anais da vi escola regional de informática da sociedade brasileira
TRANSCRIPT

Anais da VI Escola Regional deInformática da Sociedade Brasileira
de Computação (SBC) -Regional de Mato Grosso
Realização: Promoção: Patrocínio:
ERIMT2015ELOS DIGITAIS: EDUCAÇÃO, CULTURA E INTERAÇÃO
16 a 18 de novembro • Cuiabá • Mato Grosso
VI Escola Regional de Informáticade Mato Grosso

Anais da VI Escola Regional de Informática de Mato Grosso
(ERIMT-2015)
Cuiabá – MT – Brasil 16 a 18 de Novembro de 2015

VI Escola Regional de Informática de Mato Grosso
(ERIMT-2015)
http://anaiserimt.ic.ufmt.br/index.php/erimt
16-18 de Novembro de 2015 Cuiabá – MT – Brasil
Organizadores Karen da Silva Figueiredo (UFMT)
Pedro Clarindo da Silva Neto (IFMT)
Comitê Científico Eunice Pereira dos Santos Nunes (UFMT) Maurício Fernando Lima Pereira (UFMT)
Realização
Universidade Federal de Mato Grosso (UFMT) Instituto Federal de Mato Grosso (IFMT)
Promoção
Sociedade Brasileira de Computação (SBC)

Este volume contém os artigos apresentados na VI Escola Regional de Informática de Mato Grosso (ERIMT 2015). A inclusão nesta publicação não necessariamente constitui endosso pelos editores e/ou organizadores.
A fonte e os direitos da SBC devem ser devidamente referenciados. As cópias não devem ser utilizadas de nenhum modo que implique o endosso da SBC. Cópias da obra não podem ser colocadas à venda sem a autorização expressa da SBC.
Permissão para fazer cópias impressas ou digitais de todo ou parte deste trabalho para uso pessoal ou acadêmico é concedido sem taxas desde que copias não sejam feitas ou distribuídas para renda ou vantagem comercial e que cópias contenham esta observação e citação completa na primeira página.
FichaCatalográficaelaboradapeloBibliotecárioDanielS.DalbertoCRB-1:2723
Sociedade Brasileira de Computação CNPJ no. 29.532.264/0001-78 Inscrição Estadual isenta CCM no 18115128 http://www.sbc.org.br
Av. Bento Gonçalves, 9500 – Setor 4 – Sala 116 – Prédio 43424 – Agronomia CEP 91501-970 – Porto Alegre – RS, Brasil
Produzido em Cuiabá-MT-Brasil.
1
B74a Escola Regional de Informática (6. : 2015 : Cuiabá).
Anais da VI Escola de Informática de Mato Grosso – 2015 [recurso eletrônico] / Eunice P. dos Santos Nunes, Maurício Fernando Lima, Pedro Clarindo da Silva Neto (Organizadores) - Cuiabá: Sociedade Brasileira de Computação, 2015.
ISSN (CD): 2179-1953 ISSN (Online): 2447-5386
1. Ciência da Computação. 2. Informática. 3. Mato Grosso. 4. UFMT.
2
CDU – 004.03(063)

VI Escola Regional de Informática de Mato Grosso (ERIMT 2015)
iv
Prefácio
A Escola Regional de Informática de Mato Grosso (ERI-MT) é um evento anual
apoiado pela Sociedade Brasileira de Computação (SBC), que ocorre desde 2009 e
que tem contribuído para troca de ideias e conhecimentos entre pesquisadores,
estudantes e profissionais das diversas áreas acadêmicas do estado de Mato Grosso e
estados vizinhos.
Este ano a ERI-MT 2015 realizou-se em Cuiabá-MT, tendo sido organizada pelo
Instituto de Computação da Universidade Federal de Mato Grosso (UFMT) e pelo
Instituto Federal de Ciência e Tecnologia de Mato Grosso (IFMT), campus Tangará
da Serra.
Na ERI-MT, os pesquisadores têm a chance de apresentar seus trabalhos em
sessões técnicas com apresentação oral (artigos completos) ou por meio da exposição
de pôsteres que tratam de artigos curtos. Os trabalhos apresentados no evento
representam uma grande oportunidade para os participantes se atualizarem a respeito
das metodologias e tecnologias mais recentes, o que implica em ganhos acadêmicos e
profissionais aos participantes.
Os anais da ERI-MT 2015 reúnem todos os artigos selecionados para apresentação
no evento, tanto os artigos completos quanto os artigos curtos, como forma de
disseminar o conhecimento entre os participantes do evento, como também para toda
a comunidade da área de computação e áreas correlatas interessadas nas tendências de
metodologias e tecnologias que têm sido investigadas na área de Computação,
especialmente, por pesquisadores da região Centro-Oeste do nosso país.
Agradecemos à comunidade pelo interesse, submetendo artigos e compartilhando
conhecimentos e, em especial, a todos aqueles que colaboraram com o evento
apresentando os seus trabalhos e divulgando a ERI-MT 2015 pelo país, como também
aos membros do Comitê Científico e revisores convidados, pelas valiosas
contribuições nas avaliações dos trabalhos submetidos no evento.
Eunice Pereira dos Santos Nunes Mauricio Fernando Lima Pereira

VI Escola Regional de Informática de Mato Grosso (ERIMT 2015)
v
ComitêCientíficoCoordenadora: Eunice Pereira dos Santos Nunes (UFMT-Cuiabá) Vice-Coordenador: Maurício Fernando Lima Pereira (UFMT-Cuiabá)
Membros:Allan Gonçalves de Oliveira (UFMT-Cuiabá) Ana Claudia de Oliveira (FATEC-SP) Andreia Gentil Bonfante (UFMT-Cuiabá) Beatriz de Almeida Pacheco (Mackenzie) Claudia Aparecida Martins (UFMT-Cuiabá) Claudia Cappelli (UNIRIO) Cleber Gimenez (POLI-USP) Clovis dos Santos Júnior (UFMT-Rondonópolis) Cristiano Maciel (UFMT-Cuiabá) Ed'Wilson Tavares Ferreira (IFMT) Evandro César Freiberger (IFMT) Fernando Selleri Silva (UNEMAT) Gleber Nelson Marques (UNEMAT) Ildeberto Rodello (FEARP-USP) Ivairton Monteiro (UFMT-Barra) Jésus Franco Bueno (UFMT-VG) João Paulo Ignácio F. Ribas (UFMT-Cuiabá) Josiel Maimone de Figueiredo (UFMT-Cuiabá) Juliana Fonseca Antunes (IFMT) Juliana Saragiotto Silva (IFMT) Linder Cândido da Silva (UFMT-Barra) Luciana Correia Lima de Faria Borges (UFMT-Cuiabá) Marcelo Paiva (UNIFESP) Maria Amelia Eliseo (Mackenzie) Nelcileno Araújo (UFMT-Cuiabá) Patricia Cristiane de Souza (UFMT-Cuiabá) Raphael Rosa de Souza Gomes (UFMT-Cuiabá) Raul Teruel dos Santos (UFMT-Cuiabá) Roberto Benedito Oliveira Pereira (UFMT-Cuiabá) Robson Augusto Siscoutto (UNOESTE) Ronaldo Correia (UNESP-Presidente Prudente) Ruy de Oliveira (IFMT) Scheila Martins (Loyola University Maryland) Soraia Silva Prietch (UFMT-Rondonópolis) Tales Nereu Bogoni (UNEMAT) Thiago Meirelles Ventura (UFMT-Cuiabá) Vanessa de Oliveira Campos (UFMT-Cuiabá) Vinícius Carvalho Pereira (UFMT-Cuiabá)

VI Escola Regional de Informática de Mato Grosso (ERIMT 2015)
vi
SumárioArtigosCompletosUma Ferramenta como Objeto de Aprendizagem para a Disciplina de Estrutura de Dados Anthony F. La Marca, Marcus Vinícius B. Da Silva, Windelimarcos F. De Borba
1-6
Desenvolvimento de um Dicionário Controlado para Dispositivos Móveis Como Ferramenta de Auxílio à Alunos com Deficiência Motora Kaio Alexandre da Silva, Jones Fernando Giacon, Michel da Silva
7-13
Aplicando gamificação em ambientes corporativos Nathalia R. Sampaio, Filipe E. Botti, Roberta C. D. Taddeo, Francisco G. Maranhão, Leandro da Silva Taddeo
14-22
Modelagem virtual da biblioteca da Universidade Estadual do Sudoeste da Bahia - UESB usando softwares livres Henrique Junior Caires Santos
23-29
Desenvolvimento de um Sistema CAD para Detecção e Auxílio ao Diagnóstico de Doenças da Mama Roger Resmini, Adriel dos S. Araújo, Otavio B. Nantes, Claudinéia Araújo, Aura Conci
30-37
Avaliação do Processo de Software de uma Pequena Empresa na Cidade de Barra do Garças - MT Reinaldo A. S. Bocchi, Thiago P. Silva
38-43
Desenvolvimento de dashboards através de dados de distribuição de energia elétrica fornecidos pela ANEEL Vinícius F. M. Leão, Ariel R. Machado, Nilton H. Takagi, Thiago A. Araújo, Crischarles D. Arruda, Kelvyn Yago S. Zanato
44-49
Alocando horários de aulas nos cursos de Bacharelado em Sistemas de Informação e Licenciatura em Computação do Campus Universitário Vale do Teles Pires utilizando FET Timetabling – Um estudo de Caso Jonata da Silva Rodrigues, Francisco Sanches Banhos Filho, Cristiano Campos de Miranda
50-55

VI Escola Regional de Informática de Mato Grosso (ERIMT 2015)
vii
Descoberta Dinâmica de Serviços por meio da Ontologia Owl-S Josemar C. Silva, Evandro C. Freiberger
56-61
Uma Análise da Participação Feminina no Curso de Sistemas de Informação da Universidade Federal de Mato Grosso Luana Bulgarelli Mendes, Karen da Silva Figueiredo
62-68
PD4CAT: Um Método de Design Participativo para Tecnologia Assistiva Personalizada Luciana Correia Lima de Faria Borges, Lucia Vilela Leite Filgueiras, Cristiano Maciel, Vinicius Carvalho Pereira
69-74
Projeto Centrado no Usuário do Website do Conselho Municipal dos Direitos da Pessoa com Deficiência de Rondonópolis-MT Maysa Roberta de Souza Pereira, Soraia Silva Prietch
75-81
Uma Proposta de Ferramenta para Apoiar a Avaliação por Inspeção Heurística e Semiótica Gabriel Gonçalves Alves, Ana Claudia M. T. Gomes de Oliveira, Eunice P. dos Santos Nunes
82-87
Análise da Usabilidade do Website da empresa aérea Avianca e Proposições de melhorias Silvester Silva Nunes, Henrique Gabriel Pinheiro, Daniel Lamego, Ricardo Schneider, Soraia Silva Prietch
88-93
Avaliação de Usabilidade de um Sistema Desenvolvido por Modelos Pablo de Souza Melo, Thiago Pereira da Silva
94-99
Sistema de Entrega para Suporte Varejista Utilizando a Metaheurística GRASP Gil Romeu A. Pereira, Ivairton M. Santos
100-106
Algoritmo PSI: busca de tuplas duplicadas por meio de similaridade fonética e numérica Tiago Luís de Andrade, Beatriz A. Acosta F. da Cruz
107-112
Ferramentas e Aplicações para Banco de Dados NoSQL: Um Levantamento com Base em Revisão Sistemática Marcos Hiroshi Fukui, Fernando Selleri Silva
113-119

VI Escola Regional de Informática de Mato Grosso (ERIMT 2015)
viii
Desenvolvimento de Miniestações Agrometeorológicas de baixo custo aplicadas à agricultura de precisão Matteus V. S. Silva, Maurício F. L. Pereira, Allan G. Oliveira, Roberto B. O. Pereira
120-126
Utilização de Regras de Redução em Grafos Power Law: problema da cobertura por vértices Edgar de Oliveira Cabral Filho, Mariana Oliveira da Silva, André Luís Vignatti
127-132
Redes Neurais Artificiais em Série Temporal Não-Linear de Índice Pluviométrico Para Determinação de Inundação em Bacias do Pantanal Gerson K. Kida, Gracyeli S. S. Guarienti, César E. Guarienti, Josiel M. Figueiredo
133-138
Política de Privacidade e Dados Pessoais: Um Estudo sobre o Valor da Informação e a Consciência de Uso Gabriel José da Silva Rodrigues, André S. Abade
139-144
Avaliação de um Conjunto de Dados Quanto à sua Qualidade na Especificação de Perfis de Ataque e Não-Ataque Numa Rede IEEE 802.11w Rodrigo Fonseca de Moraes, Nelcileno Virgílio de Souza Araújo, Cristiano Maciel
145-150 Utilizando o transceptor NRF24L01 em redes de sensores sem fio operando sobre TCP/IP Evaldo J. Klock Neto, Mauricio F. Lima Pereira, Roberto B. de Oliveira Pereira
151-157
Arquitetura de Rede de Sensores para Uso de Sensores Heterogêneos, Móveis e de Aplicação Genérica Adriel Maycon Shepard Silva, Ivairton Monteiro Santos
158-163
Avaliação de Mapas de Zonas de Manejo Utilizando Métodos Estatísticos Ludmilla Fernandes Oliveira Galvão, Raul Teruel dos Santos
164-169
Definição de Zonas de Manejo Utilizando Algoritmos de Agrupamento Alexandre Lucas Oliveira Lima, Raul Teruel dos Santos
170-175
Medidor de Umidade de Solo Baseado em Resistência Elétrica do Solo para Aplicação Agrícola Wellington Sales E. Santos, Mauricio Fernando Lima Pereira, Roberto Benedito de Oliveira Pereira, Aloisio Bianchini
176-182

VI Escola Regional de Informática de Mato Grosso (ERIMT 2015)
ix
Utilização da Internet das Coisas para o desenvolvimento de miniestação de baixo custo para monitoramento de condições do tempo em áreas agrícolas Bruno Silva Afonso, Roberto Benedito de O. Pereira, Mauricio F. Lima Pereira
183-189
ArtigosCurtosReconhecimento de Expressões Faciais em Processos de Comunicação Usando Visão Computacional Marcos Alves dos Santos, Marcos Wagner Souza Ribeiro
190-192 Projeto de um serious game imersivo, de baixo custo e alta portabilidade, voltado ao aprendizado de pessoas com Dislexia e Discalculia Giancarlo Santana Batista Fleuri, Marcos Wagner de Souza Ribeiro
193-195
Aplicativo de Realidade Aumentada para Alfabetização Leandro Rodrigues Lima, Tales Nereu Bogoni
196-198
Um Estudo de Caso: análise sobre a eficácia do software Coelho Sabido na Terra do Queijo Carolina G. Marinho, Any C. Romero, Shirlene R. Souza, Max R. Marinho
199-201
Site para Divulgação de Jogos do Emiep Marcela de Oliveira Sampaio, Janaina Sandes Figueiredo
202-204
Construção do Saber por meio da Automação Janaina Sandes Figueiredo, Marcela de Oliveira Sampaio
205-207
Uso de Ambientes Virtualizados para o Ensino de Infraestrutura de Redes Francisco Renato Cavalcante Araújo
208-210
Uma ferramenta para a aplicação de Gamificação com Storytelling no Ensino Superior Alan R. S. Marcon, Ketelem L. Campos, Cleder A. Cruz, Karen S. Figueiredo
211-213
Jogos Educacionais no Processo de Ensino-Aprendizagem da Matemática: Estudo sobre o Software TuxMath Daniele D. de Paula, Jones F. Giacon
214-216

VI Escola Regional de Informática de Mato Grosso (ERIMT 2015)
x
Sistema de Automação de Baixo Custo para Irrigação: estudo de caso em uma Horta Caseira Natural Kaue S. A. Arima, Roberto B. O. Pereira, Mauricio F. L. Pereira
217-219
Estudo comparativo entre as versões do protocolo HTTP 1.1 e HTTP/2 Faride Fernandes S. Junior, Luiz Paulo P. Silva, Rothschild Alencastro Antunes
220-222
Neurofeedback e Reabilitação Virtual na terapêutica posterior ao Acidente Vascular Cerebral Dyeimys Franco Correa, Marcos Wagner S. Ribeiro
223-225 Proposta de arquitetura do processo de implantação de indicadores de desempenho de projetos utilizando metodologia de Business Intelligence Rondinely Oliveira, Nilton H. Takagi, João Luiz Oliveira Ribeiro, Josiel M. Figueiredo
226-228
Desenvolvimento de Sistema para reportar problemas encontrados em vias urbanas Bárbara Cardoso, Gabriele Nunes, Gustavo da Silva, Isabella Jacomeli, Kaio Alexandre, Marco Antonio Augusto de Andrade, Thaynara Celestino
229-231
Um Framework Conceitual para Gestão e Monitoramento do Consumo de Energia Elétrica e Água Tratada em Residências: Insight Sustentável de Consumo André S. Abade
232-234
SASA – Sistema de Gestão de Processos em Análise de Alimentos Evaldo José Klock Neto, Hussein Mohamad Hallak, Carlos Uéslei Rodrigues de Oliveira
235-237
UWall: compartilhando informações e promovendo a comunicação via murais digitais Alessandro R. Luz, Caio Rodrigues, Deógenes Júnior, Matteus V. S. Silva, Paulo V. Benedito, Cristiano Maciel
238-240
Avaliação de itens que implementam acessibilidade em conteúdos Web em Dispositivos Móveis para Deficientes Visuais para construção de métrica de pontuação Cheiene Batista Oliveira, Pedro Clarindo da Silva Neto
241-243

VI Escola Regional de Informática de Mato Grosso (ERIMT 2015)
xi
Uma abordagem comparativa na resolução do problema dos Cubos Coloridos Johnnes S. V. da Cruz, Matteus V. S. Silva, Cláudia A. Martins
244-246
Comparativo de métodos de detecção de outliers em dados meteorológicos Johnata Rodrigo Pinheiro Montanher, Gilson Pereira Carvalho, Thiago Meirelles Ventura, Luy Lucas Ribeiro Santana, Claudia Aparecida Martins
247-249
Integração entre o software R e um sistema para mineração de dados meteorológicos em Java Vinicius R. Angelo, Claudia A. Martins, Allan G. Oliveira
250-252

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
1
Uma Ferramenta como Objeto de Aprendizagem para a Disciplina de Estrutura de Dados
Anthony F. La Marca, Marcus Vinícius B. Da Silva, Windelimarcos F. De Borba
Instituto Ciências Exatas e da Terra (ICET) – Universidade Federal de Mato Grosso
(UFMT) - Barra do Garças – MT.
anthonyferreiralamarca, marcusbrito17, [email protected]
Abstract. With the appearance of studies in the area of Human-Computer Interaction, were created different tools which provided users greater ease of interaction with the machines. These tools have great potential, because new technologies associated, making it viable to studies in the academic environment. Thus, the work discusses the creation of an application using the Kinect device to assist in teaching data structure. The idea of the application is to increase student interaction to / with the system through mechanisms that provide natural interaction, providing an assistance tool for teaching, in order to minimize the problems of abandonment and rejection. Resumo. Com o surgimento de estudos na área de Interação Humano-Computador, foram criadas diversas ferramentas que proporcionavam aos usuários maior facilidade de interação com as máquinas. Tais ferramentas possuem grande potencial, devido as novas tecnologias associadas, tornando-as viáveis para os estudos no meio acadêmico. Desta forma, o trabalho aborda a criação de uma aplicação utilizando o dispositivo Kinect para auxiliar no ensino de estrutura de dados. A ideia da aplicação é aumentar a interação dos alunos para/com o sistema por meio de mecanismos que ofereçam a interação natural, proporcionando uma ferramenta de auxilio para o ensino, a fim de minimizar os problemas de desistência e reprovação.
1. Introdução O aprendizado não é apenas em uma sala de aula com professores e livros, está em todos os momentos em que o ser humano passa por novas experiências. Em muitos casos, os métodos tradicionais não são tão eficazes, pois cada aluno possui suas próprias características, interesses, capacidades e necessidades de aprendizagem. Desta forma, faz-se necessário desenvolver um meio onde alcance o interesse de todos, para que assim, tenham um melhor aproveitamento do ensino. Um dos grandes diferenciais observados atualmente no ensino é o de uso de tecnologias computacionais, na qual se consegue maior atenção dos alunos por oferecerem recursos que aumentem o realismo para/com o ensino. Com o avanço tecnológico, observou-se que a interação homem-máquina aumentou significativamente, proporcionando melhor interação, imersão e navegação entre o homem e sistemas computadorizados. Neste contexto, rastreadores de movimentos “casados” com aplicações de Realidade Virtual, surgiram para trazer inovações ao mundo de pesquisa e de ensino.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
2
Entre os rastreadores disponíveis, o Kinect lançado em 2010, proporcionava aos usuários um comportamento livre, sem a necessidade de controle, apenas utilizando o próprio movimento do corpo, diferentemente de outros lançamentos da época. O que este rastreador de movimento proporciona aos usuários, chamamos de Interação Natural, sendo um sistema capaz de entender ações naturais do ser humano e repassa-las em tempo real para o ambiente tridimensional, modificando-o. [Valli, 2005]. Devido ao potencial do dispositivo, foi desenvolvido uma ferramenta como alternativa no ensino da disciplina de estrutura de dados, visto que, atualmente, na Universidade Federal do Mato Grosso, campus Araguaia, o número de desistências e de reprovações de alunos é grande, conforme ilustra a Figura 1. Para minimizar o problema, a ferramenta dispõe do uso de Interação Natural através do dispositivo Kinect para tornar a criação e a manipulação das estruturas mais intuitivas e interativas. Desta forma, deseja-se utilizá-la como objeto de aprendizagem para proporcionar uma alternativa na metodologia de ensino do professor.
Figura 1 – Índice de Reprovações – UFMT [SIGA, 2014]
2. Dispositivo de Rastreamento – Kinect
É comum que o ser humano utilize o auxílio da linguagem gestual para se comunicar, por ser uma forma natural e simples. Assim, utilizar de interfaces que proveem mecanismos de interação natural (NUI) para tornar simples ações, como gestos, expressões e movimentos, em entradas de sistemas para manipula-los e receber feedbacks em tempo real, se tornou atrativo e competitivo no mercado, devido aos diversos dispositivos de baixo custo existentes e a disponibilização de ferramentas para desenvolvedores [Valli, 2005].
Estes dispositivos, denominados como dispositivos de rastreamentos, são utilizados para acompanhar a posição do corpo e os movimentos do usuário, assim como a posição de outros objetos por ele utilizados. Após a captação destes movimentos, eles são repassados ao mundo tridimensional modificando-o em tempo real, além do feedback para o usuário.
Um destes dispositivos é o Kinect, lançado em 2010 pela Microsoft com o objetivo de mudar a forma de interação das pessoas com os jogos, sendo uma tecnologia onde as pessoas não teriam necessidade de utilizar controle físico para jogar, mas sim, o próprio movimento do corpo.
O Kinect tornou-se uma ferramenta de grande potencial para aplicações com Interação Natural (IN) em diversas áreas. Dentre os âmbitos que o Kinect está sendo inserido, além do de jogos, há pesquisas na área de medicina, de engenharia, de segurança, e principalmente na de ensino, que é a abordagem deste trabalho [Medeiros, 2012].

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
3
3. Estrutura de Dados O mundo computacional, desde sua criação durante a segunda guerra mundial, onde surgiram os primeiros computadores conhecidos atualmente, sofre constantes evoluções criando novas perspectivas. Como consequência dessas evoluções, a quantidade de dados a serem manipulados e armazenados teve um aumento extraordinário, tornando a eficiência de como controlá-los um fator de grande importância. Para resolver esse problema, começaram a criar novas técnicas para melhorar o aproveitamento de memória e de processamento para o controle desses dados. Essas técnicas foram chamadas de estrutura de dados, que segundo Laureano (2012), nada mais é do que formas de armazenamento utilizadas no mundo real adaptadas para o mundo computacional com a finalidade de otimizar a manipulação e o tratamento de dados eletronicamente.
Neste trabalho foram utilizadas diversas estruturas de dados: a pilha, a fila, a lista simplesmente encadeada e as árvores: binária e de múltiplos filhos (m-ária).
4. Descrição do Trabalho A aplicação foi desenvolvida utilizando a linguagem de programação C# com o ambiente de desenvolvimento Visual Studio 2012, devido ao Software Development Kit (SDK) ter sido disponibilizado oficialmente pela fabricante (Microsoft) para este ambiente de desenvolvimento [Microsoft, 2014]. As principais tarefas do sistema são inserção e remoção de elementos nas estruturas citadas acima, além de representações gráficas e comandos via interação natural, a fim de proporcionar imersão e envolvimento com o sistema virtual. Na interface gráfica, todo os objetos devem estar dentro da área de um componente chamado KinectRegion, para que possam ser controlados por meio de interações com o Kinect. Além da KinectRegion, o SDK fornece o KinectScrollViewers e o KinectTileButtons, que respectivamente representam as barras de rolagem e os botões, ambos acionados pelo dispositivo de rastreamento. Dentro da área do KinectRegion, onde os objetos estão contidos, é capturado automaticamente o posicionamento de uma das mãos do usuário à frente do Kinect. Já nessa aplicação foram feitas alterações na Dynamic-Link Library (DLL) ou Biblioteca de Vínculo Dinâmico, responsável pelo fluxo de interação. Desta forma, é possível o rastreio das duas mãos do usuário simultaneamente. A interação com um botão, ou seja, pressioná-lo é feita por meio do movimento de empurrar a mão em direção ao sensor Kinect, dando a impressão de estar realmente apertando um objeto. A KinectScrollViewer, ou barra de rolagem do Kinect, é manipulada por meio do fechamento da mão. Após fechar a mão é possível arrastar a barra na direção desejada.
Os movimentos utilizados para os comandos devem ser bem distintos, pois a precisão do Kinect não é perfeita, podendo ocorrer confusão para o sistema em definir uma pose ou um movimento. Há diversas técnicas para a detecção de movimentos, dentre elas a de redes neurais, a de comparação de um gesto previamente armazenado e a de detecção por algoritmos especializados [Cardoso 2013].

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
4
O trabalho utilizou o algoritmo especializado chamado keyframes. O método keyframe utiliza quadros-chaves, onde é definido valores a certos parâmetros que variam com o tempo em cada movimento, como posição ou cor. Por meio desses valores é calculada a evolução dos parâmetros em cada quadro de imagem em um determinado tempo [Gomide et al, 2009]. Este limite entre os parâmetros do quadro inicial até o quadro no tempo final é utilizado para identificar a velocidade necessária para que o movimento seja aceito como um comando na aplicação [Cardoso 2013]. O movimento de aceno com o braço direito é responsável pela inserção nas estruturas. Esse movimento é composto por uma lista de quadros com três poses, onde é necessário que inicialmente a mão direita do usuário esteja em uma posição maior que a posição do cotovelo direito em um eixo horizontal. Na pose seguinte, a mão e o cotovelo do usuário devem estar em uma mesma posição no eixo horizontal e a mão em uma posição superior em relação ao eixo vertical. Como última pose, a mão direita deve estar em uma posição inferior com relação ao eixo horizontal, conforme ilustra a Figura 2. Já o movimento de remoção é similar, mas deve ser executado utilizando o braço esquerdo. Com relação ao movimento para retornar ao menu principal, basta posicionar os braços à frente do corpo e baixa-los.
Figura 2 – Comando de Inserção
Para realizar as operações de manipulação nas estruturas descritas no capítulo de resultados, deve-se posicionar a mão em frente ao dispositivo Kinect e direcionar o rastreador, presente no ambiente virtual, para o número que deseja selecionar e pressioná-lo, empurrando a mão em direção ao Kinect. Após compor o número, basta realizar os movimentos de inserção e remoção descritos anteriormente. Os processos de manupilação das estruturas seguem de acordo com a particularidade de cada uma.
5. Resultados Foi obtida uma interface simples e de fácil manuseio para o usuário, por meio de interações naturais. Efetuando movimentos diante do Kinect é possível utilizar toda a funcionalidade da aplicação, dispensando a utilização de dispositivos convencionais, como mouse e teclado. A Figura 3 ilustra a interface inicial do sistema.
Figura 3 – Tela do Menu Principal

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
5
Na interface gráfica do menu principal é disponibilizado botões para selecionar as opções de temas disponíveis relacionados a disciplina de estrutura de dados. Dentre os temas à serem escolhidos estão a pilha, a fila, a lista e as árvores, além de estar disponível a opção de ajuda que identifica todos os comandos possíveis da aplicação e como executá-los.
Após a escolha de uma das estruturas é mostrada a sua respectiva interface. A Figura 4 apresenta as interfaces das estruturas Pilha e Fila.
Figura 4 – Estrutura Pilha e Fila
A interface da estrutura lista pode ser analisada na Figura 5. Nesta estrutura há uma representação de um ponteiro para o elemento inicial da lista, um indicando o seu elemento sucessor e um para o último elemento da lista, indicando o final da lista com um endereço nulo. Quando há uma remoção de um elemento interno, há um percurso do novo ponteiro do elemento anterior ao que será removido até o elemento posterior, além do elemento removido ficar vazio, indicando endereço nulo, conforme ilustrado na Figura 5.
Figura 5 – Estrutura Lista e Remoção
A última estrutura disponível na aplicação é a arvore binária e a de múltiplos filhos, tendo o posicionamento de seus elementos de forma análoga a ramificações de uma árvore, havendo um reposicionamento de acordo com o elemento a ser inserido ou removido. Esse reposicionamento de elementos pode ser vistos ao comparar a Figuras 6 com a Figura 7, onde um novo elemento, contendo o valor 110 (cento e dez), é inserido. Com a inserção do valor, a altura da árvore é incrementada e seus elementos reposicionados.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
6
Figura 6 – Interface da Estrutura Arvore (Binária e Múltiplos filhos à direita)
Figura 7 – Redimensionamento dos Elementos após a Inserção
6. Conclusão O escopo do trabalho foi utilizar técnicas que garantissem fácil acesso à ferramenta pelas comunidades interessadas, disponibilizando um ambiente integrado na qual a partir dele, seja possível interagir com as estruturas utilizadas na disciplina proposta.
Assim, conclui-se que a ferramenta é favorável no auxílio para o ensino da disciplina, devido utilizar recursos tecnológicos, gráficos e interativos para a representação das estruturas de dados.
Como trabalhos futuros, novas estruturas podem ser incorporadas ao trabalho, devido a sua programação modular, além de animações para melhorar a interação em sua manipulação. Outro trabalho importante seria aplicar a ferramenta em sala de aula, seguido de análises dos feedbacks de professores e alunos para futuras correções e melhorias.
8. Referências
Cardoso, Gabriel, S. Microsoft Kinect: Crie aplicações interativas com o microsoft kinect. Casa do Código. São Paulo, 2013.
Gomide, João V. b; Pacheco, Daniel; Araújo, Arnaldo de a. Captura de movimento e
animação de personagens em jogos. Universidade Fumec e Universidade Federal de Minas Gerais. Rio de Janeiro – RJ, 2009.
Laureano, Marcos. Estrutura de dados com algoritmos e c. Curitiba: Brasport livros e
multimídia ltda, 2012. Medeiros, Anna Soares. Interação natural baseada em gestos como interface de controle
para modelos tridimensionais. Universidade Federal da Paraíba. João Pessoa, 2012. Microsoft. Kinect for windows sdk. Disponível em: < http://msdn.microsoft.com/en-
us/library/hh855347.aspx >. Acesso em: julho de 2014. Siga. Sistema de Informações de Gestão Acadêmica. Disponível em:
https://sia.ufmt.br/www-siga/htmldelphi/login/LoginUnico/login.htm. Acesso em: agosto de 2014.
Valli, A. Notes on natural interaction. 2005.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
7
Desenvolvimento de um Dicionário Controlado para Dispositivos Móveis Como Ferramenta de Auxílio à Alunos
com Deficiência Motora
Kaio Alexandre da Silva¹, Jones Fernando Giacon¹, Michel da Silva²
1Centro Universitário Luterano de Ji-Paraná (CEULJI/ULBRA) Caixa Postal 76.907-438 – Ji-Paraná – RO – Brasil
2Instituto Federal de Educação, Ciência e Tecnologia de Rondônia (IFRO) Ji-Paraná – RO – Brasil.
[email protected], [email protected], [email protected];
Abstract. The development of a controlled dictionary, to the area of biology using Supervised Learning in textual documents through Text Mining Techniques to be used on the Android operating system, aiming to help students with physical disabilities, improve their academic performance. Where textual documents will be devices for mounting dictionaries controlled in enclosed areas. The methodology used was the Cross-Industry Standard Process for Data Mining (CRISP-DM), originally designed for data mining in the database.
Resumo. O desenvolvimento de um dicionário controlado, para a área da Biologia utilizando Aprendizado Supervisionado em Documentos Textuais, através de Técnicas de Mineração de Textos, para serem utilizados no sistema operacional Android, visando auxiliar alunos com deficiência motora, a melhorar o seu desempenho acadêmico. Onde os documentos textuais serão artifícios para a montagem de dicionários controlados em domínios fechados. A metodologia utilizada foi a Cross-Industry Standard Process for Data Mining (CRISP-DM), concebida originalmente para mineração de dados em banco de dados.
1. Introdução
A preocupação com a Acessibilidade é cada vez maior nas instituições públicas e privadas. Acessibilidade é um processo de transformação do ambiente e de mudança da organização das atividades humanas, que diminui o efeito de uma deficiência. Para esta transformação do ambiente, para ajudar estas pessoas, a tecnologia é uma aliada poderosa neste processo. As tecnologias que ajudam pessoas com deficiência, são denominada Tecnologias Assistivas (TA).
Dentre as TA’s, o uso de computadores para amenizar as dificuldades das pessoas com deficiência é uma das classificações existentes segundo as leis que compõem a ADA (American with Disabilities Act) [ADA, 1994]. O uso de técnicas de Aprendizado Supervisionado e Mineração de Textos (Text Mining) e, documentos

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
8
textuais são artifícios para a montagem de dicionários controlados em domínios fechados.
Assim este trabalho promoveu o desenvolvimento de um dicionário controlado na área da Biologia utilizando Aprendizado Supervisionado em Documentos Textuais através de Técnicas de Mineração de Textos para serem utilizados no sistema operacional Android, visando auxiliar alunos com deficiência na escrita a melhorar o seu desempenho acadêmico.
1.1. Problemática
Tendo o curso de biologia do Centro Universitário Luterano de Ji-Paraná - CEULJI/ULBRA como objeto de pesquisa, viu-se a dificuldade de escrita de alguns alunos que possuem necessidades especiais, pois várias palavras são de língua estrangeira e os corretores ortográficos não possuem recursos para notificar o aluno da ortográfica exata dessas palavras.
1.2. Solução Proposta
Uma forma de auxiliar os alunos a resolver este problema, principalmente durante as aulas e nos momentos de estudo é disponibilizar um aplicativo que terá um dicionário com as palavras específicas desse conhecimento, possibilitando assim que os alunos consigam anotar com mais facilidade as palavras durante a aula ou durante o seu estudo.
Para se criar esse dicionário, deve-se notar a necessidade da mineração de textos. Sendo que a mineração de texto visa ajudar no processo da extração de conhecimento através de informações semi-estruturadas e não-estruturadas, através de textos, e-mail, artigos, documentos (atas, memorandos, ofícios), dentre outros. A busca de padrões e conhecimento nestes documentos é muito comum. Porém, na maioria das vezes, o resultado obtido é falho: documentos não relacionados, volume muito alto de informações dispensáveis, entre outros.
Através de artigos relacionados ao campo da biologia, serão aplicadas as técnicas de mineração de texto, com o objetivo de encontrar as palavras específicas desse campo de conhecimento, facilitando assim a tomada de decisão das palavras a serem escolhidas. Considerando que a tomada de decisão é um processo de investigação, de reflexão e de análise, onde tem-se a necessidade de informações qualitativas que contenham alto valor agregado.
2. Metodologia
A metodologia aplicada foi a Cross-Industry Standard Process for Data Mining (CRISP-DM), concebida originalmente para mineração de dados. Para a CRISP-DM, o ciclo de vida do processo de DCBD segue uma sequência de etapas [CHAPMAN et al, 2000]. Essas etapas são executadas de forma interativa, sendo elas dispostas de acordo com a figura 1.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
9
Figura 1 - CHAPMAN, P.; et al. The CRISP-DM Process Model. 2000.
Assim, pelas entradas e respostas providas pelo usuário, a sequência da execução pode ser alterada. O encadeamento das ações, dependendo do objetivo e de como as informações se encontram, permite retorno a passos já realizados.
A Compreensão do Negócio procura identificar as necessidades e os objetivos do negócio do cliente, convertendo esse conhecimento numa tarefa de mineração de dados. Busca detectar eventuais problemas e/ou restrições que, se desconsideradas, poderão implicar perda de tempo e esforço em obter respostas corretas para questões erradas. Essa tarefa compreende ainda descrição do cliente, seus objetivos e descrição dos critérios utilizados para determinar o sucesso do seu negócio.
A Compreensão dos Dados visa a identificar informações que possam ser relevantes para o estudo e uma primeira familiarização com seu conteúdo, descrição, qualidade e utilidade. A coleção inicial dos dados procura adquirir a informação com a qual se irá trabalhar, relacionando suas fontes, o procedimento de leitura e os problemas detectados. Nessa tarefa, descreve-se ainda a forma como os dados foram adquiridos, listando seu formato, volume, significado e toda informação relevante. Durante essa etapa, são realizadas as primeiras descobertas.
A Preparação dos Dados consiste numa série de atividades destinadas a obter o conjunto final de dados, a partir do qual será criado e validado o modelo. Nessa fase, são utilizados programas de extração, limpeza e transformação dos dados. Compreende a junção de tabelas e a agregação de valores, modificando seu formato, sem mudar seu significado a fim de que reflitam as necessidades dos algoritmos de aprendizagem.
Na Modelagem, são selecionadas e aplicadas as técnicas de mineração de dados mais apropriadas, dependendo dos objetivos pretendidos. A criação de um conjunto de

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
10
dados para teste permite construir um mecanismo para comprovar a qualidade e validar os modelos que serão obtidos. A modelagem representa a fase central da mineração, incluindo escolha, parametrização e execução de técnica(s) sobre o conjunto de dados visando à criação de um ou vários modelos.
A Avaliação do Modelo consiste na revisão dos passos seguidos, verificando se os resultados obtidos vão ao encontro dos objetivos, previamente, determinados na Compreensão do Negócio, como também as próximas tarefas a serem executadas. De acordo com os resultados alcançados, na revisão do processo, decide-se pela sua continuidade ou se deverão ser efetuadas correções, voltando às fases anteriores ou ainda, iniciando novo processo.
A Distribuição (Aplicação) é o conjunto de ações que conduzem à organização do conhecimento obtido e à sua disponibilização de forma que possa ser utilizado eficientemente pelo cliente. Nessa fase, gera-se um relatório final para explicar os resultados e as experiências, procurando utilizá-los no negócio.
3. Ferramentas Utilizadas
Para o desenvolvimento do trabalho, foram utilizadas diversas ferramentas, para a coleta dos artigos foi utilizado a plataforma Scientific Electronic Library Online (SciELO), que é uma biblioteca eletrônica que abrange uma coleção selecionada de periódicos científicos brasileiros [SCIELO, 2002].
Para o processamento dos dados, foi utilizado a ferramenta Text Mining Suite, desenvolvido pela empresa InText Mining, onde a principal técnica do software é a análise de conceitos presentes nos textos [INTEXT, 2005].
Para a modelagem do diagrama de classe, foi utilizado a ferramenta RAD Studio XE6 e para a modelagem do diagrama entidade-relacionamento, foi utilizado a ferramenta MySQL Workbench 6.2 CE.
Para o desenvolvimento do Sistema de Avaliação de Palavras, foi utilizada a Linguagem de Marcação de Hipertexto (HTML), a Folha de Estilo em Cascata (CSS), a linguagem de programação Hypertext Preprocessor (PHP) e o banco de dados MySQL.
Para o desenvolvimento do aplicativo, foi utilizado o ambiente de desenvolvimento do Android Studio.
4. Avaliação
Essa fase constitui na avaliação dos dados gerado pelo modelo, verificando os resultados obtidos e o alcance dos objetivos do negócio. Para essa fase foi estipulado a avaliação das palavras pelos especialistas na área da biologia, que neste trabalho estão sendo representados pelo corpo de professores do curso de Ciências Biológicas do Centro Universitário Luterano de Ji-Paraná.
Para a avaliação das palavras foi desenvolvido um sistema de avaliação de

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
11
palavras. Onde foi construído um banco de dados para armazenar todas as doze mil palavras que foram obtidas na modelagem. Para isso foi criada uma tabela com o nome de “Conjunto”, sua função é apenas guardar as palavras que vem da modelagem. Foi criada mais duas tabelas, uma nomeada de “Tipo”, que tem apenas dois registros, que guardam os valores: “1” para Comum e “2” para Específico. E a tabela criada foi nomeada de “Palavras”, que guarda as palavras e relaciona com o tipo de categoria que o especialista irá determinar.
Como meio de acessar essas palavras no banco de dados foi criado um sistema web utilizando as tecnologias HTML, CSS e PHP. Sistema através do qual o especialista tem acesso a palavra e conta com três opções de ação: Específico, Comum e Deletar.
5. Aplicação
Como resultado final da etapa de aplicação, foi desenvolvido um aplicativo para a plataforma Android, nomeado de “Palavras da Botânica”, que tem por objetivo adicionar as palavras específicas da botânica ao dicionário do sistema operacional. Possibilitando aos usuários a autocorreção e o autocomplemento da palavra no momento da digitação.
A interface do aplicativo é apresentada na figura 2. Nela encontram-se dois botões, o primeiro, “Adicionar Palavras”, adiciona as palavras disponibilizadas pelo aplicativo ao dicionário, atualmente o aplicativo tem duzentas palavras específicas. O segundo botão, “Mostrar Palavras”, abre a lista de palavras que o aplicativo contém, possibilitando ao usuário identificar uma palavra antes de adicionar as mesmas para o dicionário do sistema operacional, ou visualizar quais foram as palavras adicionadas.
Figura 2 – Interfaces do Aplicativo “Palavras da Botânica”

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
12
6. Teste e Avaliação do Aplicativo
O aplicativo foi testado em pesquisa qualitativa, em um ambiente controlado, com dois alunos do curso de Ciências Biológicas, sendo um aluno com deficiência motora e outro sem deficiência. O teste consistiu em digitar duas vezes, uma sequência de cinco palavras específicas da biologia, na primeira vez os alunos utilizaram o celular pessoal, sem o uso do aplicativo, enquanto que na segunda vez os alunos utilizaram as palavras já inseridas no dicionário através do aplicativo.
O aluno com deficiência motora, na primeira etapa levou dois minutos para digitar as cinco palavras, enquanto que na segunda etapa, com o uso do aplicativo, ele levou quarenta e cinco segundos, reduzindo seu tempo em 62,5%.
O aluno sem deficiência, na primeira etapa levou um minuto e vinte e cinco segundos para digitar as cinco palavras, enquanto que na segunda etapa, com o uso do aplicativo, ele levou trinta segundos, reduzindo seu tempo em 64,7%.
Ambos responderam que utilizariam o aplicativo no dia-a-dia e na pergunta sobre a opinião sobre o aplicativo o aluno portador da deficiência complementou que com o uso do aplicativo, aumentaria a eficiência do aprendizado no dia-a-dia.
7. Considerações Finais e Trabalhos Futuros
O presente trabalho visou estabelecer um meio para ajudar as pessoas com deficiência motora a ter um melhor desenvolvimento pedagógico nas disciplinas de biologia, além de focar no estudo da descoberta de conhecimento em texto.
Com os resultados deste estudo pode-se criar dicionários para outras áreas de domínio, ajudando não apenas alunos com deficiência motora, mas sim todos os alunos que estejam estudando aquela área de domínio.
Como foi demonstrado na avaliação do aplicativo, nota-se que o aplicativo não ajuda apenas os alunos com deficiência, mas também os alunos que não possuem nenhum tipo de deficiência e em ambos os casos se notou uma melhora de mais de 60% em relação ao tempo de digitação, o que facilita para o aluno acompanhar o conteúdo que está sendo ministrado e confiança de estar digitando corretamente.
No que diz respeito da aplicação metodológica, obteve total êxito, visto que o projeto de mineração texto foi conduzido pela metodologia CRISP-DM, criada para projetos de mineração de dados. Na prática, verificou-se que não há restrição metodológica para a condução de projetos dessa natureza.
Como trabalhos futuros, pretende-se a finalização da avaliação das palavras, realizar o acompanhamento por um tempo maior dos alunos que estão utilizando o aplicativo a fim de descobrir o impacto no aprendizado, o desenvolvimento de um teclado próprio, para que possa integrar o dicionário ao teclado e ao sugerir as palavras, poder destacar com cores diferentes as palavras específicas das palavras comuns. Também se pretende a disponibilização do aplicativo na loja de aplicativos, bem como a distribuição em outros idiomas e ampliação das áreas de domínio.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
13
Referências
Americans with Disabilities Act 1994. Disponível em: <http://www.resna.org/taproject/library/laws/techact94.htm>. Acessado em 28 de maio de 2015
CHAPMAN, P.; CLINTON, J.; KERBER, R.; KHABAZA, T.; REINARTZ, T.; SHEARER, C. & WIRTH, R. CRISPDM 1.0 step-by-step data mining guide. Technical report, CRISP-DM.
INTEXT. Manual do Software: Text Mining Suite v.2.4.7. InText Mining Ltda. Versão 10. 2005.
LOH, Stanley; WIVES, Leandro Krug; PALAZZO M. de Oliveira, José. Descoberta Proativa de Conhecimento em Textos: Aplicações em Inteligência Competitiva. In: III International Symposium on Knowledge Management/Document Management, 2000, Curitiba/PR. ISKM/DM 2000. Curitiba : PUC-PR, 2000. v. 1. p. 125-147.
SCIELO. SciELO – Scientific Electronic Library Online. Disponível em: <http://www.scielo.br/scielo.php?script=sci_home&lng=pt&nrm=iso#about>. Acessado em 30 de maio de 2015.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
14
Aplicando gamificação em ambientes corporativos
Nathalia R. Sampaio1, Filipe E. Botti1, Roberta C. D. Taddeo1, Francisco G. Maranhão1, Leandro da Silva Taddeo1
1 Faculdade Sete de Setembro (Fa7) Fortaleza – CE – Brasil
nathalias18,[email protected], [email protected], filipebotti,[email protected]
Abstract. Organizations face many contemporary problems due to changes in the organizational climate, such as: high levels of stress, low sense of community, little loyalty and high turnover. In this context, the introduction of gamification in workspaces emerges as an innovative alternative to meet these challenges. This article presents the experience of this application in a public institution, with the techniques and methods used and the results obtained in order to evaluate the effectiveness of using gamification as engagement strategy developers and real addressing these business challenges.
Resumo. As organizações enfrentam diversos problemas contemporâneos, decorrentes de alterações no clima organizacional, tais como: altos níveis de estresse, baixo senso de comunidade, pouca lealdade e alta rotatividade. Neste contexto, a introdução de gamificação em espaços de trabalho surge como uma alternativa inovadora para enfrentar estes desafios. O presente artigo apresenta a experiência desta aplicação em uma instituição pública estadual, apresentando as técnicas e métodos empregados e os resultados obtidos a fim de avaliar a efetividade da utilização da gamificação como estratégia de engajamento de colaboradores e real enfrentamento desses desafios corporativos.
1. Introdução O Núcleo de Digitalização é um setor do Tribunal de Justiça do Estado do Ceará que tem o objetivo de converter os processos físicos, em tramitação na comarca de Fortaleza, em processos eletrônicos. O processo de digitalização consiste na codificação de documentos capturados através de um scanner ou máquina fotográfica digital, com posterior disponibilização em forma de imagem, texto ou som para armazenagem, transmissão e recuperação em sistemas computadorizados, sendo fundamental o entendimento das suas oito fases: higienização, digitalização, controle de qualidade, indexação, assinatura, importação, conferência e arquivamento.
A higienização corresponde à retirada de poeira e outros resíduos estranhos aos documentos, por meio de técnicas apropriadas, com vista à sua preservação [Bellotto e Camargo 1996]. Cassares e Moi [2000] afirmam que o processo de limpeza de acervos e arquivos se restringe à limpeza de superfície e, portanto, é mecânica, feita a seco. Essa fase é aplicada com o objetivo de reduzir resíduos (poeira, partículas sólidas, excrementos de insetos) na superfície do documento. Para fins de digitalização, é nessa fase que grampos e bailarinas são retirados dos processos.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
15
A digitalização é a fase de captura do documento através de um scanner ou máquina fotográfica digital, e posterior disponibilização em forma de imagem.
O controle de qualidade é a etapa onde as imagens são inspecionadas e comparadas com o documento original, obedecendo às recomendações apresentadas por Nascimento et al. [2006].
Vieira [1998] afirma que a indexação é uma técnica de análise de conteúdo que condensa a informação significativa de um documento, através da atribuição de termos, criando uma linguagem intermediária entre o usuário e o documento. É um dos processos básicos de recuperação da informação. Pode ser realizada pelo homem (indexação manual), ou por programas de computador (indexação automática). Para os processos judiciais, a indexação será a tipificação do documento em termo de distribuição, decisão, despacho, ato ordinatório, certidão, entre outros.
A fim de garantir a integridade das imagens e atender à lei do processo eletrônico, número 11.419 de 2006, todas as imagens geradas são assinadas digitalmente por um servidor do Tribunal, através de um Certificado Digital padrão ICP-Brasil, tipo a3, sendo essa a única atividade da tarefa.
A importação consiste na inclusão das imagens geradas para o processo no sistema SAJ, onde tramitará eletronicamente.
A conferência é a segunda estação de controle de qualidade, onde verificamos, no sistema, se as imagens foram importadas corretamente e se o sistema consegue apresentar todas as imagens geradas.
O arquivamento consiste no acondicionamento do documento em sacos plásticos, que são lacrados e acondicionados em caixas de papel que, quando cheias, também serão lacradas e encaminhadas ao setor de Arquivo.
Essa atividade é realizada pelo Tribunal desde 2009, quando o processo eletrônico foi implantado, porém, todos os clientes do serviço reclamavam da qualidade do trabalho, da velocidade da entrega e do comportamento dos colaboradores, ocasionados por um ambiente de trabalho desfavorável, que, em termos gerais, contribuía para a grande rotatividade da equipe, nos instigando a buscar alternativas para os desafios identificados: (1) motivar o trabalho em equipe; (2) aumentar o engajamento dos participantes; (3) estimular o aumento da produtividade; (4) reduzir a rotatividade da equipe; e (5) melhorar o clima organizacional.
Dado o perfil jovem dos colaboradores, a adoção de elementos de design de jogos em contextos não-jogo proposta por Raftopoulos e Walz [2013], com os trabalhos apresentados por Senna e Coelho [2012], Cohen [2011], apontam a gamificação do espaço de trabalho como possível solução para os desafios acima endereçados.
O presente artigo apresenta a experiência de aplicar a gamificação na digitalização de processos judiciais e seus resultados. A seção 2 aborda os principais aspectos do clima organizacional. Posteriormente, apresentamos os fundamentos da gamificação. Na seção 4, são descritas as regras e procedimentos propostos e, no capítulo seguinte, apresentamos os dados e analisamos os resultados obtidos.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
16
2. Clima organizacional Sbragia [1983] afirma que o clima organizacional tem-se tornado um conceito cada vez mais importante para descrever as percepções das pessoas em relação às organizações em que trabalham. O clima é um conceito abrangente, por ser um modo de resumir numerosas percepções em um pequeno número de dimensões. Embora o conceito de clima tenda a ser usado para descrever organizações, o termo também pode ser usado para caracterizar as percepções das pessoas sobre os grupos ou equipes em que trabalham.
Coda [1993] afirma que o “clima organizacional é o indicador do grau de satisfação dos membros de uma empresa, em relação a diferentes aspectos da cultura ou realidade aparente da organização, tais como: política de RH, modelo de gestão, missão da empresa, processo de comunicação, valorização profissional e identificação com a empresa”.
Para Payne e Mansfield [1973] “o clima organizacional é considerado como o elo conceitual de ligação entre o nível individual e o nível organizacional, no sentido de expressar a compatibilidade ou congruência das expectativas, valores e interesses individuais com as necessidades, valores e diretrizes formais”.
Segundo Chiavenato [2003] “clima organizacional envolve uma visão mais ampla e flexível da influência ambiental sobre a motivação. É a qualidade ou propriedade do ambiente organizacional que é percebida ou experimentada pelos membros da organização e influencia no seu comportamento. Refere-se ao ambiente interno existente entre as pessoas que convivem no meio organizacional e está relacionado com o grau de motivação de seus participantes”.
Moran e Volkwein [1992] apresentam uma definição abrangente e esclarecedora, segundo a qual "clima organizacional é uma característica relativamente duradoura de uma organização que a distingue das demais e: (1) inclui percepções coletivas dos membros sobre sua organização com relação a dimensões como autonomia, confiança, coesão, apoio, reconhecimento, inovação, honestidade etc.; (2) é produzido pela interação dos membros; (3) serve como uma base para interpretar as situações; (4) reflete as atitudes, normas e os valores prevalecentes da cultura da organização; e (5) atua como uma fonte de influência para comportamentos apresentados".
O clima organizacional é capaz de afetar o comportamento organizacional e este afeta o desempenho. Para o diagnóstico do clima organizacional e posterior intervenção, consideramos os seguintes fatores: cultura organizacional, liderança, motivação, trabalho em equipe, comunicação interna, relações interpessoais e gestão de pessoas. O conhecimento de tais aspectos propicia aos gestores uma maior e melhor possibilidade de gerenciamento da organização.
3. Gamificação A necessidade de tornar o ambiente de trabalho mais agradável remonta de 1973, e foi a partir dessa temática que Coonradt [2008] criou sua empresa “Games of Work”, com o objetivo de pesquisar o porquê das empresas americanas estarem perdendo produtividade em seus ambientes de trabalho, que como resultado apresentou os cinco

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
17
princípios fundamentais da gamificação moderna: objetivos claramente definidos; melhor visualização de placar/notas; feedback frequente; treinamento consistente.
Monson [1970] afirmou que “quando o desempenho é medido, ele aumenta; quando adicionamos feedback, a taxa de melhoria é potencializada”; e Krogue [2012] a expandiu dizendo que “o aumento da frequência do feedback melhora a qualidade e a quantidade do desempenho”, complementando-a com a ideia de que: “Quando o feedback é apresentado na forma de quadros e gráficos, o impacto é ainda maior.”
Werbach [2012] sugere que a gamificação, em essência, não é um jogo, mas uma série de elementos de design de jogos introduzidos em aplicações não-jogo.
Suits [1967] fornece uma compreensão de como um jogo é definido ao afirmar que “um jogo é se engajar em atividade direcionada para provocar um estado específico de interesse, usando apenas meios permitidos por regras específicas, onde os meios permitidos pelas regras são mais limitados em escopo do que seriam na ausência de regras, e onde a única razão para aceitar tal limitação é tornar possível tal atividade.”
Woods [2012], a partir de uma perspectiva de negócios diz que “Gamificação nos leva a atingir objetivos utilizando um conjunto de interações baseadas em medições”, permitindo aos gestores apresentar os resultados atualizados, aos colaboradores, em ciclos menores de feedback. Afirmando, ainda, que quando a gamificação é incorporada aos ciclos de feedback empresariais, permite aos gestores um controle mais efetivo da produtividade, podendo se tornar parte integral do processo de negócios se incorporado aos sistemas existentes.
Schell [2009] afirma que "um jogo é uma atividade de resolução de problemas abordados com atitude lúdica." O jogo permite aos jogadores percorrer caminhos que se ramificam ao longo da atividade, permitindo aos jogadores fazer escolhas ao longo do caminho.
Werbach [2012] elabora, "O jogo oferece o ambiente para fazer essas escolhas, a estrutura e as regras." Portanto, um jogo tem caminhos, ramificados para fazer escolhas no decorrer da atividade, quando os jogadores fazem escolhas e percorrem os caminhos (jogam) A estrutura é o que fornece as possibilidades de escolha e nos dá sensação de liberdade.
Zimmerman [2009] também fala do "círculo mágico" que "representa a ideia de que os jogos têm lugar dentro dos limites de tempo e espaço e são sistemas de significado autocontidos". Isto dá aos jogadores um jogo fronteira entre o mundo real e o jogo. A tarefa do designer de jogos é levar os jogadores para o jogo e motivá-los a continuar jogando, a fim de alcançar este objetivo; o jogo deve ter sentido e prover valor para o jogador.
Mehta e Kass [2012] verificaram que apesar dos jogos se provarem eficientes para atrair usuários, eles não foram necessariamente desenvolvidos para mudar comportamentos fora do jogo em si. Isto sugere que a principal preocupação das organizações para gamificar espaços de trabalho é prover as alterações necessárias para suportar essa nova atividade.
Atualmente, muitas organizações apontam a gamificação como uma alternativa para resolver algumas questões fundamentais de negócios.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
18
Ambiente de trabalho gamificado pode oferecer às organizações soluções para resolver algumas questões trabalhistas. De acordo com Meloni [2012], engajamento é a questão principal a ser resolvida ou apoiada pelas organizações. Werbach e Hunter [2012] afirmam que "engajamento tem o valor. Estudos sugerem que cerca de 70% dos trabalhadores americanos não estão totalmente engajados em seu trabalho." Quando os funcionários não estão envolvidos, eles reduzem sua motivação e produtividade.
A gamificação não é um conceito novo para produtos de consumo, como cartões de crédito ou sites de mídia social, como o Foursquare e Twitter. As empresas estão começando a reconhecer os benefícios ao negócio quando adicionamos o lúdico ao ambiente de trabalho.
McGonigal [2011] sugere que as pessoas podem sentir-se mais recompensadas no mundo virtual do que na vida real, afirmando, ainda, que com um pequeno investimento em sistemas de TI, Gamificação, utilizada corretamente, pode promover recompensas intrínsecas que custam menos dinheiro do que o aumento de recompensas extrínsecas, tais como remuneração.
O Gartner Group [2011] prevê que até 2015, 50% de todas as empresas vão gamificar sistemas e processos. O objetivo da Gamificação é aumentar a participação e engajamento onde uma "particular, convincente, dinâmica e sustentada experiência gamificada pode ser usada para alcançar uma variedade de objetivos de negócios". McGonigal [2011] ratifica as previsões, afirmando que aqueles que ignoram os jogos estarão em desvantagem por não saber como aproveitá-los dentro de suas empresas; perderão uma chance potencial de resolver problemas e criar oportunidades.
4. Gamificação no Tribunal de Justiça do Estado do Ceará Cientes do clima organizacional desfavorável e dispostos a realizar a interdição necessária à correção de rumo do trabalho desenvolvido, foram utilizadas as seguintes técnicas de engajamento: Conquistas: sistemas de recompensa, onde o jogador recebe pontos ou desbloqueia material bônus ao concluir uma tarefa [Fitz-Walter et al. 2011]. Medalhas: são artefatos virtuais com representação visual, concedidos aos usuários que obtiverem conquistas específicas. [Antin e Churchill 2011]. Desafios: são propostas de execução de um conjunto de ações, trilhados pelo projeto de gamificação, podendo envolver uma única ou várias tarefas. [Duggan e Shoup 2013]. Leaderboards: Seu propósito é mostrar aos jogadores sua posição entre os jogadores. Muitas vezes, o ranqueamento pode provocar o desejo de jogar. O simples objetivo de subir no ranking serve como um poderoso motivador para continuar [Duggan e Shoup 2013]. Barra de progresso: é uma ferramenta que mostra ao jogador uma imagem clara do começo, meio e fim da atividade, motivando-o a completar uma tarefa [Hayes 2013].
Inicialmente, foram definidos os desafios a serem enfrentados diariamente pelos colaboradores. O desafio foi estabelecido pela criação de uma meta diária e uma supermeta diária baseada na produtividade média de cada uma das atividades, conforme podemos observar na tabela 1.
Para melhorar o feedback dos usuários, foi introduzido no sistema SAD (sistema de apoio a digitalização) uma tela de consulta de produtividade, onde cada usuário do sistema pode acompanhar seu desempenho durante o dia. Posteriormente, para algumas

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
19
atividades, foi acrescentada, a essa consulta, uma barra de progresso visual, que muda de cor à medida que o trabalho é desenvolvido.
A tabela 2 demonstra os valores estabelecidos para cada atividade, neste caso, os valores apresentados na tabela são baseados no número mínimo de imagens necessário para trocar a cor da barra de progresso, sendo que todas as atividades começam com a cor vermelha.
Tabela1: Meta diária por atividade
Atividade Meta Supermeta Higienização 20 processos 30 processos Digitalização 24.000 imagens 30.000 imagens Controle de Qualidade 8.000 imagens 10.000 imagens Indexação 8.000 imagens 10.000 imagens Assinatura 100% dos processos indexados Importação 100% dos processos assinados Conferência 40 processos 60 processos Arquivamento 100% dos processos conferidos
Adicionalmente, foi concedida uma estrela para cada colaborador que atingisse a meta diária, e uma estrela especial é dada ao colaborador que atingir a supermeta. As estrelas de meta conquistadas são perdidas se o usuário não atingir a meta do dia. A cada cinco estrelas de meta obtidas, uma medalha é dada ao empregado, possibilitando ao mesmo a possibilidade de trocá-la por um dia de folga. O empregado pode, ainda, trocar uma estrela especial por uma chegada atrasada ou saída antecipada.
Tabela2: Regras de Progressão
Atividade Amarelo
Verde Azul
Digitalização 12.000 24.000 30.000 Controle de Qualidade 5.000 8.000 10.000 Indexação 5.000 8.000 10.000
5. Resultados obtidos Consideramos essencial para a boa compreensão dos resultados obtidos, a apresentação do cenário anterior à gamificação e do cenário atual, a fim de poder comparar os resultados de produtividade, rotatividade da equipe, satisfação com a liderança, motivação pessoal e promoções obtidas.
5.1. Cenário anterior A equipe era formada por 40 pessoas, divididas em 4 faixas salariais distintas e compatíveis com as atividades exercidas. Existia uma reclamação generalizada entre os clientes do serviço, que o mesmo era lento e ineficiente. Naquele período de 36 meses, houve uma enorme rotação da equipe, sendo necessária a substituição de 30 colaboradores e não houve nenhuma promoção no período, havendo, ainda, uma média de 3,2 faltas por colaborador/mês.
Naquele contexto, os colaboradores responderam uma pesquisa de clima organizacional, na forma de questionário, que concluiu que o clima organizacional era desfavorável, apontando sério descontentamento com a liderança.
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
20
5.2. Cenário atual O número de colaboradores não foi alterado, porém foram adicionadas 4 faixas salariais. Ainda existem reclamações pontuais de digitalização, porém, hoje, o foco da reclamação está na falta de agenda para atendimento aos interessados.
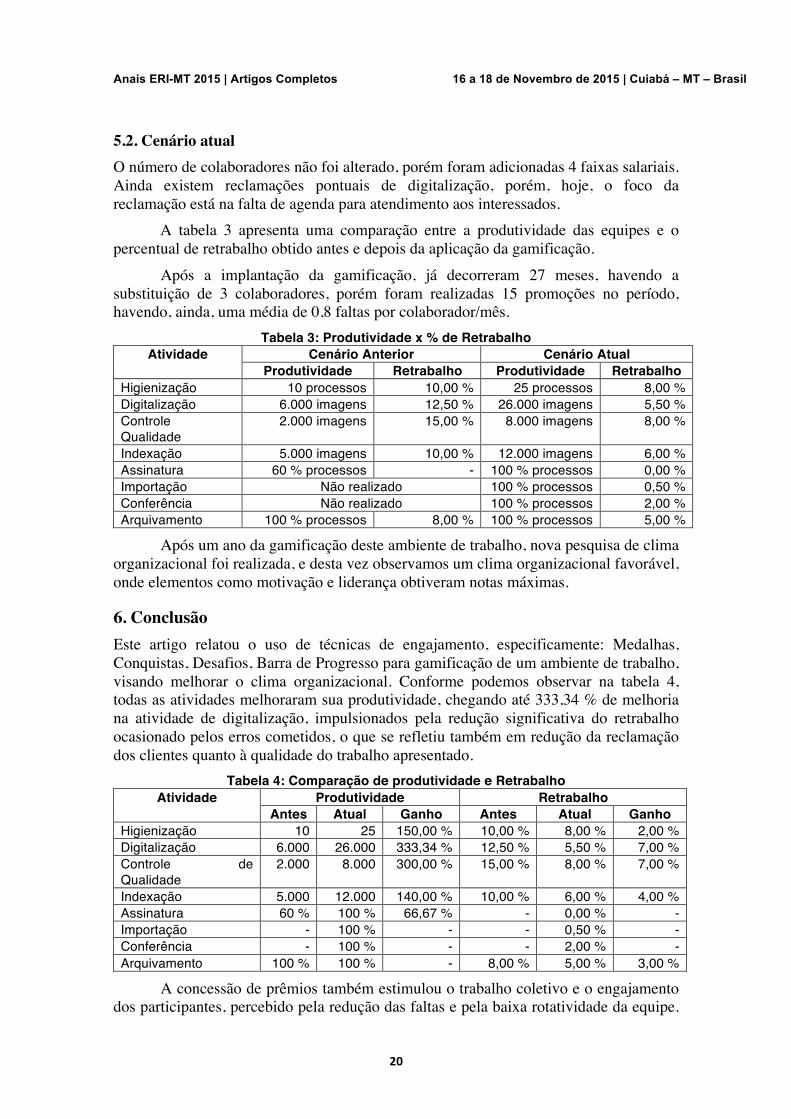
A tabela 3 apresenta uma comparação entre a produtividade das equipes e o percentual de retrabalho obtido antes e depois da aplicação da gamificação.
Após a implantação da gamificação, já decorreram 27 meses, havendo a substituição de 3 colaboradores, porém foram realizadas 15 promoções no período, havendo, ainda, uma média de 0,8 faltas por colaborador/mês.
Tabela 3: Produtividade x % de Retrabalho Atividade Cenário Anterior Cenário Atual
Produtividade Retrabalho Produtividade Retrabalho Higienização 10 processos 10,00 % 25 processos 8,00 % Digitalização 6.000 imagens 12,50 % 26.000 imagens 5,50 % Controle Qualidade
2.000 imagens 15,00 % 8.000 imagens 8,00 %
Indexação 5.000 imagens 10,00 % 12.000 imagens 6,00 % Assinatura 60 % processos - 100 % processos 0,00 % Importação Não realizado 100 % processos 0,50 % Conferência Não realizado 100 % processos 2,00 % Arquivamento 100 % processos 8,00 % 100 % processos 5,00 %
Após um ano da gamificação deste ambiente de trabalho, nova pesquisa de clima organizacional foi realizada, e desta vez observamos um clima organizacional favorável, onde elementos como motivação e liderança obtiveram notas máximas.
6. Conclusão Este artigo relatou o uso de técnicas de engajamento, especificamente: Medalhas, Conquistas, Desafios, Barra de Progresso para gamificação de um ambiente de trabalho, visando melhorar o clima organizacional. Conforme podemos observar na tabela 4, todas as atividades melhoraram sua produtividade, chegando até 333,34 % de melhoria na atividade de digitalização, impulsionados pela redução significativa do retrabalho ocasionado pelos erros cometidos, o que se refletiu também em redução da reclamação dos clientes quanto à qualidade do trabalho apresentado.
Tabela 4: Comparação de produtividade e Retrabalho Atividade Produtividade Retrabalho
Antes Atual Ganho Antes Atual Ganho Higienização 10 25 150,00 % 10,00 % 8,00 % 2,00 % Digitalização 6.000 26.000 333,34 % 12,50 % 5,50 % 7,00 % Controle de Qualidade
2.000 8.000 300,00 % 15,00 % 8,00 % 7,00 %
Indexação 5.000 12.000 140,00 % 10,00 % 6,00 % 4,00 % Assinatura 60 % 100 % 66,67 % - 0,00 % - Importação - 100 % - - 0,50 % - Conferência - 100 % - - 2,00 % - Arquivamento 100 % 100 % - 8,00 % 5,00 % 3,00 %
A concessão de prêmios também estimulou o trabalho coletivo e o engajamento dos participantes, percebido pela redução das faltas e pela baixa rotatividade da equipe.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
21
O entendimento das metas diárias, com o acompanhamento em tempo real da sua produtividade, permitiu ao usuário entender os critérios objetivos utilizados para promoção. Por fim, concluímos que as ações de engajamento propostas a partir da aplicação da gamificação contribuíram para a melhoria do clima organizacional, aumento da produtividade e da gestão de pessoas. Referencias Antin, J. and Churchill, E.F. (2011) “Badges in social media a social psychological
perspective”, In: Proceedings of the CHI Conference on Human Factors in Computing Systems, Vancouver. ACM Press.
Bellotto, H. L. and Camargo, A. M. (1996) “Dicionário de terminologia arquivística”, São Paulo: Associação de Arquivistas Brasileiros.
Cassares, N. C. and Moi, C. (2000) “Como fazer conservação preventiva em arquivos e bibliotecas”, São Paulo: Arquivo do Estado: Imprensa Oficial.
Chiavenato, I. (2003) “Introdução à teoria geral da administração: uma visão abrangente da moderna administração das organizações”, Rio de Janeiro: Elsevier, 7. Ed.
Coda, R. (1993) “Estudo sobre clima organizacional traz contribuição para aperfeiçoamento de pesquisa na área de RH”, In: Boletim Administração em Pauta, suplemento da Revista de Administração, São Paulo. IA-USP, n. 75, dez.
Cohen, A.M. (2011) “The Gamification of Education”, Futurist. 45 (5). Coonradt, C. A. (2008) “O jogo do trabalho: como transformar sua profissão no seu
esporte favorito”, Rio de Janeiro: Sextante. Duggan, K. and Shoup, K., (2013) “Business Gamification for Dummies”, Hoboken,
NJ: John Wiley & Sons. Fitz-Walter, Z., Tjondronegoro, D. and Wyeth, P. (2011) “Orientation Passport: using
gamification to engage university students”, In Proceedings of the 23rd Australian Computer-Human Interaction Conference
Gartner group (2011) “Gartner Says by 2015, More Than 50 Percent of Organizations That Manage Innovation Processes Will Gamify Those Processes”, http://www.gartner.com/it/page.jsp?id=1629214, Julho.
Hayes, M. (2013) “How to Use Gamification to Increase Sales”, http://www.shopify.com/blog/7988857-how-to-usegamification-to-increase-sales, Julho.
Krogue, K. (2012) “5 Gamification rules from the grandfather of gamification”, http://www.forbes.com/sites/kenkrogue/2012/09/18/5-gamification-rules-from-the-grandfather-of-gamification/, Julho.
Meloni, W. (2012) “Gamification in 2012”, http://www.ebah.com.br/content/ABAAAfjvEAK/gamification-in-2012, Julho.
Mcgonigal, J. (2011) “Reality Is Broken: Why Games Make Us Better and How They Can Change the World”, Penguin.
Mehta, M., Kass, A. (2012) “Scores, Badges, Leaderboards and Beyon: Gamification and Sustainable Behavior Change Accenture”,

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
22
http://www.accenture.com/SiteCollectionDocuments/PDF/Accenture-Gamification-Sustainable-Behavior-Change.pdf, Julho.
Moran, E.T. and Volkwein, J.F. (1992) “The cultural approach to the formation of organizational climate”, Human Relations, v. 45, n. 1.
Nascimento, A.C.A.A.; Peres, C.V.; Oliveira, M.J. and Silva, K.I.C. (2006). “Guia para digitalização de documentos. Versão 2.0”, Brasília: EMBRAPA
Payne, R. L. and Mansfield, R. (1973) “Relationship of perceptions of organizational climate to organizational structure, context e hierarchical position”, Administrative Science Quarterly, v. 18, n. 4.
Raftopoulos, M. and Walz., S.P. (2013) “Designing events as gameful and playful experiences”, CHI’13. Paris, France. ACM 978-1
Sbragia, R. (1983) “Um estudo empírico sobre o clima organizacional em instituições de pesquisa”, Revista de Administração da Universidade de São Paulo, 18(2).
Schell, J. (2008) “The Art of Game Design: A book of lenses”, Burlington MA: Morgan Kaufman Publishers.
Senna, A. and Coelho, D.K., (2012) “Gameficação: uma análise das técnicas de engajamento atualmente utilizadas”, Jogos eletrônicos na prática: livro de tutoriais do SBGames.
Suits, B. (1967) “What is a Game?”, Philosophy of Science, Vol. 34, N0.2. Vieira, S.B., (1988) “Indexação automática e manual: revisão de literatura”, Brasília:
Senado Federal. Werbach, K. (2012) “Definition of Gamification”,
https://class.coursera.org/gamification, Fevereiro. Werbach, K. and Hunter, D. (2012) “Game thinking can revolutionize your business”,
Wharton Digital Press: The Wharton School University of Pennsylvania: Philladelphia, PA
Wood, L. (2012) “Gamification Goes Mainstream”, Computer World, 24. Zimmerman, E. (2009) “Gaming literacy: Game design as a model for literacy in the
twenty-first century”, The video game theory reader, 2.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
23
Modelagem virtual da biblioteca da Universidade Estadual do Sudoeste da Bahia - UESB usando softwares livres
Henrique Junior Caires Santos Departamento de Ciências Exatas e Tecnológicas – DCET - Universidade Estadual do Sudoeste da Bahia
(UESB) Caixa Postal 95 – 45.031-900 – Vitória da Conquista – BA – Brasil
Abstract. This paper deals with the use of technologies to create 3D virtual environment. After exploratory research, conducted is directed to the three-dimensional modeling of the State University of Central Library of environment of Southwest Bahia, Vitoria da Conquista Campus. The work considered modeling techniques of architectural elements so that it had the maximum preservation of the natural characteristics. The developed computational solution enables users to interactively perform a walk inside the building, viewing dimension aspects of its structure, materials and details of physical space.
Resumo. Este trabalho trata da utilização de tecnologias para criações de ambientes virtuais 3D. Após pesquisa exploratória, procedeu-se à modelagem tridimensional do ambiente da Biblioteca Central da Universidade Estadual do Sudoeste da Bahia-UESB, Campus de Vitória da Conquista. Para o trabalho foram consideradas técnicas de modelagem dos elementos arquitetônicos de forma que se tivesse a máxima preservação das características naturais. A solução computacional desenvolvida possibilita que os usuários realizem interativamente um passeio dentro do prédio, visualizando aspectos da dimensão sua estrutura, materiais e detalhes do espaço físico.
1. Introdução A ideia de inserir pessoas em um mundo virtual não é nova, surgiu em 1965 com Ivan Sutherland criador do sketchpad, mais o uso da computação gráfica na arquitetura é recente, e vem sendo um importante meio de visualização seja de projetos que nem saíram do papel ou de arquiteturas já construídas, a exemplo, museus ou patrimônios históricos que podem estar localizados do outro lado do mundo e acessado seu ambiente de virtual de qualquer outro lugar no globo, democratizando o acesso para qualquer pessoa com a internet.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
24
Domingues (1997, p. 20-21) afirma que “a forma mais conhecida de circulação da arte na rede esta sendo permitida pela internet que faz proliferar os websites artísticos, muitos deles com possibilidades de interação. Nessa perspectiva se colocam os netmuseus, as netgalerias, os netmagazines que disseminam informações sobre arte. As propostas artísticas na Internet são uma possibilidade para que obras de arte e acervos possam ser consultados por não importa quem no planeta. Por outro lado, websites que utilizam os suportes multimídia interativos são veículos da Net, o que configura a rede como um espaço sociocultural aberto sem vínculo com as estruturas institucionais ou partículas e abolindo o caráter hierárquico que lhes é próprio”.
2. Metodologia Utilizada
O trabalho realizado foi divido em três momentos: no primeiro foi realizada uma pesquisa documental junto à prefeitura de campus da Universidade a cerca dos projetos da construção da biblioteca suas plantas baixas e plantas altas.
No segundo momento foi utilizado como técnica de coleta de dados uma observação analítica do espaço virtual da Biblioteca Central do ponto de vista de um usuário, foi tirada fotos e realizada uma entrevista com coordenador da Biblioteca Central sobre a estrutura e organização do funcionamento da BC.
No terceiro foi feito um levantamento das necessidades, prováveis dificuldades e relevância da construção de tal aplicação para que pudessem ser escolhidas as técnicas que seriam utilizadas na construção da biblioteca virtual, usando motores de busca e em seguida um levantamento bibliográfico sobre as técnicas convencionais de Modelagem e Animação.
3. Tecnologias Utilizadas
Para a realização do projeto do ambiente virtual não-imersivo foram utilizadas ferramentas open source, ou seja, ferramentas de código livre sob licença gratuita, beneficiando o projeto desde a concepção, diminuindo os custos até sua conclusão.
3.1. Modelagem
Após uma comparação entre Softwares livres no mercado para o desenvolvimento da realidade virtual, optou-se pela utilização do Blender 2.69, que é um programa para modelagem poligonal multiplataforma disponível para diversos sistemas operacionais.
O Blender apresenta um excelente custo, já que mesmo sendo um software gratuito ele apresenta inúmeros recursos que só eram encontrados em programas pagos. O Blender também ocupa pouco espaço no disco rígido do computador e é capaz de rodar em computadores mais modestos com baixo poder de processamento. O Blender hoje é uma realidade palpável no mundo dos softwares livres profissionais, são oferecidos uma ampla gama de recursos, com seus módulos é possível realizar complexas modelagens. No entanto, o Blender apresenta algumas desvantagens em relação a outros softwares concorrentes, devido ao seu grande numero de recursos

