aula 08 - curso regular de estatística
DESCRIPTION
Aula 08 - Curso Regular de EstatísticaTRANSCRIPT

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 1
AULA 8: Estimadores pontuais e intervalos de
confiança (Retificado)
1. ESTIMADORES PONTUAIS .............................................................................................................. 2
1.1. Estimador para a média ........................................................................................................................ 4
1.2. Estimador para a variância .................................................................................................................. 5
1.3. Estimador para uma proporção .......................................................................................................... 10 2. INTERVALO DE CONFIANÇA PARA A MÉDIA ................................................................................. 11
2.1. �como uma variável aleatória ........................................................................................................... 11
2.2. Esperança e variância de � ................................................................................................................ 13
2.3. Intervalo de confiança para a média .................................................................................................. 23
2.4. Intervalo de confiança para a média quando a variância da população não é conhecida ................. 34 3. INTERVALO DE CONFIANÇA PARA PROPORÇÕES ......................................................................... 40
3.1. � como uma variável aleatória ........................................................................................................... 40
3.2. Intervalo de confiança para uma proporção ...................................................................................... 43 4. INTERVALO DE CONFIANÇA E TAMANHO DA AMOSTRA ............................................................. 47
5. FATOR DE CORREÇÃO PARA POPULAÇÕES FINITAS ..................................................................... 61
6. CARACTERÍSTICAS DOS ESTIMADORES ........................................................................................ 64
6.1. Estimador não tendencioso ................................................................................................................. 65
6.2. Estimador de variância mínima. ......................................................................................................... 67
6.3. Estimador de mínimos quadrados ....................................................................................................... 68
6.4. Estimador de máxima verossimilhança ............................................................................................... 69 7. RESUMÃO ..................................................................................................................................... 74
8. ASSUNTO DE DESTAQUE .............................................................................................................. 74
9. QUESTÕES APRESENTADAS EM AULA .......................................................................................... 75
GABARITO ............................................................................................................................................. 87

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 2
Pessoal que já tiver impresso e lido a aula 3, dada antes da retificação, não precisa reimprimir e reler essa aula. É mero repeteco.
1. ESTIMADORES PONTUAIS
Considere uma pesquisa salarial envolvendo alguns moradores de um bairro.
Esta pesquisa resultou no seguinte conjunto (dados em R$ 1.000,00).
Salário dos moradores do bairro – amostra com dez salários:
R$ 5.000,00; R$ 2.000,00; R$ 2.000,00; R$ 7.000,00; R$ 1.000,00; R$ 4.000,00, R$ 2.000,00,
R$ 4.000,00, R$ 3.000,00, R$ 6.000,00.
O conjunto dos salários de todos os moradores é a nossa população. Qualquer subconjunto não vazio da população é uma amostra.
Queremos descobrir o salário médio dos moradores do bairro. A grandeza de interesse (média salarial) se refere à população. Ou seja, estamos interessados no salário médio de todos os moradores. A média populacional é o nosso parâmetro.
Parâmetro é qualquer característica populacional.
Se, por algum motivo, não pudermos realizar um censo, nós faremos uma amostragem. Ao longo do curso, trabalharemos basicamente com a amostragem aleatória simples.
Podemos, por exemplo, calcular a média da amostra. A média amostral é, como o próprio nome diz, uma característica da amostra. É chamada de estatística.
Parâmetro: é uma característica da população
Estatística: é uma característica da amostra
Muito bem. Selecionamos uma amostra de dez pessoas. Se você calcular a média para a amostra acima indicada, obterá R$ 3.600,00.
A média amostral é de R$ 3.600,00.
A partir desta amostra, vamos estimar a média da população. Usamos a média amostral (=R$ 3.600,00) como um estimador da média populacional, desconhecida.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 3
Dizemos que R$ 3.600,00 é a média estimada, a partir da amostra feita. É uma estimativa por ponto.
Estamos dizendo que uma estimativa para a média populacional é R$ 3.600,00. Ou seja, usamos a média amostral como estimador da média populacional.
A média amostral, considerada como uma fórmula (soma dos valores da amostra, dividida por “n”), ou seja, considerada como uma função dos valores amostrais, é chamada de estatística.
Ou seja, estatística é uma função dos valores da amostra.
Um valor específico que a estatística assume é chamado de estimativa.
Então:
�� = ∑��
é a estatística. Isso porque se trata de uma função dos valores amostrais.
Já o valor 3.600,00, que é uma realização numérica de ��, é a estimativa.
A estimação por ponto se contrapõe à estimação por intervalo. Nesta última, não definimos um valor único para a estimativa; sim um intervalo de valores. Um exemplo são aquelas pesquisas eleitorais de intenção de voto. Lembram quando se diz que os “candidatos estão tecnicamente empatados”?
Se o candidato A tem entre 30% e 34% das intenções de voto, e o candidato B tem entre 28% e 32% das intenções de voto, não dá para afirmar quem vai ganhar. Aí o William Bonner diz que eles estão tecnicamente empatados.
Nesse segundo caso, a partir de uma amostra, procurou-se estabelecer um intervalo de valores provável para as intenções de voto de cada candidato. Para o candidato A, o intervalo é de 30% a 34%. Dizemos que se trata de uma estimativa por intervalo.
Por enquanto, vamos nos concentrar na estimativa por ponto.
O motivo de se fazer uma amostragem é o fato de haver alguma dificuldade em analisar toda a população. Pode ser muito caro, muito demorado. Ou pode ser inviável. Seria o caso de ver qual a tensão máxima que um material suporta. Se tivermos que submetê-lo a tensões cada vez maiores, até que ele arrebente, então não podemos analisar todos os objetos, sob pena de destruirmos todos e não sobrar mais nenhum.
Se fosse possível analisar a população inteira, conseguiríamos com exatidão saber sua média e seu desvio padrão (estes valores reais são nossos parâmetros).
Quando fazemos uma amostragem, conseguimos apenas saber a média e o desvio padrão da amostra feita. Nosso objetivo, portanto, é, a partir dos valores de média e desvio padrão

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 4
da amostra, estimar quais os valores de média e desvio padrão da população. Nosso objetivo é estimar o valor do parâmetro desconhecido.
Claro que poderíamos estar interessados em outros parâmetros que não a média e o desvio padrão. Mas, em concursos, na grande maioria das questões, são cobrados apenas esses dois parâmetros (além da variância, intimamente relacionada com o desvio padrão, e da proporção, que veremos nesta aula).
Quando escolhemos um estimador, podemos estar interessados em diversas características. Alguns tipos de estimadores são:
• Não tendenciosos (ou não viciados)
• De máxima verossimilhança
• De variância mínima
• De mínimos quadrados
Por enquanto, nós não veremos com detalhes cada uma destas características. Falamos mais sobre isso ao final da aula.
1.1. Estimador para a média
Usamos a média amostral (��) para estimar a média populacional ()
Neste ponto, é importante padronizarmos nossa linguagem.
Há dois símbolos usualmente empregados para a média. A partir de agora, é importante saber diferenciá-los, pois eles vão aparecer juntos em uma mesma questão.
Quando temos uma variável aleatória, a média desta variável é designada por . Às vezes podemos modelar uma população como uma variável aleatória. Então, sempre que quisermos nos referir à média de uma variável aleatória, ou à média de uma população, vamos usar o símbolo .
Seja X a variável aleatória que designa o resultado do lançamento de um dado. Já vimos que a média desta variável aleatória (= esperança) é de 3,5.
= 3,5
Podemos pensar que 3,5 é a média da variável aleatória X. Ou então, se pensarmos em uma população formada por todos os resultados que poderiam ser obtidos quando se lança o dado infinitas vezes, dizemos que a média dessa população é 3,5.
Pegamos o dado de seis faces e lançamos três vezes, obtendo: 6, 2, 3.
Estes três lançamentos são uma amostragem dos infinitos resultados que poderiam ocorrer.
Se quisermos nos referir à média de uma amostra, vamos utilizar o símbolo X (“X barra”):
�� = 6 + 2 + 33 = 113

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 5
Resumindo:
• Falou em média populacional: o símbolo é µ
• Falou em média de variável aleatória: o símbolo é µ (pois variáveis aleatórias são
usadas para modelar populações)
• Falou em média amostral: símbolo é X
Nosso objetivo é, a partir de uma amostra, estimar qual o parâmetro populacional. Partindo da amostra das dez pessoas acima, estimamos a média populacional em R$ 3.600,00.
O valor da média da amostra ( X ) é um estimador da média populacional ( µ ). É um
estimador não tendencioso, de variância mínima, de mínimos quadrados e, se a variável aleatória for normal, é também um estimador de máxima verossimilhança.
Ao final da aula falaremos sobre estas características dos estimadores.
Exemplos
Exemplo 1
De uma população foi extraída uma amostra com os seguintes valores: 4, 6, 8, 8. Qual a estimativa para a média da população?
Resolução.
Não sabemos a média da população ( µ ). Neste caso, vamos utilizar a média da amostra ( X
) para estimar a média da população.
A estimativa da média da população fica:
5,64
8864=
+++=X
Estimamos a média populacional em 6,5.
1.2. Estimador para a variância
Usamos a variância da amostra (s2) para estimar a variância da população (��).
A variância amostral pode ser calculada de duas maneiras.
Se o exercício pedir o estimador não-viciado, usamos n-1 no denominador:
�� = ∑��� − ���� − 1
Se o exercício pedir o estimador de máxima verossimilhança e a variável for normal, usamos n no denominador:
�� = ∑��� − ����

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 6
Vamos padronizar a simbologia. Quando quisermos nos referir à variância populacional ou à
variância de uma variável aleatória, vamos usar o símbolo 2σ . Ou então, podemos usar o símbolo V(X). Outro símbolo possível nos exercícios é Var(X).
Quando quisermos nos referir à variância de uma amostra, usamos 2s .
• Variância da população (ou da variável aleatória): )()(2
XVarXV ==σ
• Variância da amostra: 2s
Para variância, o estimador que vamos usar geralmente é:
( )1
2
2
−
−=∑
n
XXs
i,
que é a mesma fórmula vista na estatística descritiva.
Na estatística descritiva, quando se estuda a fórmula da variância amostral, aprende-se que o denominador é “ 1−n ” em vez de “n”.
Quando queremos estimar a variância da população, um dos fatores que tem influência nesse denominador é justamente a característica desejada para o estimador. Para que o estimador tenha certa característica de tal forma que ele possa ser enquadrado como não tendencioso, é necessário que o denominador seja “ 1−n ”.
Este estimador acima é o mais utilizado. Ele é não tendencioso. Contudo, no caso da variável normal, ele não é o estimador de máxima verossimilhança. O estimador de máxima verossimilhança é:
( )n
XXs
i∑ −=
2
2
Se por acaso o exercício der uma amostra de uma variável normal e pedir para calcular o estimador de máxima verossimilhança da variância utilizamos n no denominador (em vez de
1−n ). Mas acho que é improvável que isto ocorra. O que deve vai cair mesmo é com o denominador 1−n . É improvável, mas não impossível, conforme veremos em alguns exercícios de concursos durante a aula.
Exemplo 2
Considere a seguinte amostra de uma variável aleatória normal:
1, 2, 3.
Calcule:
a) o estimador não tendencioso da variância populacional
b) o estimador de máxima verossimilhança da variância populacional

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 7
Resolução
a) O estimador não tendencioso é aquele em que temos ‘ 1−n ’ no denominador.
Fica assim:
( )1
2
2
−
−=∑
n
XXs
i
( )1
13
101222
2 =−
++−=s
b) O estimador de máxima verossimilhança é aquele com ‘n’ no denominador.
( )n
XXs
i∑ −=
2
2
( )3/2
3
101222
2 =++−
=s
Questão 1 SEFAZ RJ 2008 [FGV]
Considere uma Amostra Aleatória Simples de n unidades extraídas de uma população na
qual a característica, X, estudada tem distribuição Normal com média µ e variância 2σ ,
ambas desconhecidas, mas finitas. Considere, ainda, as estatísticas média da amostra, X =
∑=
n
i
iXn 1
1, e variância da amostra ( )∑
=
−=n
i
i XXn
s1
22 1
. Então, é correto afirmar que:
(A) X e 2S são, ambos, não tendenciosos para a estimação da média e da variância da população, respectivamente.
(B) X é não-tendencioso, mas é 2S tendencioso para a estimação da média e da variância da população, respectivamente.
(C) X é tendencioso, mas 2S é não-tendencioso para a estimação da média e da variância da população, respectivamente.
(D) X e 2S são, ambos, tendenciosos para a estimação da média e da variância da população, respectivamente.
(E) X e 2S são, ambos, não-tendenciosos para a estimação da média e da variância da
população, mas apenas X é consistente.
Resolução:
Nesta questão, temos:
- a média aritmética da amostra como um estimador da média populacional: vimos que a média da amostra é um estimador não-tendencioso.
- a variância da amostra como um estimador da variância populacional: vimos que, quando se usa n no denominador, o estimador é tendencioso.
Gabarito: B

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 8
Resumindo: há diversos tipos de estimadores. Por hora, ainda não sabemos exatamente o que eles significam.
Só sabemos que, no caso de estimarmos a variância da população a partir de uma amostra, o denominador pode ser “ 1−n ” ou “n”.
Se o exercício não falar nada, utilize “ 1−n ”. Este é o estimador mais utilizado. Ele é não tendencioso.
Se o exercício pedir o estimador de máxima verossimilhança e a distribuição for normal, utilize “n”.
Questão 2 CGU 2008 [ESAF]
Qual o estimador de máxima verossimilhança da variância de uma variável X normalmente distribuída obtido a partir de uma amostra aleatória simples X1, X2, X3, ..., Xn, desta variável,
sendo nXm i /∑= o estimador de máxima verossimilhança da média?
a) 1
)(2
−
−∑n
mX i
b) 2
)(2
−
−∑n
mX i
c)
5,02
1
)(
−
−∑n
mX i
d) ∑ − 2)( mX i
e) n
mX i∑ − 2)(
Resolução.
O enunciado está usando a letra “m” para indicar a média amostral.
Vimos que o estimador de máxima verossimilhança da variância para a distribuição normal é aquele que apresenta “n” no denominador.
Gabarito: E.
Questão 3 SEFAZ SP 2009 [ESAF]
(Dados da questão anterior: 17, 12, 9, 23, 14, 6, 3, 18, 42, 25, 18, 12, 34, 5, 17, 20, 7, 8, 21, 13, 31, 24, 9.)
Considerando que as observações apresentadas na questão anterior constituem uma amostra aleatória simples X1, X2, ..., Xn de uma variável aleatória X, determine o valor mais próximo da variância amostral, usando um estimador não tendencioso da variância de X.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 9
Considere que:
38823
1
=∑=i
iX
867623
1
2 =∑=i
iX
a) 96,85
b) 92,64
c) 94,45
d) 90,57
e) 98,73
Resolução.
A média fica:
23
388
23
23
1 ==
∑=i
iX
X
A média dos quadrados das observações fica:
23
86762 =X
A variância (com n no denominador), é dada por:
22
XX −
= 2
23
388
23
8676
−
Para o estimador não tendencioso (ou não viciado, ou não enviesado), nós usamos 1−n no denominador. Portanto, precisamos ajustar o denominador.
O resultado acima considera uma divisão por 23 (= n). Precisamos multiplicar por 23, para cancelar esta divisão.
Em seguida, dividimos por 22, para que o denominador seja igual a 1−n .
O estimador não tendencioso da variância fica:
×=22
232s
−
2
23
388
23
8676
=2s2223
388
22
86762
×−
= 394,36 – 297,52 = 96,84
Gabarito: A

