probabilidade
■ Para uma v.a. contınua X, a area sob a curva de densidade de probabilidade entre dois pontos e igual aprobabilidade de que X ocorra entre esses valores, como ilustra o grafico abaixo:
DEIO/CEAUL Valeska Andreozzi – slide 16
7

Distribuicao Normal
■ e a mais importante distribuicao de probabilidade em estatıstica (tambem conhecida por distribuicaogaussiana) devido a tres razoes:
◆ suas propriedades matematicas;
◆ observacao de diversas variaveis aleatorias em varios experimentos geralmente possuem umadistribuicao de probabilidade proxima da normal;
◆ preeminencia dessa ditribuicao no teorema limite central.
■ Seja Y uma v.a. contınua com distribuicao normal (Y ∼ N(µ, σ2)). Sua funcao de densidade deprobabilidade e dada por:
f(y) = 1√2πσ2
exp{− (y−µ)2
2σ2
}
com parametros µ - media e σ2 - variancia
DEIO/CEAUL Valeska Andreozzi – slide 17
Distribuicao Normal
A distribuicao normal tem como caracterısticas:
■ simetria em relacao a media µ
■ media, mediana e moda sao iguais
■ a area sob a curva do grafico e igual a um
■ a cada um, dois, ou tres desvio-padroes da media,tem-se area de 0.68, 0.95, 0.997, respectivamente
■ ser completamente determinada pelos parametros µ
e σ
DEIO/CEAUL Valeska Andreozzi – slide 18
Distribuicao Normal Padronizada
■ A distribuicao normal padronizada e aquela que possui media igual a zero (µ = 0) e variancia igual a um(σ2 = 1).
■ Essa distribuicao padronizada pode ser obtida pela criacao da variavelz = y−µ
σ , sendo Y uma v.a normal com parametros µ e σ
■ A f.d.p. da v.a. normal z e descrita por
f(y) = 1√2π
exp{− z2
2
}
■ Como os valores da distribuicao normal padronizada sao tabelados, pode-se facilmente calcularprobabilidades de qualquer v.a. normal y atraves da criacao da variavel z
DEIO/CEAUL Valeska Andreozzi – slide 19
8

Distribuicao Normal
Exemplo:
■ Em um estudo sobre Alzheimer, a media do peso do cerebro (em gramas) e igual a 1076,80 e o desviopadrao e igual a 105,76. Extrapolando este resultado, encontre a probabilidade de um paciente comAlzheimer selecionado aleatoriamente tenha cerebro com peso menor que 800.
800 1076.8
DEIO/CEAUL Valeska Andreozzi – slide 20
Distribuicao Normal
z =y − µ
σ=
800 − 1076, 80
105, 76= −2, 62
Pr(Y < 800) = Pr(Z < −2, 62) = 0, 004
−2.62 0
DEIO/CEAUL Valeska Andreozzi – slide 21
9

Exercıcios
■ Pagina 124 a 127 do livro Daniel, W W. (2005). Biostatistics A Foundation For Analysis In The HealthSciences, 8th edition. John Wiley & Sons
■ Lista de exercıcios no RTutoriais do Prof Paulo Justiniano (topico: Distribuicao de Probabilidade)http://www.leg.ufpr.br/~paulojus/CE209/ce209praticas.pdf
DEIO/CEAUL Valeska Andreozzi – slide 22
Estimacao slide 23
Introducao
■ Inferencia estatıstica e um procedimento pelo qual pode-se retirar conclusoes sobre uma populacaobaseando-se na informacao contida numa amostra dessa mesma populacao.
■ E formada por duas grande areas: Estimacao e Teste de Hipoteses
DEIO/CEAUL Valeska Andreozzi – slide 24
Definicao
■ De acordo com Pestana & Velosa, 2008: “Um problema central em toda a inferencia estatıstica e,adotando um modelo para o que observamos, escolher os parametros mais adequados, que melhor seadaptem ao que observamos. A essa avaliacao de parametros chamamos estimacao”
DEIO/CEAUL Valeska Andreozzi – slide 25
10

Elementos da estimacao
■ Parametro
■ Espaco de Parametros
■ Estimador
■ Estimativa
Para ilustar os elementos mencionados acima, considere exemplo a seguir:
■ Vamos assumir que a distribuicao das alturas de indivıduos de uma certa populacao e normal comparametros µ e σ2, desconhecidos.
■ Caso uma amostra aleatoria de indivıduos dessa mesma populacao tenha sido observada, entao podemosfazer inferencia sobre os parametros populacionais µ e σ2.
■ O conjunto Θ de todos os possıveis valores de µ e σ2 constitui o espaco de parametros.
DEIO/CEAUL Valeska Andreozzi – slide 26
Elementos da estimacao
Exemplo (cont.):
■ Teoricamente o valor de µ pode ser qualquer numero real e a variancia, σ2, deve ser um valor positivo.
■ Logo temos que o espaco de parametros Θ e um conjunto que contem todos os pares (µ, σ2) tal que−∞ < µ < ∞ e σ2 > 0.
■ Adiante, veremos que, para uma realizacao x = (x1, . . . , xn) da amostra aleatoria X = (X1, . . . ,Xn), amedia artimetica amostral (x = 1/n
∑ni=1 xi) e uma estimativa para o parametro media populacional µ,
assim como o s2 e uma estimativa para σ2.
■ Se x e uma realizacao da a.a. X, tambem podemos dizer que x e uma realizacao da estatıstica X e s2 deS2. Chamamos de X e S2 de estimadores.
■ Em outras palavras: um estimador e uma “regra” generica , uma funcao da a.a. X, que permite, comcada realizacao x da a.a., obter uma estimativa (Pestana & Velosa, 2008)
DEIO/CEAUL Valeska Andreozzi – slide 27
Elementos da estimacao
Para cada parametro θ de interesse podemos calcular uma estimativa pontual ou intervalarEstimativa Pontual
■ e um numero (escalar) utilizado como estimativa do parametro populacional correspondente
Estimativa Intervalar
■ consiste em um intervalo no qual, com um certo grau de confianca (1 − α), podemos acreditar que oparametro θ se encontra inserido.
DEIO/CEAUL Valeska Andreozzi – slide 28
11

Propriedades dos estimadores
■ Centrado: um estimador pontual θ do parametro θ e centrado (nao tendencioso) se e so se E(θ) = θ. O
vies de um estimador nao centrado e dado por E(θ) − θ.
■ Eficiencia: Um estimador θ e um estimador de variancia mınima de θ se para qualquer outro estimadorθ∗: σ2
θ≤ σ2
θ∗para todo θ∗.
■ Consistencia: um estimador e dito consistente para estimar o parametro θ quando, a medida que, seaumenta o tamanho n da a.a. x, consegue-se uma maior precisao na estimativa. Em outras palavras, umestimador θ do parametro θ e um estimador consistente se: limn→∞P (|θ − θ| ≥ ǫ) = 0 para qualquerǫ > 0
■ Suficiencia: um estimador suficiente permite um resumo das informacoes trazidas pela amostra, ou seja,resume os dados sem perder nenhuma informacao sobre o parametro de interesse θ. Portanto, conhecidoum estimado suficiente, os dados da amostra passam a ser irrelevantes, pois nada mais dizem sobre oparametro.
DEIO/CEAUL Valeska Andreozzi – slide 29
Modelo parametrico
Conceito
■ Quando se usa a designacao parametrico, o significado do termo e o de que a forma da f.p. ou f.d.p dav.a. foi especificada a priori e nao e posta em questao. Alem disto tem-se que:
◆ as inferencias dizem respeito a um numero finito de parametros;
◆ as inferencias dependem da forma especificada para a f.d.p. ou f.p.
DEIO/CEAUL Valeska Andreozzi – slide 30
Metodos de Estimacao
Existem diversos metodos para construcao de estimadores de parametros. Vale a pena ressaltar 3 deles:
■ Metodo dos momentos
■ Metodo dos mınimos quadrados
■ Metodo da maxima verossimilhanca
DEIO/CEAUL Valeska Andreozzi – slide 31
Metodo dos momentos
■ exprime os parametros que se pretende estimar em termos dos momentos do modelo, e posteriomenteequaciona os momentos populacionais com os momentos empıricos. Em outras palavras, o metodo igualaos momentos da distribuicao aos momentos da amostra.
■ Este resultado e possıvel pois a distribuicao empırica converge estocasticamente para a funcao dedistribuicao F (X).
■ Fornece, em pratica, estimadores consistentes.
■ A desvantagem esta na possibilidade de obter mais do que um estimador para o mesmo parametro.Quando isto ocorre, adota-se como estimador aquele gerado pelo momento de menor ordem.
DEIO/CEAUL Valeska Andreozzi – slide 32
12

Metodo dos momentos
Exemplo
■ Seja X uma v.a. com distribuicao Normal (µ, σ2). Utilize o metodo dos momentos para encontrar oestimador de µ e σ2.Momento da distribuicao: E(Xk)Momento da amostra Mk = 1/n
∑Xk
i
E(X) = 1/n∑
Xi = X
E(X2) = 1/n∑
X2i
Daı temos que o estimador de µ = E(X) = 1/n∑
Xi = X.Agora temos que σ2 = var(X) = E(X2) − (E(X))2
σ2 = 1/n∑
X2i − X2
DEIO/CEAUL Valeska Andreozzi – slide 33
Metodo dos mınimos quadrados
■ A ideia do metodo dos mınimos quadrados esta em minimizar a soma dos quadrados dos erros.
■ Seja toda observacao aleatoria Xi descrita pela forma Xi = gi(θ) + ǫi, composta por uma partesistematica gi(θ), em que as funcoes gi sao conhecidas e θ e um vetor de parametros desconhecidos, epor uma parte aleatoria ǫi, que obedece as seguintes restricoes:
◆ E(ǫi) = 0
◆ V ar(ǫi) = σ2 e constante
◆ os ǫi nao sao correlacionados
■ O parametro θ e estimado pelo estimador que mininiza a soma dos quadrados dos errosSQE =
∑ni=1(Xi − gi(θ))
2 =∑n
i=1 ǫ2i . Para encontrar o estimador de mınimos quadrados, basta derivarSQE em relacao aos parametros, igualar a zero e resolver o sistema de equacoes.
DEIO/CEAUL Valeska Andreozzi – slide 34
Metodo da Maxima Verossimilhanca (MMV)
■ Consiste em adotar como estimativa do parametro populacional o valor que maximize a funcao deverossimilhanca correspondente ao resultado obtido na amostra
■ Fornece estimadores:
◆ consistentes,
◆ assintoticamente eficientes e
◆ com distribuicao assintoticamente normal
DEIO/CEAUL Valeska Andreozzi – slide 35
13

Maxima Verossimilhanca
■ Objetivo do MMV
◆ Achar uma estimativa para o parametro populacional τ que maximize a probabilidade deencontrarmos a amostra que possuımos.
◆ Em outras palavras, para determinar o estimador de maxima verossimilhanca do parametro τ , bastaachar o valor de τ que maximiza a f.d.p. ou f.m.p. f(X|τ) fixando a amostra X (L(τ |X) funcao deverossimilhanca).
DEIO/CEAUL Valeska Andreozzi – slide 36
Exemplo
■ Distribuicao normal com variancia conhecida.
■ Seja X=(12, 15, 9, 10, 17, 12, 11, 18, 15, 13) uma amostra aleatoria das idades das criancas do HospitalSao Joao que segue uma distribuicao normal de media µ e variancia conhecida e igual a 4. Qual aestimativa de maxima verossimilhanca da media µ das idades das criancas?
■ O objetivo e fazer um grafico da funcao de log-verossimilhanca e achar o ponto maximo que sera aestimativa da media µ.
DEIO/CEAUL Valeska Andreozzi – slide 37
Solucao Analıtica
1. Temos que x1, . . . , xn e uma amostra aleatoria de X ∼ N(µ, 4),
2. a f.d.p. para cada observacao e dada por f(xi) = 1√2πσ2
exp{− (xi−µ)2
2σ2
}
3. assumindo que as observacoes sao independentes a funcao de verossimilhanca e dada porL(µ) =
∏101 f(xi),
4. e o logaritmo da funcao de verossimilhanca e dada por
l(µ) =10∑
1
ln(f(xi))
= −5 ln(8π) − 1
8
(10∑
1
x2i − 2µ
10∑
1
xi + 10µ2
)
DEIO/CEAUL Valeska Andreozzi – slide 38
14

Solucao Grafica no R
1. Amostra de uma distribuicao normal com variancia igual a 4
> x <- c(12, 15, 9, 10, 17, 12, 11, 18, 15, 13)
> x
2. e calculamos as quantidades∑10
1 x2i e∑10
1 xi
> sx2 <- sum(x^2)
> sx <- sum(x)
3. Intervalo para os possıveis valores de µ (sabemos que a media aritmetica e um estimativa de µ por issocriamos valores ao redor de 13 = mean(x))
> mu.vals <- seq(11, 15, l=100)
> mu.vals
DEIO/CEAUL Valeska Andreozzi – slide 39
Solucao Grafica no R
4. e a seguir calculamos os valores de l(µ) de acordo com a equacao anterior
> lmu <- -5 * log(8 * pi) -
(sx2 - 2 * mu.vals * sx + 10 * (mu.vals^2))/8
5. Fazendo o grafico
> plot(mu.vals, lmu, type="l", xlab=expression(mu),
ylab=expression(l(mu)))
DEIO/CEAUL Valeska Andreozzi – slide 40
Solucao Grafica no R
11 12 13 14 15
−32
−31
−30
−29
−28
−27
−26
µ
l(µ)
DEIO/CEAUL Valeska Andreozzi – slide 41
15

Solucao Grafica no R
6. Obtendo o valor de µ que corresponde ao valor maximo do log da verossimilhanca
> mu.vals[lmu==max(lmu)]
[1] 13.18182
7. Comparando com a media amostral
> mean(x)
[1] 13.2
DEIO/CEAUL Valeska Andreozzi – slide 42
Exercıcio 1
Seja X o numero de consumidores que chegam em um servico e que sao observados por hora, em n horas. Seas chegadas formam um Processo de Poisson, entao X ∼ Pois(θ), onde θ representa o numero esperado dechegadas em uma hora ou equivalentemente, a taxa de chegadas. Na pratica θ e desconhecido e nos desejamosestima-lo, usando os valores observados de X (amostra). Determine o estimador de maxima verossimilhanca deθ.
DEIO/CEAUL Valeska Andreozzi – slide 43
Exercıcio 2
Seja X uma v.a. com distribuicao Bin(N, p) com probabilidade sucesso desconhecida. Determine o estimadorde maxima verossimilhanca de p para uma a.a. de tamanho n
DEIO/CEAUL Valeska Andreozzi – slide 44
Outro Exemplo - Poisson(µ)
> y<-c(5,4,6,2,2,4,5,3,3,0,1,7,6,5,3,6,5,3,7,2)
> logvero <- function(mu, dados){
sum(dpois(dados, lambda = mu, log = TRUE))}
> lambda <- seq(0,15,l=50)
> l.pois<-sapply(lambda, logvero , dados = y)
> plot(lambda, l.pois, type = "l",
xlab = expression(lambda), ylab = expression(l(lambda)))
0 5 10 15 20
−20
0−
150
−10
0−
50
λ
l(λ)
DEIO/CEAUL Valeska Andreozzi – slide 45
16

Estimativa de Maxima Verossimilhanca
■ A estimativa do metodo da maxima verossimilhanca e o valor do parametro que maximiza o logaritmo(log) da funcao de verossimilhanca
■ Em casos especiais o log das funcoes de verossimilhanca podem ser resolvidos algebricamente
■ Em outros casos e necessario estimar o parametro atraves da maximizacao numerica, por exemplo atravesdo metodo de Newton-Raphson
DEIO/CEAUL Valeska Andreozzi – slide 46
Metodo de Newton-Raphson
■ Seja l(β0, β1|yi) = l(β)
■ Para calcular os valores β que maximize a funcao de verossimilhanca temos que derivar e igualar a zero
∂l(β)
∂βk= l′(β) = 0
■ Para resolvermos a equacao numericamente fazemos uma expansao de Taylor
l′(β(0)) + (β − β(0))l′′(β(0)) ≈ 0
■ Reescrevendo, temos:
β = β(0) − l′(β(0))
l′′(β(0))
DEIO/CEAUL Valeska Andreozzi – slide 47
Metodo Iterativo
Passo1: Inıcio: assume qualquer valor inicial para β(0)
Passo2: Iteracao 1: β(1) = β(0) + ǫ onde ǫ = l′(β(0))l′′(β(0))
Passo3: Iteracao k: β(k) = β(k−1) + ǫ onde ǫ = l′(β(k−1))l′′(β(k−1))
Passo4: Volta para o passo 3 ate que ǫ seja menor que uma tolerancia desejavel
■ No R e utilizado o metodo iterativo dos mınimos quadrados ponderados, que e baseado no metodo deNewton-Raphson
■ Criterio de parada no R: ǫ = 10−8
■ Caso ǫ nao atinja este valor dizemos que o processo nao convergiu
DEIO/CEAUL Valeska Andreozzi – slide 48
Pratica
http://www.leg.ufpr.br/~paulojus/CE209/ce209praticas.pdf
DEIO/CEAUL Valeska Andreozzi – slide 49
17

Correlacao Linear slide 50
Alguns conceitos
■ Seja X uma v.a discreta com f.p. f(x), entao valor esperado de X, E(X) =∑
x xf(x)
■ Seja X uma v.a contınua com f.d.p. f(x), entao E(X) =∫∞−∞ xf(x)dx
■ Seja X uma v.a, entao V ar(X) = E[(X − E(X))2], logo V ar(X) ≥ 0Podemos calcular V ar(X) = E(X2) − [E(X)]2
■ Quando estamos interessados na distribuicao conjunta de duas v.a. X e Y , a media e a variancia sofornecem informacao sobre as suas respectivas distribuicoes marginais.
DEIO/CEAUL Valeska Andreozzi – slide 51
Alguns conceitos
■ Para estudar a relacao entre as duas variaveis ou a tendencia em que ambas variam em conjunto podemosutilizar a covariancia entre X e Y
Cov(X,Y ) = E[(X − E(X))(Y − E(Y ))] = E(XY ) − E(X)E(Y )
■ Uma outra medida de associacao entre duas variaveis aleatorias e a correlacao dada por
ρ =Cov(X,Y )
σxσy,
em que σx e σy sao os desvios-padrao. ρ mede a magnitude de associacao linear entre X e Y .
DEIO/CEAUL Valeska Andreozzi – slide 52
Propriedades do coeficiente de correlacao
■ ρ e um valor entre +1 e −1, inclusive.
■ ρ = 1 (ou -1) se todas as observacoes estiverem sobre uma linha reta.
■ ρ = 0 quando nao existe associacao linear entre X e Y (nao exclui a possibilidade de existir uma relacaonao-linear)
■ ρ > 0 correlacao positiva ou direta
■ ρ < 0 correlacao negativa ou indireta
■ ρ nao depende da unidade de medida de X e de Y , e invariante em relacao a escala de medida adotada
DEIO/CEAUL Valeska Andreozzi – slide 53
18

Coeficiente de correlacao
■ Antes de estimar os parametros do modelo de regressao, temos que avaliar se a relacao entre a variavelresposta Y e a covariavel X e linear
■ Para tal efeito vamos utilizar o coeficiente de correlacao de Pearson, para quantificar essa associacaolinear assumindo que Y e X sao duas variaveis aleatorias.
r =
∑i(xi − x)(yi − y)√∑
i(xi − x)2∑
i(yi − y)2
DEIO/CEAUL Valeska Andreozzi – slide 54
Padroes de associacao
DEIO/CEAUL Valeska Andreozzi – slide 55
19