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
25
disponíveis ele se torna muito complexo, principalmente para usuários iniciantes, tornando o aprendizado difícil e demora.
3.2 Motor de Jogo
Conforme definição de Brito (2010) o motor de jogo tem como objetivo simular a física do mundo real dentro do ambiente do jogo, o que acaba deixando todas as interações mais complexas a cargo desse software. Essa é uma tarefa extremamente complexa e ousada, mas, dependendo do nível de sofisticação do motor de jogo usado, pode atingir níveis bastante realistas.
Como já foi mencionado o Blender possui sua própria "Game Engine" (Máquina de Jogos) embutida, que possibilita a criação de aplicações interativas 3D. A "GameEngine" (Máquina de Jogos) do Blender ou a chamada "BGE" (Blender Game Engine) é uma poderosa ferramenta de programação de alto nível. Seu foco principal é o desenvolvimento de Jogos, mas a BGE pode ser utilizada para criar praticamente qualquer tipo de software interativo 3D para outras finalidades, como visualizações de cenários interativos 3D para arquitetura, ou então pesquisas físicas em educação [Wikiblender 2013].
3.3 Editor de Imagem
Para edição de imagem o GNU Image Manipulation Program mais conhecido como Gimp apresenta-se como uma boa opção, é uma ferramenta completa, multiplataforma e livre. O GIMP basicamente fornece as mesmas funcionalidades de Software renomados do mercado, para efetuar tratamento de imagens. Oferece uma suíte completa de ferramentas tanto para bitmaps ou vetoriais, possui uma série de pincéis, permite trabalhar com inúmeras camadas, converte e salva em diferentes formatos de imagens (BMP, PNG, JPG, TIG, TGA, PCX, GIF, entre outros).
4. Modelagem da Biblioteca
O primeiro passo do projeto foi importar os arquivos da planta baixa da biblioteca que estão no formato DFX Drawing Exchange Format, esse formato e típico de programas de CAD. Como o Blender 2.69 não faz essa importação nativamente desde a sua versão 2.49 quando esse tipo de importação foi descontinuado, foi necessário baixar um script para que a importação fosse possível. Outra opção de importação do arquivo .DFX e instalar a versão mais antiga do Blender no caso seria a 2.49 importar o arquivo salvar como .blend e abrir no seu Blender atual.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
26
Figura 1. Visão da modelagem da planta Figura 2. Visão da modelagem da
planta baixa do pavimento Térreo baixa do primeiro andar Fonte: Elaborado pelo autor. Fonte: Elaborado pelo autor.
Figura 3.Visão planta fachada direita. Fonte: Elaborado pelo autor.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
27
4.1. Inicio da Modelagem
Inicialmente foi feito o esboço de onde serão localizadas paredes, janelas e portas, seguindo o desenho da planta. Utilizando as ferramentas de edição e transformação, cobre-se o traçado das da planta baixa importada, com uma malha simples formada inicialmente por 4 vértices.
Terminada a primeira parte, tendo como referência a planta da fachada, que foi crucial para pegar as informações da altura das janelas e portas, em modo de edição foi selecionada toda a malha e por meio de extrusão no eixo Z as paredes foram erguidas, no primeiro momento ergueu-se 1 metro, a extrusão foi interrompida para a criação do que seria no future o inicio das janelas, depois outra extrusão no eixo z de 1.5 metros que seria altura da janela e por fim mais 5 metros.
Repetindo o procedimento para o 1° andar, segue-se para a modelagem do restante da estrutura como as colunas, janelas, portas, cadeiras, mesas, objetos e as escadas, logo em seguida são realizados a união de todas as estruturas modeladas.
Figura 4. Vista perspectiva da BC. Figura 5. Vista sala de estudo da BC. Fonte: Elaborado pelo autor. Fonte: Elaborado pelo autor.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
28
4.2. Materias e Texturas
A criação de cenários 3D, seja para jogos ou apenas para visualização, passa por dois estágios inicias que são fundamentais, para definir a aparência deste no projeto. Depois da parte dedicada a modelagem chegamos a atribuição de materiais. Os materiais determinar a aparência de um objeto desde cor solida como reflexões. Mais só materiais não podem reproduzir a gama de superfícies existentes, para isso as texturas são usadas.
Para as texturas foram tiradas varias fotografias de todos os objetos que compõe a biblioteca, para o tratamento das fotos, como por exemplo, recorte e redimensionamento o software utilizado foi o software GIMP. A aplicação de uma textura com base em imagem envolve três passos: a escolha do arquivo que representa a textura, a existência de um material associado ao objeto e a escolha do tipo de mapeamento do objeto. No modo jogo só é possível exibir texturas com base em imagens, quando elas possuem coordenadas geradas por meios de UV's. O conceito UV's é muito usado em softwares 3D e aproveita um mapeamento que determina exatamente a posição que cada parte da textura deve assumir em um modelo 3D.
Figura 6. Vista sala de estudo Figura 1.Vista sala de atendimento
texturizada da BC. texturizada da BC. Fonte: Elaborado pelo autor. Fonte: Elaborado pelo autor.
4.3. Navegação no Ambiente 3D
Para realizar a navegação no cenário da Biblioteca Virtual e necessária trabalhar com o bloco de lógica do Blender, que são pequenos conjuntos de menus e opções que são ligadas através de linhas.
Para o ator, ou seja, o objeto que vai interagir com o mundo será feito o mais simples possível, será utilizado um cubo e uma câmera, onde o cubo ira simular um corpo de uma pessoa e a câmera os olhos, como é mostrado na figura 8, a linha tracejada que aparece é a linha parental, significa que os dois objetos estão ligados em uma relação de pai e filho, nesse caso o cubo será o Pai e a câmera o filho, nessa relação quando o cubo é movimentado a câmera será movimentada junto com ele mais se a câmera for movimentada o cubo não sofrerá o movimento.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
29
Figura 8. Ator
Fonte: Elaborado pelo autor
5. Conclusão
Neste trabalho foram apresentados os conceitos relacionados a Modelagem virtual e como vem cada vez mais ganhando espaço em aplicação que necessitem ser exploradas através de ambientes 3D. Este meio é responsável por passar tanto informações técnicas quanto criativas de maneira interativa que aproxima o publico, levando a lugares que não teriam como ter acesso contribuindo assim para uma democratização de informação.
Esse processo de estudo e desenvolvimento mostrou-se edificante no sentido de lançar dificuldades e desafios que contribuíram para evolução de outros processos envolvidos, como a própria modelagem das edificações e para o aperfeiçoamento de outros processos envolvidos, podendo definir ações futuras para melhorar o trabalho.
Referências
Brito, Allan. (2011). Blender 3D jogos e Animações Interativas. São Paulo: Novatec, 365 p.
Brito, Allan. (2010). Blender 3D Guia do Usuário, 4. ed. São Paulo: Novatec, 487 p.
Domingues, Diana. (1997). “Arte no Século XXI – A Humanização das Tecnologias”. São Paulo: Editora Unesp.
Osorio, Luiz Guilherme Brandão Osorio. (2012). “Arte na internet: O Google Art Project”. Disponível em: <https://artedigitalblogdotcom.files.wordpress.com/2012/12/google-art-project-diagramac3a7c3a3o-ii.pdf>
Méndez, Ricardo Brod. (2002). Construção de Ambientes Virtuais Interativos Baseados em Imagens para estudos Arquitetônicos e Urbanísticos. Tese (Doutorado) - Curso de Computação, Instituto de Informática, Universidade Federal do Rio Grande do Sul, Rio Grande do Sul.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
30
Desenvolvimento de um Sistema CAD para Detecção e Auxílio ao Diagnóstico de Doenças da Mama
Roger Resmini1, Adriel dos S. Araújo1, Otavio B. Nantes1, Claudinéia Araújo2, Aura Conci3
1Curso de Sistemas de Informação – Universidade Federal de Mato Grosso (UFMT) Rondonópolis – MT – Brasil
2Curso de Medicina – Universidade Federal de Mato Grosso (UFMT) Rondonópolis – MT – Brasil
3Instituto de Computação – Universidade Federal Fluminense (UFF) Niterói – RJ – Brasil
[email protected], adriel.santosaraujo,braganantes,[email protected],
Abstract. This paper proposes a Computer Aided Diagnosis system for breast thermal images, it is developed on web platform with UX Design techniques. The image features are extracted from grayscale co-occurrence matrix. To classify the diagnoses a Support Vector Machine was used. The performance of the proposed method achieved a result of 94.87 % of Area under the Receiver Operational Characteristic Curve. Resumo. Este artigo propõe um sistema de Diagnóstico Assistido por Computador para análise de imagens térmicas da mama. O sistema proposto foi desenvolvido em plataforma web com técnicas de UX Design. As características das imagens foram extraídas utilizando a Matriz de Co-ocorrência em Escala de Cinza. Para classificação dos diagnósticos foi utilizada uma Máquina de Vetores de Suporte. O desempenho da metodologia proposta obteve um resultado de 94,87% de Área Abaixo da Curva ROC (do inglês Receiver Operational Characteristic).
1. Introdução Com a popularização da internet, impulsionada principalmente pelo crescimento da utilização de smartphones e tablets e os crescentes avanços na computação em geral, é possível observar que os computadores estão sendo amplamente utilizados em diversos setores da sociedade. Na área da saúde não é diferente, existem diversos sistemas computacionais sendo utilizados. Há desde software que controlam aparelhos de tomografia e Raios-X até sistemas que auxiliam o médico a elaborar um diagnóstico. Este último, denominado de sistema de Diagnóstico Assistido por Computador (do inglês Computer Aided Diagnosis, CAD) é criado com intenção de auxiliar o diagnóstico médico. É possível encontrar na literatura duas categorias de sistemas CAD: CADe e CADx [SEIXAS, 2012]. Entende-se por CADe um sistema CAD médico para detecção

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
31
de anomalias na saúde de um determinado paciente. Neste caso, o sistema identifica se existe ou não um indicativo de doença. Um exemplo seria um sistema que detecta um padrão térmico anormal na paciente (no exame de termografia), ou detecta a presença de tumor com massa (em exame de mamografia). Por outro lado, entende-se por CADx como um sistema CAD médico para diagnóstico. Desta forma, este tipo de sistema emite um relatório com o diagnóstico, cabendo ao médico aceitá-lo ou não. Um exemplo seria um sistema que informa se a alteração de padrão térmico representa um tumor maligno (exame térmico) ou se a massa encontrada é de um câncer (exame de mamografia). O trabalho desenvolvido visa a implementação de um sistema CADx open-source e gratuito disponibilizado por meio de ambiente web, para detecção de doenças da mama, neste caso, o câncer de mama. Até o momento atual, não foi realizado teste de classificação envolvendo tumores benignos, pois a proposta é trabalhar com os dois casos extremos: normal e maligno (câncer). 1.1 Relevância O câncer de mama é uma doença que tem afetado milhares de pessoas das mais diferentes faixas etárias. É o segundo tipo de câncer mais frequente em todo o mundo, sendo o mais incidente entre as mulheres. No Brasil, somente em 2014 foram estimados mais de 57 mil novos casos de câncer de mama [INCA, 2014]. Atualmente, existem poucos sistemas médicos disponibilizados por meio da internet, quantidade que diminui ainda mais quando se tratam de sistemas open source ou gratuitos. Através de buscas realizadas em indexadores de artigos, periódicos e patentes foi possível concluir que existem dois sistemas que se assemelham ao descrito neste trabalho. O primeiro chama-se Sentinel BreastScan [ARORA, 2008]. Este é um produto comercial para análise de imagens térmicas da mama que consiste em software e hardware, ou seja, tanto o programa de computador como todo o aparato para realizar a captura das imagens térmicas são desenvolvidos pela empresa. Além disso, não é possível utilizar o sistema de forma gratuita com outro equipamento de captura de imagens térmicas. O segundo é uma patente que propõe um sistema computadorizado para somente marcar as anomalias em imagens de mamografias [WEHNES, 2011]. Sendo assim, o segundo sistema não classifica automaticamente quanto à presença de câncer em uma imagem da mama, ele apenas possibilita a um médico realizar marcações nas imagens obtidas por mamografias. No trabalho de Mohamed (2015), o autor realiza a classificação de diagnósticos (por Redes Neurais) utilizando trinta e duas características estatísticas, sendo vinte delas provenientes da Matriz de Co-ocorrência em Escala de Cinza (do inglês Grey Level Cooccurrence Matrix, GLCM). O autor alcança um resultado de 96,12% de acurácia, 78,95% de sensibilidade e 97,86% de especificidade. Dessa forma, neste artigo propõe-se um sistema modular, baseado em plataforma web, para auxílio ao diagnóstico médico de câncer de mama utilizando imagens térmicas. As seções do trabalho a seguir descrevem a metodologia utilizada, os resultados obtido, discussões e as considerações finais com proposta de trabalhos futuros.
2. Metodologia Para o desenvolvimento deste sistema foram utilizadas as seguintes ferramentas e tecnologias: Python, Django, Numpy, Scikit-image, Scikit-learn, HTML, CSS,

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
32
Javascript/AJAX, Dropzone.js, Twitter Bootstrap, Brackets, GIMP e Inkscape. Durante o desenvolvimento, as atividades foram divididas em 2 etapas: planejamento e desenvolvimento da interface do usuário e aplicação de métodos de inteligência artificial, já existentes na literatura, para a classificação. 2.1. Planejamento e desenvolvimento de Interface do Usuário Inicialmente, utilizando os editores de imagem GIMP e Inkscape, foram criados os esboços da interface do sistema além das imagens necessárias para a criação da interface utilizando HTML e CSS. O sistema foi organizado na estrutura Modelo, Visualização e Gabarito (do inglês Model, View, Template; MVT) [PLEKHANOVA, 2009]. Assim, há uma separação clara do que está relacionado ao banco de dados (model), funções de interação com o sistema (views) e modelos de páginas em HTML e CSS (template). O sistema é constituído de várias páginas com funcionalidades que permitem principalmente cadastrar e configurar usuários, criar amostras de imagens e enviá-las ao servidor e visualizar as amostras do usuário. Para possibilitar a interação foram definidos os modelos necessários para criação do banco de dados e sistema de usuários com suas respectivas amostras. Desta forma, utilizando Mapeamento Objeto-Relacional [do inglês Object-relational mapping, ORM), uma técnica que permite a construção da persistência do banco de dados através de orientação a objetos [FORCIER, 2008], foram criadas as classes necessárias. As classes criadas foram: controle de acesso, gerenciador de senhas, cadastro de amostras e gerenciamento de imagens. A criação destas é uma etapa da técnica MVT, chamada model e define o banco de dados. Uma vez que os modelos de classes foram criados, iniciou-se a implementação dos algoritmos que compõe a camada View. Estes algoritmos possibilitam a integração dos modelos definidos na camada anterior, com as páginas HTML até então estáticas. É através destes algoritmos que é efetivamente possível a criação dos modelos de dados definidos na camada model. Foram criados métodos que descrevem o comportamento do sistema e permitem disponibilizar as funcionalidades propostas neste trabalho. Dentre as principais funcionalidades programadas estão o envio de arquivos, registro e controle de usuário, criação de amostras, gerenciamento de senhas, extração de características, classificação de amostras e emissão de diagnóstico. Com os modelos de páginas definitivos (templates), criados em HTML, códigos de interação (views) e modelos de banco de dados (models) finalizados, foram definidos os caminhos onde as funcionalidades podem ser acessadas. Cada caminho permite o acesso a uma funcionalidade definida na camada view que, consequentemente, está diretamente ligada às demais camadas (models e templates). Pensando-se em UX Design foi utilizado Localizador Padrão de Recursos (do inglês Uniform Resource Locator, URL) amigável para facilitar a navegação no sistema. 2.2. Aplicação de Métodos de Inteligência Artificial.
O sistema CAD médico proposto deve ser capaz de receber imagens térmicas digitais e oferecer uma classificação que contribua com o diagnóstico médico, proporcionando um parecer preciso e automático. Para isso, as imagens são submetidas a um pré-

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
33
processamento, onde são delimitadas as regiões de interesse, ROI (do inglês Region of Interest) através da segmentação manual das imagens. Uma vez segmentadas, as imagens são submetidas ao algoritmo extrator de características que cria bases de características utilizadas para treino e teste do classificador. Considera-se uma característica, neste trabalho, o valor calculado a partir da imagem utilizada segundo uma determinada medida. Este conjunto de características determina padrões para cada classe, que, quando submetidos ao algoritmo de aprendizado de máquina, também chamado de classificador, são rotulados quanto ao estado clínico das mamas da paciente. Considera-se classe o diagnóstico dado a uma paciente. Neste trabalho são utilizados dois diagnósticos: normal, com ausência de doença e maligno, com a presença de câncer. Os diagnósticos foram emitidos por médico e comprovados por biópsia ou mamografia.
O algoritmo extrator de características utilizado neste trabalho é baseado na GLCM, que pode ser entendida como uma matriz de probabilidades que armazena os valores de envolvimento de dois pixels dada uma relação espacial [HARALICK, 1973]. Após montada a GLCM, podem ser extraídas várias características, que são medidas realizadas na matriz de probabilidades (GLCM). Haralick (1973) propôs quatorze medidas estatística possíveis de serem calculadas a partir da GLCM. Contudo, Baraldi e Parmiggiani (1995), indicam que apenas seis destas medidas são suficientes para compor um conjunto significativo de características. Portanto, neste trabalho são utilizados os seis extratores de Haralick mais relevantes: Segundo Momento Angular, Entropia, Contraste, Variância, Correlação e Homogeneidade. Após a extração das características, foi realizada a fase de classificação onde foi possível identificar padrões existentes nas imagens através técnicas de Aprendizado de Máquina. Este trabalho utilizou um método supervisionado de aprendizado de máquina. Aprendizado supervisionado é uma técnica onde o algoritmo recebe o vetor de características e a informação de qual a classe está representada no vetor. Este algoritmo também é chamado de classificador base. Neste trabalho foi utilizado uma Máquina de Vetores de Suporte, SVM (do inglês Suport Vector Machines) na implementação conhecida como LibSVM [CHANG et al., 2001]. Uma SVM é fundamentada na construção, em um espaço n-dimensional, de um ou mais hiperplanos que são utilizados para a tomada de decisão. Espera-se com este tipo de classificação, uma forma eficiente do ponto de vista computacional de separação dos hiperplanos maximizando as margens entre os dados [RESMINI, 2011].
3. Resultados e discussões As imagens utilizadas neste trabalho foram obtidas do banco de imagens térmicas da mama, Database For Mastology Research, [SEQUEIROS, 2013]. Foram utilizadas quarenta imagens de pacientes com câncer e quarenta imagens de pacientes saudáveis. As imagens foram segmentadas de forma manual por um especialista não médico. As imagens segmentadas serão disponibilizadas no futuro para acesso por outros pesquisadores. A Figura 1 mostra uma tela do sistema onde são exibidas as amostras criadas pelo usuário e suas respectivas imagens térmicas.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
34
Figura 1. Página de amostras enviadas pelo usuário
Para avaliar o desempenho da classificação realizada, várias estratégias, como acurácia, sensibilidade, especificidade, área abaixo da curva ROC (do inglês Area Under the Curve, AUC) podem ser usadas. Neste trabalho utilizaram-se todas estas medidas de desempenho. A Tabela 1 mostra como é montada a tabela de distribuição dos resultados. A montagem da tabela varia conforme o objetivo da busca. Se o que se busca é por resultados com câncer, como neste trabalho, os valores de Verdadeiro Positivos (VP) são os resultados classificados (condição predita) como “com câncer” e realmente há câncer (condição real). Os Verdadeiros Negativos são resultados preditos como “normal” e realmente não há câncer. Os Falsos Positivos são resultados preditos como “com câncer” e na realidade são saudáveis. Os Falsos Negativos são resultados preditos como “normal” e na realidade há câncer. Além desse, são importantes a Taxa de Verdadeiros Positivos, que também conhecida como sensibilidade e a Taxa de Falsos Positivos.
Tabela 1. Medidas de análise de desempenho. [Fonte: baseado em Loong (2003)]
Condição real
Condição positiva real Condição negativa real
Cond
ição
pre
dita
Condição positiva predita
VP (verdadeiro positivo) FP (falso negativo)
Condição negativa predita
FN (falso negativo) VN (verdadeiro negativo)
TVP (Taxa de verdadeiro positivo)
TFP (Taxa de falso positivo)

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
35
O cálculo das medidas de desempenho utilizadas é mostrado a seguir:
1. Sensibilidade:
2. Especificidade:
3. Acurácia: 4. AUC: é o cálculo da área abaixo da curva apresentada no gráfico da curva
ROC que para ser calculado leva em consideração TVP e TFP. Os resultados obtidos pelo sistema CAD proposto, realizando a classificação entre diagnósticos normal e câncer, foi de 94,87% de AUC. A Tabela 1 mostra os resultados obtidos por Mohamed (2015) e os resultados obtidos pelo sistema aqui CAD proposto.
Tabela 2. Comparação do sistema CAD proposto com a literatura
Acurácia Sensibilidade Especificidade AUC
Mohamed (2015) 96,12 % 78,95 % 97,86 % -
CAD proposto 94,61 % 94,61 94,87 94,87 %
Embora o resultado de acurácia tenha sido melhor no trabalho de Mohamed
(2015), percebe-se que a sensibilidade alcançada pelo autor é inferior a metodologia proposta neste trabalho. O trabalho de Mohamed (2015) utiliza cento e oitenta e sete imagens de pacientes saudáveis e dezenove de pacientes com câncer. O desbalanceamento do banco de imagens utilizado por Mohamed (2015) justifica uma taxa de sensibilidade baixa, pois se o algoritmo de classificação utilizado prever todo o resultado como sendo da classe normal, será garantida à estratégia uma acurácia de 90%. Por outro lado, a base utilizada no sistema CAD proposto utiliza um banco de imagens balanceado, contendo quarenta imagens de pacientes com câncer e quarenta de pacientes saudáveis. Além disso, as taxas de acurácia, sensibilidade e AUC estão próximas, o que mostra que há quantidade semelhante de acertos na classe normal e classe com câncer. A literatura apresenta outros trabalhos, entretanto o de Mohamed (2015) foi escolhido por ser atual e conter comparações com outras metodologias expostas na literatura. Nessas comparações, o trabalho de Mohamed (2015) se apresenta como melhor trabalho.
4. Considerações finais Este trabalho propõe um sistema CAD contendo uma interface gráfica web com estratégias de UX Design e gerenciamento de amostras de imagens para classificação. Utilizou como classificador a SVM e obteve um resultado de 94,87 % de AUC.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
36
A comparação com a literatura mostra que o uso de um banco de imagens balanceado (quarenta imagens de pacientes com câncer e quarenta imagens de pacientes saudáveis) torna o sistema mais preciso por prever quantidades semelhantes de diagnósticos em ambas as classes (câncer e saudável). Também é possível observar que o sistema desenvolvido pode ser considerado uma inovação, uma vez que não existem sistemas CADx disponibilizados em ambiente web e open source, para auxílio ao exame de mamas utilizando imagens térmicas. Pretende-se no futuro permitir a adição de novos módulos para diagnóstico de outras patologias. Estes módulos poderão ser desenvolvidos pela comunidade cientifica e submetidos para a validação. Além disso, pode-se extrair novas características utilizando outros métodos para melhorar o desempenho do sistema atual. Um outro trabalho futuro será disponibilizar todas as imagens segmentadas e as características extraídas para que outros pesquisadores possa testar seus algoritmos.
5. Agradecimentos À CAPES, FAPEMAT e PROEXT/MEC 2014 pelo apoio financeiro.
Referências ARORA, Nimmi et al. Effectiveness of a noninvasive digital infrared thermal imaging
system in the detection of breast cancer. The American Journal of Surgery, v. 196, n. 4, p. 523-526, 2008.
BARALDI, A., PARMIGGIANI, F, An investigation of the textural characteristics associated with gray level cooccurrence matrix statistical parameters. Geoscience and Remote Sensing, IEEE Transactions on, v. 33, n. 2, p. 293-304, 1995.
CHANG, CC; LIN, CJ. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology (TIST), v. 2, n. 3, p. 27, 2011.
SEQUEIROS, G. O. Desenvolvimento de um Banco de Dados Acessiveis Via Web com Recuperação Baseado no Conteúdo. M. Sc. thesis, IC-UFF, 2013.
FORCIER, Jeff; BISSEX, Paul; CHUN, Wesley. Python web development with Django. Addison-Wesley Professional, 2008.
HARALICK, R. M., SHANMUGAM, K., and DINSTEIN, I. H., Textural features for image classification, IEEE Transactions on systems, man and cybernetics, 610–621, 1973.
INCA, INSTITUTO NACIONAL DE CÂNCER (Brasil). Estimativa 2014. Incidência do Câncer no Brasil. Rio de Janeiro, 2014.
LOONG, Tze-Wey. Understanding sensitivity and specificity with the right side of the brain. BMJ: British Medical Journal, v. 327, n. 7417, p. 716, 2003.
MOHAMED, Nader Abd El-Rahman. Breast Cancer Risk Detection Using Digital Infrared Thermal Images. International Journal of Bioinformatics and Biomedical Engineering. Vol. 1, No. 2, 2015, P. 185-194.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
37
RESMINI, R., Análise de Imagens Térmicas da Mama Usando Descritores de Textura. Dissertação de Mestrado do Programa de Pós-Graduação em Computação. Universidade Federal Fluminense, 2011.
SEIXAS, F. L. Sistema de Apoio à Decisão aplicado ao Diagnóstico de Demência, Doença de Alzheimer e Transtorno Cognitivo Leve. Tese de Doutorado do Programa de Pós-Graduação em Computação. Universidade Federal Fluminense, 2012.
WEHNES, Jeffrey C.; WANG, Shujun. Marking System for Computer Aided Detection of Breast Abnormalities. U.S. Patent Application 13/808,229, 6 jul. 2011.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
38
Avaliação do Processo de Software de uma Pequena Empresa na Cidade de Barra do Garças - MT
Reinaldo A. S. Bocchi¹, Thiago P. Silva¹
¹Instituto de Ciências Exatas e da Terra – Universidade Federal de Mato Grosso (UFMT) – Barra do Garças – MT – Brasil
reinaldo.bocchi, [email protected]
Abstract. This article presents the results of practical application of a methodology for evaluating and improving software processes, which is based on ISO/IEC 15504 standard, which was specially developed for the context of Micro and Small Enterprises. Resumo. Este artigo apresenta os resultados da aplicação prática de uma metodologia de avaliação e melhoria de processos de software, que se baseia na norma ISO/IEC 15504, e que foi desenvolvida especialmente para o contexto de MPEs (Micro e Pequenas Empresas).
1. Introdução Os sistemas de software estão incorporados na sociedade moderna e com a crescente demanda por produtos e serviços de software, cada vez mais tornamos dependentes deles. Portanto é essencial que os mesmos sejam confiáveis, eficientes e de fácil usabilidade. Para garantir a qualidade dos sistemas é preciso que seu desenvolvimento siga um processo de software. Para [Sommerville 2007], um processo de software é um conjunto de atividades que levam à produção de um produto de software, e neste aspecto, as Micro e Pequenas Empresas (MPEs) ficam para trás, tendo em vista a informalidade de seus processos e a falta de recursos. Assim, reconhecer as dificuldades e articular melhorias pontuais são atitudes essenciais para a consolidação de uma MPE. Atualmente existem diversas normas e modelos de avaliação e melhoria de processos de software, porém eles não são compatíveis com o contexto das MPEs. Considerando esse cenário, [Anacleto et al. 2004] desenvolveram uma Metodologia de Avaliação de Processos em Micro e Pequenas Empresas – MARES, que operacionaliza a avaliação de processos de empresas MPEs. Este artigo apresenta os resultados obtidos após observações in loco de uma empresa de desenvolvimento de software na cidade de Barra do Garças – MT, que se enquadra na categoria de MPE. Nessas observações, as práticas e os processos adotados pela empresa foram compreendidos e avaliados através da metodologia MARES. Isto permitiu a percepção por parte da empresa em relação aos seus pontos fortes e fracos, bem como traçar um caminho para que seu processo de software possa ser melhorado. Este artigo está organizado da seguinte forma: a seção 2 explica resumidamente como um processo de software pode ser avaliado e melhorado; a seção 3 descreve o método utilizado para a avaliação e a melhoria dos processos; a seção 4 exibe os

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
39
resultados obtidos com a avaliação na empresa; e a seção 5 apresenta as considerações finais.
2. Avaliação e Melhoria de Processos de Software Quando se busca obter um produto de software são executadas várias ações que resultam em diversos subprodutos. Essas ações podem ser agrupadas em processos que definem o conjunto de artefatos utilizados no desenvolvimento de um determinado produto [Humphrey 1989]. Ao buscar aprimorar o processo de software, basicamente se deseja ampliar a sua capacidade de maneira contínua e incremental, sendo esta capacidade a habilidade de um processo alcançar ou contribuir junto com os demais processos, para atingir uma meta específica. Em um programa de melhoria de processos, se faz necessária a identificação de problemas e oportunidades de melhoria no contexto da organização em que será executada.
3. Metodologia MARES A metodologia MARES [Anacleto et al. 2004] é baseada na norma ISO/IEC 15504 e composta por um método e um modelo de avaliação. [Anacleto et al. 2004] afirmam que apesar de flexível, a norma não é customizada para o contexto das MPEs e aplicá-la nesse contexto pode ser oneroso, de forma que um dos objetivos do método MARES é atender os requisitos da norma 15504 e ser de fácil aplicação a este contexto especifico. O Modelo de Avaliação de Processo MARES é fundamentado no Modelo de Avaliação Exemplar da ISO/IEC 15504-5, que inclui um Modelo de Referência de Processo, uma Estrutura de Medição, um Modelo Contexto-Processo e um Modelo Processo-Risco [Anacleto 2004]. A ISO/IEC 15504 define um modelo bidimensional para descrever os processos e os níveis de capacidade que os mesmos podem alcançar. A primeira é a dimensão de processos, que apresenta os processos relevantes em um contexto, dividindo-se em cinco categorias: Fornecimento, Engenharia, Suporte, Gerência e Organização, onde cada uma destas é discriminada por processos específicos e descrita em um modelo de referência. Este modelo contém as definições dos processos em termos de seus propósitos e resultados [ISO, 2003]. Os processos do modelo de referência são agrupados em três categorias (Processos Básicos, Processos Organizacionais e Processos de Suporte do Ciclo de Vida) que se dividem em onze grupos de processos. O método MARES utiliza estas mesmas três categorias, porém considera apenas sete destes grupos de processos em seu modelo de referência, conforme a Figura 1. Já a segunda, a dimensão da capacidade, mostra uma condição de medição formada por seis níveis, que são definidos em uma escala de capacidade e podem ser aplicadas em qualquer processo. A dimensão de capacidade do modelo utilizado é integrada pelos 4 primeiros níveis de capacidade (0 - 3) da estrutura de medição da 15504-6 [ISO, 2003]. Segundo a ISO/IEC 15504-2, os níveis de capacidade dos processos são definidos em consequência de notas atribuídas a cada atributo do processo. Podem ser uma das quatro pontuações dispostas a seguir para cada atributo: “N” (não foi atingido,

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
40
de 0 a 15% concluído), “P” (atingido parcialmente, entre 15 e 50%), “L” (atingindo largamente, entre 50 e 85%) ou “F” (completamente, do inglês fully, entre 85 a 100%).
Figura 1 - Grupos e Categorias dos Processos do Modelo de Referência do
Método MARES
O Modelo Contexto-Processo ajuda a determinar um perfil alvo e a selecionar os processos relevantes que serão avaliados, relacionando metas de negócio/melhoria e aspectos de qualidade aos processos do modelo de avaliação. O Modelo Processo-Risco busca oferecer um suporte sistemático para apontar riscos e possíveis sugestões de melhoria, no que diz respeito aos processos que foram avaliados partindo de suas capacidades. O Método de Avaliação MARES corresponde as necessidades para um programa de avaliação que acompanhe a ISO 15504, como a parte 2 da norma define. É recomendado que a avaliação se divida em três processos: i)gerenciamento, ii)contextualização e iii)execução da avaliação, conforme ilustra a Tabela 1.
Tabela 1 - Visão geral dos processos de avaliação que compõem o método MARES [Anacleto et al. 2004]
O processo de gerenciamento é iniciado ao se realizar o planejamento da contextualização, que envolvem diversas atividades, como por exemplo, a definição de

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
41
um cronograma. Em paralelo aos outros processos é feito um acompanhamento do andamento da avaliação. Se necessário ações corretivas são realizadas. O processo de contextualização compreende o processo de software da empresa e define um conjunto de perfis alvo de processo, selecionando os processos que serão avaliados [Anacleto et al. 2004]. A partir daqui a empresa pode iniciar seu programa de melhorias. O processo de execução enfatiza uma avaliação criteriosa dos processos selecionados. Anacleto (2004) assegura que são realizadas entrevistas com representantes da empresa. Fundado nestas últimas informações são elaborados os resultados, tendo como exemplo os riscos e sugestões de melhorias identificadas. Devido ao grande volume de documentos gerados e consumidos pelo método, além da quantidade de dados duplicados, para chegar aos resultados deste trabalho fez-se o uso da ferramenta FAPS [Thiry et al. 2008], que gerencia os documentos e automatiza determinados procedimentos da avaliação.
4. Resultados
A avaliação foi executada em uma pequena empresa (entre 10 e 49 funcionários) na cidade de Barra do Garças – MT, sendo a avaliação apoiada na norma ISO/IEC 15504. Na definição o Modelo Contexto-Processo foi determinado que para atender as necessidades existentes, todos os 26 processos presentes no método MARES deveriam ser avaliados. Contudo, em uma parte das práticas foram encontradas apenas evidências indiretas e em alguns casos até mesmo nenhuma evidência ou afirmação. Inclusive, em algumas situações a equipe de desenvolvimento não conseguiu identificar se determinada prática era executada. Assim, foram gastos dois dias não consecutivos para realizar a avaliação com a equipe de desenvolvimento, mas alguns dados coletados previamente em reuniões com o proprietário da empresa e com o gerente da equipe de desenvolvimento foram utilizados. Também não está sendo considerado o tempo gasto na preparação dos documentos e análise dos dados. Para cada prática encontrada foi atribuído um peso, com o objetivo de mensurar o que a atividade representa dentro do processo, por exemplo: caso haja 10 práticas compondo um processo, cada uma equivale a 10% do mesmo. Também foi calculada a média dos níveis de capacidade de cada atividade que integra o processo em questão. Esta tarefa foi realizada com todas as atividades envolvidas em todos os processos avaliados. Os dados coletados foram analisados para se obter os níveis de capacidade de cada processo avaliado. Assim foi possível compreender cada nível de capacidade dos processos, bem como qual porcentagem do mesmo foi executada, como ilustra a Figura 2.
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
42
Figura 2 – Capacidade em % dos Processos Avaliados
Em seguida, foi calculado o quanto cada processo avaliado representa dentro do processo de software da empresa, isto é, qual a porcentagem que um processo representa dentro dos 26 considerados na avaliação. Como resultado, temos que cada processo pode representar no máximo um valor próximo a 3,85%, de acordo com a Figura 3.
Figura 3 - Capacidade de um Processo em relação a todo o Processo de
Software da Empresa
Apesar de não ter de forma bem definida, a empresa utilizava esporadicamente algumas técnicas sadias de engenharia de software em seu processo. Porém, por conta da informalidade, alguns contratempos podiam ser considerados normais, como por exemplo, a dificuldade para cumprir os prazos estipulados. Mesmo com essas condições alguns dos processos da metodologia MARES estavam bem definidos, como por exemplo, o processo referente a manutenção de sistema e software, que das seis práticas básicas, 5 atingiram o nível L e uma o nível P. Dos 26 processos considerados pelo método MARES, para apenas três não foram encontrados nenhum tipo de evidência e afirmação no processo da empresa, sendo dois associados ao Grupo de Processos de Reuso e um ao Grupo de Processo de Gerência. Ou seja, mesmo que indiretamente, brevemente e/ou de maneira informal, a empresa pratica a maioria dos processos considerados pelo método. Dos processos que são executados pela empresa, apenas um alcançou o nível máximo de capacidade

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
43
possível (F), sete alcançaram o segundo nível de capacidade (L), quatorze chegaram ao terceiro nível (P) e somente um obteve o quarto e mais baixo nível de capacidade (N). Desta forma, uma sugestão de melhoria indica que caso haja no mesmo grupo, como por exemplo, o grupo dos processos de engenharia, processos com diferenças entre seus níveis de capacidade, tais desigualdades devem ser sanadas fortalecendo cada prática do grupo em questão. Isto é, ao se tomar medidas sistemáticas, fundamentadas em técnicas e conhecimentos de engenharia de software, que almejem fortalecer os princípios fundamentais dos processos que têm menor pontuação, as capacidades dos processos pertencentes ao mesmo grupo alcançarão o mesmo nível, e assim, quando todos os processos de um grupo estiverem com seus níveis equiparados, deve-se trabalhar para que todos os processos do grupo subam de nível conjuntamente, isto para todos os grupos implementados pela empresa.
5. Considerações Finais É possível concluir que o único custo gerado pela avaliação se associa ao esforço realizado por aqueles que participaram da mesma. Nota-se que o custo está diretamente relacionado ao número de processos e níveis de capacidade avaliados, como também se relaciona a quantidade de funcionários da empresa que participaram da avaliação. Assim, a avaliação pode ser considerada como de baixo custo para a empresa. Também conclui-se que a empresa avaliada cumpre aproximadamente 25,15% dos processos considerados pelo método MARES, sendo que 100% seriam os 26 processos executados no mais alto nível de capacidade. Ainda assim, a empresa considerou que a avaliação foi bem-sucedida, visto que seu processo de software foi compreendido e os pontos fortes e fracos foram elucidados. Porém, por ter poucos funcionários atuando diretamente com o desenvolvimento, o programa de melhorias ainda não foi iniciado, pois os profissionais que ali estão são essenciais em suas atribuições e não podem ser desviados de função. Assim, a contratação de um profissional, se faz indispensável para que o processo de software da empresa possa evoluir, e dessa maneira propiciar o aperfeiçoamento até o nível máximo de capacidade dos processos e que a empresa possa prestar um serviço com mais qualidade, agilidade e confiabilidade para seus clientes.
Referências Anacleto, A. "Método e Modelo de Avaliação para Melhoria de Processos de Software em
Micro e Pequenas Empresas", Florianópolis - SC, 2004.
Anacleto, A. et al. “A Method for Process Assessment in Small Software Companies”. SPICE Conference. Estoril, 2004.
Humphrey, W. S. “Managing the Software Process”. Addison-Wesley Publishing Co., Reading, Massachusetts, 1989.
International Organization for Standardization (ISO). ISO/IEC 15504: Information Technology Process Assessment, Part 1 to Part 5. ISO/IEC International Standard, 2003-2005.
Sommerville, I. “Engenharia de Software”, 8ª edição, Pearson Addison-Wesley, 2007.
Thiry, M. et al. “FAPS: Ferramenta para apoiar avaliações integradas de processo de software”. Anais do IV Workshop de Implementadores MPS.BR, 2008.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
44
Desenvolvimento de dashboards através de dados de distribuição de energia elétrica fornecidos pela ANEEL
Vinícius F. M. Leão, Ariel R. Machado, Nilton H. Takagi, Thiago A. Araújo, Crischarles D. Arruda, Kelvyn Yago S. Zanato
Instituto de Computação - Universidade Federal de Mato Grosso (UFMT)
Av. Fernando Corrêa da Costa, nº 2367 - Bairro Boa Esperança. Cuiabá - MT - 78060-900 [email protected], [email protected],
[email protected], [email protected],
[email protected],[email protected]
Abstract. Any user connected to the Internet can access the data for the management of public bodies that disseminate information of popular interest in order to make possible a greater participation of society in the monitoring of its management. Although that information is available openly, there is much difficulty in filtering and interpretation of this data because it is large volumes. The purpose of this paper is to present an ETL methodology for data manipulation so they can be analyzed in context with the creation of dashboards. Case were used as electrical power distribution data released by ANEEL (Brazilian Electricity Regulatory Agency).
Resumo. Qualquer usuário conectado à internet pode ter acesso a dados referentes a gestão de órgãos públicos, que divulgam informações do interesse popular com a finalidade de tornar possível uma maior participação da sociedade na fiscalização de sua gestão. Apesar dessas informações serem disponibilizadas abertamente, há muita dificuldade na filtragem e interpretação desses dados por se tratar de grandes volumes. A proposta deste artigo é apresentar uma metodologia ETL de manipulação de dados para que possam ser analisados de forma contextualizada a partir da criação de dashboards. Como case foram utilizados dados de distribuição de energia elétrica divulgados pela ANEEL (Agência Nacional de Energia Elétrica).
1. Introdução Existem muitos dados referentes a gestão de órgãos públicos brasileiros disponíveis na internet, seja através de sites ou web services que fornecem informações de livre acesso a todos os usuários. Nos últimos anos o governo brasileiro está realizando ações de disseminação de dados governamentais para o livre uso da sociedade com objetivo de uma maior participação popular na fiscalização e acompanhamento da gestão pública [Angélico 2012].
Em maio de 2012 entrou em vigor a Lei de Acesso a Informação (Lei nº 12.527/2011), que criou um meio de qualquer pessoa solicitar informações públicas sem qualquer justificativa, tais informações são chamados de Dados Abertos [Acesso a Informação 2015]. “Dados Abertos é a publicação e disseminação de dados e informações públicas na Web, seguindo alguns critérios que possibilitam sua

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
45
reutilização e o desenvolvimento de aplicativos por toda a sociedade” [Portal brasileiro de dados abertos 2012 p.1].
A ANEEL (Agência Nacional de Energia Elétrica) é uma agência reguladora vinculada ao Ministério de Minas e Energia, que foi criada para desempenhar a função de regular e fiscalizar a produção, transmissão e comercialização de energia elétrica, em conformidade com as políticas e diretrizes do governo federal [Siscomex 2015]. “A missão da ANEEL é proporcionar condições favoráveis para que o mercado de energia elétrica se desenvolva com equilíbrio entre os agentes e em benefício da sociedade” [ANEEL 2015].
Neste artigo serão utilizados dados referentes a distribuição de energia elétrica divulgados pela ANEEL, onde será demonstrada uma metodologia de ETL (Extração, Transformação e Carregamento de dados) para manipulação de dados públicos divulgados na internet, que foram usados para criar dashboards com a finalidade de utilizar essas informações de forma contextualizada. Com isso foi possível analisar os desempenhos das distribuidoras, através da utilização de indicadores técnicos e comerciais como: consumo de energia de cada região; quantidade de conjuntos e consumo; qualidade do fornecimento (número de interrupções e duração); tempo médio de atendimento a interrupções de fornecimento; períodos críticos de fornecimento.
2. Preparação dos dados Em comparação aos outros órgãos, a ANEEL disponibiliza as informações de forma mais sintética através de planilhas, o que torna mais intuitiva a filtragem dos dados, porém a coleta se torna muito onerosa. Outros órgãos como a Previdência Social, IBGE, INEP, disponibilizam os dados em forma de arquivo em formato de CSV, XLS, XML, entre outros.
2.1 Seleção das bases de dados Foi selecionado três bases referentes a dados de Distribuição de Energia Elétrica que são: Atributos Físicos Elétricos, são atributos que agrupam informações sobre energia consumida, extensão de redes, potência de transformadores, quantidade de transformadores, entre outros; Tempos Médios de Atendimento, é uma base que contém indicadores de qualidade de atendimento a ocorrências emergências na manutenção da rede elétrica de cada distribuidora de energia; Indicadores Coletivos de Continuidade, esta base possui indicadores de qualidade no fornecimento de energia elétrica avaliando a frequência com que ocorre a interrupção do fornecimento e a sua duração.
2.2 Modelo Estrela Para armazenar os dados foi criada uma modelagem de um banco, onde foram armazenados após a transformação, conforme a Figura 1. Para cada base foi criada uma Fato, onde as dimensões são compartilhadas para todas as Fatos. Na base da ANEEL, nem todas as bases possuíam atributos para todas dimensões, então estas informações foram inseridas durante o processo de transformação, como na base de Atributos Físicos Elétricos que não possuía os atributos de estados que cada conjunto pertence.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
46
Figura 1. Modelo estrela das bases de distribuição de energia elétrica
3. Transformação e Carregamento dos Dados Na extração dos dados, as bases foram carregadas para documentos com formato XLS, por ser compatível com o formato das planilhas disponibilizadas pela ANEEL. Para a manipulação dos dados foi utilizado o software Talend Big Data1, por se tratar de uma ferramenta open source e oferecer recursos completos para a manipulação dos dados, além de possuir uma boa avaliação no quadrado mágico pela empresa de consultoria Gartner [Gartner 2015].
3.1 Criação das Jobs das dimensões A fim de demonstrar a criação de uma dimensão, foi usada a dimensão Conjunto_dm, de acordo com a Figura 2, é exibida a criação da job nos seguintes passos: 1) são colhidas as informações dos Metadata (dados e estrutura) das três bases; 2) é realizada a união dos conjuntos; 3) os dados duplicados são excluídos; 4) realiza-se uma associação para carregar os dados no banco e em um arquivo TXT.
Figura 2. Job da Dimensão Conjunto
3.2 Criação das Jobs do fato Para demonstrar a criação de uma Fato, foi utilizada a base de Atributos Físicos Elétricos de acordo com a Figura 3, seguindo os passos: 1º São colhidas informações da Metadata da base; 2º Ocorre uma modificação nas strings; 3º Ocorre uma associação da 1 Talend Open Studio Big Data 6.0.0 – Junho, 2015

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
47
base de dados, dimensões e outra associação com a base de Indicadores de Continuidade; 4º O Fato é replicado para ser carregado no banco e em um arquivo TXT.
Figura 3. Job da Fato Atributos Físicos Elétricos
4. Resultados
Após realizar todos os processos de ETL, os dados foram utilizados para criar dashboards com gráficos dinâmicos, utilizando o software QlikView2, pois este software permite que os dados sejam extraídos diretamente do banco, além de se tratar de uma versão gratuita e ser uma das mais conceituadas ferramentas de BI do mercado de acordo com o quadrante mágico do Gartner [Gartner 2015]. Usando os dashboards é possível avaliar os desempenhos das distribuidoras de energia elétrica, fazendo um comparativo entre as regiões brasileiras. Na Figura 4, é demonstrado o dashboard de Atributos Físicos Elétricos, onde se tem uma visão geral do perfil de consumo de cada região, exibindo dados como: Consumo de energia acumulado de um ano; Quantidade de UC (Unidades Consumidoras) em relação a potência de transformadores e quantidade de conjuntos; Percentual de UC de cada região; Extensão de redes de distribuição; Percentual de Consumo acumulado divido por classe; Quantidade de UC divididas por região.
Figura 4. Dashboard de Atributos Físicos Elétricos
Na Figura 5, é demonstrado o dashboard de Tempo Médio de Atendimento, onde o gráfico Ocorrência/Interrupção mostra a quantidade de ocorrências emergenciais 2 QlikView 11.00.11154.0 – Maio, 2015
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
48
de cada ano separadas por meses, sendo que a linha vermelha mostra quanto dessas ocorrências ocasionaram interrupção de energia. Ao lado direito exibe o percentual de ocorrências com interrupção de energia elétrica, abaixo o tempo total gasto para atender a ocorrência dividido por tempo de planejamento, deslocamento e execução.
Figura 5. Dashboard de Tempo médio de atendimento
Na Figura 6, é demonstrado o dashboard de Indicadores de continuidade, que avalia a qualidade do fornecimento de energia de uma distribuidora de energia, pois exibe os indicadores de continuidade de cada ano separados por mês, além de mostrar um percentual de aumento ou retrocesso desses indicadores. O DEC é um indicador de duração de interrupção de fornecimento de energia, enquanto o FEC é um indicador de frequência de interrupção do fornecimento.
Figura 6. Dashboard de Indicadores de continuidade
5. Conclusões A metodologia apresentada conseguiu atender todas as necessidades exigidas para uma boa interpretação e manipulação dos dados livres, demonstrando uma boa forma de utilização dos dados divulgados pelos órgãos públicos. O principal objetivo da construção deste artigo é demonstrar todo o processo desde a transformação de dados, até a criação de dashboards com alto nível de análise. Essa proposta surgiu com o intuito de sanar a necessidade de possuir um meio que sirva como orientação para a sociedade, pois não basta que a informação esteja disponível sem que haja uma maneira mais efetiva na fiscalização de órgãos públicos.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
49
Os dashboards criados trazem uma visão diferente em relação aos dados do site
da ANEEL, tratando a informação de forma mais contextualizada e intuitiva, pois é necessário apenas um conhecimento básico das informações para que os gráficos possam ser interpretados, dando uma visão do cenário nacional distribuição de energia elétrica. O site da ANEEL apesar de trazer as informações de forma sintética, é necessário que o usuário tenha conhecimentos bem específicos dos vários dados e a que eles estão relacionados, tornando a aprendizagem mais onerosa, além de não fornecer as opções de relacionar os dados como foi realizado nos dashboards. Em trabalhos futuros, planejamos concentrarmos em análises de dados voltadas para gestão das distribuidoras, com o a finalidade de auxiliar na tomada de decisão e no planejamento estratégico da empresa. Com isso, ela poderá direcionar de forma mais efetiva seus recursos nas áreas mais ineficientes apontadas pelos indicadores. Para isso será necessário um estudo de caso mais aprofundado, pois neste artigo foi abordada uma perspectiva nacional do desempenho de cada região brasileira. Outro trabalho futuro será disponibilizar na internet os dashboards e mais detalhes da produção deste trabalho, servindo de auxílio a replicação desta obra.
Referências Acesso a Informação (2015) “LAI: A Lei de Acesso à Informação”,
http://www.acessoainformacao.gov.br/assuntos/conheca-seu-direito/a-lei-de-acesso-a-informacao. Acesso em Agosto/2015.
ANEEL (2015) “Distribuição de Energia Elétrica”, http://www.aneel.gov.br/area.cfm?idArea=77&idPerfil=2&idiomaAtual=0. Acesso em Agosto/2015.
Angélico, F. (2012) “Lei de Acesso à Informação Pública e seus possíveis desdobramentos para a accountability democrática no Brasil”. São Paulo, Fundação Getúlio Vargas, p. 12-28.
Gartner (2015) “Browse by Market: Find Vendors and Products by Market”, https://www.gartner.com/reviews/markets. Acesso em Outubro/2015.
Portal Brasileiro de Dados Abertos (2015) “Cartilha Técnica para Publicação de Dados Abertos no Brasil v 1.0”, http://dados.gov.br/cartilha-publicacao-dados-abertos. Acesso em Agosto/2015.
Siscomex (2015) “Agência Nacional de Energia Elétrica”, http://portal.siscomex.gov.br/orgaos/agencia-nacional-de-energia-eletrica-aneel. Acesso em Agosto/2015.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
50
Alocando horários de aulas nos cursos de Bacharelado em Sistemas de Informação e Licenciatura em Computação do Campus Universitário Vale do Teles Pires utilizando FET
Timetabling – Um estudo de Caso
Jonata da Silva Rodrigues, Francisco Sanches Banhos Filho, Cristiano Campos de Miranda
Departamento de Computação – Universidade Estado de Mato Grosso (UNEMAT) 78500-000 – Colíder – MT – Brasil
[email protected], fsanches,[email protected]
Abstract. This article will discuss the main problems that universities are to generate operating hours in Higher Education courses and present an alternative solution through a software to minimize them. The specific purpose of this article will be the implementation of the FET software as the main resource to generate the grids hours of courses Degree in Computer Science and Bachelor of Information Systems Colíder Campus of the University of the State of Mato Grosso, as with the FET is possible to treat problems of incompatibility of schedules between teachers, subjects and prerequisites.
Resumo. Neste artigo serão abordados os principais problemas que as universidades encontram ao gerar grades horárias em cursos de Ensino Superior e apresentar uma solução alternativa através de um software para minimizá-los. O objetivo específico deste artigo será a implantação do software FET como principal recurso para gerar as grades de horários dos cursos Licenciatura em Computação e Bacharelado em Sistemas de Informação do Campus de Colíder, da Universidade do Estado de Mato Grosso, pois, com o FET é possível tratar problemas de incompatibilidade de horários entre professores, disciplinas e pré-requisitos.
1. Introdução Atualmente, observa-se que o problema em se alocar os horários das aulas de maneira satisfatória para professores e alunos tem sido algo bastante difícil. Existem problemas como: conflitos, contratações de novos docentes, dias específicos para que cada professor possa lecionar, disciplinas com pré-requisitos, alunos com dependência em disciplinas. Problemas deste tipo geralmente têm sido resolvidos de maneira manual, utilizando planilhas eletrônicas, sem qualquer inteligência envolvida. Soluções desta forma, tem se gastado muito tempo e nem sempre a solução agrada a todos os envolvidos. Barata (2010) relaciona ainda que o problema de alocação de horários também conhecido como School Timetabling, é considerado como uma aplicação da otimização combinatória da classe NP-difícil. Isso porque o número de variáveis a serem

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
51
consideradas é muito grande. Algumas vezes o problema pode não ter nenhuma solução e outras vezes várias soluções diferentes. Pelo problema de Alocação de horário ser considerado NP-difícil, não existe solução ótima que se resolva o problema. Desta forma, tem-se utilizado principalmente soluções baseadas em heurísticas. O software utilizado no presente trabalho é baseado em heurísticas. Este trabalho tem como propósito apresentar um estudo de caso utilizando o Free Timetabling Software – FET[1] implantado para gerar o horário dos cursos de Licenciatura em Computação e Bacharelado em Sistemas de Informação. A escolha dessa ferramenta se deu para que o horário das aulas possa ser confeccionado de maneira automática propiciando atender demandas dos professores e alunos. A utilização deste programa é bastante difundida. Em Mansor, Arbain e Hassan (2002) possui uma implantação similar a apresentada neste trabalho. Este artigo está organizado da seguinte maneira: Na seção 2 é apresentado detalhes do software utilizado, Free Timetabling Software - FET. A seção 3 apresenta como foi realizado o estudo do FET. Na seção 4, são apresentados os resultados obtidos com a utilização do FET. Na seção 5 são apresentados os trabalhos futuros utilizando o FET.
2. Free Timetabling Software – FET O Software Livre Timetabling foi desenvolvido no ano de 2002 por Gheorghe Liviu Lalescu, utilizando algoritmos genéticos para a geração de horários, no entanto este método era muito lento e gerava apenas horários fáceis. Finalmente, no ano de 2007 foi descoberta uma nova forma de se resolver o problema de lentidão do FET, utilizando-se de algoritmo de heurística (com base em recursividade), nomeado “swap recursiva”, que simula um procedimento manual de encontrar um horário, algoritmo este, que foi implementado a partir da versão FET 5.0.0. O FET é um software livre, licenciado sob a GNU / AGPL 3 (Affero General Public License), é implementado usando a linguagem de programação C++ e encontra-se disponível para download no site oficial de Liviu Lalescu. As plataformas de implementação também são independentes, podendo assim, rodar em GNU / Linux, Windows, Mac OS X e qualquer outro sistema que suporte Qt. Este software possui algoritmo de geração de grades horárias totalmente automáticas, mas também permite a alocação semiautomáticas ou manual. Existem outras ferramentas que também resolvem o problema de alocação de horários. Alguns exemplos são o Asc Timetables e o UniTime. Para utilizar o Asc Timetables é necessário pagar uma taxa de licença de software, essa taxa em 2015 é de U$ 120.00. O UniTime é um software com bastante funcionalidade, mas a documentação não apresenta o software de maneira clara e objetiva. Em Souza, Maculan e Ochi (2001) também foi proposto resolver o problema de alocação de horário utilizando heurísticas, nessa solução é apresentado toda a representação matemática e isso foi algo pouco prática e não possível de ser implementado. A escolha recaiu sobre o FET, pois o mesmo é um software livre e possui uma vasta documentação.
1Disponível em: http://lalescu.ro/liviu/fet/

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
52
3. Estudo do Software Para a utilização do software FET foi necessário estudar o software. Desta forma, o período de estudo compreendeu os meses de julho de 2014 a dezembro de 2014. O estudo foi conduzido de acordo com os preceitos da Engenharia de Software, realizando primeiramente um levantamento bibliográfico sobre as diversas formas em se automatizar o problema de tabelas de horários. Após, foi escolhido o Software FET devido ao software oferecer boa documentação e principalmente por outros artigos relatando casos de sucesso com a implantação do software em questão. Após essa escolha foi realizado um período de testes, simulação, adaptação e estudo com casos reais. Tudo para identificar e principalmente conhecer como o software lidaria com alguns problemas comuns como o professor lecionar apenas em dias específicos na semana ou mesmo ofertar disciplinas que são sequenciais em um mesmo horário, para propiciar que alunos em dependência consigam se matricular em um número maior de disciplinas como é o caso de Algoritmos I e Algoritmos II. Para a realização do estudo do software, foi utilizada a versão FET 5.23.1 de 2014. Atualmente esta versão não está disponível para download, pois esta foi atualizada para a versão FET 5.27.8 de agosto de 2015.
3.1. Interface Gráfica do FET A interface do FET é bem simples, mas possui muitas opções. O menu oferece diversos tipos de restrição para se confeccionar o horário. O estudo de cada uma delas exigiu muito tempo e principalmente dedicação. É necessário entender principalmente todos os grupos de opções apresentadas em cada aba da tela inicial. Ao executar o software FET, irá aparecer uma tela como mostrado na Figura 1, onde poderão ser criadas novas grades horárias e abrir horários existentes no computador. A Figura 2 apresenta a tela onde os dados iniciais deverão ser cadastrados. Nesta tela são inseridos os nomes dos professores e alunos, quais as disciplinas do curso, as atividades a serem feitas, nome da instituição e dados sobre a hora e dias letivos por semana. Na aba mais a direita “Horário” é possível cadastrar todas as restrições de horário. Após cadastrar os dados iniciais, as restrições na aba “Horário” e as salas na aba “Espaço” é possível gerar a tabela de horário. A tabela de horário gerada é mostrada na Figura 3.
Figura 1. Interface inicial FET

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
53
Figura 2: Interface de inserção dos dados
Também na Figura 3 é possível visualizar que o horário apresentado corresponde ao primeiro semestre do curso de Bacharelado em Sistemas de Informação. Tendo como disciplinas alocadas as disciplinas de Fundamentos de Matemática Elementar, Língua Portuguesa Nivelamento, Fundamentos de Sistemas de Informação, Lógica, Psicologia Aplicada a Sistemas de Informação e Introdução à Computação.
Figura 3. Exemplo de visualização da grade horária para impressão
4. Resultados Após cadastrar todos os professores, salas de aula e disciplinas no FET, foi possível começar a pensar nas regras necessárias para atender demandas de alunos e professores. As demandas observadas e implantadas estão de acordo com o que segue: 1) Todos os professores que atuam nos cursos de Computação (SI - Bacharelado em Sistemas de Informação e LC - Licenciatura em Computação) possuem carga horária de 12 (doze) horas semanais em ensino. Nos cursos de Computação é adotada hora relógio, desta forma, das 19 (dezenove) horas às 23 (vinte e três) horas são contabilizadas 4 (quatro) aulas. Assim 12 (doze) horas em ensino precisou ser dividido em 3 (dias) dias,

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
54
4 (quatro) aulas por dia. A regra pensada foi que todos os professores só estariam no Campus apenas 3 (três) dias para ensino. 2) É necessário minimizar a questão de choques de horários. Então, foi pensado em uma regra para colocar todas as disciplinas que são sequencias (Algoritmos I e Algoritmos II, por exemplo) ou que são pré-requisitos em um mesmo horário. As disciplinas de Algoritmos I e Algoritmos II foram alocadas ambas na terça-feira as 4 aulas. A figura 4 ilustra como foi realizado o cadastro desta regra. O nome dos professores foi suprimido. 3) O Campus Universitário no semestre de 2015/2 não disponibilizou 8 (oito) salas de aulas para os Cursos de Computação. Embora os cursos possuam 8 (oito) fases, foi necessário pensar em uma regra para se utilizar apenas 7 (sete) salas. Essa regra foi implantada organizando a oferta das disciplinas de Estágio Supervisionado I, II e III. O problema foi resolvido colocando a oferta das disciplinas de Estágio de maneira sequencial. Na segunda-feira foi ofertado Estágio Supervisionado I, na terça-feira e na quarta-feira Estágio Supervisionado II e quinta-feira e sexta-feira Estágio Supervisionado III. Com os Estágios Supervisionados ofertados desta maneira foi possível em apenas 2 salas ofertar as disciplinas da sexta, sétima e oitava fase do curso. 4) A disciplina de Libras encontra-se atualmente sendo ofertada na oitava fase do curso de Licenciatura em Computação. Sempre houve problema em se encontrar professor habilitado para lecionar a disciplina. Desta forma, ofertou a disciplina de maneira que todos os alunos da sexta, sétima e oitava fase do curso de Licenciatura pudessem cursá-la. Depois de implantada essa regra no semestre de 2015/2 não foi necessário ofertar a disciplina de Libras. 5) Todos os alunos que não possuem dependência em nenhuma disciplina e que estão regularmente matriculados na quinta e na sexta fase do curso de Licenciatura em Computação tiveram a possibilidade de adiantar as disciplinas de Informática na Educação Infantil ofertada na sétima fase do curso e Administração e Gerência em Informática ofertada na oitava fase do curso. 6) As disciplinas de AOC - Arquitetura e Organização de Computadores - e POO - Programação Orientada à Objetos - são comum dos dois cursos de Computação (SI e LC). AOC está na terceira fase de SI e na quinta fase de LC. POO esta na terceira fase de SI e na quarta fase de LC. Como ambas as disciplinas não tiveram mais de 40 alunos matriculados optou-se em ofertar apenas uma turma de AOC e uma turma de POO para os dois cursos de Computação.
Figura 4. Cadastro da Regra de Algoritmos I e II

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
55
5. Trabalhos Futuros O Campus Universitário Vale do Teles Pires possui dois cursos de graduação que se admite ingresso semestral, Bacharelado em Sistemas de Informação e Licenciatura em Geografia. Como o entendimento é que cada professor que atua no campus deve ser lotado na Faculdade de Ciências Exatas e Tecnológicas, como trabalhos futuros pensa-se em implantar um horário para a faculdade. Respeitando o que é diferente em cada curso, mas possibilitando aos professores que atuam nos dois cursos terem seus horários melhor organizados. Para os alunos facilitaria a questão em poder cursar as disciplinas em qualquer um dos dois cursos, ou mesmo, ofertar disciplinas em conjunto.
Referências Barata, B. M., Medeiros, R. C., Vieira, C. E., & Silva, J. C. (2010). Problema de
Alocação de Horários: um estudo de caso utilizando o Software Livre FET. Revista Eletrônica TECCEN, 3, 13-22.
Mansor, Z., Arbain, J., & Hassan, M. A. (2002). Implementation of fet application in generating a university course and examination timetabling. The Second International Conference on Information Technology and Business Application.
Souza, M. J., Maculan, N. F., & Ochi, L. S. (2001). Uma heurística para o problema de programação de horários em escolas. Sociedade Brasileira de Matemática Aplicada e Computacional, pp. 213-222.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
56
Descoberta Dinâmica de Serviços por meio da Ontologia Owl-S
Josemar C. Silva1, Evandro C. Freiberger2
1Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Caixa Postal 2367 – 78.060-900 – Cuiabá – MT – Brasil
2Instituto Federal de Educação, Ciência e Tecnologia de Mato Grosso (IFMT) Caixa Postal 953 – 78.043-400 – Cuiabá – MT – Brasil
[email protected],[email protected]
Abstract. This paper discusses the concepts of Web Services and Semantic Web Services and makes a discussion at the text on the benefits of Semantic services such as composition, execution and in particular the discovery of services. It was also developed an experiment to the storage process of the profile data from a semantic web service in a UDDI repository and a tool for manipulating the data in the repository.
Resumo. Este trabalho aborda os conceitos de Serviços Web e Serviços Web Semânticos e faz uma discussão durante o texto sobre os benefícios dos Serviços Semânticos como composição, execução e, em especial, a descoberta de serviços. Também foi desenvolvido um experimento para o processo de armazenamento dos dados do perfil de um serviço web semântico em um repositório UDDI e uma ferramenta para manipulação dos dados no repositório.
1. Introdução Com o avanço da Web e meios de comunicações, as aplicações Web não se limitam apenas fornecer conteúdos estáticos, mas aplicações dinâmicas que atendam usuários finais em suas atividades. Por exemplo, educação a distância e transação bancária. Atualmente o desenvolvimento orientado a serviços com tecnologia Web Services está sendo utilizado como forma de integração nas aplicações por utilizar como troca de mensagens o padrão XML (Extensible Markup Language), possibilitando uma nova forma de utilização da Internet entre os meios coorporativos e governamentais.
Entretanto a Internet atual está baseada em documentos espalhados em milhares de servidores Web existentes que se encontram geograficamente distribuídos, pelo fato das aplicações possuírem a lógica da aplicação dentro dos servidores Web. Nos provedores de serviços não existe uma forma de descobrir Serviços Web sem intervenção humana [Santos e Ribeiro, 2006]. Contudo, a forma de representar e manipular as informações na Web vem sofrendo modificações pelo desenvolvimento de aplicações com uso da Web Semântica. A ideia central da Web Semântica é categorizar a informação de maneira padronizada, facilitando seu acesso.
Para os Web Services, a Web Semântica poderá trazer várias possibilidades de utilização e este trabalho demonstra como a marcação semântica nos serviços, pode melhorar , a descoberta e execução automática de serviços.
O objetivo deste trabalho foi projetar e implementar uma solução baseada na ontologia OWL-S para recuperação dinâmica de serviços no repositório UDDI. Especificamente implementar serviço com marcação semântica e implementar o

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
57
processo de descoberta dinâmica do serviço com ferramentas para leitura de serviços web semânticos. A sequência deste artigo está estruturado da seguinte forma: a seção 2 expõe os matérias e métodos utilizados no trabalho; a seção 3 faz definição de serviços web e web semântica; a seção 4 descreve o experimento desenvolvidos e ferramentas utilizadas; finalmente a seção 5 apresenta a conclusão.
2. Matérias e Métodos A metodologia para desenvolvimento deste trabalho foi desenvolvida por meio de pesquisa bibliográfica, na área de Computação Orientada a Serviços e Web Services para melhor entendimento dos atuais conceitos e tecnologias que envolvem os Serviços Web. Para realizar essa etapa foram lidos livros, periódicos e orientações técnicas nas áreas de Serviços Web Semânticos, ontologias na qual são desenvolvidos Serviços Semânticos, web semântica e ferramentas para desenvolvimento de Serviços Semânticos. Também foi feito um estudo de sistemas com o objetivo de subsidiar o desenvolvimento de um serviço de consulta, para chegar à implementação de um experimento e desenvolvimento de uma ferramenta baseada na abordagem proposta por [Srinivasan, Paolucci e Sycara 2004].
Esta abordagem, é uma extensão do trabalho proposto por Paolucci et al (2002), na qual consiste das adições da ontologia OWL-S Profile ao mecanismo de registro do UDDI e adição de um matchmaker que realiza as inferências através da utilização de filtros semânticos nos conceitos da ontologia de domínio que persistida nos registros do UDDI semântico, durante o processo de descoberta do serviço Web semântico. Srinivasan, Paolucci e Sycara (2004), também desenvolveram a ferramenta OWL-S UDDI Matchmaker, que realiza o registro e a descoberta de serviços semânticos no repositório UDDI.
Para desenvolvimento dos serviços semânticos foi feito analise dos sistemas utilizados no Biocardios (Centro de Cardiologia Aplicada) localizado em Cuiabá/Mato Grosso-Brasil. Exceto informações dos pacientes todos os dados do banco de dados do software utilizado para captura de imagens e laudos médicos foi cedido, em especial laudos médicos relacionados às doenças do coração. Os dados obtidos no Biocardios foram analisados, para depois selecionar aqueles a serem recuperadas no serviço. Além desse trabalho, foi preciso promover reuniões com médicos envolvidos na elaboração dos laudos médicos, para definir quais laudos médicos que seriam disponibilizados para consulta via Web Service.
3. Serviços Web e Web Semântica Para Martin et al. (2004), Serviços Web são sistemas de software identificados por URI especificados por um documento de descrição que é baseado na linguagem XML. O documento proporciona que outros sistemas possam identificar o Serviço Web.
Segundo Berners-Lee et al. (2001) a Web Semântica tem como proposta estruturar o conteúdo da Web para que aplicações possam processar não apenas palavras-chaves em documentos na web. As aplicações chegarão ao ponto de tomarem decisões a partir da semântica em conteúdo da Web. Uma nova forma de conteúdo Web que pode ser entendido e manipulado por computador vai trazer novas possibilidades para serviços e aplicações.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
58
4. Experimento Desenvolvido Essa seção apresenta as tecnologias e os procedimentos realizados em um experimento que demonstra os resultados obtidos neste trabalho.
Todas as ferramentas utilizadas são projetos open sources desenvolvidos por terceiros. Segue abaixo descrição dessas ferramentas.
OWL-S Editor - utilizado para criar as descrições OWL-S dos serviços semânticos a partir de arquivo WSDL.
OWL-S UDDI Matchmaker - a ferramenta OWL-S/UDDI Matchmaker [PAOLUCCI; KAWAMURA; BLASIO, 2003], serviu para o processo de armazenamento de dados da classe Profile da OWL-S.
Pellet - já vem instalado na OWL-S/UDDI Matchmaker. No presente trabalho essa ferramenta é o motor responsável pela inferência no casamento entre as entradas e saídas dos dados armazenados no banco de dado jUDDI,
OWL-S UDDI Matchmaker Client - a API OWL-S UDDI Matchmaker Client é o cliente para utilização da OWL-S UDDI Matchmake. Ela permitiu interagir com os dados armazenados no UDDI, assim como publicação do Profile do serviço no UDDI Machmaker, consulta (descoberta do serviço pelo parâmetro de entrada e saída) e remoção do anúncio do serviço semântico no repositório UDDI.
OWL-S API - permitiu criar, ler, escrever, validar e executar serviços semânticos simples ou compostos descritos em OWL-S.
WSDL2OWL-S - a ferramenta WSDL2OWL-S foi necessária para tradução do WSDL para a ontologia OWL-S. A ferramenta usa como entrada a URL do WSDL do serviço, o Service Name (nome do serviço), Text Description (descrições geradas do serviço), Logical URI (URL do Serviço Web Semântico), Inputs (parâmetro de entrada para procura e execução automática do serviço), Outputs (parâmetros de saída do serviço, ou seja, resultado esperado pelo serviço), Namespaces (identificadores gerados no Serviço).
Com o resultado da produção do OWL-S foi feito incremento manual de atributos referente ao ator do serviço na ontologia Profile, pois esses atributos não foram gerados automaticamente e não têm como inserir pela ferramenta WSDL2OWL-S. Os atributos são necessários para identificação do proprietário do serviço. O passo seguinte foi a validação do arquivo OWL-S pela ferramenta OWL-editor. Na sequência, o arquivo OWL-S, foi publicado no servidor web Apache Tomcat.
Para descoberta dinâmica do serviço por meio da ontologia OWL-S e validação da proposta deste trabalho, foi desenvolvida uma ferramenta com os seguintes módulos:
Módulo para registro de serviço - este módulo é responsável por registrar serviços no repositório UDDI a ontologia OWL-S Profile do serviço. O módulo foi desenvolvido com a API OWL-S Matchmaker Client que é um cliente da ferramenta OWL-S UDDI Matchmake e a API OWL-S API.
Módulo para consulta de serviços – este módulo é responsável pela descoberta dinâmica do serviço. As API OWL-S Matchmaker Client e OWL-S API foram utilizadas para desenvolvimento deste módulo.
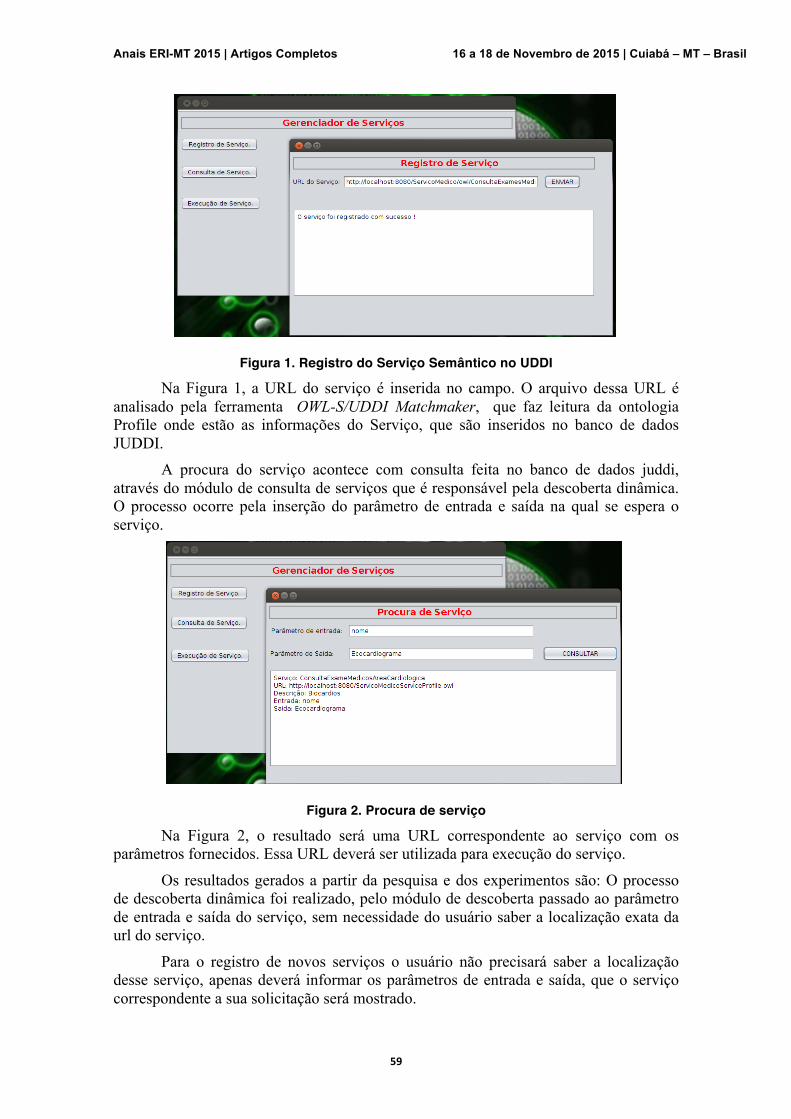
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
59
Figura 1. Registro do Serviço Semântico no UDDI
Na Figura 1, a URL do serviço é inserida no campo. O arquivo dessa URL é analisado pela ferramenta OWL-S/UDDI Matchmaker, que faz leitura da ontologia Profile onde estão as informações do Serviço, que são inseridos no banco de dados JUDDI.
A procura do serviço acontece com consulta feita no banco de dados juddi, através do módulo de consulta de serviços que é responsável pela descoberta dinâmica. O processo ocorre pela inserção do parâmetro de entrada e saída na qual se espera o serviço.
Figura 2. Procura de serviço
Na Figura 2, o resultado será uma URL correspondente ao serviço com os parâmetros fornecidos. Essa URL deverá ser utilizada para execução do serviço.
Os resultados gerados a partir da pesquisa e dos experimentos são: O processo de descoberta dinâmica foi realizado, pelo módulo de descoberta passado ao parâmetro de entrada e saída do serviço, sem necessidade do usuário saber a localização exata da url do serviço.
Para o registro de novos serviços o usuário não precisará saber a localização desse serviço, apenas deverá informar os parâmetros de entrada e saída, que o serviço correspondente a sua solicitação será mostrado.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
60
Entretanto as características dos serviços web semânticos como execução automática e composição, discutido neste trabalho não foram implementadas. Eles serão abordados em trabalhos futuros.
5. Conclusão Foram abordados problemas da descoberta enfrentados em serviços Web, ao se utilizar uma arquitetura orientada a serviços tradicionais. A web semântica aponta soluções para problemas na entidade de registro do serviço que podem ser resolvidos por meio da tecnologia da Web Semântica, resultando na maior eficiência no serviço de descoberta, permitindo assim que unidades registradoras retornem com maior precisão os serviços requisitados. Os objetivos deste trabalho foram atingidos, o desenvolvimento do serviço para marcação semântica e o processo de descoberta dinâmica foram realizados. Alguns resultados foram obtidos, entre eles:
O processo de registro torna-se transparente ao usuário do serviço, ou seja, para novos serviços desenvolvidos que seja registrado no repositório UDDI, ele estará disponível para uso quando for consultado pelos parâmetros de entrada e saída.
O processo de descoberta dinâmica foi realizado. Um agente de software pode interpretar as informações que o serviço disponibiliza pelos parâmetros de entrada e saída, dessa forma será mostrado o serviço solicitado de forma mais rápida. Uma proposta viável para marcação semântica de serviço web pela ontologia OWL-S Profile. Assim como registro e descoberta de serviço.
Entretanto algumas limitações são destacadas, entre elas estão: Não poder fazer a composição do serviço, ou seja, quando um usuário procurar
determinado serviço no repositório UDDI, mas não seja encontrado, deverá ser mostrado um serviço candidato.
Os módulos para registro e descoberta dinâmica, tem em suas linhas de códigos o usuário, a senha e o endereço do computador onde está instalado o banco de dados com o repositório UDDI. Caso seja necessário fazer alguma alteração do usuário, da senha ou endereço do computador onde esteja instalado o banco de dados do repositório UDDI. Essas alterações deveram ser feitas nas linhas de código do módulo para registro e descoberta dinâmica.
Referências API OWL-S UDDI Matchmaker Client. Disponível em:
http://www.cs.cmu.edu/~softagents/atlas/matchmaker/inst-mmclient.htm. Acesso em Janeiro/2015.
Berners-Lee, T., Hendler, J., and Lassila, O. (2001). “The Semantic Web”, Scientific American, 284(5):35–43.
Martin, D. et al. (2004). Bringing Semantics to Web Services. The OWL-S Approach. In: First International Workshop on Semantic Web Services and Web Process Composition (SWSWPC), San Diego, USA.
Paolucci, Massimo et al. (2002). Importing the Semantic Web in UDDI, In: Proceedings of Web Services, Ebusiness and Semantic Web Workshop.
Pellet. Disponível em <http://clarkparsia.com/pellet/>. Acesso em Janeiro/2015.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
61
Santos, D. B. A., Ribeiro, C. M. F. A. (2006) “Utilizando Tecnologia Semântica para Descoberta Automática de Web Services”, I Congresso de Pesquisa e Inovação da Rede Norte e Nordeste de Educação Tecnológica. Natal-RN.
Srinivasan, N., Paolucci, M., and Sycara, K. (2006). Semantic Web Service Discovery in the OWL-S IDE. In HICSS ’06: Proceedings of the 39th Annual Hawaii International Conference on System Sciences, page 109.2, Washington, DC, USA. IEEE Computer Society.
Srinivasan, N., Paolucci, M., and Sycara, K. (2004). An efficient algorithm for OWL-Sbased semantic search in UDDI. In SWSWPC ’04: Proceedings of the International Workshop Semantic Web Services and Web Process Composition (SWSWPC 2004), July 6-9, 2004, San Diego, CA, USA.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
62
Uma Análise da Participação Feminina no Curso de Sistemas de Informação da Universidade Federal de Mato
Grosso Luana Bulgarelli Mendes, Karen da Silva Figueiredo
Instituto de Computação – Universidade Federal do Mato Grosso (UFMT) Cuiabá, Mato Grosso, Brasil
[email protected], [email protected]
Abstract. This paper provides an overview of female’s participation in an Information Systems course with the aim of contributing to the contextualization of the women in IT in the Mato Grosso's scenario. By describing a preliminary analysis, this work discusses aspects related to the registration, entry, exclusion and other academic events of the students.
Resumo. Este artigo apresenta um panorama da participação feminina de um curso de Bacharelado em Sistemas de Informação com intuito de contribuir para a contextualização da relação da mulher no cenário da área de T.I. do estado de Mato Grosso. Através de uma análise preliminar, são discutidos aspectos relacionados à matrícula, ingresso, afastamento, exclusão e situação acadêmica das alunas do curso.
1. Introdução O maior nível de escolaridade das mulheres tem possibilitado a ampliação da participação feminina no campo da ciência. No entanto, o avanço é pequeno em algumas áreas ainda tratadas como áreas “masculinas”, tais como as áreas de Computação e Tecnologias [LIMA 2013]. Segundo Medeiros (2005), o número de ingressantes mulheres na graduação em cursos de ciência da computação caiu de 30% para entre 5 ou 10% e somente 19% [COELHO 2013] das mulheres ingressantes escolhem cursos da área de tecnologias. A realização de estudos quantitativos e qualitativos, como os de Frigo et al. (2013), Medeiros (2005), Natansohn et al. (2011) e Leta (2003) sobre a presença feminina nos cursos e no mercado profissional das áreas de Computação e Tecnologias, ajuda a compreender o cenário atual a fim de buscar respostas para a solução de problemas da participação feminina nessas áreas. Desta forma, o objetivo deste trabalho é realizar uma análise da participação feminina no curso de Bacharelado em Sistemas de Informação da UFMT (Universidade Federal de Mato Grosso) com intuito de contribuir para a contextualização da relação da mulher no cenário da área de T.I. no estado de Mato Grosso.
2. Material e Métodos A fim de analisar os dados do curso de Bacharelado em Sistemas de Informação (SI) da UFMT, os mesmos foram coletados através do sistema SIGA (Sistema de Informações
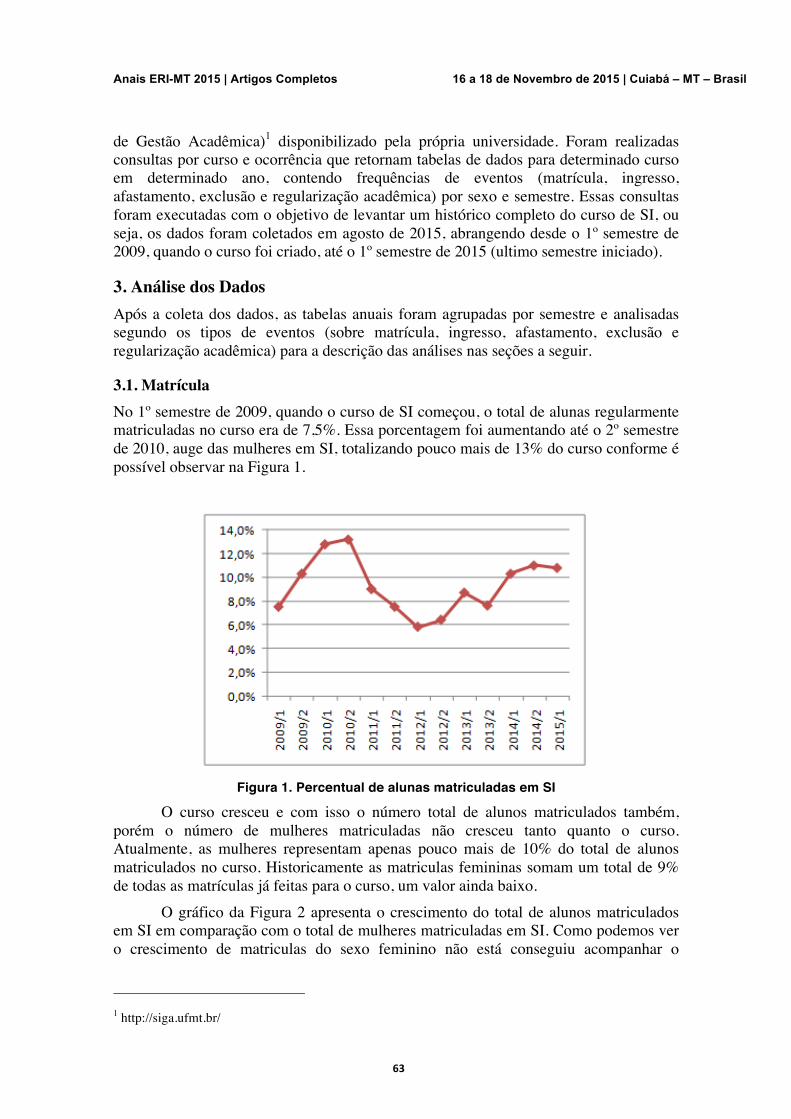
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
63
de Gestão Acadêmica)1 disponibilizado pela própria universidade. Foram realizadas consultas por curso e ocorrência que retornam tabelas de dados para determinado curso em determinado ano, contendo frequências de eventos (matrícula, ingresso, afastamento, exclusão e regularização acadêmica) por sexo e semestre. Essas consultas foram executadas com o objetivo de levantar um histórico completo do curso de SI, ou seja, os dados foram coletados em agosto de 2015, abrangendo desde o 1º semestre de 2009, quando o curso foi criado, até o 1º semestre de 2015 (ultimo semestre iniciado).
3. Análise dos Dados Após a coleta dos dados, as tabelas anuais foram agrupadas por semestre e analisadas segundo os tipos de eventos (sobre matrícula, ingresso, afastamento, exclusão e regularização acadêmica) para a descrição das análises nas seções a seguir.
3.1. Matrícula No 1º semestre de 2009, quando o curso de SI começou, o total de alunas regularmente matriculadas no curso era de 7,5%. Essa porcentagem foi aumentando até o 2º semestre de 2010, auge das mulheres em SI, totalizando pouco mais de 13% do curso conforme é possível observar na Figura 1.
Figura 1. Percentual de alunas matriculadas em SI
O curso cresceu e com isso o número total de alunos matriculados também, porém o número de mulheres matriculadas não cresceu tanto quanto o curso. Atualmente, as mulheres representam apenas pouco mais de 10% do total de alunos matriculados no curso. Historicamente as matriculas femininas somam um total de 9% de todas as matrículas já feitas para o curso, um valor ainda baixo. O gráfico da Figura 2 apresenta o crescimento do total de alunos matriculados em SI em comparação com o total de mulheres matriculadas em SI. Como podemos ver o crescimento de matriculas do sexo feminino não está conseguiu acompanhar o
1 http://siga.ufmt.br/
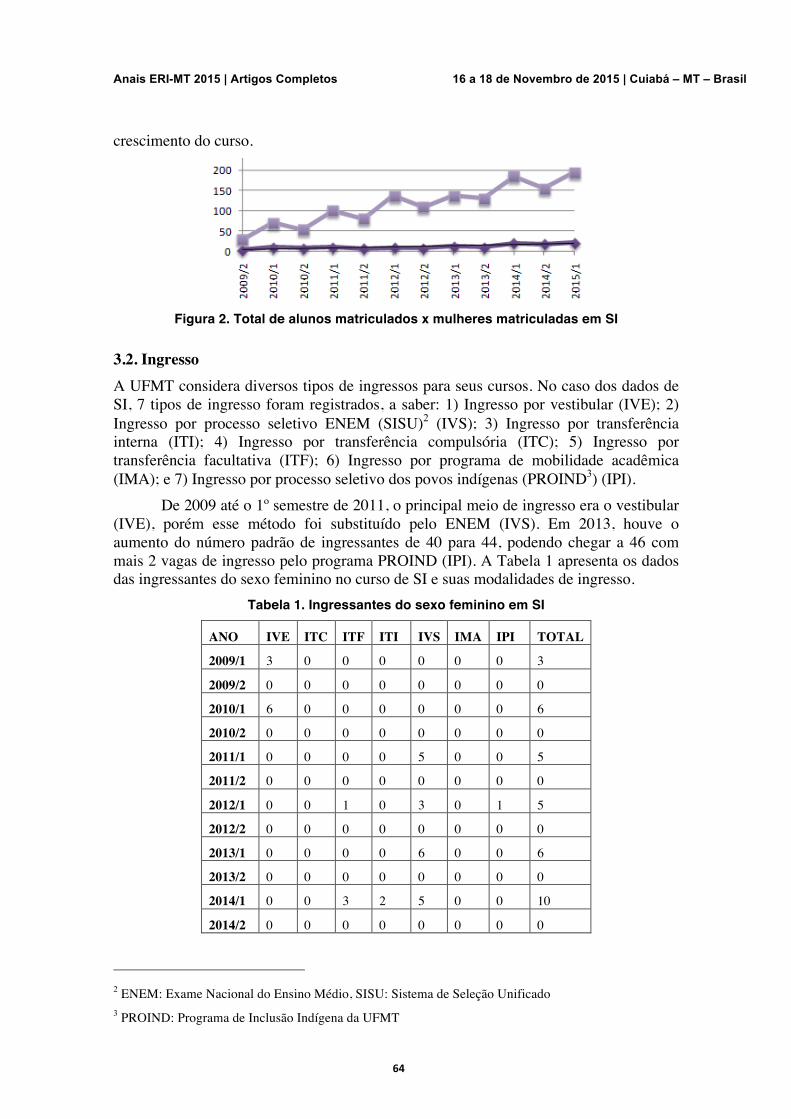
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
64
crescimento do curso.
Figura 2. Total de alunos matriculados x mulheres matriculadas em SI
3.2. Ingresso A UFMT considera diversos tipos de ingressos para seus cursos. No caso dos dados de SI, 7 tipos de ingresso foram registrados, a saber: 1) Ingresso por vestibular (IVE); 2) Ingresso por processo seletivo ENEM (SISU)2 (IVS); 3) Ingresso por transferência interna (ITI); 4) Ingresso por transferência compulsória (ITC); 5) Ingresso por transferência facultativa (ITF); 6) Ingresso por programa de mobilidade acadêmica (IMA); e 7) Ingresso por processo seletivo dos povos indígenas (PROIND3) (IPI). De 2009 até o 1º semestre de 2011, o principal meio de ingresso era o vestibular (IVE), porém esse método foi substituído pelo ENEM (IVS). Em 2013, houve o aumento do número padrão de ingressantes de 40 para 44, podendo chegar a 46 com mais 2 vagas de ingresso pelo programa PROIND (IPI). A Tabela 1 apresenta os dados das ingressantes do sexo feminino no curso de SI e suas modalidades de ingresso.
Tabela 1. Ingressantes do sexo feminino em SI
ANO IVE ITC ITF ITI IVS IMA IPI TOTAL
2009/1 3 0 0 0 0 0 0 3
2009/2 0 0 0 0 0 0 0 0
2010/1 6 0 0 0 0 0 0 6
2010/2 0 0 0 0 0 0 0 0
2011/1 0 0 0 0 5 0 0 5
2011/2 0 0 0 0 0 0 0 0
2012/1 0 0 1 0 3 0 1 5
2012/2 0 0 0 0 0 0 0 0
2013/1 0 0 0 0 6 0 0 6
2013/2 0 0 0 0 0 0 0 0
2014/1 0 0 3 2 5 0 0 10
2014/2 0 0 0 0 0 0 0 0
2 ENEM: Exame Nacional do Ensino Médio, SISU: Sistema de Seleção Unificado 3 PROIND: Programa de Inclusão Indígena da UFMT
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
65
2015/1 0 0 0 0 7 0 0 7
No curso de SI nunca houve ingresso feminino por IMA ou ITC. No caso de IMA, o curso de SI já recebeu um aluno do sexo masculino em 2012, mas ainda não contou com uma aluna estrangeira. O curso de SI também já recebeu uma ingressante indígena no ano de 2012 por IPI, no mesmo semestre o curso também recebeu um aluno indígena do sexo masculino, estes são os únicos alunos ingressantes registrados em SI via IPI.
Historicamente, SI recebeu duas vezes mais ingressantes mulheres por transferência externa que por transferência interna, ou seja, existem mais mulheres saindo de outras instituições para cursar Sistemas na UFMT do que pedindo transferência dentro da própria UFMT. Contudo o ENEM ainda é o principal método de entrada das alunas no curso de SI e no ano de 2015 os números apresentam um recorde: dos 46 alunos que ingressaram em SI pelo ENEM 15,2% eram mulheres.
3.3. Afastamento A UFMT considera três tipos de afastamento, a saber: 1) afastamento por não matrícula (ANM), 2) afastamento por trancamento de matrícula (ATR) e 3) afastamento para participação em convênio internacional (ACI) (ex.: Ciências Sem Fronteiras). Os primeiros afastamentos do curso de SI ocorreram logo no 2° semestre de 2009, após a sua criação, quando foram registrados 11 afastamentos por falta de matrícula e por trancamento, entretanto todos estes afastamentos foram realizados por alunos do sexo masculino. Os primeiros afastamentos de mulheres no curso de SI foram registrados a partir do 2° semestre de 2010 totalizando 7,6% dos afastamentos ocorridos no semestre. A partir de então os números foram subindo até o 2° semestre de 2013. NO inicio de 2014 já houve uma redução no numero de afastamentos e a partir do 2° semestre de 2014 não houve mais afastamentos por não matrícula. A maior razão dos afastamentos femininos é por falta de matrícula, totalizando 62,3% dos afastamentos femininos. A Tabela 2 apresenta um histórico dos afastamentos em SI.
Tabela 2. Afastamentos do curso de SI
Afastamentos
2009/1
2009/2
2010/1
2010/2
2011/1
2011/2
2012/1
2012/2
2013/1
2013/2
2014/1
2014/2
2015/1
Total
Por Não Matrícula (F) 0 0 0 2 3 6 6 8 8 9 1 0 0 43 Por Não Matrícula (M) 0 8 10 23 25 42 46 70 70 71 15 0 0 380 Por Trancamento De Matrícula (F) 0 0 0 0 0 0 1 0 1 0 9 10 2 23 Por Trancamento De Matrícula (M) 0 3 1 3 4 3 3 5 9 5 77 87 22 222 P/ Part. Em Convênio Internacional (F) 0 0 0 0 0 0 1 1 1 0 0 0 0 3 P/ Part. Em Convênio Internacional (M) 0 0 0 0 0 0 0 0 0 0 0 0 0 0
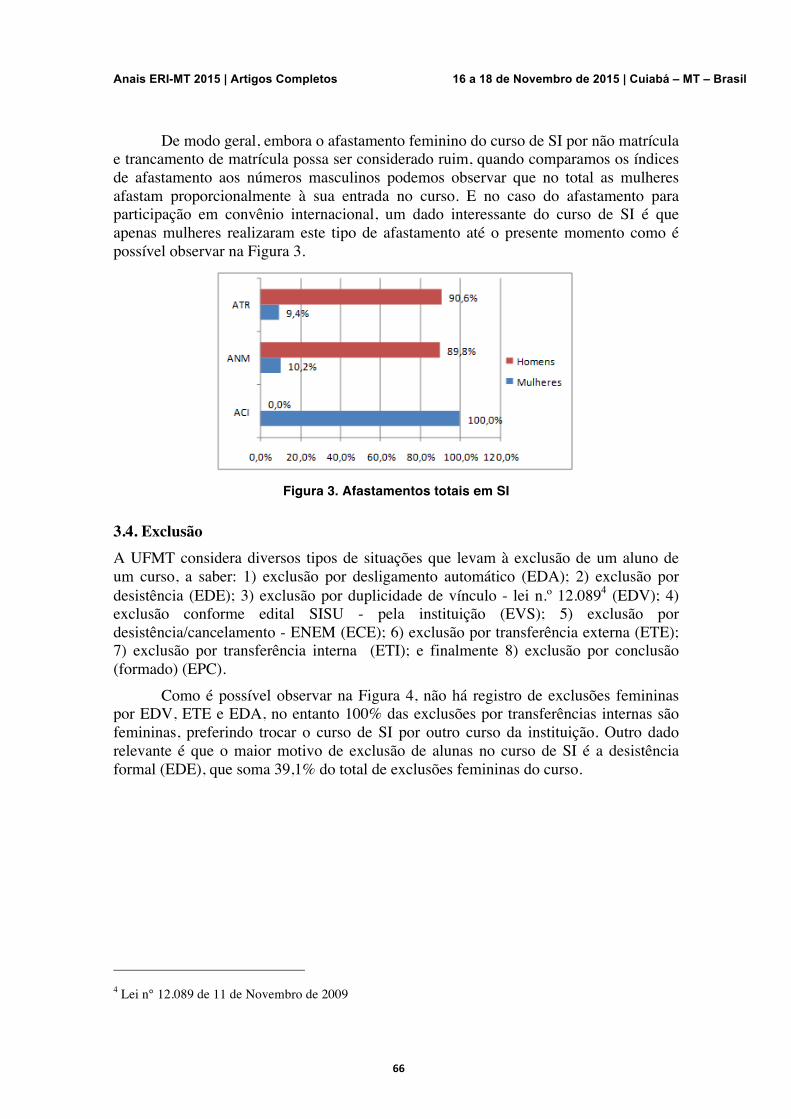
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
66
De modo geral, embora o afastamento feminino do curso de SI por não matrícula e trancamento de matrícula possa ser considerado ruim, quando comparamos os índices de afastamento aos números masculinos podemos observar que no total as mulheres afastam proporcionalmente à sua entrada no curso. E no caso do afastamento para participação em convênio internacional, um dado interessante do curso de SI é que apenas mulheres realizaram este tipo de afastamento até o presente momento como é possível observar na Figura 3.
Figura 3. Afastamentos totais em SI
3.4. Exclusão A UFMT considera diversos tipos de situações que levam à exclusão de um aluno de um curso, a saber: 1) exclusão por desligamento automático (EDA); 2) exclusão por desistência (EDE); 3) exclusão por duplicidade de vínculo - lei n.º 12.0894 (EDV); 4) exclusão conforme edital SISU - pela instituição (EVS); 5) exclusão por desistência/cancelamento - ENEM (ECE); 6) exclusão por transferência externa (ETE); 7) exclusão por transferência interna (ETI); e finalmente 8) exclusão por conclusão (formado) (EPC). Como é possível observar na Figura 4, não há registro de exclusões femininas por EDV, ETE e EDA, no entanto 100% das exclusões por transferências internas são femininas, preferindo trocar o curso de SI por outro curso da instituição. Outro dado relevante é que o maior motivo de exclusão de alunas no curso de SI é a desistência formal (EDE), que soma 39,1% do total de exclusões femininas do curso.
4 Lei n° 12.089 de 11 de Novembro de 2009

