andr´e augusto da silva pereira - unicamp
TRANSCRIPT

Andre Augusto da Silva Pereira
“Framework de kernel para Auto-protecao e
Administracao em um Sistema de Seguranca
Imunologico”
CAMPINAS
2013
i

ii

Universidade Estadual de Campinas
Instituto de Computacao
Andre Augusto da Silva Pereira
“Framework de kernel para Auto-protecao e
Administracao em um Sistema de Seguranca
Imunologico”
Orientador(a): Prof. Dr. Paulo Lıcio de Geus
Dissertacao de Mestrado apresentada ao Programa
de Pos-Graduacao em Ciencia da Computacao do Instituto de Computacao da
Universidade Estadual de Campinas para obtencao do tıtulo de Mestre em
Ciencia da Computacao.
Este exemplar corresponde a versao
final da Dissertacao defendida por
Andre Augusto da Silva Pereira, sob
orientacao de Prof. Dr. Paulo
Lıcio de Geus.
Assinatura do Orientador(a)
CAMPINAS
2013
iii

Ficha catalográficaUniversidade Estadual de Campinas
Biblioteca do Instituto de Matemática, Estatística e Computação CientíficaAna Regina Machado - CRB 8/5467
Pereira, André Augusto da Silva, 1986- P414f PerFramework de kernel para auto-proteção e administração em um sistema de
segurança imunológico / André Augusto da Silva Pereira. – Campinas, SP : [s.n.],2013.
PerOrientador: Paulo Lício de Geus. PerDissertação \\\(mestrado\\\) – Universidade Estadual de Campinas, Instituto de
Computação.
Per1. Sistemas operacionais (Computadores). 2. Redes de computadores -
Sistemas de segurança. 3. Imunoinformática. I. Geus, Paulo Lício de,1956-. II.Universidade Estadual de Campinas. Instituto de Computação. III. Título.
Informações para Biblioteca Digital
Título em inglês: A kernel framework for administration and selfprotection for a immunologicalsecurity systemPalavras-chave em inglês:Operating systems (Computers)Computer networks - Security measuresImmunoinformaticsÁrea de concentração: Ciência da ComputaçãoTitulação: Mestre em Ciência da ComputaçãoBanca examinadora:Paulo Lício de Geus [Orientador]Ricardo DahabCarlos Alberto MazieroData de defesa: 19-04-2013Programa de Pós-Graduação: Ciência da Computação
Powered by TCPDF (www.tcpdf.org)
iv



Instituto de Computacao
Universidade Estadual de Campinas
Framework de kernel para Auto-protecao e
Administracao em um Sistema de Seguranca
Imunologico
Andre Augusto da Silva Pereira1
19 de abril de 2013
Banca Examinadora:
• Prof. Dr. Paulo Lıcio de Geus
Instituto de Computacao, UNICAMP (Orientador)
• Prof. Dr. Ricardo Dahab
Instituto de Computacao, UNICAMP
• Prof. Dr. Carlos Alberto Maziero
Departamento Academico de Informatica, UTFPR
• Prof. Dr. Julio Cesar Lopez Hernandez
Instituto de Computacao, UNICAMP (suplente)
• Prof. Dr. Adriano Mauro Cansian
Instituto de Biociencias Letras e Ciencias Exatas, UNESP (suplente)
1Suporte financeiro de: Bolsa CAPES 2009 - 2010, Bolsa FAPESP (processo 2009/13240-4) 2010 -2011
vii


Abstract
According to the traditional view in computer system security, the correct specification
and implementation of security policies, along with the correct implementation and proper
configuration of computer systems, are enough to guarantee that a system is secure [33].
It happens, though, that both policy and system implementations are subject to failures
that would lead to a compromise of the system’s security as a whole.
By seeking for inspiration on nature’s systems, one can see that the human immune
system provides a model that is very close to how computer systems normally have to
behave for their security. That way, seeking for relations between the computational and
the biological models provides a rich source for research inspiration.
This work reviews the research made at the Criptography and Security Laboratory
(LASCA), University of Campinas, Brazil, in order to develop a fully functional immu-
nological security system. It also implements, in a simple to use and easy to maintain
manner, a Linux kernel framework aimed to provide all the requirements needed by this
research effort in order to build such system.
The developed framework is a Linux Security Module (LSM) and makes use of a set of
consolidated Linux tools in order to provide such requirements, like Task Control Group
(TCG) and Netfilter.
Keywords: Intrusion Detection System, Computer Immunology, Immune System,
Operating Systems, Linux kernel, Resource Control
ix


Resumo
Segundo a visao tradicional de seguranca de sistemas computacionais, a especificacao
e implantacao de polıticas de seguranca em conjunto com implementacoes corretas e
configuracao adequada garantem a seguranca de um sistema [33]. Na pratica, contudo,
percebe-se que tanto polıticas quanto implementacoes estao sujeitas a falhas que compro-
metem a seguranca do sistema como um todo.
Buscando inspiracao na natureza, o sistema imunologico humano possui caracterısticas
que representam um modelo bastante proximo das condicoes em que sistemas computa-
cionais se encontram. Desta forma, a exploracao de paralelos com este modelo biologico
e uma rica fonte de inspiracao para a pesquisa em seguranca de sistemas computacionais.
Esta dissertacao apresenta os trabalhos realizados por pesquisadores do Laboratorio
de Seguranca e Criptografia, na busca pela construcao de um sistema de seguranca imu-
nologica geral, e implementa um framework no nıvel de kernel em Linux, com objetivo
de prover todos os requisitos necessarios a implementacao do sistema proposto por es-
ses pesquisadores, atraves de um sistema com implementacao clara, funcional, de facil
manutencao e API simplificada.
O framework desenvolvido e implementado como um Linux Security Module e agrega
algumas ferramentas consolidadas do kernel Linux em sua API, tais como os frameworks
Task Control Group (TCG) e Netfilter.
Palavras-chave: Sistema de Deteccao de Intrusao, Imunologia Computacional,
Sistema Imunologico, Sistemas operacionais, Seguranca de sistemas operacionais, kernel
Linux, Controle de recursos.
xi


Dedico este trabalho a minha esposa,
Tamyres, e a minha filha, Ana Clara.
Sem voces a vida nao teria sentido.
xiii


Agradecimentos
Eu gostaria de agradecer a minha mae, Edna, que desde cedo, com seus sabios conse-
lhos ao pe do ouvido, moldou o meu carater e os meus valores. Ao meu pai, Carlos, que
com toda a experiencia acumulada ao longo de sua difıcil, porem vitoriosa, trajetoria de
vida, esteve sempre vigilante, orientando-me e preparando-me para a vida. A Deus e aos
meus pais, credito todos os meus passos ate este ponto.
Gostaria de agradecer a minha esposa, Tamyres Pereira, por assumir, durante os meus
perıodos de ausencia, os papeis de pai e mae da nossa querida Ana Clara, suportando
todas as dificuldades, e me apoiando incondicionalmente nesta jornada. Alem de todo
esse apoio, a sua confianca em mim foi fundamental nos momentos de duvida. Sem voce
eu nao teria conseguido. Te amo.
Agradeco aos colegas do Laboratorio de Administracao e Sistemas de Seguranca, Vic-
tor Ammaduci, Arthur Castro, Edmar Azevedo, Gabriel Cavalcante, Ricardo Saffi, Cleber
Paiva e Miguel Gaiowski, por toda a hospitalidade e ajuda no desenvolvimento deste tra-
balho. Agradeco tambem ao meu orientador, Prof. Dr. Paulo Lıcio de Geus, por ter me
aceitado como seu aluno e compartilhado do seu conhecimento.
Gostaria de prestar meus agradecimentos ainda ao meu colega, Carlos Macapuna, que
alem de toda a ajuda durante a nossa graduacao, mudou-se para Campinas antes de minha
chegada e ajudou bastante na minha transicao de Belem para Campinas.
Finalmente, agradeco aos orgaos de fomento a pesquisa, CAPES e FAPESP, pelo apoio
financeiro.
xv


“Somos o que repetidamente fazemos.
A excelencia, portanto, nao e um feito,
mas um habito.”
Aristoteles
xvii


Sumario
Abstract ix
Resumo xi
Dedicatoria xiii
Agradecimentos xv
Epıgrafe xvii
1 Introducao 1
2 Imunologia 5
2.1 Imunologia Biologica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Imunologia Computacional . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Modelagem de um sistema de seguranca imunologico . . . . . . . . 10
2.2.2 Forense computacional aplicada em seguranca imunologica . . . . . 11
2.2.3 Resposta Automatica em Seguranca Imunologica . . . . . . . . . . 14
2.2.4 Arquitetura Imuno e ADenoIDS . . . . . . . . . . . . . . . . . . . . 17
2.2.5 Framework Imuno . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.2.6 Outros Trabalhos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3 Kernel Linux 27
3.1 Historico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2 Aspectos Gerais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3 Gerenciamento de Processos . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3.1 Escalonador CFS . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.4 Chamadas de sistema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.5 Sistemas de Arquivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
xix


4 Ferramentas de seguranca Linux 39
4.1 Sistema de Controle de Acesso . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.1.1 Discretionary Access Control - DAC . . . . . . . . . . . . . . . . . . 43
4.1.2 Mandatory Access Control - MAC . . . . . . . . . . . . . . . . . . . 48
4.2 LSM - Linux Security Modules . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.2.1 SELinux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.2.2 AppArmor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.2.3 Smack . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.2.4 TOMOYO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.2.5 Yama . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.2.6 Outras solucoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.3 Security FS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.4 Netfilter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.5 TCG - Task Control Group . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.5.1 Arquitetura e implementacao . . . . . . . . . . . . . . . . . . . . . 64
4.5.2 Funcionamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
4.5.3 Subsistemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4.6 Conclusao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5 Framework IMN 81
5.1 Motivacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.2 Requisitos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.2.1 Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.2.2 Levantamento de Requisitos . . . . . . . . . . . . . . . . . . . . . . 84
5.2.3 Requisitos Consolidados . . . . . . . . . . . . . . . . . . . . . . . . 92
5.3 Arquitetura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
5.4 Implementacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
5.4.1 Ganchos Multifuncionais . . . . . . . . . . . . . . . . . . . . . . . . 97
5.4.2 Auto-protecao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
5.4.3 Interface Administrativa . . . . . . . . . . . . . . . . . . . . . . . . 107
5.4.4 Componentes externos . . . . . . . . . . . . . . . . . . . . . . . . . 109
6 Analises e testes 111
6.1 Atendimento de requisitos . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
6.1.1 Requisitos Funcionais . . . . . . . . . . . . . . . . . . . . . . . . . . 112
6.1.2 Requisitos de Manutencao . . . . . . . . . . . . . . . . . . . . . . . 114
6.2 Sistema de Seguranca opaco utilizando o framework IMN . . . . . . . . . . 115
6.2.1 modConsole - Modulo Administrativo . . . . . . . . . . . . . . . . . 117
6.2.2 modMonitor - Gerador de informacoes . . . . . . . . . . . . . . . . . 117
xxi


6.2.3 modResponse - Detector de Intrusao e Gerador de Respostas . . . . 119
6.2.4 modTargs - LKM Imunologico . . . . . . . . . . . . . . . . . . . . . 119
6.3 Simulacao de uso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
7 Conclusoes 125
Referencias Bibliograficas 129
A Ganchos Multifuncionais 135
xxiii


Lista de Tabelas
2.1 Paralelos entre o sistema imunologico e seguranca de redes de computadores
[23]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Analogia entre a arquitetura e o sistema imunologico humano. . . . . . . . 21
2.3 Relacionamento entre compoentes da Arquitetura Imuno e modulos do
prototipo ADenoIdS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.1 Exemplos de ofensores de manutencao de prototipos do Projeto Imuno
decorrentes de implementacoes invasivas ou utilizacao de ferramentas em
desenvolvimento. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
6.1 Recursos do framework IMN utilizados por cada modulo imunologico de
um sistema de seguranca simplificado. . . . . . . . . . . . . . . . . . . . . . 116
xxv


Lista de Figuras
2.1 Reacao entre receptor e antıgeno. . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Camadas de protecao do sistema imunologico humano. . . . . . . . . . . . 7
2.3 Modelo Estrutural proposto em [23]. . . . . . . . . . . . . . . . . . . . . . 12
2.4 Modelo de funcionamento proposto em [23]. . . . . . . . . . . . . . . . . . 12
2.5 Arquitetura de um analisador forense automatizado proposta em [30]. . . . 13
2.6 Mecanismo de resposta distribuıdo usando agentes moveis [20]. . . . . . . . 16
2.7 Modelo de ameaca considerado em [22]. . . . . . . . . . . . . . . . . . . . . 18
2.8 Nova Arquitetura de Seguranca inspirada nos sistema imunologico humano
[22]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.9 Visao dos sistemas inato e adaptativos na arquitetura imunologica. . . . . 21
2.10 Arquitetura detalhada do Framework Imuno [29]. . . . . . . . . . . . . . . 25
3.1 Relacionamento entre estados de um processo. . . . . . . . . . . . . . . . . 31
3.2 Fluxo de execucao de uma chamada de sistema. . . . . . . . . . . . . . . . 34
3.3 Fluxo de execucao de uma chamada de sistema Adaptado de [56]. . . . . . 35
3.4 Fluxo de execucao de uma operacao de escrita em disco no sistema de
arquivos EXT4. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.1 Funcionamento do sistema de controle de acesso do Linux. . . . . . . . . . 42
4.2 Arquitetura de Ganchos LSM. . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.3 TOMOYO: geracao automatica de domınios de seguranca baseada em nomes. 59
4.4 Arquitetura de ganchos do framework Netfilter. . . . . . . . . . . . . . . . 63
4.5 Exemplo de distribuicao de banda de rede baseado em grupos. . . . . . . . 66
4.6 Exemplo de distribuicao de recursos com diferentes criterios por recurso. . 67
4.7 Relacionamento entre as estruturas do TCG. Adaptado de [48]. . . . . . . 69
5.1 Timeline do Projeto Imuno. . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5.2 Arquitetura geral do framework IMN. . . . . . . . . . . . . . . . . . . . . . 94
5.3 Arquitetura do framework IMN, outra visao. . . . . . . . . . . . . . . . . . 96
5.4 Arquitetura do framework IMN. . . . . . . . . . . . . . . . . . . . . . . . . 97
5.5 Estrutura de um gancho multifuncional. . . . . . . . . . . . . . . . . . . . 99
xxvii


Capıtulo 1
Introducao
Segundo a visao tradicional de seguranca de sistemas computacionais, a especificacao
e implantacao de polıticas de seguranca em conjunto com implementacoes corretas e
configuracao adequada garantem a seguranca de um sistema [33]. Na pratica, contudo,
percebe-se que tanto polıticas quanto implementacoes estao sujeitas a falhas que compro-
metem a seguranca do sistema como um todo.
Neste contexto, necessita-se de novos mecanismos que garantam a seguranca de sis-
temas mesmo na existencia dessas eventuais falhas. Deseja-se, portanto, um novo nıvel
de seguranca, com recursos adicionais e modelos que representem melhor as condicoes em
que os sistemas computacionais encontram-se.
Partindo desta necessidade, diversos pesquisadores buscaram inspiracao em modelos
existentes na natureza, e encontraram um que representa muito bem o problema de se-
guranca em sistemas computacionais: o Sistema Imunologico Humano.
Alem de representar um modelo bastante proximo das condicoes em que a maioria das
redes de computadores se encontra, o sistema imunologico humano possui uma serie de
caracterısticas desejaveis a um sistema de seguranca, tais como deteccao de anomalias,
elaboracao de plano de resposta e contra-ataque [23].
Em 1999, o Laboratorio de Seguranca e Criptografia (LASCA) da Universidade Es-
tadual de Campinas (UNICAMP), iniciou um projeto de pesquisa chamado Imuno, o
qual se concentra no estudo dos princıpios do sistema imunologico humano aplicados em
seguranca computacional.
O foco daquele projeto era de explorar os paralelos entre o sistema imunologico humano
e sistemas de seguranca computacional dentro de uma visao integrada, e nao particulari-
zada em objetivos especıficos, tal como deteccao de intrucao ou recuperacao de ataques.
O projeto Imuno, portanto, busca desde entao construir um sistema de seguranca imu-
nologica geral, capaz de enfrentar ameacas desde o seu primeiro contato, passando por
medidas de contingencia e resposta, ate a total recuperacao do sistema, tal como o modelo
1

2 Capıtulo 1. Introducao
biologico.
Como fruto desta pesquisa, diversos prototipos de seguranca imunologica foram desen-
volvidos [22] [20] [30]. Estes prototipos tem em comum uma implementacao complexa, de
difıcil manutencao, e com grande utilizacao de recursos de nucleo do sistema operacional
onde sao implementados.
Com o crescimento da base de codigo da solucao proposta inicialmente, a complexi-
dade inerente a implementacao do sistema de seguranca imunologico geral almejado pelo
projeto passou a representar uma barreira para o avanco da pesquisa. Neste contexto,
em 2006, Martim Carbone propos um framework a ser utilizado como base comum para
implementacao dos diversos componentes do sistema de seguranca em desenvolvimento.
O objetivo da ferramenta era reunir toda a complexidade de implementacao de recursos
a nıvel de nucleo de sistema operacional, provendo uma API simplificada, em espaco de
usuario, aos demais pesquisadores do projeto Imuno, que poderiam, entao, concentrar
ainda mais seus esforcos na pesquisa de solucoes imunologicas, diminuindo a grande carga
que a implementacao de recursos no nıvel de kernel representava.
O trabalho de Carbone obteve sucesso na comprovacao de sua tese, resultando em um
prototipo capaz de comprovar a viabilidade de sua solucao.
Este trabalho, portanto, vem dar continuidade aquele, e tem como objetivo entregar
um framework funcional aos pesquisadores do projeto Imuno, atraves da consolidacao e
extensao do framework imunologico proposto por Carbone.
Este texto e organizado da seguinte forma: o Capıtulo 2 inicia a revisao bibliografica
realizada nesta pesquisa, apresentando alguns conceitos fundamentais sobre o funciona-
mento do sistema imunologico humano e os objetivos das pesquisas na area de seguranca
imunologica. Neste capıtulo serao apresentados tambem todos os trabalhos desenvolvidos
pelo projeto Imuno ate o presente momento, alem de referencias a pesquisas relacionadas.
Avancando com a revisao bibliografica, o Capıtulo 3 apresenta o funcionamento do
kernel Linux, plataforma sobre a qual este trabalho foi implementado, discutindo algumas
de suas caracterısticas fundamentais e introduzindo importantes estruturas do sistema que
serao amplamente utilizadas neste trabalho.
Finalizando a revisao bibliografica, o Capıtulo 4 traz uma visao de diversos aspectos
de seguranca do kernel Linux, apresentando algumas de suas importantes ferramentas.
O Capıtulo 5 discute o trabalho realizado nesta pesquisa. Neste capıtulo serao dis-
cutidas todas as etapas de desenvolvimento do framework IMN, desde sua concepcao,
atraves de sua analise de requisitos, passando pelos aspectos de projeto e implementacao
da solucao. Por fim, no Capıtulo 6, sera feita uma analise do trabalho desenvolvido, bem
como alguns testes funcionais, a partir do desenvolvimento de um sistema de seguranca
simplificado, capaz de exercitar as diferentes funcionalidades disponibilizadas pela API
do framework desenvolvido.

3
O Capıtulo 7 encerra esta dissertacao com algumas consideracoes finais sobre o traba-
lho e as principais linhas de pesquisa futura a serem seguidas pelo autor.


Capıtulo 2
Imunologia
2.1 Imunologia Biologica
O Sistema Imunologico Humano e um sistema biologico composto de diversas celulas,
orgaos e tecidos, cuja principal funcao e proteger o corpo contra a invasao de microbios1,
denominados patogenos [52].
A chave para o funcionamento do sistema imunologico esta na sua habilidade de dife-
renciar celulas self (ou seja, que fazem parte do corpo) de celulas non-self (estranhas ao
corpo) e na sua capacidade de eliminar as celulas non-self.
O sistema imunologico humano e dividido em sistema inato e sistema adaptativo. O
sistema imunologico inato representa a primeira linha de defesa do organismo e possui
resposta nao-especıfica (a mesma para a maioria dos patogenos), sendo muitas vezes
insuficiente. Seus principais componentes sao as barreiras fısicas e quımicas (pele, acidos
gastricos, proteınas do sangue) e celulas de deteccao nao-especıfica (fagocitos). O sistema
imunologico inato tem origem congenita e hereditaria, permanecendo inalterado ao longo
da vida.
Ja o sistema adaptativo e capaz de identificar especializadamente um agente pa-
togenico, respodendo de maneira mais eficiente. Este sistema tem capacidade de apren-
dizado e auto-ajuste, sendo capaz de memorizar um agente e responder de forma mais
rapida e eficiente no caso de uma nova exposicao.
O sistema imunologico adaptativo e a segunda camada de defesa do sistema imu-
nologico e seus componentes basicos sao celulas denominadas linfocitos, que podem ser
dos tipos B e T, e seus produtos: anticorpos e linfocinas. Ao contrario do sistema inato,
onde um receptor pode reconhecer varios antıgenos diferentes, no sistema adaptativo os
receptores dos linfocitos realizam reconhecimento especıfico.
1Microbios sao pequenos organismos causadores de infeccoes, tais como bacterias, vırus, parasitas efungos.
5

6 Capıtulo 2. Imunologia
O funcionamento geral do sistema imunologico e como segue: primeiro os patogenos
devem vencer as barreiras fısicas e quımicas do sistema inato, ou seja, penetrar na pele
ou sobreviver aos acidos estomacais. Caso essa primeira etapa seja vencida e o microbio
adentre o organismo, e hora do sistema imunologico iniciar a sua resposta, a qual e dividida
nas fases de deteccao, ativacao do sistema adaptativo e contra-ataque [23].
A fase de deteccao ocorre quando os receptores dos fagocitos reagem com os
antıgenos dos patogenos na corrente sanguınea (Figura 2.1). Nestes casos, inicia-se a
fagocitose, processo pelo qual uma celula envolve uma partıcula com seu proprio corpo,
dissolvendo o microbio em seu interior. Com essa dissolucao, o fagocito passa a produzir
moleculas de proteına chamadas MHC (Major Histocompatibility Complex) contendo frag-
mentos do antıgeno do microbio. Estas moleculas sao expelidas pela membrana plasmatica
dos fagocitos.
Figura 2.1: Reacao entre receptor e antıgeno.
A fase de ativacao do sistema adaptativo inicia-se com um processo de apre-
sentacao dos antıgenos estranhos aos linfocitos T, capazes de reconhecer antıgenos es-
pecıficos nas moleculas MHC na superfıcie dos fagocitos. Apos esta ativacao quımica do
sistema adaptativo, os linfocitos B e T atraıdos para o local reproduzem-se2, aumentando
o exercito de combate. Em seguida, estes linfocitos passam por um processo de maturacao
de afinidade, no qual sao evoluıdos de forma a aumentar ainda mais a sua afinidade com
o antıgeno em questao. Parte destes linfocitos sao convertidos em celulas de memoria
e passam a constituir uma memoria imunologica, a qual contem informacoes sobre os
antıgenos que serao usadas em futuras exposicoes.
Em seguida, inicia-se a fase de contra-ataque (tambem conhecida como resposta se-
cundaria ou especıfica). Estimulados pelos linfocitos T, os linfocitos B iniciam a producao
de anticorpos, que entao reagem com os antıgenos presentes na superfıcie dos patogenos,
2Processo conhecido como evolucao clonal

2.1. Imunologia Biologica 7
deixando-os marcados para destruicao por parte dos fagocitos. Os linfocitos T tambem
destroem as celulas infectadas, a fim de impedir a reproducao do organismo invasor.
Finalmente a infeccao e contida e os estımulos imunologicos vao diminuindo ate que
a resposta imunologica chegue ao fim.
O processo descrito deixa clara a existencia de diversas camadas de protecao existentes
no sistema imunologico. A Figura 2.2 ilustra estas diferentes camadas de protecao.
Figura 2.2: Camadas de protecao do sistema imunologico humano.
O sistema imunologico, portanto, possui uma serie de caracterısticas que conferem
eficacia na tarefa de manutencao da vida humana, atraves da protecao do organismo
contra ataques de agentes externos. Estas caracterısticas sao:
• Distribuicao e paralelismo: a deteccao de uma celula de defesa nao e iniciada por
algum mecanismo centralizador, mas quando alguma condicao nao usual e detectada
pela celula. Ademais, o sistema imunologico pode atuar em diferentes pontos do
organismo em um dado momento;
• Multiplas camadas de protecao: a atuacao do sistema imunologico humano acontece
atraves de diferentes mecanismos especializados que, cooperativamente, garantem a

8 Capıtulo 2. Imunologia
protecao do organismo;
• Diversidade: introduzindo uma variedade de indivıduos com caracterısticas parti-
culares de defesa e possıvel garantir a sobrevivencia de uma especie;
• Descartabilidade: nenhum componente isolado do sistema imunologico e essencial;
• Autonomia: o sistema imunologico como um todo nao requer gerenciamento ou
manutencao externos;
• Adaptabilidade e memoria: o sistema imunologico possui a capacidade de assimi-
lar a deteccao de novos patogenos, armazenando a habilidade de reconhecimento
adquirida na memoria imunologica. A capacidade de reconhecimento especializa-se
a cada agente patogenico similar reconhecido, tornando as resposta futuras mais
eficientes se comparadas as anteriores;
• Mudanca dinamica de cobertura: visando maximizar a capacidade de deteccao,
o sistema imunologico mantem uma amostra aleatoria de detectores que circulam
pelo corpo. Essa amostra e constantemente renovada atraves da morte de celulas e
a producao de novas celulas;
• Identificacao por comportamento: uma celula pode ser analisada atraves das
substancias que ela secreta;
• Deteccao de anomalia: o sistema imunologico tem a capacidade de detectar agentes
patogenicos atraves da identificacao de atividade nao usual;
• Deteccao de danos: muitos patogenos nao causam ameaca ao corpo e, nesse caso,
uma resposta imunologica para elimina-los poderia prejudicar o proprio corpo. En-
tretanto, a ocorrencia de danos em tecidos de um organismo e essencial para a
ativacao dos linfocitos T, que irao sobreviver equanto houver evidencias desses da-
nos. Essa caracterıstica coestimulatoria diminui as chances do sistema imunologico
desencadear uma reacao autoimune;
• Deteccao imperfeita: por possibilitar uma deteccao imperfeita ou parcial, o sis-
tema imunologico aumenta a flexibilidade na alocacao de recursos. Desta forma,
detectores menos especıficos podem responder a uma variedade maior de patogenos,
contudo irao ser menos eficientes na deteccao de um patogeno especıfico;
• Recrutamento dinamico: o sistema imunologico regula o numero de celulas de ma-
neira a desenvolver um contra-ataque suficiente para a quantidade atual de agentes
patogenicos. Assim que a ameaca e eliminada, essa quantidade de celulas e reduzida.

2.2. Imunologia Computacional 9
2.2 Imunologia Computacional
Diversos sistemas biologicos costumam ser estudados para fornecer inspiracao para o
desenvolvimento de solucoes da ciencia e engenharia. Dentre eles, o sistema imunologico
humano possui uma serie de princıpios que podem ser aplicados em seguranca computaci-
onal. A Imunologia Computacional explora estes princıpios com o objetivo de reproduzir
o comportamento do sistema imunologico humano em ambientes computacionais, visando
uma elevacao dos nıveis de seguranca destes ambientes.
Em 1999, no Laboratorio de Seguranca e Criptografia (LASCA) da Universidade Esta-
dual de Campinas (UNICAMP), iniciou-se um projeto de pesquisa denominado Imuno. Os
pesquisadores deste projeto revisaram trabalhos de pesquisa em imunologia computacional
e, motivados pelas diversas analogias observadas entre o sistema imunologico humano e as
necessidades de um sistema de seguranca computacional, propuseram o desenvolvimento
de uma arquitetura de seguranca baseada no modelo do sistema imunologico humano[23].
Apos estudo criterioso do funcionamento do sistema imunologico humano, o grupo
constatou que as pesquisas que vinham sendo desenvolvidas naquela epoca focavam ape-
nas em mecanismos isolados do sistema imunologico, deixando de lado a visao do seu
funcionamento integrado. Por este motivo, o projeto Imuno trabalha desde entao em
pesquisas relacionada a construcao de um sistema de seguranca imunologico geral, onde
seja possıvel detectar-se anomalias, elaborar um plano de resposta especializado e efe-
tuar o contra-ataque. O sistema deve ainda ter capacidade de aprendizado e adaptacao,
possibilitando, portanto, reacao contra ataques desconhecidos.
A proposta original [23] foi refinada [24] [25] e os principais aspectos de seguranca
imunologica, tais como analise forense [30] e resposta automatizada [20] foram estudados,
culminando com a concepcao de uma Arquitetura para Sistema de Seguranca Imunologico
Computacional completo[22] [25] [24].
Em seguida, foi feita a implementacao de um prototipo chamado ADenoIDS (Ac-
quired Defense System based on the Immune System), o qual implementa parcialmente
a arquitetura proposta no sistema operacional GNU/Linux. O prototipo ADenoIDS e
concentrado nas funcionalidades de deteccao e resposta automatica para ataques do tipo
buffer overflow remotos, podendo ser visto como um prototipo do sistema Imuno com
escopo reduzido.
Com o objetivo de facilitar o processo de desenvolvimento do sistema de seguranca
imunologico completo inicialmente proposto, em 2006 Carbone [29] iniciou o desenvolvi-
mento de um framework3 de seguranca imunologica em ambiente Linux4.
3Um framework e uma abstracao que une codigos comuns entre varios projetos de software, provendouma funcionalidade generica
4Neste documento o termo “Linux” sera utilizado para referenciar o nucleo (kernel) do sistema ope-racional GNU/Linux, desenvolvido por Linus Torvalds.

10 Capıtulo 2. Imunologia
Estes trabalhos sao apresentados com mais detalhes a seguir, nas Secoes 2.2.1, 2.2.2,
2.2.3, 2.2.4 e 2.2.5. Na Secao 2.2.6, serao listados outros projetos de pesquisa relacionados
a imunologia computacional.
2.2.1 Modelagem de um sistema de seguranca imunologico
Neste trabalho, Diego Fernandes, Fabrıcio de Paula e Marcelo Reis estabeleceram uma
analogia entre imunologia e seguranca de sistemas computacionais (Tabela 2.1).
Sistema Imunologico Seguranca Computacional
Sistema de filtragem composto por cılios, pele, muco-sas e acidos
Firewall de rede
Amıgdalas Bode expiatorio (boddy traps) armados pelo adminis-trador de seguranca
Insercao de DNA de vırus no interior de celulas ataca-das
Buffer overflow e instalacao de trojan horses
Deteccao de agentes patogenicos por macrofagos Sistema de deteccao de intrusao
Producao de moleculas MHC com fragmentos deantıgenos
Analise do comportamento de processos
Ativacao de linfocitos especıficos Analise forense
Antıgenos de agentes patogenicos Assinaturas digitais de ataques
Memoria Imunologica Alimentacao de uma base de dados
Destruicao de celulas contaminadas e de agentes pa-togenicos
Medidas de contencao, tais como finalizacao de pro-cessos e encerramento de conexoes
Tabela 2.1: Paralelos entre o sistema imunologico e seguranca de redes de computadores[23].
Avancando na analise dos paralelos biologicos computacionais, alguns prıncipios orga-
nizacionais do sistema imunologico foram considerados base importante para o desenvol-
vimento de um sistema de seguranca computacional:
• Descentralizacao e localidade: a acao de uma celula de defesa nao e iniciada por
um mecanismo centralizador, mas sim pela propria celula na constatacao de alguma
anormalidade. Esta abordagem elimina a existencia de um ponto central de falha e
permite a atuacao paralela em diferentes pontos de infeccao;
• Arquitetura multi-camada: o funcionamento do sistema imunologico depende da
combinacao de varios mecanismos diferentes de desesa. Cada um destes mecanismos
e especializado e resolve bem pequenos problemas. A combinacao destes mecanismos
e o que garante a defesa completa do organismo;
• Diversidade: o corpo humano pode ser exposto a um grande numero de agentes
patogenicos. Por este motivo, o sistema imunologico e capaz de identificar uma
grande variedade de invasores e agir de maneira especializada para cada um deles;

2.2. Imunologia Computacional 11
• Robustez e tolerancia a falhas: nenhuma celula componente de algum mecanismo e
essencial, por isso, em caso de comprometimento (infeccao ou morte) de uma celula,
nao ha comprometimento do funcionamento do sistema;
• Autonomia: o sistema imunologico humano nao requer nenhum tipo de gerencia-
mento externo para promover o seu funcionamento;
• Adaptabilidade e memoria: apesar de ser gerado (nascer) com algumas defesas
prontas, o sistema imunologico e capaz tambem de identificar agentes patogenicos
totalmente desconhecidos e desenvolver uma estrategia de defesa contra eles. Uma
vez que esta habilidade e desenvolvida, o sistema a perpetua, construindo uma
memoria biologica, de tal forma que em caso de nova exposicao a estrategia de
defesa ja seja conhecida;
• Auto-protecao: o sistema imunologico e capaz de defender nao somente celulas de
outros sistemas humanos, mas tambem e capaz de proteger as suas proprias celulas,
uma vez que estas tambem podem ser vıtimas de ataque de agentes patogenicos;
• Identificacao por meio de comportamento: alem da capacidade de detectar agentes
patogenicos, o sistema imunologico e capaz tambem de detectar anomalias atraves
do comportamento de celulas proprias do organismo, concluindo que estao conta-
minadas e atacando-as;
• Tamanho do exercito: o sistema imunologico humano e capaz de regular o tamanho
do ataque a agentes patogenicos, em termos de numero de linfocitos utilizados, de
maneira proporcional e suficiente.
Por fim o trabalho estabeleceu um modelo estrutural e um modelo de funcionamento
de um sistema computacional de seguranca imunologico, composto pelos sistemas inato
e adaptativo. O modelo estrutural definiu componentes capazes atender aos princıpios
organizacionais do sistema imunologico anteriormente apresentados. As interacoes entre
os componentes do modelo estrutural devem gerar comportamento global analogo ao
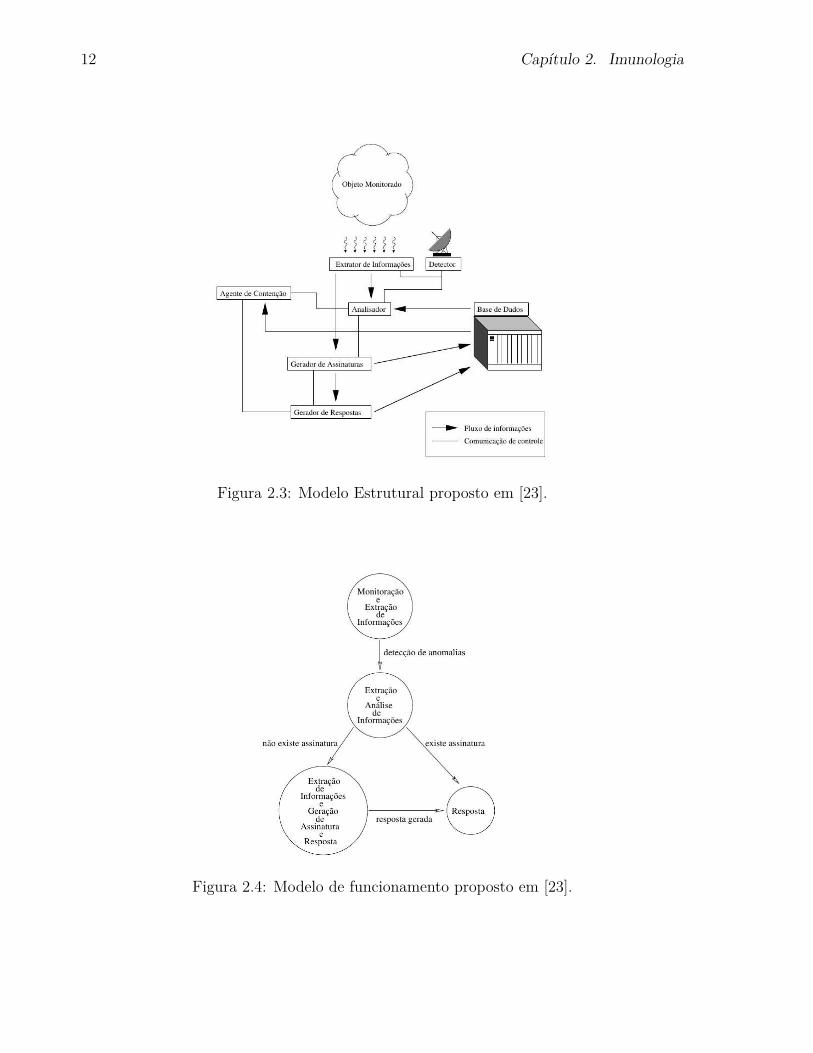
sistema imunologico humano. O modelo estrutural proposto e apresentado na Figura 2.3.
O funcionamento deste modelo e ilustrado na Figura 2.4.
2.2.2 Forense computacional aplicada em seguranca imu-
nologica
Forense computacional e uma forma de deteccao de intrusao postuma baseada em
evidencias, ou seja, uma invasao somente e detectada apos ter ocorrido com sucesso,
12 Capıtulo 2. Imunologia
Figura 2.3: Modelo Estrutural proposto em [23].
Figura 2.4: Modelo de funcionamento proposto em [23].

2.2. Imunologia Computacional 13
atraves da analise feita sobre o estado e o comportamento (evidencias) do sistema com-
prometido.
Do ponto de vista imunologico, um analisador forense automatizado corresponderia
ao modulo detector, conforme no modelo estrutural de sistema imunologico apresentado
na Figura 2.3.
A analise forense correlaciona diversas evidencias para definir a assinatura de um
ataque. Dentre estas evidencias podem estar o tipo de falha explorada, as acoes do
invasor, origem do ataque e outros. Estas evidencias e suas inter-relacoes podem ser
descritas previamente, baseando-se na experiencia do investigador. Desta forma, pode-se
criar uma base de dados de evidencias forenses e utiliza-la em um sistema automatizado
de analise forense.
Figura 2.5: Arquitetura de um analisador forense automatizado proposta em [30].
Macelo Reis, em sua tese de mestrado, criou uma arquitetura extensıvel para desen-
volvimento de um analisador forense automatizado capaz de coletar informacoes, iden-
tificar e correlacionar evidencias de uma intrusao. A arquitetura proposta utiliza um
modelo distribuido do tipo cliente-servidor, onde o cliente possui um modulo coletor de
informacoes e o servidor, batizado de estacao forense, tem o papel de identificar e cor-
relacionar as evidencias recebidas do cliente, na tentativa de detectar eventuais ataques
naquela maquina. A Figura 2.5 ilustra esta arquitetura.
O investigador deve determinar quais informacoes devem ser coletadas pelo modulo
coletor. Uma vez coletados, os dados devem ser enviados para o servidor utilizando
preferencialmente um canal seguro. O modulo coletor reune informacoes de fontes de
possıveis evidencias, abaixo listadas:

14 Capıtulo 2. Imunologia
• registradores e cache
• memoria
• estado do sistema (conexoes de rede, tabela de roteamento, processos em execucao,
usuarios logados, data e hora do sistema, dentre outras)
• trafego de rede
• dispositivos de armazenagem secundaria (analise de dados em disco)
A busca e extracao de evidencias e feita no servidor, de forma automatizada, atraves
da utilizacao de plugins especializados em subconjuntos ou categorias de evidencias. Se-
gundo o autor, diferentes tecnicas de deteccao de intrucao baseadas em evidencias estao
disponıveis, cada uma com pontos fortes e fracos. Contudo, nenhuma delas e totalmente
eficaz [7]. Desta forma, cada plugin representa uma tecnica de deteccao, e o empilha-
mento destes oferece um aumento da eficacia global do sistema de deteccao, conferindo a
caracterıstica de extensibilidade a arquitetura.
O autor iniciou um protopipo, o AFA (Automated Forensic Analyser). Este prototipo
implementou a arquitetura proposta limitando-se a coleta de informacoes na maquina
cliente e, no servidor, desenvolvimento de um plugin. Nao houve, contudo, testes para
exercitar o prototipo.
2.2.3 Resposta Automatica em Seguranca Imunologica
Dentro da visao de construcao de um sistema de seguranca imunologico geral, Diego
Fernandes, em sua dissertacao de mestrado, trabalhou no desenvolvimento de um me-
canismo de resposta automatica [20], parte integrante de um sistema de seguranca
imunologico, representando o modulo “Agente de Contencao” do modelo apresentado na
Figura 2.3.
Mecanismos de resposta devem disponibilizar um conjunto de recursos capazes de
retardar a acao de um ataque, bloquea-lo e restaurar o sistema a um estado seguro.
Ataques conhecidos devem possuir mecanismos especıficos e resposta, ao passo que devem
existir esquemas de contencao para ataques desconhecidos, visando reduzir o seu impacto,
uma vez que nao existem solucoes especıficas estes ataques.
O mecanismo de resposta desenvolvido e dividido em dois esquemas de resposta:
primaria e secundaria. As acoes de resposta do mecanismo sao classificadas em nıveis.
Acoes em nıvel de processo atuam no sentido de limitar a capacidade de processamento
de processos suspeitos, bem como restringir o acesso destes a outros recursos de sistema.
Ja as acoes em nıvel de rede atuam sobre o trafego de rede gerado por estes processos

2.2. Imunologia Computacional 15
suspeitos. As acoes desenvolvidas dispoem da capacidade de revogacao, para que em
casos onde processos sob suspeita sejam considerados legıtimos, possa-se retornar a sua
execucao normal. Ambos esquemas de resposta, primario e secundarios, atuam nestes
dois nıveis.
O mecanismo possui uma arquitetura distribuida e utiliza tecnologia de agentes moveis.
A Figura 2.6 ilustra a arquitetura do mecanismo, onde cada maquina da rede (ponto de
resposta) em um dado instante pode ter diferentes agentes moveis. Estes agentes, abaixo
listados, possuem funcionalidades distintas e interagem entre si de forma a coordenar os
esquemas de respostas.
• initAgent: agente de inicializacao. Responsavel pela inicializacao do sistema de
resposta;
• primaryresponseAgent: agente de resposta primaria. Responsavel pelo gerencia-
mento de respostas primarias em um ponto de resposta;
• secondaryresponseAgent: agente de resposta secundaria. Responsavel pelo geren-
ciamento de respostas secundarias em um ponto de resposta;
• alarmAgent: agente de alarme. Responsavel pela comunicacao entre os pontos de
resposta;
• logAgent: agente de registro. Responsavel por registrar em disco os eventos ocor-
ridos no mecanismo de resposta;
• directReactionAgent: agente de reacao direta. Responsavel pelo gerenciamento
de acoes de contecao diretas em um ponto de resposta;
• stimulatedReactionAgent: agente de reacao estimulada. Responsavel pelo geren-
ciamento de acoes de contencao estimuladas em um ponto de resposta.
Os agentes de resposta fazem uso de componentes locais de reacao, os quais dao suporte
aos agentes de resposta, implementando e executando todas as acoes possıveis de uma
resposta. O mecanismo implementado considera a diponibilidade das seguintes acoes em
componente local de reacao:
• Nıvel de processos:
– Limite de uso de memoria: capacidade de limitar a quantidade de memoria
fısica utilizada por um processo;
– Limite de consumo de CPU: capacidade de limitar o tempo de CPU utilizado
por um processo;

16 Capıtulo 2. Imunologia
– Numero maximo de conexoes: capacidade de limitar o numero de conexoes
abertas por um processo;
– Quantidade de processos filhos: capacidade de limitar o numero de processos
filhos criados por um processo;
– Limite de transacoes de acesso a disco: capacidade de limitar a leitura ou
escrita de dados em disco, em termos de volume de dados, por um processo;
– Limite de acesso a disco: capacidade de limitar operacoes de leitura ou escrita
em disco, em termos de permissoes, por um processo;
– Finalizacao de processos: capacidade de finalizar processos;
– Paralizacao de processos: capacidade paralizacao e eventual continuacao na
execucao de processos.
• Nıvel de rede:
– Bloqueio de trafego: capacidade de bloquear trafego por maquina, servico,
protocolo ou porta;
– Limite de conexoes: capacidade de limitar o numero de conexoes por servico
ou porta;
– Bloqueio de trafego por usuario: capacidade de bloquear trafego de rede por
usuario.
Figura 2.6: Mecanismo de resposta distribuıdo usando agentes moveis [20].

