análise estatística e topológica do webgraph - inf.ufrgs.brburiol/papers/webgraph.pdf ·...
TRANSCRIPT

Análise Estatística e Topológica do Webgraph
Luciana Salete Buriol
Grupo de algoritmos: estudos no WebgraphCoordenação: Prof. Dr. Stefano Leonardi
Universidade de Roma “La Sapienza”

Webgraph
O Webgraph é o grafo direcionado gerado pela estrutura de links das páginas web. cada página web é um vértice
cada hyperlink entre páginas é um arco direcionado.
É um grafo esparso e desconexo

Sumário
Motivação Extração, armazenamento e compactação do grafo Características topológicas e propriedades do grafo Algoritmos de classificação Bases de dados alternativas Algoritmos de acesso à memória secundária Algoritmos de Data Stream Conclusões

Motivações
Grande dimensão: atualmente possui mais de 24 bilhões de vértices e 360 bilhões de arcos
1998: 24 milhões de páginas 1999: 200 milhões 2003: 3.5 bilhões de páginas 2005: 11.5 bilhões de páginas 2006: 24 bilhões de páginas

Motivações
É o grafo utilizado por ferramentas de busca para classificação das páginas web
Não possui controle de expansão
Não se assemelha a outras redes
Diversidade de tópicos, estilos e línguas

Coleta das páginas
A coleta das páginas é realizada por uma máquina de busca (web crawler)
Faz a busca a partir de um conjunto de páginas iniciais
Após extrair a página, identifica seus links
Página Web

Coleta das páginas
É preciso possuir links entrantes para ser coletada
Uma máquina de busca de grande dimensão deve: Identificar eficientemente páginas já extraídas
Processar em paralelo
Usar banda de rede limitada
Usar a política da “boa educação”

Coleta das páginas
Problemas práticos: Tempo x espaço. Ex: 42 milhões de páginas html do
domínio italiano, tendo em média 10 KB por página.
Espaço
400 GB: 1.33 discos de 300GB
24 bilhões de páginas: mais de 200 discos.
Tempo
Banda disponível: 2 Mbps
3 pontos de coleta
5.5 milhões de páginas por dia
8 dias executando

Coleta das páginas
As máquinas de busca mais conhecidas na literatura: WIRE: Universidade do Chile
UbiCrawler: Universidade Estadual de Milão;
Nutch (www.nutch.org): USA, implementado em Java, fácil instalação e utilização, opções para usuário
As máquinas de busca comerciais, como Google, Alta Vista, não são de domínio público

Recuperação de Informação na Web
Trata da representação, armazenamento, organização e acesso à informação referente às páginas web
R. BaezaYates e B. RibeiroNeto, Modern Information Retrieval, 1999, www2.dce.ufmg.br/livros/irbook

Indexação
Indexação Invertida: para cada palavra criase uma referência a todos os arquivos que a contém
As palavras e páginas recebem IDs
São cerca de 100 milhões de palavras indexadas
MG4J (http://mg4j.dsi.unimi.it) e SMART ( ftp://ftp.cs.cornell.edu/pub/smart) indexadores de domínio público

Armazenamento do webgraph
Armazenamento do webgrafo e/ou conteúdo das páginas?
Uma página html sem figuras, tem tamanho médio de 10 a 14 Kb
Representação do grafo: lista de adjacência
Dividido em vários arquivos e unidades de disco