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 10
1.3. Estimador para uma proporção
Usamos a proporção amostral (�̂) para estimar a proporção populacional (p)
Considere que a proporção de moradores de uma cidade que pretendem votar num candidato A é de 40%. É um valor que se refere à população inteira. É um parâmetro. Vamos padronizar. Sempre que nos referirmos à proporção da população, usamos o símbolo p .
%40=p
Suponha que nós não conhecemos esta proporção referente à população (40%) e, para estimá-la, entrevistamos 10 pessoas. Destas, 5 pretendem votar no candidato A.
A proporção verificada na amostra é 50%. Chamamos de p̂ .
%50ˆ =p
Vamos usar p̂ como estimador de p .
Resumindo:
• Proporção da população: p
• Proporção amostral: p̂
Exemplo 3
Para uma pesquisa de intenções de voto para a Prefeitura de uma cidade, foram entrevistadas 100 pessoas. Verificou-se que, nesta amostra, 30 eleitores pretendem voltar no candidato A. Qual a estimativa da proporção populacional de intenções de voto do candidato A?
Resolução.
Não sabemos qual a proporção populacional (ou seja, referente a todos os eleitores da cidade). Vamos usar a proporção verificada na amostra para estimar a proporção populacional.
Na amostra temos:
3,0%30ˆ ==p
Dizemos que a estimativa da proporção populacional é de 30%.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 11
Estimadores pontuais
- Usamos a média amostral para estimar a média populacional ( X é um estimador de µ );
- Usamos a variância amostral para estimar a variância populacional. Se o estimador for não-viciado (ou não-tendencioso) usamos 1−n no denominador. Se o estimador for de máxima verossimilhança e a variável for normal, usamos n no denominador.
- Usamos a proporção amostral para estimar a proporção populacional.
2. INTERVALO DE CONFIANÇA PARA A MÉDIA
2.1. ��como uma variável aleatória
Muitas populações podem ser modeladas segundo uma variável aleatória. Como exemplo, considere a temperatura de um local, medida com nosso termômetro mágico de infinitas casas após a vírgula.
Nosso objetivo é estimar a temperatura média do local em um dado dia. Para tanto, consideramos que a temperatura se comporta como uma variável aleatória X.
Deste modo, encontrar a temperatura média do local é o mesmo que encontrar a esperança de X.
?)( == µXE
Num dado dia, vamos lá nesse local e, em dez instantes diferentes, medimos a temperatura. Agora temos uma amostragem de tamanho 10 para a temperatura no local.
Suponha que esta média tenha sido 21 =X °C.
Neste ponto, não custa nada lembrar a simbologia que padronizamos.
• X é a média de uma amostra
• µ é a média da população (é o valor que pretendemos estimar)
Só que os instantes em que realizamos a amostragem foram aleatoriamente escolhidos. Se, por acaso, outros instantes tivessem sido escolhidos, cada uma das medições poderia ser
ligeiramente diferente. Seria possível ter obtido uma segunda média igual a 1,22 =X °C.
Ou também seria possível ter obtido uma terceira média 051,23 =X °C.
Quando nos referimos a uma única amostra, X representa um número, a média aritmética daquela amostra.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 12
Mas também podemos nos referir a X de forma diferente. Podemos pensar em inúmeras
amostras, com X assumindo valores diferentes em cada uma delas. Assim, X seria uma variável.
�� pode ser vista como uma variável aleatória
Quando nos referimos a �� como uma variável aleatória, é porque estamos pensando em todas as diferentes amostras que poderiam ter sido extraídas. Nesse caso, �� é vista apenas como uma fórmula, um método de cálculo: somamos todos os valores da amostra e dividimos por “n”. Nesse caso, dizemos que �� é uma estatística.
Por outro lado, quando nos referimos a uma amostra em particular, que fornece um único valor para a média amostral, nesse caso, �� assumirá um valor único, fixo. Por exemplo, �� = 2. Nesta situação, quando nos referimos a �� como algo fixo, dizemos que �� = 2 é uma estimativa da média populacional.
Na verdade, esses nomes “estatística”, “estimativa”, “parâmetro”, tudo isso não cai em prova. Até hoje não vi uma questão só explorando as diferenças conceituais de um nome para o outro, ok?
De todo esse blá blá blá acima, só o que importa é: �� pode ser vista como algo que varia (caso estejamos pensando em todas as possíveis amostras) ou pode ser vista como algo fixo (quando pensamos em uma amostra em particular).
Questão 4 TJ PI 2009 [FCC]
Seja uma população constituída pelos valores 1, 2, 3, 4, 5 e 6. Todas as amostras com tamanho 2, sem reposição, são selecionadas. A probabilidade de que a média amostral seja superior a 5 é de
(A) 1/4
(B) 1/6
(C) 2/3
(D) 1/3
(E) 1/15
Resolução:
Vejam como o exercício explora �� como uma variável aleatória.
A cada possível amostra de tamanho 2, �� assume um valor diferente.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 13
Exemplo: se a amostra for (1, 3), a média amostral será 2.
Se a amostra for (1, 5), a média amostral será 3.
Ou seja, se pensarmos em todas as possíveis amostras de tamanho 2, �� varia, �� é uma variável aleatória.
Abaixo temos todas as amostras possíveis, de tamanho 2, sem reposição:
1, 2 1, 3 1,4 1,5 1,6
2,3 2,4 2,5 2,6 3,4
3,5 3,6 4,5 4,6 5,6
São quinze amostras possíveis.
Em um único caso a média é maior que 5. Trata-se da amostra (5,6).
Temos um caso favorável em quinze possíveis. A probabilidade de que a média seja maior que 5 é de:
� = 115
Gabarito: E
Destaco que não era necessário escrever todas as amostras para contar quantas são. Poderíamos usar análise combinatória para tanto.
No caso das amostras possíveis, queremos formar conjuntos de dois elementos, a partir dos seis valores disponíveis. Temos combinação de 6, tomados 2 a 2.
��,� = 6!4! × 2! = 15
No caso dos casos favoráveis, temos um único caso favorável (5, 6).
Dividindo o número de casos favoráveis pelo número de casos possíveis, temos:
� = 115
2.2. Esperança e variância de ��
�� tem esperança igual a e variância igual a �� ÷ .
"��� =
#���� = ��
Além disso, �� é aproximadamente normal. A aproximação será tanto melhor quanto maior for o tamanho da amostra.
Como exemplo, considere um tetraedro regular. Nas suas faces temos os números 1, 2, 3, 4.
Lançamos o tetraedro sobre uma mesa. X representa o valor da face que fica em contato com a mesa.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 14
Vamos realizar um estudo dos possíveis resultados deste lançamento. Para tanto, lançamos duas vezes (amostra de tamanho 2).
Saíram os resultados 1 e 3.
Para esta amostra em particular a média amostral foi:
22
31=
+=X
Ok, fizemos uma única amostra. Neste caso, X é um número. É simplesmente a média aritmética dos valores pertencentes à amostra.
Acontece que não estamos interessados em uma amostra específica, que fornece um valor
único para X . Estamos interessados na variável aleatória X .
O resultado do lançamento do dado é aleatório. Seria possível que tivéssemos obtido outras amostras. Se o tetraedro for homogêneo, as possíveis amostras seriam:
1 e 1 1 e 2 1 e 3 1 e 4
2 e 1 2 e 2 2 e 3 2 e 4
3 e 1 3 e 2 3 e 3 3 e 4
4 e 1 4 e 2 4 e 3 4 e 4
Seriam 16 amostras possíveis, todas elas com a mesma probabilidade de ocorrer. O valor da média amostral em cada uma dessas amostras seria:
Valores da amostra X 1 e 1 1
1 e 2 1,5
1 e 3 2
1 e 4 2,5
2 e 1 1,5
2 e 2 2
2 e 3 2,5
2 e 4 3
3 e 1 2
3 e 2 2,5
3 e 3 3
3 e 4 3,5
4 e 1 2,5
4 e 2 3
4 e 3 3,5
4 e 4 4
Repare que X pode ser visto como uma variável aleatória que assume diversos valores.
A média de todos os possíveis valores de X fica:
)45,335,25,335,2235,225,15,225,11(16
1)( +++++++++++++++×=XE

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 15
5,2)( =XE
Vamos agora calcular a média da variável aleatória X.
A variável aleatória X assume os valores 1, 2, 3, 4, cada um com probabilidade 1/4.
Portanto:
44
13
4
12
4
11
4
1)( ×+×+×+×== µXE
5,2=µ
Concluindo: a esperança da média amostral é igual à esperança da população. Isto significa que, se fosse possível fazer um número muito grande de amostras, a média de todas as médias amostrais seria igual à média da população.
X pode ser vista como uma variável aleatória com esperança µ . Ou seja, a média das
médias amostrais é a média da população
Ainda não estudamos as diversas características dos estimadores. Mas podemos falar sobre uma delas: o estimador não tendencioso (ou não viciado, ou não viesado).
O fato da média de X ser igual à média da população nos permite classificar X como estimador não tendencioso (ou não viciado). Usando esse estimador, em média (considerando as inúmeras amostras que poderiam ser feitas), nós estamos realmente acertando o valor do parâmetro desconhecido.
Sempre que a esperança de um estimador for igual ao parâmetro estimado, estamos diante de um estimador não tendencioso.
µ=)(XE :
A média de X é igual ao parâmetro estimado; se fizéssemos inúmeras amostragens, em média, acertaríamos a média populacional.
Sabendo que X pode ser vista como uma variável aleatória, é possível calcular a sua variância.
Seja 2σ a variância da população.
É possível demonstrar que, sendo ‘n’ o tamanho das amostras, a variância de X fica:
nXV
2
)(σ
=
Um outro símbolo possível para a variância de X seria: 2
Xσ . Portanto:

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 16
nX
22 σ
σ =
A variância da média amostral é igual à variância da população dividido por n.
Por consequência, o desvio padrão da média amostral é:
nX
σσ =
Ou seja, o desvio padrão de X é igual ao desvio padrão da população dividido por raiz de n.
Estas fórmulas da variância e desvio padrão só são válidas se a variável aleatória tiver população infinita (ou seja, assume infinitos valores, como no caso de uma variável aleatória contínua).
Caso a população seja finita (como foi o caso do lançamento do tetraedro), o resultado continua valendo, desde que a amostragem seja feita com reposição.
Caso a população seja finita e a amostragem seja feita sem reposição, as fórmulas devem ser adaptadas (aplicamos o fator de correção para populações finitas, assunto que abordado posteriormente).
X pode ser vista como uma variável aleatória com esperança µ e variância n
2σ (e,
consequentemente, desvio padrão n
σ).
Ou seja, a média de X é igual à média da população. E a variância de X é igual à variância
da população dividida por n. O desvio padrão de X é igual ao desvio padrão da população dividido por raiz de n.
Agora vem o grande detalhe. Pelo teorema do limite central é possível demonstrar que a
variável aleatória X tem distribuição aproximadamente normal. A aproximação é melhor quanto maior o tamanho das amostras (quanto maior o valor de n). Isto vale mesmo que a variável X não seja normal.
Caso a variável X seja normal, a variável X também será normal (aí já não é aproximação).
Ou seja, para a variável X nós podemos utilizar a tabela de áreas para a variável normal. Isto é de extrema utilidade na determinação dos chamados intervalos de confiança.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 17
X pode ser vista como uma variável aleatória normal (ou aproximadamente normal), com
média µ , variância n
2σ e desvio padrão
n
σ.
A aproximação vale mesmo que X não seja normal. Quanto maior o tamanho das amostras, melhor a aproximação.
Questão 5 TRF 1ª Região/2001 [FCC]
Para responder à questão seguinte, considere a tabela abaixo, referente à distribuição normal padrão.
z )(zF
1,20 0,885
1,60 0,945
1,64 0,950
Uma máquina de empacotar leite em pó o faz segundo uma normal com média µ e desvio
padrão 10g. O peso médio µ deve ser regulado para que apenas 5,5% dos pacotes tenham
menos do que 1000 g. Com a máquina assim regulada, a probabilidade de que o peso total de 4 pacotes escolhidos ao acaso seja inferior a 4.040 g é:
a) 0,485
b) 0,385
c) 0,195
d) 0,157
e) 0,115
Resolução.
A questão poderia ter sido mais clara, explicitando o que significa F(z).
É muito comum utilizarmos o símbolo F(z) para representar a função distribuição de probabilidade (FDP).
Relembrando o significado da FDP, ela nos fornece probabilidades para a variável aleatória Z, normal, de média 0 e desvio padrão unitário.
Assim, na primeira linha da tabela temos que F(1,2) = 0,885.
Isto significa que a probabilidade de Z assumir valores menores que 1,2 é de 88,5%.
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 18
Analogamente, da segunda linha temos que a probabilidade de Z assumir valores menores que 1,6 é de 94,5%.
Por fim, da terceira linha temos que a probabilidade de Z assumir valores menores que 1,64 é de 95%.
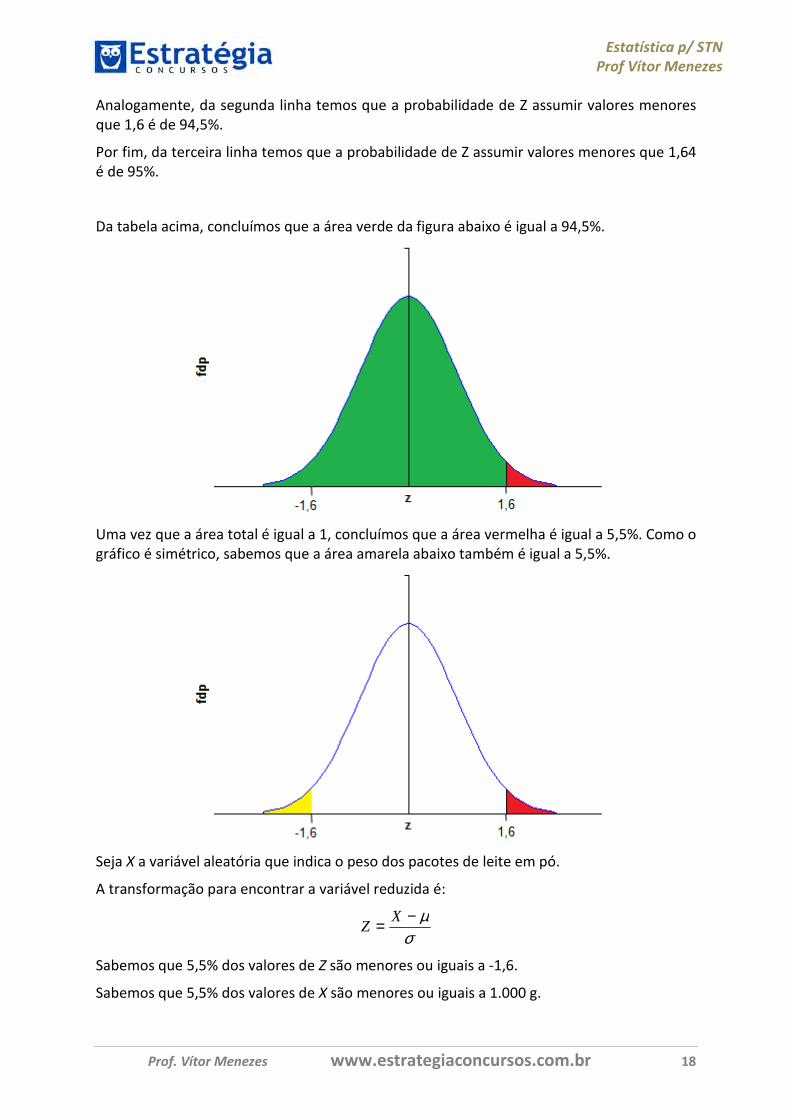
Da tabela acima, concluímos que a área verde da figura abaixo é igual a 94,5%.
Uma vez que a área total é igual a 1, concluímos que a área vermelha é igual a 5,5%. Como o gráfico é simétrico, sabemos que a área amarela abaixo também é igual a 5,5%.
Seja X a variável aleatória que indica o peso dos pacotes de leite em pó.
A transformação para encontrar a variável reduzida é:
σ
µ−=
XZ
Sabemos que 5,5% dos valores de Z são menores ou iguais a -1,6.
Sabemos que 5,5% dos valores de X são menores ou iguais a 1.000 g.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 19
Logo, quando Z vale -1,6, X vale 1.000.
101610001610
10006,1 =⇒−=−⇒
−=− µµ
µ
Encontramos o peso médio dos pacotes.
Os pesos dos pacotes se comportam como uma variável normal de média 1016 e desvio padrão de 10 gramas.
A pergunta é: qual a probabilidade de o peso total de uma amostra de 4 pacotes ser inferior a 4040g?
Lembrando que 10104
4040= , temos que essa pergunta equivale a:
Qual a probabilidade de o peso médio de uma amostra de 4 pacotes ser inferior a 1010 g?
Seja X a variável aleatória que designa o peso médio em amostras de 4 pacotes. X tem distribuição normal. Sua média é dada por:
1016][ == µXE
Sua média é igual à média da população.
Seu desvio padrão é dado por:
52
10][ ====
nXV
X
σσ
X é uma variável aleatória com média 1016 e desvio padrão igual a 5.
Queremos saber a probabilidade de X ser inferior a 1010g. Precisamos consultar a tabela de áreas fornecida na prova. Para tanto, precisamos achar o valor da variável normal reduzida Z que corresponde a 1010.
E agora cuidado!
A variável aleatória em estudo é X . Na hora de obter a variável Z, temos que fazer uma subtração e uma divisão.
Subtraímos a média da variável X (no caso, 1016). E dividimos pelo desvio padrão de X (no caso, 5).
X
XZ
σ
µ−=
Quando X vale 1010, Z vale:
2,15
10161010−=
−=Z
Vamos achar a probabilidade de Z ser menor que -1,2.
A tabela fornecida nos diz que a área verde da figura abaixo é de 0,885.
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 20
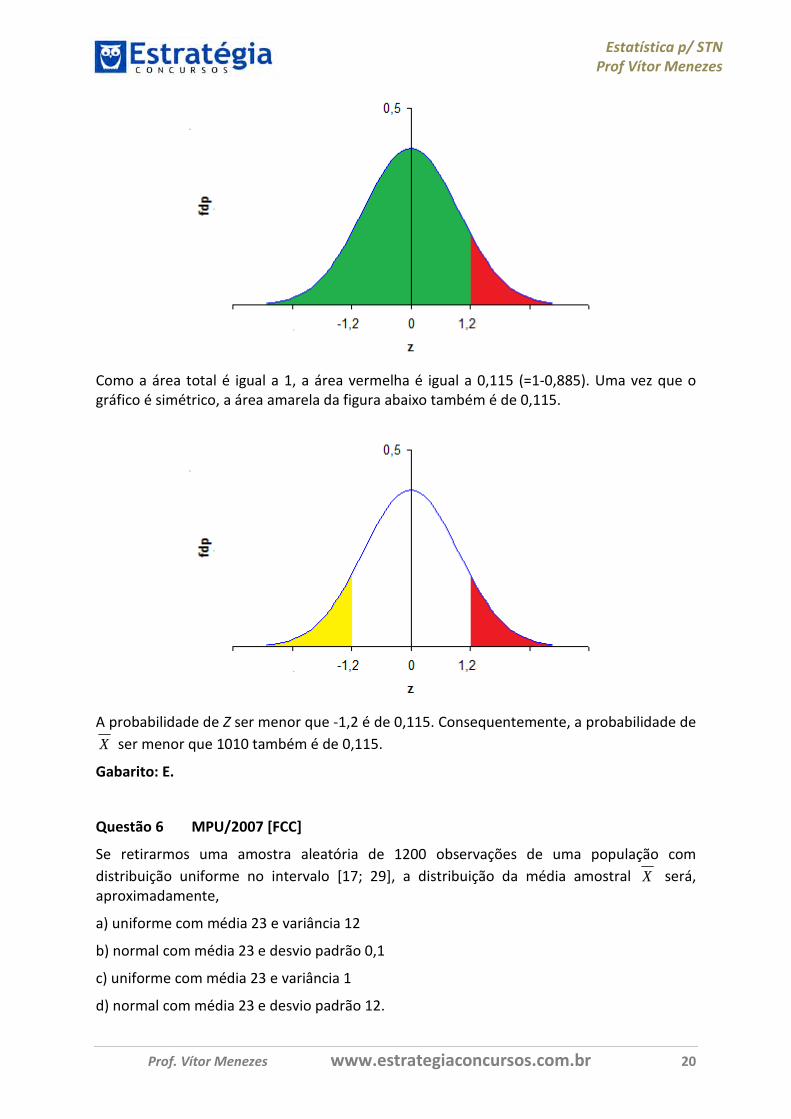
Como a área total é igual a 1, a área vermelha é igual a 0,115 (=1-0,885). Uma vez que o gráfico é simétrico, a área amarela da figura abaixo também é de 0,115.
A probabilidade de Z ser menor que -1,2 é de 0,115. Consequentemente, a probabilidade de
X ser menor que 1010 também é de 0,115.
Gabarito: E.
Questão 6 MPU/2007 [FCC]
Se retirarmos uma amostra aleatória de 1200 observações de uma população com
distribuição uniforme no intervalo [17; 29], a distribuição da média amostral X será, aproximadamente,
a) uniforme com média 23 e variância 12
b) normal com média 23 e desvio padrão 0,1
c) uniforme com média 23 e variância 1
d) normal com média 23 e desvio padrão 12.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 21
e) normal com média 23 e desvio padrão 1.
Resolução.
Quando a população tem distribuição normal, X também é uma variável aleatória normal.
Quando a população não for normal, X será aproximadamente normal. A aproximação será tanto melhor quanto maior for a amostra.
Nesse caso, em que X é uniforme, X é aproximadamente normal. Note que a amostra é bem grande (n = 1200).
Estudamos na aula passada que, para calcular a média de uma variável aleatória uniforme, basta pegar o ponto médio do intervalo em que ela é diferente de zero. Neste caso, a esperança de X fica:
232
1729][ =
+=XE
A média de X coincide com a média populacional.
23][ == µXE
Para terminar a questão, ainda falta achar o desvio padrão da média amostral. Para tanto, precisamos da variância da população (não informada).
Vimos na aula passada que, se uma variável aleatória é uniforme no intervalo [a, b], sua variância fica:
12
)()(
2abXV
−=
Neste caso, a variável é uniforme no intervalo entre 17 e 29.
#��� = �29 − 17��12 = 12�12 = 12
Sabendo que X tem variância 12, temos:
01,01200
122
2 ===nX
σσ
1,0=X
σ
Portanto, X tem distribuição aproximadamente normal, com média 23 e desvio padrão 0,1.
Gabarito: B.
Questão 7 PETROBRAS 2010 [CESGRANRIO]
A distribuição de probabilidades da variável aleatória X é tal que X = -1 com 50% de probabilidade ou X = 1 com 50% de probabilidade. A média, �� , de quatro realizações de X, sucessivas e independentes, é uma variável aleatória de média e desvio padrão, respectivamente, iguais a