2.2. Imunologia Computacional 17
O funcionamento do mecanismo possui uma etapa de inicializacao, onde um initAgent
e criado. Este agente, por sua vez, cria agentes de resposta primaria e secundaria
(primaryresponseAgent e secondaryresponseAgent) para cada ponto de resposta. Uma
vez criados, os agentes de resposta movimentam-se para os seus respectivos pontos de res-
posta e criam um agente de registro (logAgent) para cada ponto. Uma vez ativado, o
mecanismo esta pronto para receber mensagens dos sistemas de deteccao de mau-uso ou
anomalia em seus nos, alertando sobre um ataque. Quando um agente de resposta recebe
uma mensagem dessas, ele cria um agente de reacao direta (directReactionAgent). O
agente de resposta cria tambem agentes de alarme (alarmAgents), os quais serao res-
ponsaveis por comunicar agentes de resposta em outros pontos de resposta sobre a de-
teccao e resposta que esta acontecendo.
O mecanismo desenvolvido requer a definicao de polıticas de resposta para cada pondo
de resposta do sistema. Estas polıcias devem estabelecer diferentes estrategias de respostas
primaria e secundaria, visando minimizar possıveis riscos de respostas sobre processos
validos. Os pontos de respostas devem ser distinguidos entre as classes: servidor externo,
servidor interno, estacao de trabalho e componente de rede. Cada uma dessas classes
possui a sua propria polıtica de resposta.
2.2.4 Arquitetura Imuno e ADenoIDS
O professor Fabrıcio de Paula, em sua tese de doutorado [22], reafirma a visao inicial
do projeto Imuno de que sistemas de deteccao de intrucao imunologicos que exploram
apenas parcialmente as caracterısticas do sistema imunologico humano, incorrem em um
alto ındice de alarmes-falsos (falsos positivos) devido a falta de uma visao geral do sistema
biologico.
Considerando uma visao geral do sistema imunologico humano, Fabrıcio defende a
hipotese de que e possıvel identificar ataques desconhecidos, por meio de analise au-
tomatica de evidencias de intrusao, tornando-os conhecidos. Um ataque desconhecido,
portanto, deve permanecer indetectavel ate o inicio da exploracao do alvo, momento no
qual o ataque comeca a gerar evidencias de intrusao suficientes para sua deteccao.
Para validar esta hipotese, o trabalho tem o objetivo de construir uma arquitetura de
seguranca computacional baseada no sistema imunologico humano, atraves da qual seja
possıvel a identificacao precisa de ataques conhecidos, deteccao de ataque desconhecidos
atraves de evidencias de intrusao, mecanismos de resposta para ambos os tipos de intrusao,
alem da capacidade de extracao de assinaturas de ataques desconhecidos de forma a torna-
los conhecidos.
Essa arquitetura foi concebida para proteger um ambiente formado por um conjunto
de computadores interligados em rede e com acesso a Internet. A Figura 2.7 ilustra

18 Capıtulo 2. Imunologia
o ambiente considerado. Neste ambiente, um ataque conhecido pode ser identificado e
bloqueado por um IDS baseado em conhecimento, um ataque desconhecido, contudo,
pode nao ser detectado inicialmente e ter sucesso na invasao da maquina atacada. Apesar
de concebida em nıvel de rede, a arquitetura e diretamente aplicavel em nıvel de host,
bastando para isso a definicao de diferentes assinaturas (baseadas em fluxo de informacoes,
chamadas de sistema, parametros de processo, dentre outros).
Figura 2.7: Modelo de ameaca considerado em [22].
A arquitetura proposta e uma evolucao do modelo inicial do projeto Imuno [23] e o
principal aspecto do sistema imunologico considerado foi a sua capacidade de tolerancia
a invasao. De fato, conforme visto na Secao 2.1, o sistema imunologico humano em
muitos momentos e invadido por patogenos que causam danos a saude antes que haja
uma reacao que consiga elimina-los. Apos tal invasao bem sucedida, contudo, o sistema
imunologico aprende a lidar com este tipo de patogeno, diminuindo ou eliminando o
impacto de exposicoes futuras, e tambem restaura o organismo protegido a uma condicao
saudavel. Os principais objetivos da arquitetura sao:
• Deteccao precisa de ataques conhecidos e resposta efetiva contra estes;
• Deteccao de ataques desconhecidos atraves da analise de evidencias de intrusao no
sistema;
• Habilidade de lidar com ataques desconhecidos de modo a manter o sistema em
condicoes aceitaveis durante a analise das evidencias;
• Habilidade de aprendizado a respeito de ataques previamente desconhecidos, de
modo a extrair assinaturas destes para deteccao futura;

2.2. Imunologia Computacional 19
• Habilidade de armazenamento de informacoes referentes ao ataque de forma a pos-
sibilitar analise futura;
• Restauracao de partes do sistema afetadas pela intrusao;
• Deteccao precisa de ataques que o sistema aprendeu automaticamente a reconhecer.
A Figura 2.8 apresenta a arquitetura proposta. Os retangulos de linha solida repre-
sentam os seus componentes e as setas de linha solida representam o fluxo de informacao
dentre estes componentes. As setas de linha tracejada representam o fluxo de controle
correspondente a ativacao de componentes e os retangulos de linha tracejada representam
um agrupamento logico de componentes.
Figura 2.8: Nova Arquitetura de Seguranca inspirada nos sistema imunologico humano[22].
Nesta arquitetura, a manipulacao de ataques conhecidos e feita atraves da deteccao
baseada em conhecimento (analise da ocorrencia de assinaturas de ataque conhecidas no
fluxo de informacao monitorado) associada a uma resposta especıfica (conjunto de medidas
de bloqueio do ataque identificado), realizada pelos componentes Detector Baseado em
Conhecimento(1) e Agente de Resposta Adaptativa (2).
Ja a deteccao de ataques desconhecidos e feita por meio de analise de evidencias de
intrusao, feita pelo componente Detector Baseado em Evidencias (3), atraves de busca
por possıveis violacoes de polıticas de seguranca no fluxo de eventos provenientes do com-
ponente Fonte de Informacao, e pelo componente Detector Baseado em Comportamento

20 Capıtulo 2. Imunologia
(6), atraves de diferente analise sobre estas mesmas informacoes. O Detector Baseado
em Comportamento busca nas informacoes que analisa comportamentos que extrapolem
limiares pre-estabelecidos para identificacao de uma provavel invasao. Este componente
recebe constantementes informacoes do Detector Baseado em Evidencias, utilizadas para
reforcar suas avaliacoes.
Para lidar com ataques desconhecidos, o componente Agente de Resposta Inata (5) e
acionado na ocorrencia de suspeita de invasao, iniciando medidas de contencao capazes de
retardar a evolucao do provavel ataque, sem contudo elimina-lo, reduzindo desta forma o
impacto de atuacao sobre falsos-positivos. Ademais, os componentes Extrator de Assina-
tura (7), Gerador de Respostas (8) e Repositorio (9) completam os requisitos necessarios
para lidar com ataques desconhecidos. O primeiro tem papel de, baseando-se nas in-
formacoes disponıveis no sistema de seguranca, extrair uma assinatura que identifique de
maneira precisa o ataque, permitindo facil identificacao em eventuais exposicoes futuras.
O Gerador de assinaturas, por sua vez, deve definir um conjunto de acoes de resposta a
serem impostas na ocorrencia de uma dada assinatura. O ultimo, Repositorio para Su-
porte Forense, e responsavel pelo armazenamento seguro das informacoes coletadas pelo
sistema.
Avancando na composicao da arquitetura, o componente Console (10) representa a
interface entre o administrador e sistema de seguranca, atraves da qual e possıvel o
ajuste de parametros de configuracao e visualizacao de resultados e alertas do sistema
o componente Fonte de Informacao. Completando a sua composicao, o componente Fonte
de Informacoes (4) tem papel de coleta, armazenamento temporario e disponibilizacao de
dados relevantes ao funcionamento dos componentes na arquitetura proposta.
Apesar de nao ilustrado na Figura 2.8, a arquitetura conta ainda com mecanismos
de auto-protecao, garantindo que os seus componentes continuem seguros e funcionais
mesmo durante a ocorrencia de uma invasao.
Esta arquitetura possui clara relacao com o sistema imunologico humano. A Tabela
2.2 ilustra algumas analogias entre a arquitetura e o sistema imunologico. Outra visao do
relacao da arquitetura com o sistema imunologico pode ser feita em termos da abrangencia
dos seus componentes com o funcionamento dos sistema imunologicos inato e adaptativo.
A Figura 2.9 ilustra essa visao.
Para fins de validacao das ideias introduzidas atraves de testes e analises de resultados
praticos, esta arquitetura foi parcialmente implementada em um prototipo de sistema de
seguranca voltado para identificacao e extracao de assinaturas de ataques a aplicacoes
do tipo buffer overflow. O prototipo desenvolvido foi batizado de ADenoIdS (Acquired
Defense System Based on the Immune System) 5.
5Segundo o autor, alem do significado direto da sigla, o nome do prototipo tambem refencia os termos“adenoides”, que sao nodulos linfaticos que contem celulas imunologicas especializadas em proteger o

2.2. Imunologia Computacional 21
Sistema Imunologico Seguranca Computacional
Console Imunidade adquirida artificialmente
Fonte de Informacao Fonte de proeınas self e nonself
Detector Baseado em Comportamento Deteccao de anomalias do sistema inato
Extrator de assinatura Digestao de antıgenos e apresentacao de seus fragmen-tos
Detector Baseado em Conhecimento Deteccao precisa atraves de celulas de memoria de altaafinidade
Agente de Resposta Adaptativa Resposta especıfica do sistema adaptativo
Gerador de respostas Producao de anticorpos especıficos
Tabela 2.2: Analogia entre a arquitetura e o sistema imunologico humano.
Figura 2.9: Visao dos sistemas inato e adaptativos na arquitetura imunologica.

22 Capıtulo 2. Imunologia
Modulo ADenoIdS Relacionamento com a Arquitetura Imuno
ADCON ConsoleADDS Fonte de InformacaoADEID Detector Baseado em EvidenciasADBID Detector Baseado em ComportamentoADIRA Agente de Resposta InataADSIG Extrator de AssinaturaADFSR Repositorio para Suporte Forense
Tabela 2.3: Relacionamento entre compoentes da Arquitetura Imuno e modulos doprototipo ADenoIdS.
O ADenoIdS foi desenvolvido para monitorar processos de um computador isolado, na
busca por evidencias de ataques do tipo buffer overflow remoto em processos vitimados.
Os componentes idealizados na arquitetura da Figura 2.8 foram implementados atraves
de modulos6. A Tabela 2.3 relaciona os modulos do prototipo com os componentes da
Arquitetura Imuno. Alem dos modulos, o prototipo implementou tambem uma ferra-
menta batizada de UNDOFS, a qual disponibiliza recuros capazes de restaurar sistemas
de arquivo, atraves de primitivas do tipo undo e redo.
Diversos testes com diferentes bases de dados foram feitos com o prototipo [22]. O
mecanismo de deteccao de evidencias apresentou taxas de falso-positivos e falsos-negativos
iguais a zero. O mecanismo de recuperacao foi capaz de restaurar o sistema a um estado
funcional, comprovando a sua eficacia, e as assinaturas geradas pelo modulo extrator de
assinaturas obtiveram precisa e automatica deteccao dos ataques em simulacoes de nova
exposicao.
Estes bons resultados permitiram ao autor comprovar a factibilidade da deteccao de
intrusao baseada em evidencias, bem como demonstrar a precisao do algoritmo de deteccao
desenvolvido por ele. Os resultados foram divulgados em publicacoes cientıficas [26] [21] e
tiveram boa aceitacao tanto na area de computacao evolutiva quanto na area de seguranca
de redes.
2.2.5 Framework Imuno
A partir da analise dos trabalhos anteriormente desenvolvidos no projeto Imuno, Mar-
tim Carbone notou uma questao comum a todos eles: alta complexidade de implementacao
dos conceitos propostos. Segundo sua avaliacao, o esforco envolvido no processo de desen-
sistema respiratorio humano, e IDS (Intrusion Detection System - Sistema de deteccao de Intrusoes).6Tres componentes da arquitetura nao chegaram a ser implementados no prototipo: Detector Baseado
em Conhecimento, Agente de Resposta Adaptativa e Gerador de Respostas.

2.2. Imunologia Computacional 23
volvimento dos prototipos de alguma forma diminuia o tempo util de concepcao e avaliacao
das solucoes, representando um consideravel ofensor na proposta inicial de desenvolver um
sistema imunologico de escopo geral e funcional.
Outra questao observada foi que, apesar de todos os trabalhos terem sido concebidos
sobre uma arquitetura comum, explorando diferentes mecanismos de sua composicao, as
suas implementacoes utilizavam arquiteturas de implementacao de software direferentes,
fazendo com que nao houvesse qualquer tipo de interoperabilidade funcional entre os
trabalhos.
Apos estudo detalhado das implementacoes, Carbone constatou ainda que os trabalhos
desenvolvidos possuiam complexa manutencao, uma vez que alteravam diversos mecanis-
mos internos do sistema operacional sobre o qual eram implementados.
Diante deste cenario, Carbone propos entao o desenvolvimento de uma base comum de
software a ser utilizada como plataforma para o desenvolvimento de modulos de seguranca
imunologicos. Esta ferramenta, portanto, deveria ser um framework que implementasse re-
quisitos comuns aos trabalhos de pesquisa em imunologia computacional e disponibilizasse
uma API (Application Programming Interface) simplificada, que pudesse ser acessada em
espaco de usuario pelos demais participantes do projeto.
Devido as caracteristicas dos requisitos dos sistemas imunologicos, tais como capaci-
dade de monitoramento e controle de recursos utilizados por processos, interceptacao de
chamadas de sistema, captura de trafego de rede, dentre outros, o framework, batizado
de Framework Imuno, foi implementado todo em nıvel de kernel do sistema operacio-
nal GNU/Linux, disponibilizando uma API a ser utilizada pelos processos imunologicos
diretamente do espaco de usuario.
O Framework Imuno foi projetado para atender os seguintes requisitos:
• Medidas de Prevencao:
– Controle de acesso
– Autenticacao
– Filtros de Rede
• Medidas de monitoramento:
– Monitoramento de chamadas de sistema
– Estado de processos ativos
– Captura de trafego de rede
– Registro de eventos
– Monitoramento de consumo de recusos de hardware por processos ativos

24 Capıtulo 2. Imunologia
• Medidas de Resposta:
– Controle de Recursos (cotas e garantias)
– Controle de atributos de processos (prioridade de escalonamento, ID, grupo,
etc)
– Restauracao do sistema (restauracao de danos provocados por ataques no sis-
tema de arquivos)
• Analise Forense:
– Sistema de arquivos (acesso ao estado corrente e historico de alteracoes)
– Memoria principal (acesso ao estado corrente e dumps para disco de regioes
especıficas para manutencao de historico de alteracoes)
– Trafego de rede (acesso ao historico de dados recebidos e enviados via rede)
• Auto-protecao:
– Protecao de processos imunologicos
– Protecao de repositorios forenses em disco
Em sua implementacao, Carbone utilizou ferramentas disponıveis e consolidadas no
Linux, considerando-as parte integrante de sua solucao, incorporou ferramentas extenas ao
Linux e, para os casos ainda assim nao atendidos, desenvolveu ferramentas que atendessem
aos requisitos levantados.
Dentre os componentes nativos do Linux utilizados no Framework Imuno estao: LSM,
Netfilter, ptrace(), syslog, controle de atributos via chamadas de sistema, /dev/mem
/dev/kmem, Linux Capabilities System e SEClvl. As ferramentas externas incorporadas
foram: CKRM, RelayFS e UNDOFS. Para completar o atendimento dos requisitos le-
vantados, foram implementados ainda uma infraestrutura de Ganchos Multifuncionais,
mecanismos de autoprotecao e mecanismos de bloqueio e desbloqueio administrativo. A
Figura 2.10 ilustra a arquitetura da solucao.
2.2.6 Outros Trabalhos
Diversos outros trabalhos de pesquisa em sistemas computacionais inspirados no sis-
tema imunologico humano estao disponıveis na literatura.
Um dos maiores grupos de pesquisa no segmento de seguranca computacional e o
grupo liderado por Stephanie Forest, pesquisador com diversos trabalhos de relevancia
publicados, dentre os quais trabalhos de deteccao de anomalias por selecao negativa [27]

2.2. Imunologia Computacional 25
Figura 2.10: Arquitetura detalhada do Framework Imuno [29].
[28] [31], propostas de arquitetura de sistemas imunologicos artificiais [39] [34] e trabalhos
de mecanismo de resposta automatica [60] [59].
O professor Dasgupta, juntamente com sua equipe de pesquisa, possui alguns trabalhos
de relevancia na area de seguranca computacional, nas areas de deteccao de intrusao
baseada em anomalias[19] e tecnicas de deteccao com a utilizacao de agentes moveis [17]
[18].
O trabalho [42], de Kephart et al., propoe ainda um sistema de anti-vırus inspirado
em principios de aprendizado do sistema imunologico humano.
Ademais, diversos trabalhos sobre sistemas imunologicos artificiais podem ser encon-
trados nos anais das edicoes da conferencia ICARIS (International Conference on Artificial
Immune Systems, especializada em reunir trabalhos de imunologia computacional.


Capıtulo 3
Kernel Linux
O conjunto basico de aplicacoes para o funcionamento de um equipamento de hard-
ware e conhecido como Sistema Operacional. O componente fundamental de um sistema
operacional e o seu nucleo, kernel, em ingles1. Os demais programas do sistema opera-
cional sao conhecidos como aplicacoes de usuario e geralmente disponibilizam recursos e
funcionalidades para usuarios finais do equipamento.
O principal proposito do nucleo de sistema operacional e fazer toda a interacao com
o hardware do equipamento e disponibilizar um ambiente que permita a execucao das
demais aplicacoes. Por este motivo, existe uma separacao conceitual entre os tipos de
codigo em execucao sobre um hardware: aplicacoes em nıvel usuario, que sao aplicacoes
menos privilegiadas que fazem uso do ambiente criado pelo nucleo do sistema operacional;
e aplicacoes em nıvel de kernel, que e o proprio codigo do nucleo, executando em nıvel
privilegiado e com acesso total aos recursos providos pelo hardware2.
Existe ampla disponibilidade de sistemas operacionais para as mais diferentes arquite-
turas de computadores modernos. Dentre os mais conhecidos na industria, pode-se citar
o Windows, OS/X, Solaris, HP/UX e o GNU/Linux 3. Este ultimo, foi o escolhido para
a implementacao deste trabalho, por motivos que serao devidamente apontados na Secao
3.1.
Este capıtulo tambem apresentara uma breve revisao de alguns importantes conceitos
do kernel Linux. A Secao 3.2 introduz aspectos gerais do kernel, enquanto as Secoes
1Neste texto, ambos termos “nucleo” e “kernel”, sao utilizados em referencias ao nucleo de sistemasoperacionais.
2Os sistemas operacionais dependem de recursos de hardware que implementem estes dois nıveis deprivilegio no acesso a recursos fısicos, de tal forma que aplicacoes em espaco de usuario nao possamultrapassar os limites impostos pelo nucleo.
3O termo GNU/Linux e uma referencia ao sistema operacional composto pelo kernel Linux e aplicacoesutilitarias do projeto GNU. Neste texto, o termo “Linux” referencia o kernel desenvolvido por LinusTorvalds.
27

28 Capıtulo 3. Kernel Linux
3.3, 3.4 e 3.5 discorrem sobre o funcionamento de tres importantes funcionalidades do
Linux: gerenciamento de processos, chamadas de sistema e gerenciamento de sistemas de
arquivos. Estes conceitos sao fundamentais no entendimento da solucao proposta nesta
dissertacao.
3.1 Historico
Motivado pela carencia de sistemas operacionais Unix de baixo custo, no ano de 1991
Linus Torvalds iniciou o desenvolvimento do Linux, um sistema operacional baseado em
sistemas Unix, sem, contudo, compartilhar codigo pre-existente.
A principal diferenca do sistema operacional Linux com relacao aos demais sistemas
operacionais existentes aquela epoca, estava na sua licenca de distribuicao. O Linux
foi inicialmente distribuıdo com a licenca GPL [4]. Esta licenca, garante que o codigo
fonte seja distribuıdo livremente, podendo ser utilizado, modificado e evoluıdo livremente
pelos usuarios, desde que respeitada a condicao de que os sub-produtos de codigos GPL
continuassem sendo distribuıdos sob esta mesma licenca.
O Linux ganhou rapidamente popularidade no ambiente universitario e, em pouco
tempo tinha alcance internacional. Hoje, o Linux e um kernel completo, rico em recursos
e distribuıdo para varias plataformas de hardware e continua sob constante evolucao,
atraves do trabalho colaborativo de milhares de programadores ao redor do mundo, ainda
sob forte controle do seu criador e principal mantenedor, Linus Torvalds.
O Linux e, contudo, apenas o nucleo do sistema operacional. O Linux torna-se um
sistema operacional completo quando combinado com aplicacoes em espaco de usuario.
Grande parte destas sao desenvolvidas pelo projeto GNU (GNU is not Unix). Diversas
instituicoes ao redor do mundo reunem o nucleo Linux com aplicacoes GNU e outras
mais, distribuindo montagens prontas para uso final do GNU/Linux. Estes sistemas sao
conhecidos como distribuicoes Linux. Uma lista nao exaustiva de distribuicoes seria:
Gentoo, Ubuntu, Mandriva, Suse, Slackware, Debian, dentre outras.
Por tratar-se de um sistema operacional livre, com codigo fonte disponıvel e por ser
um sistema moderno e amplamente utilizado na academia e na industria, este trabalho e
implementado utilizando este sistema.
3.2 Aspectos Gerais
O GNU/Linux e um sistema operacional multiusuario. Esta caracterıstica implica que
aplicacoes de diferentes usuarios podem ser executadas de maneira concorrente, sem que
quaisquer uma delas tenha conhecimento da existencia das demais. Um sistema operaci-

3.3. Gerenciamento de Processos 29
onal multiusuario demanda uma serie de cuidados em sua implementacao, que garantam
um mınimo de seguranca para aplicacoes de diferentes usuarios, a saber: protecao de
memoria, autenticacao e controle de acesso.
O GNU/Linux e tambem um sistema operacional multiprocessado e multiprocessa-
dor. Em um sistema multiusuario, espera-se a existencia de varios processos de forma
simultanea. Portanto, em sistemas com um numero de processos maior que o numero de
CPUs disponıveis, o sistema operacional deve ser capaz de fazer uma divisao deste es-
casso recurso, preservando a nocao de que processos de usuario nao tem conhecimento da
existencia dos demais processos. Esta caracterıstica, conhecida como multiprocessamento,
onde mais de um processo utiliza “simultaneamente um unico processador, tambem aplica-
se em sistemas com mais de um processador, ou multiprocessados, que podem possuir,
um numero maior de processos que o numero de processadores.
E importante observar que o termo “simultaneamente, neste contexto, nao esta em-
pregado em seu sentido literal, uma vez que um unico CPU e capaz de executar uma unica
instrucao em um dado instante. Desta forma, a caracterıstica de multiprocessamento de
sistemas operacionais e obtida atraves de uma multiplexacao no tempo dos diferentes pro-
cessos que concorrem pelos recursos de processamento. Esta multiplexacao e feita pelo
escalonador de processos do sistema operacional. O funcionamento do escalonador do
Linux sera apresentado na Secao 3.3.1.
Outras importantes caracterısticas do Linux sao: reentrancia e preempcao. Um kernel
reentrante permite que mais de uma aplicacao de espaco de usuario esteja executando
em modo kernel em um dado instante. Esta abordagem exige um cuidado especial no
sincronismo entre processos, uma vez que pode haver concorrencia na utilizacao de estru-
turas internas do kernel. A preempcao, por sua vez, significa que uma rotina em nıvel de
kernel pode ser interrompida, de forma a permitir a execucao de outras atividades, sendo
retomada em momento futuro, criando a ilusao de que multiplas rotinas de kernel sao
executadas simultaneamente.
Por fim, o kernel Linux e do tipo monolıtico, contudo, pode admitir a inclusao e
exclusao dinamica de codigo objeto, atraves do mecanismo de Linux Kernel Modules
(LKMs).
3.3 Gerenciamento de Processos
Processos sao a abstracao fundamental de um sistema operacional. Um processo e
uma instancia em execucao de um determinado programa [16]. Um dado processo possui
tambem uma serie de recursos atribuıdos a ele, tais como arquivos abertos, sinais penden-
tes, informacoes de estado, espaco de memoria, uma ou mais threads de execucao, dentre
outros atributos.

30 Capıtulo 3. Kernel Linux
O Linux disponibiliza para processos uma abstracao de processador e memoria virtual,
dando a estes a ilusao de que eles sao unicos e utilizam o hardware exclusivamente. O
processador virtual e disponibilizado pelo escalonador de processos, que sera detalhado
a seguir. A memoria virtual permite que processos nao tenham acesso ao espaco de
enderecamento de outros processos. Diferentes threads de um mesmo processo, contudo,
compartilham o mesmo espaco de memoria.
Todos estes recursos e informacoes sobre processos manipulados pelo Linux ficam ar-
mazenados em estruturas de dados conhecidas como descritores. Um descritor de processo
e uma estrutura do tipo struct task_struct. Uma listagem parcial dos atributos ar-
mazenados nesta estrutura e listado a seguir:
struct task_struct {
...
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
pid_t pid;
pid_t tgid;
struct files_struct *files;
struct signal_struct *signal;
struct sigpending pending;
struct sched_entity se;
int on_cpu;
int on_rq;
int prio, static_prio, normal_prio;
struct task_group *sched_task_group;
struct css_set __rcu *cgroups;
struct task_struct __rcu *parent;
struct list_head children;
const struct cred __rcu *cred;
char comm[TASK_COMM_LEN];
...
};
Processos podem estar em diferentes estados. Estes estados sao descritos abaixo e
relacionados na Figura 3.1. O estado de um processo fica armazenado na variavel inteira
state, do seu descritor de processo.
• RUNNING: estado em que um processo esta pronto para ser executado. O processo
pode estar realmente em execucao em um processador, ou pode estar aguardando
pela sua fatia de tempo de processamento, em uma fila de execucao;

3.3. Gerenciamento de Processos 31
• INTERRUPTIBLE: estado em que um processo esta bloqueado ou “dormindo”. Este
estado e mantido enquanto um processo aguarda por uma condicao necessaria a con-
tinuacao da sua execucao, tal como a conclusao da leitura de um arquivo em disco,
por exemplo. Quando tal condicao torna-se verdadeira, o kernel muda o estado do
processo para RUNNING, transferindo novamente este para uma fila de execucao. Pro-
cessos no estado INTERRUPTIBLE podem ser acordados antes da condicao pela qual
aguardam tornar-se verdadeira, por meio do recebimento de um sinal proveniente
de outro processo;
• UNINTERRUPTIBLE: estado semelhante ao anterior. Neste estado, contudo, o processo
sempre permanecera bloqueado enquanto aguarda por uma condicao, nao sendo
desbloqueado para responder a sinais vindos de outros processos;
• ZOMBIE: estado de um processo logo apos a sua finalizacao, equanto o seu descritor
ainda existe. A liberacao do descritor de um processo finalizado deve ser feita pelo
processo pai, atraves da chamada de sistema wait4();
• STOPPED: estado no qual um processo esta paralisado e nao pode retomar sua
execucao. Este estado e obtido quando um processo recebe o sinal SIGSTOP.
Figura 3.1: Relacionamento entre estados de um processo.

32 Capıtulo 3. Kernel Linux
3.3.1 Escalonador CFS
O escalonador de processos do Linux e o componente responsavel pela criacao da
abstracao de um processador virtual para um determinado processo. Este componente
cria a ilusao de que cada processo possui um processador dedicado.
Na verdade, o trabalho deste componente e interromper um processo em execucao e
selecionar o proximo processo a ser executado, sendo portanto o coracao de um sistema
operacional multiprocessado. A escolha do processo e feita atraves de analise algorıtmica
de diversos fatores, dentre eles o estado do processo, prioridade de execucao e polıtica de
escalonamento. A interrupcao de um processo, por sua vez, acontece quando a fatia de
tempo estabelecida a um processo acaba ou quando um processo sofre uma interrupcao.
O algoritmo de escalonamento utilizado no Linux, a partir da versao 2.6.23, e o Com-
pletely Fair Scheduler (CFS). Este algoritmo tem como objetivo uma divisao justa de
tempo entre processos sem, contudo, prejudicar as necessidades de interatividade do sis-
tema. Do ponto de vista de um escalonador, justica significa uma evolucao coerente entre
processos concorrentes. O contrario de justica seria um avanco significativo de um pro-
cesso em detrimento de outro, que ficaria esperando por um longo perıodo de tempo para
utilizar o processador. Sucessor do algoritmo O(1) [6], este escalonador busca tambem
corrigir algumas deficiencias de seu predecessor [49].
O CFS possui uma estrutura modular, implementando diferentes classes (ou polıticas)
de escalonamento. A classe normal de compartilhamento de tempo entre processos e cha-
mada SCHED_OTHER. As demais classes disponıveis sao: SCHED_RT (real-time), SCHED_FIFO
(First In First Out) e SCHED_RR (Round Robin).
O CFS usa uma unica estrutura de arvore, do tipo red-black tree (arvore RB) [9],
por CPU e baseia-se no tempo de execucao (p->se.vruntime) para rastrear todos os
processos executaveis do sistema. Portanto, ideias como: prioridade de filas de execucao,
identificacao de processos interativos e fatias de tempo baseadas em prioridade, todas
utilizadas no escalonador O(1), nao estao presentes no CFS.
Este escalonador introduz ainda as nocoes de escalonamento justo em nıvel de gru-
pos (group-fair) ou em nıvel de usuarios (user-fair). Justica de escalonamento em nıvel
de grupo atribui tempo de processamento equivalente a diferentes grupos de processos.
Escalonamento justo a nıvel de usuario, por sua vez, busca um equilıbrio de tempo de
execucao de processos pertencentes a diferentes usuarios do sistema operacional. A Secao
4.5 ilustra a utilizacao destes conceitos por parte de diferentes subsistemas do framework
TCG.
Portanto, o CFS foi projetado para contemplar os seguintes objetivos:
• Oferecer bom desempenho interativo ao mesmo tempo em que oferece utilizacao
maxima de CPU;

3.4. Chamadas de sistema 33
• Oferecer distribuicao justa entre as entidades escalonaveis. Estas entidades podem
ser usuarios, grupos de usuarios, “containers” (grupos de processos) e processos;
• Estrutura modular, introduzindo a nocao de classes de escalonamento.
A logica de escalonamento do CFS e a de sempre tentar escalonar o processo cujo
atributo se.vruntime, que corresponde ao tempo real de execucao do processo norma-
lizado pelo numero total de processos, possua o menor valor, tentando assim, modelar
um sistema de multiprocessamento ideal, onde todos os processos teriam o seu tempo de
execucao igual a qualquer momento.
A estrutura basica do escalonador e a sua fila de execucao, definida atraves da estrutura
struct rq. O CFS define uma unica fila de execucao para cada CPU do sistema, nao
possuindo a nocao de filas diferenciadas de execucao.
As filas de execucao do CFS sao ordenadas de acordo com o valor do atributo
p->se.vruntime. Este valor, portanto, e utilizado para determinar o posicionamento
de novas entidades na arvore RB da fila.
Esta arvore define uma linha de tempo para execucoes futuras. O CFS sempre sele-
ciona para escalonamento o elemento mais a esquerda da arvore. Conforme um processo
executa, ele e colocado mais a direita da arvore, garantindo, contudo que todos os proces-
sos executaveis tornem-se em algum momento o elemento mais a esquerda na estrutura.
Em suma, o CFS permite a execucao de um processo por um determinado tempo.
Quando um processo escalona (ou um tick do escalonador acontece), o uso de CPU daquele
processo e contabilizado. O tempo medido e, entao, somado ao valor atual do atribuıdo
p->se.vruntime. Uma vez que este valor torne-se suficientemente grande para que outro
processo se torne o elemento mais a esquerda da arvore RB, o novo elemento e escalonado
e o processo atual sofre preempcao.
3.4 Chamadas de sistema
Chamadas de sistema representam a interface padrao de comunicacao entre aplicacoes
no espaco de usuario e nucleo de sistemas operacionais [61]. No Linux, as chamadas de
sistema sao a unica forma valida de comunicacao entre processos de usuario e o kernel4.
Chamadas de sistema sao invocadas por processos em espaco de usuario atraves de
chamadas de funcao presentes em bibliotecas de programacao, tal como GLIBC [3]. Estas
funcoes intermedeiam o acionamento de chamadas de sistema, tipicamente fazendo alguns
4No kernel Linux, e relativamente comum a utilizacao de diferentes sistemas de arquivos virtuais(pseudo-filesystems) para troca de informacoes kernel-userspace. Esta abordagem, contudo, utiliza cha-madas de sistema em ultima instancia, em operacoes como abertura, leitura e escrita sobre arquivos dopseudo-filesystem.

34 Capıtulo 3. Kernel Linux
ajustes sobre os parametros informados na chamada de funcao feita pela aplicacao, e
acionando as chamadas de sistema. A Figura 3.2 ilustra este processo.
Figura 3.2: Fluxo de execucao de uma chamada de sistema.
O Linux dispoe atualmente de 382 chamadas de sistema. A lista completa de chamadas
esta disponıvel em [2]. Cada uma destas chamadas possui um escopo especıfico e bem
definido. Um exemplo de implementacao de uma chamada de sistema do kernel Linux e
ilustrado abaixo:
asmlinkage long sys_getpid(void)
{
return current->tgid;
}
O modificador asmlinkage indica ao compilador que a funcao definida e uma chamada
de sistema. O Linux adota ainda o padrao de prefixo “sys_” em suas chamadas de sistema.
Cada chamada do kernel e identificada atraves de um numero. Este numero e utilizado por
funcoes em espaco de usuario para identificar a chamada de sistema a ser acionada. Desta
forma, e importante que uma chamada sempre possua o mesmo numero, independente de
compilacao, caso contrario aplicacoes em espaco de usuario podem falhar totalmente em
caso de nova compilacao do kernel.
Como nao e possıvel a aplicacoes de espaco de usuario fazer chamadas de funcao de
kernel, sistemas operacionais lancam mao de recursos de hardware para obter o compor-
tamento desejado na interface de chamadas de sistema. Em arquiteturas x865, o processo
e como segue:
• Uma funcao em espaco de usuario escreve no registrador eax do processador o
numero da chamada de sistema que deseja executar e, em seguida, atraves de meca-
nismos de hardware, sinaliza ao kernel que deseja executar uma chamada de sistema.
A passagem de parametros segue a mesma abordagem, utilizando outros registra-
dores do processador para armazenamento dos parametros (ebx, ecx, edx, esi e
edi);
5Em outras arquitetura, o processo e semelhante, guardadas as particularidades de cada processador.

3.5. Sistemas de Arquivos 35
• Uma vez em espaco de kernel, a funcao system_call() (tratador de chamadas de
sistema) verifica o numero da chamada desejada e, caso se trate de uma chamada
valida, procede com a execucao da chamada desejada;
• Apos a execucao da funcao de kernel alvo da chamada, o tratador system_call()
escreve o valor de retorno no registrador eax, e sinaliza ao hardware para retornar
a espaco de usuario;
• Ao ter seu processo novamente escalonado, a funcao da biblioteca responsavel pelo
acionamento da chamada de sistema le o valor retornado e prossegue com a sua
execucao, alheia a toda a complexidade envolvida no processo de execucao da cha-
mada.
A Figura 3.3 ilustra este processo.
Figura 3.3: Fluxo de execucao de uma chamada de sistema Adaptado de [56].
3.5 Sistemas de Arquivos
A implementacao de diferentes sistemas de arquivos no kernel Linux e feita atraves
de um middleware chamado Virtual File System (VFS). Este importante componente do
Linux disponibiliza uma interface comum para a implementacao de qualquer sistema de
arquivos do sistema operacional, inclusive sistemas de arquivos especiais, como aqueles
utilizados por dispositivos ou pelo pelo proprio kernel, como o procfs, por exemplo.
Esta interface implementa uma camada de abstracao com todas as operacoes basicas
possıveis em sistemas de arquivos. Para viabilizar tal implementacao, todos estes sistemas
devem considerar as mesmas abstracoes inerentes a sistemas de arquivos introduzidas pelo
VFS.
Desta forma, para qualquer chamada de sistema relacionada a manipulacao de arqui-
vos, como a chamada write(), por exemplo, o trabalho comum a realizacao da operacao,
tal como checagem de permissoes de acesso, e feito pelo VFS. Os detalhes de imple-
mentacao inerentes a um tipo especıfico de sistema de arquivo, por outro lado, e executado
pela implementacao do sistema em si.

36 Capıtulo 3. Kernel Linux
A Figura 3.4 ilustra o fluxo de execucao em uma operacao de escrita sobre um arquivo
no Linux.
Figura 3.4: Fluxo de execucao de uma operacao de escrita em disco no sistema de arquivosEXT4.
O comportamento do VFS, e consequentemente de todos os sistemas de arquivos do
Linux, considera as seguintes abstracoes:
• Sistema de arquivos (filesystem): organizacao hierarquica6 com uma estrutura es-
pecıfica. Sistemas de arquivos devem conter arquivos, diretorios e outras informacoes
de controle associadas. Objetos deste tipo estao sujeitos a um conjunto de operacoes,
tais como criacao, montagem e desmontagem;
• Arquivo (file): uma sequencia de bytes, onde o primeiro byte marca o inıcio do
arquivo e o ultimo byte identifica o seu final. Arquivos possuem atributos, como o
seu nome, utilizados na sua identificacao e credenciais, utilizados em checagens de
controle de acesso. Arquivos tambem estao sujeitos a algumas operacoes especıficas,
tais como abertura, leitura, escrita, dentre outras;
• Diretorio (directory): arquivos especiais que contem referencias para outros ar-
quivos, utilizados na composicao da hierarquia de sistemas de arquivos. Diretorios
possuem as mesmas caracterısticas de arquivos regulares e estao sujeitos as mesmas
operacoes. Ademais, algumas operacoes sobre arquivos sao especıficas para criacao
e remocao de diretorios (mkdir e rmdir);
• Caminho (path): uma sequencia de diretorios dentro de um hierarquia, tal como
“/imuno/tcg/suspects”;
• Entrada de diretorio (dentry): componentes de um caminho. No exemplo anterior,
imuno, tcg e suspects sao dentries;
6No Linux, todos os sistemas de arquivos sao ancorados, ou “montados”, em um determinado pontode uma hierarquia global unica (“/”). Desta forma, todos os sistemas de arquivos estao dentro de umunico namespace.

3.5. Sistemas de Arquivos 37
• Inode: o Linux diferencia as informacoes associadas a arquivos do conceito de
arquivo propriamente dito. Estas informacoes, conhecidas como metada, ficam ar-
mazenadas e objetos do tipo inode. Estes objetos armazenam informacoes como
credenciais de acesso, data de criacao, tamanho, data de modificacao, atributos
estendidos (xattr), dentre outras. Inodes tambem estao sujeitos a um conjunto
particular de operacoes, tais como link, symlink, mknod e setxattr;
• Super bloco (superblock): estrutura responsavel pelo armazenamento de in-
formacoes de controle (metadata) de sistemas de arquivos.
A implementacao de sistemas de arquivos no Linux e feita atraves da definicao de
callbacks7 para as diversas operacoes inerentes a cada tipo de objeto do VFS. Um sistema
de arquivo deve definir tais funcoes, e declara-las ao VFS atraves das seguintes estruturas:
• struct super_operations: operacoes sobre objetos do tipo superblock;
• struct inode_operations: operacoes sobre objetos do tipo inode;
• struct dentry_operations: operacoes sobre objetos do tipo dentry;
• struct file_operations: operacoes sobre objetos do tipo file.
A implementacao de sistemas de arquivos atraves da API do VFS, que manipula
os diferentes objetos de sua abstracao com o mesmo conjunto de operacoes, baseado
em callbacks, permite aos mais diferentes sistemas de arquivos uma implementacao com
caracterısticas bastante similares. Atualmente, o Linux possui implementados mais de 50
(cinquenta) tipos diferentes de sistemas de arquivos e, gracas a esta abordagem, todos
podem interoperar de maneira simples e transparente.
7Callbacks sao trechos de codigo executaveis que sao passados como parametro para outros trechos decodigo. Em C, as callbacks sao implementadas na forma de ponteiros para funcoes.


