análise de modelos de aprendizagem
DESCRIPTION
O presente documento do SMART Mail está enquadrado na “Linha de investigação de Modelos de Aprendizagem”. Pretende efetuar um levantamento do estado da arte das principais técnicas e abordagens no domínio da aprendizagem automática, assim como, de plataformas ou frameworks já existentes que possam servir de guia e de exemplo com as melhores aproximações e abordagens.TRANSCRIPT

SmartMail| Entidade Promotora: Parceiros:
1/2 Projeto em curso com o apoio de:
15/04/2014
Análise de Modelos de Aprendizagem

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Índice
Introdução ......................................................................................................................................... 4
Linhas de Investigação ...................................................................................................................... 5
Abordagem TF-IDF (term frequency/inverse document frequency) ............................................ 5
Abordagem Naive Bayes ............................................................................................................. 14
Abordagem SVM (Support Vector Machines) ............................................................................. 27
Abordagem em Algoritmos Genéticos ........................................................................................ 33
Abordagem com Distâncias em Espaços Vetoriais ..................................................................... 41

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Índice de Figuras
Figura 1: Abertura e logotipo do Wolfram CDF ................................................................................ 6
Figura 2: Menu principal do Wolfram CDF ........................................................................................ 6
Figura 3: Texto em bruto a ser analisado .......................................................................................... 8
Figura 4: Evidencia dos termos mais frequentes no corpus do texto ............................................... 9
Figura 5: Ocultação dos termos mais frequentes no corpus .......................................................... 10
Figura 6: Termos mais frequentes no texto em análise .................................................................. 11
Figura 7: Inverso da frequência de termos no texto em análise .................................................... 12
Figura 8: TF-IDF com stop words aplicado ao texto em análise...................................................... 13
Figura 9: Menu principal do WEKA ................................................................................................. 15
Figura 10: Explorer do WEKA .......................................................................................................... 16
Figura 11:Selecção de dados ........................................................................................................... 17
Figura 12: Exemplo de dados no formato .arff ............................................................................... 18
Figura 13: Visualização e exploração dos dados ............................................................................. 19
Figura 14: Seleção de filtros ............................................................................................................ 20
Figura 15: Separador de Cassificação .............................................................................................. 21
Figura 16: Seleção de algoritmo de classificação ............................................................................ 22
Figura 17: Algoritmo e condições de teste...................................................................................... 22
Figura 18:Inicio de processamento ................................................................................................. 23
Figura 19: Resultados finais ............................................................................................................. 24
Figura 20: Resultados em detalhe ................................................................................................... 25
Figura 21: Carregamento dos dados ............................................................................................... 28
Figura 22: Seleção do algoritmo de SVM ........................................................................................ 29
Figura 23: Parâmetros do algoritmo ............................................................................................... 30
Figura 24: Parâmetros de teste ....................................................................................................... 30
Figura 25: Finalização do algoritmo ................................................................................................ 31
Figura 26: Detalhe dos resultados finais ......................................................................................... 32
Figura 27: Visão geral inicial ............................................................................................................ 35
Figura 28: Visão geral (fase intermédia) no decorrer de um teste ................................................. 36
Figura 29: Visão geral, fase final de um teste ................................................................................. 37
Figura 30: Gráfico de evolução ao longo das gerações ................................................................... 38
Figura 31: Mapa geral de onde se encontram os diferentes exemplares em teste ....................... 38
Figura 32: Status dos concorrentes do teste atual ......................................................................... 39
Figura 33: Parâmetros de configuração .......................................................................................... 40

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 34: Exemplo de aplicação do k-Nearest Neighbor ............................................................... 42
Figura 35: Exemplo de teste com o k = 1 ........................................................................................ 43
Figura 36: exemplo de teste com k = 9 ........................................................................................... 44
Figura 37: Exemplo de teste com o k = 17 ...................................................................................... 45
Figura 38: Exemplo de teste com o k = 51 ...................................................................................... 46
Figura 39: Exemplo de teste com k = 71 ......................................................................................... 47

