algoritmos distribuídos
TRANSCRIPT

© Markus Endler 1
Algoritmos Distribuídos
Markus Endler Sala RDC 503
[email protected] www.inf.puc-rio.br/~endler/courses/DA

© Markus Endler 2
Roteiro
1. Introdução 2. Causalidade e noções de tempo 3. Exclusão Mútua Distribuída 4. Eleição de Coordenador 5. Detecção de Predicados Globais e Snapshots 6. Problemas de Acordo Distribuído (Distributed Agreement) 7. Detectores de Falha 8. Serviços de Grupo (Comunicação confiável e Pertinência)

© Markus Endler 3
Avaliação e Datas
Avaliação: • Dois trabalhos práticos T1, T2 (com relatórios) – simulação de algoritmos • Monografia sobre um problema de coordenação distribuída e seus algoritmos • Apresentação (40 mins) sobre a monografia: nos últimos 15 dias • Prova PF (apenas se houver necessidade), Data : 3/julho • Cáclulo do Grau final:
M = (T1 + T2 + APRES+MONO) /4 se > 7.0 passou. Senão, precisa fazer a PF M = (PF + M)/2
Pré-requisitos: • experiência com Java • Desejável: ter noções basicas de Redes de Computadores e Sist. Operacionais
Dinânica de aula: Em casa: eventualmente, leitura dos textos (capitulos de livro ou artigos) Em sala de aula: aulas expositivas + discussão sobre o material lido Obs: Na web-page da disciplina há os slides, enunciados dos trabalhos, notas, avisos, etc.

© Markus Endler 4
Livro texto
Ajay D. Kshemkalyani, Mukesh Singhal, Distributed ComputingPrinciples, Algorithms, and Systems, Cambridge University Pres, 2008 (Capítulos 1-4, 5.6, 6,9, 11,14, 15)

© Markus Endler 5
Bibliografia Complementar
R.Chow & T.Johnson, Distributed Operating Systems and Algorithms, Addison
Wesley, 1997 (Capítulos 9-12) V. Garg, Elements of Distributed Computing, John Wiley & Sons, 2002. (Capítulos
2-3, 6-7, 9-12,16-17, 21, 23, 26-28) G.Coulouris & J.Dollimore, T.Kindberg, Distributed Systems: Concepts and Design,
Addison Wesley, 1997 (Capítulos 2,10,11,14) Alguns artigos sobre problemas e algoritmos específicos.

© Markus Endler 8
Ferramenta de Simulação
Sinalgo: http://dcg.ethz.ch/projects/sinalgo/ • Open Source (licença BSD) em Java • Asynchronous and synchronous simulation (event-based and lock-step) • Customizable visualization of the network graph • Tutorial:
– http://disco.ethz.ch/projects/sinalgo/tutorial/Documentation.html • Each node executes a code to:
– send a message to a specific neighbor or all its neighbors, – react to received messages, – set timers to schedule actions in the future
• Allows customizaton of several models: – mobility & distribution models: initial location of each node and how it changes its
position over time (only in synchronous mode) – connectivity model: when two nodes are able to communicate – reliability model: for each message, whether it should arrive or not – transmission model: how long it takes for a message to arrive
• There is no explicit node failure model ènode just does not react to events

© Markus Endler 9
Sinalgo
• Can be executed in batch or step-by-step execution (for debugging) • Execution with animation (colors indicate the node and link states) • A execution log can be examined

© Markus Endler 10
O Que são Sistemas Distribuídos?
• Uma coleção de entidades independentes (nós) que cooperam entre sí para resolver um problema que não pode ser resolvido individualmente por cada nó.
Existem muitos exemplos na natureza

© Markus Endler 11
O Que são sistemas Distribuidos?
Exemplos da humanidade: • requerem comunicação para delegação, coordenação e
manutenção/atualização da força tarefa

© Markus Endler 12
O Que são Sistemas Distribuídos?
Sistema Distribuído :: sempre que houver comunicação entre nós autonômicos (“agentes inteligentes”) para atualização/coordenação de seus estados. Principais Características: • distribuição geográfica dos nós; • sem referência a tempo global; • Sem meio de comunicação compartilhado (canais P2P)

© Markus Endler 13
O Que são Sistemas Distribuídos?
Algumas Definições: • “You know you are using one (Distributed System) when the
crash of a computer you have never heard of prevents you from doing work.” [L. Lamport].
• “A collection of independent computers that appears to the users of the system as a single coherent computer” [A. Tanenbaum]
• “A collection of computers that do not share common memory and a common physical clock, that communicate by message passing over a communication network, and where each computer has its own memory and runs its own operating system.
• Typically the computers are semi-autonomous and are loosely coupled while they cooperate to address a problem collectively” [Singhal & Shivaratri, 94].

© Markus Endler 14
Algoritmos Distribuidos?
A distributed algorithm implements a Distributed Service that has components/agents that execute on different networked computers, which communicate and coordinate actions by only passing messages to one another. The components interact with each other to achieve a common goal. Some infra-structure characteristics that are commonly assumed: • Concurrency of components; • Lack of a global clock; and • Independent failure of components • Independent delay and failure of network links.
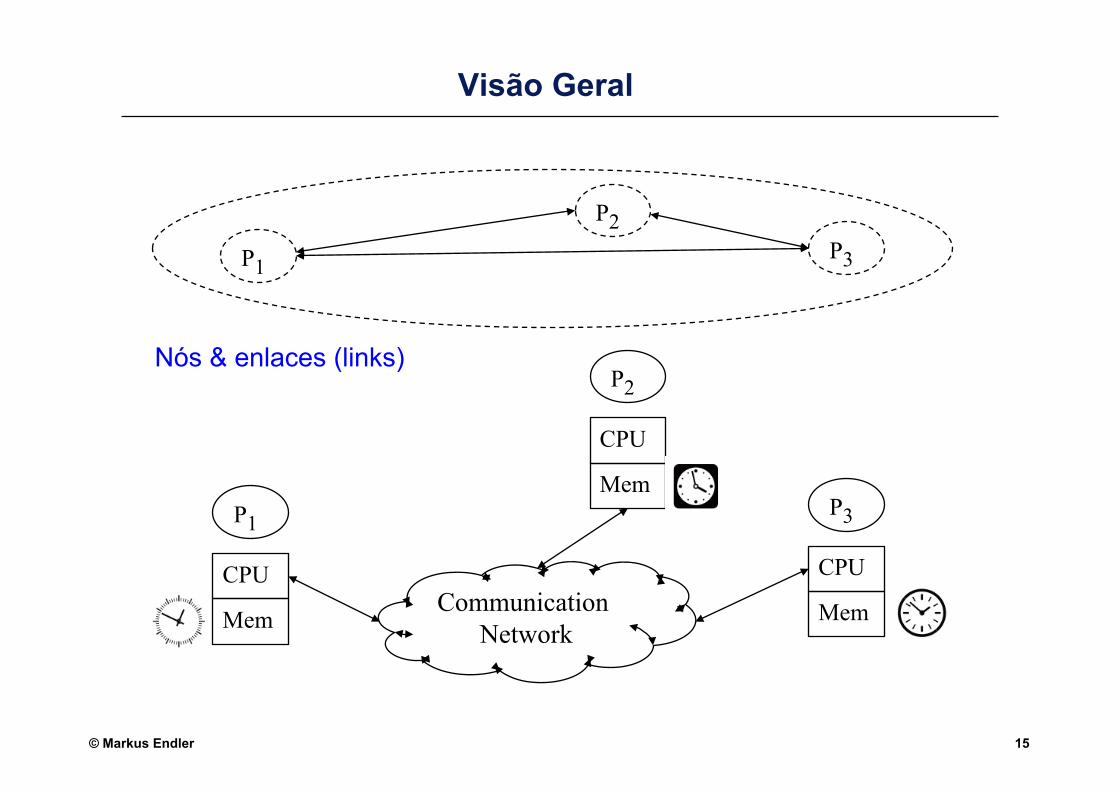
© Markus Endler 15
Visão Geral
CPU
Mem Communication
Network
CPU
Mem
CPU
Mem
P2
P1 P3
P2
P1 P3
Nós & enlaces (links)