Link Analysis
Identificação da estrutura topológica do grafo
Cálculo de diversas propriedades do grafo
classificação das páginas web
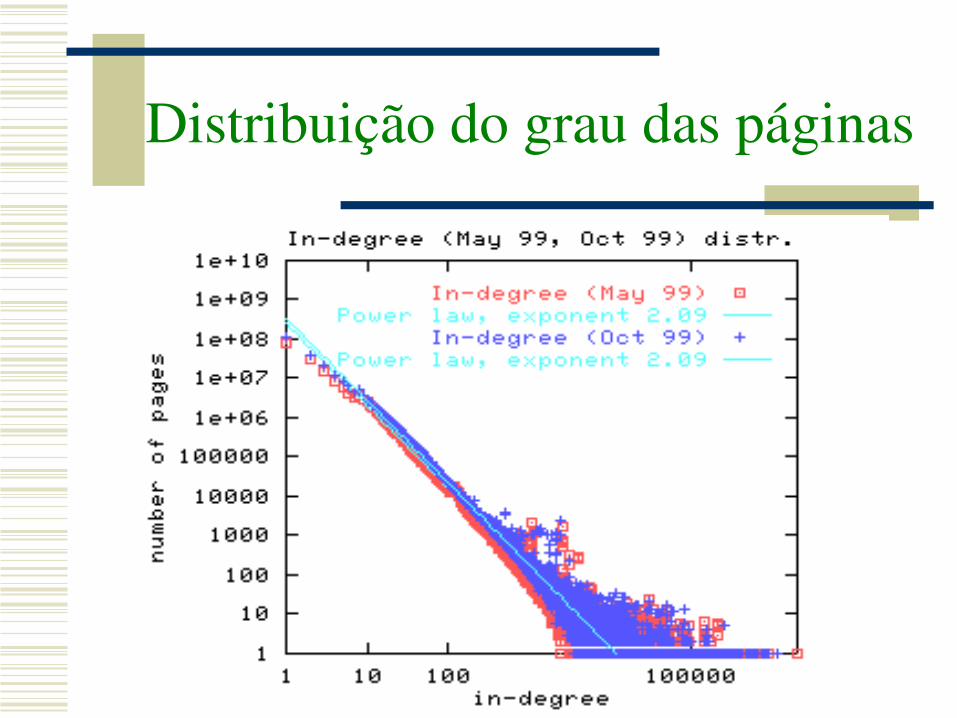
Distribuição do grau das páginas
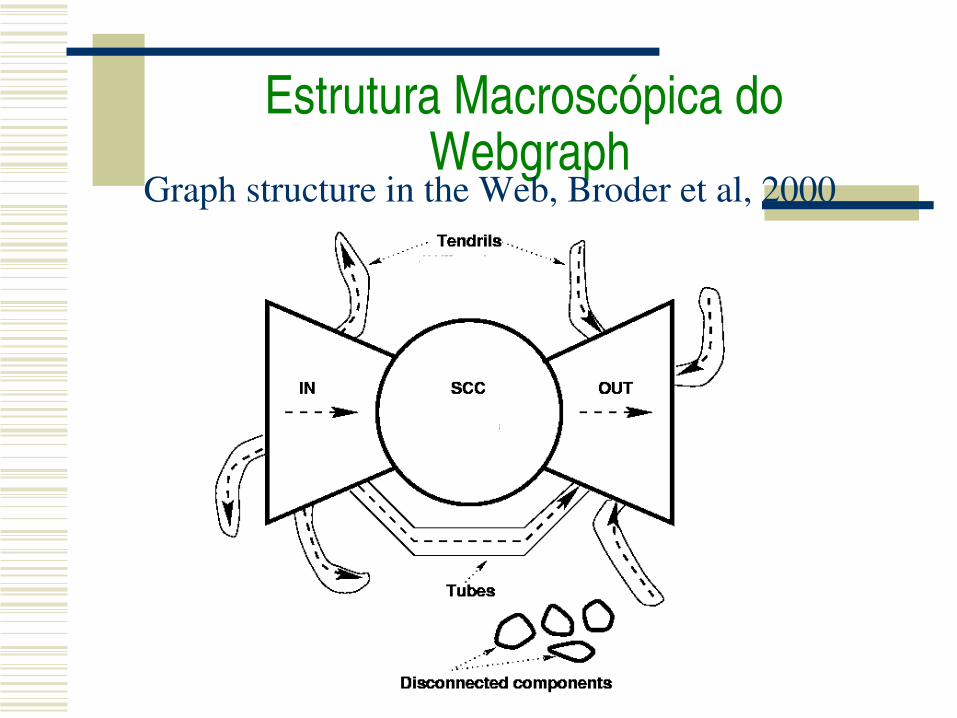