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
67
Figura 4. Exclusões totais em SI
O curso de SI já registrou até o presente momento 19 exclusões por conclusão, ou seja, formou 19 alunos. Dentre estes, 16 do sexo masculino e 3 do sexo feminino, representando (15,8%). Apesar do número ainda baixo, proporcionalmente observa-se que o número de formandas é maior que a média geral de ingressantes e matriculadas no curso.
3.5. Regularização Acadêmica Um discente em processo de regularização acadêmica é um aluno que não se encaixa em nenhuma das outras ocorrências descritas anteriormente. O processo de regularização ocorre quando o aluno já perdeu a matrícula e o mesmo monta um processo para reaver essa matrícula e regressar ao seu curso. Nesta situação, estão registrados 77 alunos do sexo masculino e 6 do sexo feminino no presente momento.
4. Conclusões Este artigo apresentou um panorama da participação feminina no curso de Bacharelado em Sistemas de Informação da UFMT, com intuito de contribuir para a contextualização da relação da mulher no cenário da área de T.I. do estado de Mato Grosso. A análise realizada, ainda que muito preliminar, ressaltou aspectos relacionados à matrícula, ingresso, afastamento, exclusão e situação acadêmica das alunas do curso.
Referências Coelho, R. (2013) “Mulheres e Meninas na Computação: Realidade e Desafio”, Revista
Computação Brasil, n. 3, p. 68-75. Frigo, L. et al. (2013) “Análise da Diferença de Gênero na Educação: Estudo de caso na
cidade de Araranguá - Sul do Brasil”, In: Conferencia Latino Americana en Informática, Naiguatá, Venezuela, LAWCC 2013, p. 32-37.
Leta, J. (2003) “As mulheres na ciência brasileira: crescimento, contrastes e um perfil de sucesso”, Estudos Avançados, v. 17, n. 49, p. 271-284.
Lima, M. (2013) “As mulheres na Ciência da Computação”, Revista Estudos Feministas, v. 21, n. 3, p. 793-816.
Medeiros, C. “From subject of change to agent of change: women and IT in Brazil”, In: Proceedings of the international symposium on Women and ICT: creating global transformation. ACM, 2005. p. 15.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
68
Natansohn, G. et al. (2011) “Mulheres na Cultura Digital: perspectivas e desafios”, Trabalho apresentado no DT, v. 7, 2011.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
69
PD4CAT: Um Método de Design Participativo para Tecnologia Assistiva Personalizada
Luciana Correia Lima de Faria Borges1,2, Lucia Vilela Leite Filgueiras1, Cristiano
Maciel2, Vinicius Carvalho Pereira3
1LTS - Escola Politécnica - Universidade de São Paulo
2LAVI – Instituto de Computação – UFMT
3 Instituto de Linguagens – UFMT [email protected],[email protected],[email protected],
Abstract. Studies presenting recommendations for Participatory Design (PD) including people with special needs are scarce. To fill in that gap, this research aims to propose PD4CAT – Participatory Design for Customized Assistive Technology, a method that helps multidisciplinary teams conceive customized computational solutions by means of PD to actively engage the team (including the disabled person, his/her therapists and caregivers) in the design and development cycle. The method of the study consisted in literature review and action research in two case studies of computational solutions development in a rehab institution. The results are guidelines for PD4CAT. Resumo. São raros os estudos que apresentam recomendações para o Design Participativo (DP) incluindo pessoas com deficiência. Visando preencher essa lacuna, esta pesquisa tem o objetivo de propor o PD4CAT – Participatory Design for Customized Assistive Technology, método que objetiva auxiliar equipes multidisciplinares a conceberem soluções computacionais customizadas utilizando o DP para o envolvimento ativo da equipe - que inclui a pessoa com deficiência, seus terapeutas e cuidadores - no ciclo de design e desenvolvimento. A metodologia adotada foi o levantamento bibliográfico e a pesquisa-ação com dois estudos de caso aplicados ao desenvolvimento das soluções computacionais em uma instituição de reabilitação. Os resultados obtidos foram diretrizes que compõem o PD4CAT.
1. Introdução Tecnologias assistivas computacionais, ou Alta Tecnologia Assistiva (ATA) não podem prescindir de customização para atender efetivamente pessoas com deficiência nas atividades de vida diária e em terapia de reabilitação. Hoje, tais tecnologias são ofertadas de forma padronizada, cabendo aos terapeutas adaptá-las para que seus pacientes possam usá-las. O design participativo (DP), como abordagem de envolvimento ativo do usuário no processo de projeto [Rocha e Baranauskas, 2003] [Muller, Wildman e White, 1992], adéqua-se bem à ideia de customização de ATAs. Assim, este artigo tem como objetivo apresentar o PD4CAT – Participatory Design for Assistive Technology [Borges, 2014] – um método para a concepção de

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
70
soluções em tecnologias assistivas personalizadas, utilizando a abordagem de Design Participativo (DP), contando com uma cadeia de stakeholders (pessoas interessadas nos resultados) que, nesse caso, são pessoas com deficiências, seus terapeutas e cuidadores. Tal método visa apontar premissas que auxiliem profissionais da computação a envolver ativamente esta cadeia de stakeholders no ciclo de design de forma a atender às necessidades e desejos dos usuários finais em suas soluções tecnológicas. Por esse método, também são consideradas premissas básicas de DP relacionadas ao “querer” e ao “poder” dos stakeholders em todas as fases do ciclo de design. A metodologia adotada para propor tal método embasou-se no levantamento bibliográfico e na pesquisa-ação. Pelo levantamento bibliográfico, encontrou-se: a) os princípios consagrados do DP [Rocha e Baranauskas, 2003], [Muller, Wildman e White, 1992], [Preece, Rogers e Sharp, 2005], [Moffatt, 2004], [Bratteteig et al., 2012]; b) métodos de DP reconhecidos pelos princípios consagrados [Bratteteig et al., 2012]; c) Métodos de DP para pessoas com deficiência [Melo et al., 2006], [Guha, Druin e Fails, 2008], [Wu, Richards e Baecker, 2004]; e d) pesquisas de DP relacionadas a pessoas com deficiências [Hornof, 2009], [Frauenberger, Good e Alcorn, 2012], [Slegers, Wilkinson e Hendriks, 2013], [Wu, Richards e Baecker, 2004], [Moffatt, 2004], [Galliers et al., 2012], [Lindsay et al., 2012], [Prior, 2010], [Mayer e Zach, 2013], [Hirano et al., 2010], [Allen, Mcgrenere e Purves, 2007], [Garzotto e Bordogna, 2010]. A pesquisa-ação foi realizada por meio de dois estudos de caso em uma instituição de reabilitação, sendo apresentados nos artigos [Borges et al., 2012] e [Borges et al., 2013], gerando um método mais refinado, o qual é apresentado nas seções subsequentes.
2. O PD4CAT O PD4CAT é um método com base na estrutura convencional de um ciclo de desenvolvimento de software iterativo, no qual protótipos são sucessivamente refinados baseando-se na avaliação analítica e empírica de suas qualidades, tais como vários modelos de design centrados no usuário, p.e. [Mayhew, 1999], [Hix e Hartson, 1993], bem como no modelo incremental [Sommerville, 2011]. O PD4CAT é composto por quatro fases: 1. Composição da equipe; 2. Descoberta da solução; 3. Especificação detalhada da solução; 4. Design da solução. Essas fases acontecem com o apoio de dois processos: processo de acomodação para o DP e processo de avaliação participativa, como se vê na Figura 1. Tais fases foram baseadas em modelos tradicionais de desenvolvimento de software, porém houve necessidade de adaptações de técnicas, de forma a permitir a inclusão do usuário com deficiência nas práticas de DP para atuarem como co-designers na personalização da solução. O processo de acomodação para o DP não afeta diretamente a produção da solução tecnológica personalizada, mas dá apoio às outras fases do processo, adaptando estratégias utilizadas e gerando os artefatos necessários para a execução das atividades de DP. Já o processo de avaliação participativa, o qual também dá apoio à todas as outras fases do método, é responsável por avaliar os resultados obtidos pelo PD4CAT, tanto com relação ao processo de design, como com relação aos resultados associados ao produto em desenvolvimento.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
71
Figura 1. Diagrama do PD4CAT com fases e processos
2.1 Papéis no método Está sendo chamado coletivamente de stakeholders as pessoas que integrarão a equipe multidisciplinar da pesquisa e atuarão como designers participativos por meio do PD4CAT. Tais stakeholders podem incluir gestores da instituição de saúde, a pessoa com deficiência (PCD ou SCD), terapeutas do PCD, cuidadores, desenvolvedores e especialistas de domínios específicos. Note-se que um desses stakeholders deverá atuar como moderador da prática de design participativo.
2.2 Propósito das fases e processos do PD4CAT
2.2.1 Fase 1 – Composição da equipe
Visa estabelecer contato e parceria com a instituição de reabilitação, e os prováveis integrantes da equipe, para definir, em comum acordo com cada integrante, todas as pessoas que irão compor a equipe para atuar como co-designers participativos.
2.2.2 Processo de Acomodação
Propicia a criação de estratégias – técnicas personalizadas e artefatos - para inserir os stakeholders no processo de design, atuando como co-designers. Em especial, para propiciar a inclusão do usuário com deficiência no DP.
2.2.3 Fase 2 – Descoberta da solução
Analisa, como no estudo de viabilidade do processo clássico dos projetos de engenharia, o contexto do paciente e suas necessidades de vida diária e terapêuticas. Como resultado dessa fase, uma proposta de solução tecnológica que melhore a autonomia do paciente é indicada pela equipe.
2.2.4 Fase 3 – Especificação detalhada da solução
Detalha as funcionalidades da solução, indicadas na fase 2 por práticas de DP com todos os stakeholders. Ao final desta fase devem-se obter os requisitos de software e as acomodações físicas necessárias para a solução. Para tanto, os stakeholders terapeutas, cuidadores e PCD especificam detalhes relevantes para a solução, ao passo que os

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
72
desenvolvedores fomentam a discussão e a reflexão sobre a solução computacional proposta na fase 2 e sua usabilidade. Ademais, os stakeholders terapeutas e cuidadores auxiliam a propor uma prática de DP adaptada para permitir que o PCD atue como co-designer.
2.2.5 Fase 4 – Design da solução
Obtém o desenho das interfaces da solução, relacionado às suas funcionalidades, através de práticas de DP com todos os stakeholders, especialmente o PCD, por meio do processo de acomodação.
2.2.6 Processo de Avaliação Participativa
Visa à avaliação dos resultados concebidos no design referentes à solução personalizada e às práticas de DP aplicadas no processo de acomodação (processo de design) ao longo das demais fases do PD4CAT, no que tange à efetiva inclusão do PD em seu “querer” e “poder”. Verifica-se ainda junto aos stakeholders (inclusive ao PCD, por meio do processo de acomodação) se o design gerado atendeu às expectativas inclusive com relação aos atributos de usabilidade, a fim de, se necessário, propor melhorias. Tal avaliação se dá também após entrega da solução para que o usuário final a utilize no dia-a-dia, colhendo feedeback do usuário com deficiência e do cuidador via diário de campo, monitoração do software utilizado, entrevistas, observação do usuário com deficiência utilizando o recurso etc.
3. Considerações Finais Este artigo apresenta o PD4CAT - método para concepção de ATAs personalizadas e que aponta premissas que auxiliem profissionais da computação a envolver ativamente uma cadeia de stakeholders composta pelo usuário com deficiência, seus terapeutas e cuidador no ciclo de design. A inovação do PD4CAT reside em apresentar um processo sistematizado de design, com estratégias adaptadas para permitir a concepção de uma TA customizada, incluindo o PCD no processo de DP, considerando premissas fundamentais ao DP que visam garantir o querer e o poder dos stakeholders em todo o processo, o que não foi encontrado na revisão da literatura. Com relação à inserção dos stakeholders com deficiência no processo de DP, o diferencial deste método está em contar com o know-how dos stakeholders terapeutas, especialmente no processo de acomodação para DP; pela criação e adaptação de técnicas (meta-design), esses stakeholders propõem novas técnicas personalizadas ao seu paciente, as quais garantem a sua inclusão no processo de DP. A aplicação de tal método para novos estudos de caso é um trabalho futuro recomendado, com vistas a consolidar o PD4CAT.
Referências Allen, M., McGrenere, J. and Purves, B. (2007). “The design and field evaluation of
PhotoTalk: a digital image communication application for people”. Proceedings of

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
73
the 9th international ACM SIGACCESS conference on Computers and accessibility. Tempe, Arizona, USA: ACM: 187-194 p.
Borges, L.C.L.F., Filgueiras, L.V.L, Maciel, C. and Pereira, V. (2013) “A customized mobile application for a cerebral palsy user”. Proceedings of the 31st ACM international conference on Design of communication. Greenville, North Carolina, USA: ACM: 7-16 p.
______. (2012) “Customizing a communication device for a child with cerebral palsy using participatory design practices: contributions towards the PD4CAT method”. Proceedings of the 11th Brazilian Symposium on Human Factors in Computing Systems. Cuiaba, Brazil: Brazilian Computer Society: 57-66 p.
Bratteteig, T., Dittrich, P.H.M., Dittrich, Y., Mogensen, P.H. and Simonsen, J. (2012)”Methods: organizing principles and general guidelines for partipatory design projects”. In: (Ed.). Routledge International Handbook of Participatory Design: Routledge, p.320. ISBN 041569440X.
Frauenberger, C., Good, J., Keay-Bright, W. and Pain, H. (2012) “Challenges, opportunities and future perspectives in including children with disabilities in the design of interactive technology”. Proceedings of the 11th International Conference on Interaction Design and Children. Bremen, Germany: ACM: 367-370 p.
Galliers, J., Roper, A., Cocks, N., Marshall, J., Muscroft, S. and Pring, T. (2012) “Words are not enough: empowering people with aphasia in the design process”. Proceedings of the 12th Participatory Design Conference: Research Papers - Volume 1. Roskilde, Denmark: ACM: 51-60 p.
Garzotto, F. and Bordogna, M. (2010) “Paper-based multimedia interaction as learning tool for disabled children”. Proceedings of the 9th International Conference on Interaction Design and Children 978-1-60558-951-0. Barcelona, Spain: ACM: 79-88p.
Guha, M.L., Druin, A., Chipman, G., Fails, J.A., Simms, S. and Farber, A. (2008) “Designing with and for children with special needs: an inclusionary model”. Proceedings of the 7th international conference on Interaction design and children. Chicago, Illinois: ACM: 61-64 p.
Hirano, S.H., Marcu, G., Nguyen, D.H., Boyd, L.A. and Hayes, G.R. (2010) “vSked: Evaluation of a system to support classroom activities for children with autism”. Atlanta, GA. p.1633-1642.
Hix, D. and Hartson, H. (1993) “Developing user interfaces: ensuring usability through product and process”. New York. NY: John Wiley & Sons.
Hornof, A. J. (2009) “Designing with children with severe motor impairments”. Proceedings of the 27th international conference on Human factors in computing systems. Boston, MA, USA: ACM: 2177-2180 p.
Lindsay, S., Jackson, D., Ladha, C., Ladha, K. and Olivier, P. (2012) “Empathy, participatory design and people with dementia”. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. Austin, Texas, USA: ACM: 521-530 p.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
74
Mayer, J. M. and Zach, J. (2013) “Lessons learned from participatory design with and for people with dementia”. Proceedings of the 15th international conference on Human-computer interaction with mobile devices and services. Munich, Germany: ACM: 540-545 p.
Mayhew, D. (1999) “The usability engineering lifecycle: a practioner´s handbook for user interface design”. San Francisco. CA.: Morgan Kaufmann.
Melo, A. M. and Baranauskas, M.C.C. (2006) “Design para a inclusão: desafios e proposta”. Proceedings of VII Brazilian symposium on Human factors in computing systems. Natal, RN, Brazil: ACM: 11-20 p.
Moffatt, K. (2004) “Designing technology for and with special populations: an exploration of participatory design with people with aphasia”. Department of Computer Science. The University of British Columbia, Department of Computer Science. The University of British Columbia, Department of Computer Science. The University of British Columbia.
Muller, M.J, Wildman, D.M. and White, E.A. (1992) “Taxonomy of participatory design practices: a participatory poster”. Posters and Short Talks of the 1992 SIGCHI Conference on Human Factors in Computing Systems. Monterey, California: ACM: 34-34 p.
Preece, J., Rogers, Y. and Sharp, H. (2005) “Design de interação: além da interação homem computador”. Porto Alegre: Bookman.
Prior, S. (2010) “HCI methods for including adults with disabilities in the design of CHAMPION”, Atlanta, GA. p.2891-2894.
Rocha, H.V.D. and Baranauskas, M.C.C. (2003) “Design e avaliação de interfaces humano computador”. Campinas, SP: NIED/UNICAMP: 244p.
Slegers, K., Wilkinson, A. and Hendriks, N. (2013) “Active collaboration in healthcare design: participatory design to develop a dementia care app”. CHI '13 Extended Abstracts on Human Factors in Computing Systems. Paris, France: ACM: 475-480 p.
Sommerville, I. (2011)” Software engineering”. Boston: Pearson. ISBN 0-13-705346-0. Wu, M., Richards, B. and Baecker, R. (2004) “Participatory design with individuals
who have amnesia. Proceedings of the eighth conference on Participatory design: Artful integration: interweaving media, materials and practices - Volume 1”, Toronto, Ontario, Canada: ACM: 214-223 p.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
75
Projeto Centrado no Usuário do Website do Conselho Municipal dos Direitos da Pessoa com Deficiência de
Rondonópolis-MT Maysa Roberta de Souza Pereira, Soraia Silva Prietch
Curso de Sistemas de Informação – Universidade Federal de Mato Grosso (UFMT) Câmpus Universitário de Rondonópolis – Rondonópolis – MT – Brasil
[email protected], [email protected]
Abstract. This paper aims to present the contextual analysis of user-centered design of the Rondonopolis Council for the Rights of People with Disabilities website. The methodological procedures adopted were: literature review, analysis of related systems, and interviews with potential users. As a result, we obtained a list of requirements as a starting point for the CMDPD website’s conception. Resumo. O presente artigo tem por objetivo apresentar a análise contextual do projeto centrado no usuário para a concepção do website do Conselho Municipal dos Direitos da Pessoa com Deficiência, de Rondonópolis. Os procedimentos metodológicos adotados foram os seguintes: revisão de literatura, análise de sistemas correlatos, e entrevistas com potenciais usuários. Como resultado, obteve-se a lista de requisitos como ponto de partida para a concepção do website do CMDPD.
1. Introdução O Conselho Municipal dos Direitos da Pessoa com Deficiência (CMDPD) de Rondonópolis – MT foi criado através da Lei Municipal nº 6.129/2009, a qual foi substituída posteriormente pela Lei Municipal nº 8.346/2015, e está diretamente vinculado à Secretaria Municipal de Promoção e Assistência Social. Com a nova lei, a composição do conselho agrega 14 (catorze) titulares e 14 (catorze) suplentes nomeados publicamente em Diários Oficiais (Diorondon nº 3123/2013 e Decreto nº 7.594/2015). Dentre os 28 membros (titulares e suplentes), representantes de órgãos, associações e instituições, 50% são da sociedade civil organizada e 50% são órgãos do governo.
O Conselho tem o objetivo de deliberar e fiscalizar políticas de atendimento nas áreas da educação, saúde, trabalho, assistência social, transporte, cultura, desporto, lazer e acessibilidade, no município de Rondonópolis. No entanto, mesmo tendo se colocado à disposição da população através do atendimento ao público, mesmo as reuniões sendo abertas à sociedade, mesmo tendo divulgado sua existência e finalidade na mídia local, e mesmo tendo realizado a I Conferência Municipal dos Direitos da Pessoa com Deficiência (Decreto nº 7.607/2015) em junho do ano corrente, ainda assim a procura pelo serviço voluntário do conselho é escassa em sua sede e a procura informal, externa à sede com consulta individual aos conselheiros, é volumosa.
Levando esse problema em consideração, o objetivo deste artigo é apresentar os resultados da análise contextual para o projeto do website do CMDPD, de Rondonópolis, tendo como foco seus potenciais usuários, seguindo o ciclo de projeto de IHC (Interação Humano-Computador). O interesse social é manter a população informada sobre as ações desenvolvidas pelo CMDPD e sobre as notícias e legislações

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
76
nacionais, regionais/estaduais e locais de interesse do público-alvo; sendo que esta proposta segue os preceitos da Lei nº 12.527/2011 para assegurar o direito fundamental dos cidadãos brasileiros de acesso à informação.
2. Materiais e métodos Para definir os materiais e métodos da pesquisa, inicialmente um fluxograma de atividades foi elaborado de modo que a equipe de trabalho estivesse ciente dos passos a serem realizados, bem como da relação de dependência entre uma atividade e outra. Neste aspecto, o fluxograma de atividades contempla três fases, as quais descrevem a sequência cronológica de realização das atividades a seguir: (Fase I - Análise contextual): Levantamento e análise de sistemas correlatos; elaboração das entrevistas; aplicação das entrevistas com usuários específicos do conselho; revisão da literatura especializada; e, levantamento de requisitos; (Fase II - Concepção): Construção e adequação dos wireframes; engenharia do produto; prototipação; e, avaliação automática de acessibilidade; (Fase III - Avaliação): Preparação da avaliação do protótipo; aplicação da avaliação com os potenciais usuários; análise dos resultados obtidos; finalização da implementação; e entrega.
3. Referencial teórico Conforme Hewett et al. (1992), a área de Interação Humano-Computador (IHC) averigua o “projeto (design), avaliação e implementação de sistemas computacionais interativos para uso humano, juntamente com os fenômenos associados a este uso”. Segundo Prates e Barbosa (2003), os estudos relacionados à avaliação de IHC buscam avaliar a qualidade de um projeto de interface, tanto ao longo do processo de desenvolvimento quanto o software pronto. Para Barbosa e Silva (2010, p. 8) apud Sharp et al. (2007), a usabilidade “enfoca a maneira como o uso de um sistema interativo no ambiente de trabalho é afetado por características do usuário (sua cognição, sua capacidade de agir sobre a interface e [...] de perceber as respostas do sistema)”.
Neste aspecto, ao conceber sistemas que leve em consideração o Projeto Centrado no Usuário, os projetistas demonstram a importância das características do público-alvo. Rogers (2013) refere-se à acessibilidade como o grau em que um produto interativo é acessível para tantas pessoas quanto o possível, o foco está em pessoas com deficiência. Barbosa e Silva (2010), complementam a afirmação de Rogers, ressaltando que o critério de acessibilidade está relacionado com a capacidade de o usuário acessar o sistema para interagir com ele, sem que a interface imponha obstáculos.
Considerando o foco maior de interesse exposto, conforme Kulak (2000) apud César (2008), requisitos estabelecem uma declaração completa “do que” um sistema deverá fazer sem referir-se a “como” deverá fazê-lo; isto é, define uma forma específica, características ou princípios que o sistema deverá prover, depois de construído. Os requisitos levantados neste trabalho foram classificados como requisitos funcionais (comportamental) e não funcionais (qualidade). Além da literatura citada, as seguintes referências são de grande relevância para o levantamento de requisitos: Ferreira e Nunes (2008), Nielsen (1993), Corradi (2007), ISO/IEC 25010:2011, e WCAG (2008).

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
77
4. Resultados e discussão Esta se encontra dividida em subseções, as quais compreendem os resultados obtidos por meio da execução da Fase I (Análise contextual) do trabalho.
4.1. Análise de sistemas correlatos Na busca por sistemas correlatos, verificou-se que são poucos os conselhos que disponibilizam online suas informações. Para a análise, foram escolhidos, aleatoriamente, 02 (dois) websites de Conselhos Municipais: do CMPD de São Paulo/SP1 e da Assessoria Especial de Assistência à Pessoa com Deficiência (AEAPcD) de Curitiba/PR2.
Ao analisar o website do Conselho de São Paulo, verificou-se que as práticas de acessibilidade não são utilizadas (como por exemplo, acesso a uma página sem nenhum link/botão para a pagina inicial), além de apresentar dificuldades no acesso às informações e a estética da interface não ser agradável. Porém possui um formulário de SAC pequeno, contendo os campos principais e as cores padrão não altera de acordo com a navegação dentro do website. Com relação ao website da AEAPcD, este apresenta mais prática de acessibilidade do que o outro website analisado (por exemplo botões de acessibilidade como contraste, zoom, descrição nas imagens, facilidade de acesso aos links e conteúdos), sua interface é esteticamente agradável, e os usuários podem encontrar as informações sem precisar de ajuda de terceiros.
É importante mencionar que, além destes websites, outros são fonte de inspiração para o levantamento de requisitos, tais como: libras.ufsc.br/, laratec.org.br/, www.cnse.es/, acessoparatodos.com.br, acessibilidade.bento.ifrs.edu.br/, tvines.com.br/.
4.2. Entrevistas com potenciais usuários Primeiramente, vale ressaltar quem são considerados os potenciais usuários do website. Os potenciais usuários são: (a) os usuários primários ou diretos: Pessoas com Deficiência (PcD), indivíduos que trabalham com as PcD (professores, profissionais da saúde, dentre outros), familiares e círculo de convívio social das PcD, dentre outros; e, (b) os usuários secundários ou indiretos: empresários que pretendem contratar PcD, membros de conselhos municipais de outras cidades, funcionários da prefeitura e/ou da secretaria de promoção e assistência social, imprensa, dentre outros.
No que se refere ao perfil dos entrevistados, tem-se que, dentre os quatro voluntários entrevistados, três são mulheres, com 30, 31 e 24 anos, respectivamente, sendo uma pessoa sem deficiência, uma com deficiência visual e uma com deficiência física, e um homem com 24 anos, sendo deficiente visual. Com relação ao nível de escolaridade, as três mulheres informaram possuir ensino superior completo e o entrevistado do sexo masculino mencionou ter ensino superior incompleto. As formações de ensino superior dos participantes são na área de serviço social, psicologia e direito. Vale mencionar que três das entrevistas foram realizadas no Núcleo do Conselho, pessoalmente, com anotações feitas em papel, e uma foi realizada por e-mail,
1 Disponível em: http://goo.gl/auqyT4, acesso dia 24/03/2015. 2 Disponível em: http://goo.gl/F0488U, acesso dia 24/03/2015.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
78
sendo três participantes membros titulares do Conselho e um participante é pessoa assídua das reuniões do Conselho.
Com relação às perguntas, foi elaborado um questionário com quatro questões para auxiliar a condução das entrevistas. A primeira pergunta interessa-se em saber a opinião do potencial usuário sobre quem este considerava que deveria ficar responsável pelas atualizações do website do Conselho após sua implantação. Para esta questão, as respostas obtidas foram unânimes, para a qual todos responderam que uma pessoa específica (estagiário/técnico) deverá ficar responsável pelas as atualizações do website. Um respondente mencionou que, além disso, as postagens efetuadas pelo estagiário/técnico devem ser previamente validadas por algum membro do Conselho.
A segunda pergunta interessava-se em saber a opinião dos entrevistados referente ao acesso a websites que considerava acessível ou de fácil utilização, sendo que os respondentes deveriam que indicar três websites como exemplo. Para esta questão, as respostas obtidas foram os seguintes websites: cefess; pessoacomdeficiencia; mundocegal; informática sem barreiras; acessibilidade em foco; brailleroo; cfp; CMPD de São Paulo. A terceira questão, interessava-se na opinião dos entrevistados sobre o conhecimento de websites de conselhos municipais dos direitos da PcD de outras cidades e caso a resposta fosse afirmativa, citar quais foram. Para esta pergunta, dos quatro entrevistados, apenas um afirmou ter visitado o website de conselho municipal de São Paulo e, os que responderam que não acessaram, afirmaram que acessou apenas websites de secretarias. Por fim, de acordo com as respostas para a questão quatro, dois entrevistados acrescentariam parcerias e links importantes, ouvidoria, legislações, publicações com links de RSS, vídeos, entrevistas, áudio-descrição e notícias.
4.3. Levantamento de requisitos O levantamento de requisitos foi realizado tomando como base os estudos efetuados previamente: revisão de literatura, análise dos sistemas correlatos e análise das entrevistas aplicadas aos potenciais usuários. Para documentar este levantamento, a equipe de trabalho seguiu as orientações definidas na norma IEEE/ISO/IEC 29148-2011, os quais constam descritos na sequência:
• (1.1) Propósito do documento de requisitos: Descrever e especificar as necessidades do Conselho Municipal dos Direitos da Pessoa com Deficiência de Rondonópolis, que devem ser atendidas pelo website;
• (1.2) Escopo do produto. (1.2.1) Nome do produto: Website do Conselho Municipal dos Direitos da Pessoa com Deficiência de Rondonópolis. O logotipo, na Figura 1, foi criado para garantir a identificação visual do Conselho associada à bandeira do município; (1.2.2) Missão do produto: Manter a sociedade informada sobre as ações desenvolvidas pelo CMDPD e sobre as informações e notícias nacionais, regionais/estaduais e locais de interesse do público-alvo do Conselho; (1.2.3) Benefício do Produto: Divulgar o que o CMDPD-Rondonópolis está realizando no município, promover a conscientização sobre os direitos e deveres das PcD, criar mecanismos facilitados de acesso a informações de interesses específicos e proporcionar mais um canal de interação com a sociedade;
• (1.3) Visão Geral do Produto. (1.3.1) Perspectiva do Produto: Pretende-se que o website do Conselho seja vinculado ao portal da Prefeitura de Rondonópolis, de

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
79
modo que fique claro o seu vínculo com as ações do município e que tenha visibilidade nos diferentes âmbitos de governo; (1.3.2) Características dos usuários: Usuários primários e usuários secundários (descritos na subseção 4.2); (1.3.3) Limitações: (a) O website deverá ser administrado por usuário que tenha um conhecimento básico de linguagem web; (b) O conselho deverá ter autonomia de hospedagem para efetuar a manutenção do website.
Figura 1. Logotipo do CMDPD de Rondonópolis
• (1.4) Descrições Gerais: tem-se como finalidade garantir o acesso a informações relativas ao CMDPD, respeitando as normas de acessibilidade para websites da WCAG (2008), das diretrizes dispostas na literatura, das ideias verificadas nos sistemas correlatos e das opiniões dos potenciais usuários;
• (2) Referências: sistemas correlatos e websites referências em acessibilidade digital, entrevistas com usuários, literatura e WCAG;
• (3) Requisitos específicos. a lista de requisitos funcionais agrega 8 (oito) itens e, na lista de requisitos não funcionais, constam 82 itens. Alguns exemplos dos requisitos levantados são apresentados no Quadro 1.
Quadro 2. Exemplos de alguns requisitos levantados
Requisitos Funcionais Requisitos Não Funcionais Possibilitar a consulta de notícias específicas Permitir a escolha da opção de contraste de cores Atualizar notícias, incluindo a mais recente no topo da lista
Oferecer uma mesma informação em diferentes formatos (imagem, vídeo, texto, áudio)
Contemplar área restrita para membros do conselho, efetuando registro e login Garantir informações disponíveis em Libras
Desabilitar membros do conselho após encerramento de gestão ou desligamentos Fornecer feedback após realização de comandos
Registrar usuários para receber notícias, para efetuar denúncias online, dentre outros
Possibilitar a ampliação ou a redução do tamanho da fonte do texto
Emitir relatórios sob demanda (mensal, anual) Disponibilizar teclas de atalho como opção de navegação no website
Registrar diário de atendimento presencial ao público pelos membros do conselho Garantir descrição textual para as imagens
Fornecer status de denúncias realizadas Apresentar ao usuário os formatos de entradas de dados permitidos pelo sistema
Na documentação dos requisitos, para cada item foram definidas as seguintes informações: código, nome identificador, descrição, origem (a partir de qual fonte o requisito foi levantado? Proveniente da literatura, de entrevistas ou de sistemas correlatos), e nível de prioridade (essencial: alta, importante: média, ou desejável: baixa). No que se refere aos demais itens da lista dos requisitos não funcionais, 18 quesitos de usabilidade, de acessibilidade e de arquitetura da informação são

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
80
incorporados para garantir a qualidade de uso do sistema: consistência; feedback; nível de habilidade e comportamento do usuário; percepção humana; metáforas; minimização da carga de memória; eficiência do diálogo, movimento e pensamento; classificação funcional dos comandos; manipulação direta; exibição exclusiva de informação relevante; uso de abreviações, mensagens e rótulos claros; uso adequado de janelas; projeto independente da tela/monitor; mecanismos de ajuda e prevenção de erros; tratamento de erros; sistema de navegação; sistema de organização; e, sistema de busca.
5. Considerações finais Os objetivos parciais do presente trabalho foram alcançados, tendo em vista que se conclui a Fase I do projeto como um todo. Ao longo do desenvolvimento da Fase I, pode-se observar que as maiores dificuldades encontradas foram as aplicações das entrevistas, devido à falta de disponibilidade dos membros do conselho e o número reduzido de sistemas correlatos existentes. Considera-se que se esses pontos não fossem falhos, facilitaria o processo de elucidação de requisitos, tornando o Projeto Centrado no Usuário mais efetivo.
Como continuidade deste trabalho, tem-se a realização da Fase II e III descritas na Seção 2, a qual já se encontra em andamento. Vale notar que em todas as etapas, de análise contextual, de concepção e de avaliação, os potenciais usuários são consultados para conhecer sua opinião sobre a evolução do projeto, tendo certo caráter de design participativo. Após a avaliação e a implantação do website, pretende-se verificar a possibilidade de sua hospedagem no Portal da Prefeitura Municipal de Rondonópolis e efetuar o lançamento para a sociedade local e estadual.
Referências Barbosa, S.D.J. Silva, B.S. (2010). Interação humano-computador. Rio de Janeiro:
Elsevier, 2010. Série ABC, Sociedade Brasileira de Computação. César, A. C. F. (2008) Qualidade de Documento de Requisitos, visando alguns Padrões,
Normas e Modelo. Monografia apresentada ao Curso de pós-graduação em Ciência da Computação, Centro de Informática, Universidade Federal de Pernambuco”.
Corradi, Juliane A. M. (2007). Ambientes Informacionais Digitais e Usuários Surdos: Questões de Acessibilidade. Dissertação de Mestrado, UNESP, Marília/SP.
Ferreira, Simone B.L.; Nunes, R.R. (2008). e-Usabilidade. Rio de Janeiro: LTC, 2008. Hewett, T.; et al. (1992). ACM SIGCHI Curricula for Human-ComputerInteraction.
ACM SIGCHI Report, ACM, NY. Disponível em: http://sigchi.org/cdg/, acesso dia: 12/2014.
Nielsen, Jakob. (1993). Usability Engineering. Chestnut Hill, MA, Academic Press. Prates, R.O.; Barbosa, S.D.J. (2003). Avaliação de Interfaces de Usuário - Conceitos e
Métodos Anais do XXIII Congresso Nacional da Sociedade Brasileira de Computação. XXII Jornadas de Atualização em Informática (JAI). Janeiro de 2015.
Rogers, Y. Sharp, H., Preece, J. (2013) Design de interação: além da interação humano-computador. 3ª Ed. – Porto Alegre: Bookman, 2013.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
81
WCAG. (2008). Web Content Accessibility Guidelines 2.0. Tradução: 2014. Disponível em: http://www.w3.org/Translations/WCAG20-pt-br/, acesso dia: 18/11/2014.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
82
Uma Proposta de Ferramenta para Apoiar a Avaliação por Inspeção Heurística e Semiótica
Gabriel Gonçalves Alves1, Ana Claudia M. T. Gomes de Oliveira1, Eunice P. dos Santos Nunes2
1Faculdade de Tecnologia Ipiranga (FATEC) R. Frei João, 59 – Bairro Vila Nair – São Paulo – SP – Brasil
2Instituto de Computação – Universidade Federal de Mato Grosso (UFMT)
Av. Fernando Corrêa da Costa, nº 2367 – Bairro Boa Esperança – Cuiabá – MT – Brasil [email protected], [email protected],
Abstract. This paper presents a proposal to develop a tool that aims to improve the process of heuristic and semiotics evaluation. Furthermore, the main concepts of usability and HCI evaluation are highlighted. It is also presented a study of applicability to understand how it is possible to structure this procedure with the use of a particular tool.
Resumo. Neste artigo é apresentada a proposta de desenvolvimento de uma ferramenta que tem como objetivo melhorar o processo de avaliação heurística e semiótica. Além disso, são destacados os principais conceitos de usabilidade e da avaliação de IHC. Também é apresentado um estudo de aplicabilidade de como é possível estruturar este procedimento com o uso de uma nova ferramenta específica.
1. Introdução O crescente desenvolvimento de novas tecnologias resulta em diferentes interfaces para manusear os diversos sistemas. Desse modo, a área de Avaliação em Interação Humano-Computador (IHC) tem sido alvo de pesquisas, especialmente em relação ao estudo de usabilidade das interfaces, haja vista a diversidade de usuários que interagem com os diferentes recursos computacionais disponíveis, como as tecnologias móveis. Segundo Oliveira (2011) “a essência da usabilidade é o acordo entre interface, usuário, tarefa e ambiente. A harmoniosa relação entre usuários e aplicação pode ser o fator decisivo na escolha de um sistema”. Para se desenvolver sistemas com qualidade no que diz respeito à usabilidade com o usuário, é necessário empregar formas de avaliação durante o processo de desenvolvimento de software, tornando possível a prevenção de falhas do sistema quando este for utilizado pelo usuário final. É necessário minimizar essas falhas, como forma de evitar sentimentos negativos do usuário em relação ao sistema como, por exemplo, irritação, frustração e confusão. Além disso, uma interface que promova uma interação simples e intuitiva pode estimular a produtividade e melhorar a satisfação de experiência do usuário [Barbosa 2010; Nielsen 1993; Rogers 2005]. Diante disso, o processo de avaliação de interface torna-se um procedimento importante tanto no ciclo de vida de desenvolvimento de software quanto na fase de

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
83
implantação do sistema [Rocha 2011]. Entre os diversos métodos de avaliação de IHC, a avaliação heurística e inspeção semiótica se destacam por verificar se o sistema está de acordo com as características recomendadas de usabilidade (não haja violação de heurísticas) e também por buscar assegurar a comunicabilidade e aprendizado cognitivo do usuário, respectivamente. Estas avaliações costumam ser aplicadas de forma manual e, consequentemente, se tornam onerosas. Logo, propõem-se uma ferramenta de apoio ao processo de avaliação heurística e inspeção semiótica que promova uma avaliação de IHC incluindo os dois tipos de avaliação por inspeção e que centralize os resultados da avaliação do sistema, de forma coerente e concisa, por meio de relatórios gerados automaticamente.
2. Trabalhos Correlatos A ciência da usabilidade de IHC abrange em seu fundamento básico o nível de facilidade do usuário no que diz respeito à aprendizagem e uso da interface, além do nível de satisfação deste mesmo usuário em decorrência da própria experiência de uso [Nielsen 1993]. Na literatura são encontrados alguns estudos que desenvolveram sistemas computacionais para apoiar o procedimento de avaliação de IHC, de forma específica. Um dos estudos desenvolveu a ferramenta Heva [Oeiras et al. 2008], multiplataforma, que tem como objetivo apoiar a avaliação de IHC com base em inspeção heurística. O avaliador captura as interfaces que deseja analisar, avaliando-as conforme as heurísticas de usabilidade propostas por Nielsen (1993). O relatório apresenta, para cada interface capturada, as marcações das heurísticas violadas. Ainda no contexto de avaliação por inspeção heurística, encontra-se a ferramenta Mockup DUE [Rivero et al., 2013], que oferece recursos de avaliação heurística, geração de mockups, detecção de erros e simulação de interação entre os mockups por meio da criação de links em áreas pré-selecionadas. Em relação à inspeção semiótica, tem-se o MISTOOL [Silva 2010], ambiente online que oferece funcionalidades de inspeção semiótica que engloba a reconstrução da meta-mensagem dos signos (i.e., estático, dinâmico, metalinguístico) e na comparação destas meta-mensagens com a intenção de verificar possíveis significados ambíguos ou contraditórios. O diferencial dos trabalhos encontrados na literatura em relação à ferramenta proposta neste estudo é oferecer à comunidade de IHC e áreas correlatas, uma ferramenta de apoio que agrupe dois tipos de avaliação por inspeção - avaliação heurística e inspeção semiótica em um único projeto. Além disso, os relatórios gerados são consolidados, de forma a mesclar os dois métodos de avaliação. A ferramenta pretende apoiar o avaliador indicando as heurísticas violadas, a fim de oferecer subsídios para o avaliador fazer os julgamentos necessários para adequar a interface ao padrão de qualidade de usabilidade.
3. Avaliação de IHC Nem sempre os processos de design e desenvolvimento de software já conhecidos são suficientes para garantir um alto nível de qualidade de uso do software. Antes de

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
84
declarar o software como pronto para uso, é preciso verificar se ele atende aos critérios de qualidade desejados.
Diante disso, a avaliação de IHC deve fazer parte do ciclo de desenvolvimento de software a fim de verificar a qualidade de uso da solução e se existem falhas na IHC que prejudiquem a compreensão da interface do sistema [Cristina et al., 2009]. Além da promessa de uma boa experiência de uso do software, Tognazzini (2000) destaca algumas razões para realizar a avaliação de IHC em sistemas interativos: (1) é possível realizar a descoberta de problemas de IHC antes de o produto final ser lançado; (2) uma vez que a questão de usabilidade será tratada pela equipe de IHC, a equipe de desenvolvedores pode se concentrar somente no processo desenvolvimento; (3) o modelo de interação passa a ser responsabilidade não somente do engenheiro de software; e (4) idealmente, o produto terá seu primeiro lançamento mais cedo, e se existir problemas na interação, certamente serão de menores proporções, uma vez que os ajustes na interface serão tratados desde o início do desenvolvimento do sistema.
Durante o processo de design e redesign da interface de um projeto, o designer pode, a partir dos dados que ele tem ao seu favor, decidir aplicar uma avaliação de IHC em dois momentos do ciclo de desenvolvimento do sistema [Gabbard et al. 2003]. Em um primeiro momento, pode-se optar por realizar a avaliação de IHC durante o processo de design, denominada avaliação formativa ou construtiva, com o propósito de antecipar possíveis problemas na interface. No segundo momento o designer pode optar por realizar a avaliação ao final de seu processo de design, denominada avaliação somativa ou conclusiva
3.1. Métodos de Avaliação Existem três tipos principais de métodos de avaliação, sendo eles investigação, observação e inspeção. Cada método é agrupado por tipo e busca atender um grupo específico de requisitos [Barbosa et al. 2010]. As avaliações por investigação se baseiam no levantamento de opiniões, comportamentos, expectativas, entre outros. As avaliações por observação fornecem dados, em sua maioria, mais próximos da realidade, uma vez que o avaliador pode presenciar e analisar os problemas do usuário em um contexto prático (seja em laboratório ou em um ambiente comum de trabalho). As avaliações por inspeção se baseiam no exame da solução de IHC para identificar possíveis problemas de usabilidade ou quebra de um padrão ou guia de estilo. Este tipo de avaliação, além de ser em geral mais rápido, possui um custo menor de projeto e pode ser utilizado durante todo o processo de design da solução de IHC [Barbosa et al. 2010]. Considerando que a ferramenta proposta está embasada nos métodos de avaliação heurística e inspeção semiótica, estas serão apresentadas nas próximas seções.
3.2. Avaliação Heurística Os principais precursores do método de avaliação heurística foram Nielsen e Molich por volta da década de 90 com o objetivo de orientar o avaliador no processo de inspeção da interface. A base deste método é descrita em 10 principais heurísticas iniciais (desenvolvidas por Nielsen) que descrevem o que uma boa interface deve apresentar. Isto não impede a criação de novas heurísticas para adaptação de contexto e ambiente.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
85
Deste modo, uma boa interface deve possuir: i) visibilidade do estado do sistema; ii) correspondência entre o sistema e o mundo real; iii) controle e liberdade do usuário; iv) consistência e padronização; v) reconhecimento em vez de memorização; vi) flexibilidade e eficiência de uso; vii) projeto estético e minimalista; viii) prevenção de erros; ix) ajude os usuários a reconhecerem, diagnosticarem e se recuperarem de erros; x) ajuda e documentação [Nielsen 1993].
3.3. Inspeção Semiótica Baseado no estudo de Engenharia Semiótica, o objetivo principal da inspeção semiótica é avaliar a intenção e comunicabilidade entre o designer e o usuário por meio do estudo dos signos da interface (estáticos, dinâmicos e metalinguísticos) [Barbosa et al. 2010]. Os símbolos estáticos são representados por todo estado do sistema em um dado instante (e.g., rótulos, imagens, botões). Os símbolos dinâmicos são representados por eventos e processos de interações do usuário com o sistema (e.g., clique do mouse, mudança de foco de um formulário). Os símbolos metalinguísticos são representados pela ajuda online, documentações de usuários, etc. A principal ferramenta utilizada pelo avaliador no processo de inspeção semiótica é a paráfrase de modelo, utilizada na elaboração de perguntas que auxiliam o processo de reconstrução da meta-mensagem. O objetivo das perguntas é validar se a intenção do designer está sendo atendida na solução de IHC.
4. Proposta de uma Ferramenta de Avaliação Heurística e Semiótica A ferramenta proposta tem a sua interface principal ilustrada na Figura 1. O avaliador poderá executar avaliações de sistemas web ou desktop. A ferramenta permite ao avaliador optar entre os dois métodos de avaliação por inspeção, ou seja, se deseja aplicar uma avaliação heurística ou inspeção semiótica ou ainda se pretende aplicar ambas, simultaneamente. Se optar por realizar a avaliação aplicando os dois métodos, simultaneamente, o processo será particular a cada tipo de avaliação, porém o relatório apresentará as informações de ambos os processos. Ao final da avaliação, o avaliador poderá gerar um relatório consolidado com todas as informações unificadas referentes ao projeto analisado, considerando as heurísticas violadas, como também das meta-mensagens reconstruídas com o propósito de melhorar a qualidade de comunicação designer-usuário no sistema. A ferramenta também prevê unir múltiplas avaliações sobre o mesmo projeto, realizadas por diferentes avaliadores e mostrar o cruzamento de dados no relatório consolidado. O propósito da ferramenta é auxiliar e apoiar o processo de avaliação tanto da interface quanto de interação. Nesta primeira versão foram escolhidas a inspeção heurística e semiótica, após a avaliação desta versão novos métodos de avaliação serão implementados. A linguagem adotada para o desenvolvimento da ferramenta é o Java SE por possibilitar implementar um sistema multiplataforma. A persistência dos dados será realizada por meio de arquivos XML, uma vez que não há necessidade de preparar um SGBD específico. Deste modo, é possível promover a portabilidade dos projetos criados pelo avaliador.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
86
Figura 1. Protótipo da interface principal do sistema
Os principais componentes ilustrados na interface inicial do sistema (Figura 1) são apresentados a seguir: (i) Canvas principal – exibe a imagem da interface capturada (pressionando a tecla printscreen) e que será avaliada pela ferramenta; (ii) Container vertical localizado na área esquerda da interface - possibilita visualizar as miniaturas de todas as imagens já avaliadas ou pendentes de avaliação, referentes ao projeto corrente; (iii) Conjunto de guias localizado na área inferior da interface - lista as heurísticas violadas; a análise dos signos da inspeção semiótica e também as informações básicas do projeto em andamento e (iv) Barra de ferramentas localizada na área superior da interface, com as seguintes funções: 1. Marcar área na qual a heurística será avaliada ou onde será feita a análise dos signos (inspeção semiótica) - assim que o avaliador realizar a marcação desejada, o sistema abre uma caixa de diálogo perguntando qual o método de avaliação; 2. Copiar, 3. Recortar e 4. Colar, é permitido entre as marcações realizadas na imagem do projeto; 5. Salvar, 6. Salvar e Finalizar Avaliação (caso não exista mais interfaces a serem avaliadas) e 7. Geração do relatório consolidado do projeto.
Outras funcionalidades do sistema serão guiadas por interfaces secundárias/ auxiliares, como: (1) Gerenciamento, listagem e estruturação dos projetos de avaliação (incluindo seu versionamento); (2) Gerenciamento de novos critérios de heurísticas (de acordo com as necessidades do avaliador); (3) Gerenciamento de formulários para apoiar o processo de inspeção semiótica e avaliação heurística e (4) Gerenciamento do formato dos relatórios gerados, sendo os formatos adotados: .DOC e .PDF.
5. Conclusão Neste trabalho foram apresentados os principais conceitos sobre avaliação de IHC. O artigo teve como principal contribuição a proposta de uma ferramenta capaz de dar suporte na aplicação de dois métodos de avaliação por inspeção (avaliação heurística e inspeção semiótica). A ferramenta poderá ser aplicada em diferentes contextos, apoiando os profissionais da área nas atividades inerentes a qualidade de software, em

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
87
especial, em relação aos quesitos de usabilidade dos sistemas. Salienta-se que o processo de design pode ser avaliado em diferentes estágios. Os próximos passos desta pesquisa são a implementação da ferramenta e a realização de uma pesquisa de campo com potenciais usuários do sistema.
Referências Barbosa, S. D. J.; Silva, B. S. (2010). Interação Humano-Computador. São Paulo: Campus/Elsevier, v. 1. Jesus, A.; Silva, E. J. (2010). MISTool: um ambiente colaborativo para aplicação do Método de Inspeção Semiótica. In: Anais IHC 2010 - Simpósio Brasileiro de Interação Humano-Computador, Belo Horizonte-MG. Joseph L. et al. (2003). Usability Engineering for Complex Interactive Systems Development. Engineering for Usability, In Proceedings of Human Systems Integration Symposium 2003, Vienna, VA, June 23-25. Nielsen, J. (1993). Usability Engineering. New York, NY: Academic Press. Oeiras Lachi, J. Y. Y.; Bentolila, D. L. M.; Figueiredo, M. C. (2008). Heva: uma ferramenta de suporte à avaliação heurística para sistemas Web. In: VIII Simpósio Brasileiro de Fatores Humanos em Sistemas Computacionais, 2008, Porto Alegre (RS): Sociedade Brasileira de Computação, v. 1. p. 1-10. Oliveira, H. S. (2011). Aplicação do método de avaliação heurística no sistema colaborativo HEDS. Revista Científica do ITPAC, Araguaína, V.4, n.3, pub.1. Oliveira, S. R. B.; Bastos, J. C. S. (2010). Práticas de IHC versus Processos de Engenharia de Software: Uma Análise para Adoção. In: VIII Encontro Anual de Computação, Catalão, ENACOMP 2010. Rivero, L.; Santos, D. V.; Conte, T. U. (2013). Mockup DUE: Uma Ferramenta de Apoio ao Processo de Inspeção de Usabilidade de Mockups de Aplicações Web. In: Anais do IX Workshop Anual do MPS (WAMPS 2013), Campinas. Rocha, J. A. P.; Alves, Dorirley R.; Lima, T. F. M. (2011). Aplicação do modelo de qualidade da NBR ISO/IEC 9126 para avaliação de website com nível de acessibilidade AAA conforme o e-MAG. In: Anais Computer on the Beach 2011, Florianópolis - SC. v. 1. p. 79-87. Rogers, Y; Sharp, H.; Preece, J. (2013). Design de interação: além da interação humano-computador. 3. ed. Porto Alegre: Bookman. Tognazzini, B. (2000). How user testing saves money, Ask Tog. Disponível em: <http://www.asktog.com/columns/037TestOrElse.html>.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
88
Análise da Usabilidade do Website da empresa aérea Avianca e Proposições de melhorias
Lucia Silvester Silva Nunes, Henrique Gabriel Pinheiro, Daniel Lamego, Ricardo Schneider, Soraia Silva Prietch
Curso de Sistemas de Informação – Universidade Federal de Mato Grosso (UFMT) Câmpus Universitário de Rondonópolis – Rondonópolis – MT - Brasil
[email protected], [email protected], [email protected], [email protected], [email protected]
Abstract. The goal of this paper is to present results from the website usability analysis of the airline Avianca. This analysis includes performing three activities of contextual analysis: website inspection, observation of related websites, and brainstorming conduction; in order to propose improvements. It was found that even though Avianca is a nationally known company, and its website is heavily used, various usability problems were observed. Resumo. O objetivo deste artigo é apresentar os resultados obtidos a partir da análise de usabilidade do website da empresa aérea Avianca. A referida análise inclui a realização de três atividades de análise contextual: inspeção de páginas do website, observação de websites correlatos, e a realização de brainstorming; com a finalidade de propor melhorias. Verificou-se que mesmo sendo a Avianca uma empresa nacionalmente conhecida, e seu website ser intensamente utilizado, foram evidenciadas diversas falhas de usabilidade.
1. Introdução O objetivo deste artigo é apresentar os resultados obtidos a partir da análise
contextual realizada no website da empresa aérea brasileira, chamada Avianca (www.avianca.com.br). Essa análise inclui a realização de três atividades (inspeção, observação da websites correlatos e brainstorming) com a finalidade de propor melhorias para o website observado. A ideia de aplicar diferentes técnicas na sequência descrita permitiu que novas sugestões surgissem e se complementassem, de modo que também houvesse espaço para ideias inovadoras durante a realização do brainstorming.
A escolha da Avianca como foco deste trabalho foi para cumprir a proposta de projeto exigido pela matéria de IHM (Interface Homem-Máquina). A equipe deveria optar por um website e então realizar as atividades mencionadas e propor melhorias.
2. Embasamento teórico De acordo com Rogers, Sharp e Preece (2013, p.18) “A usabilidade visa a assegurar que produtos interativos sejam fáceis de aprender a usar, eficazes e agradáveis – na perspectiva do usuário. Isso implica otimizar as interações estabelecidas pelas pessoas com produtos interativos, de modo a permitir que realizem suas atividades no trabalho, na escola e no cotidiano”.
A fim de encontrar trabalhos correlatos, uma busca foi realizada no Google Acadêmico, sem restrição de ano de publicação, com as seguintes 14 palavras-chave em

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
89
língua portuguesa1. Entretanto, dentre estes, somente dois trabalhos de natureza semelhante foram encontrados em busca exploratória: Ferreira e Leite (2003); Rodrigues, Vieira e Fell (2013).
No trabalho de Ferreira e Leite (2003), os autores analisam os requisitos não funcionais de usabilidade do website de comércio eletrônico, chamado Submarino. Neste caso, nenhum questionário foi criado a partir dos critérios da taxonomia de usabilidade, neste sentido, a metodologia dos autores foi: navegar e testar o website, e anotar as falhas observadas conforme os critérios. Como resultado, diversas falhas de usabilidade foram apresentadas, servindo como um exemplo real de como uma empresa de comércio eletrônico pode trazer dificuldades de acesso e de alcance dos objetivos aos usuários (potenciais consumidores) do website.
Rodrigues, Vieira e Fell (2013) utilizaram os critérios da Taxonomia dos Requisitos Não Funcionais de Usabilidade [Ferreira e Nunes 2008] para inspecionar algumas páginas do website Onofre em Casa. As páginas analisadas foram Home, Sistema de busca, Informações sobre o produto e Funcionalidades do carrinho de compras. O mesmo método utilizado por Ferreira e Leite (2003), também foi aplicado por Rodrigues, Vieira e Fell (2013). Como resultado, dentre os nove critérios, somente um não apresentou falhas.
3. Análise do Website O questionário de inspeção foi elaborado, pela equipe de estudantes responsável pelo projeto, com base nos critérios da Taxonomia dos Requisitos Não Funcionais de Usabilidade [Ferreira e Nunes 2008]. A taxonomia da usabilidade foi escolhida porque ela contempla as regras de Nielsen, porém consegue desdobra-las em quesitos mais fáceis para identifica-los nas interfaces e interações.
No total, o questionário de inspeção foi composto por 16 (dezesseis) perguntas. A inspeção foi realizada em 04 (quatro) páginas do website: Home, Cadastro, Compra e Ajuda. As quatro páginas definidas foram inspecionadas em conjunto (não isoladamente), considerando cada uma das dezesseis questões. Como resposta para cada questão, foram incluídas: a identificação de falha ou acerto, sua justificativa e a captura de tela do detalhe da página para ilustrar o resultado.
Com relação aos websites correlatos, primeiro, foram definidas as empresas aéreas cujos websites seriam observados; no caso, TAM, Gol e Azul. Em seguida, os membros da equipe navegaram pelo website, em especial, pelas mesmas páginas inspecionadas do website da Avianca. Os pontos positivos dos websites correlatos foram relacionados em uma lista. Com respeito à realização do brainstorming, estas técnicas foram aplicadas entre os membros da equipe. Durante o brainstorming, a
1 (i) “Inspeção de usabilidade” AND “website de companhia aérea” (zero); (ii) “Inspeção de usabilidade” AND website AND “companhia aérea” (um); (iii) “Inspeção de usabilidade” AND “website de empresa aérea” (zero); (iv) “Inspeção de usabilidade” AND website AND “empresa aérea” (zero); (v) “Inspeção de usabilidade” AND “website da Avianca” (zero); (vi) “Teste de usabilidade” AND “website da Avianca” (zero); (vii) “Avaliação de usabilidade” AND “website da Avianca” (zero); (viii) Usabilidade AND “website da Avianca” (zero); (ix) Usabilidade AND Avianca (cinco); (x) “avaliação de interface” AND “website da Avianca” (zero); (xi) “avaliação de interface” AND Avianca; (xii) “interface de usuário” AND Avianca (zero); (xiii) “interface web” AND Avianca (um); (xiv) “usabilidade web” AND “empresa aérea” (zero). No entanto, no que se refere aos artigos localizados inicialmente, com as palavras-chave (ii), (ix) e (xiii), nenhum trabalho era correlato à presente proposta de estudo.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
90
equipe procurou alternativas para proporcionar uma melhor experiência ao usuário antes, durante e após o voo.
No que tange à Questão 1 (A apresentação visual da página é limpa e padronizada?), relativa à Consistência, foi evidenciada uma falha. Apesar das páginas serem totalmente livres de banners indesejáveis e ter um visual agradável, o mesmo não pode ser dito da padronização. A empresa adota dois estilos de apresentação diferentes para as páginas, dependendo da modalidade de voo que o usuário irá comprar, nacional ou internacional, e isso pode ser confuso ao usuário.
A Questão 2 (O menu e os itens de menu são bem organizados e apresentados de maneira coerente?), do critério Consistência, também foi atribuída com falha, justificando que para acessar os subitens do menu, o usuário precisa clicar na seta, aumentando a quantidade de cliques que o usuário precisa acionar para atingir seu objetivo. Com relação à Questão 3 (O sistema fornece feedback para todas as ações do usuário?), referente ao Feedback, evidenciou-se acerto. Apesar de não informar qual o tempo previsto para o término de determinado processamento, o sistema apresenta feedback ao usuário e, para as ações realizadas, o tempo de resposta foi rápido.
A Questão 4 (Os itens selecionados de uma lista são realçados visualmente de imediato?), ainda relacionada ao critério Feedback, apresentou acertos como resposta, sendo evidenciados na parte de seleção do valor da passagem e da data da viagem. Com respeito à Questão 5 (Os ícones/botões utilizados são distintos entre si e de fácil identificação?), relativa ao Nível de habilidade e comportamento do usuário, uma falha foi evidenciada ao adotar o mesmo estilo e cor de botão a nomes/funcionalidades diferentes. Para a Questão 6 (O sistema é acessível para pessoas com capacidade limitada?), referente ao critério Percepção Humana, foram encontradas falhas. Dentre as páginas analisadas, não foi encontrado nenhum guia com informações em Libras (Língua Brasileira de Sinais). No entanto, para pessoas com baixa visão, existe a maximizar o zoom na página, que é uma opção conferida pelo navegador e não pelo website.
A Questão 7 (As denominações das opções são familiares ao usuário?), relativa às Metáforas, foi respondida com acerto. Considerou-se que os ícones utilizados para as opções são de fácil compreensão pelo usuário e correspondem aos padrões globais utilizados em outros websites. No que se refere à Questão 8 (O sistema resgata informações digitadas anteriormente para trazer comodidade ao usuário?), do critério Minimização da carga de memória, foi evidenciado acerto. Durante a compra de passagens o usuário pode preencher os dados do passageiro automaticamente ao clicar no botão “Trazer meus dados de cadastro”, caso a passagem seja para ele mesmo.
A Questão 9 (A estrutura de menu é concebida de modo a diminuir os passos necessários para a seleção?), que se refere ao critério de Eficiência no diálogo, movimento e pensamentos, percebeu-se que durante a compra os passos a serem percorridos são bem claros, uma vez que as abas de menu da tela central são denotadas na cor vermelha e aquelas cujos formulários já foram preenchidos ou ainda estão por preencher ficam na cor cinza.
No que tange à Questão 10 (A quantidade de opções no menu principal está dentro da quantidade recomendada?), sobre classificação funcional dos comandos, verificou-se que, dentre as páginas analisadas, todas possuem entre 5 e 9 itens de menu.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
91
Observando ainda o menu, é possível responder à Questão 11 (É sempre o usuário quem comanda a navegação entre os campos de um formulário?), referente ao quesito de Manipulação direta, sendo que o usuário não pode retornar para o formulário anterior (aba) durante a compra da passagem; a única opção seria fechar a página e abrir novamente, caso o usuário desejasse alterar alguma informação.
Com relação à Questão 12 (As caixas, de diálogo e de mensagem, apresentadas são claras e objetivas?), quesito Uso de rótulos, abreviações e mensagens claras, o sistema apresenta uma mensagem clara para o caso de inatividade, sendo que este informa ao usuário sobre o tempo restante para que a sessão expire. Neste caso, a mensagem foi a seguinte “Aviso! Devido a inatividade sua sessão irá expirar em 00:00:30. Para estender sua sessão em 5 minutos, por favor pressione o botão Estender”.
Na Questão 13 (É responsivo com outros dispositivos?), relativa ao critério de Projeto independente do monitor/tela, foi verificado que o sistema possui uma versão para dispositivo móvel, porém esta versão se limita a apenas fazer a consulta dos voos disponíveis, não há opção para compra da passagem ou acesso ao cadastro através.
No que se refere aos critérios avaliados para entrada de dados, para o quesito Mecanismos de ajuda foi realizada a Questão 14 (Possui algum tipo de guia, em formulários, caso necessário?). Para esta questão observou-se que a única tela de ajuda do sistema não auxiliou a equipe durante os testes realizados na inspeção. Em qualquer uma das telas do website o campo “Pesquisar” é visível, sendo posicionada sempre no mesmo local na tela, no canto superior direito. No entanto, na ocasião da inspeção, não foi possível encontrar informações de ajuda. A opção “Fale conosco” também pode ser uma opção de ajuda para o usuário. Entretanto, como este é um mecanismo de comunicação assíncrono [Pimentel, Gerosa e Fuks 2011], o usuário não pode sanar dúvidas imediatamente, no caso de urgência. Além disso, o botão para realizar o login ou cadastro no sistema estava com pouco destaque, ficando praticamente imperceptível para usuários de primeiro acesso, denominados “Minha conta” (para login) e “Registrar” (para cadastro). Contudo, um ponto positivo com relação ao quesito mecanismos de ajuda, observou-se que os campos obrigatórios no formulário de cadastro são marcados com asteriscos vermelhos. No campo data de nascimento também consta um exemplo de como o usuário precisa preencher (dd/mm/aaaa).
No que se refere ao quesito Prevenção de erros, analisado na Questão 15 (Os campos de entrada de dados são explicativos?), um exemplo positivo é que o sistema informa ao usuário que o CPF do usuário/cliente utilizado já existe, ou seja, previne que o usuário efetue novo cadastro sem necessidade. No entanto, uma falha observada no quesito prevenção de erros, foi que o sistema não possui calendário próprio para controle, efetuando a busca de data do computador do usuário. Neste caso, se a data do computador estiver incorreta, a data do calendário para compra de passagem também fica errada. Um exemplo disso é que a inspeção foi realizada em novembro de 2014 e a consulta por passagens utilizou o calendário do computador com data de março de 2014.
Como resposta para a Questão 16 (Quando o usuário realiza uma ação incorreta, o mesmo permite que este retorne e corrija o erro?), referente ao quesito tratamento de erros, verificou-se que ao tentar enviar o formulário com alguns campos em branco ou com informações inseridas em formato incorreto, o sistema retorna ao formulário destacando em vermelho os campos que estão incorretos e precisam ser corrigidos. Além disso, acompanhados aos campos falhos também são apresentadas mensagens do

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
92
tipo: “Informe um número de CPF válido”, “Esse campo aceita somente letras”, dentre outras. Entretanto, uma falha foi observada no que se refere ao quesito de tratamento de erro. No campo da compra de passagem, caso o voo não tenha assento disponível, as passagens ficam disponíveis para compra; isso ocorreu quando a equipe testou a compra de passagem em voos que a data de saída coincide com a data do dia corrente.
Ao final da inspeção, considerando as telas analisadas, no total, observou-se 10 (dez) falhas e 10 (dez) acertos. No entanto, não significa que tendo empate entre o número de falhas e acertos que o website está adequado. O ideal é que nenhuma falha fosse encontrada, para facilitar o uso do sistema pelo usuário.
No que se refere aos pontos positivos de sistemas correlatos, os websites das seguintes empresas aéreas foram observados: TAM, Gol e Azul. No caso da TAM, o website conta com o avatar virtual, chamado Júlia, cujo banner em destaque no canto superior direito consta a mensagem “Olá, Eu sou a Júlia. Posso ajudar em sua busca no site?”. O website da TAM também oferecia a opção para escolha de hotéis ou aluguel de carros para o destino da compra de passagens (na aba “Serviços e Reservas” ou nos ícones com os desenhos “Carro e chave” e “Cliente deitado na cama”), o que é bastante útil para o usuário. Além disso, o login consta em destaque no topo das páginas, e as consultas de passagens internacionais podem ser realizadas no mesmo website.
No caso da empresa aérea Gol, o banner “Posso ajudar?” em destaque na parte inferior da página, com as seguintes opções: viaje sem dúvidas, atendimento on-line, twitter, e-mail e telefones; ou seja, apresenta mais opções de contatos com os potenciais clientes do que a opção “Fale conosco” disponível no website da Avianca. A Gol ainda oferece um guia para usuários que nunca viajaram de avião, o que pode facilitar a navegação pelo website. Além disso, os rótulos para os hiperlinks das opções “Fazer login” e “Cadastre-se” são de mais fácil compreensão.
Nos três websites correlatos percebeu-se muito boa apresentação visual e da disposição dos itens de menu; e, o acesso aos sistemas de fidelidade das três companhias pode ser realizado no próprio website da empresa aérea, diferente da Avianca que, na ocasião da inspeção, seu sistema de fidelidade era hospedado em outro endereço. No website da Azul o que se destacou foi o excelente uso da versão mobile.
4. Proposição de melhorias As sugestões de melhorias identificadas, durante a inspeção, foram as seguintes: (1) Reunir as informações dos voos nacionais e internacionais em um mesmo website; (2) Diminuir a quantidade de cliques para que os usuários possam atingir seu objetivo final; (3) Diferenciar as cores de botões que possuem funcionalidades diferentes; (4) Disponibilizar mais opções de acessibilidade no website para anteder a uma gama maior de usuários; (5) Possibilitar ao usuário retornar em passos anteriores durante a compra de passagens; (6) Prover uma versão para acesso em dispositivos móveis que seja mais completa, semelhante àquela disponível no website; (7) Oferecer opções de ajuda mais efetivas e fáceis de encontrar aos usuários; (8) Tornar mais claras as denominações para efetuar login e efetuar cadastro, bem como posicionar estas opções em local de maior destaque na tela; (9) Buscar informações de calendário com informações reais e atualizadas, não usando os dados do dispositivo acessado pelo usuário; (10) Efetuar verificação de quantidade de assentos vagos antes de finalizar a compra.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
93
No que se refere aos trabalhos correlatos, as sugestões de melhorias para o website avaliado são: (1) Criar campos para reserva de hotéis e aluguel de carros para que o usuário possa adquirir os serviços para o destino do voo; (2) Incluir um guia interativo para passageiros de primeira viagem; (3) Providenciar mais ajudas ao usuário; (4) Disponibilizar uma versão mobile enxuta, porém eficiente.
No que tange ao brainstorming, as seguintes ideias foram levantadas: (1) Criar um tour virtual dentro do avião para que o usuário possa ter conhecimento de como será sua acomodação durante o voo e também para sanar dúvidas a respeito da aeronave; (2) Permitir que o usuário compartilhe em redes sociais as compras feitas no sistema, criando assim um meio de propaganda gratuita para o sistema; (3) Disponibilizar um questionário de avalição pós voo; (4) Permitir que o usuário manipule a forma de pagamento de ida-volta, caso este queira gastar os pontos de fidelização somente para um dos voos, sem que este faça dois processos de compra; (5) Creditar automaticamente a pontuação no programa de fidelização assim que for concluída a viagem.
5. Considerações finais Como sugestão de melhorias das técnicas utilizadas, recomenda-se a atribuição de pesos aos quesitos (ou questões de inspeção) que sejam consideradas mais graves para o contexto da aplicação e do perfil dos usuários. Na inspeção realizada, isso não foi aplicado. Um fator extremamente relevante é entrevistar usuários experientes do sistema, pois estes podem informar pontos positivos e negativos de suas vivências, que talvez uma inspeção técnica não poderia apontar tais pontos; outrossim, designar tarefas a usuários sem experiência de uso do website também pode ser um bom indicador de falhas e acertos.
Referências Ferreira, S. B. L.; Leite, J. C. S. P. (2003). "Avaliação da usabilidade em sistemas de
informação: o caso do Sistema Submarino. Em: Rev. adm. contemp. vol.7 no.2 Curitiba Apr./June. Disponível em: http://www.scielo.br/, acesso dia 10/07/2015.
Ferreira, S. B. L., Nunes, R. R. (2008). e-Usabilidade. Rio de Janeiro, LTC. Pimentel, Mariano; Gerosa, Marco Aurélio; Fuks, Hugo. (2011). Sistemas de
comunicação para colaboração (Capítulo 5). Em: Pimentel, Mariano; Fuks, Hugo (Org.). Sistemas colaborativos. Rio de Janeiro: Elsevier.
Rodrigues, G. C.; Vieira, A. I. J.; Fell, A. F. A. (2013). Avaliação de Experiência de Compra no E-Commerce a partir da Taxonomia da Usabilidade. IV ENEGI, UFPE, Recife/PE. Disponível em: http://www.enegi.com.br/anais/, acesso dia 10/07/2015.
Rogers, Y.; Sharp, H.; Preece, J. (2013). Design de interação: Além da interação humano-computador. 3º edição – Porto Alegre: Bookman.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
94
Avaliação de Usabilidade de um Sistema Desenvolvido por Modelos
Pablo de Souza Melo1, Thiago Pereira da Silva1
1Universidade Federal de Mato Grosso(UFMT) – Campus do Araguaia Caixa Postal 78.600-000 – Barra do Garças – MT – Brasil
[email protected], [email protected]
Abstract. This paper evaluates the usability of a software, automatically generated by models of the MDA (Model Driven Architeture). To assess the usability was used a valuation method based on pre-established heuristics of HCI (Human Computer Interface). The evaluation aims to provide quality indicators regarding the usability of the software development proposal from models of MDA. Resumo. Este trabalho faz uma avaliação de usabilidade de um software gerado automaticamente por ferramentas de transformação de modelos da MDA (Model Driven Architeture). Para avaliar a usabilidade foi utilizado um método de avaliação baseado em heurísticas preestabelecidas da IHC (Interface Homem Computador). A avaliação tem o objetivo de apresentar indicadores de qualidade em relação a usabilidade da proposta de desenvolvimento de software a partir de modelos da MDA.
1. Introdução O desenvolvimento de software tem sido aprimorado para garantir maior produtividade e qualidade do produto. Novas abordagens têm sido adotadas no processo de desenvolvimento para alcançar produtividade, e verificações são feitas para alinhar as abordagens com a qualidade que o usuário requer de um software.
Geralmente produtos de software dificilmente chegam a uma versão imutável, pois quando são disponibilizados aos usuários, novas funções podem ser requisitadas e adaptadas ao software. No entanto, é preciso que o software seja modificado seguindo a proposta do projeto para que de modo que o produto reflita o planejamento. Modificar um software sem consultar as restrições do projeto, ou seja, programar o software sem concordância com o projeto pode gerar o fenômeno da Erosão Arquitetural [VILLELA, 2013]. A erosão arquitetural origina-se quando existe a necessidade de evoluir um software, adicionando novas funcionalidade e requisitos, mas de forma descontrolada sem seguir o projeto, gerando, assim, um produto que não condiz com o projeto corresponde ao projeto inicial. [PONTES, 2012].
Uma forma de evitar problemas na coerência entre o projeto e produto de software é o uso de modelos abstratos em todas as fases do processo de desenvolvimento. A utilização de modelos abstratos na construção de um sistema possibilita focar apenas nos elementos essenciais da realidade observada como, por exemplo, detalhes sobre plataformas que não precisariam ser observados, quando o profissional estiver projetando as funcionalidades e o comportamento do sistema. [FILHO, 1999].

