sist706 – sistemas distribuídos · professor. trabalho 1 ... 2 - hi_adsd ....
TRANSCRIPT

Slide05Tolerância a Falhas
SIST706 – Sistemas Distribuídos2013/1
Prof. Jéfer Benedett Dörr@: [email protected]

Tolerância a Falhas
Generais BizantinosAdaptive-DSDHi-ADSDDiVHA
http://www.inf.ufpr.br/elias/sisdis/index.html
http://www.lsd.ic.unicamp.br/mc714wiki/index.php/Generais_Bizantinos

FalhasFase de desenvolvimentoPrevenção de Falhas• metodologia de desenvolvimento, verificação
Eliminação de Falhas• testes, verificação
Fase de operaçãoTolerância a Falhas• mecanismos (software e/ou hardware) quepermitem detecção e tratamento de falhas

Falha, erro e defeito
Um defeito (failure) é definido como um desvio da especificação. Defeitos não podem ser tolerados, mas deve ser evitado que o sistema apresente defeito.
Define-se que um sistema está em estado errôneo, ou em erro, se o processamento posterior a partir desse estado pode levar a um defeito.
define-se falha ou falta (fault) como a causa física ou algorítmica do erro.

Falha, erro e defeito

Dependabilidade
O objetivo de tolerância a falhas é alcançar dependabilidade. O termo dependabilidade é uma tradução literal do termo inglês dependability, que indica a qualidade do serviço fornecido por um dado sistema e a confiança depositada no serviço fornecido.
Principais atributos de dependabilidade [Prad96] são confiabilidade, disponibilidade, segurança de funcionamento (safety), segurança (security), mantenabilidade, testabilidade e comprometimento do desempenho (performability).

DependabilidadeAtributo - Significado
Dependabilidade (dependability) - qualidade do serviço fornecido por um dado sistema
Confiabilidade (reliability) - capacidade de atender a especificação, dentro de condições definidas, durante certo período de funcionamento e condicionado a estar operacional no início do período
Disponibilidade (availability) - probabilidade do sistema estar operacional num instante de tempo determinado; alternância de períodos de funcionamento e reparo
Segurança (safety) - probabilidade do sistema ou estar operacional e executar sua função corretamente ou descontinuar suas funções de forma a nãoSegurança (security) - provocar dano a outros sistema ou pessoas que dele dependam
Segurança (security) - proteção contra falhas maliciosas, visando privacidade, autenticidade, integridade e irrepudiabilidade dos dados

Técnicas para alcançar dependabilidade
prevenção de falhas - impede a ocorrência ou introdução de falhas. Envolve a seleção de falhas metodologias de projeto e de tecnologias adequadas para os seus componentes.
tolerância a falhas - fornece o serviço esperado mesmo na presença de falhas. Técnicas falhas comuns: mascaramento de falhas, detecção de falhas, localização, confinamento, recuperação, reconfiguração, tratamento.
validação - remoção de falhas, verificação da presença de falhas.
previsão de falhas - estimativas sobre presença de falhas e estimativas sobre falhas conseqüências de falhas.

Tolerância Quatro fases de Anderson e Lee
ANDERSON, T.; LEE, P. A. Fault tolerance -principles and practice.Englewood Cliffs, Prentice-Hall, 1981
detecção de errosduplicação e comparaçãotestes de limites de tempocão de guarda (watchdog timers)testes reversoscodificação: paridade, códigos de detecção de erros, Hammingteste de razoabilidade, de limites e de compatibilidadestestes estruturais e de consistênciadiagnóstico

Tolerância Quatro fases de Anderson e Lee
confinamento e avaliaçãoações atômicasoperações primitivas auto encapsuladasisolamento de processosregras do tipo tudo que não é permitido é proibidohierarquia de processoscontrole de recursos

Tolerância Quatro fases de Anderson e Lee
recuperação de erros técnicas de recuperação por retorno (backward error recovery)técnicas de recuperação por avanço (forward error recovery)
tratamento da falha diagnósticoreparo

Redundância
Redundância é a palavra mágica em tolerância a falhas.
Redundância para aumento de confiabilidade é quase tão antiga como a história dos computadores ([Crev56], [VonN56]). Todas as técnicas de tolerância a falhas envolvem alguma forma de redundância
CREVELING, C.J. Increasing the reliability of electronic equipment by the use of redundant circuits. Proceedings of the IRE. New York, 44(4):509- 515, abr. 1956.
VON NEWMANN, J. Probabilistic logics and the synthesis of reliable organisms from unreliable components. In: Automata Studies, Shannon & McCarthy eds. Princeton Univ. Press, 1956. p. 43-98.