Estrutura Macroscópica do Webgraph
Graph structure in the Web, Broder et al, 2000
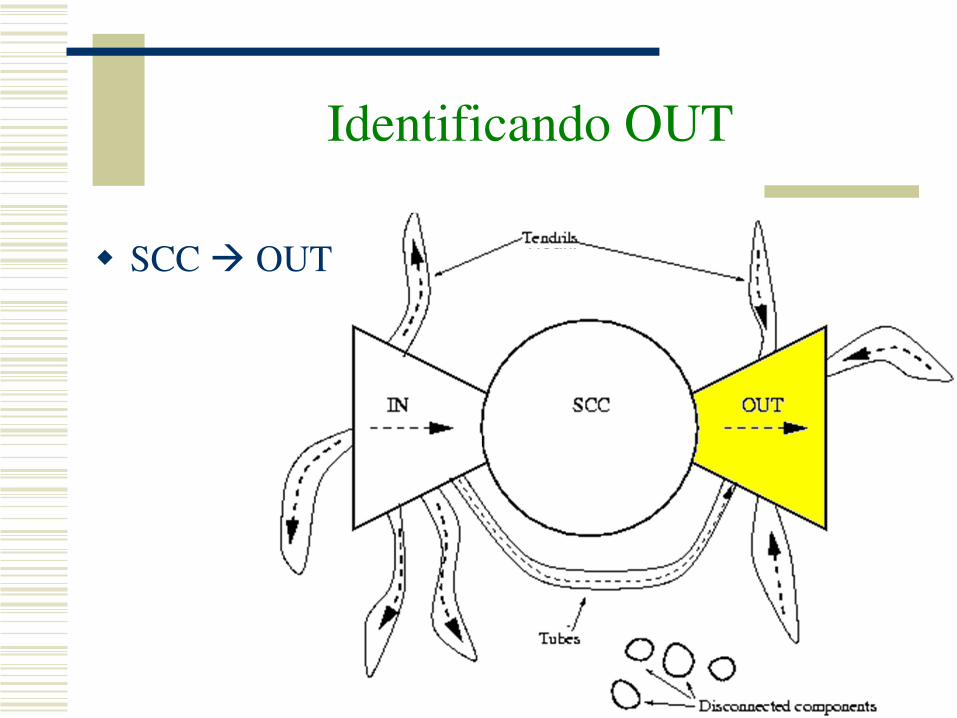
Identificando OUT
SCC OUT
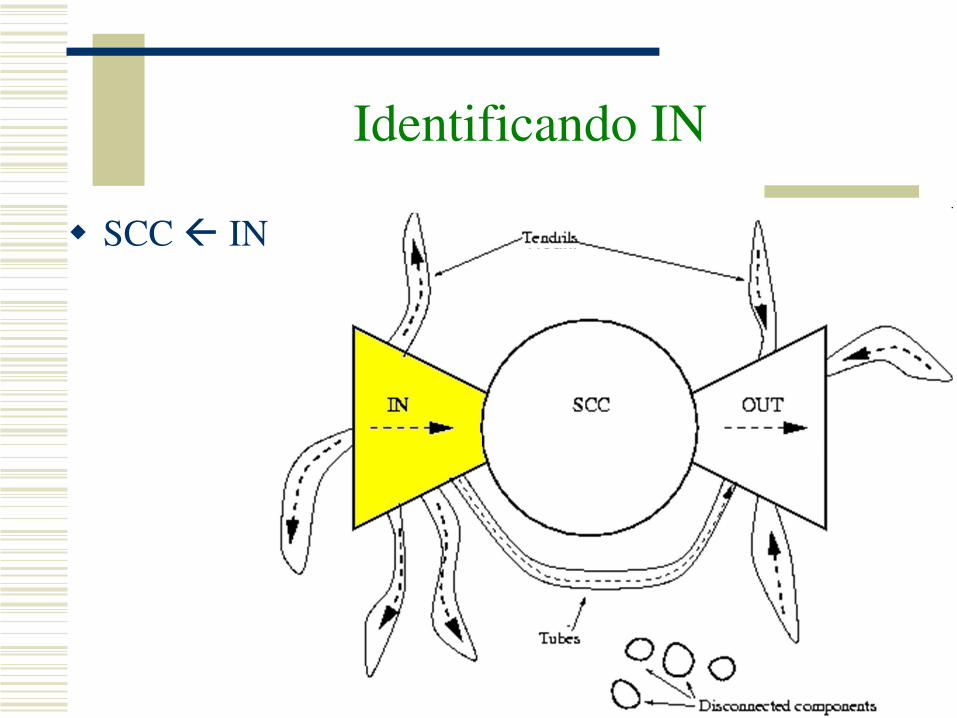
Identificando IN
SCC IN