Padroes de associacao
DEIO/CEAUL Valeska Andreozzi – slide 56
Padroes de associacao
■ No grafico d, os pontos se distribuem com uma inclinacao ascendente, da esquerda para a direita, o que indica existir umatendencia para associar os menores valores de X aos menores de Y , bem como os maiores de X aos maiores de Y . Nestecaso a correlacao e positiva e a medida que estes pontos tendem a aproximar-se mais de uma reta, mais proxima estara acorrelacao do valor +1.
■ No grafico e, verifica-se que os pontos se distribuem com uma inclinacao descendente, da esquerda para a direita, indicandouma tendencia de associacao dos menores valores de X aos maiores valores de Y e vice-versa. Neste caso a correlacao enegativa e a medida que estes pontos tendem a aproximar-se mais de uma reta, mais proxima estara a correlacao do valor -1.
■ Nos graficos c e f a correlacao e nula, contudo no grafico f ha indicacao de associacao nao linear entre as variaveis X e Y .
■ Os graficos f e h mostram que o coeficiente de correlacao nao capta relacao nao linear.
■ O grafico g mostra a influencia de outliers na correlacao
■ O grafico i sugere que existem tres subgrupos, dentro de cada subgrupo existe correlacao positiva, mas a correlacao enegativa quando os grupos sao combinados.
DEIO/CEAUL Valeska Andreozzi – slide 57
20

Padroes de associacao
Qual a correlacao dos dois grupos de dados (vermelho e azul)?
0 20 40 60 80 100
050
100
150
200
x
y
y=x+e
y=2x+0.5+e
DEIO/CEAUL Valeska Andreozzi – slide 58
Padroes de associacao
Qual a correlacao dos dois grupos de dados (vermelho e azul)?
0 20 40 60 80 100
050
100
150
200
x
y
y=x+e
y=2x+0.5+e
r= 0.9979
r= 0.9969
DEIO/CEAUL Valeska Andreozzi – slide 59
21

Padroes de associacao
r nao e uma medida de adequabilidade do modelo de regressao linear
■ Veja os exemplos g, h, j.
■ Os coeficientes de correlacao para esses exemplos sao diferentes de zero, mas o modelo de regressao linearnao e adequado.
DEIO/CEAUL Valeska Andreozzi – slide 60
Desafio
Suponha que uma v.a. X possa assumir 3 valores (-1,0,1) e que os tres valores tem igual probabilidade. Seja av.a. Y definida por Y = X2 Mostre que X e Y sao dependentes mas nao sao correlacionadas.
DEIO/CEAUL Valeska Andreozzi – slide 61
Regressao linear slide 62
Motivacao
Qual a relacao entre pressao sistolica e idade em indivıduos adultos sadios?
■ A pressao em geral aumenta com a idade
■ Relacao e exata?
■ Variacao na pressao pode nao ser explicada totalmente pela idade ⇒ Componente aleatorio
E por que gostarıamos de estimar um modelo de regressao?
■ Descrever a relacao entre as variaveis pressao e idade
■ Predicao da pressao dado que um novo indivıduo tenha 50 anos
■ Tendencia da pressao de acordo com a idade
DEIO/CEAUL Valeska Andreozzi – slide 63
22

Motivacao
O que podemos dizer da relacao entre tensao arterial e idade?
20 30 40 50 60 70
120
140
160
180
200
220
id
pa
DEIO/CEAUL Valeska Andreozzi – slide 64
Modelo de regressao linear simples
yi = β0 + β1xi + ǫi
20 30 40 50 60 70
120
140
160
180
200
220
id
pa
■ Relacao entre a idade e pressao:conforme aumenta a idade a pressaoarterial aumenta.
■ Relacao nao e perfeita, pois ospontos se apresentam dispersos emtorno da reta. Indicacao de que al-guma variacao na pressao arterialnao e explicada pela idade.
■ Reta ajustada que descreve arelacao estatıstica entre pressao eidade
yi = 98.71 + 0.97xi
DEIO/CEAUL Valeska Andreozzi – slide 65
23

Interpretacao dos coeficientes
Pressaoi = 98.71 + 0.97 × idadei
20 30 40 50 60 70
120
140
160
180
200
220
id
pa
β0 = 98.71
■ e o coeficiente linear
■ onde a reta corta o eixo das orde-nadas (Y)
■ valor estimado da pressao quando aidade e igual a zero
β1 = 0.97
■ e o coeficiente angular
■ traduz a velocidade de mudanca(tendencia) da pressao para cadauma unidade de idade
■ neste caso temos que para cada anode idade a pressao arterial media au-menta 0.97 mmHg
DEIO/CEAUL Valeska Andreozzi – slide 66
Notacao matricial
O modelo de regressao na sua forma matricial:
y = Xβ + ǫ
em que: variavel resposta: y =
y1
y2
...yn
matriz design: X =
1 x1
1 x2
...1 xn
vetor de parametros: β =
(β0
β1
)
erro: ǫ =
ǫ1ǫ2...
ǫn
DEIO/CEAUL Valeska Andreozzi – slide 67
24

Modelo de regressao linear
yi = β0 + β1x1i + β2x2i + ǫi
■ Descreve a relacao entre uma variavel dependente ou resposta (Y ) e uma ou mais variaveis independentes(ou preditoras, explicativas, covariaveis) (X1,X2,X3, · · · ,Xk)
■ Estima a direcao e a forca da associacao entre a variavel resposta e as variaveis independentes.
■ Determina quais das variaveis independentes sao importantes na predicao da variavel resposta.
■ Descreve a relacao entre as variaveis X1,X2,X3, · · · ,Xk e Y controlando o efeito de outras variaveis Z1
e Z2, por exemplo.
DEIO/CEAUL Valeska Andreozzi – slide 68
Modelo de regressao linear
yi = β0 + β1x1i + β2x2i + ǫi
■ Assume-se que a variavel resposta e uma variavel aleatoria dado que varia de forma nao previsıvel deindivıduo para indivıduo i.
■ A natureza contınua da variavel resposta sugere que a distribuicao Normal e uma escolha adequada parao modelo populacional de Yi
■ Temos entao que Yi segue uma distribuicao Normal com parametros media µi e variancia σ2
desconhecidos. (Yi ∼ N(µi, σ2))
■ Podemos tambem escrever, de forma equivalente, que cada observacao yi = µi + ǫi e que ǫi ∼ N(0, σ2)
DEIO/CEAUL Valeska Andreozzi – slide 69
Modelo de regressao linear
Ilustracao dos componentes de uma regressao linear simples.
■ Componente sistematico: β0 + β1x1i + β2x2i ou na forma matricial Xβ
■ Modelo Estatıstico/Probabilıstico: Y = Xβ + ǫ ou E(Y |X) = Xβ
DEIO/CEAUL Valeska Andreozzi – slide 70
25

Modelo de regressao linear
Representacao de um modelo de regressao linear.
■ As medias das distribuicoes de probabilidade mostram uma relacao sistematica com os nıveis de X
■ grafico da funcao de regressao: curva de regressao linear
DEIO/CEAUL Valeska Andreozzi – slide 71
Pressupostos do modelo de regressao linear
Independencia: Os valores de Yi sao estatisticamente independentes uns dos outros.
Linearidade: O valor esperado de Yi e uma funcao linear de Xi
Homocedasticidade: A variancia da distribuicao de probabilidade de Y e constante nos diversos nıveis de X eigual a σ2
Normalidade: Para um dado valor de Xi, Yi tem distribuicao Normal. Premissa necessaria para testarhipoteses e construir intervalos de confianca para os parametros β
DEIO/CEAUL Valeska Andreozzi – slide 72
Estimacao do modelo
Metodo dos Mınimos Quadrados
E(Yi|X) = β0 + β1xi
■ Estamos a procura de estimativas otimas para os parametros β0 e β1
■ Vamos utilizar o metodo dos mınimos quadrados que consiste em minimizar a soma dos quadrados doserros (SQE)
SQE =
n∑
i=1
ǫ2i
=n∑
i=1
(yi − yi)2 =
n∑
i=1
(yi − β0 − β1xi)2
■ Isto e, as estimativas dos parametros β0 e β1 sao os valores que minimizam SQE
DEIO/CEAUL Valeska Andreozzi – slide 73
26

Estimacao do modelo
Estimadores de βPara obter os estimadores, deriva-se SQE em ordem a cada parametro, obtendo um sistema de equacoes
∂SQE
∂β0=
n∑
i=1
[yi − β0 − β1xi] = 0
∂SQE
∂β1=
n∑
i=1
[xi(yi − β0 − β1xi)] = 0
As equacoes acimas sao conhecidas como equacoes normais. E o resultado do sistema acima sao as estimativasdos parametros dada por:
β0 = y − β1x
β1 =
∑ni=1(xi − x)(yi − y)∑n
i=1(xi − x)2
DEIO/CEAUL Valeska Andreozzi – slide 74
Estimacao do modelo
Estimador de σ2
■ Nota: Em regressao, ǫ e denominado resıduo e SQE e designado a soma dos quadrados dos resıduos
■ Sob a hipotese nula de que os resıduos sao variaveis aleatorias nao correlacionadas com media zero evariancia constante igual a σ2, uma estimativa nao enviesada para σ2 e calculada atraves da divisao doSQE =
∑ni=1 ǫ2i pelos graus de liberdade, que e igual a numero de observacoes menos numero de
parametros no modelo (neste caso 2)
■ E assim, um estimador para a variancia σ2 de Y e encontrado atraves da utilizacao dos estimadores demınimos quadrados de β0 e β1
σ2 =1
n − 2
n∑
i=1
[(yi − β0 − β1xi)2]
DEIO/CEAUL Valeska Andreozzi – slide 75
Regressao linear simples no R
setwd("E:/Valeska/curso/2011/bioestatistica")
dados<-read.table("pasis.dat",header=T)
names(dados)
head(dados)
plot(dados)
modelo<-lm(pa~id,data=dados)
summary(modelo)
plot(dados)
abline(modelo,col=2)
#fazer os calculos das estimativas
#calcular os resıduos
DEIO/CEAUL Valeska Andreozzi – slide 76
27

Teste de hipoteses
ANOVA
■ Anova divide a variabilidade total da seguinte forma
∑
i
(yi − y)2
︸ ︷︷ ︸variabilidade total
=∑
i
(yi − y)2
︸ ︷︷ ︸variabilidade explicada
pela regressao
+∑
i
(yi − yi)2
︸ ︷︷ ︸variabilidade nao explicada
(resıduo)
Representacao da variabilidade explicada e nao explicada pela regressao.
DEIO/CEAUL Valeska Andreozzi – slide 77
Teste de hipoteses
ANOVA
■ Teste F: Razao entre variabilidade explicada pela regressao e variabilidade nao explicada
■ Quanto maior o valor desta razao mais adequado e o modelo. Isto equivale a testar, na regressao linearsimples, a H0: β1 = 0 contra H1: β1 6= 0
∑
i
(yi − y)2
︸ ︷︷ ︸Total - SYY
=∑
i
(yi − y)2
︸ ︷︷ ︸Regression - SSreg
+∑
i
(yi − yi)2
︸ ︷︷ ︸Residual - RSS
DEIO/CEAUL Valeska Andreozzi – slide 78
28

Teste de hipoteses
ANOVA∑
i
(yi − y)2
︸ ︷︷ ︸Total - SYY
=∑
i
(yi − y)2
︸ ︷︷ ︸Regression - SSreg
+∑
i
(yi − yi)2
︸ ︷︷ ︸Residual - RSS
DEIO/CEAUL Valeska Andreozzi – slide 79
Teste de hipoteses
ANOVA
> anova(modelo)
Analysis of Variance Table
Response: pa
Df Sum Sq Mean Sq F value Pr(>F)
id 1 6394.0 6394.0 21.33 7.867e-05 ***
Residuals 28 8393.4 299.8
---
> 1-pf(21.33,1,28) #p-valor da F(df1,df2)
Rejeita-se H0: β1 = 0
DEIO/CEAUL Valeska Andreozzi – slide 80
29

Teste de hipoteses
Teste de Wald
■ A distribuicao amostral de β =
(β0
β1
)∼ NMV (β, V )
Variancia: V = σ2
(( 1
n + x2
SXX ) −( x2
SXX )
−( x2
SXX ) 1SXX
)
Erro padrao: EP (βk) =√
vkk
■ WALD: Testa H0: βk = 0 atraves da estatıstica T
■ T = βk
EP (βk)
■ Sob a H0, T segue uma distribuicao t-student com n − p graus de liberdade (p e igual ao numero deparametros do modelo) ou aproximadamente um distribuicao normal com media zero e variancia igual a 1
DEIO/CEAUL Valeska Andreozzi – slide 81
Teste de hipoteses
Teste de Wald
> summary(modelo)
lm(formula = pa ~ id, data = dados)
Residuals:
Min 1Q Median 3Q Max
-21.7243 -6.9937 -0.5204 2.9310 75.6544
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 98.7147 10.0005 9.871 1.28e-10 ***
id 0.9709 0.2102 4.618 7.87e-05 ***
Residual standard error: 17.31 on 28 degrees of freedom
Multiple R-squared: 0.4324, Adjusted R-squared: 0.4121
F-statistic: 21.33 on 1 and 28 DF, p-value: 7.867e-05
DEIO/CEAUL Valeska Andreozzi – slide 82
30

Intervalo de confianca
■ Intervalo de Confianca de 100(1 − α)% para β′s e dado por:
[βk − tn−p,α/2 × EP (βk) ; βk + tn−p,α/2 × EP (βk)]
modelo$coef
n<-nrow(dados);n
p<-2
quantil.t<-qt(0.025,n-p);quantil.t
sumario<-summary(modelo)
ep<-sqrt(diag(sumario$cov.unscaled)*sumario$sigma^2)
ep
modelo$coef[1]+c(-1,1)*quantil.t*ep[1]
modelo$coef[2]+c(-1,1)*quantil.t*ep[2]
library(Epi)
ci.lin(modelo)
DEIO/CEAUL Valeska Andreozzi – slide 83
Diagnostico
■ Avaliar as premissas dos modelos (linearidade, homocedasticidade, normalidade, independencia)
■ Uma boa analise exploratoria feita antes da etapa de formulacao do modelo reduz o tempo gasto paradiagnostico
■ Correta interpretacao dos modelos estimados depende se os modelos atenderam as premissas
■ Forma simples de diagnostico: calcular os resıduos (ǫi = yi − yi)
■ De uma forma simplista, se o modelo atende a todas as premissas, os resıduos devem se comportar comouma amostra aleatoria de uma distribuicao Normal com media zero
DEIO/CEAUL Valeska Andreozzi – slide 84
Diagnostico
Linearidade: grafico dos resıduos contra covariavel xi: nenhum padrao deve ser observado e sim uma nuvemde pontos ao redor da reta horizontal em zero.
Homocedasticidade: grafico dos resıduos contra valores ajustados yi: dispersao dos pontos no grafico deve semanter constante ao longo do eixo horizontal.
Normalidade: graficos de quantis dos resıduos contra quantis teoricos na distribuicao normal padronizada.
Independencia: graficos dos resıduos contra a ordem na qual as observacoes corespondentes sao feitas: pontosespalhados aleatoriamente ao longo do eixo horizontal indica independencia. presenca de clusters deresıduos positivos ou negativos sugere presenca de correlacao serial.
DEIO/CEAUL Valeska Andreozzi – slide 85
31

Diagnostico
20 30 40 50 60 70−
10
12
34
idade
resi
duo
−2 −1 0 1 2
−1
01
23
4
norm quantiles
res
120 130 140 150 160
−1
01
23
4
valores ajustados
resi
duo
0 5 10 15 20 25 30
−1
01
23
4índice
resi
duo
DEIO/CEAUL Valeska Andreozzi – slide 86
Modelagem Estatıstica slide 87
Modelagem
Modelagem estatıstica e um processo de descobrimento.
O que e um modelo estatıstico?
Modelo estatıstico=
modelo matematico(equacao que descreve o processo)
+incerteza
(flutuacoes devido ao acaso)
DEIO/CEAUL Valeska Andreozzi – slide 88
32

Modelagem
■ Modelo e uma versao simplificada de alguns aspectos do mundo real.
■ Podemos dizer que modelo e uma representacao em pequena escala de entidades fısicas.
■ A construcao de modelos implica numa compreensao dos dados
■ Dados disponıveis que sao um subconjunto dos dados que poderiam ser coletados
■ O modelo serve para obter inferencias para um grupo maior ou para obter compreensao do mecanismo(sistema) gerador dos dados observados
■ Os modelos variam de acordo com a acuracia da sua representacao.
■ O ponto chave da modelagem esta nesta acuracia que varia de acordo com o objetivo da analise.
DEIO/CEAUL Valeska Andreozzi – slide 89
Objetivos de um modelo
Modelo Explicativo ou Descritivo
■ Estudar a associacao entre fatores de risco e desfecho (outcome). Exemplos:
◆ Avaliar a magnitude de associacao de uma exposicao e um desfecho ajustada pelo efeitos depossıveis fatores de confundimento ou de interacao
◆ Investigar fatores determinantes de uma doenca, ie, avaliar o efeito de um determinado fator de riscona ocorrencia de uma doenca controlano por fatores de confundimento e considerando possıveisfatores modificadores de efeito da associacao principal em questao
■ Acuracia do modelo nao precisa ser perfeita
DEIO/CEAUL Valeska Andreozzi – slide 90
Objetivos de um modelo
Modelo Preditivo
■ Modelo em que o objetivo central e fazer predicao do desfecho. Exemplos:
◆ Predicao de um defecho para ajudar na tomada de decisao de um tratamento
◆ Desenvolvimento de classificacao de doenca ou estagiamento (elaboracao de um score)
◆ Identificacao de fatores biologicos que podem ajudar elucidar a patologia da doenca
■ Acuracia do modelo e importante
DEIO/CEAUL Valeska Andreozzi – slide 91
33

Construcao de um modelo
Passos envolvidos na construcao de um modelo estatıstico
1. Formulacao dos modelos
■ Especificar uma expressao matematica para descrever o comportamento geral de acordo com ascrencas do analista/investigador. Esta expressao tambem e conhecida como componentesistematico do modelo.
■ Incorporar, na parte sistematica do modelo, uma certa quantidade de flutuacoes da variavel resposta,denominada componente aleatorio do modelo
■ Especificar como combinar os componentes sistematico e aleatorio
DEIO/CEAUL Valeska Andreozzi – slide 92
Construcao de um modelo
Passos envolvidos no desenvolvimento de um modelo estatıstico
2. Inferencia dos parametros do modelo (estimacao e testes de hipoteses)
3. Avaliacao dos modelos
■ avaliar premissas dos modelos
■ avaliar o ajuste global do modelo que podera depender do objetivo do modelo
4. Reformulacao (se necessario)
DEIO/CEAUL Valeska Andreozzi – slide 93
Regressao linear multipla slide 94
Motivacao
E sabido que existe uma relacao entre a pressao sistolica e a idade em indivıduos adultos sadios - em geral,a pressao aumenta com a idade. No entanto, existem outras variaveis que influenciam os valores da pressaosistolica.
Faz sentido conseguirmos incorporar no modelo mais informacao util:
■ idade
■ peso
■ habitos tabagicos
Como considerar simultaneamente a informacao de diversas variaveis para modelar a pressao sistolica?
DEIO/CEAUL Valeska Andreozzi – slide 95
34

