avaliaÇÃo de uma proposta de intervalos de...
TRANSCRIPT

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 33
AVALIAÇÃO DE UMA PROPOSTA DE INTERVALOS DE CONFIANÇA BOOTSTRAP EM AMOSTRAGEM POR
CONJUNTOS ORDENADOS PERFEITAMENTE
Cesar Augusto TACONELI1 Maria Cecília Mendes BARRETO1
��RESUMO: O delineamento por amostras em conjuntos ordenados tem se mostrado mais eficiente que a amostragem aleatória simples na estimação de diversos parâmetros, principalmente nos casos em que não é possível extrair uma amostra numerosa, sendo indicado quando os elementos amostrais podem ser ordenados de maneira simples e eficiente antes de sua efetiva mensuração. Este trabalho tem por objetivo propor uma metodologia de reamostragem bootstrap não-paramétrico quando a amostra original é obtida por conjuntos ordenados e a ordenação antes da mensuração é perfeita, com aplicação na obtenção de estimativas intervalares para a média populacional. Foram consideradas seis populações distintas (uma real e cinco teóricas), além de quatro combinações de tamanhos de amostras e números de replicação. A metodologia tradicional e a proposta neste trabalho tiveram seus desempenhos comparados por meio da geração e análise de estimativas intervalares para a média populacional. Verificou-se por um amplo estudo via simulação que os intervalos de confiança baseados no procedimento de reamostragem bootstrap aqui proposto para amostras ordenadas perfeitamente propiciam um relevante ganho em precisão, se comparados aos intervalos de confiança bootstrap baseados em amostragem aleatória simples. Com relação à acurácea, os dois delineamentos são equivalentes. Verificou-se também a maior acurácia dos intervalos de confiança bootstrap do tipo studentizado.
��PALAVRAS-CHAVE: Amostragem por conjuntos ordenados; ordenação perfeita; intervalos de confiança para a média populacional; reamostragem bootstrap.
1 Introdução
A extração de amostras numerosas torna-se inviável quando a variável de interesse é de cara ou difícil mensuração. A utilização da amostragem aleatória simples (Simple Random Sample – SRS) com amostras de tamanhos reduzidos produz estimativas pouco precisas. Neste contexto, a amostragem por conjuntos ordenados (Ranked Set Sample - RSS) proporciona resultados mais precisos caso seja possível ordenar as unidades amostrais dentro das amostras de acordo com algum critério preestabelecido, sem de fato medi-las. Esse critério pode ser algum julgamento subjetivo (geralmente visual) ou alguma variável concomitante fortemente correlacionada com a variável de interesse.
1Departamento de Estatística, Universidade Federal de São Carlos – UFSCar, CEP 13565-905, São Carlos,
SP, Brasil. E-mail: [email protected].

34 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
Objetivando, por exemplo, estimar a produção de leite de um rebanho, amostras de ovelhas podem ser ordenadas simplesmente comparando visualmente os tamanhos de seus úberes. Já ao estimar a altura média de árvores numa região muito densa, as amostras podem ser ordenadas por meio dos perímetros dos troncos, tomado à altura do peito, caso se tenha ciência de uma forte correlação entre estas duas variáveis. Esses dois exemplos caracterizam condições propícias à utilização da amostragem por conjuntos ordenados com dois tipos de critérios de ordenação distintos (julgamento visual e variável concomitante, respectivamente).
McIntyre (1952) introduz a amostragem por conjuntos ordenados com vistas à estimação da produção média em pastagens e propõe como estimador não viciado para a
média populacional a média da amostra por conjuntos ordenados ( X ). Takahasi e Wakimoto (1968) comprovam a menor variância do estimador da média via RSS em relação a X , o estimador média amostral via SRS, sob ordenação perfeita (quando o critério utilizado para ordenação é preciso).
A estimação intervalar da média via RSS é fruto de estudo de Taconeli e Barreto
(2003), no qual analisam a distribuição de X e a viabilidade de sua utilização na obtenção de intervalos de confiança assintóticas para a média de populações com distribuição normal e exponencial. Verificam que a distribuição do estimador é normal quando a variável é normalmente distribuída e é gama para variáveis com distribuição exponencial, além de atestar a adequabilidade dos intervalos de confiança propostos apenas para dados com distribuição normal e ordenação perfeita ou aproximadamente perfeita. Estudo semelhante é apresentado em Brandão (2003), desta vez para populações com distribuição uniforme, lognormal e Gumbell, em que se diagnostica a simetria da
distribuição do estimador X para diversos tamanhos de amostras, além da adequabilidade dos intervalos assintóticos normais na estimação da média de uma distribuição uniforme via RSS.
Cesário e Barreto (2003) propõem um esquema paramétrico de reamostragem bootstrap via RSS com ordenação perfeita e avaliam diferentes intervalos de confiança concebidos por meio dessa metodologia. Baseado nas probabilidades de cobertura obtidas via simulação, os resultados alcançados são bastante positivos, principalmente na condição de conhecimento do valor do parâmetro de escala (σ ). Caso este valor seja desconhecido, os intervalos do tipo studentizado apresentam melhor desempenho.
O presente trabalho apresenta uma proposta original de reamostragem bootstrap em amostragem por conjuntos ordenados perfeitamente pelo julgamento visual. A originalidade reside na utilização do bootstrap em sua versão não-paramétrica, o que pode ser altamente favorável ao passo que torna desnecessária qualquer suposição quanto à distribuição populacional, nem sempre avaliável ante as restrições citadas quanto à extração de grandes amostras.
2 Seleção da amostra por conjuntos ordenados e sua aplicação na estimação da média e da função distribuição acumulada
O esquema de seleção de uma amostra por conjuntos ordenados parte da seleção de n amostras de tamanho n , com reposição, da população de interesse. Ordenam-se as unidades amostrais dentro de cada amostra de acordo com a variável de interesse, mas