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
95
Uma abordagem que se mostra promissora para permitir a utilização de modelos em todas as etapas do desenvolvimento é o Desenvolvimento Dirigido por Modelos (MDD, do inglês, - Model Driven Development). Esta abordagem faz uso dos modelos (que podem ser diagramas UML1), e os esforços com a programação do código-fonte são reduzidos, pois o foco está nos modelos e o sistema pode ser gerado, quase que por completo, por ferramentas automáticas a partir dos modelos. [SANDRI, 2015]. Dessa forma é possível obter maior produtividade, pois grande parte do código-fonte é gerado automaticamente. A Arquitetura Dirigida por Modelos (MDA) faz parte do conjunto de abordagens MDD e foi criada e definida com base nos padrões da OMG2 (Object Management Group). A MDA utiliza metamodelos para definir elementos, relacionamentos, semântica e transformações entre modelos. A MDA possui um conjunto de modelos que compõe sua estrutura. São eles: CIM (Computer Indepedent Model), PIM (Plataform Independent Model) e PSM (Plataform Specific Model). A partir de transformações entre estes modelos, sistemas completos podem ser construídos. Mas é necessário verificar se os sistemas gerados possuem qualidade.
Uma das formas de verificar se um sistema possui qualidade é avaliar a sua usabilidade. Para avaliar a usabilidade de um sistema construído a partir da abordagem MDA é necessário coletar dados e verificar a sua coerência com base em heurísticas preestabelecidas por especialistas da área de IHC (Interação Homem Computador). A coleta e análise dos dados pode ser feita de duas formas: a) na construção dos modelos [PANACH, 2011]; ou b) segundo PRATES (2003, apud, Nielsen, 1994) implica em uma avaliação analítica no produto identificando elementos para verificar sua coerência em relação às heurísticas. Segundo [PRATES, 2003] a avaliação com base em heurísticas pode ser feita sem a intervenção do usuário do sistema.
Portanto, trabalho apresenta a avaliação de usabilidade de um software construído a partir de modelos MDA. A avaliação utiliza o método com base em heurísticas para obter indicadores de qualidade sobre os produtos de software gerados a partir de modelos abstratos da MDA. Este artigo está organizado da seguinte forma: a seção 2 discorre sobre a criação de sistemas utilizando MDA e a aplicação construída a partir de modelos para ser utilizada na avaliação de usabilidade deste trabalho; a seção 3 apresenta a avaliação de usabilidade do sistema; e a seção 4 traz as conclusões e as discussões sobre os resultados obtidos.
2. Desenvolvimento de Sistemas com MDA Para desenvolver sistemas utilizando modelos da MDA são necessárias ferramentas capazes de auxiliar desde o processo de desenvolvimento dos modelos do sistema até transformações automáticas destes para código-fonte. Estas ferramentas requerem que os modelos tenham uma definição precisa da estrutura, da semântica e das restrições de grupos de modelos, além de compartilharem entre si algumas especificações. Estas definições podem ser obtidas através de metamodelos que contêm as definições formais e regras de construções necessárias para criação de modelos semânticos. Assim, os metamodelos possibilitam a instanciação de modelos do sistema. De acordo com Calliari (2007) cada modelo instanciado contém elementos definidos no metamodelo que estão de acordo com a semântica e restrições definidas neste.
1 Disponível em: http://www.uml.org/ 2 Disponível em: http://www.omg.org/

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
96
Para prover uma estrutura padronizada de metamodelos para definição de modelos da MDA, a OMG implementou o MOF3 (MetaObject Facility), que define a semântica, os relacionamentos e as restrições dos metamodelos. Sobre a meta modelagem para concepção de modelos da MDA Medeiros (2004) corrobora que “[…] a estrutura da MDA por definição é composta por quatro camadas (ou meta níveis) de modelagem […] estas camadas são chamadas de M0, M1, M2 e M3”. [MEDEIROS, 2004]
Ao prover estas definições dos modelos, a MDA possibilita que ferramentas implementem um ambiente de trabalho que possibilita a criação, a edição e a transformação de modelos do sistema.
A ferramenta utilizada neste trabalho para criação e edição de modelos foi o MagicDraw4. Esta ferramenta possui uma estrutura que possibilita a criação dos modelos PIM do sistema. O PIM é um modelo que faz parte do conjunto de modelos da MDA e tem o objetivo de especificar funcionalidades e o comportamento do sistema, posto que pode ser editado quantas vezes for necessário para se alcançar a precisão do modelo que se adéque aos requisitos do sistema [BORGES, 2011]. O MagicDraw contém estereótipos que podem ser usados nos modelos PIM para que, no momento das transformações, a ferramenta possa gerar o código-fonte do sistema refletindo, portanto, nas funcionalidades exigidas pelo PIM do sistema.
2.1. Implementação do PIM da aplicação Jgnuteca O presente trabalho implementou a aplicação Jgnuteca, criada por Mourão (2012) em que o autor apresenta uma estrutura simplificada de um sistema de informação para bibliotecas quando do gerenciamento de obras literárias. A Tabela 1 mostra o diagrama de caso de uso desta aplicação e contém as principais funcionalidades que um sistema de informação requer, por exemplo, gerenciamento de objetos (criar, ler, atualizar, remover).
A aplicação é baseada no estilo arquitetura MVC e a implementação completa pode ser encontrada no site do projeto Jgnuteca5.
2.2. Transformação Automática do PIM para Código-fonte O MDA fornece orientação para o mapeamento de elementos entre modelos por meio das marcações com estereótipos, assim, modelos PIM podem ser transformados para outros modelos de forma automatizada. A exemplo do PSM, que é um modelo com detalhes específicos das tecnologias envolvidas no sistema ou para o código fonte do 3 http://www.omg.org/mof/ 4 http://www.nomagic.com/ 5 https://sites.google.com/site/jgnuteca/
Figura 1: Diagrama Caso de Uso da aplicação Jgnuteca

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
97
sistema [MONNOX, 2005]. E marcar o PIM com estereótipos é um forma de mapeamento que a ferramenta AndroMDA6 requer para efetuar a geração automática do código fonte do sistema.
A ferramenta MagicDraw possui o conjunto de estereótipos que o AndroMDA dá suporte para criação do modelo PIM. Este pode ser exportado em formato de arquivo XMI7, e utilizado como entrada no AndroMDA, para o processo automático de geração de código-fonte do sistema. A geração de código do sistema pelo AndroMDA é gerida de acordo com as marcações feitas no PIM (estereótipos nos modelos). Dessa maneira, um sistema completo pode ser gerado. Por exemplo, ao marcar classes no diagrama de classe do sistema com estereótipos <<entity>> e <<manageable>>, será sinalizado para o AndroMDA que as classes marcadas devem gerar uma entidade no banco de dados e que as interfaces de cadastro, de exclusão, de atualização e de pesquisa devem, também, ser geradas.
O AndroMDA possui o conceito de cartuchos que são componentes utilizados para gerar o código-fonte. Através de um cartucho é possível gerar componentes para qualquer linguagem de programação, desde que sejam programados para a linguagem específica [PINHEIRO, 2011]. Para a aplicação Jgnuteca o código fonte foi gerado na linguagem Java e o banco de dados utilizado foi o MySql.
3. Avaliação de Usabilidade Para avaliar a usabilidade da aplicação Jgnuteca foi utilizado o método de avaliação proposto por Panach (2011) que consiste na criação de indicadores a partir de heurísticas preestabelecidas por profissionais da área IHC. Se segundo ao autor, a principal vantagem deste método é a possibilidade de avaliar o sistema sem a intervenção do usuário. Partindo do exposto, este trabalho avaliou três características de usabilidade definidas pela norma NBR ISO/IEC 9126 de 2003 Inteligibilidade, Apreensibilidade, Operacionalidade. A Tabela 1 mostra os dados obtidos pela avaliação e na coluna III estão presentes os valores coletados através de métricas criadas por Panach (2011). Após obter os valores categóricos para cada métrica foi feito o agrupamento dos indicadores seguindo os passos:
• Passo 1: Converter os valores categóricos em valores numéricos, cada valor no intervalo de 1 a 5 representa uma categoria, sendo Muito Ruim (VB) atribuído a 1, Ruim (B) atribuído a 2, Médio (M) atribuído a 3, Bom (G) atribuído a 4 e Muito Bom (VG) atribuído a 5.
• Passo 2: Ao obter os valores numéricos é calculada a média de cada grupo de valores.
• Passo 3: os valores numéricos obtidos das médias são convertidos em valores categóricos atribuindo VB para o intervalo de 1 a 1.80, atribuindo B para o intervalo de 1.81 a 2.6, atribuindo M para o intervalo 2.61 a 3.4, atribuindo G para o intervalo 3.41 a 4.2 e VG para 4, 3 a 5.
6 http://andromda.org/ 7 http://www.omg.org/spec/XMI/

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
98
Seguindo estes passos e agrupando os resultados obtém-se, então, a usabilidade dos atributos, as características e a usabilidade geral do sistema.
Na Tabela 1 os valores numéricos da coluna III foram obtidos por meio da aplicação das métricas criadas por Panach (2011) e logo após esses valores foram convertidos e agrupados seguindo as instruções dos passos 1, 2 e 3, até que obtivemos a usabilidade geral do sistema, neste caso a usabilidade foi média.
4. Conclusão O processo de desenvolvimento da aplicação Jgnuteca apresentou um ganho considerável em relação à produtividade no sentindo de que os esforços gastos por programação de código-fonte foram dispensados, porque todo código-fonte foi gerado automaticamente a partir dos modelos. No entanto, em relação à usabilidade, alguns pontos precisam ser observados, pois, conforme a Tabela 1, os resultados da avaliação de usabilidade da aplicação e usabilidade geral do sistema tiveram um indicador Médio (M, do inglês Medium). É possível concluir com base nas características Inteligibilidade, Operacionalidade e Apreensibilidade que apresentaram indicadores que influenciaram consideravelmente o resultado da usabilidade geral. A Inteligibilidade apresentou um indicador de qualidade Bom (G, do inglês Good), pois os atributos apresentaram resultados de qualidade Muito Boa (VG, do inglês Very Good), ou seja, atributos como Densidade de Informação (ID, do inglês Information Density), Navegabilidade (NV) são atributos que as incoerências são tratadas nos modelos abstratos antes de gerar a aplicação.
Entretanto a Apreensibilidade e Operacionalidade tiveram seus indicadores ruins
Tabela 1: Resultados da Avaliação

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
99
influenciados pela automatização do processo de construção do sistema, por exemplo, o indicador determinação de Ação (AD, do inglês Action) enfraqueceu a usabilidade, pois este atributo avalia a capacidade de o sistema ter rótulos personalizados para as ações que o usuário for executar no sistema e, neste caso de análise, não foi possível a personalização devido ao processo automático de geração do sistema.
Apesar da abordagem MDA para o desenvolvimento de sistema apresentar ganhos na produtividade, o sistema gerado possui usabilidade média, o que nos permite inferir que o processo de desenvolvimento ainda não pode ser automatizado completamente e algumas funcionalidades devem ser programadas pelo analista para que o sistema possa ter uma usabilidade muito boa.
Referências VILLELA, R. T. N. B. A Recommendation System for Repairing Software Architecture
Erosion. 2013.
PONTES, D. P. N. Evolução de Software Baseada em Avaliação de Arquiteturas. 2012. Dissertação – POLI-USP, São Paulo, 2012.
SANDRI, A. Viabilidade de Construção de Software com MDD e MDA. Disponível em: <http://www.andresandri.com.br/artigos/MDA/Artigo_MDD_MDA.pdf>. Acesso em: 6 Mai. de 2015.
FILHO, J. L.; IOCHPE, C. Um Estudo Sobre Modelos Conceituais de Dados para Projeto de Bancos de Dados Geográficos. Revista IP-Informática Pública, v. 1, n. 2, p. 37-90, 1999.
PANACH, J. I. et al. Early Usability Measurement in Model-Driven Development: Definition and Empirical Evaluation. In: International Journal of Software Engineering and Knowledge Engineering, v. 21, n. 03, p. 339-365, 2011.
PRATES, R. O; BARBOSA, Simone Diniz Junqueira. Avaliação de Interfaces de Usuário–Conceitos e Métodos. In: Jornada de Atualização em Informática do Congresso da Sociedade Brasileira de Computação, Capítulo. 2003.
CALIARI, G. L. P. Transformações e Mapeamentos da MDA e sua Implementação em Três Ferramentas. 2007. 780 f. Tese (Doutorado). Universidade de São Paulo, São Paulo - SP.
MEDEIROS, F. L. Metamodelagem com Meta Object Facility. 2004. 789 f. Dissertação (Graduação) - Ciências da Computação. Universidade Federal de Santa Catarina, Florianópolis - SC.
BORGES, H. P. et al. Uma arquitetura baseada em modelos-MDA. 2011.
MOURÃO, W. Tutorial JGnuteca. Jgnuteca, 2012. Disponível em: <https://sites.google.com/site/jgnuteca/>. Acesso em: 9 jul. De 2015
MONNOX, A.. R. j2ee™ Development: an adaptive foundation for enterprise applications. Prentice Hall Press, 2005.
PINHEIRO, B. F. Revisão Sistemática das Características Existentes em Processos de Desenvolvimento MDD (Model Driven Development) e o seu Suporte para as Áreas de Processo de RD (Requirements Development) e TS (Technical Solution) do CMMI. 2011.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
100
Sistema de Entrega para Suporte Varejista Utilizando a Metaheurística GRASP
Gil Romeu A. Pereira1, Ivairton M. Santos1
1Universidade Federal de Mato Grosso(UFMT) – Campus Universitário do Araguaia – Instituto de Ciências Exatas e da Terra – Barra do Garças – MT – Brasil
[email protected], [email protected]
Abstract. This paper proposes and develops a prototype of delivery management system. This system is intended to small companies, in order to improve the service quality and reduce the costs. It was developed using Web Server technology, and have functionality to customer data management, route definition and delivery process monitoring, using mobile devices (cell phone). Resumo. Este trabalho propõe e implementa um protótipo de um sistema de gestão de entrega. Este sistema destina-se a pequenas empresas, a fim de melhorar a qualidade do serviço e reduzir os custos. Ele foi desenvolvido utilizando tecnologia Web Service e disponibiliza funcionalidades como gestão dos dados de clientes, definição de rotas e acompanhamento das entregas, por meio de dispositivos móveis (celular).
1. Introdução O mercado de logística vem crescendo muito nos últimos anos, além disso tem papel fundamental no crescimento econômico do país. Um dos fatores responsáveis por esse crescimento se dá através de auxílios de tecnologias e principalmente na gestão da logísticas. “Estas ferramentas têm potencial para auxiliar a organização a obter tanta vantagem em custo e produtividade, como a vantagem em valor” (Ferreira & Ribeiro, 2003). Com isso o mercado exigiu que as empresas se empenhem ao máximo para se tornarem mais ágeis na prestação dos serviços de logística e ter vantagens competitivas em relação aos seus concorrentes. Segundo Rosa (2007), entre outros aspectos, é fundamental para as empresas terem serviços de qualidade para garantir uma atuação das empresas de forma veloz e flexível. No setor varejista há uma demanda grande por qualidade nos serviços de entregas de produtos. Esse contexto ocorre devido aos problemas que as empresas enfrentam por conta de rotas mal planejadas. A principal consequência é a ineficiência no processo e o impacto nos custos. Por isso muitas empresas têm investido em sistemas de roteirização para melhorar a qualidade desses serviços (Barradas, 2012). No entanto, para empresas de pequeno porte investir em sistema de roteirização pode representar um alto custo, se tornando inviável. Conforme Melo e Fillho (2001) muitos dos sistemas de roteirização comercializados no Brasil são desenvolvidos no exterior e por vezes são complexos. Muitas empresas no ramo varejista oferecem serviços de entregas para seus consumidores, porém há uma deficiência no planejamento das rotas de entregas por que

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
101
geralmente essas rotas são planejadas manualmente. Planejar rotas é um processo complexo, pois caracteriza-se como um problema categorizado como NP-Completo. Para problemas como este, de otimização combinatória, é necessário utilizar métodos computacionais especiais, como as metaheurística, para resolvê-los em tempo computacional viável. Esse artigo propõe e implementa um protótipo de um sistema de suporte a entregas, desenvolvido para atender as necessidades de logística de empresas varejistas de pequeno e médio porte. Tem como objetivo facilitar os processos de localização de endereço, definição de rotas eficientes, redução do tempo de entrega e redução do consumo de combustível dos veículos.
2. Desenvolvimento do Sistema O Sistema de Gerenciamento de Entrega (SiGE) desenvolvido consiste de um conjunto de aplicativos, sendo: interface do sistema implementada na plataforma Android (para dispositivos móveis); Web Service implementado em linguagem Java; e metaheurística GRASP (Greedy Randomized Adaptive Search Procedure), proposta por Feo e Resendo (1995), para definição das rotas. As principais funções desse sistema são: gerenciar os dados dos clientes (incluindo sua localização exata por meio de coordenadas geográficas); determinar uma rota otimizada que visita todos os clientes com entregas a serem feitas; e prover uma interface amigável para o usuário por meio de um dispositivo portátil. A arquitetura do sistema é apresentada na Figura 1. No momento que o usuário deseja realiza um cadastro de um cliente, por meio da interface no dispositivo móvel, ele comunica-se com o Web Service enviando os dados, que serão armazenados no banco de dados. Quando ocorre a solicitação da geração da rota de entrega, o Web Service recupera as informações de todos os clientes que estão na lista de entrega, comunica-se com os Serviços do Google para obter informações das distâncias de cada cliente e então calcula a rota otimizada, por meio do GRASP, devolvendo o resultado obtido para o usuário, que poderá utilizar o serviço de GPS para encontrar os endereços.
Figura 1: Arquitetura do SiGE.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
102
2.1. Aplicativo para dispositivo móvel O aplicativo desenvolvido tem duas funcionalidades importantes. A primeira é permitir ao usuário (entregador) manipular os dados dos clientes (cadastro, alteração e exclusão). A segunda é solicitar a geração de rotas, com base na lista de clientes cadastrados aguardando por uma entrega. Uma das especialidades desse aplicativo é permitir ao usuário o cadastro do endereço do cliente por meio de um mapa e imagens de satélite, registrando as coordenadas geográficas (latitude e longitude). A partir desse recurso é possível realizar uma entrega no endereço indicado sem dificuldade (usando GPS). Ao realizar qualquer função do aplicativo, ele comunica-se com o Web Service que provê diversos serviços, como a persistência de dados e o cálculo das rotas. Na função de gerar rota o aplicativo usa a lista de clientes para o módulo que calcula a rota e recebe como resposta a rota obtida. Quando o entregador recebe essa rota otimizada ele utiliza o dispositivo para realizar as entregas e opcionalmente pode utilizar um navegador de GPS que interage com a rota calculada. Na Figura 2 podemos visualizar um exemplo da tela do dispositivo com os clientes aguardando suas entregas. A Figura 3 mostra um exemplo do cadastro de endereço de cliente por meio da imagem de satélite. Após o cálculo da rota de entrega pela metaheurística, o aplicativo recebe o percurso que o entregador deverá fazer, como mostra a Figura 4. Na rota obtida, cada marcador possui um identificador numérico, que corresponde à sequência de visitas que o entregador deve executar.
Figura 2: Tela com a relação de clientes a receber uma entrega.
Figura 3: Cadastro de endereço por meio da imagem de satélite.
Figura 4: Rota calculada obtida.
2.2. Web Service As tecnologias de Web Services fornecem um ambiente capaz de integrar diversas linguagens de programação e desta forma é possível a integração de aplicações dentro e fora da empresa. A integração de aplicativos através do Web Service produz um sistema

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
103
de negócio bastante flexível. Isso se dá pela facilidade de integrar e implementar novos recursos de maneira independente da tecnologia já utilizada (Gottschalk, Graham, Kreger, & Snell, 2002). Conforme Kreger (2001) um Web Services é uma interface que descreve uma coleção de operações que são acessíveis pela rede através de mensagens XML padronizadas. O papel do Web Service na composição do SiGE é justamente o fato de integrar diversos equipamentos conectados em rede, rodando aplicações desenvolvidas em diferentes linguagens e a comunicação desses serviços por meio do acesso à Internet. Neste trabalho, o Web Service foi desenvolvido utilizando o framework Apache Axis2. O framework facilita a criação de serviços a partir de uma classe Java. Após a criação do Web Service, usando a IDE Eclipse, foi gerado o documento WSDL (Web Services Description Language) que tem como função definir os métodos que estão disponíveis como serviço.
2.3. Metaheurística GRASP Bocceneri (2012) define que uma metaheurística é como um conjunto de conceitos que podem ser usados para definir métodos heurísticos, os quais podem ser aplicados a diferentes contextos de problemas. Ele ainda afirma que é uma estratégia de busca que tenta explorar eficientemente o espaço das soluções viáveis. Existem diversos métodos heurísticos para resolver problema de otimização combinatória, dentre eles temos os mais conhecidos que são: Algoritmo Genéticos; Simulated Annealing; GRASP; Busca Tabu; Colônia de Formigas; Colônia de Abelhas, entre outros (Boussaïda, Lepagnotb, & Siarryb, 2013). Este trabalho utiliza a metaheurística GRASP. Conforme Júnior e Ochi (2003), os resultados computacionais mostram que o algoritmo GRASP é e competitivo quando comparado com outras metaheurísticas para o problema de roteamento. Neste trabalho, o desenvolvimento da metaheurística GRASP passou por um processo iterativo, até atender aos requisitos do problema proposto. A cada etapa desenvolvida avaliava-se os resultados e alguns ajustes de parâmetros eram feitos, realizando-se novos testes. O algoritmo GRASP foi elaborado conforme a especificação de Feo e Resende (1995), com duas fases que constituem a construção da solução inicial e a fase da busca local. Na fase da construção da solução inicial é utilizado um procedimento guloso com base na menor distância entre os pontos de entrega. Ou seja, a partir do depósito escolhe-se o cliente mais próximo e então a partir desse cliente é escolhido o seguinte, também com base na distância. Esse processo se repete sucessivamente até estabelecer uma rota que visita a todos os clientes e retorna ao depósito. Na segunda fase, que consiste da busca por soluções melhores, o objetivo é otimizar a rota por meio de uma busca aprimorada, com base na solução inicial. Este processo foi desenvolvido utilizando as técnicas sugeridas por Feo e Resende (1995), no entanto foram feitos alguns ajustes na intenção de obter resultados aprimorados para o contexto da aplicação, usando o método empírico. Além disso, foi desenvolvido um processo de perturbação, com o objetivo de escapar de ótimos locais. Assim, a fase de

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
104
busca local, denominada de Método de Refinamento é interrompida após o limite de 1000 iterações pelo Método de Perturbação. No Método de Refinamento é realizado um sorteio de um vértice (que representa cada cliente) qualquer e então realiza-se a troca de posição com o vizinho a esquerda desse vértice. Em seguida é feita uma verificação a fim de observar se houve melhora na solução. Se isso ocorreu então atualiza-se a rota e executa novamente a busca a partir da rota atualizada. O algoritmo executa até que alcance o número de iterações definido como limite. Ao atingir o limite de iterações do Método de Refinamento, é aplicado o Método de Perturbação. Esse método é semelhante ao anterior, porém ao invés de realizar o sorteio de um vértice, é feito o sorteio de dois vértices (não vizinhos). Como o Método de Perturbação busca a fuga de ótimos locais, ele é executado de maneira intercalada com o Método de Refinamento. Ou seja, a cada execução do Método de Refinamento, o Métodos de Perturbação é executado. Esse processo ocorre por 10 vezes. A busca realiza sucessivas trocas no intuito de encontrar uma melhora na solução, e sempre que uma boa solução é encontra ela é armazenada para ser comparada pelas soluções seguintes. Todas essas fases e métodos são o que constituem o Algoritmo GRASP deste trabalho, para tomarmos conhecimento desse algoritmo de um modo mais geral apresentamos o pseudocódigo no Algoritmo 1.
Algoritmo 1 – Pseudo código do GRASP
Entrada: Rota[]; 01: fase de construção inicial(); 02: enquanto (contador1 < 10) faça 03: enquanto (contator2 < 1000) faça 04: método de refinamento(); Atualiza a melhor solução se for o caso 05: contador2 ← contador2 +1; 06: fim enquanto 07: método de perturbação(); 08: contador1 ← contador1 + 1; 09: fim enquanto 09: retorna (melhor solução encontrada)
3. Teste com algoritmo GRASP Os testes foram feitos com 20 simulações para cada arquivo de entrada, contendo 10, 20, 50, 100, 200, 500 e 1000 vértices (clientes). O algoritmo GRASP obteve resultados melhores em relação à solução inicial para todos os casos. A Tabela 1 apresenta o tempo de execução do algoritmo (Tempo) e a média dos resultados obtidos, sendo que o campo Custo Inicial (rota obtida da fase de construção inicial) e Custo Final (melhor rota obtida na busca) representam a distância das rotas obtidas.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
105
Tabela 1: Resultados do Algoritmo GRASP
4. Conclusão Este artigo apresentou um sistema de suporte logística, que otimiza rotas para entregas para empresas no ramo varejista. A implementação de um Web Service na composição do SiGE mostrou-se eficaz na integração de dispositivos móveis e proporcionou facilidade na implementação de métodos para composição de novos serviços. Dessa forma, o SiGE pode melhorar a qualidade dos serviços prestados pelas empresas, garantindo melhor satisfação dos clientes e redução de custos. Novas funcionalidades podem ser implementadas no sistema, como por exemplo o acompanhamento on line pelo o cliente do entregador com o seu produto, por meio de um aplicativo a ser instalado em seu celular.
Referências Barradas, J. F. (2012). Roterização na logística. Universidade Cândido Mendes, Rio de
Janeiro. Becceneri, J. C. (4 de Junho de 2012). Meta-heurísticas e Otimização Combinatória:
Aplicações em Problemas Ambientais. Minicurso. Boussaïda, I., Lepagnotb, J., & Siarryb, P. (2013). A survey on optimization
metaheuristics. Information Sciences, 237, 82–117. Feo, T., & Resende, M. (1995). Greedy Randomized Adaptive Search Procedures.
Journal of Global Optiimzation, 109-134. Ferreira, K. A., & Ribeiro, P. C. (21 de Outubro de 2003). Tenologia da Informação e
Logística: Os Impactos do EDI nas Operações Logísticas de uma Empresa do Setor Automobilístico. XXIII Encontro Nacional de Engenharia de Produção.
Gottschalk, K., Graham, S., Kreger, H., & Snell, J. (November de 2002). Introduction to Web services architecture. IBM SYSTEMS JOURNAL, 41(2).
Júnior, A. C., & Ochi, L. S. (4 de Novembro de 2003). UMA METAHEURÍSTICA HÍBRIDA GRASP+TABU PARA O PROBLEMA DE ROTEAMENTO PERIÓDICO DE UMA FROTA DE VEÍCULOS. XXXV - SBPO.
Kreger, H. (Maio de 2001). Web Services Conceptual Architecture WSCA 1.0. IBM Software Group.
Melo, A. C., & Filho, V. J. (2 de Julio de 2001). SISTEMAS DE ROTEIRIZAÇÃO E PROGRAMA DE VEÍCULOS.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
106
Rosa, A. C. (2007). GESTÃO DO TRANSPORTE NA LOGÍSTICA DE DISTRIBUIÇÃO FÍSICA: uma análise da minimização do custo operacional. Dissertação.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
107
Algoritmo PSI: busca de tuplas duplicadas por meio de similaridade fonética e numérica
Tiago Luís de Andrade1, Beatriz A. Acosta F. da Cruz2
1Departamento de Computação Universidade do Estado de Mato Grosso (UNEMAT) – Cáceres, MT – Brasil
2Departamento de Letras Universidade do Estado de Mato Grosso (UNEMAT) – Cáceres, MT – Brasil
tiago,[email protected]
Abstract. In order to ensure greater reliability and consistency of data stored in the database, this work aims to detect duplicate records through phonetic similarity as initial task and part of the process of knowledge discovery in databases. The proposal is to offer the possibility to act in the process without the need to know the subject or the characteristics of the stored information but to provide computing resources duplicate tuples identification automatically and supported in phonetic aspects of the data stored. Resumo. Com o objetivo de garantir uma maior confiabilidade e consistência dos dados armazenados em banco de dados, este trabalho visa a detecção de registros duplicados por meio de similaridade fonética como tarefa inicial e integrante do processo de descoberta de conhecimento em bases de dados. A proposta é oferecer a possibilidade de atuar no processo sem a necessidade de conhecer o tema ou as características das informações armazenadas, mas sim oferecer recursos computacionais de identificação de tuplas duplicadas automaticamente e amparadas em aspectos fonéticos dos dados armazenados.
1. Introdução Parte integrante do processo de Descoberta de Conhecimento em Base de Dados – KDD, a limpeza de dados consiste em melhorar a qualidade das informações armazenadas nas bases de dados, eliminando ruídos e dados errados. Diante disso, surgiu a perspectiva de desenvolvimento de um algoritmo baseado na língua portuguesa, com a finalidade de identificar os registros duplicados em bases de dados por meio da transcrição fonética de palavras em português, tornando-se possível a identificação de palavras que possuem o mesmo significado e sons, mas armazenadas com grafias diferentes, favorecendo desta forma a limpeza de dados. Fato este é relevante e motivador, visto que muitos dados são digitados e posteriormente armazenados não obedecendo às regras ortográficas de escrita.
2. Identificação de tuplas duplicadas através da similaridade fonética Para um melhor aproveitamento das informações armazenadas e elaboração de estratégias e tomadas de decisões, é importante que os dados estejam armazenados corretamente, pois dados errados podem influenciar negativamente no resultado de uma pesquisa .

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
108
Dentre os problemas identificados na limpeza de dados há o de registros duplicados, que passou a ser atacado por diversos pesquisadores a fim de solucionar e melhorar a qualidade das informações armazenadas, convertendo dados ruins em dados de formatos compatíveis e bem definidos, para que posteriormente ocorra a etapa de eliminação de registros duplicados, garantindo uma melhor integridade e confiabilidade dos dados da base que serão trabalhados na aquisição de informações [Christen 2009]. Considerado um dos maiores problemas da etapa de limpeza de dados, a detecção de registro duplicado é que identifica se um dado armazenado tem uma outra representação armazenada igual ou semelhante na base de dados, detectando todos os casos em que um mesmo objeto do mundo real tem múltiplas representações em um banco de dados [Weis, Naumann, Jehle, Lufter and Schuster 2008]. A maioria dos estudos científicos vem se aprofundando em técnicas que trabalham com similaridade textual para determinar se há registros duplicados nas bases, utilizando-se de algoritmos de identificação de similaridade [Arasu and Kaushik 2009]. Nesse contexto, a utilização da fonética tem um papel fundamental para a identificação de registros duplicados. Assim, a fonética pode ser definida como a ciência que utiliza métodos para a descrição, classificação e transcrição dos sons da fala, utilizados pela linguagem humana. A fonética será utilizada na identificação de registros duplicados numa base de dados textual partindo do pressuposto de que uma determinada palavra pode ser escrita de diferentes formas, podendo obedecer as características de pronunciação, dialetos regionalizados do país, ou a falta de conhecimento das regras ortográficas e gramaticais da língua nacional. Para a detecção de tuplas duplicadas, diversos são os algoritmos desenvolvidos, aplicados para esta finalidade e difundidos na literatura que podem ser utilizados. Entre os mais conhecidos cita-se os Algoritmos Soundex, Nysiis e Metaphone, cada um com as suas características de funcionamento e aplicação. Utilizam método de transformação de caracteres de uma string de entrada em códigos para posteriormente efetuar uma comparação com registros armazenados nas bases de dados. Esses algoritmos trabalham baseados em métricas de similaridade e apenas com a codificação de letras, ignorando aqueles que possuem como parte de seu registro caracteres numéricos. Cada caracter de uma string é substituído por um código de determinado algoritmo empregado, formando uma sequência de códigos representativos. Para exemplificar, quando se busca codificar através do Algoritmo Soundex as palavras “20 de Maio”, “22 de Maio”, “25 de Maio”, e assim sucessivamente, a codificação originada é “d500”. Observa-se que este algoritmo de codificação despreza completamente o caracter numérico, partindo diretamente para o próximo caracter da frase. O mesmo acontece com o Algoritmo Metaphone, que ignora a ocorrência de caracteres numéricos. Dessa forma, evidencia-se a necessidade de desenvolvimento de um algoritmo que aborde o tratamento numérico e que seja capaz de codificar os principais caracteres alfanuméricos, buscando-se resultados mais precisos. Agregando-se a esta necessidade, a fonética será utilizada para transcrever de diversas formas possíveis uma determinada palavra. Nesse sentido, o desenvolvimento do Algoritmo PSI tem a finalidade de abordar o tratamento de caracteres alfabéticos e numéricos, o que até então os algoritmos Soundex, Nysiis e Metaphone não abordam, e melhorar qualitativamente o resultado da busca realizada.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
109
Para atingir o objetivo deste trabalho, será utilizada para a aplicação a língua portuguesa. Diversas transcrições fonéticas das 26 letras do alfabeto foram realizadas, baseando-se nas explicações das obras de Maurizio Babini [Babini 2002] e Thaïs Cristófaro Silva [Silva 2000]. Exemplo pode ser dado através da consoante “c”, que pode ser transcrita foneticamente por /c/, /k/ e /s/, que utiliza os fonemas [k] e [s]. A seguir será descrita a funcionalidade do algoritmo desenvolvido, bem como a sua metodologia de funcionamento e o resultado parcial de experimento realizado.
3. Algoritmo PSI Denominado como Algoritmo PSI (Phonetic Similarity Identification) tem como principal característica a identificação de registros duplicados independente do domínio do banco de dados, abrangendo os caracteres alfanuméricos, como letras e números, e de trabalhar com variações fonéticas dos caracteres da palavra. O Algoritmo PSI é dividido em cinco passos para o seu funcionamento, seguindo uma série de regras e rotinas pré-estabelecidas. Estas regras devem ser respeitadas, todas elas obedecendo a uma sequência lógica de execução.
3.1. Transformação dos caracteres em minúsculo O primeiro passo do algoritmo proposto é transformar todos os caracteres de entrada em caracteres minúsculos, favorecendo a uniformidade no tratamento dos dados. O mesmo procedimento é adotado para os registros no banco de dados.
3.2. Eliminação de preposições e do artigo “e” O segundo passo do algoritmo proposto é eliminar as ocorrências das preposições “da”, “de”, “di”, “do”, “du”, “das”, “dos”, e do artigo “e”. Esse procedimento é necessário visto que muitos casos não são considerados como parte integrante do termo, podendo ser descartado ou não tendo o seu valor devido, como no exemplo de nome “Benedito dos Santos” e “Benedito Santos”. Embora o primeiro registro possua a preposição entre os dois nomes diferindo do segundo registro, pode-se tratar da mesma pessoa, justificando a eliminação do uso das preposições.
3.3. Eliminação de acentos O terceiro passo do Algoritmo PSI é eliminar os acentos dos caracteres acentuados. Tal eliminação é importante para que não haja diferença na busca por registro acentuado ou não. Portanto, com este procedimento é possível identificar registros iguais armazenados com ou sem acentos em suas vogais, tanto na entrada de dados como na busca por registros de dados do banco.
3.4. Eliminação de caracteres repetidos O quarto passo do Algoritmo PSI é eliminar os caracteres repetidos seguidamente. Tal procedimento é adotado tanto nos termos de entrada na busca de dados quanto nos registros armazenados na base. Trata-se de um passo importante e que se justifica por tratar da fonética, onde o que importa é o som do caractere e da pronunciação da palavra.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
110
3.5. Transformação fonética Este quinto e último passo do Algoritmo PSI é a etapa principal do algoritmo, pois é responsável pela transcrição fonética do termo de busca para posteriores pesquisas na base de dados. O funcionamento desta transformação acontece por meio da transcrição individual de cada letra que compõe uma palavra, formando diversos resultados e combinações que posteriormente poderão ser buscados na base de dados. Exemplo é apresentado na “Figura 1”.
Figura 1. Exemplo de transcrições fonéticas.
Assim, o algoritmo proposto é capaz de identificar valores similarmente armazenados e duplicados nas bases de dados, principalmente com a realização das diferentes transcrições fonéticas de uma palavra. Portanto, o algoritmo utiliza técnicas de transformação de caracteres em seus respectivos valores similares foneticamente como forma de buscar registros duplicados existentes na base de dados.
4. Experimento Para a realização de experimentos foi construída uma ferramenta utilizando a linguagem de programação Java, executada sobre um computador com processador Intel Core i5 com 1.80 GHz de frequência, memória de 6 Gigabytes e com sistema operacional Windows 8.1. O banco de dados utilizado é o Sistema Aberto de Gestão Unificada – SAGU, que cataloga registros de alunos, professores e técnicos administrativos da Universidade do Estado de Mato Grosso – UNEMAT, e o Gerenciador de Banco de Dados utilizado é o PostgreSQL v9.3. Com a aplicação dos algoritmos Soundex, Metaphone e PSI, alguns resultados foram extraídos, embora ainda representem dados parciais do trabalho que está sendo executado. Como forma de exemplificar resultado do experimento, foi realizada a busca

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
111
pelo termo “Walter” na tabela que contém dados pessoais de alunos da instituição no SAGU, especificamente na coluna que armazena nomes. Por meio do algoritmo Soundex, a codificação originada foi “W436” e retornados 94 registros, variando-se entre o próprio termo de busca e nomes discrepantes, como “Waldeir”, “Waldirene”, “Waltair”, “Wilder”, entre outros, pois ignora a presença de vogais nas palavras e utiliza codificação similar em algumas consoantes. O resultado é apresentado na Figura 2.
Figura 2. Resultados da busca utilizando o algoritmo Soundex.
Ao utilizar o algoritmo Metaphone foram retornados 92 registros através da codificação originada “WLTR”, entre os quais o próprio termo pesquisado e nomes como “Walderson”, “Waldira” e “Welder”, o que aponta resultados abrangentes e que desfavorece uma busca precisa na identificação de registros duplicados, conforme apresentado na Figura 3.
Figura 3. Resultados da busca utilizando o algoritmo Metaphone.
Com a aplicação do algoritmo PSI foram retornados 102 registros que continham o termo de busca transcrito foneticamente, variando entre “Walter” e “Valter”, obtendo resultados mais precisos, não discrepantes do termo de busca como os obtidos na utilização dos outros dois algoritmos exemplificados. Neste caso, foneticamente a consoante “W” pode assumir os valores “W” e “V”, retornando as ocorrências das palavras conforme é apresentado na “Figura 4”.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
112
Figura 4. Resultados da busca utilizando o algoritmo PSI.
5. Conclusões Embora apresente resultados parciais da pesquisa que está sendo executada, a análise tem demonstrado que a utilização do Algoritmo PSI tem favorecido a buscas em base de dados sujeitos a registros que possuam erros ortográficos ou que foram armazenados com grafias diferentes. Também é possível buscar por registros que contenham como parte integrante um dado numérico, que serão apresentados em trabalhos futuros. Isto tem colaborado para detectar dados que, embora discrepantes na ortografia, podem ter o mesmo significado, favorecendo a identificação de dados duplicados para posteriormente ser executada a tarefa de limpeza de dados, com o objetivo de melhorar a qualidade dos dados armazenados que favorecerão a tomada de decisões.
Referências Arasu, A., Kaushik, R. (2009). A Grammar-based Entity Representation Framework do
Data Cleaning”. In ACM - 35th SIGMOD International Conference on Management of Data, pages 233-244.
Babini, M. (2002). Fonética, Fonologia e Ortoépia da Língua Italiana, Annablume, p. 144.
Christen, P. (2009). Development and User Experiences of an Open Source Data Cleaning, Deduplication and Record Linkage System. In ACM SIGKDD Explorations Newsletter, pages 39-48.
Weis, M., Naumann, F., Jehle, U., Lufter, J., Schuster, H. (2008). Industry-Scale Duplicate Detection. In ACM - Proceedings of the VLDB Endowment, pages 1253-1264
Silva, T. C. (2000). Fonética e Fonologia do Português: roteiro de estudos e guia de exercícios, Contexto, p. 254.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
113
Ferramentas e Aplicações para Banco de Dados NoSQL: Um Levantamento com Base em Revisão Sistemática
Marcos Hiroshi Fukui, Fernando Selleri Silva
Ciência da Computação – Universidade do Estado de Mato Grosso (UNEMAT) Caixa Postal 92 – 78.390-000 – Barra do Bugres – MT – Brasil
[email protected], [email protected]
Abstract. This paper identifies the major tools and applications of NoSQL Database. A survey was conducted based on Systematic Literature Review in order to collect and analyze the studies on the topic discussed, in the context of literature in Portuguese Language. As result, 32 studies have been included, being 12 papers, 9 Master’s Dissertation, 9 Undergraduate Monographs and 2 Technologist Undergraduate Monographs. They address the tools MongoDB, Neo4J and Cassandra as the most cited. A list of uses/applications of NoSQL Databases was also considered. Resumo. O presente trabalho tem por objetivo identificar as principais ferramentas e aplicações de Banco de Dados NoSQL. Foi realizado um levantamento com base em Revisão Sistemática de Literatura, a fim de coletar e analisar trabalhos científicos sobre o tema abordado, no contexto da literatura em Língua Portuguesa. Ao todo, foram incluídos 32 trabalhos relevantes ao tema, sendo 12 Artigos, 9 Dissertações de Mestrado, 9 TCCs de Graduação e 2 TCCs de Nível Tecnólogo. Com base nos resultados, é possível considerar que as ferramentas MongoDB, Neo4J e Cassandra são as mais abordadas em estudos da área. Também é possível considerar uma lista de usos/aplicações dos Bancos de Dados NoSQL.
1. Introdução A grande quantidade de dados gerados diariamente e a complexidade de configuração de algumas aplicações atuais, deu origem a bancos de dados que vão além do modelo relacional, definido por Edgar F. Codd na década de 1970 [Silberschatz, Korth e Sudarshan 2006]. Esses novos bancos de dados, denominados Bancos de Dados NoSQL, visam garantir disponibilidade, desempenho e escalabilidade dos dados. O presente trabalho busca sistematizar dados sobre as pesquisas desenvolvidas sobre esse novo modelo de banco de dados e suas principais ferramentas e aplicações, principalmente no contexto nacional. Dessa forma, os resultados podem ser usados como base para aprofundar os estudos em Banco de Dados NoSQL. Como metodologia para este trabalho, foi definida a Pesquisa Bibliográfica [Marconi e Lakatos 1990], incluindo conceitos de Revisão Sistemática de Literatura [Kitchenham e Charters 2007]. Este artigo está organizado em seis seções. A Seção 2 corresponde à fundamentação teórica. Na Seção 3, o método de revisão é detalhado. A Seção 4 apresenta os resultados gerais e a Seção 5 corresponde à síntese. Considerações finais são descritas na Seção 6.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
114
2. Banco de Dados NoSQL Segundo Sadalage e Fowler (2013), o termo NoSQL foi sugerido em uma reunião com desenvolvedores em junho de 2009. Para Queiroz, Monteiro e Câmara (2013), os Bancos de Dados NoSQL atendem aplicações web de empresas como Google, Amazon e Facebook, que precisam realizar análise sobre grandes quantidades de dados de fontes não estruturadas como documentos HTML, PDF, arquivos de texto, mensagens eletrônicas e outras. Também são utilizados por comunidades científicas para atender às dificuldades em armazenar, processar e analisar dados em grande quantidade. Pereira et al. (2013) salientam a possibilidade de usar de forma híbrida o modelo relacional e o NoSQL, obtendo-se, assim, as melhores características de ambos. Os Bancos de Dados NoSQL possuem diferentes tipos, brevemente abordados a seguir [Sadalage e Fowler 2013]:
• Banco de dados chave-valor: é visto como uma tabela simples, na qual o acesso ao banco de dados é feito através da coluna chave primária. É com a chave-primária que se pode pesquisar, inserir e apagar um valor no banco de dados, o qual pode ser um texto, um JSON (JavaScript Object Notation), um XML (eXtensible Markup Language), entre outros.
• Banco de dados de documentos: é semelhante aos bancos de dados chave-valor, porém na parte valor são armazenados documentos. Esses documentos podem ser XML, JSON, BSON (Binary JSON), entre outros, e serem analisados durante uma pesquisa de algum valor, sem a necessidade de recuperar o documento inteiro através da chave.
• Banco de dados de famílias de colunas: os dados são indexados por uma tripla (linha, coluna e timestamp), na qual linhas e colunas são identificadas por chaves e o timestamp diferencia múltiplas versões de um mesmo dado. Cada coluna faz parte de uma única família de colunas e atua como uma unidade de acesso.
• Banco de dados de grafos: considera uma entidade (tabela) como nodo ou vértice e um relacionamento como uma aresta, que possui significância direcional e dados. Neste modelo é comum que os nodos tenham poucas propriedades e que hajam muitas interconexões entre os nodos.
3. Método de Revisão O levantamento utilizou conceitos de revisão sistemática de literatura [Kitchenham e Charters 2007]. Nesta seção, é apresentado brevemente o protocolo seguido na revisão.
3.1. Busca automática e manual A busca foi realizada em maio de 2014, com o escopo da pesquisa em Língua Portuguesa, visando identificar trabalhos que facilitem ao público nacional iniciar o estudo sobre o tema. A inclusão de trabalhos em Língua Inglesa é recomendada como trabalho futuro. Inicialmente, foi realizada uma busca manual nos sites do Simpósio Brasileiro de Banco de Dados (SBBD) e Workshop de Teses e Dissertações em Banco de Dados (WTDBD), escolhidos por serem de relevância nacional na área. As pesquisas

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
115
foram realizadas do ano de 2009 em diante, ano em que teve início o conceito de NoSQL. Na busca manual foram considerados 270 resultados. Em seguida, conduziu-se uma busca automática, para a qual foi definida uma string de busca contendo os termos, sinônimos ou palavras relacionadas, considerados relevantes. Os termos da string foram agrupados da seguinte forma: ("banco de dados" OR "base de dados" OR "sgbd") AND ("nosql" OR "not only sql" OR "não relacional"). Foram selecionados mecanismos de indexação de trabalhos na área, definidos por meio da consulta a outros trabalhos. Os locais pesquisados e os resultados retornados são mostrados na Tabela 1. A busca automática e a manual totalizaram 1.535 resultados.
Tabela 1. Resultados da busca automática Local Pesquisado Resultados
Domínio Público (www.dominiopublico.gov.br) 150* Google Acadêmico (scholar.google.com.br) 337 Google Geral (www.google.com) 200* MCT - Ministério da Ciência e Tecnologia (www.mct.gov.br) 200* PUCRio (www.puc-rio.br) 19 Scielo (www.scielo.org) 0 UNICAMP - Universidade de Campinas (www.unicamp.br) 15 USP - Universidade de São Paulo (www.usp.br) 344
TOTAL 1265
* Resultado considerado, a partir do qual os demais resultados passaram a ser claramente irrelevantes à revisão.
3.2. Seleção dos estudos Após realizar a leitura do título e resumo dos resultados, eliminando estudos retornados por mais de um mecanismo e estudos que claramente não tinham foco em NoSQL, foram considerados 83 trabalhos potencialmente relevantes. A próxima etapa foi a leitura desses trabalhos, aplicando-se os seguintes critérios de inclusão/exclusão:
• Critérios de Inclusão: estudo acadêmico ou da indústria; com dados científicos práticos, bibliográficos ou relato de experiência; aborda ferramentas e aplicações de Banco de Dados NoSQL; nacional ou em outro país, em Língua Portuguesa.
• Critérios de Exclusão: ser meramente uma opinião de especialista; abordar desenvolvimento ou manutenção da própria ferramenta de NoSQL; estar em formato de editorial, prefácio, resumo, entrevista, notícia, slide, pôster e outros. Esta etapa resultou em 32 trabalhos incluídos, os quais são listados na Tabela 2.
3.3. Extração de dados Na extração dos dados foram coletados de cada trabalho: título, autor, local e ano da publicação, tipo (artigo ou outro), nível (acadêmico ou profissional), local da pesquisa, natureza (estudo de caso, relato de experiência ou outra), objetivo, ferramentas, aplicações, benefícios e limitações. Uma planilha foi usada para facilitar a síntese.
4. Resultados Gerais Dentre os 32 trabalhos incluídos estão 12 artigos, 9 dissertações de mestrado, 9 TCCs de graduação e 2 TCCs de nível tecnólogo. A Figura 1 (a) representa o percentual da quantidade de cada tipo. Os artigos foram publicados em 9 eventos e 3 periódicos. Os trabalhos acadêmicos são de 17 universidades (11 do Brasil e 6 de Portugal).

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
116
A Figura 1 (b) apresenta a natureza da pesquisa dos trabalhos incluídos. Os resultados obtidos foram: 21 Estudos de Caso; 8 Relatos de Experiência; 2 Revisões de Literatura; e 1 Pesquisa-ação. Com relação ao ano, em 2009 não houve trabalhos incluídos. Observa-se um aumento desde o ano de 2010 (2 trabalhos), 2011 (6 trabalhos) até 2012 (13 trabalhos), seguido de uma queda nos anos de 2013 (9 trabalhos) e 2014 (2 trabalhos). Observa-se que em 2014 as buscas foram realizadas até o mês de maio.
Tabela 2. Trabalhos Incluídos no Levantamento Nº Título Autor 1 NoSQL no Suporte à Análise de Grande Volume de Dados Joel Alexandre; Luís Cavique 2 Padrão CQRS para sistemas distribuídos de larga escala Carlos Miguel Brites da Silva Ferreira 3 Sistemas de Base de Dados Orientados por Colunas Raquel Gouveia Ribeiro 4 Bases de Dados Alternativas para Websites Nuno Miguel Queirós Arantes dos Santos 5 hNode multiscreen alert hub and message exchange server Frederico Wasserman 6 BCLaaS: implementação de uma base de conhecimento linguístico as-a-service Mário Mourão; Jośe Saias 7 Uma Arquitetura de Cloud Computing para análise de Big Data provenientes
Recuperando dados da Internet Of Things Diogo Filipe Dornelas Falcão
8 Banco de Dados NoSQL Conceitos e Aplicabilidade Claudiomiro Machado Brites 9 Desenvolvimento de Aplicação para o Controle de SRUM com MongoDB Raduan Silva dos Santos
10 Ruby on Rails Escalável: Estudo e Soluções Gabriel Gonçalves Nunes Mazetto 11 Identificação de Concorrência de Termos em Textos Científicos Ineias Silva Fernandes 12 Uma Avaliação Experimental de Desempenho entre Sistemas Gerenciadores de
Bancos de Dados Colunares e Relacionais Bruno Eduardo Soares
13 Controle distribuído em Redes de Data Center baseado em Gerenciadores de Rack e Serviços de Diretório/Topologia
Carlos A. B. Macapuna; Christian Esteve Rothenberg; Maurício F. Magalhães
14 Projeto Cassandra Marcelo Roberto Laux 15 Banco de Dados em Nuvem: Conceitos, Características, Gerenciamento e Desafios Darlan Florêncio de Arruda; José Almir
Freire de Moura Júnior 16 Framework para Integração de Serviços Móveis Baseado em Rede Social Renan Shin Iti Matsushita 17 Estudo Comparativo entre Banco de Dados Relacionais e Banco de Dados NoSQL
na Utilização por Aplicações de Business Intelligence Felipe Gustavo de Sousa Issa
18 Distribuição de dados em escala global com Cassandra Mário S. C. Marroquim; Ricardo M. Ramos 19 Proposta de Gerenciamento de Ativos com Computação em Nuvem e
Armazenamento NoSQL Ederson Fontana
20 Utilização da Classe de Banco de Dados NoSQL como Solução para Manipulação de Diversas Estruturas de Dados
Ricardo Cardoso de Almeida; Parcilene Fernandes de Brito
21 GeoNoSQL: Banco de dados geoespacial em NoSQL Luís E. O. Lizardo; Mirella M. Moro; Clodoveu A. Davis Jr.
22 Recomendação de pessoas em redes sociais com base em conexões entre usuários
Rafael Jessen Werneck de Almeida Martins
23 Análise Experimental de Bases de Dados Relacionais e NoSQL no Processamento de Consultas sobre Data Warehouse
Rafael Jessen Werneck de Almeida Martins
24 Investigação e Desenvolvimento de um Sistema Automático de Mapeamento e Visualização de Ativos Numa Rede Empresarial de Grande Dimensão
João Miguel Ribeiro Martins
25 Fabular.us Plataforma para autoria de narrativas colaborativas online Endel Dreyer; Tiago R. C. Lopes 26 T-Stratus - confiabilidade e privacidade com nuvens de armazenamento de dados António Miguel Carneirinho Guiomar 27 O Modelo de Dados Semiestruturado em Bases Bibliográficas: do CDS/ISIS ao
Apache CouchDB Luciano G. S. Ramalho
28 Ontologia Aplicada ao Desenvolvimento de Sistemas de Informação Luiz Cláudio Hogrefe 29 As Bibliotecas Digitais Musicais no novo Ecossistema da Informação e
Comunicação José Marcelo de Miranda
30 Representação de redes semânticas de termos biomédicos André Filipe Fidalgo Vechina 31 Sistema de controle de consultas em clínicas médicas utilizando Técnicas
de Computação em Nuvem e Mobilidade Jonathan do Nascimento Sales; Thiago V. dos Santos; Carlos Natalino da Silva
32 Cassandra – Um sistema de armazenamento NoSQL altamente escalável Tiago Pasqualini da Silva
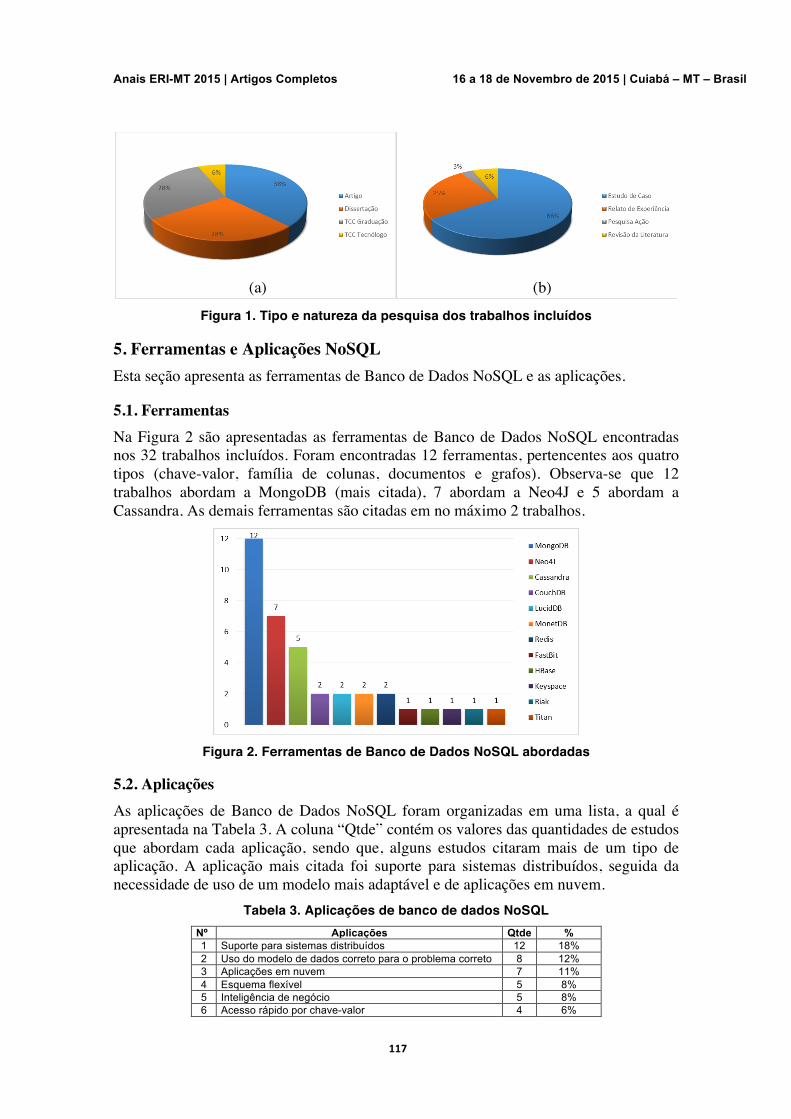
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
117
Figura 1. Tipo e natureza da pesquisa dos trabalhos incluídos
5. Ferramentas e Aplicações NoSQL Esta seção apresenta as ferramentas de Banco de Dados NoSQL e as aplicações.
5.1. Ferramentas Na Figura 2 são apresentadas as ferramentas de Banco de Dados NoSQL encontradas nos 32 trabalhos incluídos. Foram encontradas 12 ferramentas, pertencentes aos quatro tipos (chave-valor, família de colunas, documentos e grafos). Observa-se que 12 trabalhos abordam a MongoDB (mais citada), 7 abordam a Neo4J e 5 abordam a Cassandra. As demais ferramentas são citadas em no máximo 2 trabalhos.
Figura 2. Ferramentas de Banco de Dados NoSQL abordadas
5.2. Aplicações As aplicações de Banco de Dados NoSQL foram organizadas em uma lista, a qual é apresentada na Tabela 3. A coluna “Qtde” contém os valores das quantidades de estudos que abordam cada aplicação, sendo que, alguns estudos citaram mais de um tipo de aplicação. A aplicação mais citada foi suporte para sistemas distribuídos, seguida da necessidade de uso de um modelo mais adaptável e de aplicações em nuvem.
Tabela 3. Aplicações de banco de dados NoSQL Nº Aplicações Qtde % 1 Suporte para sistemas distribuídos 12 18% 2 Uso do modelo de dados correto para o problema correto 8 12% 3 Aplicações em nuvem 7 11% 4 Esquema flexível 5 8% 5 Inteligência de negócio 5 8% 6 Acesso rápido por chave-valor 4 6%
(a) (b)

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
118
7 Performance em escrita 4 6% 8 Análise de texto 3 5% 9 Manutenção 2 3%
10 Performance em escrita massiva 2 3% 11 Redes de sensores 2 3% 12 Tipos de dados flexíveis 2 3% 13 Acesso rápido 1 2% 14 Administração 1 2% 15 Alta disponibilidade 1 2% 16 Big Data 1 2% 17 Data Warehouse 1 2% 18 Desempenho 1 2% 19 Jogos 1 2% 20 Migração de esquemas 1 2% 21 Redes sociais 1 2%
6. Considerações Com base nos resultados, considera-se que dentre os Bancos de Dados NoSQL existem ferramentas que podem ter desempenho superior ao modelo relacional, porém há ferramentas cujo desempenho é inferior. O desempenho depende da escolha do modelo de dados adequado e do contexto da aplicação. Os trabalhos incluídos recomendam o uso de Banco de Dados NoSQL, sobretudo, porque muitas aplicações desenvolvidas atualmente necessitam de um modelo de dados que facilite o gerenciamento de grandes volumes de dados. É necessário estar familiarizado com as ferramentas NoSQL e suas aplicações, para melhor avaliar qual modelo usar de acordo com o problema em questão. Os trabalhos apontaram os seguintes benefícios relacionados ao uso de Banco de Dados NoSQL: melhor configuração de aplicações; alta escalabilidade; acesso rápido aos dados; desempenho e flexibilidade; replicação eficiente; e código aberto. Como limitações foram citadas: menor desempenho em inserções e em consultas com muitos atributos; pouca aderência às propriedades ACID (Atomicidade, Consistência, Isolamento e Durabilidade); consistência eventual (valores não atualizados imediatamente); não recomendado para bases de dados pequenas; complexidade no armazenamento e acesso; poucos desenvolvedores no mercado. Entre os trabalhos futuros, está a realização de uma revisão no mesmo contexto deste trabalho, com abrangência de estudos em Língua Inglesa; o aprofundamento do estudo sobre a aplicação de Banco de Dados NoSQL em sistemas distribuídos e em Big Data; e o estudo das principais ferramentas dos modelos de dados chave-valor, de documentos, família de colunas e grafos, a fim de sugerir uma abordagem que facilite a modelagem e projeto de Banco de Dados NoSQL.
Referências Kitchenham, B. e Charters, S. (2007), Guidelines for performing Systematic Literature
Reviews in Software Engineering, Technical Report, School of Computer Science and Mathematics, Keele University.
Marconi, M. A. e Lakatos, E. M. (1990), Técnicas de pesquisa: planejamento e execução de pesquisas, amostragens e técnicas de pesquisa, elaboração, análise e interpretação de dados, Atlas, 2ª edição.
Pereira, F. S. et al. (2013). Utilização de Banco de Dados NoSQL em Ambientes Corporativos. In E-RAC - Reunião Anual de Ciências, v. 3, n 1. Unitri.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
119
Queiroz, G. R., Monteiro, A. M. V. e Câmara, G. (2013). Bancos de Dados Geográficos e Sistemas NoSQL: onde estamos e para onde vamos. In Revista Brasileira de Cartografia, nº 65/3, p. 479-492. UNB.
Sadalage, P. J. e Fowler, M. (2013), NoSQL Essencial: um guia conciso para o mundo emergente da persistência poliglota, Novatec.
Silberschatz, A., Korth, H. F. e Sudarshan, S. (2006), Sistema de banco de dados, Elsevier, 5ª edição.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
120
Desenvolvimento de Miniestações Agrometeorológicas de baixo custo aplicadas à agricultura de precisão
Matteus V. S. Silva, Maurício F. L. Pereira, Allan G. Oliveira, Roberto B. O. Pereira
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT)
Av. Fernando Corrêa da Costa, nº 2367 - Bairro Boa Esperança. Cuiabá - MT - 78060-900
[email protected], mauricio, allan, [email protected] Abstract. The study presents the construction of a agro-meteorological network data collected from low cost monitoring stations. The article presents the development a remote geographic database which will store the data collected by these stations and a web based application for data visualization in the form of maps. The model proposed by [Oliveira 2011] organizes the information in three categories: management, metadata and ontologies. For the implementation of the database, we used the DBMS with spatial extension PostGIS. The web application is Java-based and maps are displayed from the Google Maps API. Currently the system is in the process of fixes and improvements. Resumo. O estudo apresenta a criação de uma rede de estações de monitoramento de dados agrometeorológicos de baixo custo. O artigo apresenta a etapa da criação de uma base de dados geográfica remota que armazenará os dados coletados no campo e uma aplicação Web para a visualização dos dados na forma de mapas. A modelagem, proposta por [Oliveira 2011] divide a informação em informações gerenciais, os metadados e as ontologias. Para a implementação da base de dados, utilizamos o SGBD PostgreSQL com a extensão espacial Postgis. A aplicação Web é baseada em Java e os mapas são visualizados a partir da API do Google Maps. Atualmente o sistema está em fase de correções e melhorias.
1. Introdução Na agricultura, o conhecimento de informações climáticas pode maximizar a produção agrícola Liu et al. (2010) e Lobell; Burke (2010). Diante disso, a coleta de dados agrometerológicos é um recurso amplamente utilizado tanto por produtores quanto por pesquisadores, a fim de entender/modelar fenômenos e eventos atmosféricos e relacioná-los à produção agrícola [Wart et al. 2013]. A utilização desses dados como parte integrante do planejamento da cadeia de produção agrícola pode melhorar o desempenho das propriedades agrícolas, diminuindo custos e maximizando a produção. A coleta desses dados, como ilustrado na Figura 1 é feita por estações agrometeorológicas, que têm por finalidade monitorar as condições meteorológicas no campo, coletar os dados ambientais de maior importância, quantifica-los e gerar uma série histórica dos dados coletados. Entretanto, o uso das estações meteorológicas comercializadas atualmente não é acessível a todos os produtores e/ou

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
121
pesquisadores, devido aos custos de aquisição e dificuldades operacionais de manutenção das estações Neves (2013) e Pereira (2013) Dessa forma, o projeto ao qual este trabalho está inserido tem como objetivo criar uma rede de estações de monitoramento de dados agrometereológicos de baixo custo e que são capazes de se comunicar por meio de rede sem fio e transmitir as informações de monitoramento para bases de dados remotas minimizando assim problemas operacionais como armazenamento local e coleta dos dados em locais de difícil acesso. As estações de trabalho agrometereológicas estão sendo desenvolvidas visando construir um equipamento com baixo custo de confecção e manutenção. Nelas é possível customizar o firmware, a fim de atender as necessidades específicas de cada aplicação. A arquitetura das estações agrometerológicas é composta por um sistema embarcado de coleta, baseado na plataforma Tiva da Texas Instruments, um sistema de transmissão sem fio e um sistema de armazenamento local. Na estrutura computacional (Figura 1.b), tem-se um sistema de gerenciamento de banco de dados e servidor Web para aplicações de visualização e gerenciamento dos dados.
EstaçãodeMonitoramento
#1(umidade,temperaturae
pluviosidade)
Campo
Estaçãodearmazenamentoetransmissão
SetordeTIEstaçãode
Monitoramento#3
Retransmissor
EstaçãodeMonitoramento
#2
Gateway
Aplicaçõesdemonitoramentoegerenciamento
Acessoremotoasinformaçõesdocampo
(a) (b) Figura 1. Estrutura do projeto de monitoramento remoto. (a) Estações
agrometereológicas e retransmissores no campo. (b) Estrutura computacional, com destaque na área hachurada, para o foco deste trabalho.
Este trabalho descreve o desenvolvimento do sistema de armazenamento remoto dos dados e a aplicação Web para visualização e gerenciamento dos dados coletados. Seguindo os princípios de baixo custo indicados por [Pereira 2013] e [Neves 2013], tanto o sistema de armazenamento de dados quanto a aplicação Web utilizam tecnologias abertas, diminuindo consideravelmente o custo. O primeiro consiste em uma base de dados geográficas, utilizando o Sistema de Gerenciamento de Banco de Dados de código aberto Postqresql e sua extensão geográfica, o PostGis. A aplicação Web é um front-end baseado em Java que utiliza a tecnologia do Google Maps para a visualização dos dados na forma de mapas. Nas seções a seguir são apresentadas as principais tecnologias e ferramentas utilizadas para o desenvolvimento desse trabalho, bem como os resultados obtidos nos testes realizados sobre dados simulados e as conclusões dos resultados obtidos.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
122
2. Materiais e métodos A estrutura elaborada para o armazenamento e visualização dos dados foi modelada seguindo, primeiramente, os padrões de custo proposto pelo projeto como um todo e o que já havia sido proposto por [Oliveira 2011], ilustrada na Figura 2 como sendo ideal para trabalhar com dados climáticos. Utilizamos o Sistema de Gerenciamento de Banco de Dados PostGreSQL e sua extensão geográfica, o PostGis. O PostgreSQL é um sistema de gerenciamento de banco de dados objeto-relacional de código aberto [Group 2015]. Oferece recursos como consultas complexas, chaves estrangeiras, triggers, views e replicação de dados.
Figura 2. Modelagem dos dados em alto nível. Fonte: [Oliveira 2011].
O Postgis provê suporte OpenGIS, construções topológicas (coberturas, superfícies, redes), ferramentas de interface de usuário de desktop para visualização de dados GIS [Silberschatz et al. 2010] a partir de informações numéricas advindas das mais diversas formas, como de GPS (latitude e longitude que se converte em pontos) e sensores (delimitar o raio e o converter em linhas). Assim, as modificações feitas a partir da modelagem de [Oliveira 2011] permitiram a criação de um banco de dados geográfico. Os métodos inicialmente empregados nessa fase consistiam em conectar a base de dados geográfica a um servidor de mapas, para que este fosse acessado por uma aplicação Web e exibisse na forma de mapas. Inicialmente foi utilizado o software livre GeoServer como servidor de mapas geográficos. Este software utiliza o serviço Web Standard Interface (WMS) que fornece uma interface padrão para a solicitação de uma imagem de mapa geoespacial [Foundation 2014] Para dinamizar o trabalho o número de ferramentas utilizadas não poderia ser extenso. Dessa forma, aplicamos a API do Google Maps, que permite a criação de mapas com locais definidos, controle de zoom, tipos de mapa, geração de rotas, dentre outras funcionalidades, no trabalho. A API do Google Maps funciona como servidor, assim como o GeoServer, gera os mapas em tela a partir da aplicação Web, sua programação é relativamente simples e possui uma boa plataforma de testes.
3. Resultados e Conclusões Durante o desenvolvimento foram utilizados dados fictícios a fim de testar as modelagens (iniciais e a modelagem final). Anteriormente a isso, utilizamos o que já havia sido produzido em etapas anteriores do projeto, a fim de definir o caminho a seguir.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
123
3.1. Modelagem dos Dados A partir do trabalho de [Oliveira 2011] criou-se uma versão modificada que atendesse as estações coletoras de dados agrometereológicos. As modificações ocorreram principalmente nos atributos relacionados aos locais de coletas de dados, modificando-os para tipos espaciais. Outra ferramenta importante no início do trabalho foi o software livre GeoServer. A ideia foi utilizar o GeoServer na aplicação Web com uma camada entre a fonte e o usuário final, e realizar as exibições a partir dele por meio do padrão WMS, formatar a informação proveniente do banco para exibição num arquivo ou numa página na Internet. A modelagem propõe um armazenamento em três grupos, chamados Dados, Gerenciais e Ontologias, que se relacionam com o armazenamento dos dados dos sensores, com as informações gerenciais e com os metadados para composição das ontologias (um modelo de dados que representa um conjunto de conceitos dentro de um domínio e os relacionamentos entre estes) [Oliveira 2011].
3.1.1. Dados Neste grupo encontram-se as tabelas que armazenam os dados medidos pelos sensores, dados de localização e restrição de acesso. Este conjunto de tabelas possuem as informações necessárias para o entendimento e avaliação dos dados. Para isso, o grupo de pesquisa optou por utilizar as ferramentas do Google, o API Google Maps e o Google Earth. A tabela Position foi a única alterada para a inserção de campos geográficos. Os campos inseridos nessa tabela foram: latitude e longitude (tipo de dados NUMERIC) e ponto (tipo de dado geográfico POINT). Para testar o Google Earth, as informações das estações a partir do banco de dados foram exportadas no formato .kml e importados pela ferramenta do Google. Ajustando as coordenadas, o ponto representando a estação é plotado, como observar-se na Figura 3.
Figura 3. A miniestação indicada no Google Earth em forma de ponto, bem
como os seus atributos.
3.1.2. Informações Gerenciais São informações referentes ao controle dos dados [Oliveira 2011]. Permitem gerenciar o acesso aos dados concedendo permissões a organizações, projetos e usuários. Nesse
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
124
conjunto de tabelas tem-se ainda informações dos sensores, para que seja possível interpretar falhas e garantir a qualidade dos dados, através das tabelas Sensor (organiza as informações de cada sensor e pode estar relacionada a vários tipos de dados, pois existem sensores que medem diferentes tipos de variáveis.) e Calibration (guarda as datas das calibrações feitas em cada sensor o que permite manter o histórico de calibrações e essa informação ser utilizada para interpretação e validação de dados).
3.1.3. Ontologias As ontologias são utilizadas com o intuito de garantir a flexibilidade e esconder a complexidade das informações, realiza o agrupamento dos metadados para montagem do contexto e, nesse contexto que o usuário final vai manipular os dados. As ontologias servem para definir por exmplo quais labels serão utilizados para cada tipo de dado de acordo com as ontologias pertencentes a cada projeto.
3.2. Implementação Web
A implementação Web baseou-se no código em Java produzido por [Oliveira 2011]. Tal código estava estruturado em função do padrão de projeto MVC (Model-View-Controller), utilizava JPA (Java Persistence API) e exportado como um projeto da IDE Eclipse. O projeto está estruturado em camadas Figura 4 que separa a visualização (View) das classes e métodos que trabalham os dados de entrada (Controller) e separa, também, os dados mapeados do banco de dados (Model) [Medeiros 2012]
Figura 4. Em destaque a estrutura MVC do Código. À direita apresenta-se a página
inicial da aplicação.
Dentro da camada Model estão contidos os dados mapeados do banco de dados. Para persisti-los foi utilizado a framework JPA (Java Persistence API)[Medeiros 2010]. Inicialmente, os dados estavam mapeados de acordo com a modelagem original, sendo necessário realizar algumas alterações. A classe Position, referente a tabela de mesmo nome, recebeu o acréscimo das variáveis Latitude, Longitude e Ponto. As duas primeiras variáveis são representadas no banco de dados com o tipo NUMERIC. O tipo POINT, relativo ao campo Ponto no banco de dados, não é nativo da Linguagem Java. Foi necessário adicionar o driver do PostGis, baixado direto do servidor do PostGreSQL. Ao final, o programa reconheceu e mapeou o campo corretamente.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
125
As páginas Web foram escritas na linguagem de marcação XHTML, que acessam os métodos contidos no Controller. Essas páginas exibirão ao usuário os mapas. A primeira mudança foi inserir os mapas gerados pelo Google Maps. Sua programação é através da Linguagem JavaScript. Esta API abstrai muito das dificuldades que ferramentas antigas apresentavam, além de permitir ao desenvolvedor fazer diversos testes sem a necessidade de reimplementar o banco de dados. A modelagem e a forma de visualização escolhidas ajudarão a definir as outras partes do projeto que estão sendo desenvolvidas em paralelo. A principal contribuição será na implementação do servidor que receberá as informações do campo e também ajudará a definir quais informações serão transmitidas pelas estações no campo. O escopo da modelagem escolhida é a ideal, pois abrange o projeto em si e ainda abre possibilidades de alterações conforme a evolução do projeto. Futuramente, será realizada uma alimentação deste banco de dados com uma grande quantidade de informações como forma de um grande teste. Ao final será realizado testes dos módulos separados, bem como testes do sistema completo, a fim de validá-lo e implementá-lo.
Agradecimentos Os autores agradecem à FAPEMAT (Processo 749775/2011) pelo apoio financeiro ao projeto.
Referências Foundation, O. S. G. (2014). Web Map Service — GeoServer 2.7.x User Manual.
Group, P. G. D. (2015). PostgreSQL 9.1.18 Documentation.
Liu, Y., Wang, E., Yang, X. and Wang, J. (2010). Contributions of climatic and crop varietal changes to crop production in the North China Plain, since 1980s. Global Change Biology, v. 16, n. 8, p. 2287–2299.
Lobell, D. B. and Burke, M. B. (2010). On the use of statistical models to predict crop yield responses to climate change. Agricultural and Forest Meteorology, v. 150, n. 11, p. 1443–1452.
Medeiros, H. (2010). Introdução à JPA - Java Persistence API.
Medeiros, H. (2012). Introdução ao Padrão MVC.
Neves, G. A. R. (2013). Desenvolvimento de um sistema automatizado com sensores alternativos para coleta e armazenamento de dados micrometereológicos. Universidade Federal de Mato Grosso.
Oliveira, A. G. (2011). Arquitetura de dados para gerenciamento de informações micrometereológicas. Universidade Federal de Mato Grosso.
Pereira, R. B. de O. (2013). IMPLEMENTAÇÃO POR SISTEMAS EMBARCADOS DE PROTÓTIPO PARAMETRIZÁVEL PARA COLETA DE DADOS MICROCLIMÁTICOS GEORREFERENCIADOS. Universidade Federal de Mato Grosso.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
126
Silberschatz, A., Korth, H. F. and Sudarshan, S. (2010). Database system concepts. McGraw-Hill Singapore. v. 6
Wart, J., Grassini, P. and Cassman, K. G. (2013). Impact of derived global weather data on simulated crop yields. Global change biology, v. 19, n. 12, p. 3822–3834.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
127
Utilização de Regras de Redução em Grafos Power Law: problema da cobertura por vértices
Edgar de Oliveira Cabral Filho1, Mariana Oliveira da Silva2, André Luís Vignatti1 1Instituto de Informática – Universidade Federal do Paraná (UFPR)
Caixa Postal 15.064 – 91.501-970 – Porto Alegre – RS – Brazil 2Departamento de Computação – Centro Universitário Campos de Andrade
(Uniandrade) eocfilho,[email protected], [email protected]
Abstract. A Minimum Vertex Cover is the smallest set of vertices whose removal completely disconnects a graph. In this paper we perform experiments in graphs with vertex degree based on power laws, applying reduction rules before to use a greedy algorithm, which finds a minimum vertex cover. In these experiments it was compared the results of the execution only the greedy algorithm against the results of the implementation of the reduction rules before using the greedy algorithm; resulting a vertex cover 1% smaller and reducing 86% of execution time in a instance used.
Resumo. Cobertura Mínima de Vértices é o menor conjunto de vértices cuja remoção desconecta completamente o grafo. Neste artigo realizamos experimentos com grafos com distribuição de grau de uma lei de potência (power law), aplicando regras de redução antes da aplicação de um algoritmo guloso que encontra uma cobertura mínima de vértices. Nos experimentos foi comparado o resultado da execução de um algoritmo guloso contra os resultados da aplicação das regras de redução antes da utilização do algoritmo guloso; resultando em uma cobertura 1% menor e chegando a diminuir em até 86% do tempo de execução em uma das instâncias utilizadas.
1. Introdução A teoria dos grafos é uma ferramenta matemática muito utilizada na resolução de problemas algorítmicos e computacionais, na qual modela conjuntos de elementos e relações entre estes elementos. Sistemas naturais e tecnológicos de diversos domínios podem ser representados matematicamente por grafos que possuem propriedades estatísticas bem conhecidas, uma destas propriedades pode ser encontrada na distribuição de graus dos vértices de um grafo que segue uma lei de potência (powerlaw).
Este tipo de grafo é encontrado na World-WideWeb, em redes sociais, redes biológicas entre outros [Da Silva et al. 2013]. No contexto de problemas relacionados a grafos, o problema da cobertura por vértices e a utilização de regras de redução torna-se o objeto do presente estudo.
Mais especificamente, deseja-se efetuar experimentos relacionados ao cálculo da cobertura utilizando a estratégia gulosa e regras de redução para posteriormente compará-los. A estratégia gulosa para resolver este problema foi descrita em [Da Silva