© Markus Endler 16
Características de Sistemas Distribuídos e suas implicações
• Ausência de um relógio global – impossibilidade de sincronização perfeita das ações distribuídas
• Ausência de memória compartilhada – Cada nó possui memória local, e portanto coordenação só é possível
através de envio de mensagem – Não é possível conhecer o estado global do sistema – Mensagens em trânsito precisam ser consideradas
• Separação geográfica e incerteza sobre tempos de comunicação e de processamento – Não se conhece o tempo de transmissão de mensagens – Os nós podem ter capacidades de processamento e comunicação bem
distintos
• Possibilidade de falhas independentes – de nós e da rede – Mensagens podem não chegar – Processadores podem falhar – É impossível diferenciar um processador muito lento de um
processador falho.

© Markus Endler 17
Por que estudar Algorítmos Distribuídos?
Algorítmos Distribuídos são os programas que executam nos nós de uma rede (com atrasos e confiabilidade não conhecidos)
São compostos por processos que conjuntamente - e de forma
coordenada - realizam uma tarefa (um serviço) e que precisam manter uma consistência.
Serviços Distribuídos para: • sincronização de ações (em exclusão mútua, ou processamento
uniforme) • definir ordem global de eventos independentes (p.ex.
Servidores replicados) • comunicação confiável para todo o grupo de processos • atingir o consenso entre vários processos • garantir a integridade e a autenticidade de transações • captura de estado global (p.ex. detecção de deadlock)

© Markus Endler 18
Por que estudar Algorítmos Distribuídos?
Alguns exemplos: • sistemas operacionais distribuídos e em rede: escalonamento
de processos, acesso a memória distribuida compartilhada • Tolerância à falha usando processos replicados (em um cluster
ou em nuvem) • comunicação de grupo confiável/ atômica: (com entrega
garantida para todos os membros e na mesma ordem) • manutenção da consistência em bases de dados replicadas (ex:
BD distribuídos) • Massive multiplayer games: visão coerente do estado do jogo
em tempo real. • Ambientes colaborativos (de co-edição) distribuídos • Consenso em Blockchain

© Markus Endler 19
Premissas e Propriedades Desejáveis
O que esperamos de um algoritmo? • Estar correto
– fazer aquilo a que se propõe – que termine
• Ter baixa complexidade: O(n), O(n logn), O(n2), etc. • Ser efciente na maioria dos cados
Para algoritmos distribuídos, tudo isso depende das premissas sobre o ambiente de execução (modelo de sistema), por exemplo: • Processamento síncrono x assíncrono • Garantias sobre a entrega de mensagens • Possibilidade de falhas (nós ou rede)
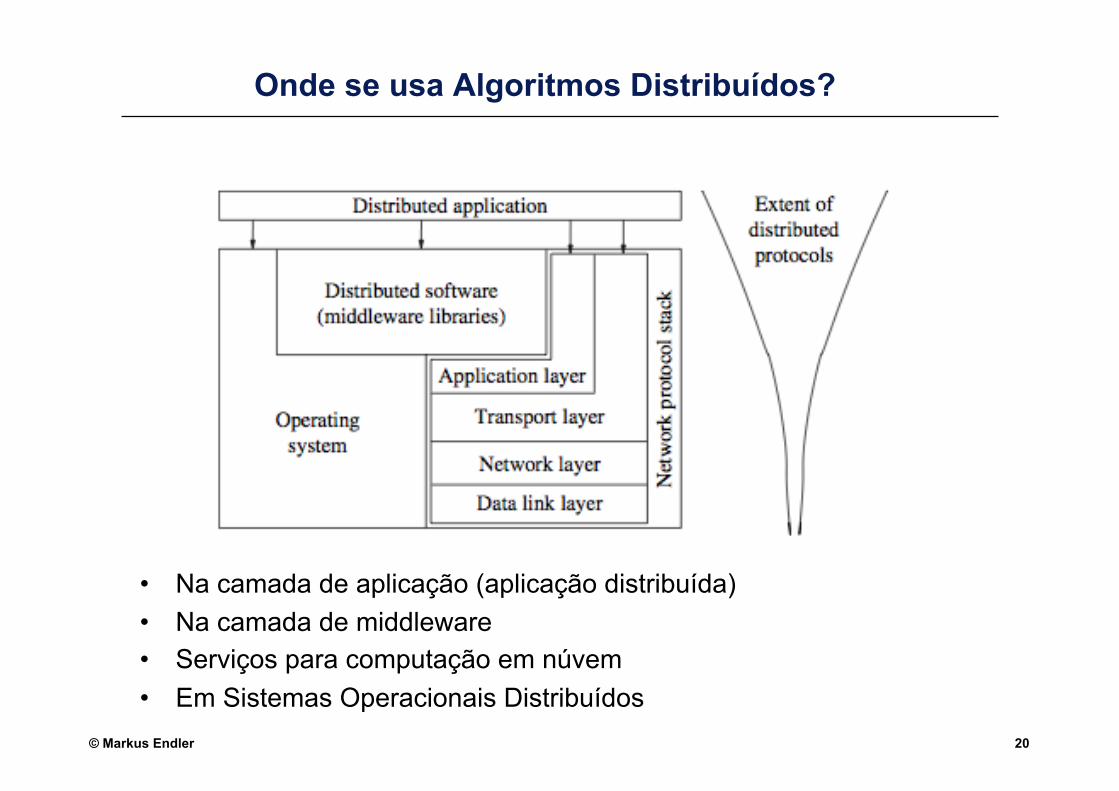
© Markus Endler 20
Onde se usa Algoritmos Distribuídos?
• Na camada de aplicação (aplicação distribuída) • Na camada de middleware • Serviços para computação em núvem • Em Sistemas Operacionais Distribuídos

© Markus Endler 21
O Modelo básico de um Sistema Distribuído
• O sistema é composto de um conjunto de processos assíncronos p1,p2,…,pi,…,pn que se comunicam por mensagem, por intermédio de uma rede de comunicação. (cada processo executa em processador próprio ).
• Processos não compartilham memória, mas somente interagem apenas através do envio e recebimento de mensagens. (mensagens unicast)
• Cada processo executa eventos locais (mudanças de estado, eventos de timers), e eventos de envio de mensagens m
• Seja Cij o canal de comunicação de processo pi para processo pj, e mij uma messagem enviada de pi para pj .
• O delay da comunicação pelo canal Cij é finito, mas desconhecido.
• Os processos não têm acesso instantâneo a um relógio global (relógio de parede - global clock)