Exemplo
dados<-read.table("multi.dat")
names(dados)
[1] "pessoa" "pa" "id" "imc" "hf"
dados$imc<-dados$imc/100
head(dados)
pessoa pa id imc hf
1 1 135 45 28.76 n~ao
2 2 122 41 32.51 n~ao
3 3 130 49 31.00 n~ao
4 4 148 52 37.68 n~ao
5 5 146 54 29.79 sim
6 6 129 47 27.90 sim
DEIO/CEAUL Valeska Andreozzi – slide 96
Exemplo
Antes de qualquer tentativa de construcao de um modelo e preciso explorar os dados. Nomeadamente:
■ Conhecer o tipo de variaveis de que dispomos
■ Descrever os dados relativos a cada uma das variaveis atraves
◆ de estatısticas sumarias
◆ de representacoes graficas
■ Avaliar o comportamento conjunto das variaveis
◆ calculando medidas de associacao
◆ atraves de representacoes graficas
DEIO/CEAUL Valeska Andreozzi – slide 97
Exemplo
summary(dados)
pessoa pa id
Min. : 1.00 Min. :120.0 Min. :41.00
1st Qu.: 8.75 1st Qu.:134.8 1st Qu.:48.00
Median :16.50 Median :143.0 Median :53.50
Mean :16.50 Mean :144.5 Mean :53.25
3rd Qu.:24.25 3rd Qu.:152.0 3rd Qu.:58.25
Max. :32.00 Max. :180.0 Max. :65.00
imc hf
Min. :23.68 n~ao:15
1st Qu.:30.22 sim:17
Median :33.80
Mean :34.41
3rd Qu.:37.76
Max. :46.37
DEIO/CEAUL Valeska Andreozzi – slide 98
35

Exemplo
par(mfrow=c(1,2))
boxplot(dados$"pa",ylab="press~ao sistolica",
col="red",main="boxplot")
hist(dados$"pa",breaks=5,freq=F,
xlab="press~ao sistolica",
ylab="frequencia",main="histograma",col=2)
lines(density(dados$pa),col="blue",lw=2)
DEIO/CEAUL Valeska Andreozzi – slide 99
Exemplo
120
130
140
150
160
170
180
boxplot
pres
são
sist
ólic
a
histograma
pressão sistólica
freq
uênc
ia
120 140 160 180
0.00
00.
005
0.01
00.
015
0.02
00.
025
DEIO/CEAUL Valeska Andreozzi – slide 100
36
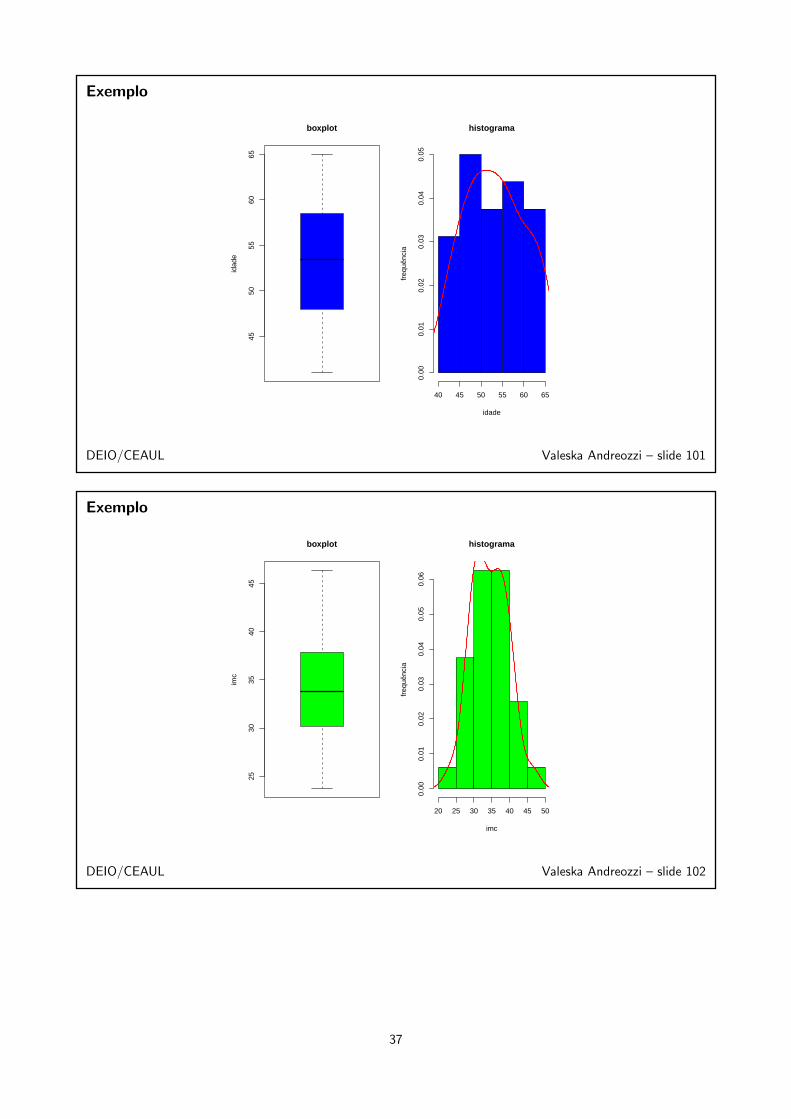
Exemplo
4550
5560
65
boxplot
idad
e
histograma
idadefr
equê
ncia
40 45 50 55 60 65
0.00
0.01
0.02
0.03
0.04
0.05
DEIO/CEAUL Valeska Andreozzi – slide 101
Exemplo
2530
3540
45
boxplot
imc
histograma
imc
freq
uênc
ia
20 25 30 35 40 45 50
0.00
0.01
0.02
0.03
0.04
0.05
0.06
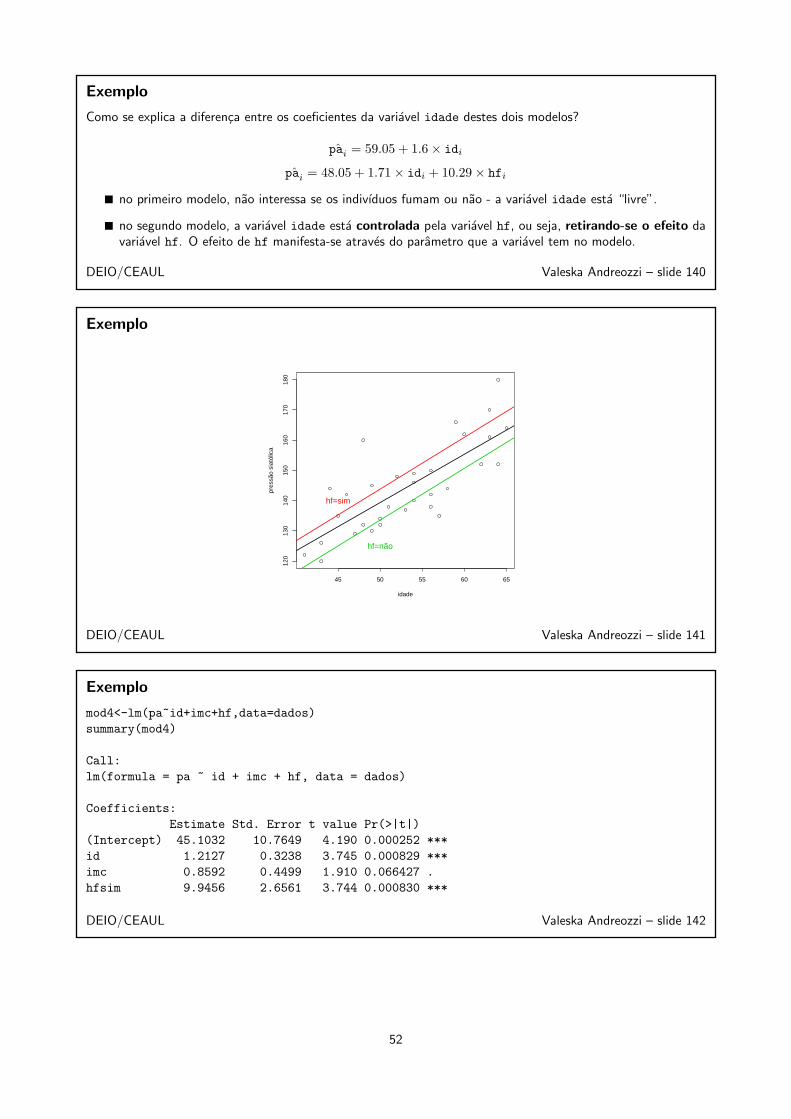
DEIO/CEAUL Valeska Andreozzi – slide 102
37

Exemplo
Como se comportam conjuntamente as variaveis?
library(car)
scatterplot.matrix(dados[,2:4])
|| | ||| ||| ||| || || ||| | |||| ||| | | || |
pa
45 50 55 60 65
120
130
140
150
160
170
180
4550
5560
65
|| | | || ||| ||| |||||| ||| ||| |||| ||| |
id
120 130 140 150 160 170 180 25 30 35 40 45
2530
3540
45
| || ||| ||| || | |||| || | | | ||| ||| | | || |
imc
DEIO/CEAUL Valeska Andreozzi – slide 103
Exemplo
Como se comportam conjuntamente as variaveis?
cor(dados[,2:4])
pa id imc
pa 1.000000 0.775204 0.742004
id 0.775204 1.000000 0.802751
imc 0.742004 0.802751 1.000000
DEIO/CEAUL Valeska Andreozzi – slide 104
38

Exemplo
Considerando idade como variavel regressora e ajustando um modelo de regressao simples
mod1<-lm(pa~id,data=dados)
summary(mod1)
Call:
lm(formula = pa ~ id, data = dados)
Residuals:
Min 1Q Median 3Q Max
-15.548 -6.990 -2.481 5.765 23.892
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 59.0916 12.8163 4.611 6.98e-05 ***
id 1.6045 0.2387 6.721 1.89e-07 ***
---
Residual standard error: 9.245 on 30 deg of freedom
Multiple R-Squared: 0.6009, Adjusted R-squared: 0.5876
F-statistic: 45.18 on 1 and 30 DF, p-value: 1.894e-07
DEIO/CEAUL Valeska Andreozzi – slide 105
Exemplo
Se tomarmos imc como variavel regressora
mod2<-lm(pa~imc,data=dados)
summary(mod2)
Call:
lm(formula = pa ~ imc, data = dados)
Residuals:
Min 1Q Median 3Q Max
-19.231 -7.145 -1.604 7.799 22.531
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 70.5764 12.3219 5.728 2.99e-06 ***
imc 2.1492 0.3545 6.062 1.17e-06 ***
---
Residual standard error: 9.812 on 30 deg of freedom
Multiple R-Squared: 0.5506,Adjusted R-squared: 0.5356
F-statistic: 36.75 on 1 and 30 DF, p-value: 1.172e-06
DEIO/CEAUL Valeska Andreozzi – slide 106
39

Exemplo
Para representar graficamente os pontos e respectivas rectas de regressao:
par(mfrow=c(1,2))
plot(dados$id,dados$pa,xlab="idade",
ylab="press~ao sistolica")
abline(mod1,lwd=2,col=2)
text(50,170,"E(y)=59.05+1.6x",col=2,cex=1.3)
plot(dados$imc,dados$pa,xlab="imc",
ylab="press~ao sistolica")
abline(mod2,lwd=2,col=2)
text(33,170,"E(y)=70.58+2.15x",col=2,cex=1.3)
DEIO/CEAUL Valeska Andreozzi – slide 107
Exemplo
45 50 55 60 65
120
130
140
150
160
170
180
idade
pres
são
sist
ólic
a
y=59.05+1.6x
25 30 35 40 45
120
130
140
150
160
170
180
imc
pres
são
sist
ólic
a
y=70.58+2.15x
DEIO/CEAUL Valeska Andreozzi – slide 108
O modelo
Se dispusermos de medicoes de mais de duas variaveis e se assume que uma delas e dependente das restantes,entao encontramo-nos num cenario de regressao multipla.
O modelo de regressao simples pode ser expandido:
E(press~ao sistolicai) = β0 + β1idadei + β2imci.
DEIO/CEAUL Valeska Andreozzi – slide 109
40

O modelo
Em vez de uma unica variavel independente, X, consideramos agora simultaneamente um conjunto de mvariaveis independentes (explanatorias) que denotaremos por X1, . . . ,Xm.
E(Yi) = β0 + β1xi1 + β2xi2 + ... + βmxim,
onde
■ Yi - variavel dependente do i−esimo indivıduo,i = 1, ..., n;
■ xij - valor da variavel Xj para o i−esimo indivıduo,i = 1, ..., n, j = 1, ...,m;
■ βj - coeficiente de regressao associado a j−esima variavel (independente), j = 1, ...,m.
DEIO/CEAUL Valeska Andreozzi – slide 110
O modelo
Uma equacao deste tipo define uma superfıcie num espaco m−dimensional - um hiperplano.
A populacao a que se refere a equacao atras nao estara, certamente, toda sobre o hiperplano pelo que serarepresentada por
yi = β0 + β1xi1 + β2xi2 + ... + βmxim + ǫi,
onde
■ ǫi e designado por resıduo ou erro e representa o quanto Yi difere do previsto (estimado) pelo modelo
E(Yi) = yi = β0 + β1xi1 + β2xi2 + ... + βmxim,
sendo a soma de todos os ǫi igual a zero.
DEIO/CEAUL Valeska Andreozzi – slide 111
41

O modelo
No caso da regressao linear simples, os desvios sao medidos na vertical, correspondendo, em valor absoluto, adiferenca yi − yi.
DEIO/CEAUL Valeska Andreozzi – slide 112
O modelo
Na presenca de uma amostra da populacao contendo as m + 1 variaveis (Y,X1, ...,Xm), podemos estimar osparametros populacionais do modelo: β0, β1, ..., βm.
A funcao de regressao resultante de uma amostra e
yi = β0 + β1xi1 + β2xi2 + ... + βmxim
onde β0, β1, β2, ..., βm sao as estimativas de β0, β1, β2, ..., βm, respectivamente.
DEIO/CEAUL Valeska Andreozzi – slide 113
42

Notacao matricial
Modelo em notacao matricialO modelo de regressao linear na sua forma matricial:
Y = Xβ + ǫ
em que: variavel resposta: Y =
y1
y1
...yn
matriz design: X =
1 x11 x12 · · · x1k
1 x21 x22 · · · x2k
......
......
1 xn1 xn2 · · · xnk
vetor de parametros: β =
β0
β1
β2
...βk
, erro: ǫ =
ǫ1ǫ1...
ǫn
DEIO/CEAUL Valeska Andreozzi – slide 114
Distribuicao multivariada
Notacao matricial
■ Seja Z um vetor de v.a que segue uma distribuicao multivariada com vetor media igual aµ = (µ1, µ2, . . . , µn)′ em que cada elemento e a media de Zi.
■ Logo podemos escrever E(Z) = µ.
■ A matrix de covariancia Σ da distribuicao de Z, tem na diagonal principal a variancia de cada Zi e ascovariancias entre Zi e Zj com i 6= j fora da diagonal principal.
■ Alguns resultados matriciais importantescov(Z) = E(ZZ ′) − E(Z)E(Z ′)E(AZ + b) = Aµ + bcov(AZ + b) = AΣA′
para toda matriz A e vetor b constantes
DEIO/CEAUL Valeska Andreozzi – slide 115
Notacao matricial
■ Assim sendo, o modelo de regressao linear pode ser definido como
Y = Xβ + ǫ
■ em que ǫ tem vetor media zero e matrix de covariancia igual a σ2I. Utilizando as propriedades dadistribuicao multivariada, tem-se entao que
E(Y ) = Xβ
cov(Y ) = σ2I
DEIO/CEAUL Valeska Andreozzi – slide 116
43

Pressupostos do Modelo de Regressao Linear
Independencia: Os valores de Y sao estatisticamente independentes uns dos outros. Analogamente temos: ǫsao variaveis aleatorias mutuamente independente
Linearidade: O valor esperado de Y e linear nos parametrosQuais desses modelos sao lineares nos parametros?
E(Y |X) = β1x1 + β2x2 (1)
E(Y |X) = ax1 + bx21 + cx2 (2)
E(log(Y )|X) = α0 + α1x1 (3)
log(E(Y |X)) = α0 + α1x1 (4)
Homocedasticidade: A variancia da distribuicao de probabilidade de Y e constante nos diversos nıveis de X eigual a σ2. Analogamente temos: ǫ tem variancia constante igual a σ2.
Normalidade: Para um dado valor de X, Y tem distribuicao Normal. Analogamente temos: ǫ tem distribuicaoN(0, σ2).
Note que: Y e variavel aleatoria e X e uma variavel fixa sem erro de medida.
DEIO/CEAUL Valeska Andreozzi – slide 117
Interpretacao dos β’s
βj expressa o quanto Y varia com o incremento de uma unidade na variavel Xj , considerando que todas asrestantes variaveis do modelo se mantem constantes.
De forma equivalente, βj e uma medida de associacao de Y com a variavel Xj , controlada pelas restantesvariaveis do modelo.
Isto e, trata-se de uma medida da intensidade da associacao de Y com Xj , apos se remover o efeito das restantesvariaveis.
DEIO/CEAUL Valeska Andreozzi – slide 118
Estimacao
Dada uma amostra e considerando a equacao de regressao
yi = β0 + β1xi1 + β2xi2 + ... + βmxim + ǫi,
coloca-se a questao de encontrar os valores para β0, β1, ..., βm (encontrar estimativas) que facam com que Yseja o mais possıvel expresso por X1, ...,Xm. Isto e, que produzam resıduos mınimos segundo algum criterio -criterio dos mınimos quadrados.
Segundo o criterio dos mınimos quadrados, as estimativas obtidas para os parametros sao aquelas que, para oconjunto de dados considerado, produzem uma colecao de resıduos cuja soma dos quadrados e mınima:
SQE =
n∑
i=1
ǫ2i =
n∑
i=1
(yi − yi)2
=
n∑
i=1
(yi − β0 − β1xi1 − β2xi2 − ... − βmxim)2
objetivo: minimizar SQE
DEIO/CEAUL Valeska Andreozzi – slide 119
44

Estimacao
Os β’s assim determinados tem boas propriedades:
■ Fazem sentido em termos geometricos;
■ Se os erros forem i.i.d. com distribuicao normal(0, σ2), entao tambem sao estimadores de maximaverosimilhanca. Isto quer dizer que estas estimativas sao as que maximizam a probabilidade de ocorrenciados dados que foram observados.
A segunda propriedade tem uma implicacao particularmente conveniente:
■ Permite fazer inferencia sobre os parametros e, consequentemente, sobre o modelo.
DEIO/CEAUL Valeska Andreozzi – slide 120
Estimacao do modelo linear geral
O metodo dos mınimos quadrados em notacao matricial toma a seguinte forma:
S(β) =
n∑
i=1
ǫ2i
= ǫ′ǫ
= (Y − Xβ)′(Y − Xβ)
= Y ′Y − 2β′X ′Y + β′X ′Xβ
e facil demostrar que o estimador de mınimos quadrados de β e da forma AY :
β = (X ′X)−1X ′Y (5)
Logo, tem-se dois resultados:E(β) = β
Cov(β) = σ2(X ′X)−1
DEIO/CEAUL Valeska Andreozzi – slide 121
Estimacao do modelo linear geral
■ Apos obter o estimador de mınimos quadrados para β, podemos calcular os valores ajustados Y , assim
Y = Xβ
= X(X ′X)−1X ′Y
Substituindo β por (5).
■ Podemos simplificar, escrevendo:Y = HY
em que H = X(X ′X)−1X ′. A matriz H e denominada matriz hat
■ O vetor de resıduos ǫ pode tambem ser calculado da seguinte forma:
ǫ = Y − Y = Y − Xβ
= Y − HY = (I − H)Y
DEIO/CEAUL Valeska Andreozzi – slide 122
45