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 22
(A) 0 e 2
(B) 0 e 1
(C) 1 e 0.5
(D) 1 e 0
(E) 0 e 0.5
Resolução
Primeiro calculamos a média de X:
"��� = �−1� × ��� = −1� + 1 × ��� = 1� "��� = −1 × 0,5 + 1 × 0,5 = 0
Agora calculamos a variância de X:
"���� = �−1�� × ��� = −1� + 1� × ��� = 1� = 1 × 0,5 + 1 × 0,5 = 1
#��� = "���� − "���� = 1 − 0 = 1
Logo:
� = '#��� = 1
�� é uma variável aleatória com média igual à média de X. Logo, tem média 0.
��é uma variável aleatória com desvio padrão dado por: �√ = 1√4 = 0,5
��tem média 0 e desvio padrão 0,5.
Gabarito: E
Questão 8 MPOG 2012 [ESAF]
Uma variável aleatória possui distribuição normal com média igual a 10, μ = 10, e variância igual a 4, ��= 4. Retirando-se desta população uma amostra de tamanho n = 100, tem-se que a distribuição amostral das médias, ou distribuição amostral de ��é uma distribuição:
a) não normal com μ =10 e �= 1/5
b)normal com μ =10 e � = 1/5
c) normal com μ =100 e�� = 4
d)normal com μ =10 e �� = 2
e)não normal com μ =100 e �� = 4
Resolução:
Quando X é normal, a distribuição das médias também é normal.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 23
a) não normal com μ =10 e �= 1/5
b)normal com μ =10 e � = 1/5
c) normal com μ =100 e�� = 4
d)normal com μ =10 e �� = 2
e)não normal com μ =100 e �� = 4
A esperança de ��coincide com a média da população. No caso, vale 10.
b)normal com μ =10 e � = 1/5
c) normal com μ =100 e�� = 4
d)normal com μ =10 e �� = 2
Gabarito: B A variância de ��é igual à variância da população, dividida por "n". Onde "n" é o tamanho das amostras:
�)�� = �� = 4100
O desvio padrão é a raiz quadrada da variância.
�)� = * 4100 = 210 = 15
O que confirma a correção da letra B.
2.3. Intervalo de confiança para a média
O intervalo de confiança para a média é dado por:
�� ± ,- × �)� Onde Z0 é o valor para a distribuição normal reduzida que delimita a área fixada pelo nível de confiança.
Acima já vimos o resultado final, aquilo que você tem que saber para resolver as questões. Se estiver satisfeito em decorar isso, blz, já dá para ir diretamente para os exercícios.
A seguir, ou apenas mostrar um exemplo, para entendermos melhor do que se trata o assunto.
Por enquanto, não se preocupem em fazer contas. Não se preocupem em decorar ou gravar qualquer coisa. Só quero que entendam a ideia geral.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 24
Depois, nos exercícios de concurso, aí veremos o passo a passo da construção do intervalo de confiança. Ou seja, posteriormente é que nos concentraremos em como resolver as questões. Neste momento, não se preocupem com isso.
Seja X uma variável aleatória que representa uma população infinita com variância
conhecida ( 2σ ). Este “infinita” é só para ser rigoroso. Caso a população seja finita, os resultados que veremos só se aplicam se a amostragem for feita com reposição.
Pois bem, então X é nossa variável aleatória com variância conhecida ( 2σ ). X representa nossa população. Apesar de conhecermos sua variância, não conhecemos sua média ( µ ).
Nosso objetivo será obter uma amostra e, a partir dela, definir o chamado intervalo de confiança para µ .
Vamos supor que a variância da população seja de 16.
16)(2 == σXV
A média da população, esta nós não conhecemos. Vamos chamá-la de µ .
?)( == µXE
Vamos obter uma amostra de tamanho 4.
4=n
A média de uma amostra de tamanho 4 é X .
Antes de efetivamente fazer uma amostragem (o que nos fornecerá um valor específico
para X ), vamos pensar em todas as amostras que poderiam ser obtidas (com tamanho 4).
Em cada uma delas, X assume um valor diferente. Conforme visto no começo da aula, X pode ser vista como uma variável aleatória normal (ou aproximadamente normal) de média µ .
Sabemos também que X tem uma variância dada por:
nXV
2
)(σ
=
44
16)( ==XV
Portanto, o desvio padrão da variável X é dado por:
24 ==X
σ
Vamos criar a seguinte variável transformada:
X
XZ
σ
µ−=
A variável Z, conforme já estudado na aula anterior, tem média zero e desvio padrão unitário. É a nossa variável normal reduzida.
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 25
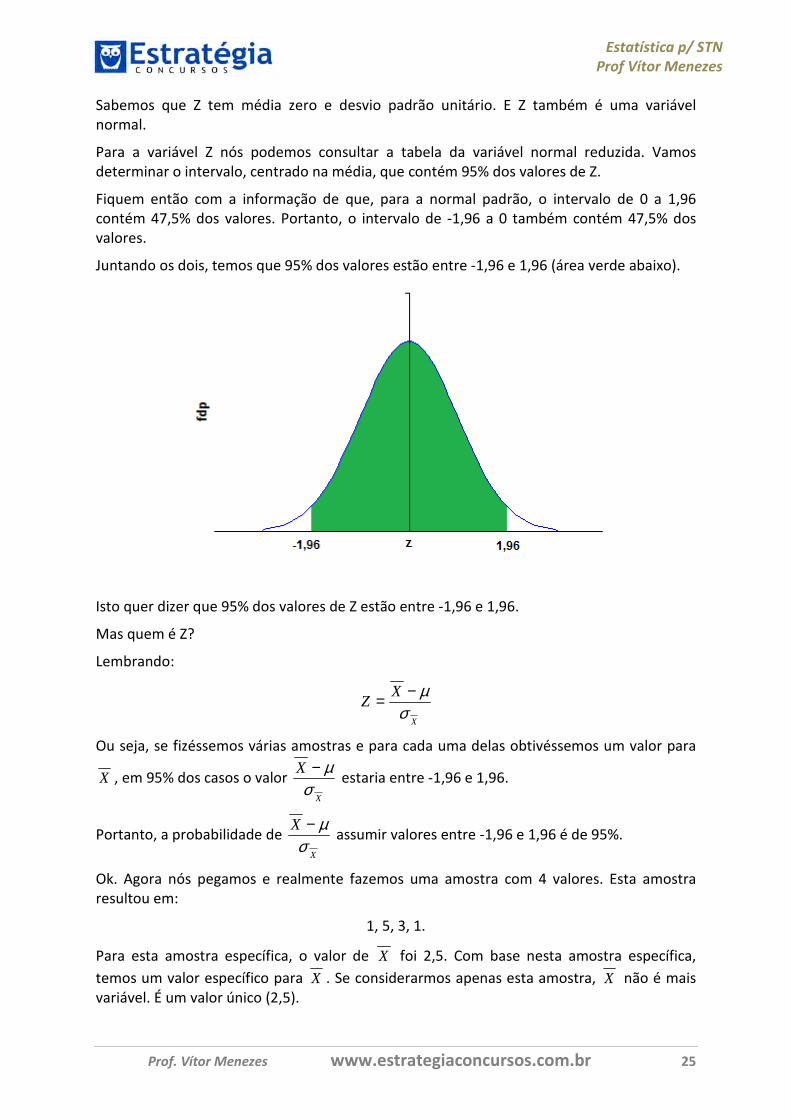
Sabemos que Z tem média zero e desvio padrão unitário. E Z também é uma variável normal.
Para a variável Z nós podemos consultar a tabela da variável normal reduzida. Vamos determinar o intervalo, centrado na média, que contém 95% dos valores de Z.
Fiquem então com a informação de que, para a normal padrão, o intervalo de 0 a 1,96 contém 47,5% dos valores. Portanto, o intervalo de -1,96 a 0 também contém 47,5% dos valores.
Juntando os dois, temos que 95% dos valores estão entre -1,96 e 1,96 (área verde abaixo).
Isto quer dizer que 95% dos valores de Z estão entre -1,96 e 1,96.
Mas quem é Z?
Lembrando:
X
XZ
σ
µ−=
Ou seja, se fizéssemos várias amostras e para cada uma delas obtivéssemos um valor para
X , em 95% dos casos o valor X
X
σ
µ− estaria entre -1,96 e 1,96.
Portanto, a probabilidade de X
X
σ
µ− assumir valores entre -1,96 e 1,96 é de 95%.
Ok. Agora nós pegamos e realmente fazemos uma amostra com 4 valores. Esta amostra resultou em:
1, 5, 3, 1.
Para esta amostra específica, o valor de X foi 2,5. Com base nesta amostra específica,
temos um valor específico para X . Se considerarmos apenas esta amostra, X não é mais variável. É um valor único (2,5).

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 26
E para esta amostra específica o valor de Z é:
2
5,2 µ−=Z .
A probabilidade de este valor estar no intervalo de -1,96 a 1,96 não é mais 95%. Isto porque a expressão acima não assume mais valores diversos, aleatórios. É um valor único.
2,5 é um número, uma constante.
O valor de µ é também um número, constante. É desconhecido. Mas é constante. A média
da população é um número, um valor único.
E, por fim, o denominador 2 também é constante.
Fazendo a conta 2
5,2 µ−, obtemos um valor que pode ou não estar no intervalo -1,96 a
1,96.
Quando substituímos a variável X por um valor obtido para uma dada amostra específica, não falamos mais em probabilidade.
É errado afirmar que, com probabilidade de 95%, o valor 2
5,2 µ− estará entre -1,96 e 1,96.
Mas, supondo que este valor esteja entre -1,96 e 1,96, ficamos com:
96,12
5,296,1 ≤
−≤−
µ
92,35,292,3 ≤−≤− µ
5,292,392,35,2 −≤−≤−− µ
42,142,6 ≤−≤− µ
42,642,1 ≤≤− µ
Este intervalo entre -1,42 e 6,42 é chamado de intervalo de 95% de confiança para a média da população.
Repare que não temos certeza de que a média da população ( µ ) esteja neste intervalo.
Nem podemos dizer que a probabilidade de ela estar neste intervalo seja de 95%.
Tentando explicar de outra forma o que foi feito.
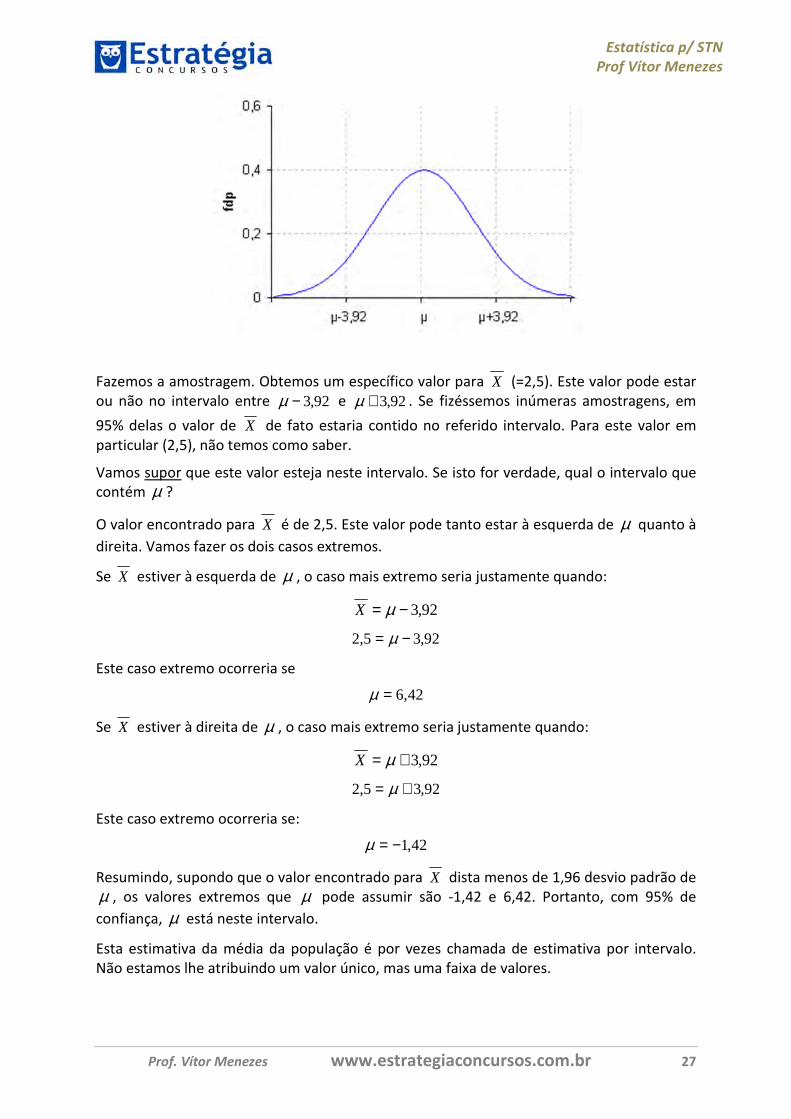
Em 95% dos casos, X está distante menos de 1,96 desvios padrão da média µ .
Como o desvio padrão de X é 2, temos que em 95% dos casos X dista menos que 3,92 da média µ .
Ou seja, em 95% dos casos X está entre 92,3−µ e 92,3+µ .
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 27
Fazemos a amostragem. Obtemos um específico valor para X (=2,5). Este valor pode estar ou não no intervalo entre 92,3−µ e 92,3+µ . Se fizéssemos inúmeras amostragens, em
95% delas o valor de X de fato estaria contido no referido intervalo. Para este valor em particular (2,5), não temos como saber.
Vamos supor que este valor esteja neste intervalo. Se isto for verdade, qual o intervalo que contém µ ?
O valor encontrado para X é de 2,5. Este valor pode tanto estar à esquerda de µ quanto à
direita. Vamos fazer os dois casos extremos.
Se X estiver à esquerda de µ , o caso mais extremo seria justamente quando:
92,3−= µX
92,35,2 −= µ
Este caso extremo ocorreria se
42,6=µ
Se X estiver à direita de µ , o caso mais extremo seria justamente quando:
92,3+= µX
92,35,2 += µ
Este caso extremo ocorreria se:
42,1−=µ
Resumindo, supondo que o valor encontrado para X dista menos de 1,96 desvio padrão de µ , os valores extremos que µ pode assumir são -1,42 e 6,42. Portanto, com 95% de
confiança, µ está neste intervalo.
Esta estimativa da média da população é por vezes chamada de estimativa por intervalo. Não estamos lhe atribuindo um valor único, mas uma faixa de valores.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 28
No começo desta aula vimos como fazer a estimativa por ponto. Na estimativa por ponto não determinávamos uma faixa de valores. Sim um valor único. Estimávamos o valor de µ
com o valor de X .
Vamos fazer mais um exemplo. Desta vez vou colocar o “passo a passo”, para gente começar a fixar como fazer.
Questão 9 INFRAERO 2009 [FCC]
Em um determinado ramo de atividade, os salários dos empregados são considerados normalmente distribuídos com uma média μ e uma variância populacional igual a 1.600 (R$)2. Uma amostra aleatória com 100 destes empregados apresentou uma média de R$ 1.000,00 para os salários. Deseja-se, com base nesta amostra, obter um intervalo de confiança para a média μ com um nível de confiança de 95%, considerando a população de tamanho infinito e a informação da distribuição normal padrão (Z) que a probabilidade P (z > 2) = 0,025. O intervalo, com os valores em R$, é igual a
(A) [960,00; 1.040,00]
(B) [992,00; 1.008,00]
(C) [994,00; 1.006,00]
(D) [996,00; 1.004,00]
(E) [920,00; 1.080,00]
Resolução:
Para determinação do intervalo de confiança, seguimos 4 passos.
Primeiro passo: precisamos determinar o intervalo, para a variável normal reduzida (Z), que contém 95% dos valores (pois este é o nível de confiança solicitado no enunciado). Chamamos este valor de Z0 associado a 95% de confiança.
O exercício disse que este valor é igual a 2.
Vejam:
��, > 2� = 2,5%
Logo:
��, < −2� = 2,5%
Portanto:
��−2 < , < 2� = 100% − 2,5% − 2,5% = 95%
Logo, 95% dos valores de Z estão no intervalo de -2 até 2.
Por isso, o valor de Z0 procurado é 2.
,- = 2

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 29
Segundo passo: determinar o valor específico de ��para a amostragem feita.
�� = 1.000�fornecidopeloenunciado�
Terceiro passo: determinar o desvio padrão de ��. A amostra tem tamanho 100. (n = 100)
O desvio padrão de �� fica:
#���� = �� = 1.600100 = 16
�)� = √16 = 4
Quarto passo: determinar o intervalo de confiança.
Para tanto, sabemos que em 95% dos casos o valor de Z estará entre -2, e 2.
−,- ≤ , ≤ ,-
Vamos substituir Z:
−,- ≤ �� − �)� ≤ ,-
Isolando a média populacional:
�� − ,- × �)� ≤ ≤ �� + ,- × �)�
O que isto significa? Significa que a probabilidade de a média populacional estar no intervalo acima definido é de 95%.
Adotando a abordagem frequentista da probabilidade, temos o seguinte. Se fosse possível realizar, inúmeras vezes, uma amostragem de tamanho n, em 95% das vezes o intervalo acima definido conteria a média populacional.
Muito bem. Aí a gente pega e faz uma única amostra, obtendo um único valor para a média amostral. Com isso, obtemos:
1.000 − 2 × 4 ≤ ≤ 1.000 + 2 × 4
992 ≤ ≤ 1.008
Agora não falamos mais em probabilidade. É errado dizer que a probabilidade de a média populacional estar no intervalo acima é de 95%. Isto porque, acima, não temos mais nenhuma variável.
992 é um número, 1.008 é outro número, é um número (desconhecido, mas é constante, fixo).
Quando substituímos a variável �� pelo seu valor específico obtido para a amostra feita, falamos em confiança. Dizemos que, com 95% de confiança, a média populacional está contida no intervalo entre 992 e 1.008
Gabarito: B

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 30
Vocês podem guardar que o intervalo de confiança será sempre da forma
�� − ,- × �)� ≤ ≤ �� + ,- × �)�
E, para memorizar, é só pensar assim.
Nós obtemos a média da amostra (no caso 1.000). Nós queremos achar um intervalo que contenha a média da população. É razoável supor que a média da população seja próxima de 1.000.
Então, para achar esse intervalo, nós andamos um pouco para esquerda e um pouco para a direita, ao longo da reta real. Ou seja, a média populacional deve estar no seguinte intervalo:
1.000±? Nós partimos de 1.000 (média amostral). A partir deste número, nós vamos andar um pouquinho para esquerda (vamos subtrair alguma coisa) e um pouquinho para direita (vamos somar alguma coisa). E que coisa é essa?
Nós vamos andar um certo número de desvios-padrão para um lado e para o outro.
1.000 ± �)� ×? 1.000 ± 4 ×? E quantos desvios-padrão nós vamos andar?
O exercício é que vai dizer o quanto vamos andar para um lado e para o outro. Isto será dito pelo nível de confiança. Nós vamos andar Z0 desvios-padrão.
1.000 ± 4 × 2
O intervalo de confiança nos permite determinar uma faixa de valores em que se pode estar a média populacional. É uma estimativa “por intervalo”, pois não atribui à média populacional um valor único, sim um intervalo real.
Cálculo do intervalo de confiança para a média da população
1° Passo: Achar o valor de Z0 associado ao nível de confiança dado no exercício.
2° Passo: Encontrar o valor específico de X para a amostra feita.
3° Passo: Encontrar o desvio padrão de X . Utilizar a fórmula: n
X
σσ =
4° Passo: Determinar o intervalo de confiança:
XXZXZX σµσ ×+≤≤×− 00