Identificando tentáculos e tubos
IN tentáculos_INOUT tentáculos_OUT
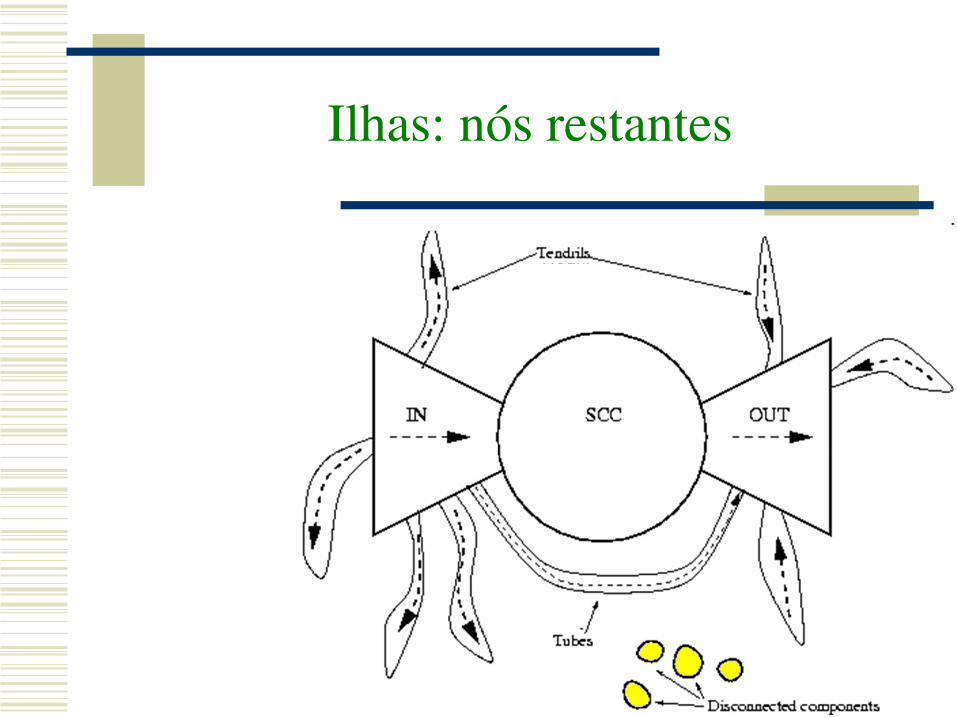
Ilhas: nós restantes