Exemplo
Exemplo (cont.): Para o conjunto de 32 indivıduos atras referido foram registados os valores das seguintesvariaveis: press~ao arterial (pa), idade (id), ındice de masssa corporal (imc) e o habito de fumo
(hf).Sabendo-se que os valores da pressao arterial estao associados a idade e a condicao fısica do indivıduo, fazsentido procurar um modelo que permita explicar os valores da pressao arterial enquanto funcao destas duasvariaveis:
press~aoi = β0 + β1idadei + β2imci + ǫi
DEIO/CEAUL Valeska Andreozzi – slide 123
Exemplo
mod3<-lm(pa~id+imc,data=dados)
summary(mod3)
Call:
lm(formula = pa ~ id + imc, data = dados)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 55.3234 12.5347 4.414 0.000129 ***
id 1.0452 0.3861 2.707 0.011253 *
imc 0.9751 0.5402 1.805 0.081489 .
O modelo estimado eyi = 55.3234 + 1.0452 × idadei + 0.9751 × imci
DEIO/CEAUL Valeska Andreozzi – slide 124
Exemplo
yi = 55.3234 + 1.0452 × idadei + 0.9751 × imci
Interpretacao dos coeficientes:
■ por cada ano de idade a mais, a press~ao aumenta 1.0452 mmHg, sendo este efeito controlado pelo imc
■ por cada unidade a mais de imc, a press~ao aumenta 0.9751 mmHg, sendo este efeito controlado peloidade
DEIO/CEAUL Valeska Andreozzi – slide 125
46

Exemplo
O comando anova do R, quando tendo por argumento um modelo contendo varias variaveis explanatorias,permite-nos avaliar o quanto um modelo progride ao serem incorporadas, sucessivamente, as variaveis no modelo.
anova(mod3)
Analysis of Variance Table
Response: pa
Df Sum Sq Mean Sq F value Pr(>F)
id 1 3861.6 3861.6 48.5766 1.160e-07 ***
imc 1 259.0 259.0 3.2576 0.08149 .
Residuals 29 2305.4 79.5
DEIO/CEAUL Valeska Andreozzi – slide 126
Exemplo
A ordem pela qual sao introduzidas as variaveis na especificacao do modelo e importante.
mod3a<-lm(pa~imc+id,data=dados)
summary(mod3a)
Call:
lm(formula = pa ~ imc + id, data = dados)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 55.3234 12.5347 4.414 0.000129 ***
imc 0.9751 0.5402 1.805 0.081489 .
id 1.0452 0.3861 2.707 0.011253 *
---
Residual standard error: 8.916 on 29 deg of freedom
Multiple R-Squared: 0.6412, Adjusted R-squared: 0.6165
F-statistic: 25.92 on 2 and 29 DF, p-value: 3.505e-07
DEIO/CEAUL Valeska Andreozzi – slide 127
Exemplo
anova(mod3a)
Analysis of Variance Table
Response: pa
Df Sum Sq Mean Sq F value Pr(>F)
imc 1 3537.9 3537.9 44.5048 2.573e-07 ***
id 1 582.6 582.6 7.3293 0.01125 *
Residuals 29 2305.4 79.5
DEIO/CEAUL Valeska Andreozzi – slide 128
47

Exemplo
Para o mesmo grupo de indivıduos e tambem conhecida a variavel habito de fumo (hf). Trata-se de umavariavel que temos interesse em incorporar no modelo.
pai = β0 + β1idi + β2imci + β3hfi + ǫi
No entanto, para cada indivıduo, sabe-se apenas se e fumador ou nao:
head(dados)
pessoa pa id imc hf
...
3 3 13.0 49 31.00 n~ao
4 4 14.8 52 37.68 n~ao
5 5 14.6 54 29.79 sim
6 6 12.9 47 27.90 sim
...
DEIO/CEAUL Valeska Andreozzi – slide 129
Variaveis categoricas
A variavel habito de fumo e categorica. Isto significa que se trata de uma variavel qualitativa, ou seja, os seusvalores (mesmo que numericos) sao apenas rotulos das categorias que a variavel assume.
Exemplo: hf=”sim”ou hf=”nao”.
Codificacao das variaveis categoricas:e frequente atribuir as categorias valores numericos. No entanto trata-se apenas da substituicao de um rotulonao numerico por um rotulo numerico. A variavel nao passa a ser de tipo quantitativo.
Exemplo: hf=1(=”sim”) ou hf=0(=”nao”).
DEIO/CEAUL Valeska Andreozzi – slide 130
Variaveis categoricas
No R, os dados introduzidos como texto sao imediatamente reconhecidos como factores,
is.factor(dados$hf)
[1] TRUE
e podem ser incorporados no modelo sem tratamento previo especial. No caso de terem rotulos numericos, enecessario dar indicacao de que sao factores.
DEIO/CEAUL Valeska Andreozzi – slide 131
48

Variaveis dummy
A criacao de variaveis dummy foi a forma encontrada para incorporar variaveis categoricas num modelo.
Sao variaveis binarias (tomam valor 1 ou 0) indicando se o indivıduo (observacao) pertence aquela categoria ounao.
Para incorporar num modelo uma variavel categorica contendo k + 1 categorias sao criadas k variaveis dummy.As categorias da variavel sao, por conveniencia, numeradas de 0 a k, designando-se a categoria zero por classede referencia.
Se a observacao pertence a classe de referencia, todas as variaveis dummy tomam o valor zero. Se a observacaopertence a categoria i, todas as variaveis dummy tomam o valor zero, com excepcao da i-esima, que toma o valorum.
DEIO/CEAUL Valeska Andreozzi – slide 132
Variaveis dummy
Faz sentido pensar em introduzir uma variavel categorica no modelo quando existe a suspeita de que a variavelresposta tem um comportamento diferente consoante os indivıduos pertancem a uma ou outra(s) classe(s) dareferida variavel.
No caso do exemplo apresentado, fara sentido introduzir a variavel hf no modelo se os valores da pressao sistolicaapresentarem valores diferentes para fumadores e nao fumadores.
Isto e algo que deve ser averiguado na fase da analise exploratoria dos dados de forma a conferir uma maiorsensibilidade a analise.
Uma possibilidade consiste em construir diagramas boxplot paralelas para a variavel dependente com os indivıduosseparados pelas classes da variavel categorica.
DEIO/CEAUL Valeska Andreozzi – slide 133
Exemplo
No caso da variavel habito de fumo (hf), e criada apenas uma variavel dummy. O R ordena os rotulos (labels)das categorias por ordem alfabetica ou numerica crescente e toma para classe de referencia a primeira das classesassim ordenadas.
Antes de passarmos a inclusao da variavel no modelo, faz sentido averiguarmos se a variavel pa tem um compor-tamento diferente nos grupos.
semhf<-which(dados$hf=="n~ao")
semhf
[1] 1 2 3 4 13 14 19 20 22 23 24 27 29 31 32
comhf<-which(dados$hf=="sim")
comhf
[1] 5 6 7 8 9 10 11 12 15 16 17 18
21 25 26 28 30
DEIO/CEAUL Valeska Andreozzi – slide 134
49

Exemplo
plot(density(dados[comhf,"pa"]),lwd=2,ylim=c(0,0.04),
col=2,main="density plot",
xlab="press~ao sistolica")
lines(density(dados[semhf,"pa"]),lwd=2)
text(140,0.031,"n~ao fumadores")
text(185,0.01,"fumadores",col=2)
100 120 140 160 180 200
0.00
0.01
0.02
0.03
0.04
density plot
pressão sistólica
Den
sity
não fumadores
fumadores
DEIO/CEAUL Valeska Andreozzi – slide 135
Exemplo
boxplot(pa~hf,data=dados,
col=c("green","red"),names=c("hf=n~ao","hf=sim"),
ylab="press~ao sistolica")
Valores de press~ao sistolica por habito de fumo
hf=não hf=sim
120
130
140
150
160
170
180
pres
são
sist
ólic
a
DEIO/CEAUL Valeska Andreozzi – slide 136
50

Exemplo
Comecemos por considerar apenas uma variavel explanatoria contınua e a variavel explanatoria categorica hf.
mod4a<-lm(pa~id+hf,data=dados)
summary(mod4a)
Call:
lm(formula = pa ~ id + hf, data = dados)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 48.0496 11.1296 4.317 0.000168 ***
id 1.7092 0.2018 8.471 2.47e-09 ***
hfsim 10.2944 2.7681 3.719 0.000853 ***
---
Residual standard error: 7.738 on 29 deg of freedom
Multiple R-Squared: 0.7298, Adjusted R-squared: 0.7112
F-statistic: 39.16 on 2 and 29 DF, p-value: 5.746e-09
DEIO/CEAUL Valeska Andreozzi – slide 137
Exemplo
A equacao do modelo e:pai = 48.05 + 1.71 × idi + 10.29 × hfi
■ Como interpretar este modelo?
■ E como compara-lo com o modelo que considera apenas idade como variavel regressora?
pai = 59.05 + 1.6 × idi
DEIO/CEAUL Valeska Andreozzi – slide 138
Exemplo
Interpretacao do modelo:
■ sendo 48.05 a pressao sistolica estimada para um indivıduo com idade zero
■ por cada ano de idade a mais, a pressao sistolica aumenta 1.71 mmHg, ajustado pelo habito de fumar
■ se o indivıduo for fumador, acrescem 10.29mmHg a pressao sistolica esperada, quando comparado com umindivıduo da mesma idade mas que nao seja fumador.
DEIO/CEAUL Valeska Andreozzi – slide 139
51
Exemplo
Como se explica a diferenca entre os coeficientes da variavel idade destes dois modelos?
pai = 59.05 + 1.6 × idi
pai = 48.05 + 1.71 × idi + 10.29 × hfi
■ no primeiro modelo, nao interessa se os indivıduos fumam ou nao - a variavel idade esta “livre”.
■ no segundo modelo, a variavel idade esta controlada pela variavel hf, ou seja, retirando-se o efeito davariavel hf. O efeito de hf manifesta-se atraves do parametro que a variavel tem no modelo.
DEIO/CEAUL Valeska Andreozzi – slide 140
Exemplo
45 50 55 60 65
120
130
140
150
160
170
180
idade
pres
são
siat
ólic
a
hf=sim
hf=não
DEIO/CEAUL Valeska Andreozzi – slide 141
Exemplo
mod4<-lm(pa~id+imc+hf,data=dados)
summary(mod4)
Call:
lm(formula = pa ~ id + imc + hf, data = dados)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 45.1032 10.7649 4.190 0.000252 ***
id 1.2127 0.3238 3.745 0.000829 ***
imc 0.8592 0.4499 1.910 0.066427 .
hfsim 9.9456 2.6561 3.744 0.000830 ***
DEIO/CEAUL Valeska Andreozzi – slide 142
52

Exemplo
O modelo ajustado epai = 45.10 + 1.21 × idi + 0.86 × imci + 9.95 × hfi
Interpretacao dos coeficientes:
■ por cada ano de idade a mais, a press~ao aumenta 1.21 mmHg, ajustado por imc e habito de fumar
■ por cada unidade a mais de imc, a press~ao aumenta 0.86 mmHg, ajustado por idade e habito de fumar
DEIO/CEAUL Valeska Andreozzi – slide 143
Exemplo
Relativamente a interpretacao do coeficiente da variavel dummy:
■ se o indivıduo e nao fumador, hf=0 e nada mais ha a acrescentar. O valor estimado para a pressao arteriale dado por
pai = 45.10 + 0.121 × idi + 0.86 × imci
■ se o indivıduo e fumador, hf=1 e entao o modelo e
pai = 45.10 + 1.21 × idi + 0.86 × imci + 9.95
= 55.05 + 1.21 × idi + 0.86 × imci
correspondendo a um modelo com intercepto diferente consoante o indivıduo e fumador ou nao.
Em media, estima-se que um fumador apresente um valor de pressao arterial superior em 9.95 mmHg quandocomparado com um indivıduo nao fumador.
DEIO/CEAUL Valeska Andreozzi – slide 144
Inferencia
A inferencia habitualmente realizada sobre o modelo de regressao assenta na validade de pressupostos:
■ Para qualquer combinacao dos X ′s existe uma diversidade de valores de Y , seguindo uma distribuicaonormal. Isto implica que, para cada combinacao dos X ′s, o mesmo suceda para os ǫ′s;
■ Existe homocedasticidade, isto e, homogeneidade das variancias (a variancia de Y e igual a variancia de ǫ);
DEIO/CEAUL Valeska Andreozzi – slide 145
ANOVA
Um dos procedimentos destinados a avaliar o ajustamento do modelo consiste em analisar a forma como avariabilidade nos dados se reparte - ANOVA.
Variacao total=variacao devida a regressao + variacao residual
∑(yi − y)2 =
∑(yi − y)2 +
∑(yi − yi)
2
De uma forma simplificada, o que se faz, e comparar o peso dos dois termos em que se reparte a variacao total.Se o modelo se ajustar bem, entao o termo correspondente a variacao devida a regressao e “muito maior”do queo termo correspondente a variacao devida ao erros (variacao devida a aleatoriedade).
DEIO/CEAUL Valeska Andreozzi – slide 146
53

ANOVA
∑(yi − y)2 =
∑(yi − y)2 +
∑(yi − yi)
2
Representacao grafica:
DEIO/CEAUL Valeska Andreozzi – slide 147
ANOVA
Fonte de Soma de graus de Quadradosvariacao quadrados (SS) liberdade (df) medios (MS)
Total∑
(yi − y)2 n − 1SSTotal
n − 1
Regressao∑
(yi − y)2 mSSRegressao
m
Residual∑
(yi − yi)2 n − m − 1
SSResidual
n − m − 1
DEIO/CEAUL Valeska Andreozzi – slide 148
54

ANOVA
Sob a validade dos pressupostos atras enumerados,
F =SSRegressao
m
SSResidualn−m−1
=MSRegressao
MSResidual∼ Fm,n−m−1.
Neste contexto, a estatıstica F pode ser utilizada para testar
H0 : β1 = β2 = ... = βm = 0
que pode escrever-se comoH0 : βi = 0 ∀i vs H1 : ∃i : βi 6= 0
Valores grandes da estatıstica de teste apontam no sentido de H1 pelo que, a um nıvel de significancia α, serejeita H0 em favor de H1 se
Fobservado > Fm;n−m−1;1−α,
ou seja, se o valor-p do teste for inferior a α.
DEIO/CEAUL Valeska Andreozzi – slide 149
Coeficiente de determinacao
O racio
R2 =SSRegressao
SSTotal
corresponde ao coeficiente de determinacao do modelo.
Corresponde a proporcao da variabilidade total existente nos dados (Y ) que pode ser atribuıda ao modelo deregressao tal como este se apresenta. Diz-se, entao, que o modelo explica
R2 × 100%
da variabilidade existente nos dados.
DEIO/CEAUL Valeska Andreozzi – slide 150
Coeficiente dedeterminacao ajustado
R2 nao deve ser visto (nem utilizado) como medida de qualidade de ajustamento do modelo nem deve ser usadocomo medida de comparacao entre modelos.Uma medida considerada aceitavel enquando medida de qualidade de ajustamento do modelo e o coeficientede determinacao ajustado:
R2a = 1 − MSResidual
MSTotal,
que pode escrever-se como funcao de R2 atraves de
R2a = 1 − n − 1
n − m − 1(1 − R2).
Enquanto R2 aumenta sempre que uma nova variavel explanatoria e adicionada ao modelo, R2a aumentara apenas
se a nova variavel proporcionar um melhor ajuste do modelo aos dados.
DEIO/CEAUL Valeska Andreozzi – slide 151
55

Coeficiente decorrelacao multipla
A raız quadrada do coeficiente de determinacao corresponde ao coeficiente de correlacao multipla:
R =√
R2.
R corresponde tambem ao coeficiente de correlacao de Pearson, r, entre os valores observados yi e os valoresestimados pelo modelo yi.
DEIO/CEAUL Valeska Andreozzi – slide 152
Teste de Wald
■ Em geral, o objecto de interesse e averiguar a utilidade de incorporar a variavel Xj no modelo, pelo que ahipotese a testar e:
H0 : βj = 0 vs H1 : βj 6= 0.
■ A estatıstica de teste a considerar sera
T =βj
EP (βj)∼ t(n−m−1),
■ onde EP (βj) e o erro padrao de βj e dado pela raiz quadrada dos elementos da diagonal da matriz de
covariancia V = Cov(β) = σ2(X ′X)−1.
■ Sob a H0, T segue uma distribuicao t-student com n − p graus de liberdade (p e igual ao numero deparametros do modelo) ou aproximadamente um distribuicao normal com media zero e variancia igual a 1
DEIO/CEAUL Valeska Andreozzi – slide 153
Exemplo
mod1<-lm(pa~id,data=dados)
summary(mod1)
Call:
lm(formula = pa ~ id, data = dados)
Residuals:
Min 1Q Median 3Q Max
-15.548 -6.990 -2.481 5.765 23.892
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 59.0916 12.8163 4.611 6.98e-05 ***
id 1.6045 0.2387 6.721 1.89e-07 ***
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 9.245 on 30 degrees of freedom
Multiple R-squared: 0.6009, Adjusted R-squared: 0.5876
F-statistic: 45.18 on 1 and 30 DF, p-value: 1.894e-07
DEIO/CEAUL Valeska Andreozzi – slide 154
56

Exemplo
mod2<-lm(pa~imc,data=dados)
summary(mod2)
Call:
lm(formula = pa ~ imc, data = dados)
Residuals:
Min 1Q Median 3Q Max
-19.231 -7.145 -1.604 7.799 22.531
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 70.5764 12.3219 5.728 2.99e-06 ***
imc 2.1492 0.3545 6.062 1.17e-06 ***
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 9.812 on 30 degrees of freedom
Multiple R-squared: 0.5506, Adjusted R-squared: 0.5356
F-statistic: 36.75 on 1 and 30 DF, p-value: 1.172e-06
DEIO/CEAUL Valeska Andreozzi – slide 155
Exemplo
mod3<-lm(pa~id+imc,data=dados)
summary(mod3)
Call:
lm(formula = pa ~ id + imc, data = dados)
Residuals:
Min 1Q Median 3Q Max
-11.667 -6.793 -2.732 5.318 19.600
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 55.3234 12.5347 4.414 0.000129 ***
id 1.0452 0.3861 2.707 0.011253 *
imc 0.9751 0.5402 1.805 0.081489 .
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 8.916 on 29 degrees of freedom
Multiple R-squared: 0.6412, Adjusted R-squared: 0.6165
F-statistic: 25.92 on 2 and 29 DF, p-value: 3.505e-07
DEIO/CEAUL Valeska Andreozzi – slide 156
57