© Markus Endler 22
O Modelo básico de um Sistema Distribuído
• A execução de processos e a transferência de
mensagens é assíncrona – o processo remetente (sender) não espera até que a mensagem seja entregue no destinatário.
• O estado global de uma computação distribuída
consiste da união dos estados (locais) dos processos e dos estados dos canais de comunicação: – O estado de processo pi é dado pelo estado de sua
memória local e depende de seu contexto. – O estado de um canal de comunicação Cij é caracterizado
pelo conjunto de mensagens de Pi para Pj em trânsito no canal.
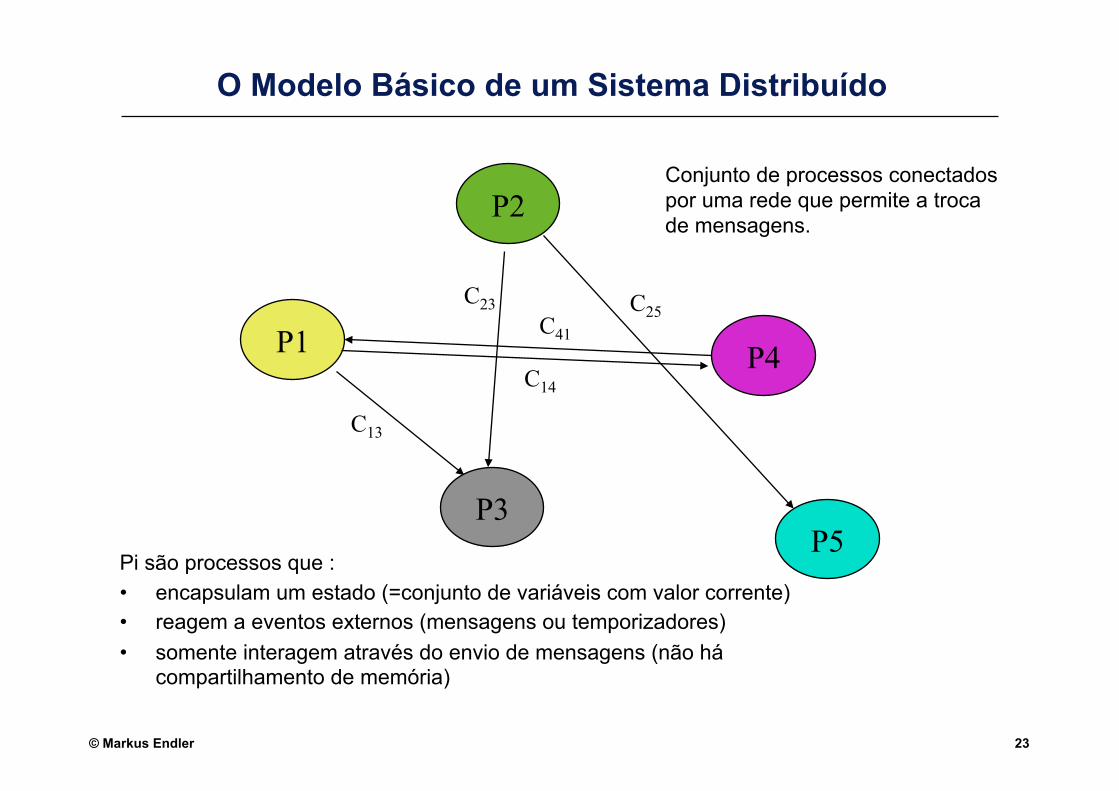
© Markus Endler 23
O Modelo Básico de um Sistema Distribuído
Pi são processos que : • encapsulam um estado (=conjunto de variáveis com valor corrente) • reagem a eventos externos (mensagens ou temporizadores) • somente interagem através do envio de mensagens (não há
compartilhamento de memória)
P1
P2
P4
P3 P5
Conjunto de processos conectados por uma rede que permite a troca de mensagens.
C25 C23
C13
C41
C14

© Markus Endler 25
Mecanismos de Sincronizacão
• A única forma de sincronizar os estados locais de processos é através de mensagens.
• Tal sincronização é essencial para que os processos (de um sistema distribuido) possam adquirir uma visão (parcial) do estado global do sistema, e se coordenarem para uma ação conjunta.
• Os mecanismos de sincronização também servem para a gestão de concorrência no acesso a recursos.
• Alguns exemplos de problemas que requerem sincronização:
– Sincronização de relógios locais – Eleição de líder – Exclusão Mútua – Detecção de término – Coleta de lixo distribuida

© Markus Endler 26
Tempo e estado global
• Alguma noção consistente de tempo é necessária. • Isso pode ser através da sincronização de relógios físico ou através
da noção de tempo lógico. • Tempo lógico é uma abstração de ocorrência de eventos e sua
relações. Precisa ser coerente com o tempo real (de parede). • Tempo lógico permite:
– (i) expressar a causalidade entre eventos no programa distribuído, e
– (ii) acompanhar o progresso relativo em cada processo. – (iii) decidir sobre o que é um estado global correto do sistema
distribuído • Devido à natureza distribuída, não é trivial um processo capturar o
estado global do sistema (todos os processos), • Para tal, precisa-se capturar os estados locais de cada processo de
forma coordenada • E lembrar que o estado global também engloba mensagens em
trânsito

© Markus Endler 32
Alguns problemas Fundamentais de AD
• Eleição: Escolher um único processo, e fazer com que todos os demais saibam qual é;
• Exclusão mútua: garantir acesso exclusivo a um recurso compartilhado (p.ex. base de dados);
• Terminação: detectar, com certeza, que o processamento distribuído terminou;
• Consenso: determinar um único valor a ser escolhido por todos os processos;
• Snapshot: obter uma “fotografia” correta de um estado distribuído do sistema a partir de coleta de estados nos processos;
• Multicast: garantir a entrega confiável de mensagens a todos os processos (e que estes saibam que todos receberam)
• Buscar: encontrar, de forma eficiente, um dado em um conjunto de processos
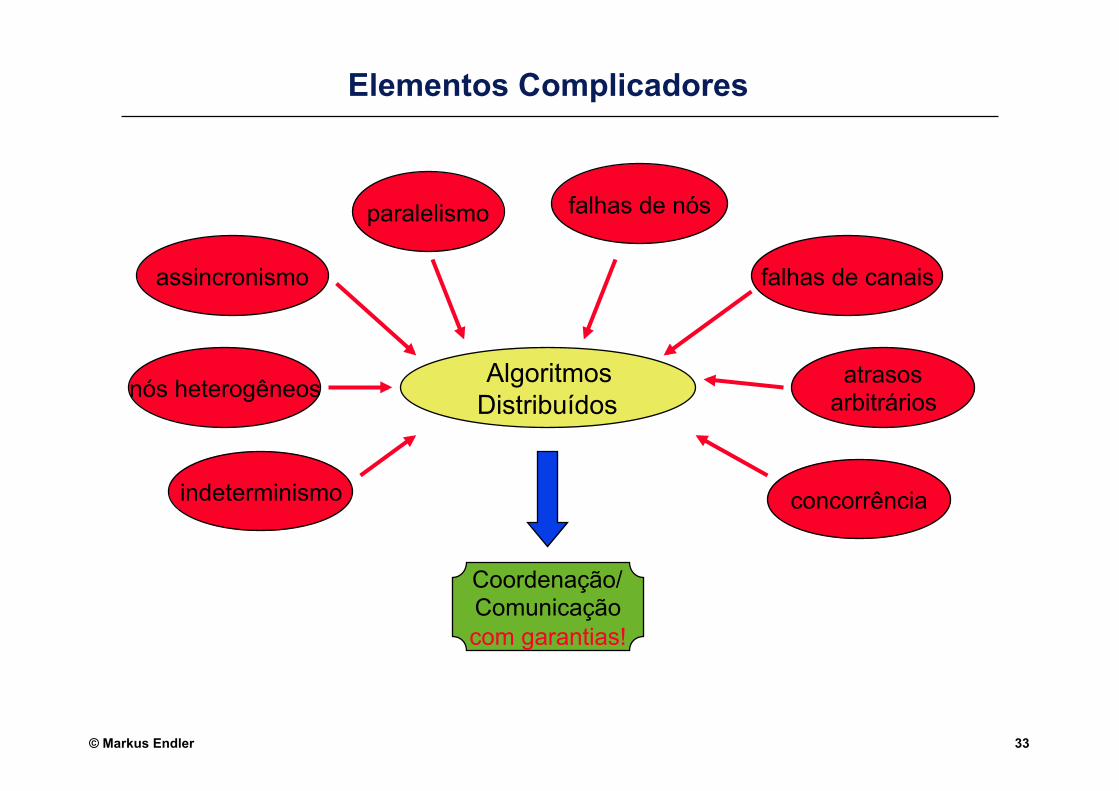
© Markus Endler 33
Elementos Complicadores
Algoritmos Distribuídos
indeterminismo
assincronismo
paralelismo falhas de nós
falhas de canais
atrasos arbitrários
Coordenação/ Comunicação com garantias!
concorrência
nós heterogêneos