Webgraph do domínio .br
Um novo retrato da web brasileira, M. Modesto, A. Pereira, N. Ziviani, C. Castillos, R. BaezaYates, 2005 (Brasil + Chile)
domínio .br
7.7 milhões de páginas e 126 milhões de links (média de 16 links por página)

Webgraph do domínio .br
Média de 14,4 Kb por página. Anteriormente era de 9 Kb (Um retrato da web brasileira, Veloso et al, 2000)
6.4% das páginas são duplicadas
41.7% das páginas são dinâmicas

Webgraph do domínio .br
Idioma: português 88,6% inglês 11,2% e espanhol 1,16%
Domínio: 91.1% com.br 2.7% org.br 0,3% edu.br
Extensão: html: 97.92% pdf: 0.88 % doc: 0.48%

Propriedades Avançadas
Cálculo do número de triângulos do grafo
Cálculo do número de cliques bipartidos de pequena dimensão
Cálculo do coeficiente de clustering
??
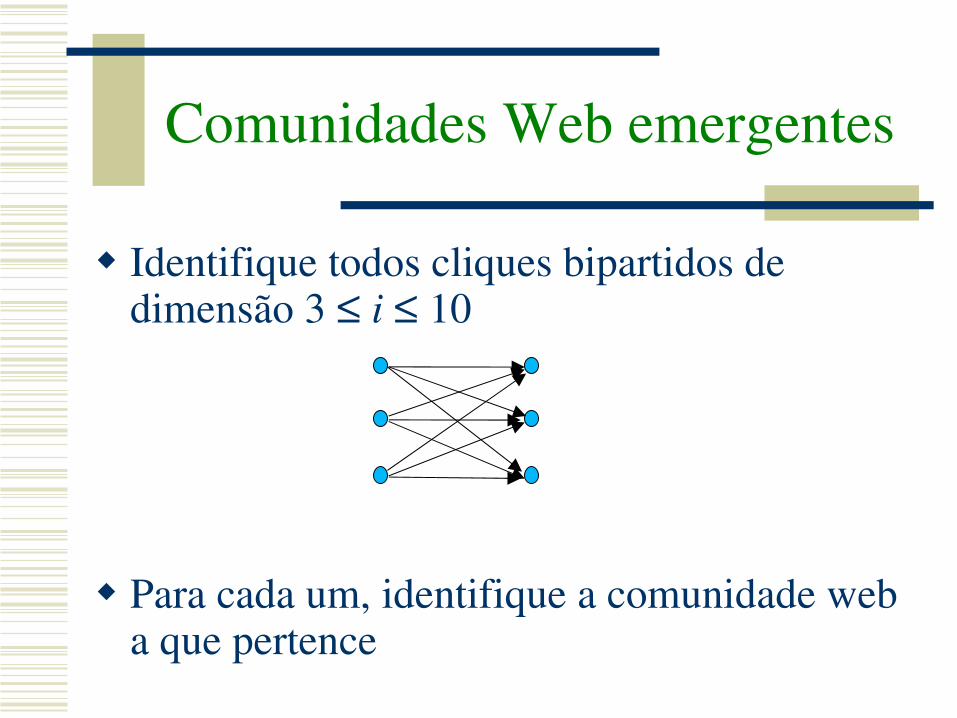
Comunidades Web emergentes
Identifique todos cliques bipartidos de dimensão 3 ≤ i ≤ 10
Para cada um, identifique a comunidade web a que pertence

Pagerank
As páginas web são apresentadas em ordem decrescente de seu pagerank
PageRank (PR) é um valor numérico que representa o quão importante uma página é
1/31/31/3
Simula o procedimento de um Internauta. Seleciona uma página aleatória: Repita até convergir:
Com probabilidade α visita uma página vizinha Com probabilidade 1α visita outra página aleatória.
Em geral α = 0.15

PageRank: propagação do ranking

Cálculo do Pagerank
PR(p): PageRank da página p p1 … pn: n páginas que apontam para página p D(p): grau de saída da página p N: número total de páginas web do grafo
PR p=PR p α. {PR p1
D p1 .. .
PR pn
D pn }1−α∣N ∣
PR p=0, 590,85 .{ 0, 32D p1
0, 17
D pn }0,15∣N∣