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 35
baseado apenas no critério estabelecido. Mensura-se, finalmente, na r-ésima amostra a observação julgada como tendo a r-ésima menor medida quanto à variável de interesse, para nr ,...,2,1= resultando em uma amostra por conjuntos ordenados de tamanho n. Este procedimento pode ser replicado m vezes, originando uma amostra de tamanho
mnN = , denotada por
).,....2,1;,,...2,1;( ][ minrx ir == (2.1)
Neste caso, irx ][ refere-se à observação que foi julgada como estatística de ordem r,
no i-ésimo ciclo realizado. Subentende-se que o índice r denota, além da ordem que foi julgada a unidade amostral, o “número” da amostra de origem, ou seja, irx ][ foi julgada como de ordem r na r-ésima amostra do i-ésimo ciclo ou repetição. Sob ordenação perfeita o índice r de fato identifica a qual classe das estatísticas de ordem corresponde a observação. Ressalve-se o fato de as unidades amostrais serem independentes, já que provém de amostras selecionadas independentemente, mas não identicamente distribuídas, devido à classificação em diferentes ordens. A utilização de réplicas possibilita a obtenção de amostras maiores sem a necessidade de ordenar amostras numerosas, uma vez que tal ordenação pode se tornar laboriosa e pouco precisa, sobretudo quando se utiliza algum julgamento visual como critério de ordenação.
Algumas propriedades de estatísticas de ordem são aplicáveis na obtenção da precisão de diversos estimadores originados via RSS. Considere uma variável aleatória X com distribuição )(, XF σµ , sendo µ e σ , respectivamente, os parâmetros de locação e
escala. Segundo Pigato e Barreto (2004), a função de distribuição desta variável pode ser expressa na forma:
.0 ��
���
� −σ
µXF (2.2)
A média, xµ , e a variância, 2xσ , são funções dos parâmetros de locação e escala
( µ e σ ), e da média, 0µ , e variância, 20σ , da distribuição básica 0F . Tais relações
podem ser expressas da seguinte forma: 0σµµµ +=x , 20
22 σσσ =x . Quando
0F define uma distribuição simétrica, 00 =µ , de modo que µµ =x .
Considere )()2()1( ,...,, nXXX estatísticas de ordem de uma amostra de tamanho n
e seja
σµ−
= )()(
rr
XU , nr ,...,1= (2.3)

36 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
as variáveis reduzidas ordenadas. Então, para nr ...,,1= , rrUE α=)( )( e
rrUVar ν=)( )( dependem apenas do tamanho da amostra, da ordem e da função
distribuição da variável reduzida ( ) σµ /−X (David, 1981). McIntyre (1952) propõe como estimador não viciado da média populacional a média
da amostra por conjuntos ordenados, como apresentado em (2.4)
.1
1 1][��
= ==
n
r
m
iirX
mnX (2.4)
Sua variância é dada por
.1
))((1
)(1
)(1
22][
122
1 1][22 �=+�=��=
=== =
n
rrr
n
r
m
i
n
rir mn
UmVarnm
xVarnm
XVar νσσµ (2.5)
Takahasi e Wakimoto (1968) comprovam matematicamente a maior eficiência de
X em relação a X , o estimador média amostral via SRS. Por se tratarem de dois estimadores não viciados, pode-se compará-los pela precisão relativa (RP)
�
==
=
n
rrmn
mnX
XXXRP
12
2
1
1
)var(
)var(),(
ν
σ=
1
12
22)(11
−
= ���
����
��
−−n
r X
r
n σσαα (2.6)
que é sempre maior que 1, a menos que o critério adotado para ordenação das amostras seja completamente arbitrário, caso em que RP se iguala a 1.
Outro estimador de relevante importância neste trabalho é a função distribuição empírica (f.d.e.). Como verificado para a média, a amostragem por conjuntos ordenados ocasiona também uma estimação mais precisa da função distribuição acumulada (f.d.a.). Stokes e Sager (1988) propõem o estimador f.d.e. via RSS, verificam suas principais propriedades e efetuam uma análise comparativa deste estimador com seu similar, obtido via SRS. Alguns desses resultados são apresentados na seqüência.
Considere, inicialmente, NXXX ,...,, 21 uma amostra aleatória simples extraída de uma população com distribuição F . A função distribuição empírica calculada a partir desta amostra é dada por
)(1
)(ˆ1
),( tIN
tFN
j jx�==
−∞ (2.7)
onde )(() ⋅I é a função indicadora.
As variáveis )(),...,(),( ),0(),0(),0( 21tItItI
Nxxx têm distribuição de Bernoulli,
com parâmetro )(tF . Logo,

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 37
( ) )()(1
)(1
)(1
)(1
))(ˆ(
1
1),(
1),(
tFtNFN
tFN
tIEN
tIN
EtFE
N
j
N
jjx
N
jjx
==�=
=��
���
��=�
�
���
��=
=
=−∞
=−∞
(2.8)
Como NXXX ,...,, 21 são independentes, )(),...,(),( ),0()2,0()1,0( tItItINxxx também
o são. Logo, a variância de F é dada por
ntFtF
tFtnFn
tIVarn
tIn
VartFVarn
j jx
n
j jx
)](1)[()](1)[(
1
)(1
)(1
))(ˆ(
2
1),(2
1),(
−=−=
=��
���
��=�
�
���
��=
=−∞
=−∞
(2.9)
Considere agora uma amostra por conjuntos ordenados de tamanho mnN = , dada por { }minrX ir ...,,1;,,...1:][ == , originária de uma população com distribuição F . A função distribuição empírica, calculada a partir da amostra em conjuntos ordenados, é dada por
)(1
)(1 1
),( ][tI
mntF
n
r
m
ix ir��
= =−∞
∗ = (2.10)
As observações { }irX ][ são independentes, mas identicamente distribuídas com
distribuição ][rF apenas para algum r fixado. Logo,
)(),...,(),( ),0(),0(),0( ][2][1][tItItI
mrrr xxx
têm distribuição Bernoulli com parâmetro )(][ tF r . Desse modo,
)(1
)(1
)(1
))((1
][1 1
),(1 1
),( ][][tF
ntIE
mntI
mnEtFE
n
rr
n
r
m
ix
n
r
m
ix irir �����
== =−∞
= =−∞
∗ =��
���
�=��
���
�= (2.11)
Dell e Clutter (1972) apresentam o seguinte resultado
ffn
n
rr =�
=1][
1 (2.12)
Utilizando o resultado (2.12) em (2.11) tem-se
)()(1
))((1
][ tFtFn
tFEn
rr == �
=
∗ (2.13)
demonstrando que )(tF ∗ é um estimador não viciado de )(tF .