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 31
Questão 10 CGU 2008 [ESAF]
Construa um intervalo de 95% de confiança para a média de uma população normal a partir dos dados de uma amostra aleatória simples de tamanho 64 desta população, que forneceu uma média de 48 e um desvio-padrão amostral de 16, considerando que F(1,96) = 0,975, onde F(z) é a função de distribuição de uma variável aleatória normal padrão Z.
a) 44,08 a 51,92.
b) 41,78 a 54,22.
c) 38,2 a 57,8.
d) 35,67 a 60,43.
e) 32,15 a 63,85.
Resolução:
Repare que não conhecemos a variância da população. Sempre que isso acontece, nós devemos adotar os seguintes procedimentos:
- utilizamos a variância da amostra no lugar da variância da população
- consultamos a tabela da distribuição T, em vez da tabela da distribuição normal.
Nós falaremos um pouco mais sobre isso no próximo tópico que vamos estudar.
Dito isso, concluímos que o certo seria utilizar a distribuição T. Contudo, o exercício não forneceu a tabela da distribuição T. Forneceu apenas alguns valores da função distribuição de probabilidade da variável normal reduzida (= variável normal padrão).
Não temos saída, teremos que utilizar os valores da variável reduzida. O mais exato seria resolver o exercício considerando a distribuição T. Mas não vamos “brigar” com o enunciado. Se o enunciado só deu informações sobre a variável normal, vamos usar a variável normal.
Vamos considerar que essa amostra já é razoavelmente grande, de forma que a diferença entre usar a distribuição normal no lugar da distribuição T não é tão grande.
Primeiro passo: determinando o valor de Z0 associado a 95% de confiança.
Se F(1,96) = 0,975, isto significa que a probabilidade de Z assumir valores menores ou iguais a 1,96 é de 97,5%.
Ou seja, a área verde da figura abaixo é de 97,5%.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 32
Sabemos que a área inteira da figura acima é igual a 1 (a probabilidade de Z assumir um valor qualquer é de 100%).
Portanto, a área amarela é de 2,5%. Como o gráfico é simétrico, a área à esquerda de -1,96 também é de 2,5%. Deste modo, a área verde da figura abaixo é de 95%.
Os valores -1,96 e 1,96 delimitam o intervalo de confiança de 95% para a variável reduzida Z. Ou seja, o valor de Z0 associado a 95% é 1,96.
96,10
=Z
Segundo passo: determinar o valor de X específico para a amostra feita.
48=X
Terceiro passo: determinar o desvio padrão de X .
A amostra tem tamanho 64 (n = 64).
O desvio padrão de X é dado pela fórmula:
nX
σσ =

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 33
Não conhecemos o desvio padrão da população. Estamos considerando que a amostra é muito grande a tal ponto que a sua variância seja um excelente estimador da população. Vamos considerar que a variância amostral é igual à variância da população. Portanto, o desvio padrão da população também é igual ao desvio padrão da amostra (=16).
16=σ
264
16==
Xσ
Quarto: determinar o intervalo de confiança.
O intervalo de confiança é da forma: XX
ZXZX σµσ ×+≤≤×− 00
Substituindo os valores:
XXZXZX σµσ ×+≤≤×− 00
296,148296,148 ×+≤≤×− µ
92,34892,348 +≤≤− µ
92,5108,44 ≤≤ µ
Gabarito: A.
Questão 11 TRT 2ª Região 2008 [FCC]
A vida das lâmpadas fabricadas por uma empresa apresenta uma distribuição normal com uma variância populacional igual a 400 (horas)2
. Extrai-se uma amostra de 64 lâmpadas e verifica-se que a respectiva vida média é igual a 1.200 horas. Considerando a população de tamanho infinito e a informação da distribuição normal padrão (Z) que a probabilidade P(Z
> 2) = 2,5%, tem-se que o intervalo de confiança de 95% para a vida média das lâmpadas é
(A) [1.160 , 1.240]
(B) [1.164 , 1.236]
(C) [1.180 , 1.220]
(D) [1.184 , 1.216]
(E) [1.195 , 1.205]
Resolução:
Primeiro passo:
,- = 2
Segundo passo:
�� = 1200
Terceiro passo:

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 34
�)� = �√ = 20√64 = 208 = 2,5
Quarto passo:
�� ± �)� × ,-
1.200 ± 2,5 × 2
1.200 ± 5 A1.195; 1.205C Gabarito: E
2.4. Intervalo de confiança para a média quando a variância da população
não é conhecida
Grande parte dos exercícios de concurso sobre intervalo de confiança não são resolvidos por meio da distribuição normal. Eles envolvem o conhecimento da distribuição T de Student. A grande vantagem é que a forma de se resolverem os exercícios de intervalo de confiança por meio da distribuição T é exatamente a mesma daquela vista acima, para a distribuição normal. A única coisa que muda é a tabela em que fazemos a consulta. No final da aula há duas tabelas. A única coisa que vai mudar é que vamos consultar a tabela II, em vez da tabela I.
Sabemos que X pode ser visto como uma variável aleatória normal (ou aproximadamente
normal). Portanto, para X podemos utilizar a tabela de áreas da variável normal.
Para utilizar esta tabela, precisamos encontrar a variável normal reduzida Z:
X
XZ
σ
µ−= .
Onde X
σ é o desvio padrão da variável X . Sua fórmula é: n
X
σσ = .
Entretanto, se não soubermos a variância da população ( 2σ ), não temos como calcular X
σ .
Nestes casos, utilizamos a variância da amostra no lugar da variância da população. Em problemas assim, na verdade, nós estamos estimando duas grandezas ao mesmo tempo. Estamos estimando a média e a variância da população.
Como não temos certeza nem sobre o valor da média nem sobre o valor da variância da população, nosso intervalo de confiança tem que ser maior que aquele que seria obtido
caso conhecêssemos o valor de 2σ , para mantermos o mesmo nível de confiança. É exatamente esta a ideia da distribuição T.
Para ilustrar, seguem alguns gráficos gerados com o excel.
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 35
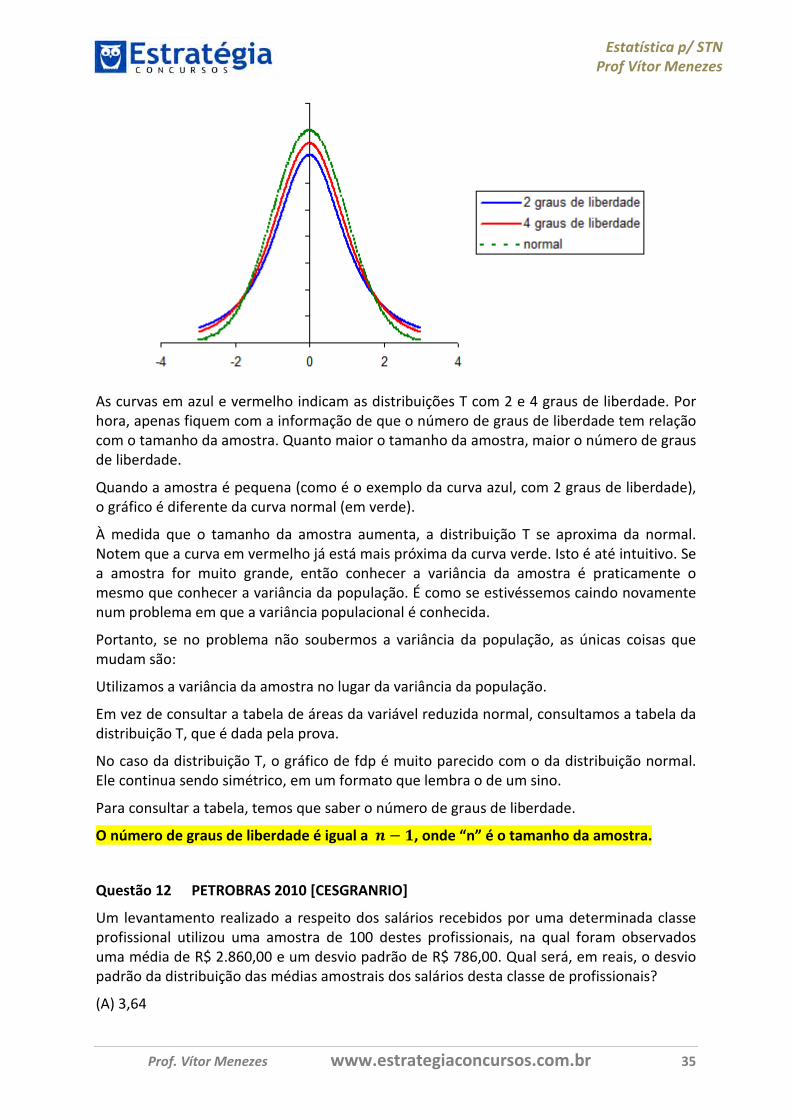
As curvas em azul e vermelho indicam as distribuições T com 2 e 4 graus de liberdade. Por hora, apenas fiquem com a informação de que o número de graus de liberdade tem relação com o tamanho da amostra. Quanto maior o tamanho da amostra, maior o número de graus de liberdade.
Quando a amostra é pequena (como é o exemplo da curva azul, com 2 graus de liberdade), o gráfico é diferente da curva normal (em verde).
À medida que o tamanho da amostra aumenta, a distribuição T se aproxima da normal. Notem que a curva em vermelho já está mais próxima da curva verde. Isto é até intuitivo. Se a amostra for muito grande, então conhecer a variância da amostra é praticamente o mesmo que conhecer a variância da população. É como se estivéssemos caindo novamente num problema em que a variância populacional é conhecida.
Portanto, se no problema não soubermos a variância da população, as únicas coisas que mudam são:
Utilizamos a variância da amostra no lugar da variância da população.
Em vez de consultar a tabela de áreas da variável reduzida normal, consultamos a tabela da distribuição T, que é dada pela prova.
No caso da distribuição T, o gráfico de fdp é muito parecido com o da distribuição normal. Ele continua sendo simétrico, em um formato que lembra o de um sino.
Para consultar a tabela, temos que saber o número de graus de liberdade.
O número de graus de liberdade é igual a D − E, onde “n” é o tamanho da amostra.
Questão 12 PETROBRAS 2010 [CESGRANRIO]
Um levantamento realizado a respeito dos salários recebidos por uma determinada classe profissional utilizou uma amostra de 100 destes profissionais, na qual foram observados uma média de R$ 2.860,00 e um desvio padrão de R$ 786,00. Qual será, em reais, o desvio padrão da distribuição das médias amostrais dos salários desta classe de profissionais?
(A) 3,64

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 36
(B) 7,86
(C) 78,60
(D) 786,00
(E) 7.860,00
Resolução.
Quando o desvio padrão da população é conhecido, �� é normal com média igual a e
desvio padrão F√G.
Se o desvio padrão da população é desconhecido, substituímos este valor por sua estimativa.
O desvio padrão amostral (= s) é um estimador do desvio padrão da população (�).
Ou seja, como � é desconhecido, substituímos este valor por s, que é seu estimador.
Consequentemente, �� terá distribuição T de Student, com média igual a e desvio padrão H√G.
�√ = 786√100 = 78610 = 78,6
Gabarito: C
Alguns alunos confundem estas variâncias que surgiram. Cuidado para não confundir! Relembrando:
1 - �� é a variância da população. Tomamos cada valor da população. Subtraímos da média populacional, obtendo os desvios em relação à média. Em seguida, calculamos a média dos quadrados dos desvios. Isto é a variância populacional.
2 – s2 é a variância da amostra. É um estimador de ��. Tomamos cada valor da amostra. Subtraímos da média amostral, obtendo os desvios. Em seguida, calculamos a média dos quadrados dos desvios. Isto é a variância amostral.
3 –�)��é a variância de ��. Tomamos todos os possíveis valores de ��.Subtraímos da média desta variável aleatória, obtendo os desvios. Calculamos a média dos quadrados dos desvios, obtendo a variância de ��.
Já estudamos que �)�� = FIG
4 - �)��é a estimativa da variância de ��.
É obtida substituindo, na fórmula acima indicada, a variância populacional pela amostral.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 37
�)�� = ��
Questão 13 IPEA 2004 [ESAF]
Deseja-se estimar o gasto médio efetuado por grupos de 4 pessoas, num restaurante, por meio de um intervalo de confiança com coeficiente de 95%. Uma amostra de 16 grupos produziu os valores R$ 150,00 e R$ 20,00 para a média e o desvio padrão amostrais, respectivamente. Assinale a opção que corresponde ao intervalo procurado. Use a hipótese de normalidade da distribuição dos gastos e a tabela abaixo da função de distribuição de Student (Tr) para a escolha do quantil apropriado aos cálculos.
γ=≤ )( xTP r
γ
r
0,900 0,950 0,975 0,990
14 1,345 1,761 2,145 2,625
15 1,341 1,753 2,131 2,603
16 1,337 1,746 2,120 2,584
17 1,333 1,740 2,110 2,567
a) [139,34; 160,66]
b) [139,40; 160,60]
c) [141,23; 158,77]
d) [141,19; 158,81]
e) [140,00; 160,00]
Resolução.
O índice ‘r’, na simbologia usada no enunciado, indica o número de graus de liberdade. Creio que isso poderia ser dito expressamente para evitar quaisquer dúvidas.
Não conhecemos a variância da população. Vamos usar, portanto, os valores da distribuição t. Como a amostra tem tamanho 16, temos 15 graus de liberdade. Devemos consultar, portanto, a linha em que r = 15.
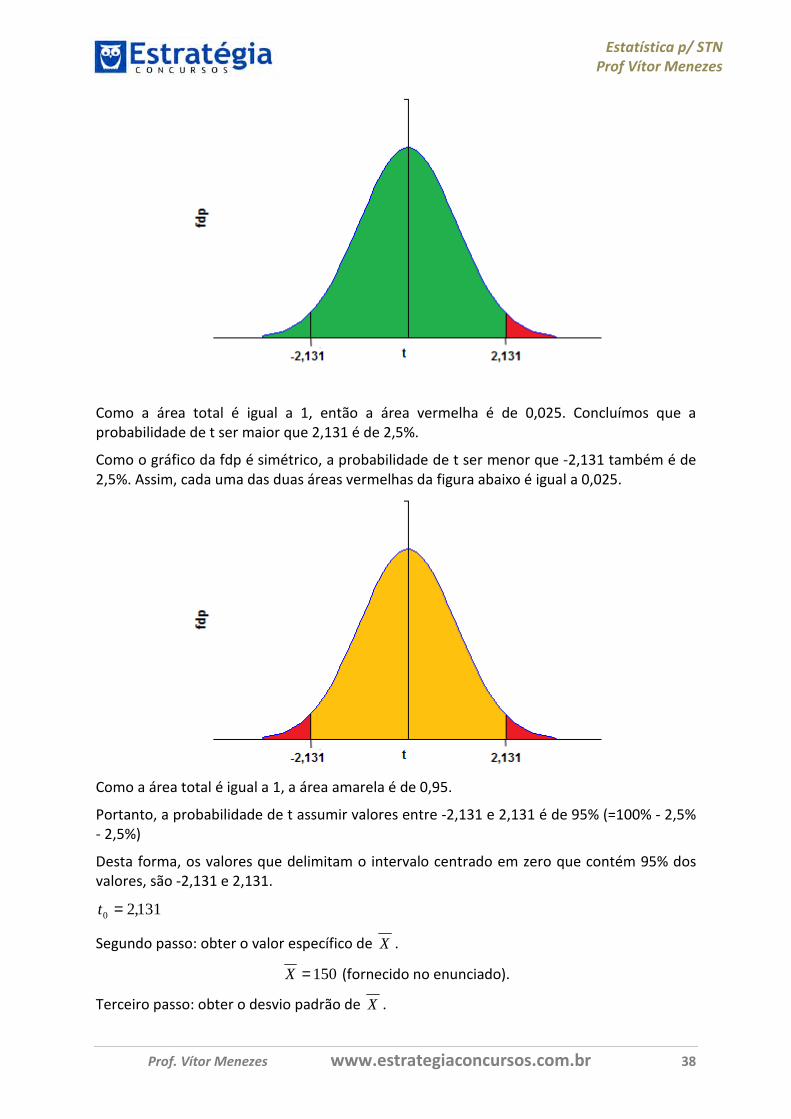
Primeiro passo: obter o valor de t0 associado a 95% de confiança.
Da tabela, temos que a probabilidade de t ser menor ou igual a 2,131 é de 0,975.
A área verde da figura abaixo é de 0,975.
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 38
Como a área total é igual a 1, então a área vermelha é de 0,025. Concluímos que a probabilidade de t ser maior que 2,131 é de 2,5%.
Como o gráfico da fdp é simétrico, a probabilidade de t ser menor que -2,131 também é de 2,5%. Assim, cada uma das duas áreas vermelhas da figura abaixo é igual a 0,025.
Como a área total é igual a 1, a área amarela é de 0,95.
Portanto, a probabilidade de t assumir valores entre -2,131 e 2,131 é de 95% (=100% - 2,5% - 2,5%)
Desta forma, os valores que delimitam o intervalo centrado em zero que contém 95% dos valores, são -2,131 e 2,131.
131,20
=t
Segundo passo: obter o valor específico de X .
150=X (fornecido no enunciado).
Terceiro passo: obter o desvio padrão de X .