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Introdução
O presente documento do QREN SMART Mail está enquadrado na “Linha de investigação de
Modelos de Aprendizagem”. Pretende efetuar um levantamento do estado da arte das principais
técnicas e abordagens no domínio da aprendizagem automática, assim como, de plataformas ou
frameworks já existentes que possam servir de guia e de exemplo com as melhores
aproximações e abordagens.
O objetivo de apreender tal conhecimento prende-se diretamente com o próprio conceito do
projeto SMART Mail, onde se pretende integrar esses mecanismos no contexto do email, de
forma a incrementar a produtividade, eficiência e inteligência obtida do email como ferramenta
empresarial diária.
O documento terá como estrutura a presente Introdução, seguida de uma análise genérica às
diferentes linhas de investigação no contexto dos modelos de aprendizagem. Essas linhas de
investigação serão o TF-IDF (term frequency/inverse document frequency), a linha de
investigação do Naive Bayes, dos SVM (suport vector machines), algoritmos genéticos e por fim a
abordagem com recurso a Distâncias em Espaços Vetoriais.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Linhas de Investigação
Apresentam-se de seguida as diversas linhas de investigação seguidas na criação de modelos de
aprendizagem experimentais, assim como a apresentação do protótipo ou ferramenta utilizada
no processo experimental, assim como os dados utilizados para o ensaio e testes. Estas
experiências foram sempre tidas em conta para serem o mais visual e intuitivo possível, tanto
para facilitar a experimentação como a interação com as mesmas.
Abordagem TF-IDF (term frequency/inverse document frequency)
A medida TF-IDF, abreviação do inglês “term frequency–inverse document frequency” e que
significa frequência do termo–inverso da frequência nos documentos, é uma medida estatística
que tem o intuito de indicar a importância de uma palavra de um documento em relação a uma
coleção de documentos ou em um corpus linguístico. Esta medida é frequentemente utilizada
como fator de ponderação na recuperação de informações e na extração e mineração de dados.
A medida TF-IDF de uma palavra aumenta proporcionalmente à medida que aumenta o número
de ocorrências dessa palavra num documento, no entanto, esse valor é equilibrado pela
frequência da palavra no corpus, em que uma palavra muito recorrente em todo o corpus acaba
por perder importância nas contagens locais ao nível do documento. Isso auxilia a distinguir
entre um termo muito recorrente e um termo realmente importante.
Para se observar o funcionamento do TF-IDF, o caminho mais frequente passa por utilizar
diferentes bibliotecas matemáticas e algoritmos já presentes em diversas linguagens de
programação. No entanto, a sua aplicação e utilização nem sempre é fácil ou intuitiva para se
poder observar visualmente o funcionamento do TF-IDF propriamente dito. Tendo como objetivo
a obtenção de um protótipo mais visual, o leque de pesquisa foi alargado de modo a considerar
uma ferramenta mais gráfica e mais compreensível do conceito subjacente.
A ferramenta selecionada foi o Wolfram, nomeadamente o Wolfram CDF Player que permite
explorar de forma gráfica e interativa diversos algoritmos matemáticos, incluído o TF-IDF.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 1: Abertura e logotipo do Wolfram CDF
Após a instalação do Wolfram, este pode então ser executado. Durante o seu arranque surge a
Figura 1 com o seu logotipo.
Após a etapa de carregamento, surge o menu principal (Figura 2) onde é possível aceder a
diversos conteúdos informativos sobre o programa, e a diversos recursos e exemplos prontos a
serem explorados.
Figura 2: Menu principal do Wolfram CDF

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Para o teste do TF-IDF foi efetuada uma pesquisa nos recursos do Wolfram para encontrar uma
aplicação que para além de usar esse algoritmo matemático já contivesse uma coleção de textos
(corpus) pronta a ser utilizada.
Neste caso o corpus utilizado é um conjunto de 200 000 relatórios judiciais dos tribunais de
Londres entre 1674 e 1913 extraídos do Old Bailey Online.
Na análise propriamente dita do texto informativo foi selecionado do corpus, um texto
aleatoriamente, para aplicar visualmente as diferentes medidas de contagem do documento e do
corpus, como será apresentado e demonstrado nas imagens seguintes, onde os diferentes
termos, podem ser ocultados ou tomarem diferentes tamanhos consoante as suas contagens e
pesos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 3: Texto em bruto a ser analisado
Na Figura 3 é possível observar o texto em análise já carregado e exibido. Também é possível
observar no topo da aplicação vários botões de controlo que permitem ativar as várias medidas
de contagem sobre o corpus e este texto específico, nomeadamente a frequência dos termos no
documento, a frequência dos termos no corpus, o inverso da frequência no documento e por fim
o TF-IDF.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 4: Evidencia dos termos mais frequentes no corpus do texto
Na Figura 4 aparece o mesmo texto, mas com a métrica de frequência de termos de todo o
corpus, isto é, aqui aparecem quanto maiores as palavras que são muito recorrentes na coleção
dos vários documentos que constituem o corpus. No presente texto essas palavras são
destacadas com diferentes tamanhos. Esta medida das palavras frequentes em todo o corpus são
de extrema importância pois serão consideradas stop words, palavras descartadas por serem tão
ocorrentes que se tornam irrelevantes na análise e classificação do texto.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 5: Ocultação dos termos mais frequentes no corpus
Na Figura 5, essas palavras muito recorrentes já se encontram marcadas como stop words do
corpus, dai estarem semiocultas em cinzento.
É de relembrar que em qualquer algoritmo de TF-IDF é extremamente importante ter um
conjunto de stop words de modo a aumentar a eficiência e qualidade dos dados obtidos pelo TF-
IDF. Tal deve-se ao facto de as palavras muito recorrentes introduzem ruido supérfluo no
funcionamento destes algoritmos, pois essas palavras não contribuem na identificação do tema
ou assunto do documento nem a identificar o seu contexto. Exemplos dessas palavras
normalmente selecionadas para stop words são por exemplo (o, a, e, é, de, da, do, etc). Essas