38 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
A variância de ∗F é calculada da seguinte maneira:
.)](1)[(1
)](1)[(1
))(var()(
1))((
1][][2
1][][22
1 1)][,(2
� −=� −
=��=
==
= =−∞
∗
n
rrr
n
rrr
n
r
m
i irx
tFtFmn
tFtFmnm
tImn
tFVar (2.14)
A precisão relativa de ∗F em relação a F é apresentada a seguir
�
�� −−== �
=
∗n
rr ntFtFtFtFtFVartFVartRP
1
2][ /)]([)(/)](1)[())]((/[))](ˆ([)( (2.15)
Se o critério utilizado para ordenação das unidades amostrais for completamente arbitrário, não faz sentido a classificação em ordens, tornando )()(][ tFtF r = , para
nr ,...,2,1= e fazendo com que RP se iguale a 1. Caso contrário, RP é superior a 1, aumentando conforme a eficiência do procedimento de ordenação.
3 Uma proposta original de reamostragem bootstrap em amostragem por conjuntos ordenados perfeitamente
Elaborado por Efron (1979), o bootstrap é um procedimento de reamostragem amplamente utilizado na obtenção de estimativas pontuais e intervalares, bem como na avaliação da acurácia de estimativas e testes. Consiste, basicamente, na replicação do processo de estimação via reamostragem pela amostra ou distribuição da variável, caso seja conhecida, com parâmetros estimados via amostra. Efron e Tibshirani (1993) e Davison e Hinkley (1997) apresentam de maneira detalhada várias aplicações dos métodos bootstrap em diversas metodologias estatísticas.
Seja nXXX ,...,, 21 uma amostra aleatória simples de tamanho n com função distribuição de probabilidade F. Suponha que se esteja interessado em inferir sobre uma
quantidade populacional )(Ft=θ , e seja θ um estimador para este parâmetro. Com o procedimento de reamostragem bootstrap, tem-se condições de fazer inferência sobre a
distribuição de θθ −ˆ . Isto é possível a partir da determinação de uma distribuição F~
, denominada função plug-in, de modo que
.ˆ)~
( θ=Ft (3.1)
Tendo encontrado uma distribuição F~
como a apresentada em (3.1) pode-se através
dela obter um estimador ∗θ de θ . De acordo com Canty (2000), usando reamostragem
bootstrap, as réplicas de θ , indicadas por ∗θ , tornam possível a aproximação
).ˆˆ()ˆ( θθθθ −≈− ∗D
(3.2)

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 39
O bootstrap não paramétrico consiste da utilização de F como função plug-in. Isso
é possível pela geração de reamostras com reposição da amostra original, ou seja, de F , que corresponde à distribuição empírica dos elementos amostrais.
Dado que o estimador de F sob RSS, ∗F , é mais preciso que F , seu análogo em SRS, como apresentado em (2.15), propõe-se neste trabalho, seguindo os passos de Taconeli (2005), um procedimento de reamostragem bootstrap não paramétrico original, a
partir da substituição da função plug-in de F para ∗F , ou seja, fundamentado na extração de amostras e geração de reamostras segundo o delineamento de amostragem por conjuntos ordenados.
Desse modo o algoritmo de reamostragem bootstrap para o delineamento por conjuntos ordenados perfeitamente considera (2.1), ou seja,
{ }( )minrX ir ...,,1;...,1,][ == ,
a amostra por conjuntos ordenados, e X , o estimador média amostral. Assim, conforme abordado em Taconeli (2005), o algoritmo é descrito pelos
seguintes passos:
1) Extração de B reamostras { } BjminrXjir ...,,1;...,,1;...,,1,][ ===∗ , com
reposição, também via amostragem por conjuntos ordenados, da amostra original;
2) Cálculo de BjX j ,...,1, =∗ as respectivas médias amostrais.
Com as estimativas geradas a partir do algoritmo proposto, os intervalos de confiança bootstrap apresentados em Davison e Hinkley (1997) foram adaptados usando o
estimador X . Assim, o intervalo bootstrap normal, que pressupõe normalidade à distribuição de
)( XX µ− com %)21( α− de confiança é dado por
���
��� −− − )(,)(1 XVarzXXVarzX BB αα (3.3)
sendo 2
1)
11
)( ∗
=
∗ −�−
= XXB
XVarB
bbB , �=
=
∗∗ B
bbX
BX
1
1 e αz e α−1z quantis da
distribuição normal padronizada. O intervalo bootstrap studentizado, que é uma alternativa a aproximação com a
distribuição normal com estimativas mais acuradas para pequenas amostras, é dado por
���
��� −− ∗
+∗
−+ )(,)( )1(()1)(1(( XVarzXXVarzX BBBB αα (3.4)
sendo

40 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
)( ∗
∗∗ −=
b
bb
XVar
XXZ . (3.5)
O cálculo da estatística ∗bz requer o conhecimento de )( ∗
bXVar . Quando não se
dispõe de tal quantidade, uma maneira de calcular o valor de )( ∗bXVar é pelo duplo
bootstrap, ou seja, realizando um número R de reamostragens para a b-ésima amostra bootstrap e calculando a variância das R estimativas obtidas, da maneira como descrito para o intervalo bootstrap normal, apenas substituindo B por R O elevado número requerido de reamostragens neste processo representa um custo computacional bastante grande.
O intervalo bootstrap percentil baseia-se na distribuição empírica das B estimativas originárias das reamostras bootstrap, simplesmente utilizando os quantis
( )BB XX ∗−
∗)1()( , αα (3.6)
como delimitantes de um intervalo com )21( α− % de confiança. O intervalo de confiança bootstrap básico também considera os quantis descritos em
(3.6). Caso se conhecesse a distribuição de XX µ− , seria possível determinar um valor
αa que satisfizesse
αµ α =<− )( aXP X e αµ α −=−< 1)( aXP X . (3.7)
Por meio de (3.7), torna-se possível a obtenção do seguinte limite de confiança (1-α)
αα aXX −=−1 (3.8)
e, analogamente, um intervalo de confiança bilateral )21( α− para θ tem a seguinte forma
),( 1 αα aXaX −− − . (3.9)
Os quantis αa e α−1a podem ser estimados via bootstrap como em (3.10)
XXa BB −= ∗+ ))1((;ˆ αα . (3.10)
Davison & Hinkley (1997) apresentam o seguinte intervalo de confiança a partir dos quantis estimados em (3.10) e baseado no intervalo proposto em (3.9):