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
128
et al. 2013] e as regras de redução foram descritas em [Abu-Khzam et al. 2004] e algumas são especificadas na seção 3.1.
A maior motivação desse estudo, encontra-se na aproximação encontrada por [Da Silva et al. 2013] em relação a solução ótima do problema da cobertura por vértices, sem aplicação de nenhuma regra de redução em seus experimentos. Este fato leva a crer que o uso de tais regras aproxima ainda mais da cobertura por vértices ótima, e ainda, com tempo de redução mais aceitável.
2. Grafos Power Law A teoria dos grafos é uma ferramenta matemática simples e poderosa, usada para construção de modelos e resolução de problemas [Garey e Johnson 2002], tais como: fluxos em redes, escolha de uma rota ótima entre dois pontos em um mapa, logística [Costa et al. 2007], representação de imagens [Gold e Rangarajan 1996] e diversos outros.
Para [West et al. 2001], um grafo simples G = (V,E) consiste de um conjunto finito de vértices V (G) = v1,v2,...,vn (ou nós) e um outro conjunto E(G) = e1,e2,...,em, chamados de arestas, tal que cada aresta de E é um conjunto de dois vértices de V . Se e = vi,vj, dizemos que e conecta vi a vj, Demonstramos também a aresta vi,vj da seguinte maneira simplificada: vivj. Em um grafo G = (V,E), se uma aresta e conecta um vértice vi a um vértice vj, dizemos que esta aresta é incidente a estes vértices.
2.1. Redes Power Law
Grafos power law existem em grandes quantidades na natureza e na sociedade, que surgem seguindo os princípios de expansão contínua (adição de novos vértices) e uma certa preferência: os novos vértices da rede tendem a se conectar com “hubs” (vértices de grau muito alto). Esta expansão é conhecida como redes de ligação preferencial(“preferentialattachment”) e comumente são powerlaw[Silva et al. 2013].
Muitos sistemas físicos, químicos, biológicos e sociais, podem ser interpretados como grafos onde os indivíduos são representados por vértices e suas interações por arestas. A maioria deles apresentam as características discutidas acima [Barabási e Albert 1999]. Uma propriedade respeita uma powerlaw, se a relação entre dois números ye ié tal que ela possa ser escrita como y=ai−β, onde ae βsão constantes. No contexto da teoria dos grafos podemos definir grafos powerlawcomo na Definição 1.
Definição1Umgraforespeitaadistribuição de lei de potência seafraçãodevérticescomgrauiéproporcionalài−βparaalgumβconstanteemaiorque1. 3. Problema de cobertura por vértices
A coberturaporvérticesé um problema clássico em ciência da computação e um dos primeiros problemas que foi provado ser NP-Completo [Karp 1972]. Segundo [West et al. 2001], trata-se de encontrar um conjunto de vértices que “toca” todas as arestas de um grafo, ou seja, dado uma grafo G, pede-se um subconjunto de vértices, V0⊆V tal que para cada aresta (u,v)∈E, u∈V0ou v∈V0[Cormen et al. 2001]. O problema da cobertura por vértices mínima refere-se ao menor conjunto de uma cobertura de um

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
129
grafo. Existem duas versões para o problema da cobertura por vértices, o problema de decisão e o problema de otimização.
• Cobertura por vértices - Otimização: uma cobertura de vértices de tamanho mínimo é chamada de cobertura ótima, quando se procura um elemento no conjunto de soluções viáveis que seja o melhor possível em relação a algum critério. Resultados teóricos mostram que o problema da cobertura por vértices mínima é (NP-difícil) [Arora e Barak 2009, Cormen et al. 2001] uma vez que ele é tão difícil de solucionar quanto os problemas mais difíceis na classe NP.
Algoritmos para problema de otimização se dividem em dois tipos: algoritmosexatose algoritmosheurísticos.
• Algoritmos exatos: incluem principalmente algoritmos branch-and-bound[Cormen et al. 2001], que garantem a otimalidade das soluções encontradas, mas nem sempre dão uma solução num prazo razoável de tempo para grandes instâncias, já que no pior caso gastam tempo exponencial.
• Algoritmosheurísticos: incluem diversas estratégias, sendo que estas estratégias não garantem a otimalidade de suas soluções, mas encontram soluções próximas da ótima ou satisfatória para instâncias grandes e difíceis, dentro de um tempo razoável [Cai et al. 2013].
3.1. Regras de redução para cobertura por vértices
A redução ao núcleo (kernelization) é uma técnica utilizada para desenvolver algoritmos eficientes e, muitas vezes, é conseguida através da aplicação de um conjunto de regras de pré-processamento, que eliminam partes da instância que são consideravelmente fáceis de manusear, deixando apenas um “kernel” (núcleo) a ser tratado [Abu-Khzam et al. 2004].
A proposta deste trabalho é a utilização de regras de redução ao núcleo, na resolução do problema da cobertura por vértices mínima, a fim de reduzir o tamanho da entrada original do problema (em tempo polinomial), para uma pequena parte da instância original (núcleo do problema), a ser resolvida em tempo exponencial.
As regras de redução mostradas a seguir foram apresentadas por [Abu-Khzam et al. 2004], estas regras exigem custo O(n2) com constantes modestas de proporcionalidade, aplicadas num grafo não direcionado com nvértices.
Regra 1: existindo um vértice de grau 0, ele não pode estar numa cobertura de vértices ótima, uma vez que não existe nenhuma aresta incidente em cima de tal vértice, então não há nenhum benefício em incluí-lo na cobertura. Seja C o conjunto de todos os vértices isolados de G, o tamanho do grafo passa a ser n = n − |C|, ou seja, n é reduzido pela quantidade de vértices isolados do grafo. Aplica-se esta regra até que não exista nenhum vértice de grau 0.
Regra 2: dado um vértice de grau 1, existe uma cobertura ótima que não contém este vértice, mas contém o seu vizinho. Seja o vértice u de grau 1 com vizinho v, a aresta uv estará coberta, caso o vértice u, ou v estejam na cobertura. Caso a cobertura ótima seja constituída pelo vértice u, não há problema em trocá-lo pelo seu vizinho (vértice v), uma vez que o tamanho da cobertura ótima continua a mesma. Repete-se

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
130
esta regra até que todos os vizinhos dos vértices de grau 1 sejam inseridos na cobertura e suas arestas incidentes removidas. Esta regra pode gerar novos vértices isolados que são eliminados pela a regra 1, reduzindo assim n pelo número de vértices removidos pela regra 1 mais os vértices inseridos na cobertura. Seja S o conjunto formado por todos os vértices inseridos na cobertura pela regra 2, e C o conjunto de todos os vértices isolados de G, após a aplicação da regra 2, o grafo resultante passa a ter o tamanho de n = n − |C| − |S|.
Regra 3: se existe um vértice de grau 2, com vizinhos adjacentes (triângulos), então há uma cobertura ótima que inclui ambos os vizinhos deste vértice. Se u é um vértice de grau 2 e v e w são os seus vizinhos, para cobrir as arestas, (u,v), (u,w) e (v,w) de forma ótima, dois dos três vértices devem estar na cobertura. Ao escolher os vértices u e v, todas as arestas estarão cobertas, o mesmo se aplica ao escolher os vértices u e w. Mas, trocando o vértice u por um de seus vizinhos, v ou w (caso algum não tenha sido escolhido para a cobertura), o tamanho da cobertura ótima não modifica (continua sendo exatamente formada por dois vértices), porém caso v e/ou w contenham vizinhos além do vértice u, as arestas incidentes entre v e w e seus vizinhos também estarão cobertas. Logo existe uma cobertura por vértices ótima que inclui v e w, mas não u. Isto ainda reduz n ao número de vértices inseridos na cobertura e os removidos pela regra 1 e 2. Aplica-se esta regra até que todos os vizinhos dos vértices de grau dois (desde que sejam adjacentes), sejam inseridos na cobertura, após a utilização da regra 3, aplica-se a regra 2 e por fim a regra 1.
Após aplicada estas regras de redução, o grafo original G é reduzido para G0. Estas regras facilitam na resolução do problema da cobertura por vértices mínima, pois além de diminuir o tamanho da instância original [Abu-Khzam et al. 2004], garante não "desviar" da cobertura ótima.
Assim, é ideal a utilização destas regras de redução, na busca de uma cobertura por vértices mínima em grafos que contém características de uma power law. Como os grafos power law contém uma distribuição de grau onde a maioria dos seus vértices tem grau baixo e poucos dos seus vértices tem grau elevado, a aplicação destas regras de redução que tratam grau baixo, sugere que sua aplicação diminua significativamente uma instância do problema da cobertura por vértices.
4. Resultados e Considerações Neste trabalho foi realizado um estudo experimental em relação ao comportamento de um algoritmo baseado em uma estratégia de aplicação de regras de redução em grafos power law, com o objetivo de reduzir o tamanho do grafo, para posterior aplicação de um algoritmo do problema da cobertura por vértices. Das três regras de redução descritas na seção 3.1, somente a regra 1 e regra 2 foram aplicadas.
O resultado deste estudo foi comparado com o tamanho inicial do grafo e verificado a redução do tamanho do grafo. Os experimentos foram realizados numa máquina com sistema operacional Linux Mint 17 Cinnamon 64-bit, com Kernel do Linux:4:0:1Kernel+ e processador: AMD FX(tm)-6300 Six-Core Processor x3. Os grafos utilizados foram retirados do banco de dados [Rossi e Ahmed 2013].
Foram realizadas três análises distintas da aplicação das regras de redução para resolução do problema da cobertura por vértices:
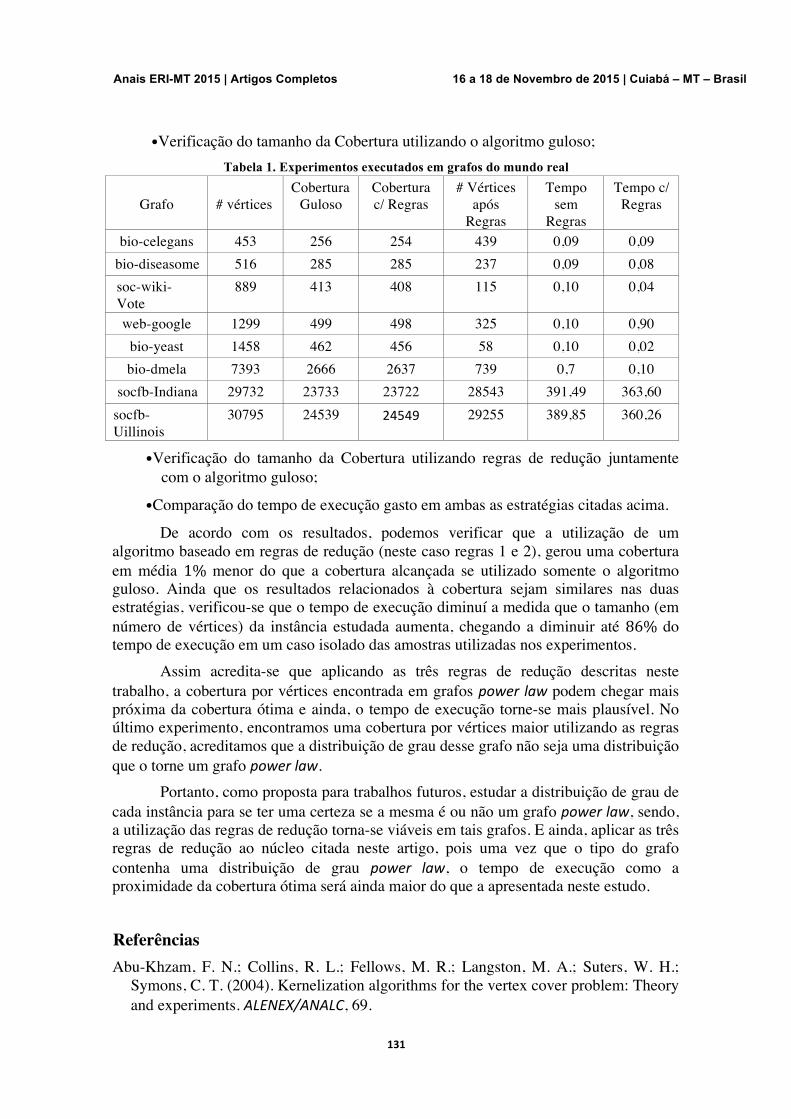
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
131
• Verificação do tamanho da Cobertura utilizando o algoritmo guloso; Tabela 1. Experimentos executados em grafos do mundo real
Grafo # vértices Cobertura
Guloso Cobertura c/ Regras
# Vértices após
Regras
Tempo sem
Regras
Tempo c/ Regras
bio-celegans 453 256 254 439 0,09 0,09 bio-diseasome 516 285 285 237 0,09 0,08 soc-wiki-Vote
889 413 408 115 0,10 0,04
web-google 1299 499 498 325 0,10 0,90 bio-yeast 1458 462 456 58 0,10 0,02 bio-dmela 7393 2666 2637 739 0,7 0,10
socfb-Indiana 29732 23733 23722 28543 391,49 363,60 socfb-Uillinois
30795 24539 24549 29255 389,85 360,26
• Verificação do tamanho da Cobertura utilizando regras de redução juntamente com o algoritmo guloso;
• Comparação do tempo de execução gasto em ambas as estratégias citadas acima.
De acordo com os resultados, podemos verificar que a utilização de um algoritmo baseado em regras de redução (neste caso regras 1 e 2), gerou uma cobertura em média 1%menor do que a cobertura alcançada se utilizado somente o algoritmo guloso. Ainda que os resultados relacionados à cobertura sejam similares nas duas estratégias, verificou-se que o tempo de execução diminuí a medida que o tamanho (em número de vértices) da instância estudada aumenta, chegando a diminuir até 86%do tempo de execução em um caso isolado das amostras utilizadas nos experimentos.
Assim acredita-se que aplicando as três regras de redução descritas neste trabalho, a cobertura por vértices encontrada em grafos powerlawpodem chegar mais próxima da cobertura ótima e ainda, o tempo de execução torne-se mais plausível. No último experimento, encontramos uma cobertura por vértices maior utilizando as regras de redução, acreditamos que a distribuição de grau desse grafo não seja uma distribuição que o torne um grafo powerlaw.
Portanto, como proposta para trabalhos futuros, estudar a distribuição de grau de cada instância para se ter uma certeza se a mesma é ou não um grafo powerlaw, sendo, a utilização das regras de redução torna-se viáveis em tais grafos. E ainda, aplicar as três regras de redução ao núcleo citada neste artigo, pois uma vez que o tipo do grafo contenha uma distribuição de grau power law, o tempo de execução como a proximidade da cobertura ótima será ainda maior do que a apresentada neste estudo.
Referências Abu-Khzam, F. N.; Collins, R. L.; Fellows, M. R.; Langston, M. A.; Suters, W. H.;
Symons, C. T. (2004). Kernelization algorithms for the vertex cover problem: Theory and experiments. ALENEX/ANALC, 69.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
132
Arora, S.; Barak, B. (2009). Computationalcomplexity:amodernapproach. Cambridge University Press.
Barabási, A.-L.; Albert, R. (1999). Emergence of scaling in random networks. science, 286(5439):509–512.
Cai, S.; Su, K.; Luo, C.; Sattar, A. (2013). Numvc: An efficient local search algorithm for minimum vertex cover. Journal of Artificial Intelligence Research, pages 687–716.
Cormen, T. H., Leiserson, C. E., Rivest, R. L., Stein, C., et al. (2001). Introduction to algorithms, volume 2. MIT press Cambridge.
Costa, L. D. F.; Rodrigues, F. A.; Travieso, G.; Villas Boas, P. R. (2007). Characterization of complex networks: A survey of measurements. Advances in Physics, 56(1):167–242.
Ferreira, C. E. (2001). Uma introdução sucinta a algoritmos de aproximação. IMPA. Garey, M. R.; Johnson, D. S. (2002). Computers and intractability, volume 29. wh
freeman. Gold, S.; Rangarajan, A. (1996). A graduated assignment algorithm for graph matching.
Pattern Analysis and Machine Intelligence, IEEE Transactions on, 18(4):377– 388. Karp, R. M. (1972). Reducibility among combinatorial problems. Springer. Rossi, R. A.; Ahmed, N. K. (2013). Network repository. Silva, M. O.; Gimenez-Lugo, G. A.; Silva, M. V. (2013). Vertex cover in complex
networks. International Journal of Modern Physics C, 24(11). West, D. B. et al. (2001). Introduction to graph theory, volume 2. Prentice hall Upper
Saddle River.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
133
Redes Neurais Artificiais em Série Temporal Não-Linear de Índice Pluviométrico Para Determinação de Inundação em
Bacias do Pantanal Gerson K. Kida1, Gracyeli S. S. Guarienti1, César E. Guarienti1, Josiel M.
Figueiredo2
1Programa de Pós-Graduação em Física Ambiental – Universidade Federal de Mato Grosso (UFMT) – Cuiabá, MT – Brasil
2Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) – Cuiabá, MT – Brasil
gersonkida, gracyeli, [email protected], [email protected]
Abstract. The aim of this study is to find a suitable forecasting model to the water level in 17 basins in the Mato Grosso Pantanal, with the input variable daily rainfall basins under study, for the study will be compared the method of neural networks for time series non-linear autoregressive with feedback (NARX), and the method of neural networks, non-linear autoregressive time series with a feedforward network. The results demonstrate that the methods chosen for the study are adequate, even when used in common computers. Resumo. O objetivo deste estudo é encontrar um modelo de previsão adequado ao nível de água em 17 bacias do Pantanal Mato-grossense, tendo como variável de entrada a precipitação diária das bacias em estudo, para o estudo são comparados: o método de redes neurais para série temporal não-linear auto regressivo com retroalimentação (NARX), e o método de redes neurais para série temporal não-linear auto regressivo com alimentação unidirecional. Os resultados obtidos demonstram que os métodos escolhidos são adequados para o estudo, mesmo quando utilizados em computadores comuns.
1. Introdução A hidrologia do Pantanal Mato-grossense é conduzida por processos de precipitação e evapotranspiração, onde águas de superfície se move lentamente a jusante. Eventos de alta precipitação, em suas bacias, durante o período de outubro a março têm impacto local imediato, esses eventos são altamente não-lineares (Figura 1) [Lima et al., 2011]. O desenvolvimento de ferramenta de modelagem para um ambiente complexo que é o foco deste estudo, permitirá o gerenciamento em uma grande quantidade de problemas, como os impactos no uso de solo e obras hidráulicas, alerta de inundações, gerenciamento da navegação, entre outros [Allasia et al., 2004]. Este artigo apresenta uma parte desse ambiente complexo, que é o uso de RNA para análise do comportamento dos dados. Outras técnicas e algoritmos podem ser utilizados, mas não é o foco deste artigo.
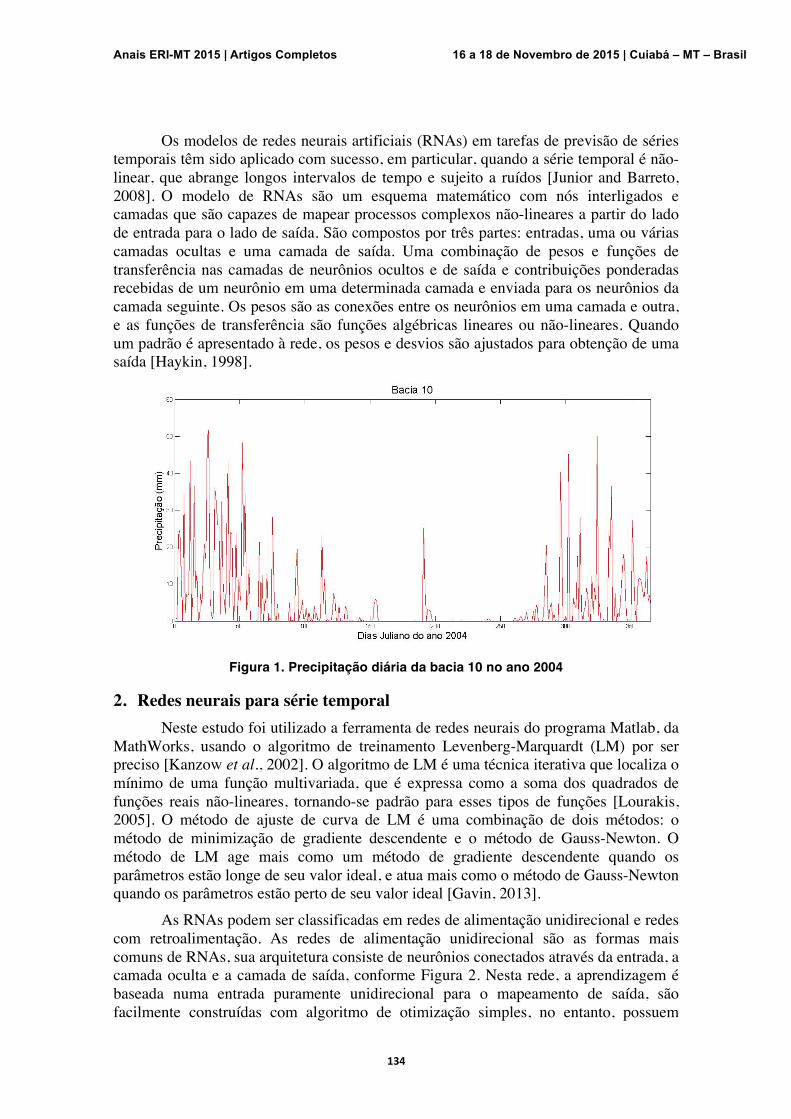
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
134
Os modelos de redes neurais artificiais (RNAs) em tarefas de previsão de séries temporais têm sido aplicado com sucesso, em particular, quando a série temporal é não-linear, que abrange longos intervalos de tempo e sujeito a ruídos [Junior and Barreto, 2008]. O modelo de RNAs são um esquema matemático com nós interligados e camadas que são capazes de mapear processos complexos não-lineares a partir do lado de entrada para o lado de saída. São compostos por três partes: entradas, uma ou várias camadas ocultas e uma camada de saída. Uma combinação de pesos e funções de transferência nas camadas de neurônios ocultos e de saída e contribuições ponderadas recebidas de um neurônio em uma determinada camada e enviada para os neurônios da camada seguinte. Os pesos são as conexões entre os neurônios em uma camada e outra, e as funções de transferência são funções algébricas lineares ou não-lineares. Quando um padrão é apresentado à rede, os pesos e desvios são ajustados para obtenção de uma saída [Haykin, 1998].
Figura 1. Precipitação diária da bacia 10 no ano 2004
2. Redes neurais para série temporal Neste estudo foi utilizado a ferramenta de redes neurais do programa Matlab, da MathWorks, usando o algoritmo de treinamento Levenberg-Marquardt (LM) por ser preciso [Kanzow et al., 2002]. O algoritmo de LM é uma técnica iterativa que localiza o mínimo de uma função multivariada, que é expressa como a soma dos quadrados de funções reais não-lineares, tornando-se padrão para esses tipos de funções [Lourakis, 2005]. O método de ajuste de curva de LM é uma combinação de dois métodos: o método de minimização de gradiente descendente e o método de Gauss-Newton. O método de LM age mais como um método de gradiente descendente quando os parâmetros estão longe de seu valor ideal, e atua mais como o método de Gauss-Newton quando os parâmetros estão perto de seu valor ideal [Gavin, 2013].
As RNAs podem ser classificadas em redes de alimentação unidirecional e redes com retroalimentação. As redes de alimentação unidirecional são as formas mais comuns de RNAs, sua arquitetura consiste de neurônios conectados através da entrada, a camada oculta e a camada de saída, conforme Figura 2. Nesta rede, a aprendizagem é baseada numa entrada puramente unidirecional para o mapeamento de saída, são facilmente construídas com algoritmo de otimização simples, no entanto, possuem

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
135
deficiência por causa da convergência lenta e a necessidade de um grande conjunto de dados de treinamento. As redes neurais para série temporal não-linear auto regressivo com retroalimentação (NARX) fornece uma poderosa capacidade de aprendizagem, os pesos resultantes são ajustáveis para explicar o estado dos neurônios das camadas de entrada, oculta e saída, sendo 19 dados de entrada e 17 dados de saída, conforme ilustrado na Figura 3, essa rede requer menos conjuntos de dados de treinamento em comparação com a rede de alimentação unidirecional [Ali, 2009].
Figura 2. Rede neural para série temporal não-linear auto regressivo com
alimentação unidirecional
Figura 3. Rede neural para série temporal não-linear auto regressivo com
retroalimentação
A rede NARX padrão usada aqui é uma rede de alimentação de entrada de duas camadas, com uma função sigmoide na camada escondida e uma função de transferência linear na camada de saída. Esta rede utiliza também linhas de atraso para armazenar valores anteriores de entrada, x(t), e de saída, y(t). Há duas entradas para a rede, o x(t) e y(t), onde y(t) é considerada um sinal de retroalimentação e também uma saída [Arbain and Wibono, 2012].
3. Materiais e Métodos A princípio foram utilizados os dados de precipitação diária do período de 2004 a 2010, obtidos pelo produto 3B42 disponibilizados pelo projeto Tropical Rainfall Measuring Mission (TRMM), satélite lançado em dezembro de 1997, que fornece estimativas de precipitação acumulada em 24 horas (mm dia-1), com uma resolução espacial de 0,25° x 0,25° [Viana et al., 2010], a seguir, foram somados seus valores de contribuição em cada bacia do estudo, proporcionalmente a área de cada uma delas, obtendo-se dessa forma a matriz de entrada de dados, x(t), que é composta de 19 dados, com as seguintes informações: dia juliano, ano, e dados de precipitação das 17 bacias. Após, por meio de imagens do sensor Moderate Resolution Imaging Spectroradiometer (MODIS), a bordo do satélite Terra, lançado em dezembro de 1999 no projeto Earth Observing System (EOS), disponibilizado pelo produto MOD13Q1 com resolução temporal de 16 dias e resolução espacial de 250m [Anderson et al., 2003], foram obtidos os valores dos níveis de água nas bacias em estudo, y(t), que é representado por 17 dados de inundação das bacias em estudo.
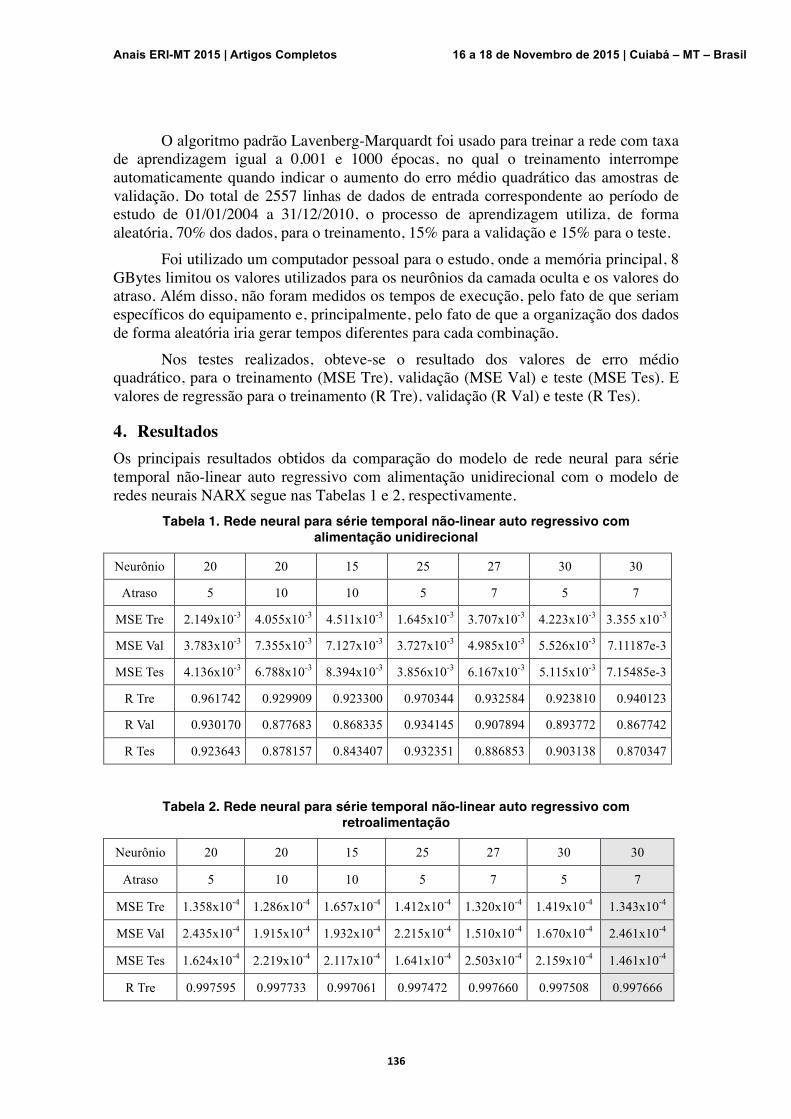
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
136
O algoritmo padrão Lavenberg-Marquardt foi usado para treinar a rede com taxa de aprendizagem igual a 0,001 e 1000 épocas, no qual o treinamento interrompe automaticamente quando indicar o aumento do erro médio quadrático das amostras de validação. Do total de 2557 linhas de dados de entrada correspondente ao período de estudo de 01/01/2004 a 31/12/2010, o processo de aprendizagem utiliza, de forma aleatória, 70% dos dados, para o treinamento, 15% para a validação e 15% para o teste.
Foi utilizado um computador pessoal para o estudo, onde a memória principal, 8 GBytes limitou os valores utilizados para os neurônios da camada oculta e os valores do atraso. Além disso, não foram medidos os tempos de execução, pelo fato de que seriam específicos do equipamento e, principalmente, pelo fato de que a organização dos dados de forma aleatória iria gerar tempos diferentes para cada combinação.
Nos testes realizados, obteve-se o resultado dos valores de erro médio quadrático, para o treinamento (MSE Tre), validação (MSE Val) e teste (MSE Tes). E valores de regressão para o treinamento (R Tre), validação (R Val) e teste (R Tes).
4. Resultados Os principais resultados obtidos da comparação do modelo de rede neural para série temporal não-linear auto regressivo com alimentação unidirecional com o modelo de redes neurais NARX segue nas Tabelas 1 e 2, respectivamente.
Tabela 1. Rede neural para série temporal não-linear auto regressivo com alimentação unidirecional
Neurônio 20 20 15 25 27 30 30
Atraso 5 10 10 5 7 5 7
MSE Tre 2.149x10-3 4.055x10-3 4.511x10-3 1.645x10-3 3.707x10-3 4.223x10-3 3.355 x10-3
MSE Val 3.783x10-3 7.355x10-3 7.127x10-3 3.727x10-3 4.985x10-3 5.526x10-3 7.11187e-3
MSE Tes 4.136x10-3 6.788x10-3 8.394x10-3 3.856x10-3 6.167x10-3 5.115x10-3 7.15485e-3
R Tre 0.961742 0.929909 0.923300 0.970344 0.932584 0.923810 0.940123
R Val 0.930170 0.877683 0.868335 0.934145 0.907894 0.893772 0.867742
R Tes 0.923643 0.878157 0.843407 0.932351 0.886853 0.903138 0.870347
Tabela 2. Rede neural para série temporal não-linear auto regressivo com retroalimentação
Neurônio 20 20 15 25 27 30 30
Atraso 5 10 10 5 7 5 7
MSE Tre 1.358x10-4 1.286x10-4 1.657x10-4 1.412x10-4 1.320x10-4 1.419x10-4 1.343x10-4
MSE Val 2.435x10-4 1.915x10-4 1.932x10-4 2.215x10-4 1.510x10-4 1.670x10-4 2.461x10-4
MSE Tes 1.624x10-4 2.219x10-4 2.117x10-4 1.641x10-4 2.503x10-4 2.159x10-4 1.461x10-4
R Tre 0.997595 0.997733 0.997061 0.997472 0.997660 0.997508 0.997666

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
137
R Val 0.995702 0.996630 0.996666 0.996276 0.997477 0.997085 0.995697
R Tes 0.997201 0.996100 0.996287 0.997150 0.995494 0.996037 0.997228
Obteve-se o melhor resultado com o modelo de redes neurais NARX utilizando 30 neurônios na camada escondida e 7 como valor de atraso, obtendo-se os seguintes valores de erro médio quadrático (MSE), para o treinamento, validação e teste igual a 1,343x10-4, 2,461x10-4 e 1,461x10-4, respectivamente. E valores de regressão (R) iguais a 0,997666, 0,995697 e 0,997228 para o treinamento, validação e teste, respectivamente.
5. Conclusão Neste estudo, avaliamos a capacidade de previsão de inundação em 17 bacias que fazem parte do Pantanal Mato-grossense, tendo como dados de entrada a precipitação na região. A comparação de desempenho foi realizada entre os modelos de redes neurais para série temporal não-linear auto regressivo com alimentação unidirecional e o NARX. Nos resultados obtidos, o melhor desempenho foi fornecido pelo modelo NARX com valores bem inferiores de erro médio quadrático e valores de regressão muito próximos a 1. Esse resultado com menor erro obtido na utilização do NARX demonstra que esse modelo de previsão é adequado ao estudo e também que o mesmo pode ser aplicado em equipamentos com baixa limitação de processamento.
6. Referência Bibliográfica Ali, A. (2009) “Nonlinear multivariate rainfall–stage model for large wetland systems”,
Journal of Hydrology 374 (2009) 338–350 Allasia, D. G., Collischonn, W., Tucci, C. E. M., et al. (2004) “Modelo hidrológico da
bacia do Alto Paraguai”, In: SIMPÓSIO DE RECURSOS HÍDRICOS DO CENTRO-OESTE, 3, 2004, Goiânia. Anais... Goiânia: Associação Brasileira de Recursos Hídricos, 2004.
Anderson, L.O., Latorre, M.L., Shimabukuro, Y.E., Arai, E., Carvalho, O.A. (2003) “Sensor MODIS: uma abordagem geral”, INPE São José dos Campos/ SP 2003.
Arbain, S. H. and Wibono, A. (2012) “Neural Networks Based Nonlinear Time Series Regression for Water Level Forecasting of Dungun River”, In: Journal of Computer Science 8 (9): 1506-1513, 2012, Science Publications
Gavin, H.P. (2013) “The Levenberg-Marquardt method for nonlinear least squares curve-fitting problems”, Department of Civil and Environmental Engineering, Duke University, October 9, 2013
Haykin, S. (1998) “Neural Networks: A Comprehensive Foundation”, 2nd Prentice Hall PTR Upper Saddle River, NJ, USA,1998
Junior, J. M. P. and Barreto, G. A. (2008) “Multistep-Ahead Prediction of Rainfall Precipitation Using the NARX Network”, 2nd European Symposium on Time Series Prediction (TSP'2008)
Kanzow, C., Yamashita, N. and Fukushima, M. (2002) “Levenberg–Marquardt methods with strong local convergence properties for solving nonlinear equations with convex

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
138
constraints”, Journal of Computational and Applied Mathematics, Volume 177, Issue 2, May 2002,Page 172
Lima, I.B.T., Resende, E.K. and Comastri Filho, J.A. (2011) “O ciclo das águas no Pantanal e a cheia de 2011”. Corumbá: Embrapa Pantanal, 2011. 3p. ADM – Artigo de Divulgação na Mídia, n.144. Disponível em: . Acesso em: 01 Setembro. 2011
Lourakis, M.I.A (2005) “A Brief Description of the Levenberg-Marquardt Algorithm Implemented by Levmar”, Technical Report; Institute of Computer Science, Foundation for Research and Technology, Hellas: Crete, Greece, 2005
Viana, D.R.; Ferreira, N.J.; Conforte, J.C. (2010) “Avaliação das estimativas de precipitação 3B42 e 3B43 do satélite TRMM na Região Sul do Brasil”, In: Congresso Brasileiro de Meteorologia (CBMet), XVI., 2010, Belém. Anais São José dos Campos: INPE, 2010

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
139
Política de Privacidade e Dados Pessoais: Um Estudo sobre o Valor da Informação e a Consciência de Uso
Gabriel José da Silva Rodrigues, André S. Abade Departamento de Informática – Instituto Federal de Educação, Ciência e Tecnologia de
Mato Grosso (IFMT) – Campus Barra do Garças Estrada de Acesso a BR-158, s/n – 78.600-000 – Barra do Garças – MT – Brasil
[email protected], [email protected]
Abstract. Context: Companies every day carry over their applications for cloud. This characteristic makes numerous services to be available all the time for users. By means of a critical analytical survey, it elaborated a study confronted the privacy policies adopted by some popular services for social networking, portal services and e-commerce with the laws in effect in Brazil that deal with personal data and privacy individual. The study tries to establish what level of awareness of users about the value of your personal information and what is the privacy policy regarding the services they use.
Resumo. As empresas a cada dia mais portam suas aplicações para nuvem. Esta característica faz com que inúmeros serviços fiquem disponíveis todo tempo para os usuários. Assim, o volume de informações e seu valor agregado tornam-se um verdadeiro tesouro. Por meio de um levantamento analítico crítico, elaborou-se um estudo que confrontou as políticas de privacidade adotadas por alguns serviços populares de redes sociais, portal de serviço e comércio eletrônico com as legislações vigentes no Brasil que tratam sobre os dados pessoais e a privacidade do individuo. O estudo tenta estabelecer qual o nível de consciência dos usuários sobre o valor de suas informações pessoais e o que representa a política de privacidade quanto aos serviços por eles utilizados.
1. Introdução Alinhados ao crescimento fenomenal das aplicações, a facilidade de acesso e a distribuição de conteúdo por meio de portais de serviços, comércio eletrônico e redes sociais os usuários vulgarizam seus dados sem se atentarem para o valor e a relevância agregados à estas informações [Dhawan et al. 2014]. Contudo, estas características e facilidades evidenciam fragilidades até então presentes apenas no mudo físico. Perfis falsos, informações adulteradas, dados roubados, dossiês eletrônicos e transações financeiras eletrônicas não autorizadas são alguns exemplos de ataques que fazem uso dos dados pessoais armazenados na nuvem.
Recentemente, um site especializado em venda de dados pessoais causou um enorme alarde midiático no Brasil, expondo à fragilidade da legislação sobre a regulação e proteção dos dados do indivíduo como cidadão brasileiro. O portal denominado “Tudo sobre Todos”1, vendia dados pessoais de todo e qualquer cidadão brasileiro com informações que assombraram os seus proprietários pela fidedignidade das informações e invasão de privacidade.
Este estudo tem como objetivo analisar e avaliar as políticas de privacidade adotadas pelas empresas e a legislação brasileira que trata sobre os dados pessoais e os princípios da individualidade que vão da Lei de Acesso a Informação ao Marco Civil da Internet Brasileira. Adicionalmente, investigamos as atitudes e consciência dos usuários quanto a relevância das políticas de privacidade e a utilização de seus dados privados por terceiros.
O restante deste artigo está organizado da seguinte forma: A próxima seção provê uma contextualização teórica. A metodologia de investigação é apresentada na Seção 3. Na sequência, a Seção 4 relata a análise elaborada. Na Seção 5 são apresentados os 1 http://tudosobretodos.se/

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
140
trabalhos relacionados. Finalmente, na Seção 6 são apresentadas as conclusões e trabalhos futuros.
2. Contextualização O conceito de dados pessoais pode ser definido por um conjunto de elementos de informação que associado e registrado a uma singularidade pode caracterizar um indivíduo. Os dados pessoais podem, ou não, ser classificados como sensíveis de acordo com alguns contextos de aplicações morais e éticas. Comumente, são consideradas sensíveis as informações sobre saúde, convicções políticas ou religiosas, características genéticas ou raciais, entre outros [Li 2014].
A definição e a classificação dos dados pessoais podem influenciar o equilíbrio de poder entre o indivíduo e aquele que coleta e utiliza suas informações [Lang et al., 2009]. Assim, o individuo pode consentir, por meio de uma manifestação livre, expressa e objetiva o uso de seus dados pessoais para uma determinada finalidade. Isso se aplica, por exemplo, aos casos em que usuários aceitam termos de uso e políticas de privacidade de aplicações que deixam explícita a coleta e utilização de seus dados.
Os termos de uso e políticas de privacidade geralmente são disponibilizados pelas aplicações que coletam e utilizam os dados pessoais de seus usuários com alguma finalidade [Dhami et al. 2013]. Este documento celebra o aceite e consentimento entre as partes sobre o ônus e o bônus que existe entre o usuário e o responsável ou operador das informações pessoais do outrem.
O consentimento do titular é uma regra geral a legitimar o tratamento de dados pessoais, salvo em alguns casos excepcionais. Algumas exceções conhecidas são: dados que já são de acesso público ou casos em que leis específicas dispensem o consentimento [BRASIL 2011]. Por outro lado, existem casos particulares em que o consentimento torna-se ainda mais relevante, como no caso dos dados sensíveis. Assim, o consentimento e avaliação do usuário possui um papel fundamental na proteção dos dados pessoais enquanto ferramenta de efetivo controle do cidadão sobre suas próprias informações.
Para possibilitar que os termos de uso e as políticas de privacidade possuam garantias efetivas ao cidadão em relação aos seus dados, e que tutelem a sua autodeterminação informacional e a eficácia do seu direito de titularidade de seus dados pessoais, é necessário que a legislação trate as violações sobre dados pessoais com olhar presente e prospecção futura [Ministério da Justiça, 2015]. A proteção dos dados pessoais por meio de Leis está diretamente condicionada aos processos tecnológicos dinâmicos e mutáveis que exigem um modelo sancionatório veloz e adequado às mudanças e inovações tecnológicas.
No Brasil, a legislação atual que versa sobre o trato dos dados pessoais ainda é considerada omissa e ineficaz, comparada com países como os Estados Unidos e a União Europeia. Basicamente, o direito do cidadão brasileiro está ancorado na Lei 12.965, de 23 de Abril de 2014, que estabelece os princípios, garantias, direitos e deveres para o uso da internet no Brasil (i.e. Lei do Marco Civil) e a Lei 12.527, de 18 de Novembro de 2011 (i.e. Lei de Acesso a Informação). Não existe uma lei no Brasil que verse especificamente sobre os princípios, garantias, direitos e obrigações referentes a proteção de dados pessoais. Atualmente, é possível encontrar algumas iniciativas que tramitam como projetos de lei (e.g. Projeto de Lei do Senado no. 181, de 2014 e o Projeto de Lei 4060/2012 da Câmara Federal) [Rêgo 2014; Monti 2012; BRASIL 2011, 2014].
Outra questão relevante que pouco é tratada na Legislação Brasileira, é a caracterização da informação como produto, ou seja, a informação é um somatório da análise de dados, que unidos sobre um determinado esquema lógico, recebe sentido, direção para um ou vários objetivos [Kielgast e Hubbard 1997; Gonçalves et al. 2008]. Assim, a informação é algo dinâmico, com a capacidade de receber valor ao seu significado primário e que pode, por si só, também agregar valor a processos e negócios.
3. Método de Pesquisa Primeiramente este estudo avaliou e construiu uma análise crítica [Marconi e Lakatos 2003] sobre os termos de uso e políticas de privacidade confrontando seus princípios e

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
141
diretrizes, garantias, direitos e deveres com a legislação brasileira. Cada aplicação foi categorizada conforme suas características e organizadas em três segmentos, sendo eles: Redes Sociais, Portal de Serviços e Comércio Eletrônico.
A segunda parte do estudo fez uso de duas estratégias de pesquisa mesclando características quantitativas e qualitativas [Barros e Souza Lehfeld 2000] para esboçar um instrumento capaz de fornecer parâmetros sobre a percepção de valor e a consciência do usuário quanto ao uso de seus dados pessoais em aplicações baseadas na nuvem.
Como o estudo está centrado em duas variáveis subjetivas, sendo elas a consciência e atribuição de valor de um bem não palpável, elaborou-se um formulário com questões quantitativas que traduz tudo aquilo que pode ser quantificável, ou seja, transformam em números as opiniões e informações para então obter a análise dos dados e, posteriormente, chegar a uma conclusão. Aliados a esta característica, um enredo sob forma de entrevista foi elaborado, pois quando se trata do sujeito, levam-se em consideração seus traços subjetivos e suas particularidades.
Para coleta de dados por meio dos questionários e entrevistas foi delimitado uma amostra com 250 pessoas com características sociais diversificadas. Toda população da amostra era residente na cidade Barra do Garças - Mato Grosso e o anonimato foi uma premissa ética observada.
4. Análises e Avaliações Preliminares Nesta seção é apresentada a síntese da análise e avaliação preliminar realizada por este estudo. Cabe ressaltar que a segunda parte da proposta deste estudo que versa sobre as estratégias de pesquisa quantitativas e qualitativas, ainda não é passível de síntese. Tão logo, não serão discutidas ou apresentadas.
O critério de seleção para as aplicações listadas na Tabela 1 foi pautado por meio de avaliações realizadas utilizando Alexa Analytic2 e o Traffic Estimate3. Estas ferramentas computam e classificam as aplicações web de acordo com número de acessos realizados por usuários. Assim, foram eleitos para análise os web site com maior número de acessos para cada segmento computados entre os meses de Maio, Junho e Julho de 2015. Posteriormente foram consideradas questões fundamentais formuladas por especialistas que debatem os problemas sobre privacidade, segurança e dados pessoais que atuam no fórum de debates do Ministério da Justiça do Governo Federal Brasileiro4 e pela EFF (Eletronic Frontier Foundation)5 uma ONG norte-americana de direitos na área digital.
Tabela 1: Web sites avaliados conforme a Categoria da Aplicação
Categoria Descrição URL
Redes Sociais Facebook www.facebook.com WhatsApp www.whatsapp.com
Twitter www.twitter.com Comércio Eletrônico Mercado Livre www.mercadolivre.com.br
Americanas www.americanas.com.br Portal de Serviços Google www.google.com
Na Tabela 2 é apresentada uma analogia utilizada entre um símbolo gráfico e o nível de satisfação utilizado para representar a qualidade do termo de uso e política de privacidade com relação a legislação e as boa práticas recomendadas. Cada questão apresentada na Tabela 3 foi analisada e avaliada conforme os critérios de sua categoria de aplicação e consequentemente fora atribuído um índice que representava o nível de satisfação alcançado. 2 http://www.alexa.com 3 http://www.trafficestimate.com 4 http://www.mj.gov.br 5 http://www.eff.org
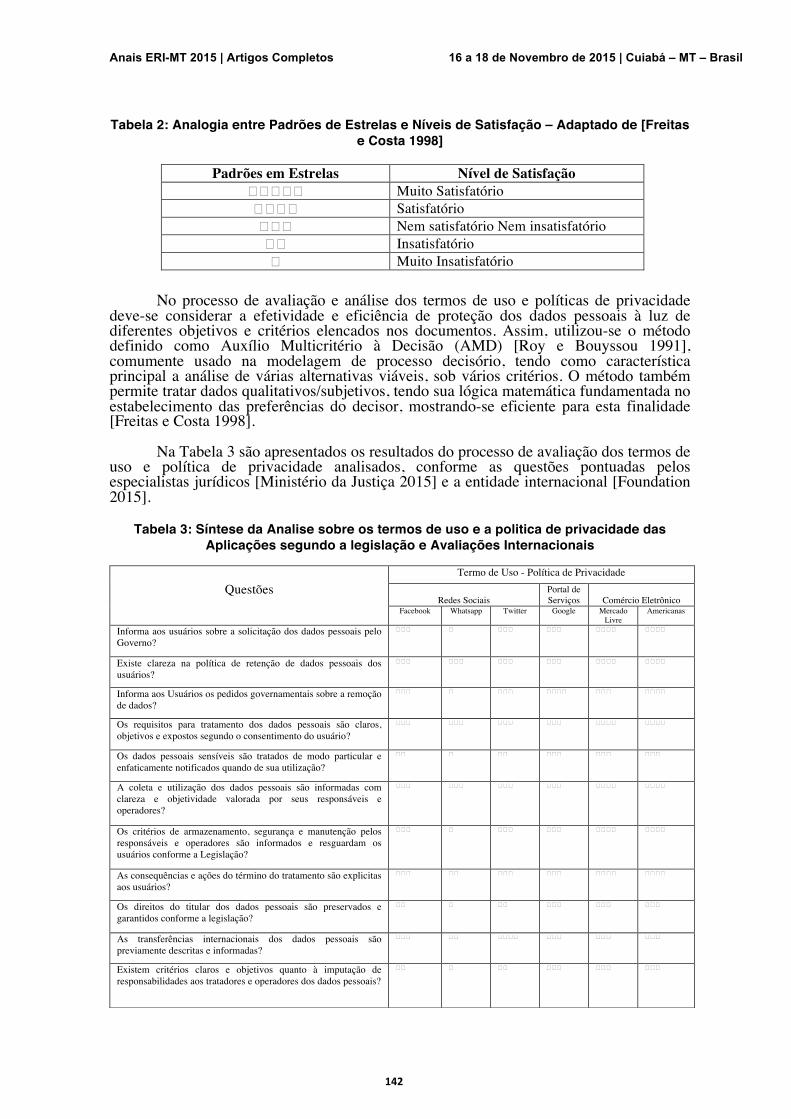
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
142
Tabela 2: Analogia entre Padrões de Estrelas e Níveis de Satisfação – Adaptado de [Freitas e Costa 1998]
Padrões em Estrelas Nível de Satisfação Muito Satisfatório Satisfatório Nem satisfatório Nem insatisfatório Insatisfatório Muito Insatisfatório
No processo de avaliação e análise dos termos de uso e políticas de privacidade deve-se considerar a efetividade e eficiência de proteção dos dados pessoais à luz de diferentes objetivos e critérios elencados nos documentos. Assim, utilizou-se o método definido como Auxílio Multicritério à Decisão (AMD) [Roy e Bouyssou 1991], comumente usado na modelagem de processo decisório, tendo como característica principal a análise de várias alternativas viáveis, sob vários critérios. O método também permite tratar dados qualitativos/subjetivos, tendo sua lógica matemática fundamentada no estabelecimento das preferências do decisor, mostrando-se eficiente para esta finalidade [Freitas e Costa 1998].
Na Tabela 3 são apresentados os resultados do processo de avaliação dos termos de uso e política de privacidade analisados, conforme as questões pontuadas pelos especialistas jurídicos [Ministério da Justiça 2015] e a entidade internacional [Foundation 2015].
Tabela 3: Síntese da Analise sobre os termos de uso e a politica de privacidade das
Aplicações segundo a legislação e Avaliações Internacionais
Questões
Termo de Uso - Política de Privacidade
Redes Sociais Portal de Serviços
Comércio Eletrônico
Facebook Whatsapp Twitter Google Mercado Livre
Americanas
Informa aos usuários sobre a solicitação dos dados pessoais pelo Governo?
Existe clareza na política de retenção de dados pessoais dos usuários?
Informa aos Usuários os pedidos governamentais sobre a remoção de dados?
Os requisitos para tratamento dos dados pessoais são claros, objetivos e expostos segundo o consentimento do usuário?
Os dados pessoais sensíveis são tratados de modo particular e enfaticamente notificados quando de sua utilização?
A coleta e utilização dos dados pessoais são informadas com clareza e objetividade valorada por seus responsáveis e operadores?
Os critérios de armazenamento, segurança e manutenção pelos responsáveis e operadores são informados e resguardam os usuários conforme a Legislação?
As consequências e ações do término do tratamento são explicitas aos usuários?
Os direitos do titular dos dados pessoais são preservados e garantidos conforme a legislação?
As transferências internacionais dos dados pessoais são previamente descritas e informadas?
Existem critérios claros e objetivos quanto à imputação de responsabilidades aos tratadores e operadores dos dados pessoais?

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
143
5. Trabalhos Relacionados Os estudos de Dhami et al. (2013) propõem uma pesquisa com preocupações voltadas para a segurança e os conceitos de privacidade como critérios de confiança para redes sociais. A pesquisa tem como objetivo compreender o impacto das preocupações com segurança, privacidade e confiança quanto ao compartilhamento de informações por usuários de redes sociais. A pesquisa concentrou sua investigação no Facebook e uma de suas conclusões é a forte relação entre confiança prévia e critérios de privacidade. Um estudo muito similar proposto por Talib et al. (2014), examina as preocupações com privacidade e consciências de uso dos dados pessoais em uma população de alunos de graduação que fazem uso do Twitter como rede social.
De acordo com Sherchan et al. (2013) a popularização das redes sociais e sua consequente capacidade de compartilhar informações, torna a confiança um elemento essencial para exploração destes serviços por empresas e governo. Assim, o estudo proposto faz um levantamento na literatura sobre as definições de confiança e tenta aplicar estes conceitos ao definir a confiança social no contexto das redes sociais.
6. Conclusões e Trabalhos Futuros Por meio das análises e avaliações parciais realizadas, tendo em vista que os resultados apresentados correspondem apenas a uma parte do trabalho, já foi possível estabelecer o que a literatura já vem afirmando quanto a fragilidade e a falta de compromisso dos responsáveis legais pelas aplicações que fazem uso de dados pessoais de seus usuários.
No estudo realizado os resultados preliminares demonstram que as aplicações na categoria de Rede Sociais possuem as maiores fragilidades e necessidades de adequações com a legislação e boas práticas quanto aos critérios de confiança social. Um agravante a esta constatação está diretamente relacionada com o volume crescente de usuários e o enorme tráfego e compartilhamento de informações presentes nestas aplicações. Ainda é possível afirmar que apesar da literatura já tratar com devida ênfase os problemas de privacidade, consciência e valor dos dados pessoais em Redes Sociais, poucos estudos abordam essa problemática em outras categorias de aplicações (i.e. Comércio Eletrônico e Portais de Serviços). Nota-se também que as aplicações na categoria de comércio Eletrônico possuem termos de uso e políticas de privacidades em maior sintonia com a legislação e com os critérios de privacidade dos dados de seus usuários. Por tratarem de relações de consumo de bens físicos estas soluções estão sujeitas a fiscalizações e intervenções de agências reguladoras (i.e. PROCON), o que de certo modo favorece aos usuários.
Já na categoria de Portais de Serviços, a Google com seu cluster de aplicações acaba por omitir muitos detalhes técnicos e jurídicos de seus usuários. Uma característica dos termos de uso e políticas de privacidade adotados pela Google é que encontra-se em seus documentos com muita clareza as cláusulas de sessão dos dados pessoais do usuários, porém existem informações dúbias e com pouco detalhes técnicos de como estes dados serão utilizados e até que ponto estes dados são coletados.
Esta primeira parte do estudo foi fundamental para elaboração dos instrumentos aplicados aos usuários, pois direcionou o enfoque da pesquisa eliminando possíveis vieses na definição dos critérios e questionamentos. Assim, as tarefas futuras estão concentradas na coleta dos dados da população definida e sua consequente tabulação. Estes dados possibilitarão estabelecer com clareza a consciência dos usuários e qual valor de seus
O termo de segurança e sigilo dos dados descrevem as medidas técnicas e administrativas sobre os cuidados e proteções adotados?
O termo de uso e a política de privacidade estão de acordo com as boas práticas nacionais e internacionais sobre o uso de dados pessoais?
O termo de uso e a política de privacidade estão de acordo com Marco Civil e a Lei de acesso a Informação?
Existem referências e orientações aos usuários quanto a Legislação e o termo de uso e políticas de privacidade dos dados pessoais?

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
144
dados pessoais, apontando também as fragilidades da legislação, usuários e aplicações. Referências Barros, A. J. P.; Souza Lehfeld, N. A. (2000). Fundamentos de metodologia: um guia para
a iniciação cientıfica. Makron Books, São Paulo, 2 edição. BRASIL (2011). Lei No. 12.527, De 18 De Novembro DE 2011. Diário Oficial da União. BRASIL (2014). Lei No. 12.965, De 23 De Abril De 2014. Diário Oficial da União. Dhami, A.; Agarwal, N.; Chakraborty, T., Singh, B., Minj, J. (2013). Impact of trust,
security and privacy concerns in social networking. (IACC), 2013, IEEE, pages 465–469.
Dhawan, S.; Singh, K.; Goel, S. (2014). Impact of privacy attitude, concern and awareness on use of online social networking. (Confluence), 2014, 5th International Conference,pages 14–17.
Rêgo, V. (2014). Projeto de lei do senado no. 181 de 2014. acessado em: Maio, 2015. Foundation, E. F. (2015). Who has your back? protecting your data from government
request. acessado em: Junho, 2015. Freitas, A. L. P.; Costa, H. G. (1998). Avaliação e classificação da qualidade de serviços
utilizando uma abordagem multicritério. Gestão & Produção, 5:272 – 283. Gonçalves, M. R.; Gouveia, S. M.; Petinari, V. S. (2008). A informação como produto de
alto valor no mundo dos negócios. Revista CRB-8 Digital, Vol. 1:43–54. Kielgast, S.; Hubbard, B. A. (1997). Valor agregado à informação. Ciência da Informação,
26. Lang, M.; Devitt, J.; Kelly, S.; Kinneen, A.; O’Malley, J.; Prunty, D. (2009). Social
networking and personal data security: A study of attitudes and public awareness in ireland. In Management of e-Commerce and e-Government, 2009. ICMECG ’09. pages 486–490.
Li, J. (2014). Data protection in healthcare social networks. Software, IEEE, 31(1):46–53. Marconi, M.; Lakatos, E. (2003). Fundamentos de metodologia científica. Atlas Editora. Ministério da Justiça (2015). Proteção de dados pessoais. Acessado em: Maio, 2015. Monti, M. (2012). Projeto de lei 4060 de 2012. Acessado em: Maio, 2015. Roy, B.; Bouyssou, D. (1991). Decision aid: An elementary introduction with emphasis on multicriteria.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
145
Avaliação de um Conjunto de Dados Quanto à sua Qualidade na Especificação de Perfis de Ataque e Não-Ataque Numa
Rede IEEE 802.11w
Rodrigo Fonseca de Moraes1, Nelcileno Virgílio de Souza Araújo1, Cristiano Maciel1
1Instituto de Computação – Universidade Federal de Mato Grosso (UFMT)
Av. Fernando Corrêa da Costa, nº 2367 - Bairro Boa Esperança. Cuiabá-MT/ 78060-900
[email protected], [email protected], [email protected]
Abstract. The objective of this study was to evaluate a set of data through three recognition patterns algorithms to assess the quality of this base to define attack profiles and non-attack on a Wi-Fi network with IEEE 802.11w implemented security amendment. An existing database was used and adapted for this work. The results show that the data set is feasible to evaluate various IDS techniques, once the records have been properly identified as being normal or a particular type of attack, except the implementation of LivSVM algorithm, which was not a good classifier.
Resumo. O objetivo deste artigo foi avaliar um conjunto de dados por meio de três algoritmos de reconhecimento padrões, para avaliar a qualidade desta base em definir perfis de ataque e não-ataque em uma rede Wi-Fi com a emenda de segurança IEEE 802.11w implementada. Foi utilizada uma base de dados já existente e adaptada para este trabalho. Os resultados mostram que o conjunto de dados é viável para avaliar diversas técnicas IDS, uma vez que os registros foram adequadamente identificados como sendo normal ou de um determinado tipo de ataque, exceto com a implementação do algoritmo LivSVM, que não foi um bom classificador.
1. Introdução O padrão de redes sem fio mais utilizado, atualmente, é a norma Institute of Eletronic and Eletrical Enginers nº 802.11 - IEEE 802.11 [IEEE, 1999]. Apesar de sua ampla utilização, existem relatos de falhas em relação a seus mecanismos de segurança, o que representa um importante desafio a ser solucionado em relação a este tipo de padrão. Dentre as várias atualizações de segurança para este padrão está a emenda de segurança IEEE 802.11w, apresentada em 2009 [IEEE, 2009]. Esta emenda contempla proteção a alguns quadros de gerenciamento, como o Beacon and Probe Request/Response, Authentication and De-authentication, possibilitando a troca destes quadros de forma segura [AHAMAD; TADAKAMADLA, 2011], o mesmo não ocorrendo para quadros de controle. Para explorar as vulnerabilidades das redes sem fio utiliza-se ataques de negação de serviço (Denial of Service – DoS), que tem o objetivo de afetar a disponibilidade de recursos e serviços da rede [SANDSTROM, 2001]. No caso do padrão IEEE 802.11w, é

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
146
explorado a ausência de proteção aos quadros de controle. No Quadro 1 estão apresentados os tipos de ataque utilizados neste estudo.
Quadro 1. Tipos de ataque.
Beacon Flood Deauthentication Request-to-Send (RTS) Flood,
Extensible Authentication Protocol (EAP) over LAN (EAPoL-Start)
Quadro do tipo gerenciamento, onde milhões de beacons ilegítimos são transmitidos para dificultar que uma máquina identifique um AP legítimo. Este quadro ajuda as estações na localização do Basic Service Set (BSS - Grupo de Serviço Básico) (PLÓSZ et al., 2014). Quadro de gerenciamento inoculado na rede e enviado como pedidos fictícios para desautenticar um cliente autêntico (BELLARDO; SAVAGE, 2003). Quadro tipo controle. O adversário envia em um curto período de tempo uma grande quantidade de frames RTS, o que ocasiona o congestionamento de reservas do canal sem fio, e por sua vez, a negação do serviço aos demais hosts que estiverem na WLAN (LI; JOSHI; FININ, 2013). Envia uma carga excessiva de frames EAPOL-Start, que sobrecarrega o AP, tirando-o do serviço (SPERTI et al., 2013).
Os Sistemas de Detecção de Intrusos [IDS] possuem a função de combater os ataques de DoS nas redes sem fio, possibilitando a redução de incidentes ocasionados por eles nas redes, e atuam tanto baseado em assinatura, analisando o tráfego monitorado a partir de um conjunto de assinaturas de ataque, quanto baseado em anomalia, construindo modelos de comportamento normal que caracteriza como evento intrusivo todo tráfego que difere deste modelo. Portanto, o principal objetivo do IDS é identificar eventos anômalos, sem comprometer o funcionamento da rede (WU; BANZHAF, 2010).
Neste artigo procurou-se avaliar a qualidade de uma base de dados em definir perfis de ataque e não-ataque em uma rede Wi-Fi com a emenda de segurança IEEE 802.11w implementada, e para isso utilizou-se três algoritmos de reconhecimento padrões.
2. Material e métodos Foi utilizada uma base de dados previamente construída por Vilela (2014) e adaptada para este estudo. Para a construção deste conjunto de dados, Vilela (2014) implementou um cenário de rede sem fio acadêmica com a emenda de segurança IEEE 802.11w habilitada. A distribuição do conjunto de dados do autor está apresentada na Tabela 1.
Tabela 1. Distribuição das amostras/ameaças no conjunto de dados original
Classe Conjunto de dados Normal 10886309 Deauthentication 323976 Beaconflood 545481 EAPOL-Start 539692 RTS flood 2113

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
147
Total 12297571 Por questões de capacidade computacional, o arquivo original [VILELA, 2014]
de 12 (doze) milhões de linhas, sendo que cada linha representa a leitura de uma tentativa de ataque, foi inicialmente dividido em diversos arquivos de 400 (quatrocentas) mil linhas (tamanho máximo suportado pela máquina utilizada neste estudo). Posteriormente, de forma aleatória, estes arquivos foram tratados no Waikato Environment for Knowledge Analysis (WEKA) de forma a obter um arquivo que apresentasse ocorrências para todos os ataques. Este conjunto, portanto, apresenta tráfego normal e tráfego oriundo de ataques. Foram utilizados 75% da base para treinamento e 25% para teste. A quantidade de registros utilizados neste estudo está apresentada na Tabela 2.
Tabela2.Distribuiçãodasamostras/ameaçasnoconjuntodedados.
Tipo Conjunto de dados de Vilela [2014] Contagem Normal 10.886.309 239.605
BeaconFlood 323.976 10.787 EAPOLStart 545.481 6.648
Deauthentication 539.692 141.894 RTSFlood 2.113 1.066
Total de amostras 12.297.571 400.000 No presente estudo, utilizou-se a ferramenta Weka para avaliar o conjunto dados
de Vilela (2014) pelo emprego de algoritmos de classificação e reconhecimento de padrões para verificar a qualidade desta base em definir perfis de ataque e não-ataque em uma rede WIFI com a emenda de segurança IEEE 802.11w implementada. Não se realizou nenhuma customização de parâmetros no Weka, portanto todas as análises foram efetuadas com os valores default. Utilizou-se um computador INTEL® com processador Core ™ i5-3210m 2.5GHz, com 6GB de memória RAM com pentes DDR3 de 1333MHz e sistema operacional Windows 8.1Pró, arquitetura de 64 bits.
O algoritmo IBk é um algorítmo baseado em instâncias, utilizado para implementar tarefas de clusterização por classificação e regressão. É uma versão do método de clusterização k- nearest neighbor (K-NN). Este método considera cada instância um ponto de dados em um espaço d-dimensional (d = número de atributos). A cada instância ele calcula sua proximidade com os demais pontos de dados do conjunto por meio de medidas de proximidade, como a distância euclidiana, e classifica os K vizinhos mais próximos de uma dada instância z como pertencentes à mesma classe de z. É um algoritmo simples que tem sido frequentemente empregada em propostas de IDS [OM; KUNDU, 2012].
Já o algoritmo J48 é uma implementação em Java do algoritmo C4.5 no programa Weka e está baseado em classificadores de árvores de decisão. As árvores de decisão possuem o princípio de agrupar instâncias de forma recursiva, com isso minimizando a variabilidade das classes dentro dos grupos (entropia), desta forma, a cada nó, o algoritmo escolhe o atributo que subdivide o conjunto das amostras em subconjuntos homogêneos e caracterizados por sua classe da forma mais eficiente. Isto é feito por meio da deposição de atributos de nós não folha em nós folha pelos algoritmos desse tipo. Cada nó interno corresponde a uma decisão de classificação. O J48 consegue processar atributos de qualquer tipo, diferente dos demais tipos de algoritmos baseados em árvores. Eles, no entanto, desempenham apenas papel de classificador, não realizando regressão, logo os atributos das classes devem ser discretos [NAGLE;

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
148
CHATURVEDI, 2013; HALL et al., 2009].
Em relação ao LibSVM, este configura-se como uma biblioteca de implementações de Support Vector Machines (SVM) com a finalidade de realizar várias tarefas de reconhecimento de padrões, como classificação, a regressão e a estimativa de distribuição [ALMEIDA, 2010]. As SVM baseiam-se na teoria de aprendizado estatístico. Considerando um conjunto de dados as SVM predizem para novas entradas de dados, a classe à qual as novas entradas pertencem. Possuem boa generalização, ou seja, são capazes de prever corretamente a classe de novos dados do mesmo domínio em que o aprendizado ocorreu [LORENA; CARVALHO, 2007].
Para avaliar a capacidade da base de dados criada por Vilela (2014) em definir perfis de ataque e não ataque, foram escolhidos três métricas de medidas de erro: erro médio absoluto, erro quadrático médio e o coeficiente Kappa.
O erro médio absoluto (EMA) corresponde à média da diferença entre valores reais e calculados de um dado conjunto de dados. Os valores mais próximos de zero indicam que ocorreu melhor classificação. O erro quadrático médio (EQM), por sua vez, corresponde à média do quadrado do erro. Em geral o processo de estimação consiste em escolher o estimador que apresente o menor erro quadrático médio. O coeficiente Kappa é uma métrica utilizada para medir o grau de concordância entre duas medidas. Valores mais próximos de um [01] indicam ótima concordância ou classificação correta, enquanto que valores mais próximos de zero indicam que a classificação se deu ao acaso [FERREIRA, 2014].
3. Resultados e discussão A partir das análises realizadas e apresentadas na Tabela 3,pode-se deduzir com base nos valores relativamente baixos dos EMA e EQM que os classificadores escolhidos funcionaram bem no conjunto de dados do estudo. Os resultados da Classificação Correta e do Coeficiente Kappa foram aceitáveis, apesar de baixos, para os classificadores J48 e IBk. Portanto, pode-se observar que, ao se implementar os algoritmos IBk e J48 a base de dados utilizada neste estudo foi capaz de definir melhor os perfis de ataque do que a partir da implementação de LibSVM. Assim, para este algoritmo, os registros desta base foram pouco significativos para a descrição de perfis de ataque e não ataque.
Tabela 3. Avaliação da base de dados de Vilela [2014] na representação de perfis [ataque e normal] em redes IEEE 802.11w.
Algoritmo Erro Médio Absoluto
Erro Quadrático Médio
Classificação Correta [%]
Coeficiente Kappa
IBk 0.1354 0.2602 72.34 0.5055 J48 0.1357 0.2605 72.34 0.5055 LibSVM 0.2021 0.4496 49.46 0.2567
O Gráfico 1 apresenta os resultados obtidos a partir da utilização dos algoritmos de classificação e de reconhecimento de padrões IBk, J48 e LibSVM, no conjunto de dados utilizados neste estudo, em situações de tráfego normal e sob a implementação de diferentes ataques em uma rede com emenda IEEE 802.11w implementada.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
149
Gráfico 1. Precisão dos ataques do conjunto de dados com a emenda IEEE 802.11w implementada.
Pode-se observar que em situações de tráfego normal dos dados, os algoritmos J48 e IBk apresentaram igual precisão (92,7%), isto é, igual capacidade em identificar padrões. A precisão de todos os algoritmos foi considerada boa (> 70%).
Ao se implementar os ataques, o comportamento dos algoritmos foi bastante diferenciado em cada ataque. O ataque Beacon Flood, que ataca quadros de gerenciamento, foi o pior caracterizado por todos os algoritmos. Outro ataque aos quadros de gerenciamento é realizado pelo ataque Deauthentication. Nenhum algoritmo testado apresentou boa precisão para este tipo de ataque, mas os resultados foram melhores do que os obtidos para o ataque Beacon Flood.
O ataque RTS Flood, que ataca os quadros de controle, foi bem caracterizado por este conjunto de dados, obtendo precisão de aproximadamente 100% para todos os algoritmos. Isto pode ser explicado pelo fato de a emenda de segurança implementada no conjunto de dados apresentar falha de segurança contra este tipo de ataque.
Estes resultados estão de acordo com os apresentados na Tabela 3, onde pode-se perceber pela estatística kappa que os algoritmos J48 e IBk foram os que apresentaram melhores resultados de concordância, embora tenham sido baixos.
Os resultados mostram que o conjunto de dados proposto é viável para avaliar diversas técnicas IDS, uma vez que os registros foram adequadamente identificados como sendo normal ou de um determinado tipo de ataque, exceto com a implementação do algoritmo LivSVM, que não foi um bom classificador neste conjunto de dados.
Os resultados para o Coeficiente Kappa seguiram a mesma tendência que os resultados de classificação correta, confirmando a integridade dos dados.
4. Conclusão Os algoritmos IBk e J48 apresentaram resultados semelhantes de classificação e se mostraram melhores do que o algoritmo LibSVM. Foram capazes de definir melhor os perfis de ataque dos quadros de controle como o RTS Flood e também foram bons classificadores para o ataque EAPOL Start.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
150
Sugere-se que esta é uma base de dados viável para ser utilizada na avaliação de técnicas de IDS, embora tenha apresentado péssima caracterização do perfil Beacon Flood. Porém isto pode estar relacionado ao fato de este perfil ser parecido com o perfil normal, portanto, qualquer algoritmo utilizado apresentaria resultados insatisfatórios. É válido ressaltar que a formação deste conjunto de dados a partir dos dados de Vilela (2014) pode ter interferido no desempenho dos algoritmos na avaliação de alguns perfis de ataque, uma vez que esta base de dados não apresenta a mesma proporção de amostras que o conjunto original.
Referências Ferreira, E. T. (2014) “Utilização do coeficiente kappa para avaliar algoritmos de
classificação para uso em sistemas de detecção de intrusos em redes sem fio”, Jornada de Pesquisa e Extensão do Instituto Federal de Educação, Ciência e Tecnologia. Mato Grosso, 2014.
Hall, M.et al. (2009) “The WEKA Data Mining Software: an update; SIGKDD Explorations Newsletter”, v.11, n.1, p.10-18.
IEEE Std 802.11 TM (1999): wireless LAN medium access control [MAC] and physical layer [PHY]. Piscataway: IEEE, 1999. 1184 p. [Specification, 1999].
IEEE Std IEEE 802.11wTM (2009): wireless LAN medium access control [MAC] and physical layer [PHY]: Protected Management Frames. Piscataway: IEEE, 2009. 91 p.
Li, W.; Joshi, A.; Finin, T. (2013)“Cast: context-aware security and trust framework for mobile ad-hoc networks using policies”, Distributed and Parallel Databases, New York. v. 31, n. 2,p. 353-376.
Lorena, A.C.; Carvalho, A. C. P. L. F. (2007) “Uma Introdução às Support Vector Machines”, RITA, v.14, n.2.
Nagle, Manish Kumar; CHATURVEDI, Setu Kumar. (2013) “Feature Extraction Based Classification Technique for Intrusion Detection System”, International Journal of Engineering Research and Development, v. 8, n. 2, p. 23–38.
Shiravi, A.; Shiravi, H.; Tavallaee, M. Ghorbani, A. A. (2012)“Toward developing a systematic approach to generate benchmark datasets for intrusion detection”, Computers & Security, New Brunswick, Canada, v. 31, n. 3, p. 357-374.
Sommer, R.; Paxson, V. (2010 ) “Out side the closed world: on using machine learning for network intrusion detection”. In: IEEE SYMPOSIUM ON SECURITY AND PRIVACY (SP), 2010, Berkeley. Symposium... Berkeley: IEEE, 2010. p. 305-316.
Vilela, D.W.F.L. (2014)“Segurança em redes sem fio: estudo sobre o desenvolvimento de conjuntos de dados para comparação de IDS”. Dissertação [mestrado] - Universidade Estadual Paulista. Faculdade de Engenharia de Ilha Solteira. Ilha Solteira: [s.n.],.
Wu, S. X.; Banzhaf, W. (2010) “The use of computational intelligence in intrusion detection systems: a review”, Applied Soft Computing, New York, v. 10, n. 1, 35 p., Jan.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
151
Utilizando o transceptor NRF24L01 em redes de sensores sem fio operando sobre TCP/IP
Evaldo J. Klock Neto, Mauricio F. Lima Pereira, Roberto B. de Oliveira Pereira
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Cuiabá – MT – Brasil
[email protected], [email protected], [email protected]
Abstract. This article discusses the application of the concepts of Wireless Sensor Networks (WSN) low cost and low energy consumption, using the Wireless transceiver NRF24L01 manufactured by Nordic Semiconductor. The paper presents and describes the use of libraries RF24 the operation of the device on the TCP / IP protocol. This helps reduce costs while maintaining compatibility of the WSN with conventional Ethernet network devices. Shipping packages were tested between the 3 of us and the gateway with distances between them ranging from 1 to 35 meters. Packages were sent to maximum capacity supported in- formation. After that evaluated the minimum, average and maximum response. Depending on the results it was observed that the network behaved satisfactorily. Such behavior is confirmed when comparing the results with devices that use the IP protocol with the wireless N standard, using the same pattern as the previous tests. Resumo. Este artigo aborda a aplicação dos conceitos das Redes de Sensores Sem Fio (RSSF) de baixo custo e de baixo consumo energético, utilizando-se do Transceptor sem fio NRF24L01 fabricado pela Nordic Semiconductor. O trabalho apresenta e descreve o uso das bibliotecas RF24 na operação deste dispositivo sobre o protocolo TCP/IP. Isso ajuda a reduzir custos mantendo a compatibilidade das RSSF com os dispositivos convencionais de redes Ethernet. Foram testados envios de pacotes entre os 3 nós e o gateway com distâncias entre eles variando de 1 a 35 metros. Foram enviados pacotes a capacidade máxima de informação suportada. Depois disso avaliou-se o tempo mínimo, médio e máximo de resposta. Em função dos resultados observou-se que a rede se comportou de maneira satisfatória. Tal comportamento se confirma quando comparados os resultados com dispositivos que utilizam o protocolo IP com o padrão Wireless N, utilizando o mesmo padrão dos testes anteriores.
1. Introdução Há 21 anos Mark Weiser introduziu o conceito de computação ubíqua. Para ele os computadores deveriam estar integrados e/ou fazer parte da vida humana de uma maneira inconsciente, portanto, a computação se tornaria pervasiva na vida dos seres humanos [Weiser 1994]. Nesse cenário tais dispositivos ubíquos, em sua maioria, formam uma rede local podendo também se conectar à Internet para compartilhar informações com outros dispositivos ubíquos gerando, em um processo final, algum tipo de informação útil.
Nesse campo, as redes de sensores sem fio são dispositivos ubíquos que se utilizam desse tipo de computação/conceito. Em função dos recentes avanços nos sistemas microeletrônico-mecânicos (MEMS) as redes de sensores sem fio podem ser consideradas como uma das tecnologias mais promissoras do século 21. Tais redes são tecnologias baratas e podem ser implantadas em uma área física formando redes entre si e com a Internet. Podem ser utilizadas para uma grande variedade de aplicações, como por