Exemplo
mod4<-lm(pa~id+imc+hf,data=dados)
summary(mod4)
Call:
lm(formula = pa ~ id + imc + hf, data = dados)
Residuals:
Min 1Q Median 3Q Max
-13.5420 -6.1812 -0.7282 5.2908 15.7050
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 45.1032 10.7649 4.190 0.000252 ***
id 1.2127 0.3238 3.745 0.000829 ***
imc 0.8592 0.4499 1.910 0.066427 .
hfsim 9.9456 2.6561 3.744 0.000830 ***
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 7.407 on 28 degrees of freedom
Multiple R-squared: 0.7609, Adjusted R-squared: 0.7353
F-statistic: 29.71 on 3 and 28 DF, p-value: 7.602e-09
DEIO/CEAUL Valeska Andreozzi – slide 157
Intervalo de confiancapara β
A partir de
T =βj − βj
EP (βj)∼ t(n−m−1),
constroi-se a expressao para o intervalo de 100(1 − α)% para βj :
(βj − t1−α
2 ;n−m−1EP (βj); βj + t1−α2 ;n−m−1EP (βj)
)
Note-se que o intervalo de confianca corresponde a regiao de nao rejeicao do teste de hipoteses para o mesmoparametro. Desta forma, qualquer valor pertencente ao intervalo de confianca levaria a uma decisao de naorejeicao da hipotese nula caso fosse proposto como verdadeiro valor do parametro e o teste fosse realizado como mesmo conjunto de dados.Na pratica, o maior interesse resume-se a verificar se o zero pertence ou nao ao intervalo de confianca. Quandopertence, conclui-se (ao nıvel de significancia correspondente) que a variavel nao e significativa.
DEIO/CEAUL Valeska Andreozzi – slide 158
58

Exemplo
interv<-function(beta,se,df,alfa=0.05){
li<-beta-qt(1-alfa/2,df)*se
ls<-beta+qt(1-alfa/2,df)*se
interv<-paste("Int. Conf",1-alfa,"=")
print(paste(interv,"(",round(li,3),
";",round(ls,3),")"))
}
> interv(45.1032,10.7649,28)
[1] "Int. Conf 0.95 = ( 23.052 ; 67.154 )"
> interv(1.2127,0.3238,28)
[1] "Int. Conf 0.95 = ( 0.549 ; 1.876 )"
> interv(0.8592,0.4499,28)
[1] "Int. Conf 0.95 = ( -0.062 ; 1.781 )"
> interv(9.9456,2.6561,28)
[1] "Int. Conf 0.95 = ( 4.505 ; 15.386 )"
DEIO/CEAUL Valeska Andreozzi – slide 159
Multicolinearidade
Em geral, um valor significativo da estatıstica F resultante do teste sobre a dependencia de Y relativamente atodos os Xj esta associado a significancia de algum ou alguns dos βj , que se comprova atraves do teste de Wald.
No entanto, e possıvel que Fobs seja significativo sem que algum dos t’s o seja, ou mesmo que algum dos t’s serevele significativo sem que Fobs o seja.
Estas situacoes sao indicadoras da existencia de correlacao elevada entre as covariaveis Xj .
Se F produzir um valor nao significativo, isto e, se nao for rejeitada a hipotese de que todas as covariaveis saonao significativas, e desapropriado fazer-se inferencia sobre cada βj individualmente.
DEIO/CEAUL Valeska Andreozzi – slide 160
Multicolinearidade
Se duas covariaveis, sejam elas X1 e X2 (ditas independentes), sao correlacionadas, entao os correspondentescoeficientes no modelo, β1 e β2, nao podem ser vistos como reflectindo exactamente a dependencia existente napopulacao entre Y e X1 e entre Y e X2.
Esta correlacao existente entre variaveis independentes designa-se por multicolinearidade. Na pratica, nao temconsequencias de vulto se a correlacao entre as covariaveis for reduzida.
Quando a multicolinearidade e elevada, as conclusoes retiradas da inferencia sobre os parametros podem nao servalidas.
DEIO/CEAUL Valeska Andreozzi – slide 161
59

Multicolinearidade
Deve suspeitar-se de multicolinearidade elevada se os coeficientes da regressao tomarem valores surpreendentestais como apresentarem sinal contrario ao naturalmente esperado ou se apresentarem magnitude ou significanciaque facam pouco sentido segundo o entendimento pratico que se tenha do problema em estudo.
Outro sinal de alerta e a ocorrencia de mudanca significativa no valor de um ou mais coeficientes de outrasvariaveis regressoras quando se retira ou introduz uma variavel no modelo.
DEIO/CEAUL Valeska Andreozzi – slide 162
Multicolinearidade
Na presenca de multicolinearidade, o erro padrao das estimativas dos coeficientes da regressao (EP (βj)) pode
apresentar valores muito elevados, indicando que βj e uma estimativa imprecisa da relacao de dependenciaexistente na populacao.
Consequentemente, nao se pode dizer que βj e significativo (significativamente diferente de zero), mesmo quese saiba que existe na populacao uma relacao entre Y e Xj .
Uma forma de detectar multicolinearidade nos dados e analisar a matriz de correlacao das covariaveis. Se existirempares de variaveis altamente correlacionadas, entao deve-se eliminar uma delas, deixando aquela que fizer maissentido do ponto de vista pratico. Seguidamente deve-se calcular nova matriz de correlacao considerando apenasas variaveis mantidas na analise.
DEIO/CEAUL Valeska Andreozzi – slide 163
Multicolinearidade
■ Outra forma de avaliar a multicolinearidade e atraves do calculo do VIF (Variance Inflation factor).
■ O VIF fornece uma medida de quanto a variancia da estimativa dos coeficientes e inflacionada comparadoquando as covariaveis nao estao linearmente dependente.
V IFj =1
1 − R2j
■ em que R2j e um coeficiente de determinacao multipla da regressao da covariavel Xj em todas as outras
covariaveis.
■ Suponha 3 covariaveis, X1, X2, X3. R21 e igual ao coeficiente de determinacao da regressao
X1 ∼ X2 + X3, e assim sucessivamente.
DEIO/CEAUL Valeska Andreozzi – slide 164
60

Multicolinearidade
■ Quando V IFj ≈ 1, isto e, R2j ≈ 0, temos que as covariaveis sao independentes e quando V IFj e maior
que 10 implica que as covariaveis estao linearmente dependente (este ponto de corte e arbitrario).
■ A raiz quadrada de V IFj pode ser interpretada como uma aproximacao de quantas vezes o erro padraoda covariavel Xj esta aumentado comparado com o seu erro padrao caso nao houvesse colinearidade.
> library(faraway)
> vif(mod4)
id imc hfsim
2.866968 2.825581 1.024687
DEIO/CEAUL Valeska Andreozzi – slide 165
Multicolinearidade
O que fazer quando multicolinearidade esta presente:
1. Ignorar o problema. Quanto o objetivo da analise e predicao, os resultado devem ser adequados.
2. Aumentar o tamanho da amostra, principalmente se os dados sao poucos. Isto pode reduzir a correlacaoentre as covariaveis.
3. Nao considerar algumas variaveis e ajustar um modelo mais simples.
4. Recodificar a covariavel ou usar uma proxy.
DEIO/CEAUL Valeska Andreozzi – slide 166
Comparacao de modelos
Um dos aspectos fundamentais na construcao de um modelo util e a parcimonia: queremos o modelo maissimples que seja solucao para o problema em maos. No contexto da regressao multipla existem, entao, doisobjectivos em conflito:
■ queremos incluir o maior numero possıvel de variaveis, para que “nenhuma informacao com valor fiquede fora”, de forma a ganharmos em acuracia;
■ queremos incluir o menor numero possıvel de variaveis, para que o modelo final seja facil de compreender,facil de utilizar, consuma o mınimo de recursos e permita controlar a variabilidade das previsoes.
Inevitavelmente, o que acontece na pratica e a necessidade de encontrarmos uma solucao de compromisso.
DEIO/CEAUL Valeska Andreozzi – slide 167
61

Comparacao de modelos
Existem, basicamente, duas situacoes em estudos envolvendo modelos de regressao:
1. Dispomos de um conjunto (eventualmente reduzido) de variaveis, que utilizamos para ajustar um modelo aoconjunto de dados. No entanto, suspeitamos da existencia de redundancia entre as variaveis regressoras.Neste caso, o que pretendemos e testar se um determinado subconjunto de variaveis “acrescenta algo”deutil ao modelo, ou seja, se acrescenta informacao relevante que nao esteja contida nas outras variaveisincluıdas no modelo.
2. Dispomos de um conjunto (eventualmente grande) de variaveis candidatas a variaveis regressoras a respeitodas quais nao temos ideia sobre quais as mais relevantes para o modelo. Queremos simplesmente determinaro “melhor”conjunto de variaveis para modelar a variavel resposta no presente contexto.
DEIO/CEAUL Valeska Andreozzi – slide 168
Comparacao de modelos
Solucao:
Caso 1: Teste a significancia de um subconjunto especıfico de variaveis
Caso 2: Selecao de variaveis
Modelos encaixados:Dados dois modelos Mp e Mq envolvendo, respectivamente, p e q parametros (p < q), dizemos que Mp estaaninhado em Mq, (Mp ⊂ Mq), se todos os parametros presentes no modelo Mp estao presentes no modelo Mq.
DEIO/CEAUL Valeska Andreozzi – slide 169
Comparacao demodelos encaixados
Neste caso, o que pretendemos e testar a hipotese:
H0 : As variaveis que estao presentes no modelo Mq mas nao estao presentes no modelo Mp sao todas irrelevantespara modelar Y
contra a hipotese alternativa
H1 : Pelo menos uma daquelas variaveis e relevante para modelar Y
Esta hipotese corresponde a testar simultaneamente que q − p parametros sao nulos. Tratando-se de modelosencaixados (e desde que tenham sido estimados com base exactamente nos mesmos dados), o procedimentode teste consiste em avaliar a porcao de variacao “a mais” explicada pelo modelo com mais variaveis quandocomparado com o modelo mais pequeno - ANOVA.
F =(SSRegq − SSRegp)/(q − p)
RSSq/(n − q)∼ Fq−p,n−q
DEIO/CEAUL Valeska Andreozzi – slide 170
62

Comparacao demodelos encaixados
No R, tendo-se estimado dois modelos encaixados, o comando anova() realiza o teste descrito.
Retomando o exemplo da aula anterior, se pretendermos averiguar se vale a pena incorporar as variaveis imc ehf (mod4) ao modelo contendo apenas id como variavel regressora (mod1):H0: βimc = βhf = 0 contra H1: pelo menos um dos parametros (βimc, βhf ) e diferente de zero
anova(mod1,mod4)
Analysis of Variance Table
Model 1: pa ~ id
Model 2: pa ~ id + imc + hf
Res.Df RSS Df Sum of Sq F Pr(>F)
1 30 2564.3
2 28 1536.1 2 1028.2 9.3707 0.0007663 ***
DEIO/CEAUL Valeska Andreozzi – slide 171
Comparacao demodelos encaixados
A conclusao e que e de rejeitar a hipotese de que estas duas variaveis sejam, ambas, desinteressantes para omodelo.
No entanto, nao podemos concluir que ambas sejam uteis para modelar pa.
Atribuindo apenas um argumento (modelo) a funcao anova() obtemos como resultado uma analise faseada.Comecando com o modelo nulo (sem variaveis regressoras), vao-nos sendo apresentados os resultados dos testescorrespondentes ao ganho associado a inclusao de mais uma variavel (uma de cada vez), pela mesma ordem pelaqual foram introduzidas aquando da escrita do comando que levou a estimacao do modelo em questao.
DEIO/CEAUL Valeska Andreozzi – slide 172
Comparacao demodelos encaixados
mod4
Call:
lm(formula = pa ~ id + imc + hf, data = dados)
anova(mod4)
Analysis of Variance Table
Response: pa
Df Sum Sq Mean Sq F value Pr(>F)
id 1 3861.6 3861.6 70.3877 3.987e-09 ***
imc 1 259.0 259.0 4.7202 0.03843 *
hf 1 769.2 769.2 14.0212 0.00083 ***
Residuals 28 1536.1 54.9
DEIO/CEAUL Valeska Andreozzi – slide 173
63

Comparacao demodelos encaixados
A contribuicao partial da variavel imc no modelo do slide anterior e dada pela diferenca entre a soma dosquadrados do modelo com idade+imc e a soma dos quadrados do modelo com somente idade.
media<-mean(dados$pa)
#sum of square de imc
ssregful<-sum((lm(pa~id+imc,data=dados)$fitted.values-media)^2)
ssregsemimc<-sum((lm(pa~id,data=dados)$fitted.values-media)^2)
ssregful-ssregsemhf
#f-value
259.0/54.9
#sum of square de hf
ssregful<-sum((lm(pa~id+imc+hf,data=dados)$fitted.values-media)^2)
ssregsemimc<-sum((lm(pa~id+imc,data=dados)$fitted.values-media)^2)
ssregful-ssregsemimc
#f-value
769.2335/54.9
DEIO/CEAUL Valeska Andreozzi – slide 174
Comparacao demodelos nao encaixados
Tambem podera haver interesse em comparar modelos que nao estao encaixados. Podera, por exemplo, colocar-sea questao de decidir sobre que variavel mais introduzir no modelo.
Exemplo: Uma vez considerada a variavel id, sera preferıvel introduzir no modelo a variavel imc ou a variavelhf?
Uma possibilidade consiste em comparar o coeficiente de determinacao ajustado e escolher o modelo que ap-resentar valor mais elevado para esta medida. No entanto, isto nao permite testar que um dos modelos esignificativamente melhor do que o outro.
DEIO/CEAUL Valeska Andreozzi – slide 175
64

Comparacao demodelos nao encaixados
mod5<-lm(pa~id+imc,data=dados)
summary(mod5)
...
Estimate Std. Error t value Pr(>|t|)
(Intercept) 55.3234 12.5347 4.414 0.000129 ***
id 1.0452 0.3861 2.707 0.011253 *
imc 0.9751 0.5402 1.805 0.081489 .
...
Adjusted R-squared: 0.6165
mod6<-lm(pa~id+hf,data=dados)
summary(mod6)
...
Estimate Std. Error t value Pr(>|t|)
(Intercept) 48.0496 11.1296 4.317 0.000168 ***
id 1.7092 0.2018 8.471 2.47e-09 ***
hfsim 10.2944 2.7681 3.719 0.000853 ***
Adjusted R-squared: 0.7112
DEIO/CEAUL Valeska Andreozzi – slide 176
Comparacao demodelos nao encaixados
AIC - Akaike Information Criteria:
AIC e uma medida de qualidade de ajustamento de um modelo estimado. De uma forma generica, pode dizer-seque engloba a precisao e a complexidade do modelo.
AIC = −2 ln(L) + 2k
onde L representa a verosimilhanca do modelo e k o numero de parametros presentes no modelo.
Quanto maior for o numero de variaveis consideradas no modelo (e consequente mais parametros), maior sera ovalor da verosimilhanca, pelo que ln(L) cresce com a complexidade do modelo. Por outro lado, porque um modelomais complexo acarreta maiores custos (a todos os nıveis), a introducao de variaveis no modelo e penalizada.
DEIO/CEAUL Valeska Andreozzi – slide 177
65

Comparacao demodelos nao encaixados
A medida AIC e uma ferramenta para a selecao de modelos. Perante um conjunto de dados e varios modeloscandidatos, estes podem ser ordenados de acordo com o AIC, considerando-se o melhor modelo aquele queapresentar menor valor de AIC. Isto permite dizer que um modelo e preferıvel a outro mas nao e possıvelestabelecer um valor para o AIC acima do qual um modelo deva ser “rejeitado”’.
extractAIC(mod5)
[1] 3.0000 142.8724
extractAIC(mod6)
[1] 3.0000 133.8005
Comparando os dois modelos, concluımos que o mod6 e preferıvel a mod5. Isto e, e preferıvel juntar a variavel hfa id do que juntar a variavel imc. No entanto esta medida nao da qualquer informacao sobre a significanciados modelos.
DEIO/CEAUL Valeska Andreozzi – slide 178
Metodo de selecao das variaveis
■ Na presenca de um determinado numero de variaveis independentes tidas a partida como interessantes, aprimeira ideia podera ser a de considera-las todas na construcao do modelo.
■ Se por um lado um modelo contendo mais variaveis consegue uma melhor descricao da variaveldependente, esse modelo nao sera, necessariamente, o melhor sob o ponto de vista de predicao, porexemplo. Outro aspecto importante e o da interpretabilidade do modelo, que fica simplificada se estenao envolver um numero demasiado elevado de variaveis.
■ Existem varios metodos que podem ser usados na busca do “melhor”modelo. Tendo pontos de partidadiferentes, estes metodos nao conduzem todos ao mesmo resultado nem tampouco reunem consensorelativamente a qual apresenta maiores vantagens.
DEIO/CEAUL Valeska Andreozzi – slide 179
Metodo de selecao das variaveis
Considerando uma situacao em que existem m covariaveis, uma possibilidade seria ajustar
■ um modelo contendo as m variaveis,
■ os m(m − 1)/2 modelos contendo todas as combinacoes de m − 1 das m variaveis,
■ os(mk
)modelos contendo todas as combinacoes de k das m variaveis, k = m − 2, ..., 1
■ e para terminar, ajustar o modelo sem variaveis regressoras, ou seja, E(Y ) = β0.
Apos ajustarmos∑m
k=0
(mk
)= 2m modelos, poderıamos escolher aquele que produzisse menor erro quadratico
medio ou, de forma equivalente, maior coeficiente de determinacao ajustado R2a ou menor estimativa para o
erro padrao, caso o objetivo do estudo fosse predicao.
DEIO/CEAUL Valeska Andreozzi – slide 180
66

Metodo de selecao das variaveis
A utilizacao desta metodologia e, obviamente, desaconselhada mesmo para problemas envolvendo um numerorelativamente reduzido de covariaveis dado o numero de equacoes de regressao a estimar, para alem de outrasquestoes relacionadas com o criterio de classificacao do “melhor”modelo.
O procedimento seguinte - backward elimination (step-down) - permite decidir se um modelo e ou naopreferıvel a outro:
1. Construir o modelo contendo todas as variaveis disponıveis;
2. Analisar o resultado do teste H0 : βj = 0 para cadaj = 1, ...,m.Se todos os coeficientes forem significativos, entao conclui-se que todas as variaveis Xj sao importantespara explicar Y e nenhuma deve ser eliminada do modelo.
DEIO/CEAUL Valeska Andreozzi – slide 181
Metodo de selecao das variaveis
3. Se, pelo contrario, alguns coeficientes forem nao significativos, retira-se do modelo aquela que apresentar omaior valor-p (essa variavel e aquela a qual corresponde a estatıstica t com valor absoluto mais baixo) eajusta-se um novo modelo considerando as variaveis restantes.
4. Repetem-se os passos acima ate que restem no modelo apenas variaveis consideradas significativas.
Este procedimento produz, em geral, resultados tao bons quanto aquele em que sao comparados todas as com-binacoes possıveis de covariaveis.Para uma variavel categorica, deve-se utilizar o teste F para testar a hipotese nula de que todos os parametrosda variavel dummy associada sao iguais a zero.
DEIO/CEAUL Valeska Andreozzi – slide 182
Metodo de selecao das variaveis
Um outro procedimento comum e o designado por forward selection (step-up).
Neste procedimento, comeca-se por considerar o modelo mais simples, com apenas uma variavel. De seguida,passa-se a considerar o modelo com duas variaveis, depois tres, e assim sucessivamente, parando-se quando asvariaveis que se acrescentam ao modelo nao sao significativas.
Esta metodologia tem o problema da determinacao do melhor modelo em cada uma das fases, para alem de sermuito dispendioso em termos de calculo pois envolve a estimacao de um numero elevado de modelos durante oprocesso de selecao.
DEIO/CEAUL Valeska Andreozzi – slide 183
67