Capıtulo 4
Ferramentas de seguranca Linux
Em 1996, o Departamento de Defesa dos Estados Unidos publicou um padrao a ser
adotado na avaliacao do nıvel de seguranca de sistemas computacionais: DoDD 5200.28-
STD[51]. Dentre os requisitos de seguranca fundamentais de sistemas computacionais
apontados pelo documento, estava a necessidade de que tais sistemas deveriam definir uma
polıtica de seguranca a ser utilizada. Tal polıtica poderia ser de dois tipos: mandatoria
(MAC) ou discricionaria (DAC).
Polıticas DAC (Discretionary Access Control) consistem em polıticas onde a metodo-
logia de controle de acesso e baseada na identidade das entidades do sistema e na sua
autorizacao para acessar os recursos do sistema. Neste sistema, o usuario tem o poder
sobre a informacao de sua propriedade, sendo capaz de permitir o acesso de terceiros aos
objetos de acordo com sua propria vontade.
Ja nas polıticas MAC (Mandatory Access Control), o controle de acesso e feito baseado
na comparacao de rotulos de seguranca atribuidos a objetos do sistema com o nıvel de
acesso atribuıdo aos sujeitos que tentam acessa-los. Nesta metodologia, um sujeito nao
pode permitir a outro sujeto o acesso a um determinado objeto, mesmo que o primeiro
possua acesso a este. Existe, portanto, a figura de um administrador de polıticas de
seguranca, o qual centraliza a responsabilidade pelo estabelecimento dos nıveis de acesso.
Ate a versao 2.4 do Linux, o modelo de controle de acesso aos recursos do sistema
operacional era meramente discricionario (DAC), baseado em usuarios, grupos, listas de
controle de acesso e capacidades. O acesso a arquivos e recursos do sistema era feito
baseado no conceito de propriedade e atributos de permissao de acesso de terceiros para
cada um destes recursos e nao existia qualquer tipo de suporte para mecanismos de
seguranca mais sofisticados.
O Modelo de seguranca atual, contudo, e flexıvel e permite ao administrador do sistema
escolher dentre polıticas DAC ou MAC, sendo que primeira possui implementacao unica no
kernel e e considerada o comportamento padrao do sistema; e a segunda e implementada
39

40 Capıtulo 4. Ferramentas de seguranca Linux
na forma de modulos de seguranca e e oferecida em diferentes solucoes.
A Secao 4.1 deste capıtulo apresentara o funcionamento do sistema de controle de
acesso do Linux, considerando sua arquitetura e funcionamento padrao (discricionario). A
Secao 4.2 apresentara o framework LSM (Linux Security Modules), utilizado para estender
as funcionalidades de controle de acesso do Linux atraves da implementacao de diferentes
sistemas de controle de acesso mandatorio. Essa Secao tambem apresentara brevemente
as solucoes MAC disponıveis no Linux padrao e alguns projetos de pesquisa relacionados.
Este capıtulo abordara ainda outros recursos relacionados a seguranca no ambiente do
sistema operacional Linux, a saber: SecurityFS, um sistema de arquivos virtual utilizado
como interface para modulos LSM (Secao 4.3); Netfilter, um framework para interceptacao
e filtro de pacotes de rede (Secao 4.4); e Task Control Group, um framework para agru-
pamento de processos e contabilizacao de uso de recursos por estes grupos, utilizado para
monitorar o uso de recursos do sistema operacional e prevenir abusos (Secao 4.5).
4.1 Sistema de Controle de Acesso
O sistema de controle de acesso do Linux considera diferentes objetos em suas che-
cagens de seguranca. As checagens sao feitas em nıvel de kernel nas situacoes onde um
objeto atua sobre outro.
Estes objetos (objects1) sao diferentes componentes do sistema operacional que podem
ser manipulados diretamente por aplicacoes em espaco de usuario, podendo ser: proces-
sos, arquivos e inodes, sockets, message queues, segmentos de memoria compartilhada,
semaforos e chaves. Estes objetos possuem um conjunto de credenciais (credentials),
variavel de acordo com o tipo de objeto.
As credenciais armazenadas em objetos do tipo arquivo podem variar de acordo com o
sistema de arquivos utilizado, podendo incluir as seguintes informacoes: UID, GID, modo,
Windows user ID, ACLs, rotulo LSM, bits de escalada de privilegios (SUID e SGID), e
bits de capacidades (capabilities mask). Ja as credenciais de processos podem ser: UID,
GID, grupos (/etc/groups), chaves e campo LSM. As informacoes de credenciais de
processos ficam armazenadas em sua estrutura task struct atraves de dois ponteiros
para estruturas do tipo cred: real cred e cred. Estas estruturas possuem a seguinte
assinatura2:
struct cred {
...
1Os termos em fonte <negrito italico> representam a nomenclatura utilizada no Linux para identi-ficar os componentes do seu sistema de controle de acesso.
2Apenas campos que armazenam informacoes de credenciais estao exibidos abaixo. Informacoes decontrole estao omitidas.

4.1. Sistema de Controle de Acesso 41
kuid_t uid; /* real UID */
kgid_t gid; /* real GID */
kuid_t suid; /* saved UID */
kgid_t sgid; /* saved GID */
kuid_t euid; /* effective UID*/
kgid_t egid; /* effective GID*/
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less sec management */
void *security; /* subjective LSM security */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct user_struct *user; /* real user ID subscription */
kernel_cap_t cap_inheritable; /* caps children can inherit */
kernel_cap_t cap_permitted; /* caps we’re permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
unsigned charjit_keyring; /* keyring */
struct key *thread_keyring; /* this thread’s keyring */
struct key *request_key_auth; /* assumed request_key authority */
struct thread_group_cred *tgcred; /* thread-group shared credentials */
...
};
Um subconjunto das credenciais de um objeto, o seu objective context, e utilizado
nas avaliacoes de controle de acesso do Linux quando tal objeto e acessado. Em sistemas
de arquivo Linux o contexto objetivo e representado pelo conjunto UID e GID (Group
IDentification - IDentificacao de Grupo). Em processos, o contexto objetivo e represen-
tado pela estrutura apontada pelo ponteiro struct cred *real cred.
Outra definicao importante considerada e a de sujeito (subject), que representa uma
entidade que esta exercendo uma acao sobre outro. O exemplo mais direto de sujeito sao
os processos do sistema operacional, uma vez que tratam-se de instancias em execucao
que podem atuar sobre outros objetos. Contudo, outros objetos dos sistema operacional
tambem podem, em algumas situacoes, ser considerados sujeitos [40]. As acoes (actions)
de sujeitos sobre objetos podem ser operacoes de leitura, escrita, criacao ou remocao de
arquivos, criacao de processos, sinalizacao, dentre outras.
Quando sujeitos atuam sobre objetos, um outro subconjunto de suas credenciais, sub-
jective context, e utilizado nas avaliacoes de controle de acesso. O subjective context de
um processo e armazenado na estrutura apontada pelo ponteiro struct cred *cred.
A avaliacao de controle de acesso do kernel e feita atraves de um calculo envolvendo os

42 Capıtulo 4. Ferramentas de seguranca Linux
componentes anteriormente apresentados (subject, object, action, subjetive context, obje-
tive context) e um conjunto de uma ou mais regras (rules) aplicaveis ao contexto. Estas
regras podem ser dos tipos DAC, que ficam armazenadas em cada objeto, ou MAC, onde
existe um conjunto de regras definido para o sistema operacional como um todo.
O fluxo de avaliacoes do sistema de controle de acesso do Linux e ilustrado na Figura
4.1.
Figura 4.1: Funcionamento do sistema de controle de acesso do Linux.
As regras do DAC do Linux sao divididas em tres diferentes solucoes: mascaras de
permissao, ACLs (Access Control Lists) e POSIX Capabilities. O funcionamento destas
implementacoes DAC sera brevemente apresentado a seguir.
Ja as regras MAC sao implementadas de maneira modular atraves do framework LSM,
o qual sera apresentado em detalhes na Secao 4.2.
E importante notar que as regras MAC sao avaliadas somente apos as regras DAC.
Ou seja, para os casos em que uma das regras DAC impeca o acesso a um objeto por um
sujeito, o acesso sera negado mesmo que as regras MAC nao oferecam restricao ao acesso.
Portanto, os sistemas MAC disponıveis para Linux sao do tipo restritivo: sao capazes de
negar acesso a objetos em pontos onde tais acessos estavam prestes a ser autorizados pelo
controle de acesso DAC. O contrario, contudo, autorizar acessos negados nas avaliacoes

4.1. Sistema de Controle de Acesso 43
DAC, nao e possıvel a priori.
4.1.1 Discretionary Access Control - DAC
Mascaras de permissao
Mascaras de permissao sao o tipo mais basico de DAC no Linux. Estas mascaras
podem ser vistas como uma lista de controle de acesso (ACL) simplificada.
Nesta implementacao, os objetos carregam em suas credenciais uma mascara simples,
de 16 bits, que regula as permissoes de acesso a estes objetos por diferentes classes de
sujeitos. Como na arquitetura do Linux todos os objetos sao definidos como arquivos,
todos eles possuem uma estrutura do tipo inode. Esta mascara de 16 bits, portanto, fica
armazenada na estrutura inode do objeto, em uma variavel de nome mode. Esta variavel
e do tipo short int3.
Nestas mascaras, os bits determinam o perfil de acesso autorizado (leitura, escrita e
execucao) para tres classes distintas de sujeitos (user4, group5 e other6).
Os tres bits menos significativos representam permissoes de execucao, escrita e leitura
(partindo do bit menos significativo para o mais significativo) para sujeitos do tipo other.
Os dois grupos de tres bits subsequentes representam as mesmas permissoes para sujeitos
do tipo group e sujeitos do tipo user, respectivamente. Cada bit com valor igual a um na
mascara significa que a permissao deve ser concedida.
Os tres bits subsequentes aos nove descritos anteriormente, representam, tambem do
menos significativo para o mais significativo, as opcoes: sticky bit, SGID e SUID. A funcao
do sticky bit varia de acordo com o tipo de objeto e sistema de arquivos, sua aplicacao
mais usual e garantir que apenas proprietarios de arquivos possam apaga-los em ambientes
onde todos podem ler e escrever, como por exemplo no diretorio /tmp. Os bits SUID e
SGID, por sua vez, permitem que, ao serem executados, estes objetos gerem credenciais
com UID e GID iguais as da credencial do objeto, e nao do sujeito que o executou, ou seja,
executa o arquivo com as permissoes do proprietario, e nao do processo que o invocou.
Esta funcionalidade e suas aplicacoes serao detalhadas na Secao POSIX Capabilities.
Os quatro ultimos bits utilizados na variavel mode identificam o tipo do objeto, que
pode ser: regular file, directory, link, socket, block device, character device ou FIFO.
Todas essas mascaras estao definidas no arquivo
/linux-src/include/uapi/linux/stat.h. Suas representacoes em base numerica
octal7 sao as seguintes:
3Tamanho de palavra de 16 bits em CPUs de 32 bits.4Sujeito com UID igual ao do objeto.5Sujeito com GID igual ao do objeto6Sujeito com UID e GID diferentes dos armazenados nas credenciais do objeto7A representacao em base numerica octal e comumente utilizada por facilitar a rapida interpretacao

44 Capıtulo 4. Ferramentas de seguranca Linux
• 0140000: objeto e do tipo socket;
• 0120000: objeto e do tipo Link;
• 0100000: objeto e do tipo regular file;
• 0060000: objeto e do tipo block device;
• 0040000: objeto e do tipo diretorio;
• 0020000: objeto e do tipo character device;
• 0010000: objeto e do tipo FIFO;
• 0004000: SUID habilitado;
• 0002000: SGID habilitado;
• 0001000: Sticky bit habilitado;
• 00700: operacoes de leitura, escrita e execucao permitidas para user ;
• 00400: operacoes de leitura sao permitidas para user ;
• 00200: operacoes de escrita sao permitidas para user ;
• 00100: operacoes de execucao sao permitidas para user ;
• 00070: operacoes de leitura, escrita e execucao sao permitidas para group;
• 00040: operacoes de leitura sao permitidas para group;
• 00020: operacoes de escrita sao permitidas para group;
• 00010: operacoes de execucao sao permitidas para group;
• 00007: operacoes de leitura, escrita e execucao sao permitidas para other ;
• 00004: operacoes de leitura sao permitidas para other ;
• 00002: operacoes de escrita sao permitidas para other ;
• 00001: operacoes de execucao sao permitidas para other ;
da mascara, uma vez que cada dıgito representa um bloco de tres dıgitos de sua composicao. Nestarepresentacao, o primeiro dıgito zero apenas indica que o numero esta escrito em base octal

4.1. Sistema de Controle de Acesso 45
POSIX Access Control Lists - ACLs
A implementacao de POSIX ACLs no Linux tem como objetivo definir um melhor
controle DAC atraves de um esquema mais elaborado de listas de controle de acesso.
Nesta solucao, dois tipos diferentes de ACL sao permitidas: ACL relacionada dire-
tamente ao objeto e ACL relacionada a criacao de novos objetos dentro de um diretorio
(aplicavel somente em objetos do tipo diretorio). Para cada tipo de ACL, pode ser defi-
nido um conjunto de regras. Cada regra e representada por uma entrada (entry) daquela
ACL.
Uma entrada estabelece permissoes de acesso (leitura, escrita e execucao) para um tipo
de sujeito. Cada entrada possui um rotulo (tag) que indica o contexto de aplicacao daquela
regra. Uma entrada pode possuir ainda um qualificador (tag qualifier) que representa um
usuario (UID) ou grupo (GID) ao qual aquela regra se aplica.
A implementacao Linux do POSIX ACLs introduz duas novas variaveis nas credenciais
de objetos do tipo inode, uma para cada tipo de ACL do padrao, sao elas: struct
posix acl *i acl e struct posix acl *i default acl.
A estrutura posix acl possui uma lista de variaveis do tipo struct
*posix acl entry. Esta ultima estrutura representa uma entrada do POSIX ACL,
armazenando os seus atributos tag, tag qualifier e permissoes de acesso. A estrutura
possui a seguinte declaracao:
struct posix_acl_entry {
short e_tag;
unsigned short e_perm;
union {
kuid_t e_uid;
kgid_t e_gid;
};
};
Os seguintes valores sao validos para o atributo e tag:
• ACL USER OBJ: permissoes definidas na entrada aplicam-se a sujeitos do pro-
prietario do objeto
• ACL USER: permissoes definidas na entrada aplicam-se a sujeitos com UID igual
ao definido no atributo (tag modifier) e uid
• ACL GROUP OBJ: permissoes definidas na entrada aplicam-se a sujeitos que fazem
parte do mesmo grupo do objeto

46 Capıtulo 4. Ferramentas de seguranca Linux
• ACL GROUP: permissoes definidas na entrada aplicam-se a sujeitos que tenham
GID igual ao definido no tag modifier e gid
• ACL MASK: permissoes definidas na entrada representam o maximo acesso permi-
tido a objetos do tipo ACL USER, ACL GROUP OBJ ou ACL GROUP
• ACL OTHER: permissoes definidas na entrada aplicam-se aos objetos que nao se
enquadram no perfil de nenhuma outra entrada
Uma ACL valida deve conter exatamente uma entrada do tipo ACL USER OBJ e
uma entrada do tipo ACL GROUP OBJ. Entradas do tipo ACL USER e ACL GROUP
sao opcionais e podem aparecer em qualquer numero em uma ACL. Sempre que pelo
menos uma entrada desses dois ultimos tipos compor uma ACL, uma entrado do tipo
ACL MASK passa a ser obrigatoria, em casos contrario este tipo de entrada e opcional.
As seguintes permissoes de acesso sao validas para o atributo e perm:
• ACL READ: leitura
• ACL WRITE: escrita
• ACL EXECUTE: execucao
POSIX Capabilities
O modelo de controle de acesso discricionario tradicional do Linux, composto inicial-
mente por mascaras de permissao e, posteriormente refinados atraves do uso de ACLs,
avalia a legitimidade de um acesso baseado na ideia de propriedade, atraves da nocao da
existencia das entidades usuarios e informacao, onde um (processo) usuario e proprietario
da sua informacao e tem poderes ilimitados sobre ela, podendo inclusive permitir ou negar
acesso a ela para terceiros.
Neste modelo existe ainda uma outra categoria de processos: a dos processos privi-
legiados (aqueles onde o UID do usuario e igual a 0, ou seja, aqueles pertencentes ao
super-usuario, conhecido como usuario root). Um processo privilegiado consegue ignorar
todas as checagens de permissao do kernel e ter acesso a virtualmente todas as informacoes
do sistema.
Em alguns momentos, contudo, processos de usuario precisam fazer acesso a in-
formacoes privilegiadas do sistema, sem contudo terem ou, por questoes de seguranca,
poderem ter permissao de acesso a elas. Por exemplo, um usuario deve ter a habilidade de
alterar a sua propria senha de acesso. No Linux, o banco de dados de senhas consultado
por aplicacoes de autenticacao fica localizado no arquivo /etc/shaddow. Este arquivo
contem a senha de todos os usuarios do sistema, inclusive a senha do superusuario e, por

4.1. Sistema de Controle de Acesso 47
razoes obvias de seguranca, um usuario comum nao possui acesso de leitura ou escrita
sobre este arquivo.
Para solucionar este impasse, o Linux mantem em suas credenciais um atributo (bit
setuid) que permite a arquivos executaveis de usuario serem executados no contexto de
outro usuario (UID efetivo - EUID). Desta forma, uma aplicacao do usuario pode interme-
diar o acesso a objetos de sistema aos quais seu proprietario nao possua acesso, mas, em
determinado momento, precisa utiliza-los legitimamente, nos casos em que o seu EUID
for igual ao do superusuario, ou seja, zero.
Esta solucao, contudo, apesar de ser amplamente utilizada, possui uma fragilidade:
mesmo quando processos precisam de apenas alguns privilegios de root, eles sempre rece-
bem todos os seus privilegios, o que certamente e um exagero. Uma consequencia negativa
desta caracterıstica e o fato de que falhas em aplicacoes SUID root podem ser exploradas
por usuarios maliciosos para obtencao de acesso total, comprometendo a seguranca do
sistema como um todo.
Diante deste cenario, a partir da versao 2.2, o Linux passou a dividir os privilegios
atribuıdos ao usuario root em subgrupos, conhecidos como capabilities [8]. Estes grupos
sao atribuıdos a processos e podem ser habilitados e desabilitados independentemente.
A implementacao de POSIX Capabilities permite, portanto, que processos com UID
(ou SUID) zero sejam executados com capacidades reduzidas, limitando o poder de acesso
destes aos recursos do sistema operacional, garantindo uma granularidade ainda mais fina
no controle de acesso discricionario padrao do Linux.
Esta implementacao e feita a partir da adicao das chamadas de sistema capset()
e capget(), adicao de informacoes nas credenciais de processos e arquivos e, diversos
pontos de checagem espalhados pelo kernel.
As informacoes de credenciais adicionadas aos processos estao na forma de variaveis
do tipo kernel cap t8 adicionadas a estrutura de credenciais (struct cred). Processos
carregam tres destas variaveis, representando os seguintes conjuntos de capabilities: ef-
fective, permitted e inheritable: O primeiro conjunto e aquele que e efetivamente avaliado
pelas checagens de permissoes do kernel. O segundo representa o conjunto de capabilites
que um processo pode habilitar, ou seja, tornar efetivo, via chamada de sistema capset().
Ja o conjunto inheritable capabilities representa o conjunto de capabilites que podem ser
repassadas a um processo filho.
O VFS (Virtual File System) permite que inodes possuam em suas credenciais uma
mascara identificando o seus conjuntos de capabilities, de tal forma que, ao serem execu-
tados via syscall execve(), o novo processo criado possua suas capacidades como uma
composicao entre capacidades do processo que o criou (inheritable capabilities) e as capaci-
8Um conjunto de capabilities e representado por um inteiro de 32 bits. Na versao 3.7, o Linux dispoede 36 capabilities, definidos no arquivo linux-src/include/capabilities.h.

48 Capıtulo 4. Ferramentas de seguranca Linux
dades armazenadas no seu inode. A metodologia de calculo desta composicao e detalhada
em [35].
4.1.2 Mandatory Access Control - MAC
O Linux admite diferentes solucoes de controle de acesso mandatorio (MAC). Estas
solucoes sao implementadas atraves da utilizacao do framework LSM (Linux Security
Modules). O LSM e os modulos de seguranca existentes atualmente no kernel Linux serao
apresentados na Secao 4.2.
Existem ainda outras solucoes do tipo MAC em desenvolvimento em projetos de pes-
quisa e que nao fazem parte da versao oficial do Linux. Uma breve listagem sera apresen-
tada da Secao 4.2.6
4.2 LSM - Linux Security Modules
Ate as versoes anteriores ao Linux 2.4, apesar de diversas solucoes MAC serem pes-
quisadas e propostas para compor o kernel [44] [53] [55], nenhuma solucao havia sido
aceita e incorporada ao codigo oficial do Linux, que permanecia limitado as solucoes DAC
apresentadas na Secao anterior. A principal razao para esta realidade estava na falta
de consenso entre desenvolvedores e pesquisadores de qual seria a melhor ou mais geral
solucao de seguranca.
Diante desta falta de consenso, o mantenedor do Linux, Linus Torvalds, defendeu a
ideia de que deveria existir um mecanismo que permitisse uma implementacao modular de
diferentes modelos de seguranca. Neste contexto, foi incorporado ao Linux um framework
de seguranca capaz de disponibilizar uma API generica para o desenvolvimento destes
diferentes modelos: o LSM (Linux Security Modules) [64].
A abordagem adotada na concepcao do LSM9, foi a de intermediar o acesso aos objetos
do kernel, permitindo que modulos de seguranca (modulos LSM) avaliassem se aqueles
objetos poderiam ou nao ser acessados, segundo o criterio de cada solucao. Para isso,
o LSM implementou ganchos (hooks) em pontos imediatamente anteriores aos pontos de
acesso aos objetos. Estes ganchos desviam o fluxo de execucao para funcoes de avaliacao
implementadas pelos modulos de seguranca, que podem permitir ou negar o acesso aquele
objeto. A Figura 4.2 ilustra este processo.
Alem desta intermediacao no acesso a objetos de seguranca, o LSM tambem incluiu
campos de seguranca opacos nas credenciais de diversos objetos do kernel, de tal forma
que os modulos LSM possam atualiza-los em rotinas de auditoria de seguranca.
9Neste texto, o termo LSM e adotado para referenciar o framework LSM.

4.2. LSM - Linux Security Modules 49
Figura 4.2: Arquitetura de Ganchos LSM.
Os ganchos LSM sao, em sua maioria, do tipo restritivos, ou seja, estao distribuıdos de
tal forma em pontos do kernel que o modulo LSM podem negar o acesso a objetos onde
este acesso estava prestes a ser autorizado. Em situacoes onde o kernel nega o acesso a um
determinado objeto, o framework LSM pouco oferece mecanismos para que os modulos
sejam consultados e, eventualmente, permitam o acesso anteriormente negado (ganchos
permissivos).
Os ganchos do LSM nada mais sao que chamadas de funcoes do LSM espalhadas por
todo o kernel, em pontos com as caracterısticas descritas acima, que possuem callbacks
para funcoes tratadoras implementadas pelos modulos de seguranca. Por exemplo, quando
uma aplicacao no espaco de usuario deseja criar um novo processo, ela invoca a chamada
de biblioteca fork(), que por sua vez utiliza a chamada de sistema sys_fork(). Esta
chamada de sistema utiliza a funcao do_fork() que, em ultima estancia, chama a funcao
copy_process() para criar o novo processo. Nesta ultima funcao, imediatamente antes da
criacao do novo processo, e feita uma chamada para a funcao security_task_create(),
que e um gancho LSM. Abaixo a sua implementacao:
/*
* linux-src/kernel/fork.c
*/
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start, struct pt_regs *regs,
unsigned long stack_size, int __user *child_tidptr,
struct pid *pid, int trace)

50 Capıtulo 4. Ferramentas de seguranca Linux
{
int retval;
struct task_struct *p;
...
retval = security_task_create(clone_flags); /* Gancho LSM */
if (retval)
return ERR_PTR(retval);
...
/* Copia o Processo */
...
return p;
}
A funcao security_task_create(), simplesmente chama a callback tratadora deste
gancho e retorna o valor por ela retornado:
/*
* linux-src/security/security.c
*/
int security_task_create(unsigned long clone_flags)
{
return security_ops->task_create(clone_flags);
}
O valor de retorno da funcao tratadora do gancho, implementada pelo modulo LSM,
e testado no ponto do kernel onde o gancho foi implantado e desviou o fluxo de execucao.
Caso este valor seja diferente de zero, a operacao que estava preste a ser executada nao
acontece (acesso negado). Ou seja, o modulo LSM e capaz de negar uma operacao que ja
havia sido autorizada pela avalizacao do kernel e estava prestes a ser executada.
Todas as callbacks dos modulos LSM sao registradas na variavel global security_ops,
do tipo struct security_operations, na forma de ponteiros para funcoes. O LSM
permite apenas a definicao de uma funcao tratadora (callback) para cada gancho do
kernel, e esta funcao devera ter exatamente a mesma assinatura do gancho. Estas funcoes
tratadoras sao definidas no momento do registro do modulo LSM junto ao kernel, o qual
acontece no momento da inicializacao do sistema operacional.
Um modulo de seguranca deve, portanto, definir todos os ganchos que ira tratar
atraves de uma variavel tipo struct security_operations e registra-la junto ao ker-
nel, atraves da funcao register_security(). Esta funcao faz com que a variavel global
security_ops referencie a variavel struct security_operations do modulo de segu-
ranca, conforme abaixo:

4.2. LSM - Linux Security Modules 51
/**
* linux-src/security/security.c
* @ops: ponteiro para struct security_options do modulo a ser registrado
*/
int __init register_security(struct security_operations *ops)
{
...
security_ops = ops;
return 0;
}
Uma possıvel definicao de struct security_operations de um modulo de seguranca
de nome modlsm e com callback definida apenas para o gancho inode mkdir(), portanto,
seria como:
struct security_operations modlsm_security_ops =
{
.name = "modlsm",
.inode_mkdir = modlsm_mkdir,
};
O LSM nao permite a execucao concomitante de mais de um modulo de seguranca,
tampouco permite o carregamento de modulos de seguranca em tempo de execucao,
atraves de modulos dinamicamente carregaveis (Linux Kernel Module - LKM)10.
Na versao 3.7.6 do Linux, o LSM possui 188 ganchos, divididos em categorias conforme
abaixo:
• Ganchos para operacoes de execucao de programas
• Ganchos para operacoes com sistema de arquivos
• Ganchos para operacoes com inodes
• Ganchos para operacoes sobre arquivos
• Ganchos para operacoes com processos
• Ganchos para Netlink messaging
10O projeto original do LSM permitia que um modulo LSM fosse criado a partir de um LKM (Linux
Kernel Module) e registrado no LSM em tempo de execucao. Contudo, a partir do kernel 2.6.24, estesımbolo deixou de ser exportado e a interface com o LSM passou a ser estatica. Desta forma, todos osmodulos LSM passaram a ter a necessidade de serem compilados internamente (built in) no kernel.

52 Capıtulo 4. Ferramentas de seguranca Linux
• Ganchos para Unix domain networking
• Ganchos para operacoes com sockets
• Ganchos para operacoes XFRM
• Ganchos para mecanismos de comunicacao interprocessos (IPC).
• Ganchos para auditoria de seguranca
Os modulos LSM devem implementar suas interfaces com o espaco de usuario atraves
de sistema de arquivos virtual, do tipo securityfs, de tal forma que parametros de funci-
onamento possam ser ajustados e dados possam ser lidos. A API do Security FS para a
criacao destas interfaces ser apresentada na Secao 4.3.
Nas proximas Secoes, serao apresentadas alguns modulos de seguranca implementados
utilizando o LSM e suas principais funcionalidades serao analisadas.
4.2.1 SELinux
O SELinux (Security Enhanced Linux) e um LSM que implementa diferentes modelos
de MAC no Linux. Este LSM foi desenvolvido inicialmente por pesquisadores do NSA
(National Information Assurance Research Laboratory [10]), como implementacao de uma
arquitetura flexıvel de controle de acesso mandatorio desenvolvido por aquele mesmo
grupo, chamada Arquitetura Flask [44].
A arquitetura Flask partiu da necessidade de um modelo de seguranca flexıvel, capaz
de suportar diferentes polıticas de seguranca. Seu principal objetivo era disponibilizar
um sistema MAC capaz de atender diferentes sistemas computacionais com diferentes
requisitos de seguranca, partindo da hipotese de que nenhuma polıtica MAC isolada seria
capaz de atender a todos os requisitos de seguranca de todos os sistemas possıveis [46].
Para atender a este objetivo, a arquitetura baseia-se em um modelo com clara separacao
entre o mecanismo de controle de acesso (enforcement mechanism) e logica de polıticas de
seguranca. Desta forma, a arquitetura oferece uma interface onde e possıvel a definicao
de diferentes polıticas especificadas por administradores de seguranca.
O prototipo inicial do SELinux foi desenvolvido diretamente no kernel Linux e sua
distribuicao era feita atraves de patches. Posteriormente, o SELinux motivou a criacao e
inclusao do framework LSM no kernel Linux [64]. O SELinux foi entao reimplementado
utilizando o framework LSM e tornou-se o primeiro modulo LSM a fazer parte das versoes
oficiais do Linux em dezembro de 2004, no Linux 2.6.
Respeitando a arquitetura Flask, o SELinux e dividido em dois componentes: Security
Server (SS) e o Enforcement Mechanism. Este ultimo atua no controle de acesso de

4.2. LSM - Linux Security Modules 53
diferentes subsistemas do Linux, tais como operacoes sobre processos, arquivos e sockets,
atraves da utilizacao dos ganchos disponibilizados pelo LSM.
O SS, por sua vez, e responsavel pela logica de decisao de controle de acesso, atraves
da implementacao das polıticas de seguranca definidas pelo administrador do sistema.
O SELinux permite a utilizacao de diferentes SS, onde cada um implementa um modelo
de MAC. Os modelos de MAC aplicados pelo SELinux, portanto, podem ser facilmente
alterados atraves da definicao de novas polıticas de seguranca.
As decisoes de seguranca tomadas pelo SS sao baseadas em contextos de seguranca
(security contexts), os quais sao representados por rotulos (labels). Um contexto de segu-
ranca e um tipo de dado, independente de polıtica, que pode ser manipulado por diversas
partes do sistema e que e interpretado pelo SS em suas tomadas de decisao. Um con-
texto deve conter todos os atributos de seguranca relacionados ao objeto rotulado que sao
necessarios ao processo de tomada de decisao de uma polıtica.
Outro tipo de dado independente de polıtica de seguranca definido pelo SELinux e o
security identifier (SID). SIDs sao definidos em tempo de execucao e relacionam objetos
a security contexts. SIDs associados a objetos sao utilizados como base para tomada de
decisao pelo SS.
O SELinux e distribuıdo com um SS padrao, o qual implementa os modelos de segu-
ranca TE (Type Enforcement) e RBAC (Role-Base Access Control) [58]. Apesar de estas
definicoes nao serem estritamente necessarias, uma vez que um administrador pode, a par-
tir de definicao de polıticas, definir totalmente um SS que implemente o modelo MAC que
melhor lhe convir, este SS padrao e incluıdo por representar um modelo suficientemente
geral para suportar diversos requisitos de seguranca.
O RBAC do SELinux mantem contextos de seguranca baseados em tres atributos de
seguranca: identidade (identity), papel (role) e tipo (type). Todos os processos do sistema
operacional sao associados a identidades (nao necessariamente o UID do processo que os
criou). Um papel e utilizado para definir acoes permitidas aos usuarios. O atributo tipo
e utilizado para expressar controles de acesso mais refinados.
As polıticas de seguranca a serem aplicadas em kernel pelo enforcement mechanism
sao definidas em arquivos de texto. Uma vez definidas, polıticas podem ser ajustadas para
atender a requisitos especıficos de seguranca. O RBAC e TE do SELinux sao distribuıdos
juntamente com o modulo LSM com este proposito.
Os arquivos de configuracao de polıticas sao escritos utilizando uma linguagem propria
do SELinux, e devem ser compilados para serem carregados pelo SS.
O TE define tipos de objetos e classifica-os em classes. Operacoes permitidas entre
objetos de uma classe sao definidas da seguinte forma:
allow type_1 type_2:class { perm_1 ... perm_n }

54 Capıtulo 4. Ferramentas de seguranca Linux
O TE define ainda algumas transicoes automaticas entre tipos em algumas situacoes.
Define tambem rotulos padrao para novos objetos criados no sistema. Estas definicoes
sao feitas no arquivo de configuracao da seguinte forma:
type_transition type_1 type_2: file
default_file_type;
type_transition type_1 type_2: process
default_process_domain;
Ja os papeis do RBAC sao definidos como segue:
role rolename types { type_1 ... type_n };
Transicoes entre papeis podem ser definidas de forma a permitir mudancas de pri-
vilegio. Estas transicoes sao definidas da seguinte forma:
role_transition current_role program_type new_role;
Estas construcoes no arquivo de configuracao sao utilizadas para definir o comporta-
mento do TE e do RBAC do SELinux de acordo com as especificidades desejadas. Por
exemplo, para utilizacao do domınio de administracao do sistema, uma polıtica poderia
ser estabelecida para permitir que apenas a aplicacao login tenha acesso a este domınio,
impedindo acessos remotos de obterem os privilegios deste domınio. Tal polıtica poderia
ser implementada como segue:
type_transition getty_t login_exec_t:process
local_login_t;
allow local_login_t sysadm_t:process transition;
allow newrole_t sysadm_t:process transition;
O processo de definicao de polıticas para o SELinux e complexo e resulta em um
numero muito alto de regras. Muitas distribuicoes GNU/Linux estabelecem as suas
proprias polıticas e as entregam prontas para uso aos seus usuarios, como forma de faci-
litar o uso deste LSM. Outros sistemas MAC, por sua vez, tentam implementar geracao
automatica de polıticas e MACs simplificados, a saber LSMs TOMOYO e SMACK. Estes
LSMs serao brevemente apresentados nas Secoes 4.2.4 e 4.2.3, repectivamente. Ademais,
pesquisadores buscam maneiras mais simples de definir polıticas de seguranca [38].

4.2. LSM - Linux Security Modules 55
4.2.2 AppArmor
O AppArmor e um modulo de seguranca Linux que implementa um MAC voltado
para proteger e isolar processos. Este modulo LSM implementa o sistema de seguranca
SubDomain [14]. O AppArmor foi inicialmente desenvolvido pela empresa WireX, posteri-
ormente passou a ser desenvolvido e mantido pela Novell e distribuıdo em sua distribuicao
SuSe Linux. Atualmente este projeto e mantido pela Canonical, mantenedora da distri-
buicao Ubuntu Linux. A versao 2.4 do AppArmor, lancada por esta ultima empresa, foi
aceita e incluıda no Linux, a partir de sua versao 2.6.36.
O Subdomain foi concebido com a intencao de ter implementacao e utilizacao simples.
Caracterısticas essas que, segundo os seus autores, sao fundamentais para um sistema se-
guro, uma vez que implementacoes muito complexas de ferramentas de seguranca estariam
muito sujeitas a falhas de desenvolvimento que poderiam comprometer parcialmente ou
totalmente a seguranca do sistema. Configuracao complexa tambem e um fator conside-
rado crıtico para sistemas de seguranca, uma vez que pode induzir os administradores de
sistemas a operar incorretamente as ferramentas adotadas, colocando assim a seguranca
do sistema em risco.
O AppArmor mantem essas caracterısticas e utiliza os ganchos LSM para aplicar
diferentes regras de acesso para diferentes perfis de processos. Estes perfis devem ser
definidos em espaco de usuario e carregados para o modulo. Desta maneira, o AppArmor
prove um mecanismo de isolamento de processos. Estas polıticas nao sao globais, uma
vez que devem ser definidas por processo e aqueles processos que nao possuam polıticas
definidas nao sofrem qualquer interferencia do modulo, tendo seu controle de acesso regido
apenas pelas funcionalidades DAC do Linux. Ja os processos confinados, passam por
checagens MAC definidas em seus perfis.
Tal isolamento tem como objetivo proteger o sistema operacional de ataques internos
e externos, limitando o poder de acao de cada processo e forcando-os a manter um padrao
de comportamento esperado. Desta forma, ate mesmo falhas desconhecidas em aplicacoes
(zero-day) podem, segundo os autores da ferramenta, ser prevenidas atraves de polıticas
bem definidas por processo, uma vez que, em caso de comprometimento, o processo ata-
cado nao tera grandes poderes de atuacao sobre o sistema operacional. Esta ferramenta
e tipicamente utilizada para isolar aplicacoes de servicos de rede, visando minimizar a
possibilidade de ataque por comprometimento destes servicos.
Para facilitar ainda mais o seu uso, o AppArmor disponibiliza algumas polıticas pre-
definidas, que podem ser conciliadas com ajustes especıficos do administrador. Outro
recurso disponibilizado pela ferramenta e o modo de aprendizagem, onde aplicacoes sao
monitoradas segundo polıticas definidas, e os casos de violacao sao registrados, sem serem
evitados, para posterior analise e eventual ajuste de polıtica por parte do administrador.

56 Capıtulo 4. Ferramentas de seguranca Linux
4.2.3 Smack
O Smack (Simplified Mandatory Access Control Kernel), como sugere a sua sigla,
tem como objetivo a implementacao de um sistema de controle de acesso mandatorio
simplificado.
O Smack adiciona restricoes de acesso de sujeitos a objetos baseando-se em rotulos
(labels) adicionados a ambas credenciais e regras de acesso globais (mandatorias). Rotulos
sao strings de um a 23 caracteres, sensıveis a caixa e nao estruturados. As unicas operacoes
que sao feitas sobre os rotulos sao operacoes de comparacao, feitas durante a avaliacao de
regras de acesso. Alguns rotulos especiais sao definidos pelo modulo LSM para estabelecer
comportamentos especıficos nas avaliacoes de acesso, a saber:
• * (start): utilizado para definir objetos que sao acessados universalmente, contudo
nao devem compartilhar informacoes (ex. /dev/null). Sujeitos com este rotulo
nao podem acessar nenhum objeto do sistema. Objetos com este rotulo podem ser
acessados por sujeitos com qualquer rotulo diferente deste;
• (floor): utilizado para definir sujeitos de sistema. Sujeitos com este rotulo possuem
acesso de leitura para objetos com rotulo floor ;
• ˆ (hat): utilizado para definir sujeitos com acesso de leitura global. Sujeitos com
este rotulo possuem acesso de leitura a qualquer objeto do sistema.
As regras de acesso (rules) consideram os mesmos tipos de acesso padrao do Linux: lei-
tura, escrita e execucao. Acessos do tipo append (concatenacao) e transmute tambem sao
considerados nas regras do Smack. Estas regras sao compostas na forma “subject-label
object-label access”, onde access admite os valores r, w, x, a e t para representar
respectivamente o modos de acesso anteriormente descritos. Este ultimo modo de acesso,
transmute representa permissao para um objeto do tipo diretorio forcar que o rotulo de
um objeto criado dentro de sua hierarquia seja igual ao seu, e nao igual ao do sujeitos que
o criou. Para os casos em que nenhum acesso deve ser permitido, o caractere “-” deve ser
utilizado sozinho no campo access da regra.
Alguns exemplos de regras validas sao:
TopSecret Secret rx
Secret Unclass R
Manager Game x
User HR w
New Old rRrRr
Closed Off -

4.2. LSM - Linux Security Modules 57
Estas regras regras sao definidas no arquivo /etc/smack/accesses, de forma a serem
carregadas na inicializacao do sistema operacional e podem, a qualquer tempo serem
definidas atraves do arquivo /smack/load disponibilizado pela interface SecurityFS do
LSM Smack.
Todos os processos do sistema operacional recebem rotulos. Os rotulos de processos do
sistema sao definidos como “ ” automaticamente pelo Smack em tempo de boot. Rotulos
de processos de usuario sao definidos de acordo com as regras estabelecidas no arquivo de
configuracao /etc/smack/user.
Os rotulos de objetos sao definidos atraves do atributo estendido de seguranca (xattr
security namespace, Secao 3.5) SMACK64.
As regras de acesso sao avaliadas pelo Smack da seguinte forma:
1. Acessos de qualquer natureza feitos por sujeitos com rotulo “*” sao negados;
2. Acessos de leitura e execucao feitos por sujeitos com rotulo “ˆ” sao autorizados;
3. Acessos de leitura e execucao feitos sobre objetos com rotulo “ ” sao autorizados;
4. Acessos de qualquer natureza feitos sobre objetos com rotulo “*” sao autorizados;
5. Acessos de qualquer natureza feitos por sujeitos de rotulo igual ao do objeto sendo
acesso sao autorizados;
6. Acessos cujo perfil corresponda a alguma regra explicitamente definida no conjunto
de regras carregado sao autorizados;
7. Qualquer outro tipo de acesso e negado.
Sistemas MAC baseados em comportamento de aplicacoes, tais como SELinux e
AppArmor, devem ser customizados para cada distribuicao GNU/Linux em quem sao
utilizados. Desenvolvedores de sistemas embarcados, por sua vez, nao costumam desejar
as integracoes oferecidas por tais distribuicoes. Dada a sua simplicidade e independencia
de aplicacoes especıficas, o Smack tem sido muito utilizado em sistemas com Linux em-
barcado [57].
4.2.4 TOMOYO
O TOMOYO Linux e uma implementacao de controle de acesso mandatorio (MAC)
para kernel Linux. Este modulo LSM difere dos apresentados anteriormente pois seu
criterio de avaliacao nao e baseado em permissoes de acesso a objetos (inode based secu-
rity), mas sim em controle de acesso baseado em domınios (name based security).

58 Capıtulo 4. Ferramentas de seguranca Linux
Conforme ilustrado no funcionamento das solucoes apresentadas ate o momento, o
comportamento de solucoes MAC e totalmente controlado pelas suas polıticas. Diante
da complexidade observada na elaboracao de polıticas de seguranca para alguns sistemas
de controle de acesso mandatorio, os desenvolvedores do TOMOYO constataram que a
geracao de polıticas e a chave para melhorar a seguranca de sistemas Linux [37]. A partir
desta constatacao, estes desenvolvedores iniciaram pesquisas por uma solucao de geracao
automatica de polıticas, baseando-se na observacao da execucao de processos [38].
O objetivo original do projeto era a geracao automatica de polıticas para o SELinux,
o que nao foi possıvel devido a falta de hierarquia na definicao dos domınios de seguranca
daquele LSM. A evolucao da pesquisa, contudo, resultou na criacao do LSM TOMOYO,
um sistema MAC que implementa uma metodologia de criacao automatica de polıticas de
seguranca baseada na observacao de mudancas de estados de processo. Esta observacao e
feita basicamente atraves da observacao da sequencia historica de comandos (path names)
invocados por processos.
O TOMOYO introduz os seguintes conceitos nas suas definicoes de polıticas: cada
processo faz parte de um unico domınio. A criacao de domınios e o transito entre eles
acontece sempre que um novo processo e executado. A divisao de domınios e feita auto-
maticamente em nıvel de kernel. Cada domınio possui suas restricoes de acesso a objetos
com granularidade do tipo rwx (leitura, escrita e execucao). As polıticas MAC sao criadas
automaticamente a partir da observacao do comportamento dos domınios.
Permissoes sao atribuıdas a domınios, e nao a objetos ou sujeitos. Por este motivo,
nao existe o conceito de object owner (UID). O domınio inicial e <kernel>. Os domınios
subsequentes sao definidos atraves da concatenacao do historico de comandos invocados
por processos. A Figura 4.3 ilustra como os domınios deste modulo LSM sao estabelecidos
e seus respectivos nomes.
As regras MAC do TOMOYO atuam sobre arquivos, conexoes de rede (em nıvel de
porta e protocolo11), e POSIX Capabilities. E possıvel a definicao de trusted domains,
que sao domınios onde apenas as checagens DAC serao feitas.
4.2.5 Yama
Adicionado no Linux 3.4, o Yama e um modulo LSM que tem como objetivo aumentar
a granularidade de controle de acesso a chamada de sistema ptrace().
A chamada de sistema ptrace() permite a um processo observar e controlar a execucao
de processos com UID igual ao seu, podendo examinar e alterar seus comportamentos.
Os principais objetivos desta chamada sao monitoramento de chamadas de sistema e
implementacao de breakpoints para depuracao de codigo [1]. Esta caracterıstica permite a
11Layer 3 - TCP ou UDP

4.2. LSM - Linux Security Modules 59
Figura 4.3: TOMOYO: geracao automatica de domınios de seguranca baseada em nomes.
um atacante com um processo comprometido, utilizar esta chamada para continuar com
o seu ataque. Exemplos de ataques com este perfil sao: roubo de sessoes SSH e ataques
de injecao de codigo [12].
Por este motivo, o Yama implementa uma logica de maior granularidade para controle
de acesso a esta chamada. Este LSM define nıveis, onde o comportamento do controle de
acesso a chamada possui diferentes caracterısticas, a saber:
• Modo 0: permissoes tradicionais da chamada ptrace(). Um processo pode fa-
zer a chamada ptrace(PTRACE_ATTACH, pid, ...) desde que possua o possua o
mesmo UID do processo indicado pela variavel pid e este processo tenha habilitado
operacoes de depuracao (prctl(PR_SET_DUMPABLE, ...));
• Modo 1: acesso restrito a chamada ptrace(). Um processo pode fazer a chamada
ptrace(PTRACE_ATTACH, pid, ...) desde que possua o mesmo UID do processo
indicado pela variavel pid, este processo tenha habilitado operacoes de depuracao
(prctl(PR_SET_DUMPABLE, ...)) e o processo a ser monitorado seja seu filho;
• Modo 2: somente administradores. Apenas processos com CAP SYS PTRACE
podem fazer chamadas ptrace(PTRACE_ATTACH, ...);
• Modo 3: acesso bloqueado. Nenhum processo pode fazer chamadas ptrace() do
tipo PTRACE_ATTACH. Uma vez definido, este nıvel nao pode ser mudado nem mesmo
pelos administradores do sistema.