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
152
exemplo, monitoramento ambiental, controle de processos industriais, sistemas de vigilância e também para os processos de automação tanto industrial quanto residencial [Zheng e Jamalipour 2009, p 1]. A segunda seção aborda aspectos e conceitos relativos as redes de sensores sem fio, ao transceptor NRF24L01 e as bibliotecas utilizadas para programá-lo. Finaliza-se a seção abordando o Arduino. A seção seguinte aborda os resultados e conclusões do trabalho.
2. Materiais e Métodos
2.1 Redes de Sensores sem Fio (RSSF) Redes de Sensores Sem Fio (RSSF), diferentemente das redes de computadores tradicio-nais, são formadas por nós distribuídos que podem ter restrições energéticas, dotados de mecanismos de autoconfiguração para lidar com problemas de falha de comunicação e perda de nós. Tais nós são compostos por sensores, microcontroladores e transmissores de rádio que se comunicam a uma curta distância, via redes de sensores sem fio [Zheng e Jamalipour 2009, Loureiro et al. 2003].
Em relação aos aspectos arquiteturais, um nó sensor pode ser constituído de estru-turas básicas (Figura 1): (i) unidade sensora; (ii) unidade de comunicação; (iii) uni- dade de processamento e a (iv) unidade de energia [Zheng e Jamalipour 2009].
Figura 1. Arquitetura Básica de um Nó Sensor [Zheng e Jamalipour 2009, p 20]
2.2 Arduino Arduino (Figura 2) é uma plataforma de prototipação de código aberto que se utiliza do conceito DIY (Do It Yourself), traduzindo do Inglês, faça você mesmo, onde o objetivo principal é o de prover a fácil utilização tanto do hardware quanto do software. A plata-forma nasceu no Interaction Design Institute como uma ferramenta de fácil prototipagem, destinada a estudantes sem conhecimento aprofundado em eletrônica e programação. Ela é capaz de ler entradas (botão pressionado, sensor de luminosidade, etc) e produzir uma saída (ligar um motor, acender um LED, enviar alguma informação a determinado servidor, etc.) [Arduino 2015, Banzi 2008].
Figura 2. Placa de Prototipação Arduino UNO [Arduino 2015]
2.3 Transceptor NRF24L01
O NRF24L01 (Figura 3) é um transceptor 2.4 Ghz integrado de baixo consumo energéti-

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
153
co que opera na banda de frequência ISM (Industrial, Scientific and Medical), possui um alcance que pode variar de 100 m até 1000 m, com o uso de antenas e uma taxa de transmissão de até 2 Mbps, utiliza a interface SPI como via de comunicação, possui picos de tensão menores que 14mA nos modos TX/RX, gerenciamento avançado de energia podendo operar nos intervalos de 1.9 a 3.6V. O NRF24L01 oferece uma solução ULP (Ultra Low Power) que permite gerenciar o consumo de energia resultando em um baixo consumo e aumento da autonomia energética [Semiconductor 2007].
Figura 3. Transceptor NRF24L01 [Semiconductor 2007]
2.4 Bibliotecas RF24 A biblioteca RF24Ethernet foi criada como uma ferramenta de teste para uma outra biblioteca, a RF24Network que opera sobre Camada 3 do modelo de referencia OSI, responsável pelo roteamento controle de tráfego de sub-rede, mapeamento do endereço físico para o lógico e fragmentação de quadros para transmissão. A biblioteca utiliza a pilha uIP que possibilita a criação de uma rede baseada no protocolo TCP/IP utilizando-se do transceptor NRF24L01, juntamente com as plataformas de prototipação baseadas em Arduino. Ela fornece uma interface muito semelhante à biblioteca Arduino Ethernet, permitindo que dispositivos locais ou remotos se conectem aos nós sensores para enviar ou receber informações.
Os nós também podem agir como servidores Web individuais, servidores de controle simples ou até estabelecer conexões via TCP/IP. Os endereços RF24Network são atribuídos com endereços MAC e os endereços IP podem ser configurados de acordo com os critérios do usuário. O nó mestre, para fazer o mapeamento de endereços IP com os endereços de Hardware, pode utilizar tanto ARP (Address Resolution Protocol) quanto o RF24Mesh (uma biblioteca que permite a criação de redes “Mesh” com os transceptores NRF24L01). A biblioteca RF24Gateway também pode ser utilizada para a criação de um Gateway entre a rede de sensores com a internet ou ser utilizada como um repositório de informação, utilizando, por exemplo, uma plataforma de prototipação mais robusta, como: Raspberry Pi, Intel Galileo e entre outras [TMRh20 2015].
2.5 Organização da Arquitetura da RSSF Para mostrarmos a construção da RSSF operando sobre TCP/IP, assim como seu potencial e escalabilidade, organizaremos uma arquitetura rede composta de 3 Nós (Figura 4) utilizando os seguintes componentes:
• Primeiro Nó (Raspberry PI (Rpi) + Transceptor NRF2401) - O Rpi terá o papel de rotear as conexões para os endereços IP destino dos outros nós. Ele utilizará a biblioteca RF24Gateway e terá o endereço IP 10.10.2.2;
• Segundo Nó (Plataforma de Prototipação Arduino Uno + Transceptor NRF24L01) - Esse nó utilizará a biblioteca RF24Ethernet e terá o endereço IP 10.10.2.3;

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
154
• Terceiro Nó Terceiro Nó (Plataforma de Prototipação Arduino Uno + Transceptor NRF24L01) - Esse nó utilizará a biblioteca RF24Ethernet e terá o endereço IP 10.10.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
155
Figura 4. Organização da Arquitetura da RSSF
3. Resultados A rede foi instalada em um ambiente a uma temperatura de 29º Celsius. Para validação de desempenho da Arquitetura da RSSF, foram realizados 3 testes de ping, onde o nó Gateway envia pacotes aos nós 2 e 3. No primeiro teste, foram enviados 80 pacotes de 124 bytes (Tamanho máximo de pacotes suportado pelas bibliotecas RF24) a uma distância de 1m do nó Gateway (Primeiro teste), 10m do nó Gateway (Segundo teste), e 35m (Terceiro teste). Foi observada uma taxa de transmissão/recepção máxima de 0.144 KB/s e um percentual de perda de pacotes de 0% nos nós da arquitetura. Para efeito de comparação também são feitos os mesmos testes em um dispositivo que utiliza o padrão Wireless N.
3.1 Teste Nº 1 - 80 pacotes de 124 bytes - 1m de distância do Gateway
Conforme a Figura 5, foram observados, para o nó 2, os tempos mínimo, médio e má-ximo de resposta, respectivamente de: 14.821 ms, 15.201 ms e 15.868 ms. Para o nó 3, foram observados os tempos mínimo, médio e máximo de resposta, respectivamente de: 14.818 ms, 15.159 ms e 15.688 ms.
Figura 5. Tempos de resposta para 1m de distância do gateway
3.2 Teste Nº 2 - 80 pacotes de 124 bytes - 10m de distância do Gateway Conforme a Figura 6, foram observados, para o nó 2, os tempos mínimo, médio e máximo de resposta, respectivamente, de: 14.789 ms, 15.174 ms e 19.335 ms. Para o nó 3, foram observados os tempos mínimo, médio e máximo de resposta, respectivamente, de: 14.852 ms, 15.411 ms e 17.234 ms.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
156
Figura 6. Tempos de resposta para 10m de distância do gateway
3.3 Teste Nº 3 - 80 pacotes de 124 bytes - 35m de distância do Gateway Conforme a Figura 7, foram observados, para o nó 2, os tempos mínimo, médio e máximo de resposta, respectivamente, de: 16.834 ms, 16.299 ms e 20.014 ms. Para o nó 3, foram observados os tempos mínimo, médio e máximo de resposta, respectivamente, de: 16.794 ms, 15.875 ms e 19.855 ms.
Figura 7. Tempos de resposta para 10m de distância do gateway
4. Conclusão Conclui-se que o transceptor NRF24L01 é adequado ao uso em aplicações no campo devido ao baixo consumo de energia quando comparado a outros transceptores. O estudo mostrou a possibilidade de implementação de redes de sensores sem fio operando sobre TCP/IP a partir das bibliotecas RF24. Em função dos resultados observou-se que a rede se comportou de maneira satisfatória. Devido à natureza da aplicação, onde o fluxo de dados é pequeno e existem restrições de fonte de alimentação, ainda que o dispositivo Wireless N tenha um melhor desempenho, o NRF24L01 entrega a informação em um tempo satisfatório.
Podemos esperar resultados ainda mais satisfatórios, no quesito de desempenho da rede, se utilizarmos antenas nos transceptores para aumentarmos o ganho de sinal, visto que nos testes utilizamos apenas as antenas internas dos transceptores e por fim podemos notar a escalabilidade de utilização dos dispositivos abordados em aplicações mais robustas, coleta de dados de sensores, por exemplo.
Agradecimentos Os autores agradecem à FAPEMAT (Processo 749775/2011) pelo apoio ao projeto.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
157
Referências Arduino (2015). What is arduino? Disponível em <https://www.arduino.cc/en/Guide/
Introduction> Banzi, M. (2008). Getting Started with Arduino. Make Books - Imprint of: O’Reilly
Media, Sebastopol, CA, ill edition. Loureiro, A. A.; Nogueira, J. M. S.; Ruiz, L. B.; Mini, R. A. d. F.; Nakamura, E. F.;
Figueiredo, C. M. S. (2003). Redes de sensores sem fio. In Simpósio Brasileiro de Redes de Computadores (SBRC), pp. 179–226.
Semiconductor, N. (2007). nrf24l01 single chip 2.4 ghz transceiver product spe-cification. Disponível em <http://www.nordicsemi.com/eng/Products/2.4GHz-RF/ nRF24L01>
TMRh20 (2015). Rf24ethernet - tcp/ip over rf24network. Disponível em <http://tmrh20.github. io/RF24Ethernet/>
Weiser, M. (1994). The world is not a desktop. Disponível em <http://doi.acm.org/10.1145/ 174800.174801>
Zheng, J.; Jamalipour, A. (2009). Wireless sensor networks: a networking perspective. John Wiley & Sons.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
158
Arquitetura de Rede de Sensores para Uso de Sensores Heterogêneos, Móveis e de Aplicação Genérica
Adriel Maycon Shepard Silva1, Ivairton Monteiro Santos1
1Universidade Federal de Mato Grosso (UFMT) – Campus Universitário do Araguaia – Instituto de Ciências Exatas e da Terra – Barra do Garças – MT – Brasil
[email protected], [email protected]
Abstract. This paper proposes an architecture to wireless sensor network systems, using a hydric environment-monitoring context as an application reference. The main characteristic of architecture is the capability to append new sensors, with new functionalities, without reconfigure the control system. This way, the system improve the wireless sensor network use, considering the possibility to use heterogeneous and mobile sensor nodes. A prototype was developed to proof of concepts and the results showed a proper functioning.
Resumo. Este artigo propõe uma arquitetura para um sistema de redes de sensores sem fio, usando como referência um contexto de aplicação de monitoramento de ambientes hídricos. A principal característica da arquitetura é a capacidade de permitir a adição novos sensores, com novas funcionalidades, sem a necessidade de alterar o sistema de controle. Dessa forma, o sistema facilita o emprego de redes de sensores com nós heterogêneos e também está preparado para utilização de nós sensores móveis. Um protótipo foi desenvolvido como prova de conceito e os resultados demonstraram um funcionamento adequado.
1. Introdução As Redes de Sensores Sem Fio (RSSF) (AKYILDIZ, et al., 2002) são redes ad hoc, com aplicação em contextos específicos. Por essa razão têm desenvolvimento orientado ao contexto, o que limita sua aplicação e eleva custos. Dessa forma, na mudança de requisitos do sistema, ou mudança de aplicação, o sistema se torna inadequado, o que geralmente exige uma reestruturação e reprogramação. Este trabalho propõe uma arquitetura com o objetivo de generalizar parcialmente a aplicação de RSSF. Busca tornar a reutilização mais simples, em especial para que o sistema esteja preparado para a utilização de qualquer tipo de sensor. Assim, possibilita o emprego de nós sensores heterogêneos e/ou móveis, sem a necessidade de adaptação do sistema lógico computacional. Será apresentada a arquitetura usando como referência um contexto de aplicação de monitoramento hídrico ambiental. Além disso, será discutido o funcionamento do protocolo de roteamento de dados, bem como os resultados obtidos com a implementação de um protótipo.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
159
2. Arquitetura do sistema Geralmente uma aplicação de RSSF tem uma rígida configuração de hardware e software, atendendo de maneira específica a aplicação a que a rede de sensores se destina. Uma mudança de contexto implica em uma readequação dessa rede para atender aos novos requisitos (Hill, et al., 2004). Diferentes iniciativas têm sido lançadas com o objetivo de ampliar a generalização da utilização das RSSF (CAO, 2014), mesmo que conceitualmente isso possa contrariar a definição original das redes de sensores. Essa generalização sofre alguns limites, em razão da grande diversidade de problemas e seus requisitos. Dessa forma, alguns contextos de aplicação devem ser levados em consideração como delimitadores. Este trabalho utiliza como referência o contexto de sistemas de monitoramento hídrico. As RSSF têm potencial de utilização nesse tipo de aplicação, especialmente pela possibilidade de monitorar continuamente locais remotos, garantir o registro de uma série histórica consistente, utilizar diferentes tipos de sensores, entre outros benefícios. Entretanto, dependendo do projeto de monitoramento, do local, ou mesmo época do ano, a maneira como a rede de sensores será configurada pode mudar. Esse tipo de situação pode acarretar uma série de mudanças lógicas na configuração da rede de sensores. É nesse sentido que este trabalho propõe uma arquitetura organizacional, minimizando as mudanças lógicas necessárias e ampliando os contextos de aplicação da RSSF. Por exemplo, um desafio comum é ajustar o sistema para a inclusão de um novo tipo de sensor, sabendo que diferentes sensores fornecem dados em padrões diferentes (intervalo, grandeza, precisão, etc). Dessa maneira, a arquitetura deve ser capaz de registrar os diferentes tipos de sensores, bem como o tipo de dado e a maneira como esses dados (registrados pelos sensores) devem ser manipulados. A Figura 1 ilustra a arquitetura do sistema, composta pelos componentes RSSF, nó sorvedouro (sink), servidor e base de dados. Além do protocolo de comunicação que permite a generalização de sensores.
Figura 1 - Arquitetura do sistema.
O funcionamento da RSSF ocorre da forma clássica, os dados são registrados pelos nós sensores e enviados para o nó sink, que entrega para o servidor onde os dados serão persistidos (obedecendo a um protocolo de comunicação específico). No entanto, nesta proposta há uma readequação na organização lógica do sistema, gerenciada pelo

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
160
servidor. Todos os tipos de sensores empregados na rede são registrados e armazenados na base de dados. Dessa forma, sensores diferentes são tratados de maneira diferente, especialmente pela informação de como os dados coletados pelo sensor devem ser processados (a função que deve ser aplicada).
A Figura 2 apresenta o DER da base de dados. Observa-se duas características importantes: a primeira é o registro da coordenada geográfica do nó sensor e dos dados enviados pelo nó. Isso é necessário em razão dos contextos onde os nós sensores são móveis; a segunda está relacionada com o método de tratamento dos dados, informações a respeito do tipo do sensor (tabela TipoDado).
Figura 2 - DER da base de dados do sistema.
Cada nó sensor envia o dado bruto, sem nenhum tipo de processamento. Quando este dado chega ao servidor o sistema verifica qual é o tipo do dado por meio de um identificador e determina, de acordo com os registros na base de dados, qual é o processamento (função) que deve ser aplicada, então processa e registra. O sistema é dependente da base de dados, pois não apenas os dados são armazenados na base, mas também o método de como esses dados devem ser processados. O processo de identificação do tipo de dado obedece a um protocolo de comunicação específico, que será detalhado a seguir.
2.1 Protocolo de comunicação O sistema define um protocolo de comunicação de modo a identificar diferentes tipos de dados presentes em um pacote. Assim, um pacote será processado de tal forma que primeiro se verifica em que consiste o dado que será lido, seguido então do dado. Isso ocorre sucessivamente, até o fim do pacote. O pacote está organizado de tal maneira que o início e o fim são demarcados por um caractere especial, com função de delimitador. A Figura 3 traz um exemplo de um pacote de dados com os respectivos delimitadores, identificadores e dados. Por padrão, foi definido que o início da sequência do pacote traz o endereço do nó sensor. No exemplo, o código “9” representa a identificação que o dado a ser lido consiste do endereço do nó sensor, seguido pelo valor correspondente ao endereço (“141”). O caractere especial “_” é utilizado para delimitar o fim da sequência de bytes que compõe o dado. No exemplo, o tipo de dado subsequente (código “8”) corresponde a um dado de coordenada geográfica, fornecido pelo sensor de GPS, seguido pelo dado em si. Isso ocorre sucessivamente até o termino do pacote.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
161
Figura 3 - Exemplo de um pacote de dados e como o protocolo de comunicação padroniza e reconhece a sequência.
O sistema trabalha verificando byte a byte do pacote de dados, essa estratégia não está imune a falhas por conta de pacotes de dados corrompidos.
3. Protótipo Para prova de conceito, foi implementado um protótipo utilizando nós sensores Radiuino (baseado na arquitetura Arduino (BANZI, 2009)) (BRANQUINHO, 2011), modelo DK 102 (RADIOIT, 2012). A implementação do software embarcado nos nós sensores utiliza uma versão modificada da biblioteca RADIUINOEZRF. Essa biblioteca implementa as funções básicas para comunicação entre módulos DK 102, no entanto apresenta uma limitação na comunicação em broadcast. Uma modificação foi implementada no intuito de superar essa limitação e permitir a comunicação irrestrita entre os nós sensores no modo broadcast. O software implementado para os nós sensores foi escrito em linguagem C, usando o ambiente de desenvolvimento Arduino versão 1.0.6, com suporte à placa BE900 (3.3V, 8 MHz) com processador ATMega 328. O software teve como lógica ler os dados registrados pelos sensores acoplados ao nó, montar o pacote de dados com o respectivo identificador do tipo do dado e enviar para o sink. O software do sink também foi desenvolvido em linguagem C e teve como lógica receber os dados dos nós sensores. Ao receber um conjunto de dados de um mesmo nó sensor o sink constrói o pacote de dados de acordo com o protocolo de comunicação descrito na Seção 2.1. Algumas verificações são feitas durante este processo buscando minimizar falhas provenientes de comunicação com pacotes corrompidos. O servidor teve seu software desenvolvido em linguagem Python na versão 2.7.8. O servidor recebe os pacotes construídos pelo sink e os processa de modo a identificar os tipos e os dados presentes no pacote. Os dados foram armazenados no banco de dados MySQL (versão 5.6.17). A rede foi construída buscando avaliar o funcionamento da arquitetura do sistema. Foram empregados nós sensores com diferentes especificações de tipo de dados (alguns tinham apenas o sensor GPS, outros apenas o sensor de temperatura, outros ambos, entre outros tipos de sensores). Um aspecto relevante para o funcionamento da rede de sensores é o protocolo de roteamento de dados, que define o modo como os nós irão se comunicar e alcançar o sink. A seção seguinte trata deste assunto.
3.1 Protocolo de roteamento de dados Para efeito de testes, o protocolo de roteamento de dados adotado baseou-se na estratégia de flooding (inundação) (TANEMBAUM, 2003).

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
162
A lógica do protocolo de roteamento de dados empregado pode ser descrita como: (1) inicialmente o nó sink envia um pacote de configuração para a rede de sensores (em broadcast); (2) os nós sensores ao alcance do sink recebem esse pacote de configuração, mudam seu estado de “escutando” para “enviando” e definem a rota para quem os pacotes de dados devem ser enviados; (3) após a configuração, o nó retransmite o pacote de configuração em broadcast, e; (4) Inicia o registro e o envio dos dados dos seus sensores de acordo com a rota definida. O pacote de configuração tem a informação da distância (número de saltos) que ele está da base. Quando um nó sensor recebe um pacote de configuração ele compara a distância atual (essa distância é inicializada com valor “infinito”) até a base com a distância recebida no pacote de configuração. Caso a distância recebida seja menor o nó sensor atualiza sua rota para o novo caminho, caso contrário ele apenas descarta o pacote. O sink envia um pacote de configuração periodicamente buscando a manutenção das rotas na rede, a recuperação de falhas e a inclusão de novos nós sensores.
4. Resultados Os testes foram elaborados com o objetivo de verificar o funcionamento da arquitetura do sistema. Dessa forma, foram utilizadas diferentes quantidades de nós sensores, com diferentes configurações em relação ao sensores acoplados aos nós. O primeiro teste consistiu de dois nós sensores, um atuando como nó sensor e o outro como sink e então avaliou-se a comunicação após um intervalo de tempo. Outros testes foram feitos com diferentes quantidades de nós sensores, chegando até o número máximo de 7 nós sensores mais o sink. Todos os pacotes recebidos no servidor tiveram sua origem identificada corretamente e dados processados adequadamente. Foi observado que alguns pacotes de dados foram perdidos durante a execução dos testes. Isso ocorreu em razão da colisão de pacotes, característica dependente do protocolo de roteamento de dados e não da arquitetura. Também foram observados pacotes de dados corrompidos recebidos pelo sink. Nesse caso, algumas possibilidades podem ocorrer: caso a parte corrompida seja o endereço do nó sensor ou o identificador do tipo do dado, os dados são descartados; o pior caso é quando a parte corrompida consiste apenas do valor do dado, nesse caso o valor “corrompido” será armazenado na base de dados. A ocorrência desse contexto foi detectada poucas unidades de vezes, caracterizando como um evento raro. Os ensaios demonstraram a viabilidade do sistema. Em todos os testes, os pacotes foram recebidos pelo servidor, corretamente identificados, manipulados e armazenados no banco de dados.
5. Conclusão Neste trabalho foi apresentada uma arquitetura que permite a utilização de rede de sensores sem fio de maneira prática, menos dependente do contexto da aplicação. Dessa forma é possível acoplar novos sensores aos nós da rede, utilizar sensores heterogêneos e ainda empregar nós sensores móveis. Foi implementado um protótipo para prova de conceito e por meio dos testes observou-se o correto funcionamento dos componentes da arquitetura.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
163
As próximas etapas do projeto preveem testes de longa duração, uma utilização em um contexto real e o aprimoramento do protocolo de roteamento de dados, buscando minimizar a colisão de pacotes.
Referências Akyildiz, I. F., Su, W., Sankarasubramaniam, Y., and Cayirci, E. (2002). “Wireless
sensor networks: A survey”, In: Computer Networks, v. 38, pp. 393–422. Banzi, M. (2009). Getting started with Arduino, O'Reilly, 1ª edition. Branquinho, O, (2011). Plataforma Radiuino para estudos em redes de sensores sem fio.
Acesso online <http://www.radiuino.cc>. Cao, Trang minh; Bellata, Boris; Oliver, Miquel. Design of a generic management
system for wireless sensor network. Ad Hoc Networks, V. 20, pp 16-25, 2014. Hill, J., Horton, M., Kling, R. E Krishnamurthy, L. (2004). “The Platforms Enabling
Wireless Sensor Networks”, In: Commun. ACM, v. 47, n. 6, pp 41–46. Radioit (2012). BE 900 Datasheet. Acesso online
<http://www.radioit.com.br/sites/default/files/downloads/BE900 Datasheet.pdf>. Tanembaum, A. S., Redes de computadores, Tradução da 4a Edição, Rio de Janeiro:
Campus, 2003.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
164
Avaliação de Mapas de Zonas de Manejo Utilizando Métodos Estatísticos
Ludmilla Fernandes Oliveira Galvão1, Raul Teruel dos Santos1
1Instituto de Computação– Universidade Federal de Mato Grosso (UFMT) CEP 78060-900 – Cuiabá– MT – Brazil
[email protected],[email protected]
Abstract. The population growth results in the need to produce a greater quantity of food to feed the general population. And for this it is necessary to optimize the most of the plantations, reducing costs and increasing the quantity and quality of agricultural production. The objective of this work is to evaluate management zone maps generated by PAM and Agnes clustering algorithms, using the statistical methods Kruskal-Wallis test and ANOVA one way. The tests were performed using the Software R. It was concluded that groups of each map are significantly different and it was possible to identify the best map. Resumo. O aumento populacional resulta na necessidade de produzir uma quantidade maior de alimentos para suprir a população em geral. E para isso, é necessário otimizar ao máximo as plantações, reduzindo os custos e aumentando a quantidade e a qualidade da produção agrícola. O objetivo do trabalho é avaliar mapas de zonas de manejo gerados pelos algoritmos de agrupamento PAM e Agnes, utilizando-se dos métodos estatísticos Teste de Kruskal-Wallis e ANOVA one way. Os testes foram realizados utilizando o Software R. Concluiu-se que os grupos de cada um dos mapas são significantemente diferentes e foi possível identificar o melhor mapa.
1. Introdução Com o avanço crescente da tecnologia de ponta, a agricultura pode ter suas técnicas e métodos completamente aprimorados, como colheitadeiras que facilitam o dia a dia dos agricultores, reduzindo o gasto com mão de obra, sensores que enviam as condições do solo e da plantação para o smartphone do produtor ou para um banco de dados para serem analisados. Apesar de haver muitas inovações tecnológicas que proporcionam um melhor rendimento da produção, ainda há técnicas e métodos que necessitam da tecnologia para aprimorar o seu uso e aumentar a produção.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
165
É nesse contexto que entra a necessidade de melhorar a aplicação de insumos agrícolas no solo, pois essas práticas podem causar degradação química do solo, como resultado do acúmulo de elementos ou compostos em níveis indesejáveis [NÚÑEZ et al. 1999].
Para melhor administrar o consumo de insumos, evitando a aplicação insuficiente de nutrientes em algumas regiões e quantidades excessivas em outras, uma das soluções encontradas é dividir o talhão em áreas menores, que assemelham-se em características físicas e químicas, conhecido como zonas de manejo, gerando mapas de zonas de manejo com auxílio de algoritmos de agrupamento.
O objetivo do trabalho realizado foi avaliar os mapas gerados pelos algoritmos de agrupamento PAM (Partinioning Around Medoids) e Agnes (Agglomerative Nesting), utilizando-se os métodos estatísticos Análise de Variância (ANOVA) e Teste de Kruskal-Wallis, com auxílio do Software R.
2. Materiais e Métodos Os dados utilizados nesse trabalho são provenientes de um talhão de 133,96 ha, próximo ao município de Tibagi no estado do Paraná, contendo 62 amostras de solo distantes aproximadamente 165 metros [SANTOS, 2014].
Neste trabalho foram usados os mapas gerados pelos algoritmos de agrupamento Agnes e PAM [Kaufman, Rousseeuw 1990], como podemos ver nas Figuras 1 e 2, respectivamente.
Figura 1. Mapa gerado pelo algoritmo de agrupamento Agnes.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
166
Figura 2. Mapa gerado pelo algoritmo de agrupamento PAM.
Os métodos estatísticos utilizados para este estudo de caso foram o teste de Kruskal-Wallis e o ANOVA one-way.
O ANOVA one-way é um teste paramétrico usado para comparar mais de 2 amostras independentes, verificando a existência diferenças significativas entre 2 ou mais grupos, mas sem identificar quais grupos são diferentes [Filho 1999]. Os dados a serem comparados por este teste foram agrupados com base em um único critério. As amostras devem seguir uma distribuição normal, além disso, os grupos (ou amostras) devem ser independentes e deve haver homogeneidade das variâncias entre os grupos, ou seja, as variâncias dentro de cada grupo devem ter valores similares entre os grupos. O ANOVA one-way irá testar a hipótese nula (H0) de que todas as populações têm médias idênticas contra a hipótese alternativa (H1) de que uma ou mais médias são diferentes das demais [Filho 1999].
O teste não-paramétrico análogo ao ANOVA one-way é denominado Teste de Kruskal-Wallis [Filho 1999]. Este método é mais simples e menos exigente que o ANOVA, além de não exigir uma distribuição normal da população, o Kruskal-Wallis tende a ser menos sensível que o ANOVA one-way, podendo falhar na detecção de diferenças significativas entre os grupos [Pallant 2010]. Ele é utilizado para comparar 2 ou mais amostras, além de não ter a necessidade das amostras seguirem algum tipo de distribuição ou serem independentes. O teste é utilizado, assim como o ANOVA one-way, ou seja, testa a hipótese de que há pelo menos uma amostra cuja média é diferente das demais (teste de hipótese). Foram utilizados os métodos teste Kruskal-Wallis e o ANOVA one-way, pois além deles serem testes claros e concisos e possuírem aplicabilidade no Software R, ambos são testes análogos, sendo interessante analisar os mapas utilizando os dois testes listados acima, que apesar de gerar resultados similares, suas estruturas e complexidade são completamente diferentes.
As principais diferenças entre os métodos estatísticos ANOVA one-way e teste de Kruskal-Wallis estão presentes na Tabela 1. No quesito categoria, os testes podem ser paramétricos, exigindo que os dados apresentem uma distribuição normal e que sejam independentes, ou não-paramétricos, que não possuem requisitos fortes, mas não

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
167
são tão confiáveis quanto os paramétricos. Quanto a relação dos dados, eles podem ser variáveis dependentes, ou seja, dependerão do valor de outra medida variável, ou independentes, não dependendo de nenhuma outra medida variável. Na categoria variâncias assumidas, as amostras podem ser homogêneas, ou seja, as variâncias podem ser de valores próximos ou idênticos, ou heterogêneas, com variâncias podendo ser de valores diferentes. As distribuições podem ser diversas, todavia a distribuição que será considerada nesse estudo é a distribuição normal ou gaussiana, onde a curva de Gauss é simétrica em relação à média, apresentando um gráfico na forma de sino e a área total da curva é igual a 1.
Tabela 1. Características dos métodos estatísticos teste de Kruskal-Wallis e ANOVA one-way.
Características Teste de Kruskal-Wallis ANOVA
Categoria Teste não-paramétrico Teste paramétrico
Relação entre os dados
Qualquer uma Independentes
Variância assumida Qualquer uma Homogênea
Distribuição assumida Qualquer uma Normal
Fórmula no Software R
Kruskal.tes(x,...) aov(formula, data = NULL, projections = FALSE, qr = TRUE,
contrasts = NULL, ...)
O ANOVA one-way e o Teste de Kruskal-Wallis foram utilizados para verificar se houve uma diferença significativa entre os grupos de cada mapa. Além disso, foi utilizado o Software R, uma ferramenta robusta e com uma vasta quantidade de bibliotecas, para efetuar os testes com os métodos estatísticos nos mapas.
Os testes foram primeiro efetuados utilizando o Teste de Kruskal-Wallis, para depois serem confirmados com os resultados obtidos no teste feito utilizando o ANOVA one-way. Apesar do ANOVA one-way ser usado para verificar se há uma diferença significativa entre grupos, não fornece nenhuma informação sobre quais grupos são diferentes entre si. Outro fator considerado no ANOVA one-way, foi o valor F obtido nos resultados dos testes no Software R, sendo F= dispersão entre os grupos/dispersão

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
168
dentro dos grupos. Quanto maior for o valor de F, melhor será a separação entre os grupos em relação a variação dos grupos, e consequentemente, maior a probabilidade de rejeitar a hipótese nula [FILHO, 1999]. O F foi utilizado para escolher qual dos mapas é o mais adequado, pois quanto mais distintos forem os grupos entre si, melhor será o mapa.
3. Resultados e Discussões O resultado obtido pela análise feita nos mapas gerados pelos algoritmos PAM e Agnes, ambos subdivididos em 5 zonas de manejo para esse estudo de caso, utilizando o método estatístico Teste de Kruskal-Wallis, foi que há uma diferença significativa entre os grupos do mapa PAM, pois o resultado obtido foi um p-value < 2.2e-16, logo, como ele é menor que 0,05 refuta-se a hipótese nula (H0), confirmando a existência de diferença significativa entre os grupos do mapa Agnes, pois o p-value <2.2e-16.
Através do ANOVA one-way, o resultado obtido no Kruskal-Wallis foi confirmado, ou seja, há uma diferença significativa entre os grupos do mapa gerado pelo algoritmo de agrupamento PAM, pois o p-value resultante foi menor que 0,05. Além disso, foi obtido através do ANOVA one-way um F= 4516. Nos grupos do mapa gerado pelo algoritmo Agnes também foi possível atestar que há uma diferença entre os grupos. Foi obtido um F=4122.
A partir dos valores F que foram encontrados pelos testes do ANOVA one-way aplicados nos mapas gerados pelo PAM (F= 4516) e pelo Agnes (F=4122), é constatado que o mapa gerado pelo PAM apresenta grupos mais homogêneos.
4. Conclusões Apesar do ANOVA one-way ser bem mais exigente em seus requisitos que o teste de Kruskal-Wallis, ele forneceu em seu resultado qual dos mapas era mais satisfatório. A principal vantagem do teste de Kruskal-Wallis foi ele ser mais flexível em relação as características dos dados, principalmente por não exigir que os dados possuam distribuição normal. Desta forma, pode-se confirmar que os algoritmos PAM e Agnes geraram mapas com zonas de manejo significativamente diferentes. Com o resultado obtido no Kruskal-Wallis, e depois confirmado com o resultado do ANOVA one-way, foi-se comprovado que há uma diferença significativa entre os grupos dos mapas gerados pelo algoritmo de agrupamento PAM e Agnes.
Pelos resultados obtidos pelo valor F encontrado nos testes feitos utilizando o ANOVA one-way, infere-se que o mapa mais adequado para o estudo do caso é o mapa gerado pelo PAM, pois seus grupos apresentaram uma melhor separação do que os do Agnes. Como os grupos são bem distintos, pode-se ter um melhor aproveitamento, pois

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
169
os insumos serão aplicados em quantidade mais próxima do necessário, evitando desperdícios, por exemplo. 5. Agradecimentos
Os autores agradecem à FAPEMAT (PROCESSO N°. 33080/2012) pelo apoio financeiro ao projeto e pela concessão de bolsa de iniciação científica através da cooperação técnica com a UFMT (Nº. 005/2015).
6. Referências Bibliográficas Filho, U. D. (1999). Introdução a Bioestatística - Para simples mortais. São Paulo: Negócio Elsevier. 158 p. Localização: 311:61, D696i. Id: 299. Kaufman, L.; Rousseeuw, P. J. (1990). Finding Groups in Data: An Introduction to
Cluster Analysis. New York, 1 Ed. Editora Wiley. Núñez, J. E. V., Amaral Sobrinho, N. M. B., Palmieri, F., Mesquita, A. A. (1999). “As conseqüências de diferentes sistemas de preparo do solo sobre a contaminação do solo, sedimentos e água por metais pesados”. R. Bras. Ci. Solo, 23:981-990. Pallant, J. (2010). SPSS Survival Manual: A Step By Step Guide to Data Analysis Using SPSS. 4th ed. Maidenhead: Open University Press/McGraw-Hill.
Santos, R. T. (2014). Um modelo de referência para o processo de definição de zonas de manejo em agricultura de precisão. R.T. dos Santos. -- versão corr. --São Paulo. 113 p.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
170
Definição de Zonas de Manejo Utilizando Algoritmos de Agrupamento
Alexandre Lucas Oliveira Lima1, Raul Teruel dos Santos1
1Instituto de Computação– Universidade Federal de Mato Grosso (UFMT) CEP 78060-900 – Cuiabá– MT – Brazil
[email protected], [email protected]
Abstract. From the need to produce more to remain competitive in the globalized world, it must improve to the maximum the mode of production of food in applying the optimal amounts of agricultural inputs thus avoiding waste. To do this, it needs to generate management zones, which takes place through the grouping of agricultural data. In this article, it was compared two clustering methods, Fuzzy C-Means and DIANA, which maps generated from 2 to 6 groups. It was found that the DIANA algorithm obtained better results.
Resumo. A partir da necessidade de produzir mais para manter a competitividade no mundo globalizado, deve-se aprimorar ao máximo a produção de alimentos de modo a aplicar quantidades adequadas de insumos agrícolas evitando assim desperdícios. Para tal, é necessário a geração de zonas de manejo que podem ser obtidas através do agrupamento dos dados agrícolas. Neste artigo, foram avaliados dois métodos de agrupamento, o Fuzzy C-Means e o DIANA, os quais geraram mapas de 2 a 6 grupos. Foi constatado que o algoritmo DIANA obteve melhores resultados.
1. Introdução Dada a necessidade em aumentar a eficiência para manter a competitividade no mundo globalizado e otimizar a produtividade a fim de diminuir custos, a agricultura com o auxílio das novas tecnologias de informação, como o GPS e o geoprocessamento, está ficando mais moderna. Surgiu então a agricultura de precisão o qual pode trazer inúmeros benefícios e para que isso ocorra são utilizadas as zonas de manejo. Estas são áreas as quais representam uma sub-região do campo e possuem uma combinação de fatores limitantes de produtividade e de qualidade para a qual se pode aplicar uma dose uniforme de insumos [RODRIGUES JUNIOR et al., 2011] Tendo isso em mente, surge a necessidade de um modelo para a criação de zonas de manejo, a fim de melhor administrar o uso de insumos agrícolas. Para tal, pode–se utilizar algoritmos que possuam a capacidade de agrupar as diversas necessidades dos dados agrícolas. O objetivo deste artigo é a comparação de métodos de agrupamento para mapas de dados agrícolas. Para isso, foi realizado a determinação dos pré-requisitos para o agrupamento, o estudo comparativo de métodos aplicáveis à etapa de definição de zonas de manejo, especificação das tarefas necessárias para o agrupamento de dados e como aplicar os métodos em dados agrícolas.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
171
2. Materiais e métodos Para a realização dessa pesquisa estudou-se dois métodos de agrupamento. O mais utilizado pela literatura acerca da área, o algoritmo Fuzzy C-Means [SANTOS, 2014] e o pouco conhecido método hierárquico, DIANA (DIvisive ANAlysis Clustering) [KAUFMAN e ROUSSEEUW, 1990], [VALE, 2005]. Ademais, realizou-se o estudo do Software R [TEAM, 2015] no qual os experimentos seriam realizados. O Fuzzy C-Means é um algoritmo de agrupamento por otimização de função. É um método particional, no qual o propósito é minimizar uma função de custo, onde os padrões são agrupados em um número k de grupos definidos previamente. Começa supondo os centros de cada agrupamento, sendo normalmente suposições incorretas, e gera um grau de pertinência para cada agrupamento. A cada iteração os centros de cada agrupamento e os graus de pertinência são atualizados para minimizar a função que representa a distância de cada padrão em relação ao centro de cada agrupamento avaliado pelo grau de pertinência do padrão.
A função a qual ele tem por objetivo minimizar é !!! !!" !! !!" onde !! é o peso da amostra i, !!" é o grau de pertinência da amostra i no centro j, !!" é a distância entre a amostra i e o centro j e m é o grau de fuzzificação especificado [SANTOS, 2014]. O valor para m é sempre maior que 1, e por padrão o sua medida é 2. Por padrão o número de iterações é 100. Para a utilização do método no software R é necessária a biblioteca e1071 [DIMITRIADOU et al., 2015]. Também é necessário a utilização de uma matriz de dados e também o número de grupos desejado para o mapa. O algoritmo DIANA é um método hierárquico no qual utiliza técnicas simples, na qual os dados são particionados sucessivamente, produzindo assim uma representação hierárquica dos agrupamentos. Deste modo, é possível ver a formação dos grupos em cada estágio e qual a semelhança entre eles. Por isso, os métodos hierárquicos não requerem um número a priori de grupos, visto que, por meio da análise do dendrograma (diagrama o qual mostra a hierarquia e a relação dos agrupamentos em uma estrutura) é possível inferir o número de grupos desejados [VALE, 2005]. O método DIANA necessita de uma matriz de dissimilaridades entre os agrupamentos o qual mostra a distância entre os agrupamentos em cada estágio do algoritmo. Para o surgimento da matriz, são utilizados os métodos de distância entre grupos para calcular os valores de proximidade entre os agrupamentos. São vários os métodos, no entanto somente está disponível no algoritmo DIANA, os métodos manhattan e euclidean. Caso seja dado uma matriz de dissimilaridades, o algoritmo irá executar mais rapidamente, visto que, o processamento desta exige muito tempo de processamento. Se não for possível, pode-se utilizar uma matriz de dados. A biblioteca em que se encontra no software R é a cluster [MAECHKER et al., 2015]. O algoritmo DIANA iterativamente executa deste modo:
1. No início todos os objetos estão no mesmo agrupamento. 2. O algoritmo irá procurar o objeto mais dissimilar dentro do cluster e definirá
ele como o primeiro elemento do grupo.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
172
3. Após isso, reagrupará os dados que podem estar mais próximas do novo grupo do que no grupo original. O produto será a criação de dois novos grupos.
4. O algoritmo irá encerrar quando cada ponto ser um cluster.
Para o estudo, foram utilizados os dados obtidos em uma fazenda no interior do Paraná. Vieram de um talhão de 133,96 há, contendo 62 amostras com 13 atributos possuindo distância de aproximadamente 165 metros. Os elementos foram interpolados com a finalidade de estimar os valores dos atributos em locais não amostrados. Deste modo aumenta a densidade de pontos dos mapas e/ou adéqua a grade amostral dos distintos atributos quando estes são amostrados utilizando grades com densidades diferentes. A fim de realizar os testes com os métodos de agrupamento, utilizou-se o software R versão 3.2.1 uma ferramenta robusta, gratuita e com diversas bibliotecas. As configurações do computador no qual foram realizados os testes é: CPU Intel Core i5- 4210M, Memória RAM 8 GB, SO Windows 10 64 Bits, R na versão 3.2.1. 64 Bits. Para conseguir o número de grupos desejados no algoritmo DIANA deve-se utilizar a função cutree(), o qual “corta” dendrogama na altura desejada. Também está disponível na biblioteca cluster.
3. Resultados e Discussão Após o uso dos métodos citados acima foram obtidos os seguintes mapas:
Figura 1 – Grupos gerados pelo algoritmo DIANA
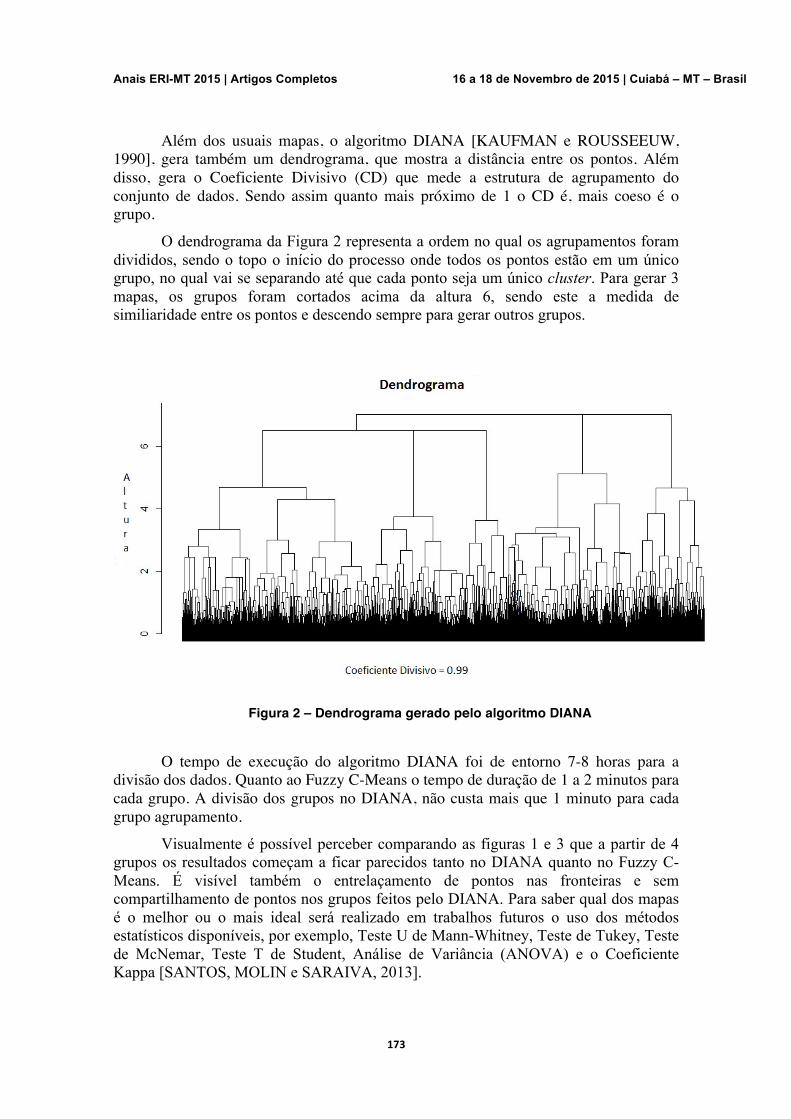
Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
173
Além dos usuais mapas, o algoritmo DIANA [KAUFMAN e ROUSSEEUW, 1990], gera também um dendrograma, que mostra a distância entre os pontos. Além disso, gera o Coeficiente Divisivo (CD) que mede a estrutura de agrupamento do conjunto de dados. Sendo assim quanto mais próximo de 1 o CD é, mais coeso é o grupo.
O dendrograma da Figura 2 representa a ordem no qual os agrupamentos foram divididos, sendo o topo o início do processo onde todos os pontos estão em um único grupo, no qual vai se separando até que cada ponto seja um único cluster. Para gerar 3 mapas, os grupos foram cortados acima da altura 6, sendo este a medida de similiaridade entre os pontos e descendo sempre para gerar outros grupos.
Figura 2 – Dendrograma gerado pelo algoritmo DIANA
O tempo de execução do algoritmo DIANA foi de entorno 7-8 horas para a divisão dos dados. Quanto ao Fuzzy C-Means o tempo de duração de 1 a 2 minutos para cada grupo. A divisão dos grupos no DIANA, não custa mais que 1 minuto para cada grupo agrupamento.
Visualmente é possível perceber comparando as figuras 1 e 3 que a partir de 4 grupos os resultados começam a ficar parecidos tanto no DIANA quanto no Fuzzy C-Means. É visível também o entrelaçamento de pontos nas fronteiras e sem compartilhamento de pontos nos grupos feitos pelo DIANA. Para saber qual dos mapas é o melhor ou o mais ideal será realizado em trabalhos futuros o uso dos métodos estatísticos disponíveis, por exemplo, Teste U de Mann-Whitney, Teste de Tukey, Teste de McNemar, Teste T de Student, Análise de Variância (ANOVA) e o Coeficiente Kappa [SANTOS, MOLIN e SARAIVA, 2013].

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
174
Figura 3 – Grupos feitos com o método Fuzzy C-Means
4. Conclusões A proposta deste estudo foi apresentar dois algoritmos de agrupamento, sendo um frequentemente usado na definição de zonas de manejo, o Fuzzy C-Means, e o outro, o DIANA, um método pouco usado e que tem como grande vantagem a geração do dendrograma o qual ajuda no momento em que for dividir os grupos, por mostrar a medida de similaridade entre os pontos. Apesar do Fuzzy C-Means conseguir calcular de maneira mais rápida, fica difícil a definição de quantos grupos são necessários. Já o DIANA ele gera o dendrograma o qual nos auxilia nesta escolha. Outra desvantagem do Fuzzy C-Means é que a escolha do parâmetro m é muito subjetiva podendo criar agrupamentos pouco similares. Em ambos, é possível observar que a partir de quatro grupos eles ficam semelhantes, com a vantagem do DIANA onde os agrupamentos dispõem uma melhor delimitação nas fronteiras. Para definir, qual dos dois mapas é o melhor, há de se passar em trabalhos posteriores para a avaliação através dos métodos estáticos disponíveis citados acima o qual irá mostrar se há diferença significativa entre os mapas.
5. Agradecimentos Os autores agradecem à FAPEMAT (PROCESSO N°. 33080/2012) pelo apoio financeiro ao projeto e pela concessão de bolsa de iniciação científica através da cooperação técnica com a UFMT (Nº. 005/2015).

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
175
6. Referências Dimitriadou, e. et al. (2011) e1071: misc functions of the Department of Statistics
(e1071), TU Wien. R package version 1.5-25. [Software do R] Vienna, Austria 2011. Santos, R. T.; Molin, J. P.; Saraiva, a. M. (2013) “A Reference Process for Management
Zone Delineation”. EFITA-WCCA-CIGR Conference “Sustainable Agriculture through ICT Innovation”, Turin, Italy, p. 595-602, 24-27.
Kaufman, L.; Rousseeuw, P.J. (1990). Finding Groups in Data: An Introduction to
Cluster Analysis. New York, 1 Ed. Editora Wiley,1990. Vale, M. N. do. (2005) Agrupamentos de Dados: Avaliação de Métodos e
Desenvolvimento de Aplicativo para Análise de Grupos. Rio de Janeiro, 2005. 120p. Dissertação de Mestrado - Departamento de Engenharia Elétrica, Pontifícia Universidade Católica do Rio de Janeiro.
Santos, R. T. (2014) Um modelo de referência para o processo de definição de zonas de manejo em agricultura de precisão. 113p. Tese (Doutorado em Ciências) – Universidade de São Paulo, São Paulo, 2014. [Orientador: Prof. Dr. Antonio Mauro
Saraiva]. Team, R. C. (2015) R: a language and environment for statistical computing. Version
3.2.1. [Software] Vienna, Austria: R Foundation for Statistical Computing. Rodrigues Junior F. A.; Vieira L. B.; Queiroz d. M.; Santos N. T., (2011) Geração de
zonas de manejo para cafeicultura empregando-se sensor SPAD e análise foliar. Revista Brasileira de Engenharia Agrícola e Ambiental, v.15, n.8, p.778–787. Disponível em: http://www.scielo.br/pdf/rbeaa/v15n8/03.pdf. Acesso em: 13/08/2015.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
176
Medidor de Umidade de Solo Baseado em Resistência Elétrica do Solo para Aplicação Agrícola
Wellington Sales E. Santos1, Mauricio Fernando Lima Pereira1, Roberto Benedito de Oliveira Pereira1, Aloisio Bianchini2
1Instituto de Computação – Universidade Federal de Mato Grosso (UFMT)
Cuiabá – MT – Brasil
2 Faculdade de Agronomia e Medicina Veterinária – Universidade Federal de Mato Grosso (UFMT) Cuiabá – MT – Brasil
[email protected], mauricio, [email protected], [email protected]
Abstract. Soil moisture is one of the most important variables for agricultural management and together with temperature, pressure and solar radiation lev-el are the main topics investigated in the literature in order to make a good use of water and benefit agriculture. This paper presents the development of soil moisture meter, which is based on the reading of the electrical resistance of the soil to estimate the value of this moisture. The scope of this project in-cludes since the sensor hardware design to build a prototype PCB and testing in the laboratory. The meter applies an alternating current into the ground through a probe which makes it possible to determine the variations of soil moisture between wet and dry. The equipment records the data collected in SD card. The sensor is a low-cost alternative for use in the field and / or as part of an agrometeorological station. Resumo. A umidade do solo é uma das variáveis mais importantes para o ma-nejo agrícola e juntamente com a temperatura, pressão e nível de radiação so-lar são os principais tópicos investigados na literatura com o objetivo de fa-zer-se um bom uso da água e beneficiar a atividade agrícola. Este trabalho apresenta o desenvolvimento de medidor de umidade do solo, que baseia-se na leitura da resistência elétrica do solo para estimar o valor dessa umidade. O escopo desse projeto engloba desde o projeto do hardware do sensor até a construção de um protótipo em PCB e testes em laboratório. O medidor aplica uma corrente alternada no solo através de uma sonda o que possibilita deter-minar as variações da umidade do solo entre úmido e seco. O equipamento grava os dados coletados em cartão SD. O sensor é uma alternativa de baixo custo para utilização no campo e/ou como parte integrante de uma miniesta-ção agrometeorológica.
1. Introdução Medidores de umidade do solo são necessários para o sucesso de qualquer atividade agrícola, pois o controle da umidade do solo é importante e permite garantir o aprovei-tamento da água para as culturas. Os sensores de umidade do solo podem ser utilizados para monitorar o teor de água presente no substrato proporcionando uma valiosa ferra-menta aos produtores que podem através desses dados diminuir ou aumentar a duração

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
177
dos ciclos de produção bem como evitar o desperdício de água que está vinculado à irrigação descontrolada do solo [Bayer et al. 2013]. Visando a construção de um sistema de monitoramento remoto que tenha como um dos seus princípios a construção de dispositivos e sensores de baixo custo, optou-se por monitorar a umidade de solo usando técnicas simples, mas precisas para obtenção dessa informação. Neste trabalho apresenta-se o desenvolvimento de um medidor de umidade do solo de baixo custo, que se baseia na leitura de uma corrente elétrica aplica-da no solo. O valor dessa corrente é resultante da variação da resistência do solo influ-enciada pela sua umidade e pelas texturas do solo. Existe no mercado uma gama de pro-dutos com propósitos semelhantes, porém com menos recursos quando comparados os custos. No trabalho desenvolveu-se o projeto de hardware e firmware e com os resulta-dos obtidos pode-se construir um equipamento dedicado de monitoramento, mas que também pode ser acoplado a uma estação agrometereológica. No projeto do medidor teve-se a preocupação com o armazenamento de informações em memória não volátil, que pode ser transportada facilmente para computadores pessoais. Além disso, o equi-pamento se diferencia dos demais por ter uma interface baseada em LCD gráfico para apresentação de informações ao usuário. Os caminhos e pesquisas que levaram aos re-sultados serão apresentados nas seções seguintes.
2. Revisão de Literatura
2.1 Tiva C O Tiva C, é um kit de desenvolvimento de baixo custo e de fácil programação que segue a filosofia Arduino. Embora compartilhe das mesmas facilidades de programação do arduino, o Tiva C possui um hardware superior que oferece uma maior robustez para diferentes tipos de utilização. Composto por um microcontrolador ARM de 32bits Cor-tex M4 de 80 MHz. Seus conectores expostos dos dois lados da placa permitem cone-xões a diferentes módulos. Assim como no Arduino, podem ser utilizados módulos de temperatura e de umidade, controles de motores, display de LCD, cartão SD e outros módulos disponíveis. A versão da placa utilizada possui um total de 40 pinos, divididos entre pinos de entrada e de saída, PWM, entradas digitais e analógicas de 12 bits, cone-xão a barramentos SPI e I2C, além de uma conexão USB host e device. A alimentação pode ser feita tanto pelo acesso direto aos pinos de alimentação, através de uma fonte externa de 3,3V a 5V, quanto pela porta USB [Sri Saiteja and Khasim 2014].
2.2. Métodos de extração de medidas de umidade de solo. Existem métodos diretos e indiretos de determinação da umidade do solo. O método gravimétrico é um método direto e consiste em amostrar o solo e, por meio de pesagens, determinar a sua umidade gravimétrica, relacionando a massa de água com a massa de sólidos da amostra ou a umidade volumétrica, relacionando o volume de água contido na amostra e o seu volume. O método gravimétrico é um dos mais usados, mas possui a desvantagem de necessitar de 24 horas ou mais para obter o resultado. Contudo, é o método-padrão para calibração dos métodos indiretos. Por possuir determinação instan-tânea da umidade do solo, os sensores se tornam mais adequados para indicar o início e a duração da irrigação. Os principais métodos indiretos baseiam-se em medidas como a

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
178
sonda de nêutrons, a resistência do solo à passagem de corrente elétrica, a constante dielétrica do solo e a tensão da água no solo. Essas são características do solo que vari-am com a sua umidade [Calbo and Silva 2005],[Teixeira et al. 2005].
3. Metodologia Nesta seção aborda-se sobre a construção do sistema de medição. Aborda-se os aspectos da construção do hardware do equipamento e também sobre o desenvolvimento do fir-mware utilizado para realizar extração de medidas de tensão, as quais estão relacionadas à medida de umidade do solo. 3.1. Construção do hardware do medidor Para extração de medida de umidade do solo, aplica-se, através de uma sonda, uma cor-rente elétrica no solo. Sabendo-se o valor de tensão aplicado e o valor de tensão lido pelo equipamento, pode-se estimar o valor da resistência elétrica do solo. Utilizando-se a técnica gravimétrica, se tem a priori o valor da umidade de uma determinada amostra de solo, através da calibração dos valores lidos com os valores estabelecidos pela técni-ca gravimétrica estabelece-se uma correlação entre as medidas, o que torna possibilita de forma rápida, ter-se uma estimativa da medida de umidade do solo. A corrente aplicada não deve ser continua, visto devido a características do solo podem ocorrer efeitos indesejados com a corrosão ou oxidação dos eletrodos metálicos da sonda ou a polarização dos eletrodos, o que pode influenciar nos valores de resistên-cia e consequentemente nas medidas lidas. Assim, o sensor de umidade do solo desen-volvido, gera através de seu microcontrolador e de um circuito oscilante, um sinal de corrente alternada que é aplicada no solo através de uma sonda, mostrada na Figura 1, a qual dotada de três agulhas de teste feitas de aço inoxidável. A oscilação pode variar de 100 Hz a 50 KHz e os dados adquiridos em todas as frequências de oscilação são grava-dos pelo medidor.
Figura 1. Sonda dotada de agulhas de aço
A corrente elétrica, ao percorrer o solo, encontra uma resistência natural do solo, que pode ser atenuada com a presença da umidade. Essa variação de resistência é utili-zada para mensurar a quantidade de umidade presente no solo por unidade de área esta-belecida pelo diâmetro da sonda apresentada na Figura 1. Desta forma é possível men-surar a corrente que percorre o solo na entrada da ponte H utilizando um divisor de tensão, onde este é composto por uma resistência física de 1 KΩ e a outra resistência é composta pela resistência do solo que varia de acordo com a umidade fornecendo assim diferentes níveis de tensão para cada nível de umidade do solo. A ponte H [Patsko 2006] mencionada é utilizada para gerar a corrente oscilante do medidor de umidade.
Para o desenvolvimento do medidor foram definidos os requisitos do siste-ma, formas de comunicação com usuário e a disposição dos componentes nas

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
179
placas de forma que aumentar autonomia e reduzir o custo. A ferramenta utili-zada para modelagem do hardware foi o Eagle, em sua versão 6.3 que oferece facilidade de operação e disponibilidade de informações e de componentes prontos, tendo assim diversas bibliotecas de componentes No Eagle foram projetados os esquemáticos do medidor, (
Figura 2) e em seguida foram geradas as placas de circuito impresso (PCB).
Para a geração das placas foram utilizados os métodos de transferência térmica [Borba 2011]] e através de uma fresadora CNC, a qual é mais moderna e precisa, pois nela a placa limpa é fixada sobre a mesa e então o desenho da placa gerada é carregada e a fresadora, que faz o desgaste da placa restando apenas o circuito final.
Figura 2. Esquemático da placa do medidor de umidade do solo, apresentando as cone-
xões do Tiva com LCD, LEDs e a sonda

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
180
3.1. Firmware do medidor de umidade de solo O firwmare para coleta de informações foi construído no ambiente Energia, que facilita a programação de LaunchPads da Texas Instruments [Energia 2015]. O ambiente é se-melhante à plataforma de desenvolvimento do Arduino.
O firmware de coleta de umidade está organizado em duas funções básicas denominadas setup() e loop(), onde a primeira configura o hardware do microcontrolador e seus periféricos e a segunda função é repetidamente
executada. Foram desenvolvidas funções auxiliares para controle do hardware e captura das informações. Na função setup do medidor de umi-
dade, são inicializados o LCD Gráfico, o RTC (Real Time Clock), o acesso a sonda e um timer do microcontrolador, o qual será utilizado para gerar as
frequências e para extração de medidas. Uma vez executada a função setup, ativa-se a função loop. Ela realiza duas ações principais: atualizar informa-ções de data/hora no LCD gráfico; configurar a taxa de oscilação da corren-
te, executar a amostragem de dados, exibir o que foi adquirido no LCD e fazer a gravação das informações coletadas no módulo SD-Card. As ações de coleta de amostras são ativadas quando o usuário pressiona um botão dedi-
cado a ativar a leitura. A Figura apresenta a organização do algoritmo do firmware do coletor de umidade, usan-do comandos em alto nível.
Figura 3. Algoritmo das funções setup e loop do firmware do Coletor de Umidade.
4. Resultados Depois de finalizados os projetos esquemáticos das placas, a preparação dos PCBs e a implementação do firmware, desenvolveu-se o protótipo do equipamento, mostrado na Figura 3. Como todo o projeto foi organizado e montado dentro do grupo de pesquisa, o equipamento apresentou um custo de aproximadamente R$100,00. O custo foi conside-rado baixo tanto para desenvolvimento quanto para manutenção.
void setup() Inicialização de pinos de LEDs, botões, etc. Ajuste de parâmetros da sonda; Inicialização do LCD Nokia5110; Ajuste do timer de verificação e amostragem; Configuração de SD Card;
void loop () Ler RTC e atualizar LCD; Verificar tensão na bateria; Se (ativadaAmostragemUmidade) Gerar frequência de oscilação da Sonda; Medir tensão no solo; Exibir dado coletado no LCD; Gravar dado coletado no SD Card;

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
181
Figura 3. Equipamento final
Os valores lidos pelo equipamento são processados, organizados em formato CSV e armazenados no cartão SD que está inserido no equipamento. Para cada frequên-cia de oscilação gerado pelo equipamento, cria-se uma linha no arquivo CSV, de forma que pode-se fazer uma análise da frequência que oferece a melhor resposta. No arquivo CSV também são guardadas as informações de data e hora do amostragem e versão de firmware. Todos os valores lidos são apresentados no LCD do medidor, de forma que o usuário pode acompanhar a medição em tempo real e quanto tempo falta para concluir o teste. Foram realizados testes em laboratório para validar o projeto de criação, onde o mesmo funcionou corretamente conforme foi projetado. Foram coletados durante uma hora, os dados do sensor de umidade do solo e as informações de data e hora, através do RTC incorporado à placa. Após o período de testes, o cartão SD que continha os dados coletados foi retirado do dispositivo de coleta e utilizou-se um microcomputador para ler os dados do cartão e verificar a consistência das informações coletadas através da placa desenvolvida pelo grupo. Os dados estavam consistentes e coerentes com as vari-ações de umidades lidas externamente no período amostrado. Após todas as calibrações feitas o sensor pode ser incorporado como um dos sensores de uma miniestação agro-meteorológica e também pode se tornar um equipamento comercialmente independente
5. Conclusão O protótipo construído possui vantagens em relação aos encontrados no mercado devido ao seu custo, pela forma de visualização dos dados em tempo real e também um sistema de logger que permite uma rápida análise dos dados em um microcomputador. O pró-ximo passo será a realização de novos testes e o desenvolvimento de uma case para acomodar o dispositivo e protegê-lo de intempéries climáticas. Com relação ao custo, equipamentos semelhantes disponíveis no mercado variam entre R$ 4000,00 à R$ 5000,00. O protótipo tem custo estimado em R$100,00.
Agradecimentos Os autores agradecem à FAPEMAT (Processo 749775/2011) pelo apoio financeiro ao projeto.
Referências Bayer, A., Mahbub, I., Chappell, M., Ruter, J. and Van Iersel, M. W. (2013). Water use and growth of Hibiscus acetosella “Panama Red”grown with a soil moisture sensor-

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
182
controlled irrigation system. HortScience, v. 48, n. 8, p. 980–987.
Borba, G. B. (2011). Construção eletrônica e placa de circuito impresso (PCI). paginapessoal.utfpr.edu.br/gustavobborba/material/files/SLIDES_pci_EL66J.pdf, [accessed on Jun 29].
Calbo, A. G. and Silva, W. L. C. (2005). Sistema Irrigas para manejo de irrigação: fundamentos, aplicações e desenvolvimentos. Adonai Gimenez Calbo.
Energia (2015). Energia. http://energia.nu/.
Patsko, L. F. (2006). TUTORIAL DE MONTAGEM DA PONTE H.
Sri Saiteja, G. and Khasim, M. K. N. V. (2014). Design of The CAN Bus Booster Pack and The Implementation of The CAN Protocol on the TIVA C Launch pad Evaluation Board. IJRCCT; Vol 3, No 10 (2014): October,
Teixeira, C. F. A., Moraes, S. O. and Simonete, M. A. (2005). Desempenho do tensiômetro, TDR e sonda de nêutrons na determinação da umidade e condutividade hidráulica do solo . Revista Brasileira de Ciência do Solo . scielo .

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
183
Utilização da Internet das Coisas para o desenvolvimento de miniestação de baixo custo para monitoramento de condições
do tempo em áreas agrícolas Bruno Silva Afonso1, Roberto Benedito de O. Pereira1, Mauricio F. Lima Pereira1
1Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Cuiabá, MT – Brazil
[email protected], roberto, [email protected]
Abstract. The Precision Farming is a systemic management technique and optimized livestock production system through the information field with the use of various technologies. This article discusses the application of the concepts of Internet of Things (IoT) with meteorological ministation inexpensive for monitoring agricultural areas. The paper presents and describes the use of MySensors library in through the transceiver data transmission wireless operation of Nordic nRF24L01+ a set of climatic Nodes data collectors to a base in charge of receiving this information. Resumo. A Agricultura de Precisão é uma técnica de gerenciamento sistêmico e otimizado do sistema de produção pecuária através do domínio da informação com a utilização de várias tecnologias. Este artigo aborda a aplicação dos conceitos da Internet das Coisas (IoT) com miniestações agrometeorológicas de baixo custo para monitoramento de áreas agrícolas. O trabalho apresenta e descreve o uso da arquitetura MySensors na operação de transmissão de dados por meio do tranceptor sem fio da Nordic nRF24l01+ de um conjunto de Nós coletores de dados climáticos até uma base responsável por receber estas informações e armazena-la em um cartão SD.
1. Introdução A Agricultura de Precisão é uma técnica de gerenciamento sistêmico e otimizado do sistema de produção pecuária através do domínio da informação, com a utilização de uma série de tecnologias e tendo como peça chave o posicionamento geográfico estratégico [VIANA, 2008]. A essência da agricultura de precisão é a contínua obtenção de informações espacialmente detalhadas da cultura seguida da utilização adequada dessas informações para aperfeiçoar o manejo [TORRE NETO, 2002]. A agricultura de precisão define-se como aplicar no local correto, no momento adequado, as quantidades de insumos necessários para produção agrícola, para áreas cada vez menores e correções mais precisas.
A Internet das coisas (IoT), tem por finalidade interligar todos os equipamentos eletrônicos que usamos no dia a dia a internet ou bases de dados com o uso de redes de sensores, processar essas informações e retornar em benefícios ao usuário. O projeto propõe o desenvolvimento de uma rede de estações de monitoramento de dados agrometeorológicos de baixo custo, que são capazes de se comunicar através de uma rede sem fio e transmitir informações de monitoramento para bases de dados remotas utilizando do conceito da IoT através de uma arquitetura responsável por prover o meio de comunicação entre as miniestações. A MySensors é uma arquitetura de comunicação

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
184
desenvolvida com a finalidade de conectar todos os pequenos dispositivos de uma rede se sensores, que neste caso usaremos como miniestações. A partir desses dados de monitoramento coletados, tem se o intuito de melhorar o planejamento estratégico das propriedades agrícolas e ampliar-se o uso das técnicas de agricultura de precisão no campo.
2. Fundamentação Teórica
2.1. Arduino É uma plataforma de prototipagem eletrônica open-source que se baseia em hardware e software flexíveis e fáceis de usar. É destinado a artistas, designers, hobbistas e qualquer pessoa interessada em criar objetos ou ambientes interativos. Através dele pode adquirir informações do estado do ambiente que o cerca por meio da recepção de sinais de sensores e pode interagir com os seus arredores, controlando luzes, motores e outros atuadores.
O microcontrolador na placa é programado com a linguagem de programação Arduino, baseada na linguagem C/C++, e o ambiente de desenvolvimento Arduino, baseado no ambiente Wiring. Os projetos desenvolvidos nessa plataforma podem ser autônomos ou podem comunicar-se com um computador para a realização da tarefa, com uso de software específico [ARDUINO 2015].
A placa Arduino UNO foi a escolhida para a execução dos testes, pois além de estar disponível no grupo de pesquisa, apresenta os requisitos necessários para trabalhar com a arquitetura do protocolo proposto.
2.2. Internet das coisas A Internet das Coisas é um paradigma que vem ganhando espaço no cenário moderno das telecomunicações wireless [ATZORI, IERA & MORABITO, 2010]. A ideia consiste em poder conectar uma variedade de objetos, como sensores, tags RFID, smartphones, computadores, e até objetos de uso mais comum, entre si. Estes objetos geram um fluxo de dados e a conexão permite que eles transmitam estes dados para outros objetos no meio, formando assim uma Internet de coisas.
Este termo confunde-se com o termo 'Comunicações Machine-to-Machine ‘(M2M Communications), que trata da comunicação máquina a máquina, entre dois ou mais dispositivos, sem um usuário final envolvido no processo da troca de informações. Com esta comunicação abre-se um leque de aplicações que podem, entre outras coisas, registrar, tratar e manipular os dados gerados e transmitidos pelos objetos que estão interligados. Dessa forma, uma aplicação que recebe de maneira contínua dados de um sensor que mede a temperatura de um ambiente e, com base nos dados obtidos, pode gerar estatísticas que descrevem as leituras do sensor em um espaço de tempo para depois emitir um alerta via e-mail ou Short Message Service (SMS) para um ou mais indivíduos caso a temperatura tenha atingido níveis muito altos, ou até publicar estas informações para outro dispositivo que poderia utilizá-las de outra forma, entre outras coisas [MARTINS & ZEM, 2014].
Ainda não há uma padronização para a Internet das Coisas, por isso existem diversas arquiteturas de comunicação como MQTT, MySensors e REST. O MQTT é

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
185
baseado na estrutura de comunicação publish-subscribe sobre o TCP/IP. O REST é uma arquitetura escalável que trabalha sobre o protocolo HTTP. O MySensors é uma arquitetura semelhante ao MQTT trabalhando em forma bi-direcional de comunicação, sendo ele o foco deste trabalho.
2.3. Arquitetura MySensors A função do MySensors é prover uma plataforma para transmissão de dados de sensores e ajudar o próprio usuário a construir sua rede sem fio, onde quem a usa tem pleno controle sobre o que está acontecendo. Ele combina a plataforma Arduino e outros, com um tranceptor de dados da Nordic modelo nRF24L01+, para formar uma rede de sensores sem fio (RSSF), de baixo consumo de energia. A comunicação dos sensores, por meio dela, é baseada na topologia estrela, que coneta todos os componentes ativos, confrome o apresentado na Figura 1.
Figura 1. Topologia do MySensors [MySensors 2015]
Em sua estrutura, conforme Figura 1, existem 03 tipos de Nós, são eles: • Nó Coletor - É a própria miniestação na imagem simbolizado pela letra “S”. Ele
é responsável por fazer continuamente a leitura dos dados e os status dos sensors e envia-los pela rede sem fio até o gateway.
• Nó Repetidor - Este Nó tem a missão exclusiva de repassar a mensagem até o gateway caso a miniestação esteja localizada a uma distância que ultrapasse o alcance do transmissor. Diferentes estações podem usar um único repetidor, na imagem ele é simbolizado pela letra “R”.
• Nó concentrador - Também chamado de “gateway” e representado pela letra “G” na imagem. Este nó é responsável por receber os dados enviados pelos outros nós e armazená-los ou executar alguma outra ação quando os receber. O transceptor é capaz de transportar até 32 bytes por pacote, mas destes, 7 bytes
são usados no cabeçalho de apresentação da arquitetura, restando apenas 25 bytes para serem enviados por pacotes. Neste cabeçalho, vão informações sobre os nós, rota e destino. A rota é importante em casos onde se faz uso de um repetidor, fazendo saber por onde aquela mensagem passou até chegar ao destino. A forma como o pacote é enviado pode ser observado conforme a figura 2.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
186
Figura 2 Apresentação de como os pacotes são enviados.
A descrição e o formato das mensagens utilizadas, pelos nós coletores e pelo gateway são apresentados pelas Figuras 3 e 4, respectivamente.
Figura 3. Apresentação dos Nós para o gateway
Figura 4. Apresentação dos campos do gateway
3. Materiais e métodos O projeto utilizou como base o princípio e a estrutura da IoT, cuja finalidade é de interligar todos os equipamentos eletrônicos usados no dia a dia à internet ou bases de dados com o uso de redes de sensores, processar essas informações e retornar ao usuário. Dessa forma implementou-se uma rede de estações de monitoramento agrometeorológico de baixo custo e também baixo consumo energético, capaz de se comunicar através de uma rede sem fio, conforme o diagrama apresentado na Figura 5.
Figura 5. Modelo para validação das miniestações
Para isso foram utilizados dois Nós coletores, um com a finalidade de coletar a luminosidade do ambiente, chamado de S10 e outro chamado de S20, cuja finalidade é a de coletar a temperatura e umidade relativa do ar. Ambas informações serão enviadas dos Nós coletores ao gateway, chamado de GW, que estão posicionados a uma distância de dez metros do gateway.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
187
O Nó S10 usado para teste é composto por um arduino com um sensor LDR usando uma protoboard para interligação, ao microcontrolador também está conectado o transceptor nRF24L01+ para envio dos dados coletados.
O Nó S20 é composto por outro arduino equipado com um sensor de temperatura e umidade DHT11 usando outra protoboard para ligar o sensor ao arduino que também contra com um transceptor nRF24L01+.
O Nó GW receberá todos os pacotes que serão enviados dos outros Nós e o armazenará em um cartão SD e mostrará pela serial as informações recebidas. Para isso ele é equipado com uma Shield SD Card, mais o transceptor nRF24L01+ e o arduino como microcontrolador
Os testes serão feitos em duas fases, a primeira, referente à inicialização e a sincronização das informações entre os Nós coletores e o gateway do sistema e a segunda, a transmissão dos dados coletados pelos Nós e armazenados no gateway. Para tal, as miniestações coletoras foram acomodadas em um ambiente controlado, seguindo o diagrama apresentado na Figura 5.
4. Resultados Na primeira fase do teste, logo após a energização dos módulos, foi possível visualizar as primeiras mensagens de sincronizações dos Nós coletores com o gateway conforme pode ser visto na Figura 6. 1 2 3 4 5 67
(a) (b)
Figura 6. Inicialização dos nós coletores (a) Nó de id 10 enviando dados de luminosidade
(b) Nó de id 20 enviando dados de temperatura e umidade
Dessa forma, como o apresentado na Figura 6.a, em sua primeira linha, o Nó carregou a sua ID 10. Na segunda linha, ele informa ao gateway qual a versão da biblioteca utilizada. Na terceira linha é requisitada a informação de configuração do gateway. Na quarta linha são informados os tipos de sensores presentes no Nó coletor. Na quinta linha é transmitida a versão do firmware do Nó coletor para o gateway. Na sexta linha a versão da biblioteca sobre o Nó é informada ao gateway. Na sétima linha o dado de luminosidade coletado é enviado ao gateway.
Da mesma forma que o Nó com ID 10, mostrado na Figura 6.a, o Nó com ID 20, apresentado na Figura 6.b, incia a sua sincronização com o gateway informando a ele a versão da biblioteca instalada no Nó coletor, o tipo de sensor presente, a versão do código instalado e em seguida sua primeira leitura de dados de temeratura e umidade relativa do ar.
Na segunda fase do teste, as informações foram transmitidas dos Nós coletores ao gateway e então armazenadas no cartão SD como o apresentado na Figura 7.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
188
1 2 3 4 5 6
Figura 7. Gateway recebendo os dados coletados pelos Nós de ID 10 e 20
Na primeira linha é apresentada a mensagem recebida pelo gateway do Nó com ID 10 e sua informação de luminosidade. Na segunda linha são os mesmos dados armazenados no cartão SD no formato CSV. Na terceira linha é apresentada a confirmação de armazenamento no cartão SD. Já da quarta a sexta linha são apresentados os dados recebidos pelo Nó com ID 20 e então armazenados no cartão SD e a sua respectiva confirmação.
5. Conclusão A transmissão de dados por meio da arquitetura MySensors funcionou conforme o previsto, sendo possível identificar os Nós de envio e recebimento sem problemas. A tecnologia de IoT permitiu a implementação de uma rede de sensores sem fio onde todas as miniestações estão interligadas a um único receptor responsável por receber e armazenar os dados, transmitidos. A plataforma de desenvolvimento Arduino mostrou-se eficiente para o desenvolvimento das miniestações.
Futuramente os dados coletados pela miniestações serão enviados até a uma base de dados que está atualmente em desenvolvimento, os dados serão enviados para a internet através de um módulo GPRS.
6. Agradecimento Agradeço as instituições de fomento FAPEMAT (Processo 749775/2011) CNPQ, CAPES pelo apoio ao projeto.
Referências Arduino (2015). Arduino. http://playground.arduino.cc/Portugues/HomePage. ATZORI, Luigi; IERA, Antonio; MORABITO, Giacomo (2010). The Internet of things:
a survey. The International Journal of Computer and Telecommunications Networking, Amsterdam. v.54.
MARTINS, I. R., ZEM, J. L. 2015. Aplicações Machine-To-Machine E Internet Das Coisas Revista Técnica Fatec AM, v. 3, n. 1, p. 64-87.
MySensors (2015). Internet of Your Things. http://www.mysensors.org/about/iot. PIRES, J. L. F., CUNHA, J. R., PASINATO, A., FRANÇA, S., RAMBO, L. 2004.
Discutindo Agricultura de Precisão – Aspectos Gerais. EMBRAPA. TORRE NETO, A.; JORGE, L. A. C.; Agricultura de Precisão. In: Workshop o
Agronegócio na sociedade da informação, 2002. Agrosoft. Brasília, 2002.