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 39
Como não temos a variância da população, na verdade vamos obter a estimativa do desvio
padrão de X :
516
20===
n
ss
X
Quarto passo: obter o intervalo de confiança.
O intervalo de confiança é da forma:
XXstXstX ×+≤≤×− 00 µ
5131,21505131,2150 ×+≤≤×− µ
655,10150655,10150 +≤≤− µ
655,160345,139 ≤≤ µ
O intervalo mais próximo é o fornecido na letra A.
Gabarito: A.
Questão 14 MIN 2012 [ESAF]
Uma amostra aleatória simples de tamanho 9 de uma população com distribuição normal levou ao cálculo de uma média amostral igual a 32 e ao cálculo de uma variância amostral igual a 225. Construa um intervalo de 95% de confiança para a média da população.
a) 27,1 a 36,9
b) 22,2 a 41,8
c) 12,4 a 51,6
d) 2,6 a 61,4
e) -17 a 81
Resolução:
A questão foi anulada, possivelmente pela falta de informação dos valores referentes à distribuição T de Student.
O intervalo de confiança tem o seguinte formato:
�� ± �√ × J-
Onde:
• �� é a média amostral (=32)
• “s” é o desvio padrão amostral (no caso, é igual à raiz de 225, ou seja, vale 15)
• “n” é o tamanho da amostra (=9)
• t0 é o valor da distribuição T associado a 95% de confiança e 8 graus de liberdade (o número de graus de liberdade é sempre igual a “n – 1”)

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 40
Substituindo os valores:
32 ± 15√9 × J-
32 ± 153 × J-
32 ± 5 × J-
E para terminar o cálculo, precisaríamos do valor de J-, não fornecido pela questão.
Gabarito: anulado
3. INTERVALO DE CONFIANÇA PARA PROPORÇÕES
3.1. �K como uma variável aleatória
Seja � a proporção de casos favoráveis em uma população e �̂ a proporção de casos favoráveis em uma amostra. Vimos que �̂ é um estimador para �.
Para ficar mais claro, vamos analisar o exemplo do dado que é lançado três vezes. Consideramos caso favorável quando sai um múltiplo de 3.
Na população (formada por todos os possíveis resultados do lançamento do dado), a proporção de casos favoráveis é igual a 1/3. Por esse motivo, a probabilidade de sucesso em um único lançamento é igual a 1/3. Assim, a proporção de casos favoráveis na população é igual à probabilidade de sucesso em um lançamento.
Ficamos com:
3/1=p (proporção de casos favoráveis na população = probabilidade de sucesso em um
lançamento)
3/2=q (proporção de casos desfavoráveis na população = probabilidade de fracasso em
um lançamento).
Lançamos o dado três vezes. Obtemos os seguintes resultados: 1, 3, 6.
Na amostra de tamanho 3, a proporção de casos favoráveis foi de 2/3.
3/2ˆ =p
Usamos a proporção amostral para estimar a proporção da população. Caso não soubéssemos que o dado tem 1/3 de faces com múltiplos de 3, a partir do resultado obtido na amostragem acima, estimaríamos esta proporção em 2/3.
Quando temos uma única amostra, p̂ é um valor, um número, fixo, constante.
Mas podemos pensar em p̂ de forma diferente. Podemos pensar em inúmeras amostras
possíveis. Se lançássemos o dado três vezes novamente, obtendo outra amostra, p̂ poderia
assumir outros valores. Quando consideramos as inúmeras amostras possíveis, p̂ é uma
variável aleatória.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 41
Neste exemplo do dado, as amostras de tamanho 3 possíveis seriam:
Todas essas amostras são equiprováveis. Podemos montar o seguinte quadro:
p̂ Probabilidade
0 64/216
1/3 96/216
2/2 48/216
3/3 8/216
A esperança de p̂ fica:
3/1216
8
3
3
216
48
3
2
216
96
3
1
216
640)ˆ( ˆ =×+×+×+×== ppE µ
A esperança da proporção amostral é igual à esperança da proporção da população.
A variância de p̂ fica:
27
2
216
8
3
11
216
48
3
1
3
2
216
96
3
1
3
1
216
64
3
10
2222
2
ˆ =×
−+×
−+×
−+×
−=pσ
Sabendo que a proporção amostral pode ser vista como uma variável, é importante ver um meio mais rápido para calcular sua média e sua variância.
Nesse exemplo do lançamento do dado, seja X o número de casos favoráveis em ‘n’ lançamentos. Vimos na aula passada que X é uma variável binomial com média e variância dadas por:
npX =µ
npqX =2
σ
Onde ‘n’ é o número de experimentos, p é a probabilidade de sucesso e q é a probabilidade de fracasso. Nesse exemplo, n = 3; p = 1/3; q = 2/3.
1 1 1 2 1 1 3 1 1 4 1 1 5 1 1 6 1 1
1 1 2 2 1 2 3 1 2 4 1 2 5 1 2 6 1 2
1 1 3 2 1 3 3 1 3 4 1 3 5 1 3 6 1 3
1 1 4 2 1 4 3 1 4 4 1 4 5 1 4 6 1 4
1 1 5 2 1 5 3 1 5 4 1 5 5 1 5 6 1 5
1 1 6 2 1 6 3 1 6 4 1 6 5 1 6 6 1 6
1 2 1 2 2 1 3 2 1 4 2 1 5 2 1 6 2 1
1 2 2 2 2 2 3 2 2 4 2 2 5 2 2 6 2 2
1 2 3 2 2 3 3 2 3 4 2 3 5 2 3 6 2 3
1 2 4 2 2 4 3 2 4 4 2 4 5 2 4 6 2 4
1 2 5 2 2 5 3 2 5 4 2 5 5 2 5 6 2 5
1 2 6 2 2 6 3 2 6 4 2 6 5 2 6 6 2 6
1 3 1 2 3 1 3 3 1 4 3 1 5 3 1 6 3 1
1 3 2 2 3 2 3 3 2 4 3 2 5 3 2 6 3 2
1 3 3 2 3 3 3 3 3 4 3 3 5 3 3 6 3 3
1 3 4 2 3 4 3 3 4 4 3 4 5 3 4 6 3 4
1 3 5 2 3 5 3 3 5 4 3 5 5 3 5 6 3 5
1 3 6 2 3 6 3 3 6 4 3 6 5 3 6 6 3 6
1 4 1 2 4 1 3 4 1 4 4 1 5 4 1 6 4 1
1 4 2 2 4 2 3 4 2 4 4 2 5 4 2 6 4 2
1 4 3 2 4 3 3 4 3 4 4 3 5 4 3 6 4 3
1 4 4 2 4 4 3 4 4 4 4 4 5 4 4 6 4 4
1 4 5 2 4 5 3 4 5 4 4 5 5 4 5 6 4 5
1 4 6 2 4 6 3 4 6 4 4 6 5 4 6 6 4 6
1 5 1 2 5 1 3 5 1 4 5 1 5 5 1 6 5 1
1 5 2 2 5 2 3 5 2 4 5 2 5 5 2 6 5 2
1 5 3 2 5 3 3 5 3 4 5 3 5 5 3 6 5 3
1 5 4 2 5 4 3 5 4 4 5 4 5 5 4 6 5 4
1 5 5 2 5 5 3 5 5 4 5 5 5 5 5 6 5 5
1 5 6 2 5 6 3 5 6 4 5 6 5 5 6 6 5 6
1 6 1 2 6 1 3 6 1 4 6 1 5 6 1 6 6 1
1 6 2 2 6 2 3 6 2 4 6 2 5 6 2 6 6 2
1 6 3 2 6 3 3 6 3 4 6 3 5 6 3 6 6 3
1 6 4 2 6 4 3 6 4 4 6 4 5 6 4 6 6 4
1 6 5 2 6 5 3 6 5 4 6 5 5 6 5 6 6 5
1 6 6 2 6 6 3 6 6 4 6 6 5 6 6 6 6 6

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 42
Ficamos com:
1== npXµ
3/22
== npqXσ
X tem média 1 e variância 2/3. Isso significa que, em três lançamentos, esperamos 1 caso favorável (e dois desfavoráveis). Ou seja, se fosse possível fazer infinitos conjuntos de três lançamentos do dado, o número médio de casos favoráveis seria igual a 1.
Seja ‘ p̂ ’ a proporção de casos favoráveis verificada numa dada amostra de tamanho ‘n’. A
variável ‘ p̂ ’ pode ser obtida a partir de X.
n
Xp =ˆ
Para ficar mais claro, suponhamos um conjunto de lançamentos em particular. Lançamos o dado três vezes, obtendo: 1, 3, 6.
Nessa situação, o número de casos favoráveis é igual a 2 (X = 2). E a proporção de casos favoráveis fica:
n
Xp =ˆ
3
2ˆ =p
Em dois terços dos casos, tivemos sucesso.
Fácil, né? Para achar a proporção de casos favoráveis na amostra, basta pegar a variável X e dividir por ‘n’.
Sabemos como calcular a média e a variância da variável binomial. Sabemos que a variável ‘
p̂ ’, que indica a proporção de casos favoráveis na amostra, pode ser obtida por: n
Xp =ˆ .
Para obtermos ‘ p̂ ’, dividimos a variável ‘X’ por uma constante ‘n’.
Quando dividimos uma variável por uma constante, a média também fica dividida por essa constante. A média de p̂ é:
pn
np
n
X
p ===µ
µ ˆ
Concluímos que a esperança de p̂ é justamente a probabilidade de sucesso em um
experimento.
Quando lançamos o dado três vezes (obtendo uma única amostra de tamanho 3), teremos um determinado valor para a proporção amostral ( p̂ ). Esse valor pode ser igual a 1/3 ou
não. No exemplo acima (com resultados 1, 3 e 6), inclusive, foi diferente.
Mas, se fosse possível repetir infinitas vezes o conjunto de três lançamentos, obtendo para cada amostra um valor de p̂ , teríamos que a média de p̂ seria igual a 1/3.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 43
Vejamos agora a variância de p̂ . Quando dividimos uma variável por uma constante, a
variância sofre a variação ao quadrado.
n
pq
n
npq
nn
Xp X
p ===⇒=22
2
2
ˆˆ
σσ
E seu desvio padrão fica:
n
pqp =ˆσ
Então o que importa para gente é saber isso. Se p̂ for a variável que indica a proporção de
casos favoráveis na amostra, então p̂ tem média e desvio padrão dados por:
pp =ˆµ
n
pqp =ˆσ
Proporção de casos favoráveis na amostra
Pode ser vista como uma variável com média e desvio padrão dados por:
pp =ˆµ
n
pqp =ˆσ
Onde ‘p’ é a proporção de casos favoráveis na população e ‘q’ é a proporção de casos desfavoráveis na população.
3.2. Intervalo de confiança para uma proporção
Quando estudamos intervalo de confiança para uma média, queríamos justamente estimar um intervalo para a média de uma população ( µ ).
Agora queremos estimar uma proporção (p). O procedimento será análogo.
Vimos que o intervalo de confiança para a média da variável X é dado por:
XXZXZX σµσ ×+≤≤×− 00
O intervalo de confiança para a proporção é muito semelhante. Onde tinha média amostral, colocamos a proporção amostral. Onde tinha média populacional, colocamos a proporção populacional.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 44
E o intervalo de confiança para uma proporção é da seguinte forma:
pp ZppZp ˆ0ˆ0ˆˆ σσ ×+≤≤×−
Então para gente o que importa é isso. Interessa saber qual o intervalo de confiança para a proporção.
Intervalo de confiança para a proporção
pp ZppZp ˆ0ˆ0ˆˆ σσ ×+≤≤×−
Questão 15 SEFAZ SP 2009 [FCC]
Em uma pesquisa de tributos de competência estadual, em 2008, realizada com 400 recolhimentos escolhidos aleatoriamente de uma população considerada de tamanho infinito, 80% referiam-se a determinado imposto. Deseja-se construir um intervalo de confiança de 95,5% para a estimativa dessa proporção. Considerando normal a distribuição amostral da frequência relativa dos recolhimentos desse imposto e que na distribuição normal padrão a probabilidade P (−2 ≤ Z ≤ 2) = 95,5%, o intervalo é
(A) [0,70; 0,90]
(B) [0,72; 0,88]
(C) [0,74; 0,86]
(D) [0,76; 0,84]
(E) [0,78; 0,82]
Resolução:
Primeiro passo: determinar o valor de Z0. O enunciado disse que:
,- = 2
Segundo passo:
�̂ = 0,8 → MN = 1 − 0,8 = 0,2
Terceiro passo:
�ON = *�̂ × MN

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 45
�ON = *0,8 × 0,2400 = *0,16400 = 0,420 = 0,02
Quarto passo: encontrando o intervalo de confiança.
�̂ ± ,- × �ON 0,8 ± 2 × 0,02
0,8 ± 0,04 A0,76; 0,84C Gabarito: D
Questão 16 TRT 4ª REGIÃO 2009 [FCC]
Se Z tem distribuição normal padrão, então:
P (Z > 1,64) = 0,05; P(Z > 2) = 0,02; P(0< Z < 1,75) = 0,46
Deseja-se estimar a proporção (p) de processos julgados por um tribunal regional do trabalho durante o período de 2000 até 2008. Uma amostra aleatória de 10.000 processos, selecionada da população (suposta infinita) de todos os processos, revelou que 5.000 foram julgados no referido período. Um intervalo de confiança, com coeficiente de confiança de 90% para p, baseado nessa amostra, é dado por
(A) 0,5 ± 0,005
(B) 0,5 ± 0,0062
(C) 0,5 ± 0,0065
(D) 0,5 ± 0,0082
(E) 0,5 ± 0,01
Resolução:
Primeiro passo: determinar o valor de Z0.
Temos:
��, > 1,64� = 5% → ��, < −1,64� = 5%
Logo:
��−1,64 < , < 1,64� = 100% − 5% − 5% = 90%
Concluímos que:
,- = 1,64
Segundo passo:
�̂ = 5.00010.000 = 0,5
MN = 1 − �̂ = 1 − 0,5 = 0,5

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 46
Terceiro passo:
�ON = *�̂ × MN
�ON = *0,5 × 0,510.000 = 0,5100 = 0,005
Quarto passo: encontrando o intervalo de confiança.
�̂ ± ,- × �ON 0,5 ± 1,64 × 0,005
0,5 ± 0,0082
Gabarito: D
Questão 17 MPOG 2012 [ESAF]
Para estimar a proporção P de pessoas acometidas por uma virose, foi retirada uma amostra aleatória de 1600 pessoas. Na amostra foi constatado que 160 pessoas estavam acometidas pela virose. Sabe-se que, para construir um intervalo com 95% de confiança para a proporção de pessoas acometidas pela virose, o valor tabelado é 1,96. Com essas informações, o intervalo de confiança é dado por:
Q�� R0,10 ± 1,96 S0,340TU = 95%
V�� R0,10 ± 1,96 S400,3TU = 95%
W�� R0,10 ± 1,96 S0,340TU = 5%
X�� R0,10 ± 1,96 S400,3TU = 5%
Y�� R0,10 ± 1,96 S0,0340 TU = 95%
Resolução:
Rigorosamente falando, todas as alternativas estão incorretas, pois atribuem ao intervalo de confiança uma probabilidade de 95%. Mas é errado falar em probabilidade, pois todos os intervalos não contemplam qualquer variável aleatória. Se não há variáveis aleatórias envolvidas, não há como se falar em probabilidade. Fala-se apenas em confiança. Há 95% de confiança de que o intervalo especificado na alternativa correta contenha a proporção populacional. Em todo caso, não vamos brigar com o enunciado. Igoneremos este problema.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 47
O intervalo de confiança tem o seguinte formato:
�̂ ± ,- ×*�̂ × MN
Onde:
• �̂é a proporção amostral de sucessos (160 em 1600 corresponde a 10%)
• MN = 1 − �̂ = 0,9
• “n” é o tamanho da amostra (no caso, vale 1600)
• Z0 é o valor tabelado da normal reduzida (1,96 para 95% de confiança)
Substituindo os valores:
�̂ ± ,- ×*�̂ × MN
0,1 ± 1,96 × *0,1 × 0,91600
0,1 ± 1,96 × 0,340
Gabarito: A
4. INTERVALO DE CONFIANÇA E TAMANHO DA AMOSTRA
São comuns alguns tipos de exercícios em que se pede o tamanho que deve ter a amostra para que se consiga uma determinada amplitude do intervalo de confiança.
Antes de vermos esse tipo de exercício, é bom termos uma noção da relação entre a amplitude do intervalo de confiança e o erro da estimativa.
Exemplo 4
Considere o intervalo de confiança de 90,10% para a média de uma população normal com variância 16, construído a partir da seguinte amostra: 2, 6, 6, 10. Qual o erro máximo cometido na estimativa da média populacional? (Dado: ,- = 1,65).
Resolução.
A média amostral é:
�� = 2 + 6 + 6 + 104 = 6
O desvio padrão da média amostral é:

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 48
�)� = √16√4 = 2
O intervalo de confiança fica:
6 ± 1,65 × 2
Os limites do intervalo são:
[2,7 ; 9,3]
Com 90,10% de confiança, a média populacional está entre 2,7 e 9,3.
Qual o maior erro que cometemos quando usamos a média amostral para estimar a média populacional? Isso, é claro, considerando um coeficiente de confiança de 90,10%.
A média amostral está bem no meio do intervalo de confiança. Logo, o erro será maior se a média populacional estiver em uma das extremidades do intervalo de confiança. O erro será máximo se a média populacional for igual a 2,7 ou se ela for igual a 9,3.
No primeiro caso, o erro cometido fica:
µ−= Xerro
3,37,26 =−=erro
No segundo caso, o erro cometido é:
3,33,96 −=−=erro
Em qualquer um desses dois casos, o módulo do erro é de 3,3. É comum que os exercícios ignorem a palavra módulo e digam apenas “erro”. Desse modo, dizemos que, nos dois casos acima, o erro cometido foi de 3,3.
Então, quando o exercício se referir a erro máximo cometido, ele quer que a gente suponha que a média populacional está justamente na extremidade do intervalo de confiança.
Note que o erro máximo é sempre metade da amplitude do intervalo de confiança. Nesse exemplo, o intervalo de confiança era [2,7 ; 9,3]
Sua amplitude é:
6,67,23,9 =−=Amplitude
E a metade da amplitude é:
3,32
6,6
2==
Amplitude
Erro máximo cometido, para determinado nível de confiança:
Corresponde à metade da amplitude do intervalo de confiança

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 49
No caso do intervalo de confiança para a média, quando a variância da população é conhecida, temos:
XXZXZX σµσ 00 +≤≤−
A amplitude do intervalo de confiança é:
( ) ( )XXX
ZZXZXAmplitude σσσ 000 2=−−+=
Logo, o erro, que é igual à metade da amplitude, é expresso por:
XZerro σ
0max_ =
No caso do intervalo de confiança para a média, quando a variância da população é desconhecida, os cálculos são análogos. Ficamos com:
Xsterro
0max_ =
Por fim, no caso do intervalo de confiança para a proporção, o erro máximo é:
psZerro ˆ0max_ =
Erro máximo cometido
Estimação da média, com variância populacional conhecida:
XZerro σ
0max_ =
Estimação da média, com variância populacional desconhecida:
Xsterro
0max_ =
Estimação da proporção:
psZerro ˆ0max_ =
Sabendo disso, vamos aos exercícios de concurso.
Questão 18 DNOCS 2010 [FCC]
Seja X uma variável aleatória normalmente distribuída representando o salário dos empregados em um determinado ramo de atividade. Uma amostra aleatória de 100 empregados foi selecionada e apurou-se um intervalo de confiança de 95% para a média de X como sendo [760,80; 839,20], supondo a população de tamanho infinito e sabendo-se que o desvio padrão populacional é igual a R$ 200,00. Caso o tamanho da amostra tivesse sido

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 50
de 1.600 e obtendo-se a mesma média anterior, o intervalo de confiança de 95% apresentaria uma amplitude igual a
(A) R$ 78,40.
(B) R$ 39,20.
(C) R$ 49,00.
(D) R$ 58,80.
(E) R$ 19,60.
Resolução:
A amplitude do intervalo de confiança é dada por:
Z = 2,- × �)� Z = 2,- × �√
Quando o tamanho da amostra é 100, a amplitude é:
839,20 − 760,80 = 78,4
Em seguida, o tamanho da amostra é aumentado para 1600. Vou chamar este novo tamanho de amostra de [. O tamanho da amostra é multiplicado por 16.
[ = 16
A nova amplitude (Z′) fica:
Z[ = 2,- × �√[ Z[ = 2,- × �√16
Z[ = 2,- × �√ × 1√16
Z[ = S2,- × �√T × 14
Entre parêntesis, temos a amplitude original:
Z[ = 78,4 × 14 = 19,60
Gabarito: E
Resumindo o que fizemos:
O tamanho da amostra foi multiplicado por 16. Logo, √ foi multiplicado por 4.
Como √ está no denominador, então a amplitude foi dividida por 4.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 51
Questão 19 TRE PI 2009 [FCC]
A duração de vida de um determinado equipamento apresenta uma distribuição normal com uma variância populacional igual a 100 (dias)2. Uma amostra aleatória de 64 desses equipamentos forneceu uma média de duração de vida de 1.000 dias. Considerando a população de tamanho infinito, um intervalo de confiança de ( α−1 ) com amplitude de 4,75 dias para a média foi construído. Caso o tamanho da amostra tivesse sido de 400, obtendo-se a mesma média de 1.000 dias, a amplitude do intervalo de confiança de ( α−1 ) seria de
(A) 0,950 dias.
(B) 1,425 dias.
(C) 1,900 dias.
(D) 2,375 dias.
(E) 4,750 dias.
Resolução:
Aproveitando o raciocínio da questão anterior.
O tamanho da amostra saltou de 64 para 400. Ou seja, foi multiplicado por 6,25.
Logo, √ foi multiplicado por 2,5.
Consequentemente, a amplitude será dividida por 2,5 4,752,5 = 1,9
Gabarito: C
Questão 20 AFPS 2002 [ESAF]
Tem-se uma população normal com média µ e variância 225. Deseja-se construir, a partir de uma amostra de tamanho n dessa população, um intervalo de confiança para µ com amplitude 5 e coeficiente de confiança de 95%. Assinale a opção que corresponde ao valor de n. Use como aproximadamente 2 o quantil de ordem 97,5% da distribuição normal padrão.
a) 225
b) 450
c) 500
d) 144
e) 200
Resolução:
Como a variância é de 225, então o desvio padrão é 15 (= raiz quadrada de 225).