60 Capıtulo 4. Ferramentas de seguranca Linux
A manipulacao dos nıveis de controle de acesso e feita atraves de um arquivo disponi-
bilizado na interface SecurityFS do Yama, no qual pode-se ler o estado atual do sistema
ou pode-se definir um novo estado. Apenas processos com CAP SYS PTRACE podem
alterar este arquivo de controle:
/proc/sys/kernel/yama/ptrace_scope
4.2.6 Outras solucoes
Varios outros projetos de pesquisa em seguranca buscam o desenvolvimento de solucoes
que elevem o nıvel de seguranca do Linux atraves de diferentes metodologias de controle
de acesso. Muitos nao utilizam o framework LSM, por considerarem que este representa
um limitador para a implementacao de solucoes realmente seguras [54] [5].
O projeto GRSecurity [32] trabalha no desenvolvimento de um sistema de seguranca
de kernel capaz de oferecer protecao contra ataques desconhecidos (zero day) atraves
de melhorias no sistema de autenticacao, auditoria em importantes eventos do sistema
operacional e controle de acesso MAC do tipo RBAC. Este projeto nao utiliza LSM em
sua implementacao.
O RSBAC [53] implementa um framework de kernel que permite a utilizacao de di-
ferentes modelos de seguranca a partir modulos de decisao dinamicamente carregaveis.
Estes modulos podem ser: MAC, ACL, Anti-vırus, dentre outros. Este trabalho tambem
nao utiliza LSM em sua implementacao.
Hallyn et al [36] desenvolveu um mecanismo de controle de acesso chamado Domain
Type Enforcement (DTE) para Linux. Esta solucao e uma variacao do Type Enforcement
que utiliza mecanismos baseados em nomes de arquivos (pathnames).
Outras solucoes de seguranca, por sua vez, utilizam o framework LSM para imple-
mentacao de solucoes nao diretamente relacionadas a controle de acesso. Os trabalhos
do projeto Imuno, descritos na Secao 2.2, por exemplo, visam a construcao de sistema
de seguranca imunologico geral, implementado em ambiente Linux. O trabalho proposto
nesta tese de mestrado e parte integrante desta pesquisa e utiliza o framework LSM na
implementacao do sistema proposto. Ja Takamasa utiliza o LSM no desenvolvimento de
um sistema de monitoramento de seguranca [41].
4.3 Security FS
O Security FS e um sistema de arquivos virtual criado com o proposito de ser API
comum para a criacao de interfaces de modulos de seguranca que utilizem o framework
LSM. Motivado pela constatacao de que varios modulos LSM estavam implementando

4.3. Security FS 61
suas proprias interfaces [13], o Security FS procura minimizar o impacto no codigo do
kernel gerado por esta pratica, alem de simplificar a manutencao de modulos LSM.
Neste sistema de arquivos, todos os arquivos e diretorios sao definidos (criados) por
um modulo LSM. Uma aplicacao em espaco de usuario podera fazer operacoes de leitura e
escrita sobre os arquivos disponibilizados. Nao podera, contudo, criar ou remover arquivos
e diretorios, tampouco mudar permissoes de leitura e escrita dos arquivos existentes.
As operacoes de leitura e escrita em espaco de usuario sobre os arquivos do Security
FS serao tratadas atraves de callbacks pelo modulo LSM, o qual recebera uma copia
dos parametros das chamadas de sistema das respectivas operacoes e atuara de maneira
adequada, ajustando o seu comportamento a partir de parametros recebidos do espaco
de usuarios (operacoes de escrita) ou enviando informacoes de espaco de kernel para o
espaco de usuario (operacoes de leitura).
O sistema de arquivos e montado automaticamente em /sys/kernel/security.
A API do sistema de arquivo exporta tres funcoes basicas: securityfs create dir(),
securityfs create file e securityfs remove(). Estas funcoes estao definidas em
linux-src/security/inode.c e possuem as seguintes assinaturas:
extern struct dentry *securityfs_create_file(const char *name, umode_t mode,
struct dentry *parent,
void *data,
const struct file_operations *fops);
extern struct dentry *securityfs_create_dir(const char *name,
struct dentry *parent);
extern void securityfs_remove(struct dentry *dentry);
Para utilizar este sistema de arquivos, um modulo LSM deve primeiramente incluir
o cabecalho <linux/security.h>. Em seguida, o modulo deve definir as callbacks que
farao o tratamento das chamadas do sistema de arquivos virtual. Esta definicao e feita
atraves da declaracao de uma estrutura do tipo file operations. Um possıvel exemplo
para um modulo LSM chamado mod seria:
static const struct file_operations mod_operations = {
.read = mod_callback_for_read,
.write = mod_callback_for_write,
.open = mod_callback_for_open,
.release = mod_callback_for_release,
};

62 Capıtulo 4. Ferramentas de seguranca Linux
Por fim, o modulo LSM deve criar uma funcao de inicializacao do sistema de arquivos,
onde devem ser definidos os diretorios e arquivos que o compoe, e, posteriormente, fazer
uma chamada para a macro fs initcall() para inicializar o sistema.
Continuando o exemplo anterior, possıveis implementacoes da funcao de iniciacao e
da callback open() para o modulo mod sao apresentadas abaixo.
• Inicializacao do sistema de arquivos Security FS, feita atraves da chamada
fs initcall(mod vfs init). Esta funcao cria um diretorio mod na raiz do sistema
de arquivos e, em seguida, um arquivo chamado readme no diretorio recem criado:
int mod_vfs_init(void)
{
struct dentry *op_dir;
op_dir = securityfs_create_dir("mod", NULL);
securityfs_create_file("readme", 0400, op_dir,
NULL, &mod_operations);
return 0;
}
• Callback para tratamento de chamadas de sistema open() sobre arquivos do Security
FS. Esta funcao verifica o nome do arquivo lido e, caso seja readme, cria em memoria
um arquivo com a string “This is a LSM Module”, a qual posteriormente sera
enviada para espaco de usuario atraves da chamada de sistema read():
int mod_callback_for_open(struct inode *inode, struct file *file)
{
struct qstr *file_name;
struct mod_data *data;
char buffer[200] = "This is a LSM Module";
file_name = &(file->f_dentry->d_name);
if (strcmp(file_name->name, "readme") == 0) {
data = kmalloc(sizeof(*data), GFP_KERNEL);
if (data){
data->read_eof = false;
data->buffer = kmalloc(IO_BUFFER_SIZE, GFP_KERNEL);
memcpy(data->buffer, buffer, len);
}
file->private_data = data;
}

4.4. Netfilter 63
return 0;
}
4.4 Netfilter
O Netfilter e um framework do kernel Linux que adiciona ganchos em pontos do seu
codigo onde e possıvel interceptar o fluxo de pacotes de rede.
Os ganchos Netfilter estao dispostos em diferentes pontos do fluxo de pacotes de rede
do kernel, conforme ilustra a Figura 4.4. O Netfilter permite o registro de varias funcoes
tratadoras para cada um desses ganchos.
Figura 4.4: Arquitetura de ganchos do framework Netfilter.
Quando alcancados, os ganchos Netfilter desviam para a um funcao controladora de
gancho, NF_HOOK(), a qual aciona sequencialmente os tratadores registrados para aquele
determinado gancho, enviando um copia do pacote capturado. Cada funcao tratadora
deve entao analisar o conteudo do pacote enviado e retornar um dos valores abaixo:
• NF DROP
• NF ACCEPT
• NF STOLEN
• NF QUEUE
• NF REPEAT
• NF STOP

64 Capıtulo 4. Ferramentas de seguranca Linux
O controlador de ganchos aciona a proxima funcao tratadora de um determinado
gancho sempre que recebe o valor NF_ACCEPT como retorno da ultima tratadora executada.
Caso o valor de retorno seja NF_DROP, o pacote e imediatamente rejeitado pelo Netfilter.
Caso o valor seja NF_STOP, o pacote e imediatamente aceito sem que outras tratadoras
sejam invocadas. Uma funcao tratadora pode ignorar um determinado pacote sem aceita-
lo ou rejeita-lo retornado o valor NF_STOLEN, que fara com que o controlador desconsidere
aquele tratador e acione o proximo na lista. Um tratador pode ainda solicitar que seja
reinvocado, retornando o valor NF_REPEAT. Por fim, um pacote pode ser enviado para
analise em espaco de usuario sempre que um tratador retornar o valor NF_QUEUE. Os
pacotes enviados para espaco de usuario sao recebidos e tratados por aplicacoes atraves
do uso da biblioteca libiqp. A aplicacao em espaco de usuario responsavel pela avaliacao
do pacote deve retornar sua decisao sobre o pacote para o gerenciador de ganchos do
Netfilter.
4.5 TCG - Task Control Group
O TCG Task Control Group, e um framework do Linux, inserido a partir de sua versao
2.6.24[47], com o objetivo de disponibilizar funcionalidades de separacao e organizacao de
processos em grupos, onde, para cada grupo, fosse possıvel definir regras de comporta-
mento aos processos que o compoe. Desta forma, o TCG disponibiliza uma API para
agrupamento e monitoramento de processos do sistema operacional. Esta API e requi-
sito comum para mecanismos de controle de recursos do sistema operacional, tais como
mecanismos para controle de consumo de CPU, uso de banda de rede, uso de memoria e
outros, de tal forma que os desenvolvedores destes mecanismos nao precisam se preocupar
em como agrupar e monitorar processos, tampouco em ter de desenvolver uma interface
de usuario especifica do mecanismo. Desta forma, o TCG simplifica a implementacao de
mecanismos de controle de recursos, chamados de subsistemas, e permite que estes repre-
sentem um menor impacto no codigo do kernel uma vez que evita duplicacao de rotinas
e estruturas de dados.
4.5.1 Arquitetura e implementacao
Para atender as necessidades comuns de diferentes subsistemas, o framework TCG foi
projetado para atender os seguintes requisitos[48]:
1. Multiplos subsistemas independentes: como os subsistemas do TCG sao tipicamente
ferramentas de contabilizacao e controle do uso de diferentes recursos, deve ser
possıvel o funcionamento concorrente de diferentes subsistemas. Deve ser possıvel

4.5. TCG - Task Control Group 65
tambem ao usuario escolher quais dos subsistemas disponıveis serao utilizados em
um dado momento
2. Mobilidade: um usuario com permissoes adequadas deve ter o poder de mover os
processos entre grupos
3. Inescapabilidade: uma vez estabelecidos os grupos aos quais cada processo pertence,
um processo nao deve ser capaz de mudar de grupo sem a intervencao de um usuario
administrador que possua o nıvel de permissao adequado para a tarefa
4. Interface extensıvel: diferentes subsistemas possuem diferentes parametros a serem
configurados. Os usuarios, contudo, esperam padronizacao na utilizacao destes sub-
sistemas. O TCG deve, portanto, fornecer uma interface extensıvel e com algum
nıvel de padronizacao. Neste contexto, duas possıveis solucoes seriam: nova cha-
mada de sistema (syscall) ou um sistema de arquivos virtual, em que os subsistemas
disponibilizassem arquivos virtuais onde os parametros de configuracao pudessem
ser ajustados diretamente atraves de operacoes de leitura e escrita, em espaco de
usuario, sobre eles. A primeira alternativa oferece um alto grau de padronizacao e
bom desempenho. Esta abordagem, contudo, pode ser muito restritiva para os sub-
sistemas, devido a variabilidade de seus conjuntos de parametros de configuracao.
A segunda opcao, por sua vez, apesar de possuir um desempenho menor que a
primeira, prove grande flexibilidade aos subsistemas e tem a vantagem de ser facil-
mente manipulavel atraves de ferramentas padrao e rotinas de biblioteca em espaco
de usuario. O TCG foi implementado utilizando esta ultima abordagem
5. Nıveis estruturados de grupos: para alguns subsistemas, pode ser interessante a
habilidade de estruturar os grupos de processos em diferentes nıveis hierarquicos.
Nesta estrutura, e possıvel que uma parcela dos recursos alocados a um grupo de
processos seja reservada a um sub-grupo. A Figura 4.5 ilustra uma possıvel uti-
lizacao desta funcionalidade por um eventual subsistema que implemente controle
do uso de banda de rede.
6. Multiplas particoes: considerando o Requisito 1, independencia entre subsistemas,
a definicao de uma unica divisao hierarquica dos grupos de processos apresentada
no requisito anterior penaliza a independencia entre os subsistemas, uma vez que
diferentes subsistemas precisariam compartilhar o mesmo criterio de divisao de pro-
cessos. Por isso mesmo, o TCG deve permitir a criacao de diferentes hierarquias,
de tal forma que seja possıvel estabelecer diferentes criterios de divisao para cada
subsistema. A Figura 4.6 ilustra uma possıvel utilizacao de multiplas particoes. E
desejavel tambem que, para os casos onde dois ou mais subsistemas compartilhem o

66 Capıtulo 4. Ferramentas de seguranca Linux
mesmo criterio de divisao de grupos, a definicao de hierarquias seja feita de maneira
simplificada
7. Associacao de objetos genericos a grupos: para alguns subsistemas, somente objetos
do tipo processo podem nao ser suficientes para a implementacao de monitoramento
e controle sobre o recurso desejado. Este requisito permite que um subsistema
associe a ele outros tipos de objetos, tais como paginas de memoria, descritores de
arquivos e sockets de rede
8. Desempenho: por fim, a implementacao deve ser feita de maneira tal que sobrecar-
regue minimamente o processamento.
Figura 4.5: Exemplo de distribuicao de banda de rede baseado em grupos.
O TCG e implementado atraves da inclusao de ganchos em pontos do kernel relaci-
onados a criacao e finalizacao de processos (fork() e exit()). Sempre que esses gan-
chos sao atingidos, o controle e desviado para as funcoes do TCG que implementam a
logica de agrupamento de processos tal como descrito nos requisitos apresentados. Estas
funcoes, atualizam as estruturas que compoem a arquitetura do TCG, relacionadas abaixo
e, quando aplicavel, deviam o fluxo de execucao para os respectivos subsistemas atuarem
sobre os processos. O relacionamento entre estas estruturas e apresentado na Figura 4.7.
• css set: representa o conjunto de processos monitorados por um determinado
grupo. Nesta estrutura sao armazenados o grau de parentesco entre os gru-
pos da hierarquia, flags de estado do grupo e ponteiros para o conjunto de
container subsys state, sendo um para cada subsistema utilizado. Nesta es-
trutura nao sao mantidas informacoes sobre a lista de processos que fazem parte
do grupo, uma vez que operacoes que acessam os dados armazenados em css set
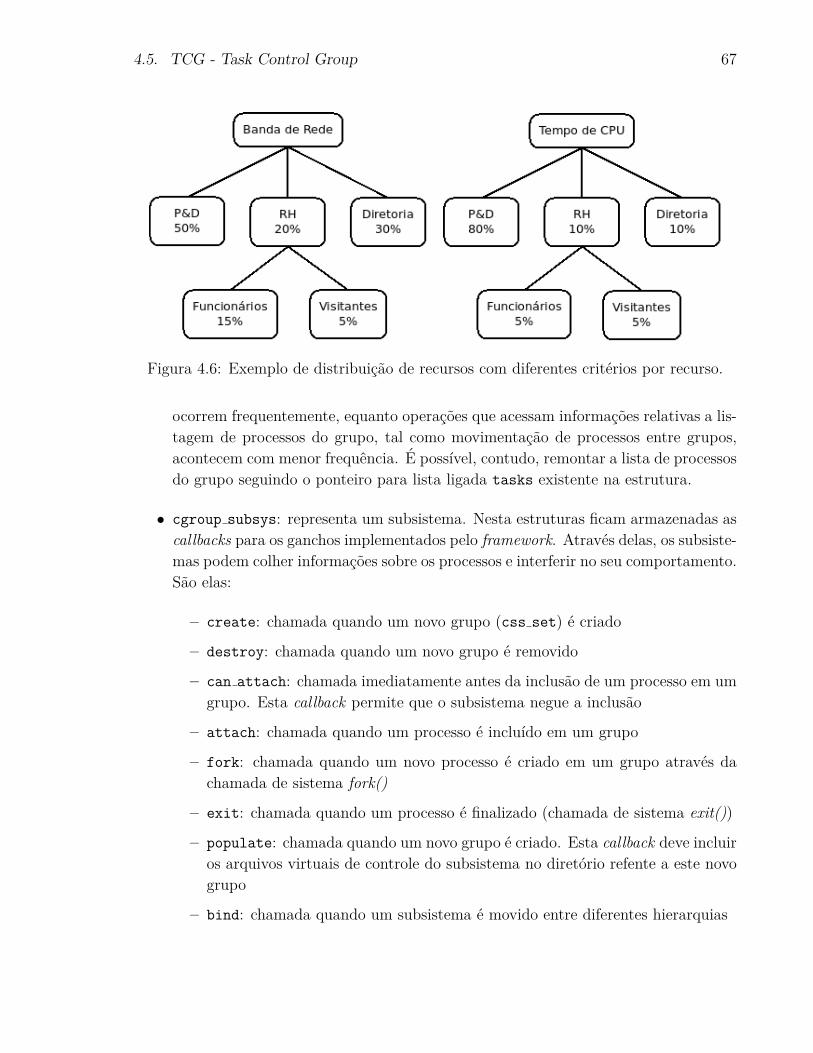
4.5. TCG - Task Control Group 67
Figura 4.6: Exemplo de distribuicao de recursos com diferentes criterios por recurso.
ocorrem frequentemente, equanto operacoes que acessam informacoes relativas a lis-
tagem de processos do grupo, tal como movimentacao de processos entre grupos,
acontecem com menor frequencia. E possıvel, contudo, remontar a lista de processos
do grupo seguindo o ponteiro para lista ligada tasks existente na estrutura.
• cgroup subsys: representa um subsistema. Nesta estruturas ficam armazenadas as
callbacks para os ganchos implementados pelo framework. Atraves delas, os subsiste-
mas podem colher informacoes sobre os processos e interferir no seu comportamento.
Sao elas:
– create: chamada quando um novo grupo (css set) e criado
– destroy: chamada quando um novo grupo e removido
– can attach: chamada imediatamente antes da inclusao de um processo em um
grupo. Esta callback permite que o subsistema negue a inclusao
– attach: chamada quando um processo e incluıdo em um grupo
– fork: chamada quando um novo processo e criado em um grupo atraves da
chamada de sistema fork()
– exit: chamada quando um processo e finalizado (chamada de sistema exit())
– populate: chamada quando um novo grupo e criado. Esta callback deve incluir
os arquivos virtuais de controle do subsistema no diretorio refente a este novo
grupo
– bind: chamada quando um subsistema e movido entre diferentes hierarquias

68 Capıtulo 4. Ferramentas de seguranca Linux
• cgroup subsys state: estrutura para armazenamento de informacoes de estado por
dupla grupo/subsistema. As principais informacoes armazenadas nessa estrutura
sao:
– cgroup: ponteiro para o grupo ao qual este subsistema esta anexado. Impor-
tante para a obtencao de informacoes sobre estrutura hierarquia
– refctn: observando a Requisito 7 apresentado anteriormente, esta variavel e
um contador de referencias a objetos que nao sejam do tipo processo perten-
centes ao subsistema. Esta variavel garante que nao seja possıvel a remocao de
um grupo que tenha objetos genericos associados, mesmo quando nao houver
mais nenhum processo associado a ele
• task group: armazena ponteiros para cada subsistema registrado e outras variaveis
de controle de comportamento especıficas de cada subsistema. Manter ponteiros
referentes ao controle de grupos (hierarquias, subsistemas, etc) no contexto de um
processo foi considerado um desperdıcio pelos desenvolvedores do TCG, principal-
mente para os casos onde subsistemas estiverem compilados no kernel, sem contudo
serem utilizados. Alem disso, diversos processos membros de um mesmo grupo,
compartilhariam as mesmas informacoes de subsistemas e hierarquias, o que re-
forcaria o desperdıcio. Desta forma, com a definicao desta estrutura, os descritores
de processo task struct podem ser simplesmente acrescidos de um ponteiro para
a estrutura task group do grupo ao qual o processo pertence
Na Figura 4.7, tem-se um kernel compilado com tres subsistemas disponıveis: A, B e C.
O administrador do sistema monta uma unica hierarquia com os subsistemas A e B ligados
a ela. Dois grupos, grp1 e grp2, sao criados. Os processos T1 e T2 sao alocados em grp1
e o processo T3 e alocado em grp2. Tem-se entao uma estrutura cgroup subsys state
para cada par grupo/subsistema e uma estrutura task group para cada grupo.
O registro de subsistemas e feito em tempo de compilacao do kernel. Por essa razao,
nao e possıvel criar um subsistema na forma de LKM.
O TCG nao e classificado exatamente como um framework de seguranca do Linux,
contudo, sera visto no Capıtulo 5 que a capacidade de controlar a oferta e uso de recursos
do sistema operacional por processos e um requisito de grande importancia na imple-
mentacao de mecanismos de resposta a ataques em um sistema de seguranca imunologico.
4.5.2 Funcionamento
O TCG faz interface com o espaco de usuario via sistema de arquivos virtual proprio,
do tipo cgroup, atraves do qual e possıvel criar e manter hierarquias, movimentar pro-
cessos entre grupos, alem de ajustar os parametros oferecidos pelos subsistemas.
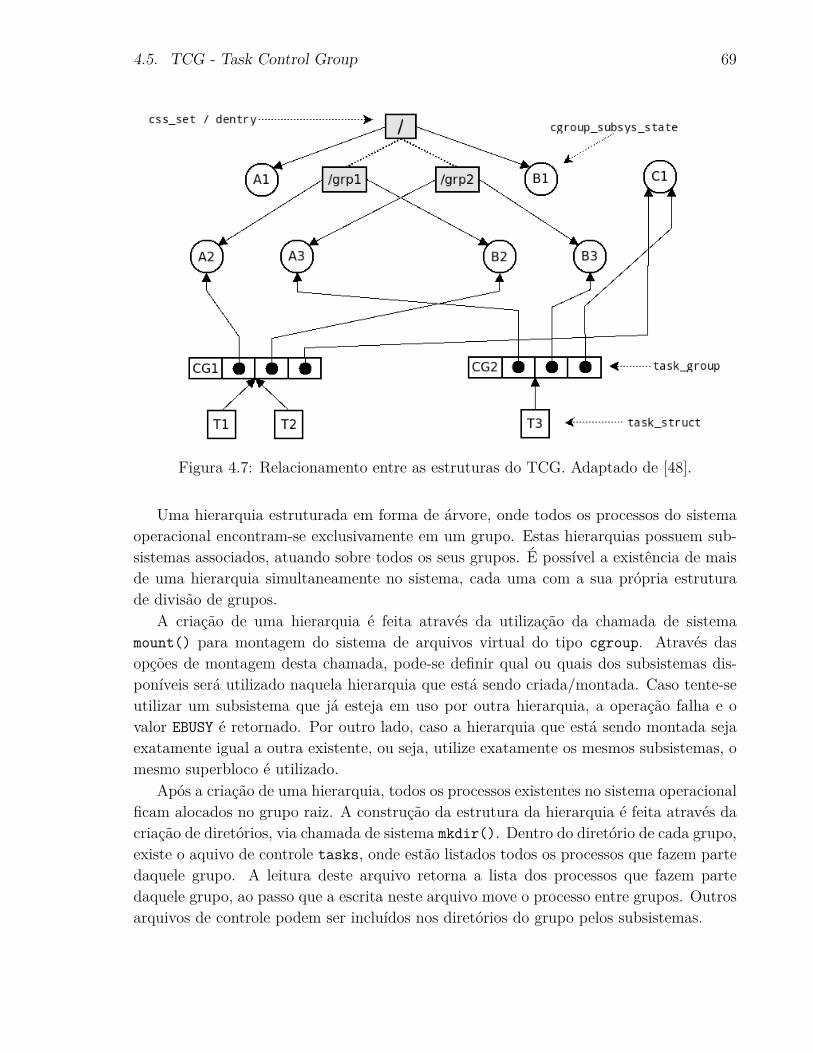
4.5. TCG - Task Control Group 69
Figura 4.7: Relacionamento entre as estruturas do TCG. Adaptado de [48].
Uma hierarquia estruturada em forma de arvore, onde todos os processos do sistema
operacional encontram-se exclusivamente em um grupo. Estas hierarquias possuem sub-
sistemas associados, atuando sobre todos os seus grupos. E possıvel a existencia de mais
de uma hierarquia simultaneamente no sistema, cada uma com a sua propria estrutura
de divisao de grupos.
A criacao de uma hierarquia e feita atraves da utilizacao da chamada de sistema
mount() para montagem do sistema de arquivos virtual do tipo cgroup. Atraves das
opcoes de montagem desta chamada, pode-se definir qual ou quais dos subsistemas dis-
ponıveis sera utilizado naquela hierarquia que esta sendo criada/montada. Caso tente-se
utilizar um subsistema que ja esteja em uso por outra hierarquia, a operacao falha e o
valor EBUSY e retornado. Por outro lado, caso a hierarquia que esta sendo montada seja
exatamente igual a outra existente, ou seja, utilize exatamente os mesmos subsistemas, o
mesmo superbloco e utilizado.
Apos a criacao de uma hierarquia, todos os processos existentes no sistema operacional
ficam alocados no grupo raiz. A construcao da estrutura da hierarquia e feita atraves da
criacao de diretorios, via chamada de sistema mkdir(). Dentro do diretorio de cada grupo,
existe o aquivo de controle tasks, onde estao listados todos os processos que fazem parte
daquele grupo. A leitura deste arquivo retorna a lista dos processos que fazem parte
daquele grupo, ao passo que a escrita neste arquivo move o processo entre grupos. Outros
arquivos de controle podem ser incluıdos nos diretorios do grupo pelos subsistemas.

70 Capıtulo 4. Ferramentas de seguranca Linux
A sequencia de comandos abaixo listada ilustra a criacao da hierarquia apresentada
na Figura 4.712:
# mkdir /tcg
# mount -t cgroup -o A,B none /tcg
# mkdir /tcg/grp1 /tcg/grp2
# echo 1011 > /tcg/grp1/tasks
# echo 1012 > /tcg/grp1/tasks
# echo 1013 > /tcg/grp2/tasks
O TCG disponibiliza ainda outros dois aquivos de controle: /proc/cgroups, que
contem informacoes sobre o uso dos subsistemas disponıveis (compilados) no kernel e
/proc/<PID>/cgroup, que lista o caminho dos grupos aos quais o processo faz parte em
cada hierarquia ativa.
Quando uma hierarquia e desmontada, e necessario que nao haja nenhum subgrupo
existente para que a hierarquia seja extinta e os seus subsistemas liberados para utilizacao
por outras hierarquias. Caso existam subgrupos, o sistema de arquivos virtual da hierar-
quia e desmontado, porem a hierarquia continua existindo, assim como o seu superbloco,
apesar e nao estar visivelmente montada no sistema de arquivos. A remocao de grupos
e feita atraves da chamada rmdir() e so pode ser feita caso nao haja nenhum processo
atrelado ao grupo que esta sendo removido.
4.5.3 Subsistemas
Abaixo sao apresentados brevemente os subsistemas disponıveis na versao 3.7.6 do
Linux.
cpusets
O subsistema cpusets pode ser considerado como o primeiro subsistema TCG a fazer
parte da versao oficial do Linux. Este subsistema, na verdade, ja estava disponıvel no
kernel antes mesmo do TCG e foi um dos motivadores para a criacao do framework
[48]. Com a disponibilidade do TCG, a partir do Linux 3.6.24, o cpusets foi remodelado
como um subsistema TCG, o que resultou em uma reducao significativa no tamanho do
seu codigo, devido a eliminacao dos trechos responsaveis por gerenciamento de grupo de
processos e tratamento de interface. Este subsistema e compilado no kernel habilitando-se
a variavel CONFIG CPUSETS e e atribuıdo a uma hierarquia atraves da opcao cpuset da
chamada de sistema mount().
12Neste exemplo considera-se que os PIDs de T1, T2 e T3 sao, respectivamente, 1011, 1012 e 1013.

4.5. TCG - Task Control Group 71
Este subsistema prove mecanismos para atribuicao de subconjuntos de CPUs e nos de
memoria exclusivamente para um conjunto de processos, alem de oferecer outros recursos
avancados no uso de CPU e memoria.
O subsistema cpusets disponibiliza os seguintes arquivos de controle:
• cpuset.cpus: CPUs validos para o grupo
• cpuset.mems: nos de memoria validos para o grupo
• cpuset.cpu exclusive: flag de exclusividade. Caso um grupo tenha esse
parametro habilitado, nenhum outro grupo alem dos seus pais ou filhos podem
compartilhar uma CPU
• cpuset.mem exclusive: flag de exclusividade. Caso um grupo tenha esse
parametro habilitado, nenhum outro grupo alem dos seus pais ou filhos podem
compartilhar nos de memoria
• cpuset.mem hardwall: restringe alocacoes de kernel para paginas, buffers e outros
dados que sao compartilhados entre aplicacoes em espaco de usuario
• cpuset.memory migrate: uma vez que uma pagina e alocada, esta pagina per-
manece no mesmo no enquanto ela permanecer alocada, mesmo que a polıtica de
gerenciamento de memoria (cpuset.mems) do seu grupo mude. Se este flag estiver
habilitado, contudo, as paginas alocadas a um processo do grupo serao migradas
para os nos dentro da nova polıtica do grupo
• cpuset.memory pressure: metrica da taxa com que processos estao tentando libe-
rar memoria utilizada para atender a novas requisicoes de uso de memoria. E um
numero inteiro que representa a taxa recente de requisicoes de pagina por processo
do grupo em numero de requisicoes por segundo vezes mil
• cpuset.memory spread page: flag booleana que controla a localizacao da alocacao
de memoria para buffers de sistemas de arquivos e estruturas de dados de kernel
relacionadas. Desabilitado por padrao. Caso habilitado, permite que tais espacos
possam ser alocados em qualquer no de memoria ao qual o processo possua acesso,
e nao exatamente no no onde o processo esta rodando
• cpuset.memory spread slab: flag booleana que controla a localizacao da alocacao
memoria para estruturas de dados de kernel. Desabilitado por padrao. Caso habili-
tado, permite que tais espacos possam ser alocados em qualquer no de memoria ao
qual o processo possua acesso, e nao exatamente no no onde o processo esta rodando

72 Capıtulo 4. Ferramentas de seguranca Linux
• cpuset.sched load balance: quando habilitada (configuracao padrao), esta flag
garante o balanceamento de carga entre as CPUs do grupo
• cpuset.sched relax domain level: controla o comportamento de busca por CPUs
ociosas no grupo
Group CPU Scheduler
Introduzido a partir da versao 2.6.24, o subsistema Group CPU Scheduler e compilado
no kernel habilitando-se a variavel CONFIG CGROUP SCHED e e montado atraves da opcao
cpu da chamada de sistema mount().
Este subsistema tem como objetivo implementar o mecanismo de escalonamento ba-
seado em grupos do CFS.
O escalonador CFS, introduzido no kernel 2.6.23, foi desenvolvido com o objetivo de
entregar uma distribuicao justa de tempo de CPU[63]. No seu comportamento padrao,
este escalonador opera sobre processos individuais do sistema operacional e tenta prover
tempos de CPU iguais para eles.
Contudo, algumas vezes deseja-se agrupar conjuntos de processos e prover tempo de
CPU justo para cada processo do grupo. Por exemplo, pode-se desejar primeiro prover
tempo de CPU justo para cada usuario do sistema e, entao, tempo justo para cada processo
pertencente a um usuario. Este desejo parte da necessidade de evitar que um usuario possa
criar muitos processos e, consequentemente, receber mais tempo de CPU que um outro
usuario (com menos processos). Por exemplo: quando tem-se quatro usuarios rodando
um processo cada um, o escalonador tende a oferecer 25% de tempo de CPU para cada um
deles, o que e justo. Contudo, caso um destes usuarios (usuario A) crie mais 96 processos,
o escalonador passara a oferecer 1% de CPU para cada um dos 100 processos, ou seja
o usuario A usara 97% de CPU, enquanto os outros tres usuarios usarao apenas 1% de
CPU cada um, o que pode ser considerado injusto.
Por este motivo, o CFS introduziu o conceito de Group Scheduling
(CONFIG GROUP SCHED), onde o escalonador pode ser ajustado de forma a entregar
tempos de CPU iguais para grupos de processo, independente de quantos processos fazem
parte de cada grupo. Esta abordagem elimina o problema de justica de escalonamento
apresentado no paragrafo anterior.
O CFS permite dois mecanismos mutuamente exclusivos de agrupamento de processos:
baseado em usuarios (CONFIG USER SCHED) e baseado em grupos (CONFIG CGROUP SCHED).
No primeiro caso, os processos sao agrupados por usuario, de acordo com o seu UID (User
IDentification). Um diretorio e criado no sistema de arquivos virtual sysfs para cada
usuario (/sys/kernel/uids/<UID>) e um arquivo de controle cpu share e adicionado
nestes diretorios. No segundo caso, os processos sao agrupados usando a infraestrutura

4.5. TCG - Task Control Group 73
do TCG, onde cada cgroup possui um arquivo de controle cpu share.
Em ambos os casos, a razao entre os valores dos arquivos cpu share dos diferentes
usuarios/grupos define a razao do tempo de CPU de cada grupo.
CFS Bandwidth Control
Introduzido a partir da versao 3.2 do Linux, o CFS Bandwidth Control e uma extensao
do subsistema Group CPU Scheduler e e compilado no kernel habilitando-se a variavel
CONFIG CFS BANDWIDTH. Este subsistema tambem e atribuıdo a uma hierarquia atraves
da opcao cpu da chamada de sistema mount.
Um escalonador de processos em um sistema operacional divide o tempo de CPU
entre os processos que desejam ser executados (multiprocessamento). Nao existem limites
superiores para o uso de CPU por um processo quando nao existem outros processos
competido por este recurso. Em algumas situacoes, contudo, pode ser desejavel limitar
o uso de CPU por um dado processo, ou grupo de processos, mesmo que nao existam
outros processos tentando ser executados. Por este motivo, o CFS Bandwidth Control
implementa um mecanismo para limitacao do tempo de uso de CPU por parte de um
grupo de processos [62].
A definicao deste limite e feita atraves da definicao de um perıodo de tempo de pro-
cessamento e, posteriormente, configuracao de uma quota de tempo a ser utilizada pelo
grupo dentro de cada perıodo determinado.
O subsistema utiliza os seguintes arquivos de controle:
• cpu.cfs period: tempo, em microsegundos, da unidade de referencia (perıodo). O
valor maximo desta variavel e 1000000µs (um segundo)
• cpu.cfs quota: tempo maximo, em microsegundos, de utilizacao de CPU para cada
perıodo. Caso essa variavel possua valor negativo, nao serao impostos limites. O
mınimo valor possıvel desta variavel e 1000µs (um milisegundo).
Simple CPU Accounting
Introduzido a partir da versao 2.6.29 do Linux, o subsistema cpuacct e compilado no
kernel habilitando-se a variavel CONFIG CGROUP CPUACCT e e atribuıdo a uma hierarquia
atraves da opcao cpuacct da chamada de sistema mount().
Este subsistema permite a contabilizacao do tempo de CPU utilizada pelos processos
dos seus respectivos grupos, onde o tempo de CPU utilizado por processos de grupos filho
tambem e contabilizado pelo grupo pai.
O subsistema cpuacct cria os seguintes arquivos de controle:

74 Capıtulo 4. Ferramentas de seguranca Linux
• cpu usage: tempo de CPU acumulado, em nanosegundos, de todos os processos
membros do grupo e de grupos filhos, desde a sua inclusao em cada grupo
• cpu usage cpu: divide o tempo informado no arquivo anterior por cada CPU do
sistema
• cpu stat: estatısticas de uso do tempo de CPU do grupo. Este arquivo apresenta
a separacao do tempo de CPU em espaco de usuario e em espaco de nucleo. A
unidade utilizada e USER HZ
Device Controller
Introduzido a partir da versao 2.6.29 do Linux, o subsistema Device Controller e
compilado no kernel habilitando-se a variavel CONFIG CGROUP DEVICE e e atribuıdo a uma
hierarquia atraves da opcao devices da chamada de sistema mount().
Este subsistema monitora as chamadas de sistema open e mknod em arquivos espe-
ciais de dispositivos, podendo aplicar restricoes de acessos a estes arquivos, baseando-se
em listas de permissoes de acesso (blacklist e whitelist) definidas pelo administrador da
hierarquia.
O subsistema devices cria os seguintes arquivos de controle:
• devices.allow: arquivo de entrada dos atributos de controle de acesso para dispo-
sitivos permitidos
• devices.deny: arquivo de entrada dos atributos de controle de acesso para dispo-
sitivos nao permitidos
• devices.list: listagem de todos os dispositivos com acesso permitido ao grupo
A sintaxe para escrita nos arquivos devices.allow e devices.deny e do tipo <type>
<major>:<minor> <access> . Para o campo <type> sao aceitos os valores b, c e a para,
respectivamente, dispositivos de bloco, caractere e ambos. O segundo e terceiro campo
recebem os numeros que identificam o dispositivo. Nestes campos, o caractere * e aceito
e corresponde a todos os numeros daquele campo. Finalmente, o campo <access> recebe
as regras de acesso da diretiva, podendo ser uma combinacao dos valores r (leitura), w
(escrita) e m (mknod).
O grupo raiz de uma hierarquia que utilize o subsistema devices inicia com acesso
total (rwm) a todos os dispositivos do sistema. Um grupo filho herda as permissoes do
grupo pai e, nao pode receber permissoes de acesso a dispositivos aos quais o pai nao
possua acesso. Contudo, caso uma permissao comum a grupos pai e filho seja removida
do grupo pai, ela nao e automaticamente removida do grupo filho.

4.5. TCG - Task Control Group 75
Freezer
Introduzido a partir da versao 2.6.28, o subsistema Freezer e compilado no kernel
habilitando-se a variavel CONFIG CGROUP FREEZER e e atribuıdo a uma hierarquia atraves
da opcao freezer da chamada de sistema mount().
Este subsistema usa a infraestrutura do TCG para definir grupos nos quais e possıvel
parar e reiniciar processos, sendo especialmente util no gerenciamento de processos em
lote, permitindo ao administrador agendar a execucao de tarefas de acordo com a sua
necessidade.
Outra aplicacao e a criacao de checkpoints13 de grupos de aplicacoes, o que permite que
sejam obtidas imagens consistentes dos processos de um grupo. Estas imagens podem ser
utilizadas para retornar os processos a um estado consistente apos uma falha ou mesmo
para mover os processos entre diferentes nos de um cluster14, por exemplo. Para gerar
tais imagens, o grupo deve ser congelado, enquanto um outro processo usa as informacoes
disponıveis em /proc ou atraves de outras interfaces de kernel para analisar o processo.
A utilizacao deste sistema nao e equivalente a utilizacao de sinais do sistema operaci-
onal. As sequencias de sinais SIGSTOP e SIGCONT nem sempre sao suficientes para parar
e reiniciar processos no espaco de usuario. Isso acontece porque, embora o sinal SIGSTOP
nao possa ser ignorado, ele pode ser observado pelo processo que o recebe (ou seja o
processo sabe que recebeu tal sinal). Ja o sinal SIGCONT pode ser tratado pelo processo
que o recebe, fazendo com que ele haja de maneira diferente do esperado ao receber tal
sinal. Portanto, um processo ao voltar a ser executado atraves do sinal SIGCONT, pode
escolher proceder de maneira diferente do que normalmente o faria, uma vez que sabe que
foi anteriormente parado atraves do sinal SIGSTOP. Um exemplo deste comportamento
pode ser observado na aplicacao bash. Um processo bash ao receber a sequencia de sinais
SIGSTOP e SIGCONT e finalizado, ao inves de simplesmente ser paralisado e voltar a execu-
tar normalmente. Esta e uma decisao de programacao da aplicacao, que e possıvel gracas
as caracterısticas da manipulacao de processos atraves de sinais ora apresentada. Desta
forma, fica claro que a utilizacao de sinais nao e eficaz para a manutencao de checkpoints.
O subsistema freezer cria um arquivo de controle, freezer.state, que ao ser lido
informa o estado do grupo. A escrita neste mesmo arquivo e utilizada para modificar o
estado do grupo. Este arquivo pode assumir os seguintes valores:
• FROZEN: processos do grupo estao congelados (nao estao rodando)
• THAWED: processos do grupo estao sendo executados normalmente (nao estao conge-
13Tecnica que permite que o estado de uma aplicacao em um determinado momento seja salvo, permi-tindo avaliacao e retomada da execucao a partir daquele ponto
14Conjunto de computadores utilizados simultaneamente, de maneira coordenada, visando o atendi-mento de um unico objetivo

76 Capıtulo 4. Ferramentas de seguranca Linux
lados)
• FREEZING: alguns processos do grupo estao congelados e outros rodando. Nos casos
em que o subsistema nao conseguir congelar todos os processos do grupo, a operacao
de escrita em freezer.state falha, retornando o valor EBUSY e o estado FREEZING
passar a ser lido neste arquivo. Nestes casos, o usuario do subsistema pode escrever
THAWED no arquivo de controle, para fazer com que todos os processos voltem a
executar normalmente, ou escrever FROZEN, numa nova tentativa de congelar todos
os processos do grupo.
Memory Resource Controller
Introduzido a partir da versao 2.6.29 do Linux, o subsistema Memory Re-
source Controller e compilado no kernel habilitando-se as variaveis CONFIG MEMCG e
CONFIG MEMCG SWAP e e atribuıdo a uma hierarquia atraves da opcao memory da chamada
de sistema mount().
Este subsistema permite o controle do uso de paginas de memoria (fısica e swap)
por parte de grupos de processos. Desta forma, e possıvel estabelecer um mecanismo de
isolamento onde aplicacoes que consomem muita memoria possam ser limitadas a uma
quantidade menor da memoria total disponıvel.
O subsistema Memory Resource Controller cria os seguintes arquivos de controle:
• memory.failcnt: contador do numero de tentativas de alocacao de memoria que
falharam
• memory.usage in bytes: contator da quantidade de memoria fısica consumida pelo
grupo
• memory.limit in bytes: valor limite de uso de memoria fısica pelo grupo
• memory.soft limit in bytes: valor limite de uso de memoria fısica pelo grupo.
Este valor pode ser ultrapassado pelo grupo, desde que permaneca abaixo do limite
estabelecido na variavel anterior. Contudo, caso o sistema operacional precise de
memoria, ele ira solicitar dos grupos que tiverem extrapolado este limite
• memory.max usage in bytes: consumo maximo de memoria fısica registrado
• memory.memsw.failcnt: contador semelhante a memory.failcnt, aplicado a
memoria do tipo swap
• memory.memsw.usage in bytes: contador semelhante a memory.usage in bytes,
aplicado a memoria do tipo swap

4.5. TCG - Task Control Group 77
• memory.memsw.limit in bytes: semelhante a memory.limit in bytes, aplicado a
memoria do tipo swap
• memory.memsw.max usage in bytes: semelhante a memory.max usage in bytes,
aplicado a memoria do tipo swap
• memory.force empty: variavel de controle utilizada para zerar os contadores de uso
de memoria do grupo. Deve ser utilizada somente quando nao existem processos
atribuıdos ao grupo (arquivo tasks deve estar vazio)
• memory.swappiness: variavel de controle utilizada para habilitar ou desabilitar a
capacidade do grupo de utilizar memoria do tipo swap
• memory.stat: diversas estatısticas sobre o uso de memoria
• memory.use hierarchy: habilita contabilizacao hierarquica
HugeTLB Resource Controller
Introduzido a partir da versao 3.5 do Linux, o subsistema HugeTLB Resource Control-
ler e compilado no kernel habilitando-se a variavel CONFIG CGROUP HUGETLB e e atribuıdo
a uma hierarquia atraves da opcao hugetlb da chamada de sistema mount().
Este subsistema implementa os mesmos mecanismos de controle sobre paginas de
memoria do Memory Resource Controller em paginas de memoria do tipo Huge TLB [45]
[43]. A sua utilizacao e semelhante aquele subsistema, atraves de arquivos de controle
prefixados por hugetlb.
Network Priority Cgroup
Introduzido a partir da versao 3.3 do Linux, o subsistema Network Priority Cgroup
e compilado no kernel habilitando-se a variavel CONFIG NETPRIO CGROUP e e atribuıdo a
uma hierarquia atraves da opcao net prio da chamada de sistema mount().
Este subsistema permite um mapeamento de prioridades de trafego gerado por dife-
rentes aplicacoes, por interface de rede. A sua utilizacao e feita atraves dos seguintes
arquivos de controle:
• net prio.prioidx: valor inteiro utilizado no kernel para identificar o grupo. Este
valor e definido automaticamente pelo subsistema, portanto o arquivo possui carater
informativo e e do tipo somente-leitura
• net prio.ifpriomap: mapa com lista de prioridades estabelecidas para trafego de
rede originado pelos processos deste grupo. Para definir uma regra neste mapa, uma

78 Capıtulo 4. Ferramentas de seguranca Linux
string do tipo <interface> <prio>, onde o primeiro campo representa o nome da
interface de rede para a qual o prioridade esta sendo definida e o segundo e um
numero inteiro da escala de prioridades, deve ser escrita neste arquivo de controle.
Um exemplo valido seria: eth0 5.
Resource Counters
Introduzido a partir da versao 2.6.29 do Linux, o subsistema resource counter e com-
pilado no kernel habilitando-se a variavel CONFIG RESOURCE COUNTERS.
Diferentemente de outros subsistemas, esse nao e um subsistema montavel e pronto
para uso, mas sim uma API que pode ser utilizada para o desenvolvimento de diversos
subsistemas. Este subsistema tem como objetivo facilitar o gerenciamento de recursos de
diferentes controladores, fornecendo atributos comuns de contabilizacao. Estes atribuıdos
sao disponibilizados atraves de uma estrutura chamada res counter e diversas funcoes
para a manipulacao desta.
A estrutura res counter possui a seguinte forma:
struct res_counter {
unsigned long long usage;
unsigned long long max_usage;
unsigned long long limit;
unsigned long long failcnt;
spinlock_t lock;
struct res_counter *parent;
};
Onde os seus atributos representam as seguintes informacoes:
• usage: nıvel de consumo atual do recurso pelo grupo. A unidade deve ser definida
pelo desenvolvedor do subsistema
• max usage: valor maximo de consumo do recurso pelo grupo em uma curva historica
• limit: valor limite para utilizacao do recurso. Um requisicao de alocacao de recursos
capaz de exceder este limite deve ser negada pelo subsistema, garantindo sempre
que usage seja menor ou igual a limit
• soft limit: valor limite inicial para utilizacao do recurso. Um requisicao de
alocacao de recursos capaz de exceder este limite deve ser permitida somente nos
casos em que o limite maximo nao seja excedido, ou seja, quando usage permanecer
menor ou igual a limit

4.6. Conclusao 79
• failcnt: contador do numero de tentativas de alocacao do recurso que falharam
• lock: variavel utilizada para garantir exclusao mutua no acesso a estrutura
• *parent: ponteiro para a estrutura res counter do grupo pai. Utilizada para
contabilidade hierarquica.
Desta forma, um subsistema para fazer uso desta API deve:
• incluir o cabecalho da API (linux/res counter.h)
• incluir uma variavel do tipo struct res counter na sua estrutura task group
• incluir ganchos nos pontos onde sao feitas alocacao e liberacao dos recursos a se-
rem contabilizados/controlados pelo subsistema, de tal forma que, sempre que estes
eventos ocorrerem os atributos de contabilizacao sejam atualizadas. A manipulacao
destes atributos deve ser feita atraves das funcoes definidas pelo resource counter,
e nao por meio de acesso direto as variaveis da estrutura
• incluir arquivos de controle do TCG para leitura dos parametros contabilizados e
escrita dos limites a serem impostos
4.6 Conclusao
Este capıtulo apresentou brevemente o funcionamento do sistema de controle de acesso
do Linux, considerando sua arquitetura e funcionamento padrao (discricionario), alem das
possibilidades de extensao destas funcionalidades atraves aplicacao de sistemas de controle
de acesso do tipo mandatorio. Foi apresentado o framework LSM, utilizado no Linux como
ferramenta padrao para a implementacao de diferentes modelos de controle de acesso.
Este capıtulo abordou ainda outros recursos relacionados a seguranca no ambiente do
sistema operacional Linux: SecurityFS, um sistema de arquivos virtual utilizado como
interface para modulos LSM (Secao 4.3); Netfilter, um framework para interceptacao e
filtro de pacotes de rede (Secao 4.4); e Task Control Group, um framework para agrupa-
mento de processos e contabilizacao de uso de recursos por estes grupos, utilizado para
monitorar o uso de recursos do sistema operacional e prevenir abusos (Secao 4.5).
Finalizada a revisao bibliografica, a partir do proximo capıtulo sera apresentado a
ferramenta desenvolvida neste trabalho.