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
palavras são normalmente artigos auxiliares à articulação da linguagem, mas que nada
acrescentam à informação extraída do texto.
Figura 6: Termos mais frequentes no texto em análise
Na Figura 6 já está selecionado o modo que indica as palavras mais frequentes. Ao contrário do
modo anterior (stop words), que eram as mais frequentes em todos os documentos (corpus),
aqui são as mais frequentes especificamente deste documento. Esta métrica é importante para
obter o próximo passo para o cálculo do TF-IDF que é obter a parte do IDF.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Aqui, as palavras mais recorrentes também são destacadas com uma fonte de maiores
dimensões.
Figura 7: Inverso da frequência de termos no texto em análise
Chegando a esta etapa (Figura 7) já é apresentado o texto com as stop words ocultas e em
evidência as palavras que são o inverso da frequência no documento. Desta forma, agregando
esta medida e excluindo as stop words já temos o que em teoria de informação é designado
pelos termos mais informativos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 8: TF-IDF com stop words aplicado ao texto em análise
Por fim, na Figura 8 é apresentado o resultado do TF-IDF tendo por base o corpus inicialmente
apresentado, o texto de estudo e a agregação das métricas anteriormente apresentadas nas
figuras anteriores.
Assim, os termos assinalados pelo TF-IDF são os termos de maior informação para servirem de
base para extração de informação, ou tarefas de classificação automática sobre o mesmo.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Abordagem Naive Bayes
A aprendizagem Probabilística ou Bayesiana representa uma grande família de algoritmos de
aprendizagem automática. Esta família tem algo comum na sua base de funcionamento; cálculos
probabilísticos que têm como princípio o teorema de Bayes.
O algoritmo Naive Bayes é um dos algoritmos de aprendizagem automática mais conhecido e
utilizado que tem como base para o seu funcionamento um classificador probabilístico baseado
no teorema de Bayes.
A designação "Naive" provém do algoritmo pressupor que os vários atributos que descrevem os
objetos são independentes, o que na realidade raramente acontece.
Assim, entre os vários atributos que discriminam a classe do objeto, cada atributo contribui
independentemente para a probabilidade do objeto fazer parte de uma classe ou outra, não
havendo qualquer correlação entre os diversos atributos na hora de decidir a classe do objeto.
No entanto, o facto de o algoritmo fazer essa simplificação, não implica que ele obtenha maus
resultados. Pelo contrário, o algoritmo Naive Bayes é um algoritmo que na maior parte dos
domínios apresenta bons resultados médios.
Para explorar e experimentar esta abordagem com recurso a algoritmos de aprendizagem da
família do Naive Bayes, o caminho mais comum passa por utilizar diferentes bibliotecas
matemáticas e de algoritmos que permitem aplicar estes algoritmos a conjuntos de dados para
criar modelos de aprendizagem e consequentes classificações automáticas. No entanto essa
abordagem não seria a mais intuitiva para uma fase preliminar de testes e experimentação.
Dessa forma tentou-se achar outras ferramentas que tornassem esse processo mais intuitivo,
visual e permissivo à experimentação.
Dessa forma, a ferramenta selecionada de acordo com este propósito foi o WEKA.
O WEKA é uma ferramenta open source e desenvolvida pela universidade de Waikato e é uma
das ferramentas mais amplamente utilizadas na área de IA no que diz respeito a aprendizagem
máquina e automática. O WEKA disponibiliza de uma forma agregada um conjunto bastante
grande e completo de famílias de algoritmos de IA, tem ainda diversas ferramentas para

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
importar diferentes fontes de dados e de informação, assim como diversos meios de visualização
de dados e de resultados.
Figura 9: Menu principal do WEKA
No menu inicial do WEKA (Figura 9) são apresentadas quatro diferentes formas de interagir com
o programa onde será utilizada a primeira, pois é a mais apropriada para a realização de
experiências pontuais e de exploração. Já a abordagem Experimenter e KnowledgeFlow são mais
adequadas para experiências que já estão moduladas e que se pretende que sejam repetidas
várias vezes para diversos conjuntos de dados. Por fim, o modo simple CLI é o modo consola do
WEKA, em que todas as instruções são executadas via linha de comandos. Esta abordagem é
importante para quando se pretende automatizar procedimentos ou aplicar o WEKA a contextos
de Big Data.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 10: Explorer do WEKA
Na Figura 10 é então apresentado o especto gráfico do WEKA no modo explorer.
Inicialmente apenas encontra-se disponível o separador Preprocess. Neste é possível selecionar a
origem dos dados, aplicar filtros aos mesmos, assim como analisar a sua distribuição pelas
diferentes classes de atributos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 11:Selecção de dados
Na Figura 11 é apresentada uma seleção dos dados para processamento. Nativamente o WEKA
utiliza o formato arff, que é bastante utilizado por outras aplicações e ferramentas de machine
learning. No entanto o WEKA não esta limitado a esse formato, podendo consumir dados em
outros formatos, existindo para tal uma biblioteca (interna ao WEKA) para converter e trabalhar
com esses outros formatos mais comuns.
Para realizar esta experiência utilizou-se um conjunto de dados sobre intenções de voto, em que
consoante a opinião sobre diversas questões, era apresentada a escolha eleitoral, no contexto
dos Estados Unidos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 12: Exemplo de dados no formato .arff
Na Figura 12 é apresentado um exemplo de dados consumidos pelo WEKA. Numa primeira parte
são enumerados os diferentes atributos que vão ser tidos em conta. Sendo o ultimo atributo a
“Classe” a conclusão que se pretende estudar e efetuar inferências sobre ela. Na segunda parte
do ficheiro aparecem os dados propriamente ditos, com os valores concretos para os atributos
anteriormente referidos, assim como a classe a que pertencem.
Neste exemplo simples, os atributos são binários, no entanto, em casos mais complexos,
poderiam ser nominais, numéricos inteiros, reais ou normalizados.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 13: Visualização e exploração dos dados
Após a abertura do ficheiro com os dados pretendidos (Figura 13), é apresentada uma listagem
dos atributos e dos valores observados para cada um. É ainda possível explora-los
individualmente e visualizar a sua distribuição tanto na forma de tabela como de gráficos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 14: Seleção de filtros
Caso seja necessário, é possível aplicar filtros aos dados de entrada (Figura 14) tanto para
eliminar dados que se pretende ignorar, limpar dados aberrantes ou fora de um determinado
intervalo, ou até mesmo efetuar transformações sobre os mesmos.
Para este exemplo concreto de dados, consoante o tipo de algoritmo escolhido posteriormente,
poderia ser necessário converter os valores de resposta nominais (‘y’,’n’) para um formato
binário (1 ou 0). No entanto, para experimentar o Naive Bayes, tal transformação não é
necessária.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 15: Separador de Cassificação
Avançando para o segundo separador do WEKA, “Classify” (Figura 15), onde se seleciona o
algoritmo de aprendizagem a aplicar aos dados previamente carregados e tratados.
Inicialmente este ecrã encontra-se totalmente vazio, consistindo o primeiro passo em selecionar
então a família de algoritmos e de seguida o algoritmo específico para realizar os testes como
pode ser observado na Figura 16.
Neste caso vamos selecionar a família de algoritmos “Bayes”, e de seguida o algoritmo Naive
Bayes para aplicação aos dados.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 16: Seleção de algoritmo de classificação
Figura 17: Algoritmo e condições de teste