Metodo de selecao das variaveis
De entre todos os procedimentos de selecao de variaveis, o mais amplamente utilizado e o que se designa porstepwise selection.
Este procedimento envolve inclusao e eliminacao de variaveis. Pode comecar como o step-up, partindo do modelonulo (so com intercept), ou como o step-down, partindo do modelo contendo todas as variaveis disponıveis.Cada vez que uma variavel e incluıda (retirada) no modelo, todas as variaveis sao analisadas com o objectivo dedeterminar se devera ser eliminada do modelo naquele passo.
Na presenca de multicolinearidade severa, qualquer destes procedimentos de selecao de variaveis pode produzirresultados espurios. Em tais casos, e frequente que com a inclusao e/ou exclusao de variaveis no modelo, oscoeficientes das restantes variaveis sofram mudancas de grande amplitude e, inclusivamente, mudancas de sinal.
DEIO/CEAUL Valeska Andreozzi – slide 184
Exemplo
Para ilustrar os procedimentos de selecao de variaveis, consideremos o seguinte conjunto de dados recolhidos em50 estados dos EUA. As variaveis sao:
■ population estimate as of July 1, 1975
■ per capita income (1974)
■ illiteracy (1970, percent of population)
■ life expectancy in years (1969-71)
■ murder and non-negligent manslaughter rate per 100,000 population (1976)
■ percent high-school graduates (1970)
DEIO/CEAUL Valeska Andreozzi – slide 185
Exemplo
■ mean number of days with min temperature less than 32 degrees (1931-1960) in capital or large city
■ land area in square miles
Life expectancy (esperanca de vida) e a variavel resposta, considerando-se as restantes variaveis como ex-planatorias.
library(faraway)
state <- data.frame(state.x77,row.names=state.abb,
check.names=T)
nomes<-names(state)
nomes
[1] "Population" "Income" "Illiteracy" "Life.Exp"
[5] "Murder" "HS.Grad" "Frost" "Area"
DEIO/CEAUL Valeska Andreozzi – slide 186
68

Exemplo
names(state)<-tolower(nomes)
nomes<-names(state)
nomes
[1] "population" "income" "illiteracy"
[4] "life.exp" "murder" "hs.grad"
[7] "frost" "area"
head(state)
population income illiteracy life.exp murder
AL 3615 3624 2.1 69.05 15.1
AK 365 6315 1.5 69.31 11.3
AZ 2212 4530 1.8 70.55 7.8
AR 2110 3378 1.9 70.66 10.1
CA 21198 5114 1.1 71.71 10.3
CO 2541 4884 0.7 72.06 6.8
DEIO/CEAUL Valeska Andreozzi – slide 187
Exemplo
hs.grad frost area
AL 41.3 20 50708
AK 66.7 152 566432
AZ 58.1 15 113417
AR 39.9 65 51945
CA 62.6 20 156361
CO 63.9 166 103766
> summary(state)
population income illiteracy
Min. : 365 Min. :3098 Min. :0.500
1st Qu.: 1080 1st Qu.:3993 1st Qu.:0.625
Median : 2838 Median :4519 Median :0.950
Mean : 4246 Mean :4436 Mean :1.170
3rd Qu.: 4968 3rd Qu.:4814 3rd Qu.:1.575
Max. :21198 Max. :6315 Max. :2.800
DEIO/CEAUL Valeska Andreozzi – slide 188
69

Exemplo
life.exp murder hs.grad
Min. :67.96 Min. : 1.400 Min. :37.80
1st Qu.:70.12 1st Qu.: 4.350 1st Qu.:48.05
Median :70.67 Median : 6.850 Median :53.25
Mean :70.88 Mean : 7.378 Mean :53.11
3rd Qu.:71.89 3rd Qu.:10.675 3rd Qu.:59.15
Max. :73.60 Max. :15.100 Max. :67.30
frost area
Min. : 0.00 Min. : 1049
1st Qu.: 66.25 1st Qu.: 36985
Median :114.50 Median : 54277
Mean :104.46 Mean : 70736
3rd Qu.:139.75 3rd Qu.: 81163
Max. :188.00 Max. :566432
DEIO/CEAUL Valeska Andreozzi – slide 189
Exemplo
O objectivo e seleccionar o melhor modelo utilizando a metodologia backward selection, ou seja, step-down.Para isso, comecamos por ajustar o modelo contendo todas as variaveis.
modcomp<-lm(life.exp~.,data=state)
summary(modcomp)
Call:
lm(formula = life.exp ~ ., data = state)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.094e+01 1.748e+00 40.586 < 2e-16
population 5.180e-05 2.919e-05 1.775 0.0832
income -2.180e-05 2.444e-04 -0.089 0.9293
illiteracy 3.382e-02 3.663e-01 0.092 0.9269
murder -3.011e-01 4.662e-02 -6.459 8.68e-08
hs.grad 4.893e-02 2.332e-02 2.098 0.0420
frost -5.735e-03 3.143e-03 -1.825 0.0752
area -7.383e-08 1.668e-06 -0.044 0.9649
DEIO/CEAUL Valeska Andreozzi – slide 190
70
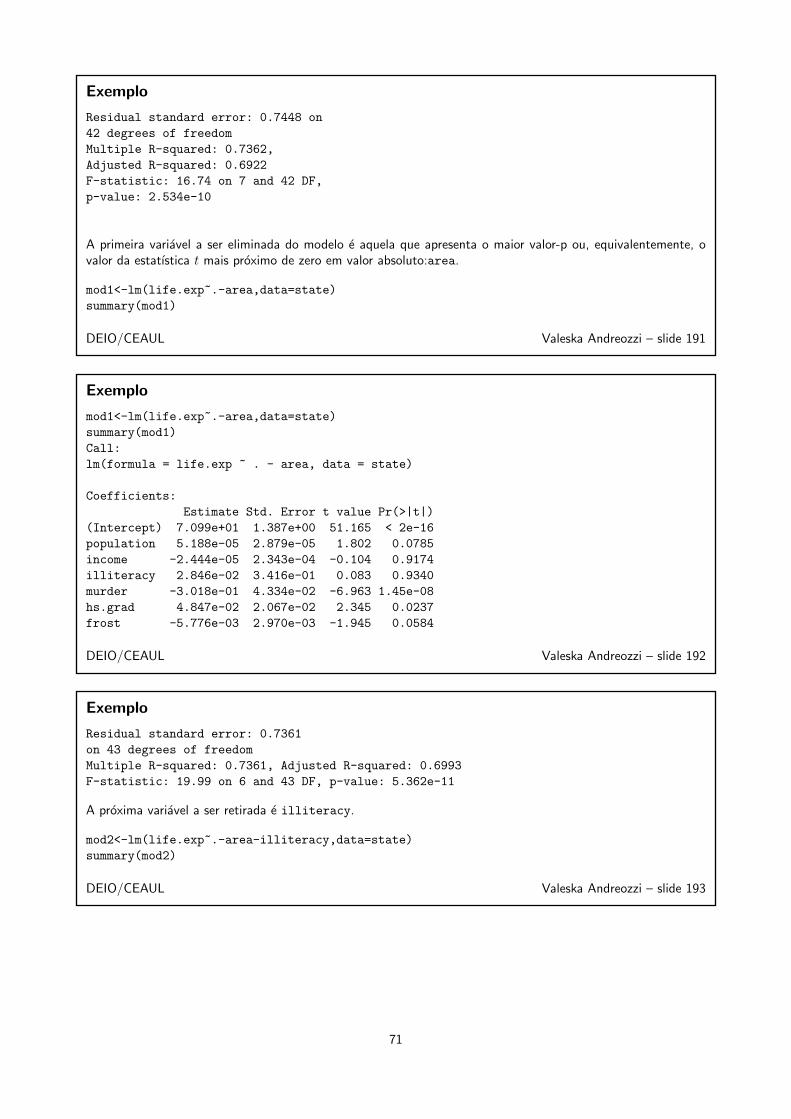
Exemplo
Residual standard error: 0.7448 on
42 degrees of freedom
Multiple R-squared: 0.7362,
Adjusted R-squared: 0.6922
F-statistic: 16.74 on 7 and 42 DF,
p-value: 2.534e-10
A primeira variavel a ser eliminada do modelo e aquela que apresenta o maior valor-p ou, equivalentemente, ovalor da estatıstica t mais proximo de zero em valor absoluto:area.
mod1<-lm(life.exp~.-area,data=state)
summary(mod1)
DEIO/CEAUL Valeska Andreozzi – slide 191
Exemplo
mod1<-lm(life.exp~.-area,data=state)
summary(mod1)
Call:
lm(formula = life.exp ~ . - area, data = state)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.099e+01 1.387e+00 51.165 < 2e-16
population 5.188e-05 2.879e-05 1.802 0.0785
income -2.444e-05 2.343e-04 -0.104 0.9174
illiteracy 2.846e-02 3.416e-01 0.083 0.9340
murder -3.018e-01 4.334e-02 -6.963 1.45e-08
hs.grad 4.847e-02 2.067e-02 2.345 0.0237
frost -5.776e-03 2.970e-03 -1.945 0.0584
DEIO/CEAUL Valeska Andreozzi – slide 192
Exemplo
Residual standard error: 0.7361
on 43 degrees of freedom
Multiple R-squared: 0.7361, Adjusted R-squared: 0.6993
F-statistic: 19.99 on 6 and 43 DF, p-value: 5.362e-11
A proxima variavel a ser retirada e illiteracy.
mod2<-lm(life.exp~.-area-illiteracy,data=state)
summary(mod2)
DEIO/CEAUL Valeska Andreozzi – slide 193
71

Exemplo
Call:
lm(formula = life.exp ~ . - area - illiteracy,
data = state)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.107e+01 1.029e+00 69.067 < 2e-16
population 5.115e-05 2.709e-05 1.888 0.0657
income -2.477e-05 2.316e-04 -0.107 0.9153
murder -3.000e-01 3.704e-02 -8.099 2.91e-10
hs.grad 4.776e-02 1.859e-02 2.569 0.0137
frost -5.910e-03 2.468e-03 -2.395 0.0210
Residual standard error: 0.7277
on 44 degrees of freedom
Multiple R-squared: 0.7361, Adjusted R-squared: 0.7061
F-statistic: 24.55 on 5 and 44 DF, p-value: 1.019e-11
DEIO/CEAUL Valeska Andreozzi – slide 194
Exemplo
A variavel income e a que apresenta agora valor-p mais elevado e por isso e a proxima a ser retirada.
mod3<-lm(life.exp~.-area-illiteracy
-income,data=state)
summary(mod3)
Call:
lm(formula = life.exp ~ . - area -
illiteracy - income, data = state)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.103e+01 9.529e-01 74.542 < 2e-16
population 5.014e-05 2.512e-05 1.996 0.05201
murder -3.001e-01 3.661e-02 -8.199 1.77e-10
hs.grad 4.658e-02 1.483e-02 3.142 0.00297
frost -5.943e-03 2.421e-03 -2.455 0.01802
DEIO/CEAUL Valeska Andreozzi – slide 195
72

Exemplo
Residual standard error: 0.7197
on 45 degrees of freedom
Multiple R-squared: 0.736, Adjusted R-squared: 0.7126
F-statistic: 31.37 on 4 and 45 DF, p-value: 1.696e-12
A unica variavel que resta no modelo e que apresenta um valor-p superior a 0.05 e population, sendo a proximaa ser retirada.
mod4<-lm(life.exp~.-area-
illiteracy-income-population,data=state)
summary(mod4)
DEIO/CEAUL Valeska Andreozzi – slide 196
Exemplo
Call:
lm(formula = life.exp ~ . - area -
illiteracy - income - population,
data = state)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 71.036379 0.983262 72.246 < 2e-16
murder -0.283065 0.036731 -7.706 8.04e-10
hs.grad 0.049949 0.015201 3.286 0.00195
frost -0.006912 0.002447 -2.824 0.00699
Residual standard error: 0.7427
on 46 degrees of freedom
Multiple R-squared: 0.7127, Adjusted R-squared: 0.6939
F-statistic: 38.03 on 3 and 46 DF, p-value: 1.634e-12
DEIO/CEAUL Valeska Andreozzi – slide 197
Exemplo
O modelo final e
ˆlife.expi = 71.03 − 0.28 × murderi
+ 0.05 × hs.gradi − 0.007 × frosti.
Nao vamos ilustrar aqui a aplicacao do procedimento step-up.
No R o procedimento de selecao stepwise parte do modelo completo.
step(modcomp)
Start: AIC=-22.18
life.exp ~ population + income + illiteracy
+ murder + hs.grad
+ frost + area
DEIO/CEAUL Valeska Andreozzi – slide 198
73

Exemplo
Df Sum of Sq RSS AIC
- area 1 0.001 23.298 -24.182
- income 1 0.004 23.302 -24.175
- illiteracy 1 0.005 23.302 -24.174
<none> 23.297 -22.185
- population 1 1.747 25.044 -20.569
- frost 1 1.847 25.144 -20.371
- hs.grad 1 2.441 25.738 -19.202
- murder 1 23.141 46.438 10.305
Step: AIC=-24.18
life.exp ~ population + income + illiteracy
+ murder + hs.grad + frost
DEIO/CEAUL Valeska Andreozzi – slide 199
Exemplo
Df Sum of Sq RSS AIC
- illiteracy 1 0.004 23.302 -26.174
- income 1 0.006 23.304 -26.170
<none> 23.298 -24.182
- population 1 1.760 25.058 -22.541
- frost 1 2.049 25.347 -21.968
- hs.grad 1 2.980 26.279 -20.163
- murder 1 26.272 49.570 11.568
Step: AIC=-26.17
life.exp ~ population + income + murder
+ hs.grad + frost
DEIO/CEAUL Valeska Andreozzi – slide 200
Exemplo
Df Sum of Sq RSS AIC
- income 1 0.006 23.308 -28.161
<none> 23.302 -26.174
- population 1 1.887 25.189 -24.280
- frost 1 3.037 26.339 -22.048
- hs.grad 1 3.495 26.797 -21.187
- murder 1 34.739 58.041 17.457
Step: AIC=-28.16
life.exp ~ population + murder + hs.grad + frost
DEIO/CEAUL Valeska Andreozzi – slide 201
74

Exemplo
Df Sum of Sq RSS AIC
<none> 23.308 -28.161
- population 1 2.064 25.372 -25.920
- frost 1 3.122 26.430 -23.876
- hs.grad 1 5.112 28.420 -20.246
- murder 1 34.816 58.124 15.528
DEIO/CEAUL Valeska Andreozzi – slide 202
Exemplo
O modelo final e:
Call:
lm(formula = life.exp ~ population + murder + hs.grad
+ frost,data = state)
Coefficients:
(Intercept) population murder hs.grad
7.103e+01 5.014e-05 -3.001e-01 4.658e-02
frost
-5.943e-03
DEIO/CEAUL Valeska Andreozzi – slide 203
Exemplo
A funcao step() do R merece uma atencao particular.
step(object, scope, scale = 0,
direction = c("both", "backward", "forward"),
trace = 1, keep = NULL, steps = 1000, k = 2, ...)
Exercıcio: Analisar o output de
step2<-step(modcomp,direction="both")
summary(step2)
extractAIC(step2)
DEIO/CEAUL Valeska Andreozzi – slide 204
Diagnostico do modelo
Nao se deve esquecer que um modelo e apenas uma aproximacao da realidade.
Todos os modelos envolvem varias premissas em relacao aos dados.
Contudo, na maioria das vezes apenas uma porcao dos dados se mostra consoante as premissas domodelo.
Logo, torna-se essencial avaliar se as premissas dos modelos ajustados foram respeitadas para garantir ainterpretabilidade do modelo.
DEIO/CEAUL Valeska Andreozzi – slide 205
75

Diagnostico do modelo
Topicos a serem verificados na etapa de diagnostico do modelo
■ Verificar se o modelo se ajusta aos dados
■ Procurar pontos outliers
■ Procurar pontos influentes
■ Medida global de ajuste
■ Necessidade de inclusao de covariaveis
■ Escolha correta da funcao de ligacao
■ Escolha da escala das covariaveis
DEIO/CEAUL Valeska Andreozzi – slide 206
Diagnostico do modelo
■ Regression diagnostics are used after fitting to check if a fitted mean function and assumptions areconsistent with observed data.
■ The basic statistics here are the residuals or possibly rescaled residuals.
■ If the fitted model does not give a set of residuals that appear to be reasonable, then some aspect ofthe model, either the assumed mean function or assumptions concerning the variance function, may becalled into doubt.
DEIO/CEAUL Valeska Andreozzi – slide 207
Valores ajustados e resıduos
■ Using the matrix notation, we begin by deriving the properties of residuals.
■ The basic multiple linear regression model is given byY = Xβ + ǫ and V ar(ǫ) = σ2I
■ X is a known matrix with n rows and p columns, including a column of 1s for the intercept
■ β is the unknown parameter vector p × 1
■ ǫ consists of unobservable errors that we assume are equally variable and uncorrelated
DEIO/CEAUL Valeska Andreozzi – slide 208
Valores ajustados e resıduos
■ We estimate β by β = (XT X)−1XT Y and the fitted values Y
Y = Xβ (6)
= X(XT X)−1XT Y (7)
= HY (8)
■ where H is a n × n called hat matrix because it transforms the vector of observed responses Y into thevector of fitted responses Y
DEIO/CEAUL Valeska Andreozzi – slide 209
76

Valores ajustados e resıduos
■ The vector of residuals ǫ is defined by
ǫ = Y − Y (9)
= Y − Xβ (10)
= Y − X(XT X)−1XT Y (11)
= (I − H)Y (12)
DEIO/CEAUL Valeska Andreozzi – slide 210
Valores ajustados e resıduos
■ The errors ǫ are unobservable random variables, assumed to have zero mean and uncorrelated elements,each with common variance σ2. The residuals ǫ are computed quantities that can be graphed orotherwise studied. Their mean and variance, using equation 12, are:
E(ǫ) = 0
V ar(ǫ) = σ2(I − H)
■ Like the errors, each of the residuals has zero mean, but each residual may have a different variance.
■ Unlike the errors, the residuals are correlated
■ The residuals are linear combinations of the errors. If the errors are normally distributed, so are theresiduals.
DEIO/CEAUL Valeska Andreozzi – slide 211
Valores ajustados e resıduos
■ In scalar form, the variance of the ith residual is
V ar(ǫi) = σ2(1 − hii) (13)
■ where hii is the ith diagonal element of H
■ Diagnostic procedures are based on the computed residuals, which we would like to assume behave asthe unobservable errors would.
DEIO/CEAUL Valeska Andreozzi – slide 212
77

Valores ajustados e resıduos
Helpful relationships can be found between the hij :
■∑n
i=1 hii = p and∑n
i=1 hij =∑n
j=1 hij = 1
■ Each diagonal element hii is bounded below by 1/n and above by 1/r, if r is the number of rows of Xidentical to xi
■ As can be seen from (13), cases with large values of hii will have small values for V ar(ǫi); as hii getscloser to 1, this variance will approach 0. For such a case, no matter what value of yi is observed for theith case, we are nearly certain to get a residual near 0.
■ Using a scalar version of Y = HY , we have
yi =n∑
j=1
(hijyj) = hiiyi +n∑
j 6=i
(hijyj)
■ as hii approaches 1, yi gets closer to yi . For this reason, they called hii the leverage of the ith case.
DEIO/CEAUL Valeska Andreozzi – slide 213
Resıduos
Suppose that U is equal to one of the terms in the mean function, or some linear combination of the terms.Residuals are generally used in scatterplots of the residuals ǫ against U . The key features of these residualplots when the correct model is fit are as follows:
1. The mean function is E(ǫ|U) = 0. This means that the scatterplot of residuals on the horizontal axisversus any linear combination of the terms should have a constant mean function equal to 0.
2. Since V ar(ǫ|U) = σ2(1 − hii) even if the fitted model is correct, the variance function is not quiteconstant. The variability will be smaller for high-leverage cases with hii close to 1.
3. The residuals are correlated, but this correlation is generally unimportant and not visible in residual plots.
When the model is correct, residual plots should look like null plots.
DEIO/CEAUL Valeska Andreozzi – slide 214
Graficos
■ Toda esta historia para chegarmos a conclusao de que devemos utilizar resıduos padronizados
■ Vejamos alguns exemplos
DEIO/CEAUL Valeska Andreozzi – slide 215
78