Generais Bizantinos
Um sistema confiável deve ser capaz de lidar com falhas de um ou mais componentes;
Um componente com falhas pode enviar informações conflitantes para diferentes partes do sistema;
O problema enfrentado com esse tipo de defeito é expressado abstratamente como o Problema dos Generais Bizantinos.

Generais BizantinosProblema dos Generais BizantinosAlcançar consenso na presença de traidores
Generais Bizantinos cercam uma cidade
Existem:Generais leaisGenerais traidores
Objetivo:Os Generais devem chegar a um consenso se atacam ou se esperamSó vencerão se todos os Generais leais atacarem!
Os Generais traidores não deverão atrapalhar o consenso

Generais Bizantinos
TEOREMA 1Se 2/3 + 1 dos generais (processos) forem leais (não falharem),existe uma solução (algoritmo) que resultará numa ação comum, idendendente de possíveis mensagens enviadas pelos traidores
TEOREMA 2Se 1/3 ou mais dos generais (processos) forem traidores(falharem), não existe solução para este problema.

Generais BizantinosNo caso de poder haver um general (processo) traidor, existe umasolução para 4 generais, mas não para 3.Algoritmo para 4 generais (assuma que um general, o comandante,iniciará a ação)1 - o comandante transmite sua decisão2 - cada genenal (não comandante retransmite a decisão do comandantepara os outros comandados3 - cada comandado depois de receber a mensagem do comandantemais de outros 2 comandados, decide pelo voto da maioria entre as3 mensagensHá 2 casos a serem considerados:1 - o comandante é leal2 - o comandante é taidor
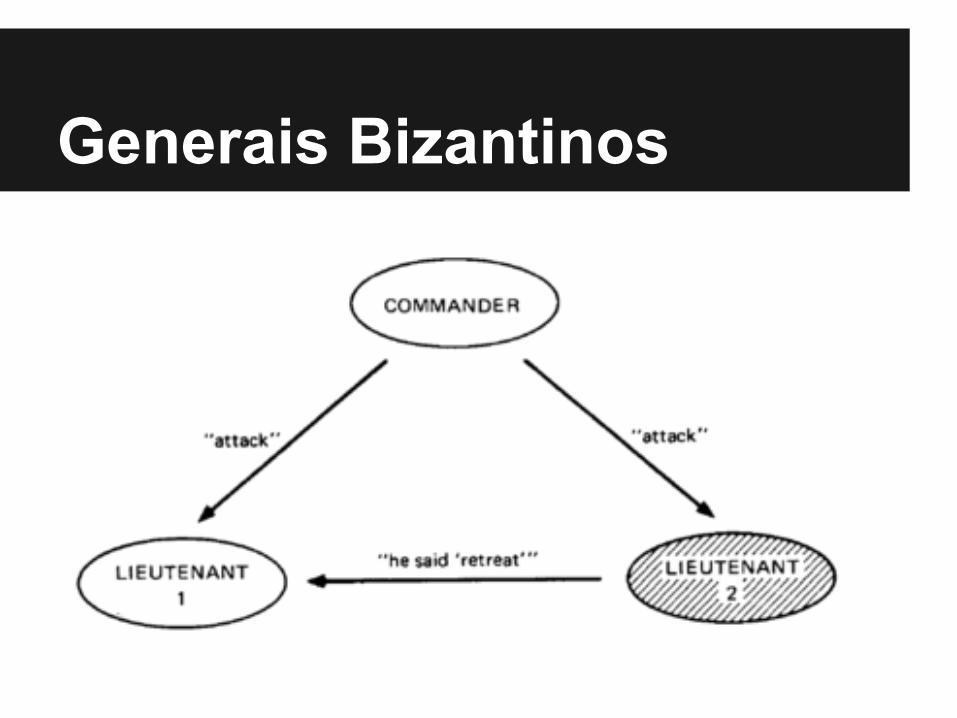
Generais Bizantinos