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 52
A amplitude do intervalo de confiança é dada por:
Z = 2 × ,- × �√
Substituindo os valores fornecidos pelo enunciado:
5 = 2 × 2 × 15√
√ = 2 × 2 × 15 ÷ 5 = 12
= 12� = 144
Gabarito: D
Questão 21 MDIC 2002 [ESAF]
Deseja-se determinar, para uma população com N elementos, em um esquema de amostragem aleatória simples, o tamanho de amostra n necessário para estimar a média populacional do atributo X. Deseja-se que o erro em valor absoluto do procedimento não seja superior a 10% da média populacional, com probabilidade de 95%. De um estudo piloto obtém-se que a variância de X tem o valor 80 e que a média tem o valor 20. Tomando como aproximadamente 2 o quantil de ordem 0,975 da distribuição normal padrão, supondo que a média da amostra tem distribuição aproximadamente normal e desprezando a fração de amostragem n/N, assinale a opção que dá o valor de n.
a) 1000
b) 100
c) 80
d) 200
e) 150
Resolução:
O erro amostral é igual a metade da amplitude do intervalo de confiança:
Y = ,- × �)� O erro máximo é 10% da média amostral (10% × 20 = 2).
2 = ,- × �)� O valor de Z0 é igual a 2 (dado no enunciado):
2 = 2 × �)� O desvio padrão da média amostral é igual ao desvio padrão amostral dividido por raiz quadrada de “n”:
2 = 2 × �√

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 53
2 = 2 × √80√
√ = √80
= 80
Gabarito: C
Questão 22 MPOG 2012 [ESAF]
Para estimar por intervalo a média μ de uma população normal com variância igual a 9, retirou-se uma amostra de 16 elementos, obtendo-se ��= 5. Para um nível de confiança de 95%, o valor tabelado é igual a 1,96. Desse modo, a semi-amplitude do intervalo ou erro de estimação ─ como também é chamado ─ é igual a:
a) 2,94
b) 1,47
c) 0,5625
d) 0,7350
e) 0,47
Resolução:
O erro de estimação é dado por:
Y = ,- × �√
Onde:
• ,- é o valor tabelado da normal reduzida (1,96)
• �é o desvio padrão populacional (a variância é 9, então o desvio padrão é igual a 3)
• é o tamanho da amostra: 16
Substituindo os valores:
Y = ,- × �√
Y = 1,96 × 3√16
Y = 1,96 × 34 = 1,47
Gabarito: B

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 54
Exemplo 5
Deseja-se estimar a proporção de eleitores de um município que votará no candidato A. Para tanto, busca-se que, com um coeficiente de confiança de 95%, o erro máximo cometido seja de 2% (para mais, ou para menos).
a) é possível, com os dados fornecidos, determinar o tamanho da amostra para que o erro máximo seja de 2%? Por quê?
b) supondo variância máxima, qual o tamanho da amostra para que o erro máximo seja de 2%?
c) maximizando o valor de n, qual o tamanho da amostra para que o erro máximo seja de 2%?
d) supondo que a última pesquisa indicou 36% de votos para esse candidato, qual o tamanho da amostra para que o erro máximo seja de 2%
Resolução.
Letra A.
A fórmula do erro máximo é:
psZerro ˆ0max_ =
O erro máximo fixado é igual a 0,02. O nível de confiança é de 95%, o que implica em Z0
igual a 1,96. E sabemos que n
qps p
ˆˆˆ = .
Substituindo todas essas informações:
n
qp ˆˆ96,102,0 ×=
Lembrando que: pq ˆ1ˆ −= .
n
pp )ˆ1(ˆ96,102,0
−××=
Temos uma única equação e duas variáveis. Para descobrirmos o valor de ‘n’, precisamos do valor de p̂ . Precisamos do valor da proporção amostral.
Aí ficou difícil. Ainda não fizemos a amostragem. Queremos justamente calcular que tamanho deve ter essa amostra para que o erro seja de, no máximo, 2% (para um coeficiente de confiança de 95%). Depois que soubermos o tamanho da amostra, aí sim fazemos a amostragem. Só então obteremos a proporção amostral.
Resumindo: para descobrir o tamanho de ‘n’, precisamos da proporção amostral. E só faremos a amostragem (obtendo a proporção amostral), depois que soubermos o valor de ‘n’.
Ficamos sem saída. Não dá para resolver o problema com o enunciado fornecido.
O que fazer?

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 55
Bom, há duas opções, listadas nas letras B, C e D.
Letras B e C.
Uma forma de resolver o problema listado na letra A é a que segue.
A estimativa da variância de p̂ é dada por:
n
ppp
)ˆ1(ˆ2
ˆ
−×=σ
pn
pnn
ppp
ˆ1
ˆ1ˆˆ 2
22
ˆ +−
=−
=σ
Para um dado valor de ‘n’, que valor de ‘ p̂ ’ maximiza a variância acima?
De outra forma: para um valor fixado de ‘n’, qual o valor de ‘ p̂ ’ que torna a variância a
maior possível?
Podemos interpretar a equação acima como uma função de segundo grau (o gráfico é uma parábola). Isto é matéria lá do ensino médio. Lá a gente estuda como encontrar o vértice da parábola (que corresponde aos valores de máximo ou mínimo).
Considere uma função de segundo grau do tipo:
cbxaxy ++=2
O valor de x que maximiza (ou minimiza, dependendo do valor de ‘a’) a função y é:
abx 2/−=
Aplicando este resultado ao nosso caso, temos que o valor de p que maximiza a variância é:
5,0)/1(2
/1ˆ =
−×
−=
n
np
O caso em que a variância é a maior possível ocorre quando a proporção populacional é igual a 50%.
Vimos que: fixado n, a variância será máxima se 5,0ˆˆ == qp .
Por outro lado, fixado o valor do erro, n será máximo se 5,0ˆˆ == qp .
Vejam:
psZerro ˆ0max_ =
0max_ Zerro =
n
qp ˆˆ×
Logo:
2
2
0max)_(
ˆˆ
erro
qpZn =
2
2
0max)_(
)ˆ1(ˆ
erro
ppZn
−×=

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 56
Para um dado valor de Z0, fixado o erro máximo, temos que n será máximo quando maximizarmos o numerador )ˆ1(ˆ pp −× . Temos uma parábola, em que o vértice ocorre
justamente no ponto 0,5.
Ou seja, use 5,0ˆˆ == qp se a questão disser:
- use n máximo;
- use variância máxima
No cálculo do tamanho da amostra para estimar uma proporção, supor que 5,0=p
sempre que o exercício disser:
- Considere variância máxima
- Considere n máximo.
Quando fixamos a proporção em 0,5, para efeitos de determinação do tamanho da amostra, na verdade, estamos trabalhando com a hipótese mais conservadora. Esta é a alternativa que maximiza o valor de ‘n’. Trabalhar com uma amostra maior sempre é algo mais conservador.
Assim, um modo de “fugir” do problema listado na letra “A” é supor que a proporção é igual a 50%. Assim, trabalharemos com um valor de ‘n’ grande.
Agora podemos achar o tamanho da amostra.
psZerro ˆ0max_ =
n
pp )ˆ1(ˆ96,102,0
−××=
Supondo que 5,0ˆˆ == qp , temos:
2401495,0
96,102,02 ==⇒×= n
n
A amostra precisa ter tamanho 2401 (tanto na letra B quanto na letra C).
Letra D.
Outra saída para o problema listado na letra A é fazer uma amostragem preliminar. Pode-se fazer uma amostragem menor, mais rápida, de modo a obter um valor de p̂ . Ou então usar

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 57
alguma informação anterior disponível. Obtido esse valor preliminar de p̂ , podemos
calcular o valor de ‘n’ e, em seguida, fazer a amostragem “para valer”.
Na letra D, sabemos que a última pesquisa revelou que o candidato tem 36% das intenções de voto.
Vamos usar os dados dessa pesquisa anterior para calcularmos o valor de ‘n’. Vamos supor que p̂ é 36%. Desse modo, temos:
psZerro ˆ0max_ =
n
64,036,096,102,0
××=
762,212.28,06,0
96,102,0 =⇒×
×= nn
Aproximando para o número inteiro seguinte:
213.2=n
A amostra precisa ter tamanho 2.213. Note o tamanho encontrado para a amostra na letra D foi menor que o encontrado nas letras B e C. Isso porque, nas letras B e C, usamos a hipótese em que n é o maior possível. É a hipótese mais conservadora (supor que p = 0,5).
Questão 23 Ministério da Saúde 2007 [FCC]
Para responder à questão seguinte considere, dentre os dados abaixo, aqueles que julgar apropriados. Se Z tem distribuição normal padrão, então:
023,0)2( =>ZP ; 445,0)6,10( =<< ZP ; 84,0)1( =<ZP ; 49,0)33,20( =<< ZP
Para estimar a proporção de cura de um medicamento antiparasitário realizou-se um experimento clínico, aplicando-se o medicamento em ‘n’ doentes escolhidos ao acaso. Nesta amostra foi considerado que 80% dos doentes foram curados. Com base nestas informações e utilizando o Teorema Central do Limite, o valor de n, para que o erro cometido na estimação seja no máximo 0,08, com confiança de 89%, é de:
a) 16
b) 25
c) 36
d) 49
e) 64
Resolução.
Podemos interpretar que, na amostra preliminar, a proporção de cura verificada foi de 80%. A partir desse valor, podemos calcular o valor de ‘n’ para uma segunda amostragem, de tal forma que o erro máximo seja de 0,08.
A fórmula do erro máximo é:
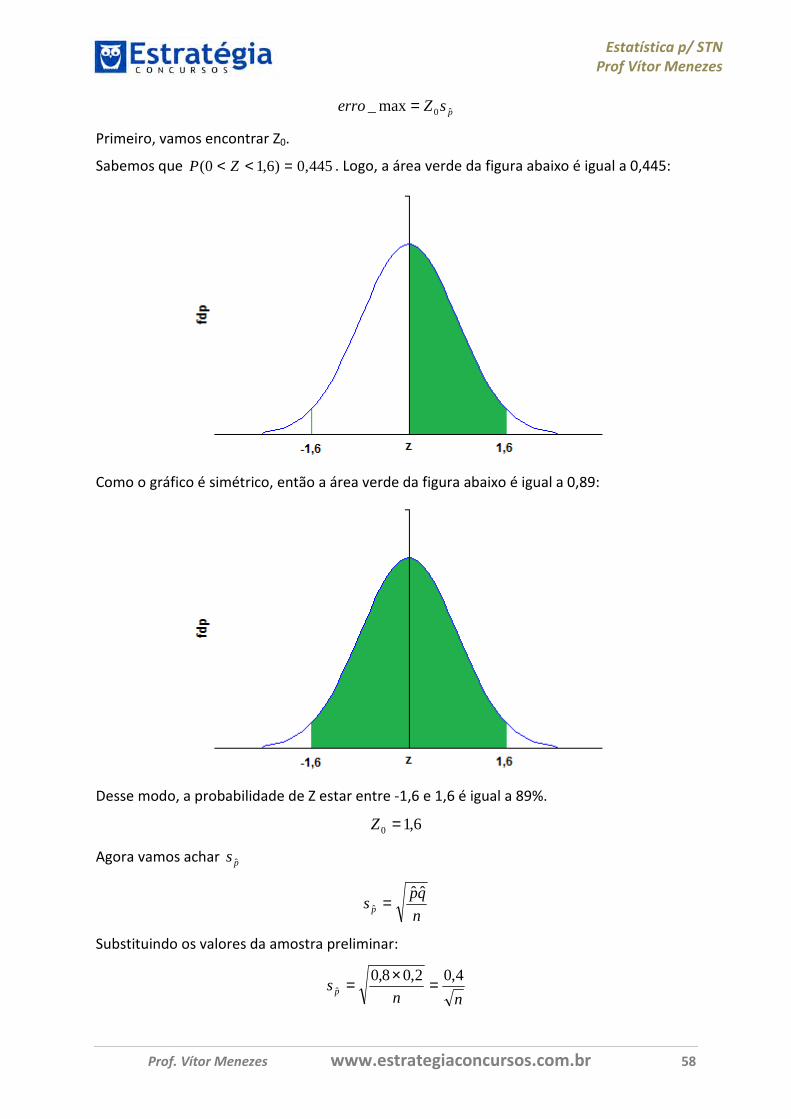
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 58
psZerro ˆ0max_ =
Primeiro, vamos encontrar Z0.
Sabemos que 445,0)6,10( =<< ZP . Logo, a área verde da figura abaixo é igual a 0,445:
Como o gráfico é simétrico, então a área verde da figura abaixo é igual a 0,89:
Desse modo, a probabilidade de Z estar entre -1,6 e 1,6 é igual a 89%.
6,10
=Z
Agora vamos achar ps ˆ
n
qps p
ˆˆˆ =
Substituindo os valores da amostra preliminar:
nns p
4,02,08,0ˆ =
×=

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 59
Voltando na fórmula do erro máximo:
psZerro ˆ0max_ =
n
4,06,108,0 ×=
Isolando n:
648
64=⇒= nn
Gabarito: E.
Questão 24 TRT 2ª Região 2008 [FCC]
Em uma cidade, considerada com uma população de tamanho infinito, é feito um estudo objetivando detectar a proporção de habitantes que preferem a marca do sabonete X. Uma amostra piloto forneceu um valor de 20% para essa proporção. Deseja-se obter um intervalo de confiança de 95% para a proporção, tendo o intervalo uma amplitude de 10%. Se a distribuição amostral da freqüência relativa dos habitantes que preferem a marca do sabonete X é normal e utilizando a informação da distribuição normal padrão (Z) que a probabilidade P(|Z| ≤ 2) = 95%, tem-se que o tamanho da amostra deve ser de
(A) 400
(B) 361
(C) 324
(D) 289
(E) 256
Resolução:
O valor de Z0 dado na questão é igual a 2.
Agora usamos a fórmula da amplitude do intervalo de confiança:
Z = 2 × ,- × �ON Z = 2 × ,- × *�̂ × MN
0,1 = 2 × 2 × *0,2 × 0,8
√ = 2 × 2 × √0,2 × 0,80,1 = 16
= 256
Gabarito: E

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 60
Questão 25 SEFAZ RJ 2007 [FGV]
Uma pesquisa recente foi realizada para avaliar o percentual da população favorável à eleição de um determinado ponto turístico para constar no selo comemorativo de aniversário da cidade. Para isso, selecionou-se uma amostra aleatória simples extraída de uma população infinita. O resultado apurou 50% de intenção de votos para esse ponto turístico. Considerando que a margem de erro foi de 2 pontos percentuais, para mais ou para menos, e que o nível de confiança utilizado foi de 95%, foram ouvidas, aproximadamente:
(A) 50 pessoas.
(B) 100 pessoas.
(C) 1.200 pessoas.
(D) 2.400 pessoas.
(E) 4.800 pessoas.
Resolução:
O erro máximo é dado por:
n
qpZerro
ˆˆmax_ 0 ×=
Podemos fazer a consulta de Z0 na tabela da distribuição normal colocada ao final da aula. Mas, de tanto aparecer este percentual de 95%, já sabemos que Z0 é igual a 1,96.
Substituindo os valores:
n
5,05,096,102,0
××=
n
5,096,102,0 ×=
=×=02,0
5,096,1n 49
=n 2401
Foram ouvidas 2401 pessoas. Aproximando, temos 2.400.
Gabarito: D
Questão 26 MIN 2012 [ESAF]
Pretende-se estimar por amostragem a proporção de famílias com renda inferior a cinco salários mínimos em uma populosa cidade. Usando a estimativa �̂= 5/7, obtida em um levantamento preliminar, determine o menor tamanho de amostra aleatória simples

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 61
necessária para estimar com um intervalo de 95% de confiança e com um erro de
amostragem ]'�̂�1 − �̂�/ ≤ 4%
a) 420
b) 490
c) 560
d) 630
e) 684
Resolução:
O erro máximo deve ser de 4%. Assim, o tamanho mínimo da amostra é tal que:
]*�̂�1 − �̂� = 4%
Onde "z" é o valor da normal padrão associado a 95% de confiança. Esse valor deve ser de conhecimento do candidato.
] = 1,96
Substituindo os valores fornecidos pelo enunciado:
1,96*57 × S1 − 57T ÷ = 4%
1,96*57 × 27 × 1 = 4%
1,967 × *10 = 4%
√ = 1,967 × 0,04 × √10
√ = 7 × √10
= 7� × 10 = 490
Gabarito: B
5. FATOR DE CORREÇÃO PARA POPULAÇÕES FINITAS
Quando a amostragem é feita sem reposição, a partir de uma população finita, cada extração não é independente das demais.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 62
Apesar disso, se pudermos considerar a população bem grande, é razoável considerar que cada extração é independente das demais.
Contudo, quando o tamanho da população (em relação ao tamanho da amostra) não for tão grande, a aproximação fica ruim.
Segundo o autor William J Stevenson, se a amostra for superior a 5% da população, a aproximação fica ruim.
Nestes casos, quando estivermos calculando o intervalo de confiança, precisaremos aplicar um fator de correção. É o chamado fator de correção para população finita.
O fator de correção é:
1−
−
N
nN
onde N é o tamanho da população e n é o tamanho da amostra.
Neste caso, os valores dos desvios-padrão da média amostral e da proporção amostral ficam:
1−
−×=
N
nN
nX
σσ
×=n
qps p
ˆˆˆ
1−
−
N
nN
Este fator de correção acima estudado, com a raiz quadrada, vale para os desvios padrão.
Para corrigirmos a variância, o fator é elevado ao quadrado, tornando-se: _ − _ − 1
Questão 27 TRT 4ª REGIÃO 2009 [FCC]
Uma população possui 15 elementos e tem variância 2σ . Desta população retira-se uma amostra aleatória sem reposição de n elementos. Sabendo-se que a média amostral ��
desses n elementos tem variância igual a 28
2σ , o valor de n é dado por
(A) 5
(B) 10
(C) 14
(D) 25
(E) 28
Resolução:

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 63
�)�� = �� × _ − _ − 1
��28 = �� × 15 − 15 − 1
128 = 1 × 15 − 14
12 = 1 × 15 − 1
= 2 × �15 − � = 30 − 2
3 = 30
= 10
Gabarito: B
Questão 28 TRF-2 2007 [FCC]
Em uma população de 100 elementos, com variância populacional 50, foram tomadas amostras casuais simples de tamanho 10. Nestas condições, as variâncias da média amostral na amostragem, com e sem reposição, são respectivamente
a) 1/5 e 90/99
b) 2 e 90/99
c) 4 e 450/99
d) 5 e 200/99
e) 5 e 450/99
Resolução:
Amostragem com reposição:
�)� = �� = 5010 = 5
Amostragem sem reposição:
�)� = �� × _ − _ − 1 = 5 × 100 − 10100 − 1
�)� = 45099
Gabarito: E

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 64
Questão 29 MINISTÉRIO DA INTEGRAÇÃO NACIONAL 2012 [ESAF]
Considere uma amostra aleatória simples de tamanho 50 extraída sem reposição de uma população finita de tamanho 500. Sendo �� = 100 a variância da população, determine o valor mais próximo da variância da média amostral.
a) 1,6
b) 1,8
c) 2,0
d) 2,2
e) 2,4
Resolução:
A variância da média amostral é dada por:
�)�� = �� × _ − _ − 1
Onde:
• _ é o tamanho da população
• é o tamanho da amostra
Substituindo os valores:
�)�� = 10050 × 500 − 50499
�)�� = 2 × 450499
�)�� ≈ 1,8
Gabarito: B
6. CARACTERÍSTICAS DOS ESTIMADORES
Como já adiantamos, algumas características dos estimadores são:
• Não tendenciosos (ou não viciados)
• De máxima verossimilhança
• De variância mínima
• De mínimos quadrados

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 65
6.1. Estimador não tendencioso
Seja a um estimador para o parâmetro α . Dizemos que a é um estimador não tendencioso se:
α=)(aE
Ou seja, a esperança do estimador é igual ao parâmetro estimado.
Nós vimos que a média amostral ( X ) é um estimador não-tendencioso para a média populacional.
Vamos agora estudar o estimador não tendencioso da variância. Ou seja, vamos calcular a variância da amostra. Para comparação, faremos dois cálculos: um com o denominador n e outro com o denominador 1−n .
Considere um tetraedro homogêneo, com faces 1, 2, 3 e 4.
Vamos lançá-lo 2 vezes, obtendo uma amostra de tamanho 2. O quadro abaixo traz todas as possíveis amostras.
1 e 1 1 e 2 1 e 3 1 e 4
2 e 1 2 e 2 2 e 3 2 e 4
3 e 1 3 e 2 3 e 3 3 e 4
4 e 1 4 e 2 4 e 3 4 e 4
Seriam 16 amostras possíveis, todas elas com a mesma probabilidade de ocorrer.
Para cada possível amostra, vamos calcular a variância amostral.
Para diferenciar, quando utilizarmos o denominador n, vamos adotar o símbolo *s .