Graficos
■ Vejamos alguns exemplos
DEIO/CEAUL Valeska Andreozzi – slide 216
Graficos
■ Vejamos alguns exemplos
DEIO/CEAUL Valeska Andreozzi – slide 217
Graficos
Residual plots:
■ (a) null plot;
■ (b) right-opening megaphone;
■ (c) left-opening megaphone;
■ (d) double outward box;
■ (e) - (f) nonlinearity;
■ (g) - (h) combinations of nonlinearity and nonconstant variance function.
DEIO/CEAUL Valeska Andreozzi – slide 218
79

Definicao do resıduo
Resıduo ordinarior = yi − µi
Resıduo de Pearson
rp =yi − µi√
σ2
Resıduo de Pearson Padronizado
r′p =yi − µi√
σ2(1 − hii)
DEIO/CEAUL Valeska Andreozzi – slide 219
Resıduo no R
mod4<-lm(pa~id+imc+hf,data=dados)
names(mod4)
res.ord<-dados$pa-fitted(mod4) #resıduos ordinarios
sigma<-summary(mod4)$sigma
res.pearson<-res.ord/sigma #resıduos de Pearson
hii<-hatvalues(mod4)
#resıduos de Pearson padronizado
res.pearsonpad<-res.ord/(sigma*sqrt(1-hii))
summary(res.ord)
summary(res.pearson)
summary(res.pearsonpad)
#outra forma de calcular o resıduo
#padronizado
summary(rstandard(mod4, type="pearson"))
DEIO/CEAUL Valeska Andreozzi – slide 220
Normalidade
Verificacao do pressuposto de normalidade:Os resıduos devem comportar-se de acordo com o pressuposto de normalidade. Para verificar se tal acontece,representam-se graficamente os resıduos padronizados contra os quantis da normal padrao correspondentes aovalor da funcao de distribuicao empırica dos resıduos - QQplot
qqnorm(res.pearsonpad)
abline(0,1,lwd=2)
Se o pressuposto de normalidade for cumprido, os pontos apresentar-se-ao proximos da recta y = x.
DEIO/CEAUL Valeska Andreozzi – slide 221
80

Normalidade
−2 −1 0 1 2
−2
−1
01
2
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
DEIO/CEAUL Valeska Andreozzi – slide 222
Homocedasticidade
Verificacao do pressuposto de homocedasticidade:Para verificar se este pressuposto e cumprido, representam-se os resıduos padronizados contra os valores estimadosde y, yi. E de esperar que a nuvem de pontos nao apresente padrao, o que significara que a dispersao nao variacom as mudancas em y.
No R, os valores estimados de y estao no campo fitted.values do objecto em que se guardou o resultado doajustamento do modelo.
plot(mod4$fitted.values,res.pearsonpad,
main="resıduos padronizados vs valores ajustados",
ylab="resıduos padronizados",
xlab="valores ajustados",pch=21,bg=2,col=2)
abline(h=0,lty=2)
DEIO/CEAUL Valeska Andreozzi – slide 223
81

Homocedasticidade
120 130 140 150 160 170
−2
−1
01
2
resíduos padronizados vs valores ajustados
valores ajustados
resí
duos
pad
roni
zado
s
DEIO/CEAUL Valeska Andreozzi – slide 224
Independencia
Verificacao do pressuposto de independencia:Para verificar se este pressuposto e cumprido, representam-se os resıduos contra a ordem pela qual os dados foramrecolhidos. E de esperar que a nuvem de pontos nao apresente padrao, o que significara que as observacoes foramrecolhidas de forma independente.
No R, o comando plot com apenas um vector como argumento produz um scatterplot dos valores do vectordado contra o ındice dos valores do vector.
plot(res.pearsonpad,
main="resıduos vs index",
ylab="resıduos padronizados",pch=21,bg=2,col=2)
DEIO/CEAUL Valeska Andreozzi – slide 225
82
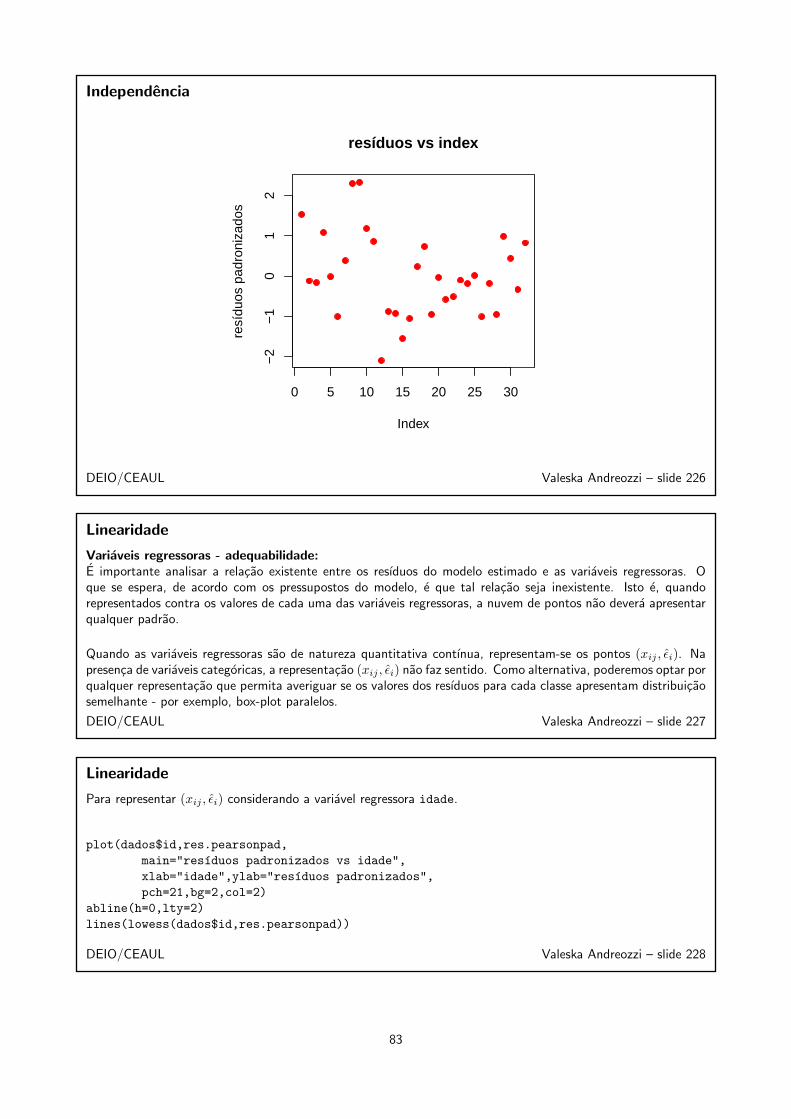
Independencia
0 5 10 15 20 25 30
−2
−1
01
2
resíduos vs index
Index
resí
duos
pad
roni
zado
s
DEIO/CEAUL Valeska Andreozzi – slide 226
Linearidade
Variaveis regressoras - adequabilidade:E importante analisar a relacao existente entre os resıduos do modelo estimado e as variaveis regressoras. Oque se espera, de acordo com os pressupostos do modelo, e que tal relacao seja inexistente. Isto e, quandorepresentados contra os valores de cada uma das variaveis regressoras, a nuvem de pontos nao devera apresentarqualquer padrao.
Quando as variaveis regressoras sao de natureza quantitativa contınua, representam-se os pontos (xij , ǫi). Napresenca de variaveis categoricas, a representacao (xij , ǫi) nao faz sentido. Como alternativa, poderemos optar porqualquer representacao que permita averiguar se os valores dos resıduos para cada classe apresentam distribuicaosemelhante - por exemplo, box-plot paralelos.
DEIO/CEAUL Valeska Andreozzi – slide 227
Linearidade
Para representar (xij , ǫi) considerando a variavel regressora idade.
plot(dados$id,res.pearsonpad,
main="resıduos padronizados vs idade",
xlab="idade",ylab="resıduos padronizados",
pch=21,bg=2,col=2)
abline(h=0,lty=2)
lines(lowess(dados$id,res.pearsonpad))
DEIO/CEAUL Valeska Andreozzi – slide 228
83

Linearidade
45 50 55 60 65
−2
−1
01
2
resíduos padronizados vs idade
idade
resí
duos
pad
roni
zado
s
DEIO/CEAUL Valeska Andreozzi – slide 229
Inclusao de nova variavel
Para avaliar a inclusao de uma nova variavel no modelo utilizamos o grafico
■ Graficos dos resıduos do modelo vs a nova covariavel nao incluıda no modelo
■ Nao existe evidencia de associacao da variavel resposta e a nova variavel caso um padrao nulo sejaencontrado
DEIO/CEAUL Valeska Andreozzi – slide 230
Relacao linear das covariaveis
Estamos interessados em avaliar a relacao linear parcial da variavel resposta Y com a covariavel xj (“controlando” pelas outrascovariaveis presentes no modelo) e nao na relacao marginal (ignorando as outras covariaveis).Neste caso o grafico util na avaliacao da relacao linear da covariavel e Component-plus-residuals plot tambem conhecido comopartial-residuals plot
■ E composto pelo resıduo parcial da covariavel xj dado por r(j)i
= ri + Bjxij versus a propria covariavel xj .
■ O resıduo parcial r(j)i
e definido atraves da adicao do termo linear da relacao entre yi e xij aos resıduos do modelo ri, quepodem conter um componente nao linear
■ Por construcao, o coeficiente Bj e a inclinacao da relacao linear entre r(j) e xj , mas a nao-linearidade podera ser aparenteneste grafico.
■ E aconselhado incluir um funcao de alisamento no grafico
■ Pode-se identificar neste grafico se a relacao e motononica ou nao
library(car)
crPlots(mod4,terms=~id)
DEIO/CEAUL Valeska Andreozzi – slide 231
84

Relacao linear das covariaveis
45 50 55 60 65
−20
−10
010
20
Component+Residual Plot
id
Com
pone
nt+
Res
idua
l(pa)
DEIO/CEAUL Valeska Andreozzi – slide 232
Relacao nao-linear das covariaveis
Quando a relacao entre a variavel resposta e a covariavel contınua e nao linear o que devemos fazer?
■ Categorizar a covariavel, caso a nao-linearidade seja caracterizada por uma funcao escada.
■ Adicionar termos polinomiais. Podemos incluir termos quadraticos da covariavel em questao, ou seja X2j ,
mas nem sempre a nao-linearidade e de natureza parabolica.
■ A adicao de termos polinominais pode ser uma solucao, contudo apresentam algumas propriedades naodesejaveis (presenca de picos e depressoes; problemas em modelar dados com threshold)
■ Uma outra alternativa e incluir termos nao lineares atraves de funcoes de alisamento (parametricos ounao parametricos). Desta forma sao caracterizados os modelos aditivos generalizados.
DEIO/CEAUL Valeska Andreozzi – slide 233
85

Spline
■ Splines sao polinomios em intervalos de x.
■ Suponha que x seja dividida em intervalos com limites a, b, c chamados nos (knots)
■ Uma versao muito simplificada do spline e a funcao linear segmentada dada por
f(X) = β0 + β1X + β2(X − a)+ + β3(X − b)+ + β4(X − c)+
em que:
(u)+ = u, u > 0
0, u ≤ 0
■ O numero de nos pode variar dependendo da quantidade de dados disponıveis para ajustar a funcao.
DEIO/CEAUL Valeska Andreozzi – slide 234
Spline
■ A funcao linear segmentada pode ser reescrita da seguinte forma:
f(X) = β0 + β1X, X ≤ a
β0 + β1X + β2(X − a), a < X ≤ b
β0 + β1X + β2(X − a) + β3(X − b), b < X ≤ c
β0 + β1X + β2(X − a) + β3(X − b) + β4(X − c), c < X
0 1 2 3 4 5 6
02
46
810
X
F(X
)
Função linear segmentada com nós a=1, b=3, c=5
DEIO/CEAUL Valeska Andreozzi – slide 235
86

Spline
■ O modelo de regressao linear podera ser reescrito assumindo uma linearidade segmentada em X atravesda incorporacao de novas variaveis X2,X3,X4 tal que:
E(Y |X) = f(X) = Xβ
em que: Xβ = β0 + β1X1 + β2X2 + β3X3 + β4X4 e
X1 = X X2 = (X − a)+
X3 = (X − b)+ X4 = (X − c)+
■ Para modelar o incremento de X no intervalo (a, b] em termos de (X − a)+, a funcao e restrita de talmodo a “encontrar” os nos.
■ A linearidade global em X e testada por H0 : β2 = β3 = β4 = 0
DEIO/CEAUL Valeska Andreozzi – slide 236
Spline Cubico
■ Embora o spline linear seja simples e acomode muitas relacoes nao-lineares entre Y e X, nao e suave osuficiente e nao ajustara funcoes altamente curvas
■ Este problema pode ser resolvido atraves de polinomios segmentados (piecewise polinomials) de ordemsuperior ao primeiro grau
■ Polinomios cubicos apresentam propriedades adequadas para ajustar formas muitos curvas.
■ Cubic splines sao feitos para serem suaves nos pontos de juncao (knots). Esta caracterıstica e adquirida acusta de forcar a primeira e segunda derivada da funcao coincidir com os knots.
DEIO/CEAUL Valeska Andreozzi – slide 237
Spline Cubico
■ A funcao de alisamento (smooth) cubic splines com tres knots (a, b, c) pode se escrita da seguinte forma:
f(X) = β0 + β1X + β2X2 + β3X
3 +
β4(X − a)3+ + β5(X − b)3+ + β6(X − c)3+
■ Se a funcao tem k knots, sera necessario estimar k + 3 coeficientes de regressao alem do intercepto.
■ Maiores detalhes sobre funcoes de alisamento, como escolher o numero de knots e modelos aditivos seraodados no final no curso (caso haja tempo)
DEIO/CEAUL Valeska Andreozzi – slide 238
87

Pontos atıpicos
Discrepancias isoladas (pontos atıpicos) podem ser caracterizadas por ter hii eou resıduo grandes, serinconsistente eou ser influente Em geral, pode-se classificar uma observacao como:
■ ponto de alavanca (bom ou ruim): hii alto;
■ inconsistente: o ponto nao segue a tendencia dos dados;
■ outlier: hii baixo e resıduo grande;
■ influente: afeta, de forma significativa, o ajuste do modelo.
DEIO/CEAUL Valeska Andreozzi – slide 239
Pontos atıpicos
Assim, uma observacao influente e aquela cuja omissao do conjunto de dados resulta em mudancas substanciaisem certos aspectos do modelo. Ela pode ser um outlier, ou nao. Uma observacao pode ser influente de diversasmaneiras, isto e,
■ no ajuste geral do modelo;
■ no conjunto de estimativas dos parametros;
■ na estimativa de um determinado parametro;
■ na escolha de uma transformacao de uma variavel explanatoria.
As estatısticas mais utilizadas para a verificacao de pontos atıpicos sao hii:
DEIO/CEAUL Valeska Andreozzi – slide 240
Leverage
■ O valor ajustado e a media ponderada dos valores observados e que o peso de ponderacao e o valor de hii.
■ Assim, o elemento da diagonal de H e o peso com que a observacao yi participa do processo de obtencaodo valor ajustado µi.
■ Valores com hii > 2p/n indicam observacoes que merecem uma analise mais apurada.
h<-hatvalues(mod4)
p <- dim(model.matrix(mod4))[[2]] #num de parametros
n <- dim(model.matrix(mod4))[[1]] #num de observac~oes
hnew<-h/(p/n)
plot(hnew, ylab = "Leverage h/(p/n)", xlab = "Indice",
cex.lab = 1.5, pch = 19)
abline(h=2, lty = 2)
levalto<-identify(hnew)
levalto
dados[levalto,]
res.pearsonpad[levalto]
DEIO/CEAUL Valeska Andreozzi – slide 241
88

Leverage
0 5 10 15 20 25 30
0.5
1.0
1.5
2.0
Índice
Leve
rage
h/(
p/n)
2 10
DEIO/CEAUL Valeska Andreozzi – slide 242
Distancia de Cooks
Informacao conjunta do Leverage e Resıduo
Ci =
(n − p
p
hii
1 − hii
)1/2
|rse(i)|
em que rse(i) = yi−µi
σ(i)
√1−hii
e σ(i) = estimativa de σ omitindo a observacao i.
x<-influence.measures(mod4)
cook<-x$infmat[,"cook.d"]
plot(cook, ylab = "Cooks Distance", xlab = "Indice",cex.lab = 1.5)
#quais observac~oes s~ao influentes
influentes<-which(apply(x$is.inf, 1, any))
influentes
points(influentes,cook[influentes],col="red",pch=19)
# ou simplesmente
library(car)
plot(cookd(mod4))
DEIO/CEAUL Valeska Andreozzi – slide 243
89

Distancia de Cooks
0 5 10 15 20 25 30
0.0
0.1
0.2
0.3
0.4
Index
cook
d(m
od4)
DEIO/CEAUL Valeska Andreozzi – slide 244
Predicao
Uma vez ajustado um modelo de regressao, interessa muitas vezes calcular o valor esperado (valor ajustado ouvalor predito) da variavel dependente, Y , para uma certa combinacao de valores das variaveis regressoras.
Consideremos o modelo ajustadoY = b0 + b1X1 + ... + bmXm
e designemos por X0 = (1,X01, ...,X0m) o vector correspondente a uma nova combinacao das variaveis regres-soras. Entao, dado X0, o valor esperado (predito) para a variavel Y e dado por
YX0= b0 + b1X01 + ... + bmX0m = X0b,
onde b = (b0, b1, ..., bm)′.
DEIO/CEAUL Valeska Andreozzi – slide 245
Predicao
E necessario ter-se em atencao que o modelo nao devera ser utilizado para fazer predicoes considerando com-binacoes de valores das variaveis regressoras que caiam fora dos intervalos considerados para estas aquando daconstrucao do modelo.
mod4<-lm(pa~id+imc+hf,data=dados)
summary(mod4)
names(mod4)
mod4$coefficients
DEIO/CEAUL Valeska Andreozzi – slide 246
90