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 41
( )=−− − αα ;1; , BB aXaX ( ) ( )( )=−−−− ∗+
∗−+ XXXXXX BB ))(1(()1)(1(( , αα
( ) ( )( )∗+
∗−+ −−= ))(1(()1)(1(( 2,2 αα BB XXXX
(3.11)
O método BCa (forma abreviada para bias corrected and accelerated) constitui uma versão aperfeiçoada do método percentil, apresentado em (3.6). Os percentis utilizados na delimitação dos intervalos de confiança dependem de duas quantidades a e
0z denominados, respectivamente, correção para tendência e aceleração. De acordo com Efron & Tibshirani (1993), um intervalo de confiança BCa
)21( α− é dado por
),( )2()1( αα ∗∗ XX , onde (3.13)
���
����
�
+−+
+Φ=
���
����
�
+−+
+Φ=
−
−
)ˆ(ˆ1ˆ
ˆ
,)ˆ(ˆ1
ˆˆ
)1(0
)1(0
02
)(0
)(0
01
α
α
α
α
α
α
zzazz
z
zzazz
z (3.14)
onde ( )⋅Φ refere-se à função distribuição acumulada de uma normal padrão e )(αz ao
percentil α100 desta distribuição. O intervalo de confiança percentil pode ser
considerado um caso particular do intervalo BCa, em que a e 0z são ambos iguais a zero.
O valor 0z mede a discrepância entre a mediana de ∗X e X , em unidades normais. Seu valor é computado como a seguir
��
�
�
��
�
� <Φ=∗
−
BXX
z b )(#ˆ 10 (3.15)
sendo ( )⋅Φ −1 a inversa da distribuição acumulada normal padrão.
A interpretação do valor a , segundo Canty (2004), não é simples. Uma estimativa não paramétrica para esta quantidade é apresentada na seqüência
( ) 2/32
3
6ˆ
�
�=
j
j
l
la (3.16)
sendo l denominada função influência. Martinez e Louzada-Neto (2000) apresentam um método de obtenção do valor a via jackknife, utilizado neste trabalho.

42 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
4 Análise do desempenho do esquema de reamostragem proposto na estimação intervalar da média populacional
A metodologia proposta teve seu desempenho avaliado por um estudo via simulação (Taconeli, 2005), em que se analisou a performance de intervalos de confiança concebidos por meio deste procedimento na estimação intervalar da média populacional. Foram consideradas cinco distribuições teóricas (normal, exponencial, uniforme, lognormal e Gumbell), além de uma distribuição de referência baseada nas médias diárias de MP10 da estação Ibirapuera, na cidade de São Paulo nos anos 2000 e 2001, fornecidas pela Companhia de Tecnologia de Saneamento Ambiental (CETESB). Avaliou-se quatro combinações de tamanhos de amostras e números de replicação
)3,5;5,3;3,3;4,2( ======== nmnmnmnm . Foram gerados para cada configuração, resultante da combinação dos tamanhos de amostras e distribuições, intervalos de confiança bootstrap de acordo com as metodologias tradicional e a proposta neste trabalho, provendo condições de confrontar as duas metodologias pela comparação da precisão e da acurácia das estimativas originadas.
Para cada uma das configurações consideradas foram simulados K intervalos de confiança bootstrap para a média. A partir desses K intervalos, tomou-se como medida de acurácia a probabilidade de cobertura constatada, e como medidas de precisão o comprimento médio e o desvio-padrão dos comprimentos dos intervalos gerados. O valor atribuído a K foi determinado por um estudo relativo à convergência da probabilidade de cobertura. Da mesma forma, os valores de B e M foram determinados pela análise da
convergência de )(XVarB , no caso dos intervalos bootstrap normal e studentizado, e dos devidos quantis, para os demais intervalos de confiança. Verificou-se convergência a partir dos valores K=400, B=200 e R=200. Obedecendo tais resultados, não foram utilizados números de reamostragens e intervalos de confiança inferiores aos mencionados. Os valores mínimos necessários somente foram adotados para intervalos do tipo studentizados, pois estes requerem um maior esforço computacional. Para os demais, atribuiu-se K=1000 e B=1000.
Considerando a distribuição de referência das 722 médias diárias de MP10 da estação Ibirapuera, cuja média é de 42,26 µg /m³, foram selecionadas amostras por conjuntos ordenados de acordo com as configurações anteriormente citadas.
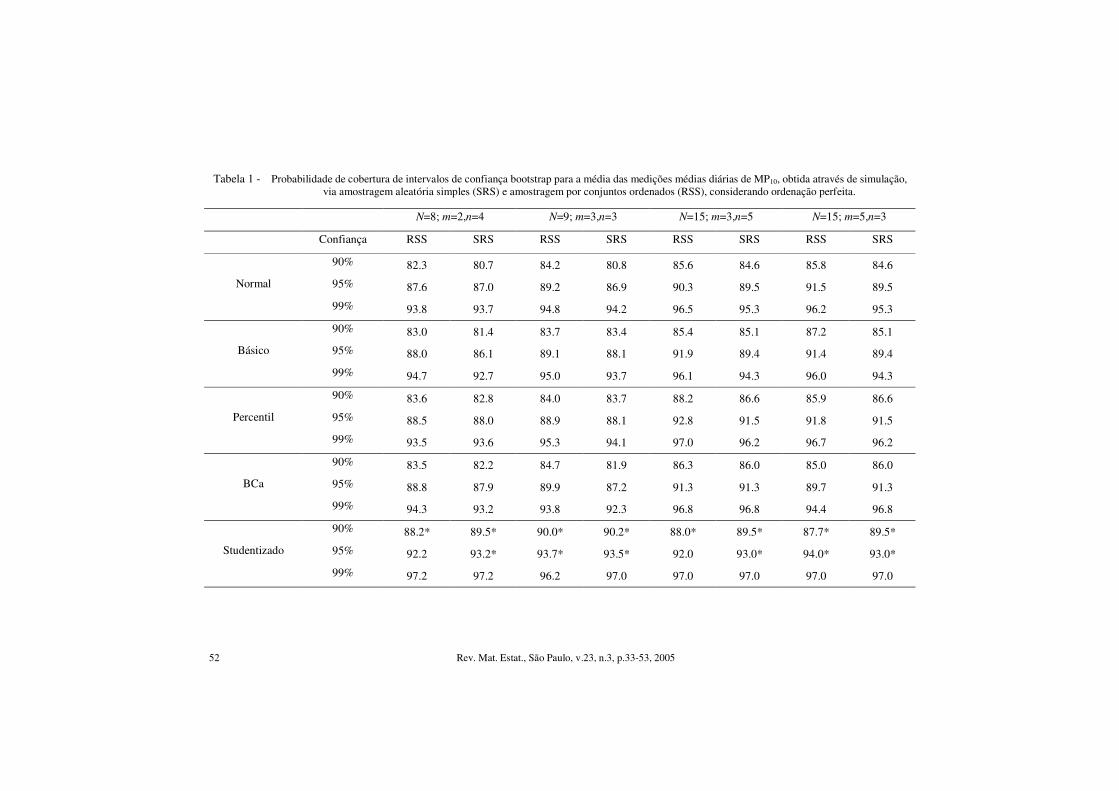
A Tabela 1 apresenta as probabilidades de cobertura obtidas via simulação dos cinco intervalos de confiança considerados, via RSS e SRS, na estimação da média das medições médias diárias de MP10 na estação Ibirapuera no biênio 2000/2001. Nesta tabela, valores em negrito indicam que os intervalos gerados a partir de amostras por conjuntos ordenados apresentam igual ou melhor acurácia em relação aos intervalos bootstrap obtidos via amostragem aleatória simples, para a configuração escolhida de tamanho de amostra, número de réplicas e grau de imperfeição dos erros. Valores acompanhados de um asterisco indicam que, para essa configuração, não se pode rejeitar a hipótese da probabilidade de cobertura obtida via simulação ser a inicialmente desejada (90, 95 ou 99%) a um nível de 95% de confiança. Tal hipótese é verificada por meio de um teste para proporções, baseado na distribuição binomial com parâmetros n e p, sendo n o número de intervalos de confiança simulados e p o nível de confiança considerado. Os comprimentos médios desses intervalos e o desvio-padrão dos comprimentos servem como medida de precisão e são apresentados na Tabela 2.