© Markus Endler 37
Principais Objetivos
Alguns objetivos gerais no projeto de um algoritmo distribuído:
• evitar deadlocks = nenhum processo consegue prosseguir • evitar starvation = um processo nunca ganha acesso • garantir fairness = todos os processos têm chances iguais • evitar livelock = subconjunto dos processos interagem, mas processamento global não progride
Propriedades podem ser classificadas em duas categorias:
Segurança/Safety: Uma propriedade segura é aquela que vale para qualquer execução e em todo estado (global) alcançável da execução. Exemplos: Ausência de deadlock, de starvation, ...
Progresso/Liveness: Uma propriedade de progresso é aquela que vale para qualquer execução e se manifesta em algum estado alcançável da execução. Exemplos: um consenso é alcançado, um processo consegue entrar na sessão crítica, etc.

© Markus Endler 39
Modelando Sistemas Distribuidos • Computação: Processos, comportamento determinístico vs
probabilistico
• Interação: através de mensagens, que acarretam: • Fluxo (compartilhamento) de informação • Coordenação: sincronizacnao e ordem de atividades • Ordem é preservada?
• Falhas: quais tipos de falha podem ocorrer? • Falhas benignas vs malignas (Bisantinas) • No processamento vs na comunicação • Falhas ocorrem aleatóriamente • Temporárias vs definitivas
• Tempo: pode-se fazer alguma premissa sobre limites de tempo na – comunicação e – nas velocidades de processamento

© Markus Endler 40
Modelando Sistemas Distribuidos
• Processos Determinísticos: o processamento local e as mensagens enviadas pelo processo dependem direta- e exclusivamente do estado corrente e das mensagens recebidas previamente
• Processos Probailísticos: processos acessam oráculos para escolhar aleatoriamente a computação local e a nova mensagem a ser enviada.
© Markus Endler 41
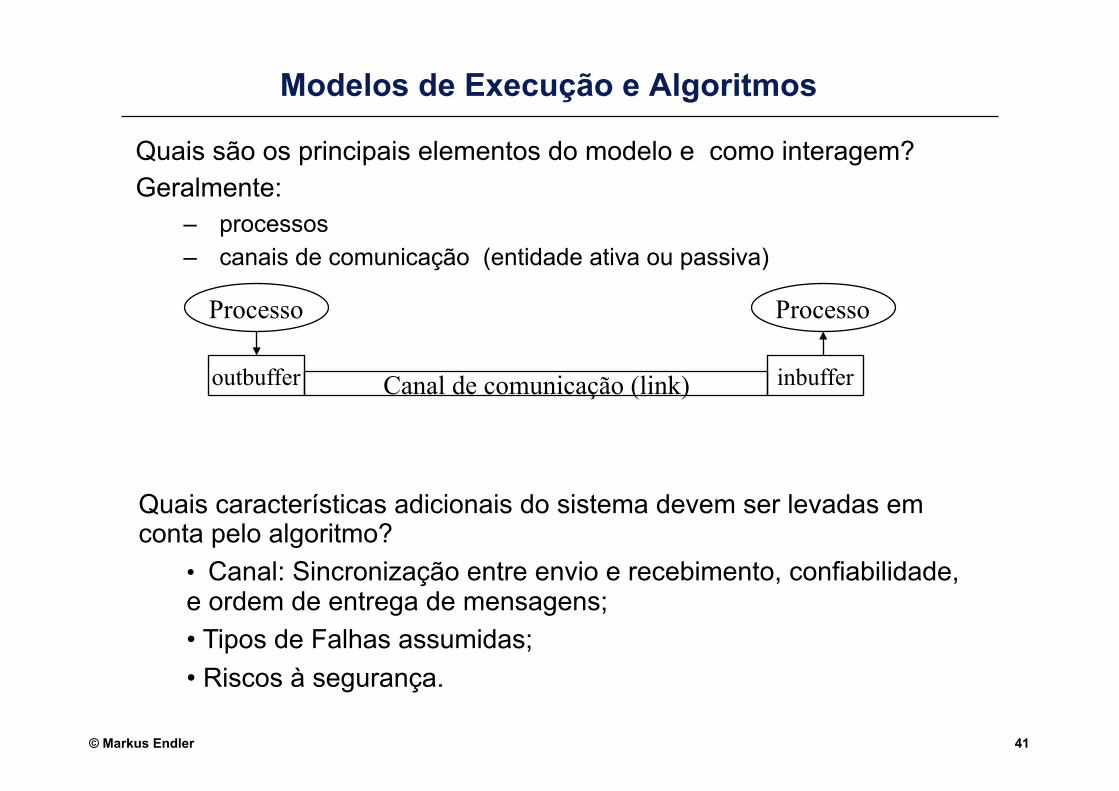
Modelos de Execução e Algoritmos
Quais são os principais elementos do modelo e como interagem? Geralmente:
– processos – canais de comunicação (entidade ativa ou passiva)
Quais características adicionais do sistema devem ser levadas em conta pelo algoritmo?
• Canal: Sincronização entre envio e recebimento, confiabilidade, e ordem de entrega de mensagens; • Tipos de Falhas assumidas; • Riscos à segurança.
Processo Processo
Canal de comunicação (link) outbuffer inbuffer

© Markus Endler 42
O Modelo de Execução e Corretude de algoritmos A corretude de um algorítmo distribuído (suas propriedades desejáveis), só pode
ser verificada em relação ao modelo de sistema assumido. Cada modelo expressa um conjunto de características gerais (premissas) de tipo
específico de sistema/rede (p.ex.: propriedades de atraso ou confiabilidade). A corretude de um AD depende da prova de que o mesmo satisfaz as
propriedades, em qualquer execução (i.e. na presença de qualquer conjunto de eventos possíveis no modelo).
Modelo 2
Possíveis propriedades desejáveis: 1) mensagens são sempre entregues na ordem em que foram enviadas 2) o algoritmo eventualmente termina/converge 3) Sempre existe um único coordenador 4) Todos as réplicas possuem sempre o mesmo estado
Premissas do Modelo 1: • latência máxima de transmissão é conhecida • mensagens nunca são duplicadas ou modificadas
Premissas do Modelo 2: • latência de transmissão arbitrária • toda mensagem enviada em algum momento chega • mensagens nunca são duplicadas ou modificadas
P1
Modelo 1
P2 P3
P1
P2 P3

© Markus Endler 43
Premissas de Modelos de Execução
Premissas devem ser elaboradas fazendo perguntas como:
• há conjunto estático ou dinâmico de processos? • a topologia/ grafo de canais de comunicação é fixo ou variável? • os tempos máximos de transmissão de mensagens são conhecidos? • o processamento nos processos é síncrona (em rodadas, ou barreiras de sincronização?) • os relógios dos processos diferem de no máximo Δt ? • qual é modelo de falhas de nós (persistência de estado, falha detectável por outros processos)? • qual é modelo de falhas de comunicação? • qual é o modelo de compartilhamento de recursos (no nó e no canal de comunicação)?