Algoritmos de Classificação
Outros alg. de classificação: HITs, Salsa, ExpertRank
Avaliação: Classificação adequada Cálculo rápido Estabilidade Menos susceptível a link spamming

Pagerank Temporal
Pagerank considera somente o webgraph no cálculo da classificação das páginas
Outros fatores podem ser considerados: idade da página, número de atualizações e freqüência das atualizações
Como considerar tais fatores? Tema de interesse atual Em 2004 apareceram as primeiras propostas de
algoritmos na literatura

Bases de Dados Alternativas
Wikipedia www.wikipedia.org: maior enciclopédia online do mundo Cada artigo é um nó e cada hyperlink entre artigos é um
arco do grafo Poucos links externos Um grafo pode ser gerado para cada língua Língua Inglesa: 1.250.000 nós (15 arcos por nó) Possui informação temporal

Página Principal: www.wikipedia.org

Algoritmos de memória secundária
O grafo não pode ser carregado em memória principal, mas armazenado em memória secundária
Tratandose de grafos de grande dimensão, quase na totalidade os algoritmos não são executados em memória principal
Algoritmos de memória principal, semiexternos e de memória secundária
Buscam minimizar acesso a disco e o uso de seek()

Algoritmos de Data Stream
algoritmos de aproximação baseados em probabilidade
usam memória limitada; Originalmente: dados são lidos uma única vez
em forma de stream Usam sketch ou amostragem

Algoritmos de data stream
O webgrafo é lido como um stream de arcos
podem considerar estrutura de armazenamento
podem ler dados mais de uma vez
Usados para aproximar cálculo de propriedades avançadas do webgraph. Já propostos: triângulos, cliques bipartidos e coeficiente de clustering.

Contando o Número de Triângulos de um Grafo
• Dado um grafo G=(V,E), onde V e o conjunto de nós e E o conjunto de arcos, considere todas as triplas de três nós ∈ V;

Contando o Número de Triângulos de um Grafo
Melhores resultados anteriores por Yossef, Kumar e Sivakumar: Reductions in Streaming Algorithms, with an Application to Counting Triangles in Graphs, 2002
O 1ε3
. log 1δ .1T 1T 2
T 3 3
. logn O 1
ε2 . log 1δ .1T 1T 2
T 3 • L. Buriol, G. Frahling, S. Leonardi, C. Soher, A. Marchetti, “Counting Triangles in Data
Streams”, PODS 2006

Compressão
Níveis de compressão: Conteúdo da página URL da página Webgraph
Usa técnicas especializadas que permitem grande compressão e rápido acesso aos dados.