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 43
Pode-se reparar, pela Tabela 1, que na maior parte das configurações consideradas houve uma discreta melhora quanto a acurácia dos intervalos gerados via RSS. Os intervalos do tipo studentizado confirmaram ser os mais acurados, sendo capazes de produzir probabilidades de cobertura mais próximas aos níveis de confiança preestabelecidos. Os demais intervalos ficaram aquém ao desejado, em relação às probabilidades de cobertura obtidas, sob ambos delineamentos amostrais.
Verificou-se uma substancial melhora quanto à precisão das estimativas obtidas pelo esquema de reamostragem proposto em relação às estimativas convencionais, baseadas em amostragem aleatória simples. Observe que os comprimentos médios dos intervalos de confiança via RSS com mn=8 pouco diferem daqueles observados via SRS com amostras de tamanho N=15. Este fato indica que o procedimento de reamostragem proposto neste trabalho possibilita a extração de uma amostra bem mais reduzida, sem grande prejuízo na precisão das estimativas geradas.
Esses resultados podem ser verificados graficamente nas Figuras 1 e 2, que ilustram o desempenho dos intervalos de confiança bootstrap percentil e studentizado, respectivamente, na estimação da média das medições médias diárias de MP10, sob ambas metodologias. Os resultados provenientes dos demais intervalos de confiança bootstrap são omitidos por apresentarem resultados muito semelhantes aos intervalos do tipo percentil, como pode ser verificado nas Tabelas 1 e 2. Tal similaridade também foi verificada na estimação da média das distribuições teóricas.
Dando prosseguimento a análise, procedeu-se com um estudo via simulação análogo ao realizado na estimação da média de MP10 aplicado, desta vez, à estimação da média de uma população com distribuição N(0,1). As Figuras 3 e 4 apresentam o desempenho dos intervalos de confiança dos tipos percentil e studentizado, respectivamente, via RSS e SRS. Observa-se mais um significativo aumento de precisão decorrente da utilização da metodologia proposta em detrimento à original. As amplitudes médias dos intervalos obtidos via RSS são bastante inferiores às verificadas via SRS, sobretudo para pequenos tamanhos de amostra. Quanto a acurácia, as duas metodologias proporcionam estimativas equivalentes. Mais uma vez os intervalos de confiança do tipo studentizado forneceram as estimativas mais acuradas. Os demais tipos de intervalos de confiança bootstrap mostram-se menos acurados, sob ambos os delineamentos amostrais.
Finalmente, estendeu-se o estudo realizado para a estimação da média de uma população com distribuição assimétrica, no caso a lognormal, com parâmetro de locação
0=µ e parâmetro de escala 1=σ . Pela análise das Figuras 5 e 6, mais uma vez fica nítido que o bootstrap baseado em RSS possibilita a obtenção de estimativas intervalares não paramétricas bem mais precisas em relação ao procedimento original, fundamentado em SRS, sem maiores comprometimentos em relação a acurácia. Para esta distribuição, torna-se evidente que o bootstrap não paramétrico, sob ambos delineamentos amostrais, produz intervalos de confiança pouco acurados, uma vez que as probabilidades de cobertura se afastam dos níveis de confiança preestabelecidos. Os intervalos do tipo studentizado apresentam performance diferenciada devido à maior acurácia das estimativas fornecidas.
Resultados similares foram obtidos para as distribuições exponencial, uniforme e Gumbell (Taconeli, 2005).