© Markus Endler 46
Modelos de Execução Fundamentais: Principais Aspectos
Principais aspectos dos Modelos de Execução: Modelo de Interação & Sincronismo:
– toda comunicação e sincronização é através de mensagens – topologia, grau de confiabilidade das mensagens e sincronismo – definição do possivel atraso na comunicação & grau de
sincronismo (capacidade de sincronizar ações)
Modelo de Falhas: – os tipos de falha esperados (omissão ou aleatória) – número máximo de falhas simultâneas è permite definir a estratégia para mascarar as falhas (k resiliência)
Modelo de Segurança: – definição das possíveis formas de ameaças/ataques èpermite uma escolha dos mecanismos & protocolos para impedir
(ou dificultar) os ataques (algoitmos criptográficos, gerenciamento de chaves, certificados,…)

© Markus Endler 47
Modelos de Interação e Sincronização
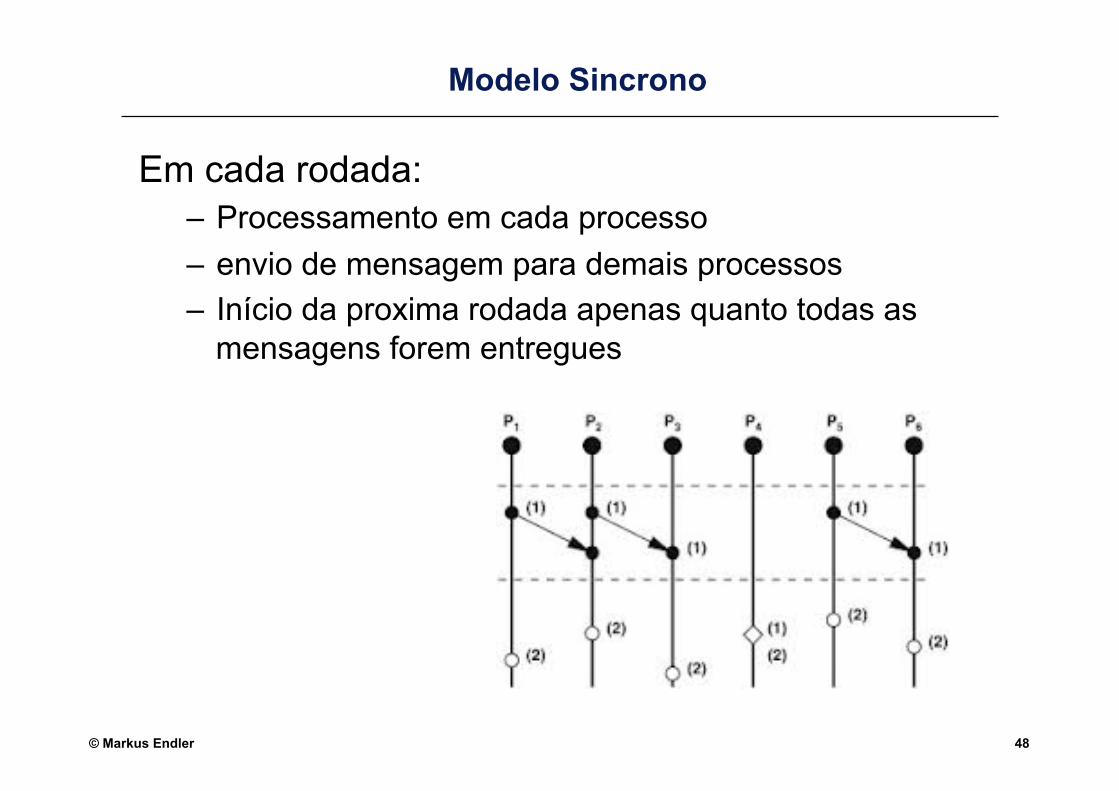
O Modelo Síncrono: • cada “passo de execução” em um processo demora entre [min, max] unidades de tempo • a transmissão de qualquer mensagem demora um limite máximo de tempo • o relógio local a cada processo tem uma defasagem limitada em relação ao relógio real
A execução ocorre em rodadas de “processamento & comunicação” perfetamente sincronizadas:
è O não-recebimento de uma mensagem em determinado período também traz informação!!
Obs: Em sistemas reais, é difícil determinar estes limites de tempo. Mas este modelo é adequado quando a rede é dedicada e as tarefas (processos) têm tempos de processamento fixos e bem conhecidos (p.ex. controle de processos, processador paralelo)
Todos processos processam Todos processos interagem
© Markus Endler 48
Modelo Sincrono
Em cada rodada: – Processamento em cada processo – envio de mensagem para demais processos – Início da proxima rodada apenas quanto todas as
mensagens forem entregues

© Markus Endler 49
Exemplo de Algoritmo para Modelo Síncrono Algoritmo para Consenso: Cada nó escolhe um valor v ∈ [0, max] e difunde este valor para todos
os demais nós na rede. Quando um nó tiver recebido o valor de todos os demais nós, escolhe o valor mais votado (ou no caso de empate, um valor default) como o valor de consenso d.
Pseudo-código para nó i: Init => {
escolhe valor v; broadcast (v:i) para todos os vizinhos localset ← {(v:i)}
} Nova rodada => {
recebe conjunto c de mensagens dos demais; diff ← c - localset; // diferença entre conjuntos se diff ≠ ∅ { localset ← localset ∪ diff; broadcast diff para vizinhos; } senão se (já recebeu de todos nós) { d ← acha_mais_votado(localset); terminou ← true; }
} Terminou => imprime o valor de consenso d;
Propriedade: Assumindo-se comunicação
confiável e rede com N processos, após N-1 rodadas, deverá ter recebido o valor de todos os nós ativos (não falhos).

© Markus Endler 50
Consenso para sitema síncrono
• “assumindo-se comunicação confiável” ènão há perda de mensagens
• Todos os nós repassam aos seus vizinhos os novos valores recebidos è isso garante a difusão dos valores para nós ainda não alcançados
• Com N-1 rodadas, garante-se ter atingido todos os nós, mesmo na topologia em cadeira (a menos favorável)
• A rede tem N nós, mas não diz-se nada sobre a conectividade mútua entre os nós. è não exclui-se a possibilidade de partição de rede

© Markus Endler 51
Modelos de Interação e Sincronização
Modelo assíncrono: • não há um limite máximo de tempo para a execução em um processo • não há limite máximo de tempo de transmissão de uma mensagem • não há limite máximo para a defasagem entre os relógios dos nós
O Modelo assíncrono não permite qualquer suposição sobre tempos de
qualquer execução. Muitos sistemas/ redes (p.ex. Internet) são assíncronos, devido ao compartilhamento de roteadores e o uso de buffers, e a heterogeneidade de nós
Por exemplo: – Comunicação: delays em roteadores, contenção no meio de transmissão – Processos: escalonamento dos processos desconhecido, acesso concorrente a
recursos locais, acesso a disco, etc. OBS: • O modelo síncrono é um caso particular do modelo assíncrono. • Existem alguns problemas que simplesmente não têm solução em um modelo
puramente assíncrono. Por isto é comum adotar-se modelos semi-síncronos è com algumas suposições sobre tempos máximos.