Observações levadas em consideração para compressão
Consecutividade: muitos links num mesmo web site são similares lexicograficamente.
Ex: http://my.sample.com/whitepaper/nodeA.htmlhttp://my.sample.com/whitepaper/nodeB.html
Localidade: cerca de 80% dos links são locais, ou seja, apontam para páginas no mesmo domínio
Similaridade: Páginas do mesmo domínio tendem a ter muitos links que apontam para as mesmas páginas
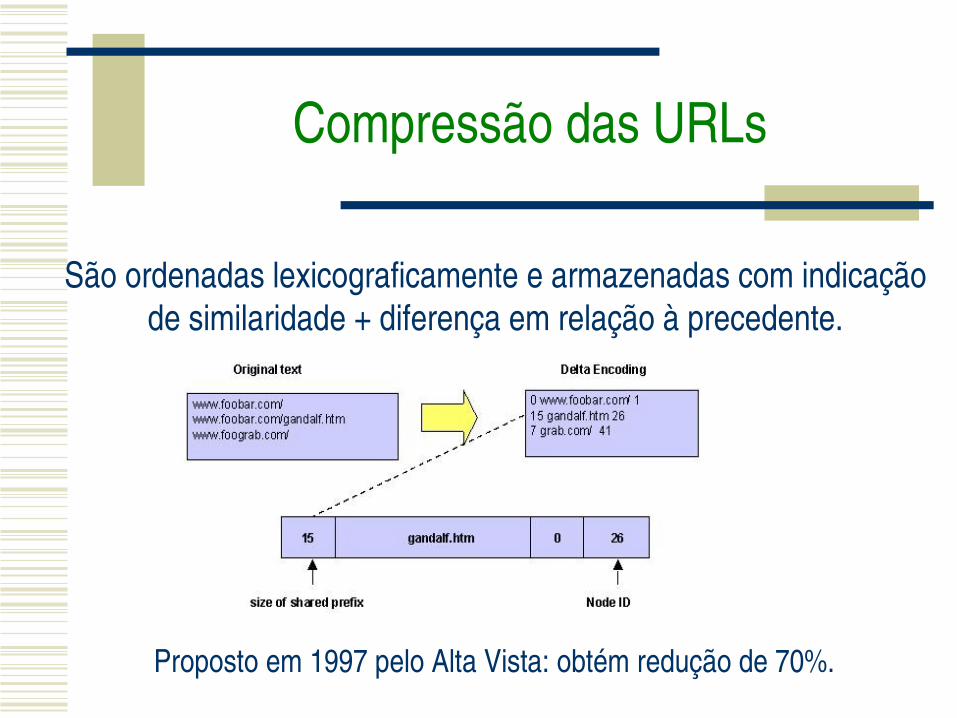
Compressão das URLs
São ordenadas lexicograficamente e armazenadas com indicação de similaridade + diferença em relação à precedente.
Proposto em 1997 pelo Alta Vista: obtém redução de 70%.