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Depois de selecionar o algoritmo, como visível na Figura 17, falta ainda selecionar a modalidade
de teste. Em certas situações mais reais e extraídas do dia-a-dia, existe um conjunto de dados
para efetuar a criação do modelo de aprendizagem e existe outro conjunto para efetuar o treino
ou a classificação. No entanto, em situações que só exista um conjunto de dados não é
necessário particionar esses dados manualmente para obter os dois conjuntos (treino e teste).
Nestas situações costuma-se utilizar a abordagem de validação cruzada em que o conjunto de
dados é particionado em múltiplas frações sendo testado assim sobre esses conjuntos. Os
conjuntos são repetidos ao longo de toda a amostragem para evitar desvios ou viciação dos
resultados obtidos.
Neste caso concreto essa partição será efetuada em dez partes de igual dimensão.
Figura 18:Inicio de processamento

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Depois desta etapa, é então possível fazer iniciar o processamento para gerar o modelo e ao
mesmo tempo efetuar o teste com as partições. Nessa altura é apresentado o ecrã que surge na
Figura 18, sendo um resumo dos dados a serem processados.
No fim do processamento estar concluído, são então apresentados os resultados e métricas que
permitem concluir se foram obtidos bons ou maus resultados, como apresentado na Figura 19
Figura 19: Resultados finais

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Nos resultados há a destacar métricas como:
Precisão: é a métrica que nos permite avaliar a qualidade da classificação de um
determinado algoritmo de aprendizagem automática. A precisão permite saber do
conjunto dos elementos classificados como pertencentes a uma classe, os que de facto o
são, permitindo assim observar o tipo do erro ocorrido. Por outras palavras, é o grau de
pureza da classificação efetuada.
Cobertura: é a métrica semelhante à precisão que permite observar o tipo de erro
ocorrido na classificação de determinado algoritmo de aprendizagem automática. No
entanto ao invés de dar a "pureza" da classificação efetuada, esta métrica dá-nos a noção
da informação relevante que foi perdida durante a classificação.
Medida F1: é a métrica que combina a precisão e a cobertura. Isto surge da necessidade
de ter uma métrica que dê uma visão global do desempenho do algoritmo, visto que,
usando apenas uma delas corre-se o risco de ter bons valores perto de 100%, tendo no
entanto na outra métrica muito maus resultados, o que levanta dúvidas quanto a
globalidade do desempenho do algoritmo.
Por fim existe ainda a matriz de confusão que permite contabilizar todos os casos de corretos
positivos, corretos negativos, falsos positivos e falsos negativos, como é observável na Figura 20.
Figura 20: Resultados em detalhe