© Markus Endler 52
Modelo de Falhas
Em um SD tanto processos como os canais de comunicação podem falhar.
O Modelo de Falhas define a maneira pela qual os elementos podem falhar.
Usa-se as seguintes macro-categorias: • Omissão: quando um processo/canal deixa de executar uma ação
(p.ex. uma transmissão) • Arbitrárias (ou Bizantinas): quando qualquer comportamento é
possível • Temporização: (somente sistemas síncronos) quando o relógio local
pode diferir da hora real, ou o tempo de execução em um processo (ou de comunicação) ultrapassam limites pré-estabelecidos

© Markus Endler 53
Falhas: uma classificação mais precisa
As principais categorias são: • fail-stop: processo pára e permanece neste estado, e isto é detectável
pelos outros processos • crash: processo pára e permanece neste estado; outros processos
podem ser incapazes de detectar isto • omissão (de um canal): uma mensagem enviada por um processo
não é recebida pelo outro processo • omisão de envio (de processo): um processo completa o send(m),
mas m não é inserida no buffer de envio do processo • omissão de recebimento (de processo): mensagem é colocada no
buffer de recebimento, processo nunca recebe a mensagem • arbitrária/bizantina: o processo ou canal apresentam comportamento
qualquer (p.ex. envio de menagens quaisquer, a qualquer momento, omissão ou parada)
Tem-se a seguinte hierarquia entre os tipos de falha: fail-stop ⊂ crash ⊂ omissão ⊂ bizantina

© Markus Endler 56
Modelo de Interação e Sincronização
Uma computação distribuída consiste de um conjunto de sequências de eventos eij, cada uma ocorrendo em um dos processos Pi.
Comp = ∪i=1..N [ei1, ei2, ei3… ] Onde cada eij pode ser: • qualquer evento interno a Pi • Send(j, m) - envio de m para Pj • Receive(k, m) – chegada de m de Pk Se houvesse a noção global/consistente de tempo (com precisão infinita),
poderia-se identificar exatamente a ordem de ocorrência de eventos na execução de um AD (p.ex.: colocando um timestamp global em cada evento)
No Modelo Interleaving (intercalação), uma execução de um AD é representada como uma sequência global de eventos:
Exemplo de sequência:
1. P1 executa send(2,m) 2. P1 executa evento local 3. P1 executa receive(2,m2)
4. P2 executa evento local 5. P2 executa receive(1,m) 6. P1 executa send(1,m2)

© Markus Endler 57
Modelo de Interação e Sincronização
Problemas: • É impossível identificar exatamente a ordem global (total) de eventos
distribuídos (um problema relativistico), pois os relógios dos computadores precisariam estar perfeitamente sincronizados (impossível)
• O conhecimento da ordem exata de eventos de uma execução não fornece muitas informações sobre outras possíveis execuções do mesmo algoritmo
è Em compensação, em sistemas distribuídos apenas a ordem parcial de ocorrência de eventos de uma computação distribuída pode ser observada. Ordem parcial é definida pela causalidade.
Por isso, adota-se o Modelo de Causalidade (partial order ou happened before), ou causalidade potencial.
Modelo de causalidade: a ordem sequencial em cada processo define causalidade de eventos locais e eventos A:send(B,m) e B:receive(A,m) são causalmente dependentes
Modelo de causalidade potencial: difere do Modelo de Causalidade apenas pelo fato de que em cada processo também podem haver eventos locais concorrentes
© Markus Endler 58
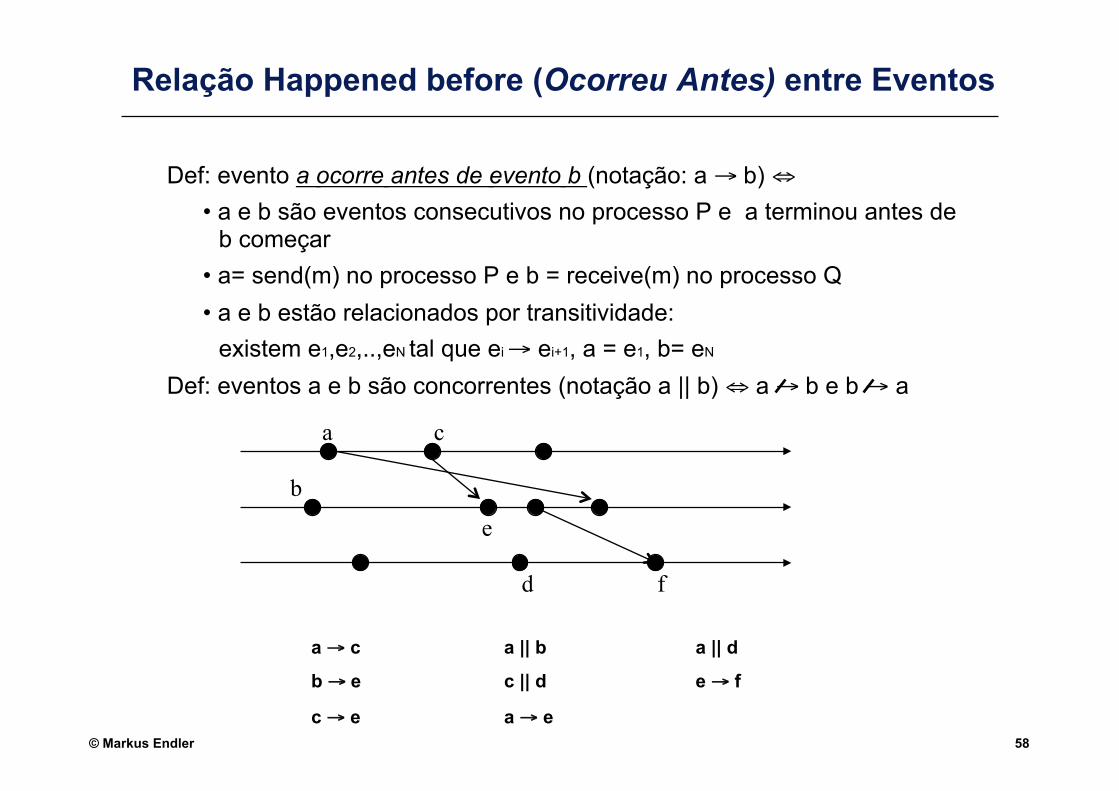
Relação Happened before (Ocorreu Antes) entre Eventos
Def: evento a ocorre antes de evento b (notação: a → b) ⇔ • a e b são eventos consecutivos no processo P e a terminou antes de
b começar • a= send(m) no processo P e b = receive(m) no processo Q • a e b estão relacionados por transitividade: existem e1,e2,..,eN tal que ei → ei+1, a = e1, b= eN
Def: eventos a e b são concorrentes (notação a || b) ⇔ a → b e b → a
a → c a || b a || d
b → e c || d e → f
c → e a → e
a c
e b
d f
© Markus Endler 59
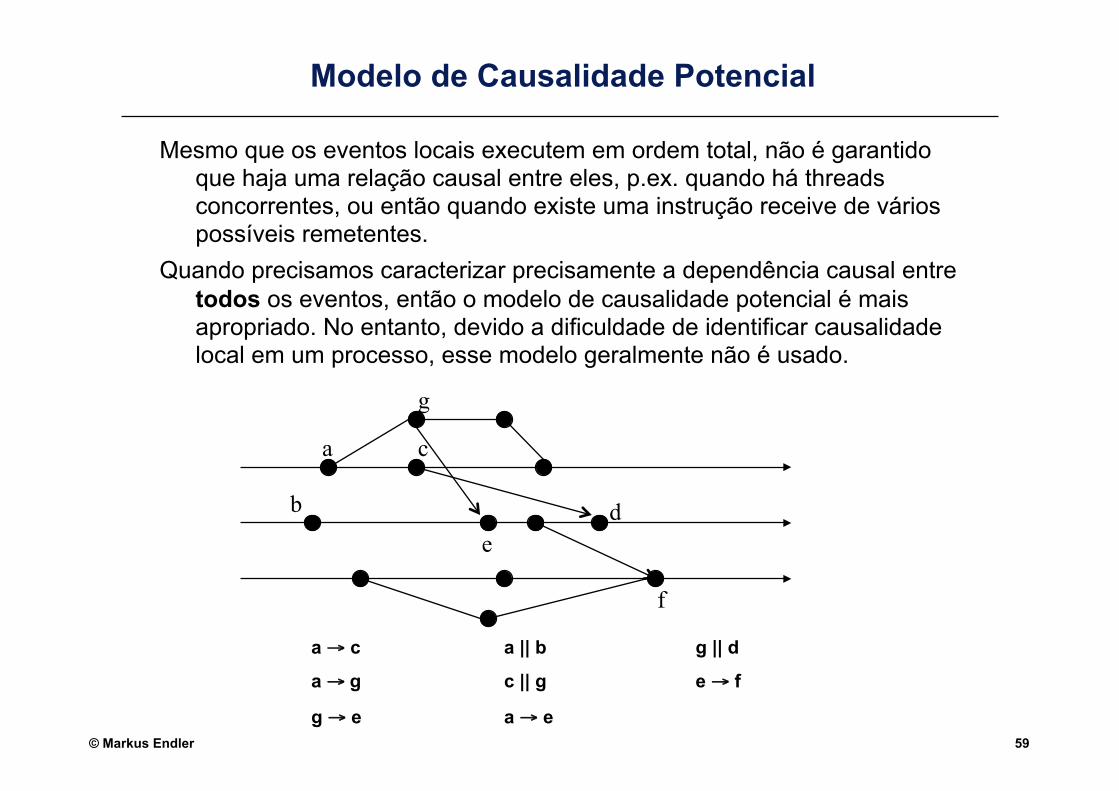
Modelo de Causalidade Potencial
Mesmo que os eventos locais executem em ordem total, não é garantido que haja uma relação causal entre eles, p.ex. quando há threads concorrentes, ou então quando existe uma instrução receive de vários possíveis remetentes.
Quando precisamos caracterizar precisamente a dependência causal entre todos os eventos, então o modelo de causalidade potencial é mais apropriado. No entanto, devido a dificuldade de identificar causalidade local em um processo, esse modelo geralmente não é usado.
a → c a || b g || d
a → g c || g e → f
g → e a → e
a c
e b d
f
g