Capıtulo 5
Framework IMN
Nos Capıtulos 2, 3 e 4 foram apresentados conceitos e definicoes pertinentes levantados
na etapa de revisao bibliografica deste trabalho. O Capıtulo 2 apresentou a estrutura e
funcionamento basico do sistema imunologico humano, fonte de inspiracao de pesquisa
para diversos trabalhos de pesquisa em seguranca computacional, alguns dos quais foram
brevemente descritos naquele capıtulo. Dentre os trabalhos apresentados, a pesquisa
realizada pelo projeto Imuno, do Laboratorio de Seguranca e Criptografia da Universidade
Estadual de Campinas (LASCA - UNICAMP), motivou esta dissertacao de mestrado.
Na Secao 2.2.4, foi apresentado o trabalho de De Paula [22], que propunha o desen-
volvimento de um Sistema de Deteccao de Intrusao (IDS - Intrusion Detection System)
baseado no sistema imunologico humano e implementado no nucleo do sistema operacional
GNU/Linux. Este sistema operacional, pelas caracterısticas apresentados na Secao 3.1,
foi o escolhido para as implementacoes dos trabalhos de pesquisa desenvolvidos pelo pro-
jeto Imuno. Por este motivo, os Capıtulos 3 e 4 apresentaram a estrutura, funcionamento,
recursos de seguranca e ferramentas de gerenciamento do kernel Linux.
Neste capıtulo, sera apresentada a motivacao, levantamento de requisitos e imple-
mentacao do framework IMN. Na Secao 5.1, sera apresentado o contexto e as dificuldades
do projeto Imuno que motivaram a elaboracao deste trabalho. Na Secao 5.2 sera feita uma
analise dos requisitos comuns aos trabalhos desenvolvidos no projeto, a partir de analise
dos trabalhos apresentados na Secao 2.2. Na Secao 5.3 sera apresentada a arquitetura e
detalhes de implementacao do framework IMN, trabalho fruto desta dissertacao.
5.1 Motivacao
Com o amadurecimento da pesquisa e o desenvolvimento de alguns prototipos de
escopo reduzido, o projeto Imuno notou a necessidade de uma plataforma de desenvolvi-
mento comum para os prototipos que vinham sendo trabalhados. Esta necessidade partiu
81

82 Capıtulo 5. Framework IMN
da constatacao de que o processo de desenvolvimento dos prototipos era muito complexo,
demandando grande esforco de desenvolvimento e manutencao de codigo. Essa realidade
configurou uma das grandes barreiras no desenvolvimento do sistema imunologico geral
proposto inicialmente, uma vez que muito esforco era dirigido para a implementacao de
pequenos requisitos, diminuindo assim o tempo de trabalho util no desenvolvimento e
implementacao dos conceitos imunologicos.
Outra importante constatacao, foi a grande dificuldade envolvida no processo de manu-
tencao e atualizacao dos prototipos desenvolvidos para versoes mais recentes do ambiente
de desenvolvimento. Conforme visto anteriormente, estes prototipos eram em grande
parte implementados em nıvel de kernel do Linux. A cada nova versao do kenrel, eram
detectadas mudancas profundas na estrutura de alguns de seus componentes, o que, con-
sequentemente, implicava em mudancas nas APIs utilizadas pelos prototipos do Imuno.
O primeiro impacto desta caracterıstica do ambiente de desenvolvimento, era um au-
mento da dificuldade relatada no paragrafo anterior: alem da complexidade inerente ao
desenvolvimento de ferramentas em nıvel de kernel, os pesquisadores ainda enfrentavam
um grande esforco de programacao a cada nova versao do Linux. Desta forma, o tempo
demandado no desenvolvimento era somado ao tempo consumido em manutencao das
ferramentas desenvolvidas, diminuindo ainda mais o tempo de trabalho util na pesquisa
dos conceitos imunologicos.
O segundo impacto, e talvez o mais consideravel para a evolucao da pesquisa, era o
alto ındice de abandono de codigo decorrente das constantes mudancas do Linux. Com
a entrada de novos pesquisadores no projeto, e saıda de outros, houve interrupcao no
processo de desenvolvimento dos prototipos. Quando da entrada de novos pesquisado-
res, apos algum esforco de manutencao e atualizacao dos codigos existentes, notou-se
uma tendencia natural de abandono da base de codigo existente, e reimplementacao dos
conceitos pesquisados e introduzidos anteriormente.
Diante desta realidade, Martim Carbone [29] propos o desenvolvimento de um fra-
mework a ser implementado em nıvel de kernel, sobre o qual os demais pesquisadores do
projeto poderiam desenvolver, em espaco de usuario, os modulos do sistema imunologico
por eles pesquisados. Desta forma, o processo de desenvolvimento seria simplificado.
Alem disso, as questoes de manutencao e atualizacao das implementacoes de kernel ine-
rentes as atualizacoes do Linux ficariam concentradas neste ponto da arquitetura Imuno,
o framework Imunologico, podendo ser tratado de maneira isolada e por equipes indepen-
dentes.
Outra importante vantagem da solucao proposta por Carbone seria o aumento da ca-
pacidade de interoperacao entre os modulos desenvolvidos pelos diferentes pesquisadores,
uma vez que todos utilizariam essa mesma plataforma. O framework concebido por Car-
bone chegou a ser implementado na forma de um prototipo inicial de escopo reduzido,

5.2. Requisitos 83
com algumas das funcionalidades inicialmente propostas.
Este trabalho, portanto, teve como objetivo inicial a conclusao do prototipo desenvol-
vido por Carbone, o framework Imuno.
O resultado esperado e um framework funcional, estavel, e em producao no ambiente
do projeto Imuno. A visao do trabalho e implementar a solucao de maneira tal que venha
ao encontro das praticas de projeto adotadas pelos desenvolvedores do Linux, de forma
que possa ser eventualmente aceito na versao oficial do kernel.
5.2 Requisitos
5.2.1 Metodologia
Para atender aos objetivos deste trabalho, em sua proposta inicial [15] foram definidas
as seguintes etapas de atuacao:
1. Atualizacao do prototipo de escopo reduzido desenvolvido por Carbone: resgatar o
framework Imuno, atualizando-o para a versao corrente do Linux e restaurando o
seu funcionamento;
2. Implementacao de requisitos levantados mas nao implementados: o prototipo de
Carbone referenciou funcionalidades importantes para o framework que nao haviam
sido implementadas, ou estavam apenas parcialmente disponıveis. Estas funciona-
lidades, descritas na secao de sugestoes de trabalhos futuros, deveriam entao ser as
primeiras novas funcionalidades a serem incorporadas ao framework Imuno atuali-
zado;
3. Levantamento de novos requisitos para o framework: uma vez funcional e com
os requisitos pre-estabelecidos implementados, a proxima etapa seria uma serie de
entrevistas com pesquisadores do projeto, de forma a levantar novos requisitos de
funcionalidades que deveriam compor o rol de funcionalidades do framework;
4. Implementacao das novas funcionalidades levantadas na etapa anterior.
5. Testes: exercıcios de prova de funcionalidades e desempenho do framework desen-
volvido.
Na Secao 5.2.2 serao descritas as atividades realizadas em cada uma destas etapas,
bem como os requisitos levantados. A implementacao destes requisitos e detalhamento
da arquitetura e funcionalidades do framework serao descritas na Secao 5.3.

84 Capıtulo 5. Framework IMN
5.2.2 Levantamento de Requisitos
Etapa 1
Conforme apresentado na Secao 2.2.5 e ilustrado na Figura 2.10, o framework Imuno e
um modulo LSM que implementa uma abstracao capaz de permitir que diferentes LKMs
registrem funcoes tratadoras para ganchos LSM. Esta funcionalidade foi batizada de Gan-
chos Multifuncionais e e manipulada atraves de uma nova chamada de sistema introduzida
com o framework (chamada imuno()). A estrutura de ganchos multifuncionais e o cerne
do Imuno.
Para garantir que apenas processos componentes do sistema de seguranca imunologico
possam utilizar as funcionalidades da arquitetura de ganchos multifuncionais, o framework
Imuno implementa uma logica de registro de processos atraves da chamada imuno() e
da interface administrativa (sistema de arquivos virtual do tipo RelayFS). Nesta logica,
somente os processos registrados junto ao framework, ou “Processos Imunologicos”, podem
ter acesso aos recursos e dados da ferramenta.
Desta forma, alem dos ganchos e logica de registro de processos, o Imuno implementa
uma barreira de auto-protecao para garantir que processos nao imunologicos nao possam
interferir na seguranca do sistema. Esta barreira utiliza os POSIX Capabilities para
impedir que processos nao imunologicos carreguem ou descarreguem LKMs, e implementa
alguns tratadores em ganchos LSM relacionados a operacoes sobre processos e inodes
(na forma de LKMs, como um modulo imunologico), visando garantir o isolamento de
processos imunologicos e repositorios de seguros do sistema de seguranca.
Outros importantes recursos do framework sao:
• Ganchos UndoFS: middleware desenvolvido por De Paula [22] para disponibilizacao
das diretivas undo() e redo() em sistemas de arquivo Linux;
• Ganchos Netfilter: framework do kernel Linux que disponibiliza ganchos em pontos
do kernel onde e possıvel a interceptacao do fluxo de pacotes de rede (Secao 4.4);
• CKRM: framework Linux1 que implementa controle de recursos do sistema opera-
cional baseado em classes de processos [50].
O primeiro passo para atualizacao do Imuno, desenvolvido para o Linux 2.6.12, para a
versao 2.6.31 (versao do Linux do momento do inıcio do desenvolvimento deste trabalho),
foi desabilitar todos os recursos auxiliares daquele framework e compilar o LKM, junta-
mente com a logica de ganchos multifuncionais, sobre a versao mais recente do Linux e
carregar o modulo LSM neste sistema operacional. A conclusao com sucesso desta etapa
representaria uma atualizacao das funcionalidades basicas do Imuno para o novo kernel.
1Projeto de pesquisa descontinuado, nao chegou a fazer parte de versoes oficiais do Linux

5.2. Requisitos 85
Este simples exercıcio de manutencao da ferramenta, ilustrou bem o obstaculo repre-
sentado pela manutencao das ferramentas desenvolvidas em kernel pelo projeto Imuno:
a partir da versao 2.6.24 do Linux, o framework LSM deixou de permitir que modulos
de seguranca fossem registrados como LKMs. A alegacao dos mantenedores do sistema
operacional era de que esta caracterıstica poderia comprometer a seguranca do sistema
como um todo, uma vez que processos maliciosos poderiam em tese remover modulos LSM
em execucao e tambem incluir os seus proprios modulos para mudar o comportamento
dos sistemas de controle de acesso do Linux, permitindo um sem numero de diferentes
ataques (negacao de servico, roubo de informacao, dentre outros).
Desta forma, a arquitetura sobre a qual o framework fora concebido, modulo de kernel,
vira por terra. Diversas tentativas de ajuste no codigo do framework foram feitas na busca
por alternativas a esta limitacao imposta pelo LSM. Todas sem sucesso. Uma possıvel
solucao seria entao alterar o codigo do Linux de forma a permitir novamente modulos LSM
na forma de modulos de kernel, permitindo entao o restabelecimento do funcionamento
do Imuno.
A revisao feita sobre os trabalhos implementados pelo projeto Imuno (Capıtulo 2) e
o estudo apresentado sobre o funcionamento do kernel Linux (Capıtulos 3 e 4) levaram
a constatacao de que implementacoes que alteram profundamente diferentes pontos do
kernel sao difıceis de manter. Estas solucoes tambem possuem grandes restricoes sobre
seu aceite junto aos desenvolvedores do Linux, uma vez que estao sujeitas a falhas de
implementacao que nao se limitariam a funcionalidade em si, podendo prejudicar tambem
os pontos onde houveram alteracao, o que poderia comprometer a estabilidade e seguranca
do sistema como um todo.
Por este motivo, este trabalho tem como diretriz a implementacao de solucoes com
mınimo impacto no codigo do Linux e consoantes com as diretrizes e boas praticas adota-
das pelos mantenedores do Linux, mantendo a visao de qualidade, usabilidade e possibi-
lidade de aceite da ferramenta como um LSM do Linux oficial. A solucao de modificar o
kernel para permitir LSMs em forma de LKMs, portanto nao foi explorada por nao aten-
der as diretrizes deste trabalho. Tal solucao implica em mudancas profundas no kernel
e e oposta a visao de projeto dos mantenedores do Linux, que haviam decidido por bem
tornar os modulos LSM completamente built-in.
A Etapa 1 teve entao seu escopo alterado: uma vez que uma simples atualizacao do
framework Imuno nao seria possıvel, os objetivos do trabalho deveriam entao ser atin-
gidos por meio de uma re-arquitetura e reimplementacao. Esta nova implementacao foi
batizada, framework IMN.
O maior desafio deste novo framework era, mantendo as atuais caracterısticas do
LSM, permitir o carregamento dinamico de funcoes tratadoras por modulos imunologicos.
Este requisito foi atendido com sucesso atraves de uma nova implementacao da infra-

86 Capıtulo 5. Framework IMN
estrutura de ganchos multifuncionais para este novo LSM. A Secao 5.3 ira detalhar a
solucao implementada e a arquitetura geral do IMN.
Etapa 2
Apos minucioso estudo do trabalho desenvolvido por Martim e do prototipo Imuno,
as funcionalidades abaixo foram levantadas:
• Funcionalidades Implementadas
– Ganchos Multifuncionais via LSM implementado em LKM
– Ganchos Netfilter
– Interface administrativa via sistema de arquivos virtual RelayFS
– Auto-protecao e repositorio seguro
– Controle de recursos via CKRM. Apenas controle de tempo de CPU disponi-
bilizado
– Ganchos Netfilter para monitoramento de pacotes de rede
– UndoFS. Apenas ganchos de monitoramento de chamadas disponibilizados
• Funcionalidades Nao Implementadas
– Dump de paginas de memoria para disco
– Monitoracao de recursos
– Posicionamento de gancho multifuncional para todos os ganchos LSM
– UndoFS. Foi implementado apenas a interceptacao de chamadas e registro de
dados. A reconstrucao de arquivos nao foi implementada
– Criacao de novos ganchos no kernel. Ex.: dados das chamadas write() e
truncate() nao sao interceptados, uma vez que nao guardam relacao com
controle de acesso, contudo seriam interessantes ao sistema imuno
– Sistema mais eficiente para monitoramento de chamadas de sistema
– Otimizacao de desempenho
– Substituir ganchos UNDOFS por ganchos multifuncionais
– Mecanismo de auto-protecao mais flexıveis. Possivelmente utilizando SELinux
ou outra estrategia menos restritiva que o capabilities.

5.2. Requisitos 87
Todas essas funcionalidades passaram a compor, entao, o conjunto inicial de requi-
sitos para framework IMN. Inicialmente, contudo, somente a infraestrutura de ganchos
multifuncionais modulares sobre o LSM IMN builtin foi implementado, conforme descrito
anteriormente. Uma levantamento mais completo de requisitos foi feito antes da definicao
final da arquitetura da solucao e de sua efetiva implementacao.
Etapa 3
Neste ponto do trabalho, alem de um estudo detalhado dos prototipos ja realizados
pelo grupo, seria de fundamental importancia entrevistas sistematicas com os demais
integrantes do projeto, afim de conhecer melhor suas necessidades e dificuldades. Este co-
nhecimento todo seria entao compilado em uma proposta de solucao que buscasse oferecer
a maior parte possıvel dos recursos necessarios, da forma mais simples possıvel.
O projeto Imuno, contudo, no ano de 2010, passou por mudancas significativas em sua
estrutura. O foco da pesquisa acabou sendo direcionado para outras areas de seguranca
de sistemas e o objetivo de construcao de um sistema de seguranca imunologico geral foi
temporariamente adiado.
Desta forma, este trabalho foi parcialmente prejudicado pois nao mais haveriam so-
licitacoes de requisitos por parte dos pesquisadores empenhados na construcao de um
sistema de seguranca imunologico, tampouco haveria um feedback deles sobre as imple-
mentacoes iniciais do framework IMN, de forma a contribuir com sugestoes de melhorias.
Por outro lado, toda a pesquisa sobre o kernel Linux e suas questoes relativas a controle
de acesso, controle de recursos e seguranca em geral, motivaram o autor deste trabalho a
seguir com o seu desenvolvimento. Primeiramente, ja havia ampla disponibilidade de re-
quisitos necessarios para uma solucao imunologica. Alem disso, a generalidade da solucao
que estava sendo concebida poderia ser utilizada como plataforma para o desenvolvimento
de outras solucoes de seguranca, nao necessariamente relacionadas com os princıpios de
funcionamento do sistema imunologico humano.
Assim sendo, este trabalho prosseguiu com o estudo detalhado dos prototipos desenvol-
vidos pelo projeto Imuno, buscando extrair suas principais funcionalidades e observando
atentamente os pontos em que eles falharam, seja na implementacao quanto na manu-
tencao, de forma a evitar a repeticao de erros e elevar a qualidade do framework em
desenvolvimento.
O primeiro trabalho analisado, “Forense computacional e sua aplicacao em
seguranca imunologica” [30], o qual propunha uma arquitetura extensıvel para ana-
lisadores forenses, desenvolvida por Marcelo Reis, tal como apresentado na Secao 2.2.2,
realiza analise forense sobre informacoes coletadas em maquinas suspeitas de ataque.
A proposta do trabalho era implementar um prototipo para analise automatica. Este

88 Capıtulo 5. Framework IMN
prototipo foi dividido em dois modulos: coletor de informacoes e analisador forense auto-
matizado.
Este prototipo, contudo, nao chegou ter uma versao funcional. O trabalho concentrou-
se na introducao dos conceitos imunologicos, conceitos de deteccao de intrusao e forense
computacional, bem como em uma detalhada especificacao de uma arquitetura extensıvel
para analise forense automatizada.
Uma caracterıstica interessante do esforco de programacao do prototipo AFA, e que ele
implementa totalmente o modulo de coleta de informacoes. Este modulo, apesar de funda-
mental, uma vez que reune toda a informacao necessaria para a analise forense proposta,
pode ser considerado como um ferramental para o exercıcio da pesquisa realizada.
Nota-se naquele trabalho, uma extensa busca por mecanismos capazes de proceder com
toda a coleta de informacoes necessaria para atendimento do analisador. A dissertacao de
mestrado fruto daquela pesquisa [30] possui inclusive um extenso apendice das diferentes
estrategias adotadas ou implementadas para obtencao de tais informacoes. Este grande
trabalho pode ter sido um fator determinante para a impossibilidade de conclusao da
implementacao do analisador proposto.
Daquele trabalho portanto, foram extraıdos os principais requisitos para deteccao
de intrusao desejados para o framework IMN, a saber:
• Informacoes de memoria principal (dump de memoria)
• Monitoramento de sinais enviados a processos
• Monitoramento de trafego de rede
• Informacoes sobre processos
• Arquivos abertos por processos
• Informacoes de estados de interfaces e conexoes de rede
• Informacoes de tabelas e cache de roteamento
• Cache de resolucao de enderecos MAC
• Cache de resolucao de nomes
• Listagem de modulos de kernel carregados
• Espelhamento de discos para analise forense
• Acesso a informacoes de inode

5.2. Requisitos 89
Boa parte dos requisitos acima sao atendidos por ferramentas de espaco de usuario,
com permissoes de root. O papel do IMN, portanto, deve ser o de proteger e garantir a
integridade destas ferramentas.
O trabalho desenvolvido por Diego Fernandes, “Resposta Automatica em um
Sistema de Seguranca Imunologico” [20], tambem possui uma serie de requisitos
que devem conferir ao sistema de seguranca imunologico a capacidade de limitar a acao
de um possıvel ataque.
O sistema proposto por Marcelo utiliza agentes moveis em uma arquitetura distribuıda.
Em ultima instancia, o prototipo faz uso de “componentes locais de reacao”, capazes de
efetivamente atuar (responder) sobre os processos suspeitos. Naquele trabalho, ha uma
clara divisao entre a concepcao do sistema de seguranca imunologico, ou seja, utilizacao
de agentes moveis para implantacao de mecanismos imunologicos de resposta primaria e
secundaria e o ferramental necessario para atuar de maneira desejada sobre os processos
investigados, os componentes locais de reacao.
Estes componentes locais sao foco do framework IMN e devem ser capazes de atuar em
nıvel de processo e em nıvel de rede, disponibilizando as funcionalidades abaixo listadas,
as quais compoem o conjunto de requisitos para mecanismos de resposta:
• Nıvel de processos:
– Limite de uso de memoria: capacidade de limitar a quantidade de memoria
fısica utilizada por um processo
– Limite de consumo de CPU: capacidade de limitar o tempo de CPU utilizado
por um processo
– Numero maximo de conexoes: capacidade de limitar o numero de conexoes
abertas por um processo
– Quantidade de processos filhos: capacidade de limitar o numero de processos
filhos criados por um processo
– Limite transacoes de acesso a disco: capacidade de limitar a leitura ou escrita
de dados em disco, em termos de volume de dados, por um processo
– Limite de acesso a disco: capacidade de limitar operacoes de leitura ou escrita
em disco, em termos de permissoes, por um processo
– Finalizacao de processos: capacidade de finalizar processos
– Paralisacao de processos: capacidade paralisacao e eventual continuacao na
execucao de processos
• Nıvel de rede:

90 Capıtulo 5. Framework IMN
– Bloqueio de trafego: capacidade de bloquear trafego por maquina, servico,
protocolo ou porta
– Limite de conexoes: capacidade de limitar o numero de conexoes por servico
porta
– Bloqueio de trafego por usuario: capacidade de bloquear trafego de rede por
usuario
Na implementacao do seu prototipo, Marcelo desenvolveu em nıvel de kernel Linux
varios mecanismos de reacao para atender aos requisitos da solucao:
• Nıvel de rede: iptables + patch de kernel contabilizacao de conexoes simultaneas
• Nıvel de processos:
– cpulimit: limitacao de uso de CPU (diretiva cpulimit() desenvolvida por
Diego sobre o escalonador O(1))
– conectionlimit: limitacao do numero de conexoes (feito via iptables)
– fslimit: monitoramento de syscalls de manipulacao de sistemas de arquivos.
Implementado via LKM que cria uma nova syscall para forcar polıticas sobre
as chamadas de manipulacao de sistemas de arquivos
– kill e stop: acoes de emergencia feitas via sinais do Linux
Os requisitos de controle de recursos introduzidos passam a compor o conjunto de
requisitos do framework IMN.
Apesar de funcional a nıvel de pesquisa, este prototipo traz consigo algumas carac-
terısticas nocivas a manutencao e evolucao do seu codigo em um sistema de seguranca
imunologico geral, a saber:
• Aplica um patch de terceiros sobre um componente do kernel (contabilizacao de
conexoes Netfilter): ferramentas em desenvolvimento e que nao fazem parte do
kernel costumam sofrer grande alteracoes entre versoes e estao sob constante risco
de simplesmente serem abandonadas, uma vez que sao mantidas por desenvolvedores
isolados, e nao pela comunidade Linux;
• Inclui uma nova chamada de sistema no Linux: conforme visto no Capıtulo, 3, a
introducao novas chamadas de sistema deve ser evitada;
• Altera o codigo do escalonador do Linux para atendimento de um requisito es-
pecıfico: trata-se de uma profunda alteracao em um ponto de grande importancia
do sistema operacional. Alem de difıcil de manter, esta abordagem envolve risco de
comprometimento da estabilidade do sistema como um todo.

5.2. Requisitos 91
Outro ponto importante sobre o prototipo de Marcelo, e que ele nao implementa qual-
quer mecanismo de auto-protecao, uma vez que este seria um esforco de programacao que
desviaria do foco da pesquisa, e esta limitacao fora considerada aceitavel por tratar-se
de um prototipo com objetivo de comprovar a eficacia da utilizacao de agentes moveis
para implantacao de um modulo de resposta automatica de um sistema de seguranca imu-
nologico. Um sistema geral, contudo, deve possuir mecanismos de auto-protecao capazes
de regular o funcionamento do sistema mesmo na ocorrencia de ataques.
Por fim, o prototipo ADenoIDS, de De Paula [22], introduz varios requisitos funcionais
para o framework IMN. Abaixo, estes requisitos serao apresentados no contexto de cada
modulo do sistema proposto. Modulos nao implementados ou puramente imunologicos,
nao serao apresentados abaixo, uma vez que nao introduzem requisitos ao IMN.
• Fonte de informacao (ADDS):
– Monitoramento de processos: operacoes sobre sistemas de arquivo, criacao e
execucao de processos (processos filhos devem ser monitorados), insercao e
remocao modulos de kernel, IPC (sinais e sockets);
– Monitoramento de trafego de rede;
• Agente de resposta inata (ADIRA): bloqueia todos os processos em espaco de usuario
(SIGSTOP), recupera o sistema (UNDOFS), mata processos invasores, desbloqueia
o restante dos processos bloqueados (SIGCONT) e utiliza o UNDOFS para recuperar
alteracoes feitas no sistema de arquivos;
• Repositorio para suporte forense (ADFSR): repositorio seguro para armazenamento
de informacoes do ADDS;
• Ferramentas de apoio:
– Auto-protecao. Bloqueio de sinais de processos normais para processos ADE-
NOIDS e protecao dos arquivos de configuracao e log do sistema;
– UNDOFS: middleware do VFS que implementa operacoes undo() e redo().
Assim como os demais prototipos desenvolvidos no projeto, o ADenoIDS obtem su-
cesso na implementacao dos seus requisitos atraves de profundas alteracao no kernel Li-
nux. Posteriormente, o prototipo deixou de ser mantido devido a sua complexidade de
implementacao.
Um resumo das funcionalidades, pontos positivos e principais ofensores de imple-
mentacao/manutencao dos trabalhos desenvolvidos pelo projeto Imuno e ilustrado na
Figura 5.1. O conjunto de requisitos consolidado para o framework IMN e apresentado
na Secao 5.2.3.

92 Capıtulo 5. Framework IMN
Figura 5.1: Timeline do Projeto Imuno.
Etapas 4 e 5
A implementacao do framework IMN sera apresentada na Secao 5.3. Os testes prati-
cados com a ferramenta serao apresentados no Capıtulo 6.
5.2.3 Requisitos Consolidados
Os requisitos levantados na Secao anterior foram consolidados em quatro grandes
grupos: monitoramento, resposta, auto-protecao e administracao. Abaixo os requisitos
de cada grupo sao detalhados:
1. Monitoramento:
• Processos:
– Operacoes sobre sistemas de arquivo;
– Criacao e execucao de processos;
– Insercao e remocao de modulos de kernel;
– IPC (Sinais e Sockets);
• Rede:

5.3. Arquitetura 93
– Servicos;
– Protocolos ;
– Numero de Conexoes;
– Volume de dados;
• Host:
– dump de memoria;
– informacoes sobre processos;
2. Resposta:
• Bloqueio e desbloqueio de processos de espaco de usuario;
• Finalizacao de processos invasores;
• Recuperacao de alteracoes feitas no sistema de arquivos durante um ataque;
• Controle de recursos (bloqueios/limitacoes/garantias) em nıvel de processo;
3. Auto-protecao:
• Repositorio Seguro para suporte forense;
• Protecao de caminhos especıficos do sistema de arquivos;
• Protecao de processos imunologicos;
• Protecao do framework IMN e seus componentes externos (LKMs imunologicos,
e outras ferramentas de kernel);
4. Administracao:
• Interface de comunicacao eficiente entre o framework e os modulos imunologicos
(espaco de kernel e espaco de usuario);
• Mecanismo de registro e desregistro de modulos imunologicos;
• Mecanismo de ativacao e desativacao de auto-protecao;
• Mecanismo de registro de tratadores de ganchos LSM por modulos imunologicos
(LKMs imunologicos).
5.3 Arquitetura
O framework IMN possui uma arquitetura geral composta basicamente de tres dife-
rentes tipos de componentes: o framework, LKMs imunologicos e modulos imunologicos.
A Figura 5.2 ilustra tal arquitetura.
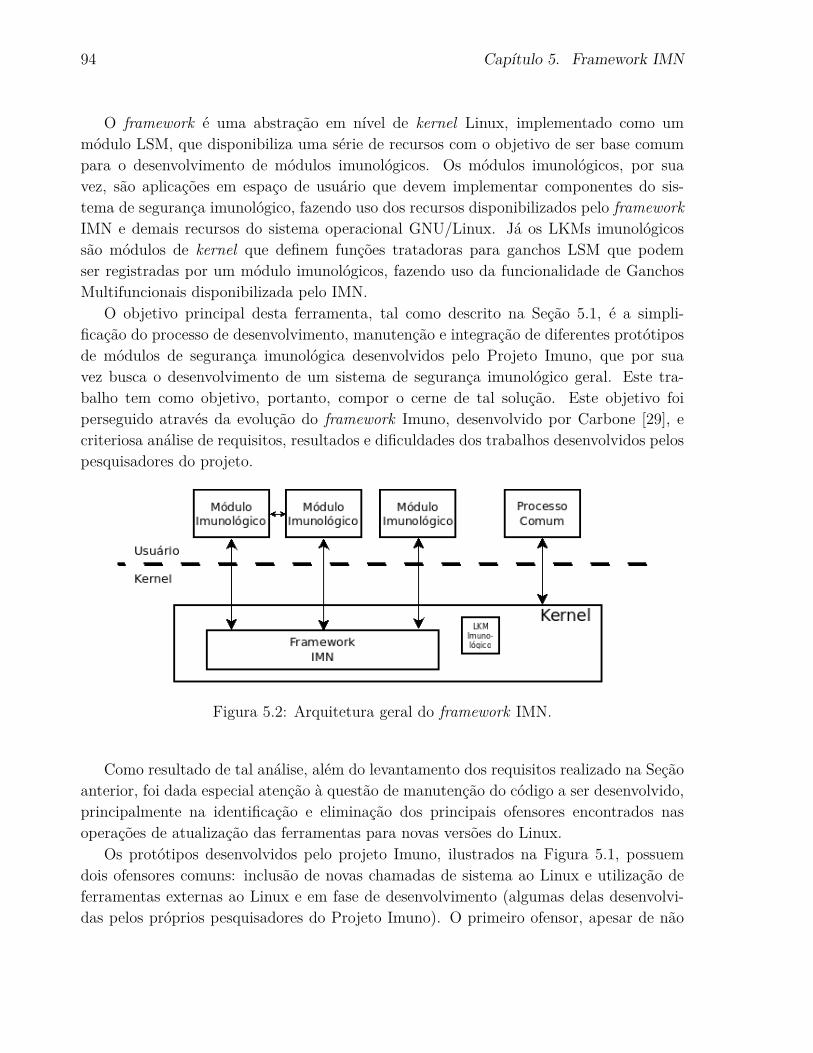
94 Capıtulo 5. Framework IMN
O framework e uma abstracao em nıvel de kernel Linux, implementado como um
modulo LSM, que disponibiliza uma serie de recursos com o objetivo de ser base comum
para o desenvolvimento de modulos imunologicos. Os modulos imunologicos, por sua
vez, sao aplicacoes em espaco de usuario que devem implementar componentes do sis-
tema de seguranca imunologico, fazendo uso dos recursos disponibilizados pelo framework
IMN e demais recursos do sistema operacional GNU/Linux. Ja os LKMs imunologicos
sao modulos de kernel que definem funcoes tratadoras para ganchos LSM que podem
ser registradas por um modulo imunologicos, fazendo uso da funcionalidade de Ganchos
Multifuncionais disponibilizada pelo IMN.
O objetivo principal desta ferramenta, tal como descrito na Secao 5.1, e a simpli-
ficacao do processo de desenvolvimento, manutencao e integracao de diferentes prototipos
de modulos de seguranca imunologica desenvolvidos pelo Projeto Imuno, que por sua
vez busca o desenvolvimento de um sistema de seguranca imunologico geral. Este tra-
balho tem como objetivo, portanto, compor o cerne de tal solucao. Este objetivo foi
perseguido atraves da evolucao do framework Imuno, desenvolvido por Carbone [29], e
criteriosa analise de requisitos, resultados e dificuldades dos trabalhos desenvolvidos pelos
pesquisadores do projeto.
Figura 5.2: Arquitetura geral do framework IMN.
Como resultado de tal analise, alem do levantamento dos requisitos realizado na Secao
anterior, foi dada especial atencao a questao de manutencao do codigo a ser desenvolvido,
principalmente na identificacao e eliminacao dos principais ofensores encontrados nas
operacoes de atualizacao das ferramentas para novas versoes do Linux.
Os prototipos desenvolvidos pelo projeto Imuno, ilustrados na Figura 5.1, possuem
dois ofensores comuns: inclusao de novas chamadas de sistema ao Linux e utilizacao de
ferramentas externas ao Linux e em fase de desenvolvimento (algumas delas desenvolvi-
das pelos proprios pesquisadores do Projeto Imuno). O primeiro ofensor, apesar de nao

5.3. Arquitetura 95
representar um grande impacto de manutencao, representa uma barreira para a inclusao
da ferramenta em versoes oficiais do Linux.
O uso de ferramentas em desenvolvimento, por sua vez, foi considerado o maior ofensor
de manutencao, pois estas ferramentas, por estarem em fase de desenvolvimento estao
sujeitas a grandes alteracoes entre versoes, abandono de projeto, ou mesmo rejeite de
inclusao no Linux. Estas ferramentas, portanto, representam um grande obstaculo de
manutencao dos prototipos e podem afastar ainda mais eles de um eventual aceite junto
ao Linux. A Tabela 5.1 ilustra as ferramentas externas utilizadas em alguns prototipos
do projeto e as dificuldades de manutencao decorrentes destas escolhas.
Prototipo Ferramenta Auxiliar Ofensor
Response Agent Diretiva cpulimit() para O(1) Ferramenta altamente invasiva
Ferramenta deixou de ser mantida pelo autor
A partir da versao 2.6.23 o Linux passou autilizar o escalonador CFS, eliminando a utili-dade deste patch
ADenoIDS UNDOFS Ferramenta deixou de ser mantida pelo autor
CKRM Ferramenta deixou de ser mantida pelo autor
Framework Imuno RelayFS Ferramenta deixou de ser mantida pelo autor
UNDOFS Carbone assumiu em seu trabalho a tarefa deatualizacao desta ferramenta. Apenas umasatualizacao parcial foi feita. A ferramenta foientao novamente abandonada
Tabela 5.1: Exemplos de ofensores de manutencao de prototipos do Projeto Imuno decor-rentes de implementacoes invasivas ou utilizacao de ferramentas em desenvolvimento.
Em decorrencia do aprendizado destas experiencias de desenvolvimento, o IMN tem
como regras de projeto a implementacao de solucoes pouco invasivas e utilizacao de
ferramentas Linux consolidadas, visando principalmente a clareza do codigo e facilidade
de manutencao do mesmo. Desta forma, funcionalidades requeridas pelo projeto Imuno
somente sao atendidas pelo IMN nos casos em que for possıvel disponibiliza-las sem violar
estas regras. Requisitos nao atendidos por este motivo, serao devidamente apontados.
Necessidades urgentes deverao ser implementadas e mantidas pelos pesquisadores ate o
momento que uma solucao semelhante seja incluıda no Linux, quando passara a compor
o IMN.
Os recursos com implementacao pouco invasiva desenvolvidos para o IMN sao:
• Infra-estrutura de ganchos multifuncionais
• Mecanismos de auto-protecao

96 Capıtulo 5. Framework IMN
• Interface administrativa com troca de informacoes de espaco de kernel para espaco
de usuario sem utilizacao de novas chamadas de sistema
Outros recursos externos sao acoplados ao IMN atraves da garantia de auto-protecao
sobre estes recursos, garantindo que apenas processos imunologicos possam fazer uso de
tais ferramentas.
Dentro dessa visao da arquitetura do IMN, ilustrada na Figura 5.3, tem-se uma boa
cobertura dos requisitos levantados atraves de uma implementacao pouco invasiva e uti-
lizacao de ferramental consolidado e estavel no ambiente Linux. Eventuais requisitos
indisponıveis e que nao foram implementados pelo IMN por nao atender as regras de
projeto, ilustrados pelos blocos pontilhados na Figura 5.3, podem ser implementados e
mantidos a parte por desenvolvedores de modulos imunologicos ate que uma solucao equi-
valente seja disponibilizada na versao oficial do Linux, quando passara a fazer parte do
framework IMN.
Figura 5.3: Arquitetura do framework IMN, outra visao.
A Figura 5.4 ilustra detalhadamento a arquitetura do IMN, bem como a relacao entre
os seus componentes. A implementacao desta arquitetura e discutida na Secao 5.4.
5.4 Implementacao
Nas secoes a seguir, sera detalhada a implementacao dos diferentes componentes do
framework IMN.