44 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
Conclusão
O método de reamostragem bootstrap proposto neste trabalho e em Taconeli (2005) mostrou-se bastante eficaz, o que fica nítido pela obtenção de estimativas intervalares bem mais precisas que as obtidas por meio do bootstrap em sua versão tradicional. A utilização de um método não-paramétrico de reamostragem bootstrap, aliado à amostragem por conjuntos ordenados, esquema amostral capaz de gerar estimativas mais precisas ante a restrições quanto à seleção de amostras numerosas, possibilitou a estimação da média de maneira mais eficiente.
TACONELI, C. A.; BARRETO, M. C. M. The availability of a bootstrap confidence interval proposal in perfect ranked set sampling. Rev. Mat. Est., São Paulo, v.23, n.3, p.33-53, 2005.
��ABSTRACT: The design of ranked set samples is more efficient than single random samples in the estimation of several parameters, mainly for small samples. The aim of this work is to present a new methodology for nonparametric bootstrap resampling when the original sampling is drawn by perfect ranked set design, with application to confidence intervals for population mean. The simulation study has investigated the behaviour of confidence intervals under six distinct populations, four sample sizes and replications. The results point out the precision of the bootstrap confidence interval in perfect ranked set design over single random samples and between the different bootstrap confidence intervals. The studentized intervals were also shown to be more accurate.
��KEYWORDS: Ranked set sampling; perfect ranked; confidence intervals for population mean; bootstrap resampling methods.
Referências
BRANDÃO, J. S. Intervalos de confiança assintóticos para o parâmetro de locação em distribuições assimétricas na família locação-escala usando amostragem em conjuntos ordenados. Relatório de iniciação cientifica. São Carlos: Universidade Federal de São Carlos, FAPESP, 2003. 54p.
CANTY, A. The bootstrap and confidence intervals. Disponível em: <www.mathstat.concordia.ca/canty/teaching/mast679t.html>. Acesso em: 25 ago 2004.
CESÁRIO, L. C.; BARRETO, M. C. M. Um estudo sobre o desempenho de intervalos de confiança bootstrap para a média de uma distribuição normal usando amostragem por conjuntos ordenados perfeitamente. Rev. Mat. Estat., São Paulo, v.21, p.7-20, 2003.
DAVID, H. Order statistics. 2nd. ed. New York: Wiley,1981, 360p.
DAVISON, A. C.; HINKLEY, D.V. Bootstrap methods and their application. New York: Cambridge University Press, 1997. 582p.
DELL, T. R.; CUTTLER, J. L. Ranked set sampling theory with order statistics background. Biometrics, Washington, v.28, p.545-555, 1972.
EFRON, B. Bootstrap methods: another look at the jackknife. Ann. Stat., Hayward, v.7, p.1-26, 1979.

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 45
EFRON, B.; TIBSHIRANI, R. J. An Introduction to the bootstrap. New York: Chapman & Hall, 1993. 436p.
MARTINEZ, E. Z.; LOUZADA-NETO, F. Uma introdução à estimativa intervalar via bootstrap: Relatório técnico do DES/UFSCar, série A: teoria e métodos. São Carlos, 2000. 37p.
MCINTYRE, G. A. A method for unbiased seletive sampling, using ranked sets. Aust. J. Agric. Res., Collingwood, v.3, p.385-390. 1952.
PIGATTO, F. J.; BARRETO, M. C. M. Desempenho de estimadores da média populacional de distribuições assimétricas baseadas em amostragem por conjuntos ordenados. Rev. Mat. Estat., São Paulo, v.21, p.19-29, 2004.
REVISTA MEIO AMBIENTE INDUSTRIAL. São Paulo, v.4, n.22, 2000. 88p.
STOKES, S. L.; SAGER, T. W. Characterization of a ranked-set sample with application to estimating distribution functions. J. Am. Stat. Assoc., New York, v.83, p.374-381, 1988.
TACONELI, C. A. Reamostragem bootstrap em amostragem por conjuntos ordenados e intervalos de confiança não paramétricos para a média. 2005, 120f. Dissertação (Mestrado em Estatística) – Universidade Federal de São Carlos, São Carlos, 2005.
TACONELI, C. A.; BARRETO, M. C. M. Intervalos de confiança para a média populacional usando amostragem em conjuntos ordenados. Rev. Mat. Estat., São Paulo, v.21, p.41-66, 2003.
TAKAHASHI, K., WAKIMOTO, K. On biased estimates of population mean based on sample stratified by means of ordering. Ann. Inst. Stat. Math., Tokio, v.20, p.1-31, 1968.
Recebido em 21.03.2005.
Aprovado após revisão em 10.01.2006.


Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 47
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
1015
2025
3035
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
1015
2025
3035
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
1015
2025
3035
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Com
prim
ento
méd
io
1015
2025
3035
90%
95%
99%
Nível de confiança
N=9; m=3,n=3Com
prim
ento
méd
io
1015
2025
3035
90%
95%
99%
Nível de confiança
N=15; m=3,n=5Com
prim
ento
méd
io
1015
2025
3035
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Com
prim
ento
méd
io
1015
2025
3035
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
1015
2025
3035
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
( + ) SRS ( ) RSS (Ordenação perfeita)
FIGURA 1 - Probabilidades de cobertura e comprimentos médios de intervalos de confiança bootstrap percentil para a média das verificações médias diárias de MP10 na estação Ibirapuera (2000/2001), via SRS e RSS com ordenação perfeita.