Anais ERI-MT 2015 | Artigos Completos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
189
Viana, J. H. M., Rafael, E., Fernandes, P., & Rodrigues, F. A. (2008). Congresso brasileiro de agricultura de precisão - 2008. Congresso Brasileiro de Agricultura de Precisão, (1), 46–59.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
190
Reconhecimento de Expressões Faciais em Processos de Comunicação Usando Visão Computacional
Marcos Alves dos Santos, Marcos Wagner Souza Ribeiro
Universidade Federal de Goiás - Campus Jataí (UFG) BR 364, km 195, nº 3800 – 75801-615 – Jataí – GO – Brazil marcosdourado23, [email protected]
Abstract. The objective of this research is to investigate the use of facialexpression recognition in CMC (Computer-Mediated Communication) processes, implementing a system of recognition of faces and recognize facialfeatures, listing a set of facial features that can portray an emotion andultimately integrating the system instant messaging.
Resumo. O objetivo desta pesquisa e investigar a utilização de reconhecimento de expressões faciais em processos de CMC (Comunicação Mediada por computadores), implementando um sistema de reconhecimento de faces e reconhecimento de características faciais, elencando um conjunto de características faciais que podem retratar uma emoção e, finalmente, integrando a sistemas de mensagens instantâneas.
1. Introdução Durante o processo de comunicação entre duas ou mais pessoas, os participantes deste processo, utilizam-se de diversos sinais para indicar aos outros o que estão sentindo, enviando assim informações que incluem expressões faciais, vocais, corporais e gestuais. Estes sinais são uma parte importante da comunicação humana, uma vez que por meio deles é possível identificar diversas informações [Robinson 2014]. Tais sinais fazem parte da comunicação não verbal e as informações presentes são importantes para uma comunicação mais efetiva entre os indivíduos, pois a partir disso, decisões em relação a comunicação podem ser tomadas [Yu 2014]. Desde do surgimento da internet e sua consequente expansão, tem se observado o surgimento de diferentes canais eletrônicos de comunicação e um grande aumento na Comunicação Mediada por Computador (CMC), como assíncrona (por exemplo o e-mail) e CMC síncrono (por exemplo mensagens instantâneas (MI)) [Luor et al. 2010]. O uso de dispositivos móveis tem crescido nos últimos anos, dentre as diversas funções utilizadas nos mesmos, a comunicação por meio de redes sociais e serviços de mensagens instantâneas móvel (MIM) têm sido crescente. Serviços de MIM proporcionam aos seus usuários a comunicação por meio do envio de textos em tempo real por meio de dispositivos móveis (por exemplo celulares), permitindo conversas privadas e em grupo. Segundo Yu (2014), um número grande de informações relacionadas a comunicação não verbal são perdidas, quando utiliza-se computadores para a comunicação, esta perda de informações e chamada de problema do comportamento social bloqueado, que nada mais e que a falta de comunicação não verbal. Tal perda

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
191
acarreta uma falha na comunicação, uma vez que os indivíduos não tem acesso a uma parte fundamental da mesma, levando assim a uma ruptura no processo de interação social. Um dos problemas causados por essa ruptura e a dificuldade de resolver ambiguidades nas mensagens, pois essas informações são muitas vezes decisivas para a desambiguação [Valle e Prata 2014]. Uma possível solução para este problema e fazer com que todos os indivíduos participantes do processo de comunicação tenham acesso as emoções de seus parceiros, diminuindo assim a ruptura existente neste processo. Uma área da Ciência da Computac ao que tem como objetivo fazer com que o computador tenha capacidade de reconhecer, compreender e de expressar emoções é a Computação Afetiva [Picard 1997 apud Gonzalez-Sanchez et al. 2011]. Uma vez que o computador possua tais capacidades, ele poderá adaptar-se de acordo com as emoções que o indivíduo apresenta, além de poder comunicar-se de forma mais efetiva com o mesmo.
2. Trabalhos Relacionados
Dentro da computac ao afetiva diversas iniciativas têm tentado deduzir emoções por diversos meios, tais como a utilização de aprendizado de máquina para inferir a emoção do usuário a partir do texto digitado (utilizando-se para isso de um banco de dados de textos classificados de acordo com a emoção expressa no mesmo) [Lee et al. 2012]; reconhecimento por meio de expressões faciais [Bonnet, Ammi e Martin 2011]; reconhecimento por meio de sensores no corpo [Ayyagari et al. 2015]; dentre outros. Para tentar auxiliar na resolução do problema de bloqueio de comunicação não verbal em CMC, diversos autores tem utilizado o reconhecimento de emoções com relativo sucesso [Lee et al. 2012] [Yu 2014] [Pong, Wang e Hsu 2014].
3. Metodologia
Este trabalho terá como produto um sistema que ira auxiliar na resolução do problema da falta de comunicação não verbal em CMC. Esse sistema será um MIM que terá um modulo de reconhecimento de expressões faciais, o qual será responsável pela a captura de expressões faciais dos usuários e a partir disso será inferido a emoção expressa. Para o desenvolvimento do módulo de reconhecimento de faces, será feito um levantamento bibliográfico, buscando tanto na área acadêmica quanto na área comercial, sistemas que implementem as funcionalidades necessárias para o trabalho. Também será feito tal levantamento para buscar sistemas de mensagens instantâneas de código aberto, que tenham suporte para a integração de módulos. Uma revisão bibliográfica será feita, para definir o conjunto de características faciais que podem retratar uma emoção, buscando na literatura trabalhos que tratem da relação de características faciais e emoções. Além disso, para avaliar o sistema proposto serão utilizados metodologias já existentes na literatura. Com o objetivo de testar o módulo de reconhecimento de faces, será feito um levantamento documental, para elencar bases de dados de faces e de expressões faciais e para encontrar a forma mais adequada de apresentar as emoções aos usuários participantes da CMC, será feito também um levantamento bibliográfico.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
192
O produto desta pesquisa será avaliado inicialmente quanto a sua capacidade de inferir emoções e posteriormente será feita uma avaliação final, para verificar a efetividade do sistema no auxílio da resolução do problema apresentado.
4. Conclusão
O presente trabalho encontra-se ainda em processo de pesquisa, atualmente a investigação está focada no reconhecimento de expressões faciais. Está sendo feito assim, uma revisão sistemática na literatura, buscando encontrar as melhores técnicas para resolução deste problema.
Referências Ayyagari, S. S. D. P. et al. (2015). CoSense: Creating Shared Emotional Experiences. p.
2007–2012. Bonnet, D.; Ammi, M.; Martin, J. C. (2011). Improvement of the recognition of facial
expressions with haptic feedback. IEEE International Workshop on Haptic Audio Visual Environments and Games, p.81–87.
Gonzalez-Sanchez, J. et al. (2011) Affective Computing Meets Design Patterns: A Pattern-Based Model for a Multimodal Emotion Recognition Framework. EuroPloP’11: Proceedings of the 16th European Conference on Pattern Languages of Programs.
Lee, H. et al. (2012). for Affective Social Communication. p. 260–264. Luor, T. et al. (2010). The effect of emoticons in simplex and complex task-oriented
communication: An empirical study of instant messaging. Computers in Human Behavior, Elsevier Ltd, v. 26, n.5, p.889–895.
Picard, R.W. (1997). Affective Computing. [S.l.]:MITPress. Pong, K.-C.; Wang, C.-A.; Hsu, S. H. (2014). GamIM: Affecting chatting behavior by
visualizing atmosphere of conversation. In: Proceedings of the extended abstracts of the 32nd annual ACM conference on Human factors in computing systems - CHI EA’14. p. 2497–2502.
Robinson, P. (2014). Computation of Emotions.p.409–410. Valle, T.; Prata, W. (2014). Non-Verbal Communications in Mobile Text Chat –
Emotion-Enhanced Mobile.p.443–446. Yu, Y. C. (2014). A social interaction system based on cloud computing for mobile
video telephony. Science China-Information Sciences, v.57, n.3, p.10.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
193
Projeto de um serious game imersivo, de baixo custo e alta portabilidade, voltado ao aprendizado de pessoas com
Dislexia e Discalculia
Giancarlo Santana Batista Fleuri, Marcos Wagner de Souza Ribeiro
Departamento de Ciências da Computação – Universidade Federal de Goiás (UFG) BR 364, km 195, nº 3800, CEP 75801-615
[email protected], [email protected]
Abstract. This work aims the development of an immersive serious game to assist in the learning process of dyslexic and dyscalculic individuals. Considering that most of the patients under specific treatment are kids, this paper proposes the combination of serious games and Virtual Reality (VR) to increase the motivation of these patients. The choice of VR has as goal the improvement in the visual and auditory concentration of these individuals, since the distractions present in the real environment can affect the effectiveness of the treatment while conducting learning activities.
Resumo. Este trabalho apresenta a proposta do desenvolvimento de um serious game (jogo sério) imersivo para auxiliar no processo de aprendizado de indivíduos disléxicos e discalculicos, uma vez que a maioria dos pacientes sob tratamento específico são crianças. Este trabalho propõe a combinação de serious games e Realidade Virtual (RV) para aumentar o nível de motivação destes pacientes. A escolha da RV tem como objetivo melhorar a concentração visual e auditiva destes indivíduos, pois as distrações presentes no ambiente real podem comprometer a efetividade do tratamento durante a realização das atividades de aprendizado.
1. Introdução
O processo de ensino-aprendizagem para pessoas com dislexia e discalculia vai muito além da relação aluno-professor em sala de aula. Os portadores destes transtornos precisam de um diagnóstico e tratamento específico, visando a melhora no aprendizado e qualidade de vida. Estima-se que cerca de 10 a 15% da população mundial é disléxica, enquanto que 10% são portadores de discalculia [IDA 2003] [ABD 2002] [BDA 2014]. A dislexia é caracterizada pela dificuldade no reconhecimento preciso e/ou fluente da palavra, na habilidade de decodificação e em soletração. Essas dificuldades normalmente resultam de um déficit no componente fonológico da linguagem. Podem ser originados de algum trauma ou não [IDA 2003] [ABD 2002]. A discalculia, por sua vez, é um transtorno de aprendizado específico caracterizado pela dificuldade no aprendizado de aritmética básica, processamento de magnitude numérica e processamento de cálculos precisos e fluentes [BDA 2014] [Isaacs 2011]. A discalculia é conhecida como a “dislexia Matemática” e segundo um estudo conduzido em Cuba,

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
194
que avaliou cerca de 1500 crianças, este transtorno é mais comum que a dislexia [Romagnoli 2008]. Ambos são transtornos genéticos e hereditários, possuem origem neurobiológica e são perceptíveis no início da alfabetização. São frequentemente confundidos com desmotivação, déficit de atenção, problemas psicológicos ou falta de inteligência [Romagnoli 2008] [IDA 2003] [ABD 2002]. Nesse cenário, este trabalho tem como objetivo geral o desenvolvimento de um jogo sério (seriou game) para auxiliar no processo de ensino-aprendizado, melhorar concentração e aumentar o nível de motivação do indivíduo portador de dislexia e discalculia, durante a realização dos exercícios. Para atingir o objetivo geral, os seguintes objetivos específicos foram definidos:
a) Apresentar, por meio de revisão bibliográfica, um levantamento dos principais problemas enfrentados pelos portadores destes transtornos, e como a Computação pode ajudar a resolvê-los;
b) Criar um acervo de exercícios tradicionais, já existentes e utilizados no tratamento para a dislexia e discalculia que serão adaptados para o AV posteriormente;
c) Desenvolver o jogo sério, composto por um AV interativo em 360º, imersivo, visando proporcionar maior nível de concentração visual por meio de uma interface limpa;
d) Adaptar os exercícios coletados, respeitando os resultados obtidos na revisão bibliográfica, aplicando as boas práticas para este tipo de sistema;
e) Criar um assistente de voz com o objetivo de auxiliar o usuário com dificuldades cognitivas e ao mesmo tempo prover um nível maior de concentração auditiva;
f) Testar a jogabilidade e validar o sistema.
2. Trabalhos Relacionados e Justificativa Impulsionada pelos avanços tecnológicos de uma forma geral e a necessidade de estratégias mais específicas por parte de psicopedagogos, a utilização de recursos computacionais na intervenção para os casos de dislexia vêm crescendo nos últimos anos. Apesar de duas áreas distintas, a combinação da Psicopedagogia e Computação pode gerar resultados positivos, como os apresentados pela literatura deste projeto [De Lisi e Wolford 2002] [Mitchell e Savill-Smith 2004] [Zyda 2005] [Mattar 2010]. Dentre as diversas aplicações já existentes e originadas dessa combinação, destacam-se os jogos criados para fins de tratamento e auxílio de diversas doenças e transtornos, visando mais do que o simples entretenimento, conhecidos como serious games, uma vez que a maioria dos pacientes submetidos ao tratamento da dislexia e discalculia são crianças em idade escolar. A utilização de jogos digitais faz com que estes pacientes tenham maior interesse na realização do tratamento [Mattar 2010]. Como justificativa para a elaboração deste trabalho faz-se referência ao grande número de pessoas portadoras de dislexia e discalculia, amparada pela literatura que apresenta um acervo composto de vários trabalhos que reforçam a investigação no sentido do uso de jogos para o tratamento de ambos os transtornos, aliado aos recursos de Realidade Virtual [Romagnoli 2008] [De Lisi e Wolford 2002] [Mitchell e Savill-Smith 2004] [Zyda 2005] [Mattar 2010].

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
195
3. Metodologia Para atingir os objetivos deste trabalho, os seguintes procedimentos devem ser contemplados: i) pesquisar os problemas enfrentados por pessoas com dislexia e discalculia durante o processo de aprendizado; ii) criar um acervo de protocolos de exercícios tradicionais; iii) desenvolver o jogo/adaptar exercícios para o AVI; iv) definir critérios e roteiros do jogo; v) implementar o assistente de voz; vi) testar a jogabilidade; vii) validar o sistema.
4. Conclusão Por fim, este trabalho pretende aplicar técnicas de Realidade Virtual, por meio da criação de um jogo inserido em um Ambiente Virtual Tridimensional (AV 3D), interativo e imersivo, visando a eliminação das distrações do ambiente real em que se encontra o indivíduo. Para a implementação do jogo, serão utilizados exercícios já existentes na área de Psicopedagogia voltados ao tratamento de dislexia e discalculia. Estes exercícios serão, então, readaptados para o AV, substituindo o papel e caneta por um serious game, de forma imersiva e interativa.
Referências ABD – “Associação Brasileira de Dislexia”. Disponível em: http://www.dislexia.org.br.
Acesso em: Abril/2015. BDA – “Associação Britânica de Dislexia” (British Dyslexia Association). Disponível
em: http://www.bdadyslexia.org.uk. Acesso em: Maio/2015. De Lisi, R.; Wolford, J. L. (2002). “Improving children’s mental rotation accuracy with
computer game playing”. Journal of Genetic Psychology, [S.l], v. 163, 3a ed., p. 272–282.
IDA, “Associação Internacional de Dislexia” (International Dyslexia Association). Disponível em: http://eida.org/. Acesso em Junho/2015.
Isaacs, E. B. et al (2001). “Calculation difficulties in children of very low birthweight: a neural correlate. Brain”, [S.l., s.n.], v. 124, p. 1701-1707.
Mattar, J. (2010). “Games em educação: como nativos digitais aprendem”. São Paulo: Person.
Mitchell, A.; Savill-Smith, C. (2004). “The use of computer and video games for learning: A review of the literature”. London: Learning and Skills Development Agency.
Ribeiro, M. W. S. (2006). “Arquitetura para distribuição de ambientes virtuais multidisciplinares”. 176p. Tese (Doutorado em Engenharia Elétrica) – Faculdade de Engenharia Elétrica, Universidade Federal de Uberlândia, Uberlândia.
Romagnoli, G. C. (2008). “Discalculia: Um desafio na Matemática”. Trabalho de Conclusão de Curso. Centro de Referência em Distúrbios de Aprendizagem (CRDA), São Paulo.
Zyda, M. (2005). “From visual simulation to virtual reality to games”. Computer, [S.l.], v. 38, 9a ed., p. 25-32.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
196
Aplicativo de Realidade Aumentada para Alfabetização
Leandro Rodrigues Lima, Tales Nereu Bogoni
Faculdade e Ciências Exatas e Tecnológicas – Campus Universitário Vale do Teles Pires UNEMAT – Colíder – MT
[email protected], [email protected]
Abstract. This paper presents an Augmented Reality game to help the portuguese teachers to learning process of first cycle of basic education in the literacy task.
Resumo. Este trabalho apresenta um jogo em Realidade Aumentada para auxiliar os professores de língua portuguesa no processo de alfabetização dos alunos do 1º ano do ensino fundamental.
1. Introdução A alfabetização nas escolas brasileira ocorre no 1º ano do ensino fundamental. Normalmente são utilizadas associações de signos às sílabas e palavras para que estas sejam fixadas pelos alunos. Para Araújo et al. (2014) “o primeiro passo para alfabetizar consiste em ajudar a criança a compreender o princípio alfabético”. Isto requer o desenvolvimento da consciência da existência dos fonemas e das letras que os representam. Neste sentido os alunos devem aprender a grafia das letras, formar sílabas e posteriormente formar palavras, atribuindo a elas um significado. Sistemas computacionais podem auxiliar na alfabetização de crianças com o uso de novas tecnologias. O uso de ferramentas multimídia como projetores, vídeos e jogos podem auxiliar os professores quanto à materialização do conteúdo. Saussure (2002) afirma que a linguística é constituída da união de dois termos vinculados e associados em nosso cérebro, um signo e seu significado. O signo linguístico une um conceito a uma imagem acústica, ou seja, quando se tem a ideia ou conceito de uma palavra o que se tem em mente é a imagem correspondente a essa ideia. Partindo do pressuposto da associação de imagens com as palavras o objetivo deste trabalho é desenvolver um jogo que utiliza técnicas de Realidade Aumentada (RA) para auxiliar os alunos no processo de alfabetização. Técnicas empregando o uso de jogos para o ensino vêm sendo utilizadas como objetos de aprendizagem e isso gera uma alteração na concepção do professor. Ele passa de apenas detentor e transmissor do conhecimento para quem vai analisar, orquestrar, indagar e motivar o aluno no processo de aprendizagem. Através destas novas concepções no processo de ensino, o jogo forçará o aluno a refletir novas conjecturas (SILVIA e KODAMA, 2004).
2. Realidade Aumentada Segundo Siscouto e Kirner (2007) a técnica de RA surgiu na década de 90, quando foi possível introduzir objetos virtuais em ambientes reais. Azuma (1997) relata que a RA faz a sobreposição de objetos virtuais no mundo real. Esta sobreposição é feita em tempo real e o usuário pode manipular o objeto tridimensional, e, com o auxílio de um monitor poderá ver as alterações instantaneamente.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
197
Uma maneira simples de desenvolver uma aplicação de RA consiste na utilização de um computador, uma webcam e um software que, através de técnicas de visão computacional e processamento de imagem, irá misturar a cena do mundo real capturada pela webcam com objetos virtuais gerados pelo computador (KIRNER e ZORZAL, 2005).
3. Descrição do Jogo de Alfabetização A ideia do jogo é inserir uma nova forma de executar a atividade de ditado em sala de aula. No jogo o professor cadastra uma lista de palavras no sistema e solicita aos alunos que a escrevam utilizando os marcadores de RA que representam as letras do alfabeto (Figura 1a). Quando a palavra estiver correta será exibida uma imagem 3D que corresponde a um signo da palavra escrita. Os marcadores foram criados utilizando folhas de sulfite e papelão. Após a impressão dos marcadores nas folhas de sulfite os mesmo foram recortados e colados no papelão para que as letras não dobrassem. Para a leitura dos marcadores foi desenvolvida uma estrutura metálica com 60 cm de altura e na ponta um braço de 30 cm de comprimento. A armação possui um suporte para fixar na borda de uma mesa. Na ponta do braço foi fixada a webcam voltada para a mesa (Figura 1b).
Figura 1 - (a) Marcadores; (b) Setup Físico para Leitura dos Marcadores
Para o desenvolvimento da aplicação foram utilizadas as ferramentas: • FLARManager: É um framework de desenvolvimento de RA para web através da biblioteca do FLARToolkit, que é uma versão do ARTollKit para internet. • FlashDevelop: Trata-se de uma Integrated Development Environment (IDE) de código aberto que trabalha com ActionScript 2 e 3, que é uma linguagem de script para web, executada em máquinas virtuais. • Artoolkit Marker Generator: Aplicativo responsável por criar um arquivo com a imagem binarizada dos marcadores. • Adobe Flex SDK: O Adobe Flex é um Software Development Kit (SDK) para desenvolvimento de conteúdos web, criado pela empresa Adobe e lançado em 2004. • Java Development Kit (JDK): É um conjunto de ferramentas para desenvolvimento e execução de aplicações Java.
A B

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
198
5. Avaliação Nos testes realizados pode-se notar que a fixação da webcam deve ser bem firme para que não haja movimentos na hora do rastreamento dos marcadores. A webcam utilizada nos teste foi uma Logitech C270 que possui ajuste automático da luminosidade e dependendo do iluminação do ambiente o rastreamento dos marcadores é perdido. Houve também problemas de oclusão, pois os usuários colocavam as mãos sobre os marcadores fazendo com que o rastreamento ficasse prejudicado. Até este estágio do trabalho os testes foram feitos para verificar a funcionalidade do jogo, sem verificar sua eficácia como objeto de aprendizado.
6. Considerações Finais Este trabalho visou o desenvolvimento de um jogo em RA voltada para auxiliar os professores de língua portuguesa do 1º ciclo do ensino fundamental. O jogo pode ser proposto como uma atividade de ditado, mas ao invés dos alunos escreverem as palavras no caderno com lápis ou caneta, o aluno utiliza marcadores para formar as palavras. Caso a ortografia esteja correta é exibida uma imagem 3D que pode ser manipulada aluno com um marcador. Futuramente serão realizados testes para verificar a eficiência do jogo em sala de aula.
Referências ARAUJO, João Batista et al. “Alfabetização no Brasil”. Revista USP, n. 100, p. 21-32,
2014. AZUMA, R. T. “A Survey of Augmented Reality”. Malibu – CA, 1997. KIRNER, C. ZORZAL, E. R. “Aplicações educacionais em ambientes colaborativos
com realidade aumentada”. XVI Simpósio Brasileiro de Informática na Educação, 2005.
SAUSSURE, F. “Curso de Lingüistica Geral”. São Paulo – SP, 2002. SILVIA, A. F. KODAMA,H. M. Y. “Jogos no ensino de matemática .” II Bienal da
Sociedade Brasileira de Matemática – UNESP, São José do Rio Preto, 2004. SISCOUTO, R. A. KIRNER, C. “Fundamentos da Realidade Virtual e Aumentada”. IX
Symposium on Virtual and Augmented Reality, Petrópolis–RJ, 2007.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
199
Um Estudo de Caso: análise sobre a eficácia do software Coelho Sabido na Terra do Queijo
Carolina G. Marinho1, Any C. Romero1, Shirlene R. Souza2, Max R. Marinho2
1Universidad Gran Asunción (UNIGRAN) – Pedro Ruan Caballero – Paraguay
2Universidade do Estado de Mato Grosso (UNEMAT) – Alto Araguaia – MT – Brasil
[email protected], [email protected], [email protected], [email protected]
Abstract. This paper discusses the technology used in multiresources rooms that serve children with some degree of disability. It is, more specifically, a research on the effectiveness of the educational software Coelho Sabido na Terra do Queijo, developed to support the work of teachers in early grades. The proposal is to verify results presented in Portuguese activities. The check was given through testings with Portuguese exercises. The theoretical framework was based on Meneghetti, Giraffa, Kirk and Gallagher, Sassaki, Tajra, Valente and Freire, among others. Resumo. Este artigo trata da tecnologia utilizada em salas multirecursos, que atendem crianças com algum grau de deficiência. Trata-se, de uma investigação sobre a eficácia do software Educacional Coelho Sabido na Terra do Queijo, desenvolvido para apoiar o trabalho do professor em séries iniciais. A proposta é verificar resultados apresentados nas atividades de Língua Portuguesa. A verificação se deu por meio de testagens com exercícios de Língua Portuguesa. O aporte teórico foi baseado em Meneghetti, Giraffa, Kirk e Gallagher, Sassaki, Tajra, Valente e Freire, entre outros.
1. Introdução As crianças não possuem o mesmo ritmo de aprendizagem, tampouco têm desempenho igual todo o tempo, em todas as disciplinas. O professor lida constantemente com alunos que apresentam diferentes graus de déficit de aprendizagem, obrigando-o a buscar caminhos para ajudar essas crianças a desenvolver suas habilidades fundamentais. Para atender a esses alunos as escolas oferecem recursos e metodologias diversificadas para seus desenvolvimentos. Em uma sala multirecursos da rede pública estadual do Mato Grosso, um grupo de crianças – com diferentes graus de deficit de aprendizagem, algumas portadoras de algum tipo de deficiência – é acompanhado nesta pesquisa, visto que esse grupo recebe atendimento personalizado, com diversas atividades, dentre as quais, exercícios que são realizados por meio de tecnologias digitais, como o software Educacional “Coelho Sabido na Terra do Queijo”. O software “Coelho Sabido na Terra do Queijo” segue a linha instrucionista, ou seja, o aluno acompanha as atividades, orientadas pelo professor; por meio de instruções digitais, o software ajuda o aluno a passar por cada etapa das atividades. O software foi desenvolvido para crianças de 6 a 9 anos, multidisciplinar, visando o atual 3º ano das escolas.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
200
A questão que se investiga é o tipo de contribuição do software e a sua eficácia no processo ensino-aprendizagem em que essas crianças estão envolvidas. Escolheu-se estudar o software “Coelho Sabido na Terra do Queijo” por alguns motivos específicos: 1) sua popularidade entre docentes; 2) sua apresentação didático-pedagógica; 3) su metodologia instrucionista. Dessa maneira, a pesquisa pretende investigar, de forma sistemática, por uma metodologia de pesquisa qualitativa, os resultados imediatos e os resultados a médio prazo desse software no desenvolvimento cognitivo das crianças. O grupo pesquisado possui idade que entre 7 e 16 anos, e tal variação é importante porque corresponde à realidade que o professor encontra em salas dessa natureza. Tomou-se a Língua Portuguesa como referência, visto que os objetivos da disciplina é fundamental para o desenvolvimento de outras, que dependem de boa leitura e compreensão.
Esta pesquisa se orienta a partir da seguinte hipótese: qual o grau de eficiência do software educativo Coelho Sabido na Terra do Queijo, aplicado a crianças com algum tipo de deficiência? As atividades do software ajudam o aluno a desenvolver suas capacidades de leitura, escrita e outras? É o que se verá no decorrer desta investigação.
2. Fundamentação Teórica Em todos os sistemas educacionais do mundo, o atendimento e a inclusão social às crianças com algum tipo de deficiência têm-se tornado um tema importante. O Brasil tem milhares de pessoas com algum tipo de deficiência. Em um Censo realizado em 2010, verificou-se esses números com mais propriedade: idade, gênero, escolaridade, tipo de deficiência. A pesquisa do IBGE resultou na Cartilha do Censo 2010 – Pessoas com Deficiência1 com dados estatísticos de pessoas com algum tipo ou grau de deficiência visual, auditiva, motora e intelectual.
Segundo Kirk (1996), de acordo com o Artigo 208 da Constituição Brasileira, os portadores de deficiência devem ser atendidos preferencialmente na rede regular de ensino, com direito à convivência social e à atenção especial relativa à sua deficiência específica. A escola deve estar preparada para receber essas crianças, o que significa muito mais que oferecer uma estrutura física a esses alunos: é preciso preparar-se com uma capacitação didático-pedagógica de todos os profissionais, em especial os professores, a fim de oferecer uma atenção verdadeiramente adequada a essas crianças.
Dentre os recursos utilizados pelo professor para atender às crianças com algum tipo de deficiência há o computador com seus múltiplos recursos e ferramentas. O computador torna-se, conforme Jucá (2011), uma ligação entre o aluno, o professor e o conhecimento. Os softwares servem como um importante elo de mediação deste conhecimento. Tajra (2011) adverte que não existe um modelo universal a ser seguido: cada educador, cada professor deve procurar sua maneira de usar a tecnologia como ferramenta pedagógica em suas aulas.
No estado de Mato Grosso a sala de Atendimento Educacional Especializado, município de Alto Araguaia, instaurou-se a partir de 2009, seguindo as diretrizes da Lei 8.806, de 10 de Janeiro de 2008, que institui o Plano Estadual de Educação de Mato Grosso. Acredita-se que a informática pode contribuir de forma positiva na educação especial dos estudantes que precisam de apoio para superar suas dificuldades de
1http://www.pessoacomdeficiencia.gov.br/app/sites/default/files/publicacoes/cartilha-censo-2010-pessoas-com-deficienciareduzido.pdf

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
201
aprendizagem, uma vez que esta nova geração de alunos se encontra mergulhada em ambientes digitais.
3. Caso de Estudo Esta pesquisa foi realizada no período de Março a Julho de 2015, com um grupo de 15 alunos na sala de Atendimento Educacional Especializado, da Escola Estadual Arlinda Pessoa Morbeck, do município de Alto Araguaia-MT. Realizaram-se as atividades do software Coelho Sabido na Terra do Queijo com exercícios de Língua Portuguesa e Ciências, utilizando-se recursos interdisciplinares, pois um dos desafios da sala é o de ajudar os alunos a desenvolver suas habilidades de leitura e de escrita. Foi selecionado um aluno para este trabalho, pois a avaliação da pesquisa ainda se encontra em execução. O aluno D.L.P.N de 10 anos, cursa o 4° ano, 1ª fase, 2° ciclo “B”. Ao iniciar suas aulas não estava alfabetizado e dava indícios de deficiência intelectual; com idade avançada, ainda não sabia ler e escrever, além de inquietude e comportamento agressivo com colegas. Iniciou-se o atendimento no mês de fevereiro, e no mês de março inseriram-se as aulas no computador. Com este recurso, ele se mostrou muito interessado com os jogos, mas, como não sabia ler e escrever necessitava de auxílio da professora para poder jogar, e isso acabou por motivá-lo a querer aprender. Hoje lê palavras e pequenas frases, faz ditado de sílabas simples e complexas, e o que é mais importante na visão dele é poder jogar sozinho no computador.
Por fim, a utilização do computador na sala de Atendimento Educacional Especializado, como ferramenta de auxílio da aprendizagem de alunos portadores de necessidades especiais, foi muito importante para a construção do conhecimento dos alunos, podendo-se ressaltar algumas vantagens como:
i. Propiciou-se a integração professor-aluno. ii. Um certo aprendizado da língua materna começou a desafiar os alunos; deu-se
de uma maneira criativa, prazerosa, desafiadora e mostrando resultados positivos. iii. O aluno sentiu uma imensa alegria, motivação, emoção, cooperação e interação.
4. Considerações Finais Escola, professor e metodologia devem se adaptar às novas situações. Os professores, não conseguem acompanhar o ritmo das mudanças, mas é preciso insistir e encontrar um caminho, onde cada educador deve encontrar o seu. Mediante resultados parciais da pesquisa, pôde-se perceber que o computador não veio para ameaçar a educação, mas sim colaborar no processo ensino-aprendizagem.
Referências Jucá, S. C. S. (2011). A relevância dos Softwares Educativos na Educação Profissional,
Ciências e Cognição, v. 8. Kirk, S. A., Gallagher, J. J. (1996). Educação da criança excepcional, Ed. Martins
Fontes, São Paulo. Sassaki, R. K. (2002). Terminologia sobre deficiência na era da inclusão. Revista
Nacional de Reabilitação, São Paulo, ano 5, n. 24, jan./fev. p. 6-9. Tajra, S. F. (2011). Informática na Educação: Novas Ferramentas Pedagógicas para o
Professor na Atualidade, Ed. Érica, 9º ed., São Paulo-SP.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
202
Site para Divulgação de Jogos do Emiep Marcela de Oliveira Sampaio, Janaina Sandes Figueiredo
Técnico em Informática - Escola Estadual Desembargador Milton Armando Pompeu De Barros (EEDMAPB) – Colíder – MT – Brasil
[email protected], [email protected]
Abstract. The paper presents the development of a website to publicize the students of the Escola Estadual Desembargador Milton Armando Pompeu de Barros, encouraging the creation of new games. Which will address both the construction site, as well as the construction of the games, and exemplify their HTML and CSS markup languages along with explanation of the database and the specific programs used in game development, such as PowerPoint and Game Maker. This tool displays the talents of students, encouraging future work.
Resumo. O artigo apresenta a elaboração de um site para divulgar os jogos de alunos da Escola Estadual Desembargador Milton Armando Pompeu de Barros, incentivando a criação de novos jogos. Neste, será abordado tanto a construção do site, como também a construção dos jogos, além de exemplificar as respectivas linguagens de marcação HTML e CSS, juntamente com explanação sobre Banco de Dados e os específicos programas utilizados nos desenvolvimentos dos jogos, como o PowerPoint e o Game Maker. Esta ferramenta expõe os talentos dos alunos, incentivando trabalhos futuros.
1. Introdução Este artigo teve como proposta a criação de um site para expor jogos desenvolvidos pelos alunos do Ensino Médio Integrado ao Ensino Profissionalizante Técnico em Informática, da Escola Estadual Desembargador Milton Armando Pompeu de Barros nos anos anteriores a 2015, incentivando e mostrando a importância dos jogos na formação e na instrução da criança e do jovem, e também o conhecimento para criação de jogos de computadores. Dessa forma, o site encontra-se disponível anexado à página da escola, no endereço: www.eedmapb.org/jogosemiep.
Estudou-se como criar um site e qual a melhor linguagem de programação e marcação a ser utilizada, além de pesquisar a importância de jogos no ambiente escolar e coletar os jogos desenvolvidos pelos alunos para publicá-los.
Como todos os anos são criados muitos jogos pelos alunos do EMIEP - sendo que estes tão bem desenvolvidos nunca foram divulgados ao público - o site proporcionou a oportunidade tanto dos alunos internos e externos, assim como a comunidade em geral de apreciar, aprender e usufruir da criatividade dos alunos exposta nos jogos. Além disso, sabendo da divulgação estes alunos tiveram um estímulo maior em realizar a atividade com mais qualidade, melhorando também o nível de aprendizagem do aluno criador do jogo.
2. Linguagens de Marcação Uma linguagem de marcação é um documento representado por um conjunto de códigos, com a finalidade de adicionar informações e características específicas de uma página web [Mundo Educação 2013].

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
203
Atualmente o HTML é a linguagem de marcação mais utilizada, por ser uma linguagem simples de ser escrita utilizando apenas um programa que permita a criação do documento. Ele é escrito a partir de um conjunto de comandos também chamados de Tags, que atribuem as características de como deve ser exibida a página com a qual se definem as páginas web.
O CSS (Cascading Style Sheets), em português, Folhas de Estilo em Cascata. É um conjunto de informações sobre a formatação e exibição dos componentes de layout de uma página web escrito dentro do código HTML. Ela é um código separado que altera as características da página e específica como as páginas são apresentadas aos usuários.
3. Construção de Jogos Para construção de jogos, os alunos necessitam de pelo menos uma plataforma desenvolvedora, sendo assim, contam com programas como: PowerPoint, que apesar de pouco conhecido como criador de jogos, é de ótimo desenvolvimento para pessoas sem nenhuma experiência na área de produção de jogos, e o Game Maker, um programa que cria jogos com ótima interface e fácil de manusear.
Por ser de fácil utilização, o PowerPoint é o programa mais utilizado pelos alunos da escola Pompeu na criação de seus jogos. O processo de desenvolvimento neste programa não exige experiência, apenas conhecimento do mesmo. Geralmente os jogos são de perguntas e respostas, as quais estão linkadas à telas que informam se a resposta escolhida é correta ou não. Não se realiza uma contagem de pontos, estes jogos são somente para entretenimento e aprendizado.
Já o Game Maker, é um programa de simples manuseio que auxilia no desenvolvimento do raciocínio lógico, programado a partir da linguagem Delphi acompanhado de C++. A utilização deste aplicativo está disponível apenas para o sistema operacional Windows, no entanto, uma vez feito o jogo, é possível exportá-lo para diversas plataformas, como: Ubuntu Linux, Mac, Android, IOS, Windows Phone e diversas outras [Dias 2014].
4. Banco de Dados Houve a necessidade de utilização de um Banco de Dados (BD) no site, para exposição dos jogos facilitando o acesso e download, possibilitando o armazenamento dos jogos de maneira estruturada e com a menor redundância possível. Os jogos, dessa forma, podem ser utilizados por programas e usuários diferentes.
Um BD é um ambiente de armazenamento de dados importantes, sem ele, não haveria como as informações ficarem salvas. É como se fosse uma “caixinha” virtual onde os dados inseridos pelo usuário ficam guardados até posteriores utilizações.
Como o site da escola é privado, foi necessário o auxílio da professora orientadora para ter acesso ao banco de dados, com usuário e senha. Previamente foi definido o URL (endereço do site) de acesso à página de jogos, o qual ficou definido como: http://eedmapb.org/jogosemiep.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
204
5. Desenvolvimento do Site 5.1 Estrutura
A criação do site baseou-se em uma sequência de passos, primeiramente foi definido o seu layout, altura, largura, e formatação. Essa formatação foi feita em CSS, para melhor desenvolvimento e facilidade.
5.2 Jogos Através de pesquisas de campo, foram coletados os jogos ainda existentes sob o domínio da professora de Aulas Práticas e TCC. Estes jogos após serem reunidos foram, posteriormente, testados e selecionados pelas autoras do artigo.
Após sua devida triagem, os jogos escolhidos foram armazenados organizadamente em uma determinada pasta para subsequentemente serem introduzidos ao banco de dados.
Como o site não é independente, estando anexado ao site da Escola Estadual Desembargador Milton Armando Pompeu de Barros, os jogos foram incorporados ao banco de dados do site da escola.
5.3 Site Pronto As imagens do background e topo do site foram desenvolvidas no Adobe Photoshop CS6, enquanto as imagens apresentadas dos jogos foram apenas capturas de telas dos jogos desenvolvidos pelos alunos.
Dessa forma, o site fica disponível à utilização de qualquer pessoa que deseja conhecer, aprender ou apenas entreter com o talento dos ex-alunos da Escola Estadual Desembargador Milton Armando Pompeu de Barros, uma vez que, os alunos responsáveis por estes jogos já se encontram formados no ensino médio.
6. Conclusão Para a realização deste trabalho, foi necessário estudar a linguagem de marcação escolhida para construção do site, além de estudar a forma de armazenamento de um BD, para inserção dos jogos em rede. Teve-se a necessidade de coletar os jogos desenvolvidos pelos alunos com a professora portadora, selecionando-os e então publicá-los.
O site forneceu a oportunidade dos alunos mostrarem seu trabalho, possibilitando futuramente uma carreira nessa área.
Além disso, a exposição possibilitou o uso destes jogos como base para criação de novos projetos em escolas e universidades de todo o país, como também ser utilizado como apoio ao ensino.
Referências
Dias, Raphael. Game Maker: Studio (O guia completo do iniciante). 2014. Disponível em: < http://producaodejogos.com/fazendo-jogos-com-gamemaker/>. Acesso em: Ago. 2015.
Mundo Educação, Eliene. Linguagem de Marcação. 2013. Disponível em: <http://www.mundoeducacao.com/informatica/linguagem-marcacao.htm>. Acesso em: Jun. 2015.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
205
Construção do Saber por meio da Automação Janaina Sandes Figueiredo, Marcela de Oliveira Sampaio
Técnico em Informática – Escola Estadual Desembargador Milton Armando Pompeu De Barros (EEDMAPB) – Colíder – MT – Brasil
[email protected], [email protected]
Abstract. With this article the aim is to show the scientific path taken by students from the Ensino médio Integrado a Educação Profissional – Técnico em informática the Escola Estadual Desembargador Milton Armando Pompeu de Barros, where we introduce a tutorial to the automation of eletric equipaments. It describes the processes and materials used in the construction of the prototype, shows the logic of automation through the programation and comproves by itself the cognitive capacity when put to practice the theory learned in the class room and seek extra elements to this learning, giving meaning to the content.
Resumo. Com este artigo pretendeu-se mostrar o caminho cientifico tomado por alunos do Ensino médio Integrado a Educação Profissional – Técnico em informática da Escola Estadual Desembargador Milton Armando Pompeu de Barros, onde apresentará um tutorial para a automação de equipamentos elétricos. Descreve os processos e materiais utilizados na construção do protótipo, apresenta a lógica da automação através da programação e comprova por si a capacidade de cognição ao colocar em prática a teoria aprendida em sala de aula e buscar elementos extras a esse aprendizado, dando significado aos conteúdos.
1. Introdução
Este trabalho apresenta uma proposta de criação de um protótipo utilizando a plataforma arduino, que simule a automatização de equipamentos elétricos, como ar condicionado, ventilador dentre outros.
Em paralelo à construção do protótipo, foi elaborado um tutorial detalhado mostrando passo a passo os materiais aplicados na construção do mesmo.
2. Metodologia
Para o desenvolvimento do protótipo foram utilizados alguns materiais como: madeira, cooler de computador, parafusos, arduino, bateria, placa protoboard e um transistor.
O cooler simulou um aparelho elétrico. Este foi posicionado a uma casinha de madeira, pois assim ficou um protótipo organizado, onde passou a ideia de simulação de aparelhos de ar condicionado ou ventilador, enfim, vai da imaginação de cada um. E uma interface que trabalhou juntamente com o arduino se comunicando e realizando a transferência de comandos que possibilitam o controle total do projeto.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
206
3. Desenvolvimento
A parte da construção é o momento em que a aprendizagem se solidifica, e a transformação do que foi produzido em algo público inicia os estudantes ao mundo cientifico. Chassot (2003, p. 91) declara “a alfabetização científica pode ser considerada como uma das dimensões para potencializar alternativas que privilegiam uma educação mais comprometida”.
Dessa forma percebe-se a importância aqui de apresentar a metodologia adotada para a construção do protótipo, o que resultou em um pequeno tutorial explicando passo a passo essa montagem.
O motor do cooler foi conectado na placa protoboard e posicionou-se o transistor NPN BD 139, em qualquer lugar da placa. Utilizou-se a porta PWMD arduino UNO, junto com um jumper, ligando no primeiro pino do transistor BD 139. Foi utilizado outro jumper, ligando o GND do arduino ao negativo da bateria e conectando o positivo do motor, no positivo da bateria. Por fim, ligamos o negativo do motor, ao pino do meio do transistor BD 139 e conectamos o ultimo pino do transistor BD 139 ao negativo da bateria.
Nas Figuras 1 e 2, uma apresentação de como resultou todo o processo de colocação dos componentes e o protótipo completo.
Figura 1. Interior da casinha com os componentes instalados

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
207
Figura 2. Protótipo completo
Em seguida, iniciou-se a construção dos programas, para assim ter-se um sistema automatizado, conforme a proposta deste trabalho.
Foi realizada uma programação do acionamento e desligamento do cooler e uma interface utilizando a linguagem de programação C# (C-Sharp). A interface, por meio de botões e outros elementos visuais, transmitirão comandos para a placa microcontroladora arduino, que interpretará esses comandos e irão executar a ação pré-definida, seja essa ação de ligar o cooler, ou de desligar, ou ainda de colocar em programação automática, e o cooler vai ligar e desligar em um intervalo de tempo.
4. Conclusão
Por meio da automação, os horários agendados no sistema para ligar e desligar os equipamentos foram executados, comprovando assim que gastos desnecessários de energia, devido ao esquecimento não aconteceriam. Ao relacionar a automação chega-se a conclusão que as falhas humanas podem ser amenizadas pelos dispositivos criados que realizam e oferece suporte a automatização de equipamentos eletros eletrônicos.
Também se conclui que é possível a materialização do que se é estudado nos cursos técnicos de informática, elevando ainda mais o conhecimento do aluno, tornando-o um cientista.
Referências
Chassot, Attico. Alfabetização científica: uma possibilidade para a inclusão social. Revista Brasileira de Educação, n. 22, p. 89-100, jan. 2003.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
208
Uso de Ambientes Virtualizados para o Ensino de Infraestrutura de Redes
Francisco Renato Cavalcante Araújo
Campus Quixadá – Universidade Federal do Ceará (UFC) Quixadá – CE – Brasil [email protected]
Abstract. This article provides a description of technologies such as virtualization and cloud computing, by focusing on the use of OpenNebula in educational infrastructure of computer networks, presenting a case study with PfSense tool in virtualized cloud environment with the KVM hypervisor. Resumo. Este artigo apresenta uma descrição de tecnologias como a virtualização e a computação em nuvem, dando enfoque no uso do OpenNebula no ensino de infraestrutura de redes de computadores, apresentando um estudo de caso com a ferramenta PfSense no ambiente de nuvem virtualizado com o hipervisor KVM.
1. Introdução Atualmente, com a constante demanda por recursos computacionais e a evolução do hardware de desktops, houve uma necessidade de prover uma melhor utilização desses recursos, e para isso, foi resgatada a ideia de virtualização – uma técnica que permite a instalação de um sistema operacional (SO) dentro de outro, de forma a compartilhar o hardware entre os sistemas instalados. Essa tecnologia ressurgiu nos dias atuais por paradigmas como a computação em nuvem, redes definidas por software, network functions virtualization e mobile cloud computing. A nuvem é uma metáfora para a Internet ou infraestrutura de comunicação entre os componentes arquiteturais, baseada em uma abstração que oculta a complexidade da infraestrutura [Sousa, Moreira e Machado 2009]. Essa tecnologia apresenta facilidade no uso e vem ganhando um vasto espaço no mercado, atraindo usuários. Este artigo retrata as vantagens do uso da virtualização e computação em nuvem no ensino de cursos da área de Tecnologia da Informação (TI). Além disso, um estudo de caso é apresentado.
2. Virtualização com KVM A virtualização dispõe de diversas vantagens, dentre as quais é possível destacar: segurança, disponibilidade, custo, adaptação às diferentes cargas de trabalho, balanceamento de carga e suporte a aplicações legadas [Menascé 2005].
O monitor de máquina virtual (VMM) ou hipervisor é o software responsável por gerenciar as máquinas virtuais (MV), permite a abstração de recursos e fornece às MVs interfaces similares à interface real de hardware. Diversos trabalhos tem utilizado virtualização em ambientes acadêmicos. O trabalho de [Younge et al. 2011] mostrou que o KVM e VirtualBox obtiveram os melhores desempenhos em ambientes de Computação de Alto Desempenho (CAD), com o KVM sobressaindo-se em capacidade de computação e de expansibilidade de memória.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
209
Para o gerenciamento das MVs criadas neste estudo foi utilizado o hipervisor KVM. Como critérios de escolha, foram levados em consideração as vantagens de desempenho e o fato de ser de código aberto.
3. Infraestrutura como um Serviço com OpenNebula A computação em nuvem é um modelo computacional que permite o acesso conveniente, sob demanda de rede a um conjunto compartilhado de recursos computacionais que podem ser rapidamente provisionados e liberados com uma interação mínima do provedor de serviços [NIST 2014]. Este artigo trata do modelo IaaS (Infrastructure as a Service), cujo objetivo é tornar mais fácil e acessível o fornecimento de recursos, tais como servidores, rede, armazenamento e outros recursos de computação fundamentais para construir um ambiente de computação sob demanda, que pode incluir SO e aplicativos. Para gerenciar a infraestrutura da nuvem foi usado a ferramenta OpenNebula – um software de código livre desenvolvido para gerenciar a complexidade e heterogeneidade de grandes infraestruturas distribuídas, pode ser usado para a criação de nuvens públicas, privadas e híbridas. Ele é formado por um conjunto de ferramentas que tem como objetivo fornecer uma camada de gerenciamento flexível, aberta, escalável e abrangente [Wen et al. 2012].
4. Estudo de Caso Nas práticas de laboratório de infraestrutura de redes é importante estudar a configuração de roteadores e switches, bem como aplicar conhecimentos adquiridos previamente sobre controle de acesso, firewall, e configuração de outros serviços em servidores Linux/Windows. Portanto, a instalação e configuração da ferramenta PfSense é uma prática importante para o aprendizado dos alunos de cursos de TI. O PfSense, é um sistema operacional de código aberto usado para transformar o computador em um roteador, com suporte a firewall, VLANs, Proxy, DHCP, etc. Baseado na distribuição FreeBSD e no projeto m0n0wall, é uma distribuição de firewall poderoso e leve, toma decisões de todas as suas funções, e foi adicionado uma variedade de serviços de rede mais usados [Williamson 2011]. O PfSense requer uma máquina com duas interfaces de rede, em que a primeira deve ser conectada à rede WAN, enquanto a segunda à rede LAN. Dessa maneira a Internet é distribuída para as máquinas da rede local. Para realizar essa aula prática são necessárias no mínimo, três máquinas físicas (MF), além de um switch e cabos par trançado para interligar os dispositivos e construir um ambiente de rede local, assim como mostra a Figura 1 (a). O experimento descrito anteriormente pode ser realizado em um ambiente virtualizado, dispensando preocupações com requisitos de hardware para a instalação de software, como também o uso de equipamentos como switch, que é substituído por interfaces bridge do Linux, enquanto que as MFs da LAN são substituídas por MVs, permanecendo apenas a MF com a nuvem instalada, como retrata a Figura 1 (b). Todas essas entidades virtuais são executadas na nuvem, podendo ser utilizada uma ou mais MFs, dependendo do tamanho do experimento e da disponibilidade de MFs no laboratório da instituição.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
210
(a) Ambiente real (b) Ambiente virtualizado
Figura 1. Topologia de rede do estudo de caso.
O estudo de caso implementou a topologia da Figura 1 (b), o PfSense foi executado em uma MV configurada com duas interfaces virtuais de rede, seguindo a mesma proposta da Figura 1 (a), mas dispensando o uso de dispositivos físicos da LAN.
5. Conclusão Esse trabalho apresentou uma forma eficiente para fazer toda a prática de configuração do PfSense em um ambiente virtual, utilizando a virtualização e computação em nuvem para realizar os experimentos de laboratório de infraestrutura de redes de computadores. Pode-se notar que, ao utilizar essas tecnologias, é possível melhorar o ensino, uma vez que é mais fácil aliar as atividades práticas às teóricas, o que enriquece as experiências dos alunos, mesmo em ambientes que não disponibilizam de equipamentos necessários para a realização das aulas e experimentos. Além disso, pode-se ressaltar a redução de gastos com aquisição e manutenção de equipamentos ao utilizar a virtualização. Economia de energia e redução de espaços físicos, também se tornam evidentes com a prática da virtualização. Como trabalhos futuros, pretende-se fazer uma avaliação de desempenho no tráfego da rede do PfSense no ambiente virtual e no ambiente físico.
Referências Menascé, Daniel A. Virtualization: Concepts, Applications, and Performance Modeling.
Int. CMG Conference 2005: 407-414. NIST. (2014). NIST Cloud Computing Program. Disponível em:
<http://www.nist.gov/itl/cloud/>. Sousa, F.; Moreira, L.; Machado, J. Computação em nuvem: conceitos, tecnologias,
aplicações e desafios. In: 3th Escola Regional de Computação Ceará, Maranhão e Piauí ERCEMAPI. PI: EDUFPI, 2009. p. 150-175.
Wen, X. et al. Comparison of open-source cloud management platforms: OpenStack and OpenNebula. In: 9th International Conference on Fuzzy Systems and Knowledge Discovery. Anais...Sichuan: IEEE, 2012. p. 2457-2461.
Williamson, Matt. (2011). PfSense 2 Cookbook, Packt Publishing Ltd. Younge, A. J., Henschel, R., Brown, J. T., von Laszewski, G., Qiu, J., Fox, G. C.,
(2011). Analysis of virtualization technologies for high performance computing environments. IEEE International Conference on Cloud Computing (CLOUD).

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
211
Uma ferramenta para a aplicação de Gamificação com Storytelling no Ensino Superior
Alan R. S. Marcon, Ketelem L. Campos, Cleder A. Cruz, Karen S. Figueiredo
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Av. Fernando Corrêa da Costa, nº 2367 – Bairro Boa Esperança – Cuiabá – MT – Brasil
alanrodrigo,[email protected], ketelemlemos,[email protected]
Abstract. With the aim of demonstrating the potential of gamification as a learning motivator for higher level courses, this article proposes a web application with emphasis on the use of the storytelling method, by applying its concepts both in the preparation of the curse's program, and in the interaction between teachers and students. Resumo. Visando expor as potencialidades da aplicação de gamificação como motivador de aprendizagem em cursos de nível superior, este artigo apresenta uma proposta de ferramenta web com ênfase na utilização do método de storytelling, aplicando seus conceitos tanto na elaboração do conteúdo programático, quanto na interação entre professores e alunos.
1. Introdução As práticas pedagógicas tem sido impactadas pelas mudanças nos paradigmas socioculturais, impulsionadas pelo surgimento de tecnologias digitais. Nesse cenário emerge a gamificação, que é “uso de elementos de design de jogos em contextos não relacionados a jogos” [Deterding et al. 2011]. Destacamos que a utilização dessas ferramentas hoje, já não é uma inovação, sendo estudada e aplicada como uma estratégia de ensino. Neste artigo, buscamos ainda explorar além dos conceitos de gamificação, também o envolvimento trazido pelos jogos eletrônicos por meio de seu enredo (também conhecido como narrativa ou storytelling). Se tratando do uso de gamificação na educação, diversas elementos e técnicas podem ser adotadas para estimular o aprendizado. Assim, o objetivo deste trabalho é propor uma ferramenta que aplique conceitos de gamificação e storytelling para motivar professores a alunos no ensino superior, com uso inicial em disciplinas de cursos com ênfase em tecnologia da informação.
2. Fundamentação Teórica Storytelling seria a capacidade de contar uma história de forma atrativa, esta ideia foi absorvida pelos jogos eletrônicos nos levando ao conceito de digital storytelling, Gils (2011) que trata de contar essa história utilizando-se de mídias digitais. Os jogos geralmente trazem uma interação entre quem conta a história e o seu público alvo, neste aspecto, fica claro o potencial no ensino, ao reformular o conteúdo programático análogo a um jogo com suas fases, conquistas e relacionamento entre os participantes. Segundo Ohler (2007) digital storytelling permite aos estudantes “falarem sua própria língua” em sala de aula, ao passo que atualmente os jogos e/ou a interatividade

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
212
digital estão presentes no dia a dia da maior parte dos alunos, Ohler enfatiza o valor de uma história bem elaborada acima da tecnologia empregada. Kapp (2012) diz que “as pessoas compreendem melhor os fatos quando estes estão inseridos em uma história ao invés de ver uma simples lista de tópicos”. Algo que podemos inferir empiricamente em crianças e adultos. Ao utilizar a prática do ensino gamificado através do storytelling, a prioridade é integrar ainda mais o aluno ao processo de ensino, vinculando de preferência um grupo a um personagem(s) na história, como acontece em jogos de RPG (Rolling Playng Game). Uma característica marcante neste método é o trabalho em grupo, na qual a colaboração entre os participantes é fundamental.
3. A Ferramenta: Game in Class Storytelling A proposta deste trabalho consiste no desenvolvimento de um ambiente web interativo, para acesso do educador como administrador e do aluno como usuário prático “jogador”, onde o conteúdo estudado será adaptado para um novo formato utilizando a temática de jogos e storytelling. A principal funcionalidade é a possibilidade dos alunos acompanharem sua evolução na disciplina, bem como ter acesso ao conteúdo passado, de uma forma que desperte o interesse dos participantes. Outro aspecto é a capacidade do professor e do próprio aluno analisarem o desempenho dos alunos por uma nova perspectiva evolutiva que remete ao modelo de jogos. O apelo visual e a dinâmica são primordiais neste desenvolvimento, elementos notórios em jogos, trazendo para o trabalho uma grande ênfase na área de Interação Humano-Computador (IHC), ampliando os estudos envolvidos. A Figura 1 esboça como seria a interface principal da ferramenta.
Na Figura 1, cada linha representa um participante ou grupo e seu respectivo desempenho em cada capítulo que seria o conteúdo abordado, nessa intersecção constam várias informações, atalhos, estatísticas dentre outras funcionalidades que a ferramente pretende disponibilizar.
Figura 1. Página de acompanhamento geral da ferramenta

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
213
As Figuras 2 e 3 mostram exemplos de abordagens interativas com usuário, exibindo informações no estilo de pop-ups. A ideia é se utilizar os aspectos considerados eficientes (estéticas, mecânicas, imersividade e dinâmicas) em jogos para “emular os benefícios que costumam ser alcançados por eles” [Vianna 2013].
4. Conclusões Estudos têm mostrado que novos ambientes de aprendizado exercem um impacto positivo no ensino em sala de aula [Ware 2008]. Este artigo é fruto experiências positivas utilizando gamificação no ensino superior em computação, como podemos observar em outros trabalhos, como em Figueiredo (2015). Um aspecto delicado é saber avaliar a relevância de se ter um “vencedor” ao final de um capítulo/disciplina, neste caso a vitória ocorre quando todos concluem o conteúdo com êxito. Este trabalho apresentou uma promissora ferramenta de auxílio pedagógico, esperamos expor resultados práticos de seu desempenho em trabalhos futuros, aplicando estes conceitos em sala, contando com a participação voluntária dos alunos, para assim dar continuidade às pesquisas.
Referências Deterding, S. et al. (2011). From game design elements to gamefulness: defining
gamification. In: Proceedings of the 15th International Academic MindTrek. Figueiredo K. S. (2015). Proposta de Gamificação de Disciplinas em um Curso de
Sistemas de Informação (SBSI 2015). Gils, F. (2011). Potential Applications of Digital Storytelling in Education. Disponível
em http://wwwhome.ctit.utwente.nl/~theune/VS/Frank_van_Gils.pdf . Acessado em 15/12/2011. Conference: Envisioning Future Media Environments, ACM, p.9-15.
Kapp, K. M. (2012). Games, Gamification, and the Quest for Learner Engagement. Ohler, J. (2007). Digital Storytelling in the Classroom:New Media Pathways to
Literacy, Learning and Creativity. Thousand Oaks, CA: Corwin Press. Vianna, Y. et al. (2013). Gamification, Inc: como reinventar empresas a partir de jogos.
[S.l.]: Rio de janeiro: MJV Press, 2013. 1, 5, 6. Ware, P. (2008). Language learners and multimedia literacy in and after school.
Pedagogies:An International Journal, 3, 37-51.
Figura 3. Perfil do aluno jogador Figura 2. Descrição do conteúdo de um capítulo

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
214
Jogos Educacionais no Processo de Ensino-Aprendizagem da Matemática: Estudo sobre o Software TuxMath
Daniele D. de Paula, Jones F. Giacon
Curso de Sistemas de Informação Centro Universitário Luterano de Ji-Paraná (CEULJI/ULBRA)
Ji-Paraná – RO – Brasil [email protected], [email protected]
Abstract. This study aims to verify the use of TuxMath software will provide the aggregation of math skills. The study is being conducted. To date it selected a group of the 3rd year of primary school, with students aged 09-12 years who were assessed for computer skills, at the Municipal School of Early Childhood Education and Elementary Education Jamil Vilas Boas, in the municipality of Ji-Paraná - RO. Resumo. Este estudo tem como principal objetivo verificar se o uso do software TuxMath irá proporcionar a agregação de conhecimentos de matemática. O estudo está sendo realizado. Até o presente momento foi selecionada uma turma do 3° ano do ensino fundamental, com alunos entre 09 a 12 anos, que foram avaliados quanto aos conhecimentos de informática, na Escola Municipal de Educação Infantil e Ensino Fundamental Jamil Vilas Boas, no município de Ji-Paraná - RO.
1. Introdução Atualmente a matemática é um dos pontos que precisa de mais atenção nas escolas, sendo a área que os alunos possuem menor rendimento. De acordo com dados divulgados pelo MEC (2015), houve uma queda de 7,3 % no desempenho da prova de matemática no e Exame Nacional de Ensino Médio (ENEM) 2014, comparado com o ano de 2013.
Os alunos não estão aprendendo o mínimo esperado em matemática, terminando o ensino médio com um nível de aprendizagem abaixo do que deveriam ter [IG 2010 e G1 2014]. Resultados da prova Brasil no município de Ji-Paraná mostram que 49% dos alunos do 5° ano possuem o aprendizado adequado para sua série, enquanto apenas 12% dos alunos do 9° ano apresentam o nível esperado de aprendizagem da matemática [INEP 2013].
Sabendo desta carência no ensino da matemática, como os jogos educacionais podem contribuir na aprendizagem de matemática? A utilização do software educacional TuxMath proporciona um aprendizado esperado no estudo de matemática?
Desde modo, a intenção desta pesquisa consiste em mostrar como o uso de softwares educacionais podem contribuir no ensino-aprendizagem da matemática, para este estudo será utilizado o software TuxMath, trata-se de um jogo educacional que possui operações matemáticas de adição, subtração, divisão e multiplicação, este pode ser encontrado no sistema Linux Educacional.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
215
2. Objetivos
2.1. Objetivo Geral Este trabalho tem como objetivo analisar o software educacional TuxMath, e verificar se o uso deste software proporciona a agregação de conhecimento de matemática.
2.2 . Objetivos Específicos • Analisar sobre os benefícios da utilização de jogos educacionais no processo de
aprendizagem. • Verificar o desempenho obtidos pelos (as) alunos (as) através da utilização do
software educacional TuxMath. • Relatar sobre as dificuldades encontradas quanto a utilização do software
educacional TuxMath no ensino.
3. A Utilização de Software para Auxiliar no Processo de Aprendizagem O crescimento acentuado das tecnologias é notório a cada dia, sempre algo novo é inserido no mundo tecnológico, com este avanço se faz necessário à inovação em vários campos da vida das pessoas e, porque não inovar também no processo de ensino-aprendizagem?
Muitas crianças e adolescentes ficam por horas jogando, empenhados em avançar o próximo nível do jogo, a fim de vencer cada desafio que este o propõe [Savi e Ulbricht 2008]. Deste modo, é possível notar que a utilização destas tecnologias pode ajudar no processo de ensino-aprendizagem, contribuindo para um ensino melhor [Scarduelli e Elias, 2006].
Papert (1994), afirma que o processo de ensino precisa mudar tanto no aspecto do conteúdo que é ensinado quanto ao modo dos educadores ensinarem, é preciso despertar o interesse das crianças, fazendo com que elas busquem pelo conhecimento e queiram de fato aprender. Através da utilização de jogos educacionais é possível despertar o interesse dos alunos no processo de aprendizagem, proporcionando um ensino mais divertido, permitindo que os mesmos aprendam “brincando”. Assim, estudar matemática se tornará um desafio, onde os alunos se empenharão para avançar o próximo nível do jogo. Tornando-se uma tarefa divertida, onde os alunos terão vontade de aprender cada vez mais.
O software TuxMath também conhecido como Tux Of Math Command, é um jogo matemático inicialmente desenvolvido para Linux, tendo versões para o Windows e para MacOS. O objetivo do jogo consiste na eliminação de meteoros que caem com intenção de destruir os iglus que abrigam os pinguins do jogo. Para acabar com a ameaça o jogador precisa acertar as operações matemáticas, lançando um laser no meteoro quando o resultado estiver correto [Sousa 2013]. Este software tem como objetivo estimular o raciocínio do aluno, fazendo com que o ele pense rápido na resposta para conseguir avançar para a próxima etapa. Desde modo, a pesquisa objetiva comprovar se o uso do TuxMath proporcionará um raciocínio lógico esperado, acabando assim com a deficiência no processo de aprendizagem da matemática.
4. Metodologia Será realizada uma pesquisa sobre jogos educacionais no processo de ensino

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
216
aprendizagem da matemática utilizando o software TuxMath. A mesma terá uma abordagem qualitativa, com objetivo de analisar o desempenho dos alunos neste processo. Para realizar este estudo serão utilizados como instrumentos, a observação, entrevista com os professores e alunos, verificando assim o desempenho e rendimento dos alunos na disciplina em questão e atividades prática no laboratório de informática. Com a utilização deste software os alunos terão uma atividade mais atrativa, o que poderá contribuir no processo de aprendizagem.
A realização deste processo ocorrerá na Escola Municipal de Educação Infantil e Ensino Fundamental Jamil Vilas Boas, com alunos entre 09 a 12 anos, do 3° ano do ensino fundamental, devendo ocorrer no primeiro semestre do ano de 2016.
5. Resultados Esperados Espera-se com o desenvolvimento desta pesquisa, mostrar que o uso do software TuxMath irá proporcionar a agregação de conhecimentos de matemática, contribuindo para o desenvolvimento do raciocínio lógico do aluno. Pretende-se, ainda, demonstrar que o uso do software TuxMath pode auxiliar no processo de aprendizado tornando o ensino mais atrativo para os alunos.
Referências G1, Portal. (2014). “Cai para 11% o índice de alunos que aprendem o esperado em
matemática”. Disponível em <http://g1.globo.com/educacao/noticia/2014/12/cai-para-11-o-indice-de-alunos-que-aprendem-o-esperado-em-matematica.html>.
IG, Portal. (2010). “90% Saem do ensino médio sem aprender o esperado em matemática”, Disponível em <http://ultimosegundo.ig.com.br/educacao/90+saem+do+ensino+médio+sem+aprender+o+esperado+em+matematica/n1237845405859.html>.
INEP, Prova Brasil. (2013). “Aprendizado dos alunos: Ji-Paraná”, Disponível em <http://www.qedu.org.br/cidade/4437-ji-parana/aprendizado>.
MEC. Enem. (2015). “2014: nota dos alunos do ensino médio em redação e matemática piora”, Disponível em <http://www.ebc.com.br/educacao/2015/01/enem-2014-constata-piora-em-redacao-e-matematica-no-ensino-medio>.
Papert, S. (1994). “A máquina das crianças: Repensando a escola na era da informática”, Trad. Sandra Costa. – Porto Alegre, Artes Médicas.
Savi, R.; Ulbricht, V. R. (2008). “Jogos Digitais Educacionais: Benefícios e Desafios”. Disponível em <http://www.seer.ufrgs.br/renote/article/viewFile/14405/8310>.
Scarduelli, A. M.; Elias, K. (2006). “Informática na educação com software livre”. Disponível em <http://classe.geness.ufsc.br/images/d/d9/Tcc-informatica_na_educacao-esucri-nov2006-parte-I.pdf>.
Sousa, J. D. (2013). “Os jogos como recursos didáticos para a melhoria da aprendizagem dos aprendentes nas aulas de matemática”. Disponível em <http://bit.profmat-sbm.org.br/xmlui/bitstream/handle/123456789/868/2011_00645_JOAO_DEHON_DE_SOUSA.pdf?sequence=1>.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
217
Sistema de Automação de Baixo Custo para Irrigação: estudo de caso em uma Horta Caseira Natural
Kaue S. A. Arima, Roberto B. O. Pereira, Mauricio F. L. Pereira
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Av. Fernando Corrêa da Costa, nº 2367 – Boa Esperança – Cuiabá – MT – 78060-900
[email protected], [email protected], [email protected]
Abstract. The purpose of this study was to create a low-cost automation system to monitor and control irrigation of agricultural crops, with the case study in a home garden, taking into account the humidity, providing a better use of water and assisting the user in planting by sending messages, stating the day of composting and the current stage of planting. To this end, Arduino architecture was used with an Ethernet Shield for control and sending messages, and a plate was also developed that controls the irrigation process. Two experiments, one with arugula and mint and others with arugula and radish were performed. It is noteworthy that the system worked correctly in both scenarios.
Resumo. A proposta desse estudo foi criar um sistema de automação de baixo custo para monitorar e controlar a irrigação de cultivos agrícolas, com o estudo de caso em uma horta caseira, levando em consideração a umidade do ar, proporcionando uma melhor utilização da água e auxiliando o usuário no plantio através de envio de mensagens, informando o dia de adubar e o atual estágio do plantio. Para tal, foi utilizada a arquitetura do Arduino com uma Shield ethernet para controle e envio de mensagens, e também foi desenvolvida uma placa que controla o processo de irrigação. Foram realizados dois experimentos, um com rúcula e hortelã e outros com rúcula e rabanete. Ressalta-se que o sistema funcionou corretamente nos dois cenários.
1. Introdução A irrigação é uma etapa fundamental para o bom desenvolvimento de um cultivo agrícola, pois por meio da aplicação de água, aumenta-se a eficiência de uso de outros insumos, como fertilizantes e adubos [Queiroz et al., 2008]. Contudo, quando aplicada em excesso, a irrigação aumenta o custo de produção e reduz a produção [Marouelli et al. 2003]. Diante disso, esse estudo tem como objetivo criar um sistema de automação de baixo custo para irrigação, que leva em consideração a umidade do ar, para melhorar o controle e o monitoramento da água que está sendo utilizada. Dessa forma, pretende-se possibilitar aos pequenos e médios agricultores uma melhor qualidade em seus produtos finais. Ressalta-se que o monitoramento do cultivo será efetuado por meio de mensagens enviadas ao usuário, tratando sua irrigação, sem o desperdício de água e auxiliando em relação ao período de colheita e seus respectivos processos para o melhor cuidado de seu plantio.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
218
2. Métodos
2.1 Hardwares Para a realização desse trabalho foi elaborado um levantamento de requisitos de hardware, levando em consideração que o equipamento deveria ser de baixo custo e de fácil manipulação. A partir desses requisitos, foi utilizado o Arduino Uno para controlar a estrutura de irrigação, pois atende a todas as necessidades do projeto além de ser de baixo custo. Para a comunicação via web foi utilizado uma shield Ethernet e para controle do tempo utilizou-se o RTC (Real Time Clock) DS1307. Com relação ao controle de temperatura e umidade relativa do ar foi utilizado o DHT22, é um sensor digital de baixo consumo de energia [Sparkfun 2010] . Para controle do fluxo de água foram utilizadas válvulas solenoides. Foi projetada uma placa de circuito impresso para facilitar a conexão entre os componentes do projeto. Também foi construída uma estrutura de irrigação que desse suporte ao plantio, feita de ferro para ser parafusado na parede. Para irrigar as plantas, foram feitos furos de 2mm no cano de PVC, espaçados a cada 3cm.
2.2 Softwares Para a elaboração do firmware do sistema, foi realizado um levantamento de requisitos necessários para atender as demandas deste trabalho. Assim, foi criado um webserver no Arduino que possibilitava a configuração do plantio via web. Este sistema permite o envio de e-mails de alerta para o usuário, informando o dia de colheita ou o dia de adubação. Também foi implementado um fator de correção para ajustar o tempo de irrigação do plantio, que de acordo com a umidade relativa do ar, ajusta o período de irrigação para mais ou menos tempo. As opções de cultivos desse sistema foram previamente estabelecidas no firmware contendo os prazos de colheita e adubação, que serão informados pelos alertas nos dias esperados. 2.3 Cenários de testes No primeiro cenário de plantio, foram utilizados dois cultivos para o experimento, usando sementes de rúcula e de hortelã. Plantadas por meio de covas de aproximadamente dois centímetros e uma cobertura de capim. Já no segundo cenários de plantio, foram utilizadas sementes de rúcula e de rabanete. Plantadas em linhas com profundidade de aproximadamente de um centímetro sem a cobertura de capim e revirando o solo antes de criar as linhas.
3. Resultados Após a construção do hardware dedicado e o desenvolvimento do firmware do sistema microcontrolado, foi possível efetuar a irrigação nos dois horários do dia. Como resultado do sistema de configuração foram geradas duas páginas, uma que contém uma opção para o usuário escolher quantos cultivos será plantado, qual porta do sistema que cada um utilizaria e um campo para inserir o e-mail para envio dos informativos, conforme o apresentado na Figura 1 (a), e a outra página criada para o reset do sistema. Para o cenário 1, o sistema funcionou corretamente irrigando todos os dias no horário marcado, porém nem um cultivo germinou, devido a falhas no plantio da planta.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
219
Já no cenário 2 as sementes germinaram e cresceram corretamente conforme a Figura 1 (b).
a) b)
Figura 1. (a) Pagina de Configuração Principal – (b) Vasos do Cultivo - Cultivo de Rúcula, Cultivo de Rabanete.
Contudo, com o passar dos dias e com alguns centímetros já crescidos, o cultivo de rúcula foi atacado por lagartas e o do rabanete por fungos, o que não possibilitou a colheita dos produtos.
4. Conclusão O sistema de irrigação funcionou corretamente, atuando nos horários estabelecidos e fazendo as correções necessárias com base na umidade relativa do ar. A interface web desenvolvida possibilitou a configuração de forma intuitiva, atendendo as demandas desse trabalho. A plataforma de desenvolvimento Arduino mostrou-se robusta e eficiente para o bom gerenciamento do cultivo. O hardware desenvolvido atendeu a todas as necessidades para o bom funcionamento dos cenários, assim, de forma satisfatória a este trabalho.
Agradecimento Agradecemos à FAPEMAT (Processo 749775/2011) pelo apoio ao projeto.
Referências Queiroz, T. M. D.; BOTREL, T. A.; FRIZZONE, J. A. (2008). Desenvolvimento de
software e hardware para irrigação de precisão usando pivô central. Rev. Bras. Eng. Agaric. Am, SciELO Brasil, v. 28, n. 1, p. 44–54.
Marouelli, W. A.; CALBO, A. G.; CARRIJO, O. A. (2003). Viabilidade do uso de sensores do tipo irrigas R para o manejo da irrigação de hortaliças cultivadas em substratos. Horticultura Brasileira, Brasília, v. 21, n. 2, p. 286.
Sparkfun. DHT22. [S.l.], (2010). Disponível em: <https://www.sparkfun.com/datasheets/Sensors/Temperature/DHT22.pdf>.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
220
Estudo comparativo entre as versões do protocolo HTTP 1.1 e HTTP/2
Faride Fernandes S. Junior, Luiz Paulo P. Silva, Rothschild Alencastro Antunes
Instituto Federal de Educação, Ciência e Tecnologia de Mato Grosso
Rua Professora Zulmira Canavarros, 93 Cuiabá – MT– Brasil [email protected], [email protected],
Abstract. This article has the goal to perform a comparative report between current HTTP/ 1.1 protocol version and new version of this, HTTP/2. This report will present improvements and features of this new version.Resumo. Este artigo tem como objetivo realizar um estudo comparativo entre a versão atual do protocolo HTTP 1.1 e a sua mais recente versão, o HTTP/2. Serão apresentadas as melhorias e as características da nova versão.
1. IntroduçãoO Protocolo de Transferência de Hipertexto ou HTTP é um protocolo usado para programas que se comunicam na Web. Existem muitas utilizações para este protocolo, entretanto a mais utilizada é a comunicação entre servidores Web e os navegadores de internet.
Para que os navegadores da Web de todo mundo, aplicações Web e servidores Web possam se comunicar é necessária a utilização de um protocolo que organize e estabeleça as regras que deverão ser utilizadas. Atualmente este protocolo é o HTTP ou Hipertext Transfer Protocol e por isso é considerado o idioma da internet global moderna.
Deste modo, este artigo apresenta as principais diferenças entre as duas últimas versões e as principais novidades da versão mais recente (HTTP/2).
2. Como funciona o HTTP/1.1Segundo Fielding et. al. (1999), o protocolo HTTP é um protocolo focado na solicitação e resposta de conteúdos Web. Estes conteúdos ficam guardados em servidores Web e por este motivo estes servidores também são conhecidos como servidores HTTP. Estes servidores aguardam uma solicitação de um cliente para então enviar os conteúdos solicitados. O cliente envia uma solicitação HTTP na forma de um método de solicitação bem como todas as outras informações necessárias tais como: a URI, versão do protocolo e etc. Uma vez que o servidor Web recebe a solicitação enviada pelo cliente, este responde com a informação solicitada, caso esta esteja disponível, ou responde com uma mensagem informando o erro de solicitação. A maioria das comunicações HTTP é iniciada pelos clientes e juntos eles formam os componentes básicos da World Wide Web. O protocolo HTTP foi projetado para ser simples, entretanto esta simplicidade trouxe um custo no desempenho das aplicações, pois os clientes que utilizam esta

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
221
versão precisam abrir múltiplas conexões para reduzir latência provocando uma concorrência entre estas conexões. E como o protocolo HTTP utiliza uma conexão TCP para transporte dos dados, isto provoca um excesso de informações desnecessárias uma vez que já existe uma conexão TCP aberta e esta versão não utiliza nenhum tipo de compressão dos cabeçalhos. Esta técnica é conhecida como pipelling. Conforme Grigorik (2015) este comportamento tem uma consequência direta no modelo de entrega desta versão e garante que somente uma resposta pode ser entregue em cada vez por conexão. Isto tem consequências indesejáveis, uma vez que resulta em um fenômeno conhecido como HOL blocking, ou seja, uma limitação no desempenho que ocorre quando uma linha de pacotes é segurada pelo primeiro pacote, bem como o ineficiente uso da conexão TCP.
3. HTTP/2Entre as novidades desta nova versão do protocolo, será destacada a mais significante, a introdução de uma camada de enquadramento binário no cabeçalho do protocolo HTTP/2 o que possibilitou a utilização da técnica de multiplexação. Esta nova camada removeu as limitações, citadas na seção anterior que trata sobre a versão 1.1, elimina a necessidade de múltiplas conexões para habilitar o processamento paralelo e habilita a utilização de multiplexação completa de solicitações e resposta permitindo que cliente e servidor desmembrem em pequenos pedaços as mensagens HTTP e transmita-os em pacotes independentes tornado as aplicações mais rápidas, mais simples e mais baratas para implementar, assim como afirmado em Grigorik (2015).
Conforme Belche et.al. (2015), a técnica de multiplexação foi implementada para diminuir o número de conexões TCP abertas que tinham como objetivo reduzir a latência nos streams HTTP e também o tráfego desnecessário de informações geradas devido a abertura de cada nova conexão TCP aberta, ou seja, tornou-se possível enviar diversos pacotes, intercalando o envio de solicitação e resposta utilizando apenas uma conexão por stream e não mais múltiplas conexões TCP para cada stream como na versão 1.1. Isto está ilustrado na Figura 1.
Figura 1. HTTP/2 multiplexação de solicitação e resposta dentro de uma conexão
compartilhada. A eficiência desta técnica de multiplexação de streams é garantida pela priorização e também pelo mecanismo de controle de fluxo. O primeiro garante que recursos limitados sejam direcionados para os streams mais importantes. E o segundo ajuda a garantir que somente os dados que sejam usados por um receptor sejam transmitidos, assim como é afirmado na RFC7540. A Figura 2 ilustra uma conexão HTTP/2 onde é mostrada a utilização da priorização das mensagens dentro de um stream.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
222
Figura 2. Representação gráfica de uma conexão HTTP/2.
4. ConclusãoApós essa breve descrição sobre uma das melhorias implementadas na nova versão do protocolo HTTP/2, pode-se concluir que houveram benefícios consideráveis no desempenho das aplicações Web, tais como redução no tempo das respostas de solicitação de uma página ou conteúdo Web e a redução de tráfego de rede desnecessário causado pelas conexões TCP abertas pela técnica de pipelining utilizado na versão 1.1. Os principais navegadores utilizados atualmente suportam esta nova versão do protocolo HTTP e os usuários deverão experimentar uma navegação mais rápida e um detalhe muito importante é que as aplicações existentes podem ser entregues sem a necessidade de modificações uma vez que o núcleo da funcionalidade e semântica do protocolo não sofreram alterações. Entretanto é de grande utilidade que a atualização dos servidores da Web ocorra no menor tempo possível para que os benefícios desta nova versão do protocolo possam ser aproveitados por todos os usuários da World Wide Web.
ReferênciasBelshe, M.; BitGo; R. Peon (2015). “Request for Comments: 7540”, Internet
Engineering Task Force (IETF).
Fielding, R. UC Irvine, J. Gettys Compaq/W3C, J. C. Mogul Compaq, H. Frystyk W3C/MIT, L. Masinter Xerox, P. Leach Microsoft, T. Berners-Lee W3C/MIT (1999). “Request for Comments: 2068”, Network Working Group.
Gourley, David; Totty, B.; Sayer, M.; Aggarwal, A.; Reddy, S. (2002). “HTTP:The Definitive Guide”, Published by O´Reilly Media, Inc 1005 Gravenstein Highway North, Sebastopol, CA.
Grigorik, Ilya (2015). “HTTP/2: A New Excerpt from High Performance Browser Networking”, Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
223
Neurofeedback e Reabilitação Virtual na terapêutica posterior ao Acidente Vascular Cerebral
Dyeimys Franco Correa, Marcos Wagner S. Ribeiro
Instituto de Ciências Exatas e Tecnológicas (ICET) - Universidade Federal de Goiás BR 364, km 195, nº 3800, CEP 75801-615
[email protected], [email protected]
Resumo. O objetivo geral dessa pesquisa é criar uma aplicação que use interação natural por meio de Neurofeedback no processo da recuperação ao acometimento por AVC, definindo protocolos e/ou práticas que visem a reabilitação motora de pacientes espásticos no pós AVC e construção de um ambiente de interação natural para auxiliar na reabilitação de pacientes com sequelas oriundas do AVC. Abstract. The overall objective of this research is create an application that use natural interaction through Neurofeedback in the recovery process of stroke patients by defining protocols and/or practices aimed at motor rehabilitation of spastic patients after stroke and building an environment of interaction natural to assist in the rehabilitation of patients with sequels resulting from stroke.
1. Introdução Segundo a Organização Mundial da Saúde (2006), o Acidente Vascular Cerebral (AVC) é um distúrbio neurovascular de início súbito, podendo levar à morte. O AVC é uma patologia dispendiosa pelo fato de ser responsável por um grande número de mortes prematuras e acarretar incapacidades contínuas em muitos sobreviventes. Este distúrbio causa a interrupção do suprimento sanguíneo no cérebro, acarretando a morte de células e causando lesões no Sistema Nervoso Central (SNC). Os sobreviventes do AVC tendem a apresentar algumas sequelas, tendo como consequência danos motores, cognitivos e social. Uma das principais causas da perda funcional é a espasticidade1, portanto, este fator deve ser priorizado em intervenções terapêuticas, neste sentido, a reabilitação faz-se necessária, pois a ausência de terapêuticas nesse aspecto influenciará drasticamente na qualidade de vida dos indivíduos [Teive et al. 1998; Assis 2010]
Neuroplasticidade é a capacidade que o SNC possui em modificar algumas das suas propriedades morfológicas e funcionais em resposta às alterações do ambiente, desempenhando um papel fundamental no quadro de reabilitação [Oliveira et al. 2001]. Dentre as técnicas que utilizam a Neuroplasticidade como suporte à reabilitação, a Terapia de Restrição e Indução do Movimento (TRIM) apresenta um bom prognóstico. A literatura tem apontado que a utilização da prática mental acompanhado da metodologia TRIM apresenta resultados satisfatórios [Bastos et al. 2013; Assis 2010].
De modo complementar, o Biofeedback é uma técnica comportamental de condicionamento operante utilizada na aprendizagem de controle voluntário de
1 Distúrbio de controle muscular, caracterizado por músculos tensos ou rígidos e uma incapacidade de
controlar tais músculos

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
224
respostas fisiológicas específicas. No domínio do Biofeedback, existe o Neurofeedback (EEG biofeedback), que monitora a atividade das ondas eletroencefalográficas a partir de sensores colocados no couro cabeludo do paciente. Tais sensores são utilizados no tratamento de várias patologias [Muratori e Muratori 2012]. Para Bastos et al. (2013), estudos utilizando técnicas comportamentais e de neuroimagem confirmam a existência de um forte paralelismo entre a imaginação e a execução de um determinado movimento.
Dessa forma, o uso de Ambientes Virtuais e Interação Natural pode ser uma solução extremamente viável para pessoas que necessitam do processo de reabilitação. A utilização de Ambiente Virtual para fins de reabilitação é conhecida como Reabilitação Virtual. Esse tipo de reabilitação tem recebido atenção de pesquisadores e médicos que reconhecem seus benefícios devido ao seu potencial terapêutico e demonstram que existe uma aparente eficácia neste modelo de reabilitação [Longo 2015; Turolla et al. 2013].
Há uma discussão na literatura científica a respeito do fato de sistemas de Interface Cérebro-Máquina (ICM) possuírem potencial para auxiliar na reabilitação de pacientes com deficiências motoras por meio de Neurofeedback, particularmente as resultantes de lesões no SNC devidas ao AVC. Neste caso, os sistemas usados são os dispositivos ICM baseados em imaginação de movimento [Brandão et al. 2014]. Estes utilizam sinais elétricos cerebrais para ativar computadores, interruptores ou próteses. É importante destacar que este modelo de Interface apresenta caráter interdisciplinar, integrando a neurociência, fisiologia, psicologia, engenharias, ciência da computação e outras disciplinas técnicas e da saúde [Costa e Oliveira 2012].
2. Metodologia A aplicação será composta por um ambiente virtual, com o qual o usuário poderá interagir por meio de técnicas de ICM. O ambiente virtual será composto por um humanoide (Representação 3D de um ser humano) que representará os movimentos do paciente, movimentos estes pensados na prática mental.
3. Trabalhos Relacionados Como justificativa para a elaboração deste trabalho, a literatura apresenta um vasto acervo de trabalhos que ratificam a investigação no sentido do uso da Reabilitação Virtual. Demonstram ainda, que a integração da metodologia TRIM e a prática mental, traz um ganho satisfatório [Souza et al. 2012; Muratori e Muratori 2012; Costa e Oliveira 2012; Assis 2010].
4. Terapêutica posterior ao Acidente Vascular Cerebral O processo de reabilitação em indivíduos acometidos por AVC, quando iniciado prematuramente, apresenta um melhor prognóstico, pois a melhora funcional destes pacientes é mais rápida durante os primeiros meses após o AVC [Souza et al. 2012]. Porém, cabe ressaltar que, com o uso de terapêuticas de reabilitação, os ganhos funcionais podem continuar anos mais tarde. Estes ganhos são provenientes da Neuroplasticidade [Souza et al. 2012].
A Terapia de Restrição e Indução do Movimento (TRIM) é um método fisioterápico para reabilitação motora, que enfatiza a prática de atividades com o Membro Superior (MS) afetado e restringindo o MS não acometido [Souza et al. 2012].