5.4. Implementacao 97
Figura 5.4: Arquitetura do framework IMN.
5.4.1 Ganchos Multifuncionais
Os ganchos do framework LSM, conforme visto na Secao 4.2, estao espalhados por todo
o kernel Linux em pontos relacionados a operacoes de controle de acesso. Estes ganchos
sao de grande utilidade na implementacao do sistema de seguranca imunologico geral,
uma vez que permitem facil acesso a pontos de monitoramento e controle de permissoes
sobre de operacoes de processos em nıvel de kernel, tais como operacoes sobre arquivos,
criacao de processos, mecanismos de IPC, dentre outros.
O LSM, contudo, admite o registro de apenas um unico modulo de seguranca por
instancia de execucao do Linux. Desta forma, um usuario do sistema operacional deve
escolher entre um dos modulos LSM disponıveis ou mesmo desenvolver o seu. Nao e
possıvel, contudo, a utilizacao concomitante de diferentes modulos LSM. O administrador
do sistema deve analisar dentre as opcoes disponıveis, e escolher aquela que melhor o
atende. Por este motivo, uma implementacao de um sistema de seguranca imunologico
admitiria que apenas um modulo imunologico fizesse uso dos ganchos LSM. Os demais

98 Capıtulo 5. Framework IMN
deveriam ser implementados sem a utilizacao destes recursos.
A arquitetura do sistema de seguranca imunologico geral proposta pelo projeto Imuno,
por outro lado, conforme apresentado na Secao 2.2.4, preve uma implementacao modular
deste sistema, onde cada modulo representaria um componente do modelo biologico. Desta
forma, a utilizacao de ganchos ficaria limitada a um unico modulo imunologico. Este
modulo, por sua vez, provavelmente utilizaria apenas um subconjunto dos ganchos para
implementacao do seu escopo. Os demais modulos do sistema deveriam entao buscar
outros mecanismos de implementacao, que nao fizessem uso dos ganchos LSM.
Visando contornar esta limitacao e permitir a diferentes modulos do sistema de se-
guranca imunologico o acesso a ganchos do LSM, Carbone concebeu a funcionalidade
batizada de “Ganchos Multifuncionais” [29].
O framework IMN e implementado como modulo LSM, ou seja, registra-se junto ao
framework LSM no momento da inicializacao do sistema, passando a ter acesso total a
todos os ganchos daquele framework e impedindo que outros modulos LSM sejam utiliza-
dos naquela instancia de execucao. O IMN nao utiliza os ganchos LSM para implementar
um modelo completo de controle de acesso mandatorio, utilizando apenas alguns gan-
chos para implementacao do seu mecanismo de auto-protecao (Secao 5.4.2). Portanto,
o IMN implementa a arquitetura de ganchos multifuncionais proposta por Carbone para
disponibilizar o acesso a ganchos LSM por parte de modulos imunologicos.
A Figura 5.5 ilustra o funcionamento da arquitetura de ganchos multifuncionais.
A estrutura dos ganchos multifuncionais e implementada pelo componente “Contro-
lador de Gancho”. Um modulo de seguranca imunologica deve utilizar a interface admi-
nistrativa do IMN (Secao 5.4.3) para registrar-se a um determinado gancho LSM. Uma
vez registrado, um modulo imunologico pode definir diversas funcoes tratadoras para este
gancho. Nao e possıvel o registro de mais de um modulo imunologico por gancho, con-
tudo e possıvel que um modulo registre-se em varios ganchos, desde que nenhum deles
ja esteja registrado para outro modulo. As funcoes tratadoras devem ser implementadas
em LKMs (chamados de LKMs imunologicos) e ter os seus nomes exportados atraves da
macro EXPORT_SYMBOL().
E possıvel ainda a um modulo registrar-se em ganchos que ja sao utilizados pelo IMN.
Nestes casos, a funcao tratadora interna do framework e executada primeiro e, caso o
acesso nao seja negado por ela, as funcoes tratadoras registradas pelo modulo imunologico
do gancho sao invocadas.
O IMN define funcoes tratadoras simplificadas para todos os ganchos do LSM2. Quando
um determinado gancho LSM e alcancado no kernel, o controle de execucao e desviado
para para o tratador simplificado correspondente aquele gancho. O tratador, por sua vez,
2Todos os ganchos LSM disponibilizados pelo IMN com suas respectivas assinaturas de funcao e umabreve descricao de funcionamento estao listados no Apendice A

5.4. Implementacao 99
Figura 5.5: Estrutura de um gancho multifuncional.
aciona o Controlador de Ganchos do IMN. Os tratadores simplificados do IMN possuem
a seguinte forma3:
int imn_file_open(struct file *file, const struct cred *cred)
{
return imn_hook_start(ID_FILE_OPEN, file, cred);
}
Desta forma, sempre que um gancho LSM e alcancado, o fluxo de execucao e desviado
para o controlador de ganchos, o qual recebe uma lista variavel de parametros, de acordo
com o gancho alcancado. O controlador de ganchos, entao, verifica se existem funcoes
tratadoras registradas para aquele determinado gancho e desvia o fluxo de execucao para
o primeiro tratador, repassando os seus parametros e ponteiros para os canais de entrada
e saıda do gancho.
Apos o retorno do primeiro tratador, o controlador de ganchos itera sobre os demais
tratadores, de acordo com o modo de execucao definido no momento do registro do gan-
cho, pelo modulo imunologico, ate que o ultimo tratador seja atingido ou ate que um
3A funcao imn hook start() implementa o controlador de ganchos do IMN

100 Capıtulo 5. Framework IMN
dos tratadores retorne um valor que interrompa a sequencia de execucao, permitindo ou
negando o acesso ao recurso.
O valor retornado por cada tratador de um determinado gancho controla o compor-
tamento do controlador de ganchos multifuncionais. Quando um valor menor ou igual ao
valor -2 e retornado por um tratador, o controlador encerra o processo de iteracao sobre
os tratadores e retorna este numero negativo para o LSM, o que implica em negacao de
acesso ao objeto no contexto em questao. O valor de retorno -1 indica ao controlador
que a iteracao sobre tratadores deve ser interrompida e o valor 0 deve ser retornado ao
LSM, permitindo o acesso ao objeto. Valores de retorno maiores ou igual a 0 indicam ao
controlador de ganchos qual tratador deve ser acionado em seguida. Esta ultima opcao e
valida apenas para os modos de execucao 1 e 2.
O modos de execucao dos ganchos multifuncionais sao os seguintes:
• 0: executa os tratadores registrados para um determinado gancho do primeiro ao
ultimo, sequencialmente, ate que o ultimo tratador seja alcancado ou um dos trata-
dores retornem um valor negativo;
• 1: executa o primeiro tratador registrado. O valor retornado, caso maior ou igual
a zero, determina qual o proximo tratador a ser executado. A iteracao entre os
tratadores so termina quando um dos tratadores retornar um valor negativo;
• 2: executa o primeiro tratador registrado e, apos o retorno deste tratador,
paralisa a execucao do processo que invocou o gancho, atraves da funcao
set_current_state() com o parametro TASK_UNINTERRUPTIBLE. Durante o
perıodo em que o processo nao esta sendo executado, o modulo imunologico que
registrou o gancho pode ler os dados da funcao tratadora escrita no canal de saıda
do gancho na interface do IMN e decidir qual o proximo tratador a ser executado,
escrevendo no canal de entrada do gancho o inteiro identificador do tratador a ser
acionado. O controlador de ganchos entao coloca o processo invocador novamente
na fila de processos executaveis (wake_up_process()) e em seguida invoca o trata-
dor cujo ındice foi escrito pelo modulo imunologico no canal de entrada do gancho.
O processo continua ate que um tratador retorne valor negativo.
A utilizacao dos modos de execucao 1 e 2 requer muito cuidado por parte dos desen-
volvedores do sistema de seguranca imunologico pois esta sujeita a ocorrencia de loops
infinitos entre os tratadores registrados, uma vez que o controlador de ganchos so inter-
rompe a iteracao no nomento em que um dos tratadores retornar uma valor negativo.
Uma importante consideracao a ser feita sobre a implantacao da arquitetura de Gan-
chos Multifuncionais no framework IMN, e que difere sensivelmente da implementacao do
framework Imuno, e que ela nao envolve a inclusao de uma nova chamada de sistema ao

5.4. Implementacao 101
Linux, tampouco utiliza ferramentas estranhas ao kernel (patches de terceiros) em sua
implementacao. O registro de tratadores para ganchos e feito diretamente sobre arqui-
vos de controle da interface do IMN. Quando um modulo imunologico registra-se em um
gancho, um arquivo de controle e criado para aquele gancho. Este arquivo, chamado de
“canal de entrada e saıda”, e o ponto de troca de informacao entre o IMN e os modulos
imunologicos (espacos de nucleo e usuario).
Em espaco de nucleo, o IMN e os LKMs imunologicos tem acesso a buffers que re-
presentam estes caracteres. Em espaco de usuario, estes canais sao manipulados pelos
modulos imunologicos como arquivos comuns.
Definicao de funcoes tratadoras
A Funcao target_for_mkdir(), ilustrada abaixo, e uma possıvel implementacao de
um tratador a ser registrado para o gancho multifuncional ID_MKDIR do IMN:
int target_for_mkdir(va_list args, char *ochan)
{
struct inode *dir;
struct dentry *dentry;
int mode;
dir = va_arg(args, struct inode *);
dentry = va_arg(args, struct dentry *);
mode = va_arg(args, int);
sprintf(ochan, "PID %d criou o diretorio %s.\n",
current->pid, dentry->d_name.name");
return -1;
}
Esta funcao, uma vez definida em um LKM e registrada por um modulo imunologico
junto ao framework IMN, ira monitorar as ocorrencias da chamada de sistema mkdir()
e regista-las no canal de saıda do gancho. Um modulo imunologico de monitoramento
poderia utilizar este tratador para gerar um arquivo de log das ocorrencias desta chamada.
5.4.2 Auto-protecao
O mecanismo de auto-protecao do framework IMN tem como objetivo primario a
protecao do sistema operacional de tal forma que este mantenha-se funcional mesmo na
ocorrencia de ataques bem sucedidos.

102 Capıtulo 5. Framework IMN
Como o sistema de seguranca imunologico deve ter a capacidade de detectar e respon-
der a tais ataques, e fundamental que o mecanismo de auto-protecao do IMN seja capaz
de garantir total protecao aos processos imunologicos, aos repositorios de informacao fo-
rense (repositorios seguros), aos componentes externos do framework e ao proprio IMN,
pois, caso algum destes elementos seja comprometido, o ataque pode conseguir inibir uma
atuacao eficaz do sistema de seguranca.
Desta forma, o mecanismo de auto-protecao do IMN utiliza a arquitetura de ganchos
multifuncionais apresentada na Secao 5.4.1 para proteger os diferentes componentes do
sistema de seguranca imunologico. Por questoes de administracao do IMN, este mecanismo
pode ser habilitado e desabilitado atraves da flag global selfprot, facilmente manipulavel
atraves da interface administrativa do framework, tal como sera apresentado na Secao
5.4.3.
A protecao dos componentes do sistema de seguranca imunologico e feita utilizando-
se diversos conjuntos de ganchos LSM. A seguir serao apresentados estes conjuntos e os
diferentes componentes protegidos pelos seus tratadores.
Ganchos de operacoes sobre processos
De acordo com a arquitetura do framework IMN, apresentada na Figura 5.4, os
modulos imunologicos sao os unicos processos em espaco de usuario que sao considerados
componentes do sistema de seguranca imunologico. Desta forma, a abordagem utilizada
na protecao dos modulos imunologicos foi a criacao de tratadores de auto-protecao para
ganchos LSM de operacoes sobre processos. Apenas ganchos em funcoes capazes de alterar
de alguma forma o comportamento ou estruturas de processos foram consideradas.
Estes tratadores negam o acesso em operacoes sobre processos sempre que o mecanismo
de auto-protecao estiver ativada e um sujeito nao-imunologico tentar atuar sobre um
processo imunologico. Os ganchos LSM utilizados sao os seguintes:
• security_task_kill(): intercepta solicitacoes feitas em espaco de usuario atraves
da chamada de sistema kill(), permitindo a checagem de permissoes antes do envio
de sinais a um dado processo p;
• security_task_setpgid(): intercepta solicitacoes feitas em espaco de usuario
atraves da chamada de sistema setpgid(), permitindo a checagem de permissoes
antes da alteracao do GID de um dado processo p;
• security_task_setnice(): intercepta solicitacoes feitas em espaco de usuario
atraves da chamada de sistema nice(), permitindo a checagem de permissoes antes
da alteracao do nıvel de prioridade de escalonamento de um dado processo p;

5.4. Implementacao 103
• security_task_setioprio(): intercepta solicitacoes feitas de espaco de usuario
atraves da chamada de sistema ioprio_set(), permitindo a checagem de permissoes
antes da alteracao do nıvel de prioridade em operacoes de entrada e saıda de um
dado processo p;
• security_task_setrlimit(): intercepta solicitacoes feitas a partir do espaco de
usuario atraves da chamada setrlimit(), permitindo a checagem de permissoes
antes da alteracao de valores limites para diferentes recursos de um dado processo
p, tais como valores limites para prioridade de escalonamento (nice), tamanho de
pilha, fila de sinais pendentes, dentre outros;
• security_task_setscheduler(): intercepta solicitacoes feitas a partir do espaco
de usuario atraves da chamada schec_setscheduler(), permitindo a checagem
de permissoes da alteracao da polıtica de escalonamento de um dado processo p
(SCHED_OTHER, SCHED_BATCH, SCHED_IDLE, SCHED_FIFO e SCHED_RR).
Os tratadores de auto-protecao destes ganchos referenciam uma funcao de checagem
de permissoes do framework IMN, imn_selfprot_check_pid(), listada abaixo, que e a
responsavel pelo processo de tomada de decisao de acesso.
int imn_selfprot_check_pid(struct task_struct *p)
{
spin_lock(&selfprot_lock);
if (selfprot == 1) {
spin_unlock(&selfprot_lock);
if(imn_check_pid(p->pid) == 0)
if (imn_check_pid(current->pid) == 0)
return 0;
else return -EACCES;
else
return 0;
} else {
spin_unlock(&selfprot_lock);
return 0;
}
}
A funcao imn_check_pid() verifica se o processo correspondente ao PID informado
esta na lista de processos imunologicos do framework, retornando zero em caso afirmativo
ou um inteiro negativo em caso contrario.

104 Capıtulo 5. Framework IMN
Ganchos de operacoes sobre inodes
Conforme visto na secao 3.5, o VFS e uma camada de abstracao do Linux que funciona
como middleware para implementacao de diferentes sistemas de arquivos. O VFS define
os elementos que compoem um sistema de arquivo, bem como toda a logica de operacoes
e manipulacoes sobre estes diferentes elementos. A implementacao efetiva de cada uma
das operacoes definidas pelo VFS para os diferentes objetos, por sua vez, fica a cargo do
codigo dos diferentes sistemas de arquivo. Acoes (chamadas de sistema) de sujeitos sobre
objetos da hierarquia de arquivos do Linux, sao interceptadas pelo VFS, que executa
checagens e verificacoes e, em seguida, encaminha para efetiva execucao do sistema de
arquivos do objeto em questao.
Desta forma, para cada um dos ganchos LSM restritivos de operacoes sobre obje-
tos VFS do tipo inode, o IMN registra um tratador que implementa parte do seu
mecanismo de auto-protecao. Todos estes tratadores executam a mesma logica de ve-
rificacao: quando o mecanismo de auto-protecao estiver ativo, o acesso a objetos do
tipo inode imunologico somente sera permitido a processos imunologicos. A funcao
imn_selfprot_check_inode(), abaixo, implementa esta logica:
int imn_selfprot_check_inode(struct inode *inode)
{
spin_lock(&selfprot_lock);
if (selfprot == 1) {
spin_unlock(&selfprot_lock);
if(imn_check_inode(inode) == 0)
return 0;
else {
if (imn_check_pid(current->pid) == 0 ||
imn_check_pid(current->parent->pid) == 0)
return 0;
else return -EACCES;
}
} else {
spin_unlock(&selfprot_lock);
return 0;
}
return 0;
}
As funcoes imn_check_inode() e imn_check_pid() verificam, respectivamente, se o

5.4. Implementacao 105
inode e o processo informados sao imunologicos, retornando zero em caso afirmativo ou
um inteiro negativo em caso contrario.
A definicao de inodes imunologicos e feita de maneira bem simples atraves do car-
regamento de uma listagem dos arquivos a serem protegidos, via interface do IMN. Esta
abordagem permite a criacao de repositorios seguros, atendendo de maneira direta este
importante requisito do framework.
Ganchos do POSIX Capabilities
Usuarios comuns do sistema operacional GNU/Linux tem poderes bastante restritos
de atuacao sobre os diversos componentes do sistema operacional. Por outro lado, o
usuario privilegiado root possui plenos poderes sobre o sistema. Por este motivo, a
implementacao Linux do POSIX Capabilities, apresentada na Secao 4.1.1, busca limitar
os poderes de processos com UID root a grupos de operacoes pre-determinados, chamados
de capabilities (capacidades), numa tentativa de elevar a seguranca do sistema como um
todo.
O mecanismo de auto-protecao do IMN busca elevar ainda mais este nıvel de segu-
ranca, atraves da implementacao de controle de acesso mandatorio sobre algumas
destas capacidades. Desta forma, processos nao imunologicos nao sao capazes de exe-
cutar determinadas acoes, mesmo que tais processos possuam as devidas permissoes DAC
(mascaras de permissoes, ACLs e capacidades). Ou seja, mesmo um processo root, com
autorizacao para todas as capacidades do Linux em suas credenciais, nao podera atuar
sobre os componentes desejados caso nao seja um processo imunologico.
Esta implementacao protege diferentes componentes do sistema Imuno. As capaci-
dades restritas aos processos imunologicos e os respectivos objetivos de tais restricoes
sao:
• CAP SYS MODULE: impedir que processos nao imunologicos sejam capazes re-
mover LKMs imunologicos ou carregar seus proprios LKMs, introduzindo codigo
malicioso no kernel;
• CAP SYS RAWIO: impedir o acesso de processos nao imunologicos a arquivos es-
peciais de dispositivos que contenham informacao de kernel. A limitacao desta ca-
pacidade impede o acesso ao arquivo /dev/kmem, que contem a imagem da memoria
principal do computador;
• CAP NET ADMIN: impedir manipulacao do framework Netfilter, componente ex-
terno do IMN utilizado para o atendimento de requisitos de monitoramento e res-
posta em nıvel de rede. A limitacao desta capacidade impede ainda que processos
nao imunologicos executem outras atividades privilegiadas no subsistema de rede

106 Capıtulo 5. Framework IMN
do Linux, tal como alteracoes de configuracao de interfaces de rede e tabelas de
roteamento;
• CAP SYS PTRACE: impedir que processos nao imunologicos observem ou alterem
o comportamento de outros processos atraves do uso da chama de sistema ptrace().
O controle de acesso mandatorio sobre este subgrupo de capacidades Linux e obtido
atraves da implementacao do tratador imn_selfprot_capable() para o gancho LSM
security_capable(). A implementacao do tratador e bem simples e e ilustrada parcial-
mente abaixo:
int imn_selfprot_capable(va_list args, char *ochan)
{
...
spin_lock(&selfprot_lock);
if (selfprot == 1) {
if (imn_check_pid(current->pid) == 0) {
spin_unlock(&selfprot_lock);
return 0;
} else {
spin_unlock(&selfprot_lock);
if (cap == CAP_SYS_RAWIO)
return -EACCES;
else if (cap == CAP_NET_ADMIN)
return -EACCES;
else if (cap == CAP_SYS_MODULE)
return -EACCES;
else return 0;
}
} else {
spin_unlock(&selfprot_lock);
return 0;
}
}
O codigo acima verifica se a auto-protecao do IMN esta ativa. Caso nao esteja, permite
o acesso. Caso contrario, libera acesso somente para modulos imunologicos. Para outros
processos, o tratador checa se acao que o processo deseja executar requer alguma das
capacidades exclusivas de processos imunologico, negando o acesso em caso positivo e
autorizando em caso contrario.

5.4. Implementacao 107
Ganchos de operacoes sobre sistemas de arquivos
Completando a implementacao do mecanismo de auto-protecao do IMN, sao implemen-
tados tratadores para os ganchos LSM security_sb_mount() e security_sb_umount(),
os quais interceptam solicitacoes feitas em espaco de usuario atraves das chamadas
mount() e umount(), respectivamente.
Os tratadores de auto-protecao do IMN para estes ganchos sao utilizados na protecao
de dois componentes do framework: Interface SecurityFS e TCG, sendo este ultimo um
componente externo do IMN, apresentado na Secao 4.5.
A protecao destes componentes e feita atraves da negacao do acesso em execucoes das
chamadas mount() e mount() por processos nao imunologicos com objetivo de montagem
ou desmontagem de sistemas de arquivo do tipo cgroup ou securityfs, sempre que o
mecanismo de auto-protecao estiver ativado.
5.4.3 Interface Administrativa
A Interface Administrativa do IMN utiliza o sistema de arquivos virtual SecurityFS,
apresentado na Secao 4.3, para disponibilizar as seguintes operacoes sobre os recursos do
framework:
• Ganchos multifuncionais:
– Registro e desregistro de ganchos para processos imunologicos;
– Registro e desregistro de tratadores para ganchos de processos imunologicos;
• Auto-protecao:
– Registro e desregistro de processos imunologicos (modulos imunologicos);
– Registro e desregistro de inodes imunologicos (definicao de repositorios segu-
ros);
– Ativacao e desativacao do recurso de auto-protecao.
No momento de inicializacao do sistema operacional, quando o IMN registra-
se junto ao LSM, a interface SecurityFS e montada automaticamente em
/sys/kernel/security/imn e os seguintes arquivos de controle sao criados na raiz do
sistema de arquivos virtual:
• immune_tasks: lista dos PIDs dos modulos imunologicos. Operacoes de leitura
sobre este arquivo recuperam a lista dos PIDs dos processos registrados no IMN.
Arquivo regular, somente leitura;

108 Capıtulo 5. Framework IMN
• hooks: lista dos ganchos multifuncionais, modulos imunologicos registrados por gan-
cho e seus respectivos modos de execucao. Operacoes de leitura sobre este arquivo
recuperam a lista de todos os ganchos disponibilizados pela arquitetura de ganchos
multifuncionais do IMN, bem como o PID dos processos registrados por gancho e o
seu modo de execucao. Arquivo regular, somente leitura;
• targets: lista das funcoes tratadoras (nome e endereco) por gancho. Operacoes de
leitura sobre este arquivo recuperam a lista de tratadores registrados por modulos
imunologicos por gancho. Arquivo regular, somente leitura;
• selfprot: controle da funcionalidade de auto-protecao do IMN. Operacoes de lei-
tura indicam o estado do recurso: 0 desabilitado e 1 habilitado. Operacoes de escrita
sobre este arquivo por parte de processos imunologicos habilitam ou desabilitam o
recurso.
Alem destes arquivos, os diretorios operations, hook_channels e saferepo disponi-
bilizam mais arquivos de controle:
• operations:
– REG_TASK e UNREG_TASK: arquivos de controle, somente escrita, para registro
de modulos imunologicos. A escrita de strings representando o PID do modulo
nestes arquivos permitem, respectivamente, o registro e desregistro do processo
no framework. Quando o mecanismo de auto-protecao esta habilitado, apenas
processos imunologicos podem registrar novos modulos imunologicos;
– REG_HOOK e UNREG_HOOK: arquivos de controle, somente escrita, para registro
de ganchos multifuncionais para modulos imunologicos. O registro de gan-
chos para modulos imunologicos e feita atraves da escrita de strings na forma
“<GANCHO> <N>”, onde o <GANCHO> representa o identificador do gancho mul-
tifuncional4 e N representa o modo de execucao: 0, 1 ou 2. Uma string valida
seria: ID_MKDIR 0. O gancho e registrado para o PID do processo que escreveu
sobre o arquivo de controle. Somente processos imunologicos podem escrever
neste arquivo. Caso o gancho ja esteja registrado para outro processo, o erro
-EADDRINUSE e retornado;
– REG_TARGET e UNREG_TARGET: arquivos de controle, somente escrita, para
registro de funcoes tratadoras para ganchos multifuncionais. Os trata-
dores de ganchos sao registrados atraves da escrita de strings na forma
4A listagem completa dos ganchos disponibilizados pelo IMN esta disponıvel no Apendice A. Estalistagem tambem pode ser obtida atraves da leitura do arquivo hooks do framework IMN.

5.4. Implementacao 109
“<GANCHO> <SIMBOLO>”, onde SIMBOLO e o nome de uma funcao trata-
dora, definida em um LKM imunologico e exportada atraves da macro
EXPORT_SYMBOL(<SIMBOLO>);
• hook_channels:
– <GANCHO>: cada gancho multifuncional do IMN disponibiliza um arquivo regu-
lar de leitura e escrita no diretorio hook_channels. Estes arquivos sao os canais
de troca de informacao entre espaco de kernel e os modulos imunologicos;
• saferepo:
– list: operacao de leitura sobre este arquivo de controle listam todos os arqui-
vos protegidos pelo mecanismo de auto-protecao do IMN;
– load: operacoes de escrita neste arquivo de controle definem uma nova lista
de arquivos protegidos. Os elementos da listagem anterior sao descartados;
– append: operacoes de escrita neste arquivo de controle adionam arquivos a
lista de inodes protegidos;
– remove: operacoes de escrita sobre este arquivo de controle remove arquivos da
lista de arquivos protegidos, caso o nomes listados existam e estejam presentes
na lista;
– safebin: operacoes de escrita neste arquivo de controle definem um lista de
inodes com permissoes de escrita negadas, ao passo que operacoes de leitura
recuperam a lista atual de arquivos protegidos.
5.4.4 Componentes externos
Os frameworks Netfilter e Task Control Group, apresentados nas Secoes 4.4 e 4.5, res-
pectivamente, atendem a uma grande parte dos requisitos do sistema de seguranca imu-
nologico, levantados na Secao 5.2. Como estas ferramentas estao em estagio de producao
e fazem parte do kernel Linux oficial, elas sao incluıdas integralmente no framework IMN,
atraves da protecao destas por meio do recurso de auto-protecao do framework.
Alem destes componentes, outros componentes externos podem ser incluıdos no fra-
mework IMN, tal como ilustrado na Figura 5.3, atraves da extensao do mecanismo de
auto-protecao por meio de uso de modulos imunologicos e LKMs imunologicos ou de-
finicao de repositorios seguros.


Capıtulo 6
Analises e testes
No Capıtulo 5, os requisitos a serem atendidos pelo framework IMN foram detalha-
dos, assim como a arquitetura do framework e aspectos de implementacao. Na etapa de
levantamento de requisitos, Secao 5.2.2, foi feita uma analise dentre os trabalhos desenvol-
vidos no projeto Imuno visando nao somente o levantamento de requisitos, mas tambem
um entendimento dos principais ofensores encontrados no desenvolvimento do sistema de
seguranca imunologico geral proposto pelo projeto.
Fruto desta analise, passou a ser objetivo do framework imunologico nao somente o
atendimento dos requisitos funcionais do sistema de seguranca imunologico em desenvol-
vimento, mas tambem caracterısticas como facilidade de manutencao e atualizacao da
ferramenta. Desta forma, definiu-se uma diretriz a ser seguida na nova implementacao do
framework de seguranca imunologica do projeto Imuno: “O framework imunologico deve
implementar solucoes com mınimo impacto no kernel Linux e consoantes com as diretrizes
e boas praticas adotadas pelos desenvolvedores do Linux”.
Dentro desta diretriz, o projeto do framework imunologico foi redesenhado e alguns
pontos fundamentais foram alterados. O projeto passou a ser implementado utilizando
exclusivamente APIs padrao do kernel Linux e ferramentas consolidadas do kernel, ou
seja, nao foram feitas alteracoes no codigo de qualquer funcionalidade do Linux, tam-
pouco foram incluıdos patches com ferramentas externas ao kernel (nao oficiais ou em
desenvolvimento) ou novas chamadas de sistema.
Neste capıtulo, serao feitas analises e testes sobre a ferramenta desenvolvida. Na Secao
6.1, sera avaliada a cobertura dos requisitos levantados na Secao 5.2.3, onde eventuais
omissoes por conta do atendimento a diretriz de projeto do framework serao apontadas.
Na Secao 6.2, sera apresentado um pequeno sistema seguranca implementado segundo
a arquitetura desejada para a solucao do projeto Imuno e fazendo uso dos recursos do
framework IMN. O objetivo desta implementacao e fazer um ensaio sobre a arquitetura
do sistema de seguranca imunologica, alem de exercitar importantes aspectos funcionais
111

112 Capıtulo 6. Analises e testes
do IMN. Por fim, na Secao 6.3, e feita uma simulacao de ataque bem sucedido a um
sistema utilizando a ferramenta descrita na secao anterior, bem como o comportamento
da mesma com relacao a aspectos de deteccao e resposta do ataque.
6.1 Atendimento de requisitos
6.1.1 Requisitos Funcionais
Os requisitos de funcionalidades em nıvel de kernel a serem atendidos pelo framework
IMN foram divididos em quatro diferentes grupos de tipo de funcionalidades, a saber:
monitoramento, resposta, auto-protecao e administracao do sistema.
O grupo de requisitos de auto-protecao deve garantir a protecao de todos os com-
ponentes do sistema de seguranca imunologica: o framework, os modulos imunologicos,
os LKMs imunologicos, o repositorio de analise forense e outros pontos dos sistema de
arquivos, indicados pelos modulos imunologicos. O grupo de requisitos de administracao
do sistema deve prover uma interface de comunicacao entre os componentes de kernel da
solucao e os componentes em espaco de usuario (modulos imunologicos), de forma a permi-
tir a manipulacao das funcionalidades do framework, bem como troca de informacao entre
espaco de nucleo e usuario. Estes dois grupos de requisitos foram integralmente atendidos
na implementacao do IMN, conforme detalhamento apresentado nas Secoes 5.4.2 e 5.4.3.
Ja as funcionalidades do grupo de requisitos de monitoramento de processos devem
ser capazes rastrear processos e registrar operacoes como: criacao e execucao de pro-
cessos, insercao e remocao de modulos de kernel (LKMs), utilizacao de mecanismos de
comunicacao interprocessos (IPC) e operacoes sobre o sistema de arquivos. Obtencao de
imagens de memoria, informacoes sobre processos e monitoramento de trafego de rede
tambem fazem parte deste grupo de requisitos.
Com a utilizacao da infra-estrutura de ganchos multifuncionais disponibilizada pelo
IMN, um LKM imunologico pode definir de maneira bem simples funcoes tratadoras para
os ganchos LSM pertinentes, possibilitando a interceptacao de operacoes de processos, co-
leta das informacoes necessarias para analise por parte de modulos imunologicos e escrita
destes dados nos canais de saıda de cada gancho. Um modulo imunologico de monitora-
mento podera, entao, registrar-se nos ganchos necessarios, definir suas funcoes tratadoras
para os ganchos e, em seguida, ler os dados escritos nos canais de forma a gerar um
repositorio com estas informacoes.
Os requisitos de mecanismos de resposta imunologica, por sua vez, incluem diversas
capacidades de controle sobre o comportamento de processos, a saber:
• Controle de recursos com estabelecimento de bloqueios, limites e garantias;

6.1. Atendimento de requisitos 113
• Bloqueio e desbloqueio de processos em espaco de usuario;
• Finalizacao de processos invasores;
• Recuperacao de alteracoes feitas no sistema de arquivos durante o ataque de um
processo invasor.
O framework TCG atende boa parte destes requisitos. Conforme visto na Secao 4.5,
este framework disponibiliza uma serie de subsistemas, cada um com uma caracterıstica
funcional diferente.
Uma relacao direta entre o subsistema do TCG, os requisitos de mecanismos de res-
posta atendidos e uma possıvel utilizacao do recurso em um sistema de seguranca imu-
nologica e listada a seguir:
• Cpusets: estabelecimento de garantia de recursos de memoria e CPU para processos.
Um modulo imunologico pode, por exemplo, reservar um CPU e um modulo de
memoria do sistema exclusivamente para processos imunologicos;
• CFS Bandwidth Control: estabelecimento de limites para utilizacao de tempo de
CPU. Permite a modulos imunologicos limitar a capacidade de processamento de
um processo suspeito;
• Device Controller : bloqueio de acesso a dispositivos do sistema operacional. Um
modulo imunologico pode impedir um processo de acessar qualquer dispositivo dis-
ponıvel no sistema operacional, como uma porta USB, por exemplo;
• Freezer : bloqueio e desbloqueio de processos de maneira eficaz, sem utilizacao de
sinais, de tal forma que o processo paralisado nao tenha conhecimento de que foi
bloqueado por um perıodo de tempo. Esta abordagem e considerada superior a
utilizacao dos sinais SIGSTOP e SIGCONT, uma vez que nesta ultima abordagem
um processo pode mudar seu comportamento apos tomar conhecimento de que foi
bloqueado;
• Memory Resource Controller e HugeTLB Resource Controller : permitem o estabe-
lecimento de limites para utilizacao (em bytes) de memoria fısica, swap e grandes
paginas de memoria virtual (HugeTLB). Um modulo imunologico pode limitar o
consumo de memoria RAM por parte de um processo suspeito.
Dentre os requisitos de resposta nao atendidos pelo TCG, a finalizacao de processos
pode ser facilmente feita em nıvel de usuario atraves do envio do sinal SIGKILL, por parte
de um modulo imunologico, ao processo invasor.

114 Capıtulo 6. Analises e testes
Ja a funcionalidade de recuperacao de alteracoes feitas no sistema de arquivos, por um
processo invasor durante um ataque, nao e atendida em nıvel de kernel pelo framework.
Apesar da disponibilidade do prototipo UndoFS para atendimento deste requisito, de-
senvolvido por Fabrıcio [22] e ja utilizado anteriormente no framework Imuno [29], este
trabalho nao utilizou tal ferramenta, deixando a cargo dos desenvolvedores do sistema
imunologico a implementacao de uma alternativa, ate que uma solucao deste tipo seja
incluıda no Linux.
A atualizacao do UndoFS para o Linux atual, apesar de ser uma opcao para o aten-
dimento deste requisito, nao e encorajada devido as dificuldades de atualizacao e manu-
tencao inerentes da solucao, conforme exposto anteriormente. Uma alternativa seria o
trabalho [11], o qual implementa, em espaco de usuario, um mecanismo de recuperacao
de alteracoes em disco.
Por fim, e importante ressaltar que a implementacao de modulos de monitoramento,
deteccao e resposta, por tratarem-se de solucoes particulares, inerentes a pesquisa relacio-
nada ao sistema de seguranca imunologico, nao sao considerados requisitos do framework
IMN e estao fora do escopo deste trabalho, devendo ser implantados por modulos imu-
nologicos.
O modulo de auto-protecao, contudo, apesar de ser considerado um componente imu-
nologico, e implementado diretamente pelo framework, por ser necessidade comum a todos
os diferentes prototipos ja desenvolvidos pelo projeto Imuno e por ser fundamental no con-
texto de pesquisa em seguranca computacional.
6.1.2 Requisitos de Manutencao
Visando minimizar a carga de manutencao necessaria para atualizacao da ferramenta,
conforme visto anteriormente, o IMN foi desenvolvido sob a seguinte diretriz: “O fra-
mework imunologico deve implementar solucoes com mınimo impacto no kernel Linux e
consoantes com as diretrizes e boas praticas adotadas pelos desenvolvedores do Linux”.
Por este motivo, o framework nao adiciona novas chamadas de sistema ou ferramentas
nao oficiais (externas). Tampouco foram feitas alteracoes em qualquer ponto do Linux. O
IMN e implementado utilizando somente APIs bem definidas, sem qualquer alteracao1 no
codigo do kernel. Desta forma, a prova do tempo, ou seja, experiencias de atualizacao do
1Dentro da hierarquia de diretorios do codigo fonte do Linux, o diretorio linux-src/security/ temem sua raiz os arquivos-fonte das ferramentas de seguranca: LSM, SecurityFS e Linux Capabilities.Neste mesmo diretorio, existem alguns subdiretorios, um para cada modulo LSM do Linux. Por estemotivo, o patch do IMN adiciona o diretorio linux-src/security/imn/, onde ficam localizados todosos arquivos do seu codigo fonte. Os unicos arquivos do kernel alterados pelo patch do framework IMN saolinux-src/security/Kconfig e linux-src/security/Makefile, responsaveis pela inclusao das opcoesde compilacao do framework (CONFIG SECURITY IMN).

6.2. Sistema de Seguranca opaco utilizando o framework IMN 115
framework IMN, sao um bom indicador do grau de sucesso do atendimento aos requisitos
de manutencao.
O IMN teve seu desenvolvimento iniciado sobre a versao 2.6.31 do kernel Linux. Desde
entao, vem sendo atualizado a cada nova versao do kernel e, no momento da escrita deste
trabalho, encontra-se em pleno funcionamento sobre a versao 3.8 do Linux. O historico de
manutencao, com poucas intervencoes para atualizacao do sistema, demonstra o sucesso
da arquitetura adotada pelo IMN com relacao ao quesito manutencao de codigo.
O maior “salto” entre versoes do Linux ocorrido, foi a atualizacao do IMN do Linux
versao 2.6.36 para 3.8, onde foi detectada apenas uma alteracao de API no Linux que
demandou intervencao no codigo do framework. Neste exemplo, houve uma alteracao de
API na forma de declaracao de variaveis do tipo spin_lock e rw_spin_lock, o que gerou
a necessidade de alteracao de duas linhas de codigo do framework para retoma-lo a um
estado funcional no Linux 3.8:
- imn_hooks_lock = SPIN_LOCK_UNLOCKED;
- imn_tasks_lock = RW_LOCK_UNLOCKED;
+ imn_hooks_lock = __SPIN_LOCK_UNLOCKED();
+ imn_tasks_lock = __RW_LOCK_UNLOCKED();
Alem das alteracoes de API, quaisquer mudancas entre versoes dos arquivos do Linux
alterados pelo IMN requerem intervencoes manuais de atualizacao. No exemplo anterior,
a adicao de novos modulos LSM ao Linux exigiu reposicionamento de linhas incluıdas pelo
IMN nos arquivos security/Kconfig e security/Makefile.
6.2 Sistema de Seguranca opaco utilizando o fra-
mework IMN
Nesta secao, sera montado um cenario simples de utilizacao do framework IMN. Este
cenario utiliza um sistema de seguranca simplificado, implementado exclusivamente para
fins de exercıcio e validacao da utilizacao do framework IMN na criacao de um sistema
de seguranca imunologico geral. O sistema simplificado e composto por tres modulos
imunologicos e um LKM imunologico, descritos a seguir:
• modConsole: Modulo imunologico de administracao do sistema de seguranca. Sessao
de linha de comandos (bash), responsavel por tarefas administrativas do sistema
junto ao framework IMN;
• modMonitor: Modulo imunologico gerador de informacoes. Aplicacao em C, res-
ponsavel pela leitura dos canais de ganchos multifuncionais e geracao de base de
dados de acesso;

116 Capıtulo 6. Analises e testes
• modResponse: Modulo de deteccao e resposta. Aplicacao em C, responsavel pela
analise do repositorio de informacoes gerado pelo modMonitor e intervencoes sobre
processos suspeitos;
• modTargs: LKM imunologico que implementa alguns tratadores de ganchos multi-
funcionais utilizados pelo modMonitor para coleta de informacoes sobre o sistema
operacional.
Este sistema de seguranca simplificado simula um sistema de deteccao de intrusao
baseado em comportamento, e funciona da seguinte forma: quaisquer acoes negadas pelo
mecanismo de auto-protecao do framework IMN sao consideradas como comportamento
suspeito. Apos a deteccao de um limite de acoes suspeitas por parte de um processo
(soft limit), este passa a ser considerado suspeito e o sistema de seguranca responde
diminuindo a oferta de recursos de CPU ao processo em questao. No caso de deteccao de
mais acoes suspeitas por parte de um processo suspeito (hard limit), o mesmo e finalizado
pelo modulo de resposta.
Neste cenario, cada modulo exercita diferentes funcionalidades do IMN, conforme ilus-
trado na Tabela 6.1. A seguir, serao detalhados funcionamento e implementacao de cada
componente do sistema de seguranca. Na Secao 6.3 sera apresentada uma simulacao de
utilizacao da ferramenta.
Componente Funcionalidade Escopo
modConsole Interface SecurityFS Ajuste de parametros do sistema de segurancae consulta de estado de componentes do fra-
mework
modMonitor Interface SecurityFS Leitura de canais de saıda de ganchos multi-funcionais
Ganchos Multifuncionais Utilizacao de tratadores de monitoramentopara alimentacao de repositorio de informacoes
Auto-protecao Utilizacao do registro historico de negacoes deacesso do mecanismo de auto-protecao paraalimentacao de repositorio de informacoes
modResponse TCG Limitacao recursos de CPU para processosconsiderados suspeitos
modTargs Ganchos Multifuncionais Registro de tratadores de monitoramento
Tabela 6.1: Recursos do framework IMN utilizados por cada modulo imunologico de umsistema de seguranca simplificado.