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Ainda se observa que os resultados foram bastante positivos, tendo obtido um F1 médio de 90%
para as duas classes em estudo.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Abordagem SVM (Support Vector Machines)
As Máquinas de Vetores de Suporte, mais conhecidas por SVM's do inglês “Support Vector
Machines” são uma família de algoritmos de aprendizagem automática desenvolvida
inicialmente por Vapnik e Chervonenkis.
De uma maneira muito simplista o seu funcionamento parte do pressuposto que temos os
objetos da nossa coleção que pretendemos classificar. Esses objetos podem ser classificados de
modo binário, tomando as classes C e C', e são caracterizados pelos atributos do conjunto A =
{A1, A2, ..., An}.
Cada objeto pode ser representado na estrutura de SVM's como sendo um vetor n-dimensional
num espaço vetorial de dimensão n obtendo uma determinada disposição geográfica consoante
os valores dos seus atributos.
O classificador dos SVM's surge como um algoritmo que vai obter e otimizar um hiperplano de
dimensão n-1 dentro do nosso espaço n-dimensional, que separa as duas classes. Esse
hiperplano pode ser visto como uma fronteira, mas ao invés de ser uma fronteira bi-dimensional
como a dos mapas, é uma fronteira de dimensão n-1.
Quando qualquer novo objeto for adicionado à coleção e se pretender a sua classificação
referente à classe C ou C', basta representar esse objeto no espaço vetorial n-dimensional, e ver
se a sua representação ocorre de um lado ou de outro da "fronteira" que separa as duas classes.
No entanto, no espaço vetorial pode existir uma infinidade de hiperplanos capazes de dividir as
duas classes de objetos, levantando a questão de qual hiperplano se adequa melhor. Sendo o
algoritmo SVM's responsável por essa decisão.
A ferramenta que foi utilizada para experimentar a família de algoritmos dos SVM foi o WEKA. A
mesma ferramenta utilizada anteriormente na abordagem Naive Bayes. Tal é possível, porque
como foi introduzido anteriormente, o WEKA é uma framework de algoritmos de machine
learning e permite efetuar experiencias em diversas famílias distintas de algoritmos.
Para aumentar a relevância desta experiência, tendo em conta que a ferramenta utilizada é a
mesma, exceto o algoritmo utilizado, foi decidido utilizar os mesmos dados de entrada. Desta
forma será válido efetuar uma comparação de resultados entre os diferentes algoritmos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Todo o processo inicial de arrancar com o WEKA e carregar os dados em análise é semelhante ao
procedimento efetuado na abordagem do Naive Bayes. Chegando ao fim desse procedimento
obtém-se o ecrã visível na Figura 21.
Figura 21: Carregamento dos dados
Tendo os dados carregados é necessário escolher o algoritmo pretendido, como visível na Figura
22. O algoritmo escolhido é o designado por SMO, que é o algoritmo convencional de SVM, mas
que no WEKA tem essa designação por ser uma variante com otimizações.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 22: Seleção do algoritmo de SVM
Após a seleção do algoritmo, esse aparece no campo do separador Classify seguido de um grande
conjunto de parâmetros, como visível na Figura 23. Esse parâmetros são específicos do algoritmo
de SVM e permitem efetuar fine tuning ao funcionamento do mesmo em caso de dados muito
específicos ou especializados. No entanto, serão utilizados os parâmetros por omissão, visto que
são os melhores para casos genéricos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 23: Parâmetros do algoritmo
De seguida tem de ser escolhido o mecanismo de testes. Também será escolhida a validação
cruzada com dez partições (Figura 24) à semelhança do Naive Bayes para permitir uma posterior
comparação entre ambos os algoritmos.
Figura 24: Parâmetros de teste
Após indicar o formato do teste a efetuar, pode-se então dar ordem de execução do processo de
aprendizagem para a criação do modelo e o posterior processo de testes.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 25: Finalização do algoritmo
O WEKA ao finalizar o seu processamento, apresenta então o output dos testes realizados, visível
na Figura 25.
Esses resultados podem ser observados em maior detalhe na Figura 26, onde se voltam a
destacar métricas como a precisão, cobertura, medida F1 e a matriz de confusão que permite
contabilizar todos os casos de corretos positivos, corretos negativos, falsos positivos e falsos
negativos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 26: Detalhe dos resultados finais
Nas métricas há ainda a destacar o resultado de F1 médio de 96% para as duas classes em
estudo, que é um resultado bastante bom.
A título de comparação o mesmo teste utilizando o algoritmo Naive Bayes apresentou um
resultado de F1 médio de 90%. Embora não se possam tirar grandes ilações desta comparação,
pois os dados utilizados, embora sendo os mesmos, foram apenas dados de testes, não
refletindo qualquer cenário real ou de aplicação prática, este valor poderá indicar que os SVM
são melhores do que o Naive Bayes neste tipo de classificações.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Abordagem em Algoritmos Genéticos
Os algoritmos genéticos são um tipo de abordagem adaptativa para a resolução de problemas.
Ao contrário dos problemas em que é construído deterministicamente e imperativamente um
algoritmo estático para resolver esse problema, nos algoritmos genéticos, esse algoritmo de
resolução é dinâmico e sabe-se avaliar a si próprio, para poder realizar alterações e evoluções
sobre ele próprio ao longo das diversas iterações em que tenta resolver o problema original.
Para efetuar a análise desta abordagem, procurou-se um protótipo que oferecesse um caso de
estudo pronto a utilizar, e ao mesmo tempo fosse interativo, permitindo o utilizador alterar as
variáveis de sistema e observar os efeitos e impactos dessas medidas.
O protótipo selecionado foi um modelo de algoritmo genético aplicado à geração aleatória de
carros com diferentes características e testados numa pista sinuosa. À medida que o algoritmo
genético vai alterando os carros, estes vão-se tornando mais eficientes. Assim, e de geração para
geração são selecionados apenas os melhores. Esses melhores exemplos, depois são
selecionados para sofrerem mutações numa tentativa de apurar uma próxima geração ainda
mais eficiente.
O protótipo está disponível em http://rednuht.org/genetic_cars_2/ sendo totalmente open
source. Este protótipo foi contruído sobre um motor de física 2D designado de Box2D disponível
em http://box2d.org/ e que simula um conjunto de fenómenos físicos, como a aplicação de
forças e aceleração e deteção de colisões.
É ainda importante informar sobre o genoma envolvido na experiencia. O genoma nos
algoritmos genéticos é o conjunto de variavas/parâmetros que podem sofrer mutação e criar
descendentes com piores ou melhores performances. Dai todas as gerações serem testadas de
forma e eliminar as mutações com piores resultados e a iterar, para um novo ciclo de mutação e
teste, os elementos em que as mutações tiveram efeitos positivos. Neste cenário específico o
genoma era composto por:
Forma (8 genes, um por aresta)