© Markus Endler 60
Relógio Lógico
Proposto por Leslie Lamport em Time, Clocks and the ordering of events in a distributed System. Communications of the ACM, 1978
Laureado com o Prêmio Alan Turing em 2013

© Markus Endler 61
Relógio Lógico
Leslie Lamport propôs o conceito de relógio lógico que é consistente com a relação de causalidade entre eventos:
Idéia Central: • cada processo p tem um contador local LT(p), com valor inicial 0 • para cada evento executado (exceto receive) faça LT(p) := LT(p) + 1 • ao enviar uma mensagem m, adicione o valor corrente LT(m):= LT(p) • quando mensagem m é entregue a processo q, este faz LT(q) := max(LT(m),LT(q))+1
P1
P2
P3
P4
LT(a)=1
LT(b)=1
LT(p2)=2
LT(p2)=3 LT(c)=4
LT(d)=1
LT(c)=5
LT(e)=5
Consistência com a causalidade significa: !• se a → b então LT(a) < LT(b)
• se a || b então LT(a) e LT(b) podem ter valores arbitrários

© Markus Endler 62
Relógio Lógico (cont.)
O mecanismo propost por Lamport funciona define uma ordem parcial consistente com a dependência causal entre eventos:
se a → b, então (independentemente de a, b estarem ou não no mesmo processo), o valor LT(b) vai ser maior do que LT(a)
Apesar de não permitir a comparação de eventos concorrentes, o
mecanismo pode ser estendido para impor uma ordem total (arbitrária) sobre todos os eventos.
Para isto, basta adicionar o process-ID ao LT a fim de "desempatar" os
casos em que o LT(a) = LT(b) Outra vantagem é conhecer, para cada evento, o número de eventos
(considerando todos os processos) que potencialmente causaram/influenciaram o evento.(i.e. a altura do evento).

© Markus Endler 63
Modelo de Sistema para o Relógio Lógico
Relógio Lógico é um exemplo de protocolo/mecanismo distribuído, que:
• não assume nada com relação a sincronismo e tempos de transmissão • é tolerante às falhas de omissão (crash ou perda de mensagem) • permite uso por um número variável de participantes • impõe um overhead mínimo ao sistema • está totalmente desvinculado do relógio real e mesmo assim pode ser usado para impor uma ordem total "consistente" ao conjunto de eventos distribuídos
Em quais condições ele não funciona? Só não é tolerante à corrupção de mensagens, em particular do time-stamp e da informação sobre remetente (falha arbitrária)
E todos os processos precisam aderir ao protocolo.

© Markus Endler 64
Exercício para 19/03
Ler caps 1 & 2 do Livro (Kshemkalyani & Singhal) Dar exemplos de: • um sistema que garante entrega FIFO, mas não
garante entrega causal de mensagens; • Uma coleção de estados locais gravados (não
respeitando a causalidade) e que formam um estado global incorreto;
Obs: tente ser o mais formal/preciso possivel (usando a notação do livro)

© Markus Endler 78
Comunicação de Grupo e Multicasts
Em algumas aplicações há a necessidade de descrever a comunicação para um grupo de elementos (processos).
A noção de um grupo é essencial para aplicações distribuídas que: • lidam com coordenação de atividades/ações distribuídas • lidam com difusão de dados (exemplo: video-sob-demanda) • Implemantam tolerância a falhas e alta disponibilidade através da
replicação de dados/processamento. Principal Objetivo: Liberar o desenvolvedor da aplicação da tarefa de
gerenciar várias comunicações ponto-a-ponto para os membros do grupo.
Principal vantagem: è transparência de replicação
Serviço de grupo é um serviço de middleware que provê uma API e
protocolos eficientes para: • comunicação 1-para-N • gerenciamnto de pertinência no grupo.

© Markus Endler 79
Usos de Multicasts
Cliente Server
Server Server
Servidores replicados Exemplo: Tolerância à falhas
Server.
Client
Client
Client
Difusão de dados/eventos Exemplo: Streaming
P1
P2
P3
Aplicações Multi-Peer Exemplo: Instant Messaging

© Markus Endler 80
Comunicação de Grupo: Confiabilidade
Existem três categorias de requisitos de confiabilidade para comunicação de grupo:
a) Multicast não-confiável: o quanto mais membros receberem a mensagem, melhor. • se ocorrerem falhas nos enlaces e/ou nos processos, alguns membros do grupo podem eventualmente não receber a mensagem de multicast Exemplo: IP multicast (è principal objetivo: eficiência da difusão)
b) Melhor dos esforços (best-effort multicast): garante-se que em algum
momento futuro todos os destinatários conectados irão receber a mensagem • se necessário, a mensagem pode ser replicada, e destinatários devem ser capazes de descartar mensagens repetidas • destinatários não necessariamente precisam manter seus estados consistentes (p.ex. stateless servers) • Remetente não precisa saber quem efetivamente recebeu a mensagem
è A entrega a todos é garantida através da retransmissão da mensagem (p.ex. Flooding)