Lista de Adjacência em Código Delta
Lista AdjVértices
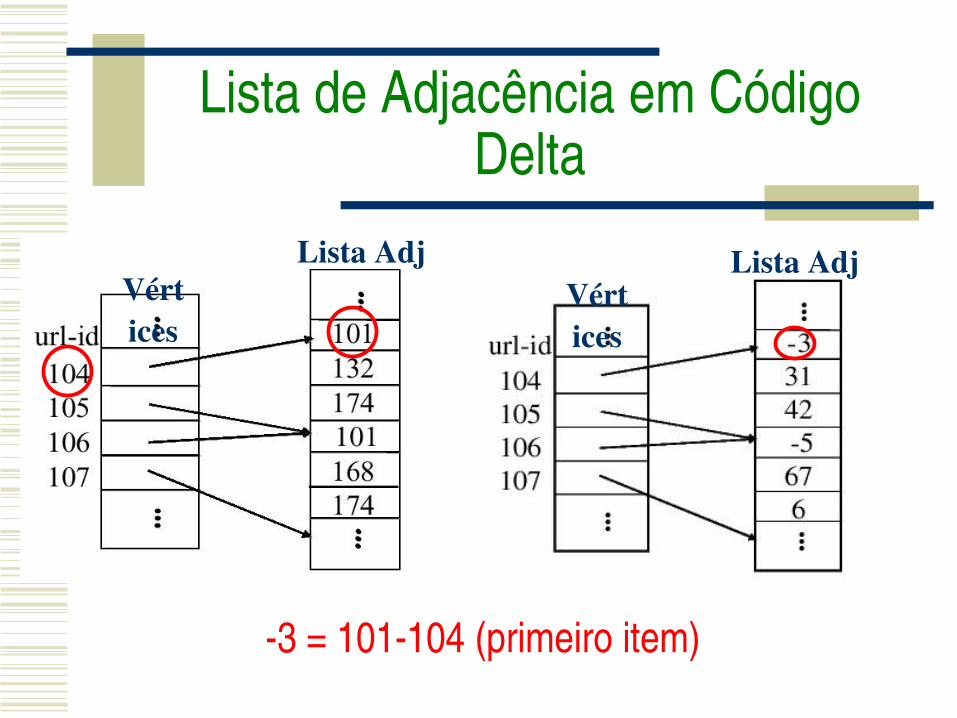
Lista de Adjacência em Código Delta
3 = 101104 (primeiro item)
Lista AdjVértices
Lista AdjVértices
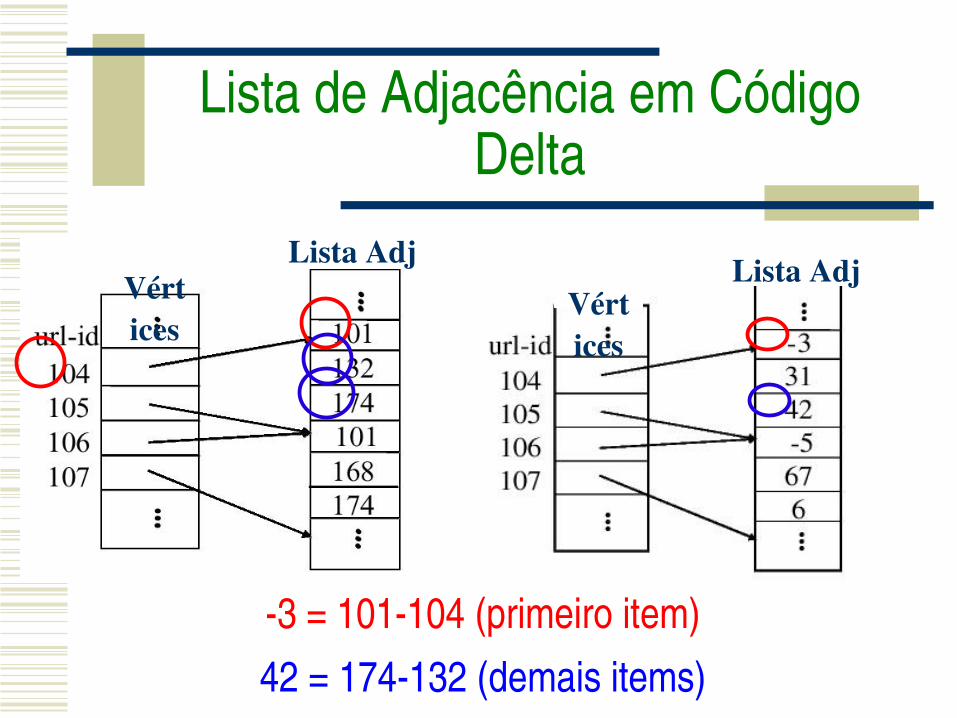
Lista de Adjacência em Código Delta
3 = 101104 (primeiro item)42 = 174132 (demais items)
Lista AdjVértices
Lista AdjVértices

Compressão do Webgraph
Melhor compressão = (3.08 + 2.89) bits por arco: Universidade Estadual de Milão (http://webgraph.dsi.unimi.it)
Compressão vs. tempo de acesso
Acesso seqüencial e aleatório

Tópicos de Interesse
evolução temporal do grafo: geração de grafos, propriedades e classificação.
determinar como tais propriedades podem aprimorar as ferramentas de busca
propor algoritmos de data stream para o cálculo de propriedades avançadas
alg de memória secundária

Projeto de Pesquisa
Luciana Buriol, Leila Ribeiro, Fernando Dotti, Viviane Orengo e Marcus Ritt
Futura cooperação com o grupo de mineração e banco de dados?
Tópicos Especiais em Recuperação de Informações: Viviane, Leandro, Luciana

Conclusões
Necessidade de integração de diversas áreas
Necessita de conhecimento geral, mas um pesquisador em geral se especializa em subáreas
Probabilidade tem grande importância
Os estudos são recentes, de interesse atual, e ainda carece de muita pesquisa
Muitos problemas de dimensões diversas

Contato
Luciana Salete [email protected]
www.inf.ufrgs.br/~buriol
Os slides da palestra estão disponíveis na minha página