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Tamanho das rodas (2 genes, um por roda)
Posição das rodas (2 genes, um por roda)
Densidade das rodas (2 genes, um por roda)
Densidade do chassi (1 gene)
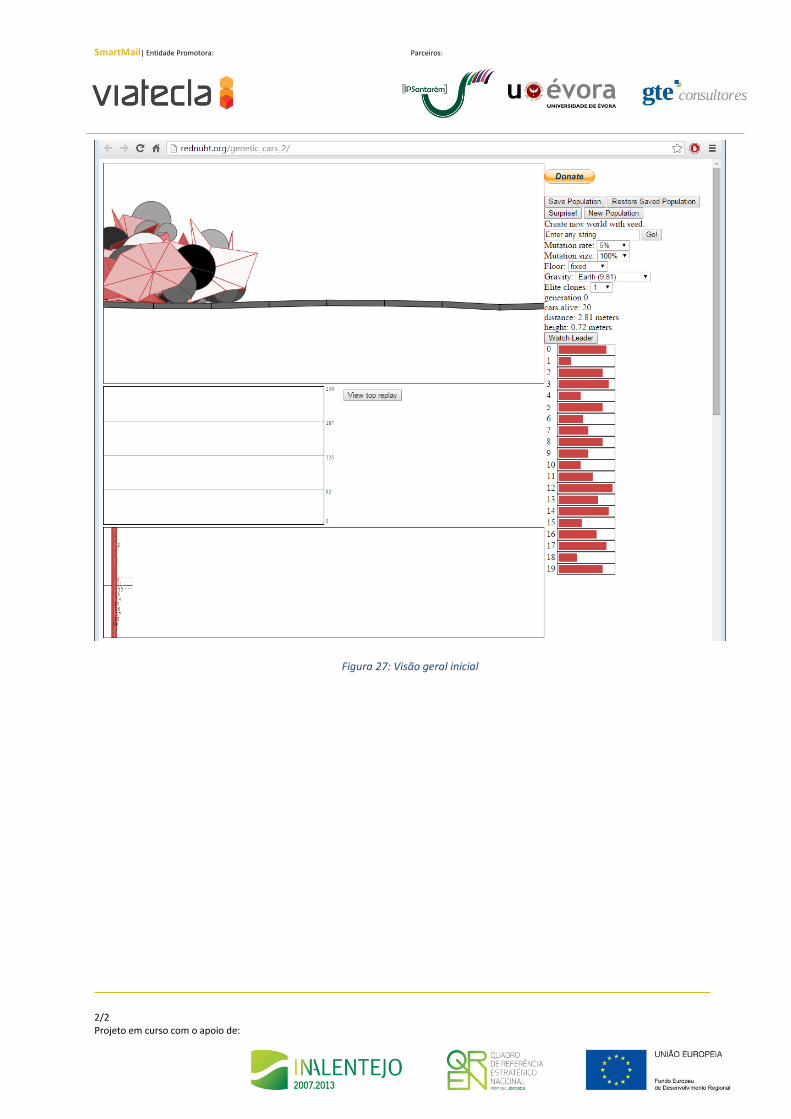
Na Figura 27 é possível visualizar o aspeto geral do protótipo. No topo surge uma área onde
surgem os diversos veículos e onde será visível a ultrapassarem os obstáculos. Por baixo dessa
área irão surgir gráficos informativos com dados estatísticos que irão ser recolhidos ao longo da
evolução das diversas gerações e iterações de veículos. Do lado direito, surge um conjunto de
campos de input para modular o sistema e a indicação dos veículos lideres que serão utilizados
na criação da geração seguinte.
SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 27: Visão geral inicial