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
225
Adicionalmente, levantamentos feitos por [Bastos et al. 2013; Assis 2010] investigam os efeitos da prática mental na aprendizagem da habilidade motora, concluíram que a prática mental, quando combinada com a prática física pode elevar o desenvolvimento motor do paciente.
5. Conclusão Tendo como premissa os trabalhos que apontam a viabilidade do uso da metodologia TRIM em conjunto com prática mental e as possibilidades de avanço da Reabilitação Virtual, este projeto deve gerar como produto um sistema que auxilie o processo de reabilitação motora de membros superiores de pacientes espásticos acometidos por AVC.
Referências Assis, G. A. (2010). NeuroR - sistema de apoio à reabilitação dos membros superiores
de pacientes vítimas de acidentes vasculares encefálicos. Tese de Doutorado, Universidade de São Paulo, 158p.
Bastos, A. F., Souza, G. G. L., Pinto, T. P., de Souza, M. M. R., Lemos, T.; Imbiriba, L. A. (2013). Simulação mental de movimentos: Da teoria à aplicação na reabilitação motora. Revista Neurociencias, 21(4): 604–619.
Brandão, A. F., Jordan, G., Brasil, C., Roberto, D., Dias, C., Regina, S., Almeida, M., Castelhano, G.; Trevelin, L. C. (2014). Realidade Virtual e Reconhecimento de Gestos Aplicada as Áreas de Saúde. Tendências e Técnicas em Realidade Virtual e Aumentada, 1(4): 33–48.
Costa, R. C.; Oliveira, V. M. D. (2012). Um Estudo sobre Interface Cérebro-Computador. Trabalho de Conclusão de Curso de Ciência da Computação, Universidade de Brasília, 157p.
Longo, B. B. (2015). Desenvolvimento de Ferramentas para Pesquisas em Tecnologias Assistivas Baseadas em Sinais Biológicos. Dissertação de Mestrado. Programa de Pós-Graduação em Biotecnologia do Centro de Ciências da Saúde, Universidade Federal do Espírito Santo, 70p.
Muratori, M. F. P.; Muratori, T. M. P. (2012). Neurofeedback na reabilitação neuropsicológica pós-acidente vascular cerebral. Revista Neurociencias, 20(3):427–436.
Souza, R. C. P., Terra, F. R., Carbonero, F. C.; Campos, D. (2012). Terapia de restrição e indução do movimento em hemiparéticos. Revista Neurociencias, 20(4):604–611.
Oliveira, C. E. N., Salina, M. E.; Annunciato, N. F. (2001). Fatores ambientais que influenciam a plasticidade do snc. Acta Fisiátrica, 8(1):6–13.
Organização Mundial da Saúde, OMS (2006). Manual STEPS de Acidentes Vascular Cerebrais da OMS: enfoque passo a passo para a vigilância de acidentes vascular cerebrais. Genebra, Organização Mundial de Saúde, pages 1–121.
Teive, H. a. G., Zonta, M.; Kumagai, Y. (1998). Tratamento da espasticidade: Uma atualizacao. Arquivos de Neuro-Psiquiatria, 56(4):852–858.
Turolla, A., A., Dam, M., Ventura, L., Tonin, P., Agostini, M., Zucconi, C., Kiper, P., Cagnin, A.; Piron, L. (2013). Virtual reality for the rehabilitation of the upper limb motor function after stroke: a prospective controlled trial. Journal of neuroengineering and rehabilitation, 10(1):85.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
226
Proposta de arquitetura do processo de implantação de indicadores de desempenho de projetos utilizando
metodologia de Business Intelligence Rondinely Oliveira, Nilton H. Takagi, João Luiz Oliveira Ribeiro, Josiel M.
Figueiredo
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT)
Av. Fernando Corrêa da Costa, 2367 – Boa Esperança – Cuiabá – MT – Brasil [email protected], [email protected], [email protected],
Abstract. This work proposes the initiative to create an architecture of a performance indicator deployment process on web platform of existing projects at the Computer Institute of the Federal University of Mato Grosso (IC-UFMT) using techniques of Business Intelligence. The presentation of consolidated dashboards aims to further verify the potential impact that this action will result in the development and success of the projects
Resumo. Este trabalho tem como proposta a iniciativa de criação de uma arquitetura de um processo de implantação de indicadores de desempenho em plataforma web dos projetos existentes no Instituto de Computação da Universidade Federal de Mato Grosso (IC-UFMT), utilizando técnicas de Business Intelligence. A apresentação de Dashboards consolidados visa verificar posteriormente os possíveis impactos que esta ação implicará no desenvolvimento e sucesso dos projetos.
1. Introdução O êxito de uma organização depende diretamente de sua habilidade em tomar decisões assertivas. Par tal é primordial a compreensão dos dados internos da organização, sendo necessário convertê-los em informação que lhes proporcionem vantagens competitivas. [ELLIOTT, 2004; ALMEIDA e CAMARGO, 2015]. Nessa linha, a área de Business Intelligence (BI) auxilia nesse processo. O BI são tecnologias, técnicas, conceitos e ferramentas que têm a finalidade de disponibilizar suporte a um ambiente de informação seguindo um processo inteligente de coleta, organização, análise, compartilhamento e monitoração de dados auxiliando os gestores no processo decisório, otimizando seus recursos de negócio e alcançando melhores resultados [PETRINI, 2006; WU et. al., 2007; 2010; PRIMAK, 2008]. Nesse contexto, o Instituto de Computação da Universidade Federal de Mato Grosso (IC-UFMT) tem projetos de extensão, pesquisa e ensino os quais geram quantidades de dados que podem ser analisados de forma gerencial, utilizando indicadores similares a um PMO [REIS et. al., 2014]. Este resumo apresenta uma iniciativa de criação de uma arquitetura de um processo de implantação de indicadores de desempenho na plataforma web. Esses indicadores têm como meta fornecer informações atualizadas e em tempo real para medição do desempenho de uma

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
227
atividade ou rotina especifica, constatando se o que está sendo feito se encaixa nos parâmetros esperados [CASTELLANI, 2014; MENDONÇA, 2002].
2. Arquitetura do processo A Figura 1 mostra a arquitetura do processo de BI a qual é decomposta em dois níveis:
• Área Interna: compreende a extração dos dados de origem (projetos de pesquisa, ensino e extensão) do IC-UFMT que estão armazenados no sistema de gerenciamento de projetos GP-WEB. O processo de extração, transformação e carga (extract, transform and load - ETL) realiza procedimentos responsáveis pela extração de dados de várias fontes de origem, realizando consolidação de dados e inserindo-os em outro repositório de com foco gerencial [FERREIRA et al., 2010]. O processo de ETL ocorre semanalmente e o repositório segue o padrão adotado na literatura, orientado por assunto, integrado, não-volátil e variável em relação ao tempo [INMON, 2002; TURBAN et. al., 2009; KIMBALL e ROSS, 2002; FERREIRA et. al., 2010].
• Área Externa: os dados carregados no repositório gerencial são apresentados com indicadores previamente definidos em Dashboards. Proporciona uma visão abrangente, dinâmica e objetiva, propiciando uma visão real e imediata da situação dos projetos [TURBAN et al., 2009].
A ferramenta selecionada para os processos de ETL e front end foi o Pentaho. Uma ferramenta completa de BI composta por diversas aplicações que foram desenvolvidas, distribuídas e implantadas como open source. A aplicação tem grande flexibilidade, independência, confiabilidade e segurança [OLIVEIRA, 2013].
Para o ETL foi utilizado o Pentaho Data Integration (Kettle) e o Pentaho Business Analysis Services (BI Server) para o front end.
Figura 1. Arquitetura do processo de transformação de dados

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
228
3. Conclusão e trabalhos futuros Atualmente é necessário gerenciar inúmeros projetos e uma grande variedade e quantidade de dados. O processo de Business Intelligence auxilia na gestão, com indicadores consolidados e dinâmicos. No futuro se espera comparar esses indicadores ajudaram a melhorar a performance dos projetos. Verificar se a utilização de indicadores de desempenho implantado em plataforma web acarretará no desenvolvimento e na evolução da maturidade dos projetos do IC-UFMT. Melhorar a gestão pelos alunos, professores e demais colaboradores que fazem parte dos projetos atendidos, solidificará o aprendizado e retornará mais resultado para toda a comunidade.
Referências Almeida, A. M. R.; Camargo, S. S. (2015). “Aplicando Técnicas de Business
Intelligence sobre dados de desempenho Acadêmico: Um estudo de caso”. XI Escola Regional de Banco de Dados. Caxias do Sul-RS.
Castellani, M. A. (2004). “Mitos e Verdades na Definição de Indicadores”. Project Builder. Disponível em: http://pt.scribd.com/doc/234662613/Mitos-e-Verdades-Na-Definicao-deIndicadores-de-Desempenho. Acesso em: jul. 2015.
Reis, M. P.; Brock, D. F.; Garcia, P. H.; Souza, J. F.; Takagi, N. H.; Figueiredo, J. M. (2013). “Indicadores em um PMO de Projetos de Pesquisa”. Anais da V Escola Regional de Informática de Mato Grosso-2014, 27.
Elliott, T. (2004). “Why Business Objects is the Best Choice”. Disponível www.businessobjects.com. Acesso em: Jul. 2015.
Ferreira, J.; Miranda, M.; Abelha, A.; Machado, J. (2010). “O Processo ETL em Sistemas Data Warehouse”. In INForum.
Inmon, W. H. (2002) “Building the Data Warehouse”. 3rd Edition. John Wiley & Sons, Inc., New York, NY, USA.
Kimball, R.; Ross, M. (2002). “The Data Warehouse Toolkit” 2nd ed., John Willey & Sons.
Mendonça, M. TAM (2002) “Técnicas para Análise e Melhoria de Processos”. Curso em Fita de Vídeo, LinkQuality.
Oliveira, V. (2013). “Pentaho: visão geral. ”. Disponível em: http://www.binapratica.com.br/#!visao-pentaho/c7gy. Acesso em: jul. 2015.
Petrini, M.; Freitas, M. T.; Pozzebon, M. (2006). “Inteligência de negócios ou inteligência competitiva: noivo neurótico, noiva nervosa”. Encontro da Associação Nacional de Pós-Graduacão e Pesquisa em Administração (EnANPAD).
Primak, Fábio Vinicius. (2008) “Decisões com B.I. (Business Intelligence). ” 1ª Ed. Ciência Moderna.
Wu, L; Barash, G.; Bartolini, C. (2007). “A Service-oriented Architecture for Business Intelligence, Service-Oriented Computing and Applications”. SOCA '07. IEEE International Conference on (pp.279, 285).

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
229
Desenvolvimento de Sistema para reportar problemas encontrados em vias urbanas
Bárbara Cardoso, Gabriele Nunes, Gustavo da Silva, Isabella Jacomeli,
Kaio Alexandre, Marco Antonio Augusto de Andrade, Thaynara Celestino
Escola SENAI Ji-Paraná – Rua Francisco Benites Lopes, 435 – Jardim Aurélio Bernardes –76.907-440 – Ji-Paraná – RO
[email protected], [email protected]
[email protected], [email protected], [email protected], [email protected], [email protected]
Abstract. The application usage has aimed to bring citizens closer to city hall, save time with regard to information problems , and a likely problem solving, show that there is the importance of an application to organize these notifications, and is found in only one place to be resolved.
Resumo. O uso do aplicativo tem objetivo de aproximar o cidadão da prefeitura, economizar tempo com relação à informação de problemas, e uma provável resolução, mostrar que há a importância de um aplicativo que organize essas notificações, e que estas sejam encontradas em apenas um lugar para ser resolvida.
1. Introdução Este artigo apresenta o processo inicial de análise e projeto do desenvolvimento de uma aplicação móvel para reportar problemas encontrados em vias urbanas municipais, tais como buracos, falta de sinalização, falta de iluminação, dentre outros, utilizando dados de coordenadas geográficas e conteúdo multimídia. A proposta do aplicativo busca economizar tempo e enviar informações aos órgãos públicos, especialmente prefeituras, e se justifica pela quantidade de problemas encontrados nos municípios e pela falta de comunicação ágil, uma vez que tais informações não têm alcançado o seu destino principal e, por conseguinte, não são resolvidos. Os problemas encontrados nas vias públicas de um município muitas vezes não são oficialmente registrados, assim não geram demanda para a resolução dos mesmos. Um aplicativo móvel, no qual os próprios moradores e usuários das vias públicas, informe eventuais problemas, simplifica e facilita o atendimento das demandas, haja vista que as dificuldades encontradas serão reportadas diretamente aos órgãos competentes como, por exemplo, a secretaria de obras do município. O objetivo da coleta de dados por meio do aplicativo proposto é facilitar o acesso à informação e o conhecimento do problema encontrado em vias urbanas específicas, auxiliando na reparação e manutenção da via, seja esta via principal, transversal ou coletora, tendo a ligação direta entre os usuários, o problema encontrado e as autoridades responsáveis pelas manutenções das vias.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
230
Segundo Cahali (1996), a conservação e fiscalização das ruas, estradas, rodovias e logradouros públicos é de responsabilidade da administração pública, devendo proporcionar segurança às pessoas e aos veículos que transitam por elas. Ainda de acordo com Peixoto e Silva (2002), se a administração pública não cumpre esses deveres, é obrigação do estado indenizar os prejudicados pela falta de tráfego nos locais. 2. Metodologia O aplicativo desenvolvido usará o GPS geográfico dos dispositivos Android, no qual o usuário irá se cadastrar e comunicar ao administrador através de notificações sobre a ausência de sinalização, buracos nas vias, falta de faixas para pedestres, obstáculos e obras. A base de dados será atualizada, de forma colaborativa, e enviada a equipe de campo para sua resolução, a avaliação do aplicativo será feita com o passar de seu desenvolvimento, o usuário poderá avaliar o aplicativo, de acordo com a sua satisfação, ao uso do tal, e serão informados dos problemas em resolução e dos problemas resolvidos.
Figura 1 – Caso de uso do aplicativo
No caso de uso apresentado na Figura 1 o usuário, no papel de cidadão, fará o login e irá notificar o problema, que chegará ao administrador, e este vai encaminhar o problema para a equipe de campo gerar a ordem de serviço, organizando todas as ocorrências, em cada setor. A ordem de serviço será encaminhada ao setor da prefeitura responsável pelo tipo de problema reportado. Após a solução do problema, seja ela definitiva ou provisória, o sistema enviará um feedback ao usuário. 3. Resultados Esperados e Trabalhos Futuros O uso da tecnologia relacionado com a manutenção das vias, tem como foco principal, além de agilizar o processo de reparação das mesmas, minimizar o gasto com o pagamento de indenizações, assegurando a qualidade das vias. Além disso, busca priorizar a qualidade de vida dos pedestres e proporcionando ao cidadão um envolvimento maior com os órgãos responsáveis pela manutenção das vias e o conhecimento de dados relacionados às vias urbanas.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
231
Será acrescentada a opção de visualização com o uso do GPS dos dispositivos Android, como visualizações de buracos no percurso que o usuário estiver trafegando, orientação sobre o tráfego, impedimentos (barreira) na via e mostrar vias alternativas, caso haja no percurso. O aplicativo não apresenta resultados parciais concretos, pois ainda não fora desenvolvido, há apenas um protótipo. O objetivo do aplicativo é possibilitar a comunicação direta por meio dos órgãos públicos envolvidos como, por exemplo, Departamento de Trânsito (DETRAN), Empresa Metropolitana de Transportes Urbanos (EMTU), Companhia de Águas e Esgotos de Rondônia (CAERD), Circunscrição Regional de Trânsito (CIRETRAN). Além disso, poderá armazenar o registro das denúncias/demandas em bancos de dados por meio de um canal direto com a prefeitura do Município de Ji-Paraná. Referências
Cahali, Y. S. (1996). “Responsabilidade Civil do Estado”. 2. Ed. São Paulo: Malheiros. Peixoto, L. S.; Silva A. C. Q. “Acidentes decorrentes de vias públicas urbanas danificadas: a responsabilidade civil do município”. Disponível em <http://www.ambitojuridico.com.br/site/?n_link=revista_artigos_leitura&artigo_id=11884> 10 de janeiro de (2002). Acesso em 12/102015.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
232
Um Framework Conceitual para Gestão e Monitoramento do Consumo de Energia Elétrica e Água Tratada em Residências:
Insight Sustentável de Consumo André S. Abade
Departamento de Informática – Instituto Federal de Educação, Ciência e Tecnologia de Mato Grosso - Campus Barra do Garças (IFMT)
Estrada de Acesso a BR-158, s/n - 78.600-000 - Barra do Garças - MT - Brasil [email protected]
Abstract. The water crisis in the twenty-first century involves scarcity and water stress, however, the management of water resources are major challenges to society. New and creative possibilities management and water governance can be developed from an interaction between researchers, government and society. Thus, exploring a solution to structure a Conceptual Framework Management and Monitoring Energy Consumption and Water treated in homes, it becomes an interesting challenge. The study uses a qualitative approach imprint applied to exploratory nature. The expected results as develop and implement a solution that represents a model /process replicable and reusable method according to the features of the community and socioeconomic conditions. Resumo. A crise da água no século XXI envolve a escassez e o estresse de água, entretanto, o gerenciamento dos recursos hídricos constituem os maiores desafios à sociedade. Novas e criativas possibilidades de gerenciamento e governança de água podem ser desenvolvidas, a partir de uma interação entre pesquisadores, governo e sociedade. Assim, prospectar uma solução para estruturar um Framework Conceitual de Gestão e Monitoramento do Consumo de Energia Elétrica e Água tratada em residências, torna-se um desafio interessante. O estudo utilizará uma abordagem qualitativa de cunho aplicado, com natureza exploratória. Espera-se como resultados o desenvolver e aplicar uma solução que represente um modelo/processo replicável e reutilizável de acordo com as características e condições socioeconômicas da comunidade.
1. Introdução Por meio do desenvolvimento sustentável, é possível manter a comodidade adquirida e amenizar os danos aos recursos naturais, valendo-se de ações de eficiência de consumo responsável e potencializando processos e modelos de gestão e monitoramento de consumo [Elkington, 2011]. Aprimorar estes processos e modelos por meio de tecnologias inovadoras com padrões de sustentabilidade constitui uma necessidade crescente dado os desafios atuais [Wolfs et al., 2015]. Os recursos hídricos e enérgicos utilizados pelo ser humano como base econômica e de subsistência são desencadeadores dos maiores desafios quanto à preservação, uso, reuso e consumo responsável [Fac. de Engenharia Grupo de Eficiência Energética, 2010]. Estabelecer padrões de conservação e uso racional de recursos hídricos e energéticos consiste em uma série de ações e medidas de caráter técnico, gerencial e comportamental, que visam à otimização do consumo primando pela sustentabilidade. Nesse contexto, um

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
233
Framework [Gamma et al., 1995] conceitual que é compreendido como um conjunto de conceitos utilizados para resolver problemas de um domínio específico, pode ser implementado, aprimorado e aplicado para reutilização de projetos, técnicas e padrões de consumo e sustentabilidade já conhecidos [Shaikh & Karjaluoto, 2015].
2. Metodologia e Avaliação A escolha por um estudo de caso múltiplo nas residências de nossa comunidade é pautado primordialmente na necessidade do envolvimento da comunidade das diferentes esferas socioeconômicas e consequentemente em seus critérios de consumo de energia e água tratada, assim como conclusões obtidas por meio de diversos casos são, em princípio, mais contundentes do que conclusões obtidas por meio de apenas um caso único [Yin, 2005]. Serão escolhidas residências na comunidade que atendam de alguma forma os indicares sociais e econômicos fornecidos pelo IBGE já divulgados, categorizadas por grupo de consumo hídrico e enérgico conforme os últimos seis meses demonstrados em fatura de consumo. Um fator de destaque da proposta está fundamentado nas características de reuso e replicação do framework, visto que o método de estudo de caso múltiplo é holístico, pois apresenta uma única unidade de análise em cada caso de estudo, e objetiva resultados semelhantes, com a utilização de sua replicação literal [Yin, 2005; Marconi & Lakatos, 2003]. Primeiramente será proposto o framework conceitual para gestão e monitoramento do consumo de energia elétrica e água tratada. Serão realizadas buscas de conceitos e técnicas que incorporem o consumo responsável e sustentável, a fim de constituírem uma base de dados capaz de subsidiar o desenvolvimento, aprimoramento e consequente aplicação do framework. Posteriormente, serão selecionadas as residências da comunidade de Barra do Garças - MT e desenvolvido o protocolo de coleta de dados. Um estudo de caso piloto já foi realizado com objetivo de testar o instrumento de pesquisa [Marconi & Lakatos, 2003]. Caso alguma descoberta importante ocorra será necessário uma revisão do instrumento. O estudo de caso piloto é utilizado de maneira mais formativa, auxiliando no desenvolvimento e alinhamento das questões relevantes e possivelmente até providenciando algumas elucidações conceituais para o projeto [Yin, 2005]. Os resultados alcançados na aplicação do estudo de caso piloto demonstraram que o instrumento desenvolvido está alinhado às características das residências conforme suas categorias socioeconômicas. A abordagem possui uma característica fundamental que é o interesse na aplicação, utilização e consequências práticas dos conhecimentos adquiridos. Sua natureza exploratória também está alinhada com as questões da pesquisa, que buscam responder "Como o uso de um Framework Conceitual poderia otimizar o consumo de fontes energéticas e hídricas e quais as vantagens de sua reutilização e sustentabilidade em diferentes contextos socioeconômicos?".
3. Resultados Esperados As comunidades de consumo possuem características diversas, multifacetadas, com diferentes necessidades, expectativas, valores e potencialidades, próprios de suas regiões e conjunturas. Junta-se a isto, o fato de não existir um instrumento simples que possa ser replicado ou

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
234
adotado nos mesmos moldes em regiões díspares. Assim, a aplicação do framework proposto irá considerar o impacto social, econômico e ambiental de cada comunidade, o que potencializará a sua capacidade de reusabilidade, adequação e sensibilidade. A necessidade de aperfeiçoar o consumo sustentável de recursos energéticos e hídricos por meio de um conjunto de conceitos e técnicas como um modelo ou processo de um domínio específico, constitui um desafio interessante e viável de acordo com o contexto da escassez de recursos naturais e a crescente demanda por tecnologias sustentáveis. Desenvolver e aplicar uma solução que represente um modelo/processo replicável e reutilizável de acordo com as características e condições socioeconômicas de nossas comunidades, certamente será um problema de muitas questões. Assim, o Framework Conceitual irá muito além de uma mera pesquisa quantitativa restrita a aferições e contagens [Shaikh & Karjaluoto, 2015]. Questões de pesquisa qualitativa deverão permear o framework com principal objetivo de descrever e analisar por meio de percepções e compreensão do contexto o problema como um todo.
Referências Elkington, J. (2011). Sustentabilidade, canibais de garfo e faca. M. Books, São Paulo. Fac. de Engenharia. Grupo de Eficiência Energética. (2010). Manual de Economia de Energia.
Pontifícia Universidade Católica do Rio Grande do Sul, Porto Alegre. Gamma, E., Helm, R., Johnson, R. E., and Vlissides, J. (1995). Design patterns: elements of
reusable object-oriented software, volume 206. Marconi, M. and Lakatos, E. (2003). Fundamentos de metodologia científica. Shaikh, A. and Karjaluoto, H. (2015). Making the most of information technology and
systems usage: A literature review, framework and future research agenda. Computers in Human Behavior, 49:541–566.
Wolfs, V., Meert, P., and Willems, P. (2015). Modular conceptual modelling approach and software for river hydraulic simulations. Environmental Modelling and Software, 71:60–77.
Yin, R. K. (2005). Estudo de Caso: Planejamento e Métodos. Bookman, Porto Alegre, 3a edição.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
235
SASA – Sistema de Gestão de Processos em Análise de Alimentos
Evaldo José Klock Neto, Hussein Mohamad Hallak, Carlos Uéslei Rodrigues de Oliveira
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Av. Fernando Corrêa da Costa, nº 2367 – Bairro Boa Esperança – Cuiabá – MT – Brasil
[email protected], [email protected], [email protected]
Abstract. This article describes the work currently carried out by the Applied Computing Research Group (GPE-CA) IC / UFMT that aims to develop an information system which will provide assistance to the sensory analysis of food processes using as a case study scenario current researchers Science Course and UFMT of Food Technology which showed the need for computerization of processes. Interviews were conducted with researchers to requirements gathering, analysis of documents and participation of sensory food analysis sessions.
Resumo. Este artigo descreve o trabalho realizado atualmente pelo Grupo de Pesquisa de Computação Aplicada (GPE-CA) do IC/UFMT que tem por objetivo desenvolver um sistema de informação que servirá de auxílio aos processos de análise sensorial de alimentos utilizando como estudo de caso o cenário atual dos pesquisadores do Curso de Ciência e Tecnologia de Alimentos da UFMT onde foi evidenciada a necessidade de informatização dos processos. Foram feitas entrevistas com os pesquisadores para levantamento de requisitos, análise de documentos e participação de sessões de análise sensorial de alimentos.
1. Introdução A análise sensorial de alimentos é uma área que nos últimos 60 anos cresceu e se tornou um dos principais e essenciais componentes do processo de pesquisa e desenvolvimento de gêneros alimentícios em todo mundo, sendo considerada, inclusive, de grande valia para as indústrias, pois, permite, através dos órgãos dos sentidos humanos, avaliar e assegurar a qualidade de produtos.
Nesse cenário, foram estabelecidos padrões de organização e aplicação dos métodos de análise sensorial. Percebe-se que muitos dos métodos de aplicação dos testes de análise sensorial ainda são pouco ou não totalmente informatizados tornando, portanto, dispendiosos os trabalhos de criação, aplicação e processamento dos resultados obtidos [Stone et al. 2012]. Na segunda seção discorreremos sobre os aspectos concernentes ao campo de Análise Sensorial de Alimentos e em seguida a metodologia utilizada para projeto e desenvolvimento do sistema.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
236
2. Materiais e Métodos
2.1 Análise Sensorial de Alimentos A análise sensorial é definida como uma disciplina cientifica que evoca, mede, analisa e interpreta reações das características de alimentos e materiais como são percebidas pelos órgãos da visão, olfato, gosto, tato e audição. Esse tipo de análise é realizada por um grupo especifico de pessoas que avaliarão as características sensoriais de um determinado produto para um fim especifico [Stone et al. 2012; Teixeira 2009].
2.2 Sistemas de Informação Um Sistema de Informação é definido como um conjunto de componentes inter-relacionados que coletam (ou recuperam), processam, armazenam e distribuem informações destinadas a apoiar a tomada de decisões [Laudon e Laudon 2009].
2.3 SASA O SASA é uma proposta de um sistema informação gratuito que servirá de auxílio a pesquisas no contexto de Análise Sensorial com o objetivo de auxiliar os pesquisadores a obterem de forma rápida, simplificada e segura os resultados das aplicações dos testes. Ele consistirá de uma plataforma online que poderá ser utilizada em qualquer dispositivo (computadores de mesa, notebooks, tablets e smartphones) fornecendo a funcionalidade de manter on-line os dados das pesquisas garantindo com isso uma maior segurança e garantia de entrega dos dados. Sendo utilizado também outras tecnologias, como a linguagem estatística R que servirá de auxílio para a geração de relatórios. No mercado existem sistemas semelhantes, como o SIMS, por exemplo, no entanto, tal sistema não atende a uma das características essenciais da proposta do SASA: ser gratuito. Para projetar o sistema de informação o GPE-CA utilizou-se de entrevistas com os pesquisadores do curso Ciência e Tecnologia de Alimentos como umas das técnicas de elicitação de requisitos. Os requisitos (que refletem as necessidades dos clientes) de um sistema são descrições dos serviços fornecidos pelo sistema e suas restrições operacionais. Ao processo de descoberta desses requisitos é dado o nome de elicitação de requisitos [Sommerville et al. 2003]. Os pesquisadores do GPE-CA participaram de duas sessões de análise sensorial, e, por fim, foram feitas análises de documentos e normas que padronizam e classificam os tipos de análise sensorial existentes onde foram observados os tipos de formulários utilizados assim como as metodologias de análise das respostas obtidas. Observou-se que o processo de análise sensorial de alimentos e a gestão de seus dados obtidos pelos pesquisadores do Curso de Ciência e Tecnologia de Alimentos da UFMT são realizados quase que totalmente de forma manual, evidenciando, inclusive, vários pontos de riscos que possam vir a prejudicar todo o trabalho realizado pelas pesquisas, como por exemplo, perda de dados coletados e coleta de dados incorretos. Após os devidos levantamentos, os processos foram otimizados e mapeados para um fluxograma (Figura 1) que evidência, além das principais entidades e suas respectivas atividades em uma sessão de análise, os cenários os quais o SASA é utilizado.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
237
Figura 1. Fluxograma dos processos otimizados ao utilizar o SASA.
3. Considerações Finais O SASA é um sistema proposto que está em estágio de desenvolvimento e se utiliza de tecnologias de desenvolvimento Microsoft (ASP.NET MVC, C#, Visual Studio e banco de dados SQL Server). No estágio em que se encontra o desenvolvimento, o SASA já realiza controle de acesso e cadastro de usuários, possibilita o cadastro de pesquisadores, provadores, projetos e sessões de análise. Conclui-se que O SASA colaborará para a melhoria da gestão dos dados coletados pelos pesquisadores do curso de Ciências e Tecnologia de Alimentos da UFMT possibilitando que esses pesquisadores direcionem seus esforços para a análise desses dados e com isso aumentar a produtividade de seus trabalhos. A pesquisa necessitará de estudos auxiliares, como por exemplo, os métodos de criação dos formulários de análise (que seguem normas especificas e devem dar a possibilidade de cadastro dinâmico) e também do estudo de outras tecnologias que serão incorporadas ao ambiente desse Sistema de Informação como o processamento de imagens, criação de dispositivos eletrônicos personalizados utilizando as plataformas de prototipação Arduino/Raspberry Pi para a realizar essa coleta de dados de forma fácil e intuitiva.
4. Referências Laudon, K.; Laudon, J. (2009). Management Information Systems: International
Edition, 11/E. Citeseer.
Sommerville, I.; Melnikoff, S. S. S.; Arakaki, R.; Andrade Barbosa, E. (2003). Engenharia de Software, volume 6. Addison Wesley: Sao Paulo.
Stone, H.; Bleibaum, R.; Thomas, H. A. (2012). Sensory evaluation practices. Academic press.
Teixeira, L. V. (2009). Análise sensorial na indústria de alimentos. Revista do Instituto de Laticínios Candido Tostes, 64(366), p. 12–21.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
238
UWall: compartilhando informações e promovendo a comunicação via murais digitais
Alessandro R. Luz, Caio Rodrigues, Deógenes Júnior, Matteus V. S. Silva, Paulo V. Benedito, Cristiano Maciel
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Av. Fernando Corrêa da Costa, nº 2367 – Boa Esperança – Cuiabá – MT – Brasil deogenesj, caiohsr, alsrluz, crismac, [email protected],
Abstract. Currently, traditional media used in University shows inefficient, whereas current technology brought a new way to propagate information. Thus, this paper purposes a solution of simulate physical murals on an application through mobile computing for the problematic of the lack of information and the weak communication in the campus. The application will report detailed data about what is being disclosed (events, internships, administrative notices etc.) as well as the user notifications and a relationship module similar to a social network with smart form of control. Its development is based on the software engineering’s principles. At the end, the system will be implemented and the results will be compared to similar systems on the market today. Resumo. Atualmente, os meios de comunicação tradicionais usados dentro da Universidade se mostram ineficientes, visto que as atuais tecnologias trouxeram uma nova forma de propagar a informação. Assim, este artigo propõe uma solução de simular murais físicos em um aplicativo através de computação móvel para a problemática da falta de informação e da fraca comunicação dentro do campus. Este aplicativo informará dados detalhados sobre o que estiver sendo divulgado (eventos, estágios, avisos administrativos etc.), bem como avisos ao usuário e um módulo de relacionamento semelhante a uma rede social com uma forma de controle inteligente. Seu desenvolvimento é baseado nos princípios de Engenharia de Software. Ao final, o sistema será implementado e os resultados serão comparados a outros sistemas semelhantes no mercado atualmente.
1. Introdução A Universidade é um espaço que constrói conhecimento e alimenta a comunidade em que se encontra. Essa precisa ter canais de comunicação eficazes para não permanecer estática, podendo discutir temáticas importantes, promover ações e alimentar o ecossistema em que se encontra. Para isso, são necessários canais de comunicação e de informação eficientes. A tecnologia é uma boa opção, principalmente a computação móvel, que pode ser utilizada para propiciar vários processos na Universidade. De acordo com [Procopiou et al. 2013], em ambientes educacionais, a presença dos dispositivos móveis, como Tablets e Smartphones, permite que as informações sejam disseminadas rapidamente. Assim, os ganhos obtidos pelo uso dessas tecnologias podem ser direcionados à processos educacionais mais dinâmicos e interativos.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
239
A aplicação será construída tendo em vista as características do usuário, dessa forma [Júnior 2014] propõe uma arquitetura de sistema ligada diretamente ao perfil dos usuários, a fim de elaborar uma ferramenta que atenda às suas necessidades. Para implementar um sistema multiplataforma complexo, o trabalho desenvolvido por [Campos et al. 2014] servirá de base durante as etapas iniciais do projeto. Face ao exposto, o trabalho propõe criar um sistema de comunicação inteligente chamado “UWall”, baseado nos murais da Universidade, que informará dados detalhados sobre o que estiver sendo publicado (eventos, estágios etc.), notificações ao usuário e um módulo de relacionamento similar a uma rede social. O aplicativos permitirá buscas avançadas e um sistema de recomendações ao usuário. O público-alvo focado no ambiente universitário.
2. Metodologia O projeto UWall surgiu na disciplina de Engenharia de Software, com base no tema "Campus Inteligente". Para desenvolvê-lo, foi utilizado técnicas de Engenharia de Software. O modelo de desenvolvimento é o Incremental, pois de acordo com [Sommerville 2011], este modelo é usado em projetos de software no qual há muitos módulos dentro deles e também em projetos onde há um grande fluxo de dados. Inicialmente, a ideia do aplicativo passou por um estudo de viabilidade. Dada que a problemática é justificável, a solução não é complexa e que há muitas ferramentas disponíveis, o projeto foi considerável viável. Após, realizou-se uma análise de mercado buscando em periódicos online se haviam soluções parecidas implementadas para este problema. Dentre os exemplos escolhidos, a proposta mais similar é o “Mural Virtual” da UnB [Júnior et al. 2014]. O aplicativo é um projeto desenvolvido durante a Monografia do curso de Jornalismo da Universidade de Brasília. A aplicação funciona como suporte na criação, busca, visualização e divulgação de eventos e atividades ocorridas na UnB, voltados aos usuários do sistema operacional iOS. Tanto o “Mural Virtual” quanto o “UWall” permitem ao usuário organizar e buscar seus eventos de interesse, utilizar do serviço de registro de redes sociais para se cadastrar no aplicativo e notificações de eventos. Porém, diferente de outras propostas, o UWall utilizará recursos de Inteligência Artificial em seu funcionamento. Além de técnicas de gameficação que auxiliarão no envolvimento do usuário com o aplicativo. Os aplicativos Events e Koosh também foram selecionados pois ambos fornecem informações relativas a eventos. O aplicativo Sydy [Procopiou et al. 2013], serviu como base para entender a dinâmica em ambientes educacionais, onde este propõe um modelo de aplicativo móvel que atua no meio acadêmico. Posteriormente, foram realizadas a elicitação de requisitos, através de questionários, observação, leitura de documentos e reuniões com Brainstorming. O intuito era definir a representação dos murais virtualmente, os critérios de publicação, funcionalidades e organização do sistema. Como observação, todos os murais da UFMT foram fotografados. Ficou constatado que a divulgação nos murais é geralmente desorganizada. A leitura de documentos enriqueceu a base teórica para o processo de desenvolvimento. Nos Brainstormings foram definidos o objetivo e os requisitos fundamentais do aplicativo. O aplicativo deve ter boa usabilidade, abranger toda a Universidade e estimular a comunicação. Com base nestas características levantadas foram elicitadas treze requisitos funcionais e sete requisitos não funcionais.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
240
3. Sobre o UWall O aplicativo tem um sistema de avaliação da postagem (bom ou ruim), semelhante ao utilizado no Youtube. Cada postagem é referenciada por uma tag, que funciona como filtro na opção de busca, podendo ser: festa, eventos de cunho acadêmico, ofertas de estágio etc. Com base nesses interesses, o aplicativo cria um perfil para o usuário, sugerindo publicações de forma que ele não perca oportunidades. O aplicativo terá um sistema de notificação que o avisa sobre as atividades que estão para iniciar. Cada postagem terá uma área de comentário, contribuindo com a manutenção do uso do aplicativo. Durante a implementação dessas funcionalidades, o objetivo será garantir uma satisfatória usabilidade. Para garantir isso, foram criados protótipos de baixa e alta fidelidade, exemplificados na Figura . O aplicativo respeitará a privacidade do usuário, onde este terá controle sobre as ações do aplicativo. Para evitar postagens de caráter duvidoso, serão inseridas técnicas de Inteligência Artificial baseadas em agentes inteligentes com capacidade de aprendizado e reconhecimento de padrões. Isso permitirá a moderação automática de postagens, que ficará mais sofisticada devido ao aprendizado. Elas também organizarão as postagens do feed de notícias do UWall. A arquitetura proposta é o MVC (Model-View-Controller). Juntamente, será utilizada a plataforma Xamarin, que desenvolve simultaneamente para iOS, Android e Windows Phone. A facilidade de uso é uma característica emergente deste software.
Figura 1. Protótipos de baixa e alta fidelidade, respectivamente, do UWall.
4. Conclusão A implementação e validação com usuários são etapas futuras do projeto. O UWall promoverá a facilidade do acesso à informação, compartilhamento e comunicação dentro da UFMT. Ele por si só não oferece problemas de privacidade ou implicações culturais e seu impacto será avaliado pelo volume de informações trafegando no dispositivo e o uso pelo público. Futuramente, almeja-se avaliar a possibilidade da proposta ser expandida para displays públicos, acreditando que os usuários se familiarizarão tanto com a tecnologia quanto com a sua aplicação, já que murais e aplicativos móveis são muito comuns.
Referências Campos, K. L. De, Oliveira, B. H. De, Miranda, A. L., Almeida, C. E Maciel, C. (2014).
E-con: uma proposta para modernização do Procon – MT. V Escola Regional de Informática de Mato Grosso – 2014, p. 164-166.
Júnior, P. N. de O. (2014). Mural Virtual: Um aplicativo móvel para encontrar eventos. Procopiou, A. T., Araújo, A. N., Noite, A. A., Maciel, C. e Nogueira, D. M. (2013).
Sydy: Um Modelo de Software Direcionado à Interatividade em Ambientes Educacionais. IV - Escola Regional de Informática: “Imagem, Processamento e Análise”, p. 71–73.
Sommerville, I. (2011), Software Engineering, Pearson Education, 9th edition.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
241
Avaliação de itens que implementam acessibilidade em conteúdos Web em Dispositivos Móveis para Deficientes
Visuais para construção de métrica de pontuação Cheiene Batista Oliveira1, Pedro Clarindo da Silva Neto2
1Instituto Federal de Educação, Ciência e Tecnologia de Mato Grosso Campus Pontes e Lacerda (IFMT)
Rodovia MT-473, s/n – 78.250-000 – Pontes e Lacerda – MT – Brasil
2Instituto Federal de Educação, Ciência e Tecnologia de Mato Grosso Campus Avançado de Tangará da Serra(IFMT)
Rua 28, 980N – 78.300-000 – Tangará da Serra – MT – Brasil
[email protected], [email protected]
Abstract. Web mobile accessibility means that all people can use the web contents in any devices. This paper approaches the selection of items that implements web content accessible to build a metric, through a scoreboard, to create a rating of accessible web content for visually impaired in mobile devices.
Resumo. Entende-se como acessibilidade web mobile (móvel) como a inclusão de todo tipo de usuário ao acesso a conteúdos em dispositivos móveis. Este trabalho visa determinar a escolha de itens que possibilitem a implementação de páginas web acessíveis para deficientes visuais em dispositivos móveis com a finalidade de construir uma métrica através de um scoreboard.
1. Introdução Entende-se como acessibilidade web mobile (móvel) como a inclusão de todo tipo de usuário ao acesso a conteúdos em dispositivos móveis (smartphones, tablets, etc). Segundo a Anatel, o Brasil registrou 283,52 milhões de acessos em dispositivos de telefonia móvel apenas em abril de 2015, onze milhões a mais que 2014. Dentre as diferentes motivações existentes para que sites invistam em acessibilidade, se encontram fatores legais e políticas de planejamento que indiquem que o conteúdo web em ambientes móveis, além de atender as recomendações da W3C (World Wide Web Consortium) e as diretrizes de acessibilidade para computadores comuns, deve também se adequar as pequenas telas e a resposta de informações (principalmente para dispositivos touch). Este trabalho apresenta os resultados de uma revisão bibliográfica que selecionou 10 itens que implementam páginas web acessíveis para deficientes visuais em dispositivos móveis, com a finalidade de construir posteriormente uma métrica através de um scoreboard de pontuação de seu nível de acessibilidade.
2. Trabalhos Relacionados Em sua pesquisa, Bach et. al (2009) avaliou características dos métodos de avaliação de acessibilidade web, através de um estudo comparativo, ressaltando prós e contras desses métodos, com a participação de especialistas e usuários com deficiência visual,

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
242
resultando um conjunto de recomendações a serem consideradas na avaliação de acessibilidade web. Já Freire (2008) realizou uma análise do cenário brasileiro a respeito da acessibilidade web, utilizando-se de métricas. Seu estudo verificou que apesar de ser um tema crescente, ainda tem muito a ser explorado. Uma das vertentes com pouca visibilidade é a acessibilidade web para ambientes móveis. Contudo, não foi encontrado entre os trabalhos pesquisados nas bases da Capes, W3C, IEEE Xplorer, ACM, BDBComp (Biblioteca Digital Brasileira de Computação), implementações e avaliações de acessibilidade web para pessoas com deficiência visual, voltada para ambientes móveis. Fundamentado nesses dados, mostrou-se que pesquisas nessa área são escassas.
3. Itens Avaliados Foram pesquisados e selecionados 10 dos principais itens de uma página web que permitem maior interação e acessibilidade a pessoas com deficiência visual, através de estudos de trabalhos relacionados ao tema acessibilidade web móvel conforme relacionados a seguir. O item 1 (idioma) é baseado em Alves e Ferreira (2011), Lazzarin e Souza (2015) e nas recomendações da WCAG (Web Content Accessibility Guidelines), que declaram que a identificação do idioma permite que os leitores de tela pronunciem adequadamente as palavras. O item 2 (frames) foi escolhido baseado nos trabalhos de Sousa; Osorio; Andrade (2008), Sonza (2008) e Ferreira, Cianconi (2011) que afirmam que frames geralmente apresentam restrições dificultando ao usuário com deficiência visual compreender o conteúdo exibido. Os itens 5 (links), 6 (etiquetagem) e 9 (acesso pelo teclado) foram baseados no manual para deficientes visuais, Brasil (2010) e em Queiroz (2008), que dizem que pensando em usuários com deficiência visual, links devem ser claros e fáceis de identificar e que imagens e outras mídias de natureza visual devem conter etiquetagem com uma descrição do que se é mostrado. Os itens 3 (pop-ups), 4 (redirecionamento) e 7 (estilo de fonte) foram baseados em Rabin e Mccathienevile (2008); Ferreira (2008); Machado, Machado e Conforto (2014); Rocha e Duarte (2013) e recomendações da WCAG 2.0, os quais explicam o porquê da não utilização desses três itens, além de dificultarem a compreensão do conteúdo na utilização através do dispositivo móvel. O item 8 (título da página) foi baseado em Queiroz (2009) e Nóbrega (2011), que explicam que o título da página é essencial para o usuário navegar entre as abas do navegador. A barra de acessibilidade (item 10) é recomendada para facilitar a navegação dos usuários com necessidades especiais, possuindo itens importantes como os atalhos principais.
4. Considerações Finais
Esta proposta baseia-se em uma série de itens que comporão uma métrica de acessibilidade web móvel para deficientes visuais, a fim de facilitar a avaliação e estudos relacionados a esse tema. São dez itens baseados no WCAG, easy checks de acessibilidade web e nas boas práticas de acessibilidade web mobile da W3C. Por meio

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
243
dessa métrica poderá ser gerado um scoreboard de uma página em um dispositivo móvel para acessibilidade de deficientes visuais e contribuir com desenvolvimento acessível de páginas web. A pesquisa encontra-se em estado de início de aplicação da métrica em sites para demonstração do uso da tabela e exemplificação da importância dos dez itens na acessibilidade web.
Referências Alves, A. S.; Ferreira, S. B. (2011) “Um Mergulho nas Recomendações de
Acessibilidade para Conteúdo Web do W3C (WCAG2.0)”. Relatório Técnico, Rio de Janeiro: UNIRIO.
Bach, C. F.; Ferreira, S. B. L.; Silveira, D. (2009) “Avaliação de Acessibilidade na Web: Estudo Comparativo entre Métodos de Avaliação com a Participação de Deficientes Visuais”. ENANPAD Encontro Nacional dos Programas de Pós Graduação em Administração, São Paulo.
Ferreira, G. A; Cianconi, R. B. (2011) “Acessibilidade dos Deficientes Visuais e Cegos às Informações de Bibliotecas Universitárias Na Web” Inf. & Soc.:Est., v.21, n.2, p. 151-163, João Pessoa.
Freire, A. P. (2008) “Acessibilidade no desenvolvimento de sistemas Web: um estudo sobre o cenário brasileiro”. Dissertação (Mestrado) - Instituto de Ciências Matemáticas e de Computação, Universidade de São Paulo, São Carlos.
Lazzarin, F. A.; Sousa, M. R. F. (2015) “Aspectos Que Interferem No Acesso à Informação e Interação dos Usuários Cegos com o OPAC em Bibliotecas Universitárias”. Perspectivas em Ciência da Informação, v. 20, n. 1.
Machado, D. R.; Machado, R. P.; Conforto, D. (2014) “Dispositivos móveis e usuários cegos: recomendações de acessibilidade em discussão”. Nuevas Ideas en Informática Educativa TISE.
Nóbrega, G. C. (2011) “Acessibilidade aos conteúdos visuais em ambientes virtuais de aprendizagem.” Revista Brasileira de Tradução Visual (RBTV).
Queiroz, M. A. (2008) “Acessibilidade Legal”, http://www.acessibilidadelegal.com/, Abril.
Rabin, J.; Mccathienevile, C. (2008) “Mobile Web Best Practices”, http://www.w3.org/TR/mobile-bp/, Agosto.
Rocha, J. A. P.; Alves, C. D.; Duarte, A. B. S. (2011) “E-acessibilidade e usuários da informação com deficiência”. Inc. Soc., Brasília, DF, v. 5 n. 1, p.78-91, jul./dez.
Sonza, A. P. (2008) “Ambientes Virtuais Acessíveis sob a perspectiva de usuários com limitação visual”. Tese (Doutorado). Universidade Federal do Rio Grande do Sul, Programa de Pós-Graduação em Informática na Educação, Porto Alegre.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
244
Uma abordagem comparativa na resolução do problema dos Cubos Coloridos
Johnnes S. V. da Cruz, Matteus V. S. Silva, Cláudia A. Martins
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Av. Fernando Corrêa da Costa, nº 2367 - Bairro Boa Esperança. Cuiabá - MT - Brasil
vargas.simao,[email protected], [email protected]
Abstract. In this article is presented an analyze to the problem of colored cubes, that consists of a grouping of eight equal colored cubes, each of the six sides of the cube is painted in a different color. They were implemented two programs, the A* search and the Best First search. The Alfa-Beta pruning procedure is also included in both programs. Once implemented some test cases were created. Two relatively common computers in terms of requirements were used as test platforms. The compilation and execution times were recorded and analyzed in order to determine which technique is best performance. In the end, the search A * with Alfa-Beta pruning proved the best option. Resumo. Neste artigo é apresentada uma análise entre algoritmos de busca para o problema dos cubos coloridos, que consiste em um agrupamento de oito cubos coloridos iguais, cada um dos seis lados dos cubos é pintado de uma cor diferente. Foram implementados dois programas de busca, o A* e o Best First. O procedimento de Poda Alfa-Beta também foi implementado em ambos os programas. Uma vez implementada alguns casos de teste foram testados. Dois computadores relativamente comuns em termos de requisitos foram utilizados como plataformas de teste. Os tempos de compilação e execução foram registrados e analisados a fim de definir qual técnica tem o melhor desempenho. Ao final, a busca A* com Poda Alfa-Beta se mostrou a melhor opção.
1. Introdução Algoritmos bastante conhecidos e utilizados na área de Inteligência Artificial são os métodos de busca, os quais a partir de um estado inicial, e uma série de transições de estados, tentam chegar a uma solução ou estado final. Vários problemas de busca “de brinquedo” são utilizados para testar novos métodos e algoritmos. Um dos problemas mais conhecidos é o do Cubo Colorido, que consiste em um agrupamento de 8 (oito) cubos coloridos iguais, cada um dos 6 (seis) lados dos cubos possui uma cor diferente. Agrupa-se os 8 (oito) cubos em 2 (duas) linhas e 2 (duas) colunas, ou seja, uma matriz 2x2. O estado meta é deixar cada lado desse novo agrupamento com a mesma cor. O presente trabalho consiste em analisar os métodos de busca A* e Best First, com a Poda Alfa-Beta comparando o desempenho de cada um deles.
2. Metodologia Inicialmente, foi simulado o que seriam os cubos individuais e o agrupamento dos cubos (matriz 2x2) usando as estruturas de dados denominados tCubo e tCuboColorido, respectivamente. Para agilizar o processo, diversas definições de constantes relativas às cores e os lados dos cubos foram feitas para que o desenvolvimento fosse mais intuitivo e ágil.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
245
Também, foi implementado uma estrutura de dados chamado tBusca, relativa ao método de busca A*, que utiliza a função f(n) = g(n) + h(n), na qual g(n) é o custo do estado inicial até o nó atual (n), h(n) é a heurística utilizada, ou seja, a estimativa de custo do estado atual (n) até a meta [Patel 2015]. Dois procedimentos foram criados: A-star.cpp e Best-first.cpp. O primeiro, implementa a busca A*, como descrito anteriormente. O segundo, a busca Best First, que usa a função heurística f(n) = h(n) na busca pela meta. Esta procura tenta expandir o nó cuja estimativa h(n) é mais próximo à meta. A heurística é aplicada globalmente, isto é, o caminho a ser seguido é selecionado entre todos os nó abertos até o momento, o nó aberto com a melhor nota é escolhido para a expansão [Felner et al. 2003]. A heurística trabalha cada face de cada cubo. O método heuristica verifica se a cor está na sua posição correta. Caso esteja, é acrescido um ponto no somatório. Do contrário, nada é alterado. Quando o somatório alcançar 24 pontos, o cubo está ajustado. Assim, a implementação da busca consiste em quatro etapas: expansão de nós (árvore); cálculo da heurística; cálculo de f(n) e seleção do melhor nó. O critério que define o melhor nó é o maior valor de f(n) dentre todos os nós já expandidos, mesmo não estando no mesmo nível. Dentro da etapa da expansão é chamado o método PodaAlfaBeta, que elimina os nós que, garantidamente, não serão selecionados, utilizando como critério de escolha para remoção a heurística.
3. Resultado e Análise O principal método para a geração de casos de teste é o Inicia, que consiste em gerar um cubo Colorido. A função srand juntamente com a biblioteca time.h, ambas nativas do C++, permitem que a cada execução uma nova sequência de cubos seja gerado. Ao final do cubo inicial, as informações de custo de armazenamento (nós expandidos), a posição do nó solução dentro da estrutura, o valor da heurística, a profundidade da busca e o cubo final são exibidos em tela. Para comparar as implementações foi criado o procedimento chamado Analise- Tempo.cpp, que executa os dois procedimentos descritos anteriormente e retorna os tempos de cada caso de teste e um log é gerado com estes valores no formato .txt. O programa foi testado em dois computadores distintos. O primeiro computador (Comp-1) possui um processador Intel Core 2 Duo de 2.93 GHz, memória de 4 GB e Sistema Operacional Windows 7 Professional 64 bis. O segundo computador (Comp-2) possui um processador Intel Core i3 de 1.80 GHz última geração, memória de 4 GB e Sistema Operacional Windows 10 Professional 64 bis. O resultado dos testes em cada máquina estão resumidos na Tabela 1, que mostra a quantidade de nós expandidos (#Nós) e o tempo de execução nos Comp-1 (tComp-1) e Comp-2(tComp-2) para os algoritmos Best First sem Alfa-Beta (BF), Best First com Alfa-Beta (BFαβ), A* sem Alfa-Beta (A*) e A* com Alfa-Beta (A*αβ).
Tabela 1. Resultado de Execução de Comp-1 e Comp-2
BF BFαβ A* A*αβ
#Nós 5761 4105 5761 3321
tComp-1 0.065200s 0.029200s 0.043800s 0.02340s0
tComp-2 0.029200s 0.043800s 0.023400s 0.06520s0

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
246
É possível observar na Tabela 1 que sem a poda Alfa-Beta, os dois algoritmos tiveram o mesmo número de nós expandidos na busca. No entanto, com o procedimento da poda Alfa-Beta, o algoritmo A* teve um número significativo menor de nós expandidos. O computador utilizado para o desenvolvimento (Comp-0) é claramente superior aos computadores utilizados nos testes, já que possui o processador Intel Core i5 com 4GB de memoria, sendo este utilizado em projeto de pesquisa, e assim é claramente superior aos computadores utilizados nos testes, que podem ser considerados comuns. O primeiro é um desktop e o segundo um laptop, sendo que a configuração do segundo é superior. Mesmo assim, a diferença entre ambos não foi tão significativa nos resultados finais. É importante ressaltar que o código tem capacidade de gerar n casos de teste, suportando bem a quantidade de dados analisados. Isso pode ser devido à linguagem C++ com suas estruturas de dados e o modo de implementação que utilizou apenas recursos nativos da linguagem.
4. Conclusão Geralmente, o algoritmo de busca Best First por si só é eficiente, mas foi o A* que teve um desempenho melhor nos testes, como esperado, de acordo com os dados acima. Evidentemente, os tempos de cada busca sem a poda são maiores. A razão se dá na maior quantidade de nós expandidos, os quais o algoritmo deve levar em consideração para seguir a busca. O Best First foi o que expandiou mais nós e teve as maiores médias de tempo, como esperado. Este trabalho visa encontrar as principais características que resolvam o problema com o melhor desempenho. O intuito é dar suporte a futuras pesquisas que utilizem métodos de busca de Inteligência Artificial visando alto desempenho. Seguindo este princípio concluímos que as técnicas de busca, de poda e a linguagem de programação não são os únicos fatores determinantes para obter sucesso. A heurística adotada é fundamental para todo o progresso da busca. A estrutura adotada neste trabalho dá suporte a escalonamento de técnicas, possibilitando a realização de muitos testes de vários modos diferentes até definir um ideal e a testes de várias heurísticas, visto que basta apenas alterar o método heurística(). Uma possível alteração de heurística, por exemplo, seria dar um ponto para cada face de um cubo pequeno correto e menos um ponto para cada face de um cubo pequeno errado. Apesar de algumas diferenças de tempo entre cada computador, [Russell e Norvig 2014] descreve que a busca A* sempre executa a busca ótima em um problema, se a heurística for admissível, como neste caso. Assim, visto pelo desempenho, a busca A* é o algoritmo mais recomendável para este problema. Como trabalhos futuros, novos algoritmos serão implementados e comparados a outros tipos de problemas.
References Felner, A., Kraus, S. e Korf, R. E. (2003). KBFS: K-Best-First Search. Annals of
Mathematics and Artificial Intelligence, v. 39, n. 1-2, p. 19–39. Patel, A. (2015). Introduction to A*. Disponível em
<http://theory.stanford.edu/~amitp/GameProgramming/>. Russell, S. e Norvig, P. (2014). Artificial Intelligence: A Modern Approach, Third
edition.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
247
Comparativo de métodos de detecção de outliers em dados meteorológicos
Johnata Rodrigo Pinheiro Montanher, Gilson Pereira Carvalho, Thiago Meirelles Ventura, Luy Lucas Ribeiro Santana, Claudia Aparecida Martins
Instituto de Computação – Universidade Federal de Mato Grosso (UFMT) Av. Fernando Corrêa da Costa, nº 2367 – Bairro Boa Esperança – Cuiabá – MT – Brasil
johnata05,[email protected], [email protected], thiago,[email protected]
Abstract. We can obtain meteorological data using sensors, which are studied to interpret weather events. This data can have outliers. In this work we compare the performance of three outliers detection methods to check the applicability of this type of data: Box-Plot, Z-score modified and Limits. Tests were performed in two different simulations, with 4 climate variables. The method that showed the best results was the Z-score modified. Resumo. Com a utilização de sensores obtemos dados meteorológicos, que são estudados para interpretar fenômenos climáticos. Estes dados vêm em séries que podem aparecer dados fora do comum, chamados de outliers. Neste trabalho comparamos o desempenho de três métodos de detecção de outliers para verificar a aplicabilidade nesse tipo de dados, são eles: Box-Plot, Z-score modificado e limites. Foram realizados testes com duas simulações diferentes, testando quatro variáveis climáticas. O método que mostrou os melhores resultados foi o Z-score modificado.
1. Introdução Os fenômenos climáticos que ocorrem na natureza devem ser estudados para que se possam ser entendidos e analisados. Com a instalação de sensores em campos abertos, podem-se captar dados meteorológicos no qual serão armazenados em um banco de dados e, posteriormente, analisados para gerar interpretações desses fenômenos. Nessa análise pode ser identificada a presença de outliers. Outliers são dados que parecem desviar significativamente dos outros membros da amostra da qual faz parte [Grubbs 1969].
Há diversos métodos para detecção de outliers. Em Chen et al. (2010) são mostradas as categorias para separar os métodos que possuem esta finalidade. Contudo, como cada tipo de dado possui comportamentos diferentes, há a necessidade de avaliar se determinados métodos são capazes de realizar a detecção de outliers em diferentes variáveis meteorológicas. Portanto, este trabalho tem como objetivo avaliar soluções para resolver o problema dos dados fora de série quando utiliza dados meteorológicos.
2. Metodologia Em Hodge e Austin (2004) são apresentados diversos métodos de detecção de outliers. Neste trabalho foram avaliados o BoxPlot, o qual é um gráfico no qual o eixo vertical representa a variável a ser analisada e o eixo horizontal um fator de interesse, Z-Score
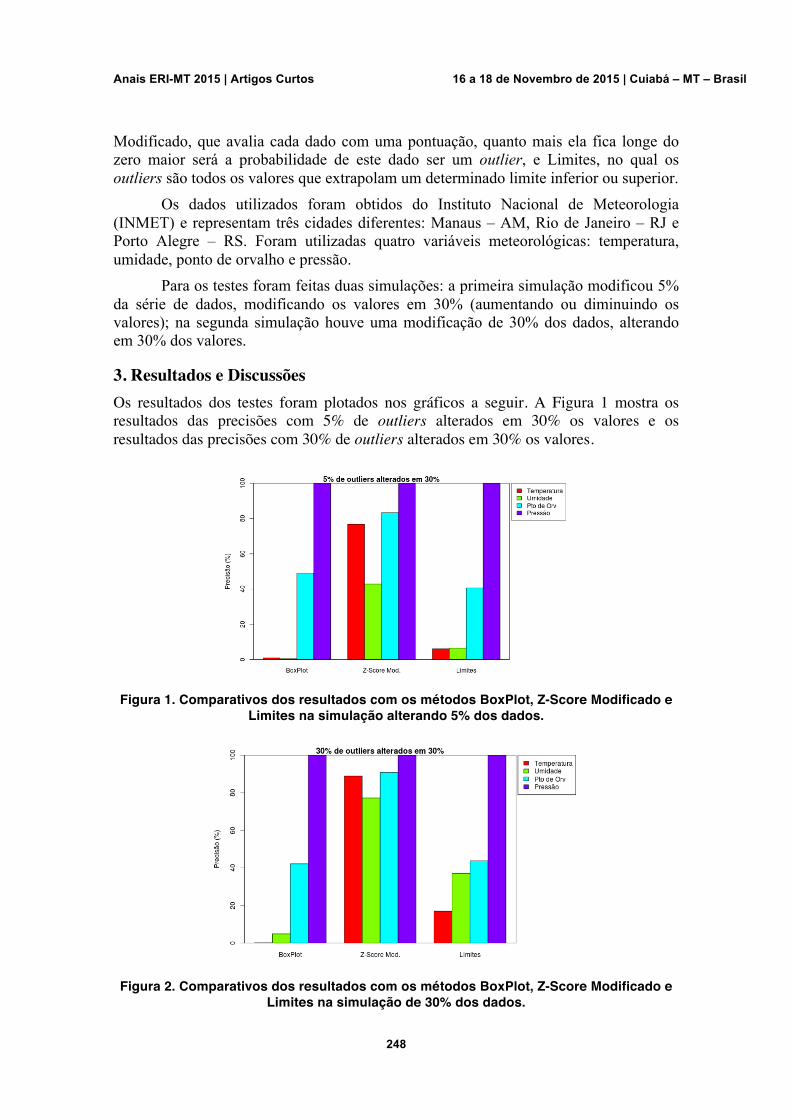
Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
248
Modificado, que avalia cada dado com uma pontuação, quanto mais ela fica longe do zero maior será a probabilidade de este dado ser um outlier, e Limites, no qual os outliers são todos os valores que extrapolam um determinado limite inferior ou superior. Os dados utilizados foram obtidos do Instituto Nacional de Meteorologia (INMET) e representam três cidades diferentes: Manaus – AM, Rio de Janeiro – RJ e Porto Alegre – RS. Foram utilizadas quatro variáveis meteorológicas: temperatura, umidade, ponto de orvalho e pressão. Para os testes foram feitas duas simulações: a primeira simulação modificou 5% da série de dados, modificando os valores em 30% (aumentando ou diminuindo os valores); na segunda simulação houve uma modificação de 30% dos dados, alterando em 30% dos valores.
3. Resultados e Discussões Os resultados dos testes foram plotados nos gráficos a seguir. A Figura 1 mostra os resultados das precisões com 5% de outliers alterados em 30% os valores e os resultados das precisões com 30% de outliers alterados em 30% os valores.
Figura 1. Comparativos dos resultados com os métodos BoxPlot, Z-Score Modificado e
Limites na simulação alterando 5% dos dados.
Figura 2. Comparativos dos resultados com os métodos BoxPlot, Z-Score Modificado e
Limites na simulação de 30% dos dados.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
249
Em ambas as simulações, o melhor método foi o Z-Score Modificado, tendo os maiores índices de precisão. A Tabela 1 apresenta os valores de precisão dos seus respectivos métodos segundo suas variáveis meteorológicas. Em destaque está o método Z-Score Modificado, evidenciando seus índices elevados.
Tabela 1. Precisões obtidas das variáveis meteorológicas nos respectivos testes
Simulação Métodos Temperatura Umidade Pto de Orv. Pressão
5%
BoxPlot (%) 0,93 0,47 49,07 100,00
Z-Score Mod (%) 76,79 42,80 83,33 100,00
Limites (%) 6,06 6,49 40,65 100,00
30%
BoxPlot (%) 0,15 4,87 42,19 100,00
Z-Score Mod (%) 88,88 77,22 90,82 100,00
Limites (%) 17,00 37,14 43,74 100,00
É possível identificar também que a variável de pressão atmosférica é a mais fácil de detectar um possível outlier, tendo 100% de precisão em todas as simulações e em todos os métodos. Isso pode ser explicado devido ao comportamento desta variável climática, que possui uma constância durante todo o período do dia, ou seja, alterações em seus valores são mais fáceis de serem observadas. O mesmo não acontece para as outras variáveis climáticas, as quais possuem grandes variações durante os dias.
4. Considerações Finais Este trabalho analisou métodos para a detecção de outliers em dados meteorológicos, com objetivo de avaliar soluções para resolver problemas de anomalias em séries de dados. Para avaliarmos os métodos selecionados foram realizadas duas simulações diferentes, além de realizar testes com quatro variáveis distintas. Em todos os testes o método Z-Score Modificado teve os melhores índices de precisão. Trabalhos futuros desta pesquisa contemplarão a geração de novas simulações, englobando menores diferenças do outlier para um dado real, outras variáveis climáticas e maiores quantidades de outliers simulados na série de dados. Além disso, novos métodos podem ser testados.
Referências Chen, S., Wang, W., Zuylen H. (2010). “A comparison of outlier detection algorithms
for ITS data”. Expert Systems with Applications 37, 1169-1178. Grubbs, F. E. (1969). “Procedures for detecting outlying observations in samples”.
Technometrics 11, p 1–21. Hodge, V. J., Austin, J. (2004). “A Survey of Outlier Detection Methodologies”.
Kluwer Academic Publishers, p 13-18.

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
250
Integração entre o software R e um sistema para mineração de dados meteorológicos em Java Vinicius R. Angelo1, Claudia A. Martins2, Allan G. Oliveira2
1Departamento de Estatística – Universidade Federal de Mato Grosso (UFMT) 2Instituto de Computação – Universidade Federal de Mato Grosso (UFMT)
Av. Fernando Corrêa da Costa, nº 2367 – Bairro Boa Esperança – Cuiabá – MT – Brasil [email protected], claudia,[email protected]
Abstract. This article is a study of Mimi meteorological data mining platform, that the goal is to build a function in R language to automate statistical analysis of time series. Also, it will be optimized this function, including the prediction of time series and the integration of this function in R language with an interface web based developed in Java.
Resumo. Este artigo representa um estudo da plataforma de mineração de dados meteorológicos MiMi, com o objetivo de construir uma função na linguagem R para automatizar a análise estatística de séries temporais. Também, pretende-se otimizar essa função, incluindo a previsão das séries temporais e a integração dessa função em linguagem R com a interface web desenvolvida em Java.
1. Introdução A linguagem R tem sido amplamente utilizada em diversas áreas devido ao grande conjunto de funções contidas em bibliotecas específicas, além de ser open source. Dentre os diversos usos da linguagem, os trabalhos envolvendo dados meteorológicos tem se beneficiado do uso do R, como em Holsten (2013), Oliver (2015) e Pauling (2014). Entretanto, nos diversos usos encontrados na literatura, percebe-se que a utilização se dá por meio do contato direto com a linguagem, nesse contexto, é importante salientar que nem todo usuário de dados meteorológicos tem familiaridade com uma linguagem de programação. Desse modo, o objetivo desse trabalho é a integração de uma plataforma para mineração de dados meteorológicos, em desenvolvimento, com a linguagem R, a fim de facilitar o uso dos algoritmos e facilidades apresentadas pelo R por meio de uma interface gráfica web based já desenvolvida nesta plataforma.
2. Metodologia A linguagem R, desenvolvida para a estatística computacional, é baseada na linguagem C [R Core Team 2015] e fornece diversas bibliotecas para os mais variados processamentos. Dentre as facilidades disponíveis, está a integração com outras linguagens e acesso a sistemas gerenciadores de banco de dados. Neste trabalho os dados, minerados a partir da Plataforma Computacional para Mineração de Dados Meteorológicos - MiMi [Oliveira 2015], são submetidos à linguagem R para análise

Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
251
estatística e visualização gráfica, usando as diversas bibliotecas disponibilizadas que apresentam um bom desempenho. As funções implementadas em R serão executadas na aplicação desenvolvida em Java por meio de interfaces Java/R utilizando a API (Application Programming Interface) JRI (Java R Interface) que permite a execução de códigos R dentro de aplicações java em uma única thread. Os dados utilizados para validação da integração são dados de uma estação meteorológica instalada na Universidade Federal de Mato Grosso, coletados entre 2011 e 2012, são dados de Temperatura, Umidade Relativa do Ar, Velocidade do Vento e Radiação Solar. Para analise dos dados serão utilizadas as técnicas de estatística de séries temporais [Morettin 2006]. Para teste inicial foi criada uma função que calcula e plota os gráficos de estatísticas descritivas, histogramas, séries temporais, gráficos de auto correlação (ACF) e gráficos de decomposição da série temporal.
3. Resultados Parciais e Perspectivas Foi realizada a princípio uma análise descritiva dos dados, os histogramas são mostrados na Figura 1. Nota-se que a variável temperatura aparenta ter uma distribuição normal, enquanto que a Umidade Relativa do Ar aparenta ter uma distribuição uniforme, a Velocidade do Vento parece ter uma distribuição exponencial e a variável Radiação solar parece não ter nenhuma distribuição conhecida. A Temperatura apresentou uma média de 27,66 graus Celsius e um desvio-padrão de 5,16, a Umidade Relativa do Ar apresentou uma média de 64,23% de umidade e um desvio-padrão de 20,52, a Velocidade do Vento obteve uma média de 1,04 m/s e um desvio-padrão de 0,78, enquanto que a Radiação Solar apresentou uma média de 199,88 W/m² e um desvio-padrão de 287,17.
Figura 1. Histograma das variáveis temporais Figura 2. ACF das séries
Para avaliar se as séries são estacionárias, utilizou-se o método dos autocorrelogramos (Figura 2). É possível observar que todas as séries são não estacionárias, ou seja, são sazonais. Assim, o objetivo a posteriori é fazer previsões de possíveis valores para todas as variáveis, utilizando o método de Médias Móveis e os modelos ARMA, ARIMA e SARIMA [Morettin 2006]. Assim, o gráfico das séries temporais, representadas na Figura 3, mostram claramente que existe sazonalidade em todas elas, o que é o esperado para dados meteorológicos, a
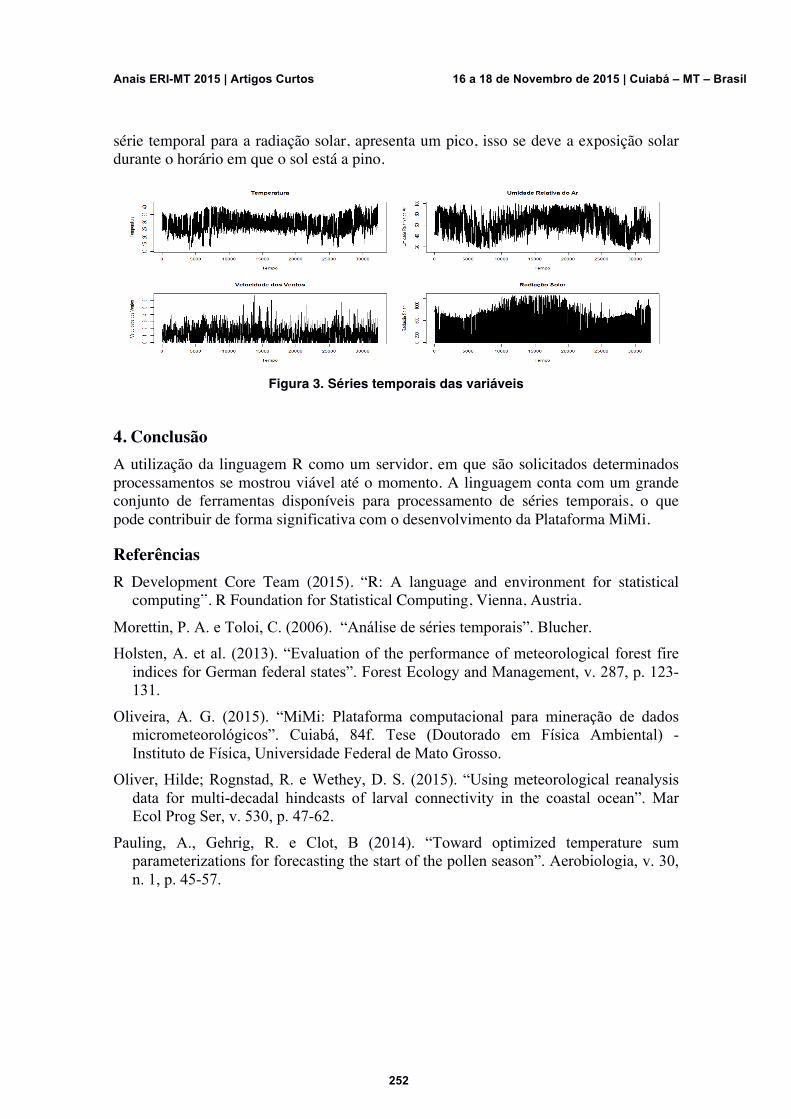
Anais ERI-MT 2015 | Artigos Curtos 16 a 18 de Novembro de 2015 | Cuiabá – MT – Brasil
252
série temporal para a radiação solar, apresenta um pico, isso se deve a exposição solar durante o horário em que o sol está a pino.
Figura 3. Séries temporais das variáveis
4. Conclusão A utilização da linguagem R como um servidor, em que são solicitados determinados processamentos se mostrou viável até o momento. A linguagem conta com um grande conjunto de ferramentas disponíveis para processamento de séries temporais, o que pode contribuir de forma significativa com o desenvolvimento da Plataforma MiMi.
Referências R Development Core Team (2015). “R: A language and environment for statistical
computing”. R Foundation for Statistical Computing, Vienna, Austria.
Morettin, P. A. e Toloi, C. (2006). “Análise de séries temporais”. Blucher. Holsten, A. et al. (2013). “Evaluation of the performance of meteorological forest fire
indices for German federal states”. Forest Ecology and Management, v. 287, p. 123-131.
Oliveira, A. G. (2015). “MiMi: Plataforma computacional para mineração de dados micrometeorológicos”. Cuiabá, 84f. Tese (Doutorado em Física Ambiental) - Instituto de Física, Universidade Federal de Mato Grosso.
Oliver, Hilde; Rognstad, R. e Wethey, D. S. (2015). “Using meteorological reanalysis data for multi-decadal hindcasts of larval connectivity in the coastal ocean”. Mar Ecol Prog Ser, v. 530, p. 47-62.
Pauling, A., Gehrig, R. e Clot, B (2014). “Toward optimized temperature sum parameterizations for forecasting the start of the pollen season”. Aerobiologia, v. 30, n. 1, p. 45-57.