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 66
Valores da amostra
12
)(2
1
2
2
−
−
=
∑=i
i xx
s 2
)(
*
2
1
2
2
∑=
−
= i
i xx
s
1 e 1 0 0
1 e 2 0,5 0,25
1 e 3 2 1
1 e 4 4,5 2,25
2 e 1 0,5 0,25
2 e 2 0 0
2 e 3 0,5 0,25
2 e 4 2 1
3 e 1 2 1
3 e 2 0,5 0,25
3 e 3 0 0
3 e 4 0,5 0,25
4 e 1 4,5 2,25
4 e 2 2 1
4 e 3 0,5 0,25
4 e 4 0 0
total 20 10
Note que:
25,116
20)(
2 ==sE
625,016
10)*(
2 ==sE
Vamos agora calcular a variância da variável aleatória X.
5,24
4321)( =
+++=XE
5,74
16941)(
2 =+++
=XE
22)()()( XEXEXV −=
25,15,25,7)(2
=−=XV
O parâmetro é igual a 1,25. Os estimadores foram 1,25 (s2 , com o denominador 1−n ) e
0,625 ( 2*s , com o denominador n).
Por isso dizemos que o estimador variância amostral deve ter 1−n no denominador. Isto garante um estimador não-viciado.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 67
6.2. Estimador de variância mínima.
Vamos continuar com o exemplo do tetraedro com faces 1, 2, 3, 4 e as possíveis amostras de tamanho 2.
Queremos estimar a variância da população. Quem tem acesso a todas as faces do tetraedro, sabe que:
5,24
4321=
+++=µ
Já quem desconhece as faces do tetraedro, poderá apenas estimar a média da população, com base no resultado de uma amostra de tamanho 2.
Durante toda a aula, nós trabalhamos com o estimador X (média aritmética da amostra).
Pois bem, vamos criar outro estimador para a média populacional. Vou chamá-lo de *X , para diferenciar do símbolo anterior.
Esse nosso novo estimador será uma média ponderada dos valores da amostra, em que o primeiro valor da amostra tem peso 2 e o segundo valor da amostra tem peso 1.
Exemplificando: se a amostra for: (2, 3), nosso estimador será:
333,23
1322* =
×+×=X
A tabela abaixo traz todas as amostras possíveis, bem como os valores dos estimadores.
Valores da amostra
X *X
1 e 1 1 1
1 e 2 1,5 1,333333
1 e 3 2 1,666667
1 e 4 2,5 2
2 e 1 1,5 1,666667
2 e 2 2 2
2 e 3 2,5 2,333333
2 e 4 3 2,666667
3 e 1 2 2,333333
3 e 2 2,5 2,666667
3 e 3 3 3
3 e 4 3,5 3,333333
4 e 1 2,5 3
4 e 2 3 3,333333
4 e 3 3,5 3,666667
4 e 4 4 4
total 40 40
Interessante observar que:
5,216
40)*()( === XEXE

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 68
Ou seja, o estimador *X também é não-tendencioso.
Qualquer média ponderada dos valores da amostra será um estimador não-tendencioso da média populacional.
Aí vem a pergunta: Ah, então qualquer média ponderada será um bom estimador?
Não necessariamente. Depende das características que você quer para o seu estimador.
Uma característica interessante é que o estimador tenha variância mínima.
Se você calcular a variância dos estimadores *X e X , verá que eles têm variâncias diferentes. Não vou reproduzir os cálculos aqui, vou apenas dar o resultado:
625,0)( =XV
6944,0)*( =XV
Note que X tem uma variância menor que *X . Isto pode ser interessante. Se fizéssemos inúmeras amostras, em média, acertaríamos o valor do parâmetro nos dois casos (com qualquer um destes dois estimadores).
Só que o estimador *X tem maior dispersão. Ele apresenta, com maior frequência, valores
afastados da média populacional. Por isso, o estimador X é melhor.
Assim, uma característica que se costuma buscar é que o estimador tenha variância mínima. Ou seja, que a variância do estimador escolhido seja menor que a variância de qualquer outro estimador.
Dentre os estimadores lineares (ou seja, aqueles que são obtidos a partir de uma média ponderada com os valores da amostra), é possível demonstrar que a média aritmética
simples ( X ) apresenta variância mínima.
É possível comparar a eficiência entre dois estimadores diferentes. Basta dividir suas
variâncias. Assim, a eficiência relativa de *X , em comparação com X , é dada por:
%906944,0
625,0=
6.3. Estimador de mínimos quadrados
Outro tipo de estimador é aquele que minimiza a soma dos quadrados dos desvios. Por enquanto, não veremos este tipo de estimador com mais detalhes. Falaremos mais a respeito na aula de regressão linear, em que será muito frequente realizarmos a operação que minimiza a soma dos quadrados dos desvios.
Interessante observar que X e p̂ são estimadores de mínimos quadrados. Ou seja, a
média amostral e a proporção amostral estimam a média e a proporção populacionais, obedecendo ao critério de mínimos quadrados.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 69
6.4. Estimador de máxima verossimilhança
Um estimador de máxima verossimilhança é aquele que maximiza a probabilidade (se a variável aleatória for discreta) ou a densidade de probabilidade (se a variável aleatória for contínua) de a amostra observada ter sido obtida.
Para explicar, vou adaptar um exemplo extraído do livro Estatística para Economistas, do Rodolfo Hoffmann.
Considere um tetraedro que possui faces azuis e brancas. Lançamos o tetraedro. O resultado obtido corresponde à face que fica em contato com o solo.
Caso saia uma face azul, temos um caso favorável. Caso saia uma face branca, temos um caso desfavorável.
O tetraedro é lançado 3 vezes, resultado em 1 caso favorável (1 resultado azul e 2 brancos).
Nós só temos acesso ao resultado desta amostra e temos que estimar a proporção populacional, ou seja, a proporção de faces azuis no tetraedro.
Para achar o estimador de máxima verossimilhança, nós temos que ver qual a proporção que maximiza a probabilidade de esta amostra ter sido obtida. O quadro abaixo resume os cálculos.
Número de faces azuis
probabilidade de sucesso em 1 experimento
Probabilidade de, em 3 lançamentos, termos exatamente 1 caso favorável
0 0 0
1 0,25 0,421875
2 0,5 0,375
3 0,75 0,140625
4 1 0
A maior probabilidade (0,421875) ocorre quando temos 1 face azul. Logo, o estimador de máxima verossimilhança é 0,25.
Neste exemplo, a proporção populacional só poderia assumir alguns valores (0; 0,25; 0,5; 0,75; 1,0). É uma variável discreta.
Acaso a proporção populacional p possa assumir qualquer valor no intervalo entre 0 e 1,
então é possível demonstrar que a proporção amostral (n
Xp =ˆ , onde X é a variável
binomial) é um estimador de mínimos quadrados e de máxima verossimilhança.
Se a variável aleatória for normal, o estimador de máxima verossimilhança para a variância é dado por:
n
xx
s
n
i
i∑=
−
= 1
2
2
)(
*
Se a variável aleatória for normal, a média aritmética da amostra ( X ) é um estimador de máxima verossimilhança para a média populacional.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 70
Texto para Questão 30 e Questão 31.
Para responder às questões seguintes, considere as distribuições amostrais de cinco estimadores propostos para estimar o parâmetro T de uma população, ilustradas na figura apresentada a seguir.
Questão 30 INEP 2008 [CESGRANRIO]
Se o interesse for um estimador não viesado, deve-se utilizar apenas
(A) T1
(B) T4
(C) T1 ou T4
(D) T2 ou T5
(E) T1 ou T2 ou T3
Resolução.
Estimador não viesado é sinônimo de estimador não tendencioso. Queremos que a média do estimador seja igual a T.
Os únicos estimadores que apresentam esta característica são T1, T2 e T3.
Gabarito: E

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 71
Questão 31 INEP 2008 [CESGRANRIO]
Levando-se em conta as propriedades de um bom estimador, o melhor dentre os estimadores propostos é
(A) T1
(B) T2
(C) T3
(D) T4
(E) T5
Resolução.
Entre os estimadores T1, T2 e T3, o que apresenta variância mínima é T2, pois apresenta uma curva mais afilada, o que indica que a proporção de valores próximos à média é maior.
Gabarito: B
Questão 32 PETROBRAS 2010 [CESGRANRIO]
Quando se lança uma certa moeda, a probabilidade de o resultado ser cara é p. A moeda foi lançada dez vezes, sucessivas e independentes, e o resultado foi de 2 caras e 8 coroas. Tendo em vista este experimento, a estimativa de máxima verossimilhança de p é
(A) 0.2
(B) 0.25
(C) 0.3
(D) 0.35
(E) 0.4
Resolução.
A proporção amostral é um estimador de máxima verossimilhança da proporção populacional.
Na amostra, foram 2 caras em 10 lançamentos.
�̂ = 210 = 0,2
Gabarito: A
Questão 33 CGU 2008. [ESAF]
Seja T um estimador de um parâmetro θ de uma população. Se θ=)(TE , diz-se que T é
um estimador de θ :
a) eficiente

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 72
b) não enviesado
c) consistente
d) de mínimos quadrados
e) de máxima verossimilhança
Resolução.
Vimos que o fato da esperança do estimador ser igual ao parâmetro permite classificar o estimador como não viciado (ou não tendencioso, ou não enviesado). Todas essas expressões são sinônimas.
Gabarito: B.
Questão 34 TRE PI 2009 [FCC]
Seja (X1, X2, X3) uma amostra aleatória simples de uma distribuição normal com média µ .
Foram obtidos 3 estimadores para µ :
3
321
1
XXXY
++=
321232 XXXY −+=
321223 XXXY −+=
Então, APENAS
(A) Y1 é não viesado.
(B) Y1 e Y3 são não viesados.
(C) Y1 e Y3 são viesados.
(D) Y1 e Y3 são viesados.
(E) Y2 e Y3 são viesados.
Resolução.
Um estimador é viesado quando sua esperança é diferente do parâmetro estimado.
Um estimador é não viesado quando sua esperança é igual ao parâmetro estimado.
"�ab� = " S�b + �� + �c3 T = "��b + �� + �c�3 = "��b� + "���� + "��c�3 = 33 =
"�a�� = "�2�b + �� − 3�c� = 2"��b� + "���� − 3"��c� = 2 + − 3 = 0
"�ac� = "��b + 2�� − 2�c� = "��b� + 2"���� − 2"��c� = + 2 − 2 =
Observem que Y1 e Y3 apresentam esperança igual a . Logo, são não viesados.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 73
Já Y2 apresenta esperança igual a 0. Portanto, não temos garantias de que seja não viesado, pois não sabemos se = 0.
Gabarito: B
Questão 35 MIN 2012 [ESAF]
Considere um estimador T de um parâmetro θ de uma população. Se E(T) = θ, então T é um estimador
a) não viesado.
b) viesado.
c) consistente.
d) tendencioso.
e) eficiente.
Resolução:
Quando a esperança do estimador é igual ao parâmetro estimado, temos um estimador não tendencioso, não viesado, ou não viciado.
Ele nos indica que, se fizéssemos várias e várias amostragens, em média, acertaríamos o valor do parâmetro.
Gabarito: A
O estimador é viesado ou tendencioso (letras "b" e "d") quando sua esperança diverge do valor do parâmetro.
O estimador é eficiente (letra "e") quando apresenta variância pequena.
O estimador é consistente (letra "c") quando sua dispersão tende para zero, à medida que aumentamos o tamanho da amostra.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 74
7. RESUMÃO
Tópico Lembrete
Estimadores pontuais �� é um estimador de S2 é um estimador de �� �̂ é um estimador de p.
Distribuições amostrais �� tem média e desvio padrão �/√
�̂ tem média p e desvio padrão dOeG
Intervalo de confiança para média com variância populacional conhecida
XXZXZX σµσ ×+≤≤×− 00
Intervalo de confiança para média com variância populacional desconhecida
XXstXstX ×+≤≤×− 00 µ
Intervalo de confiança para proporção pp ZppZp ˆ0ˆ0
ˆˆ σσ ×+≤≤×−
Erro máximo cometido e tamanho da amostra
XZerro σ
0max_ =
Xsterro
0max_ =
psZerro ˆ0max_ =
Características dos estimadores - Não tendenciosos: esperança do
estimador = parâmetro.
- De variância mínima;
- De mínimos quadrados: minimiza a soma
dos quadrados dos desvios
- De máxima verossimilhança: maximiza a
probabilidade de a amostra ter sido
observada.
8. ASSUNTO DE DESTAQUE
A coisa mais importante da aula de hoje é a seguinte. Temos que ter claro em nossa cabeça que a média amostral �� e a proporção amostral �̂ podem ser vistos como variáveis aleatórias. Assim sendo, eles têm uma esperança e uma variância.
Saber as fórmulas dessas esperanças e dessas variâncias é fundamental:
"���� =
#���� = �� ÷
"��̂� = �

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 75
#��̂� = �̂ × MN
Compreender que �� e �̂ podem ser vistas como variáveis aleatórias é muito importante. Isso é a base para os intervalos de confiança e para os testes de hipóteses, que estudaremos na próxima aula.
9. QUESTÕES APRESENTADAS EM AULA
Questão 1 SEFAZ RJ 2008 [FGV]
Considere uma Amostra Aleatória Simples de n unidades extraídas de uma população na
qual a característica, X, estudada tem distribuição Normal com média µ e variância 2σ ,
ambas desconhecidas, mas finitas. Considere, ainda, as estatísticas média da amostra, X =
∑=
n
i
iXn 1
1, e variância da amostra ( )∑
=
−=n
i
i XXn
s1
22 1
. Então, é correto afirmar que:
(A) X e 2S são, ambos, não tendenciosos para a estimação da média e da variância da população, respectivamente.
(B) X é não-tendencioso, mas é 2S tendencioso para a estimação da média e da variância da população, respectivamente.
(C) X é tendencioso, mas 2S é não-tendencioso para a estimação da média e da variância da população, respectivamente.
(D) X e 2S são, ambos, tendenciosos para a estimação da média e da variância da população, respectivamente.
(E) X e 2S são, ambos, não-tendenciosos para a estimação da média e da variância da
população, mas apenas X é consistente.
Questão 2 CGU 2008 [ESAF]
Qual o estimador de máxima verossimilhança da variância de uma variável X normalmente distribuída obtido a partir de uma amostra aleatória simples X1, X2, X3, ..., Xn, desta variável,
sendo nXm i /∑= o estimador de máxima verossimilhança da média?
a) 1
)(2
−
−∑n
mX i
b) 2
)(2
−
−∑n
mX i
c)
5,02
1
)(
−
−∑n
mX i
d) ∑ − 2)( mX i

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 76
e) n
mX i∑ − 2)(
Questão 3 SEFAZ SP 2009 [ESAF]
(Dados da questão anterior: 17, 12, 9, 23, 14, 6, 3, 18, 42, 25, 18, 12, 34, 5, 17, 20, 7, 8, 21, 13, 31, 24, 9.)
Considerando que as observações apresentadas na questão anterior constituem uma amostra aleatória simples X1, X2, ..., Xn de uma variável aleatória X, determine o valor mais próximo da variância amostral, usando um estimador não tendencioso da variância de X.
Considere que:
38823
1
=∑=i
iX
867623
1
2 =∑=i
iX
a) 96,85
b) 92,64
c) 94,45
d) 90,57
e) 98,73
Questão 4 TJ PI 2009 [FCC]
Seja uma população constituída pelos valores 1, 2, 3, 4, 5 e 6. Todas as amostras com tamanho 2, sem reposição, são selecionadas. A probabilidade de que a média amostral seja superior a 5 é de
(A) 1/4
(B) 1/6
(C) 2/3
(D) 1/3
(E) 1/15
Questão 5 TRF 1ª Região/2001 [FCC]
Para responder à questão seguinte, considere a tabela abaixo, referente à distribuição normal padrão.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 77
z )(zF
1,20 0,885
1,60 0,945
1,64 0,950
Uma máquina de empacotar leite em pó o faz segundo uma normal com média µ e desvio
padrão 10g. O peso médio µ deve ser regulado para que apenas 5,5% dos pacotes tenham
menos do que 1000 g. Com a máquina assim regulada, a probabilidade de que o peso total de 4 pacotes escolhidos ao acaso seja inferior a 4.040 g é:
a) 0,485
b) 0,385
c) 0,195
d) 0,157
e) 0,115
Questão 6 MPU/2007 [FCC]
Se retirarmos uma amostra aleatória de 1200 observações de uma população com
distribuição uniforme no intervalo [17; 29], a distribuição da média amostral X será, aproximadamente,
a) uniforme com média 23 e variância 12
b) normal com média 23 e desvio padrão 0,1
c) uniforme com média 23 e variância 1
d) normal com média 23 e desvio padrão 12.
e) normal com média 23 e desvio padrão 1.
Questão 7 PETROBRAS 2010 [CESGRANRIO]
A distribuição de probabilidades da variável aleatória X é tal que X = -1 com 50% de probabilidade ou X = 1 com 50% de probabilidade. A média, �� , de quatro realizações de X, sucessivas e independentes, é uma variável aleatória de média e desvio padrão, respectivamente, iguais a
(A) 0 e 2
(B) 0 e 1
(C) 1 e 0.5
(D) 1 e 0
(E) 0 e 0.5
Questão 8 MPOG 2012 [ESAF]
Uma variável aleatória possui distribuição normal com média igual a 10, μ = 10, e variância igual a 4, ��= 4. Retirando-se desta população uma amostra de tamanho n = 100, tem-se que a distribuição amostral das médias, ou distribuição amostral de ��é uma distribuição:
a) não normal com μ =10 e �= 1/5