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Na Figura 28 já é possível observar uma fase intermédia do teste para detetar os melhores
espécimes desta geração, em que alguns dos veículos ficaram para trás e foram eliminados, daí
serem visíveis menos do que na Figura 27.
Figura 28: Visão geral (fase intermédia) no decorrer de um teste
SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
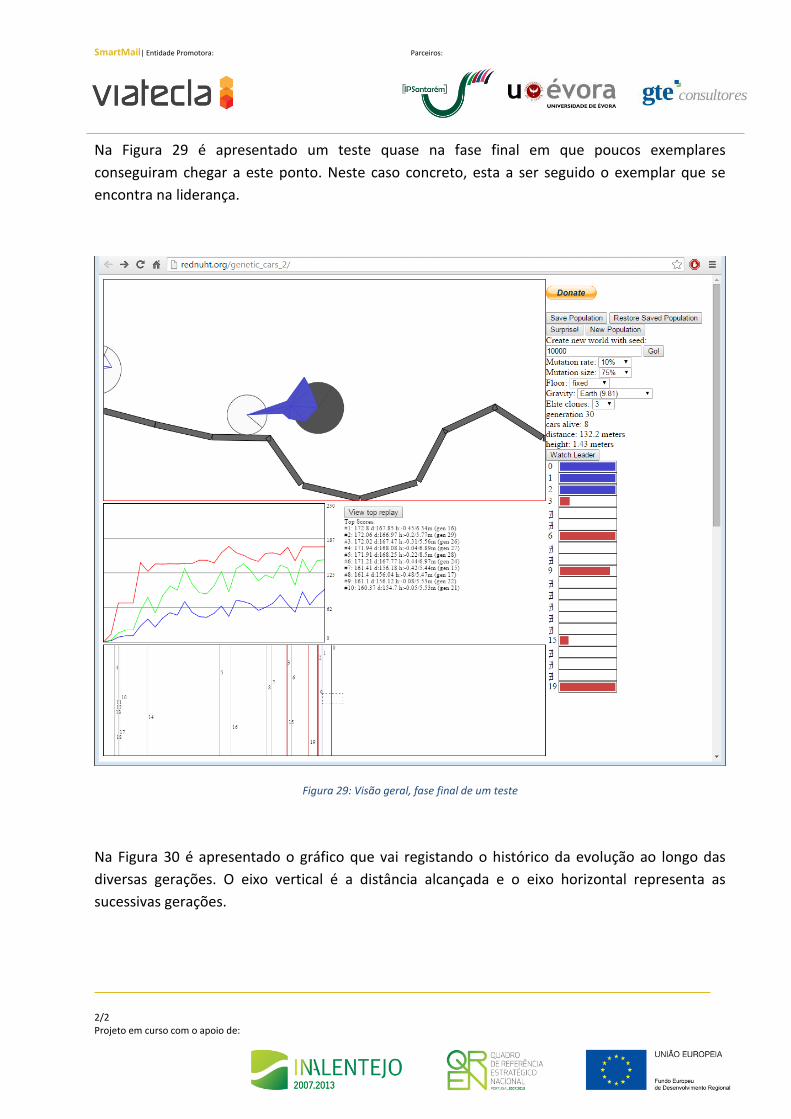
Na Figura 29 é apresentado um teste quase na fase final em que poucos exemplares
conseguiram chegar a este ponto. Neste caso concreto, esta a ser seguido o exemplar que se
encontra na liderança.
Figura 29: Visão geral, fase final de um teste
Na Figura 30 é apresentado o gráfico que vai registando o histórico da evolução ao longo das
diversas gerações. O eixo vertical é a distância alcançada e o eixo horizontal representa as
sucessivas gerações.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Em relação as cores presentes no gráfico, a cor vermelha representa a maior distância obtida em
cada geração. A linha verde representa a média do Top 10 de cada geração e por fim, a linha azul
representa a média de toda a presente geração.
Este gráfico facilita bastante a análise e evolução genética dos participantes ao longo das várias
iterações e evoluções entre gerações.
Do lado direito do gráfico, apenas para referência vão sendo assinalados os diversos registos
obtidos.
Figura 30: Gráfico de evolução ao longo das gerações
Figura 31: Mapa geral de onde se encontram os diferentes exemplares em teste
Na Figura 31 é apresentada a visão geral do teste naquele preciso momento, em que se pode
visualizar a posição dos diversos elementos ao longo do trajeto. Cada linha representa um
participante. As linhas a cinzento são elementos que já foram eliminados do teste por não

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
superar os obstáculos. As linhas vermelhas e azuis são de elementos ainda ativos - os líderes da
geração anterior, e que estão a ser postos à prova com elementos derivados desses mesmos
líderes.
Figura 32: Status dos concorrentes do teste atual
Em cada teste que decorre é ainda apresentado um indicador de atividade de cada elemento
(Figura 32). Quando a atividade desse elemento chega a zero é excluído da competição. Esse
indicador, para o caso concreto, os primeiros três estão destacados a azul porque foram os
finalistas vencedores da geração anterior e que serviram para gerar a nova geração. Com esta
diferença de cores é possível observar, se a nova geração (vermelho) vai superar ou não os
antepassados (azul).
Por fim, mas não menos importante é apresentado o quadro com os campos referentes às
variáveis envolvidas na modulação do cenário de testes (Figura 33).

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
As variáveis de taxa da mutação e tamanho de mutação são as mais importantes para qualquer
algoritmo genético, pois permitem controlar a quantidade e tamanho das mutações entre
gerações. Neste caso específico, a taxa de mutação de pai para filho é limitada a 10% do genoma,
com uma variação máxima de 75% na amplitude do gene mutado.
Destas variáveis de controlo, existe ainda outra bastante importante que é o número de
elementos de elite selecionados para serem os geradores da próxima geração.
Neste caso específico, é 3, ou seja, em cada teste para os três melhores finalistas, é aproveitado
o seu genoma para aplicar mutações e criar uma nova geração mais eficiente.
Figura 33: Parâmetros de configuração