48 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
1020
3040
5060
70
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
1020
3040
5060
70
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
1020
3040
5060
70
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Com
prim
ento
méd
io
1020
3040
5060
70
90%
95%
99%
Nível de confiança
N=9; m=3,n=3Com
prim
ento
méd
io
1020
3040
5060
70
90%
95%
99%
Nível de confiança
N=15; m=3,n=5Com
prim
ento
méd
io
1020
3040
5060
70
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Com
prim
ento
méd
io
1020
3040
5060
70
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
1020
3040
5060
70
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
( + ) SRS ( ) RSS (Ordenação perfeita)
FIGURA 2 - Probabilidades de cobertura e comprimentos médios de intervalos de confiança bootstrap studentizado para a média das verificações médias diárias de MP10 na estação Ibirapuera (2000/2001), via SRS e RSS com ordenação perfeita.

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 49
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Prob
. de
cobe
rtur
a
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
0.4
0.6
0.8
1.0
1.2
1.4
1.6
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
0.4
0.6
0.8
1.0
1.2
1.4
1.6
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
0.4
0.6
0.8
1.0
1.2
1.4
1.6
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Com
prim
ento
méd
io
0.4
0.6
0.8
1.0
1.2
1.4
1.6
90%
95%
99%
Nível de confiança
N=9; m=3,n=3Com
prim
ento
méd
io
0.4
0.6
0.8
1.0
1.2
1.4
1.6
90%
95%
99%
Nível de confiança
N=15; m=3,n=5Com
prim
ento
méd
io
0.4
0.6
0.8
1.0
1.2
1.4
1.6
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Com
prim
ento
méd
io
0.4
0.6
0.8
1.0
1.2
1.4
1.6
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
0.4
0.6
0.8
1.0
1.2
1.4
1.6
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
( + ) SRS ( ) RSS (Ordenação perfeita)
FIGURA 3 - Probabilidades de cobertura e comprimentos médios de intervalos de confiança bootstrap percentil para a média de uma variável com distribuição normal, via SRS e RSS com ordenação perfeita.

50 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
Prob
. de
cobe
rtur
a
8590
9510
0
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
8590
9510
0
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
8590
9510
0
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
8590
9510
0
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
8590
9510
0
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
8590
9510
0
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
8590
9510
0
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Prob
. de
cobe
rtur
a
8590
9510
0
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
0.5
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
0.5
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
0.5
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Com
prim
ento
méd
io
0.5
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=9; m=3,n=3Com
prim
ento
méd
io
0.5
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=15; m=3,n=5Com
prim
ento
méd
io
0.5
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Com
prim
ento
méd
io
0.5
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
0.5
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
( + ) SRS ( ) RSS (Ordenação perfeita)
FIGURA 4 - Probabilidades de cobertura e comprimentos médios de intervalos de confiança bootstrap studentizado para a média de uma variável com distribuição normal, via SRS e RSS com ordenação perfeita.

Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 51
Prob
. de
cobe
rtur
a
7075
8085
9095
100
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
7075
8085
9095
100
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Prob
. de
cobe
rtur
a
7075
8085
9095
100
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
7075
8085
9095
100
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Prob
. de
cobe
rtur
a
7075
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
7075
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Prob
. de
cobe
rtur
a
7075
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Prob
. de
cobe
rtur
a
7075
8085
9095
100
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=8; m=2,n=4
Com
prim
ento
méd
io
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=9; m=3,n=3
Com
prim
ento
méd
io
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=9; m=3,n=3Com
prim
ento
méd
io
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=15; m=3,n=5Com
prim
ento
méd
io
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=15; m=3,n=5
Com
prim
ento
méd
io
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
Com
prim
ento
méd
io
1.0
1.5
2.0
2.5
90%
95%
99%
Nível de confiança
N=15; m=5,n=3
( + ) SRS ( ) RSS (Ordenação perfeita)
FIGURA 5 - Probabilidades de cobertura e comprimentos médios de intervalos de confiança bootstrap percentil para a média de uma variável com distribuição lognormal, via SRS e RSS com ordenação perfeita.
52 Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005
Tabela 1 - Probabilidade de cobertura de intervalos de confiança bootstrap para a média das medições médias diárias de MP10, obtida através de simulação, via amostragem aleatória simples (SRS) e amostragem por conjuntos ordenados (RSS), considerando ordenação perfeita.
N=8; m=2,n=4 N=9; m=3,n=3 N=15; m=3,n=5 N=15; m=5,n=3
Confiança RSS SRS RSS SRS RSS SRS RSS SRS
90% 82.3 80.7 84.2 80.8 85.6 84.6 85.8 84.6
95% 87.6 87.0 89.2 86.9 90.3 89.5 91.5 89.5 Normal
99% 93.8 93.7 94.8 94.2 96.5 95.3 96.2 95.3
90% 83.0 81.4 83.7 83.4 85.4 85.1 87.2 85.1
95% 88.0 86.1 89.1 88.1 91.9 89.4 91.4 89.4 Básico
99% 94.7 92.7 95.0 93.7 96.1 94.3 96.0 94.3
90% 83.6 82.8 84.0 83.7 88.2 86.6 85.9 86.6
95% 88.5 88.0 88.9 88.1 92.8 91.5 91.8 91.5 Percentil
99% 93.5 93.6 95.3 94.1 97.0 96.2 96.7 96.2
90% 83.5 82.2 84.7 81.9 86.3 86.0 85.0 86.0
95% 88.8 87.9 89.9 87.2 91.3 91.3 89.7 91.3 BCa
99% 94.3 93.2 93.8 92.3 96.8 96.8 94.4 96.8
90% 88.2* 89.5* 90.0* 90.2* 88.0* 89.5* 87.7* 89.5*
95% 92.2 93.2* 93.7* 93.5* 92.0 93.0* 94.0* 93.0* Studentizado
99% 97.2 97.2 96.2 97.0 97.0 97.0 97.0 97.0
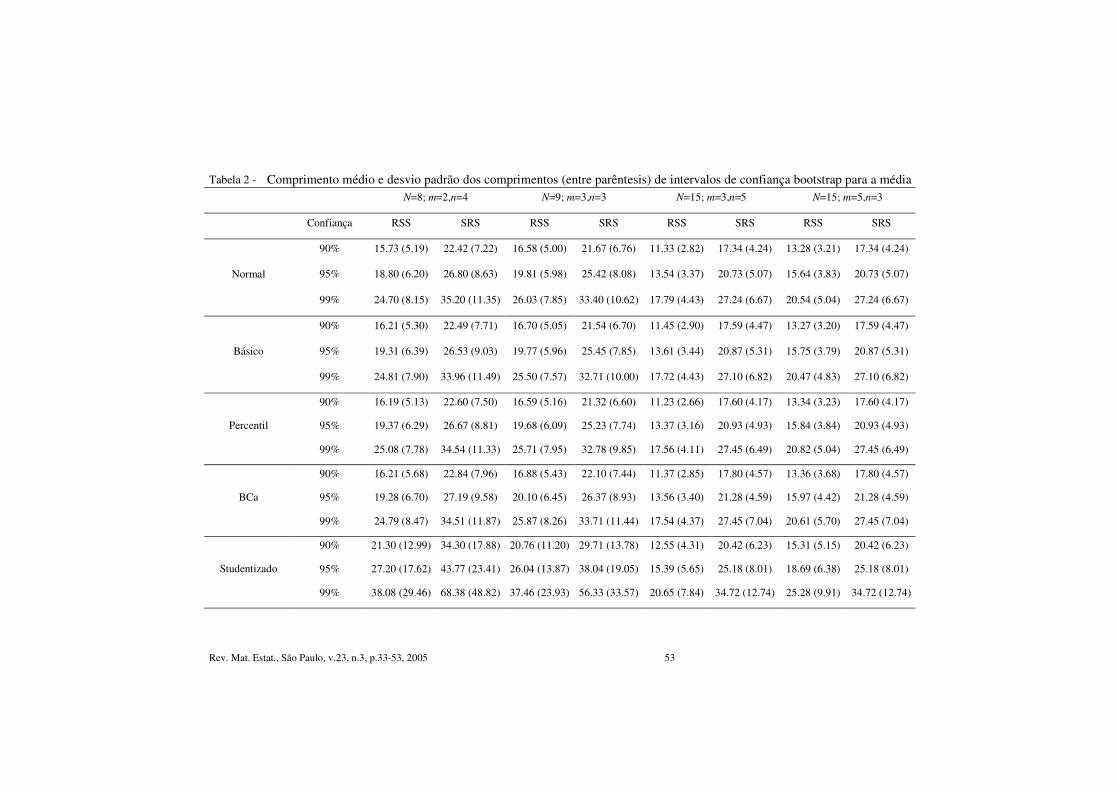
Rev. Mat. Estat., São Paulo, v.23, n.3, p.33-53, 2005 53
Tabela 2 - Comprimento médio e desvio padrão dos comprimentos (entre parêntesis) de intervalos de confiança bootstrap para a média das medições médias diárias de MP10, obtida através de simulação, via amostragem aleatória simples (SRS) e amostragem N=8; m=2,n=4 N=9; m=3,n=3 N=15; m=3,n=5 N=15; m=5,n=3
Confiança RSS SRS RSS SRS RSS SRS RSS SRS
90% 15.73 (5.19) 22.42 (7.22) 16.58 (5.00) 21.67 (6.76) 11.33 (2.82) 17.34 (4.24) 13.28 (3.21) 17.34 (4.24)
95% 18.80 (6.20) 26.80 (8.63) 19.81 (5.98) 25.42 (8.08) 13.54 (3.37) 20.73 (5.07) 15.64 (3.83) 20.73 (5.07) Normal
99% 24.70 (8.15) 35.20 (11.35) 26.03 (7.85) 33.40 (10.62) 17.79 (4.43) 27.24 (6.67) 20.54 (5.04) 27.24 (6.67)
90% 16.21 (5.30) 22.49 (7.71) 16.70 (5.05) 21.54 (6.70) 11.45 (2.90) 17.59 (4.47) 13.27 (3.20) 17.59 (4.47)
95% 19.31 (6.39) 26.53 (9.03) 19.77 (5.96) 25.45 (7.85) 13.61 (3.44) 20.87 (5.31) 15.75 (3.79) 20.87 (5.31) Básico
99% 24.81 (7.90) 33.96 (11.49) 25.50 (7.57) 32.71 (10.00) 17.72 (4.43) 27.10 (6.82) 20.47 (4.83) 27.10 (6.82)
90% 16.19 (5.13) 22.60 (7.50) 16.59 (5.16) 21.32 (6.60) 11.23 (2.66) 17.60 (4.17) 13.34 (3.23) 17.60 (4.17)
95% 19.37 (6.29) 26.67 (8.81) 19.68 (6.09) 25.23 (7.74) 13.37 (3.16) 20.93 (4.93) 15.84 (3.84) 20.93 (4.93) Percentil
99% 25.08 (7.78) 34.54 (11.33) 25.71 (7.95) 32.78 (9.85) 17.56 (4.11) 27.45 (6.49) 20.82 (5.04) 27.45 (6.49)
90% 16.21 (5.68) 22.84 (7.96) 16.88 (5.43) 22.10 (7.44) 11.37 (2.85) 17.80 (4.57) 13.36 (3.68) 17.80 (4.57)
95% 19.28 (6.70) 27.19 (9.58) 20.10 (6.45) 26.37 (8.93) 13.56 (3.40) 21.28 (4.59) 15.97 (4.42) 21.28 (4.59) BCa
99% 24.79 (8.47) 34.51 (11.87) 25.87 (8.26) 33.71 (11.44) 17.54 (4.37) 27.45 (7.04) 20.61 (5.70) 27.45 (7.04)
90% 21.30 (12.99) 34.30 (17.88) 20.76 (11.20) 29.71 (13.78) 12.55 (4.31) 20.42 (6.23) 15.31 (5.15) 20.42 (6.23)
95% 27.20 (17.62) 43.77 (23.41) 26.04 (13.87) 38.04 (19.05) 15.39 (5.65) 25.18 (8.01) 18.69 (6.38) 25.18 (8.01) Studentizado
99% 38.08 (29.46) 68.38 (48.82) 37.46 (23.93) 56.33 (33.57) 20.65 (7.84) 34.72 (12.74) 25.28 (9.91) 34.72 (12.74)