6.2. Sistema de Seguranca opaco utilizando o framework IMN 117
6.2.1 modConsole - Modulo Administrativo
O modulo imunologico modConsole e um processo do programa bash, utilizado na
configuracao do sistema de seguranca, atraves da manipulacao da interface SecurityFS
do IMN. Neste modulo, deverao ser feitos os diversos procedimentos necessarios para a
configuracao inicial do sistema de seguranca, bem como algumas consultas sobre o estado
dos componentes do framework IMN.
As atividades de configuracao realizadas com este componente sao:
– Registro de processos imunologicos;
– Configuracao inicial da hierarquia TCG do sistema de seguranca;
– Carregamento de LKM imunologico;
– Registro de ganchos e tratadores;
– Ativacao do mecanismo de auto-protecao.
Algumas possıveis rotinas de consulta realizadas por este modulo sao:
– Listagem de processos imunologicos registrados;
– Listagem de tratadores de ganchos registrado no sistema;
– Listagem de arquivos protegidos pelo mecanismo de auto-protecao;
– Consulta do estado do mecanismo de auto protecao;
– Leitura manual sobre canais de saıda de gancho;
– Escrita manual sobre canais de entrada de ganho.
6.2.2 modMonitor - Gerador de informacoes
O modulo imunologico modMonitor, e uma aplicacao em espaco de usuario que gera
uma thread de execucao para leitura de cada um dos canais dos ganchos imunologicos e
uma unica thread de escrita, para escrita serial no arquivo de log do repositorio seguro.
As threads de leitura executam um loop, realizando operacoes de leitura sobre o arquivo
do seu canal. Apesar da implementacao com utilizacao de espera ociosa, estas threads nao
tendem a utilizar muito tempo CPU. Isto acontece devido ao fato de que a implementacao
do IMN para operacoes de leitura sobre arquivos do tipo SecurityFS nao retorna um
arquivo vazio quando nao ha dados no buffer do canal, mas sim coloca a aplicacao que
invocou a chamada de leitura sobre o arquivo no estado TASK_INTERRUPTIBLE, ate que
haja algum dado a ser lido no canal. Desta forma, as threads de leitura do modMonitor
tendem a ficar boa parte do tempo dormindo, aguardando por dados a serem lidos. Apos

118 Capıtulo 6. Analises e testes
a leitura de um buffer de dados do seu respectivo canal, uma thread de leitura inclui estes
dados ao final de uma lista ligada de jobs a serem escritos no arquivo de log.
A implementacao das threads de leitura esta ilustrada abaixo:
int read_channel(void *arg)
{
...
while (1) {
channel = fopen(channel[hook], "r");
if (channel) {
for (i = 0; fread(&buffer[i], 1, 1, channel) == 1; i++) {}
buffer[i] = ’\0’;
fclose(channel);
if (add_job(buffer, strlen(buffer)) == 0)
sem_post(&job_queue_count);
} else
fprintf(stderr, "Could not open channel %s.\n", channel[hook]);
}
}
A thread de escrita, por sua vez, le os jobs da fila e os escreve serialmente no arquivo
de log. As operacoes de leitura e escrita na fila de jobs e sincronizada com a utilizacao
de um semaforo. Desta forma, a thread de escrita executa em loop apenas enquanto
houverem dados a serem escritos. Nos momentos em que a fila estiver vazia, a thread
ficara dormindo. A implementacao da thread de escrita esta ilustrada abaixo:
int write_jobs(void *arg)
{
...
while (1) {
sem_wait(&job_queue_count);
if (get_job(buf, 1024) == 0) {
db = fopen(db_path, "a");
if (db) {
fprintf(db, "%s", buf);
fclose(db);
}
}
}
return 0;

6.2. Sistema de Seguranca opaco utilizando o framework IMN 119
}
Por padrao, os tratadores de auto-protecao de IMN escrevem nos canais de saıda dos
seus respectivos ganchos, notificacoes de acessos negados. Ademais, o LKM imunologico
deste sistema de seguranca adiciona outros tratadores para registro de atividades do sis-
tema imunologico (modResponse) sobre processos suspeitos. Desta forma, o repositorio
forense esperado e um arquivo de log com registro de todas as atividades suspeitas rea-
lizadas por processos imunologicos e todas as intervencoes sobre processos suspeitos por
parte do sistema de seguranca.
6.2.3 modResponse - Detector de Intrusao e Gerador de Respos-
tas
O terceiro e ultimo modulo imunologico deste sistema de seguranca simplificado acu-
mula duas das caracterısticas desejadas ao sistema de seguranca imunologica geral a ser
desenvolvido pelo projeto Imuno: deteccao e resposta. Trata-se de uma aplicacao desen-
volvida em C, a qual implementa a logica de deteccao de intrusao do sistema e os seus
dois mecanismos de resposta: diminuicao da capacidade de processamento e finalizacao
de um processo suspeito.
A deteccao e feita atraves da constante leitura e analise dos dados do repositorio forense
gerado por modMonitor. Qualquer negacao de acesso realizada pelo modulo de auto-
protecao do IMN e considerada uma atitude suspeita e e contabilizada pelo modResponse.
Sempre que um dado processo atingir a marca de cinco ocorrencias suspeitas, ele e movido
para a classe de processos suspeitos, a qual impoe capacidade limitada de utilizacao de
tempo de CPU. Aqueles processos que atingirem a marca de 10 atividades suspeitas, sao
imediatamente finalizados.
A diminuicao do poder de processamento e feito atraves da criacao de um grupo cha-
mado suspects em hierarquia TCG com o subsistema CFS Bandwidth Control ativado.
O grupo suspects deve ter o atributo cpu.cfs_quota_us configurado para dez por cento
do valor do atributo cpu.cfs_period_us. Desta forma, garante-se que a soma de pro-
cessamento de todos os processos deste grupo nao ultrapassara 10% da capacidade de
processamento total do sistema. A finalizacao do processo, por sua vez, e feita atraves do
simples envio do sinal SIGKILL para o processo suspeito.
6.2.4 modTargs - LKM Imunologico
Por fim, o LKM imunologico modTargs define duas funcoes tratadoras, responsaveis
por registrar nos canais de saıda dos seus respectivos ganchos as atuacoes de proces-
sos imunologicos sobre processos suspeitos. Os ganchos utilizados por este modulo sao:

120 Capıtulo 6. Analises e testes
ID_TASK_KILL e ID_FILE_OPEN. O tradador imuno_file_open(), quando registrado no
gancho ID_FILE_OPEN, escreve no canal de saıda do gancho operacoes de abertura para
escrita em arquivos de nome tasks, diretorio suspects e sistema de arquivo do tipo
cgroup. Sua implementacao e apresentada abaixo:
int imuno_file_open(va_list args, char *ochan)
{
...
file = va_arg(args, struct file *);
...
if (strcmp(file->f_dentry->d_inode->i_sb->s_type->name, "cgroup") == 0
&& strcmp(file->f_dentry->d_parent->d_name.name, "suspects") == 0
&& strcmp(file->f_dentry->d_name.name, "tasks") == 0)
snprintf(ochan, 1024, "%s [IMN:modMonitor][%d][%d] [LOG]"
"[@file_open()]: [fstype %s dname %s]\n",
date, current->parent->pid, current->pid,
file->f_dentry->d_inode->i_sb->s_type->name,
file->f_dentry->d_name.name);
return 0;
}
O tratador imn_task_kill(), por sua vez, registra todas as ocorrencias da chamada
de sistema kill(SIGKILL), e possui a seguinte implementacao:
int imuno_task_kill(va_list args, char *ochan)
{
...
sig = va_arg(args, int);
...
if (sig == SIGKILL)
snprintf(ochan, 1024, "%s [IMN:modMonitor][%d][%d] [LOG]"
"[@task_kill()]: [pid %d signal SIGKILL]\n",
timestamp, current->parent->pid, current->pid, p->pid);
return 0;
}
Os registros abaixo ilustram possıveis saıdas destes tratadores:
[21:27:47] [IMN:modMonitor][701][702] [LOG][@file_open()]: [fstype cgroup dname tasks]
[21:29:56] [IMN:modMonitor][455][466] [LOG][@task_kill()]: [pid 569 signal SIGKILL]

6.3. Simulacao de uso 121
6.3 Simulacao de uso
Na secao anterior, foi apresentado o funcionamento dos componentes integrantes de
um pseudo sistema de seguranca imunologico. Nesta secao, sera apresentada uma si-
mulacao de ataque sobre este sistema, bem como o comportamento de cada um dos seus
componentes.
Setup Inicial
Inicialmente, os tres modulos imunologicos do sistema de seguranca devem ser execu-
tados. Uma configuracao inicial deve entao ser feita pelo modConsole. Este modulo deve
primeiramente registrar os processos imunologicos: ele proprio e os modulos modMonitor
e modResponse, que possuem os PIDs 405, 459 e 505, respectivamente:
# cd /var/sys/kernel/security/imn
# echo $$ > operations/REG_TASK
# echo 459 > operations/REG_TASK
# echo 505 > operations/REG_TASK
# cat immune_tasks
405
459
505
A seguir, deve-se registrar os ganchos multifuncionais e tratadores de ganchos a serem
utilizados pelo modulo modMonitor.
• Registro de ganchos:
# echo ID_FILE_OPEN 0 > operations/REG_HOOK
# echo ID_TASK_KILL 0 > operations/REG_HOOK
# cat hooks | grep $$
# Hook_Name PID MODEXEC NTARGS
43 ID_FILE_OPEN 405 0 0
63 ID_TASK_KILL 405 0 1
• Registro de tratadores:
# insmod ˜/modTargs.ko
# cat targets
#Hook #Target Target_Name
43 0 imuno_file_open+0x0/0x140 [targs]

122 Capıtulo 6. Analises e testes
63 0 imn_selfprot_task_kill+0x0/0xc0
63 1 imuno_task_kill+0x0/0x100 [targs]
# cat hooks | grep $$
# Hook_Name PID MODEXEC NTARGS
43 ID_FILE_OPEN 416 0 1
63 ID_TASK_KILL 416 0 2
Os passos finais da inicializacao do sistema sao a configuracao do repositorio seguro
do mecanismo de auto-protecao do IMN e ajustes do framework TCG de acordo com as
necessidades do sistema de seguranca.
• Definicao de arquivos do repositorio seguro:
# mkdir -p /imuno/saferepo
# touch /imuno/saferepo/forensic.db
# echo -e ’/imuno/saferepo/forensic.db\n’ > saferepo/load
# cat saferepo/list
/srv/saferepo/forensic.db
• Configuracao do framework TCG:
# mkdir /imuno/tcg
# mount -t cgroup -o freezer,cpu cgroup /imuno/tcg/
# mkdir /imuno/tcg/suspects
# echo 100000 > /imuno/tcg/suspects/cpu.cfs_period_us
# echo 10000 > /imuno/tcg/suspects/cpu.cfs_quota_us
Finalmente o sistema de seguranca pode ser ativado, a partir da habilitacao do meca-
nismo de auto-protecao do framework IMN:
# echo 1 > selfprot
Simulacao de Ataque
Neste ponto, considera-se que houve um ataque bem sucedido no sistema operacional e
um processo malicioso conseguiu iniciar uma sessao de bash como usuario root. O atacante
inicia entao uma serie de comandos visando desabilitar os mecanismos de protecao do
sistema e os registros de suas atividades, conforme abaixo:

6.3. Simulacao de uso 123
# cat /imuno/tcg/suspects/tasks
cat: /imuno/tcg/suspects/tasks: Operation not permitted
# umount /imuno/tcg
umount: /imuno/tcg: must be superuser to umount
# mount -t securityfs securityfs /tmp/
mount: permission denied
# insmod /tmp/targs.ko
insmod: error inserting ’/tmp/targs.ko’: -1 Operation not permitted
# cat /imuno/saferepo/forensic.db
cat: /imuno/saferepo/forensic.db: Operation not permitted
# echo "" > /imuno/saferepo/forensic.db
-su: /imuno/saferepo/forensic.db: Operation not permitted
# iptables -L
iptables v1.4.4: can’t initialize iptables table ‘filter’:
Permission denied (you must be root)
# kill -9 405
-su: kill: (405) - Operation not permitted
# kill -9 459
-su: kill: (459) - Operation not permitted
# kill -9 505
-su: kill: (505) - Operation not permitted
Connection to imn closed.
A negacao de acesso para todos os comandos acima e decorrente do exercıcio de di-
ferentes tratadores de ganchos multifuncionais do mecanismo de auto-protecao do IMN,
conforme visto na Secao 5.4.2. A cada negacao de acesso, o tratador de auto-protecao
registra no seu respectivo canal de gancho alguns dados da ocorrencia. No sistema de
seguranca implementado, o modulo modMonitor captura estes registros e os escreve no
arquivo /imuno/selfprot/forensic.db. Para a sequencia de comandos acima, o se-
guinte arquivo de log e gerado pelo modulo imunologico:
[IMN:Selfprot][574][590] [DENIED][@inode_permission()]: [fstype cgroup]
[IMN:Selfprot][574][596] [DENIED][@sb_umount()]: [fstype cgroup]
[IMN:Selfprot][574][612] [DENIED][@sb_mount()]: [fstype securityfs]
[IMN:Selfprot][574][631] [DENIED][@capable()]: [CAP_SYS_MODULE]
[IMN:Selfprot][574][662] [DENIED][@inode_permission()]: [inode df2a98f0]
[IMN:modMonitor][504][505] [LOG][@file_open()]:[fstype cgroup]
[IMN:Selfprot][573][574] [DENIED][@inode_permission()]: [inode df2a98f0]
[IMN:Selfprot][574][691] [DENIED][@capable()]: [CAP_NET_ADMIN]

124 Capıtulo 6. Analises e testes
[IMN:Selfprot][573][574] [DENIED][@task_kill()]: [pid 405]
[IMN:Selfprot][573][574] [DENIED][@task_kill()]: [pid 459]
[IMN:Selfprot][573][574] [DENIED][@task_kill()]: [pid 505]
[IMN:modMonitor][504][505] [LOG][@task_kill()]: [pid 574 signal SIGKILL]
As duas linhas com prefixo [IMN:modMonitor] na listagem acima indicam as acoes
realizadas pelo modulo modResponse, capturadas pelo LKM modTargs e escritas no ar-
quivo de log pelo modulo modMonitor: inicialmente, o processo suspeito tem seu poder de
processamento limitado atraves de sua inclusao no grupo suspects do framework TCG.
Em seguida, como o o modulo imunologico constata que trata-se de um ataque e finaliza
o processo suspeito atraves da chama de sistema kill(SIGKILL).

Capıtulo 7
Conclusoes
Ao longo do seu desenvolvimento, este trabalho sofreu algumas alteracoes de escopo.
O planejamento inicial era a atualizacao de uma ferramenta de software desenvolvida
pelo projeto Imuno e ampliacao do seu rol de funcionalidades, atraves do levantamento
de novos requisitos funcionais junto aos pesquisadores integrantes do grupo de pesquisa.
A primeira mudanca ocorreu ainda nas etapas iniciais deste trabalho. No Capıtulo
4, foram apresentadas diversas ferramentas de seguranca existentes na versao oficial do
kernel do sistema operacional GNU/Linux. Diferentemente do cenario existente no mo-
mento das implementacoes de prototipos do projeto Imuno anteriores a este trabalho,
onde grande parte do ferramental utilizado estava em fase de desenvolvimento ou mesmo
foi implementado pelo grupo, devido a nao existencia de solucoes equivalentes, as ferra-
mentas apresentadas naquele capıtulo sao consolidadas, estaveis e oferecem boa cobertura
dos requisitos necessarios ao sistema de seguranca imunologico, levantados na Secao 5.2,
sendo, portanto, utilizadas em conjunto com as funcionalidades implementadas pelo IMN.
Ademais, a revisao de conceitos fundamentais do funcionamento do kernel Linux,
apresentados no Capıtulo 3, somada as experiencias acumuladas nos trabalhos de Marcelo,
Diego, Fabrıcio e Martim, apresentados nas Secoes 2.2 e 5.2, levaram a conclusao de que,
solucoes implementadas em nıvel de kernel, e que alterem profundamente o seu codigo,
possuem uma manutencao muito onerosa, devendo ser evitadas sempre que possıvel.
Como o objetivo do final deste trabalho era disponibilizar uma ferramenta funcional e
de manutencao tao simples quanto possıvel, a arquitetura do framework imunologico foi
refeita e em seguida implementada atraves ferramenta batizada de IMN.
Chegara entao a hora da execucao de outra etapa previsa na proposta inicial deste
trabalho: levantamento de requisitos de novas funcionalidades necessarias ao framework
imunologico. Naquele momento, contudo, o projeto Imuno passou por mudancas profun-
das em sua estrutura. O foco da pesquisa foi direcionado para outras areas de seguranca
de sistemas e o objetivo de construcao de um sistema de seguranca imunologico geral foi
125

126 Capıtulo 7. Conclusoes
temporariamente adiado.
Apesar de parcialmente afetado com estas mudancas, considerando toda a pesquisa
sobre o kernel Linux e suas questoes relativas a controle de acesso, controle de recur-
sos e seguranca em geral, optou-se pela continuidade do desenvolvimento deste trabalho,
por dois principais motivos: primeiramente, ja havia ampla disponibilidade de requisitos
necessarios para uma solucao imunologica; depois, a generalidade da solucao que estava
sendo concebida poderia ser utilizada como plataforma para o desenvolvimento de outras
solucoes de seguranca, nao necessariamente relacionadas com os princıpios de funciona-
mento do sistema imunologico humano.
A partir dos resultados apresentados no Capıtulo 6, pode-se afirmar que o framework
IMN cumpre sua proposta inicial de entregar aos seus usuarios, desenvolvedores de
modulos de seguranca inspirados no sistema imunologico humano, um pacote de funciona-
lidades com flexibilidade e simplicidade de uso e manutencao, reduzindo a complexidade
de implementacao do sistema proposto. Cumpre tambem o objetivo de ser uma ferramenta
a ser utilizada como base comum para implementacao do sistema de seguranca proposto,
diminuindo, portanto, o retrabalho inerente a implementacao de requisitos comuns, como
auto-protecao, no desenvolvimento de diferentes modulos do sistema de seguranca imu-
nologica.
Desta forma, este trabalho traz as seguintes contribuicoes ao projeto Imuno e a comu-
nidade cientıfica:
• Farta documentacao sobre as ferramentas de seguranca atualmente disponıveis no
kernel Linux; certamente um importante produto deste trabalho, e que podera ser
de grande utilidade para os integrantes do projeto e outros pesquisadores interessa-
dos no funcionamento dos aspectos de seguranca do Linux e na implementacao de
ferramentas relacionadas;
• Diminuicao significativa do onus de manutencao e atualizacao do framework imu-
nologico a ser utilizado como plataforma para o desenvolvimento de um sistema de
seguranca imunologico geral, aproximando ainda mais essa peca de software de uma
versao com maturidade suficiente para pleitear uma admissao na versao oficial do
Linux;
• Nova arquitetura de ganchos multifuncionais, a qual permite que funcoes tratadoras
para ganchos LSM possam ser implementadas na forma de LKMs. Esta imple-
mentacao, alem de ter sua utilidade no escopo do projeto Imuno, pode ser utilizada
para acelerar o processo de desenvolvimento e depuracao de sistemas de seguranca
que facam uso do framework LSM, uma vez que, a partir da versao 2.6.24 do Li-
nux, um modulo LSM nao mais pode ser definido como um LKM, o que dificulta

127
o processo de desenvolvimento, uma vez que exige uma compilacao geral do ker-
nel e reinicializacao do sistema operacional a cada pequena alteracao no codigo do
modulo LSM em desenvolvimento. Portanto, utilizar a caracterıstica modular do
IMN durante o processo de desenvolvimento de um modulo LSM certamente torna-
ria o processo mais celere. A generalidade da solucao desenvolvida permite ainda
o desenvolvimento de outros sistemas de seguranca, nao necessariamente inspirados
no sistema imunologico humano.
• Implementacao de um controle de acesso mandatorio simplificado, o mecanismo
de auto-protecao, que, assim como o mecanismo de ganchos multifuncionais com
tratadores modulares, alem de atender as necessidades do sistema de de seguranca
do projeto Imuno, pode ser utilizado para outros fins, reforcando ainda mais a
seguranca do sistema operacional GNU/Linux.
Dentre os trabalhos futuros que o autor pretende desenvolver a partir dos resultados
obtidos neste trabalho, estao:
• Extensao do mecanismo de auto-protecao, de forma a permitir o estabelecimento
polıticas de controle de acesso mandatorio mais flexıveis, de uma forma similar
aquela desenvolvida pelo LSM SMACK, apresentado na Secao 4.2.3. Na imple-
mentacao atual, um administrador de servicos de rede, por exemplo, deve registrar
um shell imunologico para proceder com algumas tarefas administrativas, tal como
o ajuste de regras de firewall do sistema. Outra alternativa seria desabilitar a auto-
protecao durante a execucao de rotinas administrativas. Ambas abordagens sao
extremas e podem ser evitadas atraves da implementacao de polıticas de controle
de acesso mais flexıveis;
• Desenvolvimento de um modulo de controle de acesso capaz de aplicar controle de
acesso mandatorio sobre credenciais Linux do tipo capabilities. Tal modulo devera
permitir ao administrador estabelecer grupos de processos ou usuarios e definir quais
as capacidades devem ser atribuıdas as credenciais daquele grupo. Atualmente, o
controle de acesso sobre este tipo de credencial e feito de maneira discricionaria,
uma vez que as credenciais de objetos sao armazenadas em inodes e herdadas por
processos que tenham permissoes discricionarias (propriedade) sobre tais arquivos;
• Extensao do framework de forma a permitir um empilhamento de diferentes modulos
LSM. Conforme apresentado no Capıtulo 4, kernel Linux possui diversos modulos
LSM, todos com caracterısticas especıficas. Estes modulo, contudo, nao podem
coexistir, pois utilizam a mesma estrutura de ganchos LSM. O framework IMN,
por sua vez, permite o registro de varios tratadores diferentes para um mesmo

128 Capıtulo 7. Conclusoes
gancho LSM. Portanto, o empilhamento de modulos LSM atraves da utilizacao do
mecanismo de ganchos multifuncionais do IMN e, em tese, possıvel;
• Implementacao eficiente de sistema de arquivos com funcionalidades de recuperacao
de dados com as caracterısticas do middleware UNDOFS.

Referencias Bibliograficas
[1] Linux programmer’s manual: ptrace. [Online; acessado em 16 de fevereiro de 2013].
[2] Linux programmer’s manual: syscalls. [Online; acessado em 16 de marco de 2013].
[3] Overview of standard C libraries on Linux. [Online; acessado em 16 de marco de
2013].
[4] GNU General Public License. [Online; acessado em 20 de marco de 2013].
[5] Why GRSecurity cannot use LSM. [Online; acessado em 25 de janeiro de 2013].
[6] Josh Aas. Understanding the Linux 2.6.8.1 CPU scheduler. Retrieved Oct, 16, 2005.
[7] R. Anderson and A. Khattak. The use of information retrieval techniques for intrusion
detection. In Proceedings of First International Workshop on the Recent Advances in
Intrusion Detection (RAID), 1998.
[8] Michael Bacarella. Taking advantage of Linux capabilities. Linux Journal, 2002.
[9] Paolo Baldan, Andrea Corradini, Javier Esparza, Tobias Heindel, Barbara Konig,
and Vitali Kozioura. Verifying red-black trees. In Proc. of COSMICAH, 2005.
[10] Mark Burgess. NSA National Information Assurance Reserach Laboratory. [Online;
acessado em 10 de fevereiro de 2013].
[11] Gabriel Dieterich Cavalcante. Deteccao e Recuperacao de Intrusao com uso de
Controle de Versao. Dissertacao de Mestrado, Universidade Estadual de Campinas,
2010.
[12] Kees Cook. Yama documentation. [Online; acessado em 16 de fevereiro de 2013].
[13] Jonathan Corbet. SecurityFS. [Online; acessado em 2 de fevereiro de junho de 2013].
129

130 REFERENCIAS BIBLIOGRAFICAS
[14] Crispin Cowan, Steve Beattie, Greg Kroah-Hartman, Calton Pu, Perry Wagle, and
Virgil Gligor. Subdomain: Parsimonious server security. In USENIX 14th Systems
Administration Conference (LISA), 2000.
[15] Andre Augusto da Silva Pereira. Implementacao de controle de recursos e extensao de
funcionalidades de framework de seguranaca imunologica. Technical report, Proposta
de Mestrado, Universidade Estadual de Campinas, 2009.
[16] P Bovet Daniel and Cesati Marco. Understanding the Linux kernel. Sebastopol, CA,
US, O’Reilly, 2005.
[17] Dipankar Dasgupta. Immunity-based Intrusion Detection System: a General
Framework. In Proceedings of the 22nd NISSC, pages 147–160, 1999.
[18] Dipankar Dasgupta and Hal Brian. Mobile Security Agents for Network Traffic
Analysis. In DARPA Information Survivability Conference & Exposition II, 2001.
DISCEX’01. Proceedings. IEEE, 2001.
[19] Dipankar Dasgupta and Fabio Gonzalez. An Immunity-based Technique to
Characterize Intrusions in Computer Networks. Evolutionary Computation, IEEE
Transactions on, pages 281–291, 2002.
[20] Diego Assis de Monteiro Fernandes. Resposta Automatica em um Sistema de
Seguranca Imunologico Computacional. Dissertacao de Mestrado, Universidade Es-
tadual de Campinas, 2003.
[21] Fabricio de Paula and Paulo Licio de Geus. Attack evidence detection, recovery, and
signature extraction with ADENOIDS. Telecommunications and Networking-ICT
2004, pages 1083–1092, 2004.
[22] Fabrıcio Sergio de Paula. Uma Arquitetura de Seguranca Computacional Inspirada
no Sistema Imunologico. Tese de Doutorado, Universidade Estadual de Campinas,
2004.
[23] Fabrıcio Sergio de Paula, Marcelo Abdalla dos Reis, Diego Fernandes, and Paulo Lıcio
de Geus. Modelagem de um Sistema de Seguranca Imunologico. Anais do III
Simposio de Seguranca em Informatica, pages 91–100, 2001.
[24] Fabrıcio Sergio de Paula, Marcelo Abdalla dos Reis, Diego Fernandes, and Paulo Lıcio
de Geus. ADENOIDS: A Hybrid IDS Based on the Immune System. Proceedings
of the 9th International Conference on Neural Information Processing, 2002.

REFERENCIAS BIBLIOGRAFICAS 131
[25] Fabrıcio Sergio de Paula, Marcelo Abdalla dos Reis, Diego Fernandes, and Paulo Lıcio
de Geus. A Hybrid IDS Architecture Based on the Immune System. Anais do II
Workshop Brasileiro de Seguranca de Sistemas Computacionais, pages 33–40, 2002.
[26] F.S. de Paula, L.N. de Castro, and P.L. de Geus. An intrusion detection system
using ideas from the immune system. In Evolutionary Computation, 2004. CEC2004.
Congress on, volume 1, pages 1059–1066. IEEE, 2004.
[27] Patrik D’haeseleer, Stephanie Forrest, and Paul Helman. An Immunological
Approach to Change Detection: Algorithms, Analysis and Implications. Procee-
dings of the 1996 IEEE Symposium on Computer Security and Privacy, 1996.
[28] Patrik D’haeseleer, Stephanie Forrest, and Paul Helman. A Distributed Apporach
to Anomaly Detection. ACM Transactions on Information System Security, 1997.
[29] Martim d’Orey Posser de Andrade Carbone. Framework de Kernel para um Sistema
de Seguranca Imunologico. Dissertacao de Mestrado, Universidade Estadual de Cam-
pinas, 2006.
[30] Marcelo Abdalla dos Reis. Forense Computacional e sua Aplicacao em Seguranca
Imunologica. Dissertacao de Mestrado, Universidade Estadual de Campinas, 2003.
[31] Fernando Esponda, Elena Ackley, Stephanie Forrest, and Paul Helman. On-line
Negative Databases. Proceedings of the 3rd International Conference on Artificial
Immune Systems, 2004.
[32] Michael Fox, John Giordano, Lori Stotler, and Arun Thomas. SELinux and
GRSecurity: a case study comparing Linux security kernel enhancements. 2009.
[33] Simson Garfinkel, Gene Spafford, and Alan Schwartz. Practical Unix & Internet
Security, 3rd Edition. O’Reilly Media, Inc., 2003.
[34] Matthew Glickman, Justin Balthrop, and Stephanie Forrest. A Machine Learning
Evaluation of an Artificial Immune System. Evolutionary Computation, pages 179–
212, 2005.
[35] S.E. Hallyn and A.G. Morgan. Linux capabilities: making them work. In Linux
Symposium, page 163, 2008.
[36] Serge Edward Hallyn and Phil Kearns. Domain and Type Enforcement in Linux.
PhD thesis, College of William and Mary, 2003.

132 REFERENCIAS BIBLIOGRAFICAS
[37] T Harada, T Horie, and K Tanaka. Towards a manageable Linux security. In Linux
Conference, volume 2005, 2005.
[38] Toshiharu Harada, Takashi Horie, and Kazuo Tanaka. Access policy generation
system based on process execution history. Network Security Forum, 2003.
[39] Steven Hofmyer and Stephanie Forrest. Immunity by design: An Artificial Immune
System. Proceedings of the Genetic and Evolutionary Computation Conference, 1999.
[40] David Howells. Credentiasl in Linux. [Online; acessado em 13 de fevereiro de 2013].
[41] Takamasa Isohara, Keisuke Takemori, Yutaka Miyake, Ning Qu, and Adrian Perrig.
LSM-based secure system monitoring using kernel protection schemes. In Availa-
bility, Reliability, and Security, 2010. ARES’10 International Conference on, pages
591–596. IEEE, 2010.
[42] Jeffrey O. Kephart. A Biologically Inspired Immune System for Computers. Arti-
ficial Life IV: Proceedings of the 4th International Workshop on the Synthesis and
Simulation of Living Systems, pages 130–139, 1994.
[43] R. Krishnakumar. HugeTLB — Large Page Support in the Linux Kernel. Linux
Gazette, 155, 2008.
[44] J. Lepreau, R. Spencer, S. Smalley, P. Loscocco, M. Hibler, and D. Andersen. The
Flask security architecture: System suporte for diverse security policies. Proceedings
of the Eighth USENIX Security Symposium, 1999.
[45] A.G. Litke. “turning the page” on hugetlb interfaces. In Linux Symposium, page
277, 2007.
[46] Peter Loscocco and Stephen D Smalley. Meeting critical security objectives with
Security-Enhanced Linux. In Proceedings of the 2001 Ottawa Linux Symposium,
pages 115–134, 2001.
[47] Paul Menage. Control Groups definition, implementation details, examples and API.
[Online; acessado em 17 de julho de 2009].
[48] Paul B Menage. Adding Generic Process Containers to the Linux Kernel. Procee-
dings of the Linux Symposium, 2007.
[49] Ingo Molnar. Modular Scheduler Core and Completely Fair Scheduler. [Online;
acessado em 2 de marco de 2013].

REFERENCIAS BIBLIOGRAFICAS 133
[50] Shailabh Nagar, Humbertur Franke, Jonghyuk Choi, Chandra Seetharaman, Sott
Kaplan, Nivedita Singhvi, Vivek Kashyap, and Mike Kravetz. Class-based Prioritized
Resource Control in Linux. Proceedings of the 2003 Ottawa Linux Symposium, pages
161–180, 2003.
[51] United States Government Department of Defense. DoDD 5200.28-STD. Trusted
Computer System Evaluation Criteria, 1986.
[52] U.S. Department of Health and Human Services. Understanding the Immune System.
National Institutes of Health, 2003.
[53] A. Ott and S. Fischer-Hubner. The ‘Rule Set Based Access Control’(RSBAC)
framework for Linux. In Proceedings of the 8th International Linux Kongress, 2001.
[54] Amon Ott. Why RSBAC does not use LSM. [Online; acessado em 25 de janeiro de
2013].
[55] NSA Peter Loscocco. Integrating flexible support for security policies into the Linux
operating system. In Proceedings of the FREENIX Track: 2001 USENIX Annual Te-
chnical Conference, June 25-30, 2001, Boston, Massachusetts, USA, page 29. USE-
NIX Association, 2001.
[56] Love Robert. Linux kernel development. Pearson Education India, 2004.
[57] Casey Schaufler. Smack in embedded computing. In Proceedings of the 10th Linux
Symposium, 2008.
[58] Stephen Smalley and Timothy Fraser. A security policy configuration for the
Security-Enhanced Linux. Technical report, NAI Labs Technical Report, 2001.
[59] Anil Somayaji. Operating System Stability and Security through Process Homeostasis.
Tese de Doutorado, University of New Mexico, 2002.
[60] Anil Somayaji and Stephanie Forrest. Automated Response Using System-call
Delays. Proceedings of the 9th USENIX Security Symposium, 2000.
[61] Andrew S Tanenbaum. Modern operating systems, volume 2. Prentice Hall New
Jersey, 1992.
[62] P Turner, BB Rao, and N Rao. CPU bandwidth control for CFS. Proceedings of
the Ottawa Linux Symposium, 2010.

134 REFERENCIAS BIBLIOGRAFICAS
[63] Chee Siang Wong, Ian Tan, Rosalind Deena Kumari, and Fun Wey. Towards achi-
eving fairness in the Linux scheduler. ACM SIGOPS Operating Systems Review -
Research and developments in the Linux kernel, 2008.
[64] Chris Wright, Crispin Cowan, James Morris, Stephen Smalley, and Greg Kroah-
Hartman. Linux Security Modules: General Security Support for the Linux Kernel.
Proceedings of the 11th USENIX Security Symposium, 2002.

Apendice A
Ganchos Multifuncionais
O mecanismo de ganchos multifuncionais apresentado na Secao 5.4.1 disponibiliza
uma interface para registro de funcoes tratadoras definidas em LKMs (Linux kernel mo-
dules) para fins de monitoramento ou implementacao de mecanismos de controle de acesso
particulares.
As funcoes tratadoras devem ter assinaturas, de acordo com o tipo de retorno esperado
pelo gancho LSM, da seguinte forma:
int nome(va_list args, char *ochan);
ou
void nome(va_list args, char *ochan);
A lista de argumentos args varia de acordo com o gancho utilizado. Os parametros
sao recuperados pela funcao va_arg() na ordem em que sao definidos na assinatura do
gancho LSM original.
A funcao abaixo ilustra a definicao de um tratador para o grancho multifuncional
ID_MKDIR, incluindo a recuperacao dos parametros originais do gancho:
int target_for_mkdir(va_list args, char *ochan)
{
struct inode *dir;
struct dentry *dentry;
int mode;
dir = va_arg(args, struct inode *);
dentry = va_arg(args, struct dentry *);
mode = va_arg(args, int);
sprintf(ochan, "PID %d criou o diretorio %s.\n",
current->pid, dentry->d_name.name");
135
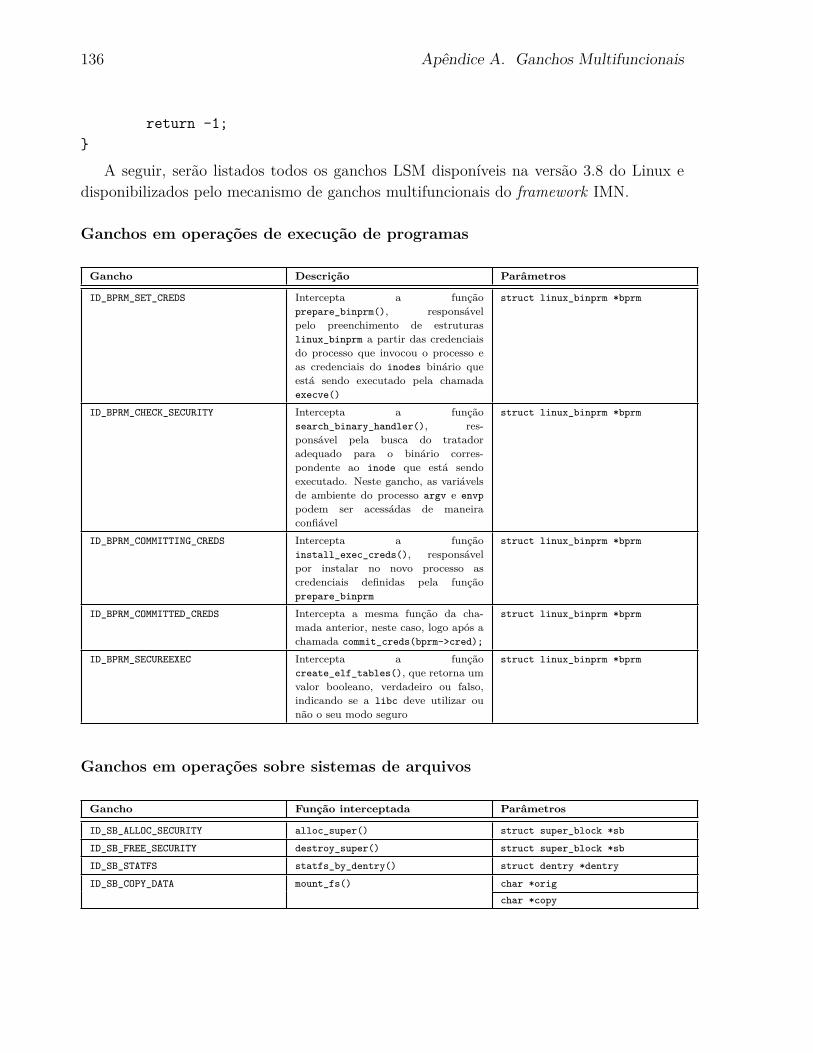
136 Apendice A. Ganchos Multifuncionais
return -1;
}
A seguir, serao listados todos os ganchos LSM disponıveis na versao 3.8 do Linux e
disponibilizados pelo mecanismo de ganchos multifuncionais do framework IMN.
Ganchos em operacoes de execucao de programas
Gancho Descricao Parametros
ID_BPRM_SET_CREDS Intercepta a funcao
prepare_binprm(), responsavel
pelo preenchimento de estruturas
linux_binprm a partir das credenciais
do processo que invocou o processo e
as credenciais do inodes binario que
esta sendo executado pela chamada
execve()
struct linux_binprm *bprm
ID_BPRM_CHECK_SECURITY Intercepta a funcao
search_binary_handler(), res-
ponsavel pela busca do tratador
adequado para o binario corres-
pondente ao inode que esta sendo
executado. Neste gancho, as variavels
de ambiente do processo argv e envp
podem ser acessadas de maneira
confiavel
struct linux_binprm *bprm
ID_BPRM_COMMITTING_CREDS Intercepta a funcao
install_exec_creds(), responsavel
por instalar no novo processo as
credenciais definidas pela funcao
prepare_binprm
struct linux_binprm *bprm
ID_BPRM_COMMITTED_CREDS Intercepta a mesma funcao da cha-
mada anterior, neste caso, logo apos a
chamada commit_creds(bprm->cred);
struct linux_binprm *bprm
ID_BPRM_SECUREEXEC Intercepta a funcao
create_elf_tables(), que retorna um
valor booleano, verdadeiro ou falso,
indicando se a libc deve utilizar ou
nao o seu modo seguro
struct linux_binprm *bprm
Ganchos em operacoes sobre sistemas de arquivos
Gancho Funcao interceptada Parametros
ID_SB_ALLOC_SECURITY alloc_super() struct super_block *sb
ID_SB_FREE_SECURITY destroy_super() struct super_block *sb
ID_SB_STATFS statfs_by_dentry() struct dentry *dentry
ID_SB_COPY_DATA mount_fs() char *orig
char *copy
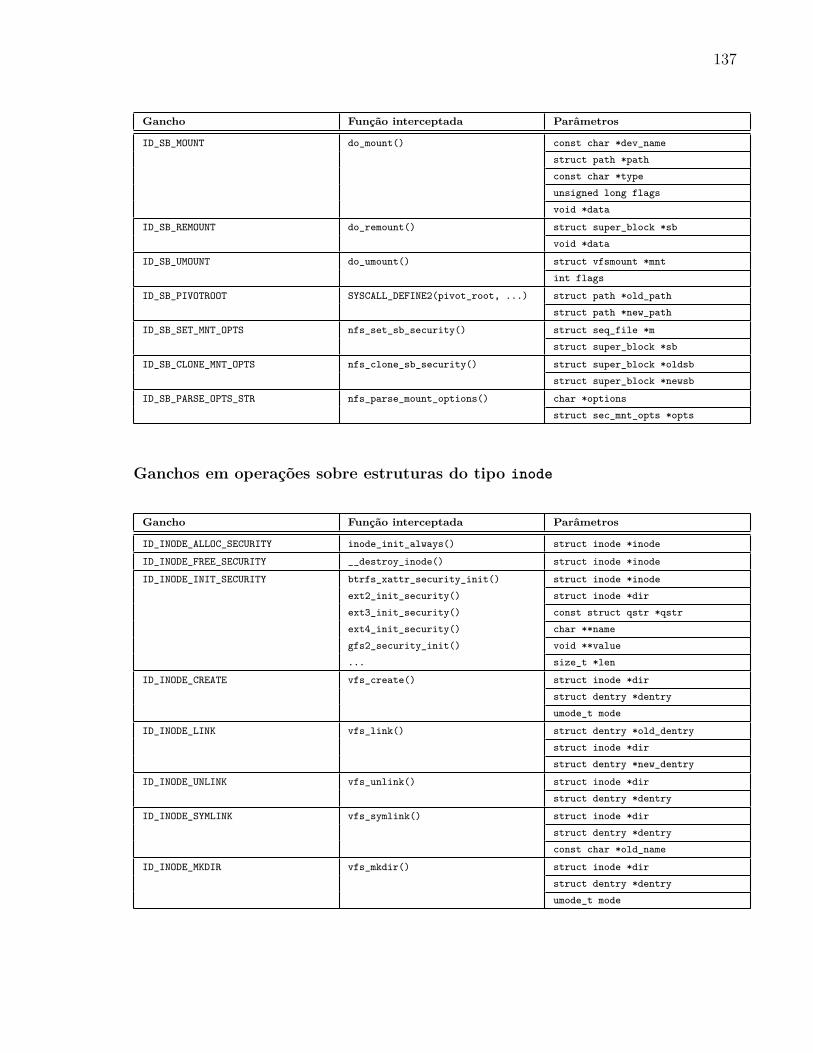
137
Gancho Funcao interceptada Parametros
ID_SB_MOUNT do_mount() const char *dev_name
struct path *path
const char *type
unsigned long flags
void *data
ID_SB_REMOUNT do_remount() struct super_block *sb
void *data
ID_SB_UMOUNT do_umount() struct vfsmount *mnt
int flags
ID_SB_PIVOTROOT SYSCALL_DEFINE2(pivot_root, ...) struct path *old_path
struct path *new_path
ID_SB_SET_MNT_OPTS nfs_set_sb_security() struct seq_file *m
struct super_block *sb
ID_SB_CLONE_MNT_OPTS nfs_clone_sb_security() struct super_block *oldsb
struct super_block *newsb
ID_SB_PARSE_OPTS_STR nfs_parse_mount_options() char *options
struct sec_mnt_opts *opts
Ganchos em operacoes sobre estruturas do tipo inode
Gancho Funcao interceptada Parametros
ID_INODE_ALLOC_SECURITY inode_init_always() struct inode *inode
ID_INODE_FREE_SECURITY __destroy_inode() struct inode *inode
ID_INODE_INIT_SECURITY btrfs_xattr_security_init() struct inode *inode
ext2_init_security() struct inode *dir
ext3_init_security() const struct qstr *qstr
ext4_init_security() char **name
gfs2_security_init() void **value
... size_t *len
ID_INODE_CREATE vfs_create() struct inode *dir
struct dentry *dentry
umode_t mode
ID_INODE_LINK vfs_link() struct dentry *old_dentry
struct inode *dir
struct dentry *new_dentry
ID_INODE_UNLINK vfs_unlink() struct inode *dir
struct dentry *dentry
ID_INODE_SYMLINK vfs_symlink() struct inode *dir
struct dentry *dentry
const char *old_name
ID_INODE_MKDIR vfs_mkdir() struct inode *dir
struct dentry *dentry
umode_t mode
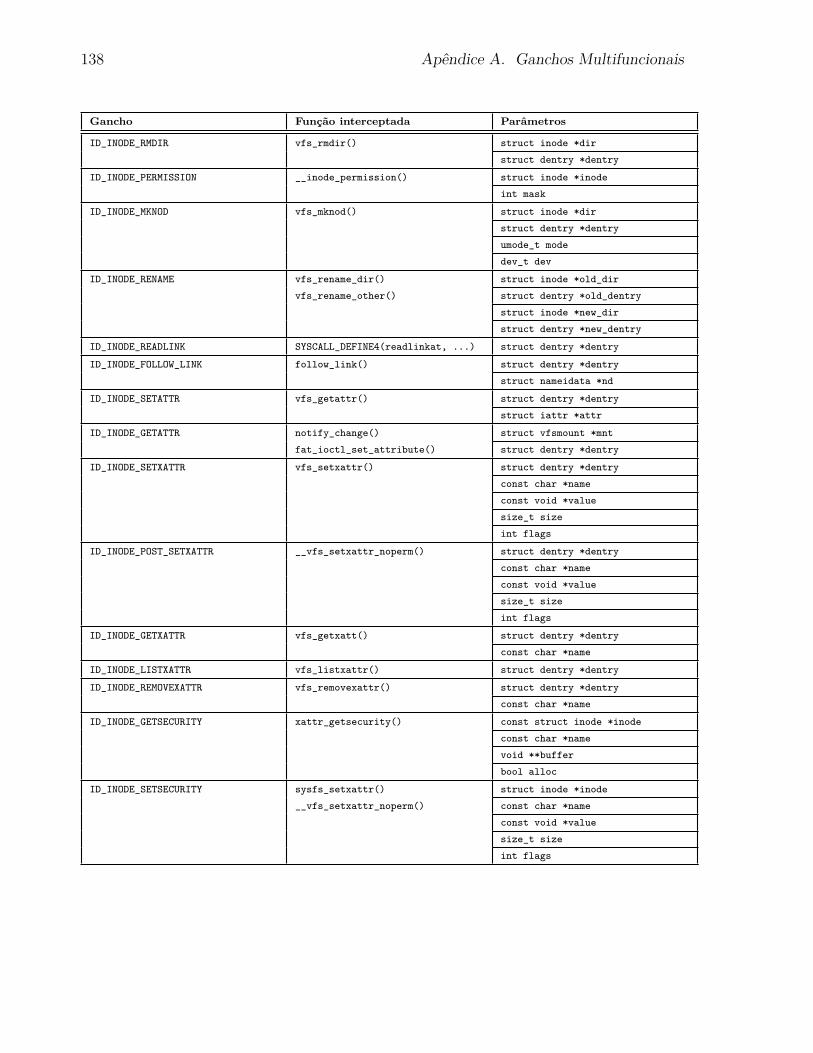
138 Apendice A. Ganchos Multifuncionais
Gancho Funcao interceptada Parametros
ID_INODE_RMDIR vfs_rmdir() struct inode *dir
struct dentry *dentry
ID_INODE_PERMISSION __inode_permission() struct inode *inode
int mask
ID_INODE_MKNOD vfs_mknod() struct inode *dir
struct dentry *dentry
umode_t mode
dev_t dev
ID_INODE_RENAME vfs_rename_dir() struct inode *old_dir
vfs_rename_other() struct dentry *old_dentry
struct inode *new_dir
struct dentry *new_dentry
ID_INODE_READLINK SYSCALL_DEFINE4(readlinkat, ...) struct dentry *dentry
ID_INODE_FOLLOW_LINK follow_link() struct dentry *dentry
struct nameidata *nd
ID_INODE_SETATTR vfs_getattr() struct dentry *dentry
struct iattr *attr
ID_INODE_GETATTR notify_change() struct vfsmount *mnt
fat_ioctl_set_attribute() struct dentry *dentry
ID_INODE_SETXATTR vfs_setxattr() struct dentry *dentry
const char *name
const void *value
size_t size
int flags
ID_INODE_POST_SETXATTR __vfs_setxattr_noperm() struct dentry *dentry
const char *name
const void *value
size_t size
int flags
ID_INODE_GETXATTR vfs_getxatt() struct dentry *dentry
const char *name
ID_INODE_LISTXATTR vfs_listxattr() struct dentry *dentry
ID_INODE_REMOVEXATTR vfs_removexattr() struct dentry *dentry
const char *name
ID_INODE_GETSECURITY xattr_getsecurity() const struct inode *inode
const char *name
void **buffer
bool alloc
ID_INODE_SETSECURITY sysfs_setxattr() struct inode *inode
__vfs_setxattr_noperm() const char *name
const void *value
size_t size
int flags
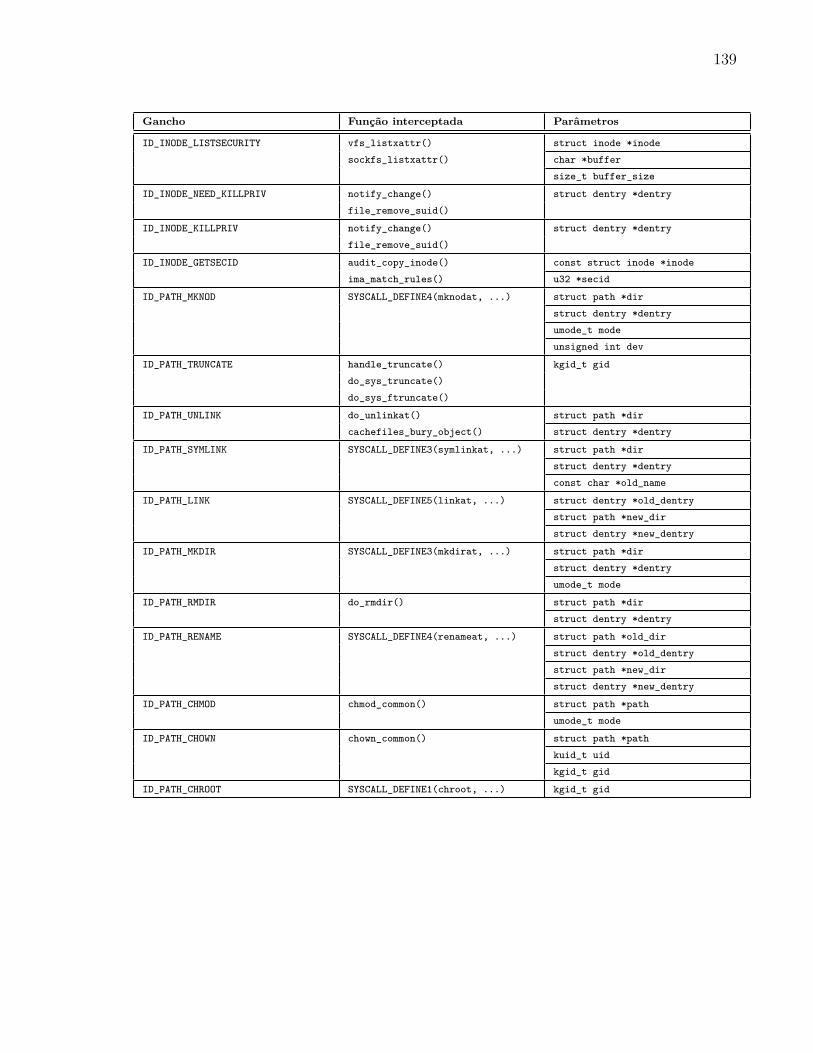
139
Gancho Funcao interceptada Parametros
ID_INODE_LISTSECURITY vfs_listxattr() struct inode *inode
sockfs_listxattr() char *buffer
size_t buffer_size
ID_INODE_NEED_KILLPRIV notify_change() struct dentry *dentry
file_remove_suid()
ID_INODE_KILLPRIV notify_change() struct dentry *dentry
file_remove_suid()
ID_INODE_GETSECID audit_copy_inode() const struct inode *inode
ima_match_rules() u32 *secid
ID_PATH_MKNOD SYSCALL_DEFINE4(mknodat, ...) struct path *dir
struct dentry *dentry
umode_t mode
unsigned int dev
ID_PATH_TRUNCATE handle_truncate() kgid_t gid
do_sys_truncate()
do_sys_ftruncate()
ID_PATH_UNLINK do_unlinkat() struct path *dir
cachefiles_bury_object() struct dentry *dentry
ID_PATH_SYMLINK SYSCALL_DEFINE3(symlinkat, ...) struct path *dir
struct dentry *dentry
const char *old_name
ID_PATH_LINK SYSCALL_DEFINE5(linkat, ...) struct dentry *old_dentry
struct path *new_dir
struct dentry *new_dentry
ID_PATH_MKDIR SYSCALL_DEFINE3(mkdirat, ...) struct path *dir
struct dentry *dentry
umode_t mode
ID_PATH_RMDIR do_rmdir() struct path *dir
struct dentry *dentry
ID_PATH_RENAME SYSCALL_DEFINE4(renameat, ...) struct path *old_dir
struct dentry *old_dentry
struct path *new_dir
struct dentry *new_dentry
ID_PATH_CHMOD chmod_common() struct path *path
umode_t mode
ID_PATH_CHOWN chown_common() struct path *path
kuid_t uid
kgid_t gid
ID_PATH_CHROOT SYSCALL_DEFINE1(chroot, ...) kgid_t gid
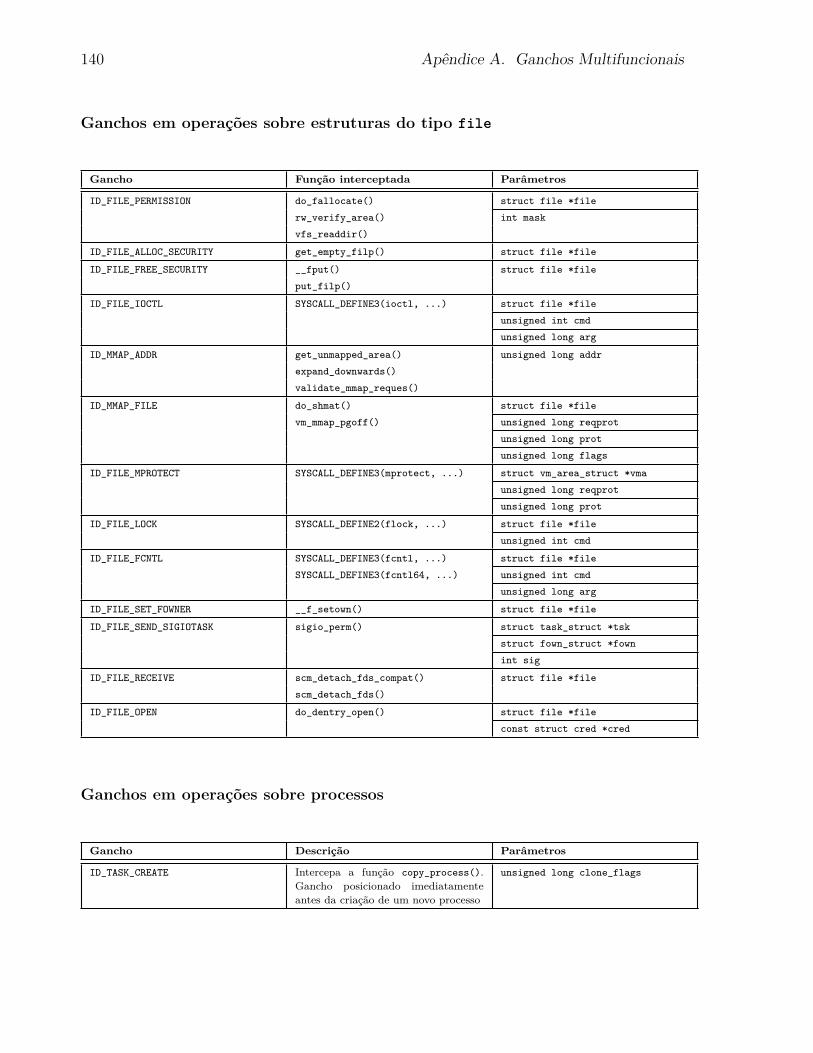
140 Apendice A. Ganchos Multifuncionais
Ganchos em operacoes sobre estruturas do tipo file
Gancho Funcao interceptada Parametros
ID_FILE_PERMISSION do_fallocate() struct file *file
rw_verify_area() int mask
vfs_readdir()
ID_FILE_ALLOC_SECURITY get_empty_filp() struct file *file
ID_FILE_FREE_SECURITY __fput() struct file *file
put_filp()
ID_FILE_IOCTL SYSCALL_DEFINE3(ioctl, ...) struct file *file
unsigned int cmd
unsigned long arg
ID_MMAP_ADDR get_unmapped_area() unsigned long addr
expand_downwards()
validate_mmap_reques()
ID_MMAP_FILE do_shmat() struct file *file
vm_mmap_pgoff() unsigned long reqprot
unsigned long prot
unsigned long flags
ID_FILE_MPROTECT SYSCALL_DEFINE3(mprotect, ...) struct vm_area_struct *vma
unsigned long reqprot
unsigned long prot
ID_FILE_LOCK SYSCALL_DEFINE2(flock, ...) struct file *file
unsigned int cmd
ID_FILE_FCNTL SYSCALL_DEFINE3(fcntl, ...) struct file *file
SYSCALL_DEFINE3(fcntl64, ...) unsigned int cmd
unsigned long arg
ID_FILE_SET_FOWNER __f_setown() struct file *file
ID_FILE_SEND_SIGIOTASK sigio_perm() struct task_struct *tsk
struct fown_struct *fown
int sig
ID_FILE_RECEIVE scm_detach_fds_compat() struct file *file
scm_detach_fds()
ID_FILE_OPEN do_dentry_open() struct file *file
const struct cred *cred
Ganchos em operacoes sobre processos
Gancho Descricao Parametros
ID_TASK_CREATE Intercepa a funcao copy_process().
Gancho posicionado imediatamente
antes da criacao de um novo processo
unsigned long clone_flags