Predicao
x0<-c(1,56,22.3,1)
previsto<-mod4$coefficients%*%x0
print(paste("valor predito para um indivıduo
com idade=",x0[2],", imc=", x0[3]," e habito de
fumo=",x0[4],":",round(previsto,2),"mmHg"))
DEIO/CEAUL Valeska Andreozzi – slide 247
Predicao
> mod4<-lm(pa~id+imc+hf,data=dados)
> summary(mod4)
Call:
lm(formula = pa ~ id + imc + hf, data = dados)
Residuals:
Min 1Q Median 3Q Max
-13.5420 -6.1812 -0.7282 5.2908 15.7050
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 45.1032 10.7649 4.190 0.000252 ***
id 1.2127 0.3238 3.745 0.000829 ***
imc 0.8592 0.4499 1.910 0.066427 .
hfsim 9.9456 2.6561 3.744 0.000830 ***
DEIO/CEAUL Valeska Andreozzi – slide 248
Predicao
Residual standard error: 7.407 on 28 deg of freedom
Multiple R-squared: 0.7609,Adj R-squared: 0.7353
F-statistic: 29.71 on 3 and 28 DF, p-value: 7.602e-09
> names(mod4)
[1] "coefficients" "residuals" "effects" "rank"
[5] "fitted.values" "assign" "qr""df.residual"
[9] "contrasts" "xlevels" "call" "terms"
[13] "model"
> mod4$coefficients
(Intercept) id imc hfsim
45.1031924 1.2127146 0.8592449 9.9455678
DEIO/CEAUL Valeska Andreozzi – slide 249
91

Predicao
> x0<-c(1,56,22.3,1)
> predito<-mod4$coefficients%*%x0
> print(paste("valor predito para um indivıduo
com idade=",x0[2],", imc=", x0[3]," e habito de
fumo=",x0[4],":",round(predito,2),"mmHg"))
"valor predito para um indivıduo com
idade= 56 , imc= 22.3 e habito de fumo= 1 :
142.12 mmHg"
DEIO/CEAUL Valeska Andreozzi – slide 250
Intervalo de Confiancapara uma observacao individual
Mais do que uma estimativa pontual para o valor da variavel resposta dada uma combinacao das variaveisregressoras, interessa-nos muitas vezes obter um intervalo de confianca para a predicao de uma observacaoindividual.
Para tal necessitamos de calcular a variancia associada a estimativa de um valor futuro:No caso do modelo de regressao simples, isto e, com apenas uma variavel regressora,
SYX0= σ
√1 +
1
n+
(X0 − X)2
(n − 1)S2X
onde σ e o desvio padrao estimado para a variavel resposta condicional ao modelo estimado, ou seja, o residual
standard error e S2X =
∑i(Xi − X)2.
DEIO/CEAUL Valeska Andreozzi – slide 251
Intervalo de Confiancapara uma observacao individual
Donde, o intervalo de 100(1 − α)% de confianca para a predicao (pontual) e:
YX0± t1−α/2;n−m−1SYX0
.
Note-se como SYX0varia com o quanto X0 se afasta de X:
SYX0= σ
√1 +
1
n+
(X0 − X)2
(n − 1)S2X
Quanto mais afastada da media se encontrar o novo valor da variavel regressora, maior sera a variancia associadaa estimativa e, consequentemente, mais amplo sera o intervalo de confianca.
DEIO/CEAUL Valeska Andreozzi – slide 252
92

Intervalo de Confiancapara uma observacao individual
No caso do modelo de regressao multipla, isto e, na presenca de m > 1 variaveis regressoras, o calculo davariancia e feito de forma diferente:
SYX0= σ
√1 + X0(X ′X)−1X ′
0,
onde X e a matriz (design) dos dados considerando-se apenas as variaveis presentes no modelo.
O intervalo de confianca tem a mesma expressao:
YX0± t1−α/2;n−m−1SYX0
.
DEIO/CEAUL Valeska Andreozzi – slide 253
Intervalo de Confiancapara a media
Outra questao que se coloca e a de obter uma predicao para o valor medio de Y quando as variaveis regressorasassumem uma determinada combinacao X0 = (1,X01, ...,X0m).
O cenario assemelha-se ao anteriormente descrito mas, em vez de estarmos interessados no que se espera dovalor de Y para aquela combinacao das variaveis regressoras (predicao pontual), estamos interessados no que seespera que observe em media para um conjunto de indivıduos que possuam a mesma combinacao das variaveisregressoras.
Embora o valor predito seja o mesmo (corresponde ao valor esperado de Y condicional a X0), a variabilidade quese espera da media dos valores preditos e inferior a variabilidade para um unico valor - a media de um conjuntode valores e mais consistente em torno do valor medio do que cada observacao isoladamente.
DEIO/CEAUL Valeska Andreozzi – slide 254
Intervalo de Confiancapara a media
Neste caso, interessa-nos:
■ No caso da regressao linear simples,
SYX0= σ
√1
n+
(X0 − X)2
(n − 1)S2X
,
■ No caso da regressao linear multipla,
SYX0= σ
√X0(X ′X)−1X ′
0.
DEIO/CEAUL Valeska Andreozzi – slide 255
93

Intervalo de Confiancapara a media
Pelo que o intervalo de 100(1 − α)% de confianca para o valor medio de Y dado X0 e ainda dado por
YX0± t1−α/2;n−m−1SYX0
mas com SYX0dado por uma das expressoes atras conforme o caso (regressao linear simples ou multipla).
DEIO/CEAUL Valeska Andreozzi – slide 256
Exemplo
No R, a obtencao destes intervalos faz-se atraves da funcao predict. Exemplificamos para o modelo maissimples, mod1:
mod1<-lm(pa~id,data=dados)
Simulando valores para idade:
mean(dados$id)
sd(dados$id)
x<-round(rnorm(20,53,7),1)
Os valores devem ser guardados ordenados num data.frame com indicacao da variavel a que dizem respeito(id, neste caso)
x<-sort(x)
new<-data.frame(id=x)
head(new)
DEIO/CEAUL Valeska Andreozzi – slide 257
Exemplo
predict(mod1,new,se.fit=TRUE)
pred.w.plim <- predict(mod1, new,
interval="prediction")
head(pred.w.plim)
pred.w.clim <- predict(mod1, new,
interval="confidence")
head(pred.w.clim)
matplot(new$id,cbind(pred.w.clim,
pred.w.plim[,-1]),lty=c(1,2,2,3,3),
type="l",lwd=2, col=c(1,2,2,4,4),
ylab="predicted y",xlab="idade",
main="Intervalos de predic~ao e
de confianca")
DEIO/CEAUL Valeska Andreozzi – slide 258
94

Exemplo
mean(dados$id)
[1] 53.25
sd(dados$id)
[1] 6.956083
x<-round(rnorm(20,53,7),1)
x<-sort(x)
new<-data.frame(id=x)
head(new)
id
1 22.9
2 40.2
3 41.7
4 41.9
5 42.6
6 44.9
DEIO/CEAUL Valeska Andreozzi – slide 259
Exemplo
predict(mod1,new,se.fit=TRUE)
$fit
1 2 3 4 5 6 7
95.83468 123.59253 125.99928 126.32017 127.44333 131.13368 131.61503
8 9 10 11 12 13 14
131.77548 138.19348 140.27933 140.76067 143.64878 144.45103 145.57417
15 16 17 18 19 20
148.14138 148.14138 149.90633 160.65648 165.46997 171.24617
$se.fit
1 2 3 4 5 6 7 8
7.427087 3.517943 3.205178 3.164202 3.022350 2.577662 2.522692 2.504556
9 10 11 12 13 14 15 16
1.886875 1.752531 1.727972 1.639641 1.634420 1.641725 1.720370 1.720370
17 18 19 20
1.819534 2.902903 3.517943 4.297533
DEIO/CEAUL Valeska Andreozzi – slide 260
95

Exemplo
$df
[1] 30
$residual.scale
[1] 9.245428
pred.w.plim <- predict(mod1, new,
interval="prediction")
head(pred.w.plim)
fit lwr upr
1 95.83468 71.61505 120.0543
2 123.59253 103.39014 143.7949
3 125.99928 106.01513 145.9834
4 126.32017 106.36328 146.2771
5 127.44333 107.57835 147.3083
6 131.13368 111.53187 150.7355
DEIO/CEAUL Valeska Andreozzi – slide 261
Exemplo
pred.w.clim <- predict(mod1, new,
interval="confidence")
head(pred.w.clim)
fit lwr upr
1 95.83468 80.66654 111.0028
2 123.59253 116.40793 130.7771
3 125.99928 119.45343 132.5451
4 126.32017 119.85801 132.7823
5 127.44333 121.27086 133.6158
6 131.13368 125.86939 136.3980
plot(new$id,pred.w.clim[,1])
matplot(new$id,cbind(pred.w.clim, pred.w.plim[,-1]),
lty=c(1,2,2,3,3), type="l",lwd=2,
col=c(1,2,2,4,4),ylab="predicted y",xlab="idade",
main="Intervalos de predic~ao e de confianca")
DEIO/CEAUL Valeska Andreozzi – slide 262
96

Exemplo
45 50 55 60 65 70
120
140
160
180
200
Intervalos de predição e de confiança
idade
pred
icte
d y
DEIO/CEAUL Valeska Andreozzi – slide 263
Miscelanias slide 264
Confundimento
■ Confundimento ocorre quando uma aparente associacao entre um fator de risco (ou preditor oucovariavel) e um desfecho (ou outcome ou variavel dependente ou variavel resposta) e alterado pelarelacao de uma terceira covariavel com o fator de risco e com o desfecho. Para essa terceira covariavel serconsiderada variavel de confundimento, ela deve estar associada ao fator de risco ao mesmo tempo quepossui uma relacao causal com o desfecho.
DEIO/CEAUL Valeska Andreozzi – slide 265
Interacao
■ Interacao
◆ Quando a associacao entre uma covariavel (exemplo idade) e a variavel resposta e a mesma paracada nıvel de um fator de risco (exemplo: grupo), entao nao existe interacao entre covariavel e fatorde risco. Graficamente a ausencia de interacao e representada pelo paralelismo entre as retas deregressao.
◆ Quando a interacao esta presente, a associacao entre fator de risco e a variavel resposta varia deacordo com o valor uma terceira covariavel. Na epidemiologia essa terceira covariavel e chamada demodificadora de efeito. Graficamente teremos curvas que possuem inclinacoes diferentes.
DEIO/CEAUL Valeska Andreozzi – slide 266
97

Interacao ou confundimento?
■ Variavel de confusao altera o valor do coeficiente de uma covariavel de interesse ou pode somente alterara sua precisao.
■ Contudo, quando temos interacao no modelo nao devemos falar em confundimento, pois em geral quandoo termo de interacao esta presente, o valor do coeficiente de uma das variaveis envolvidas na interacaosera alterado.
■ Uma variacao “clinicamente” importante na estimativa do coeficiente para um fator de risco pode serconsiderado um confundimento, mesmo que estatisticamente essa diferenca nao seja significativa.
■ A interacao so deve ser mantida no modelo quando possui um significado “clınico” e significanciaestatıstica.
■ Princıpio da marginalidade: um modelo que inclui um termo de interacao deve manter o efeitosprincipais
DEIO/CEAUL Valeska Andreozzi – slide 267
Interacao ou confundimento?
x (fator de risco)
y (d
esfe
cho)
grupo Agrupo B
Sem interação
x (fator de risco)
y (d
esfe
cho)
grupo Agrupo B
Com interação
DEIO/CEAUL Valeska Andreozzi – slide 268
Interacao ou confundimento?
Exemplo no R
■ Dados: sleep1
■ variavel resposta: TS
■ preditores: x1=log2(BodyWt) e x2=D (danger index)
■ A partir do modelo mais simples, E(TS) = β0 + β1x1, comparar os seguintes modelos: diferentesinterceptos e inclinacoes para cada categoria de x2; curvas paralelas; intercepto comum para as diferentescategorias de x2; curvas de regressao coincidentes
library(alr3)
data(sleep1)
?sleep1
DEIO/CEAUL Valeska Andreozzi – slide 269
98

Variancia nao constante
■ Quando a variancia nao e constante, temos como alternativa utilizar o metodo dos mınimos quadradosponderados na estimacao dos parametros do modelo de regressao.
■ Seja o modelo E(Yi|Xi) = βxi e V ar(Yi|Xi) = σ2/wi com i = 1, · · · , n e wi > 0 constantes conhecidas
■ Podemos descrever o modelo tambem da seguinte forma: Yi|Xi = βxi + ǫi/√
wi com i = 1, · · · , n
■ Temos: E(ǫi) = 0 e V ar(ǫi) = σ2
■ A interpretacao do valor constante σ2 nos modelos estimados pelos mınimos quadrados ponderadosdepende dos pesos, mas em geral podemos dizer que σ2 e a variancia de um subgrupo que tem peso iguala 1
DEIO/CEAUL Valeska Andreozzi – slide 270
Variancia nao constante
Alguns exemplos em que a variancia nao e constante e os pesos sao conhecidos:
■ Se yi e a media de mi observacoes independentes, cada uma com variancia σ2, entaoV ar(Yi|Xi) = σ2/mi e os pesos wi = mi
■ Se yi e a soma de mi observacoes independentes, entao V ar(Yi|Xi) = miσ2 e os pesos wi = 1/mi
■ Se a variancia e uma funcao positiva de um preditor, V ar(Yi|Xi) = x2i σ
2, entao os pesos wi = 1/x2i
DEIO/CEAUL Valeska Andreozzi – slide 271
Variancia nao constante
Exemplo no R
library(alr3)
data(physics)
?physics
mod.ls<-lm(y~x,data=physics)
summary(mod.ls)
plot(physics$x,physics$y,ylim=c(150,400))
win.graph()
plot(physics$y,physics$x)
abline(mod.ls)
mod.wls<-lm(y~x,data=physics,weights=1/SD)
summary(mod.wls)
abline(mod.wls, col=2)
DEIO/CEAUL Valeska Andreozzi – slide 272
99

Transformacoes
■ Tanto a variavel resposta como as covariaveis podem ser transformadas
■ As transformacoes servem para tornar a distribuicao de uma variavel mais simetrica
■ Tambem serve para tornar a relacao entre Y e X linear.
■ Transformacao potenciaX → Xp
X deve ser estritamente positiva
DEIO/CEAUL Valeska Andreozzi – slide 273
Transformacoes
Transformacao potencia no R
library(alr3)
data(brains)
#BrainWt ~ BodyW
#graficos de transformac~oes da var resposta e de x
#para p=-1,0,1/3,1/2
plot((brains$BodyWt),(brains$BrainWt))
p<--1
x<-(brains$BodyWt)^p
y<-(brains$BrainWt)^p
plot(x,y)
abline(lm(y~x))
DEIO/CEAUL Valeska Andreozzi – slide 274
Transformacoes
■ Transformacoes Box-Cox
X → X(p) ≡ Xp − 1
p
■ X deve ser estritamente positiva
■ Temos que limp→0Xp−1
p = ln(X), logo por convencao, quando p = 0, temos ln(X)
■ Caracterıstica: transformacao Box-Cox preserva a direcao de associacao.
■ Se Y e X estao associadas positivamente, Y e X(p) tambem estarao para qualquer valor de p. O mesmonao acontece para a transformacao potencia quando p < 0
■ Em geral os valores mais utilizados para a escolha de p sao: −1,−1/2, 0, 1/3, 1/2, 1
DEIO/CEAUL Valeska Andreozzi – slide 275
100

Transformacoes
Box-Cox no R
library(MASS)
hist(trees$Volume)
p<-boxcox(Volume ~ 1, data = trees,
lambda = seq(-1, 1, length = 10))
lambda<-p$x[p$y==max(p$y)]
lambda
hist((trees$Volume^lambda-1)/lambda)
library(car)
attach(Prestige)
hist(income)
qq.plot(income)
DEIO/CEAUL Valeska Andreozzi – slide 276
Transformacoes
Box-Cox no R
p<-boxcox(income ~ 1, data = trees,
lambda = seq(-1, 1, length = 10))
lambda<-p$x[p$y==max(p$y)]
lambda
box.cox.powers(income)
hist((income^.18-1)/.18)
qq.plot((income^.18-1)/.18)
qq.plot(log(income))
plot(income, education)
box.cox.powers(cbind(income, education))
plot(box.cox(income, .26), box.cox(education, .42))
DEIO/CEAUL Valeska Andreozzi – slide 277
Transformacoes
Box-Cox no R
#Outros exemplos:
library(alr3)
data(ufcwc)
#Height ~ Dbh
data(brains)
#BrainWt ~ BodyWt
DEIO/CEAUL Valeska Andreozzi – slide 278
101

Modelos com efeitos aleatorios
Exemplo: Dados de ortodontia (library(nlme); ?Orthodont)
distij = β0 + β1ageij + β2sexi + β3sexiageij + b0i + b1iageij + ǫij (14)
Forma matricialdisti = Xiβ + Zibiǫi (15)
■ Xi = [1 ageij sexi sexi × ageij ]
■ Zi = [1 ageij ]
■ β = efeitos fixos
■ bi = efeitos aleatorios representando a variabilidade entre criancas
■ ǫi = representa a variabilidade intra crianca
DEIO/CEAUL Valeska Andreozzi – slide 279
Modelos com efeitos aleatorios
■ Y i, condicionado aos efeitos aleatorios bi, tem distribuicao normal com media Xiβ + Zibi e matriz ecovariancia Σi.
Y i ∼ N(Xiβ + Zibi,Σi) (16)
E(Y i|bi) = Xiβ + Zibi
V ar(Y i|bi) = Σi
■ O modelo (16) e denominado modelo condicional ou modelo hierarquico.
■ Este modelo descreve o valor esperado e a distribuicao do erro para Y i condicional a bi.
■ Os erros ǫi sao os desvios dos dados ao valor esperado individual.
DEIO/CEAUL Valeska Andreozzi – slide 280
Modelos com efeitos aleatorios
■ A funcao de densidade marginal de yi e funcao das covariaveis e dos efeitos aleatorios
f(yi) =
∫f(yi|Xi, bi)f(bi)dbi (17)
■ Temos entao que o o modelo marginal e definido como
Y i ∼ N(Xiβ,ZiDZ′i + Σi) (18)
■ Esse modelo descreve o valor esperado e o erro para Y i nao condicionado aos bi, que e o que observamos.
■ Os erros no modelo marginal sao os desvios dos dados do valor esperado da populacao (Xiβ).
DEIO/CEAUL Valeska Andreozzi – slide 281
102

Exemplo
■ No formato matricial a variancia de Y i para o modelo Y i ∼ N(X ′iβ,Z ′
iDZi + Σi) e igual a
V ar(Y i) =
1 agei1
1 agei2
1 agei3
1 agei4
[d11 d12
d21 d22
] [1 1 1 1
agei1 agei2 agei3 agei4
]
+
σ2 0 0 00 σ2 0 00 0 σ2 00 0 0 σ2
■ em que d11 = var(b0i), d22 = var(b1i), d12 = d21 = cov(b1i, b0i),
DEIO/CEAUL Valeska Andreozzi – slide 282
Exemplo
■ var(distij) = d11 + 2d12ageij + d22age2ij + σ2
■ cov(distij , distik) = d22ageijageik + d12(ageij + ageik) + d11
■ O modelo marginal com efeitos aleatorios no intercepto e na inclinacao implica que a funcao decovariancia tenha um comportamento quadratico ao longo do tempo e curvatura positiva (d22).
DEIO/CEAUL Valeska Andreozzi – slide 283
Exemplo
■ Caso o modelo da distancia ortodontica so tivesse interceptos diferentes (b0i), terıamos:
cov(distij , distik) = d11 + σ2
■ e correlacao positiva entre quaisquer duas medidas igual a
ρ1 =d11
d11 + σ2
■ A correlacao acima e denominada uniforme (compound symmetry).
■ Note que ela e alta quando a variabilidade entre as criancas (d11) e maior que a variabilidade intracriancas (σ2)
DEIO/CEAUL Valeska Andreozzi – slide 284
Modelos com efeitos aleatorios no R
■ Exemplos e exercıcios no ficheiro randomeffects.r
DEIO/CEAUL Valeska Andreozzi – slide 285
103