Generais Bizantinos

Generais BizantinosResumo•Não há solução para 3 generais se existe pelo menos 1traidor•Para tolerar até m falhas:•Pelo menos 3m+1 generais têm que estar presentes.•Pelo menos 2m+1 caminhos de comunicação•Pelo menos m+1 rodadas de comunicação
Para tolerar m falhas, pelo menos 3m + 1 nós são necessários3.1 + 1 = 43.2 + 1 = 73.3 + 1 = 103.4 + 1 = 13

Sistemas Confiáveis
Aplicações de Sistemas Tolerantes a Falhas

Modelo de Falhas

TF Pentium
Tolerância a falhas nos processadores PentiumNo microprocessador Intel 486 foi usada verificação de paridade para as transferênciasinternas de dados entre caches e unidades de execução. Já no Pentium, adicionalmente àparidade nas caches, a TLB e a memória de microcódigo também são verificadasquando à paridade. No Pentium foram introduzidos recursos adicionais para verificaçãode exceções suportada por hardware (machine check exception). Também o esquema demestre-verificador (usado inicialmente no iapx432) com dois chips voltou a ser adotadopela Intel a partir do Pentium.O Pentium Pro mantém todas as técnicas do Pentium e adicionalmente:� paridade nos bytes de dados substituída por 8 bits de ECC� 2 bits de paridade para barramento de endereço associado a técnicas de retry� bits de paridade para sinais de controleNo Pentium Pro verificação de exceções é conduzida pela MCA (machine checkarchitecture) que adiciona 3 registradores de controle e 5 bancos de 4 registradores deerro aos recursos do microprocessador.

ObjetivosTrabalho: Este slide define o objetivo do trabalho de acordo com os tópicos abaixo.São 4 tópicos que serão desenvolvidos pelos integrantes da turma divididos em 4 grupos.Cada grupo irá executar e relatar o objetivo e funcionamento de cada um dos algoritmos de tolerância a falhas. Eles devem ser compreendidos e executados. O relatório deve apresentar a descrição da função que o fonte realiza, demonstrando e explicando da melhor forma possível, utilizando desenhos, metáforas, exemplos.Este trabalho será iniciado na aula de 18/3 e finalizado na aula do 22/3 onde cada grupo irá apresentar o trabalho ao professor.

TRABALHO
1 - Adaptative_DSD http://www.inf.ufpr.br/jbdorr/disciplinas/sisdis/fase1/index.html2 - HI_ADSD http://www.inf.ufpr.br/jbdorr/disciplinas/sisdis/fase2/index.html3 - DIVHA http://www.inf.ufpr.br/jbdorr/disciplinas/sisdis/fase3/index.html4 - HIPER BONE http://www.inf.ufpr.br/nunom/SIST_DISTRB/trab4/trab4.html

Perguntas1. Nos algoritmos, o que faz a biblioteca smpl.h?2. O que a cisj.h fornece?3. Qual é a função do HyperBone? 4. O que faz o algoritmo de Dijkstra?5. Em sist. dist., qual a diferença entre o requisito “safety” e o
requisito “security”?6. O que é um HA-clusters?

ReferênciasDUARTE AND NANYA: A HIERARCHICAL ADAPTIVE DISTRIBUTED SYSTEM-LEVEL DIAGNOSIS ALGORITHM, IEEE TRANSACTIONS ON COMPUTERS, VOL. 47, NO. 1, JANUARY 1998
Self Diagnosis Based on the Distributed Virtual Hypercube Algorithm - Luis C. E. Bona, Elias P. Duarte Jr, Keiko V. O. Fonseca - LAACS 2006
L. Lamport, R. Shostak, M. Pease, The Byzantine Generals Problem[1], ACM Transactions on Programming Languages and Systems, vol. 4 n. 3, pp. 382–401, July 1982.
ANDERSON, T.; LEE, P. A. Fault tolerance -principles and practice.Englewood Cliffs, Prentice-Hall, 1981
CREVELING, C.J. Increasing the reliability of electronic equipment by the use of redundant circuits. Proceedings of the IRE. New York, 44(4):509- 515, abr. 1956.
VON NEWMANN, J. Probabilistic logics and the synthesis of reliable organisms from unreliable components. In: Automata Studies, Shannon & McCarthy eds. Princeton Univ. Press, 1956. p. 43-98.

Bibliografia

ATENÇÃOEstes slides tem o objetivo de serem material de apoio durante as aulas, de forma alguma substituem o uso de outros fontes.Este slide é insuficiente para uma total compreensão dos conteúdos nele apresentados.
Busquem os livros na biblioteca.
Busquem outras fontes.