141
Gancho Descricao Parametros
ID_TASK_FREE Nao trata-se de gancho restritivo
(return void). Este gancho e po-
sicionado imediatamente antes da
funcao free_task(), responsavel pela
liberacao de recursos relacionados a
processos
struct task_struct *task
ID_CRED_ALLOC_BLANK Gancho para credenciais LSM
(cred->security).
struct cred *cred
Tratador deve alocar memoria para o
campo cred->security de tal forma
que o gancho cred_transfer() nao re-
torne o erro -ENOMEM
gfp_t gfp
ID_CRED_FREE Gancho para credenciais LSM
(cred->security). Tratador deve
desalocar (cred->security)
struct cred *cred
ID_CRED_PREPARE Gancho para credenciais LSM
(cred->security).
struct cred *new
Tratador deve definir new como copia
de old
struct cred *old
gfp_t gfp
ID_CRED_TRANSFER Gancho para credenciais LSM
(cred->security).
struct cred *new
Tratador deve transferir credenciais de
old para new
struct cred *old
ID_KERNEL_ACT_AS Intercepta a funcao
set_security_override(). Nao
trata-se de um gancho restritivo.
Permite ao modulo LSM ajustar as
struct cred *new
credenciais de um processo com um
novo rotudo, definindo um novo con-
texto de execucao
u32 secid
ID_KERNEL_CREATE_FILES_AS Intercepta a funcao
set_create_files_as(). Nao trata-se
de um gancho restritivo. Permite ao
modulo LSM a criacao de
struct cred *new
arquivos com mesmo contexto de segu-
ranca (UID e GID), do objeto inode
struct inode *inode
ID_KERNEL_MODULE_REQUEST Gancho permissivo. Permite ao kernel
utilizar a funcao __request_module(),
responsavel por tentar carregar um
LKM utilizando o carregador de
modulos disponıvel em espaco de
usuario
char *kmod_name
ID_TASK_FIX_SETUID Nao trata-se de um gancho retristivo.
Permite ao modulo LSM atualizar atri-
butos de identidade do processo
struct cred *new
current sempre que uma chamada de
sistema da famılia set*uid for execu-
tada. As alteracoes devem informacoes
const struct cred *old
devem ser feitas em cred *new, e nao
em current->cred
int flags
ID_TASK_SETPGID Intercepta a chamada de sistema
getpgid()
struct task_struct *p
pit_t pgid
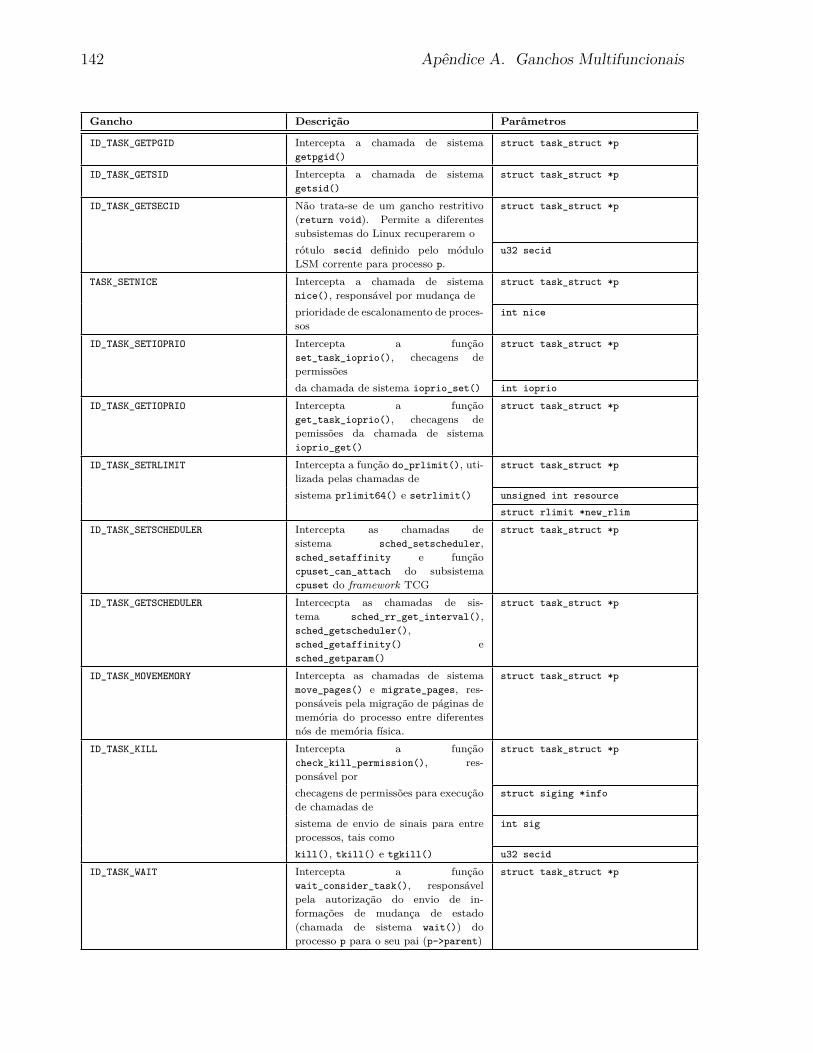
142 Apendice A. Ganchos Multifuncionais
Gancho Descricao Parametros
ID_TASK_GETPGID Intercepta a chamada de sistema
getpgid()
struct task_struct *p
ID_TASK_GETSID Intercepta a chamada de sistema
getsid()
struct task_struct *p
ID_TASK_GETSECID Nao trata-se de um gancho restritivo
(return void). Permite a diferentes
subsistemas do Linux recuperarem o
struct task_struct *p
rotulo secid definido pelo modulo
LSM corrente para processo p.
u32 secid
TASK_SETNICE Intercepta a chamada de sistema
nice(), responsavel por mudanca de
struct task_struct *p
prioridade de escalonamento de proces-
sos
int nice
ID_TASK_SETIOPRIO Intercepta a funcao
set_task_ioprio(), checagens de
permissoes
struct task_struct *p
da chamada de sistema ioprio_set() int ioprio
ID_TASK_GETIOPRIO Intercepta a funcao
get_task_ioprio(), checagens de
pemissoes da chamada de sistema
ioprio_get()
struct task_struct *p
ID_TASK_SETRLIMIT Intercepta a funcao do_prlimit(), uti-
lizada pelas chamadas de
struct task_struct *p
sistema prlimit64() e setrlimit() unsigned int resource
struct rlimit *new_rlim
ID_TASK_SETSCHEDULER Intercepta as chamadas de
sistema sched_setscheduler,
sched_setaffinity e funcao
cpuset_can_attach do subsistema
cpuset do framework TCG
struct task_struct *p
ID_TASK_GETSCHEDULER Intercecpta as chamadas de sis-
tema sched_rr_get_interval(),
sched_getscheduler(),
sched_getaffinity() e
sched_getparam()
struct task_struct *p
ID_TASK_MOVEMEMORY Intercepta as chamadas de sistema
move_pages() e migrate_pages, res-
ponsaveis pela migracao de paginas de
memoria do processo entre diferentes
nos de memoria fısica.
struct task_struct *p
ID_TASK_KILL Intercepta a funcao
check_kill_permission(), res-
ponsavel por
struct task_struct *p
checagens de permissoes para execucao
de chamadas de
struct siging *info
sistema de envio de sinais para entre
processos, tais como
int sig
kill(), tkill() e tgkill() u32 secid
ID_TASK_WAIT Intercepta a funcao
wait_consider_task(), responsavel
pela autorizacao do envio de in-
formacoes de mudanca de estado
(chamada de sistema wait()) do
processo p para o seu pai (p->parent)
struct task_struct *p
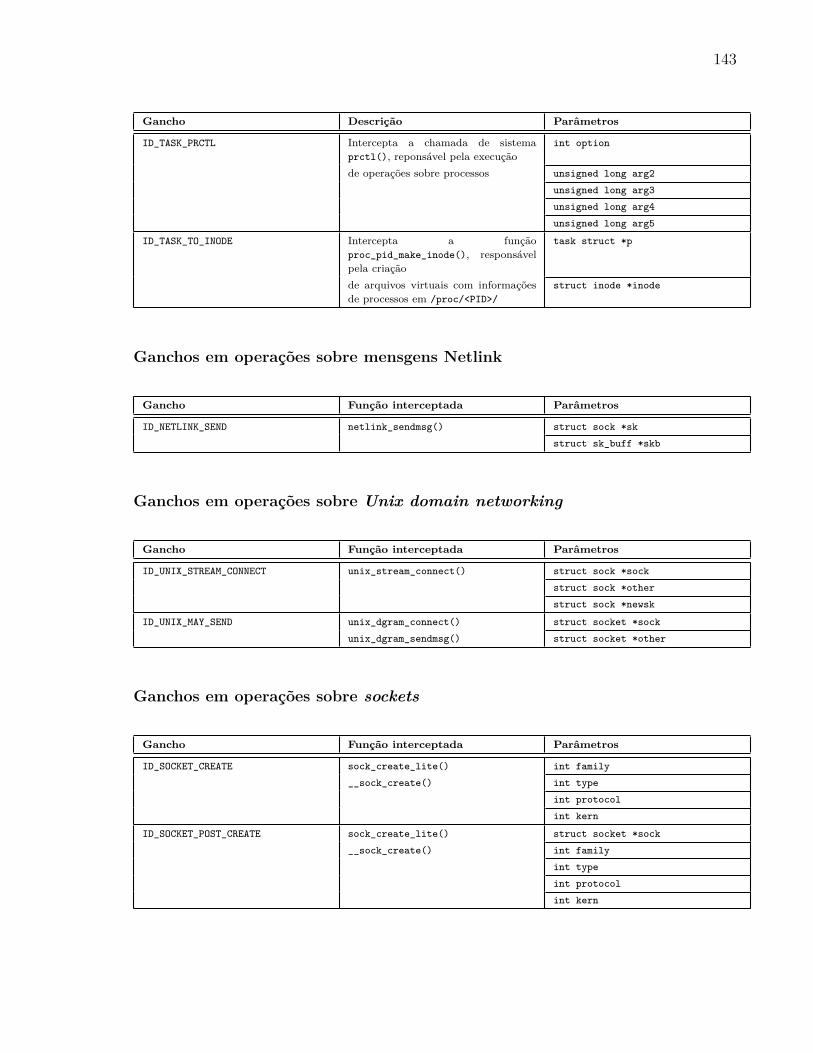
143
Gancho Descricao Parametros
ID_TASK_PRCTL Intercepta a chamada de sistema
prctl(), reponsavel pela execucao
int option
de operacoes sobre processos unsigned long arg2
unsigned long arg3
unsigned long arg4
unsigned long arg5
ID_TASK_TO_INODE Intercepta a funcao
proc_pid_make_inode(), responsavel
pela criacao
task struct *p
de arquivos virtuais com informacoes
de processos em /proc/<PID>/
struct inode *inode
Ganchos em operacoes sobre mensgens Netlink
Gancho Funcao interceptada Parametros
ID_NETLINK_SEND netlink_sendmsg() struct sock *sk
struct sk_buff *skb
Ganchos em operacoes sobre Unix domain networking
Gancho Funcao interceptada Parametros
ID_UNIX_STREAM_CONNECT unix_stream_connect() struct sock *sock
struct sock *other
struct sock *newsk
ID_UNIX_MAY_SEND unix_dgram_connect() struct socket *sock
unix_dgram_sendmsg() struct socket *other
Ganchos em operacoes sobre sockets
Gancho Funcao interceptada Parametros
ID_SOCKET_CREATE sock_create_lite() int family
__sock_create() int type
int protocol
int kern
ID_SOCKET_POST_CREATE sock_create_lite() struct socket *sock
__sock_create() int family
int type
int protocol
int kern
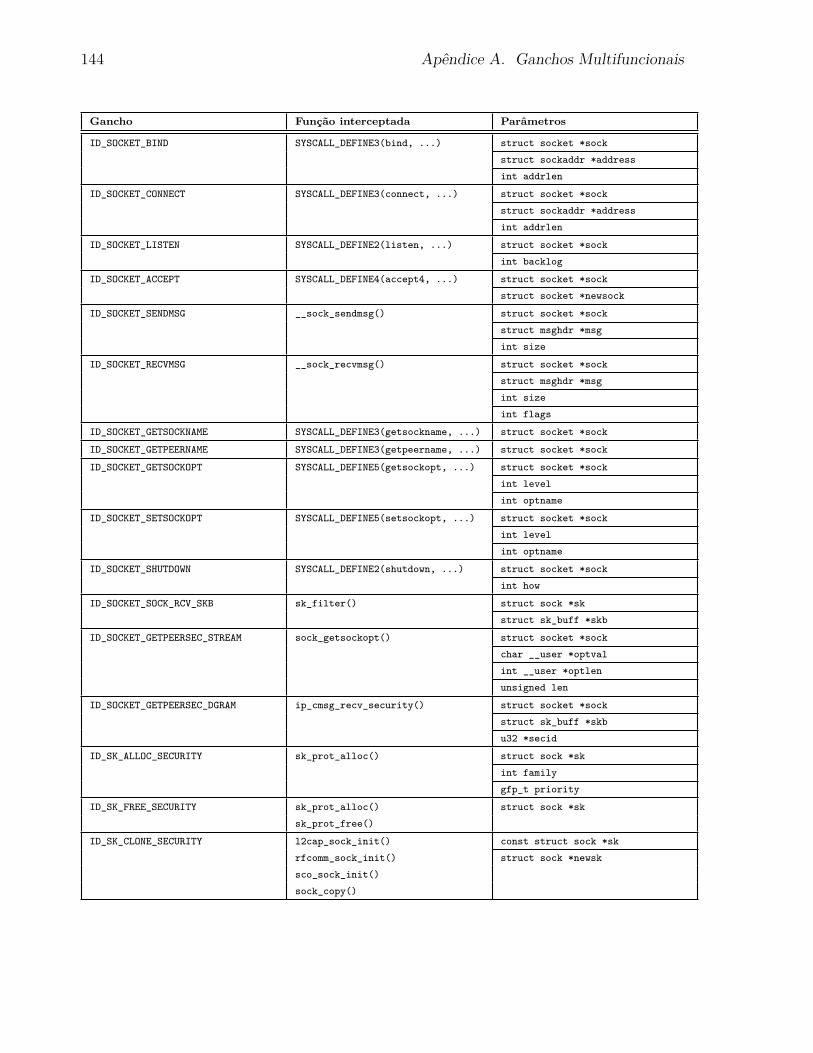
144 Apendice A. Ganchos Multifuncionais
Gancho Funcao interceptada Parametros
ID_SOCKET_BIND SYSCALL_DEFINE3(bind, ...) struct socket *sock
struct sockaddr *address
int addrlen
ID_SOCKET_CONNECT SYSCALL_DEFINE3(connect, ...) struct socket *sock
struct sockaddr *address
int addrlen
ID_SOCKET_LISTEN SYSCALL_DEFINE2(listen, ...) struct socket *sock
int backlog
ID_SOCKET_ACCEPT SYSCALL_DEFINE4(accept4, ...) struct socket *sock
struct socket *newsock
ID_SOCKET_SENDMSG __sock_sendmsg() struct socket *sock
struct msghdr *msg
int size
ID_SOCKET_RECVMSG __sock_recvmsg() struct socket *sock
struct msghdr *msg
int size
int flags
ID_SOCKET_GETSOCKNAME SYSCALL_DEFINE3(getsockname, ...) struct socket *sock
ID_SOCKET_GETPEERNAME SYSCALL_DEFINE3(getpeername, ...) struct socket *sock
ID_SOCKET_GETSOCKOPT SYSCALL_DEFINE5(getsockopt, ...) struct socket *sock
int level
int optname
ID_SOCKET_SETSOCKOPT SYSCALL_DEFINE5(setsockopt, ...) struct socket *sock
int level
int optname
ID_SOCKET_SHUTDOWN SYSCALL_DEFINE2(shutdown, ...) struct socket *sock
int how
ID_SOCKET_SOCK_RCV_SKB sk_filter() struct sock *sk
struct sk_buff *skb
ID_SOCKET_GETPEERSEC_STREAM sock_getsockopt() struct socket *sock
char __user *optval
int __user *optlen
unsigned len
ID_SOCKET_GETPEERSEC_DGRAM ip_cmsg_recv_security() struct socket *sock
struct sk_buff *skb
u32 *secid
ID_SK_ALLOC_SECURITY sk_prot_alloc() struct sock *sk
int family
gfp_t priority
ID_SK_FREE_SECURITY sk_prot_alloc() struct sock *sk
sk_prot_free()
ID_SK_CLONE_SECURITY l2cap_sock_init() const struct sock *sk
rfcomm_sock_init() struct sock *newsk
sco_sock_init()
sock_copy()
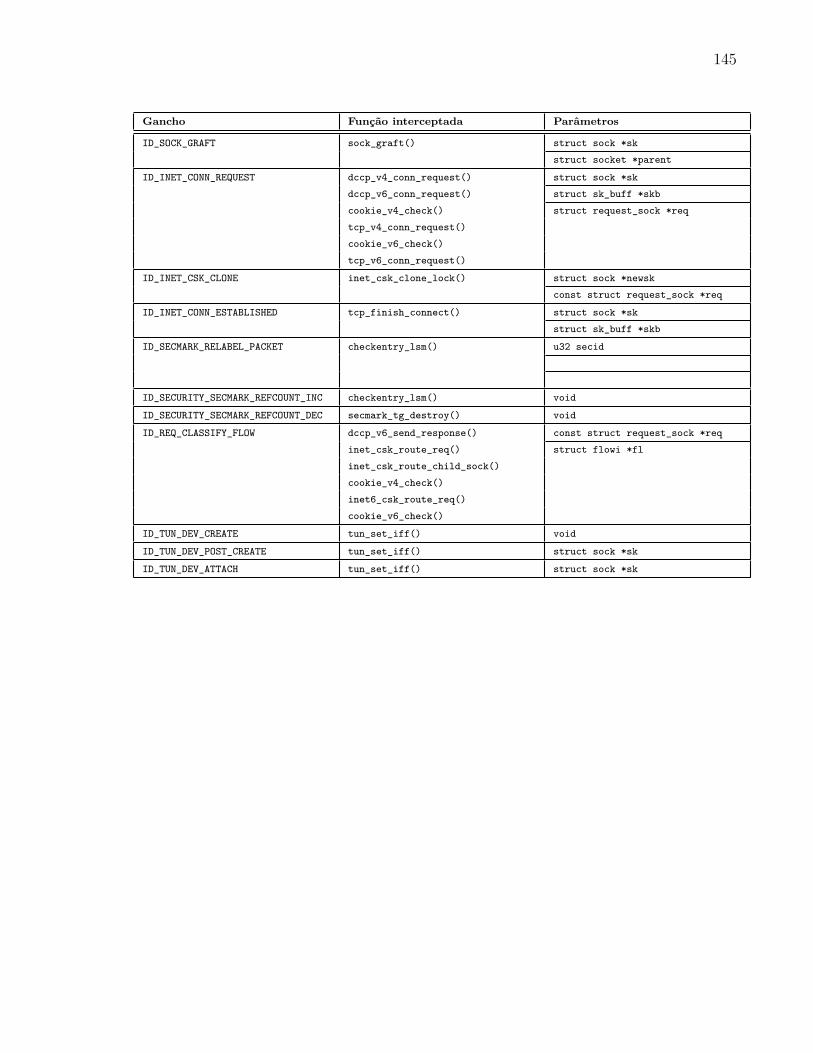
145
Gancho Funcao interceptada Parametros
ID_SOCK_GRAFT sock_graft() struct sock *sk
struct socket *parent
ID_INET_CONN_REQUEST dccp_v4_conn_request() struct sock *sk
dccp_v6_conn_request() struct sk_buff *skb
cookie_v4_check() struct request_sock *req
tcp_v4_conn_request()
cookie_v6_check()
tcp_v6_conn_request()
ID_INET_CSK_CLONE inet_csk_clone_lock() struct sock *newsk
const struct request_sock *req
ID_INET_CONN_ESTABLISHED tcp_finish_connect() struct sock *sk
struct sk_buff *skb
ID_SECMARK_RELABEL_PACKET checkentry_lsm() u32 secid
ID_SECURITY_SECMARK_REFCOUNT_INC checkentry_lsm() void
ID_SECURITY_SECMARK_REFCOUNT_DEC secmark_tg_destroy() void
ID_REQ_CLASSIFY_FLOW dccp_v6_send_response() const struct request_sock *req
inet_csk_route_req() struct flowi *fl
inet_csk_route_child_sock()
cookie_v4_check()
inet6_csk_route_req()
cookie_v6_check()
ID_TUN_DEV_CREATE tun_set_iff() void
ID_TUN_DEV_POST_CREATE tun_set_iff() struct sock *sk
ID_TUN_DEV_ATTACH tun_set_iff() struct sock *sk
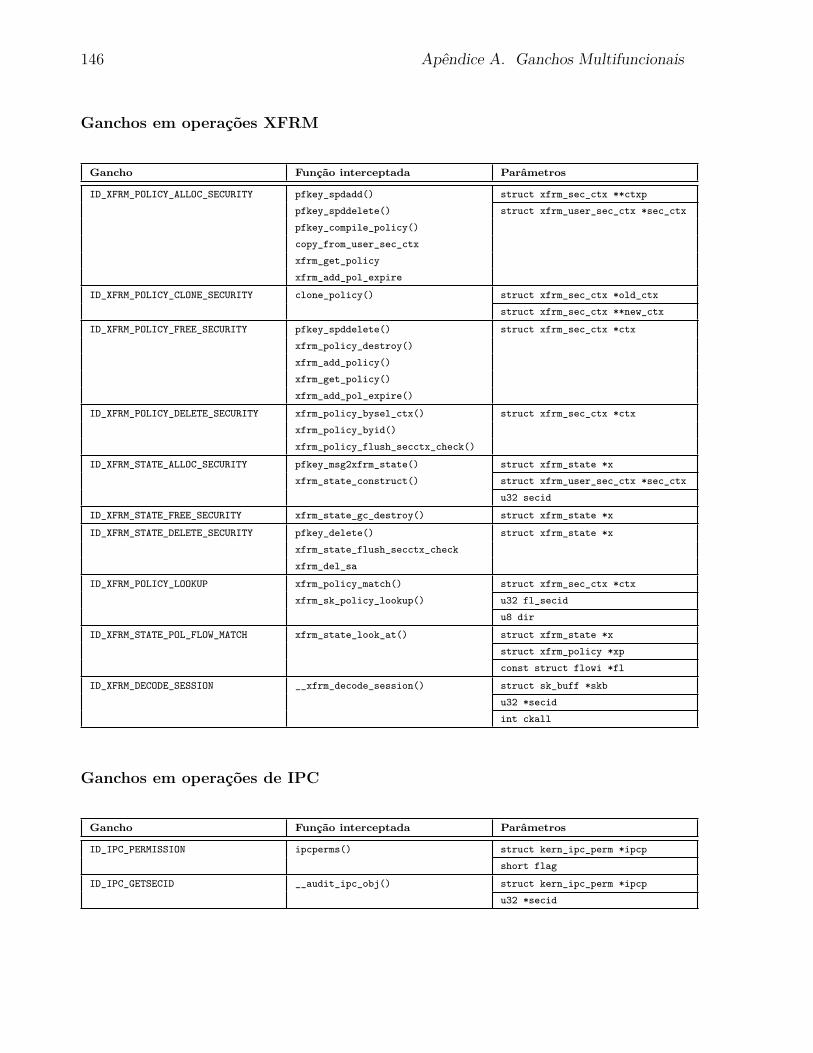
146 Apendice A. Ganchos Multifuncionais
Ganchos em operacoes XFRM
Gancho Funcao interceptada Parametros
ID_XFRM_POLICY_ALLOC_SECURITY pfkey_spdadd() struct xfrm_sec_ctx **ctxp
pfkey_spddelete() struct xfrm_user_sec_ctx *sec_ctx
pfkey_compile_policy()
copy_from_user_sec_ctx
xfrm_get_policy
xfrm_add_pol_expire
ID_XFRM_POLICY_CLONE_SECURITY clone_policy() struct xfrm_sec_ctx *old_ctx
struct xfrm_sec_ctx **new_ctx
ID_XFRM_POLICY_FREE_SECURITY pfkey_spddelete() struct xfrm_sec_ctx *ctx
xfrm_policy_destroy()
xfrm_add_policy()
xfrm_get_policy()
xfrm_add_pol_expire()
ID_XFRM_POLICY_DELETE_SECURITY xfrm_policy_bysel_ctx() struct xfrm_sec_ctx *ctx
xfrm_policy_byid()
xfrm_policy_flush_secctx_check()
ID_XFRM_STATE_ALLOC_SECURITY pfkey_msg2xfrm_state() struct xfrm_state *x
xfrm_state_construct() struct xfrm_user_sec_ctx *sec_ctx
u32 secid
ID_XFRM_STATE_FREE_SECURITY xfrm_state_gc_destroy() struct xfrm_state *x
ID_XFRM_STATE_DELETE_SECURITY pfkey_delete() struct xfrm_state *x
xfrm_state_flush_secctx_check
xfrm_del_sa
ID_XFRM_POLICY_LOOKUP xfrm_policy_match() struct xfrm_sec_ctx *ctx
xfrm_sk_policy_lookup() u32 fl_secid
u8 dir
ID_XFRM_STATE_POL_FLOW_MATCH xfrm_state_look_at() struct xfrm_state *x
struct xfrm_policy *xp
const struct flowi *fl
ID_XFRM_DECODE_SESSION __xfrm_decode_session() struct sk_buff *skb
u32 *secid
int ckall
Ganchos em operacoes de IPC
Gancho Funcao interceptada Parametros
ID_IPC_PERMISSION ipcperms() struct kern_ipc_perm *ipcp
short flag
ID_IPC_GETSECID __audit_ipc_obj() struct kern_ipc_perm *ipcp
u32 *secid

147
Ganchos em operacoes do sistema de gerenciamento de chaves do Linux
Gancho Funcao interceptada Parametros
ID_KEY_ALLOC key_alloc() struct key *key
const struct cred *cred
unsigned long flags
ID_KEY_FREE key_gc_unused_keys() struct key *key
ID_KEY_PERMISSION key_task_permission() key_ref_t key_ref
const struct cred *cred
key_perm_t perm
ID_KEY_GETSECURITY keyctl_get_security() struct key *key
char **_buffer
Ganchos em operacoes de filas de mensagems de IPC
Gancho Funcao interceptada Parametros
ID_MSG_MSG_ALLOC_SECURITY load_msg() struct msg_msg *msg
ID_MSG_MSG_FREE_SECURITY free_msg() struct msg_msg *msg
ID_MSG_QUEUE_ALLOC_SECURITY newque() struct msg_queue *msq
ID_MSG_QUEUE_FREE_SECURITY newque() struct msg_queue *msq
freeque()
ID_MSG_QUEUE_ASSOCIATE msg_security() struct msg_queue *msq
int msqflg
ID_MSG_QUEUE_MSGCTL SYSCALL_DEFINE3(msgctl, ...) struct msg_queue *msq
int cmd
ID_MSG_QUEUE_MSGSND do_msgsnd() struct msg_queue *msq
struct msg_msg *msg
int msqflg
ID_MSG_QUEUE_MSGRCV pipelined_send() struct msg_queue *msq
do_msgrcv() struct msg_msg *msg
struct task_struct *target
long type
int mode
Ganchos em operacoes de memoria compartilhada
Gancho Funcao interceptada Parametros
ID_SHM_ALLOC_SECURITY newseg() struct shmid_kernel *shp
ID_SHM_FREE_SECURITY shm_destroy() struct shmid_kernel *shp
newseg()

148 Apendice A. Ganchos Multifuncionais
Gancho Funcao interceptada Parametros
ID_SHM_ASSOCIATE shm_security() struct shmid_kernel *shp
int shmflg
ID_SHM_SHMCTL SYSCALL_DEFINE3(shmctl, ...) struct shmid_kernel *shp
int cmd
ID_SHM_SHMAT do_shmat() struct shmid_kernel *shp
char __user *shmaddr
int shmflg
Ganchos em operacoes de Semaforos
Gancho Funcao interceptada Parametros
ID_SEM_ALLOC_SECURITY newary() struct sem_array *sma
ID_SEM_FREE_SECURITY newary() struct sem_array *sma
freeary()
ID_SEM_ASSOCIATE sem_security() struct sem_array *sma
int semflg
ID_SEM_SEMCTL semctl_nolock() struct sem_array *sma
semctl_main() int cmd
semctl_down()
ID_SEM_SEMOP SYSCALL_DEFINE4(semtimedop, ...) struct sem_array *sma
struct sembuf *sops
unsigned nsops
int alter
ID_PTRACE_ACCESS_CHECK __ptrace_may_access() struct task_struct *child
unsigned int mode
ID_PTRACE_TRACEME ptrace_traceme() struct task_struct *parent
ID_CAPGET struct task_struct *target
kernel_cap_t *effective
kernel_cap_t *inheritable
kernel_cap_t *permitted
ID_CAPSET cap_get_target_pid() struct cred *new
const struct cred *old
const kernel_cap_t *effective
const kernel_cap_t *inheritable
const kernel_cap_t *permitted
ID_CAPABLE pci_read_config() const struct cred *cred
has_ns_capability() struct user_namespace *ns
ns_capable() int cap
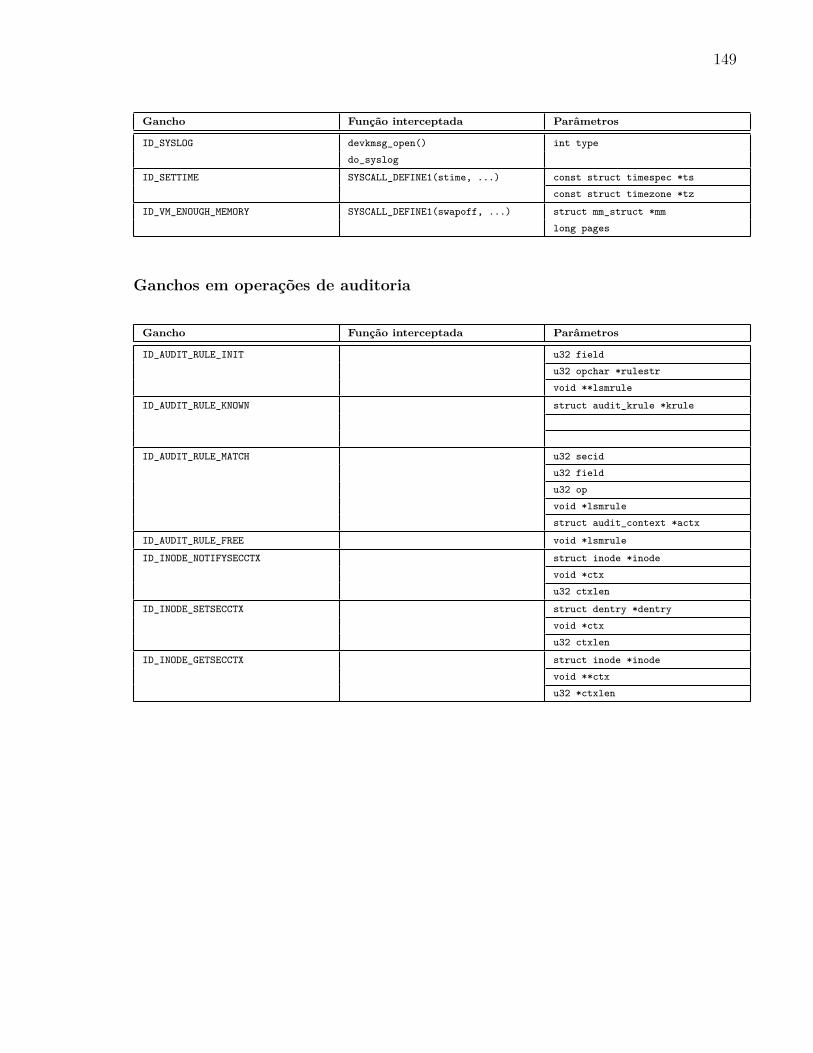
149
Gancho Funcao interceptada Parametros
ID_SYSLOG devkmsg_open() int type
do_syslog
ID_SETTIME SYSCALL_DEFINE1(stime, ...) const struct timespec *ts
const struct timezone *tz
ID_VM_ENOUGH_MEMORY SYSCALL_DEFINE1(swapoff, ...) struct mm_struct *mm
long pages
Ganchos em operacoes de auditoria
Gancho Funcao interceptada Parametros
ID_AUDIT_RULE_INIT u32 field
u32 opchar *rulestr
void **lsmrule
ID_AUDIT_RULE_KNOWN struct audit_krule *krule
ID_AUDIT_RULE_MATCH u32 secid
u32 field
u32 op
void *lsmrule
struct audit_context *actx
ID_AUDIT_RULE_FREE void *lsmrule
ID_INODE_NOTIFYSECCTX struct inode *inode
void *ctx
u32 ctxlen
ID_INODE_SETSECCTX struct dentry *dentry
void *ctx
u32 ctxlen
ID_INODE_GETSECCTX struct inode *inode
void **ctx
u32 *ctxlen