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 78
b)normal com μ =10 e � = 1/5
c) normal com μ =100 e�� = 4
d)normal com μ =10 e �� = 2
e)não normal com μ =100 e �� = 4
Questão 9 INFRAERO 2009 [FCC]
Em um determinado ramo de atividade, os salários dos empregados são considerados normalmente distribuídos com uma média μ e uma variância populacional igual a 1.600 (R$)2. Uma amostra aleatória com 100 destes empregados apresentou uma média de R$ 1.000,00 para os salários. Deseja-se, com base nesta amostra, obter um intervalo de confiança para a média μ com um nível de confiança de 95%, considerando a população de tamanho infinito e a informação da distribuição normal padrão (Z) que a probabilidade P (z > 2) = 0,025. O intervalo, com os valores em R$, é igual a
(A) [960,00; 1.040,00]
(B) [992,00; 1.008,00]
(C) [994,00; 1.006,00]
(D) [996,00; 1.004,00]
(E) [920,00; 1.080,00]
Questão 10 CGU 2008 [ESAF]
Construa um intervalo de 95% de confiança para a média de uma população normal a partir dos dados de uma amostra aleatória simples de tamanho 64 desta população, que forneceu uma média de 48 e um desvio-padrão amostral de 16, considerando que F(1,96) = 0,975, onde F(z) é a função de distribuição de uma variável aleatória normal padrão Z.
a) 44,08 a 51,92.
b) 41,78 a 54,22.
c) 38,2 a 57,8.
d) 35,67 a 60,43.
e) 32,15 a 63,85.
Questão 11 TRT 2ª Região 2008 [FCC]
A vida das lâmpadas fabricadas por uma empresa apresenta uma distribuição normal com uma variância populacional igual a 400 (horas)2
. Extrai-se uma amostra de 64 lâmpadas e verifica-se que a respectiva vida média é igual a 1.200 horas. Considerando a população de tamanho infinito e a informação da distribuição normal padrão (Z) que a probabilidade P(Z
> 2) = 2,5%, tem-se que o intervalo de confiança de 95% para a vida média das lâmpadas é
(A) [1.160 , 1.240]
(B) [1.164 , 1.236]
(C) [1.180 , 1.220]
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 79
(D) [1.184 , 1.216]
(E) [1.195 , 1.205]
Questão 12 PETROBRAS 2010 [CESGRANRIO]
Um levantamento realizado a respeito dos salários recebidos por uma determinada classe profissional utilizou uma amostra de 100 destes profissionais, na qual foram observados uma média de R$ 2.860,00 e um desvio padrão de R$ 786,00. Qual será, em reais, o desvio padrão da distribuição das médias amostrais dos salários desta classe de profissionais?
(A) 3,64
(B) 7,86
(C) 78,60
(D) 786,00
(E) 7.860,00
Questão 13 IPEA 2004 [ESAF]
Deseja-se estimar o gasto médio efetuado por grupos de 4 pessoas, num restaurante, por meio de um intervalo de confiança com coeficiente de 95%. Uma amostra de 16 grupos produziu os valores R$ 150,00 e R$ 20,00 para a média e o desvio padrão amostrais, respectivamente. Assinale a opção que corresponde ao intervalo procurado. Use a hipótese de normalidade da distribuição dos gastos e a tabela abaixo da função de distribuição de Student (Tr) para a escolha do quantil apropriado aos cálculos.
γ=≤ )( xTP r
γ
r
0,900 0,950 0,975 0,990
14 1,345 1,761 2,145 2,625
15 1,341 1,753 2,131 2,603
16 1,337 1,746 2,120 2,584
17 1,333 1,740 2,110 2,567
a) [139,34; 160,66]
b) [139,40; 160,60]
c) [141,23; 158,77]
d) [141,19; 158,81]
e) [140,00; 160,00]
Questão 14 MIN 2012 [ESAF]
Uma amostra aleatória simples de tamanho 9 de uma população com distribuição normal levou ao cálculo de uma média amostral igual a 32 e ao cálculo de uma variância amostral igual a 225. Construa um intervalo de 95% de confiança para a média da população.
a) 27,1 a 36,9
b) 22,2 a 41,8
c) 12,4 a 51,6

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 80
d) 2,6 a 61,4
e) -17 a 81
Questão 15 SEFAZ SP 2009 [FCC]
Em uma pesquisa de tributos de competência estadual, em 2008, realizada com 400 recolhimentos escolhidos aleatoriamente de uma população considerada de tamanho infinito, 80% referiam-se a determinado imposto. Deseja-se construir um intervalo de confiança de 95,5% para a estimativa dessa proporção. Considerando normal a distribuição amostral da frequência relativa dos recolhimentos desse imposto e que na distribuição normal padrão a probabilidade P (−2 ≤ Z ≤ 2) = 95,5%, o intervalo é
(A) [0,70; 0,90]
(B) [0,72; 0,88]
(C) [0,74; 0,86]
(D) [0,76; 0,84]
(E) [0,78; 0,82]
Questão 16 TRT 4ª REGIÃO 2009 [FCC]
Se Z tem distribuição normal padrão, então:
P (Z > 1,64) = 0,05; P(Z > 2) = 0,02; P(0< Z < 1,75) = 0,46
Deseja-se estimar a proporção (p) de processos julgados por um tribunal regional do trabalho durante o período de 2000 até 2008. Uma amostra aleatória de 10.000 processos, selecionada da população (suposta infinita) de todos os processos, revelou que 5.000 foram julgados no referido período. Um intervalo de confiança, com coeficiente de confiança de 90% para p, baseado nessa amostra, é dado por
(A) 0,5 ± 0,005
(B) 0,5 ± 0,0062
(C) 0,5 ± 0,0065
(D) 0,5 ± 0,0082
(E) 0,5 ± 0,01
Questão 17 MPOG 2012 [ESAF]
Para estimar a proporção P de pessoas acometidas por uma virose, foi retirada uma amostra aleatória de 1600 pessoas. Na amostra foi constatado que 160 pessoas estavam acometidas pela virose. Sabe-se que, para construir um intervalo com 95% de confiança para a proporção de pessoas acometidas pela virose, o valor tabelado é 1,96. Com essas informações, o intervalo de confiança é dado por:
Q�� R0,10 ± 1,96 S0,340TU = 95%
V�� R0,10 ± 1,96 S400,3TU = 95%

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 81
W�� R0,10 ± 1,96 S0,340TU = 5%
X�� R0,10 ± 1,96 S400,3TU = 5%
Y�� R0,10 ± 1,96 S0,0340 TU = 95%
Questão 18 DNOCS 2010 [FCC]
Seja X uma variável aleatória normalmente distribuída representando o salário dos empregados em um determinado ramo de atividade. Uma amostra aleatória de 100 empregados foi selecionada e apurou-se um intervalo de confiança de 95% para a média de X como sendo [760,80; 839,20], supondo a população de tamanho infinito e sabendo-se que o desvio padrão populacional é igual a R$ 200,00. Caso o tamanho da amostra tivesse sido de 1.600 e obtendo-se a mesma média anterior, o intervalo de confiança de 95% apresentaria uma amplitude igual a
(A) R$ 78,40.
(B) R$ 39,20.
(C) R$ 49,00.
(D) R$ 58,80.
(E) R$ 19,60.
Questão 19 TRE PI 2009 [FCC]
A duração de vida de um determinado equipamento apresenta uma distribuição normal com uma variância populacional igual a 100 (dias)2. Uma amostra aleatória de 64 desses equipamentos forneceu uma média de duração de vida de 1.000 dias. Considerando a população de tamanho infinito, um intervalo de confiança de ( α−1 ) com amplitude de 4,75 dias para a média foi construído. Caso o tamanho da amostra tivesse sido de 400, obtendo-se a mesma média de 1.000 dias, a amplitude do intervalo de confiança de ( α−1 ) seria de
(A) 0,950 dias.
(B) 1,425 dias.
(C) 1,900 dias.
(D) 2,375 dias.
(E) 4,750 dias.
Questão 20 AFPS 2002 [ESAF]
Tem-se uma população normal com média µ e variância 225. Deseja-se construir, a partir de uma amostra de tamanho n dessa população, um intervalo de confiança para µ com amplitude 5 e coeficiente de confiança de 95%. Assinale a opção que corresponde ao valor de n. Use como aproximadamente 2 o quantil de ordem 97,5% da distribuição normal padrão.
a) 225

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 82
b) 450
c) 500
d) 144
e) 200
Questão 21 MDIC 2002 [ESAF]
Deseja-se determinar, para uma população com N elementos, em um esquema de amostragem aleatória simples, o tamanho de amostra n necessário para estimar a média populacional do atributo X. Deseja-se que o erro em valor absoluto do procedimento não seja superior a 10% da média populacional, com probabilidade de 95%. De um estudo piloto obtém-se que a variância de X tem o valor 80 e que a média tem o valor 20. Tomando como aproximadamente 2 o quantil de ordem 0,975 da distribuição normal padrão, supondo que a média da amostra tem distribuição aproximadamente normal e desprezando a fração de amostragem n/N, assinale a opção que dá o valor de n.
a) 1000
b) 100
c) 80
d) 200
e) 150
Questão 22 MPOG 2012 [ESAF]
Para estimar por intervalo a média μ de uma população normal com variância igual a 9, retirou-se uma amostra de 16 elementos, obtendo-se ��= 5. Para um nível de confiança de 95%, o valor tabelado é igual a 1,96. Desse modo, a semi-amplitude do intervalo ou erro de estimação ─ como também é chamado ─ é igual a:
a) 2,94
b) 1,47
c) 0,5625
d) 0,7350
e) 0,47
Questão 23 Ministério da Saúde 2007 [FCC]
Para responder à questão seguinte considere, dentre os dados abaixo, aqueles que julgar apropriados. Se Z tem distribuição normal padrão, então:
023,0)2( =>ZP ; 445,0)6,10( =<< ZP ; 84,0)1( =<ZP ; 49,0)33,20( =<< ZP
Para estimar a proporção de cura de um medicamento antiparasitário realizou-se um experimento clínico, aplicando-se o medicamento em ‘n’ doentes escolhidos ao acaso. Nesta amostra foi considerado que 80% dos doentes foram curados. Com base nestas

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 83
informações e utilizando o Teorema Central do Limite, o valor de n, para que o erro cometido na estimação seja no máximo 0,08, com confiança de 89%, é de:
a) 16
b) 25
c) 36
d) 49
e) 64
Questão 24 TRT 2ª Região 2008 [FCC]
Em uma cidade, considerada com uma população de tamanho infinito, é feito um estudo objetivando detectar a proporção de habitantes que preferem a marca do sabonete X. Uma amostra piloto forneceu um valor de 20% para essa proporção. Deseja-se obter um intervalo de confiança de 95% para a proporção, tendo o intervalo uma amplitude de 10%. Se a distribuição amostral da freqüência relativa dos habitantes que preferem a marca do sabonete X é normal e utilizando a informação da distribuição normal padrão (Z) que a probabilidade P(|Z| ≤ 2) = 95%, tem-se que o tamanho da amostra deve ser de
(A) 400
(B) 361
(C) 324
(D) 289
(E) 256
Questão 25 SEFAZ RJ 2007 [FGV]
Uma pesquisa recente foi realizada para avaliar o percentual da população favorável à eleição de um determinado ponto turístico para constar no selo comemorativo de aniversário da cidade. Para isso, selecionou-se uma amostra aleatória simples extraída de uma população infinita. O resultado apurou 50% de intenção de votos para esse ponto turístico. Considerando que a margem de erro foi de 2 pontos percentuais, para mais ou para menos, e que o nível de confiança utilizado foi de 95%, foram ouvidas, aproximadamente:
(A) 50 pessoas.
(B) 100 pessoas.
(C) 1.200 pessoas.
(D) 2.400 pessoas.
(E) 4.800 pessoas.
Questão 26 MIN 2012 [ESAF]
Pretende-se estimar por amostragem a proporção de famílias com renda inferior a cinco salários mínimos em uma populosa cidade. Usando a estimativa �̂= 5/7, obtida em um levantamento preliminar, determine o menor tamanho de amostra aleatória simples

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 84
necessária para estimar com um intervalo de 95% de confiança e com um erro de
amostragem ]'�̂�1 − �̂�/ ≤ 4%
a) 420
b) 490
c) 560
d) 630
e) 684
Questão 27 TRT 4ª REGIÃO 2009 [FCC]
Uma população possui 15 elementos e tem variância 2σ . Desta população retira-se uma amostra aleatória sem reposição de n elementos. Sabendo-se que a média amostral ��
desses n elementos tem variância igual a 28
2σ , o valor de n é dado por
(A) 5
(B) 10
(C) 14
(D) 25
(E) 28
Questão 28 TRF-2 2007 [FCC]
Em uma população de 100 elementos, com variância populacional 50, foram tomadas amostras casuais simples de tamanho 10. Nestas condições, as variâncias da média amostral na amostragem, com e sem reposição, são respectivamente
a) 1/5 e 90/99
b) 2 e 90/99
c) 4 e 450/99
d) 5 e 200/99
e) 5 e 450/99
Questão 29 MINISTÉRIO DA INTEGRAÇÃO NACIONAL 2012 [ESAF]
Considere uma amostra aleatória simples de tamanho 50 extraída sem reposição de uma população finita de tamanho 500. Sendo �� = 100 a variância da população, determine o valor mais próximo da variância da média amostral.
a) 1,6
b) 1,8
c) 2,0
d) 2,2
e) 2,4
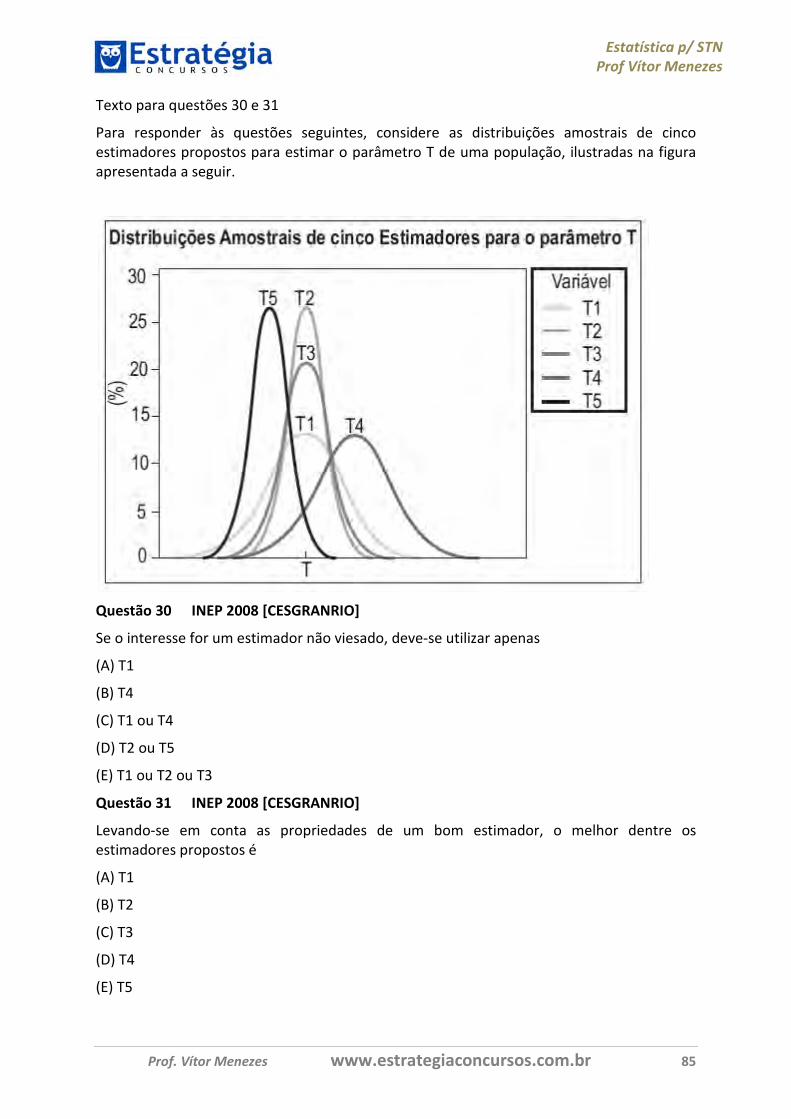
Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 85
Texto para questões 30 e 31
Para responder às questões seguintes, considere as distribuições amostrais de cinco estimadores propostos para estimar o parâmetro T de uma população, ilustradas na figura apresentada a seguir.
Questão 30 INEP 2008 [CESGRANRIO]
Se o interesse for um estimador não viesado, deve-se utilizar apenas
(A) T1
(B) T4
(C) T1 ou T4
(D) T2 ou T5
(E) T1 ou T2 ou T3
Questão 31 INEP 2008 [CESGRANRIO]
Levando-se em conta as propriedades de um bom estimador, o melhor dentre os estimadores propostos é
(A) T1
(B) T2
(C) T3
(D) T4
(E) T5

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 86
Questão 32 PETROBRAS 2010 [CESGRANRIO]
Quando se lança uma certa moeda, a probabilidade de o resultado ser cara é p. A moeda foi lançada dez vezes, sucessivas e independentes, e o resultado foi de 2 caras e 8 coroas. Tendo em vista este experimento, a estimativa de máxima verossimilhança de p é
(A) 0.2
(B) 0.25
(C) 0.3
(D) 0.35
(E) 0.4
Questão 33 CGU 2008. [ESAF]
Seja T um estimador de um parâmetro θ de uma população. Se θ=)(TE , diz-se que T é
um estimador de θ :
a) eficiente
b) não enviesado
c) consistente
d) de mínimos quadrados
e) de máxima verossimilhança
Questão 34 TRE PI 2009 [FCC]
Seja (X1, X2, X3) uma amostra aleatória simples de uma distribuição normal com média µ .
Foram obtidos 3 estimadores para µ :
3
321
1
XXXY
++=
321232 XXXY −+=
321223 XXXY −+=
Então, APENAS
(A) Y1 é não viesado.
(B) Y1 e Y3 são não viesados.
(C) Y1 e Y3 são viesados.
(D) Y1 e Y3 são viesados.
(E) Y2 e Y3 são viesados.
Questão 35 MIN 2012 [ESAF]
Considere um estimador T de um parâmetro θ de uma população. Se E(T) = θ, então T é um estimador
a) não viesado.

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 87
b) viesado.
c) consistente.
d) tendencioso.
e) eficiente.
GABARITO
1 b
2 e
3 a
4 e
5 e
6 b
7 e
8 b
9 b
10 a
11 e
12 c
13 a
14 anulado
15 d
16 d
17 a
18 e
19 c
20 d
21 c
22 b
23 e
24 e
25 d
26 b
27 b
28 e

Estatística p/ STN
Prof Vítor Menezes
Prof. Vítor Menezes www.estrategiaconcursos.com.br 88
29 b
30 e
31 b
32 a
33 b
34 b
35 a