© Markus Endler 81
Comunicação de Grupo
c) Confiável (reliable muticast): é necessário garantir que todos os membros do grupo mantenham os seus estados sincronizados • para tal, toda requisição deve ser ou recebida por todos os servidores, ou então por nenhum deles (propriedade de atomicidade, all-or-nothing) • para isto, cada membro do grupo precisa armazenar temporariamete toda mensagem recebida e executar um protocolo de confirmação (entre as réplicas) para decidir/confirmar se a mensagem pode ser entregue para a aplicação. • quando o grupo muda (falha ou entrada de um membro): - a entrega de mensagens deve ser consistente (todos os membros que permanecem ativos devem receber os multicasts pendentes), - os novos membros devem receber o estado dos membros antigos
d) Sincronia Virtual (View-synchonous ou virtual synchony): • Apenas os processos não-falhos estabelecem pontos de sincronização
virtual (geralmente eliminando processos faltosos) • Garante-se a entrega de todas as mensagens até a sincronização das
visões
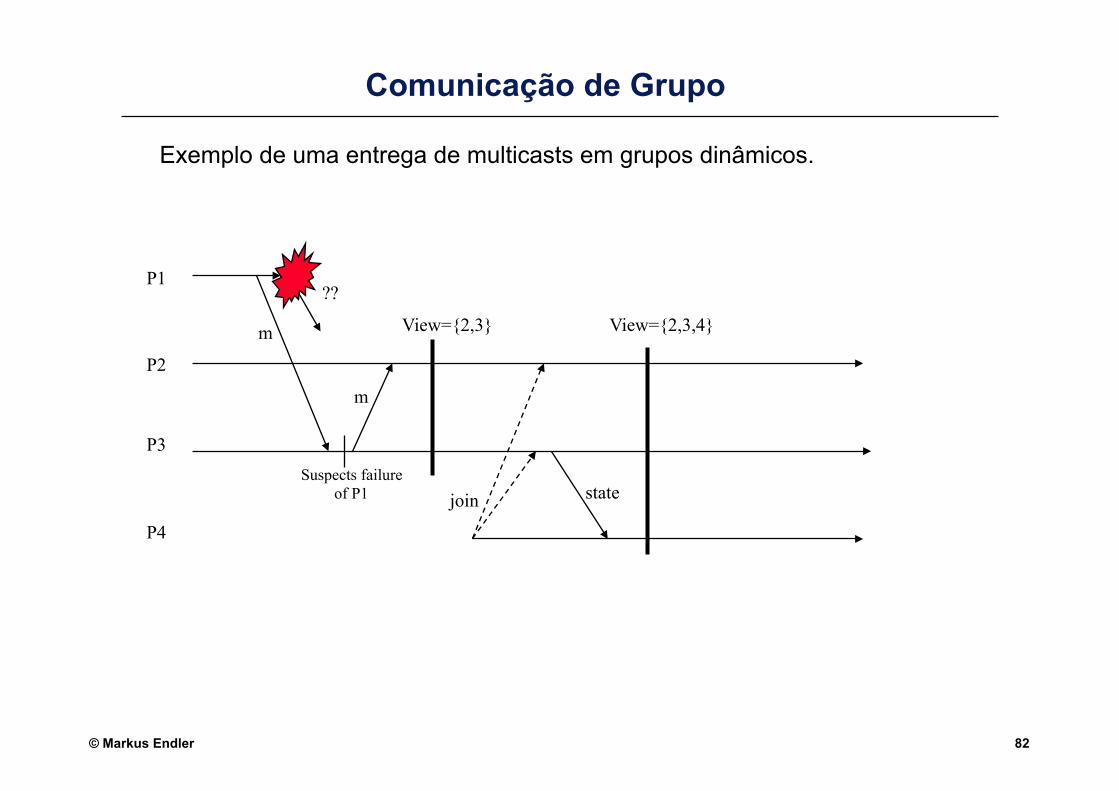
© Markus Endler 82
Comunicação de Grupo
Exemplo de uma entrega de multicasts em grupos dinâmicos.
P1
P2
P3
P4
??
m
Suspects failure of P1
m
View={2,3}
join state
View={2,3,4}

© Markus Endler 83
Manutenção da Consistência Para manter a consistência entre as réplicas, possivelmente também é
necessário impor certa política de entrega de mensagens para a aplicação. Idealmente, a entrega de um multicast m deveria ocorrer instantanemente (no
momento do seu envio) para todas réplicas. Mas devido à ausência de relógios perfeitamente sincronizados e de diferentes tempos de transmissão, duas mensagens podem chegar em uma ordem diferente em duas réplicas
As possíves políticas de entrega de mensagens m1 e m2 multicast são:
FIFO: se m1 → m2 tiverem sido geradas pelo mesma fonte, então m1 será entregue antes de m2 em qualquer réplica Causal: se m1 → m2 tiverem sido geradas em qualquer processo, então m1 será entregue antes de m2 Total: para qualquer m1 e m2, ou todas as réplicas recebem m1 antes de m2 ou vice-versa Sincronia Virtual: se m tiver sido recebida por um membro ativo na troca de visão, então m será recebido por todos membros que participaram da troca de visão

© Markus Endler 84
Duas formas de Implementação Grupo com um coordenador (sequenciador): Ex: Amoeba
• sequenciador recebe todas as requisições, atribui um número de sequência e re-transmite a mensagem para as demais réplicas • todos membros confirmam o recebimento • sequenciador eventualmente retransmite mensagens não confirmadas • perda de mensagem pode ser detectada devido ausência de ACK ou envio de negACK (+) ordem total pode ser obtida de forma simples (+) falha (crash) do sequenciador requer uma eleição de um novo sequenciador e consulta ao log das retransmissões pendentes
Grupo homogêneo (Peer-to-Peer): Ex: ISIS,Horus
• qualquer membro que receber a requisição inicia o protocolo (iniciador) • todos os membros ativos confirmam o recebimento, ou acusam perda • qualquer membro pode retransmitir mensagens (ou o estado, p/ novos membros) (-) protocolo é mais complexo e requer logs em todos os membros (-) ordem total é mais difícil de ser implementada (+) não requer a eleição de um coordenador

© Markus Endler 97
Algoritmos Distribuídos: Considerações Gerais
Além da corretude (p.ex. segurança, progresso, fairness, etc.), as seguintes propriedades são desejáveis:
• Simetria de papéis: todos os processos executam a mesma funcão(eventualmente com dados “particulares”, p.ex. PID)
• Robustez a falhas: o quanto menos restritivo for o modelo de falhas, melhor • Genericidade: menor dependência possível das características da rede
Por exemplo: Topologia qualquer, Sistema assíncrono, ausência de relógios sincronizados, ou comunicação não confiável
• Baixa complexidade de comunicação e espaço: menor possível número de mensagens e/ou tamanho pequeno das mensagens
• Baixa complexidade de tempo : menor número de rodadas (para algorítmos síncronos)
• Simplicidade: quanto mais complexo for o algoritmo, maior é a dificuldade de: – Implementação e depuração – teste para todos os casos especiais – Entendimento e manutenção (p.ex. fazer extensões)

© Markus Endler 98
Algoritmos Distribuídos: Considerações Gerais As premissas mais frequentes sobre o Modelo • processos não falham ou têm apenas falhas fail-stop • cada processo P tem conjuntos estáticos e bem definidos de processos dos
quais recebe mensagens (INP) e para os quais envia mensagens (OUTP) è a topologia de interconexão é fornecida a priori e é fixa
• Canal de comunicação é seguro: não há duplicação, geração espontânea ou modificação das mensagens
• Canal de comunicação é FIFO: ordem de entrega igual à ordem de envio • Canal de comunicação é confiável: mensagens nunca se perdem
• tempo máximo de transmissão de mensagens é fixo e conhecido Obs: • Algoritmos determinísticos p/ modelos assíncronos geralmente não são
robustos a qq tipo de falha • Algoritmos deterministicos para modelos síncronos são capazes de tolerar
falhas não triviais (bizantinas) • Algoritmos auto-estabilizantes em modelos assíncronos: toleram falhas e
possivelmente converge para o estado terminal