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Abordagem com Distâncias em Espaços Vetoriais
Uma das formas base de efetuar classificação automática de classes de objetos é recorrendo a
distâncias em espaços vetoriais. Partindo do pressuposto que os objetos que pretendem ser
classificados têm atributos, cada atributo irá dar origem a uma dimensão no espaço vetorial. Os
valores que esse atributo podem tomar, serão então o domínio dessa dimensão vetorial. Assim,
cada objeto ao ser mapeado para esse espaço vetorial ira, no conjunto dos objetos, criar uma
distribuição espacial nesse espaço vetorial com um numero de dimensões igual ao numero de
atributos que discrimina esses objetos.
Para analisar e estudar a abordagem baseada em distâncias em espaços vetoriais, foi utilizada
como ferramenta base de trabalho o Wolfram, ferramenta muito conhecida e utilizada no estudo
de algoritmos matemáticos dos mais variados tipos. Essa ferramenta já foi apresentada na
secção da Abordagem TF-IDF.
Existem diversas técnicas e algoritmos que nos permitiriam explorar e descobrir esta abordagem
baseada em distâncias em espaços vetoriais. No entanto uma das mais conhecidas, robusta e
interessante para efetuar uma experimentação visual é a k-Nearest Neighbor. Esta ao contrário
de outras que trabalham em projeções para espaços vetoriais de múltiplas dimensões e híper-
planos tornam a sua visualização e compreensão gráfica praticamente impossível, restrição essa
que não acontece com o k-Nearest Neighbor. Matematicamente esta abordagem é muito
simples, pois quando pretende identificar a classe de um novo elemento num conjunto de dados,
vai analisar a sua vizinhança num determinado raio e contabilizar os diferentes tipos de
elementos que a circundam. Se houver uma predominância de uma classe, então vai-se assumir
que este novo elemento também faz parte dessa classe maioritária. Muitas vezes, a grande
questão é determinar esse raio de vizinhança de modo a ser o mais correto na maioria dos casos.

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Figura 34: Exemplo de aplicação do k-Nearest Neighbor
A título de simples exemplo explicativo, a Figura 34, apresenta uma ilustração do que foi
referido. Nesse exemplo surge um novo elemento (verde) que se pretende que seja classificado
como pertencente à classe azul ou vermelha. Se o nosso k (raio de vizinhança) for 3 é
representado pela linha sólida, e nessa situação o elemento verde seria classificado como
pertencente à classe dos triângulos vermelhos. Por outro lado, se o nosso k (raio de vizinhança)
for de 5, então ai o elemento verde já seria classificado como pertencente à classe azul.
Voltando ao protótipo de experimentação do Wolfram, foi então carregado um modelo
matemático interativo para testar e aplicar o k-Nearest Neighbor, obtendo-se o apresentado na
Figura 35. Os elementos dos dados de teste são discriminados por duas classes diferentes (verde
e vermelho), cada elemento é descriminado por duas variáveis numéricas (x1 e x2) e existe um
total de 200 elementos com a distribuição apresentada na Figura 35.
No exemplo também é aplicada a técnica de tesselação de Voronoi para pintar as áreas que
seriam de classificação para as classes (verde e vermelha) consoante o k selecionado, obtendo
assim um protótipo interativo de estudo muito interessante.
Ainda presente no gráfico de visualização está uma linha azul escura que foi adicionada apenas
para comparação, e representa qual seria a distribuição e divisão de classes efetuada pela
abordagem do Naive Bayes (técnica essa que também já foi analisada neste mesmo documento).

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
A Figura 35 apresenta os dados de estudo e com o k = 1. Nesta situação é quando pode haver
problemas de sobre ajustamento, ou seja uma classificação muito próxima dos dados, mas que
no entanto vai perder generalidade e capacidade de contemplar novas situações.
Figura 35: Exemplo de teste com o k = 1

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
No caso da Figura 36, o k utilizado já foi com o valor 9. Não sendo tão sobre ajustado e próximo
como no exemplo anterior, ainda assim aparenta ser pouco genérico. Um dos fatores que leva a
observar isso é facto de existirem “ilhas” de uma classe dentro de áreas de outra classe, como é
visível neste exemplo.
Figura 36: exemplo de teste com k = 9

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
No exemplo da Figura 37 com o valor de k = 17, o exemplo obtido já aparenta não ter problemas
de sobre ajustamento e ser suficientemente genérico para classificar corretamente novos
exemplos.
Figura 37: Exemplo de teste com o k = 17

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Continuando a aumentar o valor de k, desta vez para 51, as áreas de deteção de cada classe já
aparentam ser demasiado simplistas e genéricas. Aqui, recorrendo à comparação com a linha
(azul) traçada pela classificação do Naive Bayes, facilmente se comprova que com o k a 51 se
perdem muitas zonas de deteção obtendo-se assim um modelo sub ajustado.
Figura 38: Exemplo de teste com o k = 51

SmartMail| Entidade Promotora: Parceiros:
2/2 Projeto em curso com o apoio de:
Por fim na Figura 39 o k utilizado toma o valor de 71. Como é possível de observar não existe
grande alteração em relação ao modelo obtido na Figura 38 com o k = 51.
Neste novo caso (com k = 71) o resultado obtido continua a ser bastante grosseiro e simplista
apresentado indícios fortes de sub ajustamento.
Figura 39: Exemplo de teste com k = 71